
hexsha
stringlengths 40
40
| size
int64 6
14.9M
| ext
stringclasses 1
value | lang
stringclasses 1
value | max_stars_repo_path
stringlengths 6
260
| max_stars_repo_name
stringlengths 6
119
| max_stars_repo_head_hexsha
stringlengths 40
41
| max_stars_repo_licenses
list | max_stars_count
int64 1
191k
⌀ | max_stars_repo_stars_event_min_datetime
stringlengths 24
24
⌀ | max_stars_repo_stars_event_max_datetime
stringlengths 24
24
⌀ | max_issues_repo_path
stringlengths 6
260
| max_issues_repo_name
stringlengths 6
119
| max_issues_repo_head_hexsha
stringlengths 40
41
| max_issues_repo_licenses
list | max_issues_count
int64 1
67k
⌀ | max_issues_repo_issues_event_min_datetime
stringlengths 24
24
⌀ | max_issues_repo_issues_event_max_datetime
stringlengths 24
24
⌀ | max_forks_repo_path
stringlengths 6
260
| max_forks_repo_name
stringlengths 6
119
| max_forks_repo_head_hexsha
stringlengths 40
41
| max_forks_repo_licenses
list | max_forks_count
int64 1
105k
⌀ | max_forks_repo_forks_event_min_datetime
stringlengths 24
24
⌀ | max_forks_repo_forks_event_max_datetime
stringlengths 24
24
⌀ | avg_line_length
float64 2
1.04M
| max_line_length
int64 2
11.2M
| alphanum_fraction
float64 0
1
| cells
list | cell_types
list | cell_type_groups
list |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
4a9d545de48b83bd7e65462623293329b94d66f9
| 13,260 |
ipynb
|
Jupyter Notebook
|
Introduction to ML.ipynb
|
anikannal/ML_Projects
|
ae58eb8928a1aff7f205ab663adaeb15376d0183
|
[
"MIT"
] | null | null | null |
Introduction to ML.ipynb
|
anikannal/ML_Projects
|
ae58eb8928a1aff7f205ab663adaeb15376d0183
|
[
"MIT"
] | null | null | null |
Introduction to ML.ipynb
|
anikannal/ML_Projects
|
ae58eb8928a1aff7f205ab663adaeb15376d0183
|
[
"MIT"
] | null | null | null | 33.15 | 387 | 0.594495 |
[
[
[
"# Introduction to Machine Learning",
"_____no_output_____"
],
[
"## What is Machine Learning?\n",
"_____no_output_____"
],
[
"Machine Learning is the field of study that gives computers the capability to learn without being explicitly programmed.\n\nI like to think of it as a comparison rather than a definition.\n\n- If you **can** give clear instructions on how to do the task - traditional computing\n- If you **cannot** give clear instructions but can give lots of examples - machine learning\n\nLet's look at a few illustrations - \n\n1. Complex mathematical calculations - can give clear instructions: traditional computing\n2. Processing a financial transaction - can give clear instructions: traditional computing\n3. Differentiate between pictures of cats and dogs - cant give instructions but can give examples: machine learning\n4. Playing chess - can give clear instructions for how to play but cannot give instructions on how to win! We can give a lot of past games as examples though: machine learning\n5. Customer segmentation - dont know what the segments/groupings are, so giving clear instructions is out of question. Can give a large amount of examples with customer demographic data and purchase history: machine learning\n\nSo we can say that traditional programming takes data and program to give us output, while machine learning takes data and output (examples) to give us a program!",
"_____no_output_____"
],
[
"<img src='https://drive.google.com/uc?id=1SAu0GNpDqDNRNxEtXRqBX-t20BuB0HcR' align = 'left'/>",
"_____no_output_____"
],
[
"## Data is the New Oil!\n\nData is absolutely **critical** to creating a viable Machine Learning model. Here's simple representation of how data helps us create a model and a model helps us make predictions.",
"_____no_output_____"
],
[
"<img src=\"https://drive.google.com/uc?id=1rM6SBXOMeAcFXu1OLtvk4HOWsXdY_xGU\" width=500 height=300 align=\"left\"/>",
"_____no_output_____"
],
[
"Here's a short explainer video if the pictures didnt really do it for you...",
"_____no_output_____"
]
],
[
[
"## Run this cell (shift+enter) to see the video\n\nfrom IPython.display import IFrame\nIFrame(\"https://www.youtube.com/embed/f_uwKZIAeM0\", width=\"600\", height=\"400\")",
"_____no_output_____"
]
],
[
[
"## What are the Different Types of Machine Learning?",
"_____no_output_____"
],
[
"<img src=\"https://drive.google.com/uc?id=1ESgroj56fbOoE0_xiMhsaibVa8D-_80H\" align=\"left\" width=\"1000\" height=\"800\"/>",
"_____no_output_____"
],
[
"---\n## Course Overview",
"_____no_output_____"
],
[
"This course is designed for the 'do-ers'. Our entire focus during this course will be to apply and experiment. Conceptual understanding is very important and we will build a strong conceptual foundation but it will always be in context of a project rather than just a theoretical understanding.\n\nWe will be exploring a variety of Machine Learning algorithms. For each we will use an appropriate real world dataset, work on a real problem statement, and execute a project that can become the foundation of your ML skills portfolio and your resume.\n\nYou now have access to a full scale ML lab-on-cloud. This is a very powerful tool, IF you use it. Make the most of what you have - explore, experiment, break a few things. You learn the most out of failure!",
"_____no_output_____"
],
[
"### What Will We Do?\n\n- We will understand the life cycle of a typical ML project and exercise it through real projects\n- We will be exploring a slew of ML algorithms (supervised and un-supervised learning)\n- For each of these algorithms we will understand how it works and apply it in a project\n- We will extensively work on real world datasets and strive to be hands-on",
"_____no_output_____"
],
[
"### What Will We NOT Do?\n\n- We will not cover every ML algorithm under the sun\n- We will not cover reinforced learning and deep learning in this course\n- We will not go deep into the mathematical, probabilistic, and statistical foundations of ML",
"_____no_output_____"
],
[
"## Course Curriculum\n\n**Key Concepts Covered**\n1. Lifecycle of a typical ML project\n2. Data Pre-processing</td>\n - Data acquisition and loading\\n\n - Data integration\\n\n - Exploratory data analysis\n - Data cleaning\n - Feature selection\n - Encoding\n - Normalization\n3. Picking the Right Algorithm\n4. Evaluating Your Model\n - Train - Test Split\n - Evaluation Metrics\n - Under and Over Fitting\n5. Other key concepts \n - Imputation\n - Kernel Functions\n - Bagging\n - Hyperparameters\n - Boosting\n\n**Algorithms Covered**\n1. Linear Regression\n2. Logistic Regression\n3. K Nearest Neighbors\n4. Decision Trees\n5. Random Forest\n6. Naive Bayes\n7. Support Vector Machine\n8. K Means Clustering\n9. Hierarchical Clustering\n\n**Datasets Used**\n1. Healthcare - patient data on drug efficacy\n2. Telecom - customer profiles\n3. Retail - customer profiles\n4. Automobile - automobile catalogue make, model, engine specs, etc.\n5. Environment - CO2 emmissions data\n6. Health Informatics - cancer cell biopsy observations",
"_____no_output_____"
],
[
"---\n## Life Cycle of a Typical ML Project",
"_____no_output_____"
],
[
"A typical ML project goes through 5 major steps - \n\n1. Define Project Objectives\n2. Acquire, Explore and Prepare Data\n3. Model Data\n4. Interpret and Communicate the Insights\n5. Implement, Document, and Maintain\n\nWe will work through steps 1 thru 4 during this course. We will **not** be deploying, documenting or maintaining our models.\n\n<img src=\"https://drive.google.com/uc?id=1hQrE2Q7D_j4T8y5aM8pW-ejuS4VUP7Co\" align=\"left\"/>\n\n\n\n\nLet's look at each of steps in further detail - \n\n1. **Define Project Objectives** - this is very important step that most of us tend to forget. Without a clear understand of why you are doing any project, the project will fail. What the business or clients expects as outcome of the project has to be discussed and understood before you start off.\n\n\n2. **Acquire, Explore, and Prepare Data** - you will spend a lot of your time on this step when you do an ML project. This is a critical step - exploring the data will help you decide which models you might want to employ, based this preliminary hypothesis you will prepare the data for the next step (Model Data). Here are a few things you will end up doing within this step - \n - Data acquisition and loading\n - Data integration\n - Exploratory data analysis\n - Data cleaning\n - Feature selection\n - Encoding\n - Normalization\n\n\n3. **Model Data** - this is the heart of our project. But, most students of ML get stuck on fancy algorithm names. There's a lot more to it than just claiming that you have done a project using SVM or Logistic Regression. You have to be able to articulate how you picked a model, how you trained it, and why did you conclude that the output looks good.\n - Select the algorithm(s) to use\n - Train the model(s)\n - Evaluate performance\n - Tweak parameters and re-evaluate\n\n\n4. **Interpret and Communicate the Insights** - just modeling the data, showing a few visualizations, and reducing the error is not enough. As an ML engineer you have to be able to talk to your client and help them interpret the outcome of all your hard work. Be ready to answer a few questions - \n - What interesting patterns did you notice in the data?\n - Did you notice any intrinsic dependencies, correlation, or causation in the features?\n - Why did you pick the algorithm that you did?\n - How did you split the train-test data? why?\n - Is this error rate acceptable? why?\n - How will the outcome of this project help the client?\n\n\n5. **Implement, Document, and Maintain** - at a real client, you will have to deploy your model in production, document it extensively, and also maintain it going forward. We will not go into this step given we are not going to be deploying our models in production.\n",
"_____no_output_____"
],
[
"## Kick Start!\nHere's a 12 minute crash course on ML to kick-start our journey!",
"_____no_output_____"
]
],
[
[
"## Run this cell (shift+enter) to see the video\n\nfrom IPython.display import IFrame\nIFrame(\"https://www.youtube.com/embed/z-EtmaFJieY\", width=\"814\", height=\"509\")",
"_____no_output_____"
]
],
[
[
"Here's a great article that summarizes Machine Learning really well.\n\nhttps://machinelearningmastery.com/basic-concepts-in-machine-learning/",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a9d6f67fbdedc6eafa2d09f9009d9a0098a213d
| 16,872 |
ipynb
|
Jupyter Notebook
|
3_building_xrrays_with_ard_and_brute_force/1_what_does_c2ARD_look_like_answer_non_existant.ipynb
|
tonybutzer/c-experiments
|
750393ed5e24c492162db392da10d4958ef632ee
|
[
"MIT"
] | null | null | null |
3_building_xrrays_with_ard_and_brute_force/1_what_does_c2ARD_look_like_answer_non_existant.ipynb
|
tonybutzer/c-experiments
|
750393ed5e24c492162db392da10d4958ef632ee
|
[
"MIT"
] | null | null | null |
3_building_xrrays_with_ard_and_brute_force/1_what_does_c2ARD_look_like_answer_non_existant.ipynb
|
tonybutzer/c-experiments
|
750393ed5e24c492162db392da10d4958ef632ee
|
[
"MIT"
] | null | null | null | 19.943262 | 181 | 0.495792 |
[
[
[
"from cubelib.stac_eco import Stac_eco\nfrom cubelib.fm_map import Fmap",
"_____no_output_____"
],
[
"import pandas as pd\n# pd.set_option('display.max_colwidth', None)\n# pd.set_option('display.max_rows', None)\n# pd.set_option('display.max_columns', None)\n# pd.set_option('display.width', 2000)",
"_____no_output_____"
],
[
"#! cp ../2_Gridding_For_Scale/*.geojson .\n! ls *.geojson",
"_____no_output_____"
],
[
"geojson_file = 'one_tile.geojson'\nse = Stac_eco(geojson_file)",
"_____no_output_____"
],
[
"se",
"_____no_output_____"
],
[
"se.set_collection('landsat-c2ard-sr')",
"_____no_output_____"
],
[
"se",
"_____no_output_____"
],
[
"fm = Fmap()\nfm.sat_geojson(geojson_file)",
"_____no_output_____"
],
[
"dates=\"2020-04-01/2020-10-31\"",
"_____no_output_____"
],
[
"search_object_eco = se.search(dates, cloud_cover=100)",
"_____no_output_____"
],
[
"number_of_matched_scenes = search_object_eco.matched()",
"_____no_output_____"
],
[
"print(f\"I found {number_of_matched_scenes} Scenes yay!\")",
"_____no_output_____"
],
[
"so = search_object_eco",
"_____no_output_____"
],
[
"gdf1 = se.items_gdf(so)",
"_____no_output_____"
],
[
"#gdf1",
"_____no_output_____"
],
[
"gdf1.T",
"_____no_output_____"
],
[
"import pandas as pd\npd.set_option('display.max_colwidth', None)\ngdf1['stac_extensions']",
"_____no_output_____"
],
[
"se.plot_polygons(so)",
"_____no_output_____"
],
[
"gdf1['properties.landsat:grid_vertical']",
"_____no_output_____"
],
[
"gdf1['properties.landsat:grid_horizontal']",
"_____no_output_____"
],
[
"gdf2 = gdf1[gdf1['properties.landsat:grid_horizontal']=='29']",
"_____no_output_____"
],
[
"gdf2.T",
"_____no_output_____"
],
[
"gdf3 = gdf2[gdf2['properties.landsat:grid_vertical']=='03']",
"_____no_output_____"
],
[
"gdf3[['properties.landsat:grid_horizontal', 'properties.landsat:grid_vertical']]",
"_____no_output_____"
],
[
"len(gdf3[['properties.landsat:grid_horizontal', 'properties.landsat:grid_vertical']])",
"_____no_output_____"
],
[
"dir(se)",
"_____no_output_____"
],
[
"se.df_assets(so)",
"_____no_output_____"
],
[
"import boto3\nfrom rasterio.session import AWSSession\naws_session = AWSSession(boto3.Session(), requester_pays=True)",
"_____no_output_____"
],
[
"import rasterio as rio\nimport xarray as xr\ndef create_dataset(row, bands = ['Swirs', 'Green'], chunks = {'band': 1, 'x':2048, 'y':2048}):\n datasets = []\n with rio.Env(aws_session):\n for band in bands:\n print(row[band]['href'])\n url = row[band]['href']\n #url = url.replace('usgs-landsat', 'usgs-landsat-ard')\n #da = xr.open_rasterio(url, chunks = chunks)\n da = xr.open_rasterio(url)\n daSub=da\n# daSub = da.sel(x=slice(ll_corner[0], ur_corner[0]), y=slice(ur_corner[1], ll_corner[1]))\n daSub = daSub.squeeze().drop(labels='band')\n DS = daSub.to_dataset(name = band)\n datasets.append(DS)\n DS = xr.merge(datasets)\n return DS",
"_____no_output_____"
],
[
"def asset_gdf(my_gdf,bands):\n #print(my_gdf.keys)\n i_dict_array = []\n for i,item in my_gdf.iterrows():\n i_dict ={}\n print(item.id)\n i_dict['id'] = item.id\n for band in bands:\n href = f'assets.{band}.href'\n #print(item[href])\n i_dict[band] = {'band': band,\n 'href': item[href]\n }\n i_dict_array.append(i_dict)\n print(i_dict_array)\n new_gdf = pd.DataFrame(i_dict_array)\n return new_gdf",
"_____no_output_____"
],
[
"gdf3",
"_____no_output_____"
],
[
"bands=['blue','green','red','nir08','swir16','swir22','qa_pixel']\ngdf4=asset_gdf(gdf3,bands)",
"_____no_output_____"
],
[
"gdf4.id",
"_____no_output_____"
],
[
"datasets = []\nfor i,row in gdf4.iterrows():\n try:\n print('loading....', row.id)\n \n ds = create_dataset(row,bands)\n datasets.append(ds)\n except Exception as e:\n print('Error loading, skipping')\n print(e)",
"_____no_output_____"
],
[
"! aws s3 ls --request-payer requester s3://usgs-landsat/collection02/oli-tirs/2020/CU/029/003/LC08_CU_029003_20200419_20210504_02/LC08_CU_029003_20200419_20210504_02_SR_B2.TIF",
"_____no_output_____"
],
[
"! aws s3 ls --request-payer requester s3://usgs-landsat/collection02/oli-tirs/2020/CU/029/003/",
"_____no_output_____"
],
[
"! aws s3 ls --request-payer requester s3://usgs-landsat-ard/collection02/oli-tirs/2020/CU/029/003/",
"_____no_output_____"
],
[
"datasets",
"_____no_output_____"
],
[
"! date",
"_____no_output_____"
],
[
"gdf3",
"_____no_output_____"
],
[
"gdf3.keys()",
"_____no_output_____"
],
[
"gdf3['properties.start_datetime'].tolist()",
"_____no_output_____"
],
[
"len(gdf3)",
"_____no_output_____"
],
[
"gdf3.index.tolist()",
"_____no_output_____"
],
[
"from datetime import datetime\nmy_date_list = gdf3.index.tolist()\nmy_str_date_list=[]\nfor dt in my_date_list:\n print(dt)\n str_dt = dt.strftime('%Y-%m-%d')\n print(str_dt)\n my_str_date_list.append(str_dt)",
"_____no_output_____"
],
[
"DS = xr.concat(datasets, dim= pd.DatetimeIndex(my_str_date_list, name='time'))",
"_____no_output_____"
],
[
"print('Dataset Size (Gb): ', DS.nbytes/1e9)",
"_____no_output_____"
],
[
"DS",
"_____no_output_____"
],
[
"DS['red'].isel(time=0).plot()",
"_____no_output_____"
],
[
"DS['red'][1].plot()",
"_____no_output_____"
],
[
"DS['red'][15].plot()",
"_____no_output_____"
],
[
"ds_mini = DS.isel(x=slice(0,5000,10), y=slice(0,5000,10))",
"_____no_output_____"
],
[
"ds_mini",
"_____no_output_____"
],
[
"%matplotlib inline\n\ndisplay_color = 'blue'\n# \nds_mini[display_color].plot.imshow('x','y', col='time', col_wrap=6, cmap='viridis')\n#ds_mini[display_color].plot.imshow('x','y', col='time', col_wrap=6, cmap='viridis', vmin=7000, vmax=19000)",
"_____no_output_____"
],
[
"ds_mini.hvplot()",
"_____no_output_____"
],
[
"ds_mini['red'][0].hvplot.image(rasterize=True)",
"_____no_output_____"
],
[
"ds_mini['red'][0].plot()",
"_____no_output_____"
],
[
"d2 = ds_mini.transpose('time', 'y', 'x')",
"_____no_output_____"
],
[
"d2['red'].hvplot.image(rasterize=True)",
"_____no_output_____"
],
[
"d2",
"_____no_output_____"
],
[
"dir(d2)",
"_____no_output_____"
],
[
"#d2.swap_dims({'time')",
"_____no_output_____"
],
[
"#help(d2.swap_dims)",
"_____no_output_____"
],
[
"#help(d2.rename)",
"_____no_output_____"
],
[
"#d2.swap_dims({'time':'x'})",
"_____no_output_____"
],
[
"#d2.dims",
"_____no_output_____"
],
[
"#d2.drop_dims()",
"_____no_output_____"
],
[
"help(d2.drop_dims)",
"_____no_output_____"
],
[
"d2['red'].hvplot.image(rasterize=True, x='x', y='y', width=600, height=400, cmap='viridis', clim=(4000,20000))",
"_____no_output_____"
],
[
"help(d2['red'].hvplot.image)",
"_____no_output_____"
],
[
"d2['qa_pixel'].hvplot.image(rasterize=True, x='x', y='y', width=600, height=400, cmap='viridis')",
"_____no_output_____"
],
[
"DS.time.attrs = {} #this allowed the nc to be written\n#ds.SCL.attrs = {}\n\nDS.to_netcdf('~/maine_one_tile_swir_also.nc')",
"_____no_output_____"
],
[
"! ls -lh ~/*.nc",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9dbbb8480f87c44abe72c7e961fd245760a9a4
| 141,906 |
ipynb
|
Jupyter Notebook
|
notebooks/Troubleshooting.ipynb
|
granttremblay/hyperscreen
|
f39029cdd835ffefb9a9a483f264f5cd76b7f58c
|
[
"MIT"
] | 2 |
2020-07-01T12:24:38.000Z
|
2021-05-16T23:49:07.000Z
|
notebooks/Troubleshooting.ipynb
|
granttremblay/hyperscreen
|
f39029cdd835ffefb9a9a483f264f5cd76b7f58c
|
[
"MIT"
] | 15 |
2019-10-12T02:38:16.000Z
|
2020-05-21T01:20:31.000Z
|
notebooks/Troubleshooting.ipynb
|
granttremblay/hyperscreen
|
f39029cdd835ffefb9a9a483f264f5cd76b7f58c
|
[
"MIT"
] | null | null | null | 94.983936 | 23,740 | 0.605048 |
[
[
[
"\nimport warnings\n\nimport matplotlib as mpl\nimport matplotlib.pyplot as plt\nfrom matplotlib.colors import LogNorm\n\nfrom astropy.io import fits\nfrom astropy.table import Table\n\nimport pandas as pd\nimport numpy as np\nnp.seterr(divide='ignore')\n\n\nwarnings.filterwarnings(\"ignore\", category=RuntimeWarning)\n\n\nclass HRCevt1:\n '''\n A more robust HRC EVT1 file. Includes explicit\n columns for every status bit, as well as calculated\n columns for the f_p, f_b plane for your boomerangs.\n Check out that cool new filtering algorithm!\n '''\n\n def __init__(self, evt1file):\n\n # Do a standard read in of the EVT1 fits table\n self.filename = evt1file\n self.hdulist = fits.open(evt1file)\n self.data = Table(self.hdulist[1].data)\n self.header = self.hdulist[1].header\n self.gti = self.hdulist[2].data\n self.hdulist.close() # Don't forget to close your fits file!\n\n fp_u, fb_u, fp_v, fb_v = self.calculate_fp_fb()\n\n self.gti.starts = self.gti['START']\n self.gti.stops = self.gti['STOP']\n\n self.gtimask = []\n # for start, stop in zip(self.gti.starts, self.gti.stops):\n # self.gtimask = (self.data[\"time\"] > start) & (self.data[\"time\"] < stop)\n\n self.gtimask = (self.data[\"time\"] > self.gti.starts[0]) & (\n self.data[\"time\"] < self.gti.stops[-1])\n\n self.data[\"fp_u\"] = fp_u\n self.data[\"fb_u\"] = fb_u\n self.data[\"fp_v\"] = fp_v\n self.data[\"fb_v\"] = fb_v\n\n # Make individual status bit columns with legible names\n self.data[\"AV3 corrected for ringing\"] = self.data[\"status\"][:, 0]\n self.data[\"AU3 corrected for ringing\"] = self.data[\"status\"][:, 1]\n self.data[\"Event impacted by prior event (piled up)\"] = self.data[\"status\"][:, 2]\n # Bit 4 (Python 3) is spare\n self.data[\"Shifted event time\"] = self.data[\"status\"][:, 4]\n self.data[\"Event telemetered in NIL mode\"] = self.data[\"status\"][:, 5]\n self.data[\"V axis not triggered\"] = self.data[\"status\"][:, 6]\n self.data[\"U axis not triggered\"] = self.data[\"status\"][:, 7]\n self.data[\"V axis center blank event\"] = self.data[\"status\"][:, 8]\n self.data[\"U axis center blank event\"] = self.data[\"status\"][:, 9]\n self.data[\"V axis width exceeded\"] = self.data[\"status\"][:, 10]\n self.data[\"U axis width exceeded\"] = self.data[\"status\"][:, 11]\n self.data[\"Shield PMT active\"] = self.data[\"status\"][:, 12]\n # Bit 14 (Python 13) is hardware spare\n self.data[\"Upper level discriminator not exceeded\"] = self.data[\"status\"][:, 14]\n self.data[\"Lower level discriminator not exceeded\"] = self.data[\"status\"][:, 15]\n self.data[\"Event in bad region\"] = self.data[\"status\"][:, 16]\n self.data[\"Amp total on V or U = 0\"] = self.data[\"status\"][:, 17]\n self.data[\"Incorrect V center\"] = self.data[\"status\"][:, 18]\n self.data[\"Incorrect U center\"] = self.data[\"status\"][:, 19]\n self.data[\"PHA ratio test failed\"] = self.data[\"status\"][:, 20]\n self.data[\"Sum of 6 taps = 0\"] = self.data[\"status\"][:, 21]\n self.data[\"Grid ratio test failed\"] = self.data[\"status\"][:, 22]\n self.data[\"ADC sum on V or U = 0\"] = self.data[\"status\"][:, 23]\n self.data[\"PI exceeding 255\"] = self.data[\"status\"][:, 24]\n self.data[\"Event time tag is out of sequence\"] = self.data[\"status\"][:, 25]\n self.data[\"V amp flatness test failed\"] = self.data[\"status\"][:, 26]\n self.data[\"U amp flatness test failed\"] = self.data[\"status\"][:, 27]\n self.data[\"V amp saturation test failed\"] = self.data[\"status\"][:, 28]\n self.data[\"U amp saturation test failed\"] = self.data[\"status\"][:, 29]\n self.data[\"V hyperbolic test failed\"] = self.data[\"status\"][:, 30]\n self.data[\"U hyperbolic test failed\"] = self.data[\"status\"][:, 31]\n self.data[\"Hyperbola test passed\"] = np.logical_not(np.logical_or(\n self.data['U hyperbolic test failed'], self.data['V hyperbolic test failed']))\n self.data[\"Hyperbola test failed\"] = np.logical_or(\n self.data['U hyperbolic test failed'], self.data['V hyperbolic test failed'])\n\n self.obsid = self.header[\"OBS_ID\"]\n self.obs_date = self.header[\"DATE\"]\n self.target = self.header[\"OBJECT\"]\n self.detector = self.header[\"DETNAM\"]\n self.grating = self.header[\"GRATING\"]\n self.exptime = self.header[\"EXPOSURE\"]\n\n self.numevents = len(self.data[\"time\"])\n self.goodtimeevents = len(self.data[\"time\"][self.gtimask])\n self.badtimeevents = self.numevents - self.goodtimeevents\n\n self.hyperbola_passes = np.sum(np.logical_or(\n self.data['U hyperbolic test failed'], self.data['V hyperbolic test failed']))\n self.hyperbola_failures = np.sum(np.logical_not(np.logical_or(\n self.data['U hyperbolic test failed'], self.data['V hyperbolic test failed'])))\n\n if self.hyperbola_passes + self.hyperbola_failures != self.numevents:\n print(\"Warning: Number of Hyperbola Test Failures and Passes ({}) does not equal total number of events ({}).\".format(\n self.hyperbola_passes + self.hyperbola_failures, self.numevents))\n\n # Multidimensional columns don't grok with Pandas\n self.data.remove_column('status')\n self.data = self.data.to_pandas()\n\n def __str__(self):\n return \"HRC EVT1 object with {} events. Data is packaged as a Pandas Dataframe\".format(self.numevents)\n\n def calculate_fp_fb(self):\n '''\n Calculate the Fine Position (fp) and normalized central tap\n amplitude (fb) for the HRC U- and V- axes.\n\n Parameters\n ----------\n data : Astropy Table\n Table object made from an HRC evt1 event list. Must include the\n au1, au2, au3 and av1, av2, av3 columns.\n\n Returns\n -------\n fp_u, fb_u, fp_v, fb_v: float\n Calculated fine positions and normalized central tap amplitudes\n for the HRC U- and V- axes\n '''\n a_u = self.data[\"au1\"] # otherwise known as \"a1\"\n b_u = self.data[\"au2\"] # \"a2\"\n c_u = self.data[\"au3\"] # \"a3\"\n\n a_v = self.data[\"av1\"]\n b_v = self.data[\"av2\"]\n c_v = self.data[\"av3\"]\n\n with np.errstate(invalid='ignore'):\n # Do the U axis\n fp_u = ((c_u - a_u) / (a_u + b_u + c_u))\n fb_u = b_u / (a_u + b_u + c_u)\n\n # Do the V axis\n fp_v = ((c_v - a_v) / (a_v + b_v + c_v))\n fb_v = b_v / (a_v + b_v + c_v)\n\n return fp_u, fb_u, fp_v, fb_v\n\n def threshold(self, img, bins):\n nozero_img = img.copy()\n nozero_img[img == 0] = np.nan\n\n # This is a really stupid way to threshold\n median = np.nanmedian(nozero_img)\n thresh = median*5\n\n thresh_img = nozero_img\n thresh_img[thresh_img < thresh] = np.nan\n thresh_img[:int(bins[1]/2), :] = np.nan\n # thresh_img[:,int(bins[1]-5):] = np.nan\n return thresh_img\n\n\n def hyperscreen(self):\n '''\n Grant Tremblay's new algorithm. Screens events on a tap-by-tap basis.\n '''\n\n data = self.data\n\n #taprange = range(data['crsu'].min(), data['crsu'].max() + 1)\n taprange_u = range(data['crsu'].min() -1 , data['crsu'].max() + 1)\n taprange_v = range(data['crsv'].min() - 1, data['crsv'].max() + 1)\n\n bins = [200, 200] # number of bins\n\n # Instantiate these empty dictionaries to hold our results\n u_axis_survivals = {}\n v_axis_survivals = {}\n\n for tap in taprange_u:\n # Do the U axis\n tapmask_u = data[data['crsu'] == tap].index.values\n if len(tapmask_u) < 2:\n continue\n keep_u = np.isfinite(data['fb_u'][tapmask_u])\n\n hist_u, xbounds_u, ybounds_u = np.histogram2d(\n data['fb_u'][tapmask_u][keep_u], data['fp_u'][tapmask_u][keep_u], bins=bins)\n thresh_hist_u = self.threshold(hist_u, bins=bins)\n\n posx_u = np.digitize(data['fb_u'][tapmask_u], xbounds_u)\n posy_u = np.digitize(data['fp_u'][tapmask_u], ybounds_u)\n hist_mask_u = (posx_u > 0) & (posx_u <= bins[0]) & (\n posy_u > -1) & (posy_u <= bins[1])\n\n # Values of the histogram where the points are\n hhsub_u = thresh_hist_u[posx_u[hist_mask_u] -\n 1, posy_u[hist_mask_u] - 1]\n pass_fb_u = data['fb_u'][tapmask_u][hist_mask_u][np.isfinite(\n hhsub_u)]\n\n u_axis_survivals[\"U Axis Tap {:02d}\".format(\n tap)] = pass_fb_u.index.values\n\n for tap in taprange_v:\n # Now do the V axis:\n tapmask_v = data[data['crsv'] == tap].index.values\n if len(tapmask_v) < 2:\n continue\n keep_v = np.isfinite(data['fb_v'][tapmask_v])\n\n hist_v, xbounds_v, ybounds_v = np.histogram2d(\n data['fb_v'][tapmask_v][keep_v], data['fp_v'][tapmask_v][keep_v], bins=bins)\n thresh_hist_v = self.threshold(hist_v, bins=bins)\n\n posx_v = np.digitize(data['fb_v'][tapmask_v], xbounds_v)\n posy_v = np.digitize(data['fp_v'][tapmask_v], ybounds_v)\n hist_mask_v = (posx_v > 0) & (posx_v <= bins[0]) & (\n posy_v > -1) & (posy_v <= bins[1])\n\n # Values of the histogram where the points are\n hhsub_v = thresh_hist_v[posx_v[hist_mask_v] -\n 1, posy_v[hist_mask_v] - 1]\n pass_fb_v = data['fb_v'][tapmask_v][hist_mask_v][np.isfinite(\n hhsub_v)]\n\n v_axis_survivals[\"V Axis Tap {:02d}\".format(\n tap)] = pass_fb_v.index.values\n\n # Done looping over taps\n\n u_all_survivals = np.concatenate(\n [x for x in u_axis_survivals.values()])\n v_all_survivals = np.concatenate(\n [x for x in v_axis_survivals.values()])\n\n # If the event passes both U- and V-axis tests, it survives\n all_survivals = np.intersect1d(u_all_survivals, v_all_survivals)\n survival_mask = np.isin(self.data.index.values, all_survivals)\n failure_mask = np.logical_not(survival_mask)\n\n num_survivals = sum(survival_mask)\n num_failures = sum(failure_mask)\n\n percent_tapscreen_rejected = round(\n ((num_failures / self.numevents) * 100), 2)\n\n # Do a sanity check to look for lost events. Shouldn't be any.\n if num_survivals + num_failures != self.numevents:\n print(\"WARNING: Total Number of survivals and failures does \\\n not equal total events in the EVT1 file. Something is wrong!\")\n\n legacy_hyperbola_test_survivals = sum(\n self.data['Hyperbola test passed'])\n legacy_hyperbola_test_failures = sum(\n self.data['Hyperbola test failed'])\n percent_legacy_hyperbola_test_rejected = round(\n ((legacy_hyperbola_test_failures / self.goodtimeevents) * 100), 2)\n\n percent_improvement_over_legacy_test = round(\n (percent_tapscreen_rejected - percent_legacy_hyperbola_test_rejected), 2)\n\n hyperscreen_results_dict = {\"ObsID\": self.obsid,\n \"Target\": self.target,\n \"Exposure Time\": self.exptime,\n \"Detector\": self.detector,\n \"Number of Events\": self.numevents,\n \"Number of Good Time Events\": self.goodtimeevents,\n \"U Axis Survivals by Tap\": u_axis_survivals,\n \"V Axis Survivals by Tap\": v_axis_survivals,\n \"U Axis All Survivals\": u_all_survivals,\n \"V Axis All Survivals\": v_all_survivals,\n \"All Survivals (event indices)\": all_survivals,\n \"All Survivals (boolean mask)\": survival_mask,\n \"All Failures (boolean mask)\": failure_mask,\n \"Percent rejected by Tapscreen\": percent_tapscreen_rejected,\n \"Percent rejected by Hyperbola\": percent_legacy_hyperbola_test_rejected,\n \"Percent improvement\": percent_improvement_over_legacy_test\n }\n\n return hyperscreen_results_dict\n\n def hyperbola(self, fb, a, b, h):\n '''Given the normalized central tap amplitude, a, b, and h,\n return an array of length len(fb) that gives a hyperbola.'''\n hyperbola = b * np.sqrt(((fb - h)**2 / a**2) - 1)\n\n return hyperbola\n\n def legacy_hyperbola_test(self, tolerance=0.035):\n '''\n Apply the hyperbolic test.\n '''\n\n # Remind the user what tolerance they're using\n # print(\"{0: <25}| Using tolerance = {1}\".format(\" \", tolerance))\n\n # Set hyperbolic coefficients, depending on whether this is HRC-I or -S\n if self.detector == \"HRC-I\":\n a_u = 0.3110\n b_u = 0.3030\n h_u = 1.0580\n\n a_v = 0.3050\n b_v = 0.2730\n h_v = 1.1\n # print(\"{0: <25}| Using HRC-I hyperbolic coefficients: \".format(\" \"))\n # print(\"{0: <25}| Au={1}, Bu={2}, Hu={3}\".format(\" \", a_u, b_u, h_u))\n # print(\"{0: <25}| Av={1}, Bv={2}, Hv={3}\".format(\" \", a_v, b_v, h_v))\n\n if self.detector == \"HRC-S\":\n a_u = 0.2706\n b_u = 0.2620\n h_u = 1.0180\n\n a_v = 0.2706\n b_v = 0.2480\n h_v = 1.0710\n # print(\"{0: <25}| Using HRC-S hyperbolic coefficients: \".format(\" \"))\n # print(\"{0: <25}| Au={1}, Bu={2}, Hu={3}\".format(\" \", a_u, b_u, h_u))\n # print(\"{0: <25}| Av={1}, Bv={2}, Hv={3}\".format(\" \", a_v, b_v, h_v))\n\n # Set the tolerance boundary (\"width\" of the hyperbolic region)\n\n h_u_lowerbound = h_u * (1 + tolerance)\n h_u_upperbound = h_u * (1 - tolerance)\n\n h_v_lowerbound = h_v * (1 + tolerance)\n h_v_upperbound = h_v * (1 - tolerance)\n\n # Compute the Hyperbolae\n with np.errstate(invalid='ignore'):\n zone_u_fit = self.hyperbola(self.data[\"fb_u\"], a_u, b_u, h_u)\n zone_u_lowerbound = self.hyperbola(\n self.data[\"fb_u\"], a_u, b_u, h_u_lowerbound)\n zone_u_upperbound = self.hyperbola(\n self.data[\"fb_u\"], a_u, b_u, h_u_upperbound)\n\n zone_v_fit = self.hyperbola(self.data[\"fb_v\"], a_v, b_v, h_v)\n zone_v_lowerbound = self.hyperbola(\n self.data[\"fb_v\"], a_v, b_v, h_v_lowerbound)\n zone_v_upperbound = self.hyperbola(\n self.data[\"fb_v\"], a_v, b_v, h_v_upperbound)\n\n zone_u = [zone_u_lowerbound, zone_u_upperbound]\n zone_v = [zone_v_lowerbound, zone_v_upperbound]\n\n # Apply the masks\n # print(\"{0: <25}| Hyperbolic masks for U and V axes computed\".format(\"\"))\n\n with np.errstate(invalid='ignore'):\n # print(\"{0: <25}| Creating U-axis mask\".format(\"\"), end=\" |\")\n between_u = np.logical_not(np.logical_and(\n self.data[\"fp_u\"] < zone_u[1], self.data[\"fp_u\"] > -1 * zone_u[1]))\n not_beyond_u = np.logical_and(\n self.data[\"fp_u\"] < zone_u[0], self.data[\"fp_u\"] > -1 * zone_u[0])\n condition_u_final = np.logical_and(between_u, not_beyond_u)\n\n # print(\" Creating V-axis mask\")\n between_v = np.logical_not(np.logical_and(\n self.data[\"fp_v\"] < zone_v[1], self.data[\"fp_v\"] > -1 * zone_v[1]))\n not_beyond_v = np.logical_and(\n self.data[\"fp_v\"] < zone_v[0], self.data[\"fp_v\"] > -1 * zone_v[0])\n condition_v_final = np.logical_and(between_v, not_beyond_v)\n\n mask_u = condition_u_final\n mask_v = condition_v_final\n\n hyperzones = {\"zone_u_fit\": zone_u_fit,\n \"zone_u_lowerbound\": zone_u_lowerbound,\n \"zone_u_upperbound\": zone_u_upperbound,\n \"zone_v_fit\": zone_v_fit,\n \"zone_v_lowerbound\": zone_v_lowerbound,\n \"zone_v_upperbound\": zone_v_upperbound}\n\n hypermasks = {\"mask_u\": mask_u, \"mask_v\": mask_v}\n\n # print(\"{0: <25}| Hyperbolic masks created\".format(\"\"))\n # print(\"{0: <25}| \".format(\"\"))\n return hyperzones, hypermasks\n\n\n def boomerang(self, mask=None, show=True, plot_legacy_zone=True, title=None, cmap=None, savepath=None, create_subplot=False, ax=None, rasterized=True):\n\n # You can plot the image on axes of a subplot by passing\n # that axis to this function. Here are some switches to enable that.\n\n if create_subplot is False:\n self.fig, self.ax = plt.subplots(figsize=(12, 8))\n elif create_subplot is True:\n if ax is None:\n self.ax = plt.gca()\n else:\n self.ax = ax\n\n if cmap is None:\n cmap = 'plasma'\n\n if mask is not None:\n self.ax.scatter(self.data['fb_u'], self.data['fp_u'],\n c=self.data['sumamps'], cmap='bone', s=0.3, alpha=0.8, rasterized=rasterized)\n\n frame = self.ax.scatter(self.data['fb_u'][mask], self.data['fp_u'][mask],\n c=self.data['sumamps'][mask], cmap=cmap, s=0.5, rasterized=rasterized)\n\n else:\n frame = self.ax.scatter(self.data['fb_u'], self.data['fp_u'],\n c=self.data['sumamps'], cmap=cmap, s=0.5, rasterized=rasterized)\n\n if plot_legacy_zone is True:\n hyperzones, hypermasks = self.legacy_hyperbola_test(\n tolerance=0.035)\n self.ax.plot(self.data[\"fb_u\"], hyperzones[\"zone_u_lowerbound\"],\n 'o', markersize=0.3, color='black', alpha=0.8, rasterized=rasterized)\n self.ax.plot(self.data[\"fb_u\"], -1 * hyperzones[\"zone_u_lowerbound\"],\n 'o', markersize=0.3, color='black', alpha=0.8, rasterized=rasterized)\n\n self.ax.plot(self.data[\"fb_u\"], hyperzones[\"zone_u_upperbound\"],\n 'o', markersize=0.3, color='black', alpha=0.8, rasterized=rasterized)\n self.ax.plot(self.data[\"fb_u\"], -1 * hyperzones[\"zone_u_upperbound\"],\n 'o', markersize=0.3, color='black', alpha=0.8, rasterized=rasterized)\n\n self.ax.grid(False)\n\n if title is None:\n self.ax.set_title('{} | {} | ObsID {} | {} ksec | {} counts'.format(\n self.target, self.detector, self.obsid, round(self.exptime / 1000, 1), self.numevents))\n else:\n self.ax.set_title(title)\n\n self.ax.set_ylim(-1.1, 1.1)\n self.ax.set_xlim(-0.1, 1.1)\n\n self.ax.set_ylabel(r'Fine Position $f_p$ $(C-A)/(A + B + C)$')\n self.ax.set_xlabel(\n r'Normalized Central Tap Amplitude $f_b$ $B / (A+B+C)$')\n\n if create_subplot is False:\n self.cbar = plt.colorbar(frame, pad=-0.005)\n self.cbar.set_label(\"SUMAMPS\")\n\n if show is True:\n plt.show()\n\n if savepath is not None:\n plt.savefig(savepath, dpi=150, bbox_inches='tight')\n print('Saved boomerang figure to: {}'.format(savepath))\n\n\n def image(self, masked_x=None, masked_y=None, xlim=None, ylim=None, detcoords=False, title=None, cmap=None, show=True, savepath=None, create_subplot=False, ax=None):\n '''\n Create a quicklook image, in detector or sky coordinates, of the \n observation. The image will be binned to 400x400. \n '''\n\n # Create the 2D histogram\n nbins = (400, 400)\n\n if masked_x is not None and masked_y is not None:\n x = masked_x\n y = masked_y\n img_data, yedges, xedges = np.histogram2d(y, x, nbins)\n else:\n if detcoords is False:\n x = self.data['x'][self.gtimask]\n y = self.data['y'][self.gtimask]\n elif detcoords is True:\n x = self.data['detx'][self.gtimask]\n y = self.data['dety'][self.gtimask]\n img_data, yedges, xedges = np.histogram2d(y, x, nbins)\n\n extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]]\n\n # Create the Figure\n styleplots()\n\n # You can plot the image on axes of a subplot by passing\n # that axis to this function. Here are some switches to enable that.\n if create_subplot is False:\n self.fig, self.ax = plt.subplots()\n elif create_subplot is True:\n if ax is None:\n self.ax = plt.gca()\n else:\n self.ax = ax\n\n self.ax.grid(False)\n\n if cmap is None:\n cmap = 'viridis'\n\n self.ax.imshow(img_data, extent=extent, norm=LogNorm(),\n interpolation=None, cmap=cmap, origin='lower')\n\n if title is None:\n self.ax.set_title(\"ObsID {} | {} | {} | {:,} events\".format(\n self.obsid, self.target, self.detector, self.goodtimeevents))\n else:\n self.ax.set_title(\"{}\".format(title))\n if detcoords is False:\n self.ax.set_xlabel(\"Sky X\")\n self.ax.set_ylabel(\"Sky Y\")\n elif detcoords is True:\n self.ax.set_xlabel(\"Detector X\")\n self.ax.set_ylabel(\"Detector Y\")\n \n if xlim is not None:\n self.ax.set_xlim(xlim)\n if ylim is not None:\n self.ax.set_ylim(ylim)\n\n if show is True:\n plt.show(block=True)\n\n if savepath is not None:\n plt.savefig('{}'.format(savepath))\n print(\"Saved image to {}\".format(savepath))\n\n\ndef styleplots():\n\n mpl.rcParams['agg.path.chunksize'] = 10000\n\n # Make things pretty\n plt.style.use('ggplot')\n\n labelsizes = 10\n\n plt.rcParams['font.size'] = labelsizes\n plt.rcParams['axes.titlesize'] = 12\n plt.rcParams['axes.labelsize'] = labelsizes\n plt.rcParams['xtick.labelsize'] = labelsizes\n plt.rcParams['ytick.labelsize'] = labelsizes\n",
"_____no_output_____"
],
[
"from astropy.io import fits\nimport os",
"_____no_output_____"
],
[
"os.listdir('../tests/data/')",
"_____no_output_____"
],
[
"fitsfile = '../tests/data/hrcS_evt1_testfile.fits.gz'\nobs = HRCevt1(fitsfile)",
"_____no_output_____"
],
[
"obs.image(obs.data['detx'][obs.gtimask], obs.data['dety'][obs.gtimask], xlim=(26000, 41000), ylim=(31500, 34000))",
"_____no_output_____"
],
[
"results = obs.hyperscreen()",
"_____no_output_____"
],
[
"obs.image(obs.data['detx'][results['All Failures (boolean mask)']], obs.data['dety'][results['All Failures (boolean mask)']], xlim=(26000, 41000), ylim=(31500, 34000))",
"_____no_output_____"
],
[
"obs.data['crsv'].min()",
"_____no_output_____"
],
[
"obs.data['crsv'].max()",
"_____no_output_____"
],
[
"obs.data['crsv']",
"_____no_output_____"
],
[
"obs.numevents",
"_____no_output_____"
],
[
"from astropy.io import fits",
"_____no_output_____"
],
[
"header = fits.getheader(fitsfile, 1)",
"_____no_output_____"
],
[
"header",
"_____no_output_____"
],
[
"from hyperscreen import hypercore",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9dee80986eec1f155aa0cb04810f40729468be
| 21,775 |
ipynb
|
Jupyter Notebook
|
notebooks/7. Parameterizing with Continuous Variables.ipynb
|
sean578/pgmpy_notebook
|
102549516322f47bd955fa165c8ae1d6786bfa77
|
[
"MIT"
] | 326 |
2015-03-12T15:14:17.000Z
|
2022-03-24T15:02:44.000Z
|
notebooks/7. Parameterizing with Continuous Variables.ipynb
|
sean578/pgmpy_notebook
|
102549516322f47bd955fa165c8ae1d6786bfa77
|
[
"MIT"
] | 48 |
2015-03-06T09:42:17.000Z
|
2022-03-18T13:22:40.000Z
|
notebooks/7. Parameterizing with Continuous Variables.ipynb
|
sean578/pgmpy_notebook
|
102549516322f47bd955fa165c8ae1d6786bfa77
|
[
"MIT"
] | 215 |
2015-02-11T13:28:22.000Z
|
2022-01-17T08:58:17.000Z
| 26.171875 | 691 | 0.53341 |
[
[
[
"# Parameterizing with Continuous Variables",
"_____no_output_____"
]
],
[
[
"from IPython.display import Image",
"_____no_output_____"
]
],
[
[
"## Continuous Factors",
"_____no_output_____"
],
[
"1. Base Class for Continuous Factors\n2. Joint Gaussian Distributions\n3. Canonical Factors\n4. Linear Gaussian CPD",
"_____no_output_____"
],
[
"In many situations, some variables are best modeled as taking values in some continuous space. Examples include variables such as position, velocity, temperature, and pressure. Clearly, we cannot use a table representation in this case. \n\nNothing in the formulation of a Bayesian network requires that we restrict attention to discrete variables. The only requirement is that the CPD, P(X | Y1, Y2, ... Yn) represent, for every assignment of values y1 ∈ Val(Y1), y2 ∈ Val(Y2), .....yn ∈ val(Yn), a distribution over X. In this case, X might be continuous, in which case the CPD would need to represent distributions over a continuum of values; we might also have X’s parents continuous, so that the CPD would also need to represent a continuum of different probability distributions. There exists implicit representations for CPDs of this type, allowing us to apply all the network machinery for the continuous case as well.",
"_____no_output_____"
],
[
"### Base Class for Continuous Factors",
"_____no_output_____"
],
[
"This class will behave as a base class for the continuous factor representations. All the present and future factor classes will be derived from this base class. We need to specify the variable names and a pdf function to initialize this class.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nfrom scipy.special import beta\n\n# Two variable drichlet ditribution with alpha = (1,2)\ndef drichlet_pdf(x, y):\n return (np.power(x, 1)*np.power(y, 2))/beta(x, y)\n\nfrom pgmpy.factors.continuous import ContinuousFactor\ndrichlet_factor = ContinuousFactor(['x', 'y'], drichlet_pdf)",
"_____no_output_____"
],
[
"drichlet_factor.scope(), drichlet_factor.assignment(5,6)",
"_____no_output_____"
]
],
[
[
"This class supports methods like **marginalize, reduce, product and divide** just like what we have with discrete classes. One caveat is that when there are a number of variables involved, these methods prove to be inefficient and hence we resort to certain Gaussian or some other approximations which are discussed later.",
"_____no_output_____"
]
],
[
[
"def custom_pdf(x, y, z):\n return z*(np.power(x, 1)*np.power(y, 2))/beta(x, y)\n\ncustom_factor = ContinuousFactor(['x', 'y', 'z'], custom_pdf)",
"_____no_output_____"
],
[
"custom_factor.scope(), custom_factor.assignment(1, 2, 3)",
"_____no_output_____"
],
[
"custom_factor.reduce([('y', 2)])\ncustom_factor.scope(), custom_factor.assignment(1, 3)",
"_____no_output_____"
],
[
"from scipy.stats import multivariate_normal\n\nstd_normal_pdf = lambda *x: multivariate_normal.pdf(x, [0, 0], [[1, 0], [0, 1]])\nstd_normal = ContinuousFactor(['x1', 'x2'], std_normal_pdf)\nstd_normal.scope(), std_normal.assignment([1, 1])",
"_____no_output_____"
],
[
"std_normal.marginalize(['x2'])\nstd_normal.scope(), std_normal.assignment(1)",
"_____no_output_____"
],
[
"sn_pdf1 = lambda x: multivariate_normal.pdf([x], [0], [[1]])\nsn_pdf2 = lambda x1,x2: multivariate_normal.pdf([x1, x2], [0, 0], [[1, 0], [0, 1]])\nsn1 = ContinuousFactor(['x2'], sn_pdf1)\nsn2 = ContinuousFactor(['x1', 'x2'], sn_pdf2)\nsn3 = sn1 * sn2\nsn4 = sn2 / sn1\nsn3.assignment(0, 0), sn4.assignment(0, 0)",
"_____no_output_____"
]
],
[
[
"The ContinuousFactor class also has a method **discretize** that takes a pgmpy Discretizer class as input. It will output a list of discrete probability masses or a Factor or TabularCPD object depending upon the discretization method used. Although, we do not have inbuilt discretization algorithms for multivariate distributions for now, the users can always define their own Discretizer class by subclassing the pgmpy.BaseDiscretizer class.",
"_____no_output_____"
],
[
"### Joint Gaussian Distributions",
"_____no_output_____"
],
[
"In its most common representation, a multivariate Gaussian distribution over X1………..Xn is characterized by an n-dimensional mean vector μ, and a symmetric n x n covariance matrix Σ. The density function is most defined as -",
"_____no_output_____"
],
[
"$$\np(x) = \\dfrac{1}{(2\\pi)^{n/2}|Σ|^{1/2}} exp[-0.5*(x-μ)^TΣ^{-1}(x-μ)]\n$$\n",
"_____no_output_____"
],
[
"The class pgmpy.JointGaussianDistribution provides its representation. This is derived from the class pgmpy.ContinuousFactor. We need to specify the variable names, a mean vector and a covariance matrix for its inialization. It will automatically comute the pdf function given these parameters.",
"_____no_output_____"
]
],
[
[
"from pgmpy.factors.distributions import GaussianDistribution as JGD\ndis = JGD(['x1', 'x2', 'x3'], np.array([[1], [-3], [4]]),\n np.array([[4, 2, -2], [2, 5, -5], [-2, -5, 8]]))\ndis.variables",
"_____no_output_____"
],
[
"dis.mean",
"_____no_output_____"
],
[
"dis.covariance",
"_____no_output_____"
],
[
"dis.pdf([0,0,0])",
"_____no_output_____"
]
],
[
[
"This class overrides the basic operation methods **(marginalize, reduce, normalize, product and divide)** as these operations here are more efficient than the ones in its parent class. Most of these operation involve a matrix inversion which is O(n^3) with repect to the number of variables.",
"_____no_output_____"
]
],
[
[
"dis1 = JGD(['x1', 'x2', 'x3'], np.array([[1], [-3], [4]]),\n np.array([[4, 2, -2], [2, 5, -5], [-2, -5, 8]]))\ndis2 = JGD(['x3', 'x4'], [1, 2], [[2, 3], [5, 6]])\ndis3 = dis1 * dis2\ndis3.variables",
"_____no_output_____"
],
[
"dis3.mean",
"_____no_output_____"
],
[
"dis3.covariance",
"_____no_output_____"
]
],
[
[
"The others methods can also be used in a similar fashion.",
"_____no_output_____"
],
[
"### Canonical Factors",
"_____no_output_____"
],
[
"While the Joint Gaussian representation is useful for certain sampling algorithms, a closer look reveals that it can also not be used directly in the sum-product algorithms. Why? Because operations like product and reduce, as mentioned above involve matrix inversions at each step. \n\nSo, in order to compactly describe the intermediate factors in a Gaussian network without the costly matrix inversions at each step, a simple parametric representation is used known as the Canonical Factor. This representation is closed under the basic operations used in inference: factor product, factor division, factor reduction, and marginalization. Thus, we can define a set of simple data structures that allow the inference process to be performed. Moreover, the integration operation required by marginalization is always well defined, and it is guaranteed to produce a finite integral under certain conditions; when it is well defined, it has a simple analytical solution.\n\nA canonical form C (X; K,h, g) is defined as:",
"_____no_output_____"
],
[
"$$C(X; K,h,g) = exp(-0.5X^TKX + h^TX + g)$$",
"_____no_output_____"
],
[
"We can represent every Gaussian as a canonical form. Rewriting the joint Gaussian pdf we obtain,",
"_____no_output_____"
],
[
"N (μ; Σ) = C (K, h, g) where:",
"_____no_output_____"
],
[
"$$\nK = Σ^{-1}\n$$\n$$\nh = Σ^{-1}μ\n$$\n$$\ng = -0.5μ^TΣ^{-1}μ - log((2π)^{n/2}|Σ|^{1/2}\n$$",
"_____no_output_____"
],
[
"Similar to the JointGaussainDistribution class, the CanonicalFactor class is also derived from the ContinuousFactor class but with its own implementations of the methods required for the sum-product algorithms that are much more efficient than its parent class methods. Let us have a look at the API of a few methods in this class.",
"_____no_output_____"
]
],
[
[
"from pgmpy.factors.continuous import CanonicalDistribution\n\nphi1 = CanonicalDistribution(['x1', 'x2', 'x3'],\n np.array([[1, -1, 0], [-1, 4, -2], [0, -2, 4]]),\n np.array([[1], [4], [-1]]), -2)\nphi2 = CanonicalDistribution(['x1', 'x2'], np.array([[3, -2], [-2, 4]]),\n np.array([[5], [-1]]), 1)\n\nphi3 = phi1 * phi2\nphi3.variables",
"_____no_output_____"
],
[
"phi3.h",
"_____no_output_____"
],
[
"phi3.K",
"_____no_output_____"
],
[
"phi3.g",
"_____no_output_____"
]
],
[
[
"This class also has a method, to_joint_gaussian to convert the canoncial representation back into the joint gaussian distribution.",
"_____no_output_____"
]
],
[
[
"phi = CanonicalDistribution(['x1', 'x2'], np.array([[3, -2], [-2, 4]]),\n np.array([[5], [-1]]), 1)\njgd = phi.to_joint_gaussian()\njgd.variables",
"_____no_output_____"
],
[
"jgd.covariance",
"_____no_output_____"
],
[
"jgd.mean",
"_____no_output_____"
]
],
[
[
"### Linear Gaussian CPD",
"_____no_output_____"
],
[
"A linear gaussian conditional probability distribution is defined on a continuous variable. All the parents of this variable are also continuous. The mean of this variable, is linearly dependent on the mean of its parent variables and the variance is independent.\n\nFor example,\n$$\nP(Y ; x1, x2, x3) = N(β_1x_1 + β_2x_2 + β_3x_3 + β_0 ; σ^2)\n$$\n\nLet Y be a linear Gaussian of its parents X1,...,Xk:\n$$\np(Y | x) = N(β_0 + β^T x ; σ^2)\n$$\n\nThe distribution of Y is a normal distribution p(Y) where:\n$$\nμ_Y = β_0 + β^Tμ\n$$\n$$\n{{σ^2}_Y = σ^2 + β^TΣβ}\n$$\n\nThe joint distribution over {X, Y} is a normal distribution where:\n\n$$Cov[X_i; Y] = {\\sum_{j=1}^{k} β_jΣ_{i,j}}$$\n\nAssume that X1,...,Xk are jointly Gaussian with distribution N (μ; Σ). Then:\nFor its representation pgmpy has a class named LinearGaussianCPD in the module pgmpy.factors.continuous. To instantiate an object of this class, one needs to provide a variable name, the value of the beta_0 term, the variance, a list of the parent variable names and a list of the coefficient values of the linear equation (beta_vector), where the list of parent variable names and beta_vector list is optional and defaults to None.",
"_____no_output_____"
]
],
[
[
"# For P(Y| X1, X2, X3) = N(-2x1 + 3x2 + 7x3 + 0.2; 9.6)\nfrom pgmpy.factors.continuous import LinearGaussianCPD\ncpd = LinearGaussianCPD('Y', [0.2, -2, 3, 7], 9.6, ['X1', 'X2', 'X3'])\nprint(cpd)",
"P(Y | X1, X2, X3) = N(-2*X1 + 3*X2 + 7*X3 + 0.2; 9.6)\n"
]
],
[
[
"A Gaussian Bayesian is defined as a network all of whose variables are continuous, and where all of the CPDs are linear Gaussians. These networks are of particular interest as these are an alternate form of representaion of the Joint Gaussian distribution.\n\nThese networks are implemented as the LinearGaussianBayesianNetwork class in the module, pgmpy.models.continuous. This class is a subclass of the BayesianModel class in pgmpy.models and will inherit most of the methods from it. It will have a special method known as to_joint_gaussian that will return an equivalent JointGuassianDistribution object for the model.",
"_____no_output_____"
]
],
[
[
"from pgmpy.models import LinearGaussianBayesianNetwork\n\nmodel = LinearGaussianBayesianNetwork([('x1', 'x2'), ('x2', 'x3')])\ncpd1 = LinearGaussianCPD('x1', [1], 4)\ncpd2 = LinearGaussianCPD('x2', [-5, 0.5], 4, ['x1'])\ncpd3 = LinearGaussianCPD('x3', [4, -1], 3, ['x2'])\n# This is a hack due to a bug in pgmpy (LinearGaussianCPD\n# doesn't have `variables` attribute but `add_cpds` function\n# wants to check that...)\ncpd1.variables = [*cpd1.evidence, cpd1.variable]\ncpd2.variables = [*cpd2.evidence, cpd2.variable]\ncpd3.variables = [*cpd3.evidence, cpd3.variable]\nmodel.add_cpds(cpd1, cpd2, cpd3)\njgd = model.to_joint_gaussian()\njgd.variables",
"_____no_output_____"
],
[
"jgd.mean",
"_____no_output_____"
],
[
"jgd.covariance",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4a9defcfefcaba64a116ec59dd62154fe9545681
| 208,737 |
ipynb
|
Jupyter Notebook
|
examples/paper_examples/hyperopt-fashion-lgb.ipynb
|
jpjuvo/wideboost
|
ba2ec3bc62d70aecce3c2728197ac6abd011a434
|
[
"MIT"
] | 11 |
2020-07-22T18:40:03.000Z
|
2022-02-18T13:43:02.000Z
|
examples/paper_examples/hyperopt-fashion-lgb.ipynb
|
jpjuvo/wideboost
|
ba2ec3bc62d70aecce3c2728197ac6abd011a434
|
[
"MIT"
] | 3 |
2020-10-31T01:45:27.000Z
|
2021-04-02T07:37:21.000Z
|
examples/paper_examples/hyperopt-fashion-lgb.ipynb
|
jpjuvo/wideboost
|
ba2ec3bc62d70aecce3c2728197ac6abd011a434
|
[
"MIT"
] | 2 |
2020-09-15T15:13:36.000Z
|
2020-10-28T06:11:19.000Z
| 87.337657 | 366 | 0.401663 |
[
[
[
"import numpy as np\nimport lightgbm as lgb\nfrom wideboost.wrappers import wlgb\n\nimport tensorflow_datasets as tfds\nfrom matplotlib import pyplot as plt\n\n(ds_train, ds_test), ds_info = tfds.load(\n 'fashion_mnist',\n split=['train', 'test'],\n shuffle_files=True,\n as_supervised=True,\n with_info=True,\n)\n\nfor i in ds_train.batch(60000):\n a = i\n break\n \nfor i in ds_test.batch(60000):\n b = i\n break",
"_____no_output_____"
],
[
"xtrain = a[0].numpy().reshape([-1,28*28])\nytrain = a[1].numpy()\n\nxtest = b[0].numpy().reshape([-1,28*28])\nytest = b[1].numpy()\n\n#dtrain = xgb.DMatrix(xtrain,label=ytrain)\n#dtest = xgb.DMatrix(xtest,label=ytest)\n\ntrain_data = lgb.Dataset(xtrain, label=ytrain)\ntest_data = lgb.Dataset(xtest, label=ytest)",
"_____no_output_____"
],
[
"from hyperopt import fmin, tpe, hp, STATUS_OK, space_eval\n\nbest_val = 1.0\n\ndef objective(param):\n global best_val\n #watchlist = [(dtrain,'train'),(dtest,'test')]\n ed1_results = dict()\n print(param)\n param['num_leaves'] = round(param['num_leaves']+1)\n param['min_data_in_leaf'] = round(param['min_data_in_leaf'])\n wbst = lgb.train(param,\n train_data,\n num_boost_round=20,\n valid_sets=test_data,\n evals_result=ed1_results)\n output = min(ed1_results['valid_0']['multi_error'])\n \n if output < best_val:\n print(\"NEW BEST VALUE!\")\n best_val = output\n \n return {'loss': output, 'status': STATUS_OK }\n\nspc = {\n 'objective': hp.choice('objective',['multiclass']),\n 'metric':hp.choice('metric',['multi_error']),\n 'num_class':hp.choice('num_class',[10]),\n 'learning_rate': hp.loguniform('learning_rate', -7, 0),\n 'num_leaves' : hp.qloguniform('num_leaves', 0, 7, 1),\n 'feature_fraction': hp.uniform('feature_fraction', 0.5, 1),\n 'bagging_fraction': hp.uniform('bagging_fraction', 0.5, 1),\n 'min_data_in_leaf': hp.qloguniform('min_data_in_leaf', 0, 6, 1),\n 'min_sum_hessian_in_leaf': hp.loguniform('min_sum_hessian_in_leaf', -16, 5),\n 'lambda_l1': hp.choice('lambda_l1', [0, hp.loguniform('lambda_l1_positive', -16, 2)]),\n 'lambda_l2': hp.choice('lambda_l2', [0, hp.loguniform('lambda_l2_positive', -16, 2)])\n}\n\n\nbest = fmin(objective,\n space=spc,\n algo=tpe.suggest,\n max_evals=100)",
"{'bagging_fraction': 0.7251796751234882, 'feature_fraction': 0.5933005337725001, 'lambda_l1': 1.3372979090365175e-06, 'lambda_l2': 0, 'learning_rate': 0.533315059142865, 'metric': 'multi_error', 'min_data_in_leaf': 1.0, 'min_sum_hessian_in_leaf': 0.00026298877164697437, 'num_class': 10, 'num_leaves': 33.0, 'objective': 'multiclass'}\n[1]\tvalid_0's multi_error: 0.2029 \n[2]\tvalid_0's multi_error: 0.1716 \n[3]\tvalid_0's multi_error: 0.1623 \n[4]\tvalid_0's multi_error: 0.1593 \n[5]\tvalid_0's multi_error: 0.155 \n[6]\tvalid_0's multi_error: 0.152 \n[7]\tvalid_0's multi_error: 0.1489 \n[8]\tvalid_0's multi_error: 0.1466 \n[9]\tvalid_0's multi_error: 0.1444 \n[10]\tvalid_0's multi_error: 0.1431 \n[11]\tvalid_0's multi_error: 0.1416 \n[12]\tvalid_0's multi_error: 0.1377 \n[13]\tvalid_0's multi_error: 0.1379 \n[14]\tvalid_0's multi_error: 0.1354 \n[15]\tvalid_0's multi_error: 0.1354 \n[16]\tvalid_0's multi_error: 0.1334 \n[17]\tvalid_0's multi_error: 0.1318 \n[18]\tvalid_0's multi_error: 0.1309 \n[19]\tvalid_0's multi_error: 0.1297 \n[20]\tvalid_0's multi_error: 0.1292 \nNEW BEST VALUE! \n{'bagging_fraction': 0.9133916565984483, 'feature_fraction': 0.687387924389055, 'lambda_l1': 0, 'lambda_l2': 0, 'learning_rate': 0.0013938906142289271, 'metric': 'multi_error', 'min_data_in_leaf': 12.0, 'min_sum_hessian_in_leaf': 0.054411653079058195, 'num_class': 10, 'num_leaves': 187.0, 'objective': 'multiclass'}\n[1]\tvalid_0's multi_error: 0.1746 \n[2]\tvalid_0's multi_error: 0.1573 \n[3]\tvalid_0's multi_error: 0.1493 \n[4]\tvalid_0's multi_error: 0.1444 \n[5]\tvalid_0's multi_error: 0.1414 \n[6]\tvalid_0's multi_error: 0.1399 \n[7]\tvalid_0's multi_error: 0.1387 \n[8]\tvalid_0's multi_error: 0.1391 \n[9]\tvalid_0's multi_error: 0.1376 \n[10]\tvalid_0's multi_error: 0.1378 \n[11]\tvalid_0's multi_error: 0.1375 \n[12]\tvalid_0's multi_error: 0.1368 \n[13]\tvalid_0's multi_error: 0.1359 \n[14]\tvalid_0's multi_error: 0.1356 \n[15]\tvalid_0's multi_error: 0.1341 \n[16]\tvalid_0's multi_error: 0.1346 \n[17]\tvalid_0's multi_error: 0.1338 \n[18]\tvalid_0's multi_error: 0.1339 \n[19]\tvalid_0's multi_error: 0.1324 \n[20]\tvalid_0's multi_error: 0.1332 \n{'bagging_fraction': 0.8784490298751432, 'feature_fraction': 0.5754265828265155, 'lambda_l1': 0, 'lambda_l2': 0, 'learning_rate': 0.001544459969705883, 'metric': 'multi_error', 'min_data_in_leaf': 350.0, 'min_sum_hessian_in_leaf': 5.973742769148399e-06, 'num_class': 10, 'num_leaves': 9.0, 'objective': 'multiclass'}\n[1]\tvalid_0's multi_error: 0.24 \n[2]\tvalid_0's multi_error: 0.2234 \n[3]\tvalid_0's multi_error: 0.2158 \n[4]\tvalid_0's multi_error: 0.2095 \n[5]\tvalid_0's multi_error: 0.206 \n[6]\tvalid_0's multi_error: 0.2031 \n[7]\tvalid_0's multi_error: 0.2034 \n[8]\tvalid_0's multi_error: 0.2006 \n[9]\tvalid_0's multi_error: 0.1986 \n[10]\tvalid_0's multi_error: 0.1996 \n[11]\tvalid_0's multi_error: 0.1998 \n[12]\tvalid_0's multi_error: 0.1981 \n[13]\tvalid_0's multi_error: 0.1984 \n[14]\tvalid_0's multi_error: 0.1988 \n[15]\tvalid_0's multi_error: 0.2 \n[16]\tvalid_0's multi_error: 0.1992 \n[17]\tvalid_0's multi_error: 0.1977 \n[18]\tvalid_0's multi_error: 0.1989 \n[19]\tvalid_0's multi_error: 0.1984 \n[20]\tvalid_0's multi_error: 0.1973 \n{'bagging_fraction': 0.933326869280898, 'feature_fraction': 0.8920093644678171, 'lambda_l1': 3.1562199243279184e-07, 'lambda_l2': 0, 'learning_rate': 0.8471486601007923, 'metric': 'multi_error', 'min_data_in_leaf': 92.0, 'min_sum_hessian_in_leaf': 0.018226830691217735, 'num_class': 10, 'num_leaves': 395.0, 'objective': 'multiclass'}\n[1]\tvalid_0's multi_error: 0.1827 \n[2]\tvalid_0's multi_error: 0.166 \n[3]\tvalid_0's multi_error: 0.1538 \n[4]\tvalid_0's multi_error: 0.1448 \n[5]\tvalid_0's multi_error: 0.142 \n[6]\tvalid_0's multi_error: 0.1393 \n[7]\tvalid_0's multi_error: 0.1376 \n[8]\tvalid_0's multi_error: 0.1346 \n[9]\tvalid_0's multi_error: 0.1314 \n[10]\tvalid_0's multi_error: 0.13 \n[11]\tvalid_0's multi_error: 0.1285 \n[12]\tvalid_0's multi_error: 0.1258 \n[13]\tvalid_0's multi_error: 0.1264 \n[14]\tvalid_0's multi_error: 0.1254 \n[15]\tvalid_0's multi_error: 0.1231 \n[16]\tvalid_0's multi_error: 0.1209 \n[17]\tvalid_0's multi_error: 0.1211 \n[18]\tvalid_0's multi_error: 0.1187 \n[19]\tvalid_0's multi_error: 0.1205 \n[20]\tvalid_0's multi_error: 0.1192 \nNEW BEST VALUE! \n{'bagging_fraction': 0.9280201314348633, 'feature_fraction': 0.9516881941592565, 'lambda_l1': 0, 'lambda_l2': 0, 'learning_rate': 0.061443689698515325, 'metric': 'multi_error', 'min_data_in_leaf': 266.0, 'min_sum_hessian_in_leaf': 0.019968563796704895, 'num_class': 10, 'num_leaves': 3.0, 'objective': 'multiclass'}\n[1]\tvalid_0's multi_error: 0.324 \n[2]\tvalid_0's multi_error: 0.3025 \n[3]\tvalid_0's multi_error: 0.2738 \n[4]\tvalid_0's multi_error: 0.2664 \n[5]\tvalid_0's multi_error: 0.2588 \n[6]\tvalid_0's multi_error: 0.253 \n[7]\tvalid_0's multi_error: 0.2522 \n[8]\tvalid_0's multi_error: 0.2509 \n[9]\tvalid_0's multi_error: 0.249 \n[10]\tvalid_0's multi_error: 0.2475 \n[11]\tvalid_0's multi_error: 0.2426 \n[12]\tvalid_0's multi_error: 0.2398 \n[13]\tvalid_0's multi_error: 0.2382 \n"
],
[
"print(best_val)\nprint(space_eval(spc, best))",
"0.112\n{'bagging_fraction': 0.6169757023287703, 'feature_fraction': 0.8932740248835392, 'lambda_l1': 0.09422621802317309, 'lambda_l2': 0, 'learning_rate': 0.832326366852246, 'metric': 'multi_error', 'min_data_in_leaf': 51.0, 'min_sum_hessian_in_leaf': 8.927831603309363e-07, 'num_class': 10, 'num_leaves': 682.0, 'objective': 'multiclass'}\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a9dfc38d9b6acf114cd523b590b198d4599fa54
| 14,673 |
ipynb
|
Jupyter Notebook
|
intro-to-pytorch/Part 1 - Tensors in PyTorch (Exercises).ipynb
|
nduas77/deep-learning-v2-pytorch
|
0f78d219a9a4728a4e3c6d00f79e89606f682f82
|
[
"MIT"
] | 2 |
2018-12-30T13:55:06.000Z
|
2019-05-31T06:51:17.000Z
|
intro-to-pytorch/Part 1 - Tensors in PyTorch (Exercises).ipynb
|
nduas77/deep-learning-v2-pytorch
|
0f78d219a9a4728a4e3c6d00f79e89606f682f82
|
[
"MIT"
] | null | null | null |
intro-to-pytorch/Part 1 - Tensors in PyTorch (Exercises).ipynb
|
nduas77/deep-learning-v2-pytorch
|
0f78d219a9a4728a4e3c6d00f79e89606f682f82
|
[
"MIT"
] | null | null | null | 42.407514 | 674 | 0.624617 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4a9e0cc0b381c7fafe0d699a40cc827c1d127e9a
| 50,527 |
ipynb
|
Jupyter Notebook
|
site/ja/tutorials/load_data/text.ipynb
|
phoenix-fork-tensorflow/docs-l10n
|
2287738c22e3e67177555e8a41a0904edfcf1544
|
[
"Apache-2.0"
] | 491 |
2020-01-27T19:05:32.000Z
|
2022-03-31T08:50:44.000Z
|
site/ja/tutorials/load_data/text.ipynb
|
phoenix-fork-tensorflow/docs-l10n
|
2287738c22e3e67177555e8a41a0904edfcf1544
|
[
"Apache-2.0"
] | 511 |
2020-01-27T22:40:05.000Z
|
2022-03-21T08:40:55.000Z
|
site/ja/tutorials/load_data/text.ipynb
|
phoenix-fork-tensorflow/docs-l10n
|
2287738c22e3e67177555e8a41a0904edfcf1544
|
[
"Apache-2.0"
] | 627 |
2020-01-27T21:49:52.000Z
|
2022-03-28T18:11:50.000Z
| 28.988526 | 408 | 0.526075 |
[
[
[
"##### Copyright 2018 The TensorFlow Authors.\n",
"_____no_output_____"
]
],
[
[
"#@title Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# https://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.",
"_____no_output_____"
]
],
[
[
"# tf.data を使ったテキストの読み込み",
"_____no_output_____"
],
[
"<table class=\"tfo-notebook-buttons\" align=\"left\">\n <td><a target=\"_blank\" href=\"https://www.tensorflow.org/tutorials/load_data/text\"><img src=\"https://www.tensorflow.org/images/tf_logo_32px.png\">TensorFlow.org で表示</a></td>\n <td> <a target=\"_blank\" href=\"https://colab.research.google.com/github/tensorflow/docs-l10n/blob/master/site/ja/tutorials/load_data/text.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\">Google Colab で実行</a> </td>\n <td> <a target=\"_blank\" href=\"https://github.com/tensorflow/docs-l10n/blob/master/site/ja/tutorials/load_data/text.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\">GitHub でソースを表示</a> </td>\n <td> <a href=\"https://storage.googleapis.com/tensorflow_docs/docs-l10n/site/ja/tutorials/load_data/text.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\">ノートブックをダウンロード</a> </td>\n</table>",
"_____no_output_____"
],
[
"このチュートリアルでは、テキストを読み込んで前処理する 2 つの方法を紹介します。\n\n- まず、Keras ユーティリティとレイヤーを使用します。 TensorFlow を初めて使用する場合は、これらから始める必要があります。\n\n- このチュートリアルでは、`tf.data.TextLineDataset` を使ってテキストファイルからサンプルを読み込む方法を例示します。`TextLineDataset` は、テキストファイルからデータセットを作成するために設計されています。この中では、元のテキストファイルの一行一行がサンプルです。これは、(たとえば、詩やエラーログのような) 基本的に行ベースのテキストデータを扱うのに便利でしょう。",
"_____no_output_____"
]
],
[
[
"# Be sure you're using the stable versions of both tf and tf-text, for binary compatibility.\n!pip uninstall -y tensorflow tf-nightly keras\n\n!pip install -q -U tf-nightly\n!pip install -q -U tensorflow-text-nightly",
"_____no_output_____"
],
[
"import collections\nimport pathlib\nimport re\nimport string\n\nimport tensorflow as tf\n\nfrom tensorflow.keras import layers\nfrom tensorflow.keras import losses\nfrom tensorflow.keras import preprocessing\nfrom tensorflow.keras import utils\nfrom tensorflow.keras.layers.experimental.preprocessing import TextVectorization\n\nimport tensorflow_datasets as tfds\nimport tensorflow_text as tf_text",
"_____no_output_____"
]
],
[
[
"## 例 1: StackOverflow の質問のタグを予測する\n\n最初の例として、StackOverflow からプログラミングの質問のデータセットをダウンロードします。それぞれの質問 (「ディクショナリを値で並べ替えるにはどうすればよいですか?」) は、1 つのタグ (`Python`、`CSharp`、`JavaScript`、または`Java`) でラベルされています。このタスクでは、質問のタグを予測するモデルを開発します。これは、マルチクラス分類の例です。マルチクラス分類は、重要で広く適用できる機械学習の問題です。",
"_____no_output_____"
],
[
"### データセットをダウンロードして調査する\n\n次に、データセットをダウンロードして、ディレクトリ構造を調べます。",
"_____no_output_____"
]
],
[
[
"data_url = 'https://storage.googleapis.com/download.tensorflow.org/data/stack_overflow_16k.tar.gz'\ndataset_dir = utils.get_file(\n origin=data_url,\n untar=True,\n cache_dir='stack_overflow',\n cache_subdir='')\n\ndataset_dir = pathlib.Path(dataset_dir).parent",
"_____no_output_____"
],
[
"list(dataset_dir.iterdir())",
"_____no_output_____"
],
[
"train_dir = dataset_dir/'train'\nlist(train_dir.iterdir())",
"_____no_output_____"
]
],
[
[
"`train/csharp`、`train/java`, `train/python` および `train/javascript` ディレクトリには、多くのテキストファイルが含まれています。それぞれが Stack Overflow の質問です。ファイルを出力してデータを調べます。",
"_____no_output_____"
]
],
[
[
"sample_file = train_dir/'python/1755.txt'\nwith open(sample_file) as f:\n print(f.read())",
"_____no_output_____"
]
],
[
[
"### データセットを読み込む\n\n次に、データをディスクから読み込み、トレーニングに適した形式に準備します。これを行うには、[text_dataset_from_directory](https://www.tensorflow.org/api_docs/python/tf/keras/preprocessing/text_dataset_from_directory) ユーティリティを使用して、ラベル付きの `tf.data.Dataset` を作成します。これは、入力パイプラインを構築するための強力なツールのコレクションです。\n\n`preprocessing.text_dataset_from_directory` は、次のようなディレクトリ構造を想定しています。\n\n```\ntrain/\n...csharp/\n......1.txt\n......2.txt\n...java/\n......1.txt\n......2.txt\n...javascript/\n......1.txt\n......2.txt\n...python/\n......1.txt\n......2.txt\n```",
"_____no_output_____"
],
[
"機械学習実験を実行するときは、データセットを[トレーニング](https://developers.google.com/machine-learning/glossary#training_set)、[検証](https://developers.google.com/machine-learning/glossary#validation_set)、および、[テスト](https://developers.google.com/machine-learning/glossary#test-set)の 3 つに分割することをお勧めします。Stack Overflow データセットはすでにトレーニングとテストに分割されていますが、検証セットがありません。以下の `validation_split` 引数を使用して、トレーニングデータの 80:20 分割を使用して検証セットを作成します。",
"_____no_output_____"
]
],
[
[
"batch_size = 32\nseed = 42\n\nraw_train_ds = preprocessing.text_dataset_from_directory(\n train_dir,\n batch_size=batch_size,\n validation_split=0.2,\n subset='training',\n seed=seed)",
"_____no_output_____"
]
],
[
[
"上記のように、トレーニングフォルダには 8,000 の例があり、そのうち 80% (6,400 件) をトレーニングに使用します。この後で見ていきますが、`tf.data.Dataset` を直接 `model.fit` に渡すことでモデルをトレーニングできます。まず、データセットを繰り返し処理し、いくつかの例を出力します。\n\n注意: 分類問題の難易度を上げるために、データセットの作成者は、プログラミングの質問で、*Python*、*CSharp*、*JavaScript*、*Java* という単語を *blank* に置き換えました。",
"_____no_output_____"
]
],
[
[
"for text_batch, label_batch in raw_train_ds.take(1):\n for i in range(10):\n print(\"Question: \", text_batch.numpy()[i])\n print(\"Label:\", label_batch.numpy()[i])",
"_____no_output_____"
]
],
[
[
"ラベルは、`0`、`1`、`2` または `3` です。これらのどれがどの文字列ラベルに対応するかを確認するには、データセットの `class_names` プロパティを確認します。\n",
"_____no_output_____"
]
],
[
[
"for i, label in enumerate(raw_train_ds.class_names):\n print(\"Label\", i, \"corresponds to\", label)",
"_____no_output_____"
]
],
[
[
"次に、検証およびテスト用データセットを作成します。トレーニング用セットの残りの 1,600 件のレビューを検証に使用します。\n\n注意: `validation_split` および `subset` 引数を使用する場合は、必ずランダムシードを指定するか、`shuffle=False`を渡して、検証とトレーニング分割に重複がないようにします。",
"_____no_output_____"
]
],
[
[
"raw_val_ds = preprocessing.text_dataset_from_directory(\n train_dir,\n batch_size=batch_size,\n validation_split=0.2,\n subset='validation',\n seed=seed)",
"_____no_output_____"
],
[
"test_dir = dataset_dir/'test'\nraw_test_ds = preprocessing.text_dataset_from_directory(\n test_dir, batch_size=batch_size)",
"_____no_output_____"
]
],
[
[
"### トレーニング用データセットを準備する",
"_____no_output_____"
],
[
"注意: このセクションで使用される前処理 API は、TensorFlow 2.3 では実験的なものであり、変更される可能性があります。",
"_____no_output_____"
],
[
"次に、`preprocessing.TextVectorization` レイヤーを使用して、データを標準化、トークン化、およびベクトル化します。\n\n- 標準化とは、テキストを前処理することを指します。通常、句読点や HTML 要素を削除して、データセットを簡素化します。\n\n- トークン化とは、文字列をトークンに分割することです(たとえば、空白で分割することにより、文を個々の単語に分割します)。\n\n- ベクトル化とは、トークンを数値に変換して、ニューラルネットワークに入力できるようにすることです。\n\nこれらのタスクはすべて、このレイヤーで実行できます。これらの詳細については、[API doc](https://www.tensorflow.org/api_docs/python/tf/keras/layers/experimental/preprocessing/TextVectorization) をご覧ください。\n\n- デフォルトの標準化では、テキストが小文字に変換され、句読点が削除されます。\n\n- デフォルトのトークナイザーは空白で分割されます。\n\n- デフォルトのベクトル化モードは `int` です。これは整数インデックスを出力します(トークンごとに1つ)。このモードは、語順を考慮したモデルを構築するために使用できます。`binary` などの他のモードを使用して、bag-of-word モデルを構築することもできます。\n\nこれらについてさらに学ぶために、2 つのモードを構築します。まず、`binary` モデルを使用して、bag-of-words モデルを構築します。次に、1D ConvNet で `int` モードを使用します。",
"_____no_output_____"
]
],
[
[
"VOCAB_SIZE = 10000\n\nbinary_vectorize_layer = TextVectorization(\n max_tokens=VOCAB_SIZE,\n output_mode='binary')",
"_____no_output_____"
]
],
[
[
"`int` の場合、最大語彙サイズに加えて、明示的な最大シーケンス長を設定する必要があります。これにより、レイヤーはシーケンスを正確に sequence_length 値にパディングまたは切り捨てます。",
"_____no_output_____"
]
],
[
[
"MAX_SEQUENCE_LENGTH = 250\n\nint_vectorize_layer = TextVectorization(\n max_tokens=VOCAB_SIZE,\n output_mode='int',\n output_sequence_length=MAX_SEQUENCE_LENGTH)",
"_____no_output_____"
]
],
[
[
"次に、`adapt` を呼び出して、前処理レイヤーの状態をデータセットに適合させます。これにより、モデルは文字列から整数へのインデックスを作成します。\n\n注意: Adapt を呼び出すときは、トレーニング用データのみを使用することが重要です (テスト用セットを使用すると情報が漏洩します)。",
"_____no_output_____"
]
],
[
[
"# Make a text-only dataset (without labels), then call adapt\ntrain_text = raw_train_ds.map(lambda text, labels: text)\nbinary_vectorize_layer.adapt(train_text)\nint_vectorize_layer.adapt(train_text)",
"_____no_output_____"
]
],
[
[
"これらのレイヤーを使用してデータを前処理した結果を確認してください。",
"_____no_output_____"
]
],
[
[
"def binary_vectorize_text(text, label):\n text = tf.expand_dims(text, -1)\n return binary_vectorize_layer(text), label",
"_____no_output_____"
],
[
"def int_vectorize_text(text, label):\n text = tf.expand_dims(text, -1)\n return int_vectorize_layer(text), label",
"_____no_output_____"
],
[
"# Retrieve a batch (of 32 reviews and labels) from the dataset\ntext_batch, label_batch = next(iter(raw_train_ds))\nfirst_question, first_label = text_batch[0], label_batch[0]\nprint(\"Question\", first_question)\nprint(\"Label\", first_label)",
"_____no_output_____"
],
[
"print(\"'binary' vectorized question:\", \n binary_vectorize_text(first_question, first_label)[0])",
"_____no_output_____"
],
[
"print(\"'int' vectorized question:\",\n int_vectorize_text(first_question, first_label)[0])",
"_____no_output_____"
]
],
[
[
"上記のように、`binary` モードは、入力に少なくとも 1 回存在するトークンを示す配列を返しますが、`int` モードは、各トークンを整数に置き換えて、順序を維持します。レイヤーで `.get_vocabulary()` を呼び出すことにより、各整数が対応するトークン (文字列) を検索できます",
"_____no_output_____"
]
],
[
[
"print(\"1289 ---> \", int_vectorize_layer.get_vocabulary()[1289])\nprint(\"313 ---> \", int_vectorize_layer.get_vocabulary()[313])\nprint(\"Vocabulary size: {}\".format(len(int_vectorize_layer.get_vocabulary())))",
"_____no_output_____"
]
],
[
[
"モデルをトレーニングする準備がほぼ整いました。最後の前処理ステップとして、トレーニング、検証、およびデータセットのテストのために前に作成した `TextVectorization` レイヤーを適用します。",
"_____no_output_____"
]
],
[
[
"binary_train_ds = raw_train_ds.map(binary_vectorize_text)\nbinary_val_ds = raw_val_ds.map(binary_vectorize_text)\nbinary_test_ds = raw_test_ds.map(binary_vectorize_text)\n\nint_train_ds = raw_train_ds.map(int_vectorize_text)\nint_val_ds = raw_val_ds.map(int_vectorize_text)\nint_test_ds = raw_test_ds.map(int_vectorize_text)",
"_____no_output_____"
]
],
[
[
"### パフォーマンスのためにデータセットを構成する\n\n以下は、データを読み込むときに I/O がブロックされないようにするために使用する必要がある 2 つの重要な方法です。\n\n`.cache()` はデータをディスクから読み込んだ後、データをメモリに保持します。これにより、モデルのトレーニング中にデータセットがボトルネックになることを回避できます。データセットが大きすぎてメモリに収まらない場合は、この方法を使用して、パフォーマンスの高いオンディスクキャッシュを作成することもできます。これは、多くの小さなファイルを読み込むより効率的です。\n\n`.prefetch()` はトレーニング中にデータの前処理とモデルの実行をオーバーラップさせます。\n\n以上の 2 つの方法とデータをディスクにキャッシュする方法についての詳細は、[データパフォーマンスガイド](https://www.tensorflow.org/guide/data_performance)を参照してください。",
"_____no_output_____"
]
],
[
[
"AUTOTUNE = tf.data.AUTOTUNE\n\ndef configure_dataset(dataset):\n return dataset.cache().prefetch(buffer_size=AUTOTUNE)",
"_____no_output_____"
],
[
"binary_train_ds = configure_dataset(binary_train_ds)\nbinary_val_ds = configure_dataset(binary_val_ds)\nbinary_test_ds = configure_dataset(binary_test_ds)\n\nint_train_ds = configure_dataset(int_train_ds)\nint_val_ds = configure_dataset(int_val_ds)\nint_test_ds = configure_dataset(int_test_ds)",
"_____no_output_____"
]
],
[
[
"### モデルをトレーニングする\n\nニューラルネットワークを作成します。`binary` のベクトル化されたデータの場合、単純な bag-of-words 線形モデルをトレーニングします。",
"_____no_output_____"
]
],
[
[
"binary_model = tf.keras.Sequential([layers.Dense(4)])\nbinary_model.compile(\n loss=losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer='adam',\n metrics=['accuracy'])\nhistory = binary_model.fit(\n binary_train_ds, validation_data=binary_val_ds, epochs=10)",
"_____no_output_____"
]
],
[
[
"次に、`int` ベクトル化レイヤーを使用して、1D ConvNet を構築します。",
"_____no_output_____"
]
],
[
[
"def create_model(vocab_size, num_labels):\n model = tf.keras.Sequential([\n layers.Embedding(vocab_size, 64, mask_zero=True),\n layers.Conv1D(64, 5, padding=\"valid\", activation=\"relu\", strides=2),\n layers.GlobalMaxPooling1D(),\n layers.Dense(num_labels)\n ])\n return model",
"_____no_output_____"
],
[
"# vocab_size is VOCAB_SIZE + 1 since 0 is used additionally for padding.\nint_model = create_model(vocab_size=VOCAB_SIZE + 1, num_labels=4)\nint_model.compile(\n loss=losses.SparseCategoricalCrossentropy(from_logits=True),\n optimizer='adam',\n metrics=['accuracy'])\nhistory = int_model.fit(int_train_ds, validation_data=int_val_ds, epochs=5)",
"_____no_output_____"
]
],
[
[
"2 つのモデルを比較します。",
"_____no_output_____"
]
],
[
[
"print(\"Linear model on binary vectorized data:\")\nprint(binary_model.summary())",
"_____no_output_____"
],
[
"print(\"ConvNet model on int vectorized data:\")\nprint(int_model.summary())",
"_____no_output_____"
]
],
[
[
"テストデータで両方のモデルを評価します。",
"_____no_output_____"
]
],
[
[
"binary_loss, binary_accuracy = binary_model.evaluate(binary_test_ds)\nint_loss, int_accuracy = int_model.evaluate(int_test_ds)\n\nprint(\"Binary model accuracy: {:2.2%}\".format(binary_accuracy))\nprint(\"Int model accuracy: {:2.2%}\".format(int_accuracy))",
"_____no_output_____"
]
],
[
[
"注意: このサンプルデータセットは、かなり単純な分類問題を表しています。より複雑なデータセットと問題は、前処理戦略とモデルアーキテクチャに微妙ながら重要な違いをもたらします。さまざまなアプローチを比較するために、さまざまなハイパーパラメータとエポックを試してみてください。",
"_____no_output_____"
],
[
"### モデルをエクスポートする\n\n上記のコードでは、モデルにテキストをフィードする前に、`TextVectorization` レイヤーをデータセットに適用しました。モデルで生の文字列を処理できるようにする場合 (たとえば、展開を簡素化するため)、モデル内に `TextVectorization` レイヤーを含めることができます。これを行うには、トレーニングしたばかりの重みを使用して新しいモデルを作成します。",
"_____no_output_____"
]
],
[
[
"export_model = tf.keras.Sequential(\n [binary_vectorize_layer, binary_model,\n layers.Activation('sigmoid')])\n\nexport_model.compile(\n loss=losses.SparseCategoricalCrossentropy(from_logits=False),\n optimizer='adam',\n metrics=['accuracy'])\n\n# Test it with `raw_test_ds`, which yields raw strings\nloss, accuracy = export_model.evaluate(raw_test_ds)\nprint(\"Accuracy: {:2.2%}\".format(binary_accuracy))",
"_____no_output_____"
]
],
[
[
"これで、モデルは生の文字列を入力として受け取り、`model.predict` を使用して各ラベルのスコアを予測できます。最大スコアのラベルを見つける関数を定義します。",
"_____no_output_____"
]
],
[
[
"def get_string_labels(predicted_scores_batch):\n predicted_int_labels = tf.argmax(predicted_scores_batch, axis=1)\n predicted_labels = tf.gather(raw_train_ds.class_names, predicted_int_labels)\n return predicted_labels",
"_____no_output_____"
]
],
[
[
"### 新しいデータで推論を実行する",
"_____no_output_____"
]
],
[
[
"inputs = [\n \"how do I extract keys from a dict into a list?\", # python\n \"debug public static void main(string[] args) {...}\", # java\n]\npredicted_scores = export_model.predict(inputs)\npredicted_labels = get_string_labels(predicted_scores)\nfor input, label in zip(inputs, predicted_labels):\n print(\"Question: \", input)\n print(\"Predicted label: \", label.numpy())",
"_____no_output_____"
]
],
[
[
"モデル内にテキスト前処理ロジックを含めると、モデルを本番環境にエクスポートして展開を簡素化し、[トレーニング/テストスキュー](https://developers.google.com/machine-learning/guides/rules-of-ml#training-serving_skew)の可能性を減らすことができます。\n\n`TextVectorization` レイヤーを適用する場所を選択する際に性能の違いに留意する必要があります。モデルの外部で使用すると、GPU でトレーニングするときに非同期 CPU 処理とデータのバッファリングを行うことができます。したがって、GPU でモデルをトレーニングしている場合は、モデルの開発中に最高のパフォーマンスを得るためにこのオプションを使用し、デプロイの準備ができたらモデル内に TextVectorization レイヤーを含めるように切り替えることをお勧めします。\n\nモデルの保存の詳細については、この[チュートリアル](https://www.tensorflow.org/tutorials/keras/save_and_load)にアクセスしてください。",
"_____no_output_____"
],
[
"## テキストをデータセットに読み込む\n",
"_____no_output_____"
],
[
"以下に、`tf.data.TextLineDataset` を使用してテキストファイルから例を読み込み、`tf.text` を使用してデータを前処理する例を示します。この例では、ホーマーのイーリアスの 3 つの異なる英語翻訳を使用し、与えられた 1 行のテキストから翻訳者を識別するようにモデルをトレーニングします。",
"_____no_output_____"
],
[
"### データセットをダウンロードして調査する\n\n3 つのテキストの翻訳者は次のとおりです。\n\n- [ウィリアム・クーパー](https://en.wikipedia.org/wiki/William_Cowper) — [テキスト](https://storage.googleapis.com/download.tensorflow.org/data/illiad/cowper.txt)\n\n- [エドワード、ダービー伯爵](https://en.wikipedia.org/wiki/Edward_Smith-Stanley,_14th_Earl_of_Derby) — [テキスト](https://storage.googleapis.com/download.tensorflow.org/data/illiad/derby.txt)\n\n- [サミュエル・バトラー](https://en.wikipedia.org/wiki/Samuel_Butler_%28novelist%29) — [テキスト](https://storage.googleapis.com/download.tensorflow.org/data/illiad/butler.txt)\n\nこのチュートリアルで使われているテキストファイルは、ヘッダ、フッタ、行番号、章のタイトルの削除など、いくつかの典型的な前処理が行われています。前処理後のファイルをローカルにダウンロードします。",
"_____no_output_____"
]
],
[
[
"DIRECTORY_URL = 'https://storage.googleapis.com/download.tensorflow.org/data/illiad/'\nFILE_NAMES = ['cowper.txt', 'derby.txt', 'butler.txt']\n\nfor name in FILE_NAMES:\n text_dir = utils.get_file(name, origin=DIRECTORY_URL + name)\n\nparent_dir = pathlib.Path(text_dir).parent\nlist(parent_dir.iterdir())",
"_____no_output_____"
]
],
[
[
"### データセットを読み込む\n\n`TextLineDataset` を使用します。これは、テキストファイルから `tf.data.Dataset` を作成するように設計されています。テキストファイルでは各例は、元のファイルのテキスト行ですが、`text_dataset_from_directory` は、ファイルのすべての内容を 1 つの例として扱います。`TextLineDataset` は、主に行があるテキストデータ(詩やエラーログなど)に役立ちます。\n\nこれらのファイルを繰り返し処理し、各ファイルを独自のデータセットに読み込みます。各例には個別にラベルを付ける必要があるため、`tf.data.Dataset.map` を使用して、それぞれにラベラー関数を適用します。これにより、データセット内のすべての例が繰り返され、 (`example, label`) ペアが返されます。",
"_____no_output_____"
]
],
[
[
"def labeler(example, index):\n return example, tf.cast(index, tf.int64)",
"_____no_output_____"
],
[
"labeled_data_sets = []\n\nfor i, file_name in enumerate(FILE_NAMES):\n lines_dataset = tf.data.TextLineDataset(str(parent_dir/file_name))\n labeled_dataset = lines_dataset.map(lambda ex: labeler(ex, i))\n labeled_data_sets.append(labeled_dataset)",
"_____no_output_____"
]
],
[
[
"次に、これらのラベル付きデータセットを 1 つのデータセットに結合し、シャッフルします。\n",
"_____no_output_____"
]
],
[
[
"BUFFER_SIZE = 50000\nBATCH_SIZE = 64\nTAKE_SIZE = 5000",
"_____no_output_____"
],
[
"all_labeled_data = labeled_data_sets[0]\nfor labeled_dataset in labeled_data_sets[1:]:\n all_labeled_data = all_labeled_data.concatenate(labeled_dataset)\n \nall_labeled_data = all_labeled_data.shuffle(\n BUFFER_SIZE, reshuffle_each_iteration=False)",
"_____no_output_____"
]
],
[
[
"前述の手順でいくつかの例を出力します。データセットはまだバッチ処理されていないため、`all_labeled_data` の各エントリは 1 つのデータポイントに対応します。",
"_____no_output_____"
]
],
[
[
"for text, label in all_labeled_data.take(10):\n print(\"Sentence: \", text.numpy())\n print(\"Label:\", label.numpy())",
"_____no_output_____"
]
],
[
[
"### トレーニング用データセットを準備する\n\nKeras `TextVectorization` レイヤーを使用してテキストデータセットを前処理する代わりに、[`tf.text` API](https://www.tensorflow.org/tutorials/tensorflow_text/intro) を使用してデータを標準化およびトークン化し、語彙を作成し、`StaticVocabularyTable` を使用してトークンを整数にマッピングし、モデルにフィードします。\n\ntf.text はさまざまなトークナイザーを提供しますが、`UnicodeScriptTokenizer` を使用してデータセットをトークン化します。テキストを小文字に変換してトークン化する関数を定義します。`tf.data.Dataset.map` を使用して、トークン化をデータセットに適用します。",
"_____no_output_____"
]
],
[
[
"tokenizer = tf_text.UnicodeScriptTokenizer()",
"_____no_output_____"
],
[
"def tokenize(text, unused_label):\n lower_case = tf_text.case_fold_utf8(text)\n return tokenizer.tokenize(lower_case)",
"_____no_output_____"
],
[
"tokenized_ds = all_labeled_data.map(tokenize)",
"_____no_output_____"
]
],
[
[
"データセットを反復処理して、トークン化されたいくつかの例を出力できます。\n",
"_____no_output_____"
]
],
[
[
"for text_batch in tokenized_ds.take(5):\n print(\"Tokens: \", text_batch.numpy())",
"_____no_output_____"
]
],
[
[
"次に、トークンを頻度で並べ替え、上位の `VOCAB_SIZE` トークンを保持することにより、語彙を構築します。",
"_____no_output_____"
]
],
[
[
"tokenized_ds = configure_dataset(tokenized_ds)\n\nvocab_dict = collections.defaultdict(lambda: 0)\nfor toks in tokenized_ds.as_numpy_iterator():\n for tok in toks:\n vocab_dict[tok] += 1\n\nvocab = sorted(vocab_dict.items(), key=lambda x: x[1], reverse=True)\nvocab = [token for token, count in vocab]\nvocab = vocab[:VOCAB_SIZE]\nvocab_size = len(vocab)\nprint(\"Vocab size: \", vocab_size)\nprint(\"First five vocab entries:\", vocab[:5])",
"_____no_output_____"
]
],
[
[
"トークンを整数に変換するには、`vocab` セットを使用して、`StaticVocabularyTable`を作成します。トークンを [`2`, `vocab_size + 2`] の範囲の整数にマップします。`TextVectorization` レイヤーと同様に、`0` はパディングを示すために予約されており、`1` は語彙外 (OOV) トークンを示すために予約されています。",
"_____no_output_____"
]
],
[
[
"keys = vocab\nvalues = range(2, len(vocab) + 2) # reserve 0 for padding, 1 for OOV\n\ninit = tf.lookup.KeyValueTensorInitializer(\n keys, values, key_dtype=tf.string, value_dtype=tf.int64)\n\nnum_oov_buckets = 1\nvocab_table = tf.lookup.StaticVocabularyTable(init, num_oov_buckets)",
"_____no_output_____"
]
],
[
[
"最後に、トークナイザーとルックアップテーブルを使用して、データセットを標準化、トークン化、およびベクトル化する関数を定義します。",
"_____no_output_____"
]
],
[
[
"def preprocess_text(text, label):\n standardized = tf_text.case_fold_utf8(text)\n tokenized = tokenizer.tokenize(standardized)\n vectorized = vocab_table.lookup(tokenized)\n return vectorized, label",
"_____no_output_____"
]
],
[
[
"1 つの例でこれを試して、出力を確認します。",
"_____no_output_____"
]
],
[
[
"example_text, example_label = next(iter(all_labeled_data))\nprint(\"Sentence: \", example_text.numpy())\nvectorized_text, example_label = preprocess_text(example_text, example_label)\nprint(\"Vectorized sentence: \", vectorized_text.numpy())",
"_____no_output_____"
]
],
[
[
"次に、`tf.data.Dataset.map` を使用して、データセットに対して前処理関数を実行します。",
"_____no_output_____"
]
],
[
[
"all_encoded_data = all_labeled_data.map(preprocess_text)",
"_____no_output_____"
]
],
[
[
"### データセットをトレーニングとテストに分割する\n",
"_____no_output_____"
],
[
"Keras `TextVectorization` レイヤーでも、ベクトル化されたデータをバッチ処理してパディングします。バッチ内のサンプルは同じサイズと形状である必要があるため、パディングが必要です。これらのデータセットのサンプルはすべて同じサイズではありません。テキストの各行には、異なる数の単語があります。`tf.data.Dataset` は、データセットの分割と埋め込みバッチ処理をサポートしています ",
"_____no_output_____"
]
],
[
[
"train_data = all_encoded_data.skip(VALIDATION_SIZE).shuffle(BUFFER_SIZE)\nvalidation_data = all_encoded_data.take(VALIDATION_SIZE)",
"_____no_output_____"
],
[
"train_data = train_data.padded_batch(BATCH_SIZE)\nvalidation_data = validation_data.padded_batch(BATCH_SIZE)",
"_____no_output_____"
]
],
[
[
"`validation_data` および `train_data` は(`example, label`) ペアのコレクションではなく、バッチのコレクションです。各バッチは、配列として表される (*多くの例*、*多くのラベル*) のペアです。以下に示します。",
"_____no_output_____"
]
],
[
[
"sample_text, sample_labels = next(iter(validation_data))\nprint(\"Text batch shape: \", sample_text.shape)\nprint(\"Label batch shape: \", sample_labels.shape)\nprint(\"First text example: \", sample_text[0])\nprint(\"First label example: \", sample_labels[0])",
"_____no_output_____"
]
],
[
[
"パディングに 0 を使用し、語彙外 (OOV) トークンに 1 を使用するため、語彙のサイズが 2 つ増えました。",
"_____no_output_____"
]
],
[
[
"vocab_size += 2",
"_____no_output_____"
]
],
[
[
"以前と同じように、パフォーマンスを向上させるためにデータセットを構成します。",
"_____no_output_____"
]
],
[
[
"train_data = configure_dataset(train_data)\nvalidation_data = configure_dataset(validation_data)",
"_____no_output_____"
]
],
[
[
"### モデルをトレーニングする\n\n以前と同じように、このデータセットでモデルをトレーニングできます。",
"_____no_output_____"
]
],
[
[
"model = create_model(vocab_size=vocab_size, num_labels=3)\nmodel.compile(\n optimizer='adam',\n loss=losses.SparseCategoricalCrossentropy(from_logits=True),\n metrics=['accuracy'])\nhistory = model.fit(train_data, validation_data=validation_data, epochs=3)",
"_____no_output_____"
],
[
"loss, accuracy = model.evaluate(validation_data)\n\nprint(\"Loss: \", loss)\nprint(\"Accuracy: {:2.2%}\".format(accuracy))",
"_____no_output_____"
]
],
[
[
"### モデルをエクスポートする",
"_____no_output_____"
],
[
"モデルが生の文字列を入力として受け取ることができるようにするには、カスタム前処理関数と同じ手順を実行する `TextVectorization` レイヤーを作成します。すでに語彙をトレーニングしているので、新しい語彙をトレーニングする `adapt` の代わりに、`set_vocaublary` を使用できます。",
"_____no_output_____"
]
],
[
[
"preprocess_layer = TextVectorization(\n max_tokens=vocab_size,\n standardize=tf_text.case_fold_utf8,\n split=tokenizer.tokenize,\n output_mode='int',\n output_sequence_length=MAX_SEQUENCE_LENGTH)\npreprocess_layer.set_vocabulary(vocab)",
"_____no_output_____"
],
[
"export_model = tf.keras.Sequential(\n [preprocess_layer, model,\n layers.Activation('sigmoid')])\n\nexport_model.compile(\n loss=losses.SparseCategoricalCrossentropy(from_logits=False),\n optimizer='adam',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"# Create a test dataset of raw strings\ntest_ds = all_labeled_data.take(VALIDATION_SIZE).batch(BATCH_SIZE)\ntest_ds = configure_dataset(test_ds)\nloss, accuracy = export_model.evaluate(test_ds)\nprint(\"Loss: \", loss)\nprint(\"Accuracy: {:2.2%}\".format(accuracy))",
"_____no_output_____"
]
],
[
[
"エンコードされた検証セットのモデルと生の検証セットのエクスポートされたモデルの損失と正確度は、予想どおり同じです。",
"_____no_output_____"
],
[
"### 新しいデータで推論を実行する",
"_____no_output_____"
]
],
[
[
"inputs = [\n \"Join'd to th' Ionians with their flowing robes,\", # Label: 1\n \"the allies, and his armour flashed about him so that he seemed to all\", # Label: 2\n \"And with loud clangor of his arms he fell.\", # Label: 0\n]\npredicted_scores = export_model.predict(inputs)\npredicted_labels = tf.argmax(predicted_scores, axis=1)\nfor input, label in zip(inputs, predicted_labels):\n print(\"Question: \", input)\n print(\"Predicted label: \", label.numpy())",
"_____no_output_____"
]
],
[
[
"## TensorFlow Datasets (TFDS) を使用してより多くのデータセットをダウンロードする\n",
"_____no_output_____"
],
[
"[TensorFlow Datasets](https://www.tensorflow.org/datasets/catalog/overview) からさらに多くのデータセットをダウンロードできます。例として、[IMDB Large Movie Review データセット](https://www.tensorflow.org/datasets/catalog/imdb_reviews)をダウンロードし、それを使用して感情分類のモデルをトレーニングします。",
"_____no_output_____"
]
],
[
[
"train_ds = tfds.load(\n 'imdb_reviews',\n split='train[:80%]',\n batch_size=BATCH_SIZE,\n shuffle_files=True,\n as_supervised=True)",
"_____no_output_____"
],
[
"val_ds = tfds.load(\n 'imdb_reviews',\n split='train[80%:]',\n batch_size=BATCH_SIZE,\n shuffle_files=True,\n as_supervised=True)",
"_____no_output_____"
]
],
[
[
"いくつかの例を出力します。",
"_____no_output_____"
]
],
[
[
"for review_batch, label_batch in val_ds.take(1):\n for i in range(5):\n print(\"Review: \", review_batch[i].numpy())\n print(\"Label: \", label_batch[i].numpy())",
"_____no_output_____"
]
],
[
[
"これで、以前と同じようにデータを前処理してモデルをトレーニングできます。\n\n注意: これはバイナリ分類の問題であるため、モデルには `losses.SparseCategoricalCrossentropy` の代わりに `losses.BinaryCrossentropy` を使用します。",
"_____no_output_____"
],
[
"### トレーニング用データセットを準備する",
"_____no_output_____"
]
],
[
[
"vectorize_layer = TextVectorization(\n max_tokens=VOCAB_SIZE,\n output_mode='int',\n output_sequence_length=MAX_SEQUENCE_LENGTH)\n\n# Make a text-only dataset (without labels), then call adapt\ntrain_text = train_ds.map(lambda text, labels: text)\nvectorize_layer.adapt(train_text)",
"_____no_output_____"
],
[
"def vectorize_text(text, label):\n text = tf.expand_dims(text, -1)\n return vectorize_layer(text), label",
"_____no_output_____"
],
[
"train_ds = train_ds.map(vectorize_text)\nval_ds = val_ds.map(vectorize_text)",
"_____no_output_____"
],
[
"# Configure datasets for performance as before\ntrain_ds = configure_dataset(train_ds)\nval_ds = configure_dataset(val_ds)",
"_____no_output_____"
]
],
[
[
"### モデルをトレーニングする",
"_____no_output_____"
]
],
[
[
"model = create_model(vocab_size=VOCAB_SIZE + 1, num_labels=1)\nmodel.summary()",
"_____no_output_____"
],
[
"model.compile(\n loss=losses.BinaryCrossentropy(from_logits=True),\n optimizer='adam',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"history = model.fit(train_ds, validation_data=val_ds, epochs=3)",
"_____no_output_____"
],
[
"loss, accuracy = model.evaluate(val_ds)\n\nprint(\"Loss: \", loss)\nprint(\"Accuracy: {:2.2%}\".format(accuracy))",
"_____no_output_____"
]
],
[
[
"### モデルをエクスポートする",
"_____no_output_____"
]
],
[
[
"export_model = tf.keras.Sequential(\n [vectorize_layer, model,\n layers.Activation('sigmoid')])\n\nexport_model.compile(\n loss=losses.SparseCategoricalCrossentropy(from_logits=False),\n optimizer='adam',\n metrics=['accuracy'])",
"_____no_output_____"
],
[
"# 0 --> negative review\n# 1 --> positive review\ninputs = [\n \"This is a fantastic movie.\",\n \"This is a bad movie.\",\n \"This movie was so bad that it was good.\",\n \"I will never say yes to watching this movie.\",\n]\npredicted_scores = export_model.predict(inputs)\npredicted_labels = [int(round(x[0])) for x in predicted_scores]\nfor input, label in zip(inputs, predicted_labels):\n print(\"Question: \", input)\n print(\"Predicted label: \", label)",
"_____no_output_____"
]
],
[
[
"## まとめ\n\nこのチュートリアルでは、テキストを読み込んで前処理するいくつかの方法を示しました。次のステップとして、Web サイトで他のチュートリアルをご覧ください。また、[TensorFlow Datasets](https://www.tensorflow.org/datasets/catalog/overview) から新しいデータセットをダウンロードできます。",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a9e3abd1e8e93ed22e672b6944b51cdc2a9912a
| 44,646 |
ipynb
|
Jupyter Notebook
|
ML0101EN-Clas-K-Nearest-neighbors-CustCat-py-v1.ipynb
|
jarmirezciro/IIBM-Machine-Learning-with-Python
|
332deb29160731ae3cbb8a0f5fad57e6a140ad27
|
[
"BSD-4-Clause-UC"
] | null | null | null |
ML0101EN-Clas-K-Nearest-neighbors-CustCat-py-v1.ipynb
|
jarmirezciro/IIBM-Machine-Learning-with-Python
|
332deb29160731ae3cbb8a0f5fad57e6a140ad27
|
[
"BSD-4-Clause-UC"
] | null | null | null |
ML0101EN-Clas-K-Nearest-neighbors-CustCat-py-v1.ipynb
|
jarmirezciro/IIBM-Machine-Learning-with-Python
|
332deb29160731ae3cbb8a0f5fad57e6a140ad27
|
[
"BSD-4-Clause-UC"
] | null | null | null | 38.421687 | 6,408 | 0.607132 |
[
[
[
"<center>\n <img src=\"https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/Logos/organization_logo/organization_logo.png\" width=\"300\" alt=\"cognitiveclass.ai logo\" />\n</center>\n\n# K-Nearest Neighbors\n\nEstimated time needed: **25** minutes\n\n## Objectives\n\nAfter completing this lab you will be able to:\n\n- Use K Nearest neighbors to classify data\n",
"_____no_output_____"
],
[
"In this Lab you will load a customer dataset, fit the data, and use K-Nearest Neighbors to predict a data point. But what is **K-Nearest Neighbors**?\n",
"_____no_output_____"
],
[
"**K-Nearest Neighbors** is an algorithm for supervised learning. Where the data is 'trained' with data points corresponding to their classification. Once a point is to be predicted, it takes into account the 'K' nearest points to it to determine it's classification.\n",
"_____no_output_____"
],
[
"### Here's an visualization of the K-Nearest Neighbors algorithm.\n\n<img src=\"https://ibm.box.com/shared/static/mgkn92xck0z05v7yjq8pqziukxvc2461.png\">\n",
"_____no_output_____"
],
[
"In this case, we have data points of Class A and B. We want to predict what the star (test data point) is. If we consider a k value of 3 (3 nearest data points) we will obtain a prediction of Class B. Yet if we consider a k value of 6, we will obtain a prediction of Class A.\n",
"_____no_output_____"
],
[
"In this sense, it is important to consider the value of k. But hopefully from this diagram, you should get a sense of what the K-Nearest Neighbors algorithm is. It considers the 'K' Nearest Neighbors (points) when it predicts the classification of the test point.\n",
"_____no_output_____"
],
[
"<h1>Table of contents</h1>\n\n<div class=\"alert alert-block alert-info\" style=\"margin-top: 20px\">\n <ol>\n <li><a href=\"#about_dataset\">About the dataset</a></li>\n <li><a href=\"#visualization_analysis\">Data Visualization and Analysis</a></li>\n <li><a href=\"#classification\">Classification</a></li>\n </ol>\n</div>\n<br>\n<hr>\n",
"_____no_output_____"
]
],
[
[
"!pip install scikit-learn==0.23.1",
"Collecting scikit-learn==0.23.1\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/d9/3a/eb8d7bbe28f4787d140bb9df685b7d5bf6115c0e2a969def4027144e98b6/scikit_learn-0.23.1-cp36-cp36m-manylinux1_x86_64.whl (6.8MB)\n\u001b[K |████████████████████████████████| 6.9MB 2.7MB/s eta 0:00:01 |████████████████████████▏ | 5.2MB 5.7MB/s eta 0:00:01\n\u001b[?25hRequirement already satisfied: scipy>=0.19.1 in /home/jupyterlab/conda/envs/python/lib/python3.6/site-packages (from scikit-learn==0.23.1) (1.5.4)\nCollecting threadpoolctl>=2.0.0 (from scikit-learn==0.23.1)\n Downloading https://files.pythonhosted.org/packages/f7/12/ec3f2e203afa394a149911729357aa48affc59c20e2c1c8297a60f33f133/threadpoolctl-2.1.0-py3-none-any.whl\nRequirement already satisfied: numpy>=1.13.3 in /home/jupyterlab/conda/envs/python/lib/python3.6/site-packages (from scikit-learn==0.23.1) (1.19.4)\nCollecting joblib>=0.11 (from scikit-learn==0.23.1)\n\u001b[?25l Downloading https://files.pythonhosted.org/packages/55/85/70c6602b078bd9e6f3da4f467047e906525c355a4dacd4f71b97a35d9897/joblib-1.0.1-py3-none-any.whl (303kB)\n\u001b[K |████████████████████████████████| 307kB 17.2MB/s eta 0:00:01\n\u001b[?25hInstalling collected packages: threadpoolctl, joblib, scikit-learn\n Found existing installation: scikit-learn 0.20.1\n Uninstalling scikit-learn-0.20.1:\n Successfully uninstalled scikit-learn-0.20.1\nSuccessfully installed joblib-1.0.1 scikit-learn-0.23.1 threadpoolctl-2.1.0\n"
]
],
[
[
"Lets load required libraries\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport pandas as pd\nimport numpy as np\nfrom sklearn import preprocessing\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"<div id=\"about_dataset\">\n <h2>About the dataset</h2>\n</div>\n",
"_____no_output_____"
],
[
"Imagine a telecommunications provider has segmented its customer base by service usage patterns, categorizing the customers into four groups. If demographic data can be used to predict group membership, the company can customize offers for individual prospective customers. It is a classification problem. That is, given the dataset, with predefined labels, we need to build a model to be used to predict class of a new or unknown case. \n\nThe example focuses on using demographic data, such as region, age, and marital, to predict usage patterns. \n\nThe target field, called **custcat**, has four possible values that correspond to the four customer groups, as follows:\n 1- Basic Service\n 2- E-Service\n 3- Plus Service\n 4- Total Service\n\nOur objective is to build a classifier, to predict the class of unknown cases. We will use a specific type of classification called K nearest neighbour.\n",
"_____no_output_____"
],
[
"Lets download the dataset. To download the data, we will use !wget to download it from IBM Object Storage.\n",
"_____no_output_____"
]
],
[
[
"!wget -O teleCust1000t.csv https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-ML0101EN-SkillsNetwork/labs/Module%203/data/teleCust1000t.csv",
"--2021-03-18 21:25:38-- https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-ML0101EN-SkillsNetwork/labs/Module%203/data/teleCust1000t.csv\nResolving cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud (cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud)... 169.63.118.104\nConnecting to cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud (cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud)|169.63.118.104|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 36047 (35K) [text/csv]\nSaving to: ‘teleCust1000t.csv’\n\nteleCust1000t.csv 100%[===================>] 35.20K --.-KB/s in 0.02s \n\n2021-03-18 21:25:39 (1.88 MB/s) - ‘teleCust1000t.csv’ saved [36047/36047]\n\n"
]
],
[
[
"**Did you know?** When it comes to Machine Learning, you will likely be working with large datasets. As a business, where can you host your data? IBM is offering a unique opportunity for businesses, with 10 Tb of IBM Cloud Object Storage: [Sign up now for free](http://cocl.us/ML0101EN-IBM-Offer-CC)\n",
"_____no_output_____"
],
[
"### Load Data From CSV File\n",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv('teleCust1000t.csv')\ndf.head()",
"_____no_output_____"
]
],
[
[
"<div id=\"visualization_analysis\">\n <h2>Data Visualization and Analysis</h2> \n</div>\n",
"_____no_output_____"
],
[
"#### Let’s see how many of each class is in our data set\n",
"_____no_output_____"
]
],
[
[
"df['custcat'].value_counts()",
"_____no_output_____"
]
],
[
[
"#### 281 Plus Service, 266 Basic-service, 236 Total Service, and 217 E-Service customers\n",
"_____no_output_____"
],
[
"You can easily explore your data using visualization techniques:\n",
"_____no_output_____"
]
],
[
[
"df.hist(column='income', bins=50)",
"_____no_output_____"
]
],
[
[
"### Feature set\n",
"_____no_output_____"
],
[
"Lets define feature sets, X:\n",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
]
],
[
[
"To use scikit-learn library, we have to convert the Pandas data frame to a Numpy array:\n",
"_____no_output_____"
]
],
[
[
"X = df[['region', 'tenure','age', 'marital', 'address', 'income', 'ed', 'employ','retire', 'gender', 'reside']] .values #.astype(float)\nX[0:5]\n",
"_____no_output_____"
]
],
[
[
"What are our labels?\n",
"_____no_output_____"
]
],
[
[
"y = df['custcat'].values\ny[0:5]",
"_____no_output_____"
]
],
[
[
"## Normalize Data\n",
"_____no_output_____"
],
[
"Data Standardization give data zero mean and unit variance, it is good practice, especially for algorithms such as KNN which is based on distance of cases:\n",
"_____no_output_____"
]
],
[
[
"X = preprocessing.StandardScaler().fit(X).transform(X.astype(float))\nX[0:5]",
"_____no_output_____"
]
],
[
[
"### Train Test Split\n\nOut of Sample Accuracy is the percentage of correct predictions that the model makes on data that that the model has NOT been trained on. Doing a train and test on the same dataset will most likely have low out-of-sample accuracy, due to the likelihood of being over-fit.\n\nIt is important that our models have a high, out-of-sample accuracy, because the purpose of any model, of course, is to make correct predictions on unknown data. So how can we improve out-of-sample accuracy? One way is to use an evaluation approach called Train/Test Split.\nTrain/Test Split involves splitting the dataset into training and testing sets respectively, which are mutually exclusive. After which, you train with the training set and test with the testing set. \n\nThis will provide a more accurate evaluation on out-of-sample accuracy because the testing dataset is not part of the dataset that have been used to train the data. It is more realistic for real world problems.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\nX_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=4)\nprint ('Train set:', X_train.shape, y_train.shape)\nprint ('Test set:', X_test.shape, y_test.shape)",
"_____no_output_____"
]
],
[
[
"<div id=\"classification\">\n <h2>Classification</h2>\n</div>\n",
"_____no_output_____"
],
[
"<h3>K nearest neighbor (KNN)</h3>\n",
"_____no_output_____"
],
[
"#### Import library\n",
"_____no_output_____"
],
[
"Classifier implementing the k-nearest neighbors vote.\n",
"_____no_output_____"
]
],
[
[
"from sklearn.neighbors import KNeighborsClassifier",
"_____no_output_____"
]
],
[
[
"### Training\n\nLets start the algorithm with k=4 for now:\n",
"_____no_output_____"
]
],
[
[
"k = 4\n#Train Model and Predict \nneigh = KNeighborsClassifier(n_neighbors = k).fit(X_train,y_train)\nneigh",
"_____no_output_____"
]
],
[
[
"### Predicting\n\nwe can use the model to predict the test set:\n",
"_____no_output_____"
]
],
[
[
"yhat = neigh.predict(X_test)\nyhat[0:5]",
"_____no_output_____"
]
],
[
[
"### Accuracy evaluation\n\nIn multilabel classification, **accuracy classification score** is a function that computes subset accuracy. This function is equal to the jaccard_score function. Essentially, it calculates how closely the actual labels and predicted labels are matched in the test set.\n",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\nprint(\"Train set Accuracy: \", metrics.accuracy_score(y_train, neigh.predict(X_train)))\nprint(\"Test set Accuracy: \", metrics.accuracy_score(y_test, yhat))",
"_____no_output_____"
]
],
[
[
"## Practice\n\nCan you build the model again, but this time with k=6?\n",
"_____no_output_____"
]
],
[
[
"# write your code here\n\n\n",
"_____no_output_____"
]
],
[
[
"<details><summary>Click here for the solution</summary>\n\n```python\nk = 6\nneigh6 = KNeighborsClassifier(n_neighbors = k).fit(X_train,y_train)\nyhat6 = neigh6.predict(X_test)\nprint(\"Train set Accuracy: \", metrics.accuracy_score(y_train, neigh6.predict(X_train)))\nprint(\"Test set Accuracy: \", metrics.accuracy_score(y_test, yhat6))\n\n```\n\n</details>\n",
"_____no_output_____"
],
[
"#### What about other K?\n\nK in KNN, is the number of nearest neighbors to examine. It is supposed to be specified by the User. So, how can we choose right value for K?\nThe general solution is to reserve a part of your data for testing the accuracy of the model. Then chose k =1, use the training part for modeling, and calculate the accuracy of prediction using all samples in your test set. Repeat this process, increasing the k, and see which k is the best for your model.\n\nWe can calculate the accuracy of KNN for different Ks.\n",
"_____no_output_____"
]
],
[
[
"Ks = 10\nmean_acc = np.zeros((Ks-1))\nstd_acc = np.zeros((Ks-1))\n\nfor n in range(1,Ks):\n \n #Train Model and Predict \n neigh = KNeighborsClassifier(n_neighbors = n).fit(X_train,y_train)\n yhat=neigh.predict(X_test)\n mean_acc[n-1] = metrics.accuracy_score(y_test, yhat)\n\n \n std_acc[n-1]=np.std(yhat==y_test)/np.sqrt(yhat.shape[0])\n\nmean_acc",
"_____no_output_____"
]
],
[
[
"#### Plot model accuracy for Different number of Neighbors\n",
"_____no_output_____"
]
],
[
[
"plt.plot(range(1,Ks),mean_acc,'g')\nplt.fill_between(range(1,Ks),mean_acc - 1 * std_acc,mean_acc + 1 * std_acc, alpha=0.10)\nplt.fill_between(range(1,Ks),mean_acc - 3 * std_acc,mean_acc + 3 * std_acc, alpha=0.10,color=\"green\")\nplt.legend(('Accuracy ', '+/- 1xstd','+/- 3xstd'))\nplt.ylabel('Accuracy ')\nplt.xlabel('Number of Neighbors (K)')\nplt.tight_layout()\nplt.show()",
"_____no_output_____"
],
[
"print( \"The best accuracy was with\", mean_acc.max(), \"with k=\", mean_acc.argmax()+1) ",
"_____no_output_____"
]
],
[
[
"<h2>Want to learn more?</h2>\n\nIBM SPSS Modeler is a comprehensive analytics platform that has many machine learning algorithms. It has been designed to bring predictive intelligence to decisions made by individuals, by groups, by systems – by your enterprise as a whole. A free trial is available through this course, available here: <a href=\"https://www.ibm.com/analytics/spss-statistics-software\">SPSS Modeler</a>\n\nAlso, you can use Watson Studio to run these notebooks faster with bigger datasets. Watson Studio is IBM's leading cloud solution for data scientists, built by data scientists. With Jupyter notebooks, RStudio, Apache Spark and popular libraries pre-packaged in the cloud, Watson Studio enables data scientists to collaborate on their projects without having to install anything. Join the fast-growing community of Watson Studio users today with a free account at <a href=\"https://www.ibm.com/cloud/watson-studio\">Watson Studio</a>\n",
"_____no_output_____"
],
[
"### Thank you for completing this lab!\n\n## Author\n\nSaeed Aghabozorgi\n\n### Other Contributors\n\n<a href=\"https://www.linkedin.com/in/joseph-s-50398b136/\" target=\"_blank\">Joseph Santarcangelo</a>\n\n## Change Log\n\n| Date (YYYY-MM-DD) | Version | Changed By | Change Description |\n| ----------------- | ------- | ---------- | ---------------------------------- |\n| 2021-01-21 | 2.4 | Lakshmi | Updated sklearn library |\n| 2020-11-20 | 2.3 | Lakshmi | Removed unused imports |\n| 2020-11-17 | 2.2 | Lakshmi | Changed plot function of KNN |\n| 2020-11-03 | 2.1 | Lakshmi | Changed URL of csv |\n| 2020-08-27 | 2.0 | Lavanya | Moved lab to course repo in GitLab |\n| | | | |\n| | | | |\n\n## <h3 align=\"center\"> © IBM Corporation 2020. All rights reserved. <h3/>\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a9e3c31d8b6f89d21711968fcca2103db5e2f73
| 643,132 |
ipynb
|
Jupyter Notebook
|
clustering/kmeans_ap_clustering/kmeans_ap_clustering.ipynb
|
Geeksongs/new-algorithm
|
f15cefd3a78cbbc2ad8ab2a0c914b95f04f83aff
|
[
"MIT"
] | 5 |
2020-10-06T05:48:37.000Z
|
2021-04-28T02:23:33.000Z
|
clustering/kmeans_ap_clustering/kmeans_ap_clustering.ipynb
|
Geeksongs/new-algorithm
|
f15cefd3a78cbbc2ad8ab2a0c914b95f04f83aff
|
[
"MIT"
] | null | null | null |
clustering/kmeans_ap_clustering/kmeans_ap_clustering.ipynb
|
Geeksongs/new-algorithm
|
f15cefd3a78cbbc2ad8ab2a0c914b95f04f83aff
|
[
"MIT"
] | null | null | null | 229.28057 | 248,432 | 0.9016 |
[
[
[
"# 使下面的代码支持python2和python3\nfrom __future__ import division, print_function, unicode_literals\n\n# 查看python的版本是否为3.5及以上\nimport sys\nassert sys.version_info >= (3, 5)\n\n# 查看sklearn的版本是否为0.20及以上\nimport sklearn\nassert sklearn.__version__ >= \"0.20\"\n\nimport numpy as np\nimport pandas as pd\nfrom matplotlib import pyplot as plt\nimport os \n\n# 在每一次的运行后获得的结果与这个notebook的结果相同\nnp.random.seed(42) \n\n# 让matplotlib的图效果更好\n%matplotlib inline\nimport matplotlib as mpl\nmpl.rc('axes', labelsize=14)\nmpl.rc('xtick', labelsize=12)\nmpl.rc('ytick', labelsize=12)\n\n# 设置保存图片的途径\nPROJECT_ROOT_DIR = \".\"\nIMAGE_PATH = os.path.join(PROJECT_ROOT_DIR, \"images\")\nos.makedirs(IMAGE_PATH, exist_ok=True)\n\ndef save_fig(fig_id, tight_layout=True):\n '''\n 运行即可保存自动图片\n \n :param fig_id: 图片名称\n '''\n path = os.path.join(PROJECT_ROOT_DIR, \"images\", fig_id + \".png\")\n print(\"Saving figure\", fig_id)\n if tight_layout:\n plt.tight_layout()\n plt.savefig(path, format='png', dpi=300)\n \n# 忽略掉没用的警告 (Scipy issue #5998)\nimport warnings\nwarnings.filterwarnings(action=\"ignore\", category=FutureWarning, module='sklearn', lineno=196)",
"_____no_output_____"
],
[
"# 读取数据集\ndf = pd.read_excel('Test_2.xlsx')\ndf.head()",
"_____no_output_____"
],
[
"# 查看数据集是否有空值,看需不需要插值\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 2272 entries, 0 to 2271\nData columns (total 12 columns):\nTRUE VALUE 2272 non-null int64\nSiO2 (wt. %) 2272 non-null float64\nTiO2 (wt. %) 2272 non-null float64\nAl2O3 (wt. %) 2272 non-null float64\nCr2O3 (wt. %) 2272 non-null float64\nFeO (wt. %) 2272 non-null float64\nMnO (wt. %) 2272 non-null float64\nMgO (wt. %) 2272 non-null float64\nCaO (wt. %) 2272 non-null float64\nNa2O (wt. %) 2272 non-null float64\nIV (Al) 2272 non-null float64\nH2O (wt. %) 2272 non-null float64\ndtypes: float64(11), int64(1)\nmemory usage: 213.1 KB\n"
],
[
"'''\n# 插值\ndf.fillna(0, inplace=True)\n# 或者是参考之前在多项式回归里的插值方式\n'''",
"_____no_output_____"
],
[
"# 将真实的分类标签与特征分开\ndata = df.drop('TRUE VALUE', axis=1)\nlabels = df['TRUE VALUE'].copy()\nnp.unique(labels)",
"_____no_output_____"
],
[
"labels",
"_____no_output_____"
],
[
"# 获取数据的数量和特征的数量\nn_samples, n_features = data.shape\n# 获取分类标签的数量\nn_labels = len(np.unique(labels))",
"_____no_output_____"
],
[
"np.unique(labels)",
"_____no_output_____"
],
[
"labels.value_counts()",
"_____no_output_____"
]
],
[
[
"# KMeans算法聚类",
"_____no_output_____"
]
],
[
[
"from sklearn import metrics\n\ndef get_marks(estimator, data, name=None, kmeans=None, af=None):\n \"\"\"\n 获取评分,有五种需要知道数据集的实际分类信息,有三种不需要,参考readme.txt\n 对于Kmeans来说,一般用轮廓系数和inertia即可\n \n :param estimator: 模型\n :param name: 初始方法\n :param data: 特征数据集\n \"\"\"\n estimator.fit(data)\n print(20 * '*', name, 20 * '*')\n if kmeans:\n print(\"Mean Inertia Score: \", estimator.inertia_)\n elif af:\n cluster_centers_indices = estimator.cluster_centers_indices_\n print(\"The estimated number of clusters: \", len(cluster_centers_indices))\n print(\"Homogeneity Score: \", metrics.homogeneity_score(labels, estimator.labels_))\n print(\"Completeness Score: \", metrics.completeness_score(labels, estimator.labels_))\n print(\"V Measure Score: \", metrics.v_measure_score(labels, estimator.labels_))\n print(\"Adjusted Rand Score: \", metrics.adjusted_rand_score(labels, estimator.labels_))\n print(\"Adjusted Mutual Info Score: \", metrics.adjusted_mutual_info_score(labels, estimator.labels_))\n print(\"Calinski Harabasz Score: \", metrics.calinski_harabasz_score(data, estimator.labels_))\n print(\"Silhouette Score: \", metrics.silhouette_score(data, estimator.labels_))",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\n\n# 使用k-means进行聚类,设置簇=2,设置不同的初始化方式('k-means++'和'random')\nkm1 = KMeans(init='k-means++', n_clusters=n_labels-1, n_init=10, random_state=42)\nkm2 = KMeans(init='random', n_clusters=n_labels-1, n_init=10, random_state=42)\nprint(\"n_labels: %d \\t n_samples: %d \\t n_features: %d\" % (n_labels, n_samples, n_features))\nget_marks(km1, data, name=\"k-means++\", kmeans=True)\nget_marks(km2, data, name=\"random\", kmeans=True)",
"n_labels: 3 \t n_samples: 2272 \t n_features: 11\n******************** k-means++ ********************\nMean Inertia Score: 13102.675332509456\nHomogeneity Score: 0.01656074913787492\nCompleteness Score: 0.021735466104332666\nV Measure Score: 0.01879849480018157\nAdjusted Rand Score: -0.015412609393170065\nAdjusted Mutual Info Score: 0.016066305780084188\nCalinski Harabasz Score: 1782.1626131414523\nSilhouette Score: 0.37788086665168275\n******************** random ********************\nMean Inertia Score: 13102.675332509456\nHomogeneity Score: 0.01656074913787492\nCompleteness Score: 0.021735466104332666\nV Measure Score: 0.01879849480018157\nAdjusted Rand Score: -0.015412609393170065\nAdjusted Mutual Info Score: 0.016066305780084188\nCalinski Harabasz Score: 1782.1626131414523\n"
],
[
"# 聚类后每个数据的类别\nkm1.labels_",
"_____no_output_____"
],
[
"# 类别的类型\nnp.unique(km1.labels_)",
"_____no_output_____"
],
[
"# 将聚类的结果写入原始表格中\ndf['km_clustering_label'] = km1.labels_\n# 以csv形式导出原始表格\n#df.to_csv('result.csv')",
"_____no_output_____"
],
[
"# 区别于data,df是原始数据集\ndf.head()",
"_____no_output_____"
],
[
"from sklearn.model_selection import GridSearchCV\n\n# 使用GridSearchCV自动寻找最优参数,kmeans在这里是作为分类模型使用\nparams = {'init':('k-means++', 'random'), 'n_clusters':[2, 3, 4, 5, 6], 'n_init':[5, 10, 15]}\ncluster = KMeans(random_state=42)\n# 使用调整的兰德系数(adjusted_rand_score)作为评分,具体可参考readme.txt\nkm_best_model = GridSearchCV(cluster, params, cv=3, scoring='adjusted_rand_score',\n verbose=1, n_jobs=-1)\n# 由于选用的是外部评价指标,因此得有原数据集的真实分类信息\nkm_best_model.fit(data, labels)",
"Fitting 3 folds for each of 30 candidates, totalling 90 fits\n"
],
[
"# 最优模型的参数\nkm_best_model.best_params_",
"_____no_output_____"
],
[
"# 最优模型的评分\nkm_best_model.best_score_",
"_____no_output_____"
],
[
"# 获得的最优模型\nkm3 = km_best_model.best_estimator_\nkm3",
"_____no_output_____"
],
[
"# 获取最优模型的8种评分,具体含义参考readme.txt\nget_marks(km3, data, name=\"k-means++\", kmeans=True)",
"******************** k-means++ ********************\nMean Inertia Score: 10617.445840438206\nHomogeneity Score: 0.04517523511343203\nCompleteness Score: 0.03618016915891193\nV Measure Score: 0.04018043208847294\nAdjusted Rand Score: 0.04635544048189519\nAdjusted Mutual Info Score: 0.03540345197160239\nCalinski Harabasz Score: 1364.722000333955\nSilhouette Score: 0.2898868570766755\n"
],
[
"from sklearn.metrics import silhouette_score\nfrom sklearn.metrics import calinski_harabasz_score\nfrom matplotlib import pyplot as plt\n\ndef plot_scores(init, max_k, data, labels):\n '''画出kmeans不同初始化方法的三种评分图\n \n :param init: 初始化方法,有'k-means++'和'random'两种\n :param max_k: 最大的簇中心数目\n :param data: 特征的数据集\n :param labels: 真实标签的数据集\n '''\n \n i = []\n inertia_scores = []\n y_silhouette_scores = []\n y_calinski_harabaz_scores = []\n \n for k in range(2, max_k):\n kmeans_model = KMeans(n_clusters=k, random_state=1, init=init, n_init=10)\n pred = kmeans_model.fit_predict(data)\n i.append(k)\n inertia_scores.append(kmeans_model.inertia_)\n y_silhouette_scores.append(silhouette_score(data, pred))\n y_calinski_harabaz_scores.append(calinski_harabasz_score(data, pred))\n \n new = [inertia_scores, y_silhouette_scores, y_calinski_harabaz_scores]\n for j in range(len(new)):\n plt.figure(j+1)\n plt.plot(i, new[j], 'bo-')\n plt.xlabel('n_clusters')\n if j == 0:\n name = 'inertia'\n elif j == 1:\n name = 'silhouette'\n else:\n name = 'calinski_harabasz'\n plt.ylabel('{}_scores'.format(name))\n plt.title('{}_scores with {} init'.format(name, init))\n save_fig('{} with {}'.format(name, init))",
"_____no_output_____"
],
[
"plot_scores('k-means++', 18, data, labels)",
"Saving figure inertia with k-means++\nSaving figure silhouette with k-means++\nSaving figure calinski_harabasz with k-means++\n"
],
[
"plot_scores('random', 10, data, labels)",
"Saving figure inertia with random\nSaving figure silhouette with random\nSaving figure calinski_harabasz with random\n"
],
[
"from sklearn.metrics import silhouette_samples, silhouette_score\nfrom matplotlib.ticker import FixedLocator, FixedFormatter\n\ndef plot_silhouette_diagram(clusterer, X, show_xlabels=True,\n show_ylabels=True, show_title=True):\n \"\"\"\n 画轮廓图表\n \n :param clusterer: 训练好的聚类模型(这里是能提前设置簇数量的,可以稍微修改代码换成不能提前设置的)\n :param X: 只含特征的数据集\n :param show_xlabels: 为真,添加横坐标信息\n :param show_ylabels: 为真,添加纵坐标信息\n :param show_title: 为真,添加图表名\n \"\"\"\n \n y_pred = clusterer.labels_\n silhouette_coefficients = silhouette_samples(X, y_pred)\n silhouette_average = silhouette_score(X, y_pred)\n \n padding = len(X) // 30\n pos = padding\n ticks = []\n for i in range(clusterer.n_clusters):\n coeffs = silhouette_coefficients[y_pred == i]\n coeffs.sort()\n \n color = mpl.cm.Spectral(i / clusterer.n_clusters)\n plt.fill_betweenx(np.arange(pos, pos + len(coeffs)), 0, coeffs,\n facecolor=color, edgecolor=color, alpha=0.7)\n ticks.append(pos + len(coeffs) // 2)\n pos += len(coeffs) + padding\n \n plt.axvline(x=silhouette_average, color=\"red\", linestyle=\"--\")\n \n plt.gca().yaxis.set_major_locator(FixedLocator(ticks))\n plt.gca().yaxis.set_major_formatter(FixedFormatter(range(clusterer.n_clusters)))\n \n if show_xlabels:\n plt.gca().set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])\n plt.xlabel(\"Silhouette Coefficient\")\n else:\n plt.tick_params(labelbottom=False)\n if show_ylabels:\n plt.ylabel(\"Cluster\")\n if show_title:\n plt.title(\"init:{} n_cluster:{}\".format(clusterer.init, clusterer.n_clusters))",
"_____no_output_____"
],
[
"plt.figure(figsize=(15, 4))\nplt.subplot(121)\nplot_silhouette_diagram(km1, data)\nplt.subplot(122)\nplot_silhouette_diagram(km3, data, show_ylabels=False)\nsave_fig(\"silhouette_diagram\")",
"Saving figure silhouette_diagram\n"
]
],
[
[
"# MiniBatch KMeans",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import MiniBatchKMeans",
"_____no_output_____"
],
[
"# 测试KMeans算法运行速度\n%timeit KMeans(n_clusters=3).fit(data)",
"94.7 ms ± 4.04 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"# 测试MiniBatchKMeans算法运行速度\n%timeit MiniBatchKMeans(n_clusters=5).fit(data)",
"29 ms ± 2.56 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)\n"
],
[
"from timeit import timeit\n\ntimes = np.empty((100, 2))\ninertias = np.empty((100, 2))\nfor k in range(1, 101):\n kmeans = KMeans(n_clusters=k, random_state=42)\n minibatch_kmeans = MiniBatchKMeans(n_clusters=k, random_state=42)\n print(\"\\r Training: {}/{}\".format(k, 100), end=\"\")\n times[k-1, 0] = timeit(\"kmeans.fit(data)\", number=10, globals=globals())\n times[k-1, 1] = timeit(\"minibatch_kmeans.fit(data)\", number=10, globals=globals())\n inertias[k-1, 0] = kmeans.inertia_\n inertias[k-1, 1] = minibatch_kmeans.inertia_",
" Training: 100/100"
],
[
"plt.figure(figsize=(10, 4))\n\nplt.subplot(121)\nplt.plot(range(1, 101), inertias[:, 0], \"r--\", label=\"K-Means\")\nplt.plot(range(1, 101), inertias[:, 1], \"b.-\", label=\"Mini-batch K-Means\")\nplt.xlabel(\"$k$\", fontsize=16)\nplt.ylabel(\"Inertia\", fontsize=14)\nplt.legend(fontsize=14)\n\nplt.subplot(122)\nplt.plot(range(1, 101), times[:, 0], \"r--\", label=\"K-Means\")\nplt.plot(range(1, 101), times[:, 1], \"b.-\", label=\"Mini-batch K-Means\")\nplt.xlabel(\"$k$\", fontsize=16)\nplt.ylabel(\"Training time (seconds)\", fontsize=14)\nplt.axis([1, 100, 0, 6])\nplt.legend(fontsize=14)\n\nsave_fig(\"minibatch_kmeans_vs_kmeans\")\nplt.show()",
"Saving figure minibatch_kmeans_vs_kmeans\n"
]
],
[
[
"# 降维后聚类",
"_____no_output_____"
]
],
[
[
"from sklearn.decomposition import PCA\n\n# 使用普通PCA进行降维,将特征从11维降至3维\npca1 = PCA(n_components=n_labels)\npca1.fit(data)\n\nkm4 = KMeans(init=pca1.components_, n_clusters=n_labels, n_init=10)\nget_marks(km4, data, name=\"PCA-based KMeans\", kmeans=True)",
"******************** PCA-based KMeans ********************\nMean Inertia Score: 10618.402509379326\nHomogeneity Score: 0.044898784228055495\nCompleteness Score: 0.03594204734710607\nV Measure Score: 0.03992423623331697\nAdjusted Rand Score: 0.04418121532369815\nAdjusted Mutual Info Score: 0.03516550164974287\nCalinski Harabasz Score: 1364.4985488323168\nSilhouette Score: 0.2909828000505603\n"
],
[
"# 查看训练集的维度,已降至3个维度\nlen(pca1.components_)",
"_____no_output_____"
],
[
"# 使用普通PCA降维,将特征降至2维,作二维平面可视化\npca2 = PCA(n_components=2)\nreduced_data = pca2.fit_transform(data)\n# 使用k-means进行聚类,设置簇=3,初始化方法为'k-means++'\nkmeans1 = KMeans(init=\"k-means++\", n_clusters=3, n_init=3)\nkmeans2 = KMeans(init=\"random\", n_clusters=3, n_init=3)\nkmeans1.fit(reduced_data)\nkmeans2.fit(reduced_data)",
"_____no_output_____"
],
[
"# 训练集的特征维度降至2维\nlen(pca2.components_)",
"_____no_output_____"
],
[
"# 2维的特征值(降维后)\nreduced_data",
"_____no_output_____"
],
[
"# 3个簇中心的坐标\nkmeans1.cluster_centers_",
"_____no_output_____"
],
[
"from matplotlib.colors import ListedColormap\n\ndef plot_data(X, real_tag=None):\n \"\"\"\n 画散点图\n \n :param X: 只含特征值的数据集 \n :param real_tag: 有值,则给含有不同分类的散点上色\n \"\"\"\n try:\n if not real_tag:\n plt.plot(X[:, 0], X[:, 1], 'k.', markersize=2)\n except ValueError:\n types = list(np.unique(real_tag))\n for i in range(len(types)):\n plt.plot(X[:, 0][real_tag==types[i]], X[:, 1][real_tag==types[i]],\n '.', label=\"{}\".format(types[i]), markersize=3)\n plt.legend()\n\ndef plot_centroids(centroids, circle_color='w', cross_color='k'):\n \"\"\"\n 画出簇中心\n \n :param centroids: 簇中心坐标\n :param circle_color: 圆圈的颜色\n :param cross_color: 叉的颜色\n \"\"\"\n plt.scatter(centroids[:, 0], centroids[:, 1],\n marker='o', s=30, zorder=10, linewidths=8,\n color=circle_color, alpha=0.9)\n plt.scatter(centroids[:, 0], centroids[:, 1],\n marker='x', s=50, zorder=11, linewidths=50,\n color=cross_color, alpha=1)\n\ndef plot_centroids_labels(clusterer):\n labels = np.unique(clusterer.labels_)\n centroids = clusterer.cluster_centers_\n for i in range(centroids.shape[0]):\n t = str(labels[i])\n plt.text(centroids[i, 0]-1, centroids[i, 1]-1, t, fontsize=25,\n zorder=10, bbox=dict(boxstyle='round', fc='yellow', alpha=0.5))\n \ndef plot_decision_boundaried(clusterer, X, tag=None, resolution=1000, \n show_centroids=True, show_xlabels=True,\n show_ylabels=True, show_title=True,\n show_centroids_labels=False):\n \"\"\"\n 画出决策边界,并填色\n \n :param clusterer: 训练好的聚类模型(能提前设置簇中心数量或不能提前设置都可以)\n :param X: 只含特征值的数据集\n :param tag: 只含真实分类信息的数据集,有值,则给散点上色\n :param resolution: 类似图片分辨率,给最小的单位上色\n :param show_centroids: 为真,画出簇中心\n :param show_centroids_labels: 为真,标注出该簇中心的标签\n \"\"\"\n mins = X.min(axis=0) - 0.1\n maxs = X.max(axis=0) + 0.1\n xx, yy = np.meshgrid(np.linspace(mins[0], maxs[0], resolution),\n np.linspace(mins[1], maxs[1], resolution))\n Z = clusterer.predict(np.c_[xx.ravel(), yy.ravel()])\n Z = Z.reshape(xx.shape)\n \n # 可用color code或者color自定义填充颜色\n # custom_cmap = ListedColormap([\"#fafab0\", \"#9898ff\", \"#a0faa0\"])\n plt.contourf(xx, yy, Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),\n cmap=\"Pastel2\")\n plt.contour(xx, yy, Z, extent=(mins[0], maxs[0], mins[1], maxs[1]),\n colors='k')\n \n try:\n if not tag:\n plot_data(X)\n except ValueError:\n plot_data(X, real_tag=tag)\n if show_centroids:\n plot_centroids(clusterer.cluster_centers_)\n if show_centroids_labels:\n plot_centroids_labels(clusterer)\n if show_xlabels:\n plt.xlabel(r\"$x_1$\", fontsize=14)\n else:\n plt.tick_params(labelbottom=False)\n if show_ylabels:\n plt.ylabel(r\"$x_2$\", fontsize=14, rotation=0)\n else:\n plt.tick_params(labelleft=False)\n if show_title:\n plt.title(\"init:{} n_cluster:{}\".format(clusterer.init, clusterer.n_clusters))",
"_____no_output_____"
],
[
"plt.figure(figsize=(15, 4))\nplt.subplot(121)\nplot_decision_boundaried(kmeans1, reduced_data, tag=labels)\nplt.subplot(122)\nplot_decision_boundaried(kmeans2, reduced_data, show_centroids_labels=True)\nsave_fig(\"real_tag_vs_non\")\nplt.show()",
"Saving figure real_tag_vs_non\n"
],
[
"kmeans3 = KMeans(init=\"k-means++\", n_clusters=3, n_init=3)\nkmeans4 = KMeans(init=\"k-means++\", n_clusters=4, n_init=3)\nkmeans5 = KMeans(init=\"k-means++\", n_clusters=5, n_init=3)\nkmeans6 = KMeans(init=\"k-means++\", n_clusters=6, n_init=3)\n\nkmeans3.fit(reduced_data)\nkmeans4.fit(reduced_data)\nkmeans5.fit(reduced_data)\nkmeans6.fit(reduced_data)",
"_____no_output_____"
],
[
"plt.figure(figsize=(15, 8))\nplt.subplot(221)\nplot_decision_boundaried(kmeans3, reduced_data, show_xlabels=False, show_centroids_labels=True)\nplt.subplot(222)\nplot_decision_boundaried(kmeans4, reduced_data, show_ylabels=False, show_xlabels=False)\nplt.subplot(223)\nplot_decision_boundaried(kmeans5, reduced_data, show_centroids_labels=True)\nplt.subplot(224)\nplot_decision_boundaried(kmeans6, reduced_data, show_ylabels=False)\nsave_fig(\"reduced_and_cluster\")\nplt.show()",
"Saving figure reduced_and_cluster\n"
]
],
[
[
"# AP算法聚类",
"_____no_output_____"
]
],
[
[
"from sklearn.cluster import AffinityPropagation\n\n# 使用AP聚类算法\naf = AffinityPropagation(preference=-500, damping=0.8)\naf.fit(data)",
"_____no_output_____"
],
[
"# 获取簇的坐标\ncluster_centers_indices = af.cluster_centers_indices_\ncluster_centers_indices",
"_____no_output_____"
],
[
"# 获取分类的类别数量\naf_labels = af.labels_\nnp.unique(af_labels)",
"_____no_output_____"
],
[
"get_marks(af, data=data, af=True)",
"******************** None ********************\nThe estimated number of clusters: 8\nHomogeneity Score: 0.12856452303045612\nCompleteness Score: 0.05715983518747723\nV Measure Score: 0.07913584430055559\nAdjusted Rand Score: 0.030229435212232002\nAdjusted Mutual Info Score: 0.05567741585725629\nCalinski Harabasz Score: 991.5024239771674\nSilhouette Score: 0.23779642413811647\n"
],
[
"# 将AP聚类聚类的结果写入原始表格中\ndf['ap_clustering_label'] = af.labels_\n# 以csv形式导出原始表格\ndf.to_csv('test2_result.csv')",
"_____no_output_____"
],
[
"# 最后两列为两种聚类算法的分类信息\ndf.head()",
"_____no_output_____"
],
[
"from sklearn.model_selection import GridSearchCV\n# from sklearn.model_selection import RamdomizedSearchCV\n\n# 使用GridSearchCV自动寻找最优参数,如果时间太久(约4.7min),可以使用随机搜索,这里是用AP做分类的工作\nparams = {'preference':[-50, -100, -150, -200], 'damping':[0.5, 0.6, 0.7, 0.8, 0.9]}\ncluster = AffinityPropagation()\naf_best_model = GridSearchCV(cluster, params, cv=5, scoring='adjusted_rand_score', verbose=1, n_jobs=-1)\naf_best_model.fit(data, labels)",
"Fitting 5 folds for each of 20 candidates, totalling 100 fits\n"
],
[
"# 最优模型的参数设置\naf_best_model.best_params_",
"_____no_output_____"
],
[
"# 最优模型的评分,使用调整的兰德系数(adjusted_rand_score)作为评分\naf_best_model.best_score_",
"_____no_output_____"
],
[
"# 获取最优模型\naf1 = af_best_model.best_estimator_\naf1",
"_____no_output_____"
],
[
"# 最优模型的评分\nget_marks(af1, data=data, af=True)",
"******************** None ********************\nThe estimated number of clusters: 15\nHomogeneity Score: 0.2429519620051099\nCompleteness Score: 0.08101355849560997\nV Measure Score: 0.1215092455215798\nAdjusted Rand Score: 0.028992799939499304\nAdjusted Mutual Info Score: 0.07883578305157266\nCalinski Harabasz Score: 807.4918320113964\nSilhouette Score: 0.22767258566642778\n"
],
[
"\"\"\"\nfrom sklearn.externals import joblib\n\n# 保存以pkl格式最优模型\njoblib.dump(af1, \"af1.pkl\")\n\"\"\"",
"_____no_output_____"
],
[
"\"\"\"\n# 从pkl格式中导出最优模型\nmy_model_loaded = joblib.load(\"af1.pkl\")\n\"\"\"",
"_____no_output_____"
],
[
"\"\"\"\nmy_model_loaded\n\"\"\"",
"_____no_output_____"
],
[
"from sklearn.decomposition import PCA\n\n# 使用普通PCA进行降维,将特征从11维降至3维\npca3 = PCA(n_components=n_labels)\nreduced_data = pca3.fit_transform(data)\n\naf2 = AffinityPropagation(preference=-200, damping=0.8)\nget_marks(af2, reduced_data, name=\"PCA-based AF\", af=True)",
"******************** PCA-based AF ********************\nThe estimated number of clusters: 14\nHomogeneity Score: 0.23228105088102896\nCompleteness Score: 0.08046260497248087\nV Measure Score: 0.11952241453868143\nAdjusted Rand Score: 0.026689336886429438\nAdjusted Mutual Info Score: 0.07836094881583511\nCalinski Harabasz Score: 1092.8504706237084\nSilhouette Score: 0.28107910264270003\n"
]
],
[
[
"# 基于聚类结果的分层抽样",
"_____no_output_____"
]
],
[
[
"# data2是去掉真实分类信息的数据集(含有聚类后的结果)\ndata2 = df.drop(\"TRUE VALUE\", axis=1)\ndata2.head()",
"_____no_output_____"
],
[
"# 查看使用kmeans聚类后的分类标签值,两类\ndata2['km_clustering_label'].hist()",
"_____no_output_____"
],
[
"from sklearn.model_selection import StratifiedShuffleSplit\n\n# 基于kmeans聚类结果的分层抽样\nsplit = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)\nfor train_index, test_index in split.split(data2, data2[\"km_clustering_label\"]):\n strat_train_set = data2.loc[train_index]\n strat_test_set = data2.loc[test_index]",
"_____no_output_____"
],
[
"def clustering_result_propotions(data):\n \"\"\"\n 分层抽样后,训练集或测试集里不同分类标签的数量比\n :param data: 训练集或测试集,纯随机取样或分层取样\n \"\"\"\n return data[\"km_clustering_label\"].value_counts() / len(data)",
"_____no_output_____"
],
[
"# 经过分层抽样的测试集中,不同分类标签的数量比\nclustering_result_propotions(strat_test_set)",
"_____no_output_____"
],
[
"# 经过分层抽样的训练集中,不同分类标签的数量比\nclustering_result_propotions(strat_train_set)",
"_____no_output_____"
],
[
"# 完整的数据集中,不同分类标签的数量比\nclustering_result_propotions(data2)",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\n\n# 纯随机取样\nrandom_train_set, random_test_set = train_test_split(data2, test_size=0.2, random_state=42)\n\n# 完整的数据集、分层抽样后的测试集、纯随机抽样后的测试集中,不同分类标签的数量比\ncompare_props = pd.DataFrame({\n \"Overall\": clustering_result_propotions(data2),\n \"Stratified\": clustering_result_propotions(strat_test_set),\n \"Random\": clustering_result_propotions(random_test_set),\n}).sort_index()\n\n# 计算分层抽样和纯随机抽样后的测试集中不同分类标签的数量比,和完整的数据集中不同分类标签的数量比的误差\ncompare_props[\"Rand. %error\"] = 100 * compare_props[\"Random\"] / compare_props[\"Overall\"] - 100\ncompare_props[\"Start. %error\"] = 100 * compare_props[\"Stratified\"] / compare_props[\"Overall\"] - 100\n\ncompare_props",
"_____no_output_____"
],
[
"from sklearn.linear_model import LogisticRegression\nfrom sklearn.metrics import f1_score\n\ndef get_classification_marks(model, data, labels, train_index, test_index):\n \"\"\"\n 获取分类模型(二元或多元分类器)的评分:F1值\n :param data: 只含有特征值的数据集\n :param labels: 只含有标签值的数据集\n :param train_index: 分层抽样获取的训练集中数据的索引\n :param test_index: 分层抽样获取的测试集中数据的索引\n :return: F1评分值\n \"\"\"\n m = model(random_state=42)\n m.fit(data.loc[train_index], labels.loc[train_index])\n test_labels_predict = m.predict(data.loc[test_index])\n score = f1_score(labels.loc[test_index], test_labels_predict, average=\"weighted\")\n return score",
"_____no_output_____"
],
[
"# 用分层抽样后的训练集训练分类模型后的评分值\nstart_marks = get_classification_marks(LogisticRegression, data, labels, strat_train_set.index, strat_test_set.index)\nstart_marks",
"/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.\n FutureWarning)\n/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:469: FutureWarning: Default multi_class will be changed to 'auto' in 0.22. Specify the multi_class option to silence this warning.\n \"this warning.\", FutureWarning)\n"
],
[
"# 用纯随机抽样后的训练集训练分类模型后的评分值\nrandom_marks = get_classification_marks(LogisticRegression, data, labels, random_train_set.index, random_test_set.index)\nrandom_marks",
"/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.\n FutureWarning)\n/usr/local/lib/python3.7/site-packages/sklearn/linear_model/logistic.py:469: FutureWarning: Default multi_class will be changed to 'auto' in 0.22. Specify the multi_class option to silence this warning.\n \"this warning.\", FutureWarning)\n"
],
[
"import numpy as np\nfrom sklearn.metrics import f1_score\nfrom sklearn.model_selection import StratifiedKFold\nfrom sklearn.base import clone, BaseEstimator, TransformerMixin\n\nclass stratified_cross_val_score(BaseEstimator, TransformerMixin):\n \"\"\"实现基于分层抽样的k折交叉验证\"\"\"\n \n def __init__(self, model, data, labels, random_state=0, cv=5):\n \"\"\"\n :model: 训练的模型(回归或分类)\n :data: 只含特征值的完整数据集\n :labels: 只含标签值的完整数据集\n :random_state: 模型的随机种子值\n :cv: 交叉验证的次数\n \"\"\"\n self.model = model\n self.data = data\n self.labels = labels\n self.random_state = random_state\n self.cv = cv\n self.score = [] # 储存每折测试集的模型评分\n self.i = 0 \n \n def fit(self, X, y):\n \"\"\"\n :param X: 含有特征值和聚类结果的完整数据集\n :param y: 含有聚类结果的完整数据集\n :return: 每一折交叉验证的评分\n \"\"\"\n skfolds = StratifiedKFold(n_splits=self.cv, random_state=self.random_state)\n\n for train_index, test_index in skfolds.split(X, y):\n # 复制要训练的模型(分类或回归)\n clone_model = clone(self.model)\n strat_X_train_folds = self.data.loc[train_index]\n strat_y_train_folds = self.labels.loc[train_index]\n strat_X_test_fold = self.data.loc[test_index]\n strat_y_test_fold = self.labels.loc[test_index]\n \n # 训练模型\n clone_model.fit(strat_X_train_folds, strat_y_train_folds)\n # 预测值(这里是分类模型的分类结果)\n test_labels_pred = clone_model.predict(strat_X_test_fold)\n \n # 这里使用的是分类模型用的F1值,如果是回归模型可以换成相应的模型\n score_fold = f1_score(labels.loc[test_index], test_labels_pred, average=\"weighted\")\n \n # 避免重复向列表里重复添加值\n if self.i < self.cv:\n self.score.append(score_fold)\n else:\n None\n \n self.i += 1\n \n return self.score\n \n def transform(self, X, y=None):\n return self\n\n def mean(self):\n \"\"\"返回交叉验证评分的平均值\"\"\"\n return np.array(self.score).mean()\n \n def std(self):\n \"\"\"返回交叉验证评分的标准差\"\"\"\n return np.array(self.score).std()",
"_____no_output_____"
],
[
"from sklearn.linear_model import SGDClassifier\n\n# 分类模型\nclf_model = SGDClassifier(max_iter=5, tol=-np.infty, random_state=42)\n# 基于分层抽样的交叉验证,data是只含特征值的完整数据集,labels是只含标签值的完整数据集\nclf_cross_val = stratified_cross_val_score(clf_model, data, labels, cv=5, random_state=42)",
"_____no_output_____"
],
[
"# data2是含有特征值和聚类结果的完整数据集\nclf_cross_val_score = clf_cross_val.fit(data2, data2[\"km_clustering_label\"])\n\n# 每折交叉验证的评分\nclf_cross_val.score",
"/usr/local/lib/python3.7/site-packages/sklearn/metrics/classification.py:1439: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no true samples.\n 'recall', 'true', average, warn_for)\n/usr/local/lib/python3.7/site-packages/sklearn/metrics/classification.py:1437: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n/usr/local/lib/python3.7/site-packages/sklearn/metrics/classification.py:1439: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no true samples.\n 'recall', 'true', average, warn_for)\n/usr/local/lib/python3.7/site-packages/sklearn/metrics/classification.py:1437: UndefinedMetricWarning: F-score is ill-defined and being set to 0.0 in labels with no predicted samples.\n 'precision', 'predicted', average, warn_for)\n"
],
[
"# 交叉验证评分的平均值\nclf_cross_val.mean()",
"_____no_output_____"
],
[
"# 交叉验证评分的标准差\nclf_cross_val.std()",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e49e24e41167b24ae2d0e34ab156012f65d35
| 37,979 |
ipynb
|
Jupyter Notebook
|
devel_notes/notebooks/.ipynb_checkpoints/Alphafold1_bpp_visualization-checkpoint.ipynb
|
mekhub/alphafold
|
8d89abf73ea07841b550b968aceae794acb244df
|
[
"MIT"
] | 3 |
2019-05-15T16:46:20.000Z
|
2019-07-19T13:27:45.000Z
|
devel_notes/notebooks/Alphafold1_bpp_visualization.ipynb
|
mekhub/alphafold
|
8d89abf73ea07841b550b968aceae794acb244df
|
[
"MIT"
] | null | null | null |
devel_notes/notebooks/Alphafold1_bpp_visualization.ipynb
|
mekhub/alphafold
|
8d89abf73ea07841b550b968aceae794acb244df
|
[
"MIT"
] | 4 |
2020-02-08T02:43:01.000Z
|
2021-08-22T09:23:17.000Z
| 263.743056 | 17,516 | 0.927592 |
[
[
[
"import sys, os\nsys.path.append(os.path.join(os.getcwd(), '..'))\nfrom alphafold.partition import *\n(Z,bpp,dZ) = partition( 'CGGGGCCGAAAACGGCAACCCGA', circle=True)\nprint bpp[12][7]\n",
"sequence = CGGGGCCGAAAACGGCAACCCGA\ncutpoint = -----------------------\ncircle = True\nZ = 3.52669096843e+11\n0.979140435532\n"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\nf, ax = plt.subplots(figsize=(9,9))\nsns.heatmap( bpp, linewidths=0.1,square=True, vmin=0, vmax=1,ax=ax)",
"_____no_output_____"
],
[
"(Z,bpp,dZ) = partition( 'CGGCAACCCGACGGGGCCGAAAA', circle=True)\nprint bpp[0][18]",
"sequence = CGGCAACCCGACGGGGCCGAAAA\ncutpoint = -----------------------\ncircle = True\nZ = 3.52669096843e+11\n0.979140435532\n"
],
[
"f, ax = plt.subplots(figsize=(9,9))\nsns.heatmap( bpp, linewidths=0.1,square=True, vmin=0, vmax=1,ax=ax)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a9e50c2758c142d35b0e9e2bf9778f4848990b5
| 651,755 |
ipynb
|
Jupyter Notebook
|
scripts/UBE3A_HUN_paper_plots.ipynb
|
CCSB-DFCI/UBE3A_HUN_paper_pub
|
3d44ad1722574aa26b342bd2129c122b6f692899
|
[
"MIT"
] | null | null | null |
scripts/UBE3A_HUN_paper_plots.ipynb
|
CCSB-DFCI/UBE3A_HUN_paper_pub
|
3d44ad1722574aa26b342bd2129c122b6f692899
|
[
"MIT"
] | null | null | null |
scripts/UBE3A_HUN_paper_plots.ipynb
|
CCSB-DFCI/UBE3A_HUN_paper_pub
|
3d44ad1722574aa26b342bd2129c122b6f692899
|
[
"MIT"
] | null | null | null | 808.629032 | 32,134 | 0.939275 |
[
[
[
"# notebook that produces all plots for UBE3A_HUN_paper\n\nimport matplotlib.pyplot as plt\nimport config\n% matplotlib inline\n\nmodes = ['UBE3A','CAMK2D']\n",
"_____no_output_____"
],
[
"# UBE3A and CAMK2D network\n# plot the distribution of the fraction of seeds retained in the randomly built networks \n# and compare to the fraction of seeds in the real network\n\nfor mode in modes:\n file_graphs = config.output_path + 'summary_test_signif_' + mode + '_QBCHL_rand_graph_stats.txt'\n file1 = open(file_graphs,'r')\n entries_graphs = file1.readlines()\n file1.close()\n\n fracs_seeds = []\n for line in entries_graphs[1:]:\n tab_list = str.split(line[:-1],'\\t')\n seeds_in_n = int(tab_list[2])\n seeds_start = int(tab_list[1])\n frac_seeds = seeds_in_n/float(seeds_start)\n if tab_list[0] == 'real':\n real_frac = frac_seeds\n else:\n fracs_seeds.append(frac_seeds)\n\n plt.hist(fracs_seeds,bins=20,color=\"grey\")\n plt.xlabel('Fraction of seed genes in ' + mode + ' network',fontsize=12)\n plt.ylabel('Frequency',fontsize=12)\n plt.title('Significance of fraction of\\nseed genes in ' + mode + ' network',fontsize=14)\n plt.xlim([0,1])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_frac,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + 'QBCHL_signif_frac_seeds_in_' + mode + '_network.pdf')\n plt.show()\n\n num_fracs_larger = filter(lambda x: x >= real_frac,fracs_seeds)\n print 'Significance of fraction of seed genes that are retained in', mode, 'network:', float(len(num_fracs_larger))/len(fracs_seeds)",
"_____no_output_____"
],
[
"# UBE3A and CAMK2D network\n# plot the distribution of the LCC size of the randomly built networks \n# and compare to the LCC size of the real network\n\nfor m,mode in enumerate(modes):\n file_graphs = config.output_path + 'summary_test_signif_' + mode + '_QBCHL_rand_graph_stats.txt'\n file1 = open(file_graphs,'r')\n entries_graphs = file1.readlines()\n file1.close()\n\n lcc_sizes = []\n for line in entries_graphs[1:]:\n tab_list = str.split(line[:-1],'\\t')\n lcc_size = int(tab_list[5])\n if tab_list[0] == 'real':\n real_lcc = lcc_size\n else:\n lcc_sizes.append(lcc_size)\n\n plt.hist(lcc_sizes,bins=20,color=\"grey\")\n plt.xlabel('LCC size of ' + mode + ' network',fontsize=12)\n plt.ylabel('Frequency',fontsize=12)\n plt.title('Significance of LCC size of ' + mode + ' network',fontsize=14)\n plt.xlim([0,220])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_lcc,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + 'QBCHL_signif_LCCsize_in_' + mode + '_network.pdf')\n plt.show()\n\n num_lccs_larger = filter(lambda x: x >= real_lcc,lcc_sizes)\n print 'Significance of LCC size of', mode, 'network:', float(len(num_lccs_larger))/len(lcc_sizes)",
"_____no_output_____"
],
[
"# HUN network\n# plot the distribution of the LCC size of the randomly built networks \n# and compare to the LCC size of the real network\ninfile_rand = config.output_path + 'HUN_network_QBCHL.node_attributes_rand_lccs.txt'\nfile1 = open(infile_rand,'r')\nentries = file1.readlines()\nfile1.close()\nlcc_sizes = []\nfor line in entries[1:]:\n tab_list = str.split(line[:-1],'\\t')\n lcc_size = int(tab_list[1])\n if tab_list[0] == 'real':\n real_lcc = lcc_size\n else:\n lcc_sizes.append(lcc_size)\n \nplt.hist(lcc_sizes,bins=20,color=\"grey\")\nplt.xlabel('LCC size of HUN network',fontsize=12)\nplt.ylabel('Frequency',fontsize=12)\nplt.title('Significance of LCC size of HUN network',fontsize=14)\nplt.xlim([0,200])\nax = plt.gca()\nylim = ax.get_ylim()\nxlim = ax.get_xlim()\nx = xlim[1] - xlim[0]\ny = ylim[1] - ylim[0]\nplt.arrow(real_lcc,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\nplt.tight_layout()\nplt.savefig(config.plot_path + 'QBCHL_signif_LCCsize_in_HUN_network.pdf')\nplt.show()\n\nnum_lccs_larger = filter(lambda x: x >= real_lcc,lcc_sizes)\nprint 'Significance of LCC size of HUN network:', float(len(num_lccs_larger))/len(lcc_sizes)",
"_____no_output_____"
],
[
"# CAMK2D - HUN complex closeness\n# draw the distribution of the number of CAMK2D preys that interact with HUN core complex proteins \n# as obtained from randomized networks and show where the real observation lies\nprefixes = ['CAMK2D_HUN','CAMK2D_HN','CAMK2D_UBE3A']\ntitles = ['HUN complex','HN complex','UBE3A']\nfor i,prefix in enumerate(prefixes):\n infile_rand = config.output_path + prefix + '_counts_preys_connected_to_core_complex_members_rand_distr.txt'\n file1 = open(infile_rand,'r')\n entries = file1.readlines()\n file1.close()\n rand_values = []\n for line in entries[1:]:\n tab_list = str.split(line[:-1],'\\t')\n value = int(tab_list[1])\n if tab_list[0] == 'real':\n real_count = value\n else:\n rand_values.append(value)\n\n plt.figure(figsize=(5,4))\n plt.hist(rand_values,bins=range(7),color=\"grey\",edgecolor='black')\n plt.xlabel('Number of CAMK2D preys linked\\nto ' + titles[i] + ' core members',size=12)\n plt.ylabel('Frequency',size=12)\n plt.title('Significance of closeness\\nof CAMK2D preys to ' + titles[i] + ' core members',size=14)\n plt.xlim([0,7])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_count,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + prefix + '_counts_preys_connected_to_core_complex_members.pdf')\n plt.show()\n\n num_more = filter(lambda x: x >= real_count,rand_values)\n print 'Significance of number of CAMK2D preys linked to ' + titles[i] + ' core members:', float(len(num_more))/len(rand_values)",
"_____no_output_____"
],
[
"# CAMK2D - HUN complex closeness\n# draw the distribution of the number of CAMK2D preys that interact with HUN complex preys\n# as obtained from randomized networks and show where the real observation lies\nfor i,prefix in enumerate(prefixes):\n infile_rand = config.output_path + prefix + '_counts_preys_connected_to_complex_preys_rand_distr.txt'\n file1 = open(infile_rand,'r')\n entries = file1.readlines()\n file1.close()\n rand_values = []\n for line in entries[1:]:\n tab_list = str.split(line[:-1],'\\t')\n value = int(tab_list[1])\n if tab_list[0] == 'real':\n real_count = value\n else:\n rand_values.append(value)\n\n plt.figure(figsize=(5,4))\n plt.hist(rand_values,bins=18,color=\"grey\")\n plt.xlabel('Number of CAMK2D preys\\nlinked to ' + titles[i] + ' preys',size=12)\n plt.ylabel('Frequency',size=12)\n plt.title('Significance of closeness of\\nCAMK2D preys to ' + titles[i] + ' preys',size=14)\n plt.xlim([0,60])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_count,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + prefix + '_counts_preys_connected_to_complex_preys.pdf')\n plt.show()\n\n num_more = filter(lambda x: x >= real_count,rand_values)\n print 'Significance of number of CAMK2D preys linked to ' + titles[i] + ' preys:', float(len(num_more))/len(rand_values)",
"_____no_output_____"
],
[
"# CAMK2D - HUN complex closeness\n# draw the distribution of the number of HUN complex members that interact with \n# CAMK2D preys as obtained from randomized networks and show where the real observation lies\nfor i,prefix in enumerate(prefixes):\n infile_rand = config.output_path + prefix + '_counts_complex_preys_connected_to_preys_rand_distr.txt'\n file1 = open(infile_rand,'r')\n entries = file1.readlines()\n file1.close()\n rand_values = []\n for line in entries[1:]:\n tab_list = str.split(line[:-1],'\\t')\n value = int(tab_list[1])\n if tab_list[0] == 'real':\n real_count = value\n else:\n rand_values.append(value)\n\n plt.figure(figsize=(5,4))\n plt.hist(rand_values,bins=18,color=\"grey\")\n plt.xlabel('Number of ' + titles[i] + ' preys\\nthat interact with CAMK2D preys',size=12)\n plt.ylabel('Frequency',size=12)\n plt.title('Significance of closeness of\\n' + titles[i] + ' preys to CAMK2D preys',size=14)\n plt.xlim([0,130])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_count,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + prefix + '_counts_complex_preys_connected_to_preys.pdf')\n plt.show()\n\n num_more = filter(lambda x: x >= real_count,rand_values)\n print 'Significance of number of ' + titles[i] + ' preys linked to CAMK2D preys:', float(len(num_more))/len(rand_values)",
"_____no_output_____"
],
[
"# significance of closeness of preys per bait\nxupper = [14,15,8,150,30,10,60,35,90,20,400]\nnum_bins = [12,12,6,20,10,4,20,10,20,10,20]\nseed_files = ['CAMK2D_seed_file.txt','ECH1_seed_file.txt','ECI2_seed_file.txt','HERC2_seed_file.txt',\\\n 'HIF1AN_seed_file.txt','MAPK6_seed_file.txt','NEURL4_seed_file.txt','UBE3A_seed_file.txt',\\\n 'UBE3A_seed_file_with_proteasome.txt','UBE3A_seed_file_no_Y2H.txt','HUN_complex_seed_file.txt']\nfor i,seed_file in enumerate(seed_files):\n infile_rand = config.output_path + seed_file[:-4] + '_rand_lccs.txt'\n file1 = open(infile_rand,'r')\n entries = file1.readlines()\n file1.close()\n lcc_sizes = []\n for line in entries[1:]:\n tab_list = str.split(line[:-1],'\\t')\n lcc_size = (float(tab_list[1]))\n if tab_list[0] == 'real':\n real_lcc = lcc_size\n else:\n lcc_sizes.append(lcc_size)\n\n plt.hist(lcc_sizes,bins=num_bins[i],color=\"grey\")\n plt.xlabel('LCC size of ' + seed_file[:-4],fontsize=12)\n plt.ylabel('Frequency',fontsize=12)\n plt.title('Significance of LCC size of ' + seed_file[:-4],fontsize=14)\n plt.xlim([0,xupper[i]])\n ax = plt.gca()\n ylim = ax.get_ylim()\n xlim = ax.get_xlim()\n x = xlim[1] - xlim[0]\n y = ylim[1] - ylim[0]\n plt.arrow(real_lcc,y/4.0,0,y/7.0*(-1),color='red',head_width=x/60.0,head_length=y/20.0)\n plt.tight_layout()\n plt.savefig(config.plot_path + 'QBCHL_signif_LCCsize_in_' + seed_file[:-4] + '.pdf')\n plt.show()\n\n num_lccs_larger = filter(lambda x: x >= real_lcc,lcc_sizes)\n print 'Significance of LCC size of ' + seed_file[:-4], float(len(num_lccs_larger))/len(lcc_sizes)\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e55f81a8571f08c325c44c612a6985833ca49
| 166,242 |
ipynb
|
Jupyter Notebook
|
st17_sns.ipynb
|
aykuli/stepic-ml-courses
|
83f079e71dde288d13f211eb4f12fa231e750d20
|
[
"MIT"
] | null | null | null |
st17_sns.ipynb
|
aykuli/stepic-ml-courses
|
83f079e71dde288d13f211eb4f12fa231e750d20
|
[
"MIT"
] | null | null | null |
st17_sns.ipynb
|
aykuli/stepic-ml-courses
|
83f079e71dde288d13f211eb4f12fa231e750d20
|
[
"MIT"
] | null | null | null | 412.511166 | 73,460 | 0.926673 |
[
[
[
"import pandas as pd\nimport numpy as np",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"st = pd.read_csv('./data/StudentsPerformance.csv')",
"_____no_output_____"
],
[
"st",
"_____no_output_____"
],
[
"st = st.rename(columns={\"parental level of education\" : 'parental_level_of_education',\n 'race/ethnicity' : 'race', \n 'test preparation course':'test_preparation_course', \n 'math score':'math_score',\n 'reading score':'reading_score',\n 'writing score':'writing_score'})",
"_____no_output_____"
],
[
"ax = sns.lmplot(x=\"math_score\", y=\"writing_score\", data=st, hue=\"gender\",fit_reg=False)\nax.set_xlabels('Math score')\nax.set_ylabels('Writing score')",
"_____no_output_____"
],
[
"st.math_score.hist()",
"_____no_output_____"
],
[
"st.plot.scatter(x = 'math_score', y = 'reading_score')",
"_____no_output_____"
],
[
"ax = sns.lmplot(x = 'math_score', y = 'reading_score', data = st, hue=\"parental_level_of_education\", fit_reg=False)\nax.set_xlabels('Math score')\nax.set_titles=['0', '1']",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e579a958490c5fa95081ae78abf0fb5c13f10
| 18,148 |
ipynb
|
Jupyter Notebook
|
utils.ipynb
|
leonardocunha2107/SinGAN
|
751a52be28dc180f0a08282ff5cd9b968e54c8c1
|
[
"MIT"
] | null | null | null |
utils.ipynb
|
leonardocunha2107/SinGAN
|
751a52be28dc180f0a08282ff5cd9b968e54c8c1
|
[
"MIT"
] | null | null | null |
utils.ipynb
|
leonardocunha2107/SinGAN
|
751a52be28dc180f0a08282ff5cd9b968e54c8c1
|
[
"MIT"
] | null | null | null | 67.716418 | 6,068 | 0.81447 |
[
[
[
"from skimage.io import imread,imsave,imshow\nfrom skimage.transform import resize\n\nim1=imread('Input/Images/eiffel.jpg')\nim2=imread('Input/Images/purse.png')\n\n",
"_____no_output_____"
],
[
"im=imread('Input/Paint/eiffel_paint.png')\nim=resize(im,(26,26))\nimshow(im)",
"_____no_output_____"
],
[
"img=imread('Input/Images/purse.jpg')\nimsave('Input/Images/purse.png',img)",
"_____no_output_____"
],
[
"diff=abs(im1-im2[:,:,:3])\n\ndiff[diff!=0]=1\nimshow(diff*255)",
"_____no_output_____"
],
[
"imsave('Input/Editing/purse_ref_mask.png',diff)",
"<ipython-input-41-d927a93c4c28>:1: UserWarning: Input/Editing/purse_ref_mask.png is a low contrast image\n imsave('Input/Editing/purse_ref_mask.png',diff)\n"
],
[
"mask=imread('Input/Editing/eiffel_ref_mask.png')",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\n\ndef quant2centers(paint, centers):\n kmeans = KMeans(n_clusters=5, init=centers, n_init=1).fit(arr)\n labels = kmeans.labels_\n #centers = kmeans.cluster_centers_\n x = centers[labels]\n x = torch.from_numpy(x)\n x = move_to_gpu(x)\n x = x.type(torch.cuda.FloatTensor) if torch.cuda.is_available() else x.type(torch.FloatTensor)\n #x = x.type(torch.cuda.FloatTensor)\n x = x.reshape(paint.shape)\n return x\n\n return paint\nprev=im2\nfor k in range(2,8):\n arr = prev.reshape((-1, 3))\n kmeans = KMeans(n_clusters=k, random_state=0).fit(arr)\n labels = kmeans.labels_\n centers = kmeans.cluster_centers_\n x = centers[labels]\n quant= x.reshape(prev.shape)\n imsave(f'Output/quant/purse{k}.png',quant)\n\n\n",
"Lossy conversion from float64 to uint8. Range [154.35836712835552, 248.30585133667034]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float64 to uint8. Range [109.42729641694618, 251.9961955207563]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float64 to uint8. Range [79.0001438538508, 253.70741808753024]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float64 to uint8. Range [70.3643105228654, 254.06431061745252]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float64 to uint8. Range [49.81046034147363, 254.22474342904994]. Convert image to uint8 prior to saving to suppress this warning.\nLossy conversion from float64 to uint8. Range [41.05836322138862, 254.29932514510884]. Convert image to uint8 prior to saving to suppress this warning.\n"
],
[
"imsave('quant.png',quant)",
"Lossy conversion from float64 to uint8. Range [79.00014385385083, 253.70741808753021]. Convert image to uint8 prior to saving to suppress this warning.\n"
],
[
"import torch\n\nreals=torch.load('TrainedModels/eiffel/scale_factor=0.750000,alpha=10/reals.pth')",
"_____no_output_____"
],
[
"for r in reals:\n print(r.shape)",
"torch.Size([1, 3, 26, 26])\ntorch.Size([1, 3, 33, 33])\ntorch.Size([1, 3, 42, 42])\ntorch.Size([1, 3, 54, 54])\ntorch.Size([1, 3, 70, 70])\ntorch.Size([1, 3, 90, 90])\ntorch.Size([1, 3, 117, 117])\ntorch.Size([1, 3, 150, 150])\ntorch.Size([1, 3, 194, 194])\ntorch.Size([1, 3, 250, 250])\n"
],
[
"len(reals)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e66a3f505d77c7ff97cd53ac4df8d9f0eb18d
| 73,230 |
ipynb
|
Jupyter Notebook
|
New_Zealand_Universities/Lincoln_University/Lincoln_University .ipynb
|
mohansah/Web_Scraping
|
3668af35f03748a21b5153c7133fdd72fb90811f
|
[
"MIT"
] | null | null | null |
New_Zealand_Universities/Lincoln_University/Lincoln_University .ipynb
|
mohansah/Web_Scraping
|
3668af35f03748a21b5153c7133fdd72fb90811f
|
[
"MIT"
] | null | null | null |
New_Zealand_Universities/Lincoln_University/Lincoln_University .ipynb
|
mohansah/Web_Scraping
|
3668af35f03748a21b5153c7133fdd72fb90811f
|
[
"MIT"
] | 1 |
2021-02-09T18:21:57.000Z
|
2021-02-09T18:21:57.000Z
| 50.054682 | 91 | 0.597679 |
[
[
[
"import requests\nimport bs4\nimport csv\n\nlist=[]\nlis_h=['Course_Name','Link']\nlist.append(lis_h)",
"_____no_output_____"
],
[
"res1=requests.get('http://www.lincoln.ac.nz/Study/Courses/') \nsoup1=bs4.BeautifulSoup(res1.text,'lxml')",
"_____no_output_____"
],
[
"s1=soup1.select('a')\nfor i in s1[3:]:\n print(str(i.text)[11:])\n print(i.get('href'))",
"Academic English for Postgraduate Study\nhttp://www.lincoln.ac.nz/ACEN 301\nFurther Academic English for Postgraduate Study\nhttp://www.lincoln.ac.nz/ACEN 302\nAcademic Skills for Postgraduate Study\nhttp://www.lincoln.ac.nz/ACEN 303\nAccounting Fundamentals\nhttp://www.lincoln.ac.nz/ACCT 101\nManagement Accounting\nhttp://www.lincoln.ac.nz/ACCT 202\nAccounting Information Systems\nhttp://www.lincoln.ac.nz/ACCT 203\nFinancial Accounting\nhttp://www.lincoln.ac.nz/ACCT 211\nAuditing\nhttp://www.lincoln.ac.nz/ACCT 302\nTaxation\nhttp://www.lincoln.ac.nz/ACCT 306\nAdvanced Management Accounting\nhttp://www.lincoln.ac.nz/ACCT 308\nAdvanced Financial Accounting\nhttp://www.lincoln.ac.nz/ACCT 310\nAdvanced Management Accounting\nhttp://www.lincoln.ac.nz/ACCT 603\nContemporary Issues in Financial Accounting\nhttp://www.lincoln.ac.nz/ACCT 605\nAdvanced Taxation\nhttp://www.lincoln.ac.nz/ACCT 609\nCPA Ethics and Governance\nhttp://www.lincoln.ac.nz/ACCT 620\nCPA Strategic Management Accounting\nhttp://www.lincoln.ac.nz/ACCT 621\nCPA Financial Reporting\nhttp://www.lincoln.ac.nz/ACCT 622\nCPA Global Strategy and Leadership\nhttp://www.lincoln.ac.nz/ACCT 623\nCPA Advanced Audit and Assurance\nhttp://www.lincoln.ac.nz/ACCT 624\nCPA Financial Risk Management\nhttp://www.lincoln.ac.nz/ACCT 625\nResearch Essay\nhttp://www.lincoln.ac.nz/ACCT 698\n- Practicum: Practical Experience in Agribusiness and Commerce\nhttp://www.lincoln.ac.nz/PREFIX 393\nAgricultural Practicum\nhttp://www.lincoln.ac.nz/AGRI 393\nLivestock Production Systems\nhttp://www.lincoln.ac.nz/ANSC 021\nBeef and Deer Production\nhttp://www.lincoln.ac.nz/ANSC 071\nDairy Production\nhttp://www.lincoln.ac.nz/ANSC 072\nSheep Production\nhttp://www.lincoln.ac.nz/ANSC 073\nAnimal Science\nhttp://www.lincoln.ac.nz/ANSC 105\nAnimal Health\nhttp://www.lincoln.ac.nz/ANSC 207\nLivestock Production Science\nhttp://www.lincoln.ac.nz/ANSC 213\nDairy Production Science\nhttp://www.lincoln.ac.nz/ANSC 312\nMeat and Wool Production Science\nhttp://www.lincoln.ac.nz/ANSC 314\nAnimal Physiology\nhttp://www.lincoln.ac.nz/ANSC 319\nAnimal Nutrition, Biochemistry and Metabolism\nhttp://www.lincoln.ac.nz/ANSC 327\nAdvanced Livestock Production\nhttp://www.lincoln.ac.nz/ANSC 635\nTopics in Advanced Livestock Production\nhttp://www.lincoln.ac.nz/ANSC 636\nAdvanced Animal Science\nhttp://www.lincoln.ac.nz/ANSC 637\nTopics in Advanced Animal Science\nhttp://www.lincoln.ac.nz/ANSC 638\nBiochemistry II\nhttp://www.lincoln.ac.nz/BICH 207\nPrinciples of Malting and Brewing\nhttp://www.lincoln.ac.nz/BICH 209\nGeneral Biochemistry\nhttp://www.lincoln.ac.nz/BICH 601\nProtein Biochemistry\nhttp://www.lincoln.ac.nz/BICH 633\nPlant Cell Physiology\nhttp://www.lincoln.ac.nz/BICH 634\nPlant Biochemistry\nhttp://www.lincoln.ac.nz/BICH 636\nNutritional Biochemistry\nhttp://www.lincoln.ac.nz/BICH 637\nPlant and Animal Health\nhttp://www.lincoln.ac.nz/BIOS 021\nPlant Health\nhttp://www.lincoln.ac.nz/BIOS 022\nPlant and Animal Health for Organics\nhttp://www.lincoln.ac.nz/BIOS 023\nBiological Sciences\nhttp://www.lincoln.ac.nz/BIOS 110\nAdvanced Toxicology A\nhttp://www.lincoln.ac.nz/BIOS 604\nQuantitative Genetics\nhttp://www.lincoln.ac.nz/BIOS 606\nPrinciples of Management\nhttp://www.lincoln.ac.nz/BMGT 116\nSustainable Sourcing\nhttp://www.lincoln.ac.nz/BMGT 201\nProductivity Management\nhttp://www.lincoln.ac.nz/BMGT 211\nOrganisation and Human Resource Management\nhttp://www.lincoln.ac.nz/BMGT 221\nBusiness and Sustainability\nhttp://www.lincoln.ac.nz/BMGT 301\nBusiness Strategy\nhttp://www.lincoln.ac.nz/BMGT 306\nSupply Chain System Optimisation\nhttp://www.lincoln.ac.nz/BMGT 308\nQuality Systems\nhttp://www.lincoln.ac.nz/BMGT 314\nProject Planning and Management\nhttp://www.lincoln.ac.nz/BMGT 315\nEntrepreneurship and Small Business Management\nhttp://www.lincoln.ac.nz/BMGT 321\nAccommodation Management\nhttp://www.lincoln.ac.nz/BMGT 322\nInternational Management\nhttp://www.lincoln.ac.nz/BMGT 324\nAdvanced Business Strategy\nhttp://www.lincoln.ac.nz/BMGT 618\nManaging Programmes of Change\nhttp://www.lincoln.ac.nz/BMGT 686\nIntroductory Statistics\nhttp://www.lincoln.ac.nz/COMM 111\nFinancial Information for Business\nhttp://www.lincoln.ac.nz/COMM 112\nManaging People\nhttp://www.lincoln.ac.nz/COMM 201\nIntegrated Business Analysis\nhttp://www.lincoln.ac.nz/COMM 301\nPrinciples of Managerial Economics\nhttp://www.lincoln.ac.nz/COMM 601\nPrinciples of Accounting and Finance\nhttp://www.lincoln.ac.nz/COMM 602\nPrinciples of Business Management\nhttp://www.lincoln.ac.nz/COMM 603\nPrinciples of Marketing\nhttp://www.lincoln.ac.nz/COMM 604\nResearch for Managers\nhttp://www.lincoln.ac.nz/COMM 605\nStrategic Business Analysis\nhttp://www.lincoln.ac.nz/COMM 606\nCommunication for Development Professionals\nhttp://www.lincoln.ac.nz/COMN 604\nComputing and Communication\nhttp://www.lincoln.ac.nz/COMP 021\nProblem Solving and Data Management\nhttp://www.lincoln.ac.nz/COMP 112\nComputer Modelling and Simulation\nhttp://www.lincoln.ac.nz/COMP 308\nComputer Modelling of Environmental & Biological Systems\nhttp://www.lincoln.ac.nz/COMP 622\nNeural Networks Applications\nhttp://www.lincoln.ac.nz/COMP 627\nAgent-Based Computing\nhttp://www.lincoln.ac.nz/COMP 635\nDigital Tools for Design\nhttp://www.lincoln.ac.nz/DESN 101\nIntroduction to 3D Design\nhttp://www.lincoln.ac.nz/DESN 102\nVisual Communication\nhttp://www.lincoln.ac.nz/DESN 103\nHistory of Design and Culture\nhttp://www.lincoln.ac.nz/DESN 104\nDesign Theory\nhttp://www.lincoln.ac.nz/DESN 301\nAdvanced Design Project\nhttp://www.lincoln.ac.nz/DESN 603\nEcology I: New Zealand Ecology and Conservation\nhttp://www.lincoln.ac.nz/ECOL 103\nBiological Diversity\nhttp://www.lincoln.ac.nz/ECOL 202\nMolecular Ecology and Evolution\nhttp://www.lincoln.ac.nz/ECOL 204\nField Ecology Methods\nhttp://www.lincoln.ac.nz/ECOL 293\nApplied Ecology and Conservation\nhttp://www.lincoln.ac.nz/ECOL 302\nAgroEcology\nhttp://www.lincoln.ac.nz/ECOL 309\nResearch Methods in Ecology\nhttp://www.lincoln.ac.nz/ECOL 608\nConservation Biology\nhttp://www.lincoln.ac.nz/ECOL 609\nWildlife Management\nhttp://www.lincoln.ac.nz/ECOL 612\nAnimal Behaviour\nhttp://www.lincoln.ac.nz/ECOL 631\nEconomies and Markets\nhttp://www.lincoln.ac.nz/ECON 113\nLand Economics\nhttp://www.lincoln.ac.nz/ECON 211\nInternational Trade\nhttp://www.lincoln.ac.nz/ECON 212\nMacroeconomic Issues and Policies\nhttp://www.lincoln.ac.nz/ECON 216\nMarkets, firms and consumers\nhttp://www.lincoln.ac.nz/ECON 217\nInternational Economics\nhttp://www.lincoln.ac.nz/ECON 302\nEconometrics\nhttp://www.lincoln.ac.nz/ECON 307\nThe Economics of Food Markets and Policy\nhttp://www.lincoln.ac.nz/ECON 325\nThe Economics of Natural Resources and the Environment\nhttp://www.lincoln.ac.nz/ECON 326\nThe Economics of Development\nhttp://www.lincoln.ac.nz/ECON 327\nInternational Trade\nhttp://www.lincoln.ac.nz/ECON 602\nDevelopment Economics\nhttp://www.lincoln.ac.nz/ECON 603\nQuantitative Economic Analysis\nhttp://www.lincoln.ac.nz/ECON 609\nApplied Research Methods\nhttp://www.lincoln.ac.nz/ECON 615\nEngineering I\nhttp://www.lincoln.ac.nz/ENGN 023\nEngineering II\nhttp://www.lincoln.ac.nz/ENGN 076\nBuilding Construction\nhttp://www.lincoln.ac.nz/ENGN 105\nLand Surfaces, Water and Structures\nhttp://www.lincoln.ac.nz/ENGN 106\nPrecision Agriculture\nhttp://www.lincoln.ac.nz/ENGN 201\nFood Engineering\nhttp://www.lincoln.ac.nz/ENGN 230\nBuildings Facilities Management\nhttp://www.lincoln.ac.nz/ENGN 232\nAgricultural Engineering\nhttp://www.lincoln.ac.nz/ENGN 276\nWinery Equipment and Structure\nhttp://www.lincoln.ac.nz/ENGN 361\nAdvanced Entomology\nhttp://www.lincoln.ac.nz/ENTO 612\nEnvironmental Analysis\nhttp://www.lincoln.ac.nz/ERST 201\nEnvironmental Analysis with Geographic Information Systems\nhttp://www.lincoln.ac.nz/ERST 202\nEnvironmental Monitoring and Resource Assessment\nhttp://www.lincoln.ac.nz/ERST 203\nPrinciples of Urban and Regional Planning\nhttp://www.lincoln.ac.nz/ERST 205\nEnvironmental Policy\nhttp://www.lincoln.ac.nz/ERST 302\nGIS and Applications in Natural Resource Analysis\nhttp://www.lincoln.ac.nz/ERST 310\nCatchment Management\nhttp://www.lincoln.ac.nz/ERST 313\nRisk and Resilience\nhttp://www.lincoln.ac.nz/ERST 330\nEnvironmental Planning\nhttp://www.lincoln.ac.nz/ERST 340\nDesign or Research Essay\nhttp://www.lincoln.ac.nz/ERST 398\nResearch Essay\nhttp://www.lincoln.ac.nz/ERST 399\nAdvanced Theory in Resource Studies\nhttp://www.lincoln.ac.nz/ERST 601\nAdvanced Urban, Regional and Resource Planning\nhttp://www.lincoln.ac.nz/ERST 604\nAdvanced Geographic Information Systems A\nhttp://www.lincoln.ac.nz/ERST 606\nAdvanced Geographic Information Systems B\nhttp://www.lincoln.ac.nz/ERST 607\nAdvanced Energy and Transport Planning\nhttp://www.lincoln.ac.nz/ERST 608\nAdvanced Risk and Resilience\nhttp://www.lincoln.ac.nz/ERST 609\nAdvanced Environmental Management Systems\nhttp://www.lincoln.ac.nz/ERST 620\nPrinciples of Environmental Impact Assessment\nhttp://www.lincoln.ac.nz/ERST 621\nAdvanced Professional Planning Methods and Practice\nhttp://www.lincoln.ac.nz/ERST 624\nSystems Thinking and Dynamics\nhttp://www.lincoln.ac.nz/ERST 625\nEnvironmental Policy and Planning\nhttp://www.lincoln.ac.nz/ERST 630\nEconomics in Environmental Policy\nhttp://www.lincoln.ac.nz/ERST 632\nApplied Policy Analysis\nhttp://www.lincoln.ac.nz/ERST 634\nGroup Case Study\nhttp://www.lincoln.ac.nz/ERST 635\nAspects of Sustainability: An International Perspective\nhttp://www.lincoln.ac.nz/ERST 636\nFinance Fundamentals\nhttp://www.lincoln.ac.nz/FINC 101\nFinancial Management\nhttp://www.lincoln.ac.nz/FINC 204\nInvestments\nhttp://www.lincoln.ac.nz/FINC 211\nCorporate Financial Strategy\nhttp://www.lincoln.ac.nz/FINC 304\nInvestment Management\nhttp://www.lincoln.ac.nz/FINC 305\nInternational Finance\nhttp://www.lincoln.ac.nz/FINC 307\nInternational Financial Markets, Institutions and Policy\nhttp://www.lincoln.ac.nz/FINC 310\nFutures and Options\nhttp://www.lincoln.ac.nz/FINC 312\nFinance Theory and Corporate Policy\nhttp://www.lincoln.ac.nz/FINC 601\nCommercial Banking\nhttp://www.lincoln.ac.nz/FINC 603\nFinance, Futures and Options\nhttp://www.lincoln.ac.nz/FINC 604\nMicrofinance\nhttp://www.lincoln.ac.nz/FINC 605\nFinancial Reporting and Analysis\nhttp://www.lincoln.ac.nz/FINC 615\nInvestment Management\nhttp://www.lincoln.ac.nz/FINC 616\nFood Quality and Consumer Acceptance\nhttp://www.lincoln.ac.nz/FOOD 101\nProcessing Food for Consumers\nhttp://www.lincoln.ac.nz/FOOD 201\nFood Safety and Microbiology\nhttp://www.lincoln.ac.nz/FOOD 202\nFood Product Innovation and Quality\nhttp://www.lincoln.ac.nz/FOOD 301\nAdvanced Food Processing\nhttp://www.lincoln.ac.nz/FOOD 302\nFood Biochemistry and Biotechnology\nhttp://www.lincoln.ac.nz/FOOD 303\nMicrobial Biotechnology\nhttp://www.lincoln.ac.nz/FOOD 304\nDesign or Research Essay\nhttp://www.lincoln.ac.nz/FOOD 398\nResearch Placement\nhttp://www.lincoln.ac.nz/FOOD 399\nFood Processing and Quality\nhttp://www.lincoln.ac.nz/FOOD 601\nFood and Nutritional Biochemistry\nhttp://www.lincoln.ac.nz/FOOD 602\nFood Product Innovation\nhttp://www.lincoln.ac.nz/FOOD 604\nDesign or Research Essay\nhttp://www.lincoln.ac.nz/FOOD 698\nResearch Placement\nhttp://www.lincoln.ac.nz/FOOD 699\nApplied Agroforestry\nhttp://www.lincoln.ac.nz/FORS 070\nApplied Agroforestry\nhttp://www.lincoln.ac.nz/FORS 270\nAgroforestry\nhttp://www.lincoln.ac.nz/FORS 304\nGenetics\nhttp://www.lincoln.ac.nz/GENE 201\nApplied Genetics and Breeding\nhttp://www.lincoln.ac.nz/GENE 301\nAdvanced Breeding and Genetics\nhttp://www.lincoln.ac.nz/GENE 601\nPropagation and Nursery\nhttp://www.lincoln.ac.nz/HORT 022\nAmenity Horticulture\nhttp://www.lincoln.ac.nz/HORT 071\nFruit Crop Production\nhttp://www.lincoln.ac.nz/HORT 072\nFruit Crop Production\nhttp://www.lincoln.ac.nz/HORT 272\nDevelopment Policy, Theory and Issues\nhttp://www.lincoln.ac.nz/IRDV 601\nLandscape Planting Practice\nhttp://www.lincoln.ac.nz/LASC 206\nPlanting Design and Management\nhttp://www.lincoln.ac.nz/LASC 211\nLandscape Analysis, Planning and Design\nhttp://www.lincoln.ac.nz/LASC 215\nSite Design\nhttp://www.lincoln.ac.nz/LASC 216\nDesign Details\nhttp://www.lincoln.ac.nz/LASC 217\nLandscape and Culture\nhttp://www.lincoln.ac.nz/LASC 218\nSpecial Topic in Food Landscapes\nhttp://www.lincoln.ac.nz/LASC 230\nLandscape Ecology\nhttp://www.lincoln.ac.nz/LASC 312\nInnovative Design (A)\nhttp://www.lincoln.ac.nz/LASC 316\nLandscape Assessment and Planning\nhttp://www.lincoln.ac.nz/LASC 318\nInnovative Design (B)\nhttp://www.lincoln.ac.nz/LASC 319\nStructure Plans\nhttp://www.lincoln.ac.nz/LASC 321\nSustainable Design and Planning\nhttp://www.lincoln.ac.nz/LASC 322\nPracticum: Applied Landscape Practice\nhttp://www.lincoln.ac.nz/LASC 393\nAdvanced Design Theory\nhttp://www.lincoln.ac.nz/LASC 401\nComplex Design\nhttp://www.lincoln.ac.nz/LASC 406\nMajor Design\nhttp://www.lincoln.ac.nz/LASC 409\nDesign Critique\nhttp://www.lincoln.ac.nz/LASC 410\nLandscape Architecture Professional Practice (Special Topic)\nhttp://www.lincoln.ac.nz/LASC 415\nAdvanced Site Design\nhttp://www.lincoln.ac.nz/LASC 610\nAdvanced Practice in Landscape Architecture\nhttp://www.lincoln.ac.nz/LASC 612\nAdvanced Theory in Landscape Architecture\nhttp://www.lincoln.ac.nz/LASC 613\nAdvanced Landscape Planning and Policy\nhttp://www.lincoln.ac.nz/LASC 615\nLandscape Management\nhttp://www.lincoln.ac.nz/LASC 616\nAdvanced Design Study\nhttp://www.lincoln.ac.nz/LASC 617\nLandscape Assessment\nhttp://www.lincoln.ac.nz/LASC 620\nDesign or Research Essay\nhttp://www.lincoln.ac.nz/LASC 698\nIntroduction to Commercial Law\nhttp://www.lincoln.ac.nz/LWST 114\nCommercial Law 1\nhttp://www.lincoln.ac.nz/LWST 201\nProperty Law\nhttp://www.lincoln.ac.nz/LWST 203\nResource Management Law\nhttp://www.lincoln.ac.nz/LWST 302\nAdvanced Resource Management and Planning Law\nhttp://www.lincoln.ac.nz/LWST 602\nLand, People and Economies\nhttp://www.lincoln.ac.nz/LINC 101\nSustainable Futures\nhttp://www.lincoln.ac.nz/LINC 201\nFarm Management Systems A\nhttp://www.lincoln.ac.nz/MGMT 024\nFarm Management Systems B\nhttp://www.lincoln.ac.nz/MGMT 025\nHorticultural Management Systems A\nhttp://www.lincoln.ac.nz/MGMT 026\nHorticultural Management Systems B\nhttp://www.lincoln.ac.nz/MGMT 027\nHorticultural Management\nhttp://www.lincoln.ac.nz/MGMT 072\nFarm Management\nhttp://www.lincoln.ac.nz/MGMT 073\nPrimary Industry Systems\nhttp://www.lincoln.ac.nz/MGMT 103\nGlobal Food Systems\nhttp://www.lincoln.ac.nz/MGMT 106\nPrinciples of Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 201\nAnalysis of Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 202\nAgricultural Systems and Sustainability\nhttp://www.lincoln.ac.nz/MGMT 203\nHorticultural Systems\nhttp://www.lincoln.ac.nz/MGMT 214\nHorticultural Management Analysis\nhttp://www.lincoln.ac.nz/MGMT 216\nThe Agribusiness Environment\nhttp://www.lincoln.ac.nz/MGMT 222\nThe Food Regulatory Environment\nhttp://www.lincoln.ac.nz/MGMT 223\nAnalysis and Planning in Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 316\nDevelopment and Investment in Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 317\nOpportunity Analysis in Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 318\nVineyard and Winery Management\nhttp://www.lincoln.ac.nz/MGMT 325\nAgribusiness Strategic Management\nhttp://www.lincoln.ac.nz/MGMT 340\nIntegrated Agribusiness and Food Marketing Strategy\nhttp://www.lincoln.ac.nz/MGMT 341\nManagement Research Methods\nhttp://www.lincoln.ac.nz/MGMT 611\nPlanning and Assessing International Development Projects\nhttp://www.lincoln.ac.nz/MGMT 615\nInternational Agribusiness Systems\nhttp://www.lincoln.ac.nz/MGMT 624\nAgribusiness in Developing Economies\nhttp://www.lincoln.ac.nz/MGMT 628\nResearch for Agricultural Systems Managers\nhttp://www.lincoln.ac.nz/MGMT 634\nAdvanced Agricultural Systems Management\nhttp://www.lincoln.ac.nz/MGMT 635\nInnovation in Agricultural Systems\nhttp://www.lincoln.ac.nz/MGMT 636\nAgribusiness Value Chains\nhttp://www.lincoln.ac.nz/MGMT 637\nAgribusiness Organisations\nhttp://www.lincoln.ac.nz/MGMT 638\nDecision Tools for Agricultural Systems Management\nhttp://www.lincoln.ac.nz/MGMT 639\nResearch Essay\nhttp://www.lincoln.ac.nz/MGMT 698\nResearch Placement\nhttp://www.lincoln.ac.nz/MGMT 699\nTe Tiriti O Waitangi (The Treaty of Waitangi)\nhttp://www.lincoln.ac.nz/MAST 104\nNgÄ Tikanga MÄori (MÄori Cultural Studies)\nhttp://www.lincoln.ac.nz/MAST 106\nMahinga Kai\nhttp://www.lincoln.ac.nz/MAST 120\nTe Pia I\nhttp://www.lincoln.ac.nz/MAST 121\nTe Pia II\nhttp://www.lincoln.ac.nz/MAST 122\nTe Kaitiakitaka (MÄori Environmental Management)\nhttp://www.lincoln.ac.nz/MAST 319\nMana Kaitiaki (Maori Resource Management)\nhttp://www.lincoln.ac.nz/MAST 603\nTe Puawaitaka (Advanced Maori Development)\nhttp://www.lincoln.ac.nz/MAST 605\nPrinciples of Marketing\nhttp://www.lincoln.ac.nz/MKTG 115\nSocial Marketing and Ethics\nhttp://www.lincoln.ac.nz/MKTG 202\nConsumer Behaviour and Wellbeing\nhttp://www.lincoln.ac.nz/MKTG 205\nLogistics Management\nhttp://www.lincoln.ac.nz/MKTG 210\nMarketing Analytics and Research\nhttp://www.lincoln.ac.nz/MKTG 301\nServices Marketing\nhttp://www.lincoln.ac.nz/MKTG 304\nMarketing of New Zealand Products and Services\nhttp://www.lincoln.ac.nz/MKTG 308\nProduct Design\nhttp://www.lincoln.ac.nz/MKTG 311\nPromotion Management\nhttp://www.lincoln.ac.nz/MKTG 321\nRetailing and Sales Management\nhttp://www.lincoln.ac.nz/MKTG 322\nSupply Chain Management\nhttp://www.lincoln.ac.nz/MKTG 323\nAdvanced Services Marketing and Management\nhttp://www.lincoln.ac.nz/MKTG 605\nSupply Chain Theory\nhttp://www.lincoln.ac.nz/MKTG 608\nMarketing Strategy\nhttp://www.lincoln.ac.nz/MKTG 672\nManaging Marketing\nhttp://www.lincoln.ac.nz/MKTG 681\nAdvanced Microbiology\nhttp://www.lincoln.ac.nz/MICR 604\nPhilosophy and Critical Thinking\nhttp://www.lincoln.ac.nz/PHIL 103\nSocial and Environmental Ethics\nhttp://www.lincoln.ac.nz/PHIL 304\nChemistry IA\nhttp://www.lincoln.ac.nz/PHSC 101\nEnvironmental Physics\nhttp://www.lincoln.ac.nz/PHSC 103\nIntroduction to Earth and Ecological Sciences\nhttp://www.lincoln.ac.nz/PHSC 107\nChemistry and the Environment\nhttp://www.lincoln.ac.nz/PHSC 210\nLand, Water and Atmosphere\nhttp://www.lincoln.ac.nz/PHSC 211\nPlant Pest Management\nhttp://www.lincoln.ac.nz/PLPT 203\nPlant Diseases\nhttp://www.lincoln.ac.nz/PLPT 305\nSustainable Plant Protection\nhttp://www.lincoln.ac.nz/PLPT 306\nGrape Pest and Disease Management\nhttp://www.lincoln.ac.nz/PLPT 323\nIntegrated Plant Protection\nhttp://www.lincoln.ac.nz/PLPT 611\nPlant Pathology\nhttp://www.lincoln.ac.nz/PLPT 613\nPlant Studies\nhttp://www.lincoln.ac.nz/PLSC 021\nPlant Husbandry\nhttp://www.lincoln.ac.nz/PLSC 024\nAnnual Crop Production\nhttp://www.lincoln.ac.nz/PLSC 071\nPasture Management\nhttp://www.lincoln.ac.nz/PLSC 074\nPlant Science I\nhttp://www.lincoln.ac.nz/PLSC 104\nPlant Science II: Plant Function\nhttp://www.lincoln.ac.nz/PLSC 201\nPlant Production Systems\nhttp://www.lincoln.ac.nz/PLSC 204\nCrop Science\nhttp://www.lincoln.ac.nz/PLSC 320\nPasture Agronomy\nhttp://www.lincoln.ac.nz/PLSC 321\nEnvironmental Plant Biology\nhttp://www.lincoln.ac.nz/PLSC 325\nSeed Technology\nhttp://www.lincoln.ac.nz/PLSC 331\n Agronomy\nhttp://www.lincoln.ac.nz/PLSC 601A\n Agronomy\nhttp://www.lincoln.ac.nz/PLSC 601B\nPasture Ecosystems\nhttp://www.lincoln.ac.nz/PLSC 610\n Plant and Crop Physiology\nhttp://www.lincoln.ac.nz/PLSC 611A\n Plant and Crop Physiology\nhttp://www.lincoln.ac.nz/PLSC 611B\nPasture Management Science\nhttp://www.lincoln.ac.nz/PLSC 625\nPlant Breeding and Genetics\nhttp://www.lincoln.ac.nz/PLSC 626\nIntroduction to Psychology\nhttp://www.lincoln.ac.nz/PSYC 101\nIntroduction to Social Psychology\nhttp://www.lincoln.ac.nz/PSYC 102\nMotivation and Participation\nhttp://www.lincoln.ac.nz/PSYC 202\nEnvironmental Psychology\nhttp://www.lincoln.ac.nz/PSYC 203\nSocial Psychology of Wellbeing\nhttp://www.lincoln.ac.nz/PSYC 302\nAdvanced Social Psychology of Wellbeing\nhttp://www.lincoln.ac.nz/PSYC 602\nBiometrics\nhttp://www.lincoln.ac.nz/QMET 201\nStatistics for Business\nhttp://www.lincoln.ac.nz/QMET 204\nExperimentation\nhttp://www.lincoln.ac.nz/QMET 306\nExperimentation\nhttp://www.lincoln.ac.nz/QMET 608\nBusiness Statistics\nhttp://www.lincoln.ac.nz/QMET 615\nConcepts in Sport and Recreation\nhttp://www.lincoln.ac.nz/RECN 110\nProfessional Studies in Sport and Recreation Management\nhttp://www.lincoln.ac.nz/RECN 111\nEvent Planning\nhttp://www.lincoln.ac.nz/RECN 213\nRecreation, Sport and Adventure in Outdoor Environments\nhttp://www.lincoln.ac.nz/RECN 215\nPrinciples of Physical Activity, Exercise and Health\nhttp://www.lincoln.ac.nz/RECN 216\nSport and Society\nhttp://www.lincoln.ac.nz/RECN 217\nRecreation and Tourism in Protected Natural Areas\nhttp://www.lincoln.ac.nz/RECN 341\nSport and Recreation Management\nhttp://www.lincoln.ac.nz/RECN 343\nEvent Management\nhttp://www.lincoln.ac.nz/RECN 344\nFundamentals of Sport and Exercise Science\nhttp://www.lincoln.ac.nz/RECN 345\nPracticum: Practical Experience in Sport and Recreation Management\nhttp://www.lincoln.ac.nz/RECN 393\nSport Physical Activity and Fitness\nhttp://www.lincoln.ac.nz/RECN 604\nNatural Resource Recreation and Tourism\nhttp://www.lincoln.ac.nz/RECN 626\nAdvanced Sport and Recreation Management\nhttp://www.lincoln.ac.nz/RECN 627\nEvents and Festivals: Contexts and Concepts\nhttp://www.lincoln.ac.nz/RECN 640\n8 - Design or Research Essay\nhttp://www.lincoln.ac.nz/(PREFIX) 398\n9 - Research Placement\nhttp://www.lincoln.ac.nz/(PREFIX) 399\n7 - Research Issues in (PREFIX)\nhttp://www.lincoln.ac.nz/(PREFIX) 697\n8 - Design or Research Essay\nhttp://www.lincoln.ac.nz/(PREFIX) 698\n9 - Research Placement\nhttp://www.lincoln.ac.nz/(PREFIX) 699\nAdvanced Field Research\nhttp://www.lincoln.ac.nz/SCIE 393\nntroduction to Organics\nhttp://www.lincoln.ac.nz/SCIE024\nSociety, Culture and Environment\nhttp://www.lincoln.ac.nz/SOCI 116\nIntroduction to New Zealand Government and Public Policy\nhttp://www.lincoln.ac.nz/SOCI 117\nResearch Methods\nhttp://www.lincoln.ac.nz/SOCI 204\nThe Living City\nhttp://www.lincoln.ac.nz/SOCI 214\nThemes in New Zealand History (Special Topic)\nhttp://www.lincoln.ac.nz/SOCI 219\nInternational Rural Development\nhttp://www.lincoln.ac.nz/SOCI 303\nProfessional Practice\nhttp://www.lincoln.ac.nz/SOCI 314\nPolicy and Practice\nhttp://www.lincoln.ac.nz/SOCI 315\nDesign or Research Essay\nhttp://www.lincoln.ac.nz/SOCI 398\nSocial Science Research Methods (Quantitative)\nhttp://www.lincoln.ac.nz/SOCI 601\nSocial Science Research Methods (Qualitative)\nhttp://www.lincoln.ac.nz/SOCI 602\nAdvanced International Rural Development\nhttp://www.lincoln.ac.nz/SOCI 608\nSpecial Topic in Society and Climate Change\nhttp://www.lincoln.ac.nz/SOCI 626\nSoils and Soil Management\nhttp://www.lincoln.ac.nz/SOSC 021\nSoil Science I\nhttp://www.lincoln.ac.nz/SOSC 106\nSoil Science II\nhttp://www.lincoln.ac.nz/SOSC 222\nPhysical landscapes: formation and function\nhttp://www.lincoln.ac.nz/SOSC 223\nSoil Management\nhttp://www.lincoln.ac.nz/SOSC 224\nAdvanced Soil Science\nhttp://www.lincoln.ac.nz/SOSC 301\nAdvanced Soil Management\nhttp://www.lincoln.ac.nz/SOSC 340\nSoil Resources\nhttp://www.lincoln.ac.nz/SOSC 627\nSoil Chemistry\nhttp://www.lincoln.ac.nz/SOSC 628\nSoil Physics\nhttp://www.lincoln.ac.nz/SOSC 629\nSoil Fertility and Management\nhttp://www.lincoln.ac.nz/SOSC 630\nIntroduction to Tourism\nhttp://www.lincoln.ac.nz/TOUR 101\nTourism Systems\nhttp://www.lincoln.ac.nz/TOUR 202\nTourist Behaviour\nhttp://www.lincoln.ac.nz/TOUR 203\nDestination Planning and Development\nhttp://www.lincoln.ac.nz/TOUR 303\nHeritage Interpretation for Tourism and Recreation\nhttp://www.lincoln.ac.nz/TOUR 304\nTourism Management\nhttp://www.lincoln.ac.nz/TOUR 603\nTourist Behaviour\nhttp://www.lincoln.ac.nz/TOUR 604\nLanguage and Writing for Tertiary Study\nhttp://www.lincoln.ac.nz/LUAC 001\nMathematics and Statistics for Tertiary Study 1\nhttp://www.lincoln.ac.nz/LUAC 002\nCommunication and Information Technology\nhttp://www.lincoln.ac.nz/LUAC 003\nEnvironments, Economies and Numeracies\nhttp://www.lincoln.ac.nz/LUAC 004\nAcademic Communication and Study Skills\nhttp://www.lincoln.ac.nz/LUAC 010\nMathematics and Statistics for Tertiary Study 2\nhttp://www.lincoln.ac.nz/LUAC 011\nBusiness and Economics\nhttp://www.lincoln.ac.nz/LUAC 012\nScience for Tertiary Study\nhttp://www.lincoln.ac.nz/LUAC 013\nTe-Tu-a-Uri: Introduction to Maori Culture and Society\nhttp://www.lincoln.ac.nz/LUAC 014\nLand and Environment\nhttp://www.lincoln.ac.nz/LUAC 015\nIntroduction to Property\nhttp://www.lincoln.ac.nz/VAPM 101\nPrinciples of Urban Property Management\nhttp://www.lincoln.ac.nz/VAPM 201\nReal Estate Marketing and Management\nhttp://www.lincoln.ac.nz/VAPM 205\nPrinciples of Valuation\nhttp://www.lincoln.ac.nz/VAPM 207\nPrinciples of Rural Valuation\nhttp://www.lincoln.ac.nz/VAPM 208\nProperty Analytical Methods\nhttp://www.lincoln.ac.nz/VAPM 308\nProperty Investment and Portfolio Analysis\nhttp://www.lincoln.ac.nz/VAPM 309\nThe Valuation of Investment Property\nhttp://www.lincoln.ac.nz/VAPM 310\nUrban Valuation\nhttp://www.lincoln.ac.nz/VAPM 311\nRural Valuation\nhttp://www.lincoln.ac.nz/VAPM 312\nProperty and Facilities Management\nhttp://www.lincoln.ac.nz/VAPM 313\nProperty Development\nhttp://www.lincoln.ac.nz/VAPM 314\nFreshwater Resources\nhttp://www.lincoln.ac.nz/WATR 201\nWater on Land: Quality and Quantity\nhttp://www.lincoln.ac.nz/WATR 202\nWater Resource Management\nhttp://www.lincoln.ac.nz/WATR 301\nWater on Land: Application and Management\nhttp://www.lincoln.ac.nz/WATR 302\nAdvanced Water Resources\nhttp://www.lincoln.ac.nz/WATR 601\nWater Quality and Quantity Assessment\nhttp://www.lincoln.ac.nz/WATR 602\nWater Management, Policy and Planning\nhttp://www.lincoln.ac.nz/WATR 603\nResearch Methods and Communication\nhttp://www.lincoln.ac.nz/WATR 605\nIntroduction to the Winegrowing Industry\nhttp://www.lincoln.ac.nz/WINE 101\nViticulture I\nhttp://www.lincoln.ac.nz/WINE 201\nPrinciples of Wine Science\nhttp://www.lincoln.ac.nz/WINE 202\nViticulture II\nhttp://www.lincoln.ac.nz/WINE 301\nWine Quality Assessment\nhttp://www.lincoln.ac.nz/WINE 302\nScience of Grapes and Wine\nhttp://www.lincoln.ac.nz/WINE 303\nWine Chemistry and Technology\nhttp://www.lincoln.ac.nz/WINE 304\nTopics in Oenology\nhttp://www.lincoln.ac.nz/WINE 602\nAdvanced Oenology\nhttp://www.lincoln.ac.nz/WINE 604\n"
