
code
stringlengths 5
1M
| repo_name
stringlengths 5
109
| path
stringlengths 6
208
| language
stringclasses 1
value | license
stringclasses 15
values | size
int64 5
1M
|
|---|---|---|---|---|---|
package monocle
/**
* Show how could we use Optics to manipulate some Json AST
*/
class JsonExample extends MonocleSuite {
sealed trait Json
case class JsString(s: String) extends Json
case class JsNumber(n: Int) extends Json
case class JsArray(l: List[Json]) extends Json
case class JsObject(m: Map[String, Json]) extends Json
val jsString = Prism[Json, String]{ case JsString(s) => Some(s); case _ => None}(JsString.apply)
val jsNumber = Prism[Json, Int]{ case JsNumber(n) => Some(n); case _ => None}(JsNumber.apply)
val jsArray = Prism[Json, List[Json]]{ case JsArray(a) => Some(a); case _ => None}(JsArray.apply)
val jsObject = Prism[Json, Map[String, Json]]{ case JsObject(m) => Some(m); case _ => None}(JsObject.apply)
val json = JsObject(Map(
"first_name" -> JsString("John"),
"last_name" -> JsString("Doe"),
"age" -> JsNumber(28),
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(23)
)),
JsObject(Map(
"first_name" -> JsString("Robert"),
"age" -> JsNumber(25)
))
))
))
test("Json Prism") {
jsNumber.getOption(JsString("plop")) shouldEqual None
jsNumber.getOption(JsNumber(2)) shouldEqual Some(2)
}
test("Use index to go into an JsObject or JsArray") {
(jsObject composeOptional index("age") composePrism jsNumber).getOption(json) shouldEqual Some(28)
(jsObject composeOptional index("siblings")
composePrism jsArray
composeOptional index(1)
composePrism jsObject
composeOptional index("first_name")
composePrism jsString
).set("Robert Jr.")(json) shouldEqual JsObject(Map(
"first_name" -> JsString("John"),
"last_name" -> JsString("Doe"),
"age" -> JsNumber(28),
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(23)
)),
JsObject(Map(
"first_name" -> JsString("Robert Jr."), // name is updated
"age" -> JsNumber(25)
))
))
))
}
test("Use at to add delete fields") {
(jsObject composeLens at("nick_name")).set(Some(JsString("Jojo")))(json) shouldEqual JsObject(Map(
"first_name" -> JsString("John"),
"nick_name" -> JsString("Jojo"), // new field
"last_name" -> JsString("Doe"),
"age" -> JsNumber(28),
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(23)
)),
JsObject(Map(
"first_name" -> JsString("Robert"),
"age" -> JsNumber(25)
))
))
))
(jsObject composeLens at("age")).set(None)(json) shouldEqual JsObject(Map(
"first_name" -> JsString("John"),
"last_name" -> JsString("Doe"), // John is ageless now
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(23)
)),
JsObject(Map(
"first_name" -> JsString("Robert"),
"age" -> JsNumber(25)
))
))
))
}
test("Use each and filterIndex to modify several fields at a time") {
(jsObject composeTraversal filterIndex((_: String).contains("name"))
composePrism jsString
composeOptional headOption
).modify(_.toLower)(json) shouldEqual JsObject(Map(
"first_name" -> JsString("john"), // starts with lower case
"last_name" -> JsString("doe"), // starts with lower case
"age" -> JsNumber(28),
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(23)
)),
JsObject(Map(
"first_name" -> JsString("Robert"),
"age" -> JsNumber(25)
))
))
))
(jsObject composeOptional index("siblings")
composePrism jsArray
composeTraversal each
composePrism jsObject
composeOptional index("age")
composePrism jsNumber
).modify(_ + 1)(json) shouldEqual JsObject(Map(
"first_name" -> JsString("John"),
"last_name" -> JsString("Doe"),
"age" -> JsNumber(28),
"siblings" -> JsArray(List(
JsObject(Map(
"first_name" -> JsString("Elia"),
"age" -> JsNumber(24) // Elia is older
)),
JsObject(Map(
"first_name" -> JsString("Robert"),
"age" -> JsNumber(26) // Robert is older
))
))
))
}
}
|
NightRa/Monocle
|
example/src/test/scala/monocle/JsonExample.scala
|
Scala
|
mit
| 4,762 |
/*
* Scala (https://www.scala-lang.org)
*
* Copyright EPFL and Lightbend, Inc.
*
* Licensed under Apache License 2.0
* (http://www.apache.org/licenses/LICENSE-2.0).
*
* See the NOTICE file distributed with this work for
* additional information regarding copyright ownership.
*/
package scala.annotation.meta
/**
* Consult the documentation in package [[scala.annotation.meta]].
*/
final class beanGetter extends scala.annotation.StaticAnnotation
|
scala/scala
|
src/library/scala/annotation/meta/beanGetter.scala
|
Scala
|
apache-2.0
| 461 |
package org.unisonweb
import org.unisonweb.Builtins._
import org.unisonweb.Pattern._
import org.unisonweb.Term.Syntax._
import org.unisonweb.Term._
import org.unisonweb.compilation._
import org.unisonweb.util.PrettyPrint
import Terms.Int64Ops._
import org.unisonweb.Value.Lambda.ClosureForming
object CompilationTests {
import EasyTest._
import Terms._
val env = Environment(
Builtins.builtins,
userDefined = Map.empty,
BuiltinTypes.dataConstructors,
BuiltinTypes.effects)
def eval(t0: Term, doRoundTrip: Boolean = true): Term = {
val bytes = Codecs.encodeTerm(t0)
// println("bytes: " + bytes.toList.flatten)
// println("bytes: " + util.Bytes.fromChunks(bytes))
def roundTrip(t: Term) =
if (doRoundTrip) Codecs.decodeTerm(Codecs.encodeTerm(t))
else t
roundTrip(normalize(env)(roundTrip(t0)))
}
val tests = suite("compilation")(
test("zero") { implicit T =>
equal(eval(zero), zero)
},
test("one") { implicit T =>
equal(eval(one), one)
},
test("id") { implicit T =>
equal(eval(id(one)), one)
},
test("const") { implicit T =>
equal(eval(const(one, 2)), one)
},
test("1 + 1 = 2") { implicit T =>
equal(eval(onePlusOne), 2:Term)
},
test("1 + 2 = 3") { implicit T =>
equal(eval((1:Term) + (2:Term)), 3:Term)
},
suite("Int64")(
test("arithmetic +-*/") { implicit T =>
0 until 100 foreach { _ =>
val x = long; val y = long
val xt: Term = x
val yt: Term = y
equal1(eval(xt + yt), (x + y):Term)
equal1(eval(xt - yt), (x - y):Term)
equal1(eval(xt * yt), (x * y):Term)
equal1(eval(xt / yt), (x / y):Term)
}
ok
}
),
test("UInt64") { implicit T =>
// toInt64 should be monotonic, also tests <= on Int64
0 until 100 foreach { _ =>
val toInt64 = Builtins.termFor(Builtins.UInt64_toInt64)
val add = Builtins.termFor(Builtins.UInt64_add)
val x = long; val y = long
// toInt64 and <
equal1[Term](
eval(toInt64(uint(x)) < toInt64(uint(y))),
x < y)
// toInt64 and +
equal1[Term](
eval(toInt64(uint(x)) + toInt64(uint(y))),
eval(toInt64(add(uint(x),uint(y)))))
// inc
val inc = Builtins.termFor(Builtins.UInt64_inc)
equal1[Term](eval(inc(uint(x))), uint(x + 1))
// isEven and isOdd
val isEven = Builtins.termFor(Builtins.UInt64_isEven)
val isOdd = Builtins.termFor(Builtins.UInt64_isOdd)
val not = Builtins.termFor(Builtins.Boolean_not)
equal1[Term](eval(isEven(x)), x % 2 == 0)
equal1[Term](eval(isEven(x)), eval(not(isOdd(uint(x)))))
// multiply
val mul = Builtins.termFor(Builtins.UInt64_mul)
equal1[Term](eval(mul(uint(x), uint(y))), uint(x * y))
// drop and minus
val drop = Builtins.termFor(Builtins.UInt64_drop)
val minus = Builtins.termFor(Builtins.UInt64_sub)
val i = int.toLong.abs; val j = int.toLong.abs
equal1[Term](eval(drop(i,j)), uint((i - j).max(0)))
equal1[Term](eval(minus(x,y)), uint(x - y))
}
val lt = Builtins.termFor(Builtins.UInt64_lt)
val gt = Builtins.termFor(Builtins.UInt64_gt)
val gteq = Builtins.termFor(Builtins.UInt64_gteq)
val lteq = Builtins.termFor(Builtins.UInt64_lteq)
equal1[Term](eval { gt(uint(-1), uint(1)) }, true)
equal1[Term](eval { gt(uint(2), uint(1)) }, true)
equal1[Term](eval { lt(uint(2), uint(1)) }, false)
equal1[Term](eval { lteq(uint(-1), uint(1)) }, false)
equal1[Term](eval { gteq(uint(-1), uint(1)) }, true)
ok
},
test("float") { implicit T =>
0 until 100 foreach { _ =>
val x = double; val y = double
// addition and subtraction
val add = Builtins.termFor(Builtins.Float_add)
val sub = Builtins.termFor(Builtins.Float_sub)
equal1[Term](eval(add(float(x), float(y))), float(x + y))
equal1[Term](eval(sub(float(x), float(y))), float(x - y))
// multiplication and division
val mul = Builtins.termFor(Builtins.Float_mul)
val div = Builtins.termFor(Builtins.Float_div)
equal1[Term](eval(mul(float(x), float(y))), float(x * y))
equal1[Term](eval(div(float(x), float(y))), float(x / y))
// comparisons
val lt = Builtins.termFor(Builtins.Float_lt)
val gt = Builtins.termFor(Builtins.Float_gt)
val gteq = Builtins.termFor(Builtins.Float_gteq)
val lteq = Builtins.termFor(Builtins.Float_lteq)
equal1[Term](eval(lt(float(x), float(y))), x < y)
equal1[Term](eval(gt(float(x), float(y))), x > y)
equal1[Term](eval(gteq(float(x), float(y))), x >= y)
equal1[Term](eval(lteq(float(x), float(y))), x <= y)
}
ok
},
test("sum4(1,2,3,4)") { implicit T =>
equal(eval(sum4(1,10,100,1000)), (1+10+100+1000):Term)
},
test("partial application does specialization") { implicit T =>
equal(eval(const(zero)), Lam('y)(zero))
},
test("partial application") { implicit T =>
equal(eval(Let('f -> const(one))('f.v(42))), one)
},
test("closure-forming partial application") { implicit T =>
val body: Computation =
(r,rec,top,stackU,x1,x0,stackB,x1b,x0b) => {
r.boxed = UnboxedType.Int64
top.u(stackU, 3) - top.u(stackU, 2) - x1 - x0
}
val lam = Term.Compiled(
new ClosureForming(List("a","b","c","d"), body, 42))
val p = Let('f -> lam(1))('f.v(2,3,4))
val p2 = Let('f -> lam(1), 'g -> 'f.v(2))('g.v(3,4))
val p3 = Let('f -> lam(1), 'g -> 'f.v(2), 'h -> 'g.v(3))('h.v(4))
val p4 = lam(1,2,3,4)
equal1[Term](eval(p,false), -8)
equal1[Term](eval(p2,false), -8)
equal1[Term](eval(p3,false), -8)
equal1[Term](eval(p4,false), -8)
ok
},
test("partially apply builtin") { implicit T =>
equal(eval(onePlus), onePlus)
equal(eval(ap(onePlus, one)), eval(onePlusOne))
},
test("partially apply triangle") { implicit T =>
val p: Term =
Let('tri -> triangle(100))('tri.v(0))
equal[Term](eval(p), eval(triangle(100,0)))
},
test("let") { implicit T =>
equal(eval(Let('x -> one)(one + 'x)), eval(onePlusOne))
},
test("let2") { implicit T =>
equal(eval(Let('x -> one, 'y -> (2:Term))(
'x.v + 'y
)), 3:Term)
},
test("let3") { implicit T =>
equal(eval(Let('x -> one, 'y -> (10:Term), 'z -> (100:Term))(
'x.v + 'y + 'z
)), 111:Term)
},
test("let7") { implicit T =>
equal(eval(Let('x1 -> (5:Term), 'x2 -> (2:Term), 'x3 -> (3:Term),
'x4 -> (7:Term), 'x5 -> (11:Term), 'x6 -> (13:Term),
'x7 -> (17:Term))(
'x1.v * 'x2 * 'x3 * 'x4 * 'x5 * 'x6 * 'x7
)), 510510:Term)
},
test("dynamic non-tail call with K args") { implicit T =>
equal(eval(Let('x -> const)('x.v(one, 2) + one)), 2:Term)
},
test("dynamic non-tail call with K+n args") { implicit T =>
equal(eval(Let('x -> sum4)('x.v(one, 2, 3, 4) + one)), 11:Term)
},
test("if") { implicit T =>
equal1(eval(If(one, one, zero + one + one)), one)
equal1(eval(If(one - one, one, zero + one + one)), 2:Term)
equal1(eval(If(one > zero, one, zero + one + one)), one)
equal1(eval(If(one < zero, one, zero + one + one)), 2:Term)
ok
},
test("fib") { implicit T =>
note("pretty-printed fib implementation")
note(PrettyPrint.prettyTerm(fib).render(40))
0 to 20 foreach { n =>
equal1(eval(fib(n:Term)), scalaFib(n):Term)
}
ok
},
test("fib-ANF") { implicit T =>
note("pretty-printed fib implementation in ANF")
note(PrettyPrint.prettyTerm(Term.ANF(fib)).render(40))
val fibANF = Term.ANF(fib)
0 to 20 foreach { n =>
equal1(eval(fibANF(n:Term)), scalaFib(n):Term)
}
ok
},
test("==") { implicit T =>
equal1(eval(one unisonEquals one), eval(true))
equal1(eval(one unisonEquals onePlusOne), eval(false))
ok
},
test("triangle") { implicit T =>
10 to 10 foreach { n =>
equal1(eval(triangle(n:Term, zero)), (0 to n).sum:Term)
}
ok
},
test("triangle4arg") { implicit T =>
10 to 50 foreach { n =>
equal1(eval(triangle4arg(n:Term, zero, zero, zero)), (0 to n).sum:Term)
}
ok
},
test("evenOdd") { implicit T =>
0 to 50 foreach { n =>
equal1(eval(odd(n:Term)), n % 2 :Term)
}
ok
},
test("nested invokeDynamic") { implicit T =>
val nestedInvokeDynamic =
Let(
'id0 -> id(id),
'id1 -> 'id0.v('id0),
'id2 -> 'id1.v('id1)
) {
'id2.v(10)
}
equal(eval(nestedInvokeDynamic), 10:Term)
},
test("countDown") { implicit T =>
val p = LetRec(
'countDown ->
Lam('n)(If('n.v, 'countDown.v('n.v-1), 42))
)('countDown.v(10))
equal[Term](eval(p), 42)
},
test("overapply") { implicit T =>
equal(eval(id(id, id, 10:Term)), 10:Term)
},
test("shadow") { implicit T =>
equal(eval(LetRec('fib -> Lam('fib)('fib.v + 1))('fib.v(41))), 42:Term)
},
test("shadow2") { implicit T =>
val fib = LetRec('fib -> Lam('fib)('fib.v + 1))('fib.v(41))
val fibNested = LetRec('fib -> (1: Term))(fib)
equal(eval(fibNested), 42:Term)
},
test("let rec example 1") { implicit T =>
val ex = LetRec(
'a -> 1,
'b -> 10,
'x -> 100,
'y -> 1000
)('a.v + 'b + 'x + 'y)
equal(eval(ex), 1111: Term)
},
test("let rec example 2") { implicit T =>
val ex = LetRec(
'a -> 1,
'b -> 10,
'x -> 100,
'y -> 1000
)('a.v + 'x + 'y)
equal(eval(ex), 1101: Term)
},
test("let rec example 3") { implicit T =>
val ex = LetRec(
'a -> 1,
'b -> 10,
'x -> 100,
'y -> 1000
)('b.v + 'x + 'y)
equal(eval(ex), 1110: Term)
},
test("let rec example 4") { implicit T =>
val ex = LetRec(
'a -> 1,
'b -> 10,
'x -> 100,
'y -> 1000
)('x.v + 'y)
equal(eval(ex), 1100: Term)
},
{
def ex(t: Term) =
Let('a -> 1, 'b -> 10)(LetRec(
'x -> 100, 'y -> 1000
)(t))
suite("let/letrec")(
test("abxy") { implicit T =>
equal(eval(ex('a.v + 'b + 'x + 'y)), 1111: Term)
},
test("axy") { implicit T =>
equal(eval(ex('a.v + 'x + 'y)), 1101: Term)
},
test("bxy") { implicit T =>
equal(eval(ex('b.v + 'x + 'y)), 1110: Term)
},
test("xy") { implicit T =>
equal(eval(ex('x.v + 'y)), 1100: Term)
}
)
},
test("mutual non-tail recursion") { implicit T =>
0 to 20 foreach { n =>
equal1(eval(fibPrime(n:Term)), scalaFib(n):Term)
}
ok
},
suite("sequence")(
test("take") { implicit T =>
1 to 20 foreach { n =>
val xs = replicate(intIn(0,n))(int).map(x => x: Term)
val mySeq = Sequence(xs:_*)
val theirSeq = Sequence(xs.take(n):_*)
equal1(eval(Sequence.take(n, mySeq)), eval(theirSeq))
}
ok
},
test("ex1") { implicit T =>
equal(eval(Sequence.size(Sequence(1,2,3))), 3.unsigned)
},
test("ex2 (underapplication)") { implicit T =>
val t: Term =
Let('x -> Sequence(1,2,3),
'fn -> Sequence.take(2))(Sequence.size('fn.v('x)))
equal(eval(t), 2.unsigned)
}
),
suite("text") (
test("examples") { implicit T =>
equal1(eval(Text.concatenate("abc", "123")), "abc123": Term)
equal1(eval(Text.concatenate(Text.empty, "123")), "123": Term)
equal1(eval(Text.concatenate("123", Text.empty)), "123": Term)
equal1(eval(Text.drop(3, "abc123")), "123": Term)
equal1(eval(Text.take(3, "abc123")), "abc": Term)
equal1(eval(Text.equal("abc", "abc")), true: Term)
equal1(eval(Text.lt("Alice", "Bob")), true: Term)
equal1(eval(Text.lteq("Runar", "Runarorama")), true: Term)
equal1(eval(Text.lt("Arya", "Arya-orama")), true: Term)
equal1(eval(Text.gt("Bob", "Alice")), true: Term)
equal1(eval(Text.gteq("Runarorama", "Runar")), true: Term)
equal1(eval(Text.gteq("Arya-orama", "Arya")), true: Term)
ok
}
),
suite("pattern")(
test("literal") { implicit T =>
/* let x = 42; case 10 of 10 -> x + 1 */
val v: Term = 43
val c = MatchCase(LiteralU(10, UnboxedType.Int64), 'x.v + 1)
val p = Let('x -> (42:Term))(Match(10)(c))
equal(eval(p), v)
},
test("pattern guard") { implicit T =>
/* let x = 42
case 10 of
10 | true -> x + 1
*/
val v: Term = 43
val c = MatchCase(LiteralU(10, UnboxedType.Int64),
Some(true:Term), 'x.v + 1)
val p = Let('x -> (42:Term))(Match(10)(c))
equal(eval(p), v)
},
test("wildcard") { implicit T =>
/* let x = 42; case 10 of
10 | false -> x + 1;
y -> y + 4
should be 14
*/
val v: Term = 14
val c1 = MatchCase(LiteralU(10, UnboxedType.Int64),
Some(false:Term), 'x.v + 1)
val c2 = MatchCase(Wildcard, ABT.Abs('y, 'y.v + 4))
val p = Let('x -> (42:Term))(Match(10)(c1, c2))
equal(eval(p), v)
},
test("wildcard0") { implicit T =>
/* case 10 of y -> y + 4 */
val v: Term = 14
val c = MatchCase(Wildcard, ABT.Abs('y, 'y.v + 4))
val p = Match(10)(c)
equal(eval(p), v)
},
test("uncaptured") { implicit T =>
/* let x = 42; case 10 of 10 | false -> x + 1; _ -> x + 2
should return 44
*/
val v: Term = 44
val c1 = MatchCase(LiteralU(10, UnboxedType.Int64),
Some(false:Term), 'x.v + 1)
val c2 = MatchCase(Uncaptured, 'x.v + 2)
val p = Let('x -> (42:Term))(Match(10)(c1, c2))
equal(eval(p), v)
},
test("shadowing") { implicit T =>
/* let x = 42; case 10 of 10 | false -> x+1; x -> x+4 */
val v: Term = 14
val c1 = MatchCase(LiteralU(10, UnboxedType.Int64),
Some(false:Term), 'x.v + 1)
val c2 = MatchCase(Wildcard, ABT.Abs('x, 'x.v + 4))
val p = Let('x -> (42:Term))(Match(10)(c1, c2))
equal(eval(p), v)
},
test("data pattern 1") { implicit T =>
/* case (2,4) of (x,_) -> x */
val v: Term = 2
val c = MatchCase(Pattern.Tuple(Wildcard, Uncaptured), ABT.Abs('x, 'x))
val p = Match(intTupleTerm(2, 4))(c)
equal(eval(p), v)
},
test("data pattern 2") { implicit T =>
/* let x = 42; case (2,4) of (x,y) -> x+y; x -> x + 4 */
val v: Term = 6
val c1 = MatchCase(Pattern.Tuple(Wildcard, Wildcard),
ABT.Abs('x, ABT.Abs('y, 'x.v + 'y.v)))
val c2 = MatchCase(Wildcard, ABT.Abs('x, 'x.v + 4))
val p = Let('x -> (42:Term))(Match(intTupleTerm(2, 4))(c1, c2))
equal(eval(p), v)
},
test("big non-nested data pattern") { implicit T =>
/* let x = 42; case (1,10,100) of (a,b,c) -> a+b+c */
val v: Term = 111
val c1 = MatchCase(
Pattern.Tuple(Wildcard, Wildcard, Wildcard),
ABT.AbsChain('a, 'b, 'c)('a.v + 'b + 'c))
val p = Let('x -> (42:Term))(Match(intTupleTerm(1, 10, 100))(c1))
equal(eval(p), v)
},
test("bigger non-nested data pattern") { implicit T =>
/* let x = 42; case (1,10,100,1000) of (a,b,c,d) -> a+b+c+d */
val v: Term = 1111
val c1 = MatchCase(
Pattern.Tuple(Wildcard, Wildcard, Wildcard, Wildcard),
ABT.AbsChain('a, 'b, 'c, 'd)('a.v + 'b + 'c + 'd))
val p = Let('x -> (42:Term))(Match(intTupleTerm(1, 10, 100, 1000))(c1))
equal(eval(p), v)
},
test("nested data patterns") { implicit T =>
/* let x = 42; case ((3,4),(5,6)) of ((x,y),(_,z)) -> x+y+z; x -> x + 4 */
val v: Term = 13
val c1 =
MatchCase(Pattern.Tuple(
Pattern.Tuple(Wildcard, Wildcard),
Pattern.Tuple(Uncaptured, Wildcard)),
ABT.AbsChain('x, 'y, 'z)('x.v + 'y + 'z))
val c2 = MatchCase(Wildcard, ABT.Abs('x, 'x.v + 4))
val p = Let('x -> (42:Term))(
Match(Terms.tupleTerm(intTupleV(3, 4), intTupleV(5, 6)))(c1, c2))
equal(eval(p), v)
},
test("fall through data pattern") { implicit T =>
/* let x = 42; case (2,4) of (x,y) -> x+y; x -> x + 4 */
val v: Term = 6
val c1 = MatchCase(Pattern.Left(Wildcard), ABT.Abs('x, 'x))
val c2 = MatchCase(Pattern.Right(Wildcard), ABT.Abs('x, 'x))
val p = Match(intRightTerm(6))(c1, c2)
equal(eval(p), v)
},
test("fall through data pattern 2") { implicit T =>
/* let x = 42; case (2,4) of (x,y) -> x+y; x -> x + 4 */
val v: Term = 8
val c1 = MatchCase(Pattern.Left(Wildcard), ABT.Abs('x, 'x.v + 1))
val c2 = MatchCase(Pattern.Right(Wildcard), ABT.Abs('x, 'x.v + 2))
val p = Match(intRightTerm(6))(c1, c2)
equal(eval(p), v)
},
test("patterns that read the stack array") { implicit T =>
/* let x = 42; case (2,4) of (x,y) -> x+y; x -> x + 4 */
val c1 = MatchCase(Pattern.Left(Wildcard), ABT.Abs('x, 'x.v + 'a))
val c2 = MatchCase(Pattern.Right(Wildcard), ABT.Abs('x, 'x.v + 'a))
val p =
Let('a -> 1, 'b -> 10)(Match(intRightTerm(6))(c1, c2))
equal[Term](eval(p), 7)
},
test("as pattern") { implicit T =>
/* case 3 of x@(y) -> x + y */
val v: Term = 6
val c =
MatchCase(Pattern.As(Pattern.Wildcard),
ABT.AbsChain('x, 'y)('x.v + 'y))
val p = Match(3)(c)
equal(eval(p), v)
},
test("as-as-literal") { implicit T =>
/* case 3 of x@(y@(3)) -> x + y */
val v: Term = 6
val c =
MatchCase(Pattern.As(Pattern.As(Pattern.LiteralU(3, UnboxedType.Int64))),
ABT.AbsChain('x, 'y)('x.v + 'y))
val p = Match(3)(c)
equal(eval(p), v)
},
test("as-guard-literal 1") { implicit T =>
/* case 3 of
x@(y@(3)) | x + y > 4 -> x + y
*/
val v: Term = 6
val c =
MatchCase(
Pattern.As(
Pattern.As(
Pattern.LiteralU(3, UnboxedType.Int64)
)), Some[Term](ABT.AbsChain('x, 'y)('x.v + 'y > 4)), ABT.AbsChain('x, 'y)('x.v + 'y))
val p = Match(3)(c)
equal(eval(p), v)
},
test("as-guard-literal 2") { implicit T =>
/* case 1 of
x@(y@(3)) | x + y > 4 -> x + y
_ -> 2
*/
val v: Term = 2
val c =
MatchCase(
Pattern.As(
Pattern.As(
Pattern.LiteralU(3, UnboxedType.Int64)
)), Some[Term](ABT.AbsChain('x, 'y)('x.v + 'y > 4)), ABT.AbsChain('x, 'y)('x.v + 'y))
val c2 = MatchCase[Term](Pattern.Uncaptured, 2)
val p = Match(1)(c, c2)
equal(eval(p), v)
},
),
test("nested applies") { implicit T =>
val p = Apply(Apply(triangle, 10), 0)
equal(eval(p), eval(triangle(10, 0)))
},
test("partially applied dynamic call") { implicit T =>
val p = Let('f -> Lam('g)('g.v(1)),
'g -> Lam('a, 'b)('a.v + 'b))('f.v('g)(2))
equal[Term](eval(p), 3)
},
test("partially applied data constructor") { implicit T =>
val pair = BuiltinTypes.Tuple.lambda
val unit = BuiltinTypes.Unit.term
val p = Let('f -> pair(42))('f.v(pair(43, unit)))
equal[Term](eval(p), eval(BuiltinTypes.Tuple.term(42,43)))
},
// test("closure forming 2") { implicit T =>
// }
// todo: partially applied 3-arg data constructor
// todo: partially applied N-arg data constructor
// similar to above, or just manually construct closure forming lambda
// of appropriate arity
test("fully applied self non-tail call with K args") { implicit T =>
val fib2: Term =
LetRec('fib ->
Lam('n, 'm)(If('n.v < 'm,
'n,
'fib.v('n.v - 1, 'm) + 'fib.v('n.v - 2, 'm)))
)('fib)
equal[Term](eval(fib2(10, 2)), scalaFib(10))
},
test("fully applied self non-tail call with K+1 args") { implicit T =>
val fib2: Term =
LetRec('fib ->
Lam('n, 'm, 'o)(If('n.v < 'm,
If('n.v < 'o, 'o, 'n),
'fib.v('n.v - 1, 'm, 'o) + 'fib.v('n.v - 2, 'm, 'o)))
)('fib)
equal[Term](eval(fib2(10, 2, -1)), scalaFib(10))
},
test("let within body of tailrec function") { implicit T =>
val ant: Term = Term.ANF(triangle)
equal[Term](eval(triangle(10, 0)), (1 to 10).sum)
},
test("letrec within body of tailrec function") { implicit T =>
val trianglePrime =
LetRec('triangle ->
Lam('n, 'acc)(
If('n.v > 0,
LetRec('n2 -> ('n.v - 1), 'acc2 -> ('acc.v + 'n))(
'triangle.v('n2, 'acc2)),
'acc.v))
)('triangle)
equal[Term](eval(trianglePrime(10, 0)), (1 to 10).sum)
},
test("lambda with non-recursive free variables") { implicit T =>
equal(eval(Let('x -> 1, 'inc -> Lam('y)('x.v + 'y))('inc.v(one))), 2:Term)
},
suite("stream")(
test("decompile-empty") { implicit T =>
equal[Term](eval(termFor(Builtins.Stream_empty)),
termFor(Builtins.Stream_empty))
},
test("decompile-cons") { implicit T =>
equal[Term](eval(termFor(Builtins.Stream_cons)(1, termFor(Builtins.Stream_empty))),
termFor(Builtins.Stream_cons)(1, termFor(Builtins.Stream_empty)))
},
test("map") { implicit T =>
equal[Term](
eval(Stream.foldLeft(0, Int64.+, Stream.take(100, Stream.map(Int64.inc, Stream.fromInt64(0))))),
scala.Stream.from(0).map(1+).take(100).foldLeft(0)(_+_)
)
}
),
{ import BuiltinTypes._
import Effects._
suite("algebraic-effects")(
test("ex1") { implicit T =>
/*
let
state : s -> <State s> a -> a
state s <a> = a
state s <get -> k> = handle (state s) (k s)
state _ <put s -> k> = handle (state s) (k ())
handle (state 3)
x = State.get + 1
y = State.set (x + 1)
State.get + 11
*/
val p = LetRec(
('state, Lam('s, 'action) {
Match('action)(
// state s <a> = a
MatchCase(Pattern.EffectPure(Pattern.Wildcard),
ABT.Abs('a, 'a)),
// state s <get -> k> = handle (state s) (k s)
MatchCase(State.Get.pattern(Pattern.Wildcard),
ABT.Abs('k, Handle('state.v('s))('k.v('s)))),
// state _ <put s -> k> = handle (state s) (k ())
MatchCase(State.Set.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('s2, 'k)(Handle('state.v('s2))('k.v(BuiltinTypes.Unit.term))))
)
})
) {
Handle('state.v(3)) {
Let(
('x, State.Get.term + 1),
('y, State.Set.term('x.v + 1))
)(State.Get.term + 11)
}
}
note("pretty-printed algebraic effects program")
note(PrettyPrint.prettyTerm(Term.ANF(p)).render(40))
equal[Term](eval(Term.ANF(p)), 16)
},
test("simple effectful handlers") { implicit T =>
/*
let
state : s -> {State Integer} a -> a
state s {a} = a
state s {get -> k} = handle (state s) (k s)
state _ {put s -> k} = handle (state s) (k ())
state' : s -> {State Integer} Integer -> {State Integer} Integer
state' s {a} = State.get * s
state' s {get -> k} = handle (state' s) (k s)
state' _ {put s -> k} = handle (state' s) (k ())
handle (state 10)
handle (state' 3)
2
*/
val p = LetRec(
('state, Lam('s0, 'action0) {
Match('action0)(
MatchCase(Pattern.EffectPure(Pattern.Wildcard), ABT.Abs('a, 'a)),
MatchCase(State.Get.pattern(Pattern.Wildcard),
ABT.Abs('k, Handle('state.v('s0))('k.v('s0)))),
MatchCase(State.Set.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('s2, 'k)(Handle('state.v('s2))('k.v(BuiltinTypes.Unit.term))))
)
}),
('state2, Lam('s1, 'action1) {
Match('action1)(
// state s {a} = State.get * s
MatchCase(Pattern.EffectPure(Pattern.Wildcard),
ABT.Abs('a, State.Get.term * 's1)),
// ABT.Abs('a, 's1)), <-- this works fine!