],
[
"import requests\nimport bs4\nimport csv\n\nlist=[]\nlis_h=['Course_Name','Link']\nlist.append(lis_h)\n\nres1=requests.get('http://www.lincoln.ac.nz/Study/Courses/') \nsoup1=bs4.BeautifulSoup(res1.text,'lxml')\n\ns1=soup1.select('a')\nfor i in s1[3:]:\n list.append([str(i.text)[11:],i.get('href')])\n \nlist",
"_____no_output_____"
],
[
"len(list)",
"_____no_output_____"
],
[
"with open('Lincoln_University .csv','w',encoding='latin-1',newline=\"\") as file:\n write=csv.writer(file)\n for row in list:\n write.writerow(row)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e6928327ea90fe333f7ffcad5794e71ae2cc4
| 1,771 |
ipynb
|
Jupyter Notebook
|
27_Mixture_of_Bernoulli.ipynb
|
Dzeiberg/multiinstance
|
95b70e066610b1935cda9086d8fb8609809e7d15
|
[
"Apache-2.0"
] | null | null | null |
27_Mixture_of_Bernoulli.ipynb
|
Dzeiberg/multiinstance
|
95b70e066610b1935cda9086d8fb8609809e7d15
|
[
"Apache-2.0"
] | null | null | null |
27_Mixture_of_Bernoulli.ipynb
|
Dzeiberg/multiinstance
|
95b70e066610b1935cda9086d8fb8609809e7d15
|
[
"Apache-2.0"
] | null | null | null | 23.613333 | 99 | 0.464145 |
[
[
[
"import numpy as np\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nfrom easydict import EasyDict",
"_____no_output_____"
],
[
"def var(pi,m1,m2):\n p = (pi*m1 + (1-pi) * m2)\n return p * (1 - p)",
"_____no_output_____"
],
[
"plt.plot([p * (1-p) for p in np.arange(-10,10,.01)])",
"_____no_output_____"
],
[
"fig,ax = plt.subplots(3,3,figsize=(16,16),)\nfor k,pi in enumerate(np.arange(0.1,1,.1)):\n vals = np.zeros((11,11))\n for i,m1 in enumerate(np.arange(0,1.1,.1)):\n for j,m2 in enumerate(np.arange(0,1.1,.1)):\n vals[i,j] = var(pi,m1,m2) - m1*(1-m1) - m2*(1-m2)\n \n sns.heatmap(vals[::-1],\n ax=ax[int(k/3),k%3],\n xticklabels=[\"{:.1f}\".format(i) for i in np.arange(0,1.1,.1)],\n yticklabels=[\"{:.1f}\".format(i) for i in np.arange(1,-.1,-.1)],)\n ax[int(k/3),k%3].set_title(\"$\\pi$ = {:.1f}\\n avg={:.3f}\".format(pi,np.mean(vals)))\nplt.show()",
"_____no_output_____"
],
[
"c",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e69f058b09ff79f52ceb40b479cd0e39104d0
| 114,108 |
ipynb
|
Jupyter Notebook
|
notebooks/using_usaspending_api_directly.ipynb
|
mbaumer/us_hep_funding
|
b333bdee551bf7f37631515916396192f72537b3
|
[
"BSD-3-Clause"
] | 4 |
2018-03-05T18:37:32.000Z
|
2022-03-10T21:14:29.000Z
|
notebooks/using_usaspending_api_directly.ipynb
|
mbaumer/us_hep_funding
|
b333bdee551bf7f37631515916396192f72537b3
|
[
"BSD-3-Clause"
] | 16 |
2017-03-10T22:57:32.000Z
|
2022-02-15T23:52:15.000Z
|
notebooks/using_usaspending_api_directly.ipynb
|
mbaumer/us_hep_funding
|
b333bdee551bf7f37631515916396192f72537b3
|
[
"BSD-3-Clause"
] | 1 |
2019-03-04T19:13:38.000Z
|
2019-03-04T19:13:38.000Z
| 44.434579 | 1,222 | 0.310785 |
[
[
[
"import pandas as pd\nfrom datetime import datetime, timedelta\nimport time\nimport requests\nimport numpy as np\nimport json\nimport urllib\nfrom pandas.io.json import json_normalize\nimport re\nimport os.path\nimport zipfile\nfrom glob import glob",
"_____no_output_____"
],
[
"url =\"https://api.usaspending.gov/api/v1/awards/?limit=100\"\nr = requests.get(url, verify=False)\nr.raise_for_status()\ntype(r)\ndata = r.json() \nmeta = data['page_metadata']\ndata = data['results']\ndf_API_data = pd.io.json.json_normalize(data)",
"/Users/mbaumer/anaconda2/lib/python2.7/site-packages/urllib3/connectionpool.py:858: InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings\n InsecureRequestWarning)\n"
],
[
"df_API_data.col",
"_____no_output_____"
],
[
"base_url = \"https://api.usaspending.gov\"\nendpt_trans = \"/api/v2/search/spending_by_award/?limit=10\"\n\nparams = {\n \"filters\": {\n \"time_period\": [\n {\n \"start_date\": \"2016-10-01\",\n \"end_date\": \"2017-09-30\"\n }\n ]\n}\n\n}\n\nurl = base_url + endpt_trans\nr = requests.post(url, json=params)\nprint(r.status_code, r.reason)\nr.raise_for_status()\nr.headers\nr.request.headers\ndata = r.json() \nmeta = data['page_metadata']\ndata = data['results']\ndf_trans = pd.io.json.json_normalize(data) ",
"(422, 'Unprocessable Entity')\n"
],
[
"currentFY = 2019\nn_years_desired = 10\n\ndef download_latest_data(currentFY,n_years_desired):\n\n #find latest datestamp on usaspending files\n usaspending_base = 'https://files.usaspending.gov/award_data_archive/'\n save_path = '../new_data/'\n r = requests.get(usaspending_base, allow_redirects=True)\n r.raise_for_status()\n datestr = re.findall('_(\\d{8}).zip',r.content)[0]\n\n for FY in np.arange(currentFY-n_years_desired+1,currentFY+1):\n doe_contracts_url = usaspending_base+str(FY)+'_089_Contracts_Full_' + datestr + '.zip'\n doe_grants_url = usaspending_base+str(FY)+'_089_Assistance_Full_' + datestr + '.zip'\n nsf_grants_url = usaspending_base+str(FY)+'_049_Assistance_Full_' + datestr + '.zip'\n doe_sc_url = 'https://science.energy.gov/~/media/_/excel/universities/DOE-SC_Grants_FY'+str(FY)+'.xlsx'\n\n for url in [doe_contracts_url,doe_grants_url,nsf_grants_url,doe_sc_url]:\n\n filename = url.split('/')[-1]\n if os.path.exists(save_path+filename): continue\n\n if url == doe_sc_url: \n verify='doe_cert.pem'\n else:\n verify=True\n\n try: \n r = requests.get(url, allow_redirects=True,verify=verify)\n r.raise_for_status()\n except:\n print 'could not find', url\n continue\n\n # DOE website stupidly returns a 200 HTTP code when displaying 404 page :/\n page_not_found_text = 'The page that you have requested was not found.'\n if page_not_found_text in r.content: \n print 'could not find', url\n continue\n\n open(save_path+filename, 'wb+').write(r.content)\n zipper = zipfile.ZipFile(save_path+filename,'r')\n zipper.extractall(path='../new_data')\n print 'Data download complete'\n \ndef unzip_all():\n for unzip_this in glob('../new_data/*.zip'):\n zipper = zipfile.ZipFile(unzip_this,'r')\n zipper.extractall(path='../new_data')",
"_____no_output_____"
],
[
"print 'Generating DOE Contract data...'\n\ncontract_file_list = glob('../new_data/*089_Contracts*.csv')\ncontract_df_list = []\nfor contract_file in contract_file_list:\n contract_df_list.append(pd.read_csv(contract_file))\nfulldata = pd.concat(contract_df_list,ignore_index=True)\n\nprint len(fulldata)\n\nsc_awarding_offices = ['CHICAGO SERVICE CENTER (OFFICE OF SCIENCE)',\n 'OAK RIDGE OFFICE (OFFICE OF SCIENCE)',\n 'SC CHICAGO SERVICE CENTER',\n 'SC OAK RIDGE OFFICE']\n\nsc_funding_offices = ['CHICAGO SERVICE CENTER (OFFICE OF SCIENCE)',\n 'OAK RIDGE OFFICE (OFFICE OF SCIENCE)',\n 'SCIENCE',\n 'SC OAK RIDGE OFFICE',\n 'SC CHICAGO SERVICE CENTER'\n ]\n\nsc_contracts = fulldata[(fulldata['awarding_office_name'].isin(\n sc_awarding_offices)) | (fulldata['funding_office_name'].isin(sc_funding_offices))]\n\nprint len(sc_contracts)\n\n#sc_contracts.to_pickle('../cleaned_data/sc_contracts.pkl')",
"Generating DOE Contract data...\n89160\n9626\n"
],
[
"print 'Generating NSF Grant data...'\ngrant_file_list = glob('../new_data/*049_Assistance*.csv')\ngrant_df_list = []\nfor grant_file in grant_file_list:\n grant_df_list.append(pd.read_csv(grant_file))\nfulldata = pd.concat(grant_df_list,ignore_index=True)\nlen(fulldata)",
"Generating NSF Grant data...\n"
],
[
"mps_grants = fulldata[fulldata['cfda_title'] == 'MATHEMATICAL AND PHYSICAL SCIENCES']\nlen(mps_grants)",
"_____no_output_____"
],
[
"mps_grants['recipient_congressional_district'].unique()",
"_____no_output_____"
],
[
" mps_grants = mps_grants.dropna(subset=['principal_place_cd'])\n\n strlist = []\n for code in mps_grants['principal_place_cd'].values:\n if code == 'ZZ':\n code = '00'\n if len(str(int(code))) < 2:\n strlist.append('0' + str(int(code)))\n else:\n strlist.append(str(int(code)))\n\n mps_grants['cong_dist'] = mps_grants['principal_place_state_code'] + strlist\n pd.to_pickle(mps_grants, '../cleaned_data/nsf_mps_grants.pkl')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9e6d804126afa84bf10505cdd6c35f65919f75
| 129,157 |
ipynb
|
Jupyter Notebook
|
ClassificationDemo-Python.ipynb
|
amolnayak311/microsoft-professional-program-artificial-intelligence
|
4d28f8c3a5c263b2ae984bb41916b21ef5179531
|
[
"Apache-2.0"
] | 3 |
2019-02-04T06:15:13.000Z
|
2019-05-02T07:04:54.000Z
|
ClassificationDemo-Python.ipynb
|
thomasxmeng/microsoft-professional-program-artificial-intelligence
|
4d28f8c3a5c263b2ae984bb41916b21ef5179531
|
[
"Apache-2.0"
] | null | null | null |
ClassificationDemo-Python.ipynb
|
thomasxmeng/microsoft-professional-program-artificial-intelligence
|
4d28f8c3a5c263b2ae984bb41916b21ef5179531
|
[
"Apache-2.0"
] | 8 |
2018-08-04T21:17:32.000Z
|
2020-04-18T08:26:09.000Z
| 129,157 | 129,157 | 0.924588 |
[
[
[
"# Understanding Classification and Logistic Regression with Python\n\n## Introduction\n\nThis notebook contains a short introduction to the basic principles of classification and logistic regression. A simple Python simulation is used to illustrate these principles. Specifically, the following steps are performed:\n\n- A data set is created. The label has binary `TRUE` and `FALSE` labels. Values for two features are generated from two bivariate Normal distribion, one for each label class.\n- A plot is made of the data set, using color and shape to show the two label classes. \n- A plot of a logistic function is computed. \n- For each of three data sets a logistic regression model is computed, scored and a plot created using color to show class and shape to show correct and incorrect scoring.",
"_____no_output_____"
],
[
"## Create the data set\n\nThe code in the cell below computes the two class data set. The feature values for each label level are computed from a bivariate Normal distribution. Run this code and examine the first few rows of the data frame.",
"_____no_output_____"
]
],
[
[
"def sim_log_data(x1, y1, n1, sd1, x2, y2, n2, sd2):\n import pandas as pd\n import numpy.random as nr\n \n wx1 = nr.normal(loc = x1, scale = sd1, size = n1)\n wy1 = nr.normal(loc = y1, scale = sd1, size = n1)\n z1 = [1]*n1\n wx2 = nr.normal(loc = x2, scale = sd2, size = n2)\n wy2 = nr.normal(loc = y2, scale = sd2, size = n2)\n z2 = [0]*n2\n \n df1 = pd.DataFrame({'x': wx1, 'y': wy1, 'z': z1})\n df2 = pd.DataFrame({'x': wx2, 'y': wy2, 'z': z2}) \n return pd.concat([df1, df2], axis = 0, ignore_index = True) \nsim_data = sim_log_data(1, 1, 50, 1, -1, -1, 50, 1)\nsim_data.head()",
"_____no_output_____"
]
],
[
[
"## Plot the data set\n\nThe code in the cell below plots the data set using color to show the two classes of the labels. Execute this code and examine the results. Notice that the posion of the points from each class overlap with each other. ",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\ndef plot_class(df):\n import matplotlib.pyplot as plt\n fig = plt.figure(figsize=(5, 5))\n fig.clf()\n ax = fig.gca()\n df[df.z == 1].plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'Red', marker = 'x', s = 40) \n df[df.z == 0].plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'DarkBlue', marker = 'o', s = 40) \n ax.set_xlabel('X')\n ax.set_ylabel('Y')\n ax.set_title('Classes vs X and Y')\n return 'Done'\nplot_class(sim_data)",
"_____no_output_____"
]
],
[
[
"## Plot the logistic function\n\nLogistic regression computes a binary {0,1} score using a logistic function. A value of the logistic function above the cutoff (typically 0.5) are scored as a 1 or true, and values less than the cutoff are scored as a 0 or false. Execute the code and examine the resulting logistic function.",
"_____no_output_____"
]
],
[
[
"def plot_logistic(upper = 6, lower = -6, steps = 100):\n import matplotlib.pyplot as plt\n import pandas as pd\n import math as m\n step = float(upper - lower) / float(steps)\n x = [lower + x * step for x in range(101)]\n y = [m.exp(z)/(1 + m.exp(z)) for z in x]\n \n fig = plt.figure(figsize=(5, 4))\n fig.clf()\n ax = fig.gca()\n ax.plot(x, y, color = 'r')\n ax.axvline(0, 0.0, 1.0)\n ax.axhline(0.5, lower, upper)\n ax.set_xlabel('X')\n ax.set_ylabel('Probabiltiy of positive response')\n ax.set_title('Logistic function for two-class classification')\n return 'done'\n\nplot_logistic()",
"_____no_output_____"
]
],
[
[
"## Compute and score a logistic regression model\n\nThere is a considerable anount of code in the cell below. \n\nThe fist function uses scikit-learn to compute and scores a logsitic regression model. Notie that the features and the label must be converted to a numpy array which is required for scikit-learn. \n\nThe second function computes the evaluation of the logistic regression model in the following steps:\n- Compute the elements of theh confusion matrix.\n- Plot the correctly and incorrectly scored cases, using shape and color to identify class and classification correctness.\n- Commonly used performance statistics are computed.\n\nExecute this code and examine the results. Notice that most of the cases have been correctly classified. Classification errors appear along a boundary between those two classes. ",
"_____no_output_____"
]
],
[
[
"def logistic_mod(df, logProb = 1.0):\n from sklearn import linear_model\n\n ## Prepare data for model\n nrow = df.shape[0]\n X = df[['x', 'y']].as_matrix().reshape(nrow,2)\n Y = df.z.as_matrix().ravel() #reshape(nrow,1)\n ## Compute the logistic regression model\n lg = linear_model.LogisticRegression()\n logr = lg.fit(X, Y)\n ## Compute the y values\n temp = logr.predict_log_proba(X) \n df['predicted'] = [1 if (logProb > p[1]/p[0]) else 0 for p in temp]\n return df\n\ndef eval_logistic(df):\n import matplotlib.pyplot as plt\n import pandas as pd\n\n truePos = df[((df['predicted'] == 1) & (df['z'] == df['predicted']))] \n falsePos = df[((df['predicted'] == 1) & (df['z'] != df['predicted']))] \n trueNeg = df[((df['predicted'] == 0) & (df['z'] == df['predicted']))] \n falseNeg = df[((df['predicted'] == 0) & (df['z'] != df['predicted']))]\n\n fig = plt.figure(figsize=(5, 5))\n fig.clf()\n ax = fig.gca()\n truePos.plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'DarkBlue', marker = '+', s = 80) \n falsePos.plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'Red', marker = 'o', s = 40) \n trueNeg.plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'DarkBlue', marker = 'o', s = 40) \n falseNeg.plot(kind = 'scatter', x = 'x', y = 'y', ax = ax, \n alpha = 1.0, color = 'Red', marker = '+', s = 80) \n ax.set_xlabel('X')\n ax.set_ylabel('Y')\n ax.set_title('Classes vs X and Y')\n \n TP = truePos.shape[0]\n FP = falsePos.shape[0]\n TN = trueNeg.shape[0]\n FN = falseNeg.shape[0]\n \n confusion = pd.DataFrame({'Positive': [FP, TP],\n 'Negative': [TN, FN]},\n index = ['TrueNeg', 'TruePos'])\n accuracy = float(TP + TN)/float(TP + TN + FP + FN) \n precision = float(TP)/float(TP + FP) \n recall = float(TP)/float(TP + FN) \n \n print(confusion)\n print('accracy = ' + str(accuracy))\n print('precision = ' + str(precision))\n print('recall = ' + str(recall))\n \n return 'Done' \n\nmod = logistic_mod(sim_data)\neval_logistic(mod)",
"/home/nbuser/anaconda2_20/lib/python2.7/site-packages/scipy/stats/_continuous_distns.py:17: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility. Expected 96, got 88\n from . import _stats\n"
]
],
[
[
"## Moving the decision boundary\n\nThe example above uses a cutoff at the midpoint of the logistic function. However, you can change the trade-off between correctly classifying the positive cases and correctly classifing the negative cases. The code in the cell below computes and scores a logistic regressiion model for three different cutoff points. \n\nRun the code in the cell and carefully compare the results for the three cases. Notice, that as the logistic cutoff changes the decision boundary moves on the plot, with progressively more positive cases are correctly classified. In addition, accuracy and precision decrease and recall increases. ",
"_____no_output_____"
]
],
[
[
"def logistic_demo_prob():\n logt = sim_log_data(0.5, 0.5, 50, 1, -0.5, -0.5, 50, 1)\n \n probs = [1, 2, 4]\n for p in probs:\n logMod = logistic_mod(logt, p)\n eval_logistic(logMod)\n return 'Done'\nlogistic_demo_prob()",
" Negative Positive\nTrueNeg 38 12\nTruePos 13 37\naccracy = 0.75\nprecision = 0.755102040816\nrecall = 0.74\n Negative Positive\nTrueNeg 28 22\nTruePos 8 42\naccracy = 0.7\nprecision = 0.65625\nrecall = 0.84\n Negative Positive\nTrueNeg 24 26\nTruePos 4 46\naccracy = 0.7\nprecision = 0.638888888889\nrecall = 0.92\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4a9e7ca5c73f2a56123665d7969e44bd6a69e5f6
| 116,902 |
ipynb
|
Jupyter Notebook
|
Ch05_Linear_Neural_Networks/Implementation_of_Softmax_Regression_from_Scratch.ipynb
|
milk-ways/d2l-pytorch
|
f76d21bd6bb744ffeb5804f881fc8d17088f2454
|
[
"Apache-2.0"
] | 1 |
2021-10-02T10:19:22.000Z
|
2021-10-02T10:19:22.000Z
|
Ch05_Linear_Neural_Networks/Implementation_of_Softmax_Regression_from_Scratch.ipynb
|
milk-ways/d2l-pytorch
|
f76d21bd6bb744ffeb5804f881fc8d17088f2454
|
[
"Apache-2.0"
] | null | null | null |
Ch05_Linear_Neural_Networks/Implementation_of_Softmax_Regression_from_Scratch.ipynb
|
milk-ways/d2l-pytorch
|
f76d21bd6bb744ffeb5804f881fc8d17088f2454
|
[
"Apache-2.0"
] | null | null | null | 70.93568 | 9,049 | 0.715103 |
[
[
[
"# Implementation of Softmax Regression from Scratch\n\n:label:`chapter_softmax_scratch`\n\n\nJust as we implemented linear regression from scratch,\nwe believe that multiclass logistic (softmax) regression\nis similarly fundamental and you ought to know\nthe gory details of how to implement it from scratch.\nAs with linear regression, after doing things by hand\nwe will breeze through an implementation in Gluon for comparison.\nTo begin, let's import our packages.",
"_____no_output_____"
]
],
[
[
"import sys\nsys.path.insert(0, '..')\n\n%matplotlib inline\nimport d2l\nimport torch\nfrom torch.distributions import normal",
"_____no_output_____"
]
],
[
[
"We will work with the Fashion-MNIST dataset just introduced,\ncuing up an iterator with batch size 256.",
"_____no_output_____"
]
],
[
[
"batch_size = 256\ntrain_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)",
"_____no_output_____"
]
],
[
[
"## Initialize Model Parameters\n\nJust as in linear regression, we represent each example as a vector.\nSince each example is a $28 \\times 28$ image,\nwe can flatten each example, treating them as $784$ dimensional vectors.\nIn the future, we'll talk about more sophisticated strategies\nfor exploiting the spatial structure in images,\nbut for now we treat each pixel location as just another feature.\n\nRecall that in softmax regression,\nwe have as many outputs as there are categories.\nBecause our dataset has $10$ categories,\nour network will have an output dimension of $10$.\nConsequently, our weights will constitute a $784 \\times 10$ matrix\nand the biases will constitute a $1 \\times 10$ vector.\nAs with linear regression, we will initialize our weights $W$\nwith Gaussian noise and our biases to take the initial value $0$.",
"_____no_output_____"
]
],
[
[
"num_inputs = 784\nnum_outputs = 10\n\nW = normal.Normal(loc = 0, scale = 0.01).sample((num_inputs, num_outputs))\nb = torch.zeros(num_outputs)",
"_____no_output_____"
]
],
[
[
"Recall that we need to *attach gradients* to the model parameters.\nMore literally, we are allocating memory for future gradients to be stored\nand notifiying PyTorch that we want gradients to be calculated with respect to these parameters in the first place.",
"_____no_output_____"
]
],
[
[
"W.requires_grad_(True)\nb.requires_grad_(True)",
"_____no_output_____"
]
],
[
[
"## The Softmax\n\nBefore implementing the softmax regression model,\nlet's briefly review how `torch.sum` work\nalong specific dimensions in a PyTorch tensor.\nGiven a matrix `X` we can sum over all elements (default) or only\nover elements in the same column (`dim=0`) or the same row (`dim=1`).\nNote that if `X` is an array with shape `(2, 3)`\nand we sum over the columns (`torch.sum(X, dim=0`),\nthe result will be a (1D) vector with shape `(3,)`.\nIf we want to keep the number of axes in the original array\n(resulting in a 2D array with shape `(1,3)`),\nrather than collapsing out the dimension that we summed over\nwe can specify `keepdim=True` when invoking `torch.sum`.",
"_____no_output_____"
]
],
[
[
"X = torch.tensor([[1, 2, 3], [4, 5, 6]])\ntorch.sum(X, dim=0, keepdim=True), torch.sum(X, dim=1, keepdim=True)",
"_____no_output_____"
]
],
[
[
"We are now ready to implement the softmax function.\nRecall that softmax consists of two steps:\nFirst, we exponentiate each term (using `torch.exp`).\nThen, we sum over each row (we have one row per example in the batch)\nto get the normalization constants for each example.\nFinally, we divide each row by its normalization constant,\nensuring that the result sums to $1$.\nBefore looking at the code, let's recall\nwhat this looks expressed as an equation:\n\n$$\n\\mathrm{softmax}(\\mathbf{X})_{ij} = \\frac{\\exp(X_{ij})}{\\sum_k \\exp(X_{ik})}\n$$\n\nThe denominator, or normalization constant,\nis also sometimes called the partition function\n(and its logarithm the log-partition function).\nThe origins of that name are in [statistical physics](https://en.wikipedia.org/wiki/Partition_function_(statistical_mechanics))\nwhere a related equation models the distribution\nover an ensemble of particles).",
"_____no_output_____"
]
],
[
[
"def softmax(X):\n X_exp = torch.exp(X)\n partition = torch.sum(X_exp, dim=1, keepdim=True)\n return X_exp / partition # The broadcast mechanism is applied here",
"_____no_output_____"
]
],
[
[
"As you can see, for any random input, we turn each element into a non-negative number. Moreover, each row sums up to 1, as is required for a probability.\nNote that while this looks correct mathematically,\nwe were a bit sloppy in our implementation\nbecause failed to take precautions against numerical overflow or underflow\ndue to large (or very small) elements of the matrix,\nas we did in\n:numref:`chapter_naive_bayes`.",
"_____no_output_____"
]
],
[
[
"# X = nd.random.normal(shape=(2, 5))\nX = normal.Normal(loc = 0, scale = 1).sample((2, 5))\nX_prob = softmax(X)\nX_prob, torch.sum(X_prob, dim=1)",
"_____no_output_____"
]
],
[
[
"## The Model\n\nNow that we have defined the softmax operation,\nwe can implement the softmax regression model.\nThe below code defines the forward pass through the network.\nNote that we flatten each original image in the batch\ninto a vector with length `num_inputs` with the `view` function\nbefore passing the data through our model.",
"_____no_output_____"
]
],
[
[
"def net(X):\n return softmax(torch.matmul(X.reshape((-1, num_inputs)), W) + b)",
"_____no_output_____"
]
],
[
[
"## The Loss Function\n\nNext, we need to implement the cross entropy loss function,\nintroduced in :numref:`chapter_softmax`.\nThis may be the most common loss function\nin all of deep learning because, at the moment,\nclassification problems far outnumber regression problems.\n\n\nRecall that cross entropy takes the negative log likelihood\nof the predicted probability assigned to the true label $-\\log p(y|x)$.\nRather than iterating over the predictions with a Python `for` loop\n(which tends to be inefficient), we can use the `gather` function\nwhich allows us to select the appropriate terms\nfrom the matrix of softmax entries easily.\nBelow, we illustrate the `gather` function on a toy example,\nwith 3 categories and 2 examples.",
"_____no_output_____"
]
],
[
[
"y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])\ny = torch.tensor([0, 2])\ntorch.gather(y_hat, 1, y.unsqueeze(dim=1)) # y has to be unsqueezed so that shape(y_hat) = shape(y)",
"_____no_output_____"
]
],
[
[
"Now we can implement the cross-entropy loss function efficiently\nwith just one line of code.",
"_____no_output_____"
]
],
[
[
"def cross_entropy(y_hat, y):\n return -torch.gather(y_hat, 1, y.unsqueeze(dim=1)).log()",
"_____no_output_____"
]
],
[
[
"## Classification Accuracy\n\nGiven the predicted probability distribution `y_hat`,\nwe typically choose the class with highest predicted probability\nwhenever we must output a *hard* prediction. Indeed, many applications require that we make a choice. Gmail must catetegorize an email into Primary, Social, Updates, or Forums. It might estimate probabilities internally, but at the end of the day it has to choose one among the categories.\n\nWhen predictions are consistent with the actual category `y`, they are correct. The classification accuracy is the fraction of all predictions that are correct. Although we cannot optimize accuracy directly (it is not differentiable), it's often the performance metric that we care most about, and we will nearly always report it when training classifiers.\n\nTo compute accuracy we do the following:\nFirst, we execute `y_hat.argmax(dim=1)`\nto gather the predicted classes\n(given by the indices for the largest entires each row).\nThe result has the same shape as the variable `y`.\nNow we just need to check how frequently the two match. The result is PyTorch tensor containing entries of 0 (false) and 1 (true). Since the attribute `mean` can only calculate the mean of floating types,\nwe also need to convert the result to `float`. Taking the mean yields the desired result.",
"_____no_output_____"
]
],
[
[
"def accuracy(y_hat, y):\n return (y_hat.argmax(dim=1) == y).float().mean().item()",
"_____no_output_____"
]
],
[
[
"We will continue to use the variables `y_hat` and `y`\ndefined in the `gather` function,\nas the predicted probability distribution and label, respectively.\nWe can see that the first example's prediction category is 2\n(the largest element of the row is 0.6 with an index of 2),\nwhich is inconsistent with the actual label, 0.\nThe second example's prediction category is 2\n(the largest element of the row is 0.5 with an index of 2),\nwhich is consistent with the actual label, 2.\nTherefore, the classification accuracy rate for these two examples is 0.5.",
"_____no_output_____"
]
],
[
[
"accuracy(y_hat, y)",
"_____no_output_____"
]
],
[
[
"Similarly, we can evaluate the accuracy for model `net` on the data set\n(accessed via `data_iter`).",
"_____no_output_____"
]
],
[
[
"# The function will be gradually improved: the complete implementation will be\n# discussed in the \"Image Augmentation\" section\ndef evaluate_accuracy(data_iter, net):\n acc_sum, n = 0.0, 0\n for X, y in data_iter:\n acc_sum += (net(X).argmax(dim=1) == y).sum().item()\n n += y.size()[0] # y.size()[0] = batch_size\n return acc_sum / n",
"_____no_output_____"
]
],
[
[
"Because we initialized the `net` model with random weights,\nthe accuracy of this model should be close to random guessing,\ni.e. 0.1 for 10 classes.",
"_____no_output_____"
]
],
[
[
"evaluate_accuracy(test_iter, net)",
"_____no_output_____"
]
],
[
[
"## Model Training\n\nThe training loop for softmax regression should look strikingly familiar\nif you read through our implementation\nof linear regression earlier in this chapter.\nAgain, we use the mini-batch stochastic gradient descent\nto optimize the loss function of the model.\nNote that the number of epochs (`num_epochs`),\nand learning rate (`lr`) are both adjustable hyper-parameters.\nBy changing their values, we may be able to increase the classification accuracy of the model. In practice we'll want to split our data three ways\ninto training, validation, and test data, using the validation data to choose the best values of our hyperparameters.",
"_____no_output_____"
]
],
[
[
"num_epochs, lr = 5, 0.1\n\n# This function has been saved in the d2l package for future use\ndef train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, trainer=None):\n for epoch in range(num_epochs):\n train_l_sum, train_acc_sum, n = 0.0, 0.0, 0\n for X, y in train_iter:\n y_hat = net(X)\n l = loss(y_hat, y).sum()\n l.backward()\n if trainer is None:\n d2l.sgd(params, lr, batch_size)\n else:\n # This will be illustrated in the next section\n trainer.step(batch_size)\n train_l_sum += l.item()\n train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()\n n += y.size()[0]\n test_acc = evaluate_accuracy(test_iter, net)\n print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'\n % (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc))\n\ntrain_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)",
"epoch 1, loss 0.7884, train acc 0.747, test acc 0.794\nepoch 2, loss 0.5722, train acc 0.812, test acc 0.804\nepoch 3, loss 0.5248, train acc 0.825, test acc 0.817\nepoch 4, loss 0.5007, train acc 0.833, test acc 0.826\nepoch 5, loss 0.4853, train acc 0.837, test acc 0.825\n"
]
],
[
[
"## Prediction\n\nNow that training is complete, our model is ready to classify some images.\nGiven a series of images, we will compare their actual labels\n(first line of text output) and the model predictions\n(second line of text output).",
"_____no_output_____"
]
],
[
[
"for X, y in test_iter:\n break\n\ntrue_labels = d2l.get_fashion_mnist_labels(y.numpy())\npred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())\ntitles = [truelabel + '\\n' + predlabel for truelabel, predlabel in zip(true_labels, pred_labels)]\n\nd2l.show_fashion_mnist(X[10:20], titles[10:20])",
"_____no_output_____"
]
],
[
[
"## Summary\n\nWith softmax regression, we can train models for multi-category classification. The training loop is very similar to that in linear regression: retrieve and read data, define models and loss functions,\nthen train models using optimization algorithms. As you'll soon find out, most common deep learning models have similar training procedures.\n\n## Exercises\n\n1. In this section, we directly implemented the softmax function based on the mathematical definition of the softmax operation. What problems might this cause (hint - try to calculate the size of $\\exp(50)$)?\n1. The function `cross_entropy` in this section is implemented according to the definition of the cross-entropy loss function. What could be the problem with this implementation (hint - consider the domain of the logarithm)?\n1. What solutions you can think of to fix the two problems above?\n1. Is it always a good idea to return the most likely label. E.g. would you do this for medical diagnosis?\n1. Assume that we want to use softmax regression to predict the next word based on some features. What are some problems that might arise from a large vocabulary?",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a9e80af61dd3066d90556817d3228843fee327a
| 331,239 |
ipynb
|
Jupyter Notebook
|
2 - Improving Deep Neural Networks/Optimization_methods_v1b.ipynb
|
pvs313/Deep_Learning
|
a650830ce0422672ac9d00c6c9c49889f12cffe1
|
[
"MIT"
] | null | null | null |
2 - Improving Deep Neural Networks/Optimization_methods_v1b.ipynb
|
pvs313/Deep_Learning
|
a650830ce0422672ac9d00c6c9c49889f12cffe1
|
[
"MIT"
] | null | null | null |
2 - Improving Deep Neural Networks/Optimization_methods_v1b.ipynb
|
pvs313/Deep_Learning
|
a650830ce0422672ac9d00c6c9c49889f12cffe1
|
[
"MIT"
] | null | null | null | 208.064698 | 62,492 | 0.873412 |
[
[
[
"# Optimization Methods\n\nUntil now, you've always used Gradient Descent to update the parameters and minimize the cost. In this notebook, you will learn more advanced optimization methods that can speed up learning and perhaps even get you to a better final value for the cost function. Having a good optimization algorithm can be the difference between waiting days vs. just a few hours to get a good result. \n\nGradient descent goes \"downhill\" on a cost function $J$. Think of it as trying to do this: \n<img src=\"images/cost.jpg\" style=\"width:650px;height:300px;\">\n<caption><center> <u> **Figure 1** </u>: **Minimizing the cost is like finding the lowest point in a hilly landscape**<br> At each step of the training, you update your parameters following a certain direction to try to get to the lowest possible point. </center></caption>\n\n**Notations**: As usual, $\\frac{\\partial J}{\\partial a } = $ `da` for any variable `a`.\n\nTo get started, run the following code to import the libraries you will need.",
"_____no_output_____"
],
[
"### <font color='darkblue'> Updates to Assignment <font>\n\n#### If you were working on a previous version\n* The current notebook filename is version \"Optimization_methods_v1b\". \n* You can find your work in the file directory as version \"Optimization methods'.\n* To see the file directory, click on the Coursera logo at the top left of the notebook.\n\n#### List of Updates\n* op_utils is now opt_utils_v1a. Assertion statement in `initialize_parameters` is fixed.\n* opt_utils_v1a: `compute_cost` function now accumulates total cost of the batch without taking the average (average is taken for entire epoch instead).\n* In `model` function, the total cost per mini-batch is accumulated, and the average of the entire epoch is taken as the average cost. So the plot of the cost function over time is now a smooth downward curve instead of an oscillating curve.\n* Print statements used to check each function are reformatted, and 'expected output` is reformatted to match the format of the print statements (for easier visual comparisons).",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport scipy.io\nimport math\nimport sklearn\nimport sklearn.datasets\n\nfrom opt_utils_v1a import load_params_and_grads, initialize_parameters, forward_propagation, backward_propagation\nfrom opt_utils_v1a import compute_cost, predict, predict_dec, plot_decision_boundary, load_dataset\nfrom testCases import *\n\n%matplotlib inline\nplt.rcParams['figure.figsize'] = (7.0, 4.0) # set default size of plots\nplt.rcParams['image.interpolation'] = 'nearest'\nplt.rcParams['image.cmap'] = 'gray'",
"_____no_output_____"
]
],
[
[
"## 1 - Gradient Descent\n\nA simple optimization method in machine learning is gradient descent (GD). When you take gradient steps with respect to all $m$ examples on each step, it is also called Batch Gradient Descent. \n\n**Warm-up exercise**: Implement the gradient descent update rule. The gradient descent rule is, for $l = 1, ..., L$: \n$$ W^{[l]} = W^{[l]} - \\alpha \\text{ } dW^{[l]} \\tag{1}$$\n$$ b^{[l]} = b^{[l]} - \\alpha \\text{ } db^{[l]} \\tag{2}$$\n\nwhere L is the number of layers and $\\alpha$ is the learning rate. All parameters should be stored in the `parameters` dictionary. Note that the iterator `l` starts at 0 in the `for` loop while the first parameters are $W^{[1]}$ and $b^{[1]}$. You need to shift `l` to `l+1` when coding.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: update_parameters_with_gd\n\ndef update_parameters_with_gd(parameters, grads, learning_rate):\n \"\"\"\n Update parameters using one step of gradient descent\n \n Arguments:\n parameters -- python dictionary containing your parameters to be updated:\n parameters['W' + str(l)] = Wl\n parameters['b' + str(l)] = bl\n grads -- python dictionary containing your gradients to update each parameters:\n grads['dW' + str(l)] = dWl\n grads['db' + str(l)] = dbl\n learning_rate -- the learning rate, scalar.\n \n Returns:\n parameters -- python dictionary containing your updated parameters \n \"\"\"\n\n L = len(parameters) // 2 # number of layers in the neural networks\n\n # Update rule for each parameter\n for l in range(L):\n ### START CODE HERE ### (approx. 2 lines)\n parameters[\"W\" + str(l+1)] = parameters[\"W\" + str(l + 1)] - learning_rate * grads[\"dW\" + str(l + 1)]\n parameters[\"b\" + str(l+1)] = parameters[\"b\" + str(l + 1)] - learning_rate * grads[\"db\" + str(l + 1)]\n ### END CODE HERE ###\n \n return parameters",
"_____no_output_____"
],
[
"parameters, grads, learning_rate = update_parameters_with_gd_test_case()\n\nparameters = update_parameters_with_gd(parameters, grads, learning_rate)\nprint(\"W1 =\\n\" + str(parameters[\"W1\"]))\nprint(\"b1 =\\n\" + str(parameters[\"b1\"]))\nprint(\"W2 =\\n\" + str(parameters[\"W2\"]))\nprint(\"b2 =\\n\" + str(parameters[\"b2\"]))",
"W1 =\n[[ 1.63535156 -0.62320365 -0.53718766]\n [-1.07799357 0.85639907 -2.29470142]]\nb1 =\n[[ 1.74604067]\n [-0.75184921]]\nW2 =\n[[ 0.32171798 -0.25467393 1.46902454]\n [-2.05617317 -0.31554548 -0.3756023 ]\n [ 1.1404819 -1.09976462 -0.1612551 ]]\nb2 =\n[[-0.88020257]\n [ 0.02561572]\n [ 0.57539477]]\n"
]
],
[
[
"**Expected Output**:\n\n```\nW1 =\n[[ 1.63535156 -0.62320365 -0.53718766]\n [-1.07799357 0.85639907 -2.29470142]]\nb1 =\n[[ 1.74604067]\n [-0.75184921]]\nW2 =\n[[ 0.32171798 -0.25467393 1.46902454]\n [-2.05617317 -0.31554548 -0.3756023 ]\n [ 1.1404819 -1.09976462 -0.1612551 ]]\nb2 =\n[[-0.88020257]\n [ 0.02561572]\n [ 0.57539477]]\n```",
"_____no_output_____"
],
[
"A variant of this is Stochastic Gradient Descent (SGD), which is equivalent to mini-batch gradient descent where each mini-batch has just 1 example. The update rule that you have just implemented does not change. What changes is that you would be computing gradients on just one training example at a time, rather than on the whole training set. The code examples below illustrate the difference between stochastic gradient descent and (batch) gradient descent. \n\n- **(Batch) Gradient Descent**:\n\n``` python\nX = data_input\nY = labels\nparameters = initialize_parameters(layers_dims)\nfor i in range(0, num_iterations):\n # Forward propagation\n a, caches = forward_propagation(X, parameters)\n # Compute cost.\n cost += compute_cost(a, Y)\n # Backward propagation.\n grads = backward_propagation(a, caches, parameters)\n # Update parameters.\n parameters = update_parameters(parameters, grads)\n \n```\n\n- **Stochastic Gradient Descent**:\n\n```python\nX = data_input\nY = labels\nparameters = initialize_parameters(layers_dims)\nfor i in range(0, num_iterations):\n for j in range(0, m):\n # Forward propagation\n a, caches = forward_propagation(X[:,j], parameters)\n # Compute cost\n cost += compute_cost(a, Y[:,j])\n # Backward propagation\n grads = backward_propagation(a, caches, parameters)\n # Update parameters.\n parameters = update_parameters(parameters, grads)\n```\n",
"_____no_output_____"
],
[
"In Stochastic Gradient Descent, you use only 1 training example before updating the gradients. When the training set is large, SGD can be faster. But the parameters will \"oscillate\" toward the minimum rather than converge smoothly. Here is an illustration of this: \n\n<img src=\"images/kiank_sgd.png\" style=\"width:750px;height:250px;\">\n<caption><center> <u> <font color='purple'> **Figure 1** </u><font color='purple'> : **SGD vs GD**<br> \"+\" denotes a minimum of the cost. SGD leads to many oscillations to reach convergence. But each step is a lot faster to compute for SGD than for GD, as it uses only one training example (vs. the whole batch for GD). </center></caption>\n\n**Note** also that implementing SGD requires 3 for-loops in total:\n1. Over the number of iterations\n2. Over the $m$ training examples\n3. Over the layers (to update all parameters, from $(W^{[1]},b^{[1]})$ to $(W^{[L]},b^{[L]})$)\n\nIn practice, you'll often get faster results if you do not use neither the whole training set, nor only one training example, to perform each update. Mini-batch gradient descent uses an intermediate number of examples for each step. With mini-batch gradient descent, you loop over the mini-batches instead of looping over individual training examples.\n\n<img src=\"images/kiank_minibatch.png\" style=\"width:750px;height:250px;\">\n<caption><center> <u> <font color='purple'> **Figure 2** </u>: <font color='purple'> **SGD vs Mini-Batch GD**<br> \"+\" denotes a minimum of the cost. Using mini-batches in your optimization algorithm often leads to faster optimization. </center></caption>\n\n<font color='blue'>\n**What you should remember**:\n- The difference between gradient descent, mini-batch gradient descent and stochastic gradient descent is the number of examples you use to perform one update step.\n- You have to tune a learning rate hyperparameter $\\alpha$.\n- With a well-turned mini-batch size, usually it outperforms either gradient descent or stochastic gradient descent (particularly when the training set is large).",
"_____no_output_____"
],
[
"## 2 - Mini-Batch Gradient descent\n\nLet's learn how to build mini-batches from the training set (X, Y).\n\nThere are two steps:\n- **Shuffle**: Create a shuffled version of the training set (X, Y) as shown below. Each column of X and Y represents a training example. Note that the random shuffling is done synchronously between X and Y. Such that after the shuffling the $i^{th}$ column of X is the example corresponding to the $i^{th}$ label in Y. The shuffling step ensures that examples will be split randomly into different mini-batches. \n\n<img src=\"images/kiank_shuffle.png\" style=\"width:550px;height:300px;\">\n\n- **Partition**: Partition the shuffled (X, Y) into mini-batches of size `mini_batch_size` (here 64). Note that the number of training examples is not always divisible by `mini_batch_size`. The last mini batch might be smaller, but you don't need to worry about this. When the final mini-batch is smaller than the full `mini_batch_size`, it will look like this: \n\n<img src=\"images/kiank_partition.png\" style=\"width:550px;height:300px;\">\n\n**Exercise**: Implement `random_mini_batches`. We coded the shuffling part for you. To help you with the partitioning step, we give you the following code that selects the indexes for the $1^{st}$ and $2^{nd}$ mini-batches:\n```python\nfirst_mini_batch_X = shuffled_X[:, 0 : mini_batch_size]\nsecond_mini_batch_X = shuffled_X[:, mini_batch_size : 2 * mini_batch_size]\n...\n```\n\nNote that the last mini-batch might end up smaller than `mini_batch_size=64`. Let $\\lfloor s \\rfloor$ represents $s$ rounded down to the nearest integer (this is `math.floor(s)` in Python). If the total number of examples is not a multiple of `mini_batch_size=64` then there will be $\\lfloor \\frac{m}{mini\\_batch\\_size}\\rfloor$ mini-batches with a full 64 examples, and the number of examples in the final mini-batch will be ($m-mini_\\_batch_\\_size \\times \\lfloor \\frac{m}{mini\\_batch\\_size}\\rfloor$). ",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: random_mini_batches\n\ndef random_mini_batches(X, Y, mini_batch_size = 64, seed = 0):\n \"\"\"\n Creates a list of random minibatches from (X, Y)\n \n Arguments:\n X -- input data, of shape (input size, number of examples)\n Y -- true \"label\" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)\n mini_batch_size -- size of the mini-batches, integer\n \n Returns:\n mini_batches -- list of synchronous (mini_batch_X, mini_batch_Y)\n \"\"\"\n \n np.random.seed(seed) # To make your \"random\" minibatches the same as ours\n m = X.shape[1] # number of training examples\n mini_batches = []\n \n # Step 1: Shuffle (X, Y)\n permutation = list(np.random.permutation(m))\n shuffled_X = X[:, permutation]\n shuffled_Y = Y[:, permutation].reshape((1,m))\n\n # Step 2: Partition (shuffled_X, shuffled_Y). Minus the end case.\n num_complete_minibatches = math.floor(m/mini_batch_size) # number of mini batches of size mini_batch_size in your partitionning\n for k in range(0, num_complete_minibatches):\n ### START CODE HERE ### (approx. 2 lines)\n mini_batch_X = shuffled_X[:,k*mini_batch_size:(k+1)*mini_batch_size]\n mini_batch_Y = shuffled_Y[:,k*mini_batch_size:(k+1)*mini_batch_size]\n ### END CODE HERE ###\n mini_batch = (mini_batch_X, mini_batch_Y)\n mini_batches.append(mini_batch)\n \n # Handling the end case (last mini-batch < mini_batch_size)\n if m % mini_batch_size != 0:\n ### START CODE HERE ### (approx. 2 lines)\n mini_batch_X = shuffled_X[:,num_complete_minibatches * mini_batch_size:]\n mini_batch_Y = shuffled_Y[:,num_complete_minibatches * mini_batch_size:]\n ### END CODE HERE ###\n mini_batch = (mini_batch_X, mini_batch_Y)\n mini_batches.append(mini_batch)\n \n return mini_batches",
"_____no_output_____"
],
[
"X_assess, Y_assess, mini_batch_size = random_mini_batches_test_case()\nmini_batches = random_mini_batches(X_assess, Y_assess, mini_batch_size)\n\nprint (\"shape of the 1st mini_batch_X: \" + str(mini_batches[0][0].shape))\nprint (\"shape of the 2nd mini_batch_X: \" + str(mini_batches[1][0].shape))\nprint (\"shape of the 3rd mini_batch_X: \" + str(mini_batches[2][0].shape))\nprint (\"shape of the 1st mini_batch_Y: \" + str(mini_batches[0][1].shape))\nprint (\"shape of the 2nd mini_batch_Y: \" + str(mini_batches[1][1].shape)) \nprint (\"shape of the 3rd mini_batch_Y: \" + str(mini_batches[2][1].shape))\nprint (\"mini batch sanity check: \" + str(mini_batches[0][0][0][0:3]))",
"shape of the 1st mini_batch_X: (12288, 64)\nshape of the 2nd mini_batch_X: (12288, 64)\nshape of the 3rd mini_batch_X: (12288, 20)\nshape of the 1st mini_batch_Y: (1, 64)\nshape of the 2nd mini_batch_Y: (1, 64)\nshape of the 3rd mini_batch_Y: (1, 20)\nmini batch sanity check: [ 0.90085595 -0.7612069 0.2344157 ]\n"
]
],
[
[
"**Expected Output**:\n\n<table style=\"width:50%\"> \n <tr>\n <td > **shape of the 1st mini_batch_X** </td> \n <td > (12288, 64) </td> \n </tr> \n \n <tr>\n <td > **shape of the 2nd mini_batch_X** </td> \n <td > (12288, 64) </td> \n </tr> \n \n <tr>\n <td > **shape of the 3rd mini_batch_X** </td> \n <td > (12288, 20) </td> \n </tr>\n <tr>\n <td > **shape of the 1st mini_batch_Y** </td> \n <td > (1, 64) </td> \n </tr> \n <tr>\n <td > **shape of the 2nd mini_batch_Y** </td> \n <td > (1, 64) </td> \n </tr> \n <tr>\n <td > **shape of the 3rd mini_batch_Y** </td> \n <td > (1, 20) </td> \n </tr> \n <tr>\n <td > **mini batch sanity check** </td> \n <td > [ 0.90085595 -0.7612069 0.2344157 ] </td> \n </tr>\n \n</table>",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- Shuffling and Partitioning are the two steps required to build mini-batches\n- Powers of two are often chosen to be the mini-batch size, e.g., 16, 32, 64, 128.",
"_____no_output_____"
],
[
"## 3 - Momentum\n\nBecause mini-batch gradient descent makes a parameter update after seeing just a subset of examples, the direction of the update has some variance, and so the path taken by mini-batch gradient descent will \"oscillate\" toward convergence. Using momentum can reduce these oscillations. \n\nMomentum takes into account the past gradients to smooth out the update. We will store the 'direction' of the previous gradients in the variable $v$. Formally, this will be the exponentially weighted average of the gradient on previous steps. You can also think of $v$ as the \"velocity\" of a ball rolling downhill, building up speed (and momentum) according to the direction of the gradient/slope of the hill. \n\n<img src=\"images/opt_momentum.png\" style=\"width:400px;height:250px;\">\n<caption><center> <u><font color='purple'>**Figure 3**</u><font color='purple'>: The red arrows shows the direction taken by one step of mini-batch gradient descent with momentum. The blue points show the direction of the gradient (with respect to the current mini-batch) on each step. Rather than just following the gradient, we let the gradient influence $v$ and then take a step in the direction of $v$.<br> <font color='black'> </center>\n\n\n**Exercise**: Initialize the velocity. The velocity, $v$, is a python dictionary that needs to be initialized with arrays of zeros. Its keys are the same as those in the `grads` dictionary, that is:\nfor $l =1,...,L$:\n```python\nv[\"dW\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"W\" + str(l+1)])\nv[\"db\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"b\" + str(l+1)])\n```\n**Note** that the iterator l starts at 0 in the for loop while the first parameters are v[\"dW1\"] and v[\"db1\"] (that's a \"one\" on the superscript). This is why we are shifting l to l+1 in the `for` loop.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_velocity\n\ndef initialize_velocity(parameters):\n \"\"\"\n Initializes the velocity as a python dictionary with:\n - keys: \"dW1\", \"db1\", ..., \"dWL\", \"dbL\" \n - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.\n Arguments:\n parameters -- python dictionary containing your parameters.\n parameters['W' + str(l)] = Wl\n parameters['b' + str(l)] = bl\n \n Returns:\n v -- python dictionary containing the current velocity.\n v['dW' + str(l)] = velocity of dWl\n v['db' + str(l)] = velocity of dbl\n \"\"\"\n \n L = len(parameters) // 2 # number of layers in the neural networks\n v = {}\n \n # Initialize velocity\n for l in range(L):\n ### START CODE HERE ### (approx. 2 lines)\n v[\"dW\" + str(l+1)] = np.zeros((parameters[\"W\"+str(l+1)].shape[0],parameters[\"W\"+str(l+1)].shape[1]))\n v[\"db\" + str(l+1)] = np.zeros((parameters[\"b\"+str(l+1)].shape[0],1))\n ### END CODE HERE ###\n \n return v",
"_____no_output_____"
],
[
"parameters = initialize_velocity_test_case()\n\nv = initialize_velocity(parameters)\nprint(\"v[\\\"dW1\\\"] =\\n\" + str(v[\"dW1\"]))\nprint(\"v[\\\"db1\\\"] =\\n\" + str(v[\"db1\"]))\nprint(\"v[\\\"dW2\\\"] =\\n\" + str(v[\"dW2\"]))\nprint(\"v[\\\"db2\\\"] =\\n\" + str(v[\"db2\"]))",
"v[\"dW1\"] =\n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db1\"] =\n[[ 0.]\n [ 0.]]\nv[\"dW2\"] =\n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db2\"] =\n[[ 0.]\n [ 0.]\n [ 0.]]\n"
]
],
[
[
"**Expected Output**:\n\n```\nv[\"dW1\"] =\n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db1\"] =\n[[ 0.]\n [ 0.]]\nv[\"dW2\"] =\n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db2\"] =\n[[ 0.]\n [ 0.]\n [ 0.]]\n```",
"_____no_output_____"
],
[
"**Exercise**: Now, implement the parameters update with momentum. The momentum update rule is, for $l = 1, ..., L$: \n\n$$ \\begin{cases}\nv_{dW^{[l]}} = \\beta v_{dW^{[l]}} + (1 - \\beta) dW^{[l]} \\\\\nW^{[l]} = W^{[l]} - \\alpha v_{dW^{[l]}}\n\\end{cases}\\tag{3}$$\n\n$$\\begin{cases}\nv_{db^{[l]}} = \\beta v_{db^{[l]}} + (1 - \\beta) db^{[l]} \\\\\nb^{[l]} = b^{[l]} - \\alpha v_{db^{[l]}} \n\\end{cases}\\tag{4}$$\n\nwhere L is the number of layers, $\\beta$ is the momentum and $\\alpha$ is the learning rate. All parameters should be stored in the `parameters` dictionary. Note that the iterator `l` starts at 0 in the `for` loop while the first parameters are $W^{[1]}$ and $b^{[1]}$ (that's a \"one\" on the superscript). So you will need to shift `l` to `l+1` when coding.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: update_parameters_with_momentum\n\ndef update_parameters_with_momentum(parameters, grads, v, beta, learning_rate):\n \"\"\"\n Update parameters using Momentum\n \n Arguments:\n parameters -- python dictionary containing your parameters:\n parameters['W' + str(l)] = Wl\n parameters['b' + str(l)] = bl\n grads -- python dictionary containing your gradients for each parameters:\n grads['dW' + str(l)] = dWl\n grads['db' + str(l)] = dbl\n v -- python dictionary containing the current velocity:\n v['dW' + str(l)] = ...\n v['db' + str(l)] = ...\n beta -- the momentum hyperparameter, scalar\n learning_rate -- the learning rate, scalar\n \n Returns:\n parameters -- python dictionary containing your updated parameters \n v -- python dictionary containing your updated velocities\n \"\"\"\n\n L = len(parameters) // 2 # number of layers in the neural networks\n \n # Momentum update for each parameter\n for l in range(L):\n \n ### START CODE HERE ### (approx. 4 lines)\n # compute velocities\n v[\"dW\" + str(l+1)] = (beta * v[\"dW\" + str(l+1)]) + (1-beta)*grads['dW'+str(l+1)]\n v[\"db\" + str(l+1)] = (beta * v[\"db\" + str(l+1)]) + (1-beta)*grads['db'+str(l+1)]\n # update parameters\n parameters[\"W\" + str(l+1)] = parameters[\"W\" + str(l+1)] - (learning_rate * beta * v[\"dW\" + str(l+1)])\n parameters[\"b\" + str(l+1)] = parameters[\"b\" + str(l+1)] - (learning_rate * beta * v[\"db\" + str(l+1)])\n ### END CODE HERE ###\n \n return parameters, v",
"_____no_output_____"
],
[
"parameters, grads, v = update_parameters_with_momentum_test_case()\n\nparameters, v = update_parameters_with_momentum(parameters, grads, v, beta = 0.9, learning_rate = 0.01)\nprint(\"W1 = \\n\" + str(parameters[\"W1\"]))\nprint(\"b1 = \\n\" + str(parameters[\"b1\"]))\nprint(\"W2 = \\n\" + str(parameters[\"W2\"]))\nprint(\"b2 = \\n\" + str(parameters[\"b2\"]))\nprint(\"v[\\\"dW1\\\"] = \\n\" + str(v[\"dW1\"]))\nprint(\"v[\\\"db1\\\"] = \\n\" + str(v[\"db1\"]))\nprint(\"v[\\\"dW2\\\"] = \\n\" + str(v[\"dW2\"]))\nprint(\"v[\\\"db2\\\"] = v\" + str(v[\"db2\"]))",
"W1 = \n[[ 1.62533592 -0.61278666 -0.52898318]\n [-1.07342087 0.86459686 -2.30092334]]\nb1 = \n[[ 1.74492237]\n [-0.76036471]]\nW2 = \n[[ 0.3192802 -0.2498477 1.46273043]\n [-2.05978363 -0.32179875 -0.38329367]\n [ 1.13437356 -1.09987987 -0.17142263]]\nb2 = \n[[-0.87806939]\n [ 0.04071992]\n [ 0.58214737]]\nv[\"dW1\"] = \n[[-0.11006192 0.11447237 0.09015907]\n [ 0.05024943 0.09008559 -0.06837279]]\nv[\"db1\"] = \n[[-0.01228902]\n [-0.09357694]]\nv[\"dW2\"] = \n[[-0.02678881 0.05303555 -0.06916608]\n [-0.03967535 -0.06871727 -0.08452056]\n [-0.06712461 -0.00126646 -0.11173103]]\nv[\"db2\"] = v[[ 0.02344157]\n [ 0.16598022]\n [ 0.07420442]]\n"
]
],
[
[
"**Expected Output**:\n\n```\nW1 = \n[[ 1.62544598 -0.61290114 -0.52907334]\n [-1.07347112 0.86450677 -2.30085497]]\nb1 = \n[[ 1.74493465]\n [-0.76027113]]\nW2 = \n[[ 0.31930698 -0.24990073 1.4627996 ]\n [-2.05974396 -0.32173003 -0.38320915]\n [ 1.13444069 -1.0998786 -0.1713109 ]]\nb2 = \n[[-0.87809283]\n [ 0.04055394]\n [ 0.58207317]]\nv[\"dW1\"] = \n[[-0.11006192 0.11447237 0.09015907]\n [ 0.05024943 0.09008559 -0.06837279]]\nv[\"db1\"] = \n[[-0.01228902]\n [-0.09357694]]\nv[\"dW2\"] = \n[[-0.02678881 0.05303555 -0.06916608]\n [-0.03967535 -0.06871727 -0.08452056]\n [-0.06712461 -0.00126646 -0.11173103]]\nv[\"db2\"] = v[[ 0.02344157]\n [ 0.16598022]\n [ 0.07420442]]\n```",
"_____no_output_____"
],
[
"**Note** that:\n- The velocity is initialized with zeros. So the algorithm will take a few iterations to \"build up\" velocity and start to take bigger steps.\n- If $\\beta = 0$, then this just becomes standard gradient descent without momentum. \n\n**How do you choose $\\beta$?**\n\n- The larger the momentum $\\beta$ is, the smoother the update because the more we take the past gradients into account. But if $\\beta$ is too big, it could also smooth out the updates too much. \n- Common values for $\\beta$ range from 0.8 to 0.999. If you don't feel inclined to tune this, $\\beta = 0.9$ is often a reasonable default. \n- Tuning the optimal $\\beta$ for your model might need trying several values to see what works best in term of reducing the value of the cost function $J$. ",
"_____no_output_____"
],
[
"<font color='blue'>\n**What you should remember**:\n- Momentum takes past gradients into account to smooth out the steps of gradient descent. It can be applied with batch gradient descent, mini-batch gradient descent or stochastic gradient descent.\n- You have to tune a momentum hyperparameter $\\beta$ and a learning rate $\\alpha$.",
"_____no_output_____"
],
[
"## 4 - Adam\n\nAdam is one of the most effective optimization algorithms for training neural networks. It combines ideas from RMSProp (described in lecture) and Momentum. \n\n**How does Adam work?**\n1. It calculates an exponentially weighted average of past gradients, and stores it in variables $v$ (before bias correction) and $v^{corrected}$ (with bias correction). \n2. It calculates an exponentially weighted average of the squares of the past gradients, and stores it in variables $s$ (before bias correction) and $s^{corrected}$ (with bias correction). \n3. It updates parameters in a direction based on combining information from \"1\" and \"2\".\n\nThe update rule is, for $l = 1, ..., L$: \n\n$$\\begin{cases}\nv_{dW^{[l]}} = \\beta_1 v_{dW^{[l]}} + (1 - \\beta_1) \\frac{\\partial \\mathcal{J} }{ \\partial W^{[l]} } \\\\\nv^{corrected}_{dW^{[l]}} = \\frac{v_{dW^{[l]}}}{1 - (\\beta_1)^t} \\\\\ns_{dW^{[l]}} = \\beta_2 s_{dW^{[l]}} + (1 - \\beta_2) (\\frac{\\partial \\mathcal{J} }{\\partial W^{[l]} })^2 \\\\\ns^{corrected}_{dW^{[l]}} = \\frac{s_{dW^{[l]}}}{1 - (\\beta_2)^t} \\\\\nW^{[l]} = W^{[l]} - \\alpha \\frac{v^{corrected}_{dW^{[l]}}}{\\sqrt{s^{corrected}_{dW^{[l]}}} + \\varepsilon}\n\\end{cases}$$\nwhere:\n- t counts the number of steps taken of Adam \n- L is the number of layers\n- $\\beta_1$ and $\\beta_2$ are hyperparameters that control the two exponentially weighted averages. \n- $\\alpha$ is the learning rate\n- $\\varepsilon$ is a very small number to avoid dividing by zero\n\nAs usual, we will store all parameters in the `parameters` dictionary ",
"_____no_output_____"
],
[
"**Exercise**: Initialize the Adam variables $v, s$ which keep track of the past information.\n\n**Instruction**: The variables $v, s$ are python dictionaries that need to be initialized with arrays of zeros. Their keys are the same as for `grads`, that is:\nfor $l = 1, ..., L$:\n```python\nv[\"dW\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"W\" + str(l+1)])\nv[\"db\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"b\" + str(l+1)])\ns[\"dW\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"W\" + str(l+1)])\ns[\"db\" + str(l+1)] = ... #(numpy array of zeros with the same shape as parameters[\"b\" + str(l+1)])\n\n```",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: initialize_adam\n\ndef initialize_adam(parameters) :\n \"\"\"\n Initializes v and s as two python dictionaries with:\n - keys: \"dW1\", \"db1\", ..., \"dWL\", \"dbL\" \n - values: numpy arrays of zeros of the same shape as the corresponding gradients/parameters.\n \n Arguments:\n parameters -- python dictionary containing your parameters.\n parameters[\"W\" + str(l)] = Wl\n parameters[\"b\" + str(l)] = bl\n \n Returns: \n v -- python dictionary that will contain the exponentially weighted average of the gradient.\n v[\"dW\" + str(l)] = ...\n v[\"db\" + str(l)] = ...\n s -- python dictionary that will contain the exponentially weighted average of the squared gradient.\n s[\"dW\" + str(l)] = ...\n s[\"db\" + str(l)] = ...\n\n \"\"\"\n \n L = len(parameters) // 2 # number of layers in the neural networks\n v = {}\n s = {}\n \n # Initialize v, s. Input: \"parameters\". Outputs: \"v, s\".\n for l in range(L):\n ### START CODE HERE ### (approx. 4 lines)\n v[\"dW\" + str(l+1)] = np.zeros_like(parameters[\"W\"+str(l+1)])\n v[\"db\" + str(l+1)] = np.zeros_like(parameters[\"b\"+str(l+1)])\n s[\"dW\" + str(l+1)] = np.zeros_like(parameters[\"W\"+str(l+1)])\n s[\"db\" + str(l+1)] = np.zeros_like(parameters[\"b\"+str(l+1)])\n ### END CODE HERE ###\n \n return v, s",
"_____no_output_____"
],
[
"parameters = initialize_adam_test_case()\n\nv, s = initialize_adam(parameters)\nprint(\"v[\\\"dW1\\\"] = \\n\" + str(v[\"dW1\"]))\nprint(\"v[\\\"db1\\\"] = \\n\" + str(v[\"db1\"]))\nprint(\"v[\\\"dW2\\\"] = \\n\" + str(v[\"dW2\"]))\nprint(\"v[\\\"db2\\\"] = \\n\" + str(v[\"db2\"]))\nprint(\"s[\\\"dW1\\\"] = \\n\" + str(s[\"dW1\"]))\nprint(\"s[\\\"db1\\\"] = \\n\" + str(s[\"db1\"]))\nprint(\"s[\\\"dW2\\\"] = \\n\" + str(s[\"dW2\"]))\nprint(\"s[\\\"db2\\\"] = \\n\" + str(s[\"db2\"]))",
"v[\"dW1\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db1\"] = \n[[ 0.]\n [ 0.]]\nv[\"dW2\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db2\"] = \n[[ 0.]\n [ 0.]\n [ 0.]]\ns[\"dW1\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\ns[\"db1\"] = \n[[ 0.]\n [ 0.]]\ns[\"dW2\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\ns[\"db2\"] = \n[[ 0.]\n [ 0.]\n [ 0.]]\n"
]
],
[
[
"**Expected Output**:\n\n```\nv[\"dW1\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db1\"] = \n[[ 0.]\n [ 0.]]\nv[\"dW2\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\nv[\"db2\"] = \n[[ 0.]\n [ 0.]\n [ 0.]]\ns[\"dW1\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]]\ns[\"db1\"] = \n[[ 0.]\n [ 0.]]\ns[\"dW2\"] = \n[[ 0. 0. 0.]\n [ 0. 0. 0.]\n [ 0. 0. 0.]]\ns[\"db2\"] = \n[[ 0.]\n [ 0.]\n [ 0.]]\n```",
"_____no_output_____"
],
[
"**Exercise**: Now, implement the parameters update with Adam. Recall the general update rule is, for $l = 1, ..., L$: \n\n$$\\begin{cases}\nv_{W^{[l]}} = \\beta_1 v_{W^{[l]}} + (1 - \\beta_1) \\frac{\\partial J }{ \\partial W^{[l]} } \\\\\nv^{corrected}_{W^{[l]}} = \\frac{v_{W^{[l]}}}{1 - (\\beta_1)^t} \\\\\ns_{W^{[l]}} = \\beta_2 s_{W^{[l]}} + (1 - \\beta_2) (\\frac{\\partial J }{\\partial W^{[l]} })^2 \\\\\ns^{corrected}_{W^{[l]}} = \\frac{s_{W^{[l]}}}{1 - (\\beta_2)^t} \\\\\nW^{[l]} = W^{[l]} - \\alpha \\frac{v^{corrected}_{W^{[l]}}}{\\sqrt{s^{corrected}_{W^{[l]}}}+\\varepsilon}\n\\end{cases}$$\n\n\n**Note** that the iterator `l` starts at 0 in the `for` loop while the first parameters are $W^{[1]}$ and $b^{[1]}$. You need to shift `l` to `l+1` when coding.",
"_____no_output_____"
]
],
[
[
"# GRADED FUNCTION: update_parameters_with_adam\n\ndef update_parameters_with_adam(parameters, grads, v, s, t, learning_rate = 0.01,\n beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8):\n \"\"\"\n Update parameters using Adam\n \n Arguments:\n parameters -- python dictionary containing your parameters:\n parameters['W' + str(l)] = Wl\n parameters['b' + str(l)] = bl\n grads -- python dictionary containing your gradients for each parameters:\n grads['dW' + str(l)] = dWl\n grads['db' + str(l)] = dbl\n v -- Adam variable, moving average of the first gradient, python dictionary\n s -- Adam variable, moving average of the squared gradient, python dictionary\n learning_rate -- the learning rate, scalar.\n beta1 -- Exponential decay hyperparameter for the first moment estimates \n beta2 -- Exponential decay hyperparameter for the second moment estimates \n epsilon -- hyperparameter preventing division by zero in Adam updates\n\n Returns:\n parameters -- python dictionary containing your updated parameters \n v -- Adam variable, moving average of the first gradient, python dictionary\n s -- Adam variable, moving average of the squared gradient, python dictionary\n \"\"\"\n \n L = len(parameters) // 2 # number of layers in the neural networks\n v_corrected = {} # Initializing first moment estimate, python dictionary\n s_corrected = {} # Initializing second moment estimate, python dictionary\n \n # Perform Adam update on all parameters\n for l in range(L):\n # Moving average of the gradients. Inputs: \"v, grads, beta1\". Output: \"v\".\n ### START CODE HERE ### (approx. 2 lines)\n v[\"dW\" + str(l+1)] = (beta1 * v[\"dW\" + str(l+1)]) + (1-beta1)*grads['dW'+str(l+1)]\n v[\"db\" + str(l+1)] = (beta1 * v[\"db\" + str(l+1)]) + (1-beta1)*grads['db'+str(l+1)]\n ### END CODE HERE ###\n\n # Compute bias-corrected first moment estimate. Inputs: \"v, beta1, t\". Output: \"v_corrected\".\n ### START CODE HERE ### (approx. 2 lines)\n v_corrected[\"dW\" + str(l+1)] = v[\"dW\" + str(l+1)]/(1-np.power(beta1,t))\n v_corrected[\"db\" + str(l+1)] = v[\"db\" + str(l+1)]/(1-np.power(beta1,t))\n ### END CODE HERE ###\n\n # Moving average of the squared gradients. Inputs: \"s, grads, beta2\". Output: \"s\".\n ### START CODE HERE ### (approx. 2 lines)\n s[\"dW\" + str(l+1)] = (beta2 * s[\"dW\" + str(l+1)]) + ((1-beta2)*np.power(grads['dW'+str(l+1)],2))\n s[\"db\" + str(l+1)] = (beta2 * s[\"db\" + str(l+1)]) + ((1-beta2)*np.power(grads['db'+str(l+1)],2))\n ### END CODE HERE ###\n\n # Compute bias-corrected second raw moment estimate. Inputs: \"s, beta2, t\". Output: \"s_corrected\".\n ### START CODE HERE ### (approx. 2 lines)\n s_corrected[\"dW\" + str(l+1)] = s[\"dW\" + str(l+1)]/(1-np.power(beta2,t))\n s_corrected[\"db\" + str(l+1)] = s[\"db\" + str(l+1)]/(1-np.power(beta2,t))\n ### END CODE HERE ###\n\n # Update parameters. Inputs: \"parameters, learning_rate, v_corrected, s_corrected, epsilon\". Output: \"parameters\".\n ### START CODE HERE ### (approx. 2 lines)\n parameters[\"W\" + str(l+1)] = parameters[\"W\" + str(l+1)] - (learning_rate*(v_corrected[\"dW\"+str(l+1)]/(np.sqrt(s_corrected[\"dW\"+str(l+1)])+epsilon)))\n parameters[\"b\" + str(l+1)] = parameters[\"b\" + str(l+1)] - (learning_rate*(v_corrected[\"db\"+str(l+1)]/(np.sqrt(s_corrected[\"db\"+str(l+1)])+epsilon))) \n ### END CODE HERE ###\n\n return parameters, v, s",
"_____no_output_____"
],
[
"parameters, grads, v, s = update_parameters_with_adam_test_case()\nparameters, v, s = update_parameters_with_adam(parameters, grads, v, s, t = 2)\n\nprint(\"W1 = \\n\" + str(parameters[\"W1\"]))\nprint(\"b1 = \\n\" + str(parameters[\"b1\"]))\nprint(\"W2 = \\n\" + str(parameters[\"W2\"]))\nprint(\"b2 = \\n\" + str(parameters[\"b2\"]))\nprint(\"v[\\\"dW1\\\"] = \\n\" + str(v[\"dW1\"]))\nprint(\"v[\\\"db1\\\"] = \\n\" + str(v[\"db1\"]))\nprint(\"v[\\\"dW2\\\"] = \\n\" + str(v[\"dW2\"]))\nprint(\"v[\\\"db2\\\"] = \\n\" + str(v[\"db2\"]))\nprint(\"s[\\\"dW1\\\"] = \\n\" + str(s[\"dW1\"]))\nprint(\"s[\\\"db1\\\"] = \\n\" + str(s[\"db1\"]))\nprint(\"s[\\\"dW2\\\"] = \\n\" + str(s[\"dW2\"]))\nprint(\"s[\\\"db2\\\"] = \\n\" + str(s[\"db2\"]))",
"W1 = \n[[ 1.63178673 -0.61919778 -0.53561312]\n [-1.08040999 0.85796626 -2.29409733]]\nb1 = \n[[ 1.75225313]\n [-0.75376553]]\nW2 = \n[[ 0.32648046 -0.25681174 1.46954931]\n [-2.05269934 -0.31497584 -0.37661299]\n [ 1.14121081 -1.09244991 -0.16498684]]\nb2 = \n[[-0.88529979]\n [ 0.03477238]\n [ 0.57537385]]\nv[\"dW1\"] = \n[[-0.11006192 0.11447237 0.09015907]\n [ 0.05024943 0.09008559 -0.06837279]]\nv[\"db1\"] = \n[[-0.01228902]\n [-0.09357694]]\nv[\"dW2\"] = \n[[-0.02678881 0.05303555 -0.06916608]\n [-0.03967535 -0.06871727 -0.08452056]\n [-0.06712461 -0.00126646 -0.11173103]]\nv[\"db2\"] = \n[[ 0.02344157]\n [ 0.16598022]\n [ 0.07420442]]\ns[\"dW1\"] = \n[[ 0.00121136 0.00131039 0.00081287]\n [ 0.0002525 0.00081154 0.00046748]]\ns[\"db1\"] = \n[[ 1.51020075e-05]\n [ 8.75664434e-04]]\ns[\"dW2\"] = \n[[ 7.17640232e-05 2.81276921e-04 4.78394595e-04]\n [ 1.57413361e-04 4.72206320e-04 7.14372576e-04]\n [ 4.50571368e-04 1.60392066e-07 1.24838242e-03]]\ns[\"db2\"] = \n[[ 5.49507194e-05]\n [ 2.75494327e-03]\n [ 5.50629536e-04]]\n"
]
],
[
[
"**Expected Output**:\n\n```\nW1 = \n[[ 1.63178673 -0.61919778 -0.53561312]\n [-1.08040999 0.85796626 -2.29409733]]\nb1 = \n[[ 1.75225313]\n [-0.75376553]]\nW2 = \n[[ 0.32648046 -0.25681174 1.46954931]\n [-2.05269934 -0.31497584 -0.37661299]\n [ 1.14121081 -1.09245036 -0.16498684]]\nb2 = \n[[-0.88529978]\n [ 0.03477238]\n [ 0.57537385]]\nv[\"dW1\"] = \n[[-0.11006192 0.11447237 0.09015907]\n [ 0.05024943 0.09008559 -0.06837279]]\nv[\"db1\"] = \n[[-0.01228902]\n [-0.09357694]]\nv[\"dW2\"] = \n[[-0.02678881 0.05303555 -0.06916608]\n [-0.03967535 -0.06871727 -0.08452056]\n [-0.06712461 -0.00126646 -0.11173103]]\nv[\"db2\"] = \n[[ 0.02344157]\n [ 0.16598022]\n [ 0.07420442]]\ns[\"dW1\"] = \n[[ 0.00121136 0.00131039 0.00081287]\n [ 0.0002525 0.00081154 0.00046748]]\ns[\"db1\"] = \n[[ 1.51020075e-05]\n [ 8.75664434e-04]]\ns[\"dW2\"] = \n[[ 7.17640232e-05 2.81276921e-04 4.78394595e-04]\n [ 1.57413361e-04 4.72206320e-04 7.14372576e-04]\n [ 4.50571368e-04 1.60392066e-07 1.24838242e-03]]\ns[\"db2\"] = \n[[ 5.49507194e-05]\n [ 2.75494327e-03]\n [ 5.50629536e-04]]\n```",
"_____no_output_____"
],
[
"You now have three working optimization algorithms (mini-batch gradient descent, Momentum, Adam). Let's implement a model with each of these optimizers and observe the difference.",
"_____no_output_____"
],
[
"## 5 - Model with different optimization algorithms\n\nLets use the following \"moons\" dataset to test the different optimization methods. (The dataset is named \"moons\" because the data from each of the two classes looks a bit like a crescent-shaped moon.) ",
"_____no_output_____"
]
],
[
[
"train_X, train_Y = load_dataset()",
"_____no_output_____"
]
],
[
[
"We have already implemented a 3-layer neural network. You will train it with: \n- Mini-batch **Gradient Descent**: it will call your function:\n - `update_parameters_with_gd()`\n- Mini-batch **Momentum**: it will call your functions:\n - `initialize_velocity()` and `update_parameters_with_momentum()`\n- Mini-batch **Adam**: it will call your functions:\n - `initialize_adam()` and `update_parameters_with_adam()`",
"_____no_output_____"
]
],
[
[
"def model(X, Y, layers_dims, optimizer, learning_rate = 0.0007, mini_batch_size = 64, beta = 0.9,\n beta1 = 0.9, beta2 = 0.999, epsilon = 1e-8, num_epochs = 10000, print_cost = True):\n \"\"\"\n 3-layer neural network model which can be run in different optimizer modes.\n \n Arguments:\n X -- input data, of shape (2, number of examples)\n Y -- true \"label\" vector (1 for blue dot / 0 for red dot), of shape (1, number of examples)\n layers_dims -- python list, containing the size of each layer\n learning_rate -- the learning rate, scalar.\n mini_batch_size -- the size of a mini batch\n beta -- Momentum hyperparameter\n beta1 -- Exponential decay hyperparameter for the past gradients estimates \n beta2 -- Exponential decay hyperparameter for the past squared gradients estimates \n epsilon -- hyperparameter preventing division by zero in Adam updates\n num_epochs -- number of epochs\n print_cost -- True to print the cost every 1000 epochs\n\n Returns:\n parameters -- python dictionary containing your updated parameters \n \"\"\"\n\n L = len(layers_dims) # number of layers in the neural networks\n costs = [] # to keep track of the cost\n t = 0 # initializing the counter required for Adam update\n seed = 10 # For grading purposes, so that your \"random\" minibatches are the same as ours\n m = X.shape[1] # number of training examples\n \n # Initialize parameters\n parameters = initialize_parameters(layers_dims)\n\n # Initialize the optimizer\n if optimizer == \"gd\":\n pass # no initialization required for gradient descent\n elif optimizer == \"momentum\":\n v = initialize_velocity(parameters)\n elif optimizer == \"adam\":\n v, s = initialize_adam(parameters)\n \n # Optimization loop\n for i in range(num_epochs):\n \n # Define the random minibatches. We increment the seed to reshuffle differently the dataset after each epoch\n seed = seed + 1\n minibatches = random_mini_batches(X, Y, mini_batch_size, seed)\n cost_total = 0\n \n for minibatch in minibatches:\n\n # Select a minibatch\n (minibatch_X, minibatch_Y) = minibatch\n\n # Forward propagation\n a3, caches = forward_propagation(minibatch_X, parameters)\n\n # Compute cost and add to the cost total\n cost_total += compute_cost(a3, minibatch_Y)\n\n # Backward propagation\n grads = backward_propagation(minibatch_X, minibatch_Y, caches)\n\n # Update parameters\n if optimizer == \"gd\":\n parameters = update_parameters_with_gd(parameters, grads, learning_rate)\n elif optimizer == \"momentum\":\n parameters, v = update_parameters_with_momentum(parameters, grads, v, beta, learning_rate)\n elif optimizer == \"adam\":\n t = t + 1 # Adam counter\n parameters, v, s = update_parameters_with_adam(parameters, grads, v, s,\n t, learning_rate, beta1, beta2, epsilon)\n cost_avg = cost_total / m\n \n # Print the cost every 1000 epoch\n if print_cost and i % 1000 == 0:\n print (\"Cost after epoch %i: %f\" %(i, cost_avg))\n if print_cost and i % 100 == 0:\n costs.append(cost_avg)\n \n # plot the cost\n plt.plot(costs)\n plt.ylabel('cost')\n plt.xlabel('epochs (per 100)')\n plt.title(\"Learning rate = \" + str(learning_rate))\n plt.show()\n\n return parameters",
"_____no_output_____"
]
],
[
[
"You will now run this 3 layer neural network with each of the 3 optimization methods.\n\n### 5.1 - Mini-batch Gradient descent\n\nRun the following code to see how the model does with mini-batch gradient descent.",
"_____no_output_____"
]
],
[
[
"# train 3-layer model\nlayers_dims = [train_X.shape[0], 5, 2, 1]\nparameters = model(train_X, train_Y, layers_dims, optimizer = \"gd\")\n\n# Predict\npredictions = predict(train_X, train_Y, parameters)\n\n# Plot decision boundary\nplt.title(\"Model with Gradient Descent optimization\")\naxes = plt.gca()\naxes.set_xlim([-1.5,2.5])\naxes.set_ylim([-1,1.5])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"Cost after epoch 0: 0.702405\nCost after epoch 1000: 0.668101\nCost after epoch 2000: 0.635288\nCost after epoch 3000: 0.600491\nCost after epoch 4000: 0.573367\nCost after epoch 5000: 0.551977\nCost after epoch 6000: 0.532370\nCost after epoch 7000: 0.514007\nCost after epoch 8000: 0.496472\nCost after epoch 9000: 0.468014\n"
]
],
[
[
"### 5.2 - Mini-batch gradient descent with momentum\n\nRun the following code to see how the model does with momentum. Because this example is relatively simple, the gains from using momemtum are small; but for more complex problems you might see bigger gains.",
"_____no_output_____"
]
],
[
[
"# train 3-layer model\nlayers_dims = [train_X.shape[0], 5, 2, 1]\nparameters = model(train_X, train_Y, layers_dims, beta = 0.9, optimizer = \"momentum\")\n\n# Predict\npredictions = predict(train_X, train_Y, parameters)\n\n# Plot decision boundary\nplt.title(\"Model with Momentum optimization\")\naxes = plt.gca()\naxes.set_xlim([-1.5,2.5])\naxes.set_ylim([-1,1.5])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"Cost after epoch 0: 0.702413\nCost after epoch 1000: 0.671435\nCost after epoch 2000: 0.642459\nCost after epoch 3000: 0.610431\nCost after epoch 4000: 0.582909\nCost after epoch 5000: 0.562944\nCost after epoch 6000: 0.544857\nCost after epoch 7000: 0.526676\nCost after epoch 8000: 0.510664\nCost after epoch 9000: 0.493146\n"
]
],
[
[
"### 5.3 - Mini-batch with Adam mode\n\nRun the following code to see how the model does with Adam.",
"_____no_output_____"
]
],
[
[
"# train 3-layer model\nlayers_dims = [train_X.shape[0], 5, 2, 1]\nparameters = model(train_X, train_Y, layers_dims, optimizer = \"adam\")\n\n# Predict\npredictions = predict(train_X, train_Y, parameters)\n\n# Plot decision boundary\nplt.title(\"Model with Adam optimization\")\naxes = plt.gca()\naxes.set_xlim([-1.5,2.5])\naxes.set_ylim([-1,1.5])\nplot_decision_boundary(lambda x: predict_dec(parameters, x.T), train_X, train_Y)",
"Cost after epoch 0: 0.702166\nCost after epoch 1000: 0.167845\nCost after epoch 2000: 0.141316\nCost after epoch 3000: 0.138788\nCost after epoch 4000: 0.136066\nCost after epoch 5000: 0.134240\nCost after epoch 6000: 0.131127\nCost after epoch 7000: 0.130216\nCost after epoch 8000: 0.129623\nCost after epoch 9000: 0.129118\n"
]
],
[
[
"### 5.4 - Summary\n\n<table> \n <tr>\n <td>\n **optimization method**\n </td>\n <td>\n **accuracy**\n </td>\n <td>\n **cost shape**\n </td>\n\n </tr>\n <td>\n Gradient descent\n </td>\n <td>\n 79.7%\n </td>\n <td>\n oscillations\n </td>\n <tr>\n <td>\n Momentum\n </td>\n <td>\n 79.7%\n </td>\n <td>\n oscillations\n </td>\n </tr>\n <tr>\n <td>\n Adam\n </td>\n <td>\n 94%\n </td>\n <td>\n smoother\n </td>\n </tr>\n</table> \n\nMomentum usually helps, but given the small learning rate and the simplistic dataset, its impact is almost negligeable. Also, the huge oscillations you see in the cost come from the fact that some minibatches are more difficult thans others for the optimization algorithm.\n\nAdam on the other hand, clearly outperforms mini-batch gradient descent and Momentum. If you run the model for more epochs on this simple dataset, all three methods will lead to very good results. However, you've seen that Adam converges a lot faster.\n\nSome advantages of Adam include:\n- Relatively low memory requirements (though higher than gradient descent and gradient descent with momentum) \n- Usually works well even with little tuning of hyperparameters (except $\\alpha$)",
"_____no_output_____"
],
[
"**References**:\n\n- Adam paper: https://arxiv.org/pdf/1412.6980.pdf",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a9e815221c2e125e6f9ecbffadffddf3ee960da
| 85,232 |
ipynb
|
Jupyter Notebook
|
Data of Corona.ipynb
|
AjitVerma15/Data-Analyzing-and-webscraping-of-Covid19-India
|
6cdf33a997135d2ad2deb89ab6409d5983559c40
|
[
"MIT"
] | null | null | null |
Data of Corona.ipynb
|
AjitVerma15/Data-Analyzing-and-webscraping-of-Covid19-India
|
6cdf33a997135d2ad2deb89ab6409d5983559c40
|
[
"MIT"
] | null | null | null |
Data of Corona.ipynb
|
AjitVerma15/Data-Analyzing-and-webscraping-of-Covid19-India
|
6cdf33a997135d2ad2deb89ab6409d5983559c40
|
[
"MIT"
] | null | null | null | 45.651848 | 24,552 | 0.516226 |
[
[
[
"import requests\nfrom bs4 import BeautifulSoup as soup\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nurl = \"https://en.wikipedia.org/wiki/COVID-19_pandemic_in_India\"\nresponse = requests.get(url)\nresponse = response.content\nhtml = soup(response,'html5lib')\ncorona_dates = html.findAll('div',{'class': 'barbox tright'})\ncorona_dates = corona_dates[0]\nDate = corona_dates.findAll('td',{'colspan':'2'})\nDate = [ct.text for ct in Date]\nDate = Date[8:]\npatients = corona_dates.findAll('span',{'class' : 'cbs-ibr'})\nTotal_case = []\nDeath = []\n\nNumber = [ct.text for ct in patients]\n\nlength = len(Number)\n\n\n\nfor i in range(length):\n if(i%2==0):\n Total_case.append(Number[i])\n else:\n Death.append(Number[i])\n\n# Total Death upto date \nDeath = Death[7:]\nDeaths = []\nfor i in Death:\n i = i.replace(',','')\n Deaths.append(i)\nDeaths = [int(i) for i in Deaths]\n\n#Total Cases Upto date\n\nTotal_case = Total_case[7:]\nTotal_cases = []\nfor i in Total_case:\n i = i.replace(',','')\n Total_cases.append(i)\nTotal_cases = [int(i) for i in Total_cases]\n\n\nTotal_detail = { 'Date' : Date,\n 'No. of Cases' : Total_cases,\n 'No. of Deaths' : Deaths\n }\ndf = pd.DataFrame(Total_detail)\ndf[\"New Cases\"] = df['No. of Cases'].diff(1)\ndf[\"New Death\"] = df['No. of Deaths'].diff(1)\n\n\ndf.fillna({'New Cases':0}, inplace=True)\ndf.fillna({'New Death':0}, inplace=True)\ndf.astype({'New Cases': np.int64,'New Death':np.int64})\n",
"_____no_output_____"
],
[
"plt.plot(df['Date'],df['New Cases'],label=\"No.ofcases\")\nplt.plot(df['Date'],df['New Death'],label=\"No.ofDeaths\")\nplt.xticks(rotation=90)\nplt.show()",
"_____no_output_____"
],
[
"import plotly.graph_objects as go\nimport plotly.express as px\n#fig = px.line(df, x='Date', y='New Cases')\n#fig = px.scatter(x=df['Date'], y=df['New Death'])\nfig = go.Figure()\nfig.add_trace(go.Bar(x=df['Date'], y=df['New Cases']))\n#fig = px.scatter(df,x='Date', y='New Death',color='New Death',width=1000,mode='maker')\nfig.update_layout(title='New Cases daily')\nfig.show()",
"_____no_output_____"
],
[
"# Cases over States\nS_table = html.findAll('table',{'class':'wikitable plainrowheaders sortable'})\nS_table = S_table[0]\nState = S_table.findAll('th',{'scope':'row'})",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a9e901b6d7f556ee523f25a8e13af3ada923ad2
| 125,574 |
ipynb
|
Jupyter Notebook
|
code/notebooks/.ipynb_checkpoints/psycho_orig1-checkpoint.ipynb
|
zeroknowledgediscovery/zcad
|
5642a7ab0ac29337a4066305091811032ab9032b
|
[
"MIT"
] | null | null | null |
code/notebooks/.ipynb_checkpoints/psycho_orig1-checkpoint.ipynb
|
zeroknowledgediscovery/zcad
|
5642a7ab0ac29337a4066305091811032ab9032b
|
[
"MIT"
] | null | null | null |
code/notebooks/.ipynb_checkpoints/psycho_orig1-checkpoint.ipynb
|
zeroknowledgediscovery/zcad
|
5642a7ab0ac29337a4066305091811032ab9032b
|
[
"MIT"
] | null | null | null | 266.611465 | 57,032 | 0.90854 |
[
[
[
"\n# PTSD Model Inference with IRT Features\n\n## [Center for Health Statistics](http://www.healthstats.org)\n\n## [The Zero Knowledge Discovery Lab](http://zed.uchicago.edu)\n---\n\n",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nfrom sklearn import svm\nimport pandas as pd\nimport seaborn as sns\nfrom sklearn import svm\nfrom sklearn.model_selection import train_test_split\nfrom sklearn import metrics\nfrom sklearn import neighbors, datasets\nfrom sklearn.model_selection import cross_val_score\nfrom sklearn.datasets import make_blobs\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.ensemble import ExtraTreesClassifier\nfrom sklearn.tree import DecisionTreeClassifier\nfrom sklearn.ensemble import AdaBoostClassifier\nfrom sklearn.ensemble import GradientBoostingClassifier\nfrom scipy.spatial import ConvexHull\nfrom tqdm import tqdm\nimport random\nplt.style.use('ggplot')\nimport pickle\nfrom sklearn import tree\nfrom sklearn.tree import export_graphviz\nfrom joblib import dump, load\n\n%matplotlib inline",
"_____no_output_____"
],
[
"plt.rcParams[\"font.size\"]=12\nplt.rcParams['font.family'] = 'serif'\nplt.rcParams['font.serif'] = ['Times New Roman'] + plt.rcParams['font.serif']",
"_____no_output_____"
],
[
"datafile='../../data/CAD-PTSDData.csv'",
"_____no_output_____"
],
[
"def processDATA(datafile):\n '''\n process data file \n into training data X, target labels y\n '''\n Df=pd.read_csv(datafile)\n X=Df.drop(['record_id','PTSDDx'],axis=1).values\n y=Df.drop(['record_id'],axis=1).PTSDDx.values\n [nsamples,nfeatures]=X.shape\n return X,y,nfeatures,nsamples",
"_____no_output_____"
],
[
"def pickleModel(models,threshold=0.87,filename='model.pkl',verbose=True):\n '''\n save trained model set\n '''\n MODELS=[]\n for key,mds in models.items():\n if key >= threshold:\n mds_=[i[0] for i in mds]\n MODELS.extend(mds_)\n if verbose:\n print(\"number of models (tests):\", len(MODELS))\n FS=getCoverage(MODELS,verbose=True)\n print(\"Item Use Fraction:\", FS.size/(len(MODELS)+0.0))\n dump(MODELS, filename)\n return\n\ndef loadModel(filename):\n '''\n load models\n '''\n return load(filename)\n\ndef drawTrees(model,index=0):\n '''\n draw the estimators (trees)\n in a single model\n '''\n N=len(model[index].estimators_)\n\n for count in range(N):\n estimator = model[index].estimators_[count]\n\n export_graphviz(estimator, out_file='tree.dot', \n #feature_names = iris.feature_names,\n #class_names = iris.target_names,\n rounded = True, proportion = False, \n precision = 2, filled = True)\n\n from subprocess import call\n call(['dot', '-Tpng', 'tree.dot', '-o', 'tree'+str(count)+'.png', '-Gdpi=600'])\n from IPython.display import Image\n Image(filename = 'tree'+str(count)+'.png') \n\ndef getCoverage(model,verbose=True):\n '''\n return how many distinct items (questions)\n are used in the model set.\n This includes the set of questions being\n covered by all forms that may be \n generated by the model set\n '''\n FS=[]\n for m in model:\n for count in range(len(m.estimators_)):\n clf=m.estimators_[count]\n fs=clf.tree_.feature[clf.tree_.feature>0]\n FS=np.array(list(set(np.append(FS,fs))))\n if verbose:\n print(\"Number of items used: \", FS.size)\n return FS\n\ndef getAuc(X,y,test_size=0.25,max_depth=None,n_estimators=100,\n minsplit=4,FPR=[],TPR=[],VERBOSE=False, USE_ONLY=None):\n '''\n get AUC given training data X, with target labels y\n '''\n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=test_size)\n CLASSIFIERS=[DecisionTreeClassifier(max_depth=max_depth, min_samples_split=minsplit),\n RandomForestClassifier(n_estimators=n_estimators,\n max_depth=max_depth,min_samples_split=minsplit),\n ExtraTreesClassifier(n_estimators=n_estimators,\n max_depth=max_depth,min_samples_split=minsplit),\n AdaBoostClassifier(n_estimators=n_estimators),\n GradientBoostingClassifier(n_estimators=n_estimators,max_depth=max_depth),\n svm.SVC(kernel='rbf',gamma='scale',class_weight='balanced',probability=True)]\n\n if USE_ONLY is not None:\n if isinstance(USE_ONLY, (list,)):\n CLASSIFIERS=[CLASSIFIERS[i] for i in USE_ONLY]\n if isinstance(USE_ONLY, (int,)):\n CLASSIFIERS=CLASSIFIERS[USE_ONLY]\n\n for clf in CLASSIFIERS:\n clf.fit(X_train,y_train)\n y_pred=clf.predict_proba(X_test)\n fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred[:,1], pos_label=1)\n auc=metrics.auc(fpr, tpr)\n \n if auc > 0.9:\n fpr_c=fpr\n tpr_c=tpr\n dfa=pd.DataFrame(fpr_c,tpr_c).reset_index()\n dfa.columns=['tpr','fpr']\n dfa[['fpr','tpr']].to_csv('roc_.csv')\n\n \n if VERBOSE:\n print(auc)\n\n FPR=np.append(FPR,fpr)\n TPR=np.append(TPR,tpr)\n points=np.array([[a[0],a[1]] for a in zip(FPR,TPR)])\n hull = ConvexHull(points)\n x=np.argsort(points[hull.vertices,:][:,0])\n auc=metrics.auc(points[hull.vertices,:][x,0],points[hull.vertices,:][x,1])\n if auc > 0.91:\n fpr_c=points[hull.vertices,:][x,0]\n tpr_c=points[hull.vertices,:][x,1]\n dfa=pd.DataFrame(fpr_c,tpr_c).reset_index()\n dfa.columns=['tpr','fpr']\n dfa[['fpr','tpr']].to_csv('roc.csv')\n \n return auc,CLASSIFIERS\n\n#test model\ndef getModel(P,THRESHOLD=0.9):\n '''\n Select only models with minimum AUC\n '''\n Pgood=[model for (auc,model) in zip(P[::2],P[1::2]) if auc > THRESHOLD]\n AUC=[]\n if len(Pgood)==0:\n return Pgood,len(Pgood),0,0,0,[]\n for i in tqdm(range(1000)):\n random_choice=random.randint(0,len(Pgood)-1)\n clf=Pgood[random_choice][0]\n # pretend as if we have not sen any of this data before\n # but we have!\n # need to only use test data here\n X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.8)\n y_pred=clf.predict_proba(X_test)\n fpr, tpr, thresholds = metrics.roc_curve(y_test,y_pred[:,1], pos_label=1)\n auc=metrics.auc(fpr, tpr)\n AUC=np.append(AUC,auc)\n \n DEPTH=Pgood[0][0].max_depth\n N_ESTIMATORS=Pgood[0][0].n_estimators\n \n NITEMS=DEPTH*N_ESTIMATORS\n VARIATIONS=len(Pgood)#2*DEPTH*len(Pgood)\n return Pgood,len(Pgood),np.median(AUC),NITEMS,VARIATIONS,AUC\n\ndef getSystem(X,y,max_depth=2,n_estimators=3):\n '''\n get model set with training data X and target labels y\n -> calls getAUC, and getModel\n '''\n P1=[]\n for i in tqdm(range(100)):\n #USE_ONLY=2 implies ExtraTreesClassifier is used only\n P1=np.append(P1,getAuc(X,y,minsplit=2,max_depth=max_depth,\n n_estimators=n_estimators,USE_ONLY=[2]))\n PERF=[]\n DPERF={}\n MODELS={}\n for threshold in np.arange(0.8,0.95,0.01):\n Pgood,nmodels,auc_,NITEMS,VARIATIONS,AUC=getModel(P1,threshold)\n if len(Pgood) > 0:\n PERF=np.append(PERF,[auc_,NITEMS,VARIATIONS])\n DPERF[VARIATIONS]=AUC\n MODELS[auc_]=Pgood\n PERF=PERF.reshape(int(len(PERF)/3),3) \n return PERF,DPERF,MODELS,NITEMS\n\ndef PLOT(Dperf,Nitems,N=1000,dn=''):\n '''\n Plots the achieved AUC along with \n confidence bounds against the \n number of different forms \n generated.\n '''\n NUMQ='No. of Items Per Subject: '+str(Nitems)\n Df=pd.DataFrame(Dperf)\n dfs=Df.std()\n dfm=Df.mean()\n plt.figure(figsize=[8,6])\n dfm.plot(marker='o',color='r',ms=10,markeredgecolor='w',markerfacecolor='k',lw=2)\n (dfm+2.62*(dfs/np.sqrt(N))).plot(ls='--',color='.5')\n (dfm-2.62*(dfs/np.sqrt(N))).plot(ls='--',color='.5')\n plt.xlabel('No. of different question sets')\n plt.ylabel('mean AUC')\n plt.title('AUC vs Test Variation (99% CB)',fontsize=12,fontweight='bold')\n plt.text(0.55,0.9,NUMQ,transform=plt.gca().transAxes,fontweight='bold',\n fontsize=12,bbox=dict(facecolor='k', alpha=0.4),color='w')\n pdfname='Result'+dn+'.pdf'\n plt.savefig(pdfname,dpi=300,bbox_inches='tight',pad_inches=0,transparent=False)\n return",
"_____no_output_____"
],
[
"X,y,nfeatures,nsamples=processDATA(datafile)",
"_____no_output_____"
],
[
"Perf23,Dperf23,Models23,Nitems23=getSystem(X,y,max_depth=2,n_estimators=3)\nprint(Nitems23)\nPLOT(Dperf23,Nitems23,dn='23')",
"100%|██████████| 100/100 [00:00<00:00, 152.55it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 616.93it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 618.37it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 619.45it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 597.92it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 619.26it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 634.62it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 626.86it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 621.07it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 611.52it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 615.52it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 616.50it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 595.73it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 605.23it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 604.30it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 631.42it/s]\n"
],
[
"Perf32,Dperf32,Models32,Nitems32=getSystem(X,y,max_depth=3,n_estimators=2)\nPLOT(Dperf32,Nitems32,dn='32')",
"100%|██████████| 100/100 [00:00<00:00, 185.42it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 659.86it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 655.46it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 672.59it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 645.54it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 675.30it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 652.15it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 664.33it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 663.33it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 655.73it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 636.19it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 658.38it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 661.56it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 653.95it/s]\n100%|██████████| 1000/1000 [00:01<00:00, 671.19it/s]\n"
],
[
"pickleModel(Models23,threshold=.89,filename='model_2_3.pkl')\nprint(\"--\")\npickleModel(Models32,threshold=.9,filename='model_3_2.pkl')",
"number of models (tests): 3\nNumber of items used: 26\nItem Use Fraction: 8.666666666666666\n--\nnumber of models (tests): 42\nNumber of items used: 125\nItem Use Fraction: 2.9761904761904763\n"
],
[
"drawTrees(loadModel('model_2_3.pkl'),1)",
"_____no_output_____"
],
[
"FS23=getCoverage(load('model_2_3.pkl'))\nFS32=getCoverage(load('model_3_2.pkl'))",
"_____no_output_____"
],
[
"drawTrees(loadModel('model_3_2.pkl'),1)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9eaef0fe8e8d379ca4048d29a3bc1ed32708d6
| 3,545 |
ipynb
|
Jupyter Notebook
|
CariesFinderApp.ipynb
|
johnpersson5/caries_detector
|
8738c64a7b6b2606b14b5907f1eabac8d5409cce
|
[
"Apache-2.0"
] | null | null | null |
CariesFinderApp.ipynb
|
johnpersson5/caries_detector
|
8738c64a7b6b2606b14b5907f1eabac8d5409cce
|
[
"Apache-2.0"
] | null | null | null |
CariesFinderApp.ipynb
|
johnpersson5/caries_detector
|
8738c64a7b6b2606b14b5907f1eabac8d5409cce
|
[
"Apache-2.0"
] | null | null | null | 23.791946 | 120 | 0.527786 |
[
[
[
"from fastai.vision.all import *\nfrom fastai.vision.widgets import *\nimport PIL.Image",
"_____no_output_____"
],
[
"path = Path()\ncodes = np.loadtxt(path/'codes.txt', dtype=str); codes\nname2id = {v:k for k,v in enumerate(codes)}\nvoid_code = name2id['Void']\n\ndef acc_camvid(input, target):\n target = target.squeeze(1)\n mask = target != void_code\n return (input.argmax(dim=1)[mask]==target[mask]).float().mean()",
"_____no_output_____"
],
[
"def get_y(o): return path/'labels'/f'{o.stem}_P{o.suffix}'",
"_____no_output_____"
],
[
"learn_inf = load_learner(path/'export.pkl', cpu=True)\nbtn_upload = widgets.FileUpload()\nout_pl = widgets.Output()\nlbl_pred = widgets.Label()",
"_____no_output_____"
],
[
"def on_data_change(change):\n img = PILImage.create(btn_upload.data[-1])\n out_pl.clear_output()\n outputs = learn_inf.predict(img)\n cm_hot = plt.get_cmap('tab10')\n masked = outputs[0].data\n im = np.array(masked)\n im = np.squeeze(im)\n im = cm_hot(im) \n im = PIL.Image.fromarray((im*255).astype('uint8'))\n background=img.convert(\"RGBA\")\n overlay=im.convert(\"RGBA\")\n background=background.resize((416,416))\n overlay=overlay.resize((416,416))\n new_img = Image.blend(background, overlay, 0.5)\n with out_pl: display(new_img)",
"_____no_output_____"
],
[
"btn_upload.observe(on_data_change, names=['data'])",
"_____no_output_____"
],
[
"display(VBox([widgets.Label('Select your bear!'), btn_upload, out_pl, lbl_pred]))",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9eccd9137bacdfc07ad44c609a4a41d85e3d0b
| 8,983 |
ipynb
|
Jupyter Notebook
|
Prj3_CreateImagesTest.ipynb
|
UNT-5214-P3/EmotionRecognition
|
f605307d5a84f88e9310f79876de8248d78b8e7f
|
[
"MIT"
] | null | null | null |
Prj3_CreateImagesTest.ipynb
|
UNT-5214-P3/EmotionRecognition
|
f605307d5a84f88e9310f79876de8248d78b8e7f
|
[
"MIT"
] | null | null | null |
Prj3_CreateImagesTest.ipynb
|
UNT-5214-P3/EmotionRecognition
|
f605307d5a84f88e9310f79876de8248d78b8e7f
|
[
"MIT"
] | 1 |
2020-10-26T00:13:16.000Z
|
2020-10-26T00:13:16.000Z
| 28.60828 | 103 | 0.495269 |
[
[
[
"# To begin, I created a folder called \"Project3_dataTest\". I placed the fer2013.csv\n# file within the Project3_data folder, and then I ran the following code.",
"_____no_output_____"
],
[
"import numpy as np\nimport pandas as pd\nimport os\nfrom PIL import Image",
"_____no_output_____"
],
[
"df = pd.read_csv('/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/fer2013.csv')",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df0 = df.query('emotion == 0 and Usage != \"Training\"')\ndf1 = df.query('emotion == 1 and Usage != \"Training\"')\ndf2 = df.query('emotion == 2 and Usage != \"Training\"')\ndf3 = df.query('emotion == 3 and Usage != \"Training\"')\ndf4 = df.query('emotion == 4 and Usage != \"Training\"')\ndf5 = df.query('emotion == 5 and Usage != \"Training\"')\ndf6 = df.query('emotion == 6 and Usage != \"Training\"')",
"_____no_output_____"
],
[
"os.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/0/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/1/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/2/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/3/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/4/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/5/\")\nos.mkdir(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/6/\")",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df0.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/0/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df1.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/1/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df2.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/2/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df3.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/3/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df4.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/4/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df5.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/5/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"d=0\nfor image_pixels in df6.iloc[1:,1]:\n image_string = image_pixels.split(' ')\n image_data = np.asarray(image_string, dtype=np.uint8).reshape(48,48)\n img = Image.fromarray(image_data)\n img.save(\"/Users/blakemyers/Desktop/Jupyter/Project3_dataTest/6/img_%d.jpg\"%d, \"JPEG\")\n d+=1",
"_____no_output_____"
],
[
"df99 = df.query('Usage != \"Training\"')",
"_____no_output_____"
],
[
"df99.shape",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9eccfd8a217972b5438bc5965e1d66eb56f11c
| 3,538 |
ipynb
|
Jupyter Notebook
|
examples/experimental/ionesio/Bob.ipynb
|
Bhuvan-21/PySyft
|
77ffb4fc68f141f2cbf812264c472d7f67004ae1
|
[
"Apache-2.0"
] | 2 |
2018-07-23T20:34:10.000Z
|
2020-08-01T09:09:09.000Z
|
examples/experimental/ionesio/Bob.ipynb
|
Bhuvan-21/PySyft
|
77ffb4fc68f141f2cbf812264c472d7f67004ae1
|
[
"Apache-2.0"
] | 5 |
2020-09-11T05:47:12.000Z
|
2020-10-13T08:36:17.000Z
|
examples/experimental/ionesio/Bob.ipynb
|
Bhuvan-21/PySyft
|
77ffb4fc68f141f2cbf812264c472d7f67004ae1
|
[
"Apache-2.0"
] | 1 |
2021-05-22T17:11:42.000Z
|
2021-05-22T17:11:42.000Z
| 24.4 | 182 | 0.521481 |
[
[
[
"import syft as sy\n",
"_____no_output_____"
],
[
"duet = sy.launch_duet()",
"🎤 🎸 ♪♪♪ starting duet ♫♫♫ 🎻 🎹\n\n♫♫♫ >\u001b[93m DISCLAIMER\u001b[0m:\u001b[1m Duet is an experimental feature currently \n♫♫♫ > in alpha. Do not use this to protect real-world data.\n\u001b[0m♫♫♫ >\n♫♫♫ > Punching through firewall to OpenGrid Network Node at network_url: \n♫♫♫ > http://ec2-18-216-8-163.us-east-2.compute.amazonaws.com:5000\n♫♫♫ >\n♫♫♫ > ...waiting for response from OpenGrid Network... \u001b[92mDONE!\u001b[0m\n♫♫♫ >\n♫♫♫ > \u001b[95mSTEP 1:\u001b[0m Send the following code to your duet partner!\n\nimport syft as sy\nduet = sy.join_duet('\u001b[1m42bb1dc493ed6297204685f1e438110b\u001b[0m')\n\n♫♫♫ > \u001b[95mSTEP 2:\u001b[0m The code above will print out a 'Client Id'. Have\n♫♫♫ > your duet partner send it to you and enter it below!\n\n"
],
[
"import torch as th",
"_____no_output_____"
],
[
"x = th.tensor([1,2,3.,4]).send(duet, pointable=True)",
"An AuthorizationException has been triggered by <class 'syft.core.node.common.action.get_object_action.GetObjectAction'> from <Address - Domain:<SpecificLocation:..57ef0>>\nAn AuthorizationException has been triggered by <class 'syft.core.node.common.action.get_object_action.GetObjectAction'> from <Address - Domain:<SpecificLocation:..57ef0>>\n"
],
[
"duet.requests[0].accept()",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
]
] |
4a9ed4baceb05c75f4a0ec1ce2267ca8b2f8e43a
| 170,288 |
ipynb
|
Jupyter Notebook
|
notebooks/001_python_basics.ipynb
|
WSU-DataScience/ICOTS10_Data_Visualization
|
f71b48fb1d9cf5919281e2a55db02589f541d92e
|
[
"BSD-3-Clause"
] | 1 |
2019-12-28T15:08:15.000Z
|
2019-12-28T15:08:15.000Z
|
notebooks/001_python_basics.ipynb
|
WSU-DataScience/ICOTS10_Data_Visualization
|
f71b48fb1d9cf5919281e2a55db02589f541d92e
|
[
"BSD-3-Clause"
] | null | null | null |
notebooks/001_python_basics.ipynb
|
WSU-DataScience/ICOTS10_Data_Visualization
|
f71b48fb1d9cf5919281e2a55db02589f541d92e
|
[
"BSD-3-Clause"
] | null | null | null | 171.143719 | 91,501 | 0.604952 |
[
[
[
"# Python Basics\n\n## Outline\n\n* Jupyter notebooks\n* Importing and Accessing Modules\n* Example - `panda` Data Frames\n* Working with Objects\n* Altair",
"_____no_output_____"
],
[
"## Jupyter Notebooks\n\n* Combine documentation, code, and output\n* Interactive\n* Not just Python\n * R\n * Julia\n * etc.",
"_____no_output_____"
],
[
"## Two Types of Cells\n\n* Markdown: Renders text\n* Code: Write and run Python",
"_____no_output_____"
],
[
"## Live code\n\n* Edit and run code interactively\n* Run a cell with\n * CTR/CMD + Enter\n * Shift + Enter\n * Alt + Enter",
"_____no_output_____"
]
],
[
[
"2 + 3",
"_____no_output_____"
]
],
[
[
"## JupyterHub\n\n* Host and distribute notebooks\n* Classroom features\n * Separate folder for each student\n * Assign and grade homework\n* `mybinder.org` creates a hub from a Github repo",
"_____no_output_____"
],
[
"## Python Basic - Importing a Module\n\n* Use `import mod_name as alias\n* Access object with `alias.obj_name`",
"_____no_output_____"
]
],
[
[
"import math as m\nm.sqrt(2)",
"_____no_output_____"
]
],
[
[
"## Example - Data Frames with `panda`s\n\n* `pandas` gives `R` like data frames",
"_____no_output_____"
]
],
[
[
"import pandas as pd\ndata = pd.read_csv(\"../data/World_Bank.csv\")\ndata.head()",
"_____no_output_____"
]
],
[
[
"\n## Object Oriented Design\n\n* Programming paradigm\n* All Python data are objects\n* Code is are organized in objects\n * **attributes** data/state\n * **methods** functions for transforming data\n * **Instantiate** initial creation\n\n",
"_____no_output_____"
]
],
[
[
"data.groupby(\"Country\").mean().head()",
"_____no_output_____"
]
],
[
[
"# Altair: Statistical Visualization for Python\n\n* Declarative API for statistical visualization, \n* built on top of [Vega-Lite](http://vega.github.io/vega-lite/).\n* **Link:** [Altair](http://github.com/altair-viz/altair/)",
"_____no_output_____"
],
[
"## Importing `altair`",
"_____no_output_____"
]
],
[
[
"import altair as alt\nfrom vega_datasets import data\ncars = data.cars()",
"_____no_output_____"
],
[
"# Uncomment/run this line to enable Altair in the classic notebook\n# (this is not necessary in JupyterLab)\n#alt.renderers.enable('notebook')",
"_____no_output_____"
]
],
[
[
"## Quick Altair example",
"_____no_output_____"
]
],
[
[
"chart = alt.Chart(cars).mark_circle().encode(\n x='Horsepower',\n y='Miles_per_Gallon',\n color='Origin',\n)\n\nchart",
"_____no_output_____"
]
],
[
[
"## Why use `Altair`\n\n* Power of `vega-lite`\n * JavaScript\n * Create complicated, interactive plots\n* Easier syntax and prototyping\n* Easy export to html\n * No server needed!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a9ee07d7e8999810a75e115f5f20223bb1ce5f3
| 49,618 |
ipynb
|
Jupyter Notebook
|
tutorials/05_hybrid_model.ipynb
|
innerNULL/collie
|
88752fbafd5489a7568cd913e7e4c3256248d37f
|
[
"BSD-3-Clause"
] | 70 |
2021-04-13T20:13:35.000Z
|
2021-07-08T03:01:29.000Z
|
tutorials/05_hybrid_model.ipynb
|
innerNULL/collie
|
88752fbafd5489a7568cd913e7e4c3256248d37f
|
[
"BSD-3-Clause"
] | 18 |
2021-07-13T22:06:11.000Z
|
2022-01-27T16:27:37.000Z
|
tutorials/05_hybrid_model.ipynb
|
innerNULL/collie
|
88752fbafd5489a7568cd913e7e4c3256248d37f
|
[
"BSD-3-Clause"
] | 11 |
2021-07-14T04:58:49.000Z
|
2022-03-05T00:19:22.000Z
| 28.830912 | 481 | 0.483171 |
[
[
[
"<table align=\"left\">\n <td>\n <a target=\"_blank\" href=\"https://colab.research.google.com/github/ShopRunner/collie/blob/main/tutorials/05_hybrid_model.ipynb\"><img src=\"https://www.tensorflow.org/images/colab_logo_32px.png\" /> Run in Google Colab</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://github.com/ShopRunner/collie/blob/main/tutorials/05_hybrid_model.ipynb\"><img src=\"https://www.tensorflow.org/images/GitHub-Mark-32px.png\" /> View source on GitHub</a>\n </td>\n <td>\n <a target=\"_blank\" href=\"https://raw.githubusercontent.com/ShopRunner/collie/main/tutorials/05_hybrid_model.ipynb\"><img src=\"https://www.tensorflow.org/images/download_logo_32px.png\" /> Download notebook</a>\n </td>\n</table>",
"_____no_output_____"
]
],
[
[
"# for Collab notebooks, we will start by installing the ``collie`` library\n!pip install collie --quiet",
"_____no_output_____"
],
[
"%reload_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n%env DATA_PATH data/",
"env: DATA_PATH=data/\n"
],
[
"import os\n\nimport numpy as np\nimport pandas as pd\nfrom pytorch_lightning.utilities.seed import seed_everything\nfrom IPython.display import HTML\nimport joblib\nimport torch\n\nfrom collie.metrics import mapk, mrr, auc, evaluate_in_batches\nfrom collie.model import CollieTrainer, HybridPretrainedModel, MatrixFactorizationModel\nfrom collie.movielens import get_movielens_metadata, get_recommendation_visualizations",
"_____no_output_____"
]
],
[
[
"## Load Data From ``01_prepare_data`` Notebook \nIf you're running this locally on Jupyter, you should be able to run the next cell quickly without a problem! If you are running this on Colab, you'll need to regenerate the data by running the cell below that, which should only take a few extra seconds to complete. ",
"_____no_output_____"
]
],
[
[
"try:\n # let's grab the ``Interactions`` objects we saved in the last notebook\n train_interactions = joblib.load(os.path.join(os.environ.get('DATA_PATH', 'data/'),\n 'train_interactions.pkl'))\n val_interactions = joblib.load(os.path.join(os.environ.get('DATA_PATH', 'data/'),\n 'val_interactions.pkl'))\nexcept FileNotFoundError:\n # we're running this notebook on Colab where results from the first notebook are not saved\n # regenerate this data below\n from collie.cross_validation import stratified_split\n from collie.interactions import Interactions\n from collie.movielens import read_movielens_df\n from collie.utils import convert_to_implicit, remove_users_with_fewer_than_n_interactions\n\n\n df = read_movielens_df(decrement_ids=True)\n implicit_df = convert_to_implicit(df, min_rating_to_keep=4)\n implicit_df = remove_users_with_fewer_than_n_interactions(implicit_df, min_num_of_interactions=3)\n\n interactions = Interactions(\n users=implicit_df['user_id'],\n items=implicit_df['item_id'],\n ratings=implicit_df['rating'],\n allow_missing_ids=True,\n )\n\n train_interactions, val_interactions = stratified_split(interactions, test_p=0.1, seed=42)\n\n\nprint('Train:', train_interactions)\nprint('Val: ', val_interactions)",
"Train: Interactions object with 49426 interactions between 943 users and 1674 items, returning 10 negative samples per interaction.\nVal: Interactions object with 5949 interactions between 943 users and 1674 items, returning 10 negative samples per interaction.\n"
]
],
[
[
"# Hybrid Collie Model Using a Pre-Trained ``MatrixFactorizationModel``\nIn this notebook, we will use this same metadata and incorporate it directly into the model architecture with a hybrid Collie model. ",
"_____no_output_____"
],
[
"## Read in Data",
"_____no_output_____"
]
],
[
[
"# read in the same metadata used in notebooks ``03`` and ``04``\nmetadata_df = get_movielens_metadata()\n\n\nmetadata_df.head()",
"_____no_output_____"
],
[
"# and, as always, set our random seed\nseed_everything(22)",
"Global seed set to 22\n"
]
],
[
[
"## Train a ``MatrixFactorizationModel`` ",
"_____no_output_____"
],
[
"The first step towards training a Collie Hybrid model is to train a regular ``MatrixFactorizationModel`` to generate rich user and item embeddings. We'll use these embeddings in a ``HybridPretrainedModel`` a bit later. ",
"_____no_output_____"
]
],
[
[
"model = MatrixFactorizationModel(\n train=train_interactions,\n val=val_interactions,\n embedding_dim=30,\n lr=1e-2,\n)",
"_____no_output_____"
],
[
"trainer = CollieTrainer(model=model, max_epochs=10, deterministic=True)\n\ntrainer.fit(model)",
"GPU available: False, used: False\nTPU available: False, using: 0 TPU cores\n\n | Name | Type | Params\n----------------------------------------------------\n0 | user_biases | ZeroEmbedding | 943 \n1 | item_biases | ZeroEmbedding | 1.7 K \n2 | user_embeddings | ScaledEmbedding | 28.3 K\n3 | item_embeddings | ScaledEmbedding | 50.2 K\n4 | dropout | Dropout | 0 \n----------------------------------------------------\n81.1 K Trainable params\n0 Non-trainable params\n81.1 K Total params\n0.325 Total estimated model params size (MB)\n"
],
[
"mapk_score, mrr_score, auc_score = evaluate_in_batches([mapk, mrr, auc], val_interactions, model)\n\nprint(f'Standard MAP@10 Score: {mapk_score}')\nprint(f'Standard MRR Score: {mrr_score}')\nprint(f'Standard AUC Score: {auc_score}')",
"_____no_output_____"
]
],
[
[
"## Train a ``HybridPretrainedModel`` ",
"_____no_output_____"
],
[
"With our trained ``model`` above, we can now use these embeddings and additional side data directly in a hybrid model. The architecture essentially takes our user embedding, item embedding, and item metadata for each user-item interaction, concatenates them, and sends it through a simple feedforward network to output a recommendation score. \n\nWe can initially freeze the user and item embeddings from our previously-trained ``model``, train for a few epochs only optimizing our newly-added linear layers, and then train a model with everything unfrozen at a lower learning rate. We will show this process below. ",
"_____no_output_____"
]
],
[
[
"# we will apply a linear layer to the metadata with ``metadata_layers_dims`` and\n# a linear layer to the combined embeddings and metadata data with ``combined_layers_dims``\nhybrid_model = HybridPretrainedModel(\n train=train_interactions,\n val=val_interactions,\n item_metadata=metadata_df,\n trained_model=model,\n metadata_layers_dims=[8],\n combined_layers_dims=[16],\n lr=1e-2,\n freeze_embeddings=True,\n)",
"_____no_output_____"
],
[
"hybrid_trainer = CollieTrainer(model=hybrid_model, max_epochs=10, deterministic=True)\n\nhybrid_trainer.fit(hybrid_model)",
"GPU available: False, used: False\nTPU available: False, using: 0 TPU cores\n\n | Name | Type | Params\n--------------------------------------------------------------\n0 | _trained_model | MatrixFactorizationModel | 81.1 K\n1 | embeddings | Sequential | 78.5 K\n2 | dropout | Dropout | 0 \n3 | metadata_layer_0 | Linear | 232 \n4 | combined_layer_0 | Linear | 1.1 K \n5 | combined_layer_1 | Linear | 17 \n--------------------------------------------------------------\n82.5 K Trainable params\n78.5 K Non-trainable params\n160 K Total params\n0.644 Total estimated model params size (MB)\n"
],
[
"mapk_score, mrr_score, auc_score = evaluate_in_batches([mapk, mrr, auc], val_interactions, hybrid_model)\n\nprint(f'Hybrid MAP@10 Score: {mapk_score}')\nprint(f'Hybrid MRR Score: {mrr_score}')\nprint(f'Hybrid AUC Score: {auc_score}')",
"_____no_output_____"
],
[
"hybrid_model_unfrozen = HybridPretrainedModel(\n train=train_interactions,\n val=val_interactions,\n item_metadata=metadata_df,\n trained_model=model,\n metadata_layers_dims=[8],\n combined_layers_dims=[16],\n lr=1e-4,\n freeze_embeddings=False,\n)\n\nhybrid_model.unfreeze_embeddings()\nhybrid_model_unfrozen.load_from_hybrid_model(hybrid_model)",
"_____no_output_____"
],
[
"hybrid_trainer_unfrozen = CollieTrainer(model=hybrid_model_unfrozen, max_epochs=10, deterministic=True)\n\nhybrid_trainer_unfrozen.fit(hybrid_model_unfrozen)",
"GPU available: False, used: False\nTPU available: False, using: 0 TPU cores\n\n | Name | Type | Params\n--------------------------------------------------------------\n0 | _trained_model | MatrixFactorizationModel | 81.1 K\n1 | embeddings | Sequential | 78.5 K\n2 | dropout | Dropout | 0 \n3 | metadata_layer_0 | Linear | 232 \n4 | combined_layer_0 | Linear | 1.1 K \n5 | combined_layer_1 | Linear | 17 \n--------------------------------------------------------------\n82.5 K Trainable params\n78.5 K Non-trainable params\n160 K Total params\n0.644 Total estimated model params size (MB)\n"
],
[
"mapk_score, mrr_score, auc_score = evaluate_in_batches([mapk, mrr, auc],\n val_interactions,\n hybrid_model_unfrozen)\n\nprint(f'Hybrid Unfrozen MAP@10 Score: {mapk_score}')\nprint(f'Hybrid Unfrozen MRR Score: {mrr_score}')\nprint(f'Hybrid Unfrozen AUC Score: {auc_score}')",
"_____no_output_____"
]
],
[
[
"Note here that while our ``MAP@10`` and ``MRR`` scores went down slightly from the frozen version of the model above, our ``AUC`` score increased. For implicit recommendation models, each evaluation metric is nuanced in what it represents for real world recommendations. \n\nYou can read more about each evaluation metric by checking out the [Mean Average Precision at K (MAP@K)](https://en.wikipedia.org/wiki/Evaluation_measures_(information_retrieval)#Mean_average_precision), [Mean Reciprocal Rank](https://en.wikipedia.org/wiki/Mean_reciprocal_rank), and [Area Under the Curve (AUC)](https://en.wikipedia.org/wiki/Receiver_operating_characteristic#Area_under_the_curve) Wikipedia pages. ",
"_____no_output_____"
]
],
[
[
"user_id = np.random.randint(0, train_interactions.num_users)\n\ndisplay(\n HTML(\n get_recommendation_visualizations(\n model=hybrid_model_unfrozen,\n user_id=user_id,\n filter_films=True,\n shuffle=True,\n detailed=True,\n )\n )\n)",
"_____no_output_____"
]
],
[
[
"The metrics and results look great, and we should only see a larger difference compared to a standard model as our data becomes more nuanced and complex (such as with MovieLens 10M data). \n\nIf we're happy with this model, we can go ahead and save it for later! ",
"_____no_output_____"
],
[
"## Save and Load a Hybrid Model ",
"_____no_output_____"
]
],
[
[
"# we can save the model with...\nos.makedirs('models', exist_ok=True)\nhybrid_model_unfrozen.save_model('models/hybrid_model_unfrozen')",
"_____no_output_____"
],
[
"# ... and if we wanted to load that model back in, we can do that easily...\nhybrid_model_loaded_in = HybridPretrainedModel(load_model_path='models/hybrid_model_unfrozen')\n\n\nhybrid_model_loaded_in",
"_____no_output_____"
]
],
[
[
"While our model works and the results look great, it's not always possible to be able to fully train two separate models like we've done in this tutorial. Sometimes, it's easier (and even better) to train a single hybird model up from scratch, no pretrained ``MatrixFactorizationModel`` needed.\n\nIn the next tutorial, we'll cover multi-stage models in Collie, tackling this exact problem and more! See you there! ",
"_____no_output_____"
],
[
"----- ",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4a9eedd3c3abe4077d58fe4873b7da213607de81
| 8,558 |
ipynb
|
Jupyter Notebook
|
notebooks/community/ECG.ipynb
|
hlinsen/cugraph
|
ad92c1e8a7219b3eb57104f5242452d3c5a6e9a6
|
[
"Apache-2.0"
] | null | null | null |
notebooks/community/ECG.ipynb
|
hlinsen/cugraph
|
ad92c1e8a7219b3eb57104f5242452d3c5a6e9a6
|
[
"Apache-2.0"
] | null | null | null |
notebooks/community/ECG.ipynb
|
hlinsen/cugraph
|
ad92c1e8a7219b3eb57104f5242452d3c5a6e9a6
|
[
"Apache-2.0"
] | null | null | null | 32.664122 | 375 | 0.590325 |
[
[
[
"# Ensemble Clustering for Graphs (ECG)\n# Does not run on Pascal\nIn this notebook, we will use cuGraph to identify the cluster in a test graph using the Ensemble Clustering for Graph approach. \n\n\nNotebook Credits\n* Original Authors: Bradley Rees and James Wyles\n* Created: 04/24/2020\n* Last Edit: 08/16/2020\n\nRAPIDS Versions: 0.15\n\nTest Hardware\n* GV100 32G, CUDA 10.2\n\n\n\n## Introduction\n\nThe Ensemble Clustering for Graphs (ECG) method of community detection is based on the Louvain algorithm\n\nFor a detailed description of the algorithm see: https://arxiv.org/abs/1809.05578\n\nIt takes as input a cugraph.Graph object and returns as output a \ncudf.Dataframe object with the id and assigned partition for each \nvertex as well as the final modularity score\n\nTo compute the ECG cluster in cuGraph use: <br>\n __df = cugraph.ecg(G, min_weight = 0.05 , ensemble_size = 16 )__\n \n Parameters\n ----------\n G cugraph.Graph\n cuGraph graph descriptor, should contain the connectivity information and weights. \n The adjacency list will be computed if not already present.\n min_weight: floating point\n The minimum value to assign as an edgeweight in the ECG algorithm. \n It should be a value in the range [0,1] usually left as the default value of .05\n ensemble_size: integer\n The number of graph permutations to use for the ensemble. \n The default value is 16, larger values may produce higher quality partitions for some graphs.\n \n \n Returns\n -------\n parts : cudf.DataFrame\n A GPU data frame of size V containing two columns the vertex id and the\n partition id it is assigned to.\n \n df[‘vertex’] cudf.Series\n Contains the vertex identifiers\n df[‘partition’] cudf.Series\n Contains the partition assigned to the vertices\n \n \n All vertices with the same partition ID are in the same cluster\n \n\n\n### References\n* Poulin, V., & Théberge, F. (2018, December). Ensemble clustering for graphs. In International Conference on Complex Networks and their Applications (pp. 231-243). Springer, Cham.\n",
"_____no_output_____"
],
[
"#### Some notes about vertex IDs...\n* The current version of cuGraph requires that vertex IDs be representable as 32-bit integers, meaning graphs currently can contain at most 2^32 unique vertex IDs. However, this limitation is being actively addressed and a version of cuGraph that accommodates more than 2^32 vertices will be available in the near future.\n* cuGraph will automatically renumber graphs to an internal format consisting of a contiguous series of integers starting from 0, and convert back to the original IDs when returning data to the caller. If the vertex IDs of the data are already a contiguous series of integers starting from 0, the auto-renumbering step can be skipped for faster graph creation times.\n * To skip auto-renumbering, set the `renumber` boolean arg to `False` when calling the appropriate graph creation API (eg. `G.from_cudf_edgelist(gdf_r, source='src', destination='dst', renumber=False)`).\n * For more advanced renumbering support, see the examples in `structure/renumber.ipynb` and `structure/renumber-2.ipynb`\n",
"_____no_output_____"
],
[
"### Test Data\nWe will be using the Zachary Karate club dataset \n*W. W. Zachary, An information flow model for conflict and fission in small groups, Journal of\nAnthropological Research 33, 452-473 (1977).*\n\n\n\n\nBecause the test data has vertex IDs starting at 1, the auto-renumber feature of cuGraph (mentioned above) will be used so the starting vertex ID is zero for maximum efficiency. The resulting data will then be auto-unrenumbered, making the entire renumbering process transparent to users.\n",
"_____no_output_____"
],
[
"### Prep",
"_____no_output_____"
]
],
[
[
"# Import needed libraries\nimport cugraph\nimport cudf",
"_____no_output_____"
]
],
[
[
"## Read data using cuDF",
"_____no_output_____"
]
],
[
[
"# Test file \ndatafile='../data//karate-data.csv'",
"_____no_output_____"
],
[
"# read the data using cuDF\ngdf = cudf.read_csv(datafile, delimiter='\\t', names=['src', 'dst'], dtype=['int32', 'int32'] )",
"_____no_output_____"
],
[
"# The algorithm also requires that there are vertex weights. Just use 1.0 \ngdf[\"data\"] = 1.0",
"_____no_output_____"
],
[
"# just for fun, let's look at the data types in the dataframe\ngdf.dtypes",
"_____no_output_____"
],
[
"# create a Graph - since the data does not start at '0', use the auto-renumbering feature\nG = cugraph.Graph()\nG.from_cudf_edgelist(gdf, source='src', destination='dst', edge_attr='data', renumber=True)",
"_____no_output_____"
],
[
"# Call Louvain on the graph\ndf = cugraph.ecg(G) ",
"_____no_output_____"
],
[
"df.dtypes",
"_____no_output_____"
],
[
"# How many partitions where found\npart_ids = df[\"partition\"].unique()",
"_____no_output_____"
],
[
"print(str(len(part_ids)) + \" partition detected\")",
"_____no_output_____"
],
[
"# print the clusters. \nfor p in range(len(part_ids)):\n part = []\n for i in range(len(df)):\n if (df['partition'].iloc[i] == p):\n part.append(df['vertex'].iloc[i] )\n print(\"Partition \" + str(p) + \":\")\n print(part)\n",
"_____no_output_____"
]
],
[
[
"___\nCopyright (c) 2019-2020, NVIDIA CORPORATION.\n\nLicensed under the Apache License, Version 2.0 (the \"License\"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software distributed under the License is distributed on an \"AS IS\" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.\n___",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a9f0a43d8efd07a8466a1f8647ee1ba5a8b11a6
| 32,963 |
ipynb
|
Jupyter Notebook
|
pipeline/old/dialout/.ipynb_checkpoints/Primer Dialout-checkpoint.ipynb
|
EndyLab/FreeGenes
|
1ddfeeebd8186cd2906b9e991378aa7b17ed7146
|
[
"MIT"
] | 1 |
2018-10-04T16:50:42.000Z
|
2018-10-04T16:50:42.000Z
|
pipeline/old/dialout/Primer Dialout.ipynb
|
EndyLab/FreeGenes
|
1ddfeeebd8186cd2906b9e991378aa7b17ed7146
|
[
"MIT"
] | null | null | null |
pipeline/old/dialout/Primer Dialout.ipynb
|
EndyLab/FreeGenes
|
1ddfeeebd8186cd2906b9e991378aa7b17ed7146
|
[
"MIT"
] | null | null | null | 34.807814 | 101 | 0.506143 |
[
[
[
"%matplotlib inline\n\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns",
"_____no_output_____"
],
[
"all_primers = pd.read_excel('./ysx008_supp_st_1.xlsx', names=['ID', 'Sequence', 'Keep'])\nall_primers = all_primers[all_primers['Keep'] == 'Yes']",
"_____no_output_____"
],
[
"all_primers.to_csv('./orthogonal_primers.csv')",
"_____no_output_____"
],
[
"cut_sites= [\n (\"BbsI\", \"GAAGAC\"),\n (\"BtgZI\", \"GCGATG\"),\n (\"BsaI\", \"GGTCTC\"),\n (\"BsmBI\", \"CGTCTC\"),\n (\"AarI\", \"CACCTGC\"),\n (\"BfuAI\", \"ACCTGC\")]\n\ndef cutsite_check(seq, cut_sites=cut_sites):\n seq = str(seq)\n for enzyme in cut_sites:\n if sequence_search(enzyme[1],seq):\n return False\n return True\ndef sequence_search(search,sequence):\n if search in sequence or reverse_complement(search) in sequence:\n return True\n else:\n return False\ndef reverse_complement(seq):\n return seq.translate(str.maketrans(\"ATGC\",\"TACG\"))[::-1]\n",
"_____no_output_____"
],
[
"for index, row in all_primers.iterrows():\n if not cutsite_check(row[\"Sequence\"]):\n all_primers.drop([index], inplace=True)\n print(index)",
"_____no_output_____"
],
[
"primers = all_primers[:96]['Sequence']\n\npairs = list()\nfor i in range(len(primers)):\n for j in range(i+1,len(primers)):\n pairs.append((primers.iloc[i], primers.iloc[j]))\n \nlen(pairs)",
"_____no_output_____"
],
[
"pairs = pd.DataFrame(pairs, columns=[\"Forward\", \"Reverse\"])",
"_____no_output_____"
],
[
"pairs['GeneID'] = \"\"",
"_____no_output_____"
],
[
"pairs.to_csv('./orthogonal_primers_pairs.csv')",
"_____no_output_____"
],
[
"primers",
"_____no_output_____"
],
[
"all_primers['Scale'] = '25nm'\nall_primers['Purification'] = 'STD'\nall_primers[['Sequence','Scale','Purification']].to_csv('orthogonal_primers_96.csv', sep='\\t')",
"_____no_output_____"
],
[
"!cat ./orthogonal_primers_96.csv",
"\tSequence\tScale\tPurification\r\n0\tAAACACGTGGCAAACATTCC\t25nm\tSTD\r\n1\tAAACCGGAGCCATACAGTAC\t25nm\tSTD\r\n2\tAAAGCACTCTTAGGCCTCTG\t25nm\tSTD\r\n3\tAAAGGGGCCGTCAATATCAG\t25nm\tSTD\r\n4\tAAATAAGACGACGACCCTCG\t25nm\tSTD\r\n5\tAACGATGATGCTCACTCTCG\t25nm\tSTD\r\n10\tAAGAATTACTGACCCCTCGG\t25nm\tSTD\r\n11\tAAGACGATCCGAGCCATTAC\t25nm\tSTD\r\n12\tAAGGAACTATGGCATCGAGC\t25nm\tSTD\r\n13\tAAGGACTGCATACCAGGTTG\t25nm\tSTD\r\n14\tAAGGATATGTAGACACCGCC\t25nm\tSTD\r\n15\tAAGGCCCAGAAGGATACAAC\t25nm\tSTD\r\n16\tAAGGCGCTCGGATAATACTC\t25nm\tSTD\r\n17\tAAGGTATGTATAGCGACCGC\t25nm\tSTD\r\n19\tAATAGGAACCTCTTACGCGG\t25nm\tSTD\r\n20\tAATATCACGCAAAAGCACCG\t25nm\tSTD\r\n21\tAATCAGTTTCTTTGGCAGCC\t25nm\tSTD\r\n22\tAATGCAAAGCTATTAGCGCG\t25nm\tSTD\r\n23\tAATGCGTCATTTTACACGGC\t25nm\tSTD\r\n24\tAATGTCCTTAGGCAGTCGTC\t25nm\tSTD\r\n25\tACAACGAGCAGACCGAATAG\t25nm\tSTD\r\n26\tACAAGGAGTCGGCATATCAC\t25nm\tSTD\r\n27\tACAGAACGAACAGGCACTAC\t25nm\tSTD\r\n28\tACAGGAAGCAAGGTATACGC\t25nm\tSTD\r\n29\tACAGGGTATATTGAGTGCCC\t25nm\tSTD\r\n30\tACATAAGCGATCCCAAGGTC\t25nm\tSTD\r\n32\tACATTAAATTTCGCCGTGGC\t25nm\tSTD\r\n33\tACCACAGGTCAAGATTCACG\t25nm\tSTD\r\n34\tACCCGTATCGCATAAGGATG\t25nm\tSTD\r\n35\tACGAGATGATGCACCGATAG\t25nm\tSTD\r\n36\tACGATGGGGACATAGAACAC\t25nm\tSTD\r\n37\tACGGAGCCCTTATTGTAACC\t25nm\tSTD\r\n38\tACGTATGGGGAACACTACAC\t25nm\tSTD\r\n39\tACGTGAAACTGTATCGAGCC\t25nm\tSTD\r\n40\tACGTTCAGTTTTCCAATGGC\t25nm\tSTD\r\n41\tACTAGATTAGCAAGGCACCC\t25nm\tSTD\r\n42\tACTGGACCCAATAAAAGGCC\t25nm\tSTD\r\n43\tACTTCGATTGGCAAGGACTG\t25nm\tSTD\r\n44\tAGAACATAGCATTCACGGGG\t25nm\tSTD\r\n45\tAGACAACAATCTGAGGCTGG\t25nm\tSTD\r\n46\tAGACAAGCCTTAACCGTAGG\t25nm\tSTD\r\n47\tAGACACAAGGCTGATTCCAG\t25nm\tSTD\r\n48\tAGACATGGGATTGACCACAC\t25nm\tSTD\r\n49\tAGAGAGGCATGATTGACCTC\t25nm\tSTD\r\n50\tAGAGTTGCACCTAGAATCCG\t25nm\tSTD\r\n51\tAGATAGATGCTCCGTCAAGC\t25nm\tSTD\r\n52\tAGATAGTCACGCACAAGACC\t25nm\tSTD\r\n53\tAGATTAGCCGACTTTCCTGG\t25nm\tSTD\r\n54\tAGATTAGCTGCCGATACTGG\t25nm\tSTD\r\n55\tAGATTGTTACTCCGACGGAC\t25nm\tSTD\r\n56\tAGATTTCCGACGAGATTCCC\t25nm\tSTD\r\n57\tAGCATCCGTCTAAATCTCGG\t25nm\tSTD\r\n58\tAGCTATAAGAATTGCCGGGC\t25nm\tSTD\r\n59\tAGCTATGATCCCGGTGTAAC\t25nm\tSTD\r\n60\tAGCTCAATCTAACAGTGGGG\t25nm\tSTD\r\n61\tAGGACACCAGACCAATGAAG\t25nm\tSTD\r\n62\tAGGGCTAATTACCATCAGCG\t25nm\tSTD\r\n63\tAGGTGATCTGACGAATGTCC\t25nm\tSTD\r\n64\tAGTAAAGCATAGTGCCCAGC\t25nm\tSTD\r\n66\tAGTAGTATCCGAATCGCTGC\t25nm\tSTD\r\n67\tAGTATCTCAGCAAGGGCAAC\t25nm\tSTD\r\n68\tAGTATTAGGCGTCAAGGTCC\t25nm\tSTD\r\n69\tAGTATTCTTACAGCCAGCCG\t25nm\tSTD\r\n70\tAGTATTGCCGGACTAAACCC\t25nm\tSTD\r\n72\tAGTCCCAAGTTCAGACGTAC\t25nm\tSTD\r\n73\tAGTCCGACACAATGTGACAC\t25nm\tSTD\r\n74\tAGTGAACTGACCGAATCCTC\t25nm\tSTD\r\n76\tAGTGGTCTGTAAACCGTACC\t25nm\tSTD\r\n77\tAGTGTTTTCCATTTTCCGCG\t25nm\tSTD\r\n78\tAGTTATAAGGGTCCGATGCC\t25nm\tSTD\r\n79\tAGTTGCAGTATCTAACCCGC\t25nm\tSTD\r\n80\tAGTTGTAATATCACCCGCGC\t25nm\tSTD\r\n82\tATACGTGGCTAGCATGAGAC\t25nm\tSTD\r\n83\tATACTGTAAGAACCACGCGG\t25nm\tSTD\r\n84\tATAGATCATGTCGGCAGTCG\t25nm\tSTD\r\n85\tATAGATGGTGCCTACATGCG\t25nm\tSTD\r\n87\tATCACAACAAAGGACGGGTC\t25nm\tSTD\r\n88\tATCAGACAACACAGAGGCTG\t25nm\tSTD\r\n89\tATCCAGGAGGTCTAGGAACC\t25nm\tSTD\r\n90\tATCCTAGAAAAGGCGAAGGC\t25nm\tSTD\r\n91\tATGCCATGACGACAACTAGC\t25nm\tSTD\r\n92\tATGCTAGCTGGAACTATCGG\t25nm\tSTD\r\n93\tATTAGGATTGCGAGCGACAC\t25nm\tSTD\r\n94\tATTAGTACACTCCGTGAGCG\t25nm\tSTD\r\n95\tATTCAAGGGTTGGACGACTC\t25nm\tSTD\r\n96\tATTCTCACGACGCAAGATGG\t25nm\tSTD\r\n97\tATTGACGGGAACTACACTCG\t25nm\tSTD\r\n98\tCACTCGATAGGTACAACCGG\t25nm\tSTD\r\n99\tCAGACCTACGGATCTTAGCG\t25nm\tSTD\r\n100\tCCACGAGATAAGAGGATGGC\t25nm\tSTD\r\n101\tCCAGAGCTTAGGGGACATAC\t25nm\tSTD\r\n102\tCCCGAGGGGAGAAATATACC\t25nm\tSTD\r\n103\tCCGAGGGAACCATGATACAG\t25nm\tSTD\r\n104\tCCGGGAGGAAGATATAGCAC\t25nm\tSTD\r\n105\tCCGGTTGTACCTATCGAGTG\t25nm\tSTD\r\n106\tCCGTGCGACAAGATTTCAAG\t25nm\tSTD\r\n107\tCCTTTAACAGGACATGCAGC\t25nm\tSTD\r\n108\tCGAACGCAAAAGTCCTCAAG\t25nm\tSTD\r\n109\tCGATAGAACGACCAGGTAGC\t25nm\tSTD\r\n110\tCGGATCGAACTTAGGTAGCC\t25nm\tSTD\r\n111\tCGGGAGGAAGTCTTTAGACC\t25nm\tSTD\r\n112\tCTAATATCCCTGAGCGACGG\t25nm\tSTD\r\n114\tCTAGGGAACCAGGCTTAACG\t25nm\tSTD\r\n115\tCTAGGGGATGGTCCAATACG\t25nm\tSTD\r\n116\tCTATAGAATCCGGGCTGGTC\t25nm\tSTD\r\n118\tCTGCTAGGGGCTACTTATCG\t25nm\tSTD\r\n119\tGAAAAGTCCCAATGAGTGCC\t25nm\tSTD\r\n120\tGAAGTGGTTTGCCTAAACGC\t25nm\tSTD\r\n121\tGACCATGCAAGGAGAGGTAC\t25nm\tSTD\r\n122\tGATACATAGACTTGGCCCCG\t25nm\tSTD\r\n123\tGCACGCAAAAGGACATAACC\t25nm\tSTD\r\n124\tGCAGCGTTTTAGCCTACAAG\t25nm\tSTD\r\n125\tGCATAAAGTTGACAGGCCAG\t25nm\tSTD\r\n126\tGCTAAATAGAGGGAAGCCCC\t25nm\tSTD\r\n127\tGGAAAACTAAGACAAGGCGC\t25nm\tSTD\r\n128\tGGAAACAATAACCATCGGCG\t25nm\tSTD\r\n129\tGGGCACCGATTAAGAAATGC\t25nm\tSTD\r\n130\tGGGTTGTCTCCTCTGATAGC\t25nm\tSTD\r\n131\tGTACTCAGAGATTGCCGGAG\t25nm\tSTD\r\n132\tGTATAAGATCAGCCGGACCC\t25nm\tSTD\r\n133\tGTATGTCGGCTCTCGTATCG\t25nm\tSTD\r\n134\tGTTCAGAGGTACGAACCCTC\t25nm\tSTD\r\n135\tGTTGCATCTAAGCCAAGTGC\t25nm\tSTD\r\n136\tTAAAGAGAGGGCGTCCAATC\t25nm\tSTD\r\n138\tTAACGACGTGCCGAACTTAG\t25nm\tSTD\r\n139\tTAAGATAGCACCACGGATGG\t25nm\tSTD\r\n140\tTAAGGATTCATCAGGTGCGC\t25nm\tSTD\r\n141\tTAAGGGACGATGCTTAACCC\t25nm\tSTD\r\n143\tTACCACGAAATGCACAGGAG\t25nm\tSTD\r\n144\tTACTGATAATTCGGACGCCC\t25nm\tSTD\r\n145\tTACTTGAATACCACGTGGCC\t25nm\tSTD\r\n146\tTAGCCAGGCAAAAGAGATCC\t25nm\tSTD\r\n147\tTAGCTCGATAATCAAGGGGC\t25nm\tSTD\r\n148\tTAGTGACCTAATGCCATGGG\t25nm\tSTD\r\n149\tTAGTTGAGAACACGAACCCG\t25nm\tSTD\r\n151\tTATACTGAAGAACGGCCCAG\t25nm\tSTD\r\n152\tTATCAATCCGGAACCAGTGC\t25nm\tSTD\r\n153\tTATCACGGAAGGACTCAACG\t25nm\tSTD\r\n155\tTCAAAGGAGCACGAACCTAC\t25nm\tSTD\r\n156\tTCAAGGTCCGTTATGGAACC\t25nm\tSTD\r\n157\tTCACATAGAAGGACATGGCG\t25nm\tSTD\r\n158\tTCACTTGGTATCGAGAACGG\t25nm\tSTD\r\n159\tTCAGCCTTTCATTGATTGCG\t25nm\tSTD\r\n161\tTCATCGACAAGATACAGGCG\t25nm\tSTD\r\n162\tTCCAATTATACGGAGCAGGC\t25nm\tSTD\r\n163\tTCGAATATGCTGTAACCCCG\t25nm\tSTD\r\n164\tTCGACCAGGTTATCATGAGC\t25nm\tSTD\r\n165\tTCGAGACAAGAACGATTCCC\t25nm\tSTD\r\n166\tTCTAGGACTATCACCGGAGG\t25nm\tSTD\r\n168\tTCTTCATAAGCCAGAGTGCC\t25nm\tSTD\r\n169\tTCTTGCGATAGACACAAGCC\t25nm\tSTD\r\n170\tTGAGCCATAAAAGCAAAGCG\t25nm\tSTD\r\n171\tTGAGCGCAGAACTATCAGAC\t25nm\tSTD\r\n172\tTGCATAGTATCCCAACAGGG\t25nm\tSTD\r\n173\tTGCCAAAGGGTAGAGACATC\t25nm\tSTD\r\n174\tTGCTGAATGAGAAACCTCGG\t25nm\tSTD\r\n176\tTGGGGACGACTTATAATGCC\t25nm\tSTD\r\n177\tTGTGGACCCTATCAAACGAG\t25nm\tSTD\r\n179\tTTAGCTCAGGTCCAAAGTCC\t25nm\tSTD\r\n180\tTTAGTAGGCAAGCATACCCG\t25nm\tSTD\r\n182\tTTCGGGAGCGGATTATACAC\t25nm\tSTD\r\n183\tTTCTGGGACTGGATAACACG\t25nm\tSTD\r\n184\tTTGACAGACAATCCGTAGGC\t25nm\tSTD\r\n"
],
[
"pairs['GeneID'].iloc[4] = \"test\"\n(pairs['GeneID'] == \"\").idxmax()",
"_____no_output_____"
],
[
"pairs",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f0c828e2840423f890eebc43dd20ba913aabc
| 5,084 |
ipynb
|
Jupyter Notebook
|
train_resnet50.ipynb
|
diloper/keras-cats-dogs-tutorial
|
42dcb4863f0b3745c08651510ff1cff43b1ef1ca
|
[
"MIT"
] | null | null | null |
train_resnet50.ipynb
|
diloper/keras-cats-dogs-tutorial
|
42dcb4863f0b3745c08651510ff1cff43b1ef1ca
|
[
"MIT"
] | null | null | null |
train_resnet50.ipynb
|
diloper/keras-cats-dogs-tutorial
|
42dcb4863f0b3745c08651510ff1cff43b1ef1ca
|
[
"MIT"
] | null | null | null | 44.208696 | 106 | 0.514752 |
[
[
[
"This script goes along my blog post:\nKeras Cats Dogs Tutorial (https://jkjung-avt.github.io/keras-tutorial/)\n\"\"\"\n\n\nfrom tensorflow.python.keras import backend as K\nfrom tensorflow.python.keras.models import Model\nfrom tensorflow.python.keras.layers import Flatten, Dense, Dropout\nfrom tensorflow.python.keras.applications.resnet50 import ResNet50, preprocess_input\nfrom tensorflow.python.keras.optimizers import Adam\nfrom tensorflow.python.keras.preprocessing.image import ImageDataGenerator\n\n\nDATASET_PATH = './catsdogs/sample'\nIMAGE_SIZE = (224, 224)\nNUM_CLASSES = 2\nBATCH_SIZE = 8 # try reducing batch size or freeze more layers if your GPU runs out of memory\nFREEZE_LAYERS = 2 # freeze the first this many layers for training\nNUM_EPOCHS = 20\nWEIGHTS_FINAL = 'model-resnet50-final.h5'\n\n\ntrain_datagen = ImageDataGenerator(preprocessing_function=preprocess_input,\n rotation_range=40,\n width_shift_range=0.2,\n height_shift_range=0.2,\n shear_range=0.2,\n zoom_range=0.2,\n channel_shift_range=10,\n horizontal_flip=True,\n fill_mode='nearest')\ntrain_batches = train_datagen.flow_from_directory(DATASET_PATH + '/train',\n target_size=IMAGE_SIZE,\n interpolation='bicubic',\n class_mode='categorical',\n shuffle=True,\n batch_size=BATCH_SIZE)\n\nvalid_datagen = ImageDataGenerator(preprocessing_function=preprocess_input)\nvalid_batches = valid_datagen.flow_from_directory(DATASET_PATH + '/valid',\n target_size=IMAGE_SIZE,\n interpolation='bicubic',\n class_mode='categorical',\n shuffle=False,\n batch_size=BATCH_SIZE)\n\n# show class indices\nprint('****************')\nfor cls, idx in train_batches.class_indices.items():\n print('Class #{} = {}'.format(idx, cls))\nprint('****************')\n\n# build our classifier model based on pre-trained ResNet50:\n# 1. we don't include the top (fully connected) layers of ResNet50\n# 2. we add a DropOut layer followed by a Dense (fully connected)\n# layer which generates softmax class score for each class\n# 3. we compile the final model using an Adam optimizer, with a\n# low learning rate (since we are 'fine-tuning')\nnet = ResNet50(include_top=False, weights='imagenet', input_tensor=None,\n input_shape=(IMAGE_SIZE[0],IMAGE_SIZE[1],3))\nx = net.output\nx = Flatten()(x)\nx = Dropout(0.5)(x)\noutput_layer = Dense(NUM_CLASSES, activation='softmax', name='softmax')(x)\nnet_final = Model(inputs=net.input, outputs=output_layer)\nfor layer in net_final.layers[:FREEZE_LAYERS]:\n layer.trainable = False\nfor layer in net_final.layers[FREEZE_LAYERS:]:\n layer.trainable = True\nnet_final.compile(optimizer=Adam(lr=1e-5),\n loss='categorical_crossentropy', metrics=['accuracy'])\nprint(net_final.summary())\n\n# train the model\nnet_final.fit_generator(train_batches,\n steps_per_epoch = train_batches.samples // BATCH_SIZE,\n validation_data = valid_batches,\n validation_steps = valid_batches.samples // BATCH_SIZE,\n epochs = NUM_EPOCHS)\n\n# save trained weights\nnet_final.save(WEIGHTS_FINAL)",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown"
]
] |
4a9f1850c8afb70af388adabddb7b55911fbe39b
| 159,282 |
ipynb
|
Jupyter Notebook
|
Implicit Georeferencing.ipynb
|
datawagovau/harvesters
|
ebd10c88a587aa11124753b6588dcc04d6a5980e
|
[
"MIT"
] | 2 |
2018-09-11T11:09:43.000Z
|
2019-11-15T13:41:43.000Z
|
Implicit Georeferencing.ipynb
|
datawagovau/harvesters
|
ebd10c88a587aa11124753b6588dcc04d6a5980e
|
[
"MIT"
] | null | null | null |
Implicit Georeferencing.ipynb
|
datawagovau/harvesters
|
ebd10c88a587aa11124753b6588dcc04d6a5980e
|
[
"MIT"
] | null | null | null | 65.306273 | 1,810 | 0.673296 |
[
[
[
"# Implicit Georeferencing\nThis workbook sets explicit georeferences from implicit georeferencing through names of extents given in dataset titles or keywords.\n\n\nA file `sources.py` needs to contain the CKAN and SOURCE config as follows:\n\n```\nCKAN = {\n \"dpaw-internal\":{\n \"url\": \"http://internal-data.dpaw.wa.gov.au/\",\n \"key\": \"API-KEY\" \n }\n}\n```\n\n## Configure CKAN and source",
"_____no_output_____"
]
],
[
[
"import ckanapi\nfrom harvest_helpers import *\nfrom secret import CKAN\n\nckan = ckanapi.RemoteCKAN(CKAN[\"dpaw-internal\"][\"url\"], apikey=CKAN[\"dpaw-internal\"][\"key\"])\nprint(\"Using CKAN {0}\".format(ckan.address))",
"Using CKAN http://internal-data.dpaw.wa.gov.au/\n"
]
],
[
[
"## Spatial extent name-geometry lookup\nThe fully qualified names and GeoJSON geometries of relevant spatial areas are contained in our custom dataschema.",
"_____no_output_____"
]
],
[
[
"# Getting the extent dictionary e\nurl = \"https://raw.githubusercontent.com/datawagovau/ckanext-datawagovautheme/dpaw-internal/ckanext/datawagovautheme/datawagovau_dataset.json\"\nds = json.loads(requests.get(url).content)\nchoice_dict = [x for x in ds[\"dataset_fields\"] if x[\"field_name\"] == \"spatial\"][0][\"choices\"]\ne = dict([(x[\"label\"], json.dumps(x[\"value\"])) for x in choice_dict])\nprint(\"Extents: {0}\".format(e.keys()))",
"Extents: [u'IBRA GVD01 Shield', u'IBRA SWA01 Dandaragan Platea', u'IBRA LSD02 Trainor', u'MPA Jurien Bay', u'IBRA ESP01 Fitzgerald', u'IBRA GVD04 Kintore', u'MPA Shoalwater Islands', u'IBRA OVP02 South Kimberley Interzone', u'IBRA NOK02 Berkeley', u'MPA Rowley Shoals', u'IBRA CER01 Mann-Musgrave Block', u'IBRA COO03 Eastern Goldfield', u'IBRA WAR01 Warren', u'IBRA GID01 Lateritic Plain', u'IBRA MAL02 Western Mallee', u'IBRA AVW02 Katanning', u'IBRA PIL04 Roebourne', u'IBRA GID02 Dune Field', u'IBRA LSD01 Rudall', u'IBRA CAR02 Wooramel', u'IBRA YAL01 Edel', u'MPA Swan Estuary', u'IBRA GVD02 Central', u'IBRA TAN01 Tanami Desert', u'IBRA GSD02 Mackay', u'IBRA NUL01 Carlisle', u'IBRA AVW01 Merredin', u'MPA Walpole Nornalup', u'IBRA COO02 Southern Cross', u'IBRA JAF02 Southern Jarrah Forest', u'IBRA VIB01 Keep', u'MPA Eighty Mile Beach', u'IBRA MAL01 Eastern Mallee', u'IBRA GES02 Lesueur Sandplain', u'IBRA DAL02 Pindanland', u'IBRA GAS02 Carnegie', u'IBRA PIL01 Chichester', u'IBRA GAS03 Augustus', u'IBRA DAL01 Fitzroy Trough', u'IBRA CEK02 Hart', u'IBRA PIL03 Hamersley', u'MPA Ningaloo', u'IBRA CEK03 Mount Eliza', u'MPA Shark Bay Hamelin Pool', u'IBRA MUR01 Eastern Murchison', u'IBRA ITI03 Timor Sea Coral Islands', u'IBRA CEK01 Pentecost', u'IBRA GES01 Geraldton Hills', u'IBRA GVD03 Maralinga', u'IBRA SWA02 Perth', u'IBRA NUL02 Nullarbor Plain', u'IBRA NOK01 Mitchell', u'Western Australia', u'IBRA ESP02 Recherche', u'IBRA CAR01 Cape Range', u'IBRA GAS01 Ashburton', u'IBRA GSD01 McLarty', u'IBRA COO01 Mardabilla', u'MPA Montebello Barrow', u'MPA Lalang-garram / Camden Sound', u'IBRA OVP01 Purnulul', u'MPA Marmion', u'MPA Ngari Capes', u'IBRA MUR02 Western Murchison', u'IBRA HAM01 Hampton', u'IBRA JAF01 Northern Jarrah Forest', u'IBRA YAL02 Tallering', u'IBRA PIL02 Fortescue']\n"
]
],
[
[
"## Name lookups\nRelevant areas are listed under different synonyms. We'll create a dictionary of synonymous search terms (\"s\") and extent names (index \"i\").",
"_____no_output_____"
]
],
[
[
"\n# Creating a search term - extent index lookup\n# m is a list of keys \"s\" (search term) and \"i\" (extent index)\nm = [\n {\"s\":\"Eighty\", \"i\":\"MPA Eighty Mile Beach\"},\n {\"s\":\"EMBMP\", \"i\":\"MPA Eighty Mile Beach\"},\n {\"s\":\"Camden\", \"i\":\"MPA Lalang-garram / Camden Sound\"},\n {\"s\":\"LCSMP\", \"i\":\"MPA Lalang-garram / Camden Sound\"},\n {\"s\":\"Rowley\", \"i\":\"MPA Rowley Shoals\"},\n {\"s\":\"RSMP\", \"i\":\"MPA Rowley Shoals\"},\n {\"s\":\"Montebello\", \"i\":\"MPA Montebello Barrow\"},\n {\"s\":\"MBIMPA\", \"i\":\"MPA Montebello Barrow\"},\n {\"s\":\"Ningaloo\", \"i\":\"MPA Ningaloo\"},\n {\"s\":\"NMP\", \"i\":\"MPA Ningaloo\"},\n {\"s\":\"Shark bay\", \"i\":\"MPA Shark Bay Hamelin Pool\"},\n {\"s\":\"SBMP\", \"i\":\"MPA Shark Bay Hamelin Pool\"},\n {\"s\":\"Jurien\", \"i\":\"MPA Jurien Bay\"},\n {\"s\":\"JBMP\", \"i\":\"MPA Jurien Bay\"},\n {\"s\":\"Marmion\", \"i\":\"MPA Marmion\"},\n {\"s\":\"Swan Estuary\", \"i\":\"MPA Swan Estuary\"},\n {\"s\":\"SEMP\", \"i\":\"MPA Swan Estuary\"},\n {\"s\":\"Shoalwater\", \"i\":\"MPA Shoalwater Islands\"},\n {\"s\":\"SIMP\", \"i\":\"MPA Shoalwater Islands\"},\n {\"s\":\"Ngari\", \"i\":\"MPA Ngari Capes\"},\n {\"s\":\"NCMP\", \"i\":\"MPA Ngari Capes\"},\n {\"s\":\"Walpole\", \"i\":\"MPA Walpole Nornalup\"},\n {\"s\":\"WNIMP\", \"i\":\"MPA Walpole Nornalup\"}\n]",
"_____no_output_____"
],
[
"def add_spatial(dsdict, extent_string, force=False, debug=False):\n \"\"\"Adds a given spatial extent to a CKAN dataset dict if \n \"spatial\" is None, \"\" or force==True.\n \n Arguments:\n dsdict (ckanapi.action.package_show()) CKAN dataset dict\n extent_string (String) GeoJSON geometry as json.dumps String\n force (Boolean) Whether to force overwriting \"spatial\"\n debug (Boolean) Debug noise\n \n Returns:\n (dict) The dataset with spatial extent replaced per above rules.\n \"\"\" \n if not dsdict.has_key(\"spatial\"):\n overwrite = True\n if debug:\n msg = \"Spatial extent not given\"\n elif dsdict[\"spatial\"] == \"\":\n overwrite = True\n if debug:\n msg = \"Spatial extent is empty\"\n elif force:\n overwrite = True\n msg = \"Spatial extent was overwritten\"\n else:\n overwrite = False\n msg = \"Spatial extent unchanged\"\n\n if overwrite:\n dsdict[\"spatial\"] = extent_string\n \n print(msg)\n return dsdict\n\n\ndef restore_extents(search_mapping, extents, ckan, debug=False):\n \"\"\"Restore spatial extents for datasets\n \n Arguments:\n search_mapping (list) A list of dicts with keys \"s\" for ckanapi \n package_search query parameter \"q\", and key \"i\" for the name\n of the extent\n e.g.:\n m = [\n {\"s\":\"tags:marinepark_80_mile_beach\", \"i\":\"MPA Eighty Mile Beach\"},\n ...\n ]\n extents (dict) A dict with key \"i\" (extent name) and \n GeoJSON Multipolygon geometry strings as value, e.g.:\n {u'MPA Eighty Mile Beach': '{\"type\": \"MultiPolygon\", \"coordinates\": [ .... ]', ...}\n ckan (ckanapi) A ckanapi instance\n debug (boolean) Debug noise\n Returns:\n A list of dictionaries returned by ckanapi's package_update\n \"\"\"\n for x in search_mapping:\n if debug:\n print(\"\\nSearching CKAN with '{0}'\".format(x[\"s\"]))\n found = ckan.action.package_search(q=x[\"s\"])[\"results\"]\n if debug:\n print(\"Found datasets: {0}\\n\".format([d[\"title\"] for d in found]))\n fixed = [add_spatial(d, extents[x[\"i\"]], force=True, debug=True) for d in found]\n if debug:\n print(fixed, \"\\n\")\n datasets_updated = upsert_datasets(fixed, ckan, debug=False)\n",
"_____no_output_____"
],
[
"restore_extents(m, e, ckan)",
"Spatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer sandy-shoreline-at-eighty-mile-beach-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer turtle-monitoring-at-embmpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer intertidal-infauna-at-eighty-mile-beach-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer predator-pressures-on-turtle-nests-at-embmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-sea-surface-temperature-for-the-eighty-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rainfall-relevant-to-eighty-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shorebirds-abundance-at-80-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer pilbara-islands-wgs84-shapefile\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer cyclone-activity-at-80-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer mpa-reports\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer mangrove-diversity-kimberley\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-diveristy-kimberley-parks\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-kimberley-rsmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer predator-pressures-on-turtle-nests-at-embmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sandy-shoreline-at-eighty-mile-beach-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-sea-surface-temperature-for-the-eighty-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rainfall-relevant-to-eighty-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shorebirds-abundance-at-80-mile-beach-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer camden-sound-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-dolphins-at-the-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer montgomery-reef-aerial-photo-at-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-mangrove-communities-at-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer lalang-garram-camden-sound-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photos-for-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer cyclone-activity-at-lalang-garaam-camden-sound-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer geomorphology-habitat-mapping-at-lalang-gaaram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-patrols-undertaken-at-the-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-water-temperature-at-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer finfish-statistics-for-lcsmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer whale-abundance-in-lcsmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer mangrove-diversity-kimberley\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-diveristy-kimberley-parks\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-kimberley-rsmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photos-for-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rainfall-at-cygnet-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer cultural-map-of-dugong-areas-in-kimberley\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-water-temperature-at-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer montgomery-reef-aerial-photo-at-lalang-garram-camden-sound-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer cyclones-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer reef-lagoons-at-rowley-shoals-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sailfin-snapper-at-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer potato-cod-at-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diseased-acropora-at-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-rowley-shoals-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer cyclone-activity-data-at-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-rowley-shoals-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rowley-shoals-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-seascapes-and-wilderness-at-the-rowley-shoals-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-kimberley-rsmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rowley-shoals-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer cyclones-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-staff-days-and-expenditure-related-to-mooring-management-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-community-composition-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer reef-lagoons-at-rowley-shoals-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer department-of-fisheries-patrols-and-other-activities-in-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-days-vessels-have-spent-at-rowley-shoals\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-seabirds-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer density-of-coralivorous-invertebrates-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer acanthaster-planci-at-montebello-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer reef-lagoons-at-montebello-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-and-fish-at-montebello-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer montebello-barrow-islands-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-montebello-and-barrow-islands-mp-seabirds\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-montebello-and-barrow-islands-mp-hydrocarbons\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-moorings-at-the-montebello-and-barrow-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-recruitment-at-montebello-and-barrow-islands-marine-protected-areas\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-community-monitoring-by-wammp-at-the-montebello-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-montebello-and-barrow-islands-mp-cetaceans\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer charter-vessel-catch-and-cpue-for-mbimpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer loss-and-gain-in-canopy-density-of-mangroves-at-the-mbimpa-willie-nillie-sites\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sector-other-sites-extent-product-page\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rainfall-at-the-montebello-and-barrow-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer mangrove-diversity-at-montebello-barrow-islands-marine-protected-area\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer canopy-density-of-mangroves-at-the-montebello-and-barrow-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sector-willie-nillie-canopy-density-of-mangroves-at-the-montebello-and-barrow-islands-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sector-other-sites-product-page\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sector-others-canopy-density-of-mangroves-at-the-montebello-and-barrow-islands-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer areal-extent-of-mangroves-at-the-montebello-and-barrow-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer seascapes-ningaloo\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ningaloo-marine-park-cyclones\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer dugong-mortality\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer feral-baiting-at-ningaloo\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer manta-diversity-ningaloo\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-recruitment-at-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ningaloo-whale-shark-incidents-scarring-entangle-mortality\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-moorings-at-the-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diversity-of-macroalgae-at-the-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ningaloo-marine-protected-areas-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer macroalgae-in-situ-surveys-in-western-australia-mpra\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coral-community-composition-at-the-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-staff-days-spent-on-patrols-in-the-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ningaloo-marine-park-cyclones\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer filter-feeding-communities-ningaloo\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer area-of-disturbance-of-coastal-biological-communities-at-gnaraloo-at-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer density-of-coralivorous-invertebrates-at-the-rowley-shoals-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer percent-coral-cover-at-the-ningaloo-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diversity-of-filter-feeding-communities-at-ningaloo-especially-sponges\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer mpa-reports\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer seasnakes-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer dugong-abundance-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-shark-bay-landscape\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shark-bay-marine-park-cyclones\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer turtle-surface-counts-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer dolphin-surface-counts-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shark-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-shark-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer coastal-birds-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer humpback-whale-population-in-shark-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer shark-bay-marine-park-cyclones\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer percent-cover-shark-bay-product-page\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer percent-cover-of-seagrass-communities-in-the-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer seagrass-in-situ-surveys-in-western-australia-canopy-height-at-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer seagrass-in-situ-surveys-in-western-australia-shoot-density-at-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shark-bay-marine-protected-areas-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer long-term-monitoring-of-seagrass-at-shark-bay-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer department-of-fisheries-patrols-and-other-activities-at-the-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-target-finfish-species-at-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer fishing-effort-surveys-at-shark-bay-mpa\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer jurien-bay-litter-and-debris\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-sea-lions-in-jurien-bay\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer jurien-bay-coastal-birds\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-vessels-using-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer storms-at-jurien-bay-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer jurien-coastal-bird-diversity\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer orthophosphate-concentrations-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer chlorophyll-a-concentration-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-annual-precipitation-relevant-to-jurien-bay-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer jurien-bay-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer dissolved-inorganic-nitrogen-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer heavy-metals-concentration-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-timeseries-of-annual-precipitation-relevant-to-jurien-bay-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer pesticide-concentrations-in-the-water-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-vessels-using-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer orthophosphate-concentrations-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer percent-canopy-cover-of-macroalgae-at-the-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer total-petroleum-hydrocarbon-concentration-in-coastal-waters-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer polycyclic-aromatic-hydrocarbon-concentrations-in-the-water-of-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer benzene-toluene-ethylbenzene-and-xylene-btex-concentrations-in-the-water-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer stock-photo-marmion-coastline\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer marmion-marine-park-macroalgae\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-boat-and-beach-users-at-marmion-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer marmion-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer marmion-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-marmion-mp-geomorphology\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer fishing-effort-surveys-at-marmion-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-marmion-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer orthophosphate-concentrations-in-seawater-in-marmion-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diversity-of-finfish-at-the-marmion-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer stock-photo-swan-estuary\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp-water-quality\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp-sediment-quality\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp-seagrass-communities\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp-seabirds\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-swan-estuary-mp-invertebrate-communities\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-visitors-to-the-swan-estuary-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-patrols-undertaken-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer phosphorus-concentrations-in-the-water-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer rainfall-relevant-to-the-perth-metropolitan-marine-protected-areas\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer river-discharge-into-the-swan-canning-estuary-from-the-avon-and-canning-rivers-catchment\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer phosphorus-concentrations-in-the-water-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer chlorophyll-a-concentration-at-the-swan-estuary-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diversity-of-waterbirds-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-waterbirds-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer nitrogen-concentrations-in-the-water-at-the-swan-estuary-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer stock-photo-shoalwater-islands\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer fishing-effort-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer water-quality-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-little-penguins-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shoalwater-islands-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer density-of-macroalgae-in-state-marine-parks-of-western-australia-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shoalwater-islands-mp-sediment-quality\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shoalwater-islands-mp-intertidal-reef-communities\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shoalwater-islands-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer little-penguin-nestbox-vegetation-cover-simp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-metro-parks-simp-and-mmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer chlorophyll-a-concentrations-on-the-shoreline-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer water-quality-at-the-shoalwater-islands-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-invertebrate-species-at-jurien-bay-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shoalwater-islands-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shoalwater-islands-mp-seagrass-communities\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer person-days-at-the-shoalwater-islands-mp-macroalgae-communities\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer water-quality-on-the-shoreline-at-the-shoalwater-islands-mp-orthophosphate\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer water-quality-on-the-shoreline-at-the-shoalwater-islands-mp-dissolved-inorganic-nitrogen\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer stock-photo-ngari-capes\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ngari-capes-product-page\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-invertebrate-communities-ngari-capes-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer sea-urchin-at-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer gastropod-at-the-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer capenaturalistewave-2004-2014-csv\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-seabirds-at-the-ngari-capes-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-intertidal-rock-reef-communities-ngari-capes-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-finfish-at-the-ngari-capes-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-deep-reef-communities-ngari-capes\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-south-west-ncmp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer ngari-capes-marine-park-in-situ-seawater-temperature\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rainfall-relevant-to-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer rocky-intertidal-communities-of-the-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer river-discharge-from-the-major-drains-creeks-and-rivers-relevant-to-the-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer historical-time-series-of-seawater-temperature-at-ngari-capes-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer shoot-density-ngari-capes-product-page\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer relative-abundance-of-finfish-in-the-ngari-capes-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer macroalgae-in-situ-surveys-in-western-australia-mpra\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-the-targeted-invertebrate-panulirus-cygnus-larvae\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer stock-photo-walpole-nornalup-inlet-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer annual-rainfall-recorded-at-walpole-relevant-to-the-walpole-and-nornalup-minlets-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer operational-funds-for-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer walpole-nornalup-inlets-marine-protected-areas-general-spatial-extent\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-seabirds-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer litter-at-walpole-nornalup-inlets-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer area-of-disturbance-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer abundance-of-invertebrates-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer diversity-of-finfish-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-coastal-biological-communities-in-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent was overwritten\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nSpatial extent not given\nRefreshing harvested WMS layer datasets...\n[upsert_dataset] Reading WMS layer number-of-registered-vessels-in-western-australia-south-coast-wnimp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer deep-river-and-franklin-river-discharge-at-walpole-nornalup-inlets-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer total-nitrogen-concentrations-in-the-water-of-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer dissolved-inorganic-nitrogen-concentration-in-the-water-at-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer department-of-fisheries-patrols-and-other-activities-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer stock-photo-coastal-biological-communities-in-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer species-diversity-of-primary-producers-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer total-phosphorus-concentrations-in-the-water-of-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer orthophosphate-concentration-in-the-water-at-the-walpole-and-nornalup-inlets-mp\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\n[upsert_dataset] Reading WMS layer chlorophyll-a-levels-at-walpole-and-nornalup-inlets-marine-park\n[upsert_dataset] Layer exists.\n [upsert_dataset] Existing dataset metadata were updated.\n [upsert_dataset] Existing resources were replaced with new resources.\nDone!\n"
],
[
"d = [ckan.action.package_show(id = x) for x in ckan.action.package_list()]",
"_____no_output_____"
],
[
"fix = [x[\"title\"] for x in d if not x.has_key(\"spatial\")]",
"_____no_output_____"
],
[
"len(fix)",
"_____no_output_____"
],
[
"d[0]",
"_____no_output_____"
],
[
"fix",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f33c73749d935a744dbb92621e9a3f1edb4ee
| 150,499 |
ipynb
|
Jupyter Notebook
|
4_prediction/1_just_prediction.ipynb
|
KanHatakeyama/Python_MI
|
a652afe01527ef001b784d7cb6cb1cb68a5a62f1
|
[
"MIT"
] | null | null | null |
4_prediction/1_just_prediction.ipynb
|
KanHatakeyama/Python_MI
|
a652afe01527ef001b784d7cb6cb1cb68a5a62f1
|
[
"MIT"
] | null | null | null |
4_prediction/1_just_prediction.ipynb
|
KanHatakeyama/Python_MI
|
a652afe01527ef001b784d7cb6cb1cb68a5a62f1
|
[
"MIT"
] | null | null | null | 49.006513 | 13,484 | 0.580442 |
[
[
[
"# 化合物の物性をとりあえず予測するための一通りのコード",
"_____no_output_____"
]
],
[
[
"#化合物処理の為の関数・クラス群\nfrom RDKitWrapper import draw_SMILES,Fingerprint,RDKitDescriptors\n\nimport pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n",
"_____no_output_____"
]
],
[
[
"# データベースの読み込み (data from wikipedia)",
"_____no_output_____"
]
],
[
[
"df=pd.read_csv(\"wiki.csv\")\ndf",
"_____no_output_____"
],
[
"#今回は融点を予測してみる\ndf=df[[\"SMILES\",\"Melting temperature\"]]\ndf",
"_____no_output_____"
],
[
"#抜けデータの削除\ndf2=df.dropna()\ndf2",
"_____no_output_____"
],
[
"#複数の融点がスラッシュ区切りで記録されているので、はじめのデータのみを使う\n\n#まずはスラッシュで区切られたものを分割する\nspl_y_df=df2[\"Melting temperature\"].str.split(\"/\", expand=True)\nspl_y_df",
"_____no_output_____"
],
[
"#1列目を代入\ndf2[\"Melting temperature\"]=spl_y_df[0]\ndf2",
"C:\\Users\\kan\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:2: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame.\nTry using .loc[row_indexer,col_indexer] = value instead\n\nSee the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n \n"
]
],
[
[
"# Descriptorの計算",
"_____no_output_____"
]
],
[
[
"#クラスを使用する為の初期化処理\ndesc=RDKitDescriptors()",
"_____no_output_____"
],
[
"#smilesのリストをSMILES_listに代入\nSMILES_list=df2[\"SMILES\"].values\n\n#記述子を計算。一部の化合物でエラーが出る。\ndesc_list=[desc.calc(i,dict_mode=False) for i in SMILES_list]\n\ndesc_list[:2]",
"failed to purse: c1[nH]c2c(n1)c(=O)nc(n2)N\nplease recheck SMILES\ninvalid smiles! c1[nH]c2c(n1)c(=O)nc(n2)N\nfailed to purse: O=[Cl]=O\nplease recheck SMILES\ninvalid smiles! O=[Cl]=O\nfailed to purse: [Cd+2].[Cd+2].[Cd+2].[AsH6-3].[AsH6-3]\nplease recheck SMILES\ninvalid smiles! [Cd+2].[Cd+2].[Cd+2].[AsH6-3].[AsH6-3]\nfailed to purse: [H]1[BH]2[H][BH]3[BH]24[BH]1[H][BH]4[H]3\nplease recheck SMILES\ninvalid smiles! [H]1[BH]2[H][BH]3[BH]24[BH]1[H][BH]4[H]3\nfailed to purse: [O-2]=[Ce+4]=[O-2]\nplease recheck SMILES\ninvalid smiles! [O-2]=[Ce+4]=[O-2]\nfailed to purse: B1([H]3)(C2CCCC1CCC2)[H]B34C2CCCC4CCC2\nplease recheck SMILES\ninvalid smiles! B1([H]3)(C2CCCC1CCC2)[H]B34C2CCCC4CCC2\nfailed to purse: FCl(F)(F)(F)F\nplease recheck SMILES\ninvalid smiles! FCl(F)(F)(F)F\nfailed to purse: FBr(F)(F)(F)F\nplease recheck SMILES\ninvalid smiles! FBr(F)(F)(F)F\nfailed to purse: o=c([o-])C.[N+H4]\nplease recheck SMILES\ninvalid smiles! o=c([o-])C.[N+H4]\nfailed to purse: c1=cc=c[cH+]c=c1\nplease recheck SMILES\ninvalid smiles! c1=cc=c[cH+]c=c1\nfailed to purse: [Na+].[Na+].[Na+].[PH6-3]\nplease recheck SMILES\ninvalid smiles! [Na+].[Na+].[Na+].[PH6-3]\nfailed to purse: FCl(=O)(=O)=O\nplease recheck SMILES\ninvalid smiles! FCl(=O)(=O)=O\nfailed to purse: [K+].o=c(-c(=o)o1)o[Fe-3]123(oc(-c(=o)o2)=o)oc(-c(=o)o3)=o.[K+].[K+]\nplease recheck SMILES\ninvalid smiles! [K+].o=c(-c(=o)o1)o[Fe-3]123(oc(-c(=o)o2)=o)oc(-c(=o)o3)=o.[K+].[K+]\nfailed to purse: F[Si-2](F)(F)(F)(F)F.[NH4+].[NH4+]\nplease recheck SMILES\ninvalid smiles! F[Si-2](F)(F)(F)(F)F.[NH4+].[NH4+]\n"
],
[
"#エラーになった化合物では記述子の配列の代わりに-1が返るので、それをもとに選別フィルターを作成\navailable_filter=[(False if type(i)==type(1) else True) for i in desc_list]\navailable_filter",
"_____no_output_____"
],
[
"#エラーになっていないidのデータのみ残す\ndf3=df2[available_filter]\ndf3",
"_____no_output_____"
],
[
"#yの設定\ny=df3[\"Melting temperature\"].values\ny",
"_____no_output_____"
],
[
"#文字列になっているので、floatに変換\nY=np.array(y,dtype=np.float)\nY",
"_____no_output_____"
],
[
"#scikit-learnでは、yは下記の形に変換しないと計算ができない(おまじない)\nY=Y.reshape(-1,1)\nY",
"_____no_output_____"
],
[
"#計算に失敗した記述子は削除する\nX=[x for x in desc_list if type(x)!=type(1)]\n\n#numpyに変換\nX=np.array(X)\nX[:1]",
"_____no_output_____"
],
[
"print(X.shape)\nprint(Y.shape)",
"(1047, 200)\n(1047, 1)\n"
]
],
[
[
"# 機械学習\n- 一部モデルの予測精度が悪いが、ハイパーパラメータを調節すれば基本的に改善可能 (notebook 4も参照のこと)",
"_____no_output_____"
]
],
[
[
"#線形回帰\nfrom sklearn.linear_model import LinearRegression\n\n\nmodel=LinearRegression()\nmodel.fit(X,Y)\n\n#結果の予測\npred_Y=model.predict(X)\nplt.scatter(Y,pred_Y)\n\n#係数を解析\nimport_param_df=pd.DataFrame((model.coef_[0],desc.desc_list)).T\nimport_param_df",
"_____no_output_____"
],
[
"#random forest\nfrom sklearn.ensemble import RandomForestRegressor\n\nmodel=RandomForestRegressor()\nmodel.fit(X,Y)\n\n#結果の予測\npred_Y=model.predict(X)\nplt.scatter(Y,pred_Y)\n\n#パラメータの重要度を解析\nimport_param_df=pd.DataFrame((model.feature_importances_,desc.desc_list)).T\nimport_param_df",
"C:\\Users\\kan\\anaconda3\\lib\\site-packages\\ipykernel_launcher.py:5: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples,), for example using ravel().\n \"\"\"\n"
],
[
"#lasso\nfrom sklearn.linear_model import Lasso\n\nmodel=Lasso(alpha=1)\nmodel.fit(X,Y)\n\n#結果の予測\npred_Y=model.predict(X)\nplt.scatter(Y,pred_Y)\n\n\n#係数を解析\nimport_param_df=pd.DataFrame((model.coef_,desc.desc_list)).T\nimport_param_df",
"C:\\Users\\kan\\anaconda3\\lib\\site-packages\\sklearn\\linear_model\\_coordinate_descent.py:476: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations. Duality gap: 58980295.88372781, tolerance: 22675.39266231727\n positive)\n"
],
[
"#gaussian process\nfrom sklearn.gaussian_process import GaussianProcessRegressor\n\nmodel=GaussianProcessRegressor()\nmodel.fit(X,Y)\n\n#結果の予測\npred_Y=model.predict(X)\nplt.scatter(Y,pred_Y)",
"_____no_output_____"
],
[
"#信頼区間の表示\nmodel.predict(X,return_std=True)",
"_____no_output_____"
],
[
"#neural net\nfrom sklearn.neural_network import MLPRegressor\n\nmodel=MLPRegressor()\nmodel.fit(X,Y)\n\n#結果の予測\npred_Y=model.predict(X)\nplt.scatter(Y,pred_Y)\n",
"C:\\Users\\kan\\anaconda3\\lib\\site-packages\\sklearn\\neural_network\\_multilayer_perceptron.py:1342: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().\n y = column_or_1d(y, warn=True)\nC:\\Users\\kan\\anaconda3\\lib\\site-packages\\sklearn\\neural_network\\_multilayer_perceptron.py:571: ConvergenceWarning: Stochastic Optimizer: Maximum iterations (200) reached and the optimization hasn't converged yet.\n % self.max_iter, ConvergenceWarning)\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f3449d552696698f55c3b2f5de4fb10bb6b56
| 355,783 |
ipynb
|
Jupyter Notebook
|
notebooks/03 efficient frontier.ipynb
|
avpak/okama
|
b3c4f6b7dfcc314d3171f20b3bc95cfa04268c1a
|
[
"MIT"
] | null | null | null |
notebooks/03 efficient frontier.ipynb
|
avpak/okama
|
b3c4f6b7dfcc314d3171f20b3bc95cfa04268c1a
|
[
"MIT"
] | null | null | null |
notebooks/03 efficient frontier.ipynb
|
avpak/okama
|
b3c4f6b7dfcc314d3171f20b3bc95cfa04268c1a
|
[
"MIT"
] | null | null | null | 394.437916 | 81,924 | 0.933344 |
[
[
[
"import matplotlib.pyplot as plt\nplt.rcParams['figure.figsize'] = [12.0, 6.0]\n\nimport okama as ok",
"_____no_output_____"
]
],
[
[
"**EfficientFrontier** class can be used for \"classic\" frontiers where all portfolios are **rebalanced mothly**. It's the most easy and fast way to draw an Efficient Frontier.",
"_____no_output_____"
],
[
"### Simple efficient frontier for 2 ETF",
"_____no_output_____"
]
],
[
[
"ls2 = ['SPY.US', 'BND.US']\ncurr='USD'\ntwo_assets = ok.EfficientFrontier(symbols=ls2, curr=curr, n_points=100) # n_points - specifies a number of points in the Efficient Frontier chart (default is 20)\ntwo_assets",
"_____no_output_____"
]
],
[
[
"**ef_points** property returns the dataframe (table). \nEach row has properties of portfolio or point in the frontier: \n_Risk_ - the volatility or standard deviation \n_Mean return_ - the expectation or arithmetic mean \n_CAGR_ - Compound annual growth rate\n\nAll the properties have annualized values. \nLast columns are weights for each asset. ",
"_____no_output_____"
]
],
[
[
"df = two_assets.ef_points\ndf",
"_____no_output_____"
],
[
"fig = plt.figure()\n\n# Plotting the assets\nok.Plots(ls2, curr=curr).plot_assets(kind='cagr')\nax = plt.gca()\n\n# Plotting the Efficient Frontier\nax.plot(df['Risk'], df['CAGR']);",
"_____no_output_____"
]
],
[
[
"It's possible to draw both efficient frontiers: for mean return and for CAGR with the same dataframe.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\n\n# Plotting the assets\nok.Plots(ls2, curr=curr).plot_assets(kind='cagr')\nax = plt.gca()\n\n# Plotting the Efficient Frontiers\n# EF with mean return\nax.plot(df['Risk'], df['Mean return'])\n# EF with CAGR\nax.plot(df['Risk'], df['CAGR']);",
"_____no_output_____"
]
],
[
[
"### Several assets",
"_____no_output_____"
],
[
"Let's add a popular fisical gold and real estate ETFs...",
"_____no_output_____"
]
],
[
[
"ls4 = ['SPY.US', 'BND.US', 'GLD.US', 'VNQ.US']\ncurr = 'USD'\nfour_assets = ok.EfficientFrontier(symbols=ls4, curr=curr, n_points=100)\nfour_assets",
"_____no_output_____"
],
[
"df4 = four_assets.ef_points",
"_____no_output_____"
],
[
"fig = plt.figure()\n\n# Plotting the assets\nok.Plots(ls4, curr=curr).plot_assets(kind='cagr')\nax = plt.gca()\n\n# Plotting the Efficient Frontier\nax.plot(df4['Risk'], df4['CAGR']);",
"_____no_output_____"
]
],
[
[
"### Efficient Frontier for each pair of assets",
"_____no_output_____"
],
[
"Sometimes it can be helpful to see how each pair of assets \"contributes\" to the common efficient frontier by drawing all the pair frontiers.",
"_____no_output_____"
]
],
[
[
"ok.Plots(ls4, curr=curr).plot_pair_ef();",
"_____no_output_____"
]
],
[
[
"We can see all efficent frontiers (pairs and 4 assets) in a common chart ...",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\n\n# Plotting the assets\nok.Plots(ls4, curr=curr).plot_pair_ef()\n\nax = plt.gca()\n\n# Plotting the Efficient Frontier\nax.plot(df4['Risk'], df4['Mean return'], color = 'black', linestyle='--');",
"_____no_output_____"
]
],
[
[
"### Global Minimum Variance (GMV) portfolio",
"_____no_output_____"
],
[
"GMV weights and values could be found with **gmv_weights**, **gmv_monthly** and **gmv_annualized** methods.",
"_____no_output_____"
],
[
"Weights of GMV portfolio:",
"_____no_output_____"
]
],
[
[
"four_assets.gmv_weights ",
"_____no_output_____"
]
],
[
[
"Risk and mean return on monthly basis:",
"_____no_output_____"
]
],
[
[
"four_assets.gmv_monthly",
"_____no_output_____"
]
],
[
[
"Risk and mean return annualized:",
"_____no_output_____"
]
],
[
[
"four_assets.gmv_annualized",
"_____no_output_____"
]
],
[
[
"With annualized values it's easy to draw the GMV point on the chart.",
"_____no_output_____"
]
],
[
[
"fig = plt.figure()\nax = plt.gca()\n\n# Plotting the Efficient Frontier\nax.plot(df4['Risk'], df4['CAGR']);\n\n# plotting GMV point\nax.scatter(four_assets.gmv_annualized[0], four_assets.gmv_annualized[1])\n\n# annotations for GMV point\nax.annotate(\"GMV\", # this is the text\n (four_assets.gmv_annualized[0], four_assets.gmv_annualized[1]), # this is the point to label\n textcoords=\"offset points\", # how to position the text\n xytext=(0, 10), # distance from text to points (x,y)\n ha='center'); # horizontal alignment can be left, right or center",
"_____no_output_____"
]
],
[
[
"### Monte Carlo simulation for efficient frontier",
"_____no_output_____"
],
[
"Monte Carlo simulation is useful to visualize portfolios allocation inside the Efficient Frontier. It generates N random weights and calculates their properties (risk and return metrics).",
"_____no_output_____"
],
[
"Let's create a list of popular German stocks, add US bonds ETF (AGG) and spot gold prices (GC.COMM). Portfolios currency is EUR.",
"_____no_output_____"
]
],
[
[
"ls5 = ['DBK.XETR', 'SIE.XETR', 'TKA.XETR', 'AGG.US', 'GC.COMM']\ncurr = 'EUR'\ngr = ok.EfficientFrontier(symbols=ls5, curr=curr, n_points=100)\ngr",
"_____no_output_____"
],
[
"gr.names",
"_____no_output_____"
]
],
[
[
"To create a \"cloud\" of random portfolios **get_monte_carlo** method is used.",
"_____no_output_____"
]
],
[
[
"mc = gr.get_monte_carlo(n=5000, kind='cagr') # it is possible to choose whether mean return or CAGR is used with \"kind\" attribute",
"_____no_output_____"
],
[
"mc",
"_____no_output_____"
]
],
[
[
"We can plot the random portfolios with matplotlib **scatter** method. To add the assets point to the chart **plot_assets** is used (with Plots class).",
"_____no_output_____"
]
],
[
[
"fig = plt.figure(figsize=(12,6))\nfig.subplots_adjust(bottom=0.2, top=1.5)\nok.Plots(ls5, curr='EUR').plot_assets(kind='cagr') # plot the assets points\nax = plt.gca()\n\nax.scatter(mc.Risk, mc.CAGR, linewidth=0, color='green');",
"_____no_output_____"
]
],
[
[
"As the random portfolios \"cloud\" usually does not have an obvious shape, sometimes it's worth to draw Monte Carlos simulation together with the Efficient Frontier.",
"_____no_output_____"
]
],
[
[
"ef = gr.ef_points # calculate Efficient Frontier points",
"_____no_output_____"
],
[
"fig = plt.figure(figsize=(12,6))\nfig.subplots_adjust(bottom=0.2, top=1.5)\nok.Plots(ls5, curr='EUR').plot_assets(kind='cagr') # plot the assets points\nax = plt.gca()\n\nax.plot(ef.Risk, ef['CAGR'], color='black', linestyle='dashed', linewidth=3) # plot the Efficient Frontier\n\nax.scatter(mc.Risk, mc.CAGR, linewidth=0, color='green'); # plot the Monte Carlo simulation results",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4a9f3d014467716b60e6f99da26a77b8c256281b
| 160,933 |
ipynb
|
Jupyter Notebook
|
experiments/exp_FedMNIST.ipynb
|
jan-kreischer/FedML_w_DP
|
24a4df5f1c317c5dea61eaac2d7a841ad9836f1d
|
[
"MIT"
] | 2 |
2021-12-31T01:30:24.000Z
|
2022-03-27T16:26:24.000Z
|
experiments/exp_FedMNIST.ipynb
|
jan-kreischer/FedML_w_DP
|
24a4df5f1c317c5dea61eaac2d7a841ad9836f1d
|
[
"MIT"
] | null | null | null |
experiments/exp_FedMNIST.ipynb
|
jan-kreischer/FedML_w_DP
|
24a4df5f1c317c5dea61eaac2d7a841ad9836f1d
|
[
"MIT"
] | null | null | null | 208.192755 | 69,978 | 0.874637 |
[
[
[
"<a href=\"https://colab.research.google.com/github/xavoliva6/dpfl_pytorch/blob/main/experiments/exp_FedMNIST.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"#Experiments on FedMNIST",
"_____no_output_____"
],
[
"**Colab Support**<br/>\nOnly run the following lines if you want to run the code on Google Colab",
"_____no_output_____"
]
],
[
[
"# Enable access to files stored in Google Drive\nfrom google.colab import drive\n\ndrive.mount('/content/gdrive/')",
"Mounted at /content/gdrive/\n"
],
[
"% cd /content/gdrive/My Drive/OPT4ML/src",
"/content/gdrive/My Drive/OPT4ML/src\n"
]
],
[
[
"# Main",
"_____no_output_____"
]
],
[
[
"# Install necessary requirements\n!pip install -r ../requirements.txt",
"Requirement already satisfied: torchvision~=0.9.1 in /usr/local/lib/python3.7/dist-packages (from -r ../requirements.txt (line 1)) (0.9.1+cu101)\nRequirement already satisfied: torch~=1.8.1 in /usr/local/lib/python3.7/dist-packages (from -r ../requirements.txt (line 2)) (1.8.1+cu101)\nRequirement already satisfied: numpy~=1.20.2 in /usr/local/lib/python3.7/dist-packages (from -r ../requirements.txt (line 3)) (1.20.3)\nRequirement already satisfied: opacus~=0.13.0 in /usr/local/lib/python3.7/dist-packages (from -r ../requirements.txt (line 4)) (0.13.0)\nRequirement already satisfied: pandas==1.2.4 in /usr/local/lib/python3.7/dist-packages (from -r ../requirements.txt (line 5)) (1.2.4)\nRequirement already satisfied: pillow>=4.1.1 in /usr/local/lib/python3.7/dist-packages (from torchvision~=0.9.1->-r ../requirements.txt (line 1)) (7.1.2)\nRequirement already satisfied: typing-extensions in /usr/local/lib/python3.7/dist-packages (from torch~=1.8.1->-r ../requirements.txt (line 2)) (3.7.4.3)\nRequirement already satisfied: requests>=2.25.1 in /usr/local/lib/python3.7/dist-packages (from opacus~=0.13.0->-r ../requirements.txt (line 4)) (2.25.1)\nRequirement already satisfied: scipy>=1.2 in /usr/local/lib/python3.7/dist-packages (from opacus~=0.13.0->-r ../requirements.txt (line 4)) (1.4.1)\nRequirement already satisfied: tqdm>=4.40 in /usr/local/lib/python3.7/dist-packages (from opacus~=0.13.0->-r ../requirements.txt (line 4)) (4.41.1)\nRequirement already satisfied: pytz>=2017.3 in /usr/local/lib/python3.7/dist-packages (from pandas==1.2.4->-r ../requirements.txt (line 5)) (2018.9)\nRequirement already satisfied: python-dateutil>=2.7.3 in /usr/local/lib/python3.7/dist-packages (from pandas==1.2.4->-r ../requirements.txt (line 5)) (2.8.1)\nRequirement already satisfied: idna<3,>=2.5 in /usr/local/lib/python3.7/dist-packages (from requests>=2.25.1->opacus~=0.13.0->-r ../requirements.txt (line 4)) (2.10)\nRequirement already satisfied: chardet<5,>=3.0.2 in /usr/local/lib/python3.7/dist-packages (from requests>=2.25.1->opacus~=0.13.0->-r ../requirements.txt (line 4)) (3.0.4)\nRequirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.7/dist-packages (from requests>=2.25.1->opacus~=0.13.0->-r ../requirements.txt (line 4)) (2021.5.30)\nRequirement already satisfied: urllib3<1.27,>=1.21.1 in /usr/local/lib/python3.7/dist-packages (from requests>=2.25.1->opacus~=0.13.0->-r ../requirements.txt (line 4)) (1.24.3)\nRequirement already satisfied: six>=1.5 in /usr/local/lib/python3.7/dist-packages (from python-dateutil>=2.7.3->pandas==1.2.4->-r ../requirements.txt (line 5)) (1.15.0)\n"
],
[
"# Make sure cuda support is available\nimport torch\n\nif torch.cuda.is_available():\n device_name = \"cuda:0\"\nelse:\n device_name = \"cpu\"\nprint(\"device_name: {}\".format(device_name))\ndevice = torch.device(device_name)",
"device_name: cuda:0\n"
],
[
"%load_ext autoreload\n%autoreload 2",
"The autoreload extension is already loaded. To reload it, use:\n %reload_ext autoreload\n"
],
[
"import sys\nimport warnings\n\nwarnings.filterwarnings(\"ignore\")\n\nfrom server import Server\nfrom utils import plot_exp\n\nimport matplotlib.pyplot as plt\nplt.rcParams['figure.figsize'] = [6, 6]\nplt.rcParams['figure.dpi'] = 100",
"_____no_output_____"
]
],
[
[
"### First experiment : impact of federated learning",
"_____no_output_____"
]
],
[
[
"LR = 0.01\nEPOCHS = 1\nNR_TRAINING_ROUNDS = 30\nBATCH_SIZE = 128\n\nRANGE_NR_CLIENTS = [1,5,10]",
"_____no_output_____"
],
[
"experiment_losses, experiment_accs = [], []\nfor nr_clients in RANGE_NR_CLIENTS:\n print(f\"### Number of clients : {nr_clients} ###\\n\\n\")\n server = Server(\n nr_clients=nr_clients,\n nr_training_rounds=NR_TRAINING_ROUNDS,\n data='MNIST',\n epochs=EPOCHS,\n lr=LR,\n batch_size=BATCH_SIZE,\n is_private=False,\n epsilon=None,\n max_grad_norm=None,\n noise_multiplier=None,\n is_parallel=True,\n device=device,\n verbose='server')\n\n test_losses, test_accs = server.train()\n \n experiment_losses.append(test_losses)\n experiment_accs.append(test_accs)",
"### Number of clients : 1 ###\n\n\n--- Configuration ---\nnr_clients: 1\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: False\nepsilon: None\nmax_grad_norm: None\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 20.503, test_acc: 0.923\nRound 2, test_loss: 15.046, test_acc: 0.945\nRound 3, test_loss: 11.846, test_acc: 0.956\nRound 4, test_loss: 10.470, test_acc: 0.959\nRound 5, test_loss: 9.710, test_acc: 0.965\nRound 6, test_loss: 7.948, test_acc: 0.970\nRound 7, test_loss: 7.492, test_acc: 0.971\nRound 8, test_loss: 7.151, test_acc: 0.973\nRound 9, test_loss: 6.112, test_acc: 0.975\nRound 10, test_loss: 5.819, test_acc: 0.977\nRound 11, test_loss: 5.611, test_acc: 0.980\nRound 12, test_loss: 4.716, test_acc: 0.981\nRound 13, test_loss: 4.531, test_acc: 0.982\nRound 14, test_loss: 4.223, test_acc: 0.982\nRound 15, test_loss: 4.382, test_acc: 0.982\nRound 16, test_loss: 3.798, test_acc: 0.985\nRound 17, test_loss: 3.706, test_acc: 0.984\nRound 18, test_loss: 3.489, test_acc: 0.985\nRound 19, test_loss: 3.494, test_acc: 0.985\nRound 20, test_loss: 3.192, test_acc: 0.986\nRound 21, test_loss: 3.040, test_acc: 0.987\nRound 22, test_loss: 3.039, test_acc: 0.986\nRound 23, test_loss: 3.112, test_acc: 0.986\nRound 24, test_loss: 2.893, test_acc: 0.988\nRound 25, test_loss: 3.114, test_acc: 0.988\nRound 26, test_loss: 2.764, test_acc: 0.988\nRound 27, test_loss: 2.767, test_acc: 0.988\nRound 28, test_loss: 2.703, test_acc: 0.988\nRound 29, test_loss: 2.658, test_acc: 0.988\nRound 30, test_loss: 2.552, test_acc: 0.989\nTest losses: [20.5027, 15.0455, 11.8458, 10.4703, 9.7102, 7.948, 7.4923, 7.1506, 6.112, 5.819, 5.6106, 4.7163, 4.5308, 4.2235, 4.3817, 3.7984, 3.7063, 3.4889, 3.4941, 3.1922, 3.0397, 3.0386, 3.1125, 2.8935, 3.1145, 2.7637, 2.7668, 2.7033, 2.6579, 2.552]\nTest accuracies: [0.9233, 0.9446, 0.9562, 0.9586, 0.9648, 0.9698, 0.9708, 0.9725, 0.9754, 0.9772, 0.9798, 0.9805, 0.9821, 0.9824, 0.9821, 0.985, 0.9843, 0.985, 0.9846, 0.986, 0.9873, 0.9863, 0.9862, 0.9876, 0.988, 0.9882, 0.9882, 0.9884, 0.9883, 0.9885]\nFinished\n### Number of clients : 5 ###\n\n\n--- Configuration ---\nnr_clients: 5\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: False\nepsilon: None\nmax_grad_norm: None\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 51.988, test_acc: 0.853\nRound 2, test_loss: 29.609, test_acc: 0.898\nRound 3, test_loss: 24.957, test_acc: 0.910\nRound 4, test_loss: 22.209, test_acc: 0.919\nRound 5, test_loss: 19.899, test_acc: 0.924\nRound 6, test_loss: 18.359, test_acc: 0.932\nRound 7, test_loss: 17.289, test_acc: 0.936\nRound 8, test_loss: 16.254, test_acc: 0.939\nRound 9, test_loss: 14.885, test_acc: 0.945\nRound 10, test_loss: 14.276, test_acc: 0.946\nRound 11, test_loss: 13.536, test_acc: 0.949\nRound 12, test_loss: 12.955, test_acc: 0.951\nRound 13, test_loss: 12.205, test_acc: 0.953\nRound 14, test_loss: 11.948, test_acc: 0.956\nRound 15, test_loss: 11.777, test_acc: 0.957\nRound 16, test_loss: 10.887, test_acc: 0.959\nRound 17, test_loss: 10.947, test_acc: 0.959\nRound 18, test_loss: 10.617, test_acc: 0.960\nRound 19, test_loss: 10.180, test_acc: 0.963\nRound 20, test_loss: 10.108, test_acc: 0.962\nRound 21, test_loss: 9.553, test_acc: 0.965\nRound 22, test_loss: 9.447, test_acc: 0.965\nRound 23, test_loss: 9.290, test_acc: 0.966\nRound 24, test_loss: 9.228, test_acc: 0.966\nRound 25, test_loss: 8.925, test_acc: 0.968\nRound 26, test_loss: 8.679, test_acc: 0.968\nRound 27, test_loss: 8.498, test_acc: 0.968\nRound 28, test_loss: 8.162, test_acc: 0.968\nRound 29, test_loss: 8.404, test_acc: 0.970\nRound 30, test_loss: 8.225, test_acc: 0.970\nTest losses: [51.9883, 29.6086, 24.9573, 22.2088, 19.8991, 18.3587, 17.2887, 16.254, 14.8846, 14.2762, 13.536, 12.9554, 12.2049, 11.9475, 11.7769, 10.8865, 10.9474, 10.6169, 10.1798, 10.108, 9.5525, 9.4468, 9.2897, 9.2275, 8.9249, 8.679, 8.4977, 8.1618, 8.4044, 8.2249]\nTest accuracies: [0.8528, 0.8978, 0.9099, 0.9195, 0.9241, 0.9318, 0.9364, 0.9388, 0.9454, 0.9461, 0.9489, 0.9511, 0.9532, 0.9562, 0.9568, 0.9587, 0.9591, 0.9598, 0.9631, 0.9617, 0.9647, 0.9654, 0.9658, 0.9663, 0.9675, 0.9676, 0.9679, 0.9683, 0.9704, 0.9696]\nFinished\n### Number of clients : 10 ###\n\n\n--- Configuration ---\nnr_clients: 10\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: False\nepsilon: None\nmax_grad_norm: None\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 126.150, test_acc: 0.757\nRound 2, test_loss: 48.968, test_acc: 0.861\nRound 3, test_loss: 34.799, test_acc: 0.886\nRound 4, test_loss: 29.527, test_acc: 0.901\nRound 5, test_loss: 26.519, test_acc: 0.908\nRound 6, test_loss: 24.550, test_acc: 0.913\nRound 7, test_loss: 22.857, test_acc: 0.917\nRound 8, test_loss: 21.431, test_acc: 0.921\nRound 9, test_loss: 20.574, test_acc: 0.925\nRound 10, test_loss: 19.517, test_acc: 0.927\nRound 11, test_loss: 18.568, test_acc: 0.931\nRound 12, test_loss: 17.844, test_acc: 0.933\nRound 13, test_loss: 17.569, test_acc: 0.935\nRound 14, test_loss: 17.008, test_acc: 0.936\nRound 15, test_loss: 16.248, test_acc: 0.940\nRound 16, test_loss: 15.641, test_acc: 0.941\nRound 17, test_loss: 15.036, test_acc: 0.945\nRound 18, test_loss: 14.812, test_acc: 0.945\nRound 19, test_loss: 14.413, test_acc: 0.947\nRound 20, test_loss: 14.339, test_acc: 0.950\nRound 21, test_loss: 13.754, test_acc: 0.949\nRound 22, test_loss: 13.419, test_acc: 0.950\nRound 23, test_loss: 13.191, test_acc: 0.952\nRound 24, test_loss: 12.942, test_acc: 0.953\nRound 25, test_loss: 12.614, test_acc: 0.954\nRound 26, test_loss: 12.342, test_acc: 0.955\nRound 27, test_loss: 12.035, test_acc: 0.955\nRound 28, test_loss: 12.297, test_acc: 0.957\nRound 29, test_loss: 11.836, test_acc: 0.957\nRound 30, test_loss: 11.703, test_acc: 0.958\nTest losses: [126.1503, 48.9684, 34.7994, 29.527, 26.5191, 24.55, 22.8575, 21.4315, 20.5741, 19.5171, 18.5677, 17.8443, 17.5688, 17.0084, 16.2484, 15.6411, 15.0357, 14.8117, 14.4131, 14.339, 13.754, 13.419, 13.1909, 12.9424, 12.6145, 12.3424, 12.035, 12.2965, 11.8355, 11.7034]\nTest accuracies: [0.7566, 0.8608, 0.8859, 0.9008, 0.9085, 0.9133, 0.917, 0.9208, 0.9255, 0.9275, 0.9312, 0.9334, 0.9355, 0.9361, 0.9401, 0.9413, 0.9452, 0.9451, 0.9465, 0.9495, 0.9492, 0.9499, 0.9517, 0.9526, 0.9538, 0.9547, 0.9553, 0.9574, 0.9568, 0.9575]\nFinished\n"
],
[
"names = [f'{i} clients' for i in RANGE_NR_CLIENTS]\ntitle = 'First experiment : MNIST database'\nfig = plot_exp(experiment_losses, experiment_accs, names, title)\nfig.savefig(\"MNIST_exp1.pdf\")",
"_____no_output_____"
]
],
[
[
"### Second experiment : impact of differential privacy",
"_____no_output_____"
]
],
[
[
"NR_CLIENTS = 10\nNR_TRAINING_ROUNDS = 30\nEPOCHS = 1\nLR = 0.01\nBATCH_SIZE = 128\n\nMAX_GRAD_NORM = 1.2\nNOISE_MULTIPLIER = None\n\nRANGE_EPSILON = [10,50,100]",
"_____no_output_____"
],
[
"experiment_losses, experiment_accs = [], []\nfor epsilon in RANGE_EPSILON:\n print(f\"### ε : {epsilon} ###\\n\\n\")\n server = Server(\n nr_clients=NR_CLIENTS,\n nr_training_rounds=NR_TRAINING_ROUNDS,\n data='MNIST',\n epochs=EPOCHS,\n lr=LR,\n batch_size=BATCH_SIZE,\n is_private=True,\n epsilon=epsilon,\n max_grad_norm=MAX_GRAD_NORM,\n noise_multiplier=NOISE_MULTIPLIER,\n is_parallel=True,\n device=device,\n verbose='server')\n\n test_losses, test_accs = server.train()\n experiment_losses.append(test_losses)\n experiment_accs.append(test_accs)",
"### ε : 10 ###\n\n\n--- Configuration ---\nnr_clients: 10\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: True\nepsilon: 10\nmax_grad_norm: 1.2\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 180.061, test_acc: 0.177\nRound 2, test_loss: 177.789, test_acc: 0.281\nRound 3, test_loss: 175.240, test_acc: 0.392\nRound 4, test_loss: 172.313, test_acc: 0.493\nRound 5, test_loss: 169.102, test_acc: 0.559\nRound 6, test_loss: 165.549, test_acc: 0.599\nRound 7, test_loss: 161.525, test_acc: 0.630\nRound 8, test_loss: 157.084, test_acc: 0.641\nRound 9, test_loss: 152.172, test_acc: 0.655\nRound 10, test_loss: 147.078, test_acc: 0.658\nRound 11, test_loss: 141.704, test_acc: 0.669\nRound 12, test_loss: 135.671, test_acc: 0.677\nRound 13, test_loss: 129.795, test_acc: 0.680\nRound 14, test_loss: 123.516, test_acc: 0.691\nRound 15, test_loss: 117.565, test_acc: 0.693\nRound 16, test_loss: 111.511, test_acc: 0.702\nRound 17, test_loss: 106.185, test_acc: 0.706\nRound 18, test_loss: 100.831, test_acc: 0.710\nRound 19, test_loss: 95.605, test_acc: 0.712\nRound 20, test_loss: 90.903, test_acc: 0.718\nRound 21, test_loss: 86.558, test_acc: 0.723\nRound 22, test_loss: 82.992, test_acc: 0.725\nRound 23, test_loss: 79.195, test_acc: 0.732\nRound 24, test_loss: 76.249, test_acc: 0.731\nRound 25, test_loss: 73.535, test_acc: 0.734\nRound 26, test_loss: 70.631, test_acc: 0.737\nRound 27, test_loss: 68.475, test_acc: 0.741\nRound 28, test_loss: 66.720, test_acc: 0.744\nRound 29, test_loss: 64.239, test_acc: 0.748\nRound 30, test_loss: 61.755, test_acc: 0.753\nTest losses: [180.0607, 177.7893, 175.2404, 172.3132, 169.1017, 165.5494, 161.5248, 157.0836, 152.1723, 147.0785, 141.7035, 135.6712, 129.7947, 123.5157, 117.5654, 111.5114, 106.1846, 100.8311, 95.6049, 90.9034, 86.5579, 82.9925, 79.1949, 76.2491, 73.5349, 70.6308, 68.4752, 66.7202, 64.2392, 61.7551]\nTest accuracies: [0.1772, 0.2809, 0.3916, 0.4926, 0.5591, 0.5994, 0.6305, 0.6412, 0.6554, 0.6582, 0.6694, 0.6773, 0.6803, 0.6908, 0.6932, 0.7016, 0.7058, 0.7099, 0.7124, 0.718, 0.7225, 0.7253, 0.7318, 0.7314, 0.7339, 0.7366, 0.7408, 0.7442, 0.7484, 0.7534]\nFinished\n### ε : 50 ###\n\n\n--- Configuration ---\nnr_clients: 10\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: True\nepsilon: 50\nmax_grad_norm: 1.2\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 179.708, test_acc: 0.269\nRound 2, test_loss: 177.285, test_acc: 0.309\nRound 3, test_loss: 174.659, test_acc: 0.371\nRound 4, test_loss: 171.873, test_acc: 0.441\nRound 5, test_loss: 168.893, test_acc: 0.496\nRound 6, test_loss: 165.664, test_acc: 0.547\nRound 7, test_loss: 161.894, test_acc: 0.585\nRound 8, test_loss: 157.960, test_acc: 0.611\nRound 9, test_loss: 153.588, test_acc: 0.637\nRound 10, test_loss: 148.777, test_acc: 0.650\nRound 11, test_loss: 143.890, test_acc: 0.661\nRound 12, test_loss: 138.697, test_acc: 0.670\nRound 13, test_loss: 133.067, test_acc: 0.676\nRound 14, test_loss: 127.386, test_acc: 0.684\nRound 15, test_loss: 121.923, test_acc: 0.689\nRound 16, test_loss: 116.122, test_acc: 0.695\nRound 17, test_loss: 110.205, test_acc: 0.701\nRound 18, test_loss: 104.908, test_acc: 0.707\nRound 19, test_loss: 99.555, test_acc: 0.714\nRound 20, test_loss: 94.807, test_acc: 0.716\nRound 21, test_loss: 90.174, test_acc: 0.720\nRound 22, test_loss: 85.687, test_acc: 0.725\nRound 23, test_loss: 81.910, test_acc: 0.729\nRound 24, test_loss: 78.162, test_acc: 0.731\nRound 25, test_loss: 75.148, test_acc: 0.734\nRound 26, test_loss: 72.602, test_acc: 0.736\nRound 27, test_loss: 69.799, test_acc: 0.740\nRound 28, test_loss: 67.334, test_acc: 0.743\nRound 29, test_loss: 65.318, test_acc: 0.748\nRound 30, test_loss: 63.011, test_acc: 0.752\nTest losses: [179.708, 177.2851, 174.659, 171.8731, 168.8935, 165.6638, 161.8938, 157.9598, 153.5876, 148.7774, 143.8897, 138.6968, 133.0674, 127.3856, 121.9231, 116.1224, 110.2054, 104.9077, 99.5549, 94.8074, 90.1735, 85.6867, 81.9102, 78.1623, 75.1478, 72.6022, 69.7988, 67.3338, 65.3183, 63.0108]\nTest accuracies: [0.2686, 0.309, 0.3709, 0.4405, 0.4965, 0.5466, 0.5848, 0.6111, 0.6375, 0.6498, 0.6613, 0.6703, 0.6762, 0.6841, 0.6892, 0.6948, 0.7014, 0.7065, 0.714, 0.7164, 0.7204, 0.7245, 0.7285, 0.7314, 0.7341, 0.7361, 0.7398, 0.7429, 0.7483, 0.7525]\nFinished\n### ε : 100 ###\n\n\n--- Configuration ---\nnr_clients: 10\nnr_training_rounds: 30\ndata: MNIST\nepochs: 1\nlr: 0.01\nbatch_size: 128\nis_private: True\nepsilon: 100\nmax_grad_norm: 1.2\nnoise_multiplier: None\nis_parallel: True\ndevice: <class 'torch.device'>\nverbose: server\n--- Training ---\nRound 1, test_loss: 180.452, test_acc: 0.120\nRound 2, test_loss: 178.381, test_acc: 0.195\nRound 3, test_loss: 176.163, test_acc: 0.346\nRound 4, test_loss: 173.657, test_acc: 0.402\nRound 5, test_loss: 170.825, test_acc: 0.448\nRound 6, test_loss: 167.648, test_acc: 0.491\nRound 7, test_loss: 164.125, test_acc: 0.536\nRound 8, test_loss: 160.321, test_acc: 0.578\nRound 9, test_loss: 156.170, test_acc: 0.600\nRound 10, test_loss: 151.890, test_acc: 0.618\nRound 11, test_loss: 147.280, test_acc: 0.630\nRound 12, test_loss: 142.454, test_acc: 0.639\nRound 13, test_loss: 137.312, test_acc: 0.653\nRound 14, test_loss: 132.018, test_acc: 0.662\nRound 15, test_loss: 126.665, test_acc: 0.671\nRound 16, test_loss: 121.210, test_acc: 0.678\nRound 17, test_loss: 116.004, test_acc: 0.686\nRound 18, test_loss: 110.903, test_acc: 0.693\nRound 19, test_loss: 105.793, test_acc: 0.697\nRound 20, test_loss: 100.960, test_acc: 0.704\nRound 21, test_loss: 96.462, test_acc: 0.707\nRound 22, test_loss: 92.087, test_acc: 0.711\nRound 23, test_loss: 88.127, test_acc: 0.716\nRound 24, test_loss: 84.389, test_acc: 0.721\nRound 25, test_loss: 81.063, test_acc: 0.726\nRound 26, test_loss: 78.133, test_acc: 0.730\nRound 27, test_loss: 75.239, test_acc: 0.732\nRound 28, test_loss: 72.506, test_acc: 0.736\nRound 29, test_loss: 70.157, test_acc: 0.739\nRound 30, test_loss: 67.971, test_acc: 0.744\nTest losses: [180.4524, 178.3813, 176.1627, 173.6571, 170.8254, 167.6483, 164.1252, 160.3214, 156.1696, 151.8901, 147.2797, 142.4542, 137.3117, 132.018, 126.6647, 121.2098, 116.0043, 110.9034, 105.7931, 100.9598, 96.4618, 92.0874, 88.1265, 84.3893, 81.0635, 78.1333, 75.2386, 72.5062, 70.1567, 67.9713]\nTest accuracies: [0.1202, 0.1946, 0.3462, 0.4015, 0.4475, 0.4913, 0.5358, 0.5779, 0.6002, 0.6184, 0.6297, 0.6393, 0.6532, 0.6622, 0.6713, 0.6782, 0.6856, 0.6928, 0.6972, 0.7042, 0.707, 0.7113, 0.7158, 0.7206, 0.7255, 0.7297, 0.7321, 0.7356, 0.7385, 0.7441]\nFinished\n"
],
[
"names = [f'ε = {i}' for i in RANGE_EPSILON]\ntitle = 'Second experiment : MNIST database'\nfig = plot_exp(experiment_losses, experiment_accs, names, title)\nplt.savefig('MNIST_exp2.pdf')",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4a9f3e720b12d089d4c4a149038601b8779eadb3
| 45,371 |
ipynb
|
Jupyter Notebook
|
trajectory_evaluation.ipynb
|
maufadel/mobilitynet-analysis-scripts
|
faf3dad8ed71b0b31363b7698c2611414c60c930
|
[
"BSD-3-Clause"
] | 1 |
2021-01-25T15:58:25.000Z
|
2021-01-25T15:58:25.000Z
|
trajectory_evaluation.ipynb
|
maufadel/mobilitynet-analysis-scripts
|
faf3dad8ed71b0b31363b7698c2611414c60c930
|
[
"BSD-3-Clause"
] | 7 |
2021-02-10T04:44:56.000Z
|
2021-03-22T06:52:15.000Z
|
trajectory_evaluation.ipynb
|
maufadel/mobilitynet-analysis-scripts
|
faf3dad8ed71b0b31363b7698c2611414c60c930
|
[
"BSD-3-Clause"
] | null | null | null | 40.222518 | 476 | 0.575059 |
[
[
[
"# for reading and validating data\nimport emeval.input.spec_details as eisd\nimport emeval.input.phone_view as eipv\nimport emeval.input.eval_view as eiev",
"_____no_output_____"
],
[
"# Visualization helpers\nimport emeval.viz.phone_view as ezpv\nimport emeval.viz.eval_view as ezev\nimport emeval.viz.geojson as ezgj\nimport pandas as pd",
"_____no_output_____"
],
[
"# Metrics helpers\nimport emeval.metrics.dist_calculations as emd",
"_____no_output_____"
],
[
"# For computation\nimport numpy as np\nimport math\nimport scipy.stats as stats\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"import geopandas as gpd\nimport shapely as shp\nimport folium",
"_____no_output_____"
],
[
"DATASTORE_URL = \"http://cardshark.cs.berkeley.edu\"\nAUTHOR_EMAIL = \"[email protected]\"\nsd_la = eisd.SpecDetails(DATASTORE_URL, AUTHOR_EMAIL, \"unimodal_trip_car_bike_mtv_la\")\nsd_sj = eisd.SpecDetails(DATASTORE_URL, AUTHOR_EMAIL, \"car_scooter_brex_san_jose\")\nsd_ucb = eisd.SpecDetails(DATASTORE_URL, AUTHOR_EMAIL, \"train_bus_ebike_mtv_ucb\")",
"_____no_output_____"
],
[
"import importlib\nimportlib.reload(eisd)",
"_____no_output_____"
],
[
"pv_la = eipv.PhoneView(sd_la)",
"_____no_output_____"
],
[
"pv_sj = eipv.PhoneView(sd_sj)",
"_____no_output_____"
],
[
"pv_ucb = eipv.PhoneView(sd_ucb)",
"_____no_output_____"
]
],
[
[
"### Validate distance calculations\n\nOur x,y coordinates are in degrees (lon, lat). So when we calculate the distance between two points, it is also in degrees. In order for this to be meaningful, we need to convert it to a regular distance metric such as meters.\n\nThis is a complicated problem in general because our distance calculation applies 2-D spatial operations to a 3-D curved space. However, as documented in the shapely documentation, since our areas of interest are small, we can use a 2-D approximation and get reasonable results.\n\nIn order to get distances from degree-based calculations, we can use the following options:\n- perform the calculations in degrees and then convert them to meters. As an approximation, we can use the fact that 360 degrees represents the circumference of the earth. Therefore `dist = degree_dist * (C/360)`\n- convert degrees to x,y coordinates using utm (https://en.wikipedia.org/wiki/Universal_Transverse_Mercator_coordinate_system) and then calculate the distance\n- since we calculate the distance from the ground truth linestring, calculate the closest ground truth point in (lon,lat) and then use the haversine formula (https://en.wikipedia.org/wiki/Haversine_formula) to calculate the distance between the two points\n\nLet us quickly all three calculations for three selected test cases and:\n- check whether they are largely consistent\n- compare with other distance calculators to see which are closer",
"_____no_output_____"
]
],
[
[
"test_cases = {\n \"commuter_rail_aboveground\": {\n \"section\": pv_ucb.map()[\"android\"][\"ucb-sdb-android-3\"][\"evaluation_ranges\"][0][\"evaluation_trip_ranges\"][0][\"evaluation_section_ranges\"][2],\n \"ground_truth\": sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"commuter_rail_aboveground\")\n },\n \"light_rail_below_above_ground\": {\n \"section\": pv_ucb.map()[\"android\"][\"ucb-sdb-android-3\"][\"evaluation_ranges\"][0][\"evaluation_trip_ranges\"][2][\"evaluation_section_ranges\"][7],\n \"ground_truth\": sd_ucb.get_ground_truth_for_leg(\"berkeley_to_mtv_SF_express_bus\", \"light_rail_below_above_ground\")\n },\n \"express_bus\": {\n \"section\": pv_ucb.map()[\"ios\"][\"ucb-sdb-ios-3\"][\"evaluation_ranges\"][1][\"evaluation_trip_ranges\"][2][\"evaluation_section_ranges\"][4],\n \"ground_truth\": sd_ucb.get_ground_truth_for_leg(\"berkeley_to_mtv_SF_express_bus\", \"express_bus\")\n },\n}\n\nfor t in test_cases.values():\n t[\"gt_shapes\"] = gpd.GeoSeries(eisd.SpecDetails.get_shapes_for_leg(t[\"ground_truth\"]))",
"_____no_output_____"
],
[
"importlib.reload(emd)",
"_____no_output_____"
],
[
"dist_checks = []\npct_checks = []\n\nfor (k, t) in test_cases.items():\n location_gpdf = emd.filter_geo_df(emd.to_geo_df(t[\"section\"][\"location_df\"]), t[\"gt_shapes\"].filter([\"start_loc\",\"end_loc\"]))\n gt_linestring = emd.filter_ground_truth_linestring(t[\"gt_shapes\"])\n dc = emd.dist_using_circumference(location_gpdf, gt_linestring)\n dcrs = emd.dist_using_crs_change(location_gpdf, gt_linestring)\n dmuc = emd.dist_using_manual_utm_change(location_gpdf, gt_linestring)\n dmmc = emd.dist_using_manual_mercator_change(location_gpdf, gt_linestring)\n dup = emd.dist_using_projection(location_gpdf, gt_linestring)\n dist_compare = pd.DataFrame({\"dist_circumference\": dc, \"dist_crs_change\": dcrs,\n \"dist_manual_utm\": dmuc, \"dist_manual_mercator\": dmmc,\n \"dist_project\": dup})\n dist_compare[\"diff_c_mu\"] = (dist_compare.dist_circumference - dist_compare.dist_manual_utm).abs()\n dist_compare[\"diff_mu_pr\"] = (dist_compare.dist_manual_utm - dist_compare.dist_project).abs()\n dist_compare[\"diff_mm_pr\"] = (dist_compare.dist_manual_mercator - dist_compare.dist_project).abs()\n dist_compare[\"diff_c_pr\"] = (dist_compare.dist_circumference - dist_compare.dist_project).abs()\n dist_compare[\"diff_c_mu_pct\"] = dist_compare.diff_c_mu / dist_compare.dist_circumference\n dist_compare[\"diff_mu_pr_pct\"] = dist_compare.diff_mu_pr / dist_compare.dist_circumference\n dist_compare[\"diff_mm_pr_pct\"] = dist_compare.diff_mm_pr / dist_compare.dist_circumference\n dist_compare[\"diff_c_pr_pct\"] = dist_compare.diff_c_pr / dist_compare.dist_circumference\n match_dist = lambda t: {\"key\": k,\n \"threshold\": t,\n \"diff_c_mu\": len(dist_compare.query('diff_c_mu > @t')),\n \"diff_mu_pr\": len(dist_compare.query('diff_mu_pr > @t')),\n \"diff_mm_pr\": len(dist_compare.query('diff_mm_pr > @t')),\n \"diff_c_pr\": len(dist_compare.query('diff_c_pr > @t')),\n \"total_entries\": len(dist_compare)}\n dist_checks.append(match_dist(1))\n dist_checks.append(match_dist(5))\n dist_checks.append(match_dist(10))\n dist_checks.append(match_dist(50))\n match_pct = lambda t: {\"key\": k,\n \"threshold\": t,\n \"diff_c_mu_pct\": len(dist_compare.query('diff_c_mu_pct > @t')),\n \"diff_mu_pr_pct\": len(dist_compare.query('diff_mu_pr_pct > @t')),\n \"diff_mm_pr_pct\": len(dist_compare.query('diff_mm_pr_pct > @t')),\n \"diff_c_pr_pct\": len(dist_compare.query('diff_c_pr_pct > @t')),\n \"total_entries\": len(dist_compare)}\n pct_checks.append(match_pct(0.01))\n pct_checks.append(match_pct(0.05))\n pct_checks.append(match_pct(0.10))\n pct_checks.append(match_pct(0.15))\n pct_checks.append(match_pct(0.20))\n pct_checks.append(match_pct(0.25))",
"_____no_output_____"
],
[
"# t = \"commuter_rail_aboveground\"\n# gt_gj = eisd.SpecDetails.get_geojson_for_leg(test_cases[t][\"ground_truth\"])\n# print(gt_gj.features[2])\n# gt_gj.features[2] = ezgj.get_geojson_for_linestring(emd.filter_ground_truth_linestring(test_cases[t][\"gt_shapes\"]))\n# curr_map = ezgj.get_map_for_geojson(gt_gj)\n# curr_map.add_child(ezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(test_cases[t][\"gt_shapes\"].loc[\"route\"]),\n# name=\"gt_points\", color=\"green\"))\n# curr_map",
"_____no_output_____"
],
[
"pd.DataFrame(dist_checks)",
"_____no_output_____"
],
[
"pd.DataFrame(pct_checks)",
"_____no_output_____"
],
[
"manual_check_points = pd.concat([location_gpdf, dist_compare], axis=1)[[\"latitude\", \"fmt_time\", \"longitude\", \"dist_circumference\", \"dist_manual_utm\", \"dist_manual_mercator\", \"dist_project\"]].sample(n=3, random_state=10); manual_check_points",
"_____no_output_____"
],
[
"# curr_map = ezpv.display_map_detail_from_df(manual_check_points)\n# curr_map.add_child(folium.GeoJson(eisd.SpecDetails.get_geojson_for_leg(t[\"ground_truth\"])))",
"_____no_output_____"
]
],
[
[
"### Externally calculated distance for these points is:\n\nDistance calculated manually using \n1. https://www.freemaptools.com/measure-distance.htm\n1. Google Maps\n\nNote that the error of my eyes + hand is ~ 2-3 m\n\n- 1213: within margin of error\n- 1053: 3987 (freemaptools), 4km (google)\n- 1107: 15799.35 (freemaptools), 15.80km (google)",
"_____no_output_____"
]
],
[
[
"manual_check_points",
"_____no_output_____"
]
],
[
[
"### Results and method choice\n\nWe find that the `manual_utm` and `project` methods are pretty consistent, and are significantly different from the `circumference` method. The `circumference` method appears to be consistently greater than the other two and the difference appears to be around 25%. The manual checks also appear to be closer to the `manual_utm` and `project` values. The `manual_utm` and `project` values are consistently within ~ 5% of each other, so we could really use either one.\n\n**We will use the utm approach** since it is correct, is consistent with the shapely documentation (https://shapely.readthedocs.io/en/stable/manual.html#coordinate-systems) and applicable to operations beyond distance calculation\n\n> Even though the Earth is not flat – and for that matter not exactly spherical – there are many analytic problems that can be approached by transforming Earth features to a Cartesian plane, applying tried and true algorithms, and then transforming the results back to geographic coordinates. This practice is as old as the tradition of accurate paper maps.",
"_____no_output_____"
],
[
"## Spatial error calculation",
"_____no_output_____"
]
],
[
[
"def get_spatial_errors(pv):\n spatial_error_df = pd.DataFrame()\n \n for phone_os, phone_map in pv.map().items():\n for phone_label, phone_detail_map in phone_map.items():\n for (r_idx, r) in enumerate(phone_detail_map[\"evaluation_ranges\"]):\n run_errors = []\n for (tr_idx, tr) in enumerate(r[\"evaluation_trip_ranges\"]):\n trip_errors = []\n for (sr_idx, sr) in enumerate(tr[\"evaluation_section_ranges\"]):\n # This is a Shapely LineString\n \n section_gt_leg = pv.spec_details.get_ground_truth_for_leg(tr[\"trip_id_base\"], sr[\"trip_id_base\"])\n section_gt_shapes = gpd.GeoSeries(eisd.SpecDetails.get_shapes_for_leg(section_gt_leg))\n if len(section_gt_shapes) == 1:\n print(\"No ground truth route for %s %s, must be polygon, skipping...\" % (tr[\"trip_id_base\"], sr[\"trip_id_base\"]))\n assert section_gt_leg[\"type\"] != \"TRAVEL\", \"For %s, %s, %s, %s, %s found type %s\" % (phone_os, phone_label, r_idx, tr_idx, sr_idx, section_gt_leg[\"type\"])\n continue\n if len(sr['location_df']) == 0:\n print(\"No sensed locations found, role = %s skipping...\" % (r[\"eval_role_base\"]))\n # assert r[\"eval_role_base\"] == \"power_control\", \"Found no locations for %s, %s, %s, %s, %s\" % (phone_os, phone_label, r_idx, tr_idx, sr_idx)\n continue\n \n print(\"Processing travel leg %s, %s, %s, %s, %s\" %\n (phone_os, phone_label, r[\"eval_role_base\"], tr[\"trip_id_base\"], sr[\"trip_id_base\"]))\n # This is a GeoDataFrame\n section_geo_df = emd.to_geo_df(sr[\"location_df\"])\n \n # After this point, everything is in UTM so that 2-D inside/filtering operations work\n utm_section_geo_df = emd.to_utm_df(section_geo_df)\n utm_section_gt_shapes = section_gt_shapes.apply(lambda s: shp.ops.transform(emd.to_utm_coords, s))\n filtered_us_gpdf = emd.filter_geo_df(utm_section_geo_df, utm_section_gt_shapes.loc[\"start_loc\":\"end_loc\"])\n filtered_gt_linestring = emd.filter_ground_truth_linestring(utm_section_gt_shapes)\n meter_dist = filtered_us_gpdf.geometry.distance(filtered_gt_linestring)\n ne = len(meter_dist)\n curr_spatial_error_df = gpd.GeoDataFrame({\"error\": meter_dist,\n \"ts\": section_geo_df.ts,\n \"geometry\": section_geo_df.geometry,\n \"phone_os\": np.repeat(phone_os, ne),\n \"phone_label\": np.repeat(phone_label, ne),\n \"role\": np.repeat(r[\"eval_role_base\"], ne),\n \"timeline\": np.repeat(pv.spec_details.CURR_SPEC_ID, ne), \n \"run\": np.repeat(r_idx, ne),\n \"trip_id\": np.repeat(tr[\"trip_id_base\"], ne),\n \"section_id\": np.repeat(sr[\"trip_id_base\"], ne)})\n spatial_error_df = pd.concat([spatial_error_df, curr_spatial_error_df], axis=\"index\")\n return spatial_error_df",
"_____no_output_____"
],
[
"spatial_errors_df = pd.DataFrame()\nspatial_errors_df = pd.concat([spatial_errors_df, get_spatial_errors(pv_la)], axis=\"index\")\nspatial_errors_df = pd.concat([spatial_errors_df, get_spatial_errors(pv_sj)], axis=\"index\")\nspatial_errors_df = pd.concat([spatial_errors_df, get_spatial_errors(pv_ucb)], axis=\"index\")",
"_____no_output_____"
],
[
"spatial_errors_df.head()",
"_____no_output_____"
],
[
"r2q_map = {\"power_control\": 0, \"HAMFDC\": 1, \"MAHFDC\": 2, \"HAHFDC\": 3, \"accuracy_control\": 4}\nq2r_map = {0: \"power\", 1: \"HAMFDC\", 2: \"MAHFDC\", 3: \"HAHFDC\", 4: \"accuracy\"}",
"_____no_output_____"
],
[
"spatial_errors_df[\"quality\"] = spatial_errors_df.role.apply(lambda r: r2q_map[r])\nspatial_errors_df[\"label\"] = spatial_errors_df.role.apply(lambda r: r.replace('_control', ''))\ntimeline_list = [\"train_bus_ebike_mtv_ucb\", \"car_scooter_brex_san_jose\", \"unimodal_trip_car_bike_mtv_la\"]",
"_____no_output_____"
],
[
"spatial_errors_df.head()",
"_____no_output_____"
]
],
[
[
"## Overall stats",
"_____no_output_____"
]
],
[
[
"ifig, ax_array = plt.subplots(nrows=1,ncols=2,figsize=(8,2), sharey=True)\n\nspatial_errors_df.query(\"phone_os == 'android' & quality > 0\").boxplot(ax = ax_array[0], column=[\"error\"], by=[\"quality\"], showfliers=False)\nax_array[0].set_title('android')\nspatial_errors_df.query(\"phone_os == 'ios' & quality > 0\").boxplot(ax = ax_array[1], column=[\"error\"], by=[\"quality\"], showfliers=False)\nax_array[1].set_title(\"ios\")\n\nfor i, ax in enumerate(ax_array):\n # print([t.get_text() for t in ax.get_xticklabels()])\n ax.set_xticklabels([q2r_map[int(t.get_text())] for t in ax.get_xticklabels()])\n ax.set_xlabel(\"\")\n\nax_array[0].set_ylabel(\"Spatial error (meters)\")\n# ax_array[1][0].set_ylabel(\"Spatial error (meters)\")\nifig.suptitle(\"Spatial trajectory error v/s quality (excluding outliers)\", y = 1.1)\n# ifig.tight_layout()",
"_____no_output_____"
],
[
"ifig, ax_array = plt.subplots(nrows=1,ncols=2,figsize=(8,2), sharey=True)\n\nspatial_errors_df.query(\"phone_os == 'android' & quality > 0\").boxplot(ax = ax_array[0], column=[\"error\"], by=[\"quality\"])\nax_array[0].set_title('android')\nspatial_errors_df.query(\"phone_os == 'ios' & quality > 0\").boxplot(ax = ax_array[1], column=[\"error\"], by=[\"quality\"])\nax_array[1].set_title(\"ios\")\n\nfor i, ax in enumerate(ax_array):\n # print([t.get_text() for t in ax.get_xticklabels()])\n ax.set_xticklabels([q2r_map[int(t.get_text())] for t in ax.get_xticklabels()])\n ax.set_xlabel(\"\")\n\nax_array[0].set_ylabel(\"Spatial error (meters)\")\n# ax_array[1][0].set_ylabel(\"Spatial error (meters)\")\nifig.suptitle(\"Spatial trajectory error v/s quality\", y = 1.1)\n# ifig.tight_layout()",
"_____no_output_____"
]
],
[
[
"### Split out results by timeline",
"_____no_output_____"
]
],
[
[
"ifig, ax_array = plt.subplots(nrows=2,ncols=3,figsize=(12,6), sharex=False, sharey=False)\ntimeline_list = [\"train_bus_ebike_mtv_ucb\", \"car_scooter_brex_san_jose\", \"unimodal_trip_car_bike_mtv_la\"]\nfor i, tl in enumerate(timeline_list):\n spatial_errors_df.query(\"timeline == @tl & phone_os == 'android' & quality > 0\").boxplot(ax = ax_array[0][i], column=[\"error\"], by=[\"quality\"])\n ax_array[0][i].set_title(tl)\n spatial_errors_df.query(\"timeline == @tl & phone_os == 'ios' & quality > 0\").boxplot(ax = ax_array[1][i], column=[\"error\"], by=[\"quality\"])\n ax_array[1][i].set_title(\"\")\n\nfor i, ax in enumerate(ax_array[0]):\n ax.set_xticklabels([q2r_map[int(t.get_text())] for t in ax.get_xticklabels()])\n ax.set_xlabel(\"\")\n\nfor i, ax in enumerate(ax_array[1]):\n ax.set_xticklabels([q2r_map[int(t.get_text())] for t in ax.get_xticklabels()])\n ax.set_xlabel(\"\")\n\nax_array[0][0].set_ylabel(\"Spatial error (android)\")\nax_array[1][0].set_ylabel(\"Spatial error (iOS)\")\nifig.suptitle(\"Spatial trajectory error v/s quality over multiple timelines\")\n# ifig.tight_layout()",
"_____no_output_____"
]
],
[
[
"### Split out results by section for the most complex timeline (train_bus_ebike_mtv_ucb)",
"_____no_output_____"
]
],
[
[
"ifig, ax_array = plt.subplots(nrows=2,ncols=4,figsize=(25,10), sharex=True, sharey=True)\ntimeline_list = [\"train_bus_ebike_mtv_ucb\"]\nfor i, tl in enumerate(timeline_list):\n for q in range(1,5):\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'android' & quality == @q\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i][q-1], column=[\"error\"], by=[\"section_id\"])\n ax_array[2*i][q-1].tick_params(axis=\"x\", labelrotation=45)\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'ios' & quality == @q\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i+1][q-1], column=[\"error\"], by=[\"section_id\"])\n# ax_array[i][].set_title(\"\")\n\ndef make_acronym(s):\n ssl = s.split(\"_\")\n # print(\"After splitting %s, we get %s\" % (s, ssl))\n if len(ssl) == 0 or len(ssl[0]) == 0:\n return \"\"\n else:\n return \"\".join([ss[0] for ss in ssl])\n\nfor q in range(1,5):\n ax_array[0][q-1].set_title(q2r_map[q])\n curr_ticks = [t.get_text() for t in ax_array[1][q-1].get_xticklabels()]\n new_ticks = [make_acronym(t) for t in curr_ticks]\n ax_array[1][q-1].set_xticklabels(new_ticks)\n \nprint(list(zip(curr_ticks, new_ticks)))\n# fig.text(0,0,\"%s\"% list(zip(curr_ticks, new_ticks)))",
"_____no_output_____"
],
[
"timeline_list = [\"train_bus_ebike_mtv_ucb\"]\nfor i, tl in enumerate(timeline_list):\n unique_sections = spatial_errors_df.query(\"timeline == @tl\").section_id.unique()\n ifig, ax_array = plt.subplots(nrows=2,ncols=len(unique_sections),figsize=(40,10), sharex=True, sharey=False)\n for sid, s_name in enumerate(unique_sections):\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'android' & section_id == @s_name & quality > 0\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i][sid], column=[\"error\"], by=[\"quality\"])\n ax_array[2*i][sid].set_title(s_name)\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'ios' & section_id == @s_name & quality > 0\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i+1][sid], column=[\"error\"], by=[\"quality\"])\n ax_array[2*i+1][sid].set_title(\"\")\n# ax_array[i][].set_title(\"\")",
"_____no_output_____"
]
],
[
[
"### Focus only on sections where the max error is > 1000 meters",
"_____no_output_____"
]
],
[
[
"timeline_list = [\"train_bus_ebike_mtv_ucb\"]\nfor i, tl in enumerate(timeline_list):\n unique_sections = pd.Series(spatial_errors_df.query(\"timeline == @tl\").section_id.unique())\n sections_with_outliers_mask = unique_sections.apply(lambda s_name: spatial_errors_df.query(\"timeline == 'train_bus_ebike_mtv_ucb' & section_id == @s_name\").error.max() > 1000)\n sections_with_outliers = unique_sections[sections_with_outliers_mask] \n ifig, ax_array = plt.subplots(nrows=2,ncols=len(sections_with_outliers),figsize=(17,4), sharex=True, sharey=False)\n for sid, s_name in enumerate(sections_with_outliers):\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'android' & section_id == @s_name & quality > 0\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i][sid], column=[\"error\"], by=[\"quality\"])\n ax_array[2*i][sid].set_title(s_name)\n ax_array[2*i][sid].set_xlabel(\"\")\n sel_df = spatial_errors_df.query(\"timeline == @tl & phone_os == 'ios' & section_id == @s_name & quality > 0\")\n if len(sel_df) > 0:\n sel_df.boxplot(ax = ax_array[2*i+1][sid], column=[\"error\"], by=[\"quality\"])\n ax_array[2*i+1][sid].set_title(\"\")\n print([t.get_text() for t in ax_array[2*i+1][sid].get_xticklabels()])\n ax_array[2*i+1][sid].set_xticklabels([q2r_map[int(t.get_text())] for t in ax_array[2*i+1][sid].get_xticklabels() if len(t.get_text()) > 0])\n ax_array[2*i+1][sid].set_xlabel(\"\")\n ifig.suptitle(\"\")",
"_____no_output_____"
]
],
[
[
"### Validation of outliers",
"_____no_output_____"
],
[
"#### (express bus iOS, MAHFDC)\n\nok, so it looks like the error is non-trivial across all runs, but run #1 is the worst and is responsible for the majority of the outliers. And this is borne out by the map, where on run #1, we end up with points in San Leandro!!",
"_____no_output_____"
]
],
[
[
"spatial_errors_df.query(\"phone_os == 'ios' & quality == 2 & section_id == 'express_bus' & error > 500\").run.unique()",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'ios' & quality == 2 & section_id == 'express_bus'\").boxplot(column=\"error\", by=\"run\")",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"berkeley_to_mtv_SF_express_bus\", \"express_bus\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\nerror_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'ios' & quality == 2 & section_id == 'express_bus' & run == 1\"))\ngt_16k = lambda lr: lr[\"error\"] == error_df.error.max()\nfolium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=\"red\"), name=\"sensed_values\").add_to(curr_map)\nezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=\"red\", popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\nfolium.LayerControl().add_to(curr_map)\ncurr_map",
"_____no_output_____"
],
[
"importlib.reload(ezgj)",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"berkeley_to_mtv_SF_express_bus\", \"express_bus\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\n\ncolors = [\"red\", \"yellow\", \"blue\"]\nfor run in range(3):\n error_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'ios' & quality == 2 & section_id == 'express_bus' & run == @run\"))\n gt_16k = lambda lr: lr[\"error\"] == error_df.error.max()\n print(\"max error for run %d is %s\" % (run, error_df.error.max()))\n folium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=colors[run]), name=\"sensed_values\").add_to(curr_map)\n ezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=colors[run], popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\n\nfolium.LayerControl().add_to(curr_map)\ncurr_map",
"_____no_output_____"
]
],
[
[
"#### (commuter rail aboveground android, HAMFDC)\n\nRun 0: Multiple outliers at the start in San Jose. After that, everything is fine.",
"_____no_output_____"
]
],
[
[
"spatial_errors_df.query(\"phone_os == 'android' & quality == 1 & section_id == 'commuter_rail_aboveground' & error > 500\").run.unique()",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & quality == 1 & section_id == 'commuter_rail_aboveground' & error > 500\").boxplot(column=\"error\", by=\"run\")",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"commuter_rail_aboveground\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\n\nerror_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'android' & quality == 1 & section_id == 'commuter_rail_aboveground' & run == 0\"))\nmaxes = [error_df.error.max(), error_df[error_df.error < 10000].error.max(), error_df[error_df.error < 1000].error.max()]\ngt_16k = lambda lr: lr[\"error\"] in maxes\nfolium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=\"red\"), name=\"sensed_values\").add_to(curr_map)\nezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=\"red\", popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\n\nfolium.LayerControl().add_to(curr_map)\ncurr_map",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & quality == 1 & section_id == 'commuter_rail_aboveground' & error > 10000\")",
"_____no_output_____"
]
],
[
[
"#### (walk_to_bus android, HAMFDC, HAHFDC)\n\nHuge zig zag when we get out of the BART station",
"_____no_output_____"
]
],
[
[
"spatial_errors_df.query(\"phone_os == 'android' & (quality == 1 | quality == 3) & section_id == 'walk_to_bus' & error > 500\").run.unique()",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & (quality == 1 | quality == 3) & section_id == 'walk_to_bus' & error > 500\")",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & (quality == 1 | quality == 3) & section_id == 'walk_to_bus'\").boxplot(column=\"error\", by=\"run\")",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & (quality == 1 | quality == 3) & section_id == 'walk_to_bus'\").error.max()",
"_____no_output_____"
],
[
"error_df",
"_____no_output_____"
],
[
"ucb_and_back = pv_ucb.map()[\"android\"][\"ucb-sdb-android-2\"][\"evaluation_ranges\"][0]; ucb_and_back[\"trip_id\"]\nto_trip = ucb_and_back[\"evaluation_trip_ranges\"][0]; print(to_trip[\"trip_id\"])\nwb_leg = to_trip[\"evaluation_section_ranges\"][6]; print(wb_leg[\"trip_id\"])\ngt_leg = sd_ucb.get_ground_truth_for_leg(to_trip[\"trip_id_base\"], wb_leg[\"trip_id_base\"]); gt_leg[\"id\"]",
"_____no_output_____"
],
[
"importlib.reload(ezgj)",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"walk_to_bus\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\n\nerror_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'android' & quality == 3 & section_id == 'walk_to_bus'\").sort_index(axis=\"index\"))\nmaxes = [error_df.error.max(), error_df[error_df.error < 16000].error.max(), error_df[error_df.error < 5000].error.max()]\ngt_16k = lambda lr: lr[\"error\"] in maxes\nprint(\"Checking errors %s\" % maxes)\nfolium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=\"red\"), name=\"sensed_values\").add_to(curr_map)\nezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=\"red\", popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\n\nfolium.LayerControl().add_to(curr_map)\ncurr_map",
"_____no_output_____"
]
],
[
[
"#### (light_rail_below_above_ground, android, accuracy_control)\n\nok, so it looks like the error is non-trivial across all runs, but run #1 is the worst and is responsible for the majority of the outliers. And this is borne out by the map, where on run #1, we end up with points in San Leandro!!",
"_____no_output_____"
]
],
[
[
"spatial_errors_df.query(\"phone_os == 'android' & quality == 4 & section_id == 'light_rail_below_above_ground' & error > 100\").run.unique()",
"_____no_output_____"
],
[
"spatial_errors_df.query(\"phone_os == 'android' & (quality == 4) & section_id == 'light_rail_below_above_ground'\").boxplot(column=\"error\", by=\"run\")",
"_____no_output_____"
],
[
"ucb_and_back = pv_ucb.map()[\"android\"][\"ucb-sdb-android-2\"][\"evaluation_ranges\"][0]; ucb_and_back[\"trip_id\"]\nback_trip = ucb_and_back[\"evaluation_trip_ranges\"][2]; print(back_trip[\"trip_id\"])\nlt_leg = back_trip[\"evaluation_section_ranges\"][7]; print(lt_leg[\"trip_id\"])\ngt_leg = sd_ucb.get_ground_truth_for_leg(back_trip[\"trip_id_base\"], lt_leg[\"trip_id_base\"]); gt_leg[\"id\"]",
"_____no_output_____"
],
[
"import folium",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"berkeley_to_mtv_SF_express_bus\", \"light_rail_below_above_ground\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\n\ncolors = [\"red\", \"yellow\", \"blue\"]\nfor run in range(3):\n error_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'android' & quality == 4 & section_id == 'light_rail_below_above_ground' & run == @run\"))\n gt_16k = lambda lr: lr[\"error\"] == error_df.error.max()\n print(\"max error for run %d is %s\" % (run, error_df.error.max()))\n folium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=colors[run]), name=\"sensed_values\").add_to(curr_map)\n ezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=colors[run], popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\n\nfolium.LayerControl().add_to(curr_map)\ncurr_map",
"_____no_output_____"
]
],
[
[
"#### (subway, android, HAMFDC)\n\nThis is the poster child for temporal accuracy tracking",
"_____no_output_____"
]
],
[
[
"bart_leg = pv_ucb.map()[\"android\"][\"ucb-sdb-android-3\"][\"evaluation_ranges\"][0][\"evaluation_trip_ranges\"][0][\"evaluation_section_ranges\"][5]\ngt_leg = sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"subway_underground\"); gt_leg[\"id\"]",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"subway_underground\"); print(gt_leg[\"id\"])\ncurr_map = ezgj.get_map_for_geojson(sd_ucb.get_geojson_for_leg(gt_leg), name=\"ground_truth\")\nezgj.get_fg_for_loc_df(emd.linestring_to_geo_df(eisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"]),\n name=\"gt_points\", color=\"green\").add_to(curr_map)\n\nname_err_time = lambda lr: \"%d: %d, %s, %s\" % (lr[\"index\"], lr[\"df_idx\"], lr[\"error\"], sd_ucb.fmt(lr[\"ts\"], \"MM-DD HH:mm:ss\"))\n\nerror_df = emd.to_loc_df(spatial_errors_df.query(\"phone_os == 'android' & quality == 1 & section_id == 'subway_underground' & run == 0\").sort_index(axis=\"index\"))\nmaxes = [error_df.error.max(), error_df[error_df.error < 16000].error.max(), error_df[error_df.error < 5000].error.max()]\ngt_16k = lambda lr: lr[\"error\"] in maxes\nprint(\"Checking errors %s\" % maxes)\nfolium.GeoJson(ezgj.get_geojson_for_loc_df(error_df, color=\"red\"), name=\"sensed_values\").add_to(curr_map)\nezgj.get_fg_for_loc_df(error_df, name=\"sensed_points\", color=\"red\", popupfn=name_err_time, stickyfn=gt_16k).add_to(curr_map)\n\nfolium.LayerControl().add_to(curr_map)\ncurr_map\n",
"_____no_output_____"
],
[
"gt_leg = sd_ucb.get_ground_truth_for_leg(\"mtv_to_berkeley_sf_bart\", \"subway_underground\"); gt_leg[\"id\"]\neisd.SpecDetails.get_shapes_for_leg(gt_leg)[\"route\"].is_simple",
"_____no_output_____"
],
[
"pd.concat([\n error_df.iloc[40:50],\n error_df.iloc[55:60],\n error_df.iloc[65:75],\n error_df.iloc[70:75]])",
"_____no_output_____"
],
[
"import pyproj",
"_____no_output_____"
],
[
"latlonProj = pyproj.Proj(init=\"epsg:4326\")\nxyProj = pyproj.Proj(init=\"epsg:3395\")",
"_____no_output_____"
],
[
"xy = pyproj.transform(latlonProj, xyProj, -122.08355963230133, 37.39091642895306); xy",
"_____no_output_____"
],
[
"pyproj.transform(xyProj, latlonProj, xy[0], xy[1])",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"df = pd.DataFrame({\"a\": [1,2,3], \"b\": [4,5,6]}); df",
"_____no_output_____"
],
[
"pd.concat([pd.DataFrame([{\"a\": 10, \"b\": 14}]), df, pd.DataFrame([{\"a\": 20, \"b\": 24}])], axis='index').reset_index(drop=True)",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f443dd52d44de1914b9607ec9a4824dede7bb
| 624,463 |
ipynb
|
Jupyter Notebook
|
src/ac-explore.ipynb
|
mirohu/exploring_animal-crossing
|
f438f598000f70ad2b2c28e1623bf6f569185473
|
[
"MIT"
] | null | null | null |
src/ac-explore.ipynb
|
mirohu/exploring_animal-crossing
|
f438f598000f70ad2b2c28e1623bf6f569185473
|
[
"MIT"
] | null | null | null |
src/ac-explore.ipynb
|
mirohu/exploring_animal-crossing
|
f438f598000f70ad2b2c28e1623bf6f569185473
|
[
"MIT"
] | null | null | null | 33.384817 | 38,378 | 0.483166 |
[
[
[
"import pandas as pd\nfrom urllib.request import urlopen\nimport requests\nfrom bs4 import BeautifulSoup\nfrom graphviz import Digraph\nimport re\nimport time\nimport numpy as np",
"_____no_output_____"
],
[
"an_urllib = urlopen(\"https://animalcrossing.fandom.com/wiki/Villager_list_(New_Horizons)\")",
"_____no_output_____"
],
[
"an_request = requests.get(\"https://animalcrossing.fandom.com/wiki/Villager_list_(New_Horizons)\")",
"_____no_output_____"
],
[
"# check the status code\nprint('The status code is', an_request.status_code)",
"The status code is 200\n"
],
[
"an = BeautifulSoup(an_request.text)",
"_____no_output_____"
],
[
"tables = an.find_all('table')",
"_____no_output_____"
],
[
"village_table = []\nfor row in tables[1].find_all(\"tr\"):\n row_data = []\n \n for cell in row.find_all(\"td\"):\n row_data.append(cell.text)\n \n if not row_data == []:\n village_table.append(row_data)\n\nraw_data = pd.DataFrame(village_table)",
"_____no_output_____"
],
[
"raw_data",
"_____no_output_____"
],
[
"# clean the dataframe a bit\n# remove unneccessary columns\ncleaned_data = raw_data.iloc[1:,0:7]\ncleaned_data.columns = [\"name\", \"image\", \"personality\", \"species\", \n \"birthday\", \"catchphrase\", \"hobbies\"]\ncleaned_data = cleaned_data.drop(\"image\", axis = 1)",
"_____no_output_____"
],
[
"# make the data clean a bit",
"_____no_output_____"
],
[
"cleaned_data = cleaned_data.replace(\"\\n\", \"\", regex = True)\ncleaned_data = cleaned_data.replace(\"♂\", \"\", regex = True)\ncleaned_data = cleaned_data.replace(\"♀\", \"\", regex = True)\ncleaned_data = cleaned_data.replace(\" \", \"\", regex = True)",
"_____no_output_____"
],
[
"# add gender column\ncleaned_data['gender'] = np.where((cleaned_data['personality'] == 'Cranky')|\\\n (cleaned_data['personality'] == 'Jock')|\\\n (cleaned_data['personality'] == 'Lazy')|\\\n (cleaned_data['personality'] == 'Smug'), 'male', 'female' )",
"_____no_output_____"
],
[
"cleaned_data",
"_____no_output_____"
],
[
"import altair as alt\nalt.renderers.enable('mimetype')",
"_____no_output_____"
],
[
"# find out the number of villages from each species\nalt.Chart(cleaned_data).mark_bar().encode(\n alt.X('species'),\n y = 'count()',\n color = 'gender'\n)",
"_____no_output_____"
]
],
[
[
"#### As we can see, there is more villagers that's Cat, Rabbit and Squirrel. It's rare to get a villager like Octopus or Cow.\n\n- Anteater, Cat, Duck, Kanteroo, Koala, Mouse, Ostrich, Rabbit, Sheep, Squirrel has more female than male villagers.",
"_____no_output_____"
]
],
[
[
"# find out the number of villages in different personailty\nalt.Chart(cleaned_data).mark_bar().encode(\n alt.X('personality'),\n y = 'count()',\n color = 'gender'\n)",
"_____no_output_____"
]
],
[
[
"#### There is more villagers with Normal and Lazy personality while it's relatively rare to see villagers with sistery and smug personality.\n\n- Lazy is the most common personality among male villager while Normal is the most common personality among female.",
"_____no_output_____"
]
],
[
[
"# number of male and female villagers\nalt.Chart(cleaned_data).mark_bar().encode(\n alt.X('gender'),\n y = 'count()'\n)",
"_____no_output_____"
]
],
[
[
"### As we can see, there are more male villagers than female villagers.",
"_____no_output_____"
],
[
"## Let's look at their hobbies!",
"_____no_output_____"
]
],
[
[
"alt.Chart(cleaned_data).mark_bar().encode(\n alt.X('hobbies'),\n y = 'count()',\n color = 'gender'\n)",
"_____no_output_____"
]
],
[
[
"### Hmm... It seens like no male villagers is interested in **Fashion**. The gender ration seems to be well balanced among Education and Music hobbies. There are more male villages interested into Natural and Play.",
"_____no_output_____"
]
],
[
[
"alt.Chart(cleaned_data).mark_bar().encode(\n alt.X('species'),\n y = 'count()',\n color = 'hobbies'\n)",
"_____no_output_____"
]
],
[
[
"### It seems like hobbies are pretty balanced among all species... Wait! Why there is no on interested in education among Alligator, Cow, Gorrilla, Octopus and Rhino? I can understand that there were only 4 cows and 3 Octopus so it's hard to fill in all the categories. \n### Apparently the only thing Gorilla cares is Fitness!",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4a9f478ccce4a7a6501ba8f75e8710077b37f5ea
| 18,053 |
ipynb
|
Jupyter Notebook
|
00.ipynb
|
Programmer-RD-AI/Amazon-Alexa-Reviews
|
1bed563742ea8a75633a049c3e90b3a28fe32371
|
[
"Apache-2.0"
] | null | null | null |
00.ipynb
|
Programmer-RD-AI/Amazon-Alexa-Reviews
|
1bed563742ea8a75633a049c3e90b3a28fe32371
|
[
"Apache-2.0"
] | null | null | null |
00.ipynb
|
Programmer-RD-AI/Amazon-Alexa-Reviews
|
1bed563742ea8a75633a049c3e90b3a28fe32371
|
[
"Apache-2.0"
] | null | null | null | 27.773846 | 536 | 0.518196 |
[
[
[
"import wandb\nimport nltk\nfrom nltk.stem.porter import *\nfrom torch.nn import *\nfrom torch.optim import *\nimport numpy as np\nimport pandas as pd\nimport torch,torchvision\nimport random\nfrom tqdm import *\nfrom torch.utils.data import Dataset,DataLoader\nstemmer = PorterStemmer()\nPROJECT_NAME = 'Amazon-Alexa-Reviews'\ndevice = 'cuda'",
"_____no_output_____"
],
[
"def tokenize(sentence):\n return nltk.word_tokenize(sentence)",
"_____no_output_____"
],
[
"tokenize('%100')",
"_____no_output_____"
],
[
"def stem(word):\n return stemmer.stem(word.lower())",
"_____no_output_____"
],
[
"stem('organic')",
"_____no_output_____"
],
[
"def bag_of_words(tokenized_words,all_words):\n tokenized_words = [stem(w) for w in tokenized_words]\n bag = np.zeros(len(all_words))\n for idx,w in enumerate(all_words):\n if w in tokenized_words:\n bag[idx] = 1.0\n return bag",
"_____no_output_____"
],
[
"bag_of_words(['hi'],['hi','how','hi'])",
"_____no_output_____"
],
[
"data = pd.read_csv('./data.tsv',sep='\\t')",
"_____no_output_____"
],
[
"X = data['verified_reviews']\ny = data['rating']",
"_____no_output_____"
],
[
"words = []\ndata = []\nidx = 0\nlabels = {}\nlabels_r = {}",
"_____no_output_____"
],
[
"for X_batch,y_batch in tqdm(zip(X,y)):\n if y_batch not in list(labels.keys()):\n idx += 1\n labels[y_batch] = idx\n labels_r[idx] = y_batch",
"3150it [00:00, 1287348.49it/s]\n"
],
[
"labels",
"_____no_output_____"
],
[
"for X_batch,y_batch in tqdm(zip(X,y)):\n X_batch = tokenize(X_batch)\n new_X = []\n for Xb in X_batch:\n new_X.append(stem(Xb))\n words.extend(new_X)\n data.append([new_X,np.eye(labels[y_batch]+1,len(labels))[labels[y_batch]]])",
"3150it [00:01, 2043.45it/s]\n"
],
[
"words = sorted(set(words))",
"_____no_output_____"
],
[
"np.random.shuffle(data)",
"_____no_output_____"
],
[
"np.random.shuffle(data)",
"_____no_output_____"
],
[
"X = []\ny = []",
"_____no_output_____"
],
[
"for sentence,tag in tqdm(data):\n X.append(bag_of_words(sentence,words))\n y.append(tag)",
"100%|█████████████████████████████████████| 3150/3150 [00:03<00:00, 1028.98it/s]\n"
],
[
"from sklearn.model_selection import *",
"_____no_output_____"
],
[
"X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.125,shuffle=False,random_state=2021)",
"_____no_output_____"
],
[
"X_train = torch.from_numpy(np.array(X_train)).to(device).float()\ny_train = torch.from_numpy(np.array(y_train)).to(device).float()\nX_test = torch.from_numpy(np.array(X_test)).to(device).float()\ny_test = torch.from_numpy(np.array(y_test)).to(device).float()",
"_____no_output_____"
],
[
"def get_loss(model,X,y,citerion):\n preds = model(X)\n loss = criterion(preds,y)\n return loss.item()",
"_____no_output_____"
],
[
"def get_accuracy(model,X,y):\n correct = 0\n total = 0\n preds = model(X)\n for pred,yb in zip(preds,y):\n pred = int(torch.argmax(pred))\n yb = int(torch.argmax(yb))\n if pred == yb:\n correct += 1\n total += 1\n acc = round(correct/total,3)*100\n return acc",
"_____no_output_____"
],
[
"class Model(Module):\n def __init__(self):\n super().__init__()\n self.iters = 10\n self.activation = ReLU()\n self.linear1 = Linear(len(words),512)\n self.linear2 = Linear(512,512)\n self.output = Linear(512,len(labels))\n \n def forward(self,X):\n preds = self.linear1(X)\n for _ in range(self.iters):\n preds = self.activation(self.linear2(preds))\n preds = self.output(preds)\n return preds",
"_____no_output_____"
],
[
"model = Model().to(device)\ncriterion = MSELoss()\noptimizer = Adam(model.parameters(),lr=0.001)\nepochs = 10000\nbatch_size = 8",
"_____no_output_____"
],
[
"wandb.init(project=PROJECT_NAME,name='baseline')\nfor _ in tqdm(range(epochs)):\n torch.cuda.empty_cache()\n for i in range(0,len(X_train),batch_size):\n torch.cuda.empty_cache()\n X_batch = X_train[i:i+batch_size].to(device).float()\n y_batch = y_train[i:i+batch_size].to(device).float()\n preds = model(X_batch)\n loss = criterion(preds,y_batch)\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n torch.cuda.empty_cache()\n torch.cuda.empty_cache()\n model.eval()\n torch.cuda.empty_cache()\n wandb.log({'Loss':(get_loss(model,X_train,y_train,criterion)+get_loss(model,X_batch,y_batch,criterion)/2)})\n torch.cuda.empty_cache()\n wandb.log({'Val Loss':get_loss(model,X_test,y_test,criterion)})\n torch.cuda.empty_cache()\n wandb.log({'Acc':(get_accuracy(model,X_train,y_train)+get_accuracy(model,X_batch,y_batch))/2})\n torch.cuda.empty_cache()\n wandb.log({'Val Acc':get_accuracy(model,X_test,y_test)})\n torch.cuda.empty_cache()\n model.train()\nwandb.finish()\ntorch.cuda.empty_cache()",
"\u001b[34m\u001b[1mwandb\u001b[0m: Currently logged in as: \u001b[33mranuga-d\u001b[0m (use `wandb login --relogin` to force relogin)\n\u001b[34m\u001b[1mwandb\u001b[0m: wandb version 0.12.2 is available! To upgrade, please run:\n\u001b[34m\u001b[1mwandb\u001b[0m: $ pip install wandb --upgrade\n"
],
[
"torch.save(X_train,'X_train.pt')\ntorch.save(X_test,'X_test.pth')\ntorch.save(y_train,'y_train.pt')\ntorch.save(y_test,'y_test.pth')\ntorch.save(model,'model.pt')\ntorch.save(model,'model.pth')\ntorch.save(model.state_dict(),'model-sd.pt')\ntorch.save(model.state_dict(),'model-sd.pth')\ntorch.save(X,'X.pt')\ntorch.save(X,'X.pth')\ntorch.save(y,'y.pt')\ntorch.save(y,'y.pth')",
"_____no_output_____"
],
[
"torch.save(words,'words.pt')\ntorch.save(words,'words.pth')\ntorch.save(data,'data.pt')\ntorch.save(data,'data.pth')\ntorch.save(labels,'labels.pt')\ntorch.save(labels,'labels.pth')",
"_____no_output_____"
],
[
"torch.save(idx,'idx.pt')\ntorch.save(idx,'idx.pth')",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f4ff8d486c8c35a617364bad224e46d3e9375
| 10,170 |
ipynb
|
Jupyter Notebook
|
notebooks/analysis/validate_emissions.ipynb
|
carbonplan/trace
|
5cf113891bdefa29c2afd4478dff099e0458c82c
|
[
"MIT"
] | 14 |
2021-02-15T22:40:52.000Z
|
2022-02-24T15:25:28.000Z
|
notebooks/analysis/validate_emissions.ipynb
|
carbonplan/trace
|
5cf113891bdefa29c2afd4478dff099e0458c82c
|
[
"MIT"
] | 75 |
2021-02-11T17:57:42.000Z
|
2022-03-22T00:47:57.000Z
|
notebooks/analysis/validate_emissions.ipynb
|
carbonplan/trace
|
5cf113891bdefa29c2afd4478dff099e0458c82c
|
[
"MIT"
] | 2 |
2021-09-28T01:51:19.000Z
|
2021-11-22T21:32:35.000Z
| 27.412399 | 146 | 0.549558 |
[
[
[
"<img width=\"100\" src=\"https://carbonplan-assets.s3.amazonaws.com/monogram/dark-small.png\" style=\"margin-left:0px;margin-top:20px\"/>\n\n# Forest Emissions Tracking - Validation\n\n_CarbonPlan ClimateTrace Team_\n\nThis notebook compares our estimates of country-level forest emissions to prior estimates from other\ngroups. The notebook currently compares againsts:\n\n- Global Forest Watch (Zarin et al. 2016)\n- Global Carbon Project (Friedlingstein et al. 2020)\n",
"_____no_output_____"
]
],
[
[
"import geopandas\nimport pandas as pd\nfrom io import StringIO\nimport matplotlib.pyplot as plt\n\nfrom carbonplan_styles.mpl import set_theme\n\nset_theme()",
"_____no_output_____"
],
[
"# Input data\n# ----------\n\n# country shapes from GADM36\ncountries = geopandas.read_file(\"s3://carbonplan-climatetrace/inputs/shapes/countries.shp\")\n\n# CarbonPlan's emissions\nemissions = pd.read_csv(\"s3://carbonplan-climatetrace/v0.1/country_rollups.csv\")\n\n# GFW emissions\ngfw_emissions = pd.read_excel(\n \"s3://carbonplan-climatetrace/validation/gfw_global_emissions.xlsx\",\n sheet_name=\"Country co2 emissions\",\n).dropna(axis=0)\ngfw_emissions = gfw_emissions[gfw_emissions[\"threshold\"] == 10] # select threshold\n\n# Global Carbon Project\ngcp_emissions = (\n pd.read_excel(\n \"s3://carbonplan-climatetrace/validation/Global_Carbon_Budget_2020v1.0.xlsx\",\n sheet_name=\"Land-Use Change Emissions\",\n skiprows=28,\n )\n .dropna(axis=1)\n .set_index(\"Year\")\n)\ngcp_emissions *= 3.664 # C->CO2\ngcp_emissions.index = [pd.to_datetime(f\"{y}-01-01\") for y in gcp_emissions.index]\ngcp_emissions = gcp_emissions[[\"GCB\", \"H&N\", \"BLUE\", \"OSCAR\"]]",
"_____no_output_____"
],
[
"# Merge emissions dataframes with countries GeoDataFrame\ngfw_counties = countries.merge(gfw_emissions.rename(columns={\"country\": \"name\"}), on=\"name\")\ntrace_counties = countries.merge(emissions.rename(columns={\"iso3_country\": \"alpha3\"}), on=\"alpha3\")",
"_____no_output_____"
],
[
"# reformat to \"wide\" format (time x country)\ntrace_wide = (\n emissions.drop(columns=[\"end_date\"])\n .pivot(index=\"begin_date\", columns=\"iso3_country\")\n .droplevel(0, axis=1)\n)\ntrace_wide.index = pd.to_datetime(trace_wide.index)\n\ngfw_wide = gfw_emissions.set_index(\"country\").filter(regex=\"whrc_aboveground_co2_emissions_Mg_.*\").T\ngfw_wide.index = [pd.to_datetime(f\"{l[-4:]}-01-01\") for l in gfw_wide.index]\n\ngfw_wide.head()",
"_____no_output_____"
]
],
[
[
"## Part 1 - Compare time-averaged country emissions (tropics only)\n",
"_____no_output_____"
]
],
[
[
"# Create a new dataframe with average emissions\navg_emissions = countries.set_index(\"alpha3\")\navg_emissions[\"trace\"] = trace_wide.mean().transpose()\n\navg_emissions = avg_emissions.set_index(\"name\")\navg_emissions[\"gfw\"] = gfw_wide.mean().transpose() / 1e9",
"_____no_output_____"
],
[
"# Scatter Plot\navg_emissions.plot.scatter(\"gfw\", \"trace\")\nplt.ylabel(\"Trace [Tg CO2e]\")\nplt.xlabel(\"GFW [Tg CO2e]\")",
"_____no_output_____"
]
],
[
[
"## Part 2 - Maps of Tropical Emissions\n",
"_____no_output_____"
]
],
[
[
"avg_emissions_nonan = avg_emissions.dropna()",
"_____no_output_____"
],
[
"kwargs = dict(\n legend=True,\n legend_kwds={\"orientation\": \"horizontal\", \"label\": \"Emissions [Tg CO2e]\"},\n lw=0.25,\n cmap=\"Reds\",\n vmin=0,\n vmax=1,\n)\navg_emissions_nonan.plot(\"trace\", **kwargs)\nplt.title(\"Trace v0\")",
"_____no_output_____"
],
[
"avg_emissions_nonan.plot(\"gfw\", **kwargs)\n\nplt.title(\"GFW Tropics\")",
"_____no_output_____"
],
[
"kwargs = dict(\n legend=True,\n legend_kwds={\n \"orientation\": \"horizontal\",\n \"label\": \"Emissions Difference [%]\",\n },\n lw=0.25,\n cmap=\"RdBu_r\",\n vmin=-40,\n vmax=40,\n)\navg_emissions_nonan[\"pdiff\"] = (\n (avg_emissions_nonan[\"trace\"] - avg_emissions_nonan[\"gfw\"]) / avg_emissions_nonan[\"gfw\"]\n) * 100\navg_emissions_nonan.plot(\"pdiff\", **kwargs)\nplt.title(\"% difference\")",
"_____no_output_____"
]
],
[
[
"## Part 3 - Compare global emissions timeseries to Global Carbon Project\n",
"_____no_output_____"
]
],
[
[
"ax = gcp_emissions[[\"H&N\", \"BLUE\", \"OSCAR\"]].loc[\"2000\":].plot(ls=\"--\")\ngcp_emissions[\"GCB\"].loc[\"2000\":].plot(ax=ax, label=\"GCB\", lw=3)\ntrace_wide.sum(axis=1).plot(ax=ax, label=\"Trace v0\", c=\"k\", lw=3)\nplt.ylabel(\"Emissions [Tg CO2e]\")\nplt.legend()",
"_____no_output_____"
]
],
[
[
"# Part 4 - Compare global emissions with those of other inventories\n",
"_____no_output_____"
],
[
"#### load in the inventory file from climate trace which aggregated multiple inventories (e.g. GCP, EDGAR, CAIT) into one place\n",
"_____no_output_____"
]
],
[
[
"inventories_df = pd.read_csv(\n \"s3://carbonplan-climatetrace/validation/210623_all_inventory_data.csv\"\n)",
"_____no_output_____"
]
],
[
[
"The following inventories are included:\n\n{'CAIT', 'ClimateTRACE', 'EDGAR', 'GCP', 'PIK-CR', 'PIK-TP', 'carbon monitor', 'unfccc',\n'unfccc_nai'}\n",
"_____no_output_____"
]
],
[
[
"set(inventories_df[\"Data source\"].values)",
"_____no_output_____"
],
[
"def select_inventory_timeseries(df, inventory=None, country=None, sector=None):\n if inventory is not None:\n df = df[df[\"Data source\"] == inventory]\n if country is not None:\n df = df[df[\"Country\"] == country]\n if sector is not None:\n df = df[df[\"Sector\"] == sector]\n return df",
"_____no_output_____"
]
],
[
[
"### access the different inventories and compare with our estimates. country-level comparisons are to-do.\n",
"_____no_output_____"
]
],
[
[
"select_inventory_timeseries(inventories_df, country=\"Brazil\", inventory=\"CAIT\")",
"_____no_output_____"
],
[
"select_inventory_timeseries(\n inventories_df,\n country=\"United States of America\",\n inventory=\"unfccc\",\n sector=\"4.A Forest Land\",\n)",
"_____no_output_____"
]
],
[
[
"### todo: compare our estimates with these and the same from xu2021\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
]
] |
4a9f5138fdc38d051e036620f5447e814c1d43c6
| 371,335 |
ipynb
|
Jupyter Notebook
|
days/day11/Interpolation.ipynb
|
sraejones/phys202-2015-work
|
988db3174fed541a85564b7aebeb618c3ad46075
|
[
"MIT"
] | null | null | null |
days/day11/Interpolation.ipynb
|
sraejones/phys202-2015-work
|
988db3174fed541a85564b7aebeb618c3ad46075
|
[
"MIT"
] | null | null | null |
days/day11/Interpolation.ipynb
|
sraejones/phys202-2015-work
|
988db3174fed541a85564b7aebeb618c3ad46075
|
[
"MIT"
] | null | null | null | 413.974359 | 88,828 | 0.930683 |
[
[
[
"# Interpolation",
"_____no_output_____"
],
[
"**Learning Objective:** Learn to interpolate 1d and 2d datasets of structured and unstructured points using SciPy.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport seaborn as sns",
"_____no_output_____"
]
],
[
[
"## Overview",
"_____no_output_____"
],
[
"We have already seen how to evaluate a Python function at a set of numerical points:\n\n$$ f(x) \\rightarrow f_i = f(x_i) $$\n\nHere is an array of points:",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0,4*np.pi,10)\nx",
"_____no_output_____"
]
],
[
[
"This creates a new array of points that are the values of $\\sin(x_i)$ at each point $x_i$:",
"_____no_output_____"
]
],
[
[
"f = np.sin(x)\nf",
"_____no_output_____"
],
[
"plt.plot(x, f, marker='o')\nplt.xlabel('x')\nplt.ylabel('f(x)');",
"_____no_output_____"
]
],
[
[
"This plot shows that the points in this numerical array are an approximation to the actual function as they don't have the function's value at all possible points. In this case we know the actual function ($\\sin(x)$). What if we only know the value of the function at a limited set of points, and don't know the analytical form of the function itself? This is common when the data points come from a set of measurements.\n\n[Interpolation](http://en.wikipedia.org/wiki/Interpolation) is a numerical technique that enables you to construct an approximation of the actual function from a set of points:\n\n$$ \\{x_i,f_i\\} \\rightarrow f(x) $$\n\nIt is important to note that unlike curve fitting or regression, interpolation doesn't not allow you to incorporate a *statistical model* into the approximation. Because of this, interpolation has limitations:\n\n* It cannot accurately construct the function's approximation outside the limits of the original points.\n* It cannot tell you the analytical form of the underlying function.\n\nOnce you have performed interpolation you can:\n\n* Evaluate the function at other points not in the original dataset.\n* Use the function in other calculations that require an actual function.\n* Compute numerical derivatives or integrals.\n* Plot the approximate function on a finer grid that the original dataset.\n\n**Warning:**\n\nThe different functions in SciPy work with a range of different 1d and 2d arrays. To help you keep all of that straight, I will use lowercase variables for 1d arrays (`x`, `y`) and uppercase variables (`X`,`Y`) for 2d arrays. ",
"_____no_output_____"
],
[
"## 1d data",
"_____no_output_____"
],
[
"We begin with a 1d interpolation example with regularly spaced data. The function we will use it `interp1d`:",
"_____no_output_____"
]
],
[
[
"from scipy.interpolate import interp1d",
"_____no_output_____"
]
],
[
[
"Let's create the numerical data we will use to build our interpolation.",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0,4*np.pi,10) # only use 10 points to emphasize this is an approx\nf = np.sin(x)",
"_____no_output_____"
]
],
[
[
"To create our approximate function, we call `interp1d` as follows, with the numerical data. Options for the `kind` argument includes:\n\n* `linear`: draw a straight line between initial points.\n* `nearest`: return the value of the function of the nearest point.\n* `slinear`, `quadratic`, `cubic`: use a spline (particular kinds of piecewise polynomial of a given order.\n\nThe most common case you will want to use is `cubic` spline (try other options):",
"_____no_output_____"
]
],
[
[
"sin_approx = interp1d(x, f, kind='cubic')",
"_____no_output_____"
]
],
[
[
"The `sin_approx` variabl that `interp1d` returns is a callable object that can be used to compute the approximate function at other points. Compute the approximate function on a fine grid:",
"_____no_output_____"
]
],
[
[
"newx = np.linspace(0,4*np.pi,100)\nnewf = sin_approx(newx)",
"_____no_output_____"
]
],
[
[
"Plot the original data points, along with the approximate interpolated values. It is quite amazing to see how the interpolation has done a good job of reconstructing the actual function with relatively few points.",
"_____no_output_____"
]
],
[
[
"plt.plot(x, f, marker='o', linestyle='', label='original data')\nplt.plot(newx, newf, marker='.', label='interpolated');\nplt.legend();\nplt.xlabel('x')\nplt.ylabel('f(x)');",
"_____no_output_____"
]
],
[
[
"Let's look at the absolute error between the actual function and the approximate interpolated function:",
"_____no_output_____"
]
],
[
[
"plt.plot(newx, np.abs(np.sin(newx)-sin_approx(newx)))\nplt.xlabel('x')\nplt.ylabel('Absolute error');",
"_____no_output_____"
]
],
[
[
"## 1d non-regular data",
"_____no_output_____"
],
[
"It is also possible to use `interp1d` when the x data is not regularly spaced. To show this, let's repeat the above analysis with randomly distributed data in the range $[0,4\\pi]$. Everything else is the same.",
"_____no_output_____"
]
],
[
[
"x = 4*np.pi*np.random.rand(15)\nf = np.sin(x)",
"_____no_output_____"
],
[
"sin_approx = interp1d(x, f, kind='cubic')",
"_____no_output_____"
],
[
"# We have to be careful about not interpolating outside the range\nnewx = np.linspace(np.min(x), np.max(x),100)\nnewf = sin_approx(newx)",
"_____no_output_____"
],
[
"plt.plot(x, f, marker='o', linestyle='', label='original data')\nplt.plot(newx, newf, marker='.', label='interpolated');\nplt.legend();\nplt.xlabel('x')\nplt.ylabel('f(x)');",
"_____no_output_____"
],
[
"plt.plot(newx, np.abs(np.sin(newx)-sin_approx(newx)))\nplt.xlabel('x')\nplt.ylabel('Absolute error');",
"_____no_output_____"
]
],
[
[
"Notice how the absolute error is larger in the intervals where there are no points.",
"_____no_output_____"
],
[
"## 2d structured",
"_____no_output_____"
],
[
"For the 2d case we want to construct a scalar function of two variables, given\n\n$$ {x_i, y_i, f_i} \\rightarrow f(x,y) $$\n\nFor now, we will assume that the points $\\{x_i,y_i\\}$ are on a structured grid of points. This case is covered by the `interp2d` function:",
"_____no_output_____"
]
],
[
[
"from scipy.interpolate import interp2d",
"_____no_output_____"
]
],
[
[
"Here is the actual function we will use the generate our original dataset:",
"_____no_output_____"
]
],
[
[
"def wave2d(x, y):\n return np.sin(2*np.pi*x)*np.sin(3*np.pi*y)",
"_____no_output_____"
]
],
[
[
"Build 1d arrays to use as the structured grid:",
"_____no_output_____"
]
],
[
[
"x = np.linspace(0.0, 1.0, 10)\ny = np.linspace(0.0, 1.0, 10)",
"_____no_output_____"
]
],
[
[
"Build 2d arrays to use in computing the function on the grid points:",
"_____no_output_____"
]
],
[
[
"X, Y = np.meshgrid(x, y)\nZ = wave2d(X, Y)",
"_____no_output_____"
]
],
[
[
"Here is a scatter plot of the points overlayed with the value of the function at those points:",
"_____no_output_____"
]
],
[
[
"plt.pcolor(X, Y, Z)\nplt.colorbar();\nplt.scatter(X, Y);\nplt.xlim(0,1)\nplt.ylim(0,1)\nplt.xlabel('x')\nplt.ylabel('y');",
"_____no_output_____"
]
],
[
[
"You can see in this plot that the function is not smooth as we don't have its value on a fine grid.\n\nNow let's compute the interpolated function using `interp2d`. Notice how we are passing 2d arrays to this function:",
"_____no_output_____"
]
],
[
[
"wave2d_approx = interp2d(X, Y, Z, kind='cubic')",
"_____no_output_____"
]
],
[
[
"Compute the interpolated function on a fine grid:",
"_____no_output_____"
]
],
[
[
"xnew = np.linspace(0.0, 1.0, 40)\nynew = np.linspace(0.0, 1.0, 40)\nXnew, Ynew = np.meshgrid(xnew, ynew) # We will use these in the scatter plot below\nFnew = wave2d_approx(xnew, ynew) # The interpolating function automatically creates the meshgrid!",
"_____no_output_____"
],
[
"Fnew.shape",
"_____no_output_____"
]
],
[
[
"Plot the original course grid of points, along with the interpolated function values on a fine grid:",
"_____no_output_____"
]
],
[
[
"plt.pcolor(xnew, ynew, Fnew);\nplt.colorbar();\nplt.scatter(X, Y, label='original points')\nplt.scatter(Xnew, Ynew, marker='.', color='green', label='interpolated points')\nplt.xlim(0,1)\nplt.ylim(0,1)\nplt.xlabel('x')\nplt.ylabel('y');\nplt.legend(bbox_to_anchor=(1.2, 1), loc=2, borderaxespad=0.);",
"_____no_output_____"
]
],
[
[
"Notice how the interpolated values (green points) are now smooth and continuous. The amazing thing is that the interpolation algorithm doesn't know anything about the actual function. It creates this nice approximation using only the original course grid (blue points).",
"_____no_output_____"
],
[
"## 2d unstructured",
"_____no_output_____"
],
[
"It is also possible to perform interpolation when the original data is not on a regular grid. For this, we will use the `griddata` function:",
"_____no_output_____"
]
],
[
[
"from scipy.interpolate import griddata",
"_____no_output_____"
]
],
[
[
"There is an important difference between `griddata` and the `interp1d`/`interp2d`:\n\n* `interp1d` and `interp2d` return callable Python objects (functions).\n* `griddata` returns the interpolated function evaluated on a finer grid.\n\nThis means that you have to pass `griddata` an array that has the finer grid points to be used. Here is the course unstructured grid we will use:",
"_____no_output_____"
]
],
[
[
"x = np.random.rand(100)\ny = np.random.rand(100)",
"_____no_output_____"
]
],
[
[
"Notice how we pass these 1d arrays to our function and don't use `meshgrid`:",
"_____no_output_____"
]
],
[
[
"f = wave2d(x, y)",
"_____no_output_____"
]
],
[
[
"It is clear that our grid is very unstructured:",
"_____no_output_____"
]
],
[
[
"plt.scatter(x, y);\nplt.xlim(0,1)\nplt.ylim(0,1)\nplt.xlabel('x')\nplt.ylabel('y');",
"_____no_output_____"
]
],
[
[
"To use `griddata` we need to compute the final (strcutured) grid we want to compute the interpolated function on:",
"_____no_output_____"
]
],
[
[
"xnew = np.linspace(x.min(), x.max(), 40)\nynew = np.linspace(y.min(), y.max(), 40)\nXnew, Ynew = np.meshgrid(xnew, ynew)",
"_____no_output_____"
],
[
"Xnew.shape, Ynew.shape",
"_____no_output_____"
],
[
"Fnew = griddata((x,y), f, (Xnew, Ynew), method='cubic', fill_value=0.0)",
"_____no_output_____"
],
[
"Fnew.shape",
"_____no_output_____"
],
[
"plt.pcolor(Xnew, Ynew, Fnew, label=\"points\")\nplt.colorbar()\nplt.scatter(x, y, label='original points')\nplt.scatter(Xnew, Ynew, marker='.', color='green', label='interpolated points')\nplt.xlim(0,1)\nplt.ylim(0,1)\nplt.xlabel('x')\nplt.ylabel('y');\nplt.legend(bbox_to_anchor=(1.2, 1), loc=2, borderaxespad=0.);",
"_____no_output_____"
]
],
[
[
"Notice how the interpolated function is smooth in the interior regions where the original data is defined. However, outside those points, the interpolated function is missing (it returns `nan`).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a9f5ce0ea0662ca1aaac24fc7942eaa52832964
| 14,748 |
ipynb
|
Jupyter Notebook
|
notebooks/02/Calls.ipynb
|
matthew-brett/cfd-uob
|
cc9233a26457f5e688ed6297ebbf410786cfd806
|
[
"CC-BY-4.0"
] | 1 |
2019-09-30T13:31:41.000Z
|
2019-09-30T13:31:41.000Z
|
notebooks/02/Calls.ipynb
|
matthew-brett/cfd-uob
|
cc9233a26457f5e688ed6297ebbf410786cfd806
|
[
"CC-BY-4.0"
] | 1 |
2021-03-30T01:51:11.000Z
|
2021-03-30T01:51:11.000Z
|
notebooks/02/Calls.ipynb
|
matthew-brett/cfd-uob
|
cc9233a26457f5e688ed6297ebbf410786cfd806
|
[
"CC-BY-4.0"
] | 5 |
2019-12-03T00:54:39.000Z
|
2020-09-21T14:30:43.000Z
| 25.559792 | 328 | 0.572349 |
[
[
[
"*Call expressions* invoke [functions](functions), which are named operations.\nThe name of the function appears first, followed by expressions in\nparentheses.\n\nFor example, `abs` is a function that returns the absolute value of the input\nargument:",
"_____no_output_____"
]
],
[
[
"abs(-12)",
"_____no_output_____"
]
],
[
[
"`round` is a function that returns the input argument rounded to the nearest integer (counting number).",
"_____no_output_____"
]
],
[
[
"round(5 - 1.3)",
"_____no_output_____"
],
[
"max(2, 5, 4)",
"_____no_output_____"
]
],
[
[
"In this last example, the `max` function is *called* on three *arguments*: 2,\n5, and 4. The value of each expression within parentheses is passed to the\nfunction, and the function *returns* the final value of the full call\nexpression. You separate the expressions with commas: `,`. The `max` function\ncan take any number of arguments and returns the maximum.",
"_____no_output_____"
],
[
"Many functions, like `max` can accept a variable number of arguments.\n\n`round` is an example. If you call `round` with one argument, it returns the number rounded to the nearest integer, as you have already seen:",
"_____no_output_____"
]
],
[
[
"round(3.3333)",
"_____no_output_____"
]
],
[
[
"You can also call round with two arguments, where the first argument is the number you want to round, and the second argument is the number of decimal places you want to round to. If you don't pass this second argument, `round` assumes you mean 0, corresponding to no decimal places, and rounding to the nearest integer:",
"_____no_output_____"
]
],
[
[
"# The same as above, rounding to 0 decimal places.\nround(3.3333, 0)",
"_____no_output_____"
]
],
[
[
"You can also round to - say - 2 decimal places, like this:",
"_____no_output_____"
]
],
[
[
"# Rounding to 2 decimal places.\nround(3.3333, 2)",
"_____no_output_____"
]
],
[
[
"A few functions are available by default, such as `abs` and `round`, but most\nfunctions that are built into the Python language are stored in a collection\nof functions called a *module*. An *import statement* is used to provide\naccess to a module, such as `math`.",
"_____no_output_____"
]
],
[
[
"import math\nmath.sqrt(5)",
"_____no_output_____"
]
],
[
[
"Operators and call expressions can be used together in an expression. The\n*percent difference* between two values is used to compare values for which\nneither one is obviously `initial` or `changed`. For example, in 2014 Florida\nfarms produced 2.72 billion eggs while Iowa farms produced 16.25 billion eggs\n[^eggs]. The percent difference is 100 times the absolute value of the\ndifference between the values, divided by their average. In this case, the\ndifference is larger than the average, and so the percent difference is\ngreater than 100.\n\n[^eggs]: <http://quickstats.nass.usda.gov>",
"_____no_output_____"
]
],
[
[
"florida = 2.72\niowa = 16.25\n100*abs(florida-iowa)/((florida+iowa)/2)",
"_____no_output_____"
]
],
[
[
"Learning how different functions behave is an important part of learning a\nprogramming language. A Jupyter notebook can assist in remembering the names\nand effects of different functions. When editing a code cell, press the *tab*\nkey after typing the beginning of a name to bring up a list of ways to\ncomplete that name. For example, press *tab* after `math.` to see all of the\nfunctions available in the `math` module. Typing will narrow down the list of\noptions. To learn more about a function, place a `?` after its name. For\nexample, typing `math.sin?` will bring up a description of the `sin`\nfunction in the `math` module. Try it now. You should get something like\nthis:\n\n```\nsqrt(x)\n\nReturn the square root of x.\n```\n\nThe list of [Python's built-in\nfunctions](https://docs.python.org/3/library/functions.html) is quite long and\nincludes many functions that are never needed in data science applications.\nThe list of [mathematical functions in the `math`\nmodule](https://docs.python.org/3/library/math.html) is similarly long. This\ntext will introduce the most important functions in context, rather than\nexpecting the reader to memorize or understand these lists.",
"_____no_output_____"
],
[
"### Example ###\n\nIn 1869, a French civil engineer named Charles Joseph Minard created what is\nstill considered one of the greatest graphs of all time. It shows the\ndecimation of Napoleon's army during its retreat from Moscow. In 1812,\nNapoleon had set out to conquer Russia, with over 350,000 men in his army.\nThey did reach Moscow but were plagued by losses along the way. The Russian\narmy kept retreating farther and farther into Russia, deliberately burning\nfields and destroying villages as it retreated. This left the French army\nwithout food or shelter as the brutal Russian winter began to set in. The\nFrench army turned back without a decisive victory in Moscow. The weather got\ncolder and more men died. Fewer than 10,000 returned.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
],
[
"The graph is drawn over a map of eastern Europe. It starts at the\nPolish-Russian border at the left end. The light brown band represents\nNapoleon's army marching towards Moscow, and the black band represents the\narmy returning. At each point of the graph, the width of the band is\nproportional to the number of soldiers in the army. At the bottom of the\ngraph, Minard includes the temperatures on the return journey.\n\nNotice how narrow the black band becomes as the army heads back. The crossing\nof the Berezina river was particularly devastating; can you spot it on the\ngraph?\n\nThe graph is remarkable for its simplicity and power. In a single graph,\nMinard shows six variables:\n\n- the number of soldiers\n- the direction of the march\n- the latitude and longitude of location\n- the temperature on the return journey\n- the location on specific dates in November and December\n\nTufte says that Minard's graph is \"probably the best statistical graphic ever\ndrawn.\"",
"_____no_output_____"
],
[
"Here is a subset of Minard's data, adapted from *The Grammar of Graphics* by\nLeland Wilkinson.\n\n",
"_____no_output_____"
],
[
"Each row of the column represents the state of the army in a particular\nlocation. The columns show the longitude and latitude in degrees, the name of\nthe location, whether the army was advancing or in retreat, and an estimate of\nthe number of men.\n\nIn this table the biggest change in the number of men between two consecutive\nlocations is when the retreat begins at Moscow, as is the biggest percentage\nchange.",
"_____no_output_____"
]
],
[
[
"moscou = 100000\nwixma = 55000\nwixma - moscou",
"_____no_output_____"
],
[
"(wixma - moscou)/moscou",
"_____no_output_____"
]
],
[
[
"That's a 45% drop in the number of men in the fighting at Moscow. In other\nwords, almost half of Napoleon's men who made it into Moscow didn't get very\nmuch farther.\n\nAs you can see in the graph, Moiodexno is pretty close to Kowno where the army\nstarted out. Fewer than 10% of the men who marched into Smolensk during the\nadvance made it as far as Moiodexno on the way back.",
"_____no_output_____"
]
],
[
[
"smolensk_A = 145000\nmoiodexno = 12000\n(moiodexno - smolensk_A)/smolensk_A",
"_____no_output_____"
]
],
[
[
"Yes, you could do these calculations by just using the numbers without names.\nBut the names make it much easier to read the code and interpret the results.",
"_____no_output_____"
],
[
"It is worth noting that bigger absolute changes don't always correspond to\nbigger percentage changes.\n\nThe absolute loss from Smolensk to Dorogobouge during the advance was 5,000\nmen, whereas the corresponding loss from Smolensk to Orscha during the retreat\nwas smaller, at 4,000 men.\n\nHowever, the percent change was much larger between Smolensk and Orscha\nbecause the total number of men in Smolensk was much smaller during the\nretreat.",
"_____no_output_____"
]
],
[
[
"dorogobouge = 140000\nsmolensk_R = 24000\norscha = 20000",
"_____no_output_____"
],
[
"abs(dorogobouge - smolensk_A)",
"_____no_output_____"
],
[
"abs(dorogobouge - smolensk_A)/smolensk_A",
"_____no_output_____"
],
[
"abs(orscha - smolensk_R)",
"_____no_output_____"
],
[
"abs(orscha - smolensk_R)/smolensk_R",
"_____no_output_____"
]
],
[
[
"{% data8page Calls %}",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4a9f639de68228326c21581137f26146190eba3f
| 17,438 |
ipynb
|
Jupyter Notebook
|
module-2-validate-classification-problems/LS_DS_242_Validate_classification_problems.ipynb
|
wjarvis2/DS-Unit-2-Sprint-4-Model-Validation
|
8ec0f8d149e703614c004e054a99b6e8d981a176
|
[
"MIT"
] | null | null | null |
module-2-validate-classification-problems/LS_DS_242_Validate_classification_problems.ipynb
|
wjarvis2/DS-Unit-2-Sprint-4-Model-Validation
|
8ec0f8d149e703614c004e054a99b6e8d981a176
|
[
"MIT"
] | null | null | null |
module-2-validate-classification-problems/LS_DS_242_Validate_classification_problems.ipynb
|
wjarvis2/DS-Unit-2-Sprint-4-Model-Validation
|
8ec0f8d149e703614c004e054a99b6e8d981a176
|
[
"MIT"
] | null | null | null | 33.278626 | 314 | 0.608155 |
[
[
[
"_Lambda School Data Science — Model Validation_ \n\n# Validate classification problems\n\nObjectives\n- Imbalanced Classes\n- Confusion Matrix\n- ROC AUC\n",
"_____no_output_____"
],
[
"Reading\n- [Simple guide to confusion matrix terminology](https://www.dataschool.io/simple-guide-to-confusion-matrix-terminology/)\n- [Precision and Recall](https://en.wikipedia.org/wiki/Precision_and_recall)",
"_____no_output_____"
],
[
"## Preliminary",
"_____no_output_____"
],
[
"We'll use [mlxtend](http://rasbt.github.io/mlxtend/) and [yellowbrick](http://www.scikit-yb.org/en/latest/) for visualizations. These libraries are already installed on Google Colab. But if you are running locally with Anaconda Python, you'll probably need to install them:\n\n```\nconda install -c conda-forge mlxtend \nconda install -c districtdatalabs yellowbrick\n```",
"_____no_output_____"
],
[
"We'll reuse the `train_validation_test_split` function from yesterday's lesson.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\ndef train_validation_test_split(\n X, y, train_size=0.8, val_size=0.1, test_size=0.1, \n random_state=None, shuffle=True):\n \n assert train_size + val_size + test_size == 1\n \n X_train_val, X_test, y_train_val, y_test = train_test_split(\n X, y, test_size=test_size, random_state=random_state, shuffle=shuffle)\n \n X_train, X_val, y_train, y_val = train_test_split(\n X_train_val, y_train_val, test_size=val_size/(train_size+val_size), \n random_state=random_state, shuffle=shuffle)\n \n return X_train, X_val, X_test, y_train, y_val, y_test",
"_____no_output_____"
]
],
[
[
"## Fun demo!\n\nThe next code cell does five things:\n\n#### 1. Generate data\n\nWe use scikit-learn's [make_classification](https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html) function to generate fake data for a binary classification problem, based on several parameters, including:\n- Number of samples\n- Weights, meaning \"the proportions of samples assigned to each class.\"\n- Class separation: \"Larger values spread out the clusters/classes and make the classification task easier.\"\n\n(We are generating fake data so it is easy to visualize.)\n\n#### 2. Split data\n\nWe split the data three ways, into train, validation, and test sets. (For this toy example, it's not really necessary to do a three-way split. A two-way split, or even no split, would be ok. But I'm trying to demonstrate good habits, even in toy examples, to avoid confusion.)\n\n#### 3. Fit model\n\nWe use scikit-learn to fit a [Logistic Regression](https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html) on the training data.\n\nWe use this model parameter:\n\n> **class_weight : _dict or ‘balanced’, default: None_**\n\n> Weights associated with classes in the form `{class_label: weight}`. If not given, all classes are supposed to have weight one.\n\n> The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as `n_samples / (n_classes * np.bincount(y))`.\n\n\n#### 4. Evaluate model\n\nWe use our Logistic Regression model, which was fit on the training data, to generate predictions for the validation data.\n\nThen we print [scikit-learn's Classification Report](https://scikit-learn.org/stable/modules/model_evaluation.html#classification-report), with many metrics, and also the accuracy score. We are comparing the correct labels to the Logistic Regression's predicted labels, for the validation set. \n\n#### 5. Visualize decision function\n\nBased on these examples\n- https://imbalanced-learn.readthedocs.io/en/stable/auto_examples/combine/plot_comparison_combine.html\n- http://rasbt.github.io/mlxtend/user_guide/plotting/plot_decision_regions/#example-1-decision-regions-in-2d",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib.pyplot as plt\nfrom sklearn.datasets import make_classification\nfrom sklearn.metrics import accuracy_score, classification_report\nfrom sklearn.linear_model import LogisticRegression\nfrom mlxtend.plotting import plot_decision_regions\n\n\n#1. Generate data\n\n# Try re-running the cell with different values for these parameters\nn_samples = 1000\nweights = (0.50, 0.50)\nclass_sep = 0.8\n\nX, y = make_classification(n_samples=n_samples, n_features=2, n_informative=2, \n n_redundant=0, n_repeated=0, n_classes=2, \n n_clusters_per_class=1, weights=weights, \n class_sep=class_sep, random_state=0)\n\n\n# 2. Split data\n\n# Uses our custom train_validation_test_split function\nX_train, X_val, X_test, y_train, y_val, y_test = train_validation_test_split(\n X, y, train_size=0.8, val_size=0.1, test_size=0.1, random_state=1)\n\n\n# 3. Fit model\n\n# Try re-running the cell with different values for this parameter\nclass_weight = None\n\nmodel = LogisticRegression(solver='lbfgs', class_weight=class_weight)\nmodel.fit(X_train, y_train)\n\n\n# 4. Evaluate model\n\ny_pred = model.predict(X_val)\nprint(classification_report(y_val, y_pred))\nprint('accuracy', accuracy_score(y_val, y_pred))\n\n\n# 5. Visualize decision regions\n\nplt.figure(figsize=(10, 6))\nplot_decision_regions(X_val, y_val, model, legend=0);",
"_____no_output_____"
]
],
[
[
"Try re-running the cell above with different values for these four parameters:\n- `n_samples`\n- `weights`\n- `class_sep`\n- `class_balance`\n\nFor example, with a 50% / 50% class distribution:\n```\nn_samples = 1000\nweights = (0.50, 0.50)\nclass_sep = 0.8\nclass_balance = None\n```\n\nWith a 95% / 5% class distribution:\n```\nn_samples = 1000\nweights = (0.95, 0.05)\nclass_sep = 0.8\nclass_balance = None\n```\n\nWith the same 95% / 5% class distribution, but changing the Logistic Regression's `class_balance` parameter to `'balanced'` (instead of its default `None`)\n```\nn_samples = 1000\nweights = (0.95, 0.05)\nclass_sep = 0.8\nclass_balance = 'balanced'\n```\n\nWith the same 95% / 5% class distribution, but with different values for `class_balance`:\n- `{0: 1, 1: 1}` _(equivalent to `None`)_\n- `{0: 1, 1: 2}`\n- `{0: 1, 1: 10}` _(roughly equivalent to `'balanced'` for this dataset)_\n- `{0: 1, 1: 100}`\n- `{0: 1, 1: 10000}`\n\nHow do the evaluation metrics and decision region plots change?",
"_____no_output_____"
],
[
"## What you can do about imbalanced classes",
"_____no_output_____"
],
[
"[Learning from Imbalanced Classes](https://www.svds.com/tbt-learning-imbalanced-classes/) gives \"a rough outline of useful approaches\" : \n\n- Do nothing. Sometimes you get lucky and nothing needs to be done. You can train on the so-called natural (or stratified) distribution and sometimes it works without need for modification.\n- Balance the training set in some way:\n - Oversample the minority class.\n - Undersample the majority class.\n - Synthesize new minority classes.\n- Throw away minority examples and switch to an anomaly detection framework.\n- At the algorithm level, or after it:\n - Adjust the class weight (misclassification costs).\n - Adjust the decision threshold.\n - Modify an existing algorithm to be more sensitive to rare classes.\n- Construct an entirely new algorithm to perform well on imbalanced data.\n",
"_____no_output_____"
],
[
"We demonstrated just one of these options: many scikit-learn classifiers have a `class_balance` parameter, which we can use to \"adjust the class weight (misclassification costs).\"\n\nThe [imbalance-learn](https://github.com/scikit-learn-contrib/imbalanced-learn) library can be used to \"oversample the minority class, undersample the majority class, or synthesize new minority classes.\"\n\nYou can see how to \"adjust the decision threshold\" in a great blog post, [Visualizing Machine Learning Thresholds to Make Better Business Decisions](https://blog.insightdatascience.com/visualizing-machine-learning-thresholds-to-make-better-business-decisions-4ab07f823415).",
"_____no_output_____"
],
[
"## Bank Marketing — getting started\n\nhttps://archive.ics.uci.edu/ml/datasets/Bank+Marketing\n\nThe data is related with direct marketing campaigns of a Portuguese banking institution. The marketing campaigns were based on phone calls. Often, more than one contact to the same client was required, in order to access if the product (bank term deposit) would be ('yes') or not ('no') subscribed. \n\nbank-additional-full.csv with all examples (41188) and 20 inputs, **ordered by date (from May 2008 to November 2010)**",
"_____no_output_____"
],
[
"### Download data",
"_____no_output_____"
]
],
[
[
"!wget https://archive.ics.uci.edu/ml/machine-learning-databases/00222/bank-additional.zip",
"_____no_output_____"
],
[
"!unzip bank-additional.zip",
"_____no_output_____"
],
[
"%cd bank-additional",
"_____no_output_____"
]
],
[
[
"### Load data, assign to X and y",
"_____no_output_____"
]
],
[
[
"import pandas as pd\n\nbank = pd.read_csv('bank-additional-full.csv', sep=';')\n\nX = bank.drop(columns='y')\ny = bank['y'] == 'yes'",
"_____no_output_____"
]
],
[
[
"### Split data",
"_____no_output_____"
],
[
"We want to do \"model selection (hyperparameter optimization) and performance estimation\" so we'll choose a validation method from the diagram's green box.\n\nThere is no one \"right\" choice here, but I'll choose \"3-way holdout method (train/validation/test split).\"\n \n<img src=\"https://sebastianraschka.com/images/blog/2018/model-evaluation-selection-part4/model-eval-conclusions.jpg\" width=\"600\">\n\nSource: https://sebastianraschka.com/blog/2018/model-evaluation-selection-part4.html",
"_____no_output_____"
],
[
"There's no one \"right\" choice here, but I'll choose to split by time, not with a random shuffle, based on this advice by [Rachel Thomas](\nhttps://www.fast.ai/2017/11/13/validation-sets/):\n> If your data is a time series, choosing a random subset of the data will be both too easy (you can look at the data both before and after the dates your are trying to predict) and not representative of most business use cases (where you are using historical data to build a model for use in the future).\n\n[According to UCI](https://archive.ics.uci.edu/ml/datasets/Bank+Marketing), this data is \"ordered by date (from May 2008 to November 2010)\" so if I don't shuffle it when splitting, then it will be split by time.",
"_____no_output_____"
]
],
[
[
"X_train, X_val, X_test, y_train, y_val, y_test = train_validation_test_split(\n X, y, shuffle=False)",
"_____no_output_____"
]
],
[
[
"## Bank Marketing — live coding!",
"_____no_output_____"
],
[
"# ASSIGNMENT options\n\nReplicate code from the lesson or other examples. [Do it \"the hard way\" or with the \"Benjamin Franklin method.\"](https://docs.google.com/document/d/1ubOw9B3Hfip27hF2ZFnW3a3z9xAgrUDRReOEo-FHCVs/edit)\n\nWork with one of these datasets\n- [Bank Marketing](https://archive.ics.uci.edu/ml/datasets/Bank+Marketing)\n- [Synthetic Financial Dataset For Fraud Detection](https://www.kaggle.com/ntnu-testimon/paysim1)\n- Any imbalanced binary classification dataset\n\nContinue improving your model. Measure validation performance with a variety of classification metrics, which could include:\n- Accuracy\n- Precision\n- Recall\n- F1\n- ROC AUC\n\nTry one of the other options mentioned for imbalanced classes\n- The [imbalance-learn](https://github.com/scikit-learn-contrib/imbalanced-learn) library can be used to \"oversample the minority class, undersample the majority class, or synthesize new minority classes.\"\n- You can see how to \"adjust the decision threshold\" in a great blog post, [Visualizing Machine Learning Thresholds to Make Better Business Decisions](https://blog.insightdatascience.com/visualizing-machine-learning-thresholds-to-make-better-business-decisions-4ab07f823415).",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4a9f826e7e4f84bb4a6e6f04fd5ecb5c746fc2b1
| 788,832 |
ipynb
|
Jupyter Notebook
|
ticket.ipynb
|
00FFEF/test_webscraping
|
880198f3931b8e802137272673b54abd3553684f
|
[
"Apache-2.0"
] | null | null | null |
ticket.ipynb
|
00FFEF/test_webscraping
|
880198f3931b8e802137272673b54abd3553684f
|
[
"Apache-2.0"
] | null | null | null |
ticket.ipynb
|
00FFEF/test_webscraping
|
880198f3931b8e802137272673b54abd3553684f
|
[
"Apache-2.0"
] | null | null | null | 151.610994 | 423,788 | 0.488261 |
[
[
[
"from selenium import webdriver",
"_____no_output_____"
],
[
"browser = webdriver.Chrome('./chromedriver.exe')",
"_____no_output_____"
],
[
"browser.get('http://ticket.interpark.com/Contents/Ranking')",
"_____no_output_____"
],
[
"html = browser.page_source",
"_____no_output_____"
],
[
"html",
"_____no_output_____"
],
[
"from bs4 import BeautifulSoup",
"_____no_output_____"
],
[
"soup = BeautifulSoup(html, 'html.parser')",
"_____no_output_____"
],
[
"soup",
"_____no_output_____"
],
[
"len(soup), type(soup)",
"_____no_output_____"
],
[
"tags = soup.select('div.items > ul > li')",
"_____no_output_____"
],
[
"len(tags), type(tags)",
"_____no_output_____"
],
[
"tag = tags[0]\ntag",
"_____no_output_____"
],
[
"tag.select('a.prdName')[0].text.strip()",
"_____no_output_____"
],
[
"tag.select('a.prdDuration')[0].text.strip()",
"_____no_output_____"
],
[
"contents = list()\nfor tag in tags:\n title = tag.select('a.prdName')[0].text.strip()\n date = tag.select('a.prdDuration')[0].text.strip()\n contents.append([tag.select('a.prdName')[0].text.strip(), tag.select('a.prdDuration')[0].text.strip()])\n \ncontents",
"_____no_output_____"
],
[
"import pandas as pd",
"_____no_output_____"
],
[
"pd_data = pd.DataFrame(contents, columns=['title', 'date'])",
"_____no_output_____"
],
[
"pd_data.to_excel('./saves/ticket.xls', index = False)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f870533b20621eefc02fa48d0d9700c138923
| 135,597 |
ipynb
|
Jupyter Notebook
|
vgg16_prediction.ipynb
|
PacktPublishing/Deep-Learning-using-Keras---A-Complete-and-Compact-Guide-for-Beginners
|
60c2c7cd1a22381c7d121bbbf2b50fa770ff5060
|
[
"MIT"
] | 1 |
2021-10-02T03:20:02.000Z
|
2021-10-02T03:20:02.000Z
|
.ipynb_checkpoints/vgg16_prediction-checkpoint.ipynb
|
PacktPublishing/Deep-Learning-using-Keras---A-Complete-and-Compact-Guide-for-Beginners
|
60c2c7cd1a22381c7d121bbbf2b50fa770ff5060
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/vgg16_prediction-checkpoint.ipynb
|
PacktPublishing/Deep-Learning-using-Keras---A-Complete-and-Compact-Guide-for-Beginners
|
60c2c7cd1a22381c7d121bbbf2b50fa770ff5060
|
[
"MIT"
] | 1 |
2021-10-01T20:31:01.000Z
|
2021-10-01T20:31:01.000Z
| 630.683721 | 125,284 | 0.941746 |
[
[
[
"from tensorflow.keras.models import load_model\nfrom tensorflow.keras.preprocessing.image import load_img, img_to_array\nimport matplotlib.pyplot as plt\nimport numpy as np",
"_____no_output_____"
],
[
"#import all VGG specific libraries\nfrom tensorflow.keras.applications.vgg16 import VGG16, preprocess_input, decode_predictions",
"_____no_output_____"
],
[
"#load the VGG model\nmodel = VGG16()\nmodel.summary()",
"Model: \"model\"\n_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) [(None, 224, 224, 3)] 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 224, 224, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 224, 224, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 112, 112, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 112, 112, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 112, 112, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 56, 56, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 56, 56, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 56, 56, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 56, 56, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 28, 28, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 14, 14, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 7, 7, 512) 0 \n_________________________________________________________________\nflatten (Flatten) (None, 25088) 0 \n_________________________________________________________________\ndense (Dense) (None, 512) 12845568 \n_________________________________________________________________\ndense_1 (Dense) (None, 5) 2565 \n=================================================================\nTotal params: 27,562,821\nTrainable params: 12,848,133\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
],
[
"#load an image for prediction\nimg = load_img('images/cat.jpg', target_size=(224,224))\nplt.imshow(img)\nplt.show()",
"_____no_output_____"
],
[
"#covert img to array and add dimension\nimg = img_to_array(img)\nimg = img.reshape(1,224,224,3)",
"_____no_output_____"
],
[
"#getting the prediction\nresult = model.predict(img)",
"_____no_output_____"
],
[
"#decoding proablity values into string labels\nclass_label = decode_predictions(result)",
"_____no_output_____"
],
[
"print(class_label)",
"_____no_output_____"
],
[
"class_label_single = class_label[0][0]\nprint(\"the prediction is:\")\nprint(class_label_single)",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9f95290dfb6837fac388893207d38eb6a9c8fd
| 12,568 |
ipynb
|
Jupyter Notebook
|
NLP/1_NLP_Intro__Data_Preprocessing/Intro_to_the_world_of_nlp.ipynb
|
yash1996/DL_curated_intuition
|
ae6d966bea93a0ece50dd7a2aa316ccde8c6d6b2
|
[
"CC0-1.0"
] | 33 |
2020-05-10T13:13:27.000Z
|
2021-04-22T08:40:55.000Z
|
NLP/1_NLP_Intro__Data_Preprocessing/Intro_to_the_world_of_nlp.ipynb
|
yash1996/DL_curated_intuition
|
ae6d966bea93a0ece50dd7a2aa316ccde8c6d6b2
|
[
"CC0-1.0"
] | 9 |
2020-09-26T00:39:54.000Z
|
2022-03-12T00:14:11.000Z
|
NLP/1_NLP_Intro__Data_Preprocessing/Intro_to_the_world_of_nlp.ipynb
|
nikhilpradeep/deep
|
d55562100fe3804e55ea1cf1637a669da69baec3
|
[
"CC0-1.0"
] | 18 |
2020-06-07T12:58:21.000Z
|
2022-02-21T17:18:25.000Z
| 38.910217 | 608 | 0.617043 |
[
[
[
"## Don't worry if you don't understand everything at first! You're not supposed to. We will start using some \"black boxes\" and then we'll dig into the lower level details later.\n\n## To start, focus on what things DO, not what they ARE.",
"_____no_output_____"
],
[
"# What is NLP?\n \n Natural Language Processing is technique where computers try an understand human language and make meaning out of it.\n \n\nNLP is a broad field, encompassing a variety of tasks, including:\n\n 1. Part-of-speech tagging: identify if each word is a noun, verb, adjective, etc.)\n 2. Named entity recognition NER): identify person names, organizations, locations, medical codes, time expressions, quantities, monetary values, etc)\n 3. Question answering\n 4. Speech recognition\n 5. Text-to-speech and Speech-to-text\n 6. Topic modeling\n 7. Sentiment classification\n 9. Language modeling\n 10. Translation\n\n",
"_____no_output_____"
],
[
"# What is NLU?\n \n Natural Language Understanding is all about understanding the natural language.\n \n Goals of NLU\n 1. Gain insights into cognition\n 2. Develop Artifical Intelligent agents as an assistant. ",
"_____no_output_____"
],
[
"# What is NLG?\n\nNatural language generation is the natural language processing task of generating natural language from a machine representation system such as a knowledge base or a logical form. \n\nExample applications of NLG\n 1. Recommendation and Comparison \n 2. Report Generation –Summarization \n 3. Paraphrase \n 4. Prompt and response generation in dialogue systems \n \n ",
"_____no_output_____"
],
[
"# Packages\n\n1. [Flair](https://github.com/zalandoresearch/flair)\n2. [Allen NLP](https://github.com/allenai/allennlp)\n3. [Deep Pavlov](https://github.com/deepmipt/deeppavlov)\n4. [Pytext](https://github.com/facebookresearch/PyText)\n5. [NLTK](https://www.nltk.org/)\n6. [Hugging Face Pytorch Transformer](https://github.com/huggingface/pytorch-transformers)\n7. [Spacy](https://spacy.io/)\n8. [torchtext](https://torchtext.readthedocs.io/en/latest/)\n9. [Ekphrasis](https://github.com/cbaziotis/ekphrasis)\n10. [Genism](https://radimrehurek.com/gensim/)",
"_____no_output_____"
],
[
"# NLP Pipeline",
"_____no_output_____"
],
[
"## Data Collection\n\n### Sources\n\nFor Generative Training :- Where the model has to learn about the data and its distribution \n 1. News Article:- Archives\n 2. Wikipedia Article \n 3. Book Corpus \n 4. Crawling the Internet for webpages.\n 5. Reddit\n\nGenerative training on an abundant set of unsupervised data helps in performing Transfer learning for a downstream task where few parameters need to be learnt from sratch and less data is also required.\n\nFor Determinstic Training :- Where the model learns about Decision boundary within the data.\n Generic\n 1. Kaggle Dataset\n Sentiment\n 1. Product Reviews :- Amazon, Flipkart\n Emotion:-\n 1. ISEAR\n 2. Twitter dataset\n Question Answering:-\n 1. SQUAD\n etc.\n \n### For Vernacular text\nIn vernacular context we have crisis in data especially when it comes to state specific language in India. (Ex. Bengali, Gujurati etc.) \nFew Sources are:-\n1. News (Jagran.com, Danik bhaskar)\n2. Moview reviews (Web Duniya)\n3. Hindi Wikipedia\n4. Book Corpus\n6. IIT Bombay (English-Hindi Parallel Corpus)\n\n### Tools\n1. Scrapy :- Simple, Extensible framework for scraping and crawling websites. Has numerous feature into it.\n2. Beautiful-Soup :- For Parsing Html and xml documents. \n3. Excel \n4. wikiextractor:- A tool for extracting plain text from Wikipedia dumps\n\n### Data Annotation Tool\n\n1. TagTog\n2. Prodigy (Explosion AI)\n3. Mechanical Turk \n4. PyBossa\n5. Chakki-works Doccano \n6. WebAnno\n7. Brat",
"_____no_output_____"
],
[
"## Data Preprocessing\n\n1. Cleaning\n2. Regex \n 1. Url Cleanup\n 2. HTML Tag\n 3. Date\n 4. Numbers\n 5. Lingos\n 6. Emoticons \n3. Lemmatization \n4. Stemming\n5. Chunking\n6. POS Tags\n7. NER Tags\n8. Stopwords\n9. Tokenizers\n10. Spell Correction\n11. Word Segmentation\n12. Word Processing \n 1. Elongated\n 2. Repeated\n 3. All Caps",
"_____no_output_____"
],
[
"### Feature Selection\n\n1. Bag of Words\n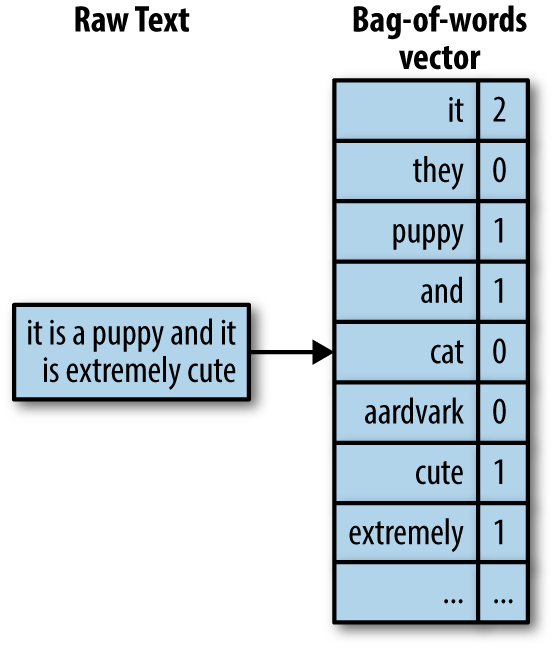\n2. TF-IDF\n\n3. Word Embeddings\n 1. Word2Vec\n \n Word2Vec is a predictive model.\n \n 2. Glove\n \n Glove is a Count-based models learn their vectors by essentially doing dimensionality reduction on the co-occurrence counts matrix.\n 3. FastText\n \n Fastext is trained in a similar fashion how word2vec model is trained, the only difference is the fastext enchriches the word vectors with subword units.\n \n [FastText works](https://www.quora.com/What-is-the-main-difference-between-word2vec-and-fastText)\n \n 4. ELMO\n \n ELMo is a deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). These word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pre-trained on a large text corpus. They can be easily added to existing models and significantly improve the state of the art across a broad range of challenging NLP problems, including question answering, textual entailment and sentiment analysis.\n \n ELMo representations are:\n\n * Contextual: The representation for each word depends on the entire context in which it is used.\n * Deep: The word representations combine all layers of a deep pre-trained neural network.\n * Character based: ELMo representations are purely character based, allowing the network to use morphological clues to form robust representations for out-of-vocabulary tokens unseen in training. ",
"_____no_output_____"
],
[
"### Modelling\n\n1. RNN\n\n\nRNN suffers from gradient vanishing problem and they do not persist long term dependencies.\n2. LSTM\n\nLong Short Term Memory networks – usually just called “LSTMs” – are a special kind of RNN, capable of learning long-term dependencies. \n\nLSTMs are explicitly designed to avoid the long-term dependency problem. Remembering information for long periods of time is practically their default behavior, not something they struggle to learn!\n\n\n\n\n\n3. BI-LSTM\n\n\n4. GRU\n\n5. CNNs\n6. Seq-Seq\n\n\n7. Seq-Seq Attention\n\n8. Pointer Generator Network\n\n8. Transformer\n\n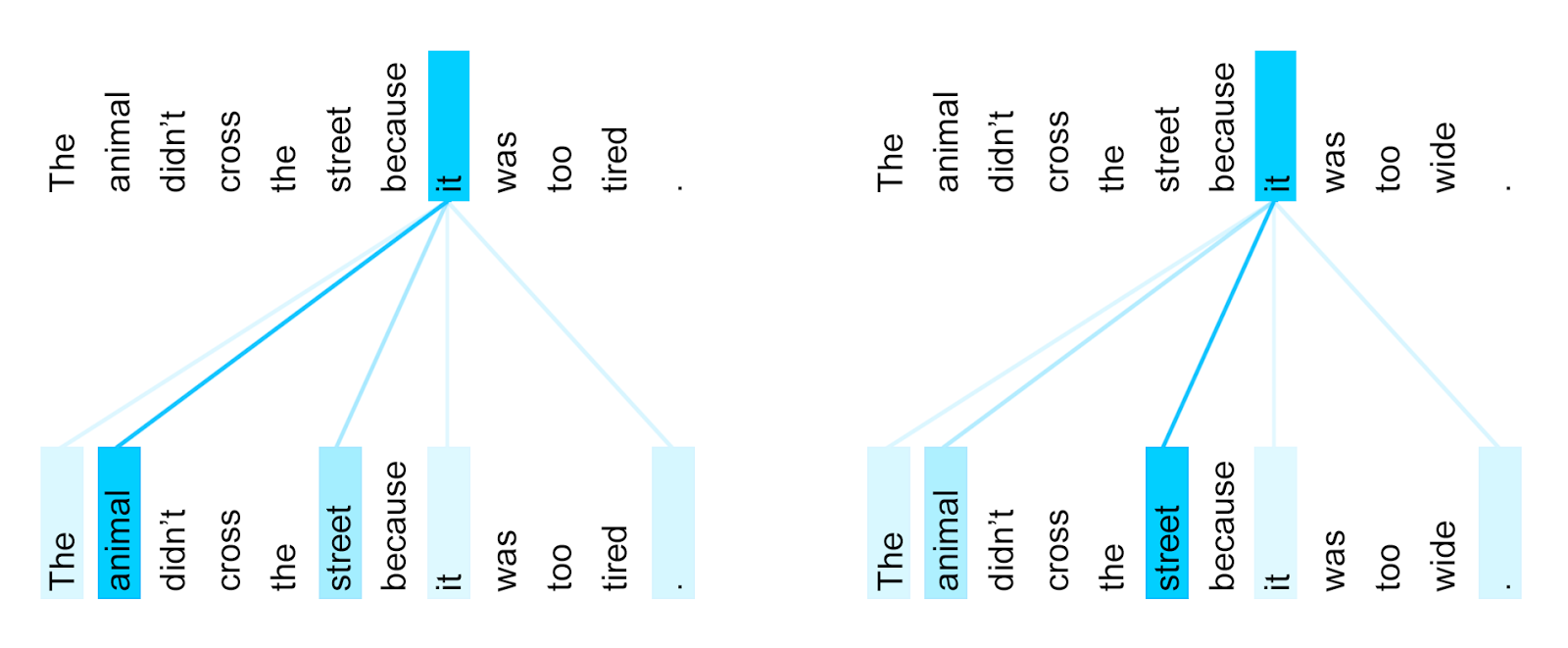\n9. GPT\n\n10. Transformer-XL\n\n11. BERT\n\nBERT’s key technical innovation is applying the bidirectional training of Transformer, a popular attention model, to language modelling.\n\nBERT is given billions of sentences at training time. It’s then asked to predict a random selection of missing words from these sentences. After practicing with this corpus of text several times over, BERT adopts a pretty good understanding of how a sentence fits together grammatically. It’s also better at predicting ideas that are likely to show up together.\n\n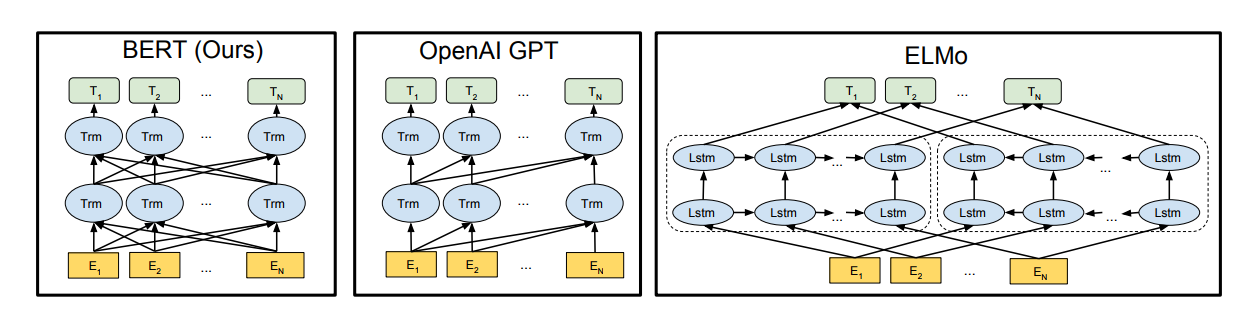\n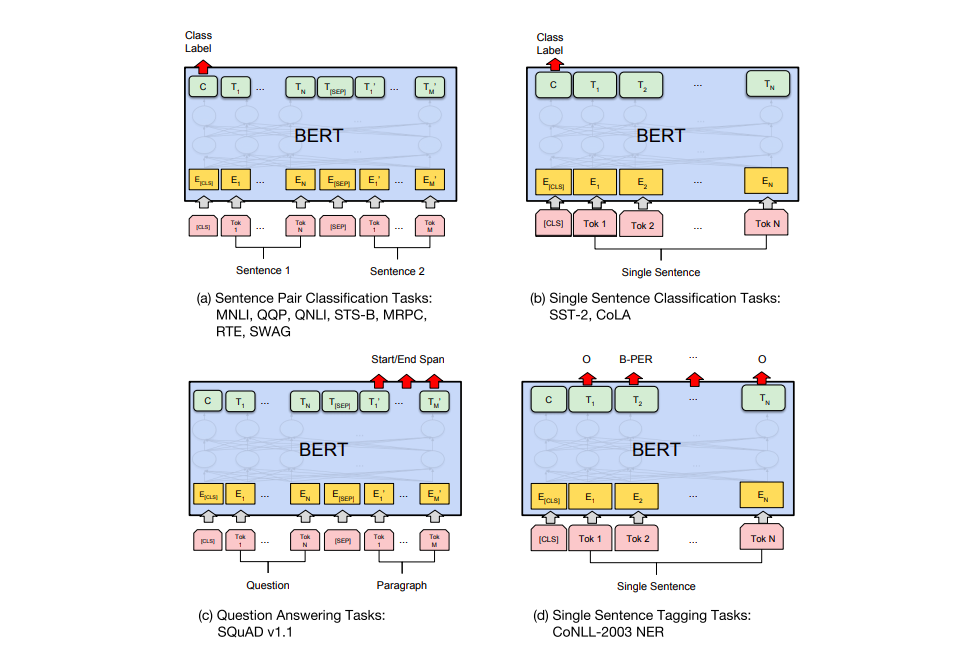\n12. GPT-2\n",
"_____no_output_____"
],
[
"## Buisness Problem\n\n1. Text Classification\n 1. Sentiment Classification\n 2. Emotion Classification\n 3. Reviews Rating\n2. Topic Modeling\n3. Named Entity Recognition\n4. Part Of Speech Tagging\n5. Language Model\n6. Machine Translation\n7. Question Answering\n8. Text Summarization\n9. Text Generation\n10. Image Captioning\n11. Optical Character Recognition\n12. Chatbots\n13. [Dependency Parsing](https://nlpprogress.com/english/dependency_parsing.html)\n14. [Coreference Resolution](https://en.wikipedia.org/wiki/Coreference) \n15. [Semantic Textual Similarity](https://nlpprogress.com/english/semantic_textual_similarity.html)",
"_____no_output_____"
]
]
] |
[
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4a9f9864e91758b84725e53fc538bc6fe45452b5
| 40,519 |
ipynb
|
Jupyter Notebook
|
notebooks/test_jupyter_dash.ipynb
|
virgilus/desert-medicaux-global
|
f51fbf437ef869d1cf1da5aa57491a08fc33ab69
|
[
"MIT"
] | null | null | null |
notebooks/test_jupyter_dash.ipynb
|
virgilus/desert-medicaux-global
|
f51fbf437ef869d1cf1da5aa57491a08fc33ab69
|
[
"MIT"
] | null | null | null |
notebooks/test_jupyter_dash.ipynb
|
virgilus/desert-medicaux-global
|
f51fbf437ef869d1cf1da5aa57491a08fc33ab69
|
[
"MIT"
] | null | null | null | 39.073288 | 91 | 0.324095 |
[
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"df_2 = pd.read_csv('departements_et_regions.csv',\n sep=',',\n header='infer',\n quotechar='\"',\n encoding='UTF-8',)",
"_____no_output_____"
],
[
"df.head(30)",
"_____no_output_____"
],
[
"available_indicators = list(df_2.columns)",
"_____no_output_____"
],
[
"type(available_indicators)",
"_____no_output_____"
],
[
"available_indicators",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9fa0a18e8530c7933ff2eff528d9cb137ef0ca
| 2,521 |
ipynb
|
Jupyter Notebook
|
Calculus_Homework/WWB09.11.ipynb
|
NSC9/Sample_of_Work
|
8f8160fbf0aa4fd514d4a5046668a194997aade6
|
[
"MIT"
] | null | null | null |
Calculus_Homework/WWB09.11.ipynb
|
NSC9/Sample_of_Work
|
8f8160fbf0aa4fd514d4a5046668a194997aade6
|
[
"MIT"
] | null | null | null |
Calculus_Homework/WWB09.11.ipynb
|
NSC9/Sample_of_Work
|
8f8160fbf0aa4fd514d4a5046668a194997aade6
|
[
"MIT"
] | null | null | null | 19.542636 | 68 | 0.491868 |
[
[
[
"from IPython.display import Image\nfrom IPython.core.display import HTML \nfrom sympy import *; x,h,t = symbols(\"x h t\")\nImage(url= \"https://i.imgur.com/FmL1lSE.png\")",
"_____no_output_____"
],
[
"# March 31 is the 90th day of the year \n# June 11 is the 162nd day of the year \nexpr = 12 + 7*sin((2*pi/365)*(t-80))\ndexpr = (diff(expr)) #getting derivative of our expression\nprint(dexpr.subs(t, 90))",
"14*pi*cos(4*pi/73)/365\n"
],
[
"print(dexpr.subs(t, 162))",
"14*pi*cos(164*pi/365)/365\n"
],
[
"Image(url= \"https://i.imgur.com/LTrMOWA.png\")",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code"
]
] |
4a9fb83bf10bae0f7b39d2ef5516104ae12d9d47
| 343,368 |
ipynb
|
Jupyter Notebook
|
Assignment 2 - Decision Trees - Dataset 2 - GPU Run Time.ipynb
|
Kaminibokefode/SVM--DecisionTree--Adaboost
|
a91bd5521e0033f0b4db028d05036b27326963b7
|
[
"Apache-2.0"
] | null | null | null |
Assignment 2 - Decision Trees - Dataset 2 - GPU Run Time.ipynb
|
Kaminibokefode/SVM--DecisionTree--Adaboost
|
a91bd5521e0033f0b4db028d05036b27326963b7
|
[
"Apache-2.0"
] | null | null | null |
Assignment 2 - Decision Trees - Dataset 2 - GPU Run Time.ipynb
|
Kaminibokefode/SVM--DecisionTree--Adaboost
|
a91bd5521e0033f0b4db028d05036b27326963b7
|
[
"Apache-2.0"
] | null | null | null | 404.915094 | 124,560 | 0.935163 |
[
[
[
"# DATASET 2 - GPU Runtime ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns #visualisation\nimport matplotlib.pyplot as plt #visualisation\n%matplotlib inline \nimport pandas as pd\nimport numpy as np\nfrom sklearn import tree\nfrom sklearn.tree import DecisionTreeClassifier,export_graphviz\nfrom sklearn.model_selection import train_test_split\nfrom matplotlib import pyplot as plt\nimport seaborn as sns\nimport graphviz \nimport pydotplus\nimport io\nfrom scipy import misc\nfrom sklearn.ensemble import AdaBoostClassifier\n",
"_____no_output_____"
],
[
"\n#importing the data\ndt = pd.read_csv(\"C:\\\\ITM SPRING 2020\\\\ML\\\\sgemm_product_dataset\\\\processed_sgemm_product.csv\")\ndf = dt.copy()\n\n#classifying numeric runtime into two classes. Run time higher than 250 is 0 and lower will be 1\ndf['target'] = np.where(df['MeanRun']>250, 0, 1)\n\n#dropping the numeric target column\ndf.drop('MeanRun',axis=1,inplace=True)\n\n#As SVM takes long time to run, sampling only 25000 records for running this algorithm\ndt = df.sample(n = 50000)\n\n#\nX_dataset=dt.drop(columns=['target'])\ny=dt['target']\n\nfrom sklearn import preprocessing\nX = preprocessing.scale(X_dataset)\n\n",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\n\ntree_g = DecisionTreeClassifier()\narray_scores_g = cross_val_score(tree_g,X,y,cv=5)\narray_mean_g = array_scores_g.mean()\n\ntree_e = DecisionTreeClassifier(criterion='entropy')\narray_scores_e = cross_val_score(tree_e,X,y,cv=5)\narray_mean_e = array_scores_e.mean()\n\n\nprint(\"GINI : Accuracy of decision tree without hyperparameter tuning: \",array_mean_g)\nprint(tree_g)\nprint()\nprint()\nprint()\nprint(\"ENTROPY :Accuracy of decision tree without hyperparameter tuning: \",array_mean_e)\nprint(tree_e)",
"GINI : Accuracy of decision tree without hyperparameter tuning: 0.9889199999999999\nDecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='gini',\n max_depth=None, max_features=None, max_leaf_nodes=None,\n min_impurity_decrease=0.0, min_impurity_split=None,\n min_samples_leaf=1, min_samples_split=2,\n min_weight_fraction_leaf=0.0, presort='deprecated',\n random_state=None, splitter='best')\n\n\n\nENTROPY :Accuracy of decision tree without hyperparameter tuning: 0.9890399999999999\nDecisionTreeClassifier(ccp_alpha=0.0, class_weight=None, criterion='entropy',\n max_depth=None, max_features=None, max_leaf_nodes=None,\n min_impurity_decrease=0.0, min_impurity_split=None,\n min_samples_leaf=1, min_samples_split=2,\n min_weight_fraction_leaf=0.0, presort='deprecated',\n random_state=None, splitter='best')\n"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\n\nmax_depth_list = [5,10,15,20,25,30]\nmax_depth_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\nfor i in max_depth_list:\n tree_g = DecisionTreeClassifier(criterion='gini',max_depth=i)\n array_scores_g = cross_val_score(tree_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n accuracy_list_g.append(array_mean_g)\n \n tree_e = DecisionTreeClassifier(criterion='entropy',max_depth=i)\n array_scores_e = cross_val_score(tree_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n accuracy_list_e.append(array_mean_e)\n \n max_depth_.append(i)\n \n\nplt.plot(max_depth_,accuracy_list_g,label='Gini')\nplt.plot(max_depth_,accuracy_list_e,label='Entropy')\nplt.xlabel('Maximum Depth')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Minimum Sample Leaf')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\nmax_leaf_nodes_list = [5,10,15,20,25,30]\nmax_leaf_nodes_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\nC_params = []\nfor i in max_leaf_nodes_list:\n tree_g = DecisionTreeClassifier(criterion='gini',max_leaf_nodes=i)\n array_scores_g = cross_val_score(tree_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n accuracy_list_g.append(array_mean_g)\n \n tree_e = DecisionTreeClassifier(criterion='entropy',max_leaf_nodes=i)\n array_scores_e = cross_val_score(tree_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n accuracy_list_e.append(array_mean_e)\n \n max_leaf_nodes_.append(i)\n \n\nplt.plot(max_leaf_nodes_,accuracy_list_g,label='Gini')\nplt.plot(max_leaf_nodes_,accuracy_list_e,label='Entropy')\nplt.xlabel('Maximum Leaf node')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Maximum Leaf Nodes')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n",
"_____no_output_____"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\nmin_samples_leaf_list = [5,10,15,20,25,30]\nmin_samples_leaf_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\n\nfor i in max_leaf_nodes_list:\n tree_g = DecisionTreeClassifier(criterion='gini',min_samples_leaf=i)\n array_scores_g = cross_val_score(tree_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n accuracy_list_g.append(array_mean_g)\n \n tree_e = DecisionTreeClassifier(criterion='entropy',min_samples_leaf=i)\n array_scores_e = cross_val_score(tree_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n accuracy_list_e.append(array_mean_e)\n \n min_samples_leaf_.append(i)\n \n\nplt.plot(min_samples_leaf_,accuracy_list_g,label='Gini')\nplt.plot(min_samples_leaf_,accuracy_list_e,label='Entropy')\nplt.xlabel('Minimum Sample Leaf ')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Minimum Sample Leaf')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n",
"_____no_output_____"
]
],
[
[
"# ADAPTIVE BOOSTING",
"_____no_output_____"
]
],
[
[
"accuracy_list = []\n\nlearning_rates =[.001,.01,.1,1]\nfor i in learning_rates:\n model = DecisionTreeClassifier(criterion='entropy',max_depth =15,min_samples_leaf=15,max_leaf_nodes=15)\n Adaboost = AdaBoostClassifier(base_estimator=model,n_estimators=10,learning_rate=i)\n #boostmodel = Adaboost.fit(X_train,y_train)\n array_scores = cross_val_score(Adaboost,X,y,cv=5)\n array_mean = array_scores.mean()\n print(\"for learning rate= \",i,\" Accuracy is : \",array_mean)\n accuracy_list.append(array_mean)\n \n\nplt.plot(np.log10(learning_rates),accuracy_list)\n#plt.plot(min_samples_leaf_,accuracy_list_e,label='Entropy')\nplt.xlabel('Learning Rates ')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Learning Rates')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)",
"No handles with labels found to put in legend.\n"
]
],
[
[
"# ADAPTIVE BOOSTING - Pruned",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\nmin_samples_leaf_list = [5,10,15,20,25,30]\nmin_samples_leaf_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\n\nfor i in min_samples_leaf_list:\n model_g = DecisionTreeClassifier(criterion='gini',min_samples_leaf =i)\n Adaboost_g = AdaBoostClassifier(base_estimator=model_g,n_estimators=100,learning_rate=1)\n array_scores_g = cross_val_score(Adaboost_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n print('GINI: for minimum sample = ',i,' mean accuracy is ',array_mean_g)\n accuracy_list_g.append(array_mean_g)\n \n model_e = DecisionTreeClassifier(criterion='entropy',min_samples_leaf =i)\n Adaboost_e = AdaBoostClassifier(base_estimator=model_e,n_estimators=100,learning_rate=1)\n array_scores_e = cross_val_score(Adaboost_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n print('ENTROPY: for minimum sample = ',i,' mean accuracy is ',array_mean_e)\n accuracy_list_e.append(array_mean_e)\n\n min_samples_leaf_.append(i)\n \n\nplt.plot(min_samples_leaf_,accuracy_list_g,label='Gini')\nplt.plot(min_samples_leaf_,accuracy_list_e,label='Entropy')\nplt.xlabel('Minimum Sample Leaf ')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Minimum Sample Leaf')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n\n",
"GINI: for minimum sample = 5 mean accuracy is 0.98688\nENTROPY: for minimum sample = 5 mean accuracy is 0.9867600000000001\nGINI: for minimum sample = 10 mean accuracy is 0.98736\nENTROPY: for minimum sample = 10 mean accuracy is 0.9874\nGINI: for minimum sample = 15 mean accuracy is 0.9873799999999999\nENTROPY: for minimum sample = 15 mean accuracy is 0.9873000000000001\nGINI: for minimum sample = 20 mean accuracy is 0.9878199999999999\nENTROPY: for minimum sample = 20 mean accuracy is 0.98856\nGINI: for minimum sample = 25 mean accuracy is 0.98798\nENTROPY: for minimum sample = 25 mean accuracy is 0.9878600000000001\nGINI: for minimum sample = 30 mean accuracy is 0.9878199999999999\nENTROPY: for minimum sample = 30 mean accuracy is 0.98734\n"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\nmax_leaf_nodes_list = [5,10,15,20,25,30]\nmax_leaf_nodes_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\n\nfor i in max_leaf_nodes_list:\n model_g = DecisionTreeClassifier(criterion='gini',max_leaf_nodes=i)\n Adaboost_g = AdaBoostClassifier(base_estimator=model_g,n_estimators=100,learning_rate=1)\n array_scores_g = cross_val_score(Adaboost_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n print('GINI: for maximum leaf node = ',i,' mean accuracy is ',array_mean_g)\n accuracy_list_g.append(array_mean_g)\n \n model_e = DecisionTreeClassifier(criterion='entropy',min_samples_leaf =i)\n Adaboost_e = AdaBoostClassifier(base_estimator=model_e,n_estimators=100,learning_rate=1)\n array_scores_e = cross_val_score(Adaboost_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n print('ENTROPY: for maximum leaf nodes = ',i,' mean accuracy is ',array_mean_e)\n accuracy_list_e.append(array_mean_e)\n\n max_leaf_nodes_.append(i)\n \n\nplt.plot(max_leaf_nodes_,accuracy_list_g,label='Gini')\nplt.plot(max_leaf_nodes_,accuracy_list_e,label='Entropy')\nplt.xlabel('Maximum Leaf Nodes ')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Maximum Lead Nodes')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n\n",
"GINI: for maximum leaf node = 5 mean accuracy is 0.97976\nENTROPY: for maximum leaf nodes = 5 mean accuracy is 0.9868600000000001\nGINI: for maximum leaf node = 10 mean accuracy is 0.98844\nENTROPY: for maximum leaf nodes = 10 mean accuracy is 0.98744\nGINI: for maximum leaf node = 15 mean accuracy is 0.98978\nENTROPY: for maximum leaf nodes = 15 mean accuracy is 0.9878399999999999\nGINI: for maximum leaf node = 20 mean accuracy is 0.98984\nENTROPY: for maximum leaf nodes = 20 mean accuracy is 0.9878800000000002\nGINI: for maximum leaf node = 25 mean accuracy is 0.98924\nENTROPY: for maximum leaf nodes = 25 mean accuracy is 0.9882799999999999\nGINI: for maximum leaf node = 30 mean accuracy is 0.9898800000000001\nENTROPY: for maximum leaf nodes = 30 mean accuracy is 0.9883400000000002\n"
],
[
"from sklearn.model_selection import cross_val_score\nfrom sklearn.metrics import accuracy_score\n\nmax_depth_list = [5,10,15,20,25,30]\nmax_depth_ =[]\naccuracy_list_g = []\naccuracy_list_e = []\n\n\n\nfor i in max_leaf_nodes_list:\n model_g = DecisionTreeClassifier(criterion='gini',max_depth=i)\n Adaboost_g = AdaBoostClassifier(base_estimator=model_g,n_estimators=100,learning_rate=1)\n array_scores_g = cross_val_score(Adaboost_g,X,y,cv=5)\n array_mean_g = array_scores_g.mean()\n print('GINI: for maximum depth = ',i,' mean accuracy is ',array_mean_g)\n accuracy_list_g.append(array_mean_g)\n \n model_e = DecisionTreeClassifier(criterion='entropy',max_depth =i)\n Adaboost_e = AdaBoostClassifier(base_estimator=model_e,n_estimators=100,learning_rate=1)\n array_scores_e = cross_val_score(Adaboost_e,X,y,cv=5)\n array_mean_e = array_scores_e.mean()\n print('ENTROPY: for maximum depth = ',i,' mean accuracy is ',array_mean_e)\n accuracy_list_e.append(array_mean_e)\n\n max_depth_.append(i)\n \n\nplt.plot(max_leaf_nodes_,accuracy_list_g,label='Gini')\nplt.plot(max_leaf_nodes_,accuracy_list_e,label='Entropy')\nplt.xlabel('Maximum Depth ')\nplt.ylabel('Accuracy') \nplt.title('Accuracy vs Maximum Depth')\nplt.legend()\nplt.show\nplt.rcParams['figure.figsize']=(8,6)\n\n\n",
"GINI: for maximum depth = 5 mean accuracy is 0.9896800000000001\nENTROPY: for maximum depth = 5 mean accuracy is 0.98996\nGINI: for maximum depth = 10 mean accuracy is 0.9875400000000001\nENTROPY: for maximum depth = 10 mean accuracy is 0.98762\nGINI: for maximum depth = 15 mean accuracy is 0.98634\nENTROPY: for maximum depth = 15 mean accuracy is 0.98614\nGINI: for maximum depth = 20 mean accuracy is 0.9881\nENTROPY: for maximum depth = 20 mean accuracy is 0.9881800000000001\nGINI: for maximum depth = 25 mean accuracy is 0.9884000000000001\nENTROPY: for maximum depth = 25 mean accuracy is 0.98874\nGINI: for maximum depth = 30 mean accuracy is 0.9883600000000001\nENTROPY: for maximum depth = 30 mean accuracy is 0.9888999999999999\n"
]
],
[
[
"# Finding Best Parameters for Decision Tree using Grid Search",
"_____no_output_____"
]
],
[
[
"from sklearn.tree import DecisionTreeClassifier\nfrom sklearn.model_selection import GridSearchCV\n\ndef dtree_grid_search(X,y,nfolds):\n #create a dictionary of all values we want to test\n param_grid = { 'criterion':['gini','entropy'],\n 'max_depth': np.arange(5, 15),\n 'max_leaf_nodes':np.arange(15,30),\n 'min_samples_leaf':np.arange(15,30)\n }\n \n\n # decision tree model\n dtree_model=DecisionTreeClassifier()\n #use gridsearch to test all values\n dtree_gscv = GridSearchCV(dtree_model, param_grid, cv=nfolds)\n #fit model to data\n dtree_gscv.fit(X, y)\n return dtree_gscv.best_params_",
"_____no_output_____"
],
[
"dtree_grid_search(X,y,3)",
"_____no_output_____"
],
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nimport graphviz \nimport pydotplus\nimport io\nfrom scipy import misc\nfrom sklearn import tree\nfrom sklearn.tree import DecisionTreeClassifier,export_graphviz\nfrom sklearn.model_selection import train_test_split\nfrom matplotlib import pyplot as plt\n%matplotlib inline",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"features = ['MWG_Ordinal', 'NWG_Ordinal', 'KWG_Ordinal', 'MDIMC_ordinal',\n 'NDIMC_ordinal', 'MDIMA_ordinal', 'NDIMB_ordinal', 'KWI_ordinal',\n 'VWM_ordinal', 'VWN_ordinal', 'STRM_1', 'STRN_1', 'SA_1', 'SB_1']",
"_____no_output_____"
],
[
"c=DecisionTreeClassifier(criterion='gini',max_depth= 8,max_leaf_nodes= 29,min_samples_leaf=15)\narray_scores = cross_val_score(c,X,y,cv=5)\nAccuracy = array_scores.mean()\nprint(Accuracy)",
"0.94228\n"
],
[
"d_t = c.fit(X,y)",
"_____no_output_____"
],
[
"def show_tree(tree, features, path):\n f = io.StringIO()\n export_graphviz(tree, out_file=f, feature_names=features)\n pydotplus.graph_from_dot_data(f.getvalue()).write_png(path)\n img = misc.imread(path)\n plt.rcParams[\"figure.figsize\"]=(20,20)\n plt.imshow(img)\n ",
"_____no_output_____"
],
[
"show_tree(d_t,features,'DT_Dataset2.png')",
"C:\\Users\\Kamini\\Anaconda3\\lib\\site-packages\\ipykernel_launcher.py:5: DeprecationWarning: `imread` is deprecated!\n`imread` is deprecated in SciPy 1.0.0, and will be removed in 1.2.0.\nUse ``imageio.imread`` instead.\n \"\"\"\n"
],
[
"ADAPTIVE BOOSTING - GRIDSEARCH",
"_____no_output_____"
],
[
"from sklearn.tree import DecisionTreeClassifier\nfrom sklearn.model_selection import GridSearchCV\n\ndef dtree_grid_search(X,y,nfolds):\n #create a dictionary of all values we want to test\n param_grid = { 'criterion':['gini','entropy'],\n 'max_depth': np.arange(5, 15),\n 'max_leaf_nodes':np.arange(15,30),\n 'min_samples_leaf':np.arange(15,30)\n }\n \n\n # decision tree model\n dtree_model=DecisionTreeClassifier()\n Adaboost_e = AdaBoostClassifier(base_estimator=dtree_model,n_estimators=100,learning_rate=1)\n #use gridsearch to test all values\n dtree_gscv = GridSearchCV(dtree_model, param_grid, cv=4)\n #fit model to data\n dtree_gscv.fit(X, y)\n return dtree_gscv.best_params_",
"_____no_output_____"
],
[
"dtree_grid_search(X,y,3)",
"_____no_output_____"
],
[
"c=DecisionTreeClassifier(criterion='gini',max_depth=8 ,max_leaf_nodes=29 ,min_samples_leaf=15)\nAdaboost = AdaBoostClassifier(base_estimator=c,n_estimators=100,learning_rate=1)\narray_scores = cross_val_score(Adaboost,X,y,cv=3)\nAccuracy = array_scores.mean()\nprint(Accuracy)",
"0.9896199915915278\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4a9fcb48dd8d023150851964edbaf06c1a40909a
| 6,538 |
ipynb
|
Jupyter Notebook
|
Tarea_4.ipynb
|
aislinngo/daa_2021_1
|
64cfb7fe2679c48ef98897f7c2ca43f3077dc771
|
[
"MIT"
] | null | null | null |
Tarea_4.ipynb
|
aislinngo/daa_2021_1
|
64cfb7fe2679c48ef98897f7c2ca43f3077dc771
|
[
"MIT"
] | null | null | null |
Tarea_4.ipynb
|
aislinngo/daa_2021_1
|
64cfb7fe2679c48ef98897f7c2ca43f3077dc771
|
[
"MIT"
] | null | null | null | 25.146154 | 226 | 0.313399 |
[
[
[
"<a href=\"https://colab.research.google.com/github/aislinngo/daa_2021_1/blob/master/Tarea_4.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"# Función: 3+log( n ) +1\n\ndef ejemplo4( n ):\n count = 0\n print (\"Nivel 1\")\n i = n\n while i >= 1:\n print (\"Nivel 2\")\n count += 1\n i = i //2\n print (\"Nivel 3\")\n basura = 3 + 2\n print (\"nivel 4\")\n return count\n\nprint(ejemplo4(1), \"\\n\")\nprint(ejemplo4(5), \"\\n\")\nprint(ejemplo4(10), \"\\n\")\nprint(ejemplo4(100), \"\\n\")\nprint(ejemplo4(1000), \"\\n\")\nprint(ejemplo4(10000), \"\\n\")\nprint(ejemplo4(100000), \"\\n\")\nprint(ejemplo4(1000000), \"\\n\")\n\n\n \n",
"Nivel 1\nNivel 2\nNivel 3\nnivel 4\n1 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n3 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n4 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n7 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n10 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n14 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n17 \n\nNivel 1\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nNivel 2\nNivel 3\nnivel 4\n20 \n\n"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
]
] |
4a9fd1602471ff4b99fd231e5b7c1bff87130737
| 17,911 |
ipynb
|
Jupyter Notebook
|
TensorflowInPractice/BasicProblems/Image&HandwritingRecognition/handwritingRecognition.ipynb
|
akashdesale98/TensorflowMaster
|
802bcc8a9fef4d727d02fe5d91295047b4ec0b05
|
[
"MIT"
] | 2 |
2020-07-26T18:33:29.000Z
|
2020-07-27T03:29:36.000Z
|
TensorflowInPractice/BasicProblems/Image&HandwritingRecognition/handwritingRecognition.ipynb
|
akashdesale98/Deep-Learning-Master
|
802bcc8a9fef4d727d02fe5d91295047b4ec0b05
|
[
"MIT"
] | null | null | null |
TensorflowInPractice/BasicProblems/Image&HandwritingRecognition/handwritingRecognition.ipynb
|
akashdesale98/Deep-Learning-Master
|
802bcc8a9fef4d727d02fe5d91295047b4ec0b05
|
[
"MIT"
] | null | null | null | 63.066901 | 5,128 | 0.624812 |
[
[
[
"import tensorflow as tf",
"c:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:523: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:524: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorflow\\python\\framework\\dtypes.py:532: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint8 = np.dtype([(\"qint8\", np.int8, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint8 = np.dtype([(\"quint8\", np.uint8, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint16 = np.dtype([(\"qint16\", np.int16, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_quint16 = np.dtype([(\"quint16\", np.uint16, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n _np_qint32 = np.dtype([(\"qint32\", np.int32, 1)])\nc:\\program files\\python37\\lib\\site-packages\\tensorboard\\compat\\tensorflow_stub\\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.\n np_resource = np.dtype([(\"resource\", np.ubyte, 1)])\n"
],
[
"mnist = tf.keras.datasets.mnist",
"_____no_output_____"
],
[
"(x_train, y_train),(x_test, y_test) = mnist.load_data()",
"Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz\n11493376/11490434 [==============================] - 3s 0us/step\n"
],
[
"model = tf.keras.models.Sequential([\n tf.keras.layers.Flatten(input_shape=(28,28)),\n tf.keras.layers.Dense(512, activation=tf.nn.relu),\n tf.keras.layers.Dense(10, activation=tf.nn.softmax)\n])\nmodel.compile(optimizer='adam',\n loss='sparse_categorical_crossentropy',\n metrics=['accuracy']\n )",
"_____no_output_____"
],
[
"class myCallback(tf.keras.callbacks.Callback):\n def on_epoch_end(self, epoch, logs={}):\n if(logs.get('accuracy')>0.99):\n print(\"\\nReached 99% accuracy so cancelling training!\")\n self.model.stop_training = True",
"_____no_output_____"
],
[
"callbacks = myCallback()",
"_____no_output_____"
],
[
"import numpy as np",
"_____no_output_____"
],
[
"np.set_printoptions(linewidth=200)\nimport matplotlib.pyplot as plt\nplt.imshow(x_train[0])\nprint(y_train[0])\nprint(x_train[0])",
"5\n[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 3 18 18 18 126 136 175 26 166 255 247 127 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 30 36 94 154 170 253 253 253 253 253 225 172 253 242 195 64 0 0 0 0]\n [ 0 0 0 0 0 0 0 49 238 253 253 253 253 253 253 253 253 251 93 82 82 56 39 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 18 219 253 253 253 253 253 198 182 247 241 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 80 156 107 253 253 205 11 0 43 154 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 14 1 154 253 90 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 139 253 190 2 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 11 190 253 70 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 35 241 225 160 108 1 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 81 240 253 253 119 25 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 45 186 253 253 150 27 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 16 93 252 253 187 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 249 253 249 64 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 46 130 183 253 253 207 2 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 39 148 229 253 253 253 250 182 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 24 114 221 253 253 253 253 201 78 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 23 66 213 253 253 253 253 198 81 2 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 18 171 219 253 253 253 253 195 80 9 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 55 172 226 253 253 253 253 244 133 11 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 136 253 253 253 212 135 132 16 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]\n [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]]\n"
],
[
"x_train = x_train / 255.0\nx_test = x_test / 255.0",
"_____no_output_____"
],
[
"model.fit(x_train, y_train, epochs=10, callbacks=[callbacks])",
"Epoch 1/10\n60000/60000 [==============================] - 10s 166us/sample - loss: 0.2017 - accuracy: 0.9403\nEpoch 2/10\n60000/60000 [==============================] - 10s 159us/sample - loss: 0.0816 - accuracy: 0.9744\nEpoch 3/10\n60000/60000 [==============================] - 10s 159us/sample - loss: 0.0519 - accuracy: 0.9838\nEpoch 4/10\n60000/60000 [==============================] - 9s 157us/sample - loss: 0.0359 - accuracy: 0.9890\nEpoch 5/10\n59776/60000 [============================>.] - ETA: 0s - loss: 0.0274 - accuracy: 0.9909\nReached 99% accuracy so cancelling training!\n60000/60000 [==============================] - 9s 157us/sample - loss: 0.0274 - accuracy: 0.9910\n"
],
[
"model.evaluate(x_test, y_test)",
"10000/10000 [==============================] - 1s 80us/sample - loss: 0.0776 - accuracy: 0.9783\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa000e3e01b68318562771638fcb4834317a82f
| 15,012 |
ipynb
|
Jupyter Notebook
|
recipes/Horovod/Horovod/Horovod.ipynb
|
mx-iao/BatchAI
|
fd9452a4d5aadee1cef50f9e513dd84e6ca8b335
|
[
"MIT"
] | null | null | null |
recipes/Horovod/Horovod/Horovod.ipynb
|
mx-iao/BatchAI
|
fd9452a4d5aadee1cef50f9e513dd84e6ca8b335
|
[
"MIT"
] | null | null | null |
recipes/Horovod/Horovod/Horovod.ipynb
|
mx-iao/BatchAI
|
fd9452a4d5aadee1cef50f9e513dd84e6ca8b335
|
[
"MIT"
] | 1 |
2020-09-30T01:43:34.000Z
|
2020-09-30T01:43:34.000Z
| 29.726733 | 266 | 0.604383 |
[
[
[
"# Horovod\n",
"_____no_output_____"
],
[
"## Introduction\n\nThis recipe shows how to run [Horovod](https://github.com/uber/horovod) distributed training framework using Batch AI.\n\nCurrently Batch AI has no native support for Horovod framework, but it's easy to run it using customtoolkit and job preparation command line.\n\n\n## Details\n\n- Standard Horovod [tensorflow_mnist.py](https://github.com/uber/horovod/blob/v0.9.10/examples/tensorflow_mnist.py) example will be used;\n- tensorflow_mnist.py downloads training data on its own during execution;\n- The job will be run on standard tensorflow container tensorflow/tensorflow:1.4.0-gpu;\n- Horovod framework will be installed in the container using job preparation command line. Note, you can build your own docker image containing tensorflow and horovod instead.\n- Standard output of the job will be stored on Azure File Share.",
"_____no_output_____"
],
[
"## Instructions\n\n### Install Dependencies and Create Configuration file.\nFollow [instructions](/recipes) to install all dependencies and create configuration file.",
"_____no_output_____"
],
[
"### Read Configuration and Create Batch AI client",
"_____no_output_____"
]
],
[
[
"from __future__ import print_function\n\nfrom datetime import datetime\nimport sys\n\nfrom azure.storage.file import FileService\nimport azure.mgmt.batchai.models as models\n\n# utilities.py contains helper functions used by different notebooks\nsys.path.append('../../')\nimport utilities\n\ncfg = utilities.Configuration('../../configuration.json')\nclient = utilities.create_batchai_client(cfg)",
"_____no_output_____"
]
],
[
[
"## 1. Prepare Training Dataset and Script in Azure Storage",
"_____no_output_____"
],
[
"### Create File Share\n\nFor this example we will create a new File Share with name `batchaisample` under your storage account. This share will be populated with sample scripts and will contain job's output.\n\n**Note** You don't need to create new file share for every cluster. We are doing this in this sample to simplify resource management for you.",
"_____no_output_____"
]
],
[
[
"azure_file_share_name = 'batchaisample'\nservice = FileService(cfg.storage_account_name, cfg.storage_account_key)\nservice.create_share(azure_file_share_name, fail_on_exist=False)\nprint('Done')",
"_____no_output_____"
]
],
[
[
"### Deploy Sample Script and Configure the Input Directories\n\n- Download original sample script:",
"_____no_output_____"
]
],
[
[
"sample_script_url = 'https://raw.githubusercontent.com/uber/horovod/v0.9.10/examples/tensorflow_mnist.py'\nutilities.download_file(sample_script_url, 'tensorflow_mnist.py')",
"_____no_output_____"
]
],
[
[
"- Create a folder in the file share and upload the sample script to it.",
"_____no_output_____"
]
],
[
[
"samples_dir = 'horovod_samples'\nservice = FileService(cfg.storage_account_name, cfg.storage_account_key)\nservice.create_directory(\n azure_file_share_name, samples_dir, fail_on_exist=False)\nservice.create_file_from_path(\n azure_file_share_name, samples_dir, 'tensorflow_mnist.py', 'tensorflow_mnist.py')",
"_____no_output_____"
]
],
[
[
"## 2. Create Azure Batch AI Compute Cluster",
"_____no_output_____"
],
[
"### Configure Compute Cluster\n\n- For this example we will use a GPU cluster of `STANDARD_NC6` nodes. Number of nodes in the cluster is configured with `nodes_count` variable;\n- We will mount file share at folder with name `afs`. Full path of this folder on a computer node will be `$AZ_BATCHAI_MOUNT_ROOT/afs`;\n- We will call the cluster `nc6`.\n\n\nSo, the cluster will have the following parameters:",
"_____no_output_____"
]
],
[
[
"azure_file_share = 'afs'\nnodes_count = 2\ncluster_name = 'nc6'\n\nvolumes = models.MountVolumes(\n azure_file_shares=[\n models.AzureFileShareReference(\n account_name=cfg.storage_account_name,\n credentials=models.AzureStorageCredentialsInfo(\n account_key=cfg.storage_account_key),\n azure_file_url = 'https://{0}.file.core.windows.net/{1}'.format(\n cfg.storage_account_name, azure_file_share_name),\n relative_mount_path=azure_file_share)\n ]\n)\n\nparameters = models.ClusterCreateParameters(\n location=cfg.location,\n vm_size=\"STANDARD_NC6\",\n virtual_machine_configuration=models.VirtualMachineConfiguration(\n image_reference=models.ImageReference(\n publisher=\"microsoft-ads\",\n offer=\"linux-data-science-vm-ubuntu\",\n sku=\"linuxdsvmubuntu\",\n version=\"latest\")),\n scale_settings=models.ScaleSettings(\n manual=models.ManualScaleSettings(target_node_count=nodes_count)\n ),\n node_setup=models.NodeSetup(\n mount_volumes=volumes\n ),\n user_account_settings=models.UserAccountSettings(\n admin_user_name=cfg.admin,\n admin_user_password=cfg.admin_password,\n admin_user_ssh_public_key=cfg.admin_ssh_key\n )\n)",
"_____no_output_____"
]
],
[
[
"### Create Compute Cluster",
"_____no_output_____"
]
],
[
[
"_ = client.clusters.create(cfg.resource_group, cluster_name, parameters).result()",
"_____no_output_____"
]
],
[
[
"### Monitor Cluster Creation\n\nutilities.py contains a helper function allowing to wait for the cluster to become available - all nodes are allocated and finished preparation.",
"_____no_output_____"
]
],
[
[
"cluster = client.clusters.get(cfg.resource_group, cluster_name)\nutilities.print_cluster_status(cluster)",
"_____no_output_____"
]
],
[
[
"## 3. Run Azure Batch AI Training Job",
"_____no_output_____"
],
[
"### Configure Input Directories\n\nThe job needs to know where to find mnist_replica.py and input MNIST dataset. We will create two input directories for this:\nThe job needs to know where to find train_mnist.py script (the chainer will download MNIST dataset on its own). So, we will configure an input directory for the script:",
"_____no_output_____"
]
],
[
[
"input_directories = [\n models.InputDirectory(\n id='SCRIPTS',\n path='$AZ_BATCHAI_MOUNT_ROOT/{0}/{1}'.format(azure_file_share, samples_dir))]",
"_____no_output_____"
]
],
[
[
"The job will be able to reference those directories using ```$AZ_BATCHAI_INPUT_SCRIPTS``` environment variable.",
"_____no_output_____"
],
[
"### Configure Output Directories\nWe will store standard and error output of the job in File Share:",
"_____no_output_____"
]
],
[
[
"std_output_path_prefix = '$AZ_BATCHAI_MOUNT_ROOT/{0}'.format(azure_file_share)",
"_____no_output_____"
]
],
[
[
"The model output will be stored in File Share:",
"_____no_output_____"
]
],
[
[
"output_directories = [\n models.OutputDirectory(\n id='MODEL',\n path_prefix='$AZ_BATCHAI_MOUNT_ROOT/{0}'.format(azure_file_share),\n path_suffix='Models')]",
"_____no_output_____"
]
],
[
[
"### Configure Job\n\n- Will use configured previously input and output directories;\n- We will use custom toolkit job to run tensorflow_mnist.py on multiple nodes (use node_count parameter to specify number of nodes). Note, Batch AI will create a hostfile for the job, it can be found via ```$AZ_BATCHAI_MPI_HOST_FILE``` environment variable;\n- Horovod framework will be installed by job preparation command line;\n- Will output standard output and error streams to file share.\n\nYou can delete ```container_settings``` from the job definition to run the job directly on host DSVM.",
"_____no_output_____"
]
],
[
[
"parameters = models.job_create_parameters.JobCreateParameters(\n location=cfg.location,\n cluster=models.ResourceId(id=cluster.id),\n node_count=2,\n input_directories=input_directories,\n output_directories=output_directories,\n std_out_err_path_prefix=std_output_path_prefix,\n container_settings=models.ContainerSettings(\n image_source_registry=models.ImageSourceRegistry(image='tensorflow/tensorflow:1.4.0-gpu')),\n job_preparation=models.JobPreparation(\n command_line='apt update; apt install mpi-default-dev mpi-default-bin -y; pip install horovod'),\n custom_toolkit_settings = models.CustomToolkitSettings(\n command_line='mpirun -mca btl_tcp_if_exclude docker0,lo --allow-run-as-root --hostfile $AZ_BATCHAI_MPI_HOST_FILE python $AZ_BATCHAI_INPUT_SCRIPTS/tensorflow_mnist.py'))",
"_____no_output_____"
]
],
[
[
"### Create a training Job and wait for Job completion\n",
"_____no_output_____"
]
],
[
[
"job_name = datetime.utcnow().strftime('horovod_%m_%d_%Y_%H%M%S')\njob = client.jobs.create(cfg.resource_group, job_name, parameters).result()\nprint('Created Job: {}'.format(job.name))",
"_____no_output_____"
]
],
[
[
"### Wait for Job to Finish\nThe job will start running when the cluster will have enough idle nodes. The following code waits for job to start running printing the cluster state. During job run, the code prints current content of stderr.txt.\n\n**Note** Execution may take several minutes to complete.",
"_____no_output_____"
]
],
[
[
"utilities.wait_for_job_completion(client, cfg.resource_group, job_name, cluster_name, 'stdouterr', 'stderr.txt')",
"_____no_output_____"
]
],
[
[
"### Download stdout.txt and stderr.txt files for the Job and job preparation command",
"_____no_output_____"
]
],
[
[
"files = client.jobs.list_output_files(cfg.resource_group, job_name,\n models.JobsListOutputFilesOptions(outputdirectoryid='stdouterr')) \nfor f in list(files):\n if f.download_url:\n utilities.download_file(f.download_url, f.name)\nprint('All files downloaded')",
"_____no_output_____"
]
],
[
[
"## 4. Clean Up (Optional)",
"_____no_output_____"
],
[
"### Delete the Job",
"_____no_output_____"
]
],
[
[
"_ = client.jobs.delete(cfg.resource_group, job_name)",
"_____no_output_____"
]
],
[
[
"### Delete the Cluster\nWhen you are finished with the sample and don't want to submit any more jobs you can delete the cluster using the following code.",
"_____no_output_____"
]
],
[
[
"_= client.clusters.delete(cfg.resource_group, cluster_name)",
"_____no_output_____"
]
],
[
[
"### Delete File Share\nWhen you are finished with the sample and don't want to submit any more jobs you can delete the file share completely with all files using the following code.",
"_____no_output_____"
]
],
[
[
"service = FileService(cfg.storage_account_name, cfg.storage_account_key)\nservice.delete_share(azure_file_share_name)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa01d2cd1ab3b2cb098edd67ffb13abef2684db
| 5,725 |
ipynb
|
Jupyter Notebook
|
pf-training-notebooks/index.ipynb
|
sanger-pathogens/PathFind-training
|
d5081b736179407446fc6bf268057b80e4f2b410
|
[
"CC-BY-4.0"
] | null | null | null |
pf-training-notebooks/index.ipynb
|
sanger-pathogens/PathFind-training
|
d5081b736179407446fc6bf268057b80e4f2b410
|
[
"CC-BY-4.0"
] | 1 |
2021-07-22T15:30:50.000Z
|
2021-07-22T16:21:10.000Z
|
pf-training-notebooks/index.ipynb
|
sanger-pathogens/PathFind-training
|
d5081b736179407446fc6bf268057b80e4f2b410
|
[
"CC-BY-4.0"
] | 1 |
2021-07-23T11:30:15.000Z
|
2021-07-23T11:30:15.000Z
| 34.281437 | 539 | 0.635808 |
[
[
[
"empty"
]
]
] |
[
"empty"
] |
[
[
"empty"
]
] |
4aa01f204b5134ac9fb8e2d61f864b014d5fb20c
| 653,250 |
ipynb
|
Jupyter Notebook
|
2020-1/06.x Subset activation mask (attempted var ellipse visualization).ipynb
|
amolk/AGI-experiments
|
ddb352c884d513ff4d9a843d0901699acb9e39b9
|
[
"MIT"
] | 5 |
2019-08-06T16:27:44.000Z
|
2020-12-12T11:03:39.000Z
|
2020-1/06.x Subset activation mask (attempted var ellipse visualization).ipynb
|
amolk/AGI-experiments
|
ddb352c884d513ff4d9a843d0901699acb9e39b9
|
[
"MIT"
] | null | null | null |
2020-1/06.x Subset activation mask (attempted var ellipse visualization).ipynb
|
amolk/AGI-experiments
|
ddb352c884d513ff4d9a843d0901699acb9e39b9
|
[
"MIT"
] | null | null | null | 653,250 | 653,250 | 0.961953 |
[
[
[
"To aid autoassociative recall (sparse recall using partial pattern), we need to two components -\n1. each pattern remembers a soft mask of the contribution of each \nelement in activating it. For example, if an element varies a lot at high activation levels, that element should be masked out when determining activation. On the other hand, if an element has a very specific value every time the element has high activation, then that element is important and should be considered (masked-in).\n2. Among the masked-in elements for a pattern, even a small subset (say 20%) perfect match should be able to activate the pattern. This can be achieved by considering number of elements that have similarity above a threshold, say 0.9. Sum up similarity of this subset and apply an activation curve that is a sharp sigmoid centered at a value that represents (# of masked-in element) * 0.2 * 0.9.",
"_____no_output_____"
]
],
[
[
"import math\nimport torch\nimport matplotlib.pyplot as plt\nimport pdb\nimport pandas as pd \nimport seaborn as sns \nimport numpy as np\n# import plotly.graph_objects as go\nfrom matplotlib.patches import Ellipse\n\n%matplotlib inline\n\ndevice = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')\nprint(device)",
"cuda:0\n"
],
[
"from sklearn.datasets import load_boston\ndef normalize(df):\n df1 = (df - df.mean())/df.std()\n return df1\n\ndef scale(df):\n min = df.min()\n max = df.max()\n\n df1 = (df - min) / (max - min)\n return df1\n\ndataset = load_boston()\ndataset = pd.DataFrame(dataset.data, columns=dataset.feature_names)\ndataset = pd.DataFrame(np.c_[scale(normalize(dataset['LSTAT'])), scale(normalize(dataset['RM']))], columns = ['LSTAT','RM'])\ndataset = torch.tensor(dataset.to_numpy()).float().to(device)\n\ndataset1 = dataset[dataset[:,0] < 0.33]\ndataset2 = dataset[(dataset[:,0] >= 0.33) & (dataset[:,0] < 0.66)]\ndataset3 = dataset[dataset[:,0] >= 0.66]\n\n# dataset = [[0.25, 0.4], [0.75, 0.75], [0.85, 0.65]]\noriginal_dataset = dataset\nprint(\"dataset\", dataset.shape)\n",
"dataset torch.Size([506, 2])\n"
],
[
"# from https://kornia.readthedocs.io/en/latest/_modules/kornia/utils/grid.html\nfrom typing import Optional\n\ndef create_meshgrid(\n height: int,\n width: int,\n normalized_coordinates: Optional[bool] = True,\n device: Optional[torch.device] = torch.device('cpu')) -> torch.Tensor:\n \"\"\"Generates a coordinate grid for an image.\n\n When the flag `normalized_coordinates` is set to True, the grid is\n normalized to be in the range [-1,1] to be consistent with the pytorch\n function grid_sample.\n http://pytorch.org/docs/master/nn.html#torch.nn.functional.grid_sample\n\n Args:\n height (int): the image height (rows).\n width (int): the image width (cols).\n normalized_coordinates (Optional[bool]): whether to normalize\n coordinates in the range [-1, 1] in order to be consistent with the\n PyTorch function grid_sample.\n\n Return:\n torch.Tensor: returns a grid tensor with shape :math:`(1, H, W, 2)`.\n \"\"\"\n # generate coordinates\n xs: Optional[torch.Tensor] = None\n ys: Optional[torch.Tensor] = None\n if normalized_coordinates:\n xs = torch.linspace(-1, 1, width, device=device, dtype=torch.float)\n ys = torch.linspace(-1, 1, height, device=device, dtype=torch.float)\n else:\n xs = torch.linspace(0, width - 1, width, device=device, dtype=torch.float)\n ys = torch.linspace(0, height - 1, height, device=device, dtype=torch.float)\n # generate grid by stacking coordinates\n base_grid: torch.Tensor = torch.stack(\n torch.meshgrid([xs, ys])).transpose(1, 2) # 2xHxW\n return torch.unsqueeze(base_grid, dim=0).permute(0, 2, 3, 1) # 1xHxWx2\n\ndef add_gaussian_noise(tensor, mean=0., std=1.):\n t = tensor + torch.randn(tensor.size()).to(device) * std + mean\n t.to(device)\n return t\n\ndef plot_patterns(patterns, pattern_lr, pattern_var, dataset):\n patterns = patterns.cpu()\n dataset = dataset.cpu()\n assert len(patterns.shape) == 2 # (pattern count, 2)\n assert patterns.shape[1] == 2 # 2D\n\n rgba_colors = torch.zeros((patterns.shape[0], 4))\n\n # for blue the last column needs to be one\n rgba_colors[:,2] = 1.0\n # the fourth column needs to be your alphas\n alpha = (1.2 - pattern_lr.cpu()).clamp(0, 1) * 0.2\n rgba_colors[:, 3] = alpha\n\n # make ellipses\n marker_list = []\n min_size = 0.02\n max_size = 2.0\n for i in range(patterns.shape[0]):\n pattern = patterns[i]\n var = pattern_var[i].clamp(0.01, 2.0)\n marker_list.append(Ellipse((pattern[0], pattern[1]), var[0], var[1], edgecolor='none', facecolor=rgba_colors[i], fill=True))\n\n plt.figure(figsize=(7,7), dpi=100)\n ax = plt.gca()\n ax.cla() # clear things for fresh plot\n ax.scatter(patterns[:, 0], patterns[:, 1], marker='.', c='b')\n ax.scatter(dataset[:, 0], dataset[:, 1], marker='.', c='r', s=10)\n ax.set_xlim(0, 1)\n ax.set_ylim(0, 1)\n\n for marker in marker_list: \n ax.add_artist(marker)\n\n plt.show()\n\n\ngrid_size = 4\npatterns = create_meshgrid(grid_size, grid_size, normalized_coordinates=False).reshape(-1, 2) / (grid_size-1)\npatterns = patterns.to(device)\npattern_lr = torch.ones((patterns.shape[0],)).to(device)\npattern_var = torch.ones_like(patterns).to(device) * 0 # start with high var indicating no specificity to any value\n\n# patterns = torch.rand((50, 2))\n\n# patterns = torch.tensor([[0.25, 0.30]])\n\n# patterns\nplot_patterns(patterns, pattern_lr, pattern_var, dataset)\n\noriginal_patterns = patterns.clone().to(device)",
"_____no_output_____"
],
[
"def similarity(x, patterns, subset_threshold=0.2):\n # Formula derivation https://www.desmos.com/calculator/iokn9kyuaq\n # print(\"x\", x)\n dist_i = ((x - patterns) ** 2)\n dist = dist_i.sum(dim=-1)\n # print(\"patterns\", patterns)\n # print(\"dist\", dist)\n #dist = dist.sum(dim=-1) # TODO: use subset activation # TODO: apply mask (inverse variance)\n winner_index = dist.min(dim=0)[1]\n # print(\"winner_index\", winner_index)\n\n winning_pattern = patterns[winner_index]\n a_scale = 0.2\n a = a_scale * ((x - winning_pattern) ** -2)\n a[a > 15000.0] = 15000.0\n # print(\"a\", a)\n s = 0.8\n sim = (-a * ((x - patterns) ** 2)).mean(dim=-1)\n # print(\"sim1\", sim)\n # scale = 0.685\n scale = 1.0\n sim = (torch.exp(sim) - s * torch.exp(sim * 0.9)) / ((1 - s) * scale)\n sim[sim>1.0] = 1.0\n\n # print(\"sim\", sim)\n\n return sim, winner_index, dist, dist_i\n\nsim, winner_index, dist, dist_i = similarity(dataset[0], patterns)",
"_____no_output_____"
],
[
"patterns = original_patterns\npattern_lr = torch.ones((patterns.shape[0],)).to(device)\npattern_var = torch.ones_like(patterns).to(device) * 10 # start with high var indicating no specificity to any value\n\ndef run_dataset(dataset, patterns, pattern_lr):\n for x in dataset:\n # print(\"-------\")\n sim, winner_index, dist, dist_i = similarity(x, patterns)\n sim = sim.unsqueeze(-1)\n # print(\"dist[winner_index]\", dist[winner_index] * 100)\n pattern_lr[winner_index] = 0.9 * pattern_lr[winner_index] + 0.1 * (1.0 - torch.exp(-dist[winner_index]))\n pattern_var[winner_index] = 0.9 * pattern_var[winner_index] + 0.1 * (1.0 - torch.exp(-dist_i[winner_index])) * 100\n\n # print(\"x\", x)\n # print(\"(x - patterns)\", (x - patterns))\n # print(\"sim\", sim)\n delta = (x - patterns) * sim * lr * pattern_lr.unsqueeze(-1)\n # print(\"delta\", delta)\n patterns = patterns + delta\n\n patterns.clamp_(0, 1)\n pattern_lr.clamp(0, 1)\n # print(\"patterns\", patterns)\n # print(\"pattern_lr\", pattern_lr)\n # print(\"pattern_var\", pattern_var)\n return patterns, pattern_lr\n\nlr = 1\nepochs = 10\nnoise = 0.0\nfor _ in range(2):\n for i in range(epochs):\n dataset = add_gaussian_noise(dataset1, std=noise)\n if i % int(epochs / 2) == 0:\n print(\"Iteration \", i)\n plot_patterns(patterns, pattern_lr, pattern_var, dataset)\n patterns, pattern_lr = run_dataset(dataset, patterns, pattern_lr)\n\n for i in range(epochs):\n dataset = add_gaussian_noise(dataset2, std=noise)\n if i % int(epochs / 2) == 0:\n print(\"Iteration \", i)\n plot_patterns(patterns, pattern_lr, pattern_var, dataset)\n patterns, pattern_lr = run_dataset(dataset, patterns, pattern_lr)\n\n for i in range(epochs):\n dataset = add_gaussian_noise(dataset3, std=noise)\n if i % int(epochs / 2) == 0:\n print(\"Iteration \", i)\n plot_patterns(patterns, pattern_lr, pattern_var, dataset)\n patterns, pattern_lr = run_dataset(dataset, patterns, pattern_lr)\n\n",
"Iteration 0\n"
],
[
"plot_patterns(patterns, pattern_lr, pattern_var, original_dataset)",
"_____no_output_____"
]
],
[
[
"Notes -\n\n- Patterns that see data (are winners) become \"sticky\", while rest of the pattern-pool remains more fluid to move towards subspaces that were previously unused. For example, learning an unrelated task. This could implications on meta-learning.\n\n- Available pattern pool gets used to locally optimally represent data. This can be seen by using a small number of patterns (say 3x3) or a large number of patterns (say 100x100). The fact that a dense grid is not required should come in handy to fight the curse of dimentionality.",
"_____no_output_____"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
]
] |
4aa021a7ef08f04e132b84c57f1b77a11ad2ab70
| 851,555 |
ipynb
|
Jupyter Notebook
|
notebooks/other/FSharp.Charting/FSharp.Charting.FurtherSamples.ipynb
|
SpaceAntelope/IfCntk
|
81868163c8c7ba52b8646b7c0baae9a56e006ade
|
[
"MIT"
] | 5 |
2019-01-31T13:18:24.000Z
|
2021-11-15T10:43:13.000Z
|
notebooks/other/FSharp.Charting/FSharp.Charting.FurtherSamples.ipynb
|
SpaceAntelope/IfCntk
|
81868163c8c7ba52b8646b7c0baae9a56e006ade
|
[
"MIT"
] | null | null | null |
notebooks/other/FSharp.Charting/FSharp.Charting.FurtherSamples.ipynb
|
SpaceAntelope/IfCntk
|
81868163c8c7ba52b8646b7c0baae9a56e006ade
|
[
"MIT"
] | null | null | null | 475.198103 | 63,018 | 0.942582 |
[
[
[
"Original samples in https://fslab.org/FSharp.Charting/FurtherSamples.html",
"_____no_output_____"
]
],
[
[
"#load \"FSharp.Charting.Paket.fsx\"\n#load \"FSharp.Charting.fsx\"",
"_____no_output_____"
]
],
[
[
"## Sample data",
"_____no_output_____"
]
],
[
[
"open FSharp.Charting\nopen System\nopen System.Drawing\n\nlet data = [ for x in 0 .. 99 -> (x,x*x) ]\nlet data2 = [ for x in 0 .. 99 -> (x,sin(float x / 10.0)) ]\nlet data3 = [ for x in 0 .. 99 -> (x,cos(float x / 10.0)) ]\nlet timeSeriesData = \n [ for x in 0 .. 99 -> (DateTime.Now.AddDays (float x),sin(float x / 10.0)) ]\n\nlet rnd = new System.Random()\nlet rand() = rnd.NextDouble()\nlet pointsWithSizes = \n [ for i in 0 .. 30 -> (rand() * 10.0, rand() * 10.0, rand() / 100.0) ]\nlet pointsWithSizes2 = \n [ for i in 0 .. 10 -> (rand() * 10.0, rand() * 10.0, rand() / 100.0) ]\n\nlet timeHighLowOpenClose = \n [ for i in 0 .. 10 ->\n let mid = rand() * 10.0 \n (DateTime.Now.AddDays (float i), mid + 0.5, mid - 0.5, mid + 0.25, mid - 0.25) ]\nlet timedPointsWithSizes = \n [ for i in 0 .. 30 -> (DateTime.Now.AddDays(rand() * 10.0), rand() * 10.0, rand() / 100.0) ]",
"_____no_output_____"
]
],
[
[
"## Examples",
"_____no_output_____"
]
],
[
[
"Chart.Line(data).WithXAxis(MajorGrid=ChartTypes.Grid(Enabled=false))",
"_____no_output_____"
],
[
"Chart.Line [ DateTime.Now, 1; DateTime.Now.AddDays(1.0), 10 ]",
"_____no_output_____"
],
[
"Chart.Line [ for h in 1 .. 50 -> DateTime.Now.AddHours(float h), sqrt (float h) ]",
"_____no_output_____"
],
[
"Chart.Line [ for h in 1 .. 50 -> DateTime.Now.AddMinutes(float h), sqrt (float h) ]",
"_____no_output_____"
],
[
"Chart.Line(data,Title=\"Test Title\")",
"_____no_output_____"
],
[
"Chart.Line(data,Title=\"Test Title\").WithTitle(InsideArea=false)",
"_____no_output_____"
],
[
"Chart.Line(data,Title=\"Test Title\").WithTitle(InsideArea=true)",
"_____no_output_____"
],
[
"Chart.Line(data,Title=\"Test Title\")\n |> Chart.WithTitle(InsideArea=true)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\")\n |> Chart.WithXAxis(Enabled=true,Title=\"X Axis\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\") \n |> Chart.WithXAxis(Enabled=false,Title=\"X Axis\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\")\n .WithXAxis(Enabled=false,Title=\"X Axis\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\")\n .WithXAxis(Enabled=true,Title=\"X Axis\",Max=10.0, Min=0.0)\n .WithYAxis(Max=100.0,Min=0.0)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(Title=\"Hello\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(Title=\"Hello\",Enabled=false)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").With3D()\n\n// TODO: x/y axis labels are a bit small by default",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\",XTitle=\"hello\", YTitle=\"goodbye\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithXAxis(Title=\"XXX\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithXAxis(Title=\"XXX\",Max=10.0,Min=4.0)\n .WithYAxis(Title=\"YYY\",Max=100.0,Min=4.0,Log=true)",