// state' s {get -> k} = handle (state' s) (k s)
MatchCase(State.Get.pattern(Pattern.Wildcard),
ABT.Abs('k, Handle('state2.v('s1))('k.v('s1.v)))),
// state' _ {put s -> k} = handle (state' s) (k ())
MatchCase(State.Set.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('s3, 'k)(
Handle('state2.v('s3))('k.v(BuiltinTypes.Unit.term))))
)
})) {
Handle('state.v(10))(Handle('state2.v(3))(2340983))
}
note(PrettyPrint.prettyTerm(p).render(80))
note(PrettyPrint.prettyTerm(Term.ANF(p)).render(80))
equal[Term](eval(Term.ANF(p)), 30)
},
test("effectful handlers") { implicit T =>
/*
let
state : s -> {State Integer} a -> a
state s {a} = a
state s {get -> k} = handle (state s) (k s)
state _ {put s -> k} = handle (state s) (k ())
state' : s -> {State Integer} Integer -> {State Integer} Integer
state' s {a} = a
state' s {get -> k} = let
outer-value = State.get
handle (state s) (k (s + outer-value))
state' _ {put s -> k} = handle (state s) (k ())
handle (state 10)
handle (state' 3)
-- x is 14
x = State.get + 1
-- Inner state is 15
y = State.set (x + 1)
-- Should be 360
State.get + 11
*/
val p = LetRec(
('state, Lam('s, 'action) {
Match('action)(
// state s <a> = a
MatchCase(Pattern.EffectPure(Pattern.Wildcard),
ABT.Abs('a, 'a)),
// state s <get -> k> = handle (state s) (k s)
MatchCase(State.Get.pattern(Pattern.Wildcard),
ABT.Abs('k, Handle('state.v('s))('k.v('s)))),
// state _ <put s -> k> = handle (state s) (k ())
MatchCase(State.Set.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('s2, 'k)(Handle('state.v('s2))('k.v(BuiltinTypes.Unit.term))))
)
}),
('state2, Lam('s, 'action) {
Match('action)(
// state s <a> = State.get * s
MatchCase(Pattern.EffectPure(Pattern.Wildcard),
ABT.Abs('a, 'a)),
// todo: ABT.Abs('a, State.Get.term * 's)),
/*
let
outer-value = State.get
handle (state s) (k (s + outer-value))
*/
MatchCase(State.Get.pattern(Pattern.Wildcard),
ABT.Abs('k, Let('outer -> State.Get.term)(
Handle('state2.v('s))('k.v('s.v + 'outer))))),
// state _ <put s -> k> = handle (state s) (k ())
MatchCase(State.Set.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('s2, 'k)(
Handle('state2.v('s2))('k.v(BuiltinTypes.Unit.term))))
)
}))(
Handle('state.v(1))(Handle('state2.v(10))(
Let('x -> (State.Get.term + 100),
'y -> State.Set.term('x.v + 1000))(State.Get.term + 10000))))
note(PrettyPrint.prettyTerm(Term.ANF(p)).render(80))
equal[Term](eval(Term.ANF(p)), 11112)
},
test("mixed effects") { implicit T =>
import BuiltinTypes.Effects._
import Builtins.termFor
val env: Term = 42 // environment for reader
// handler for Read effects
val read = Term.Lam('env, 'x) {
// case x of
Match('x)(
// {a} -> a
MatchCase(Pattern.EffectPure(Pattern.Wildcard), ABT.Abs('a,'a)),
// {Read -> k} = handle (read env) (k env)
MatchCase(
Read.Read.pattern(Pattern.Wildcard),
ABT.Abs('k, Handle('read.v('env))('k.v(env)))
)
)
}
// handler for Write effects
val write = Term.Lam('acc, 'x) {
// case x of
Match('x)(
// {a} -> acc
MatchCase(Pattern.EffectPure(Pattern.Uncaptured), 'acc),
// {Write w -> k} = handle (write (Sequence.snoc acc w) (k ()))
MatchCase(
Write.Write.pattern(Pattern.Wildcard, Pattern.Wildcard),
ABT.AbsChain('w, 'k)(
Term.Handle('write.v(termFor(Builtins.Sequence_snoc)('acc, 'w))) {
'k.v(BuiltinTypes.Unit.term)
}
)
)
)
}
val p = LetRec(
'read -> read,
'write -> write
) {
Handle('write.v(termFor(Builtins.Sequence_empty))) {
Handle('read.v(env)) {
Let(
'x -> { Read.Read.term + 1 }, // 43
'u -> Write.Write.term('x), // write 43
'u -> Write.Write.term(44),
'u -> Write.Write.term(45),
'u -> Write.Write.term(46),
'z -> { Read.Read.term + 5 }, // 47
'u -> Write.Write.term('z) // write 47
)(999)
}
}
}
val anfP = Term.ANF(p)
note(PrettyPrint.prettyTerm(p).render(80))
note(PrettyPrint.prettyTerm(anfP).render(80))
equal[Term](eval(anfP), Sequence(43,44,45,46,47))
}
)},
test("and") { implicit T =>
equal1[Term](eval(And(true, true)), true)
equal1[Term](eval(And(true, false)), false)
equal1[Term](eval(And(false, true)), false)
equal1[Term](eval(And(false, false)), false)
ok
},
test("or") { implicit T =>
equal1[Term](eval(Or(true, true)), true)
equal1[Term](eval(Or(true, false)), true)
equal1[Term](eval(Or(false, true)), true)
equal1[Term](eval(Or(false, false)), false)
ok
},
test("short-circuiting and/or") { implicit T =>
equal1[Term](eval(Or(true, Debug.crash)), true)
equal1[Term](eval(And(false, Debug.crash)), false)
ok
}
)
}
object Terms {
val zero: Term = U0
val one: Term = 1
val id: Term = Lam('x)('x)
val const: Term = Lam('x,'y)('x)
val onePlusOne: Term = one + one
val onePlus: Term = Builtins.termFor(Builtins.Int64_add)(one)
val ap: Term = Lam('f,'x)('f.v('x))
val sum4: Term = Lam('a,'b,'c,'d)('a.v + 'b + 'c + 'd)
val fib: Term =
LetRec('fib ->
Lam('n)(If('n.v < 2, 'n, 'fib.v('n.v - 1) + 'fib.v('n.v - 2))))('fib)
val fibPrime: Term =
LetRec(
'fib -> Lam('n)(If('n.v < 2, 'n, 'fib2.v('n.v - 1) + 'fib2.v('n.v - 2))),
'fib2 -> Lam('n)(If('n.v < 2, 'n, 'fib.v('n.v - 1) + 'fib.v('n.v - 2)))
)('fib)
def scalaFib(n: Int): Int =
if (n < 2) n else scalaFib(n - 1) + scalaFib(n - 2)
val triangle =
LetRec('triangle ->
Lam('n, 'acc)(
If('n.v > 0,
'triangle.v('n.v - 1, 'acc.v + 'n),
'acc.v))
)('triangle)
val triangle4arg =
LetRec('triangle ->
Lam('n, 'hahaha, 'hehehe, 'acc)(
If('n.v > 0,
'triangle.v('n.v - 1, 'hahaha, 'hehehe, 'acc.v + 'n),
'acc.v))
)('triangle)
val odd =
LetRec(
'even -> Lam('n)(If('n.v > zero, 'odd.v ('n.v - 1), one)),
'odd-> Lam('n)(If('n.v > zero, 'even.v ('n.v - 1), zero))
)('odd)
def tupleTerm(xs: Value*): Term =
Term.Compiled(tupleV(xs :_*))
def tupleV(xs: Value*): Value =
Value.Data(Id.Builtin("Tuple"), ConstructorId(0), xs.toArray)
def intTupleTerm(xs: Int*): Term =
Term.Compiled(intTupleV(xs: _*))
def intRightTerm(i: Int): Term =
Term.Compiled(intRightV(i))
def intRightV(i: Int): Value =
Value.Data(Id.Builtin("Either"), ConstructorId(1), Array(intValue(i)))
def intTupleV(xs: Int*): Value =
tupleV(xs.map(intValue): _*)
def intValue(x: Int): Value = Value.Unboxed(x.toLong, UnboxedType.Int64)
object Int64Ops {
implicit class Ops(t0: Term) {
def +(t1: Term) = Builtins.termFor(Builtins.Int64_add)(t0, t1)
def -(t1: Term) = Builtins.termFor(Builtins.Int64_sub)(t0, t1)
def *(t1: Term) = Builtins.termFor(Builtins.Int64_mul)(t0, t1)
def /(t1: Term) = Builtins.termFor(Builtins.Int64_div)(t0, t1)
def unisonEquals(t1: Term) =
Builtins.termFor(Builtins.Int64_eq)(t0, t1)
def <(t1: Term) = Builtins.termFor(Builtins.Int64_lt)(t0, t1)
def >(t1: Term) = Builtins.termFor(Builtins.Int64_gt)(t0, t1)
}
}
object Int64 {
import Builtins._
val + = termFor(Int64_add)
val inc = termFor(Int64_inc)
}
object Sequence {
import Builtins._
def apply(terms: Term*): Term =
Term.Sequence(util.Sequence(terms:_*))
val empty = termFor(Sequence_empty)
val cons = termFor(Sequence_cons)
val snoc = termFor(Sequence_snoc)
val take = termFor(Sequence_take)
val size = termFor(Sequence_size)
}
object Text {
import Builtins._
val empty = termFor(Text_empty)
val take = termFor(Text_take)
val drop = termFor(Text_drop)
val concatenate = termFor(Text_concatenate)
val size = termFor(Text_size)
val equal = termFor(Text_eq)
val lt = termFor(Text_lt)
val gt = termFor(Text_gt)
val lteq = termFor(Text_lteq)
val gteq = termFor(Text_gteq)
}
object Stream {
import Builtins._
val empty = termFor(Stream_empty)
val fromInt64 = termFor(Stream_fromInt64)
val fromUInt64 = termFor(Stream_fromUInt64)
val cons = termFor(Stream_cons)
val drop = termFor(Stream_drop)
val take = termFor(Stream_take)
val map = termFor(Stream_map)
val foldLeft = termFor(Stream_foldLeft)
}
object Debug {
import Builtins._
val crash = termFor(Debug_crash)
}
}
|
paulp/unison
|
runtime-jvm/main/src/test/scala/CompilationTests.scala
|
Scala
|
mit
| 35,959 |
/* Copyright (C) 2008-2016 University of Massachusetts Amherst.
This file is part of "FACTORIE" (Factor graphs, Imperative, Extensible)
http://factorie.cs.umass.edu, http://github.com/factorie
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License. */
package cc.factorie.optimize
import cc.factorie._
import cc.factorie.la._
import cc.factorie.model.WeightsSet
import cc.factorie.util.{FastLogging, _}
/**
* Learns the parameters of a Model by processing the gradients and values from a collection of Examples.
* @author Alexandre Passos
*/
trait Trainer {
/**
* Process the examples once.
* @param examples Examples to be processed
*/
def processExamples(examples: Iterable[Example]): Unit
/** Would more training help? */
def isConverged: Boolean
/** Repeatedly process the examples until training has converged. */
def trainFromExamples(examples: Iterable[Example]): Unit = while (!isConverged) processExamples(examples)
}
/**
* Learns the parameters of a Model by summing the gradients and values of all Examples,
* and passing them to a GradientOptimizer (such as ConjugateGradient or LBFGS).
* @param weightsSet The parameters to be optimized
* @param optimizer The optimizer
* @author Alexandre Passos
*/
class BatchTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer = new LBFGS with L2Regularization, val maxIterations: Int = -1) extends Trainer with FastLogging {
var iteration = 0
val gradientAccumulator = new LocalWeightsMapAccumulator(weightsSet.blankDenseMap)
val valueAccumulator = new LocalDoubleAccumulator(0.0)
// TODO This is sad: The optimizer determines which of gradient/value/margin it needs, but we don't know here
// so we create them all, possibly causing the Example to do more work.
def processExamples(examples: Iterable[Example]): Unit = {
iteration += 1
if (isConverged) return
gradientAccumulator.tensorSet.zero()
valueAccumulator.value = 0.0
val startTime = System.currentTimeMillis
examples.foreach(example => example.accumulateValueAndGradient(valueAccumulator, gradientAccumulator))
val ellapsedTime = System.currentTimeMillis - startTime
logger.info(TrainerHelpers.getBatchTrainerStatus(gradientAccumulator.tensorSet.oneNorm, valueAccumulator.value, ellapsedTime))
optimizer.step(weightsSet, gradientAccumulator.tensorSet, valueAccumulator.value)
}
def isConverged = (maxIterations != -1 && iteration >= maxIterations) || optimizer.isConverged
}
/**
* Learns the parameters of a model by computing the gradient and calling the
* optimizer one example at a time.
* @param weightsSet The parameters to be optimized
* @param optimizer The optimizer
* @param maxIterations The maximum number of iterations until reporting convergence
* @param logEveryN After this many examples a log will be printed. If set to -1 10 logs will be printed.
* @author Alexandre Passos
*/
class OnlineTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer = new AdaGrad, val maxIterations: Int = 3, var logEveryN: Int = -1) extends Trainer with util.FastLogging {
var iteration = 0
val valueAccumulator = new LocalDoubleAccumulator
override def processExamples(examples: Iterable[Example]): Unit = {
if (logEveryN == -1) logEveryN = math.max(100, examples.size / 10)
iteration += 1
var valuesSeenSoFar = 0.0
var timePerIteration = 0L
var i = 0
val iter = examples.iterator
while (iter.hasNext) {
val example = iter.next()
val gradientAccumulator = new SmartGradientAccumulator
if ((logEveryN != 0) && (i % logEveryN == 0) && (i != 0)) {
logger.info(TrainerHelpers.getOnlineTrainerStatus(i, logEveryN, timePerIteration, valuesSeenSoFar))
valuesSeenSoFar = 0.0
timePerIteration = 0
}
val t0 = System.currentTimeMillis()
gradientAccumulator.clear()
valueAccumulator.value = 0
example.accumulateValueAndGradient(valueAccumulator, gradientAccumulator)
valuesSeenSoFar += valueAccumulator.value
optimizer.step(weightsSet, gradientAccumulator.getMap, valueAccumulator.value)
timePerIteration += System.currentTimeMillis() - t0
i+=1
}
}
def isConverged = iteration >= maxIterations
}
/** Train using one trainer, until it has converged, and then use the second trainer instead.
Typical use is to first train with an online stochastic gradient ascent such as OnlineTrainer and AdaGrad,
and then a batch trainer, like BatchTrainer and LBFGS.
@author Alexandre Passos */
class TwoStageTrainer(firstTrainer: Trainer, secondTrainer: Trainer) {
def processExamples(examples: Iterable[Example]) {
if (!firstTrainer.isConverged)
firstTrainer.processExamples(examples)
else
secondTrainer.processExamples(examples)
}
def isConverged = firstTrainer.isConverged && secondTrainer.isConverged
}
/** This parallel batch trainer keeps a single gradient in memory and locks accesses to it.
It is useful when computing the gradient in each example is more expensive than
adding this gradient to the accumulator.
If it performs slowly then mini-batches should help, or the ThreadLocalBatchTrainer.
@author Alexandre Passos */
class ParallelBatchTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer = new LBFGS with L2Regularization, val nThreads: Int = Runtime.getRuntime.availableProcessors(), val maxIterations: Int = -1)
extends Trainer with FastLogging {
var iteration = 0
val gradientAccumulator = new SynchronizedWeightsMapAccumulator(weightsSet.blankDenseMap)
val valueAccumulator = new SynchronizedDoubleAccumulator
def processExamples(examples: Iterable[Example]): Unit = {
iteration += 1
if (isConverged) return
gradientAccumulator.l.tensorSet.zero()
valueAccumulator.l.value = 0
val startTime = System.currentTimeMillis
util.Threading.parForeach(examples.toSeq, nThreads)(_.accumulateValueAndGradient(valueAccumulator, gradientAccumulator))
val ellapsedTime = System.currentTimeMillis - startTime
logger.info(TrainerHelpers.getBatchTrainerStatus(gradientAccumulator.l.tensorSet.oneNorm, valueAccumulator.l.value, ellapsedTime))
optimizer.step(weightsSet, gradientAccumulator.tensorSet, valueAccumulator.l.value)
}
def isConverged = (maxIterations != -1 && iteration >= maxIterations) || optimizer.isConverged
}
/** This parallel batch trainer keeps a per-thread gradient to which examples add weights.
It is useful when there is a very large number of examples, processing each example is
fast, and the weights are not too big, as it has to keep one copy of the weights per thread.
@author Alexandre Passos */
class ThreadLocalBatchTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer = new LBFGS with L2Regularization, numThreads: Int = Runtime.getRuntime.availableProcessors()) extends Trainer with FastLogging {
def processExamples(examples: Iterable[Example]): Unit = {
if (isConverged) return
val gradientAccumulator = new ThreadLocal(new LocalWeightsMapAccumulator(weightsSet.blankDenseMap))
val valueAccumulator = new ThreadLocal(new LocalDoubleAccumulator)
val startTime = System.currentTimeMillis
util.Threading.parForeach(examples, numThreads)(example => example.accumulateValueAndGradient(valueAccumulator.get, gradientAccumulator.get))
val grad = gradientAccumulator.instances.reduce((l, r) => { l.combine(r); l }).tensorSet
val value = valueAccumulator.instances.reduce((l, r) => { l.combine(r); l }).value
val ellapsedTime = System.currentTimeMillis - startTime
logger.info(TrainerHelpers.getBatchTrainerStatus(grad.oneNorm, value, ellapsedTime))
optimizer.step(weightsSet, grad, value)
}
def isConverged = optimizer.isConverged
}
/** This uses read-write locks on the tensors to ensure consistency while doing
parallel online training.
The guarantee is that while the examples read each tensor they will see a consistent
state, but this might not be the state the gradients will get applied to.
The optimizer, however, has no consistency guarantees across tensors.
@author Alexandre Passos */
class ParallelOnlineTrainer(weightsSet: WeightsSet, val optimizer: GradientOptimizer, val maxIterations: Int = 3, var logEveryN: Int = -1, val nThreads: Int = Runtime.getRuntime.availableProcessors())
extends Trainer with FastLogging {
var iteration = 0
var initialized = false
var examplesProcessed = 0
var accumulatedValue = 0.0
var t0 = 0L
private def processExample(e: Example) {
val gradientAccumulator = new SmartGradientAccumulator
val value = new LocalDoubleAccumulator()
e.accumulateValueAndGradient(value, gradientAccumulator)
// The following line will effectively call makeReadable on all the sparse tensors before acquiring the lock
val gradient = gradientAccumulator.getMap
gradient.tensors.foreach({ case t: SparseIndexedTensor => t.apply(0); case _ => })
optimizer.step(weightsSet, gradient, value.value)
this synchronized {
examplesProcessed += 1
accumulatedValue += value.value
if (logEveryN != 0 && examplesProcessed % logEveryN == 0) {
val accumulatedTime = System.currentTimeMillis() - t0
logger.info(TrainerHelpers.getOnlineTrainerStatus(examplesProcessed, logEveryN, accumulatedTime, accumulatedValue))
t0 = System.currentTimeMillis()
accumulatedValue = 0
}
}
}
def processExamples(examples: Iterable[Example]) {
if (!initialized) replaceTensorsWithLocks()
t0 = System.currentTimeMillis()
examplesProcessed = 0
accumulatedValue = 0.0
if (logEveryN == -1) logEveryN = math.max(100, examples.size / 10)
iteration += 1
util.Threading.parForeach(examples.toSeq, nThreads)(processExample(_))
}
def isConverged = iteration >= maxIterations
def replaceTensorsWithLocks() {
for (key <- weightsSet.keys) {
key.value match {
case t: Tensor1 => weightsSet(key) = new LockingTensor1(t)
case t: Tensor2 => weightsSet(key) = new LockingTensor2(t)
case t: Tensor3 => weightsSet(key) = new LockingTensor3(t)
case t: Tensor4 => weightsSet(key) = new LockingTensor4(t)
}
}
initialized = true
}
def removeLocks() {
for (key <- weightsSet.keys) {
key.value match {
case t: LockingTensor => weightsSet(key) = t.base
}
}
}
private trait LockingTensor extends Tensor with SparseDoubleSeq {
val base: Tensor
def activeDomainSize = lock.withReadLock { base.activeDomainSize }
override def foreachActiveElement(f: (Int, Double) => Unit) { lock.withReadLock(base.foreachActiveElement(f)) }
val lock = new util.RWLock
def activeDomain = base.activeDomain
def isDense = base.isDense
def zero() { lock.withWriteLock(base.zero())}
def +=(i: Int, incr: Double) { lock.withWriteLock( base.+=(i,incr))}
override def +=(i: DoubleSeq, v: Double) = lock.withWriteLock(base.+=(i,v))
def dot(ds: DoubleSeq) = lock.withReadLock(base.dot(ds))
def update(i: Int, v: Double) { lock.withWriteLock(base.update(i,v)) }
def apply(i: Int) = lock.withReadLock(base.apply(i))
override def *=(d:Double): Unit = lock.withWriteLock { base *= d}
override def *=(ds:DoubleSeq): Unit = lock.withWriteLock { base *= ds }
override def /=(ds:DoubleSeq): Unit = lock.withWriteLock { base /= ds }
}
private class LockingTensor1(val base: Tensor1) extends Tensor1 with LockingTensor {
def dim1 = base.dim1
override def copy = lock.withReadLock { base.copy }
}
private class LockingTensor2(val base: Tensor2) extends Tensor2 with LockingTensor {
def dim1 = base.dim1
def dim2 = base.dim2
def activeDomain1 = lock.withReadLock(base.activeDomain1)
def activeDomain2 = lock.withReadLock(base.activeDomain2)
override def *(other: Tensor1) = lock.withReadLock(base * other)
override def leftMultiply(other: Tensor1) = lock.withReadLock(base leftMultiply other)
override def copy = lock.withReadLock { base.copy }
}
private class LockingTensor3(val base: Tensor3) extends Tensor3 with LockingTensor {
def dim1 = base.dim1
def dim2 = base.dim2
def dim3 = base.dim3
def activeDomain1 = lock.withReadLock(base.activeDomain1)
def activeDomain2 = lock.withReadLock(base.activeDomain2)
def activeDomain3 = lock.withReadLock(base.activeDomain3)
override def copy = lock.withReadLock { base.copy }
}
private class LockingTensor4(val base: Tensor4) extends Tensor4 with LockingTensor {
def dim1 = base.dim1
def dim2 = base.dim2
def dim3 = base.dim3
def dim4 = base.dim4
def activeDomain1 = lock.withReadLock(base.activeDomain1)
def activeDomain2 = lock.withReadLock(base.activeDomain2)
def activeDomain3 = lock.withReadLock(base.activeDomain3)
def activeDomain4 = lock.withReadLock(base.activeDomain4)
override def copy = lock.withReadLock { base.copy }
}
}
/** This online trainer synchronizes only on the optimizer, so reads on the weights
can be done while they are being written to.
It provides orthogonal guarantees than the ParallelOnlineTrainer, as the examples can have
inconsistent reads from the same tensor but the optimizer will always
have a consistent view of all tensors.
@author Alexandre Passos */
class SynchronizedOptimizerOnlineTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer, val nThreads: Int = Runtime.getRuntime.availableProcessors(), val maxIterations: Int = 3, var logEveryN : Int = -1)
extends Trainer with FastLogging {
var examplesProcessed = 0
var accumulatedValue = 0.0
var t0 = System.currentTimeMillis()
private def processExample(e: Example): Unit = {
val gradientAccumulator = new SmartGradientAccumulator
val value = new LocalDoubleAccumulator()
e.accumulateValueAndGradient(value, gradientAccumulator)
// The following line will effectively call makeReadable on all the sparse tensors before acquiring the lock
val gradient = gradientAccumulator.getMap
gradient.tensors.foreach({ case t: SparseIndexedTensor => t.apply(0); case _ => })
optimizer synchronized {
optimizer.step(weightsSet, gradient, value.value)
examplesProcessed += 1
accumulatedValue += value.value
if (examplesProcessed % logEveryN == 0) {
val accumulatedTime = System.currentTimeMillis() - t0
logger.info(TrainerHelpers.getOnlineTrainerStatus(examplesProcessed, logEveryN, accumulatedTime, accumulatedValue))
t0 = System.currentTimeMillis()
accumulatedValue = 0
}
}
}
var iteration = 0
def processExamples(examples: Iterable[Example]): Unit = {
if (logEveryN == -1) logEveryN = math.max(100, examples.size / 10)
iteration += 1
t0 = System.currentTimeMillis()
examplesProcessed = 0
accumulatedValue = 0.0
util.Threading.parForeach(examples.toSeq, nThreads)(processExample(_))
}
def isConverged = iteration >= maxIterations
}
/**
* A parallel online trainer which has no locks or synchronization.
* Only use this if you know what you're doing.
* @param weightsSet The parameters to optimize
* @param optimizer The optimizer
* @param nThreads How many threads to use
* @param maxIterations The maximum number of iterations
* @param logEveryN How often to log.
* @param locksForLogging Whether to lock around logging. Disabling this might make logging not work at all.
* @author Alexandre Passos
*/
class HogwildTrainer(val weightsSet: WeightsSet, val optimizer: GradientOptimizer, val nThreads: Int = Runtime.getRuntime.availableProcessors(), val maxIterations: Int = 3, var logEveryN : Int = -1, val locksForLogging: Boolean = true)
extends Trainer with FastLogging {
var examplesProcessed = 0
var accumulatedValue = 0.0
var t0 = System.currentTimeMillis()
val lock = new util.RWLock
private def processExample(e: Example): Unit = {
val gradientAccumulator = new SmartGradientAccumulator
val value = new LocalDoubleAccumulator()
e.accumulateValueAndGradient(value, gradientAccumulator)
optimizer.step(weightsSet, gradientAccumulator.getMap, value.value)
if (locksForLogging) lock.writeLock()
try {
examplesProcessed += 1
accumulatedValue += value.value
if (examplesProcessed % logEveryN == 0) {
val accumulatedTime = System.currentTimeMillis() - t0
logger.info(TrainerHelpers.getOnlineTrainerStatus(examplesProcessed, logEveryN, accumulatedTime, accumulatedValue))
t0 = System.currentTimeMillis()
accumulatedValue = 0
}
} finally {
if (locksForLogging) lock.writeUnlock()
}
}
var iteration = 0
def processExamples(examples: Iterable[Example]): Unit = {
if (logEveryN == -1) logEveryN = math.max(100, examples.size / 10)
iteration += 1
t0 = System.currentTimeMillis()
examplesProcessed = 0
accumulatedValue = 0.0
util.Threading.parForeach(examples.toSeq, nThreads)(processExample(_))
}
def isConverged = iteration >= maxIterations
}
object TrainerHelpers {
def getTimeString(ms: Long): String =
if (ms > 120000) f"${ms/60000}%d minutes" else if (ms> 5000) f"${ms/1000}%d seconds" else s"$ms milliseconds"
def getBatchTrainerStatus(gradNorm: => Double, value: => Double, ms: => Long) =
f"GradientNorm: $gradNorm%-10g value $value%-10g ${getTimeString(ms)}%s"
def getOnlineTrainerStatus(examplesProcessed: Int, logEveryN: Int, accumulatedTime: Long, accumulatedValue: Double) =
f"$examplesProcessed%20s examples at ${1000.0*logEveryN/accumulatedTime}%5.2f examples/sec. Average objective: ${accumulatedValue / logEveryN}%5.5f"
}
/** A collection of convenience methods for creating Trainers and running them with recommended default values.
@author Alexandre Passos */
object Trainer {
/**
* Convenient function for training. Creates a trainer, trains until convergence, and evaluates after every iteration.
* @param parameters The parameters to be optimized
* @param examples The examples to train on
* @param maxIterations The maximum number of iterations for training
* @param evaluate The function for evaluation
* @param optimizer The optimizer
* @param useParallelTrainer Whether to use parallel training
* @param useOnlineTrainer Whether to use online training
* @param logEveryN How often to log, if using online training
*/
def train(parameters: WeightsSet, examples: Seq[Example], maxIterations: Int, evaluate: () => Unit, optimizer: GradientOptimizer, useParallelTrainer: Boolean, useOnlineTrainer: Boolean, logEveryN: Int = -1, nThreads: Int = Runtime.getRuntime.availableProcessors(), miniBatch: Int)(implicit random: scala.util.Random) {
parameters.keys.foreach(_.value) // make sure we initialize the values in a single thread
optimizer.initializeWeights(parameters)
val actualEx: Seq[Example] = if (miniBatch == -1) examples else MiniBatchExample(miniBatch, examples).toSeq
val trainer = if (useOnlineTrainer && useParallelTrainer) new ParallelOnlineTrainer(parameters, optimizer=optimizer, maxIterations=maxIterations, logEveryN=logEveryN, nThreads=nThreads)
else if (useOnlineTrainer && !useParallelTrainer) new OnlineTrainer(parameters, optimizer=optimizer, maxIterations=maxIterations, logEveryN=logEveryN)
else if (!useOnlineTrainer && useParallelTrainer) new ParallelBatchTrainer(parameters, optimizer=optimizer, maxIterations=maxIterations, nThreads=nThreads)
else new BatchTrainer(parameters, optimizer=optimizer, maxIterations=maxIterations)
trainer match { case t: ParallelOnlineTrainer => t.replaceTensorsWithLocks(); case _ => }
try {
while (!trainer.isConverged) {
trainer.processExamples(actualEx.shuffle)
optimizer match { case o: ParameterAveraging => o.setWeightsToAverage(parameters); case _ => }
evaluate()
optimizer match { case o: ParameterAveraging => o.unSetWeightsToAverage(parameters); case _ => }
}
} finally {
trainer match { case t: ParallelOnlineTrainer => t.removeLocks(); case _ => }
optimizer.finalizeWeights(parameters)
}
}
/**
* A convenient way to call Trainer.train() for online trainers.
* @param parameters The parameters to be optimized
* @param examples The examples
* @param evaluate The evaluation function
* @param useParallelTrainer Whether to train in parallel
* @param maxIterations The maximum number of iterations
* @param optimizer The optimizer
* @param logEveryN How often to log
*/
def onlineTrain(parameters: WeightsSet, examples: Seq[Example], evaluate: () => Unit = () => (), useParallelTrainer: Boolean=false, maxIterations: Int = 3, optimizer: GradientOptimizer = new AdaGrad with ParameterAveraging, logEveryN: Int = -1 ,nThreads: Int = Runtime.getRuntime.availableProcessors(), miniBatch: Int = -1)(implicit random: scala.util.Random) {
train(parameters, examples, maxIterations, evaluate, optimizer, useParallelTrainer=useParallelTrainer, useOnlineTrainer=true, logEveryN=logEveryN, nThreads=nThreads, miniBatch)
}
/**
* A convenient way to call Trainer.train() for batch training.
* @param parameters The parameters to be optimized
* @param examples The examples
* @param evaluate The evaluation function
* @param useParallelTrainer Whether to use a parallel trainer
* @param maxIterations The maximum number of iterations
* @param optimizer The optimizer
*/
def batchTrain(parameters: WeightsSet, examples: Seq[Example], evaluate: () => Unit = () => (), useParallelTrainer: Boolean=true, maxIterations: Int = 200, optimizer: GradientOptimizer = new LBFGS with L2Regularization, nThreads: Int = Runtime.getRuntime.availableProcessors())(implicit random: scala.util.Random) {
train(parameters, examples, maxIterations, evaluate, optimizer, useParallelTrainer=useParallelTrainer, useOnlineTrainer=false, nThreads=nThreads, miniBatch= -1)
}
}
|
Craigacp/factorie
|
src/main/scala/cc/factorie/optimize/Trainer.scala
|
Scala
|
apache-2.0
| 22,542 |
package com.nthportal.shell
package impl
object WriteCommand extends Command {
override val name: String = "write"
override def execute(args: ImmutableSeq[String])(implicit sink: OutputSink): Unit = {
sink.writeln(s"${this.getClass.getName} has been executed")
}
}
|
NthPortal/app-shell
|
src/test/scala/com/nthportal/shell/impl/WriteCommand.scala
|
Scala
|
apache-2.0
| 277 |
package org.knora.webapi
package object app {
val APPLICATION_MANAGER_ACTOR_NAME = "applicationManager"
val APPLICATION_MANAGER_ACTOR_PATH = "/user/" + APPLICATION_MANAGER_ACTOR_NAME
}
|
musicEnfanthen/Knora
|
webapi/src/main/scala/org/knora/webapi/app/package.scala
|
Scala
|
agpl-3.0
| 196 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.streaming
import java.io.{File, InterruptedIOException, IOException, UncheckedIOException}
import java.nio.channels.ClosedByInterruptException
import java.util.concurrent.{CountDownLatch, ExecutionException, TimeoutException, TimeUnit}
import scala.reflect.ClassTag
import scala.util.control.ControlThrowable
import com.google.common.util.concurrent.UncheckedExecutionException
import org.apache.commons.io.FileUtils
import org.apache.hadoop.conf.Configuration
import org.scalatest.time.SpanSugar._
import org.apache.spark.{SparkConf, SparkContext, TaskContext}
import org.apache.spark.scheduler.{SparkListener, SparkListenerJobStart}
import org.apache.spark.sql._
import org.apache.spark.sql.catalyst.plans.logical.Range
import org.apache.spark.sql.catalyst.streaming.InternalOutputModes
import org.apache.spark.sql.catalyst.util.DateTimeUtils
import org.apache.spark.sql.execution.command.ExplainCommand
import org.apache.spark.sql.execution.streaming._
import org.apache.spark.sql.execution.streaming.sources.ContinuousMemoryStream
import org.apache.spark.sql.execution.streaming.state.{StateStore, StateStoreConf, StateStoreId, StateStoreProvider}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.sources.StreamSourceProvider
import org.apache.spark.sql.streaming.util.StreamManualClock
import org.apache.spark.sql.types.{IntegerType, StructField, StructType}
import org.apache.spark.util.Utils
class StreamSuite extends StreamTest {
import testImplicits._
test("map with recovery") {
val inputData = MemoryStream[Int]
val mapped = inputData.toDS().map(_ + 1)
testStream(mapped)(
AddData(inputData, 1, 2, 3),
StartStream(),
CheckAnswer(2, 3, 4),
StopStream,
AddData(inputData, 4, 5, 6),
StartStream(),
CheckAnswer(2, 3, 4, 5, 6, 7))
}
test("join") {
// Make a table and ensure it will be broadcast.
val smallTable = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
// Join the input stream with a table.
val inputData = MemoryStream[Int]
val joined = inputData.toDS().toDF().join(smallTable, $"value" === $"number")
testStream(joined)(
AddData(inputData, 1, 2, 3),
CheckAnswer(Row(1, 1, "one"), Row(2, 2, "two")),
AddData(inputData, 4),
CheckAnswer(Row(1, 1, "one"), Row(2, 2, "two"), Row(4, 4, "four")))
}
test("StreamingRelation.computeStats") {
withTempDir { dir =>
val df = spark.readStream.format("csv").schema(StructType(Seq())).load(dir.getCanonicalPath)
val streamingRelation = df.logicalPlan collect {
case s: StreamingRelation => s
}
assert(streamingRelation.nonEmpty, "cannot find StreamingRelation")
assert(
streamingRelation.head.computeStats.sizeInBytes ==
spark.sessionState.conf.defaultSizeInBytes)
}
}
test("StreamingRelationV2.computeStats") {
val streamingRelation = spark.readStream.format("rate").load().logicalPlan collect {
case s: StreamingRelationV2 => s
}
assert(streamingRelation.nonEmpty, "cannot find StreamingRelationV2")
assert(
streamingRelation.head.computeStats.sizeInBytes == spark.sessionState.conf.defaultSizeInBytes)
}
test("StreamingExecutionRelation.computeStats") {
val memoryStream = MemoryStream[Int]
val executionRelation = StreamingExecutionRelation(
memoryStream, memoryStream.encoder.schema.toAttributes)(memoryStream.sqlContext.sparkSession)
assert(executionRelation.computeStats.sizeInBytes == spark.sessionState.conf.defaultSizeInBytes)
}
test("explain join with a normal source") {
// This test triggers CostBasedJoinReorder to call `computeStats`
withSQLConf(SQLConf.CBO_ENABLED.key -> "true", SQLConf.JOIN_REORDER_ENABLED.key -> "true") {
val smallTable = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
val smallTable2 = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
val smallTable3 = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
// Join the input stream with a table.
val df = spark.readStream.format("rate").load()
val joined = df.join(smallTable, smallTable("number") === $"value")
.join(smallTable2, smallTable2("number") === $"value")
.join(smallTable3, smallTable3("number") === $"value")
val outputStream = new java.io.ByteArrayOutputStream()
Console.withOut(outputStream) {
joined.explain(true)
}
assert(outputStream.toString.contains("StreamingRelation"))
}
}
test("explain join with MemoryStream") {
// This test triggers CostBasedJoinReorder to call `computeStats`
// Because MemoryStream doesn't use DataSource code path, we need a separate test.
withSQLConf(SQLConf.CBO_ENABLED.key -> "true", SQLConf.JOIN_REORDER_ENABLED.key -> "true") {
val smallTable = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
val smallTable2 = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
val smallTable3 = Seq((1, "one"), (2, "two"), (4, "four")).toDF("number", "word")
// Join the input stream with a table.
val df = MemoryStream[Int].toDF
val joined = df.join(smallTable, smallTable("number") === $"value")
.join(smallTable2, smallTable2("number") === $"value")
.join(smallTable3, smallTable3("number") === $"value")
val outputStream = new java.io.ByteArrayOutputStream()
Console.withOut(outputStream) {
joined.explain(true)
}
assert(outputStream.toString.contains("StreamingRelation"))
}
}
test("SPARK-20432: union one stream with itself") {
val df = spark.readStream.format(classOf[FakeDefaultSource].getName).load().select("a")
val unioned = df.union(df)
withTempDir { outputDir =>
withTempDir { checkpointDir =>
val query =
unioned
.writeStream.format("parquet")
.option("checkpointLocation", checkpointDir.getAbsolutePath)
.start(outputDir.getAbsolutePath)
try {
query.processAllAvailable()
val outputDf = spark.read.parquet(outputDir.getAbsolutePath).as[Long]
checkDatasetUnorderly[Long](outputDf, (0L to 10L).union((0L to 10L)).toArray: _*)
} finally {
query.stop()
}
}
}
}
test("union two streams") {
val inputData1 = MemoryStream[Int]
val inputData2 = MemoryStream[Int]
val unioned = inputData1.toDS().union(inputData2.toDS())
testStream(unioned)(
AddData(inputData1, 1, 3, 5),
CheckAnswer(1, 3, 5),
AddData(inputData2, 2, 4, 6),
CheckAnswer(1, 2, 3, 4, 5, 6),
StopStream,
AddData(inputData1, 7),
StartStream(),
AddData(inputData2, 8),
CheckAnswer(1, 2, 3, 4, 5, 6, 7, 8))
}
test("sql queries") {
val inputData = MemoryStream[Int]
inputData.toDF().createOrReplaceTempView("stream")
val evens = sql("SELECT * FROM stream WHERE value % 2 = 0")
testStream(evens)(
AddData(inputData, 1, 2, 3, 4),
CheckAnswer(2, 4))
}
test("DataFrame reuse") {
def assertDF(df: DataFrame) {
withTempDir { outputDir =>
withTempDir { checkpointDir =>
val query = df.writeStream.format("parquet")
.option("checkpointLocation", checkpointDir.getAbsolutePath)
.start(outputDir.getAbsolutePath)
try {
query.processAllAvailable()
val outputDf = spark.read.parquet(outputDir.getAbsolutePath).as[Long]
checkDataset[Long](outputDf, (0L to 10L).toArray: _*)
} finally {
query.stop()
}
}
}
}
val df = spark.readStream.format(classOf[FakeDefaultSource].getName).load()
assertDF(df)
assertDF(df)
}
test("Within the same streaming query, one StreamingRelation should only be transformed to one " +
"StreamingExecutionRelation") {
val df = spark.readStream.format(classOf[FakeDefaultSource].getName).load()
var query: StreamExecution = null
try {
query =
df.union(df)
.writeStream
.format("memory")
.queryName("memory")
.start()
.asInstanceOf[StreamingQueryWrapper]
.streamingQuery
query.awaitInitialization(streamingTimeout.toMillis)
val executionRelations =
query
.logicalPlan
.collect { case ser: StreamingExecutionRelation => ser }
assert(executionRelations.size === 2)
assert(executionRelations.distinct.size === 1)
} finally {
if (query != null) {
query.stop()
}
}
}
test("unsupported queries") {
val streamInput = MemoryStream[Int]
val batchInput = Seq(1, 2, 3).toDS()
def assertError(expectedMsgs: Seq[String])(body: => Unit): Unit = {
val e = intercept[AnalysisException] {
body
}
expectedMsgs.foreach { s => assert(e.getMessage.contains(s)) }
}
// Running streaming plan as a batch query
assertError("start" :: Nil) {
streamInput.toDS.map { i => i }.count()
}
// Running non-streaming plan with as a streaming query
assertError("without streaming sources" :: "start" :: Nil) {
val ds = batchInput.map { i => i }
testStream(ds)()
}
// Running streaming plan that cannot be incrementalized
assertError("not supported" :: "streaming" :: Nil) {
val ds = streamInput.toDS.map { i => i }.sort()
testStream(ds)()
}
}
test("minimize delay between batch construction and execution") {
// For each batch, we would retrieve new data's offsets and log them before we run the execution
// This checks whether the key of the offset log is the expected batch id
def CheckOffsetLogLatestBatchId(expectedId: Int): AssertOnQuery =
AssertOnQuery(_.offsetLog.getLatest().get._1 == expectedId,
s"offsetLog's latest should be $expectedId")
// Check the latest batchid in the commit log
def CheckCommitLogLatestBatchId(expectedId: Int): AssertOnQuery =
AssertOnQuery(_.commitLog.getLatest().get._1 == expectedId,
s"commitLog's latest should be $expectedId")
// Ensure that there has not been an incremental execution after restart
def CheckNoIncrementalExecutionCurrentBatchId(): AssertOnQuery =
AssertOnQuery(_.lastExecution == null, s"lastExecution not expected to run")
// For each batch, we would log the state change during the execution
// This checks whether the key of the state change log is the expected batch id
def CheckIncrementalExecutionCurrentBatchId(expectedId: Int): AssertOnQuery =
AssertOnQuery(_.lastExecution.asInstanceOf[IncrementalExecution].currentBatchId == expectedId,
s"lastExecution's currentBatchId should be $expectedId")
// For each batch, we would log the sink change after the execution
// This checks whether the key of the sink change log is the expected batch id
def CheckSinkLatestBatchId(expectedId: Int): AssertOnQuery =
AssertOnQuery(_.sink.asInstanceOf[MemorySink].latestBatchId.get == expectedId,
s"sink's lastBatchId should be $expectedId")
val inputData = MemoryStream[Int]
testStream(inputData.toDS())(
StartStream(Trigger.ProcessingTime("10 seconds"), new StreamManualClock),
/* -- batch 0 ----------------------- */
// Add some data in batch 0
AddData(inputData, 1, 2, 3),
AdvanceManualClock(10 * 1000), // 10 seconds
/* -- batch 1 ----------------------- */
// Check the results of batch 0
CheckAnswer(1, 2, 3),
CheckIncrementalExecutionCurrentBatchId(0),
CheckCommitLogLatestBatchId(0),
CheckOffsetLogLatestBatchId(0),
CheckSinkLatestBatchId(0),
// Add some data in batch 1
AddData(inputData, 4, 5, 6),
AdvanceManualClock(10 * 1000),
/* -- batch _ ----------------------- */
// Check the results of batch 1
CheckAnswer(1, 2, 3, 4, 5, 6),
CheckIncrementalExecutionCurrentBatchId(1),
CheckCommitLogLatestBatchId(1),
CheckOffsetLogLatestBatchId(1),
CheckSinkLatestBatchId(1),
AdvanceManualClock(10 * 1000),
AdvanceManualClock(10 * 1000),
AdvanceManualClock(10 * 1000),
/* -- batch __ ---------------------- */
// Check the results of batch 1 again; this is to make sure that, when there's no new data,
// the currentId does not get logged (e.g. as 2) even if the clock has advanced many times
CheckAnswer(1, 2, 3, 4, 5, 6),
CheckIncrementalExecutionCurrentBatchId(1),
CheckCommitLogLatestBatchId(1),
CheckOffsetLogLatestBatchId(1),
CheckSinkLatestBatchId(1),
/* Stop then restart the Stream */
StopStream,
StartStream(Trigger.ProcessingTime("10 seconds"), new StreamManualClock(60 * 1000)),
/* -- batch 1 no rerun ----------------- */
// batch 1 would not re-run because the latest batch id logged in commit log is 1
AdvanceManualClock(10 * 1000),
CheckNoIncrementalExecutionCurrentBatchId(),
/* -- batch 2 ----------------------- */
// Check the results of batch 1
CheckAnswer(1, 2, 3, 4, 5, 6),
CheckCommitLogLatestBatchId(1),
CheckOffsetLogLatestBatchId(1),
CheckSinkLatestBatchId(1),
// Add some data in batch 2
AddData(inputData, 7, 8, 9),
AdvanceManualClock(10 * 1000),
/* -- batch 3 ----------------------- */
// Check the results of batch 2
CheckAnswer(1, 2, 3, 4, 5, 6, 7, 8, 9),
CheckIncrementalExecutionCurrentBatchId(2),
CheckCommitLogLatestBatchId(2),
CheckOffsetLogLatestBatchId(2),
CheckSinkLatestBatchId(2))
}
test("insert an extraStrategy") {
try {
spark.experimental.extraStrategies = TestStrategy :: Nil
val inputData = MemoryStream[(String, Int)]
val df = inputData.toDS().map(_._1).toDF("a")
testStream(df)(
AddData(inputData, ("so slow", 1)),
CheckAnswer("so fast"))
} finally {
spark.experimental.extraStrategies = Nil
}
}
testQuietly("handle fatal errors thrown from the stream thread") {
for (e <- Seq(
new VirtualMachineError {},
new ThreadDeath,
new LinkageError,
new ControlThrowable {}
)) {
val source = new Source {
override def getOffset: Option[Offset] = {
throw e
}
override def getBatch(start: Option[Offset], end: Offset): DataFrame = {
throw e
}
override def schema: StructType = StructType(Array(StructField("value", IntegerType)))
override def stop(): Unit = {}
}
val df = Dataset[Int](
sqlContext.sparkSession,
StreamingExecutionRelation(source, sqlContext.sparkSession))
testStream(df)(
// `ExpectFailure(isFatalError = true)` verifies two things:
// - Fatal errors can be propagated to `StreamingQuery.exception` and
// `StreamingQuery.awaitTermination` like non fatal errors.
// - Fatal errors can be caught by UncaughtExceptionHandler.
ExpectFailure(isFatalError = true)(ClassTag(e.getClass))
)
}
}
test("output mode API in Scala") {
assert(OutputMode.Append === InternalOutputModes.Append)
assert(OutputMode.Complete === InternalOutputModes.Complete)
assert(OutputMode.Update === InternalOutputModes.Update)
}
override protected def sparkConf: SparkConf = super.sparkConf
.set("spark.redaction.string.regex", "file:/[\\\\w_]+")
test("explain - redaction") {
val replacement = "*********"
val inputData = MemoryStream[String]
val df = inputData.toDS().map(_ + "foo").groupBy("value").agg(count("*"))
// Test StreamingQuery.display
val q = df.writeStream.queryName("memory_explain").outputMode("complete").format("memory")
.start()
.asInstanceOf[StreamingQueryWrapper]
.streamingQuery
try {
inputData.addData("abc")
q.processAllAvailable()
val explainWithoutExtended = q.explainInternal(false)
assert(explainWithoutExtended.contains(replacement))
assert(explainWithoutExtended.contains("StateStoreRestore"))
assert(!explainWithoutExtended.contains("file:/"))
val explainWithExtended = q.explainInternal(true)
assert(explainWithExtended.contains(replacement))
assert(explainWithExtended.contains("StateStoreRestore"))
assert(!explainWithoutExtended.contains("file:/"))
} finally {
q.stop()
}
}
test("explain") {
val inputData = MemoryStream[String]
val df = inputData.toDS().map(_ + "foo").groupBy("value").agg(count("*"))
// Test `df.explain`
val explain = ExplainCommand(df.queryExecution.logical, extended = false)
val explainString =
spark.sessionState
.executePlan(explain)
.executedPlan
.executeCollect()
.map(_.getString(0))
.mkString("\\n")
assert(explainString.contains("StateStoreRestore"))
assert(explainString.contains("StreamingRelation"))
assert(!explainString.contains("LocalTableScan"))
// Test StreamingQuery.display
val q = df.writeStream.queryName("memory_explain").outputMode("complete").format("memory")
.start()
.asInstanceOf[StreamingQueryWrapper]
.streamingQuery
try {
assert("No physical plan. Waiting for data." === q.explainInternal(false))
assert("No physical plan. Waiting for data." === q.explainInternal(true))
inputData.addData("abc")
q.processAllAvailable()
val explainWithoutExtended = q.explainInternal(false)
// `extended = false` only displays the physical plan.
assert("StreamingDataSourceV2Relation".r
.findAllMatchIn(explainWithoutExtended).size === 0)
assert("BatchScan".r
.findAllMatchIn(explainWithoutExtended).size === 1)
// Use "StateStoreRestore" to verify that it does output a streaming physical plan
assert(explainWithoutExtended.contains("StateStoreRestore"))
val explainWithExtended = q.explainInternal(true)
// `extended = true` displays 3 logical plans (Parsed/Optimized/Optimized) and 1 physical
// plan.
assert("StreamingDataSourceV2Relation".r
.findAllMatchIn(explainWithExtended).size === 3)
assert("BatchScan".r
.findAllMatchIn(explainWithExtended).size === 1)
// Use "StateStoreRestore" to verify that it does output a streaming physical plan
assert(explainWithExtended.contains("StateStoreRestore"))
} finally {
q.stop()
}
}
test("explain-continuous") {
val inputData = ContinuousMemoryStream[Int]
val df = inputData.toDS().map(_ * 2).filter(_ > 5)
// Test `df.explain`
val explain = ExplainCommand(df.queryExecution.logical, extended = false)
val explainString =
spark.sessionState
.executePlan(explain)
.executedPlan
.executeCollect()
.map(_.getString(0))
.mkString("\\n")
assert(explainString.contains("Filter"))
assert(explainString.contains("MapElements"))
assert(!explainString.contains("LocalTableScan"))
// Test StreamingQuery.display
val q = df.writeStream.queryName("memory_continuous_explain")
.outputMode(OutputMode.Update()).format("memory")
.trigger(Trigger.Continuous("1 seconds"))
.start()
.asInstanceOf[StreamingQueryWrapper]
.streamingQuery
try {
// in continuous mode, the query will be run even there's no data
// sleep a bit to ensure initialization
eventually(timeout(2.seconds), interval(100.milliseconds)) {
assert(q.lastExecution != null)
}
val explainWithoutExtended = q.explainInternal(false)
// `extended = false` only displays the physical plan.
assert("StreamingDataSourceV2Relation".r
.findAllMatchIn(explainWithoutExtended).size === 0)
assert("ContinuousScan".r
.findAllMatchIn(explainWithoutExtended).size === 1)
val explainWithExtended = q.explainInternal(true)
// `extended = true` displays 3 logical plans (Parsed/Optimized/Optimized) and 1 physical
// plan.
assert("StreamingDataSourceV2Relation".r
.findAllMatchIn(explainWithExtended).size === 3)
assert("ContinuousScan".r
.findAllMatchIn(explainWithExtended).size === 1)
} finally {
q.stop()
}
}
test("codegen-microbatch") {
val inputData = MemoryStream[Int]
val df = inputData.toDS().map(_ * 2).filter(_ > 5)
// Test StreamingQuery.codegen
val q = df.writeStream.queryName("memory_microbatch_codegen")
.outputMode(OutputMode.Update)
.format("memory")
.trigger(Trigger.ProcessingTime("1 seconds"))
.start()
try {
import org.apache.spark.sql.execution.debug._
assert("No physical plan. Waiting for data." === codegenString(q))
assert(codegenStringSeq(q).isEmpty)
inputData.addData(1, 2, 3, 4, 5)
q.processAllAvailable()
assertDebugCodegenResult(q)
} finally {
q.stop()
}
}
test("codegen-continuous") {
val inputData = ContinuousMemoryStream[Int]
val df = inputData.toDS().map(_ * 2).filter(_ > 5)
// Test StreamingQuery.codegen
val q = df.writeStream.queryName("memory_continuous_codegen")
.outputMode(OutputMode.Update)
.format("memory")
.trigger(Trigger.Continuous("1 seconds"))
.start()
try {
// in continuous mode, the query will be run even there's no data
// sleep a bit to ensure initialization
eventually(timeout(2.seconds), interval(100.milliseconds)) {
assert(q.asInstanceOf[StreamingQueryWrapper].streamingQuery.lastExecution != null)
}
assertDebugCodegenResult(q)
} finally {
q.stop()
}
}
private def assertDebugCodegenResult(query: StreamingQuery): Unit = {
import org.apache.spark.sql.execution.debug._
val codegenStr = codegenString(query)
assert(codegenStr.contains("Found 1 WholeStageCodegen subtrees."))
// assuming that code is generated for the test query
assert(codegenStr.contains("Generated code:"))
val codegenStrSeq = codegenStringSeq(query)
assert(codegenStrSeq.nonEmpty)
assert(codegenStrSeq.head._1.contains("*(1)"))
assert(codegenStrSeq.head._2.contains("codegenStageId=1"))
}
test("SPARK-19065: dropDuplicates should not create expressions using the same id") {
withTempPath { testPath =>
val data = Seq((1, 2), (2, 3), (3, 4))
data.toDS.write.mode("overwrite").json(testPath.getCanonicalPath)
val schema = spark.read.json(testPath.getCanonicalPath).schema
val query = spark
.readStream
.schema(schema)
.json(testPath.getCanonicalPath)
.dropDuplicates("_1")
.writeStream
.format("memory")
.queryName("testquery")
.outputMode("append")
.start()
try {
query.processAllAvailable()
if (query.exception.isDefined) {
throw query.exception.get
}
} finally {
query.stop()
}
}
}
test("handle IOException when the streaming thread is interrupted (pre Hadoop 2.8)") {
// This test uses a fake source to throw the same IOException as pre Hadoop 2.8 when the
// streaming thread is interrupted. We should handle it properly by not failing the query.
ThrowingIOExceptionLikeHadoop12074.createSourceLatch = new CountDownLatch(1)
val query = spark
.readStream
.format(classOf[ThrowingIOExceptionLikeHadoop12074].getName)
.load()
.writeStream
.format("console")
.start()
assert(ThrowingIOExceptionLikeHadoop12074.createSourceLatch
.await(streamingTimeout.toMillis, TimeUnit.MILLISECONDS),
"ThrowingIOExceptionLikeHadoop12074.createSource wasn't called before timeout")
query.stop()
assert(query.exception.isEmpty)
}
test("handle InterruptedIOException when the streaming thread is interrupted (Hadoop 2.8+)") {
// This test uses a fake source to throw the same InterruptedIOException as Hadoop 2.8+ when the
// streaming thread is interrupted. We should handle it properly by not failing the query.
ThrowingInterruptedIOException.createSourceLatch = new CountDownLatch(1)
val query = spark
.readStream
.format(classOf[ThrowingInterruptedIOException].getName)
.load()
.writeStream
.format("console")
.start()
assert(ThrowingInterruptedIOException.createSourceLatch
.await(streamingTimeout.toMillis, TimeUnit.MILLISECONDS),
"ThrowingInterruptedIOException.createSource wasn't called before timeout")
query.stop()
assert(query.exception.isEmpty)
}
test("SPARK-19873: streaming aggregation with change in number of partitions") {
val inputData = MemoryStream[(Int, Int)]
val agg = inputData.toDS().groupBy("_1").count()
testStream(agg, OutputMode.Complete())(
AddData(inputData, (1, 0), (2, 0)),
StartStream(additionalConfs = Map(SQLConf.SHUFFLE_PARTITIONS.key -> "2")),
CheckAnswer((1, 1), (2, 1)),
StopStream,
AddData(inputData, (3, 0), (2, 0)),
StartStream(additionalConfs = Map(SQLConf.SHUFFLE_PARTITIONS.key -> "5")),
CheckAnswer((1, 1), (2, 2), (3, 1)),
StopStream,
AddData(inputData, (3, 0), (1, 0)),
StartStream(additionalConfs = Map(SQLConf.SHUFFLE_PARTITIONS.key -> "1")),
CheckAnswer((1, 2), (2, 2), (3, 2)))
}
testQuietly("recover from a Spark v2.1 checkpoint") {
var inputData: MemoryStream[Int] = null
var query: DataStreamWriter[Row] = null
def prepareMemoryStream(): Unit = {
inputData = MemoryStream[Int]
inputData.addData(1, 2, 3, 4)
inputData.addData(3, 4, 5, 6)
inputData.addData(5, 6, 7, 8)
query = inputData
.toDF()
.groupBy($"value")
.agg(count("*"))
.writeStream
.outputMode("complete")
.format("memory")
}
// Get an existing checkpoint generated by Spark v2.1.
// v2.1 does not record # shuffle partitions in the offset metadata.
val resourceUri =
this.getClass.getResource("/structured-streaming/checkpoint-version-2.1.0").toURI
val checkpointDir = new File(resourceUri)
// 1 - Test if recovery from the checkpoint is successful.
prepareMemoryStream()
val dir1 = Utils.createTempDir().getCanonicalFile // not using withTempDir {}, makes test flaky
// Copy the checkpoint to a temp dir to prevent changes to the original.
// Not doing this will lead to the test passing on the first run, but fail subsequent runs.
FileUtils.copyDirectory(checkpointDir, dir1)
// Checkpoint data was generated by a query with 10 shuffle partitions.
// In order to test reading from the checkpoint, the checkpoint must have two or more batches,
// since the last batch may be rerun.
withSQLConf(SQLConf.SHUFFLE_PARTITIONS.key -> "10") {
var streamingQuery: StreamingQuery = null
try {
streamingQuery =
query.queryName("counts").option("checkpointLocation", dir1.getCanonicalPath).start()
streamingQuery.processAllAvailable()
inputData.addData(9)
streamingQuery.processAllAvailable()
QueryTest.checkAnswer(spark.table("counts").toDF(),
Row("1", 1) :: Row("2", 1) :: Row("3", 2) :: Row("4", 2) ::
Row("5", 2) :: Row("6", 2) :: Row("7", 1) :: Row("8", 1) :: Row("9", 1) :: Nil)
} finally {
if (streamingQuery ne null) {
streamingQuery.stop()
}
}
}
// 2 - Check recovery with wrong num shuffle partitions
prepareMemoryStream()
val dir2 = Utils.createTempDir().getCanonicalFile
FileUtils.copyDirectory(checkpointDir, dir2)
// Since the number of partitions is greater than 10, should throw exception.
withSQLConf(SQLConf.SHUFFLE_PARTITIONS.key -> "15") {
var streamingQuery: StreamingQuery = null
try {
intercept[StreamingQueryException] {
streamingQuery =
query.queryName("badQuery").option("checkpointLocation", dir2.getCanonicalPath).start()
streamingQuery.processAllAvailable()
}
} finally {
if (streamingQuery ne null) {
streamingQuery.stop()
}
}
}
}
test("calling stop() on a query cancels related jobs") {
val input = MemoryStream[Int]
val query = input
.toDS()
.map { i =>
while (!TaskContext.get().isInterrupted()) {
// keep looping till interrupted by query.stop()
Thread.sleep(100)
}
i
}
.writeStream
.format("console")
.start()
input.addData(1)
// wait for jobs to start
eventually(timeout(streamingTimeout)) {
assert(sparkContext.statusTracker.getActiveJobIds().nonEmpty)
}
query.stop()
// make sure jobs are stopped
eventually(timeout(streamingTimeout)) {
assert(sparkContext.statusTracker.getActiveJobIds().isEmpty)
}
}
test("batch id is updated correctly in the job description") {
val queryName = "memStream"
@volatile var jobDescription: String = null
def assertDescContainsQueryNameAnd(batch: Integer): Unit = {
// wait for listener event to be processed
spark.sparkContext.listenerBus.waitUntilEmpty(streamingTimeout.toMillis)
assert(jobDescription.contains(queryName) && jobDescription.contains(s"batch = $batch"))
}
spark.sparkContext.addSparkListener(new SparkListener {
override def onJobStart(jobStart: SparkListenerJobStart): Unit = {
jobDescription = jobStart.properties.getProperty(SparkContext.SPARK_JOB_DESCRIPTION)
}
})
val input = MemoryStream[Int]
val query = input
.toDS()
.map(_ + 1)
.writeStream
.format("memory")
.queryName(queryName)
.start()
input.addData(1)
query.processAllAvailable()
assertDescContainsQueryNameAnd(batch = 0)
input.addData(2, 3)
query.processAllAvailable()
assertDescContainsQueryNameAnd(batch = 1)
input.addData(4)
query.processAllAvailable()
assertDescContainsQueryNameAnd(batch = 2)
query.stop()
}
test("should resolve the checkpoint path") {
withTempDir { dir =>
val checkpointLocation = dir.getCanonicalPath
assert(!checkpointLocation.startsWith("file:/"))
val query = MemoryStream[Int].toDF
.writeStream
.option("checkpointLocation", checkpointLocation)
.format("console")
.start()
try {
val resolvedCheckpointDir =
query.asInstanceOf[StreamingQueryWrapper].streamingQuery.resolvedCheckpointRoot
assert(resolvedCheckpointDir.startsWith("file:/"))
} finally {
query.stop()
}
}
}
testQuietly("specify custom state store provider") {
val providerClassName = classOf[TestStateStoreProvider].getCanonicalName
withSQLConf("spark.sql.streaming.stateStore.providerClass" -> providerClassName) {
val input = MemoryStream[Int]
val df = input.toDS().groupBy().count()
val query = df.writeStream.outputMode("complete").format("memory").queryName("name").start()
input.addData(1, 2, 3)
val e = intercept[Exception] {
query.awaitTermination()
}
assert(e.getMessage.contains(providerClassName))
assert(e.getMessage.contains("instantiated"))
}
}
testQuietly("custom state store provider read from offset log") {
val input = MemoryStream[Int]
val df = input.toDS().groupBy().count()
val providerConf1 = "spark.sql.streaming.stateStore.providerClass" ->
"org.apache.spark.sql.execution.streaming.state.HDFSBackedStateStoreProvider"
val providerConf2 = "spark.sql.streaming.stateStore.providerClass" ->
classOf[TestStateStoreProvider].getCanonicalName
def runQuery(queryName: String, checkpointLoc: String): Unit = {
val query = df.writeStream
.outputMode("complete")
.format("memory")
.queryName(queryName)
.option("checkpointLocation", checkpointLoc)
.start()
input.addData(1, 2, 3)
query.processAllAvailable()
query.stop()
}
withTempDir { dir =>
val checkpointLoc1 = new File(dir, "1").getCanonicalPath
withSQLConf(providerConf1) {
runQuery("query1", checkpointLoc1) // generate checkpoints
}
val checkpointLoc2 = new File(dir, "2").getCanonicalPath
withSQLConf(providerConf2) {
// Verify new query will use new provider that throw error on loading
intercept[Exception] {
runQuery("query2", checkpointLoc2)
}
// Verify old query from checkpoint will still use old provider
runQuery("query1", checkpointLoc1)
}
}
}
test("streaming limit without state") {
val inputData1 = MemoryStream[Int]
testStream(inputData1.toDF().limit(0))(
AddData(inputData1, 1 to 8: _*),
CheckAnswer())
val inputData2 = MemoryStream[Int]
testStream(inputData2.toDF().limit(4))(
AddData(inputData2, 1 to 8: _*),
CheckAnswer(1 to 4: _*))
}
test("streaming limit with state") {
val inputData = MemoryStream[Int]
testStream(inputData.toDF().limit(4))(
AddData(inputData, 1 to 2: _*),
CheckAnswer(1 to 2: _*),
AddData(inputData, 3 to 6: _*),
CheckAnswer(1 to 4: _*),
AddData(inputData, 7 to 9: _*),
CheckAnswer(1 to 4: _*))
}
test("streaming limit with other operators") {
val inputData = MemoryStream[Int]
testStream(inputData.toDF().where("value % 2 = 1").limit(4))(
AddData(inputData, 1 to 5: _*),
CheckAnswer(1, 3, 5),
AddData(inputData, 6 to 9: _*),
CheckAnswer(1, 3, 5, 7),
AddData(inputData, 10 to 12: _*),
CheckAnswer(1, 3, 5, 7))
}
test("streaming limit with multiple limits") {
val inputData1 = MemoryStream[Int]
testStream(inputData1.toDF().limit(4).limit(2))(
AddData(inputData1, 1),
CheckAnswer(1),
AddData(inputData1, 2 to 8: _*),
CheckAnswer(1, 2))
val inputData2 = MemoryStream[Int]
testStream(inputData2.toDF().limit(4).limit(100).limit(3))(
AddData(inputData2, 1, 2),
CheckAnswer(1, 2),
AddData(inputData2, 3 to 8: _*),
CheckAnswer(1 to 3: _*))
}
test("streaming limit in complete mode") {
val inputData = MemoryStream[Int]
val limited = inputData.toDF().limit(5).groupBy("value").count()
testStream(limited, OutputMode.Complete())(
AddData(inputData, 1 to 3: _*),
CheckAnswer(Row(1, 1), Row(2, 1), Row(3, 1)),
AddData(inputData, 1 to 9: _*),
CheckAnswer(Row(1, 2), Row(2, 2), Row(3, 2), Row(4, 1), Row(5, 1)))
}
test("streaming limits in complete mode") {
val inputData = MemoryStream[Int]
val limited = inputData.toDF().limit(4).groupBy("value").count().orderBy("value").limit(3)
testStream(limited, OutputMode.Complete())(
AddData(inputData, 1 to 9: _*),
CheckAnswer(Row(1, 1), Row(2, 1), Row(3, 1)),
AddData(inputData, 2 to 6: _*),
CheckAnswer(Row(1, 1), Row(2, 2), Row(3, 2)))
}
test("streaming limit in update mode") {
val inputData = MemoryStream[Int]
val e = intercept[AnalysisException] {
testStream(inputData.toDF().limit(5), OutputMode.Update())(
AddData(inputData, 1 to 3: _*)
)
}
assert(e.getMessage.contains(
"Limits are not supported on streaming DataFrames/Datasets in Update output mode"))
}
test("streaming limit in multiple partitions") {
val inputData = MemoryStream[Int]
testStream(inputData.toDF().repartition(2).limit(7))(
AddData(inputData, 1 to 10: _*),
CheckAnswerRowsByFunc(
rows => assert(rows.size == 7 && rows.forall(r => r.getInt(0) <= 10)),
false),
AddData(inputData, 11 to 20: _*),
CheckAnswerRowsByFunc(
rows => assert(rows.size == 7 && rows.forall(r => r.getInt(0) <= 10)),
false))
}
test("streaming limit in multiple partitions by column") {
val inputData = MemoryStream[(Int, Int)]
val df = inputData.toDF().repartition(2, $"_2").limit(7)
testStream(df)(
AddData(inputData, (1, 0), (2, 0), (3, 1), (4, 1)),
CheckAnswerRowsByFunc(
rows => assert(rows.size == 4 && rows.forall(r => r.getInt(0) <= 4)),
false),
AddData(inputData, (5, 0), (6, 0), (7, 1), (8, 1)),
CheckAnswerRowsByFunc(
rows => assert(rows.size == 7 && rows.forall(r => r.getInt(0) <= 8)),
false))
}
test("is_continuous_processing property should be false for microbatch processing") {
val input = MemoryStream[Int]
val df = input.toDS()
.map(i => TaskContext.get().getLocalProperty(StreamExecution.IS_CONTINUOUS_PROCESSING))
testStream(df) (
AddData(input, 1),
CheckAnswer("false")
)
}
test("is_continuous_processing property should be true for continuous processing") {
val input = ContinuousMemoryStream[Int]
val stream = input.toDS()
.map(i => TaskContext.get().getLocalProperty(StreamExecution.IS_CONTINUOUS_PROCESSING))
.writeStream.format("memory")
.queryName("output")
.trigger(Trigger.Continuous("1 seconds"))
.start()
try {
input.addData(1)
stream.processAllAvailable()
} finally {
stream.stop()
}
checkAnswer(spark.sql("select * from output"), Row("true"))
}
for (e <- Seq(
new InterruptedException,
new InterruptedIOException,
new ClosedByInterruptException,
new UncheckedIOException("test", new ClosedByInterruptException),
new ExecutionException("test", new InterruptedException),
new UncheckedExecutionException("test", new InterruptedException))) {
test(s"view ${e.getClass.getSimpleName} as a normal query stop") {
ThrowingExceptionInCreateSource.createSourceLatch = new CountDownLatch(1)
ThrowingExceptionInCreateSource.exception = e
val query = spark
.readStream
.format(classOf[ThrowingExceptionInCreateSource].getName)
.load()
.writeStream
.format("console")
.start()
assert(ThrowingExceptionInCreateSource.createSourceLatch
.await(streamingTimeout.toMillis, TimeUnit.MILLISECONDS),
"ThrowingExceptionInCreateSource.createSource wasn't called before timeout")
query.stop()
assert(query.exception.isEmpty)
}
}
test("SPARK-26379 Structured Streaming - Exception on adding current_timestamp " +
" to Dataset - use v2 sink") {
testCurrentTimestampOnStreamingQuery(useV2Sink = true)
}
test("SPARK-26379 Structured Streaming - Exception on adding current_timestamp " +
" to Dataset - use v1 sink") {
testCurrentTimestampOnStreamingQuery(useV2Sink = false)
}
private def testCurrentTimestampOnStreamingQuery(useV2Sink: Boolean): Unit = {
val input = MemoryStream[Int]
val df = input.toDS().withColumn("cur_timestamp", lit(current_timestamp()))
def assertBatchOutputAndUpdateLastTimestamp(
rows: Seq[Row],
curTimestamp: Long,
curDate: Int,
expectedValue: Int): Long = {
assert(rows.size === 1)
val row = rows.head
assert(row.getInt(0) === expectedValue)
assert(row.getTimestamp(1).getTime >= curTimestamp)
row.getTimestamp(1).getTime
}
var lastTimestamp = System.currentTimeMillis()
val currentDate = DateTimeUtils.millisToDays(lastTimestamp)
testStream(df, useV2Sink = useV2Sink) (
AddData(input, 1),
CheckLastBatch { rows: Seq[Row] =>
lastTimestamp = assertBatchOutputAndUpdateLastTimestamp(rows, lastTimestamp, currentDate, 1)
},
Execute { _ => Thread.sleep(1000) },
AddData(input, 2),
CheckLastBatch { rows: Seq[Row] =>
lastTimestamp = assertBatchOutputAndUpdateLastTimestamp(rows, lastTimestamp, currentDate, 2)
}
)
}
}
abstract class FakeSource extends StreamSourceProvider {
private val fakeSchema = StructType(StructField("a", IntegerType) :: Nil)
override def sourceSchema(
spark: SQLContext,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): (String, StructType) = ("fakeSource", fakeSchema)
}
/** A fake StreamSourceProvider that creates a fake Source that cannot be reused. */
class FakeDefaultSource extends FakeSource {
override def createSource(
spark: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
// Create a fake Source that emits 0 to 10.
new Source {
private var offset = -1L
override def schema: StructType = StructType(StructField("a", IntegerType) :: Nil)
override def getOffset: Option[Offset] = {
if (offset >= 10) {
None
} else {
offset += 1
Some(LongOffset(offset))
}
}
override def getBatch(start: Option[Offset], end: Offset): DataFrame = {
val startOffset = start.map(_.asInstanceOf[LongOffset].offset).getOrElse(-1L) + 1
val ds = new Dataset[java.lang.Long](
spark.sparkSession,
Range(
startOffset,
end.asInstanceOf[LongOffset].offset + 1,
1,
Some(spark.sparkSession.sparkContext.defaultParallelism),
isStreaming = true),
Encoders.LONG)
ds.toDF("a")
}
override def stop() {}
}
}
}
/** A fake source that throws the same IOException like pre Hadoop 2.8 when it's interrupted. */
class ThrowingIOExceptionLikeHadoop12074 extends FakeSource {
import ThrowingIOExceptionLikeHadoop12074._
override def createSource(
spark: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
createSourceLatch.countDown()
try {
Thread.sleep(30000)
throw new TimeoutException("sleep was not interrupted in 30 seconds")
} catch {
case ie: InterruptedException =>
throw new IOException(ie.toString)
}
}
}
object ThrowingIOExceptionLikeHadoop12074 {
/**
* A latch to allow the user to wait until `ThrowingIOExceptionLikeHadoop12074.createSource` is
* called.
*/
@volatile var createSourceLatch: CountDownLatch = null
}
/** A fake source that throws InterruptedIOException like Hadoop 2.8+ when it's interrupted. */
class ThrowingInterruptedIOException extends FakeSource {
import ThrowingInterruptedIOException._
override def createSource(
spark: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
createSourceLatch.countDown()
try {
Thread.sleep(30000)
throw new TimeoutException("sleep was not interrupted in 30 seconds")
} catch {
case ie: InterruptedException =>
val iie = new InterruptedIOException(ie.toString)
iie.initCause(ie)
throw iie
}
}
}
object ThrowingInterruptedIOException {
/**
* A latch to allow the user to wait until `ThrowingInterruptedIOException.createSource` is
* called.
*/
@volatile var createSourceLatch: CountDownLatch = null
}
class TestStateStoreProvider extends StateStoreProvider {
override def init(
stateStoreId: StateStoreId,
keySchema: StructType,
valueSchema: StructType,
indexOrdinal: Option[Int],
storeConfs: StateStoreConf,
hadoopConf: Configuration): Unit = {
throw new Exception("Successfully instantiated")
}
override def stateStoreId: StateStoreId = null
override def close(): Unit = { }
override def getStore(version: Long): StateStore = null
}
/** A fake source that throws `ThrowingExceptionInCreateSource.exception` in `createSource` */
class ThrowingExceptionInCreateSource extends FakeSource {
override def createSource(
spark: SQLContext,
metadataPath: String,
schema: Option[StructType],
providerName: String,
parameters: Map[String, String]): Source = {
ThrowingExceptionInCreateSource.createSourceLatch.countDown()
try {
Thread.sleep(30000)
throw new TimeoutException("sleep was not interrupted in 30 seconds")
} catch {
case _: InterruptedException =>
throw ThrowingExceptionInCreateSource.exception
}
}
}
object ThrowingExceptionInCreateSource {
/**
* A latch to allow the user to wait until `ThrowingExceptionInCreateSource.createSource` is
* called.
*/
@volatile var createSourceLatch: CountDownLatch = null
@volatile var exception: Exception = null
}
|
WindCanDie/spark
|
sql/core/src/test/scala/org/apache/spark/sql/streaming/StreamSuite.scala
|
Scala
|
apache-2.0
| 45,720 |
import org.specs2.mutable._
class B extends Specification
{
"this" should {
"not work" in { 1 must_== 2 }
}
}
object A extends Specification
{
"this" should {
"not work" in { 1 must_== 2 }
}
}
|
twitter-forks/sbt
|
sbt/src/sbt-test/tests/it/changes/ClassFailModuleFail.scala
|
Scala
|
bsd-3-clause
| 203 |
package wallet
import java.util.Date
import com.fasterxml.jackson.annotation.JsonProperty
import org.hibernate.validator.constraints.NotEmpty
import org.springframework.context.annotation.Bean
import scala.beans.BeanProperty
/**
* Created by vaibhavb on 9/19/14.