"_____no_output_____"
],
[
"Chart.Combine [ Chart.Line(data,Name=\"Test Data 1 With Long Name\")\n Chart.Line(data2,Name=\"Test Data 2\") ] \n |> Chart.WithLegend(Enabled=true,Title=\"Hello\",Docking=ChartTypes.Docking.Left)",
"_____no_output_____"
],
[
"Chart.Combine [ Chart.Line(data,Name=\"Test Data 1\")\n Chart.Line(data2,Name=\"Test Data 2\") ] \n |> Chart.WithLegend(Docking=ChartTypes.Docking.Left, InsideArea=true)",
"_____no_output_____"
],
[
"Chart.Combine [ Chart.Line(data,Name=\"Test Data 1\")\n Chart.Line(data2,Name=\"Test Data 2\") ] \n |> Chart.WithLegend(InsideArea=true)",
"_____no_output_____"
],
[
"Chart.Rows \n [ Chart.Line(data,Title=\"Chart 1\", Name=\"Test Data 1\")\n Chart.Line(data2,Title=\"Chart 2\", Name=\"Test Data 2\") ] \n |> Chart.WithLegend(Title=\"Hello\",Docking=ChartTypes.Docking.Left)\n\n // TODO: this title and docking left doesn't work",
"_____no_output_____"
],
[
"Chart.Columns\n [ Chart.Line(data,Name=\"Test Data 1\")\n Chart.Line(data2,Name=\"Test Data 2\")]\n |> Chart.WithLegend(Title=\"Hello\",Docking=ChartTypes.Docking.Left)",
"_____no_output_____"
],
[
"Chart.Combine [ Chart.Line(data,Name=\"Test Data 1\")\n Chart.Line(data2,Name=\"Test Data 2\") ] \n |> Chart.WithLegend(Title=\"Hello\",Docking=ChartTypes.Docking.Bottom)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\")",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(Enabled=false)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(InsideArea=true)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(InsideArea=false)",
"_____no_output_____"
],
[
"Chart.Line(data).WithLegend().CopyAsBitmap()",
"_____no_output_____"
],
[
"Chart.Line(data)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"Test Data\").WithLegend(InsideArea=false)",
"_____no_output_____"
],
[
"Chart.Area(data)",
"_____no_output_____"
],
[
"Chart.Area(timeSeriesData)",
"_____no_output_____"
],
[
"Chart.Line(data)",
"_____no_output_____"
],
[
"Chart.Bar(data)",
"_____no_output_____"
],
[
"Chart.Bar(timeSeriesData)",
"_____no_output_____"
],
[
"Chart.Spline(data)",
"_____no_output_____"
],
[
"Chart.Spline(timeSeriesData)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Star10)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Diamond)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Cross,Color=Color.Red)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Cross,Color=Color.Red,MaxPixelPointWidth=3)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Cross,Size=3)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Cross,PointWidth=0.1)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes)\n .WithMarkers(Style=ChartTypes.MarkerStyle.Cross,PixelPointWidth=3)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes).WithMarkers(Style=ChartTypes.MarkerStyle.Circle)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes).WithMarkers(Style=ChartTypes.MarkerStyle.Square)",
"_____no_output_____"
],
[
"Chart.Bubble(pointsWithSizes).WithMarkers(Style=ChartTypes.MarkerStyle.Star6)",
"_____no_output_____"
],
[
"Chart.Combine [ Chart.Bubble(pointsWithSizes,UseSizeForLabel=true) .WithMarkers(Style=ChartTypes.MarkerStyle.Circle)\n Chart.Bubble(pointsWithSizes2).WithMarkers(Style=ChartTypes.MarkerStyle.Star10) ]",
"_____no_output_____"
],
[
"Chart.Bubble(timedPointsWithSizes)",
"_____no_output_____"
],
[
"Chart.Candlestick(timeHighLowOpenClose)",
"_____no_output_____"
],
[
"Chart.Column(data)",
"_____no_output_____"
],
[
"Chart.Column(timeSeriesData)",
"_____no_output_____"
],
[
"Chart.Pie(Name=\"Pie\", data=[ for i in 0 .. 10 -> i, i*i ])",
"_____no_output_____"
],
[
"Chart.Pie(Name=\"Pie\", data=timeSeriesData)",
"_____no_output_____"
],
[
"Chart.Doughnut(data=[ for i in 0 .. 10 -> i, i*i ])",
"_____no_output_____"
],
[
"Chart.Doughnut(timeSeriesData)",
"_____no_output_____"
],
[
"Chart.FastPoint [ for x in 1 .. 10000 -> (rand(), rand()) ]",
"_____no_output_____"
],
[
"Chart.FastPoint timeSeriesData",
"_____no_output_____"
],
[
"Chart.Polar ([ for x in 1 .. 100 -> (360.0*rand(), rand()) ] |> Seq.sortBy fst)",
"_____no_output_____"
],
[
"Chart.Pyramid ([ for x in 1 .. 100 -> (360.0*rand(), rand()) ] |> Seq.sortBy fst)",
"_____no_output_____"
],
[
"Chart.Radar ([ for x in 1 .. 100 -> (360.0*rand(), rand()) ] |> Seq.sortBy fst)",
"_____no_output_____"
],
[
"Chart.Range ([ for x in 1.0 .. 10.0 -> (x, x + rand(), x-rand()) ])",
"_____no_output_____"
],
[
"Chart.RangeBar ([ for x in 1.0 .. 10.0 -> (x, x + rand(), x-rand()) ])",
"_____no_output_____"
],
[
"Chart.RangeColumn ([ for x in 1.0 .. 10.0 -> (x, x + rand(), x-rand()) ])",
"_____no_output_____"
],
[
"Chart.SplineArea ([ for x in 1.0 .. 10.0 -> (x, x + rand()) ])",
"_____no_output_____"
],
[
"Chart.SplineRange ([ for x in 1.0 .. 10.0 -> (x, x + rand(), x - rand()) ])",
"_____no_output_____"
],
[
"Chart.StackedBar ([ [ for x in 1.0 .. 10.0 -> (x, x + rand()) ]; \n [ for x in 1.0 .. 10.0 -> (x, x + rand()) ] ])",
"_____no_output_____"
],
[
"Chart.StackedColumn ([ [ for x in 1.0 .. 10.0 -> (x, x + rand()) ]; \n [ for x in 1.0 .. 10.0 -> (x, x + rand()) ] ])",
"_____no_output_____"
],
[
"Chart.StackedArea ([ [ for x in 1.0 .. 10.0 -> (x, x + rand()) ]; \n [ for x in 1.0 .. 10.0 -> (x, x + rand()) ] ])",
"_____no_output_____"
],
[
"Chart.StackedArea ([ [ for x in 1.0 .. 10.0 -> (DateTime.Now.AddDays x, x + rand()) ]; \n [ for x in 1.0 .. 10.0 -> (DateTime.Now.AddDays x, x + rand()) ] ])",
"_____no_output_____"
],
[
"Chart.StepLine(data,Name=\"Test Data\").WithLegend(InsideArea=false)",
"_____no_output_____"
],
[
"Chart.StepLine(timeSeriesData,Name=\"Test Data\").WithLegend(InsideArea=false)",
"_____no_output_____"
],
[
"Chart.Line(data,Name=\"SomeData\").WithDataPointLabels(PointToolTip=\"Hello, I am #SERIESNAME\")",
"_____no_output_____"
],
[
"Chart.Stock(timeHighLowOpenClose)",
"_____no_output_____"
],
[
"Chart.ThreeLineBreak(data,Name=\"SomeData\").WithDataPointLabels(PointToolTip=\"Hello, I am #SERIESNAME\")",
"_____no_output_____"
],
[
"Chart.Histogram([for x in 1 .. 100 -> rand()*10.],LowerBound=0.,UpperBound=10.,Intervals=10.)",
"_____no_output_____"
],
[
"// Example of .ApplyToChart() used to alter the settings on the window chart and to access the chart child objects.\n// This can normally be done manually, in the chart property grid (right click the chart, then \"Show Property Grid\"). \n// This is useful when you want to try out carious settings first. But once you know what you want, .ApplyToChart() \n// allows programmatic access to the window properties. The two examples below are: IsUserSelectionEnabled essentially \n// allows zooming in and out along the given axes, and the longer fiddly example below does the same work as .WithDataPointLabels() \n// but across all series objects.\n[ Chart.Column(data); \n Chart.Column(data2) |> Chart.WithSeries.AxisType( YAxisType = Windows.Forms.DataVisualization.Charting.AxisType.Secondary ) ]\n|> Chart.Combine\n|> fun c -> c.WithLegend()\n .ApplyToChart( fun c -> c.ChartAreas.[0].CursorX.IsUserSelectionEnabled <- true )\n .ApplyToChart( fun c -> let _ = [0 .. c.Series.Count-1] |> List.map ( fun s -> c.Series.[ s ].ToolTip <- \"#SERIESNAME (#VALX, #VAL{0:00000})\" ) in () )",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa034b7c01623be0d4f03a802c800e6ff80f537
| 978,623 |
ipynb
|
Jupyter Notebook
|
ch02/API_Data_Extraction.ipynb
|
c-w-m/btap
|
6f96f599df1fbeb7dcffa3a4f3e5e584e9df67f0
|
[
"Apache-2.0"
] | null | null | null |
ch02/API_Data_Extraction.ipynb
|
c-w-m/btap
|
6f96f599df1fbeb7dcffa3a4f3e5e584e9df67f0
|
[
"Apache-2.0"
] | null | null | null |
ch02/API_Data_Extraction.ipynb
|
c-w-m/btap
|
6f96f599df1fbeb7dcffa3a4f3e5e584e9df67f0
|
[
"Apache-2.0"
] | null | null | null | 596.721341 | 785,708 | 0.941053 |
[
[
[
"<a href=\"https://colab.research.google.com/github/c-w-m/btap/blob/master/ch02/API_Data_Extraction.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
],
[
"Original source: [**Blueprints for Text Analysis Using Python**](https://github.com/blueprints-for-text-analytics-python/blueprints-text)<br>\nJens Albrecht, Sidharth Ramachandran, Christian Winkler\n\n# Chapter 2: API Data Extraction<div class='tocSkip'/>",
"_____no_output_____"
],
[
"## Remark<div class='tocSkip'/>\n\nThe code in this notebook differs slightly from the printed book. For example we frequently use pretty print (`pp.pprint`) instead of `print` and `tqdm`'s `progress_apply` instead of Pandas' `apply`. \n\nMoreover, several layout and formatting commands, like `figsize` to control figure size or subplot commands are removed in the book.\n\nYou may also find some lines marked with three hashes ###. Those are not in the book as well as they don't contribute to the concept.\n\nAll of this is done to simplify the code in the book and put the focus on the important parts instead of formatting.",
"_____no_output_____"
],
[
"## Setup<div class='tocSkip'/>\n\nSet directory locations. If working on Google Colab: copy files and install required libraries.",
"_____no_output_____"
]
],
[
[
"import sys, os\nON_COLAB = 'google.colab' in sys.modules\n\nif ON_COLAB:\n GIT_ROOT = 'https://github.com/c-w-m/btap/raw/master'\n os.system(f'wget {GIT_ROOT}/ch02/setup.py')\n\n%run -i setup.py",
"You are working on Google Colab.\nFiles will be downloaded to \"/content\".\nDownloading required files ...\n!wget -P /content https://github.com/c-w-m/btap/raw/master/settings.py\n!wget -P /content/packages/blueprints https://github.com/c-w-m/btap/raw/master/packages/blueprints/exploration.py\n!wget -P /content/ch02 https://github.com/c-w-m/btap/raw/master/ch02/requirements.txt\n!wget -P /content/ch02 https://github.com/c-w-m/btap/raw/master/ch02/Tweets_01:01:36.656960.txt\n\nAdditional setup ...\n!pip install -r ch02/requirements.txt\n!python -m nltk.downloader stopwords\n"
]
],
[
[
"## Load Python Settings<div class=\"tocSkip\"/>\n\nCommon imports, defaults for formatting in Matplotlib, Pandas etc.",
"_____no_output_____"
]
],
[
[
"%run \"$BASE_DIR/settings.py\"\n\nif ON_COLAB:\n %reload_ext autoreload\n %autoreload 2\n\n%config InlineBackend.figure_format = 'png'\n\n# to print output of all statements and not just the last\nfrom IPython.core.interactiveshell import InteractiveShell\nInteractiveShell.ast_node_interactivity = \"all\"\n\n# otherwise text between $ signs will be interpreted as formula and printed in italic\npd.set_option('display.html.use_mathjax', False)\n\n# path to import blueprints packages\nsys.path.append(BASE_DIR + '/packages')",
"_____no_output_____"
],
[
"# adjust matplotlib resolution for book version\nmatplotlib.rcParams.update({'figure.dpi': 200 })",
"_____no_output_____"
]
],
[
[
"# How to use APIs to extract and derive insights from text data",
"_____no_output_____"
],
[
"# Application Programming Interface",
"_____no_output_____"
],
[
"# Blueprint - Extracting data from an API using the requests module",
"_____no_output_____"
]
],
[
[
"import requests\n\nresponse = requests.get('https://api.github.com/repositories',\n headers={'Accept': 'application/vnd.github.v3+json'})\nprint(response.status_code)",
"200\n"
],
[
"print('encoding: {}'.format(response.encoding))\nprint('Content-Type: {}'.format(response.headers['Content-Type']))\nprint('server: {}'.format(response.headers['server']))",
"encoding: utf-8\nContent-Type: application/json; charset=utf-8\nserver: GitHub.com\n"
],
[
"response.headers",
"_____no_output_____"
],
[
"import json\nprint(json.dumps(response.json()[0], indent=2)[:200])",
"{\n \"id\": 1,\n \"node_id\": \"MDEwOlJlcG9zaXRvcnkx\",\n \"name\": \"grit\",\n \"full_name\": \"mojombo/grit\",\n \"private\": false,\n \"owner\": {\n \"login\": \"mojombo\",\n \"id\": 1,\n \"node_id\": \"MDQ6VXNlcjE=\",\n\n"
],
[
"response = requests.get('https://api.github.com/search/repositories')\nprint(response.status_code)",
"422\n"
],
[
"response = requests.get('https://api.github.com/search/repositories',\n params={'q': 'data_science+language:python'},\n headers={'Accept': 'application/vnd.github.v3.text-match+json'})\nprint(response.status_code)",
"200\n"
],
[
"from IPython.display import Markdown, display ###\ndef printmd(string): ###\n display(Markdown(string)) ###\n\nfor item in response.json()['items'][:5]:\n printmd('**' + item['name'] + '**' + ': repository ' +\n item['text_matches'][0]['property'] + ' - \\\"*' +\n item['text_matches'][0]['fragment'] + '*\\\" matched with ' + '**' +\n item['text_matches'][0]['matches'][0]['text'] + '**')",
"_____no_output_____"
],
[
"response = requests.get(\n 'https://api.github.com/repos/pytorch/pytorch/issues/comments')\nprint('Response Code', response.status_code)\nprint('Number of comments', len(response.json()))",
"Response Code 200\nNumber of comments 30\n"
],
[
"response.links",
"_____no_output_____"
],
[
"def get_all_pages(url, params=None, headers=None):\n output_json = []\n response = requests.get(url, params=params, headers=headers)\n if response.status_code == 200:\n output_json = response.json()\n if 'next' in response.links:\n next_url = response.links['next']['url']\n if next_url is not None:\n output_json += get_all_pages(next_url, params, headers)\n return output_json\n\n\nout = get_all_pages(\n \"https://api.github.com/repos/pytorch/pytorch/issues/comments\",\n params={\n 'since': '2020-07-01T10:00:01Z',\n 'sorted': 'created',\n 'direction': 'desc'\n },\n headers={'Accept': 'application/vnd.github.v3+json'})\ndf = pd.DataFrame(out)",
"_____no_output_____"
],
[
"pd.set_option('display.max_colwidth', -1)\nif ('body' in df.index):\n print(df['body'].count())\n print(df[['id','created_at','body']].sample(1, random_state=42))",
"_____no_output_____"
],
[
"response = requests.head(\n 'https://api.github.com/repos/pytorch/pytorch/issues/comments')\nprint('X-Ratelimit-Limit', response.headers['X-Ratelimit-Limit'])\nprint('X-Ratelimit-Remaining', response.headers['X-Ratelimit-Remaining'])\n\n# Converting UTC time to human-readable format\nimport datetime\nprint(\n 'Rate Limits reset at',\n datetime.datetime.fromtimestamp(int(\n response.headers['X-RateLimit-Reset'])).strftime('%c'))",
"X-Ratelimit-Limit 60\nX-Ratelimit-Remaining 56\nRate Limits reset at Wed Apr 21 07:51:16 2021\n"
],
[
"from datetime import datetime\nimport time\n\ndef handle_rate_limits(response):\n now = datetime.now()\n reset_time = datetime.fromtimestamp(\n int(response.headers['X-RateLimit-Reset']))\n remaining_requests = response.headers['X-Ratelimit-Remaining']\n remaining_time = (reset_time - now).total_seconds()\n intervals = remaining_time / (1.0 + int(remaining_requests))\n print('Sleeping for', intervals)\n time.sleep(intervals)\n return True",
"_____no_output_____"
],
[
"from requests.adapters import HTTPAdapter\nfrom requests.packages.urllib3.util.retry import Retry\n\nretry_strategy = Retry(\n total=5,\n status_forcelist=[500, 503, 504],\n backoff_factor=1\n)\n\nretry_adapter = HTTPAdapter(max_retries=retry_strategy)\n\nhttp = requests.Session()\nhttp.mount(\"https://\", retry_adapter)\nhttp.mount(\"http://\", retry_adapter)\n\nresponse = http.get('https://api.github.com/search/repositories',\n params={'q': 'data_science+language:python'})\n\nfor item in response.json()['items'][:5]:\n print(item['name'])",
"data-science-from-scratch\ndata-science-blogs\ndata-scientist-roadmap\ngalaxy\ndsp\n"
],
[
"from requests.adapters import HTTPAdapter\nfrom requests.packages.urllib3.util.retry import Retry\n\nretry_strategy = Retry(\n total=5,\n status_forcelist=[500, 503, 504],\n backoff_factor=1\n)\n\nretry_adapter = HTTPAdapter(max_retries=retry_strategy)\n\nhttp = requests.Session()\nhttp.mount(\"https://\", retry_adapter)\nhttp.mount(\"http://\", retry_adapter)\n\ndef get_all_pages(url, param=None, header=None):\n output_json = []\n response = http.get(url, params=param, headers=header)\n if response.status_code == 200:\n output_json = response.json()\n if 'next' in response.links:\n next_url = response.links['next']['url']\n if (next_url is not None) and (handle_rate_limits(response)): \n output_json += get_all_pages(next_url, param, header)\n return output_json",
"_____no_output_____"
],
[
"out = get_all_pages(\"https://api.github.com/repos/pytorch/pytorch/issues/comments\", param={'since': '2020-04-01T00:00:01Z'})\ndf = pd.DataFrame(out)",
"_____no_output_____"
]
],
[
[
"# Blueprint - Extracting Twitter data with Tweepy",
"_____no_output_____"
]
],
[
[
"import tweepy\n\napp_api_key = 'YOUR_APP_KEY_HERE' \napp_api_secret_key = 'YOUR_APP_SECRET_HERE'\n\napp_api_key = 'CWIBFKPrcOU4GsdRr6J5fpaps'\napp_api_secret_key = 'SghP0LINUECDj0PzIi1vmDfRtNopqJNfb5xd3fH7XpO9ZaEtme'\n\nauth = tweepy.AppAuthHandler(app_api_key, app_api_secret_key)\napi = tweepy.API(auth)\n\nprint('API Host: {}'.format(api.host))\nprint('API Version: {}'.format(api.api_root))",
"API Host: api.twitter.com\nAPI Version: /1.1\n"
],
[
"pd.set_option('display.max_colwidth', None)\nsearch_term = 'cryptocurrency'\n\ntweets = tweepy.Cursor(api.search,\n q=search_term,\n lang=\"en\").items(100)\n\nretrieved_tweets = [tweet._json for tweet in tweets]\ndf = pd.json_normalize(retrieved_tweets)\n\ndf[['text']].sample(3)",
"_____no_output_____"
],
[
"api = tweepy.API(auth,\n wait_on_rate_limit=True,\n wait_on_rate_limit_notify=True,\n retry_count=5,\n retry_delay=10)\n\nsearch_term = 'cryptocurrency OR crypto -filter:retweets'\n\ntweets = tweepy.Cursor(api.search,\n q=search_term,\n lang=\"en\",\n tweet_mode='extended',\n count=30).items(12000)\n\n# Note: the following code might return 'Rate limit reached. Sleeping for: 750\nretrieved_tweets = [tweet._json for tweet in tweets]\n\ndf = pd.json_normalize(retrieved_tweets)\nprint('Number of retrieved tweets {}'.format(len(df)))",
"Number of retrieved tweets 12000\n"
],
[
"df[['created_at','full_text','entities.hashtags']].sample(2)",
"_____no_output_____"
],
[
"def extract_entities(entity_list):\n entities = set()\n if len(entity_list) != 0:\n for item in entity_list:\n for key,value in item.items():\n if key == 'text':\n entities.add(value.lower())\n return list(entities)",
"_____no_output_____"
],
[
"df['Entities'] = df['entities.hashtags'].apply(extract_entities)\npd.Series(np.concatenate(df['Entities'])).value_counts()[:25].plot(kind='barh')",
"_____no_output_____"
],
[
"api = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)\n\ntweets = tweepy.Cursor(api.user_timeline,\n screen_name='MercedesAMGF1',\n lang=\"en\",\n tweet_mode='extended',\n count=100).items(5000)\n\nretrieved_tweets = [tweet._json for tweet in tweets]\ndf = pd.io.json.json_normalize(retrieved_tweets)\nprint('Number of retrieved tweets {}'.format(len(df)))",
"Number of retrieved tweets 3248\n"
],
[
"def get_user_timeline(screen_name):\n api = tweepy.API(auth,\n wait_on_rate_limit=True,\n wait_on_rate_limit_notify=True)\n tweets = tweepy.Cursor(api.user_timeline,\n screen_name=screen_name,\n lang=\"en\",\n tweet_mode='extended',\n count=200).items()\n retrieved_tweets = [tweet._json for tweet in tweets]\n df = pd.io.json.json_normalize(retrieved_tweets)\n df = df[~df['retweeted_status.id'].isna()]\n return df",
"_____no_output_____"
],
[
"df_mercedes = get_user_timeline('MercedesAMGF1')\nprint('Number of Tweets from Mercedes {}'.format(len(df_mercedes)))\ndf_ferrari = get_user_timeline('ScuderiaFerrari')\nprint('Number of Tweets from Ferrari {}'.format(len(df_ferrari)))",
"Number of Tweets from Mercedes 143\nNumber of Tweets from Ferrari 88\n"
],
[
"import regex as re\nimport nltk\nfrom collections import Counter\nfrom wordcloud import WordCloud\n\nstopwords = set(nltk.corpus.stopwords.words('english'))\nRE_LETTER = re.compile(r'\\b\\p{L}{2,}\\b')\n\ndef tokenize(text):\n return RE_LETTER.findall(text)\n\ndef remove_stop(tokens):\n return [t for t in tokens if t.lower() not in stopwords]\n\npipeline = [str.lower, tokenize, remove_stop]\n\ndef prepare(text):\n tokens = text\n for transform in pipeline:\n tokens = transform(tokens)\n return tokens\n\ndef count_words(df, column='tokens', preprocess=None, min_freq=2):\n\n # process tokens and update counter\n def update(doc):\n tokens = doc if preprocess is None else preprocess(doc)\n counter.update(tokens)\n\n # create counter and run through all data\n counter = Counter()\n df[column].map(update)\n\n # transform counter into data frame\n freq_df = pd.DataFrame.from_dict(counter, orient='index', columns=['freq'])\n freq_df = freq_df.query('freq >= @min_freq')\n freq_df.index.name = 'token'\n \n return freq_df.sort_values('freq', ascending=False)\n\ndef wordcloud(word_freq, title=None, max_words=200, stopwords=None):\n\n wc = WordCloud(width=800, height=400, \n background_color= \"black\", colormap=\"Paired\", \n max_font_size=150, max_words=max_words)\n \n # convert data frame into dict\n if type(word_freq) == pd.Series:\n counter = Counter(word_freq.fillna(0).to_dict())\n else:\n counter = word_freq\n\n # filter stop words in frequency counter\n if stopwords is not None:\n counter = {token:freq for (token, freq) in counter.items() \n if token not in stopwords}\n wc.generate_from_frequencies(counter)\n \n plt.title(title) \n\n plt.imshow(wc, interpolation='bilinear')\n plt.axis(\"off\")",
"_____no_output_____"
],
[
"def wordcloud_blueprint(df, colName, max_words, num_stopwords):\n # Step 1: Convert input text column into tokens\n df['tokens'] = df[colName].map(prepare)\n \n # Step 2: Determine the frequency of each of the tokens\n freq_df = count_words(df)\n \n # Step 3: Generate the wordcloud using the frequencies controlling for stopwords\n wordcloud(freq_df['freq'], max_words, stopwords=freq_df.head(num_stopwords).index)",
"_____no_output_____"
],
[
"plt.figure(figsize=(12, 4))\nplt.subplot(1, 2, 1)\nwordcloud_blueprint(df_mercedes, 'full_text',\n max_words=100,\n num_stopwords=5)\n\nplt.subplot(1, 2, 2)\nwordcloud_blueprint(df_ferrari, 'full_text',\n max_words=100,\n num_stopwords=5)",
"_____no_output_____"
],
[
"from datetime import datetime\nimport math\n\nclass FileStreamListener(tweepy.StreamListener):\n \n def __init__(self, max_tweets=math.inf):\n self.num_tweets = 0\n self.TWEETS_FILE_SIZE = 10\n self.num_files = 0\n self.tweets = []\n self.max_tweets = max_tweets \n \n def on_data(self, data):\n while (self.num_files * self.TWEETS_FILE_SIZE < self.max_tweets):\n self.tweets.append(json.loads(data))\n self.num_tweets += 1\n if (self.num_tweets < self.TWEETS_FILE_SIZE):\n return True\n else:\n filename = 'Tweets_' + str(datetime.now().time()) + '.txt'\n print(self.TWEETS_FILE_SIZE, 'Tweets saved to', filename)\n file = open(filename, \"w\")\n json.dump(self.tweets, file)\n file.close()\n self.num_files += 1\n self.tweets = []\n self.num_tweets = 0\n return True\n return False\n \n def on_error(self, status_code):\n if status_code == 420:\n print('Too many requests were made, please stagger requests')\n return False\n else:\n print('Error {}'.format(status_code))\n return False",
"_____no_output_____"
],
[
"user_access_token = 'YOUR_USER_ACCESS_TOKEN_HERE'\nuser_access_secret = 'YOUR_USER_ACCESS_SECRET_HERE'\n\napp_api_key = 'CWIBFKPrcOU4GsdRr6J5fpaps'\napp_api_secret_key = 'SghP0LINUECDj0PzIi1vmDfRtNopqJNfb5xd3fH7XpO9ZaEtme'\n\nauth = tweepy.OAuthHandler(app_api_key, app_api_secret_key)\nauth.set_access_token(user_access_token, user_access_secret)\napi = tweepy.API(auth, wait_on_rate_limit=True, wait_on_rate_limit_notify=True)",
"_____no_output_____"
],
[
"fileStreamListener = FileStreamListener(20)\nfileStream = tweepy.Stream(auth=api.auth,\n listener=fileStreamListener,\n tweet_mode='extended')\nfileStream.filter(track=['cryptocurrency'])",
"Error 401\n"
],
[
"if ON_COLAB:\n df = pd.json_normalize(json.load(open('ch02/Tweets_01:01:36.656960.txt')))\nelse:\n df = pd.json_normalize(json.load(open('Tweets_01:01:36.656960.txt')))\ndf.head(2)",
"_____no_output_____"
],
[
"import wikipediaapi\n\nwiki_wiki = wikipediaapi.Wikipedia(\n language='en',\n extract_format=wikipediaapi.ExtractFormat.WIKI\n)\n\np_wiki = wiki_wiki.page('Cryptocurrency')\nprint(p_wiki.text[:200], '....')",
"A cryptocurrency, crypto-currency, or crypto is a digital asset designed to work as a medium of exchange wherein individual coin ownership records are stored in a ledger existing in a form of a comput ....\n"
]
],
[
[
"# Closing Remarks",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4aa036ad86617100bf8fe12049d453f97bd127d0
| 891,156 |
ipynb
|
Jupyter Notebook
|
code/simple/data.ipynb
|
pinga-lab/magnetic-radial-inversion
|
ac7e04a143ddc29eb4ded78671a5382a2869d5d8
|
[
"BSD-3-Clause"
] | 1 |
2022-03-15T11:35:41.000Z
|
2022-03-15T11:35:41.000Z
|
code/simple/data.ipynb
|
pinga-lab/magnetic-radial-inversion
|
ac7e04a143ddc29eb4ded78671a5382a2869d5d8
|
[
"BSD-3-Clause"
] | null | null | null |
code/simple/data.ipynb
|
pinga-lab/magnetic-radial-inversion
|
ac7e04a143ddc29eb4ded78671a5382a2869d5d8
|
[
"BSD-3-Clause"
] | 1 |
2022-03-01T02:14:31.000Z
|
2022-03-01T02:14:31.000Z
| 3,776.084746 | 767,420 | 0.961314 |
[
[
[
"# Data of a kimberlitic model with induced magnetization",
"_____no_output_____"
],
[
"This notebook generates a toal field anomaly (TFA) data from a complex model on a regular grid.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport cPickle as pickle\nfrom IPython.display import Image as img\nfrom fatiando.gravmag import polyprism\nfrom fatiando.vis import mpl",
"/home/leo/anaconda2/lib/python2.7/site-packages/fatiando/vis/mpl.py:76: UserWarning: This module will be removed in v0.6. We recommend the use of matplotlib.pyplot module directly. Some of the fatiando specific functions will remain.\n \"specific functions will remain.\")\n"
]
],
[
[
"### The model",
"_____no_output_____"
]
],
[
[
"img(filename='model.png')",
"_____no_output_____"
]
],
[
[
"### Importing model and grid",
"_____no_output_____"
]
],
[
[
"model_dir = 'model.pickle'\ngrid_dir = 'grid.pickle'",
"_____no_output_____"
],
[
"with open(model_dir) as w:\n model = pickle.load(w)\nwith open(grid_dir) as w:\n grid = pickle.load(w)",
"_____no_output_____"
]
],
[
[
"### Generating data",
"_____no_output_____"
]
],
[
[
"data = dict()",
"_____no_output_____"
],
[
"# main field\ndata['main_field'] = [-21.5, -18.7]\n\n# TFA data\ndata['tfa'] = polyprism.tf(grid['x'], grid['y'], grid['z'], \\\n model['prisms'], data['main_field'][0], data['main_field'][1]) # predict data\n\namp_noise = 5.\ndata['tfa_obs'] = data['tfa'] + np.random.normal(loc=0., scale=amp_noise,\n size=grid['N']) # noise corrupted tfa data",
"_____no_output_____"
]
],
[
[
"### Data ploting",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(13,5))\nplt.subplot(121)\nplt.title('Predicted TFA', fontsize=20)\nplt.tricontour(grid['y'], grid['x'], data['tfa'], 20, colors='k', linewidths=.5)\nplt.tricontourf(grid['y'], grid['x'], data['tfa'], 20,\n cmap='RdBu_r', vmax=np.max(data['tfa']),\n vmin=-np.max(data['tfa'])).ax.tick_params(labelsize=12)\nplt.plot(grid['y'], grid['x'], 'ko', markersize=.5)\nplt.xlabel('$y$(km)', fontsize=18)\nplt.ylabel('$x$(km)', fontsize=18)\nclb = plt.colorbar(pad=0.025, aspect=40, shrink=1)\nclb.ax.tick_params(labelsize=13)\nclb.ax.set_title('nT')\nmpl.m2km()\n\nplt.subplot(122)\nplt.title('Observed TFA', fontsize=20)\nplt.tricontour(grid['y'], grid['x'], data['tfa'], 10, colors='k', linewidths=.5)\nplt.tricontourf(grid['y'], grid['x'], data['tfa'], 20,\n cmap='RdBu_r', vmax=np.max(data['tfa_obs']),\n vmin=-np.max(data['tfa_obs'])).ax.tick_params(labelsize=12)\nplt.plot(grid['y'], grid['x'], 'ko', markersize=.5)\nplt.xlabel('$y$(km)', fontsize=18)\nplt.ylabel('$x$(km)', fontsize=18)\nclb = plt.colorbar(pad=0.025, aspect=40, shrink=1)\nclb.ax.tick_params(labelsize=13)\nclb.ax.set_title('nT')\nmpl.m2km()\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### Saving in an outer file",
"_____no_output_____"
]
],
[
[
"file_name = 'data.pickle'\nwith open(file_name, 'w') as f:\n pickle.dump(data, f)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa037292e15c6df1855ea823464d8f00c92ef67
| 283,348 |
ipynb
|
Jupyter Notebook
|
notebooks/01-exploring-era.ipynb
|
capaci/predicao-pld-ml
|
1db9c07dd5e036807ed5b667f0feca9366900eab
|
[
"MIT"
] | 2 |
2022-01-23T15:59:59.000Z
|
2022-02-14T17:36:23.000Z
|
notebooks/01-exploring-era.ipynb
|
capaci/predicao-pld-ml
|
1db9c07dd5e036807ed5b667f0feca9366900eab
|
[
"MIT"
] | null | null | null |
notebooks/01-exploring-era.ipynb
|
capaci/predicao-pld-ml
|
1db9c07dd5e036807ed5b667f0feca9366900eab
|
[
"MIT"
] | null | null | null | 432.592366 | 223,376 | 0.925473 |
[
[
[
"# Análise Energia Armazenada (EAR)\n\nEAR é a energia associada ao volume de água disponível nos reservatórios.\n\nNão é a energia em si, mas pode ser vista como um \"potencial\" do que pode ser gerado.\n\nO EAR Máximo indica a energia que poderia ser gerada caso todos os reservatórios do sistema estivessem cheios.\n",
"_____no_output_____"
],
[
"## Referências\n\nhttps://www.aedb.br/seget/arquivos/artigos15/772265.pdf",
"_____no_output_____"
],
[
"## Dados\n\nOs dados estão agrupados por subsistema, uma vez que o PLD é dividido dessa forma, então acredito que dessa forma é como o EAR pode influenciar na formação do PLD.\n\nEstes dados foram retirados da base de dados aberta da ONS e estão disponíveis em https://dados.ons.org.br/dataset/ear-diario-por-subsistema\n",
"_____no_output_____"
]
],
[
[
"import os\n\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nfrom pylab import rcParams\n\n# Ignorar warnings não prejudiciais\nimport warnings\nwarnings.filterwarnings(\"ignore\")\n\n%matplotlib inline\n\nplt.rcParams['figure.figsize'] = [15,7]\n\nBASE_PATH = '/home/capaci/Documents/mba-usp/tcc/tcc-mba-cd-icmc'\n",
"_____no_output_____"
],
[
"filepath = os.path.join(BASE_PATH, 'data/external/ons/ear.csv')\ndf = pd.read_csv(filepath)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
],
[
"df = df.drop(columns=['nom_subsistema'])",
"_____no_output_____"
],
[
"sudeste = df.query('id_subsistema == \"SE\"')",
"_____no_output_____"
],
[
"sudeste = sudeste.set_index('ear_data')",
"_____no_output_____"
],
[
"sudeste",
"_____no_output_____"
],
[
"ax = sudeste['ear_verif_subsistema_percentual'].loc['2013':'2021'].plot()\nax.set_ylim(0, 100)\n\nplt.show()",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"axs = df.set_index('ear_data').groupby('id_subsistema')['ear_verif_subsistema_percentual'].plot(legend=True)\n\n\nfor ax in axs:\n ax.set_ylim(0, 100)\n\nplt.show()\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa05e51a4585686a2664aecb877cc90fed0a11e
| 2,386 |
ipynb
|
Jupyter Notebook
|
NetworkScience/DollarTrading.ipynb
|
joshjohnston/Teaching
|
194c9cf949839f64b8eebddd7ecb0906672aae2b
|
[
"Apache-2.0"
] | null | null | null |
NetworkScience/DollarTrading.ipynb
|
joshjohnston/Teaching
|
194c9cf949839f64b8eebddd7ecb0906672aae2b
|
[
"Apache-2.0"
] | 1 |
2019-01-06T23:11:30.000Z
|
2019-01-06T23:41:32.000Z
|
NetworkScience/DollarTrading.ipynb
|
joshjohnston/Teaching
|
194c9cf949839f64b8eebddd7ecb0906672aae2b
|
[
"Apache-2.0"
] | null | null | null | 32.243243 | 117 | 0.550712 |
[
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.animation as animation\nimport matplotlib.cm as cm\n%matplotlib notebook\n\nnumParticipants = 100\nnumStartDollars = 100\nnumIterations = 1000\n\ndef animate(accounts, showColors=True):\n def _animate(i):\n plt.clf()\n indices = np.argsort(accounts[i])\n if showColors == True:\n colors = cm.Greys([x / numParticipants for x in indices])\n else:\n colors = 'b'\n plt.setp(plt.bar(np.arange(len(accounts[i])), height=np.array(accounts[i])[indices], color=colors))\n return _animate\n\naccounts = {}\naccounts[0] = numStartDollars * np.ones(numParticipants).astype(int)\nfor i in np.arange(1, numIterations):\n change = np.zeros(numParticipants).astype(int)\n for giverIndex, giverValue in enumerate(accounts[i-1]):\n if (giverValue > 0):\n change[giverIndex] = change[giverIndex] - 1\n recipientIndex = np.random.randint(0, numParticipants)\n while recipientIndex == giverIndex:\n recipientIndex = np.random.randint(0, numParticipants)\n change[recipientIndex] = change[recipientIndex] + 1\n accounts[i] = np.array([row[0] + row[1] for row in zip(accounts[i-1], change)])\n if i % 100 == 0:\n accounts[i] = np.sort(accounts[i])\n \nfig = plt.figure(figsize=(10,6))\nani = animation.FuncAnimation(fig, animate(accounts, False), frames=numIterations, interval=100, repeat=True)\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4aa05eb4cc3169f97b9a8384aa88186ba81b2313
| 389,897 |
ipynb
|
Jupyter Notebook
|
robustsp/DependentData/examples/BIP_ARMA_MM_demo.ipynb
|
ICASSP-2020-Robustness-Tutorial/Robust-Signal-Processing-Toolbox-Python
|
967186d017c895182eb45ef7ae2eaade11904a1c
|
[
"MIT"
] | 4 |
2020-05-04T11:24:11.000Z
|
2020-11-12T19:07:12.000Z
|
robustsp/DependentData/examples/BIP_ARMA_MM_demo.ipynb
|
RobustSP/robustsp
|
293f4281fdbd475549aa42eae9fe615976af27a0
|
[
"MIT"
] | 1 |
2019-07-06T08:57:15.000Z
|
2019-07-06T08:57:15.000Z
|
robustsp/DependentData/examples/BIP_ARMA_MM_demo.ipynb
|
RobustSP/robustsp
|
293f4281fdbd475549aa42eae9fe615976af27a0
|
[
"MIT"
] | 2 |
2019-12-03T15:04:44.000Z
|
2020-05-03T04:32:29.000Z
| 870.305804 | 140,384 | 0.956878 |
[
[
[
"# Examples for Bounded Innovation Propagation (BIP) MM ARMA parameter estimation",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport scipy.signal as sps\nimport robustsp as rsp\nimport matplotlib.pyplot as plt\nimport matplotlib\n\n# Fix random number generator for reproducibility\nnp.random.seed(1) ",
"_____no_output_____"
]
],
[
[
"## Example 1: AR(1) with 30 percent isolated outliers",
"_____no_output_____"
]
],
[
[
"# Generate AR(1) observations\nN = 300\na = np.random.randn(N)\nx = sps.lfilter([1],[1,-.8],a)\np = 1\nq = 0",
"_____no_output_____"
]
],
[
[
"### Generate isolated Outliers",
"_____no_output_____"
]
],
[
[
"cont_prob = 0.3 # outlier contamination probability\noutlier_ind = np.where(np.sign(np.random.rand(N)-cont_prob)<0)# outlier index\noutlier = 100*np.random.randn(N) # contaminating process\nv = np.zeros(N) # additive outlier signal\nv[outlier_ind] = outlier[outlier_ind]\nv[0] = 0 # first sample should not be an outlier\n\nx_ao = x+v # 30% of isolated additive outliers",
"_____no_output_____"
]
],
[
[
"### BIP MM Estimation",
"_____no_output_____"
]
],
[
[
"result = rsp.arma_est_bip_mm(x_ao,p,q)",
"_____no_output_____"
],
[
"print('Example: AR(1) with ar_coeff = -0.8')\nprint('30% of isolated additive outliers')\nprint('estimaed coefficients: %.3f' % result['ar_coeffs'])\n\n%matplotlib inline\nmatplotlib.rcParams['figure.figsize'] = [10, 10]\n\nplt.subplot(2,1,1)\nplt.plot(x_ao,'-',lw=2,label='outlier contaminated AR(1)')\nplt.plot(result['cleaned_signal'],'-.',c='y',label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-AR(1) cleaned signal')\nplt.legend()\n\nplt.subplot(2,1,2)\nplt.plot(x,lw=2,label='original AR(1)')\nplt.plot(result['cleaned_signal'],'-.',label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-AR(1) cleaned signal')\nplt.legend()\nplt.show()",
"Example: AR(1) with ar_coeff = -0.8\n30% of isolated additive outliers\nestimaed coefficients: -0.771\n"
]
],
[
[
"# Example 2: ARMA(1,1) with 10% patchy outliers",
"_____no_output_____"
],
[
"## Generate ARMA(1,1) observations",
"_____no_output_____"
]
],
[
[
"N = 1000\na = np.random.randn(N)\nx = sps.lfilter([1, 0.2],[1, -.8],a)\np = 1\nq = 1",
"_____no_output_____"
]
],
[
[
"## Generate a patch of outliers of length 101 samples",
"_____no_output_____"
]
],
[
[
"v = 1000*np.random.randn(101)",
"_____no_output_____"
]
],
[
[
"## 10% of patch additive outliers",
"_____no_output_____"
]
],
[
[
"x_ao = np.array(x)\nx_ao[99:200] += v",
"_____no_output_____"
]
],
[
[
"### BIP-MM estimation",
"_____no_output_____"
]
],
[
[
"result = rsp.arma_est_bip_mm(x_ao,p,q)\n\nprint('''Example 2: ARMA(1,1) with ar_coeff = -0.8, ma_coeff 0.2' \\n\n10 percent patchy additive outliers \\n\nestimated coefficients: \\n\nar_coeff_est = %.3f \\n\nma_coeff_est = %.3f''' %(result['ar_coeffs'],result['ma_coeffs']))",
"Example 2: ARMA(1,1) with ar_coeff = -0.8, ma_coeff 0.2' \n\n10 percent patchy additive outliers \n\nestimated coefficients: \n\nar_coeff_est = -0.785 \n\nma_coeff_est = 0.246\n"
],
[
"plt.subplot(2,1,1)\nplt.plot(x_ao,'-',lw=2,label='outlier contaminated AR(1)')\nplt.plot(result['cleaned_signal'],label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-ARMA(1,1) cleaned signal')\nplt.legend()\n\nplt.subplot(2,1,2)\nplt.plot(x,lw=2,label='original ARMA(1,1)')\nplt.plot(result['cleaned_signal'],label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-ARMA(1,1) cleaned signal')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Example 3: MA(2) with 20 % isolated Outliers",
"_____no_output_____"
],
[
"## Generate MA(2) observations",
"_____no_output_____"
]
],
[
[
"N = 500\na = np.random.randn(N)\nx = sps.lfilter([1,-.7,.5],[1],a)\np=0\nq=2",
"_____no_output_____"
]
],
[
[
"## Generate isolated Outliers",
"_____no_output_____"
]
],
[
[
"cont_prob = 0.2\noutlier_ind = np.where(np.sign(np.random.rand(N)-(cont_prob))<0)\noutlier = 100*np.random.randn(N)\nv = np.zeros(N)\nv[outlier_ind] = outlier[outlier_ind]\nv[:2] = 0",
"_____no_output_____"
]
],
[
[
"## 20 % of isolated additive Outliers",
"_____no_output_____"
]
],
[
[
"x_ao = x+v",
"_____no_output_____"
]
],
[
[
"## BIP MM estimation",
"_____no_output_____"
]
],
[
[
"result = rsp.arma_est_bip_mm(x_ao,p,q)",
"_____no_output_____"
],
[
"print('''Example 3: MA(2) ma_coeff [-0.7 0.5]' \\n\n20 % of isolated additive Outliers \\n\nestimated coefficients: \\n\nma_coeff_est = ''',result['ma_coeffs'])",
"Example 3: MA(2) ma_coeff [-0.7 0.5]' \n\n20 % of isolated additive Outliers \n\nestimated coefficients: \n\nma_coeff_est = [-0.66390265 0.41921003]\n"
],
[
"plt.subplot(2,1,1)\nplt.plot(x_ao,'-',lw=2,label='outlier contaminated AR(1)')\nplt.plot(result['cleaned_signal'],label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-MA(2) cleaned signal')\nplt.legend()\n\nplt.subplot(2,1,2)\nplt.plot(x,lw=2,label='original MA(2)')\nplt.plot(result['cleaned_signal'],label='cleaned')\n\nplt.xlabel('samples')\nplt.ylabel('Amplitude')\nplt.title('BIP-MA(2) cleaned signal')\nplt.legend()\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4aa09491eac6e4423233ca63d279528f6a182d53
| 220,579 |
ipynb
|
Jupyter Notebook
|
DriveApp.ipynb
|
theshuv/Autonomous-vehicle-steering-angle-prediction
|
8a275a8124ae51ec0bcfe80a5de8caace4d06203
|
[
"MIT"
] | 2 |
2020-10-24T05:00:20.000Z
|
2021-07-12T06:28:17.000Z
|
DriveApp.ipynb
|
theshuv/Autonomous-vehicle-steering-angle-prediction
|
8a275a8124ae51ec0bcfe80a5de8caace4d06203
|
[
"MIT"
] | null | null | null |
DriveApp.ipynb
|
theshuv/Autonomous-vehicle-steering-angle-prediction
|
8a275a8124ae51ec0bcfe80a5de8caace4d06203
|
[
"MIT"
] | null | null | null | 30.336817 | 1,975 | 0.576338 |
[
[
[
"import numpy as np\nimport cv2\nfrom keras.models import load_model\n\nmodel = load_model('Autopilot.h5')\n\ndef keras_predict(model, image):\n processed = keras_process_image(image)\n steering_angle = float(model.predict(processed, batch_size=1))\n steering_angle = steering_angle * 100\n return steering_angle\n\n\ndef keras_process_image(img):\n image_x = 40\n image_y = 40\n img = cv2.resize(img, (image_x, image_y))\n img = np.array(img, dtype=np.float32)\n img = np.reshape(img, (-1, image_x, image_y, 1))\n return img\n\n\nsteer = cv2.imread('steering_wheel_image.jpg', 0)\nrows, cols = steer.shape\nsmoothed_angle = 0\n\ncap = cv2.VideoCapture('run.mp4')\nwhile (cap.isOpened()):\n ret, frame = cap.read()\n gray = cv2.resize((cv2.cvtColor(frame, cv2.COLOR_RGB2HSV))[:, :, 1], (40, 40))\n steering_angle = keras_predict(model, gray)\n print(steering_angle)\n cv2.imshow('frame', cv2.resize(frame, (500, 300), interpolation=cv2.INTER_AREA))\n smoothed_angle += 0.2 * pow(abs((steering_angle - smoothed_angle)), 2.0 / 3.0) * (\n steering_angle - smoothed_angle) / abs(\n steering_angle - smoothed_angle)\n M = cv2.getRotationMatrix2D((cols / 2, rows / 2), -smoothed_angle, 1)\n dst = cv2.warpAffine(steer, M, (cols, rows))\n cv2.imshow(\"steering wheel\", dst)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\ncap.release()\ncv2.destroyAllWindows()\n",
"-9.780517965555191\n-9.644873440265656\n-9.690410643815994\n-9.65074673295021\n-9.311851859092712\n-9.289494901895523\n-9.613565355539322\n-9.58838015794754\n-9.617098420858383\n-9.16353166103363\n-9.13667306303978\n-9.119287878274918\n-9.758543968200684\n-9.698183834552765\n-9.66874584555626\n-10.187270492315292\n-10.149353742599487\n-10.116112232208252\n-9.090591222047806\n-9.114700555801392\n-9.068182855844498\n-6.723298132419586\n-6.72885850071907\n-6.732863932847977\n-4.473483934998512\n-4.416080191731453\n-4.448652267456055\n-5.353070423007011\n-5.32684400677681\n-5.4145947098731995\n-7.229112088680267\n-7.230457663536072\n-7.21115842461586\n-9.6592016518116\n-9.654899686574936\n-9.631957858800888\n-9.712152928113937\n-6.615158915519714\n-6.596942245960236\n-6.603112816810608\n-5.013986304402351\n-4.534391313791275\n-4.576202481985092\n-2.5005169212818146\n-2.487550862133503\n-2.4719228968024254\n-3.136579692363739\n-3.13556008040905\n-3.231511637568474\n-3.2603099942207336\n-3.267877548933029\n-3.2424401491880417\n-2.001841366291046\n-2.0872173830866814\n-2.0443709567189217\n-1.7155956476926804\n-1.7211884260177612\n-1.7604639753699303\n-0.38735740818083286\n-0.41727758944034576\n-0.4039501305669546\n-2.734065428376198\n-2.732747234404087\n-2.735970728099346\n-0.22861724719405174\n-0.2835161052644253\n-0.3261836711317301\n-1.4632350765168667\n-1.4457200653851032\n-1.4370293356478214\n-1.1132246814668179\n-1.107967272400856\n-1.1138388887047768\n-1.0322394780814648\n-1.0128614492714405\n-1.0443360544741154\n0.027328083524480462\n0.02250772959087044\n0.06732476176694036\n-0.07812229450792074\n-0.017458139336667955\n0.007018825999693945\n0.013703532749786973\n0.012188824621262029\n-1.184077188372612\n-2.025201730430126\n-2.0287325605750084\n-2.649449184536934\n-1.315024495124817\n-1.262612920254469\n1.0528973303735256\n1.079901959747076\n0.9815879166126251\n-0.7231400348246098\n-0.6592581048607826\n-0.6580398883670568\n1.3631834648549557\n1.3510080985724926\n1.3386779464781284\n-1.107851229608059\n-1.1028507724404335\n-1.1122413910925388\n0.42757666669785976\n0.36338798236101866\n0.37002365570515394\n-1.5832040458917618\n-1.5673259273171425\n-1.5817977488040924\n-0.17561294371262193\n-0.17817721236497164\n-0.20442900713533163\n0.3192587522789836\n0.3051877021789551\n0.30411446932703257\n0.5668810568749905\n0.5327949766069651\n0.507362000644207\n-0.4070634953677654\n-0.3672715276479721\n-0.36194748245179653\n-1.0142863728106022\n-1.0334777645766735\n-0.9900012984871864\n0.04999145166948438\n0.04344622720964253\n0.040316127706319094\n-1.0098480619490147\n-1.024566125124693\n-1.0872013866901398\n0.43160226196050644\n0.36925238091498613\n0.3535012947395444\n-0.06529304664582014\n-0.09267643326893449\n-0.06304963026195765\n0.645859818905592\n0.6218632683157921\n0.6009066011756659\n0.7439291570335627\n0.7704950869083405\n0.7937716320157051\n-0.349360634572804\n-0.4762353841215372\n-0.42429352179169655\n-0.6691873073577881\n-0.723498547449708\n-0.6638346705585718\n-1.0527043603360653\n-1.0798740200698376\n-1.088255736976862\n-1.1159060522913933\n-1.1433317326009274\n-1.1146294884383678\n-1.7496168613433838\n-1.6032582148909569\n-1.5719501301646233\n-0.025028776144608855\n-0.03893832326866686\n-0.06709174485877156\n0.04897413309663534\n0.04275106766726822\n0.08158745476976037\n1.961304433643818\n2.0014503970742226\n1.9618941470980644\n-0.2618195256218314\n-0.23477082140743732\n-0.20076364744454622\n-0.5035161040723324\n-0.48552295193076134\n-0.505968788638711\n-1.2615416198968887\n-1.2393129989504814\n-1.2371961027383804\n-0.7178572472184896\n-0.7029693573713303\n-0.6975015625357628\n-1.231855433434248\n-1.2547608464956284\n-1.2361923232674599\n-1.9419515505433083\n-1.9408684223890305\n-1.9158083945512772\n-1.2041320092976093\n-1.2181359343230724\n-1.2144400738179684\n-1.2900560162961483\n-1.280285231769085\n-1.2772220186889172\n-3.8405142724514008\n-3.8126159459352493\n-3.791794925928116\n-4.581708461046219\n-4.57627959549427\n-4.566650837659836\n-2.244739420711994\n-2.2529223933815956\n-2.324790507555008\n-2.9723279178142548\n-2.9450170695781708\n-2.9614903032779694\n-2.371492236852646\n-2.401617541909218\n-2.4170679971575737\n-4.5229993760585785\n-4.507355019450188\n-4.468929022550583\n-4.800591245293617\n-4.656656458973885\n-4.5828137546777725\n-2.3292046040296555\n-2.329380437731743\n-2.341027930378914\n-4.534628614783287\n-4.59069088101387\n-4.599633812904358\n-3.5367101430892944\n-3.496074676513672\n-3.548406809568405\n-2.9729224741458893\n-2.923896722495556\n-2.9725996777415276\n-6.016566604375839\n-5.987409874796867\n-5.91975562274456\n-4.88322526216507\n-4.87675741314888\n-4.893580451607704\n-4.300058260560036\n-4.250425472855568\n-4.261409491300583\n-3.9383936673402786\n-3.9157532155513763\n-3.922656923532486\n-4.593361169099808\n-4.584835842251778\n-4.574286565184593\n-3.395523503422737\n-3.3652901649475098\n-3.4930244088172913\n-1.9705461338162422\n-1.905883103609085\n-1.9044877961277962\n-2.710631676018238\n-2.7071021497249603\n-2.864452265202999\n-4.612476006150246\n-4.6390872448682785\n-4.618104547262192\n-3.098006173968315\n-2.88612712174654\n-2.9063381254673004\n-2.6413213461637497\n-2.6405716314911842\n-2.573270723223686\n-3.6130383610725403\n-4.0045421570539474\n-3.9198998361825943\n-4.578747600317001\n-4.563579335808754\n-4.579803720116615\n-2.3154402151703835\n-2.3075656965374947\n-2.294081822037697\n-2.9158631339669228\n-2.888922207057476\n-2.9388178139925003\n-2.6503246277570724\n-2.6651933789253235\n-2.831035666167736\n-3.8818828761577606\n-3.8508929312229156\n-3.790518641471863\n-4.633120819926262\n-4.757033661007881\n-4.692558199167252\n-3.0510447919368744\n-3.7769313901662827\n-3.7703987210989\n-4.876258224248886\n-4.8769935965538025\n-4.9124013632535934\n-4.081856831908226\n-4.123251512646675\n-4.134214669466019\n-4.0475208312273026\n-4.016556963324547\n-4.01400551199913\n-3.1111102551221848\n-3.113473206758499\n-3.099893033504486\n-3.667568787932396\n-3.7142984569072723\n-3.714415803551674\n-5.674484744668007\n-5.656011402606964\n-5.704906210303307\n-5.203500017523766\n-5.219759792089462\n-5.22376149892807\n-3.5111024975776672\n-3.5639774054288864\n-3.4750621765851974\n-3.2533466815948486\n-3.2566238194704056\n-3.262048214673996\n-2.5484921410679817\n-2.443898841738701\n-2.438412792980671\n-2.7341023087501526\n-2.782910317182541\n-2.8077831491827965\n-5.062910541892052\n-4.995748773217201\n-4.865450039505959\n-3.5226721316576004\n-3.486086428165436\n-3.459920361638069\n-2.705487795174122\n-2.7396399527788162\n-2.7078956365585327\n-3.5730011761188507\n-3.5159923136234283\n-3.536350280046463\n-5.432965233922005\n-5.407963320612907\n-5.3953539580106735\n-4.204766824841499\n-4.243114590644836\n-4.166806116700172\n-3.9468374103307724\n-4.055045172572136\n-4.037990421056747\n-4.558847472071648\n-4.552989825606346\n-4.5938026160001755\n-4.192487522959709\n-4.192667081952095\n-4.180428758263588\n-3.2072994858026505\n-3.2119352370500565\n-3.2158341258764267\n-1.6992239281535149\n-1.7322422936558723\n-1.703508011996746\n-1.2344622984528542\n-1.3980942778289318\n-1.4228151179850101\n0.2544635673984885\n0.2316052559763193\n0.2260412322357297\n-0.2789797494187951\n-0.9401683695614338\n-0.9635264985263348\n0.9436818771064281\n0.9754476137459278\n0.9866501204669476\n-0.07996010826900601\n0.017313018906861544\n-0.07116523338481784\n-0.8405903354287148\n-0.8375396020710468\n-0.7791897282004356\n-3.510056436061859\n-3.3849675208330154\n-3.3775687217712402\n-1.2708409689366817\n-1.2581880204379559\n-1.306252833455801\n-2.4199994280934334\n-2.4471845477819443\n-2.3233016952872276\n1.0502283461391926\n1.0599378496408463\n1.053838338702917\n-0.028831965755671263\n-0.0721254269592464\n-0.03498996375128627\n-2.2286217659711838\n-2.1979108452796936\n-2.2070899605751038\n-2.599276416003704\n-2.6165595278143883\n-2.5702137500047684\n-3.6109384149312973\n-3.3065520226955414\n-3.3687714487314224\n-3.6262862384319305\n-3.677767515182495\n-3.6900315433740616\n-4.541593417525291\n-4.605671390891075\n-4.606688767671585\n-2.458302304148674\n-2.5111516937613487\n-2.447814494371414\n-1.607455313205719\n-1.6116460785269737\n-1.6255071386694908\n-2.5483351200819016\n-2.5263216346502304\n-2.588498964905739\n-1.029312890022993\n-0.9859892539680004\n-0.9926191531121731\n-2.555166743695736\n-2.568764053285122\n-2.424902655184269\n-4.074762389063835\n-4.047917947173119\n-4.144119098782539\n-1.5553039498627186\n-1.5370589680969715\n-1.5480691567063332\n-0.6820091512054205\n-0.6264195777475834\n-0.5948550067842007\n-2.1772658452391624\n-2.476358041167259\n-2.2193878889083862\n-2.2067882120609283\n-2.145632356405258\n-2.1654967218637466\n-1.998601295053959\n-1.9979119300842285\n-1.9093772396445274\n-3.6445006728172302\n-3.583276644349098\n-3.5820402204990387\n-1.7320988699793816\n-1.7150472849607468\n-1.725233905017376\n-2.893054112792015\n-3.341418132185936\n-3.3123929053545\n-0.7947142235934734\n-0.7947142235934734\n-0.8022473193705082\n-0.9275227785110474\n-0.8438383229076862\n-0.826574582606554\n-1.1556769721210003\n-1.202541682869196\n-1.1959034018218517\n-1.155312079936266\n-0.8766446262598038\n-0.8948705159127712\n-0.8025412447750568\n-0.8096675388514996\n-0.7562377955764532\n1.897122710943222\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4aa095fa3785d049c1ee9b2693bb02957f3db5d4
| 10,918 |
ipynb
|
Jupyter Notebook
|
nb_sci_ai/ai_ml_perceptron_fr.ipynb
|
jdhp-docs/python-notebooks
|
91a97ea5cf374337efa7409e4992ea3f26b99179
|
[
"MIT"
] | 3 |
2017-05-03T12:23:36.000Z
|
2020-10-26T17:30:56.000Z
|
nb_sci_ai/ai_ml_perceptron_fr.ipynb
|
jdhp-docs/python-notebooks
|
91a97ea5cf374337efa7409e4992ea3f26b99179
|
[
"MIT"
] | null | null | null |
nb_sci_ai/ai_ml_perceptron_fr.ipynb
|
jdhp-docs/python-notebooks
|
91a97ea5cf374337efa7409e4992ea3f26b99179
|
[
"MIT"
] | 1 |
2020-10-26T17:30:57.000Z
|
2020-10-26T17:30:57.000Z
| 28.506527 | 212 | 0.545796 |
[
[
[
"# Perceptron",
"_____no_output_____"
],
[
"### TODO\n\n- **[ok]** Ajouter dans le code la fonction d'évaluation du réseau\n- **[ok]** Plot de $\\sum |E|$ par itération (i.e. num updates par itération)\n- Critere d'arrêt + générale\n- Lire l'article de rérérence\n- Ajouter la preuve de convergence\n- Ajouter notations et explications\n- Tester l'autre version de la règle de mise à jours de $w$: if err then ...\n- **[ok]** Décrire et illustrer les deux fonctions de transfert: signe et heaviside\n- Plot de l'evolution de la courbe de niveau ($x_1 w_1 + x_2 w_2 + ... = 0$) dans l'espace des entrées: illustration avec 2 entrées seulement ou faire un graph de projection de type *scatter plot matrix*\n- Plot de l'evolution de $w$ dans l'espace des $w$ illustration avec 2 entrées seulement ou faire un graph de projection de type *scatter plot matrix*\n- Ajouter \"Les limites du Perceptron\"",
"_____no_output_____"
],
[
"Définition des macros LaTeX...\n\n$$\n\\newcommand{\\activthres}{\\theta}\n\\newcommand{\\activfunc}{f}\n\\newcommand{\\pot}{p}\n\\newcommand{\\learnrate}{\\eta}\n\\newcommand{\\it}{t}\n\\newcommand{\\sigin}{s_i}\n\\newcommand{\\sigout}{s_j}\n\\newcommand{\\sigoutdes}{d_j}\n\\newcommand{\\wij}{w_{ij}}\n$$",
"_____no_output_____"
],
[
"Auteur: F. Rosenblatt\n\nReference: F. Rosenblatt 1958 *The Perceptron: a Probabilistic Model for Information Storage and Organization in the Brain* Psychological Review, 65, 386-408\n\nLe modéle est constitué des éléments suivants:\n- des *unités sensitives (S-units)*: réagissent à un stimuli extérieur (lumière, son, touché, ...)\n - retournent `0` ou `1`:\n - `1` si le signal d'entrée dépasse un seuil $\\activthres$\n - `0` sinon\n- des *unités d'associations (A-units)*\n - retournent `0` ou `1`:\n - `1` si la somme des signaux d'entrée dépasse un seuil $\\activthres$\n - `0` sinon\n- des *unités de réponse (R-units)*: sortie du réseau\n - retournent `1`, `-1` ou une valeur indéterminée:\n - `1` si la somme des signaux d'entrée est positive\n - `-1` si elle est négative\n - une valeur indéterminée si elle est égale à 0\n- une *matrice d'intéractions*",
"_____no_output_____"
],
[
"Evaluation de la fonction:\n$$\n\\pot = \\sum \\sigin \\wij\n$$\n\n$$\n\\sigout = \\activfunc(\\pot - \\activthres)\n$$\n\nFonction de transfert: signe et heaviside",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\n#x = np.linspace(-5, 5, 300)\n#y = np.array([-1 if xi < 0 else 1 for xi in x])\n#plt.plot(x, y)\n\nplt.hlines(y=-1, xmin=-5, xmax=0, color='red')\nplt.hlines(y=1, xmin=0, xmax=5, color='red')\n\nplt.hlines(y=0, xmin=-5, xmax=5, color='gray', linestyles='dotted')\nplt.vlines(x=0, ymin=-2, ymax=2, color='gray', linestyles='dotted')\n\nplt.title(\"Fonction signe\")\nplt.axis([-5, 5, -2, 2])",
"_____no_output_____"
],
[
"#x = np.linspace(-5, 5, 300)\n#y = (x > 0).astype('float')\n#plt.plot(x, y)\n\nplt.hlines(y=0, xmin=-5, xmax=0, color='red')\nplt.hlines(y=1, xmin=0, xmax=5, color='red')\n\nplt.hlines(y=0, xmin=-5, xmax=5, color='gray', linestyles='dotted')\nplt.vlines(x=0, ymin=-2, ymax=2, color='gray', linestyles='dotted')\n\nplt.title(\"Fonction heaviside\")\nplt.axis([-5, 5, -2, 2])",
"_____no_output_____"
]
],
[
[
"Règle du Perceptron (mise à jour des poid $\\wij$):\n\n$$\n\\wij(\\it + 1) = \\wij(\\it) + \\learnrate (\\sigoutdes - \\sigout) \\sigin\n$$",
"_____no_output_____"
],
[
"* $\\learnrate$: pas d'apprentissage, $\\learnrate \\in [0, 1]$. Géneralement, on lui donne une valeur proche de 1 au début de l'apprentissage et on diminue sa valeur à chaque itération.\n\nPoids de depart des synapses du réseau\nNombre de neurones associatifs (A-units)\nNombre d'unités sensitives\nMotif à apprendre",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\n\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\n\nimport matplotlib.patches as patches\nimport matplotlib.lines as mlines\nimport matplotlib.patches as mpatches\n\nimport itertools",
"_____no_output_____"
],
[
"# https://github.com/jeremiedecock/neural-network-figures.git\nimport nnfigs.core as fig\n\nfig.draw_neural_network();",
"_____no_output_____"
],
[
"# Poids de depart des synapses du réseau\ninitial_weights = np.array([0., 0., 0., 0., 2.])\n\n# Pas d'apprentissage eta=1\nlearning_rate = 1.",
"_____no_output_____"
],
[
"class Log:\n def __init__(self):\n self.input_signal = []\n self.output_signal = []\n self.desired_output_signal = []\n self.error = []\n self.weights = []\n self.iteration = []\n self.current_iteration = 0\n \n def log(self, input_signal, output_signal, desired_output_signal, error, weights):\n self.input_signal.append(input_signal)\n self.output_signal.append(output_signal)\n self.desired_output_signal.append(desired_output_signal)\n self.error.append(error)\n self.weights.append(weights)\n self.iteration.append(self.current_iteration)\n \nlog = Log()",
"_____no_output_____"
],
[
"def sign_function(x):\n y = 1. if x >= 0. else -1.\n return y\n\ndef heaviside_function(x):\n y = 1. if x >= 0. else 0.\n return y",
"_____no_output_____"
],
[
"def activation_function(p):\n return heaviside_function(p)\n\ndef evaluate_network(weights, input_signal): # TODO: find a better name\n p = np.sum(input_signal * weights)\n output_signal = activation_function(p)\n return output_signal\n\ndef update_weights(weights, input_signal, desired_output_signal):\n output_signal = evaluate_network(weights, input_signal)\n error = desired_output_signal - output_signal\n weights = weights + learning_rate * error * input_signal\n log.log(input_signal, output_signal, desired_output_signal, error, weights)\n return weights\n\ndef learn_examples(example_list, label_list, weights, num_iterations):\n for it in range(num_iterations):\n log.current_iteration = it\n for input_signal, desired_output_signal in zip(example_list, label_list):\n weights = update_weights(weights, np.array(input_signal + (-1,)), desired_output_signal)\n return weights",
"_____no_output_____"
]
],
[
[
"Rappel: $\\sigin \\in \\{0, 1\\}$",
"_____no_output_____"
]
],
[
[
"example_list = tuple(reversed(tuple(itertools.product((0., 1.), repeat=4))))\n\n# Motif à apprendre: (1 0 0 1)\nlabel_list = [1. if x == (1., 0., 0., 1.) else 0. for x in example_list]\n\nprint(example_list)\nprint(label_list)",
"_____no_output_____"
],
[
"weights = learn_examples(example_list, label_list, initial_weights, 5)\nweights",
"_____no_output_____"
],
[
"for input_signal, output_signal, desired_output_signal, error, weights, iteration in zip(log.input_signal, log.output_signal, log.desired_output_signal, log.error, log.weights, log.iteration):\n print(iteration, input_signal, output_signal, desired_output_signal, error, weights)",
"_____no_output_____"
],
[
"plt.plot(log.error)",
"_____no_output_____"
],
[
"import pandas as pd\n\ndf = pd.DataFrame(np.array([log.iteration, log.error]).T, columns=[\"Iteration\", \"Error\"])\nabs_err_per_it = abs(df).groupby([\"Iteration\"]).sum()\nabs_err_per_it.plot(title=\"Sum of absolute errors per iteration\")",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4aa0b983d0cebfe02717325011bf59146c14cbc4
| 200,281 |
ipynb
|
Jupyter Notebook
|
convert2mat.ipynb
|
terry97-guel/SMInet
|
e4c158fb03096a12723bb474c3e468044eca46a6
|
[
"MIT"
] | 1 |
2022-02-24T06:57:55.000Z
|
2022-02-24T06:57:55.000Z
|
convert2mat.ipynb
|
terry97-guel/SMInet
|
e4c158fb03096a12723bb474c3e468044eca46a6
|
[
"MIT"
] | null | null | null |
convert2mat.ipynb
|
terry97-guel/SMInet
|
e4c158fb03096a12723bb474c3e468044eca46a6
|
[
"MIT"
] | null | null | null | 77.031154 | 120 | 0.521872 |
[
[
[
"## Load Weight",
"_____no_output_____"
]
],
[
[
"import torch\nimport numpy as np\npath = './output/0210/Zero/checkpoint_400.pth'\n\nimport os\nassert(os.path.isfile(path))\n\nweight = torch.load(path)\ninput_dim = weight['input_dim']\nbranchNum = weight['branchNum']\nIOScale = weight['IOScale']\nstate_dict = weight['state_dict']\n# n_layers = weight['n_layers']\nn_layers = 6",
"_____no_output_____"
]
],
[
[
"## Load Model",
"_____no_output_____"
]
],
[
[
"from model import Model\nmodel = Model(branchNum, input_dim, n_layers)\nmodel.load_state_dict(weight['state_dict'])\nmodel = model.q_layer.layers\nmodel.eval()\n",
"_____no_output_____"
]
],
[
[
"## Save to mat file",
"_____no_output_____"
]
],
[
[
"from inspect import isfunction\nfrom scipy.io import savemat\n\nname = 'SMINet'\n\nv_names,d = [],{}\n\nhdims = []\ndim = 0\nfirstflag = False\n\nfor idx,layer in enumerate(model):\n # handle Linear layer\n if isinstance(layer,torch.nn.Linear):\n layername = 'F_hid_lin_{dim}_kernel'.format(dim=dim)\n d[layername] = layer.weight.detach().numpy().T\n hdims.append(layer.weight.detach().numpy().T.shape[1])\n\n layername = 'F_hid_lin_{dim}_bias'.format(dim=dim)\n d[layername] = layer.bias.detach().numpy().T\n\n lastlayer = idx\n dim = dim+1\n\n # find fist layer\n if firstflag == False:\n firstlayer = idx\n firstflag = True\n \n # handle normalization layer\n if isinstance(layer,torch.nn.BatchNorm1d):\n layername = 'F_bn_{dim}_mean'.format(dim=dim-1)\n d[layername] = layer.running_mean.detach().numpy()\n\n layername = 'F_bn_{dim}_sigma'.format(dim=dim-1)\n sigma = torch.sqrt(layer.running_var+1e-5)\n d[layername] = sigma.detach().numpy()\n\n layername = 'F_bn_{dim}_kernel'.format(dim=dim-1)\n d[layername] = layer.weight.detach().numpy()\n\n layername = 'F_bn_{dim}_bias'.format(dim=dim-1)\n d[layername] = layer.bias.detach().numpy()\n\n# change name in last layer\nlastlayername = 'F_hid_lin_{dim}_kernel'.format(dim=dim-1)\nnewlayername = 'F_y_pred_kernel'\nd[newlayername] = d[lastlayername]\ndel d[lastlayername]\n\nlastlayername = 'F_hid_lin_{dim}_bias'.format(dim=dim-1)\nnewlayername = 'F_y_pred_bias'\nd[newlayername] = d[lastlayername]\ndel d[lastlayername]\n\nxdim = model[firstlayer].weight.detach().numpy().shape[1]\nydim = model[lastlayer].weight.detach().numpy().shape[0]\nd['xdim'] = xdim\nd['ydim'] = ydim\nd['name'] = name\nd['hdims'] = np.array(hdims[:-1])\nd['actv'] = 'leaky_relu'\nd\n",
"_____no_output_____"
],
[
"# fix random seeds for reproducibility\nSEED = 1\ntorch.manual_seed(SEED)\ntorch.cuda.manual_seed(SEED)\ntorch.backends.cudnn.deterministic = True\ntorch.backends.cudnn.benchmark = False\nnp.random.seed(SEED)\nfrom dataloader import *\n\ndata_path = './data/SorosimGrid'\ntrain_data_loader = iter(ToyDataloader(os.path.join(data_path,'train'), IOScale, n_workers=1, batch=1))\n\nx_vald = np.zeros((10,xdim))\ny_vald = np.zeros((10,ydim))\nfor i in range(10):\n (input,label) = next(train_data_loader)\n output = model(input)\n \n x_vald[i,:] = input.detach().numpy()\n y_vald[i,:] = output.detach().numpy()\n\nd['x_vald'] = x_vald\nd['y_vald'] = y_vald\ny_vald[-1,:],label",
"_____no_output_____"
],
[
"dir_path = 'nets/%s'%(name)\nmat_path = os.path.join(dir_path,'weights.mat')\nif not os.path.exists(dir_path):\n os.makedirs(dir_path)\n print (\"[%s] created.\"%(dir_path))\nsavemat(mat_path,d) # save to a mat file\nprint (\"[%s] saved. Size is[%.3f]MB.\"%(mat_path,os.path.getsize(mat_path) / 1000000))",
"[nets/SMINet/weights.mat] saved. Size is[562.768]MB.\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4aa0df135eb17deaebf96151589773692291aa5e
| 37,749 |
ipynb
|
Jupyter Notebook
|
examples/encoding/OneHotEncoder.ipynb
|
indymnv/feature_engine
|
df996b718ef9335dd4b593087b3d6177a919ccf5
|
[
"BSD-3-Clause"
] | 1 |
2022-03-13T11:40:59.000Z
|
2022-03-13T11:40:59.000Z
|
examples/encoding/OneHotEncoder.ipynb
|
indymnv/feature_engine
|
df996b718ef9335dd4b593087b3d6177a919ccf5
|
[
"BSD-3-Clause"
] | 3 |
2020-10-28T00:43:00.000Z
|
2021-07-09T20:13:38.000Z
|
examples/encoding/OneHotEncoder.ipynb
|
TremaMiguel/feature_engine
|
117ea3061ec9cf65f9d012aff4875d2b88e8cf71
|
[
"BSD-3-Clause"
] | null | null | null | 30.941803 | 199 | 0.35238 |
[
[
[
"# OneHotEncoder\nPerforms One Hot Encoding.\n\nThe encoder can select how many different labels per variable to encode into binaries. When top_categories is set to None, all the categories will be transformed in binary variables. \n\nHowever, when top_categories is set to an integer, for example 10, then only the 10 most popular categories will be transformed into binary, and the rest will be discarded.\n\nThe encoder has also the possibility to create binary variables from all categories (drop_last = False), or remove the binary for the last category (drop_last = True), for use in linear models.",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nfrom sklearn.model_selection import train_test_split\nfrom feature_engine.encoding import OneHotEncoder",
"_____no_output_____"
],
[
"# Load titanic dataset from OpenML\n\ndef load_titanic():\n data = pd.read_csv('https://www.openml.org/data/get_csv/16826755/phpMYEkMl')\n data = data.replace('?', np.nan)\n data['cabin'] = data['cabin'].astype(str).str[0]\n data['pclass'] = data['pclass'].astype('O')\n data['age'] = data['age'].astype('float')\n data['fare'] = data['fare'].astype('float')\n data['embarked'].fillna('C', inplace=True)\n data.drop(labels=['boat', 'body', 'home.dest'], axis=1, inplace=True)\n return data",
"_____no_output_____"
],
[
"data = load_titanic()\ndata.head()",
"_____no_output_____"
],
[
"X = data.drop(['survived', 'name', 'ticket'], axis=1)\ny = data.survived",
"_____no_output_____"
],
[
"# we will encode the below variables, they have no missing values\nX[['cabin', 'pclass', 'embarked']].isnull().sum()",
"_____no_output_____"
],
[
"''' Make sure that the variables are type (object).\nif not, cast it as object , otherwise the transformer will either send an error (if we pass it as argument) \nor not pick it up (if we leave variables=None). '''\n\nX[['cabin', 'pclass', 'embarked']].dtypes",
"_____no_output_____"
],
[
"# let's separate into training and testing set\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)\n\nX_train.shape, X_test.shape",
"_____no_output_____"
]
],
[
[
"One hot encoding consists in replacing the categorical variable by a\ncombination of binary variables which take value 0 or 1, to indicate if\na certain category is present in an observation.\n\nEach one of the binary variables are also known as dummy variables. For\nexample, from the categorical variable \"Gender\" with categories 'female'\nand 'male', we can generate the boolean variable \"female\", which takes 1\nif the person is female or 0 otherwise. We can also generate the variable\nmale, which takes 1 if the person is \"male\" and 0 otherwise.\n\nThe encoder has the option to generate one dummy variable per category, or\nto create dummy variables only for the top n most popular categories, that is,\nthe categories that are shown by the majority of the observations.\n\nIf dummy variables are created for all the categories of a variable, you have\nthe option to drop one category not to create information redundancy. That is,\nencoding into k-1 variables, where k is the number if unique categories.\n\nThe encoder will encode only categorical variables (type 'object'). A list\nof variables can be passed as an argument. If no variables are passed as \nargument, the encoder will find and encode categorical variables (object type).\n\n\n#### Note:\nNew categories in the data to transform, that is, those that did not appear\nin the training set, will be ignored (no binary variable will be created for them).\n",
"_____no_output_____"
],
[
"### All binary, no top_categories",
"_____no_output_____"
]
],
[
[
"'''\nParameters\n----------\n\ntop_categories: int, default=None\n If None, a dummy variable will be created for each category of the variable.\n Alternatively, top_categories indicates the number of most frequent categories\n to encode. Dummy variables will be created only for those popular categories\n and the rest will be ignored. Note that this is equivalent to grouping all the\n remaining categories in one group.\n \nvariables : list\n The list of categorical variables that will be encoded. If None, the \n encoder will find and select all object type variables.\n \ndrop_last: boolean, default=False\n Only used if top_categories = None. It indicates whether to create dummy\n variables for all the categories (k dummies), or if set to True, it will\n ignore the last variable of the list (k-1 dummies).\n'''\nohe_enc = OneHotEncoder(top_categories=None,\n variables=['pclass', 'cabin', 'embarked'],\n drop_last=False)\nohe_enc.fit(X_train)",
"_____no_output_____"
],
[
"ohe_enc.encoder_dict_",
"_____no_output_____"
],
[
"train_t = ohe_enc.transform(X_train)\ntest_t = ohe_enc.transform(X_train)\n\ntest_t.head()",
"_____no_output_____"
]
],
[
[
"### Selecting top_categories to encode",
"_____no_output_____"
]
],
[
[
"ohe_enc = OneHotEncoder(top_categories=2,\n variables=['pclass', 'cabin', 'embarked'],\n drop_last=False)\nohe_enc.fit(X_train)\nohe_enc.encoder_dict_",
"_____no_output_____"
],
[
"train_t = ohe_enc.transform(X_train)\ntest_t = ohe_enc.transform(X_train)\ntest_t.head()",
"_____no_output_____"
]
],
[
[
"### Dropping the last category for linear models",
"_____no_output_____"
]
],
[
[
"ohe_enc = OneHotEncoder(top_categories=None,\n variables=['pclass', 'cabin', 'embarked'],\n drop_last=True)\n\nohe_enc.fit(X_train)\nohe_enc.encoder_dict_",
"_____no_output_____"
],
[
"train_t = ohe_enc.transform(X_train)\ntest_t = ohe_enc.transform(X_train)\n\ntest_t.head()",
"_____no_output_____"
]
],
[
[
"### Automatically select categorical variables\n\nThis encoder selects all the categorical variables, if None is passed to the variable argument when calling the encoder.",
"_____no_output_____"
]
],
[
[
"ohe_enc = OneHotEncoder(top_categories=None,\n drop_last=True)\n\nohe_enc.fit(X_train)",
"_____no_output_____"
],
[
"train_t = ohe_enc.transform(X_train)\ntest_t = ohe_enc.transform(X_train)\n\ntest_t.head()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4aa0dfa0b8e59503dda8949be9d52526a40221b4
| 2,758 |
ipynb
|
Jupyter Notebook
|
notebook - machine learning sklearn/ipython notebook/2017-25-11-so-preprocessing-normalization-sklearn.ipynb
|
bjfisica/MachineLearning
|
20349301ae7f82cd5048410b0cf1f7a5f7d7e5a2
|
[
"MIT"
] | 52 |
2019-02-15T16:37:13.000Z
|
2022-02-17T18:34:30.000Z
|
notebook - machine learning sklearn/ipython notebook/2017-25-11-so-preprocessing-normalization-sklearn.ipynb
|
ariffyasri/Complete-Data-Science-Toolkits
|
8a65587c548c412b91d4cb7263ed5e56b249be8a
|
[
"MIT"
] | null | null | null |
notebook - machine learning sklearn/ipython notebook/2017-25-11-so-preprocessing-normalization-sklearn.ipynb
|
ariffyasri/Complete-Data-Science-Toolkits
|
8a65587c548c412b91d4cb7263ed5e56b249be8a
|
[
"MIT"
] | 22 |
2017-11-25T23:42:16.000Z
|
2019-01-07T09:22:35.000Z
| 20.42963 | 94 | 0.551124 |
[
[
[
"## Preprocessing Normalization ",
"_____no_output_____"
]
],
[
[
"import warnings\nwarnings.filterwarnings('ignore')",
"_____no_output_____"
],
[
"from sklearn.datasets import load_iris\nholder = load_iris()\nX, y = holder.data, holder.target",
"_____no_output_____"
],
[
"from sklearn.cross_validation import train_test_split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3, random_state =0)",
"_____no_output_____"
]
],
[
[
"### Normalizer ",
"_____no_output_____"
]
],
[
[
"from sklearn.preprocessing import Normalizer\nscaler = Normalizer().fit(X_train)\nnormalized_X = scaler.transform(X_train)\nnormalized_X_test = scaler.transform(X_test)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa0dff43283d9a49c74aa5f76df6140ba98e196
| 83,439 |
ipynb
|
Jupyter Notebook
|
data-exploration/complex-events/notebooks/complex-events-stats.ipynb
|
apriltuesday/eva-opentargets
|
30eeb3b174297ed6dab8cf5e631073469d7a4d86
|
[
"Apache-2.0"
] | 5 |
2020-10-30T09:43:04.000Z
|
2021-07-23T21:49:45.000Z
|
data-exploration/complex-events/notebooks/complex-events-stats.ipynb
|
apriltuesday/eva-opentargets
|
30eeb3b174297ed6dab8cf5e631073469d7a4d86
|
[
"Apache-2.0"
] | 174 |
2020-07-04T07:44:29.000Z
|
2022-03-31T08:30:32.000Z
|
data-exploration/complex-events/notebooks/complex-events-stats.ipynb
|
apriltuesday/eva-opentargets
|
30eeb3b174297ed6dab8cf5e631073469d7a4d86
|
[
"Apache-2.0"
] | 4 |
2020-08-04T17:08:22.000Z
|
2021-04-06T18:20:44.000Z
| 168.563636 | 27,784 | 0.900574 |
[
[
[
"from eva_cttv_pipeline.clinvar_xml_utils import *\nfrom consequence_prediction.repeat_expansion_variants.clinvar_identifier_parsing import parse_variant_identifier\n\nimport os\nimport sys\nimport urllib\nimport requests\nimport xml.etree.ElementTree as ElementTree\nfrom collections import Counter\n\nimport hgvs.parser\nfrom hgvs.exceptions import HGVSParseError\n\nimport numpy as np\nimport pandas as pd",
"_____no_output_____"
],
[
"sys.path.append('../')\nfrom gather_stats import counts",
"_____no_output_____"
],
[
"%matplotlib inline\nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"parser = hgvs.parser.Parser()",
"_____no_output_____"
],
[
"PROJECT_ROOT = '/home/april/projects/opentargets'\n\n# dump of all records with no functional consequences: June consequence pred + ClinVar 6/26/2021\nno_consequences_path = os.path.join(PROJECT_ROOT, 'no-consequences.xml.gz')\ndataset = ClinVarDataset(no_consequences_path)",
"_____no_output_____"
]
],
[
[
"## Gather counts\n\nAmong records with no functional consequences\n* how many of each variant type\n* how many have hgvs, sequence location w/ start/stop position at least, cytogenic location\n* of those with hgvs, how many can the library parse?\n * how many can our code parse?",
"_____no_output_____"
]
],
[
[
"total_count, variant_type_hist, other_counts, exclusive_counts = counts(no_consequences_path, PROJECT_ROOT)",
"_____no_output_____"
],
[
"print(total_count)",
"17649\n"
],
[
"plt.figure(figsize=(15,7))\nplt.xticks(rotation='vertical')\nplt.title('Variant Types (no functional consequences and incomplete coordinates)')\nplt.bar(variant_type_hist.keys(), variant_type_hist.values())",
"_____no_output_____"
],
[
"variant_type_hist",
"_____no_output_____"
],
[
"plt.figure(figsize=(15,7))\nplt.xticks(rotation='vertical')\nplt.title('Variant Descriptors (no functional consequences and incomplete coordinates)')\nplt.bar(other_counts.keys(), other_counts.values())",
"_____no_output_____"
],
[
"other_counts",
"_____no_output_____"
],
[
"def print_link_for_type(variant_type, min_score=-1):\n for record in dataset:\n if record.measure:\n m = record.measure\n if m.has_complete_coordinates:\n continue\n\n if m.variant_type == variant_type and record.score >= min_score:\n print(f'https://www.ncbi.nlm.nih.gov/clinvar/{record.accession}/')",
"_____no_output_____"
],
[
"print_link_for_type('Microsatellite', min_score=1)",
"_____no_output_____"
]
],
[
[
"### Examples\n\nSome hand-picked examples of complex variants from ClinVar. For each type I tried to choose at least one that seemed \"typical\" and one that was relatively high quality to get an idea of the variability, but no guarantees for how representative these are.\n\n* Duplication\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/1062574/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/89496/\n* Deletion\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/1011851/\n* Inversion\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/268016/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/90611/\n* Translocation\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/267959/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/267873/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/1012364/\n* copy number gain\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/523250/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/870516/\n* copy number loss\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/1047901/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/625801/\n* Complex\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/267835/\n * https://www.ncbi.nlm.nih.gov/clinvar/variation/585332/",
"_____no_output_____"
],
[
"### Appendix A: Marcos' questions\n\n* What do the HGVS parser numbers mean?\n * This is the number of records which had at least one HGVS descriptor for which the specified parser was able to extract _some_ information. For the official parser this means not throwing an exception; for our parser this means returning some non-`None` properties (though note our parser was originally written for the repeat expansion pipeline).\n* What's the total number of HGVS we can parse with either parser?\n * added to the above chart.\n* From the variants with cytogenetic location, how many did not have any of the other descriptors, if any?\n * see below",
"_____no_output_____"
]
],
[
[
"plt.figure(figsize=(10,7))\nplt.title('Variant Descriptors (no functional consequences and incomplete coordinates)')\nplt.bar(exclusive_counts.keys(), exclusive_counts.values())",
"_____no_output_____"
],
[
"exclusive_counts",
"_____no_output_____"
]
],
[
[
"### Appendix B: More HGVS parsing exploration\n\nHGVS python library [doesn't support ranges](https://github.com/biocommons/hgvs/issues/225).\n\n[VEP API](https://rest.ensembl.org/#VEP) has some limited support for HGVS.",
"_____no_output_____"
]
],
[
[
"def try_to_parse(hgvs):\n try:\n parser.parse_hgvs_variant(hgvs)\n print(hgvs, 'SUCCESS')\n except:\n print(hgvs, 'FAILED')\n\n\ntry_to_parse('NC_000011.10:g.(?_17605796)_(17612832_?)del')\ntry_to_parse('NC_000011.10:g.(17605790_17605796)_(17612832_1761283)del')\ntry_to_parse('NC_000011.10:g.17605796_17612832del')\ntry_to_parse('NC_000011.10:g.?_17612832del')",
"NC_000011.10:g.(?_17605796)_(17612832_?)del FAILED\nNC_000011.10:g.(17605790_17605796)_(17612832_1761283)del FAILED\nNC_000011.10:g.17605796_17612832del SUCCESS\nNC_000011.10:g.?_17612832del SUCCESS\n"
],
[
"def try_to_vep(hgvs):\n safe_hgvs = urllib.parse.quote(hgvs)\n vep_url = f'https://rest.ensembl.org/vep/human/hgvs/{safe_hgvs}?content-type=application/json'\n resp = requests.get(vep_url)\n print(resp.json())\n \n\ntry_to_vep('NC_000011.10:g.(?_17605796)_(17612832_?)del')\ntry_to_vep('NC_000011.10:g.(17605790_17605796)_(17612832_1761283)del')\ntry_to_vep('NC_000011.10:g.17605796_17612832del')\ntry_to_vep('NC_000011.10:g.?_17612832del')",
"{'error': \"Unable to parse HGVS notation 'NC_000011.10:g.(?_17605796)_(17612832_?)del': HGVS notation for variation with unknown location is not supported\"}\n{'error': \"Unable to parse HGVS notation 'NC_000011.10:g.(17605790_17605796)_(17612832_1761283)del': Could not parse the HGVS notation NC_000011.10:g.(17605790_17605796)_(17612832_1761283)del - can't interpret '(17612832_1761283)'\"}\n{'error': \"Unable to parse HGVS notation 'NC_000011.10:g.17605796_17612832del': Region requested must be smaller than 5kb\"}\n{'error': 'You must specify a region in the format chr, chr:start or chr:start-end at /nfs/public/release/ensweb/live/rest/www_104/.plenv/versions/5.26.1/lib/perl5/site_perl/5.26.1/x86_64-linux/Bio/DB/HTS/Tabix.pm line 104.\\n'}\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4aa0e761d3ef37e2e2a6de89f69284452b29b5b7
| 992,937 |
ipynb
|
Jupyter Notebook
|
notebook/41t-add34.ipynb
|
raijin0704/kaggle-cassava
|
ba9aa2c29257ea1211123496ff04a22aea7874d1
|
[
"MIT"
] | 1 |
2021-02-23T07:37:55.000Z
|
2021-02-23T07:37:55.000Z
|
notebook/41t-add34.ipynb
|
raijin0704/kaggle-cassava
|
ba9aa2c29257ea1211123496ff04a22aea7874d1
|
[
"MIT"
] | null | null | null |
notebook/41t-add34.ipynb
|
raijin0704/kaggle-cassava
|
ba9aa2c29257ea1211123496ff04a22aea7874d1
|
[
"MIT"
] | null | null | null | 992,937 | 992,937 | 0.938792 |
[
[
[
"# GPU",
"_____no_output_____"
]
],
[
[
"gpu_info = !nvidia-smi\r\ngpu_info = '\\n'.join(gpu_info)\r\nprint(gpu_info)",
"Thu Feb 18 07:49:09 2021 \n+-----------------------------------------------------------------------------+\n| NVIDIA-SMI 460.39 Driver Version: 460.32.03 CUDA Version: 11.2 |\n|-------------------------------+----------------------+----------------------+\n| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |\n| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |\n| | | MIG M. |\n|===============================+======================+======================|\n| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |\n| N/A 35C P0 27W / 250W | 0MiB / 16280MiB | 0% Default |\n| | | N/A |\n+-------------------------------+----------------------+----------------------+\n \n+-----------------------------------------------------------------------------+\n| Processes: |\n| GPU GI CI PID Type Process name GPU Memory |\n| ID ID Usage |\n|=============================================================================|\n| No running processes found |\n+-----------------------------------------------------------------------------+\n"
]
],
[
[
"# CFG",
"_____no_output_____"
]
],
[
[
"CONFIG_NAME = 'config41.yml'\r\ndebug = False",
"_____no_output_____"
],
[
"from google.colab import drive, auth\r\n\r\n# ドライブのマウント\r\ndrive.mount('/content/drive')\r\n# Google Cloudの権限設定\r\nauth.authenticate_user()",
"Mounted at /content/drive\n"
],
[
"def get_github_secret():\r\n import json\r\n with open('/content/drive/MyDrive/config/github.json') as f:\r\n github_config = json.load(f)\r\n return github_config\r\n\r\ngithub_config = get_github_secret()",
"_____no_output_____"
],
[
"! rm -r kaggle-cassava\r\nuser_name = github_config[\"user_name\"]\r\npassword = github_config[\"password\"]\r\n! git clone https://{user_name}:{password}@github.com/raijin0704/kaggle-cassava.git\r\n\r\nimport sys\r\nsys.path.append('./kaggle-cassava')",
"rm: cannot remove 'kaggle-cassava': No such file or directory\nCloning into 'kaggle-cassava'...\nremote: Enumerating objects: 32, done.\u001b[K\nremote: Counting objects: 100% (32/32), done.\u001b[K\nremote: Compressing objects: 100% (27/27), done.\u001b[K\nremote: Total 440 (delta 18), reused 10 (delta 5), pack-reused 408\u001b[K\nReceiving objects: 100% (440/440), 8.53 MiB | 10.40 MiB/s, done.\nResolving deltas: 100% (276/276), done.\n"
],
[
"from src.utils.envs.main import create_env\r\nenv_dict = create_env()",
"_____no_output_____"
],
[
"env_dict",
"_____no_output_____"
],
[
"# ====================================================\n# CFG\n# ====================================================\nimport yaml\n\nCONFIG_PATH = f'./kaggle-cassava/config/{CONFIG_NAME}'\nwith open(CONFIG_PATH) as f:\n config = yaml.load(f)\n\nINFO = config['info']\nTAG = config['tag']\nCFG = config['cfg']\n\nDATA_PATH = env_dict[\"data_path\"]\nenv = env_dict[\"env\"]\nNOTEBOOK_PATH = env_dict[\"notebook_dir\"]\nOUTPUT_DIR = env_dict[\"output_dir\"]\nTITLE = env_dict[\"title\"]\n\nCFG['train'] = True\nCFG['inference'] = False\n\nCFG['debug'] = debug\n\nif CFG['debug']:\n CFG['epochs'] = 1\n\n# 環境変数\nimport os\nos.environ[\"GCLOUD_PROJECT\"] = INFO['PROJECT_ID']\n\n# 間違ったバージョンを実行しないかチェック\n# assert INFO['TITLE'] == TITLE, f'{TITLE}, {INFO[\"TITLE\"]}'\nTITLE = INFO[\"TITLE\"]",
"_____no_output_____"
],
[
"import os\r\n\r\nif env=='colab':\r\n !rm -r /content/input\r\n ! cp /content/drive/Shareddrives/便利用/kaggle/cassava/input.zip /content/input.zip\r\n ! unzip input.zip > /dev/null\r\n ! rm input.zip\r\ntrain_num = len(os.listdir(DATA_PATH+\"/train_images\"))\r\nassert train_num == 21397",
"rm: cannot remove '/content/input': No such file or directory\n"
]
],
[
[
"# install apex",
"_____no_output_____"
]
],
[
[
"if CFG['apex']:\r\n try:\r\n import apex\r\n except Exception:\r\n ! git clone https://github.com/NVIDIA/apex.git\r\n % cd apex\r\n !pip install --no-cache-dir --global-option=\"--cpp_ext\" --global-option=\"--cuda_ext\" .\r\n %cd ..",
"_____no_output_____"
]
],
[
[
"# Library",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# Library\n# ====================================================\nimport os\nimport datetime\nimport math\nimport time\nimport random\nimport glob\nimport shutil\nfrom pathlib import Path\nfrom contextlib import contextmanager\nfrom collections import defaultdict, Counter\n\nimport scipy as sp\nimport numpy as np\nimport pandas as pd\nfrom matplotlib import pyplot as plt\nimport seaborn as sns\n\nfrom sklearn import preprocessing\nfrom sklearn.metrics import accuracy_score\nfrom sklearn.model_selection import StratifiedKFold\n\nfrom tqdm.auto import tqdm\nfrom functools import partial\n\nimport cv2\nfrom PIL import Image\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.optim import Adam, SGD\nimport torchvision.models as models\nfrom torch.nn.parameter import Parameter\nfrom torch.utils.data import DataLoader, Dataset\nfrom torch.optim.lr_scheduler import CosineAnnealingWarmRestarts, CosineAnnealingLR, ReduceLROnPlateau\n\nfrom albumentations import (\n Compose, OneOf, Normalize, Resize, RandomResizedCrop, RandomCrop, HorizontalFlip, VerticalFlip, \n RandomBrightness, RandomContrast, RandomBrightnessContrast, Rotate, ShiftScaleRotate, Cutout, \n IAAAdditiveGaussianNoise, Transpose, CenterCrop\n )\nfrom albumentations.pytorch import ToTensorV2\nfrom albumentations import ImageOnlyTransform\n\nimport timm\nimport mlflow\n\nimport warnings \nwarnings.filterwarnings('ignore')\n\nif CFG['apex']:\n from apex import amp\n\nif CFG['debug']:\n device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\nelse:\n device = torch.device('cuda')\n\nfrom src.utils.logger import init_logger\nfrom src.utils.utils import seed_torch, EarlyStopping\nfrom src.utils.loss.bi_tempered_logistic_loss import bi_tempered_logistic_loss\nfrom src.utils.augments.randaugment import RandAugment\nfrom src.utils.augments.augmix import RandomAugMix\n\nstart_time = datetime.datetime.now()\nstart_time_str = start_time.strftime('%m%d%H%M')",
"_____no_output_____"
]
],
[
[
"# Directory settings",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# Directory settings\n# ====================================================\nif os.path.exists(OUTPUT_DIR):\n shutil.rmtree(OUTPUT_DIR)\nif not os.path.exists(OUTPUT_DIR):\n os.makedirs(OUTPUT_DIR)",
"_____no_output_____"
]
],
[
[
"# save basic files",
"_____no_output_____"
]
],
[
[
"# with open(f'{OUTPUT_DIR}/{start_time_str}_TAG.json', 'w') as f:\r\n# json.dump(TAG, f, indent=4)\r\n \r\n# with open(f'{OUTPUT_DIR}/{start_time_str}_CFG.json', 'w') as f:\r\n# json.dump(CFG, f, indent=4)\r\n\r\nimport shutil\r\nnotebook_path = f'{OUTPUT_DIR}/{start_time_str}_{TITLE}.ipynb'\r\nshutil.copy2(NOTEBOOK_PATH, notebook_path)",
"_____no_output_____"
]
],
[
[
"# Data Loading",
"_____no_output_____"
]
],
[
[
"train = pd.read_csv(f'{DATA_PATH}/train.csv')\ntest = pd.read_csv(f'{DATA_PATH}/sample_submission.csv')\nlabel_map = pd.read_json(f'{DATA_PATH}/label_num_to_disease_map.json', \n orient='index')\n\nif CFG['debug']:\n train = train.sample(n=1000, random_state=CFG['seed']).reset_index(drop=True)",
"_____no_output_____"
]
],
[
[
"# Utils",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# Utils\n# ====================================================\ndef get_score(y_true, y_pred):\n return accuracy_score(y_true, y_pred)\n\nlogger_path = OUTPUT_DIR+f'{start_time_str}_train.log'\nLOGGER = init_logger(logger_path)\nseed_torch(seed=CFG['seed'])",
"_____no_output_____"
],
[
"def remove_glob(pathname, recursive=True):\r\n for p in glob.glob(pathname, recursive=recursive):\r\n if os.path.isfile(p):\r\n os.remove(p)\r\n\r\n\r\ndef rand_bbox(size, lam):\r\n W = size[2]\r\n H = size[3]\r\n cut_rat = np.sqrt(1. - lam)\r\n cut_w = np.int(W * cut_rat)\r\n cut_h = np.int(H * cut_rat)\r\n\r\n # uniform\r\n cx = np.random.randint(W)\r\n cy = np.random.randint(H)\r\n\r\n bbx1 = np.clip(cx - cut_w // 2, 0, W)\r\n bby1 = np.clip(cy - cut_h // 2, 0, H)\r\n bbx2 = np.clip(cx + cut_w // 2, 0, W)\r\n bby2 = np.clip(cy + cut_h // 2, 0, H)\r\n\r\n return bbx1, bby1, bbx2, bby2",
"_____no_output_____"
]
],
[
[
"# CV split",
"_____no_output_____"
]
],
[
[
"folds = train.copy()\nFold = StratifiedKFold(n_splits=CFG['n_fold'], shuffle=True, random_state=CFG['seed'])\nfor n, (train_index, val_index) in enumerate(Fold.split(folds, folds[CFG['target_col']])):\n folds.loc[val_index, 'fold'] = int(n)\nfolds['fold'] = folds['fold'].astype(int)\nprint(folds.groupby(['fold', CFG['target_col']]).size())",
"fold label\n0 0 218\n 1 438\n 2 477\n 3 2631\n 4 516\n1 0 218\n 1 438\n 2 477\n 3 2631\n 4 516\n2 0 217\n 1 438\n 2 477\n 3 2632\n 4 515\n3 0 217\n 1 438\n 2 477\n 3 2632\n 4 515\n4 0 217\n 1 437\n 2 478\n 3 2632\n 4 515\ndtype: int64\n"
]
],
[
[
"# Dataset",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# Dataset\n# ====================================================\nclass TrainDataset(Dataset):\n def __init__(self, df, transform=None):\n self.df = df\n self.file_names = df['image_id'].values\n self.labels = df['label'].values\n self.transform = transform\n \n def __len__(self):\n return len(self.df)\n\n def __getitem__(self, idx):\n file_name = self.file_names[idx]\n file_path = f'{DATA_PATH}/train_images/{file_name}'\n image = cv2.imread(file_path)\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n if self.transform:\n augmented = self.transform(image=image)\n image = augmented['image']\n label = torch.tensor(self.labels[idx]).long()\n return image, label\n \n\nclass TestDataset(Dataset):\n def __init__(self, df, transform=None):\n self.df = df\n self.file_names = df['image_id'].values\n self.transform = transform\n \n def __len__(self):\n return len(self.df)\n\n def __getitem__(self, idx):\n file_name = self.file_names[idx]\n file_path = f'{DATA_PATH}/test_images/{file_name}'\n image = cv2.imread(file_path)\n image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)\n if self.transform:\n augmented = self.transform(image=image)\n image = augmented['image']\n return image",
"_____no_output_____"
],
[
"# train_dataset = TrainDataset(train, transform=None)\n\n# for i in range(1):\n# image, label = train_dataset[i]\n# plt.imshow(image)\n# plt.title(f'label: {label}')\n# plt.show() ",
"_____no_output_____"
]
],
[
[
"# Transforms",
"_____no_output_____"
]
],
[
[
"def _get_train_augmentations(aug_list):\r\n process = []\r\n for aug in aug_list:\r\n if aug == 'Resize':\r\n process.append(Resize(CFG['size'], CFG['size']))\r\n elif aug == 'RandomResizedCrop':\r\n process.append(RandomResizedCrop(CFG['size'], CFG['size']))\r\n elif aug =='CenterCrop':\r\n process.append(CenterCrop(CFG['size'], CFG['size']))\r\n elif aug == 'Transpose':\r\n process.append(Transpose(p=0.5))\r\n elif aug == 'HorizontalFlip':\r\n process.append(HorizontalFlip(p=0.5))\r\n elif aug == 'VerticalFlip':\r\n process.append(VerticalFlip(p=0.5))\r\n elif aug == 'ShiftScaleRotate':\r\n process.append(ShiftScaleRotate(p=0.5))\r\n elif aug == 'RandomBrightness':\r\n process.append(RandomBrightness(limit=(-0.2,0.2), p=1))\r\n elif aug == 'Cutout':\r\n process.append(Cutout(max_h_size=CFG['CutoutSize'], max_w_size=CFG['CutoutSize'], p=0.5))\r\n elif aug == 'RandAugment':\r\n process.append(RandAugment(CFG['RandAugmentN'], CFG['RandAugmentM'], p=0.5))\r\n elif aug == 'RandomAugMix':\r\n process.append(RandomAugMix(severity=CFG['AugMixSeverity'], \r\n width=CFG['AugMixWidth'], \r\n alpha=CFG['AugMixAlpha'], p=0.5))\r\n elif aug == 'Normalize':\r\n process.append(Normalize(\r\n mean=[0.485, 0.456, 0.406],\r\n std=[0.229, 0.224, 0.225],\r\n ))\r\n elif aug in ['mixup', 'cutmix', 'fmix']:\r\n pass\r\n else:\r\n raise ValueError(f'{aug} is not suitable')\r\n\r\n process.append(ToTensorV2())\r\n\r\n return process\r\n\r\n\r\n\r\ndef _get_valid_augmentations(aug_list):\r\n process = []\r\n for aug in aug_list:\r\n if aug == 'Resize':\r\n process.append(Resize(CFG['size'], CFG['size']))\r\n elif aug == 'RandomResizedCrop':\r\n process.append(OneOf(\r\n [RandomResizedCrop(CFG['size'], CFG['size'], p=0.5), \r\n Resize(CFG['size'], CFG['size'], p=0.5)], p=1))\r\n elif aug =='CenterCrop':\r\n process.append(OneOf(\r\n [CenterCrop(CFG['size'], CFG['size'], p=0.5), \r\n Resize(CFG['size'], CFG['size'], p=0.5)], p=1))\r\n # process.append(\r\n # CenterCrop(CFG['size'], CFG['size'], p=1.))\r\n elif aug == 'Transpose':\r\n process.append(Transpose(p=0.5))\r\n elif aug == 'HorizontalFlip':\r\n process.append(HorizontalFlip(p=0.5))\r\n elif aug == 'VerticalFlip':\r\n process.append(VerticalFlip(p=0.5))\r\n elif aug == 'ShiftScaleRotate':\r\n process.append(ShiftScaleRotate(p=0.5))\r\n elif aug == 'RandomBrightness':\r\n process.append(RandomBrightness(limit=(-0.2,0.2), p=1))\r\n elif aug == 'Cutout':\r\n process.append(Cutout(max_h_size=CFG['CutoutSize'], max_w_size=CFG['CutoutSize'], p=0.5))\r\n elif aug == 'RandAugment':\r\n process.append(RandAugment(CFG['RandAugmentN'], CFG['RandAugmentM'], p=0.5))\r\n elif aug == 'RandomAugMix':\r\n process.append(RandomAugMix(severity=CFG['AugMixSeverity'], \r\n width=CFG['AugMixWidth'], \r\n alpha=CFG['AugMixAlpha'], p=0.5))\r\n elif aug == 'Normalize':\r\n process.append(Normalize(\r\n mean=[0.485, 0.456, 0.406],\r\n std=[0.229, 0.224, 0.225],\r\n ))\r\n elif aug in ['mixup', 'cutmix', 'fmix']:\r\n pass\r\n else:\r\n raise ValueError(f'{aug} is not suitable')\r\n\r\n process.append(ToTensorV2())\r\n\r\n return process",
"_____no_output_____"
],
[
"# ====================================================\n# Transforms\n# ====================================================\ndef get_transforms(*, data):\n \n if data == 'train':\n return Compose(\n _get_train_augmentations(TAG['augmentation'])\n )\n\n elif data == 'valid':\n try:\n augmentations = TAG['valid_augmentation']\n except KeyError:\n augmentations = ['Resize', 'Normalize']\n return Compose(\n _get_valid_augmentations(augmentations)\n )",
"_____no_output_____"
],
[
"num_fig = 5\n\ntrain_dataset = TrainDataset(train, transform=get_transforms(data='train'))\nvalid_dataset = TrainDataset(train, transform=get_transforms(data='valid'))\norigin_dataset = TrainDataset(train, transform=None)\n\nfig, ax = plt.subplots(num_fig, 3, figsize=(10, num_fig*3))\n\nfor j, dataset in enumerate([train_dataset, valid_dataset, origin_dataset]):\n for i in range(num_fig):\n image, label = dataset[i]\n if j < 2:\n ax[i,j].imshow(image.transpose(0,2).transpose(0,1))\n else:\n ax[i,j].imshow(image)\n ax[i,j].set_title(f'label: {label}') ",
"Clipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\nClipping input data to the valid range for imshow with RGB data ([0..1] for floats or [0..255] for integers).\n"
]
],
[
[
"# MODEL",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# MODEL\n# ====================================================\nclass CustomModel(nn.Module):\n def __init__(self, model_name, pretrained=False):\n super().__init__()\n self.model = timm.create_model(model_name, pretrained=pretrained)\n if hasattr(self.model, 'classifier'):\n n_features = self.model.classifier.in_features\n self.model.classifier = nn.Linear(n_features, CFG['target_size'])\n elif hasattr(self.model, 'fc'):\n n_features = self.model.fc.in_features\n self.model.fc = nn.Linear(n_features, CFG['target_size'])\n elif hasattr(self.model, 'head'):\n n_features = self.model.head.in_features\n self.model.head = nn.Linear(n_features, CFG['target_size'])\n\n def forward(self, x):\n x = self.model(x)\n return x",
"_____no_output_____"
],
[
"model = CustomModel(model_name=TAG['model_name'], pretrained=False)\ntrain_dataset = TrainDataset(train, transform=get_transforms(data='train'))\ntrain_loader = DataLoader(train_dataset, batch_size=4, shuffle=True,\n num_workers=0, pin_memory=True, drop_last=True)\n\nfor image, label in train_loader:\n output = model(image)\n print(output)\n break",
"tensor([[-0.6832, 0.1949, -0.0255, 0.4585, 0.3152],\n [ 0.0186, 0.0161, -0.0219, 0.0364, 0.0364],\n [ 0.0475, 0.0210, -0.0199, 0.0312, 0.0410],\n [ 0.0847, 0.0233, 0.0220, 0.0359, 0.0171]],\n grad_fn=<AddmmBackward>)\n"
]
],
[
[
"# Helper functions",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# Helper functions\n# ====================================================\nclass AverageMeter(object):\n \"\"\"Computes and stores the average and current value\"\"\"\n def __init__(self):\n self.reset()\n\n def reset(self):\n self.val = 0\n self.avg = 0\n self.sum = 0\n self.count = 0\n\n def update(self, val, n=1):\n self.val = val\n self.sum += val * n\n self.count += n\n self.avg = self.sum / self.count\n\n\ndef asMinutes(s):\n m = math.floor(s / 60)\n s -= m * 60\n return '%dm %ds' % (m, s)\n\n\ndef timeSince(since, percent):\n now = time.time()\n s = now - since\n es = s / (percent)\n rs = es - s\n return '%s (remain %s)' % (asMinutes(s), asMinutes(rs))\n\n\n",
"_____no_output_____"
],
[
"# ====================================================\n# loss\n# ====================================================\ndef get_loss(criterion, y_preds, labels):\n if TAG['criterion']=='CrossEntropyLoss':\n loss = criterion(y_preds, labels)\n elif TAG['criterion'] == 'bi_tempered_logistic_loss':\n loss = criterion(y_preds, labels, t1=CFG['bi_tempered_loss_t1'], t2=CFG['bi_tempered_loss_t2'])\n return loss",
"_____no_output_____"
],
[
"# ====================================================\n# Helper functions\n# ====================================================\ndef train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, device):\n batch_time = AverageMeter()\n data_time = AverageMeter()\n losses = AverageMeter()\n scores = AverageMeter()\n # switch to train mode\n model.train()\n start = end = time.time()\n global_step = 0\n for step, (images, labels) in enumerate(train_loader):\n # measure data loading time\n data_time.update(time.time() - end)\n images = images.to(device)\n labels = labels.to(device)\n batch_size = labels.size(0)\n r = np.random.rand(1)\n is_aug = r < 0.5 # probability of augmentation\n if is_aug & ('cutmix' in TAG['augmentation']) & (epoch+1>=CFG['heavy_aug_start_epoch']):\n # generate mixed sample\n # inference from https://github.com/clovaai/CutMix-PyTorch/blob/master/train.py\n lam = np.random.beta(CFG['CutmixAlpha'], CFG['CutmixAlpha'])\n rand_index = torch.randperm(images.size()[0]).to(device)\n labels_a = labels\n labels_b = labels[rand_index]\n bbx1, bby1, bbx2, bby2 = rand_bbox(images.size(), lam)\n images[:, :, bbx1:bbx2, bby1:bby2] = images[rand_index, :, bbx1:bbx2, bby1:bby2]\n # adjust lambda to exactly match pixel ratio\n lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (images.size()[-1] * images.size()[-2]))\n # compute output\n y_preds = model(images)\n loss = get_loss(criterion, y_preds, labels_a) * lam + \\\n get_loss(criterion, y_preds, labels_b) * (1. - lam)\n else:\n y_preds = model(images)\n loss = get_loss(criterion, y_preds, labels)\n # record loss\n losses.update(loss.item(), batch_size)\n if CFG['gradient_accumulation_steps'] > 1:\n loss = loss / CFG['gradient_accumulation_steps']\n if CFG['apex']:\n with amp.scale_loss(loss, optimizer) as scaled_loss:\n scaled_loss.backward()\n else:\n loss.backward()\n # clear memory\n del loss, y_preds\n torch.cuda.empty_cache()\n grad_norm = torch.nn.utils.clip_grad_norm_(model.parameters(), CFG['max_grad_norm'])\n if (step + 1) % CFG['gradient_accumulation_steps'] == 0:\n optimizer.step()\n optimizer.zero_grad()\n global_step += 1\n # measure elapsed time\n batch_time.update(time.time() - end)\n end = time.time()\n if step % CFG['print_freq'] == 0 or step == (len(train_loader)-1):\n print('Epoch: [{0}][{1}/{2}] '\n 'Data {data_time.val:.3f} ({data_time.avg:.3f}) '\n 'Elapsed {remain:s} '\n 'Loss: {loss.val:.4f}({loss.avg:.4f}) '\n 'Grad: {grad_norm:.4f} '\n #'LR: {lr:.6f} '\n .format(\n epoch+1, step, len(train_loader), batch_time=batch_time,\n data_time=data_time, loss=losses,\n remain=timeSince(start, float(step+1)/len(train_loader)),\n grad_norm=grad_norm,\n #lr=scheduler.get_lr()[0],\n ))\n return losses.avg\n\n\ndef valid_fn(valid_loader, model, criterion, device):\n batch_time = AverageMeter()\n data_time = AverageMeter()\n losses = AverageMeter()\n scores = AverageMeter()\n # switch to evaluation mode\n model.eval()\n preds = []\n start = end = time.time()\n for step, (images, labels) in enumerate(valid_loader):\n # measure data loading time\n data_time.update(time.time() - end)\n images = images.to(device)\n labels = labels.to(device)\n batch_size = labels.size(0)\n # compute loss\n with torch.no_grad():\n y_preds = model(images)\n loss = get_loss(criterion, y_preds, labels)\n losses.update(loss.item(), batch_size)\n # record accuracy\n preds.append(y_preds.softmax(1).to('cpu').numpy())\n if CFG['gradient_accumulation_steps'] > 1:\n loss = loss / CFG['gradient_accumulation_steps']\n # measure elapsed time\n batch_time.update(time.time() - end)\n end = time.time()\n if step % CFG['print_freq'] == 0 or step == (len(valid_loader)-1):\n print('EVAL: [{0}/{1}] '\n 'Data {data_time.val:.3f} ({data_time.avg:.3f}) '\n 'Elapsed {remain:s} '\n 'Loss: {loss.val:.4f}({loss.avg:.4f}) '\n .format(\n step, len(valid_loader), batch_time=batch_time,\n data_time=data_time, loss=losses,\n remain=timeSince(start, float(step+1)/len(valid_loader)),\n ))\n predictions = np.concatenate(preds)\n return losses.avg, predictions\n\n\ndef inference(model, states, test_loader, device):\n model.to(device)\n tk0 = tqdm(enumerate(test_loader), total=len(test_loader))\n probs = []\n for i, (images) in tk0:\n images = images.to(device)\n avg_preds = []\n for state in states:\n # model.load_state_dict(state['model'])\n model.load_state_dict(state)\n model.eval()\n with torch.no_grad():\n y_preds = model(images)\n avg_preds.append(y_preds.softmax(1).to('cpu').numpy())\n avg_preds = np.mean(avg_preds, axis=0)\n probs.append(avg_preds)\n probs = np.concatenate(probs)\n return probs",
"_____no_output_____"
]
],
[
[
"# Train loop",
"_____no_output_____"
]
],
[
[
"# ====================================================\n# scheduler \n# ====================================================\ndef get_scheduler(optimizer):\n if TAG['scheduler']=='ReduceLROnPlateau':\n scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=CFG['factor'], patience=CFG['patience'], verbose=True, eps=CFG['eps'])\n elif TAG['scheduler']=='CosineAnnealingLR':\n scheduler = CosineAnnealingLR(optimizer, T_max=CFG['T_max'], eta_min=CFG['min_lr'], last_epoch=-1)\n elif TAG['scheduler']=='CosineAnnealingWarmRestarts':\n scheduler = CosineAnnealingWarmRestarts(optimizer, T_0=CFG['T_0'], T_mult=1, eta_min=CFG['min_lr'], last_epoch=-1)\n return scheduler\n\n# ====================================================\n# criterion\n# ====================================================\ndef get_criterion():\n if TAG['criterion']=='CrossEntropyLoss':\n criterion = nn.CrossEntropyLoss()\n elif TAG['criterion'] == 'bi_tempered_logistic_loss':\n criterion = bi_tempered_logistic_loss\n return criterion",
"_____no_output_____"
],
[
"# ====================================================\n# Train loop\n# ====================================================\ndef train_loop(folds, fold):\n\n LOGGER.info(f\"========== fold: {fold} training ==========\")\n if not CFG['debug']:\n mlflow.set_tag('running.fold', str(fold))\n # ====================================================\n # loader\n # ====================================================\n trn_idx = folds[folds['fold'] != fold].index\n val_idx = folds[folds['fold'] == fold].index\n\n train_folds = folds.loc[trn_idx].reset_index(drop=True)\n valid_folds = folds.loc[val_idx].reset_index(drop=True)\n\n train_dataset = TrainDataset(train_folds, \n transform=get_transforms(data='train'))\n valid_dataset = TrainDataset(valid_folds, \n transform=get_transforms(data='valid'))\n\n train_loader = DataLoader(train_dataset, \n batch_size=CFG['batch_size'], \n shuffle=True, \n num_workers=CFG['num_workers'], pin_memory=True, drop_last=True)\n valid_loader = DataLoader(valid_dataset, \n batch_size=CFG['batch_size'], \n shuffle=False, \n num_workers=CFG['num_workers'], pin_memory=True, drop_last=False)\n\n # ====================================================\n # model & optimizer & criterion\n # ====================================================\n best_model_path = OUTPUT_DIR+f'{TAG[\"model_name\"]}_fold{fold}_best.pth'\n latest_model_path = OUTPUT_DIR+f'{TAG[\"model_name\"]}_fold{fold}_latest.pth'\n\n model = CustomModel(TAG['model_name'], pretrained=True)\n model.to(device)\n # # 学習途中の重みがあれば読み込み\n # if os.path.isfile(latest_model_path):\n # state_latest = torch.load(latest_model_path)\n # state_best = torch.load(best_model_path)\n # model.load_state_dict(state_latest['model'])\n # epoch_start = state_latest['epoch']+1\n # # er_best_score = state_latest['score']\n # er_counter = state_latest['counter']\n # er_best_score = state_best['best_score']\n # if 'val_loss_history' in state_latest.keys():\n # val_loss_history = state_latest['val_loss_history']\n # else:\n # val_loss_history = []\n\n # LOGGER.info(f'Load training model in epoch:{epoch_start}, best_score:{er_best_score:.3f}, counter:{er_counter}')\n\n # # 学習済みモデルを再学習する場合\n # elif os.path.isfile(best_model_path):\n if os.path.isfile(best_model_path):\n state_best = torch.load(best_model_path)\n model.load_state_dict(state_best['model'])\n epoch_start = 0 # epochは0からカウントしなおす\n er_counter = 0\n er_best_score = state_best['best_score']\n val_loss_history = [] # 過去のval_lossも使用しない\n\n LOGGER.info(f'Retrain model, best_score:{er_best_score:.3f}')\n else:\n epoch_start = 0\n er_best_score = None\n er_counter = 0\n val_loss_history = []\n\n optimizer = Adam(model.parameters(), lr=CFG['lr'], weight_decay=CFG['weight_decay'], amsgrad=False)\n scheduler = get_scheduler(optimizer)\n criterion = get_criterion()\n\n # 再開時のepochまでschedulerを進める\n # assert len(range(epoch_start)) == len(val_loss_history)\n for _, val_loss in zip(range(epoch_start), val_loss_history):\n if isinstance(scheduler, ReduceLROnPlateau):\n scheduler.step(val_loss)\n elif isinstance(scheduler, CosineAnnealingLR):\n scheduler.step()\n elif isinstance(scheduler, CosineAnnealingWarmRestarts):\n scheduler.step()\n\n # ====================================================\n # apex\n # ====================================================\n if CFG['apex']:\n model, optimizer = amp.initialize(model, optimizer, opt_level='O1', verbosity=0)\n\n # ====================================================\n # loop\n # ====================================================\n # best_score = 0.\n # best_loss = np.inf\n early_stopping = EarlyStopping(\n patience=CFG['early_stopping_round'], \n eps=CFG['early_stopping_eps'],\n verbose=True,\n save_path=best_model_path,\n counter=er_counter, best_score=er_best_score, \n val_loss_history = val_loss_history,\n save_latest_path=latest_model_path)\n \n for epoch in range(epoch_start, CFG['epochs']):\n \n start_time = time.time()\n \n # train\n avg_loss = train_fn(train_loader, model, criterion, optimizer, epoch, scheduler, device)\n\n # eval\n avg_val_loss, preds = valid_fn(valid_loader, model, criterion, device)\n valid_labels = valid_folds[CFG['target_col']].values\n\n # scoring\n score = get_score(valid_labels, preds.argmax(1))\n\n # get learning rate\n if hasattr(scheduler, 'get_last_lr'):\n last_lr = scheduler.get_last_lr()[0]\n else:\n # ReduceLROnPlateauには関数get_last_lrがない\n last_lr = optimizer.param_groups[0]['lr']\n \n # log mlflow\n if not CFG['debug']:\n mlflow.log_metric(f\"fold{fold} avg_train_loss\", avg_loss, step=epoch)\n mlflow.log_metric(f\"fold{fold} avg_valid_loss\", avg_val_loss, step=epoch)\n mlflow.log_metric(f\"fold{fold} score\", score, step=epoch)\n mlflow.log_metric(f\"fold{fold} lr\", last_lr, step=epoch)\n \n # early stopping\n early_stopping(avg_val_loss, model, preds, epoch)\n if early_stopping.early_stop:\n print(f'Epoch {epoch+1} - early stopping')\n break\n \n if isinstance(scheduler, ReduceLROnPlateau):\n scheduler.step(avg_val_loss)\n elif isinstance(scheduler, CosineAnnealingLR):\n scheduler.step()\n elif isinstance(scheduler, CosineAnnealingWarmRestarts):\n scheduler.step()\n\n elapsed = time.time() - start_time\n\n LOGGER.info(f'Epoch {epoch+1} - avg_train_loss: {avg_loss:.4f} avg_val_loss: {avg_val_loss:.4f} time: {elapsed:.0f}s')\n LOGGER.info(f'Epoch {epoch+1} - Accuracy: {score}')\n \n # log mlflow\n if not CFG['debug']:\n mlflow.log_artifact(best_model_path)\n if os.path.isfile(latest_model_path):\n mlflow.log_artifact(latest_model_path)\n \n check_point = torch.load(best_model_path)\n valid_folds[[str(c) for c in range(5)]] = check_point['preds']\n valid_folds['preds'] = check_point['preds'].argmax(1)\n\n return valid_folds",
"_____no_output_____"
],
[
"def get_trained_fold_preds(folds, fold, best_model_path):\r\n val_idx = folds[folds['fold'] == fold].index\r\n valid_folds = folds.loc[val_idx].reset_index(drop=True)\r\n check_point = torch.load(best_model_path)\r\n valid_folds[[str(c) for c in range(5)]] = check_point['preds']\r\n valid_folds['preds'] = check_point['preds'].argmax(1)\r\n\r\n return valid_folds\r\n\r\n\r\ndef save_confusion_matrix(oof):\r\n from sklearn.metrics import confusion_matrix\r\n cm_ = confusion_matrix(oof['label'], oof['preds'], labels=[0,1,2,3,4])\r\n label_name = ['0 (CBB)', '1 (CBSD)', '2 (CGM)', '3 (CMD)', '4 (Healthy)']\r\n cm = pd.DataFrame(cm_, index=label_name, columns=label_name)\r\n cm.to_csv(OUTPUT_DIR+'oof_confusion_matrix.csv', index=True)",
"_____no_output_____"
],
[
"# ====================================================\n# main\n# ====================================================\ndef get_result(result_df):\n preds = result_df['preds'].values\n labels = result_df[CFG['target_col']].values\n score = get_score(labels, preds)\n LOGGER.info(f'Score: {score:<.5f}')\n \n return score\n\n \n\ndef main():\n\n \"\"\"\n Prepare: 1.train 2.test 3.submission 4.folds\n \"\"\"\n \n if CFG['train']:\n # train \n oof_df = pd.DataFrame()\n for fold in range(CFG['n_fold']):\n best_model_path = OUTPUT_DIR+f'{TAG[\"model_name\"]}_fold{fold}_best.pth'\n if fold in CFG['trn_fold']:\n _oof_df = train_loop(folds, fold)\n elif os.path.exists(best_model_path):\n _oof_df = get_trained_fold_preds(folds, fold, best_model_path)\n else:\n _oof_df = None\n if _oof_df is not None:\n oof_df = pd.concat([oof_df, _oof_df])\n LOGGER.info(f\"========== fold: {fold} result ==========\")\n _ = get_result(_oof_df)\n # CV result\n LOGGER.info(f\"========== CV ==========\")\n score = get_result(oof_df)\n # save result\n oof_df.to_csv(OUTPUT_DIR+'oof_df.csv', index=False)\n save_confusion_matrix(oof_df)\n # log mlflow\n if not CFG['debug']:\n mlflow.log_metric('oof score', score)\n mlflow.delete_tag('running.fold')\n mlflow.log_artifact(OUTPUT_DIR+'oof_df.csv')\n \n if CFG['inference']:\n # inference\n model = CustomModel(TAG['model_name'], pretrained=False)\n states = [torch.load(OUTPUT_DIR+f'{TAG[\"model_name\"]}_fold{fold}_best.pth') for fold in CFG['trn_fold']]\n test_dataset = TestDataset(test, transform=get_transforms(data='valid'))\n test_loader = DataLoader(test_dataset, batch_size=CFG['batch_size'], shuffle=False, \n num_workers=CFG['num_workers'], pin_memory=True)\n predictions = inference(model, states, test_loader, device)\n # submission\n test['label'] = predictions.argmax(1)\n test[['image_id', 'label']].to_csv(OUTPUT_DIR+'submission.csv', index=False)",
"_____no_output_____"
]
],
[
[
"# rerun",
"_____no_output_____"
]
],
[
[
"def _load_save_point(run_id):\r\n # どこで中断したか取得\r\n stop_fold = int(mlflow.get_run(run_id=run_id).to_dictionary()['data']['tags']['running.fold'])\r\n # 学習対象のfoldを変更\r\n CFG['trn_fold'] = [fold for fold in CFG['trn_fold'] if fold>=stop_fold]\r\n # 学習済みモデルがあれば.pthファイルを取得(学習中も含む)\r\n client = mlflow.tracking.MlflowClient()\r\n artifacts = [artifact for artifact in client.list_artifacts(run_id) if \".pth\" in artifact.path]\r\n for artifact in artifacts:\r\n client.download_artifacts(run_id, artifact.path, OUTPUT_DIR)\r\n\r\n\r\ndef check_have_run():\r\n results = mlflow.search_runs(INFO['EXPERIMENT_ID'])\r\n run_id_list = results[results['tags.mlflow.runName']==TITLE]['run_id'].tolist()\r\n # 初めて実行する場合\r\n if len(run_id_list) == 0:\r\n run_id = None\r\n # 既に実行されている場合\r\n else:\r\n assert len(run_id_list)==1\r\n run_id = run_id_list[0]\r\n _load_save_point(run_id)\r\n\r\n return run_id\r\n\r\n\r\ndef push_github():\r\n ! cp {NOTEBOOK_PATH} kaggle-cassava/notebook/{TITLE}.ipynb\r\n !git config --global user.email \"[email protected]\"\r\n ! git config --global user.name \"Raijin Shibata\"\r\n !cd kaggle-cassava ;git add .; git commit -m {TITLE}; git pull; git remote set-url origin https://{user_name}:{password}@github.com/raijin0704/kaggle-cassava.git; git push origin master",
"_____no_output_____"
],
[
"def _load_save_point_copy(run_id):\r\n # # どこで中断したか取得\r\n # stop_fold = int(mlflow.get_run(run_id=run_id).to_dictionary()['data']['tags']['running.fold'])\r\n # # 学習対象のfoldを変更\r\n # CFG['trn_fold'] = [fold for fold in CFG['trn_fold'] if fold>=stop_fold]\r\n # 学習済みモデルがあれば.pthファイルを取得(学習中も含む)\r\n client = mlflow.tracking.MlflowClient()\r\n artifacts = [artifact for artifact in client.list_artifacts(run_id) if \".pth\" in artifact.path]\r\n for artifact in artifacts:\r\n client.download_artifacts(run_id, artifact.path, OUTPUT_DIR)\r\n\r\ndef check_have_run_copy(copy_from):\r\n results = mlflow.search_runs(INFO['EXPERIMENT_ID'])\r\n run_id_list = results[results['tags.mlflow.runName']==copy_from]['run_id'].tolist()\r\n # 初めて実行する場合\r\n if len(run_id_list) == 0:\r\n run_id = None\r\n # 既に実行されている場合\r\n else:\r\n assert len(run_id_list)==1\r\n run_id = run_id_list[0]\r\n _load_save_point_copy(run_id)\r\n\r\n return run_id",
"_____no_output_____"
],
[
"if __name__ == '__main__':\n if CFG['debug']:\n mlflow.set_tracking_uri(INFO['TRACKING_URI'])\n # 指定したrun_nameの学習済みモデルを取得\n _ = check_have_run_copy(TAG['trained'])\n main()\n else:\n mlflow.set_tracking_uri(INFO['TRACKING_URI'])\n mlflow.set_experiment('single model')\n # 指定したrun_nameの学習済みモデルを取得\n _ = check_have_run_copy(TAG['trained'])\n # 既に実行済みの場合は続きから実行する\n run_id = check_have_run()\n with mlflow.start_run(run_id=run_id, run_name=TITLE):\n if run_id is None:\n mlflow.log_artifact(CONFIG_PATH)\n mlflow.log_param('device', device)\n mlflow.set_tag('env', env)\n mlflow.set_tags(TAG)\n mlflow.log_params(CFG)\n mlflow.log_artifact(notebook_path)\n main()\n mlflow.log_artifacts(OUTPUT_DIR)\n # remove_glob(f'{OUTPUT_DIR}/*latest.pth')\n push_github()\n if env==\"kaggle\":\n shutil.copy2(CONFIG_PATH, f'{OUTPUT_DIR}/{CONFIG_NAME}')\n ! rm -r kaggle-cassava\n elif env==\"colab\":\n shutil.copytree(OUTPUT_DIR, f'{INFO[\"SHARE_DRIVE_PATH\"]}/{TITLE}')\n shutil.copy2(CONFIG_PATH, f'{INFO[\"SHARE_DRIVE_PATH\"]}/{TITLE}/{CONFIG_NAME}')",
"========== fold: 0 result ==========\nScore: 0.89042\n========== fold: 1 result ==========\nScore: 0.89953\n========== fold: 2 result ==========\nScore: 0.89367\n========== fold: 3 training ==========\nDownloading: \"https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_efficientnet_b5_ns-6f26d0cf.pth\" to /root/.cache/torch/hub/checkpoints/tf_efficientnet_b5_ns-6f26d0cf.pth\nRetrain model, best_score:-0.107\n"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
]
] |
4aa0eb43ebfc79c7a469709358f1338b391863c3
| 263,141 |
ipynb
|
Jupyter Notebook
|
experiments/tl_3/A_killme/cores_wisig-oracle.run1.framed/trials/0/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tl_3/A_killme/cores_wisig-oracle.run1.framed/trials/0/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null |
experiments/tl_3/A_killme/cores_wisig-oracle.run1.framed/trials/0/trial.ipynb
|
stevester94/csc500-notebooks
|
4c1b04c537fe233a75bed82913d9d84985a89177
|
[
"MIT"
] | null | null | null | 106.19088 | 74,476 | 0.700887 |
[
[
[
"# Transfer Learning Template",
"_____no_output_____"
]
],
[
[
"%load_ext autoreload\n%autoreload 2\n%matplotlib inline\n\n \nimport os, json, sys, time, random\nimport numpy as np\nimport torch\nfrom torch.optim import Adam\nfrom easydict import EasyDict\nimport matplotlib.pyplot as plt\n\nfrom steves_models.steves_ptn import Steves_Prototypical_Network\n\nfrom steves_utils.lazy_iterable_wrapper import Lazy_Iterable_Wrapper\nfrom steves_utils.iterable_aggregator import Iterable_Aggregator\nfrom steves_utils.ptn_train_eval_test_jig import PTN_Train_Eval_Test_Jig\nfrom steves_utils.torch_sequential_builder import build_sequential\nfrom steves_utils.torch_utils import get_dataset_metrics, ptn_confusion_by_domain_over_dataloader\nfrom steves_utils.utils_v2 import (per_domain_accuracy_from_confusion, get_datasets_base_path)\nfrom steves_utils.PTN.utils import independent_accuracy_assesment\n\nfrom torch.utils.data import DataLoader\n\nfrom steves_utils.stratified_dataset.episodic_accessor import Episodic_Accessor_Factory\n\nfrom steves_utils.ptn_do_report import (\n get_loss_curve,\n get_results_table,\n get_parameters_table,\n get_domain_accuracies,\n)\n\nfrom steves_utils.transforms import get_chained_transform",
"_____no_output_____"
]
],
[
[
"# Allowed Parameters\nThese are allowed parameters, not defaults\nEach of these values need to be present in the injected parameters (the notebook will raise an exception if they are not present)\n\nPapermill uses the cell tag \"parameters\" to inject the real parameters below this cell.\nEnable tags to see what I mean",
"_____no_output_____"
]
],
[
[
"required_parameters = {\n \"experiment_name\",\n \"lr\",\n \"device\",\n \"seed\",\n \"dataset_seed\",\n \"n_shot\",\n \"n_query\",\n \"n_way\",\n \"train_k_factor\",\n \"val_k_factor\",\n \"test_k_factor\",\n \"n_epoch\",\n \"patience\",\n \"criteria_for_best\",\n \"x_net\",\n \"datasets\",\n \"torch_default_dtype\",\n \"NUM_LOGS_PER_EPOCH\",\n \"BEST_MODEL_PATH\",\n \"x_shape\",\n}",
"_____no_output_____"
],
[
"from steves_utils.CORES.utils import (\n ALL_NODES,\n ALL_NODES_MINIMUM_1000_EXAMPLES,\n ALL_DAYS\n)\n\nfrom steves_utils.ORACLE.utils_v2 import (\n ALL_DISTANCES_FEET_NARROWED,\n ALL_RUNS,\n ALL_SERIAL_NUMBERS,\n)\n\nstandalone_parameters = {}\nstandalone_parameters[\"experiment_name\"] = \"STANDALONE PTN\"\nstandalone_parameters[\"lr\"] = 0.001\nstandalone_parameters[\"device\"] = \"cuda\"\n\nstandalone_parameters[\"seed\"] = 1337\nstandalone_parameters[\"dataset_seed\"] = 1337\n\nstandalone_parameters[\"n_way\"] = 8\nstandalone_parameters[\"n_shot\"] = 3\nstandalone_parameters[\"n_query\"] = 2\nstandalone_parameters[\"train_k_factor\"] = 1\nstandalone_parameters[\"val_k_factor\"] = 2\nstandalone_parameters[\"test_k_factor\"] = 2\n\n\nstandalone_parameters[\"n_epoch\"] = 50\n\nstandalone_parameters[\"patience\"] = 10\nstandalone_parameters[\"criteria_for_best\"] = \"source_loss\"\n\nstandalone_parameters[\"datasets\"] = [\n {\n \"labels\": ALL_SERIAL_NUMBERS,\n \"domains\": ALL_DISTANCES_FEET_NARROWED,\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": os.path.join(get_datasets_base_path(), \"oracle.Run1_framed_2000Examples_stratified_ds.2022A.pkl\"),\n \"source_or_target_dataset\": \"source\",\n \"x_transforms\": [\"unit_mag\", \"minus_two\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"ORACLE_\"\n },\n {\n \"labels\": ALL_NODES,\n \"domains\": ALL_DAYS,\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": os.path.join(get_datasets_base_path(), \"cores.stratified_ds.2022A.pkl\"),\n \"source_or_target_dataset\": \"target\",\n \"x_transforms\": [\"unit_power\", \"times_zero\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"CORES_\"\n } \n]\n\nstandalone_parameters[\"torch_default_dtype\"] = \"torch.float32\" \n\n\n\nstandalone_parameters[\"x_net\"] = [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\":[-1, 1, 2, 256]}},\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":1, \"out_channels\":256, \"kernel_size\":(1,7), \"bias\":False, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Conv2d\", \"kargs\": { \"in_channels\":256, \"out_channels\":80, \"kernel_size\":(2,7), \"bias\":True, \"padding\":(0,3), },},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\":80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 80*256, \"out_features\": 256}}, # 80 units per IQ pair\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\":256}},\n\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n]\n\n# Parameters relevant to results\n# These parameters will basically never need to change\nstandalone_parameters[\"NUM_LOGS_PER_EPOCH\"] = 10\nstandalone_parameters[\"BEST_MODEL_PATH\"] = \"./best_model.pth\"\n\n\n\n\n",
"_____no_output_____"
],
[
"# Parameters\nparameters = {\n \"experiment_name\": \"tl_3A:cores+wisig -> oracle.run1.framed\",\n \"device\": \"cuda\",\n \"lr\": 0.001,\n \"x_shape\": [2, 200],\n \"n_shot\": 3,\n \"n_query\": 2,\n \"train_k_factor\": 3,\n \"val_k_factor\": 2,\n \"test_k_factor\": 2,\n \"torch_default_dtype\": \"torch.float32\",\n \"n_epoch\": 50,\n \"patience\": 3,\n \"criteria_for_best\": \"target_loss\",\n \"x_net\": [\n {\"class\": \"nnReshape\", \"kargs\": {\"shape\": [-1, 1, 2, 200]}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 1,\n \"out_channels\": 256,\n \"kernel_size\": [1, 7],\n \"bias\": False,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 256}},\n {\n \"class\": \"Conv2d\",\n \"kargs\": {\n \"in_channels\": 256,\n \"out_channels\": 80,\n \"kernel_size\": [2, 7],\n \"bias\": True,\n \"padding\": [0, 3],\n },\n },\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm2d\", \"kargs\": {\"num_features\": 80}},\n {\"class\": \"Flatten\", \"kargs\": {}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 16000, \"out_features\": 256}},\n {\"class\": \"ReLU\", \"kargs\": {\"inplace\": True}},\n {\"class\": \"BatchNorm1d\", \"kargs\": {\"num_features\": 256}},\n {\"class\": \"Linear\", \"kargs\": {\"in_features\": 256, \"out_features\": 256}},\n ],\n \"NUM_LOGS_PER_EPOCH\": 10,\n \"BEST_MODEL_PATH\": \"./best_model.pth\",\n \"n_way\": 16,\n \"datasets\": [\n {\n \"labels\": [\n \"1-10.\",\n \"1-11.\",\n \"1-15.\",\n \"1-16.\",\n \"1-17.\",\n \"1-18.\",\n \"1-19.\",\n \"10-4.\",\n \"10-7.\",\n \"11-1.\",\n \"11-14.\",\n \"11-17.\",\n \"11-20.\",\n \"11-7.\",\n \"13-20.\",\n \"13-8.\",\n \"14-10.\",\n \"14-11.\",\n \"14-14.\",\n \"14-7.\",\n \"15-1.\",\n \"15-20.\",\n \"16-1.\",\n \"16-16.\",\n \"17-10.\",\n \"17-11.\",\n \"17-2.\",\n \"19-1.\",\n \"19-16.\",\n \"19-19.\",\n \"19-20.\",\n \"19-3.\",\n \"2-10.\",\n \"2-11.\",\n \"2-17.\",\n \"2-18.\",\n \"2-20.\",\n \"2-3.\",\n \"2-4.\",\n \"2-5.\",\n \"2-6.\",\n \"2-7.\",\n \"2-8.\",\n \"3-13.\",\n \"3-18.\",\n \"3-3.\",\n \"4-1.\",\n \"4-10.\",\n \"4-11.\",\n \"4-19.\",\n \"5-5.\",\n \"6-15.\",\n \"7-10.\",\n \"7-14.\",\n \"8-18.\",\n \"8-20.\",\n \"8-3.\",\n \"8-8.\",\n ],\n \"domains\": [1, 2, 3, 4, 5],\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": \"/mnt/wd500GB/CSC500/csc500-main/datasets/cores.stratified_ds.2022A.pkl\",\n \"source_or_target_dataset\": \"source\",\n \"x_transforms\": [\"unit_power\", \"take_200\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"C_A_\",\n },\n {\n \"labels\": [\n \"1-10\",\n \"1-12\",\n \"1-14\",\n \"1-16\",\n \"1-18\",\n \"1-19\",\n \"1-8\",\n \"10-11\",\n \"10-17\",\n \"10-4\",\n \"10-7\",\n \"11-1\",\n \"11-10\",\n \"11-19\",\n \"11-20\",\n \"11-4\",\n \"11-7\",\n \"12-19\",\n \"12-20\",\n \"12-7\",\n \"13-14\",\n \"13-18\",\n \"13-19\",\n \"13-20\",\n \"13-3\",\n \"13-7\",\n \"14-10\",\n \"14-11\",\n \"14-12\",\n \"14-13\",\n \"14-14\",\n \"14-19\",\n \"14-20\",\n \"14-7\",\n \"14-8\",\n \"14-9\",\n \"15-1\",\n \"15-19\",\n \"15-6\",\n \"16-1\",\n \"16-16\",\n \"16-19\",\n \"16-20\",\n \"17-10\",\n \"17-11\",\n \"18-1\",\n \"18-10\",\n \"18-11\",\n \"18-12\",\n \"18-13\",\n \"18-14\",\n \"18-15\",\n \"18-16\",\n \"18-17\",\n \"18-19\",\n \"18-2\",\n \"18-20\",\n \"18-4\",\n \"18-5\",\n \"18-7\",\n \"18-8\",\n \"18-9\",\n \"19-1\",\n \"19-10\",\n \"19-11\",\n \"19-12\",\n \"19-13\",\n \"19-14\",\n \"19-15\",\n \"19-19\",\n \"19-2\",\n \"19-20\",\n \"19-3\",\n \"19-4\",\n \"19-6\",\n \"19-7\",\n \"19-8\",\n \"19-9\",\n \"2-1\",\n \"2-13\",\n \"2-15\",\n \"2-3\",\n \"2-4\",\n \"2-5\",\n \"2-6\",\n \"2-7\",\n \"2-8\",\n \"20-1\",\n \"20-12\",\n \"20-14\",\n \"20-15\",\n \"20-16\",\n \"20-18\",\n \"20-19\",\n \"20-20\",\n \"20-3\",\n \"20-4\",\n \"20-5\",\n \"20-7\",\n \"20-8\",\n \"3-1\",\n \"3-13\",\n \"3-18\",\n \"3-2\",\n \"3-8\",\n \"4-1\",\n \"4-10\",\n \"4-11\",\n \"5-1\",\n \"5-5\",\n \"6-1\",\n \"6-15\",\n \"6-6\",\n \"7-10\",\n \"7-11\",\n \"7-12\",\n \"7-13\",\n \"7-14\",\n \"7-7\",\n \"7-8\",\n \"7-9\",\n \"8-1\",\n \"8-13\",\n \"8-14\",\n \"8-18\",\n \"8-20\",\n \"8-3\",\n \"8-8\",\n \"9-1\",\n \"9-7\",\n ],\n \"domains\": [1, 2, 3, 4],\n \"num_examples_per_domain_per_label\": 100,\n \"pickle_path\": \"/mnt/wd500GB/CSC500/csc500-main/datasets/wisig.node3-19.stratified_ds.2022A.pkl\",\n \"source_or_target_dataset\": \"source\",\n \"x_transforms\": [\"unit_power\", \"take_200\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"W_A_\",\n },\n {\n \"labels\": [\n \"3123D52\",\n \"3123D65\",\n \"3123D79\",\n \"3123D80\",\n \"3123D54\",\n \"3123D70\",\n \"3123D7B\",\n \"3123D89\",\n \"3123D58\",\n \"3123D76\",\n \"3123D7D\",\n \"3123EFE\",\n \"3123D64\",\n \"3123D78\",\n \"3123D7E\",\n \"3124E4A\",\n ],\n \"domains\": [32, 38, 8, 44, 14, 50, 20, 26],\n \"num_examples_per_domain_per_label\": 2000,\n \"pickle_path\": \"/mnt/wd500GB/CSC500/csc500-main/datasets/oracle.Run1_framed_2000Examples_stratified_ds.2022A.pkl\",\n \"source_or_target_dataset\": \"target\",\n \"x_transforms\": [\"unit_power\", \"take_200\", \"resample_20Msps_to_25Msps\"],\n \"episode_transforms\": [],\n \"domain_prefix\": \"ORACLE.run1_\",\n },\n ],\n \"seed\": 1337,\n \"dataset_seed\": 1337,\n}\n",
"_____no_output_____"
],
[
"# Set this to True if you want to run this template directly\nSTANDALONE = False\nif STANDALONE:\n print(\"parameters not injected, running with standalone_parameters\")\n parameters = standalone_parameters\n\nif not 'parameters' in locals() and not 'parameters' in globals():\n raise Exception(\"Parameter injection failed\")\n\n#Use an easy dict for all the parameters\np = EasyDict(parameters)\n\nif \"x_shape\" not in p:\n p.x_shape = [2,256] # Default to this if we dont supply x_shape\n\n\nsupplied_keys = set(p.keys())\n\nif supplied_keys != required_parameters:\n print(\"Parameters are incorrect\")\n if len(supplied_keys - required_parameters)>0: print(\"Shouldn't have:\", str(supplied_keys - required_parameters))\n if len(required_parameters - supplied_keys)>0: print(\"Need to have:\", str(required_parameters - supplied_keys))\n raise RuntimeError(\"Parameters are incorrect\")",
"_____no_output_____"
],
[
"###################################\n# Set the RNGs and make it all deterministic\n###################################\nnp.random.seed(p.seed)\nrandom.seed(p.seed)\ntorch.manual_seed(p.seed)\n\ntorch.use_deterministic_algorithms(True) ",
"_____no_output_____"
],
[
"###########################################\n# The stratified datasets honor this\n###########################################\ntorch.set_default_dtype(eval(p.torch_default_dtype))",
"_____no_output_____"
],
[
"###################################\n# Build the network(s)\n# Note: It's critical to do this AFTER setting the RNG\n###################################\nx_net = build_sequential(p.x_net)",
"_____no_output_____"
],
[
"start_time_secs = time.time()",
"_____no_output_____"
],
[
"p.domains_source = []\np.domains_target = []\n\n\ntrain_original_source = []\nval_original_source = []\ntest_original_source = []\n\ntrain_original_target = []\nval_original_target = []\ntest_original_target = []",
"_____no_output_____"
],
[
"# global_x_transform_func = lambda x: normalize(x.to(torch.get_default_dtype()), \"unit_power\") # unit_power, unit_mag\n# global_x_transform_func = lambda x: normalize(x, \"unit_power\") # unit_power, unit_mag",
"_____no_output_____"
],
[
"def add_dataset(\n labels,\n domains,\n pickle_path,\n x_transforms,\n episode_transforms,\n domain_prefix,\n num_examples_per_domain_per_label,\n source_or_target_dataset:str,\n iterator_seed=p.seed,\n dataset_seed=p.dataset_seed,\n n_shot=p.n_shot,\n n_way=p.n_way,\n n_query=p.n_query,\n train_val_test_k_factors=(p.train_k_factor,p.val_k_factor,p.test_k_factor),\n):\n \n if x_transforms == []: x_transform = None\n else: x_transform = get_chained_transform(x_transforms)\n \n if episode_transforms == []: episode_transform = None\n else: raise Exception(\"episode_transforms not implemented\")\n \n episode_transform = lambda tup, _prefix=domain_prefix: (_prefix + str(tup[0]), tup[1])\n\n\n eaf = Episodic_Accessor_Factory(\n labels=labels,\n domains=domains,\n num_examples_per_domain_per_label=num_examples_per_domain_per_label,\n iterator_seed=iterator_seed,\n dataset_seed=dataset_seed,\n n_shot=n_shot,\n n_way=n_way,\n n_query=n_query,\n train_val_test_k_factors=train_val_test_k_factors,\n pickle_path=pickle_path,\n x_transform_func=x_transform,\n )\n\n train, val, test = eaf.get_train(), eaf.get_val(), eaf.get_test()\n train = Lazy_Iterable_Wrapper(train, episode_transform)\n val = Lazy_Iterable_Wrapper(val, episode_transform)\n test = Lazy_Iterable_Wrapper(test, episode_transform)\n\n if source_or_target_dataset==\"source\":\n train_original_source.append(train)\n val_original_source.append(val)\n test_original_source.append(test)\n\n p.domains_source.extend(\n [domain_prefix + str(u) for u in domains]\n )\n elif source_or_target_dataset==\"target\":\n train_original_target.append(train)\n val_original_target.append(val)\n test_original_target.append(test)\n p.domains_target.extend(\n [domain_prefix + str(u) for u in domains]\n )\n else:\n raise Exception(f\"invalid source_or_target_dataset: {source_or_target_dataset}\")\n ",
"_____no_output_____"
],
[
"for ds in p.datasets:\n add_dataset(**ds)",
"_____no_output_____"
],
[
"# from steves_utils.CORES.utils import (\n# ALL_NODES,\n# ALL_NODES_MINIMUM_1000_EXAMPLES,\n# ALL_DAYS\n# )\n\n# add_dataset(\n# labels=ALL_NODES,\n# domains = ALL_DAYS,\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"cores.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"cores_{u}\"\n# )",
"_____no_output_____"
],
[
"# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n\n\n# add_dataset(\n# labels=ALL_SERIAL_NUMBERS,\n# domains = list(set(ALL_DISTANCES_FEET) - {2,62}),\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"oracle.Run2_framed_2000Examples_stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"source\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"oracle1_{u}\"\n# )\n",
"_____no_output_____"
],
[
"# from steves_utils.ORACLE.utils_v2 import (\n# ALL_DISTANCES_FEET,\n# ALL_RUNS,\n# ALL_SERIAL_NUMBERS,\n# )\n\n\n# add_dataset(\n# labels=ALL_SERIAL_NUMBERS,\n# domains = list(set(ALL_DISTANCES_FEET) - {2,62,56}),\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"oracle.Run2_framed_2000Examples_stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"source\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"oracle2_{u}\"\n# )",
"_____no_output_____"
],
[
"# add_dataset(\n# labels=list(range(19)),\n# domains = [0,1,2],\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"metehan.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"met_{u}\"\n# )",
"_____no_output_____"
],
[
"# # from steves_utils.wisig.utils import (\n# # ALL_NODES_MINIMUM_100_EXAMPLES,\n# # ALL_NODES_MINIMUM_500_EXAMPLES,\n# # ALL_NODES_MINIMUM_1000_EXAMPLES,\n# # ALL_DAYS\n# # )\n\n# import steves_utils.wisig.utils as wisig\n\n\n# add_dataset(\n# labels=wisig.ALL_NODES_MINIMUM_100_EXAMPLES,\n# domains = wisig.ALL_DAYS,\n# num_examples_per_domain_per_label=100,\n# pickle_path=os.path.join(get_datasets_base_path(), \"wisig.node3-19.stratified_ds.2022A.pkl\"),\n# source_or_target_dataset=\"target\",\n# x_transform_func=global_x_transform_func,\n# domain_modifier=lambda u: f\"wisig_{u}\"\n# )",
"_____no_output_____"
],
[
"###################################\n# Build the dataset\n###################################\ntrain_original_source = Iterable_Aggregator(train_original_source, p.seed)\nval_original_source = Iterable_Aggregator(val_original_source, p.seed)\ntest_original_source = Iterable_Aggregator(test_original_source, p.seed)\n\n\ntrain_original_target = Iterable_Aggregator(train_original_target, p.seed)\nval_original_target = Iterable_Aggregator(val_original_target, p.seed)\ntest_original_target = Iterable_Aggregator(test_original_target, p.seed)\n\n# For CNN We only use X and Y. And we only train on the source.\n# Properly form the data using a transform lambda and Lazy_Iterable_Wrapper. Finally wrap them in a dataloader\n\ntransform_lambda = lambda ex: ex[1] # Original is (<domain>, <episode>) so we strip down to episode only\n\ntrain_processed_source = Lazy_Iterable_Wrapper(train_original_source, transform_lambda)\nval_processed_source = Lazy_Iterable_Wrapper(val_original_source, transform_lambda)\ntest_processed_source = Lazy_Iterable_Wrapper(test_original_source, transform_lambda)\n\ntrain_processed_target = Lazy_Iterable_Wrapper(train_original_target, transform_lambda)\nval_processed_target = Lazy_Iterable_Wrapper(val_original_target, transform_lambda)\ntest_processed_target = Lazy_Iterable_Wrapper(test_original_target, transform_lambda)\n\ndatasets = EasyDict({\n \"source\": {\n \"original\": {\"train\":train_original_source, \"val\":val_original_source, \"test\":test_original_source},\n \"processed\": {\"train\":train_processed_source, \"val\":val_processed_source, \"test\":test_processed_source}\n },\n \"target\": {\n \"original\": {\"train\":train_original_target, \"val\":val_original_target, \"test\":test_original_target},\n \"processed\": {\"train\":train_processed_target, \"val\":val_processed_target, \"test\":test_processed_target}\n },\n})",
"_____no_output_____"
],
[
"from steves_utils.transforms import get_average_magnitude, get_average_power\n\nprint(set([u for u,_ in val_original_source]))\nprint(set([u for u,_ in val_original_target]))\n\ns_x, s_y, q_x, q_y, _ = next(iter(train_processed_source))\nprint(s_x)\n\n# for ds in [\n# train_processed_source,\n# val_processed_source,\n# test_processed_source,\n# train_processed_target,\n# val_processed_target,\n# test_processed_target\n# ]:\n# for s_x, s_y, q_x, q_y, _ in ds:\n# for X in (s_x, q_x):\n# for x in X:\n# assert np.isclose(get_average_magnitude(x.numpy()), 1.0)\n# assert np.isclose(get_average_power(x.numpy()), 1.0)\n ",
"{'W_A_2', 'C_A_2', 'C_A_3', 'C_A_4', 'W_A_4', 'W_A_3', 'C_A_5', 'C_A_1', 'W_A_1'}\n"
],
[
"###################################\n# Build the model\n###################################\n# easfsl only wants a tuple for the shape\nmodel = Steves_Prototypical_Network(x_net, device=p.device, x_shape=tuple(p.x_shape))\noptimizer = Adam(params=model.parameters(), lr=p.lr)",
"(2, 200)\n"
],
[
"###################################\n# train\n###################################\njig = PTN_Train_Eval_Test_Jig(model, p.BEST_MODEL_PATH, p.device)\n\njig.train(\n train_iterable=datasets.source.processed.train,\n source_val_iterable=datasets.source.processed.val,\n target_val_iterable=datasets.target.processed.val,\n num_epochs=p.n_epoch,\n num_logs_per_epoch=p.NUM_LOGS_PER_EPOCH,\n patience=p.patience,\n optimizer=optimizer,\n criteria_for_best=p.criteria_for_best,\n)",
"epoch: 1, [batch: 1 / 2081], examples_per_second: 127.2643, train_label_loss: 2.9052, \n"
],
[
"total_experiment_time_secs = time.time() - start_time_secs",
"_____no_output_____"
],
[
"###################################\n# Evaluate the model\n###################################\nsource_test_label_accuracy, source_test_label_loss = jig.test(datasets.source.processed.test)\ntarget_test_label_accuracy, target_test_label_loss = jig.test(datasets.target.processed.test)\n\nsource_val_label_accuracy, source_val_label_loss = jig.test(datasets.source.processed.val)\ntarget_val_label_accuracy, target_val_label_loss = jig.test(datasets.target.processed.val)\n\nhistory = jig.get_history()\n\ntotal_epochs_trained = len(history[\"epoch_indices\"])\n\nval_dl = Iterable_Aggregator((datasets.source.original.val,datasets.target.original.val))\n\nconfusion = ptn_confusion_by_domain_over_dataloader(model, p.device, val_dl)\nper_domain_accuracy = per_domain_accuracy_from_confusion(confusion)\n\n# Add a key to per_domain_accuracy for if it was a source domain\nfor domain, accuracy in per_domain_accuracy.items():\n per_domain_accuracy[domain] = {\n \"accuracy\": accuracy,\n \"source?\": domain in p.domains_source\n }\n\n# Do an independent accuracy assesment JUST TO BE SURE!\n# _source_test_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.test, p.device)\n# _target_test_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.test, p.device)\n# _source_val_label_accuracy = independent_accuracy_assesment(model, datasets.source.processed.val, p.device)\n# _target_val_label_accuracy = independent_accuracy_assesment(model, datasets.target.processed.val, p.device)\n\n# assert(_source_test_label_accuracy == source_test_label_accuracy)\n# assert(_target_test_label_accuracy == target_test_label_accuracy)\n# assert(_source_val_label_accuracy == source_val_label_accuracy)\n# assert(_target_val_label_accuracy == target_val_label_accuracy)\n\nexperiment = {\n \"experiment_name\": p.experiment_name,\n \"parameters\": dict(p),\n \"results\": {\n \"source_test_label_accuracy\": source_test_label_accuracy,\n \"source_test_label_loss\": source_test_label_loss,\n \"target_test_label_accuracy\": target_test_label_accuracy,\n \"target_test_label_loss\": target_test_label_loss,\n \"source_val_label_accuracy\": source_val_label_accuracy,\n \"source_val_label_loss\": source_val_label_loss,\n \"target_val_label_accuracy\": target_val_label_accuracy,\n \"target_val_label_loss\": target_val_label_loss,\n \"total_epochs_trained\": total_epochs_trained,\n \"total_experiment_time_secs\": total_experiment_time_secs,\n \"confusion\": confusion,\n \"per_domain_accuracy\": per_domain_accuracy,\n },\n \"history\": history,\n \"dataset_metrics\": get_dataset_metrics(datasets, \"ptn\"),\n}",
"_____no_output_____"
],
[
"ax = get_loss_curve(experiment)\nplt.show()",
"_____no_output_____"
],
[
"get_results_table(experiment)",
"_____no_output_____"
],
[
"get_domain_accuracies(experiment)",
"_____no_output_____"
],
[
"print(\"Source Test Label Accuracy:\", experiment[\"results\"][\"source_test_label_accuracy\"], \"Target Test Label Accuracy:\", experiment[\"results\"][\"target_test_label_accuracy\"])\nprint(\"Source Val Label Accuracy:\", experiment[\"results\"][\"source_val_label_accuracy\"], \"Target Val Label Accuracy:\", experiment[\"results\"][\"target_val_label_accuracy\"])",
"Source Test Label Accuracy: 0.9365368150684932 Target Test Label Accuracy: 0.2140625\nSource Val Label Accuracy: 0.9410316780821918 Target Val Label Accuracy: 0.21826171875\n"
],
[
"json.dumps(experiment)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa0f89f9d1610ea964483166b2de73bec9073c3
| 4,990 |
ipynb
|
Jupyter Notebook
|
Lectures/Lecture3/Numpy and Pandas (Answers).ipynb
|
alaymodi/Spring-2019-Career-Exploration-master
|
2ca9b4466090d57702e97e70fa772535b2dc00f3
|
[
"MIT"
] | null | null | null |
Lectures/Lecture3/Numpy and Pandas (Answers).ipynb
|
alaymodi/Spring-2019-Career-Exploration-master
|
2ca9b4466090d57702e97e70fa772535b2dc00f3
|
[
"MIT"
] | null | null | null |
Lectures/Lecture3/Numpy and Pandas (Answers).ipynb
|
alaymodi/Spring-2019-Career-Exploration-master
|
2ca9b4466090d57702e97e70fa772535b2dc00f3
|
[
"MIT"
] | null | null | null | 20.878661 | 279 | 0.537675 |
[
[
[
"# Answers to Exercises",
"_____no_output_____"
],
[
"**Exercise**: How would you sum the 3rd and 4th element of v?",
"_____no_output_____"
]
],
[
[
"summed = v[2] + v[3]",
"_____no_output_____"
]
],
[
[
"**Exercise:** What if you wanted the 3x3 matrix at the left of A (everything but the rightmost column)?",
"_____no_output_____"
]
],
[
[
"A[0:3, 0:3]",
"_____no_output_____"
]
],
[
[
"**Exercise:** Let's try to select the 2x2 matrix at the bottom righthand corner of the A matrix from the last exercise.\n\nLike before, leaving the 2nd argument blank in both slices below tells it to run all the way to the end.",
"_____no_output_____"
]
],
[
[
"A[-2:, -2:]",
"_____no_output_____"
]
],
[
[
"**Exercise:** What if we want to add a constant vector to each row of a matrix? In the following example, the sizes of the arrays are different, so the sum is performed elementwise. We want to create a `row_vector` that when added to `an_array`, returns the `given` matrix.",
"_____no_output_____"
]
],
[
[
"vector = np.array([1, 0, 1])",
"_____no_output_____"
]
],
[
[
"**Exercise:** Let's try an example with another 2D matrix. Uncomment A (again by deleting the #) and erase the underscore blanks, filling in numbers to make the output equal to ```[3, 12, 8]```.",
"_____no_output_____"
]
],
[
[
"A = [[2, 3, 5], [1, 9, 3]]",
"_____no_output_____"
]
],
[
[
"**Exercise:** What if we only want the numbers that are less than the mean of all the elements of the matrix?",
"_____no_output_____"
]
],
[
[
"random_matrix[random_matrix > random_matrix.mean()]",
"_____no_output_____"
]
],
[
[
"### Indexing & Axis",
"_____no_output_____"
],
[
"**Exercise:** Given the `rounded_matrix` below, first retrieve only the first 3 columns; name this `halved_matrix`. Then sum the `halved_matrix` row wise.",
"_____no_output_____"
]
],
[
[
"halved_matrix = rounded_matrix[:, :3]\nrow_sums = halved_matrix.sum(axis=1)",
"_____no_output_____"
]
],
[
[
"### Broadcasting",
"_____no_output_____"
],
[
"**Exercise:** Uncomment the x and fill in the 2 blanks so that x + y = z.",
"_____no_output_____"
]
],
[
[
"x = np.array([1, 2])",
"_____no_output_____"
]
],
[
[
"### Conditioning",
"_____no_output_____"
],
[
"We have 2 arrays, an array `x` consisting of some numbers and an array `y` consisting of letters that correspond to each number. Let's say we only want the letters whose numbers are negative. How would we do that?",
"_____no_output_____"
]
],
[
[
"y[x < 0]",
"_____no_output_____"
]
],
[
[
"### Pandas",
"_____no_output_____"
]
],
[
[
"fare = titanic_train[titanic_train['Sex'] == 'female']['Fare'].sum()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa1024ac40714055ddc9390f6bfd0ddc19b84dc
| 4,737 |
ipynb
|
Jupyter Notebook
|
notebooks/Project_Structure_and_Business_Understanding.ipynb
|
Faaizz/codiv_19_analysis
|
1d3b6cb9b2260365dccf20b20c1844c8763d46ff
|
[
"MIT"
] | null | null | null |
notebooks/Project_Structure_and_Business_Understanding.ipynb
|
Faaizz/codiv_19_analysis
|
1d3b6cb9b2260365dccf20b20c1844c8763d46ff
|
[
"MIT"
] | 5 |
2021-06-08T22:28:30.000Z
|
2022-03-12T00:48:38.000Z
|
notebooks/Project_Structure_and_Business_Understanding.ipynb
|
Faaizz/codiv_19_analysis
|
1d3b6cb9b2260365dccf20b20c1844c8763d46ff
|
[
"MIT"
] | null | null | null | 48.336735 | 2,659 | 0.677433 |
[
[
[
"## CRISP-DM\n",
"_____no_output_____"
],
[
"### Project Structure with Cookiecutter Data Science\n[Cookiecutter Data Science](https://drivendata.github.io/cookiecutter-data-science/)",
"_____no_output_____"
]
],
[
[
"# On first Run\n# !pip install cookiecutter\n# !cookiecutter https://github.com/drivendata/cookiecutter-data-science",
"Collecting cookiecutter\n Using cached cookiecutter-1.7.2-py2.py3-none-any.whl (34 kB)\nRequirement already satisfied: MarkupSafe<2.0.0 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from cookiecutter) (1.1.1)\nRequirement already satisfied: click>=7.0 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from cookiecutter) (7.0)\nProcessing /home/faaizz/.cache/pip/wheels/48/1b/6f/5c1cfab22eacbe0095fc619786da6571b55253653c71324b5c/python_slugify-4.0.1-py2.py3-none-any.whl\nCollecting jinja2-time>=0.2.0\n Using cached jinja2_time-0.2.0-py2.py3-none-any.whl (6.4 kB)\nCollecting binaryornot>=0.4.4\n Using cached binaryornot-0.4.4-py2.py3-none-any.whl (9.0 kB)\nRequirement already satisfied: Jinja2<3.0.0 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from cookiecutter) (2.11.1)\nCollecting poyo>=0.5.0\n Using cached poyo-0.5.0-py2.py3-none-any.whl (10 kB)\nCollecting requests>=2.23.0\n Using cached requests-2.24.0-py2.py3-none-any.whl (61 kB)\nRequirement already satisfied: six>=1.10 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from cookiecutter) (1.14.0)\nCollecting text-unidecode>=1.3\n Using cached text_unidecode-1.3-py2.py3-none-any.whl (78 kB)\nCollecting arrow\n Using cached arrow-0.15.7-py2.py3-none-any.whl (48 kB)\nRequirement already satisfied: chardet>=3.0.2 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from binaryornot>=0.4.4->cookiecutter) (3.0.4)\nRequirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from requests>=2.23.0->cookiecutter) (1.25.8)\nRequirement already satisfied: certifi>=2017.4.17 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from requests>=2.23.0->cookiecutter) (2019.11.28)\nRequirement already satisfied: idna<3,>=2.5 in /home/faaizz/anaconda3/lib/python3.7/site-packages (from requests>=2.23.0->cookiecutter) (2.8)\nRequirement already satisfied: python-dateutil in /home/faaizz/anaconda3/lib/python3.7/site-packages (from arrow->jinja2-time>=0.2.0->cookiecutter) (2.8.1)\nInstalling collected packages: text-unidecode, python-slugify, arrow, jinja2-time, binaryornot, poyo, requests, cookiecutter\n Attempting uninstall: requests\n Found existing installation: requests 2.22.0\n Uninstalling requests-2.22.0:\n Successfully uninstalled requests-2.22.0\nSuccessfully installed arrow-0.15.7 binaryornot-0.4.4 cookiecutter-1.7.2 jinja2-time-0.2.0 poyo-0.5.0 python-slugify-4.0.1 requests-2.24.0 text-unidecode-1.3\nYou've downloaded /home/faaizz/.cookiecutters/cookiecutter-data-science before. Is it okay to delete and re-download it? [yes]:^C\nAborted!\n"
]
],
[
[
"## Business Understanding\n### Business Objectives\nWe would like to track COVID-19 spread across the world and with particular emphasis on Nigeria.",
"_____no_output_____"
],
[
"### Goals\n- Investigate data quality\n- Automate as much as possible. This can be measured by the number of clicks required to execute the entire pipeline",
"_____no_output_____"
],
[
"## Data Understanding\n### Data Gathering\n- GITHUB\n- REST API\n- Web Scraping",
"_____no_output_____"
],
[
"## Data Preparation\n- Understand the final data structure\n- Support each data cinversion step with visual nanalytics",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4aa1084b35e76ca6e94dcd0dfc8c8dc9c74c2c3f
| 163,117 |
ipynb
|
Jupyter Notebook
|
NN&CNN/Part IV VGG-16_bak.ipynb
|
Aithosa/Notes
|
c20f2b96af498571e08cd71ce4a0fde8b8cf772c
|
[
"MIT"
] | 3 |
2018-12-25T13:34:27.000Z
|
2019-10-03T05:02:18.000Z
|
NN&CNN/Part IV VGG-16.ipynb
|
YellingF/Notes
|
8da93d406b71345cca11159e41ef4111107dd73d
|
[
"MIT"
] | null | null | null |
NN&CNN/Part IV VGG-16.ipynb
|
YellingF/Notes
|
8da93d406b71345cca11159e41ef4111107dd73d
|
[
"MIT"
] | 1 |
2018-11-25T22:48:31.000Z
|
2018-11-25T22:48:31.000Z
| 101.69389 | 19,968 | 0.8107 |
[
[
[
"# Cat Dog Classification",
"_____no_output_____"
],
[
"## 1. 下载数据\n我们将使用包含猫与狗图片的数据集。它是Kaggle.com在2013年底计算机视觉竞赛提供的数据集的一部分,当时卷积神经网络还不是主流。可以在以下位置下载原始数据集: `https://www.kaggle.com/c/dogs-vs-cats/data`。\n\n图片是中等分辨率的彩色JPEG。看起来像这样:\n\n",
"_____no_output_____"
],
[
"不出所料,2013年的猫狗大战的Kaggle比赛是由使用卷积神经网络的参赛者赢得的。最佳成绩达到了高达95%的准确率。在本例中,我们将非常接近这个准确率,即使我们将使用不到10%的训练集数据来训练我们的模型。\n\n原始数据集的训练集包含25,000张狗和猫的图像(每个类别12,500张),543MB大(压缩)。\n\n在下载并解压缩之后,我们将创建一个包含三个子集的新数据集:\n* 每个类有1000个样本的训练集,\n* 每个类500个样本的验证集,\n* 最后是每个类500个样本的测试集。\n\n数据已经提前处理好。",
"_____no_output_____"
],
[
"### 1.1 加载数据集目录",
"_____no_output_____"
]
],
[
[
"import os, shutil\n\n# The directory where we will\n# store our smaller dataset\nbase_dir = './data/cats_and_dogs_small'\n\n# Directories for our training,\n# validation and test splits\ntrain_dir = os.path.join(base_dir, 'train')\nvalidation_dir = os.path.join(base_dir, 'validation')\ntest_dir = os.path.join(base_dir, 'test')\n\n# Directory with our training cat pictures\ntrain_cats_dir = os.path.join(train_dir, 'cats')\n\n# Directory with our training dog pictures\ntrain_dogs_dir = os.path.join(train_dir, 'dogs')\n\n# Directory with our validation cat pictures\nvalidation_cats_dir = os.path.join(validation_dir, 'cats')\n\n# Directory with our validation dog pictures\nvalidation_dogs_dir = os.path.join(validation_dir, 'dogs')\n\n# Directory with our validation cat pictures\ntest_cats_dir = os.path.join(test_dir, 'cats')\n\n# Directory with our validation dog pictures\ntest_dogs_dir = os.path.join(test_dir, 'dogs')",
"_____no_output_____"
]
],
[
[
"## 2. 模型一",
"_____no_output_____"
],
[
"### 2.1 数据处理",
"_____no_output_____"
]
],
[
[
"from keras.preprocessing.image import ImageDataGenerator\n\n# All images will be rescaled by 1./255\ntrain_datagen = ImageDataGenerator(rescale=1./255)\nvalidation_datagen = ImageDataGenerator(rescale=1./255)\ntest_datagen = ImageDataGenerator(rescale=1./255)\n\n# 150*150\ntrain_generator = train_datagen.flow_from_directory(\n # This is the target directory\n train_dir,\n # All images will be resized to 150x150\n target_size=(150, 150),\n batch_size=20,\n # Since we use binary_crossentropy loss, we need binary labels\n class_mode='binary')\n\nvalidation_generator = validation_datagen.flow_from_directory(\n validation_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\ntest_generator = test_datagen.flow_from_directory(\n test_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')",
"Using TensorFlow backend.\n"
],
[
"print('train_dir: ',train_dir)\nprint('validation_dir: ',validation_dir)\nprint('test_dir: ',test_dir)",
"train_dir: ./data/cats_and_dogs_small\\train\nvalidation_dir: ./data/cats_and_dogs_small\\validation\ntest_dir: ./data/cats_and_dogs_small\\test\n"
],
[
"for data_batch, labels_batch in train_generator:\n print('data batch shape:', data_batch.shape)\n print('labels batch shape:', labels_batch.shape)\n break",
"data batch shape: (20, 150, 150, 3)\nlabels batch shape: (20,)\n"
],
[
"labels_batch",
"_____no_output_____"
]
],
[
[
"### 2.2 构建模型",
"_____no_output_____"
]
],
[
[
"from keras import layers\nfrom keras import models\n\nmodel = models.Sequential()\nmodel.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Conv2D(64, (3, 3), activation='relu'))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Conv2D(128, (3, 3), activation='relu'))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Conv2D(128, (3, 3), activation='relu'))\nmodel.add(layers.MaxPooling2D((2, 2)))\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(512, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid')) ",
"_____no_output_____"
],
[
"from keras import optimizers\n\nmodel.compile(optimizer=optimizers.RMSprop(lr=1e-4),\n loss='binary_crossentropy',\n metrics=['acc'])",
"_____no_output_____"
],
[
"history = model.fit_generator(train_generator,\n steps_per_epoch=100,\n epochs=30,\n validation_data=validation_generator,\n validation_steps=50)",
"Epoch 1/30\n100/100 [==============================] - 20s 198ms/step - loss: 0.6890 - acc: 0.5355 - val_loss: 0.6743 - val_acc: 0.5840\nEpoch 2/30\n100/100 [==============================] - 13s 135ms/step - loss: 0.6409 - acc: 0.6290 - val_loss: 0.6164 - val_acc: 0.6640\nEpoch 3/30\n100/100 [==============================] - 17s 167ms/step - loss: 0.5900 - acc: 0.6775 - val_loss: 0.6072 - val_acc: 0.6590\nEpoch 4/30\n100/100 [==============================] - 13s 134ms/step - loss: 0.5550 - acc: 0.7195 - val_loss: 0.5842 - val_acc: 0.6910cc: 0.719\nEpoch 5/30\n100/100 [==============================] - 13s 135ms/step - loss: 0.5286 - acc: 0.7340 - val_loss: 0.5821 - val_acc: 0.6830\nEpoch 6/30\n100/100 [==============================] - 13s 130ms/step - loss: 0.5004 - acc: 0.7505 - val_loss: 0.5822 - val_acc: 0.6820\nEpoch 7/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.4684 - acc: 0.7805 - val_loss: 0.5563 - val_acc: 0.7120\nEpoch 8/30\n100/100 [==============================] - 13s 130ms/step - loss: 0.4494 - acc: 0.7920 - val_loss: 0.5661 - val_acc: 0.7030\nEpoch 9/30\n100/100 [==============================] - 13s 131ms/step - loss: 0.4222 - acc: 0.8155 - val_loss: 0.5460 - val_acc: 0.7190\nEpoch 10/30\n100/100 [==============================] - 13s 130ms/step - loss: 0.4024 - acc: 0.8290 - val_loss: 0.6314 - val_acc: 0.6920\nEpoch 11/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.3815 - acc: 0.8390 - val_loss: 0.5423 - val_acc: 0.7300\nEpoch 12/30\n100/100 [==============================] - 13s 133ms/step - loss: 0.3471 - acc: 0.8480 - val_loss: 0.5538 - val_acc: 0.7400\nEpoch 13/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.3322 - acc: 0.8510 - val_loss: 0.5699 - val_acc: 0.7280\nEpoch 14/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.3063 - acc: 0.8720 - val_loss: 0.5829 - val_acc: 0.7100\nEpoch 15/30\n100/100 [==============================] - 13s 131ms/step - loss: 0.2894 - acc: 0.8815 - val_loss: 0.5498 - val_acc: 0.7220\nEpoch 16/30\n100/100 [==============================] - 13s 131ms/step - loss: 0.2666 - acc: 0.8960 - val_loss: 0.6135 - val_acc: 0.7160\nEpoch 17/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.2465 - acc: 0.9035 - val_loss: 0.6479 - val_acc: 0.7260\nEpoch 18/30\n100/100 [==============================] - 13s 132ms/step - loss: 0.2187 - acc: 0.9155 - val_loss: 0.6183 - val_acc: 0.7360\nEpoch 19/30\n100/100 [==============================] - 13s 127ms/step - loss: 0.1963 - acc: 0.9290 - val_loss: 0.6250 - val_acc: 0.7300\nEpoch 20/30\n100/100 [==============================] - 13s 127ms/step - loss: 0.1816 - acc: 0.9320 - val_loss: 0.6708 - val_acc: 0.7280\nEpoch 21/30\n100/100 [==============================] - 13s 130ms/step - loss: 0.1652 - acc: 0.9415 - val_loss: 0.7348 - val_acc: 0.7180\nEpoch 22/30\n100/100 [==============================] - 13s 130ms/step - loss: 0.1406 - acc: 0.9555 - val_loss: 0.6970 - val_acc: 0.7300\nEpoch 23/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.1316 - acc: 0.9540 - val_loss: 0.7680 - val_acc: 0.7250\nEpoch 24/30\n100/100 [==============================] - 13s 132ms/step - loss: 0.1063 - acc: 0.9660 - val_loss: 0.7493 - val_acc: 0.7350\nEpoch 25/30\n100/100 [==============================] - 13s 128ms/step - loss: 0.0912 - acc: 0.9730 - val_loss: 0.7680 - val_acc: 0.7450\nEpoch 26/30\n100/100 [==============================] - 13s 132ms/step - loss: 0.0827 - acc: 0.9790 - val_loss: 0.8558 - val_acc: 0.7310\nEpoch 27/30\n100/100 [==============================] - 14s 136ms/step - loss: 0.0747 - acc: 0.9750 - val_loss: 0.8977 - val_acc: 0.7230\nEpoch 28/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.0648 - acc: 0.9810 - val_loss: 1.2331 - val_acc: 0.6930\nEpoch 29/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.0466 - acc: 0.9920 - val_loss: 0.9854 - val_acc: 0.7220\nEpoch 30/30\n100/100 [==============================] - 13s 129ms/step - loss: 0.0372 - acc: 0.9935 - val_loss: 1.0347 - val_acc: 0.7260\n"
],
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\n%matplotlib inline\n\nplt.plot(history.history['loss'])\nplt.plot(history.history['val_loss'])\nplt.title('model loss')\nplt.ylabel('loss')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper right')\nplt.show()\n\nplt.plot(history.history['acc'])\nplt.plot(history.history['val_acc'])\nplt.title('model accuracy')\nplt.ylabel('accuracy')\nplt.xlabel('epoch')\nplt.legend(['train', 'test'], loc='upper right')\nplt.show()",
"_____no_output_____"
],
[
"val_loss_min = history.history['val_loss'].index(min(history.history['val_loss']))\nval_acc_max = history.history['val_acc'].index(max(history.history['val_acc']))\nprint('validation set min loss: ', val_loss_min)\nprint('validation set max accuracy: ', val_acc_max)",
"validation set min loss: 10\nvalidation set max accuracy: 24\n"
],
[
"from keras import layers\nfrom keras import models\n\n# vgg的做法\nmodel = models.Sequential()\nmodel.add(layers.Conv2D(32, 3, activation='relu', padding=\"same\", input_shape=(64, 64, 3)))\nmodel.add(layers.Conv2D(32, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(64, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(64, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(128, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(128, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(256, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(256, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=2))\n\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
],
[
"model.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\nconv2d_49 (Conv2D) (None, 64, 64, 32) 896 \n_________________________________________________________________\nconv2d_50 (Conv2D) (None, 64, 64, 32) 9248 \n_________________________________________________________________\nmax_pooling2d_25 (MaxPooling (None, 32, 32, 32) 0 \n_________________________________________________________________\nconv2d_51 (Conv2D) (None, 32, 32, 64) 18496 \n_________________________________________________________________\nconv2d_52 (Conv2D) (None, 32, 32, 64) 36928 \n_________________________________________________________________\nmax_pooling2d_26 (MaxPooling (None, 16, 16, 64) 0 \n_________________________________________________________________\nconv2d_53 (Conv2D) (None, 16, 16, 128) 73856 \n_________________________________________________________________\nconv2d_54 (Conv2D) (None, 16, 16, 128) 147584 \n_________________________________________________________________\nmax_pooling2d_27 (MaxPooling (None, 8, 8, 128) 0 \n_________________________________________________________________\nconv2d_55 (Conv2D) (None, 8, 8, 256) 295168 \n_________________________________________________________________\nconv2d_56 (Conv2D) (None, 8, 8, 256) 590080 \n_________________________________________________________________\nmax_pooling2d_28 (MaxPooling (None, 4, 4, 256) 0 \n_________________________________________________________________\nflatten_7 (Flatten) (None, 4096) 0 \n_________________________________________________________________\ndense_19 (Dense) (None, 256) 1048832 \n_________________________________________________________________\ndropout_13 (Dropout) (None, 256) 0 \n_________________________________________________________________\ndense_20 (Dense) (None, 256) 65792 \n_________________________________________________________________\ndropout_14 (Dropout) (None, 256) 0 \n_________________________________________________________________\ndense_21 (Dense) (None, 1) 257 \n=================================================================\nTotal params: 2,287,137\nTrainable params: 2,287,137\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"from keras import optimizers\n\nmodel.compile(optimizer=optimizers.RMSprop(lr=1e-4),\n loss='binary_crossentropy',\n metrics=['acc'])\n\n# model.compile(loss='binary_crossentropy', \n# optimizer='adam', \n# metrics=['accuracy'])",
"_____no_output_____"
]
],
[
[
"### 2.3 训练模型",
"_____no_output_____"
]
],
[
[
"history = model.fit_generator(train_generator,\n steps_per_epoch=100,\n epochs=30,\n validation_data=validation_generator,\n validation_steps=50)",
"Epoch 1/30\n100/100 [==============================] - 10s 95ms/step - loss: 0.6936 - acc: 0.4975 - val_loss: 0.6927 - val_acc: 0.5030\nEpoch 2/30\n100/100 [==============================] - 7s 74ms/step - loss: 0.6928 - acc: 0.5125 - val_loss: 0.6928 - val_acc: 0.5000\nEpoch 3/30\n100/100 [==============================] - 7s 75ms/step - loss: 0.6898 - acc: 0.5325 - val_loss: 0.6755 - val_acc: 0.5970\nEpoch 4/30\n100/100 [==============================] - 8s 78ms/step - loss: 0.6805 - acc: 0.5635 - val_loss: 0.6590 - val_acc: 0.6000\nEpoch 5/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.6634 - acc: 0.6125 - val_loss: 0.6405 - val_acc: 0.6370\nEpoch 6/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.6389 - acc: 0.6305 - val_loss: 0.6188 - val_acc: 0.6550\nEpoch 7/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.6095 - acc: 0.6690 - val_loss: 0.5825 - val_acc: 0.7000\nEpoch 8/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.5994 - acc: 0.6865 - val_loss: 0.5742 - val_acc: 0.6950\nEpoch 9/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.5784 - acc: 0.6960 - val_loss: 0.5835 - val_acc: 0.7000\nEpoch 10/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.5621 - acc: 0.7055 - val_loss: 0.6460 - val_acc: 0.6530\nEpoch 11/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.5503 - acc: 0.7315 - val_loss: 0.6073 - val_acc: 0.6870: 0.5568 - \nEpoch 12/30\n100/100 [==============================] - 8s 81ms/step - loss: 0.5256 - acc: 0.7395 - val_loss: 0.5956 - val_acc: 0.7050\nEpoch 13/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.5238 - acc: 0.7415 - val_loss: 0.5363 - val_acc: 0.7310\nEpoch 14/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.5020 - acc: 0.7660 - val_loss: 0.5234 - val_acc: 0.7260\nEpoch 15/30\n100/100 [==============================] - 8s 78ms/step - loss: 0.4787 - acc: 0.7770 - val_loss: 0.5304 - val_acc: 0.7320\nEpoch 16/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.4642 - acc: 0.7875 - val_loss: 0.5261 - val_acc: 0.7320\nEpoch 17/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.4490 - acc: 0.7970 - val_loss: 0.5188 - val_acc: 0.7440\nEpoch 18/30\n100/100 [==============================] - 8s 80ms/step - loss: 0.4228 - acc: 0.8150 - val_loss: 0.5617 - val_acc: 0.7320\nEpoch 19/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.4077 - acc: 0.8225 - val_loss: 0.5662 - val_acc: 0.7490\nEpoch 20/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.3733 - acc: 0.8355 - val_loss: 0.5196 - val_acc: 0.7460\nEpoch 21/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.3480 - acc: 0.8540 - val_loss: 0.5254 - val_acc: 0.7600\nEpoch 22/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.3290 - acc: 0.8600 - val_loss: 0.5146 - val_acc: 0.7540\nEpoch 23/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.3102 - acc: 0.8695 - val_loss: 0.6277 - val_acc: 0.7370\nEpoch 24/30\n100/100 [==============================] - 8s 78ms/step - loss: 0.2702 - acc: 0.8905 - val_loss: 0.6216 - val_acc: 0.7490\nEpoch 25/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.2484 - acc: 0.9030 - val_loss: 0.6004 - val_acc: 0.7540\nEpoch 26/30\n100/100 [==============================] - 8s 78ms/step - loss: 0.2178 - acc: 0.9140 - val_loss: 0.6769 - val_acc: 0.7630\nEpoch 27/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.1994 - acc: 0.9230 - val_loss: 0.6660 - val_acc: 0.7590\nEpoch 28/30\n100/100 [==============================] - 8s 79ms/step - loss: 0.1796 - acc: 0.9295 - val_loss: 0.7343 - val_acc: 0.7440\nEpoch 29/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.1442 - acc: 0.9465 - val_loss: 0.8302 - val_acc: 0.7340\nEpoch 30/30\n100/100 [==============================] - 8s 77ms/step - loss: 0.1350 - acc: 0.9470 - val_loss: 0.7483 - val_acc: 0.7600\n"
]
],
[
[
"### 2.4 画出表现",
"_____no_output_____"
]
],
[
[
"import matplotlib.pyplot as plt\nimport seaborn as sns\n%matplotlib inline\n\nacc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"val_loss_min = val_loss.index(min(val_loss))\nval_acc_max = val_acc.index(max(val_acc))\nprint('validation set min loss: ', val_loss_min)\nprint('validation set max accuracy: ', val_acc_max)",
"validation set min loss: 21\nvalidation set max accuracy: 25\n"
]
],
[
[
"### 2.5 测试集表现",
"_____no_output_____"
]
],
[
[
"scores = model.evaluate_generator(test_generator, verbose=0)\nprint(\"Large CNN Error: %.2f%%\" % (100 - scores[1] * 100))",
"Large CNN Error: 26.80%\n"
]
],
[
[
"## 3. 模型二 使用数据增强来防止过拟合",
"_____no_output_____"
],
[
"### 3.1 数据增强示例",
"_____no_output_____"
]
],
[
[
"datagen = ImageDataGenerator(\n rotation_range=40, # 角度值(在 0~180 范围内),表示图像随机旋转的角度范围\n width_shift_range=0.2, # 图像在水平或垂直方向上平移的范围\n height_shift_range=0.2, # (相对于总宽度或总高度的比例)\n shear_range=0.2, # 随机错切变换的角度\n zoom_range=0.2, # 图像随机缩放的范围\n horizontal_flip=True, # 随机将一半图像水平翻转\n fill_mode='nearest') # 用于填充新创建像素的方法,\n # 这些新像素可能来自于旋转或宽度/高度平移",
"_____no_output_____"
],
[
"# This is module with image preprocessing utilities\nfrom keras.preprocessing import image\n\nfnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)]\n\n# We pick one image to \"augment\"\nimg_path = fnames[3]\n\n# Read the image and resize it\nimg = image.load_img(img_path, target_size=(150, 150))\n\nimgplot_oringe = plt.imshow(img)\n\n# Convert it to a Numpy array with shape (150, 150, 3)\nx = image.img_to_array(img)\n\n# Reshape it to (1, 150, 150, 3)\nx = x.reshape((1,) + x.shape)\n\n# The .flow() command below generates batches of randomly transformed images.\n# It will loop indefinitely, so we need to `break` the loop at some point!\ni = 0\nfor batch in datagen.flow(x, batch_size=1):\n plt.figure(i)\n imgplot = plt.imshow(image.array_to_img(batch[0]))\n i += 1\n if i % 4 == 0:\n break\n\nplt.show()",
"_____no_output_____"
]
],
[
[
"### 3.2 定义数据增强",
"_____no_output_____"
]
],
[
[
"train_datagen = ImageDataGenerator(\n rescale=1./255,\n rotation_range=40,\n width_shift_range=0.2,\n height_shift_range=0.2,\n shear_range=0.2,\n zoom_range=0.2,\n horizontal_flip=True,)\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator(rescale=1./255) # 注意,不能增强验证数据\n\ntrain_generator = train_datagen.flow_from_directory(\n # This is the target directory\n train_dir,\n # All images will be resized to 150x150\n target_size=(150, 150),\n batch_size=32,\n # Since we use binary_crossentropy loss, we need binary labels\n class_mode='binary')\n\nvalidation_generator = test_datagen.flow_from_directory(\n validation_dir,\n target_size=(150, 150),\n batch_size=32,\n class_mode='binary')",
"_____no_output_____"
]
],
[
[
"### 3.3 训练网络",
"_____no_output_____"
]
],
[
[
"model = models.Sequential()\nmodel.add(layers.Conv2D(32, 3, activation='relu', padding=\"same\", input_shape=(150, 150, 3)))\nmodel.add(layers.Conv2D(32, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(64, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(64, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(128, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(128, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=(2, 2)))\n\nmodel.add(layers.Conv2D(256, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.Conv2D(256, 3, activation='relu', padding=\"same\"))\nmodel.add(layers.MaxPooling2D(pool_size=2))\n\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dropout(0.5))\nmodel.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
],
[
"# model.compile(optimizer=optimizers.RMSprop(lr=1e-4),\n# loss='binary_crossentropy',\n# metrics=['acc'])\n\nmodel.compile(loss='binary_crossentropy', \n optimizer='adam', \n metrics=['accuracy'])",
"_____no_output_____"
],
[
"history = model.fit_generator(train_generator,\n steps_per_epoch=100, # 训练集分成100批送进去,相当于每批送20个\n epochs=100, # 循环100遍\n validation_data=validation_generator,\n validation_steps=50, # 验证集分50批送进去,每批20个\n verbose=0)",
"_____no_output_____"
]
],
[
[
"### 3.4 画出表现",
"_____no_output_____"
]
],
[
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"val_loss_min = val_loss.index(min(val_loss))\nval_acc_max = val_acc.index(max(val_acc))\nprint('validation set min loss: ', val_loss_min)\nprint('validation set max accuracy: ', val_acc_max)",
"_____no_output_____"
],
[
"# train_datagen = ImageDataGenerator(rotation_range=40,\n# width_shift_range=0.2,\n# height_shift_range=0.2,\n# shear_range=0.2,\n# zoom_range=0.2,\n# horizontal_flip=True,\n# fill_mode='nearest')\n\n\n# train_datagen.fit(train_X)\n# train_generator = train_datagen.flow(train_X, train_y, \n# batch_size = 64)",
"_____no_output_____"
],
[
"# history = model_vgg16.fit_generator(train_generator, \n# validation_data = (test_X, test_y), \n# steps_per_epoch = train_X.shape[0] / 100, \n# epochs = 10)",
"_____no_output_____"
]
],
[
[
"## 4. 使用预训练的VGG-16",
"_____no_output_____"
],
[
"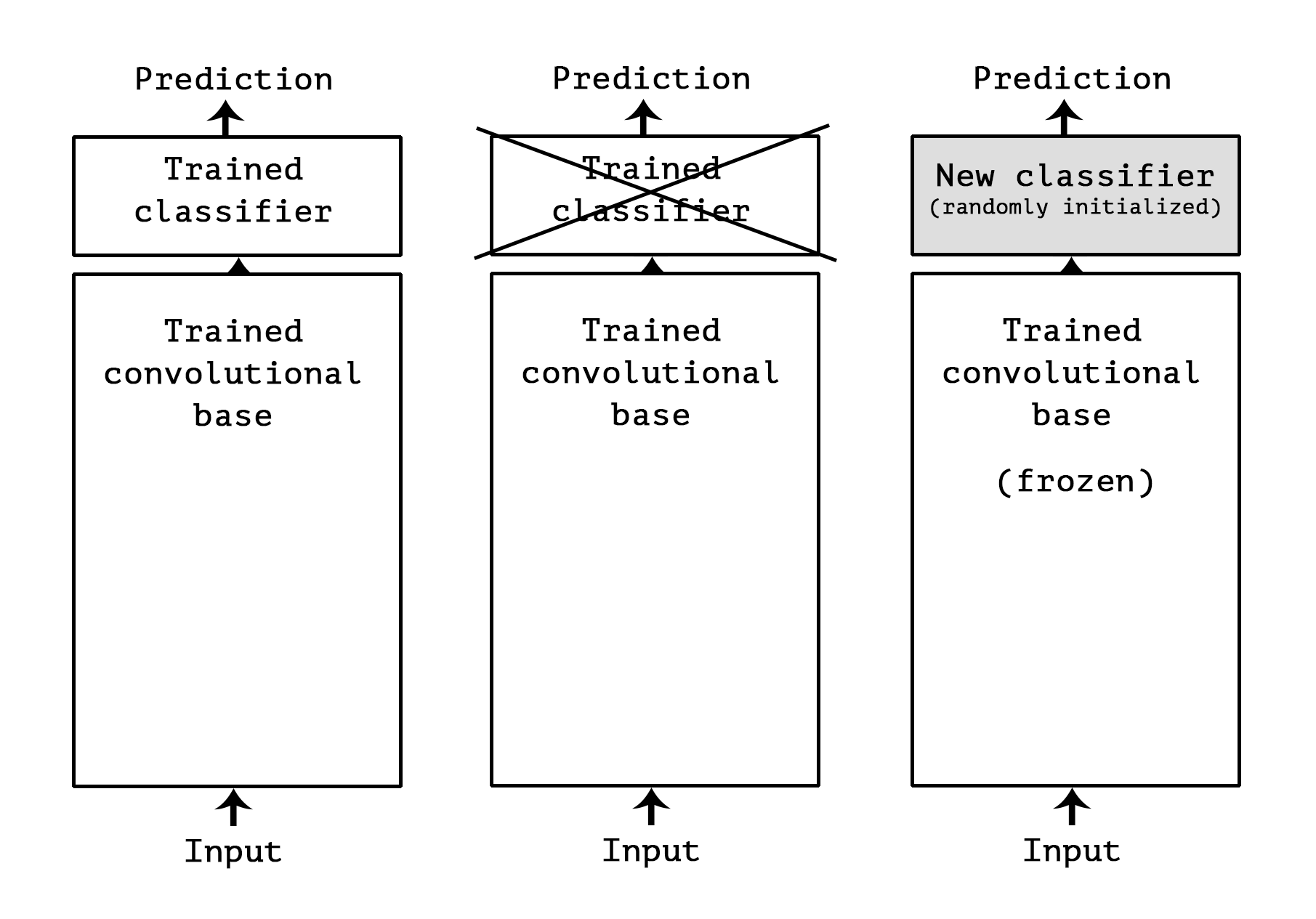",
"_____no_output_____"
]
],
[
[
"from keras.applications import VGG16\n\nconv_base = VGG16(weights='imagenet',\n include_top=False, # 不要分类层\n input_shape=(150, 150, 3))",
"_____no_output_____"
],
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 14,714,688\nNon-trainable params: 0\n_________________________________________________________________\n"
],
[
"from keras import models\nfrom keras import layers\n\nmodel = models.Sequential()\nmodel.add(conv_base)\nmodel.add(layers.Flatten())\nmodel.add(layers.Dense(256, activation='relu'))\nmodel.add(layers.Dense(1, activation='sigmoid'))\n\n# model = models.Sequential()\n# model.add(conv_base)\n# model.add(layers.Dense(256, activation='relu'))\n# model.add(layers.Dropout(0.5))\n# model.add(layers.Dense(256, activation='relu'))\n# model.add(layers.Dropout(0.5))\n# model.add(layers.Dense(1, activation='sigmoid'))",
"_____no_output_____"
],
[
"print('This is the number of trainable weights '\n 'before freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights before freezing the conv base: 30\n"
],
[
"conv_base.trainable = False",
"_____no_output_____"
],
[
"print('This is the number of trainable weights '\n 'after freezing the conv base:', len(model.trainable_weights))",
"This is the number of trainable weights after freezing the conv base: 4\n"
],
[
"from keras.preprocessing.image import ImageDataGenerator\nfrom keras import optimizers\n\ntrain_datagen = ImageDataGenerator(\n rescale=1./255,\n rotation_range=40,\n width_shift_range=0.2,\n height_shift_range=0.2,\n shear_range=0.2,\n zoom_range=0.2,\n horizontal_flip=True,\n fill_mode='nearest')\n\n# Note that the validation data should not be augmented!\ntest_datagen = ImageDataGenerator(rescale=1./255)\n\ntrain_generator = train_datagen.flow_from_directory(\n # This is the target directory\n train_dir,\n # All images will be resized to 150x150\n target_size=(150, 150),\n batch_size=20,\n # Since we use binary_crossentropy loss, we need binary labels\n class_mode='binary')\n\nvalidation_generator = test_datagen.flow_from_directory(\n validation_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\nmodel.compile(loss='binary_crossentropy',\n optimizer=optimizers.RMSprop(lr=2e-5),\n metrics=['acc'])",
"Found 2000 images belonging to 2 classes.\nFound 1000 images belonging to 2 classes.\n"
],
[
"history = model.fit_generator(\n train_generator,\n steps_per_epoch=100,\n epochs=30,\n validation_data=validation_generator,\n validation_steps=50,\n verbose=2)",
"Epoch 1/30\n - 53s - loss: 0.5863 - acc: 0.6990 - val_loss: 0.4363 - val_acc: 0.8500\nEpoch 2/30\n - 50s - loss: 0.4633 - acc: 0.7980 - val_loss: 0.3560 - val_acc: 0.8700\nEpoch 3/30\n - 50s - loss: 0.4333 - acc: 0.8100 - val_loss: 0.3234 - val_acc: 0.8810\nEpoch 4/30\n - 50s - loss: 0.4006 - acc: 0.8205 - val_loss: 0.3094 - val_acc: 0.8730\nEpoch 5/30\n - 50s - loss: 0.3862 - acc: 0.8340 - val_loss: 0.2931 - val_acc: 0.8830\nEpoch 6/30\n - 50s - loss: 0.3645 - acc: 0.8430 - val_loss: 0.2816 - val_acc: 0.8890\nEpoch 7/30\n - 50s - loss: 0.3560 - acc: 0.8405 - val_loss: 0.2764 - val_acc: 0.8880\nEpoch 8/30\n - 50s - loss: 0.3450 - acc: 0.8460 - val_loss: 0.2675 - val_acc: 0.8990\nEpoch 9/30\n - 50s - loss: 0.3500 - acc: 0.8370 - val_loss: 0.2641 - val_acc: 0.8960\nEpoch 10/30\n - 50s - loss: 0.3402 - acc: 0.8515 - val_loss: 0.2661 - val_acc: 0.8920\nEpoch 11/30\n - 50s - loss: 0.3302 - acc: 0.8610 - val_loss: 0.2608 - val_acc: 0.8930\nEpoch 12/30\n - 50s - loss: 0.3248 - acc: 0.8570 - val_loss: 0.2545 - val_acc: 0.8960\nEpoch 13/30\n - 50s - loss: 0.3133 - acc: 0.8680 - val_loss: 0.2532 - val_acc: 0.8950\nEpoch 14/30\n - 50s - loss: 0.3172 - acc: 0.8610 - val_loss: 0.2519 - val_acc: 0.9010\nEpoch 15/30\n - 50s - loss: 0.3173 - acc: 0.8625 - val_loss: 0.2491 - val_acc: 0.8990\nEpoch 16/30\n - 50s - loss: 0.3015 - acc: 0.8645 - val_loss: 0.2487 - val_acc: 0.8970\nEpoch 17/30\n - 50s - loss: 0.3218 - acc: 0.8635 - val_loss: 0.2533 - val_acc: 0.8960\nEpoch 18/30\n - 50s - loss: 0.3101 - acc: 0.8665 - val_loss: 0.2505 - val_acc: 0.9030\nEpoch 19/30\n - 50s - loss: 0.2936 - acc: 0.8705 - val_loss: 0.2476 - val_acc: 0.9020\nEpoch 20/30\n - 50s - loss: 0.3029 - acc: 0.8655 - val_loss: 0.2459 - val_acc: 0.8990\nEpoch 21/30\n - 50s - loss: 0.3025 - acc: 0.8670 - val_loss: 0.2551 - val_acc: 0.8950\nEpoch 22/30\n - 50s - loss: 0.3077 - acc: 0.8695 - val_loss: 0.2476 - val_acc: 0.8990\nEpoch 23/30\n - 50s - loss: 0.2763 - acc: 0.8830 - val_loss: 0.2494 - val_acc: 0.9050\nEpoch 24/30\n - 50s - loss: 0.2951 - acc: 0.8735 - val_loss: 0.2507 - val_acc: 0.9020\nEpoch 25/30\n - 50s - loss: 0.2870 - acc: 0.8710 - val_loss: 0.2439 - val_acc: 0.8990\nEpoch 26/30\n - 50s - loss: 0.2923 - acc: 0.8690 - val_loss: 0.2428 - val_acc: 0.9000\nEpoch 27/30\n - 50s - loss: 0.2842 - acc: 0.8760 - val_loss: 0.2494 - val_acc: 0.8970\nEpoch 28/30\n - 50s - loss: 0.2727 - acc: 0.8820 - val_loss: 0.2534 - val_acc: 0.8910\nEpoch 29/30\n - 50s - loss: 0.2749 - acc: 0.8800 - val_loss: 0.2432 - val_acc: 0.8980\nEpoch 30/30\n - 50s - loss: 0.2750 - acc: 0.8800 - val_loss: 0.2451 - val_acc: 0.9020\n"