*/
class IDCard (@JsonProperty("card_id") card_id: String,
@JsonProperty("card_name") card_name: String,
@JsonProperty("card_number") card_number: String,
@JsonProperty("expiration_date") expiration_date: String,
@JsonProperty("user_id") u_id : String) {
@BeanProperty var card_id_i: String= card_id
@BeanProperty var card_name_i: String= card_name
@BeanProperty var card_number_i: String= card_number
@BeanProperty var expiration_date_i: String= expiration_date
@BeanProperty var user_id_i:String=u_id
@NotEmpty
def getCardName() = card_name
@NotEmpty
def getCardNumber() = card_number
}
|
vaibhavabhor/CMPE273Assignment2
|
src/main/scala/wallet/IDCard.scala
|
Scala
|
mit
| 936 |
package chapter3
object Exercise3_28 {
/**
*
*/
def map[A, B](tree: Tree[A])(f: A => B): Tree[B] = tree match {
case Empty() => Empty()
case Leaf(a) => Leaf(f(a))
case Branch(left, right) => Branch(map(left)(f), map(right)(f))
}
def main(args: Array[String]): Unit = {
assert(map(Leaf(1))(_.toString) == Leaf("1"))
assert(map(Branch(Leaf(1), Leaf(2)))(_.toString) == Branch(Leaf("1"), Leaf("2")))
println("All tests successful")
}
}
|
amolnayak311/functional-programming-in-scala
|
src/chapter3/Exercise3_28.scala
|
Scala
|
unlicense
| 488 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.hive.thriftserver
import java.io._
import java.util.{ArrayList => JArrayList, Locale}
import scala.collection.JavaConverters._
import jline.console.ConsoleReader
import jline.console.history.FileHistory
import org.apache.commons.lang3.StringUtils
import org.apache.commons.logging.LogFactory
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hive.cli.{CliDriver, CliSessionState, OptionsProcessor}
import org.apache.hadoop.hive.common.{HiveInterruptCallback, HiveInterruptUtils}
import org.apache.hadoop.hive.conf.HiveConf
import org.apache.hadoop.hive.ql.Driver
import org.apache.hadoop.hive.ql.exec.Utilities
import org.apache.hadoop.hive.ql.processors._
import org.apache.hadoop.hive.ql.session.SessionState
import org.apache.log4j.{Level, Logger}
import org.apache.thrift.transport.TSocket
import org.apache.spark.internal.Logging
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.hive.HiveUtils
import org.apache.spark.util.ShutdownHookManager
/**
* This code doesn't support remote connections in Hive 1.2+, as the underlying CliDriver
* has dropped its support.
*/
private[hive] object SparkSQLCLIDriver extends Logging {
private var prompt = "spark-sql"
private var continuedPrompt = "".padTo(prompt.length, ' ')
private var transport: TSocket = _
installSignalHandler()
/**
* Install an interrupt callback to cancel all Spark jobs. In Hive's CliDriver#processLine(),
* a signal handler will invoke this registered callback if a Ctrl+C signal is detected while
* a command is being processed by the current thread.
*/
def installSignalHandler() {
HiveInterruptUtils.add(new HiveInterruptCallback {
override def interrupt() {
// Handle remote execution mode
if (SparkSQLEnv.sparkContext != null) {
SparkSQLEnv.sparkContext.cancelAllJobs()
} else {
if (transport != null) {
// Force closing of TCP connection upon session termination
transport.getSocket.close()
}
}
}
})
}
def main(args: Array[String]) {
val oproc = new OptionsProcessor()
if (!oproc.process_stage1(args)) {
System.exit(1)
}
val cliConf = new HiveConf(classOf[SessionState])
// Override the location of the metastore since this is only used for local execution.
HiveUtils.newTemporaryConfiguration(useInMemoryDerby = false).foreach {
case (key, value) => cliConf.set(key, value)
}
val sessionState = new CliSessionState(cliConf)
sessionState.in = System.in
try {
sessionState.out = new PrintStream(System.out, true, "UTF-8")
sessionState.info = new PrintStream(System.err, true, "UTF-8")
sessionState.err = new PrintStream(System.err, true, "UTF-8")
} catch {
case e: UnsupportedEncodingException => System.exit(3)
}
if (!oproc.process_stage2(sessionState)) {
System.exit(2)
}
// Set all properties specified via command line.
val conf: HiveConf = sessionState.getConf
sessionState.cmdProperties.entrySet().asScala.foreach { item =>
val key = item.getKey.toString
val value = item.getValue.toString
// We do not propagate metastore options to the execution copy of hive.
if (key != "javax.jdo.option.ConnectionURL") {
conf.set(key, value)
sessionState.getOverriddenConfigurations.put(key, value)
}
}
SessionState.start(sessionState)
// Clean up after we exit
ShutdownHookManager.addShutdownHook { () => SparkSQLEnv.stop() }
val remoteMode = isRemoteMode(sessionState)
// "-h" option has been passed, so connect to Hive thrift server.
if (!remoteMode) {
// Hadoop-20 and above - we need to augment classpath using hiveconf
// components.
// See also: code in ExecDriver.java
var loader = conf.getClassLoader
val auxJars = HiveConf.getVar(conf, HiveConf.ConfVars.HIVEAUXJARS)
if (StringUtils.isNotBlank(auxJars)) {
loader = Utilities.addToClassPath(loader, StringUtils.split(auxJars, ","))
}
conf.setClassLoader(loader)
Thread.currentThread().setContextClassLoader(loader)
} else {
// Hive 1.2 + not supported in CLI
throw new RuntimeException("Remote operations not supported")
}
val cli = new SparkSQLCLIDriver
cli.setHiveVariables(oproc.getHiveVariables)
// TODO work around for set the log output to console, because the HiveContext
// will set the output into an invalid buffer.
sessionState.in = System.in
try {
sessionState.out = new PrintStream(System.out, true, "UTF-8")
sessionState.info = new PrintStream(System.err, true, "UTF-8")
sessionState.err = new PrintStream(System.err, true, "UTF-8")
} catch {
case e: UnsupportedEncodingException => System.exit(3)
}
if (sessionState.database != null) {
SparkSQLEnv.sqlContext.sessionState.catalog.setCurrentDatabase(
s"${sessionState.database}")
}
// Execute -i init files (always in silent mode)
cli.processInitFiles(sessionState)
// Respect the configurations set by --hiveconf from the command line
// (based on Hive's CliDriver).
val it = sessionState.getOverriddenConfigurations.entrySet().iterator()
while (it.hasNext) {
val kv = it.next()
SparkSQLEnv.sqlContext.setConf(kv.getKey, kv.getValue)
}
if (sessionState.execString != null) {
System.exit(cli.processLine(sessionState.execString))
}
try {
if (sessionState.fileName != null) {
System.exit(cli.processFile(sessionState.fileName))
}
} catch {
case e: FileNotFoundException =>
logError(s"Could not open input file for reading. (${e.getMessage})")
System.exit(3)
}
val reader = new ConsoleReader()
reader.setBellEnabled(false)
reader.setExpandEvents(false)
// reader.setDebug(new PrintWriter(new FileWriter("writer.debug", true)))
CliDriver.getCommandCompleter.foreach((e) => reader.addCompleter(e))
val historyDirectory = System.getProperty("user.home")
try {
if (new File(historyDirectory).exists()) {
val historyFile = historyDirectory + File.separator + ".hivehistory"
reader.setHistory(new FileHistory(new File(historyFile)))
} else {
logWarning("WARNING: Directory for Hive history file: " + historyDirectory +
" does not exist. History will not be available during this session.")
}
} catch {
case e: Exception =>
logWarning("WARNING: Encountered an error while trying to initialize Hive's " +
"history file. History will not be available during this session.")
logWarning(e.getMessage)
}
// add shutdown hook to flush the history to history file
ShutdownHookManager.addShutdownHook { () =>
reader.getHistory match {
case h: FileHistory =>
try {
h.flush()
} catch {
case e: IOException =>
logWarning("WARNING: Failed to write command history file: " + e.getMessage)
}
case _ =>
}
}
// TODO: missing
/*
val clientTransportTSocketField = classOf[CliSessionState].getDeclaredField("transport")
clientTransportTSocketField.setAccessible(true)
transport = clientTransportTSocketField.get(sessionState).asInstanceOf[TSocket]
*/
transport = null
var ret = 0
var prefix = ""
val currentDB = ReflectionUtils.invokeStatic(classOf[CliDriver], "getFormattedDb",
classOf[HiveConf] -> conf, classOf[CliSessionState] -> sessionState)
def promptWithCurrentDB: String = s"$prompt$currentDB"
def continuedPromptWithDBSpaces: String = continuedPrompt + ReflectionUtils.invokeStatic(
classOf[CliDriver], "spacesForString", classOf[String] -> currentDB)
var currentPrompt = promptWithCurrentDB
var line = reader.readLine(currentPrompt + "> ")
while (line != null) {
if (!line.startsWith("--")) {
if (prefix.nonEmpty) {
prefix += '\\n'
}
if (line.trim().endsWith(";") && !line.trim().endsWith("\\\\;")) {
line = prefix + line
ret = cli.processLine(line, true)
prefix = ""
currentPrompt = promptWithCurrentDB
} else {
prefix = prefix + line
currentPrompt = continuedPromptWithDBSpaces
}
}
line = reader.readLine(currentPrompt + "> ")
}
sessionState.close()
System.exit(ret)
}
def isRemoteMode(state: CliSessionState): Boolean = {
// sessionState.isRemoteMode
state.isHiveServerQuery
}
}
private[hive] class SparkSQLCLIDriver extends CliDriver with Logging {
private val sessionState = SessionState.get().asInstanceOf[CliSessionState]
private val LOG = LogFactory.getLog("CliDriver")
private val console = new SessionState.LogHelper(LOG)
if (sessionState.getIsSilent) {
Logger.getRootLogger.setLevel(Level.WARN)
}
private val isRemoteMode = {
SparkSQLCLIDriver.isRemoteMode(sessionState)
}
private val conf: Configuration =
if (sessionState != null) sessionState.getConf else new Configuration()
// Force initializing SparkSQLEnv. This is put here but not object SparkSQLCliDriver
// because the Hive unit tests do not go through the main() code path.
if (!isRemoteMode) {
SparkSQLEnv.init()
} else {
// Hive 1.2 + not supported in CLI
throw new RuntimeException("Remote operations not supported")
}
override def setHiveVariables(hiveVariables: java.util.Map[String, String]): Unit = {
hiveVariables.asScala.foreach(kv => SparkSQLEnv.sqlContext.conf.setConfString(kv._1, kv._2))
}
override def processCmd(cmd: String): Int = {
val cmd_trimmed: String = cmd.trim()
val cmd_lower = cmd_trimmed.toLowerCase(Locale.ROOT)
val tokens: Array[String] = cmd_trimmed.split("\\\\s+")
val cmd_1: String = cmd_trimmed.substring(tokens(0).length()).trim()
if (cmd_lower.equals("quit") ||
cmd_lower.equals("exit")) {
sessionState.close()
System.exit(0)
}
if (tokens(0).toLowerCase(Locale.ROOT).equals("source") ||
cmd_trimmed.startsWith("!") || isRemoteMode) {
val start = System.currentTimeMillis()
super.processCmd(cmd)
val end = System.currentTimeMillis()
val timeTaken: Double = (end - start) / 1000.0
console.printInfo(s"Time taken: $timeTaken seconds")
0
} else {
var ret = 0
val hconf = conf.asInstanceOf[HiveConf]
val proc: CommandProcessor = CommandProcessorFactory.get(tokens, hconf)
if (proc != null) {
// scalastyle:off println
if (proc.isInstanceOf[Driver] || proc.isInstanceOf[SetProcessor] ||
proc.isInstanceOf[AddResourceProcessor] || proc.isInstanceOf[ListResourceProcessor] ||
proc.isInstanceOf[ResetProcessor] ) {
val driver = new SparkSQLDriver
driver.init()
val out = sessionState.out
val err = sessionState.err
val start: Long = System.currentTimeMillis()
if (sessionState.getIsVerbose) {
out.println(cmd)
}
val rc = driver.run(cmd)
val end = System.currentTimeMillis()
val timeTaken: Double = (end - start) / 1000.0
ret = rc.getResponseCode
if (ret != 0) {
// For analysis exception, only the error is printed out to the console.
rc.getException() match {
case e : AnalysisException =>
err.println(s"""Error in query: ${e.getMessage}""")
case _ => err.println(rc.getErrorMessage())
}
driver.close()
return ret
}
val res = new JArrayList[String]()
if (HiveConf.getBoolVar(conf, HiveConf.ConfVars.HIVE_CLI_PRINT_HEADER)) {
// Print the column names.
Option(driver.getSchema.getFieldSchemas).foreach { fields =>
out.println(fields.asScala.map(_.getName).mkString("\\t"))
}
}
var counter = 0
try {
while (!out.checkError() && driver.getResults(res)) {
res.asScala.foreach { l =>
counter += 1
out.println(l)
}
res.clear()
}
} catch {
case e: IOException =>
console.printError(
s"""Failed with exception ${e.getClass.getName}: ${e.getMessage}
|${org.apache.hadoop.util.StringUtils.stringifyException(e)}
""".stripMargin)
ret = 1
}
val cret = driver.close()
if (ret == 0) {
ret = cret
}
var responseMsg = s"Time taken: $timeTaken seconds"
if (counter != 0) {
responseMsg += s", Fetched $counter row(s)"
}
console.printInfo(responseMsg, null)
// Destroy the driver to release all the locks.
driver.destroy()
} else {
if (sessionState.getIsVerbose) {
sessionState.out.println(tokens(0) + " " + cmd_1)
}
ret = proc.run(cmd_1).getResponseCode
}
// scalastyle:on println
}
ret
}
}
}
|
JerryLead/spark
|
sql/hive-thriftserver/src/main/scala/org/apache/spark/sql/hive/thriftserver/SparkSQLCLIDriver.scala
|
Scala
|
apache-2.0
| 14,214 |
/** Copyright 2015 TappingStone, Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.prediction.data.storage.hbase
import io.prediction.data.storage.Event
import io.prediction.data.storage.PropertyMap
import io.prediction.data.storage.LEvents
import io.prediction.data.storage.LEventAggregator
import io.prediction.data.storage.StorageError
import io.prediction.data.storage.hbase.HBEventsUtil.RowKey
import io.prediction.data.storage.hbase.HBEventsUtil.RowKeyException
import grizzled.slf4j.Logging
import org.joda.time.DateTime
import org.apache.hadoop.hbase.NamespaceDescriptor
import org.apache.hadoop.hbase.HTableDescriptor
import org.apache.hadoop.hbase.HColumnDescriptor
import org.apache.hadoop.hbase.TableName
import org.apache.hadoop.hbase.client._
import scala.collection.JavaConversions._
import scala.concurrent.Future
import scala.concurrent.ExecutionContext
class HBLEvents(val client: HBClient, val namespace: String)
extends LEvents with Logging {
// implicit val formats = DefaultFormats + new EventJson4sSupport.DBSerializer
def resultToEvent(result: Result, appId: Int): Event =
HBEventsUtil.resultToEvent(result, appId)
def getTable(appId: Int): HTableInterface = client.connection.getTable(
HBEventsUtil.tableName(namespace, appId))
override
def init(appId: Int): Boolean = {
// check namespace exist
val existingNamespace = client.admin.listNamespaceDescriptors()
.map(_.getName)
if (!existingNamespace.contains(namespace)) {
val nameDesc = NamespaceDescriptor.create(namespace).build()
info(s"The namespace ${namespace} doesn't exist yet. Creating now...")
client.admin.createNamespace(nameDesc)
}
val tableName = TableName.valueOf(HBEventsUtil.tableName(namespace, appId))
if (!client.admin.tableExists(tableName)) {
info(s"The table ${tableName.getNameAsString()} doesn't exist yet." +
" Creating now...")
val tableDesc = new HTableDescriptor(tableName)
tableDesc.addFamily(new HColumnDescriptor("e"))
tableDesc.addFamily(new HColumnDescriptor("r")) // reserved
client.admin.createTable(tableDesc)
}
true
}
override
def remove(appId: Int): Boolean = {
val tableName = TableName.valueOf(HBEventsUtil.tableName(namespace, appId))
try {
if (client.admin.tableExists(tableName)) {
info(s"Removing table ${tableName.getNameAsString()}...")
client.admin.disableTable(tableName)
client.admin.deleteTable(tableName)
} else {
info(s"Table ${tableName.getNameAsString()} doesn't exist." +
s" Nothing is deleted.")
}
true
} catch {
case e: Exception => {
error(s"Fail to remove table for appId ${appId}. Exception: ${e}")
false
}
}
}
override
def close(): Unit = {
client.admin.close()
client.connection.close()
}
override
def futureInsert(event: Event, appId: Int)(implicit ec: ExecutionContext):
Future[Either[StorageError, String]] = {
Future {
val table = getTable(appId)
val (put, rowKey) = HBEventsUtil.eventToPut(event, appId)
table.put(put)
table.flushCommits()
table.close()
Right(rowKey.toString)
}/* .recover {
case e: Exception => Left(StorageError(e.toString))
} */
}
override
def futureGet(eventId: String, appId: Int)(implicit ec: ExecutionContext):
Future[Either[StorageError, Option[Event]]] = {
Future {
val table = getTable(appId)
val rowKey = RowKey(eventId)
val get = new Get(rowKey.toBytes)
val result = table.get(get)
table.close()
if (!result.isEmpty()) {
val event = resultToEvent(result, appId)
Right(Some(event))
} else {
Right(None)
}
}.recover {
case e: RowKeyException => Left(StorageError(e.toString))
case e: Exception => throw e
}
}
override
def futureDelete(eventId: String, appId: Int)(implicit ec: ExecutionContext):
Future[Either[StorageError, Boolean]] = {
Future {
val table = getTable(appId)
val rowKey = RowKey(eventId)
val exists = table.exists(new Get(rowKey.toBytes))
table.delete(new Delete(rowKey.toBytes))
table.close()
Right(exists)
}
}
override
def futureGetByAppId(appId: Int)(implicit ec: ExecutionContext):
Future[Either[StorageError, Iterator[Event]]] = {
futureFind(
appId = appId,
startTime = None,
untilTime = None,
entityType = None,
entityId = None,
eventNames = None,
limit = None,
reversed = None)
}
override
def futureGetByAppIdAndTime(appId: Int, startTime: Option[DateTime],
untilTime: Option[DateTime])(implicit ec: ExecutionContext):
Future[Either[StorageError, Iterator[Event]]] = {
futureFind(
appId = appId,
startTime = startTime,
untilTime = untilTime,
entityType = None,
entityId = None,
eventNames = None,
limit = None,
reversed = None)
}
override
def futureGetByAppIdAndTimeAndEntity(appId: Int,
startTime: Option[DateTime],
untilTime: Option[DateTime],
entityType: Option[String],
entityId: Option[String])(implicit ec: ExecutionContext):
Future[Either[StorageError, Iterator[Event]]] = {
futureFind(
appId = appId,
startTime = startTime,
untilTime = untilTime,
entityType = entityType,
entityId = entityId,
eventNames = None,
limit = None,
reversed = None)
}
override
def futureFind(
appId: Int,
startTime: Option[DateTime] = None,
untilTime: Option[DateTime] = None,
entityType: Option[String] = None,
entityId: Option[String] = None,
eventNames: Option[Seq[String]] = None,
targetEntityType: Option[Option[String]] = None,
targetEntityId: Option[Option[String]] = None,
limit: Option[Int] = None,
reversed: Option[Boolean] = None)(implicit ec: ExecutionContext):
Future[Either[StorageError, Iterator[Event]]] = {
Future {
val table = getTable(appId)
val scan = HBEventsUtil.createScan(
startTime = startTime,
untilTime = untilTime,
entityType = entityType,
entityId = entityId,
eventNames = eventNames,
targetEntityType = targetEntityType,
targetEntityId = targetEntityId,
reversed = reversed)
val scanner = table.getScanner(scan)
table.close()
val eventsIter = scanner.iterator()
// Get all events if None or Some(-1)
val results: Iterator[Result] = limit match {
case Some(-1) => eventsIter
case None => eventsIter
case Some(x) => eventsIter.take(x)
}
val eventsIt = results.map { resultToEvent(_, appId) }
Right(eventsIt)
}
}
override
def futureAggregateProperties(
appId: Int,
entityType: String,
startTime: Option[DateTime] = None,
untilTime: Option[DateTime] = None,
required: Option[Seq[String]] = None)(implicit ec: ExecutionContext):
Future[Either[StorageError, Map[String, PropertyMap]]] = {
futureFind(
appId = appId,
startTime = startTime,
untilTime = untilTime,
entityType = Some(entityType),
eventNames = Some(LEventAggregator.eventNames)
).map{ either =>
either.right.map{ eventIt =>
val dm = LEventAggregator.aggregateProperties(eventIt)
if (required.isDefined) {
dm.filter { case (k, v) =>
required.get.map(v.contains(_)).reduce(_ && _)
}
} else dm
}
}
}
override
def futureAggregatePropertiesSingle(
appId: Int,
entityType: String,
entityId: String,
startTime: Option[DateTime] = None,
untilTime: Option[DateTime] = None)(implicit ec: ExecutionContext):
Future[Either[StorageError, Option[PropertyMap]]] = {
futureFind(
appId = appId,
startTime = startTime,
untilTime = untilTime,
entityType = Some(entityType),
entityId = Some(entityId),
eventNames = Some(LEventAggregator.eventNames)
).map{ either =>
either.right.map{ eventIt =>
LEventAggregator.aggregatePropertiesSingle(eventIt)
}
}
}
override
def futureDeleteByAppId(appId: Int)(implicit ec: ExecutionContext):
Future[Either[StorageError, Unit]] = {
Future {
// TODO: better way to handle range delete
val table = getTable(appId)
val scan = new Scan()
val scanner = table.getScanner(scan)
val it = scanner.iterator()
while (it.hasNext()) {
val result = it.next()
table.delete(new Delete(result.getRow()))
}
scanner.close()
table.close()
Right(())
}
}
}
|
nvoron23/PredictionIO
|
data/src/main/scala/io/prediction/data/storage/hbase/HBLEvents.scala
|
Scala
|
apache-2.0
| 9,503 |
package com.typesafe.sbt
package packager
package archetypes
import Keys._
import sbt._
import sbt.Project.Initialize
import sbt.Keys.{ mappings, target, name, mainClass, normalizedName }
import linux.LinuxPackageMapping
import SbtNativePackager._
/**
* This class contains the default settings for creating and deploying an archetypical Java application.
* A Java application archetype is defined as a project that has a main method and is run by placing
* all of its JAR files on the classpath and calling that main method.
*
* This doesn't create the best of distributions, but it can simplify the distribution of code.
*
* **NOTE: EXPERIMENTAL** This currently only supports universal distributions.
*/
object JavaAppPackaging {
def settings: Seq[Setting[_]] = Seq(
// Here we record the classpath as it's added to the mappings separately, so
// we can use its order to generate the bash/bat scripts.
scriptClasspathOrdering := Nil,
// Note: This is sometimes on the classpath via dependencyClasspath in Runtime.
// We need to figure out why sometimes the Attributed[File] is corrrectly configured
// and sometimes not.
scriptClasspathOrdering <+= (Keys.packageBin in Compile, Keys.projectID, Keys.artifact in Compile in Keys.packageBin) map { (jar, id, art) =>
jar -> ("lib/" + makeJarName(id.organization, id.name, id.revision, art.name))
},
projectDependencyArtifacts <<= findProjectDependencyArtifacts,
scriptClasspathOrdering <++= (Keys.dependencyClasspath in Runtime, projectDependencyArtifacts) map universalDepMappings,
scriptClasspathOrdering <<= (scriptClasspathOrdering) map { _.distinct },
mappings in Universal <++= scriptClasspathOrdering,
scriptClasspath <<= scriptClasspathOrdering map makeRelativeClasspathNames,
bashScriptExtraDefines := Nil,
bashScriptDefines <<= (Keys.mainClass in Compile, scriptClasspath, bashScriptExtraDefines) map { (mainClass, cp, extras) =>
val hasMain =
for {
cn <- mainClass
} yield JavaAppBashScript.makeDefines(cn, appClasspath = cp, extras = extras)
hasMain getOrElse Nil
},
makeBashScript <<= (bashScriptDefines, target in Universal, normalizedName) map makeUniversalBinScript,
batScriptExtraDefines := Nil,
batScriptReplacements <<= (normalizedName, Keys.mainClass in Compile, scriptClasspath, batScriptExtraDefines) map { (name, mainClass, cp, extras) =>
mainClass map { mc =>
JavaAppBatScript.makeReplacements(name = name, mainClass = mc, appClasspath = cp, extras = extras)
} getOrElse Nil
},
makeBatScript <<= (batScriptReplacements, target in Universal, normalizedName) map makeUniversalBatScript,
mappings in Universal <++= (makeBashScript, normalizedName) map { (script, name) =>
for {
s <- script.toSeq
} yield s -> ("bin/" + name)
},
mappings in Universal <++= (makeBatScript, normalizedName) map { (script, name) =>
for {
s <- script.toSeq
} yield s -> ("bin/" + name + ".bat")
})
def makeRelativeClasspathNames(mappings: Seq[(File, String)]): Seq[String] =
for {
(file, name) <- mappings
} yield {
// Here we want the name relative to the lib/ folder...
// For now we just cheat...
if (name startsWith "lib/") name drop 4
else "../" + name
}
def makeUniversalBinScript(defines: Seq[String], tmpDir: File, name: String): Option[File] =
if (defines.isEmpty) None
else {
val scriptBits = JavaAppBashScript.generateScript(defines)
val script = tmpDir / "tmp" / "bin" / name
IO.write(script, scriptBits)
// TODO - Better control over this!
script.setExecutable(true)
Some(script)
}
def makeUniversalBatScript(replacements: Seq[(String, String)], tmpDir: File, name: String): Option[File] =
if (replacements.isEmpty) None
else {
val scriptBits = JavaAppBatScript.generateScript(replacements)
val script = tmpDir / "tmp" / "bin" / (name + ".bat")
IO.write(script, scriptBits)
Some(script)
}
// Constructs a jar name from components...(ModuleID/Artifact)
def makeJarName(org: String, name: String, revision: String, artifactName: String): String =
(org + "." +
name + "-" +
Option(artifactName.replace(name, "")).filterNot(_.isEmpty).map(_ + "-").getOrElse("") +
revision + ".jar")
// Determines a nicer filename for an attributed jar file, using the
// ivy metadata if available.
def getJarFullFilename(dep: Attributed[File]): String = {
val filename: Option[String] = for {
module <- dep.metadata.get(AttributeKey[ModuleID]("module-id"))
artifact <- dep.metadata.get(AttributeKey[Artifact]("artifact"))
} yield makeJarName(module.organization, module.name, module.revision, artifact.name)
filename.getOrElse(dep.data.getName)
}
// Here we grab the dependencies...
def dependencyProjectRefs(build: sbt.BuildDependencies, thisProject: ProjectRef): Seq[ProjectRef] =
build.classpathTransitive.get(thisProject).getOrElse(Nil)
def filterArtifacts(artifacts: Seq[(Artifact, File)], config: Option[String]): Seq[(Artifact, File)] =
for {
(art, file) <- artifacts
// TODO - Default to compile or default?
if art.configurations.exists(_.name == config.getOrElse("default"))
} yield art -> file
def extractArtifacts(stateTask: Task[State], ref: ProjectRef): Task[Seq[Attributed[File]]] =
stateTask flatMap { state =>
val extracted = Project extract state
// TODO - Is this correct?
val module = extracted.get(sbt.Keys.projectID in ref)
val artifactTask = extracted get (sbt.Keys.packagedArtifacts in ref)
for {
arts <- artifactTask
} yield {
for {
(art, file) <- arts.toSeq // TODO -Filter!
} yield {
sbt.Attributed.blank(file).
put(sbt.Keys.moduleID.key, module).
put(sbt.Keys.artifact.key, art)
}
}
}
// TODO - Should we pull in more than just JARs? How do native packages come in?
def isRuntimeArtifact(dep: Attributed[File]): Boolean =
dep.get(sbt.Keys.artifact.key).map(_.`type` == "jar").getOrElse {
val name = dep.data.getName
!(name.endsWith(".jar") || name.endsWith("-sources.jar") || name.endsWith("-javadoc.jar"))
}
def findProjectDependencyArtifacts: Initialize[Task[Seq[Attributed[File]]]] =
(sbt.Keys.buildDependencies, sbt.Keys.thisProjectRef, sbt.Keys.state) apply { (build, thisProject, stateTask) =>
val refs = thisProject +: dependencyProjectRefs(build, thisProject)
// Dynamic lookup of dependencies...
val artTasks = (refs) map { ref => extractArtifacts(stateTask, ref) }
val allArtifactsTask: Task[Seq[Attributed[File]]] =
artTasks.fold[Task[Seq[Attributed[File]]]](task(Nil)) { (previous, next) =>
for {
p <- previous
n <- next
} yield (p ++ n.filter(isRuntimeArtifact))
}
allArtifactsTask
}
def findRealDep(dep: Attributed[File], projectArts: Seq[Attributed[File]]): Option[Attributed[File]] = {
if (dep.data.isFile) Some(dep)
else {
projectArts.find { art =>
// TODO - Why is the module not showing up for project deps?
//(art.get(sbt.Keys.moduleID.key) == dep.get(sbt.Keys.moduleID.key)) &&
((art.get(sbt.Keys.artifact.key), dep.get(sbt.Keys.artifact.key))) match {
case (Some(l), Some(r)) =>
// TODO - extra attributes and stuff for comparison?
// seems to break stuff if we do...
(l.name == r.name)
case _ => false
}
}
}
}
// Converts a managed classpath into a set of lib mappings.
def universalDepMappings(deps: Seq[Attributed[File]], projectArts: Seq[Attributed[File]]): Seq[(File, String)] =
for {
dep <- deps
realDep <- findRealDep(dep, projectArts)
} yield realDep.data -> ("lib/" + getJarFullFilename(realDep))
}
|
yanns/sbt-native-packager
|
src/main/scala/com/typesafe/sbt/packager/archetypes/JavaApp.scala
|
Scala
|
bsd-2-clause
| 8,055 |
package haru.action
import scala.reflect.runtime.universe
import org.apache.http.client.methods.HttpPost
import org.apache.http.entity.StringEntity
import org.apache.http.impl.client.HttpClientBuilder
import org.joda.time.DateTimeZone
import akka.actor.Actor
import akka.actor.ActorLogging
import akka.actor.ActorSystem
import akka.actor.Props
import akka.actor.actorRef2Scala
import haru.dao.PushDao
import xitrum.Log
import xitrum.annotation.GET
import xitrum.annotation.POST
import spray.json._
import DefaultJsonProtocol._
@POST("push/register")
class PushRegister extends Api2{
def execute() {
val appid = param[String]("appid")
val pushtype = param[Int]("pushtype")
val wherevalue = param[String]("wherevalue")
val messagetype = param[Int]("messagetype")
val message = param[String]("message")
val totalcount = param[Int]("totalcount")
val sendtimezone = param[String]("sendtimezone")
val sendtime = param[Long]("sendtime")
val expirationtime = param[Long]("expirationtime")
val status = param[Int]("status")
val id = PushDao.insertPush(appid, pushtype, Some(wherevalue), message, messagetype, totalcount, DateTimeZone.forID(sendtimezone).getID(), sendtime, expirationtime, status);
log.debug(message)
sendPushActor(id._1, appid, message)
respondJson("{success:1}");
}
def sendPushActor(id :Int, appid : String, message:String){
val system = ActorSystem("MySystem")
val pushactor = system.actorOf(Props[PushActor], name = "pusher")
pushactor ! PushMessage(id, appid, message)
}
}
@GET("push/list")
class PushList extends Api2 {
def execute() {
val limit = param[Int]("limit");
val page = param[Int]("page");
val appid = param[String]("appid")
respondJson(PushDao.SelectPush(limit, page, appid));
}
}
case class PushTotal(total :Int)
object PushtotalProtocol extends DefaultJsonProtocol {
implicit val pushTotalformat = jsonFormat(PushTotal, "total")
}
case class PushMessage(id:Int, appid: String, message : String)
class PushActor extends Actor with ActorLogging {
def receive = {
case PushMessage(id, appid, message) ⇒
Log.info("Actor receive")
val url = "http://api.haru.io/1/push";
val post = new HttpPost(url)
post.addHeader("Application-Id", appid)
post.addHeader("Content-Type","application/json")
val json = "{\\"installations\\":{\\"pushType\\": \\"mqtt\\"}, \\"notification\\":"+message+"}"
Log.debug(json)
post.setEntity(new StringEntity(json));
// send the post request
val client = HttpClientBuilder.create().build();
val response = client.execute(post)
val entity = response.getEntity()
System.out.println(response.getStatusLine());
var content = ""
if (entity != null) {
val inputStream = entity.getContent()
content = scala.io.Source.fromInputStream(inputStream).getLines.mkString
println(content);
inputStream.close
}
client.close();
import PushtotalProtocol._
val jsoncontent = content.parseJson
val contentjson = jsoncontent.convertTo[PushTotal]
PushDao.updateStatus(id, 1, contentjson.total)
}
}
|
haruio/haru-admin
|
src/main/scala/haru/action/PushController.scala
|
Scala
|
mit
| 3,191 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql
/**
* A container for a [[DataFrame]], used for implicit conversions.
*
* To use this, import implicit conversions in SQL:
* {{{
* import sqlContext.implicits._
* }}}
*
* @since 1.3.0
*/
case class DataFrameHolder private[sql](private val df: DataFrame) {
// This is declared with parentheses to prevent the Scala compiler from treating
// `rdd.toDF("1")` as invoking this toDF and then apply on the returned DataFrame.
def toDF(): DataFrame = df
def toDF(colNames: String*): DataFrame = df.toDF(colNames : _*)
}
|
chenc10/Spark-PAF
|
sql/core/src/main/scala/org/apache/spark/sql/DataFrameHolder.scala
|
Scala
|
apache-2.0
| 1,351 |
package org.dbpedia.spotlight.db.io.util
/**
* A token occurrence parser reads the tokens file that is the result of processing
* Wikipedia dumps on Pig and converts it for further processing.