],
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"val_loss_min = val_loss.index(min(val_loss))\nval_acc_max = val_acc.index(max(val_acc))\nprint('validation set min loss: ', val_loss_min)\nprint('validation set max accuracy: ', val_acc_max)",
"validation set min loss: 25\nvalidation set max accuracy: 22\n"
]
],
[
[
"## Fine-tuning",
"_____no_output_____"
],
[
"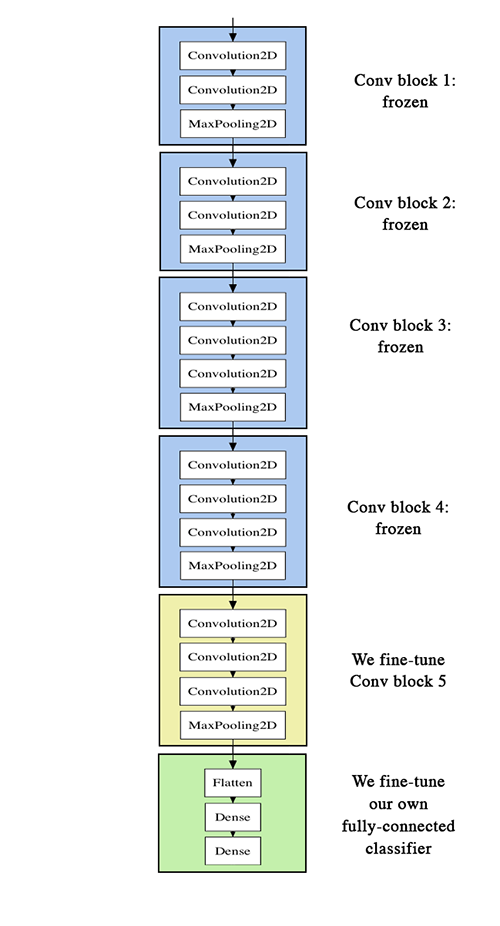",
"_____no_output_____"
]
],
[
[
"conv_base.summary()",
"_________________________________________________________________\nLayer (type) Output Shape Param # \n=================================================================\ninput_1 (InputLayer) (None, 150, 150, 3) 0 \n_________________________________________________________________\nblock1_conv1 (Conv2D) (None, 150, 150, 64) 1792 \n_________________________________________________________________\nblock1_conv2 (Conv2D) (None, 150, 150, 64) 36928 \n_________________________________________________________________\nblock1_pool (MaxPooling2D) (None, 75, 75, 64) 0 \n_________________________________________________________________\nblock2_conv1 (Conv2D) (None, 75, 75, 128) 73856 \n_________________________________________________________________\nblock2_conv2 (Conv2D) (None, 75, 75, 128) 147584 \n_________________________________________________________________\nblock2_pool (MaxPooling2D) (None, 37, 37, 128) 0 \n_________________________________________________________________\nblock3_conv1 (Conv2D) (None, 37, 37, 256) 295168 \n_________________________________________________________________\nblock3_conv2 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_conv3 (Conv2D) (None, 37, 37, 256) 590080 \n_________________________________________________________________\nblock3_pool (MaxPooling2D) (None, 18, 18, 256) 0 \n_________________________________________________________________\nblock4_conv1 (Conv2D) (None, 18, 18, 512) 1180160 \n_________________________________________________________________\nblock4_conv2 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_conv3 (Conv2D) (None, 18, 18, 512) 2359808 \n_________________________________________________________________\nblock4_pool (MaxPooling2D) (None, 9, 9, 512) 0 \n_________________________________________________________________\nblock5_conv1 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv2 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_conv3 (Conv2D) (None, 9, 9, 512) 2359808 \n_________________________________________________________________\nblock5_pool (MaxPooling2D) (None, 4, 4, 512) 0 \n=================================================================\nTotal params: 14,714,688\nTrainable params: 0\nNon-trainable params: 14,714,688\n_________________________________________________________________\n"
],
[
"conv_base.trainable = True\n\nset_trainable = False\nfor layer in conv_base.layers:\n if layer.name == 'block5_conv1':\n set_trainable = True\n if set_trainable:\n layer.trainable = True\n else:\n layer.trainable = False",
"_____no_output_____"
],
[
"model.summary()",
"_____no_output_____"
],
[
"model.compile(optimizer=optimizers.RMSprop(lr=1e-5),\n loss='binary_crossentropy', \n metrics=['acc'])\n\nhistory = model.fit_generator(train_generator,\n steps_per_epoch=100,\n epochs=100,\n validation_data=validation_generator,\n validation_steps=50,\n verbose=0)",
"_____no_output_____"
],
[
"acc = history.history['acc']\nval_acc = history.history['val_acc']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\n\nepochs = range(len(acc))\n\nplt.plot(epochs, acc, 'bo', label='Training acc')\nplt.plot(epochs, val_acc, 'b', label='Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs, loss, 'bo', label='Training loss')\nplt.plot(epochs, val_loss, 'b', label='Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"def smooth_curve(points, factor=0.8):\n smoothed_points = []\n for point in points:\n if smoothed_points:\n previous = smoothed_points[-1]\n smoothed_points.append(previous * factor + point * (1 - factor))\n else:\n smoothed_points.append(point)\n return smoothed_points\n\nplt.plot(epochs,\n smooth_curve(acc), 'bo', label='Smoothed training acc')\nplt.plot(epochs,\n smooth_curve(val_acc), 'b', label='Smoothed validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\n\nplt.figure()\n\nplt.plot(epochs,\n smooth_curve(loss), 'bo', label='Smoothed training loss')\nplt.plot(epochs,\n smooth_curve(val_loss), 'b', label='Smoothed validation loss')\nplt.title('Training and validation loss')\nplt.legend()\n\nplt.show()",
"_____no_output_____"
],
[
"smooth_val_loss = smooth_curve(val_loss)\nsmooth_val_loss.index(min(smooth_val_loss))",
"_____no_output_____"
],
[
"test_generator = test_datagen.flow_from_directory(test_dir,\n target_size=(150, 150),\n batch_size=20,\n class_mode='binary')\n\ntest_loss, test_acc = model.evaluate_generator(test_generator, steps=50)\nprint('test acc:', test_acc)",
"_____no_output_____"
],
[
"# plt.plot(history.history['loss'])\n# plt.plot(history.history['val_loss'])\n# plt.title('model loss')\n# plt.ylabel('loss')\n# plt.xlabel('epoch')\n# plt.legend(['train', 'test'], loc='upper right')\n# plt.show()",
"_____no_output_____"
],
[
"# plt.plot(history.history['acc'])\n# plt.plot(history.history['val_acc'])\n# plt.title('model accuracy')\n# plt.ylabel('accuracy')\n# plt.xlabel('epoch')\n# plt.legend(['train', 'test'], loc='upper right')\n# plt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa10a5d0764394991e3ae0fa7cd0ad55eed8827
| 229,655 |
ipynb
|
Jupyter Notebook
|
.ipynb_checkpoints/Kaggle Titanic Challenge-checkpoint.ipynb
|
bmaelum/kaggle_titanic
|
ee1788a37542518f306b5077202306e68e4dfef2
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Kaggle Titanic Challenge-checkpoint.ipynb
|
bmaelum/kaggle_titanic
|
ee1788a37542518f306b5077202306e68e4dfef2
|
[
"MIT"
] | null | null | null |
.ipynb_checkpoints/Kaggle Titanic Challenge-checkpoint.ipynb
|
bmaelum/kaggle_titanic
|
ee1788a37542518f306b5077202306e68e4dfef2
|
[
"MIT"
] | null | null | null | 48.727986 | 31,384 | 0.609854 |
[
[
[
"# Titanic: Machine Learning from Disaster\n## [Kaggle Challenge](https://www.kaggle.com/c/titanic#tutorials)",
"_____no_output_____"
],
[
"**In this challenge, we ask you to complete the analysis of what sorts of people were likely to survive. In particular, we ask you to apply the tools of machine learning to predict which passengers survived the tragedy.**",
"_____no_output_____"
],
[
"Inspired by [Titanic Data Science Solutions](https://www.kaggle.com/startupsci/titanic-data-science-solutions).",
"_____no_output_____"
],
[
"## Workflow\n1. Question or problem definition.\n2. Acquire training and testing data.\n3. Wrangle, prepare, cleanse the data.\n4. Analyze, identify patterns, and explore the data.\n5. Model, predict and solve the problem.\n6. Visualize, report, and present the problem solving steps and final solution.\n7. Supply or submit the results.\n",
"_____no_output_____"
],
[
"## 1. Question or problem definition ",
"_____no_output_____"
],
[
"**Given from Kaggle:** \nKnowing from a training set of samples listing passengers who survived or did not survive the Titanic disaster, can our model determine based on a given test dataset not containing the survival information, if these passengers in the test dataset survived or not.",
"_____no_output_____"
],
[
"**Info about the case:** \n\n* On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. Translated 32% survival rate.\n* One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew.\n* Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.\n",
"_____no_output_____"
],
[
"### Workflow goals\n\nThe data science solutions workflow solves for seven major goals.\n\n**Classifying:** We may want to classify or categorize our samples. We may also want to understand the implications or correlation of different classes with our solution goal.\n\n**Correlating:** One can approach the problem based on available features within the training dataset. Which features within the dataset contribute significantly to our solution goal? Statistically speaking is there a correlation among a feature and solution goal? As the feature values change does the solution state change as well, and visa-versa? This can be tested both for numerical and categorical features in the given dataset. We may also want to determine correlation among features other than survival for subsequent goals and workflow stages. Correlating certain features may help in creating, completing, or correcting features.\n\n**Converting:** For modeling stage, one needs to prepare the data. Depending on the choice of model algorithm one may require all features to be converted to numerical equivalent values. So for instance converting text categorical values to numeric values.\n\n**Completing.** Data preparation may also require us to estimate any missing values within a feature. Model algorithms may work best when there are no missing values.\n\n**Correcting:** We may also analyze the given training dataset for errors or possibly innacurate values within features and try to corrent these values or exclude the samples containing the errors. One way to do this is to detect any outliers among our samples or features. We may also completely discard a feature if it is not contribting to the analysis or may significantly skew the results.\n\n**Creating:** Can we create new features based on an existing feature or a set of features, such that the new feature follows the correlation, conversion, completeness goals.\n\n**Charting:** How to select the right visualization plots and charts depending on nature of the data and the solution goals.",
"_____no_output_____"
],
[
"## 2. Acquire training and testing data",
"_____no_output_____"
]
],
[
[
"# data analysis and wrangling\nimport pandas as pd\nimport numpy as np\nimport random as rnd\n\n# visualization\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n%matplotlib inline\n\n# machine learning\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.svm import SVC, LinearSVC\nfrom sklearn.ensemble import RandomForestClassifier\nfrom sklearn.neighbors import KNeighborsClassifier\nfrom sklearn.naive_bayes import GaussianNB\nfrom sklearn.linear_model import Perceptron\nfrom sklearn.linear_model import SGDClassifier\nfrom sklearn.tree import DecisionTreeClassifier",
"_____no_output_____"
]
],
[
[
"### Acquire data",
"_____no_output_____"
]
],
[
[
"df_train = pd.read_csv('titanic/train.csv') \ndf_test = pd.read_csv('titanic/test.csv')\ncombine = [df_train, df_test]",
"_____no_output_____"
]
],
[
[
"### Column description:\n**Survival** =\tSurvival \n**Pclass** =\tTicket class (1 = 1st, 2 = 2nd, 3 = 3rd) \n**Sex** =\tSex \t\n**Age** =\tAge in years \t\n**SibSp** =\t# of siblings / spouses aboard the Titanic \t\n**Parch** =\t# of parents / children aboard the Titanic \t\n**Ticket** = \tTicket number \t\n**Fare** =\tPassenger fare \t\n**Cabin** =\tCabin number \t\n**Embarked** =\tPort of Embarkation \t(C = Cherbourg, Q = Queenstown, S = Southampton)",
"_____no_output_____"
]
],
[
[
"df_train.head()",
"_____no_output_____"
],
[
"df_train.tail()",
"_____no_output_____"
]
],
[
[
"## 3. Wrangle, prepare, cleanse the data.",
"_____no_output_____"
],
[
"**What features are available?**",
"_____no_output_____"
]
],
[
[
"list(df_train)",
"_____no_output_____"
]
],
[
[
"### What features are categorical?\nThese values classify the samples into sets of similar samples. Within categorical features are the values nominal, ordinal, ratio, or interval based? Among other things this helps us select the appropriate plots for visualization. \n\n**Categorical:** Survived, Sex, Embarked \n**Ordinal:** Pclass",
"_____no_output_____"
],
[
"### What features are numerical? \nWhich features are numerical? These values change from sample to sample. Within numerical features are the values discrete, continuous, or timeseries based? Among other things this helps us select the appropriate plots for visualization. \n\n**Continuous:** Age, Fare \n**Discrete:** SibSp, Parch",
"_____no_output_____"
],
[
"### Which features have mixed data types?\nNumerical, alphanumeric data within same feature. These are candidates for correcting goal.\n\n* Ticket is a mix of numeric and alphanumeric data types. Cabin is alphanumeric.\n",
"_____no_output_____"
],
[
"### Which features may contain errors or typos?\nThis is harder to review for a large dataset, however reviewing a few samples from a smaller dataset may just tell us outright, which features may require correcting. \n* Name feature may contain errors or typos as there are several ways used to describe a name including titles, round brackets, and quotes used for alternative or short names.",
"_____no_output_____"
],
[
"### Which features contain blank, null or empty values?\nThese will require correcting.\n\n* Cabin & Age & Embarked features contain a number of null values in that order for the training dataset.\n* Cabin & Age are incomplete in case of test dataset",
"_____no_output_____"
],
[
"### What are the data types for various features?\nHelping us during converting goal. \n* Seven features are integer or floats. Six in case of test dataset\n* Six features are strings (object). Five for test dataset.",
"_____no_output_____"
]
],
[
[
"df_train.info()\nprint('-'*40)\ndf_test.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 891 entries, 0 to 890\nData columns (total 12 columns):\nPassengerId 891 non-null int64\nSurvived 891 non-null int64\nPclass 891 non-null int64\nName 891 non-null object\nSex 891 non-null object\nAge 714 non-null float64\nSibSp 891 non-null int64\nParch 891 non-null int64\nTicket 891 non-null object\nFare 891 non-null float64\nCabin 204 non-null object\nEmbarked 889 non-null object\ndtypes: float64(2), int64(5), object(5)\nmemory usage: 83.6+ KB\n----------------------------------------\n<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 418 entries, 0 to 417\nData columns (total 11 columns):\nPassengerId 418 non-null int64\nPclass 418 non-null int64\nName 418 non-null object\nSex 418 non-null object\nAge 332 non-null float64\nSibSp 418 non-null int64\nParch 418 non-null int64\nTicket 418 non-null object\nFare 417 non-null float64\nCabin 91 non-null object\nEmbarked 418 non-null object\ndtypes: float64(2), int64(4), object(5)\nmemory usage: 36.0+ KB\n"
]
],
[
[
"### What is the distribution of numerical feature values across the samples?\nThis helps determine how representative the training dataset is of the actual problem domain.\n\n* Total samples are 891 or 40% of the actual number of passengers on board the Titanic (2,224).\n* Survived is a categorical feature with 0 or 1 values.\n* Around 38% samples survived representative of the actual survival rate at 32%.\n* Most passengers (> 75%) did not travel with parents or children.\n* Nearly 30% of the passengers had siblings and/or spouse aboard.\n* Fares varied significantly with few passengers (<1%) paying as high as $512.\n* Few elderly passengers (<1%) within age range 65-80.\n",
"_____no_output_____"
]
],
[
[
"df_train.describe()",
"_____no_output_____"
]
],
[
[
"### What is the distribution of categorical features?\n* Names are unique across the dataset (count=unique=891)\n* Sex variable as two possible values with 65% male (top=male, freq=577/891)\n* Cabin values have several duplicates across samples. Alternatively several passengers shared a cabin.\n* Embarked takes three possible values. S port used by most passengers (top=S)\n* Ticket feature has high ratio (22%) of duplicate values (unique=681)",
"_____no_output_____"
]
],
[
[
"df_train.describe(include=['O'])",
"_____no_output_____"
]
],
[
[
"## 4. Analyze, identify patterns, and explore the data.",
"_____no_output_____"
],
[
"### Assumptions based on data analysis",
"_____no_output_____"
],
[
"We arrive at following assumptions based on data analysis done so far. We may validate these assumptions further before taking appropriate actions.",
"_____no_output_____"
],
[
"**Correlating:** \nWe want to know how well each feature correlates with Survival. We want to do this early in our project and match these quick correlations with modelled correlations later in the project.",
"_____no_output_____"
],
[
"**Completing:** \n1. We may want to complete Age feature as it is definitely correlated to survival \n2. We may want to complete the Embarked feature as it may also correlate with survival or another important feature.",
"_____no_output_____"
],
[
"**Correcting:**\n1. Ticket feature may be dropped from our analysis as it contains high ratio of duplicated (22%) and there may not be a correlation between Ticket and survival. \n2. Cabin feature may be dropped as it is highly incomplete or contains many null values both in training and test dataset.\n3. PassengerId may be dropped from training dataset as it does not contribute to survival.\n4. Name feature is relatively non-standard, may not contribute directly to survival, so maybe dropped.",
"_____no_output_____"
],
[
"**Creating:**\n1. We may want to create a new feature called Family based on Parch and SibSp to get total count of family members on board.\n2. We may want to engineer the Name feature to extract Title as a new feature.\n3. We may want to create new feature for Age bands. This turns a continous numerical feature into an ordinal categorical feature.\n4. We may also want to create a Fare range feature if it helps our analysis.",
"_____no_output_____"
],
[
"**Classifying:** \nWe may also add to our assumptions based on the problem description noted earlier.\n1. Women (Sex=female) were more likely to have survived.\n2. Children (Age<?) were more likely to have survived.\n3. The upper-class passengers (Pclass=1) were more likely to have survived.",
"_____no_output_____"
],
[
"### Analyze by pivoting features",
"_____no_output_____"
],
[
"To confirm some of our observations and assumptions, we can quickly analyze our feature correlations by pivoting features against each other. We can only do so at this stage for features which do not have any empty values. It also makes sense doing so only for features which are categorical (Sex), ordinal (Pclass) or discrete (SibSp, Parch) type.",
"_____no_output_____"
],
[
"* **Pclass**: We observe significant correlation (>0.5) among Pclass=1 and Survived (classifying #3). We decide to inlcude this feature to our model. \n* **Sex:** We confirm the observation during problem definition that Sex=female had very high survival rate at 74% (classifying #1)\n* **SibSp and Parch:** These features have zero correlation for certain values. It may be best to derive a feature or a set of features from these individual features (creating #1)",
"_____no_output_____"
]
],
[
[
"df_train[['Pclass', 'Survived']].groupby(['Pclass'], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"_____no_output_____"
],
[
"df_train[[\"Sex\", \"Survived\"]].groupby([\"Sex\"], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"_____no_output_____"
],
[
"df_train[['SibSp', 'Survived']].groupby(['SibSp'], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"_____no_output_____"
],
[
"df_train[['Parch', 'Survived']].groupby(['Parch'], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"_____no_output_____"
]
],
[
[
"### Analyze by visualizing data",
"_____no_output_____"
],
[
"Now we can continue confirming some of our assumptions using visualizations for analyzing the data.",
"_____no_output_____"
],
[
"**Correlating numerical features** \nStart by understanding correlations between numerical features and our solution goal (Survived). \n\nA histogram chart is useful for analyzing continuous numerical variables like Age where banding or ranges will help identify useful patterns. The histogram can indicate distribution of samples using automatically defined bins or equally ranged bands. This helps us answer questions relating to specific bands (Did infants have better survival rate?) \n\nNote that x-axis in histogram visualizations represents the count of samples or passengers.",
"_____no_output_____"
],
[
"**Observations:**\n* Infants (Age <= 4) had high survival rate\n* Oldest passengers (Age=80) survived\n* Large number of 15-25 year olds did not survive\n* Most passengers are in 15-35 range\n\n**Decisions:**\nThis simple analysis confirms our assumptions as decisions for subsequent workflow stages.\n* We should consider Age (out assumption classifying #2) in our model training.\n* Complete the Age feature for null values (completing #1).\n* We should band age groups (creating #3)",
"_____no_output_____"
]
],
[
[
"g = sns.FacetGrid(df_train, col='Survived')\ng.map(plt.hist, 'Age', bins=20);",
"_____no_output_____"
]
],
[
[
"**Correlating numerical and ordinal features** \nWe can combine multiple features for identifying correlations using a single plot. This can be done with numerical and categorical features which have numerical values.\n\n**Observations:**\n* Pclass=3 had most passengers, however most did not survive. Confirms our classifying assumption #2.\n* Infant passengers in Pclass=2 and Pclass=3 mostly survived. Further qualifies our classifying assumption #2.\n* Most passengers in Pclass=1 survived. Confirms our classifying assumption #3.\n* Pclass varies in terms of Age distribution of passengers.\n\n**Decisions:** \n* Consider Pclass for model training.\n",
"_____no_output_____"
]
],
[
[
"grid = sns.FacetGrid(df_train, col='Survived', row='Pclass', size=2.2, aspect=1.6)\ngrid.map(plt.hist, 'Age', alpha=.5, bins=20)\ngrid.add_legend();",
"_____no_output_____"
]
],
[
[
"**Correlating categorical features** \nNow we can correlate categorical features with our solution goal.\n\n**Observations:**\n* Female passengers had much better survival rates than males. Confirms classifying (#1)\n* Exception in Embarked=C where males had higher survival rate. This could be a correlation between Pclass and Embarked and in turn Pclass and Survived, not necessarily direct correlation between Embarked and Survived.\n* Males had better survival rate in Pclass=3 when compared with Pclass=2 for C and Q ports. Completing (#2).\n* Ports of embarkation have varying survival rates for Pclass=3 and among male passengers. Correlating (#1).\n\n**Decisions:** \n* Add Sex feature to model training\n* Complete and add Embarked feature to model training\n",
"_____no_output_____"
]
],
[
[
"grid = sns.FacetGrid(df_train, row='Embarked', size=2.2, aspect=1.6)\ngrid.map(sns.pointplot, 'Pclass', 'Survived', 'Sex', palette='deep')\ngrid.add_legend();",
"/anaconda3/lib/python3.6/site-packages/seaborn/axisgrid.py:703: UserWarning: Using the pointplot function without specifying `order` is likely to produce an incorrect plot.\n warnings.warn(warning)\n/anaconda3/lib/python3.6/site-packages/seaborn/axisgrid.py:708: UserWarning: Using the pointplot function without specifying `hue_order` is likely to produce an incorrect plot.\n warnings.warn(warning)\n"
]
],
[
[
"**Correlating categorical and numerical features** \nWe may also want to correlate categorical features (with non-numeric values) and numeric features. We can consider correlating Embarked (Categorical non-numeric), Sex (Categorical non-numeric), Fare (Numeric continuous), with Survived (Categorical numeric).\n\n**Observations:** \n* Higher fare paying passengers had better survival. Confirms our assumption for creating (#4) fare ranges.\n* Port of embarkation correlates with survival rates. Confirms correlating (#1) and completing (#2)\n\n**Decisions:**\n* Consider banding Fare feature",
"_____no_output_____"
]
],
[
[
"grid = sns.FacetGrid(df_train, row='Embarked', col='Survived', size=2.2, aspect=1.6)\ngrid.map(sns.barplot, 'Sex', 'Fare', alpha=.5, ci=None)\ngrid.add_legend();",
"/anaconda3/lib/python3.6/site-packages/seaborn/axisgrid.py:703: UserWarning: Using the barplot function without specifying `order` is likely to produce an incorrect plot.\n warnings.warn(warning)\n"
]
],
[
[
"### Wrangle data\nWe have collected several assumptions and decisions regarding our datasets and solution requirements. So far we did not have to change a single feature or value to arrive at these. Let us now execute our decisions and assumptions for correcting, creating and completing goals.\n\n**Correcting by dropping features:** \nThis is a good starting goal to execute. By dropping features we are dealing with fewer data points. Speeds up our notebook and eases the analysis. \n\nBased on our assumptions and decisions we want to drop the Cabin (correcting #2) and Ticket (correcting #1) features. \n\nNote that where applicable we perform operations on both training and testing datasets together to stay consistent.",
"_____no_output_____"
]
],
[
[
"print(\"Before\", df_train.shape, df_test.shape, combine[0].shape, combine[1].shape)\n\ndf_train = df_train.drop(['Ticket', 'Cabin'], axis=1)\ndf_test = df_test.drop(['Ticket', 'Cabin'], axis=1)\ncombine = [df_train, df_test]\n\nprint(\"After\", df_train.shape, df_test.shape, combine[0].shape, combine[1].shape)\n",
"Before (891, 12) (418, 11) (891, 12) (418, 11)\nAfter (891, 10) (418, 9) (891, 10) (418, 9)\n"
]
],
[
[
"**Creating new feature extracting from existing** \nWe want to analyze if Name feature can be engineered to extract titles and test correlation between titles and survival, before dropping Name and PassengerId features. \n\nIn the following code we extract Title using regular expressions. The RegEx pattern (\\w+\\.) matches the first word which ends with a dot character within Name feature. The `expand=False` flag return a DataFrame.\n\n**Observations:** \nWhen we plot Title, Age, and Survived, we note the following observations.\n* Most titles band Age groups accurately. For example: Master title has Age mean of 5 years. \n* Survival among Title Age bands varies slightly\n* Certain titles mostly survived (Mme, Lady, Sir) or did not (Don, Rev, Jonkheer)\n\n**Decision:** \n* We decide to retain the new Title feature for model training.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['Title'] = dataset.Name.str.extract(' ([A-Za-z]+)\\.', expand=False)\n \npd.crosstab(df_train['Title'], df_train['Sex'])",
"_____no_output_____"
]
],
[
[
"We can replace many titles with a more common name or classify them as `Rare`.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['Title'] = dataset['Title'].replace(['Lady', 'Countess','Capt', 'Col',\\\n \t'Don', 'Dr', 'Major', 'Rev', 'Sir', 'Jonkheer', 'Dona'], 'Rare')\n\n dataset['Title'] = dataset['Title'].replace('Mlle', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Ms', 'Miss')\n dataset['Title'] = dataset['Title'].replace('Mme', 'Mrs')\n \ndf_train[['Title', 'Survived']].groupby(['Title'], as_index=False).mean()\n",
"_____no_output_____"
]
],
[
[
"We can convert the categorical titles to ordinal.",
"_____no_output_____"
]
],
[
[
"title_mapping = {\"Mr\": 1, \"Miss\": 2, \"Mrs\": 3, \"Master\": 4, \"Rare\": 5}\nfor dataset in combine:\n dataset['Title'] = dataset['Title'].map(title_mapping)\n dataset['Title'] = dataset['Title'].fillna(0)\n\ndf_train['Title'] = df_train['Title'].apply(pd.to_numeric)\ndf_train.head()",
"_____no_output_____"
]
],
[
[
"Now we can safely drop the 'Name' feature from training and testing datasets. We also do not need the PassengerId feature in the training set.",
"_____no_output_____"
]
],
[
[
"df_train = df_train.drop(['Name', 'PassengerId'], axis=1)\ndf_test = df_test.drop(['Name'], axis=1)\ncombine = [df_train, df_test]\ndf_train.shape, df_test.shape",
"_____no_output_____"
]
],
[
[
"**Converting a categorical feature** \nNow we can convert features which contain string to numerical values. This is required by most model algorithms. Doing so will also help us in achieving the feature completing goal. \n\nLet us start by converting Sex feature to a new feature called Gender where female=1 and male=0.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['Sex'] = dataset['Sex'].map({'female': 1, 'male': 0}).astype(int)\n \ndf_train.head()",
"_____no_output_____"
]
],
[
[
"**Completing a numerical continuous feature** \nNow we should start estimating and completing features with missing or null values. We will first do this for the Age feature. \n\nWe can consider three methods to complete a numerical continuous feature. \n\n1. A simple way is to generate random numbers between mean and standard deviation.\n\n2. More accurate way of guessing missing values is to use other correlated features. In our case we note correlation among Age, Gender and Pclass. Guess Age values using median values for Age across sets of Pclass and Gender feature combinations. So, median Age for Pclass=1 and Gender=0, Pclass=1 and Gender=1, and so on...\n\n3. Combine methods 1 and 2. So instead of guessing age values based on median, use random numbers between mean and standard deviation, based on sets of Pclass and Gender combinations.\n\nMethod 1 and 3 will introduce random noise into our models. The results from multiple executions might vary. We will prefer method 2.",
"_____no_output_____"
]
],
[
[
"grid = sns.FacetGrid(df_train, row='Pclass', col='Sex', size=2.2, aspect=1.6)\ngrid.map(plt.hist, 'Age', alpha=.5, bins=20)\ngrid.add_legend()",
"_____no_output_____"
]
],
[
[
"Let us start by preparing an empty array to contain guessed Age values based on Pclass x Gender ocmbinations.",
"_____no_output_____"
]
],
[
[
"guess_ages = np.zeros((2,3))\nguess_ages",
"_____no_output_____"
],
[
"for dataset in combine:\n for i in range(0, 2):\n for j in range(0, 3):\n df_guess = dataset[(dataset['Sex'] == i) & \\\n (dataset['Pclass'] == j+1)]['Age'].dropna()\n \n # age_mean = df_guess\n # age_std = df_guess.std()\n # age_guess = rnd.uniform(age_mean - age_std, age_mean + age_std)\n \n age_guess = df_guess.median()\n \n # Convert random age float to nearest .5 age\n guess_ages[i,j] = int( age_guess/0.5 + 0.5) * 0.5\n \n for i in range(0,2):\n for j in range(0,3):\n dataset.loc[ (dataset.Age.isnull()) & (dataset.Sex == i) & (dataset.Pclass == j+1), 'Age'] = guess_ages[i,j]\n \n dataset['Age'] = dataset['Age'].astype(int)\n \ndf_train.head()",
"_____no_output_____"
]
],
[
[
"Let us create Age bands and determine correlations with Survived.",
"_____no_output_____"
]
],
[
[
"df_train['AgeBand'] = pd.cut(df_train['Age'], 5)\ndf_train[['AgeBand', 'Survived']].groupby(['AgeBand'], as_index=False).mean().sort_values(by='AgeBand', ascending=True)",
"_____no_output_____"
]
],
[
[
"Let us replace Age with ordinals based on these bands.",
"_____no_output_____"
]
],
[
[
"for dataset in combine: \n dataset.loc[ dataset['Age'] <= 16, 'Age'] = 0\n dataset.loc[(dataset['Age'] > 16) & (dataset['Age'] <= 32), 'Age'] = 1\n dataset.loc[(dataset['Age'] > 32) & (dataset['Age'] <= 48), 'Age'] = 2\n dataset.loc[(dataset['Age'] > 48) & (dataset['Age'] <= 64), 'Age'] = 3\n dataset.loc[ dataset['Age'] > 64, 'Age']\ndf_train.head()\n",
"_____no_output_____"
]
],
[
[
"We can now remove the AgeBand feature.",
"_____no_output_____"
]
],
[
[
"df_train = df_train.drop(['AgeBand'], axis=1)\ncombine = [df_train, df_test]\ndf_train.head()",
"_____no_output_____"
]
],
[
[
"**Create new feature combining existing features** \nWe can create a new feature for FamilySize which combines Parch and SibSp. This will enable us to drop Parch and SibSp from our datasets.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['FamilySize'] = dataset['SibSp'] + dataset['Parch'] + 1\n \ndf_train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index=False).mean().sort_values(by='Survived', ascending=False)\n\ndf_train.head()",
"_____no_output_____"
]
],
[
[
"We can create another feature called IsAlone.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['IsAlone'] = 0\n dataset.loc[dataset['FamilySize'] == 1, 'IsAlone'] = 1\n\ndf_train[['IsAlone', 'Survived']].groupby(['IsAlone'], as_index=False).mean()",
"_____no_output_____"
]
],
[
[
"Let us drop Parch, SibSp and FamilySize features in favor of IsAlone",
"_____no_output_____"
]
],
[
[
"df_train = df_train.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)\ndf_test = df_test.drop(['Parch', 'SibSp', 'FamilySize'], axis=1)\ncombine = [df_train, df_test]\n\ndf_train.head()",
"_____no_output_____"
]
],
[
[
"We can also create an artificial feature combining Pclass and Age.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['Age*Class'] = dataset.Age * dataset.Pclass\n \ndf_train.loc[:, ['Age*Class', 'Age', 'Pclass']].head(10)",
"_____no_output_____"
]
],
[
[
"**Completing a cetagorical feature** \nEmbarked feature takes S, Q, C values based on port of embarkation. Our training dataset has two missing values. We simply fill these with the most common occurance.",
"_____no_output_____"
]
],
[
[
"freq_port = df_train.Embarked.dropna().mode()[0]\nfreq_port",
"_____no_output_____"
],
[
"for dataset in combine:\n dataset['Embarked'] = dataset['Embarked'].fillna(freq_port)\n \ndf_train[['Embarked', 'Survived']].groupby(['Embarked'], as_index=False).mean().sort_values(by='Survived', ascending=False)",
"_____no_output_____"
]
],
[
[
"**Converting categorical feature to numeric** \nWe can now convert the EmbarkedFill feature by creating a new numeric Port feature.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset['Embarked'] = dataset['Embarked'].map({'S': 0, 'C': 1, 'Q': 2}).astype(int)\n \n\ndf_train.head()",
"_____no_output_____"
]
],
[
[
"**Quick completing and converting a numeric feature** \nWe can now complete the Fare feature for single missing value in test dataset using mode to get the value that occurs most frequently for this feature. We do this in a single line of code. \n\nNote that we are not creating an intermediate new feature or doing any further analysis for correlation to guess missing feature as we are replacing only a single value. The completion goal achieves desired requirement for model algorithm to operate on non-null values. \n\nWe may also want to round off the fare to two decimals as it represents currency.",
"_____no_output_____"
]
],
[
[
"df_test['Fare'].fillna(df_test['Fare'].dropna().median(), inplace=True)\ndf_test.head()",
"_____no_output_____"
]
],
[
[
"We can now create FareBand.",
"_____no_output_____"
]
],
[
[
"df_train['FareBand'] = pd.qcut(df_train['Fare'], 4)\ndf_train[['FareBand', 'Survived']].groupby(['FareBand'], as_index=False).mean().sort_values(by='FareBand', ascending=True)",
"_____no_output_____"
]
],
[
[
"Convert the Fare feature to ordinal values based on the FareBand.",
"_____no_output_____"
]
],
[
[
"for dataset in combine:\n dataset.loc[ dataset['Fare'] <= 7.91, 'Fare'] = 0\n dataset.loc[(dataset['Fare'] > 7.91) & (dataset['Fare'] <= 14.454), 'Fare'] = 1\n dataset.loc[(dataset['Fare'] > 14.454) & (dataset['Fare'] <= 31), 'Fare'] = 2\n dataset.loc[ dataset['Fare'] > 31, 'Fare'] = 3\n dataset['Fare'] = dataset['Fare'].astype(int)\n \ndf_train = df_train.drop(['FareBand'], axis=1)\ncombine = [df_train, df_test]\n\ndf_train.head(10)",
"_____no_output_____"
]
],
[
[
"And the test dataset.",
"_____no_output_____"
]
],
[
[
"df_test.head(10)",
"_____no_output_____"
]
],
[
[
"## 5. Model, predict and solve",
"_____no_output_____"
],
[
"Now we are ready to train a model and predict the required solution. There are 60+ predictive modelling algorithms to choose from. We must understand the type of problem and solution requirement to narrow down to a select few models which we can evaluate. Our problem is a classification and regression problem. We want to identify relationship between output (Survived or not) with other variables or features (Gender, Age, Port...). We are also performing a category of machine learning which is called supervised learning as we are training our model with a given dataset. With these two criteria - Supervised Learning plus Classification and Regression, we can narrow down our choice of models to a few. These include:\n\n* Logistic Regression\n* KNN or k-Nearest Neighbors\n* Support Vector Machines\n* Naive Bayes classifier \n* Decision Tree\n* Random Forrest\n* Perceptron\n* Artificial Neural Network\n* RVM or Relevance Vector Machine",
"_____no_output_____"
]
],
[
[
"X_train = df_train.drop(\"Survived\", axis=1)\nY_train = df_train[\"Survived\"]\nX_test = df_test.drop(\"PassengerId\", axis=1).copy()\nX_train.shape, Y_train.shape, X_test.shape",
"_____no_output_____"
],
[
"X_test.head(1)",
"_____no_output_____"
]
],
[
[
"**Logistic Regression** \nLogistic Regression is a useful model to run early in the workflow. Logistic regression measures the relationship between the categorical dependent variable(feature) and one or more independent variables (features) by estimating probabilities using a logistic function, which is the cumulative logistic function, which is the cumulative logistic distribution. Reference [Wikipedia](https://en.wikipedia.org/wiki/Logistic_regression). \n\nNote the confidence score generated by the model based on our training dataset.",
"_____no_output_____"
]
],
[
[
"logreg = LogisticRegression()\nlogreg.fit(X_train, Y_train)\nY_pred = logreg.predict(X_test)\n\nacc_log = round(logreg.score(X_train, Y_train)*100, 2)\nacc_log",
"_____no_output_____"
]
],
[
[
"We can use Logistic Regression to validate our assumptions and decisions for feature creating and completing goals. This can be done by calculating the coefficient of the features in the decision function. \n\nPositive coefficients increase the log-odds of the response (and thus increase the probability), and negative coefficients decrease the log-odds of the response (and thus decrease the probability).\n\n* Sex is the highest positive coefficient, implying as the Sex value increases (male: 0 to female: 1), the probability of Survived increases the most\n* Inversely as Pclass increases, probability of Survived=1 decreases the most\n* This way Age*Class is a good artificial feature to model as it has second highest negative correlation with Survived\n* So is the Title as second highest correlation",
"_____no_output_____"
]
],
[
[
"coeff_df = pd.DataFrame(df_train.columns.delete(0))\ncoeff_df.columns = ['Feature']\ncoeff_df[\"Correlation\"] = pd.Series(logreg.coef_[0])\n\ncoeff_df.sort_values(by='Correlation', ascending=False)",
"_____no_output_____"
]
],
[
[
"**Support Vector Machines** \nNext we model using Support Vector Machines which are supervised learning models with associated learning algorithms that analyze data used for classification and regression analysis. Given a set of training samples, each marked as belonging to one or the other of **two categories**, an SVM training algorithm builds that assigns new test samples to one category or the other, making it a non-probabilistic binary linear classifier. Reference [Wikipedia](https://en.wikipedia.org/wiki/Support-vector_machine). \n\nNote that the model generates a confidence score which is higher than Logistics Regression model.",
"_____no_output_____"
]
],
[
[
"svc = SVC()\nsvc.fit(X_train, Y_train)\nY_pred = svc.predict(X_test)\nacc_svc = round(svc.score(X_train, Y_train) * 100, 2)\nacc_svc",
"_____no_output_____"
]
],
[
[
"**k-Nearest Neighbours** \nIn pattern recognition, the k-Nearest Neighbors algorithm (or k-NN for short) is a non-parametric method used for classification and regression. A sample is classified by a majority vote of its neighbors, with the sample being assigned to the class most common among its k nearest neighbors (k is a positive integer, typically small). If k = 1, then the object is simply assigned to the class of thart single nearest neighbor. Reference [Wikipedia](https://en.wikipedia.org/wiki/K-nearest_neighbors_algorithm).\n\nKNN confidence score is better than both Logistic Regression and SVM.",
"_____no_output_____"
]
],
[
[
"knn = KNeighborsClassifier(n_neighbors = 3)\nknn.fit(X_train, Y_train)\nY_pred = knn.predict(X_test)\nacc_knn = round(knn.score(X_train, Y_train) * 100, 2)\nacc_knn",
"_____no_output_____"
]
],
[
[
"**Naive Bayes** \nIn machine learning, naive Bayes classifiers are a family of simple probabilistic classifiers based on applying Bayes' theorem with strong (naive) independence assumptions between the features. Naive Bayes classifiers are hihgly scalable, requiring a number of parameters linear in the number of variables (features) in a learning problem. Reference [Wikipedia](https://en.wikipedia.org/wiki/Naive_Bayes_classifier). \n\nThe model generated confidence score is the lowest among the models evaluated so far. ",
"_____no_output_____"
]
],
[
[
"# Gaussian Naive Bayes\n\ngaussian = GaussianNB()\ngaussian.fit(X_train, Y_train)\nY_pred = gaussian.predict(X_test)\nacc_gaussian = round(gaussian.score(X_train, Y_train) * 100, 2)\nacc_gaussian",
"_____no_output_____"
]
],
[
[
"**Perceptron** \nThe perceptron is an algorithm for supervised learning of binary classifiers (functions that can decide whether an input, represented by a vector of numbers, belongs to some specific class or not). It is a type of linear classifier, i.e. a classificatino algorithm that makes its predictions based on a linear predictor function combining a set of weights with feature vector. The algorithm allows for online learning, in that it processes elements in the training set one at a time. Reference [Wikipedia](https://en.wikipedia.org/wiki/Perceptron).",
"_____no_output_____"
]
],
[
[
"# Perceptron\n\nperceptron = Perceptron()\nperceptron.fit(X_train, Y_train)\nY_pred = perceptron.predict(X_test)\nacc_perceptron = round(perceptron.score(X_train, Y_train) * 100, 2)\nacc_perceptron",
"/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/stochastic_gradient.py:128: FutureWarning: max_iter and tol parameters have been added in <class 'sklearn.linear_model.perceptron.Perceptron'> in 0.19. If both are left unset, they default to max_iter=5 and tol=None. If tol is not None, max_iter defaults to max_iter=1000. From 0.21, default max_iter will be 1000, and default tol will be 1e-3.\n \"and default tol will be 1e-3.\" % type(self), FutureWarning)\n"
]
],
[
[
"**Linear SVC** ",
"_____no_output_____"
]
],
[
[
"linear_svc = LinearSVC()\nlinear_svc.fit(X_train, Y_train)\nY_pred = linear_svc.predict(X_test)\nacc_linear_svc = round(linear_svc.score(X_train, Y_train) * 100, 2)\nacc_linear_svc",
"_____no_output_____"
]
],
[
[
"**Stochastic Gradient Descent**",
"_____no_output_____"
]
],
[
[
"sgd = SGDClassifier()\nsgd.fit(X_train, Y_train)\nY_pred = sgd.predict(X_test)\nacc_sgd = round(sgd.score(X_train, Y_train) * 100, 2)\nacc_sgd",
"/anaconda3/lib/python3.6/site-packages/sklearn/linear_model/stochastic_gradient.py:128: FutureWarning: max_iter and tol parameters have been added in <class 'sklearn.linear_model.stochastic_gradient.SGDClassifier'> in 0.19. If both are left unset, they default to max_iter=5 and tol=None. If tol is not None, max_iter defaults to max_iter=1000. From 0.21, default max_iter will be 1000, and default tol will be 1e-3.\n \"and default tol will be 1e-3.\" % type(self), FutureWarning)\n"
]
],
[
[
"**Decision Tree** \nThis model uses a decision tree as a predictive model which maps features (tree branches) to conclusions about the target value (tree leaves). Tree models where the target variable can take a finite set of values are called classification trees; in these tree structures, leaves represent class labels and branches represent conjunctions of features that lead to those class labels. Decision trees where the target variable can take continuous values (typically real numbers) are called regression trees. Reference [Wikipedia](https://en.wikipedia.org/wiki/Decision_tree_learning). \n\nThe model confidence score is the highest among models evaluated so far.",
"_____no_output_____"
]
],
[
[
"decision_tree = DecisionTreeClassifier()\ndecision_tree.fit(X_train, Y_train)\nY_pred = decision_tree.predict(X_test)\nacc_decision_tree = round(decision_tree.score(X_train, Y_train) * 100, 2)\nacc_decision_tree",
"_____no_output_____"
]
],
[
[
"**Random Forests** \nThe next model Random Forests is one of the most popular. Random forests or random decision forests are an ensemble learning method for classification, regression and other tasks, that operate by constructing a multitude of decision trees (n_estimator=100) at training time and outputting the class that is the mode of the classes (classification) or mean prediction (regression) of the individual trees. Reference [Wikipedia](https://en.wikipedia.org/wiki/Random_forest). \n\nThe model confidence score is the highest among models evaluated so far. We decide to use this model's output (Y_pred) for creating our competition submission of results.",
"_____no_output_____"
]
],
[
[
"random_forest = RandomForestClassifier(n_estimators=100)\nrandom_forest.fit(X_train, Y_train)\nY_pred = random_forest.predict(X_test)\nrandom_forest.score(X_train, Y_train)\nacc_random_forest = round(random_forest.score(X_train, Y_train) * 100, 2)\nacc_random_forest",
"_____no_output_____"
]
],
[
[
"## 6. Visualize, report, and present the problem solving steps and final solution.",
"_____no_output_____"
]
],
[
[
"models = pd.DataFrame({\n 'Model': ['Support Vector Machines', 'KNN', 'Logistic Regression', \n 'Random Forest', 'Naive Bayes', 'Perceptron', \n 'Stochastic Gradient Decent', 'Linear SVC', \n 'Decision Tree'],\n 'Score': [acc_svc, acc_knn, acc_log, \n acc_random_forest, acc_gaussian, acc_perceptron, \n acc_sgd, acc_linear_svc, acc_decision_tree]})\nmodels.sort_values(by='Score', ascending=False)",
"_____no_output_____"
]
],
[
[
"## 7. Supply or submit the results.",
"_____no_output_____"
]
],
[
[
"submission = pd.DataFrame({ \"PassengerId\": df_test[\"PassengerId\"], \"Survived\": Y_pred\n })",
"_____no_output_____"
],
[
"submission.to_csv('submission.csv', index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4aa10ffbeda2f49f723220f2cc12fe8e1bde344b
| 8,256 |
ipynb
|
Jupyter Notebook
|
1_5_CNN_Layers/5_2. Visualize Your Net.ipynb
|
roachsinai/CVND_Exercises
|
3e44093cd881516c614d7e5771414af4a73a82d7
|
[
"MIT"
] | null | null | null |
1_5_CNN_Layers/5_2. Visualize Your Net.ipynb
|
roachsinai/CVND_Exercises
|
3e44093cd881516c614d7e5771414af4a73a82d7
|
[
"MIT"
] | null | null | null |
1_5_CNN_Layers/5_2. Visualize Your Net.ipynb
|
roachsinai/CVND_Exercises
|
3e44093cd881516c614d7e5771414af4a73a82d7
|
[
"MIT"
] | null | null | null | 32.632411 | 333 | 0.588663 |
[
[
[
"# CNN for Classification\n---\nIn this notebook, we define **and train** an CNN to classify images from the [Fashion-MNIST database](https://github.com/zalandoresearch/fashion-mnist).",
"_____no_output_____"
],
[
"### Load the [data](http://pytorch.org/docs/master/torchvision/datasets.html)\n\nIn this cell, we load in both **training and test** datasets from the FashionMNIST class.",
"_____no_output_____"
]
],
[
[
"# our basic libraries\nimport torch\nimport torchvision\n\n# data loading and transforming\nfrom torchvision.datasets import FashionMNIST\nfrom torch.utils.data import DataLoader\nfrom torchvision import transforms\n\n# The output of torchvision datasets are PILImage images of range [0, 1]. \n# We transform them to Tensors for input into a CNN\n\n## Define a transform to read the data in as a tensor\ndata_transform = transforms.ToTensor()\n\n# choose the training and test datasets\ntrain_data = FashionMNIST(root='./data', train=True,\n download=True, transform=data_transform)\n\ntest_data = FashionMNIST(root='./data', train=False,\n download=True, transform=data_transform)\n\n\n# Print out some stats about the training and test data\nprint('Train data, number of images: ', len(train_data))\nprint('Test data, number of images: ', len(test_data))",
"_____no_output_____"
],
[
"# prepare data loaders, set the batch_size\n## TODO: you can try changing the batch_size to be larger or smaller\n## when you get to training your network, see how batch_size affects the loss\nbatch_size = 20\n\ntrain_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)\ntest_loader = DataLoader(test_data, batch_size=batch_size, shuffle=True)\n\n# specify the image classes\nclasses = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', \n 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']",
"_____no_output_____"
]
],
[
[
"### Visualize some training data\n\nThis cell iterates over the training dataset, loading a random batch of image/label data, using `dataiter.next()`. It then plots the batch of images and labels in a `2 x batch_size/2` grid.",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport matplotlib.pyplot as plt\n\n%matplotlib inline\n \n# obtain one batch of training images\ndataiter = iter(train_loader)\nimages, labels = dataiter.next()\nimages = images.numpy()\n\n# plot the images in the batch, along with the corresponding labels\nfig = plt.figure(figsize=(25, 4))\nfor idx in np.arange(batch_size):\n ax = fig.add_subplot(2, batch_size/2, idx+1, xticks=[], yticks=[])\n ax.imshow(np.squeeze(images[idx]), cmap='gray')\n ax.set_title(classes[labels[idx]])",
"_____no_output_____"
]
],
[
[
"### Define the network architecture\n\nThe various layers that make up any neural network are documented, [here](http://pytorch.org/docs/master/nn.html). For a convolutional neural network, we'll use a simple series of layers:\n* Convolutional layers\n* Maxpooling layers\n* Fully-connected (linear) layers\n\nYou are also encouraged to look at adding [dropout layers](http://pytorch.org/docs/stable/nn.html#dropout) to avoid overfitting this data.\n\n---\n\n### TODO: Define the Net\n\nDefine the layers of your **best, saved model from the classification exercise** in the function `__init__` and define the feedforward behavior of that Net in the function `forward`. Defining the architecture here, will allow you to instantiate and load your best Net.",
"_____no_output_____"
]
],
[
[
"import torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n\n def __init__(self):\n super(Net, self).__init__()\n \n # 1 input image channel (grayscale), 10 output channels/feature maps\n # 3x3 square convolution kernel\n self.conv1 = nn.Conv2d(1, 10, 3)\n \n ## TODO: Define the rest of the layers:\n # include another conv layer, maxpooling layers, and linear layers\n # also consider adding a dropout layer to avoid overfitting\n \n\n ## TODO: define the feedforward behavior\n def forward(self, x):\n # one activated conv layer\n x = F.relu(self.conv1(x))\n \n # final output\n return x\n",
"_____no_output_____"
]
],
[
[
"### Load a Trained, Saved Model\n\nTo instantiate a trained model, you'll first instantiate a new `Net()` and then initialize it with a saved dictionary of parameters. This notebook needs to know the network architecture, as defined above, and once it knows what the \"Net\" class looks like, we can instantiate a model and load in an already trained network.\n\nYou should have a trained net in `saved_models/`.\n",
"_____no_output_____"
]
],
[
[
"# instantiate your Net\nnet = Net()\n\n# load the net parameters by name, uncomment the line below to load your model\n# net.load_state_dict(torch.load('saved_models/model_1.pt'))\n\nprint(net)",
"_____no_output_____"
]
],
[
[
"## Feature Visualization\n\nTo see what your network has learned, make a plot of the learned image filter weights and the activation maps (for a given image) at each convolutional layer.\n\n### TODO: Visualize the learned filter weights and activation maps of the convolutional layers in your trained Net\n\nChoose a sample input image and apply the filters in every convolutional layer to that image to see the activation map.",
"_____no_output_____"
]
],
[
[
"# As a reminder, here is how we got the weights in the first conv layer (conv1), before\nweights = net.conv1.weight.data\nw = weights.numpy()",
"_____no_output_____"
]
],
[
[
"### Question: Choose a filter from one of your trained convolutional layers; looking at these activations, what purpose do you think it plays? What kind of feature do you think it detects?\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aa115fecb3b1eca64c36fc5e0361b1d97c81aed
| 9,392 |
ipynb
|
Jupyter Notebook
|
train.ipynb
|
liuchangtai1996/MLIP
|
ec217d592b8c51e98729d8c2b2abe1b2d918e14f
|
[
"MIT"
] | null | null | null |
train.ipynb
|
liuchangtai1996/MLIP
|
ec217d592b8c51e98729d8c2b2abe1b2d918e14f
|
[
"MIT"
] | null | null | null |
train.ipynb
|
liuchangtai1996/MLIP
|
ec217d592b8c51e98729d8c2b2abe1b2d918e14f
|
[
"MIT"
] | null | null | null | 41.742222 | 135 | 0.531942 |
[
[
[
"import os\nos.environ['KERAS_BACKEND'] = 'theano'\nfrom keras.models import Sequential\nfrom keras.layers import Input, Dense, Convolution2D, MaxPooling2D, UpSampling2D, Dropout, Flatten\nfrom keras import optimizers\nfrom keras.models import Model\nfrom keras import backend as K\nimport numpy\n\n# train \ndef classifier(n):\n\t# load pima indians dataset\n\tdataset = numpy.load(\"train.npy\") # 18643 * 32768\n\tlabel = numpy.load(\"train_one_hot.npy\") # 18643 * 28\n\t# split into input (X) and output (Y) variables\n\tX = dataset\n\tX = numpy.reshape(X,(X.shape[0],64,64,8))\n\tY = label[:,n]\n\t# create model\n\tinput_img = Input(shape=(64, 64, 8))\n\tx = Convolution2D(4, (1, 1), activation='relu', padding='same')(input_img)\n\tx = MaxPooling2D((2, 2), padding='same')(x)\n\tx = Convolution2D(4, (1, 1), activation='relu', padding='same')(input_img)\n\tx = MaxPooling2D((2, 2), padding='same')(x)\n\tx = Convolution2D(2, (1, 1), activation='relu', padding='same')(input_img)\n\tx = MaxPooling2D((2, 2), padding='same')(x)\n\tx = Convolution2D(2, (1, 1), activation='relu', padding='same')(input_img)\n\tx = MaxPooling2D((2, 2), padding='same')(x)\n\tfc= Flatten()(x)\n\tfc= Dense(64, activation='relu')(fc)\n\tfc= Dropout(0.15)(fc)\n\tfc= Dense(32, activation='relu')(fc)\n\tfc= Dropout(0.15)(fc)\n\tfc= Dense(16, activation='relu')(fc)\n\tfc= Dropout(0.15)(fc)\n\tfc= Dense(8, activation='relu')(fc)\n\tfc= Dropout(0.15)(fc)\n\tfc= Dense(4, activation='relu')(fc)\n\tfc= Dropout(0.15)(fc)\n\tfc= Dense(2, activation='relu')(fc)\n\toutput= Dense(1, activation='sigmoid')(fc)\n\tmodel=Model(input_img, output)\n\t# Compile model\n\tsgd = optimizers.SGD(lr=0.01, momentum=0.9,nesterov=True)\n\tclass_weight = {0: 0.4*float((Y==0).sum()),1: float((Y==1).sum())}\n\tmodel.compile(loss='binary_crossentropy', optimizer=sgd, metrics=['accuracy'])\n\t# Fit the model\n\tmodel.fit(X, Y, epochs=5, batch_size=128,class_weight=class_weight)\n\treturn model\n\nfor n in range(28):\n\tclassifier(n).save('model_'+str(n)+'.h5')\n\t\n#classifier(0).save('model_'+str(0)+'.h5')\n\nimport torch\nimport pandas as pd\nimport numpy as np\nimport os\nimport torch.autograd as ag\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nimport prepare\nimport ResNet18\n\npath = os.getcwd()# we can change the path to fit our need\ndata_path = os.path.join(path, 'human-protein/train/')# this path is temporary\n\n#order of training set\ndf = pd.read_csv(path+'/data/train_idx.txt', sep = '\\t', header = None)\ndf.columns = ['order']\norder = list(df['order'])\n\n# labels of one hot\nlabel = np.load(path +'/data/train_one_hot.npy')\n\n# id of pictures\ntrainset = pd.read_csv(path + '/data/train.csv')\nls = trainset['Id']\nnum = trainset['Target']\n\n#hyper-parameter\nN = label.shape[0] # Training set size\nB = 28 # Minibacth size\nNB = int(N/B)-1 # Number of minibatches\nT = 2 # Number of epochs\ncriterion = nn.CrossEntropyLoss ()\n\n# training preparation\nif torch.cuda.is_available ():\n net = ResNet18.ResNet().cuda()\n ltrain = ag.Variable(torch.from_numpy(label).cuda(),requires_grad = False)\noptimizer = torch.optim .SGD(net. parameters(),lr= 0.001 ,momentum = 0.9)\n\n# start training resnet\nfor epoch in range(T):\n running_loss = 0.0\n\n for k in range(NB):\n\n idxsmp = k*B # indices of samples for k-th minibatch\n\n xt = prepare.load_batch(ls,order,data_path, B, k)\n xt = prepare.normalize(xt)\n xtrain = np.moveaxis(xt,[1,2],[2,3])\n\n inputs = ag.Variable(torch.from_numpy(xtrain).cuda(),requires_grad = True)\n\n labels0 = ltrain [ idxsmp:idxsmp+B,0 ]\n labels1 = ltrain [ idxsmp:idxsmp+B,1 ]\n labels2 = ltrain [ idxsmp:idxsmp+B,2 ]\n labels3 = ltrain [ idxsmp:idxsmp+B,3 ]\n labels4 = ltrain [ idxsmp:idxsmp+B,4 ]\n labels5 = ltrain [ idxsmp:idxsmp+B,5 ]\n labels6 = ltrain [ idxsmp:idxsmp+B,6 ]\n labels7 = ltrain [ idxsmp:idxsmp+B,7 ]\n labels8 = ltrain [ idxsmp:idxsmp+B,8 ]\n labels9 = ltrain [ idxsmp:idxsmp+B,9 ]\n labels10 = ltrain [ idxsmp:idxsmp+B,10 ]\n labels11 = ltrain [ idxsmp:idxsmp+B,11 ]\n labels12 = ltrain [ idxsmp:idxsmp+B,12 ]\n labels13 = ltrain [ idxsmp:idxsmp+B,13 ]\n labels14 = ltrain [ idxsmp:idxsmp+B,14 ]\n labels15 = ltrain [ idxsmp:idxsmp+B,15 ]\n labels16 = ltrain [ idxsmp:idxsmp+B,16 ]\n labels17 = ltrain [ idxsmp:idxsmp+B,17 ]\n labels18 = ltrain [ idxsmp:idxsmp+B,18 ]\n labels19 = ltrain [ idxsmp:idxsmp+B,19 ]\n labels20 = ltrain [ idxsmp:idxsmp+B,20 ]\n labels21 = ltrain [ idxsmp:idxsmp+B,21 ]\n labels22 = ltrain [ idxsmp:idxsmp+B,22 ]\n labels23 = ltrain [ idxsmp:idxsmp+B,23 ]\n labels24 = ltrain [ idxsmp:idxsmp+B,24 ]\n labels25 = ltrain [ idxsmp:idxsmp+B,25 ]\n labels26 = ltrain [ idxsmp:idxsmp+B,26 ]\n labels27 = ltrain [ idxsmp:idxsmp+B,27 ]\n\n # Initialize the gradients to zero\n optimizer.zero_grad ()\n # Forward propagation\n x0,x1,x2,x3,x4,x5,x6,x7,x8,x9,x10,x11,x12,x13,x14,x15,x16,x17,x18,x19,x20,x21,x22,x23,x24,x25,x26,x27 = net ( inputs )\n\n # Error evaluation\n loss0 = criterion( x0 , labels0 )\n loss1 = criterion( x1 , labels1 )\n loss2 = criterion( x2 , labels2 )\n loss3 = criterion( x3 , labels3 )\n loss4 = criterion( x4 , labels4 )\n loss5 = criterion( x5 , labels5 )\n loss6 = criterion( x6 , labels6 )\n loss7 = criterion( x7 , labels7 )\n loss8 = criterion( x8 , labels8 )\n loss9 = criterion( x9 , labels9 )\n loss10 = criterion( x10 , labels10 )\n loss11 = criterion( x11 , labels11 )\n loss12 = criterion( x12 , labels12 )\n loss13 = criterion( x13 , labels13 )\n loss14 = criterion( x14 , labels14 )\n loss15 = criterion( x15 , labels15 )\n loss16 = criterion( x16 , labels16 )\n loss17 = criterion( x17 , labels17 )\n loss18 = criterion( x18 , labels18 )\n loss19 = criterion( x19 , labels19 )\n loss20 = criterion( x20 , labels20 )\n loss21 = criterion( x21 , labels21 )\n loss22 = criterion( x22 , labels22 )\n loss23 = criterion( x23 , labels23 )\n loss24 = criterion( x24 , labels24 )\n loss25 = criterion( x25 , labels25 )\n loss26 = criterion( x26 , labels26 )\n loss27 = criterion( x27 , labels27 )\n loss_01 = loss0+loss1+loss2+loss3+loss4+loss5+loss6+loss7+loss8+loss9+loss10\n loss_02 = loss11+loss12+loss13+loss14+loss15+loss16+loss17+loss18+loss19+loss20\n loss_03 = loss21+loss22+loss23+loss24+loss25+loss26+loss27\n loss = loss_01+loss_02+loss_03\n\n # Back propagation\n loss.backward() #retain_graph=True)\n # Parameter update\n optimizer.step ()\n # Print averaged loss per minibatch every 100 mini - batches\n running_loss += loss.cpu().data[0]\n\n if k % 100 == 99:\n print ('[%d, %5d] loss : %.3f' %( epoch + 1, k + 1, running_loss/100 ))\n running_loss = 0.0\n \n torch.save(net, 'ResNet18_28outputs_epoch%d.pkl'%(epoch+1))\n \nprint ('Finished Training ')\n",
"_____no_output_____"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4aa12306c823385e8839e69bc8038096851595e9
| 120,117 |
ipynb
|
Jupyter Notebook
|
report.ipynb
|
alexgeorgousis/titanic-kaggle
|
0a901f7cdfaf197495cd8902670be046aa3d4285
|
[
"MIT"
] | null | null | null |
report.ipynb
|
alexgeorgousis/titanic-kaggle
|
0a901f7cdfaf197495cd8902670be046aa3d4285
|
[
"MIT"
] | null | null | null |
report.ipynb
|
alexgeorgousis/titanic-kaggle
|
0a901f7cdfaf197495cd8902670be046aa3d4285
|
[
"MIT"
] | null | null | null | 63.52036 | 25,668 | 0.704904 |
[
[
[
"# Titanic: Machine Learning from Disaster\n---",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport seaborn as sns\nfrom sklearn.model_selection import train_test_split, learning_curve, GridSearchCV, cross_validate\nfrom sklearn.metrics import f1_score, accuracy_score, make_scorer\nfrom sklearn.linear_model import LogisticRegression\nfrom sklearn.ensemble import AdaBoostClassifier\nfrom sklearn.svm import SVC\nimport matplotlib.pyplot as plt\nimport time\n\n%matplotlib inline",
"_____no_output_____"
],
[
"# Load the dataset\ndata = pd.read_csv(\"./data/train.csv\")",
"_____no_output_____"
]
],
[
[
"## Exploring the data",
"_____no_output_____"
]
],
[
[
"display(data.head())",
"_____no_output_____"
],
[
"train_size = data.shape[0]\npercent_positive = data[data['Survived'] == 1].shape[0] / train_size\npercent_negative = data[data['Survived'] == 0].shape[0] / train_size",
"_____no_output_____"
],
[
"print(\"Number of training examples: {}\".format(train_size))\nprint(\"Positive examples: {:2.0f}%\".format(percent_positive*100))\nprint(\"Negative examples: {:2.0f}%\".format(percent_negative*100))",
"Number of training examples: 891\nPositive examples: 38%\nNegative examples: 62%\n"
]
],
[
[
"**Note**: The data is skewed towards negative samples, so accuracy might be misleading as a metric. We'll use the F1 score instead.",
"_____no_output_____"
],
[
"---\n## Dealing with NaNs",
"_____no_output_____"
]
],
[
[
"display(data.isnull().sum())",
"_____no_output_____"
]
],
[
[
"* `Age`: it makes sense to use the mean as a replacement for missing values, to represent the \"expected\" age of the passengers.\n* `Cabin`: in this dataset, missing cabin values indicate that a passenger was not in a cabin. This could be useful information, so we'll turn missing values into their own feature called \"U\" for \"Unknown\".\n* `Embarked`: similar to cabin numbers, we're simply going to assume that the port passengers were picked up from was random. This isn't necessarily true, since richer passengers (for example) might have picked up more frequently from one port rather than another.",
"_____no_output_____"
]
],
[
[
"# Replace all Age NaNs with the mean age\ndata[\"Age\"].fillna(np.around(data[\"Age\"].mean(), decimals=1), inplace=True)",
"_____no_output_____"
],
[
"# Replace missing values with \"Unknown\"\ndata[\"Cabin\"].fillna(\"Unknown\", inplace=True)",
"_____no_output_____"
],
[
"# Forward/back fill Embarked NaNs\ndata[\"Embarked\"].fillna(method=\"ffill\", inplace=True)\ndata[\"Embarked\"].fillna(method=\"backfill\", inplace=True)",
"_____no_output_____"
],
[
"# Confirm NaNs are gone\nprint(\"Age NaN count: {}\".format(data[\"Age\"].isnull().sum()))\nprint(\"Cabin NaN count: {}\".format(data[\"Cabin\"].isnull().sum()))\nprint(\"Embarked NaN count: {}\".format(data[\"Embarked\"].isnull().sum()))",
"Age NaN count: 0\nCabin NaN count: 0\nEmbarked NaN count: 0\n"
]
],
[
[
"---\n## One-hot encoding\n\nThe categorical features `Pclass`, `Sex`, `Cabin`, and `Embarked` need one-hot encoding to be useful.\n\nIf we one-hot encoded `Cabin` as-is, we would have too many features as a result, since we would be including every single cabin passengers were in. Instead, we can discard the cabin number and only focus on the deck they were on, denoted by the letter. E.g. cabin C123 is cabin 123 on deck C. This should give us the relevant information about the passengers' location on the ship, without filling the dataset with a ton of unimportant features.",
"_____no_output_____"
]
],
[
[
"# Prepare Cabin for one-hot encoding\ndata[\"Cabin\"] = data[\"Cabin\"].apply(lambda s: s[0])",
"_____no_output_____"
],
[
"# Check cabin column\ndisplay(data[\"Cabin\"].head(10))",
"_____no_output_____"
],
[
"# Perform one-hot encoding\ndata = pd.get_dummies(data, columns=[\"Pclass\", \"Sex\", \"Cabin\", \"Embarked\"])",
"_____no_output_____"
],
[
"# Check one-hot encoded features\nprint(data.columns)",
"Index(['PassengerId', 'Survived', 'Name', 'Age', 'SibSp', 'Parch', 'Ticket',\n 'Fare', 'Pclass_1', 'Pclass_2', 'Pclass_3', 'Sex_female', 'Sex_male',\n 'Cabin_A', 'Cabin_B', 'Cabin_C', 'Cabin_D', 'Cabin_E', 'Cabin_F',\n 'Cabin_G', 'Cabin_T', 'Cabin_U', 'Embarked_C', 'Embarked_Q',\n 'Embarked_S'],\n dtype='object')\n"
]
],
[
[
"Now we can compute the correlation of the cabins labeled \"Unknown\" with the target to see if it's indeed a useful feature.",
"_____no_output_____"
]
],
[
[
"print(\"Correlation between 'Cabin_U' and 'Survived': {}\".format(data.corr()[\"Survived\"][\"Cabin_U\"]))",
"Correlation between 'Cabin_U' and 'Survived': -0.3169115231122935\n"
]
],
[
[
"Indeed, the correlation is high enough for `Cabin_U` to be considered a useful feature. This justifies our earlier decision to keep those missing values as part of the dataset.",
"_____no_output_____"
],
[
"---\n## Removing unimportant features\n\nWe are going to assume that the names of the passengers, as well as their ID and ticket number, are irrelevant to their chance of survival (i.e. they're random) and we'll remove them from the dataset.\n\nAdditionally, as we can see below that `Embarked_Q` has a very low correlation with the target (less than 0.01). So, we're going to remove that feature as well.",
"_____no_output_____"
]
],
[
[
"display(data.corr()[\"Survived\"])",
"_____no_output_____"
],
[
"# Drop uninteresting features\ndata = data.drop(columns=[\"Name\", \"Ticket\", \"PassengerId\", \"Embarked_Q\"])\ndisplay(data.head())",
"_____no_output_____"
]
],
[
[
"## Removing highly-correlated features",
"_____no_output_____"
],
[
"From the heatmap below, we can spot which features are highly correlated with each other. In this case, we notice that the 3 `Pclass` features (particularly classes 1 and 3) are highly correlated with the fare. This makes sense, since `Pclass` represents the ticket class the passengers bought, which gets more expensive the higher it is. Since `Fare` can be predicted using `Pclass`, we're going to remove `Fare` from the dataset, to eliminate duplicate information.",
"_____no_output_____"
]
],
[
[
"# Draw heatmap from the correlation table \nsns.heatmap(data.corr())\nplt.show()",
"_____no_output_____"
],
[
"# Display a table with the correlations between the 3 classes and the fare\ncorr = data.corr()\ndf = pd.DataFrame(data=[\n [corr[\"Pclass_1\"][\"Fare\"], \n corr[\"Pclass_2\"][\"Fare\"], \n corr[\"Pclass_3\"][\"Fare\"]]], \n columns=[\"Pclass_1\", \"Pclass_2\", \"Pclass_3\"], \n index=[\"Fare\"])\ndisplay(df)",
"_____no_output_____"
],
[
"# Drop the Fare from the dataset\ndata = data.drop(columns=[\"Fare\"])",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"## Feature Scaling\n\nThe only continuous feature left in the dataset is `Age`. We are going to normalise it so that it's values are between 0 and 1.",
"_____no_output_____"
]
],
[
[
"# Normalise the age feature\ndata[\"Age\"] = (data[\"Age\"] - data[\"Age\"].mean()) / (data[\"Age\"].max() - data[\"Age\"].min())",
"_____no_output_____"
]
],
[
[
"---",
"_____no_output_____"
],
[
"## Model selection",
"_____no_output_____"
],
[
"Normally, we would do a train/test split and leave the test set aside for the final model evaluation. However, we can use Kaggle's test set for that, so we don't have to sacrifice any training data. Now, let's split the data into features and labels.",
"_____no_output_____"
]
],
[
[
"# Split data into X_train and y_train\nX_train = data.iloc[:, 1:]\ny_train = data[\"Survived\"]",
"_____no_output_____"
]
],
[
[
"### Train-Predict Pipeline",
"_____no_output_____"
],
[
"The following function will serve as a train-predict pipeline.",
"_____no_output_____"
]
],
[
[
"def train_predict(model, score=\"f1\"):\n \"\"\"\n Computes the cross-validation score of a given model using a given metric.\n \n :model: model to evaluate\n :score: scoring metric to use for cross-validation\n :return: tuple with training and validation scores\n \"\"\"\n \n # Create scorer object\n if score == \"accuracy\":\n scorer = make_scorer(accuracy_score)\n elif score == \"f1\":\n scorer = make_scorer(f1_score)\n \n # 5-fold cross-valdation\n cv_results = cross_validate(model, X_train, y_train, scoring=scorer, cv=5, return_train_score=True)\n \n # Get the average scores over all validation cuts\n train_score = np.mean(cv_results[\"train_score\"])\n val_score = np.mean(cv_results[\"test_score\"])\n \n return train_score, val_score",
"_____no_output_____"
]
],
[
[
"### Model Evaluation\nNow let's use the train-predict pipeline to get the CV scores for each of our models.",
"_____no_output_____"
]
],
[
[
"# Compute the score of every model\nmodels = [LogisticRegression(random_state=42), SVC(random_state=42), AdaBoostClassifier(random_state=42)]\nscores = [train_predict(model) for model in models]",
"_____no_output_____"
],
[
"# Display a table with the scores\ndf_scores = pd.DataFrame(data=[[score[0] for score in scores], [score[1] for score in scores]], index=[\"Train\", \"Validation\"], columns=[type(model).__name__ for model in models])\ndisplay(df_scores)",
"_____no_output_____"
]
],
[
[
"From the table above we can see that AdaBoost has the highest cross-validation scores, so we'll choose that as our model.",
"_____no_output_____"
]
],
[
[
"chosen_model = AdaBoostClassifier(random_state=42)",
"_____no_output_____"
]
],
[
[
"Let's plot a learning curve for our model to assess whether it's overfitting or underfitting.",
"_____no_output_____"
]
],
[
[
"def plot_learning_curve(model):\n \n start = time.time()\n train_sizes, train_scores, test_scores = learning_curve(model, X_train, y_train, scoring=make_scorer(f1_score), random_state=42)\n end = time.time()\n print(\"Learning curve time: {:0.2f}s\".format(end-start))\n \n train_scores_mean = np.mean(train_scores, axis=1)\n train_scores_std = np.std(train_scores, axis=1)\n test_scores_mean = np.mean(test_scores, axis=1)\n test_scores_std = np.std(test_scores, axis=1)\n\n # Plot learning curve\n plt.title(\"Learning Curve\")\n plt.xlabel(\"Training examples\")\n plt.ylabel(\"Score\")\n \n plt.grid()\n plt.fill_between(train_sizes, train_scores_mean, train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color=\"r\")\n plt.fill_between(train_sizes, test_scores_mean, test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color=\"g\")\n\n plt.plot(train_sizes, train_scores_mean, 'o-', color=\"r\", label=\"Training score\")\n plt.plot(train_sizes, test_scores_mean, 'o-', color=\"g\", label=\"Cross-validation score\")\n plt.legend(loc=\"best\")\n\n plt.show()",
"_____no_output_____"
],
[
"plot_learning_curve(chosen_model)",
"Learning curve time: 2.21s\n"
]
],
[
[
"From the learning curve we can see that the training and validation scores converge just below 0.8. This indicates the default model is underfitting the data a bit. Let's perform hyperparameter tuning to see if we can improve the performance.",
"_____no_output_____"
],
[
"---\n## Hyperparameter Tuning",
"_____no_output_____"
],
[
"Since we know the model is underfitting, we'll use high numbers of estimators and a small learning rate as our parameters for tuning. ",
"_____no_output_____"
]
],
[
[
"parameters = {\"n_estimators\": [500, 1000, 2000], \"learning_rate\": [0.01, 0.05, 0.1, 0.5]}",
"_____no_output_____"
],
[
"grid_search = GridSearchCV(chosen_model, param_grid=parameters, scoring=make_scorer(f1_score))\n\nrun = True\nif run:\n start = time.time()\n grid_fit = grid_search.fit(X_train, y_train)\n end = time.time()\n print(\"Grid search time: {:2.2f}s\".format(end-start))",
"Grid search time: 69.72s\n"
],
[
"# Print the best model\nbest_clf = grid_fit.best_estimator_\nprint(best_clf)",
"AdaBoostClassifier(learning_rate=0.1, n_estimators=1000, random_state=42)\n"
],
[
"# Save tuned model to file\nfrom joblib import dump, load\ndump(best_clf, \"./tuned_model.joblib\")",
"_____no_output_____"
]
],
[
[
"---\n## Final Model Evaluation",
"_____no_output_____"
],
[
"Let's plot the learning curve and measure the cross-validation score again, to see whether our model improved.",
"_____no_output_____"
]
],
[
[
"# Learning curve\nplot_learning_curve(best_clf)",
"Learning curve time: 38.91s\n"
],
[
"f1_train, f1_val = train_predict(best_clf)\nprint(\"F1 score (train): {:0.2f}\".format(f1_train))\nprint(\"F1 score (validation): {:0.2f}\".format(f1_test))",
"F1 score (train): 0.79\nF1 score (validation): 0.76\n"
]
],
[
[
"The learning curve looks the same, but we can see that both the training and validation f1 scores have increased a little bit.",
"_____no_output_____"
],
[
"---",
"_____no_output_____"
],
[
"## Final Training and Submission",
"_____no_output_____"
]
],
[
[
"# Load the test set\ntest = pd.read_csv(\"./data/test.csv\")",
"_____no_output_____"
],
[
"# Remove missing values\ntest[\"Age\"].fillna(np.around(test[\"Age\"].mean(), decimals=1), inplace=True)\ntest[\"Cabin\"].fillna(\"Unknown\", inplace=True)\ntest[\"Embarked\"].fillna(method=\"ffill\", inplace=True)\ntest[\"Embarked\"].fillna(method=\"backfill\", inplace=True)\n\n# One-hot encoding\ntest[\"Cabin\"] = test[\"Cabin\"].apply(lambda s: s[0])\ntest = pd.get_dummies(test, columns=[\"Pclass\", \"Sex\", \"Cabin\", \"Embarked\"])\n\n# Drop unimportant features\ntest = test.drop(columns=[\"Name\", \"Ticket\", \"PassengerId\", \"Embarked_Q\"])\ntest = test.drop(columns=[\"Fare\"])\n\n# Feature scaling\ntest[\"Age\"] = (test[\"Age\"] - test[\"Age\"].mean()) / (test[\"Age\"].max() - test[\"Age\"].min())",
"_____no_output_____"
],
[
"display(test.head())",
"_____no_output_____"
],
[
"# Add missing column to test set\ntest[\"Cabin_T\"] = np.zeros(test.shape[0])",
"_____no_output_____"
],
[
"# Display test to confirm\ndisplay(test.head())",
"_____no_output_____"
],
[
"# Train the tuned model\nbest_clf = best_clf.fit(X_train, y_train)",
"_____no_output_____"
],
[
"# Predict test labels\ntest_labels = pd.Series(best_clf.predict(test))",
"_____no_output_____"
],
[
"# Load passenger IDs (to be used as labels in the submission)\ntest_orig = pd.read_csv(\"./data/test.csv\")\nids = test_orig[\"PassengerId\"]",
"_____no_output_____"
],
[
"# Create DataFrame for submission\ntest_submission = pd.DataFrame(data={\"PassengerId\": ids, \"Survived\": test_labels})\ndisplay(test_submission)",
"_____no_output_____"
],
[
"# Produce submission file\ntest_submission.to_csv(\"./data/submission.csv\", index=False)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa124a27e5ad58f6a369b4e4c066822658b2e4a
| 13,337 |
ipynb
|
Jupyter Notebook
|
16-Bonus Material - Introduction to GUIs/04-Widget Events.ipynb
|
vjsniper/Python
|
5331fb5c4d922d3eca884ac4704dbf8efa3e25d5
|
[
"Apache-2.0"
] | 8 |
2020-09-02T03:59:02.000Z
|
2022-01-08T23:36:19.000Z
|
16-Bonus Material - Introduction to GUIs/04-Widget Events.ipynb
|
vjsniper/Python
|
5331fb5c4d922d3eca884ac4704dbf8efa3e25d5
|
[
"Apache-2.0"
] | 1 |
2021-05-10T10:49:44.000Z
|
2021-05-10T10:49:44.000Z
|
16-Bonus Material - Introduction to GUIs/04-Widget Events.ipynb
|
vjsniper/Python
|
5331fb5c4d922d3eca884ac4704dbf8efa3e25d5
|
[
"Apache-2.0"
] | 6 |
2019-11-13T13:33:30.000Z
|
2021-10-06T09:56:43.000Z
| 31.754762 | 580 | 0.61798 |
[
[
[
"# Widget Events\n\nIn this lecture we will discuss widget events, such as button clicks!",
"_____no_output_____"
],
[
"## Special events",
"_____no_output_____"
],
[
"The `Button` is not used to represent a data type. Instead the button widget is used to handle mouse clicks. The `on_click` method of the `Button` can be used to register a function to be called when the button is clicked. The docstring of the `on_click` can be seen below.",
"_____no_output_____"
]
],
[
[
"import ipywidgets as widgets\n\nprint(widgets.Button.on_click.__doc__)",
"_____no_output_____"
]
],
[
[
"### Example #1 - on_click",
"_____no_output_____"
],
[
"Since button clicks are stateless, they are transmitted from the front-end to the back-end using custom messages. By using the `on_click` method, a button that prints a message when it has been clicked is shown below.",
"_____no_output_____"
]
],
[
[
"from IPython.display import display\nbutton = widgets.Button(description=\"Click Me!\")\ndisplay(button)\n\ndef on_button_clicked(b):\n print(\"Button clicked.\")\n\nbutton.on_click(on_button_clicked)",
"_____no_output_____"
]
],
[
[
"### Example #2 - on_submit",
"_____no_output_____"
],
[
"The `Text` widget also has a special `on_submit` event. The `on_submit` event fires when the user hits <kbd>enter</kbd>.",
"_____no_output_____"
]
],
[
[
"text = widgets.Text()\ndisplay(text)\n\ndef handle_submit(sender):\n print(text.value)\n\ntext.on_submit(handle_submit)",
"_____no_output_____"
]
],
[
[
"## Traitlet events\nWidget properties are IPython traitlets and traitlets are eventful. To handle changes, the `observe` method of the widget can be used to register a callback. The docstring for `observe` can be seen below.",
"_____no_output_____"
]
],
[
[
"print(widgets.Widget.observe.__doc__)",
"_____no_output_____"
]
],
[
[
"### Signatures\nMentioned in the docstring, the callback registered must have the signature `handler(change)` where `change` is a dictionary holding the information about the change.\n\nUsing this method, an example of how to output an `IntSlider`’s value as it is changed can be seen below.\n",
"_____no_output_____"
]
],
[
[
"int_range = widgets.IntSlider()\ndisplay(int_range)\n\ndef on_value_change(change):\n print(change['new'])\n\nint_range.observe(on_value_change, names='value')",
"_____no_output_____"
]
],
[
[
"# Linking Widgets\nOften, you may want to simply link widget attributes together. Synchronization of attributes can be done in a simpler way than by using bare traitlets events.",
"_____no_output_____"
],
[
"## Linking traitlets attributes in the kernel¶\n\nThe first method is to use the `link` and `dlink` functions from the `traitlets` module. This only works if we are interacting with a live kernel.\n",
"_____no_output_____"
]
],
[
[
"import traitlets",
"_____no_output_____"
],
[
"# Create Caption\ncaption = widgets.Label(value = 'The values of slider1 and slider2 are synchronized')\n\n# Create IntSliders\nslider1 = widgets.IntSlider(description='Slider 1')\nslider2 = widgets.IntSlider(description='Slider 2')\n\n# Use trailets to link\nl = traitlets.link((slider1, 'value'), (slider2, 'value'))\n\n# Display!\ndisplay(caption, slider1, slider2)",
"_____no_output_____"
],
[
"# Create Caption\ncaption = widgets.Label(value='Changes in source values are reflected in target1')\n\n# Create Sliders\nsource = widgets.IntSlider(description='Source')\ntarget1 = widgets.IntSlider(description='Target 1')\n\n# Use dlink\ndl = traitlets.dlink((source, 'value'), (target1, 'value'))\ndisplay(caption, source, target1)",
"_____no_output_____"
]
],
[
[
"Function `traitlets.link` and `traitlets.dlink` return a `Link` or `DLink` object. The link can be broken by calling the `unlink` method.",
"_____no_output_____"
]
],
[
[
"# May get an error depending on order of cells being run!\nl.unlink()\ndl.unlink()",
"_____no_output_____"
]
],
[
[
"### Registering callbacks to trait changes in the kernel\n\nSince attributes of widgets on the Python side are traitlets, you can register handlers to the change events whenever the model gets updates from the front-end.\n\nThe handler passed to observe will be called with one change argument. The change object holds at least a `type` key and a `name` key, corresponding respectively to the type of notification and the name of the attribute that triggered the notification.\n\nOther keys may be passed depending on the value of `type`. In the case where type is `change`, we also have the following keys:\n* `owner` : the HasTraits instance\n* `old` : the old value of the modified trait attribute\n* `new` : the new value of the modified trait attribute\n* `name` : the name of the modified trait attribute.\n",
"_____no_output_____"
]
],
[
[
"caption = widgets.Label(value='The values of range1 and range2 are synchronized')\nslider = widgets.IntSlider(min=-5, max=5, value=1, description='Slider')\n\ndef handle_slider_change(change):\n caption.value = 'The slider value is ' + (\n 'negative' if change.new < 0 else 'nonnegative'\n )\n\nslider.observe(handle_slider_change, names='value')\n\ndisplay(caption, slider)",
"_____no_output_____"
]
],
[
[
"## Linking widgets attributes from the client side\n\nWhen synchronizing traitlets attributes, you may experience a lag because of the latency due to the roundtrip to the server side. You can also directly link widget attributes in the browser using the link widgets, in either a unidirectional or a bidirectional fashion.\n\nJavascript links persist when embedding widgets in html web pages without a kernel.",
"_____no_output_____"
]
],
[
[
"# NO LAG VERSION\ncaption = widgets.Label(value = 'The values of range1 and range2 are synchronized')\n\nrange1 = widgets.IntSlider(description='Range 1')\nrange2 = widgets.IntSlider(description='Range 2')\n\nl = widgets.jslink((range1, 'value'), (range2, 'value'))\ndisplay(caption, range1, range2)",
"_____no_output_____"
],
[
"# NO LAG VERSION\ncaption = widgets.Label(value = 'Changes in source_range values are reflected in target_range')\n\nsource_range = widgets.IntSlider(description='Source range')\ntarget_range = widgets.IntSlider(description='Target range')\n\ndl = widgets.jsdlink((source_range, 'value'), (target_range, 'value'))\ndisplay(caption, source_range, target_range)",
"_____no_output_____"
]
],
[
[
"Function `widgets.jslink` returns a `Link` widget. The link can be broken by calling the `unlink` method.",
"_____no_output_____"
]
],
[
[
"l.unlink()\ndl.unlink()",
"_____no_output_____"
]
],
[
[
"### The difference between linking in the kernel and linking in the client\n\nLinking in the kernel means linking via python. If two sliders are linked in the kernel, when one slider is changed the browser sends a message to the kernel (python in this case) updating the changed slider, the link widget in the kernel then propagates the change to the other slider object in the kernel, and then the other slider’s kernel object sends a message to the browser to update the other slider’s views in the browser. If the kernel is not running (as in a static web page), then the controls will not be linked.\n\nLinking using jslink (i.e., on the browser side) means contructing the link in Javascript. When one slider is changed, Javascript running in the browser changes the value of the other slider in the browser, without needing to communicate with the kernel at all. If the sliders are attached to kernel objects, each slider will update their kernel-side objects independently.\n\nTo see the difference between the two, go to the [ipywidgets documentation](http://ipywidgets.readthedocs.io/en/latest/examples/Widget%20Events.html) and try out the sliders near the bottom. The ones linked in the kernel with `link` and `dlink` are no longer linked, but the ones linked in the browser with `jslink` and `jsdlink` are still linked.\n",
"_____no_output_____"
],
[
"## Continuous updates\n\nSome widgets offer a choice with their `continuous_update` attribute between continually updating values or only updating values when a user submits the value (for example, by pressing Enter or navigating away from the control). In the next example, we see the “Delayed” controls only transmit their value after the user finishes dragging the slider or submitting the textbox. The “Continuous” controls continually transmit their values as they are changed. Try typing a two-digit number into each of the text boxes, or dragging each of the sliders, to see the difference.\n",
"_____no_output_____"
]
],
[
[
"import traitlets\na = widgets.IntSlider(description=\"Delayed\", continuous_update=False)\nb = widgets.IntText(description=\"Delayed\", continuous_update=False)\nc = widgets.IntSlider(description=\"Continuous\", continuous_update=True)\nd = widgets.IntText(description=\"Continuous\", continuous_update=True)\n\ntraitlets.link((a, 'value'), (b, 'value'))\ntraitlets.link((a, 'value'), (c, 'value'))\ntraitlets.link((a, 'value'), (d, 'value'))\nwidgets.VBox([a,b,c,d])",
"_____no_output_____"
]
],
[
[
"Sliders, `Text`, and `Textarea` controls default to `continuous_update=True`. `IntText` and other text boxes for entering integer or float numbers default to `continuous_update=False` (since often you’ll want to type an entire number before submitting the value by pressing enter or navigating out of the box).",
"_____no_output_____"
],
[
"# Conclusion\nYou should now feel comfortable linking Widget events!",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
]
] |
4aa130a17b87b64c3d79f969e9f6efb091075c38
| 6,727 |
ipynb
|
Jupyter Notebook
|
examples/30Q_GHZ_Manhattan.ipynb
|
mtreinish/mthree
|
031393e6f7461e9702ece1215023816571d70723
|
[
"Apache-2.0"
] | null | null | null |
examples/30Q_GHZ_Manhattan.ipynb
|
mtreinish/mthree
|
031393e6f7461e9702ece1215023816571d70723
|
[
"Apache-2.0"
] | null | null | null |
examples/30Q_GHZ_Manhattan.ipynb
|
mtreinish/mthree
|
031393e6f7461e9702ece1215023816571d70723
|
[
"Apache-2.0"
] | null | null | null | 20.571865 | 161 | 0.4696 |
[
[
[
"# 30Q GHZ state trial on Manhattan\n\nThis notebook requires: `Qiskit >= 0.24`, and of course `mthree >= 0.4.1`. The latter must be installed from source at the moment.\n\nThis will attempt to execute a 30Q GHZ state using Manhattan. This is interesting as forming the full mitigation matrix would require $2^{60}$ elements.\n",
"_____no_output_____"
]
],
[
[
"import time\nimport numpy as np\nfrom qiskit import *\nfrom qiskit.ignis.mitigation import expectation_value",
"_____no_output_____"
],
[
"IBMQ.load_account()\nprovider = IBMQ.get_provider(group='deployed')\nbackend = provider.backend.ibmq_manhattan",
"_____no_output_____"
],
[
"import mthree\nmthree.about()",
"================================================================================\n# Matrix-free Measurement Mitigation (M3) version 0.4.1.dev1+1fabf99\n# (C) Copyright IBM Quantum, 2021\n# Paul Nation, Hwajung Kang, and Jay Gambetta\n================================================================================\n"
],
[
"layers = [[4], \n [5], \n [6,11], \n [7,17,3], \n [8,18,2], \n [12,19,1], \n [21,25,0],\n [22,33,10],\n [23,32,13],\n [26,31,14],\n [37,39,15],\n [45,24]]\n\nqubits = sum(layers, [])\nlen(qubits)",
"_____no_output_____"
]
],
[
[
"### Build 30 qubit GHZ circuit",
"_____no_output_____"
]
],
[
[
"qc = QuantumCircuit(65, len(qubits))\nqc.h(4)\n#branch 1\nqc.cx(4,5)\nqc.cx(5,6)\nqc.cx(6,7)\nqc.cx(7,8)\nqc.cx(8,12)\nqc.cx(12,21)\nqc.cx(21,22)\nqc.cx(22,23)\nqc.cx(23,26)\nqc.cx(26,37)\n#branch 2\nqc.cx(4,11)\nqc.cx(11,17)\nqc.cx(17,18)\nqc.cx(18,19)\nqc.cx(19,25)\nqc.cx(25,33)\nqc.cx(33,32)\nqc.cx(32,31)\nqc.cx(31,39)\nqc.cx(39,45)\n#branch 3\nqc.cx(4,3)\nqc.cx(3,2)\nqc.cx(2,1)\nqc.cx(1,0)\nqc.cx(0,10)\nqc.cx(10,13)\nqc.cx(13,14)\nqc.cx(14,15)\nqc.cx(15,24)\nqc.measure(qubits, range(len(qubits)))",
"_____no_output_____"
]
],
[
[
"### Instantiate M3 Instance",
"_____no_output_____"
]
],
[
[
"mit = mthree.M3Mitigation(backend)",
"_____no_output_____"
]
],
[
[
"### Calibration",
"_____no_output_____"
]
],
[
[
"mit.tensored_cals_from_system(qubits)",
"_____no_output_____"
]
],
[
[
"### Execute the circuit on the backend and compute the expectation value",
"_____no_output_____"
]
],
[
[
"ghz_job = execute(qc, backend, shots=8192, optimization_level=1)",
"_____no_output_____"
],
[
"real_counts = ghz_job.result().get_counts()\nlen(real_counts)",
"_____no_output_____"
],
[
"expectation_value(real_counts)[0]",
"_____no_output_____"
]
],
[
[
"### Measurement mitigation by M3 and compute the expectation value",
"_____no_output_____"
]
],
[
[
"quasi, details = mit.apply_correction(real_counts, qubits=qubits, details=True)\ndetails",
"_____no_output_____"
],
[
"expectation_value(quasi)[0]",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4aa130b7b2a635033a7c55a7a112b548295d0988
| 603,645 |
ipynb
|
Jupyter Notebook
|
application/physical/notebooks/tws_api.ipynb
|
cprima/finance-stuff
|
6a9389456e1068e0e8fc6bd83c87b8144a6390bf
|
[
"MIT"
] | 1 |
2018-08-28T09:09:14.000Z
|
2018-08-28T09:09:14.000Z
|
application/physical/notebooks/tws_api.ipynb
|
cprior/finance-stuff
|
6a9389456e1068e0e8fc6bd83c87b8144a6390bf
|
[
"MIT"
] | 2 |
2021-03-31T19:21:08.000Z
|
2021-12-13T20:29:49.000Z
|
application/physical/notebooks/tws_api.ipynb
|
cprima/finance-stuff
|
6a9389456e1068e0e8fc6bd83c87b8144a6390bf
|
[
"MIT"
] | null | null | null | 2,902.139423 | 198,599 | 0.962054 |
[
[
[
"# Trader Workstation API access 2018-08\n\nThe TWS API has a Python wrapper, seems there was in the past no official version but now it is available at http://interactivebrokers.github.io/ .\n\nThe download includes the code and samples:\n```bash\nls IBJts/ IBJts/samples/Python/Testbed/\nIBJts/:\nAPI_VersionNum.txt samples source\n\nIBJts/samples/Python/Testbed/:\nAvailableAlgoParams.py FaAllocationSamples.py Program.py\nContractSamples.py OrderSamples.py ScannerSubscriptionSamples.py\n```\n\nThe code in this notebook is the file Program.py stripped to bare essentials.\n\nThe API connects with the \"IB API\" variant to\n- either the Trader Workstation\n- or the IB Gateway (acting as a local socket server, without the GUI of the TWS)\nThe IB gateway is available from https://www.interactivebrokers.com/en/index.php?f=16457 (if the link is broken, search for *IB Gateway*)\nOn Linux this is a shell installer script, placing an icon on the Desktop.\n\nBy default the port is configured to 4001 but can easily be changed in the settings.\n\nAs long as the API clients are using different IDs when opening the socket connection up to 32 clients are supported. The IB gateway GUI will show the number of connected clients.",
"_____no_output_____"
]
],
[
[
"from IPython.display import display, HTML\ndisplay(HTML('''<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAFUAAABZCAIAAADAVf92AAAAA3NCSVQICAjb4U/gAAAAEHRFWHRTb2Z0d2FyZQBTaHV0dGVyY4LQCQAAEFdJREFUeNrtnHlAVNX3wO9bZmeGYZgBZgYGHDbZR3ZCEBGVgp9mLplkYhmV+FUqzVzI7Ku5lH5dMpVSs+ynSAYuCIWISLiMgiCJDMgyNGwywyLMxsx77/sHNl8TKK2ABO9f9713Z877vHPeveece++DIl94HYziAoPRXUY7P/o3/AWChIX4TpkQYs4yG4I71mh1l66VZOUWanX64eeHYfithXOmTZ0Aw0NnShJPVz9v94+27dP3GIfZ/iUeLrGTw4YSHgAAQVCQn9f0ZyMJAh9m/iA/bxRFh/69hSAoxN8HDDs/nUb9u5Dy8vIeqz2VQibw4eaHoL8HPj093dra+nFNYISMf1KpNC8vz93dfTSO/42Njbt27Zo2bdpo9H8Igli3bh1BEFFRUaORf8mSJV1dXbGxsaPR/01OTlapVCiKvvTSS6OOf+fOnVVVVQAAHx+fURf/pKamXr58ube+cOHC0cX/008/ZWRk9NbFYjGXyx1F/NXV1Xv37iUIovdw7ty5oyj+12g0GzZswDCs95DJZHp7e48i/hUrVmi1WtPhrFmzht37Gjr+lStXqlSq/wVOdPrUqVNHC//WrVvlcvmDZ8LDw/8JocdQ8B8+fLi4uPjBMwiCLFiw4J/AP+ipi8LCwqysrIdOSiQSU/SampoqlUq1Wq1IJJo3b55IJBpR/DU1NX1PxsXF9VYWL17c1tbWW29rayspKUlISIiMjBzJ/o9QKBQIBL0usAneVA4ePDjC/b/58+f3Vq5du9b3qtFoPHv27Ijl53A4EonEhNpvm4aGhhHLP2HCBFOdRCL122You8Ah5cdx/NSpU6bD4ODgvm1IJNJQ+kVDyt/T06NQKEzvf2Jior29/YMNIAhKTEwcmf0fjuPd3d0AgPr6+qVLl/ae3LJlS3x8vIODg42NTWho6P79+/s1iid4/H+wYzcYDL310tLStWvXbtiwAQAQHR0dHR09wv1/HMfVavWDZwoKCrZu3Tpa4h8cx/X6h6erMzMzDx8+PCr4NRqNKefzkLd3+vTpEc6PYdiDaY+Hyvbt2wsLC0cyv06nwweeqMVx/IMPPpDJZCOW/6Ger9+hYdmyZUqlcgTG/3Z2dgEBAY/SMiUlZfXq1SONPyIiIiIiAvxTy1+1f2Vbx3DdemdXd79jypDyF0pL1Brt0MMbjca09DMQjAwzf1WN/HDqabVG+9dV8RhxlMGQnnnukvTGX+eH/vr6XwLHBFacmCkRAoHNEDwFpVKVlZMnu1NHojLgfwI/AIAgCBwzEgQOhsAKIAiGEQhG/pb1T+jfdEsQgpLAE1ierv9+yv+U/yn/U/4hLRCT4+ofYodBw83fZ/yDrAOT/71Jv2b6ltZuiOP+5uYPQ3E2FYIxnbajWV5+6XTauR8aHx7qcKqT//TYOaFidysKFetQ1leU5RzbfV7bPVDMj/g9u3ze5NTM87fINJbFP4m/9/5ULWVXcseEvGzGA5alWycvz9SSGDbOYfPfW75ipebekuzLiKWpMcYImbVu4RJ+Ve7RbUtzy++R2E7eob5tN2rrIJ6D64AuEwDN9VWqFpbtsPL/sf3jrRXlldV6QK2puPJeiqzbOoDemIMZDb9epwvnLEwUXt8aGxn91ke5RbdklVWnjn2x/LtOndEAAMKYsuGLA59nHd+bdWDljpd4Avh/DmLApnLZzSu5J3btCW0GABCInfuLK7fv+ezM0W3fbZjxsmMPBKiiN1Nyt/v4IDgAACdFLTiQ8k10JwwAAJAhcnvWN7Ez6Vh/IujiJSm5n3p43BeHmM1Oyd0fEo7gf+b9J5GpTEtbvsezr8zyZrRcz61QazVd95VPCY8JB92ZOz8uaB43/jlHz0CewMFG5OzkGWTn5AkArpOd/M+qxIjwKS9u/pk57e14QZHJRy7bMd3Hy8vLy2/K+jMtihZ+XPKOSQ2Fm1+Pin7jk2qv+UkTgntqq35u77J2IW58TxB4j9DdlwnoDIOqphwAipOrGfnW1a1p36pvfddHhOZ2SXuXwIdank4QBIC4Y8cC49VLn2WmPrRl4o/5odgD1fKqnLTdmXsXr/GuOLJq11XCjEZn3Y9DOSJHhkF6/gJDKGZa8PqaOSa/Jr2j0sJURZH0mztcBxG1o7Gu95qupeqeHmbYuAsCZ7KdEuZO1l7anPRuyol7mtasb0oucaeNRQvw0pJrUECgN2boMdDcnB213XDQePG9FgLxkLiBygsFanMuobjRR0QtXFZcgAVHPkM26DQYeZyPGLt8vhC1tIZ+u1Xpj/1/In9d0L9O9sAkOtcp9OVVH6SkcS2XbP8FJUyuPwEwQ485Z4zpP9kz/3Mw4ODHa4quYzRW4PyVzzv7COhmhg41DRAsdmdbA+vXWT8ylcZgWQAAtCIXdyrVfuPlzo0wBEEAwDBq0HKp2oq0i9UTF00K2H5E7+9FqfzqS3lcxDjL9Wd5vsG8ipMZP5vzPMyDXn+/jwj2vfM5Nyf9e3o0/GF1j49nEFW673Qdm+f/+PbfpWhu7aBbORIwfv7rjJQG1/EBZuq796fo0bZGuZ7kJvGkPDCUwTQKk0aU5Z/S2sUnv+0hvrnjjRlTxsckpdUYjQY9jmMAAOi3gSIBAYA3H30tQDJOIpH4SCRe3p6SRWlKnabi+g1gFR1rr3MIcS3NOn7kQoXvxHA+eayT/92874u7zII/6l8EoSwqVPVMfDHI+AvXy8WxtiBLbuBYCf/M+4+iJAbLwozFMec7W5oDHMMb6yt7LyH6ghwp4M9dOZOjeshuevQ6o8jRE7q4KfHjojoVyrBqwlAEJQMAIEKr6wEsNsskntwkv22w8XFGKAxrltCDJfRgCb1sA1+wEoo6rt4oE8ZOnuM3paMg/cbPJTe7JS8kTA+yUObk3CYxyO7j+hUBAAEX/ZDePfn5qW5BvqA2+1wDw4JCM3v8+NfSNTBQI/DyYlg6ek56dg67av//XzHCvw5aRMftoyfTnKat+vZAwJnCywqiC7awFYFea0Aa6ivBM4tWx1kq7DpgsT0L9O4UhPA7lXKQ8OKKV+RZraKJgns/Zsuyj+VEHVh+7FP2oTyVpYbKdzUrz85X3iMA0pRzpvq9VW8L7h6aXYmQ3UvLS+OXJkK39q66wuY7oI2KfkUAABB94ZkL8+a/vX+MRfGhY6UcgUPflMHv8xu6lUAVvPzYCRTCejQdzbW3jiWv2rQtR+URGmhqRFZl7n6/+nKoR3zMqyuFLJKxq725LC+7pJkAVjUHk3fPf2f69o8czElGbVfbHWl1OwEAIFQ3jpz6Oj4sccd0mqb+xhcn0tra8CPrF1SHJU1/b629OaJulp8vOVFfCexcILzm4kXNcueqg/tz2HxPckvOWZm/r/qrzwvuWoWF0GoPJu+O60cEAAAYVOfOn4+JjJRuO1DUxouY8Kj5n5LCLARBvYInAwAqii+2KGowowGCYTKZyrTgiZy92Fz+wzk5vbauokTZJNfr1DAMU2lmFla2zt7BEAQ11lXIZaU6TRcEIxQqzdbR087JEwCg6e68XZTf1d6KoGSxu59Q7E7guLyytEku02nUKIlsJRzjIgntVVpjbYWstDBg4gw6k11Tfr1T1UTgwC9i2v2rA4jAScFzts0TrHZaeBaXhMX01T/0xO3/xzBj/slDdo4eDmN9UTJlgCwYnTvGhgnMBM8lrBXtmxT0QZujr42d02Dlv4a0EAQAQN/VWldR7ODmi5L6eQQE4uz/ZuI79h2tN48tid9TSpD9hOIRFf9eunSpu71JLis1Gnr6Jp0hrDTrvUUcaxdh4KsnqtReQVED7dBGn1B+sVhc+NNPISEhChS1c/JCUNJDVgBBsP/E50ds/gPDMDc3t/z8fKWiSlFTjhkNf27q4UnlNxqNBEH4+PicO3eupa68qU725x7B4Nq/0Tzo+VdnzvVj8bAmufT7fYeLirvJJtFUx6gZMX5h7jbOqj2JybdlhPWY5+YsnOQsEZDJ6vo7l47vOSKr0KMD6R/DMBRFAwMDs7Ozo6OjYQSxFjkjCPpY8yKDqH8Cdp747mtJgh8/eWXaM7O3XrVN+HA+08aoAwAAQLN8duOXqz1cFBnb31kQ/tKejLzTgNCRyNqyw8lxM+cu2CQFE99eEaKAMONA+jftoxo/fnxGRsYvlSWtDTU4ZnwsKxhEfr3t1BkuLUfff+eLnCuYpmbLoWpNWJyn8gJBED1uiZufLzo4P37ya6t+vCZTM1wdfMMhcK8q/cC24xcrG1pkl7P2FZP59tbKytKB9G80Gk0rqKOioo4fT5VXFLU2yR/rEQwiP06js6BORX2rk2cgm8tndnRXwR52PKVWQwmY7mJvEEZtS29VNknTN707gc9gsnt/Ze8q4YsDxJMT53p1FubeaupQ/Y7+TSYAAIiJifnq0KG6cmlbiwLHsUd8BIP4/lMayq+rp81KnF2S2tUM0zjWTAZEopAgdYez31igOP/tjr0XazW8gLc2f7pidtsbO04aRQAAffgnP/zLnAH1tP+4KvDL25ZuQb+jfwRBEAQxfYBk9uzZWq128eJECEYsrATwI8yRDiI/0n32y512Nq8f/DYOISBIr+4hwa0XWzGMxrGiGkpPfJ53iyMUmxcelWb+35xx/MVpMg6Zbka6vi1uYTdBs0tat7Hwa1XSt2jLwP1fb4Fh2Nvbu7r6/kYbvV5XUZzvGTyFZcH7Q/5BHf9wY+neJXPm2rn5OAos/dbfwLqkl8sMJBg1EDDLnGnFt2dz+WyqoUVNsuRx2prkAABY09ze3tZUWbD0sxpa7EK35gsD2b/RaGxsbDxy5AhBEIsWLaIxmCLXcWLPIDf/CBfJeARBHuXrOIM+/nOtuC4eITbRX25ZFaLOTs/uQlkk5Z27iHdoIM2gBwAYzR1d2bq6umatXnffJklkpgWPzRUAmHJPKddpuvvVf0NDw6SoqGVJSe3t7QkJCbhRD0GwBU/AtRFxrIR0JvtRVkcMKj9E4Tm6eAZMmpO0d+fMqU2fzVqWQbdzIiHlOecM5Bkfr42xc3b0j3kjLLLj+8/T71I5kybNDZvq7+zj4Rk0OX7jK2x6WfaZOrxfNSoUipjYWCMgUemsXbt2USiUpKSk9rv1AAAEJaEk8iM6AoMa/1Kcl+3e7Xu38U7ZhVNfr//0eDuZ7f3MVJREJmC+9YTnVsxw9+KBTln2xmWr911t8Z2xMy7puRgnji2T0LfVlV1IXfnOllIda9xv43bMaMg/9RWXx0MoTL69K4Zhdbeu1NXVwjBsa2vr6B1qYSVEkEft1wY9/i+/nqds+sXMnGNtK+Y7jDXFYQRByGUlDbW3DXodi8NzkYSasTgGve52UX5n212joYdMpXH59mJ3PxL5N59Y6uXn2zvbiFzMWBwIhmXFFxYnvLpmzZrw8AmK1i57V59+g+Lh4R+M/Ed95U1LazuaGRMlUQAg2lubZMUXAgMCi4qK+GJPG5EzSiI/Ij8yxs3vyeKHIMBkc8lUGoKSIQiCIIhMpdOZFo1NzZYCBwsrIZlCe/TvsT2J8f/9tVYmDcMwwrGyNbe0BgBCUBSCHqNTf/L4+8lhQhCEIDDyZ9YCPl3/8ZT/Kf/oLf8Fyso43N4Mt2IAAAAASUVORK5CYII=\"/>'''))\ndisplay(HTML('''<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAa0AAAESCAIAAADBqB3AAAAAA3NCSVQICAjb4U/gAAAAEHRFWHRTb2Z0d2FyZQBTaHV0dGVyY4LQCQAAIABJREFUeNrtnXt8G9WZ958zkmM7vsS5OORCEhsphEhJ2yRAaEhASQpSXAzvFmQu3X1JoZS+kUujXj4LhTbKtnS7LVsFYqUsXdh0t+0WK+y2KKSaQIkDAUq4tQVN4kSKTSA3OxfHji1fNHPeP+aikTSSJV9l6flWJTNHZ85lPPPT85wzcx6y7ksPAIIgSB7D4ClAEAR1EEEQBHUQQRAEdRBBEAR1EEEQBHUQQRAEdRBBEAR1EEEQBHUQQRAEdRBBEAR1EEEQJI/Qp/yW4glCECRXIOnooIbqUVRCBEFyQAKJpsQRRQcp6h2CILlNEomjhAAA6DNRQBRLBEFywRGO00f94GKH6ocgyMS0ApPrYUySPl7qBt1EEASZWFYhTVA+otY0Io0PKkJHk6keKiGCIBPSM6YJGkaiMkgAgOqBJmgf1dY/VEIEQSamBsaag0Q1LUIJAdDTWFMw9T8IgiAThZjRQUKjWqhsEhBnSvRqpUvcVCWgFCIIMuFsQkJUHq80TkgAgBKVIOolhYuXQZpUW1ESEQTJaumL0S2a4C2TGE2kRH5+kCbIX5wY0iSSiCAIkp3usLJHYvRRUUbRVKRAxflileZRqh4QpFp6iiOGCIJksTmokj5JrAjEv1VHiCxthBCgehqjgIryUcUBRn8YQZAJZg7SOA9Z2lf+L4qZoob6qAKq5I/GCh+NV0AURARBstgkVCkYIUTTUyYqtdRTSkH9P8UMlO3ERLsQn6lBECT7ZA/Uj8ioUmRjkNIETZS+lvxiSmmc/Knc5HjzELUPQZAs84SlzZiBQMXvFTdA/q8kiFR6hoaCHhQhpDTeR6aJ88hRqxFBECQbNZFIjwhKCkYIUYYDqfjUjCSIijrq9T0n8NwhCJLPYHwSBEHyHWn9QXPN3+O5QBAk3wjs+TXagwiCIIPEq0MQBBkdKI19E1grRdGpC8er5swE6eVg9VpaJPTpaWH6AiWl6+QxnugrZs2TipJnSC62ndALAyWzqtLXwer7v7tuGbQ8+7NXP5C21XTsee6FPecg+YEKYgnJUNeCIEieQUi8/JGk4USWGqve+vgipQIhTNwDK5+bP7u5W6WlBZNvvGru/o9aKmbPV0q+2HZiw9WL//juoWHag7JaTV/+2H3Lau5bdypRvKYvf+y+ZbOiulZRc99y/FsjCDK4IMZZggmGYbi3z7JwhiA+8EIpkWw9IAQudqlVkJZXznr98IkbllS/JkqhSgSnzJw7on7xuY5T8UkVNbctmwUde55T9LFjz3OvatmJojmppFTf/937ZZ2tqLnv9prpcbZkRc19t9fABz967n24/vbHVlWcfvOFH70BSuJp7fKloj548dlnmwEWrWu4tRrOKfkRBMkO11jUQcWHTWIYlkwuXrv+C0ApASJQSoiknoSQP73yMt/RrdMXKAeWV8460Hxijbnq9UAr0eluuda8+yAniWAS1ztNHRTVShRBTTWZOns6AFw4dS6ZOfmsIog1ty1//7n3n/3Zq3F+8bJbb6+Z3rHnuRf2wPLH7lt2/33Lf/Tc+6eh49RZgEXVy6cfg0UVADBr0RWzDsPy6QDNF04nL3/PGy01t1YvW1QNzS3LFlUDwAdvoAgiSFa6xpq7KhgdI4ogpZSRjUFxaRleEBLzl8+Y9UbzSds1iwsnTXrxz4EpM+ekEMEh+sWP3QcpDSvFOpOPEs2xqAddMRsg4fDq5YtE6+/+mthsp851AFTMvuqK2dPhg+aWZYuql191YRbA6XMXpEM1y29+f8+56ppF1csAli8COPfBS8143SFI9pmEiX5xQh4qSO+2EUIEWQrFt990jPZDL1SIFBQU9Pb2UYEftKIM/eJzF04BzNIQsgunzsGy6VNnT4cPzrXItp4si7dWJ7jDgwmuitNnLwBULFu1DM598O8vHjt13+01qyoA4NTZjpTld7zf3FGzqnr59R2z0RhEkCxjaqRj+VLT0sVXAqWRSESn00UikUgkotfrdTodLwi//d+XLugrRDuRiG/HCZQC6BhGEATCEHGUUNCyBy+e+XTDNabdBw8RIDeYq5SxwmRqm+Hzg9OnzgbN8cGOPW+0AFTU3LZ8VorDF1UnF8GW95sBoPqL11fEf3O2Q5Sw083HTkPH+82i/HWcOjtI+affeP8DgGWrls1CYxBBsowbVy5fc901FVOmVFRUzJgxY+rUqZWVlbNnz66srJw2bVrljBk3rlyu4TITop4noYKGfXfxzKe2axb/8b3mKZWzyytnHTh84oYl1R2njqdoTObjg9Cx5w9atlXzq/XPLX/svmWPfXdZvIn3YkvDrdVRh1dOf+nNjmWrVPMkLz777K3337/q9oZVsbahaIRCy0tvdEjqtmrdsuhYZLLylSoq0BhEkGyjt7f3cHOzvFQ+JNppFy5cUHvPgih/lEpSKK4hyJC49aFFS9D//pEplbPFzIoURq3CBIjFYoGcfa+uInZaGUGQbGEWuVRWUlw1d3ayDH9rDp2BMnG7rOfMgtmVomSJK8gIggCEEIBPzpy9WDRTOSp8pjWiKy6bcVlcaZ3tp3WRnpLZV8Sli+/V5fD7JOJYYcceFEEEyT5O09LTl+Boc1vyLGXKVtfkyz66GLXeAABAJ+2pRBAAii+r0iyrvHLW8P3iiYjyMA2CIEgqcJ0FBEHyHcke9GxtwnOBIEi+YblGpYPcO9/DM4IgSL6xadMm9IsRBEFQBxEEQR3EU4AgCOoggiAI6iCCIAjqIIIgCOoggiAI6iCCIAjqIIIgSB6C8YvHGUrpyZMnW1tbz5w5Iy7GO2PGjKqqqrlz5+p0Ouw1gqAO5jjhcPjNN98sLCxcuXJldXV1WVlZd3d3S0vL22+/fejQoRtuuKG4uBh7jSC5pIOs0+S3cW4rnnVZDvbt27dixYo1a9YoRlBJScmSJUuWLFly4MCB1157bfXq1SUlJdhrBBlVhjk+GPLUmmRqPaFRUk8nO2gbYipnnSY1yuGaRQ1a/mg5hm+++eaKFSssFoumJ7h69eqrr776wIEDkUgEBuma2IWQpzbmNMTva/3RnGximbEnLT7zsM6YutfhcNjlci1dupQQsnDhwkceeeTSpUvJe630VE2KS26YVwWCOpiBCNb6bT5OYhtsHo/rKeT3g9UKfn/MLWF1y83yOYLOUZLoYXDy5MnCwsI1a9akyLN69eqysrKTJ0/GJke7xsUY1waHz230bJa6GvJs9hjdPodB448WrJePt/mdbLRAtzVmWzPzyPT60qVLGzZs2Lp160cffQQAwWDwJz/5iZiepNda3Vd1NzeuCmQi6mAwGLLWR280g8MXvS2jP75JrrZkGZT0Wk9I/q0W07RvQrbBA7b6eht4GrRvUoOj3hoKBlMZm3L5IU9tTC2s01TrCbFOk9OjWEVJWpupNdzS0rJy5cpB5wRWrlzZ2tqadqnWegd4NntCkgpqDEGwDTHpVneqYYqMMmfU6yeeeOLAgQNx3/7lL395/PHHM+i11ZbsLzu8qwJBHcwAo9HANiRxvJwg/fT6bP7aBAVLlkGdvg38LFjdUSNF8yZk/azBZjMYbDYD62e1rdYG1mA0JjUuVOUbHNscwWiPWD8r6Tzrka0itQkyaDdT0NbWVl1dPWi26urqs2fPpl+swbHNAZ4GZ4O2CgLrZ622dMUso8yZ9fqFF17QzLBr164Mes36k/xlh3lVIHnHcOZJDA6fD2prTR5lTzQOQ34/OLZZoz+8Jj8LVmus06KVIS49wafTvlXr3QYAiKuGdZpMKrFLoyixUpsNahtYh9sqyYAbgBXbqFhcDZv9IYfDMHg3UxGJRMrKygbNVlJSEjtSlti1OLkzOLY5amuDbi4bp6OUXovusJaLEUzSa63uRy+50b0qENTBQaWQcyjjTrXg8zkMEAyGQqwsj5IDE+9Qa2YIBkNGWybXpixVkpPkjF7yiQKRbofkOycUDCrWkNEY9f6NxpA/CJBGN1Oed72+q6trUCns7u7W6/VaNmwqZzYE4HSyWTgzr/R6yZIlmlJoNBqT9Fqr+6zTVOtJlMKRvyoQ1MEMBMQjCoTRaLDafCkuuGQZjEZDMBgCa7pSyPpZYNnoTzwApG+RpRhja9jsCRnBb7T5osIttyoUDEr+1KDdTMXMmTNbWlo+85nPDDqgNmPGjEx+GZzOoMPH2fy1tVpKGCsLgw+/Of3DP6Favb799ts1dfCOO+7IoNdWm9UpXnKjflUguc1wxgdZ9YybasDFYLMFnarBMtYZN3KWLIPBphrYDnk8qcfbQp4GVj13ynFuq/Z4ZYaKbrOBv6HBb4yOjYWUVrENHrCJNuug3UxFdXX122+/PWi2gwcPVlVVZaaC2xwGMDi2OYJa7bHWx0yUpm5zRpkz6vV3vvOdq6++Ou7bq6666tFHH82g11rjg6N1VSCog0k9lG2wOTpfGn1Kw+Dw+YwNypNaflu8XZIsg8Hhc4M0BbsZRB2y1juCWvPFIb8flGE75b6Nf1IiLfsvrnyDo97IBm2qsq0OubVOiD6LMmg3UzBnzpze3t6mpqYUeQ4cONDZ2Tlnzpz0igx5aiUVFBu3TfPREIPD57P5a9Nrc0aZM+l1aWnpvn37tmzZctVVV4nu8He+85133nmntLR0sF6rHgNUdXekrwokvyAWiwUAduzYgecixtIN1st6N1qvwWi+WaEWwXfffTdP3ifJ+V4jWYsYrw7fL9Z0uIO2baM+l1hcXLx27do33njj6NGjK1euNBgMJSUl3d3dH3/88VtvvdXV1ZWTcpCfvUayHNTBOJ/LyYruoGGMRGH9+vUnTpx4++23fT6fsvLKggUL5s6dm3zOdMJLYR72GkG/GEEQJHv9YlyHFUGQfAd1EEEQ1EEEQRDUQQRBENRBBEEQ1EEEQRDUQQRBENRBBEEQ1EEEQRDUQQRBENRBBEEQ1MFxI1VcuvxuDIIg2auD2SAW6ljyaTYmsdmoegiSv2TVGkdWN8dlrsS1npASuCzkqW0Yx8YgCII6GG+nKcvCx0VYlNb5ixEdt1VKVm+r0YzSKIanVeLJGRw+92BtUEoWozha3ZzNH5+SWWOSdCe2+qRRJhEEmdh+8SAiaHD4OI7zOQxqQQh5ap0sKF+lLkfMxvkcBghFI6in554naYMSvFEJD5+YkkFjkndHjGMlHcRx22Az+t0Ikkc6GPL7QwAGMbKb+E9IipWj8VUK57ReVBYxLFkoGEz0XqOqJUXwkQU3tiJHvTXahiF6ylqNGbQ7MbYqRo9EkPzxi4PBkEoCDEYjQCgUlMOfJ3w1nKqUcTzZOw15GliH2ypVFPKoQ61LbRjlnqp0k/WIvrbaW47BFBNoF0GQkYcbbKx/lHTQaDQAG5LDn4umUzT8ObChGGEaGaxujlOP1IkVaYrPiPdUuzsGh49zRDWadWqEVudwNgZBctQvjnGFY1xH6V8ptHZouIFlY6coRBmyioGPYyrSyDySPdXsjirOvWgvJgQdRxAkZ/ziqOunOH8Gh88dNDllp1Q9Vxr31YjWHjMKZ3D4OKPT5FQqis6HqDxWMTExJW0hTNodq3tbsNZkis4Xb8PpYgTJRsY9Xp368ZQcIMe6gyA5zjjGq2Odsnsa8jSwUU92wmpfTnUHQdAvHgusbpvTZHJCnLc6Ucmx7iAI6uBYSUdOTZPiO3gIMpHBdbcQBEF7EMl6Fi9ejCch3zh06BCeBLQHEQRBUAcRBEFQBxEEQVAHETXeOqLG7OJGvPw6L55mBHVwQpH4vvBovEGcVdgbqUyjeavdhY/rIAjag3mM3W7nuECirRg1E711pM7lMid8EWf3ibvKfwmJbihI+QerRSpHq1IA4KLJ0QbE5K/zRjPFNXG0jGAEyWUdlFZl1Q7IpF6vVbQiPVK0Jw0D0xMNBFWrWhFbHR9KOSomv5ONZhqsDUPwYr1ek8ksC0wdSJZiwO41RyXEu5VzpWc/2htpo12yN5UNKu/Z7WnV0mhPWqm3jtjBKyUHtgTqVId7xS8a7dFMjXavS2pt8noRBHUwtQo6g/KC+JzNL6lQyFPrBLeY6LP5a6PixHqC9Zz2ovzKVxznNsrL8bNO02bYJiX7HEGnqii/+IXbGs3ktirrfyVvQ1riFzXTXKZAwGUCAOAavbDFZRdzmFwuu9frVdSt0a5pP6YL5zK7TIFGe7q1JK3U3kil5iYe7hK/sNvt6m3pwBT1Igjq4CBE10SVF+8P+f3gqFdW5aq3ilGe1Fk0UH1ltVmlUq1uVTCSuKKk5futNqt6O7qOf7I2pOUMR800F2eWnMQAx3FbNVzO4eOtM3MuSb6GXYvaLc7g8NHrHYJI5Or7JFY353bKa97LSx8Eg6EQG7NOoNU2dJlVx6JLv6iRa4Pdbq/zBgBMYDaZ7I2BGJNsJBBNwYBc7DBr8daZvfYAlU1Cbx1JU9BGqXcIkiP2oNFoEMODqEzA6JrPVne812o0GuRE2dEd6sowrLPWb/MNoZzhtYEQCiB9vLu8ZpMJgILJbufq7vQqXzXeeWcjAI3LH901Lzbv8nqjmb1yNnX+xjuXcK7AFpNyeKa1xO/GFq5dqdZ20npz8oOgDmaKwWYDccU/SZwaPCCt/s86NcbdDDabeiBPO9PQBiPZDNqcQRtibhJKAHbdxeh04ueuwJbGLYsppZQu3vLhh6atOpldd/zuDkopBSAAih8d3V28pXFL4C4p81bTFruUfscPpOQ7vdS7axfZdZdS5J3ejGuJ273jd8+bf7g0sVJ1fu3tJPXmDuo/c+weMkaM+3rUw9cg1VSseu0/1RfqZLU7K6ezTpPfpm2XxX2l2lWVb3A4jJ6gTYr4ruRPtq3Zhnj5U/6hQBcvXqzcEzQxGzKh70DNbQKHDh0iYgKJz4aMIOJ61BNeB3MPqlJAAoQCLLrqKqBA5VQUwZyVQknyCBBoPnyYyNeAnIqMlg7iultZpoBREQQKRKAUKPACBQqUUlC7SyiEuSWERBZEQgAICAIFAoQQ6XsKFA3DUQN1MMukkFICRABR9YhAgVLgeUoplRIlszBWBlETJ7I/TJT/EiCEMEAJITwFAsCIAkgII14bBGUQdTDXjUFJBKk0KyIACAJQgH5eoAIVKIhqqHjNqIC5YglK/zAAhBCGAGEIT4FQoAwwQABAAGAIoZQCaiHqYC57xBQUERQEKgAIFAQKggCHDh8VAKhARU9Zco9JvAiiJE40Q1Dep5IWMoQQoIQhDABDgGGACpQSYCgwDBEoMISohgwR1MEclEJKgVBKRfnjKfAUBAF4SnlBFEQqyHmo7B2r7wiKSjgxdDD+T0YACAFCCAGBAWAYYAjoGNBRwjCgEwcOBcoQEEShRBlEHcxVYxBEgQMiAOUp8AJEBMpTiAjA81SSRQqSCIpWISFAKergBLYHifRcKCGEEEoIMAR0AtUR0OmInqE6KlqG8iyyOESIJiHqYA4bgwBEdId5ChGBRgSICBDhpQ1eoKIUCpQCEEqBgqD2h1EFJ4gOUrUiynPCAkMIQ0BHQMcQPQN6SqmOUEYcMSGEAiGgAyKOCqMMog7moAoSIAKlAgUqucCiFMIAD/08jfCglkJKQQAqTqrEvHWAQjihDEIijQ0K4nQwIVQWQcozwOuAinPIBBgBBAKMQAUGGJBGCVEJUQdzyymWXWNKQZwj5gUaEWCAp/08HeBJP0/7eSrpoABUdJAh+mw1+sUTSgZJ3A4ByhAg4pggA3oGJukIBQIgiB4zA5QhRIi1BlEJUQdz0CmmhAAFQZkn4SkvQISHAZ7evX4pnqV843d/+pAA6AjwPBUIEa8KHSFU8qvRNR5JcF3+rDELqfSYtADSZLHoC/fxWWHl4VNrY0yfMi4sTpFB9ApBux91MDcdJXGdEQFAfE5QEMQpYzog0IiAZygfiQgwIFBpckygVJAvD6A4XYw6mIuWoGpDfnRGmjUWBOB5/PXPR3ieitNlAhXlj4jPSsVdMAjqYA7AfmvJt/aCPMeheoqQim8WU0AZzFMdpCA+G0CpIoJEdZ0gI0lOzpPERTHWXOIvi2xB6aomBIBS0fehlFLgpUem8SrNSz9B+iGklBJKqSDNFUevE5wyRntwUKJr3/scQedwwmOOsSwqixLL680IqIN5ifynl16jlJ+TQlAHh4TBUW+Nhq7TDDqcJNhxfKJqGemQp9ak2pY3o0fElBIXHDnahlt3hBKkkIovHCS78qXAnbFR28YsERnb30WqitaCMog6OAxCngZWCt6ULOiwZrDjxESDzQaSoAaDISUuaDAoBkVRByZ2g9oGjQmOHPJs9hilbI6gZ2+ydhMivmcSe+3LsXtjYviOWSIyps4BEX8S8Ykl1MGhErXMaj1GtxRqOEXQ4cRgxxqJBqNRPIL1s1arVdk2Gg1xgYmt9Q7w+0OJRcZlcyjNSRO73R7z79gmIkhuksvxi61axqFW0GHNYMdaiVabtSEYAvCzVhtnA5OfBWMwaLVJwZGNNkXVDEZjyB8ESJC5uGwGAwST2AOig0zjjAF7o8bEyZglImMGkQZJiDwpgqA9OFJGYtKgw4nBjjUTrTaj3+/xs1abFaw2K+v3+P1GmxUgPphyTCRlNXHZQqH4q190h5UP3gD5LIVEuRLEQRI8J6iDIy6Kit5pxhDWDixsNILHI403Go0G1uMBSe5igimrIinHEZvNEzORLYXkIdKqnACUIcDgxZ+fd6b0p6eEEIK/iugXj6Sz7Pabak0eUZAcDisblNJtTpPJqRiB1qSJYLDZDB6/KHHqbQAwOHwxjnSSoT91NoPDcTOEiOIIgxSaR1yVUyevzYnkozEorkBDCJGCNwFRDZhEQzshI3K2MX7x+CIOwvGUCgJEKAzwdIAnvRGhNwK9A7R3gIYH6Ne++NksuC3l97qQMeGZl/5aXECKxI8eivRMgY4W6IieAMOAjkhLEyLDRIxfjO/VjbvAxGwQQghQMUyPTrzidXix5yM6nRScRF6WXw7aSRKuHGT4oxB4CsbfJAQqDgkyolPMEIYh4tLEBQzRZ8efCI3BMUbPQAFDdAzREWAYIgWxk0eP8ZnqET7beAqyxyokhAChDICOgI6AngGegUK0B/OSQh3RM6BnpIuBATmUCUFLEHUwNzWQgBh4SZ4lZAjodERHqV4HFMh//+nDJOvyA67LP0H/3OodAqBal5+I6/JP0hG9juoY0OmIclUAUELFwRPUQtTB3DIEqfzEDAExYjfoKNEDpXLkWgKgIyQiAC+AHKcJtOI04b0xYWx/iMZponKcJlWwOgb0OjpJxxToQM+AjiEMIz5IADhZjDqYszcGpdLNQBlgBMowoKNAGcli0BHQCaAXKE+JKm6nPEiEcTsnpAwqcTsZQgCAxsftZECvk/xiMbI7YYhoNlJlzgRBHcw9X4kCZYBQAjrRUwIqPTvGUx0DoghSCuKCdBQACIN+8UT3i+U47oz4wKAkhVIcd3GYmCizxiBPqeFpRB3MRddYvB8IAUrFEXHRC2IEYAjlxXBlAlXWZ6dUWodGfUugCk44HaTyejLiD570yBRDGHGskEiPzuhiHp2hGDQLdTCXbw8CIBDCEABBWnJLIMAIREfE+E1AgQhUWoBBGlkEtT2Id8eE8osVVaTy6DBhCFDpERnZHRYtQYYhRHrMDf/KqIM5bRJSShlCBAoMQwgFQoAIlNGBwbiQClSgQCkVZMMvbnAQmbiiSJSRQgBCiDgUGAoeJaJtCJInzMgjgyiEqIM5fUcQIkkhAADVASEMUAqTdAxlqDhHrIwC0lhTEJm4ZmF0/ld5lZgQnTxcCPKEMoog6mDe3B2EAAUGgBJC5dd9dDoCVIpYFn1QBrUv16xCWRAJAXGuTJoTIdF0BHUwT0wESpShPsoQQgnoGFVwCnxKJodNQ8VNJtKAYDRkO04Sow5mCOs0+W3ZFaszgyYR+YFoIj0XTeUlCAnEPiudHVL4wj2FL9ze99vb8WYarn8cJ4hUGhgk8dmQEYfJGplIRGsd1IyLHZFCEkrRShvZe4MoLw8QQsiuu/R3vUAIIYSRPi/cXXDX/5Doe3iZfHbdU6CfFP8ZcmkUBIFIxQ65kPz9EALy31RG3pL9YhTBfLEHrW6OGwVTTlk+ddha2OAJWZWFVUOeBhZgLMzN6Ag6jXsq5o7n+TuGWqr9eV4MvuS9k9l1h/D8cCMxUXHsSikWGQHzELUvD+3BVAZdsuC/sRZZNL3WE0ywB9XlmEwmdawm9YGeJPaj1WHzN7AqUTRarZrWbMzRmk2KzZ9hgHlV3BLvnaRuF+daYnYdiiZyW83mrRwQgF11suUYkyH+I73MoCpzq8vMEMKQul1SgYoFKqYoFUnpS1wBuRDvnVIedTmEIVKTEg503RlTZh59mKhdH//ByRDUQW0pVAX/TRaAOCYocH3Qw6Yqh+PcRs9mJQj7oAcCABhttmCDeEjI0xB01NvUaqcZtjhZyer8Ppu/djjutanODltdSoBhr2sr2OtMwLnMddBIKaWUBuxecwax2L1bORellNJGO3jriB28VCpnS6BOLodz2beapfJd3FZvqnIobTRvtbu4dA/MC1Is5ojrPKIOJvFto15ysgDE8bGDDanLsdqsUmjidA6UKzN6GljRGFTnSxa2OFnJMemxMZSHIoQul12JtO71eu0ulwm4Ri9scdk1cqThMjc22qPbNOAyJdYUU77dtcWUuhy73c5xgXQPzGspRBFEHUwPtVsc9UKDwZDRqI4dnG5xGRxotVnZBqezgRXDFSctQVLYZCUHg6Fkrv3Qxvrssjx5vV4x6HqA47itZmXUvW7oZhfnihYTLSfAcWazomEmsznd4oZ8YF5IIYog6mDaw4XaAYgTYgenW2AmB1rrHcCyUWMuSQmS5CUr2Wg0yGGRNcIoD1EIXS6Oc7kkGQSzyWSXnE/ZNR3S/IW3zuy1BxILMZtMgQCnaGUgkG6BQz4w96UQRRB1cMiiqBhT8bGD0558yOi6QNP1AAAccElEQVRAg8PHqfxy7RLksMXJSjbYbEF1ZGTtMMkZCiHn3bLFy0kyCKY6e3QsDwC8dXXDH4lTFRIzKul1beXS9uKHemCOSyGK4LgzsZ6jThaAOD4osJI+uBAO9UDNEtRhi5OVbHD4fJ5adWRkd5pCFJ1JtDdSlYVnd21xmbfCloCcZnIFAi4zIXVK7sYhCWxjo5eYyVaxzC1b7MAp5TfWSROb6vTBhXCoByLIqILxi1WEPLWbYZsv+WzJOLF48eIcPNucy2wHb3QmBonh0KFDeBLGAIxfLDmmHtlnVXm1yCjhdUmP0CgP+SAI+sVZ4GvboNZkCsmuLMrgqGKvAzMhnOgYBxpRBhHUwezA4PBxDjwNY4TJFaAuPA0I6iCSIThUhCCjCo4PIgiCOoggCII6iCAIgjqIIAiCOoggCII6iCAIgjqIIAiCOoggCII6iCAIgjqIIAiCOoggCII6iCAIgjqIIAiSL+B6MxOA3FyPGkkJLjKE9iCCIAjqIIIgCOoggiAI6mD6sE7TcKMAZ2VdqfHWkREITIwgSBbrYMhTa5IYTeFhnSY1w68qTiizRzdRUhFkYulgyFNbG6znJGz+UZUSq1uuyOcIOmvlOJ55hL2RNtrxbkBQB7PL0W3wGN1ua1SoottR+y2JNmplYJ0mp0eyL1NJqsFRbw0Fg4kWaZKjonVJ6ilaf2KyuKHeTXZUujabiFkOAayCc5mJjMqyU45Rp2okxtiDKStCRgCSEjw/qIOSUPhZq82qbSY6QbLe3KBhuiXPwHok+9JtTWWGNrAGo1ESq82wTWUnJiihui6fzV/rZAGsbs5tlQxMcUO9m+yoweFc5jpopJRSSr3Q6I1XSDt4xS9pYEugTtI0b11dYEtASrd7xVTNxDQrQkYGSukQvkLyzy9OIlN+PzjqJR2z1jvA7w+lm0FtU6aw6oxun8MgOcvSlmQnsn42eV1aGQbvQtpHcY1e2OKSPFeTy2WP92oDLjkkusnlsnu9sn5xXEDJpHi+monpVISMrhSiCI4XE+t9kmAwZLQZFCfWaAz5gwCGDDJoIlptWsZnjMFptcU3JsTWmjxJMyTrwhCOCnCc2W5KaS6at6qcWLtd0sfGOtnRkocANRPTrggZUSlUe8EogmgPxguTTdtMMhoNwaCiTKFgUPJh08+QgW/urPXbfPIEioZQGo2G6ATLoB738I4ym0yBQNLBOm+d2WuXXV0ao2z2xgRvOUliOhUho2UVogiiDmoJYX3MxC0rDc4ZbDbwNEgCyTZ4wGaLtfUGzTBkUUwcxjPYbDGDhlp5EhnaUaY6O2x1eWXjz5Vi2M4blTZvncbDMJqJQ6kIGSkpRBFEvziZXDh8PqiV/Uerm3PLyW6nyWSSUx2GxONSZ0hfit1uv0lugMHhsLJBjTZ6ak0mJ8Q00lrvaKg1mZQ5k9jdZEcNJoSugOLNmrYEAjFf2hsbvcRMtoo5t2yxAyel2+sIqVOMQHvSxDQrQpDchFgsFgDYsWMHnousBdebyUNwvZmxYdOmTYDvFyMIgqAOIgiCOoggCJLf4HrUEwAcKkIQtAcRBEFQBxEEQVAHEQRBUAcRBEFQBxEEQUYBnC+eALS1teFJyDdmzpyZmBgOhw8fPXby0+Pdl7ry/PwUF0+eM2/+lUZDWWkJ6iCC5Aun286++85B4yLzWtttFVOn5/nZ6OrsOH4suH///uXLV8yZfRnqIILkPuFw+J2DB1ettVZeNgcAIryQ7/ZgSfmipctnzp332su7y268cZhWIergBKXJZWmyNLkseCbyg0NHQlULF1fMmDWQ9wqopnTKdMOipR8GuFUrrxlOOXk4TzIhAmkmp3Xnxo07W3OmUqnkJpfF1STpu7iBxHDy009mzbsiwgtD+vz+W9WVS6Of6xuahaEWlXWfWfOq28+cGebpHaYOqiO6DRp7LXVg37GXpxGpcayb3drUBBZL1RjL4KhVOi7dmYj0dHdNLqsYqlhQCrX/3HzqHfHz5KJ/q//p0VzRwcLJZX29PeOogyFPrXrp+m2weTiKkCRIyCgy9jWOiG60VlVVKbaURSLGWmtyyclR06rJZXHtlPO7mqLHqq2v6IEx5cVUquSRs8SUrDownRpjSpaNQbEGOVe0TfluKA5DLKgAVFB2b7plXbD5KC9E+Bf/cdEDTz914zWLZl+z6IG9vBDhhb0Pzb5m0exrFs2+5qEXI7wQ4Q8/XXPj00eECC9EjvysbpFqu+ZnR3khsucBKf+i2f+4J1pptBwx22h+hn9uh6ODwWDIWh9d8Nng8GlFGU43sK9iWKljDceZmVHzs9bjiRpi0cqS2WbqA4MJppxGdONkIYaV9FpPCAYNT6wdQLl2XbwhXJu+Dra2iivnAkDTztaNTSKuqp0uSYBad250gUtKBpdK0JqaxHSXpcllcSnbOzUO3Glp2hhVnWilsYU3yTmiLVE1ZPAaY7sDABZXk8sCFimfqIKu1o07pV5amvJaCYejFBSAV3b/6HvVsHC+lL772aPO1z/85PUPf3EDLwS3Wx6lv3j9w09e//CTf6IP3r29OcIbLTfTY5L2HWmBI8o2vfmWefyL33M2f+X3n4iHWP744Mu8EIkt579u9t2z+cUc1kGj0cA2aDnDQwvsq1YbOdYwx7mNns1SHSHPZo9RKrY+6GEVHXEGHbJVavNrKGGSAzVrdFuThxhWp28DPztYeOIkAZR9v3QEo+eN9bPW+nRPeVNTU1Q3LC5lmsRisbS2tsqO5saNUrpl40ZoapJFx7JxY5WUWb2tdWDVxo2WJlnmopUm5IH4zUxqjOtOCulP7DDqYKZ+8e4fLJ23Rvx4jDtf2Hy5lP7FLT+tkbM1v8LCvV+Xdtd8fTNlXwzxwuVXXLnP74vwwiv+3ZabvqhsV11hiPCUwtGWo1JFa37qWZNQzuUPOi17d7+SuzpocPh8Nn9tgt00tBC9sR6roo1WmzUUDCYUqzZEAaQcoB2lOMWBWjUmbX9cukMz0Hw6AZTV0aSShqwfVAaTqobK0ayqqorKyKByo/Kz1R51tNLYwqMMrcZ0umNxNbnAhX7x8P3imu+/1/Ky+HnwyMYv/TyU6C/zzS3HFs5fIO8uWLjg2JEQL0TW1dwQag7xu/e9XLPmJzU3vLz7Vb75WKhmzTohwm949D2P8N0Faz+3YO3nFmxhlXKO/upLUuLaz21qiqklG3VwmM/NGBw+zqEMFtaCz+cwDDFEbzpueGxsYggqw3zq0EwJQpjswBQVabY/tpw0G6kZQNngqLea/CxYraFgMEMZdKXOI+tQVUrh0j7Q4tqZaHCpK40tPM5ky7jGdLojSmGT5JNvdDXl8aNCw7jhZb9Y3Fu7Yc0//vEYL8yNSwfjvOojx4LCqmoAAGhpbq02fpkXImBbXe3e9/TR19ZveIS38esdTU8bP67ecI90oO2Rg6FHAKDlyQfvdOw7uH0NGOdV13zv+e1r1E2I1pKNjNhzMwZHvWy4DS1EbzpueGxs4pgZD9HjdAQ1wmCmODBZRZrtjy0nzUYmCaBsrXcEGzyhkN9vzEQGB5eYKosFdu6UPdqdO9Oeja2yWFpdKourSdyJqTSm8FZlS7WZQY1pdafJhU/RRJWEDvUDFKig7L685/Vq4+WJ6YLh+vXwm2f2iLv7n3kK1tfMFSgv0Mur4Te/3DO/eiEv0Murja//8imoXsgLlBf2PP7IHqUWkEozXL/+yI+j6XT/I/X7xczXihsptofyGV8dZNWjXyFPAyvd80ML0Tu40sbFJg6lW3yyA1Pk12x/TDkhj+Y4Y9oBlA02G/gbGjKQwdbW1qo0JKZq407Fk3SBa+fGqjTLr9q4c2fVTsUxbrK4LAmVxhYeHancKB+Yfo1JumPZuLFVNV9scVmalJnoKhc+Nz5k/viT64y3iJ9Hj97z44fma2Wa/1X/w/ANMdtPYPuOr0o/4vPX18wH4+r1xrhtgA0Pr9sjFXv3U/Mf375aLmdH9ZO3yDUeWCelZy3Di9sZ8tRGpTDGJVV/o3whJ0oJsbus0+S3xWzIKqTaVaZ4DQ6H0ROU0lXP8CV7FkbrwGQ1Jm1/bDk+n8OQ2KmY5sSkxVcBrNPUYJRKSYm4zsLOjRszkbURQZwfTl3p0N5siS25yWXZWbVzjDuX3cSts/AH30vGFWuLSyvwzMTR19N1+O29f3db7dAOF+N2Ttj4xSFP7WbY5ht6nPbxh3XWBuvT6UF2rzczzDf8xGcGqzaiCqbUwYPv/bWfFM4xfmYIRd1ynebYDOz+czAHTtTpYwG+5/yaVSuHo4MT6/1i1uMxOhwG2eX0TWARhJCnIWjbZsj7+12eBkFSssR05d6X/zSlcm7JlIxXmskNvdOkt7uz7XjzurXDHS+ZWDpotUGtyRSS/FL3BBURyW82OHy+XJBBi6vJAsgoM7m4+Nprrz14cP+My43TZlcVlZSjO3zhzCdtHx++esWK8rLSYZY2Yf3ifALXYUW/WKQnHP7grx+dbW/rC3fn+fkpKCyeUTnzs0vNwxTBiegX4y2B5LtVeP111+B5GHEwPgmCIKiDCIIgqIMIgiCogwiCIKiDCIIgqIMIgiCogwiCIKiDCIIgqIMIgiD5Rqr3SeQ1nhEEQSY8HMcNRQdTHIYgCIJ+MYIgCOoggiAI6iCCIAjqIIIgCOoggiAI6iCCIAjqIIIgCOoggiDIhAXjkwyXm3967Dr9x7uKVkAPDwDzZ072lO5bsf+HuvCF/fZf1QVM0NUJUHB5Yed13Yf29cx5/WfL8KQhCOpgTnH9oorf3dz2+6aDm6Z841QHDFwG06eemn3mcrhUMn9pFcDn4Fy4uqTXR/7VfN2C5Y3Ts6HNlNLe3t7e3t5IJEIpHbeLT68vKioqLi4mhKR5SDgcPnz02MlPj3df6hrHE1hcPHnOvPlXGg1lpSV4C4weJ06cGPKxc+fORR0cO54/StZv+PsHbtpddcD9QPnX340UK1919wkwoLdUXvqV8NT8a5fff8LyQfP+cW8wz/MdHR08z497SyKRyKVLl8LhcEVFhU6nGzT/6baz775z0LjIvNZ2W8XU8fxF6ersOH4suH///uXLV8yZfRneBaPEDTfcIP5OMwwj/n6L6YQQ9XbiV4SQYDCD6PU4PjhsOnu/5tf/oPPvltx4zf8M/POXp50DAGD0oNf3g/6+GS3eyFPF162vO7r+uVc7s8ESzBIRjNPlQc3ScDj8zsGDn7dYTZ+7trR8aoQXxvFTXFK+aOnyNTfd8t7773Vd6sabYPQuV4/Hc/bs2Y6OjieffLKzs7OlpeWZZ55pb2/fu3cvy7Lt7e3PPPPMsWPHLl68uH379o6Ojra2toaGhky9HLQHh8vnPzNlqpnuPUEXVq3+hw3FTx/fLxSVgkCAJ5+dHvl8eO+k627/6fnPBLvOb7h68hmhYHxb29vbm1UiqEhhOByePHlyijyHjoSqFi6umDFrgBfSLvjFb1f/wdry7M2j0+zSKdMNi5Z+GOBWrcSYwqNCf39/d3f31KnTJk0q6OzsnDp1at9Afzgcnjp1KgBQSqZNmx4Oh0tLS6dNm9bZ2Tl9+oze3nBPT09vXx/q4JjyHycfW1gyrw8Y4Xk9LSu55ey9H/cWl87Y1VnWN+2F/vMDq6e9zXd0vXXwz+uYXoHnge4FOgCdYRjoh84IVLw7pov6hMPhlN8HvC7O5LKbh17DEEvo7e1NrYMnP/1k5dqaSAoRDP7sdtsTxwAA4KbtZ366AQAECsDzQmTUzuesedVHub/iXTBaP9t9fZ2dnY888j1KhYqKKd/61rcYQkpKSx9++OGioiKg9E9/erm0tPSJnz3BC/yUKVOczs2EkIKCgr6+/tHTwXKnaS64D7mtcgI71+QEN3fCOtbnp9xpKrNJ9aq3x4GZB/3MpRnFAFBQBKSgc+rdhhtNhUTo6Bso5fkZlBSSnvCZyyLXN0wn3fwAAZ4PU7KgnwcA7vj5MW5tJBIZ5RrMdpd5NBrW0901uawiqQ4Gn6j74pGvNZ/6AgAAvPLNr/pvfuYLQCnQUdXBwsllfb09KFij9rPdd+7cuR/+8PGiosKHHvrmU089dfLkyaeffvp7jz3m+8MfAODW22770Y+2PvjgprlzL9/8zfptTz3Z1zvw/ce+19sbHl17kG2oDFnbDQAAhZ6GcoBxH/PqdHPj2YbWG+7ULbnqklAAAFPLi+lfCy519kagPxIR+vQM3x3Wleq7e/p1JRcKmD7aN0CFSNFAJBLp1xEh0j0xhpYCXpc3IKtc1NRrb/J4mtoBACotlplN7SaX3Ry1BwNeF1dpaWsSc0ClxeGwVA5PxJMbg68+9a/V7hMWWfIsP38aeCECVAAqyImvOuc+ygIAgPXf3nLfIl/QD37euVvcXOc+8bj8cxrNbPjWb33frkZNGp9hnL5z585dvHhhYGDy+fNnu7ouXrx44fz5s50d5y9evCAIQmdXR8eFjs6LHWWlJRcuXOjsuNjX13f+/Lne3v5R1cE+A8xoYNvdVgB2hgf6DLHWIisJU9RSMzoKPZ5COVHJ0+fwHXMYtE3OxELAWs6yEFcIayoH6HRzXf4Y2zBFG8CqGLPsXJOzXKzSqrZwM+dO8v/0zJpD3cIP1uq/rzsw8Oe+SREhDHo939kbmaTnha7eAR0v0GkV3bpCPhKJ9PUCgDAwUMgIur7O7L8W25s8XrC7XGZRED1NM0U9a29qbJppdzmkdC+YE5YvDzS1SwdCwOtqbDIPTwmT6+DuV9hb1j4hROJHPqN+ceuOdY/SX7z+4S0AsO/b8+7e/up/bVoIsPsHzuav/P6T+wwAAPu+/eDLX/jF2tjMrTvW3bN54ev/eguq0tjT19d78eJFp9NJKe3vH2j9+Hhvb99XvnL/8eOffPZzywmB1pbj9977le6ecPORow990/n2nw/+6j939obDfX19ukzmgDOdL+6rr+9kGypDUOhpKLfWnzUqdqJzbtBxjOMO+RyFTlliAMr9cILjDnHcCSsA65wL7kMcd4jzdfk3V4YSjc0khQSN6kRR4zrdcrGQZht8Z4MNYqXlTie4uUMcd4jjDtn8onQOkaPBnkOhrn9a2veDvt0B/8utQhGZBJNJNwAUMf0FOr5CD7TrAuVC+g/f0/0tUPjh0cL3jxb95bj+L5/S5k+yXwYDAbBYJBvQbLFAINCulV6p6SMrxqPZZG5vbxumU590Alf2f5OmN7/Cwr1frxHT13x9M2VfDEkZjrYclfKv+alnTULmyx90WvbufiX53DGq1egx0N9/6tTptra2s23tp06dnDp1evmU8pLysvIpU6aUV5RPqSivmFo+ZcqUKVMqKirKy8qLS4vb2tpOnT7T3z+69iCA9YTbv7jBOYk1nuCs4FS0hu2sd/cBgMFx1moqY6HTCgDQWe/oi+oRCyy7WLYaOoMAsRbhIIXEJmrYkoO0wdBnDJUFAQzQabPOdZpkSXWfGM6fipQy/2af/EDXf+9748L9kfruyMWe7p4iHV9MACjfQ5jySD8pLev/7Od7ST8ZGOjjCeV5AAb4Pnom++3Btvb2mSZF5CorZ7ZzbQCVienQPuqDm0lFJ8b/1Upvbjm28MYFssG4YOGCYy+FeGEubHj0Pc8PVyxYCwAAN/xLy/e/AADNLceOvvalBb+KllOzZjQHGZGkOhiJvPA//0spBUIAoKc7zOgnAYX+7j7CCCAQYAQdMLoi0Z5j5s6Z/6v//DUhzKXunuKiUdVBAGv92YbaMofvBEB55mN54zahEdMF9yEOAEKVtabFTusJzj10Pfo/C5gHOp763TuF90a+0n+Jzq+IlDERotN19gnlel3vAAzo9VXMpYqDvy9nwn0DtLCvj/CRSGSgmO9rbY3AzV/M7ktxZmVlU3s7gCh57e1tlZUWzXQA07jpoG31ekfTXmHV+mR+sXFe9ZFjQWGVOM7X0txabfyyJG22Rw6GHgGAlicfvNOx7+D2NWCcV13zvee3r1GXhDo4HpSXia/rEHlXeknhzernQ+H3+iLdEZ72He+7u9c9s3Km+vdvSllxRhUN6TlqQ7uPixvd67RZyxs8hQAQ8sxgrV1aYtdps5Yr7irrTPRGkxUyaMnpt0EehRSbYWj3cSesbNlw/OLXj1xcs6PonvcX9r/7Zzj89rMrTvzmmrO//MypXy8/9QvT8V8t+/Rfrjr5yzUdA6tuO33tXReuv/vimr/vuOEfOq7/v+2Wr1HrnVl/KVaazdDUFJAH/JrAbK7USm8f/abwAk32WfXVhz5+xPpfIWl3/yP1+wXKC0CBCgLlBcP16+E3z+yRvn3mKVhfM1egvLDn8Uf2yIUARDMf+XE0XSlN+4NqNZaID0gXkMJiXekkUjZZVzJJV3Kp59Iwix2x5wet7hN+0xUmD6SYwLW6jzlqrzCZ5ooWmTvdQjqNwStMJnWi2rHtyqgNkllqmys2Q2zJcEzU135kBog+KXLFL35ceHoqFQjR66C/n/b30oH+gQgzwOsmRQjtFwAA5FnigfaLcNOGLLvSAl5XwKsM8LnsZovD7nW5XF4pQR4JrFSlV1osZmgfz1ZXP7Tjv2HT3cbfAgDA6seDD8d+P/+r/ocfNd5yHQAArN+++6viyPaGh9d945brvgHyUavlzDv+3aZOfxgVKDsQ36LT6fW6iL5AXwCg0wuRycWTh1usxWIBgB07dmStaTy+jwdmymV/21s4uxoAqMADAI0MMANhGonwkQjlIwDARyL9A/0AUED5wMcdM++4dyybd/78+VF5hLC9ydMIdcOYDtbr9dOmTUuR4Q++l4wr1haXVmTVn7uvp+vw23v/7rZaVKgx4KE/1q+6qfJSp/6mZdd/FH6rZ6ATeP7Mka6Tl7qK+woON3f/5kuNmZa5adOmzOxBk2nxePWfNZWPdhUcd2hEypkcaiZ6nSDwIPCEj/D9A0QYIACRnrAgCPpIPwNAwj0AUCIMFH081o/gFhcXd3VlsFKLy+VKnh5oapopThQHmprA7BjOMzFFRYMMa8+ec/mF08eLjRo6eMt1Rs1Ddv85ONrn88Lp4zNiRqaQUWSb9an6tzZ++b6lx7rfF3T9Op7pB37mkinlHxc0vXVmZ+1vxsIvHimlyG0uVlSVVEyNED0A0IGIMNBHIwOE50nJgMDzkV5+gAcoAxigXYy+99Kp8rFtXlFRUU9PT/qvGCfTQdFrNoPH5WqXneShy6BOpysuHmRge4npyr0v/2lK5dySKdPHXu806e3ubDvevG6tBS/7MXOKt1/3H1/+9e2b7rlB30MiepgkTOo+3v2H9w//ZvWLBQUF4kozOekXTzCuvMOkmwEgAADQARAGAAB65AHB7h4AgM4wAMBAP5y4BPM+4sa4hdmz7pYigmmuu3XydNvBgwdnXG6cNruqqKR8HNvc19N14cwnbR8fvnrFisvnzsbLfmwQZY5Sem/Avun21R09Xec/7vj1u+/tWrIn9cvpg/rFqIN5ej319vaGw+HRf914cDMwo3VYe8LhD/760dn2tr7weL6SWFBYPKNy5meXmsvLSvFyGvurVxCEb3z4lS8tXfyffzv4iyt/XVIy9NVwMx4fRHLJvxAFaMK1fHJx8fXX4SJX+X716nS6n1/1jOu1721fsXM4IqiAOoggyMSjqKjoJ2t/PlKl4XrUCILkO6iDCIKgDiIIgqAOIgiCoA4iCIKgDiIIgqAOIgiCoA4iCIKgDiIIguQf0vvFCIIgaA8iCILkKf8fRfAGMWbL4xAAAAAASUVORK5CYII=\"/>'''))\ndisplay(HTML('''<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAApAAAAIcCAYAAABBx57zAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAN1wAADdcBQiibeAAAABl0RVh0U29mdHdhcmUAd3d3Lmlua3NjYXBlLm9yZ5vuPBoAACAASURBVHic7N15fJTVvfjxz+wzmcnMZN8XQgIhbGFHdkERtSJKXWu9bbWr7e2ve62tVttql9tVbWt7Xeq1trUWFwRxQVkEBNmXEAhk3/dJJrMvvz+eSTIJSSAIovJ9v16QzLOeeTJz5jvf85xzVEuv/3wYIYQQQgghzpD6QhdACCGEEEJ8tEgAKYQQQgghRkUCSCGEEEIIMSoSQAohhBBCiFGRAFIIIYQQQoyKBJBCCCGEEGJUJIAUQgghhBCjIgGkEEIIIYQYFQkghRBCCCHEqEgAKYQQQgghRkV7+k1kpkMhhBBCiIuLasS1UQHk8IFiWGJIIYQQQoiLgkoFw8eFSmCphbAEiEIIIYQQAjhd4jCMSgXaswseJeIUQgghhPh4GLm5erBwOJKBHLh0pIcSOAohhBBCfLz0xnf9geQpIeWgBdoB+/X9OkKgKDGkEEIIIcTHy6D7HsODVqrCA7eNNGGPnIWUPKQQQgghxMfTqX1mBqUbVeGBq8OqqCbsvjVDRJ9DrBNCCCGEEB99/dFdJHCMpBtVAzZQRW0SRktUBnJgnHhqsKgsliBSCCGEEOJjRaVCNSip2BdGRoLG/kylCm2Y8CkBY3jgf4NEbSexpBBCCCHER5IquqU6PFTUpwJVuO/+x3DUMm1vFDh0dnGoMSJPd7+kEEIIIYT4UFONnAjsCy6jA8veLGUYtIMDx/CAo4UHpTEleBRCCCGE+MgLM6ivjLIgKm4cQKVSIk6lBVsVlYHsCxzDUXFjf/P2wN43EjkKIYQQQnyk9Q3/ODhsHDQeZFS2sjeQ1EYHjtFD+vQtHzY7OfjsQgghhBDioyEq/RiJ71QqVVSLs4rBaUpVVCCpHRA4hiO5xqGykn3HH64Ze7jBJ4UQQgghxIWiGuqRanC01hswRn4PhyMBZX/TdnTCUslARgWO/fdEDsxI9q3rW99PAkYhhBBCiA+nwVHbKQOHqyLhYTjq91MykAMDyb4mbCWQDA2fjVQ2GlSEIft8CyGEEEKID6neccH7usz0xnoqFar+mx0hrAzZo/wEUPfFlVqtuyHqaKMtgESPQgghhBAfRapBjdtnuBMAWlU49D5OLIQQQgghPprOKnsIgBZAqzcy/rJPnssSCSE+gvJz85hQMP5CF+OcCoVCrNv42oUuhhBCfCwc2/gfAl63EkAKIYQQQogLJPq+wzNZHi0URKNWD7+6b/BvddQuQQDUavXAsXlQEozhUAiVSoVqhOMOE0Cq0BtNWM0a/D1uuj1hTLEmzHot0YcKh4N0d3bjGrYVXEOMxYTZoEXTt8xPZ1sPnmGLBKDGZDZhMapwd7np8Qc/mndb6kwkx+pRq1S4uzpx+AFUaHUGrFYj+gEbB+jpdtPjA7PNTIw2SFd7D+6hnrhag8kUg82owe910+3y4jv7OxHOG7XagD3OiMrnoavbi/9CF+hjS4VWq8Nk1BDyh1BpQrhdfoIXulhDCIeCeNqrae4KosZAjNlCbErcoPfCR4UaU4weddCP2xvkQ/gWFEJ8FJ1J0BjF7G4mzm5XdmFQ52rA2eOiCyNBvblvuau1Hr1Wi8aagEarizp1mJDPTcDVhUpnQh9rH/a8wwSQZvKLpnHdsiSq3trFuj0eZlw2j8vybXibuugKBAlrzaQnBtm+9jVeLevGPfgQah12awZLLptIoVVPwOMnhAZbopOXHnmLvaGRQkIrxXPncOV0Pe89v52NFW24Rtj6w8qUP5tvX5FHjE7NoVef4bHDXkBHcnoRt9w4hdSeHto63fh0RhKtAY6/u4/1+wPMu3Y+C1M6ee4Pb7HTGzjluBprEpfMn8/1RXZaju/l+a0HONL+Yfv4UhNrz+e2zxVjKj/EP/9zkKoLXaSPBT2JqTZi1Uo1EQx6aG5yY05IZ1JBLOEuFbFxPby3+STN5/CsvpbjlDd0EQqDSq0hLmcaqdbRHiVM0FPL9t/exb9qY0kkn8lz5rDwKyvJPIdlPTtabPFGQk43Tl/vF1YDyWkGnA1dw9Q/VqbMGYulqY73Shrp+iCLK4T4eBkqWAyHBy4fJrAcm5FGaaub8IBxG/slxJgxo6Mr0H8ctdFCQUosFU1tBEx2tDo94XCYsN9DvFGFxhxPo/PU+CPaKJuwW9m0bjNb21wE4ov54eemMWdxEfvLdlI+YDs1MQlZXLZ4KhOt7by1YS+76rvxYmLqojy6I89NozGTmROPBYAQnh4nTa09qK02kmxGdOhISkthgkpNZU077X4ViZmpJOuVD0+/z0ltbScuVBjNsaTEG/E6HHQEDKTEx2L0dVLd5iUmKYlUnYuTNQ68gEZrISs7DvOA83YTtthIibNAdxv1nS48ehsFybHoQ92ciOx75gxMyU9F6+mg2ptA/vgxWA6X4uxb76bqxEHWvH6MemsWq5bNZPGccZTXV6Eb4aigJt5qIzfJiMPZgyEugRS7lWPtnfT+qS2JaWRbtaiAUKiHmsp2nCj3uiYmJZFgACUT3Emzw4MfDfakRFIserQqwN/V93y1OguZWTY0rm7qG3vQWG2kJupxt3XS7AhhS4kj0ayPyjCDp6OBCoeJjCw7ZtToY+yMzUuDLheuoBZ7nBZnSyct3V76X55aYOQXqwBI5orVc8locNBFGHdPLW++VkpdUyWbm2IYPyWf2HN8Rk/DQbb98xHerPSgC4Naa2Lspd9g5TWF2EZ5LJ93NwcOz+DLL/2Eaee4nO+PnVmLx+J9r5T3ah2RFpJUrr45l/d+u5nDF7h0QoiLwFCz/Z1BNjIYCnF5cX5f4Ngfdyp9rDs6Oylp6u4LMAFirHaONnVSkBRHfXsXvpAZjSpMvAE0Gi31Tj8GY8ypQWyUUQaQJrLG5jIzxUvQHI/B086Rw3VDZDoM5OSkk5+ho2LLCUqauiPBl5sDW470baXRWSkozCMdDWZrLFZ1B+9sOkKTJY7UOBN6NKRmZYJdi6vJQThxLNdcPYPk5lpatXay4rrZ9Mou3ql3YU/JZvnicXiO7GW3O5nL504gvfMAf93UyqSlC1iiKuWBZ/fjDavQapXzpqHBYo3FomrnnU0HqLaNYcWCSSQ1vMdTW4/TnjGF25aNRV2zjV+PNoA0ZzIlXUt32Vb+FVjI16fmMsVSynbnENt6fbh8AXxaDXq1muHvOAA0McTHp5IabmRviQNzVja5iVYOVXfSEgBrciaLFi1mgbmFkhYvfn8Djsp23DoDuYWTWTZ1LHG+Zuq7uyk/6sfh8KBPyGTxktlM1juoD1qZau/k5bU72FjnJsaSzTWrp2GuOMw/nj9BzNgirrsshZq3d7Fut5viS+ZwWUESwaZqTjpjGD8mAc/xt3nkNQ85eQnEokFjjqewMBt1VQcBawaLFtgoXf8uG45EZ230SAB5plp4Y81m9vU9VmOKsZAYb6G/gUJPUmoC6fEx6AnQXNNAbbfvLJq1ezj50u95rWcZ//2LG8g06gh6vZS98TIdFGILOGmtPkzp0Tq8GIjPm0R+vo2OQzX4NK00tnTh9QYxj72UOeN7OPLmbup76ji2bS+J46x4asOkTkygq+wwJytb8NvisHnNpBYn0l3iwD5zIikmA6pQLSVvNRA3N4m2HTX4LF1gHM+4aam4y0o4ebwGFyZSJs5kbFYyJs3pn9noqDCa7OSOiSeWEM7OTmqbeit7A2lZiSSpLdiMGjQaP/Unq6kb3TdOIYTopxo4PuOAZYOYTAamTJ3aP+/LoE3Ljh+ntLm7PxjsDSJtcZxo6yTHbsbp9mEw6NFotNR1+TCYYk5bxFEGkHriExPItvgJGc1oAy4a29xDfOzrMOr16PU+XN4A/qCJ3HEZZFr0aOjm6L4amsMqsGjxN7ZQhY74oIG0CUmMy7VQsr2SQ1kpZMbrObRrT6QJ28ySq6dTHBviSEkLNfoY8rNTmT0ri5KXSnB53HR5TWQmZTBdbUan8qFPSCI3O4YimxZfZQeO3uJZtPiizjttQhLjxsRRcqCO47Xp5GSkkGpuJ2tMIsZQJ5v2VtE5quukJa0wmxyDl73HWqjynaBz+kSmToxn787eCFJHXGI6M6drcFgSmZSqo72simqHm+FbBlUYrVZy8uIJdlRx5Gg9mTFpzM5OIq2iibYWDRNnz2FRtp/Dr+zg6ePdkf3UWK1pzJ1TRFp3GevefI/32nrvSDQydXIh09I1HH9tJy+0Z5N86wyuXTqW/f93+AzvW+zhyM5drKlL4Y475zGuIIeUtVvYvvkkBfmxmFrKWbf+IFUYyMgNY9zTSlO7C9+AY3wUb1K4UGIpml6ElTB+bwclR9oxJWYwq9hKV6Ub0BCXnEVuUQrx+hB+TBTaYMPeGlq8o73VoYaSAzrmfG0pKXolN64xGCj8xA1AgJ7mQ+x86Sl2NyWTrGnBcbiSnuuLqHv2eSpMJiw2MxrHYQ686iLr4WIaj1bR5XPQdPIkVXRTstbNtM9mcWLt61Q444hL6KJqs4eZP7yE2keOMPF3d5NsMkBoL+sefIOpT85m969eQHfVHArGWrDGlXPk1Y1UNOsxajvYX+XiE6tXkJ9iYfQxZAy54/IxJLsjr/t4EiNrdHor44smMjUjgMutRZdiw0xLpLXAyuRZY7F5AnS7fYTsccw0e3nqvaZTb+0RQojhRHdmOdP7IKOyin2HQck99k0UM0IvEqPFRnVrM0un5tPpdPPeyUbM9oQzKu4oA0gHB3buUZqwTYVk3nUJS+d3UFrWRvWA7QL4/H78fh1GvQatWo3eEM+MS8aTF9PI0/traVHHM3vRbFamw7Ej1XTrNKh1GvR6HYYhz20nPVENqh58QT0adwNbdtTS7WjHC7g8Xhw9PoozMrAFnRw5VkZ7WiqTJthIMmipbeskHAa1NoHZi2axMg1KS6px6jVodFoMOh2GnjpK61qZnJPF+EwnplQdnVV7eK9xlN0/9AnMyk/EpAuTkDeFqwI2who1WePHk7N/D0pYp0Kj0WIyGggEuik92kT5sRoqu6xMGO64Kh0JCWlMzrRg7EhgSr4Ba5wee1ImYxOrKW/TkJKgQaPppLQyOiBTo9dZSbT7cDQ4aGiLfj4WEm16DPoumtqCBFo6qQ+HSU+OJw0G/V2H46CxPUDQ6aZ7qBR8Hy91lWXUVZ7RQcWw1BiMBsyE8aq0QwRKRrLGxlOQoqO9sRUXZsYXZZN5pJE2r3eUnT1ChEJqtOqhKjEPbfVl1DZmsOLb9zJHu5P//OU1ao9X4CKAcfw13HT9ApL8L/Kjq96iXHUby762mrI9+1l0+2VYt71ACd3Ulp6kRzeNVd++gyLfa/zp2OsjVHdh9PZUZtz0PZamtXDwhYfZu7OMmCnzSdK1Ubp5C2XzZ5CdYsE0qucJoEan1xNjDEW+FOvQEkLp1JdE8bQMYmuP0+pRk56SQF5GEAe9eXMVrZVH2HisDad1Et+7KY/095o4OeoyCCEuSuEwMfhIT00mMc6u3I8YyRiGQkqtrVapCAPl1bW0u4OEe3tVD/G5q+yr/D5SCOrr6SYr0c6JhnaCgQAJZj1dHjd64+lr0LMfxkelUppaw+EhPpC81LW009Sezti8NNKq2yk9VEPNzDxyI1lRtcrOpLFWfB01HDx4lI7cWCZPGCll6qC+NQQxanrqjrK+alA/bo+XbqcL/bhUdI11VJSV0ea2cuvsJPQ6Hw2tyvYatZ2JY61426o5cLCUrjGxTC7sPW+A5upGqgozKJqcg1nXxcaDDXQGwkA8l1yaT4KnmV07KkfsoGBKTSfPakDXXk+Vx4sv2ER1ay5TLCkUpRvYGQLw0dpUzdbtx6gfsPfw+Ue1wUBiehrpYS91nQ6avT14O+2kxyeRn2ZjZ1UTTe1Bggl2CnNi2FXWm4EM4Qt00dqpI99iIy1BR21fEOmkzeHD64sjJV6DFjvpKhU0t9PQf2a0GgMmqwFLrHmEEp6OgYzcLCaNMdF0tJLSxu7T9MYXQ3Owb/u+qCZsPWmDNwn76HGFcPb4cAUb2bbfSbMncBajGWQxYbKXf72yjblfvYY0o46gz0vl1o0Yli2KVExBQkFAHSIUaTtRkc7YcamYYrRAHNYRvkWrVGHC4RChEBAKEgqFIuXswNERJJwKHC+hEpiKHoMxm+Q0ABUqVQxmazy2BCtm0zSWrEwhP81+lhWbk7LD0fdA5pAyJxeAMCF8fg9dXT5cXh8nKlpoqfeSXJgUueVEjab33hO1Gs2Q9aIQQgxDpWJKdjLFkycSZ7P2B5AoY9mqVKq+TKNdG+Sd4424A6FIfTv4UEpHGhXKz3CYIccLd3d3kpcQQ48vSEt3AJ0a7Do1VgJKEHmaZuxR1rN2Zi6aS7Y3QEgfT0qoh4O7T9JyynZBOhuqeHOHnqtmZXDZ0jhmurRkWQx92ZJQqIV3D7czviCBeYvnErAlY+1rDHdR2+KgoyuHybOmkzihiR2bSzn0znYSlixh9uIFGFp9QIDOtjre3VlFi8dHj9NFNz00VzZS29ZNa081lUXJxJucNLYpH0qBYAs7D7czriCR+YvnEBpwXvA5GthX0cL42Xk4y/dzuMVDIAxgZfLMIsY4NJTtGCmA1JOTnUScSUfDviNs2dOEJwjp+nxmzDEzZkwKh88qLaHCZIxlTHY8ga4GDh08wKYqL6bMMPHxcUzOTCLJXEfprl1sMSxiwbxL+HSBB7+vkS1vHqepq4F3dx7FPHUsy5YZKXR2UX60nP0V7Zw4VMr+pNlMmjmbm4M20jy1vPz2SdoIo/O2sO+Yk1WZ2VxxeRy6uEQsZxT2hfH62iirCbIkaQxXXWXieGUHQVsGc2baKG1uoVwCyPPEQ1VZJwF9JpnJCdhCABoaSupRMdohsWIpuOZO5v7raf73Z29jRI1KrSd96q2swIQxs5CcjG2s+9nXeUfTiT99LksLx1L11pnlrsFKdlEu3pKX+fdPDvNqip/WpiCp5LP4ikP84/H7OWnSoI7zYD5lsB8b2bMWMbXJyZGyw5zQA/SQMn82Y0b1HE8nhNvZwv59DUzLTSArAOAm1NWJFiKBop+43KlcnxkgbI2ledfOqC9gQggxMhWQFGcjFAzQ3t4ORO5lHGJbo16HRqOGQCiynWrAtuG+5m8G/ozi7u5kXHIs7T0eOn1qDKYYQuEwnT43Nq1KCSLdrhGDSNWSJUvCp85Eo8Fis5GWaMDd2kGTI4QtNZ4ks35AxBkO+2isaaR1uBZejZHUJDvxA3rpuqk+2YID0FqTmJAUnSYN0NXpoLGth2CMlYwEK1a9GvBQX91Guz9IbEoWOZbeqxHC4+6mrt6BCw2xNjupiTpcLZ00d3nwYyAlI54EY4CGilY6lPQIOmsihaect5PGNhde9IybO58bigzs3LiNLdXd+MIAJnLGJhITcFJT1cFQfWF6r509KZHUWAOetnqqHQGlESw2kYlJRjw9XTR2qUhONxPq6qK+xTmoc46B1MwEEgx+6ipa6Ywa7kirjyE1LRFLwEVTaysdXkAfQ0ainXidj9rGDjq9QSyJ6WRbtahVEAw6qY7qhZ2UlEyiEcBPR1snTZ1upRd2ciKpFgM6FeB3cLw60mlIpcZkTyQ/3hhVRj8dfa+LOJLMYVpq2mjz6cgYk4Rd5aKqvA2nWoM1IYVsq9LDutvRo/TCjtfhbO6geUAvbHFmjGTkmnFWtvXf04sKg8lMvFWL3x1CowvQ0ebHnGQnxWqK3Kfnoa6qlY5AaMQAcriZaDy1ezhY3kYwBGqNjuSiSxmTAARddNSXUX6yCR867FnjyM624DjeiDo9ncS4WLS0cOKdBuIWTMbub6Ryn4PE2WPRtjfQ2hgmscCOs6qMmtp2/J27Wb++iwVf/RKLM32UHK3G6w+hSkoh0aHGWhyPs9RF4vSCSCbcRVvVCWoqGiP3G9rJKi4i1W7pq6vObCYaPYmpZkKd3XR6ApGg0ERWXgyd5W10o8JgjCUjwx7pqOTH0e7Cq4GgN5bZl2cSKmun0ekhqPbTXNNAk2+k8wkhRLQw460q7FYLiXZbZMnQAWR1fSPHOgL4wsraNLooGjeWU3aK/N7U0srJdg8u9H1ZTFdLLXE2G0506HSRGwdVKkKhIPg8hD3dBDQGDLFxp5y/dyaaYQLIi1Usk2ZOYtnMDNwHd/PSnmqaRt3pQIjz57OfuBR77MBvhM0dDv6+4Z1zcvzBAeSff3UfZSUHhtw2Mzefb9z3P+fgrA0cXPss69dspcUVIH7ZF7nlhuXkxhlGHpHgDJ1JALl8zlQm5g09GmWPx8tfXnhzhL0Tufz6fNw7j7K7ziFZdSHEWQijI4RWo8GgH3kwP4/XhycEvZGiJugbcZ9AMIg/rO6/ZxII+b2EUKHVnTqNQygUJBwIoNKoUWtOPa5MZTikHk4ePURzZQm+biddEjx+SKkxxhgwajWRACOE2+nCfRH8uV7ZtgetZmC3GX/g/OVxV916Jx53z5Dr9AbjkMtHL4Gx82/h0xOuxo8Wc2IacdZzEzyeqZ1Hyjh0cuhm994b2IfXwfY3DxB2eUc5VqwQQvRS4UeDPwhu9+k67g7MSwY1elwjjtGmPSWVqdYNX8eq1RrQn34cCwkgBwjh7nEyzOel+NAI4XG5L8pMT0vHBzvfSWpG1gdwFj3m+HTM8ekfwLmG5nC6cDjPdiipID1dMmCPEOLiolqyZEnY51ez6/CFn0xMCHFhqdQq1KoPMvf3wQgGP4wzgwshxEfPrEl1GHRBJQOZnGSlueJ3+Hy+vt4/QoiLz67SHt454jxlYNqPm3A4TPFYE0uLz35QKiGEuJjEx8ej1+u544476OjouPiasMMhD11tToJaE7Fx5tPMOy3ExWdSYSKF+fEXuhjnVVVtF/5ux+k3FEIIMaTTBJBBXB2ttHV009+fJIak3BSsWs2Io5tfeB466lvodKmJy07BpteiAryu1/je4vs5UXgLD635DrPOy7n9dDU20NbjIxgZM0WtsZIyJhkzQbwuBy31XaitcSQk24aZeWewEH6Pg+ZaB2GLnaRU+xnuJ4QQQghxbo0QQHrpaDjGa395nFcOVOA1WtAB3XUJfOb5n7IqyXYWc81+kI7x3I/v56l3bHxl/S+4KTcZPaBSx5NXPAVDTgaW83RmZ+Nenv7hT1jfasJq0qFWeeioHc/dWx5iEU6qDvyd++5Yg+mGL/H9+29i3Bkd1UPDiee558anCV5xJ/f89r+YeJ7KL4QQQggxkmEDSFdbCa/8+df8c0ssK3/8a25aXIAdKPn3v/HEKNm8cDiEo/w99tcoPRA1MXYyxkwgL8kA9NBQdpKquvZBvWVN5MycxRiLCr+3gZIdx+kYsF6HPSOXvNwMrJH2ZXdDCQfKW/H4lTRo7JjZzMiJGgvP20VDVRnH6pWp+yxpaZhc5dS1O/ET5sSuHWypzGPK4kkk6Au48gufo8eS0Tf9m7+7heryMmo6lJF/DUljKcpLx2bSAG2Ubiuh0R99E74aozWZvImFJJ+SBuzi3aceZc1+NSv/8ghfLk7BoG5g/S9fJ54g7u4Gyg5U0oUXb/1x3tu0i2BeHrnZiZgAT2MpB8ubcfkiKV9zLrNnZaN1N3B8TwUOfARbTrBn007C2bnk5ZnpPHaSqoYgqVPHkxVnRksbR7ceoSmYwKQlE0kM+XG2lnOopCEyzIgWW1oueXmZ2KQNX1wQfnraG2ltCpM4ITsyOLcQQoiPimECSBeVu7azefNxklZ8j/lTlOARoOiGG/q26jy6kacf/QUvtBYyPdlPc2s78Qu+yFdvWEBBcgM7nnuUR/++lY6MycyekIU1VM32d1qY9t1HePDWQoIdW3n4K/ez02Qja8IsJiX7qC2rwpN1OV/+xmdZUhBHoPYgG/72S/6038DE7Hi85Vs5kfcl7r/rk1ySZyHg6qBm54s8+Z/X2dtuoyjTiiU1FaO7nmMtXfhxU7L5LXrMHSQtnIjVs5NHv9LfhF3c3ULJm0/z+EvbadZmkRKookJbyMqbP8eN8/Owmo7wzHe+xZrOHuyFl7JgrAFnYxllbenccM993D4/nYGj4ZVz4kQ3Lhc0HdzI+rp85lwzm6u++1+AlzZHNUd2naADD9qaw7yz3oT6SjPJ2YmYcFP29iu8dKgBX0CDqnE/r9RM4O7ffpdVmXUc3l5KO17CDUfZtt4CS68gJc/Elmd+x2P/8bD6iQe4fW4BVg7zt2/+P9a6LuXhI//DvO5jvPGX3/DohnrSpk8hzajFllrEgqsuY1ZhKiPPdilEv3D9u7y1rw4AXUwcWVOWKjPSDKmFE1trMM+YSEqMAVW4lpI3m0i9fAYJ+HC2lnPyQAijBJBCCPGRM0wA2UFrWz1NzSlMTk8k7tSZbAAHOx9/gCf2WLnhFz/hu5Pbef2vP+BnLz7DS1nZfHVl71AgCUxbdSd3f3oJOcEN3HXNA7z1pzWcuPUHkflqddgz53DrDx7gtrwWXn38d/zqyV3sObSI6QVF1L72JH9dV07GnX/kgU9Nwfvej7nty7/jVwkF/O0Hcwk0HOHFJx9no+cSvvjtb3P77BQa9++nI6EOTVU51S02Vn7nnr4m7IHZ0AAdlbtZ+68XOGZfyTe/9VXme9bywIN/4qm/ZzJ13KeZnt27bTZXfvsBfjTHQOXOP/P1L69j24YdXDF/NTkDjpnEpMnZWA5u5qVf/pSXKOA6xw1MUGtJm34VywrnsOrzx9j37hpMc67nGwOasP2QdSlfvnI8aXYLmuN/5OCqR3j4N9NZ+vQNXP+1K9mz9WmCU67hv3/Z24R97DR/4gBdHftY++xBjLNv5As//S4LrW6q9x2l1duNDwkgxZmq4r3HfsO64HgKYkGljaXTG49tRTFDd7k5waZH1pDz2++RFGNAE97HKw++zbLLZ5CAmZRxi0k5s/s3hBBCfMi8j17YZex4tx29bjrTiuPQxQRImzCBuH/soraigjYi8zKSzsSJ6VitOiCOBLUaWltphUgAacBmHcvEIivQMUnwtwAAIABJREFUjclsIcZVhdPtxksjJUcb6O4OElu6gSf/dztaVQ/aYIjm3bupYhoWRzmlpSGyF49n0qQUAFKLi0lFxZbTPgcX7e2VnDihJmNlFpmZMVhCeeQmJrJl5xHKnd1M7tu2kHnzEgA3WnscNr8fb3cX3accM4MFn7yNz8dNpNnhhYq3+NODD/KixsC4FWbG/2rR8MVxNtPafJQdz+6MzBFdjg4IlR3nJJB72uczFA1G4xgmTDBzorGUN5/5I4eAuLzpXDK3P7Mc7a9//St+/+lGwhcfR4GY8RTOWjLM2iZ2bT1G0W+e485i8Do6aTxxFOXmjk5q9m1n/3vH6MJM9iVT0J58mxNth6h/9jEarXkkhTdT6ang7b88Qn1SIeNnJuA83oUx1UTPySo6wq20NnmIyVvCojmTSAgfZePLW2ly+QiPKWBMg4GM1TPpfvspDtQDxJI2cS7T508a8nUcDvfP+j3UsESHDh6idPvQ0zQKIcTFKCcnh6uvvvqMth0mgLQRF5dCYkIrTU3tdDkgwzZ4GzVqNUAIZaavMITDhFUqVCrVOeqhrRwLVTzJabFYYi1omcqN3y/GYC4gHvCr1KhUYcLhMFGfF6M8R5gwkf3DYUJhCKvVZz8WXsYsbro90r+7Zjq24nX85+ev0HJgPzUsYugWvwZ2vvgsj/1lC7qFV7EwPxGjxngOxlnSYI4r5oZvf52UMid01bJ32xu8+9IhOr+dwC2XnxpEms1mAudxejzx4eXSnjovar9xLPvGTbz90n38+Q3QWJIZt+hTLMZDc+lmdmzahUObS6K+hj0bu0m3uVCpdehjLMSYTRjDRrQqHQazBaMpjKN6H/vfqME2XcXxDfWkLJxGUriWvS+vx55hwL7nz7xzopCJYy2oK9fyzD9MrF6mpXzNTgLLlpGKGaNeN+x0XOFQiN07NlE8ewFarQ61euCWOp0Oi+V8daUTQoiPHpPJdMbbDhOfWBgzcy4LF25jzZtreW3ieBKXFZFkgOOvvIJ36VImxhQwf34ia94+wZ69bSwv7qLuyBE6k1PIyhtLAmcVzQ2SyqRJ6Vi3N+NPnseNN0zFolfj9+7nhd9W0sMskmx5FBVp+UflUQ4eaGDGvDS6S0tptDcNkR0cLIbExDEUjAvzdm0VNTU95LhPUNnSgn7SZYy1xDLSx+nQqnnr8X2Yr1jAtMwE9Fnzuf2Kk6z75avoxxeSD4M6DfVqp2R3CbWtYS5bfC03XToW37Yf8bfTni8Wq9WEwdBER6ePgB9ad27jSN/MGwF6XGUcqshk5e2zsXeUYHUfZ9u/2mhrb2eo+TluvfXWUT9r8fGwq7SHzmEnbbFT+Im70Fpep8rpo6u9jIMvvk3BxPm0lu5h76Z3CeU56dTWc/yYnez7FpG2wcuEVZ/i0vRENCENOx9XM+9Tn2EmHZzcVhM5rh5b7gzmXXs7k2L20fO9tTh6jnB8o5vx37iZVZOSUdX52fGPMoymeMaOtbOx9DBOWx6xhWaGGwo8GAzwzJ9/TUdrC4uWfwKDMWZAEFk4oZClxbPP4dUTQoiLx7AJLkvKJD7x+W9A6AneePJ+DryUSIwW2st03DB3IUUxNmbd8TM+WXUXrz/8HRoSAnQ4NVzyyc+y+pIsDFSfg+KZyL/iC9wX+gs/fvF3fHOrGZ1GhVqbw6KbriUBDbFpk7j+zq/Q/dzL/PPX32f33y0YU2dz7U0LWDgrh42H9/H8/T9ge8xM7vzDFwYNfaPFnjuL5auupeKfr/KXByr4T7CORtsSvnjbFYxPjhk2uzG8do7veIGtm14i1mpShjrqqaA25yq+97WlJBGDOqGI6dPW8OI7/+Bndx3j0muv5RPLx7Bs9TJ2lT3Hu3/9Cd95wYy/Zg8NELlHUY/dNpk5s7U8s/c//OKuchZc8QmuXTmV2ZctYPJ7FWz7y8+pfslKoG4/Fd7eDKIag86KNfACP7vrb7gCTpqqG8mevZzZMwqH/fAV4lR7ef5vQW74zA0UBBxU73ic0nercLAYrS6etPHTSFuynKwYWHC1jcy8Lpo5eAbHtRCXkIw93gCYMGq1aDBhimmnsz1IOAyq5kba0WCwFjLltjsxVZRTfaSUyh0HaJ6RSfIQRw2FQlSXl7Fhzf8RDoVYvOJaDEbTKZlIIYQQo6dasmRJ2G6388QTTwwxlaEfR2Md9Y1tuPqyElayJ48hUa+FUIjW8n1URyZ00BhjScrIJcOuB9y01tTR0BwgPj+bFFsMWrqoOlhOm99K3owxWHytVByqw2dJJmd8Oha8OJoaqKt1Yc7KIC3ZpmQAu+o4UtWCx6cUQq1JIK84l75WdV8PrY01VLX0AKCzpZGTkYLJVcvJ+vbIkDh2xkzPwx5qp3x/NZ6YJHImZBILeLtaaaitok0ZjQh9XCZjMhKxGDSAg6oDFbQGrIydkYedIF5XC1VHmwnFpZCVlzKoB6mThrIamrtcRDcCa8wZFBamYgSCXietdRXUdvgAI/EZGaSn2jH4Oqgqr6O9x0soel9tAmOm5hLrc9Nef4KqNh9gwJ6aTkZGPEZ/JzWV9bR2uQfsp1LFkTc9D3sogLuzjhMVrSgDFWmxJKaRkZGM5aKbi0iMRMlAGoeZiaaD6ud+we9fLYVwALXeTOGq33DLVSmoOg6z/fln2bzlOD1agPEs/+6n4d8/Yl2lH214Pv/1+Oc5+cVlbAgUkTtmHrOWmalYW4NtegK+liwuvetaMjnA899ag+GWT1Ic3MCfH92JWx1AlZ9CzFtGLn32co7d/b+cwE/InMvMK7/O6qvHDRoJQeFxu7l52RSefvpv3Pvjn3L1jZ9h4eWfQG8wUlPvxN/tkKkMhRDiDA2eyvA0AaQQ4mIycgAJ4e46qpqUm0PUOiPW5FzsJgAfPR2tdLZ1oXS/MmFPT0XnaqDd4SEYtpA0NoNQ4zHaetRoDVas8QYC3X40Jg3hgA5zghUdbhwNXajsdixaF821LXiCIUIHfsuPXyjkx098hpjqJjyAWm/BmpCK3Tz0t6DeALK9rZUXX3yRB372S1bd9gXmLl5OY6uPgLNLAkghhDhDF/1c2EKIs/P56xbT03PqncWXLF7O1+75Oea4dMxx6QNXxuRiTox6nFZIbPT6UwaANGFL672Jex/rf/gD3m7pJORPYsXDvyFHb0aTP+S4YsPS6XRce+21BAJBHvrVb9DqdCTnzER1dr3uhBBC8L6G8RFCXEwe+ceGIUc60GjO16Sms/j04+u4NQyoVGj1xrOaPjUQCGA0GrnuulW43S5+/+ifmH/VHUycMJlwOHz2oy0IIcRFbMgAMhgMyjAuQlyEAsHh3/cG45kP73BuaNAZTbzf2TaDwSChUAiLxcLNN9+Mx+Pht48+ge3mz+AsnI1Op5MgUgghhqHVaodMFAwZQL7yyivcf//9MkaaEBeZghmrWP2Zr+HxfPS/QHp9AcJh8Pv9fRWg1Wrltttuw+ns4Ze//BEP/8KNyWRCo9GcEkS2trYCkJiYONThhRDiY8/pdPKjH/2I66677pR1wzZhr169mnvuuee8FkwI8eFysMLFnuMOmhodF7oo75vf5yEUCvW1qGg0GrRaLfHx8dxxx+fwej3s37+f1atXM2nSJIxGpS93byA5ffp0QqEQW7acfk4rIYT4OHrooYeGXSf3QAoh+kwZE8OUMR+P2dHdbjeP/VhFIBAgEAj0ZSFVKhUpKSnceeedPProo6xbtw6NRkNRUREGg0HuixRCiDMgI+oKIT7WejOQgUCAYDBIW1sbGzdu5PDhw+Tk5FBbW8vf//53ysrK8Pl8F7q4QgjxkSAZSCHEx1pv87XD4cDn89HS0sK9995LfX09SUlJhMNhOjs7KS8vJysrC71+9BOYCiHExUYCSCHEx1ogEMDhcLBmzRoA7rzzTlasWMHWrVu58sorSUpKQqvVYrVa0eneb59vIYS4OEgAKc5SK4c2vsOe0jp6+pblcNnnVzBeLy8r8eHR3t7OU089xebNm0lMTGTFihXMmTOHvXv3EgqFyM/Px2g0olarz+OYluLi00PZljfYfrQOZwDAxowbb2ZukgZvz3G2vdjMuE8tJPOMjlXJG48dI++LVzD2vJZZiDMn90CKs9TK4bd2crTBiSY2ltjYWPxHX+T3T2yh9UIXTYgojzzyCHv27GH58uVkZ2fz73//m/Hjx1NUVERJSQlutxutVotOp0OtVksHGnEO9HB88xqef/sozpCR2NhYYmN97Pnby5QSxus6xlvPvkPdGR+vkjcee53y81hiIUZLUkXifUhg4qVX8Illk4kHnPP9fOWzmyn70hIszgO88lgt0751TeQbcwfHtu+nuieBaZcnUvbv/bQHKjhU1UhnZy7X/WAa5b86RsLCBt56qxm0ZtInreD2m2dhj5yt6eCbvPr6m5S2ArlL+NL1C8lNjsyFd/iffP+Z/QAY7SnMu+EbLI98VW8tfYfX1r/CoWbAOpFVN69gel4ScqfbxeHEiRNcffXVzJgxg8rKSjZs2EBdXR3jxo2jpKSE+vp64uPjJXgU51AzhzefRFuwlFWr5pERowWcHN90jJjAQZ578Dl2t3TS+P0H2Dl+Idd99lKycFH+7ptseH071S6AHC7/0mrm53ay/sHnOOAvo+n7d7M9dia33HM19sr97NzkofgzS8gCoIndL+/HlVlA8fQ8rCdf5zfPbaPZ4QVg2m0/56ZJF+yCiI8hyUCKc8ZVWUmTyYQF8Htr2P/W4ahspJvmijKOldbhpIuKfa/ytzcaSR83l+XLZ5BpaGPvusd55B0zy5cvZ9HMQlz7/48X32sHoKdyF+s276bTPo3ly5eT3/kmf39jPy3dAeAQTz64ltDU5Sxfvpx5kyfQvX0tJwF37UHeeHsr9TFTWL58OXNslfxn3VaqmpwX5BqJD45KpWLFihWsXr2aSy65hLS0NAoLC0lPT+fBBx9k7dq1eDwegsEgYZkXW5xTBowGFy0tDtzuUGSZhXFLZpCuTmXy4klkmLOZufxSLpmeh412jmxay+vbmkierdRjsxIq+ffad2luN1O0eBJp6lSmLl/OpYsnkkAAZ1slh3aW0dl3zm6qD5VwoqYNDydZ+9RrtMZPYfFlyvH8rz7FoQtzMcTHlGQgxftQwbrf3sv6J81oAU+TmWt+eTf5wOnnMUlk1uVLuezKuaSbdMAmVOiYfsWNLJ0fR9DVTGLgOC9uPUjHrNk0Hz9GVzCZ2Vdey7wMI7NT6rjvqaNULZlEfGwbJSVlGL+8lKULIejz0dXaig43DZVltHbHMuPm61iabcI3TUv5ve9S0jyLzBQLH/TkfOKDo9VqufPOO7HZbMTGxqLVaklISODyyy9n48aNdHd3M2PGDDIyMuTeR3GOJTHvthtpfeLv/OLr/8CNGlKv5CcP3sQYfTIT5heR9tcw05YuZBYAPjKL5nNVnp6E9GTMWvAVhyn5znscuXouy+YXkaw5yeSll7IIACcjD/XvoKKinNDEu1iwKI9YPXSMqZCMkTinJIAU70M68266mvlzC7ABYCZlbComoPu0+5pJTYnDaIru9ZrPrFlxAGhMJhJzczFtrqCBQjpa3eh0GaSmKrOFWMaNI735Teo8HiYzi289/zUe+sJKVlogJimHa77+MJ9Kb+VYx0l2vbiWlze/zu80AB466rO4/XMBguf2YogPGbVaTVZWFiqVqq95WqvVkpeXR3x8PG63G4vFgtVqHXIqQyHOng57RjHXfTGVhV1uAmGoX/8//Pc3w/zxkVsj9WU0PTZTD9tf/BPPvHIoUn96aKvNJScYJHTK9qczgU899Dn+9P17uf3vXQRVsOTul/nmmPf9xIToIwGkeB8MxKVnkVdQQPyA5aOv7hQN1DcAOYA/gK/LgSs+kzhM+Mxa6OjG2QNYgfZ2WmOtzNJp0WAmNf9GHvjnFXiDLup2/ZO/Pvo4Ux67iRjTOBbfcCdTPnUluX3n0WGOi5Xs48ecSqXqyyxGB4d6vZ7k5OS+ZmsJHMX5oSU2OZPYZOXRmM9fy5rFmyjjVmaesm0T727YwL7GsXzhN19nghXgEI9/bfNZ1lMmErKu4Ot/uAR3MARV/8dd3/kp2zf9kHln/4SEGEAy2uI8UKHRpBMfv51d7ylLGvbu482XXuLkiPud4LE/bwTA2dHOro1vY5wxg1Ss5OQk0tF+goMHqgHYv24dbTnZ5JgtaNjCD36wBVtyMslJScTH6gn09ODHTEZGLN3uk+w76CQ5OZnk5GTq173I9rpa3Of1GogLTaVS9f0baplare7LTEoQKc6t4zz3yLNs3FXRV8/Ur1nDO2kZZA+5fRCf10sAA/bESD21/mV21NZEDZMWTY/RGINWs5/Dh5UlJ994gze3baMBgP388Y+bcQWMSr2XYCbQ1YXMsyTOJclAirOkQqPTElKrOPWjV0VM7ERu/Px8vvD5Yh4HLAUFFKQsYrZGjQoVGq2G8Cn7LuP2zEcoLv4WmFOYestP+NvKDADiildyS3M9v/vVSv7na8C0z/HkvYvISTAAi3hw2d0UF38HAEtqPrf85HmmA0xYxuf8bh79/R0Uf7sDgGmf+wP32XMxn7+LI4S4qI3jxhvr+PkPv8k9X6jAA8BCfrbjy+SjJmBeyPKFf+WLxUsoXPBp7nnkDhYtmsfRQ7/lv5b8CoDUFSsoiLViU6lQsYQvf+UxriueTmziKn7x5r3MGzuLpYt28IPbivkFEDdzJgUJxWSq1ago5iuzHuX6239MeZMSgl716/0suUBXQ3w8qZYsWRK22+088cQT+Hw+2tvbeemllzh8+DD33HPPhS6fuGhs4rvT13L53l9z+YUuihDA9OnTCYVC7N+//0IXRQghLoiHHnqIwsJCrrvuOuLj49Hr9dxxxx10dHRIE7YQQgghhBgdCSDFh4SVnCm5Q/ROFEIIIcSHjdwDKT4kpnPXU9MvdCGEEEIIcQYkAymEEEIIIUZl2AzksWPHeOaZZz7IsgghxIdGIBAgHA5LPSiEuGiVlpZSWFg45LphA8jdu3eze/fu81YoIYT4KHjwwQcvdBGEEOKCWbVq1ZDLh78HcgIw+zyVRgghPuyeAcLApy90QYQQ4gLZNfyq4QPIXODqc14UIYT4aPgHSgAp9aAQ4mLVMvwq6UQjhBBCCCFGRQJIIYQQQggxKhJACiGEEEKIUZEAUnw41QO/uNCFEEKIi9R9gONCF0J8mMlMNOfCKyg3219zmu2agYeBn5z3Ep3qJPAf4LtRy54FMoDF5+gc/w20Rz1OAn4Q+TlaIaD7XBTqLJQDjwEzgBujlv8R2D5o26dQ3kWtwK+Bh4Y55j+AjYAn8vheoABQnZMSCyFEv18DnwDGv49jOFA+14QYhgSQ50KQ/jdaIPIzHLVMF/npi/qnpv/qh6KOoYosV0Xto4msV0WOFb09kfWaqPIEItv0rlMPc+6borZXMzAf7Y8qX3DQ8aLPFc0H/C9gjOy/CSVI/XpUmVWR37WR8wUj/xh0TaKFI/uEop5Pb5kGX7Nw5Pn0nkdN//UbfE2GCt58QGPkGF0oAXF81DX5JtA74+IrKAH5b6LWD+V5lMr4p0BqZNn9wA8jZQkPUb7eazz49TT49dG7b/RxerfrfZ69Zeu9JgD6YcoqhBje4Lq19306uA4f6b0HSj2u4tR6EU6tn6LryN7PgF7R5+2tw0OAN3JeX9S5Btczg+vb6DpV2ibFGZAA8lx7GOXNV40SgPiBu4EslCYBF3AXMBP4IkqF9A6wHugAYoGvAHmR49yGktncgjK00neBvcBzkeMHgFuApSh/TS/wf8BulMrgamAu8CuU7NddwBLgUyjBnQUlYLoUGEd/sHk38J3Ic3oCqAAMkX1XcvoARBs53tbI497naEPJ8H02cg3WRNZ5gcJI+YxRxwlFrsv6yHO6GSUz+AqwOXI97SjBmC2y7Xcjx94DXAJchpJ9PYJSkV4auS62IcrtiOy3MPL7fpRrO5TLgH+e5jr0HnM8AzOx90V+hlGyl/+Lcl30kXNfH/n9ycj+rUAbYI7sa4/s3xzZ5o7I7/8CGoAYYDUwD+Vv8SOUjOcelNfkX8+g3EKIfl7gaZR6CJQ6ZCVKHVWG0spQByQCq1DqIA3KF8d04DBKHRxCqV/zI/s9AoxFqZ9CKPXTNSj1kxeljtmJ8r5NBu5BeX+HgOOR89ZHjrEapc49DJyInP9/IsdyAn+KnFOHUo/ehlKv+4GXgbdQ6v+ZKJ8vQoxAAsjzoTdoTAQOoVQQDwMPAr8Ffh617VGU4OxzKAHUe8Ba4DNAXGQbHf0f+MdQgpr7AGvk8SaUSmEC8DpKkPSHyH5vAykoTcn/Qql8ovVWUiUozdmxKM201si6fwGTIvs3AG9G1i8Z5rnXoVRIAeAAShDZKwhcCRRHHr+FEgA+gJLlewolW3dbZH0IqAU2RPa9GyWD9w7QGfV4E0rz8t1R++UAX4o8XocSKP868pw2Rp7zYCGUYK0NuAEl2KpF+Xv2futviywD5dpOHuY6RMtCqejjgQSUd10ySrDuRwmOCyPlbwLeQPkQWBbZ349ye0A68HuUD5MrUK7xHpRgMoDy2lkOLIicbxPKa7AochwfyuvPcAZlFkIM9BrKe/YRlMBsc2R5G7AD5VagS1Hq530o7/X8yDY+lHrfjJIAeBL4WWRdCCWY+38oX+ZfBEqBOSh1ZAAlAWAGXkX5LPg6yvh876J8wV2MEjDqUD5LmlGC2OgZ6Nag1EXfRfmi/Xrk3zUowasD+EakzGuR5mtxWpKoPh8uR/ngBiXAaBph2waUAMGDEgxagUqUCgeUYPDmqO0LUIKbhsj2oARTvTc7H0bJYPU2cw6XPYs2D6Xi6ok83oHyTTaAUpElR87VhVKpNI5wrMeBP0d+VtMfBIFSmRVHPT6Ocn2skcdX0//tHpRK7lWUCvY2+pt/y1Eq09ZIudJQAvVecSiBavRjH0oleQyYglK5D+aLrJ8ROVcBSrBVHbXN+sjz+3Nk228NcZzBlqMEtC9F9vsjynPvbVI6HDnfMZS/pRolo9BrEUrwSOR57Y/8HkQJ/C9D+ds0omRvj0WO7Ygcr9f1SPAoxNk6jPJe7G1ivjSy3InyPuu9taUAJZBrjdp3JUqdBUr90xy1LhOlzgalHjAC7sjjoygJgGqU93V2pBy953UA0yKP81HqmeHsjaw/Fjm/kf66rRalhSQz8ngBypduIUYgGcgLzYcSTER3Pklj+A/6dpRvjSfpz4pV0d8RpgeleWM0nTOyUSqsepRgrQ4l69iFUgluGrT9vBGOdS9KxRRAmQLpGfqbwgdzozzP3q8xsQzsOOOJlKGAgfcPuVEqwYqoZVNGKNM8lGBrC0qwngJcx6mde7womYOJKJk9B0pFW4PSPATKtHbTGb0VkX9Ejv1nlIwoKH/TzYO2H24a0XGRMtVHytuO8sFRgvIh8Oag7eMQQpwLw9WtQZR63BR5rEepr4a7J3o0XCj1xeGoZb11Xe95jYN3GkYnSh0YrbcFxRs5Tu9nSgySXhKnJQHkhZaA8u1zEf0f9hUob+Ch1EXWfzWyfTPKPYq9xqAEV6ko35RrUZotTmcySsAXoj940aBUVitR7r8EJWAJDt55CGr6m8eHkxkp31iUb+f7GNhrMAP4JErm7m2UZnM7SjZuHEoTT+91Kh3hPO0ozfsLI7//IfIzOoAMoQSKvU3UtVH71vP+eoRXo3yb7+2Mk0p/hlmNEqyvQvnbgVLRj3Td5qJcExXKvUqgXIdZKNnOtMiyBvqzHkKI9ye6blWj1MWZKIFjb8vROPpbaIa6x3q0slHqxOn0d6A8GVk3+Ly9rRfWU46iKEJphSiIPO6mv15LipS7jf4WJ8/gAwgxkASQHyQdypt7PcqH/DSUzjKtKJmj3g97J8obeqiOKrEowchbKBWIg4FNyvNRgi03/ffYZaFk+vSRc+egZNmiTUZpPm6l/95BPUpQshklwwVK4JPH8EPzvI7yquq9f3HmMNuB0lS8CeWePz1KJvaKQduMQRmOYgNKx5n/396dx9ldF/b+f5/Zl0wmmclOFgiBABEx7BAtMSgWRVpcqtbaa4u93vZXru1tb3+29vZWrbX3Zxf7614VvXVr64LWpYKtVGXfQSGQhZA9JCGTZSaTWc45948zKVsS/CAQc/t8/sODc+bM93POTL7zOp/v5/s9L08jam+d2NbB12hPnrze54l2TIy/PY+fdPPUsDo4Q/kTefL6zrVJbkzjsPmztTWNCD04q7wyjedx8IzqC9N4jVdO3D+axs9o5mG+3/lJPpzGc79s4rb+NH7O1+fxE2yG0/j5He4PCvCDe2ka+93hNP7tjqcRkFPSOArw3TTWIT42cdtxz8E2z0/jjf2OPD4jOJJGBE5N4833we2OprFfn5zGm+x70thvXZzGvucVaezjVk98n/E0YnHOxPfbNvH8Jk9s70hvYiEC8rmxOI8vOD4vT//D//qJ/05KY4ZobR7/Iz8zjRm/e9NY85c0AqnjKY89aE4as5Wr0nj3ODvJq/P4zuqUNA61PDwxpoOHOw7OdK7P4+8sn7j+cHYah8H3phGISSN4z0zjt+RgQM3K4dfZvCaNQDvoiWt75ufpa2oWTnz9wedyTpIzJu7ryeNrjBal8bo9kEYQHz9x+315/B30wcPqnWmsQX2iOWmE8cFZxRV5egA3pfHaPTV456bxGvSk8bOdnUM71HYPenEaO/eD6xrnpjGre/APwtI0ZnsPzizMzOOzkUvT2Mk/0fw0Xo+WPD673JNGkN/3hO0szONrcS+O2Uj4YRxu39qdxr+9pBGP09LYjx1cZ31RnjwbWcmT3/gte8p2zsjjfx8OXhnjvjT2fU15fF83KY19Uz2NIyUz8vhRjovy+P7x4PKfg/uZg2vn+/L4bOTsNPa/90885rSJMVszzRFUli9fXp8yZUquvvrqjI72WzOAAAAgAElEQVSOZteuXfnyl7+c3/zObzYutQLwH9HPpPHH+dNHeyAAR8knkg8s+0CuuOKK9PX1pa2tLVdeeWUGBgYskwUAoIyABACgiIAEAKCIgAQAoMjhz8L+VhofkwTwH9HBa3W+86iOAuDo2Z+nXylgwiED8jWveU0uueSS53FEAAD8qGttbT3k7YcMyJaWlrS0uEQkAABPZw0kAABFBCQAAEUOe5x6eHg4Q0NDR3xwpVJJf3//Eb/mcGq1gWx8YDBTXzTvBfio3r3Z8L1d6XnRgkytVJ73rT0XBgYGUq1Wj/g1nZ2d6e5+Np9PN5Ld2wZyoKkzU2f0+rQqAKDIYQNy06ZNWb9+/REDce3atXnDG95whG8/mh1rH8rDWx7LcDVJOjPvJWdmYW9rxkduzl9ddVtee/3vHu4En+fQvfnbd34ly77zwVza0vy8b+25cNNNN2XWrFlpajr0JPGePXvS19eXF7/4xYe8P0nq9aE8fPvt2bg/SZrS2TszC09bnOntj+b2f/pq1raemst+7uWZ+/w8hacYz95HN+bh9Xsyef7CzJ81eeKXb3fW3L4yW4ZGJj6ytZKWtlk57cLF6ctY9j32aLZvr2TGqcel5wUZJwDwTI54pszpp5+e5cuXH/b+97///Ud49Ei2r74lX/ncN7N653BqLc1JOjN303he95YLMuPZjfc/lDe84Q3p6Og45H133HFH1q5de4RHD+ah6/8+f/ePd2d8cncaATk/Zx5ozfILjsIJUmO7cv8NX8xff+LevOht78zPXrEsM1uTZFW+8P4P54ET5mRGe2sq9WT/5pEsafmV/Kdzp2TD967P17/RlMv+4K059YUfNQBwCM9jSTyWe77+b9nQc07e/s5Lc0p/W5KB3PLJG7MvyYwk9bED2Xjbl/KpVYNJWjJ17uIsPW9p5nQ2vsPOB2/Mrd9fl4EDSWaflTe87OR0tA3mvq/dmNaXvTqndg9n5yPfyz3rKll84TmZ17wjDz64NfXeOTnx+GlpO8zIxg8M5aEbrsnd25J09ufE08/NBScfnGkdzvo7b87dq7dkcDyZtHhxpq45kOPf/NIsOEYOfzesyRfe+4V0/8Gn8p4L+pOMZdfGdVmzameGMytJMrzlgXzna9tTGxhL0p2TfmxFls7tTVtTUq/XsvbfPpNbNidp68nsUy/IxadPyc51a7Jlb1Nmn3JKplc35vabHkp94dKcvqA/nUMr8/XvjmXZa16c3qeMZmjruqzevCcz5s/K4NbVWbvljMxcMGni3pPzuvf8ei6b0Zum2ljWfuO9ed+fXZeXf/KnjvD8tueea9elPnVnHnp4d8bH6zn+ZW/JSTu/mm+u3Jf2ydNz2vmvypKJdyq7H7k3d937vWzZl6Tr+CxbvjTz+7rTnCQbvptPfWd9kqS1qzenXPjanDEryeC2rLzvjtz58O4kSf/iZTnvRSekrzNJ9uX+a/859+wYTT2VtHctyrLXnZc5SeO13vBg7r7t3mw9kHTMmZOp+ztz3JmLc8KcvrQn2Xjz5/KdtSOppymds5bmklec2phh3b8za753W25ZvStJ0rfo3Jx9+smZ8WxWKgDA8+R5DMh6arWmtLS1pPnfjxpPzflvuyxJMppaDgyvzrf/pSen9UxOhgayZtW6bG/tz5uXzU99/Z35yrXXZ/uB1nR1dWXDfZ9Ive2q/PSyrmy8/uNZM/fVOfWkvdlw42fzl9d15OdOPCfzOtfm9tsfSMcpr8jC4w8zqupYNt3y+Xzym/fnuLnzMrRpUzZs3ZmOztdn6byuDK2/LV/65+szmEmZ3NuVR677aO76XEf+85uWHWMBWU212pbujoMvfmv65p2cc+clyYZ8L7vz4P2bsrtjYaa1tSdbbs4ndrRn+jsuzgk97Xnstn/I33z17sw//vgcOLAtqx/ZlM6ut+S4Ld/PHQ+N5LSZp2T68D354ic+ngM//jtZMKs/neuuzcevPynnv+aph9WHsunhh7JxW0cueO2ZWX3D/Vm1ZlPOWHBKnt5FlTS3t6elVps4pH04m/KdT16ddYtPyPwp3Wl5+F/y+bv35pUnVFMbGczue27K94cX5jfedFKatz2U6//1ujywdSSTe3sz+MDKfHos+S+XnZtp3VvyzT/7eP6lZ2nOmppkYCjVm2/LjCuWpPbAjbnuK7dm29R5mdOZ7L71zkydMSkvWTCSOz77r/n+Y3szVk/q1Wp2PXRr1s+ak1+/cF5GBzbmtuu/muvvH8ncef3Zv/nerPy3/bnwt345s+f05cD3vpq/+fKtmTFnflKvZ/f9n82url/IL1zYn0fX3JLrrrk+j0w9PvO6koE77snk/p5MOml2up6D3woAeC48jwHZn9NfcU4e/qdb8tk/uSutHS3J1DPz1p99eeZ1NeYGm9sn55RLfi5XnT0n2b8u3/r8l3PLHSvz2LJp2X3rd7OxdXGueNNlOX1WZzZf9zv59WtuzSsvuCJnnT01/3DHmhyY05xtD69KtfMlWbNma3b1b8lwpZLjZs087Ikh46PbcvtX/zXdl/5Brrp4TvZvvitfvubruemOR7J43oI8fMud2d2/NG943aVZMrMzm699T2665sgnE/1oWpTL//tF+czH/1c++I3JSUtP5r5oeX7y0hdNrCWspHfhuXntW9+Qs2dNSrZ9Jf/tV+7Omrcsy4Kewdz8qb9P7VV/nqsum5eRXQ/nW1+4Otd/d31+cVl/KqvWZsuWXdn62Jo0dVazau3W7B86JWtuvzNTz35z+p46lMHt2bx1Z6pzzsmF55+e3nXfzz3bNubRfadkYU+SrMs3/vzDub+zLZV6PXtWb8uSK9+Y+UnWH/E5NmfamZfnHZeckp4tnfm3y69LPvPRXHXSeFZe/+l8/F/uyLY3zUtl5Z1Zu7sn57/5nbl40eQMrft8fvcPbsvKC0/LBd3rcu11q3LSR67OVecmo0ND2bJ6dZozmI2b12Tr8HG59P+5KhfNTXasXJmhSU2ppDntXbNy3oo354wZ7anURrPuhg/nDz/57Wy48E1p27AmD2+q5ey3vStvPH1qHrv70/n/7r4l40mS3bnrmi9l90t+Ne/9qdPSVB/Nuhv+NH/06e9kw4U/nt2Prsn63f15xS9elUsWJI+tWpV9vc05lt66APB/v+cxIDty3OnL85NNU7PykW0ZHE8eu++6/PFfjuU3fvXVmZamtLUvyNlnNw76pasrk3omp3vrcEayM4+sr2b2ormZNq1xPPu4ZRdm1h/dltX1n8g5552frj++PY+8fHpWbZ6XC146L8P33pK7TxtNW2tvZs8+/HnF1eraPPjgrJz/3sZ2u2bMzHHTp+fRDRuzK915ZH0tx50yN/39B7f70pzU+q3n72V63vTmjMvfkdZJ12fNYDI2uDvrb/1cPlWr52de05ukNwtPXJBZsyYOI8+amdmjI9lfq6We1bn9jplZ/sF5SZL23t7MO3Fh7r5+TXa/cUl6WzdmdNvdueWB4cx76QV57LsPZe2+E7Ljns6c/2tTnjaSfdu3Z9uO3Zl7zjmZNWVKOs+cm+/e+mi2Pbp3IiC7M/ukxTl1cmeaUknrma/O2StOyaQMPMNznJlTFveltbUpWbAgx1cWZMmSyUn2pX3a9EzZP5j92ZvBbeuz+oZ7s3rLI/lma5Lsyqrvt2Xj2FjOzal58++9Op/+i3fn3V9MOqbMzLI3/mpemeE0nXV+lqz9Vr7ywXfnn3uSecvenJ+c25/2JOe8dF3++i8+kH/cP5p66hkdfjQDW5Nt2Z+e3Y9lZGROTj5papKk/9RTc+KsRybe1GzIffdty7bNV+e37mlNZeKxu7ZW8mgmZdGSc7P0gWtz3f96d741OTnu3J/Ma1ecnM4f/hcCAJ4zz/PZFB2Zs+S8zFnS+L/hsw7k9rffltXv+vFMO+Lj2tLeXku1Op7q+MQo9+/PUGdnJqWS5tmXZFnT+3P9zYuyasFl+aUlldzw5a/k2jUX5cwTF+X4I6wXq1S609k5lP3DSbqTVMczXqul3t6WtrSlva2W8fHxVKsT2x3en/31+nPyarzQKpXJWXLxT2RJkurI9tz59c/kazc+kEdfc8EzPHJSJnUPZmgoyaQk1WrGx8Yy3tGR9u7js6j/vty/5tpcu2dhXrv8pZm74c9z983tWd30svzO7Kee5T6Y7dsfyM1f+2423/FY7vxUksGtWbltTuaedV5evChJZuSMV12ay2b05rk/R741rW0zs+gl52T+y5Zm+sStl1wyNSfNnJKWtOfs174j7d3fz47agQysuTHX/u+v5sT3XZaF88/NpT81PSev2ZahvffnW9d/Kzcf159Lz9yff/7DL+TRxRfnFfM7UkktQwN35dpPJklzWppb0tw8ktHRJB1JRkYyMj4+8dw609V1fC64/BVZ2nnwjU5zOnqOy6K0Z+qcs3LJG/uz8MHNGRx8KN+94YbcOHN6+pad+AJc7goAfjDP44XEN+XbX742N9+1IQcmbtm78oGs7+pK7zMekOvP4pO7smbNQ9m8uXECw31f/qfsOfucLGqqpKmpP8dP25jPf+72dJ60JPN7p6Syb03uuHdNKv2zjjhb09JyYl5yxu587avfS5Ls2rAhqx5Zn+5Fi9KXaVm8uDOrVj2YrVv2JEnuveZLeWhkJMdeQt6RP3v3F7N14v+qQ0PZsX59dnd3/wBr6RblouWD+dzn7kqSDO7cmQfuviftpy3JjHRlVn8la+69I2v2VTKld36WnNSV2z/3+WyacUL6n3LZoZHHHs0Dd9+fpuW/lPe86+fz8z//8/n5//qe/OKK1jx07wPZsnPkOX7eT9WTeXP7Uu9qTmffaVmxYkVWrFiRmY+tyZaRoVRzV/7iL9bl9BUrsmL5j+Xsk/uzb9267MlAHnjgvqxc353zVqzIimVnpHf/QB4b3JexDGT1fdsz5fQLs/zlK3LRS5el9aEbszlJ0plp02emtXVT7rxzQ5Lkkdtuy/fXrcv+JMn8nH9+Jbes6cxFy1+eFStWZNk5Z6Z5ze3Zlj1Zs+ae3L2yNeeuWJEVy16SaeP7smvPnow+z68SAJQ44gzk7bffngceeOBZfuvpecmLWvLJj/x+/vh3t2QkydieWfmJ//89WdzSlIkFYYfRmjkve0su2/xH+dh73poP7G/O/nmvzJ/8v2dmUlMlSXMWXnhuem/YmrPOmptJ08cy9/glWbipP/NOOPKFzZtap+Sst/5a7v/Qr+byL3ZlvHtOzv3xt+ZdF8xOS1py3I/9dF676Q/zN7/503nf/ub0nnd6Ts7wUVmD9rGPfSyVw5y4Mzw8nLlzj3QFx1Py+tfckt++/PLsSFIfb8u045flZ997UWZkIPcfccsdOeOdH84l7/+FXH55d2odfTnxx96S//HK+WlN0n/CvPRPXZglc+dm+oxJmXv2WZn68Uey5MKFaW5+YkCOZc9jm7J5Y2eWX/nanHXi45ckWjJ1U77/sa3ZtKMpYz/wK/JstGTai1fkisEv5JN/e1U+uqkRrIsu/Y28q2VyWnJyXjf7D3P55R9IUktrZ0/Of/uf55T0pN5Vy52f/2A+9KEtSXV/+s59Z3554cL0pJZ3vOPEvP39P5d/rVVTaW7O1KVLszBJ0pzeE87O8vM25FN/959z+Z+0pevkBelqmjkxg9iexT/97lz1md/L66/4k9Tq9bR19+WiK/8wV6Y7TZ0tufu2P8rlf7oxqQ5n6tKfyS+cemqevjAAAI6eyvLly+tTpkzJ1VdfndHR0eza1bh8yPj4eMbGnvlPe2fnEeb7qiMZ3DeU4dHxiRm8tvT0T05Hc1NSP5B9j42lY1rPxOV2qhkdHsnoeCUdPZ1pSTK2f2/27T+Q8VqStkmZNrkzTU2VpF5PdWwoe/dV0zGlN52V8YwM78+BanM6J3Wn7WnzqiPZu2MkbdN60lGppF6rZnjvYxkcTdLUko7unkzubP33rx7bvyf79o9kvJY07/p63vXbe/Lb//hfc0rTC5eRBw4cSP0ZDp23tLSktbX1sPfXx4eya9dQGp9nU0lLW1d6pnSnNdWMDB3IeKUlHV3tE4dWRzO460CaeydN/HzqObBnR/aNJqk0p62rJ1O6Jy6MVBvN0OBwqs0d6epsT0t9OHt2H0hzT2+6W5vyePPWUx0bzYHh0bR096T9icenqyPZNzSe1s6mjO0bS2vvpLQ3Nz0l1GsZGzmQkZGkfXJXnvxMRzM4MJLmnq50tDSnkpHs2X4gHTN6055axkdHMry/lo4p3WlNUhvdn8HBoRwYb7ymrd1TM7mzNc1NSQ7syfa9jbCsNLWkc3JfJrUlqY5m/9BgBg803u20dE5OT1dHWpuTjOzLzr3DqU38iFo6u9IylnT0TUrjocMZGtyXA+NJ0+Bd+chHV2XJ6y7PK88+Pp1JxocGsmuo8e+rUmlKZ++0iW2OZXj/vuwbnthmR096ujsb2wSAo6Svry9tbW258sorMzAwcPgZyJaWlrS0/JBLJJvbM2lKeyYd6r5KRyZPe+JFspvT1tn1pGs3tnZNTl/XIVZ+VSppbpuUqf8+2diS9u7JR/hIvvZMnv74vZWm5nRNmXGYQ7kP5ts3jWbx4kWZN68rN179uYwse29OeoGnIA93AfESlZbu9B/yAoLNae/ufsrr1ZZJfU949SuVdE6ZcejlAE1t6Z78xJ9UZ3r7D/WVlTS3tqe79RA/meb29Exu3N7Rd7g3IU1pbe/KoR6etGXS1CeOoT29M9r//XEtbZ3pecLdTW1dmdzXdeh1hB29mXGol7u5LV2T+3KoX8G092Ta9MN9Ns72rH54XQYGFuWCC/rz4A13ZufkWZkzfXoObqale+qhr+3Y3JrOnr50+tgdAH6EPY9rII9Vp+TF+Zf8j196RZYuXZpfvumi/PY7XpTmY+oakBxdM3JcZSi3fvKnsnTp0rzlrx7Ni5ddlCULul2OB4D/KzzpEHa9Xn/Gw6YAAPzHUqlUUqlUDn8Iu1Y78ud/AADwH0tz85MX4z8pIOv1uoAEAOBJmpqannRlmKfNQFar1Rd0QAAA/GgzAwkAwA/FGkgAAI7oqSdZm4EEAKCINZAAAByRGUgAAH4oTwtIM5AAADzREWcgD/UFAADwRD4LGwCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCICEgCAIgISAIAiAhIAgCItR3sAAD+s8fHx7BrYkx07tmf/0GBqtdrRHtKTVCpN6erqyrQZM9I/dWpaW+16gWObvRhwTBs+MJINGzZk+MBoJk/tT/+seak0NR/tYT1JvVbL8P6hbHt0R3YPDGTB/Pnp7Ow42sMCeNYEJHDMqlar2bJ5cw6M1TJ/0amZPKUvba1tSaVytIf2ZPV6xsbGsm/vzGxctyobN2/OCccvSGuLXTBwbLL3Ao5Zu/fszeCBsUyfPT+T+6anUmnKWK2epP4DfodHcv1fX5c9J56Ti165NFOfz8E2t2TSlL5Mnz0/WzaszcDA7syYPu353CLA80ZAAseswX37Uq1X0t3bl2otSQ6z9rG6P9tu/XB+49f/PtuSzHjJZXnbr/x+XnXycAYe3Z6BvqEcqNYy/gKMubu3L2lan8HBQQEJHLMEJHDMGh0dSSqVNLe2Z7x6mHisV7P7rj/P//y9obzjuptyZpJH77k7q+77h6w68YzUavVUa7WMv0ABWWluTSpNqY6PvQBbA3h+CEjgmFar1Q8fj0nq1ZF8+9OfysL/fmfOaW3cNuec8zMnScZX53v1emq1WsbHqxmrjeemD706v3/NmgyOVNK86Jfzkc++KwtbmlKvD2X9rZ/P3/7O+3LTjqReOyGv/LV358q3vSKzK7fnI2/7QkZOvi9f+8aaDO9/Rd5/91/mZYcbc/0HPcQO8KNJQALHtFr9yAFZHftGbrvl4rzyg7WMV5/26FTr9YkIHc+6z/23/OXgf8rHvvG69Pe05+GP/2R+7bcX5TMfWJ7t3/tirvn0prz6k6vzvmnJ3ns+m7/6yo2545ZFedW5tdTqd+S6x96W//21n0pfT3tyhBnNWq2e5EfsRB+AAgISOKY90wxktVpPPbVUDxl0tdRqEzOQ1Q2547Y9OePcWdm2eX12NyfV8y7NSX/37dxRvTTnnPqm/Nz/3JmdO1dl7UCS7v7MGl6Z7Vs3Z0e1ObX62Xn7f7k47V2tRxxPcnAGUkACxy4BCRzTnjkgJ6dz0u7s3V3LeM9T762nWm+sgaxWB7J790Du/ccPZeWX2ibyrpLOUy9OZ3UsQwMP5tYvfCzXfHtDai1JMpzdW3tz4Tk/nvHqxExmtbGW8pmuQtmYgQQ4dglI4Jj2TIew6/Vzc87LP5R/u+aeLH79izO9IxnZuydDw/vTOfOJh7DnZN4JL8p5512R15+7JF0tTanX6xlYuyrN1aFsWXdjbr21K1d86B9z4XLaLUQAAAJySURBVPRkeOdN+cqffjXjtVqq1aSex0/GecaAtAYSOMYJSOCYVq8nR5zQqzRl8avenrs++tF8sbIii6Ymo3vH0j5zQV40oy/1eiP+avWpWXzRotz27W/m2ztXpa21OfVaMrhlNKefuCCTu2Zl2pTv575vfSnDk5O9W+/KfWs25YTzG9uv15N6vZ5a/bAXE3rSmAGOZQISOGZVmpoa8VcdT1PzYXZnlaZ0Lbg0b7yyLV+95vas2pJMmnt6zjr13EzLjsx7ydJMmzErHUm6l/503lb5h3z5uyszPFpLpbkli1/7WzkhSY47Py999Y5847b7sipJx7wTc+5l52Xe8TPTnkoWrzg/PZO7f4DD19VGQf6ofVoOQIHK8uXL61OmTMnVV1+d0dHR7Nq162iPCeAHsnHTlqzftit9xy1KR/fkoz2cH8jI/n3ZuXFV5s+ckgXz5x3t4QD8QPr6+tLW1pYrr7wyAwMDaTraAwJ4tqZM6U1XWyX7BrYfExfmrlWrGdy9Mx0tyZTe3qM9HIBnTUACx6zurs7Mnjk91aFd2blpTYYHdzcOEf+IqdVqOTC0Nzs3r83Yvh05btb0TJo06WgPC+BZswYSOGY1NTVlen9fWpqbsmnr9jy67v6Mj439yJ2kUqkkzS0tmdLTnbnz56Svry/Nzd6/A8euJwVkS0tL+vr6jtZYAJ6V6dOnZ968eRk5MJJq9YX4ROtyTc3N6WjvSEdHe5qaxCNwbGlpefKc45P+r6mpKW1tbS/ogACeC+3t7YllhQAviMry5cvrlUolU6ZMOdpjAQDgR9ju3btTr9cbM5D1ej0DAwNHe0wAABwD/g/atguhqyBdLgAAAABJRU5ErkJggg==\"/>'''))\ndisplay(HTML('''<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAu4AAAKHCAYAAADe5s1YAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAN1wAADdcBQiibeAAAABl0RVh0U29mdHdhcmUAd3d3Lmlua3NjYXBlLm9yZ5vuPBoAACAASURBVHic7N13fFxXmfDx3y3TR9KoS1axJNuyZctFrnGL7cR2SJxegABJYCFvaMu+wC5sIAnvBnYJhCwsoWwIEEgCqQ4kTrGdOLEd997lrt7LzGh6u/f9Y0ayZBXLPSbn+/nYkubec+6ZmXtnnnvuc8+Rrrn9fh1BEARBEARBED7S5MvdAEEQBEEQBEEQzkwE7oIgCIIgCIJwBRCBuyAIgiAIgiBcAUTgLgiCIAiCIAhXABG4C4IgCIIgCMIVQATugiAIgiAIgnAFEIG7IAiCIAiCIFwBROAuCIIgCIIgCFcAEbgLgiAIgiAIwhVABO6CIAiCIAiCcAVQz7yKfvFbIQiCIAiCIAgfe9KQS3sF7oMH6LqI3QVBEARBEAThopEkGDwejwf0KugiMBcEQRAEQRCEy2joeFxHkkA9t6BdRPqCIAiCIAiCcO6GTos5na4netz7PjrUnyJgFwRBEARBEITz1x1Xnwrg+4Xypz2g9inX8+sQAbqI3QVBEARBEATh/J2W166ftlDS+66bSJUZutdd9LsLgiAIgiAIwoXT/17U07rXJb3vYl3qlSrTs2SAqH+AZYIgCIIgCIIgnJtTUXUiYE90r0t9VpB6raKj0qvHvW983j9Ijz8sgndBEARBEARBOG+ShHRaJ3pP+J4I1k/1zEuoOnq/QF3v+99peq0nYnhBEARBEARBGDapd0aMPlC0LYGk9+S3670eU7uj74F70wca4/1M+fCCIAiCIAiCIPQjDd3x3RPU9w7ou3vldVBPD9j1PrXpp3Xbi6BdEARBEARBEM6Jzmn3oMYf6BWv9yFJ8Ug/nikj9epx7wnY9V7x+qk0mr53tYqIXRAEQRAEQRDOWs/w7aeH66eN596rd747gFd7B+y9h4bseXzQ3vjTty4IgiAIgiAIwuB6dbcn4mpJknpltkjxn5LUE2JLvQJ4tU/Arif61gfqhe+pf7B0mcEGjxcEQRAEQRCEjxdpoL+k06PkRKDe/buuxwN5XU/ktvftoI/3uPcK2E/lvPftge9Z1rP8FBGoC4IgCIIgCMIpp0fL/SZckhJhud7rd3r/pOf37kd7UmXiAbw2eO97fKXTmjDgGDaCIAiCIAiCIPTSPZ9Sz62o3TG2JCGdSmYHPT70Y/wngNwTz6tqoKlXbefQAEEQBEEQBEEQhkU68yqDFlIlXbu0GxYEQRAEQRAEYfhO3ZwKqtHM2MV3Xs7mCIIgCIIgCIIwgCNrlhMNBeKBu/CPSMZsMaISIxCIoEkKZouKFIsSDMU49+ssVyIJRVUxGWVi4QjhqCbSvK44fffn2OVuzpnIKjaTmrjXKEYwoGGwGhLHX/QyH38SqkHFaJCIhaKEY+J4EARBuBS0WPzbS5blvmM8Eu9Q13UNCQlJlgetQwTuZ2Iwk2E3okgSAY+brkjvhRIGo4kkuwlDz2MxfJ4Avkgs/mUom0hLMWNI5BVpsQgej5+gFi9vNJlJshl7vREaAa8fTzh26svUaCXbbkDTYvi9XnzR4TQ8j089cC0VUhW///kG6tPGce8/TcF8Yj8vvbaPmnN/RU6jYLVbsBl1fG4//ti5hAAK9hQrVkU+dQ+1FsXT5SNwQSIcK2MnTeW2azOpeX8bb+2sx3khqkUlyWHFIkdxd/oJnUP55FQbZsK4nAHCSKhGMw67EUWPEQgE8QSjV1BQ1Wt/1qJ4fAECEQ0dCYvdjt0gI0sRXOf0WvXen9dxoNc248eggVggiLcnqFewJVmxGjS8Tj+BAeegGMbxe04U7ONm8b3FJcjBAF2hWt58xc38r80kreEQf/nrTk6ec91nT5aNpDjMSOEQXd4QUZKYOGM6N81NpvKtLaw61EzXJWyPIAjCx5W/vQGDqqImZ6Cop755dF1HCweI+NzIRivGJMegdYjA/QzMJdP51tLRJJsVDq16jt/sCyeWyJit6UyZMp55U7JQ3UEiyFiTguxcvZN1J9vxmWwUFE7k89ePJNLhJyarmExhdq3ZyMZ6F+6IldETpnLbtSXY3V5cQYkUh0L11o0s391ARzgeOqRMWMjDi3MJeV1sfvcNXj0eGbzBA9KJRgI0N7ZjPKegaSipzFkyh8WjI6x+Zj3r230M67yijyyW3HY1V2cacDW58aFiS9bZvWo96+s6cYXPXMPlkc2yuxcxx97EHx5fw96zLp/Lbfd1B6PrOZKUSUX5ZG6amY3WXseWPZWsPdhK4CK0/OLo3p9LyQ00s/K9bbx/pA2/7GD+9Uu4rjAJk1zN0+f0Wg3GTOHoydy1LJ/WjTtZsamKNgDSWXjjfBbme/n7bz5gky98WiA+0PELJluIXe/u4sOqdnzn3KYslszMx2LysvL5N1jVGcNkLmRMYzuBdi/B83m6Z00hOXUM9/Q5aY/h87ipb4zSEQh/9K9eCIIgnI8+o7Wc+iYwECUiGQZcT+81MdKFbIdsTqI0J4mTTR1ErQ5UgzEetEeCpJkkFFs6zd6hoygRuA/JRHlJNoaIm/poKmPGjcK+rxIvoFocTJw5nevHqxzaspHVuxpxYqS4PA+TJ0wMhdSx0/nqwgKCJ7fyv28ew2tKY8GyJVy7dAGmte+y4kj3djwc3LmNtw7CwptmMnfaGIqOduAKB4hhYdq4HGLeTpyameLiPCzHqwcJ5oxk5qaRblaRySClZ4fTCAZa2bopiOL34EbBnpxMdroNEwBh2lucdPg1krMzybaqyICu+6mr7sSbqEU1msnIyCDNBBDB1eEnZnKQbjWioJCdn8v4JBc11e24z6m7soW3XlzDTs3G3Juu58ZPXItt7du8ctBHFAmLPYns9GSscu82R4hhIrcwnVQlfmlJi/moq3UOEHgZcKRnUloMHkK0Njrp7ElbUMnKzyHDAKATDnloaOyKv86qmcy0FDJt3Qd4iNZGP8bMVByKDFgoKM4nlNhuyGglOzuNFBUgSpfTTasrwODnHxJqSjazZs3kjnFWTlYeZO323ex3qiQ70slLVfG2uWj36qTmppFujtJS24EzZqagOJ0kerW5JYDRkUpesjFRd4TONhft3lD/EyrJSkFR2qnyQR8trS48MZVkRwpZqRaMp5fpoeNsaaDJP9CyGFFDCqOzU9lb2wGpRYxLUtAlvU/wrBrs5OU7sAHxK00eWjo8+DUDaZkOMuymxAdUkKbavpcNT5U1MSLTjhmV5NR0xhT7UdpctHsZUvz4ncGyciOHt27k7e2NOIGsUQXYneGeXvv03GyyzPErQbGgm5NNHiLImK1J5GYnYelVZ9Tvpr4zgi0jlVSjgkQUS3oeZcleGus62L5pH8aQJ3G15/RjEOjZJxWyC9NJVULUVXXgU2zkFzowhjw0NHqR7MnkZNoxA6fe3+59I37sQpTW+mY6NSsj8h3YkDFaUygpzkXv8uGsq2a9V8Xb5kucyCuk9j72w12caOgijITRZGfEiBSsvZ9rwENTZxee8JVzPUgQhI+50668ZsScdMgphKX4N50O6LEYSBIKMSRJQusV2BtkCUXuNZQjENN1wmeRaWBNdlDZ7GJMdiqN7V2ENRuKpJNmBFVVafRGMJmt8bYOctIgAvehWPMoH2HEd2IDr4Rn8Y2pJUyxV7LBq5CcnElFeTq+uoPsOtCY+DIOU3WgKlHYwbxxWRgNHtZsOIkLINzF7u0nmHXXGIpKCkg9Ut93e9EoYU1DM6iYErNlkVTCtBEazTu2scoyh1ty8im1VLN3gMjdnl7MJ66byqhYO7WRFEbJEvFBgxTsySO55c7uXrcT2EaXc9u1paS42qhpq2fzJj+aLZtrFk+lONRBcyyZ8cURNizfyOoaF1GjmeKySVw7qQRHuJVGTxcnDrUSTEknK8mEikZByUhMQTOemg7cA6YmDI+uedm16Rjz7h1PUWkR6QcP4rSmUF4xlTlFdiLeCKnZRloPHOStHdU0BTNYsGwRc+wmnHXHqGxrpmvAwN1O4cgC9LQCcjJkqjds55UDTXRFNRwjxnHLjVNIbWnAZUwhx+Zi7ds72NwcxJpTxNKFExlvCFDX7sEfc7PH1YqtJJN0VUbCxqiyEuyhZnyNfkxjJ7F0ej4Glxs5xYrWXs3qDw9z1B0asHdTlpMYf9VMpo9V2LdrL2t3VFIVBLAyavzkXikNGjMXzu3Vi5zFdXcuZlIsSmv9cQ7UNRMNRZmwaDrzU2PUtzjpino5HA7iHiBwlyQ7Y8pGkZ8IRNPtPra9v4V1tUpiu8VYO1uocelk56aTZjHQ1VjN8UAS44sd1Gx9i+c2tA2QZhGgqSNCanYW+WlORowvwNLRQXNyLoU9n4ESRpODsWWjyEEhyZGMNdbKurW72NlipXzGDK6bkIvUWs/JzkbWNXoTH5USqjWT6eVlzJ+VQ7S2nbAtBQsG5Ixsyst0ouEg7iED9+7jN5Ng02H2H2nsSZ1qPVFHa+L35OwSrv/EVYwJ1lFFFuXmZpa/vZ3NLRqZOWO4447J5Hhc1Hf4MDnScQRPsvzdaijKIMOkImOjeGwJ9mgL0VaNpXeeSpWpt6YyZfpMFow24emKkJaWRoatkzf/+iFrG+yJ/bmJPzz+PkdN+dzUU/YQUuE47lo2gXR3J3VttWzZFsTt1ckrKqAs1YoBG6PKkqlevZpXj5opKskgCQXFnk5ZWRi52onmyGd+r1QZPbOIJYtnUqa3UqOlU5HcxvIVW1nfFMGRXsJtd04n3+ehsc2NlJxOeqyeN9fsYludl7O9/icIgnAp6JqGpiXybXUdXT/tfh4J0qIu3GoK8UlHdWLRCEgSFimKrhjx9EqktBsVsmwqqhz/NtKBVl+Edv8w8wwSgbg1JZUT7S4KHTa8gTAmkxFFUWnoCmOyWM9QCQye/f6xp5Jdms9Ic4SDx9qorjxJp5xJxcR0zMioihmbJUY4EsIfNpCRk8eMijKuriiiOMWMioUkq4ws+3F5T80+q/kDeBUZg8XUqwfLRHZeIbOmj6ZQ7+LAvmqqA2FiGCmYUkK+3sXOyhZqTzYStWUyblTyAD2hZkZPKmF0is6RrVv5y/tHadHOFDyHqD1ayesrd7GrNUbxtHKmZBnxd7ZT0+YjJmcxb9EoMpGxp+Ry1cxx5IRreO+9D3n27R1srK5l594TVLZ4COFix/otPP/2Aar6bFfGYstgckUZV1eMpjy/b8/dYHSfH48so1rM2FBJz85n6oQCUiIemtrcuIIWxlcUM8ph6XX22cW2Net5cc1RGod6vu/v42C7Svm0IvLtRmTsTFs4jYm2KM62tnivqSOX6VPzSMVEXlYmRbkW/N4uGk8c4a21B9jnbGTz+qOcCEXRaWft2+t5cc0xOm0ZTJs5jgIlQGubk3avQuGoQiaMTO3TO9ubLGcxZ1I64UAXJyqPJ4L24dKJhDvZ+N5G/r65nlhKJmXFdkIBH03Vx1mzYT/bGtwDX6FJMRJtaqW6qY2G9gCm1HTGjcklpWeFIFWH9vPau/s45AoQxcvejRt5btURmmWJkZNKGTFgmyI01NRzNGCibOxEZudGOXiolrZIr9MWSQKLTLCpleqmDpqdYZJzsxhTmIG9ZyU/h3fu4KW393MsFM/1l+UUJs2axvUzHTRu3c3ylZtZuacBJwGqjx3ib2/vTDzfCMGwhhaI0P+iQPfxG8YX8NAxYIK3lfJZk5mSGmL3ug95bm0VvtQils4q7PX6hGmpP8Hb7+5kS40TcjLJs0Wo3HyMY54QMTr4cOV6nl95mL6n6Crp2TlMKE3HV3WEN9/fy55mz1mmsIVpqDrCmysTz9dmQHe5aWhqpbrJhVe3MHn2aNJCLWxaf5xmInS0nuStt7ey5lBzvCOhh4Vx08qZkqVxaNNGnnv/OJ3JRdwwr4jUXu9pR0s1q97bzofH24llpjEiyT7oPi0IgnC5+d2dtFcfJtReD542wh0N+JuqcNUepfX4AXRdQ5Yl0rQu0jQPaZqHTCVIphwgSe4fjPsjMRRZIs2qkmEzYFQkfOFzuxHPZE+htr2LKaPzyU1NoqbNPaygHUSPew8Z+o70YExj+uhM7GaJ1JHlLA3biUoSBWVlFO3aQpsWJhCSsasGTAYZzZBM6fgJTBkRZsNrXlrdIfwhHU03YbcAnsR2zCYsMY1IKEwQEmkCEgajkfRMOymGAJ0uL10xDd2cy6Lx6UiSm9xRk5hvtaFYrYwsKSL3yD5q+nR12clwGDAZ3bR0xoi1O2nQdbKGTM/y4/IG8AUBkshKVTGoYSK6CbvewcbN7UTCHQRRMBmSyXBEcDW4aeo4mz42haSUPK5ZPJ1ReDm4cxft9e4Bgqm+JIsJq6YTC4UIYMBqsZOaFCPmklD1INXHjlKNl6Y+ucud1LcN4/m2BmkPhQkVJJOjKhwllfwsCQgR1Y1I/ibWb63D3ekiRIS2phaO12UytWgMS9NTSM08zLs7qmnu16UvY1AdZKfpaJ0akq7R2VTN+00B6tr8g+YSa5qTg1UyEwpzuWrWONq3HeZQ+3BfY52Y1klTJ0AUt7ONw8eczBlTyKKUJLKyD7NqRxU1zsBp209h6vyZ3F5i4Mj+E3QYVBRVwWAyJlIwAHx0ukMEujR8MY0YXTS2aWg+P11AzlDN8raxq13i+rljSWndwf7GAHN7HWCqMYNZV8/ghmyNI5WNBE0qikHFZDD0Oin10OqM0jvel+UMZk7X8LkbaKquoTakMGrgBnBkfyXSSR814dNv8NWJaWECIQOpJivJVmjot0OmkJ2moCid1LfqoHfSqEjkpzvIgkSeehiv30eXK0JqJEpk2B+n3ftzgFZfAE+rj85giOBZ9aME6PIF8AQArBSPn8BNM/MI1VZzxJm42d1mIQlwn7Gu7mPflXh/O2iQoDQzlWygE4AI/oAXpzOKGo4MkfYlCILw0RAJBXDWnyBikLFarfj9fsLhMIFAAI/Hw9SSW2Cg0VsGSVEJxXTq3CHMqoxBkah2hQhEzy1wD/s9FGSkcKKpk2g0SprNiCcYwGg+c3eICNwHYcnKpTjFjMnVQn0oRDAapK69hIykHCbmqbzR3smx2hBL0jMZU1jNByeaON5YwNgR3WGPhwMnOlmUlcX0afnsWFtLwGCntLyQ5ECQ/bVNOIF0AILUVx1nzQkjC66fxsyZ03B2fcB2tYhSm4Te1k5tJIwh6KSlK48CRyYlmQZqGnsHdz463BHC4WSy0hQUKZURZ3VThZc2V5RIjolg8zHeOeziVNqWjCPSRYfLQLE9hZw0Aw2dww0sY3jcjaz7YCt7CNPRMlBqRV+SZGXclGJSQ2GOVDXQSQSCXlweSOlqZ9/+gxzpOpdb6iyk2M3YMlXSjUaMzg5aojE0XDS06UzLBnftId6qO63Lu6maD9YHqBmRS3nZSMqnlFB9tJn2foG7RiTqptUJGUEv1Uf2s2kYAbimdbJ9Qy3Ncyq4ZsxEbtAl5O2VHGjvXsOAxaRgSLORaVB7Xbg7XYwuZwMfrg/TUj+CcUUFTJhQQnltGy3OwGmpQw4qxjqI+Vs4sOcAVTkzmTRx8LvYz16E5qpjvKu5UF11NAdSe50YSxiUVMaXJBFsqWbPvsOERicxYczgGfXdtFgHO7e4yZ+Zx6xZE+jcVtV9TnwaE8k2I5YUnWRJwknvmZ5jeL3tVB51s7goh/GjM6jf144HSM3Lxtrlpc3TRWtnjFiag7xMid16KrkxnWinizZI3Bdw7q+NP+jF5TGTbLNgz4yQajJh7pd0YiHJCnJG/GRh8IuxVkblO7BbYxw9dJBVXUVMmFF8Fu3pPvZTyMmQkaxpjNBBa3fRiviSEAThymRLyyJrzGTCPjdhXQdjCgZNQ4pEMKSHQZIGnEh0qMjJE9aoc4dQZAlX8Nxu7Q963BSlWwiENVo9IQyyhMMgIxGlKxTAaB665118Jif0PWcyUlCQQZrVSPP+StbtbMQX0clSRjFjTjLFo7JRaxrZuW0vjopRTJk7mxGlURw5adh6+pIjNBzaw0uxCdx61VTuthQRVkxk5cC+jdv58ISbcKK/vVvI1cDOqpGUTh/J1ZNHozMCuyRRfXAXH+z0oZjttJgL+adxSRTkpWFubOk1QkWAY/uqOF5YwdiZM7k74iCnJ8d9OPwc3rmTDeZ5zJ0xi88WBdDQCYea+fD9Y7S5m9iy/Qi2iUUsvtZMmbeLE4eq2FfjobrJgy8vi2nzZpEfauHDVYd6pctoBHxt7NoxZFd4Qhrzls6jDCO5hQYObtzKuqNOQkBHcw2b96SzaMwYrl+cxoxADOhi75ajHB722I5mCseM5+YcndzMKIc2VlPnC6MRZOe6DaQvXMD0hXOxtoeBKJ2t9Wzd2Ypp5Eimjc8mBRMpJpXO+mZa/UFixDhU5eOqCeksuH4+Y0PNbFpfw9bNB0iaWsrCa+dR0hUF/InXqnOQkUp0wm3VrN4YI+wrZ37ZBG62mknZXUNVcxsNrRmMLp/EbaONlDgsqKclOpyikpaZz8zpBWRgJM1mpKulheYu7wA9pO1s2NPOxPIUZl49m/KkHBxAe/9Kz52/k/2VnYk/Unst0AlH29hR6eKTRZnMWzATHFkkDSNZRNNd7Nm2h/0xnU/MHs9NZhsHnTrtbQojx5RxS0oqe/ee4ECjieJxY7g630vn9ipqwr0/YHVCPie7tu3GrJUyYfosPp0XvxHZnqZwbMMBXJ52DmzbT0n6TCoWzCOFbOyuGl7bWoeL8w3co3Q0N3PgqJMFo0tZlhYhPT0JE92vlZOtB9qYNTOTuUvnM8aaSzrQMmh9Hg6ebGdmzkjGTpvBp0ntdexrBMMdHKuLsSCzmOuvN3Ok2nnaFQg/h3ceZG/6TCbMmY1VyyC9q4bXNlTTCWSd13MVBEG4PAxGE47cQnQthq7p6OjxXHdNS6ReetGR6NDNKErfcNiohXtGljldR+Dsx87rFvC4KM1KwukL0hmWMVlsaLqGKxwkxSCRTJSuoH/I4F1auHChLmZOPZ2CIzODnGQToY4mat0RYjpI9gwm5lgI+Vzx0SUklaSUVPIzLL16QcO0NnXS5kuMTGFIZkyhA0viFC4aCdDU0IYzGt9OUoqD3Ewj/jYXLe4A2NMoyrBh0QN06hZSjRKuplrqfICkYHWkMzpVpcvtor7Df1ovnInsvHQyLCpK4hFd91F9ooOgIYmCkSkovi7qm3yop223u6/PnpHLyBQDSqK9sZiXmqr4yDKqyUJWZiYZZugezaJPm1UJCFB7og3XWd2baiK3MIN0o9KTLKDFQjTVtdDR6wkarUnkZKTi6OmYDdFc30F7UCW3KIM0NUTN8YF69LtfZ1uvNJDusqcmw3HkFFLYk2CtEejzWp0q63O2Ue8MENLA6MimNN2ELJ16rQIGE5lZ2WT1XPE69Vr17VO1UDAqEwfx98iDjNmeSlGODaMWwel00uiTyU53kGHr/aESpL6qnc6YiZGjM7H3vEcyFmsyeSOSe+4jCHQ5aez0DDj2f3x/7v3hEMPn6aKhJYApzUFOmgFPSyetHkjPSyfDEqVpwO2e/jr336/ATF7v90iSMKVkMjbD3Gv7UVydLpo7IyRlp5GVBB0971Hf1yq+P6di16J4gyFCWEi3ykCE9gHbPNAZrIItKZkRfUaH6X38qmTk5ZBriY8qEw24ON7QRbjndbYRdbloag9jzXCQ7VBwNXXS5pPIKswg3RimPnEsyIqdkcWpGINd1NW78ffeJ00ZzKwYzfhcP6v/+iFrG9wErWmU59qRe7p+dELBLurqvUhJyYzIthDqdNHc6Y+flJmTGZWVjM146rJv97HvVVRS0rMpTFaAGF0uHwFNxdHz/oaIJkbQybGqKBLoITdH6tyEkTCZk8jPT4LufSPVQU5677KCIAgfUb2Hgjzt79xoKx3YCcomZKlvyoyixzt7YvKF7d/2t9WTlpKCRzdgMJp62qJpMQgH0YNeoooRU1Jqv7LdM6eKwF0QBOGSM1NUWsr8qQWkK0bSUw00H9zNiq0nqfd/3GY2FgRBuPSMepgQhlOpMRdyzPZBaOEQmiShGvqnhmpaDC0aRZZlZLV/Umx34C5SZQRBEC65ME11J1jlrEt8CGsEPD66giJoFwRBuBTCknHIfPaLQTaaBh2GQJYVZKMyyNJTROAuCIJwyWmEAj5aA+c+P6sgCILw8aMC+H1hfvdfH17utgiCIAiCIAiCcJoZE8IYDYnAPSPdzt5N30VVVRyOoYeE03W9z5220hA5QUMtE4QrQTAYxOsdchrOfiwWC0VFRf0e1wf9o/+CM97bqw/467Do/X4ZvKYh69aH/PMs2zB06YvbDn1Yhc6mDcNvR6/3e5gNvzDtGLyWs5n0eMBVByl/+lj6Q9Z7ljv1MHblngXDrnp4u8XQmxzioL+07TjbvWDgFc+tHWcuPKx6z6EN/d7vMxS+sO0Y4v2+wJ83Z/PJPcyP3OGt0q8dw393Lmw7+u1tw2/H+X7eDXKAnvWxMkQBNdSBrEV48MEHcbvd5zZzqq7rfYJySZJ6/gmCIAiCIAiCcOGdV467rmtIehhJjt/9qmlRIpEoisGKPNBsVIIgCIIgCIIgnJN+gXvv3nRd19E0jUg4SDQaig9ar8eIRcPEYlH87jaKi8yYjDlIkoSvq4nOZjdJ2RVYrbZ+GxMEQRAEQRAE4dwMGLh357BLkkSXuwN3Zx3RcCd6LIwe1dBifkLhEJqvk4nTH0AxJAERTMmpxIyduNwBbDb76VVfPKEumqoPc7AuSlbJKEaXZDP0hLGCIAiCIAiCcGXpE7h3B+3dgbssy7g6GklLNTAifwxmVUOWctFlHV02gm5Cl5tB84JsQpYNKKoCemzAjQHgOcb7aw7gjGkoBjMls5YxKft8nkIUT91eVj3zFH9vLuaGO68h5GknxZFFwcjMXjMiXmxd1OytI9Rnuy3seruWzKVTKVDPPDanIAiCIAiCIAxmwB73aCSMx92B39+Jq3UvGY7RRDQTWrALo+pHVmTQg0hqBCIuIlErp0JYVAAAIABJREFUpqQSdN2ITmSgauO6Knn7mVdZ3ezDrIOkmKhzp5Nxz1WMOOenEKChoYbGYAXfefLbzElqYeeKPTTHLORc0sC9ic2vvE7HpIXc0bNdN9V7qlAWV1BwydohCB9lJ1j5m1U0WMtY/PlFFF7u5giCIAjCFaRfhB2LxfC56gh11YEcIcnUgKrYiMZCoHUSk0xIaChKEEkLo0ecxIKpxIwpyCYHSNpA1QJQ/f5TvHBoJv/2y08yyaQSDQY5tmED4cTyrvpKNq99h4OtQOYEPrFoNuPzk4E61j1biTqyhe2729E0MFjymH/3LRT6d7DqpbfZVCnhfvqPdM4uw5Fkw2o2JobMcbP39eV8WOUirEHGrKvIPOCj7IGrSW48zN5tIcbdOpNcADo4uLaSQFYR48ZL7HvpMFpGE3sq2wmHS7jpWzcxMtDAhhdeZo8LwEZe2UwWXV+Ea/Nmtu7aSmNjGx31tSz91FIq8owkZyRjStwzEA362Pv2U6yrBmzZlM28husrcnu229ZVT1VHO05nGHAw7a5PMy/fiiIG6/mHFoseYPljf+coJtLzZ3Dj5xeQD0Anles/YO36Sjp7F0idxufuu4ZCmwkteoDlP3mT5oxp3PTAEorOeusaPudx1v71Zfa6ejbAuPmLWHh1GalnLB+io347bz+7E8rnsOTmGcQvoLWwc8VqNu3XqLhnGTMKMjABsI9n/uVf+CD7C+SLwF0QBEEQzkqfoV8kSUKWZSLuOqzRGiZNG0fp+LGkpGWS5LCQlGbFZNVQjUEkyQcxH5LsxyA3E/ZXAaEh0mRO8u7LrVTcv5QyQzywV81myhYvpggItVexcfVrvHfIjcViwV35Hn9b9SFV7SGghjW/f5Ifv7wf1WjCYjYSq3yDX72wHbesYjAZUBUDZosZo+rk4Hvr2XqgFi/g3PUav3pzHxEMWCwWjiz/EU/88h1OEqazfjfvvbKFpp42trO/p2w965/7X376wq5EWRNE9vPqT/7Ebr8Fi8WC4m9m+5q/sXJXC4qqYlANGIwmzBYTqiwhUcU7T67gUCSKHotS/f7T/O/7DVgsFqLOaj586wXWH/UktvsST/7pPWo6I1gsFiwNa/nFH96nKTpE2pFw2YRCIaqrq/F6vX3mNTgX0V3P871HHuaRRx7iv37xW9ae7F7SwYEPXuIXj/wvqyqbiVqtBA/8nV8+9jDf+eMWwlGNWHQvf3nkP/jZk+9QdQ7bjgQ8bPj99/jpb//GkbAVq1Wi/fB+dm4/QMewagjRUbeOP/zgp/xxee9jqYmtr/2RJ37we9bXthPseXwi9zz+OP/xyF2MPYf2CoIgCMLHWb+ucUVR0FQHrkANuuxGkiNImi+ex44PWQ+AFoJoAF0LoukBFD1EOFSNpOUi60mDbKqRuvpsyvNVpH4jRYbpqD1E5VEPkz79He6ZkoZzz/P89MXDHKiZQl4GgI1x132O/7OsHKOs0bk3ytf/fROur3yJudfPpTUkc8dXPsNEjvDi63sSQYeTXSs2YZz9eT5/9yxSLSrHX9jMB6uG+/JYGXPNXXzxjhkkm1S0WDWtE69i+tLFlCZBpOsYK194iV1rqlnybzOYOqmWkZMWcscn55BzWk1arJGNr75H+qee5ivX5RJo2s3fXniZDZuPUVFqA8zkT53LJz9/M+PTrdCUwvrb1nP4u0vJN4j8+I+auro6NmzYwIQJE5g2bdp5zWGw46UXicfqYdrbK1m37hifKxnTa41MJl93F/ffu4CkozaOLHuY13/2Mtu/NJuZ53U1RiPo3cyrT66iOe+LfO/fvsl19jBtJ2poD6tk9VqzfcPv+fnyHbR6IgAU3vpDHl6WibPxQ55/7O8cxw1bXuBH9zex5KZZZPl3sXrzEVzovP6ThziaPYd/evwB5jq6qDt4kMPJqcwnQPOJNTz72N843qddKVTcfg+3LZpCjjn+yL7n/pWnNriIat3rmMkedS33/vttjA7Us3Xlq7zyzgE8ADiYfveXuH3uONKM5/P6CIIgCMJHy4CDrTtyx5I2chzhQDUSXvSYCynSDqFWCLdBuB0i7RBuRw47kSIe1HA9/s6DIPnPoRkBnK5WfL58ysrSAEgtKyM/4KfN6SReYy4zZxbG8+slCWVELlleD0PPaVnHgYNWKioKMZni5yiFS5ZQOux2ZVNRUYgxUVaWC5g0oZ2nv34f9913H1/654f43Ss7aXA66TpDTZp+mAP785g3L56UY8nMomBELrHqKtrjz5jS0kLS0hPj4eTmMsLno+s8e3OFi8PtdtPc3Ex7e/t59rhv5sUXa7E6FvDV//kCpe3tHF63lmODrJ1UOoZCswWlvo6a8943dGKxOhobQ7QcX8mP7/0iD/3Pu3hHjaGsrJiUxFrtHz7ND370U5bXZHL14mVUhNfzy+9/kYffaMacVMjEuWNJw0x6fjnzb7yGaaVjGTdhHKPy0zGTxti5i/jEjVdRaDYgUcPaP/2JF17aSAMRutr2svLPf+LVDw4QyZvPjVcXE616nyd/+mc2HG4gBDSvfIzv//R3vNs1gRtu+AQlnat59s9/4e9v76aVTio3v8z/PPwbNjYbKF1wE8tunEbgvXfZVlPPuXwaCYIgCMJHVb8ed0mSMFtsOOucNDgPkD0iFT0SQQ/7IeYCPQKxEMSC6FoASdcgGkOJOIloBrCPGmRTE6mY8mN27A1zaybQpxNZwWAwYTC04vcDJsDvx6cacBgM5zFLlJ2kpAAeX+zUtLYuF64hywwuGtnAb767gpR7v8qtOQBODq3bQtXQZw8ASDhITnbT1QXYgEiEcCSCZrViPsf2CJdPQUEBkyZNYuzYsec3Y/D6l3mpWcF26z3835vGYv7Tcyw/uo5Nlfczpqz/6k3vvMMml5PwVVcx77wnOZOx2xfw5a9UsPq329n4RjUHtmzg3TeeIH/yLXz5S19g8fgw21e9wZptAab//E5uvm0ihtm1vDr6u/z1uTV85ebbmTy/jDQ+QMqfyIJbFjMFgCCjCjIwE2XcvGu5fu64nhOB/tIonbKMe75xN9fYD9G2/UPW/nEXhxrbuHaKwvpXX2ZbVTp3PnEvNy9OpkJ6h6dWvJYoG6KjpYYTx2KMvH0+N3zyFsYZQrSWNaLnpCE63AVBEIR/JAN+80uSRFhPxeuLEIo2IMVaUQNd6JEgWqgdPeyBsA8p3AEBL3rYhax3Yow0IQUbAQbohUxhyeev4eiP/51nj4cACHu9rP31r9mFlaysPCyWOjZsiPc1Ht+4kTqzmRHZWecxJnsBs69SeOutrfh88W2ufeopjgJgwGS2oij7qayMr129di1rt2yheZDadK2Dk0e8jJg6l7lz5zIuM5n2/Zt75fUOTpbLuGq2mxde3AZAR3U1+ysrsY8fT+Y5Pz/hcklPT2fBggUUFhaeR+Bew9OPvUCnonDN7XdRnFLA0qUVNBzbx+q/rUlciQE4wksPfZElkydz7QN/YLdhGU89eQ95xjOd0p7gjce/zg1TJlMxZTIVU+7nuePNhHqWS6jWUSx55EV27trDztV/4l+vMbNr3Tre+sMLrNi4iybqOHq0DY+njfce/TQLZk1l3q3/wz5dw7NrZ+JYOl9GbLZU0tKMYDRiNBhQw2GCsSgxTrB/v4tIeCwzZtiRJJmkiqmcSiTKYMzo2cyZE2HdMw/xqasqmDntKr73Ti2BmPX8poYWBEEQhI+YQb/XsvLLCbmr8XWuw2qTkAwRNKUDOWAAuYuw5gbJiEHSiWGk5riPumYdLamFMdNtfWZg7Waf9AC/+fFTfOHuufxaj2G0pXHj95fzb8gYS67i+sW1/Obnt1HxiIFI/tV855tfZc6olIHPLobFwJjP/Cdf+fFnuX3xj/FFJEbcdiuziXfr5xZPZ8Hs93jkzgp+ZoSk8aVkKsWMH+zFUhfz7a8vZ9nNFTypgik3i5yMikQPYwlz5lh59Lff5Kkfj+frf3yEz1ScKiupdmZ9+b9Z+N3bqagwE0spZsGnvsF/XpuPelqGr/DRpygKNtt5zg588i2e3diJFo3w5jfLKXkwRtjTQbTLzOGd69jbek9ixRKWffMHfPWOWfERW1Q7WVkOFFlCG6J6COJsrOLw/v3UApBBezDct4ysYM4sZlImEBvLqIox5JX+lB8/ehCv30+YEjIyLJhM07j3qSf4bOmIxOgwICt20oG683sVziCbnGwDimLCZAJ0Ha2xodfJtYHMKbfwg5fn861ADCqX850f/oJXH32ciVfl808zRzHYXTeCIAiCcKUZNHC32pNx1xqIdnWQWhQh5leQYjE0UzNSREMPqrTWuDlcN5KariJGV9xO2XWzAAVJVgfuhVTtZM76Bq98+OVE8CChmqzxQMBgYvTVd/OTq26P34AmqxiNBgyKDMzm+ytnIJuNiQwbmeSM2/nJ6ltQMcI1X6Ds6u7smzHc8fC/gqygALItjZseXs7SB+NXAKLHfs3ntucwEgnVXsTCL/2Sd++NoQPIMjIyqqqiAN96ZQqS6VSqjqQkMfqBP7DnC4mRXiQJWVZQJBkVAyz9Kr9adD8xTcZgNmGggP/aOgfFYkSSJJLyxvKNP+zgyzFAklEMRswGpV+b4+b3lBX+MR1f8Rq7g1FMn3yept/fAkDHsS388mtLeObkPnbsbqEEAAP29CzyCgtPzXcwrPT2Mj7z2Kvc+cPE/o2C0WLqddDHcLe8zEM37+OurT/masWITTagRLy4xo1j4qhRFJDP3LnjyXj7eV59q52vzZpGZpKBSHA5/zxpHXcd+dFFnqOghCXXlfHjDe/y309U8qkHyzi8YgXHgNEANLP1/VXsOjiCT31rCRmGMkZlpWFoTCZDNWC4qG0TBEEQhEtrwMBd13VisRhtbjNGvwVVryYaUwiHJXw1bjbtNuM0XM20a77G5FnFTCY+/ruiKH1mXx0weJcNWGwDf53KiorJovb06J2iYLL2ToqXkGQVkzXRfNWA0vNMZAym3sHuRp7/q41bbxuH3a7yzq+eRL1hLaMgETybsQ7y7W60nDaaiyQhG8wM0nxQjZjV3tuWT7URkCQZg9k2QDBxepsB1D5lhX88K1YcRUPmrk9+Frs9/pi9sJBrFl7NL39XS+XuPaRICqqiosiDpePIyIqKqsj0X0PGYLJgOO2A6h3z67qPmj0/Y6npZ6ceTJvJl3/wb9x341hkoOizv2ZbXibTv/QFCn/jBsBo/jR/dT3LtYA/fxmf+cwz/MtL32bOS7/l9oce5f89dCe33jqXFTt/y4+uncSPWMKTJ5/nvhESiqKiqgoS8WNCUVSkXu2XZAVFUZBlCZAp/drf+V1lMZ/76SyS/6v7GXRf7chh9uyp1Gz6PjOsN9IGQB53/fwBrh5XKO4fEQRBEP6hSAsXLtSTk5N57LHHUFWVlJQUJElC13Xqqg7hOvZr0pTNtDRY0dLuYuy8z2FPiY/80r2eruvIstwTrHf/PK+b9i6g2he+zmeeWEenP4ah7Bv8ffmXKb7cjRKuCMFgEK+3/93Hmqb1nKyevq9bLBaKior6ldEH/aP/gjN2qOsD/joser9fBq9pyLr1If88yzYMVTpMl0fDbjcBGh1Vv+azZf+P5vnf5PfvPcyM826HPqxCZ/NaDL8dvd7vYTb8wrRj8FrOZrCiAVcdpLw+nJXOoQ0D1jbE8TXsqoe3Wwy9ySEO+kvbjrPdCwZe8dzacebCw6r3HNrQ7/0+Q+EL244h3u8L/HlzNp/cw/rIHe4q/dox/Hfnwraj3942/Hac7+fdIAfoWR8rQxRQQx3IWoQHH3wQt9s98Kgy3T8LiseT5PghMU1j0gIHBkP/vuLeAUvvsh8lhXf/ig13X+5WCP9IXC4Xu3fvprS0lPz8/MvdnH9w2/jvR0/yyS/MRJFi7PzFr9gyYjQ337yEGZe7aYIgCIJwCQ2ZiyFJEimO+KTnJ06cIDc3F3v3Nf0z6D2qTHcv/Jm2JQhXiqqqKrZv3044HGbEiBEoipgk6+KZxw9u3cTSr91PKKKBsZhbvvkoz35j1uVumCAIgiBcUmdMopYTY0U/+uijfP3rX2fWrOF/WcZiMWRZpqmpA6831OtKQBQpcWNncVHORzK9RhCGYrPZSE1NJTk5+XI35eNh7ndY/cF3LncrBEEQBOGyumh3P3YH4bqus333Mfw+DXPiBkxdDkIUFJOBQFSjtDgbRZaRZVkE7sIVoaioCFmWycnJ6Tm5FQRBEARBuJguWuDe+6bVEQV5TJk0iqyMeO+kpkvIUR1POMTjT7+NZlAZm5eGQQTtwhXCbDZTWlp6uZshCIIgCMLHyEXtKuzpiZQUFGTUnn8SsqKh6xIms5lNh1rYc6AaTRtsOpk61j37NG/u8xLrvUrIQ+PWN/nL37cNa/ZSQRAEQRAEQbhSXbTAPZ7DLvcMEwk68YGb4/90dIxGlQUzRjG7vISugMbeA4NNoF7Dmt//mp/8ZjWN0cTkR2j4nEdZ8auf88wrW0TgLgiCIAiCIPxDuywz/MTQkDUFoywxY9JoQGKnEmHvjp1Mr5gwSKlxFEdf5pV9y/jWdAUiAdr2v8PLLRZGZZ5aq2n3O7zx1koOtQGpU/ncF29mSkFqfNKjvc/xL3/cAYDZkcPVn32QZaVA5wnWrXyN17bWAzBy/me5c8lMClMA2vngyZ+z4oSXmC5jSZ7FfT/8NGUABGk8sIE3XlpBZRckl5WR2+VgwvVzmDaxEDtw4KVHeGaLm6guYyu5iW9+4xoyAdx17HjvFZ5bXwNA3szbuP36hYxOu8AvtnDJHT9+nEcfffS86znb8bovjHMca/pct3QxNzBMZzOe8MXa+gXb9LDGUL88zmqWgPMdx/1C+ai04yyczTjuF6TuS1L4olV1bnVfuJUuUukLs4Fza8NZjuV+mQ+ai/3ZeyGKPvBP91I08tQc5ZckcNe0GDFdi+e9SxKyrqMhoek6ui6hoyGrKjLWIWrJZeENOn/73Vt8evptpPlr2PDmPkquX0RmPBbHe2Izf3t3E86kSSytyKFj7xqeejmZRz5/HYXpR/ndI68QuvEBbhoBEX8Y59rlHC29Fn33B6zd2E7hvKWMS4bO45UcacokNSXIWw+9QP2oqSxabEbSopxc+Tw/f2ECv7t7IsHm46x/bxWV8liWLh1Jy5F3WbG8Ae+kcZRPLMT//i/54XqJu5deiypB1YfP8p8vZPKLu4uoPryOlStryVm4lEkOcFXXcbzmCOlpY0m9FG+KcF4CgQA1NTXk5uaSnJzc56Zqm83GlClTLmPrBEEQBEH4R5CS3HcY9rMK3B988MEhh7+bPn06Dz30UL/HdV1H10DTAV1H1yRigCaBrklouhbvENCHHgvbXnE/n3jjfp7ZeDMP+Jfzqnot35lu4q0dXYCP2soDuKLZzP30Z1hYaCE0Ew5+ZSu7b55NTnoLe/ZUYv3GMpZdC9FQCFdzM0aCHOysoanLws0zl3HDKPA0NRFKSsJMjFl3fJLZJWMpSDYgEaVpZA17v7+afXeXklp3gvomE/P/6V6WjbXjGx3kyIbVianbW9j4983kLfkPbrhxDAY5RtPIah7+/mr23f0FdHctde2wZPoylo0FX2srAZOpZyJ34aOturqatWvXMnHiRGbPnt1nHHeHw8GSJUsuY+sEQRAEQfio0nWdaDRKbW0t9fX1eDweFEUhIyOD4uJi0tLSBh2x7qwC9/vvv5+JEycOujwpKWngBgIxHSKxRJ47oAGRWGKipsQINGe8YGDJ4+6lJcx+4j8ImFdT/Om/kWVanVjoprX1GBv/soo3Vi7HogD4aa0qpiQaQ2M2D779bX5w7yIWJYMts4jb/v0ZvjgywqQld7C47s/8/p5FPG6Ccbc9yP/9zFIy7FCctZZvfv677HP50QAt6ieqL8WNH8ndjt+Xx6iS+NmQrWQUxdlZifZUc/BQFWu3fonr/ice1J0qm8z0q27h5uo/86fPL+LXZhj9ia/x9fvuJCPlzO+DcPn5/X7cbjcej+dyN+US2sNvv/gEa5zl/Otr3+Wqy90cQRAEQbgC+Xw+Nm3aRFtbG8FgkGg0iq7rNDQ0cOLECSZPnszo0aMxGAz9yp5V4F5SUkJ5eflZN1DXdWK6TlTTesZ3j2nx4D2xRiJ4P3Ndybd9kzt+eycrUr/M80uTYF/3Eis2+3g+8cUypn1yCYU9JUykZKdiQqVgwn08/vqNBGJ+GjY/y68e/zVTX/gaFY5ybvw/jzD/kz4iHZt46ufvs6Y8n6xrfPzx6y+R8oWf8IcKB6qk4elYyS+/VgeYMJttmEwtuNxABuB24fT7MQOQSXbWLL728wdYnJpMPHSXUAw2UlExJ49j8ee+x/QbvEScO3j+f7eyZksxI26dRibCR11JSQmzZs1izJgxZz2O+55n/oXHXjtAm7/7ERlb6id4+NVvM+OCt/RC8tF8/BiH21L5OJ2uCIIgCMKFEovFWLt2LS0tLcRiMTRN6xlCPRAIEAgE2Lp1K0ajkeLi4n4xxiWZOUbTYkSjWjxY1yASgWhMJxaLEY0l8t+RkeRhjONumcIPVu5j44vfZIK594IUSoptNLYdo/JYhPz8fPLz86l75Xk+bGslxBq+9a0PSM/PJz8vj+xUM+GuLsK0sn37ala800h2fj75uRmYYmGC4TAaIdwdAUzpOeTl5ZObncWeJx9nW7wh5GTnY7HU8sH7BwE49MEHbD94CC8ARSxa5OJXvz9AVlYu+fn5ZCYnsfvpX7ELJwcOrOLFV6oT28zESpRQOEQM4UrgcDiYP38+I0aMOItSB3n22/fyrV9UMvYrv+KF5a/z+uuvs/zlr1La6iZ00VorCIIgCMJHwcmTJ2lubu4J2m02G7Nnz6asrAxd19E0DZfLxbFjxwa8qn9JAncdiKIRRSOMRhSdqK4TRSciaYRiOsFYmKgeHqQGCVmREyNJKphsSditRmQSw04qMiCRPuMuvn1TKXueWEZubi65ubk8wVwm20dg5lr+e/Hb8ccLRrP0wXeZ+uCDzCKLGblpdG36v/Flkz/LpoLZXDtlCunM49FHJ/Pyl2ZQmJdLQckYfl/4JRYqMhISSWPmcfuNS/A8vZjc3Fzu/ttR1KQyshMv7ej7/8yrZS8xfnQhubm5jJ05n61zH2IOqZRn5mM/9r34NifeyRuGUhbOnkPOpXhDhPMmSRKqqp7FbL86+/7yHCt27GDkVx7jy/PLyHLYsdvtONJv42frH2Ue8atT3pNbePobi5hQPpGJ5RO4+v4neK/SnUgn28pPbr6GivHjGT+hnIkTJzKxfBJzl36FV+o04reRaDj3vM6j982jvHwi5eUTuObbz7O/wZ+oYy3fmTqZ8T11XMVN9zzJLnQ8Rz7gF19emKi3nAkL/5nnN58kcIFGpRAEQRCEj7PKysqeoF3+/+zdd3xV9f348de5eyY382bvASGEvcMQEBTBAWLVqnXXfmtbR+vo0tr+rNZad4fWjRY3DlBARkH23mRAdsgeN+POc87vjxsikIQlgtjP8/FQknPu53w+59yR9/ncz+f90WhITU1l9uzZTJgwgfDwcBRFQZZlSktLaW1t7VH+W105FYIBTiAQoNXlQ2fwISGhkSQUQFZVFAUURaGtI4DS533EOB5eMa6X7XbSR/yIP77x9ZbIsTfy3Gc38lxvh5nxPIcOPd9ze8JobnlqKbc81UuZSQ+zbd/DR2/7/eEfFGKGX8rjC6/gKYOGQOViHn12J2EhId35cdLv+ICSO3o5rjOPOX9axJw/9dZQ4funnppDLtrbhzB5hAObHcBPR3M7PkCSDFgdFvyH9vDRcw/ycmUu97z4MLNNy3jyb8/xp+csWO69jjHph4+no//P3uWD2zNo3v4M1970IW8//QFjn7wS2/7lvPzcX/lSO4PH/vNTRjW9ya//+hx3P2vhxV9dQmpk8AiS1srYBz/gpWsPDyzrpNhtov/MP7Pqn2MIK/qE3/6/5/nz0++R+ehtjEw/9px653a78Xg8Z/LiCYIgCMJ5LzQ0lMbGxu6hMdHR0cyaNQuj0UhGRgYTJkxg4cKFdHR04HK58Pl6dmiflXSQ9RVl/HflJtSuwFw9qvdOQVa9aLUBBg04ycjgO6OJgwW7KCwIof8gB4VfLKMhNJOUeCfmc9004TumifqGdjrdR27bygs3/YZ3C2vQRs7myVW/Ia2lmK1bWglPCyPU3EZrWAzJiWl8tXoXxXV1DO5+i4zjxh+lgUZCm5hEgt9H1aFqaunAVX2Affu8xOaHoKOZjuRMsiJj2LVhA0XtE0jsCty12klce+3Xs0FQ9MSlpmN0dNJaWkqr3obT5iBs4062trSQc5Jn+sorr/DCCy984ysmCIIgCN8nK1euRKPRdA+RmTZtGuHh4fh8PjQaDXl5eVRUVLB+/fo+v80/K4H7D+ZOP+Fj1PPyq/hI4sxm1mx9guf+1Qxhw7npF1MYkCySOn7fybJMZ2cnJpMJnU53EsNlTFgsBvS6Bto7AigyoB3FfQvupzLnbjYAEMDvb6KlNUBd4RreeKyA97pKO+Pj0eohcMKWefF4Wmlr91Gx8TP+WbYaY1f9yU4rfk1fuZsCuBt28+mLz/HiohJMsdHYdG4aKw7hIuskr0pQdHT0cbNPCYIgCML/Ip1OR3R0NCUlJVitVtra2li3bh1Ady+8RqPBZDJhMBgwmUw9j/FtNe7kxv2e/uO/K2xpo7npT/O56Vw3RDir6uvr2bJlC9nZ2aSlpZ3E6zeFwfl5ZG6Yx8ZFW5iUlsiQeDO6o4oZsFpTSEsNpzXhCn75yO2MDTcA7VQX1KNGRmKm4QT1WAkLSyAhPgpb/k3c/bPZDAzRAy7KdtRhjLDT+2oJbRzcu4IP395N5MxbuPeBHzNYWstLv3+SectO+rIAMHfuXObOnXtqhQRBEAThf0BOTg5lZWVUV1czf/58FEXpzixz+F9JksjKyiKXw360AAAgAElEQVQ0tGeO8LPS436YLMvdk/kO97ArinLU4jWCcD6oqqpi165d3RNLTkbq5MuZW9rBvLff5NV3/FRmR2LU7KK2+xF6QiKzmTJrBAfXbOOD1z6ipZ8daKNyr4fUiyfjiDhRLSacKYOYelEW83avY8FbWiqSLUArB7f4GHLrpUT0+oWQgdDwBDKyI9hdXciGLxdRUrmclXtLaKX/yV0UQRAEQRCOKzExkczMTAoKCvB6vb0G7XFxcWRnZ2O19vyDrU1JSXnYaDQyderU7u753nz00UeMHDmShISE02pofUMTX+5oJNlpQ68LjnX3+GQWbawiwqJgtYhR4cJ3TyAQ6HVyiNvtpqWlhZSUFOLi4k7yG6NQUofkkWRXaK2ppLKqmupqmejcXPLyhjNyTBZRphASMweSFuKhtKSE6upqqqv19J8xlbEDk7ARoLMVwlJzGDUxF6dWg6r6cLeZSBoylCFDUom0R5OZlUWk1kVp1119dbWVUTfOZERCBEZ8tDdJOAcMYfT4/gTvBQyEOGJITAnF52rH1VBNo8+IM6UfublDGDkuj6RQPd4WicisPEZPHCDWGxAEQRCEUyRJEjExMd097T6fD7/fj0ajISQkhJSUFEaMGEFCQsJRHdvLli3D6/UiTZo0SQ0JCeGxxx5Dp9PhcDh6rej666/nzjvvZNSoUafcyPrGZtaWePnnghLe+NVQokKDo24bXV5++JdN3HF5JuNSDURFhJ3gSM1sfPstNqgjuO6Howg+2k3twS2s+GQzNd2Pi2LQ9ImM6J+AjQpWvVlA1BX5ZNtMZyf/pfC94fF4aG9v77Hd6/VSU1NDREQEVqv1vB3qJQiCIAjC2aWqKoFAgJqaGmpra+ns7ESr1eJwOIiLiyM0NLTHwksPPvggra2tfQ+VOXKy6DcJSlpdbWyqUChX4/Eo9fzj8zqMBg0EVNz+AG45lHLiMFTWMU7XRmiove+DNazj3y8v4IC6g7Tpo7gkEsBNTfFmln+6DefskcQA7cXrefc/rXDTVeSnlvHlSwvJvXA4mSJwF84Qo9FIcnLyuW6GIAiCIAjnmcNrwURHR9PR0UFraytarZaIiAgcDsdx4+4+A/f169ezYMECAoEAiqKwe/dunn32WaKjo78urNPxxBNP9HlwV1s7m6tVirxR6A06Jo1Nxe+X6VRUFBRUvcLU/Ch0Oj1F3mgM1S2MkNoIDek9eN+z4DWKc27mNl7itQW7ueTW3K49FuKyxzPnp7cyEHBXL+HJ36+g+GAtQ09u+LEgCIIgCIIgnBWyLLNv3z62bdtGTU0NkiRRXV3NmDFjiI+PP7V0kKqqsm/fPpYuXUpERASKouBwOKiqqqK8vLz7YKWlpX0G7s2tLtYVtVLki8Gr0eNqDyBbbSiqguxXCCgqAVnFYtXT0B7ApNezu8WMp72acZkKYY5jZ9LuZuH8OgbfdyHTpM38488L2XVrLr0lnfM1NtLo9xOj1YoedkEQBEEQBOE7Q1VV6urq2LlzZ/fqqB6Ph4KCAmw2G6GhodjtvXdi9xm4+/1+DAZDd+B+eHlWWZaRZRlJkvD7/cyePbu73LBhw/jNb34DQHVNPbtLW/A4IpBMMq2eAC0dfgIB8AUCeGWVgKLiliVCLQASHq+fPc0NpIb4ewbu25ey0HkFL41wECr9H3NibmbptvsZOASgmb3//Yi1sxdhA3zNOjKvvIbRg5OwnDB9niAIgiAIgiCcHaqqUlZWRmdn51HbfT4f5eXlNDQ0nFrgLkkSRqORuro66urquse7H/mvXq9Hq9XyyCOPdJc7spKk+BhSiytYU7oLyZmLVzLh9vgIyODz+4OBu6zQqVcwaM0o3k7U2j2MdXaSFN9zwZdNS5aSOuVZku06tFISs6am8n9LNnHPkHTATvKgGVzz69lkAmAiPD6WKIelj5zVgvDNdHZ2UlRURGJiImFhYWd0cmprayvNzc2kpKScsWMKgiAIgvDdoKoqtbW1ve5ramqipaWlz7J9Bu5XXnklU6ZM6Q7W77nnHm644QYGDx7c/RgI5qPsjc1qYfqEYXiXrmFl2U78UQPZs7UET7sbxedHViQURaYpKowBw5Pw1O/hglgXF00ci61H3spNLP2yhnXlVzLmeS0SKnJnB1JCFpvu/wkGdFgdcWTk5pLba2sE4cwqLi5m+fLl5OXlMWnSpDO2FkFzczNvvfUWRUVF3H333SJ4FwRBEITvoba2tl63u91uPB5Pn+X6nJxqs9mw2Wzdv5vNZpxOJ0lJSSfVIEmSsNtsXDF9Ap0fLGFJpYK+zc3ztyQRagmOPHe5Fe56qZT2ylamRdUx++LpWMzmHr2XFe/NY2HabSx65UqiQ4N55r2uet5/5Ie8+e5Mbuk9g6UgfGv8fj9er7fXHO8n8t///pfGxsZe91VUVLBgwQJmzJhx2msmnFl7eOPeL7BcP4eLBqdgO3GBk+Sl9uAXvPr/qrno5Z8w+Iwd98xQVRVZlmlubqbk4EEkjY5Qhx2vuxO93khMbCx2u10sHicIgiCcFkVRTqvct7pyqiRJWK0Wrp87He8bH/I2NrIykoh2mFBVlUaXDy37mGir44a5czCZTL0MOajiq5VtXH7VdJwxUdi6Wmw3a7jo6tlseG81VVcYOd5IBZFjWzjTsrKy8Pl8ZGRk9Mi1eiKyLHPbbbcdlaHp8Ndm9957L1arlUGDBqHT9fX2XMNDE3/Jhw0ugm97I860q3j04/sZpZE4s692BZ/Hi0FWUI/dpaqo7TVse+vXXP/cRgCS8q/lF7/8NdMzpOO+JwFUJYDX7eOUPrpUhY7mLfztR3exrd/dPP+XK4mTAMr44oWneeaFJZR31zuCX370KNdkxmKUvuSXg5cwc/sTXHAyZ60oNDY1Ikk6JkyeRkNLO15/AJ0G/J5Oamur8Pl8REREiOBdEARBOGu+1cD9MLPZzK03zGbM8H3dve0AIWaJ525NZEBOP8zmvlZOjeeaF17puVlnJeWCX/Fq11/hGRf2VXs+f/hv/jdpviD0YLfbGTNmzDc6hs/nQ6/Xd/+8aNEi1q1bx/XXX09ISMgJSk/k8c2PMMNsAG8bBz55jAd/9T5PPTmXeED2e3C73fhlQKPHYjFj0Gu7gnoZt8uFRw4eSaM1YgmxEGyJSsDrwe32EFBBo/cQkHtvgRropGTdyzy3Opmnlr/KNGcN6+a/zbJ33ibqjqsZFqniafehSAF8fpngqDsNppBQzIdjXVXB7+2kI6DBaDV1fSAF8HR4UXQGTAY9miNuAFRVoaNwBTv0oxjgX8/68suZnXz4YyyDyx+4nJk3TCQeOPTZ77j996/T/4WfMTLi5J8XAJfLhcGox2yPYPeBcrw+hc4ON67ODiwmAzF2O01NzZiMRkJCj82AJQiCIAjfjrMSuEMweB8+bGj375IkYTAYGDF86HFKCcL3k9fr5YMPPmDatGmEh4dTUlLCU089xbRp07jqqqvYuHHjyR/MoMeck0PGp3U0ALG+TgpWzOe1N99iZ4OegDmHq392C3PH9yNU76Oxci/vPfIwC8r9qIoWm2MUt794H9MdJhRfI5s/fZ1XX19EmV+PbWA2oWUmJveoVMXb2cT6L3cw+lfvMc0JEMOY8aPZ2biN3TtKGDTFzbz736fKXsKO4kY622XoNHPBX1/jnpHBIW/4Gtmz6GU+2Wxjzm9vYKhZC769/OfR+biGXMk1M4cSbfq6VkVu48t5C4md9Vfy217j4083csmdYzH2clmiJl3AsH+vpFGWe35bcAI1h2pIysigpr6VUJudsFAz7o5ONFo9+0sqKK9vIcqmo7auTgTugiAIwllz1gL3I23fvr17kuvJOHYV1yN/701fQ2Oqmr2coOh5xWbS4rCck6dQ+IbKy8t56KGH2LhxIw8//DCPPfYYBoOBn//858cZInMkFxV7drPToIOAh/rNRbiHTyAemebCr1i6pYKcH7/GX8Yn0rTxZR76cAX9E6IZnVXNB3/6kPAHPuCLNAOyp5VN//k9L76whvzfTMJTuJUNhe2Mue81/jU+keJPH+WPO4pp71G/gs+3jb37hjHryLdyfDzJbKOsqopawoFStqsX8dQ/Lycl0gIb/x/j//Aqly/8CaEAxiiyR+QTeuhT1qwoJ2dGKuqePRyI7Mf0gSlHBe0ASssXrDowjCseyCa9YBAhn2xkW+dYRlsAPDRXl1KwM4xGoH7lZxRl5HCl0XDKw4dUVaXd7ae20UV4QKap/hBarYaoyAjkgJ/a5nYsOitGTeAUjywIgiAIp++cRH2XXXYZZWVlJ/34wxPFdDodBw5WIcuH/wyrgNw1lt6MM/rotHzHBvD/Xl1HmFV/Bs7g3PP4FXJiTcwcFH6umyKchszMTG699VaefPJJsrOzWbJkCQ899BA5OTkUFhaexBFKWPz359mk0SArXrz6Ifzy8clE4mJvTRWtdT7sHeWsWVMOGHGUHeRgWxt5DOL2pyLZvn0zaw6pgJ9mWyKOPbspYASmmgY02iQGDQ5mi8rIz2fAAg/B+LmZ4k2F1PkCoAknLuNkzjSbH1w1mohIS/DXkSMZWbWEauBwP7U5MpbEiDD27vyKwkkJUHSImJgcnM6er+2GxUs4NP0upieE0M4YhiW/wrZtbYweB9DEvlVr2VO8uqsHvh8/+sNsskLNp7UQW8AfoNPno7WqDbtBS1xsFLsLD1BYUgNaHXLAgKr7HvUECIIgCN9550V3rUajQVEUVFVl0ZItxMXEdO1RQfKCImENtZItK8Q7w9BqNH1OGMzvd4qDXb+jyhvcgOjtO1f8fj+tra3YbDaMRuNpTYD+8Y9/zKJFi3jwwQcZPHgwc+bMOYXSg7j1hUeYYdbjbS/ms78/x7JPC0i5Pgq/301DaTFVSz9kz+GHx6UQE25DRz27PnmDf61swGIBUPC0N+JiGBDA7w+gKCaMhq5yZjNmnb7rg6KObYs+Y6OrE0k3mCvvTyfM0UBDI3D4bdXRQTugtVrpa9ZKD6YYMgcPZH/DJgq37EbXFkVSZgLOHtmiavh80RbCh1axaFEVdNRTVh+gfNs2XOOSgTjGXj2te4z7N+H1eVFkGb8vQIc3gFmno9XVTsWhRto6fURFmPH7vJi0hhMfTBAEQRDOkPMicFdVFVVVkSSJ9H6Z/PDKryebKoqERlXZuq+MVZv3M2GYlvgIO5IkiWwywremtraWDRs20K9fP/r3739ar7XQ0FDuueceHn30UX7xi18QGRl5Gi2RMNpSmfSD2VQ+/gabLvo9AyIyyLtAS/oVV3NBUrBfu37fPjwRJnTs4v2/byfnH2/wsxwjsq+NrZ88zmsfAliJiHCgkYo4WNJKTr9QGvfu4UBDfVcQns3ch/7I3K6aA50teMa+ypL31pF7wxiSLR0c2rWHMo+RftmphFN90mcRlpxBYngBW7+cT3vSCCZHJnDsyHHX3nf4vGkkA9o3cngKgKfTgK5qI5sPOU/j2vUtJMSO391GmFVPa3sHtY0ttHXo6fTKWC1mQkwa/F43jtjoEx9MEARBEM6Q8yJwB7p70CWNDl3XF98qoEFFlYIrubb5YPX2csZkO0lL7usPuYrsa+DA2pVUdwDosEankzYwjwhTH0W6KHI5BSvqcE4dTvBLfDctVeU0tRhwDkgluGxUE+Wby9GlpREdHnL+XGDhlNTW1lJUVITFYqFfv36nXH7r1q1YrVbCwsKYMWMGoaGhrF69GoCGhoZTPJoOmz2NnKwmVi+vYMTkDNJKitjy/isU2YKvStkfzrArnESHJDB+fATvLHiFF7/Sosg+Kosr8RIFGIlKzSU9rpitH/yd6qgI2loKaGwN9LoCsc5kIe+CK9jx0jye+ccu+tldNDUGiMy6mKHpEXAKgTumKPqlOdm8YQuKKZL4hGO721vZ9MYq7D96jIevyeze2l65jU8//Ijd60s5uRUmTk5MTCxVlZUYVBWn3UCDy0+rqw2rUYNVp0EvdxAW7jgqpacgCIIgfNvOi7hSkqTuXMmqqsKRQ9ylYG98VISNScPT6egIUFRajsmgITEhpsexFLmJgi/ns7vGTkycHVDoqC2l3GDGOCjzuAvMqEoZuxftQHdk4F6+l+JSO7buwB0kjcQJk1gL57WoqChSU1NJSEg45d729PR03G43brcbgIEDB/ZY3vj4C50lc+EdFxOr/zqcNtoiyJtyNT6XhDEqjXEXTMe0eQP7DgVXX4sbMoKs8HCMhDP19mupWlZIQFHRGe0Mn/NToho1xMHXZTeup6QF4oZeTG6akaT48J6ZWzQGHGkTuep6+GzLISCM9KE5DB85iFgzQAwjL5+M/qiymcy8S086WuwRuUy9JoW44BkQGxNORNZgohPTSOglG2bE6Ov5+aTMo7bZnGmMm3Y5NR4jtuQoUgxR9J5I83C9J8dkMhEZGcmhmlp0/nZskhejPoAiBzCgxRkVRXJSEibTCe72BUEQBOEMOi8C96MclRZGDS7eomiIdIQQHmrDr0q8v6CUusaWXgN3VSmlcFU98T+/hXFxFiBAZ2MDbZ1yd69i876lbN+1n+ZOIGQg4y8eS6S5go3zvqDc3UTHa/+iNDqLtIGw96s1lLbpaXitluyR4+ifY8bd3IouPoBKOdveLcCYUcf+nU2ABqM9mQHTZpJiB/DSdGArezZtpt4D5uQ0QlpMxI4dSqIzDH3Fcj5ZuZeArKI1WEideAt533TwrnBGxMbGMmnSJEJCQk45cE9OTv6GtSeQf80xq6oarDgHTuSSw79HZzB2RgZjeyuelM+Pbup7bYPQxAFMThxwck0xWHEOnsEtvSaJiiLvwqhjtqVwwY0pwR/Dshk36/B2DxWVdcgGB1lpMfQcOR7K4Msv71mFPpSkfkNPorf9iHpPgkajIdThwGA00traitfrRQVURcFsNhMeHo7RaDzlxbcEQRAE4Zs47wJ3WZFRVAVJ0gRzM6sqChKqCooKSAparQmJvrLHmNDpW2hp8kKcBdBhiYjB0jW5zl2+jg27yrGEZ5GVZqO9eA1frAzlmmkJxOakErJVQ3zuIJJtUTjsHqIS4nHVmUjOzcEZEYKOBmr2FmBMSiPO2UjZhgWUtY9hSt5QkL10lGxm7apEoi4ZhL6xhILd22k2JJGVEYmrch271rUh52YT52xh20cr6cyeSm6EFkVW8OxcRm38FM7saF7hdOj1epxO8Ux8cx1U7FnOey8t5oA+hhFTZpMbfe4nfB7+ls9ms2GzHe97OEEQBEE4e85Z4D579uzj7r/55puZOXNmj+2KoqAoIEnBnndVlVAAhWBnvIIKqgapjwRwGm0qI66ZzpqFj/LyFwbQR5I4ZBr5EwZgoYPa4iKUkDQyRuQTF6rHn97Jgb9tonRKLqlDs3G84yFl+GiCX9g30ZaSggs7mcOHEBzteuz45GgGTL6I3JRIULw0R7RSumA/LZf0w1hbSYfHTvrE6QyIMeGJbqdqz86uci1Ul5Wjyx9F7lAjiizT2VDb61hjQTh/GQiPG8S0q6Pw2CJJSErGce7jdkEQBEH4TjpngfvDDz983P1xcXG9bldRCagEu9clQAVZhYACqgKqJjjmva/sypLGTFT2ZCaH9qMzAL7mMop3LGaVRsPE/BBaGqs4uPErCtd/jE4D4Ka1LokBKpzyKi4AhBAd25UfQyOhsdgw+WsI4CbQ1oGiRBIeFRwna4pLJNJW2jVMIJtJd1/J4n/+muc/k9GZQsid8wj5opNX+F7RYw1LInf0mZxaKgiCIAjfT+cscM/LyzutcqqqoqjBnvfg2GIJWQn2uAfD+mDg3vcSqRIarRlHfDoOQE0IIeCqp7jyEO3EYLKkM2hWPik5WUdMVDViNejOcNp0A3qjHo22A48bsAEd7XT4fV2DfCw4Ei5k5t0j8Sky7rLPWPzefJIeuPqMZs8QBEEQBEEQzg/n3cwqWZbxBxQUNRiw+wMqAVkhIMvIioysAJKmzwmDcmAdHz/9KU1dv/sa6zhUUkibPQQzDuISNZSXV9DRaSAs0klYpJP6pe9SLJ/pxY7MhIVHoMjVlBZWAlC1bT0VtVX4AdjBZ//ZhjE0grDIaELtZgId7V37hHOtvb2dDRs20NDQELxRFARBEARB+Jadd5NTVVT86te97XSNa5dRg//KCl7Zi9wzeR0AWu1Ips54g3/ddllX8B5G8qgrmXnJ8GAPe96VzJLf4L0Xf8K82mC6vuzrXuUaSY9GGs3wMW/z8m1XE5k+kyseuI6YxHgKN77As7ctYMgPbmTy1JCjU0H2dv/Q1XZz0iiGtdaz9P2f8tt/gH3IKJzGOIKLww9iZs4L/OFnj+MPKOjMDkbe/vpJp7MTvl0FBQWsWLGCpqYmpk2b1p2uVBAEQRAE4dtyXgTuh3s0JUnC5/PT1OJD0khISEhScLi73LW6akCVcXtV1L4GpEtarFk3cc9LN/VZX8iQG7hlyA297NGTOvcf/GnuEZsSRjLtFyOZdsSmCXdmHd7J5X8dcsQeA6FxF3LZA4d/V3DkXMTc383gap0GuX41n31ahd1oCj4xg37KQ//46XGujHCuaLVa9Ho9Ot2ZfwsFJ2Ar38qxBUEQBEE4f50XkYGqqt1DX8r37eZve4qO2Nf9EwoBwI9G4yc3eXKvx2r3nOkhL99EE4dKK/C0hxKXZKFmwwZctoEYDRY8J2in1y+j6yvjpfCty8zMRFEUkpOTz2gub1mWKS8vp7a2lqFDh2IwiBQrgiAIgiAEnReBO3zd6/7g/bec9pjiOIeBPRWtZ7JZ35AWpbWd+j0fs3V5J5iziBmWSn2bm4Y29wlLx8dbzkIbhd5YrVaGDh16WmVdLhd+f++zFRoaGnjllVdwuVzExcWdYAXVc6WV8t2tOHKT+lil9HR5aaltwac144gM6WURpu+DAG5XCy2t4EiMxHyumyMIgiCcV86bwF2WZXQ6HQcOViHLh4fBqICMJElYrWac0WFIktTnxNTbJnwXcynGwOyp57oRwlm0efNmTCZTj950n8/HV199xcaNG7nmmmtISEjo4wjNFG8qpM4X6Ep7qsFgiSFzSCqOb7ntQRt55rolzNz+BBec0ePWsP79zyiz5zLzhol8PxcJbuPg1s9ZuEhi1l+uo/+5bs73ikrAV0/png4iu98LXpqr62kLmIhKEjdKgiCc/86LwF2j0aAoCqqqsmjJFuJiYrr2qCB5QZGwhlrJlhXinWFoNRqxFLnwnTZr1iyio6O7f1cUhd27d/POO+/Qr18/MjMzj/Ma3subv3ycA0PScWo1oIDWayXj2tnMHDaYOBGdCP+TFDpb1/Pa7/cy69MHGAVAJzUHCijviMAsAndBEL4HzovAXe2aeCpJEun9Mvnhlfnd+xRFQqOqbN1XxqrN+5kwTEt8hP24Pe+C8F1QVVVFbGwskiTR0dHBW2+9RXNzM3fcccdJ3HjmcO2fH2GG2QABD/Xr3ubpj99lgS6e/xsdBUBr+W527NrDoXYgsh+TR/QjKsTP/uUbCAyZRK5Dwlu/i9UbXaRdMJ40QxtVZWXU+wxYFR9tjbXUe1ppafEDFjLyJ5EXa0d/TNO8rgb2b1rG/gbAFsuAgYPITepadIxODq7/ip0VzXgVgHjG/SCf4HcJMp3Nlez4aj3lnWAIh6o6D3p732ddtuYd1lcCOjMRWaOYOtAJdHCosIzqyhqalVYaG31gTmJUfh6J4dbu1Ya7y2qMOBLyGD8mDUtvZTGTOiqfvMRwTL0kC+r7fBvZt7oMn7GBkupWvF4no+aMI0lysfOLJRS0g9YMnc2dgLX7eM0l29i2u5D6TsCSSv6kPGLtJjRUsvbdMixZLRQUeLBHZDFiXDwd+7awoSiYE8uRMpghudlEW3u2U1VkDq55n83VgMFObL8RTOgfBbRRvruMhpN8fgHcTdXs27KaoiYwRqUzOG8gKZHBzF21u5axsaiBTj8QP4of5KcEn9vWMnb9txIlqpXy8k7AQFR6LnkDM4k0HnutFMBO7sUzGBDSy3U2hJOem8fATGd3vrAj67X3v5CLBrjY8Ml6SlprWPHOR7TG9mPYhCQczlhkrw1TV7n6favZtL+aNh8QO5w541LRaSV87jK2Lq5AE9dKSUkHoCc8uR95g3NwmhAEQfhOOC8Cd6A7kJE0OnRd6edVQIOKKqno9XrafLB6ezljsp2kJfc+LEYO7Gfh819wsHuLlfh+I5h40WCiey1xLlSw6s0Coq7IJ9tmQoOCt6OAVR/U0e+GiSSe6+YJ+Hw+6urqCAsLw2KxnPJNYl1dHS+++CJXX301o0ePZvny5Xz88cfcfvvtjB07lvXr15/8wXQmokZeznWet3lt6UbqRl9CSF0R/132BTsrOrDaQ6jdsZs231zmToqneuVrrLPkkztSS/vO9/nr0yX8IH08abE1FG5dxS5tGok1m1m8rhrnoBQcOj0cKmRljYH7b72A5COCRNntonDtAt5bVUxElBNXWxEVdS0YZkwjy+li++LVbC2sxCUrqCq0bPuC7ZHx/HlKKrK7lYKvPmD+4jpS0p34yho5uK+R9PThvZ5m89YPef79tcQlpeD3B9i5/yAm863kZ7go2riQ/3xSTPjwNCL1BmoPrqNKMnLj1EGEm7VHlVX8AfbvKcJlvp65g5UeZak9yOoqiZ/eOJXscPNRi10c/3yrWTP/dTZo9aQnx2LUGHCr0LBlPn//oJD+A5OQlU6qisvQ2ScA4K7ew9Iliymu92O22mg/tJ0DfomfXTIEu3Ef7z7yAp1XD6G/NYowwqguqWL9u4spCEki0Qw1dSpmhx1rdhzHxu4Nm9/jxQUbiElIwuv1se9ABUbTdYxKbWLvfxewoM/n13BUTq5AewO7Vn/CZ5vKCYuIQqoNYIuIIiIyGan4K+Z/ugKfLgSdXk/phhfQWX7NnKEWXPUbmPfXT9FcPIAUkwVc9WwvqKLNEMJFeXXHXCsNlNlOv1wAACAASURBVO5gmSuGv9w2FPsx19nrKqSwqgHVOIMRSaG0H1Ovpn4TWTlJtNS20BnooLG6lgZTAn5aKdr4FTubE5k5MAlNyUY+WrSMZr8Jg9FI+aYXUY33cvWoCDzt23j7sfkol+aSbrZBezO79pXQoHVwxYg4ROwuCMJ3wXkRuEuS1J0nW1XVr3Ojq4AU7I2PirAxaXg6HR0BikrLMRk0JCbE9DiWEtjLJ898ju3eWWQA3sZK1n9WTLPNxg/zM3r88Ts3yvjypYXkXjicTJupK3CQ0Gg1fSW5FM6yqqoq1qxZw4ABAxg0aNBpfbuzc+dOiouL+fvf/84zzzxDTk4O11xzDW1tbafeIKMBU2QkodXV1OClc98WChstjLr6Ni7MCqV2zXM8+vl2RgxKZciwCJ7bVIQyPIuS7VsxOuPZvbucdlMzzS0thA9PwVyzGVvqSC69bg7DYu1QvYCf37WZA9eOJbH7TaLQ2VrK9q92Ej3j1/w8P4bWoi956+PtbNk3kGSnDY0mlNyLJzIwNRKzFlq2P8GtDy/iwJSfEN1aye4NpaRf/XXZl0s/pL3XE2xm41tv0Zb/JHfPScHnquar957mi2X7GZQRB3iQIrOZdPktR5zvbiqGZeIwB44qK7sb2Lr4ZT5csJH8wcMBCWvSYC6+5lryE0Oh9nMevH8bB5pHkR5uPmKS7InOF0DCMfBibrxmPDE2A9DIp/9Zgu2KZ7h7VhKehmI+/+cTLHEBuKncsZ4DbieTrruSsSl22grf5IE/r2H/xP4MMwY7KhIn3cTd+UlAM3tWzuNAvYML77ibi1OgsbAQl13q5XOhkfVvv4N/ytf1Lv3gNZatLiI3NQzgOM+vga+/aAjQVlfMrm2lJM66l9tGReE5dIgmrRZoZ//yxVRHT+LncycQH2qg9MOfcM+8DVwwNDj7QW+PZuCMW7hpUAy07uKdfy+mYl8JbXnWnteq9CWuvPFzDt42mMxjrrO3bjPz31zJzq0HyUrKpOiYelu2b6dFl8X02y5ix7q9zLr7jq6hMtUUdp9LB8VfLaPcOpQfXTmNzEgT5Z/ey13/Wc+Foy5BD2gtDvpNv4X/GxYH7YV8Nu8z9m0voGVEHD3/mgiCIJx950XgfpSjMsqoKACKhkhHCOGhNvyqxPsLSqlrbOk1cAcJo2UAl955J5MBv6uIL954k3UrdlGfb2PPR1uoai5mf+0h6uoSuey+axkXG8a+effx6hY/aIxE9J/JT27NJ6LriPX7VrHwk4/YUQOhAy/hhzPzyYw2AQ2seOEZFh5oR1YlzPZR3PDID+hHBxV7trBtm8TQ68Z3DRuoYvVbW1AGhVK//CM2HNrAjod/w1rzcG566kdkye3UVzRyOMdI04HNLP7oLTZWAfEjuPaKixiRHg4U8fHjW9H3K2f56kPIMhitacy8607yI4HWCjYve5+3VpcDED/icq64aCLp4Wf8mfpea2pqorKykoiICPLy8k65fHR0NPfddx+33XYbv/3tbykqKuKVV14hNjb29AL3o7ioqWnHbI4nOSU4ZMU5ZAgxr6yh0t1J/5EjsXy0lVolwKo1DibfNJyyZSvZkZGAy2UjO81M67owMjNTiYntGrcSF0u8ZwvtqnJEPQHc7kqqq2IYNzT4XgtNTibeXEBdTQ0uxpA3Mpr3336Nz6tbCSY4raKjNIJyAth7KZuekU55r+d0gE2bI7jwoRQADFYbSQNy0L1XQA1xQBjpGYm9ny8VbNpcR6P8Mr/bHmx3W2MDbjWcegBCSE1NIiGxa3iP00lswI9HkVGOasOJztcGRDNsaCpW2+Fwv5gtW6KZ9MfgO9fkcJA2dCgxKwFaqKwsp2RdKYdqDvK5HqCeyn0GymWZoYBGk0p+/uF3vYW47GEMzVvMiid/x1oHxAy5mEsmZ9Ezv1TPepNSU9m15gB1DAdO5vkF8NHWXkNzcyzj84JDsEyxscQBUERhoY7+s5OxdZ1vytQLiXxqEwe5gAQMhIamMmhQ1+dwaAgOs5kWrxcv1p7XKiWF5JZCWgngdh9g5/oC6t0v8LvFAO1U7fOQETWCdg71qNcxeDAOZFy9vHK+VseBg5A6OokwR7D/PGnSJJxPbKGIS8hBi9WayrBhwbPDZiPEZsPc7MFz3OMKgiCcPedd4C4rMoqqIEmaYEYNVUVBQlWDCzEhKWi1JiROLsm53NlJa1MzHqMBA60c3PIpb+ySuPCyCUzOTSbRaqJu8V/43WoTt84cj+xzc3DjWzz1YQR/mt2fzortfL54KQc1/Zg8OQ53dSNVrgZiottY9Lv5VKQNYvwkI5ISoGTx2zw1fwD/ujqOpqr9bF2rIbU7cG+mcO1W5IgJ5A7LJtZWQey48Yx2pBONis9zkPWf7SL+gctJrClgxRcfs82XweTJSZTv+opPPjdgv3Im/WJq2bLwZVYdzOfnF09EL6l0bP6I519aTvaDI+nYv4rFn5cSNXEqA0OhtbycovICIsKzz1JGku+HuLg4cnJySE9PP+25FJMnT2bq1Km89957XHXVVYwbN+70G+Tx0FFdTUPaIJLRUaSXAD8BP2AAvF48ej1GjQYp9kJmWH/PqqWHWBUziyeHZrJ82V/5YvvlOB1DGOCAtSdVqYRGMqI3ePB6AQvgD+AHJJ0eLWUse/NTCtQU8kYPxKID2EnJp3V9l/X76T1Rphmz2U2nGwgBVAXF5ydgtHWNefbj9/dxvpgxm1MZeXE+X99iGQiJSiEZaDnpi3yi8+2NBbPZjdsN2AFFQfZ68WEFdOj10aTnOUgenkNYV4n8/EhyQiz0HGpuJCx2GNPnhpG8qxxXRzEbN63hq8howiZkEHrUY3upNxBAMRhOMc2mBq1Gj07nxeeFo2d3GjEaA3T4ZRQF0ALuTjot5m84CVRCI4UQGdOP9Gn5pB7enG8jvl8W4bh71ntSDBgMCoGAjHz4/sTtptNi6eXGRxAE4bvpnAXus2fPPu7+m2++mZkzZ/bYHlxVEiQp2POuqhIKoBDsjFdQQdUg9fJnr+sIdLQs5Y+zZ/M8ILs1ONJGcs0DY4ikHghnyAWjmTl3Opl2I1DD/HdWk3zlP5k1Ix5V7qAouoqn/7GCfbNTMBzcx6EmK6N/dB0z0q14GxrosFgwYWPEFXMYldaPpFADEgEOpZTzu98tYdfVNx7nzMPJHjeQJHshuRdexCUxDnTIfJ193kt95X5KyxVG3vQjZvWz0Z7l4/FXSthfXkdqDEAcF15/LbPGpqOXZJqza1l85zpKHxyMobWM8gaJC0fMYlY2tNfW4jaZRLaFUxQVFcXEiRMxm82nHbibTCYeeughdDod9913HxbLaYYP/k6qlr/Ks582Mu6nIwnFTEKCgy8LSti/v4acYTEUrfwv9QkDSbRa0WFhcGYddz27H8dlfyfeZCHaVs/bS9cy84e/JIRje137osNqTSIpsZ4VKwuZckUWtQX7KXW1kTI8gRDqKdlXg/GiK5gwNYcII2x58d9UktJn2V07d6HGjumlrjQmTuzkof9s5vq7huNubWX3+vVoB95PDFBKC7t2tpC1P7+X801j4kSFx0oj+NWPg+Pn2w8dYt/WrTQypJe6Tv98e8pgfL6LZz7Yzg9+Mpj2+nq2r1xJjXE2EEZqahgrG11EpwxjcnYkALvnz6dG7tfVq32kdkpL91FcHMHU6dOhKYzyjYtobG7GexL17tu1G0POVKJO4YzBQEhoPOHhy1iz9iDjZ6TRtn8/FXo90emJDByo5S8b9jB1QBJhkRa2zJ9P58SHSQNOf8UMHVZrMpk5EnsCqdxxSXAl6upNm6hqqaYjuX+Peg99+ilVs2aQddzjRpHT38CS3fsYNzgLZ7yd7R9+iGvsz8iEPm4YBUEQvlvOSeC+cOFCFOX4wUFcXM8/WwAqKgGVYPe6BKggqxBQQFVA1QTHvPe9RJMGk20Y1z18DyMA0GF1RBOXGI6BesBGXFwkdvvh3AUH2LmzlP/uv54pTwYr9Ht9GEMvwUU7UmMrshxHcteMPWNkZFcPoIW0mFXce8tv2NHSGcw4H+ggIF9IC3yDhWvctLQ00NGRQHq6DQBbWhrxnXtobG2hE4AwMjMikTQSIKEJDyPUU4mHEAaMvoxZJa/zxs1T+IcJMqb/H/93wxyiQo9TpdCDTqcjNPT0L9p7772HThd8+yUlJbFixQpWrlwJgNfrxW4/TmoVADbzzA+v5mVJAlWLzZrLZX+4kymJwXJRA6cwpfJ15j93G2+1GXBHDeMXt48mJdyEBGRMGo321ZWMH5+GwdpGct5wYkq0ZA6IAapP8iwkjGHJjL7kCor+dRdz5pnx2VOYeunVTB0YhY5QLr88iwfnPcItr/rRShAyegCZuHsta4iNwExiH6G0mYG3PsFl/+8O5syxo+htOIfP5qEZqV3v2ygS2cri1+7hrUe9x5yvhoG3PsLNr/+ROXOCgykskalMvf4BrsJH5Ume7YnPt7fA3czg2x5j4p9/wZw5NnR2C1ZHf5IB0OEcfhFXdLzDvKd/xgt1PgAyLnqAX2hMvXQ9mHAadGzf9gxz/lEJcif2nNncmPN1b31f9crGMNLGXcn9U5IwnPTzC6DBGtOPcRdM4K3X7mTOy2asKeO5+oZrycBA6MU/5tJ/P8If7pxHm19DW8Kl/PO3AzHzTQJ3CWNYEvmXX0Hj239kzivBT7XoAdO56rprCOml3qiJ9/MXNJjMQxg54HUennMjucMu4/ZfjzriuAYSJ9/AJdV/4elfvU+zV0t7/GSefmAwZkTgLgjC+UGaNGmSGhISwmOPPYZOp8Ph6H3AxPXXX8+dd97JqFGjet1/tny0dCfXzb0ARVG6ejolZAVkAEVG0ch8/PFa4sOtDB2c1qO83/MRdw1bzZw9f2Nyj70FzP/tBzTmTWLOVWO7JiMV8ezMJ7A+fT8XGg4Pv9GgN9oId2oo+uIDFq1rZ/wvfsaYo8aJb+Jvs5/C9aMHuGGwA52k0Na4mOd+VskPv7qbkCXv89ECDXP+fisDAdjNyz99H3nW5cy5qJ1nJnxA7rsPMftwj3vdBzw0exdzvnqQmK8+4cOPDjLqwV8zKRJoWMmfH9tAymVXcOn4Oh7vs+wfGY+Mp8NFS2MbvuYtvP3iRgzTruT6y4adYk/c/waPx0N7e+/TJU+X2+0+4Y2rTqfDaDT2sddD86FmOruPIaHVWQlzhnJkCb/bhcvVhicAGGxEOmwY9V3jCvxt1Na5sTijsWtlfO42XB1gDXdg1gZwuzoJaAyYbaauu3svrbWd6CNDMWu9NFe7MceFYwZkv5f2lgbafYDOiD0klBBz13vF20Z9Szu+QLCtOrsdfXug17IavR6dZMBkNh1R79E6G6to9gCSFoMtjKgQI1DNqnmfsb0ugvHXjyXap/Q8X8DnqqW+LTjSXqMzYHNEYTcG8LS78Sk6LCHm7nN11bvROmxY9LoeEz/7Pl8fbY2daGxWzEZ9d+CtqiqdTdW0eEDSatEZzBjRYg63YQBkTxstrjY8/mB3gzE0mnCrHo3kpumI6xys3EdnWwvNHcEwU28JJdRuw9jLxTqyXjQ6TDYHEXYjwdVbj/f89pwEL/s8tLU00uEHjcFKaGgIFkPwDL2ueprbfcgqYAojPsICqMj+TtpaZMxRIV2vyyPr1eDuca2OPl814KPD1USrWw6+dsx2QkNCMHWd65H16uxROEMMqIqMx1VPU4eK3mTDEWFGaXfjU7RYQizoAG9bIy3tHgIKYHIQG25BI4Eiu2lt8GPpfh8dfm18XVYQBOFMkGWZefPm4Xa78Xg8uN1uvF5vd2xw8cUXM2bM0d8+P/jgg7S2tp5/n0WyLOMPdAXtKiiKiqKqyKhIatdkMklzBnO4pzFtWgOXPruHW569FID2mhpWvfUK0ffcTUZCLH7/YtatK2LMJZnULFlCYUYGuWleWhrcmCPjSEyMRCN7eO+PT7KJH/BDTFitOmR5G3v3wsAc2PvBB3y+aSODZl1+gvaYcToTMJtXsnzFXibNzWHvypWUmxyMc8Zgoe44ZZvZvXsdW7fGc8MNg8BSgYUAHV5v8MZHOCvM5m86MMlEWGxsL72sR9ObQ4gw9/Hdjt6OM/5wr74Wg8VBZPdIHR3mkGPLGQl1Hr4tMBN+xCpPWr2R0Kh4ev3+wWgnynnMtwdHHPq4ZXthiYjvczyy1mglLCq2zxVXDSFO4ntcDh0mm/2YVH9GQqL6umk6XpsN2CN6jiCXJAlrRHyfGau0JjsRpt6+YTn6OgcfbMDiiMZyEhNS+q73RM9vL200mHBEx/c6D8YYEkVMj+sqodVbcRzVG3B0vT2v1dHnK+kM2MJjsPXRpt7qlTRazI4Y4o9s6DHPr9EewbEvSQCN1kLYUVmEe3ttCIIgnFvn3fKiKip+VcGPgh8VuStol1HxoeKVZbyyF7nPUFRC0vSWPu3wbomj92rp9/MP+SzteZxOJ06nk8EXz2XnyHsYjoQj9yKumTKAfY/n43Q6ueg/+9Eq0YSTzyN/yGP+zcNIiHWSkJLOiwk3M0GSkLCQMWgi43M7+NMFwWP+4P39aG39iZEA8rnppib+MG4A8c6bWXi43V1tC8nMZ/bMqbj+eQFOp5ML/tHEBZfMYUJWCBL0ctNyuGwYuVEJWPY/EDyXAbP5WJvJpDFjRaqzU3R4UbDD/wnnltT1f5EuVRAEQfg+Oy+GyhwOjCRJ4q1PN3LJxZO6gm8JSQpOTJW70sr4VZklS9fSL97BiEHpZ72twvdLX0NlWltb2bFjB5mZmcTExIhVegVBEARBOCnf+6Eyqqp2B0ble3fx5O7CI/Z1/4RCAPCj0fjJTeo5gl0QzpTi4mLWrl1LR0cH06ZN614gTBAEQRAE4dtyXgTuR3rw/ltO+BgxdEH4tplMJmw22+mncBQEQRAEQThF32rgfuQQlyM1qcGME+GS/6Qer9Gc2lB8MWxB+LalpaUhSRJxcXGn/PoUBEEQBEE4HacUuCuKctSwleM5stf7yDK1soHdSgiqpDJQasOp9R338YLwXWQ2m8nJyTnXzRAEQRAE4X/ICbsKVVVl/fr1VFdXs2jRIt5++206OztPuaJKnwGvItGk6OnwqnR6oEnR41MkKn2ntgi3IHyfeTweWlpaznUzBEEQBEH4jjmpHvd3332XhoYGFi9ezLx585gyZcoJx/ZKktTdi17iMbK1w0a83stwewcLSjWowMU5HWxps1IRMDLMAqkmb3fZo1Wy+q0l7GpsJ7h8ioTRksNFt07pWoHw7JADhSx7rYLss1yv8L/D7Xazbt06ysvLufTSSwkPDz9xIUEQBEEQ/if02eN+OD+1oij4fD6ioqLIzMw8pSEsBzqN1HqD49nb3CpK12iYoqoARVXBPOuKEtwHUOfVc6Cjt0VASln6r4Xs6vCCRoOEQsWKf/P8/E00n3RrvjklsIePn1rIgbNYp/D9U1xczI4dO3r9b9WqVbz++uvs37//W25FEZ89fbqv5W9SVvjmXBzcuoG1awvO6ufft+sAC5/5jMITP/C7y9tG1fp3+etf/8n8RVuPuxTe9+J8BUE4J/rscV+/fj2ffPIJPp+Pbdu2YbVa8fv9aDQaHnnkEcxmMzqdjscff7zX8ntdepbXWbBoVC6OaSc/rJ0tVRqGWMFi0qOo4JehrC7A+HgfZmQWVtvolDVMcar0D/Efc8QkLrjpNmbHONAqAcoGtfDgYysovTqHjr1bWbtoL62hh9i/38KIy2YybUIOrctf4d2Ve6jrAKImcte9l5Co14LfTc3aN3nik4L/z955x1VZtg/8e/Y57I1sREFkKIrKUBHcMweKplbasJwtq9csTSvtTbNtaa5yb3NvEyfiFhARENl777N+f4CECIqWjfd3vp8PH+U5z3XP6+Fcz31f93UBYNqyI32Hj6NLbcrF5NMb2H7sEqnFgHkgk2cMopVBHGv/s46LJRnkv/0+F5y7M3r6AFoWJHLq0E52RaYD4ND1WUJ7dcKhuakgdfwrqaysJC0tDSsrKwwMDB7rhTY5ORlPT08MDe9P31hcXMz+/fvJyMhg4MCBmJo2lRs1nt2Lr9NyxjN4S5/0fHkSJ9b8hv4bg3j8bAdPKnuL7Z9s5rryXnI0GeYOHenW24zkU7cx83+GINeaMSm+eYQdFyro0CcIT1uTpxz+Ko+oE9fJl9vRLkCPqA03kHXthLeTZW3WzBi2fhxDuw9H0uaptqO5lJIac40bRY7YBrZ5ZAbdfwcpnPz5BNLXB+JQcoPDP2fgPa0/Ln93s5qk4TOooawwiXP7T1Hk0Bdfc0MkD5X/t/VXhw4d/xQaXXHXarXcvHmTQ4cOcfXqVQwMDDA0NESlUtGyZUuioqKIjIxk48aNTRZsLlUjR4OpRIW+RENr/Wpu5ApZdUsfgUSCSCJhVZwB1/NEtNavRl+sxUyiRibQYCZtKutpXQMpTU2lUKFAThV5qefZuuUAUcX2BAd3wd3enMrL21l2LAlTF1+Cg4NxL9zBO8svABrKS86z4fuTiDyDCQ4OxlVfTOrV06QBRTf2s+ZoLCJbH4KDg/EoP8RHq89RrTTHI8iDFlJb2gV3p0uHlhhTSNyV4xw/lU0L35qyzFKiic1IouTJ50THv4Dk5GROnDhBdHT0E4Uf9fDwwNfXt+6nffv2aDQaoqKi6NGjB3Z2dg95Gcji0p4LpKg1f6wTfzkZROy4jUFgIIGBgQQG+tHRuyXWRnoIKpI4u/ck8aVA8U0O7zxPmlaKnoHsL0jvLMfCwQF7W1NkFBB75goJuSX8vnRgjpu/2/+IgfxPR4BYakmrDs78s9c+Gj6DKsrKkrmdbEf/8UMI8XNtpr78W/qrQ4eOfwqNLmRptVqUSiVSqRRra2vUajVKpZKqqirkcjlSqRSBQIBSqWTkyJF1cr6+vsyaNQsAa7mGZ+zKkIm07L6pIbFYQlaFgCylFLFYAwi4li0GtZKPz0hpaajkmbblVKqFWMsbM0iusuyVF9gsk4AWVIVmDP86FGcgDgX2rn4MHDeGPi0MgAJOfX0JkVM3eg3tQytTCeUdcjg8ZDfnp3ahrSqNm7ez8XhnCEM6Q2VRESUVFehRRNSFK6jMvQke+gztrGRU+BZzavRRIl7uSsDAjth/WIbfkAHUpHfK5FbeXTKKFQz1H8IAFyhOS6PKyKh2pU7H/yolJSXk5uZSUFDwxHkDrl69ire3N0KhkKKiIr755husrKyYMGECKSkpzSpDpbzAytcvoB+YyvHj2YAcB58QRr4wCu9aS+DOsRWs3XeWpEKwCpnO+6PaYVSnoEry08+zd00OAe+PwBWALCJ/PU+WXkv8+7TDgnxO/fQt2y/epVgJNoMD72tDaWY8B1cvYP9tQN+FnsNHMqynOwaNttgKn3796HPftWrEndsRt/E0h89Yk1txkhiBMz2DuuFspLjPcH+gv/IW+ISE8sIo3zrDp35/8RrNkldDMNGXgkZF0emlvLnmKgAmzu0ZOP51eruUkhIdTZaeiItHIjh69Qwln93ggGFnXlzyKt1MUjm37RL+fdph1bC/1t4MHRHG0M52wB32f3OeMsPbnLmWRnGxErBh+KefMsQGqMgn/thKFuy4CYC1d29GhI2ls139scjl+Le/UNL/ZQa1MkKbupMFX9yi++z/0NMkn9iLp7iQJsIUKI49zopP95OeUAqY0f2V6YR2csKodqn3/PcvsvwSIDHE0Xck0yd1x5w8rh89z/XLUdxVppHQhGwdjbR5eNjYut3J2/u/Yc2hq2SUANb9mDsvFCepkPKi86yfcxGxTyqnTuUCergEDGDk6EG4GwEUELHuJ7adjiWvGqz7dUGp1gJalJVJRB5Ixr+rPSXXzvPbjmsUmKRy40YRYEzHkc8zsmcHWsgBsjn03wVsiytGIxRh32cAzter8f9kDG3v60g6pzeeJyUvlhvpqWRmVoJVCO++Pwo3IzlCQFlexIkf32RTFGDiTMDA8bzS26URWXMciedMYRpXJ7/KLpkfEz53J3z2DxxOqOLy1GxOBQxk7Cu9EV/czZbtu7ieBbgOYNaE/rja1N9pq99fd8yBvLhz/LrhJ04nA45defnZoQS2sWjsYdKhQ8f/Qxo13AUCAVKplOzsbHJychAKhTg6OmJgYEB8fDxlZWWIxWJEIhFz5sypk2u49W+lULPqopp9cVo0YjFyhRqpWo1GJATUqLRqqqrUXCnQcC1ZQ3WVhpe6NLUp3opBb00kxNwQESASm+HoYYuCfECKsbElLVrcMxWyuHMnntPhxzm18QskQoASUtK9yEWIgWlvXl2YzFfTetHLoObL6Plps+hPPCkp8ZzZtYvjO35EJgQoJS3BncFaLTywAGpOu94j6JXyCyue78ViGbgPe48Zz/bF0rDhvTr+l3BycqJjx464ubk9UejSuLg43nrrLaZMmcL48eNZuXIlN27c4JtvvsHBwaHZhrtWk82Nc9vJcZjK3JkeUJBExJkL7D7YCsfRHdFe2cGa84V49nmRkU5m5F+IJkrdBr+6EjRUl2dzJyoVr7prleSlppJmaEIVkHt6M78kGDN6/BRszfW4sn4GS+nAYEBZlMnFfas4LR/MzJnulCZGcijyIMeMjRnqa9PM0ZBi0bYLgR1iOL7nB5YadmBAP398HQwecDdo2N+CpBucubCdg61cGN3RlMIG/b267TM+2WnLgjGeCDXnWL7kMl4z3qV/CyhJzybnyn7uuHjW9rc1XQf0ICm8AsnQfnRv60YrfTlC8rkdcZs2jfQ3IyqciPCdGBu/QLBbKem3DrKj2pO3Jk7C1kQBET8yY8E2fL99Bln2WXZsS8fvxZl0t4C8uCTy4s6SYRfI7yNlhI08nvA7Sga4gPbWWfZHXMEw6T/0bFNCcVYSmbIu2Fdd4mpqBd2DQxk73Api97J4xyHcnUbTxdaYjO3vMP9ONxbP9EdZksvVE7v4fqcFCnHKhgAAIABJREFUc4YbU5h5kT3ncuk+PpSZjcj+ngO4mrxG2px/6wwZdl2RRazjp4tqgoZOwqWFEekHv+aNb2zYObMrqup0Lp07QJXjJN6Z2QZybnHizFUOnnTCbogXyohf2XRLRMjISbS2NeLG1v/wraYlA9Giqs4l4VoSHijRFMRw/Nw1Wo4dx8yZDpB0ijVnTxFhb0X/dnYUHFzG0ow2zJvRDbFQw5mVb7EjoQ8PBmqtICcpnC1RBox+fjzjHUy4umE+S3/1YfGznkgEauJ2fMzakt7MmulDQXI05yLWsN3sTUI7NpS1RkYkBa+cxPP11+guN8dGX4p8Qj8yf8wmaOZzdDS2QHE7nK0no5D5jGOmtw2xh35i9T5zpo/qjk3d8nr9/kJFejTHjxwizT6UmWEtSTq3k8NHj2Fk8AxedopmPk86dOj4X6ZJw33kyJH07NkTrVbL/PnzSUhIQKVSUVpayvbt27G0tARqDJim0Gq1DPcUEpuj5kaBGkGlAK22EgQiBAjQatQolRoqq7V4mmsZ4SV6SAx3Q+zbeuLdojn+rsaYmPowevZEuvq2rbcFqYclAkQSa3x6TmOx+1gqy5M5t+cgx7fsxu19P4yN2zH8rWfwD+qART05C7kUqhvWI0Hf1JvBL8+m64hSqvPOseK7Exz3ssc6xAOTR7ZTx78VMzMzgoKCkEgkT2S4Ozs74+rqyscff0z79u1Zvnw5Q4cOpU+fPty9e/cxShKi0PflucmD8TCRg9qMkqxU8uJSyMOFnGtJmDh40SEgAFcTESpHR5QK+WO4n+Ry9WwKbQJH0r6TD5YKIc6j+rFhXzagpqzkLreiqgicNgiPVjI0rSRkJB4g61YiWb42WD9Q3hnm9+3LIgD0sPcYxltfTcBLbkmnkGDibxajcWiLX0BLFI06CQuQya3pNXQwHh5y1HZSSvPSuXHtFoUd3bnVoL8uo7pzcFEEd0e1xZki0jOSsdPzwMMD1K1bU1VVhZh8ak67yDG1M8PM0AwD51a08XDi/vfvB/vralFG6qZzJN1OptQNoCVDxw6iU5e2mIiF4Nwbt6XnSWAIrsp8MnPysDCuqV/ZsiVKrbbBy4kUVzc7zp24iCa4N+eO/4Znh66cPXuRl60lJMYnYN17BOJoSzoFtqP3wK64KyTQqoi2O4+SUV6BihKO70og+O15eHjooVUXIVcncHdLJLHDewMPk61vuGtRNtnmfM5F3qGFew/ad+mMg4EIV4fB/NrvMKdndqUdEkzNuxDy8gA8jOWgMiTzTgZRyWkUYsudyBQcvHvQwb9GtuWIPmzYmdjIfBvh5tGN/qNC8NCXQmsVbcMPUpxfSAUizh1JIXDEi3h62yJGjdnQEE4uaUqXFXj7BeLr51ejG+N61ehGWFtaCpI5dyyT7u+M+F2vclJr9coSsCNkoB/dQvywl4qATEzExti7t6WtQgpUYdvKFlOFBmcPN5wpI+bAHVRiW/xDgvCwktBKFsjZ7+O4W9QBy0b9YqrIzUgiJ1eB34t98HCQ0toojehVcSRl5NDazlG3k6tDh46mbWBDQ8O6FXR9ff3fBcRi7O3tadGiRbMqMJHDvN4iJv6ST3SSBoVMhlAsQCQUoVarUFarcbeCj3sZI//TTqBZ07GDlnWnbtPZxw/nVjUh9Q69/Ta3vvicgOJDfPutAbNnB0GpmlsKIVWZZSixxMtLxIYj8bTpEEgn7xqz4/gHHxAzZ06D7X2AbCIjL3L3rjMjR3qAXiJyVRUVVdU8wktfx78coVCIXP7kX6NSqZSFCxcSFBREaGgoarWaKVOmIJM1FlXpUW3Rw8Skti0iISKJBJFajYY8MjKFGLmbYWRcY46JDQwe86BnJsnJBtj2NEYurzH39bzb4cZRQEVlVRyRx45w+fRpvhACaFBW2TPwrfa1oVsb4sc72z4mGAABQpG01hgRkp2QwI3rezkSK8LX1xOXjo2t2AsQi1vj7l4jJTIywszYGFF0BnlYPtBfeRt3nO4cIEGjobW8D7M2F/JhqB9+YrBw78oL7y4hzDO/mWOhorIqjaxse3xb1syTxNISK5GI5Pw8ijEFpBgbKRCJa1+N9BQolEpUSLFqOYRJHxSz8CU/lonAPiCMyTPepneDE4nirt3otPoWydrjHDwSwKBdQVycdpjwfj2oqPDAp52IkmgxenoK5PfebmQyZFoNGq0WLYnE3LzDwVdC2C4E0KJR6+HSeVzt2sPDZOvTeJtfm/E2fVxSSE1LYP+qXWxcLEYoqBmfipKuPFM7TyKxAmPjWr0UixCLxQg1GtTkkJomw6KtKfr6NfOk8PTEVZjUyJiLkEr10NevzfUhlSJFgEajRUsK8QmWuLkZIBQIECDAwMMLZ5qKyGSFk6NFo7rhLLxNQqIzA5rQK5BgYKBAKhU1UXZDisnLq0IotMfSsmacZS1dsM+JJb2qsonvhwpKSgsoK7fB3q6mv1JbO2wqrlFQUkIF6Ax3HTp0NO87XKPRcPPmzccu/F4sd7kYZGIxcjnoySRIFFKEIg1ajZiqChUKubrOaP9zMqYKsX9mNktU/+GFkR24kVYBwMDvk1iDCKRdGWk+CSurGv98e/+RvPPpszURI/rMYEH1J0yZ5M+4hDIA+i6+zkqhFJFwIONGfc4wKxdadX6Fr/bNwq+FKVfXTsNqShQAHV78jv/6+GD+J/RCx/82jo6OPPfccyxcuJDZs2fj6ur6J9dgirm5irTKUsrLAf1HCjSCJdbWxSQVVFFdDciAu0ncAUCEVOJOQL+XmLLodTo2qzwxCiMjjBpeTr/IyTNxGId9zqdlJ7hw6gLO9kPxsmp4oxa1+i6pqYAjUF5OaUUFSrPWmDbW37RUkm3tGCsUIBBIsXIez7JL46Eygws717L553V4f969mWMhQiqxxtzsHJlZgA1QVEwBIDEy5uHecQKEIlPcA6bx88VpUHKLPSu3ce7AQVpP7Y/zfUPUgz5Oqzi6PJpDIUOYb+QDbl+wd581tjZdmCiC8IfW5UhLp94s2r6okcWG9EfINqPN+w7gOr0zVpb+TPlhJiF+Xg0OYqopfmi55lhZVnCrtJzKSkABJN/ljuZxz4rYYm+XTXq6Co0ViNCiTrlLapP355Gd05RuOGNvt74JvXoSDDA2liAoKKC4CDABsjJJNzWjk1RK4+a/HD2FEXqK2+TmAxZAfh7ZcgWt9PR0RrsOHTqAZmROBfj+++/p168fe/bsITs7u9mr7VqtlvJqLa+uLyIqU4NcIUVhLMXIRIGxqSGGRgr0DKTE5YmZtq2C8mptEwf9ujE//EvCGnWTMaN930l8tPRlvBt8Yj/iM45duUt2djbZ2dmsGVWbNEpuTJvXNtddv7x7Kc/WE7YZ9AE7z92p+3zd8y2QiUEolhH40TmysxM5t29WjZ+wQwCvfHO87t5Dn4Xh07zh0fH/mMrKSioqKnj//ff56KOPePPNN6moqKCiooLq6gd8sp4QMzy8rUiIvUZsVDyFhYXErtvEb2Vl9Vb8RMjklpiaRnIuvJDCwkKijxzj4KGj1HjZW9PJz4Jzv50m5W4ahYWF7Fm+pvYzMQaGNtg7xrP6x9MUFtbIX9+zn0OnzpDRrDZqUavSOXvuFInFTgwa0I/BI4ZhnXSZ3y5fJketabAKrKWiPJEtG45QWFhIQnQs127GY93OE7NG+nt47XZE3QNwEYlQKo+xYN6hmnYWlVBRrUEsa2hEiZBIoLqilOLCMqo09esXY2DoRCvXCg7uDKewsJCoiEskFpVi08r5EYZ7FdlZR/n+65M19ReXUqmmZnekkbtdXMWs/Ok4bdxdEYnFWJqacPHAQUQOdo3c3RBn+g3JYd57e+rmJCU6hv2rfyG6GdLNa7MF7X01HD0QTsyN5Lp69r8/l98eWa4F7X0tuXEpksTbdyksLOTAmvXcVTW+R9M0dgT1NGXXxkPk5+WTX5DP/jUbHqJ3BZw8doqb0QkP6IZQ6EJgkJjtaw81oleNIUYm01BeXERRUTkNgxeDIc4uNpSXJnLpfBSFhYWc2nWQitYuOBkaNrFiJseqhT0GBjmcOhJJYWEhkUdPka2vj30La3Qe7jp06IBmrrg/CfcM8K+Pl5KUr8HeTIqRkRh9Qwn6RiLEYhHqKgFlCi3FUjUZBWq+P1nBO330HuLnrkPHP4N7ickkEglCofCx9FUul7Nly5b7fl+xYsV999jZPcxAk2Nqa4ZCIEAg0MPMxrTeapwImZ4Bxqb6SABz/+d5Netzvv1qCl/mgc2Qj/haIEOEAjN7MxSIMbVux8DQjsz9JIxfAUN3d1q69cTTQI4YsO47k5kZb7LovW3klIHDs5MYEZWJApCa2hM8+nWqV84lLCwHAKeg53h54kAedHSRY2Zn3sAAqSYj+hJnLxfgOuwFOpoC+DN6ZDT/3R3O9Vb2dHe1Qlp3vxCFpBPd9NcRFrYIzFzpNWY6LwTU7HE17C++r7JxuicysRA0PXit83zCwr4AwMzVjzHTw3AjjQwjI4z05YjxYMDQ43z042zWZXvx+sb36W9+b6xq+hs4fDJpS94kLAyw7cxzEycxwMsYkGJoboqeTFxvReSerAwrg/YEWy4iLOxTAGw7D2PiyF44NDLDjsED8NskplsfZ8SyClqHDCEouYCAjtZAFnIDQ4y0inr+8TKMLU3Rl4gQAM4T1rBmzUuEhX0LgJG9ByPf+gpPsrjwCFnqXW+0zaG9a9rcYwofab7jo/9OJT67Jut11/d2MxcBpSI9zKxN+N3xS1TTZrUeEsCyxxSmZ85hyfxXSCkGu9BRPOOYiwIBwjpZEVK5ASbmgnptlWBgZoxGIUUI2IV+zscpz/Lic2tQCYQ4DhpHp9TqJla0XenpeIvNP77FV6kV9+sGUjzHf8G4T8fUzOt9elWKvokxKj1ZvXL9eH7SVl6bOJ5VwmDm7H2bVhJ9TK2M63TVyLM/YXm5/LT6LcKWAJ5hLHkzEAczKb8/C/X7C3qOHenfr4B1S2cTthpo1Zd3Jg/A1+nhmcp16NDx/wdBcHCw1sjIiM8++wyxWIyJSeNHKp977jmmTZuGn59fo5835F7m1Sc1wHWGu45/ApWVlZSWlj5wPScnh8uXL9OmTRscHR0RCp9+tHEdoKzazwd9zjMkfD7d/u7G6PgHUEpurhhzcxloVaQcX8jHh3349PNnuN/LKoGdC/dQ4NGVwUM784AHlg4dOnT8hajVatatW0dFRUXdDnxVVRUaTU049AEDBhAQEHCfzKxZsygqKnq6CQk1Gg1CoZCs7ALKSqvQ1q3nqBAIBAiFQpwcreuMdIFAoDPYdfwrSE5O5sqVK2g0GhwcGlsz1aFDx9MniTN7UrFwMwKtmsjdN3Ad9prOMNehQ8f/LE/NcL9nhGu1WiIuxlFWqkImq91EFFSCGkQyCeVKDW7OVgiFwsd2OdCh4+/C0NAQS0tLTE1NdTr7FyIU2tAuxBNdOhodNXgR2PIki3YmoNQIMXCbwus9GzPb9bFr64qJrRmPH7dJhw4dOv45PFUfd61Wi1AoxM7RDp92rbCyqIklodEKEKq0lFRXsWj5PjRiMW3sdAaQjn8Pjo6OBAcHY2VlpdPbvxCRpAPj5nX4u5uh4x+EZfBUPg9+1F0t6DJs0F/QGh06dOh4ujxVV5k6g0YgQoSQe0e21FoQiNSgFSBTKDgbk0lFUTEdvVwQNRkmt5DL27dyNr0CjRYkcju6hoXS7qlmOUrl1PpbWAztShuDxpLWlJEWe5Hww9fIqbtmje/gYDq6/NEoAHc5vvIW9s/3wk0iAlSU5t8i8lgxbUYFYPuHytbxR5HL5bRq1ervboYOHTp06NCh4/8RT+1EnUAgQCQSIRQKayPMaEEACEAgBC1axBIR3X1d6OLRksJSFTei45oorZCLW5ay8vhdVOqaaDXVFWmc2XK4Np700yKJI8v2cqO0Ek2jn5eQfOMcJw7VM9zTL7J561FuZBQ1kYCmuSSy76tfiVL+sVJ06NChQ4cOHTp0/G/wVFfcm0KNBqFGhEwkwM/HFRBwUaLi+sVLdPTxaEQiiRM/R2E181Om9nBGIgRlZR6x55KQU0ZqzGXO7o+hyDiD2NgSbDsPJcS2hPNnz5CQU0WbITMZ39UGPQmoVansX/wlv+VATcr1EEa81BMncrh26DKJd2+TWJJBerohLYjjXGYs1+d9wHm9Tkz4YgLtHmibIU7tezNyRm0Cp9zDfPjWKeLSAvG0MUYMXF//H36+rASxAuvA8bw71B0oJvHSZWKT9eg4vAs1od+TOb7qMvIQK1K3beFS8RXuzHqP8/LOvPDfMOyqS8nLLKSqVvby6ViyJekkJJQBxnQYPpZBXVpjKgXI5uiXX3AgVYVQKsWmczcc04T4Th9Ay6cxqTp06NChQ4cOHTqeKn9JDDuNRo1aq0Gr1aIBhLX/arRatFoBGq0GkViMsEnnEjkKeSFp6aVoNFpAgERugXdIJ2yoIi/1PPv2niQZD4Ja63H74FIW/RqLzMGXIKsCtm06REJZJRous3zKl9x2CCIoKAh/L3uKYnaz5VgiUMLd6wdZvfMKVQbuBAV1xjfIExu9Frj7B9I9yKN5B+JKSigWgEgkRAhkHl7EnHAJQUFBBPh6UnJiET+dygHKyUqM5kpkAkV1wrlEn4jkVrYAB183rKTWtO3Wne7d3DFHTXlRPBEHr5JNOVmJp9i47QR3lc4EBQUR5FDO0V8PcyU1DyWQefh7FkZKa/rZ0Zu8vUv4+eBVsv/QTOrQoUOHDh06dOj4u3isFfcPPvgAY2PjJj/39fVl1qxZD1zXarVoNaDRAlotWo0ANaARgFZTY7jXeNM01RxnRsyfTN5/P2L8TtAKRBi2Hc/C+c/UrlQrsHTsQO/QYfSQtSYnfi2JrTwJGd4bl2oZR0PDSayqwgNHejw3FkNfXxz0QF2Zgc3uYvYfjuROr86AMR4BXXhm9HC8TOSAjN++SMWr30CGNJq1FSCXK/s3cjpue01GeYk9/sND6draGhmZnNwcjsOIHxg6yB5NVTEumkt8t/8Cw7r7PmSkLfDs6YODPB7fQYMZoicDKkm/7x59nD27MmTsaLpZ6kOxCVHTjpCaV0iVi5KTmy/jMe73ep1KTxO17SFV6ngsKioqSExMxM7ODmNj4z/1gGpxcTFFRUW6MJM6dOjQoUOHjvtotuE+b948iouLH3qPkZFRo9e11BxIVapr/dwBDaBU12ZYrY1AQ4Pk5r8jx9azL5PntCSjVIVGreLmts94Yw58Ob8bIMXAQI6ZmRTQx0BhiZ2FEXp6YtAzwVSppEqrRYsFrjZ7mDT0P6QCoKKiWIi977PUpNjRx9raAmMTeRPtaAxjWnUZQuCUfjiRz5m1a0gtUKHVyBGSwLVrLQhcbAmAUCrB2ssT482xpPAww705yDAzM8PSUr/mVyNDjLRa1BoNmkbqtfHthPO2rD9Yp457JCYmcuLECby9venWrRuipk9VPxZFRUVs3bqV+Ph4pkyZgqOj459Srg4dOnTo0KHj30+zDXcXF5cnrkSr1aLWalFpNHXx3dUa6h34vGe8P6wUGVatvbACtFo19sYDCH/5Ckl0o/nJoE/w4ZjtuC/5ibmOAEXEnj7CybNP2DEAJBhZWOPu40Mb1Lg5Cfhx5mnOdm6JeUcrWrTIITNTC6aAWoMyv4BiCwvMgIw/Uu1DaaTenGxyn1p9//+4l1G1vLz8sWXPnj1LQUHBA9e1Wi1paWns2LGDkJAQrK2t/4ym/kFusXnOcfTCBtHTyxH9v7s5fyvV5Nw9zsYvM+n51QS8/q5mZN1g17qlLD2kou9rL/PcCD/+CZry1/E0dFJDaf5xlr8bT88Vr+HzxOUUc/v8MU6cFNDzvWG0/lPa9keJ5uc3j2H1+hh6Olv9Q+PYpxG+7jhpem70/H+nz/82Evj182NougfTM8CNpn0wnhLRm3lzyVaiU1x5fWMvrk24QNCe9/9fZdL+y3zcVSoNGg1oNKBUgkqtRa1Wo7rn/44QgbApd4PzLJy8jKt5pWgArVpN4o4dXLe1rXWVaS7l5GVWYGDrjLOzM8ZaFdd2bSL2D/fwHiL0TLvj5xXP9ahsiktc6NsHli49DEBVeRmndmxH0q0bjuhjaKihvDyG27drpK+vW8fBqCgeNOkelwfrPfbzzyT94XJ13KN169YEBgbi4+ODUPh4j1FlZSVhYWFMnTr1vp+wsDByc3MRi8W0b98eqVT6kFKSWTOhBwEBAQQEdGPAyJnsSX/I7U9MNSV5BZRVqZqIrNQYiez76kfW779SL0zqw8jl6sH1/LBkL4lP2sy/BC1qZRkF2UVUP/LeCD4bMo8jlY++8/EoJ/5WLOkqT2YtX8KUQR2x/EPlxbD2nYn0Dwio1aWan+495nKaKrLvbGLafZ+N4v3lR0khjq3zJzPkvs9mcvBP729jNK6TcT+NZ9DC041K3Dm+ik+/WEr47dImytSiUZeTn1VI1SPrv8TX4xZwIKcYNQBqSvIOsODZr7iImurKUgrzSlGSwvFVK1mz6QwZxLD2nS/ZcS2Jplrw9KiiKKeAMqW6yT3tv4bf+LBOr/bw+aRlXKv7TEVFcTHFpZXNiMZWxt3rO1gycwnrG/7dyDnJ4qmjCa7VyZm7cqhW/7FWK6uOMG/QQs7XXfm3/L2C38fqF6Lvux7H1vnfsvnUTQofu0wlpflFlFZUP+I7oYjY01v49qMtNBUv8H7uPUcL2NFomwFyOLznOs7D3mPZ+g/obSqiMC2Pisfuw7+bvySqjBZQoUGJBkFtTEg1WtQCLVqtBo1aQ6W6GpW2qT/6/sx69ybDunlzLq8MLUKMLMeyPPoVWpJf7+F/FIP49uttOAZaMQ+Q29ri4T8U/ybv78bEicsZGNCWaWX9WJW9hsGPrENM18BOLPzyANe6taTP67v4aooTVlYvg8wItwnLOf1CTfxvr4CedLj0Me90teJFoMXAgXjInTEFIITJk78mpLUj00TDWZ3yFd7N7qcI93r1ivT08Bj9MoF5zS5AxyMwNjYmKCjoieXlcjkKxe+Hsaurqzl37hzh4eGMHTv2ERlZU1j9wlh2+S7n3BoPQEV+8hV2fvk1lxe9TscnbtWfhYbqikqqlKpmGgoaVMpqKh/5RfBvQkVFcQXKP91SKqWwqJQqlS0OzoaPsdvYFGqqyl2Z8N2HDPJ1wfC+z6rIVEuwbDmG7zc01KtYwstdCPt0KoN7emEKJK1+gWGjf8Tt1xk8+f7sk9Py+WdpG7KMDeO6Mba+h1nhdc6fTUPsGEQrV4M/oSYVlSUVVNdtEYswNB/A+xsHAAX1jA0Her74Uu3/b1BVXoFEpfmbjee/k2A+PhlMjV5VU1FayZPZ1Fo06moqyyqprv27oQbIPcWSj45hEPohO7+v0cnf5s7lxMDZ9BM9bBHkUSgpL6mo90JhgU//cfj0/wNF/mXcG6uqBmOtobq8Es1TfZnToFZVUVEuaPY8azVKykvLqW60zQCZJKfoY93HHAtLfWT8/0x++FQzp0JNPHeVSk1JqQqpXIUAAUKBAA2grnWP0WgElJWr0fAQP+GWE9l1c2IjH5jRvu8k2ve993sbxnzyfr3PuzE//PdNFHHoarJDG6/C+513Gqn2FxqtFoAWBIyaSsCoBpf9prN30++/Dlp6l+yljYgbezJy9iZGzm68dKMpu0iZUu9Cm3Es2lf7/wfq7cj0tfW/WpX0WpJI9lIRWmUp8Se+5tMyF3THHf8ZqNVq9u7dS8+ePVEoFGRkZLBgwQJCQkJ47rnnuHDhwkOkU0lO9mfCN/fMIzFmjp15aVFnALRqJQknN/DD0u84nSJEY+LP9A+nEhrQGn3ROeb22InR0CS2bE4BrRAj6468+NWXjG4lRaAu5PKeVXz/7UaiS4WYBfphn6hPzwfaoEVbWcDNte8xfvl1JEKw8u7Di2+8iP65FazZdJBk0Tp+XNCB15bNJszHHlFJPD9PfoXVt6tBK8HMbgCzNr2GVeQWvpm7kutqARt2b2HIm9N5ZYwR+6buweDFMfUMyiO87XOYwVc/p0dxGhd/mcNrP0cjEYJdlxFMmv4Wfd0kDbYRzzC3xx78Ds5noEIKVJEZv5dlc1IZsuFZNHv28Ou606QZpRJ9vRi1sR8z5k6vGSuhAE1VLN+Nn8j6ZA0iuRyHngNxQ07Ny0YBV/euZfkPG7lWBBpVK0YtfJeXeilZO/5TDuSmsqfHCT6V9eOzU/PpptGQF3+BNZ9OY2usCK2+G0NenMxrY/yxFGupOr+CSf/dys20EgQC6Pafg3w23BRJXV8KiT394Fi9HOrL3dXvsnjLeVJLBKg6TePwZ6MxNxRRnLOXj4cdQNIrjWOHNPj0f4G354Xh9gd0tykcx46j5/dHuAMNDPeHjVU7zJupk0u/3UjUQ3RSJOrDcxO2sPx4AmETWtV+uWnIv3OHAhNzPDv6YKOs5FwTY1W/vWpVETHHt7FsyQoiC0CrcmLw7Dd5ZaiC3ZM/Z3diPJsHH2KBIITPIhbgm7OPz1+MYcieV/n91eAuh5buJclASuWdC+w9dYHciJ0sEQUw6wcPtk6OZWz4FwyWiUBbQuLlraz4PpM+n71PiFW91igriXiM+X1rTi/yNv3ADyt+Ja5ciEWPbtili7GpLU9dVcbOd4NYdF4MYiNadnuJhfNH0lKWTfi63Rw7dJ5EYQpxsY48t+htRnGEyZ/9SmpeBQKg59zfmD9QUU8vy7l9ci9HIgvoOPFV/DXhfDF3LQWBLzEl1B/b7PW8MKeE95c7sdzvKMHHunP42U8Jr9Swx+8wvv1f4O15foCGzPCVvLX/I5LulIPKjP6ffsvbvVphKBHUM9EECEVSZAoZUrEUmVyCCDXRJ8+g6dSZ7t5etYtfEDxvHlBjj1TkpbBh9nB+uipGa9qans++ybxxHZGJ77Bz4a9EpV3mckYq6akVoLLLI9xfAAAgAElEQVTgma9WMrPrTeZ0/4ADZWqO+p3GxTuMD1aMQLlnH6euGzN4dnuimpS1Rqg8wAd9zjMkfH6tK0c2F+tkR9BKVcXljfP4av1RbhcIUPm8zI5PxuJooYeq+mGyQ3G6sZO5X67maFQuQgH4vrqaj8e2xUwueExzNoL/PrMLYWACO3cno9YI0W/zPMt+moSrVIhWU0zM8U18+9lyrpSIMPHtgH26OUF9AVRUliay4c3prLxRiEorRGHQkw/3vUvruJ0seftbLilhy8md9HnpNSZP6oN9A33WWA9j6S9v0NlEikAoQaGvQCqSIlNIG1iEcWyd9w2b6z9He3vXGvdatJpKMuJOsey9DzmYCVq1Bb7DJzDj3RG0lYjQKFPZ/dlH/HToOrlKATYjnsFufR7Dri+hz2ON19/PX7LinnX3DieOnUcrqJkGbT1ndi0a1NpKxCI17T11mSj/PM7z8w/Qb7gD1aUF7N9xHJsBE3QZV/8hxMXFMXXqVMaNG8fs2bNZsGABGo2Gt99+G4lE8ghpJzx9E9ny43k6jW0FAgFiuQmWFgaI0VB46yR7zyfSduo2vghxIvfMD3yw9whuLczp0hrgIruLPyAiojdUl5C4dxHvf7eT7l+OQv/WRU7FFBH4wTZWhThxa8c85t9IrBey9B4aSkp+Y81WAe9ti2C0E2TduMGttNs4vfIyE3JbUODRlcFDO1Njg1ziq0k/Yzr/KBGuMtQVhZz/ZRbLv45i+bthzJinz6nrxgyZPaLWL/jGQ/pfTXZ2ODuOGTN3ZwRD7SHtwgUSMs6S4dYDu8eaiWxuVxjS+7UVrPqppr8/hEfg42SLt72MW6sWsM3jEyK29qK6JI9dc0aylmEMp4Cb4Xs4E2fN1C0RtDehdpzPcNtlDDM2zqbgvhcGLZX5SZzesZqMvmuI+NmL4thD/Lj9BPtPWjGuVwVr116j7fNf8cVALyxkcPqzz4jgP/V8N01w79ZwrNSk7P+KNVk+zFn5Me2djDm/eDAv/+DBlnd9ACUl6mQELguIiGjKc7uaopxM0lIkdf7iAoEe5vYGgAZVdTHZKSmkACBGYWRMTXCxaorzskhPMaYUSNu+gasdg3njgfJ/H6spWyLwuW+sHDBtpk76zd7Kyp7OTeqkUCzGZcRYrCf9wslRH9JLX4ymOoVLV1PRiNvQwcuAtIeO1T1KSbx4gKOnBbywIYLvzCA/ci2f7o4gqtVoXl7+LoXP7MV9xUwGWxkjQs3Dwza4MXKuP/rZ97+I+k59jje+vkGvd32QlZSQG5NIefCY+4x2UJN25PvHmF8NuZd2syNJyKAFu1gbYEf0hnf44HwuNadxlMQufZ5vLL4mIqIbysJUTqz/nCU/ObF4mhOQQWyVDaFvf0qYnx1wmW/G38D/jTVMCXHGQALhCxdyaeCsejvVetjaWmNtnU92tpJqZSb55XeJTyuhvFxNZXw8om4jcRalAUIMzAcwe6MaizmpDKnbybnLHVK5XunKK+8von87a7i6jLAvdhHd+TX8zA3qGaP6OLUbwdtLan8dAJDAzjg5Zh4tsGzEd0yrLufyqnc56r2MiGWdyLt1mq1b1rLqpC2TegHc4VJ5B2Yu/JpubuZw6Wv6L9zA4M7T+eTUJ9DQgL6v9KZlPR5qQavJDF/D+iQHXv3qAN3dzbn0/VjeW+3Oije7PuIsQhL79l5Cv8ubbPq6N60M4dKyZUQrHegqN3zYEmgTXGJ3/nSO/zYQqUDFoU+HsGRdT759sTXld6I5G5mA21ub+HFgaxIOfMnCby5Rs4Efxc9vrUM2bTMnvU0Qaau5vmYy8z+LZP1Hw3nrCwn79gsY8vl42tb2OaWBPqdum0bYrH0c/WEkhuYDmL1pQE2TljRsoxuj5s6g6L7n6DfOAaClrDCctQvPELAsgnktoCzxND9vPcLRA160fsaNzCObOUAgC9Z/UfccTdO6MOyxx+rv5y8x3J8d/eg9Je3DT6bqeGy6099qMi++FAciBbZdZvD50MczaXQ8Pdq2bcvEiRNZunQpXl5e7Nmzh/fee4927doRF/coj0BbRi7+DsE7b/PGG9UgkKBv34MpM8fgay8mMyOdyiIJdooyYmJiwNQOx7SLxBcV4QmAP++9V+vmI5Wi1649bbelkk0ZiowcxCJHOnZ0AqBNcA+896obybAgQCQ2wMymgsSIGGLKQGJoRrse3pgQz+UH7vfljTXOJCYmEhOjBarROHth/fNVomv/pDcfARKZPkbmZSReiCGmGKQtHPGxbkHjca0ehiGenlb39bfF+eukFRbiZl9JeLiI5z6p+bqW6ikIGBnKb9+rAXO8g8fg4J1NVnoMMek0Ms71UVNWlkRcrBa3QGHNvCDGTCmkOC2NLGwxdxBxOz6J2BtCzPTAafK7zdghyyEqqhwfnyCsW9QcE/MfOxbFpJPEv+uDHVIsLIMYMuFhxy3vcOCbhRxUSOt2K8TS7ryzcTL2VJJ95wjfvHG1VgdsCBj1LOPGmAPJHF9xliOb5LWGQic+2jCOB+MgNWesHq2Tvr7OdXPUuE4Kkck74dNpJQe2JxL0fCtK4uKIycjFoNsQ7MjhwEPH6h5GuHYO5eXW2WRkxhCTCeibY5ubSEpe3iOM9Obj2HMYZs/+yJHJPxBSVkJ8fBadxzQ88vy481tMSko+hkYueHnV9Mizbx88d56kxlnkDseOV9J7ulmtDpYjtHXF+HAUt3AC7Oje3YEufvdGQw9LZyGXYxK4aVWOvhRcps7CvkEr9U1MUCtVZMfHcKP0DhYOjlxPTyY7P4uks7G4BFohEDzqEI4jfft64d2u9miqjw++RXvJVv9xdw6NJp7ICwaM/K4TAOaOjni4tyHiVix5vZyAVjwztCtubuY1Ar6d8MvZQ5pW+wjjmz8gm8+tWyW4unXC0alG1jc0FMMZF4lX++P5UFkpJi0kVKSkEXcthiozsBj5Aj768icw2gGcGDu2K2KxCKFAi/+okez+8iwpL9qjzcmkssIW/4CaJZVWAf60P1BU+2Lhw6vfOZJ0J5O42HRAQ3Xbzjjuusg1fHnQMS2HqKg8HMwdKMpPI6YsDTy64P3JWc4w8g+sfAsxMO3Dm9+1425KDDH5AGqMRPpk3U0iDVNuNvIcua2/+NBS/6k8NcP9ceNa/5lxsHXU4DTuB46N+7tb8b+JSqWitLQUPT09JBLJE+nvG2+8waFDh5g2bRpt2rRhzJgxjyFtS+iijYQC6soiLm2cw3ef72f+N/2pqiok6WoE13ISOXDvdrEr3kaKRzzw1VRVVaPW6KO45zxtYIihVNqInBB90xAmLYSVHyxm8f5KhEYt6Rb6OmE9Giu7kISjq1m4MRaNVANoqa4oRSV4klgAUswd+vLif0SsXrCYxb+WIzT3pu/o1xjiZ95kGrfGkSGXN+hvZSXlKiVqCikoMMbVrHZuhUJEJqYYkwtUU5x2mX0bd3A0Oh+BGKCU9AQTGvfE06BW55OeeIfINYuJqLtuS9eupshwZfh/ZsDCNWxcuoOKygwkXRax4A0vzB/a/jJKSyXI5VIk9ybJ1BTz/BjyoJm7D20Y8/GYxn3c0cO2TSivNuLjDq0Z9t70Oh/3pnncsbpf9p5O6j1SJ0Gq0Kdz/xFEbjlGbJ45qpR0MGpLVx9HIKGZY6WkNDuKI5s2s+dyLgIJQDmZ8QYMaOgW+UewD+Xl4avY9msyHfzTyFV3ZcAD77CPO79VVFSqAT3k96IaGxpiLBbXGnT55OVXcG3T4nrBCgxwbt8fA2jkoKI7z34yE+GHK1j5TT7VFWkoun/Hx1NcMat/m6U9zjYtUKWG81u2AquuQxj822Vu3r1ATo4fwR3k/EkRc5tAgb6+hmxlFdXVQAOXdq02n8IiU7xNai9IpcgkUkRlZTx+XLA/i3LKykRIrWXUxSEwMcG06DoFj3xVcSBk4stoVmxk36rFFFblIG73NrOmdsPZQHy/W5FQgljcYFyqq6kWCZGJRLUv6yaYmQprw3ULEBqbYFiYThEq5MpKqpWGGNzbjtPTx0B2z7u8iKSTG1i88Rrl945qK4sopnMT7S6jtLSE2Avbibt48PdnuGPH+/XpsdGiqkrj4rZlLD+ajlAGUE1hppA2A7xp8jn6l/rI/yUr7jp0/K+Rk5NDZGQk7u7utG7d+okMdxMTE15//XUWLFjAjBkzHiP8Yy7RkcU4dnTGUCREIJZg6uKC+ekyyjHAzKwNnQfr4z5qNF1b1Kx5FNy5Q5WV0SMeeAPMzIwRCu9w924pbVsbUHTrFnfy8nB/4F4tSmUe2cUdeWdVXyhL4sTGTRw9fZr0Hu0aKTuaXz6PpP0PvzDdQ4ZaWUrU4a9Ztb6ptsiQy0spLFKiUgISyLp+g5pMBGoqK4so0QYwa9VgKLnFnpXbuHoxki5+/XG+rxwF+vq5ZGVrwQnUSiVZt2LJr1sLKiE9Pf++/maYmNBe3wApBnh75XLiXCahAx1RV1eTcekiKTgDhcRdu8jtPFcmf/UqXcygKHkf371/qoktbhFyuRudenSn+4vTCW1ZY+qWZmZSKhKhTxF37hjSd8ZchutLIWk1ocNWcfmNR/lfWuLspOFgaiZFxW0xN5WSExFBunc7XB8q91fy+1i99tWr+D1yrOrzu04mPVInAZEcU+dAutr/l92bbLEnG3m7Z3E3guaPVSl3b0Vy5bY1E7/8nCALKE47xor5x3icDB/NwXfUBNbNXMFZQ0Ny2wxvZM4ed36NsLLUQ5meQVp6Ga2d9CmIiSGhuLjWx90Fn/buGL02l7drV7ary8rIz85GAbX5TepTQHy8Cc+8v5DRCgkkLmPYiOVcm7KIkPvuM8feRMa1334jXNCTSdYB+HqFs+LgHhIMQnlF3NBf+c/GFs8Ohly/EE1UnAfmbc1QiCAnOhp127ZYClvj3iadS5dy6d3Vgqr8PDJyshHYd2peRvQnRh+FPIfcXMACqoqLyUpOpgRvwBwHeyE3cjPJy6vExkpO7qVLpLu1oZVA+AjZUtLSpHQYMYNeLysgbQdTXzrAlYkdcDQwrjfWMgz0W2BqcpnY2CI6tatZbS5OTCRDroevsTEKioG7nI/IYLi9MVo0ZF26RKFHLxyQU21kjp7eBeITimnX1ojixETuZGXXukDGsvnbSFw/WMKUTuaIURF/ahFLFjc1HpY4O7nj3zGUYX0CsdeveZPIun79D46zhvKSSHZtymfIylWE2kNFQTR7l28hoa7eB5+j25p/ZzgEneGuQ8cTkJ6eTkxMDBKJhFatHv9sRkxMDCkpKbi6ujJq1ChcXFy4dOkSAFlZj0qUVUjCuRNcTjRCJhCgqa4i7VIcJgNewg4ZMmdnbOJjidi+iTTLGueR8lxoMzQEk4cGvZZh5dwWh+jbXP71Z4odLMlPu0xmQQUeD9yrRVWdwfXDV7h+3QCq80jNqMKilTNGGNGihZjbcWfYs6WEgJ6dcLWwxtfXhMPHdrAlSoRGVUlcZBRF+AMKTIwNofQGh7boke/THk+3FrT3l7P+1DF2pl3DQAZpNyPIwxHQUFWWwpVDUVy5og9VWSQWgGVH+wYrxgDOdOuvZc3qHeh7NKwXQEBJRjznDm2i+LIRafE3MWvbGxdLYyRI8B/Riz07VrGl1KNG9komYpwBBZYW1hgJo/ht9xaS9CA/7QI3M0trDSRr2rQpJ3LXdsqlLQkM9cfK2B7PTibs2b4RtWONuVBVDDYdfOhkqUfatQgiS6pBJoK8a+h38mvGirkRbQI7c/LXSI7syMDUUI+4i9kEj3oFa2imW0ceUScOokywqDOkhSJHAkM7/Enxgn8fq5O7t3D3gbF6GL/r5JVff6bkoTpZg9zIFFffDmxdsJki/z481+GeY0dzx0qGqakNVvpnOb17C5kGUJh5levJuXQBwIrWrau4dmA3lQoXuob5N8NFyxRHBy0XI46wK6EtgUP8aamQImzRlQFOv7L1tBsjJjdmij/u/CqwbeOFze1DXNi1liwbM3KTr1FQoqpdW7Si25h2nN6xni2xNeOirgapvg1+LRv7O1ZC8sVzXI7QgkQIuTcw9gtu9KyUibUBFRUaxHIZ5hZG/B979x0eVZU/fvw9PTOZmUwyk957IAmEFjqEJgQBFQuKXRdlsa9t3f3qD3V1LeuuZV1XXTsWEEGKqDRJ6L1JCyQhvZdJJtPL74+EKBAQgoDlvJ4nzwMzc+q9N/ncM+eeE5mcRNPH8wm6IgSZ8sehhhSVKhiTfj2r5y3BHJtG1sBzWfWlXWSfHHoXLGD9ss+o3G1Cq4DWSshOSSVUGs7ASQPZ+NXbzKtIxNJUR41Fx9CcRLTUnjZfiSSShJg61s5bSKspiQGjz3yVeaksmeyRrXzz9jyciWBvrWLP1kJkyZmAlsR+fdEtXseahY3sD9RRuKuC7IlXEi6XIfWdLq2V2oLtHC5pBo0CmnfiSUwjQqk8YQxZjj44gdR0I8uXvMu8g+2/UaqPHkQZO5CUKCNKygA5ldsW8oUvEanPx8FddkZO7Y8RJY7IFBLj9rJx8fu494bRXL2L0rq2jqW4Q+jdO5BvNnzFF8V+SPBStGMXzfQBVOh0BlSezayYt4ymnplkZkSTOiSFrSt28u3nZeg07b9xWsphSK9e57B+vwSFMpIeSV62LpuHxwBWcwk7d5cQMHgQXV1HlYcKkXjPbZz/YpHFxcXNVqlUjB07FqlUip/fzz2mIAi/Xm63G6fz5GVKHQ4HZrOZhIQEwsLCzmrE3ePx0NTURGNjI42NjRiNRpqbmzv/73A4CAkJISDgVFtbBJGa4mPPuu+pbGqmxeJAFz+aq68fQigg15qICtbjrCvkUFk9ZrOZwD6jyE6KRq/w4nJoiOufhEnWHpb5fD4ksiDiM2MI0poINahx1B6mqNqMMqkP/ZIySO+dQJhe86M7fQkKaSBhyhLydpdgtrjQxWeRM2YE8f7+BBl8mOurqKzyEZIWT5g+ivQkFYcPFNHU3IzF4SJi6BSGREYQn5lMuEaFz1XN0RI7uohIIiPCiIkOwVlbTkVNLc1mM4EjrmRUSDhJg9IIl+kxSEtYv7cUc5sHY1o2I4cPJPqk9RHVRKdE0nxoH5VNJ5ZrxFJQRlODlJA0JXVl9fgiB3PZmAHEmton3Gii+5Dq2s2WwqaT6hwdYEAla+Ho0UrM5hP7Koq48BYO7qvA3OpP4qAUTEo1poh4gqyH2FlYh9lsxi82nT69swhX64nRWdhTUEh5dQNml55hN93G8OATxyl9eD1SNIFhRMeHoAFUwYnEKuspLq2gusGMvNc13D0+EZlUgg8vPq+B+D7xp9goxYvbaaOlqYlmsxlzx0+rxZ/EQckE/ujc0J+QzuNUYUqIITxIy+kfp1ZhOG1fqfCeyTlZd5iiqtOdkx2kMuQqf/zlCiKyhtM/xdg5Q+DM+iqFKG0gOk0bRUUVmM1m5DE9yUrpQ2ZmPOFB0cSEtlFYUEFDox8JQ1IJ6kwbh94jQaULJjY5DLVbTkB4JJERsUQbnVSVV1FTKyO6XzKhSjky/DDat7Go9RLumRLb5Yj+2R5fhT6McL2UlupCjtaY8UsbSHZ8Gj37JhKqUaGL7U8f+QHy91VjNptxK/1JGzmJnnofHrcMXXAYUTGmjilnAcTrm9m6v5CqukbMLgM5t/6BwV3M31L4+aHyDyWpRy8yUiMwBmpRKiPpP2IAiSYNMokXl11H0qA0QhQBBGhqOXzYjEx7Yl8FdvSDF7dDQ3TvRIKV8p+e1KA0kpgSiruukvKKaprMZiLHXMfQMD9kMim6qAzCWnewu8SMTWkkc9gkxmYYAR8et4Kg6CgiQgI6zpUffk8Gy0MIM9Zx4EA9HkkQcZnRaDuvwWBUp0kbItcRmWCk9sABasxmXOoAEvuNZkBiDNHxIRiMsUSrW6kqL6Oizoysx2XMGJ+GWilDKvE/Tdp4Ev2dlJQVcaSsFrNDQ98rpjEiJgDFCXfbMj8dxuAQlI37OVjRfn17QvuQO2owKeH+QAXrP60n66pwaovrMbe0ETjoJm4b0R7kyzUGgo0GfPUHOVx58rXQI8GPo0eKqW9sotViIXTEVIaFhxPfJ4UwPw0KSQ1FxVbUwWFEx5gwBCeSqm/jSHEplbVNmM1monNv6eJ3XVe8uJ1+hKbEdlz7Hpx2LQmDUgmTm4iJcFNwqKS9jfoQUrKG0z85hqiOcn98HQX0jKNpp4Tht57tggY/D5/Px549e3C73Z0/Ho+n83nP5ORkoqOPf8pp1apVOBwOJDk5OT69Xs9zzz2HXC7HYDB0VYYg/C4d2yH1RE6nk7q6OgIDA1Gr1eIZjV+lH5ZX+2E1G0G4cLyuavJeeJqto/7OI0PO/tFqQTh3m3n+uFWSfquqOXjQR0SECb1eQdEXd/PQpkt598VcLkbU6/F4mDNnDjabDbvdjs1mw+Fw4O2YvpObm8vgwYOPS/PYY4+1DyRchPoKwq+eUqkkMlKs0iMIQncUsOCZeexxNWOR5XBnLxG0C8L5pcBVuIx3vijG7PJSVexjyv0DLkrQfq5E4C4Iwu+UnoR+OegTFR3zNQXhQjGQOGAAGh8EpgzjZ9nQVRC6JYnLHpmGTq/5mZ5p+aUyktS3H63+obTYvTA6jsG9fp1z3EXgLgjC75QfQRHxBIldyYQLLoTel4yn98WuhiBgJG3Y6Red/a1Qh/dkSPipHmv/9fht32AJgiAIgiAIwm+ECNwFoRva2trYsWMHDQ0NYtdfQRAEQRAuCBG4C0I3HD58mNWrV7Njx47Op8AFQRAEQRDOJzHHXRC6wePxdK69Kpw/sbGxqNXqi12NC6qoqKjLvQMEQRAEQQTugtANqampeDweEhISkEov3hdXPp8Lu8WNQqf+zV7Mv7c18n9v7RUEQRDO3G/1b70gnFdarZbs7OyzTOXB2txEi9WBxwcgRxccgl7Z/UDN7VzB7Es3MTn/KYadVUobjZU21BFBXJjxbDtNVTZUoQY00nMJTH14PQ6aqmqwyfSYwgM7d5t0tjXT1NSMzQ2o9ISZAvBT/LCdiKX2KPVWQCJDpTcRHqgG3FhbmmlqtOBCic4URIDWT/xiFARBEH6RxBx3Qbgg3LTUfM/CV5/i0fvu4d577+Xeex/n/fyjtFyU+qzjmYl/Z9MFK287L1/7PGscrnPLxueltXgps3L6k3vlS2zreNnd1siGj5/jrunjuWzqZEbd9ASLN5Vgd7U/f2CvOsirtw3h0qlTmXLNNG588nNKG51AHTu/+jf3T51ITvZ1PLNgM7XnVkNBEARBOG/EwJIgXBB1rHv/Q3boxvL4f8eTZFQB1SyZ/SUFY2fSH3A7rNQU7qGshfYR48hY4kL8O3NorTxEUVUTNhf4hfekV7Tu+CI8DlrqyzhSZkUfHkNspAFn3VFKyqtpcQCqYFJ7xGDws1C45QgN3gYKNm0hQB1KYu9YAo7LzErd0QaszhaabVZsNg/4hdIzPQadQoYE8Lqd1BzZQUkzoPTHFBFPUpi2i7Qq/CmgzlXPka1b2OwXRkp2EoHd6EWvu5o9773HjqRBpHfe8bip3vIlX25oZPCfF/L+xBA2v3Afz3+4krTE6WRESNny3HQ+MDzPyqXT0ZWv4z+P/o1nPsvi1Vm9GHrdbIZedzXv3/8Jdd2okyAIgiBcKCJwF4QLwobVqicyzoi/5thlF8bk2TOB9iC4as8qPvj4c+oJwoaauN4juP6yMcQEKbHXFPD15++zrdiMEyX+8ZMwzRpF6LHs3Xaaj6xl/tJlrC8MZ/TUSQSpW9jy1Wfk7SrGhhqbTUPWtBu4ebibjZ9voNRbgeuzeVSGDuWGkwL3StZ9+in5xRX4Av3AAfX1EnIffIRpvcOQ4aN+fx7vvvsBdZhwoCIkdTA3X5VLQvCJacOIoIBiWwkNn8+jRNWfW7sZuJdseol/5sXw6FP92f5/xR2vNlFcXI8hLptRw3uiBcbcdjXzbt5EYWsraVTy1ddaZq2+kWiA0AwmXT+aV+ZtoWxWL5K6UQ9BEARBuBhE4C4I3eByuWhsbESv1+Pn53cGDxSGkD4sigPr17O07SgBWgXoUhl3SSaBMgluWzVbl3yJbfRsXp6SQPORfOZ9uYZVO3owfWwYxXkL2UpfbvvzRHqE+dOwYQM1Ugj1Ah4XLQdW8+ncJewPGsadf72eQVFOjq78mK31gUy4ayYjkw007XiDB99cw7Csm7n+xZvYtWI5k15+kVGnrHMDjdp+3D1rGgNi9Rz54k88MX8Hl6RPwChpYtvcd6kb9jQvX5VEa+l2Fn2xgK82pnPHFAnQhs00iJl3TSUrUg+sp23kEga+8BQT1crudXrTDv77zEbSn/iMCWEr2d75hpVWixsIQHvsSwiTiRCzmQaXCw+VVJRHkh3V8Z5CgcpgQFtfTwOIwF0QBEH41RBz3AWhG6qqqlizZg1Hjhw5ww2YtPQYN42rhsXha62itLSU75d/zFsLttOMD6fzKIcPBzNyZAIAhuho4oKDsZaW0kwtBQUeUlISMRrbp84Yhwyhp0wG+HBaD/D1e3PIZySz/nA9g6IAmigtraDxSAEbV3zBO++8w4KdNbj2H+Gw282ZbRkVTL9+PQgP1wOQNGYMpr17KPR68XqPsHuPkbFj28NeXVgY8TExOIuKaAAgjOyB6URE6s+mW0+jkY3/e5ni7L9x3yWhP/1xQRAEQfgNEiPugtANdXV1FBcXo9fr6dmz5xmm0tJj7DX0GNv+P/OeV/nDvV8z+up+9DjDULpLMhmK2GiCy5qorGyhh/5YsKzGX2NFofDSvkdUJCNuGkgPfz/ObV2XYy7ksoUH+OzVVVRPiOClP39Na/1+NpW60L+/hthbeqDRyKDRgtUKaIBmM01aLb3kcqQEExJSR20tEAK43bgsFqwGwwnTgwRBEAThl02MuAtCN4SGhpKcnExMTMwZrrtdzZaVmzhQXM+xdVXcFjThEOgAACAASURBVAt2mQw5EhTKeJKT6sjPb5+33VxWRkldPZroaAyEkJIso6CgiMYGKwANGzaw3+MBJCg1aeTecj2jEipY+s4cVhxoAQxER4djSEhh8LirmTFjBjNmzGB0jBSv9Ex3eq1j+/YDVFe1AlC4ahX1mZkkSaVIpEn06lXPqlVHAGitrqa4tBRlQgJBZ9yLZyOSKf9vNtP7xREXF0tUpBGdSkdQaABKDMTEBNJauYtNW4uw0szW+V9RHB5HglaLgjTGjmnkoxeWUYOH1vrDrFm8Afr0aZ/zLgiCIAi/EmLEXRC6ITQ0lJEjR6LVas8wcNcQGlDHV3OW8k5jGx7AerSNIf/3AMlIUKjD6D/5MvZ9OpsHVgdhR01Mr+FM7xeJCiXxOZfT/7MPeO/5NThR4B93KXcOOJa3DHVAT4Zcdw2SufNZ8I9XqLnuKib2G8rglqWseutJPre1f9KUOoXrhsuR0IvRo97lnQceIT9sCNMfvZzkk+psJMiynY/f2M/HDmjAyM23DCBILkVKEAOm3cKu957kgXUdD6emDOTGwTH4UdZF+1PJyfmQd//yCKsV/bn1hRtIP6sej2PMH2YwBgA75fs1lK4oZmhuH0IBR7/xjPj+IHP/NYNvX9dQZQ3j5jtHkGLyR4qMYQ8+T/af/sQt17yH0uvEbRzJU1dl4k8dO7+ez0fvLWLdrlIcGzeQv3QYtzw1k9y0SDRnVUdBEARBOL9E4C4I3aBQKDCZTGeRQk9sryGMV0dSa7bRPuYdSMqgVLQAciURvcdyi8ZIqRlQ6QmPjic2qP1BTr/QVHKvvJHkykZsLlBHZBApk4JsALf/I4Vg5PgH9mDsNbcRn9WEOioMXVAgA0ZfRlBiOY1tHgAMcVnE+CmQEMrI+x/GUO5AqQkjuMs660gdNJaUrChUNg8Y4hiQGoxMKgEkmHqO4tY/aCluBpRagiMTSAxWAREMvfYKXP4GDJ15mRh0xz34lZjxSYIJP9sOP44CU8x47nnZ3pmPyhjLmOl3EZ1d2L7JkiGOAelx6PzaN2DS9xzHo8+9xN5aQK7CEJNJv1gNICE6fThX/iGRCZ35G0gMNdDNR2gFQRAE4bwRgbsgXCgqI4kZRhJP8bZcpSE6Y+gpp2/oo3rQN+rEV4NJyT4WdivQBsXRe1DcD28HRtEj8KREAGhj+zI09vRVVhpjyeg7gJAu3pPKlUSkDyXipHc0hMSfnLE6MoPBkacv78zI8NNG0fOEjWu1YYn0DTtV70J41iVd3DCoMcVkYIrJ+DkqJgiCIAjnlQjcBUH4xaqoqDjDqUi/HS7XOe4uKwiCIPxmicBdEIQuxHPp/TPxyeQoLmIt3G73RSxdEARBEH5ZxKoygtANra2tbNy4kbq6ujNcx/3XRoZS7YdKKRe/JARBEAThF0L8TRaEbigoKCAvL49t27bh9Z7p8oqCIAiCIAjdJwJ3QegGhUKBSqVCqRRrjwiCIAiCcGGIOe6C0A1JSUn4fD5iYmKQSsX9ryAIgiAI558I3AWhGzQaDb179z4vebtcLlwuFxqN2P5HEARBEIQfiKFCQfgFcTgc7N69mxUrVmCxWC52dQRBEARB+AURI+6CcIFVVlZit9u7fK+mpoaPPvoIlUrFoEGD0Gq1F7h2ws+nii0LS4m8YiA/y75TF0wFmxeWE33FwC421zoXFsr3l9KqCCQmORz/nzXv3zMXrQ2lFB50ETM0jaCLWBOfz4fP58PlcmGxWHC7PSiVCrxeD/jAX6tFqVSK6YWCcA7E1SMIF9jBgwdxu90olcrjflwuF3l5eRQUFNCnTx9CQrrarxSgnHWf5lHo9vzoNSfmmgNsXL6bugvRiPOqgf15W9hXUscPtzelrPngO45evEp1wyHmPz2P/Re83HPtq/3Me3I+h7p8z0zxzh3s+r6M1rPOt4F9a74jf2MBzd2uW1cu1rlxYrkX6xp0UF+6lWVz1lJ+QcvtmsNhp7XVgsPpos3uosXmpNXqoLXNTk1NLS0tLWIlLkE4ByJwF4RucDgclJSUYLFYurWO++DBgxk3blznz+jRowkNDeXIkSP079+fuLi40+wYWsKK/37NIdfxgXtj5W6+W7iFqm616Jekjp1f57GjsAZb52s+vG4vv8UV839+RSx7ZSmHz1PuPq/vF7Z3wflt79mU6/P52vvngtfll8HlcmG325GrVPgHBuOnN+GUaGj1KLHhhxcZtbW1WK3Wi11VQfjVElNlBKEbysvLWbduHenp6fTt2/c0QfapHTp0iOTkZCQSCa2trbz55psoFApuueUWmpvPcUyy4TBrVq9gzb5aAGKGXseUoamYOp53PbDgGebucYFUSVDyWG68LpvAkzKpZsvCPTR5S9lfWoPZ7AKMDL9zJmPC2/dTdbTUsXnh66wuBvxC6TV0LOOHJ3dMg2hh77KFrNxZjNkFxiFDCN1sJvPxq+mBl7bGw6z66FN2NAEYSB44knG5kVR+s4oNuzfQ3FjOgfy+TJ51Of1DHDRXN2GpXsM7Xyu54tYhHVMCHNQc2suBEhtxQ4fjd/gbvlmziaPNgKEP1944lmSjP7Lj2uWgvmwv6788iD2klgMHWgB/koZdwthhvQnzK2X1u3sxTBpGZkgACsDj/p7FLxeT+dAlGE5IG5Kew+AYOQd3ruNQtZ34Ubdx+cAYAvzaS6ta/Tqz8+tA7k94jzFce2VfAjpqUrtvDStXr6GgAQjIZOq1Y+kZHoCcAhY8swfD4Bry85vQBw/gilv74dqwmE/WlQIQkp7D2NE5pBh/3LZClry0kO9dB2mc/RTbtX246qHJJAGtlQWs++oTNlcAIelMGDuaQccn7uTzeihZ/hqzNzSAIoC4rLFMvTQTPW7sllYsKh0eKlj36V5smlJ2FdTS1uYGTIy+625GBAO4MVcdYOVnX7DXDOqoAJxHXYRknOqkrWf16/8mvw5AhSl6IFNuH00MzRzevJcKayCZozJor/GxYxROyUdn0N7gnkwYN6ajve1pvaHlbN1Ti8PhIfPq/6N/xRu8t6EBjSmaIVNuZ1gMgI2jW79j5XdbKLcCxDDqtikMjDGz4qR+vgSDy4q50Y6zo0V1+/NYseo7ChogIHMi147tQ3jAyXsRH3cdGWIZOHICuX3COfkajGHyg1fRR9fGmo6+kvsrURuD4Edn+Y/LPdvzKrjnSMaNGcUpTo3TamlpwSeRoJSpsNrdKFUK8HlRyNTUNpqxeBwEqORUVlaSkpJy9gUIgiBG3AWhO5qbm6mqqur2zqklJSU88sgjLFmyBK/Xy/z581m/fj233347PXr0OMfaNXFgWz6b95gJzcgmOzsb9ZGdHGqsxQbUrfkPz6+Xkp2dTf9eacgPf8HbX3c1XtnM4c1LeH9ZMQERPcjOziZbe4jX31hBDeBxWDi44j2+KA4iOzubXuFSDm3+ltW7qwEw713JvE1lBMSkk52djXzze7w9bx3leLG1bGXePxdQG9Vev17Rcgp3rGLt7hZMMVGEm8KISe5Jn+w0wtRKpFSy6YuNlCuhZPmbfHtsHkdLFQc2rSGvwIy1ZD2L1uzGok0mOzubJMdG3lywmVar64R2uWit38NXC5extbq97tmxUg5uWMumg5U4qOf71dsoMls59p2G11PKpsVbqe5Iu3LZKg7Z48lO0FO54RNeX7wTZ1BPskPaWLksj8NNrR1pv+fLPF97G5MjqN/yEUva71SwlmznmzWbqVYkkJ2dTYp3Nx8u3khNkw2oZNMXb/PvPB/Z2f3JygzBXr6Fb5ccQJ3a3mfBbfWUFO+n8bi26YnLSsAoNZKcPYB+feIIAJzNFWxdvZB1jWFkZ2cT6ykk77tVfF9poyse7x6+2SQnOzub9JgAKjbNZcVeM2ChbN8+9hdU0UYjB9ct4O1vKgmPz2jvR/VeXnljBXWA29LIvu++YE1DMNnZ2cRInFQX7aO+yxL38/Fjr3MwpL1tfXvG4SpaxrzVxYCVqsMH+P646TnHjpGC6DNpr6/4R+2t5/vVc/l8O6Rm9CVbfYQ3/v4YHxaFk90rlaDG3SxcvgMzTRxYu4wV68rx7+jzFMUB5i3dTF2Tsot+dtFaf4Sdaw/QeOz4frep8/jGtlRS0mbmxB4/8TpK1lnZnbeIdUcsXVyDqQQr5NSufIN/71GTnZ1NRkIslm2rKe7I78Ryz/a8CrE2dHFenRmH3YHd4aahxYbD6cLrtONxWokw6QkJ1FFQVgMKNTU1Nd3IXRAEECPugtAtUVFRZGZmdo6Yn62goCAkEglPP/00ycnJvP7664wcOZIpU6b8DH/UbNTVlVLviGDY4IkMjYSW8nKcQVoU1LLhyw2EX/oCE8dF4PNYKQqt4c0P13M4N5nkk2tKr5zRTJg8hAiNAgbZ+WLSBg4/lYveXs7OtYWk3vQ8E/sacLcd5ptPllGyvYCa3mqKNx1AnTSQ0ZNziDMoaDTsZMn8ekCCwi+OoVdcTkB6D0L9wN12GOUnyyjZXonitlTiIwvw9hvK2NEZx30TINP34eqcT3nhu++5LjWD5ppKyuvqiRmShaPgKyzKaHImTaVfmB/2fh723r+F3VcMYJhGccKouxJTZC9GXn0l4yN0YI2i8Z8raCivwZL1U/2rxBDag+GTJjJKcxR7TSt7lHEMuTSXZI+e7Xevo6LNSiYAEnqOvo6JI42422qIoJDFeXtp6tufuoIDNLqMZE+5mmHRahwD5Bx+bBffj+tLcCBABGOuv46JKUbAQvHOrRytdjGwz0QmpoG1vh6rVMrxi4YGkzmmN+GyUvpOzGUcAC7q64o4crCVzOmzmNhTh7VYwf8+P0hBcTVJEfH4ndBCqVROxphpTBwahMtcQv7iajZuOIA5M/yETxrpf8ml5E7sg1Elh4EtzJu0jsInRtPDXMaBXWb63fAnJvbSYysPoOVg3SkC9zAGTLkMde8sojXgdTWxz9jE599uoWj08NMcCxMZZ9Leo0r+N+9AR3s7+ilnDOOHJuI/pJW5o5cT//ylTAx1cthkoXjB91SRTlhiX0ZH+BESE45OQecx2j9hAKNOKtfCD+tAWSkvOECDM4jsqzqOb10dbXodx4+3+3CecB05qneycMEqvt9bTFaSgpOuQWqYP28nPa9/u/O8CmnezfvbTlHuz3JenRmJRILL7aXFbaOtzYpK4sNkDKCqro6io5VU17fgdLlxOh3dyF0QBBCBuyB0i8lkYsSIEfj5+XUrcNfpdDzxxBNcfvnl3HnnnTQ0NDBz5kwCAgJ+hsDdRJ8Jk6iq+YJ37prGqypInfIwd06OQs4+9u0vY3PRfUz7nxTw4rI7kPmPOcXDhlqiIo2oNR3hRlAQRrsNGz7crsPs3LCL/SV3kqcEcNJa70evqanYqKO0VE7EiFB0+va0Qf36kyxbDkiQywLQs5Snb57d8SDfj9OemkSmJeaSEQT/JY/vZ8airCmjrimBkX2g4YNits3fQd7qRahlABaqCmLo3+WDcHK0WiPhEbr2/2o0+MtkOD1uPCeE+F2lVasDMRpVgB8ajYlwnR6NvxzQE+D14PIdm4+fxMCB7XMO5GoNwQkJqNcXUU0qjfXFbPsyj1VrV/CaHKCNmsJI4j0e2mscRErnfAU1ESljmDy1nk8fnsYXGogadBXXX3s1fX+ituCkzVpDU3ME/ZLb26uJjibcu5+WpiYsdBW4p9C/f/tkJIVOR0hEBPLVJdRyYuCuIybGiFLV8afEaMRos2LDg91RQXV1BGPS9O0tCAsnKjoaD10JIiVmDQ/c+ncqAfDgaPOgj57I2S+K2kV7o6IJ9+7raC+AnrBwf2QyCRiNmCRGIiPVgAe5Toe/oxUnKgL1brZ+8zbPfruvI92Jx+hUWqmrtyGXhxEergZAFRyM6qTP+XC7jlJSGsnoDEPH50yE6rTUV1fTTDQnXYMUsXtvxHHnVWhGBpHbHB3lFrN90RpWrVvZrfMqcuCV3HDdNWdwXp3M5XbhcktwOKWY2+z4K2WobQ4qqqo5WtkAgNfjxuk88VswQRDOlAjcBaEbZDIZOp3unPLo1asXU6dO5Y033mDWrFlnsaFTOFGRVZSV++gcIne5cDQ30RocgQklOlMWk26PY/hVVlwNG/jff79lbWYok3sZCTb147Yn72K48tjlL0Wh0p31MnJSaQRJ6WMZM/sOfqi5Ak1AAAYsBOid1NsduJyAH1BXR43PB3ixmNfw7ou76PvgC4wJBahl26K1lP1UoRIpqqAR9A67h0/m9KJ/w1ZqE64lQ61huzaV0Tf0J2vMAH5Yj0dNUJD2Is4JrKW2FogBPG5cllashggC8MOuTmLEVfFkTh7+o2UX/QgMN6I8aU0XGSr/OIZMmUXaIDOO1kN8M38ra9dtIfLqbEJPWwc5CoUOtfoQZjNgAixttMpk+Pn5dRFMgs9XQ10dEAW4nDhsNpwBYejPuN1S5LIAdNpGmpuBEMBmpa3NQpuhq89v5vkZXxD1lxe4PxrASsWBfL5ddMYF/kgX7W2z/Ki9XS/FerJati7/lu3l4Vz7+M2k6AD28+FDG0660TmZHxq1DLBgtcLpOk4qNWIIqKexEQgD7Hasbg8+f+0pRr2DCQ2pO/68amqkCf+OcpMYfmUcmVNGdOu8Wr7gTM+rU/C5kSLHanMg8ynxenzYXNBqdRMWasTcVI9are5OzoIgIOa4C8JFI5fLeeaZZ3jwwQd54oknUChOfmita7Hk5Ph47728zlfaGpvY9t0a/Pr2JYxqNm5cy+YdFiJiY4mNDEbptGJzufASS05OE298UEhsbCyxsbGY1CoOLp53iuX/TkWCShVHj/RKFn1b35mXtLKEvTs2U00wmZkadmzfRVV1+4O26z/6iAK3G/Dh9VhpbvIQENGeTtVUz/cb1pzBcnYSVKoABvaNZt2Cj9lY1EZqnyyUGEhKVFFSWUpto7KzPtWLPmOrte0nRkdPFEp42H527mzj2Df6381+kvVnlccxR3j77TXAicdIT2ysP/XmMo5WSDvrW798MduaGjh5PLKN0tI85s4vISw2ltioMHQyL3abDfdP1kGJwRCFyVjD6lXti1MWb9vGUaeLkIhIutopwOMp4MMP1wFgrq5h19ZtaDIzCT7jdsvQamOJjWvg6693A1C2dy/btm47xVKQNhqqrfhH/OicXDS345zUotdZaW4upqzjzm7PnDl8V1JC2xm3d/tp29s1NzarFRcaQqLa62Veu4Id1RWn/VaonZ7YWCMt5kL27m2vdM2KFWyorj7hGwQJKlU86T3NLFy4HYDqgsMcLCvHkJREl/c4xDN2rPu482r9wi87vqloP68aWrp/XmmlZ3penSwoKAipz4tO4SVQ60dpVS3fbd5NYVkVYSYDMSY1DTUV4sFUQTgHYsRdEC6CN954o/PfKpWKV1999bj3Y2JiTpNaRtKM93nq0QGkpz/Q/pI2lKzpzzLnsigkwKCIAv7zyn3cc08hAFm3vcb0hHi0SEia8Q4fvnlNZ1ptaCLTn13EvWfVAgkyTRDDb52N7V8zSE+vaK/38Ou576HHiEIC4//EH8vv5vHrX6a4GWJvvonhkhpAik4/ljuu+5rLxqfzBKBNSSE5eCCDAEhl7Jhl/PmlW3nungwe+fJZpv1o8r1EpSFk5FRGzHuasqA/8VCf9l9jpkHXcZ/7fzz59BU8cqh94s+QhxfyD6XuLEcoIrjq/mtYM+NWhj/ZiBtIvGMmQ7u1OvcorjX9g/T0u044RhICsyZzp9PCiy9P428zzABk3/0hz2pCUHLghHw0ROviia57nPT0nQAkXvJHHrxxRBebJI3kzjv+zZT0THSmqbyU9yRDwnsydtIVFP/tatKfAhIv4dE/3ceYHnq6muglk4xgnPxZ0tNLwBDHiFue4j8TIpBQeobtlqAMimXEVTMpfGI66S9AQGYmSfo+DO3y8yN57rllZExO5zVAGRhIUs7lZDUA6Og9chQH9v6LRye8jhkIy80lWRnasXrRGbQ3YRyPPnj/KdvbtXCGDx/E9zv+wfShz8JPlvvwj46FhMCsKVxTW8FLz0zgmRIIy/0rr6YHnLDxlASZxsjAG/6PI3+5nPR/A+H9mD7rz9ww2ISEhi7qJSP17s/5632ZpKef2Fft59UdrjZe/Ff3zquEcTN56IauzqufptFo0Om0lJdVEChX0j8tGpvDBV43tpYmqo8eIiM9/TR7VAiC8FMkOTk5Pr1ez3PPPYdcLsdg6PoeXxB+j+x2OxbLybNsfT4fHo8HqVSKRCLp1jz33z4PLhfIZFKkUgnuw28x7a9e/jFvJvEXu2qCIPzsfD4fbrebpqYmiouKqKmpxeXx4HQ50Wu19OrVi/DwcORyMWYo/L55PB7mzJmDzWbDbrdjs9lwOBydm5Pl5uYyePDg49I89thjmM1mMeIuCN3R1NTErl27SElJITLy17Wh/YVzmDXLmwmPDiXQqGTTOwvRT3xFBO2C8BslkUhQKBSEhISIUXVBOE9E4C4I3VBcXMyWLVtwOByEh4cjk/3USiS/R2n00b/Fc/9eTVG9E8Kn8eL0hItdKUEQBEH41RKBuyB0g0ajwWAwnPPKMr91puF38I/hd1zsagiCIAjCb4II3AWhG+Li4pBIJISHhyOVisWZBEEQBEE4/0TgLgjdoFarSUtLu9jVEARBEAThd0QMFQqCIAiCIAjCr4AI3AVBEARBEAThV0AE7oIgCIIgCILwKyACd0HoBpvNRkFBAS0tLfh8votdHUEQBEEQfgfEw6mC0A0lJSXk5eWRkZHBoEGDzmod9127dtHS0nLaz4SEhIiHX3/3dvDWrB0M/M8f6P1zZlu7lyUL57Nku4xRt15L7uAU2vfL3sdHD28m9W83kq1S/JwlCoIgCD8TEbgLQje0tbXR1NT0kwF4VxobGxkxYgRBQUFdvl9aWsrBgwd/OqOKBTzwp7lUAuqgSCbc9U+uzTjr6vyEIyx6YR3qKeMYlhaJptv51LD0yf/jE/MYXvzntbTvNWul8tA3/PeJuRzq/FwUI2++nqsn9iWYQ8x9Yi3Bf7icYTEmlOfcll+bBg5tOETyz5qnlcN79lJqMTH+lgkMSrOy8oX30U8Zx7C0Zo5sKcDoFd8gCYIg/FKJwF0QuiE+Pp4BAwaQkpLSrXXcQ0NDT7kleFtb209nULGAe2ZsYfh/nicbsDeZObz+A/Zl3Ez6WdfmdGzUlVSibXPgOZdsqjay9LAKf/OXrCq7lpuiAbw4rHak6n7cNvsaUgHznm/5dPViVgQZuHxQGzVFFcgcLrw/S1sEaKGm1gJ+CfQZmEykzMG4m6ORBOjw4+jFrpwgCILwE0TgLgjdEBgYyIgRI85qiszPaf2HbyK/9RMujzOiBHwxXhLSUpBSz65vl7N8/kZKVYXs2BHMVY/fz025fSh5eyZ/m7eHmjYg9mY++fRO4gBwUlOwhjcenc3yGoAoRt8+kztvj2bz0/9m3rotNGxdzCvyQfx50VNMCtaDy8FXfx3Fc+sAv1D65P6R2Q9fQvAp6rt57sc097mPR6X/5I9vreGmp3M63pGiVAcSHhdHHOCNHEnB3mW01jbSdspHcBzUFi/nzT/l4eldyPLlNUQNvpppQ2LY983bfLOvhV43PM9j04cT2z4HhLwnR/PYt3aQqYkcPItXX7iScIDqXXz+zsv866sCAHpe9TgP3pRLDxOw+VWm/L+F1Lc4kMqVTHp2DX8eBmCndOcy3pj9D/LqAOKZeN9d3D5tSHueVLHg0fv5z4YyrB5IuOU2UpbUM37JnxkI1B9cz0f/eJjP9wOGvtx4z0xuzM1A+xPH3Fy6l0+evZOP9gBRg7l95t3cPjq+490alj75Z9747hBNToi9+WaSP63ikjWzGdaZQz27vv2YN176mAM+GR99PI9rHh+P9LtaYq6/gktOmI/jaG1g4ROTeXUzoIlh2NSZPDorB+NP1FMQBEE4f8TDqYLQDRKJBIVCgVQqRSKRXODSN7Di2yzGXqrrnD4ikUpRqtXI8eJ2HmVzmZO0S/9Ffv673D8+C9eyZ3iuKJu/v7eM/Px8PhixgisfXQk4qC5cwCt/WUm/1/LJz89nyevXo6pcz5p8BVP/Mourh17Fg69/xNf5LzHZpEMKHH5rOi/5PU1+fj7LP/wbQ31Leenjvaeo7xbyvtMwaFgPMiZdQujSZaw5xSebd+1kR1UVHq32tNNyvJ5GKs1FSPq9Rv7cl5nkt46Xlxyg16yPyf/PH5Ee3MieyiqcQMkHt/In8/3k5+fz3VdzmRm2mIdf2wzUsX3rWvabB/HSova23xPSSGn1PprYwot/38Ho2XNZnZfP6uXfkLViNuuxcHTXXN5+5XtGvdGeZtFLE7EcXMfWbZUAVCx8hf8xmY8WrSA/P59r9r3CMrMVF2CvPsjKJXOpHvl6e9onBlOyZRmrO9KeirOxjHXz/83evq+Qn5/PnFlZVK7/mMW7mwGoXvY/PrAP56U57cf31sK3WNTchuu4XIz0HjeNGffdwa23Pskn+e9y//gMtG1WnG4PP54g43U72fv+3XwS8hz5+fl88+b9JLcs5a2FZzCFSxAEQThvROAuCL86Pnw+Cae+Xwhn2PDxTMhNRS6XIZXWsH2bmaFDeqHRyLHb7YTfeDPDvv2W71ARljCNpz99itEGO3a7HVVyCplaPZajJVTJ2m9MpFIZMrkMqUSChCMsX+7humsHYrfbwWAgpVcWht27OdBFbTwb1rMx63Kmp2lRJM/krnGrWb7S3fGumYPrXufWAQMYMGAA42d9id/Qy5g0Og3/0/aBlrCwkUyeHIU8Ooq4HuO5dkB/svoYkWdl0dfjps1mw0EJq1baueH6odjtdlxSKfHjxpOwcRM7kCCV27BYGqiram978tXXMLZnOoFIUfjVUHLEis1qx+l2k/P4bIaiJa73jcx++xGG6tvTqDMzyZLIqKuooJZKNm6wMWnKwh6xVgAAIABJREFUcPR6f+RyORNmzez4ZsNBU1MpNdUBDBuW3J4248dpT8WNxVJCUZGBSVMGIJfLSejTm6SgQOqKj9JCNdu2WRg1ZhDBIQbkcjmXzJpJ4kn5SJBIpUiP/chlSKVdn0Re7xE2rJNwxRV9sdvtSEPDSEtMQbl/P4dPe1wEQRCE80lMlRGEXx0Vfn4O7HZAfSafb6CuvpJvXnyQRS/LO+/W5WGj8cOHx1bFzsWv8/R/N2GRAbixtYYw9u6sU+RXRklxKZvuuYzPO18LInPMdE5ei8TJhg1bSYoZSHNTA+42SM3K5unlK3GMHQYEkDbsLh56Ywa9zqYLzlgVFZVVLH/4apZ23uloiOp5BQpMZObejNP2IW8+cBmveBxEjLqP+/9wGX0i+3P/Z0/zz2vu45r3LPh8Dgbcu5TZl+uRWUpYP/8NXvpgO20yABdWcyRTeo8A6qipNWAyKjg2i0oSFU0kNYAbh6OMPXnLmb9rAy931jGRywaNPc0oigeXq57m5lCCj81F0ukIAFotrbShoK5eS0CACuWxAxAVRTQF3e41n6+UwkOH2H7XZczpfDWE7Ctu7uIYC4IgCBeKCNwFoRs8Hk/76LRKhUwmu8DTZfozbuIzfLCgiBE3pGFSgcfloq25GXmXk8zDiY3px7RrHuHygekEKtojypbKSiQ4qavM44t5TmZ8uopJ4eC07GPRa4upPmX5yfTOGkb/55/hunAdAG67HavVetLKL66WDazdJ+Fo/fP8+av2cn0+MNi+ZXlTNj/7IjgniSMtLZvIhx7ltvj22dmdfYUbq1VN6uh7eHfqw1C/ln/+vxVsPdSDhMh4nDUp3PfpQv4kk+I88Bo33vlPtl7+CJFH8li+Rss9c1cxLhQcLTuZ+/xX2ACIJDHBzI7CZlwJYfgppbTs2EERAEo0mnRGXHY9N901g5FB7Xdd9uZmnErlae7B5KhUEYSG5nP4iJUBqRqctbXUuN2ojCb0hBIb08aWskZs6XHoNDJad+w4p5FxqSSVfgPHMvKpx5ka2j773mW1YnM6UZ1DvoIgCMK5EYG7IHRDQ0MD27ZtIy0tjbi4uLMO3CsqKrBarV2+V1NT85Pp+0+7g8UPvcCbppmMCwenxUZdST3ptw7v4tNB9B5mZPnqtWy0N2PS+wFQtHIHqX+5nVilgeAgF0W7t7ClDBoKN5K3dS8hkUMAf4xBUF60jx0eFz2yEglWRjHyci2z31pIYm77WvNtdc1YnBJ6XTGO2M5ynRz9eg1FaVN54fZc4k3ts9a9bidr/jWNeZ8VkDzorLqtG8IYPimQh95ZSMaU9jH9H/pqDL7C7ezZ4SC2hwnMBbQodYT7+yOnlG8W7icmPRyFSo67rBp1XCIByPDzMxDof5Aju7YQEAi1B1exbs8hkrPHAyb6jerBwm+Xs0XbhE6tYNfSDVgZBCgwGMOJiGrhu8+Woe4fDUD9wVJUWRn07ZVGYJdtkOGvj6VHLx0LFy8kaWQyNQVbqfb5MSI5Gn+09B6WxpKv17JVZyU4QM2+JetoO4fbIqksiuwxSl55dxFRY9oXpGytbMDh50+vCSOI6nbOgiAIwrkQgbsgdENZWRl79uxBIpEQGxv70wl+JDg4mO3bt//kZ04rLJenXpLxzDNzmAP4GcIYccNfSMFMYVgsSU7NcXPEjYNu4mE+5D9LvqSutX1+eb/bX6UPQMhgrrj6CP/6ag5HAE1sLCk5V5AWY0JNAjmXJ/O/xXl8sbaMaanRmJRyYi57ir9Kn+PVOdsA0EenM+6aOzm+J6y0SJO4ckI2poAfHjWVymRkX3UHB1e04jNEkZplI6DLRhpI7N+DIK0fx6/dI8VPG0HaAFXHxkF+mKLjSDAGdzzQqieudyp+Bn/kQFjuY7wke5Fn5rRP+vihr4DIOKr3fMGcOeUAxI64gaFp8eiA63IO8vj7X2C2upDKFIx/5DYyAWIGM2HCUd76ag4HAG1SEr1GTaJHeCAqIGDEnTzQ8HfeXzwXqwtCh0whdbcFDaA0xjL80mlIlnzInDl5AEQOnMqVUV0F7SFkjskgGFDoQ+k74RaaPv0Xc+ZshuCe5E6awtAkbefxndXwMnNWfEGTHUKHTqTH6oYunhM4XV8Z6TEinVCZFIlMTvJlj3LX4n/y1pzNAAQm9if3ylwRtAuCIFxEkpycHJ9er+e5555DLpdjMBgudp0E4RfDbrdjsVhOev3IkSOsW7eO9PR0+vXr16213IXfqjqKihRER+tRKKQcXXQvf10/kVdfmHAel1Js4OhRKWFhevz8ZFQse4C7vx7N269NxnTeyhQEQRC6w+PxMGfOHGw2G3a7HZvNhsPhwOtt37UkNzeXwYMHH5fmsccew2w2ixF3QeiO6OhocnJyMJlMF2E5SOGXzUb55hWsXWPHK5FwaJ2Z4Xdmn+f1z+1U7VhPfpMFj1RCwbp6cv4wRATtgiAIvzFimFAQukGlUhEXF4dWqxWBu3CCGHr3CgKfG4fDQWLuvVybHXSey4wko6cRhdyDw+Egdtw93DRYbJUkCILwWyNG3AVBEH5mAekTuDn9wpapSxvDdWljLmyhgiAIwgUlRtwFQRAEQRAE4VdABO6CIAiCIAiC8CsgAndB6Aar1crevXtpamrC5/Nd7OoIgiAIgvA7IAJ3QeiGwsJCVq9eza5duzqXbxIEQRAEQTifROAuCN3gdDo7118VBEEQBEG4EMSqMoLQDSkpKdjtdpKTk8XmS4IgCIIgXBAicBeEbtDpdAwdOrRbaVevXk1zc/Mp13/3+XxEREQwaNCgU+TgwWF1I1MrkXd7DfkVPJi1nEm7XmTUBU17PlSSP2cpe80xXHrXBOLOOJ0Pj9uNxytBrpSf4dePFop3LuXTt1qZ9MYMep32sx3HSaPq5i9aNw6rp9vpfT4vLrsdj0SByk/R0T4vHpcLp9PNDxO8ZCj9lMhlUiSnrHMt25Z8xdo9AUz661SSu9Wernhx5T3PhCeW0GwZyovb/s5Qmwe5xkXpGfezIAjC74cI3AXhIpgxYwYhISFdvldQUMD69etPk3oTz+YuYeA3TzFRrTw/FfxdqGPn1+3B6OS/TiXpZ89/LY8PW8K4HS8xrlvpN/LC1HzGfvNXBv/0h0/ise3mhWl3sSlqBq++disJcoBq1s99k9deXUGtTo0c8NiiuezZB7lpWE+C5Oda57NVxmeflnD1q0u5PTMIies7XrxpB2Pn3yl2fRUEQeiCCNwF4VfM522hqrAVmd5Bc7MLkKLSGggODca/4+q2NVVR29iC3Q0KQyQxwf7IO4eXvbgcrTTWuNDHmFAD4KS1vgWnzA99oBYFLsxVldS12vH4QGl0HFcHj9NGY3UpjTZA5ofBGIwpUIPspNpaqDrcgiLQQUODE6lcSYApHKW1gpoWN0r/QEzBIehUAG5aaqqob7Hi8gJoCU8ORy+V4HG3Unu0FYnWgdnsQ613cFyN3K3UVNXT4lITHmXCXynHUnWYyhYvSKQo/E1ER+rxWJqpq6qjsdnG0UPFaEOCMQZqUZxUbwf1xUdpcIJE5qTe7Ppx67E21VPX0IzdA6DGFB2KQeOmrrCKVm8rlYcOcVgeQERiGP54cVpbqKuqweIGUBJwynKzuP3VJPQdx6i+vBU0Dlpa3IAMjcGIyRSI+uSOBqBl12J2aMcxULaZNYemkZCu6Xgnkpybn+j8dqI+/xUefPtLMuLCyYnrOq+u/Pi8wj+YxHADcpkU8OF126grLaPZBVKlEpXSH7VChT4kANUPOVBfupsDR5XEWos5cthGZHI/bnm+B3qg9sSj0NpAXX09bU5AriM8Mhht5zcJgiAIvw8icBeEXzG3ax0vXjsP+RVKag87wOVBE5HJJbffyaQeBmiuJH/+f1m2+QjNLgX6jOt4aNZoYvyP5eCioWwlbz5RzuRP7qMvAFWsn7uUEl0Gk24aialhL5+8/F+2V1pxSWX4pUdwLHT1uuyU71rNnA/epcCixU0AaSMmMv3KHBINfifUdhv/mvYh/rfqKdpSD24bpmG3k978FXnfV0FoXybdfC9X9JHTULSfvAULyD9QQasb7NV+DP3XU9zb00Rb02pevOlLpOOV1BWpSR3S94f2WOso2r2Et+dsplw+gAceu4ZUXwWf/POvbKjV4UOGytSXGx+YSkz9VlYtXsVOi5xDteWMmz6NK8b3Pmmk11aZz0uPvkalOhCJSo4yIBgjiYCD5poiNi39itVb9vL/2bvv+CjK/IHjn+0lm91s6qZ3kkBCQu8QuhQVu9j1LJynnp7lVM56enJ6+rOcd3ZFUU9RrHSIdAgQSCghkA7pvWyyfff3xwakBAkBwfK8Xy/+YGeeme88O0m+M/Od56m1gr1RSdpdf+SO8VKWvvod+c6DVP5jHlsMY7jz1RtJaK8kd9UqVqxcS0kHONvlRE2dxY2zp5CsVx235y28eOUKZuY+Q8qh5fzr1qV4xsppLLeD1Ylv6gQuv/4qRsfouvlF3sSSt5cSetF8Jptf4fVFG7mi32R8uzmHfPv1Jd6zmU7n0eUzP81x3HnVqk/jwbtuZkSiPxKJm8bCZfzryQ+pUxuQ+aqROg3ERg7nymPKbA6x9qPl5NXvJu+1RjYqhvHHtxL4+uYtXLjuIcKP2p/T3MCO5R/z9cpN1FjV2Allwo3Xc9WoJPQq8WdMEITfD/EbTxB6wel00tbWho+PD0ql8qT16j8/Dy5JI5KU55n/txRoLWLlwi9Yv2o7I1LGYtn8NT+0xDL70fsZHmegYf16KmVuInu8fRuly74lL2Q6f3toKjEBGvL+eylziAfcWJvLyV6+GOcFzzP/wng6ytby/v82s25zNGHTUrru4B/tIG2JC5g/R0fZ8ue48/Wv6fP3fzL/j5V8ueB7CnftonlADAUb9iAfehNP39MHfyXUrX6M6+Yt5eoPr0eNC7vUgnHgo8x/og9HatzNdRT+8DkrVu3FMOEuXpiahknXyfYXnmNpxMN8/cJQXLY2di56lrfeyeP5Jydz9R12wn+yVKaTvHffoCDzab66MwNL00EWv3gfXxMPdFC5r4A236H88aUHiPWB5u1v8/CCLZT2m80Nr9zOvoHfMXn+4bITC7X1RZQc9OHif8wnww/aC5fyn0/3sDuvL7Fj4jk+df+RA6vcQ+Toh3np6Xio384H765i1/YC0mMGYzx+9bplLK8YxU2ZMcRUjiHyrY1sa5nMBD/vMdWW7GbzagXFQPP2lVQn9GWm3qeHfxDsVBx3Xu37+E7+/mkOKY9OxE/Sxs7PFmK+8DnmX5dCa+lWPnnpJfI5/p2NPlw29waKsr8n+eUHmBlswG1bwtcn7M9J/Z41rCtyMvKPr3FxRnBXP69lQGIYAyKN3TzdEQRB+G0Sibsg9EJtbS3Z2dmkpKSQlJR0HhN3CRrtAC68LMX7X4MeY0gIxl1tmGmkrMhCTEwa4eEGAALHjDnN2uEa9ux1M/iCFAwGbxqefvnlJLy5E3DR2VnCvtwm3OF5LFqUBzTSWNGKLayOJlKOuWvqlc4FF5gAG+rkgQwzVjBksBGwEOTvT02rmQ4iGHfFFHK37WH993twAaAhIC+PPK5nGAr8jAOYeWGfo7ZrpiJnJetLwhg8Yw43Tk0jSAVQzuYtLUROKGXRogrAQWurGuWBA5QwqAfHX8L6DTouX5DhjUKvp//ESWxdCOBPv5HjUOfvYc/yRezsikNWUEWh1UrqCdvSEBI1nCkX7mFb1iJKAKijvbyR2qYmWomn+7ceANQEBw9gypR473+DgjD5+mLr7KATTkjcK5cuoWnGI0wMVWFVjmRM33Vs3drAhCkAFupK99OW1YL3QUUCV94+g77Bvj1MgBspPu68Spl2AcaFuRS5xzNQUsTOnUam3e09Jw1hYaQNH05DWY823o02KisraTlUQ9meDSwqgeP7WSTugiD8XojEXRB6oaamhgMHDqDRaOjTp8+pG5wXLpwuCVKplN6PWOnE4ZQik0mQHr42USrxvhLrweNxYbeCtb6QwnrvYnVkPMl9I9D1Ou4m9q1ZwpIt1TiVSryVEFW0u3/q15UDs0yOVq9HYbHjtDpApQAc2O1qXK3FFJoPp3d+pE8fQDBQc8pY7NjtSpSHC9AlEiQKBQo8gJmKPRtYvjiHKo+2qza/jibryUpO7LTW7WLVZ9+SazXgrwVoobal4yy/iHmIpUv3oo7bxgcfbAN7O5VlVgo7tlE/JR0IIG3i1ac5As/RujmvFAqUTgd2AOw4HAoUh/tMKkUql59Bcu3G5ZLg7GinrrKQwzMnRI8fSLxfT58SCIIg/DaI33mC0AuBgYHExMQQFhZ2Hu+2n0oAMTEKNh88SG1tOuEROlp37aIhOZnYI4PRSJHJNCiVFVRWwcAwaCkro7CwkM6BqYCJ5CQ3C/aUMblfNAY/FUVLl1GIEZCj0cTTf2gcrROv5/bBYQA0FhbSJJfS+16pY8faAuT9r+CmS4YRpoHS1Y+x5ZP2n2hjJHn0RSRkONiy6Cs+9cB1M9IJ9o1m8KAQKtNm8dcL+wJga2/n4O7dPXypMY5hQ5v4ZFkRV1ydgM1spmjTJioZAbRRkl9AI0lccc81pPtB1fa3qVi79yTHbqeptoA9BWomPf9XJodAY+FS3i1ZfgZ9daLmHQtZ4pjIlCgr3vnBFPiE9CGkfiPri+LPwkXCiedV+dp11PUbRoJUikSSQFpqPWvXlTNtZjQddbUU7syl3jesl/vzxRQaRcwgDf1mXk5mrPf5wqHNm7Gqf6k/e4IgCD8PkbgLQi+EhoYybtw4/Pz8epW4r1+/Ho3mxApwgJaWljMNr4uG6KETSK5YxHdvPccSpQa5PoNL4pPgSOIuw9eYQMagZXzzz2fICwInZqqqnXifI/jQZ+KFJHz6Je+9vBGpXEGnRI4JACkavwgGZqbx7fL/8swyb4W2wieawZMm0Ns0DUIYPDiC3du+5rUDK/GRg0XSiMx9qqEvjSSNGkaMxMMnny3k1fIKrr9tMulXXcyebz7hmTzvy7JSmZaIvhO5AF9Cgv2RNK/izWfqGDN5ImOHJeJ3zDb9GHL9rax59wWeKYrEjYPmRlVXaYqBhPgYtu3N5v0XSwhUgU3SQHOHuysRT2T0qCa+eOZZ8nwyuOS+KQQFJJAcvp0vXnmGbC04JG1U1rtI73VfHa+Z7V/sxDT7CeZc/mPVvq2xmFWL5pO3oZABZ/xb/8TzqrpFziWXDyFILkVKIEMuu4ztC5/nmdxQXFiob1Dh392bsT2iwpSSTlrtMrZ8/Aobuv5sqY0ZTE0SY8oIgvD7IouJiXlSpVIxadIkpFIpavXxI0EIwu+X0+nEbref8LlMJsPX1xeFQnHaibtGo0EqlSKRSLr9p9FoMJlMaLXak22BgMho4hJC0Ut1BEfFEBsf0lWvLEPl409YbBShwQZ8fIOJDDag8zXgF2giJmMw/U16FFIdQdGxxCeG4afQERwZhVGrJdBkIia5P8NGjmZgvxiCjT74+IUTG6xF6etPYLCJlNHTmTgohfjEUHzlKvxCoogwKpH6BGIymYhPTadfYizGE/JsDYFRMcQlhuKLBJnCl5DoGKKiAtEgR+MbSHhMBKaAYELDTBiMfvj7e7eZPHIqk4b0Iz4xDINMR3B0NNExwXh76Li2kTFEBRrRB4YQHR2Mf1gf+oUosCqMmEwmwmNiSB0yjGitAq3eSECIH3pfE1GxEQQbfU4YllEdnEhSoAR0JsKjYskYPYVR/eOJDDcR5B9EYHAABoM/JpOJxIGjGTtsIH2TIvBT+ROZGIBKYSQ0LJKY+DD8Nf6YooLR+RgwmUzE9hvIiBEjyEiJIkivPe5Oik/XdxSK4Zi+AlCg9QsiIjbyuJjdSLSRDB2eSoD6x6RWrtIQYIohLCiEqLgYomIiMAX4cuKl0NHf0dF+PK/CujmvEodM4YKBESjlUiQSKdqQOGL9Zcj0JqIiA9EoFaCMYPCw+OO2q8Y/LIrY+FAMchkSiU/X+WzCoPLDFBNFZLg/Oq0RU0gwBl8tWr8gTCYTScNG0jfEgEoUuAuC8Cvj8XjYtWsXTqfzyD+Xy4XH4wEgMTGRyMhjh5FYvXo1NpsNSWZmpkev1zNv3jzkcjl+fn7d7UMQfpesVitms/l8hyEIvyJurNY8tmyJIDMziNaSbBZ98SWdaXdy27SYbi4WBEEQfl9cLhcLFizAYrFgtVqxWCzYbDbcbu8bUtOmTWPEiGOn3nvkkUdobW0VpTKCIAjC2SRB5grCvu1xrn6jGafHh+iBU7hjVLhI2gVBEM6QSNwFQRCEs0iCXBPK6Fvm0ucKJ0jkaHyNBOpPnBtWEARBOD0icReEXjCbzezbt4/Y2FgCAgJ+wSPLCMK5J5HK0AZEEBNwviMRBEH4bRGv5AtCLxw4cICsrCy2b99+pCZNEARBEATh5yQSd0HoBYlEcmRkGEEQBEEQhHNBlMoIQi/06dMHt9tNTEwM0t5PSyqcJd5ZPMX3cL45nc7zHYIgCMJvmkjcBaEXfHx8GDRo0PkOQ+hiMHjHRRfOr4KCgiPjEAuCIAhnn7hFJQjCL5CZ6gPl1LVbEPdwBUEQBMFL3HEXhHOinUN7a/AEh2AK0p+D8aw7qS2poVOux3Rkts2zoYG9P9QQND6V4LO2ze6UsviV79DdcjUzBsUdN9tmdzqoLNhKfkEVHcd8HkzG1MFEaZTiLoUgCILwqycSd0E4JypZ99F3uKdMY+aE1HOQuFuoKy2lUROB31lN3Pcw//7vmLzjRSaftW2eDdVs+t+HvL+0DF2/CHRHPk/FLzOdSI2Y+kcQBEH49ROJuyD0gt1up6GhAT8/PzQazRmNLuNxuyj84SM2HQJUBiJSRzIpLaRrqZXK3dvI2V1Mkx10iYkYD7mJuWgosVoVuBrJ+eY79raB3McHY0gMweiIGxuOb0AAHqUPCurZvboUm7qOokPNWK0uwMCAWZeQ7gfgoqOxnJysdZR0gCooCKMsgLCoCOL6Hp0E/zRzbTF52espbAI04QwaMYjkgBY2b20jflASoXoNUsDtamLX8mzUo6cR46lj78Yl7K4DVEEkDxjEgGQTql71ZBijZl/MtffOIOaEZYV8/3IBvgMayMnpwBiWTPpQfxo3lNKua6CsTE2/zDGMGBhH+7ZvWLm9mCYLEDeJuy9MRSEDa0cBP3xYiCy+nj17XISnDGX8tAE/85OH86uxsZH58+efcr0bbriBwMDAcxCRIAjC75tI3AWhF6qqqti0aRN9+/alf//+Z5S41235mDeX7iMxIRZrczPlFZWoNTcxOkFHZ0UeS1dkUdWpIThIT+26T8j5VspVE/oTo1XRsGUBbyypYsjgWBzt9excvQz047l1rJbyjRsp900loK8/2Ys+YpNUS2pSJFq5HIrX8kpnOC/eORR9ZysF67/ky43tpCSH0bx/K2u31BA78xqu62Hibm+uYPuaxawpaMUUEkTnwU18ZbZyVaaRvO++4oDsPq4ZGYFWDs79i/nPJ0VcN3AEtu2LWLSlisiIMKzVeaxsbAHVdIbH9ro7T2I38x94nJY5ExlnikBjbeVg/hbefSYLw8VDSDbEYXO4aM1fwXufL8ci90Pno2X/5//g35p/cd/UUKztW3h77n9x3jCGoYFR2GxOfusj+LvdbgoKCnj77bdPus6tt94q5jIQBEE4R0TiLgi90NjYyMGDBzEajaSlpZ3BlhrY8ulXyKa9xpzpEdgai1m1aD7rNhwgIyGFyrzdNMijmXLjFQyP8qF23QvkLa/Ac7jt/9YQcOmPbZe99SLLm7vbj4KQgdO49sqRhPgo4ZCSrGtXUHLnYPq0HmLv1kP0uepvzBkRTHtxFu+WLKK9x8fgoLmigIIDLaRcchdX9ffHUpXFf/69k719p5A5WMG/thdxycAQtDoFBcs/wzHynyR6ylm5KZ+wC737tTXk8Nn8NezNLSU5VtGLvqwm+8s3OFC09Kia+BSufvZmRhpAIvUh9bJ7+dv4WKCBnO8P4BuRxvRbHuCalCCgjY3/9zoV/qO595ZL6BeiofSz67j0zVXMnno9aiQofUMZfPVfeHR4RC/i+/UJCgriqaeeQiqV8uabb56w/Pbbb+eJJ54gOPi3/NxBEAThl0Mk7oLQC6GhoSQnJxMbG3uGkzAVsmOnibHPeRNBlZ8fETEx7FpfQh0mKqtsGAzRhIb6ABAyeDCJupauH9wT28ZkZGD6obv9BJLePwqtT1etd2QkkW37aMOJxVJBVXUoYzK8yZdvZBRxcXGU9/gYLLS0lrJ341ba6p9juwqgjbJcKepJUxk/ZSxB9+dQYB3MCF0By5YbmTo/EVnH9+Rtzqe67QXKFgF0UH3ASUrQYDrwP/2uREtwbAr9R2bwY9FGKCaFDACpNIHx42OPWT8sLIGUlKCu/1dRUCChz+RYAgK8bwXETptO5J/XsIfrGYwcH594hv9OkvbDQkNDeeyxx5BKpfz3v/898vmcOXOYO3cuYWFh5zE6QRCE3xeRuAtCLwQHBzNu3Di0Wu0ZJu6+6HTtmDsAHeBy4XQ4cKrVqFGiUoLH7cDhABRAp4UOt6vrjns3bS0WrGhPY/8SpFINKlUnFgugARx2bHY7jh5vQ4ZcFkh08hBCLx1P5OGPL/Qlol80uoAIxoV+whc/lBOpfo/lodP5PESCp8yIKSqdfldeSMKRbWkJiYslgKrTOIbDDMQOHMJF13RX494TGrRaJ9V2B04X3t+O7W206vUYerW9347w8HDmzp2L2+3mzTff5LbbbmPu3LlERPy+LmIEQRDONzFCmiD0glwux2g0olKpzjBxT2DMGDMLP88BoL2ujvy8PFT9+hGEH7GxvtTUFFFSUg/A3mXL2NfS0jW2+Yltd2RlUXN6R4KPTxRRUfWszioAoGZfAbvy8ui24qZbGgICTRhDXbS5oxg7dixjx44lzFJHXUsdFvyeXP2JAAAgAElEQVTIzIxhz/Kv+OizDcRPn0ZA134Tkp2UNwcfaROndNJcf/A0ynTOplAGDlSzbesOqipbANjw9tu0Tr2A1PMSzy9LeHg4Tz75JJs3b+app54SSbsgCMJ5IO64C8I5c4Av/r6cj19U4S3eGMoDXz7K8NtfYurTf2DGDC0udSDJE6/n8UmRKJATMmQWM6pe58Nnr+OVNjn6wf0IlSjxVoCrST+qrdzgizEknfjTikmC2j+aETOvpPC1PzHjfTXqSBN6WSwnnxd2M8/OmMHLAGgJT7mQe567ggsmNvDZJw8y44VOAKLH3srtaRH4ALKxs5nxyZ/5X+tMXp/u543eP4qxl15J84dPMuMtb6puGnAx1990HX4Un9ZReBXx9XPv8t4bPvxYIT+ap9a9yOU9KsFWEjfrQW4uu5u/XvE61R0yzCnXs/L1EWgAWy8i+q0xmUxihlpBEITzSJKZmenR6/XMmzcPuVyOn5/f+Y5JEH4xrFYrZrP5LGzJidXcicXmOGokEiU6fx1KwGZuosMOSGQoNT74an5MPZ22Djo7rTjcIG1exd/+UctNL9zCoAAdEo/nSFuJo4FdG1eytiSRPz44CUOnDbdEjlIjxd5uQ6JWo1TIuh6z2WlvsqPq2r/b5cBqbsPiBEnnAb79cjuumNFcMWsA+mOOw465yYztyLT2EmRyNT4GLTKnHWtnBxaH9wjlah0+GhVyKYALS1sbnW4Vfn7argsX8Lic2CztdNi8bWRKDVqtFqXMieWEmE/OaNTj56ujo8OG65glSnwD9KhldtrqbKiDDV1DTbpx2KzYrKAyaDn6VVh7RwvtnXZcHkDpS5BBjUQCbpcNc4sDdYDvORiH/9epoKAAz5FzQxAEQeiOy+ViwYIFWCwWrFYrFosFm812ZISuadOmMWLEiGPaPPLII7S2too77oJwbshR6/SoTzK2oto3AHW3S4rJ3t5KYGAiSUm+bP10MeZ+NxKnUiMBXK5VfLaoDzfeGE1L2SEO7NyObuzlBCFDov2x1l3je/yPuhJf/8Ppp5m6+h3s2JHI9OmhHMwv4VB7C/1jYrqZsVSJzt+/+yEi5Uq0euVJKuxlaPTGEyaCksjkqHXGbvpF3k3MP0WG2seA2udky9UYgo/uYSkKlRZFNwPGK338COhmO1KZGn1A99+SIAiCIJwLInEXhF5obW1l165dJCYmEhIScoZ17j8lnmTJBzz75F9YV2iG0It48fUBGHRyJICUcaQ1X83gwQdBFcLAC+/mmSkmTi8aHX6E0LHxVgY/Xgv6flwx5x4yM4ynuZ3zx+PxiLHEBUEQhN88kbgLQi8UFRWxceNGzGYzU6ZMQSaTnbpRLwWMvImXRt7U7TKpXMnAexex/d4z24falMQVzy7mimfPbDvnS0tLCy0tLec7DEEQBEH4WYlRZQShF1QqFT4+Pmg0xxd/CIIgCIIg/DzEHXdB6IW4uDgAIiIikErF9a8gCIIgCD8/kbgLQi9otVpSU8Xo3oIgCIIgnDsicRcEQThLtFotCoXi1Cv+hpjNZlwu16lXFARBEM6YSNwFQRDOEn9/f3x9TxxE87esrKwMi8VyvsMQBEH4XRCJuyAIvwDtlOXtp9ZqIGlYImIauN8Wj8eDx+PBbrfT1tqKzW5HqVSCx43bAzqdDq1W+7OOziQIgvBbIBJ3QegFq9VKVVUVQUFB6HS6HozjXsO2b1ZwUDeccSP6EHjULEXOPV/y8ko1l9w3g/heReOkrX4PGxa3kHZTJpG92sbJtLNn2ddklfkx9coJJPj7IANczj18Me9rCo+spyMydRRTZw3BRD15K/bQaYojtX90N5M4db+fg7t3sLs1ipBhvhR+swdPSl9S+4SdZEKnnihj5Zt7CLlmIqm+mm6G0Grn4O49FFdpSJ0aTtWK1azbWkTrkeVxTP/zJWR021Y4XTabjY6OTiQyBTKlHLt3CjEkHg8NDY3odFb8/f1F8i4IgvATxN8jQeiFQ4cOsWbNGvLz83s4xXsLBzavYsEHi8mvbcZ55PM6Vrz7XxZ+lU11r6Nx0dlazLYVedT3ehsn0bqftRt2kr34azaVtWDvKmV2u8rJ/rYITXo66enpJIepqcj+hm+yCjDTSklOHvtK6+hdAYWGwKgwAvXaM7yzUMuOxdmUWux0/w1ZqCsrIHd7Ca20UpJzgHqnL7Fdx5SuyeeNZ19jeaXjjKIQwOl0YrVZkauUyLV6XHItHQ4Z9WYXDZ0uJHI1dfX1mNvbz3eogiAIv2jijrsg9EJbWxt1dXWEhob2MHEHiCFenceWonr6mowEaoCdn/Naeyj9j6xjp/bAZr569xN2tgCEMfLKS5k5MY0AgP3f8vQHWVQ2eVPioXP+y+y4bD566kPWlVgpuKOSQcMu4KpbJhAJHNr0OZ9/v5oDjUDAKO68dxapwXpk7OTtO7dinFDJypVthMSP54aHLibhuIjLtqyhVJPMBYNyWPHDLi7qE4RGpwQkKNRRDLvwQkYDzs5y1n3xJVtzimickPyTveB2Otj45l0s2AVK/0hGXHIn1ww9pncpy92HW+pDsMkPJbBrwV95c2MLTo8MXcIlPPzAZIIwU75rK+u+2U2LXyV79rQCejIuuY5LMn3Y+tonbKzazZa/VrFEOYQ5b85hwE9GpidmwEgmXziEYIDmvgR99m+eXbiDafcO++mvVvhJHR0ddFqs+BqD6LS60Plo0KoUOJxqahpbqGpqJ9igo7S0lIwBP/0tCYIg/J6JxF0QeiEqKoqMjAySkpJ6UCZzmC8pQ6PIWZdNWd8QjOGdfPfOJgZdOxPHEwVAJ1UHsvji3XxMM+cwRwdt+9azdNt6IsJMTExpYuHbWbj7T+emvkGoZXBgyX/Y+9BljLsqk4Nv1zFqzrUMMoYQALTlr2DhxlKMAy9nTnwg9Zs/49WPA3nhtkn46xrYs24BZSF38OSc/qh8AjGdEG85O7NrMUQNYWSqgjXPbWXHDaOZoFOesKajtZXaykrM+gxONSXVwa/m8lrFUB6ZMxBneycddbsoos9Ra3RQtb8Ed3QSDqB25YvM2x3FvbdciVzqpnjZOzzzUQivXB+JuWkvq9fnEHX1lcyZEw7lm/h043q2hU+l/8VjSV7pIOL6axhlDCO2h9/SEcZ4hs/OJGzWcrbeO4yhp24hnITT4cRiseOUW7HbnbhdduxWC0GBAbiNOtYWlRHoH0t1bQ0Z5ztYQRCEXzCRuAtCLwQEBDBu3DgUCsVpJO6gjJ7OhNZ3WbVzFEmlX/OqbCafDfHjXwCoCYwaw+w/D0cbHIiPHFzJCir/byUVJRU0pniorimlY0Ac/dIS0KsgMTwcicJAe3IUgT5S+gxIJRGAdnLzi5Hq4xicmUn/QAWOhEY23rKZ7deNZqIOZLI0rrvzEgYE+XQfbMkecpXxDEtLIDptIJen3sLGnVbGTfRFgpuO5uU8PiMHDeB2aIgaMIWb/zicAKp+ogcO8cPXRYx48AkGZPjgdjqxW61A20la1bJ5xX7SZjzGgIERyKVuovzGsPWRH8i7/gbk+BKXPIoLrpjMAF8V9JWyc/NyWhod+GVGEKAOIDo1jYxgA72qnDYYMLS2HlX3LvSGRCrB7YEOi436phaUEjchgUbqmpooLq+mqr6ZNHsEDrv9fIcqCILwiyYSd0HoBalUikZzqnvL3ZDrGDs8mU8/fIe/t2aRctVy/BQbD28VJTYqtr7B319aRQMATqzmSGb1G42LDP7w73t49fYHuOSNJhwSmPT3dTwebOPEyuBm6uqKWfPe+3z+0WvIpQB2zM3ppHaV9kgkPgSeLGkHCvfmow1MICLchFwpY2JmOi9lbcOVORU5UrSGcTzwwYMM6Ypdodai89WcIkEuYl9BDFPSvPuVyuWodTqg7STrH6KoqJTvHpnNErkUicSD2+3BxzgTK6BDhlrtg6+vyru6SoVKIsHtdp+krl04H5xOJzabFadHTbvFho9STnuHhdr6BsqrGvB4ALcbm812vkMVBEH4RROJuyCcY4qRV3Lpp7fzSucs3p129JgpZsoKlrHoaw+3f7qKCUEAJXz7wtKuO74KfPzG89DHY3nA48FT9g5XzX6YtTlPkXTCXvT4+Q3gykenMWrmGEKPfC5FppD14K30YvbuLWHVgg9Z8OqTSCWA24XDXU3Wo5OYIgWJVI0+KIig0zr6KKIiyzlUAUT3ZH0TYWFjePiNO5li1HfFLUEikSKjjX2nte9eWLuW1Znjmfdz7+c3TiIBCW5kuLDbHEhcLow+GlweGZ12D6GB/jQ2VKPT/b7GwBcEQThdYlQZQTjXpJFc+/pStn73MGmaE2fZlODB5XLhcrkoWrmCVRs2UANALv/593IqKltxuly4XG6QSZEAEokUqcSFzWLFZnfixo/EPnLy9+aQs73yyPY2v/wyWW3tuH8yQA+N2VvItsVx9/zl7N6VR15eHnm79/DG1QW889b+M7ibHc+kqTI+emc5FouFlvJydn6/hD0nXT+CseOaefnFLCxWBy6XC0trC6v+72VyTrkvKXK5B6fNisVi59Rze7pxOexYLRYsFguWH+Yx8fG93HLbZPGL8gzp9QZ8NGoUrk5CjD7UNbXww9Y89pUcJNCgIypQTV3lQdLT0893qIIgCL9o4o67IPSC2+3G4XAgl8uRSqU9qHOXozX44lYpTkgCJRI1hiA9KnTExI5n2shtPHrjdP4FGDIyiIsbRYJGiZR07hy1g1v+ehOldR0ATPzXD4wF7AFDGZHxOY9Ov47+k67hrrmXkjj4Kv7i/oQX37qb14q96w/+43s8rtYjQ40hxICq21jbOVTtICkpnX5JYccsGXvTHSx4OodDkqiumLs/Vo2vDrtG2W3C2+e2Bfzl8alMnz4PVVACU29/lvvwkK31wcepRn5cX0Vc+X/M516uvuwN7E4PSp0/Fz3+JdNo5YBKi69BctQvsqPbpjL7xq/505xr+XfnSJ764WnGHhOJDKVai69egxw5Gt96Vr/+Nz55/fDywfzly3eZHtj9UQo9p1Qq8TMYOFRRgcrpJi06CGuYEbfLgaPTTFN1Gf369iU4OPh8hyoIgvCLJsnMzPTo9XrmzZuHXC7Hz0/MWSgIh1mtVsxm8wmfNzY2smPHDpKSkoiMjDytF1SF366IiAh8fX9f5R5lZWVYLD89Yr/H432KZDabqTh0iNq6OhwOJw6nE61GTWJiIqGhoSgUJz6BEgRB+K1xuVwsWLAAi8WC1WrFYrFgs9lwu73Pw6dNm8aIESOOafPII4/Q2toq7rgLQm+UlZWRk5OD0+kkPDxczPYoAN7ZQX9v58LhPzQ/RSKRHLkx5OfnR+o5iEsQBOG3SCTugtALOp2OgIAA/Pz8xN124Yj6+rM+d60gCIIgHCESd0HohejoaMaPH09wcLBI3AVBEARBOCdE4i4IvaBWq0lISDjfYQiCIAiC8DsiRjkTBEEQBEEQhF8BkbgLgiAIgiAIwq+AKJURBEEQfhHCwsJOvdI5ZDabaWtrO99hCIIgHCESd0HoBYvFQllZGWFhYej1evGCqiCcBQaD4XyHcAyXyyUSd0EQflFEqYwg9EJpaSk//PADu3bt6tE41sL5sJcFD73F+mYzrmM+76TqwCrmv/AtRae9zaPbNpC77Bu+/HIL1ae9nTNpKwjdaaZgw2I+m7+GijPc0uEJs9ra2thfUMCePXspKy+jsHA/hQcO0NLSgsvlOvWGBEE468Qdd0HoBYvFQltbW7ezqnZn1dtv88m333LiKN8jePDL0Wz/Qx6ZH93NwLMd6GmrY/t3azjQHkbmNaPpvnBhE89fuonMRQ8w9BxHd3rMVBYcwtdxfILhxtbRQGVJO52nvc2j29ppa6ilplWF7bS309O2bszNa3lvbjGZ/7mV/r3YT8PBNXz+Wi2ZL1xP39Nuf5iF0q2Lmf/BZoKn38j1M/vjnR82nwV/fY3v8iuO9KVMMY5HFz3AUDqp2LeWJQvNjHv8CpJOK+wm9q14ibseWuS9sDH05+q77uOea4dxeG7v7Neu49EFO6huByb/k/xXLuz10f02ODA311FVYeCn57E9NY/HQ3t7O3a7g9iEJDptLuwuFxLcSN1u6uqqsNlsBAQEIJeLNEIQziXxEycIvRAfH097ezt9+vRBKj31g6vRs2czcNYsXOzh3btWYLr/OibHBqNEhV6hYsDLA1Cdg7hPzUlnawvNrXrsJ12ng9qSWjrOYVS/Xx7cznbqDjX0Mhnz4LS3U1/ZhPVMwuis51B5McWHGpGW51Pe1p9UPYCVpsoApj92F5Nig1ECRe/dwWN3/Y/3/j0Th7WVhur207ywsVJVuoS3X3ZzX1YWgwHK1vPGp5/xmlLOn68YRPtXj/DXb3z4wyufMz6mlX9fdCmT/28DK+9LPJOjFLpYrVbcHhc6o5H6NgutHTYsFjst7e0oFTLigv1paKhBpVLh5+d36g0KgnDWiFIZQegFg8HA2LFjCQ0N7dH6ap0O/6AggoIMaBVqdEZ/AoKCCArSI7Wv4Z9X/R/bMVOWt5AnLv4T998/hYyMDC578A2+/vQ97r1yDBkZGdz21k5qjrrJv+T+DDIyMsgYOp6rHvmKmqP2WbziDe6+qGv5Ta+ws7S5a8k6Hh3+MKuPrOnd7/P3PM+Hiz/ktX++xhtvPMTFGVcx77uc454SeNsuty/lzxnDmHrpv9jataR6x2KeuKprf1c9znc5Vd13hstBw6I/e9fLyGDy7Hv4dPePi/d/+wJ/mNa1nelPsuZgE04AVvPQoAd46aWLu9oO5+Jb/8HqusMtm9n43t+4coy37fQnF3Ow6eSXH53l23m/q58zxt/Kq9/voh2AXF6/+Vm+Kqo5knA6bMv526Sn2XTSrQF1WTx32yyGHxPzYU6aDq3lyene2EZf8Wfe3dBwdGOWPncbFwzvOu6Me1hssXv3O/lvfF2ygNsyMpl9z3t4u6qV7Z89xw3jDq9/E2/tLOXY5z8u2hsW89RlT7Ew7x1uzpjMLXM/paC7fr7tLYpqTv70qL6slLw9B0mdPAZpUyE7c8uPWqrA58j5HMSgu2+m/+59lP1UX/0kFaGJV/PPxU8x3WTCZDJhGppOP3890qpamqlifVYVY26/lcnp/Qg3jeCZd+6k/uOFFPZ6nz2U+z43X5J55Nz9y+IfL6fMtcW8fVtXf46+grnvbqDpmKZ/5pJM7/KLX9yOzeEtsbO1N7Dgzq52k2cz98gPQwnfvvAaL/zlRmbNGtW1z5m8uL0Jb1M3nc05PHeht+3Ii2/lldW1P+5w/7f87Q/TjsT6x4+KaO3hFVRDQwMeiYwOiwu5XElSbBh940yMGpiCr4+WfeXVaHR6ysvLT70xQRDOKpG4C0IvSCQSpFIpEonkLLyY6sJhd+IGPO4mapydRM5YQO63rzHRtYxX1rZx8TNLyP3gHmzbVrO3oREnbgr/cxmPK18kNzeXrcs/5Mbg5Tz95nbceGjO/ZZPsxsY9uC35Obm8sG4Yv77xTrKGm14cOO0Ozi6Mt/jduF0GMmYcQN3//Vu5sx5nm9yP+PhCwcRdEysY/nHlnlMVU7jldxsli96gKF4MJdms3j5D2hmf0Zubi6fXePDuhWL2VJixnPc0TqcK5j3r0Ye/CaX3NxcPnn8jwTu+ZT9eGjM/pgPduI93txcltxh54XXltDQasWDG6ttNYs77ic3N5fcNf/jL0MtLPpwBfV4aMxewveHDFz3srftU0Hl7Lc3neRubwvlnc2oB79Ebm4uXz4yiPq8VWzd14YHNy6HE5fHc1TsP35HJ3C7cO7+gocfep79qffx6SdPkhnlf9TjTA/OjlZ2fv4exdPfJjc3l4WP3EhUwwaKAdjPZ4+9zL6423l/jbdPvrnfzOMPL0OqmsozK59hVtx1vJ27hk9fvYU0qtnw6XusLI3jwW+96y+b14dVn/1AZVX7UTHL8A2cwRNfPsEV6bfyfu5K3nt2Nsnd9PPbGRt55uMtNJidJ3xfeJqprd1HXWMio2cOJVEmobqslIojneHGYbNhtViwWCzkv/EuWxPjieq233tCgkQqR6GSg8uOtbOTzvwC9jU2YQsKxI8Kysv9CAvzRaORIEGKvH8ayXv2sq/X++yJ3bzzdg59b3qd1dnefp+56RlW48HZ0Uj2gqdZl+79fte/fxchtcv4ePEB3HioWfESr5b247H315Cbm8urwfvYgAu300beO3/ii9j/kJuby8pX5mAqeIM319bhwYPLuY9VNcnc+4+vvef8f8ex+IUP2W934HY62PPB82SP9bb95rn76VuXxX4AivlqUTbaYQ+waIM31hvqv2WrrY2eVKZ73B46LE5qGttoN5spLyunrKwMmceJ0VfNoboWOhweWttaf9YeFwThRCJxF4RfFAPRUSOZMCEYoqKIi5/M1SMH0KePL2RkMNjSQbPDjpNSVqxwMvvSNOrq6mhxOAlJH0JI7k720E55eQNG/wT6p3vTp4wZ0wkoP0h5e3uP/nCfHiv1ddVYrOGMGeutZE4aM5oIm43qurpuSjyUaA2NlO6uo66uDklIKKMun00SLRQWNhBoNBFolFNXV4d8xDgG5+ezxWbDDSjkk/jbY2O9m/EzENinD9F1dTTQQmFhCxGRySQneSvzh1x6CX0D/E9SD6ghOqY/kyalAhA/dAgxSiV1lZWnWQLkxLrve+a9vhjX+Lk8fds4Yk+oHPBgs5Wyd6+eyy4bAkBonz4MGzsGf29vcdWTT3DblDjkbd4+0Uy9iFHr1pLV7T5DGX3VXfz5T1Mw2bzrSwcOY0BpGbs6zD0oS+m+r/T5+ZTarCck7u7mJmrL63GPmcqouDSGDQtG0VlOReXhM2kXb99xPRdfcAEXXHAB9y8dxHPv3EBkD3vw5JrZk/UvLktIIOHWj3AOuY4HZmV01dafD3K0hg5qy+qpqfL2+6DHnmEiHmy2EnbnyZkwJpq6ujosBn9ijUG4Soo5SD15u8wMHpxBaKj35Ii+/nomKhS43UVs2aJl9jUjAQiKiSGtXz/a8vNpBKAPV101ib59uy6fR4xkTE0NBz2ebtuOmDSp60JbhlpnpaW2geqD3lhT5tzDRF89sh4cqUQqxeVyYbHbKausoaquGV+DkYKSMrbk7Ka5tQOXw4FHvJgvCOecqHEXhF+lGqprGtj091tZe+QzPfFDZqGmk/oOJ+CLzqdrkdGfwPY2mp3OnyFxt2O1dWKzGdHrD4diwM9uo9NqxQ5oj1pboZrIQ594eOHGW7n1TSeaoEQm3/QU14/toN1cy/avvmP1qoU//nKSDWCk/FT3GDpoN4NM44NG0/VRYCDBcsVJEhUlalUARmPXf3W+GFwuzJZOrJzOE5Q6tu/aTVv6TKYlxhIod3Pi/RAPbnc9Tc3BDAzs+kijxUdvwLcDwEbL/iX8+z/fkFPehEviPZ5aeyrdv27poKNyKws/+ITvsg/hkAJYaayI4Y4exXySvmrOo97lPi5xd9HcVMuB/EICx8kpLCwEiZKaqgbKKyoYHAmQwZ0f3M7MxFDUPdp/T/nTf/KjLK56FMpX88+XFvBPp52/3KxFoXDjdLrxHO5umw2bSvUzvyeSwjX/eAjPw6/x9z9X0OloIfyyD3nh1kg87mpK9u1j32O38tWR9cMYdfVAlLTS0qJCq1WjVB67RY+nmrr6ENIOP9ZSq9GqVMjbWmk/xaVPt22NRgzVADFMu/tPuP/vHd5++GOanG2ETH2eJ28bRJhWdsoz3G6z4pFLsNtddNpdyNUKmlvbKCqtorapHY1ajdNhx+kUI8sIwrkmEndB6AWXy0VHRwcajQa5XH4exnGPIy11IFFzn+b2WG/26bRaaW9pQYkeT6AGR10tNTVW4sLVmAsPUBUcwli1Gjkq1OpWmpsBI7jsdpqrqjD3+l6mGr2vP1rtTsrLO0mL19J5sJxqjYb+ej2a49Z2u1tpbBvKU99+C9Zqtn71EZ99/z0lY2cREpzKpNtGMvrCyST5etOwtooKXHrNKR4P+hESLGd3bR0NDTYiQ1S05+dTYukkpdv1LbS0lFFc3MHAJB8slRXUSKWEGo340IlS2Ym53XUkMWwuLaP7ooAwRs++Gb2+kqzPP0PCFVwwOAKt8uhopcjl0URFfs3e/HZGp/tib2ygurycxsA4oJTFH25EOfKPvP7CMMI00Fr+IQ/Myj3JsdaTs3YjhxjF4wuuId0PzDVLefGu9T1MXLvvq4rISC5RyI9J6tyOdmoObWLLjjZcVU+R0/V5Z6MUTcogqgboerTH0+PGZmuipkZOdLT3DrXD30igRo2towMLSST16WDZ7nIaBiRgMLioWLaW0iFDTvJdny0d1NSYuOzJV7lWLYey97ls1qtsvvVFRsuTGDJmEuMfeJBLwrw/R9bWViwuFxqkREY6WFdTj7ndSYBBjrW2FktwMHpJAomJH7BrdxvjB+lxtDRT39SIJyydgFNEI+2mbU1xEXUEABYaG42MvfUJZtyngspF/OkPX5I9O4mLtYZT3nVXqlTYnA7UcglOh4NWhwO5BCxOQKIgLEBPS1M9Af7+Z9yrgiCcHpG4C0Iv1NfXs23bNpKTk4mPjz8PiXso4y4PZ+77n5OQ6R1Jw262YbHKGHDlFCL6JKHfn8XWpd9gjQuiZGse/hmziDb4ICOekZMa+Pr9LAIzwN7RyPYlG6nlAkCNXq/CXnaA7Cx/7H37EG3yOy4hDCIqqp3dWWtQ+oTTd1giAWHxRIbtZMfiL9CmRlC5dwee0HQSwgNPSCbd7hKyFhYQPTAUHM0crO7EEBGBDh1+qeFkr9zB+u+cVJq8t+9rd1UQ/4fLGPyT1xU6YlOTUZVvIXv5dzRH+HMoZxsNZsWJNdsAeGitP0j2im8IqDRRsz+Hdt9IxsaEosFK+lArX6zcRFB9IBoF7Fu5mEMMOsm+wxlz/VSi3O+xcOFCrM2Tmcy66gAAACAASURBVDw+mQCtsutiQ4JSE8WA0VG8983HZDX2oa1mH9v3VaAd4409IsJAYXU+m9d1YFRAyYbvKXGGAhJkMn+C/BrYmbUeaWAUSf19CfA3ojhQSc6GLBq1ULlrKbtr7cSfEJsUhdIPgzaHHVkbwRRNYt+IE/qqcOMeIkfeRJRGddQFkgdrcy17N5QQe8+LPHnRj1uvWPcmb6zfT1lZQvd1/2fESXtzLt+8W0TMYG8pT3tpHjtbPGRMjcFIEEOnDeN/L3/C/7QN9Avq4MsXcsm8e+4Z1NX3RD271ufiVKpR+yqhrgh1cgpBSFBqwuk/Us2Cj7/EMMgbhbmmDWVEJAPHDqLvsDRWLc5h48pOiv19MBc2EX7LLAbKIhh+QTIvfv0RWa0ptNWWs78OMmb2Qd/N4LFHkx7XtqOhhE27ynElDQNaKNyxk7pmN7pALTTtwx0eRaBc3qPnSYGBgVRXV6ORuAnUKalqaOVAUyMeIDLQB53MhsTlJDY29ox7VRCE0yOLiYl5UqVSMWnSJKRSKWr12X3YKQi/Zk6nE7v9xJFJ9u/fz5YtW1AqlcTHx/doSEgvG611YEpPJEyn9t758nTSXKskYWwyBrsVh8NAbEYMBpx0tjnRBoURGRWI5ri2hoTRDHGs45NVuyguLqbOCsmTrybDD5R+4YRprFTs3UT27mKaQsZzy8xhhPurAR8S+gVzYNUKdhUXU9HURsDQmQwPDiE2I4VIjYfm6t1s216POiqKyFDjccm3iaiAA6xatZfaJg1xI/oQrAsg2KjDfGAN63OLqdf15+ILxpMaeWK2LSWEBEUuH3yfTXFZFTa/BCZeMotUA6gCYuhjsFG4awtb8vZTXFyMfty1TIzxRymz0FghJ3FCalcdrxuHxYZb5k9MaiSBATFEKJs5sCubnL3FuPqNZah/FMmjUghVKY5KWNw47W7kDj0BgRVs2ZJPrTqByZOnMCTOAGiIjA+iNjebnfn7KCouRjPhGkZrjMd9RxGo2h0oDCFExSXSNyMOn9oicktsRKfFHpW4g1SuxBiRhO7gMlZsL6ZBoiW63xgGxkV624YqKC/aQ96ufIqLi5EOv4gx2kASJ/YnVBqAn3Ifa9cW0uYwEJuRQoJRh7WlmG3bvd+9PX4wg4LjSRmW/ON5BYAMpcyAlnzWrS+hU9p9X7VETufOiwcRoDu6lsONzdpMY72SgVPGYjrqT4Pe3xe7WYYx1A+lU0v40efzMf189Pl8akFBQYAMrcwPf8tG3vhyLfn5+RS3Gxl16bVcOTEFHeATPZhkeT4b1m1jx65DSCbP5c0/pPZgD6fHYrHQ0XH4rQc/4n1qWb1xMzm7Cyiu8TDyjvuYGipDKlcSGNUXU+N6vlm/l+LiYjr9ohgwYjxxOlCbkon2FLE1Zwe7C4qxpM3k4kR/ZDIZhpgBBFZ8z9KtxVR0qkkZdwUXDwoGHHS2uPCNiCDiyM+gleZqCdGj+2JSyI9pW+eQEt5/AkOiwolOSiJZ00ZeXjYbcvZSXGUn7cpbmBrvj7IHRe4ymbecxtzeBg4rGoUUH5UMXxUo3FaUcgnJSUkEBASIWaMFoRc8Hg+7du3C6XQe+edyufB4vLeaEhMTiYw8tlxu9erV2Gw2JJmZmR69Xs+8efOQy+ViTFZBOIrVau12kqWSkhI2btxI3759GTBgwGkk7oIgnExKys9b7HK6mpqaqK2tPfWKvzEejwe3201HRwcN9fW0t5txezw4XU40ajXh4eEYDAbxe08QesnlcrFgwQIsFgtWqxWLxYLNZjsyE/u0adMYMWLEMW0eeeQRWltbRamMIPRGeHg4mZmZ+Pv7iztOgnCW1Nf/dHnIuWaxnOkcpL9OEokEmUyGXq9Hf+SNc0EQfglE4i4IvaBSqU54jCUIwplpaGg49UqCIAi/Y+I5lyAIgiAIgiD8CojEXRAEQRAEQRB+BUTiLgiCIAiCIAi/AiJxF4Re6OjoIDc3l6ampiPDNwmCIAiCIPycxMupgtALRUVFZGVl0b9/f8aPH49M1oPBkQXhV0apVBIV9fNOa/Rr5/F4KC4uPt9hCILwOyESd0HohcMTMzkcjvMdiiD8rBQKxfkO4Rft8LjLgiAI54JI3AWhF5KSknA4HKc5ayrgceFwuHB3lddI5UoUst/6OPBunHYXEoUcqUTSzZTrHtwuF06ni2OLjiTIFHJkUmmPpmn/0W7e+dN36G65mhmD4jhx7tZT8eByOHC6D0cjQaZQIv9FFRZ6cDldeCRSZLLT7R9BEATh10ok7oLQCzqdjuHDh59eI5eN9qIlzHvuI7aUNuIEht2zkL9fFtw1nflv1TZevPx7kt95gJnBBk4sKqpnx5L3+NeTX1GhUx+1PI0/vPYgl/WPxuecxerC2l7El88+w/+2HaTNCRDO7Jf/y80DDL+g7+kgK9/8nnLfVGbeMI7w8x2OIAiCcE6IxF0QzhFr+TJeeXUf/e9/hUfTIvEBNr34Ijncz0jA7bTTWnuQRgug0GAwBhKkVwE2WmvbcWClw2rH4XDjExSDv6uaQ002JDI5hpAYArUubB3ttDZ14pTZ6ex0glxLQFAABh/VkTfRO+rKqGl34uH/2bvv+KiqvPHjnzs1k8lM+mTSGxACJISEFhAIELqAIBZAFHtbxba/Fcs+rqs+uo9lbauioiAqIqggggJCCJ3QQgsEkhDSe8/0md8fAQQSIAQEWc/79eKPTE67504u33vuOedKKHRGIgxaoI28KND6+uPrqUUla51X7uZLSLAXyvPmldFYUkG9tZ7yY3nk1BsJ6mTEo1XvBNBv8t946dnJdDrjcxt1JfmUaYMx6BRIuHBYaiirkeMf6IlkaaKmooQ6M8g1nvj5+qBzO5GzoZzjeS7UDhegwicsDB/Vhc5SGb+8/gabjDP4YEkKIV4qoICvZ31MZq+n6As4rGZqKwqpMQFyNzx9fPHx1CDHTE1JI065mfomCw6HC1TehIX50lKtC7ulkaqSMhrsAEo8fHzx8fFA1SqvOwFRRjwkK1UFBdRaAeSotV74B3rgqK2hurqaaksJx48W4hboh5e25aanfedXhp+fL15eV+6WSBAEQbh0InAXhCuimT1rMtAMHkVyROipEeQBTz4JgMthpyxrE1989G/21uqwqv3plTKRe24YiL8uj+VvLeSwvZySpmZMRceQD/07t6qW8+XmMjDXEHrbPF6YpOBoxvd89sZGrN1cVBfZaLb7kDL1NqaOSsLfTY6lIofF7zzHr8dkOJDjiBjGS7Om0sm/uVVemu34pUzlrqmj6OHvhu2MvDIkXS/ufuYehoY6zpM3kkOf/sSu8v3seqOMNGV/HlvwGH3a3W+1ZHz+PD/6Ps0/74pFJzWRs2YOc/Ym8denBlK/fSVff/Ul2Q1aNCH9mTz1Job1BGji4E+fsLbGgs3sgloL0Y+/w+zhgbidt7566uoC6DEoCK325OUxlKlvPwWA02ahcO9aFsydQ1a9B3a86T7seqbfOIQozyMseWkhOe5llJ6ot9YSxuPv/J3hgSqsplL2rV/HyqUrOdQA9iYloUPGMuPO8cS3ytuTBz+9g4DMnfz4xQJ21oDTKkMfnMhNsyfhu3sDaWlp5Mq3s3vXQSY/MZNxiVGo2n1+Ddx221RGj064uK+xIAiCcFWJwF0Qrojj5OR6Yhjpja7VpGsXtuYyMr7/grLB/2LBzTFUH1rLwqVprNgRzbShAJXUBozl6btHEl02jxvvfpWf/t/HLPgimKoN/8dDny+jYNJkoIEamYY+Y5/mgSGhFKZ/xIcbdpMV0wmfrhqyFr3OCt8HmPc/g1BJdja+dxuvf5PAW38JB5ppUHnT74bHuCs5FApX88rbO9l3pDvR/sEcOS2vWubg0A9/46V300j416Dz5r3h7zPJ27Gcru+ea6oMgJnqwhK2r13L8VOfeRKV2JWUe+4h7dkvWZPyV4ZL61i02sH454bjXprJL+u3oLnhLRaMiqAhO5tiZTONAJRx3GMM/zt7LGE+Gtjzf6Q+/RW5w5+k23nPk5FuyR4s2phOmqkYT60CtBH06xeFFhfmmmNsW7kc2+g3WDAhmqZj65m7cAvrN4cRNAYgn2zFBN54bTwRvhr2/GcSL36yh+Tnk7DUHuXAbiujXl7Acz6cyrtzcx5dxrTRZvbw6Ze7iXtuAY8HgLUml9Xffsa6xQX87aEJTD4qO2uqjIk9F3N+BUEQhGuOCNwFoQNsNhs1NTXo9XrUajWSdCnLA11YbXlkH/Yl9S8xAPhERBAVcIic/GPU4A+E0ycpAh8fFfh0o4cykX6jAkEmoezWnc6VB6kCPNASHt6NxMSWwCykVyLBazZTVlWFCdixQ8nov8WjUMiQISd+zBi+fSWDAsIBT6Kje5F8MqgLCSVcvgen2YyVQnbsqCGwVyErfvoRueTCZPLCI+sg2QzC47x528NE5fH9bFpVf9pi0nBGRIVijBjM9F7v8+h7X1Mp24LjxjcY4m+lcH8xVdVG+vePAEDXpQstvbcPiGL89b3w9tG0FJWQQM/SVZTBBQJ3L3rfcj988wU/b1tLox0aa2UcM93BzSlRmJvzyMqsQQrbz9Kl+4Eq6orqsQWVU4UPEMzw4T3x9GypN2HKFLS3bSCX/vQw9GPiDB3bNixlKbSR96w2k8DMF9WkpZ1M30xRjYSz6hiFtBV4F17c+RUEQRCuOSJwF4QOKC0tZevWrcTGxtKtW7d2BO7e+PmZyWlsxmyGVvM1XDZsdhXKk3OwZTLkkgQ2B46LapkMuVyJ4uRftkKBwunE6XTiwo7VqsTztHnekkqF0trMhTe1tGK1qrFVHeVQk+rELiYa4ib0wggnRrkvhTddBkxhfKs57gANOJ1aNLZqqmQGlEozoMXltONwKLn8uxV60fuWR+h9S8tPVZv/wcznf6B3yuMEumxYTU6aiw9ysLjl9/KgSLrEBuOBCVCgUknITn4d1GrUFgsWHDTVHuTXLxexuUGPr7bluAor6ok4ZzuOs/6Tz1hW6Y1RD2ChurAK+zmnpVsv4fwKgiAI1wIRuAtCB5SXl5OTk4OHhwexsbHtyBFAwsAAdqzazPbwSEZ098ddATmrV8OIVEKUEURHlbFlSyGpI0JoKC6moLoat9gQvLFfRMuaKCo6zsGDFSQm+VN58CDFbhqivL1xw42e8U18sSGXKWG9kEkOctPTaeo5g1Cg4LzlhtIz3sjxrhN46vqeqOQy7BYLxzIyzjH15TI6voE5mxXc/OxT3CxbzKz3vmVft1mE6Iz4+Gwmc08Z/QcEYCoqokouR288X2F2Gquz2bGunpgb+xPY6vdl7FpfjG+3TgT761AAMpUKhdOBAwUaTTRxfTvRMHIm9ya15K4+epRqheLEzUwxW7YcZXR8OJ5eanJ++YXqvjcTjZ2GmkNkbLOT8v5srg+E2vx0viz//jw3PYdZPv8oCUu/484IMNXksfqzd0gvPVf60Es4v4IgCMK1QATugtABBoOB6OhoQkND2z1NJqDnaEYU/8Cybz9gzzI5Chm4+w3kRiSUmkCSxgxj34//4uXtATRZHOhCejC5VwhuHLuIlqmRN1ay5+f3yP9ZRU2TjejeI+ge6o0SJfE33Er4vPm8/tpKXEiUN4Vz6x090V/w5kBP/A1j2L98Ga+/ugIXIMlUBEQPZdwF2xROUlIzyz78N/vk3Zny7BS6tkpTR86ODcx5OQvPU5+FMuT2gch++I7q+JmM7KxEIY3mjl7/ZsmS3TxyS2cSendm6bLXeHmdL3K3UJJSh5J83sDdQWN1FuuXFKJvM3CXo7blsOLzVdRY7biA+v05xD/1ONHI0HiFkjSkO8t+/oCXf27ZHFKpDSdp+FBaqvVCVbKaT97fhRKJgkoDd9/VFy8UNOk706trOkvfe5lMd7DTQFGxjS69ztXWGMZf78WnH75MsQ6cWKgsMuPmAeBNeJiGXZuW8f7LuaTeNJr+XQIv4fwKgiAI1wJ5RETEC2q1mtTUVGQyGW5u599zQRD+TE6+IfVs7u7uBAQEEBgYiEKhaF/wrvQkODIYT7UaDy8f/A0Gug1OpZunDEmuQGeIIMxTQuZhICS6O/3696dbsAct2wYGEBoVgq+HGwrc8A4KJbJTIHqZDJlci19IOOGRepqO5VFU4E6vSUkYtb6Ed+/LkD5xBPu0/F2r/SLo7CvD4eaLIcBI7IDrGdHDF5CjcvMiICyUkCDvEzN5zqzX3S+CrgYFzTId/gYDxqAgegwYTJT2Qnn9CA73Qq3U4esXTFTX4LNeiiRH7e6JX0AABoPhtH9BhEcHonU30Kt/f6K8lMhlbvhHBOMu1xEaGYTBEIRRr0CpNxDcJZZu0RH4azTo/AIJiwrGx1194omABt/gCKJjgvBUeuAfGkZYuD/urc8shkA9MpcCd8+WcxTaYygTxifiB8gUarwCwgjylONy88FgMBDZPZ4enaPwUZWza0UhIcN6ERkWTICvP52TxzM+0QDIUKm8CYzwx03tgcFgIDQmnr7JA0nsFkGAjzc+rdrsSVhMIEq5OwaDgaDwaHoNHE7/HlGEBBnx9/XC00uPTm8gLDoEvxPnqP3n98Lkcjk+Pj7tTP3n5HK5qKqqutrNEAThGuJyudi7dy92u/3UP4fDgevEyxk7d+5MaOiZ65F+/fVXLBYLUkpKikuv1/Pqq6+iUCjw8vK6GscgCH9IZrOZxsZLn8F9ZdRwIG05P62QGP+v22jPBB7hcrrUN7b+8ahUKqKjo692M/7QnE4nhw8fvtrNEAThGuJwOFiwYAEmkwmz2YzJZMJiseB0OgEYM2YMycnJZ+SZPXs2dXV1YqqMIAiC0DabzcaxY8eudjMEQRCEE0TgLgj/NfR06jOeu2L5rxjtvfZ05sbn7kPmpW9jCs61yeVyYTKZrnYzBEEQhBNE4C4I/zXkqLVeqMVb7K8SN7wDxRohQRAE4fcju9oNEIRrUWNjI1u3bqWiouLUYhJBEARBEITfkwjcBaEDDh8+TFpaGjt27Di1mEQQBEEQBOH3JAJ3QegAhUKBSqVCeflf2ykIgiAIgtAmMcddEDqgU6dOuFwuwsLCkMku7/2vw+HAbrejVqsva7mCIAiCIFzbxIi7IHSAVqslISEBHx+fdr85tT1sNhuHDx9m48aNYjcPQRAEQRDOIEbcBeEKq6ysbPNtrADl5eXMmzcPu91O165dCQ4OvsjSLdSWlVNdryCgcyBig5lqDm8uw7tfDAa5GKe4mk4u4rbb7ZhMJhwOBwqFApfLicsFbm5uKJXKy/4ESxAE4b+JCNwF4Qrbu3cvPj4+uLmduXWgyWRi1apV7N27l+nTpxMYGHieUhrJTltHVp0TkFBpA+g2oB/h7nUc3b6GDXs9Gf/sZDr9rkfiwNRwjF1r91N56jMtQTGxxHYNxuN3rbu9svhq9o/0+/lFxmpU50lXz/F9RVi9/AkJ9ePiN3WsI3dXIa6gYEKMXrR/klM9x/cd5FBuGSZ86HpdAlG+Os5YOeG001R5lAMFckKDbRzZdoSa8/Rz6Z5fyDhuxokMdVgfRicYL/ponI4idq+uIHR0AoaLzn1uVquFxqZmmpqaMVtsKFQqXE47OF2olHI8PT3x8PAQwbsgCMI5iMBdEK6C4cOHYzD8FhI5HA727NnDxx9/TFxcHFFRUecJXho4uOorvliei0eAHpCQK49TY1GjGRd0Rdrfwk5d2Ta+eeMHZKN64g+ADw7vYKK7XuyTgqutnJ3Lf6Gm20Cu71Dgbqa6sBSnhw+BRq+LyGehtjSf7P3b2LLezvCQYILOCtydNhP5mxfydc5AHpigIGf/NnYcrsO/nx3/swL3hsNpfPbJQmqN0eho4OiqfagfeYShMRf3Si6Xq46iw8V4X8bA/eRIuyST42MIotnqpMlkxWazIANstkZKS0sJDgpC6/HHuO0TBEH4oxGBuyB0gMVioby8HB8fH9zd3Ts0zz0vL4/w8HAkSaKxsZG5c+ditVq59957sVgs58mZzy/vr8f9r2/y7HVGwImproSsbQU4Trav7DDp33/KL8VmQEvnwakkdw1BdyIizFn9ET9n20GuwrvHKKZdF0RtUQ7ZR6oI6DuAcKmInZsyqfWOJTEuEm9zFj+lNZCYmoDRXcVvR6vGN2Qg45+dRWIbLS3Z9RNrdx+j1gyEp3DfmFiUcrA0HSF94VHkkVVkZTkI7JLEoBHxyI9uZ/PWDPLrAI/OpI5NJtrfyb7vl1DefQajuijBaaWucA+bDnkwaGS3s94S20zulnVs2XeMWhvoe+gx2U5u1+nCaiphy+Lv2V8P4H6i3jDqtmewM3MnpcXlVBYeZ+ikYcQHeaOmlh3fLGRbpQOQo/XuQeq06whpdaRyVO5uuJRyJArZ+HU2irBydu+twukEpVsgyVMmE+d5dj5/4kfcQvyIbrgV/9jGG1dd2Czl7N92CJ9hTxDTWU/MszFEL1jOvrqz09az94eF5He+jRceSsEgVZH2/vMs/D6TpKevQ39G2mqyNmRT2VDE8Zoqals6ixtuTCbIXQUo0eg1KLBSU5LNrl/zsPpWkZvbBG5BJA5MJrGrseXJQuE2vv51L9WNLdO/Oo9+mJHRrb8LTU1NWGx2NDovGkw2JJkMueRCQqK6vhGV5MJdLqOouJguXbq0LkAQBEEQi1MFoSOKiopIS0vj0KFDHXoBU3FxMS+88AJr167F6XSyYsUKVq9ezYwZM+jVq9cFckvIZHYs1pNhugyNZzCJI/vTMrmmjtz8HPKOW9DpdOgaD/PTj+s5WFaHHaje9iX//uU4Op0OjVLi8KpPWJZZh72uhJx9WzhYDlQdYcOP8/lm/SHKm4CCLazILMNia/+xNhxO45s1u6mxKNDpdJSlf8RnG8oAF5bmAyz7eC7fbq9Cp/PAXaPEWryfNWvTOFBqQ6fT4TqezoIVGVTW21CZD7Lwi01U4sJqKmbT4h85YlW2uoA15m7lh7UZFDdK6HQ6yjelc9hsxgk47Af58Z2FHLTp0Ol0qG3V7N20krV7K1CoVahUKtQadzx07qgVMiRyWfnuF2xv1KDT6dCq5ZTuWMxX6/PbONpK9q3ZzN68cswUsenruby77Ahu7h7oPLRIeWuY+91Oatvdeye5sNmOkX3EQFwP/QXSFpC5V8ug8Yn4KeTI5L4kTRiMNjOTglZpqzm0cRlzF22kuAF0Oh2V2xbw5YYC7A4XTscR1ny2juNYqS3NYPFn37DmQD06nQ5L0W5+TdvA0TIzUEj6wh/IKLGh1rb0a/6KZRxpo3VmsxmT2UZdoxWL1YZCcqLERliANwG+eg4fL0Gh0VNUXHTRvSQIgvBnIUbcBaEDampqKCoqws/Pr0OBu0ajoaysjH/+85+Eh4fz7rvv0qdPH6ZMmUJ1dfUFckcw7skJzP/qVZ5epQWZCt+YMdx9RzI+ACjxjUhgxJTbGBysh5p0Sp/fTEFlLXEhdrYtWYl88D+5fUIkDks9u79/hQW/7GfAbd7odE5ycoopczuOw9lMYXk1VVX15GTuRRt9L14qJWc+WzBTkb+WD58uOVG3L3GpoxiVGkn+5s3U+SZx26RhRPuoKV2TzUOLNnFDyiTckFB7BJM08TZuj/UHzOSs/Y7CRk/63jidoZEemAp/5KUXd3FgcByDxz9A7/Rn+GhNF261fslGkrl/WOezFt82krtjHybfOCZMGkdcgBvl6YVsWFYOgCR5Eh7fl8TB1xGpBXtjHuu+/4HM9OOk/KUncbEFhHQbyPUT+5yYHmIhsEtPIvsNpKuXHKe9iSMbP2bOko0cGxJOxHnPkZaY1CncNiwGpcxJ7UEbs1/cTMGdSVzMRBqcTqzZe8gOS+H+8y15OHH8DQ3uBHvIOPkASPLQ4d5YQGOb6W3oovozetLElr6KKOSJJRmUDg3nzFnxTtRe/vRMncHtCd40HFnJJ98d4UhuOZ0CKtmz5yiaifdw88Ro9Coo2rkTeRu1SUjYHU4am0w0NDahlrnw0rnjqKmmqLickoparDYHZrP5YnpIEAThT0UE7oLQAcHBwXTv3p1OnTp1aJqMt7c3zzzzDNOmTeOJJ56gsLCQ1157DT8/v3YE7lo6XTeZu9Qh5DY4cVrN5G75hrc/czHrzk6AOwaDJ0HB+pOV4eNyYnc4cJDP3n2+XPe3lrnwcpWKoLg4tKsOUeY7Di9/A/KCXexyNaDp0ofuBZUUlR2i8LAHPSbrUanOHuNWoPWKImHkSKKgpe5II+5UkHdMRujAIDw9W5ZqGgcMIOiFLRxhEnHIcdMEERvrf6KcesrLj3FgzTZ2HdrLYiVAHbn79MTa7Tg8OnHzIC3j3nyGY3pfUl8fSnireSVVFBQ4MUQG4efbMkvd0KcvnVWrkQCZLJCunbbzf//v4ROLaS3UltowJobT0GY/G0jotY9XX3icApsDcGJpqsNk7Uc1XCBwN9CzZxAyuQxwITME4Nt8kObz5mnN6XRwID0dY8pM/C+c/CL5E9s17Iy+CnxlEzlOJ8YzvtIafH2jiI31BkAXHkGQK5u66ioaieL6Jyaw4KP3mL3WCjLofe/73NlGbQ6HA5vVhgU5tQ3NuCvluLmpOV5cRm5hBTaHE6fDju0cOy4JgiAIInAXhA7x9/dnyJAhaDSaDu/j3r9/f8aNG8f8+fOZOXMmffr0uYjc7kT0SSECcDmaifIu4MMPMim+80L7yOjx1DdQWwf4Ak4nzqYmTDodHuoAtH5BFGQu4xepKwlJ4xmvXkxG5moOW7rzmJ8Ot1ZDqQrcPSNIHDbsrDnuDtzd7VRabdjtgByoq6PW0+scI84q1OoQeg7xplNqXwJOfnyXjpAQX1SUsHnzMeLGv8ZtfM/CtCPcclv8WWVocNc4sdutWG20XN3q66lztcxxt9u28ek/VuE9/V4mGABqObxpB8fajtqBvXz67LfYx97JXWEKwEZ10TZ+WXiBLr6Mx/jhqQAAIABJREFUnI6dpKdHkPKgbztS+xNgqKa83IHLD5BcOCvKqDYEnCPob6a5+ay+0unw5Ozvsx2brYmmJkANmM2YZDKUKhVKvIhKvIG7ZiVQYbLiLFnG6/94n57fP9xqzYMLFy6XHQkHJosVyaXAZnPQaLZT32wjwMeLuppK1OqLXxosCILwZyHmuAtCB8jlcvR6PUqlssOBu0ql4sUXX+Tee+/lmWeeabU95Lnt5v1nFpFntQPgtFop3bWLQi9vWq19bCWcQYPsfPXlFgCsJhM7V61C1rsPQSjx1iuoKjpIZm4dnn6hRIfpyV63iny5Fq3a7SIuGP706O5GZuZ+ysvqAcj45huaBg2ic5vpdYSGemGiCZMrkKSkJJKSklAeyuBoYx32jG94t2goD97Wm6Txowjf/DWry84uw4cuXbQcOXKIgoKWpxa7v/+Bw83NOAGXq4aC3CYM3VvKjvR0p+LAdkrPeQwNHM+uwTMmgaSkJOJiulC/5Rfy2t0Hl86xdSVpum7EXGh6OwCh9E928cP7P3DMZsdhz+e7d7/HlZxMaJvpK0hP33lGXzUkJdFJfvbdmYmCgv2kp2cDULBnD/l2O/6BgXiQxZdf7kXtH0WvpCSSugVhyjtGq3WzgF6vRyWX4Saz4aV1o6Sihi17ssgtLMNb70G4wYPSonxiYmLa3T+CIAh/NmLEXRCugnnz5p3a7tHX15dFixad+p3D4cDf/3wTI7ozY+oeZo0bRa7VDi4lnv5DmDV3IkE00CqePYOSmLve5uEXbmDIEEDpTsCwR/l4ShRKQBcYQHBEHN0aQwgL98YYEIdRsx9DYgRaj/bvTg4Kgkc8wLSiZ3nlwbmUNEpYe8xkyUs9UQGtZzHL8e05kmmmWj764B7eOdoEQI9bXuVvajPfzf2RmKmLSNBJyNwSmTxpD3M++In4F8b9NjqPgsBBM7i56BU+fGoiz9bJ8EsdTFepGRmgUAzh4fuWc8u0IXwkB7XRgNE/njgAIujX151/zX2Gz96M4d53/8qN8X148qlOjH1oNItdTuRuaozJKXS9iF64sGOsfPcDPl+8kdw6M9LuFfxH2Z+/Lvk7Y/30HM/Kwj/lthPTcuo4vPkb3pr9BZkmMzannK8XfctNzzzC9FEJ+KGk87RXuD/3Fu4ZPQ8XoE5+kkXTOp+5L/wpkfTS7OGdv0/l2RIz1tipzP+fJDwUEvYzZqvoCVC4UbXxrwx5qxaHsQ933XMPQ7p6IcODieHreOiBl8ivbAZHM4nPr2FAG7W5u7uj03lQVFSCXiane4QBk8WGy2nH1txIVVEO0VERBAVdyS1NBUEQri1SSkqKS6/X8+qrr6JQKPDyuqilU4LwX81sNtPY2PbSvo5yOBwXXNAqSRLyViOfp3HasVhsnNzoUJIpUKqVyHHhsDtwukCuVJwYIXditzpAIUcukyEBDquJlk1pJGQKJWrlibpcTux2O05kKBQKZDiwWe0gV6KQ/7bo8URiXE4HdpsLubr1Di8tzbRitTtwuQC5EjelHEkCl8uBzdqS7/SjdDns2Ox2HM6W/pEp1KgU4LBacSrUqOQSuFw4nXbsDgmlStFqYofTbsV2og8khQKZ47d6XA4bZpvjVB9LMjkySUKuVCCdqltCoVaikMmQHFZMJ3fvkSRkcjkyJ20c74k+lsuRy13YLQ4klRK5JCHhOufxghO7zY7d7uC3b4QMpZsKuXSMD6c8ifK1xdwT3TJXvmUOuP3UeQcZCqUChUJ+qh8cVjNWR0tpklyFm6qt79FRvv/f5VTH9GPU2F74ulwgU+KmkiNJUkt7LQ7kblaO717OVx/VMeadO4h1uEAmR6lQoDj5JlqHDYvNgfPEd1qu0tBWlS6XC7vdTk1NDbm5uZSWlGK127HabHho3Ynr0YPQ0NBLeoolCIJwLXA4HCxYsACTydSy45bJhMViwelsubqPGTOG5OTkM/LMnj2buro6MeIuCB3hcrlwuVynAoyLCTTOG5C3l0yBWtPWn6+EXKE4KziUoThrUalcpUHTVrmSDIXy9DeMylGqz9Ve6cQNw/maqcKtjWZKkgJVG/kkuQKVvHUGxenzniUJmVzZZnB4sk716UWcNtwsKVS02W0AbdUtV6Fps6Na1XpGH5/ZZ9I5j7cl8FahaHNIPJIHF393RjkyuRK1pu3x89+a7Nb2uW2DJFegcmudXpLkqNzkgPXEzzIU5ypXrkQtP3+bWsqQUCqVGAyGM14+JgiCILSfmOMuCB1QV1dHeno6JSUlV7spgtABcty07mjO8aTkNxJypRtavUaM8giCIPwBiGuxIHRATk4OW7duxWQyERAQcHlG0QXhiolkzKP3tSOdlrAeNzDrtd+9QYIgCEI7iBF3QegAjUaDXq/Hw8PjajdFEARBEIQ/CTHiLggdEBkZiSRJBAUFndodRhAEQRAE4fckAndB6ACNRkNsbOzVboYgCIIgCH8iYqhQEARBEARBEK4BInAXhP8SFouFioqKq90MQRAEQRB+JyJwF4T/AmazmfT0dL744gtKS0uvdnMEQRAEQfgdiDnugtABZrOZwsJCDAYDOp3uirzpMTs7m9ra2jZ/V1VVxYIFCwgICECtPs8bkc6piaJDmWTuhYSbu1D1ayaVbsEkDOyK96U1+08ol5/e3kPQnaPpqXcXoyNXwckXpNlsNqqrq2lqakKlViOTwOlw4qHTodPpUCgU4i2tgiBcU0TgLggdkJ+fT3p6Oj169KBfv35X5D//8vJyYmNj8ff3P+Nzk8nE+++/T0lJCWPHjsXLy+tCJfHzq6+w0jWKZ2aPIQAAK7WlOezfIRF5czBFhw6Rr1PQ5bIH7nv4+OGP2XPqZy2hPVK59cGRRFzWetqjjqPbMziYr6XPTckEXrZyK9j/627sU4cTr9/D3Fm76fP2ncRdtvKrOZCWwbEmf/qMS6T97yCt4+j2X/h23noKMdL/xkmMHdYD37OTlf7MK585mfawJ8tnf0XWec5RzqoP+XLNPsqagB5TeeveAagUF3urksVXz2ynywvT6a26fP8lWa1WGhobUWu0qN09sdgdgBOF00VdXR0WiwVfX1+USqUI3gVBuGaIwF0QOqCxsZGqqipqa2txuVxXrN6wsDDCwsJO/ex0Otm8eTMbN25k9OjRBAUFXTgIKd3E4u31OF2L2VQyhsmXL2JthwqyNppJ+PRBegGgwN0zAL8r2YRTLNSWFZCT7Um3362OcIbcrm8dHF8SLSGx8Xg71OgvKp+GgOj+TLhTS9r3u6gurMLcRqri9YvZwQPM0oQz8s5bCT+ynS3p+dSfla5mxyLmrjhOWMoERoQ4WPP+O/zdL5hXb4q8yOMJYsAtg9HLL9+zCYfDgclsQqlWgdyd2iYLTc12mkzNOF1ODB4aamqqUCoU+PpdnW+fIAhCR4jAXRA6ICIigqSkJGJiYq74Pu67du2ie/fuqNVqLBYL//znPwkMDOShhx5i9+7dF8yfsXAeVX2f4ile57WF25n8eN8L5tn75dO8/eNBKpqB5CdYNnsIpvpD/PDGEvweeo4R+iK2r1jM6vwgJtx9E3HOXcxfeJiQgYMZGB/M6ZN3JMmHTr1707uNeo5v/JrPF3zNjmIg9kZefWQS3UL0QAZv3pSGYWIeixaV4xc6hsfev5uQoxks/vCfLM8GPOOYctft3DjUj50fvsku43Smj+iGvxYoXMSs1+H//ftmggGo52jGcj5783P2mGX8sm0tY+6ZydQJeja8tJ4GfRZrd+RTW5vAE98+zSBZAfMffYzviwD0RPe5gQefn0IXAOrYtXgu85asI68JDKkD8aiz0RWAQ3z3v5sZsvgRoo6vZ8ELW3B0z2f9+gpAR9zYadw+fRwxOoAK1rz5CvM35VBrg5CbbiJyaTlDFj/JmWeojqPbN5LdGMiQqUHsfms9ZY4DbMrKp6LCAgRx01vvMCNadVbvqtD5htHd10XBtmPkt3mmi1i3Yh+hN8ejVaro0luDUl7EvvSGs9LVcGB7Nl5JwxgxdAgRntD1wUPc8+56Cm6KJPSMtNUcSFvP+uU7KVLns29fHfj25/7H7yA1Phg1ufz0VhpxH/2FAY5N/HvGBjyG5rNiRQloguk79nYeviO55clP7q+89cnXrNtfDkCvu97lqbHh6M46VIvFQk1NLQHB4dQ32fD21OHn6cJm11NWXU9RRQUBXh4cy8/H28dHvPlYEIRrhgjcBaEDvL29GTx4MArFlf0Tys7O5umnn2batGk8+uijvPPOO+zatevU/PYLy2D1CiUDX+1FL9l1qP66mozH+9LnPDnKf32bN7MieOi5ewnz07LhjVu594t5/GeyH2H+xewugBERdZQf2c6W/Dj6VEGcvYBKtTud3HWcHT6eS33War7dmEPQ9X9nTu8Q9i95hY+XGnly2lBCvJsozVnMkv1Ps2TOAOQKDeryI/y64ltyY55gzlNdqdu7gnlbfmaDz00MSe3FTx9uIicpEG9tIwv/5wciH57Dbz3kQXj8MKbc3Uhglo7UR8YTq9PhQTY1Jev4Oq8vr/y/vxDu542nagsvjfyM4H/NYU4gWCpy+fXHxXz1XXdemBxL7Z5fWZZlpt9d/2R2XAD7Fv6N/zOpGQhAI6VHS2nChd1awr5DGaj7PM6cOd2gKIOvV2SyZlMkwaO70fzrF8yr6MJfXvgL4f5atrw9hVeOJrdxg2Onqa6G6jodVqzUlm3km+JO/G3WfXQL1sOWt5ny4gIGz7uL8Hb2/W9yOZDVh9ThFzprFRQUqTAMC8BLr0QGeCfGE35oNUfhrMDdjqnhMOsPltP37keY80gYh5a9xfK1W+gUcD0xAc2U55XR6HThktWRl72S0oTZzJmTSNWRDH5es5gft8Vwe796fl62EVPQ9Tx/b39CNbB3wSJ2mO9ksErH6aG30+nEZLZS02ihrr4Jh92CxdSEr483vnoNB440otdpqaisxMWVe2ImCIJwqcS6KUHoAJlMhlqtRi6XX9H5sZ06dWLgwIG8+eab7Ny5kzfffJNp06aRmpravnZsSWNNwlTu7+aGutuDTEtYzbrN58tQzs6tpSReN5CozlEYjUYm33sTlctWUaxQE2D0YeuWDCrKK6goK0OlVnP0SA6Hsw7hAPQ6HWe3ymZdyWOJiSQmJpKYOJTpsz5jPw3k5xSi9ogkaUAiRqORYRNTUWbnkF/fiB2AATzz4gSMxgD8/dxorj5OcbGWlHGDMRqNdBl+HUmSi5L8YhqjJzExdAMff5/J/o+eZ2nPp3k4weO0kQoZSrU7Ok8dWndP/Ix+eGrVJ4K/7sy8bxyx3SMxGr3RSAOZvexDZvY0YjQaCevRlT79e+K+fTeHqeNIVgm+gbH06hvX0u5J4+jk49XGxdWd0PChzLw3BaPRiLFXHF299SjKK6mnnJ1bK+gz5Dqiu7T084Q7pxJ04TMKdOHW28aS0KtzS7kTUum3P4sj7cp7lvR1rB44irFuF0roxOmQkEkSp752CgUKh/3EuTqbhpjuvRgwpDdGo5HB44ehLyujoKoG6xnpJNw04dxw6yiMRiPdenUnoWsEZXsPUo0Dk6mUijoJjbblXAyf9SCDdR6t+rrlb0GGyWyhrKqGvIISHMiorm9gz4FDFBRXYDZbcNjtiLhdEIRriQjcBeEaIpPJeP755/Hz82PChAk4nU4ef/zxdj7qd7Jh/QZ69++HDAcOp0TygL6kr9+A85x5yigu1uHvr0WtaonQ5J07E3n0CHlqNR59+xN/fA97yvKpUI1mTG8triNb2V4WQGREMIaA1jcTStUY/r1rF7t27WLXrnV8+fad9KCBmlobkuSLt3fLZUkWHEJwVSWlVsuJYFCGSnXyOK2YTEfZuvxb/jqmFz179iQh8SZeXLiZUglckoz+fZOoXPYMt7/nzvS7uqBs99VOQqk4/YZMwnH0AyYm9GypJyGF6bM+Z7/TiZNaqqpBpfJGr2+pQB4WRphK3cbjTAlJkqM4uXhTJp2ow4XrHP0c3a72ylAo5EiyE+2Vy5G7nB2IR52sXbOOlJGptOfbJEknYt6TFblcuCSp1Y1aCx3eXgb8fE+cW2MggfX1VJpNWM4sFYU8koiIlhZIWg88tVoUFeVUE82k2bPo27yUx0b0pGd8HPd/kUO9pVVlLXPcTc3Y7E6aLDYsDmhoMpObX8SxogqcLsDlxGJpI7MgCMIfmAjcBeEa4+fnx5133onVauWRRx4hIiKiXfkc5g2kbXew481bGTMyldSRo7n5jR24tq9jg/lcobuR0NAGSkrrMVta0lgOHCCva1eiUeOhjidG8TPLNx2jpudoRkVocVasZEWhCh998EXseKLHx1uF01lBZZUDAFv+MQr9/QlUtxUEq3DXxDH85of5ZOsOMjMzyczMZOe2+Twxuie+tnwWfreV+Pvns/GdMP7vueU0tz0U3A6/8uxt6UxZ1lLH7p1r+fxfU0/MYffG30/CYqmktral3dbcXPIs5nOMPJ9L2/3coVHzjrKuZ/XGZFJT2hO2GwgKNFNdUU1DkwMXDpoPZJHbOYbObaZvoKqqlLLyll6xFRZQ7OmJv8adMzcvdWG353DkSMs4vLOhgZqGehwBRnyxYzZHMuWFj1mTmUnmyn+gXvQZ6+rrW914ymQSCoWE3GUFp5OGJhMWix27U47NIcPg40lDbSU6vV7sKCMIwjVFzHEXhA5wOltG65RK5RWdLlNXV0dlZSXTp0+nsbGRmTNnUllZCXDOPd5b2MlbspzMXvfwzWNj8de1hEvWxipWvHUfPy7OY0ZIW/n86ZUcyuI1mzhkUNDg687meSsJmfgpoYBNLcPNw86OrceZOjgQb58CmopLqFJXo/C6mD1PPAjvFI7z4GZ2pm/BJyGIg8vTkbpeT4Teo83A3cs3AD//Qn5ckIb/8Jax6aJtuzF3jSamYQOrrIO4J9kPbcgMHl30NB/sGM6j/b1RnipDgUqlBHs1hbmFePr64OXZVtu0+PsrqCrIJdcJjWVHWLnwB/ICpgF6OsWGsWrFAXZvyUDT1cDBpavJr1Wd5ylGW1r3846vllHZ5hLejrJjaqilqqKA8poaaqylFOQWoQlomSbk3LyJjPAI7pLJABcOewPlx49TWFxJXXMTxbnHMei98fHTocKHuN6hLP3yF9L81PSLdLD89ZUEjH3rHPPqzeQcymFL2maC+oSQvXoTluB+hPt6n7UGwoXZXMTKJStJuSWO6mN72ZtbTuiYWLwpZs2vB5Ap/Yno5ANlFbj0nri3sTjczU2Dn48PdfW1BHhpyCuqJPNwOU6nEy8PD4yeSppqSkiIj7/ii8sFQRAuhQjcBaEDqqqq2LlzJzExMYSHh1+RwF2n07F+/fpTP3t6evL999+fkcbvnFvb1VFYF8TUCcl4uP82xqnSaEmeOI3c9BJs3fwJDpfQoMbLaMTsrkcF+A95iFnl/+DDD1+hygT0+Ttf3dqy/FCp1ROTMolxTid9e/iiU3UmccAEPDQ9CQ/SttEOLyJ6htNWfKyLGcqNg6r5atF/eG4x0GU8/3NfP4K8VICe8PiIM/Kp/aMZfsN0XAvf57nnagAIHzyD20PCKFxeR7+RN9HVxws5Xtzy3I3Mfi+Nyv6TTtuv3YdOsd3I2vMxc547zOAZ07hxjJ6AyBA0Hm6nTRcZwJP/2MbM959jF6Dy9SW0zzSGSv5oAM/465lWU838Je+wYgH4DxlCai8HRqX8tOOVULr5ENrZwW+9cv5+Dho9icS1FbSebq5C7xeAUeOFGg3+4UE4Pd1Pu5i37qsWDeRn/sS8//xyYkeZg+zN2M/4J+/k+qRgjh8uplPKJMLkLYG7uXEH8577hL0ncs9/roi9oyYz7Y4UQgDfATN5oOp1Pl70Nj83AL0e47Op59oK0kA3Yxl1R77iuaX1ED2SJ+8cTCeDGtAR2iMcL1nLvHR3ZSKDjGk899w34BXJwIl3cUtvb8Cb1B55fDB/Pp983nKzGjfzNa7T61pN7VEoFHh5edHU2ITUXEekn4ZATxV2uw2H1Yy1oZJOUVHtXNAtCILwxyGlpKS49Ho9r7766qmLnSAILcxmM42Nja0+37lzJ6tXr6Znz56MHDlSbCcnXAZ1lJbK8PHRolLJqEx7lnu/6sWHc6bw+4eXlaz/z1fUj7yTsdE65Jf1PrScHT/+xIa9nlz/7ORzTKVpYbOs4LkRWxmf/iLXXUKNLpcLp9OJ2WymtLSUiooKrFYbdqcDtVJJaGgoAQEBqFQqMVVGEIQrzuFwsGDBAkwmE2azGZPJhMViwelseVY7ZswYkpOTz8gze/Zs6urqxIi7IHSEXq/HYDDg4+Mj/uMXLpMaDm/eS53LhaSSsX/5YZJumXUFgnYAP4Y89OgVqelKkCQJuVyOVqslOjqa6Oj2LfMVBEH4oxOBuyB0QGhoKCkpKfj7+4vAXbhMIugZtYev1mZR3eyAhId5YHj7l/f+cWkwRHQlQaXhQs9zZfJwBkxycUVf5isIgnANEYG7IHSAm5sbUVFRV7sZwn8Zr4QbeCjhhqvdjMtMR1hcMmFxF04pV3Rn4uPdf/8mCYIgXKPEcnpBEARBEARBuAaIwF0QBEEQBEEQrgEicBcEQRAEQRCEa4AI3AWhA5qbm9m/fz+1tbW4XBf/cnlBEARBEISLJQJ3QeiA3Nxc1q1bx549e07tuyoIgiAIgvB7EoG7IHSAxWKhqakJk8l0tZsiCIIgCMKfhNgOUhA6oFOnTjQ3N9O5c2dkMnH/KwiCIAjC708E7oLQAZ6engwaNOhqN0MQBEEQhD8RMVQoCIIgCIIgCNcAEbgLgiAIgiAIwjVABO6CIAiCIAiCcA0QgbsgdIDdbqempgaLxSL2cRcEQRAE4YoQgbsgdEB5eTnr168nLy9PBO6CIAiCIFwRInAXhA4oKSnh0KFDInAXBEEQBOGKEdtBCkIH+Pr6EhYWRmBgIJIk/Q41NHB83w62bCrHMKA/vePD0V3W8nP55cPVFLl3ZcTtQwi9rGX/Nyhi86J1HKj2ZcjdI+milJ8jXR05O7axfUcdoUMH0ismCO0VbacgCILwZyICd0HogKCgIFJSUvDy8rqEwP0oP77xAwftjtM+0xAQ3ZeRU8I4lrmGBe/sJc7dSJfLHrjn8NM777LNbzJdWgXuNRzauJ70TTVEjhtOco8wPC5r3VdSHj+/v4y9jWZOPReRu2OIGcKN4+PRnzNfIRsWzGXh0RiMdww/T+Bey5FtK5n//jEGBkbQRQTugiAIwu9IBO6C0AEqlYqgoKBLLKWQDV9+wQp7LNNeuJmuLSXjZfTGDS+69J/Moy+l4B0fg/elN/ki1HMscz3fzzvGwK496HlNB+7FbFn0NUsqQrjlpWnEWprIXvMZczbmYNU/zv1Dws+RL4oxj/6VmHpPep4zaAfwpcewW3kssJGAhIjLfHMlCIIgCGcSgbsgXGUyWSjJkycz9IxPqzlQmMX2tfmEe3vQcHAZG9P34pn6ODOGROOd8zVPfLIFp3Eszzw9Gp+GCvYse4/Pt1QBoI3ow7iJkxnc+bdQMnv5W3yxPocaE0AF+9rdwlyWv/Ul63PKMJ36TELtEc3EJx9jsP/JJh8lbcViFm8tBCB8yAxuGdmPME+o3DCHN5YeoMHsQJIriJ7wDI8NNwCNHN+/lkUfruLYeVrQY+rL3JPsiUIGDksjB5e+zkfplQBoguNInTiVUd3OPX4OQfSfPJnh9mZyAo+zbdYq0n/ezqghOprSVvDD4q2UnEobxfWP96F6+2YyioMJvr4vYQC2Zko2fsbLS7IA8OnUhzFTxqLOO8C2teXEBocRGd7Ar+3oq+qjGaxYPI8TXXVavdMYEm1Ec54jEQRBEP68xOJUQfhDMlNVmMXWtVs5WNCEITECZVkeS1//lPTyND7613zWrK4ldkI8WnMDmYv+wcvf7oGY8dw8vCeKrEW8O3cRG482AlC1ZR7/mb+ErbZ4Jt8yg5E+9VS0uy215O7cyvq1azmg6se0GXcwfaiWzJ+/45NP1lABmEuyWP7pK/zvD9l4xo5g5syZdKvPI6c0l7z1H/LiuwvYKfVh2ow7SHE/wDf/fpo315QBNhoqj5Kxdi0HKuXE9u+HryWfLWvXUqCJZ+SQKGoOZLDg4x84brfjctjI/vZ5/mf+FkyR47h1dD/0x5bywcfzWJNVf8EjkSnk6EJC8LbZsNTWUn+qn9eyo8Kd+GE3M3PmWOINTo5t3UTa2kxKHU5cDhuHFj3Ho//+ieMefZk5cyZDIw3U7P+Z3Xn72LJ2G4dLa7G0s6/SvnmbL3eZCek3mUmJvtQc2cLatTvJq23G3rEvjCAIgvAnIEbcBeEqs9vSefmGG3gbAB3RvW/g/ueST0uhxCukL/fdcYBdry3jzQe2YCmsoPes95nWLRBZ7T7W/7SFatd1TBs3jIHBhZjKD7B74Vb2DE6mV6cAMjdt4mCeksQZKfTp3xmVfjjvLv6cC4e6p0vg1vtG0TfGH1e3AiKe/4XcjEwKGIShJIv0Xw/i1uVWRkwcTe8QNaboaOyaJtZ/nc6eowpSHhxOnz5GLFIKH/z0A+t+2cr01MEnyvYjomt/hk5O5MCxdNI3SfRJ6cuA4Y3snf8jB3bv4ohjKuEUsG7pekosiUwan8qAiHJc9QfZ/uF2dh4YRL/YhPNOV3GYzOSuXME+nY7E2Fg6AxkAhNIvZRipYwcS5SYH6jh9gozTcZy1P6RR0NSL+2ZMoXd3d2zdmjHbjrIuZ9dF99XWDUfRxE7nuhGD6e9wkrF1J1kF5+/9Q4cO8fTTT7f7bAmCIAh/LHPnzsXHx+eSyhCBuyB0QFNTE1lZWURGRuLj43NJO8vIFX15+MNnaQnVZSjVWvTUUXpGKg0+g+/j/l3beHHRXur7PMErt4ahw0m9PYfsIyaqpA28OXMk/5E7sDQ30tAYSmlVFfW4yM+vpakphC4ptQwLAAAgAElEQVSdPVAqJNTdu9MZ2HlRLXXH20eNJEm4VCpUuHDZbNgwUd9QQGGhO4brQggKUre02NsbOE5+Xj1mczhdY9yRSS11R9kXc/RINgUMPjEtRIlKqUblLkchlyPHDY1GgdxNiVKSkGxWrIDTdYSsQ2bq2cn794xkrtyJ1dREQ4OBLuXl1MA5AvcN/H3oUF5xObGYHQT3v4+n7u6LhsoTv1eh1WpQu7U9n72lXidu4VF07ere0mJ3d5R4oupgX/leF4jBoEDhCiTY2xsPnOftfZPJRHZ29nnTCIIgCH9cdvulP1MVgbsgdEB2djbr1q2jqqqK1NRU5PLzLWA8P0lyw8toxHjGp3WtEx5czIKNhVQ2A9vf4/WN03l9rBq5PJggo5YQ31v4+6cP0vNUBhkKlQolFfj7u6NWF1NSYsPRCSgo4AIDvBdBjUbjj69vExUN1dTVwW+raf0JMKhRKUsoKrbjNIKroIAiuQylMYgAuKhRf0kKJSRYhb/8Rv6x6HF6n36sSiXKc+YcwLPL/9WyjkCSkMlVqNXtv/y11Otgl62Y0jKgw+uST/aVhFWSIZMBVTVUNjViwv28OePj48nIyOhoxYIgCMJVptFc+gomEbgLQge4XC6cTucVevmSC5djD3M+Ws6RvBj+tvQBLP/7JO/99a+sHPE2I9SdGTLUwI9rN7Nqzc30HmMECljz8c8UecYx7rbB9O7TBb/0ffx/9u47Psoif+D4Z/smm2w2m957QksIvXcQUA498bAhiorl1FPvp2c9PfUsZ+/l9KyAoiiKKChNem8JBEgvpNfN9v77YwNCAgkEBMu8Xy9ewOaZZ+aZeXbyfeaZZ551aw8xt184lct+oIiTjU6fLj/Cw9Pp1z+AF3N2sHnTaPpOSqb+p7WUpKXSc3gGQVu/Z/XKfG7t1Z+SZcup8NMwZuxo4oD9p5GTVJrGxElxfP71BpZ8N4thl0QDNWxauJw8UyIX3XoBJ14nRoZKo+n2Uo2+fBOZ/8UBvvhsI9NuH4SpsJDiht0Undae2uqqH7yXs5nNm0agceyj4HAlZtI6TSmTydBoxGKTgiAIf2QicBeEbkhPT8ftdpOUlIRU2t1nvBUE6PXoPQEnmG7hmzITpA9Cozax6d3l/FTk5qLn/8GfEjIIfuyvbL72bZ69aR59PriWMXd+wPsx/+bW565i5XMAsYy7/iZumjXaNzg89UHuP3yYfy96nBkrfTno9XoCdJoTjFLLUPoF+PJWKZAixU+rI1ivRSU9MiVIRaBejy7IHzmgSRzI9fe9SOD7L/PK0zfy+dMQOvpmHukxgt5/fopHDx/m0cX3MmUpSGQKRt09n9euiAMMyBX+aPU6AjUqZMhQ+Qei07vxV8qRoMBfpyNYH4hSAlK5kgG3L2BR7KNc8+osxr8KEMHQy67ntrtOFLQr0AQHo3efqI7b17PimHntJ873m9hHuea1+xj/FWhSRnD1rVfR0+8g60+zri6c8w9qXn6Cd/4xg3dwYTPZ+CVe4yUIgiD8vkjGjh3r1Wq1PPPMM8jlcnQ63fkukyD8athsNkwm0/kuhvC74sJqteFyKQgMVOGy7OLDh5/lwzUabvjgEWZmJ4iXOAmCIPyOud1u5s2bh9VqxWazYbVasdvteDy+Z52mTp3KsGHDjkvzwAMPYDAYxIi7IAjCuWWktGAX+/e6ScuKoGXvUtaWNqOdOJVhYcEiaBcEQRBOSgTugiAI51QwPWPiqd69kDff9D0i7D9oDvdcNYUeMZ29REoQBEH4oxOBuyAIwrkWksb4ax9m/LXnuyCCIAjCb4l4c6ogdIPD4aC6uhqr1XqOVpYRBEEQBOGPTgTugtAN1dXVrF27lvz8fBG4C4IgCIJwTojAXRC6oaGhgdLSUqqqqkTgLgiCIAjCOSECd0HohsjISNLT00lMTEQiEStwC4IgCILwyxMPpwpCN0RERDB27Fg0Gs1ZC9y9Xi9Op5P6+noaGxsxm814vV5UKhV6vZ7w8HD8/PzO4IVPgiD80Xm9Xurr66mvr8doNOJ2u1EoFOh0OsLCwtBqtchksq53JAjCeSECd0HoBrlcjl6vP2v783q9GI1G8vPzkclkxMXFERYWhkKhwGg0UllZSU5ODuHh4cTHx6NQdHzfqSAIQmccDgf79+/HZrORkJBAz5498fPzw2q1UlNTQ1FRESqViqSkJAICAs53cQVBOAFZYmLiv1QqFRMnTkQqlaJWq893mQThV8PlcuFwOH7RPLxeLw6Hg3379hEaGsqoUaNITk4mLCwMvV5PaGgoMTExhIaGUlRUhNVqJSgo6DRG3gv46snFlIaGEx2mRfmLHs0fh7l0O5+//xGbm4PJSAtHdcZ7PMCCB76kJi2BOJ2G0xvzPJO050I9O5cuY+2OJkIy4wk838U5GUsDB79+mhsf+oScajlJw9IJPuuZ1PDNw7fxVnUWU7O6vvj3er14PB5aW1spKiykuroWq81CXU0NTY1NyBUKFApFl/2B1+tl7969SKVSJk6cSFpaGhEREej1evR6PVFRUURGRtLc3ExtbS0ajQal8lR7i99I+/6GWSv38e1Hb7O8IoBevaI5u5Habt68fiG2KQNIkJ9u73Emac+FClb/71v2GqSEJ4Xjd76L08br9ZKTk4PL5Tr6x+12H31mLi0tjbi4uOPSrFq1CrvdLua4C8KvQU1NDTKZjFGjRqFWq1myZAkXX3wx/fr1Y+rUqSxZsoSQkBAuuOAC6urqaG5ubvdQrIO6wlU8ecUEJkyYwIQJl/D3V78mrxXARlNVHQarA88vfiSV/PTR48y+7H4+3ViE5ejnO3hx5jOstjm7SF/K8jf+x8If99Jwwp97MDV9x30TjhznBCZMuJIHXl9O6Un3uZmnLvw367txNCfXSOGBA9RbEhk2Jg0NhXz9zDt8uekQhm7v00pDRS0Gh6sb7XQmac8FJ+aWJhobjfyyl8Fnwk1LUxHrN1u47LFn+Pt144jrOlE3hDLh7j8je/vjUzonvV4vBoMBh8NJzz59SUzvjSYkltDYFEIiYqmtraOhoQGXy9Xpfurq6jCZTEycOJGoqCj8/f2Ry+VIJBLkcjkajYbo6GhGjBiBRqOhpqYGp7P997Wc9+cc+d5N4YqbnmRVHZzb9jVTsX8edx7XB8zh2S+3UPML5OZyrOKh4/L6C3c9tZjCk6Y41b7udBgoL9lH8eEYRk3pzdm/F2KhtqgGo6c7Cy2cSdpzwYGhroGmViudf0N+O8RUGUE4z7xeLzU1NWRmZiKTyZg/fz733nsvJpMJj8eDVCpl06ZNPP3008yZM4esrCzy8/PR6/Vtc1FdNB/ewgdP/xfX5e+y5IIIwMiexavZv24DwdOCzuHRuLCZggl2bWF7QR5Z6Sn0DgOwY6htwdblCjwurK1GzCe9yPDicbuQq8fxyOd3MxAwFW5g/vzv+fTzMP46cwAdj3Yw/7eo/1kdhbaUlXCopBT/kTfTR6NCSjIX3R0PMpnoVH+zXNjslVTXxnFhZgShv9iwlpyAkD9xweAnef1/1zHqhqROt7ZYLCDxog0JoaLBgNHswGqx02xqxU+lJCksmMaGWtRqNUFBJ/+uV1VVkZGRgV6vP+lzOVKpFK1WS0ZGBnv37sVkMhEcfOSeQzn/m3U5y4e+x5LXEwEndYV7WPveh+x78ILuVUW3eHE5ZISlzODpl66lN0DJGl79/Ce+D9Vz+Zh0NGczN68dl2MIDy5/iKGAtXw3X34ynw/eD+ee60ec4I5MP277MBOZ6uz1BLaaavJz9yIZdwf9A9RixPUPTrS/IHSD0Whk48aN1NXVnfFykEdG1FJSUigtLeXNN9+ktbUVj8cXuno8HqxWK++88w6lpaX07NmT+vr6Y/J1Y7fVY7MO46KLk9BoNGg0kYyYdRV/mTaSqLatKr66n4vGDCAzM5PMPtN4s8CDty3/puKdvDCrD5mZmfS58BZeX1aAx9vAqpce5/VvtlJlBcoXMHvkDF7ZbwOPi+bdr3PjbZ9S2eGIpPQaPRJZeRkFRcVY29WP1+vFZqjlw7m+/DKHXMRtL/xInaeMH958i3fnvcsLD81hQuY1vLOrBGOH/UuQSOWoNRo0Gg3hWX0YkNmLwPp6WjjI/Puf5Zl7rmDSpEFkZt7MF3VLeXDkg6xpy9tYnc9bc3x5D7v0dv67rr6tHjzsnXc/l4/L9NXDlMfZUm/C06F9rdTVFlBcZCY8MqKtE83n80df4bN1B2hhK/+Z/jAv/edS+vXLIjMzi8EjZzO/9Of6rty+hIdm+Mow9uaXWH2wleNz+Yl/9P8/Vhz9v4mS3Z/x1K3vkgN4vc1snf8EV47w7WPivQvIq7L9XMceN0v+1la//Udz2b2LqPR4AS/e0rW8fvd0+mT6jvOaF1ZT1Oyl/VG2r6vMYZdy3ztrafA0seG9B3jkla/JrfXixYunbAHXXfMmB+xO3HYLC//qSzNo4mU8sbSqbd9eGrd/xgNXjWg7Byfw0Df7aLD79uF2FfLKdF+ZMjOHMu3ql9nh8QJVrJv3Do/NvpYrT5gWvJ5CXp7my7P/6NHMfPg5njxaVx4Klr/JrRe2nd8T7+GbfZXYj2tXN60N3/LoxY+wcPe7XNd3PNc+MJ8DXaTtqp7f/PvFJ6lnGVOmjufQd8sp6XB+H6+urg6pXEVLqx0/lR+90+LokxrFmIGZBPj7caiiFqV/ABUVFZ3up7m5mZSUlC6n1EgkEmJjYwGwWq3H/KSY/Lxh3PjXXm19jI6kvmO57sHr6NNl+7arq6ETuPqVzXg8Zg79tJA3nnuHrY1A/XpevO0mHlnwc59z7aw3OGBvP3otQSpTHO0DNL17kOGnhhYDZrx43BV8esdFDMn21X2//vewyu2kqXwjb/ztXpZWAcZDLHnpXu58bB57WoDaFTzxwBusyKvueNdAIkfVlldIj3T6Dx1EaE0tjRSx+OmXeOqOq5g2bQiZmdfzUcHXPDr1UX60OTv0dUOmzeHFFTVH+5u8r57m2gvazq0LHmJlSQOuDv2Ng+bmQg7kGYiMiT4atJ28vyrmjUv788/VHrx48Vqr2fbN6zz24koa2p3PE+9dwP4q63Hffaf9e+4b/Qgbjn5Sx45vP+ClJ7+iAPB661nx4u1MG+LLd8rjK2k0u9rKdLK+3fed8OR9xf3XTjr6nbjpw0O02E7c99TuW8OTV7TtZ9S1vPj1Hlq9tXz/5BweeH8HVca2vqfwbS697B1KO+nbwUvNype4ftqQtnNzCs9sbcDp8eL1ujE2bOOJqW19T59xzL7vE/I8XujQvu3TejA3buPxKW3te9FFXPW3p46pq45tVNdoPul371SJwF0QuiE/P5/169ezc+fOowH2mXC5XGi1WiwWC2VlZSfcpry8HLPZTEBAQLuLBTkqvwgCArfx3aKDNDY20thkwGxzHjNqncsPTZP54PO15ObmkvtGNh/c8xbFeHE0lbF+0TuUT1pAbm4uyx8eQ+vOz/lmt4TMvlocdjdWiwdHcTFVkgoOHHT45uWXlaEePZqYExU2dASTezewds1GCiotx42ee902dr/7N5b2/h+5ubls/eJxBnlW8d6iVib89VbmzprL/z35AatyP+Hm/kknmC/rxeO20drYSGNjIxXb97B930GsURFto18H+al5BM+9t4Lc3Hf4S3hQ22i7F7elkS3znmTbkI/Izc1lxbN3MURZRCkeate+y/tFcfz1zTXk5ubyw80GHnjyO0xOd7v8bZgtLqSyTHr0OFmLbufL+tls3rqb3D07+f7+GBY8PZ8KvJhKtrJs5QZ0131Fbm4uX80ZRqC8jsaT7aoDD8171rGyRMafnl1Gbm4uL2a5qXbUYgLAzaE3ZvK07g1yc3PZuWoBN8at4el3tuGimvUbttCom8kn63LJzc3l3shqylvLOf7XSce62vzJ3cQ1r+LT7+sYdunFhBvLOVhQgNFSyCcvbmbkPVeSppCy742r+F/sO+Tm5rJ+/hvMUO3nAACV5JoimH77Z75zcME1VC5dxp7qJtxs4skp/0b3mq9MO9ct4vYhBXz4zra229udpXVz6I37WNjfd7zrF33IlIbv2Xu0rr7lix3NjHrIV1er7gvjs4+XU1xtPCZgkKEN/ROPff0YM7Nv4uPc1Xz09JVEdJq263qu11528nqeOJEJxcWdTPFqawmPF7PVSU1jK61GI8VFRZSWl4PHgUYlp6qhFbPDjcls6nQ/Tqez0xH5Y6nVamQyWbt+JoXe2Tv54LXdbX1MMwaTjZ+/HV210c91tWXJu1zY+ApPLGkiKjqCyEior3fhqq2lwVxC/mHj0T5HOnoMydL298u8uJyWo31A45795NudyPXBBJDL/+54GcPMt1mzw1f3C/9ayVMPrUEVEE92toSKCidugwFDfSHFzc00NblxVVVBRgYxwcEdngPyeuwY2/Kq3LuPHVt20RIbTQgAhWw0ZPOP578jN/d9rk2LPPq8S/u+bs2bj3GB8hAFeGjY+hnz9iv5yzMrfX3RnTJeff17ag32doGsA5vNhMvVj8zMI5911l/FM/c/t3H4o7c5aLFQmb+LrdstjL1mPNJ25/P8C8IwyFo59VDSQ+3ar1hq7Mm9H/ryfTxoP7s9FtwnON6f+/Z9uCjmm292EDj8fpZs9rXLjcYf2e0wtru76sVanceqpYuxXvq57zv96p9o3vsjq7Y5mHLjVShyN7C/ug67JY83/rmJi1+4idiT9u3t2yiX3PcvYNXzn3DQ4cLlWMML135E7/d8Zdr6/fOMD93H14v2tfU9J0/rddvJ+eAFcqb4jve7F+4nu3k9+Z20kd7Pfsq1fTIicBeEblAqlfj5+Z21h7mVSiVGoxGpVHrSFWPkcjlSqRSz2dxuGxnBMUOY/Y+5qJf+nVmzZnHVnHt4ccE6DpvsbZ1iJjfeOI7wiLbZkWPGMLqslHLcmExllJWGMPXCLABiMzNJCdbRVFaGKiaWw4WFNLfUsPanvYy8YDS7f/wRk8fOxvU5pKWeMGwHoOeMKxncXMHOssMY3T//KvJ4Ctm82cvYIRGUlpZS55EQGhKNrKCgyyDGx0lT5XKemjWLWbNmcfOjn9OaNJWZl/ZD68uZq68eR0KCrl06L3Z7CXl5QVxyyQAAAlJT6Tt0KEk0cvBgI1GhIcgwUVpairPfCPrt2Ml6d3cuzAZz7z/GoVDKQCZFOWQY/aoqqcZKfX0NVls0I0amA6AfOpRBqamEnvK+jZSVNaILTiEz0zcLO2vKFPpEHQkYilm5wsH0SQm+l4QZWglIzUSfk0MecvwCJTjM9ZTmlVJaWkrY1D8zMjah3bxZL3Z7MTl7JAztF0JpaSkNchURfkG4Skqo0A9lUo9G1q1exbcvvcLO7FnMSAtELi1k9WoV18weAYA6IoJekybRC4BYxo4bx7DhbTPHs7Lob7XQ4nTgYgSPLHuZid7SE5S5q7TFrFwh58a5YwDQBAcz/JKLiT5aVzXICUSvdVNaWoo1LZNexSXkms10/iu0q7SnUM+Wruq5axKJBJfbjdXhoKSyhpp6A9qgYPIKi9mxNw+D0YzL4cTTxXmqUqkwGjvevzoRu91XM8cvCxnH7PfnceH+h5g1axZXz57LXU8sJK/R1BbgnF4bDRg3BtuuXZh0OpwOB+WFB8ndX0hodCytVeXUN9exYWMOiYkRSDrcJTBSunshj86axaxZV3HZw98i7z2Gi4al4k8Wc1/9F39O8lJ32Ff30tFT6b1pA7vVKgKC9RzctYPyw1WYHVI0SgkVxYXszi3ET63E3799n+7B0rKG/7T1N3Mf+B/FwZOYPXto20BBGjNmjKNHj47fYI+nkK3bNFx++RAA/OPj6TNmDOm0UFRUR5CfDn+VjdLSUuy9B5CZd4DtDvspPKfS1Gl/JU+cxcy4L/j3SyvYvGIVjglzGBPm6ze0QclH+42ISZMYHhFxGudkEwcPGsno0ZvEBN/xDp75F3r4a5DQed9egoIAvRdjbQ2lh3ztEj/7ZkYHaNtNY3TQ0lJO1WEVPVP8KS0tpSU4nHibm/qaGhoiJjGj5z4+XriWVS89w84LH+HahM769hO00eAhDK+rpcLrRaGcwD+/fILBztITlLnztO3bNzQhniETxhPWSRuhPPOYQUzHFIRuSElJASA2NvaM11WXSCRotVrKy8sJCgoiOzublStXdpiCk52djU6no6CggNDQ0Hb5KghLGcd9H4/jPsBUuIp331vB4h91XHtpZytDeHC5DRhNenRHBuP8/NEABosFa0Y2g2SraK75keUH+nPR68ORzZzHdzXxVBgmccGAzo4sg0kXB/Ls+t0Uxwdz5Nklr7eWqvIqDrxy/zG3Y0PJntL3FFdKUBIafwlzvr2fIae0/TFH62nEYAghuMNiHmaMxiZy1mxmx/qvf+4YY/sTJG0/H1iKVCoBLFitcHrLFDix2y04HEEEdvsJMxsWqxvQ4O/f9lGQjmCFsq3cDdTVG9j+xv1to84AgST1n4Y/4WRdPBu38zMWvnY/C52tBGTfxO1zp5AZqT7uF6jHU8fhomIKXrqfNUc/jWTIjOGocBIcGYVk+XoWVeoY9c9glEopUEd9fTg9w073mFopW/UOD72zG5cKwIPd4kIbM/UU0jZQVx/GoCN5yuQogvXosLfVVSMHflrHln2bfh5Jlfemv1rRxchVV2m7rmePayGfnayeDQYManWXqxHZHXZUChcOhxOrw4VSraLZ0EpRaQ0NBgv+Gn9cTgceT/s7Q8fT6XSUl5cTFRXV6TrtXq+XqqoqJBLJCQYm4pj932XMBpytVaz75Glef0nLP//d1TfxBG0UEIh/SzOG8BEkRUXiqV7H2lp/Qkf9iWlrcjhQsZ2G2iGMHaimY3G1pA6ew11vzSULE3kr5rF01z72FfdieLqExu1f8Ny766iy2NqmpbTSxEDwD0Dfqx899m5hc5kGc/Q0/qSz0Fq6kc3NCfQYG4G+w00JKRr9FP697HFGdnGUHeuynqamMDouHmTBbG5i/4oVbNuxgqPDMEFZjFe0P1gJUqkMicSMxQL4A5g67a8kUjtJcQlUfL2Ilcn9+PNsf8DU1m8E/NxvnDYTRqMMZYQa5ZETVx9CmFSKhK769ngm3Xwznjc/4ovnvqXZ0YR2xKM8fMsQ4jRyfu5lXTid9RTv3cm65+7n26OfJzJ5qgYFDuLiEnGs/poPDaGMf8XXYCfv2zvn9TRxYOnrPLPgAC6lL39zs4yU0Zd3nbZ9+ypVqLVBBFYeqauObfTWW+MIDu52AwAicBeEbvH39yfz5/uWZ0QikRAZGUl+fj6TJk3i1ltvpaGhgcLCQmw2G0qlksTERG655RYCAwPZtm0bCQkJxzxg5sFubaCy3ENMhm/UVRURQbReT6PNhr3TBSBlqFUxREau4cBBA0OzgrBWV1PjcOIXFo6WVLKiP+XbJXnsSLmC+1VDUY15kLdeX4wk5WLu7eLYQkdMZcR3b/LlljTMTt84klSaTv8hQ+j794e5Jtk3ZmUzGDDZbPifYEb72SNBrkgkPn4xubktjB6gw2U2Y7bbUehDiI3pxZjrJzNp8miSA32/lZoKCvB0+EXqR5A2EJksh/37TPQfdDoRuB9B2hD8/XZSXGIiMz0AR3MzZoUC/4Djt/P3a6KhAQgFl91OQ1kZreiBQMJC/XDW1FBdbSUlzo/Wgwcobm0lEoBksrIyCf/7Y9ye4RslclosGBobUWGjqUlOypibeOmyu6B2JU/ct4bdlVmkRCYfMy1JglyRzsCRoxl6+z1cnui7e2FtasLsdqMxlbJkfQFR427nvoxyHl+0mqKkGPpEppKZeZjt2xuZMjIEt92OxWCA8K7qZRdvPLiFkYsWc0syuOyN7F72Hl/+cCp1mkxWVjVbtjTwp7GhuKwWanJzqSK9ra56MvLyZPrPuJh+et9VVktZGa7wwC4eWO4qbdf1nDz6Rl6acecJ67lh2TL2Z00hpYuj8/NT43bb8VdIaXC4aHY4wevG6vQglyuJ0PljNDQRFd75PZuoqCgKCgrIysrqdI12i8VCYWHh0ZVmftbEod0m4vrF4w/I/PwIT0sntMB4ClMtOrZRfXEx1uRxRBKKVqdm3/rVrGU8N0aOYEDmBj5YvpSCgIu5Xq7sop0C6DVpOocPfMbBnD2kJPjz1RtbiLn+MR4fnYBGDtU5L/HI7c2AP0HqeMLsb7NkdzaZI2cxyn81n/64gq2S6QwJCG27a3d2SKWppKf/j917mhk/JBi31YrZbEYaGkxkRE9GzRrAyOmT6Rnku0BqLi7GHaBqd0GpRKMJQaNZw+7dRoaOCAQ6769ctZv5aI2dG554nUG18/jg0/UMvGU0YaF+uI7pN+z19ZgDA9Eed33mh1rVRHMzEAwOk4mGqirMBLXlKyGvsZbmZjtRoSqa9+yh0OlgJJ337X5YqK0NYOjV9zH5r2qo/IrbbljCjmv6EKMJOqaNlWg0GQyZPI3p189lSrSvVzLV1mJTq/FvPcj7K0oYOPspbg3/katfXsxFz88l7CR9u7yLQN7l2sKHLxZy4WefcVU8OEzFrJ7/KTtOvKxZp+3raG6mqiCfOkJP2kZngwjcBeFXIDQ0lOrqakpLS5k4cSLBwcH88MMPNDY2EhQUxKRJk+jZsyc5OTn4+fmh0+mOCdzdWI1FbFqyH7+evsDdWn6IfUbIyohFS2snOcvQBCXQZ0AUX377CUvLE2moyKdRGcrEjFj8gZhUPQcX1JAwPQqFQk5av34U/HMdo57++ykcWSoXXz+Kle9+S50lAC8glUYzZEoUb3+2kKVZvofg7AYH6og4BkTEERYmp6h4ByuXOhk0PItEfQBn53VTEpTqOPqPTuX9bz9iaXUKbrMH/6gEMkf3JbV/IltX5rDm62by2kZEGvMNZN2RROhxdzeUhMSkkRifQ+H+/RgHDTmNdauVhKurjJQAACAASURBVMSkkhC/lx1LFyBLj8bR5CZscD+yjpsvn8yoqSYWvreUwD7gtLawd80umpgI+BOb0Qt9/gq2LV1IS1wotfm7qDcceYAvgtEz03hswWcsHZQIgNPqwivVMjAuAEvJHvblNKEO84fWfbTqIgkPaF/HEpTqGPqODGbB55+j6eWbeGJtshOYHEe8J4e91hRGZqcQ1juDa7e+yNdrDhE3M5tRlw1n1bfvs7SlJx67F7kqhD7TEruol3CyswPZ/tNSlua1P96uRDB65ii+/fY9lpr6+NLuKgfS2+oqgcCytWz4ajGVkb6wrKXUSNrlU+kfpuokKOwqbdf1nJvThN8J67mWZd9XMXr2GCK6qpnwCKqqqvCTegkNUFLTZKCkohmJVEKM3g8/rKgVsg5rPrcXEhJCcXExe/bsYfDgwR3WaPd6vVgsFvbt24fBYCA2NrbdlLwadn63lr2VcfgDbrOB4h2FaEZfRyRQ22nux7eR3dxK/kEHA6dnEgyowv0xmRygkqMP0RKTmkLDgkUETQ9FpjiVMCWaPr1VbMspprSyP6npQazbt4HlplxUUijcvJZafFMB1QFK1FoVtTlmLrwyHL0yCmd9K9JoUOvO7kKLUmk0Q6dm8+K3H7C0Ph231YNKF0XmpEEk9Elgx4qtrF38NUWhvnybi1rpeUMkeoXimBFoBdrQZNJ6hLNp924MI0YTRGAn/VUYtV98xKEet3DPwCBk5cPpf2AVP+7py9SMXoQU/Nxv2OtcxEwZSXb0sWVOY8CIRlZ/sBRJOlhaytmxKQ9vek8gkNT+Waxduo31S80Uh2o5nJuL1R5w9HhP3rfHU7FvBxU1NpRBKmjeiychhYjjjvXI8caSnAprv1iEK8V3m8ZUYyFiaB8iS79jt3osN/ULxS/qz/xt+b/437JC/m/ayfr2zttUKomiVw8F+9YsZWlI++M9vfa1tJSzI6/a1/WcpI0mTpx4xlNsxQuYBKET5+IFTBKJBJlMhkwmo6SkBJlMRmpqKlOnTmX69OmMGDEChULBoUOHMBgMJCYmolarjwncZahVesJ19Wxes5vS6moaLIFkjp/M+GFpaHFhNcoJ75FEVJB/29W6E1OTmtRRPQlT+qOPikdVtZlth6oxqOMZOX4yw9J8o6xqrT9eTwQDxw4lNUxDUFggblsM4y4ZTVyHO34eHFYIiIwmNjbEN/VFH0V4Uz3WyHQGje5DhFyOLjGbJOsOVuwsobq6GkdgBJnDJ5AaEIBe66T2cCEFhVZCe6UQfbTMPl6vA7s1gKRBqSdYis2FzSQlJDmB6NDAtiDJgalJRfKoXoTLlehi0gmq3cDmA9W0yLUk9x1KL70SVWgSGVoz+Qf3c6D4MNXV1YRPuo5x0X60ny0j16hR2gwU7TqIJSaR+BA1zqP5+uE0KIjrn0aEStF2C/nnModq9IQHB2Kv2MHugmosIan069WTmACwGOREZ6YQqdGT2iuKii2bKaquptFiJ2roRQyNiiYxM56QoCiiA9zUF+ewv7gaSfpgBsWm02tgGpEaNdrkoQxgB0u3FlFdXY3Jq6THuEvJDPIjVO2mvmo/W3KKqG5ykzrhYsb3SUDb7upIKleij+tBpGkXa3b72skTmkTfQQNRNdegjs+if88UdCo/4tK0lO43kZgVT2TqUOKa1rB2XzWNdojsN46BEUocNi9++kjiEsN9d/txHXO8cWRnwLbNe6nucLyxqDtN6zveVMNq1uRW02hqxS8uGbVRx4DJWUQERZEYoqChNIc9hyqorq4maMh0RiZH4N8uJvS4nbjcQST1SyIIUHSRVtNFPTdW72dzh3o2cnDVuyzcOYBb7x1FV7OKpFIpEokEs9GA12FDJfPip5TgL/eg8NoJ8FeTlpbW7mL+xPsJCAggPz8fh8OBTCZDqVQilUqx2+3U1tayf/9+Kisrj7787fj9hZHZy8baJb5zsrbRQmDqBP5y1TAi8HTRvse3Ub3JRczwK7lqmG/NK4WfCrkihMQefcnqGUuo/vg+R37cELQXj8uFV6InMTP+6Ah5oL+SJiMER6czom8QJQcPUFrm+x5rx13OaF0YKcPSCVPIUGp0hIRnMGhoTyJ1KmTyENKy+tE7teM5AQ4sBg0pw9LpOHjrxm6REBQbR0ykrm3akxNzi5KEoRlEyOVoE/oSVr+WDXnVNHtVxPYdSXaYCqU+jlSdh4qCfewr9J1bIaNnMiZeh7Ld1aRMrUTltVGxZQ9NUUkkhQeiOWl/5eTg3gp6T7+G7BApav8AAoMUtDbLSO6XRaLGQ33xXvYXV2OP78+IjESC1e6jZY6Ua4lL1lG6fTsl1dW0Sv1IyB7HoKQ44lMj0YcmESdvoCj/APll1Sj7T2JEaBxpI3t02bfH+Fs4VJDLnoOlVLdIyZ4xi/GJJzpeLZFRUajq97Apt4zq6moUyQMYlJWKrbKS0L5jGZAUhp9cQ3IvLfm7TPQYkkr0Cft2WadtFCmPJC3ezvbt+6jucLxhyE+jfVvdLhRBsQT7RdF3WBphJ2ijwYMHo1KpzugFTJKxY8d6tVotzzzzDHK5HJ2u/QNdgvDHZbPZMJk6X63hbHG5XNTX19PQ0ICfnx8ajQaZTIbT6cRoNCKXy4++OKWzX9DCuWFvKGbnjv3Yo/oxrG/sWX6ToXB6itm5M5gBA4JxGCpZ9/lL/OS9kvtvGvALvKzmTBnY9eXnHIi+mKuHdTmH6OibU81mM42NjZjNZrxecLldaPz9iYyMJCAg4JSftWlqaqKiogK1Wk1AQAAKhQK3243ZbMblchEeHo5OpzvjZ3eEs8vRfJicHTtp1PVl1KBEzmyWtHB2eHA6yzh0SE+fPkGYq/aw9KuvqY2ayY0zenXaRm63m3nz5mG1WrHZbFitVux2+9FV6qZOncqwYcOOS/PAAw9gMBjEVBlB6A673U51dTWhoaFoNJqzEkjL5XIiIiIIDAykubkZo9GI1+tFpVId/VwuF1/ZXwtVaDLDpySf72IIAMho3PwBz65y4bQ7aDHpmHhTxq8waAcIov+MufQ/xa2P3JHTarVotWc+A1uv16PRaGhsbMRkMuH1epHL5QQFBREUFNRhCo3w66AMjmXgpNjzXQyhHY/DTuma9/j+ezdWoxmnXwQXXvLLXliJKEAQuqGiooINGzbQu3dvBgwYcNZGwI/czu7s4TFBENpLYPC4TEyHjCBVEhTTh2Ep4jt0MiqViujo6K43FAShE1IUqiQGjOqDo9gM8gAik3vTP/aXvR8iAndB6AaDwUBNTQ0RERFn/OZUQRDOnK73JC7tfb5LIQjCH4lUriIqezKXZp/DPM9dVoLw+xEXF0dWVhYZGRlivrkgCIIgCOeEGHEXhG4ICQlhzJgxqFQqEbgLgiAIgnBOiMBdELpBJpO1ezmJIAiCIAjCL0tMlREEQRAEQRCE3wARuAuCIAiCIAjCb4AI3AWhG7xeL06nE4/HI1aVEQRBEAThnBCBuyB0Q3NzM+vWraOysvJ8F0UQBEEQhD8I8XCqIHRDSUkJ27dvx+FwEB0djUwmO99FEgRBEAThd06MuAtCN2g0GoKDg8/KK8gFQRAEQRBOhRhxF4RuSEhIYNy4cURGRiKViutfQRAEQRB+eSJwF4Ru8PPzIz09/XwXQxAEQRCEPxAxVCgIgiAIgiAIvwEicBcEQRAEQRCE3wARuAuCIAiCIAjCb4AI3AWhG6xWKwcPHsRgMIgXMAmCIAiCcE6IwF0QuqG0tJSffvqJ3NxcPB7P+S6OIAiCIAh/ACJwF4RusFgstLS0YDQaz3dRBEEQBEH4gxDLQQpCNyQlJTF48GDS09PFOu6CIAiCIJwTInAXhG4IDg5m9OjRImgXBEEQBOGcEYG7IHSDRCJBLhdfH0EQBEEQzh0xXCgIgiAIgiAIvwEicBcEQRAEQRCE3wBxr18QusHtdmOxWFCr1cjlciQSyfkuUjt2WmprqK11EBAXRXhwAIrzXaSjvLidzZQfqMahCSE2JRJNt/flxNxcT1WFEWVEBJEROlRnsaSdc2BsqKO6yoJfdCQRoVqUZzkHr6eFsn2Hsar1xKVHE3CW93/67Bhqa6mptf8KzytBEITfPzHiLgjd0NDQwLp16ygrKzuDFzA1kb95Mxs3bmJbbiVWAJyYmkrZu3EHecW1WLrchxeXo4b9G7ewK6eM1qOf17Bl0cvcdcU/+GDdAZq7WcLjNJewPacMk8eDL/g2ULRzIxs3HvlzqmX2YG5ZxVNXXMfd/1zIoTMrFAc2fMB9V9zJy4u2UH0KedstVezbuJW9eYc5s8U8G9i9/C3+74r/463vd1Pf4ee+9t20OZ+mbubgcm7g2Stm8df/+5j9Z1TW9izUleSxY+Ox7beRjbtK2tr3ZGrY8uVZPq8EQRCEUyZG3AWhGw4fPkxubi5SqZSkpKRu7iWH9267k6U2N4Hpf+b5d59gVJiJspyveOqv36G7+jbufehSUjvdhweLYT0vz32WyuxZ/HvBnfQHwJ+o1H6MnhpLRoz+rIxC1699k3+uyOa/L16Ov7yWLV9/w6fvL8XUqychgLXJS1T/kVx5R1dlPp+cNFet4Pm572AaM4dH3ppL1i+Wl699l3su4JU9zzHuF8unO6rY+NmrvPHJXtQDepMUHoSrfCebG3vx16fv56Yh8SdJ509kaj9GT405a+eVIAiCcOpE4C4I3aDT6YiKiiIsLOwsTJPRIGtZyRdLZ9N/TugJt7Ae3suWnELqjC7fBwEZTJqShY4Kti7ZTg1OjA15rFr4Dc0JPek/NIrgmFSyBkcQqWkld8331JhCGTY2i6hANVIOs3HhRmqUYWRNGk+StJnSvRvYWe4bL1eFpZKd1YfE0COhmZldOw8Q0+96ImQySje8xQv//pGA6U/w2BOTSQJaysqobGpC20WZ9bKTVIOxmn25e9hf4btvENpjJIN6yClas41CQxCDZowgUS7FYS1m85I9mEPSGTQx4oS7spTtZENOCc0Wt++DwJ5MvTATtbWU7ct3U4cde1UOKxd+S0tab/r2TyboBGUOyBjHlKwwZFJfGzstBvK3LmdfHUALBbtKjrnL0Rk3FkMhW5fvoe64z1VE9simb89EdG3zbGp2L2dToQGnB9yuXKra7cnRUsnBvTs4UGMDwC8miyFZqURoHRSu/4m91SYiBs9gZIIUa/FGluxqRBebxahhyfh3KFcc4+bcxfXj++Dd/jK3/u1jXvnPd1z41S2EW4vZvGQHNUe39ScqLQF9TApZg8OJDA38eWpQzW6+2VSIzekBiZTkEX9hUAy4LO3PqxSyszJ/Pq/Mxaz/KYdqkx0vIJHqyJoymR6Bp1SpgiAIfzgicBeEboiNjWXs2LGEhIScceAulaYzengLm5Z9yJYL7iGywxYWinbuJKegBqfMD9nhLczfpaZA8iAPXOChpdaAHS8up4nGqjoagxJw0kTe2i94/Y1SRjx0OYEHl/DlOhXmuKe4PCsKddn3/OfxV6nLvo43hw2kYMfHvLNoDbVBg+irqWJ/5XK2jbmOmy4eSmKICoz72Vusp8+fwpFKS/nuhcWUafrx9xt8QTuALiEBXUJCl2V++MKO4/GOxjL2/Pgxb/9QgESfQp84LbX1WwkK17DszZf4qjCDx6cPJVEONtMu5j3Wdodh4pUnqFEzh7ZsJfdwK0hVSMvX8/7OIMpV/+SOoVZa6ltx4MFpN9JQVUdTRDIuwFKxh2ULXmf+fiU905NRla1i7fI8DDffzlVDw/A4bZSum8er//2MxujJDApuJG//IeqJPoVWdtFav4WPHvsPu4Ki6D14PIOjzOTtyKE+dBy33X0dYzJCsB9czUdvPMMy62Cm9Y+iZddq8oEjlyfOlir2fP8+7/2QhzciiyT3IXY1ruPAtBu5YUoC5ubdfPH8IqwjAol6NoW9Lz/H83v0zHwwleFdlFA/aBA9lJ+x/+ABDuBBa9rFvMceY4smhIwhkxmREoUqQsbhvJV88noJI55+kLjEcFwHV/Pdog95YUcgl49KQS6TYVixjrDLs7GuPv68yqtcxrYxc9rOq2a2f/URL721DtXICxgYpUYmqcWw2A/N7NHEnUKtCoIg/NGIwF0QukGlUpFwNEg9M1JZOMMvn4H1qddYsmwfV55gnklA2kguGx5ORJgO+eGF5F7xPJ++9h0zL7yTyXMn8uO8XVRGDWbm3XPbpsqUHZM4hfHDe7N+04+s3VXNJT0iqFi2jCKpjEEXXEYaRXzy+UJ2W4dy8z13MSP8AJ+++jyfLFlGvz4pRIfEYt23iV3K/vwjVY1MuouCQgny0GQSEk9+XJ2V+fiLEwf1xdtZvHA5h6NncO8tNzApPYjanBwsfjUn2XvntD3Hc/XkWMJ0AcjKQ9hy8fPMe20Zl064kUnXjGHVFwcxJY3girtvaJsqYyFv23K+/vEAmmmPcOOcCYRUB1F8w9u8/kk/Jg+9mADrYTZ8MZ9ce29uuPEurok4xGdUcKjCfholUxORNJIr776L6VGVfP3aS7zy6S5yiycyMEPBweUL+GGviz7338zfLkmm5cdy1uxe05bWSfPhvfyweDkVIdO56+a/MUq1kdcff5nvv1zJ8H43MGz6ddyek89tC1/nhRcTKNtQS/9ZD3L11D50NYjdsmc3hQ4H3tQ00o5+qkQfPYTL776Lv6QEAGX8kLfymFSt7Fu+gP9+U0yPW1/ljtnZKCReyjZvxGYoYk278+qz117g46PnVR2bf9jB4ZZw5s69hTmpwUg9TeQsz6OzS+Hvv/+evLy806hz4fdALpdz1113ne9iCMJ5JwJ3QTjfJFI0GeO5avIynlv1KZuU7SJ3UyX5u1ew7WANvhCxllqLA5pKKYMTjNB3FDFoEsOTN7JkyQ/kXgLbl5UgixjLVZOisVp3sj/PiNU/n5UfPsMBPxOHDzRiLJNQ3tCAiViq8vLwpE4nXqE8tSfaT6vMZhoayykrU5E6OoWExCBfmbOyAOvpr9TSWsaBHSvY9UUDTgCqaXF58JaWUg70PGGiRsrKq2hosOLZvpjX6zfgL6ul3ubCsGM7BUynt7OQnBw7gclJZKQHoFSEEp2QQAj5p1E4NUFBsSQmagAVaj81amsNFocDJ1Xk5dVhscbRLzsEqVRC8KBBJLOGwwDYaG4po6jISKtxB4vfeYoNqhaKyltprc+nxGRkAAmMvOFOLs+7gXkfl6MdMoenrh7ayT2BStYveJu6NcE4izaRpx7AzfdMIxHapgAp0GjiSEk52Xo2P5d57JhkZDIpUgkkjRxKXcm3Hc6rygONGMtoO6/i6d8/msWHSlj732coUyuRyuQMuOJRsjupwXXr1rFkyZLTqHPh90AqldLU1IREIjnuLuex/z/271Pdrqt9tE9/qtsdKfO5zP9M9tvZv091u1P5+1Tb7myW9Vzs91T3FxERgUx2svmip0YE7oLwKyBV+pM26gqyfnqQH38w4AV0ANSwdekXfPzfNchGX8LUIakEKw5RtWInpbbTyCA0i0mDk/j+fz+yYr6DjWVuomZcwYhoCdZSNWq1Cl14L4ZNGkk8wMgpQCDxmfH4U8yePS56jktCqZIBWfTN8rChbD8HD8LIHu0zO90yy5DLVCiVLpxOJy4ndH9dxUrWf/EpH72/Be1FV3Bh31gC5PspXbK1ixVnFCgVCmSycFIGDGREnzg0wMiRM4AIkgCJxA+12oPbY8NuByQuXA5H28XB2aBCrZYhlVqx2nwrFXkt1rbVhgCkyGQqlKpAIhMyGTZhCJHAyJHTAB2p8aG+pRmbCjnU4AGvF3dDAcUt0PekV3eBxPbMZkifODQjRzJZk8iwYQnAqa6U1LHMPhKkkhOfV5cfPa/0DLj8bzzerwaLwwM587j7wz3sqckg4+0r6HBatbn66qsZN+7X9aivcG60D5raf97Zdif796lud7p5/1L7PVufd7csZ7NOu7PvX9N+j/3/qe6rffruEIG7IPwaSOVoo3sxaXw2K1/ejIEQEgEwUVVSTk29k+yeAxk9YQjyzVt53es+5dDKR036iIHEf76L1Z/+QKMrnFkXZaNBjlSTyoD+WrZW2JCHDmbygGCgkg0LtlBaEkKkeQ+bLIlM6RWGWiEFIpj2z5tYfcVHfPvSy6T/+y5Gh0HjoUMU19URPSrqNMusISIiibQ0D0tycjl4cCS9BkTSuGULh9NkBIYrkBbXUFXtxZvg4fDyZewDgk+4LyPlBWXUNbtJzxzG2Im9cK5Zw3+6rK0QUtMSiIzcQa0jnKyBY0kNUQF7+O/NmwmZ3JcsZRpDButYlVtETk4jwxJqKSsooPGsrWQeTb9+sWi2b2HTxsPMzQiieu1PFAO+exBqQkOS6dVTyXcuGSEJw5ncIxAo5vtXtlCWFE9UcAnzn/uI3ZV9ufW/f6L0X88y77VP6fHGlSe506Alqd9Qxo3v064+3add5q++3MGN6eORSeHwipXUDDjReVXFhgWbfedVdCNrvqug18UjSYvQIos9QNQHe6hvbOr0rk5mZiaZmZmnWD5BEITfFxG4C0I3WCwWCgoKiI+PR6fTnZ2raL8QUofMZFzyWr44eOTTOMb9eSp7D1Sy9r1/ccsif2ipoNTsaPu5FLXfEKZM1vLEui95eEYuA0ZfyvV39u6wf1XqCIYlfMreLYchZioXZvr5Pg9O4qLbHsX72bu8/cB1LA2UA+H0u3A6M3rHYt+2mHp9FClaNYq2wwzveR2PvhvHu4/+h8duWI9OAU6Lhp4TL2HuqMFdlLk9GcHpo5h7x+04P1rEaw/OZX6AkqCsmdwVfwEzb/4TP+2fx4I7ruRHNVhqizGgOEngnsjUqy9ib9EHbHzlXvZ/oMbdXEat04NMCaBAGzSQieM/4sVt87l/xk5GXDiT2TeMJ2bEVTyKm399/BF3zvkQtUICZHDZIzeRjgSFfzjD5zzC9Kf+zqJ/z2Gdyk5DbRWutkusM6ci9ZL7ubngBl767B9cudwfe0MRNo4E7jICEwYy64678M7/jBfvvoYP/GVALKOunsmfY1389MwLfLLXxcX/+Rezh0dS97fd3PbEJ7z6cjhP3DWBE69ZdOZlfkvzGte+/QJX7XkbqUxO0oUP80hwEumdnFcBSBg5aDev//MODjSa8DgaaJHHc8Xdl5+1GhUEQfi9kYwdO9ar1Wp55plnkMvl6HS6810mQfjVsNlsmEymDp/n5OSwatUqsrKyGDt2bDfnrNloqmrEih/6aD1+gNtpx9TSgMkhQ6UJJEinQeG2YWhpxWxzths3VqOPCUHtcWNrrafJ7AakKP0CCdKrcbe20mp0oQoOItBfhQwXpsZGWm0uvPJAwiO0P48Vu53YTC00mo4E13L8g4IIDDCx5j/380Pwjdx9xWBitEfGQr143A5a6xswHx2cPdUy61G5LTTVGHArA9CFaX3rgbtstLYaMFp9SzHK/ILQa/1RYqG+vhWH5/ipGHJlALowDViMGJrtyAO1aLV+yN1WWppbsdhdx+ct8dWz2u3C2trQtlTkMWUGcJhobDH6ljVsK29wlB7/tuUgPW4n5uY6Wo97HvVIXanbjYQc277BKJ1mmuuMeNQB6EICUeLC2qGNwGaopdns4ufDlSCTawiOCGqrJzsmowGD5cgkHQUBeh0BflKsjY202iAgLBytAtyOVuobLEj9tOj1mmPK58Tc0orR7MZPryPAT8nxZ7AXz4na6CRlxmagutmMp63QSm0EYYHyTs6rtrpymWlsbMXmOlLfCrQR4QSKISVBEH7H3G438+bNw2q1YrPZsFqt2O12PG0vwJs6dSrDhg07Ls0DDzyAwWAQgbsgdOZkgfvOnTtZsWIFffv25YILLjjjh01+vTw4bTZcEiUqpRzpmd9YEARBEIQ/tDMJ3MW4hiB0Q3p6Og6Hg9TU1ONWDvj9kaJQ+5+1WdyCIAiCIHSfCNwFoRsCAwM7XA0LgiAIgiD8kn7PQ4WCIAiCIAiC8LshAndBEARBEARB+A0QgbsgCIIgCIIg/AaIOe6C0A1OpxODwUBAQAAqleqM1nH3er1UVFR0uV1oaCj+/v7dzue0GKvJO5hPab2c5AF9SI4I6v7LTH/XzFQXVGGWBxGTFI7f+S7OL8zr9S336HQ6sVgsuFwuFAoFXq8Hrxf8/PxQKpW/8we2BUEQzh8RuAtCN9TW1rJ161Z69OhBz549zyhw93g87Nixg759+550m5KSEmQy2UkCdzcWQyFbl++h7uhnAcT1ziSzTzyBp10iO3W561m2fCsV7h5clJJE/BkF7rXsXr6NQnccE6ZkoZdJ28pcRt52MwkTMwnrNH0N278pJeKiQcTLZaeZ9lQYKd9XhkmhJyEjGs1ppW1g748/UhbYh2lJ4cSccVna6spg4ejK5upkhl08iKgTbt9MwZYyvHHxJMTo29Za/2XZ7XbMZgtWqw2bw4VMocDrcYHHi9FoJCgoiMDAQBG8C4Ig/AJE4C4I3VBbW0tBQQH+/v706NHjjPenUqmYNm3aSX++ePHiTlK7aK3fxTdvL+X/2bvv8Kiq9IHj32kpkzaZ9EwaEEhIQq+hF6UJCCKCuvbe1rb2XVdXd0V/rAXbYsUFG4gFkF5DCyWQQAoJpPeeSSaZkim/PyZgyiSEgKDr+fj4PDq559z3nlvmvWfOPddl7nACAGNlFSlZ+TQ4LWBSv4ALTOjqyDhVibL3NB69cTq9LjobzGPrB2s4oJRgivyIm6OcW2I+zs+fFTHnvMl3NhveXM+oaUNbEncbFnMT2uoGOnsX64WpIX3PHvI94vC64MT9UrO3VfGoWCKUTkhsNmrT95DlrOShGbEObsLMNGrrsfk1n0v0f01msxm9QY9ULsfLNxC5yUKj3ojRZEImtYFVT1lZGTKZDHd398sQkSAIwh+LSNwFoQf8/Pzo1asXISEhF9Xbfuk44R00kjmPP8pQwFhxlK8/2szp47kMbS/vYAAAIABJREFU62cl5YcM9K4lpOVU0tQUwaxH5xAthdR1b7M1G5B7EBo3gVlXaag8tocdOw6Q65RFeVUlU+ZdxYjIQMp3r2BDchUGM8j8x3HbraNRY6SmOIPDm7Mx+lZy+rSCqDHjGDcmCu828YVz1bQytn59iBkvTcCnQ/xGStMPk7D7EIVNAIGMnHcVIyJNHFqxhfTGdCrfeZtMl1jmPjYdf2xYjVoK0w+QXuXHmAl9WxLuRk4nHKTSpx9x/cKo2e8o5q6UcrhNW1kANePuuJPRPgBm6itOs/eHn8loAJcgN3SFTXjH/FJDwb6v2XS8mAYjoB7NHXeOxaOpmEPrtyGJv4NxYYCxkvQTp6mThzJkSGi7ITbhTL3nfmb7eyG1mslPeINXP9pDwYze+GZnkLwvG517Fbm5LsRN7o+rxYa77Zd3xGZv/Q/rUnVYkaEZfxuLR9i3WFeezeHtP3CsFFCGMnLieEbFBttv6gr2sWLTcaoa7K+E7T/3L1zTr2Pr6HQ6TOZmXN3d0RmakcpkOMulYJVRrdUhs5nxUMgpLi4mKiqqy5YWBEEQLpz4LVMQeiAoKIhJkyYRGRn5G0nc27IYjRiam7FKZUio4sT21Sxfn4mzZyAREf64SySU7fqADw4aiYiIQKOSU3BkHT8mluHq6YVKpUKlDiAkIghvpRP1x75j+c4iVP4hRERE4HRqFW/9dApoRltxjB+/+p6EHAkRERr8VG4OewTCJt7LkLIP+GR3Zbu/NJCXsostm0+iV0cQERGBWp/Kj1sPUlhpxTvYFzeZG37h4YSH++KKhcbaLA78fJTsyiwOb9tISmlLVaUn2Lz9EJkVOmqOdxZzV9q3VQQRTQd5+5PdVAHmxlrSd61lS66EiIgI3BpqKTiTQXVLae2JDXy+KwcnL3tZtzNf89qadKQSCTZdJps2JKHFSFlWCocPplArc6HLd+7abDTX12OQy1FgoKowkbVfb+BosZyICA0+nnqyEg6TXlCFAag5/CXLdlYQHBJGeGgoktTDnAaataUc2/kjO/PlRERE4GfOZ9fOXZzIqwPy2bFqPWk6N4LC7O1fvnENjlrKaDSiN5ip0xkxGE1Ibc1ILEY0fl4EqD3JKihD5uJBcUnxedpZEARB6AnR4y4IPaBQKAgICLjSYbRioCJ3K+88los30Kxtxj16JHPH9sWTQsCTmAmzmDt3OH6uCqCc1Wt2EXDjcq6f5I/FUMqhjavZuSMTywsDiYk5g5tHHDOvn4iGWnav3I807k/MmTsYLxcZtXHlPPXCNk5dewfOKFAF9mfcdYuZHe7VeYge/bjhwZH846XvSJ10J77n/uCEl18fRl7dj8Co3qidwFCu4u3XkskqG8HUacMI/2cJo+bNZ5arE2CkDEDmRlh4P2w+O0lKLWJMUAjFaUnUq8MYGuFJ9urOYo6m68FN7dqq3MhP1+0m55nxRGsLyThWxcBFf+f6od405ifQlFlJLQBa0vYkYu09gxlzRxHkoUA3tJoHHtjEqQWPETdpDkkfrWTN5sWEVp7AEDaV+Gg/B88OnGL1359np7MCbDaM5RImPj2DUCAHJ3zDBjJlwSKu0ngCp8iClmEy1Rz9OQGX0Y8zf04UCokNXUEBRszUV+aQmV5D9MKnuX6gF6aaw6z8cB+ZmUX0izCRlp6NYu69zLm2D57OUHbihMNeHQkSzGYrhiYD9Q06nKU2vL3cqaypoaConNIqLaZmC0ajscsWFgRBEHpGJO6C8D9BgYdvLKMXX0dfAFzwCQklJFiFgkJARWRkAC6uipblT3MsqZBk7TPc8QWAmcZaMz79fGjoUHcJmVmFnExcyiMbXZBJwGatobRyEFWABgWengGEdZW0twgYeDs39H+YlZtn8Xjk2U+d8Va5kHFgDf9582TL+nWUZHrjc4sJc6e1yXALDqd3qB8H09IovlpCWpoJ35BehGu0/NxFzF1r11YB/vg3JtOIBYOhmNKyYCbH2gcCuWk0hIWHt5QrJTungBPbl/HUVjcUUoAaCsv7USmVE+0bwfCgal7493sMjZ/Ioif6o3b4xG8QI66dx0iVEikS5E5+RA4Nw5VawBmVKgCNxtNBuUIyMlQMuzsQqVSCRCLBIyICDxrJbzzD8T37Kc55jB1OAHoq85VMjBuPkWjmP7eQFW8u5bGfDdikMPqhz7nPwRrMFjOmZhNGZNTp9LgpZLi4NJNXVEJuURUWixWrxUyz6dI8fSAIgiC0JRJ3QfifIMPVQ0Ps6NEM7dbyPvj7D+WmFx9j+LnP5Ci9fAmkgfw2y3rg5RnD7JuuYmSQ77keYqlcRQjQfuBL19SMfHAGPz3wFpufGd/yWS3ph3aw77iESfc9RbQnwBl+XHL0/NMrOvmjCfbHmprIjm/LyddaiBkRQoCTtMuYe0aKTOaBm7KO+gbAGdAb0Dc1oVcDeODhEc2Me0YwrLeGs/P/SCSehGChsbGA9Fwr0xffQqgpg2PHiomf0svBerzoNXQYo/y9uh5G46CcStVAXZ0VNMC5EVxyFPJgoodezfR757fc2AG44B0cgDduKGJnc8/zQ6k1NmMrXsvLf3+bYT+3PjZasVmQYMFgMCG1yjGbrTQZrTQ0mQnw8aauphIXl//1iTEFQRCuDDHGXRD+kCKZPLmW7zZriYmJISYmhgA55B/eQ1GHZYMZObKZ7QerCAntQ0xMDNH9+lG+4RuH46DPxy1wHo8stLBizZGWT5pp0tXT1KwkpJ89FmlWCqdKC2g8b20KNCHB+LnUsWHtBmqcfNGEhKC4xDHbyXBzCyM8vJotm1MBKE5L5dixY9QBEMiQITYOpFSh9g0/164VP/yXVFMTNYmb2S2fzuKb4hka6Y81JYGUuh4H40AoY+IlrP0uEbPZgs1iIWfNGo7ihEoVjG9QNSmZ0nNxOReeJqsgm3pSWbHiKFKPYPrHxBDTxx9jcbGDX17Ay8sLJ7kUV2kz3h4ulFTWsC8pjeyCMnxU7kT4u1FWnHdJZloSBEEQOhI97oLQAzqdjvT0dHr37o2Pj89FP6Da2NjIkiVLOv17c3Mz8fHxF7WOthQMeOgjnnrvTkaNKgFA3TeePz35BuMo5UybZeVELHiRV1Y/y81zllKntyCVOzHzpa08j4XzvzqqLYnUnaAZNzLhqyc56r2YOfgyePBI0hLf5MEZnyGTgHrMKELkQdgHhIzi5ps+5rapE/inbBpL9r7QqtcY5JooBkWFsnNfNZqoQUSH2C9rncfcUxKc1RGMu+4Ozvzzdka9K8M9qi+hylhGASAjdPaT/K35ZZ685X1K6poBmPL3XTzXeIovfk5m+O0v0MtVgW3EELILdnFwWxIRC4dx/kFG3SGnz83/x2OvzuOqiS9jligYcM8KPkSCLCiaWfOvY/WHjzNqSQ0AfaY9zGP3TcUbuLHff7jtzpfJrWwEq5Fx/zjIOAdrcHV1xdPdnaLiEjwkcgb2DkRvasZmNWPS1VNRcJp+fSMJCnI867wgCIJwcSSTJk2yeXp6smTJEuRyOSqV6krHJAi/GQaDAZ1O1+HzpKQktm3bxqBBg5g2bRoy2YUNahCE3yObzYbFYqG2tpac7GxKSkoxme3j3j3c3Rk0cCChoaHI5aJPSBAEoTMWi4VVq1ah1+sxGAzo9XqMRiNWq32qgZkzZ3borHvuuefQarWix10QekImkyGXy0WCIvyhSCQS5HI5fn5++Pld/DtrBUEQhAsjsg5B6IG+fftitVoJDw8Xr3YXBEEQBOGyEIm7IPSAm5sbQ4d2b/4WQRAEQRCES0F0FQqCIAiCIAjC74BI3AVBEARBEAThd0Ak7oIgCIIgCILwOyASd0HoAZPJRHFxMU1NTdhstisdjiAIgiAIfwAicReEHiguLmbXrl1kZmaKxF0QBEEQhMtCJO6C0AM1NTUUFRVRVlYmEndBEARBEC4LkbgLQg8EBwcTExNDnz59kEgkVzocQRAEQRD+AMQ87oLQA35+fkyYMAGlUikSd0EQBEEQLguRuAtCD8jlclQq1ZUOQxAEQRCEPxAxVEYQBEEQBEEQfgdE4i4IgiAIgiAIvwMicRcEQRAEQRCE3wGRuAtCD2i1WhISEigtLRXTQQqCIAiCcFmIxF0QeuDMmTMcOHCA5ORkrFbrlQ5HEARBEIQ/AJG4C0IPuLi44O7ujlKpvIJR1FOQmkrGqWIarmAUgiAIgiBcHmI6SEHogd69ewOg0WiQSi/k/tdIxelMCqobaW4ZYSNRhjJoUAiuFxzFIZbe8DiHfK/j3wn/YNwFlxcEQRAE4fdEJO6C0AOurq7ExsZeWCFDOeknDvH9u1+R6e6N2sUFKeWcPBnEnc/dwNj4UYRfyQ58QRAEQRB+00TiLgiXSU36Zj5+/RNOSufy7JJ7majxQkE6X97xGG88d5rrlnzEi1O8qS3JJGnfKWrOlVQROXII/SP8aEjdyeHTVTQ1A2RQ3G4dzQ0VZJ88xIkiPQAugdEMGxiNRuUEVJC85TDZ2iYsAEhwcunF6GsG4Fx0gv2HcmkCwAn/yDgGxEbi4/zrt4sgCIIgCN0jEndBuCyqOZ5whKwCOSNfmMUQXy8UAMSw8MmZrLzxS/Z/v5uSKdOpzdrOxy99QpZfJMNGjiYmKBTfOCP12fv5dvkbrKuOYvKgUIxp28kAPFrWYNZVkb5tBR+vO0y992Ci5XmcrNhOyvS7uGvWUIJVuWx5/02+OVOGy+B5LBzuh7PSg+raFA4ve4uvjpvoP3ksEW4SSsubsCqcGDEg7Fz9giAIgiBcWSJxF4TLopKysnp0jcGEhrri1KonW9K3L70tZjLy8ygE3AHwIGLING57/C7GB7sCOpI+XsrmJB2977+DhxcNxLavip1HN9AMgJmGylNs++4nTskn89B9TzDDM4nP/u8t1v6wlWEDIvBTnV1jL2Y+8ihPxAcARsrOfMOeTdkox9zIjU88TrybgZL0HLSKzrfGbDazbNmyX6GdBEEQBOF/z6233oqvr+9F1yMSd0HoAYPBQHFxMf7+/ri7uyORSC7xGtzx9wsmKPjsI6tlZGaWo2sIYuAAX5wUUlxHjCCSDWQAYKKhIZeszAYaVWls+vx1kl3qycupo74wm/y6WvTn6g5jyGDvlv+W4+YWxbAhSr7OTeSrN/7OZsAvdhLTpsZ02ttusVj45JNPLvE2C4IgCML/pqKiIl5++WU8PC7ud2yRuAtCDxQUFLB3715iY2MZOXJkNxL3YMLCvPHyPMLpM40YYsCjJSe3nThBmlyBMiqaSKDMYXknnJ1lSKWNGAw2bDZAr2+VjEuRSV1wcnbFJziGUZPj0QDx8dMBL3pFBeGC1kG9Mtx8BrLg2ZfpW6yH2mz2bvmBL/aWYPUIwHdmDGoHpeRyOW+++eZ520kQBEEQBDuFooufsrtJJO6C0AMNDQ1UVlZSW1vbzTenejJk/mzGHspi22erSRwdzPRwH5xIYvkrm9C5j+Sehyfhg62TxD2QAQPC8Nq7g8NHirhrcDDahATOcPYkdsLTqw8DByhJbbDioYlnxgAvoIAdnyRSEBhEsL+jepupq0sh4aCUq++dgU9tOvrCo2xLb0TfpKez2xGZTMaMGTO6sd2CIAiCIFwqInEXhB4ICwtjyJAhREVFdXuYjHvQWO78hyce//o3nz5+F1/IFEiop9R8NW98dhcjI1RAbSelneg142HuzMpk2fqXuXOPO5bqHPScfThViltgf65/+GlsX6/ig6dvZ427HAhk5Lz5zOsdgCvlDuqV4eGmIdxjFc8sXIbWYqCuqpHeE25gzMj+ePagbQRBEARB+HVIJk2aZPP09GTJkiXI5XJUKtX5SwnCH4TBYECn03X43Gq1YjKZUCgUSKXSCxjjbqaxuhqt3oTl7AuYFF4EBHq2zDJjwaRvoLaqCam7FypvN1r/sGbQVlCjM2Kx/vKZVOaGT7AaFwCLicb6Wmp0ppa/KnBXe+Pp5owMA3VlNeianfDW+OAmbYnZZsHUpKWqprFlmkgpzu5eeHm64yzrbksJgiAIgtAdFouFVatWodfrMRgM6PV6jEYjVqv9y33mzJnEx8e3KfPcc8+h1WpFj7sg9IRUKsXFxaUHJeW4+QTg1unfZTi5qggIdXwD7eLlT7BXF9XLnHDzDsDN29EfXVAFBtOhZokMJzc1wW6ORrMLgiAIgvBbcSHvahcEQRAEQRAE4QoRibsgCIIgCIIg/A6IxF0QesBqtWIwGLBYLN2cVUYQBEEQBOHiiMRdEHqgpqaGhIQECgsLReIuCIIgCMJlIR5OFYQeyM/P59ixY1gsFkJDQ690OIIgCIIg/AGIxF0QesDDwwNfX1+8vb0vYCpIu4qKCoxGY5fLKJVKfHx8LibEK6yegpOl2AICCfL3wulKhlKZxvbkYmwEMujqgTh8D9VZ2gKOZ+RQoXUjakwcoR6u/D5nxCwnZVs5Qefb3m4xUV9ZSmkZBA0Ibze3fy1nDpfi0r8XQZegrayWUtL21hA0KRbfi6zryuiqrQTH9FTml6JtVhIUGdjFjFtCR1pyj5cijwglsN3UwZfC2V+TLRYLer0ek8mETCZHIrFhs9lwdnLGydn5AqdEFi6WGCojCD0QFhbG5MmTiY2NveALVmpqKnV1dRiNRof/VlRUcPr06fPU0kDGtrWsXr2a1au/46eN+8ht7M7ayzi6/hAFZkvXi2kLSd67qaX+1exOr6KpuZsbCEAJe79cR0JqId0Kq0tlHF3/I2taYlm9ei0bNidT0a2yOjK//4RPN+3jQGJWp6+3sjNQfOBnvlu3ke0JqZQ0mbB2ufzFaKT0dAZpaYU0nPusitSdSeRomzjP3umGE/z3qZWkXXQ9AI0UpiXw08q9FHf4Wy4bl60hsayOCzo8OmExH2fVi99y6rxLXsq2upS6aisBbJgM+Rxpc/7WkrF3O5s3HafyCkZ26RVxcG0iJb/qOgrY8cn37M8px/ArraG5uZmGhgbqG3TU1TdSrdVRrdVRU1tPRWUVWq1WPOt1mYked0HoARcXF/r06dPj8pMmTcLf33FfaFZWFvv37++idD0nf/4vq7aV4xdin9RdKq1E1+yK67XDCOxyzdmsX7qeUVcNIUzeSf+osYL0hA38cLCAZncf1E7lJJ3QYb1tAeP6eOF02W/3s1m/9EuqZ44gQi4FixVL9UlyXFy5c1IU7l2WzWfTJj3XfLCEPwU7n2c9FRxNqiVi/GKuvWoo/pe6+6oNLacP7eWkNoxrYkNb3n5bwM7PNhAcGkywl/J32tN/uRipK6/F1mxGpAu/J1YMDSn89H46c2YMvgS/Bv2WZfDdK1uZvWA0wVc6lB6yT8Kgx4oNT7UfzhYJukYjBpMRidSGzWKgsqoKqVSKl1dXLxgRLiWRuAvC704+25Yn4vX8v/nL6ADAir6+nKykX/r4anOPsz9hF1nVgHskU2aOIza0kQNfbCW9MZ2qd98hyzmWOY/Oov3tR23ucQ5mVhM26U7mTeyLj3MZRz94nxW7UxmiGYWTMpcNb5/CY0gVSUmNeAcPYdriEThlp7B3217ymkAZ4UFFpZFererN2bac9amNWGxSXDXjuHHRcFToKc/JIGVfLjr3SvLyXImdNJ74ob3bDTPow6xHH2OWqxOYmyg8+ClLVu2neFIUUV1u72r2F5Xgv2oZVZ1sr101abu3svtwCtrKBiozspl+63QG+XqSu3EZ60+ZQeaMetA13D4pAtBRlHGKU8dzqZFXUVTkzuAZkxkZE9LuRqKG/StWcKgGwKmlrQZhy0hi/659pBk9qTBWMnFGfyRZCaQUnyDtvx+T4z2QOY/Mob9CiklfzN6vVpOiBXBD038kk2cOOZf0lB3fzI7D6ZQ3gtega7lxfC+UTmCzWija8zlvJtUCcrxDYhk3ayp9WwKsSNvN7oPHKKoHPGO5dsF4enkrkQJWSwV7/7uKpFqQeyjAIoMuBn7UpfzEf7YYsJqsSGV+jLv1Foa3vARMV57D4R0/klwGuIYwYuJ4RsYEYb+N0pL801r25dZhsoL38NapXDO1hens3bSDMzpwDQnB16Km16BoomMk/PJDVw4bl2XgNaySQ4dqABkefn0Zf+0soj0BDBSlHGDv/mRKDeARFYVviYzI+WPo7+vZ4UtQX1PC0a3fcKQEUEUweuwExkT5AmUc+TEDvWsJ6blVNDWFM/OROURJq7tsq87b+bSD82gsmtbBVKSxefdB0ovqAQifeCvXDPLFRd52H4EL/r2HM3XeSIKoJSvxFEUlBRQ3VlFZaSR0zCJGS4+y4XAuepOV6DlPMKuvg+11CWRQ/HjGDAnF1eGednQ8t8Rcm0vi/gQOZFUDEDziWqYN74O6VUUWcyabl28itboaw5sfcLr3cKbOC7HHUZTC5q9zaSo1AB7EzpzL+L4BKFt2UMa6N9l0BpC54td3PNfOinNwRLbfRxZQj+S228dhH3hopqHiNHt/2sSpBgAVfUePZdyYKLw73b820tYvY1sOIPcgJHY8s6ZG4+6gncGTQdcuYHyvWra/t5FMyxksb77DafUgZtw+iTAHLdr6/CV8IvdeMwh3F7m9rT7MxCWmkpQUY8v+HQQZR9i3+zCFenCP9KK4ppn+reo7ffZ6JVXgFTGe6+cNxqvV9apWUUVhoTszZkwmJibE4V4+y2Qyoa1vwNsvgEajFSsSnBRSLFYZ2oZGrOZm3OVySopL8PT0FMNlLhMxVEYQfndkyOUGGhrODk6Q4uoZxKDJwwkEDOWZJOzazokqBRqNBo/a43y3+SCFVRY8A7xRSpWog4MJDvam47tf68g7VYzBtR+j4vvi4wwQyPAFI1EcOEKm3oCVPLZ/8gGfJNSh0QQR4OsJ1QUc3rOFI2UyNBoNksJcckoKzg0DqTnyNe/uLMMvIIjgoABMJ79h+ZYzgIGqgkOs/Wo9RwolaDT+qNxcztPbbMNqMmKSyZBf9PaeJUfp5Ym70h0vH3+CNL64K+TUHFjBmzur0Wg0BKg9KNj5EWuP1QJNlJ3Zy7ffbCWtQo5G44+X0qld3Fl8/89PSJZq7OVVLlQkr2PtvmKcXd3x9PLEw0NNgMYfL6U7Xj5euDm5ofIPJFijxlUCFnMqP/z7K0472evwdTGSeXgzO46XAqA7s4+1u45Ta/VEo9HgdPokWc32IT5WawZbE+rQaDRovJ3RZuzhx50Z6IDGvMP8vDORYoMbGo0Gt9JdfLw+iQa9/Zgq2/0pnxzWodFoUMlllBw72MXQjzx27itHpfJHo9HgX5PAhysPUAM0a0s5vutHduZir8uYx86duziZV2c/2o6v4/M9Bbh728tWbl1HVkutzdpyju9Zz558e1l5RRpbv/mGvadLaaKcpA37yaxtxEwBu1d8wLvb7PtJ4+tOc/Yevt1yknpAX5TKjj37yda5oNFoMGVs4ZuV6zhR24i53ZaYG2tI272anzMtaDQaXOqz2bdrKylFTUAlKdtWs3xdBlJXHzQt+6irtmrMO9JFO3c8j9o+C1JJ8s7tHDpVh7Ovff9r9+8kw6DHSgbfvfoZaXL75/7uEvKP/szPh4qAenKPbeGHzSnUWL3RWPJY9993WJ5QiadPIJr6Q7z/3wSqHWyv2lLGgYTtHGlJvtvq7HguAOo4fSyBhIN52Lztf9efTCKrpqrNEA6JRIl3kDducnd8NUH4qz1atrmaU9n5VNU62feh5Qw/fr+H07WNWICqhOW8tbvevl4vZ8qTvmf1vgIHMbbfRxrq97/HZwmVgJn6yqOs/2wzRa72GNW2cg7t3cnRrOou9u9yPjxg37/+bjbyDq3jp1btvPK7/ZQ2udrjNqXz1bd7KGiU4B3sjSuuqDXBBAZ44ej3vvbnryHpv3y+O59miw2r5QxbPv+Yrw7p0LS0la38NHv37OJkjf1aZzmTQXZlKU0t9VW3ul4F+arQJq/hi525tL5enSyXodH4o1Se/8kjs9mMTtdEk9FGfUMTMixIrEb8vZQE+aooqarDLHOmpKxUDJW5jESPuyD87kQw55mFfPH5qzy+0RVkzvhGz+aBu8ehxkhFbgYFlXKGLriDGZHuGMq38/ZryaSPHsTUGSOIeK2MUQsW2nuvO2iiQWcGPHH3aPVxgD+B1Ycpt1iwARKZL6Pm38yiOH/AROmJ3RQUw4hFd3Bdf0/qM5woTkpoGSNeQ9KG3TiNepzr50ShkFgoOV7Fa+/t5vT0BYACdWgcUxfcyFUhnfXqprHq2afZJpUAMlw8ejP3vqkEX/T2nuVFryEDiY7IxzruamZPicObKn7+fjvKyf9i0TVhWIz1pKxbwn+3JjNlaCzgjH+fIVy94EbGBTkasKOiz4ixDBozlj7uYDXVcHLXKtZsPEnTv8YwYOhA0IYxa9F0IgAimtjnV0TwjDnM7huEC2C1+BIdPxFV/CjClWBuzGP3Dz+SvC+NsiEelB9Not49mjnzZhLn70JTQQENznIk7feRqYJjW77jpyNpVMwNx3AimSpJCJPmL2CExpWmIjl/ezaRk7MGM8a1hv2rD9Nr8XIWTfbHVJvL9trTbCzrrO08iZk6lwUzBuKhkGEqaGLHvXvJ+/NIwitzOJVWTfTCp1g0UIWp5ggrP9zLqawi+kbYSN56DPfRf2L+3MF4ucgocEskIQHsSVY+2Zl6hix6mEUDVejObKE2dXMnzx14M3z+zSwaFAjmOrL2fsPn65IpWxiJNDOTGrM/42/4ExMj3Kg91sDJXWkOhthYaNLmc/JwHn0W/p1Fw7xpzE/gq++PcvJUMf1CADyInjCL+XNH4OeqAMpZ02lbNVFwMqWLdm5/HrVXT25uDnrlNKbOvoZoNVSdOoXZWY4ENf1Gj2fEuLH0cgOLvpRDm1azc8dxikcNBFwJjB7M9PnXEG0JIOO+71AuGM+8iX1xqzazfsEushlLdLvtNdWlsHbFTrJO5BLXzwd1t47nw+SPG0NpaS5VzUEbhXXoAAAgAElEQVTMm76IMcFQm5OD0avtTbhUFsqouaPZ82M6kxfNZxQAJYALQVEjmX79DYzwd4NaXzIeSyS/Xkd/vyb2fbsVr2vfZ9G0wHbrDSO8Q7uZ8Y+7mjnXjSHIQ0G5Oon7v9lHxYS5eLoGEzd+Cr5DBxHsyrntzT+RS00/507273Z8W/avo3YOHTCWWQvnEqd2hWpPjt53lBzDFKZeH0/Yqw2MX7SQyQ6PWR3Z7c7fKk0ej317mGsnhxOEBIVzEPHzb2ZRf1/ASEHiJsq17sTfcDsz+3pQd8JM9sGjLedEFYmtrldWcyNnDnzKR6v3kzNlGq2vV+ODPBxG1J4ECVYbNDQZqKipQ6sFTzdnzBYLZZW1lFTUEOTjhcFgEIn7ZSQSd0HoAb1eT25uLsHBwXh5eV3mnwiV9Bo1l7ucwyhotGI16Tm9ZzVLP7bxl3tiqKnJJWXbFhLS0/hOAaCjOMML31tMHXoYe0oqCST2XLJhQKutpqkpmD597Im3Z58+9Ao4hb1VCknPKCYt4zUe2KBAgg1zsxZtzXBqAHec8fYORNNp0g4QxMh58xnhJMPYmMOOr/fS6PwgrlT/itubz8lUX8Y8b39qQObkRGBsHG4bsygmFnDF19eLQIdJO4A/gwYc4W+P3Y29f9yCvkGPs3oq2m5GIJX60zt0L//688ctD+6ZqK+0EjIyDB3VFBVb8e0ViI+P/bcEZVgYyrNlW+8jJwXOHh64GQwYqaW0NJ8TP6dyLGk3bjIALXmn/Im3WrFxhpQTwYx5217WydOTkNhYAjtN3NVERweiUNhTNElAAL5NuTRhRNeYTXLCQUry/8JuJ4AmKnJdGR83HiMlZGW5EXtNIE7O9rJB48bR+40UwIiusZzauiCGRKkAcA8PJ0Kjoc5hDAEMGtTydIdcjkKlwsPQgIEGdJVNKBRBaDT2+Uq8Y2Pp7VnoYKYjCwZDEaWlQUyOs4/zcQvWEOR8kpKKCurxBFT0jQzExfXsAxBdtVUtpWV5nPj5ZCft3P48ai+IsYtnUfbJdt5+7AfMThB7w8vc21uBhABi+x/gpUfvphwAM7paE959fLAPqnHH19cbD08F4I3aKZDgME9kcikEBBCgS6ERCwbDGZL3HSOv+CkOOQMYqC6UM+Tmoeg7xNPV8ezDgClXU1i2kZVP381nLhA542Fum967mzOduBEYGIiff8ucMt7eqC1mTFYrVvJITi7hZN1fuXt1+/U6omHQIA1ubvY1B4wdR9CLSeQwn9HO3qjkO3n7kXepof32Ojvcv8eSikjRPc/dXzpuZ40mEO+z44F81PiaTOi7lcR2PH99hw8n+JW9ZNusBElArggkuv/Z+ZV01NRosVqDCI+wJ96qqCh6+eS0DGvK52RqCenFL3H3D1LAiqlJRzNjW86Zs9er7iXtAFabFZPJiLTZjLZRj4tcikIuo7KmjtyiCpr0RqwWCyaTqdt1ChdPJO6C0AM5OTns2rWLAQMGMG7cOGSyy/0ooSuhg+MJBWwWPaHueWS+l0rxPYNxcg5l0MRr6Dt/Mr+MYFTi30uDsuUrt3O+BAW6cFJbRGkpRAS1fJyaSkrffix0cnIwvk6Ok8IFhaKSpibACWhqRGc0tvw87InKK4a5d1zHaE/3lvISFM5qNEB+t7ZXTb/R8Yx1VWAxxxHoquf7/3zNqbdnX+T2dsULb5WWmlobqAGrFYuugSYvTzyhG7M4JLHsz6txu/spHtMA6CnJPEjC9u5HYG4+yEcvbif4nse4OQDsM3Ac4kwNgCtKpYVmsxGTCToZlOyAC66uvRg9J4qYCUPxO/e5O8He7khRo/auoba2pU6zmeaGBnRdDDRyTI5CHkS/IVO4+u55RLZavzokCG+q8fRsQquzYLUCMrDVVLfM/CNHIVfi4tyArhFwBvRNNBr0XFiK4ISLiwxowmAAFEBDA/Vms4PZaKTIZB64Keupb2hZp9GAHpC5uDgc6kCXbXW2nft10s7no8S/1wRueKAfk+saMVfu4oOPv+LAsAeY4pPGskd/RP3gU9wYBNBATlIixy9oGiEpMlkAvWImMP7Pi4k+97kzqsDAVvGe1dXx7Ix38HBm3xrGiBlaTDWH+frrLeyP9mNWnObczWTPqFCrB7LwuUdaeugBZLh6+BLkcPl66uubMVuwDwauraFGrcYbE9WlCaz+NIOoPz3GKF+AMhK/O+zgJuUsNX7+Q1j03J8Zdu4zOUqVH0HocDRYp/uUHc/fujpqPb3wxlFHkBNOzk5IpU3omwAvoFFHg6m55bkaL7xVcVz31J3EO51N7aQ4K30IBjJ6EqLNhs1qQWIz09xsxtIMnkoX9CYr9U1mvDzc0TdqcXa6ohP+/uGIMe6C0AMGgwGdTkdTU9P5F77kknjnqa/JMdr7k60mI8WHEilQq1HhRlCgGpuiltIaD+Li4oiLi0OSfpRTNRXdSDadiBjYH6+6LLas306ODiCNLz48TuyUkfgpnR18pbjg6xeIq2sxBw9mA5CdeIgTp8+gAyCU+DFG1u+qpV9Uf+Li4ugXEU75znWcueBtlyCTexHSZzzhbts4nHYh22tFV7ODt+5dTnK31hXOhAkWVq20z/Bj0us5umkLshEjuzlLRANF2fWo+tpj6hXgR9neTeRewNbabFpKC/T4tNQR5CyjKGlfyxRzPkRFeXA6K4OCAvuY5NL16znQdL4pElX06aOkQluL0ep3rs2MB7aSamjCSiSTJun56qtEAOoryjm8dSuddrh3ygkvVRB+QbWczJafW49rSQ5nCrKpJ5gRI2Rs3XqUpib7ew32fb6CnHNlNfj4lLN7t31yyPzjySSnprX0dHaXJ2Ghahrqc0lNs488T9u2jbTyMgc3ADLc3MIID69i21Z7BlyclkZ2bS3eYZ3Nyd5VW6no3burdj6ffLZuPUJxjZLouDji+mmQ1FTRYLEA9RTnNKBuOS7CVB6UHNp5gYmkDDe3UHr1qeVImuRcfB61ZeTkZDiYOrWr47mCI0cOkZxhpV9cHHFRYbjo62kwGi/BdJ29mTJFy9cb6s7FGKbyoDixs+0tYcP6Q9TW2iei3b9iBaapU+mNjWZTPdVVVgKi7PV46+vIO5XSxTSUkUyaVMsP23Xn1t32HLwY6g7nb9L339MwfDiRDjuC3AgK9MNiySfpmL27I3NPAqkF+S03HuFMmNDIN5tqzsXaK8CP0oRN5PUwQmcXF7y9VVj19firlNQ16Dh8MpP07AJcnBSE+blTV1lCZGQkUqlIJy8X0eMuCD0QGRlJY2Mjffv27dEF67PPPut0eI3VaiUwsKtJHQdyz50nuG/aJM6YLNhsCtRB03n6y/lokCKJHs9ivZaPlt9D/DP2x0NjFr7Cs27BKAnkpps+5o6rJ/KabBqv7XmZce1qV/gOYeH8Mv79/nss/uxvyCRmYm56hxfHRuKucLStUjwiRjBtUikfv3Mj8f+Q4TV0EBrn8JaZHOT0uelfvLbyUaZNfoVmiw2Fmzdz/rqWxzGQecGtJ8HDw5v+fXz5cN12Zjw9uYvtbf3VbsNqaaS6tJauX391riXod9cHPPm36cTHv4BN4YZm5jOsXNgLOVXdKD+Wl15az9jF8XwhA7mnByHDJtPfCBBIbEwACe8v5Yb4r1j0t8e5ddZA5sz+lsceXsjS+tG8tOtfTFdM5tEHNnDt9fG8KwOX4CBCgoYxGAAZgeNv46aif/DO47N4ulZK4OxXWD5FcZ4eGRl+oxZwj+kLlr52Ey/n2W8+h97zCf9QuCFFyoAHP2XxM9OJj1fg5OtDSL9xxHWrzVqToAzqz6z581n9nyeIX2JPBXtf/SCP3jsFb+R4X/8yD7x5Kzdd8wa6ZgkhNyxgNPUtZWOYPHMWuUtvIf7/5HjE9Ufj0pcBFxSDFPWgWVxbVswHr8/nnTIZPhPGECz3ddALLMFZHc7Y+Xdw+rXbiX9XjiVwKH+680FmD1YjdfjrjaKLtpLhN/I67jF21s7nE8IkzXFefede7jtZAVYTcXd9wQQPD6RM4m9//YmpN8TzkYyW9cZf4D6S4KwOY8riu6n/4Bni37Ynj2HjbuGBB+5x0OPe1fHsy2BfG5/+5xmefTYfrM30XfAvFkWEt5tlSYpSOZoJQ5fzcPxuYsfexFNLrzpPnAr6P/Axr314O/HxTwHgoYlh0dPvM8bh8rFM8tzKg7d+Sr3WTPOIx9n1Rn8USPH3H8e8ydt4cF48/5SCW79IQpyjW/Xkd1z3wIeW88T7dxMfb9//6sjR3PTEEsZSdp6Oh0ncctO73B0/keCI+bz49WMMb/P3judv88A7WPPKUNzkEswd7iylqKInck15Mcs/WEj88zK8R48gWBHcclOpoN9d7/DWp/cSH/8CAErfcOY/u4L7qe9mZ0W7rVco8FapaMgvQNZsISbUB0OzCou5mWZDI/WVhWiCAggNDRUzylxGkkmTJtk8PT1ZsmQJcrkclUp1pWMShN+Msz3r7bV/EOdCLlrdfYinyzptNqxt6pEgkUrO9YbbbDb7z5y/VIYE+xR6NpuVs0UlUqnDH2Wx2d+M56g82LBabR3K2lrKdNgGiT2u1uu1/03a8gY+aBnw6ziWs+uTSH5pE5sN+z8tn3W6va3LnlusTVu1Xo/NCvYnO1u1Zct45LP1SiUS+7K2Xz7rdE/ZrFjbNEnLstK2MZ9tJ1rvm7Pt1npdZ+toFWObdm35TCKh3T7q2M4d9lebY6Rde7aKu+22dmyzs/WeXbfDuiS/TOfYPn46K1t7lE8+O4znsKuYMyUK5bn1gu1CtrVsE88uyWXukzcyOtynQ+9V+3h/Oe46OT7O01adt7Pj86hdMG3P807O47brbdn2c8u3j7vtes+3f9rG0/nxLOnymtF6k+w7xx67BEmHeMHxceXo+tE+wJN88tB63O5cxDVDerXcNEiQSttdNxyeT0Bn+7ddmTbXrg5x2+zHcZvzWdLJNaf9dklaiko6nEet26/H19k2sZ6fzWbDYrGg0+nIy82loKAQvcFAs8WMq7Mz0dHR9O7dGxcXl1/iELrFYrGwatUq9Ho9BoMBvV6P0WjEarX/Fjdz5kzi4+PblHnuuefQarWix10QeuJiLlCX5OJ2LoHsYh2dXKAdf+F1rF/S6QW+1Rdhu3V2tW2O19vqS7Pzkh3XdzYpaPX/jre3bdmz36edrUfioBvUcWLVSWLTsTAOmqpNMJJ2y7ev11Hy07Yax/uzbZt1bOeu9ldXx0+H6Nq1Wft6z1dXh/jP/U8dBfmpnErXED/Oh9x9hyi02LgqVIMbkjYDPSVdbmshx44WY7WGEtXfgxM/bqSxzzWEeXg4/ALsPN5Ojo/zbl9n7ez4PGpXuNPzvMvzuO1B1S7u9udEd/c15z2eO79mtF7MvnPa7vMOSzk4rrpx3fqlNBKptOOvGp3cTJzT2f51WKaTz1o3UDdi7my7OjtuLuo6e4EkEsm5Dt3BQ4YweMiQC69EuORE4i4IgiD8Bqnwk3uQePg5rnuzCrwGsvj+exjWt/uzYtiF0sfpOMs/eYPnMurBfzLPvjycQLV4oO5/jwJ3tQo3Z7l4gE/4nyUSd0EQBOE3SRkyiEUvfcOii6xHNWguz7w7l2cuSVTCb1c0i1+JPv9igvA7Jm5KBaEHzGYzWq0Wk8kkXjwhCIIgCMJlIRJ3QeiByspK9uzZQ15enkjcBUEQBEG4LETiLgg9UFJSQnp6OtnZ2SJxFwRBEAThshBj3AWhB9RqNSEhIQQGBoopsIQ/HKVSeW4KOEEQhP9Fer0evb7z9+peKSJxF4Qe0Gg0TJo0CW9vb5G4C384Hh4eqNXqKx2GIAjCr6aysvI3mbiLoTKC0ANOTk6EhITg5uYmEndBOK9qUnduYv36o5RfVD2F7F6xlp0p+XR8LZqVJm0iK19ew6mLWselVMrB1T+xNTGLuisZRuY6/vHc49x///scMplpPryc++9/hOd+Q23VkLWHzz/8lM0pRRiudDCd0lFwcidrP99F4a9SfzpfPrOCIybzr1L7pZfJd/9YSWJdI9YrHQoAzdQUHubLt9/k++OX54w7+0Isk8lEZWUl2dk5FBYWUlJSTGFhAdXV1Zd8EguRuAvC5ZS7k/def5Enn3ySJ598khVJHd5r3YkCdn72IwdyK/jl/v8kK5/5krRfJ9IrpIwjP21k99FstFc6lMvK0f79X6KjIPU4R49koyWPLR+sYlNSDvWksfKpj0io1WHpVj3VpO5M5GR+pYPkzoZJf5rd3x6g5FKH3wWz6QDv3/8RKec+qSVj7wa+WbGbQmrJPHCYlKxSmi7ZGpN477ZlHOr28lXs+vIH8pWRjBo/gABpKd+/uQpd1ARGj4jEu82yZRxa+x0/bDxO5bnPLnQf9UQZx3YcJLPQiNLXDdklq/dC2+p8DFTmn+TgjlSqLlmdrRWSsHInZ8yXuqVbH5OXUjEHV+8hq8n4G0ncpbi4K1FYSjn47S7yLtNazeZm6uvrkUjlqHz8kbp4gsINmbM7Ol0TVVVVGI3GS5a8i8RdEC6X2mN8+fkGij0GcPXc67juukhSl7zKhtLuFNaSk5ROQY2OX/pighk5bwRBv1rAV4In4QNj6Rvmi+uVDuWycrR//1ep6T9+JDGhPrhQTvKmw+TpTfxeH/G2WgtI/PEIv5zGSgL7xDFsdN92SfGlUkLimoMUdXv5fA4elDJk5jUsunECEfJ0tm5TM/vehVw7awgBbZZtoDAtjfSsEhrPfRbEyPljiXR1/tUShvpTRzharqf3hBmM0HijuGQ1hzHxlklEXLL6fq9+7WPyt0KG0rsfI+JHoKj4ia2Ha371NdpsNhobm5AqZDi5edJokVJvsFFaa6CopgkTTtQ3NFJXV4fVemlub8QYd0G4TM7s20x+wBgWzLmGwRpX5NKBhGe9wB0rDzH76SFUF+3j61cPYelfwL59VeDel+mLbmbRDDf2vbeSjUcPoM1LZLVyJA8sf4wp6jNsfDeR8fH9UAMNJZms+/Cv/HgKCBzCwptu4Yb4UOAMP76+F51HJruPFaDVNgMaFr/1NgtCHMdaeHA1q75ew7FSwGcsjzz9J+J7m9n89xc4c/UHPD7OGSwGylLXsXK3L3c8OgVbRgJrPnuXXXmAajA33XszM0ZE4EoqXzyxF6fB2fy0sQCJdCxPfvUoMdVFbHrvcb5JBWX4MK69+X6uG9JA2p4DNPQaxDh/L9Sp3/DE+5sorLL3V477yxoeHWWPsc32nmurWDq+VzOJZX/ai//sPNaurcAnZBoPv3U7mpwkfvh4CZvOAJ6xzLv1JuZN7IcbABVsef0Vvjxeht4CoQuup9eOWsZ/fCv+mfvY8kMj456dT197a7FrxT57zBNjUAMpXzzB21sL0ZlAHrGYf//fAoLtQZO07kOW/GgfoBASv5BbbhxJ+VpH+9cdy96l3LzM3l/oERzFnAdeZb7D98tUsXPZG3yVmIu2GWAkf1nzFKMwtTuuYMjMG7jlzslYdq3g8zU/k14J+E3m6b/dzNAgrwvq7Uz+4gleXZlAXh0QdjMrv36E/s5ywExt0QHee/AJfioB975h+Nsi6N+vD1BK4nebsUz1J//5FfyYfYzvZyaxTHEVbxz9P6a0KwtBjF18D3/+y1z6tKy3bMsb/OmjEqrKDK3W23HIWunxjXy89EXWZQI+8Tz8/CMsPLePf9Fs3Morc48wc8sLxANQyfGNmzmQ7sWMv8SR/u/NZJUe5UDuGfLzm4AQbl7+GY8MSeaFsc+zsbqBQ8OzGDBwMX/77HpsyXvtZaMju2w/S7ORdc+M5Z8J4BIQxexH/s2zM2zs/2YzqXUhzLz/asLsLc1/7t5M4HPRHH/4FbYac0kcPpL3fK7lXy0xV2bsZcXrj/NtKtB7Kk/++SFuHNfAF0/8k1WJ+2i67Qifuw5iAImsq60hYeJYVvZewEurn2CEvbXY/83nfLT8C9Jkq/h21WrufvMZbp3QxMZ3NtPvvT8T4LKXv47aQsCNZ1i1Kh9V+ECuu+0h3Pb+jXd3VdB76t38+aH7GWcPmqP/uZuXvkmmTAdE3Mma7x6kV4dWaCDnZDIFNTamhIXhWrGL198/zYgb5zIuOhD7+21z+eimv+L62hfMlnV2bGSy+u+bKTYfZ0fKGcrKBvP8ppkkvXSAqVcNJADQlefw7Us38OERwL0vM297mCfuGGtPZtNW88Trn5OQbv+tYfzzm3j9Wj+cHJwQutN7ef/PG0g+UP3LcRWVy+t/OUjcy/dzbZ9AnIFm4xZeumYtg1Z8xA3trrU5Oz5m2fvL2VcAgdOfZukjc4kObLuMsaGKtc/P4M2DgDKM8Qsf5oVHpuALQDW73vsX763eQ34TwGie3/QvrvXzxGrcyktXb8PzmtOsWaOj//gZTLs6gPp0L2ZEG9nV6fGsRi610lSXzLu338uaIlCGhRHZZyzDAvoyo9U52Fr+qvsZ930eZrMNpWoID7fa3jbnYL/ZvPyX+7hmaBBwlLcW2Y+rGX6eyLDQULWZtx/MZMbqJxhRmcHGFa/z4repAPSb/SR/ue9Ghrb0VB18axEvfJdNvRGcoh7g6y/vIhwAJzSaMHr7w6EDJ1g4clKbm5W7776b5ORkB1vxi5kzZ/LKK690ucxZFouF8vJywiP7UVtvxF2pRO3phtHYTE19IxVVVXgrnSgtK8fT0xOlUtmtersiEndB6IHGxkYyMzMJDw9HrVZ3Y5x7NsePSAka15eIYFfkUgAPQhZdReRVG0l8ejARhmKSTx7EeeDDLF0aRcmxzWw/vpmD4bczbvFsTh2T4Xz9bCbH9iXE0xUp9RSlF9EANNeVcGjdxxzyu5Old8dQkryVnXvXsl11J1f111NVsIPVxqG8+NDthKpd4cBb3PKPrxj10U20z90bTu1g7d7T+Ex5gqVDgqnct4L3v9lB6N0zmHjtQL5c9i0F427BT3eGTV8cIOiuV3EuOsGGrVupiXuQpQ/3pvb4Ov67fRsBXtcxpl8jZWfW87N5AZ/+8yGcFR6o9VpSvl/KRtdbWLp0EPriMmoaTpGPL3Wl5dR6N2ImjS8+3IfP1Ae5d2ggrjI49tkSEkc9y7B229twej8/HNnMVrWKBSM17beIovRv+S70CVYuHYVc4YF7ZTa7N64hK+Ielt4fhTZtG98e2IKftxfTBgZQtuUTPq2K4/m//Rlvdyf2L7uRjzKvYghWvJpqKM1vaDWkxdgqZntS+fqp/2fvvsOjqNYHjn+3ZnezuwnpvZCQkFBC7yBVmnRFRPFivSLCtSsWLhbUK/7sHTugKIL03iH0EmqAJJCQ3ns2W2b298cGpCSAEUXvPZ/n4Xk0u2fOO2fPzL5z9syZ5jzz/CQ83bWc/nEaU98N5udHW5GVsY3Vm52MmvYW3b0hd/9hik5n0WzcLfS87PNN5I1/76Hrq28xJhiq8ws5vedHTjS/nYtz95P8NON7cuOH8egrYZjUkDX/aZ5/Yzvrn+2I/aJ+1QK9yQPF4WV8viufmOFPc2+cH/kbP+btrzfxwZTB+JjcrukYyF/7Fq/uNDD+2U9oHdGEM99NZthTTUl9fwSO6gr2znmbDZH/Yv7bXck7vIpPX/uClJjOgIWCM1lIZe0YNeNe0rZ6EPPxMwz3DyIYiYrCxbx0x2KiX5/P/ACoPLGVuWtXs3BFc54eCnCIRceaM3P607QJ82Tjy0P518cDWPtY3MXH6JndLFq4kIIO05n/UjyFiXN495eFBHvdy4BWF48zO50lnDmUfsH0LDuVJflkn3VgoZbizPV8tcebJ57/D71ifWHbWwyd/iUDFj7A1O+mktJ7JyPmv05fnQd+WNl7vuyVE/cTH43mhbIHWDK/H9bCEnLO7OAQ7SkvyCWnyHDBdKAqsk9koLaM5N6PJ3EofjED5r/LYJWZAMCSe5xVP87maMw05r+QQOrGb1iybC6+3g8w/Km7ObBVj//LDzE8JgIPllHUYjXD5r/DQK0Hfufr8KHNoJHcuquaVsZWDJ84kBaBvpjYQdaxdLztDpyUkbp/NvtHLWL+F2oO/fAij86cyYSHpzN/4DE+/zmJDbsO0jqsLVXLZvDcvlCenDmZpv4m0r64h5sfjyLl7YGXtEIZ+fkKTKZmREerQRmGb+Esft7YmtjgAIJNwJq3mZ4czI+axbx0e0N9w0LBmRV8erY5M6e/S5uwIHyb7GXRgdOUAo7qEnZ+/Qzz3f/F/PldqTy1nR/WzeerFb48MdTBnE9X44j7B28/1YEgPex+/23WD32JISrtJfEWcqwgn5bNnmb+1FiSl7zNwtWriQkcy4h2c3lt0XH6TvLBzahGWvsTP/jdxFP+l+xx0hK+XHUYvxFvML97BIWbd5FuK+LCM5fssJH02X2875zM/Pk9qc44yOLl3/PBzwG8dKuWha9+xj5FG6Z8OIkQA5yd9ziTX17FoP+7FbWziKN755HV7k1+nN8NN4OFExtXkXzV/vwo8WonR2a/wE9+k/nxrZ4UndrOVzPfZF37p7ip3l68nY933cu6r19Bp5QpXvpvHp4+l25f3UWTS47B5OXv88vChXh73kOXphUX9CsXyVFC+tFMKinlaNJqVu00M+mD+dzkC2nrtpJ+eg/BgZ2wL3iCJw4l8PYHL+Jj1pH8yd2MeT6CfTP7AaANDqZpTAynjpwlDy5K3GfMmEHfvn1JSUmpd2/69OnDI488Uu9r9XE6nVgsViosDgpLK/A2Oyi31mB0N+DtoSc1oxa1yp2q0lIc0vX5PVUk7oLQCCkpKWzcuJGEhAT69u2LSnW1cUo7NpsKtVrFRW816DHU1NQlgSq8faPpcktfwsPUhBg7kpaVSHZqDoq4Jpj0Joz+gYSE+10yquygqjKDlGTo88SAurLtSTubSGZqBlVxALGMv3corRNiMCsVEHQzbd7aQhqXJu5VZKRlotKH075nJ8K9VYQGDqLV/WtJqoU3fP8AACAASURBVLiJIQkPcZdPb6Z90ZVnnG9zIOFZ/i9OTe6BDErKPOg2thfhgSpCg3qTsGs1Z3LyiI8BSODhJ0YQGeaNWuGkpvQISfus9H92COHhapwhIUiyjIIMDpyPxUp5eQYlNV4EBofj4QZBz0ytd3/lYIn05BXknDpNbqfgeqYPdeKJF0cSbtAANvJOHCQ7W0evyX0JD1EjB/fg5KHVZGdkUdgadm/Jp+vg24mOaYpRo8BnwmgW7a24hp6Rz+4t2XQcMIaoZq6y/g/dxvKRa9n1aEv87WUUlZUSqQ0nPBxCAgORFQpUmhP1fL41FBWl4WF3vVcOCaFZ65ZcfokYxYinnkbW6HDTqFAqIORfE4jvuZLtz3YkGj3Bob0YdG9fwnVqoIL96zIx+TSjTZf2hHsqCb3zFlrevoHdlj4MMrldw6h7Abu3nia240jadmlPpFFJ5LT7aRe4kGXvD6OP5RS7tzkY+/Y4oqM1RDbpTsrOY5fMNdbjHeKLWWvGPzKSqCAv1DiRvYfx6rKBaEwm3FQgRyjJTMlm/77DpA2NBrwYMPwW2ndqR6RRSdiTE/jsgSWceizugiTUQk5mKoXFXgx4cAjRYWqaht1Cl40/cSIjm3at/PG+hk/zV824Y2J/+g/sTJhaCeG30O3Fnzku6xkZFYBJZSYwumndiN+1zrA/xeJ5OYz74h6io7U4IyVi2yUAeWQ3WMaAX6Q/RoWJgOhomgJgJasghTNnDAyeMYLoSDWRht7sf2cbaal5dBnmg1lnxi8snKjoUPQEYFSYCIyOumQKiQZ3zyZ4eXnhZQ4kPDq0bmT3Yip1P+7/V0+idVU4ykcy9EgFg+/oRLTKk/bbz5KSm0spAezZkE6H/pNo3S6BAL2SyH8/RGv/+ax+eyCDLtqijCQrUam0aLQAkdx5aze+XXSYsrJ4gk1mlv84h55P5NI9QEn7K/aNFtwz6TZ63tQOf5WSX2cDy9RaTrFrq4VRdX1SjlCSeTLzfNny8jMUGN3xC4wm2gfCXn8BtPVN2tERHdeBQSMGEh2mJmLsILa/foC0nApGDeuBY+Q8Vt3VljuMTVixYAG9xnyC50WbKSclOQ2VPopeg/oQ7a8iMjQUSa1GfcEdS7J0knXLSrnt47uIjtbgjNRRnJnGusR9JN96J7c89m8GKbXodFpUCoh85n66xC5h1X9GMkypxGQewPOv3U60QQPkcOaifWioP8s0l06xbnkV4+vqbepjJ2dQH5YW0oDOTP/P3TSP9keNjPftA2k5NIlUxhB8yTEYMaY/218/QMrZbFo3bWh7ABJWawEFxWWoDNFER0NEaCiyUomaLOauTOem0fcR3zIOs1ZB8AsP8H3CIjbM7Ec/ALUKtVaLWpIuuy8jJCSEvXv30rx5c/Ly8i56rWPHjixZsgST6fLfbRuiUChQKFVYaq0UlVVQXlaGt4c7SpWVjLQMzmTm4hYZgsPh4HrNBxRz3AWhESRJwuFwuA7G68YNgyGcsFDX9bTKyxsfpRJbaQlXThklrNYcCgpDr1BWhc5Ng0JZl/ZpNGgkuZ4biiooKU1h3SevcXev1rRo0YJWbe/li31plDudOFVuDB3Yk4Nvj+bBOSGMvbsZWqWFqqoUtv74NVP615VpM47/LN1HnuysO1ep0es1db9MOHE4MsjJCScywhWvQqVCrdFckjC2Zcp3z+O38CH6tGtBixYteD7RgAYJq/UUe9at5IXBCa76EobxzCfrSJfr2ydX/QbDuW9PGxbLKXYs+YmnBp4rP4YZc7aSLcs4ySbjrBehoQbUald7aePi6/2J+HLZZJxN5Ycpw+ncpiUtWrSgfdfpbHc4cOBORJux3PdwFEtvd+3PqGdnsyNH08CJuD//2T2Dgodd7+05/G6+Pa6rZ7RFjVvFFl66cyDtW7re27r9M2yx27G7WhelUoOb7lzJUgqLUlj1zouM7d6q7jN+iHknsy6Y13w1OZw9e4xvHhhElFmNUqlE4347C8qrsOHE4UghI6MZsbGuNld5eeMfGnbJfOr6KFDKdvK3TSNeo0SpVKLWRjPyiTkcP/8lHEJ0tBdGd1eraVslEHf0KEcu2k41FRVHWP3pW4yK0Lq2o+vME99tJUuWG/H9qcZNp0WtrvukNBq0svw7b9Y8ypGjcSS0do3oKlQq1G5ujRhNs1JdnUNJccT540kVGEiw3UHFVc8djaFFp1eBQoFCo8VNqUGrVYJKhUqpROF04iSTM6ePMXt8V4Lcz/WPCSyz2bj67fhK3Pr0ptehJHaWl2FhOT/+OIhxd+pRX7VvqNHrtahUlx5RThyOIySuWsEj8W71lE1g8jdv0Pb4y/Tyc2371nnlOKX6fkk14e3163laHRJKaFU1JRUV1EY/yKSBe1i/zoLkSObokVsYPfrSEfsyigprUSgC8fNznfFUbm5oVaqLzgOy8wh7tm7jqVaueFWaMPrf+ymHJAkJFW6V25l5R2e8VK54NYaRfHP215vbFQrtBee8SzXcn2XnMU6diqVFvKus0sMDn8hI11S/emlwd9eCQgEKUNQlzDLVVFQUUVUZWm9bXflmbW/aDX2Eyfd78H5b1/51euhTduVoUJJBaupxPhnZEk+dCqVSibv3A6y22erOd1fn4eFBdnY2ev2vd1LFxcWxa9eu35S0AzhlmZrqKiSHk2qLDYvDSbXVTkZWHmkZedTaHCgVTmxW63Wb4y4Sd0FohNjYWPr27UvHjh1RKq/lMGpOm7blZKZnk18oITsBHFiWrWH7LUPoA4CVGksGmZmuiwG5tIQiWUbbxKueedsXUuHmFoSvb2Yjyl7KTJMm7Rn73CyWHjrCsWPHOHbsGIcPfsadUf64OU7xwadbGP3BAZY/6+Tt1zdjk/UYjQkMufcZfjh4+HyZI0lzmHpTHB6X1aFArQ4nKCiD9HRXvM66C6GLEyEJm709T/2yngPHjnFs2VROPfUUm1Dh5taCnsPu54sDh36N8dBCXhrf/Rpu1tWi17ei/7ipfHtBvIeT5vPM0Lb4EEx4WAlZWTU4HK4Uz56czOlz0SsUgIRUF6xkd13AuU7JwYSH9eLpX1az7+hRjh07xtGjh9m+ZhpdAFk20qzbVOYfO8axxB8Y16SEXVu2NDDC6kBiEB8fO8axg9v4YlJbDs2ezeHL3neEL15dhc/d77P+gGtfkva90cDP2gCe+Hh3ZMKr77Pqws/4wIeM8jVf45dCIGFhA3hxVSK5dgeyLCPLMtaqOQxDgVrdjPDwVE6ecn2VyqUlFGRmXsNSkBJlRQv496MZPJfm2qbDlsIvb46/YHpQFmlpJVRXu1rcfvQwyS1a0PKi7bhjNnfl9qffZqfFdj4+W+1WXhnShstXoFeiVDpw1H3zyw4Ju9X6B66iAtCSli2TOXzEValTlnHYbDhQoFQ4cTol5LoAHLVW7A1ecLjhbgjCyzudM3XHk5SXR7ZGjalJE8x/6D40JJSIyJuZmXiIYod0vv2rij9n8GXv9cTXx0JR0VFOnqjbYUUPBvQ/zpxvd7PjuZksGTWGMYpr6RsNUaBWt6XPiCksr7aej8duPca8F0YRhYzN3pYnFu6mQJaRUz6k4oUnWWiz1rOtSkpKMsjMqmvrrCwyje54mc0YFAoGTZlCzucfcWDvHJYljGP4Zbm/Jz4+OpzOPAoKXfsr22yXfb5KRWu69rmXRRfE67ClsnjWeOI4zjdvLKCm8wz2lNcde9WLmBjg+btX5FEqWhATc5LjyXXHbkU5xelnGrFSkztmsw9GY2b9bYUSpcqB3Q44wekEW01N3c35TiTJl85j3+GALCPnb2KslMzaLVvIIZzoqMHMOpRCVV3fkiQ7+affc422A3J2NmeSk8kODiag/uBQKpXU1NTg4eFBTEwMx48fv8bv8ksoFKg1ShSyFSVOKqtrsNkcSE4VdllFE7MJa00Fbm5u1/DL/LURibsgNILRaKRTp074+Phc8zruLfoNwpS0hB/WJZKcnk129hKmv1PB1Af71L3DQVFBKmuXbyY7O5t9ifvJqLETEh2OCQ16PVSXFpCbXUS1dOFJXo27KZxmzWU2LtlQT9nftGeENzVTlHuYzav3k52dTXZ2Nps//4ZtBXmUrP6S+YZJPNhPjXu32xlWsJgFJyW8AnzQalNZsWDn+TI7fviZLadSqbysDiVuuggS2mtY+/MasrOzSd17gL079l2yVNkJfvhmDcePprm2mV+BxqsJOtS4m4IIi8zmpy83n69v//I1bNq9nwZ/0T1PSxMvf5p4p/PLnG3ny+9ZtIzNh49Tij+dewWya+1G0k+fITs7myVzfqagrqzBvQlG98Ps2uwqt3fpStbv2ltXrz+dezlZPGc9aafSyc7OJutsJivf+YQkasjJ2soP39TVmVdItazETadDXe/nu5u3X1vpem9OLkWVNjQmE5eO34EGo1GLrbKIvBxXTEtfnnWFJfA8iI5zJz3lADs2Hz6//xs+nE1iZdU1LuvmT6eeWjYuXcPubYdIT08nPT2d+Y8+xwaU6PQxdO6hYeEXC0hPT2f31h1s2JRYz+ivHpNJoiQ7k4z0AqoBpdKApxmKslzb3L18NT/PX0Ta+TIlrF68goP7XPV+9948fG8fQewl2w0K8cdNe4wfZq8/H9+6j79kxZHjl62prlTG06L1NpZ/73rf/vWb+OnLuZy8hpZQYMBktJKfnkFWbulvWIM8hlF3+DPv3W9JT0/n5L4DbPl5GUfxxD/ISUVxEru3uuJZPusDVqSerlu73oCnp53C9HTOZhZhwQ1vv2jCw6tZOX856enpbFyxiUyFlqioCIzXHA+ABp1Oib26iKz0HEpqGnvxEkiPfioWfbOMg3uPnW//Hx59ji2XvdeDZnGtMahLST1x8vyqSr1uHoJt/1xeX5LG2FuHAtfSNxqiRKdvSrvO2bz/8i/n49m5aCmLV6zlLCeZ/90iNm844HotqxhlkyYY6pmYBhZSkvexaomrX635ZR1Fnl5EhwZhAIgcyFjvHbz2+jo63T68nvIeNIuLxFGTyrY1W0lPT2ffnJ/YkJVz0bMJlKoY+g4uYNZzC87Hu3flWn75eSlpaDAa3ZAtJWRnuF5b8PyrrCkv/90Xm0pVLP2HevDjx9+7joWde1m9cmMjnkOgJygkCh/vYtYuWlNPW0XRut0R1v6cxunT6ZxOTWXOk9PZAUA5yUdX8MVH61z7nplHNRp0Oh0qQugzxMm37/3C8aOnSE9P50xaGvOnvVJXViI7O4tT+ZW06dy23uleFyorK+PkyWs50uunVqsJCQ6hurSAIG93ZMnBoZOnOXrqNFq1gmAvHfbqUiLCw67b06bFHHdB+LP49GDKw4W88PHXTF/oSmE6z/ieO8POvcEdf/emGG0LmDq1CALbMXb83QyIMwNmBo705T9z3mdlURwPzX6Mvl5mguOCMQFazyC6DH+Q/I+fZ+pULimrwzs0AIPhwrnLv5a9lDmuP/dIdr6d9xFTv3al3S3HvcoUs5LEPYXc+uDLhKEAUxRDJnbjuzW7sD7aj+Ej7Cye8wlTF7lO8dGDp/CAfyweHMU/KhAP9a+1q/QetBnzFEPef5SpU8EQ3oGRdz1EV6o4E+CH0sOAmhZM7H6Exz54ibN1q8r0fG2ha9UPzyB63voI0tw3XG0FhHYby4Qut9QzHcNIcPOQi/bVzS+am0dNwDn3XaZOdS0ZFtHnHu7t19o193nQszyb9xizZqymygYho++hy94sQItfWDv6DTjOux9PZT1gbtGC8NZ9ifcwoAa8Bj3LW7zBc688Q7lFQqnW0vepHxgB4NWclu4fM3Xqh7/G3LMz/lDP59uDp26exR1TvwNcq8qMeHhcPaOLzRl3T4+L+lXwmIe4Pb0AEwo0bp4ERtguWl7TM2EED8uL+HTu2yz4xDVBps3Ed3hMZ7rmEbuAgU/zvvMNHn9zMjPyXOlq31cTeQvA3Ytu973FHdNvZfRoMDZrRrOud9ExsAk69PhGBCN5GFARz/2PLWDi4w/wXXUvZh14i34eQ3j8ya3c+q/R/Eh9ZYcwKfggs9+cTF5eLfR6hcQp8a5+pfYiPN71Wbs37cKECTa+/eBVRn/l6iMtb3+ZZ0NaXzbirlY354HXJjPx/tGMfg8M4eE063Yf/f280KPDOyQIpZfxgmUKzYS1iqCJQoFKPYj7J3/N/aMnsDhhHNO/vg2jlz9BIeYGyl7wyU1ZwsynujJ69Mfo/GMZNvUdpmGG/iNITf2Aj58YzXtAwMCB9O2gJUKnRUk/nnjlK8aMvpUffEby+toX6BbUgqF3PEjB6/9i9GigaX+efPRBBsSbASNBMWF467R1I3WeRLaNwLPeTzWC7v2as/v9j5k6egP/eOdZ7r7JRHB8GF4aNYqLyirRufsSEqWrW6XHDc/AAALcPdACQcNf5ivnCzz8/P2cLXFNkBk86wD/qKdWz7ad6bfpFDuO7OdI7whaexpQdb2Lx9rs4IOzz/LEYA2gwnzVvnGuX53jQUQbV7xqdy9ueuhdHO9PYvToNwAI6z6Ohx99mkggsusRHnvjebbUrSrT67U1DHG79DJZjcGjJTd3KqXg5NuufhU7jJefvJWuUecukcJ54P4Ynnkrlv2X/7xQt7+juL+4iHc/fILR70DAwGf4vyE+mC7oV0q1lvaTv+P19ycyevRbAAS2HcKDT71KDBAzYTCH3/qUJ+/+AICQ227jjvaV+CgUKBRNiGgdfsGvLZqr9MmL62076WumPnszo0e/hyHEH7+YIcRp1PX04Qv7hsulx+CYMSV8NusFRn/LJW1lZMIrz7Bt4uOMn1eNU6Uievx0JihrMdGEVsHNyXS8zujRrlVlYoc9yZM9XOdKxr7DfB5n4uQJlFQ7UGrcGDlrJ3cjY6vJ4PjRw9h0wxjc27f+D+A6UigUeHp6UlVZSU15MRHeegLNWuwOO7KtFmtVEcGBAQQHB6NWX5+UW9G7d2+n2WzmjTfeQK1W4+lZ/+EsCP+Lamtrqaq6/BmN15+VvNTlfDY9i2Hf/4t2f0KNwrWzW1fywoBdDNv6Mj1udDB/Af7+/nh5XT7hRBAaq+zQUj75+Qjhg8YxsnsUv3/RvBvFwtmPHuABprNmcsyNDqYRnDgcReTluRMSYsCan8TP333HUd0onpnSs4ELvr8KGwWp25j76XKMI57nwZ5XG2+/ssLCQoqKrvyorXNPTrVareTn5ZGXl4el1ooky6jVKkKCgwkKCkKv11/067wkScydOxeLxUJtbS0WiwXrBfPgBw8eTNeuXS+qa9q0aZSXl4sRd0EQBEEQbizPhOFMS6hvasnfRRHHNu0ntTiFtevdmfhW+I0OqJGc2GpPsHZOGuZmRkrPnuRwup2u97X8iyftAFr8ovvx+Fv9rv7W60ShUKBQKNDr9URERhIRefmTCq43kbgLQiPY7XZKSkowm83odLprnufeMCV6cwRt+3j8xmXqhD+DUhlKx6H2a1gV5X+DxWKhtLT0RochCH8hZ9i7dhkbUvIwD36Kfh7VlJZeee2UvyrZGkGU+Xs+mF8IOn8Seo+heyT/c8d8be2137HyZxKJuyA0Qm5uLjt37iQ+Pp4WLVpch8Rdg4dfe4Y/cF3CE64zlaYVtz7T6kaH8ZdRUVFBRcX1X2hQEP6+jHS+ezJ1D3amuPDqayj9lfn1ncorfX/9/5q8vKss4Sj8WcSqMoLQCIWFhZw5c4asrCyczuv0VAVBEARBEIQrEIm7IDSCv78/zZo1Iyws7DqMtguCIAiCIFydmCojCI3g7+/PTTfdhNFoFIm7IAiCIAh/CpG4C0IjaDQafHx+31JTgiAIgiAIv4WYKiMIgiAIgiAIfwMicRcEQRAEQRCEvwGRuAuCIAiCIAjC34BI3AWhESorK9m5cyeFhYViOUhBEARBEP4UInEXhEY4deoUW7ZsYd++fciyfKPDEQRBEAThf4BI3AWhETQaDW5ubmi12hsdiiAIgiAIfzNKZeNScLEcpCA0QnR0NE6nk9DQ0EYffIIgCIIg/G8ymUxUV1df9ne9Xo9Op2uwnMg4BKERDAYDCQkJeHl5iQcwCYIgCIJwzRQKBf7+/vW+5uXlhaenZ4NlxYi7INxgDoeDyqpqai01SJJ0o8MRhEZRqVTo9HqMRiMatfhqEQRBaIhCoSA8PJyUlBRqa2vP/12r1RIWFnbFBzyKs6sg3EA1llpysrOpsTpwSA7EAjXC35UCUKvV6N2KCQ4OwqDX3+iQBEEQ/pIUCgV+fn60atWKpKQkLBYLOp2OqKgoWrVqhdFobLCsSNwF4QZxOBykpKYhOZWERUbj6eWDTieSHeHvyWqtpaykiLPpqaSmnSYuNgaNRnOjwxIEQfhLUqlUxMfHY7fbyczMJDQ0lB49euDv73/FKbgicReERrBareTl5eHt7Y27u3uj5rnnFRRSWW2hbeeeGNxdV9d2MVXmdyji+Maj1Po3JbZFGO43Opz/MUq1Bi+/QHRGE4f37iAnL5/w0JAbHZYgCMJfkkKhwM3NjYCAAOx2OyaTicDAwKuWE4m7IDRCVlYWiYmJxMfH065du0Yl7hkZZwmObI5GZ8Au1bcWfDEnNq1my+YjlJz/WxT9Jo+lnZ/HH3TwlpG26yC5Fh/i+7TC6wrvtNWcYdNXc8kOGMStt3bEfE0xH2XJK0dp8eI4oq977IUkb02ktKWGgOYh/L6FOtPY8FES/ncPoYUpjV/+PZeT518zEBDTi4F39ibo94b8X0it1RMY2pSs08kicRcEQbjOROIuCI1QVlZGTk4Ovr6+jX5yallpMXEd/HDUm7QDlJF+6AQ5VQaa9WpJE4DUncydvRzz5FFEmXRc//VsKshKPsSx8kiCerWoS8br4ZSoSt/AwmW70EXZiO3dns5N6o+5dPdyvvlEg/lfY4kypZP4/RZMz40l4rrH7kRyOpElJw5JxvG7tpXDgWXbiRnVl2aGdHbMP0rAm/cSB1BdSs7xn/nss2JuHzuKmAYb6X+UE4weXlRXVdzoSARBEP7riMRdEBohODiYVq1a0axZs0YvByk5HCiUahyOhhJ3GUk2Eti8Dd0H9SMQoFzF9nu3kzZxMKF6LQrJzu5PJ/LTYUDjTVS3cdw1vhueALm7+eXnn9h6NA+A6OHTGd8vliZ1y8Pu//RO5h4E1GaC293Offe1oWT3cpZ+/yMnHXr2JCUy4J676d+lOR6XRibZObjkBxzt76a9ah1rN56g/YiYemO2trVzdNIe0qqHE6p3IuNEctSfWOftX8TSxQtJLgCihjHl7qE0DTABB5k7JRGv/mdZt7IQj8B+3DljLB6ntrL8y685UgbuMeGo05REN5dx1G3/xIJn+W5LJhY7qEJv4+kXRuKHhYK0HWz4Zj+W4EyOHNSScMtYhg7rjO/5SJzITieSLOFwOEEZQsKg4fQEcNRQGu3Jok2H2bynDU17h1++I8fn8e/Z66mosaFQaen80Nfc3tr1UsXZg6yf9xbb0gFjHP1uG0e/LtG47m4oZPvHb7D8SB5WGQKGjCZkeyntZ92JV9oOtq+qof0jw3DVmM2enxKpDmtNu7rP6Nr2twQw03zQndwyqAfBdbdVXFg2eMQsnhzi+j2hOj+FTd/OYEMaYIim2/DbGdIn/opTkZwKlXiisCAIwh9AJO6C0Ai+vr706tULnU73u9Zxd0gyMldK3F0JpEOSsQOczSBLp0MvgyTJZC2YyqdZPXh8UmfspZkk7fqZuSu9+OdAI/vXrSe1IoL+/7iTEANkbd3I0XaetPfzpXjxo7yZ0pXnJnXDUVnI8W0/MfsXD/7Zqz3tepxGXx1E5zEDaB4ahPZc3ReQbNvZulpFu5k9iTlznL1bEzl1SzSR9cRcevQw6WoNN9fF7MSJVM82q1M3s2zzQYgbx8QxwaRt+Jx5y724d8xN+JkLOZX4BUdMk5kx6Q40bj54FqSzd/0yTvvdwsQ7Yik4upTlm5IolIfgkGTyNv8fHx704o7xIzEatGQtn8mMTwN474E4qsqOk7h9K55jJzJxUhxm/0AMF8Ukuy4w6kbvL4pZocPYvB3xqRns25/E2Z6hXDwr8TAL3luNW9/7mBBjRilLnFnzPkktHiGm+DQ7Vs7jiPstTJwUS9WpLWzcshyjcRzd4/wo3vw536X5cfddt2Fy13Jo3oMs2NWHCMmGtiyL00criD4fZyV5qWmUaUJoLslYrnl/m0LWLlbu3cqOgEAGd4qk6pKyJTvWsF/6B/EVuexf9jGJykFMnNSCmjN72LZnKZtNZm5u2/BEoYZ/RRIEQRB+D5G4C0IjqFQqTCbT796OQ5JRNpi4O5GcZ9j8+fcsm29ABWDuwh2PP0CsSYckpbN1aSodnvgPMfEGnI5AnNUZbEncS1r/rpSWZVJa0wHfkNbEBEB4UCiS0QRSBlt+OUHHqa8QE++OUyrHTU4la9FeMocOxDsgAO+KcCLim+EDUM+0E1vicva0vJvP4/2x6fsRd+wHDidPIDTm8pilqhD6v/Y80SYdkuQ8nwRfvM0qzqakYFUG075Xf2L8NIS7dWXf58fI6NsGD3cZJ6257ZGxxPi4A3aKUraSeVZDh3uHExPhRmSTYlL2luCQnUhSHoc2nSSy21RiE+Jw1ygI9R3KlntWcvDeWDxlA4ER3ek5djAxJjdXCBfFJON0gizJOOqLWaFEqVRDTTXVl+1LBXk5qdQomxHd3B+N0kloUAhKyUpxYRoZ6ZBQF7PcFDLfX8XZtAxiYmQObjpDbJ+pNG/jijlg+ADW7LK7pv5ccEHkqItRcjqRG7O/zVScPLicqrwCyiU9SZeUtQeH4pDsVJSd5uRRC23+OYqYKB1ylJaCjBXkJqeQ1zqAhlYaFom7IAjCH0Mk7oJwA9klGdUVR9xD6HTHc3Qf3QNf8tj45jSOpDroFgtat2SOHz7Jnoe7sUwF4ESym2nW6x4sUjCdJ9xPZ5gDDQAAIABJREFU+Qcf8vbYdylRQsuJXzJldFu07imcPJHG1indWVtXTnboCWkzgf7SuWRQrie5/tWONSto2fdldEoFbl6BhIR6k3jgMAOjjJfEDKBBZ3ZHy7lfGOpL3MsoKrKgUITh6aXCIcmowqLwL0gmp8ZCrORExkCTJvq6pNBCVVUuZWXBtAnW4JBkFD4B+Hr7USHLOKSzpKensn7NONbMVLoWGXc6UKqHMlhyYpSUqDQG9AZNA0mmEwlXG9jrjdl5/peFy/elPRO+mMbHE8Yw9p0qULvRd8ZOJnWtoqrqBAdWLSJl82o+VgJI2C0RDIrthU06S3p6E4LHmkHhxCE50bZoSxi76+btX1pfXQyN2V+lGiXgdDiw11OvwuiBRrJSXpNM0qY1HN+1nS+Vrj7pqA2m1+QErFfoHyJxFwRB+GOIxF0QbiDXNIyGE3fZqUTl5o7e7Ik7Hgx9+Um+uOsrErs9TW/fcEKjhnDTt2/R+cJiCiVKSYFC04IBj35E/6lOKFjO/z07j+2d/RgQFUpg6AAe//otul9WLpd9l43sXmotG1ZWkbgqng0KwOkEpy/xg5pycnSvS2L+lSTJrn2q+++Lt21A765CLi2mrFQmwAPIzyXfw5N4pQpZki+JSY1K3QS9+3EKC2QcvkBpMSUV5VhkJw7JD2+/ntz77N10Dwn8dYUZhQKlVEO2LOO84j7KyM66OKV6Yi7KI7ewgOroLgRdtg0VavcBPLKgL5OdYE95n2efeI7dK6cTpo6jwy2PcPdTDxL7a8OjUCpRSLl4+xVTWFCLNUxGpQZ7+mlynE4kSUK6LGa5bh5+Y/b30rIX13suLlSxtO5zH2NnPEqLy+K9QuIu5rcLgiD8IZQ3OgBB+DtyOp04HA7kuoSosSTZecV/spPzCZYkg5NudOhyiL3bK7Dam9KlXxafv7mWGksNNZYaco4cYtuiH0iTM9i+YSU7t5yse82GU6kCJ8hyBN1uzuXDl1eeL1eQeoqt33/NSVkBCgWyo5bqymosVodr6sn5fxJpn3/IgaGfsWzHSZYmnmTpjlN8++1MWukS2b01D+mimC/9B07qpndc9M9EQFggVeWpHNl3lMrKCvauWE51RBQB7iYUl5XT4O4RhpdvCYlrdlBZWUHyzkSOHD1EtdOJJAfSunMVC79dT2FBGTWWGqoqK9ky61UOyCDJINcbR31xgtNpx1JZQWVlBZVZR9k6712WHNPRsVt8PdvYw9fvL6egrt6aWgcKjQZkDe4evhhMyaz4ad/5tj+xfBHbkvZRJAfSurMH21dtoKigkMrKCjZ8NZtcnEiyFo2bBxrtPo7sccWRvHIpW3dspaCR+/tr37q83uQvP2W3rEJnCMQv+BS/fLfzfLwp61exbec28q/Ub2XxCGBBEIQ/ghhxF4RGKCsrIykpiWbNmhEcHNyobSgUCpyyjGvyen3UuLkbMRh0F70loftAvvl+FbmD7yFiwjye/m4ik8e/BoBHVDdueeg/RAKRUWl8/83LfPZ2FgDNx39EJ/8AtEDInfN5Y+5dTB7/JgDG4JYMeuQTegFVrZty7NsPeHX8Mvo9OpWhfdq4lqIEIJsjx72Z8Fi/iyJtEhpFi4ROnMzNxFZPzL/SY/ZrUu8a66a4oQwpyeenuQ8x+V0g7k6mPdKDwCZaQIfZvwluF7zfza85XQbeQdGnTzP5RzC1bEtIRE/C9FqUgPfg15junMarj35LpcWBQq2l5zMbuIdqcjUGjJ4yDT/XU4vR2xOdSgHocfdK4uvxQ/ja1cqEdxjHIzPvomm9ZTtyd/cPeezxdymrsrrqnbaBNgB+zblpxD04vnuFyeMLAQjtO5U7u3RwrZk/+DUm5f6D16Z8TY0Ngm6bRPukbECLT1gHuvTaz+evDGEZv3d/1ehMJuwXlL2w3rA75/ISgGconUY/if27aUwenw9AULeJjJ0w9IIVeC7mdDp/18WsIAiC0DBF7969nWazmTfeeAO1Wo2np+eNjkkQ/jJqa2upqqq67O/79+9n3bp1JCQkcPPNN6NSNZh9N2jDpi14R7TC7B1wPUIV/gs5rMt5b9QOeq98jfY3Ophr5HQ6qSzJo/Tscfrc1PNGhyMIgvCXdvbsWWbPnk1CQgK33nprg++bNm0a5eXlYqqMIDSGwWDAw8Pjd60sExISSmleBpLj0oURBeHvS5bslBdk4e8vLkgFQRCuN5G4C0IjRERE0KdPH1q1aoVS2bjDKCI8BLVcS3H2aWqrK5Ck3/esT+G/j0IZQLNuLfg7/A4qSQ5qqysoyc1ALdfSNCLsRockCILwX0fMcReERtDr9TRv3vx3bcNNq6VVyxacSkmhJLsatZs7ykZMuRH+m3nSbWJnyEql6EaHchWS5ECyWdA6a2kRF4dO53b1QoIgCMJvIhJ3QbiBPD3MJLRuRXZOLjXVVThsYtqM8PekUmtw9zISFBSNzk0k7YIgCH8EkbgLwg3mptXSNCL8RochCIIgCMJfnJjjLgiCIAiCIAh/AyJxF4RGqK2t5dSpU1RUVIg1qwVBEARB+FOIxF0QGiE9PZ1NmzZx5MgRZPF4d0EQBEEQ/gQicReERqiurqa0tJSKioobHYogCIIgCP8jROIuCI0QGRlJx44dadmyZaPXcT/nwIED1ykqQRAEQRD+m4nEXRAawdPTk169ehEcHPy7trN69WqmTJnCnj17rlNkgiAIgiD8txLLQQpCIyiVymsaaU9JSSEpKane1xwOBx999BGBgYG0a9euUXHYrauYPmg3t2x6kuCklcyfXcnQj+6jVaO2Jlw3O2bR96kfKazowTtH3qX/n1LpHmaNWkHsZ48z1M+D6/8orxy2zVvBkbJQhk6OIPG5FcgDBjG0TwuaXPe6/ggn+P46xOx0OpEkiZKSEk6npaFQqvHwNGG11KDR6ggKCsJkMqESD1MTBOEPIBJ3QfiD9erVi969e1/0N0mSeOmll7Db7fTv3x+1+iqHopzLspnP8d6eQJ59/wl6R3ijVgA4kSUZJ+B0ysiy67//d51g3rPLkG8ezC19W9YlZ9t4sfsq+iS+Rt8/JYZM5s1N4dYP1/BAgjeaP6VOuLAv/GE1OJ3IstPV32T5uq+oZLeu5IUBuxi29WV6XNctu1yPmGVZpqSkGIVSQ6++Aykur6LW7kClcCJZLeTn52C1WvH29r76cS0IgvAbibOKIPwJ7HY7CoUCtVqN0+kkMTGRL774gscee+yavtxtmfs5YAmnte4Ee1KL6RzihUmjuHKdlkoqKyupdQBaIz6eRrRqmariMpxmb0xqkG2VlJQ7MHh5YVA6qLVYsDk1uBt1l43YWisKKa22IztBY/LD1+SKW3bYqCorosoGqHWYTCZMeg1go6rEgqy0Y7HakSQnoMbk54dJ7USyW6gsqcWptWOxSIASN3cTJpM72rofM6yVRZRV25BkQG3Ez898/qR1Yb1KrR6TyYCitoJqSzW20iLyc4rR+HrirunI4z+3RHeunGSnuqyQSiug0uJu8sDDoAHsVJdZkJw2LLZf4zX6+mLWKMApY68upbDCCoBKq8fk0QTDRZm5jcqiZE6lm2iqLiY/T4F3oJ7afAtKvYPqahmNzoiHlxFlbTWVleVY7IDWHS+zEZ1WBVgpy7eg0tuprLKjUKowmL3R2koorXE0UO/lnE4nltJcymoBpRqd0RMvo/bX/lFTTkVlNVYJ1AZPvEx61CoF4KCyoIBKB4AStdYdTx8T2nrqkGrLKcrPxXJpW12xnQFbNSUVVdTaJAB0Hv40MdgpyyvDItVQkpNHwRXqtVWVUFZVi0MGdB4ENjGgUIAsWSgvrEWhc1BT4wCUaPVGTGYjbuc6tGShrLAMracJg0aFAnA6LZQXVOPp73PlRgXKy8vRuGnRG71IPpOFzSFTU11LRU01Oq0aP6OR0tIydG5ueHh6XnV7giAIv4VI3AWhESRJora2Fjc3N1QqFQpFw0m03W4nMTERo9FIq1atqKio4LXXXiMmJoYnnniC99577yq11ZK0fhvlvh0ZFWvjrWXbuKNjKEZPfcPxWSo4tOprvl+8htMVWiz+nXnyoQnc1ErFqhefIuufX/JYKxVl+z/iwRmnGfvZbMb5nGXnylUcqO3I/f/ohMeF+1Cey4qPnuGn/eXUSgqCB73Efx5KwOCwkXt0K999Movd+Xps5qYMHDmeiYPb4qE/yfwXF5DhnklKdgW11RJUqej40uc81d1IScYK3rp/Nc4etaQdrQabgsCuI7jr3tvpEqxHrshn3Rf/5qddOVTYlNj0HXny7an0DTQhX1KvIbQzYyb0w/3IUtbt3kTBsV2smdOR+9+byuDwY7w+dBkDDvwf/WUHRSl7mfPeDLblGrAbQ+g+ZDyTRnaiiSGNxW8sINlymvSySqrKHVClIuG5D3iubyBqSx4Hv5zBM2sL8NCAZ2QnRv5jMoPbeOB2vqXSWPZ/89mRc5xt006xSN2dJ39szS9DF+I2ykbyPojqMJIHnhqIbdN85v24iJNlWmp92/HQvXcxqEMEOs0+3hn7A7pRNnZvzkfpsBA5agad8mbzw85c3ILaMOzBFxnXwf2KJ3BLfgrfznyYNZlGJDcvmvUax7S7++Br0uCoKWXvks/4YcU2Mqs0NOlwL89NGkCUt0R+yiEWzJrFxgJwSmrMfh35x5tT6e99eb9MXfMF63+8tK2C0F6xnR2U7vqBl79bT0pBLRolxI1+nafGl/Hl1C/ZXVFD8sM5rGk+lEfeuJO4S2p1VBayec4bzN96ipJaFVWhA/nouX8QG+hGVck6Xh29FNXNVk4lVYFdgW9Cf27/5z30Ofdw4tJ9zJ62kIiHJ3FXmzAMSgWOkqW8PHEHb6+62rEI+Xn5hEVHk1tYjsndnSZmPZaaGlTqIE6cySSzsAxfk4aCwkKRuAuCcN2JxF0QGqG4uJh9+/bRvHlzIiIirpi4l5WVsWnTJrKzs3nhhRdYu3Ytp0+f5sMPP8RoNF69sppjJKXraNahGfEd/Gi/agFbikYT6tFQ4u6g6Mh61p200eNfX/F2+wBO/fIi767cSVjwUHr0dOfFY6U4W3pRevwopW4yKakV2LQV1NpseMXGXpS0g5XUX/6Pherb+fDbAfgYtWQtXUoKrWlemsHOFQupHvgBi0fHkH/gF75bs451wSGM7AyQyUnNIGa9P4xwbwPse53e079jzMqH8cRKtdJKYJd/s/jVGMjfw5dfbWDfruPEj2lF0apPWGwfwEsfDybSx0DO0inc+eJK2n4xFt0l9ValpZFls+F5312MTPG4ZKrMOU4cNYXs+Xk2Z3u+y+Lx8RQdX8/8patZtjec8TcB5JCq6cX0128lPsgESe/Qb9o8Uvs+Tmj1LhYsl3jg08WMj4Kikyc5nX+IInrx6y3KcYx//Z9kHltO8y+e5BY/D2TrCn5S5FDb9E0Wv9AKkCg6soF5B3Np8eBs/tMtmNMr/8NHG7cTHuxLQhhAKhlBn7B4USjFG2Yw9tX38H/5QxZPLmXNTz+zfdcuSjr0w6/BTmMhafbTbIqbxeIP2lKZfYylcz/h6/XRPDYqjIK9y1iT4c7wad8yoIUPhVu3kqWx4+A0S95cRcRLi1kcBPaKXLYveIcl3+6hy+PNLqmjobZ6kpgG2nnJnnDu6l3JypVH8O4xlSdv60aIOyR9/TWpzrt44qcnKB2wi2GLG5oqY+fshm9YVtmWx9+aQcsQE0mf3M6zX7Tm+xe7AA5qFWW4t3qFxTPioegIC+YuY8+mg7SZWHfl4dOTe24v5q1lB+kXHUBTsxvFq9eQOmBKg615US9yOqmqsVNQUkETh53SwjzUaiVeXk2w22zkl1bjrnFHUjquaXuCIAi/hVhVRhAaITMzk8OHD3Py5Mmrzpn19fVlxIgRFBcXM2fOHH766SdGjBhBt27drukG18pjx8nyaUbr+Ai8g3txW/8qdmzLr5vKUW8JsrJKMZsjad48AICY3r3xzcwis7oan1Ytydy2nUqpgK2JhXQb0I7MxG2kFZeSn1dDSIjHJdvL4cAB6NOnNQa9a+JCyPDhtMVBdfVZzp71pXefGAD8Y2OJNJspy8yiEoBmjB7dES9vg2tTHTrQPieHXAD0BAR05JZbXGXx9yfYbEZXXUUNeRw+XIyPupJD+3ayYcMGkt0jCdm3j6R66jVGRdE8Lo6AK7akE6vtDCdPenHzwHgAfCIjiQoIoDL9DKUANGXokI4EBplcRdq0pX1+HjkoULv5EtlKTeraDWzYsIGTVQ5C2l6YtDdEgcHQkfHjz90yXE1+XhFKVSitW7lKN+3WjYDSEnLKy7G5Kmb4sGBQKtC06URXc1tuuskXPD3xDgzEq7ycKz9BIJXt202MubUtACZfX+JatcKafJwCyjiTXom/fxSRTV1TQ3x79aKt2YyWNjz07n34Jrv2ceveA+TKnmhTTnH6sjoaaquG27nqzGlKMRIS7439bDI717vqUdw8ng7qa7kboIDkZCstWzbH189Vb5sxozElJpIKgIYmXh0ZM8ZVLz7e+Pv4YK6soOqCrfi060dE6lo259QgOavZvj2L/gPaXkP94MR1Y3mN1UZ6TgElFdWotTqOnTrN8ZQz1FisSA47siQezCYIwvUnRtwFoRE8PDwICAjAx8fniqPt5/Tq1Yt+/frx1VdfYTabue2229DrG57q8qsKjh07QUW6kgOJBvKPAMUqDh3aSNb4aMLqLePAbncCGs7nQm46dHYbVlnG2XIAQ2rnsu9EGVurh/HPES3ZNfMX1qX3Q+felpYhl27PSm2tFjc3JRfvqhPZacVm06E7N1dEo0EDOB127BdMIPntrFitTkpPH2RnScr5E1XkyI4E1lfvNXI6LVitevTnJryr1WiUSrDasV+xpBKDuQt3Pqvk5/dWsjG9ilrZTGy/+xg3KALzb4pCwuGQkGUtmnMTuN3ccHM4sEkS1yfdq6Gmxh3DuS6mVKLSaFBZrdiwY7eBQqPh8tsrctn7w1d8d1jGywTgoKqkmFp8f1PtDbZzrR07Idx0970o5i5l+56NVFefoWAbPPd8by7repexYbWpUKvVqM5d8+oNuNfUUP1bAvTuyq3Df+SD1aco97OSVDOEu65xKSabzYosSTjsDqpr7ejUasorq8jKL6Wqxo6vtwGb1YrOUN/sfEEQhN9HjLgLQiOEhobSu3dv4uLirilx1+v1jBo1ir59+/LPf/6T2NjYa1ourjbvMAeyHKiBmvwUUlJSSKEZHWu28NPhkgZKmfH3N1JryeZshmtctiDpIHmBgYToDahpTrfoZOZ9uIbCTt1pbYgg1OcYG9cdojIghsDLthdEXFwtSQfPYrW6fv4vPXSITNTodSEEB+Vx8GA+ABVnz5JtqcXdP+A3JrOXCqBZs3Ai+ozhsef+zcyZM5k5cyb39g3AvZ56rYWF5OXlXWUUWoFGE0FkZD579rjG/Ktyc8kuLcUtOPgqywM6sdmyOZkewX0zZzJz+mPcEutOxv4DFPzmfXPHx8cThSKHtLQyAAqPHiXX05MAU/03Y/520bRrl8/mLZkA1JaXkXn6DDRtii+eBAe7UV6WRW6Oaxy6KiWFTIsFBydZ8PFREh51tfe/n3uckR29uZZLzF9drZ1LSE52ED9oIs/NnMn/t3ff4XHd14H3v3d6w8wAGAwGvZMg2CmCIikRItWt4sgqllu8a693k+y7zr7J+2T3VZJNcTZZrdOsxErWduI4LpFtWZZEq1idpCiSotgb2NAJEB0YYPpt+weKSREkQRAUBPJ8nocPJcwt5/44mDn33F/58//vQTJvvspRTZ/GscNUVkJrawdDwykAOrZto2flSj7ckedyau78FFl7N/PWG5vpqv8EtdPcLxAIkEmMkO1zoGs63f1DtHX2EU9pZHk9BFwWtEyC7Oz5MUmmEGJ+kYq7EDPgdDopLy+f1rYtLS0YxlgddfXq1RQWFrJnz55pJPwpOvafIOpdyKc+/xi3VGRNvtL24u/wO8/sZmjZVPfeTgoWraK6eTO7fvwNjvoDdPf0seTWBsqzPViA6purOfmT3dz+uUqc7hQFZZVobwwRqbkwbQc/Sz9xP9t+vJnv/uNOrFYrNudi7l9uwRMsY8Wty/jJy9/gqT0RoiOjeIqWcmddAS5OTat9ppbFotvXcvi1nTzz7T1YLGM3OXbXYu5ruPC8iiWHBTevZ20kRFWVhV9u/znfPnyCu75wN8smB1UqONyF3HT3eg6/9g2eOlRILBbHmlvJAytKcNN2iXhMTC1Bzwdv8dROA9Qog8M6havryLnia3MQqlxK7Ykmdj37DVqC2fT2DVC6+n6qz5k15+rksu5zn2b7s3/LU01lpNJpkpYi7r1rAT7clKxYS0X7S7zzw6fY7fOhWMto+GyEAncF99yTy/d/8BTpIOhGirOtAxhUX8G5L97O968oxU0cvWsfm988w6hhwshR7Ovup9pqxaJUsWThc7zw1D/SXLCcOz+9nsLzju2l5tbbKX7uVZ7/7jGcThdtHQqPfXYduXCZG7cPyV7Bp1c/x5+8YuVzf7xw2rtFIhHOnDmDXdfJ9zsZGNVJJBP43VbcVrDpcXJDOYTDFx+BIIQQM2UtLy//E6fTyZ133onFYsHlcl1+LyFuEJqmkclkZry/1WrFNE0ymQyZTIZgMIjVakVV1cmfFRQUkJMzVfqno5lOCisXUF0ewX1OgT5YWIbflkXZghJyswupWFRC0OYhGC6kpDyM35dLQY4PByq6zUN48W3ct66W3PHpAN25BeQXLGFDw1LCHhvevBLKK5ewankFgSm6GjtDlVT500QzNpxuDwVrNlEfdmGxuwjmlxC2jRLHQ07pYtavW0ddkQ+w4fLlUlRVTMg7Mb2kA2+wgKolpQStLgJ5hZRWRfCOtRZ2l5/80mIKQn58uWXU5CpEkwY2hxuPx0PtHQ+xLMAF580uqaS2diFFPj85YQ+KomC1ZlO6sJRcl5esYITKJaUErXb8kUoK7VFGTQ/BogWsWbeBFWV+wIrTk01hZTF5fs94Am3HG4xQuaSMXEuASCDFmaiBJyuH0sWruWXdSoouKEfb8fjzKFtYQrbdhkVx4MsupGJRMRO3XjZPkHAoG7eSRrV6yKtdz93rllAQdI7tH8inoq6EoMWCYnGSlVNI+YJCfFiwOXyECosoKszBdYnzegvrqHQOMqR78OcVs2zdXdy6cKwKbM8KU5TjRjE1TLuH8JJ6bioN4bZlU7kwRGI0g8fjIZAbZtH6e1hfW05JeYSAM4u84mIK8nPxX7StLt7OK8v8gIdwwMJIKo2mOPBkl3PrJ+9nZciJxZJNQYmVRMJOMLfgnPfGrziyiykLKqQ1sDo9FK7+JJ9eV4zlgrYCsGC/aMwuIqld/HPvHTzxWBXT/eazWCzYbDYS8Rjp2AhmJoHVVLEaKZxWk4L8PMrLy/F6vdN6GieEuLFFo1H27dtHJBKhrq7uotu99dZbpNNplI0bN5p+v58nn3wSm81GUKavEmJSKpUiFotdfkMhxDwzwNY//QPeuu3P+drGC+a6vCjTNMfmyE8mGR0ZIT1+Y2+YJm6Xi0AggMvlkqRdCDEt7e3tfOc732H58uU8+uijF93uiSeeIBqNSlcZIYQQN5LTbP7LH/D26VZGwvfz+yuvrFilKAqKouD1evF6P/w8QAghri1J3IWYgUQiQVNTE8XFxQSDQamuCTFvFLDmU5+lIp7GnldFpV/maBBCzB+SuAsxA01NTbz99tssW7aMhoaGac0QI4T4OPASqa69zJz/Qgjx8SSlBiFmIJPJkEwmSaVScx2KEEIIIW4QUnEXYgZqampIpVJUV1dPa/VTIYQQQoirJYm7EDPg9/u55ZZb5joMIYQQQtxApFQohBBCCCHEPCAVdyFuWCaGniTan8GTH8Q5FxGYJgCGYaCpKpqujy2ko4Bpgs1mw2q1Tk7BJ4QQQtzIJHEXYpZlkkl6OjpIXvCKi+zCMDm+iVVEr9YoZ0/FyKopGF8l8kqZpGKHeflbHdT/0aOcv+h7mmjvKLrLg9+vMNzRw3AygzH+qqJkUTDj855P13Xi8TjDw8PE4klsdgeKYmLqOm63m2AwgNfrHU/oJXkXQghx45LEXYgZ0DSNkZERvF4vDofjvIQyEY2y7+23OYvKaP8QCd1Jdn4AB2FW3LsBn8+Fe1aiOM0rf3+A+r/7Estm5XjnGuTY1t3ESuqoX2th509f4ITVgddlRwHS/QbVn3mUO6vDV1Wpn1iBMqOq5OYXkW2xMxpPo6oqCgZqIkpPTy+RSD4+32zcJgghhBDzlyTuQsxAT08Pu3fvpra2loULF56XuAcjEX7tN38TGOToO7tpTYSpv38VYQBG6DjSjOmN0d2XQNezqbk5l+H9I4RuqmRsDccMI339DMdshCrCeOK9nG49Q99Ieuz4ZcupiaRp+eA0A0Y/J3a+j+rOp3pFOQEgPdLHmdbT9MYBR5DSilIiOd7xKn+KrqNHaB9VAbAF09O84kLWffoe6gtzcAD9+/6Fb/30fZb9/oOUqEmGzjZxvHMUAE9uMaUlJWRP4+4kk8kwGovhz84hoRqkMgk0TSeRTBFLpvDYFGyGSXd3N1VVVVJxF0IIcUOTxF2IGeju7ubEiRO4XC4WLFhwBXv2ceC112jPdpPn92HBpEgfZfuzJ1gzmbgn6W05xtFWD2sqPAwf3cv7jX3oLg8eK/QO2sm6I8zg2UESJBjo7MLjd1ECaIkhmo58wIGmXhxuH5l4Ex3RJBtWL6bA7yRxZh+vbj2CPy8bRVGIn+pmeAZL0dizsnBpGhoa8aFm9r/zHidsueQ5wdqXBocbV3nosk8WVFVlZCSG0x8iFksS8HtAN8kP5jAcT3Gg8TQVhSE6Wk9QWVl5xXEKIYQQ1xNJ3IWYgVAoRHl5OYWFhTOoApu4ym/mgQ0L8ditaOqeS2w7SltbJ0b75exHAAAgAElEQVRgJXfceRNFPuhrbESzFrDmoTUcefsA9Y9+aryrjM5wfzttHVEK1z/Mxio/6b79/OKXbbQVFZLj99Oy6wDp2nt46LZKbIpO85tP8+OW6cTcz9Etb9Lnc2EBYk1dRO55kDAqsVgnbb0OVnzhUdYVwOjZs8SsxmWPCKCgoBsm0ViK3sFhRkejuB1WfD4PA0OjdPcNk58TIJFITA5kFUIIIW5UkrgLMQMFBQXcdtttBIPBGSTuOdTWRrDZpzNE1U/FygX07jrJlp+fxuaEyIp7WWcZ62t+vgzxWA+dJ1tRM6/SswcgRmezhnt5GpU+Wlud1N2aj8WioGAhsmwZ4V0D04jDhsvrI8vvwQoEb7qLupsr8KKh5JZTU9vHiZd+Qrsf/CWLWb50ybT68RumgaqqWFWNoViCpFUhFPQx3N1Hc3sP0VgCXdNQVXUaRxNCCCGub5K4CzEDDoeDgoKCj+BMXiLVq1lrCXN2YBR19BQfvLmTcNEmFl4wVlPBYvESCBWSVVtJ7vhPKyu9REpCOIlit2tokzmwCarK9FLiIFX1ayf7uP+KDU+gkpUb3OSc6iae7qO1+ThHnAH8N5VcdtYZ0zQxdBUMjUxGw7BAJqMxEkszNJrC5/GQTsaw2eSjSgghhJAFmISYYwpBsnyttLeP/X+8t4/Thw7RD8Agx493oTkLWVFfT/2yciy93Qxp2hRHcpCVlUMw7MDiK6e+vp76+npKXTppNY5GiJpqgz17W9B1A8MwaNq5i96rij7D0FArJ5pt1NXXU79yEWGbxmg0ynSGvTqdTvz+LIzUKDlZTqKjcQ6faqX5TA8Ou52SvCyG+89SXlaGxSIfV0IIIW5sUsYSYo5ZrEWsvauEH/zL1znkBqvXhV3JZaye76PIforXX3+Npr44aDE8Kz5DjcuFwgLW1L/Gc1//G94LreC+L99OSbicZYuH2bHzh3z9F2O19JzqDWwqXIADB8UbHmbN5n/l7/72VUwUXKUVFF1V9DZ8VifmmVf5+pv9YKRxhJdzS2Ul/mns7XA4yMnO5syZTpy6SXnYTyLtRtdU0DKkR3oIZfspKyuTGWWEEELc8JSNGzeafr+fJ598EpvNRjAYnOuYhPjYSKVSxGKxGe6tk44nUU0bLp9r/C45Q2wwhSXLi9tuHeunbpoYaoyBwTg6oNhs2GwOHBY7br8bm5okOhojmdEBcGblEvDYsSigjvYzENex2tz4Q36cgKGmiMdGiKfHBojaPQH8XjcTXepT0V6iSQMTsHm92NMmrvF9f0UjOZLEsDtxuSH54ZjPZWik4yMMxTMA2Fw+snw+nNMoC5imiaZpDA8Pc6bjDN09PSRTGVRdxWm3UVZWRkV5OX6/X1ZPFUIIcd1pb2/nO9/5DsuXL+fRRx+96HZPPPEE0WhUKu5CzEQsFqOxsZGKigpyc3MvklBacXp9H0qIHfhyzu8ljqJgcWSRF8ma+mR2N4EcN4GpXsoK8eHdLHYXWdkuLnI0XIEwrnMPNuWGNtz+X71wQcznndCGMyvngjimy2azkZubSzAYpG5x3Xmzx9hsNqzWsTsOSdqFEELc6KTTqBAzcPLkSd5++2327NmDYUxv6kNxoYkqusViwW6343Q6cblck39sNptU2oUQQohxkrgLMQMTyaYklEIIIYT4qEhXGSFmYMGCBei6TkVFhcx2IoQQQoiPhCTuQsyA1+tl9erVcx2GEEIIIW4gUioUQgghhBBiHpCKuxCzTFEU7Hb7XIchhBAfe4ZhoE25oNz4ysqGga7r5802Nd8oioLVapVxUWLSxHs7FosxNDSE2+1GVVV6e3vJysrC5XJd9L0iibsQs8xqteL3T2f5ISGEuLFdbK0M0zTJZDKk02lUVUXX9TmIbnZYrVYcDgdOpxO73S7Ju0BVVdrb22lra6O7u5tQKEQsFmPbtm2UlJRQVVVFTk7OlGPoJHEXYgYymQz9/f0Eg0Hcbrd8EAshxCwxTZN0Ok08Hp/XCfsEXddJJpOoqorX68XhcMh3xg3MMAyOHz/OoUOHSCQSk9V30zTp7u6mr6+PwcFB6uvrp1wnRvq4CzEDXV1dbNmyhZMnT87rR7hCCPFxM5HoXg9J+7k0Tbsur0tcmYGBgSmT9om/M5kMTU1NnDp1ilQqdcH+UnEXYgYGBgZob28nOzubpUuXTrFFgu7TB9m19RgDZFOztp6Vi0vOX6Q0epgXn99Dv26AxY6/eDX33lVH1nn7niufVfffyuJIkA+vY5qJD3Fs28/Z2wX4ItStXMu6BbkXjb9167/y1mkNrA6CizbxyM3FU10lx7bu4uDpbhIUsObhBhZl++RDQwhxTWUymYv2ez+POkJn8wkam/rIAIGyZSypKibgms1oTNR0J43vj1DYUEfoKo+maRqqqmKzySfpjer48eMkk0mys7Opq6ub/LlpmpNV99OnT9Pc3ExFRQVut/u8/aXiLsQMRCIRamtrqaiouMgjTytufx6lNWGUoW46Wvs4/765jbd/uIdUeSU1NTVUlxVhNr3Bz147yujkvjXUTPzxp+iKZdA1ywW/tEYmSdvOF3n9qEpBTTk59HDg3a0cOpOcMvah/T/n+2/3E6qpobzYTceWn/Ha0ZEptnQSjBRTWeNj8NBpukZTyBqxQohrTVXVyz/J1EY5e7qRxtY43uJiiouLsQ900zsyRHpWozHR1QFaDrcz1afklZoYbCtuXB0dHZODsqurq7n77ru5++67ueeee1i/fj3BYHByoGoikbhgf7nlE2IG8vPzue222/B4PBdJ3J0EwtWsCntJ96Q4e8Hr2VQ3bGLF4lJyLBZMPcWZnAGe23yC3nsWUxWuZlW4enzbGCdeHmLl+gWUhz9c8TZRMz2cONhJ2Z2/wZ0rstF7j/HWWwdpauqipriK8+/Vhzi85QA5m77CPQ0l2DND5GvP8tr7J1i3uJ7zh9T6KFy4nMKFTlrf2C4fFkKIj8R0uh8mhvs509WNp3wjqxYGcAKp4WFUlwsb3ex9qRVrwQDHTgyDUk7DZ28hnIhyYsdLHOoB7EHK61Zy05JCxgr0CVo/2MH+ph4SOkAR6x/fQJnSzo7ndtAUTdP7o1GOF9WxZuNiQsBw+2H2HzhE1yjgKWP9bSspzfFinYXrE9evdDqNYRhEo1F27txJdXU1Pp8PVVU5evQox44dm9xmqps8qbgLMQM2m43s7GycTucMBxn5KV1aTs74iHHFMLCOjDLo9eL58KZnG9k5BHnBXIKOD//KmujaWbp78lmwOIQDK+7cMJGAB21gYIoK0Vmam7Kpu6kAFwpWu4/IwnK8He30zuAqhBDio5didHiA6GgOxRVjSTuAKxgky+XCSpL+9n1sbfKybv2tbLi1lmw1RdehdzikVtPQ0MDa2jxinUc43DzEWLfAHbRk8li8toGGhgaWZ7fxytYWFEseC9cuJOIpZlnDelaNd3lM957m0KkzKJHlNDQ0sCo0xI59J4nGMnPYLmI+8Pl8mKaJpmmcPHmS1157DVVVaW1t5Z133qG/vx/DMHC73VNOLS1FNCHmmqkTa3uTH706wOr/8BnyznsxRuOBJpw5ZRREcqf8hTXJoKl2bBO/31bLWMVH16fo2pIho9pxTHSSV0Cx27CqKuosXpIQQlw7BrqhYRgO7B8e8DMpzE0bVlAaCWBVIJPooqMlTsWmlZREHBgFbtKxI/Sc6WG4spqKVWsos7lwuRxYFSgMLefwN4/RdEclxUW5eO0Z8kqKiACQ5mxvHxoBKmoXUeK3oodTtD9zmjPJKvw+hyRX4qJqamro6enBNE1SqRR79+7F4XDQ19dHS0sLmqZhmiZFRUVkZWVdsL+8t4SYY2rHS/zN3x1k5X/9Xe4u957/S9nVyN6onaLFFRT5LvcAVgghxBgHPt/EE1EDw+il43QzbR1/xw4LgIGWyaJqXQgdG256eHPzNo50DDE2LFYjFa9g+ZTHThGP93Fq1xE+2LcDqwKgk04UcLtpIh1hxKUsWrSIgwcPMjw8jGma9Pf38+qrr2IYxuT4DqfTSU1NDYFA4IL9JXEXYi7tfpov/X07j/3Fn3N/sQ3Leb1uYhw73IrDHaaiIn/8y+HDFCyWfHJyd9HXC4SBRIKYrkOWH98F20coiPRy9qwJ5YBuoA4MEs3Lu+rZEoQQ4qPhxufLxus9Sk83FEQut72CouRRXLmaNZ+5m4rzXlKw0M0Hbx1CL9/IF3+tnIAd4CQv/K+jFzmeE5ermBW3l1OxZjHnzt+lWCzIDO3iUhwOBw888ACbN29maGhocqDqxHSQTqeTdevWsXDhQqzWCwt20sddiBkYGRlh+/btdHd3X2SgkYmha2TSY9Oa6Zo69t+6MV6NMeh44Y/5/N8m+M1/+hr3hnXUTJpMRhvv3mJidJ3gSMcIek4RYd+5XwUH+PZvfJPtaRVQcDiKqC5P8Pozr9OVjnL68D72n+gjWFZCFi388ps/4OU9TeP93SOsvtnJS08/S0s6RXToJK8+uwPP8mXkMUTjts088y/v0DEeo65myKRVdFNHUzOk0yq6DKwSQswpBX8oRDjLxokdWzk9rKKqKm3v7+Zo11kunIdDwW7PIVLQx7tbmjEMA8Mw6D/dRGPjcQYBRfnVMvSGYXDilVdpnBwYqGBRTHRVRdV0DFzkhuwMDXfQdKp/cp+Wbe9yfGSEaUxkKW5giqKQk5PDZz/7WTZs2EA4HMZms+HxeFi0aBGPPPII9fX1Fx1DJxV3IWbg1KlTbN++ndHRUe6+++4L7op1fYjTu3/JT/9ly3gS/A5vvFzO3b/1We5aVoqPY2x5L0pW1lm+/9Wv8n0AXORXbuLXf++TVJGkta0N1Z3HkuoKnLrOr8aWW3H7PdgnRpzbPSz8xH/k1u99jT/56s8gp5pND3ya2xd40fUhHB4XutWCOX6M8D3/P7999r/yv766FexuChq+wh9tyEHXo1jsTpwuO4quo3OGrT/4Ka/uOkUU4H/v5TmW8aWn/iNrHPLRIYS4elMVPiwWy5RLvZ/HlcfC+lswPniXt773NEkgsuJe7ggW4bN04PF7cVmtY8cCLC4fNbc8BO/+jKeffhmAYPlKbmnYRJ4F8tbV8OJbW/jhrhgA2TfVszI7htNiw+VeyNK6fbzw9HcJV67mjofqKShZziYFtr77PE//cmyy35L1j3OvJxvnZUKXVVOFoii4XC7q6+upr6+/sn03btxo+v1+nnzySWw2G8Fg8BqFKcT8k0qliMViF/z8yJEjvP322yxbtowNGzZM+TgLxr6UdF0nnU6jqiqGYWCxWHA4HLhcLhRFkQ9xIYQQYp6aWDgpnU6TyWTQdR1FUbDb7bhcLqxW66x8zz/xxBNEo1GpuAsxE5WVlQAUFxdftDJkGAaJRILOzk5aWlro6ekhlUrhcrkoLi6murqawsLCKad7EkIIIcTHm2maZDIZenp6aG5upquri1gshs1mIz8/n6qqKkpKSi6x5suVk8RdiBnweDwsWbLkoq+bpkk8Hufw4cOcOnVqcjGFiV/y48eP09LSwvr166mtrZ1M/ieS/WQyiaqqssKeEEKIeUlRFGw2G263G4/Hc90VqSaeqJ8+fZoDBw6QTCZRFAVd19E0jZaWFs6cOcPSpUtZvnz5rCXvkrgLcQ2oqkp7e/sFSXteXh6FhYUcO3aMeDzOu+++SygUIi8vD03T6OzspL29nYGBARKJBJmMLOYhhBBi/lEUBbfbTU5ODsXFxZSUlOD1eq+r7qH9/f3s37+fRCJBIBCgtLSUjo4O+vr6JudpP3jwIMFgkAULFmCzXX3aLYm7ENdALBajra1tMmm3Wq2Ulpayfv16AoEAzc3NjI6OEo/HOXjwILfffjttbW188MEHDA0NzXX4QgghxFVLJBIMDAzQ2dnJ6Ogoixcvxuv1znVYs8I0TU6ePEkikcA0TQKBAA0NDfT19bFjxw5aW1vRdZ1kMsmJEycoKSmZckGlKyWJuxDXQDKZpK+vD8MwyMrKoq6ujptvvpnS0lLOnj07OZjFMAyampq49dZb2bFjB319fXMduhBCCDGrkskkBw4coLe3F7fbPdfhzArTNCenhJ54qu7z+SgrKyMUCrF9+3YOHTrEyMgIHR0ds/YEXRJ3IWYgnU7T1dVFKBTC5/Nd8OhvYiYZ0zQJBoOsXLmS8vLyydlnJub9NQyDeDyOrut0dHTMxaUIIYQQ11wqlaKzsxPDMOY6lFlTWlo6mbRP/G2326muriYej9PS0kI0GiWZTM7adUviLsQMtLe38+6777J48WLq6+svSNytVisOh4N4PE5fXx/vvfceAFVVVQAX3KFbrVaKiopoaWn5yK9FCCGEuNZCoRBLly69bqYdN02To0ePMjIyMvl9DmNj3I4fP8577703uTKq2+2+/NoE0ySJuxAzMDIyQm9vLwUFBVMuIOLxeAiHwzQ3NzMyMsLBgwfp7e1lw4YN5OXlTXaVMU2TmpoaHA4HDQ0NpFIpurq65uCKhBBCiGsjEAiwevVqVqxYcd10lTEMg1gsxsGDBye/z0dHR2lsbGT79u2cOXOGTCaDaZqUlpbidDpn5bySuAsxA6WlpaxYsYKFCxdOOUI+KyuLsrIyzpw5QzKZJJ1O09rayuDgIIWFhYyOjmKaJl6vl5UrV2KxWCgtLeWBBx6gsbGRlpYW+vv7SaVSc3B1QgghxNWxWCyTM60sWrSI8vJyXC7XXIc1axRFYdGiRZw6dYrR0VH6+/t55ZVX6OjoIBqNomkapmnicrlYtGjRrN2wSOIuxAzk5OTQ0NCAw+GYMnG3Wq1UVFQwMjIyOb+rYRgMDAwwPDyMpml4vV4eeOABgsHg5Hy3hYWF5ObmUl9fj6Zp11VfQCGEEDcORVEmu43O5gqiHyfZ2dnccsstbNu2jWg0SjQanVwl3TRNnE4n69evp6ysTLrKCDGXrFYrHo/noq9PzF+7atUqIpEIR44coa2tjXg8jsvlYsGCBaxcuZKcnJzzPsgsFgtut/u6eZQohBBCXI8URcFisVBVVUV2djZHjhzh1KlTZDIZXC4XZWVlLF++nKKiIux2u6ycKsTHnaIoOBwOysvLKS0tPa8vvMViue4qD0IIIcSNZOKpQl5eHhs3bqShoeG81yaq7LP5fX9e4q5pGv39/bN2cCFudBO/rBPTQAohhBDi+jHxPX9uon4tXfszCCGEEEIIIa6aJO5CCCGEEELMA5K4CyGEEEIIMQ/I4FQhxEdC13Vi8QSpZAJN0+Y6nBmZmLbT7fHicbuueOyCaZpkMirxeJx0Oo1h6Nco0mvLYrHgcDrxer04LzIl6qUYhkEimSKZiKOq6pSLmM0HVqsVl9uDz+vBZpOvUyHEtSefNEKIay6VTtPd3c1IPDW5ktx8ZVEsuJwOgoEs8kIhHA77tPYzDIPRWIye3j4SyczY4hzMz3ZQULDZrLicDiLhPPz+rGkPylJVlf6BAQaHR0mnM+jz9OYFxtrB4XDg8zgpLIhcV4vLCCE+niRxF0JcU5qm0draTjyVpri0ipy8MG63d67DmhHTNEjEY/R2d9Hb04mu6xQVFly28m6aJolkkubWdhwuL+XViwhk52C3Oz6iyGeXpqmMDA/R2dFKS1s7VZUVZPm8l628G4ZBd08vfQND5IYLqIwU4c3yY1HmZ6/NdDrJYF8vHW1NpFJt1FRXYbfL16oQ4tqRTxghxDU1MDjE8EiMhctuIpidCyio+vxdEdbh9lFQWolis9F7phWfz0dOdvCS+xiGQU9vP6Zio6p2KU7X2OJdc9cO/RzfeoxUuIKaRSVc8W2UYiUrO0Sl10fjwb10ne2murL8st1FRmMxBoaihApKKSwux2qzoRug83F+P1y8rSw2J6GCYpxeH8cO7Kanr4/iwoI5i1QIcf2TxF0IcU11dnaRk1+E2+uf3UQ10U/Tzud57r1WAEJ1d7Dx9tupzAFoY/v3DuK/7zbqwgFsgKEd5IWv/4Lh1Y/z5btrrvLkCv5gHgO9PQwNDl42cdd0nbPdvVQuWobF7kTVr6R7iEFi6CTbfryZobJ7ePC+5fiuLnigl6PvbGNoiYXwgkJmWvdXrHYKSio4fugDystKLpu4Dw0NY7E5CeTkYSgKxsXaQYvT2/g6P39+DyNAdvV6Ntx1P7V5Mwz0qvRdtq0cLh+hSAmdna2SuAshrilJ3IUQ19TIyDD5FXXopoIxW4m7FqP7wIv89Lk9cNPtLAr00X5sC29rXhwP1BNxn+XAK9uJ3LyKqtws6H2db/71i2gL7mJFnhdtFuKw2h1YbQ7S6dHLbmsaBrHYCL5A7pWfW08x2PQOz7+wFd9yqF67lJWBGQb9q4jQTRPDMNF0g6sZKuzxZ5NMJjCNy19XMpFAsXmw2l0Xbwc9zWDjyzzzoyO41yxjAZAaHqLl6F6yN6wk9ypinRnj8m1lgicrSMep2EcdnBDiBiOJuxDimjJ0HRQr+ixW21ODvex/9w0st/4hn3+wlpAjQX/oZ3z//b0cbSojVDuemOoG2oF/5g+/cYTaL36BO+pvptgNmjY7sZgwrYG2pmmij7fDlZ5bTcQ4+MYrKCsfpMaxjy3bT7P0nkqgkw9+tpOuweMcP9tBX08KQrfzW//tcSp9LgztfZ75vffxrO1gx9ZecEaou+0xHn1oNX4MDNNAH/yAZ//qMAsfvI+bqwoYG1q5lx/89ouU/OHX2BieToSWad+QGYaOaSoYJhgXaQc1Mcr+155hdPGTfObBKgJAcrCfuK7j0Aw0htj/k2/x8s5GhjMAK/jcU19lld1CcmQXz//P3diWnWH3jj7AQ+ma+7nv0QeoHn9M0fL6N3j2zf30xiDvzif43V9biN2qoCaj7Pzn32bzMT7UVuZYW+kGmnaJmxzFMm9nCRJCzB+SuAshrjndMGaxm4xKdOgQRw+XcdOXFxCwGqi6i8CypRRtfYPO5jb6awwM00Q/+F3+28+6qPvt/8L9N9cSwECdxdxKN8zpL4ZhzqRPu0Ei/j57tttZ9d83UHGsmdd27qblznKKGeXsyTd47qibex9/mDsLAjQ+9xd898Xl/MFjS1H0Tg5u+SGDeb/Ff/7SI0Tbj3LgwDO8XVbJ/csMdAMMVzkVgXfZ8m4jlTk5RPx22PsiP0kU823f9NvqSubGMcxLvRcMEvEP2LujiJXfqsCjG6iALZBDAEBv4s1v/5QmexUbHt+Izwa9r/4Nf/X0Cv71qxtIJVvYs+XnpPO+wpe/tAAGTrJ77/u8ubWUvHuXoO79Id/fFWPFxi9wR14W0X272adVssowOfX8H/PjvnX8hy+tIN3bxP7Dz/PClmw+u2G8rYyx5F29SOSaPj9nCBJCzC+SuAshrjlNN2ale8r40UirIyQSWThdBtpEcml34tA1oskUKd2Kae7nR0+FuOsv/4BPrazBe5VdQqZiGNNP1kzMK28DQyO+9x2OLHqcLy8uI0Y9pV3bOXb6USIVBrrppGrVBpavvY3KoI0K2ya2/f122n+tliLTxOYMseYTD1O32ItenkU62sWJfUcYWhxCNw0Ma5CaW5aw5c/eZM+6hdzhzefQyy9Sc+9Wsm3ntO3lru0KpvfUjUu1g05GjRKL+3F7pjp/hGUP/jqLnH78fg82BWrKPsUbD7/Mrv+8nlrdSlbOau749Yeoy/GAFmLoTC/Hm9vo1yOceb8Rf9UmlqxtoNBnRS2rQkUhnWnm/TdbWf7VP6VusRdTjaCN9rB/9wHa1teNtdVluhXp0+gqJIQQV0sSdyHENacbs5m4G2j6Od0XJn9uohsmhmGg6Qo6i7j/4VGe/9N/ovSZr3Grc/anXtSvIGE1Ta64DQxNZd+2LdQ2/A9cVguO/GJCuR4ajxynoVRBN/IoKs7D47Og6Qb2mjoKWl6hSdXIV8Biq6Gqxj12Xq8fvz8bjnfSp+dOthWFn2TT4p+z69AwayNJjjfexG2/45nFf68PXdMlE3cDzTDHnpZMmSTbcZvHeOZr/8CWQ21kAMgQG7yZu3QDzVBQrF78gfE+9IoVxWpF0VRUvZvOMw6yq7NxuhQ03UDJCuAwTFS1kaN7DrD/qxvZbB2LQ00FWXz/fyKpG+e8ry6euF+r9hJCiHNJ4i6EuOY0fQbV5ouy4XAtp6zqWQ7vN6hdNv7jlpM0OV1Uhgvw690YpgPXxv/O09Xf4t/d9TBt39vM42WzFMI4wzDhChYNvdI20DK/5K3Nnbz/0jJ+aQFME8PIZ9VjtTTfswzDHKC/f4RYzCDoATrPcDa/gLBhoqGj6e2c7TTQioBEjNFEHDVQjUcf70pkmGg4WPnQJ3npr16huQi2FN7LU1dQbYcrq7hfOnEHi3UtCxb/H/bvNlhy04dfbeTlb75AasX/w589sYY8J8A7/M2dr44l+rqBCeck2BNJt4mmZ+PPTtIyGieeMPCes1aSbpRTvvgh7vjmn7LqnLMpVhs2vZnGiba6VMVdEnchxEdgfq56IYSYVwxjLPGZnT/gCuRSu3IpB/7hD3mnI0UyeYK3X9uFTjHlNUUYxlgyaWDFctv/5Kd/VMuPv/ggPz6ZIpXRZy0W4wor7ld2fJ3T3/1HTj70HTZvP8bz247x/LuN/NM//C4lmR3s392PYfazc8s2Wk61k0ym2PmTf0OrX0eRYkE3TJLJE/ziJ2+RTKboOn2KY42N+BcuJsswxwaIjiekZuGt3OTYx/Pff4XChrswr7AdrqyP+6X/ba0uH8s23caRp/5fXm9LkUymaNn2FlveeIUOY2z/c+N7/6//jJ1qZnJ/Y3wGmF/9G02cM0TNkiBH9+2ms/0syWSK5h/8M+9mMphUsnR1M//69PbJ/XoO7uO9V1+g1eC8trron3m8GrAQYv6QxF0IcY0pmKZ5RVXZy3LkULH2i3xqTR//9Bub+Moj/55fDpaw5sFPUuEDsOMOZuG0WccK4rf9b/7tjxfzi997kP/xvT6vZPUAAARHSURBVA9mJQTTNKc9KlNRFFDGVl6dvnaOHAnx+Oc3nffTvOo6aqsXoXa3E6OWdYXtPP/NL/GVRzbxzcHP88RnluOwWQALbttaVjn/ka88sonf+/q/kVjyX3hkbQiw4fT6cLvs418CRXzioWpOjN7HYxsuvQrsh5mmgTLNxw4TK6te8r1g9RBZ85/4jX+fx0u/tYmvPLKJv3/jII7qT1BILfc9tp7RnX/JE58be+2FvMfZlJeLA1AsLnzZPuy/Ohh2lwe3x4kVyG34Hb64oIMf/dHDfOWRTTydWsFqrCg2B7Vf+BZfHm+rrzyyib989jXM2ocpxfqhtpqqDcbf35dZOVYIIa6WsnHjRtPv9/Pkk0/OdSxCiOvQjl27ceaUEAgXY7FcWVL4caZl0vR1nCTktbBwwaUXdEql02x9732KFt6EJyt7liI4xZt/u5nowg1svG/NBfOba+mXeOpTO9j4yl9wQY+TC6iMvv7n/PXAY/z+Y4vGE//pScVHaD/6PhtvvRmXy3XJbU+dbqJ3VCVUsgC749LbziemYRDt7yTe08yGW9bNdThCiOvQE088QTQalYq7EOLaikQixId70TLp2a26zyHTNEnFR1D0NH6//7LbW61W8sNhon2dGPpsz21zNeL0txzjxME3eX5LgptXFWG1Tv9rwTB0or2d5OZmY7Fe/qYsEAhiNTVSsei0FmyaD0zTRFMzxAd7CIenNfG9EELMmCTuQohrqrioAKeiMdTdRio+gq5dbCbsj7+JJC0xMkhs8CxBn5NQbs5l97NZrZQVR9ASwwz3dZJJxmdhsR4voYpKCsJBppovR7HkU7mmlksvstrLiXd+zubv/5zhmz5HQ1kW1mn09jAMnUwqwUj/WdT4ABWlxdhtl5/rICc7QNDnJDbQRTw6MO9v5gxdI50YZbi3HbuZpqykeK5DEkJc56SrjBDimhsZjXHq9GmSmgWbOwuL1X75nT6OTBNdS2NkEgS9DsrLSvF6PNPaVdd1evr6ae/oRLe6sTk9KPO065Bp6OiZJIqaoLS4gPz8MLZpVNwBEskUbe3tDI4ksTi9WG3Oeds33NBU9HQch5JhQXU1gcDln74IIcRMTHSVkekghRDXnD/Lx9Ili+nsOsvoyChaMj3XIc2Ioih4HE6yC/PIywvhsE//BsRqtRIJ5+HzeOju6SWZiKJ/rLrNTJ/FasXt9RIOVxHwZ2GxTP/hrcftoqaqkt7+AYYGh8ikY1c4aPfjw2qzk5Xrp7AwgsvpnOtwhBA3AEnchRAfCYfdTkVZ6VyHMacsFgt+fxZ+f9ZchzKnbDYbhZF8CiP5cx2KEELMK9LHXQghhBBCiHlAEnchhBBCCCHmAUnchRBCCCGEmAckcRdCCCGEEGIekMRdCCGEEEKIeUDZuHGjqSjKtFb/E0IIIYQQQny0RkZGME1zbDpI0zSJRqNzHZMQQgghhBDiIv4vXhqKsbVTdVsAAAAASUVORK5CYII=\"/>'''))\ndisplay(HTML('''<img