*
* @author Joachim Daiber
*/
trait TokenOccurrenceParser {
def parse(tokens: String, minimumCount: Int): Pair[Array[String], Array[Int]]
}
object TokenOccurrenceParser {
def createDefault: TokenOccurrenceParser = new PigTokenOccurrenceParser()
}
|
Skunnyk/dbpedia-spotlight-model
|
index/src/main/scala/org/dbpedia/spotlight/db/io/util/TokenOccurrenceParser.scala
|
Scala
|
apache-2.0
| 456 |
package domain.util
import java.net.URL
import scala.xml.XML
import org.xml.sax.InputSource
import scala.xml.parsing.NoBindingFactoryAdapter
import org.ccil.cowan.tagsoup.jaxp.SAXFactoryImpl
import java.net.HttpURLConnection
import scala.xml.Node
object Html {
lazy val adapter = new NoBindingFactoryAdapter
lazy val parser = (new SAXFactoryImpl).newSAXParser
def load(url: URL): Node = {
val source = new InputSource(url.toString)
adapter.loadXML(source, parser)
}
def load(url: URL, encoding: String): Node = {
val source = new InputSource(url.toString)
source.setEncoding(encoding)
adapter.loadXML(source, parser)
}
def hasId(id: String): Node => Boolean =
node => (node \\@ "id") == id
def hasClass(className: String): Node => Boolean =
node => (node \\@ "class").split(" ").contains(className)
}
|
rori-dev/lunchbox
|
backend-play-akka-scala/app/domain/util/Html.scala
|
Scala
|
mit
| 848 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.streaming.kinesis
import scala.reflect.ClassTag
import com.amazonaws.regions.RegionUtils
import com.amazonaws.services.kinesis.clientlibrary.lib.worker.InitialPositionInStream
import com.amazonaws.services.kinesis.model.Record
import org.apache.spark.api.java.function.{Function => JFunction}
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Duration, StreamingContext}
import org.apache.spark.streaming.api.java.{JavaReceiverInputDStream, JavaStreamingContext}
import org.apache.spark.streaming.dstream.ReceiverInputDStream
object KinesisUtils {
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param ssc StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
*
* @note The AWS credentials will be discovered using the DefaultAWSCredentialsProviderChain
* on the workers. See AWS documentation to understand how DefaultAWSCredentialsProviderChain
* gets the AWS credentials.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T: ClassTag](
ssc: StreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: Record => T): ReceiverInputDStream[T] = {
val cleanedHandler = ssc.sc.clean(messageHandler)
// Setting scope to override receiver stream's scope of "receiver stream"
ssc.withNamedScope("kinesis stream") {
new KinesisInputDStream[T](ssc, streamName, endpointUrl, validateRegion(regionName),
KinesisInitialPositions.fromKinesisInitialPosition(initialPositionInStream),
kinesisAppName, checkpointInterval, storageLevel,
cleanedHandler, DefaultCredentials, None, None)
}
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param ssc StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
// scalastyle:off
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T: ClassTag](
ssc: StreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: Record => T,
awsAccessKeyId: String,
awsSecretKey: String): ReceiverInputDStream[T] = {
// scalastyle:on
val cleanedHandler = ssc.sc.clean(messageHandler)
ssc.withNamedScope("kinesis stream") {
val kinesisCredsProvider = BasicCredentials(
awsAccessKeyId = awsAccessKeyId,
awsSecretKey = awsSecretKey)
new KinesisInputDStream[T](ssc, streamName, endpointUrl, validateRegion(regionName),
KinesisInitialPositions.fromKinesisInitialPosition(initialPositionInStream),
kinesisAppName, checkpointInterval, storageLevel,
cleanedHandler, kinesisCredsProvider, None, None)
}
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param ssc StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
* @param stsAssumeRoleArn ARN of IAM role to assume when using STS sessions to read from
* Kinesis stream.
* @param stsSessionName Name to uniquely identify STS sessions if multiple principals assume
* the same role.
* @param stsExternalId External ID that can be used to validate against the assumed IAM role's
* trust policy.
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
// scalastyle:off
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T: ClassTag](
ssc: StreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: Record => T,
awsAccessKeyId: String,
awsSecretKey: String,
stsAssumeRoleArn: String,
stsSessionName: String,
stsExternalId: String): ReceiverInputDStream[T] = {
// scalastyle:on
val cleanedHandler = ssc.sc.clean(messageHandler)
ssc.withNamedScope("kinesis stream") {
val kinesisCredsProvider = STSCredentials(
stsRoleArn = stsAssumeRoleArn,
stsSessionName = stsSessionName,
stsExternalId = Option(stsExternalId),
longLivedCreds = BasicCredentials(
awsAccessKeyId = awsAccessKeyId,
awsSecretKey = awsSecretKey))
new KinesisInputDStream[T](ssc, streamName, endpointUrl, validateRegion(regionName),
KinesisInitialPositions.fromKinesisInitialPosition(initialPositionInStream),
kinesisAppName, checkpointInterval, storageLevel,
cleanedHandler, kinesisCredsProvider, None, None)
}
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param ssc StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
*
* @note The AWS credentials will be discovered using the DefaultAWSCredentialsProviderChain
* on the workers. See AWS documentation to understand how DefaultAWSCredentialsProviderChain
* gets the AWS credentials.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream(
ssc: StreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel): ReceiverInputDStream[Array[Byte]] = {
// Setting scope to override receiver stream's scope of "receiver stream"
ssc.withNamedScope("kinesis stream") {
new KinesisInputDStream[Array[Byte]](ssc, streamName, endpointUrl, validateRegion(regionName),
KinesisInitialPositions.fromKinesisInitialPosition(initialPositionInStream),
kinesisAppName, checkpointInterval, storageLevel,
KinesisInputDStream.defaultMessageHandler, DefaultCredentials, None, None)
}
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param ssc StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream(
ssc: StreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
awsAccessKeyId: String,
awsSecretKey: String): ReceiverInputDStream[Array[Byte]] = {
ssc.withNamedScope("kinesis stream") {
val kinesisCredsProvider = BasicCredentials(
awsAccessKeyId = awsAccessKeyId,
awsSecretKey = awsSecretKey)
new KinesisInputDStream[Array[Byte]](ssc, streamName, endpointUrl, validateRegion(regionName),
KinesisInitialPositions.fromKinesisInitialPosition(initialPositionInStream),
kinesisAppName, checkpointInterval, storageLevel,
KinesisInputDStream.defaultMessageHandler, kinesisCredsProvider, None, None)
}
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param jssc Java StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
* @param recordClass Class of the records in DStream
*
* @note The AWS credentials will be discovered using the DefaultAWSCredentialsProviderChain
* on the workers. See AWS documentation to understand how DefaultAWSCredentialsProviderChain
* gets the AWS credentials.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T](
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: JFunction[Record, T],
recordClass: Class[T]): JavaReceiverInputDStream[T] = {
implicit val recordCmt: ClassTag[T] = ClassTag(recordClass)
val cleanedHandler = jssc.sparkContext.clean(messageHandler.call(_))
createStream[T](jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
initialPositionInStream, checkpointInterval, storageLevel, cleanedHandler)
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param jssc Java StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
* @param recordClass Class of the records in DStream
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
// scalastyle:off
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T](
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: JFunction[Record, T],
recordClass: Class[T],
awsAccessKeyId: String,
awsSecretKey: String): JavaReceiverInputDStream[T] = {
// scalastyle:on
implicit val recordCmt: ClassTag[T] = ClassTag(recordClass)
val cleanedHandler = jssc.sparkContext.clean(messageHandler.call(_))
createStream[T](jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
initialPositionInStream, checkpointInterval, storageLevel, cleanedHandler,
awsAccessKeyId, awsSecretKey)
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param jssc Java StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param messageHandler A custom message handler that can generate a generic output from a
* Kinesis `Record`, which contains both message data, and metadata.
* @param recordClass Class of the records in DStream
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
* @param stsAssumeRoleArn ARN of IAM role to assume when using STS sessions to read from
* Kinesis stream.
* @param stsSessionName Name to uniquely identify STS sessions if multiple princpals assume
* the same role.
* @param stsExternalId External ID that can be used to validate against the assumed IAM role's
* trust policy.
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
// scalastyle:off
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream[T](
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
messageHandler: JFunction[Record, T],
recordClass: Class[T],
awsAccessKeyId: String,
awsSecretKey: String,
stsAssumeRoleArn: String,
stsSessionName: String,
stsExternalId: String): JavaReceiverInputDStream[T] = {
// scalastyle:on
implicit val recordCmt: ClassTag[T] = ClassTag(recordClass)
val cleanedHandler = jssc.sparkContext.clean(messageHandler.call(_))
createStream[T](jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
initialPositionInStream, checkpointInterval, storageLevel, cleanedHandler,
awsAccessKeyId, awsSecretKey, stsAssumeRoleArn, stsSessionName, stsExternalId)
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param jssc Java StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
*
* @note The AWS credentials will be discovered using the DefaultAWSCredentialsProviderChain
* on the workers. See AWS documentation to understand how DefaultAWSCredentialsProviderChain
* gets the AWS credentials.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream(
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel
): JavaReceiverInputDStream[Array[Byte]] = {
createStream[Array[Byte]](jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
initialPositionInStream, checkpointInterval, storageLevel,
KinesisInputDStream.defaultMessageHandler(_))
}
/**
* Create an input stream that pulls messages from a Kinesis stream.
* This uses the Kinesis Client Library (KCL) to pull messages from Kinesis.
*
* @param jssc Java StreamingContext object
* @param kinesisAppName Kinesis application name used by the Kinesis Client Library
* (KCL) to update DynamoDB
* @param streamName Kinesis stream name
* @param endpointUrl Url of Kinesis service (e.g., https://kinesis.us-east-1.amazonaws.com)
* @param regionName Name of region used by the Kinesis Client Library (KCL) to update
* DynamoDB (lease coordination and checkpointing) and CloudWatch (metrics)
* @param initialPositionInStream In the absence of Kinesis checkpoint info, this is the
* worker's initial starting position in the stream.
* The values are either the beginning of the stream
* per Kinesis' limit of 24 hours
* (InitialPositionInStream.TRIM_HORIZON) or
* the tip of the stream (InitialPositionInStream.LATEST).
* @param checkpointInterval Checkpoint interval for Kinesis checkpointing.
* See the Kinesis Spark Streaming documentation for more
* details on the different types of checkpoints.
* @param storageLevel Storage level to use for storing the received objects.
* StorageLevel.MEMORY_AND_DISK_2 is recommended.
* @param awsAccessKeyId AWS AccessKeyId (if null, will use DefaultAWSCredentialsProviderChain)
* @param awsSecretKey AWS SecretKey (if null, will use DefaultAWSCredentialsProviderChain)
*
* @note The given AWS credentials will get saved in DStream checkpoints if checkpointing
* is enabled. Make sure that your checkpoint directory is secure.
*/
@deprecated("Use KinesisInputDStream.builder instead", "2.2.0")
def createStream(
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: InitialPositionInStream,
checkpointInterval: Duration,
storageLevel: StorageLevel,
awsAccessKeyId: String,
awsSecretKey: String): JavaReceiverInputDStream[Array[Byte]] = {
createStream[Array[Byte]](jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
initialPositionInStream, checkpointInterval, storageLevel,
KinesisInputDStream.defaultMessageHandler(_), awsAccessKeyId, awsSecretKey)
}
private def validateRegion(regionName: String): String = {
Option(RegionUtils.getRegion(regionName)).map { _.getName }.getOrElse {
throw new IllegalArgumentException(s"Region name '$regionName' is not valid")
}
}
}
/**
* This is a helper class that wraps the methods in KinesisUtils into more Python-friendly class and
* function so that it can be easily instantiated and called from Python's KinesisUtils.
*/
private class KinesisUtilsPythonHelper {
def getInitialPositionInStream(initialPositionInStream: Int): InitialPositionInStream = {
initialPositionInStream match {
case 0 => InitialPositionInStream.LATEST
case 1 => InitialPositionInStream.TRIM_HORIZON
case _ => throw new IllegalArgumentException(
"Illegal InitialPositionInStream. Please use " +
"InitialPositionInStream.LATEST or InitialPositionInStream.TRIM_HORIZON")
}
}
// scalastyle:off
def createStream(
jssc: JavaStreamingContext,
kinesisAppName: String,
streamName: String,
endpointUrl: String,
regionName: String,
initialPositionInStream: Int,
checkpointInterval: Duration,
storageLevel: StorageLevel,
awsAccessKeyId: String,
awsSecretKey: String,
stsAssumeRoleArn: String,
stsSessionName: String,
stsExternalId: String): JavaReceiverInputDStream[Array[Byte]] = {
// scalastyle:on
if (!(stsAssumeRoleArn != null && stsSessionName != null && stsExternalId != null)
&& !(stsAssumeRoleArn == null && stsSessionName == null && stsExternalId == null)) {
throw new IllegalArgumentException("stsAssumeRoleArn, stsSessionName, and stsExtenalId " +
"must all be defined or all be null")
}
if (stsAssumeRoleArn != null && stsSessionName != null && stsExternalId != null) {
validateAwsCreds(awsAccessKeyId, awsSecretKey)
KinesisUtils.createStream(jssc.ssc, kinesisAppName, streamName, endpointUrl, regionName,
getInitialPositionInStream(initialPositionInStream), checkpointInterval, storageLevel,
KinesisInputDStream.defaultMessageHandler(_), awsAccessKeyId, awsSecretKey,
stsAssumeRoleArn, stsSessionName, stsExternalId)
} else {
validateAwsCreds(awsAccessKeyId, awsSecretKey)
if (awsAccessKeyId == null && awsSecretKey == null) {
KinesisUtils.createStream(jssc, kinesisAppName, streamName, endpointUrl, regionName,
getInitialPositionInStream(initialPositionInStream), checkpointInterval, storageLevel)
} else {
KinesisUtils.createStream(jssc, kinesisAppName, streamName, endpointUrl, regionName,
getInitialPositionInStream(initialPositionInStream), checkpointInterval, storageLevel,
awsAccessKeyId, awsSecretKey)
}
}
}
// Throw IllegalArgumentException unless both values are null or neither are.
private def validateAwsCreds(awsAccessKeyId: String, awsSecretKey: String) {
if (awsAccessKeyId == null && awsSecretKey != null) {
throw new IllegalArgumentException("awsSecretKey is set but awsAccessKeyId is null")
}
if (awsAccessKeyId != null && awsSecretKey == null) {
throw new IllegalArgumentException("awsAccessKeyId is set but awsSecretKey is null")
}
}
}
|
esi-mineset/spark
|
external/kinesis-asl/src/main/scala/org/apache/spark/streaming/kinesis/KinesisUtils.scala
|
Scala
|
apache-2.0
| 34,818 |
/*
* Copyright 2012 Twitter Inc.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.twitter.zipkin.cassandra
import com.twitter.cassie.connection.RetryPolicy
import com.twitter.cassie.{Cluster, ServerSetsCluster, KeyspaceBuilder}
import com.twitter.conversions.time._
import com.twitter.finagle.stats.{NullStatsReceiver, StatsReceiver}
import com.twitter.finagle.tracing.{NullTracer, Tracer}
import com.twitter.util.Duration
import java.net.InetSocketAddress
object Keyspace {
def zookeeperServerSets(
keyspaceName: String = "Zipkin",
hosts: Seq[(String, Int)],
path: String,
timeout: Duration,
username: String = "zipkin",
password: String = "",
stats: StatsReceiver = NullStatsReceiver): KeyspaceBuilder = {
val sockets = hosts map { case (h, p) => new InetSocketAddress(h, p) }
useDefaults {
new ServerSetsCluster(sockets, path, timeout.inMillis.toInt, stats)
.keyspace(keyspaceName, username, password)
}
}
def static(
keyspaceName: String = "Zipkin",
nodes: Set[String] = Set("localhost"),
port: Int = 9160,
username: String = "zipkin",
password: String = "",
stats: StatsReceiver = NullStatsReceiver,
tracerFactory: Tracer.Factory = NullTracer.factory): KeyspaceBuilder = {
useDefaults {
new Cluster(nodes, port, stats, tracerFactory)
.keyspace(keyspaceName, username, password)
}.username(username).password(password)
}
def useDefaults(keyspaceBuilder: KeyspaceBuilder): KeyspaceBuilder = {
keyspaceBuilder
.connectTimeout(10.seconds.inMillis.toInt)
.requestTimeout(20.seconds.inMillis.toInt)
.timeout(90.seconds.inMillis.toInt)
.retries(3)
.maxConnectionsPerHost(400)
.hostConnectionMaxWaiters(5000)
.retryPolicy(RetryPolicy.Idempotent)
}
}
|
lookout/zipkin
|
zipkin-cassandra/src/main/scala/com/twitter/zipkin/cassandra/Keyspace.scala
|
Scala
|
apache-2.0
| 2,342 |
package org.scaladebugger.docs.layouts.partials.common.vendor
import scalatags.Text.all._
/**
* Represents a <script ... > containing highlight.js init code.
*/
object HighlightJSInit {
def apply(): Modifier = {
script("hljs.initHighlightingOnLoad();")
}
}
|
ensime/scala-debugger
|
scala-debugger-docs/src/main/scala/org/scaladebugger/docs/layouts/partials/common/vendor/HighlightJSInit.scala
|
Scala
|
apache-2.0
| 269 |
/*
* MIT License
*
* Copyright (c) 2016 Ramjet Anvil
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in all
* copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
* SOFTWARE.
*/
package com.ramjetanvil.padrone.http.client
import akka.stream.Materializer
import com.ramjetanvil.padrone.http.client.HttpClient.HttpClient
import com.ramjetanvil.padrone.http.client.Licensing.{LicenseException, LicenseVerifier, PlayerId}
import com.ramjetanvil.padrone.http.client.oculus.Client.{Configuration, OculusHttpClient}
import scala.concurrent.{ExecutionContext, Future}
package object oculus {
def httpClient(httpClient: HttpClient, config: Configuration)
(implicit fm: Materializer, ec: ExecutionContext): OculusClient = new OculusHttpClient(httpClient, config)
def licenseVerifier(client: OculusClient)(implicit ec: ExecutionContext): LicenseVerifier[AuthToken] = new OculusLicenseVerifier(client)
def config = Configuration.fromAppConfig _
case class OculusUserId(value: String) extends PlayerId {
override def serialized: String = value
override def toString = s"oculus:$value"
}
case class UserAccessToken(value: String) extends AnyVal
case class AppId(value: String) extends AnyVal
case class AppSecret(value: String) extends AnyVal
case class Nonce(value: String) extends AnyVal
case class AuthToken(userId: OculusUserId, nonce: Nonce)
trait OculusClient {
def fetchUserId(accessToken: UserAccessToken): Future[OculusUserId]
def authenticateUser(userId: OculusUserId, nonce: Nonce): Future[OculusUserId]
}
}
|
RamjetAnvil/padrone
|
server/src/main/scala/com/ramjetanvil/padrone/http/client/oculus/package.scala
|
Scala
|
mit
| 2,526 |
// False negative test, requires overloading in Cell.
trait Cell { def setCellValue(i: Int) = () ; def setCellValue(d: Double) = () }
trait Nope {
def f = {
trait CellSetter[A] {
def setCell(cell: Cell, data: A): Unit
}
implicit val bigDecimalCellSetter = new CellSetter[math.BigDecimal]() {
def setCell(cell: Cell, data: math.BigDecimal) { cell.setCellValue(data) }
}
implicit class RichCell(cell: Cell) {
def setCellValue[A](data: A)(implicit cellSetter: CellSetter[A]) = cellSetter.setCell(cell, data)
}
}
}
|
felixmulder/scala
|
test/files/neg/t9041.scala
|
Scala
|
bsd-3-clause
| 559 |
/*
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing,
* software distributed under the License is distributed on an
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
* KIND, either express or implied. See the License for the
* specific language governing permissions and limitations
* under the License.
*/
package org.apache.samza.system.kafka_deprecated
import java.util
import java.util.{Properties, UUID}
import com.google.common.annotations.VisibleForTesting
import kafka.admin.{AdminClient, AdminUtils}
import kafka.api._
import kafka.common.TopicAndPartition
import kafka.consumer.{ConsumerConfig, SimpleConsumer}
import kafka.utils.ZkUtils
import org.apache.kafka.clients.CommonClientConfigs
import org.apache.kafka.common.errors.TopicExistsException
import org.apache.kafka.common.TopicPartition
import org.apache.samza.system.SystemStreamMetadata.SystemStreamPartitionMetadata
import org.apache.samza.system._
import org.apache.samza.system.kafka.KafkaStreamSpec
import org.apache.samza.util.{ClientUtilTopicMetadataStore, ExponentialSleepStrategy, KafkaUtil, Logging}
import org.apache.samza.{Partition, SamzaException}
import scala.collection.JavaConverters._
object KafkaSystemAdmin extends Logging {
@VisibleForTesting @volatile var deleteMessagesCalled = false
val CLEAR_STREAM_RETRIES = 3
/**
* A helper method that takes oldest, newest, and upcoming offsets for each
* system stream partition, and creates a single map from stream name to
* SystemStreamMetadata.
*/
def assembleMetadata(oldestOffsets: Map[SystemStreamPartition, String], newestOffsets: Map[SystemStreamPartition, String], upcomingOffsets: Map[SystemStreamPartition, String]): Map[String, SystemStreamMetadata] = {
val allMetadata = (oldestOffsets.keySet ++ newestOffsets.keySet ++ upcomingOffsets.keySet)
.groupBy(_.getStream)
.map {
case (streamName, systemStreamPartitions) =>
val streamPartitionMetadata = systemStreamPartitions
.map(systemStreamPartition => {
val partitionMetadata = new SystemStreamPartitionMetadata(
// If the topic/partition is empty then oldest and newest will
// be stripped of their offsets, so default to null.
oldestOffsets.getOrElse(systemStreamPartition, null),
newestOffsets.getOrElse(systemStreamPartition, null),
upcomingOffsets(systemStreamPartition))
(systemStreamPartition.getPartition, partitionMetadata)
})
.toMap
val streamMetadata = new SystemStreamMetadata(streamName, streamPartitionMetadata.asJava)
(streamName, streamMetadata)
}
.toMap
// This is typically printed downstream and it can be spammy, so debug level here.
debug("Got metadata: %s" format allMetadata)
allMetadata
}
}
/**
* A helper class that is used to construct the changelog stream specific information
*
* @param replicationFactor The number of replicas for the changelog stream
* @param kafkaProps The kafka specific properties that need to be used for changelog stream creation
*/
case class ChangelogInfo(var replicationFactor: Int, var kafkaProps: Properties)
/**
* A Kafka-based implementation of SystemAdmin.
*/
class KafkaSystemAdmin(
/**
* The system name to use when creating SystemStreamPartitions to return in
* the getSystemStreamMetadata responser.
*/
systemName: String,
// TODO whenever Kafka decides to make the Set[Broker] class public, let's switch to Set[Broker] here.
/**
* List of brokers that are part of the Kafka system that we wish to
* interact with. The format is host1:port1,host2:port2.
*/
brokerListString: String,
/**
* A method that returns a ZkUtils for the Kafka system. This is invoked
* when the system admin is attempting to create a coordinator stream.
*/
connectZk: () => ZkUtils,
/**
* Custom properties to use when the system admin tries to create a new
* coordinator stream.
*/
coordinatorStreamProperties: Properties = new Properties,
/**
* The replication factor to use when the system admin creates a new
* coordinator stream.
*/
coordinatorStreamReplicationFactor: Int = 1,
/**
* The timeout to use for the simple consumer when fetching metadata from
* Kafka. Equivalent to Kafka's socket.timeout.ms configuration.
*/
timeout: Int = Int.MaxValue,
/**
* The buffer size to use for the simple consumer when fetching metadata
* from Kafka. Equivalent to Kafka's socket.receive.buffer.bytes
* configuration.
*/
bufferSize: Int = ConsumerConfig.SocketBufferSize,
/**
* The client ID to use for the simple consumer when fetching metadata from
* Kafka. Equivalent to Kafka's client.id configuration.
*/
clientId: String = UUID.randomUUID.toString,
/**
* Replication factor for the Changelog topic in kafka
* Kafka properties to be used during the Changelog topic creation
*/
topicMetaInformation: Map[String, ChangelogInfo] = Map[String, ChangelogInfo](),
/**
* Kafka properties to be used during the intermediate topic creation
*/
intermediateStreamProperties: Map[String, Properties] = Map(),
/**
* Whether deleteMessages() API can be used
*/
deleteCommittedMessages: Boolean = false) extends SystemAdmin with Logging {
import KafkaSystemAdmin._
@volatile var running = false
@volatile var adminClient: AdminClient = null
override def start() = {
if (!running) {
running = true
adminClient = createAdminClient()
}
}
override def stop() = {
if (running) {
running = false
adminClient.close()
adminClient = null
}
}
private def createAdminClient(): AdminClient = {
val props = new Properties()
props.put(CommonClientConfigs.BOOTSTRAP_SERVERS_CONFIG, brokerListString)
AdminClient.create(props)
}
override def getSystemStreamPartitionCounts(streams: util.Set[String], cacheTTL: Long): util.Map[String, SystemStreamMetadata] = {
getSystemStreamPartitionCounts(streams, new ExponentialSleepStrategy(initialDelayMs = 500), cacheTTL)
}
def getSystemStreamPartitionCounts(streams: util.Set[String], retryBackoff: ExponentialSleepStrategy, cacheTTL: Long = Long.MaxValue): util.Map[String, SystemStreamMetadata] = {
debug("Fetching system stream partition count for: %s" format streams)
var metadataTTL = cacheTTL
retryBackoff.run(
loop => {
val metadata = TopicMetadataCache.getTopicMetadata(
streams.asScala.toSet,
systemName,
getTopicMetadata,
metadataTTL)
val result = metadata.map {
case (topic, topicMetadata) => {
KafkaUtil.maybeThrowException(topicMetadata.error.exception())
val partitionsMap = topicMetadata.partitionsMetadata.map {
pm =>
new Partition(pm.partitionId) -> new SystemStreamPartitionMetadata("", "", "")
}.toMap[Partition, SystemStreamPartitionMetadata]
(topic -> new SystemStreamMetadata(topic, partitionsMap.asJava))
}
}
loop.done
result.asJava
},
(exception, loop) => {
warn("Unable to fetch last offsets for streams %s due to %s. Retrying." format (streams, exception))
debug("Exception detail:", exception)
if (metadataTTL == Long.MaxValue) {
metadataTTL = 5000 // Revert to the default cache expiration
}
}
).getOrElse(throw new SamzaException("Failed to get system stream metadata"))
}
/**
* Returns the offset for the message after the specified offset for each
* SystemStreamPartition that was passed in.
*/
override def getOffsetsAfter(offsets: java.util.Map[SystemStreamPartition, String]) = {
// This is safe to do with Kafka, even if a topic is key-deduped. If the
// offset doesn't exist on a compacted topic, Kafka will return the first
// message AFTER the offset that was specified in the fetch request.
offsets.asScala.mapValues(offset => (offset.toLong + 1).toString).asJava
}
override def getSystemStreamMetadata(streams: java.util.Set[String]) =
getSystemStreamMetadata(streams, new ExponentialSleepStrategy(initialDelayMs = 500)).asJava
/**
* Given a set of stream names (topics), fetch metadata from Kafka for each
* stream, and return a map from stream name to SystemStreamMetadata for
* each stream. This method will return null for oldest and newest offsets
* if a given SystemStreamPartition is empty. This method will block and
* retry indefinitely until it gets a successful response from Kafka.
*/
def getSystemStreamMetadata(streams: java.util.Set[String], retryBackoff: ExponentialSleepStrategy) = {
debug("Fetching system stream metadata for: %s" format streams)
var metadataTTL = Long.MaxValue // Trust the cache until we get an exception
retryBackoff.run(
loop => {
val metadata = TopicMetadataCache.getTopicMetadata(
streams.asScala.toSet,
systemName,
getTopicMetadata,
metadataTTL)
debug("Got metadata for streams: %s" format metadata)
val brokersToTopicPartitions = getTopicsAndPartitionsByBroker(metadata)
var oldestOffsets = Map[SystemStreamPartition, String]()
var newestOffsets = Map[SystemStreamPartition, String]()
var upcomingOffsets = Map[SystemStreamPartition, String]()
// Get oldest, newest, and upcoming offsets for each topic and partition.
for ((broker, topicsAndPartitions) <- brokersToTopicPartitions) {
debug("Fetching offsets for %s:%s: %s" format (broker.host, broker.port, topicsAndPartitions))
val consumer = new SimpleConsumer(broker.host, broker.port, timeout, bufferSize, clientId)
try {
upcomingOffsets ++= getOffsets(consumer, topicsAndPartitions, OffsetRequest.LatestTime)
oldestOffsets ++= getOffsets(consumer, topicsAndPartitions, OffsetRequest.EarliestTime)
// Kafka's "latest" offset is always last message in stream's offset +
// 1, so get newest message in stream by subtracting one. this is safe
// even for key-deduplicated streams, since the last message will
// never be deduplicated.
newestOffsets = upcomingOffsets.mapValues(offset => (offset.toLong - 1).toString)
// Keep only oldest/newest offsets where there is a message. Should
// return null offsets for empty streams.
upcomingOffsets.foreach {
case (topicAndPartition, offset) =>
if (offset.toLong <= 0) {
debug("Stripping newest offsets for %s because the topic appears empty." format topicAndPartition)
newestOffsets -= topicAndPartition
debug("Setting oldest offset to 0 to consume from beginning")
oldestOffsets += (topicAndPartition -> "0")
}
}
} finally {
consumer.close
}
}
val result = assembleMetadata(oldestOffsets, newestOffsets, upcomingOffsets)
loop.done
result
},
(exception, loop) => {
warn("Unable to fetch last offsets for streams %s due to %s. Retrying." format (streams, exception))
debug("Exception detail:", exception)
metadataTTL = 5000 // Revert to the default cache expiration
}).getOrElse(throw new SamzaException("Failed to get system stream metadata"))
}
/**
* Helper method to use topic metadata cache when fetching metadata, so we
* don't hammer Kafka more than we need to.
*/
def getTopicMetadata(topics: Set[String]) = {
new ClientUtilTopicMetadataStore(brokerListString, clientId, timeout)
.getTopicInfo(topics)
}
/**
* Break topic metadata topic/partitions into per-broker map so that we can
* execute only one offset request per broker.
*/
private def getTopicsAndPartitionsByBroker(metadata: Map[String, TopicMetadata]) = {
val brokersToTopicPartitions = metadata
.values
// Convert the topic metadata to a Seq[(Broker, TopicAndPartition)]
.flatMap(topicMetadata => {
KafkaUtil.maybeThrowException(topicMetadata.error.exception())
topicMetadata
.partitionsMetadata
// Convert Seq[PartitionMetadata] to Seq[(Broker, TopicAndPartition)]
.map(partitionMetadata => {
val topicAndPartition = new TopicAndPartition(topicMetadata.topic, partitionMetadata.partitionId)
val leader = partitionMetadata
.leader
.getOrElse(throw new SamzaException("Need leaders for all partitions when fetching offsets. No leader available for TopicAndPartition: %s" format topicAndPartition))
(leader, topicAndPartition)
})
})
// Convert to a Map[Broker, Seq[(Broker, TopicAndPartition)]]
.groupBy(_._1)
// Convert to a Map[Broker, Set[TopicAndPartition]]
.mapValues(_.map(_._2).toSet)
debug("Got topic partition data for brokers: %s" format brokersToTopicPartitions)
brokersToTopicPartitions
}
/**
* Use a SimpleConsumer to fetch either the earliest or latest offset from
* Kafka for each topic/partition in the topicsAndPartitions set. It is
* assumed that all topics/partitions supplied reside on the broker that the
* consumer is connected to.
*/
private def getOffsets(consumer: SimpleConsumer, topicsAndPartitions: Set[TopicAndPartition], earliestOrLatest: Long) = {
debug("Getting offsets for %s using earliest/latest value of %s." format (topicsAndPartitions, earliestOrLatest))
var offsets = Map[SystemStreamPartition, String]()
val partitionOffsetInfo = topicsAndPartitions
.map(topicAndPartition => (topicAndPartition, PartitionOffsetRequestInfo(earliestOrLatest, 1)))
.toMap
val brokerOffsets = consumer
.getOffsetsBefore(new OffsetRequest(partitionOffsetInfo))
.partitionErrorAndOffsets
.mapValues(partitionErrorAndOffset => {
KafkaUtil.maybeThrowException(partitionErrorAndOffset.error.exception())
partitionErrorAndOffset.offsets.head
})
for ((topicAndPartition, offset) <- brokerOffsets) {
offsets += new SystemStreamPartition(systemName, topicAndPartition.topic, new Partition(topicAndPartition.partition)) -> offset.toString
}
debug("Got offsets for %s using earliest/latest value of %s: %s" format (topicsAndPartitions, earliestOrLatest, offsets))
offsets
}
/**
* @inheritdoc
*/
override def createStream(spec: StreamSpec): Boolean = {
info("Create topic %s in system %s" format (spec.getPhysicalName, systemName))
val kSpec = toKafkaSpec(spec)
var streamCreated = false
new ExponentialSleepStrategy(initialDelayMs = 500).run(
loop => {
val zkClient = connectZk()
try {
AdminUtils.createTopic(
zkClient,
kSpec.getPhysicalName,
kSpec.getPartitionCount,
kSpec.getReplicationFactor,
kSpec.getProperties)
} finally {
zkClient.close
}
streamCreated = true
loop.done
},
(exception, loop) => {
exception match {
case e: TopicExistsException =>
streamCreated = false
loop.done
case e: Exception =>
warn("Failed to create topic %s: %s. Retrying." format (spec.getPhysicalName, e))
debug("Exception detail:", e)
}
})
streamCreated
}
/**
* Converts a StreamSpec into a KafakStreamSpec. Special handling for coordinator and changelog stream.
* @param spec a StreamSpec object
* @return KafkaStreamSpec object
*/
def toKafkaSpec(spec: StreamSpec): KafkaStreamSpec = {
if (spec.isChangeLogStream) {
val topicName = spec.getPhysicalName
val topicMeta = topicMetaInformation.getOrElse(topicName, throw new StreamValidationException("Unable to find topic information for topic " + topicName))
new KafkaStreamSpec(spec.getId, topicName, systemName, spec.getPartitionCount, topicMeta.replicationFactor,
topicMeta.kafkaProps)
} else if (spec.isCoordinatorStream){
new KafkaStreamSpec(spec.getId, spec.getPhysicalName, systemName, 1, coordinatorStreamReplicationFactor,
coordinatorStreamProperties)
} else if (intermediateStreamProperties.contains(spec.getId)) {
KafkaStreamSpec.fromSpec(spec).copyWithProperties(intermediateStreamProperties(spec.getId))
} else {
KafkaStreamSpec.fromSpec(spec)
}
}
/**
* @inheritdoc
*
* Validates a stream in Kafka. Should not be called before createStream(),
* since ClientUtils.fetchTopicMetadata(), used by different Kafka clients,
* is not read-only and will auto-create a new topic.
*/
override def validateStream(spec: StreamSpec): Unit = {
val topicName = spec.getPhysicalName
info("Validating topic %s." format topicName)
val retryBackoff: ExponentialSleepStrategy = new ExponentialSleepStrategy
var metadataTTL = Long.MaxValue // Trust the cache until we get an exception
retryBackoff.run(
loop => {
val metadataStore = new ClientUtilTopicMetadataStore(brokerListString, clientId, timeout)
val topicMetadataMap = TopicMetadataCache.getTopicMetadata(Set(topicName), systemName, metadataStore.getTopicInfo, metadataTTL)
val topicMetadata = topicMetadataMap(topicName)
KafkaUtil.maybeThrowException(topicMetadata.error.exception())
val partitionCount = topicMetadata.partitionsMetadata.length
if (partitionCount != spec.getPartitionCount) {
throw new StreamValidationException("Topic validation failed for topic %s because partition count %s did not match expected partition count of %d" format (topicName, topicMetadata.partitionsMetadata.length, spec.getPartitionCount))
}
info("Successfully validated topic %s." format topicName)
loop.done
},
(exception, loop) => {
exception match {
case e: StreamValidationException => throw e
case e: Exception =>
warn("While trying to validate topic %s: %s. Retrying." format (topicName, e))
debug("Exception detail:", e)
metadataTTL = 5000L // Revert to the default value
}
})
}
/**
* @inheritdoc
*
* Delete a stream in Kafka. Deleting topics works only when the broker is configured with "delete.topic.enable=true".
* Otherwise it's a no-op.
*/
override def clearStream(spec: StreamSpec): Boolean = {
info("Delete topic %s in system %s" format (spec.getPhysicalName, systemName))
val kSpec = KafkaStreamSpec.fromSpec(spec)
var retries = CLEAR_STREAM_RETRIES
new ExponentialSleepStrategy().run(
loop => {
val zkClient = connectZk()
try {
AdminUtils.deleteTopic(
zkClient,
kSpec.getPhysicalName)
} finally {
zkClient.close
}
loop.done
},
(exception, loop) => {
if (retries > 0) {
warn("Exception while trying to delete topic %s: %s. Retrying." format (spec.getPhysicalName, exception))
retries -= 1
} else {
warn("Fail to delete topic %s: %s" format (spec.getPhysicalName, exception))
loop.done
throw exception
}
})
val topicMetadata = getTopicMetadata(Set(kSpec.getPhysicalName)).get(kSpec.getPhysicalName).get
topicMetadata.partitionsMetadata.isEmpty
}
/**
* @inheritdoc
*
* Delete records up to (and including) the provided ssp offsets for all system stream partitions specified in the map
* This only works with Kafka cluster 0.11 or later. Otherwise it's a no-op.