src=\"data:image/png;base64,iVBORw0KGgoAAAANSUhEUgAAApAAAAIcCAYAAABBx57zAAAABHNCSVQICAgIfAhkiAAAAAlwSFlzAAAN1wAADdcBQiibeAAAABl0RVh0U29mdHdhcmUAd3d3Lmlua3NjYXBlLm9yZ5vuPBoAACAASURBVHic7N13eFzVmfjx7507fTRFvVtWsS259wI2xgYMIbTQEjbZ7KZAsstukk3bBJIfCUkWkmw2yaaH9JCyJAQMGELHYOOCe5flIsvqZVRH0+/9/XFGVrFkW8ZgwO/nefTYmtvOvTM68973lKtddtPtJkIIIYQQQpwhy/kugBBCCCGEeHuRAFIIIYQQQoyLBJBCCCGEEGJcJIAUQgghhBDjIgGkEEIIIYQYFwkghRBCCCHEuEgAKYQQQgghxkUCSCGEEEIIMS4SQAohhBBCiHGRAFIIIYQQQoyL9fSryJMOhRBCCCEuLNoplw4JIMcOFE2JIYUQQgghLgiaBmPHhSqwtIIpAaIQQgghhABOlzg00TSwnl3wKBGnEEIIIcQ7w6mbq0cyzVQGcvirp/pVAkchhBBCiHeWgfhuMJA8KaQc8YJ12HYn/nuKQFFiSCGEEEKId5YR/R7NEQs1c/i6qSbsU2chJQ8phBBCCPHOdPKYmRHpRs0cvtjUhjRhn1gySvQ5yjIhhBBCCPH2NxjdpQLHVLpRG7aCNmQVEytDMpDD48STg8XTNm8LIYQQQoi3IQ1tRFLxRBiZChoHM5UaVhPzpIBxrBbwk5ZKLCmEEEII8bakjWipPjms0wDzRP/HwYDSxDoQBY6eXRxtjsjT9ZcUQgghhBBvadqpE4FDg8uhTdxaKvFoHRk4msP2Zo5IY0rwKIQQQgjxtmcyYqyMekEb8ttQmqaykQNZyBODaAYDR3NI3DjYvD189M05K74QQgghhDgfTpr+cYz5IIdkKwcCSevQwHHolD4nXh86R+SouU6JJoUQQggh3l5ObqPWNG1Ei/PwNKU2JJC0DgsczVSucSB2HJqVBE49Z+Sph94IIYQQQog3nzbab9rIaE1lFk/83xwIKM2Tl6qJxIcHjkNHZQ8LGM0hzdimOWYbuRBCCCGEeOsY7XEww0ZWp5qlVcJxIFQc+u+ggVdPNGGrQHK0bKQ5GHUOacI2GZ6tFEIIIYQQbw+mNmTIzEAsqGloAwlDTUutZA7+OzAnpAlWW7gltfEZHe4UvwkhhBBCiLcL7QxeGWsVq2Ya5/DAQgghhBDi7ekMUoODg2hAtzspX/meN7JEQgghhBDibe7wi4+SjIZVACnE+aYBlgs0p22MnGdVCCHEhWVwksUze30oI4lusYy9+ESfxsF1zGQSE7BYLMPn5iE1xsUw0DQN7RT7HT2ANDXsLhc+j048FKYvbOLwuUmz6wzblZmkt6uHkDHGiZk6bq+LNId1yHZxujpCRMYsEmBacKW5SHNqRHrC9MWSmG/D2MK0ucj1OrBoEO7ppDuuOqRabQ58fif2YWsnCfX2E4qCO+DBY03S0xEiPNp+LTpulxu/UycRDdPTHyE21ntwvphg0R34053osQjdPVHib7EivmOYGlabDZdTx4gbaLpBOBQn+Za83hp2j5cMp4ZJkkg0Tqg3SuItWdbTMC04PXb0RJxwNMlb7U9QCPE2dSZB4xDe/lYCgYDahJMboUP9/XTjJGn3nHitv70Ru9WK6ctEt9qGHNrEiIVJ9veAzYXdGxjzuGNkID2UV83hxstzqH9+E09siTDr8ou5qsJPrKWb7oSBafVQmJXg1Uf/zhOH+wiPDJotNgK+Qi69fDrTfDaSkQRJdHzZvTz+/Rd47ZQ5Fx8zFy/imrkOtv5lPc8e7SB0irXfqmwVC/n8leV4bBZ2r/kdP94XA2xkF0zltvfOoigUoqMrTNTmJMuXoGbDNtbsSLDwuotZkdfFX773Aq/GEyft1+LLZtHSpby3KkBb9VYeemUnezrPvi/rG8OC11/B+z88B9/hXfzpr7s4Kl+wr59pJyvfj8+iLmYyGaa1OYwro4Dpk7zQo+FND7F17WGaz+FhdU+AYp8di6YqmN5gK+3Rcb6hJljsaUxbvoJrAzGCdFFT28yO9UdpOYdlPSumFV+mE/rC9A0Eg6aD7AIHocYe+kc9VR8zFpXja25gy75mut/kIgsh3kFGCxZNc8QDqUcPLMsL89nXEcY0TTVvo2kOTvUIZLo8pGGjOzm4H4szjUm5Xo40d5BwB7Da7JimiRmPkOnQ0N0ZNIVOjj+GGmcTdhsvPb6WtcF+IpmzuefDc1m0YhrbD23i0LDzseDOLObyS2czK62DF57cxsamXiKai2nLy4gCmKBbPRSVZOBVZ0Qk1EtzWwiL30+2z4UdK9n5eVRZLNTWBemIa2QW55NnV+vHY33UH+8ipGk4PF7yMlzEurroSDrIy/DhjnZSG4ziyskmXw9zpL6LiAm6NY2ikvQhx+2hua0XwxsgLz0NraeDhq4Q/Y4AlTle7EYfNXVdjOv70nQwa1I+1nAntdFMKqaU4t1bTe+JFcIcq9nJX5+upi5QzI2XLWDloskcbjiG7RS7xbSQ4QswMctBV18Ie3omeQEf1cGuExk+T1Y+E31WNMBIhjheG6RXU31ds7KzyXaAygR30dIVIa7p+HOyyPfYsWpAvIeaum6igNWWRtEEP9b+Xhqb1HuTl2Un0tFFS5eBLy+dbI992AcpGmzicI+LguJ0vFhwugOUlxdg9oQIJa0EMmyEWjtpHZZ5sgGn/rAKgBwuv2kJpY3ddGsG4VA9zz11gOOttbzc4mbSrIrU5/rcsfqymDlnFkszdBIaGMkExw9uY+2+LvrGGUPa9Bym5Lfwlwc2sn+gWeItcWMRYP7ychKbDrC5oTvVQpLHVe+byK7vrGXnW6KMQoh3tNGe9ncG2cikYXDlrAqME/N2k5ptR03S09nVxZ6W3hMBJoDLF2B/SxeTctJp7OghanjQNZNMO+hWK419cexO98lB7BDjDCDdFFdMZH5flHhaBs5IkD17GmgZuW/TwYSSQiYVWjn60iH2tPYQ0TQgzN61e0+splt9VFSWU4wFj9eHVw+y/oW9NHrTyc9wYUcnr7iQ2elWws3dJLMruPbdcyloqafVls6E9B5eenwzrzT2E8ibwBWXTCG+ZysbIzlcuXgqE4Lb+enaDqpWLOMK9vGVP3YRQcNq8zGpspwidDw+L146WPfSTo4ESrlq6XTyGl7jV+uqaSmeyT+uLMdat55v1nWpwPcMGZ4i5uRb6atey++5hP+cWcYszwHWjZJK1aIxQrEEMZsVh8XC2D0OwLS6ycjIpdBo5rW93XgmTKA008fuuk5akhppucVcsuwSVrjb2dseIR5roudokH67g5LKGVwxq4KsaCsNfT0c2R+nqyuCLbOI5ZcuYo6ti/qkjzn+LlY/toFnG8O40yZwzU1z8R/ZzR//cghH2TRuvCKHxuc38/iWMLOWLObKSdmYzXXUhNxUlmYSr36B7z0doaQ8Ex86trQMKqsmoNUGifsKuWSZn5o1G3ly79CsjR0JIM+MSSvPPryWLScCMAtOdxrZ6WmknXh4lJ2s/CwKM1w4SNB2vJG63hjJcUdrVvJnzOYSWx1/fKyG1qSJplsorCzDZ3bRa7HiT8+iLM+DHYPu9naOt8dIK0jDbrjITrNjs2pE2urZ1WqjdEouufY0JpZmE2yPYQtAsCmCJzuTokwXtv4oPbY4wfowrjwHoeMdtMcN0NKYONlN39EwvlIvjqgdEp0cq+/Hnp1BcU4aLpJ0NLVwvKuf2Lnu82JqON0BJpZm4MOgr6uT4ydSvA7yirPI0r0EnBZ0PU7joTrqY+e2CEKIC8hA0DY0qBwjkHO6HMycNYth8eOQVWsOHmRfa+9gMDgQRPrTOdTRRYnfQ18khsNuR7daaeiJYXe5T1vEcQaQNjKyMynxJkg4PdjiIZo7wsRHWc9lt+GwxeiPJIgn3ZRMKWRCmh2dXvZvO06zpmF4rSSbW6nFRnrCwdyp2UwpTWPv+lp2TchlQoaD3Zu3ppqwPSy9di7zvQZ797RR53QzqTifRQuK2bd6H73hMN0xJ6XZhcy3pGHXYlizcpk4wcMMn5X4kU661JN5MNKsJFLHzUg6yKvKYUppOrt3NnCgoZDS/FzyPUHyJ2bhNLp5aWstXQMTaJ4RK7lVEyhzRNhxsJ26+CGCc6Yze1omWzb3nbhG6VkFLJinU+HNYlaejc6Dx6jtCVM15n41nD4/JWWZmJ217NvXSKEnn4tKssmrbaatzUrVwoWsnJBg3+r1/OZw6liaBa8vn8WLplLcU8MTz73GxuDAu+Zkxowq5uXrHH5yE3/umkDO++dz/coWtj+4lzP7Duxj78aNPNSYy0duX8rUySXkP/YyG146REXFHHytR1jzxC6Oag4KSk2cWztoDfaP2HdoHNf3Qudl6rxppGkm8WiQfXuCODILmTfbR+hoGEydQG4xJVW5ZNoN4pqLKp/JU9vqaY0a47vMppfywiR7XjxOMGkAGmbSoH7vIbBoOL1ZTJ8xlRlp/XSYLry5XnbsDJIxt4IJsSThSJyEK5PKKVaa/9ZOVq4Pr9VORpaffOxMnK5zMNpH0fQSiu0RukN2ciusVD/dRMayDI4/vIVgPIpJNhdfPoGjD7YweWU57G2mriNGX7+fsqpiitKSxAwnUwI6L++qo643fhb9pj1MnDIJR16/qtPMTHJTS6wOH5OnTmNOQYL+iA1bjp80ozVVgfqYtqCc9HCCUDRGPJDOQleEX21pHaPpWwghRjF0MMuZ9oMcklU8sRtU9vHEg2JO0WXQkeanrr2VlbMq6OoLs/lIM55A5hkVd5wBZDc7N2xlbbCfqKuSwn+7iMsu7mT/wQ6ODSt/gmg8QSxhw2nXsVos2O2ZzF0yhUnuJn63rZ5WSwbzL1nIDQUaB/Yco8euY7FZsTtsOEY9doDCTAtoYWKGA2u4mbUb6+nrDhIB+iNRuvviZBUW4Uv2sefAQToK8ple5SPXaaWhowvTBF3PZP4lC7ghHw7sraPHpqPbdBx2G65QA/sb2pk9oZjKwj7seXa6j25hc0tiYMr2M2LYM1lUkY3LZpJRPovrkz4M3UJx5RQm7tiayrpp6FYrLqeTeKKPA/tbOHrgOEd7fEweY7+mZiMjM49ZxWk4OzKZM8lBWsCBP7uIiqw6jnTo5Kdbseqd7D82dPiNBYfVT3YgTldTN43tcQbTnGlk+e047d00dyahtYs606QoL5NCE46e0Rn30BxMYvRG6B4tBT9Ai9JYW0Nj7cDvZ7RzMYKGjsPpwKMZxDQr+klrOCkqy2Bynp3OpjZCWhqV00oo3tNCezTKeHvLahoYo72tpo7fHyDH28eGFzaxw8xj5ZIScnJ82EwLsdaD/H13E0FLOf/y8SKKzWpee7mGouJsdr5WR3dZBROxk5Pjx51o5aV1e6mxlnBz7oRTfjTi4RCHtm9hU6+L8pmzqSoJEGtspNNwUTqpiJIjbTT1xs/w5mfYmWK323A7nalcuBUrBmDB5clm1pwiAseraYvoFOZmUlaUJGiC6lZkIVi7l2cPttPtn8Fd7y2n4LXWEV17hBBiDKaJmxiFuTlkZQRUf0RTJa4MQ9XaFouGCRw5Vk9HJImZGlWtjfK9O7If5FhVUSzUS3F2gENNQZKJBFkeOz2RMDan67RFPvtpfLTUA3DMUWJbLUp9WwfNHfmUl+dTcDzIvt11HFtQRlkqK2rRAsws9xML1rFz5z7ay7zMqPKM3NMQ3TR2GOC20F+/jzXHh4zj1sCIROnr68c2OQ9bYz1Ha2poifj54MJs7LYoTe0RwES3BJhR7ifacYwdO/cTLPcxs2rgQiVoq23i6JRCZsyciMfaw/O7GulMGkAmi1ZMIifSwuZXa09uth/CmVdIhc+BvaOB2miUWLKFY+2lzPPmMT3fwXoAYrQ31/Hy+moahrVZ+8bcr8XhJLOggCIjSkNXNy2xEP096RRkZjMpz8fGYy00dyZIZAWoKnGxYSADiUEs0U1bl40qj5/8TCt1nQPNxX20d8eIxALkpuugBSjWNMzmIA0nztGCVXfg9Nlxe90EgMZTvFNjMh0UlE5gRqmTtn217GvuJSJfsONm0sX29dsGm7Cxk3fSOnH6+g36+mNEkk2s39FHSywx/umCtD6ONupcM62AXeuO0J5qws4rL8aobkjdJGupm2QNCwPPVw1R3xomGjOxEKHnFAceeGSWpoFp0bAM1C24SHNpaCGTRE4GxcBRksTivXT0qBs6kzj9kQjhUIxIopUte/o53hsZd5Cs9HFwd6oPpAaYJWQsmphaZhBLhOnuiRGJxTh8NEZrQ5TMyuxUJaqhD8yGYbGgj1YvCiHEWDSNWcU5zJ4xjQy/b0gACcbAlDqpTGNAT/JKTTPhhDFqhlLTNExMlYVEPaJ6tPoo0ttFWaabUDRJaziBzQLpVgs+EiqIPE0z9jgDyHTmL19CcTRB0pFBoRFi92uHRgmmknQ3HeO5DXauWVDI5ZelMz9kpShtcLCFYbbx6p4g0ydlcfGlS4gHcgmQ4DgA/Rxv6yHYU8KMBfPIrGpmw9oD7HllPc+tWMHFly7F1hEHEnR11LNh4zFaIjH6+vrpoY/22mYaOnpo7q/jyNQcMl29NAVVhZ4w2tiwJ8i0SVlcvGIJCX8O/iGN8InuJrYebaNqYRn9h7azqz1KwtAAH9PnT2VKt4VD608VQNqZUJJNhstG0749vLS1lUgSsu0VLFqURmlZLjsPj++qKxoul5eykgyS3U3s3rmDF47HsBeZpKenM6c4h+w9jRzcvJkXHMtZcfFF/NOUKPFYEy8/c5Cm3iY2bdqPd1Y5l1/hpLKvlyP7DrP9aJDDu/ezNWcRcxYs5AOGn6JwPY+9eJh2TKzRNrZW93JrUQlXrUrHmpGNd9TJhUYyicQ7OHg8yaqcMq5+t4uDtZ3E/IUsmu+npqWNw829p57OSZylCHU1XSQcRUzIycJvAOg07W1EIznOwCZOw549bJszlRtXFRHVwDSStNYfYANJwt1BmroLWLrqUmaZdmzdTbzW2k3WlDMdyhOjpbkHW34Zl191KRf1aPi8FjrpYuuBLK69aDGFCZNkn04/yeGbajGa6xo5mGanIjuLYgOgm+DhFurPIv84NoNwXxs7tzUxd2IWxQmAMEZX55Dsbxz/xFncNCFJ0pdGx8aNQ27AhBDi1DQgO92PmUwQDAaBE2NhTuKy29B1CySM1HrasHXNE83fDP93iEhvF5OzvQRDETrjFhwuN4Zp0hUL47dqKogM958yiNRWrlxpnvQkGlMnLeAnP8tBpL2T5i4Df34GOSNG25pmjOa6JtrGmMTN1J3kZQfI8tiHVLRh6g630QlYfdlMyx6aJk3Q09VNU3uIhMdHUaYPv90CRGis66AjliQtr5jStIHjGUTCvdQ3dNOPjjcQIC/LTritk5buCHEc5BRlku2M03S0nWDSxNQ0rL6sUY7bRVN7P1HNTvnipdw21cHmZ9fxUn2P6pBvuphQkUVaoo+62s5TjD7V8Wdnke91EG1v4FhPAgMNzZvFjGwnkVAPTT0a2QUezJ4emlr7hmfhTAe5xZlkOeI0Hmmnc0hq2mp3k5efhTfRT0tbG8GYhml3U5QVINMW43hzJ12RJO6cAkp9au7NZLKPuqODo7Czc3LISY3C7mzvoqUrTEzT8edkU5Bmx6YBsW6q67pVsKBZcAWymJzhHFLIOJ3tnWoUdn4G2R6D9roO2mM2CsqyydD6OXa4gx5dx5eZy0SfFUjQ2x0ilLQRyLASaumkZcgobJlI/AyZTgpKPYSOdtB9orbQcLg8pPutJPsNNFuC7o447px0cn0D841GaDjWTjBunNWcqlZ/DlMyneiauhsONh+nMaxhala8/gDFmW5sGPR2ddIcjOPOcUN3iM5wHAMnhWUe+o500Ku7yS9y0H2sm4TbTcCn0dUWxZURIN/vRHPlsGyqnV0v72Zzt05Frhe7rmH29RN0mfTXR3DlWumu7yakoabfyfCTl+FBfUKjtDR00BZOjG9eRtNOVr4Hs6uXzoFtTRdF5W56DnfQg4bd5aWoMEAaAAm6giGiFkhGvcy7oghLTZDmUISkJU5rXRPNJ3cOF0KIMZhUejXSfWlkBvynXLOusZkDXYkTgwULzR6qJpcP7Gb4+BsNWtvaqemM0I/9RBYz3FZPut9PHzastlTHQU3DMJJosQhmpJeE7sDuTT/p+ANPohk9gLxQmV6mLZjO5fMLie54jUe3H6c5Ms5BB+KsSAB5Zj5yzQoC3uFdPVo7u/n931859wUDbl6xmJK8rFGXtQS7efDpc3Bc0035tEqWzSogw26h58AuntpZR2P47ILds3HVollMKysedVkoEuWnjzw79sZmFitvrCCxcT+bG7ulW4YQ4iyY2DGw6jp22ykn8yMSixFNgpkKBvVkDId97G0SySRx03KizySAEY9ioqHb7CetbxhJzEQCTbdg0U/erwSQozEtuNLceF06sd4+eqIqeyjeeOO6yqYFp8eB0zrwZCSDcF8/4bfaXOpnaDxNyjnpPnR9+LCZeCJBe1fvGFu8Ppm+NOxjVEzn7LimBYfbhc9jx4pBpC9ETyR+FlMOnb1AmhuXc/The4Zh0BI8xTThpo7Hb8fsjxI+ywyvEEK8XcizsEejGYRDfYRPzNUo3wRvlnH1y9MMwv3hM+qJ+U7T2tnzph6vo6fv9Cu9XppBNByiLTx0ktQ392+vq6+frr7+s9tYSxLqSX0apcoQQlwgrADhUIxffeuNaQITQgghhBDvDAurothtqQAyJ9tH06PfJRaLnRj9I4QQQgghBEBGRgZ2u5077riDzs7OC68J2zQi9Ab7SOgu0tI9nNx9VAghhBBCnMppAsgk/Z3tdHT1ETsxQMFNZkkOfqv+Fu/uE6GzsY3usI5/Qg5+m5rWJhp+mruX30tN5fv50iOfZukbMvAiTk9zEx2h+IkJjS0WL9mlOaSRJNrfTXtTL5ovncxs3xhP3hnJIB7tpq2+G9MTIDMvgPP0GwkhhBBCnHOnCCCjdDUd4Nmf/5rHdh0l4kzDDoTrs7j5kXt5b4Z/lEeovZVU8/BXv8qD6zL4x6fu4wMTsnEAFksGZbNnYispwPcGPSqir3krf7j7v3gs6CTgsmHRIvTVV3HnK19nldFH3a4/8LWPPIrt1o/z6a/cwrQzKkeE5kMP85Vbf0fkqtv53P/8I7PlURdCCCGEOA/GDCDDHftY87Pv8H8v+7nqK//N+y6ZRAZw4KGH6XJZ0QDTMOg5vIXtDWr0ou4OkF9WRUWWAwjRfOgwtfXBYU8b0fBQNH8e5Wka8WgTBzYcpGPYcju+womUTSzAn5o9JNK4n51H2wjHVT7PXbaQhROGzI4e7aH5WA0HGtWUIp78fNzhIzQEQ0TROLJ5A+uPlFG1fBo5tklccfuHCaUVUpQKwBK9bdQdqaGuUz29wpZdzrSyAgIuHejg4Pr9NMYTg8dDx+nLoXTaFHJPSh/2sOU3P+HRnVZW/uKHfHJmDk5LI0/f/zzZZpJwbxOHdh6jmyh640G2vbQZrbSMiROycAPRpmp2HW0hlEr5amkTmT9/ArZwEzVbj9BJnHjbIXas3YS1uJTSUjc91YepazLInj2Z4oAHGx1Ur9tHSzKTyuVTyTHihNqOsGd/E2FAw4avYCKlpYUETj3dlBBCCCHEScYIIPs5tvlVXnnpEP6rP8/SGSp4BKi89aYTa/Xse5Hf/+hb/KVzMgty4rS0deJddjufvHkpU3Ka2PTQj/nhH16hvXA6iyqLCRjH2bQuyJQvfp9vvXcKRtcr/PjOe1nn8lNUNZ+Z2XEaD9XRP+EKbv/UP7GyIh3j+G6e+c23+d9ddmaUZBA/tI69FR/ja/96E0vL0kj2d1G/4VF+87dn2NLlZ2qRD1duHq5IIwfaeogSoXrtCyTdXXiXTyU9uomf3TnYhL24u439zz7IA4+9SoutiIL4MQ5aK7nufR/ifReX4Xft5Y+f/yx/6QrhrbyU5WUOQs2HqOks5vq77+ZDSwoY/sjxI9Qc7qE/bNK+63mePl7B3OsWcOUX/hHMKMHuOvZtPkSQMJa6PWx4yon+Lg/ZE7JwE+bQi2t4dE8jsaSOtWkHjzVV8fn//hw3FjWw99VqOoiSbNrPxic9WFY4ySpzsu4P3+cXD8e46jf38OEFk/Czhwc//R880X8Z39j3TVZ2V/PCz7/Lj55pImvuDIqcNrx501hy9UoWTslNPVlDCCGEEOLMjBFAdtIebKStLZdJBVkEMhhlor5uXvvl1/jlDh/XfvNe/t+0IM8/8CXuXf0HHplQwievUT0kLWQx/T2385/vX05Z4u986vqv8fxPHmH/+77AFABspBct4pa7vsqHS9t45pff5zu/3cS2PcuYV1FF89O/4YGnjpJz+w/46j/MJLHpXj7wb9/jW1mTmPmFRRiNe3js17/mmcRi7vjMp/mnBbm0bN9BW3YD9mOHaWrL4F2fu/tEE/bwZy8n6Dq6lSf+7xH2Z1zLpz5zJytCT/D1+37Kb/9UxKwpH2BB6uEUOiVc9rl7+cYCB3Ubf8qn73ySzU9v5MqLbqR82LXJZsa0Ely71vLkN7/O00zmqt6bmKXZyJrzLq6sXMR1t1ezc+Oj2BbfyJ3DmrDjmBMu5WNXT6YwkIbtwE/YedMP+el357Litzdzw7+/ix2v/I7IzGv5+DdTTdhm9Wne4gS9Xdt54s+7sS18Lx/+xmdYmRamftt+mqM9xMg9zfZCCCGEEMO9jlHYNWzc3I7LPo85c9KxOhPkTa0k+6HXaKo9SptWBoCFAmZMK8Dns2GSTrrFgrWtg1YNpgAaDtL9FUyb5gOjF2eaB0+ojr5wmIjWxP4DjfT2JXFWP81vfrEBm6UXW9Kga+tWDmuzyeg9QvXBJBMuraRyugqGcufMJheNjac9h346Oo9y5IiFohklFBW5cSdLmZidiWXLPg6F+piVGimkU8VFF2WCEUbPSCcQj9Pf3cvJ0zoXsuTm9/PRjGm0dEfQj7zIj75xH2t0BxVXeZjy7WVjF6e3lWDrfjb8aROqwfyItN1khwAAIABJREFUGiV+sIZqDSrH8/acoON0lFI1xUN1835eePAnVJvgK53LksWDmeWhfvGLXxCPy4N8hRBCiAtJSUkJV1999RmtO0YA6Sc9kEtG5os0twTp6QZ8I9exqAd2mwaGAWCCoR7jpWnn6qnG6hgWLZ3sfC9pXg9WZnHTf87B5ZlEFmCeKIepHhw+TpqmoWlgDmxvmurJxJqG5SxPwixawK0fXKDO4Ng80uY+waP3r6Fz5y5qtWUUjrpVE1tW/5EHHliPsewqlldk4tSd52CeJR13YDbv+ewnyDjUi9bTwPZ1z7Jh9W46P5vJP1xecVIQ6fF4JIAUQgghLjBO55nP7zJGfJLGxPlLuHjZeh5+dg1/nzqF7JVV5Drg0GNr6Fm1gtnOSVy8JIe/vHKQrVs7uG5mDw179tOWk8PFpaVkn000d5I8pk8tIu3VHYRzLuKWm2bitVuIx3bw2HeP0ct8Cn1lVFVa+X3tPvbuamLx4nz69h2gPqNllOzgSG4yM8qoKDd5ur6W48dDTOo7wpHWdozpVzDJ48U+7tOoY+2vdmC76mLmFWTiKLmIf7riEM9+6+/0Vk6m0oTRnx4cZP/W/dS3ayxZfj23XlpG8pV7ePC0x0vD53Vht7fT2RknnoDgqxvYlUimlifoD9ew51gR13xwAZnBfaSHDrLh4SDBziDJUfZ42223jfekhRBCCHEBGTPB5cmdxtUf/Q+05K95+tdfZe/qTNw69NY4eNeypcxy+pl7+9e45fidPPmDz/OJjAQdfRYW3PQhbllUjJO6c1A8F2VX3c49xs/50t++x2dedmOzaDhspSx433XkmDppBdO54faP0/PQYzz0319gW24atryFXPfepSybV8qLu7fz6FfvYodzAbf98KPMHXH6/tL5XP6ea6n5v6f45b2HeTzRyHH/pdzxgVVUZrvPYqqiIAc3PMKLa1fj8zrRTdBCtRwru5pP/9sK8kw3joxpzJ61mr+t+xPfvvMAl1x/Pe9eNZGVN67ktYN/ZdsvvsZ/PuImUbeNBgaSv3YCvuksmGfnt9v+ynfvPMzFV17LNdfOYMFlFzPztT+w+Wf388VHvRj1uzgaS6TKbsFh8+GPPcI3/+03hBIh2upaKFi4igVzpxB43e+REEIIIS402sqVK81AIMADDzwwyqMM4/Q0N9DQHCScmhFbw0fhjIlk26xgGHQc2UFdKtWnOdLILpxIUcAOhOk43kBzWxJ/eTG5fjc2eqjbdZSOhJcJc0vxx9qp3dNILC2H4sn5eInS3dJEY0M/ruIi8gcm2e5pYN+xNiKpaXwslgxKZk8kfaCYsRAdzcc51p6aTsiXR0lhLu7+Bg43BgnHDTT8FM8pI8MIcnTncSKubIqrCvEB0Z52murrCKZG2OiBQsoKs/A6dKCbup1H6Uj6KZlbSgZJov1t1B1oxQjkUlg2chRzH801x2npDQ/L7lk8BVROycMJGNEQ7fVHqO+OA07SCwrIzwvgjHVSd7SBjlBs2JglXc9kwqwS/LEwnQ2HOdYZAxz48/IpKMjAFeui4Vgjbb0Rhs6LrpGuymwkiHQ1cKi2AzVRkY4nK5+Cghy8F9yziIQQQggxXiMfZXiaAFIIIYQQQlzoRgaQlvNdICGEEEII8fYiAaQQQgghhBiXUXvAJZNJEonEaIuEEEIIIcQFwmq1ousnDykeNYB84oknuPfee/F4PG94wYQQ4q2oo6MDgMzMzPNcEiGEOD9CoRBf/vKXueGGG05aNuYY3Jtuuom77rrrDS2YEEK8Vc2bNw/DMHj55ZfPd1GEEOK8uP/++8dcJn0ghRBCCCHEuEgAKYQQQgghxkUCSCGEEEIIMS4SQAohhBBCiHGRB9mJs9TO3hfWsWV/A32pV3RKWfaxVUyzysdKCHGh6+PQy8/z6v56ehOgkcHMW29habZOtP8grz7aRtn7l1Jinn5PUMsLPztI4cdXMeWM1hfijScZSHGW2tn3wmb2toSw+Lx4vV6S+1bzv795hdbzXTQhhDiv+qh56REeenE/PYYLr9eL1xtlx2+fYI9mEuuv5qU/rueYdqb7q+WFnz9L9RmvL8QbT1JF4nXIpHLFKq5bMYMsIHRRgn//6Fr23bEcX89Onvx5A1M/cw2VJkAnNRt2UhvKYOYVWdQ+tJOO5DF2H2uit2si77p7Fg3fOkhgaQsvvtgMVg/5M67iA7fOJyN1tNZdz/HUM89zoAOYuJyP3biMidlqrlJ915/5/J92AuDw57Lo1k/xrjK1Xcf+9Tz91BPsbgMC07j21quYX5qF/c29WEKIC0Yb+18+ApNXcP0NF1HssgJ9HHqpGltyF3/9r4d4ra2b+i/E2DX5Et79oeWUmv0c3fAcf392A3VhsDCR5R+/kWUlnTxz30Nsix+i9gt3sSttAe+5+13kHN3BprVRpv3zckpNgBa2Pb6DnqLJzJ5TSkbNs3znr+tp7YkCMO0D9/GBaefzmoh3GslAinMmfLSOZo8brwmJ2HF2vrCX1hN3zGHajtZwoLqRPnqo3fEkv3uukYLJi7h81Vwm2DvYseaX/OhVF6tWreKSeZWEt/2Oh7cEAeg/8hpPvrSNrvTZrFq1iknB5/ntMzto7U0Au/nt/U8RmbWKVatWcdGMKkLrnqBag8jx3Tz/4joaPTNYtWoVi9PqeOTJVzjW2jfWaQghxOvkwOHop62tm3DYSL2WRsWl85hAHtOWz6DIU8KcVStYPHci6WaQfS+t4ekNbWQuUvXYwkAtf3t8I22dHqqWz6DAkseMK6/g0uVTyTET9AVr2b25huCJY/ZyfPcBauo7iGiHWfO7Z2nOnMkll6n9aWt+yzbJYIpzSDKQ4qyZHOHp/7mHZ37lxmqC0eLj8u/8J1NNSJ5mW41sZl+xkpXvWkSh0wa8hIaTaVfewool6SRDreTEq/nbut10zJ9PR81BOo0c5r/repYVOFmUXc89v99P7YrpZHg72Le/Gtu/rmDFUkjGYvS0taObYZpra2jp8zL7tvewothFfLbO0Xs2s6ttPoU5abjfjAslhLjAZLPoA7fQ+ss/8t+f/BP9pgUK38VXvv5eKmw5VF1cRf4DMHPlUuYbADEsU5dwdZmDjIJs0qwQm2Ww7/Nb2XHNIq68uIo8/QhVK1aw1ADo49S3wN0crT1MfPrHufiSMnx26JpYiyn9J8U5JAGkOGsahSx637tZtnASAUDDQ3Z5Hi44TeUG4CEnLx2H0zZkf+XMWZAOgO52kVE6Efe6Wuq1KfQH+7HaC8nNcwLgrpxMccvzHItFmMkCPvnXO/nmHddzfRq4siZw1ad+wD8XtnO4+zBbVj/OYy8/zQ90gAi9jRO46aPJ0wa5QghxdmwECmdzw8fzWNoTJmFCyxPf5T8+Bz/43m2c/HBMO35niE2P/JTfP7mbbgAi9NSXkp1MYpy0/ulU8d77PsTPv/D/+NAfeklosOSLq/lC6es+MSFOkABSvA4OAgXFlE6aRNaw18df3QGYtNDcBBQD8QSJ7h7CmYVkmi40lw2CfYRCgBe09iDtfi8zdRs6HnLLb+WeP11JNNFPy+Y/8/Mf/ZqZP7sZj3MSS2+5nWnvv5KKE3ffNtzpXsk+CiHeQFa8OUV4c9RvZR+7limXrmWv5TYuOWndFjY98wybWyv45//5BNO9AHv43Sdexnk2hzZdZBat4t+/v5hw0kCr/T2f+M/7eHHtF1lxdtWzECeRPpDiDaChW/JJD6xny2b1SvPW7bzwyGoOn3K7an77s+cBCAWDbHz+Bcw58yjER0lJFr3BQ+zdWQfAzjVPcryohBKPBysv8+W7X8afk0NOTjYZaQ6SoRAxLY2CAj/h0GF27+ojJyeHnJwcmh9fzdqmBkJv6DUQQly4DvLwj/7Ic6/V0p96pfkvj7K2uIDyUZuRk8SiURI48GepeqplzWo21tef2H44G06HG13bwd496pWjzzzHC+vW0wSg7eCnP1lLKOEkOyeHnAwPRk8P0XN/ouICJhlIcZY0dJsV3WLh5H7ZGq606bzv9ov4+O1z+D3gnDyJivzlLNEtaGjoVh3dog3bVuMyPljwM+bM+Syk5TLrH+7lN9cWAuCfcw23tdbzvW9dz3f+HZj7IX715WWUZjiAS7jvkruYMefzAHjyKrj5a39hsQFMXcE/x/r58f/ezpzPqu7m0z78fb7mK8H7hl4fIcSFazI339zAd778H9xzhwoibSznC5s+TqVpIem6hCuX/Ip/m7WCqmUf5DM/+BCXXLyYAzu+x0cv/RYAgauvYqYvgF/T0MxL+djtv+S6WfP4ftaNfOn5u1lRtoBVyzZw1wfm8F3As2A+VdmzmKVrYM7mzjk/5j0f/CqHW9Wt8mXf2c5Vkn0U55C2cuVKMxAI8MADDxCLxQgGg6xevZq9e/dy1113ne/yiQvGS3xp3hoWbv8210klJ94C5s2bh2EYbN++/XwXRQghzov777+fyspKbrjhBjIyMrDb7dxxxx10dnZKE7YQQgghhBgfCSDFW4SPCTMnnpg0XAghhBBvXdIHUrxFzOWOX8892wHcQgghhHgTSQZSCCGEEEKMy5gZyOrqah588ME3syxCCPGWkUgkME1T6kEhxAXrwIEDVFZWjrpszAByy5YtbNmy5Q0rlBBCvB3cd99957sIQghx3txwww2jvj52H8gqHRZLF0khxAXqd6lplz/oOL/lEEKI82VTYsxFY0eIpRa4xv5GFEcIId76/hAFE6kHhRAXrtaxR7bKIBohhBBCCDEuEkAKIYQQQohxkQBSCCGEEEKMiwSQ4q2p0YD7+s93KYQQ4sL0pX7olic7iLHJMOtz4fGY6mx/3Wk627cY8L8R+Ib7TSnWMIeS8NcYfME1+NofolBogUtt5+YYd/ZB0Bz8PccCX3JB9lncpyRN6DVPv94b4WgSHojCXB1uHjIC94dhWD9iRNrv08CqQbsB3w7DNz2j7/P/ovB0HMKpc/qqGyZZQNPemHMQQly4vh1W30dT9LPfR48pTwYTpyQB5LmQBIxUYJBI/WumfgAG4rO4CbHUjwUVeJDaNplaX0O9KwOBRcwEPXUMDbBpw9cHtVwfEogkhvzh66hjjXbs99kH17cAliH7iJuDn44kw/enjxH0xIBfpYFLU9u/FIc/x+DfnYNlHrg2A/tJDnl96DUZykydjzFwPqntjFGumWlCIvWakdrnwPUbeU1GC95iJjQbah89JnQakJ4KgOPAZ10wL3VhnojCF/vh2x5Vjvjol4WHY9Blwn+5IS+1r6+F4S6nKotpjn2NR36eRn4+BrbVU8uHfo4GrhWo92PgmgDYJXAVYtxG1q36GHX4qf72QH0naEPq8qHLR9ZPQ+vIge+AAaMd1wCiQ+r7gWONrGdG1rcj62LzPN3Ai7cNCSDPte9H1FWtNVQAEjfhbjcUW+DLYQiZ8C8hmG+Ff3GqCmldHNbEVfYuoMG/OtU0ShYNbuuDG2zwUgImWlQGcXtSZbS6Uvt/vwMus6nKIGrCg1HYmFAVxXU2WGSD+8MQQR17hQ0+4FDreTVoM1UWclLqmDETvhSGTzvVOf0qAocNcAKX2eEa2+kDECswSYe1qYzdKwl4MgZ+Te3rww5YYIVHYrA2DlFgmgX+1QXOERVkp6muz9YE3OZQmcEnYvBiHPqBLIsKxvyaWvczIVhkhdeSsMQKq2zwlxjsTapKdqVVTc3iH+Ucuk3YkoCLdPX+bU/AyjEyy5fb4Q+x038mOg2YrEP2kON9OZUJNk1oN+EXEThkgAP1XtxgV9f4l1HoMdR71GGqMv8/F/hT+2k11XyF/+xQ0y38XxQaTEjT4Ga7On+rBnf3q2zEawkV6P4y7fTlFkIMiprw+whsSqZanGxwnUPVUTVJ+FMMjhvq7/w9dlXH6xp8NQzFGuxMqnouacKX3VCuw0EDfhCGCh32JNWyy+xq3/5Uff7nKLyaUDe1BRb4ogvc2uBx/xiFehMqLOpvfm0CdiehJqz+9v/HrfbVB/w0DAcMFVQussI/OMCRuuF/PA7PxVQZF+jnrwVIvG1IAPlGiJtwt0sFNrsT8OMIfN8D97vhO2H41pBmzgNJOGrARxxQaYXX4vBYTAUE6amAw6YNfuEfSMK2BNzjBp8G1QmV6auxQJUVnompIOlHHlVJvBhXWa8vuVVF9OURzed+CyQM2JeAApsKKDfEwYeqdB6Kwgwd7nJDUxKei8OGBCwfo9m7IRUEJYFdCZg6pAklCVxth9mpj90LMRVQf8Otsny/jcDDUXh/KnA1gHoDnoqpbb/ohDxdBdzdqcA8zwIvxdQ1/mLq3Exgog4fTwVpT8TUeX3Xrc73hVQlOZJhqv22mXCLTQWSxw31fg7c9bcbcDx1m/5ifDAbeSoluqroMzT1Y9MgR1PBehwVWFfpqvwthqrEX4mrLxJQXxyfckKBDj+MqIldV9nU61vj6n1KoILDVXZYaoODqc9FlqY+F6BuDL7vUV8YQojxeSam/mZ/7FGZvrWpJocOU9WJl1rhUjvsSKifTIsKDEH9nX/bAx4NtsXh11H4eqq+MlA30//hguYkrI6rIG+RRdUxSeC7HhU0PhWDByLwSZe68dyQusFdblPdlGzAR53qZvI99sG/fYC/RaHIAp9zq5vaZ2Lq51qHurnuNuDTLlXmJ6LSfC1OSwbRvBEut6vgEWCGVQVBY2kyVOUSQQWHXgscSarmYFDB4PuG9MObbIFb7WqQyYEkmJrKXHal7hb3GiqAGGjmHCt7NtRiqypHKPX7hoTKgCWAakOdy4EkdKMqs4ZTnM8vIvCTiOpDeNxU2c4BU/TB4BGgxoCZVhXcgQoutyQHl3eaKrgyNPjHVPAIKuB2a9CWugZ5OuwYsl3AAlcNOe/01J38nqRaf4YVMkdrvkYF5At1FZhOtqisa92Q810TV+f3k4ja16ecY1+LAVfYVPb40Zja7qcRde4DTUr7DMhNXeNOU72nQz8zy2wqeARYZVVZUUhtm1QZ1V4TWkwVHB5IqmvWyfA+qTc6JHgU4mztMdTf4kDz9IpUHdOXuvGck6rbJumD/aIHXGNXwSOo+qdpyLIii6qzQdVlNqA/9Xe7P6n6ktem6q5iC+xK1XW9JvQweNwKXd2sjmV7Eiboaj8DdUVtqhwNhuqrXpT63rrYploxhDgFyUCebxGgOjm8ssm3wFhxX9BUgzEG7jYBjg3ZttcENyrwPFMTdBU8NhoqC3fcgOlW1XTaYqi74KEuPsWgm3vcqg9kwoTNCTVQ57Ou0dcNmeo8B25jvJqqiAeEUxXzFEuqj6k2uN3+JBweEjTOOkXFebFNBVtr4ypYz9NUMJU94iJFTVXJTtVV9rHbUE3EdUnV3ATwT44zyzqOtMqufkBlDX8agf9OZSBaR7nGi8a4xpOt0BJV71UUlYWosKoM8rEkPDui2SlDvgSEOCd6TXXjOvJPKomqx12pBfbUa2fQu+W0+kzVsrBryGszU3VRAoiY6ib3TATNwazpgBmpuixiqq5DA9WOW5P0kjgtCSDPtyxNNT8ssw4O1jiaHLxbHaneUBnKTzjV+q2GyvoNKLfAwaTKoOmmWr/4DEbizUr1jzPMwWeg6xrM0dXd88TUPjpTA0xOx4JqWg2bY68zwaLKV66DB9XsM7TJu8gCtzpU5o646hsYSN0lV+qw0KoqOlCZw7EEDbXfS2zq/9+LqGan7CHrDATObQYc19T/QVW6TSb0vo72nLqkupvPSL2/eRZVYYO6TrN1NWKyNHXuXcboTewDllhVNwcN1Y8J1OdlsRWusKsbEFCDgc7DgH8h3pHKLaqeybOBxVRZuyJdBY7pqWzeZF393VkY7IL0epTqqiVkjnVwAOXhVF3kRvWZP2aorGdX6ri+MSK/GbpqWZqUqmd6h9RrORZV7qCpbqyrkyooFuIUJIB8M9lQQdWamPqSn2uFMh3a46pvoXtIhi3bPnoW0qepYOT5uKq4ekyVJRxwkVVls0KoyiRhqgDSidrfmhiUWFSGcagZOmxLqsDq9tRtqB2VbVsbV31kQPWjK9fHnprnmbj6VCWBhqQK8sYyN7XvZ2JqwMihpGruHao0FcA+FYMn4qpJfIausptPxwYH8/QaMGWMY7UZqvwOTTUNBTQYOYYkiep3eKNjeP/OI0lYH1fN5mer2VTXYuD93J+Ey22DI6oXp67DvtQ1jpuqKSp3jGu82Ao/iKr9vTt1zhmaCqxfiKkgG1SQusCq+rMKIV6fi0fUrUlTBZABTQWXr8RVX+egoV4rOAcpvIWpuq7FHMwIxkwVBKZboMwCL8dV0iBuwjRdBZAFFtWt54ih6hqHprq6vJJaF9R3Q65FdY+pSAWQz8dVS1C7oY4jxClIAHkuTLEMTqmz2HryF/8tqcghTVODHw4bEEhtkGuBhTaVfetMvTZLH2yWuHlEFFmQmrexOqnuIPMtqu/gQN+VSqsamVyTGik4O3W3mWlRgVGtMXhnOdM6OBI5X4dLUn3pylLb2DQV5FkZvOvNs6gAdDTX2IdnHIv0wb49JZaT+9SU6SqgGziX+VaYlfpI+jRYmdp2kg6mXQVYCXOwn8/O5OBIwSWpdV0aXDkiCC2wqKbegaziZbaTA2BL6tqNbJ4uTAX63lSGL3+Mc3drJwe/A2boKphrTB2/yKKu1cA0H3Osql/VodTyXE2Nwgd17JwR122CDpenRlcPZJe9FlX2XcnBPqrllsG+uJfZxs5qCyFOr9Kqbu4PGcPrVk+qnjQTqp7Jsqg6PDP1t7fCqgLKARbg2lS9nqUN1pEDZlsHs5eTraqe2JEYnJ5saaqOStPU37yZUDf+OUNaOVbYBuvHgXvfOalR4QdSAWSGNpiNzNdhPqqfeK+pBvX5tOEzYggxgrZy5UozEAjwwAMPEIvFCAaDrF69mrvW3QMfOdPOFUII8Q5zW68KFP7sPd8lEUKI8+NXEb5x0Ve44YYbyMjIwG63c8cdd9DZ2SndZIUQQgghxPhIACmEEEIIIcZFAkghhBBCCDEuEkAKIYQQQohxGXsU9vOpR9YJIcSFaGAi6I/2nddiCCHEedNvwkWjLxo7gIyinswhhBAXsk6pB4UQYqSxA8irbTKNjxDiwiXT+AghLnS/GvuRRNIHUgghhBBCjIsEkEIIIYQQYlwkgBRCCCGEEOMiAaR46+swoC55vkshhBAXtn4TqqUuFsrYg2iEOJV6A1oNKLNAYMh9yLo4DK1ffBrMSX3MGgyImzBRH32f/Sa8lpo6ygFU6mrfu5NwOAkf0dW/aRrkvs57n+0JmKKDW3t9+xFCvLM0GlCTqsSm6JD3DsmzJFP162Lb2e+j1YDfR+Hr7nNXLvG29Q75yxBvqpgJmxLwpxgcMlTFNOAnETiUVD/7kvBMDPamgsJdCdg4xtyiIRMeiw1ueyAJO0dZt82AnnMwrcpfohA0Xv9+hBDvLN2GqoMej8Hed1C2LQH8Inq+SyHeQSQDKcav3oCQAQUaHEtCuQXSh2TyBqZ/iprwchyei8O003zUtiRUhvIzLvV7vwlHRqm8nRoMvYHemVCVfRLItMBlqYXthtqnT1PlBajSVVZzUwLaTXg6Dt4E3GwHi2QihRBAlVX9/Hbs6UuG6TVha0Jl5zI1mGGFnFRu5mACDhgQMaHQAoutoGvq96fjUKjBkVT9VGKB2VZwaLA5AYYJHaa6uQa4wgbpqf0OtNa0GGDXVL1WOaRlpzp13KipXp+uw99iEDbhoShkWWBlqq5sMtTNfbcJHg0WWdXyAc/HVTciG+CXelIMkgykGL+apJofb6lVNSl3jJERNFGB3ZnUOc/G4Bb74O9uDaaPEnRuS0BtqsKtScCmOOip9fcnYENcLWszYHVMBaFuTWVNX0uoYNKuqW2cmjRhCyHOXsSE7XEVKLo1FUy2puqnuqQKBKOmWrYtATtSrSphEx6OqgynWwMD2JUc7F+4Ka4Ct4FtOwxYk6rb4qbqgrM/dcyImaoXU9seSx03ltq2OlVfuzRVF7s1GJjiOWjA1rgKRN2aKvuGuMrCAuxJwMa4WmbRBssvBJKBFOPVZahKstgCU62qAmw21O+OVDD2v2H1bxxVid3sOP1+m83x92vclIRSHZbbVFB4OAkPRGBJ6s46Q4MVNijU1V38H6PqbvsiGzyqwXIrFI3RH1MIIU6n34Q9xv9v777j7CoL/I9/zzn3zp1eM5M26ZNCAgkJaRAgITSRIoJiAQFFAQVWVgFX3V11VVBwrWvNT7Cg0kXaSJUWeqQEkkASEpJJmUmZXu+95/n9cc5tk0l5gJBEPu/Xi51kbjszmb1+5innSAuiwfthm59ZA740KZW6wftMmSs9H5ceSUiHhe9PBU7w3jXaCyKwPlzCMzX8n+WDPOkDeZmA/EqXdE4suErckkTwmlMjUoeR7u+TXk0Gz7U0Gawdnx8JXn99MhgqOikq3dMnnZL1i/oGP7jS0jFRaYQXzNzc0CtNNlKZpEfj0tFR6ahoELP1Rtr+LzStj3eEgISdTb5kjDQmEkx3HOIF6xUne5mAPDxrjrlY0vi9FGlrktJr4ciio+C37K1Zo6HFThCPUnCsroKoBYB3Q6+C0btx4ftMadYvwRv84P2xOHxfPCQi/SprDWLMyWwozHeCX4Lbs96/RmRt8qtyM1PZCSO9lAzC797wgu1NJpgeT73uoVmvOyL1/jvATFFLuJ59rZ+pgZV+5n1yhS+dF96Qp2Bq/wUCEgECEnY2+tJDCem5ZPCG122CTS1HR6XK8D6z3saP1WRPWpGQplnsECx2gnU8lVnT0BGmpAG8RzwFI4ndJvMLdEqhE2xcSYb36zDBmux3ypVU60pn5eV+PrVusSB83YSC6NuVqKRpkWA5UraR4XOVOsFxl4TT7F1cFx4ZrIHEntuUDALy5Kh0Wb50UUy6PD9YdL0kEUzDvF0n50m/6Q1+m5eCqfK/9+36MZPC0/qM8oLb3pKqAAAgAElEQVTfjCd4A+/cBoC9IV/S0HDTixSse0ydAmiMG0xJbw/fFx+OByOD71TUCTYuvuVnNvw4Ct6bpeDUam+EI5SS9Ghf7pkysg1yg1OmxZV5rk1+EI1ScLz14ftwj6THmMJBBiOQ2HNNRpIjzYsGUyopJyk4pc8x7yAg61zpknzpP7qC39bLHOmc3fz6vDAqPdQnXdkZTCV5ks7fg/WWUrCm59puqUvSr4oYuQQQ+Edc+lNvMNrmxaW/9EpXFgTnhOyvOFzH+Mde6Za+YOTujPB9a1Yk2Mx3TZfUKWmiK12cv+Nz2MqXdFKedEev9NmO4HOTvOBsEpI0OxJshvluV/D+tiD8n3lP0hwveEydJ/1HgTTalXoiwYbDn4a7zhdGpMPC1zotT/pNT/CYmIIpeSDkLFy40JSXl2vRokXq6+vTtu3bddfdd+tri78lnR/RrrfQMpz9vuKbYBrDk+Rk/VwYE0yXRCT1acepnJSkCX5kdhZrvsldoxhVsPMv+3EJE/xIek7mObMHHSPhbb4Jpo6iWa+V/djsx+X1+3oASfpEe/Bzd1PJvj4SvJf6v6dImfeigZjwfSv8/VqRrPsmTGZTjRve5jiZx+RlPWf2+1zcBPf3sm7vzZomT73n+lnP7e3kdb3wPyn4XOrMGKnX9sPnMv3un3pPjJvM63jha+bxfvm+cX2PvnvEN3X66aersrJSeXl5uvDCC9Xc3ByMQJrUf45kjJHruPJcV0njarcBmdq8sDs7exqT9QdnwBvehuy46f+5d/N13mdcZ+BFD07WuRl3NQDo7eZNx3UGfnz24/rHp+dk3hz7P1f/Y81+7M4eB+D9zfa9wXF2vtYw4gw8zzfQY7Lf56IDvFdm/2Ke/Z5r87oR7fh5dxfHv7NjAZT6UTKSSY0uGclxHLmOp2T6/4sG+gEyWR+MdhtixhngeUzux9RvcNlPZfOza7IekPM4J/fPJisiTdYLDvhaBCYAAEC28HcRIyPJNyZsSEeuG5Hk7RhlqZ5yTCb4cgKyf3A5/T72Z3L/bFLPtadDm/2fJjXE7w4QkWaA+xvtNIAHDFmCEgAAvL+lB7P9sAd9IxnHkeNGJOMpmAdMRVnWI1Ohl/ro+FmjkQoek242J+u/zM3p+2c/1ukXo3vSkgOONrpZXejkzGBnprEHCN+cr6Hfi6eDuf83AwAA4P0jHZDGGCV8KeFLRp6iLXnyl0UkuXKcMP6yAsoYXzLJsK98GflZo4cK7hg+zknFo+Pk3Bw8UTDmaYJ5dKWizqTiNH2/XQSbkxW4TtbrpUdOsxfDmaznMqmx16ybc0cjjQmj1pjwz5mbjfHD49zN8QE48KTejl7g1FAA3qea/J3elA7IpG+U9IOIrB4yVMdXHy+97kiOK+O4WfGXqidfTir4TBBiTr+ADAb/HDmOG37WyRksNOH/dUxWMBojR2GsDTjlPICcJY7ZARmMpmqHVzVZA6DhNycrKnec3pbkp2IzdZySb3wlZeT4vuTv/JsM4AD0gfDj0n16FACw7wyWamtrB7wpvQs76RslkkYJ32j8xMkaO/4gJf3gzAK+0s2UTjPXzWx0dR3JdZzcM6FkTYn7Mqk23GFZYbBhJ+jT1PM54d9Tt+/R6J6Tef7+H7ObML0iM+c1Mn/OHFc4dpo6NmWOMX3c4VS4Ez4he9UAAMD7QXoEMu5L8aRRPCkl/Mx0dtIP10UakwnIVOy5TvrUU65rdgxIEwZoOiaDkEwN/2UHmevuGKPBa6XGLne5FzyzFSY8zlSw+v3v6GSeKzsgg9NnOf2C0oRx68hLhaQbnm5LJlgraoyME85yOwMfIwAAwL+S9Gl8EkmjuG/CkAxiMh2RJoi/VEE6CoIr4oanzHIl189EXzrmfJMOSN9IyXRABtPhQZyZIBxTAekqPSKZHXpSKs4GzsickUcFIelnj3qa1JOYrOd1ciM2FatO5hg8x5HrGPlZwZw+jDCa3fAIGIMEAADvBzlT2MEIpFFf0qgvEY5ImtxRSCecqvVcKeIaea6jiB+OQCorILNGH5O+CQMyFXRBqLkKHuClRjQdyXOdICoHDMjU0OWOX0j2yKOkTDymRj+zJs8dmZxp6Zw/KzMCGhyPkedIEU+KpEZTU2f7N6l4DI+RUUgAAPA+kJ7CToRrIONJo3hCat26SS2b1qTXP0q56wiDwHJVNXFOMBLpZ9YNpqaOk77k+ya4qpKfGokMRiH9ZKOW//IJDf/iR1StMNacMB7dTNClX08KT/HTbytOquXCxY4Dr4Ns0pJrH1b1FR9TreNmTvTjmB2msV056el4L/wv4jpBDIcRmR4+Nbkby/UujkK+8MIL6unp2eV9amtrNXr06Lfx7Fv0yv0vqCFaq5kLD1HN2zpCAADwfpWzCzsRxl7cN+rp6tTE0UM1ffr0nT74+ht+p5KEke9m1gg6wQl95BtJ6lHj43fpkcXPaGN7lwpKxmrWpy/RmJIC+fFeNf5zpUriUnG41jBnM00Yk1LmRECZNvPTn1fq86nINanxTSe99tKoT5teeF3RuFFVOIUtZa11zIpIT0ZuuLHHc6Wo6yjpmnD01JHxMseYmprPBK4yO43eocbGRp1++umKxQa+NuCKFSu0ffv2XT6H8dfr1qu+qrs2S45iqpl4lM689HwdUdGtrevWam1egaZkfe/2ri69ufhe3Xz3Gxp92sd06hF1KpYkLdNNX/21Hli/TX2SHLkqKV+gz/z8M5pp2rX2paf09LOuZl98vMa9J8cJAAB2JxOQ4Xkgk36woSYpqaysTCNHjtzlE8ST4RRxVogFO697tfXxO7SkKaaxH7xY0/I9FRUk1XJfvTad+SGVJyLB2su4UbeCtY/p9ZBZ6xIVRmlOQKaHQnfcYJM58U5m57fvBFfU8eNGvU7uFHgwJR+ORDpO+PrBKGjEleKuFPMkP/jKJDlhYAah6ZvMVHzqid+lhtSIESOUn58/4G1NTU27Ccj1uvWyi3R33VX6xkXDJcW17c03terWu1V10bR34egsdWzSmjWrtWrFm0pOWa0N0+o0sUiSOrRxWVSH/eeXdWx5sdxkQqv+fI1+dM0Q/eA/Dld36xY1vOVqynt/xAAAYCfSayBT08t+GJFmD09rmAgfbFxHbji9G6x37FHjCl9lI0dp8NhxihlHvnyVnThUvu+qL+nJJLrV9OwNuvWvD8pPRDX2iNM190MfVoUXTi8vvVV/u/sevbWlU3nzL9MFpx6paLRXjT/7nuIX/o9GRXvV/OpiPf/YSh168UWqdbfptcWvKlE+QhOmjZVnnGAzjeMF6zyTRj2O5PW2qune7+gvi9fIGzxZU0+7WEdPHibJyHN71fyPm1T/wP3a0htX7Rlnq/bmVZr4uys13XHlucF0f8Rx5LvhFLmTiVap3xT7PrNaLz05Vh/63yM1Pj8iyWjsqHGa2pdU1GzVBkntz92ibz35Q725sk2uhuuE71yjS+aOVElEMsmk7v/6sfreM5JKazX7Y1fp2rPHasWD9XpqXUSHffTDOrT3Sf38mrvVddIF+vT8CarefIs+f3WXvvSr8zWu39E0rXxDL7/ZrIOOnKbmtcv0xhvTNHH6kPDWIlWPHau6qjJ5Jqnqz52sJ/9tud50D1flTr++pfr9ZQ8rPm6F7nhglbq6EjryGw/qY0s/q8vueEslIw/RR6/6mc49OLj3Ww9fr1/+9g96ZqOkocfpq9+5UMeMq1GepMgj39aR//OwJKmwZow+9LUbdNGhkrPxJd12w//pZw+ukiSNP/M/dcUnj9PEKklq0K2XfkG/fK1NvvFUNfhUfenWyzXPl6ROrXr8dv3mh9fruRap+Ii5mtQ4SLM+f7pOnFmncknPXPMhfe2BVvlOVJUzL9RPrv2oRkhympbrvj/8WN+/53VJ0thTvqQvnnuaprHOAACwH8lcoiW96cRkjeLtnjHBObR9P5i6zuy6zlP50HY1tm9WZ2dcvqR40lWysFDGD6bMuxNP6aWeuTrvG9frkq9/SzNqjJYsXqpO3yh/3aN6cHOhJp17nS7+3o36bMFDevClBvXE8zVhdoWaWhyZvl7F2l7Xmt7Nau5wFOlqUWRQiZyaITJJpXeVJ5LBl2l8KZnok/fqTbqv/FO68Oob9dmPnaLahnq91NClvoSUt2axFndXa/YlP9Xl196o01sW69EtW9WXyOxK97NPbZTe9u28R1PBe6pWI2qf0C23NIR/d+TlxVRYXKioJGmNntpcog+c/2PV19fr/m/N0ZIb79TS1g75ktb+8hx9P/ZV1dfX6+brLtfYZT/StQ93amh1ofJjXdraLLmbNuiNhuf10uo29fRK7qoVWnfwLI3Z4Vi2asPGN9XWOVZzT5ujus52rVrfoM0DHXYyqXW33qUXa4dq+C6/n3F1tjyiuzrO1KI/3qmH/v0w3XXFUfpeydf191t/p/8+sliP3ne/Nktqe/k+/eXpzZr8ud+ovr5ef/iIdP3vH9CGpk5Jj+trX3lFp/66XvX19frjtd/UqCd/refdJi154Um92jVX37opuO0LJY1atWWFmp3n9OMzv6215y7S3ffW6767btOXD/unfvyjZyRJXW8u02OLV2jQuT9VfX29rp5aqO1rX1RDX0JG0sY/Xa6rmj+lu+65T/f99WZdUXOPrvzpM5K269VXn9CzGw7W1/8cvOblw/vUsPFlNb3NnwIAAPYGd/d32bXs8zDmXKjF5KvqA+drRkmTHr76XP3w4hP0h1/+Ue3d3UoaI994Ksg/VguOmKSkF1Nn0TAlems07M316jVxbXh5nerKq1RdU62EG1PkqM+p5+HFak8aJWoP0wsvLlV3R4t6N6/WsEnTtWLlm2resEZuR6NKigvTu7B9ZZ0L0jdKJDr01qOrNX/eIUp6MWnoFJniyepaukxdflzrX1qviYOqNah6kBJOTCXHXqAxeQUy6fNihiOs4Uhr6vnNfjX6KEl1uvju23TU7R/W9OnTNX3uCTr323/TumQyPNIxOvG0kzTnyLEqKChQdP5czduyXesTcflapb//PaGzLjhRBQUFGjyqVocfPlM9L7+s3opydbW1qGHtm3p56asaPnKE1q1cqfb2Vv3jH49rbN2YHX+oGpu0cXOnoofP15ET5ujIOTH1blmvxqbUuO1T+sFxCzRr+nTNmHW4vlQ/WVf9/JMavZsgdzRLHz/7EFVWFSvyoQ/og/58feqCCcqvrtKgmdM0YV2DNjhtWrtms/JLR2viwaPkuq4Gn3qc5q1crae7O9TjGBlntdatceW6roqHDdVxX7hIs3zJOG1qa92m1ubgtinnfFwnTZykCjNbl9/2C10+rVwRz5UXi2ncx0/T5Eef1JNulxobN6g7MVxzFkxVQUGBph07X4dOqFOBJGmdHnu0U6d+fIE8z5OXH9O4s07VxMcW60lXkjrU0bFFLduD15z0kQ/rpGnT2OgEANivpNdApi5VnV4TuIdPkLNmMVwHmHp8IhlT6fzz9dGjzpdvjCpW3a6f3XCXTrrwo4rtuJE6ff5GmaSam/KVLI2ldzl3RUs1bPV69fhGTRWTNfuNh7Vl3MHasHyKJp04RF1LntWGQ2rl+cUqLlS6bHO+Dkfy/T5tWluhoZFgRDLuROR1JFTU1KY+k1BLY75MZVTGCTYUdcXKNcwJd5b7Rr5xwp3pzs4vkPNuLYJ8hxx3vC7724u6TFJf02rVL/pffe+HMf3nVZN388D1Wr9hhA4fEf49FlOsrFT5W7aqccxk1VWv19atT+qxFZWqOfVgnfrH5XquuVbtDfN1wkKv35P5atqySesbNmrI5EHaunWrqmqGadurm9XY2Ci/RnJ0hK546Es6o6os8wP5bl0Z0ulUe8dbevrG+3Xr7b+SF/6bRTVTn/E8OWa+vv3cj/TNo4/X8Vcb5ZcP0fFf+r2+uKBGh536acW7b9CvLjpe/+vHNewDX9GVnz1Fhw7x1bv0T/riVX/W6129wY+a76is+jQdr151d3eoN16piorgtUxVlaqKitQnSc5mbdz8lv72xQ/rbid1ZtN8DRt/hk5WpaYs/JTO7v6Dfv6F4/V/Jq4hx1yqL37uLM0ZEVX/7ywAAPtKRMqcGNx1nOBKK67k7OHYpBfePx2QjuT4kqOkert7ZLyoIpGoEkmptXaO6lbepKQjRRw//bpeeBBuuMHFdSKqGZnQpvwuJRK+CqKeClrWauO0SRrvOYr4pTpk9Co985avtxbO18xhbdq2ZbVe6KzR6NHjNVyZ4w/WKIY14jiKejGNmtKhprY+VZbkye3rVLIwqc4RwxRVVDUjk2qMdqsv7qswz1Xetre0xvc1TspkddYJy/ebWtxBhxrX96liRGWwzq+yXGNmHqphjzareXcPNXWaPHGdXnulU6dOK5Lf2amWTY3qGTFbw/xalVV4WvvYg3pAC/TFQQt16IwHdOPtd+mNocfqJpObOX5iuzZuWKKnH1mm7S98WneGn0+2Vah01mxNnbyXryFuSlRVMU0fuHSGZn30JB1ckCdJ6t62XYmyUkXVqcbGw/TNxx/XN+Md2vDYIl19ww16ceFFmtpZoiknfVm/O+trcpoe10/++2E9vWqiRg9t1W+/9oTGX3ObfnlomVwT14ZXf6+ffaNFUoFKSsqVn7dKGzf0amptTPG31mvD9mYVSpIZqQlj5+q8yy/RBaNrgo1YyaS6mlvk+gn19BRo3JGX6P+d/GU5W5/Wb65+QM+99qrqRkxnFBIAsN9ID/h4jhOcz9GVouHl+lpbW7V+/fpdPkHUcxQJRyBTHeU7km+61Lr8NXXKk8oKlEwYlTQ8qw1HHaKpUUd5Sgav60lRI8kx8lxfjit5XlQ1Uydq+bIGda/4p6qKCxR5/X4NWvAplbiOPMeRBg/VS7c9qtn/dppipRF1dMS1ZesyTZ45T3lezpl95Ie7tT3PUZ5brGFHHaLHn3tCxWOHyG1rUDzepsrJc5TneCqdOknLV2xU9/IX1VOSr9bVD6g10Zc+D2Vqijp75/cO3qWebGho2OlpfHZ3Ch9phW6/7jlN+MzhqjJSfPsmvfjoMvVO+6SGGqlxl48doWM+PF5fuvkmvejPUOeW9Xp+eZNGnXSwqiTFamJqWNek3iERFZcVa8TYOq255V65nzgn2E6f5qt700Ytf75RE676hb5+cl36lrX3fF8//udrapgyfC8vHS3WiPE1enLVs3rqnscUrxskSVr/+MsqPuc0HVm1VncsWqm5J0+Qkt3avqFV+UMOUbFp09rXX9SKV5MaPaVabstqtcWKNaqgQBH5Gj4sX0tXv6qXVCgl+vTMjbdptY6TlK/qYWM0uPwlvfj3v2vwYSO1YclTWtHQqKmSpCGae2KprrjhXs04fbpcR0p092r9y2tU94UPqmjNEv3zmT7VHTpYTutqNXsFGlRUFK5bBQBg/5AJSNdRxA1iMOk6yi8s0oq1a7R8zb3p9Y3pdX7h1FtBxWDFvOCxblYG+HLkm1JNmjVSSx58SC88vkLdflJFpTN0wrnHqDLqyjh5qppWp6KIo+BENa5KaiqVVJEKPEeJYTN1RFerHnviPq1s7lLejI/r1IOGKOa5wSl5xh2umRNdTRhWrDxPqp5wtA6rcjW8Kj8IyKyIM4qqevp4lUQc5Tt58g86RcdtvUH33/egvKqxGnfUmTq4ukDGGHUPnq7ZHdv1+BP36I2OPo1YcLQmlC1VLDzFT/D1Z18hZ++MPtbU1Ojhhx/e5X1GjBixi1tn6pKvbNa3v7tIGyU5KlLt5JN07idmq9Js0aARozQqWqWC9D9bucYcNkGVsagcScM++h39+9bLtGjREqmoRpOPu1DnzQ72RJeMOUiHL/yIhg8+VLWDClQ1c75OWhBTyTFjFPVyA7JPvkqHzdaJR9blHN2YeSfqyO0b5KhII2dN0JBoZIDvZFTFVcM1bpKrkh1uK9WoQ8erqDAWTu0O0qSjJqnaSFJEhWXDNO7gXpVJKppwpD7uJ3X73+7Ron90SpLGnnaFLiiqVJ4qdekHXtJFixZJkmIVQzX/gjM1xUhO7QhtfulWLVq0QZJUe8yndXTdaJUa6ZzLjtGVN9ys3z6SkDxPgxZ8QWesSKjCSPnDp+iY41rVdduNWrRIKpwwVGVDx6na9eRKqv7gFfqB+0N967eL5BspWlyheZ/5rqYayRkyVk15N2nRonWSpGHzPqGjDp6gil38SwMA8F5zFi5caEpKy/TdH/5CnT192rK9Vb0Jk74edv9LGSq8WkvqGtjBx8x1sKXgdEDJcHd2wqQuZxheC9tPbToJTuO4u9Enp19VmNRpHLMiLnMlGScr7Ew4uewEpynyTdbpilKXWjTpv2c23fSptz2pWH5M+fme8lbfqd//o1BnX3qCaiKu8qNSftRRvucoFpEinqOoK0XCE59n1pHi/atHra3t6ustVXVNTO1Lb9FP7tyuOWd+WPMnD1bevj48AAAsVVZWKi8vTxdeeKGam5szayAjrqOoF/wnBesRU9e5TprUJQgzgea5jjwFM5ZuVsQFG2GcdJSlTuuT8E368+nNMv1PvD1AUPYPyNS9s4M1dS3r4LgzI4OZgAw2vyjrmEwqHMM4TiqMSPnyt67U6vXr1JXsk1m3TGMWXqRK11HES0VzsFY0NY3tpP/wzv+B8K8grrYNy/X8k2vVVeiq6fVXlaxboLFDK4hHAMC/hGAK2wlG0vKjnsqKCxVPhpc19E36vIeZSwRmbbgJ1z4GMZUZdQt2KWdGIYMRyNQIYOZ61ZIG2Mm8Q0Lm/s3JfDY9EpmaXs6ZWs56RpN5HT818hiejscPR0azz19ZWVuqpi1JdbV2K3/aGZp36HCVxiKKRRzFoq7yI45ikUxwR1wn2Hgk5YQt3q+KNHb0RDVv2KwlDZ2qmHqiPrjwcB1UW8FaRgDAAcnzcjfJptdARl1J0YjKSgqVCAMymQzCKpmKPhNsIklfr9oNL+snE6yLTG1SDu+bibXMORmNnzlRefrckWlmJ/m44zl/HCkrGp2cSx6m1mimNtKk4zF8/fTX5Bsls/4exK6RKZqmY0ZNk+MGG4uinquoF0RjLOIqFnWV5znKi7iKuo4inhOOfAYfARVP1fFjpur4fX0cAADsBekpbM8NpnplMmsck27WVVfCHHNSH9Mjf06w5i9r5C0zjW3SawtT6w9lnDAed5yvHujskwP2WPhJN5WXqajMGnrMflx6N7bpf1yukr6fXp+ZDsjUOSSdzOaiqOcoGo46ek6w9tMNozUzomoszqAJAABwYHD6Te/m7MKWMptUXMeRZyTfDdYuBtL7kCXHyFU44pbavBLempmqdtIjgNkfc9rx7ZzDJT0KmRp5zN1Ys2N2mszrm/Bk4Ca4X9J3w6vLpNZtGvkms9vcy4rIYMNMeLojR3KMCb/21BfkyCchAQDAv5idBqTjBOv4fD9Y05gZOcxccSXnlNlZp7VJj0ymp7CNPCdzS/rxWeGYffpoZw8iMuyzzGOknHMypv4w8BhkJlyTSl3D2pGME4yyZu/CDkcpU1+rm7XLPOo68lwTbKLpNwKZjto92FkOAABwIEsHpOsEUZc6IbjbLx5zd7s4ubHWb+NIagwu89jM6sbM0+0s9QY24NrIHZdGhn/u/4zB9LyR5IVxqPBrC6LRyTqNT2pKOhPFqavleG5q3We/K+/swfEDAAD8qwgD0klvSsmNwmC9YzD6N9D6xIHrKfOpMBpTtZdVgeZdqK5drY/cQfiCxgnXKaam1R0nvcPcT0dzZi2jmzplUPbO8zAiHZlg9DT1vTE7bgICAAA40Bljcqax06fxcVwn3GWd2QpijK9kIinf9+V5nlzXzQlJZw9yKXfau/+tb7ciU2OIFnJGK8OvMtym7TuOZIzc1DMPGMtKjzzmLOJ0gtFNpq4BAMD7RXoXtqNw/Z7xFU8k1Nraqo6ODvnJYLWi7/vhyb/72V3F7ayq3o1533ewASf1+PTphFJRafpFZCosnWA00sikTx8kBedFyo/FVFZWpsLCwh0WmQIAAPyrifT/RF9fn5qbmxWPx1VcVCTP8+Q4uWONtom0X47MpTcGpfIx6/RCA9hhjWUwRCvf9xWPx7Vt2za1t7ervLxcsVhsrx46AADAvpQTkL7vq6urS/F4XIWFhcGUdeidjKvtj2NyqTWY6Q03ZvfHmb3mM1jW6cjzPHmep1gspr6+Pm3btk1lZWUqKCgIz4+5P371AAAAe67/LHROQCYSCXV1dSkSieTE455JqKu1SQ1vNsurGaqhwwvU07BRm7ckVTauVjWlhfvVZdx2OFNk/6Dcw8elP+84isVichxHra2tkqSCgoJ3dpAAAAD7oR1GIBOJhIqKinbxkG41vPiiVrf1hafpcVVQNFx1syq1+Z9/0TWX/l3F516qy786Ra//4Qf61Z9adcwv/0sXHD1ZVe/4cLdq+eOvaZszWBOPmqTq3d6/R5uXvarVWzuU9Adp/Pwpqkk2avmTK7S13z0dFap67GDl97aqacN29UhyVaHRcw5SbUGeXEnJxOb0Yx3lqaR6pMZNqVVZ1vPk5eXJGKPW1lZ5nqe8vLx3/FUDAADsT3ZYA2mM2cXo41Yte/Qh/fm6P2vNlImqdVz5cSneNkhnzPlsbiCaEtUePFsLT+nWQTVlendWBS7VH/7ti3o4eoq+veRqnejv+t7d65/Tn3/3az3y0FJt7F2g/3z1Rzo1uUFL6uu1LLyP092idSuX6pXNg3Xav39Sc0rbtPzpZ/X8s69o3ZaD9fn7v6ezawcpJimZaNCS+nv0QutaLX2iUcNO+Kyu/PF5mt5v2WReXp6SyaTa2tpUUVHxNkZzAQAA9l87BKS04+VqUhpfukO/+Pb1enPUF/Sdq8/WjIinRHe3Vj35lKJG6sm5d0wVQ0drwiF9GlpSkH6h9lcf1N0vN8o3khPN15DpJ+rYCSWSutS4+lUtefoNbc8+Frqx/SQAABT2SURBVBVr9JHzddjIbr18x2KtSfqK60098ceb1F0+QbNPnqFhAx1s5zo9ffMjapgyRROfXaOm3uDT0dhhOu/7h4V3Sqjt9cf1+2tXaXVslMaMnqvjjx6hD50+U4s+903duCX3KfPyZ+q870/Rccv/rG888Tt17eSbmprO7uzsVFdX125GdAEAAA4sAwbkwDbpmb88oKXbKnTs907RVNcLnqCgQJOOP1YyzXot++7OVi198JZgCnvkSI0eXqn4K/W6/hc/0U3dh+uTM8rU+MK9+tNzW5T43Nk6cVK31i+9X9dfc5NWDztY8+bO0qSijVr80DIlVyf1zS8erM7WLvVJMqZPnS0tanO7FQ/P5ZirU2sX36lHm0fr5LOG6OmbH9AOc9aSFG/V+pVL9NTrCR30wbmac8gIFdp893YhtbGmvb1d+fn5jEICAIADVv9NNBZVs0kbNvYoGR+lMWM9OdY91KKX7/y9bnqmRzPOuUSXXnaJPnf+PEWfuFU3PfCaWtIHVKmJ807RuZdfpksvO0tHjI6pof5xvdpepSM/e7wmeq7y8ibpA5ddrHM/MU+jBjjrTufKZ3THs82qW3iEZg4p185WIXZt2ayli/+hpupDNGfe0RpfYfs17Vo0GpXjOOrs7Hx3nxgAAGAfshiBfIec9Vq6bKviiR6tv/M6fe0RR33db6m9u1vu8hVa74wN7qZSDR0yRIMGxSRTqMJIVHntnWrz/T08n+RmvfzIMsVHzdXhs0aqLG/7wHeLt6txxWO6/7ku1S6Yp6OmD9O7vWfadV0VFBSoq6tL+fn5ikTeu283AADA3mJRNGM1oa5Ikdde09JX4vLnS57NKKTJV0GBq4gzWnPOOF5HhFPgp3zIU1H5CNUaabXVoe9Muxqb1mjZK89q1XN3KU/NWt3Uqh69rJsv/Z1G/OICzTJSd/MWPV9/m9YW1enM+cdrfOm78uI78DxP0Wg0vaEGAADgQGcRkOWa87lPaN7TP9Dia6/RzWO/p3NGRdXX0amX/vo3xc49aTdPNlJzZo7Uolde1/Lm8fr6R0ZJ6tO2hqd0z+9eVNGMee/sK0mr1dHnfV7jt7arT5L0mv68/C1t6R6lwz+zQOOMpESXmt+o19+e9TV0wUIdN3PQu7RLfGDZG2o4NyQAADjQWc2plgw7Qf/+6xpVX/E1/ebiM3VrniPjR1RcPFcXn6fdnOcxprqz/0d/KbtOH/7Z5/WhP0blKKrKoUfprP8+R2NMIn1qnZ0ys3TWGaN1zy2P6LrTztIdoz6oi356vmbkzG0XqGrkeFWNTP29Tw/FovJUrpEzRqtSUm9nu566/UatK6nTmSecqnHpnTNv6eFf3aC/1D+tNzY2qUXr9bsLz9e90Xn6/F3/oSM7HtH/fvInWtzboia1yjx1vb522lM68sxP6uzz5mv0TubYs3dl5+XlsaEGAAAcUPpvonEWLlxoysvLtWjRInV1dWn9+vUqKyvbycMlKaGu5hZ1xFMnYXTkRQpUXFkot7dLHa29cgqKVFQSUbK9Q53dRrGyYhXGosGOnd42NbX29HtssWJKqq+7Sx3tffKKilVUFFNEcXW1tKurz1VBZYkKI56SHdu1vSvR77G70qeObW3qTkZVXF2qAseR8ZPqbt2mLhNVQUmFitKXyEmou71Dnd19yj3FZEwlNaXK93vUtrVdvTm3ecorLFJxcf4ua9wYo+7ubnmep5KSkl0eMQAAwP6kpKRE0WhUF154oZqbm9/OJpqICisGDXy6m1ixKmqK03+NlpQrv38rxUpVUzPQgkNPeQUlqsyZ4Y2qsLwy57UixZXKeok9kKfiqkHKfojjeiqsqBnga4iooKRcBTvrO7dAZTVvfwo6NQoZi8UUje5PF3YEAADYc2wLfo84jiPXddMRWVq6l3btAAAA7GUE5HvIcRxFIhElEgn19PQoFtubW3cAAAD2DgLyPea6rqLRqHp7e+V5njzP29eHBAAAsEvv4Eo0eDekRiFd11Vvb+8O/yAAAAD7u5wRyJ6eHr355psqLHy3rgiNnUkkEkokEorFYpzWBwAA7LcqKip22LuRE5DNzc2qr69XTU3Ne3pgAAAA2P9s27ZN06ZNU21tbc7FUHZYA1leXq6pU6eqra3tPT1AAAAA7F96e3sH/PyAm2g6OzvV0NCwVw8IAAAA+7fOzs4BP8/iOwAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAVghIAAAAWCEgAQAAYIWABAAAgBUCEgAAAFYISAAAAFghIAEAAGCFgAQAAIAVAhIAAABWCEgAAABYISABAABghYAEAACAFQISAAAAViL9P9HR0aG1a9eqpaVlXxwPAAAA9hN9fX0Dfj4nIAsLCzVu3DhJUmlp6d4/KgAAAOzXBmrCnIAsKyvTwoUL37MDAoB3QyKR0PbmVm3Z0qSuzg75vr+vDymH67oqKCjUoJoaVVVUKBrdYfIHAPZrsVgs5+8572KRSEQVFRXv6QEBwDvR3dOrdevWqaunT0NHjlVhUYlcd/9a3u0bX92dnWpr3qptzc0aNXKkCgvy9/VhAcAei0Ryf/Hl12AAB6xkMqmNGzaoO+5rZN1klZZXKi+aJznOvj60fozifX1qbxus9WveUMOGDRozepSiEd6CARyYePcCcMBqaW1Te09c1UNHqrRykBzHVdxq+nqtHv/1g9pSN0vzjztUg8xeO1TJi6i4vErVQ0dq07rVam5uUU31oL34ggCw9xCQAA5YHe3t8o2jorJKJX1J2kk8Jru05Zkf66tX3awGSVWHnqxPXn61Pji+Wy2NTdpa1amepK/E3gzIUFFZpeS+pY6ODgISwAGLgARwwOrr65VxHLnRmOLJncSjSapjyf/pW1d362MPPqW5vrTlxX9qxcu3alndIUr6Rr7vK570FX8PAtLxojKOq2QivvdfDAD2EgISwAHN940SO4tHSSbZq8f//CcNvnKJ5nlG8qQhs+dqiCTFV2qlCQIymfAVT8b1/HUn6zt/XaWOPkfexEv1f3/6N01wXRnTqfXP3abf/te39eRWyfXHav4VX9H55xyrWud5/f5Td6h74jLdU79Cia7j9eWXf67jkwMXqW/eg1IFgL2IgARwQPPNrgMymfi7Xnj2WM291leif9A5vnxjwgiNa/3NV+pnXefqN38/Q1UlMa3/7Ud05dfH6Q/fXaCtS/+qO/+0WQtuXKn/qjLqePFm/frep/TSM+NUM9uXb17Q/dvO0fX3nKXKkpjUl1RiZ8fsG0n720YfANhzBCSAA9ruRiCTSSMjo0QiqUT/uzl+ego7kVynf77QqoNmD9HmjW+p1ZOSR5ygg/70hJ7yT9KRk87Sef+9Vdu2va43myWVVGhod1ybNm1UY9KVb2bqYxcfq1hhdJfHI6VGIAlIAAcuAhLAAW33AVmqguIWtbf4ShT1v9UoaYySvq9Eslktzdu0/JYfaPWd0TDvXJUcdKwKE3F1bV+hJbdfr78+9pbiUUnqUcemMs2YdYISSck3kp/0lUj68vbgmAHgQEZAAjig7W4K2/izNWPBdXro9lc05SMHa3BM6mtrVUd3t2JDMlPYyeQwjRhziGbMPV0fnTVZRRFXxhi1rH5DSnZq09qn9cxzJTrxB7do/iCpZ9tTqv/JfeoMX99XaiRzDwKSNZAADnAEJIADmjHB6N9OOa7Gn3i+Xvp/1+uv7nxNKJf62uKKDhmlyYMr5BvJGCPfr1Dd0XV65okH9cSW15UXjcgYo44NcU2qG6VBBYM1qOw1LXvkb0qWSG2bl+iVVQ0adriRb5zgOcJj2d2ZKOlHAAc6AhLAActxXRkZ+cmEXG8nb2eOq/xRJ+nDn8lT/d9e0MqNUuHwgzVj0izVmC1qO3S6ymoGq0BS8YyP61POLfrr4hXq6fMlN6K6U7+q8UbSsDmad9IW1b/wilZKio6o0/RT5qp21GAVGEd1C+coVlK4B9PXyaAg97ur5QDAniMgARywYrECuepWX0+X8otKd35HN0/F407SR790Ur8bqjV+wTE5nymefpY+NX2A5ygcpNqjz9fnjh74JWZ8bOQeHXO8p0sySeXlxfbo/gCwP3L39QEAwNtVXl6mwjxHHc1NB8SJuf1kUp0tW1UQkcrKyvb14QDA20ZAAjhgFRUWaNjgaiU7t2tbwyp1d7QEU8T7Gd/31dPZpm0bVivevkXDhlSrpLh4Xx8WALxtTGEDOGC5rqvqqkp5nquGTU3asuY1xeNxaX/bpOJIkUhE5SVFGj5ymKoqg2MGgANVTkBGIhFVVlbuq2MBgLelurpaI0eMUG9Pr5LJnV3/Zd9yPU/5sXzl58fkusQjgANLJJI75pjzN9d1lZeX954eEAC8G2KxmMSyQgB4TzgLFy40juOovLx8Xx8LAAAA9mMtLS0yxgQjkMYYNTc37+tjAgAAwAHg/wOWKhnH3iXULQAAAABJRU5ErkJggg==\"/>'''))\n#display(HTML('''<img src=\"\"/>'''))\n",
"_____no_output_____"
],
[
"from ibapi.wrapper import EWrapper\nfrom ibapi.client import EClient\nfrom threading import Thread\nimport queue\n",
"_____no_output_____"
],
[
"#to easily extend/override EWrapper\n#Jupyter notebooks needs this all in one cell!\nclass OtrmWrapper(EWrapper):\n def __init__(self):\n pass\n\nclass OtmrClient(EClient):\n def __init__(self, wrapper):\n EClient.__init__(self, wrapper)\n\n#https://interactivebrokers.github.io/tws-api/connection.html\n#Once our two main objects have been created, EWrapper and ESocketClient, the client application can connect via the IBApi.EClientSocket object:\nclass OtmrApp(OtrmWrapper, OtmrClient):\n def __init__(self):\n OtrmWrapper.__init__(self)\n OtmrClient.__init__(self, wrapper=self)",
"_____no_output_____"
],
[
"app = OtmrApp()\napp.connect(\"127.0.0.1\", 4001, clientId=4711)",
"_____no_output_____"
],
[
"s = \"serverVersion: {}\\nconnectionTime: {}\"\nprint(s.format(app.serverVersion(), app.twsConnectionTime()))",
"serverVersion: 118\nconnectionTime: b'20180815 22:42:51 CET'\n"
],
[
"app.disconnect()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa13b82bfe2f193be33b543527239ef624248d2
| 44,704 |
ipynb
|
Jupyter Notebook
|
spark-training/spark-python/jupyter-advanced/06 - Broadcast Variables - Full.ipynb
|
kryvokhyzha/examples-and-courses
|
477e82ee24e6abba8a6b6d92555f2ed549ca682c
|
[
"MIT"
] | 1 |
2021-12-13T15:41:48.000Z
|
2021-12-13T15:41:48.000Z
|
spark-training/spark-python/jupyter-advanced/06 - Broadcast Variables - Full.ipynb
|
kryvokhyzha/examples-and-courses
|
477e82ee24e6abba8a6b6d92555f2ed549ca682c
|
[
"MIT"
] | 15 |
2021-09-12T15:06:13.000Z
|
2022-03-31T19:02:08.000Z
|
spark-training/spark-python/jupyter-advanced/06 - Broadcast Variables - Full.ipynb
|
kryvokhyzha/examples-and-courses
|
477e82ee24e6abba8a6b6d92555f2ed549ca682c
|
[
"MIT"
] | 1 |
2022-01-29T00:37:52.000Z
|
2022-01-29T00:37:52.000Z
| 36.344715 | 1,801 | 0.408219 |
[
[
[
"# Broadcast Variables\n\nWe already saw so called *broadcast joins* which is a specific impementation of a join suitable for small lookup tables. The term *broadcast* is also used in a different context in Spark, there are also *broadcast variables*.\n\n### Origin of Broadcast Variables\n\nBroadcast variables where introduced fairly early with Spark and were mainly targeted at the RDD API. Nontheless they still have their place with the high level DataFrames API in conjunction with user defined functions (UDFs).\n\n### Weather Example\n\nAs usual, we'll use the weather data example. This time we'll manually implement a join using a UDF (actually this would be again a manual broadcast join).",
"_____no_output_____"
],
[
"# 1 Load Data\n\nFirst we load the weather data, which consists of the measurement data and some station metadata.",
"_____no_output_____"
]
],
[
[
"storageLocation = \"s3://dimajix-training/data/weather\"",
"_____no_output_____"
]
],
[
[
"## 1.1 Load Measurements\n\nMeasurements are stored in multiple directories (one per year). But we will limit ourselves to a single year in the analysis to improve readability of execution plans.",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.functions import *\nfrom functools import reduce\n\n# Read in all years, store them in an Python array\nraw_weather_per_year = [spark.read.text(storageLocation + \"/\" + str(i)).withColumn(\"year\", lit(i)) for i in range(2003,2015)]\n\n# Union all years together\nraw_weather = reduce(lambda l,r: l.union(r), raw_weather_per_year) ",
"_____no_output_____"
]
],
[
[
"Use a single year to keep execution plans small",
"_____no_output_____"
]
],
[
[
"raw_weather = spark.read.text(storageLocation + \"/2003\").withColumn(\"year\", lit(2003))",
"_____no_output_____"
]
],
[
[
"### Extract Measurements\n\nMeasurements were stored in a proprietary text based format, with some values at fixed positions. We need to extract these values with a simple SELECT statement.",
"_____no_output_____"
]
],
[
[
"weather = raw_weather.select(\n col(\"year\"),\n substring(col(\"value\"),5,6).alias(\"usaf\"),\n substring(col(\"value\"),11,5).alias(\"wban\"),\n substring(col(\"value\"),16,8).alias(\"date\"),\n substring(col(\"value\"),24,4).alias(\"time\"),\n substring(col(\"value\"),42,5).alias(\"report_type\"),\n substring(col(\"value\"),61,3).alias(\"wind_direction\"),\n substring(col(\"value\"),64,1).alias(\"wind_direction_qual\"),\n substring(col(\"value\"),65,1).alias(\"wind_observation\"),\n (substring(col(\"value\"),66,4).cast(\"float\") / lit(10.0)).alias(\"wind_speed\"),\n substring(col(\"value\"),70,1).alias(\"wind_speed_qual\"),\n (substring(col(\"value\"),88,5).cast(\"float\") / lit(10.0)).alias(\"air_temperature\"),\n substring(col(\"value\"),93,1).alias(\"air_temperature_qual\")\n)",
"_____no_output_____"
]
],
[
[
"## 1.2 Load Station Metadata\n\nWe also need to load the weather station meta data containing information about the geo location, country etc of individual weather stations.",
"_____no_output_____"
]
],
[
[
"stations = spark.read \\\n .option(\"header\", True) \\\n .csv(storageLocation + \"/isd-history\")",
"_____no_output_____"
]
],
[
[
"### Convert Station Metadata\n\nWe convert the stations DataFrame to a normal Python map, since we want to discuss broadcast variables. This means that the variable `py_stations` contains a normal Python object which only lives on the driver. It has no connection to Spark any more.\n\nThe resulting map converts a given station id (usaf and wban) to a country.",
"_____no_output_____"
]
],
[
[
"py_stations = stations.select(concat(stations[\"usaf\"], stations[\"wban\"]).alias(\"key\"), stations[\"ctry\"]).collect()\npy_stations = {key:value for (key,value) in py_stations}\n\n# Inspect result\nlist(py_stations.items())[0:10]",
"_____no_output_____"
]
],
[
[
"# 2 Using Broadcast Variables\n\nIn the following section, we want to use a Spark broadcast variable inside a UDF. Technically this is not required, as Spark also has other mechanisms of distributing data, so we'll start with a simple implementation *without* using a broadcast variable.",
"_____no_output_____"
],
[
"## 2.1 Create a UDF\n\nFor the initial implementation, we create a simple Python UDF which looks up the country for a given station id, which consists of the usaf and wban code. This way we will replace the `JOIN` of our original solution with a UDF implemented in Python.",
"_____no_output_____"
]
],
[
[
"def lookup_country(usaf, wban):\n return py_stations.get(usaf + wban)\n \n# Test lookup with an existing station\nprint(lookup_country(\"007026\", \"99999\")) \n\n# Test lookup with a non-existing station (better should not throw an exception)\nprint(lookup_country(\"123\", \"456\"))",
"AF\nNone\n"
]
],
[
[
"## 2.2 Not using a broadcast variable\n\nNow that we have a simple Python function providing the required functionality, we convert it to a PySpark UDF using a Python decorator.",
"_____no_output_____"
]
],
[
[
"@udf('string')\ndef lookup_country(usaf, wban):\n return py_stations.get(usaf + wban)",
"_____no_output_____"
]
],
[
[
"### Replace JOIN by UDF\n\nNow we can perform the lookup by using the UDF instead of the original `JOIN`.",
"_____no_output_____"
]
],
[
[
"result = weather.withColumn('country', lookup_country(weather[\"usaf\"], weather[\"wban\"]))\nresult.limit(10).toPandas()",
"_____no_output_____"
]
],
[
[
"### Remarks\n\nSince the code is actually executed not on the driver, but istributed on the executors, the executors also require access to the Python map. PySpark automatically serializes the map and sends it to the executors on the fly.",
"_____no_output_____"
],
[
"### Inspect Plan\n\nWe can also inspect the execution plan, which is different from the original implementation. Instead of the broadcast join, it now contains a `BatchEvalPython` step which looks up the stations country from the station id.",
"_____no_output_____"
]
],
[
[
"result.explain()",
"== Physical Plan ==\n*(2) Project [2003 AS year#84, substring(value#82, 5, 6) AS usaf#87, substring(value#82, 11, 5) AS wban#88, substring(value#82, 16, 8) AS date#89, substring(value#82, 24, 4) AS time#90, substring(value#82, 42, 5) AS report_type#91, substring(value#82, 61, 3) AS wind_direction#92, substring(value#82, 64, 1) AS wind_direction_qual#93, substring(value#82, 65, 1) AS wind_observation#94, (cast(cast(substring(value#82, 66, 4) as float) as double) / 10.0) AS wind_speed#95, substring(value#82, 70, 1) AS wind_speed_qual#96, (cast(cast(substring(value#82, 88, 5) as float) as double) / 10.0) AS air_temperature#97, substring(value#82, 93, 1) AS air_temperature_qual#98, pythonUDF0#192 AS country#174]\n+- BatchEvalPython [lookup_country(substring(value#82, 5, 6), substring(value#82, 11, 5))], [value#82, pythonUDF0#192]\n +- *(1) FileScan text [value#82] Batched: false, Format: Text, Location: InMemoryFileIndex[s3://dimajix-training/data/weather/2003], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<value:string>\n"
]
],
[
[
"## 2.2 Using a Broadcast Variable\n\nNow let us change the implementation to use a so called *broadcast variable*. While the original implementation implicitly sent the Python map to all executors, a broadcast variable makes the process of sending (*broadcasting*) a Python variable to all executors more explicit.\n\nA Python variable can be broadcast using the `broadcast` method of the underlying Spark context (the Spark session does not export this functionality). Once the data is encapsulated in the broadcast variable, all executors can access the original data via the `value` member variable.",
"_____no_output_____"
]
],
[
[
"# First create a broadcast variable from the original Python map\nbc_stations = spark.sparkContext.broadcast(py_stations)\n\n@udf('string')\ndef lookup_country(usaf, wban):\n # Access the broadcast variables value and perform lookup\n return bc_stations.value.get(usaf + wban)",
"_____no_output_____"
]
],
[
[
"### Replace JOIN by UDF\nAgain we replace the original `JOIN` by the UDF we just defined above",
"_____no_output_____"
]
],
[
[
"result = weather.withColumn('country', lookup_country(weather[\"usaf\"], weather[\"wban\"]))\nresult.limit(10).toPandas()",
"_____no_output_____"
]
],
[
[
"### Remarks\n\nActually there is no big difference to the original implementation. But Spark handles a broadcast variable slightly more efficiently, especially if the variable is used in multiple UDFs. In this case the data will be broadcast only a single time, while not using a broadcast variable would imply sending the data around for every UDF.",
"_____no_output_____"
],
[
"### Execution Plan\n\nThe execution plan does not differ at all, since it does not provide information on broadcast variables.",
"_____no_output_____"
]
],
[
[
"result.explain()",
"== Physical Plan ==\n*(2) Project [2003 AS year#84, substring(value#82, 5, 6) AS usaf#87, substring(value#82, 11, 5) AS wban#88, substring(value#82, 16, 8) AS date#89, substring(value#82, 24, 4) AS time#90, substring(value#82, 42, 5) AS report_type#91, substring(value#82, 61, 3) AS wind_direction#92, substring(value#82, 64, 1) AS wind_direction_qual#93, substring(value#82, 65, 1) AS wind_observation#94, (cast(cast(substring(value#82, 66, 4) as float) as double) / 10.0) AS wind_speed#95, substring(value#82, 70, 1) AS wind_speed_qual#96, (cast(cast(substring(value#82, 88, 5) as float) as double) / 10.0) AS air_temperature#97, substring(value#82, 93, 1) AS air_temperature_qual#98, pythonUDF0#247 AS country#229]\n+- BatchEvalPython [lookup_country(substring(value#82, 5, 6), substring(value#82, 11, 5))], [value#82, pythonUDF0#247]\n +- *(1) FileScan text [value#82] Batched: false, Format: Text, Location: InMemoryFileIndex[s3://dimajix-training/data/weather/2003], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<value:string>\n"
]
],
[
[
"## 2.3 Pandas UDFs\n\nSince we already learnt that Pandas UDFs are executed more efficiently than normal UDFs, we want to provide a better implementation using Pandas. Of course Pandas UDFs can also access broadcast variables.",
"_____no_output_____"
]
],
[
[
"from pyspark.sql.functions import pandas_udf, PandasUDFType\n\n@pandas_udf('string', PandasUDFType.SCALAR)\ndef lookup_country(usaf, wban):\n # Create helper function\n def lookup(key):\n # Perform lookup by accessing the Python map\n return bc_stations.value.get(key)\n # Create key from both incoming Pandas series\n usaf_wban = usaf + wban\n # Perform lookup\n return usaf_wban.apply(lookup)",
"_____no_output_____"
]
],
[
[
"### Replace JOIN by Pandas UDF\n\nAgain, we replace the original `JOIN` by the Pandas UDF.",
"_____no_output_____"
]
],
[
[
"result = weather.withColumn('country', lookup_country(weather[\"usaf\"], weather[\"wban\"]))\nresult.limit(10).toPandas()",
"_____no_output_____"
]
],
[
[
"### Execution Plan\n\nAgain, let's inspect the execution plan.",
"_____no_output_____"
]
],
[
[
"result.explain(True)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa14d121fc982af25a16668b752bd0b1e8b1ebe
| 15,044 |
ipynb
|
Jupyter Notebook
|
examples/cp/jupyter/sudoku.ipynb
|
arani-mohammad/docplex
|
375f12aaa3b99f7f362adc7c614e5a4322222d78
|
[
"Apache-2.0"
] | 1 |
2018-12-08T01:41:00.000Z
|
2018-12-08T01:41:00.000Z
|
examples/cp/jupyter/sudoku.ipynb
|
arani-mohammad/docplex
|
375f12aaa3b99f7f362adc7c614e5a4322222d78
|
[
"Apache-2.0"
] | null | null | null |
examples/cp/jupyter/sudoku.ipynb
|
arani-mohammad/docplex
|
375f12aaa3b99f7f362adc7c614e5a4322222d78
|
[
"Apache-2.0"
] | 1 |
2019-02-21T16:59:14.000Z
|
2019-02-21T16:59:14.000Z
| 27.859259 | 294 | 0.509904 |
[
[
[
"# Sudoku\n\nThis tutorial includes everything you need to set up decision optimization engines, build constraint programming models.\n\n\nWhen you finish this tutorial, you'll have a foundational knowledge of _Prescriptive Analytics_.\n\n>This notebook is part of the **[Prescriptive Analytics for Python](https://rawgit.com/IBMDecisionOptimization/docplex-doc/master/docs/index.html)**\n\n>It requires a **local installation of CPLEX Optimizers**. \n\nTable of contents:\n\n- [Describe the business problem](#Describe-the-business-problem)\n* [How decision optimization (prescriptive analytics) can help](#How--decision-optimization-can-help)\n* [Use decision optimization](#Use-decision-optimization)\n * [Step 1: Download the library](#Step-1:-Download-the-library)\n * [Step 2: Model the Data](#Step-2:-Model-the-data)\n * [Step 3: Set up the prescriptive model](#Step-3:-Set-up-the-prescriptive-model)\n * [Define the decision variables](#Define-the-decision-variables)\n * [Express the business constraints](#Express-the-business-constraints)\n * [Express the objective](#Express-the-objective)\n * [Solve with Decision Optimization solve service](#Solve-with-Decision-Optimization-solve-service)\n * [Step 4: Investigate the solution and run an example analysis](#Step-4:-Investigate-the-solution-and-then-run-an-example-analysis)\n* [Summary](#Summary)\n****",
"_____no_output_____"
],
[
"### Describe the business problem\n\n* Sudoku is a logic-based, combinatorial number-placement puzzle.\n* The objective is to fill a 9x9 grid with digits so that each column, each row,\nand each of the nine 3x3 sub-grids that compose the grid contains all of the digits from 1 to 9.\n* The puzzle setter provides a partially completed grid, which for a well-posed puzzle has a unique solution.",
"_____no_output_____"
],
[
"#### References\n* See https://en.wikipedia.org/wiki/Sudoku for details",
"_____no_output_____"
],
[
"*****\n## How decision optimization can help\n* Prescriptive analytics technology recommends actions based on desired outcomes, taking into account specific scenarios, resources, and knowledge of past and current events. This insight can help your organization make better decisions and have greater control of business outcomes. \n\n* Prescriptive analytics is the next step on the path to insight-based actions. It creates value through synergy with predictive analytics, which analyzes data to predict future outcomes. \n\n* Prescriptive analytics takes that insight to the next level by suggesting the optimal way to handle that future situation. Organizations that can act fast in dynamic conditions and make superior decisions in uncertain environments gain a strong competitive advantage. \n<br/>\n\n+ For example:\n + Automate complex decisions and trade-offs to better manage limited resources.\n + Take advantage of a future opportunity or mitigate a future risk.\n + Proactively update recommendations based on changing events.\n + Meet operational goals, increase customer loyalty, prevent threats and fraud, and optimize business processes.\n",
"_____no_output_____"
],
[
"## Use decision optimization",
"_____no_output_____"
],
[
"### Step 1: Download the library\n\nRun the following code to install Decision Optimization CPLEX Modeling library. The *DOcplex* library contains the two modeling packages, Mathematical Programming and Constraint Programming, referred to earlier.",
"_____no_output_____"
]
],
[
[
"import sys\ntry:\n import docplex.cp\nexcept:\n if hasattr(sys, 'real_prefix'):\n #we are in a virtual env.\n !pip install docplex\n else:\n !pip install --user docplex",
"_____no_output_____"
]
],
[
[
"Note that the more global package <i>docplex</i> contains another subpackage <i>docplex.mp</i> that is dedicated to Mathematical Programming, another branch of optimization.",
"_____no_output_____"
]
],
[
[
"from docplex.cp.model import *\nfrom sys import stdout",
"_____no_output_____"
]
],
[
[
"### Step 2: Model the data",
"_____no_output_____"
],
[
"#### Grid range",
"_____no_output_____"
]
],
[
[
"GRNG = range(9)",
"_____no_output_____"
]
],
[
[
"#### Different problems",
"_____no_output_____"
],
[
"_zero means cell to be filled with appropriate value_",
"_____no_output_____"
]
],
[
[
"SUDOKU_PROBLEM_1 = ( (0, 0, 0, 0, 9, 0, 1, 0, 0),\n (2, 8, 0, 0, 0, 5, 0, 0, 0),\n (7, 0, 0, 0, 0, 6, 4, 0, 0),\n (8, 0, 5, 0, 0, 3, 0, 0, 6),\n (0, 0, 1, 0, 0, 4, 0, 0, 0),\n (0, 7, 0, 2, 0, 0, 0, 0, 0),\n (3, 0, 0, 0, 0, 1, 0, 8, 0),\n (0, 0, 0, 0, 0, 0, 0, 5, 0),\n (0, 9, 0, 0, 0, 0, 0, 7, 0),\n )\n\nSUDOKU_PROBLEM_2 = ( (0, 7, 0, 0, 0, 0, 0, 4, 9),\n (0, 0, 0, 4, 0, 0, 0, 0, 0),\n (4, 0, 3, 5, 0, 7, 0, 0, 8),\n (0, 0, 7, 2, 5, 0, 4, 0, 0),\n (0, 0, 0, 0, 0, 0, 8, 0, 0),\n (0, 0, 4, 0, 3, 0, 5, 9, 2),\n (6, 1, 8, 0, 0, 0, 0, 0, 5),\n (0, 9, 0, 1, 0, 0, 0, 3, 0),\n (0, 0, 5, 0, 0, 0, 0, 0, 7),\n )\n\nSUDOKU_PROBLEM_3 = ( (0, 0, 0, 0, 0, 6, 0, 0, 0),\n (0, 5, 9, 0, 0, 0, 0, 0, 8),\n (2, 0, 0, 0, 0, 8, 0, 0, 0),\n (0, 4, 5, 0, 0, 0, 0, 0, 0),\n (0, 0, 3, 0, 0, 0, 0, 0, 0),\n (0, 0, 6, 0, 0, 3, 0, 5, 4),\n (0, 0, 0, 3, 2, 5, 0, 0, 6),\n (0, 0, 0, 0, 0, 0, 0, 0, 0),\n (0, 0, 0, 0, 0, 0, 0, 0, 0)\n )",
"_____no_output_____"
],
[
"try:\n import numpy as np\n import matplotlib.pyplot as plt\n VISU_ENABLED = True\nexcept ImportError:\n VISU_ENABLED = False",
"_____no_output_____"
],
[
"def print_grid(grid):\n \"\"\" Print Sudoku grid \"\"\"\n for l in GRNG:\n if (l > 0) and (l % 3 == 0):\n stdout.write('\\n')\n for c in GRNG:\n v = grid[l][c]\n stdout.write(' ' if (c % 3 == 0) else ' ')\n stdout.write(str(v) if v > 0 else '.')\n stdout.write('\\n')",
"_____no_output_____"
],
[
"def draw_grid(values):\n %matplotlib inline\n fig, ax = plt.subplots(figsize =(4,4))\n min_val, max_val = 0, 9\n R = range(0,9)\n for l in R:\n for c in R:\n v = values[c][l]\n s = \" \"\n if v > 0:\n s = str(v)\n ax.text(l+0.5,8.5-c, s, va='center', ha='center')\n ax.set_xlim(min_val, max_val)\n ax.set_ylim(min_val, max_val)\n ax.set_xticks(np.arange(max_val))\n ax.set_yticks(np.arange(max_val))\n ax.grid()\n plt.show()",
"_____no_output_____"
],
[
"def display_grid(grid, name):\n stdout.write(name)\n stdout.write(\":\\n\")\n if VISU_ENABLED:\n draw_grid(grid)\n else:\n print_grid(grid)",
"_____no_output_____"
],
[
"display_grid(SUDOKU_PROBLEM_1, \"PROBLEM 1\")\ndisplay_grid(SUDOKU_PROBLEM_2, \"PROBLEM 2\")\ndisplay_grid(SUDOKU_PROBLEM_3, \"PROBLEM 3\")",
"_____no_output_____"
]
],
[
[
"#### Choose your preferred problem (SUDOKU_PROBLEM_1 or SUDOKU_PROBLEM_2 or SUDOKU_PROBLEM_3)\nIf you change the problem, ensure to re-run all cells below this one.",
"_____no_output_____"
]
],
[
[
"problem = SUDOKU_PROBLEM_3",
"_____no_output_____"
]
],
[
[
"### Step 3: Set up the prescriptive model",
"_____no_output_____"
]
],
[
[
"mdl = CpoModel(name=\"Sudoku\")",
"_____no_output_____"
]
],
[
[
"#### Define the decision variables",
"_____no_output_____"
]
],
[
[
"grid = [[integer_var(min=1, max=9, name=\"C\" + str(l) + str(c)) for l in GRNG] for c in GRNG]",
"_____no_output_____"
]
],
[
[
"#### Express the business constraints",
"_____no_output_____"
],
[
"Add alldiff constraints for lines",
"_____no_output_____"
]
],
[
[
"for l in GRNG:\n mdl.add(all_diff([grid[l][c] for c in GRNG]))",
"_____no_output_____"
]
],
[
[
"Add alldiff constraints for columns",
"_____no_output_____"
]
],
[
[
"for c in GRNG:\n mdl.add(all_diff([grid[l][c] for l in GRNG]))",
"_____no_output_____"
]
],
[
[
"Add alldiff constraints for sub-squares",
"_____no_output_____"
]
],
[
[
"ssrng = range(0, 9, 3)\nfor sl in ssrng:\n for sc in ssrng:\n mdl.add(all_diff([grid[l][c] for l in range(sl, sl + 3) for c in range(sc, sc + 3)]))",
"_____no_output_____"
]
],
[
[
"Initialize known cells",
"_____no_output_____"
]
],
[
[
"for l in GRNG:\n for c in GRNG:\n v = problem[l][c]\n if v > 0:\n grid[l][c].set_domain((v, v))",
"_____no_output_____"
]
],
[
[
"#### Solve with Decision Optimization solve service",
"_____no_output_____"
]
],
[
[
"print(\"\\nSolving model....\")\nmsol = mdl.solve(TimeLimit=10)",
"_____no_output_____"
]
],
[
[
"### Step 4: Investigate the solution and then run an example analysis",
"_____no_output_____"
]
],
[
[
"display_grid(problem, \"Initial problem\")\nif msol:\n sol = [[msol[grid[l][c]] for c in GRNG] for l in GRNG]\n stdout.write(\"Solve time: \" + str(msol.get_solve_time()) + \"\\n\")\n display_grid(sol, \"Solution\")\nelse:\n stdout.write(\"No solution found\\n\")",
"_____no_output_____"
]
],
[
[
"## Summary\n\nYou learned how to set up and use the IBM Decision Optimization CPLEX Modeling for Python to formulate and solve a Constraint Programming model.",
"_____no_output_____"
],
[
"#### References\n* [CPLEX Modeling for Python documentation](https://rawgit.com/IBMDecisionOptimization/docplex-doc/master/docs/index.html)\n* [Decision Optimization on Cloud](https://developer.ibm.com/docloud/)\n* Need help with DOcplex or to report a bug? Please go [here](https://developer.ibm.com/answers/smartspace/docloud)\n* Contact us at [email protected]",
"_____no_output_____"
],
[
"Copyright © 2017, 2018 IBM. IPLA licensed Sample Materials.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
]
] |
4aa14dc81b917ffc2b15331b3420ab394a5558c6
| 76,603 |
ipynb
|
Jupyter Notebook
|
notebooks/Assignment3Part2.ipynb
|
j-Myles/2300-LEED-Project
|
c8a99c811c4c6e5f2b1b565e5b0d3e9721b70dd1
|
[
"MIT"
] | null | null | null |
notebooks/Assignment3Part2.ipynb
|
j-Myles/2300-LEED-Project
|
c8a99c811c4c6e5f2b1b565e5b0d3e9721b70dd1
|
[
"MIT"
] | null | null | null |
notebooks/Assignment3Part2.ipynb
|
j-Myles/2300-LEED-Project
|
c8a99c811c4c6e5f2b1b565e5b0d3e9721b70dd1
|
[
"MIT"
] | 1 |
2018-10-24T11:16:54.000Z
|
2018-10-24T11:16:54.000Z
| 95.040943 | 36,072 | 0.769043 |
[
[
[
"Assignment 3 Part 2",
"_____no_output_____"
]
],
[
[
"import data.prepare as prep\nimport data.process as proc\nimport data.clean as cl\nimport data.plot as pl\nimport matplotlib.pyplot as plt\n%matplotlib inline\n",
"_____no_output_____"
],
[
"dpath = 'raw/boston_projects.xlsx'\ndata_dir = 'C:\\\\Users\\\\Annie Waye\\\\Desktop\\\\NEU Sept 5\\\\EECE 2300\\\\code\\\\leed_building_analysis\\\\data\\\\'\nfilepath = data_dir + dpath",
"_____no_output_____"
]
],
[
[
"\n### Get Data\n",
"_____no_output_____"
]
],
[
[
"raw_data = prep.fetch_data(filepath)\nraw_data.head(10)",
"_____no_output_____"
]
],
[
[
"### Arrange Data in Columns\n",
"_____no_output_____"
]
],
[
[
"pre_data = prep.pre_arrange_cols(raw_data)\nvalid_frames = prep.get_valid_frames(pre_data)\nreal_data = prep.arrange_cols(pre_data, valid_frames)\nreal_data.head(10)",
"_____no_output_____"
]
],
[
[
"\n### Clean/Format Data\n",
"_____no_output_____"
]
],
[
[
"real_data = cl.remove_duplicates(real_data)\nreal_data = cl.convert_dates(real_data)\nreal_data.head()",
"_____no_output_____"
]
],
[
[
"### Start Analyzing Data\n\n",
"_____no_output_____"
]
],
[
[
"proc_data = proc.fit_encode(real_data)\nproc_date_data = proc.analyze_by_date(proc_data)\nproc_date_data.head(10)",
"_____no_output_____"
],
[
"proc_date_data.describe()",
"_____no_output_____"
]
],
[
[
"### Start Plotting Data\n",
"_____no_output_____"
]
],
[
[
"axes = proc_date_data.columns\nfig=plt.figure(figsize=(20, 5), dpi= 80, facecolor='w', edgecolor='k')\nfor i, axis in enumerate(axes):\n plt.subplot(1, len(axes), i + 1)\n pl.primary_plot(proc_date_data, axis, title=axis + ' across dates', rotation_angle=45)\nplt.show()",
"_____no_output_____"
],
[
"pl.primary_plot(proc_date_data, axes, rotation_angle=45)\nplt.show()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
]
] |
4aa178c6c50d4c8d1546db9921b06e13a62dd201
| 14,870 |
ipynb
|
Jupyter Notebook
|
Ising_model_lee.ipynb
|
LDongWoo/thermalphysics
|
2b61fbecb950d7a25d0a9ddf6e2e2fd298a23887
|
[
"MIT"
] | null | null | null |
Ising_model_lee.ipynb
|
LDongWoo/thermalphysics
|
2b61fbecb950d7a25d0a9ddf6e2e2fd298a23887
|
[
"MIT"
] | null | null | null |
Ising_model_lee.ipynb
|
LDongWoo/thermalphysics
|
2b61fbecb950d7a25d0a9ddf6e2e2fd298a23887
|
[
"MIT"
] | null | null | null | 73.251232 | 5,730 | 0.757969 |
[
[
[
"<a href=\"https://colab.research.google.com/github/LDongWoo/thermalphysics/blob/main/Ising_model_lee.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport random \nimport matplotlib.pyplot as plt",
"_____no_output_____"
],
[
"N = 50\n\n#초기상태 격자 생성\nspin = np.random.random((N,N))\n\n#스핀을 무작위로 배치\n# spin[spin > 0.5] = 1\n# spin[spin <= 0.5] = -1\n\n#spin을 모두 -1로 정렬, T = 0K 인 바닥상태\nspin[spin > 0] = -1\n\nE0 = 0\n\nfor i in range (N):\n for j in range (N):\n a = i\n b = j\n r = spin[a, b]\n e = spin[(a+1)%N,b] + spin[a,(b+1)%N] + spin[(a-1)%N,b] + spin[a,(b-1)%N]\n s = -(r*e)\n E0 += s\n\nprint(\"initial energy =\",E0)\n\nplt.imshow(spin)\nprint(spin.sum()) ",
"initial energy = -10000.0\n-2500.0\n"
],
[
"spin = np.random.random((N,N))\nspin[spin > 0] = -1\n\n# beta = (볼츠만 상수 * 온도)\nbeta = (4)*10**(-1)\n\nT = 10*6\n\nE0 = 0\n\n#몬테카를로 \nfor p in range (T):\n for i in range (N):\n for j in range (N):\n a = np.random.randint(0, N) #임의의 원자 지정\n b = np.random.randint(0, N)\n r = spin[a, b] \n e = spin[(a+1)%N,b] + spin[a,(b+1)%N] + spin[(a-1)%N,b] + spin[a,(b-1)%N] #인접 원자들의 상태합\n E = -(r*e) #임의의 원자와 그 인점 원자들로 구성된 계의 energy\n dE = -2*E #energy 변화량\n\n if dE <= 0: #계의 energy가 감소했다면 spin을 반전시킨다\n spin[a, b] *= -1 \n \n elif random.random() < np.exp(-dE*beta): #계의 energy가 증가했다면, 볼츠만 인자를 따르는 확률로 spin 반전을 결정한다\n spin[a, b] *= -1\n\n# energy 산출 \nE1 = 0\n\nfor i in range (N):\n for j in range (N):\n a = i\n b = j\n r = spin[a, b]\n e = spin[(a+1)%N,b] + spin[a,(b+1)%N] + spin[(a-1)%N,b] + spin[a,(b-1)%N]\n s = -(r*e)\n E1 += s\n\n# print(n)\nprint(\"final energy =\",E1)\nprint(\"beta =\", beta)\n\nplt.imshow(spin)\nprint(spin.sum()) \n ",
"final energy = -5680.0\nbeta = 0.4\n-1006.0\n"
],
[
"",
"_____no_output_____"
]
]
] |
[
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4aa17b3249776c9e49c78e07f4058d6ce6c0418d
| 784,198 |
ipynb
|
Jupyter Notebook
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2021-07-16.ipynb
|
pvieito/Radar-STATS
|
9ff991a4db776259bc749a823ee6f0b0c0d38108
|
[
"Apache-2.0"
] | 9 |
2020-10-14T16:58:32.000Z
|
2021-10-05T12:01:56.000Z
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2021-07-16.ipynb
|
pvieito/Radar-STATS
|
9ff991a4db776259bc749a823ee6f0b0c0d38108
|
[
"Apache-2.0"
] | 3 |
2020-10-08T04:48:35.000Z
|
2020-10-10T20:46:58.000Z
|
Notebooks/RadarCOVID-Report/Daily/RadarCOVID-Report-2021-07-16.ipynb
|
Radar-STATS/Radar-STATS
|
61d8b3529f6bbf4576d799e340feec5b183338a3
|
[
"Apache-2.0"
] | 3 |
2020-09-27T07:39:26.000Z
|
2020-10-02T07:48:56.000Z
| 88.670059 | 140,188 | 0.739451 |
[
[
[
"# RadarCOVID-Report",
"_____no_output_____"
],
[
"## Data Extraction",
"_____no_output_____"
]
],
[
[
"import datetime\nimport json\nimport logging\nimport os\nimport shutil\nimport tempfile\nimport textwrap\nimport uuid\n\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker\nimport numpy as np\nimport pandas as pd\nimport pycountry\nimport retry\nimport seaborn as sns\n\n%matplotlib inline",
"_____no_output_____"
],
[
"current_working_directory = os.environ.get(\"PWD\")\nif current_working_directory:\n os.chdir(current_working_directory)\n\nsns.set()\nmatplotlib.rcParams[\"figure.figsize\"] = (15, 6)\n\nextraction_datetime = datetime.datetime.utcnow()\nextraction_date = extraction_datetime.strftime(\"%Y-%m-%d\")\nextraction_previous_datetime = extraction_datetime - datetime.timedelta(days=1)\nextraction_previous_date = extraction_previous_datetime.strftime(\"%Y-%m-%d\")\nextraction_date_with_hour = datetime.datetime.utcnow().strftime(\"%Y-%m-%d@%H\")\ncurrent_hour = datetime.datetime.utcnow().hour\nare_today_results_partial = current_hour != 23",
"_____no_output_____"
]
],
[
[
"### Constants",
"_____no_output_____"
]
],
[
[
"from Modules.ExposureNotification import exposure_notification_io\n\nspain_region_country_code = \"ES\"\ngermany_region_country_code = \"DE\"\n\ndefault_backend_identifier = spain_region_country_code\n\nbackend_generation_days = 7 * 2\ndaily_summary_days = 7 * 4 * 3\ndaily_plot_days = 7 * 4\ntek_dumps_load_limit = daily_summary_days + 1",
"_____no_output_____"
]
],
[
[
"### Parameters",
"_____no_output_____"
]
],
[
[
"environment_backend_identifier = os.environ.get(\"RADARCOVID_REPORT__BACKEND_IDENTIFIER\")\nif environment_backend_identifier:\n report_backend_identifier = environment_backend_identifier\nelse:\n report_backend_identifier = default_backend_identifier\nreport_backend_identifier",
"_____no_output_____"
],
[
"environment_enable_multi_backend_download = \\\n os.environ.get(\"RADARCOVID_REPORT__ENABLE_MULTI_BACKEND_DOWNLOAD\")\nif environment_enable_multi_backend_download:\n report_backend_identifiers = None\nelse:\n report_backend_identifiers = [report_backend_identifier]\n\nreport_backend_identifiers",
"_____no_output_____"
],
[
"environment_invalid_shared_diagnoses_dates = \\\n os.environ.get(\"RADARCOVID_REPORT__INVALID_SHARED_DIAGNOSES_DATES\")\nif environment_invalid_shared_diagnoses_dates:\n invalid_shared_diagnoses_dates = environment_invalid_shared_diagnoses_dates.split(\",\")\nelse:\n invalid_shared_diagnoses_dates = []\n\ninvalid_shared_diagnoses_dates",
"_____no_output_____"
]
],
[
[
"### COVID-19 Cases",
"_____no_output_____"
]
],
[
[
"report_backend_client = \\\n exposure_notification_io.get_backend_client_with_identifier(\n backend_identifier=report_backend_identifier)",
"_____no_output_____"
],
[
"@retry.retry(tries=10, delay=10, backoff=1.1, jitter=(0, 10))\ndef download_cases_dataframe():\n return pd.read_csv(\"https://raw.githubusercontent.com/owid/covid-19-data/master/public/data/owid-covid-data.csv\")\n\nconfirmed_df_ = download_cases_dataframe()\nconfirmed_df_.iloc[0]",
"_____no_output_____"
],
[
"confirmed_df = confirmed_df_.copy()\nconfirmed_df = confirmed_df[[\"date\", \"new_cases\", \"iso_code\"]]\nconfirmed_df.rename(\n columns={\n \"date\": \"sample_date\",\n \"iso_code\": \"country_code\",\n },\n inplace=True)\n\ndef convert_iso_alpha_3_to_alpha_2(x):\n try:\n return pycountry.countries.get(alpha_3=x).alpha_2\n except Exception as e:\n logging.info(f\"Error converting country ISO Alpha 3 code '{x}': {repr(e)}\")\n return None\n\nconfirmed_df[\"country_code\"] = confirmed_df.country_code.apply(convert_iso_alpha_3_to_alpha_2)\nconfirmed_df.dropna(inplace=True)\nconfirmed_df[\"sample_date\"] = pd.to_datetime(confirmed_df.sample_date, dayfirst=True)\nconfirmed_df[\"sample_date\"] = confirmed_df.sample_date.dt.strftime(\"%Y-%m-%d\")\nconfirmed_df.sort_values(\"sample_date\", inplace=True)\nconfirmed_df.tail()",
"_____no_output_____"
],
[
"confirmed_days = pd.date_range(\n start=confirmed_df.iloc[0].sample_date,\n end=extraction_datetime)\nconfirmed_days_df = pd.DataFrame(data=confirmed_days, columns=[\"sample_date\"])\nconfirmed_days_df[\"sample_date_string\"] = \\\n confirmed_days_df.sample_date.dt.strftime(\"%Y-%m-%d\")\nconfirmed_days_df.tail()",
"_____no_output_____"
],
[
"def sort_source_regions_for_display(source_regions: list) -> list:\n if report_backend_identifier in source_regions:\n source_regions = [report_backend_identifier] + \\\n list(sorted(set(source_regions).difference([report_backend_identifier])))\n else:\n source_regions = list(sorted(source_regions))\n return source_regions",
"_____no_output_____"
],
[
"report_source_regions = report_backend_client.source_regions_for_date(\n date=extraction_datetime.date())\nreport_source_regions = sort_source_regions_for_display(\n source_regions=report_source_regions)\nreport_source_regions",
"_____no_output_____"
],
[
"def get_cases_dataframe(source_regions_for_date_function, columns_suffix=None):\n source_regions_at_date_df = confirmed_days_df.copy()\n source_regions_at_date_df[\"source_regions_at_date\"] = \\\n source_regions_at_date_df.sample_date.apply(\n lambda x: source_regions_for_date_function(date=x))\n source_regions_at_date_df.sort_values(\"sample_date\", inplace=True)\n source_regions_at_date_df[\"_source_regions_group\"] = source_regions_at_date_df. \\\n source_regions_at_date.apply(lambda x: \",\".join(sort_source_regions_for_display(x)))\n source_regions_at_date_df.tail()\n\n #%%\n\n source_regions_for_summary_df_ = \\\n source_regions_at_date_df[[\"sample_date\", \"_source_regions_group\"]].copy()\n source_regions_for_summary_df_.rename(columns={\"_source_regions_group\": \"source_regions\"}, inplace=True)\n source_regions_for_summary_df_.tail()\n\n #%%\n\n confirmed_output_columns = [\"sample_date\", \"new_cases\", \"covid_cases\"]\n confirmed_output_df = pd.DataFrame(columns=confirmed_output_columns)\n\n for source_regions_group, source_regions_group_series in \\\n source_regions_at_date_df.groupby(\"_source_regions_group\"):\n source_regions_set = set(source_regions_group.split(\",\"))\n confirmed_source_regions_set_df = \\\n confirmed_df[confirmed_df.country_code.isin(source_regions_set)].copy()\n confirmed_source_regions_group_df = \\\n confirmed_source_regions_set_df.groupby(\"sample_date\").new_cases.sum() \\\n .reset_index().sort_values(\"sample_date\")\n confirmed_source_regions_group_df = \\\n confirmed_source_regions_group_df.merge(\n confirmed_days_df[[\"sample_date_string\"]].rename(\n columns={\"sample_date_string\": \"sample_date\"}),\n how=\"right\")\n confirmed_source_regions_group_df[\"new_cases\"] = \\\n confirmed_source_regions_group_df[\"new_cases\"].clip(lower=0)\n confirmed_source_regions_group_df[\"covid_cases\"] = \\\n confirmed_source_regions_group_df.new_cases.rolling(7, min_periods=0).mean().round()\n confirmed_source_regions_group_df = \\\n confirmed_source_regions_group_df[confirmed_output_columns]\n confirmed_source_regions_group_df = confirmed_source_regions_group_df.replace(0, np.nan)\n confirmed_source_regions_group_df.fillna(method=\"ffill\", inplace=True)\n confirmed_source_regions_group_df = \\\n confirmed_source_regions_group_df[\n confirmed_source_regions_group_df.sample_date.isin(\n source_regions_group_series.sample_date_string)]\n confirmed_output_df = confirmed_output_df.append(confirmed_source_regions_group_df)\n\n result_df = confirmed_output_df.copy()\n result_df.tail()\n\n #%%\n\n result_df.rename(columns={\"sample_date\": \"sample_date_string\"}, inplace=True)\n result_df = confirmed_days_df[[\"sample_date_string\"]].merge(result_df, how=\"left\")\n result_df.sort_values(\"sample_date_string\", inplace=True)\n result_df.fillna(method=\"ffill\", inplace=True)\n result_df.tail()\n\n #%%\n\n result_df[[\"new_cases\", \"covid_cases\"]].plot()\n\n if columns_suffix:\n result_df.rename(\n columns={\n \"new_cases\": \"new_cases_\" + columns_suffix,\n \"covid_cases\": \"covid_cases_\" + columns_suffix},\n inplace=True)\n return result_df, source_regions_for_summary_df_",
"_____no_output_____"
],
[
"confirmed_eu_df, source_regions_for_summary_df = get_cases_dataframe(\n report_backend_client.source_regions_for_date)\nconfirmed_es_df, _ = get_cases_dataframe(\n lambda date: [spain_region_country_code],\n columns_suffix=spain_region_country_code.lower())",
"_____no_output_____"
]
],
[
[
"### Extract API TEKs",
"_____no_output_____"
]
],
[
[
"raw_zip_path_prefix = \"Data/TEKs/Raw/\"\nbase_backend_identifiers = [report_backend_identifier]\nmulti_backend_exposure_keys_df = \\\n exposure_notification_io.download_exposure_keys_from_backends(\n backend_identifiers=report_backend_identifiers,\n generation_days=backend_generation_days,\n fail_on_error_backend_identifiers=base_backend_identifiers,\n save_raw_zip_path_prefix=raw_zip_path_prefix)\nmulti_backend_exposure_keys_df[\"region\"] = multi_backend_exposure_keys_df[\"backend_identifier\"]\nmulti_backend_exposure_keys_df.rename(\n columns={\n \"generation_datetime\": \"sample_datetime\",\n \"generation_date_string\": \"sample_date_string\",\n },\n inplace=True)\nmulti_backend_exposure_keys_df.head()",
"WARNING:root:NoKeysFoundException(\"No exposure keys found on endpoint 'https://radarcovid.covid19.gob.es/dp3t/v2/gaen/exposed/?originCountries=PT' (parameters: {'origin_country': 'PT', 'endpoint_identifier_components': ['PT'], 'backend_identifier': 'PT@ES', 'server_endpoint_url': 'https://radarcovid.covid19.gob.es/dp3t'}).\")\n"
],
[
"early_teks_df = multi_backend_exposure_keys_df[\n multi_backend_exposure_keys_df.rolling_period < 144].copy()\nearly_teks_df[\"rolling_period_in_hours\"] = early_teks_df.rolling_period / 6\nearly_teks_df[early_teks_df.sample_date_string != extraction_date] \\\n .rolling_period_in_hours.hist(bins=list(range(24)))",
"_____no_output_____"
],
[
"early_teks_df[early_teks_df.sample_date_string == extraction_date] \\\n .rolling_period_in_hours.hist(bins=list(range(24)))",
"_____no_output_____"
],
[
"multi_backend_exposure_keys_df = multi_backend_exposure_keys_df[[\n \"sample_date_string\", \"region\", \"key_data\"]]\nmulti_backend_exposure_keys_df.head()",
"_____no_output_____"
],
[
"active_regions = \\\n multi_backend_exposure_keys_df.groupby(\"region\").key_data.nunique().sort_values().index.unique().tolist()\nactive_regions",
"_____no_output_____"
],
[
"multi_backend_summary_df = multi_backend_exposure_keys_df.groupby(\n [\"sample_date_string\", \"region\"]).key_data.nunique().reset_index() \\\n .pivot(index=\"sample_date_string\", columns=\"region\") \\\n .sort_index(ascending=False)\nmulti_backend_summary_df.rename(\n columns={\"key_data\": \"shared_teks_by_generation_date\"},\n inplace=True)\nmulti_backend_summary_df.rename_axis(\"sample_date\", inplace=True)\nmulti_backend_summary_df = multi_backend_summary_df.fillna(0).astype(int)\nmulti_backend_summary_df = multi_backend_summary_df.head(backend_generation_days)\nmulti_backend_summary_df.head()",
"_____no_output_____"
],
[
"def compute_keys_cross_sharing(x):\n teks_x = x.key_data_x.item()\n common_teks = set(teks_x).intersection(x.key_data_y.item())\n common_teks_fraction = len(common_teks) / len(teks_x)\n return pd.Series(dict(\n common_teks=common_teks,\n common_teks_fraction=common_teks_fraction,\n ))\n\nmulti_backend_exposure_keys_by_region_df = \\\n multi_backend_exposure_keys_df.groupby(\"region\").key_data.unique().reset_index()\nmulti_backend_exposure_keys_by_region_df[\"_merge\"] = True\nmulti_backend_exposure_keys_by_region_combination_df = \\\n multi_backend_exposure_keys_by_region_df.merge(\n multi_backend_exposure_keys_by_region_df, on=\"_merge\")\nmulti_backend_exposure_keys_by_region_combination_df.drop(\n columns=[\"_merge\"], inplace=True)\nif multi_backend_exposure_keys_by_region_combination_df.region_x.nunique() > 1:\n multi_backend_exposure_keys_by_region_combination_df = \\\n multi_backend_exposure_keys_by_region_combination_df[\n multi_backend_exposure_keys_by_region_combination_df.region_x !=\n multi_backend_exposure_keys_by_region_combination_df.region_y]\nmulti_backend_exposure_keys_cross_sharing_df = \\\n multi_backend_exposure_keys_by_region_combination_df \\\n .groupby([\"region_x\", \"region_y\"]) \\\n .apply(compute_keys_cross_sharing) \\\n .reset_index()\nmulti_backend_cross_sharing_summary_df = \\\n multi_backend_exposure_keys_cross_sharing_df.pivot_table(\n values=[\"common_teks_fraction\"],\n columns=\"region_x\",\n index=\"region_y\",\n aggfunc=lambda x: x.item())\nmulti_backend_cross_sharing_summary_df",
"/tmp/ipykernel_1597/4280397781.py:2: FutureWarning: `item` has been deprecated and will be removed in a future version\n teks_x = x.key_data_x.item()\n/tmp/ipykernel_1597/4280397781.py:3: FutureWarning: `item` has been deprecated and will be removed in a future version\n common_teks = set(teks_x).intersection(x.key_data_y.item())\n"
],
[
"multi_backend_without_active_region_exposure_keys_df = \\\n multi_backend_exposure_keys_df[multi_backend_exposure_keys_df.region != report_backend_identifier]\nmulti_backend_without_active_region = \\\n multi_backend_without_active_region_exposure_keys_df.groupby(\"region\").key_data.nunique().sort_values().index.unique().tolist()\nmulti_backend_without_active_region",
"_____no_output_____"
],
[
"exposure_keys_summary_df = multi_backend_exposure_keys_df[\n multi_backend_exposure_keys_df.region == report_backend_identifier]\nexposure_keys_summary_df.drop(columns=[\"region\"], inplace=True)\nexposure_keys_summary_df = \\\n exposure_keys_summary_df.groupby([\"sample_date_string\"]).key_data.nunique().to_frame()\nexposure_keys_summary_df = \\\n exposure_keys_summary_df.reset_index().set_index(\"sample_date_string\")\nexposure_keys_summary_df.sort_index(ascending=False, inplace=True)\nexposure_keys_summary_df.rename(columns={\"key_data\": \"shared_teks_by_generation_date\"}, inplace=True)\nexposure_keys_summary_df.head()",
"/opt/hostedtoolcache/Python/3.8.11/x64/lib/python3.8/site-packages/pandas/core/frame.py:4110: SettingWithCopyWarning: \nA value is trying to be set on a copy of a slice from a DataFrame\n\nSee the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy\n return super().drop(\n"
]
],
[
[
"### Dump API TEKs",
"_____no_output_____"
]
],
[
[
"tek_list_df = multi_backend_exposure_keys_df[\n [\"sample_date_string\", \"region\", \"key_data\"]].copy()\ntek_list_df[\"key_data\"] = tek_list_df[\"key_data\"].apply(str)\ntek_list_df.rename(columns={\n \"sample_date_string\": \"sample_date\",\n \"key_data\": \"tek_list\"}, inplace=True)\ntek_list_df = tek_list_df.groupby(\n [\"sample_date\", \"region\"]).tek_list.unique().reset_index()\ntek_list_df[\"extraction_date\"] = extraction_date\ntek_list_df[\"extraction_date_with_hour\"] = extraction_date_with_hour\n\ntek_list_path_prefix = \"Data/TEKs/\"\ntek_list_current_path = tek_list_path_prefix + f\"/Current/RadarCOVID-TEKs.json\"\ntek_list_daily_path = tek_list_path_prefix + f\"Daily/RadarCOVID-TEKs-{extraction_date}.json\"\ntek_list_hourly_path = tek_list_path_prefix + f\"Hourly/RadarCOVID-TEKs-{extraction_date_with_hour}.json\"\n\nfor path in [tek_list_current_path, tek_list_daily_path, tek_list_hourly_path]:\n os.makedirs(os.path.dirname(path), exist_ok=True)\n\ntek_list_base_df = tek_list_df[tek_list_df.region == report_backend_identifier]\ntek_list_base_df.drop(columns=[\"extraction_date\", \"extraction_date_with_hour\"]).to_json(\n tek_list_current_path,\n lines=True, orient=\"records\")\ntek_list_base_df.drop(columns=[\"extraction_date_with_hour\"]).to_json(\n tek_list_daily_path,\n lines=True, orient=\"records\")\ntek_list_base_df.to_json(\n tek_list_hourly_path,\n lines=True, orient=\"records\")\ntek_list_base_df.head()",
"_____no_output_____"
]
],
[
[
"### Load TEK Dumps",
"_____no_output_____"
]
],
[
[
"import glob\n\ndef load_extracted_teks(mode, region=None, limit=None) -> pd.DataFrame:\n extracted_teks_df = pd.DataFrame(columns=[\"region\"])\n file_paths = list(reversed(sorted(glob.glob(tek_list_path_prefix + mode + \"/RadarCOVID-TEKs-*.json\"))))\n if limit:\n file_paths = file_paths[:limit]\n for file_path in file_paths:\n logging.info(f\"Loading TEKs from '{file_path}'...\")\n iteration_extracted_teks_df = pd.read_json(file_path, lines=True)\n extracted_teks_df = extracted_teks_df.append(\n iteration_extracted_teks_df, sort=False)\n extracted_teks_df[\"region\"] = \\\n extracted_teks_df.region.fillna(spain_region_country_code).copy()\n if region:\n extracted_teks_df = \\\n extracted_teks_df[extracted_teks_df.region == region]\n return extracted_teks_df",
"_____no_output_____"
],
[
"daily_extracted_teks_df = load_extracted_teks(\n mode=\"Daily\",\n region=report_backend_identifier,\n limit=tek_dumps_load_limit)\ndaily_extracted_teks_df.head()",
"_____no_output_____"
],
[
"exposure_keys_summary_df_ = daily_extracted_teks_df \\\n .sort_values(\"extraction_date\", ascending=False) \\\n .groupby(\"sample_date\").tek_list.first() \\\n .to_frame()\nexposure_keys_summary_df_.index.name = \"sample_date_string\"\nexposure_keys_summary_df_[\"tek_list\"] = \\\n exposure_keys_summary_df_.tek_list.apply(len)\nexposure_keys_summary_df_ = exposure_keys_summary_df_ \\\n .rename(columns={\"tek_list\": \"shared_teks_by_generation_date\"}) \\\n .sort_index(ascending=False)\nexposure_keys_summary_df = exposure_keys_summary_df_\nexposure_keys_summary_df.head()",
"_____no_output_____"
]
],
[
[
"### Daily New TEKs",
"_____no_output_____"
]
],
[
[
"tek_list_df = daily_extracted_teks_df.groupby(\"extraction_date\").tek_list.apply(\n lambda x: set(sum(x, []))).reset_index()\ntek_list_df = tek_list_df.set_index(\"extraction_date\").sort_index(ascending=True)\ntek_list_df.head()",
"_____no_output_____"
],
[
"def compute_teks_by_generation_and_upload_date(date):\n day_new_teks_set_df = tek_list_df.copy().diff()\n try:\n day_new_teks_set = day_new_teks_set_df[\n day_new_teks_set_df.index == date].tek_list.item()\n except ValueError:\n day_new_teks_set = None\n if pd.isna(day_new_teks_set):\n day_new_teks_set = set()\n day_new_teks_df = daily_extracted_teks_df[\n daily_extracted_teks_df.extraction_date == date].copy()\n day_new_teks_df[\"shared_teks\"] = \\\n day_new_teks_df.tek_list.apply(lambda x: set(x).intersection(day_new_teks_set))\n day_new_teks_df[\"shared_teks\"] = \\\n day_new_teks_df.shared_teks.apply(len)\n day_new_teks_df[\"upload_date\"] = date\n day_new_teks_df.rename(columns={\"sample_date\": \"generation_date\"}, inplace=True)\n day_new_teks_df = day_new_teks_df[\n [\"upload_date\", \"generation_date\", \"shared_teks\"]]\n day_new_teks_df[\"generation_to_upload_days\"] = \\\n (pd.to_datetime(day_new_teks_df.upload_date) -\n pd.to_datetime(day_new_teks_df.generation_date)).dt.days\n day_new_teks_df = day_new_teks_df[day_new_teks_df.shared_teks > 0]\n return day_new_teks_df\n\nshared_teks_generation_to_upload_df = pd.DataFrame()\nfor upload_date in daily_extracted_teks_df.extraction_date.unique():\n shared_teks_generation_to_upload_df = \\\n shared_teks_generation_to_upload_df.append(\n compute_teks_by_generation_and_upload_date(date=upload_date))\nshared_teks_generation_to_upload_df \\\n .sort_values([\"upload_date\", \"generation_date\"], ascending=False, inplace=True)\nshared_teks_generation_to_upload_df.tail()",
"/tmp/ipykernel_1597/1873217990.py:4: FutureWarning: `item` has been deprecated and will be removed in a future version\n day_new_teks_set = day_new_teks_set_df[\n"
],
[
"today_new_teks_df = \\\n shared_teks_generation_to_upload_df[\n shared_teks_generation_to_upload_df.upload_date == extraction_date].copy()\ntoday_new_teks_df.tail()",
"_____no_output_____"
],
[
"if not today_new_teks_df.empty:\n today_new_teks_df.set_index(\"generation_to_upload_days\") \\\n .sort_index().shared_teks.plot.bar()",
"_____no_output_____"
],
[
"generation_to_upload_period_pivot_df = \\\n shared_teks_generation_to_upload_df[\n [\"upload_date\", \"generation_to_upload_days\", \"shared_teks\"]] \\\n .pivot(index=\"upload_date\", columns=\"generation_to_upload_days\") \\\n .sort_index(ascending=False).fillna(0).astype(int) \\\n .droplevel(level=0, axis=1)\ngeneration_to_upload_period_pivot_df.head()",
"_____no_output_____"
],
[
"new_tek_df = tek_list_df.diff().tek_list.apply(\n lambda x: len(x) if not pd.isna(x) else None).to_frame().reset_index()\nnew_tek_df.rename(columns={\n \"tek_list\": \"shared_teks_by_upload_date\",\n \"extraction_date\": \"sample_date_string\",}, inplace=True)\nnew_tek_df.tail()",
"_____no_output_____"
],
[
"shared_teks_uploaded_on_generation_date_df = shared_teks_generation_to_upload_df[\n shared_teks_generation_to_upload_df.generation_to_upload_days == 0] \\\n [[\"upload_date\", \"shared_teks\"]].rename(\n columns={\n \"upload_date\": \"sample_date_string\",\n \"shared_teks\": \"shared_teks_uploaded_on_generation_date\",\n })\nshared_teks_uploaded_on_generation_date_df.head()",
"_____no_output_____"
],
[
"estimated_shared_diagnoses_df = shared_teks_generation_to_upload_df \\\n .groupby([\"upload_date\"]).shared_teks.max().reset_index() \\\n .sort_values([\"upload_date\"], ascending=False) \\\n .rename(columns={\n \"upload_date\": \"sample_date_string\",\n \"shared_teks\": \"shared_diagnoses\",\n })\ninvalid_shared_diagnoses_dates_mask = \\\n estimated_shared_diagnoses_df.sample_date_string.isin(invalid_shared_diagnoses_dates)\nestimated_shared_diagnoses_df[invalid_shared_diagnoses_dates_mask] = 0\nestimated_shared_diagnoses_df.head()",
"_____no_output_____"
]
],
[
[
"### Hourly New TEKs",
"_____no_output_____"
]
],
[
[
"hourly_extracted_teks_df = load_extracted_teks(\n mode=\"Hourly\", region=report_backend_identifier, limit=25)\nhourly_extracted_teks_df.head()",
"_____no_output_____"
],
[
"hourly_new_tek_count_df = hourly_extracted_teks_df \\\n .groupby(\"extraction_date_with_hour\").tek_list. \\\n apply(lambda x: set(sum(x, []))).reset_index().copy()\nhourly_new_tek_count_df = hourly_new_tek_count_df.set_index(\"extraction_date_with_hour\") \\\n .sort_index(ascending=True)\n\nhourly_new_tek_count_df[\"new_tek_list\"] = hourly_new_tek_count_df.tek_list.diff()\nhourly_new_tek_count_df[\"new_tek_count\"] = hourly_new_tek_count_df.new_tek_list.apply(\n lambda x: len(x) if not pd.isna(x) else 0)\nhourly_new_tek_count_df.rename(columns={\n \"new_tek_count\": \"shared_teks_by_upload_date\"}, inplace=True)\nhourly_new_tek_count_df = hourly_new_tek_count_df.reset_index()[[\n \"extraction_date_with_hour\", \"shared_teks_by_upload_date\"]]\nhourly_new_tek_count_df.head()",
"_____no_output_____"
],
[
"hourly_summary_df = hourly_new_tek_count_df.copy()\nhourly_summary_df.set_index(\"extraction_date_with_hour\", inplace=True)\nhourly_summary_df = hourly_summary_df.fillna(0).astype(int).reset_index()\nhourly_summary_df[\"datetime_utc\"] = pd.to_datetime(\n hourly_summary_df.extraction_date_with_hour, format=\"%Y-%m-%d@%H\")\nhourly_summary_df.set_index(\"datetime_utc\", inplace=True)\nhourly_summary_df = hourly_summary_df.tail(-1)\nhourly_summary_df.head()",
"_____no_output_____"
]
],
[
[
"### Official Statistics",
"_____no_output_____"
]
],
[
[
"import requests\nimport pandas.io.json\n\nofficial_stats_response = requests.get(\"https://radarcovid.covid19.gob.es/kpi/statistics/basics\")\nofficial_stats_response.raise_for_status()\nofficial_stats_df_ = pandas.io.json.json_normalize(official_stats_response.json())",
"_____no_output_____"
],
[
"official_stats_df = official_stats_df_.copy()\nofficial_stats_df[\"date\"] = pd.to_datetime(official_stats_df[\"date\"], dayfirst=True)\nofficial_stats_df.head()",
"_____no_output_____"
],
[
"official_stats_column_map = {\n \"date\": \"sample_date\",\n \"applicationsDownloads.totalAcummulated\": \"app_downloads_es_accumulated\",\n \"communicatedContagions.totalAcummulated\": \"shared_diagnoses_es_accumulated\",\n}\naccumulated_suffix = \"_accumulated\"\naccumulated_values_columns = \\\n list(filter(lambda x: x.endswith(accumulated_suffix), official_stats_column_map.values()))\ninterpolated_values_columns = \\\n list(map(lambda x: x[:-len(accumulated_suffix)], accumulated_values_columns))",
"_____no_output_____"
],
[
"official_stats_df = \\\n official_stats_df[official_stats_column_map.keys()] \\\n .rename(columns=official_stats_column_map)\nofficial_stats_df[\"extraction_date\"] = extraction_date\nofficial_stats_df.head()",
"_____no_output_____"
],
[
"official_stats_path = \"Data/Statistics/Current/RadarCOVID-Statistics.json\"\nprevious_official_stats_df = pd.read_json(official_stats_path, orient=\"records\", lines=True)\nprevious_official_stats_df[\"sample_date\"] = pd.to_datetime(previous_official_stats_df[\"sample_date\"], dayfirst=True)\nofficial_stats_df = official_stats_df.append(previous_official_stats_df)\nofficial_stats_df.head()",
"_____no_output_____"
],
[
"official_stats_df = official_stats_df[~(official_stats_df.shared_diagnoses_es_accumulated == 0)]\nofficial_stats_df.sort_values(\"extraction_date\", ascending=False, inplace=True)\nofficial_stats_df.drop_duplicates(subset=[\"sample_date\"], keep=\"first\", inplace=True)\nofficial_stats_df.head()",
"_____no_output_____"
],
[
"official_stats_stored_df = official_stats_df.copy()\nofficial_stats_stored_df[\"sample_date\"] = official_stats_stored_df.sample_date.dt.strftime(\"%Y-%m-%d\")\nofficial_stats_stored_df.to_json(official_stats_path, orient=\"records\", lines=True)",
"_____no_output_____"
],
[
"official_stats_df.drop(columns=[\"extraction_date\"], inplace=True)\nofficial_stats_df = confirmed_days_df.merge(official_stats_df, how=\"left\")\nofficial_stats_df.sort_values(\"sample_date\", ascending=False, inplace=True)\nofficial_stats_df.head()",
"_____no_output_____"
],
[
"official_stats_df[accumulated_values_columns] = \\\n official_stats_df[accumulated_values_columns] \\\n .astype(float).interpolate(limit_area=\"inside\")\nofficial_stats_df[interpolated_values_columns] = \\\n official_stats_df[accumulated_values_columns].diff(periods=-1)\nofficial_stats_df.drop(columns=\"sample_date\", inplace=True)\nofficial_stats_df.head()",
"_____no_output_____"
]
],
[
[
"### Data Merge",
"_____no_output_____"
]
],
[
[
"result_summary_df = exposure_keys_summary_df.merge(\n new_tek_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = result_summary_df.merge(\n shared_teks_uploaded_on_generation_date_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = result_summary_df.merge(\n estimated_shared_diagnoses_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = result_summary_df.merge(\n official_stats_df, on=[\"sample_date_string\"], how=\"outer\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = confirmed_eu_df.tail(daily_summary_days).merge(\n result_summary_df, on=[\"sample_date_string\"], how=\"left\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df = confirmed_es_df.tail(daily_summary_days).merge(\n result_summary_df, on=[\"sample_date_string\"], how=\"left\")\nresult_summary_df.head()",
"_____no_output_____"
],
[
"result_summary_df[\"sample_date\"] = pd.to_datetime(result_summary_df.sample_date_string)\nresult_summary_df = result_summary_df.merge(source_regions_for_summary_df, how=\"left\")\nresult_summary_df.set_index([\"sample_date\", \"source_regions\"], inplace=True)\nresult_summary_df.drop(columns=[\"sample_date_string\"], inplace=True)\nresult_summary_df.sort_index(ascending=False, inplace=True)\nresult_summary_df.head()",
"_____no_output_____"
],
[
"with pd.option_context(\"mode.use_inf_as_na\", True):\n result_summary_df = result_summary_df.fillna(0).astype(int)\n result_summary_df[\"teks_per_shared_diagnosis\"] = \\\n (result_summary_df.shared_teks_by_upload_date / result_summary_df.shared_diagnoses).fillna(0)\n result_summary_df[\"shared_diagnoses_per_covid_case\"] = \\\n (result_summary_df.shared_diagnoses / result_summary_df.covid_cases).fillna(0)\n result_summary_df[\"shared_diagnoses_per_covid_case_es\"] = \\\n (result_summary_df.shared_diagnoses_es / result_summary_df.covid_cases_es).fillna(0)\n\nresult_summary_df.head(daily_plot_days)",
"_____no_output_____"
],
[
"def compute_aggregated_results_summary(days) -> pd.DataFrame:\n aggregated_result_summary_df = result_summary_df.copy()\n aggregated_result_summary_df[\"covid_cases_for_ratio\"] = \\\n aggregated_result_summary_df.covid_cases.mask(\n aggregated_result_summary_df.shared_diagnoses == 0, 0)\n aggregated_result_summary_df[\"covid_cases_for_ratio_es\"] = \\\n aggregated_result_summary_df.covid_cases_es.mask(\n aggregated_result_summary_df.shared_diagnoses_es == 0, 0)\n aggregated_result_summary_df = aggregated_result_summary_df \\\n .sort_index(ascending=True).fillna(0).rolling(days).agg({\n \"covid_cases\": \"sum\",\n \"covid_cases_es\": \"sum\",\n \"covid_cases_for_ratio\": \"sum\",\n \"covid_cases_for_ratio_es\": \"sum\",\n \"shared_teks_by_generation_date\": \"sum\",\n \"shared_teks_by_upload_date\": \"sum\",\n \"shared_diagnoses\": \"sum\",\n \"shared_diagnoses_es\": \"sum\",\n }).sort_index(ascending=False)\n\n with pd.option_context(\"mode.use_inf_as_na\", True):\n aggregated_result_summary_df = aggregated_result_summary_df.fillna(0).astype(int)\n aggregated_result_summary_df[\"teks_per_shared_diagnosis\"] = \\\n (aggregated_result_summary_df.shared_teks_by_upload_date /\n aggregated_result_summary_df.covid_cases_for_ratio).fillna(0)\n aggregated_result_summary_df[\"shared_diagnoses_per_covid_case\"] = \\\n (aggregated_result_summary_df.shared_diagnoses /\n aggregated_result_summary_df.covid_cases_for_ratio).fillna(0)\n aggregated_result_summary_df[\"shared_diagnoses_per_covid_case_es\"] = \\\n (aggregated_result_summary_df.shared_diagnoses_es /\n aggregated_result_summary_df.covid_cases_for_ratio_es).fillna(0)\n\n return aggregated_result_summary_df",
"_____no_output_____"
],
[
"aggregated_result_with_7_days_window_summary_df = compute_aggregated_results_summary(days=7)\naggregated_result_with_7_days_window_summary_df.head()",
"_____no_output_____"
],
[
"last_7_days_summary = aggregated_result_with_7_days_window_summary_df.to_dict(orient=\"records\")[1]\nlast_7_days_summary",
"_____no_output_____"
],
[
"aggregated_result_with_14_days_window_summary_df = compute_aggregated_results_summary(days=13)\nlast_14_days_summary = aggregated_result_with_14_days_window_summary_df.to_dict(orient=\"records\")[1]\nlast_14_days_summary",
"_____no_output_____"
]
],
[
[
"## Report Results",
"_____no_output_____"
]
],
[
[
"display_column_name_mapping = {\n \"sample_date\": \"Sample\\u00A0Date\\u00A0(UTC)\",\n \"source_regions\": \"Source Countries\",\n \"datetime_utc\": \"Timestamp (UTC)\",\n \"upload_date\": \"Upload Date (UTC)\",\n \"generation_to_upload_days\": \"Generation to Upload Period in Days\",\n \"region\": \"Backend\",\n \"region_x\": \"Backend\\u00A0(A)\",\n \"region_y\": \"Backend\\u00A0(B)\",\n \"common_teks\": \"Common TEKs Shared Between Backends\",\n \"common_teks_fraction\": \"Fraction of TEKs in Backend (A) Available in Backend (B)\",\n \"covid_cases\": \"COVID-19 Cases (Source Countries)\",\n \"shared_teks_by_generation_date\": \"Shared TEKs by Generation Date (Source Countries)\",\n \"shared_teks_by_upload_date\": \"Shared TEKs by Upload Date (Source Countries)\",\n \"shared_teks_uploaded_on_generation_date\": \"Shared TEKs Uploaded on Generation Date (Source Countries)\",\n \"shared_diagnoses\": \"Shared Diagnoses (Source Countries – Estimation)\",\n \"teks_per_shared_diagnosis\": \"TEKs Uploaded per Shared Diagnosis (Source Countries)\",\n \"shared_diagnoses_per_covid_case\": \"Usage Ratio (Source Countries)\",\n\n \"covid_cases_es\": \"COVID-19 Cases (Spain)\",\n \"app_downloads_es\": \"App Downloads (Spain – Official)\",\n \"shared_diagnoses_es\": \"Shared Diagnoses (Spain – Official)\",\n \"shared_diagnoses_per_covid_case_es\": \"Usage Ratio (Spain)\",\n}",
"_____no_output_____"
],
[
"summary_columns = [\n \"covid_cases\",\n \"shared_teks_by_generation_date\",\n \"shared_teks_by_upload_date\",\n \"shared_teks_uploaded_on_generation_date\",\n \"shared_diagnoses\",\n \"teks_per_shared_diagnosis\",\n \"shared_diagnoses_per_covid_case\",\n\n \"covid_cases_es\",\n \"app_downloads_es\",\n \"shared_diagnoses_es\",\n \"shared_diagnoses_per_covid_case_es\",\n]\n\nsummary_percentage_columns= [\n \"shared_diagnoses_per_covid_case_es\",\n \"shared_diagnoses_per_covid_case\",\n]",
"_____no_output_____"
]
],
[
[
"### Daily Summary Table",
"_____no_output_____"
]
],
[
[
"result_summary_df_ = result_summary_df.copy()\nresult_summary_df = result_summary_df[summary_columns]\nresult_summary_with_display_names_df = result_summary_df \\\n .rename_axis(index=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping)\nresult_summary_with_display_names_df",
"_____no_output_____"
]
],
[
[
"### Daily Summary Plots",
"_____no_output_____"
]
],
[
[
"result_plot_summary_df = result_summary_df.head(daily_plot_days)[summary_columns] \\\n .droplevel(level=[\"source_regions\"]) \\\n .rename_axis(index=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping)\nsummary_ax_list = result_plot_summary_df.sort_index(ascending=True).plot.bar(\n title=f\"Daily Summary\",\n rot=45, subplots=True, figsize=(15, 30), legend=False)\nax_ = summary_ax_list[0]\nax_.get_figure().tight_layout()\nax_.get_figure().subplots_adjust(top=0.95)\n_ = ax_.set_xticklabels(sorted(result_plot_summary_df.index.strftime(\"%Y-%m-%d\").tolist()))\n\nfor percentage_column in summary_percentage_columns:\n percentage_column_index = summary_columns.index(percentage_column)\n summary_ax_list[percentage_column_index].yaxis \\\n .set_major_formatter(matplotlib.ticker.PercentFormatter(1.0))",
"/opt/hostedtoolcache/Python/3.8.11/x64/lib/python3.8/site-packages/pandas/plotting/_matplotlib/tools.py:307: MatplotlibDeprecationWarning: \nThe rowNum attribute was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use ax.get_subplotspec().rowspan.start instead.\n layout[ax.rowNum, ax.colNum] = ax.get_visible()\n/opt/hostedtoolcache/Python/3.8.11/x64/lib/python3.8/site-packages/pandas/plotting/_matplotlib/tools.py:307: MatplotlibDeprecationWarning: \nThe colNum attribute was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use ax.get_subplotspec().colspan.start instead.\n layout[ax.rowNum, ax.colNum] = ax.get_visible()\n/opt/hostedtoolcache/Python/3.8.11/x64/lib/python3.8/site-packages/pandas/plotting/_matplotlib/tools.py:313: MatplotlibDeprecationWarning: \nThe rowNum attribute was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use ax.get_subplotspec().rowspan.start instead.\n if not layout[ax.rowNum + 1, ax.colNum]:\n/opt/hostedtoolcache/Python/3.8.11/x64/lib/python3.8/site-packages/pandas/plotting/_matplotlib/tools.py:313: MatplotlibDeprecationWarning: \nThe colNum attribute was deprecated in Matplotlib 3.2 and will be removed two minor releases later. Use ax.get_subplotspec().colspan.start instead.\n if not layout[ax.rowNum + 1, ax.colNum]:\n"
]
],
[
[
"### Daily Generation to Upload Period Table",
"_____no_output_____"
]
],
[
[
"display_generation_to_upload_period_pivot_df = \\\n generation_to_upload_period_pivot_df \\\n .head(backend_generation_days)\ndisplay_generation_to_upload_period_pivot_df \\\n .head(backend_generation_days) \\\n .rename_axis(columns=display_column_name_mapping) \\\n .rename_axis(index=display_column_name_mapping)",
"_____no_output_____"
],
[
"fig, generation_to_upload_period_pivot_table_ax = plt.subplots(\n figsize=(12, 1 + 0.6 * len(display_generation_to_upload_period_pivot_df)))\ngeneration_to_upload_period_pivot_table_ax.set_title(\n \"Shared TEKs Generation to Upload Period Table\")\nsns.heatmap(\n data=display_generation_to_upload_period_pivot_df\n .rename_axis(columns=display_column_name_mapping)\n .rename_axis(index=display_column_name_mapping),\n fmt=\".0f\",\n annot=True,\n ax=generation_to_upload_period_pivot_table_ax)\ngeneration_to_upload_period_pivot_table_ax.get_figure().tight_layout()",
"_____no_output_____"
]
],
[
[
"### Hourly Summary Plots ",
"_____no_output_____"
]
],
[
[
"hourly_summary_ax_list = hourly_summary_df \\\n .rename_axis(index=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping) \\\n .plot.bar(\n title=f\"Last 24h Summary\",\n rot=45, subplots=True, legend=False)\nax_ = hourly_summary_ax_list[-1]\nax_.get_figure().tight_layout()\nax_.get_figure().subplots_adjust(top=0.9)\n_ = ax_.set_xticklabels(sorted(hourly_summary_df.index.strftime(\"%Y-%m-%d@%H\").tolist()))",
"_____no_output_____"
]
],
[
[
"### Publish Results",
"_____no_output_____"
]
],
[
[
"github_repository = os.environ.get(\"GITHUB_REPOSITORY\")\nif github_repository is None:\n github_repository = \"pvieito/Radar-STATS\"\n\ngithub_project_base_url = \"https://github.com/\" + github_repository\n\ndisplay_formatters = {\n display_column_name_mapping[\"teks_per_shared_diagnosis\"]: lambda x: f\"{x:.2f}\" if x != 0 else \"\",\n display_column_name_mapping[\"shared_diagnoses_per_covid_case\"]: lambda x: f\"{x:.2%}\" if x != 0 else \"\",\n display_column_name_mapping[\"shared_diagnoses_per_covid_case_es\"]: lambda x: f\"{x:.2%}\" if x != 0 else \"\",\n}\ngeneral_columns = \\\n list(filter(lambda x: x not in display_formatters, display_column_name_mapping.values()))\ngeneral_formatter = lambda x: f\"{x}\" if x != 0 else \"\"\ndisplay_formatters.update(dict(map(lambda x: (x, general_formatter), general_columns)))\n\ndaily_summary_table_html = result_summary_with_display_names_df \\\n .head(daily_plot_days) \\\n .rename_axis(index=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping) \\\n .to_html(formatters=display_formatters)\nmulti_backend_summary_table_html = multi_backend_summary_df \\\n .head(daily_plot_days) \\\n .rename_axis(columns=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping) \\\n .rename_axis(index=display_column_name_mapping) \\\n .to_html(formatters=display_formatters)\n\ndef format_multi_backend_cross_sharing_fraction(x):\n if pd.isna(x):\n return \"-\"\n elif round(x * 100, 1) == 0:\n return \"\"\n else:\n return f\"{x:.1%}\"\n\nmulti_backend_cross_sharing_summary_table_html = multi_backend_cross_sharing_summary_df \\\n .rename_axis(columns=display_column_name_mapping) \\\n .rename(columns=display_column_name_mapping) \\\n .rename_axis(index=display_column_name_mapping) \\\n .to_html(\n classes=\"table-center\",\n formatters=display_formatters,\n float_format=format_multi_backend_cross_sharing_fraction)\nmulti_backend_cross_sharing_summary_table_html = \\\n multi_backend_cross_sharing_summary_table_html \\\n .replace(\"<tr>\",\"<tr style=\\\"text-align: center;\\\">\")\n\nextraction_date_result_summary_df = \\\n result_summary_df[result_summary_df.index.get_level_values(\"sample_date\") == extraction_date]\nextraction_date_result_hourly_summary_df = \\\n hourly_summary_df[hourly_summary_df.extraction_date_with_hour == extraction_date_with_hour]\n\ncovid_cases = \\\n extraction_date_result_summary_df.covid_cases.item()\nshared_teks_by_generation_date = \\\n extraction_date_result_summary_df.shared_teks_by_generation_date.item()\nshared_teks_by_upload_date = \\\n extraction_date_result_summary_df.shared_teks_by_upload_date.item()\nshared_diagnoses = \\\n extraction_date_result_summary_df.shared_diagnoses.item()\nteks_per_shared_diagnosis = \\\n extraction_date_result_summary_df.teks_per_shared_diagnosis.item()\nshared_diagnoses_per_covid_case = \\\n extraction_date_result_summary_df.shared_diagnoses_per_covid_case.item()\n\nshared_teks_by_upload_date_last_hour = \\\n extraction_date_result_hourly_summary_df.shared_teks_by_upload_date.sum().astype(int)\n\ndisplay_source_regions = \", \".join(report_source_regions)\nif len(report_source_regions) == 1:\n display_brief_source_regions = report_source_regions[0]\nelse:\n display_brief_source_regions = f\"{len(report_source_regions)} 🇪🇺\"",
"/tmp/ipykernel_1597/1648546741.py:55: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.covid_cases.item()\n/tmp/ipykernel_1597/1648546741.py:57: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.shared_teks_by_generation_date.item()\n/tmp/ipykernel_1597/1648546741.py:59: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.shared_teks_by_upload_date.item()\n/tmp/ipykernel_1597/1648546741.py:61: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.shared_diagnoses.item()\n/tmp/ipykernel_1597/1648546741.py:63: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.teks_per_shared_diagnosis.item()\n/tmp/ipykernel_1597/1648546741.py:65: FutureWarning: `item` has been deprecated and will be removed in a future version\n extraction_date_result_summary_df.shared_diagnoses_per_covid_case.item()\n"
],
[
"def get_temporary_image_path() -> str:\n return os.path.join(tempfile.gettempdir(), str(uuid.uuid4()) + \".png\")\n\ndef save_temporary_plot_image(ax):\n if isinstance(ax, np.ndarray):\n ax = ax[0]\n media_path = get_temporary_image_path()\n ax.get_figure().savefig(media_path)\n return media_path\n\ndef save_temporary_dataframe_image(df):\n import dataframe_image as dfi\n df = df.copy()\n df_styler = df.style.format(display_formatters)\n media_path = get_temporary_image_path()\n dfi.export(df_styler, media_path)\n return media_path",
"_____no_output_____"
],
[
"summary_plots_image_path = save_temporary_plot_image(\n ax=summary_ax_list)\nsummary_table_image_path = save_temporary_dataframe_image(\n df=result_summary_with_display_names_df)\nhourly_summary_plots_image_path = save_temporary_plot_image(\n ax=hourly_summary_ax_list)\nmulti_backend_summary_table_image_path = save_temporary_dataframe_image(\n df=multi_backend_summary_df)\ngeneration_to_upload_period_pivot_table_image_path = save_temporary_plot_image(\n ax=generation_to_upload_period_pivot_table_ax)",
"[0716/230907.227028:WARNING:headless_browser_main_parts.cc(106)] Cannot create Pref Service with no user data dir.\n[0716/230907.278002:ERROR:gpu_init.cc(440)] Passthrough is not supported, GL is swiftshader\n"
]
],
[
[
"### Save Results",
"_____no_output_____"
]
],
[
[
"report_resources_path_prefix = \"Data/Resources/Current/RadarCOVID-Report-\"\nresult_summary_df.to_csv(\n report_resources_path_prefix + \"Summary-Table.csv\")\nresult_summary_df.to_html(\n report_resources_path_prefix + \"Summary-Table.html\")\nhourly_summary_df.to_csv(\n report_resources_path_prefix + \"Hourly-Summary-Table.csv\")\nmulti_backend_summary_df.to_csv(\n report_resources_path_prefix + \"Multi-Backend-Summary-Table.csv\")\nmulti_backend_cross_sharing_summary_df.to_csv(\n report_resources_path_prefix + \"Multi-Backend-Cross-Sharing-Summary-Table.csv\")\ngeneration_to_upload_period_pivot_df.to_csv(\n report_resources_path_prefix + \"Generation-Upload-Period-Table.csv\")\n_ = shutil.copyfile(\n summary_plots_image_path,\n report_resources_path_prefix + \"Summary-Plots.png\")\n_ = shutil.copyfile(\n summary_table_image_path,\n report_resources_path_prefix + \"Summary-Table.png\")\n_ = shutil.copyfile(\n hourly_summary_plots_image_path,\n report_resources_path_prefix + \"Hourly-Summary-Plots.png\")\n_ = shutil.copyfile(\n multi_backend_summary_table_image_path,\n report_resources_path_prefix + \"Multi-Backend-Summary-Table.png\")\n_ = shutil.copyfile(\n generation_to_upload_period_pivot_table_image_path,\n report_resources_path_prefix + \"Generation-Upload-Period-Table.png\")",
"_____no_output_____"
]
],
[
[
"### Publish Results as JSON",
"_____no_output_____"
]
],
[
[
"def generate_summary_api_results(df: pd.DataFrame) -> list:\n api_df = df.reset_index().copy()\n api_df[\"sample_date_string\"] = \\\n api_df[\"sample_date\"].dt.strftime(\"%Y-%m-%d\")\n api_df[\"source_regions\"] = \\\n api_df[\"source_regions\"].apply(lambda x: x.split(\",\"))\n return api_df.to_dict(orient=\"records\")\n\nsummary_api_results = \\\n generate_summary_api_results(df=result_summary_df)\ntoday_summary_api_results = \\\n generate_summary_api_results(df=extraction_date_result_summary_df)[0]\n\nsummary_results = dict(\n backend_identifier=report_backend_identifier,\n source_regions=report_source_regions,\n extraction_datetime=extraction_datetime,\n extraction_date=extraction_date,\n extraction_date_with_hour=extraction_date_with_hour,\n last_hour=dict(\n shared_teks_by_upload_date=shared_teks_by_upload_date_last_hour,\n shared_diagnoses=0,\n ),\n today=today_summary_api_results,\n last_7_days=last_7_days_summary,\n last_14_days=last_14_days_summary,\n daily_results=summary_api_results)\n\nsummary_results = \\\n json.loads(pd.Series([summary_results]).to_json(orient=\"records\"))[0]\n\nwith open(report_resources_path_prefix + \"Summary-Results.json\", \"w\") as f:\n json.dump(summary_results, f, indent=4)",
"_____no_output_____"
]
],
[
[
"### Publish on README",
"_____no_output_____"
]
],
[
[
"with open(\"Data/Templates/README.md\", \"r\") as f:\n readme_contents = f.read()\n\nreadme_contents = readme_contents.format(\n extraction_date_with_hour=extraction_date_with_hour,\n github_project_base_url=github_project_base_url,\n daily_summary_table_html=daily_summary_table_html,\n multi_backend_summary_table_html=multi_backend_summary_table_html,\n multi_backend_cross_sharing_summary_table_html=multi_backend_cross_sharing_summary_table_html,\n display_source_regions=display_source_regions)\n\nwith open(\"README.md\", \"w\") as f:\n f.write(readme_contents)",
"_____no_output_____"
]
],
[
[
"### Publish on Twitter",
"_____no_output_____"
]
],
[
[
"enable_share_to_twitter = os.environ.get(\"RADARCOVID_REPORT__ENABLE_PUBLISH_ON_TWITTER\")\ngithub_event_name = os.environ.get(\"GITHUB_EVENT_NAME\")\n\nif enable_share_to_twitter and github_event_name == \"schedule\" and \\\n (shared_teks_by_upload_date_last_hour or not are_today_results_partial):\n import tweepy\n\n twitter_api_auth_keys = os.environ[\"RADARCOVID_REPORT__TWITTER_API_AUTH_KEYS\"]\n twitter_api_auth_keys = twitter_api_auth_keys.split(\":\")\n auth = tweepy.OAuthHandler(twitter_api_auth_keys[0], twitter_api_auth_keys[1])\n auth.set_access_token(twitter_api_auth_keys[2], twitter_api_auth_keys[3])\n\n api = tweepy.API(auth)\n\n summary_plots_media = api.media_upload(summary_plots_image_path)\n summary_table_media = api.media_upload(summary_table_image_path)\n generation_to_upload_period_pivot_table_image_media = api.media_upload(generation_to_upload_period_pivot_table_image_path)\n media_ids = [\n summary_plots_media.media_id,\n summary_table_media.media_id,\n generation_to_upload_period_pivot_table_image_media.media_id,\n ]\n\n if are_today_results_partial:\n today_addendum = \" (Partial)\"\n else:\n today_addendum = \"\"\n\n def format_shared_diagnoses_per_covid_case(value) -> str:\n if value == 0:\n return \"–\"\n return f\"≤{value:.2%}\"\n\n display_shared_diagnoses_per_covid_case = \\\n format_shared_diagnoses_per_covid_case(value=shared_diagnoses_per_covid_case)\n display_last_14_days_shared_diagnoses_per_covid_case = \\\n format_shared_diagnoses_per_covid_case(value=last_14_days_summary[\"shared_diagnoses_per_covid_case\"])\n display_last_14_days_shared_diagnoses_per_covid_case_es = \\\n format_shared_diagnoses_per_covid_case(value=last_14_days_summary[\"shared_diagnoses_per_covid_case_es\"])\n\n status = textwrap.dedent(f\"\"\"\n #RadarCOVID – {extraction_date_with_hour}\n\n Today{today_addendum}:\n - Uploaded TEKs: {shared_teks_by_upload_date:.0f} ({shared_teks_by_upload_date_last_hour:+d} last hour)\n - Shared Diagnoses: ≤{shared_diagnoses:.0f}\n - Usage Ratio: {display_shared_diagnoses_per_covid_case}\n\n Last 14 Days:\n - Usage Ratio (Estimation): {display_last_14_days_shared_diagnoses_per_covid_case}\n - Usage Ratio (Official): {display_last_14_days_shared_diagnoses_per_covid_case_es}\n\n Info: {github_project_base_url}#documentation\n \"\"\")\n status = status.encode(encoding=\"utf-8\")\n api.update_status(status=status, media_ids=media_ids)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa17c138ccf155b706db5ad8402e116022f6ed5
| 5,350 |
ipynb
|
Jupyter Notebook
|
Algorithms/KaratsubaMultiplication.ipynb
|
aadhityasw/Data-Structures-Algorithms
|
acb3a6634f5c5e771a61fe30bbffed6ce5439ded
|
[
"MIT"
] | null | null | null |
Algorithms/KaratsubaMultiplication.ipynb
|
aadhityasw/Data-Structures-Algorithms
|
acb3a6634f5c5e771a61fe30bbffed6ce5439ded
|
[
"MIT"
] | null | null | null |
Algorithms/KaratsubaMultiplication.ipynb
|
aadhityasw/Data-Structures-Algorithms
|
acb3a6634f5c5e771a61fe30bbffed6ce5439ded
|
[
"MIT"
] | null | null | null | 27.864583 | 92 | 0.408224 |
[
[
[
"# Karatsuba Multiplication\nOrder is O(n^1.59) as opposed to O(n^2) asin the case of normal multiplication.<br>\nThis is a recursive technique performed with the divide and conquer technique.",
"_____no_output_____"
],
[
"## By retaining the numbers in the same base",
"_____no_output_____"
]
],
[
[
"def addition(m, n, r) :\n res = 0\n a = m\n b = n\n po = 0\n c = 0\n while(a>0 or b>0 or c==1) :\n if a==0 :\n s = b%10 + c\n elif b == 0 :\n s = a%10 + c\n else :\n s = a%10 + b%10 + c\n if s<r :\n c=0\n else :\n c=1\n s = s-r\n res = ((10**po)*s) + res\n po += 1\n a = a//10\n b = b//10\n return(res)\n\ndef subtraction(m, n, r) :\n res = 0\n a = m\n b = n\n po = 0\n c = 0\n while(a>0 or b>0 or c==1) :\n if a==0 :\n s = b%10 - c\n elif b == 0 :\n s = a%10 - c\n else :\n s = a%10 - b%10 - c\n if s>=0 :\n c=0\n else :\n c=1\n s = s+r\n res = ((10**po)*s) + res\n po += 1\n a = a//10\n b = b//10\n return(res)\n\ndef karatsuba_multiplication(m, n, r) :\n if len(str(m)) == 1 or len(str(n)) == 1:\n return m*n\n dig = max(len(str(m)), len(str(n))) // 2\n a = m//(10**dig)\n b = m%(10**dig)\n c = n//(10**dig)\n d = n%(10**dig)\n ac = karatsuba_multiplication(a,c,r)\n bd = karatsuba_multiplication(b,d,r)\n a_plus_b = addition(a,b,r)\n c_plus_d = addition(c,d,r)\n aplusd_cplusd = karatsuba_multiplication(a_plus_b,c_plus_d,r)\n sub1 = subtraction(aplusd_cplusd,ac,r)\n ad_plus_bc = subtraction(sub1, bd, r)\n t1 = addition(ac * (10**(2*dig)), (ad_plus_bc * 10**dig), r)\n res = addition(t1, bd, r)\n #print(res)\n return(res)\n\ndef convert_to_decimal(n, r) :\n a = 1\n b = n\n c = 0\n res = 0\n while(b>0) :\n c = b%10\n b = b//10\n res = res + (a*c)\n a = a*r\n return(res)\n\nr = int(input('Enter the base of the numbers entered :- '))\na = int(input('Enter the first number :- '))\nb = int(input('Enter the second number :- '))\nres = karatsuba_multiplication(a, b, r)\nprint('The product is :- ', res)\nif r!=10 :\n print('The product in decimal form is :- ', convert_to_decimal(res, r))",
"_____no_output_____"
]
],
[
[
"## By converting numbers of any base to decimal and then calculating the product",
"_____no_output_____"
]
],
[
[
"def karatsuba(x,y):\n if len(str(x)) == 1 or len(str(y)) == 1:\n return x*y\n else:\n n = max(len(str(x)),len(str(y)))\n dig = n // 2\n a = x // 10**(dig)\n b = x % 10**(dig)\n c = y // 10**(dig)\n d = y % 10**(dig)\n ac = karatsuba(a,c)\n bd = karatsuba(b,d)\n ad_plus_bc = karatsuba(a+b,c+d) - ac - bd\n prod = ac * 10**(2*dig) + (ad_plus_bc * 10**dig) + bd\n return prod\n\ndef convert_to_decimal(n, r) :\n a = 1\n b = n\n c = 0\n res = 0\n while(b>0) :\n c = b%10\n b = b//10\n res = res + (a*c)\n a = a*r\n return(res)\n\nr = int(input('Enter the base of the numbers entered :- '))\na = convert_to_decimal(int(input('Enter the first number :- ')), r)\nb = convert_to_decimal(int(input('Enter the second number :- ')), r)\nres = karatsuba(a, b)\nprint('The product is :- ', res)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa1903a910851250e831c87217aaeb31e70c1d6
| 6,149 |
ipynb
|
Jupyter Notebook
|
colabs/conversion_upload_from_biguery.ipynb
|
quan/starthinker
|
4e392415d77affd4a3d91165d1141ab38efd3b8b
|
[
"Apache-2.0"
] | null | null | null |
colabs/conversion_upload_from_biguery.ipynb
|
quan/starthinker
|
4e392415d77affd4a3d91165d1141ab38efd3b8b
|
[
"Apache-2.0"
] | null | null | null |
colabs/conversion_upload_from_biguery.ipynb
|
quan/starthinker
|
4e392415d77affd4a3d91165d1141ab38efd3b8b
|
[
"Apache-2.0"
] | null | null | null | 37.042169 | 271 | 0.537974 |
[
[
[
"#1. Install Dependencies\nFirst install the libraries needed to execute recipes, this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"!pip install git+https://github.com/google/starthinker\n",
"_____no_output_____"
]
],
[
[
"#2. Get Cloud Project ID\nTo run this recipe [requires a Google Cloud Project](https://github.com/google/starthinker/blob/master/tutorials/cloud_project.md), this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"CLOUD_PROJECT = 'PASTE PROJECT ID HERE'\n\nprint(\"Cloud Project Set To: %s\" % CLOUD_PROJECT)\n",
"_____no_output_____"
]
],
[
[
"#3. Get Client Credentials\nTo read and write to various endpoints requires [downloading client credentials](https://github.com/google/starthinker/blob/master/tutorials/cloud_client_installed.md), this only needs to be done once, then click play.\n",
"_____no_output_____"
]
],
[
[
"CLIENT_CREDENTIALS = 'PASTE CREDENTIALS HERE'\n\nprint(\"Client Credentials Set To: %s\" % CLIENT_CREDENTIALS)\n",
"_____no_output_____"
]
],
[
[
"#4. Enter Conversion Upload BigQuery Parameters\nMove from BigQuery to CM.\n 1. Specify a CM Account ID, Floodligh Activity ID and Conversion Type.\n 1. Include BigQuery dataset and table.\n 1. Columns: Ordinal, timestampMicros, encryptedUserId | encryptedUserIdCandidates | gclid | mobileDeviceId\n 1. Include encryption information if using encryptedUserId or encryptedUserIdCandidates.\nModify the values below for your use case, can be done multiple times, then click play.\n",
"_____no_output_____"
]
],
[
[
"FIELDS = {\n 'account': '',\n 'floodlight_activity_id': '',\n 'auth_read': 'user', # Credentials used for reading data.\n 'floodlight_conversion_type': 'encryptedUserId',\n 'encryption_entity_id': '',\n 'encryption_entity_type': 'DCM_ACCOUNT',\n 'encryption_entity_source': 'DATA_TRANSFER',\n 'bigquery_dataset': '',\n 'bigquery_table': '',\n 'bigquery_legacy': True,\n}\n\nprint(\"Parameters Set To: %s\" % FIELDS)\n",
"_____no_output_____"
]
],
[
[
"#5. Execute Conversion Upload BigQuery\nThis does NOT need to be modified unles you are changing the recipe, click play.\n",
"_____no_output_____"
]
],
[
[
"from starthinker.util.project import project\nfrom starthinker.script.parse import json_set_fields\n\nUSER_CREDENTIALS = '/content/user.json'\n\nTASKS = [\n {\n 'conversion_upload': {\n 'auth': 'user',\n 'encryptionInfo': {\n 'encryptionEntityId': {'field': {'kind': 'integer','name': 'encryption_entity_id','order': 3,'default': ''}},\n 'encryptionEntityType': {'field': {'kind': 'choice','choices': ['ADWORDS_CUSTOMER','DBM_ADVERTISER','DBM_PARTNER','DCM_ACCOUNT','DCM_ADVERTISER','ENCRYPTION_ENTITY_TYPE_UNKNOWN'],'name': 'encryption_entity_type','order': 4,'default': 'DCM_ACCOUNT'}},\n 'encryptionSource': {'field': {'kind': 'choice','choices': ['AD_SERVING','DATA_TRANSFER','ENCRYPTION_SCOPE_UNKNOWN'],'name': 'encryption_entity_source','order': 5,'default': 'DATA_TRANSFER'}}\n },\n 'conversion_type': {'field': {'kind': 'choice','choices': ['encryptedUserId','encryptedUserIdCandidates','gclid','mobileDeviceId'],'name': 'floodlight_conversion_type','order': 2,'default': 'encryptedUserId'}},\n 'bigquery': {\n 'table': {'field': {'kind': 'string','name': 'bigquery_table','order': 7,'default': ''}},\n 'dataset': {'field': {'kind': 'string','name': 'bigquery_dataset','order': 6,'default': ''}},\n 'legacy': {'field': {'kind': 'boolean','name': 'bigquery_legacy','order': 8,'default': True}}\n },\n 'activity_id': {'field': {'kind': 'integer','name': 'floodlight_activity_id','order': 1,'default': ''}},\n 'account_id': {'field': {'kind': 'string','name': 'account','order': 0,'default': ''}}\n }\n }\n]\n\njson_set_fields(TASKS, FIELDS)\n\nproject.initialize(_recipe={ 'tasks':TASKS }, _project=CLOUD_PROJECT, _user=USER_CREDENTIALS, _client=CLIENT_CREDENTIALS, _verbose=True, _force=True)\nproject.execute(_force=True)\n",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa194e228db21f76dc1a6637d1b573ac500fb4b
| 107,521 |
ipynb
|
Jupyter Notebook
|
Real Estate Price Prediction/Dragon Real Estates Price Prediction.ipynb
|
shailcastic/Data-Science-Machine-Learning-Practice
|
997cf3d4e3eb2db47cdf31ccda2d1390421386e7
|
[
"MIT"
] | 1 |
2022-01-17T12:50:42.000Z
|
2022-01-17T12:50:42.000Z
|
Real Estate Price Prediction/Dragon Real Estates Price Prediction.ipynb
|
shailcastic/Data-Science-Machine-Learning-Practice
|
997cf3d4e3eb2db47cdf31ccda2d1390421386e7
|
[
"MIT"
] | null | null | null |
Real Estate Price Prediction/Dragon Real Estates Price Prediction.ipynb
|
shailcastic/Data-Science-Machine-Learning-Practice
|
997cf3d4e3eb2db47cdf31ccda2d1390421386e7
|
[
"MIT"
] | null | null | null | 51.942512 | 25,884 | 0.666233 |
[
[
[
"## Dragon Real Estate - Price Predictor",
"_____no_output_____"
]
],
[
[
"import pandas as pd",
"_____no_output_____"
],
[
"housing = pd.read_csv(\"data.csv\")",
"_____no_output_____"
],
[
"housing.head()",
"_____no_output_____"
],
[
"housing.info()",
"<class 'pandas.core.frame.DataFrame'>\nRangeIndex: 506 entries, 0 to 505\nData columns (total 14 columns):\nCRIM 506 non-null float64\nZN 506 non-null float64\nINDUS 506 non-null float64\nCHAS 506 non-null int64\nNOX 506 non-null float64\nRM 501 non-null float64\nAGE 506 non-null float64\nDIS 506 non-null float64\nRAD 506 non-null int64\nTAX 506 non-null int64\nPTRATIO 506 non-null float64\nB 506 non-null float64\nLSTAT 506 non-null float64\nMEDV 506 non-null float64\ndtypes: float64(11), int64(3)\nmemory usage: 55.4 KB\n"
],
[
"housing['CHAS'].value_counts()",
"_____no_output_____"
],
[
"housing.describe()",
"_____no_output_____"
],
[
"%matplotlib inline",
"_____no_output_____"
],
[
"# # For plotting histogram\n# import matplotlib.pyplot as plt\n# housing.hist(bins=50, figsize=(20, 15))",
"_____no_output_____"
]
],
[
[
"## Train-Test Splitting",
"_____no_output_____"
]
],
[
[
"# For learning purpose\nimport numpy as np\ndef split_train_test(data, test_ratio):\n np.random.seed(42)\n shuffled = np.random.permutation(len(data))\n print(shuffled)\n test_set_size = int(len(data) * test_ratio)\n test_indices = shuffled[:test_set_size]\n train_indices = shuffled[test_set_size:] \n return data.iloc[train_indices], data.iloc[test_indices]",
"_____no_output_____"
],
[
"# train_set, test_set = split_train_test(housing, 0.2)",
"_____no_output_____"
],
[
"# print(f\"Rows in train set: {len(train_set)}\\nRows in test set: {len(test_set)}\\n\")",
"_____no_output_____"
],
[
"from sklearn.model_selection import train_test_split\ntrain_set, test_set = train_test_split(housing, test_size=0.2, random_state=42)\nprint(f\"Rows in train set: {len(train_set)}\\nRows in test set: {len(test_set)}\\n\")",
"Rows in train set: 404\nRows in test set: 102\n\n"
],
[
"from sklearn.model_selection import StratifiedShuffleSplit\nsplit = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)\nfor train_index, test_index in split.split(housing, housing['CHAS']):\n strat_train_set = housing.loc[train_index]\n strat_test_set = housing.loc[test_index]",
"_____no_output_____"
],
[
"strat_test_set['CHAS'].value_counts()",
"_____no_output_____"
],
[
"strat_train_set['CHAS'].value_counts()",
"_____no_output_____"
],
[
"# 95/7",
"_____no_output_____"
],
[
"# 376/28",
"_____no_output_____"
],
[
"housing = strat_train_set.copy()",
"_____no_output_____"
]
],
[
[
"## Looking for Correlations",
"_____no_output_____"
]
],
[
[
"corr_matrix = housing.corr()\ncorr_matrix['MEDV'].sort_values(ascending=False)",
"_____no_output_____"
],
[
"# from pandas.plotting import scatter_matrix\n# attributes = [\"MEDV\", \"RM\", \"ZN\", \"LSTAT\"]\n# scatter_matrix(housing[attributes], figsize = (12,8))",
"_____no_output_____"
],
[
"housing.plot(kind=\"scatter\", x=\"RM\", y=\"MEDV\", alpha=0.8)",
"_____no_output_____"
]
],
[
[
"## Trying out Attribute combinations\n",
"_____no_output_____"
]
],
[
[
"housing[\"TAXRM\"] = housing['TAX']/housing['RM']",
"_____no_output_____"
],
[
"housing.head()",
"_____no_output_____"
],
[
"corr_matrix = housing.corr()\ncorr_matrix['MEDV'].sort_values(ascending=False)",
"_____no_output_____"
],
[
"housing.plot(kind=\"scatter\", x=\"TAXRM\", y=\"MEDV\", alpha=0.8)",
"_____no_output_____"
],
[
"housing = strat_train_set.drop(\"MEDV\", axis=1)\nhousing_labels = strat_train_set[\"MEDV\"].copy()",
"_____no_output_____"
]
],
[
[
"## Missing Attributes",
"_____no_output_____"
]
],
[
[
"# To take care of missing attributes, you have three options:\n# 1. Get rid of the missing data points\n# 2. Get rid of the whole attribute\n# 3. Set the value to some value(0, mean or median)",
"_____no_output_____"
],
[
"a = housing.dropna(subset=[\"RM\"]) #Option 1\na.shape\n# Note that the original housing dataframe will remain unchanged",
"_____no_output_____"
],
[
"housing.drop(\"RM\", axis=1).shape # Option 2\n# Note that there is no RM column and also note that the original housing dataframe will remain unchanged",
"_____no_output_____"
],
[
"median = housing[\"RM\"].median() # Compute median for Option 3",
"_____no_output_____"
],
[
"housing[\"RM\"].fillna(median) # Option 3\n# Note that the original housing dataframe will remain unchanged",
"_____no_output_____"
],
[
"housing.shape",
"_____no_output_____"
],
[
"housing.describe() # before we started filling missing attributes",
"_____no_output_____"
],
[
"from sklearn.impute import SimpleImputer\nimputer = SimpleImputer(strategy=\"median\")\nimputer.fit(housing)",
"_____no_output_____"
],
[
"imputer.statistics_",
"_____no_output_____"
],
[
"X = imputer.transform(housing)",
"_____no_output_____"
],
[
"housing_tr = pd.DataFrame(X, columns=housing.columns)",
"_____no_output_____"
],
[
"housing_tr.describe()",
"_____no_output_____"
]
],
[
[
"## Scikit-learn Design",
"_____no_output_____"
],
[
"Primarily, three types of objects\n1. Estimators - It estimates some parameter based on a dataset. Eg. imputer. It has a fit method and transform method. Fit method - Fits the dataset and calculates internal parameters\n\n2. Transformers - transform method takes input and returns output based on the learnings from fit(). It also has a convenience function called fit_transform() which fits and then transforms.\n\n3. Predictors - LinearRegression model is an example of predictor. fit() and predict() are two common functions. It also gives score() function which will evaluate the predictions.",
"_____no_output_____"
],
[
"## Feature Scaling",
"_____no_output_____"
],
[
"Primarily, two types of feature scaling methods:\n1. Min-max scaling (Normalization)\n (value - min)/(max - min)\n Sklearn provides a class called MinMaxScaler for this\n \n2. Standardization\n (value - mean)/std\n Sklearn provides a class called StandardScaler for this\n",
"_____no_output_____"
],
[
"## Creating a Pipeline",
"_____no_output_____"
]
],
[
[
"from sklearn.pipeline import Pipeline\nfrom sklearn.preprocessing import StandardScaler\nmy_pipeline = Pipeline([\n ('imputer', SimpleImputer(strategy=\"median\")),\n # ..... add as many as you want in your pipeline\n ('std_scaler', StandardScaler()),\n])\n",
"_____no_output_____"
],
[
"housing_num_tr = my_pipeline.fit_transform(housing)",
"_____no_output_____"
],
[
"housing_num_tr.shape",
"_____no_output_____"
]
],
[
[
"## Selecting a desired model for Dragon Real Estates",
"_____no_output_____"
]
],
[
[
"from sklearn.linear_model import LinearRegression\nfrom sklearn.tree import DecisionTreeRegressor\nfrom sklearn.ensemble import RandomForestRegressor\n# model = LinearRegression()\n# model = DecisionTreeRegressor()\nmodel = RandomForestRegressor()\nmodel.fit(housing_num_tr, housing_labels)",
"c:\\users\\haris\\appdata\\local\\programs\\python\\python37-32\\lib\\site-packages\\sklearn\\ensemble\\forest.py:245: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.\n \"10 in version 0.20 to 100 in 0.22.\", FutureWarning)\n"
],
[
"some_data = housing.iloc[:5]",
"_____no_output_____"
],
[
"some_labels = housing_labels.iloc[:5]",
"_____no_output_____"
],
[
"prepared_data = my_pipeline.transform(some_data)",
"_____no_output_____"
],
[
"model.predict(prepared_data)",
"_____no_output_____"
],
[
"list(some_labels)",
"_____no_output_____"
]
],
[
[
"## Evaluating the model",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics import mean_squared_error\nhousing_predictions = model.predict(housing_num_tr)\nmse = mean_squared_error(housing_labels, housing_predictions)\nrmse = np.sqrt(mse)",
"_____no_output_____"
],
[
"rmse",
"_____no_output_____"
]
],
[
[
"## Using better evaluation technique - Cross Validation",
"_____no_output_____"
]
],
[
[
"# 1 2 3 4 5 6 7 8 9 10\nfrom sklearn.model_selection import cross_val_score\nscores = cross_val_score(model, housing_num_tr, housing_labels, scoring=\"neg_mean_squared_error\", cv=10)\nrmse_scores = np.sqrt(-scores)",
"_____no_output_____"
],
[
"rmse_scores",
"_____no_output_____"
],
[
"def print_scores(scores):\n print(\"Scores:\", scores)\n print(\"Mean: \", scores.mean())\n print(\"Standard deviation: \", scores.std())",
"_____no_output_____"
],
[
"print_scores(rmse_scores)",
"Scores: [3.04485171 2.48131898 4.63312016 2.8778676 3.41281409 3.03586684\n 4.85712775 3.52571837 2.89743852 4.18037857]\nMean: 3.494650261111624\nStandard deviation: 0.762041223886678\n"
]
],
[
[
"Quiz: Convert this notebook into a python file and run the pipeline using Visual Studio Code",
"_____no_output_____"
],
[
"## Saving the model",
"_____no_output_____"
]
],
[
[
"from joblib import dump, load\ndump(model, 'Dragon.joblib') ",
"_____no_output_____"
]
],
[
[
"## Testing the model on test data",
"_____no_output_____"
]
],
[
[
"X_test = strat_test_set.drop(\"MEDV\", axis=1)\nY_test = strat_test_set[\"MEDV\"].copy()\nX_test_prepared = my_pipeline.transform(X_test)\nfinal_predictions = model.predict(X_test_prepared)\nfinal_mse = mean_squared_error(Y_test, final_predictions)\nfinal_rmse = np.sqrt(final_mse)\n# print(final_predictions, list(Y_test))",
"_____no_output_____"
],
[
"final_rmse",
"_____no_output_____"
],
[
"prepared_data[0]",
"_____no_output_____"
]
],
[
[
"## Using the model",
"_____no_output_____"
]
],
[
[
"from joblib import dump, load\nimport numpy as np\nmodel = load('Dragon.joblib') \nfeatures = np.array([[-5.43942006, 4.12628155, -1.6165014, -0.67288841, -1.42262747,\n -11.44443979304, -49.31238772, 7.61111401, -26.0016879 , -0.5778192 ,\n -0.97491834, 0.41164221, -66.86091034]])\nmodel.predict(features)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa19d04c5662ca5ae1d9d15f201a05c594466d1
| 884,041 |
ipynb
|
Jupyter Notebook
|
Jupyter Notebooks/Blog Post 4.ipynb
|
arshg285/arshg285.github.io
|
df1230459735dc04473c39d751c25cc65e0cd95d
|
[
"MIT"
] | null | null | null |
Jupyter Notebooks/Blog Post 4.ipynb
|
arshg285/arshg285.github.io
|
df1230459735dc04473c39d751c25cc65e0cd95d
|
[
"MIT"
] | null | null | null |
Jupyter Notebooks/Blog Post 4.ipynb
|
arshg285/arshg285.github.io
|
df1230459735dc04473c39d751c25cc65e0cd95d
|
[
"MIT"
] | null | null | null | 841.94381 | 64,308 | 0.952972 |
[
[
[
"import numpy as np\nfrom sklearn import datasets\nfrom scipy.optimize import minimize\nfrom matplotlib import pyplot as plt\nfrom sklearn.metrics.pairwise import euclidean_distances\nimport warnings\nwarnings.simplefilter(\"ignore\")",
"_____no_output_____"
],
[
"n = 200\nnp.random.seed(1111)\nX, y = datasets.make_blobs(n_samples=n, shuffle=True, random_state=None, centers = 2, cluster_std = 2.0)\nplt.scatter(X[:,0], X[:,1])",
"_____no_output_____"
],
[
"from sklearn.cluster import KMeans\nkm = KMeans(n_clusters = 2)\nkm.fit(X)\n\nplt.scatter(X[:,0], X[:,1], c = km.predict(X))",
"_____no_output_____"
],
[
"np.random.seed(1234)\nn = 200\nX, y = datasets.make_moons(n_samples=n, shuffle=True, noise=0.05, random_state=None)\nplt.scatter(X[:,0], X[:,1])",
"_____no_output_____"
],
[
"km = KMeans(n_clusters = 2)\nkm.fit(X)\nplt.scatter(X[:,0], X[:,1], c = km.predict(X))",
"_____no_output_____"
]
],
[
[
"# Part A",
"_____no_output_____"
]
],
[
[
"epsilon = 0.4",
"_____no_output_____"
],
[
"dist = euclidean_distances(X, X)\nA = [[1 if dist[i, j] < epsilon else 0 for j in range(n)] for i in range(n)]\nA = np.array(A)\nnp.fill_diagonal(A, 0)",
"_____no_output_____"
],
[
"A",
"_____no_output_____"
]
],
[
[
"# Part B",
"_____no_output_____"
]
],
[
[
"degree = [sum(A[i, :]) for i in range(A.shape[0])]",
"_____no_output_____"
]
],
[
[
"### B.1. Cut term",
"_____no_output_____"
]
],
[
[
"def cut(A, y):\n l = []\n for i in range(len(A[:, 1])):\n for j in range(int(len(A[1, :]))):\n if A[i, j] != 0 and y[i] != y[j]:\n l.append(A[i, j])\n return(len(l)/2)",
"_____no_output_____"
],
[
"cut_of_y = cut(A, y)\ncut_of_y",
"_____no_output_____"
],
[
"num = 0\n\nfor i in range(20):\n random_array = np.random.randint(0, 2, size = 200)\n cut_of_random_array = cut(A, random_array)\n if cut_of_random_array <= cut_of_y:\n print(\"Oops, cut of random array was smaller\")\n num = 1\n break\n\nif num == 0: \n print(\"Cut of y was always smaller\")",
"Cut of y was always smaller\n"
]
],
[
[
"### B.2. Volume term",
"_____no_output_____"
]
],
[
[
"def vols(A, y):\n v0 = sum([degree[i] for i in range(len(y)) if y[i] == 0])\n v1 = sum([degree[i] for i in range(len(y)) if y[i] == 1])\n return (v0, v1)",
"_____no_output_____"
],
[
"def normcut(A, y):\n v0, v1 = vols(A, y)\n cut_y = cut(A, y)\n return (cut_y * ((1/v0) + (1/v1)))",
"_____no_output_____"
],
[
"normcut_of_y = round(normcut(A, y), 3)\nnormcut_of_y",
"_____no_output_____"
],
[
"for i in range(10):\n random_array = np.random.randint(0, 2, size = 200)\n cut_of_random_array = cut(A, random_array)\n print(\"Cut of y :\", normcut_of_y, \", Cut of random array :\", round(normcut(A, random_array), 3))",
"Cut of y : 0.012 , Cut of random array : 0.986\nCut of y : 0.012 , Cut of random array : 1.006\nCut of y : 0.012 , Cut of random array : 1.03\nCut of y : 0.012 , Cut of random array : 0.959\nCut of y : 0.012 , Cut of random array : 1.031\nCut of y : 0.012 , Cut of random array : 1.022\nCut of y : 0.012 , Cut of random array : 1.012\nCut of y : 0.012 , Cut of random array : 0.986\nCut of y : 0.012 , Cut of random array : 1.017\nCut of y : 0.012 , Cut of random array : 1.017\n"
]
],
[
[
"# Part C",
"_____no_output_____"
]
],
[
[
"def transform(A, y):\n v0, v1 = vols(A, y)\n z = [1/v0 if y[i] == 0 else -1/v1 for i in range(len(y))]\n return np.array(z)",
"_____no_output_____"
],
[
"norm_1 = normcut(A, y)\nz = transform(A, y)\nD = np.diag(degree)\nnorm_2 = (z @ (D - A) @ z)/(z @ D @ z)\nnp.isclose(norm_1, norm_2)",
"_____no_output_____"
],
[
"z @ D @ np.ones(n)",
"_____no_output_____"
]
],
[
[
"# Part D",
"_____no_output_____"
]
],
[
[
"def orth(u, v):\n return (u @ v) / (v @ v) * v\n\ne = np.ones(n) \n\nd = D @ e\n\ndef orth_obj(z):\n z_o = z - orth(z, d)\n return (z_o @ (D - A) @ z_o)/(z_o @ D @ z_o)",
"_____no_output_____"
],
[
"output = minimize(fun = orth_obj, x0 = z, method = 'Nelder-Mead')",
"_____no_output_____"
],
[
"z_min = output.x",
"_____no_output_____"
]
],
[
[
"# Part E",
"_____no_output_____"
]
],
[
[
"def set_color():\n colors = []\n for i in range(len(z_min)):\n if z_min[i] >= 0:\n colors.append(\"red\")\n if z_min[i] < 0:\n colors.append(\"blue\")\n return colors\n\nplt.scatter(X[:, 0], X[:, 1], c = set_color())\nplt.savefig(fname = \"/Users/arshmacbook/Desktop/PIC 16B/arshg285.github.io/images/blog-post-4-e\", bbox_inches = 'tight')\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Part F",
"_____no_output_____"
]
],
[
[
"L = np.linalg.inv(D) @ (D - A)",
"_____no_output_____"
],
[
"def second_smallest_eigenvector(L):\n Lam, U = np.linalg.eig(L)\n ix = Lam.argsort()\n Lam, U = Lam[ix], U[:, ix]\n z_eig = U[:, 1]\n return z_eig",
"_____no_output_____"
],
[
"z_eig = second_smallest_eigenvector(L)",
"_____no_output_____"
],
[
"def set_color(z_eig):\n colors = []\n for i in range(len(z_eig)):\n if z_eig[i] >= 0:\n colors.append(\"red\")\n if z_eig[i] < 0:\n colors.append(\"blue\")\n return colors\n\nplt.scatter(X[:, 0], X[:, 1], c = set_color(z_eig))\nplt.savefig(fname = \"/Users/arshmacbook/Desktop/PIC 16B/arshg285.github.io/images/blog-post-4-f\", bbox_inches = 'tight')\nplt.show()",
"_____no_output_____"
]
],
[
[
"# Part G",
"_____no_output_____"
]
],
[
[
"def spectral_clustering(X, epsilon):\n \n # Constructing the similarity matrix\n dist = euclidean_distances(X, X)\n A = np.array([[1 if dist[i, j] < epsilon else 0 for j in range(n)] for i in range(n)])\n np.fill_diagonal(A, 0)\n \n # Constructing the laplacian matrix\n degree = [sum(A[i, :]) for i in range(A.shape[0])]\n L = np.linalg.inv(np.diag(degree)) @ (np.diag(degree) - A)\n \n # Compute the eigenvector with second-smallest eigenvalue of the Laplacian matrix\n z_eig = second_smallest_eigenvector(L)\n y = [1 if z_eig[i] > 0 else 0 for i in range(len(z_eig))]\n \n # Return labels based on this eigenvector\n return y",
"_____no_output_____"
],
[
"y = spectral_clustering(X, epsilon)",
"_____no_output_____"
]
],
[
[
"# Part H",
"_____no_output_____"
]
],
[
[
"np.random.seed(1234)\nn = 1000\nnoise_values = np.linspace(0, 0.2, 5)\nnum = 0\n\nfor elem in noise_values[1:]:\n\n X, y = datasets.make_moons(n_samples=n, shuffle=True, noise=elem, random_state=None)\n y = spectral_clustering(X, epsilon = 0.4)\n\n def set_color(vector):\n colors = []\n for i in range(len(vector)):\n if vector[i] == 0:\n colors.append(\"red\")\n if vector[i] == 1:\n colors.append(\"blue\")\n return colors\n \n num += 1\n print(\"For epsilon = \", elem)\n plt.scatter(X[:, 0], X[:, 1], c = set_color(y))\n plt.savefig(fname = f\"/Users/arshmacbook/Desktop/PIC 16B/arshg285.github.io/images/blog-post-4-h{num}\", bbox_inches = 'tight')\n plt.show()",
"For epsilon = 0.05\n"
]
],
[
[
"# Part I",
"_____no_output_____"
]
],
[
[
"n = 2000\nnoise_values = np.linspace(0, 1, 11)\nnum = 0\n\nfor elem in noise_values[1:]:\n\n X, y = datasets.make_circles(n_samples=n, shuffle=True, noise=elem, random_state=None, factor = 0.4)\n\n def set_color(vector):\n colors = []\n for i in range(len(vector)):\n if vector[i] == 0:\n colors.append(\"red\")\n if vector[i] == 1:\n colors.append(\"blue\")\n return colors\n\n num += 1\n print(\"For epsilon = \", elem)\n plt.scatter(X[:, 0], X[:, 1], c = set_color(y))\n plt.savefig(fname = f\"/Users/arshmacbook/Desktop/PIC 16B/arshg285.github.io/images/blog-post-4-i{num}\", bbox_inches = 'tight')\n plt.show()",
"For epsilon = 0.1\n"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa1ba2b26c3f653998a31cdaf8322f0f133746e
| 10,438 |
ipynb
|
Jupyter Notebook
|
writing-efficient-code-with-pandas/2. Replacing values in a DataFrame/notebook_section_2.ipynb
|
nhutnamhcmus/datacamp-playground
|
25457e813b1145e1d335562286715eeddd1c1a7b
|
[
"MIT"
] | 1 |
2021-05-08T11:09:27.000Z
|
2021-05-08T11:09:27.000Z
|
writing-efficient-code-with-pandas/2. Replacing values in a DataFrame/notebook_section_2.ipynb
|
nhutnamhcmus/datacamp-playground
|
25457e813b1145e1d335562286715eeddd1c1a7b
|
[
"MIT"
] | 1 |
2022-03-12T15:42:14.000Z
|
2022-03-12T15:42:14.000Z
|
writing-efficient-code-with-pandas/2. Replacing values in a DataFrame/notebook_section_2.ipynb
|
nhutnamhcmus/datacamp-playground
|
25457e813b1145e1d335562286715eeddd1c1a7b
|
[
"MIT"
] | 1 |
2021-04-30T18:24:19.000Z
|
2021-04-30T18:24:19.000Z
| 38.375 | 346 | 0.623204 |
[
[
[
"# Replacing scalar values I\nIn this exercise, we will replace a list of values in our dataset by using the .replace() method with another list of desired values.\n\nWe will apply the functions in the poker_hands DataFrame. Remember that in the poker_hands DataFrame, each row of columns R1 to R5 represents the rank of each card from a player's poker hand spanning from 1 (Ace) to 13 (King). The Class feature classifies each hand as a category, and the Explanation feature briefly explains each hand.\n\nThe poker_hands DataFrame is already loaded for you, and you can explore the features Class and Explanation.\n\nRemember you can always explore the dataset and see how it changes in the IPython Shell, and refer to the slides in the Slides tab.",
"_____no_output_____"
]
],
[
[
"import pandas as pd \npoker_hands = pd.read_csv('../datasets/poker_hand.csv')\npoker_hands",
"_____no_output_____"
],
[
"# Replace Class 1 to -2 \npoker_hands['Class'].replace(1, -2, inplace=True)\n# Replace Class 2 to -3\npoker_hands['Class'].replace(2, -3, inplace=True)\n\nprint(poker_hands[['Class']])",
"_____no_output_____"
]
],
[
[
"# Replace scalar values II\nAs discussed in the video, in a pandas DataFrame, it is possible to replace values in a very intuitive way: we locate the position (row and column) in the Dataframe and assign in the new value you want to replace with. In a more pandas-ian way, the .replace() function is available that performs the same task.\n\nYou will be using the names DataFrame which includes, among others, the most popular names in the US by year, gender and ethnicity.\n\nYour task is to replace all the babies that are classified as FEMALE to GIRL using the following methods:\n\n- intuitive scalar replacement\n- using the .replace() function",
"_____no_output_____"
]
],
[
[
"names = pd.read_csv('../datasets/Popular_Baby_Names.csv')\nnames.head()",
"_____no_output_____"
],
[
"import time\nstart_time = time.time()\n\n# Replace all the entries that has 'FEMALE' as a gender with 'GIRL'\nnames['Gender'].loc[names['Gender'] == 'FEMALE'] = 'GIRL'\n\nprint(\"Time using .loc[]: {} sec\".format(time.time() - start_time))",
"_____no_output_____"
],
[
"start_time = time.time()\n\n# Replace all the entries that has 'FEMALE' as a gender with 'GIRL'\nnames['Gender'].replace('FEMALE', 'GIRL', inplace=True)\n\nprint(\"Time using .replace(): {} sec\".format(time.time() - start_time))",
"_____no_output_____"
]
],
[
[
"# Replace multiple values I\nIn this exercise, you will apply the .replace() function for the task of replacing multiple values with one or more values. You will again use the names dataset which contains, among others, the most popular names in the US by year, gender and Ethnicity.\n\nThus you want to replace all ethnicities classified as black or white non-hispanics to non-hispanic. Remember, the ethnicities are stated in the dataset as follows: ```['BLACK NON HISP', 'BLACK NON HISPANIC', 'WHITE NON HISP' , 'WHITE NON HISPANIC']``` and should be replaced to 'NON HISPANIC'",
"_____no_output_____"
]
],
[
[
"start_time = time.time()\n\n# Replace all non-Hispanic ethnicities with 'NON HISPANIC'\nnames['Ethnicity'].loc[(names[\"Ethnicity\"] == 'BLACK NON HISP') | \n (names[\"Ethnicity\"] == 'BLACK NON HISPANIC') | \n (names[\"Ethnicity\"] == 'WHITE NON HISP') | \n (names[\"Ethnicity\"] == 'WHITE NON HISPANIC')] = 'NON HISPANIC'\n\nprint(\"Time using .loc[]: {0} sec\".format(time.time() - start_time))",
"_____no_output_____"
],
[
"start_time = time.time()\n\n# Replace all non-Hispanic ethnicities with 'NON HISPANIC'\nnames['Ethnicity'].replace(['BLACK NON HISP', 'BLACK NON HISPANIC', 'WHITE NON HISP' , 'WHITE NON HISPANIC'], 'NON HISPANIC', inplace=True)\n\nprint(\"Time using .replace(): {} sec\".format(time.time() - start_time))",
"_____no_output_____"
]
],
[
[
"# Replace multiple values II\nAs discussed in the video, instead of using the .replace() function multiple times to replace multiple values, you can use lists to map the elements you want to replace one to one with those you want to replace them with.\n\nAs you have seen in our popular names dataset, there are two names for the same ethnicity. We want to standardize the naming of each ethnicity by replacing\n\n- 'ASIAN AND PACI' to 'ASIAN AND PACIFIC ISLANDER'\n- 'BLACK NON HISP' to 'BLACK NON HISPANIC'\n- 'WHITE NON HISP' to 'WHITE NON HISPANIC'\n\nIn the DataFrame names, you are going to replace all the values on the left by the values on the right.",
"_____no_output_____"
]
],
[
[
"start_time = time.time()\n\n# Replace ethnicities as instructed\nnames['Ethnicity'].replace(['ASIAN AND PACI','BLACK NON HISP', 'WHITE NON HISP'], ['ASIAN AND PACIFIC ISLANDER','BLACK NON HISPANIC','WHITE NON HISPANIC'], inplace=True)\n\nprint(\"Time using .replace(): {} sec\".format(time.time() - start_time))",
"_____no_output_____"
]
],
[
[
"# Replace single values I\nIn this exercise, we will apply the following replacing technique of replacing multiple values using dictionaries on a different dataset.\n\nWe will apply the functions in the data DataFrame. Each row represents the rank of 5 cards from a playing card deck, spanning from 1 (Ace) to 13 (King) (features R1, R2, R3, R4, R5). The feature 'Class' classifies each row to a category (from 0 to 9) and the feature 'Explanation' gives a brief explanation of what each class represents.\n\nThe purpose of this exercise is to categorize the two types of flush in the game ('Royal flush' and 'Straight flush') under the 'Flush' name.",
"_____no_output_____"
]
],
[
[
"# Replace Royal flush or Straight flush to Flush\npoker_hands.replace({'Royal flush':'Flush', 'Straight flush':'Flush'}, inplace=True)\nprint(poker_hands['Explanation'].head())",
"_____no_output_____"
]
],
[
[
"# Replace single values II\nFor this exercise, we will be using the names DataFrame. In this dataset, the column 'Rank' shows the ranking of each name by year. For this exercise, you will use dictionaries to replace the first ranked name of every year as 'FIRST', the second name as 'SECOND' and the third name as 'THIRD'.\n\nYou will use dictionaries to replace one single value per key.\n\nYou can already see the first 5 names of the data, which correspond to the 5 most popular names for all the females belonging to the 'ASIAN AND PACIFIC ISLANDER' ethnicity in 2011.",
"_____no_output_____"
]
],
[
[
"# Replace the number rank by a string\nnames['Rank'].replace({1:'FIRST', 2:'SECOND', 3:'THIRD'}, inplace=True)\nprint(names.head())",
"_____no_output_____"
]
],
[
[
"# Replace multiple values III\nAs you saw in the video, you can use dictionaries to replace multiple values with just one value, even from multiple columns. To show the usefulness of replacing with dictionaries, you will use the names dataset one more time.\n\nIn this dataset, the column 'Rank' shows which rank each name reached every year. You will change the rank of the first three ranked names of every year to 'MEDAL' and those from 4th and 5th place to 'ALMOST MEDAL'.\n\nYou can already see the first 5 names of the data, which correspond to the 5 most popular names for all the females belonging to the 'ASIAN AND PACIFIC ISLANDER' ethnicity in 2011.",
"_____no_output_____"
]
],
[
[
"# Replace the rank of the first three ranked names to 'MEDAL'\nnames.replace({'Rank': {1:'MEDAL', 2:'MEDAL', 3:'MEDAL'}}, inplace=True)\n\n# Replace the rank of the 4th and 5th ranked names to 'ALMOST MEDAL'\nnames.replace({'Rank': {4:'ALMOST MEDAL', 5:'ALMOST MEDAL'}}, inplace=True)\nprint(names.head())",
"_____no_output_____"
]
],
[
[
"# Most efficient method for scalar replacement\nIf you want to replace a scalar value with another scalar value, which technique is the most efficient??\n\nReplace using dictionaries.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aa1c521f7845e221fd0c7923050c765d37f9b29
| 185,415 |
ipynb
|
Jupyter Notebook
|
DeepLearning AI/Sequence Time Series and Prediction/Code/Week 4/exercise_1_w4.ipynb
|
Ace5584/Machine-Learning-Notes
|
8d721895165833f6ea2ac3c75326ec5ed29111eb
|
[
"Apache-2.0"
] | 2 |
2021-10-01T07:28:58.000Z
|
2022-01-23T00:20:34.000Z
|
DeepLearning AI/Sequence Time Series and Prediction/Code/Week 4/exercise_1_w4.ipynb
|
Ace5584/TF_ML_Notes
|
8d721895165833f6ea2ac3c75326ec5ed29111eb
|
[
"Apache-2.0"
] | null | null | null |
DeepLearning AI/Sequence Time Series and Prediction/Code/Week 4/exercise_1_w4.ipynb
|
Ace5584/TF_ML_Notes
|
8d721895165833f6ea2ac3c75326ec5ed29111eb
|
[
"Apache-2.0"
] | null | null | null | 203.305921 | 83,282 | 0.820926 |
[
[
[
"import tensorflow as tf\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\ndef plot_series(time, series, format=\"-\", start=0, end=None):\r\n plt.plot(time[start:end], series[start:end], format)\r\n plt.xlabel(\"Time\")\r\n plt.ylabel(\"Value\")\r\n plt.grid(True)",
"_____no_output_____"
],
[
"!wget --no-check-certificate \\\r\n https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-min-temperatures.csv \\\r\n -O /tmp/daily-min-temperatures.csv",
"--2021-01-10 09:03:04-- https://raw.githubusercontent.com/jbrownlee/Datasets/master/daily-min-temperatures.csv\nResolving raw.githubusercontent.com (raw.githubusercontent.com)... 151.101.0.133, 151.101.64.133, 151.101.128.133, ...\nConnecting to raw.githubusercontent.com (raw.githubusercontent.com)|151.101.0.133|:443... connected.\nHTTP request sent, awaiting response... 200 OK\nLength: 67921 (66K) [text/plain]\nSaving to: ‘/tmp/daily-min-temperatures.csv’\n\n\r /tmp/dail 0%[ ] 0 --.-KB/s \r/tmp/daily-min-temp 100%[===================>] 66.33K --.-KB/s in 0.001s \n\n2021-01-10 09:03:04 (53.7 MB/s) - ‘/tmp/daily-min-temperatures.csv’ saved [67921/67921]\n\n"
],
[
"import csv\r\ntime_step = []\r\ntemps = []\r\n\r\nwith open('/tmp/daily-min-temperatures.csv') as csvfile:\r\n reader = csv.reader(csvfile, delimiter=',')\r\n next(reader)\r\n step=0\r\n for row in reader:\r\n temps.append(float(row[1]))\r\n time_step.append(step)\r\n step = step + 1\r\n\r\nseries = np.array(temps)\r\ntime = np.array(time_step)\r\nplt.figure(figsize=(10, 6))\r\nplot_series(time, series)",
"_____no_output_____"
],
[
"split_time = 2500\r\ntime_train = time[:split_time]\r\nx_train = series[:split_time]\r\ntime_valid = time[split_time:]\r\nx_valid = series[split_time:]\r\n\r\nwindow_size = 30\r\nbatch_size = 32\r\nshuffle_buffer_size = 1000\r\n",
"_____no_output_____"
],
[
"def windowed_dataset(series, window_size, batch_size, shuffle_buffer):\r\n series = tf.expand_dims(series, axis=-1)\r\n ds = tf.data.Dataset.from_tensor_slices(series)\r\n ds = ds.window(window_size + 1, shift=1, drop_remainder=True)\r\n ds = ds.flat_map(lambda w: w.batch(window_size + 1))\r\n ds = ds.shuffle(shuffle_buffer)\r\n ds = ds.map(lambda w: (w[:-1], w[1:]))\r\n return ds.batch(batch_size).prefetch(1)",
"_____no_output_____"
],
[
"def model_forecast(model, series, window_size):\r\n ds = tf.data.Dataset.from_tensor_slices(series)\r\n ds = ds.window(window_size, shift=1, drop_remainder=True)\r\n ds = ds.flat_map(lambda w: w.batch(window_size))\r\n ds = ds.batch(32).prefetch(1)\r\n forecast = model.predict(ds)\r\n return forecast",
"_____no_output_____"
],
[
"tf.keras.backend.clear_session()\r\ntf.random.set_seed(51)\r\nnp.random.seed(51)\r\nwindow_size = 64\r\nbatch_size = 256\r\ntrain_set = windowed_dataset(x_train, window_size, batch_size, shuffle_buffer_size)\r\nprint(train_set)\r\nprint(x_train.shape)\r\n\r\nmodel = tf.keras.models.Sequential([\r\n tf.keras.layers.Conv1D(filters=32, kernel_size=5,\r\n strides=1, padding=\"causal\",\r\n activation=\"relu\",\r\n input_shape=[None, 1]),\r\n tf.keras.layers.LSTM(64, return_sequences=True),\r\n tf.keras.layers.LSTM(64, return_sequences=True),\r\n tf.keras.layers.Dense(30, activation=\"relu\"),\r\n tf.keras.layers.Dense(10, activation=\"relu\"),\r\n tf.keras.layers.Dense(1),\r\n tf.keras.layers.Lambda(lambda x: x * 400)\r\n])\r\n\r\nlr_schedule = tf.keras.callbacks.LearningRateScheduler(\r\n lambda epoch: 1e-8 * 10**(epoch / 20))\r\noptimizer = tf.keras.optimizers.SGD(lr=1e-8, momentum=0.9)\r\nmodel.compile(loss=tf.keras.losses.Huber(),\r\n optimizer=optimizer,\r\n metrics=[\"mae\"])\r\nhistory = model.fit(train_set, epochs=100, callbacks=[lr_schedule])\r\n",
"<PrefetchDataset shapes: ((None, None, 1), (None, None, 1)), types: (tf.float64, tf.float64)>\n(2500,)\nEpoch 1/100\n10/10 [==============================] - 9s 30ms/step - loss: 31.0287 - mae: 31.5267\nEpoch 2/100\n10/10 [==============================] - 0s 29ms/step - loss: 30.7698 - mae: 31.2675\nEpoch 3/100\n10/10 [==============================] - 0s 28ms/step - loss: 29.9371 - mae: 30.4346\nEpoch 4/100\n10/10 [==============================] - 0s 27ms/step - loss: 28.6752 - mae: 29.1725\nEpoch 5/100\n10/10 [==============================] - 0s 29ms/step - loss: 27.2988 - mae: 27.7959\nEpoch 6/100\n10/10 [==============================] - 0s 29ms/step - loss: 25.7600 - mae: 26.2569\nEpoch 7/100\n10/10 [==============================] - 0s 29ms/step - loss: 24.0420 - mae: 24.5384\nEpoch 8/100\n10/10 [==============================] - 0s 28ms/step - loss: 21.3711 - mae: 21.8673\nEpoch 9/100\n10/10 [==============================] - 0s 29ms/step - loss: 18.2363 - mae: 18.7317\nEpoch 10/100\n10/10 [==============================] - 0s 30ms/step - loss: 14.7508 - mae: 15.2438\nEpoch 11/100\n10/10 [==============================] - 0s 28ms/step - loss: 10.9192 - mae: 11.4082\nEpoch 12/100\n10/10 [==============================] - 0s 29ms/step - loss: 8.2913 - mae: 8.7768\nEpoch 13/100\n10/10 [==============================] - 0s 29ms/step - loss: 6.7101 - mae: 7.1949\nEpoch 14/100\n10/10 [==============================] - 0s 29ms/step - loss: 6.0213 - mae: 6.5063\nEpoch 15/100\n10/10 [==============================] - 0s 27ms/step - loss: 5.5972 - mae: 6.0800\nEpoch 16/100\n10/10 [==============================] - 0s 29ms/step - loss: 5.2279 - mae: 5.7091\nEpoch 17/100\n10/10 [==============================] - 0s 31ms/step - loss: 4.8161 - mae: 5.2937\nEpoch 18/100\n10/10 [==============================] - 0s 27ms/step - loss: 4.4989 - mae: 4.9753\nEpoch 19/100\n10/10 [==============================] - 0s 28ms/step - loss: 4.1894 - mae: 4.6654\nEpoch 20/100\n10/10 [==============================] - 0s 30ms/step - loss: 3.9044 - mae: 4.3780\nEpoch 21/100\n10/10 [==============================] - 0s 31ms/step - loss: 3.7619 - mae: 4.2335\nEpoch 22/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.6205 - mae: 4.0911\nEpoch 23/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.4861 - mae: 3.9565\nEpoch 24/100\n10/10 [==============================] - 0s 31ms/step - loss: 3.4054 - mae: 3.8753\nEpoch 25/100\n10/10 [==============================] - 0s 28ms/step - loss: 3.3180 - mae: 3.7867\nEpoch 26/100\n10/10 [==============================] - 0s 30ms/step - loss: 3.2707 - mae: 3.7396\nEpoch 27/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.1700 - mae: 3.6381\nEpoch 28/100\n10/10 [==============================] - 0s 28ms/step - loss: 3.1260 - mae: 3.5938\nEpoch 29/100\n10/10 [==============================] - 0s 27ms/step - loss: 3.0668 - mae: 3.5341\nEpoch 30/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.9934 - mae: 3.4589\nEpoch 31/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.9235 - mae: 3.3882\nEpoch 32/100\n10/10 [==============================] - 0s 27ms/step - loss: 2.8721 - mae: 3.3367\nEpoch 33/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.7975 - mae: 3.2618\nEpoch 34/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.7602 - mae: 3.2249\nEpoch 35/100\n10/10 [==============================] - 0s 35ms/step - loss: 2.6992 - mae: 3.1636\nEpoch 36/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.6423 - mae: 3.1062\nEpoch 37/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.6070 - mae: 3.0705\nEpoch 38/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.5638 - mae: 3.0269\nEpoch 39/100\n10/10 [==============================] - 0s 27ms/step - loss: 2.4936 - mae: 2.9558\nEpoch 40/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.4803 - mae: 2.9425\nEpoch 41/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.4298 - mae: 2.8911\nEpoch 42/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.3792 - mae: 2.8395\nEpoch 43/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.3388 - mae: 2.7984\nEpoch 44/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.3327 - mae: 2.7921\nEpoch 45/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.2473 - mae: 2.7054\nEpoch 46/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.2291 - mae: 2.6873\nEpoch 47/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.2033 - mae: 2.6615\nEpoch 48/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.1647 - mae: 2.6223\nEpoch 49/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.1297 - mae: 2.5877\nEpoch 50/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.1057 - mae: 2.5637\nEpoch 51/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.0778 - mae: 2.5358\nEpoch 52/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.0650 - mae: 2.5223\nEpoch 53/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.0339 - mae: 2.4905\nEpoch 54/100\n10/10 [==============================] - 0s 28ms/step - loss: 2.0144 - mae: 2.4710\nEpoch 55/100\n10/10 [==============================] - 0s 28ms/step - loss: 1.9966 - mae: 2.4522\nEpoch 56/100\n10/10 [==============================] - 0s 27ms/step - loss: 1.9773 - mae: 2.4328\nEpoch 57/100\n10/10 [==============================] - 0s 30ms/step - loss: 1.9625 - mae: 2.4171\nEpoch 58/100\n10/10 [==============================] - 0s 28ms/step - loss: 1.9227 - mae: 2.3774\nEpoch 59/100\n10/10 [==============================] - 0s 29ms/step - loss: 1.9123 - mae: 2.3665\nEpoch 60/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.1231 - mae: 2.5815\nEpoch 61/100\n10/10 [==============================] - 0s 29ms/step - loss: 2.5798 - mae: 3.0477\nEpoch 62/100\n10/10 [==============================] - 0s 26ms/step - loss: 3.0403 - mae: 3.5153\nEpoch 63/100\n10/10 [==============================] - 0s 31ms/step - loss: 3.5191 - mae: 3.9980\nEpoch 64/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.5400 - mae: 4.0196\nEpoch 65/100\n10/10 [==============================] - 0s 28ms/step - loss: 4.2772 - mae: 4.7642\nEpoch 66/100\n10/10 [==============================] - 0s 31ms/step - loss: 4.4058 - mae: 4.8920\nEpoch 67/100\n10/10 [==============================] - 0s 27ms/step - loss: 4.5842 - mae: 5.0707\nEpoch 68/100\n10/10 [==============================] - 0s 29ms/step - loss: 4.7869 - mae: 5.2734\nEpoch 69/100\n10/10 [==============================] - 0s 29ms/step - loss: 5.3540 - mae: 5.8443\nEpoch 70/100\n10/10 [==============================] - 0s 29ms/step - loss: 5.3128 - mae: 5.7964\nEpoch 71/100\n10/10 [==============================] - 0s 30ms/step - loss: 4.1546 - mae: 4.6308\nEpoch 72/100\n10/10 [==============================] - 0s 29ms/step - loss: 6.1648 - mae: 6.6590\nEpoch 73/100\n10/10 [==============================] - 0s 30ms/step - loss: 5.6392 - mae: 6.1294\nEpoch 74/100\n10/10 [==============================] - 0s 27ms/step - loss: 4.5428 - mae: 5.0246\nEpoch 75/100\n10/10 [==============================] - 0s 28ms/step - loss: 3.5683 - mae: 4.0458\nEpoch 76/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.9510 - mae: 4.4303\nEpoch 77/100\n10/10 [==============================] - 0s 32ms/step - loss: 3.9910 - mae: 4.4746\nEpoch 78/100\n10/10 [==============================] - 0s 30ms/step - loss: 4.3117 - mae: 4.7983\nEpoch 79/100\n10/10 [==============================] - 0s 30ms/step - loss: 2.9558 - mae: 3.4266\nEpoch 80/100\n10/10 [==============================] - 0s 28ms/step - loss: 3.8986 - mae: 4.3791\nEpoch 81/100\n10/10 [==============================] - 0s 29ms/step - loss: 3.7005 - mae: 4.1833\nEpoch 82/100\n10/10 [==============================] - 0s 30ms/step - loss: 3.8822 - mae: 4.3660\nEpoch 83/100\n10/10 [==============================] - 0s 28ms/step - loss: 4.7941 - mae: 5.2838\nEpoch 84/100\n10/10 [==============================] - 0s 28ms/step - loss: 5.0423 - mae: 5.5309\nEpoch 85/100\n10/10 [==============================] - 0s 27ms/step - loss: 5.7031 - mae: 6.1926\nEpoch 86/100\n10/10 [==============================] - 0s 29ms/step - loss: 6.9965 - mae: 7.4876\nEpoch 87/100\n10/10 [==============================] - 0s 27ms/step - loss: 8.0784 - mae: 8.5761\nEpoch 88/100\n10/10 [==============================] - 0s 28ms/step - loss: 8.6148 - mae: 9.1117\nEpoch 89/100\n10/10 [==============================] - 0s 27ms/step - loss: 9.6800 - mae: 10.1784\nEpoch 90/100\n10/10 [==============================] - 0s 30ms/step - loss: 10.9564 - mae: 11.4545\nEpoch 91/100\n10/10 [==============================] - 0s 27ms/step - loss: 15.2611 - mae: 15.7563\nEpoch 92/100\n10/10 [==============================] - 0s 30ms/step - loss: 18.5362 - mae: 19.0309\nEpoch 93/100\n10/10 [==============================] - 0s 28ms/step - loss: 32.2535 - mae: 32.7533\nEpoch 94/100\n10/10 [==============================] - 0s 30ms/step - loss: 38.0906 - mae: 38.5906\nEpoch 95/100\n10/10 [==============================] - 0s 28ms/step - loss: 40.0733 - mae: 40.5733\nEpoch 96/100\n10/10 [==============================] - 0s 32ms/step - loss: 46.4896 - mae: 46.9896\nEpoch 97/100\n10/10 [==============================] - 0s 29ms/step - loss: 51.1449 - mae: 51.6449\nEpoch 98/100\n10/10 [==============================] - 0s 30ms/step - loss: 58.3621 - mae: 58.8621\nEpoch 99/100\n10/10 [==============================] - 0s 30ms/step - loss: 64.7617 - mae: 65.2617\nEpoch 100/100\n10/10 [==============================] - 0s 30ms/step - loss: 73.7028 - mae: 74.2028\n"
],
[
"plt.semilogx(history.history[\"lr\"], history.history[\"loss\"])\r\nplt.axis([1e-8, 1e-4, 0, 60])",
"_____no_output_____"
],
[
"tf.keras.backend.clear_session()\r\ntf.random.set_seed(51)\r\nnp.random.seed(51)\r\ntrain_set = windowed_dataset(x_train, window_size=60, batch_size=100, shuffle_buffer=shuffle_buffer_size)\r\nmodel = tf.keras.models.Sequential([\r\n tf.keras.layers.Conv1D(filters=32, kernel_size=5,\r\n strides=1, padding=\"causal\",\r\n activation=\"relu\",\r\n input_shape=[None, 1]),\r\n tf.keras.layers.LSTM(64, return_sequences=True),\r\n tf.keras.layers.LSTM(64, return_sequences=True),\r\n tf.keras.layers.Dense(30, activation=\"relu\"),\r\n tf.keras.layers.Dense(10, activation=\"relu\"),\r\n tf.keras.layers.Dense(1),\r\n tf.keras.layers.Lambda(lambda x: x * 400)\r\n])\r\n\r\n\r\n\r\noptimizer = tf.keras.optimizers.SGD(lr=5e-5, momentum=0.9)\r\nmodel.compile(loss=tf.keras.losses.Huber(),\r\n optimizer=optimizer,\r\n metrics=[\"mae\"])\r\nhistory = model.fit(train_set,epochs=150)\r\n \r\n# EXPECTED OUTPUT SHOULD SEE AN MAE OF <2 WITHIN ABOUT 30 EPOCHS",
"Epoch 1/150\n25/25 [==============================] - 3s 15ms/step - loss: 12.5626 - mae: 13.0494\nEpoch 2/150\n25/25 [==============================] - 0s 14ms/step - loss: 3.6031 - mae: 4.0839\nEpoch 3/150\n25/25 [==============================] - 0s 16ms/step - loss: 2.3592 - mae: 2.8213\nEpoch 4/150\n25/25 [==============================] - 0s 15ms/step - loss: 2.1525 - mae: 2.6105\nEpoch 5/150\n25/25 [==============================] - 0s 15ms/step - loss: 2.0748 - mae: 2.5329\nEpoch 6/150\n25/25 [==============================] - 0s 14ms/step - loss: 2.1021 - mae: 2.5599\nEpoch 7/150\n25/25 [==============================] - 0s 15ms/step - loss: 2.0792 - mae: 2.5371\nEpoch 8/150\n25/25 [==============================] - 0s 14ms/step - loss: 1.9928 - mae: 2.4477\nEpoch 9/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8975 - mae: 2.3515\nEpoch 10/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.9039 - mae: 2.3579\nEpoch 11/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8718 - mae: 2.3251\nEpoch 12/150\n25/25 [==============================] - 0s 14ms/step - loss: 1.8512 - mae: 2.3051\nEpoch 13/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.9239 - mae: 2.3790\nEpoch 14/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.8642 - mae: 2.3171\nEpoch 15/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8413 - mae: 2.2941\nEpoch 16/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.9597 - mae: 2.4156\nEpoch 17/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.9162 - mae: 2.3702\nEpoch 18/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.8642 - mae: 2.3188\nEpoch 19/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8033 - mae: 2.2551\nEpoch 20/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.9826 - mae: 2.4393\nEpoch 21/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7701 - mae: 2.2210\nEpoch 22/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8857 - mae: 2.3392\nEpoch 23/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.9040 - mae: 2.3585\nEpoch 24/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8096 - mae: 2.2620\nEpoch 25/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8214 - mae: 2.2736\nEpoch 26/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.8082 - mae: 2.2603\nEpoch 27/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7623 - mae: 2.2142\nEpoch 28/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7219 - mae: 2.1709\nEpoch 29/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.8028 - mae: 2.2545\nEpoch 30/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6672 - mae: 2.1145\nEpoch 31/150\n25/25 [==============================] - 1s 17ms/step - loss: 1.7904 - mae: 2.2426\nEpoch 32/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6538 - mae: 2.1000\nEpoch 33/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7687 - mae: 2.2203\nEpoch 34/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7704 - mae: 2.2214\nEpoch 35/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.8816 - mae: 2.3367\nEpoch 36/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.8558 - mae: 2.3092\nEpoch 37/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.7079 - mae: 2.1583\nEpoch 38/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5976 - mae: 2.0427\nEpoch 39/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7760 - mae: 2.2268\nEpoch 40/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.7220 - mae: 2.1739\nEpoch 41/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6428 - mae: 2.0872\nEpoch 42/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6623 - mae: 2.1108\nEpoch 43/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6597 - mae: 2.1086\nEpoch 44/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7896 - mae: 2.2414\nEpoch 45/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6489 - mae: 2.0943\nEpoch 46/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.7082 - mae: 2.1574\nEpoch 47/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6214 - mae: 2.0676\nEpoch 48/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.7279 - mae: 2.1786\nEpoch 49/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7292 - mae: 2.1783\nEpoch 50/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6981 - mae: 2.1476\nEpoch 51/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6393 - mae: 2.0880\nEpoch 52/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6686 - mae: 2.1189\nEpoch 53/150\n25/25 [==============================] - 1s 17ms/step - loss: 1.6098 - mae: 2.0547\nEpoch 54/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5576 - mae: 2.0014\nEpoch 55/150\n25/25 [==============================] - 1s 17ms/step - loss: 1.6493 - mae: 2.0985\nEpoch 56/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6607 - mae: 2.1092\nEpoch 57/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6012 - mae: 2.0466\nEpoch 58/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6511 - mae: 2.0991\nEpoch 59/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6357 - mae: 2.0838\nEpoch 60/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6195 - mae: 2.0661\nEpoch 61/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6269 - mae: 2.0743\nEpoch 62/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6063 - mae: 2.0537\nEpoch 63/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.7135 - mae: 2.1633\nEpoch 64/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5948 - mae: 2.0398\nEpoch 65/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6311 - mae: 2.0774\nEpoch 66/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6164 - mae: 2.0633\nEpoch 67/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5879 - mae: 2.0331\nEpoch 68/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5562 - mae: 1.9987\nEpoch 69/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6495 - mae: 2.0978\nEpoch 70/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5630 - mae: 2.0065\nEpoch 71/150\n25/25 [==============================] - 0s 14ms/step - loss: 1.6632 - mae: 2.1123\nEpoch 72/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6102 - mae: 2.0574\nEpoch 73/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5761 - mae: 2.0214\nEpoch 74/150\n25/25 [==============================] - 0s 14ms/step - loss: 1.5684 - mae: 2.0129\nEpoch 75/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6271 - mae: 2.0746\nEpoch 76/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6402 - mae: 2.0877\nEpoch 77/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6318 - mae: 2.0806\nEpoch 78/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5861 - mae: 2.0307\nEpoch 79/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5994 - mae: 2.0457\nEpoch 80/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6045 - mae: 2.0519\nEpoch 81/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5859 - mae: 2.0307\nEpoch 82/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5593 - mae: 2.0042\nEpoch 83/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5997 - mae: 2.0452\nEpoch 84/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6633 - mae: 2.1122\nEpoch 85/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5502 - mae: 1.9940\nEpoch 86/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5742 - mae: 2.0183\nEpoch 87/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5948 - mae: 2.0407\nEpoch 88/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5986 - mae: 2.0439\nEpoch 89/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6089 - mae: 2.0569\nEpoch 90/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5683 - mae: 2.0126\nEpoch 91/150\n25/25 [==============================] - 1s 18ms/step - loss: 1.5535 - mae: 1.9967\nEpoch 92/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.6341 - mae: 2.0810\nEpoch 93/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5564 - mae: 1.9998\nEpoch 94/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5216 - mae: 1.9629\nEpoch 95/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5518 - mae: 1.9952\nEpoch 96/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5555 - mae: 2.0007\nEpoch 97/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6275 - mae: 2.0746\nEpoch 98/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6738 - mae: 2.1229\nEpoch 99/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5706 - mae: 2.0165\nEpoch 100/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6319 - mae: 2.0789\nEpoch 101/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5512 - mae: 1.9946\nEpoch 102/150\n25/25 [==============================] - 0s 14ms/step - loss: 1.5568 - mae: 2.0013\nEpoch 103/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5305 - mae: 1.9718\nEpoch 104/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5736 - mae: 2.0193\nEpoch 105/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5764 - mae: 2.0213\nEpoch 106/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5616 - mae: 2.0075\nEpoch 107/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5857 - mae: 2.0308\nEpoch 108/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6016 - mae: 2.0480\nEpoch 109/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5176 - mae: 1.9583\nEpoch 110/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5155 - mae: 1.9552\nEpoch 111/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5539 - mae: 1.9987\nEpoch 112/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5058 - mae: 1.9445\nEpoch 113/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5805 - mae: 2.0265\nEpoch 114/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5692 - mae: 2.0125\nEpoch 115/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6286 - mae: 2.0747\nEpoch 116/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5433 - mae: 1.9854\nEpoch 117/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5321 - mae: 1.9746\nEpoch 118/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5520 - mae: 1.9944\nEpoch 119/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5823 - mae: 2.0267\nEpoch 120/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5633 - mae: 2.0083\nEpoch 121/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5444 - mae: 1.9888\nEpoch 122/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5629 - mae: 2.0065\nEpoch 123/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5014 - mae: 1.9404\nEpoch 124/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5739 - mae: 2.0184\nEpoch 125/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5357 - mae: 1.9776\nEpoch 126/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5523 - mae: 1.9973\nEpoch 127/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5067 - mae: 1.9468\nEpoch 128/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5424 - mae: 1.9860\nEpoch 129/150\n25/25 [==============================] - 1s 17ms/step - loss: 1.5417 - mae: 1.9841\nEpoch 130/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5718 - mae: 2.0161\nEpoch 131/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5215 - mae: 1.9624\nEpoch 132/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5730 - mae: 2.0175\nEpoch 133/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5254 - mae: 1.9668\nEpoch 134/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5269 - mae: 1.9681\nEpoch 135/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.5451 - mae: 1.9887\nEpoch 136/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5908 - mae: 2.0353\nEpoch 137/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.6486 - mae: 2.0963\nEpoch 138/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5333 - mae: 1.9755\nEpoch 139/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5440 - mae: 1.9872\nEpoch 140/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5295 - mae: 1.9717\nEpoch 141/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5400 - mae: 1.9819\nEpoch 142/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5366 - mae: 1.9794\nEpoch 143/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5483 - mae: 1.9920\nEpoch 144/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5139 - mae: 1.9554\nEpoch 145/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5914 - mae: 2.0384\nEpoch 146/150\n25/25 [==============================] - 0s 15ms/step - loss: 1.5188 - mae: 1.9612\nEpoch 147/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5369 - mae: 1.9798\nEpoch 148/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5314 - mae: 1.9734\nEpoch 149/150\n25/25 [==============================] - 1s 16ms/step - loss: 1.5820 - mae: 2.0274\nEpoch 150/150\n25/25 [==============================] - 0s 16ms/step - loss: 1.6494 - mae: 2.0974\n"
],
[
"rnn_forecast = model_forecast(model, series[..., np.newaxis], window_size)\r\nrnn_forecast = rnn_forecast[split_time - window_size:-1, -1, 0]",
"_____no_output_____"
],
[
"plt.figure(figsize=(10, 6))\r\nplot_series(time_valid, x_valid)\r\nplot_series(time_valid, rnn_forecast)\r\n\r\n# EXPECTED OUTPUT. PLOT SHOULD SHOW PROJECTIONS FOLLOWING ORIGINAL DATA CLOSELY",
"_____no_output_____"
],
[
"tf.keras.metrics.mean_absolute_error(x_valid, rnn_forecast).numpy()\r\n\r\n# EXPECTED OUTPUT MAE < 2 -- I GOT 1.789626",
"_____no_output_____"
],
[
"print(rnn_forecast)\r\n# EXPECTED OUTPUT -- ARRAY OF VALUES IN THE LOW TEENS",
"[13.026956 12.646249 13.731774 ... 14.552678 14.632726 15.748829]\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa1e2c969c71301c40d940334e7c68d4dc47e9a
| 29,029 |
ipynb
|
Jupyter Notebook
|
exercicio_aula_27_newton_cotes_quadratura.ipynb
|
alcapriles/seven
|
1418b3660e343087152f02ba26416b3220a2f10b
|
[
"MIT"
] | null | null | null |
exercicio_aula_27_newton_cotes_quadratura.ipynb
|
alcapriles/seven
|
1418b3660e343087152f02ba26416b3220a2f10b
|
[
"MIT"
] | null | null | null |
exercicio_aula_27_newton_cotes_quadratura.ipynb
|
alcapriles/seven
|
1418b3660e343087152f02ba26416b3220a2f10b
|
[
"MIT"
] | null | null | null | 52.398917 | 19,388 | 0.790761 |
[
[
[
"### Exercícios do capítulo 24",
"_____no_output_____"
]
],
[
[
"import math\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\n%matplotlib inline",
"_____no_output_____"
],
[
"def trap(f,a,b):\n return (b-a)*(f[0]+f[1])/2\n\n\n\ndef simpson13(f,a,b):\n \n s = f[0] + 4*f[1] + f[2] \n s *= (b-a)/6\n \n \n #print(\"pontos usados:\")\n #print(\"a\")\n #print(a)\n #print(\"ponto médio\")\n #print(((b-a)/2))\n #print(\"b\")\n #print(b)\n \n \n return s\n\n\n\n\n\ndef simpson38(f,a,b):\n \n s = f[0] + 3*f[1] + 3*f[2] + f[3]\n s *= (b-a)/8\n \n #print(\"pontos usados:\")\n #print(\"a\")\n #print(a)\n #print(\"ponto médio 1\")\n #print(a + (b-a)/3 )\n #print(\"ponto médio 2\")\n #print(a + (2*(b-a)/3))\n #print(\"b\")\n #print(b)\n\n return s",
"_____no_output_____"
]
],
[
[
"<img src='241.JPG'>",
"_____no_output_____"
],
[
"<img src='242.JPG'>",
"_____no_output_____"
],
[
"Alterando para escala de 24h apenas para plotar o gráfico, para o gráfico fazer mais sentido:",
"_____no_output_____"
]
],
[
[
"h = [0,2,4,5,6,7,8,9,10.5,11.5,12.5,14,16,17,18,19,20,21,22,23,24]\nf = [2,2,0,2,6,7,23,11,4,11,12,8,7,26,20,10,8,10,8,7,3]",
"_____no_output_____"
],
[
"plt.figure(figsize=(7,7))\nplt.plot(h,f, color='blue')\nplt.grid()\nplt.show()",
"_____no_output_____"
]
],
[
[
"Retornando à escala original:",
"_____no_output_____"
],
[
"h = [0,2,4,5,6,7,8,9,10.5,11.5,12.5,2,4,5,6,7,8,9,10,11,12]\n\n\n\n\n\n\nf = [2,2,0,2,6,7,23,11,4,11,12,8,7,26,20,10,8,10,8,7,3]",
"_____no_output_____"
]
],
[
[
"taxas = []",
"_____no_output_____"
],
[
"f = [2,2,0]\n\nres = simpson13(f, 0, 4)\nprint(res)\ntaxas.append(res)",
"6.666666666666666\n"
],
[
"f = [0,2,6]\n\nres = simpson13(f, 4, 6)\nprint(res)\ntaxas.append(res)",
"4.666666666666666\n"
],
[
"f = [6,7,23,11]\n\nres = simpson38(f, 6, 9)\nprint(res)\ntaxas.append(res)",
"40.125\n"
],
[
"f = [11,4]\n\nres = trap(f, 9, 10.5)\nprint(res)\ntaxas.append(res)",
"11.25\n"
],
[
"f = [4,11,12]\n\nres = simpson13(f, 10.5, 12.5)\nprint(res)\ntaxas.append(res)",
"20.0\n"
],
[
"f = [12,8]\n\nres = trap(f, 12.5, 14)\nprint(res)\ntaxas.append(res)",
"15.0\n"
],
[
"f = [8,7]\n\nres = trap(f, 14, 16)\nprint(res)\ntaxas.append(res)",
"15.0\n"
],
[
"f = [7,26,20]\n\nres = simpson13(f, 16, 18)\nprint(res)\ntaxas.append(res)",
"43.666666666666664\n"
],
[
"f = [20,10,8]\n\nres = simpson13(f, 18, 20)\nprint(res)\ntaxas.append(res)",
"22.666666666666664\n"
],
[
"f = [8,10,8]\n\nres = simpson13(f, 20, 22)\nprint(res)\ntaxas.append(res)",
"18.666666666666664\n"
],
[
"f = [8,7,3]\n\nres = simpson13(f, 22, 24)\nprint(res)\ntaxas.append(res)",
"13.0\n"
],
[
"print(sum(taxas))",
"210.70833333333331\n"
]
],
[
[
"### Portanto, o resultado da área da curva fica igual a 210.7083. (Unidade: horas*carros/(minuto))",
"_____no_output_____"
]
],
[
[
"print(sum(taxas)/24)",
"8.779513888888888\n"
]
],
[
[
"## Portanto, dividindo o valor encontrado por 24 horas, o resultado da taxa fica igual a 8.77951 carros/minuto.",
"_____no_output_____"
],
[
"### Uma vez que o dia tem 24*60 minutos, o total de carros que passa na intersecção por dia é de:",
"_____no_output_____"
]
],
[
[
"print(8.77951*24*60)",
"12642.4944\n"
]
],
[
[
"### 12642.4944\n### Uma vez que não existe 0,49 carro, aproxima-se para 12643 carros",
"_____no_output_____"
],
[
"<img src='243.JPG'>",
"_____no_output_____"
],
[
"<img src='244.JPG'>",
"_____no_output_____"
],
[
"1481",
"_____no_output_____"
],
[
"<img src='245.JPG'>",
"_____no_output_____"
],
[
"### n = 5",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
4aa1e59eec0333e7fbfb690b9d83927d7f15ded7
| 46,251 |
ipynb
|
Jupyter Notebook
|
Project 6 - Social Media Sentiment Analyzer/SMSA.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | 1 |
2020-09-11T18:11:54.000Z
|
2020-09-11T18:11:54.000Z
|
Project 6 - Social Media Sentiment Analyzer/SMSA.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | null | null | null |
Project 6 - Social Media Sentiment Analyzer/SMSA.ipynb
|
BhuvaneshHingal/LetsUpgrade-AI-ML
|
63f7114d680b2738c9c40983996adafe55c0edd2
|
[
"MIT"
] | 1 |
2020-07-22T19:47:15.000Z
|
2020-07-22T19:47:15.000Z
| 211.191781 | 36,813 | 0.87276 |
[
[
[
"import sys,tweepy,csv,re\nfrom textblob import TextBlob\nimport matplotlib.pyplot as plt\n\n\nclass SentimentAnalysis:\n\n def __init__(self):\n self.tweets = []\n self.tweetText = []\n\n def DownloadData(self):\n # authenticating\n consumerKey = '59oDfXxmBBm22p2j3Gowy4lEE'\n consumerSecret = \"bZufUMPivqtX94xG4Bt3QmsmqyL7TsDbkW8Kuo3cGYeFfKoysY\"\n accessToken = \"3060838521-u5eXreDFHOqaxUcvTYMFyuEXImu5RlpdiY436h8\"\n accessTokenSecret = \"Q55FxITLmzlJWW4xpNbwnsW2UPXQZL4KiOWf9QdsDlYKt\"\n auth = tweepy.OAuthHandler(consumerKey, consumerSecret)\n auth.set_access_token(accessToken, accessTokenSecret)\n api = tweepy.API(auth)\n\n # input for term to be searched and how many tweets to search\n searchTerm = input(\"Enter Keyword/Tag to search about: \")\n NoOfTerms = int(input(\"Enter how many tweets to search: \"))\n\n # searching for tweets\n self.tweets = tweepy.Cursor(api.search, q=searchTerm, lang = \"en\").items(NoOfTerms)\n\n # Open/create a file to append data to\n csvFile = open('result.csv', 'a')\n\n # Use csv writer\n csvWriter = csv.writer(csvFile)\n\n\n # creating some variables to store info\n polarity = 0\n positive = 0\n wpositive = 0\n spositive = 0\n negative = 0\n wnegative = 0\n snegative = 0\n neutral = 0\n\n\n # iterating through tweets fetched\n for tweet in self.tweets:\n #Append to temp so that we can store in csv later. I use encode UTF-8\n self.tweetText.append(self.cleanTweet(tweet.text).encode('utf-8'))\n # print (tweet.text.translate(non_bmp_map)) #print tweet's text\n analysis = TextBlob(tweet.text)\n # print(analysis.sentiment) # print tweet's polarity\n polarity += analysis.sentiment.polarity # adding up polarities to find the average later\n\n if (analysis.sentiment.polarity == 0): # adding reaction of how people are reacting to find average later\n neutral += 1\n elif (analysis.sentiment.polarity > 0 and analysis.sentiment.polarity <= 0.3):\n wpositive += 1\n elif (analysis.sentiment.polarity > 0.3 and analysis.sentiment.polarity <= 0.6):\n positive += 1\n elif (analysis.sentiment.polarity > 0.6 and analysis.sentiment.polarity <= 1):\n spositive += 1\n elif (analysis.sentiment.polarity > -0.3 and analysis.sentiment.polarity <= 0):\n wnegative += 1\n elif (analysis.sentiment.polarity > -0.6 and analysis.sentiment.polarity <= -0.3):\n negative += 1\n elif (analysis.sentiment.polarity > -1 and analysis.sentiment.polarity <= -0.6):\n snegative += 1\n\n\n # Write to csv and close csv file\n csvWriter.writerow(self.tweetText)\n csvFile.close()\n\n # finding average of how people are reacting\n positive = self.percentage(positive, NoOfTerms)\n wpositive = self.percentage(wpositive, NoOfTerms)\n spositive = self.percentage(spositive, NoOfTerms)\n negative = self.percentage(negative, NoOfTerms)\n wnegative = self.percentage(wnegative, NoOfTerms)\n snegative = self.percentage(snegative, NoOfTerms)\n neutral = self.percentage(neutral, NoOfTerms)\n\n # finding average reaction\n polarity = polarity / NoOfTerms\n\n # printing out data\n print(\"How people are reacting on \" + searchTerm + \" by analyzing \" + str(NoOfTerms) + \" tweets.\")\n print()\n print(\"General Report: \")\n\n if (polarity == 0):\n print(\"Neutral\")\n elif (polarity > 0 and polarity <= 0.3):\n print(\"Weakly Positive\")\n elif (polarity > 0.3 and polarity <= 0.6):\n print(\"Positive\")\n elif (polarity > 0.6 and polarity <= 1):\n print(\"Strongly Positive\")\n elif (polarity > -0.3 and polarity <= 0):\n print(\"Weakly Negative\")\n elif (polarity > -0.6 and polarity <= -0.3):\n print(\"Negative\")\n elif (polarity > -1 and polarity <= -0.6):\n print(\"Strongly Negative\")\n\n print()\n print(\"Detailed Report: \")\n print(str(positive) + \"% people thought it was positive\")\n print(str(wpositive) + \"% people thought it was weakly positive\")\n print(str(spositive) + \"% people thought it was strongly positive\")\n print(str(negative) + \"% people thought it was negative\")\n print(str(wnegative) + \"% people thought it was weakly negative\")\n print(str(snegative) + \"% people thought it was strongly negative\")\n print(str(neutral) + \"% people thought it was neutral\")\n\n self.plotPieChart(positive, wpositive, spositive, negative, wnegative, snegative, neutral, searchTerm, NoOfTerms)\n\n\n def cleanTweet(self, tweet):\n # Remove Links, Special Characters etc from tweet\n return ' '.join(re.sub(\"(@[A-Za-z0-9]+)|([^0-9A-Za-z \\t]) | (\\w +:\\ / \\ / \\S +)\", \" \", tweet).split())\n\n # function to calculate percentage\n def percentage(self, part, whole):\n temp = 100 * float(part) / float(whole)\n return format(temp, '.2f')\n\n def plotPieChart(self, positive, wpositive, spositive, negative, wnegative, snegative, neutral, searchTerm, noOfSearchTerms):\n labels = ['Positive [' + str(positive) + '%]', 'Weakly Positive [' + str(wpositive) + '%]','Strongly Positive [' + str(spositive) + '%]', 'Neutral [' + str(neutral) + '%]',\n 'Negative [' + str(negative) + '%]', 'Weakly Negative [' + str(wnegative) + '%]', 'Strongly Negative [' + str(snegative) + '%]']\n sizes = [positive, wpositive, spositive, neutral, negative, wnegative, snegative]\n colors = ['yellowgreen','lightgreen','darkgreen', 'gold', 'red','lightsalmon','darkred']\n patches, texts = plt.pie(sizes, colors=colors, startangle=90)\n plt.legend(patches, labels, loc=\"best\")\n plt.title('How people are reacting on ' + searchTerm + ' by analyzing ' + str(noOfSearchTerms) + ' Tweets.')\n plt.axis('equal')\n plt.tight_layout()\n plt.show()\n\n\n\nif __name__== \"__main__\":\n sa = SentimentAnalysis()\n sa.DownloadData()",
"Enter Keyword/Tag to search about: BJP\nEnter how many tweets to search: 1000\nHow people are reacting on BJP by analyzing 1000 tweets.\n\nGeneral Report: \nWeakly Negative\n\nDetailed Report: \n10.60% people thought it was positive\n15.30% people thought it was weakly positive\n0.60% people thought it was strongly positive\n12.70% people thought it was negative\n9.80% people thought it was weakly negative\n1.90% people thought it was strongly negative\n48.40% people thought it was neutral\n"
]
]
] |
[
"code"
] |
[
[
"code"
]
] |
4aa1ed55362dd32b666d808ecf3f56ca4c24614e
| 108,532 |
ipynb
|
Jupyter Notebook
|
data cleaning.ipynb
|
hhlcode/pythonlearn
|
fe991ca1b7fc327f9782c483fc54496bf0d2c961
|
[
"MIT"
] | null | null | null |
data cleaning.ipynb
|
hhlcode/pythonlearn
|
fe991ca1b7fc327f9782c483fc54496bf0d2c961
|
[
"MIT"
] | null | null | null |
data cleaning.ipynb
|
hhlcode/pythonlearn
|
fe991ca1b7fc327f9782c483fc54496bf0d2c961
|
[
"MIT"
] | null | null | null | 30.563785 | 93 | 0.37084 |
[
[
[
"## <font color='blue'>数据清洗案例",
"_____no_output_____"
],
[
"### 1. 导入相关包",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n%matplotlib inline \n#jupyter notebook一定运行这一行代码,在cell中显示图形",
"_____no_output_____"
]
],
[
[
"### 2.导入数据集",
"_____no_output_____"
]
],
[
[
"df=pd.read_csv('qunar_freetrip.csv',index_col=0)",
"_____no_output_____"
],
[
"df.head(2)",
"_____no_output_____"
]
],
[
[
"### 3. 初步探索数据",
"_____no_output_____"
]
],
[
[
"#查看数据形状\ndf.shape",
"_____no_output_____"
],
[
"#快速了解数据的结构\ndf.info()",
"<class 'pandas.core.frame.DataFrame'>\nInt64Index: 5100 entries, 0 to 5099\nData columns (total 13 columns):\n # Column Non-Null Count Dtype \n--- ------ -------------- ----- \n 0 出发地 5098 non-null object \n 1 目的地 5099 non-null object \n 2 价格 5072 non-null float64\n 3 节省 5083 non-null float64\n 4 路线名 5100 non-null object \n 5 酒店 5100 non-null object \n 6 房间 5100 non-null object \n 7 去程航司 5100 non-null object \n 8 去程方式 5100 non-null object \n 9 去程时间 5100 non-null object \n 10 回程航司 5100 non-null object \n 11 回程方式 5100 non-null object \n 12 回程时间 5100 non-null object \ndtypes: float64(2), object(11)\nmemory usage: 557.8+ KB\n"
],
[
"#快速查看数据的描述性统计信息\ndf.describe() #显示数值型数据的描述统计",
"_____no_output_____"
]
],
[
[
"### 4.简单数据处理",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
],
[
"df.head(2)",
"_____no_output_____"
],
[
"col = df.columns.values",
"_____no_output_____"
],
[
"col",
"_____no_output_____"
],
[
"col[0].strip() #strip函数一次只能处理一个数据",
"_____no_output_____"
],
[
"[x.strip() for x in col]\n#strip去除前后空格",
"_____no_output_____"
],
[
"df.columns = [x.strip() for x in col]",
"_____no_output_____"
],
[
"df.columns",
"_____no_output_____"
]
],
[
[
"### 5.重复值的处理",
"_____no_output_____"
],
[
"#### 检查重复值duplicated()\nDuplicated函数功能:查找并显示数据表中的重复值 \n这里需要注意的是: \n- 当两条记录中所有的数据都相等时duplicated函数才会判断为重复值 \n- duplicated支持从前向后(first),和从后向前(last)两种重复值查找模式 \n- 默认是从前向后进行重复值的查找和判断,也就是后面的条目在重复值判断中显示为True ",
"_____no_output_____"
]
],
[
[
"#第一行数据\n#第二行数据和第一行一样\n#从前向后就把第二行数据判断为重复值\n#从后向前就把第一行数据判断为重复值",
"_____no_output_____"
],
[
"df.duplicated() #返回布尔型数据,告诉重复值的位置",
"_____no_output_____"
],
[
"df.duplicated().sum()#说明有100个重复值",
"_____no_output_____"
],
[
"#查看重复的记录\ndf[df.duplicated()]",
"_____no_output_____"
]
],
[
[
"#### 删除重复值drop_duplicates() \ndrop_duplicates函数功能是:删除数据表中的重复值,判断标准和逻辑与duplicated函数一样 ",
"_____no_output_____"
]
],
[
[
"df.drop_duplicates(inplace=True) \n#inplace=True表示直接在源数据上进行操作",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
],
[
"df",
"_____no_output_____"
],
[
"df.shape[0]",
"_____no_output_____"
],
[
"range(df.shape[0])",
"_____no_output_____"
],
[
"df.index = range(df.shape[0])",
"_____no_output_____"
],
[
"df.index",
"_____no_output_____"
]
],
[
[
"### 6.异常值的处理",
"_____no_output_____"
]
],
[
[
"df.describe().T",
"_____no_output_____"
],
[
"#找出'价格'异常值\nsta=(df['价格']-df['价格'].mean())/df['价格'].std()",
"_____no_output_____"
],
[
"sta[:10]",
"_____no_output_____"
],
[
"sta.abs()[:10]",
"_____no_output_____"
],
[
"sta.abs()>3",
"_____no_output_____"
],
[
"df[sta.abs()>3]",
"_____no_output_____"
],
[
"df.head(10)",
"_____no_output_____"
],
[
"sum(df.价格>df.节省)",
"_____no_output_____"
],
[
"#找出'节省'异常值\ndf[df.节省>df.价格]",
"_____no_output_____"
]
],
[
[
"- 对于建模来说,通常会删掉异常值 \n- 但是对于业务来说,异常值中可能包含有更多的价值",
"_____no_output_____"
]
],
[
[
"pd.concat([df[df.节省>df.价格],df[sta.abs()>3]])",
"_____no_output_____"
],
[
"pd.concat([df[df.节省>df.价格],df[sta.abs()>3]]).index",
"_____no_output_____"
],
[
"delindex = pd.concat([df[df.节省>df.价格],df[sta.abs()>3]]).index",
"_____no_output_____"
],
[
"df.drop(delindex,inplace=True)",
"_____no_output_____"
],
[
"df.shape",
"_____no_output_____"
]
],
[
[
"### 7.缺失值的处理",
"_____no_output_____"
],
[
"- df.isnull() #查看缺失值\n- df.notnull() #查看不是缺失值的数据\n- df.dropna() #删除缺失值\n- df.fillna() #填补缺失值 ",
"_____no_output_____"
]
],
[
[
"df.isnull().sum()",
"_____no_output_____"
],
[
"df[df.出发地.isnull()]",
"_____no_output_____"
],
[
"[str(x)[:2] for x in df.loc[df.出发地.isnull(),'路线名']]",
"_____no_output_____"
],
[
"df.loc[df.出发地.isnull(),'出发地'] = [str(x)[:2] for x in df.loc[df.出发地.isnull(),'路线名']]",
"_____no_output_____"
],
[
"df[df.出发地.isnull()]",
"_____no_output_____"
],
[
"df.出发地.isnull().sum()",
"_____no_output_____"
],
[
"df[df.目的地.isnull()]",
"_____no_output_____"
],
[
"str(df.loc[df.目的地.isnull(),'路线名'].values)[5:7]",
"_____no_output_____"
],
[
"df.loc[df.目的地.isnull(),'目的地'] = str(df.loc[df.目的地.isnull(),'路线名'].values)[5:7]",
"_____no_output_____"
],
[
"round(df['价格'].mean(),0)",
"_____no_output_____"
],
[
"#处理价格缺失值\ndf['价格'].fillna(round(df['价格'].mean(),0),inplace=True)",
"_____no_output_____"
],
[
"#处理节省缺失值\ndf['节省'].fillna(round(df['节省'].mean(),0),inplace=True)",
"_____no_output_____"
],
[
"df.isnull().sum()",
"_____no_output_____"
]
],
[
[
"### 8. 处理文本型数据",
"_____no_output_____"
]
],
[
[
"# 如果我们想要在一系列文本提取信息,可以使用正则表达式\n# 正则表达式通常被用来检索某个规则的文本",
"_____no_output_____"
],
[
"df.head(10)",
"_____no_output_____"
],
[
"df.酒店[:10]",
"_____no_output_____"
],
[
"df.酒店.str.extract('(\\d\\.\\d)分/5分',expand=True)[:10]",
"_____no_output_____"
],
[
"#提取酒店评分\ndf['酒店评分'] = df.酒店.str.extract('(\\d\\.\\d)分/5分',expand=False)\n\n#expand=False (return Index/Series)\n#expand=True (return DataFrame)",
"_____no_output_____"
],
[
"df.head(2)",
"_____no_output_____"
],
[
"df.酒店[:10]",
"_____no_output_____"
],
[
"df.酒店.str.extract(' (.+) ',expand=False)[:5]",
"_____no_output_____"
],
[
"#提取酒店等级\ndf['酒店等级'] = df.酒店.str.extract(' (.+) ',expand=False)#+号表示的是贪婪模式,也就是所有的数据都要提取出来",
"_____no_output_____"
],
[
"#提取天数信息\ndf['天数']=df.路线名.str.extract('(\\d+)天\\d晚',expand=False)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
]
] |
4aa1fad03bb58a0c03bba0f25576d5377442209f
| 669,538 |
ipynb
|
Jupyter Notebook
|
PCA_KMeans_All_Piscicultura.ipynb
|
christianadriano/PCA_AquacultureSystem
|
510af3829a361a217c54064816248340f37a12bb
|
[
"MIT"
] | 2 |
2021-09-25T12:55:57.000Z
|
2021-12-16T05:35:47.000Z
|
PCA_KMeans_All_Piscicultura.ipynb
|
christianadriano/PCA_AquacultureSystem
|
510af3829a361a217c54064816248340f37a12bb
|
[
"MIT"
] | null | null | null |
PCA_KMeans_All_Piscicultura.ipynb
|
christianadriano/PCA_AquacultureSystem
|
510af3829a361a217c54064816248340f37a12bb
|
[
"MIT"
] | 1 |
2021-12-16T08:40:02.000Z
|
2021-12-16T08:40:02.000Z
| 204.564009 | 137,730 | 0.833528 |
[
[
[
"<a href=\"https://colab.research.google.com/github/christianadriano/PCA_AquacultureSystem/blob/master/PCA_KMeans_All_Piscicultura.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>",
"_____no_output_____"
]
],
[
[
"import pandas as pd #tables for data wrangling\nimport numpy as np #basic statistical methods \nimport io #for uploading data\n\n#Manual option\nfrom google.colab import files\nuploaded = files.upload() #choose file dados_relativizados_centralizados_piscicultura.csv\n\n",
"_____no_output_____"
],
[
"#Upload data from cvs file\ndf = pd.read_csv(io.StringIO(uploaded['dados_relativizados_centralizados_piscicultura.csv'].decode('utf-8'))) \n#print(df)",
"_____no_output_____"
],
[
"column_names = df.columns\n#Select fatores Ambientais \nfeature_names = [name for name in column_names if name.startswith(\"E\")] \n\n#feature_names = list(df.columns[\"A2_DA\":\"A4_EUC\"])\n#print(feature_names)\nlist_names = ['fazenda'] + feature_names\ndf_cultivo = df[list_names]\ndf_cultivo.head()\n\n",
"_____no_output_____"
],
[
"#Look at correlations \nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\ncorr = df_cultivo.corr()\n\n# using a styled panda's dataframe from https://stackoverflow.com/a/42323184/1215012\ncmap = 'coolwarm'\n\ncorr.style.background_gradient(cmap, axis=1)\\\n .set_properties(**{'max-width': '80px', 'font-size': '10pt'})\\\n .set_precision(2)\\\n\n",
"/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning: pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.\n import pandas.util.testing as tm\n"
],
[
"#smaller chart\nsns.heatmap(corr, xticklabels=corr.columns, yticklabels=corr.columns, cmap='coolwarm')",
"_____no_output_____"
],
[
"#check which ones are statiscally significant\nfrom scipy.stats import pearsonr\nimport pandas as pd\n\ndef calculate_pvalues(df):\n df = df.dropna()._get_numeric_data()\n dfcols = pd.DataFrame(columns=df.columns)\n pvalues = dfcols.transpose().join(dfcols, how='outer')\n for r in df.columns:\n for c in df.columns:\n pvalues[r][c] = round(pearsonr(df[r], df[c])[1], 4)\n return pvalues\n\np_values = calculate_pvalues(df_cultivo)\n\n",
"_____no_output_____"
],
[
"#Plot p-values\ndef highlight_significant(val):\n '''\n highlight in blue only the statistically significant cells\n '''\n color = 'blue' if val < 0.05 else 'grey'\n return 'color: %s' % color\n\np_values.style.applymap(highlight_significant)",
"_____no_output_____"
],
[
"#Smaller plot of p-values\nimport matplotlib.pyplot as plt\nfrom matplotlib import colors\nimport numpy as np\n\nnp.random.seed(101)\nzvals = np.random.rand(100, 100) * 10\n\n# make a color map of fixed colors\ncmap_discrete = colors.ListedColormap(['lightblue', 'white'])\nbounds=[0,0.05,1]\nnorm_binary = colors.BoundaryNorm(bounds, cmap_discrete.N)\n\n# tell imshow about color map so that only set colors are used\nimg = plt.imshow(zvals, interpolation='nearest', origin='lower',\n cmap=cmap_discrete, norm=norm_binary)\n\nsns.heatmap(p_values, xticklabels=p_values.columns, yticklabels=p_values.columns, cmap=cmap_discrete, norm=norm_binary)",
"_____no_output_____"
]
],
[
[
"**PCA** \nNow we do the PCA ",
"_____no_output_____"
]
],
[
[
"#Normalize the data to have MEAN==0\nfrom sklearn.preprocessing import StandardScaler\n\nx = df_cultivo.iloc[:,1:].values\nx = StandardScaler().fit_transform(x) # normalizing the features\n#print(x)\n",
"_____no_output_____"
],
[
"#Run PCA \nfrom sklearn.decomposition import PCA\npca = PCA(n_components=2)\n\nprincipalComponents = pca.fit_transform(x)\nprincipalDf = pd.DataFrame(data = principalComponents\n , columns = ['principal component 1', 'principal component 2'])\nfinalDf = pd.concat([principalDf, df_cultivo[['fazenda']]], axis = 1)",
"_____no_output_____"
],
[
"#Visualize results of PCA in Two Dimensions\nimport matplotlib.pyplot as plt\nfig = plt.figure(figsize = (12,12))\nax = fig.add_subplot(1,1,1) \nax.set_xlabel('Principal Component 1', fontsize = 15)\nax.set_ylabel('Principal Component 2', fontsize = 15)\nax.set_title('2 component PCA', fontsize = 20)\ntargets = df_cultivo['fazenda'].to_numpy()\nprint(targets)\nfor target in targets:\n indicesToKeep = finalDf['fazenda'] == target\n x = finalDf.loc[indicesToKeep, 'principal component 1']\n y = finalDf.loc[indicesToKeep, 'principal component 2']\n ax.scatter(x,y,s = 100)\n ax.annotate(target, (x+0.1,y))\n\n#for name in targets: \n \nax.legend(targets, loc='top right')\nax.grid()",
"[ 1 2 3 4 5 6 7 8 10 11 12 13]\n"
],
[
"variance_list =pca.explained_variance_ratio_\nprint(\"variance explained by each component:\", variance_list)\nprint(\"total variance explained:\", sum(variance_list))\n",
"variance explained by each component: [0.41714191 0.22495845]\ntotal variance explained: 0.6421003596886915\n"
],
[
"#principal components for each indicador\n#print(principalComponents)\n#print(targets)\ndf_clustering = pd.DataFrame({'fazenda': targets, 'pc1':list(principalComponents[:,0]), 'pc2': list(principalComponents[:,1])}, columns=['fazenda', 'pc1','pc2'])\n#df_clustering",
"_____no_output_____"
],
[
"#Find clusters \nfrom sklearn.cluster import KMeans\n#4 clusters\nmodel = KMeans(4)\nmodel.fit(df_clustering.iloc[:,1:3])\n#print(model.cluster_centers_)\n\n#Plot clusters\nplt.scatter(df_clustering.iloc[:,1],df_clustering.iloc[:,2], c=model.labels_.astype(float));\nplt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1], s=50, marker=\"x\", color=\"grey\"); # Show the \n",
"_____no_output_____"
],
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')",
"_____no_output_____"
],
[
"#5 clusters\nmodel = KMeans(5)\nmodel.fit(df_clustering.iloc[:,1:3])\n#print(model.cluster_centers_)\n\n#Plot clusters\nplt.scatter(df_clustering.iloc[:,1],df_clustering.iloc[:,2], c=model.labels_.astype(float));\nplt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1], s=50, marker=\"x\", color=\"grey\"); # Show the \n",
"_____no_output_____"
]
],
[
[
"In my view, we have two large clusters and three outliers, as the graph above shows.",
"_____no_output_____"
]
],
[
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')",
"_____no_output_____"
],
[
"#6 clusters\nmodel = KMeans(6)\nmodel.fit(df_clustering.iloc[:,1:3])\n#print(model.cluster_centers_)\n\n#Plot clusters\nplt.scatter(df_clustering.iloc[:,1],df_clustering.iloc[:,2], c=model.labels_.astype(float));\nplt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1], s=50, marker=\"x\", color=\"grey\"); # Show the \n",
"_____no_output_____"
],
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')",
"_____no_output_____"
]
],
[
[
"Now we analyze 3 Principal Components\n",
"_____no_output_____"
]
],
[
[
"#Normalize the data to have MEAN==0\nfrom sklearn.preprocessing import StandardScaler\n\nx = df_cultivo.iloc[:,1:].values\nx = StandardScaler().fit_transform(x) # normalizing the features\n#print(x)",
"_____no_output_____"
],
[
"#Run PCA \nfrom sklearn.decomposition import PCA\npca = PCA(n_components=3)\n\nprincipalComponents = pca.fit_transform(x)\nprincipalDf = pd.DataFrame(data = principalComponents\n , columns = ['principal component 1', 'principal component 2','principal component 3'])\nfinalDf = pd.concat([principalDf, df_cultivo[['fazenda']]], axis = 1)",
"_____no_output_____"
],
[
"variance_list =pca.explained_variance_ratio_\nprint(\"variance explained by each component:\", variance_list)\nprint(\"total variance explained:\", sum(variance_list))",
"variance explained by each component: [0.41714191 0.22495845 0.15992274]\ntotal variance explained: 0.8020230985323334\n"
]
],
[
[
"Now we search for clusters for 3 principal components",
"_____no_output_____"
]
],
[
[
"#Find clusters \nfrom sklearn.cluster import KMeans\n#4 clusters\nmodel = KMeans(4)\nmodel.fit(df_clustering.iloc[:,1:4])\n#print(model.cluster_centers_)",
"_____no_output_____"
],
[
"#principal components for each indicador\n#print(principalComponents)\n#print(targets)\ndf_clustering = pd.DataFrame({'fazenda': targets, 'pc1':list(principalComponents[:,0]),\n 'pc2': list(principalComponents[:,1]),'pc3': list(principalComponents[:,2])},\n columns=['fazenda', 'pc1','pc2','pc3'])\n#df_clustering",
"_____no_output_____"
],
[
"#4 clusters \nfrom sklearn.cluster import KMeans\nmodel = KMeans(4)\nmodel.fit(df_clustering.iloc[:,1:4])\n#print(model.cluster_centers_)\n\n#Plot clusters\nfig = plt.figure(figsize = (12,12))\nax = fig.add_subplot(111, projection='3d')\nax.set_xlabel('Principal Component 1', fontsize = 15)\nax.set_ylabel('Principal Component 2', fontsize = 15)\nax.set_zlabel('Principal Component 3', fontsize = 15)\nax.set_title('3-components PCA', fontsize = 20)\ntargets = df_cultivo['fazenda'].to_numpy()\n\nfor target in targets:\n indicesToKeep = finalDf['fazenda'] == target\n x = finalDf.loc[indicesToKeep, 'principal component 1']\n y = finalDf.loc[indicesToKeep, 'principal component 2']\n z = finalDf.loc[indicesToKeep, 'principal component 3']\n ax.scatter(x,y,z,s = 100)\n\nax.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],model.cluster_centers_[:,2], s=150, marker='x', color=\"black\"); # Show the \n \nax.legend(targets)\nax.grid()",
"_____no_output_____"
]
],
[
[
"Now we search for clusters for the 3 principal components",
"_____no_output_____"
]
],
[
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')\n",
"_____no_output_____"
]
],
[
[
"Comparing k-means of PC12 with PC123, we see that the cluster membership changes completely.",
"_____no_output_____"
]
],
[
[
"#5 clusters \nfrom sklearn.cluster import KMeans\nmodel = KMeans(5)\nmodel.fit(df_clustering.iloc[:,1:4])\n#print(model.cluster_centers_)\n\n#Plot clusters\n#plt.scatter(df_clustering.iloc[:,1],df_clustering.iloc[:,2], c=model.labels_.astype(float));\n#plt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1], s=50, color=\"red\"); # Show the \n\nfig = plt.figure(figsize = (12,12))\nax = fig.add_subplot(111, projection='3d')\nax.set_xlabel('Principal Component 1', fontsize = 15)\nax.set_ylabel('Principal Component 2', fontsize = 15)\nax.set_zlabel('Principal Component 3', fontsize = 15)\nax.set_title('3-components PCA', fontsize = 20)\ntargets = df_cultivo['fazenda'].to_numpy()\n\nfor target in targets:\n indicesToKeep = finalDf['fazenda'] == target\n x = finalDf.loc[indicesToKeep, 'principal component 1']\n y = finalDf.loc[indicesToKeep, 'principal component 2']\n z = finalDf.loc[indicesToKeep, 'principal component 3']\n ax.scatter(x,y,z,s = 100)\n #ax.annotate(target, (x,y))\n\nax.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],model.cluster_centers_[:,2], s=150, marker='x', color=\"black\"); # Show the \n\n#for name in targets: \n \nax.legend(targets)\nax.grid()",
"_____no_output_____"
],
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')",
"_____no_output_____"
],
[
"#6 clusters \nfrom sklearn.cluster import KMeans\nmodel = KMeans(6)\nmodel.fit(df_clustering.iloc[:,1:4])\n#print(model.cluster_centers_)\n\n#Plot clusters\n#plt.scatter(df_clustering.iloc[:,1],df_clustering.iloc[:,2], c=model.labels_.astype(float));\n#plt.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1], s=50, color=\"red\"); # Show the \n\nfig = plt.figure(figsize = (12,12))\nax = fig.add_subplot(111, projection='3d')\nax.set_xlabel('Principal Component 1', fontsize = 15)\nax.set_ylabel('Principal Component 2', fontsize = 15)\nax.set_zlabel('Principal Component 3', fontsize = 15)\nax.set_title('3-components PCA', fontsize = 20)\ntargets = df_cultivo['fazenda'].to_numpy()\n\nfor target in targets:\n indicesToKeep = finalDf['fazenda'] == target\n x = finalDf.loc[indicesToKeep, 'principal component 1']\n y = finalDf.loc[indicesToKeep, 'principal component 2']\n z = finalDf.loc[indicesToKeep, 'principal component 3']\n ax.scatter(x,y,z,s = 100)\n #ax.annotate(target, (x,y))\n\nax.scatter(model.cluster_centers_[:,0], model.cluster_centers_[:,1],model.cluster_centers_[:,2], s=150, marker='x', color=\"black\"); # Show the \n\n#for name in targets: \n \nax.legend(targets)\nax.grid()",
"_____no_output_____"
],
[
"#To which cluster each point belongs?\ndf1= df_clustering.assign(cluster=pd.Series(model.labels_).values)\ndf1.sort_values(by='cluster')",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
]
] |
4aa213c6f2b27d40d26242a9468d3efd74aaa86f
| 9,722 |
ipynb
|
Jupyter Notebook
|
examples/mnist/mnist_tf.ipynb
|
bopopescu/TensorFlow_Spark_Example
|
a6f805760fc639f2fadcb784a5596c4a28e87cb8
|
[
"Apache-2.0"
] | null | null | null |
examples/mnist/mnist_tf.ipynb
|
bopopescu/TensorFlow_Spark_Example
|
a6f805760fc639f2fadcb784a5596c4a28e87cb8
|
[
"Apache-2.0"
] | null | null | null |
examples/mnist/mnist_tf.ipynb
|
bopopescu/TensorFlow_Spark_Example
|
a6f805760fc639f2fadcb784a5596c4a28e87cb8
|
[
"Apache-2.0"
] | 2 |
2020-07-23T15:15:58.000Z
|
2021-02-13T04:54:31.000Z
| 29.550152 | 371 | 0.581773 |
[
[
[
"# TensorFlowOnSpark with InputMode.TENSORFLOW",
"_____no_output_____"
],
[
"This notebook demonstrates TensorFlowOnSpark using `InputMode.TENSORFLOW`, which launches a distributed TensorFlow cluster on the Spark executors, where each TensorFlow process reads directly from disk.",
"_____no_output_____"
],
[
"### Start a Spark Standalone Cluster\n\nFirst, in a terminal/shell window, start a single-machine Spark Standalone Cluster with three workers:\n```\nexport MASTER=spark://$(hostname):7077\nexport SPARK_WORKER_INSTANCES=3\nexport CORES_PER_WORKER=1\nexport TOTAL_CORES=$((${CORES_PER_WORKER}*${SPARK_WORKER_INSTANCES})) \n${SPARK_HOME}/sbin/start-master.sh; ${SPARK_HOME}/sbin/start-slave.sh -c $CORES_PER_WORKER -m 3G ${MASTER}\n```",
"_____no_output_____"
],
[
"### Convert the MNIST zip files using Spark\n\nThis notebook assumes that you have already [downloaded the MNIST dataset](https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_Standalone#download-mnist-data). If so, you can convert it to TFRecord format as follows:\n```\nexport TFoS_HOME=</path/to/TensorFlowOnSpark>\ncd ${TFoS_HOME}\n# rm -rf examples/mnist/tfr\n${SPARK_HOME}/bin/spark-submit \\\n--master ${MASTER} \\\n${TFoS_HOME}/examples/mnist/mnist_data_setup.py \\\n--output examples/mnist/tfr \\\n--format tfr\nls -lR examples/mnist/tfr\n```",
"_____no_output_____"
],
[
"### Launch the Spark Jupyter Notebook\n\nNow, in the same terminal window, launch a Pyspark Jupyter notebook:\n```\n# export TFoS_HOME=</path/to/TensorFlowOnSpark>\ncd ${TFoS_HOME}/examples/mnist\nPYSPARK_DRIVER_PYTHON=\"jupyter\" \\\nPYSPARK_DRIVER_PYTHON_OPTS=\"notebook\" \\\npyspark --master ${MASTER} \\\n--conf spark.cores.max=${TOTAL_CORES} \\\n--conf spark.task.cpus=${CORES_PER_WORKER} \\\n--py-files ${TFoS_HOME}/examples/mnist/tf/mnist_dist.py \\\n--conf spark.executorEnv.JAVA_HOME=\"$JAVA_HOME\"\n```\n\nThis should open a Jupyter browser pointing to the directory where this notebook is hosted.\nClick on this notebook and begin executing the steps of the notebook.",
"_____no_output_____"
],
[
"NOTE: the `SparkContext` should be available as the `sc` variable. You can use it to navigate to the Spark UI's \"Executors\" tab, where you will find the logs for each Spark executor. For TensorFlowOnSpark, each executor will correspond to a specific TensorFlow instance in the cluster, and the TensorFlow logs will be reported in each executor's `stderr` logs. ",
"_____no_output_____"
]
],
[
[
"sc",
"_____no_output_____"
],
[
"from __future__ import absolute_import\nfrom __future__ import division\nfrom __future__ import print_function\n\nimport argparse\nimport subprocess\nfrom tensorflowonspark import TFCluster\n\n# main TensorFlow code for this example\nimport mnist_dist",
"_____no_output_____"
],
[
"parser = argparse.ArgumentParser()\nparser.add_argument(\"--batch_size\", help=\"number of records per batch\", type=int, default=100)\nparser.add_argument(\"--epochs\", help=\"number of epochs\", type=int, default=1)\nparser.add_argument(\"--export\", help=\"HDFS path to export model\", type=str, default=\"mnist_export\")\nparser.add_argument(\"--format\", help=\"example format: (csv2|tfr)\", choices=[\"csv2\", \"tfr\"], default=\"tfr\")\nparser.add_argument(\"--images_labels\", help=\"HDFS path to MNIST image_label files in parallelized format\")\nparser.add_argument(\"--mode\", help=\"train|inference\", default=\"train\")\nparser.add_argument(\"--model\", help=\"HDFS path to save/load model during train/test\", default=\"mnist_model\")\nparser.add_argument(\"--output\", help=\"HDFS path to save test/inference output\", default=\"predictions\")\nparser.add_argument(\"--rdma\", help=\"use rdma connection\", default=False)\nparser.add_argument(\"--readers\", help=\"number of reader/enqueue threads per worker\", type=int, default=10)\nparser.add_argument(\"--shuffle_size\", help=\"size of shuffle buffer\", type=int, default=1000)\nparser.add_argument(\"--steps\", help=\"maximum number of steps\", type=int, default=1000)\nparser.add_argument(\"--tensorboard\", help=\"launch tensorboard process\", action=\"store_true\")",
"_____no_output_____"
],
[
"num_executors = sc.defaultParallelism\nnum_executors",
"_____no_output_____"
]
],
[
[
"### Run Distributed Training",
"_____no_output_____"
]
],
[
[
"# verify training images and labels\ntrain_images_files = \"tfr/train\"\nprint(subprocess.check_output([\"ls\", \"-l\", train_images_files]).decode(\"utf-8\"))",
"_____no_output_____"
],
[
"# parse arguments for training\nargs = parser.parse_args(['--mode', 'train', \n '--steps', '600', \n '--epochs', '1',\n '--images_labels', train_images_files])\nargs",
"_____no_output_____"
],
[
"# remove any existing models\nsubprocess.call([\"rm\", \"-rf\", args.model, args.export])",
"_____no_output_____"
],
[
"# start the cluster for training\ncluster = TFCluster.run(sc, mnist_dist.map_fun, args, num_executors, 1, args.tensorboard, TFCluster.InputMode.TENSORFLOW)\n",
"_____no_output_____"
],
[
"# shutdown the cluster. \n# NOTE: this will block until all TensorFlow nodes have completed\ncluster.shutdown()",
"_____no_output_____"
],
[
"print(subprocess.check_output([\"ls\", \"-l\", args.model]).decode(\"utf-8\"))",
"_____no_output_____"
],
[
"print(subprocess.check_output([\"ls\", \"-lR\", args.export]).decode(\"utf-8\"))",
"_____no_output_____"
]
],
[
[
"### Run Distributed Inference",
"_____no_output_____"
]
],
[
[
"test_images_files = \"tfr/test\"\nprint(subprocess.check_output([\"ls\", \"-l\", test_images_files]).decode(\"utf-8\"))",
"_____no_output_____"
],
[
"#Parse arguments for inference\nargs = parser.parse_args(['--mode', 'inference',\n '--images_labels', test_images_files])\nargs",
"_____no_output_____"
],
[
"#remove existing output if any\nsubprocess.call([\"rm\", \"-rf\", args.output])",
"_____no_output_____"
],
[
"#Start the cluster for inference\ncluster = TFCluster.run(sc, mnist_dist.map_fun, args, num_executors, 1, False, TFCluster.InputMode.SPARK)",
"_____no_output_____"
],
[
"cluster.shutdown()",
"_____no_output_____"
],
[
"print(subprocess.check_output([\"ls\", \"-l\", args.output]).decode(\"utf-8\"))",
"_____no_output_____"
]
],
[
[
"### Shutdown\n\nIn your terminal/shell window, you can type `<ctrl-C>` to exit the Notebook server.\n\nThen, stop the Standalone Cluster via:\n```\n${SPARK_HOME}/sbin/stop-slave.sh; ${SPARK_HOME}/sbin/stop-master.sh\n```",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4aa219807d94f6f962727bd85141521b32ee89c3
| 15,538 |
ipynb
|
Jupyter Notebook
|
docs/source/Tutorials/Basis_2D_Plane.ipynb
|
spatala/byxtal
|
0250673f42ba2dc31337d08bb668edf8f6b78b7f
|
[
"BSD-3-Clause"
] | null | null | null |
docs/source/Tutorials/Basis_2D_Plane.ipynb
|
spatala/byxtal
|
0250673f42ba2dc31337d08bb668edf8f6b78b7f
|
[
"BSD-3-Clause"
] | 3 |
2021-04-16T12:58:23.000Z
|
2021-04-21T14:17:04.000Z
|
docs/source/Tutorials/Basis_2D_Plane.ipynb
|
spatala/byxtal
|
0250673f42ba2dc31337d08bb668edf8f6b78b7f
|
[
"BSD-3-Clause"
] | null | null | null | 42.686813 | 964 | 0.619771 |
[
[
[
"# Determine the 2D Basis of a Plane",
"_____no_output_____"
],
[
"The first step in simulating interfaces is the determination of the two-dimensional periodicity (i.e. the basis vectors) of the plane. The interfaces are two-dimensional sections of the underlying three-dimensional lattice, and hence, the interface will exhibit the periodicity of the corresponding 2D lattice of the plane. The technique to determine the basis vectors is outlined in the following article:\n\n[**An efficient algorithm for computing the primitive bases of a general lattice plane.**](https://scripts.iucr.org/cgi-bin/paper?rg5087)\nJournal of Applied Crystallography\nBanadaki, A. D., & Patala, S. (2015). , 48(2), 585-588.\n\nIn this tutorial, we will discuss the steps involved in determining the basis vectors of the 2D plane using the **byxtal** package. Please follow the installation steps (link needed!!) to acquire the byxtal package and import all the required packages that we need for completing this tutorial.",
"_____no_output_____"
],
[
"## Miller Indices and Conventions:\n\n1. Miller Indices are often used to refer to a given crystallographic plane in crystals. \n2. However, various conventions are commonly used in determining the Miller Indices that can change the indices of the plane. For example, in the FCC lattice, one could either use the cubic unit-cell or the primitive cell to index planes and directions, resulting in completely different indices for the same plane. Therefore, we would like to declare our conventions in defining the Miller Indices to avoid potential confusion. \n3. By definition, the Miller indices of a plane, denoted by $(h \\, k \\, l)$, refer to the indices of the lattice vector perpendicular to the plane expressed in the reciprocal lattice. Therefore, the indices will depend on the reference lattice used (e.g. the cubic unit-cell or the primitive cell).\n4. In the **byxtal** package, we perform the calculations in the primitve cell. The reason simply is that, in the primitive lattice, all the lattice points are expressed using integers. This helps with some of the algebraic manipulations that are preformed in the package.\n5. **Unless otherwise specified, the indices in byxtal package are in reference to the primitve cell.**\n6. In the present tutorial, we also discuss how to convert the indices from one reference frame to the other (e.g. from the primitive cell to the cubic unit-cell).\n\n\n[//]: # \"Miller Indices are defined as the reciprocal of intercepts of a crystallographic plane with the Unit Cell Basis Vectors. The confusion is often caused by the definition of the Unit Cell. In f.c.c and b.c.c lattices primitive basis vectors are non-orthogonal while the supercell basis vectors are orthogonal. Most importantly since the reciprocal and direct lattices are the identical in f.c.c and b.c.c, the Miller Indices (defined in supercell unit cell) are the same as the plane normal indices. This unique property and convenience of using an orthogonal set of basis vectors is the root cause of the bipartisan approach to defining the Miller Indices. The downfall of such an approach is the fact that it does not have much utility in other types of lattices e.g. hcp. Therefore in GBpy whenever we use the term Miller Indices, we are referring to the reciprocals of intercepts of a crystallographic plane with the primitive Basis Vectors.\"\n[//]: # (Miller Indices: reciprocal of intercepts of a crystallographic plane with the primitive Basis Vectors, or alternatively, Miller Indices: normal vector indices of the plane defined in primitive reciprocal lattice. The above interchangeable definitions are consistently used in GBpy for referring to Miller Indices. Other conventions in defining the Miller Indices are ultimately converted to the above definition. In the present tutorial we manually extract various Indices and demonstrate how they can be fed to the GBpy. In practice such conversions are not necessary as long as the user is consistent with the definitions of GBpy, and can be used for verifying the answer.)\n\nLet's start with importing the **byxtal** package and other modules that we will use in this tutorial.",
"_____no_output_____"
]
],
[
[
"import byxtal as bxt\nimport numpy as np\nfrom sympy.matrices import Matrix, eye, zeros;",
"_____no_output_____"
]
],
[
[
"## Problem Definition:\n\nIn the tutorial, we will determine the planar basis of a crystallographic plane in the FCC lattice. Consider the plane whose normal vector is along the direction $[2 3 1]$ expressed in the cubic unit-cell reference frame. Since the normal vector to the plane is provided in the orthogonal unit-cell basis, we will first determine the Miller Indices of the plane (using the primitive cell bases).",
"_____no_output_____"
],
[
"### Finding Miller Indices:\n\nA vector in the space can be expressed in any basis, of course with varying components. Vector $\\vec{v}$ in basis A can be expressed as:\n\n\\begin{equation}\n\\vec{v} = \\mathcal{B}_A v_A\n\\end{equation}\n\nSimilarly we can define the plane normal $\\vec{n}$ in any basis. For instance we can define $\\vec{n}$ in unit-cell basis ($\\mathcal{B}_{PO}$) or in primitive-cell basis $\\mathcal{B}_P$; we can write:\n\n\\begin{equation}\n\\vec{n} = \\mathcal{B}_{PO} n_{PO} = \\mathcal{B}_{P} n_{P}\n\\end{equation}\n\nThe conversion from one basis to the other can be determined by using the components of the basis vectors of one of the frames (e.g. $P$) in the other frame (e.g. $PO$):\n\n\\begin{equation}\n\\mathcal{B}_{P} = \\mathcal{B}_{PO} \\Lambda_{P}^{PO}\n\\end{equation}\n\nwhere, $\\Lambda_P^{PO}$ is a $3 \\times 3$ matrix with its columns representing the components of basis vectors of $P$ frame in the $PO$ basis. For example, for an FCC lattice, $\\Lambda_P^{PO}$ is given below.",
"_____no_output_____"
]
],
[
[
"l_p_po = 1.0 * Matrix([[0.,0.5,0.5],[0.5,0.,0.5],[0.5,0.5,0.]])\nl_p_po",
"_____no_output_____"
]
],
[
[
"We can now determine the components of the vector $\\vec{n}$ in the $P$ reference frame as follows:\n\n\\begin{align}\n\\mathcal{B}_{P} n_{P} &= \\mathcal{B}_{PO} n_{P0} \\\\ \\nonumber\n\\mathcal{B}_{PO} \\Lambda_{P}^{PO} n_{P} &= \\mathcal{B}_{PO} n_{P0} \\\\ \\nonumber\n\\Lambda_{P}^{PO} n_{P} &= \\mathcal{B}_{PO} n_{P0} \\\\ \\nonumber\nn_{P} &= \\Lambda_{PO}^{P} n_{P0}\n\\end{align}\n\nwhere $\\Lambda_{P}^{PO} = \\left( \\Lambda_{PO}^{P} \\right)^{-1}$.\n\n\n1. **To determine the Miller indices**, we have to express the components of the normal vector $\\vec{n}$ in the reference frame of the reciprocal lattice (the reciprocal of the primitive cell).\n\n2. The basis vectors of the reciprocal of the primitve lattice are denoted using the symbol $\\mathcal{B}^*_{P}$, and are given in the $PO$ reference frame as:\n\n\\begin{equation}\n\\mathcal{B}^*_{P} = \\mathcal{B}_{PO} \\Lambda_{P*}^{PO}\n\\end{equation}\n\n3. $\\Lambda_{P*}^{PO}$ can be computed using the byxtal package using the function `bxt.find_csl_dsc.reciprocal_mat()`. For the sake of convenience we abbreviate the imported module `bxt.find_csl_dsc` as `fcd`. The code is shown below.",
"_____no_output_____"
]
],
[
[
"import byxtal.find_csl_dsc as fcd\nl_rp_po = fcd.reciprocal_mat(l_p_po)\nl_rp_po",
"_____no_output_____"
]
],
[
[
"where we use the variable `l_rp_po` to represent $\\Lambda_{P*}^{PO}$. Now, we can determine the indices of $\\vec{n}$ in the $P^*$ reference frame, using equation (4) as:\n\n\\begin{equation}\nn_{P^*} = \\Lambda_{PO}^{P*} n_{P0}\n\\end{equation}\n\nUse the following code to determine the components $n_{P^*}$:",
"_____no_output_____"
]
],
[
[
"l_po_rp = (l_rp_po).inv()\nn_po = Matrix([[2], [3], [1]])\nn_rp = l_po_rp*n_po\nn_rp",
"_____no_output_____"
]
],
[
[
"Remember, that the Miller Indices ought to be integers (without common factors). We have to find a common scaling factor for all the components such that the result is going to be scalar. We have implemented a function named `int_finder` that performs this task for a variety of input types (e.g. rows and columns of matrices). For irrational numbers int_finder accepts a tolerance and performs the same operation on the closest rational number within the specified tolerance. You can find this function in the package as: `byxtal.integer_manipulations.int_finder()`. Therefore, we repeat the previous steps and pass the results to the `int_finder` function to obtain the integer Miller indices.",
"_____no_output_____"
]
],
[
[
"import byxtal.integer_manipulations as iman\nni_rp = iman.int_finder(n_rp)\nni_rp",
"_____no_output_____"
]
],
[
[
"## Finding the Planar Basis:\n\n1. From the previous section, we found the Miller Indices of an FCC plane with the normal along $n_{PO} = [2 3 1]$ to be $(4 3 5)$. \n\n2. Now all we have to do is to pass the obtained indices to `bp_basis`, which is a function that gets the Miller Indices (expressed using the primitive cell) as the input and returns a $3 \\times 2$ matrix, where the columns represent the components of the basis vectors in the primitive $(P)$ reference frame.\n\n3. Also the obtained vectors are in the [reduced form](https://en.wikipedia.org/wiki/Lenstra%E2%80%93Lenstra%E2%80%93Lov%C3%A1sz_lattice_basis_reduction_algorithm). You can find the bp_basis function in the following path: `byxtal.bp_basis.bp_basis()`. To find the basis vector of a plane with the Miller Indices of $(4 3 5)$ use the following syntax:",
"_____no_output_____"
]
],
[
[
"import byxtal.bp_basis as bpb\nl_2D_p = Matrix(bpb.bp_basis(ni_rp))\nl_2D_p",
"_____no_output_____"
]
],
[
[
"To express the obtained basis in the orthogonal basis (i.e. supercell f.c.c) one needs to perform the following conversion of bases:\n\n\\begin{equation}\n\\Lambda_{2D}^{PO} = \\Lambda_{P}^{PO} \\times \\Lambda_{2D}^{P}\n\\end{equation}\n",
"_____no_output_____"
]
],
[
[
"l_2D_po = l_p_po*l_2D_p\nl_2D_po",
"_____no_output_____"
]
],
[
[
"## Summary\n\n1. At the interface of a bicrystal, the $\\Lambda_{2D}^{PO}$ provides a basis for the interface. \n2. If the two crystals are related to each other by a $\\Sigma$-rotation, the obtained $\\Lambda_{2D}^{po}$ is the two-dimensional basis for the two-dimensional coincidence site lattice at the interface. Therefore, the bicrystal conserves its periodicity in the obtained 2D-basis. \n3. In other words the obtained basis is in fact the basis for the unit cell of the bicrystal and since it is in the reduced form, it is going to have the least skewness, hence ideal for constructing a periodic simulation box.\n\nThe above process is frquently repeated for simulation of grain boundaries. Therefore, we have developed a set of functions that make the conversion of indices more convenient and will accept various conventions for the Miller Indices. Please refer to the grain boundary 2D-CSL tutorial for how to use these functions.",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aa219ed1732719ee87f645d210c180e67cfb5d9
| 2,264 |
ipynb
|
Jupyter Notebook
|
collections.counter().ipynb
|
beertino/MyHackerRank
|
69f56ed5fbc6ea8b70bf504baac13d1cf0ef4be4
|
[
"MIT"
] | null | null | null |
collections.counter().ipynb
|
beertino/MyHackerRank
|
69f56ed5fbc6ea8b70bf504baac13d1cf0ef4be4
|
[
"MIT"
] | null | null | null |
collections.counter().ipynb
|
beertino/MyHackerRank
|
69f56ed5fbc6ea8b70bf504baac13d1cf0ef4be4
|
[
"MIT"
] | null | null | null | 22.64 | 130 | 0.498675 |
[
[
[
"from collections import Counter\n\nmyList = [1,1,2,3,4,5,3,2,3,4,2,1,2,3]\nprint(dict(Counter(myList)))",
"{1: 3, 2: 4, 3: 4, 4: 2, 5: 1}\n"
],
[
"nShoe=int(input('No of shoe'))\nshoeList=[int(x) for x in input('List of Shoes').split()]\nshoeDict=dict(Counter(shoeList))\nprint(shoeDict)\nnCustomer=int(input('No of Customer'))\nmoney=0\nfor i in range(0,nCustomer):\n size, price = [int(x) for x in input('Customer size').split()]\n print(size, price)\n try:\n if int(shoeDict[size])>=1:\n money=money+price\n shoeDict[size]=shoeDict[size]-1\n print(money)\n except KeyError:\n continue\nprint(money)",
"{2: 1, 3: 1, 4: 1, 5: 2, 6: 2, 8: 1, 7: 1, 18: 1}\n6 55\n55\n6 45\n100\n6 55\n4 40\n140\n18 60\n200\n10 50\n\n200\n"
],
[
"s, i = 's i'.split()\nprint(s)\nprint(i)",
"s\ni\n"
]
]
] |
[
"code"
] |
[
[
"code",
"code",
"code"
]
] |
4aa2266c41f02dd363f123073d4ad4f8770635a2
| 90,750 |
ipynb
|
Jupyter Notebook
|
week02_classification/seminar.ipynb
|
roman-baldaev/nlp_course
|
5e3995324018192f8f99f21937d2381bb00ebf3f
|
[
"MIT"
] | null | null | null |
week02_classification/seminar.ipynb
|
roman-baldaev/nlp_course
|
5e3995324018192f8f99f21937d2381bb00ebf3f
|
[
"MIT"
] | null | null | null |
week02_classification/seminar.ipynb
|
roman-baldaev/nlp_course
|
5e3995324018192f8f99f21937d2381bb00ebf3f
|
[
"MIT"
] | null | null | null | 41.936229 | 12,356 | 0.65632 |
[
[
[
"# Large scale text analysis with deep learning (3 points)\n\nToday we're gonna apply the newly learned tools for the task of predicting job salary.\n\n<img src=\"https://storage.googleapis.com/kaggle-competitions/kaggle/3342/media/salary%20prediction%20engine%20v2.png\" width=400px>\n\n_Special thanks to [Oleg Vasilev](https://github.com/Omrigan/) for the core assignment idea._",
"_____no_output_____"
]
],
[
[
"import numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\n%matplotlib inline",
"_____no_output_____"
]
],
[
[
"### About the challenge\nFor starters, let's download and unpack the data from [here]. \n\nYou can also get it from [yadisk url](https://yadi.sk/d/vVEOWPFY3NruT7) the competition [page](https://www.kaggle.com/c/job-salary-prediction/data) (pick `Train_rev1.*`).",
"_____no_output_____"
]
],
[
[
"# !wget https://ysda-seminars.s3.eu-central-1.amazonaws.com/Train_rev1.zip\n# !unzip Train_rev1.zip\ndata = pd.read_csv(\"./Train_rev1.csv\", index_col=None)\ndata.shape",
"_____no_output_____"
],
[
"data.head()",
"_____no_output_____"
]
],
[
[
"One problem with salary prediction is that it's oddly distributed: there are many people who are paid standard salaries and a few that get tons o money. The distribution is fat-tailed on the right side, which is inconvenient for MSE minimization.\n\nThere are several techniques to combat this: using a different loss function, predicting log-target instead of raw target or even replacing targets with their percentiles among all salaries in the training set. We gonna use logarithm for now.\n\n_You can read more [in the official description](https://www.kaggle.com/c/job-salary-prediction#description)._",
"_____no_output_____"
]
],
[
[
"data['Log1pSalary'] = np.log1p(data['SalaryNormalized']).astype('float32')\n\nplt.figure(figsize=[8, 4])\nplt.subplot(1, 2, 1)\nplt.hist(data[\"SalaryNormalized\"], bins=20);\n\nplt.subplot(1, 2, 2)\nplt.hist(data['Log1pSalary'], bins=20);",
"_____no_output_____"
]
],
[
[
"Our task is to predict one number, __Log1pSalary__.\n\nTo do so, our model can access a number of features:\n* Free text: __`Title`__ and __`FullDescription`__\n* Categorical: __`Category`__, __`Company`__, __`LocationNormalized`__, __`ContractType`__, and __`ContractTime`__.",
"_____no_output_____"
]
],
[
[
"text_columns = [\"Title\", \"FullDescription\"]\ncategorical_columns = [\"Category\", \"Company\", \"LocationNormalized\", \"ContractType\", \"ContractTime\"]\nTARGET_COLUMN = \"Log1pSalary\"\n\ndata[categorical_columns] = data[categorical_columns].fillna('NaN') # cast missing values to string \"NaN\"\n\ndata.sample(3)",
"_____no_output_____"
]
],
[
[
"### Preprocessing text data\n\nJust like last week, applying NLP to a problem begins from tokenization: splitting raw text into sequences of tokens (words, punctuation, etc).\n\n__Your task__ is to lowercase and tokenize all texts under `Title` and `FullDescription` columns. Store the tokenized data as a __space-separated__ string of tokens for performance reasons.\n\nIt's okay to use nltk tokenizers. Assertions were designed for WordPunctTokenizer, slight deviations are okay.",
"_____no_output_____"
]
],
[
[
"print(\"Raw text:\")\nprint(data[\"FullDescription\"][2::100000])",
"Raw text:\n2 Mathematical Modeller / Simulation Analyst / O...\n100002 A successful and high achieving specialist sch...\n200002 Web Designer HTML, CSS, JavaScript, Photoshop...\nName: FullDescription, dtype: object\n"
],
[
"import nltk\n#TODO YOUR CODE HERE\n\ntokenizer = nltk.tokenize.WordPunctTokenizer()\ndef tokenize(text):\n tokens = tokenizer.tokenize(str(text).lower())\n return \" \".join(tokens)",
"_____no_output_____"
],
[
"data[text_columns] = data[text_columns].applymap(tokenize)",
"_____no_output_____"
],
[
"data[\"FullDescription\"][2][:50]",
"_____no_output_____"
]
],
[
[
"Now we can assume that our text is a space-separated list of tokens:",
"_____no_output_____"
]
],
[
[
"print(\"Tokenized:\")\nprint(data[\"FullDescription\"][2::100000])\nassert data[\"FullDescription\"][2][:50] == 'mathematical modeller / simulation analyst / opera'\nassert data[\"Title\"][54321] == 'international digital account manager ( german )'",
"Tokenized:\n2 mathematical modeller / simulation analyst / o...\n100002 a successful and high achieving specialist sch...\n200002 web designer html , css , javascript , photosh...\nName: FullDescription, dtype: object\n"
],
[
"from itertools import chain\n\n# example of iterator chaining\ndescs= pd.Series(['desc1', 'desc2', 'desc3'])\ntitles= pd.Series(['title1', 'title2', 'titl3'])\n\ndesc_title_iter = chain(descs, titles)\nfor text in desc_title_iter:\n print(text)",
"desc1\ndesc2\ndesc3\ntitle1\ntitle2\ntitl3\n"
]
],
[
[
"Not all words are equally useful. Some of them are typos or rare words that are only present a few times. \n\nLet's count how many times is each word present in the data so that we can build a \"white list\" of known words.",
"_____no_output_____"
]
],
[
[
"from collections import Counter\nsentenses = chain(data[\"FullDescription\"], data[\"Title\"])\ntoken_counts = Counter(\" \".join(sentenses).split(\" \"))\n\n# Count how many times does each token occur in both \"Title\" and \"FullDescription\" in total\n#TODO <YOUR CODE>",
"_____no_output_____"
],
[
"%%time\nsentenses = chain(data[\"FullDescription\"], data[\"Title\"])\ntoken_counts = Counter(\" \".join(sentenses).split(\" \"))",
"Wall time: 13.3 s\n"
],
[
"%%time\ntoken_counts2 = Counter()\nfor row in data[text_columns].values.flatten():\n token_counts2.update(row.split())\n ",
"Wall time: 13.4 s\n"
],
[
"assert token_counts == token_counts2",
"_____no_output_____"
],
[
"print(\"Total unique tokens :\", len(token_counts))\nprint('\\n'.join(map(str, token_counts.most_common(n=5))))\nprint('...')\nprint('\\n'.join(map(str, token_counts.most_common()[-3:])))\n\nassert token_counts.most_common(1)[0][1] in range(2600000, 2700000)\nassert len(token_counts) in range(200000, 210000)\nprint('Correct!')",
"Total unique tokens : 202704\n('and', 2657388)\n('.', 2523216)\n(',', 2318606)\n('the', 2080994)\n('to', 2019884)\n...\n('improvemen', 1)\n('techniciancivil', 1)\n('mlnlycke', 1)\nCorrect!\n"
],
[
"# Let's see how many words are there for each count\nplt.hist(list(token_counts.values()), range=[0, 10**4], bins=50, log=True)\nplt.xlabel(\"Word counts\");",
"_____no_output_____"
]
],
[
[
"__Task 1.1__ Get a list of all tokens that occur at least 10 times.",
"_____no_output_____"
]
],
[
[
"min_count = 10\n\n# tokens from token_counts keys that had at least min_count occurrences throughout the dataset\ntokens = sorted(t for t, c in token_counts.items() if c >= min_count)#TODO<YOUR CODE HERE>\n\n# Add a special tokens for unknown and empty words\nUNK, PAD = \"UNK\", \"PAD\"\ntokens = [UNK, PAD] + tokens",
"_____no_output_____"
],
[
"print(\"Vocabulary size:\", len(tokens))\nassert type(tokens) == list\nassert len(tokens) in range(32000, 35000)\nassert 'me' in tokens\nassert UNK in tokens\nprint(\"Correct!\")",
"Vocabulary size: 34158\nCorrect!\n"
],
[
"for i, t in enumerate(tokens[:5]):\n print(i)\n print(t)",
"0\nUNK\n1\nPAD\n2\n\"\n3\n$\n4\n$****\n"
]
],
[
[
"__Task 1.2__ Build an inverse token index: a dictionary from token(string) to it's index in `tokens` (int)",
"_____no_output_____"
]
],
[
[
"token_to_id = {t: i for i, t in enumerate(tokens)}",
"_____no_output_____"
],
[
"assert isinstance(token_to_id, dict)\nassert len(token_to_id) == len(tokens)\nfor tok in tokens:\n assert tokens[token_to_id[tok]] == tok\n\nprint(\"Correct!\")",
"Correct!\n"
]
],
[
[
"And finally, let's use the vocabulary you've built to map text lines into neural network-digestible matrices.",
"_____no_output_____"
]
],
[
[
"UNK_IX, PAD_IX = map(token_to_id.get, [UNK, PAD])\n\ndef as_matrix(sequences, max_len=None):\n \"\"\" Convert a list of tokens into a matrix with padding \"\"\"\n if isinstance(sequences[0], str):\n sequences = list(map(str.split, sequences))\n \n max_len = min(max(map(len, sequences)), max_len or float('inf'))\n \n matrix = np.full((len(sequences), max_len), np.int32(PAD_IX))\n for i,seq in enumerate(sequences):\n row_ix = [token_to_id.get(word, UNK_IX) for word in seq[:max_len]]\n matrix[i, :len(row_ix)] = row_ix\n \n return matrix",
"_____no_output_____"
],
[
"print(\"Lines:\")\nprint('\\n'.join(data[\"Title\"][::100000].values), end='\\n\\n')\nprint(\"Matrix:\")\nprint(as_matrix(data[\"Title\"][::100000]))",
"Lines:\nengineering systems analyst\nhr assistant\nsenior ec & i engineer\n\nMatrix:\n[[10807 30161 2166 1 1]\n [15020 2844 1 1 1]\n [27645 10201 16 15215 10804]]\n"
]
],
[
[
"Now let's encode the categirical data we have.\n\nAs usual, we shall use one-hot encoding for simplicity. Kudos if you implement more advanced encodings: tf-idf, pseudo-time-series, etc.",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction import DictVectorizer\n\n# we only consider top-1k most frequent companies to minimize memory usage\ntop_companies, top_counts = zip(*Counter(data['Company']).most_common(1000))\nrecognized_companies = set(top_companies)\ndata[\"Company\"] = data[\"Company\"].apply(lambda comp: comp if comp in recognized_companies else \"Other\")\n\ncategorical_vectorizer = DictVectorizer(dtype=np.float32, sparse=False)\ncategorical_vectorizer.fit(data[categorical_columns].apply(dict, axis=1))",
"_____no_output_____"
]
],
[
[
"### The deep learning part\n\nOnce we've learned to tokenize the data, let's design a machine learning experiment.\n\nAs before, we won't focus too much on validation, opting for a simple train-test split.\n\n__To be completely rigorous,__ we've comitted a small crime here: we used the whole data for tokenization and vocabulary building. A more strict way would be to do that part on training set only. You may want to do that and measure the magnitude of changes.",
"_____no_output_____"
]
],
[
[
"from sklearn.model_selection import train_test_split\n\ndata_train, data_val = train_test_split(data, test_size=0.2, random_state=42)\ndata_train.index = range(len(data_train))\ndata_val.index = range(len(data_val))\n\nprint(\"Train size = \", len(data_train))\nprint(\"Validation size = \", len(data_val))",
"Train size = 195814\nValidation size = 48954\n"
],
[
"import torch\n\nprint(torch.cuda.is_available())\nprint(torch.cuda.get_device_name(0))",
"True\nNVIDIA GeForce GTX 1660 Ti\n"
],
[
"def to_tensors(batch, device):\n batch_tensors = dict()\n for key, arr in batch.items():\n if key in [\"FullDescription\", \"Title\"]:\n batch_tensors[key] = torch.tensor(arr, device=device, dtype=torch.int64)\n else:\n batch_tensors[key] = torch.tensor(arr, device=device)\n return batch_tensors\n\ndef make_batch(data, max_len=None, word_dropout=0, device=torch.device('cpu')):\n \"\"\"\n Creates a keras-friendly dict from the batch data.\n :param word_dropout: replaces token index with UNK_IX with this probability\n :returns: a dict with {'title' : int64[batch, title_max_len]\n \"\"\"\n batch = {}\n batch[\"Title\"] = as_matrix(data[\"Title\"].values, max_len)\n batch[\"FullDescription\"] = as_matrix(data[\"FullDescription\"].values, max_len)\n batch['Categorical'] = categorical_vectorizer.transform(data[categorical_columns].apply(dict, axis=1))\n \n if word_dropout != 0:\n batch[\"FullDescription\"] = apply_word_dropout(batch[\"FullDescription\"], 1. - word_dropout)\n \n if TARGET_COLUMN in data.columns:\n batch[TARGET_COLUMN] = data[TARGET_COLUMN].values\n \n return to_tensors(batch, device)\n\ndef apply_word_dropout(matrix, keep_prop, replace_with=UNK_IX, pad_ix=PAD_IX,):\n dropout_mask = np.random.choice(2, np.shape(matrix), p=[keep_prop, 1 - keep_prop])\n dropout_mask &= matrix != pad_ix\n return np.choose(dropout_mask, [matrix, np.full_like(matrix, replace_with)])",
"_____no_output_____"
],
[
"batch_example = make_batch(data_train[:3], max_len=10)",
"_____no_output_____"
],
[
"batch_example['Title'].shape",
"_____no_output_____"
],
[
"batch_example['FullDescription'].shape",
"_____no_output_____"
],
[
"batch_example['Categorical'].shape",
"_____no_output_____"
],
[
"batch_example[TARGET_COLUMN].shape",
"_____no_output_____"
],
[
"target = batch_example[TARGET_COLUMN]",
"_____no_output_____"
]
],
[
[
"#### Architecture\n\nOur basic model consists of three branches:\n* Title encoder\n* Description encoder\n* Categorical features encoder\n\nWe will then feed all 3 branches into one common network that predicts salary.\n\n",
"_____no_output_____"
],
[
"This clearly doesn't fit into keras' __Sequential__ interface. To build such a network, one will have to use PyTorch.",
"_____no_output_____"
]
],
[
[
"import torch\nimport torch.nn as nn\nimport torch.functional as F",
"_____no_output_____"
]
],
[
[
"### Simple NN on description",
"_____no_output_____"
]
],
[
[
"class Reorder(nn.Module):\n # helper to reorder with Conv1d specs (num_batches, n_channels (emb_size in our case), input_length)\n def forward(self, input):\n return input.permute((0, 2, 1))",
"_____no_output_____"
],
[
"def iterate_minibatches(data, batch_size=256, shuffle=True, cycle=False, device=torch.device('cpu'), **kwargs):\n \"\"\" iterates minibatches of data in random order \"\"\"\n while True:\n indices = np.arange(len(data))\n if shuffle:\n indices = np.random.permutation(indices)\n\n for start in range(0, len(indices), batch_size):\n batch = make_batch(data.iloc[indices[start : start + batch_size]], **kwargs)\n yield batch\n \n if not cycle: break",
"_____no_output_____"
]
],
[
[
"#### example of iterator usage and network layers\n",
"_____no_output_____"
]
],
[
[
"iterator = iterate_minibatches(data_train, 3)\nbatch = next(iterator)\nprint(batch['FullDescription'].shape)",
"torch.Size([3, 204])\n"
],
[
"example_emb = nn.Embedding(num_embeddings=len(tokens), embedding_dim=64)\nemb_batch = example_emb(torch.tensor(batch['FullDescription']).type(torch.LongTensor))",
"C:\\Users\\balda\\AppData\\Local\\Temp/ipykernel_11168/2775824426.py:2: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).\n emb_batch = example_emb(torch.tensor(batch['FullDescription']).type(torch.LongTensor))\n"
],
[
"emb_batch.shape",
"_____no_output_____"
],
[
"emb_batch = Reorder()(emb_batch)",
"_____no_output_____"
],
[
"emb_batch.shape",
"_____no_output_____"
],
[
"conv_l = nn.Conv1d(\n in_channels=64,\n out_channels=128,\n kernel_size=5\n)",
"_____no_output_____"
],
[
"emb_batch = conv_l(emb_batch)",
"_____no_output_____"
],
[
"emb_batch.shape",
"_____no_output_____"
],
[
"apool_l = nn.AdaptiveMaxPool1d(2)",
"_____no_output_____"
],
[
"emb_batch = apool_l(emb_batch)",
"_____no_output_____"
],
[
"emb_batch.shape",
"_____no_output_____"
]
],
[
[
"#### Create simple model as nn.Sequantial",
"_____no_output_____"
]
],
[
[
"N_TOKENS = len(tokens)\nN_CAT_FEATURES = len(categorical_vectorizer.vocabulary_)\nHID_SIZE = 64\nN_MAXIMUS = 2\n\nsimple_model = nn.Sequential()\nsimple_model.add_module('emb', nn.Embedding(\n num_embeddings=N_TOKENS,\n embedding_dim=HID_SIZE))\nsimple_model.add_module('reorder', Reorder())\nsimple_model.add_module('conv1', nn.Conv1d(\n in_channels=HID_SIZE,\n out_channels=HID_SIZE * 2,\n kernel_size=3\n))\nsimple_model.add_module('relu1', nn.ReLU())\nsimple_model.add_module('conv2', nn.Conv1d(\n in_channels=HID_SIZE * 2,\n out_channels=HID_SIZE * 2,\n kernel_size=3\n))\nsimple_model.add_module('relu2', nn.ReLU())\nsimple_model.add_module('bn1', nn.BatchNorm1d(HID_SIZE*2))\nsimple_model.add_module('adaptive_pool', nn.AdaptiveMaxPool1d(N_MAXIMUS))\nsimple_model.add_module('flatten', nn.Flatten())\nsimple_model.add_module('linear_out', nn.Linear(HID_SIZE * 2 * N_MAXIMUS, 1))",
"_____no_output_____"
],
[
"b = simple_model(torch.tensor(batch['FullDescription']).type(torch.LongTensor))",
"C:\\Users\\balda\\AppData\\Local\\Temp/ipykernel_11168/1765480579.py:1: UserWarning: To copy construct from a tensor, it is recommended to use sourceTensor.clone().detach() or sourceTensor.clone().detach().requires_grad_(True), rather than torch.tensor(sourceTensor).\n b = simple_model(torch.tensor(batch['FullDescription']).type(torch.LongTensor))\n"
],
[
"b.shape",
"_____no_output_____"
],
[
"data_train.columns",
"_____no_output_____"
],
[
"len(data_train)",
"_____no_output_____"
]
],
[
[
"#### Training simple model",
"_____no_output_____"
]
],
[
[
"from IPython.display import clear_output\nfrom random import sample\n\nN_EPOCHS = 1\ndevice = torch.device('cuda:0') if torch.cuda.is_available() else torch.device('cpu')\n\nmodel = simple_model\nmodel.to(device)\nopt = torch.optim.Adam(model.parameters())\nloss_func = nn.MSELoss()\n\nhistory = []\nfor rpoch_num in range(N_EPOCHS):\n for idx, batch in enumerate(iterate_minibatches(data_train, device=device)):\n _batch = batch['FullDescription'].to(device)\n target = batch[TARGET_COLUMN].to(device)\n \n predictions = model(_batch)\n predictions = predictions.view(predictions.size(0))\n \n loss = loss_func(target, predictions)\n loss.backward()\n opt.step()\n opt.zero_grad()\n \n history.append(loss.item())\n if (idx+1)%10 == 0:\n clear_output(True)\n plt.plot(history, label='loss')\n plt.legend()\n plt.show()",
"_____no_output_____"
]
],
[
[
"#### Simple model evaluation",
"_____no_output_____"
]
],
[
[
"model.eval()",
"_____no_output_____"
],
[
"from tqdm import tqdm, tqdm_notebook\n\n\ndef print_metrics(model, data, batch_size=256, name=\"\", **kw):\n squared_error = abs_error = num_samples = 0.0\n for batch in tqdm(\n iterate_minibatches(data, batch_size=256, shuffle=False, **kw)\n ):\n _batch = batch[\"FullDescription\"].to(device)\n targets = batch[TARGET_COLUMN].to(device)\n batch_pred = model(_batch)[:, 0]\n squared_error += loss_func(batch_pred, targets).item()\n abs_error += np.sum(np.abs(batch_pred.cpu().data.numpy() - targets.cpu().data.numpy()))\n num_samples += len(targets)\n print(\"%s results:\" % (name or \"\"))\n print(\"Mean square error: %.5f\" % (squared_error / num_samples))\n print(\"Mean absolute error: %.5f\" % (abs_error / num_samples))\n return squared_error, abs_error\n\n\nprint_metrics(model, data_train, 256, name=\"Train\", device=device)\nprint_metrics(model, data_val, 256, name=\"Val\", device=device)",
"765it [00:42, 17.88it/s]\n"
],
[
"data[TARGET_COLUMN].var()",
"_____no_output_____"
],
[
"data[TARGET_COLUMN].std()",
"_____no_output_____"
],
[
"class SalaryPredictor(nn.Module):\n def __init__(self, n_tokens=len(tokens), n_cat_features=len(categorical_vectorizer.vocabulary_), hid_size=64):\n super().__init__()\n # YOUR CODE HERE\n \n def forward(self, batch):\n # YOUR CODE HERE\n \n ",
"_____no_output_____"
],
[
"model = SalaryPredictor()",
"_____no_output_____"
],
[
"model = SalaryPredictor()\nbatch = make_batch(data_train[:100])\ncriterion = nn.MSELoss()\n\ndummy_pred = model(batch)\ndummy_loss = criterion(dummy_pred, batch[TARGET_COLUMN])\nassert dummy_pred.shape == torch.Size([100])\nassert len(torch.unique(dummy_pred)) > 20, \"model returns suspiciously few unique outputs. Check your initialization\"\nassert dummy_loss.ndim == 0 and 0. <= dummy_loss <= 250., \"make sure you minimize MSE\"",
"_____no_output_____"
]
],
[
[
"#### Training and evaluation\n\nAs usual, we gonna feed our monster with random minibatches of data. \n\nAs we train, we want to monitor not only loss function, which is computed in log-space, but also the actual error measured in dollars.",
"_____no_output_____"
],
[
"### Model training\n\nWe can now fit our model the usual minibatch way. The interesting part is that we train on an infinite stream of minibatches, produced by `iterate_minibatches` function.",
"_____no_output_____"
]
],
[
[
"import tqdm\n\nBATCH_SIZE = 16\nEPOCHS = 5\nDEVICE = torch.device('cpu')",
"_____no_output_____"
],
[
"def print_metrics(model, data, batch_size=BATCH_SIZE, name=\"\", **kw):\n squared_error = abs_error = num_samples = 0.0\n model.eval()\n with torch.no_grad():\n for batch in iterate_minibatches(data, batch_size=batch_size, shuffle=False, **kw):\n batch_pred = model(batch)\n squared_error += torch.sum(torch.square(batch_pred - batch[TARGET_COLUMN]))\n abs_error += torch.sum(torch.abs(batch_pred - batch[TARGET_COLUMN]))\n num_samples += len(batch_pred)\n mse = squared_error.detach().cpu().numpy() / num_samples\n mae = abs_error.detach().cpu().numpy() / num_samples\n print(\"%s results:\" % (name or \"\"))\n print(\"Mean square error: %.5f\" % mse)\n print(\"Mean absolute error: %.5f\" % mae)\n return mse, mae\n",
"_____no_output_____"
],
[
"model = SalaryPredictor().to(DEVICE)\ncriterion = nn.MSELoss(reduction='sum')\noptimizer = torch.optim.SGD(model.parameters(), lr=1e-4)\n\nfor epoch in range(EPOCHS):\n print(f\"epoch: {epoch}\")\n model.train()\n for i, batch in tqdm.tqdm_notebook(enumerate(\n iterate_minibatches(data_train, batch_size=BATCH_SIZE, device=DEVICE)),\n total=len(data_train) // BATCH_SIZE\n ):\n pred = model(batch)\n loss = criterion(pred, batch[TARGET_COLUMN])\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n \n print_metrics(model, data_val)\n\n ",
"_____no_output_____"
]
],
[
[
"### Bonus part: explaining model predictions\n\nIt's usually a good idea to understand how your model works before you let it make actual decisions. It's simple for linear models: just see which words learned positive or negative weights. However, its much harder for neural networks that learn complex nonlinear dependencies.\n\nThere are, however, some ways to look inside the black box:\n* Seeing how model responds to input perturbations\n* Finding inputs that maximize/minimize activation of some chosen neurons (_read more [on distill.pub](https://distill.pub/2018/building-blocks/)_)\n* Building local linear approximations to your neural network: [article](https://arxiv.org/abs/1602.04938), [eli5 library](https://github.com/TeamHG-Memex/eli5/tree/master/eli5/formatters)\n\nToday we gonna try the first method just because it's the simplest one.",
"_____no_output_____"
]
],
[
[
"def explain(model, sample, col_name='Title'):\n \"\"\" Computes the effect each word had on model predictions \"\"\"\n sample = dict(sample)\n sample_col_tokens = [tokens[token_to_id.get(tok, 0)] for tok in sample[col_name].split()]\n data_drop_one_token = pd.DataFrame([sample] * (len(sample_col_tokens) + 1))\n\n for drop_i in range(len(sample_col_tokens)):\n data_drop_one_token.loc[drop_i, col_name] = ' '.join(UNK if i == drop_i else tok\n for i, tok in enumerate(sample_col_tokens)) \n\n *predictions_drop_one_token, baseline_pred = model.predict(make_batch(data_drop_one_token))[:, 0]\n diffs = baseline_pred - predictions_drop_one_token\n return list(zip(sample_col_tokens, diffs))",
"_____no_output_____"
],
[
"from IPython.display import HTML, display_html\n\n\ndef draw_html(tokens_and_weights, cmap=plt.get_cmap(\"bwr\"), display=True,\n token_template=\"\"\"<span style=\"background-color: {color_hex}\">{token}</span>\"\"\",\n font_style=\"font-size:14px;\"\n ):\n \n def get_color_hex(weight):\n rgba = cmap(1. / (1 + np.exp(weight)), bytes=True)\n return '#%02X%02X%02X' % rgba[:3]\n \n tokens_html = [\n token_template.format(token=token, color_hex=get_color_hex(weight))\n for token, weight in tokens_and_weights\n ]\n \n \n raw_html = \"\"\"<p style=\"{}\">{}</p>\"\"\".format(font_style, ' '.join(tokens_html))\n if display:\n display_html(HTML(raw_html))\n \n return raw_html\n ",
"_____no_output_____"
],
[
"i = 36605\ntokens_and_weights = explain(model, data.loc[i], \"Title\")\ndraw_html([(tok, weight * 5) for tok, weight in tokens_and_weights], font_style='font-size:20px;');\n\ntokens_and_weights = explain(model, data.loc[i], \"FullDescription\")\ndraw_html([(tok, weight * 10) for tok, weight in tokens_and_weights]);",
"_____no_output_____"
],
[
"i = 12077\ntokens_and_weights = explain(model, data.loc[i], \"Title\")\ndraw_html([(tok, weight * 5) for tok, weight in tokens_and_weights], font_style='font-size:20px;');\n\ntokens_and_weights = explain(model, data.loc[i], \"FullDescription\")\ndraw_html([(tok, weight * 10) for tok, weight in tokens_and_weights]);",
"_____no_output_____"
],
[
"i = np.random.randint(len(data))\nprint(\"Index:\", i)\nprint(\"Salary (gbp):\", np.expm1(model.predict(make_batch(data.iloc[i: i+1]))[0, 0]))\n\ntokens_and_weights = explain(model, data.loc[i], \"Title\")\ndraw_html([(tok, weight * 5) for tok, weight in tokens_and_weights], font_style='font-size:20px;');\n\ntokens_and_weights = explain(model, data.loc[i], \"FullDescription\")\ndraw_html([(tok, weight * 10) for tok, weight in tokens_and_weights]);",
"_____no_output_____"
],
[
"from cnn import Vocab",
"_____no_output_____"
],
[
"import pathlib\nimport os\nimport sys\npathlib.Path(__name__)",
"_____no_output_____"
],
[
"import os\nos.os.getcwd()",
"_____no_output_____"
],
[
"project_path_os = os.path.dirname(os.getcwd())",
"_____no_output_____"
],
[
"project_path_os",
"_____no_output_____"
],
[
"project_path = os.path.dirname(os.getcwd())\nif project_path not in sys.path:\n sys.path.append(project_path)",
"_____no_output_____"
],
[
"sys.path",
"_____no_output_____"
],
[
"from app.vocab import Vocab",
"_____no_output_____"
],
[
"project_path.as_uri()",
"_____no_output_____"
]
],
[
[
"__Terrible start-up idea #1962:__ make a tool that automaticaly rephrases your job description (or CV) to meet salary expectations :)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
]
] |
4aa24015039ec63100b5d65908a1d2b548ffb585
| 76,743 |
ipynb
|
Jupyter Notebook
|
Train_model.ipynb
|
Draco666888/Semantic-Segmentation-of-Remote-Sensing-Images
|
0e485add683a21f1da71b5a55d912f6da83915ed
|
[
"MIT"
] | null | null | null |
Train_model.ipynb
|
Draco666888/Semantic-Segmentation-of-Remote-Sensing-Images
|
0e485add683a21f1da71b5a55d912f6da83915ed
|
[
"MIT"
] | null | null | null |
Train_model.ipynb
|
Draco666888/Semantic-Segmentation-of-Remote-Sensing-Images
|
0e485add683a21f1da71b5a55d912f6da83915ed
|
[
"MIT"
] | null | null | null | 91.143705 | 22,588 | 0.760682 |
[
[
[
"from osgeo import gdal\nimport numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nimport os\nimport datetime\nimport random\nimport xlwt\n\nimport tensorflow as tf\nfrom tensorflow.keras.models import Model\nfrom tensorflow.keras.layers import Input, BatchNormalization, Conv2D, MaxPooling2D, Dropout, concatenate, UpSampling2D\nfrom tensorflow.keras.optimizers import Adam\nfrom tensorflow.keras.callbacks import ModelCheckpoint\nfrom keras.layers import merge\nimport keras",
"_____no_output_____"
],
[
"print(gdal.__version__)",
"3.2.3\n"
],
[
"print(tf.__version__)",
"2.4.0\n"
],
[
"print(keras.__version__)",
"2.4.3\n"
]
],
[
[
"#### Asign GPU memory ",
"_____no_output_____"
]
],
[
[
"'''\nGPU == 1080ti\nCUDA version == 11.3.55\ncudnn-11.3-windows-x64-v8.2.0.53\n'''",
"_____no_output_____"
],
[
"'''\nNecessary, other wise will have error in train_generator() (index out of range)\n'''\nos.environ[\"CUDA_VISIBLE_DEVICES\"] = '0' #The first GPU\nconfig=tf.compat.v1.ConfigProto()\n# The program can only occupy up to 90% of the specified GPU memory\nconfig.gpu_options.per_process_gpu_memory_fraction = 0.9 \n#The program allocates memory on demand\nconfig.gpu_options.allow_growth = True \nsess=tf.compat.v1.Session(config=config)",
"_____no_output_____"
]
],
[
[
"#### Test GPU",
"_____no_output_____"
]
],
[
[
"os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\nprint('GPU', tf.test.is_gpu_available())\n\na = tf.constant(2.0)\nb = tf.constant(4.0)\nprint(a + b)",
"WARNING:tensorflow:From <ipython-input-7-dc3bef497b92>:3: is_gpu_available (from tensorflow.python.framework.test_util) is deprecated and will be removed in a future version.\nInstructions for updating:\nUse `tf.config.list_physical_devices('GPU')` instead.\nGPU True\ntf.Tensor(6.0, shape=(), dtype=float32)\n"
]
],
[
[
"#### Define def",
"_____no_output_____"
]
],
[
[
"def normalize(img):\n #min of each channel\n minlist = [414, 457, 408, 325, 321, 352, 273, 262, 246, 258, 151, 124, 114, 119, 108, 135, 107, 99, 117, 93, 121, 127, 125, 138, 109, 107, 97, 100, 101, 68, 62, 57]\n #max - min (channel)\n diflist = [599, 566, 615, 698, 702, 671, 750, 761, 777, 765, 872, 899, 909, 904, 915, 888, 876, 848, 906, 703, 900, 896, 872, 762, 656, 682, 672, 739, 635, 510, 445, 198]\n img = img.astype(np.float32)\n \n #make sure all data in 0~1\n #(i-min)/(max-min)\n for i in range(32):\n img[i][np.where(img[i]==0)]=minlist[i]\n img[i] = (img[i]-minlist[i])/diflist[i]\n img[i] = img[i]*255\n return img",
"_____no_output_____"
],
[
"def load_img(path):\n dataset = gdal.Open(path)\n im_width = dataset.RasterXSize\n im_height = dataset.RasterYSize\n im_data = dataset.ReadAsArray(0,0,im_width,im_height)\n \n im_data = im_data.transpose((1,2,0))\n return im_data\ndef dataPreprocess(img, label, classNum, colorDict_GRAY):\n # normalize\n img = img / 255.0\n for i in range(colorDict_GRAY.shape[0]):\n label[label == colorDict_GRAY[i][0]] = i\n # Extend the data thickness to the classNum (including background) layer\n new_label = np.zeros(label.shape + (classNum,))\n # Turn each type of flat label into a separate layer\n for i in range(classNum):\n new_label[label == i,i] = 1 \n label = new_label\n return (img, label)\n",
"_____no_output_____"
],
[
"# read .tif image\ndef readTif(fileName):\n dataset = gdal.Open(fileName)\n im_width = dataset.RasterXSize\n im_height = dataset.RasterYSize\n if dataset == None:\n print(fileName + \"file can not open\")\n return dataset\n# save .tif image\ndef writeTiff(im_data, im_geotrans, im_proj, path):\n if 'int8' in im_data.dtype.name:\n datatype = gdal.GDT_Byte\n elif 'int16' in im_data.dtype.name:\n datatype = gdal.GDT_UInt16\n else:\n datatype = gdal.GDT_Float32\n if len(im_data.shape) == 3:\n im_bands, im_height, im_width = im_data.shape\n elif len(im_data.shape) == 2:\n im_data = np.array([im_data])\n im_bands, im_height, im_width = im_data.shape\n #创建文件\n driver = gdal.GetDriverByName(\"GTiff\")\n dataset = driver.Create(path, int(im_width), int(im_height), int(im_bands), datatype)\n if(dataset!= None):\n dataset.SetGeoTransform(im_geotrans) #Write affine transformation parameters\n dataset.SetProjection(im_proj) #Write projection\n for i in range(im_bands):\n dataset.GetRasterBand(i + 1).WriteArray(im_data[i])\n del dataset",
"_____no_output_____"
],
[
"def color_dict(labelFolder, classNum):\n colorDict = []\n # Get the file name in the folder\n ImageNameList = os.listdir(labelFolder)\n for i in range(len(ImageNameList)):\n ImagePath = labelFolder + \"/\" + ImageNameList[i]\n img = cv2.imread(ImagePath).astype(np.uint32)\n img[img==255]=0\n # If it is grayscale, convert to RGB\n if(len(img.shape) == 2):\n img = cv2.cvtColor(img, cv2.COLOR_GRAY2RGB).astype(np.uint32)\n # In order to extract the unique value, convert RGB into a number\n img_new = img[:,:,0] * 1000000 + img[:,:,1] * 1000 + img[:,:,2]\n unique = np.unique(img_new)\n # Add the unique value of the i-th pixel matrix to the colorDict\n for j in range(unique.shape[0]):\n colorDict.append(unique[j])\n # Take the unique value for the unique value in the current i pixel matrix\n colorDict = sorted(set(colorDict))\n # If the number of unique values is equal to the total number of classes (including background) ClassNum, \n #stop traversing the remaining images\n if(len(colorDict) == classNum):\n break\n # RGB dictionary storing colors, used for rendering results during prediction\n colorDict_RGB = []\n for k in range(len(colorDict)):\n # Add zeros to the left of the result that does not reach nine digits\n color = str(colorDict[k]).rjust(9, '0')\n # The first 3 digits are R, the middle 3 digits are G, and the last 3 digits are B\n color_RGB = [int(color[0 : 3]), int(color[3 : 6]), int(color[6 : 9])]\n colorDict_RGB.append(color_RGB)\n colorDict_RGB = np.array(colorDict_RGB)\n # GRAY dictionary to store colors\n colorDict_GRAY = colorDict_RGB.reshape((colorDict_RGB.shape[0], 1 ,colorDict_RGB.shape[1])).astype(np.uint8)\n colorDict_GRAY = cv2.cvtColor(colorDict_GRAY, cv2.COLOR_BGR2GRAY)\n return colorDict_RGB, colorDict_GRAY",
"_____no_output_____"
],
[
"def trainGenerator(batch_size, train_image_path, train_label_path, classNum, colorDict_GRAY, resize_shape = None):\n imageList = os.listdir(train_image_path)\n labelList = os.listdir(train_label_path)\n\n img = load_img(train_image_path + \"/\" + imageList[0])\n # generate data\n while(True):\n img_generator = np.zeros((batch_size, img.shape[0], img.shape[1], img.shape[2]))\n label_generator = np.zeros((batch_size, img.shape[0], img.shape[1]), np.uint8)\n if(resize_shape != None):\n img_generator = np.zeros((batch_size, resize_shape[0], resize_shape[1], resize_shape[2]))\n label_generator = np.zeros((batch_size, resize_shape[0], resize_shape[1]), np.uint8)\n # randomly select a starting point for batch\n rand = random.randint(0, len(imageList) - batch_size)\n for j in range(batch_size): \n img = load_img(train_image_path + \"/\" + imageList[rand + j])\n #normalize\n img = img.swapaxes(1, 2)\n img = img.swapaxes(1, 0)\n \n img = normalize(img)\n \n img = img.swapaxes(1, 0)\n img = img.swapaxes(1, 2)\n\n # change shape\n if(resize_shape != None):\n img = np.resize(img, (resize_shape[0], resize_shape[1], resize_shape[2]))\n \n img_generator[j] = img\n \n label = cv2.imread(train_label_path + \"/\" + labelList[rand + j])\n label[label==255]=0\n \n # color to grayscale\n if(len(label.shape) == 3):\n label = cv2.cvtColor(label, cv2.COLOR_RGB2GRAY)\n if(resize_shape != None):\n label = cv2.resize(label, (resize_shape[0], resize_shape[1]))\n label_generator[j] = label\n img_generator, label_generator = dataPreprocess(img_generator, label_generator, classNum, colorDict_GRAY)\n yield (img_generator,label_generator)",
"_____no_output_____"
]
],
[
[
"#### Define unet",
"_____no_output_____"
]
],
[
[
"def unet(pretrained_weights = None, input_size = (256, 256, 32), classNum = 5, learning_rate = 1e-4):\n inputs = Input(input_size)\n # 2D-Dimensional Convolution Layer\n conv1 = BatchNormalization()(Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs))\n conv1 = BatchNormalization()(Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1))\n # Max Pooling to the data\n pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)\n conv2 = BatchNormalization()(Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1))\n conv2 = BatchNormalization()(Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2))\n pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)\n conv3 = BatchNormalization()(Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2))\n conv3 = BatchNormalization()(Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3))\n pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)\n conv4 = BatchNormalization()(Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3))\n conv4 = BatchNormalization()(Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4))\n # Dropout regularization and avoid overfitting\n drop4 = Dropout(0.5)(conv4)\n pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)\n \n conv5 = BatchNormalization()(Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4))\n conv5 = BatchNormalization()(Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5))\n drop5 = Dropout(0.5)(conv5)\n # transposed convolution\n up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))\n \n try:\n merge6 = concatenate([drop4,up6],axis = 3)\n except:\n merge6 = merge([drop4,up6], mode = 'concat', concat_axis = 3)\n conv6 = BatchNormalization()(Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6))\n conv6 = BatchNormalization()(Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6))\n \n up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))\n try:\n merge7 = concatenate([conv3,up7],axis = 3)\n except:\n merge7 = merge([conv3,up7], mode = 'concat', concat_axis = 3)\n conv7 = BatchNormalization()(Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7))\n conv7 = BatchNormalization()(Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7))\n \n up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))\n try:\n merge8 = concatenate([conv2,up8],axis = 3)\n except:\n merge8 = merge([conv2,up8],mode = 'concat', concat_axis = 3)\n conv8 = BatchNormalization()(Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8))\n conv8 = BatchNormalization()(Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8))\n \n up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))\n try:\n merge9 = concatenate([conv1,up9],axis = 3)\n except:\n merge9 = merge([conv1,up9],mode = 'concat', concat_axis = 3)\n conv9 = BatchNormalization()(Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9))\n conv9 = BatchNormalization()(Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9))\n conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)\n conv10 = Conv2D(classNum, 1, activation = 'softmax')(conv9)\n \n model = Model(inputs = inputs, outputs = conv10)\n \n # Used to configure the training model (optimizer, objective function, model evaluation criteria)\n model.compile(optimizer = Adam(lr = learning_rate), loss = 'categorical_crossentropy', metrics = ['accuracy'])\n \n if(pretrained_weights):\n model.load_weights(pretrained_weights)\n \n return model",
"_____no_output_____"
]
],
[
[
"#### All the parameter",
"_____no_output_____"
]
],
[
[
"'''\nPATH parameter\n'''\n# training image PATH\ntrain_image_path = \"./comp/train/imagescut\"\n# training label PATH\ntrain_label_path = \"./comp/train/labelscut\"\n# validation image PATH\nvalidation_image_path = \"./comp/train/it\"\n# validation label PATH\nvalidation_label_path = \"./comp/train/lt\"\n\n'''\nModel parameter\n'''\n# batch size\nbatch_size = 2\n# number of label\nclassNum = 5\n# shape of input images (2**n)\ninput_size = (256, 256, 32)\n# epochs\nepochs = 10\n# learning rate\nlearning_rate = 1e-2\n# pretrained model PATH\n# premodel_path = \"./Model/unet_model.hdf5\"\npremodel_path = None\n# save model PATH\nmodel_path = \"./Model/unet_model.hdf5\"\n\n# number of training set\ntrain_num = len(os.listdir(train_image_path))\n# number of validation set\nvalidation_num = len(os.listdir(validation_image_path))\n# how much batch size in each epoch for training set\nsteps_per_epoch = train_num / batch_size\n# how much batch size in each epoch for validation set\nvalidation_steps = validation_num / batch_size\n# color directory for label\ncolorDict_RGB, colorDict_GRAY = color_dict(train_label_path, classNum)",
"_____no_output_____"
]
],
[
[
"#### Model training",
"_____no_output_____"
]
],
[
[
"# get a generator to generate training data at the rate of batch_size\ntrain_Generator = trainGenerator(batch_size,\n train_image_path, \n train_label_path,\n classNum ,\n colorDict_GRAY,\n input_size)\n\n# get a generator to generate validation data at the rate of batch_size\nvalidation_data = trainGenerator(batch_size,\n validation_image_path,\n validation_label_path,\n classNum,\n colorDict_GRAY,\n input_size)\n# define the model\nmodel = unet(pretrained_weights = premodel_path, \n input_size = input_size, \n classNum = classNum, \n learning_rate = learning_rate)\n# print model structure\nmodel.summary()\n# Callback\nmodel_checkpoint = ModelCheckpoint(model_path,\n monitor = 'loss',\n verbose = 1,\n save_best_only = True)\n\n# get time\nstart_time = datetime.datetime.now()\n\n# model training\nhistory = model.fit(train_Generator,\n steps_per_epoch = steps_per_epoch,\n epochs = epochs,\n callbacks = [model_checkpoint],\n validation_data = validation_data,\n validation_steps = validation_steps)\n\n# total training time\nend_time = datetime.datetime.now()\nlog_time = \"Total training time: \" + str((end_time - start_time).seconds / 60) + \"m\"\nprint(log_time)\nwith open('TrainTime.txt','w') as f:\n f.write(log_time)",
"Model: \"model\"\n__________________________________________________________________________________________________\nLayer (type) Output Shape Param # Connected to \n==================================================================================================\ninput_1 (InputLayer) [(None, 256, 256, 32 0 \n__________________________________________________________________________________________________\nconv2d (Conv2D) (None, 256, 256, 64) 18496 input_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization (BatchNorma (None, 256, 256, 64) 256 conv2d[0][0] \n__________________________________________________________________________________________________\nconv2d_1 (Conv2D) (None, 256, 256, 64) 36928 batch_normalization[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_1 (BatchNor (None, 256, 256, 64) 256 conv2d_1[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d (MaxPooling2D) (None, 128, 128, 64) 0 batch_normalization_1[0][0] \n__________________________________________________________________________________________________\nconv2d_2 (Conv2D) (None, 128, 128, 128 73856 max_pooling2d[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_2 (BatchNor (None, 128, 128, 128 512 conv2d_2[0][0] \n__________________________________________________________________________________________________\nconv2d_3 (Conv2D) (None, 128, 128, 128 147584 batch_normalization_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_3 (BatchNor (None, 128, 128, 128 512 conv2d_3[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_1 (MaxPooling2D) (None, 64, 64, 128) 0 batch_normalization_3[0][0] \n__________________________________________________________________________________________________\nconv2d_4 (Conv2D) (None, 64, 64, 256) 295168 max_pooling2d_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_4 (BatchNor (None, 64, 64, 256) 1024 conv2d_4[0][0] \n__________________________________________________________________________________________________\nconv2d_5 (Conv2D) (None, 64, 64, 256) 590080 batch_normalization_4[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_5 (BatchNor (None, 64, 64, 256) 1024 conv2d_5[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_2 (MaxPooling2D) (None, 32, 32, 256) 0 batch_normalization_5[0][0] \n__________________________________________________________________________________________________\nconv2d_6 (Conv2D) (None, 32, 32, 512) 1180160 max_pooling2d_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_6 (BatchNor (None, 32, 32, 512) 2048 conv2d_6[0][0] \n__________________________________________________________________________________________________\nconv2d_7 (Conv2D) (None, 32, 32, 512) 2359808 batch_normalization_6[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_7 (BatchNor (None, 32, 32, 512) 2048 conv2d_7[0][0] \n__________________________________________________________________________________________________\ndropout (Dropout) (None, 32, 32, 512) 0 batch_normalization_7[0][0] \n__________________________________________________________________________________________________\nmax_pooling2d_3 (MaxPooling2D) (None, 16, 16, 512) 0 dropout[0][0] \n__________________________________________________________________________________________________\nconv2d_8 (Conv2D) (None, 16, 16, 1024) 4719616 max_pooling2d_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_8 (BatchNor (None, 16, 16, 1024) 4096 conv2d_8[0][0] \n__________________________________________________________________________________________________\nconv2d_9 (Conv2D) (None, 16, 16, 1024) 9438208 batch_normalization_8[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_9 (BatchNor (None, 16, 16, 1024) 4096 conv2d_9[0][0] \n__________________________________________________________________________________________________\ndropout_1 (Dropout) (None, 16, 16, 1024) 0 batch_normalization_9[0][0] \n__________________________________________________________________________________________________\nup_sampling2d (UpSampling2D) (None, 32, 32, 1024) 0 dropout_1[0][0] \n__________________________________________________________________________________________________\nconv2d_10 (Conv2D) (None, 32, 32, 512) 2097664 up_sampling2d[0][0] \n__________________________________________________________________________________________________\nconcatenate (Concatenate) (None, 32, 32, 1024) 0 dropout[0][0] \n conv2d_10[0][0] \n__________________________________________________________________________________________________\nconv2d_11 (Conv2D) (None, 32, 32, 512) 4719104 concatenate[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_10 (BatchNo (None, 32, 32, 512) 2048 conv2d_11[0][0] \n__________________________________________________________________________________________________\nconv2d_12 (Conv2D) (None, 32, 32, 512) 2359808 batch_normalization_10[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_11 (BatchNo (None, 32, 32, 512) 2048 conv2d_12[0][0] \n__________________________________________________________________________________________________\nup_sampling2d_1 (UpSampling2D) (None, 64, 64, 512) 0 batch_normalization_11[0][0] \n__________________________________________________________________________________________________\nconv2d_13 (Conv2D) (None, 64, 64, 256) 524544 up_sampling2d_1[0][0] \n__________________________________________________________________________________________________\nconcatenate_1 (Concatenate) (None, 64, 64, 512) 0 batch_normalization_5[0][0] \n conv2d_13[0][0] \n__________________________________________________________________________________________________\nconv2d_14 (Conv2D) (None, 64, 64, 256) 1179904 concatenate_1[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_12 (BatchNo (None, 64, 64, 256) 1024 conv2d_14[0][0] \n__________________________________________________________________________________________________\nconv2d_15 (Conv2D) (None, 64, 64, 256) 590080 batch_normalization_12[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_13 (BatchNo (None, 64, 64, 256) 1024 conv2d_15[0][0] \n__________________________________________________________________________________________________\nup_sampling2d_2 (UpSampling2D) (None, 128, 128, 256 0 batch_normalization_13[0][0] \n__________________________________________________________________________________________________\nconv2d_16 (Conv2D) (None, 128, 128, 128 131200 up_sampling2d_2[0][0] \n__________________________________________________________________________________________________\nconcatenate_2 (Concatenate) (None, 128, 128, 256 0 batch_normalization_3[0][0] \n conv2d_16[0][0] \n__________________________________________________________________________________________________\nconv2d_17 (Conv2D) (None, 128, 128, 128 295040 concatenate_2[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_14 (BatchNo (None, 128, 128, 128 512 conv2d_17[0][0] \n__________________________________________________________________________________________________\nconv2d_18 (Conv2D) (None, 128, 128, 128 147584 batch_normalization_14[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_15 (BatchNo (None, 128, 128, 128 512 conv2d_18[0][0] \n__________________________________________________________________________________________________\nup_sampling2d_3 (UpSampling2D) (None, 256, 256, 128 0 batch_normalization_15[0][0] \n__________________________________________________________________________________________________\nconv2d_19 (Conv2D) (None, 256, 256, 64) 32832 up_sampling2d_3[0][0] \n__________________________________________________________________________________________________\nconcatenate_3 (Concatenate) (None, 256, 256, 128 0 batch_normalization_1[0][0] \n conv2d_19[0][0] \n__________________________________________________________________________________________________\nconv2d_20 (Conv2D) (None, 256, 256, 64) 73792 concatenate_3[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_16 (BatchNo (None, 256, 256, 64) 256 conv2d_20[0][0] \n__________________________________________________________________________________________________\nconv2d_21 (Conv2D) (None, 256, 256, 64) 36928 batch_normalization_16[0][0] \n__________________________________________________________________________________________________\nbatch_normalization_17 (BatchNo (None, 256, 256, 64) 256 conv2d_21[0][0] \n__________________________________________________________________________________________________\nconv2d_22 (Conv2D) (None, 256, 256, 2) 1154 batch_normalization_17[0][0] \n__________________________________________________________________________________________________\nconv2d_23 (Conv2D) (None, 256, 256, 5) 15 conv2d_22[0][0] \n==================================================================================================\nTotal params: 31,073,105\nTrainable params: 31,061,329\nNon-trainable params: 11,776\n__________________________________________________________________________________________________\nEpoch 1/10\n"
]
],
[
[
"#### Accuracy and loss",
"_____no_output_____"
]
],
[
[
"# plot loss and accuracy\nacc = history.history['accuracy']\nval_acc = history.history['val_accuracy']\nloss = history.history['loss']\nval_loss = history.history['val_loss']\nbook = xlwt.Workbook(encoding='utf-8', style_compression=0)\nsheet = book.add_sheet('test', cell_overwrite_ok=True)\nfor i in range(len(acc)):\n sheet.write(i, 0, acc[i])\n sheet.write(i, 1, val_acc[i])\n sheet.write(i, 2, loss[i])\n sheet.write(i, 3, val_loss[i])\nbook.save(r'AccAndLoss.xls')\nepochs = range(1, len(acc) + 1)\nplt.plot(epochs, acc, 'r', label = 'Training acc')\nplt.plot(epochs, val_acc, 'b', label = 'Validation acc')\nplt.title('Training and validation accuracy')\nplt.legend()\nplt.savefig(\"accuracy.png\",dpi = 300)\nplt.figure()\nplt.plot(epochs, loss, 'r', label = 'Training loss')\nplt.plot(epochs, val_loss, 'b', label = 'Validation loss')\nplt.title('Training and validation loss')\nplt.legend()\nplt.savefig(\"loss.png\", dpi = 300)\nplt.show() \n",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa248994f1680cf4abbcaf043d4fc23f15459c8
| 11,155 |
ipynb
|
Jupyter Notebook
|
hacker_news_query.ipynb
|
douglaswchung/sql-practice
|
33b795db4333f5f1e55585d90888da10c8eda5c6
|
[
"MIT"
] | null | null | null |
hacker_news_query.ipynb
|
douglaswchung/sql-practice
|
33b795db4333f5f1e55585d90888da10c8eda5c6
|
[
"MIT"
] | null | null | null |
hacker_news_query.ipynb
|
douglaswchung/sql-practice
|
33b795db4333f5f1e55585d90888da10c8eda5c6
|
[
"MIT"
] | null | null | null | 74.865772 | 2,264 | 0.535007 |
[
[
[
"# Get Started\n\nAfter forking this notebook, run the code in the following cell:",
"_____no_output_____"
]
],
[
[
"# import package with helper functions \nimport bq_helper\n\n# create a helper object for this dataset\nhacker_news = bq_helper.BigQueryHelper(active_project=\"bigquery-public-data\",\n dataset_name=\"hacker_news\")\n\n# print the first couple rows of the \"comments\" table\nhacker_news.head(\"comments\")",
"_____no_output_____"
]
],
[
[
"# Question\nUsing the Hacker News dataset in BigQuery, answer the following questions:\n\n#### 1) How many stories (use the \"id\" column) are there of each type (in the \"type\" column) in the full table?",
"_____no_output_____"
]
],
[
[
"# Your Code Here\nquery = \"\"\" SELECT type, COUNT(id)\n FROM `bigquery-public-data.hacker_news.full`\n GROUP BY type\n\"\"\"\nstories_of_each_type = hacker_news.query_to_pandas_safe(query)\nstories_of_each_type.head()",
"_____no_output_____"
]
],
[
[
"#### 2) How many comments have been deleted? (If a comment was deleted the \"deleted\" column in the comments table will have the value \"True\".)",
"_____no_output_____"
]
],
[
[
"# Your Code Here\nquery = \"\"\" SELECT deleted, COUNT(id)\n FROM `bigquery-public-data.hacker_news.comments`\n GROUP BY deleted\n\"\"\"\nnum_deleted_comments = hacker_news.query_to_pandas_safe(query)\nnum_deleted_comments.head()",
"_____no_output_____"
]
],
[
[
"#### 3) Modify one of the queries you wrote above to use a different aggregate function.\nYou can read about aggregate functions other than COUNT() **[in these docs](https://cloud.google.com/bigquery/docs/reference/standard-sql/functions-and-operators#aggregate-functions)**",
"_____no_output_____"
]
],
[
[
"# Your Code Here\nquery = \"\"\" SELECT type, MAX(time)\n FROM `bigquery-public-data.hacker_news.full`\n GROUP BY type\n\"\"\"\nlatest_time_of_each_type = hacker_news.query_to_pandas_safe(query)\nlatest_time_of_each_type.head()",
"_____no_output_____"
]
],
[
[
"---\n\n# Keep Going\n[Click here](https://www.kaggle.com/dansbecker/order-by) to move on and learn about the ORDER BY clause.\n\n# Feedback\nBring any questions or feedback to the [Learn Discussion Forum](kaggle.com/learn-forum).\n\n----\n\n*This exercise is part of the [SQL Series](https://www.kaggle.com/learn/sql) on Kaggle Learn.*",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aa24948c2bede8edf02c2e6bad603f4a439f8ff
| 15,733 |
ipynb
|
Jupyter Notebook
|
scripts/eval3.ipynb
|
MariaCout0/si
|
77c0e6923f4c099bf5c698a0c943a11e37b7b24b
|
[
"Apache-2.0"
] | null | null | null |
scripts/eval3.ipynb
|
MariaCout0/si
|
77c0e6923f4c099bf5c698a0c943a11e37b7b24b
|
[
"Apache-2.0"
] | null | null | null |
scripts/eval3.ipynb
|
MariaCout0/si
|
77c0e6923f4c099bf5c698a0c943a11e37b7b24b
|
[
"Apache-2.0"
] | null | null | null | 25.092504 | 86 | 0.385241 |
[
[
[
"# Ensemble (voting)",
"_____no_output_____"
]
],
[
[
"import os\nos.chdir('C:\\\\Users\\\\MJ Couto\\\\Desktop\\\\sib_git\\\\si\\\\src')",
"_____no_output_____"
],
[
"from si.data import Dataset\nfrom si.util import util \nfrom si.util.util import summary\nfrom si.util.cv import CrossValidationScore",
"_____no_output_____"
],
[
"DIR = os.path.dirname(os.path.realpath('.'))\nfilename = os.path.join(DIR, 'datasets/breast-bin.data')\ndataset = Dataset.from_data(filename)\nsummary(dataset)",
"_____no_output_____"
],
[
"# Use accuracy as scorring function\nfrom si.util.metrics import accuracy_score",
"_____no_output_____"
]
],
[
[
"### Decision Tree",
"_____no_output_____"
]
],
[
[
"from si.supervised.dt import DecisionTree",
"_____no_output_____"
],
[
"dt = DecisionTree()",
"_____no_output_____"
],
[
"cv = CrossValidationScore(dt,dataset,score=accuracy_score)\ncv.run()\ncv.toDataframe()",
"_____no_output_____"
]
],
[
[
"### Logistic regression",
"_____no_output_____"
]
],
[
[
"from si.supervised.logreg import LogisticRegression\nlogreg = LogisticRegression()\n",
"_____no_output_____"
],
[
"cv = CrossValidationScore(logreg,dataset,score=accuracy_score)\ncv.run()\ncv.toDataframe()",
"_____no_output_____"
]
],
[
[
"### KNN",
"_____no_output_____"
]
],
[
[
"from si.supervised.knn import KNN",
"_____no_output_____"
],
[
"knn = KNN(7)",
"_____no_output_____"
],
[
"cv = CrossValidationScore(knn,dataset,score=accuracy_score)\ncv.run()\ncv.toDataframe()",
"_____no_output_____"
]
],
[
[
"## Ensemble",
"_____no_output_____"
]
],
[
[
"def fvote(preds):\n return max(set(preds), key=preds.count)",
"_____no_output_____"
],
[
"from si.supervised.ensemble import Ensemble\nen = Ensemble([dt,logreg,knn],fvote,accuracy_score)",
"_____no_output_____"
],
[
"cv = CrossValidationScore(en,dataset,score=accuracy_score)\ncv.run()\ncv.toDataframe()",
"_____no_output_____"
]
],
[
[
"## Confusion Matrix",
"_____no_output_____"
]
],
[
[
"from si.util.metrics import ConfusionMatrix\ncm = ConfusionMatrix(cv.true_Y, cv.pred_Y)\ncm.toDataframe()",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown"
],
[
"code",
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code"
],
[
"markdown"
],
[
"code"
]
] |
4aa251ab28f1d500b64adbf508597dce2b727406
| 11,644 |
ipynb
|
Jupyter Notebook
|
openmdao/docs/openmdao_book/features/warning_control/warnings.ipynb
|
sebasgo/OpenMDAO
|
b78d840780b73209dc3a00a2fb3dbf729bfeb8d5
|
[
"Apache-2.0"
] | null | null | null |
openmdao/docs/openmdao_book/features/warning_control/warnings.ipynb
|
sebasgo/OpenMDAO
|
b78d840780b73209dc3a00a2fb3dbf729bfeb8d5
|
[
"Apache-2.0"
] | null | null | null |
openmdao/docs/openmdao_book/features/warning_control/warnings.ipynb
|
sebasgo/OpenMDAO
|
b78d840780b73209dc3a00a2fb3dbf729bfeb8d5
|
[
"Apache-2.0"
] | null | null | null | 37.928339 | 228 | 0.505754 |
[
[
[
"try:\n import openmdao.api as om\nexcept ImportError:\n !python -m pip install openmdao[notebooks]\n import openmdao.api as om",
"_____no_output_____"
]
],
[
[
"# Warning Control\n\nOpenMDAO has several classes of warnings that may be raised during operation.\nIn general, these warnings are useful and the user should pay attention to them.\nSometimes these warnings can be unnecessarily noisy.\nFiltering out noisy \"low-priority\" warnings can make other more important ones more obvious.\n\n(om_specific_warning_categories)=\n## OpenMDAO-Specific Warning Categories\n\nClass **OpenMDAOWarning** serves as the base-class for all OpenMDAO-specific warnings.\nAll OpenMDAO-specific warnings default to a filter of 'always'. The following table shows all OpenMDAOWarning-derived classes.\n\n| Warning Class | Description |\n|-----------------------|-------------------------------------------------------------------------------------|\n| CacheWarning | Issued when cache is invalid and must be discarded. |\n| CaseRecorderWarning | Issued when a problem is encountered by a case recorder or case reader. |\n| DerivativesWarning | Issued when the approximated partials or coloring cannot be evaluated as expected. |\n| DriverWarning | Issued when a problem is encountered during driver execution. |\n| OMDeprecationWarning | Issued when a deprecated OpenMDAO feature is used. |\n| SetupWarning | Issued when a problem is encountered during setup. |\n| SolverWarning | Issued when a problem is encountered during solver execution. |\n| UnusedOptionWarning | Issued when a given option or argument has no effect. |\n\nNote that the OpenMDAO-Specific **OMDeprecationWarning** behaves a bit differently than the default Python DeprecationWarning. **OMDeprecationWarning** is is always displayed by default, but can be silenced by the user.\n\nFor finer control over which warnings are displayed during setup, the following warning classes derive from **SetupWarning**. Using a filter to silence SetupWarning will silence **all** of the following.\n\n| Warning Class | Description |\n|-----------------------------|----------------------------------------------------------------------|\n| DistributedComponentWarning | Issued when problems arise with a distributed component. |\n| MPIWarning | Issued when MPI is not available or cannot be used. |\n| PromotionWarning | Issued when there is ambiguity due to variable promotion. |\n| UnitsWarning | Issued when unitless variable is connected to a variable with units. |\n\n(filtering_warnings)=\n## Filtering Warnings\n\nPython's built-in warning filtering system can be used to control which warnings are displayed when using OpenMDAO.\nThe following script generates an OpenMDAO model which will generate UnitsWarning due to connecting unitless outputs to inputs with units.\n\nIn the following code, the UnitsWarning will be displayed as expected:",
"_____no_output_____"
]
],
[
[
"\"\"\"\nTest nominal UnitsWarning.\n\"\"\"\nimport warnings\n\nclass AComp(om.ExplicitComponent):\n\n def initialize(self):\n pass\n\n def setup(self):\n self.add_input('a', shape=(10,), units='m')\n self.add_input('x', shape=(10,), units='1/s')\n self.add_input('b', shape=(10,), units='m/s')\n\n self.add_output('y', shape=(10,), units='m')\n self.add_output('z', shape=(10,), units='m/s')\n\n self.declare_coloring(wrt='*', form='cs')\n\n def compute(self, inputs, outputs):\n outputs['y'] = inputs['a'] * inputs['x'] + inputs['b']\n outputs['z'] = inputs['b'] * inputs['x']\n\np = om.Problem()\n\np.model.add_subsystem('a_comp', AComp())\np.model.add_subsystem('exec_comp',\n om.ExecComp('foo = y + z',\n y={'shape': (10,)},\n z={'shape': (10,)},\n foo={'shape': (10,)}))\n\np.model.connect('a_comp.y', 'exec_comp.y')\np.model.connect('a_comp.z', 'exec_comp.z')\np.driver.declare_coloring()\n\np.setup()\n\nwith warnings.catch_warnings(record=True) as w:\n p.setup()\n unit_warnings = [wm for wm in w if wm.category is om.UnitsWarning]\n assert(len(unit_warnings) == 2)",
"_____no_output_____"
]
],
[
[
"The warnings can be completely turned off by filtering them using Python’s filterwarnings function:",
"_____no_output_____"
]
],
[
[
"\"\"\"\nTest the ability to ignore UnitsWarning\n\"\"\"\nimport warnings\nimport openmdao.api as om\n\nclass AComp(om.ExplicitComponent):\n\n def initialize(self):\n pass\n\n def setup(self):\n self.add_input('a', shape=(10,), units='m')\n self.add_input('x', shape=(10,), units='1/s')\n self.add_input('b', shape=(10,), units='m/s')\n\n self.add_output('y', shape=(10,), units='m')\n self.add_output('z', shape=(10,), units='m/s')\n\n self.declare_coloring(wrt='*', form='cs')\n\n def compute(self, inputs, outputs):\n outputs['y'] = inputs['a'] * inputs['x'] + inputs['b']\n outputs['z'] = inputs['b'] * inputs['x']\n\np = om.Problem()\n\np.model.add_subsystem('a_comp', AComp())\np.model.add_subsystem('exec_comp',\n om.ExecComp('foo = y + z',\n y={'shape': (10,)},\n z={'shape': (10,)},\n foo={'shape': (10,)}))\n\np.model.connect('a_comp.y', 'exec_comp.y')\np.model.connect('a_comp.z', 'exec_comp.z')\np.driver.declare_coloring()\n\nwarnings.filterwarnings('ignore', category=om.UnitsWarning)\n\nwith warnings.catch_warnings(record=True) as w:\n p.setup()\n unit_warnings = [wm for wm in w if wm.category is om.UnitsWarning]\n assert (len(unit_warnings) == 0)",
"_____no_output_____"
]
],
[
[
"If you want to clean your code and remove warnings, it can be useful to promote them to errors so that they cannot be ignored. The following code filters **all** OpenMDAO associated warnings to Errors:",
"_____no_output_____"
]
],
[
[
"\"\"\"\nTest the ability to raise a UnitWarning to an error.\n\"\"\"\nimport warnings\nimport openmdao.api as om\n\nclass AComp(om.ExplicitComponent):\n\n def initialize(self):\n pass\n\n def setup(self):\n self.add_input('a', shape=(10,), units='m')\n self.add_input('x', shape=(10,), units='1/s')\n self.add_input('b', shape=(10,), units='m/s')\n\n self.add_output('y', shape=(10,), units='m')\n self.add_output('z', shape=(10,), units='m/s')\n\n self.declare_coloring(wrt='*', form='cs')\n\n def compute(self, inputs, outputs):\n outputs['y'] = inputs['a'] * inputs['x'] + inputs['b']\n outputs['z'] = inputs['b'] * inputs['x']\n\np = om.Problem()\n\np.model.add_subsystem('a_comp', AComp())\np.model.add_subsystem('exec_comp',\n om.ExecComp('foo = y + z',\n y={'shape': (10,)},\n z={'shape': (10,)},\n foo={'shape': (10,)}))\n\np.model.connect('a_comp.y', 'exec_comp.y')\np.model.connect('a_comp.z', 'exec_comp.z')\np.driver.declare_coloring()\n\nwarnings.filterwarnings('error', category=om.OpenMDAOWarning)\n\nexpected = \"<model> <class Group>: Output 'a_comp.y' with units of 'm' is connected to \" \\\n \"input 'exec_comp.y' which has no units.\"\n\ntry:\n p.setup()\nexcept om.UnitsWarning as e:\n if str(e) != expected:\n raise RuntimeError(f\"{str(e.exception)} != {expected}\")\n else:\n print(str(e))\nelse:\n raise RuntimeError(f\"Exception '{expected}' not raised\")",
"_____no_output_____"
]
],
[
[
"(notes_for_developers)=\n## Notes for Developers\n\nPython's treatment of warnings inside UnitTest tests can be somewhat confusing.\nIf you wish to test that certain warnings are filtered during testing, we recommend using the `om.reset_warnings()` method in the `setUp` method that is run before each test in a `TestCase`.\n\n```python\n import unittest\n import openmdao.api as om\n\n class MyTestCase(unittest.TestCase):\n\n def setUp(self):\n \"\"\"\n Ensure that OpenMDAO warnings are using their default filter action.\n \"\"\"\n om.reset_warnings()\n\n def test_a(self):\n ...\n```",
"_____no_output_____"
]
]
] |
[
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
]
] |
4aa254bf96377571d1e4df85b001562108a2c4d6
| 21,595 |
ipynb
|
Jupyter Notebook
|
week2/Linear Algebra, Distance and Similarity (Completed).ipynb
|
lynkeib/dso-560-nlp-and-text-analytics
|
9fa1314b2ed32a51fa41443f40bf549e4320948d
|
[
"MIT"
] | null | null | null |
week2/Linear Algebra, Distance and Similarity (Completed).ipynb
|
lynkeib/dso-560-nlp-and-text-analytics
|
9fa1314b2ed32a51fa41443f40bf549e4320948d
|
[
"MIT"
] | null | null | null |
week2/Linear Algebra, Distance and Similarity (Completed).ipynb
|
lynkeib/dso-560-nlp-and-text-analytics
|
9fa1314b2ed32a51fa41443f40bf549e4320948d
|
[
"MIT"
] | null | null | null | 36.233221 | 4,398 | 0.582218 |
[
[
[
"<h1>Table of Contents<span class=\"tocSkip\"></span></h1>\n<div class=\"toc\"><ul class=\"toc-item\"><li><span><a href=\"#Linear-Algebra\" data-toc-modified-id=\"Linear-Algebra-1\"><span class=\"toc-item-num\">1 </span>Linear Algebra</a></span><ul class=\"toc-item\"><li><span><a href=\"#Dot-Products\" data-toc-modified-id=\"Dot-Products-1.1\"><span class=\"toc-item-num\">1.1 </span>Dot Products</a></span><ul class=\"toc-item\"><li><span><a href=\"#What-does-a-dot-product-conceptually-mean?\" data-toc-modified-id=\"What-does-a-dot-product-conceptually-mean?-1.1.1\"><span class=\"toc-item-num\">1.1.1 </span>What does a dot product conceptually mean?</a></span></li></ul></li><li><span><a href=\"#Exercises\" data-toc-modified-id=\"Exercises-1.2\"><span class=\"toc-item-num\">1.2 </span>Exercises</a></span></li><li><span><a href=\"#Using-Scikit-Learn\" data-toc-modified-id=\"Using-Scikit-Learn-1.3\"><span class=\"toc-item-num\">1.3 </span>Using Scikit-Learn</a></span></li><li><span><a href=\"#Bag-of-Words-Models\" data-toc-modified-id=\"Bag-of-Words-Models-1.4\"><span class=\"toc-item-num\">1.4 </span>Bag of Words Models</a></span></li></ul></li><li><span><a href=\"#Distance-Measures\" data-toc-modified-id=\"Distance-Measures-2\"><span class=\"toc-item-num\">2 </span>Distance Measures</a></span><ul class=\"toc-item\"><li><span><a href=\"#Euclidean-Distance\" data-toc-modified-id=\"Euclidean-Distance-2.1\"><span class=\"toc-item-num\">2.1 </span>Euclidean Distance</a></span><ul class=\"toc-item\"><li><span><a href=\"#Scikit-Learn\" data-toc-modified-id=\"Scikit-Learn-2.1.1\"><span class=\"toc-item-num\">2.1.1 </span>Scikit Learn</a></span></li></ul></li></ul></li><li><span><a href=\"#Similarity-Measures\" data-toc-modified-id=\"Similarity-Measures-3\"><span class=\"toc-item-num\">3 </span>Similarity Measures</a></span><ul class=\"toc-item\"><li><span><a href=\"#Cosine-Similarity\" data-toc-modified-id=\"Cosine-Similarity-3.1\"><span class=\"toc-item-num\">3.1 </span>Cosine Similarity</a></span><ul class=\"toc-item\"><li><span><a href=\"#Shift-Invariance\" data-toc-modified-id=\"Shift-Invariance-3.1.1\"><span class=\"toc-item-num\">3.1.1 </span>Shift Invariance</a></span></li></ul></li></ul></li><li><span><a href=\"#Exercise-(20-minutes):\" data-toc-modified-id=\"Exercise-(20-minutes):-4\"><span class=\"toc-item-num\">4 </span><span style=\"background-color: #ffff00\">Exercise (20 minutes):</span></a></span><ul class=\"toc-item\"><li><ul class=\"toc-item\"><li><ul class=\"toc-item\"><li><span><a href=\"#3.-Define-your-cosine-similarity-functions\" data-toc-modified-id=\"3.-Define-your-cosine-similarity-functions-4.0.0.1\"><span class=\"toc-item-num\">4.0.0.1 </span>3. Define your cosine similarity functions</a></span></li><li><span><a href=\"#4.-Get-the-two-documents-from-the-BoW-feature-space-and-calculate-cosine-similarity\" data-toc-modified-id=\"4.-Get-the-two-documents-from-the-BoW-feature-space-and-calculate-cosine-similarity-4.0.0.2\"><span class=\"toc-item-num\">4.0.0.2 </span>4. Get the two documents from the BoW feature space and calculate cosine similarity</a></span></li></ul></li></ul></li></ul></li><li><span><a href=\"#Challenge:-Use-the-Example-Below-to-Create-Your-Own-Cosine-Similarity-Function\" data-toc-modified-id=\"Challenge:-Use-the-Example-Below-to-Create-Your-Own-Cosine-Similarity-Function-5\"><span class=\"toc-item-num\">5 </span>Challenge: Use the Example Below to Create Your Own Cosine Similarity Function</a></span><ul class=\"toc-item\"><li><ul class=\"toc-item\"><li><span><a href=\"#Create-a-list-of-all-the-vocabulary-$V$\" data-toc-modified-id=\"Create-a-list-of-all-the-vocabulary-$V$-5.0.1\"><span class=\"toc-item-num\">5.0.1 </span>Create a list of all the <strong>vocabulary $V$</strong></a></span><ul class=\"toc-item\"><li><span><a href=\"#Native-Implementation:\" data-toc-modified-id=\"Native-Implementation:-5.0.1.1\"><span class=\"toc-item-num\">5.0.1.1 </span>Native Implementation:</a></span></li></ul></li><li><span><a href=\"#Create-your-Bag-of-Words-model\" data-toc-modified-id=\"Create-your-Bag-of-Words-model-5.0.2\"><span class=\"toc-item-num\">5.0.2 </span>Create your Bag of Words model</a></span></li></ul></li></ul></li></ul></div>",
"_____no_output_____"
],
[
"# Linear Algebra\n\nIn the natural language processing, each document is a vector of numbers.\n\n\n## Dot Products\n\nA dot product is defined as\n\n$ a \\cdot b = \\sum_{i}^{n} a_{i}b_{i} = a_{1}b_{1} + a_{2}b_{2} + a_{3}b_{3} + \\dots + a_{n}b_{n}$\n\nThe geometric definition of a dot product is \n\n$ a \\cdot b = $\\|\\|b\\|\\|\\|\\|a\\|\\|\n\n### What does a dot product conceptually mean?\n\nA dot product is a representation of the **similarity between two components**, because it is calculated based upon shared elements. It tells you how much one vector goes in the direction of another vector.\n\nThe actual value of a dot product reflects the direction of change:\n\n* **Zero**: we don't have any growth in the original direction\n* **Positive** number: we have some growth in the original direction\n* **Negative** number: we have negative (reverse) growth in the original direction",
"_____no_output_____"
]
],
[
[
"A = [0,2]\nB = [0,1]\n\ndef dot_product(x,y):\n return sum(a*b for a,b in zip(x,y))\n\ndot_product(A,B)\n# What will the dot product of A and B be?",
"_____no_output_____"
]
],
[
[
"",
"_____no_output_____"
],
[
"## Exercises",
"_____no_output_____"
],
[
"What will the dot product of `A` and `B` be?",
"_____no_output_____"
]
],
[
[
"A = [1,2]\nB = [2,4]\ndot_product(A,B)",
"_____no_output_____"
]
],
[
[
"What will the dot product of `document_1` and `document_2` be?",
"_____no_output_____"
]
],
[
[
"document_1 = [0, 0, 1]\ndocument_2 = [1, 0, 2]",
"_____no_output_____"
]
],
[
[
"## Using Scikit-Learn",
"_____no_output_____"
]
],
[
[
"from sklearn.feature_extraction.text import CountVectorizer\nvectorizer = CountVectorizer()\ndata_corpus = [\"John likes to watch movies. Mary likes movies too.\", \n\"John also likes to watch football games. Mary does not like football much.\"]\nX = vectorizer.fit_transform(data_corpus) \nprint(vectorizer.get_feature_names())",
"['also', 'does', 'football', 'games', 'john', 'like', 'likes', 'mary', 'movies', 'much', 'not', 'to', 'too', 'watch']\n"
]
],
[
[
"## Bag of Words Models",
"_____no_output_____"
]
],
[
[
"corpus = [\n \"Some analysts think demand could drop this year because a large number of homeowners take on remodeling projectsafter buying a new property. With fewer homes selling, home values easing, and mortgage rates rising, they predict home renovations could fall to their lowest levels in three years.\", \n \n \"Most home improvement stocks are expected to report fourth-quarter earnings next month.\",\n \n \"The conversation boils down to how much leverage management can get out of its wide-ranging efforts to re-energize operations, branding, digital capabilities, and the menu–and, for investors, how much to pay for that.\",\n \n \"RMD’s software acquisitions, efficiency, and mix overcame pricing and its gross margin improved by 90 bps Y/Y while its operating margin (including amortization) improved by 80 bps Y/Y. Since RMD expects the slower international flow generator growth to continue for the next few quarters, we have lowered our organic growth estimates to the mid-single digits. \"\n]\n\nX = vectorizer.fit_transform(corpus).toarray() \nimport numpy as np\nfrom sys import getsizeof\n\nzeroes = np.where(X.flatten() == 0)[0].size \npercent_sparse = zeroes / X.size\nprint(f\"The bag of words feature space is {round(percent_sparse * 100,2)}% sparse. \\n\\\nThat's approximately {round(getsizeof(X) * percent_sparse,2)} bytes of wasted memory. This is why sklearn uses CSR (compressed sparse rows) instead of normal matrices!\")",
"The bag of words feature space is 72.63% sparse. \nThat's approximately 2777.34 bytes of wasted memory. This is why sklearn uses CSR (compressed sparse rows) instead of normal matrices!\n"
]
],
[
[
"# Distance Measures\n\n\n## Euclidean Distance\n\nEuclidean distances can range from 0 (completely identically) to $\\infty$ (extremely dissimilar). \n\nThe distance between two points, $x$ and $y$, can be defined as $d(x,y)$:\n\n$$\nd(x,y) = \\sqrt{\\sum_{i=1}^{n}(x_{i}-y_{i})^2}\n$$\n\nCompared to the other dominant distance measure (cosine similarity), **magnitude** plays an extremely important role.",
"_____no_output_____"
]
],
[
[
"from math import sqrt\n \ndef euclidean_distance_1(x,y):\n distance = sum((a-b)**2 for a, b in zip(x, y))\n return sqrt(distance)",
"_____no_output_____"
]
],
[
[
"There's typically an easier way to write this function that takes advantage of Numpy's vectorization capabilities:",
"_____no_output_____"
]
],
[
[
"import numpy as np\ndef euclidean_distance_2(x,y):\n x = np.array(x)\n y = np.array(y)\n return np.linalg.norm(x-y)",
"_____no_output_____"
]
],
[
[
"### Scikit Learn",
"_____no_output_____"
]
],
[
[
"from sklearn.metrics.pairwise import euclidean_distances\nX = [document_1, document_2]\neuclidean_distances(X)",
"_____no_output_____"
]
],
[
[
"# Similarity Measures\n\nSimilarity measures will always range between -1 and 1. A similarity of -1 means the two objects are complete opposites, while a similarity of 1 indicates the objects are identical.\n\n\n## Cosine Similarity\n\nThe cosine similarity of two vectors (each vector will usually represent one document) is a measure that calculates $ cos(\\theta)$, where $\\theta$ is the angle between the two vectors.\n\nTherefore, if the vectors are **orthogonal** to each other (90 degrees), $cos(90) = 0$. If the vectors are in exactly the same direction, $\\theta = 0$ and $cos(0) = 1$.\n\nCosine similiarity **does not care about the magnitude of the vector, only the direction** in which it points. This can help normalize when comparing across documents that are different in terms of word count.\n\n\n\n### Shift Invariance\n\n* The Pearson correlation coefficient between X and Y does not change with you transform $X \\rightarrow a + bX$ and $Y \\rightarrow c + dY$, assuming $a$, $b$, $c$, and $d$ are constants and $b$ and $d$ are positive.\n* Cosine similarity does, however, change when transformed in this way.\n\n\n<h1><span style=\"background-color: #FFFF00\">Exercise (20 minutes):</span></h1>\n\n>In Python, find the **cosine similarity** and the **Pearson correlation coefficient** of the two following sentences, assuming a **one-hot encoded binary bag of words** model. You may use a library to create the BoW feature space, but do not use libraries other than `numpy` or `scipy` to compute Pearson and cosine similarity:\n\n>`A = \"John likes to watch movies. Mary likes movies too\"`\n\n>`B = \"John also likes to watch football games, but he likes to watch movies on occasion as well\"`",
"_____no_output_____"
],
[
"#### 3. Define your cosine similarity functions\n\n```python\nfrom scipy.spatial.distance import cosine # we are importing this library to check that our own cosine similarity func works\nfrom numpy import dot # to calculate dot product\nfrom numpy.linalg import norm # to calculate the norm\n\ndef cosine_similarity(A, B):\n numerator = dot(A, B)\n denominator = norm(A) * norm(B)\n return numerator / denominator\n\ndef cosine_distance(A,B):\n return 1 - cosine_similarity\n\nA = [0,2,3,4,1,2]\nB = [1,3,4,0,0,2]\n\n# check that your native implementation and 3rd party library function produce the same values\nassert round(cosine_similarity(A,B),4) == round(cosine(A,B),4)\n```\n\n#### 4. Get the two documents from the BoW feature space and calculate cosine similarity\n\n```python\ncosine_similarity(X[0], X[1])\n```\n>0.5241424183609592",
"_____no_output_____"
]
],
[
[
"from scipy.spatial.distance import cosine\nfrom numpy import dot\nimport numpy as np\nfrom numpy.linalg import norm\n\ndef cosine_similarity(A, B):\n numerator = dot(A, B)\n denominator = norm(A) * norm(B)\n return numerator / denominator # remember, you take 1 - the distance to get the distance\n\ndef cosine_distance(A,B):\n return 1 - cosine_similarity\n\nA = [0,2,3,4,1,2]\nB = [1,3,4,0,0,2]\n\n# check that your native implementation and 3rd party library function produce the same values\nassert round(cosine_similarity(A,B),4) == round(1 - cosine(A,B),4)\n\n# check for shift invariance\ncosine(np.array(A), B)",
"_____no_output_____"
],
[
"from sklearn.feature_extraction.text import CountVectorizer\nvectorizer = CountVectorizer()\n\n# take two very similar sentences, should have high similarity\n# edit these sentences to become less similar, and the similarity score should decrease\ndata_corpus = [\"John likes to watch movies. Mary likes movies too.\", \n\"John also likes to watch football games\"]\n\nX = vectorizer.fit_transform(data_corpus) \nX = X.toarray()\nprint(vectorizer.get_feature_names())\ncosine_similarity(X[0], X[1])",
"['also', 'football', 'games', 'john', 'likes', 'mary', 'movies', 'to', 'too', 'watch']\n"
]
],
[
[
"# Challenge: Use the Example Below to Create Your Own Cosine Similarity Function\n\n### Create a list of all the **vocabulary $V$**\n\nUsing **`sklearn`**'s **`CountVectorizer`**:\n```python\nfrom sklearn.feature_extraction.text import CountVectorizer\nvectorizer = CountVectorizer()\ndata_corpus = [\"John likes to watch movies. Mary likes movies too\", \n\"John also likes to watch football games, but he likes to watch movies on occasion as well\"]\nX = vectorizer.fit_transform(data_corpus) \nV = vectorizer.get_feature_names()\n```\n\n#### Native Implementation:\n```python\ndef get_vocabulary(sentences):\n vocabulary = {} # create an empty set - question: Why not a list?\n for sentence in sentences:\n # this is a very crude form of \"tokenization\", would not actually use in production\n for word in sentence.split(\" \"):\n if word not in vocabulary:\n vocabulary.add(word)\n return vocabulary\n```\n\n### Create your Bag of Words model\n```python\nX = X.toarray()\nprint(X)\n```\nYour console output:\n```python\n[[0 0 0 1 2 1 2 1 1 1]\n [1 1 1 1 1 0 0 1 0 1]]\n```",
"_____no_output_____"
]
],
[
[
"vectors = [[0,0,0,1,2,1,2,1,1,1],\n [1,1,1,1,1,0,0,1,0,1]]",
"_____no_output_____"
],
[
"import math\ndef find_norm(vector):\n total = 0\n for element in vector:\n total += element ** 2\n \n return math.sqrt(total)",
"_____no_output_____"
],
[
"norm(vectors[0]) # Numpy\nfind_norm(vectors[0]) # your own",
"_____no_output_____"
],
[
"dot_product(vectors[0], vectors[1]) / (find_norm(vectors[0]) * find_norm(vectors[1]))",
"_____no_output_____"
],
[
"from sklearn.metrics.pairwise import cosine_distances, cosine_similarity\ncosine_similarity(vectors)",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code"
] |
[
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code",
"code",
"code",
"code",
"code"
]
] |
4aa25e979b89ddf64cbdc64115b35f698fab707b
| 183,767 |
ipynb
|
Jupyter Notebook
|
DA0101EN_Review_Data_Wrangling.ipynb
|
Brillianttyagi/Data-Analysis-with-Python
|
99b4aafbd3050dd00c13956f70d1af17741e15d0
|
[
"MIT"
] | null | null | null |
DA0101EN_Review_Data_Wrangling.ipynb
|
Brillianttyagi/Data-Analysis-with-Python
|
99b4aafbd3050dd00c13956f70d1af17741e15d0
|
[
"MIT"
] | null | null | null |
DA0101EN_Review_Data_Wrangling.ipynb
|
Brillianttyagi/Data-Analysis-with-Python
|
99b4aafbd3050dd00c13956f70d1af17741e15d0
|
[
"MIT"
] | null | null | null | 39.434979 | 8,734 | 0.41693 |
[
[
[
"<h2>What is the purpose of Data Wrangling?</h2>",
"_____no_output_____"
],
[
"Data Wrangling is the process of converting data from the initial format to a format that may be better for analysis.",
"_____no_output_____"
],
[
"<h3>What is the fuel consumption (L/100k) rate for the diesel car?</h3>",
"_____no_output_____"
],
[
"<h3>Import data</h3>\n<p>\nYou can find the \"Automobile Data Set\" from the following link: <a href=\"https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data\">https://archive.ics.uci.edu/ml/machine-learning-databases/autos/imports-85.data</a>. \nWe will be using this data set throughout this course.\n</p>",
"_____no_output_____"
],
[
"<h4>Import pandas</h4> ",
"_____no_output_____"
]
],
[
[
"import pandas as pd\nimport matplotlib.pylab as plt",
"_____no_output_____"
]
],
[
[
"URL of the dataset",
"_____no_output_____"
]
],
[
[
"filename = \"https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/auto.csv\"",
"_____no_output_____"
]
],
[
[
" Python list <b>headers</b> containing name of headers ",
"_____no_output_____"
]
],
[
[
"headers = [\"symboling\",\"normalized-losses\",\"make\",\"fuel-type\",\"aspiration\", \"num-of-doors\",\"body-style\",\n \"drive-wheels\",\"engine-location\",\"wheel-base\", \"length\",\"width\",\"height\",\"curb-weight\",\"engine-type\",\n \"num-of-cylinders\", \"engine-size\",\"fuel-system\",\"bore\",\"stroke\",\"compression-ratio\",\"horsepower\",\n \"peak-rpm\",\"city-mpg\",\"highway-mpg\",\"price\"]",
"_____no_output_____"
]
],
[
[
"Use the Pandas method <b>read_csv()</b> to load the data from the web address. Set the parameter \"names\" equal to the Python list \"headers\".",
"_____no_output_____"
]
],
[
[
"df = pd.read_csv(filename, names = headers)",
"_____no_output_____"
]
],
[
[
" Use the method <b>head()</b> to display the first five rows of the dataframe. ",
"_____no_output_____"
]
],
[
[
"# To see what the data set looks like, we'll use the head() method.\ndf.head()",
"_____no_output_____"
]
],
[
[
"As we can see, several question marks appeared in the dataframe; those are missing values which may hinder our further analysis. \n<div>So, how do we identify all those missing values and deal with them?</div> \n\n\n<b>How to work with missing data?</b>\n\nSteps for working with missing data:\n<ol>\n <li>dentify missing data</li>\n <li>deal with missing data</li>\n <li>correct data format</li>\n</ol>",
"_____no_output_____"
],
[
"<h2 id=\"identify_handle_missing_values\">Identify and handle missing values</h2>\n\n\n<h3 id=\"identify_missing_values\">Identify missing values</h3>\n<h4>Convert \"?\" to NaN</h4>\nIn the car dataset, missing data comes with the question mark \"?\".\nWe replace \"?\" with NaN (Not a Number), which is Python's default missing value marker, for reasons of computational speed and convenience. Here we use the function: \n <pre>.replace(A, B, inplace = True) </pre>\nto replace A by B",
"_____no_output_____"
]
],
[
[
"import numpy as np\n\n# replace \"?\" to NaN\ndf.replace(\"?\", np.nan, inplace = True)\ndf.head(5)",
"_____no_output_____"
]
],
[
[
"dentify_missing_values\n\n<h4>Evaluating for Missing Data</h4>\n\nThe missing values are converted to Python's default. We use Python's built-in functions to identify these missing values. There are two methods to detect missing data:\n<ol>\n <li><b>.isnull()</b></li>\n <li><b>.notnull()</b></li>\n</ol>\nThe output is a boolean value indicating whether the value that is passed into the argument is in fact missing data.",
"_____no_output_____"
]
],
[
[
"missing_data = df.isnull()\nmissing_data.head(5)",
"_____no_output_____"
]
],
[
[
"\"True\" stands for missing value, while \"False\" stands for not missing value.",
"_____no_output_____"
],
[
"<h4>Count missing values in each column</h4>\n<p>\nUsing a for loop in Python, we can quickly figure out the number of missing values in each column. As mentioned above, \"True\" represents a missing value, \"False\" means the value is present in the dataset. In the body of the for loop the method \".value_counts()\" counts the number of \"True\" values. \n</p>",
"_____no_output_____"
]
],
[
[
"for column in missing_data.columns.values.tolist():\n print(column)\n print (missing_data[column].value_counts())\n print(\"\") ",
"symboling\nFalse 205\nName: symboling, dtype: int64\n\nnormalized-losses\nFalse 164\nTrue 41\nName: normalized-losses, dtype: int64\n\nmake\nFalse 205\nName: make, dtype: int64\n\nfuel-type\nFalse 205\nName: fuel-type, dtype: int64\n\naspiration\nFalse 205\nName: aspiration, dtype: int64\n\nnum-of-doors\nFalse 203\nTrue 2\nName: num-of-doors, dtype: int64\n\nbody-style\nFalse 205\nName: body-style, dtype: int64\n\ndrive-wheels\nFalse 205\nName: drive-wheels, dtype: int64\n\nengine-location\nFalse 205\nName: engine-location, dtype: int64\n\nwheel-base\nFalse 205\nName: wheel-base, dtype: int64\n\nlength\nFalse 205\nName: length, dtype: int64\n\nwidth\nFalse 205\nName: width, dtype: int64\n\nheight\nFalse 205\nName: height, dtype: int64\n\ncurb-weight\nFalse 205\nName: curb-weight, dtype: int64\n\nengine-type\nFalse 205\nName: engine-type, dtype: int64\n\nnum-of-cylinders\nFalse 205\nName: num-of-cylinders, dtype: int64\n\nengine-size\nFalse 205\nName: engine-size, dtype: int64\n\nfuel-system\nFalse 205\nName: fuel-system, dtype: int64\n\nbore\nFalse 201\nTrue 4\nName: bore, dtype: int64\n\nstroke\nFalse 201\nTrue 4\nName: stroke, dtype: int64\n\ncompression-ratio\nFalse 205\nName: compression-ratio, dtype: int64\n\nhorsepower\nFalse 203\nTrue 2\nName: horsepower, dtype: int64\n\npeak-rpm\nFalse 203\nTrue 2\nName: peak-rpm, dtype: int64\n\ncity-mpg\nFalse 205\nName: city-mpg, dtype: int64\n\nhighway-mpg\nFalse 205\nName: highway-mpg, dtype: int64\n\nprice\nFalse 201\nTrue 4\nName: price, dtype: int64\n\n"
]
],
[
[
"Based on the summary above, each column has 205 rows of data, seven columns containing missing data:\n<ol>\n <li>\"normalized-losses\": 41 missing data</li>\n <li>\"num-of-doors\": 2 missing data</li>\n <li>\"bore\": 4 missing data</li>\n <li>\"stroke\" : 4 missing data</li>\n <li>\"horsepower\": 2 missing data</li>\n <li>\"peak-rpm\": 2 missing data</li>\n <li>\"price\": 4 missing data</li>\n</ol>",
"_____no_output_____"
],
[
"<h3 id=\"deal_missing_values\">Deal with missing data</h3>\n<b>How to deal with missing data?</b>\n\n<ol>\n <li>drop data<br>\n a. drop the whole row<br>\n b. drop the whole column\n </li>\n <li>replace data<br>\n a. replace it by mean<br>\n b. replace it by frequency<br>\n c. replace it based on other functions\n </li>\n</ol>",
"_____no_output_____"
],
[
"Whole columns should be dropped only if most entries in the column are empty. In our dataset, none of the columns are empty enough to drop entirely.\nWe have some freedom in choosing which method to replace data; however, some methods may seem more reasonable than others. We will apply each method to many different columns:\n\n<b>Replace by mean:</b>\n<ul>\n <li>\"normalized-losses\": 41 missing data, replace them with mean</li>\n <li>\"stroke\": 4 missing data, replace them with mean</li>\n <li>\"bore\": 4 missing data, replace them with mean</li>\n <li>\"horsepower\": 2 missing data, replace them with mean</li>\n <li>\"peak-rpm\": 2 missing data, replace them with mean</li>\n</ul>\n\n<b>Replace by frequency:</b>\n<ul>\n <li>\"num-of-doors\": 2 missing data, replace them with \"four\". \n <ul>\n <li>Reason: 84% sedans is four doors. Since four doors is most frequent, it is most likely to occur</li>\n </ul>\n </li>\n</ul>\n\n<b>Drop the whole row:</b>\n<ul>\n <li>\"price\": 4 missing data, simply delete the whole row\n <ul>\n <li>Reason: price is what we want to predict. Any data entry without price data cannot be used for prediction; therefore any row now without price data is not useful to us</li>\n </ul>\n </li>\n</ul>",
"_____no_output_____"
],
[
"<h4>Calculate the average of the column </h4>",
"_____no_output_____"
]
],
[
[
"avg_norm_loss = df[\"normalized-losses\"].astype(\"float\").mean(axis=0)\nprint(\"Average of normalized-losses:\", avg_norm_loss)",
"Average of normalized-losses: 122.0\n"
]
],
[
[
"<h4>Replace \"NaN\" by mean value in \"normalized-losses\" column</h4>",
"_____no_output_____"
]
],
[
[
"df[\"normalized-losses\"].replace(np.nan, avg_norm_loss, inplace=True)",
"_____no_output_____"
]
],
[
[
"<h4>Calculate the mean value for 'bore' column</h4>",
"_____no_output_____"
]
],
[
[
"avg_bore=df['bore'].astype('float').mean(axis=0)\nprint(\"Average of bore:\", avg_bore)",
"Average of bore: 3.3297512437810957\n"
]
],
[
[
"<h4>Replace NaN by mean value</h4>",
"_____no_output_____"
]
],
[
[
"df[\"bore\"].replace(np.nan, avg_bore, inplace=True)",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #1: </h1>\n\n<b>According to the example above, replace NaN in \"stroke\" column by mean.</b>\n</div>",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \navg_stroke = df['stroke'].astype('float').mean(axis = 0)\nprint(\"Average of stroke:\", avg_stroke)\ndf['stroke'].replace(np.nan,avg_stroke,inplace = True)",
"Average of stroke: 3.2554228855721337\n"
]
],
[
[
"Double-click <b>here</b> for the solution.\n\n<!-- The answer is below:\n\n# calculate the mean vaule for \"stroke\" column\navg_stroke = df[\"stroke\"].astype(\"float\").mean(axis = 0)\nprint(\"Average of stroke:\", avg_stroke)\n\n# replace NaN by mean value in \"stroke\" column\ndf[\"stroke\"].replace(np.nan, avg_stroke, inplace = True)\n\n-->\n",
"_____no_output_____"
],
[
"<h4>Calculate the mean value for the 'horsepower' column:</h4>",
"_____no_output_____"
]
],
[
[
"avg_horsepower = df['horsepower'].astype('float').mean(axis=0)\nprint(\"Average horsepower:\", avg_horsepower)",
"Average horsepower: 104.25615763546799\n"
]
],
[
[
"<h4>Replace \"NaN\" by mean value:</h4>",
"_____no_output_____"
]
],
[
[
"df['horsepower'].replace(np.nan, avg_horsepower, inplace=True)",
"_____no_output_____"
]
],
[
[
"<h4>Calculate the mean value for 'peak-rpm' column:</h4>",
"_____no_output_____"
]
],
[
[
"avg_peakrpm=df['peak-rpm'].astype('float').mean(axis=0)\nprint(\"Average peak rpm:\", avg_peakrpm)",
"Average peak rpm: 5125.369458128079\n"
]
],
[
[
"<h4>Replace NaN by mean value:</h4>",
"_____no_output_____"
]
],
[
[
"df['peak-rpm'].replace(np.nan, avg_peakrpm, inplace=True)",
"_____no_output_____"
]
],
[
[
"To see which values are present in a particular column, we can use the \".value_counts()\" method:",
"_____no_output_____"
]
],
[
[
"df['num-of-doors'].value_counts()",
"_____no_output_____"
]
],
[
[
"We can see that four doors are the most common type. We can also use the \".idxmax()\" method to calculate for us the most common type automatically:",
"_____no_output_____"
]
],
[
[
"df['num-of-doors'].value_counts().idxmax()",
"_____no_output_____"
]
],
[
[
"The replacement procedure is very similar to what we have seen previously",
"_____no_output_____"
]
],
[
[
"#replace the missing 'num-of-doors' values by the most frequent \ndf[\"num-of-doors\"].replace(np.nan, \"four\", inplace=True)",
"_____no_output_____"
]
],
[
[
"Finally, let's drop all rows that do not have price data:",
"_____no_output_____"
]
],
[
[
"# simply drop whole row with NaN in \"price\" column\ndf.dropna(subset=[\"price\"], axis=0, inplace=True)\n\n# reset index, because we droped two rows\ndf.reset_index(drop=True, inplace=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"<b>Good!</b> Now, we obtain the dataset with no missing values.",
"_____no_output_____"
],
[
"<h3 id=\"correct_data_format\">Correct data format</h3>\n<b>We are almost there!</b>\n<p>The last step in data cleaning is checking and making sure that all data is in the correct format (int, float, text or other).</p>\n\nIn Pandas, we use \n<p><b>.dtype()</b> to check the data type</p>\n<p><b>.astype()</b> to change the data type</p>",
"_____no_output_____"
],
[
"<h4>Lets list the data types for each column</h4>",
"_____no_output_____"
]
],
[
[
"df.dtypes",
"_____no_output_____"
]
],
[
[
"<p>As we can see above, some columns are not of the correct data type. Numerical variables should have type 'float' or 'int', and variables with strings such as categories should have type 'object'. For example, 'bore' and 'stroke' variables are numerical values that describe the engines, so we should expect them to be of the type 'float' or 'int'; however, they are shown as type 'object'. We have to convert data types into a proper format for each column using the \"astype()\" method.</p> ",
"_____no_output_____"
],
[
"<h4>Convert data types to proper format</h4>",
"_____no_output_____"
]
],
[
[
"df[[\"bore\", \"stroke\"]] = df[[\"bore\", \"stroke\"]].astype(\"float\")\ndf[[\"normalized-losses\"]] = df[[\"normalized-losses\"]].astype(\"int\")\ndf[[\"price\"]] = df[[\"price\"]].astype(\"float\")\ndf[[\"peak-rpm\"]] = df[[\"peak-rpm\"]].astype(\"float\")",
"_____no_output_____"
]
],
[
[
"<h4>Let us list the columns after the conversion</h4>",
"_____no_output_____"
]
],
[
[
"df.dtypes",
"_____no_output_____"
]
],
[
[
"<b>Wonderful!</b>\n\nNow, we finally obtain the cleaned dataset with no missing values and all data in its proper format.",
"_____no_output_____"
],
[
"<h2 id=\"data_standardization\">Data Standardization</h2>\n<p>\nData is usually collected from different agencies with different formats.\n(Data Standardization is also a term for a particular type of data normalization, where we subtract the mean and divide by the standard deviation)\n</p>\n \n<b>What is Standardization?</b>\n<p>Standardization is the process of transforming data into a common format which allows the researcher to make the meaningful comparison.\n</p>\n\n<b>Example</b>\n<p>Transform mpg to L/100km:</p>\n<p>In our dataset, the fuel consumption columns \"city-mpg\" and \"highway-mpg\" are represented by mpg (miles per gallon) unit. Assume we are developing an application in a country that accept the fuel consumption with L/100km standard</p>\n<p>We will need to apply <b>data transformation</b> to transform mpg into L/100km?</p>\n",
"_____no_output_____"
],
[
"<p>The formula for unit conversion is<p>\nL/100km = 235 / mpg\n<p>We can do many mathematical operations directly in Pandas.</p>",
"_____no_output_____"
]
],
[
[
"df.head()",
"_____no_output_____"
],
[
"# Convert mpg to L/100km by mathematical operation (235 divided by mpg)\ndf['city-L/100km'] = 235/df[\"city-mpg\"]\n\n# check your transformed data \ndf.head()",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #2: </h1>\n\n<b>According to the example above, transform mpg to L/100km in the column of \"highway-mpg\", and change the name of column to \"highway-L/100km\".</b>\n</div>",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \ndf['highway-mpg'] = 235/df['highway-mpg']\ndf.rename(columns={'highway-mpg':'highway-L/100km'}, inplace=True)\ndf.head()",
"_____no_output_____"
]
],
[
[
"Double-click <b>here</b> for the solution.\n\n<!-- The answer is below:\n\n# transform mpg to L/100km by mathematical operation (235 divided by mpg)\ndf[\"highway-mpg\"] = 235/df[\"highway-mpg\"]\n\n# rename column name from \"highway-mpg\" to \"highway-L/100km\"\ndf.rename(columns={'\"highway-mpg\"':'highway-L/100km'}, inplace=True)\n\n# check your transformed data \ndf.head()\n\n-->\n",
"_____no_output_____"
],
[
"<h2 id=\"data_normalization\">Data Normalization</h2>\n\n<b>Why normalization?</b>\n<p>Normalization is the process of transforming values of several variables into a similar range. Typical normalizations include scaling the variable so the variable average is 0, scaling the variable so the variance is 1, or scaling variable so the variable values range from 0 to 1\n</p>\n\n<b>Example</b>\n<p>To demonstrate normalization, let's say we want to scale the columns \"length\", \"width\" and \"height\" </p>\n<p><b>Target:</b>would like to Normalize those variables so their value ranges from 0 to 1.</p>\n<p><b>Approach:</b> replace original value by (original value)/(maximum value)</p>",
"_____no_output_____"
]
],
[
[
"# replace (original value) by (original value)/(maximum value)\ndf['length'] = df['length']/df['length'].max()\ndf['width'] = df['width']/df['width'].max()",
"_____no_output_____"
]
],
[
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Questiont #3: </h1>\n\n<b>According to the example above, normalize the column \"height\".</b>\n</div>",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \ndf['height'] = df['height']/df['height'].max()\ndf[[\"length\",\"width\",\"height\"]].head()",
"_____no_output_____"
]
],
[
[
"Double-click <b>here</b> for the solution.\n\n<!-- The answer is below:\n\ndf['height'] = df['height']/df['height'].max() \n# show the scaled columns\ndf[[\"length\",\"width\",\"height\"]].head()\n\n-->",
"_____no_output_____"
],
[
"Here we can see, we've normalized \"length\", \"width\" and \"height\" in the range of [0,1].",
"_____no_output_____"
],
[
"<h2 id=\"binning\">Binning</h2>\n<b>Why binning?</b>\n<p>\n Binning is a process of transforming continuous numerical variables into discrete categorical 'bins', for grouped analysis.\n</p>\n\n<b>Example: </b>\n<p>In our dataset, \"horsepower\" is a real valued variable ranging from 48 to 288, it has 57 unique values. What if we only care about the price difference between cars with high horsepower, medium horsepower, and little horsepower (3 types)? Can we rearrange them into three ‘bins' to simplify analysis? </p>\n\n<p>We will use the Pandas method 'cut' to segment the 'horsepower' column into 3 bins </p>\n\n",
"_____no_output_____"
],
[
"<h3>Example of Binning Data In Pandas</h3>",
"_____no_output_____"
],
[
" Convert data to correct format ",
"_____no_output_____"
]
],
[
[
"df[\"horsepower\"]=df[\"horsepower\"].astype(int, copy=True)",
"_____no_output_____"
]
],
[
[
"Lets plot the histogram of horspower, to see what the distribution of horsepower looks like.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib as plt\nfrom matplotlib import pyplot\nplt.pyplot.hist(df[\"horsepower\"])\n\n# set x/y labels and plot title\nplt.pyplot.xlabel(\"horsepower\")\nplt.pyplot.ylabel(\"count\")\nplt.pyplot.title(\"horsepower bins\")",
"_____no_output_____"
]
],
[
[
"<p>We would like 3 bins of equal size bandwidth so we use numpy's <code>linspace(start_value, end_value, numbers_generated</code> function.</p>\n<p>Since we want to include the minimum value of horsepower we want to set start_value=min(df[\"horsepower\"]).</p>\n<p>Since we want to include the maximum value of horsepower we want to set end_value=max(df[\"horsepower\"]).</p>\n<p>Since we are building 3 bins of equal length, there should be 4 dividers, so numbers_generated=4.</p>",
"_____no_output_____"
],
[
"We build a bin array, with a minimum value to a maximum value, with bandwidth calculated above. The bins will be values used to determine when one bin ends and another begins.",
"_____no_output_____"
]
],
[
[
"bins = np.linspace(min(df[\"horsepower\"]), max(df[\"horsepower\"]), 4)\nbins",
"_____no_output_____"
]
],
[
[
" We set group names:",
"_____no_output_____"
]
],
[
[
"group_names = ['Low', 'Medium', 'High']",
"_____no_output_____"
]
],
[
[
" We apply the function \"cut\" the determine what each value of \"df['horsepower']\" belongs to. ",
"_____no_output_____"
]
],
[
[
"df['horsepower-binned'] = pd.cut(df['horsepower'], bins, labels=group_names, include_lowest=True )\ndf[['horsepower','horsepower-binned']].head(20)",
"_____no_output_____"
]
],
[
[
"Lets see the number of vehicles in each bin.",
"_____no_output_____"
]
],
[
[
"df[\"horsepower-binned\"].value_counts()",
"_____no_output_____"
]
],
[
[
"Lets plot the distribution of each bin.",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib as plt\nfrom matplotlib import pyplot\npyplot.bar(group_names, df[\"horsepower-binned\"].value_counts())\n\n# set x/y labels and plot title\nplt.pyplot.xlabel(\"horsepower\")\nplt.pyplot.ylabel(\"count\")\nplt.pyplot.title(\"horsepower bins\")",
"_____no_output_____"
]
],
[
[
"<p>\n Check the dataframe above carefully, you will find the last column provides the bins for \"horsepower\" with 3 categories (\"Low\",\"Medium\" and \"High\"). \n</p>\n<p>\n We successfully narrow the intervals from 57 to 3!\n</p>",
"_____no_output_____"
],
[
"<h3>Bins visualization</h3>\nNormally, a histogram is used to visualize the distribution of bins we created above. ",
"_____no_output_____"
]
],
[
[
"%matplotlib inline\nimport matplotlib as plt\nfrom matplotlib import pyplot\n\na = (0,1,2)\n\n# draw historgram of attribute \"horsepower\" with bins = 3\nplt.pyplot.hist(df[\"horsepower\"], bins = 3)\n\n# set x/y labels and plot title\nplt.pyplot.xlabel(\"horsepower\")\nplt.pyplot.ylabel(\"count\")\nplt.pyplot.title(\"horsepower bins\")",
"_____no_output_____"
]
],
[
[
"The plot above shows the binning result for attribute \"horsepower\". ",
"_____no_output_____"
],
[
"<h2 id=\"indicator\">Indicator variable (or dummy variable)</h2>\n<b>What is an indicator variable?</b>\n<p>\n An indicator variable (or dummy variable) is a numerical variable used to label categories. They are called 'dummies' because the numbers themselves don't have inherent meaning. \n</p>\n\n<b>Why we use indicator variables?</b>\n<p>\n So we can use categorical variables for regression analysis in the later modules.\n</p>\n<b>Example</b>\n<p>\n We see the column \"fuel-type\" has two unique values, \"gas\" or \"diesel\". Regression doesn't understand words, only numbers. To use this attribute in regression analysis, we convert \"fuel-type\" into indicator variables.\n</p>\n\n<p>\n We will use the panda's method 'get_dummies' to assign numerical values to different categories of fuel type. \n</p>",
"_____no_output_____"
]
],
[
[
"df.columns",
"_____no_output_____"
]
],
[
[
"get indicator variables and assign it to data frame \"dummy_variable_1\" ",
"_____no_output_____"
]
],
[
[
"dummy_variable_1 = pd.get_dummies(df[\"fuel-type\"])\ndummy_variable_1.head()",
"_____no_output_____"
]
],
[
[
"change column names for clarity ",
"_____no_output_____"
]
],
[
[
"dummy_variable_1.rename(columns={'fuel-type-diesel':'gas', 'fuel-type-diesel':'diesel'}, inplace=True)\ndummy_variable_1.head()",
"_____no_output_____"
]
],
[
[
"We now have the value 0 to represent \"gas\" and 1 to represent \"diesel\" in the column \"fuel-type\". We will now insert this column back into our original dataset. ",
"_____no_output_____"
]
],
[
[
"# merge data frame \"df\" and \"dummy_variable_1\" \ndf = pd.concat([df, dummy_variable_1], axis=1)\n\n# drop original column \"fuel-type\" from \"df\"\ndf.drop(\"fuel-type\", axis = 1, inplace=True)",
"_____no_output_____"
],
[
"df.head()",
"_____no_output_____"
]
],
[
[
"The last two columns are now the indicator variable representation of the fuel-type variable. It's all 0s and 1s now.",
"_____no_output_____"
],
[
"<div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #4: </h1>\n\n<b>As above, create indicator variable to the column of \"aspiration\": \"std\" to 0, while \"turbo\" to 1.</b>\n</div>",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \ndummy_variable_2 = pd.get_dummies(df['aspiration'])\n\ndummy_variable_2.rename(columns = {'std':'aspiration-std','turbo':'aspiration-turbo'},inplace = True)\ndummy_variable_2.head()",
"_____no_output_____"
]
],
[
[
"Double-click <b>here</b> for the solution.\n\n<!-- The answer is below:\n\n# get indicator variables of aspiration and assign it to data frame \"dummy_variable_2\"\ndummy_variable_2 = pd.get_dummies(df['aspiration'])\n\n# change column names for clarity\ndummy_variable_2.rename(columns={'std':'aspiration-std', 'turbo': 'aspiration-turbo'}, inplace=True)\n\n# show first 5 instances of data frame \"dummy_variable_1\"\ndummy_variable_2.head()\n\n-->",
"_____no_output_____"
],
[
" <div class=\"alert alert-danger alertdanger\" style=\"margin-top: 20px\">\n<h1> Question #5: </h1>\n\n<b>Merge the new dataframe to the original dataframe then drop the column 'aspiration'</b>\n</div>",
"_____no_output_____"
]
],
[
[
"# Write your code below and press Shift+Enter to execute \ndf = pd.concat([df,dummy_variable_2],axis=1)\ndf.drop('aspiration',axis=1,inplace=True)\ndf.head()",
"_____no_output_____"
]
],
[
[
"Double-click <b>here</b> for the solution.\n\n<!-- The answer is below:\n\n#merge the new dataframe to the original datafram\ndf = pd.concat([df, dummy_variable_2], axis=1)\n\n# drop original column \"aspiration\" from \"df\"\ndf.drop('aspiration', axis = 1, inplace=True)\n\n-->",
"_____no_output_____"
],
[
"save the new csv ",
"_____no_output_____"
]
],
[
[
"df.to_csv('clean_df.csv')",
"_____no_output_____"
]
],
[
[
"<h1>Thank you for completing this notebook</h1>",
"_____no_output_____"
],
[
"<div class=\"alert alert-block alert-info\" style=\"margin-top: 20px\">\n\n <p><a href=\"https://cocl.us/DA0101EN_NotbookLink_Top_bottom\"><img src=\"https://s3-api.us-geo.objectstorage.softlayer.net/cf-courses-data/CognitiveClass/DA0101EN/Images/BottomAd.png\" width=\"750\" align=\"center\"></a></p>\n</div>",
"_____no_output_____"
],
[
"<h3>About the Authors:</h3>\n\nThis notebook was written by <a href=\"https://www.linkedin.com/in/mahdi-noorian-58219234/\" target=\"_blank\">Mahdi Noorian PhD</a>, <a href=\"https://www.linkedin.com/in/joseph-s-50398b136/\" target=\"_blank\">Joseph Santarcangelo</a>, Bahare Talayian, Eric Xiao, Steven Dong, Parizad, Hima Vsudevan and <a href=\"https://www.linkedin.com/in/fiorellawever/\" target=\"_blank\">Fiorella Wenver</a> and <a href=\" https://www.linkedin.com/in/yi-leng-yao-84451275/ \" target=\"_blank\" >Yi Yao</a>.\n\n<p><a href=\"https://www.linkedin.com/in/joseph-s-50398b136/\" target=\"_blank\">Joseph Santarcangelo</a> is a Data Scientist at IBM, and holds a PhD in Electrical Engineering. His research focused on using Machine Learning, Signal Processing, and Computer Vision to determine how videos impact human cognition. Joseph has been working for IBM since he completed his PhD.</p>",
"_____no_output_____"
],
[
"<hr>\n<p>Copyright © 2018 IBM Developer Skills Network. This notebook and its source code are released under the terms of the <a href=\"https://cognitiveclass.ai/mit-license/\">MIT License</a>.</p>",
"_____no_output_____"
]
]
] |
[
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown",
"code",
"markdown"
] |
[
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown"
],
[
"code",
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code"
],
[
"markdown"
],
[
"code",
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown"
],
[
"code"
],
[
"markdown",
"markdown",
"markdown",
"markdown"
]
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.