*/
override def deleteMessages(offsets: util.Map[SystemStreamPartition, String]) {
if (!running) {
throw new SamzaException(s"KafkaSystemAdmin has not started yet for system $systemName")
}
if (deleteCommittedMessages) {
val nextOffsets = offsets.asScala.toSeq.map { case (systemStreamPartition, offset) =>
(new TopicPartition(systemStreamPartition.getStream, systemStreamPartition.getPartition.getPartitionId), offset.toLong + 1)
}.toMap
adminClient.deleteRecordsBefore(nextOffsets)
deleteMessagesCalled = true
}
}
/**
* Compare the two offsets. Returns x where x < 0 if offset1 < offset2;
* x == 0 if offset1 == offset2; x > 0 if offset1 > offset2.
*
* Currently it's used in the context of the broadcast streams to detect
* the mismatch between two streams when consuming the broadcast streams.
*/
override def offsetComparator(offset1: String, offset2: String): Integer = {
offset1.toLong compare offset2.toLong
}
}
|
bharathkk/samza
|
samza-kafka/src/main/scala/org/apache/samza/system/kafka_deprecated/KafkaSystemAdmin.scala
|
Scala
|
apache-2.0
| 21,492 |
package org.jetbrains.plugins.scala.lang.psi.types.api
import com.intellij.openapi.project.Project
import com.intellij.psi._
import com.intellij.psi.search.GlobalSearchScope
import org.jetbrains.plugins.scala.extensions.PsiTypeExt
import org.jetbrains.plugins.scala.lang.psi.api.toplevel.typedef.ScClass
import org.jetbrains.plugins.scala.lang.psi.types._
import org.jetbrains.plugins.scala.lang.psi.types.api.designator.ScDesignatorType
/**
* @author adkozlov
*/
trait PsiTypeBridge {
typeSystem: TypeSystem =>
/**
* @param treatJavaObjectAsAny if true, and paramTopLevel is true, java.lang.Object is treated as scala.Any
* See SCL-3036 and SCL-2375
*/
def toScType(`type`: PsiType,
treatJavaObjectAsAny: Boolean)
(implicit visitedRawTypes: Set[PsiClass],
paramTopLevel: Boolean): ScType = `type` match {
case arrayType: PsiArrayType =>
JavaArrayType(arrayType.getComponentType.toScType())
case PsiType.VOID => Unit
case PsiType.BOOLEAN => Boolean
case PsiType.CHAR => Char
case PsiType.BYTE => Byte
case PsiType.SHORT => Short
case PsiType.INT => Int
case PsiType.LONG => Long
case PsiType.FLOAT => Float
case PsiType.DOUBLE => Double
case PsiType.NULL => Null
case null => Any
case diamondType: PsiDiamondType =>
import scala.collection.JavaConversions._
diamondType.resolveInferredTypes().getInferredTypes.toList map {
toScType(_, treatJavaObjectAsAny)
} match {
case Nil if paramTopLevel && treatJavaObjectAsAny => Any
case Nil => AnyRef
case head :: _ => head
}
case wildcardType: PsiCapturedWildcardType =>
toScType(wildcardType.getWildcard, treatJavaObjectAsAny)
case intersectionType: PsiIntersectionType =>
typeSystem.andType(intersectionType.getConjuncts.map {
toScType(_, treatJavaObjectAsAny)
})
case _ => throw new IllegalArgumentException(s"psi type ${`type`} should not be converted to ${typeSystem.name} type")
}
def toPsiType(`type`: ScType, noPrimitives: Boolean = false): PsiType
final def stdToPsiType(std: StdType, noPrimitives: Boolean = false): PsiType = {
val stdTypes = std.projectContext.stdTypes
import stdTypes._
def javaObject = createJavaObject
def primitiveOrObject(primitive: PsiPrimitiveType) =
if (noPrimitives) javaObject else primitive
std match {
case Any => javaObject
case AnyRef => javaObject
case Unit if noPrimitives =>
Option(createTypeByFqn("scala.runtime.BoxedUnit"))
.getOrElse(javaObject)
case Unit => PsiType.VOID
case Boolean => primitiveOrObject(PsiType.BOOLEAN)
case Char => primitiveOrObject(PsiType.CHAR)
case Byte => primitiveOrObject(PsiType.BYTE)
case Short => primitiveOrObject(PsiType.SHORT)
case Int => primitiveOrObject(PsiType.INT)
case Long => primitiveOrObject(PsiType.LONG)
case Float => primitiveOrObject(PsiType.FLOAT)
case Double => primitiveOrObject(PsiType.DOUBLE)
case Null => javaObject
case Nothing => javaObject
case _ => javaObject
}
}
protected def createType(psiClass: PsiClass,
substitutor: PsiSubstitutor = PsiSubstitutor.EMPTY,
raw: Boolean = false): PsiType = {
val psiType = factory.createType(psiClass, substitutor)
if (raw) psiType.rawType
else psiType
}
protected def createJavaObject: PsiType =
createTypeByFqn("java.lang.Object")
private def createTypeByFqn(fqn: String): PsiType =
factory.createTypeByFQClassName(fqn, GlobalSearchScope.allScope(projectContext))
protected def factory: PsiElementFactory =
JavaPsiFacade.getInstance(projectContext).getElementFactory
}
object ExtractClass {
def unapply(`type`: ScType): Option[PsiClass] = {
`type`.extractClass
}
def unapply(`type`: ScType, project: Project): Option[PsiClass] = {
`type`.extractClass
}
}
object arrayType {
def unapply(scType: ScType): Option[ScType] = scType match {
case ParameterizedType(ScDesignatorType(cl: ScClass), Seq(arg))
if cl.qualifiedName == "scala.Array" => Some(arg)
case JavaArrayType(arg) => Some(arg)
case _ => None
}
}
|
loskutov/intellij-scala
|
src/org/jetbrains/plugins/scala/lang/psi/types/api/ScTypePsiTypeBridge.scala
|
Scala
|
apache-2.0
| 4,325 |
package shardakka
import com.google.protobuf.ByteString
abstract class Codec[A] extends Encoder[A] with Decoder[A]
trait Encoder[A] {
def toString(bytes: ByteString): String
def toBytes(value: A): ByteString
}
trait Decoder[A] {
def fromBytes(bytes: ByteString): A
}
final object StringCodec extends Codec[String] {
override def toString(bytes: ByteString): String = bytes.toStringUtf8
override def toBytes(value: String): ByteString = ByteString.copyFromUtf8(value)
override def fromBytes(bytes: ByteString): String = bytes.toStringUtf8
}
|
VikingDen/actor-platform
|
actor-server/actor-core/src/main/scala/shardakka/Codec.scala
|
Scala
|
mit
| 560 |
/*
* Code Pulse: A real-time code coverage testing tool. For more information
* see http://code-pulse.com
*
* Copyright (C) 2014 Applied Visions - http://securedecisions.avi.com
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.secdec.codepulse.tracer
import java.io.{ OutputStream, OutputStreamWriter }
import com.secdec.codepulse.data.model._
import com.fasterxml.jackson.core.{ JsonFactory, JsonGenerator }
import net.liftweb.http.OutputStreamResponse
import net.liftweb.json.Printer
/** Generates treemap JSON data in a streaming fashion.
*
* @author robertf
*/
object TreemapDataStreamer {
private val Json = new JsonFactory
private def writeJson(treeNodeData: TreeNodeDataAccess, jg: JsonGenerator)(node: TreeNode) {
import treeNodeData.ExtendedTreeNodeData
jg.writeStartObject
jg.writeNumberField("id", node.data.id)
for (parentId <- node.data.parentId) jg.writeNumberField("parentId", parentId)
jg.writeStringField("name", node.data.label)
jg.writeStringField("kind", node.data.kind.label)
for (size <- node.data.size) jg.writeNumberField("lineCount", size)
for (traced <- node.data.traced) jg.writeBooleanField("traced", traced)
jg.writeBooleanField("isSurfaceMethod", node.data.isSurfaceMethod.getOrElse(false))
if (!node.children.isEmpty) {
jg writeArrayFieldStart "children"
node.children.foreach(writeJson(treeNodeData, jg))
jg.writeEndArray
}
jg.writeEndObject
}
def streamTreemapData(treeNodeData: TreeNodeDataAccess, tree: List[TreeNode]): OutputStreamResponse = {
def writeData(out: OutputStream) {
val jg = Json createGenerator out
try {
jg.writeStartArray
tree.foreach(writeJson(treeNodeData, jg))
jg.writeEndArray
} finally jg.close
}
OutputStreamResponse(writeData, -1L, List("Content-Type" -> "application/json; charset=utf-8"), Nil, 200)
}
}
|
secdec/codepulse
|
codepulse/src/main/scala/com/secdec/codepulse/tracer/TreemapDataStreamer.scala
|
Scala
|
apache-2.0
| 2,376 |
package com.shorrockin.cascal
import org.junit.Test
import jmx.CascalStatistics
class TestCascalStatistics {
@Test def testMultipleMBeanRegistration() {
// if recalling this doesn't throw an exception - we treat that as success
CascalStatistics.reinstallMBean
CascalStatistics.reinstallMBean
}
}
|
shorrockin/cascal
|
src/test/scala/com/shorrockin/cascal/TestCascalStatistics.scala
|
Scala
|
apache-2.0
| 328 |
package ontology_debugging_tool
import java.awt.Dimension
import scala.swing.Action
import scala.swing.BorderPanel
import scala.swing.Button
import scala.swing.CheckBox
import scala.swing.FlowPanel
import scala.swing.GridPanel
import scala.swing.ListView
import scala.swing.MainFrame
import scala.swing.ScrollPane
import scala.swing.SimpleSwingApplication
import scala.swing.Table
import com.hp.hpl.jena.rdf.model.Property
import com.hp.hpl.jena.rdf.model.Resource
import com.hp.hpl.jena.rdf.model.ResourceFactory
import com.hp.hpl.jena.tdb.TDBFactory
import javax.swing.BorderFactory
import scala.collection.JavaConversions._
import scala.collection.mutable.Map
import scala.collection.mutable.Set
import com.hp.hpl.jena.vocabulary.RDFS
import javax.swing.table.DefaultTableModel
import scala.swing.event.ListSelectionChanged
import scala.swing.event.TableRowsSelected
class PropertyRefinementPanel extends GridPanel(4, 1) {
val propertyInfoDefinitionClassSetMap = Map[PropertyInfo, Set[Resource]]()
val propertyInfoCommonSiblingClassSetMap = Map[PropertyInfo, Set[Resource]]()
val inheritedPropertyTable = new Table() {
override lazy val model = super.model.asInstanceOf[javax.swing.table.DefaultTableModel]
model.addColumn("継承プロパティ")
model.addColumn("定義上位クラス数")
peer.setAutoCreateRowSorter(true)
}
val inheritedPropertyDefinedClassListView = new ListView[Resource]()
val removeInheritedPropertiesButton = new Button(Action("定義クラスからプロパティを削除") {})
val showPropertiesOfDefinedClassButton = new Button(Action("定義クラスのプロパティを表示") {})
val showInheritedPropertiesDefinedInSpecificPropertiesButton = new CheckBox("固有プロパティに定義されている継承プロパティのみ表示")
val inheritedPropertyPanel = new BorderPanel() {
val listPanel = new GridPanel(1, 2) {
contents += new ScrollPane(inheritedPropertyTable)
contents += new ScrollPane(inheritedPropertyDefinedClassListView) {
border = BorderFactory.createTitledBorder("継承プロパティの定義クラス")
}
}
val buttonPanel = new GridPanel(2, 1) {
contents += new FlowPanel(FlowPanel.Alignment.Left)(removeInheritedPropertiesButton, showPropertiesOfDefinedClassButton)
contents += new FlowPanel(FlowPanel.Alignment.Left)(showInheritedPropertiesDefinedInSpecificPropertiesButton)
}
add(listPanel, BorderPanel.Position.Center)
add(buttonPanel, BorderPanel.Position.South)
}
val siblingCommonPropertyTable = new Table() {
override lazy val model = super.model.asInstanceOf[javax.swing.table.DefaultTableModel]
model.addColumn("兄弟クラス共通プロパティ")
model.addColumn("定義兄弟クラス数")
model.addColumn("定義兄弟クラス数の割合")
peer.setAutoCreateRowSorter(true)
}
val siblingCommonPropertyDefinedClassListView = new ListView[Resource]()
val moveSiblingCommonPropertiesToUpperClassButton = new Button(Action("上位クラスに兄弟クラス共通プロパティを移動") {})
val suggestedPropertyPanel = new BorderPanel() {
add(new ScrollPane(siblingCommonPropertyTable), BorderPanel.Position.Center)
add(new ScrollPane(siblingCommonPropertyDefinedClassListView) {
border = BorderFactory.createTitledBorder("定義兄弟クラス")
}, BorderPanel.Position.East)
add(new FlowPanel(FlowPanel.Alignment.Left)(moveSiblingCommonPropertiesToUpperClassButton), BorderPanel.Position.South)
}
val specificPropertyTable = new Table() {
override lazy val model = super.model.asInstanceOf[javax.swing.table.DefaultTableModel]
model.addColumn("固有プロパティ")
model.addColumn("定義インスタンス数")
model.addColumn("定義インスタンス数の割合")
peer.setAutoCreateRowSorter(true)
}
val subClassListView = new ListView[Resource]()
val removeSpecificPropertiesButton = new Button(Action("固有プロパティの削除") {})
val moveSpecificPropertiesToSubClassButton = new Button(Action("下位クラスに固有プロパティを移動") {})
val specificPropertyPanel = new BorderPanel() {
val centerPanel = new BorderPanel() {
add(new ScrollPane(specificPropertyTable), BorderPanel.Position.Center)
add(new ScrollPane(subClassListView) {
border = BorderFactory.createTitledBorder("下位クラス")
}, BorderPanel.Position.East)
}
val buttonPanel = new FlowPanel(FlowPanel.Alignment.Left)(removeSpecificPropertiesButton, moveSpecificPropertiesToSubClassButton)
add(centerPanel, BorderPanel.Position.Center)
add(buttonPanel, BorderPanel.Position.South)
}
val removedPropertyListView = new ListView[String]()
val returnSpecificPropertiesButton = new Button(Action("固有プロパティに戻す") {})
val removedPropertyPanel = new BorderPanel() {
add(new ScrollPane(removedPropertyListView) {
border = BorderFactory.createTitledBorder("削除プロパティ")
}, BorderPanel.Position.Center)
add(new FlowPanel(FlowPanel.Alignment.Left)(returnSpecificPropertiesButton), BorderPanel.Position.South)
}
def getSelectedValue(table: Table): PropertyInfo = {
val selectedIndex = table.selection.rows.leadIndex
// println(selectedIndex)
// println(alignmentResultsTable.selection.rows.size)
if (0 <= selectedIndex && 0 < table.selection.rows.size) {
val propertyInfo = table.model.getValueAt(selectedIndex, 0)
return propertyInfo.asInstanceOf[PropertyInfo]
}
return null
}
listenTo(inheritedPropertyTable.selection, siblingCommonPropertyTable.selection, specificPropertyTable.selection)
reactions += {
case ListSelectionChanged(source, range, live) =>
case TableRowsSelected(source, range, live) =>
if (source == inheritedPropertyTable) {
val propertyInfo = getSelectedValue(inheritedPropertyTable)
propertyInfoDefinitionClassSetMap.get(propertyInfo) match {
case Some(classSet) =>
inheritedPropertyDefinedClassListView.listData = classSet.toList
case None =>
}
println("継承プロパティ:" + propertyInfo)
} else if (source == siblingCommonPropertyTable) {
val propertyInfo = getSelectedValue(siblingCommonPropertyTable)
propertyInfoCommonSiblingClassSetMap.get(propertyInfo) match {
case Some(classSet) =>
siblingCommonPropertyDefinedClassListView.listData = classSet.toList
case None =>
}
println("共通兄弟プロパティ:" + propertyInfo)
} else if (source == specificPropertyTable) {
val propertyInfo = getSelectedValue(specificPropertyTable)
println("固有プロパティ:" + propertyInfo)
}
}
contents += inheritedPropertyPanel
contents += suggestedPropertyPanel
contents += specificPropertyPanel
contents += removedPropertyPanel
val directory = "refined_jwo_tdb";
val tdbModel = TDBFactory.createModel(directory);
val rdfType = ResourceFactory.createProperty("http://www.w3.org/1999/02/22-rdf-syntax-ns#type")
def getDefinitionPropertyInfoSet(clsRes: Resource): Set[PropertyInfo] = {
val propertyInfoMap = Map[Property, PropertyInfo]()
val instanceList = tdbModel.listSubjectsWithProperty(rdfType, clsRes).toList
for (instanceRes <- instanceList) {
val propertySet = Set[Property]() // あるインスタンスに含まれるプロパティのセット
for (stmt <- tdbModel.listStatements(instanceRes, null, null).toList) {
val property = stmt.getPredicate()
if (property != rdfType) {
propertySet.add(property)
}
}
for (property <- propertySet) {
propertyInfoMap.get(property) match {
case Some(info) => info.num += 1
case None =>
propertyInfoMap.put(property, PropertyInfo(property, 1))
}
}
}
val propertyInfoSet = Set[PropertyInfo]()
for (pinfo <- propertyInfoMap.values) {
propertyInfoSet.add(pinfo)
}
return propertyInfoSet
}
def getSuperClassSet(clsRes: Resource, supClassSet: Set[Resource]): Unit = {
for (stmt <- clsRes.listProperties(RDFS.subClassOf).toList()) {
val supClsRes = stmt.getObject().asResource()
supClassSet.add(supClsRes)
getSuperClassSet(supClsRes, supClassSet)
}
}
def getSubClassSet(clsResource: Resource): Set[Resource] = {
val subClassSet = Set[Resource]()
for (stmt <- tdbModel.listStatements(null, RDFS.subClassOf, clsResource).toList()) {
val subClsRes = stmt.getSubject()
subClassSet.add(subClsRes)
}
return subClassSet
}
def getSiblingClassSet(clsRes: Resource): Set[Resource] = {
val siblingClassSet = Set[Resource]()
for (stmt <- clsRes.listProperties(RDFS.subClassOf).toList()) {
val supClsRes = stmt.getObject().asResource()
siblingClassSet ++= tdbModel.listSubjectsWithProperty(RDFS.subClassOf, supClsRes).toList() - clsRes
}
return siblingClassSet
}
def clearTable(table: Table) = {
while (table.model.getRowCount() != 0) {
table.model.asInstanceOf[DefaultTableModel].removeRow(0)
}
}
val jwoPropertyNs = "http://www.yamaguti.comp.ae.keio.ac.jp/wikipedia_ontology/property/"
def setPropertyInfo(cls: String) = {
val clsRes = tdbModel.getResource(cls)
val instanceNum: Double = tdbModel.listSubjectsWithProperty(rdfType, clsRes).toList.size
println("instance num : " + instanceNum)
val defPropertyInfoSet = getDefinitionPropertyInfoSet(clsRes)
val clsPropertyInfoSetMap = Map[Resource, Set[PropertyInfo]]()
val siblingClassSet = getSiblingClassSet(clsRes)
val subClassSet = getSubClassSet(clsRes)
val superClassSet = Set[Resource]()
getSuperClassSet(clsRes, superClassSet)
def setSpecificPropertyInfo() = {
clearTable(specificPropertyTable)
for (p <- defPropertyInfoSet.toSeq.sortBy(-_.num)) {
val ratio = (p.num / instanceNum).formatted("%1.3f")
specificPropertyTable.model.addRow(Array[AnyRef](p, p.num.toString, ratio))
println("定義プロパティ: " + p.propertyRes + ": " + p.num + ": " + instanceNum)
}
clsPropertyInfoSetMap.put(clsRes, defPropertyInfoSet)
}
def setPropertyInfoDefinitionClassSetMap() = {
for (supClass <- superClassSet) {
val propertyInfoSet = getDefinitionPropertyInfoSet(supClass)
clsPropertyInfoSetMap.put(supClass, propertyInfoSet)
for (p <- propertyInfoSet) {
propertyInfoDefinitionClassSetMap.get(p) match {
case Some(classSet) => classSet.add(supClass)
case None =>
propertyInfoDefinitionClassSetMap.put(p, Set[Resource](supClass))
}
}
}
}
def setInheritedPropertyInfo() = {
clearTable(inheritedPropertyTable)
for ((propertyInfo, clsSet) <- propertyInfoDefinitionClassSetMap.toSeq.sortWith(_._2.size > _._2.size)) {
inheritedPropertyTable.model.addRow(Array[AnyRef](propertyInfo, clsSet.size.toString))
if (defPropertyInfoSet.contains(propertyInfo)) {
println("(+定義)継承プロパティ: " + propertyInfo.propertyRes)
} else {
println("継承プロパティ: " + propertyInfo.propertyRes)
}
println("定義クラス: " + clsSet)
}
println(propertyInfoDefinitionClassSetMap.keySet.size)
}
def setSubClassListView() = {
subClassListView.listData = subClassSet.toList
}
def setPropertyInfoCommonSiblingClassSetMap() = {
println(siblingClassSet)
for (siblingClass <- siblingClassSet) {
val propertyInfoSet = getDefinitionPropertyInfoSet(siblingClass)
clsPropertyInfoSetMap.put(siblingClass, propertyInfoSet)
val commonSiblingPropertySet = defPropertyInfoSet & propertyInfoSet
for (cp <- commonSiblingPropertySet) {
propertyInfoCommonSiblingClassSetMap.get(cp) match {
case Some(classSet) => classSet.add(siblingClass)
case None =>
val classSet = Set[Resource](siblingClass)
propertyInfoCommonSiblingClassSetMap.put(cp, classSet)
}
}
}
}
def setSiblingCommonPropertyInfo() = {
clearTable(siblingCommonPropertyTable)
for ((propertyInfo, cset) <- propertyInfoCommonSiblingClassSetMap.toSeq.sortWith(_._2.size > _._2.size)) {
val siblingClassNum: Double = siblingClassSet.size
val ratio = (cset.size / siblingClassNum).formatted("%1.3f")
siblingCommonPropertyTable.model.addRow(Array[AnyRef](propertyInfo, cset.size.toString, ratio.toString))
println(propertyInfo.propertyRes + ": " + cset.size + ": " + siblingClassSet.size)
println(cset)
}
}
setSpecificPropertyInfo()
setPropertyInfoDefinitionClassSetMap()
setInheritedPropertyInfo()
setSubClassListView()
setPropertyInfoCommonSiblingClassSetMap()
setSiblingCommonPropertyInfo()
}
}
object PropertyRefinementPanelTest extends SimpleSwingApplication {
val propertyRefinementPanel = new PropertyRefinementPanel()
propertyRefinementPanel.setPropertyInfo("http://www.yamaguti.comp.ae.keio.ac.jp/wikipedia_ontology/class/日本の小説家")
// propertyRefinementPanel.setPropertyInfo("http://nlpwww.nict.go.jp/wn-ja/08412749-n")
def top = new MainFrame {
title = "プロパティ洗練パネル"
contents = propertyRefinementPanel
size = new Dimension(1024, 700)
centerOnScreen()
}
}
case class PropertyInfo(val propertyRes: Property, var num: Int) {
val jwoPropertyNs = "http://www.yamaguti.comp.ae.keio.ac.jp/wikipedia_ontology/property/"
override def equals(x: Any): Boolean = propertyRes == x.asInstanceOf[PropertyInfo].propertyRes
override def toString(): String = {
return propertyRes.getURI().replace(jwoPropertyNs, "")
}
}
|
t-morita/JWO_Refinement_Tools
|
src/main/scala/ontology_debugging_tool/PropertyRefinementPanel.scala
|
Scala
|
apache-2.0
| 14,272 |
package isuda
import skinny.micro.{ApiFormats, SkinnyMicroFilter, NotFound, Ok}
import scala.util.control.Exception.allCatch
trait Static extends ApiFormats {
self: SkinnyMicroFilter =>
addMimeMapping("image/x-icon", "ico")
get("/(?:(?:css|js|img)/.*|favicon[.]ico)".r) {
val ext = requestPath.split("[.]").lastOption
response.contentType = ext.flatMap(formats.get(_))
val maybeFile =
allCatch.opt(new java.io.File(getClass.getResource(requestPath).toURI))
maybeFile.fold(NotFound())(Ok(_))
}
}
|
dekokun/isucon6-qualify
|
webapp/scala/isuda/src/main/scala/isuda/Static.scala
|
Scala
|
mit
| 530 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.carbondata.spark.testsuite.directdictionary
import java.sql.Timestamp
import org.apache.spark.sql.Row
import org.apache.spark.sql.hive.HiveContext
import org.scalatest.BeforeAndAfterAll
import org.apache.carbondata.core.constants.CarbonCommonConstants
import org.apache.carbondata.core.keygenerator.directdictionary.timestamp.TimeStampGranularityConstants
import org.apache.carbondata.core.util.CarbonProperties
import org.apache.spark.sql.test.util.QueryTest
/**
* Test Class for detailed query on timestamp datatypes
*/
class TimestampDataTypeDirectDictionaryWithNoDictTestCase extends QueryTest with BeforeAndAfterAll {
var hiveContext: HiveContext = _
override def beforeAll {
try {
CarbonProperties.getInstance()
.addProperty(TimeStampGranularityConstants.CARBON_CUTOFF_TIMESTAMP, "2000-12-13 02:10.00.0")
CarbonProperties.getInstance()
.addProperty(TimeStampGranularityConstants.CARBON_TIME_GRANULARITY,
TimeStampGranularityConstants.TIME_GRAN_SEC.toString
)
CarbonProperties.getInstance().addProperty("carbon.direct.dictionary", "true")
sql(
"""
CREATE TABLE IF NOT EXISTS directDictionaryTable
(empno String, doj Timestamp, salary Int)
STORED BY 'org.apache.carbondata.format' TBLPROPERTIES ('DICTIONARY_EXCLUDE'='empno')"""
)
CarbonProperties.getInstance()
.addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT, "yyyy-MM-dd HH:mm:ss")
val csvFilePath = s"$resourcesPath/datasample.csv"
sql("LOAD DATA local inpath '" + csvFilePath + "' INTO TABLE directDictionaryTable OPTIONS"
+ "('DELIMITER'= ',', 'QUOTECHAR'= '\"')");
} catch {
case x: Throwable => CarbonProperties.getInstance()
.addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT, "dd-MM-yyyy")
}
}
test("select doj from directDictionaryTable") {
checkAnswer(
sql("select doj from directDictionaryTable"),
Seq(Row(Timestamp.valueOf("2016-03-14 15:00:09.0")),
Row(Timestamp.valueOf("2016-04-14 15:00:09.0")),
Row(null)
)
)
}
test("select doj from directDictionaryTable with equals filter") {
checkAnswer(
sql("select doj from directDictionaryTable where doj='2016-03-14 15:00:09'"),
Seq(Row(Timestamp.valueOf("2016-03-14 15:00:09")))
)
}
test("select doj from directDictionaryTable with greater than filter") {
checkAnswer(
sql("select doj from directDictionaryTable where doj>'2016-03-14 15:00:09'"),
Seq(Row(Timestamp.valueOf("2016-04-14 15:00:09")))
)
}
override def afterAll {
sql("drop table directDictionaryTable")
CarbonProperties.getInstance()
.addProperty(CarbonCommonConstants.CARBON_TIMESTAMP_FORMAT, "dd-MM-yyyy")
CarbonProperties.getInstance().addProperty("carbon.direct.dictionary", "false")
}
}
|
shivangi1015/incubator-carbondata
|
integration/spark-common-test/src/test/scala/org/apache/carbondata/spark/testsuite/directdictionary/TimestampDataTypeDirectDictionaryWithNoDictTestCase.scala
|
Scala
|
apache-2.0
| 3,703 |
/** This does NOT crash unless it's in the interactive package.
*/
package scala.tools.nsc
package interactive
trait MyContextTrees {
val self: Global
val NoContext = self.analyzer.NoContext
}
//
// error: java.lang.AssertionError: assertion failed: trait Contexts.NoContext$ linkedModule: <none>List()
// at scala.Predef$.assert(Predef.scala:160)
// at scala.tools.nsc.symtab.classfile.ClassfileParser$innerClasses$.innerSymbol$1(ClassfileParser.scala:1211)
// at scala.tools.nsc.symtab.classfile.ClassfileParser$innerClasses$.classSymbol(ClassfileParser.scala:1223)
// at scala.tools.nsc.symtab.classfile.ClassfileParser.classNameToSymbol(ClassfileParser.scala:489)
// at scala.tools.nsc.symtab.classfile.ClassfileParser.sig2type$1(ClassfileParser.scala:757)
// at scala.tools.nsc.symtab.classfile.ClassfileParser.sig2type$1(ClassfileParser.scala:789)
|
folone/dotty
|
tests/pending/pos/trait-force-info.scala
|
Scala
|
bsd-3-clause
| 867 |
/*
* This file is part of Kiama.
*
* Copyright (C) 2013-2015 Anthony M Sloane, Macquarie University.
*
* Kiama is free software: you can redistribute it and/or modify it under
* the terms of the GNU Lesser General Public License as published by the
* Free Software Foundation, either version 3 of the License, or (at your
* option) any later version.
*
* Kiama is distributed in the hope that it will be useful, but WITHOUT ANY
* WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS
* FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for
* more details.
*
* You should have received a copy of the GNU Lesser General Public License
* along with Kiama. (See files COPYING and COPYING.LESSER.) If not, see
* <http://www.gnu.org/licenses/>.
*/
package org.kiama
package example.grammar
/**
* Simple context-free grammar abstract syntax.
*/
object GrammarTree {
import org.kiama.relation.Tree
/**
* Tree type for grammars.
*/
type GrammarTree = Tree[GrammarNode,Grammar]
/**
* Abstract syntax tree nodes.
*/
sealed abstract class GrammarNode extends Product
/**
* Grammars.
*/
case class Grammar (startRule : Rule, rules : List[Rule]) extends GrammarNode
/**
* Production rules.
*/
case class Rule (lhs : NonTermDef, rhs : ProdList) extends GrammarNode
/**
* Production lists.
*/
sealed abstract class ProdList extends GrammarNode
/**
* Empty symbol list.
*/
case class EmptyProdList () extends ProdList
/**
* Non-empty symbol list.
*/
case class NonEmptyProdList (head : Prod, tail : ProdList) extends ProdList
/**
* Production.
*/
case class Prod (symbols : SymbolList) extends GrammarNode
/**
* Symbol lists.
*/
sealed abstract class SymbolList extends GrammarNode
/**
* Empty symbol list.
*/
case class EmptySymbolList () extends SymbolList
/**
* Non-empty symbol list.
*/
case class NonEmptySymbolList (head : Symbol, tail : SymbolList) extends SymbolList
/**
* Grammar symbols.
*/
sealed abstract class Symbol extends GrammarNode
/**
* Terminal symbol.
*/
case class TermSym (name : String) extends Symbol
/**
* Non-terminal symbol.
*/
case class NonTermSym (nt : NonTermUse) extends Symbol
/**
* A non-terminal reference.
*/
sealed abstract class NonTerm extends GrammarNode {
def name : String
}
/**
* Non-terminal defining occurrence.
*/
case class NonTermDef (name : String) extends NonTerm
/**
* Non-terminal applied occurrence.
*/
case class NonTermUse (name : String) extends NonTerm
/**
* End of input terminal assumed to appear at the end of any sentential form.
*/
val EOI = TermSym ("$")
// Smart constructors
/**
* Smart constructor for rules.
*/
def mkRule (lhs : NonTermDef, prods : Prod*) : Rule =
Rule (lhs, mkProdList (prods.toList))
/**
* Smart constructor for production lists.
*/
def mkProdList (prods : List[Prod]) : ProdList =
if (prods == Nil)
EmptyProdList ()
else
NonEmptyProdList (prods.head, mkProdList (prods.tail))
/**
* Smart constructor for productions.
*/
def mkProd (rhs : Symbol*) : Prod =
Prod (mkSymbolList (rhs.toList))
/**
* Smart constructor for symbol lists.
*/
def mkSymbolList (symbols : List[Symbol]) : SymbolList =
if (symbols == Nil)
EmptySymbolList ()
else
NonEmptySymbolList (symbols.head, mkSymbolList (symbols.tail))
}
|
adeze/kiama
|
library/src/org/kiama/example/grammar/GrammarTree.scala
|
Scala
|
gpl-3.0
| 3,771 |
package debop4s.core.retry
import java.util.concurrent.atomic.{AtomicBoolean, AtomicInteger}
import debop4s.core.utils.JavaTimer
import debop4s.core._
import debop4s.core.concurrent._
import org.scalatest.BeforeAndAfterAll
import scala.concurrent.ExecutionContext.Implicits.global
import scala.concurrent.Future
import scala.concurrent.duration._
/**
* PolicyFunSuite
* @author [email protected]
*/
class PolicyFunSuite extends AbstractCoreFunSuite with BeforeAndAfterAll {
implicit val timer = JavaTimer()
override def afterAll() {
timer.stop()
}
def forwardCountingFutureStream(value: Int = 0): Stream[Future[Int]] =
Future(value) #:: forwardCountingFutureStream(value + 1)
def backwardCountingFutureStream(value: Int): Stream[Future[Int]] = {
if (value < 0) Stream.empty
else Future(value) #:: backwardCountingFutureStream(value - 1)
}
def time[@miniboxed T](f: => T): Duration = {
val before = System.currentTimeMillis()
f
Duration(System.currentTimeMillis() - before, MILLISECONDS)
}
test("Directly - 지정된 횟수만큼 재시도 합니다.") {
implicit val successful = Successful[Int](_ == 3)
val tries = forwardCountingFutureStream().iterator
val result = Directly(3)(tries.next()).await(1 millis)
successful.predicate(result) shouldEqual true
}
test("Directly - 작업 실패 시") {
val successful = implicitly[Successful[Option[Int]]]
val tries = Future(None: Option[Int])
val result = Directly(2)(tries).await(1 millis)
successful.predicate(result) shouldEqual false
}
test("Directly - 재시도 횟수 제한 여부") {
implicit val successful = Successful.always
val policy = Directly(3)
val counter = new AtomicInteger()
val future = policy {
val c = counter.incrementAndGet()
Future.failed(new RuntimeException(s"always failing - $c"))
}
// Asyncs.stay(future, Duration.Inf)
future.stay(Duration.Inf)
counter.get() shouldEqual 4
}
test("Directly - 성공한 결과에 대한 테스트") {
implicit val successful = Successful.always
val counter = new AtomicInteger()
val future = Directly(1) {
counter.getAndIncrement match {
case 1 => Future.successful("yay!")
case _ => Future.failed(new RuntimeException("failed"))
}
}
val result = future.await(Duration.Inf)
counter.get shouldBe 2
result shouldEqual "yay!"
}
test("Pause - 실패 시 pause 하는지 여부") {
implicit val successful = Successful[Int](_ == 3)
val tries = forwardCountingFutureStream().iterator
val policy = Pause(3, 30.millis)
val took = time {
val result = policy(tries.next()).await(90.millis + 50.millis)
successful.predicate(result) shouldEqual true
}
log.debug(s"took = $took")
(took >= 90.millis) shouldEqual true
(took <= 140.millis) shouldEqual true
}
test("Backoff") {
implicit val successful = Successful[Int](_ == 2)
val tries = forwardCountingFutureStream().iterator
val policy = Backoff(2, 30.millis)
val took = time {
val result = policy(tries.next()).await(90.millis + 50.millis)
successful.predicate(result) shouldEqual true
}
log.debug(s"took = $took")
(took >= 90.millis) shouldEqual true
(took <= 150.millis) shouldEqual true
}
test("When - 재시도 조건이 왔을 때") {
implicit val successful = Successful[Int](_ == 2)
val tries = forwardCountingFutureStream().iterator
val policy = When {
case 0 => When {
case 1 => Pause(delay = 2.seconds)
}
}
val future = policy(tries.next())
val result = future.await(2.seconds)
successful.predicate(result) shouldEqual true
}
test("When - 조건을 맞났을 때") {
implicit val successful = Successful[Int](_ == 2)
val tries = forwardCountingFutureStream().iterator
val policy = When {
case 1 => Directly()
}
val future = policy(tries.next())
val result = future.await(1.millis)
successful.predicate(result) shouldEqual false
}
test("When - 예외 발생 시") {
implicit val successful = Successful[Boolean](identity)
case class RetryAfter(duration: FiniteDuration) extends RuntimeException
val retried = new AtomicBoolean()
def run() = {
if (retried.get()) Future(true)
else {
retried.set(true)
Future.failed(RetryAfter(1.seconds))
}
}
val policy = When {
case RetryAfter(duration) => Pause(delay = duration)
}
val result = policy(run()).await(Duration.Inf)
result shouldEqual true
}
}
|
debop/debop4s
|
debop4s-core/src/test/scala/debop4s/core/retry/PolicyFunSuite.scala
|
Scala
|
apache-2.0
| 4,643 |
package ch.bsisa.hyperbird.documents
import java.io.InputStream
import java.util.Date
import org.apache.poi.ss.usermodel._
import org.apache.poi.ss.util.CellReference
import org.jsoup.Jsoup
import play.api.Logger
import securesocial.core.Identity
import scala.collection.JavaConversions._
/**
* Encapsulate logic and external libraries dependencies required to produce XLS spreadsheet reports.
* General supported workflow:
*
* - Take a Workbook containing a dataSheet and a parameterSheet
* - Extract parameterSheet XQuery name and parameters
* - Obtain XQuery result in HTML format expected to contain a single HTML table
* - Convert the HTML table to Spreadsheet rows and cells and merge them to the dataSheet
*
* @author Patrick Refondini
*/
object SpreadSheetBuilder {
// ==================================================================
// Constants
// ==================================================================
val Col0 = 0
val Col1 = 1
val Col2 = 2
val Row0 = 0
val Row1 = 1
val DateCssClassName = "date"
val NumericCssClassName = "num"
val ParameterSheetName = "Parametres"
val AbsRow = true
val AbsCol = true
val XQueryFileNameCellRef = new CellReference(ParameterSheetName, Row0, Col1, AbsRow, AbsCol)
val ResultInsertStartCellRef = new CellReference(ParameterSheetName, Row1, Col1, AbsRow, AbsCol)
// Hyperbird default date format formatter
val sdf = new java.text.SimpleDateFormat("yyyy-MM-dd")
/**
* Creates Workbook from provided input stream.
*/
def getWorkbook(workBookStream: InputStream): Workbook = WorkbookFactory.create(workBookStream)
/**
* Get the xquery file name defined in the Workbook `wb`
*/
def getXQueryFileName(wb: Workbook): String = {
wb.getSheet(XQueryFileNameCellRef.getSheetName)
.getRow(XQueryFileNameCellRef.getRow)
.getCell(XQueryFileNameCellRef.getCol)
.getRichStringCellValue.getString
}
/**
* Adds user info to Workbook sheets footers.
*/
def insertWorkBookUserDetails(wb: Workbook, userDetails: Identity): Unit = {
// dateTimeFormat information could be obtained within userDetails or
// obtained thanks to it (user profile, language, locale...)
val dateTimeFormat = "dd.MM.yyyy HH:mm"
val dtSdf = new java.text.SimpleDateFormat(dateTimeFormat)
for (i <- 0 until wb.getNumberOfSheets) {
val sheet = wb.getSheetAt(i)
val footer = sheet.getFooter
val preservedFooterCenterContent = if (footer.getCenter.trim.nonEmpty) " - " + footer.getCenter else ""
footer.setCenter(userDetails.identityId.userId + " - " + dtSdf.format(new Date()) + preservedFooterCenterContent)
}
}
/**
* Inserts page x / n at footer right position of all Workbook
* sheet appending to existing content if any (useful for
* templates update). x: current page, n: total number of pages.
*
* Note: Could not find common org.apache.poi.ss.usermodel way
* to set page numbers! Indeed common interface:
* <code>org.apache.poi.ss.usermodel.HeaderFooter</code>
* does not provide page() and numPages() in POI 3.10-FINAL
*/
def insertWorkBookPageNumbers(wb: Workbook): Unit = {
for (i <- 0 until wb.getNumberOfSheets) {
val sheet = wb.getSheetAt(i)
val footer = sheet.getFooter
import org.apache.poi.hssf.usermodel.HeaderFooter
import org.apache.poi.xssf.usermodel.XSSFWorkbook
if (wb.isInstanceOf[XSSFWorkbook]) {
footer.setRight(footer.getRight + " page &P / &N")
} else {
footer.setRight(footer.getRight + " page " + HeaderFooter.page + " / " + HeaderFooter.numPages)
}
}
}
/**
* Updates workbook `wb` parameter sheet with `queryString` values.
*/
def updateParameterWorkBook(wb: Workbook, queryString: Map[String, Seq[String]]): Unit = {
Logger.debug("SpreadSheetBuilder.updateParameterWorkBook called.")
val parameterSheet: Sheet = wb.getSheet(XQueryFileNameCellRef.getSheetName)
// Fill parameters values associated to xquery if any
for (row: Row <- parameterSheet) {
for (cell: Cell <- row) {
val cellRef: CellReference = new CellReference(row.getRowNum, cell.getColumnIndex)
// Rows 0 and 1 contain XQuery request name and insert result cell position.
if (cellRef.getRow > 1 && cellRef.getCol == 0) {
// Get the parameter name specified in the spread sheet
val parameterName = cell.getCellTypeEnum match {
case CellType.STRING => cell.getRichStringCellValue.getString
case _ =>
Logger.error(s"Parameter name should be of string type! found: ${cell.getCellTypeEnum.name()}") // TODO: throw exception
s"ERROR - Parameter name should be of string type! found: ${cell.getCellTypeEnum.name()}"
}
// From the query string try to find the parameter value corresponding to the parameter name specified in the spread sheet
val parameterValue = queryString.get(parameterName) match {
case Some(value) => value.head
case None =>
Logger.error(s"No value found in query string for parameter $parameterName") // TODO: throw exception
s"ERROR - No value found for parameter $parameterName"
}
Logger.debug(s"Found parameter named: $parameterName with value >$parameterValue<")
// Check the parameter value cell type and convert the matching
// query parameter value to the given type to preserve parameter
// value cell type while updating its content.
val paramValueCell = row.getCell(1)
paramValueCell.getCellTypeEnum match {
case CellType.BLANK =>
Logger.debug(s"Updated BLANK parameter value cell with string = $parameterValue")
paramValueCell.setCellValue(parameterValue)
case CellType.STRING =>
Logger.debug(s"Updated STRING parameter value cell with string = $parameterValue")
paramValueCell.setCellValue(parameterValue)
case CellType.NUMERIC =>
Logger.debug(s"Updated parameter value cell with double = $parameterValue")
Logger.warn("Request parameter used to set numeric cell. Untested operation, date and numeric conversion need extended support.")
paramValueCell.setCellValue(parameterValue.toDouble)
// TODO: date and numeric values need a defined format while passed as request parameter and a corresponding formatter
// val format = new java.text.SimpleDateFormat("dd-MM-yyyy")
// if (DateUtil.isCellDateFormatted(paramValueCell)) paramValueCell. paramValueCell.setCellValue(Date.parse(parameterValue)) else paramValueCell.getNumericCellValue()
// TODO: date and numeric values need a defined format while passed as request parameter and a corresponding formatter
case CellType.BOOLEAN =>
Logger.debug(s"Updated parameter value cell with string = $parameterValue")
Logger.warn("Request parameter used to set boolean cell. Untested operation.")
paramValueCell.setCellValue(parameterValue)
case CellType.FORMULA =>
Logger.debug(s"Parameter value cell NOT updated")
Logger.error("Request parameter used to set formula cell operation currently not supported.")
case CellType.ERROR =>
Logger.warn(s"Parameter value cell of type ERROR NOT updated...")
case _ =>
Logger.warn("Unknown Cell type!")
}
}
// Logger.debug(s"${cellRef.formatAsString()} content: ${cellContent} ")
}
}
}
/**
* Merge `htmlTable` string expected to contain a simple HTML
* document containing a single HTML table within the provided
* `wb` Workbook first sheet.
*/
def mergeHtmlTable(wb: Workbook, htmlTable: String): Unit = {
Logger.debug("SpreadSheetBuilder.mergeHtmlTable called.")
val resultDataStartCellRefString =
wb.getSheet(ResultInsertStartCellRef.getSheetName)
.getRow(ResultInsertStartCellRef.getRow)
.getCell(ResultInsertStartCellRef.getCol())
.getRichStringCellValue.getString
val resultDataStartCellRef = new CellReference(resultDataStartCellRefString)
//Logger.debug(s"resultDataStartCellRefString = ${resultDataStartCellRefString}, resultDataStartCellRef = ${resultDataStartCellRef}")
// By convention the resultDataStartCellRef is considered to be on the first sheet
val dataSheet = wb.getSheetAt(0)
// Make use of a temporarySheet to perform formulas references adjustments
// using row shifting without affecting dataSheet formulas we want to keep
// references untouched (Header totals for instance).
val temporarySheet = wb.cloneSheet(0)
// Get the first row as example
val templateRow = dataSheet.getRow(resultDataStartCellRef.getRow)
//Logger.debug(s"templateRow last cell num = ${templateRow.getLastCellNum()}");
import scala.collection.JavaConversions._
// Parse report HTML table result as org.jsoup.nodes.Document
val htmlReportDoc = Jsoup.parse(htmlTable)
// We expect a single table per document
val tables = htmlReportDoc.select("table")
// Check htmlTable structure
if (tables.size() == 0) throw HtmlTableNotFoundException(s"HTML query result is expected to contain a single table but none was found query ${getXQueryFileName(wb)}")
else if (tables.size() > 1) throw MoreThanOneHtmlTableFoundException(s"HTML query result is expected to contain a single table but ${tables.size()} were found for query ${getXQueryFileName(wb)}")
// By convention we expect results to be contained in a single HTML table
val dataTable = tables.get(0)
// Make the iterator a collection to allow repeated traversals
val dataTableTrCollection = dataTable.select("tr").toIndexedSeq
// Safe guard limit after which we stop looping in search of formula cell
val MAX_COL_WITHOUT_FORMULA = 4
// ================================================================
// ==== Deal with formula - START
// ================================================================
var rowIdxFormulaPass: Integer = resultDataStartCellRef.getRow()
var maxCellIdxFormulaPass: Integer = 0
// Index used to check for last loop
var currFormulaPassIdx = 0
// Loop on HTML table result rows
for (row <- dataTableTrCollection) {
var cellIdxFormulaPass: Integer = resultDataStartCellRef.getCol.toInt
var nbColWithoutFormula = 0
// Always create row at start position, it will be shifted down a position afterward
val dataRow = temporarySheet.createRow(resultDataStartCellRef.getRow)
// Loop on HTML table result row columns
for (cell <- row.select("td")) {
val currSheetCell = dataRow.createCell(cellIdxFormulaPass)
currSheetCell.setCellValue("SHOULD NEVER BE VISIBLE :: TO BE DELETED WITH temporarySheet :: " + cell.text)
cellIdxFormulaPass = cellIdxFormulaPass + 1
}
// keep looping while MAX_COL_WITHOUT_FORMULA not reached or last template columns reached
while (nbColWithoutFormula < MAX_COL_WITHOUT_FORMULA && cellIdxFormulaPass < templateRow.getLastCellNum) {
val exampleCell = templateRow.getCell(cellIdxFormulaPass)
// Check if next template column contains a formula
exampleCell.getCellTypeEnum match {
case CellType.FORMULA =>
val formula = exampleCell.getCellFormula
if (formula.trim().length() > 0) {
val currSheetCell = dataRow.createCell(cellIdxFormulaPass)
currSheetCell.setCellType(exampleCell.getCellTypeEnum)
currSheetCell.setCellFormula(exampleCell.getCellFormula)
currSheetCell.setCellStyle(exampleCell.getCellStyle)
// Leave nbColWithoutFormula untouched
} else {
nbColWithoutFormula = nbColWithoutFormula + 1
}
case _ =>
nbColWithoutFormula = nbColWithoutFormula + 1
}
// Go a column forward
cellIdxFormulaPass = cellIdxFormulaPass + 1
}
currFormulaPassIdx = currFormulaPassIdx + 1
// Do not shift row on last loop
if (currFormulaPassIdx < dataTableTrCollection.length) {
// Perform shifting on temporarySheet to preserve dataSheet from side effect on "static" formulas
temporarySheet.shiftRows(resultDataStartCellRef.getRow, rowIdxFormulaPass, 1)
}
if (cellIdxFormulaPass > maxCellIdxFormulaPass) maxCellIdxFormulaPass = cellIdxFormulaPass
rowIdxFormulaPass = rowIdxFormulaPass + 1
}
// ================================================================
// ==== Deal with formula - END
// ================================================================
// ================================================================
// ==== Deal with data - START
// ================================================================
var rowIdx: Integer = resultDataStartCellRef.getRow()
var maxCellIdx: Integer = 0
// Loop on HTML table result rows
for (row <- dataTableTrCollection) {
var cellIdx: Integer = resultDataStartCellRef.getCol.toInt
var nbColWithoutFormula = 0
// Create row on dataSheet for each HTML table result row
val dataRow = dataSheet.createRow(rowIdx)
// Loop on HTML table result row columns
for (cell <- row.select("td")) {
val currSheetCell = dataRow.createCell(cellIdx)
if (!cell.text.isEmpty) {
// Cell type is defined after td class names.
// Currently supported names for type specific {"date","num"}
if (cell.text.startsWith("=")) {
currSheetCell.setCellFormula(cell.text.substring(1))
} else {
cell.className() match {
case DateCssClassName =>
currSheetCell.setCellValue(sdf.parse(cell.text))
case NumericCssClassName =>
currSheetCell.setCellValue(java.lang.Double.parseDouble(cell.text))
case _ =>
currSheetCell.setCellValue(cell.text)
}
}
} else {
currSheetCell.setCellValue(cell.text)
}
// Copy example row cells style
if (templateRow.getCell(cellIdx) != null) {
val cellStyle = templateRow.getCell(cellIdx).getCellStyle
currSheetCell.setCellStyle(cellStyle)
}
cellIdx = cellIdx + 1
}
// ==============================================================
// Proceed with formulas columns if any
// ==============================================================
// keep doing while MAX_NO_FORMULA_FOUND reached
while (nbColWithoutFormula < MAX_COL_WITHOUT_FORMULA && cellIdx < templateRow.getLastCellNum) {
val exampleCell = templateRow.getCell(cellIdx)
// Check if next template column contains a formula
exampleCell.getCellTypeEnum match {
case CellType.FORMULA =>
//val fRange = exampleCell.getArrayFormulaRange()
//val cachedResult = exampleCell.getCachedFormulaResultType()
val formula = exampleCell.getCellFormula
//val style = exampleCell.getCellStyle()
//Logger.debug(s"Formula found: >${formula}<, cachedResult: >${cachedResult}<")
//Logger.debug(s"Formula range: \\nfirst col: ${fRange.getFirstColumn()}\\nlast col : ${fRange.getLastColumn()}\\nfirst row: ${fRange.getFirstRow()} \\nlast row : ${fRange.getLastRow()} \\nnb of cells: ${fRange.getNumberOfCells()}")
if (formula.trim().length() > 0) {
//Logger.debug(s"formula.trim().length() = ${formula.trim().length()}")
val currSheetCell = dataRow.createCell(cellIdx)
currSheetCell.setCellType(exampleCell.getCellTypeEnum)
// Get the formula with correct references from temporarySheet
val shiftedFormulaFromTemporarySheet = temporarySheet.getRow(currSheetCell.getRowIndex).getCell(currSheetCell.getColumnIndex).getCellFormula
//Logger.debug(s"shiftedFormulaFromTemporarySheet = ${shiftedFormulaFromTemporarySheet}")
currSheetCell.setCellFormula(shiftedFormulaFromTemporarySheet)
currSheetCell.setCellStyle(exampleCell.getCellStyle)
// Leave nbColWithoutFormula untouched
} else {
nbColWithoutFormula = nbColWithoutFormula + 1
}
case _ => nbColWithoutFormula = nbColWithoutFormula + 1
}
cellIdx = cellIdx + 1
}
if (cellIdx > maxCellIdx) maxCellIdx = cellIdx
rowIdx = rowIdx + 1
}
// Get rid of the temporary fake sheet.
wb.removeSheetAt(wb.getSheetIndex(temporarySheet))
// ================================================================
// ==== Deal with data - END
// ================================================================
// ================================================================
// ==== Deal with Print - START
// ================================================================
val maxColIdx = maxCellIdx
val maxRowIdx = rowIdx
definePrintRange(wb, resultDataStartCellRef, maxColIdx, maxRowIdx)
//Logger.debug(s"maxColIdx = ${maxColIdx}, maxRowIdx = ${maxRowIdx}")
// ================================================================
// ==== Deal with Print - END
// ================================================================
// Disabled autoSizeColumn upon user request. Full fixed layout control on
// template is prefered to unpredictable dynamic resize.
// Note: Text wrap can be defined on template example data row and will be preserved for dynamic data.
/*
val firstDataRow = dataSheet.getRow(resultDataStartCellRef.getRow() - 1) // -1 to use data header
val colDataRange = Range(resultDataStartCellRef.getCol(): Int, firstDataRow.getLastCellNum(): Int, step = 1)
for (i <- colDataRange) {
dataSheet.autoSizeColumn(i);
}
*/
}
/**
* Deal with print range for dataSheet adapting from already existing print range.
*/
def definePrintRange(wb: Workbook, resultDataStartCellRef: CellReference, maxColIdx: Int, maxRowIdx: Int): Unit = {
for (i <- 0 until wb.getNumberOfSheets) {
// Only deal with sheets that do not have an already defined print area
if (wb.getPrintArea(i) == null) {
val printRangeStart = "$A$1"
val printRangeStartCellRef = new CellReference(printRangeStart)
// Compute resultDataEndCellAbsRef column position
val endCol = if (printRangeStartCellRef.getCol > resultDataStartCellRef.getCol) {
maxColIdx - (printRangeStartCellRef.getCol - resultDataStartCellRef.getCol)
} else {
maxColIdx + (resultDataStartCellRef.getCol - printRangeStartCellRef.getCol)
}
// Define new print range end position
val resultDataEndCellAbsRef = new CellReference(maxRowIdx - 1, endCol, AbsRow, AbsCol)
val newPrintRange = printRangeStart + ":" + resultDataEndCellAbsRef.formatAsString()
wb.setPrintArea(i, newPrintRange)
}
}
}
/**
* HSSF and XSSF compatible formulas evaluation.
*/
def evaluateAllFormulaCells(wb: Workbook): Unit = {
val evaluator = wb.getCreationHelper.createFormulaEvaluator()
for (i <- 0 until wb.getNumberOfSheets) {
val sheet = wb.getSheetAt(i)
for (row <- sheet) {
for (cell <- row) {
if (cell.getCellTypeEnum == CellType.FORMULA) {
try {
evaluator.evaluateFormulaCellEnum(cell)
} catch {
case e: Throwable =>
Logger.warn(s"Problem evaluating formulae for cell row ${cell.getRowIndex}, column ${cell.getColumnIndex} : ${e.getMessage}")
}
}
}
}
}
}
}
/**
* Exception thrown when the expected HTML table is not found within the HTML query result.
*/
case class HtmlTableNotFoundException(message: String = null, cause: Throwable = null) extends Exception(message, cause)
/**
* Exception thrown when the HTML result contains more than a single expected HTML table.
*/
case class MoreThanOneHtmlTableFoundException(message: String = null, cause: Throwable = null) extends Exception(message, cause)
|
bsisa/hb-api
|
app/ch/bsisa/hyperbird/documents/SpreadSheetBuilder.scala
|
Scala
|
gpl-2.0
| 20,679 |
import scala.collection._
trait IterableViewLike[+A,
+Coll,
+This <: IterableView[A, Coll] with IterableViewLike[A, Coll, This]] {
def viewToString: String = ""
protected[this] def viewIdentifier: String = ""
trait Transformed[+B]
}
trait IterableView[+A, +Coll] extends IterableViewLike[A, Coll, IterableView[A, Coll]]
trait SeqView[+A, +Coll] extends SeqViewLike[A, Coll, SeqView[A, Coll]]
trait SeqViewLike[+A,
+Coll,
+This <: SeqView[A, Coll] with SeqViewLike[A, Coll, This]]
extends Seq[A] with SeqOps[A, Seq, Seq[A]] with IterableView[A, Coll] with IterableViewLike[A, Coll, This]
trait Foo[+A,
+Coll,
+This <: SeqView[A, Coll] with SeqViewLike[A, Coll, This]]
extends Seq[A] with SeqOps[A, Seq, Seq[A]] with IterableView[A, Coll] with IterableViewLike[A, Coll, This] {
self =>
trait Transformed[+B] extends SeqView[B, Coll] with super.Transformed[B] {
def length: Int
def apply(idx: Int): B
override def toString = viewToString
}
trait Reversed extends Transformed[A] {
override def iterator: Iterator[A] = createReversedIterator
def length: Int = self.length
def apply(idx: Int): A = self.apply(length - 1 - idx)
final override protected[this] def viewIdentifier = "R"
private def createReversedIterator = {
var lst = List[A]()
for (elem <- self) lst ::= elem
lst.iterator
}
}
}
|
scala/scala
|
test/files/pos/specializes-sym-crash.scala
|
Scala
|
apache-2.0
| 1,362 |
/* * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * *\\
* @ @ *
* # # # # (c) 2017 CAB *
* # # # # # # *
* # # # # # # # # # # # # *
* # # # # # # # # # *
* # # # # # # # # # # # # # # # # # # *
* # # # # # # # # # # # # # # # # # *
* # # # # # # # # # # # # # *
* # # # # # # # # # # # # # # *
* # # # # # # # # # # # # # # # # # # *
* @ @ *
\\* * http://github.com/alexcab * * * * * * * * * * * * * * * * * * * * * * * * * */
package mathact.core.app.infrastructure
import akka.actor.SupervisorStrategy.Stop
import akka.actor._
import akka.event.{Logging, LoggingAdapter}
import mathact.core.bricks.data.SketchData
import mathact.core.model.config.MainConfigLike
import mathact.core.model.enums.SketchStatus
import mathact.core.model.holders.MainUIRef
import mathact.core.model.messages.M
/** Application controller actor
* Created by CAB on 20.06.2016.
*/
private[core] abstract class MainControllerActor(config: MainConfigLike, doStop: Int⇒Unit)
extends Actor{
//Strategy
override val supervisorStrategy = OneForOneStrategy(){case _: Throwable ⇒ Stop}
//Objects
val log: LoggingAdapter = Logging.getLogger(context.system, this)
//Sub actors (abstract fields defined here to capture this actor context)
val mainUi: MainUIRef
//Variables
var sketchList = List[(SketchData, SketchStatus)]()
var currentSketch: Option[(ActorRef,SketchData)] = None
var lastError: Option[Throwable] = None
//Abstract methods
def createSketchController(config: MainConfigLike, sketchData: SketchData): ActorRef
//Functions
def stopAppByNormal(): Unit = {
log.debug(s"[MainControllerActor.stopApp] Normal stop, application will terminated.")
self ! PoisonPill}
def stopAppByError(error: Throwable): Unit = {
log.error(error, s"[MainControllerActor.fatalError] Stop by fatal error, application will terminated.")
lastError = Some(error)
self ! PoisonPill}
def runSketch(sketch: SketchData): Unit = {
//Create actor
val sketchController = createSketchController(config, sketch)
context.watch(sketchController)
//Run actor
sketchController ! M.LaunchSketch
//Set current
currentSketch = Some((sketchController, sketch))}
def setSketchSate(className: String, newState: SketchStatus): Unit = {
sketchList = sketchList.map{
case (s,_) if s.className == className ⇒ (s, newState)
case s ⇒ s}}
def forSketch(className: String)(proc: SketchData ⇒ Unit): Unit = sketchList.find(_._1.className == className) match{
case Some((sketch, _)) if sketch.className == className ⇒
proc(sketch)
case _ ⇒
val msg = s"[MainControllerActor.forSketch] Not found sketch for className: $className , sketchList: $sketchList"
log.error(msg)
stopAppByError(new IllegalArgumentException(msg))}
def forCurrentSketch(className: String)(proc: (ActorRef, SketchData) ⇒ Unit): Unit = currentSketch match{
case Some((actor, sketch)) if sketch.className == className ⇒
proc(actor, sketch)
case cs ⇒
log.error(s"[MainControllerActor.forCurrentSketch] No or wrong current sketch, currentSketch: $cs")}
def setAndShowUISketchTable(): Unit =
mainUi ! M.SetSketchList(sketchList.map{ case (d,s) ⇒ d.toSketchInfo(s)})
//Actor reaction on messages
def receive: PartialFunction[Any, Unit] = {
//Main controller start
case M.MainControllerStart(sketches) ⇒
//Set sketch list
sketchList = sketches.map(s ⇒ (s, SketchStatus.Ready))
//If exist auto-run sketch then run, otherwise show UI
sketches.find(_.autorun) match{
case Some(sketch) ⇒
log.debug("[MainControllerActor @ MainControllerStart] Auto-run sketch: " + sketch)
runSketch(sketch)
case None ⇒
log.debug("[MainControllerActor @ MainControllerStart] No sketch to auto-run found, show UI.")
mainUi ! M.SetSketchList(sketchList.map{ case (d,s) ⇒ d.toSketchInfo(s) })}
//Run selected sketch
case M.RunSketch(sketchInfo) if currentSketch.isEmpty ⇒ forSketch(sketchInfo.className){ sketch ⇒
runSketch(sketch)}
//New sketch context, redirect to sketch controller if exist
case M.NewSketchContext(workbench, sketchClassName) ⇒ forCurrentSketch(sketchClassName){ case (actor, sketch) ⇒
actor ! M.GetSketchContext(sender)}
//Sketch built, hide UI
case M.SketchBuilt(className) ⇒ forCurrentSketch(className){ case (_, sketch) ⇒
mainUi ! M.HideMainUI}
//Sketch fail, hide UI
case M.SketchFail(className) ⇒ forCurrentSketch(className){ case (_, sketch) ⇒
mainUi ! M.HideMainUI}
//Sketch done successfully
case M.SketchDone(className) ⇒ forCurrentSketch(className){ case (actor, sketch) ⇒
setSketchSate(className, SketchStatus.Ended)
context.unwatch(sender)
setAndShowUISketchTable()
currentSketch = None}
//Sketch done with error
case M.SketchError(className, errors) ⇒ forCurrentSketch(className){ case (actor, sketch) ⇒
log.error("[MainControllerActor @ SketchError] Sketch failed.")
errors.foreach(e ⇒ log.error(e, "[MainControllerActor @ SketchError] Error."))
setSketchSate(className, SketchStatus.Failed)
context.unwatch(sender)
setAndShowUISketchTable()
currentSketch = None}
//Main close hit, terminate if to sketch ran
case M.MainCloseBtnHit if currentSketch.isEmpty ⇒
stopAppByNormal()
//Termination of actor
case Terminated(actor) ⇒ actor match{
case a if a == mainUi.ref ⇒
val msg = s"[MainControllerActor @ Terminated] Main UI terminated suddenly, currentSketch: $currentSketch"
log.error(msg)
stopAppByError(new Exception(msg))
case a if currentSketch.map(_._1).contains(a) ⇒
log.error(s"[MainControllerActor @ Terminated] Current sketch terminated suddenly, currentSketch: $currentSketch")
setSketchSate(currentSketch.get._2.className, SketchStatus.Failed)
setAndShowUISketchTable()
currentSketch = None
case a ⇒
log.error("[MainControllerActor @ Terminated] Unknown actor: " + a)}
//Unknown message
case m ⇒
log.error(s"[MainControllerActor @ ?] Unknown message: $m")}
//Do stop on termination
override def postStop(): Unit = {
log.debug("[MainControllerActor.postStop] Call doStop.")
doStop(if(lastError.nonEmpty) -1 else 0)}}
|
AlexCAB/MathAct
|
mathact_core/src/main/scala/mathact/core/app/infrastructure/MainControllerActor.scala
|
Scala
|
mit
| 7,094 |
package system.cell.processor.route.actors
import akka.actor.{ActorRef, Props}
import com.actors.TemplateActor
import system.names.NamingSystem
import system.ontologies.messages.Location._
import system.ontologies.messages.MessageType.Route
import system.ontologies.messages.MessageType.Route.Subtype.{Info, Response}
import system.ontologies.messages._
/**
* This Actor manages the processing of Route from a cell A to a cell B.
*
* It either calculates the route from scratch or retrieves it from a caching actor
*
* Created by Alessandro on 11/07/2017.
*/
class RouteManager extends TemplateActor {
private var cacher: ActorRef = _
private var processor: ActorRef = _
override def preStart: Unit = {
super.preStart()
cacher = context.actorOf(Props(new CacheManager(cacheKeepAlive = 2500L)), NamingSystem.CacheManager)
processor = context.actorOf(Props(new RouteProcessor(parent)), NamingSystem.RouteProcessor)
}
override protected def receptive: Receive = {
case AriadneMessage(Route, Info, _, info: RouteInfo) =>
if (info.request.isEscape) manageEscape(info)
else {
log.info("Requesting route from Cache...")
context.become(waitingForCache, discardOld = true)
cacher ! info
}
case _ => desist _
}
private def waitingForCache: Receive = {
case AriadneMessage(Route, Info, _, info: RouteInfo) =>
if (info.request.isEscape) manageEscape(info) else stash
case cnt@RouteInfo(_, _) if sender == cacher =>
log.info("No cached route is present, sending data to Processor...")
processor ! cnt
context.become(receptive, discardOld = true)
unstashAll
case cnt@RouteResponse(_, _) if sender == cacher =>
log.info("A valid cached route is present, sending data to Core...")
parent ! AriadneMessage(
Route,
Response,
Location.Cell >> Location.User,
cnt
)
context.become(receptive, discardOld = true)
unstashAll
case _ => desist _
}
private val manageEscape = (cnt: RouteInfo) => {
log.info("Escape route request received, becoming evacuating...")
processor forward cnt
}
}
|
albertogiunta/arianna
|
src/main/scala/system/cell/processor/route/actors/RouteManager.scala
|
Scala
|
gpl-3.0
| 2,414 |
package com.solidfire.jsvcgen.client
import java.io.StringReader
import java.util
import com.solidfire.gson.internal.LinkedTreeMap
import com.solidfire.gson.stream.JsonReader
import com.solidfire.gson.{Gson, JsonObject, JsonParser}
import com.solidfire.jsvcgen.JavaClasses._
import com.solidfire.jsvcgen.javautil.Optional
import com.solidfire.jsvcgen.serialization.GsonUtil
import org.mockito.Matchers.anyString
import org.mockito.Mockito.when
import org.scalatest.mock.MockitoSugar
import org.scalatest.{BeforeAndAfterAll, Matchers, WordSpec}
class ServiceBaseSuite extends WordSpec with BeforeAndAfterAll with MockitoSugar with Matchers {
val mockJsonObject = new JsonParser( ).parse( "{ error : { message : 'anErrorMessage' } }" ).getAsJsonObject
val Port = 9999
val Host = "localhost"
val Path = "/rpc-json/7.0"
val _requestDispatcher = mock[RequestDispatcher]
val _serviceBase = new ServiceBase( _requestDispatcher )
"sendRequest" should {
"return a result when request succeeds" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{ 'result': {} }" )
val responseObject = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[LinkedTreeMap[_, _]] )
responseObject shouldBe a[LinkedTreeMap[_, _]]
responseObject should have size 0
}
"map all response values" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result':{'a':'b','c':'d'}}" )
_serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[LinkedTreeMap[_, _]] ) should have size 2
}
"map empty response values" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result':{'a':'','c':''}}" )
_serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[LinkedTreeMap[_, _]] ) should have size 2
}
"map empty response values as empty" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result':{'a':'','c':''}}" )
_serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[LinkedTreeMap[String, Object]] ).get( "a" ) should not be null
}
"map empty response values as empty with an object" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { 'bar':'', 'baz':'' } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[Foo] )
myFoo.getBar should not be null
myFoo.getBar should be( "" )
}
"map empty optional string response values as optional empty string \\"\\"" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { 'bar':'', 'baz':'' } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[Foo] )
myFoo.getBaz should not be null
myFoo.getBaz should be( Optional.of( "" ) )
}
"map null optional response values as empty in non-null objects with a completely empty complex object" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[FooFoo] )
myFoo.getBar shouldBe null
myFoo.getBaz should not be null
myFoo.getBaz should be( Optional.empty( ) )
}
"map null optional response values as empty with a complex object" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { 'bar':{}, 'baz': null } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[FooFoo] )
myFoo.getBar should not be null
myFoo.getBaz should not be null
myFoo.getBar.getBar shouldBe null
myFoo.getBar.getBaz should not be null
myFoo.getBar.getBaz should be( Optional.empty( ) )
myFoo.getBaz should be( Optional.empty( ) )
}
"map null optional response values as empty with an all null complex object" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { 'bar':{ 'bar':null, 'baz': null } }, 'baz': null } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[FooFoo] )
myFoo.getBar should not be null
myFoo.getBaz should not be null
myFoo.getBar.getBar shouldBe null
myFoo.getBar.getBaz should not be null
myFoo.getBar.getBaz should be( Optional.empty( ) )
myFoo.getBaz should be( Optional.empty( ) )
}
"map array of null optional response values as empty with an all null complex object" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{'result': { 'bar': [{ 'bar':null, 'baz': null } ], 'baz': null } }" )
val myFoo = _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[FooArray] )
myFoo.getBar should not be null
myFoo.getBaz should not be null
myFoo.getBar( )( 0 ).getBar shouldBe null
myFoo.getBar( )( 0 ).getBaz should not be null
myFoo.getBar( )( 0 ).getBaz should be( Optional.empty( ) )
myFoo.getBaz should be( Optional.empty( ) )
}
"map error message" in {
when( _requestDispatcher.dispatchRequest( anyString ) ).thenReturn( "{ error: { name: 'anErrorName', code: 500, message: 'anErrorMessage' } }" )
val thrown = the[ApiServerException] thrownBy _serviceBase.sendRequest( "aMethod", new Object, classOf[Object], classOf[LinkedTreeMap[_, _]] )
thrown should not be null
thrown.getName shouldBe "anErrorName"
thrown.getCode shouldBe "500"
thrown.getMessage shouldBe "anErrorMessage"
}
"throw exception when method is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.sendRequest( null, AnyRef, classOf[AnyRef], classOf[AnyRef] )
}
}
"throw exception when method is empty" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.sendRequest( "", AnyRef, classOf[AnyRef], classOf[AnyRef] )
}
}
"throw exception when request parameter is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.sendRequest( "method", null, classOf[AnyRef], classOf[AnyRef] )
}
}
"throw exception when request parameter class is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.sendRequest( "method", AnyRef, null, classOf[AnyRef] )
}
}
"throw exception when result parameter class is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.sendRequest( "method", AnyRef, classOf[AnyRef], null )
}
}
}
"encodeRequest" should {
"throw exception when method is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.encodeRequest( null, AnyRef, classOf[AnyRef] )
}
}
"throw exception when method is empty" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.encodeRequest( "", AnyRef, classOf[AnyRef] )
}
}
"throw exception when request parameter is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.encodeRequest( "method", null, classOf[AnyRef] )
}
}
"throw exception when request parameter class is null" in {
a[IllegalArgumentException] should be thrownBy {
_serviceBase.encodeRequest( "method", AnyRef, null )
}
}
}
"decodeResponse" should {
"handle simple empty map conversion" in {
_serviceBase.decodeResponse( "{'result':{}}", classOf[FooMap] ) should be( empty )
}
"handle simple map conversion" in {
_serviceBase.decodeResponse( "{'result':{'key':'value'}}", classOf[FooMap] ) should not be empty
}
"map simple key->value" in {
_serviceBase.decodeResponse( "{'result':{'key':'value'}}", classOf[FooMap] ).get( "key" ) should be( "value" )
}
"handle empty map conversion" in {
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringMap should be( empty )
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringArrayMap should be( empty )
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{}, fooMap:{}}}", classOf[ComplexFooMap] ).getFooMap should be( empty )
}
"handle map conversion" in {
_serviceBase.decodeResponse( "{'result':{stringMap:{'key':'value'}, stringArrayMap:{}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringMap should not be empty
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{'key':['value']}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringArrayMap should not be empty
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{}, fooMap:{'key':{'key1':'value'}}}}", classOf[ComplexFooMap] ).getFooMap should not be empty
}
"map key->value" in {
_serviceBase.decodeResponse( "{'result':{stringMap:{'key':'value'}, stringArrayMap:{}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringMap.get( "key" ) should be( "value" )
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{'key':['value']}, fooMap:{}}}", classOf[ComplexFooMap] ).getStringArrayMap.get( "key" )( 0 ) should be( "value" )
_serviceBase.decodeResponse( "{'result':{stringMap:{}, stringArrayMap:{}, fooMap:{'key':{'key1':'value'}}}}", classOf[ComplexFooMap] )
.getFooMap.get( "key" ).asInstanceOf[java.util.Map[String, Object]].get( "key1" ) should be( "value" )
}
"convert nested hashmaps with arrays to arrays (no arrayLists)" in {
_serviceBase.decodeResponse( "{'result':{'map': []}}", classOf[FooMap] ).get( "map" ).getClass.isArray should be( true )
_serviceBase.decodeResponse( "{'result':{'map': ['One']}}", classOf[FooMap] ).get( "map" ).asInstanceOf[Array[Object]]( 0 ) should be( "One" )
_serviceBase.decodeResponse( "{'result':{'map': {'map1' : ['One']}}}", classOf[FooMap] )
.get( "map" ).asInstanceOf[LinkedTreeMap[String, Object]].get( "map1" ).asInstanceOf[Array[Object]]( 0 ) should be( "One" )
}
"throw apiException when the response is null" in {
the[ApiException] thrownBy {
_serviceBase.decodeResponse( null, classOf[Any] )
} should have message "There was a problem parsing the response from the server. ( response=null )"
}
"throw apiException when the response is empty" in {
the[ApiException] thrownBy {
_serviceBase.decodeResponse( "", classOf[Any] )
} should have message "There was a problem parsing the response from the server. ( response= )"
}
"throw apiException when the response is not json" in {
the[ApiException] thrownBy {
_serviceBase.decodeResponse( "I Cause Errors", classOf[Any] )
} should have message "There was a problem parsing the response from the server. ( response=I Cause Errors )"
}
}
def convertResponseToJsonObject( response: String ): JsonObject = {
val gson: Gson = GsonUtil.getDefaultBuilder.create
val reader: JsonReader = new JsonReader( new StringReader( response ) )
reader.setLenient( true )
gson.fromJson( reader, classOf[JsonObject] )
}
"extractApiError" should {
"always return a non null instance" in {
_serviceBase.extractApiError( convertResponseToJsonObject( "{}" ) ) should not be null
}
"map fields to exception" in {
val error = _serviceBase.extractApiError( convertResponseToJsonObject( "{'name':'aName', 'code':'aCode', 'message':'aMessage'}" ) )
error.getName should be( "aName" )
error.getCode should be( "aCode" )
error.getMessage should be( "aMessage" )
}
}
}
|
solidfire/jsvcgen
|
jsvcgen-client-java/src/test/scala/com/solidfire/jsvcgen/client/ServiceBaseSuite.scala
|
Scala
|
apache-2.0
| 11,927 |
package io.github.daviddenton.finagle.aws
import io.github.daviddenton.finagle.aws.AwsHmacSha256.hash
class AwsStringToSign(canonicalRequest: AwsCanonicalRequest, requestScope: AwsCredentialScope, requestDate: AwsRequestDate) {
private val stringToSign =
s"""${AwsStringToSign.ALGORITHM}
|${requestDate.full}
|${requestScope.awsCredentialScope(requestDate)}
|${hash(canonicalRequest.toString)}""".stripMargin
override def toString: String = stringToSign
}
object AwsStringToSign {
val ALGORITHM = "AWS4-HMAC-SHA256"
}
|
daviddenton/finagle-aws
|
src/main/scala/io/github/daviddenton/finagle/aws/AwsStringToSign.scala
|
Scala
|
apache-2.0
| 552 |
package ca.uwaterloo.gsd.rangeFix
import collection.mutable
import collection._
import ConditionalCompilation._
object SMTFixGenerator {
var testNewAlgorithm:Boolean = false
val guardPrefix = "__gd__"
type Diagnosis = Set[String]
type SemanticDiagnosis = (Diagnosis, Diagnosis)
type SemanticDiagnoses = Iterable[SemanticDiagnosis]
var useAlgorithm:Boolean = false
var divideUnits:Boolean = true
//true->use new algorithm;false->use the old algorithm
private def toGuardVar(v:String):String = guardPrefix + v
private def toNormalVar(v:String):String = v.substring(guardPrefix.size)
private def conf2constr(v:String, l:SMTLiteral):SMTExpression = {
val guardVar = toGuardVar(v)
(!SMTVarRef(guardVar)) | (SMTVarRef(v) === l)
}
def generateSimpleDiagnoses(configuration:Map[String, SMTLiteral],
varSet:Set[String],
constraints: Iterable[SMTExpression],
types:Map[String, SMTType],
funcsToDeclare:Seq[SMTFuncDefine],
optTypesToDeclare:Set[SMTType] = null):Iterable[Diagnosis] = {
/*if (kconfigtemptest.flag){
assert(configuration == kconfigtemptest.configuration &&
varSet == kconfigtemptest.varSet &&
constraints == kconfigtemptest.constraints &&
types == kconfigtemptest.types &&
funcsToDeclare == kconfigtemptest.funcsToDeclare &&
optTypesToDeclare == kconfigtemptest.optTypesToDeclare)
println("matched")
}
else {
kconfigtemptest.configuration = configuration
kconfigtemptest.varSet = varSet
kconfigtemptest.constraints = constraints
kconfigtemptest.types = types
kconfigtemptest.funcsToDeclare = funcsToDeclare
kconfigtemptest.optTypesToDeclare = optTypesToDeclare
kconfigtemptest.flag = true
}*/
import org.kiama.rewriting.Rewriter._
val typesToDeclare = if (optTypesToDeclare == null) varSet.map(v => types(v)) else optTypesToDeclare
val z3 = new Z3()
z3.enableUnsatCore
try {
// assert ( collects { case x:SMTVarRef => x.id } (constraints) == varSet )
z3.declareTypes(typesToDeclare)
z3.declareVariables(varSet.map(v=>(v, types(v))))
z3.declareVariables(varSet.map(v => (toGuardVar(v), SMTBoolType)))
funcsToDeclare.foreach(z3.declareFunc)
for (c <- constraints)
z3.assertConstraint(c)
for (v <- varSet)
z3.assertConstraint(conf2constr(v, configuration(v)))
def getMinimalCore(removedVars:Traversable[String]):Option[List[String]] =
z3.getMinimalUnsatCore(varSet.map(v=>toGuardVar(v)) -- removedVars).map(_.toList)
def getCore(removedVars:Traversable[String]):Option[List[String]] =
z3.getUnsatCore(varSet.map(v=>toGuardVar(v)) -- removedVars).map(_.toList)
var diagnoses = List[List[String]]()
/* def test(){
val fr= new java.io.FileWriter("newAl.txt",true)
val d1 = Timer.measureTime(1)(DiagnoseGenerator.getDiagnoses[String](getMinimalCore))
val t1 = Timer.lastExecutionMillis
val d2 = Timer.measureTime(1)(DiagnoseGenerator.getDiagnoses[String](getCore))
val t2 = Timer.lastExecutionMillis
fr.write("%s\\t%s\\n%s\\t%s\\n".format(d1.toString(),t1.toString(),d2.toString(),t2.toString()))
fr.close
assert(d1.forall(dd1=>d2.exists(_.intersect(dd1).size>=dd1.size)) && d2.forall(dd2=>d1.exists(_.intersect(dd2).size>=dd2.size)),
"%s\\n%s\\n".format(d1,d2))
// println("%s,%s\\n%s%s\\n"format(d1.toString(),d2.toString(),t1.toString(),t2.toString()))
}
if (testNewAlgorithm)
test()*/
if (SMTFixGenerator.useAlgorithm){
diagnoses = DiagnoseGenerator.getDiagnoses[String](getCore)
}
else {
IF[CompilationOptions.USE_MINIMAL_CORE#v] {
diagnoses = (new HSDAG[String]()).getDiagnoses(getMinimalCore, true)
}
IF[(NOT[CompilationOptions.USE_MINIMAL_CORE])#v] {
diagnoses = (new HSDAG[String]()).getDiagnoses(getCore, false)
}
}
// println("diagnoses:%s" format diagnoses)
diagnoses.map(_.map(toNormalVar).toSet)
}
finally {
z3.exit()
}
}
// This version is not supported any more, it is kept here because some tests rely on it and these tests also ensure the conformance of Z3
// configuration by default includes all semantic vars and syntatic vars
// constraints include semantic var definitions
@deprecated("Use generateSimpleDiagnoses instead", "Since 2011/12")
def generateDiagnoses(configuration:Map[String, SMTLiteral],
changeableVars:Set[String],
semanticVars:Set[String],
constraints:Iterable[SMTExpression],
types:Map[String, SMTType],
funcsToDeclare:Iterable[SMTFuncDefine]):SemanticDiagnoses = {
import org.kiama.rewriting.Rewriter._
val z3 = new Z3()
z3.enableUnsatCore
try {
val varSet = changeableVars ++ semanticVars
assert ( collects { case x:SMTVarRef => x.id } (constraints) == varSet )
val allTypes = varSet.map(v => types(v))
z3.declareTypes(allTypes)
funcsToDeclare.foreach(z3.declareFunc)
z3.declareVariables(varSet.map(v=>(v, types(v))))
z3.declareVariables(varSet.map(v => (toGuardVar(v), SMTBoolType)))
for (c <- constraints)
z3.assertConstraint(c)
for (v <- varSet)
z3.assertConstraint(conf2constr(v, configuration(v)))
def getCore(changeableVars:Set[String])(removedVars:Traversable[String]):Option[List[String]] = z3.getUnsatCore(changeableVars.map(v=>toGuardVar(v)) -- removedVars).map(_.toList)
val semanticDiagnoses = (new HSDAG[String]()).getDiagnoses(getCore(semanticVars))
(for(sd <- semanticDiagnoses) yield {
val nsd = sd.map(toNormalVar(_))
val fixedVars = semanticVars.toSet -- nsd
z3.push()
for (v <- fixedVars)
z3.assertConstraint(toGuardVar(v))
val diagnoses = (new HSDAG[String]()).getDiagnoses(getCore(changeableVars))
z3.pop()
(diagnoses.map(d=>(d.map(toNormalVar(_)).toSet, nsd.toSet)))
} ).flatten
}
finally {
z3.exit()
}
}
def simpleDiagnoses2Fixes(configuration:Map[String, Literal],
constraints:Iterable[Expression],
types:Expression.Types,
ds:Iterable[Diagnosis],
getRelatedVars:Expression=>Set[String]):Iterable[DataFix] = {
import org.kiama.rewriting.Rewriter._
val fixconstraints =
for(d <- ds) yield {
constraints.filter(a=>d.exists(getRelatedVars(a).contains)).map ( c => {
def replace(id:String) = if (!d.contains(id)) Some(configuration(id)) else None
val result = Expression.assignVar(c, replace, types)
assert(result != BoolLiteral(false))
result
} ).filter(_ != BoolLiteral(true)).map(ExpressionHelper.simplifyWithReplacement(_,types)).filter(_!=BoolLiteral(true))
}
val z3 = new Z3()
try{
fixconstraints.map(constraint2DataFix(z3, types, _))
}
finally{
z3.exit()
}
}
//wj begin
def getVariableValue(z3:Z3, translator:Expression2SMT, varTypes:Map[String, Type], constraint:Expression)
: (Array[String],Array[String],Array[String])=
{
var SMTTypes:Map[String,SMTType] = varTypes.map(a=>(a._1, translator.type2SMTType(a._2)))
z3.declareTypes(SMTTypes.map(_._2).toSet)
z3.declareVariables(SMTTypes)
z3.push()
z3.assertConstraint(translator.convert(constraint))
assert(z3.checkSat(),"The expression is unsat!")
var (resultFromZ3,groupNum)=z3.getValValueMap()
z3.pop()
var resultInGroup:Array[Array[String]]=new Array(groupNum.toInt)
var resultAfterSplit=resultFromZ3.split(" ")
var groupLength=List[Int]()
var group=0
var count=0
var braceBegin=0
var braceEnd=0
var braceNum=0
for(eachString<-resultAfterSplit)//将每一个define进行分组,但首先要确定组在split后的list里面的上界和下界,这里用braceBegin表示下界,braceEnd表示上界
{
var length=eachString.length()//拆分后每个字符串的长度
for(i <- 0 to (length-1))//这里确定一组开始和结束的方法是,在每一组开始和结束左括号和右括号都是匹配的,在组的开始处braceNum=0,之后遇到一个左括号该值加一,遇到一个右括号该值减一,到结尾的时候该值为0
{
if(eachString.charAt(i)=='(')//之所以要遍历一个字符串的每个字符而不用contain,是因为一个字符串里面可能有多个括号,比如"()",所以要遍历每个字符
{
if(braceNum==0)
braceBegin=count//count记录当前字符串的位置
braceNum=braceNum+1
}
else if(eachString.charAt(i)==')')
{
braceNum=braceNum-1
if(braceNum==0)
{
braceEnd=count
var eachGroupLength=braceEnd-braceBegin+1//每一组的长度
groupLength=groupLength:::List(eachGroupLength)//用list存放每组字符串的个数,之所以要存放,是因为返回BitVec和返回boolean int scalar的字符串的个数不一样,后面三个是一样的
resultInGroup(group)=new Array(eachGroupLength)
for(i <- 0 to (eachGroupLength-1))//将从braceBegin到braceEnd的字符串复制到每一组里面,一组表示对一个变量的赋值
resultInGroup(group)(i)=resultAfterSplit(braceBegin+i)
group=group+1
}
}
}
count=count+1
}
var variableName:Array[String]=new Array(group)//存放每个变量的名字
var variableType:Array[String]=new Array(group)//存放每个变量的类型,BitVec存的是BitVec类型
var variableValue:Array[String]=new Array(group)//存放每个变量的值
var indexCount=0
//println(groupLength)
for(len <- groupLength)//对每组进行遍历
{
//println(len)
if(len==8)//如果当前组的字符串数目为8,说明为int bool scalar三种类型之一
{
variableName(indexCount)=resultInGroup(indexCount)(1)
variableType(indexCount)=resultInGroup(indexCount)(3)
var indexBrace=resultInGroup(indexCount)(7).indexOf(')')//去掉每个值最后一个括号,因为含值的字符串为"value)"
resultInGroup(indexCount)(7)=resultInGroup(indexCount)(7).substring(0,indexBrace)
variableValue(indexCount)=resultInGroup(indexCount)(7)
}
else if(len==10)//如果当前组的字符串数目为10,说明为BitVec,但也可能是scala类型的
{
//println("In BitVec")
variableName(indexCount)=resultInGroup(indexCount)(1)
variableType(indexCount)=resultInGroup(indexCount)(4)
var indexBrace=resultInGroup(indexCount)(9).indexOf(')')
resultInGroup(indexCount)(9)=resultInGroup(indexCount)(9).substring(0,indexBrace)
variableValue(indexCount)=resultInGroup(indexCount)(9)
}
indexCount=indexCount+1
}
(variableName,variableType,variableValue);
}
def temp_divideConstraint(z3:Z3, translator:Expression2SMT, constraint:Expression,
variableName:Array[String],variableType:Array[String],variableValue:Array[String])
:Map[Array[String], Expression]=
{
import org.kiama.rewriting.Rewriter._
val variableNum = variableName.size
var backMap = Map[Array[String],Expression]()
if(variableNum==1)
{
backMap+=(variableName -> constraint)
return backMap
}
else
{
val maxBit=((1<<variableNum)-2)/2
var maxGroup=0
var k=1
var sign=false
while(k<=maxBit)
{
var result=new Array[Expression](2)
result(0)=constraint
result(1)=constraint
var count=0
for( i <- 0 to variableNum-1)
{
var resultIndex=0
if(((1<<i)&k)!=0)
resultIndex=1
else
resultIndex=0
if(resultIndex==1) count=count+1//统计result(1)尚有多少变量
if(variableType(i)=="Bool") result(resultIndex)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>BoolLiteral(variableValue(i).toBoolean)}))(result(resultIndex)))
else if(variableType(i)=="Int") result(resultIndex)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>IntLiteral(variableValue(i).toInt)}))(result(resultIndex)))
else if(variableType(i)=="BitVec")//如果返回的是BitVec类型
result(resultIndex)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>SetLiteral(translator.bitVector2Set(BitVecToBoolean(variableValue(i)))) }))(result(resultIndex)))
else //scalar类型
result(resultIndex)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) => ScalarToEnumLiteral(variableValue(i),variableType(i),translator) }))(result(resultIndex)))
}
if(checkDivide(z3,result,constraint,translator))//表示可以拆分
{
sign=true
var (tempVariableName,tempVariableType,tempVariableValue)=DivideOfVariable(k,variableNum,count,variableName,variableType,variableValue)
var tempMap = Map[Array[String],Expression]()//记录当前拆分发得到的结果
tempMap=tempMap++temp_divideConstraint(z3,translator,result(0),tempVariableName(0),tempVariableType(0),tempVariableValue(0))
tempMap=tempMap++temp_divideConstraint(z3,translator,result(1),tempVariableName(1),tempVariableType(1),tempVariableValue(1))
if(maxGroup<tempMap.size)
{
maxGroup=tempMap.size//寻找能够拆分的最大组数
backMap=tempMap
}
}
k=k+1
}
if(!sign)//如果不能拆分,就返回原来的表达式和变量
backMap+=(variableName -> constraint)
return backMap
}
}
def DivideOfVariable(k:Int,variableNum:Int,count:Int,variableName:Array[String],variableType:Array[String],variableValue:Array[String]):
(Array[Array[String]],Array[Array[String]],Array[Array[String]])=
{
var tempVariableName=new Array[Array[String]](2)
var tempVariableType=new Array[Array[String]](2)
var tempVariableValue=new Array[Array[String]](2)
tempVariableName(0)=new Array[String](count)
tempVariableName(1)=new Array[String](variableNum-count)
tempVariableType(0)=new Array[String](count)
tempVariableType(1)=new Array[String](variableNum-count)
tempVariableValue(0)=new Array[String](count)
tempVariableValue(1)=new Array[String](variableNum-count)
var firCount=0
var secCount=0
for( i <- 0 to variableNum-1)
{
if(((1<<i)&k)!=0)//存放第一个表达式尚有的变量名、类型、以及值
{
tempVariableName(0)(firCount)=variableName(i)
tempVariableType(0)(firCount)=variableType(i)
tempVariableValue(0)(firCount)=variableValue(i)
firCount=firCount+1
}
else//存放第二个表达式尚有的变量名、类型、以及值
{
tempVariableName(1)(secCount)=variableName(i)
tempVariableType(1)(secCount)=variableType(i)
tempVariableValue(1)(secCount)=variableValue(i)
secCount=secCount+1
}
}
return (tempVariableName,tempVariableType,tempVariableValue)
}
def ScalarToEnumLiteral(varValue:String,varType:String,translator:Expression2SMT)
:EnumLiteral={
var variableValue=varValue.substring(varValue.lastIndexOf('_')+1,varValue.length)//最后一个'_'后面的字符串表示value
var variableType=varType.substring(varType.lastIndexOf('_')+1,varType.length)//最后一个'_'后面的字符串表示type
var flag=false//用来判断值是string还是int
for(j <- 0 to variableValue.length-1)
{
if(variableValue.charAt(j)>'9')
flag=true//flag为true表示此值为string类型
}
if(flag==false)//int
return EnumLiteral(IntLiteral(variableValue.toLong), translator.scala2EnumType(variableType.toInt))
else//string
return EnumLiteral(StringLiteral(variableValue), translator.scala2EnumType(variableType.toInt))
}
def BitVecToBoolean(variableValue:String):Array[Boolean]={
val bitVecSize=variableValue.length
var valueOfVaribale=variableValue.substring(2)//去掉"#x"和"#b"
var arrSize=0//读出来的数转成二进制后的位数,也即boolean数组的大小
if(variableValue.charAt(1)=='x') //如果是十六进制,转为二进制的时候位数应该乘以4,这里的位数都不包括"#x"和"#b",所以要将Length-2
arrSize=(variableValue.length-2)*4
else if(variableValue.charAt(1)=='b')
arrSize=variableValue.length-2
var bitVecArray:Array[Boolean]=new Array(arrSize)
if(variableValue.charAt(1)=='x')
valueOfVaribale=BigInt(valueOfVaribale,16).toString(2) //如果variableValue(i)是十六进制,将十六进制转为二进制
var number=arrSize-1
for(j <- 0 to valueOfVaribale.length-1)//因为在将十六进制转为二进制的时候忽略前导0,比如0a会转为1010,所以在填充boolean数组时从后往前填,如果variableValue到第0个位置,说明boolean数组前面的都该填为false
{
if(valueOfVaribale.charAt(valueOfVaribale.length-1-j)=='0')
bitVecArray(number)=false
else if(valueOfVaribale.charAt(valueOfVaribale.length-1-j)=='1')
bitVecArray(number)=true
number=number-1
}
for(j <- 0 to number)//variableValue到第0个位置,说明boolean数组前面的都该填为false
bitVecArray(number-j)=false
return bitVecArray
}
def checkDivide(z3:Z3,result:Array[Expression],origionConstraint:Expression,translator:Expression2SMT):Boolean=
{
val AndResult=ExpressionHelper.simplify(result(0)&result(1))
val AndResultFir=Not(AndResult)&origionConstraint
val AndResultSec=Not(origionConstraint)&AndResult
z3.push()
z3.assertConstraint(translator.convert(ExpressionHelper.simplify(AndResultFir)))
if(z3.checkSat())
{
z3.pop()
return false//如果!(P(A,b)&&P(a,B))&&R(A,B)为真,说明不可拆分
}
z3.pop()
z3.push()
z3.assertConstraint(translator.convert(ExpressionHelper.simplify(AndResultSec)))
if(z3.checkSat())//如果(P(A,b)&&P(a,B))&&!R(A,B)为真,说明不可拆分
{
z3.pop()
return false
}
z3.pop()
return true
}
def divideConstraint(z3:Z3, translator:Expression2SMT, varTypes:Map[String, Type], constraint:Expression)
: Iterable[(Iterable[String], Expression)]=
{
var SMTTypes:Map[String,SMTType] = varTypes.map(a=>(a._1, translator.type2SMTType(a._2)))
z3.push()
z3.declareVariables(SMTTypes)
z3.assertConstraint(translator.convert(constraint))
assert(z3.checkSat(),"The expression is unsat!")
var (resultFromZ3,groupNum)=z3.getValValueMap()
var resultInGroup:Array[Array[String]]=new Array(groupNum.toInt)
// assert(groupNum.toInt<=2,"The number of variable we get from z3 is more than 2!")
//assert(groupNum.toInt>=2,"The number of variable we get from z3 is less than 2!")
val result=new Array[Expression](2)
var resultAfterSplit=resultFromZ3.split(" ")
var groupLength=List[Int]()
var group=0
var count=0
var braceBegin=0
var braceEnd=0
var braceNum=0
for(eachString<-resultAfterSplit)//将每一个define进行分组,但首先要确定组在split后的list里面的上界和下界,这里用braceBegin表示下界,braceEnd表示上界
{
var length=eachString.length()//拆分后每个字符串的长度
for(i <- 0 to (length-1))//这里确定一组开始和结束的方法是,在每一组开始和结束左括号和右括号都是匹配的,在组的开始处braceNum=0,之后遇到一个左括号该值加一,遇到一个右括号该值减一,到结尾的时候该值为0
{
if(eachString.charAt(i)=='(')//之所以要遍历一个字符串的每个字符而不用contain,是因为一个字符串里面可能有多个括号,比如"()",所以要遍历每个字符
{
if(braceNum==0)
braceBegin=count//count记录当前字符串的位置
braceNum=braceNum+1
}
else if(eachString.charAt(i)==')')
{
braceNum=braceNum-1
if(braceNum==0)
{
braceEnd=count
var eachGroupLength=braceEnd-braceBegin+1//每一组的长度
groupLength=groupLength:::List(eachGroupLength)//用list存放每组字符串的个数,之所以要存放,是因为返回BitVec和返回boolean int scalar的字符串的个数不一样,后面三个是一样的
resultInGroup(group)=new Array(eachGroupLength)
for(i <- 0 to (eachGroupLength-1))//将从braceBegin到braceEnd的字符串复制到每一组里面,一组表示对一个变量的赋值
resultInGroup(group)(i)=resultAfterSplit(braceBegin+i)
group=group+1
}
}
}
count=count+1
}
var variableName:Array[String]=new Array(group)//存放每个变量的名字
var variableType:Array[String]=new Array(group)//存放每个变量的类型,BitVec存的是BitVec类型
var variableValue:Array[String]=new Array(group)//存放每个变量的值
var indexCount=0
for(len <- groupLength)//对每组进行遍历
{
if(len==8)//如果当前组的字符串数目为8,说明为int bool scalar三种类型之一
{
variableName(indexCount)=resultInGroup(indexCount)(1)
variableType(indexCount)=resultInGroup(indexCount)(3)
var indexBrace=resultInGroup(indexCount)(7).indexOf(')')//去掉每个值最后一个括号,因为含值的字符串为"value)"
resultInGroup(indexCount)(7)=resultInGroup(indexCount)(7).substring(0,indexBrace)
variableValue(indexCount)=resultInGroup(indexCount)(7)
}
else if(len==10)//如果当前组的字符串数目为10,说明为BitVec,但也可能是scala类型的
{
variableName(indexCount)=resultInGroup(indexCount)(1)
val temp=resultInGroup(indexCount)(7).substring(1,resultInGroup(indexCount)(7).length)
if(temp=="as")//scala类型
{//(define-fun z () T (as A T))
variableType(indexCount)=resultInGroup(indexCount)(3)
variableValue(indexCount)=resultInGroup(indexCount)(8)
}
else//BitVec类型
{
variableType(indexCount)=resultInGroup(indexCount)(4)
var indexBrace=resultInGroup(indexCount)(9).indexOf(')')
resultInGroup(indexCount)(9)=resultInGroup(indexCount)(9).substring(0,indexBrace)
variableValue(indexCount)=resultInGroup(indexCount)(9)
}
}
indexCount=indexCount+1
}
import org.kiama.rewriting.Rewriter._
for(i <- 0 to 1)//只考虑拆分成两个表达式
{
if(variableType(i)=="Bool") result(i)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>BoolLiteral(variableValue(i).toBoolean)}))(constraint))
else if(variableType(i)=="Int") result(i)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>IntLiteral(variableValue(i).toInt)}))(constraint))
else if(variableType(i)=="BitVec")//如果返回的是BitVec类型
{
val bitVecSize=variableValue(i).length
var valueOfVaribale=variableValue(i).substring(2)//去掉"#x"和"#b"
var arrSize=0//读出来的数转成二进制后的位数,也即boolean数组的大小
if(variableValue(i).charAt(1)=='x') //如果是十六进制,转为二进制的时候位数应该乘以4,这里的位数都不包括"#x"和"#b",所以要将Length-2
arrSize=(variableValue(i).length-2)*4
else if(variableValue(i).charAt(1)=='b')
arrSize=variableValue(i).length-2
var bitVecArray:Array[Boolean]=new Array(arrSize)
if(variableValue(i).charAt(1)=='x')
valueOfVaribale=BigInt(valueOfVaribale,16).toString(2) //如果variableValue(i)是十六进制,将十六进制转为二进制
var k=arrSize-1
for(j <- 0 to valueOfVaribale.length-1)//因为在将十六进制转为二进制的时候忽略前导0,比如0a会转为1010,所以在填充boolean数组时从后往前填,如果variableValue到第0个位置,说明boolean数组前面的都该填为false
{
if(valueOfVaribale.charAt(valueOfVaribale.length-1-j)=='0')
bitVecArray(k)=false
else if(valueOfVaribale.charAt(valueOfVaribale.length-1-j)=='1')
bitVecArray(k)=true
k=k-1
}
for(j <- 0 to k)//variableValue到第0个位置,说明boolean数组前面的都该填为false
bitVecArray(k-j)=false
var resultSet = Set[String]()
resultSet = translator.bitVector2Set(bitVecArray)
//在这里得到的是名为bitVecArray的boolean数组,下面需要将数组传到SMTBVLiteral里面,然后用老师写的函数得到值用rewrite替换变量即可
result(i)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) =>SMTBVLiteral(bitVecArray)}))(constraint))
}
else //scalar类型
{
//在这里得到的是变量的string类型的值,下面需要将该值传到SMTScalarLiteral里面,然后用老师写的函数得到值用rewrite替换变量即可
variableValue(i)=variableValue(i).substring(variableValue(i).lastIndexOf('_')+1,variableValue(i).length)//最后一个'_'后面的字符串表示value
variableType(i)=variableType(i).substring(variableType(i).lastIndexOf('_')+1,variableType(i).length)//最后一个'_'后面的字符串表示type
var flag=false//用来判断值是string还是int
for(j <- 0 to variableValue(i).length-1)
{
if(variableValue(i).charAt(j)>'9')
flag=true//flag为true表示此值为string类型
}
if(flag==false)
{//int
result(i)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) => EnumLiteral(StringLiteral(variableValue(i)), translator.scala2EnumType(variableType(i).toInt)) }))(constraint))
}
else
{//string
result(i)= ExpressionHelper.simplify(rewrite(everywherebu(rule { case IdentifierRef(a) if a==variableName(i) => EnumLiteral(IntLiteral(variableValue(i).toLong), translator.scala2EnumType(variableType(i).toInt)) }))(constraint))
}
}
}
val AndResult=ExpressionHelper.simplify(result(0)&result(1))
val AndResultFir=Not(AndResult)&constraint
val AndResultSec=Not(constraint)&AndResult
z3.assertConstraint(translator.convert(ExpressionHelper.simplify(AndResultFir)))
assert(z3.checkSat()==false,"Can not be divided!")//如果!(P(A,b)&&P(a,B))&&R(A,B)为真,说明不可拆分
z3.assertConstraint(translator.convert(ExpressionHelper.simplify(AndResultSec)))
assert(z3.checkSat()==false,"Can not be divided!")//如果(P(A,b)&&P(a,B))&&!R(A,B)为真,说明不可拆分
z3.pop()
val varSet = varTypes.keySet
for(i <- 0 to 1)
yield (varSet.filter(_!=variableName(i)),result(i))//返回两个拆分后的Expression和其含的变量
}
//wj end
// This version is not supported anymore
@deprecated("Use simpleDiagnoses2Fixes instead", "Since 2011/12")
def diagnoses2Fixes(configuration:Map[String, Literal],
constraints:Iterable[Expression], // may contain semantic vars
semanticVars:Map[String, Expression],
semanticVarValues:Map[String, Literal],
ds:SemanticDiagnoses):Iterable[DataFix] = {
import org.kiama.rewriting.Rewriter._
val diagMap = mutable.Map[Diagnosis, Set[Diagnosis]]()
for ((synt, semtc) <- ds) {
diagMap.put(synt, diagMap.getOrElse(synt, Set()) + semtc)
}
val fixconstraints =
for ((synt, semntcs) <- diagMap) yield {
//semantic part
assert(semntcs.size > 0)
val semntcsUnion = semntcs.reduce(_ ++ _)
def svars2Constrts(svars:Diagnosis):Iterable[Expression] = {
svars.map(v => IdentifierRef(v) === semanticVarValues(v))
}
val fixedSemntcConstrts = svars2Constrts(semanticVars.keySet -- semntcsUnion)
val nonFixedConstraints =
if (semntcs.size > 1)
List(semntcs.map(d => semntcsUnion -- d).map(svars => {
assert(svars.size > 0)
svars2Constrts(svars).reduce(_ & _)
} ).reduce(_ | _))
else List()
val semntcConstrts = fixedSemntcConstrts ++ nonFixedConstraints
//syntactic & semantic part
val syntConstrts = (constraints ++ semntcConstrts).map ( c => {
val replaced = rewrite(everywheretd(repeat(rule{
case IdentifierRef(id) if (!synt.contains(id) && !semanticVars.contains(id)) => configuration(id)
case IdentifierRef(id) if (semanticVars.contains(id)) => semanticVars(id)
} )))(c)
val result = ExpressionHelper.simplify(replaced)
assert( result != BoolLiteral(false) )
result
} ).filter(_ != BoolLiteral(true))
syntConstrts
}
fixconstraints.map(constraint2DataFix(_))
}
private def constraint2DataFix(constraints:Iterable[Expression]):DataFix = {
type Clause = Map[Expression, Boolean]
def clause2GExpr(c:Clause) = c.foldLeft[Expression](BoolLiteral(true))((expr, pair) => {
val unitExpr = if (pair._2) pair._1 else Not(pair._1)
if (expr == BoolLiteral(true)) unitExpr else Or(expr, unitExpr)
} )
def toCNF(constraint:Expression, expected:Boolean = true):List[Clause] = {
def times(fs1:List[Clause], fs2:List[Clause]):List[Clause] = {
val result =
(for{f1 <- fs1
f2 <- fs2
if (f1.forall(pair => {val (e,b1) = pair; val b2= f2.get(e); b2==None || b2.get==b1}))}
yield f1 ++ f2)
simplifyCNF(result)
}
constraint match {
case Not(e) => toCNF(e, !expected)
case And(e1, e2) =>
if (expected) {
val fs1:List[Clause] = toCNF(e1, true)
val fs2:List[Clause] = toCNF(e2, true)
simplifyCNF(fs1 ++ fs2)
}
else {
toCNF(Or(Not(e1), Not(e2)), true)
}
case Or(e1, e2) =>
if (expected) times(toCNF(e1, true), toCNF(e2, true))
else toCNF(And(Not(e1), Not(e2)), true)
case Implies(e1, e2) =>
toCNF(Or(Not(e1), e2))
case e:Expression => {
List(Map(e -> expected))
}
}
}
def simplifyCNF(cnf:Iterable[Clause]) = {
val toVisitClauses = mutable.Map[Expression, Boolean]() ++ cnf.filter(_.size == 1).map(_.head)
val visitedClauses = mutable.Map[Expression, Boolean]()
def removeContradict(cs:Iterable[Clause]):Iterable[Clause] =
if (toVisitClauses.size > 0) {
val (expr:Expression, b:Boolean) = toVisitClauses.head
val resultCs = cs.map(c =>
if (c.get(expr) == Some(!b)) {
val result = c - expr
if ( result.size == 0 ) { //the whole CNF is false
return List(Map())
}
if (result.size == 1) {
if (visitedClauses.contains(result.head._1))
assert(visitedClauses(result.head._1) == result.head._2)
else
toVisitClauses += result.head
}
result
}
else c
)
toVisitClauses -= expr
visitedClauses put (expr, b)
removeContradict(resultCs)
}
else cs
def included(small:Clause, big:Clause):Boolean = {
small.forall(pair => {val vb = big.get(pair._1); vb.isDefined && vb.get == pair._2})
}
var result = List[Clause]()
removeContradict(cnf).foreach( f => {
def filter(result:List[Clause]):List[Clause] =
if (result.isEmpty) List(f)
else if (included(f, result.head)) filter(result.tail)
else if (included(result.head, f)) result
else result.head::(filter(result.tail))
result = filter(result)
} )
result
}
if (constraints.size == 0) return new DataFix(List())
val orgCNF = constraints.map(toCNF(_)).flatten
val cnf = simplifyCNF(orgCNF)
type Pair = (Clause, Set[String])
val cnfVars:List[Pair] = cnf.map(clause => (clause,
clause.keySet.map(org.kiama.rewriting.Rewriter.collects {case IdentifierRef(id:String) => id}(_)).flatten))
// find all clauses that share the same set of variables as cur
def separateEqClass(cur:Pair, remainingClauses:Traversable[Pair]):(List[Pair], List[Pair]) = {
val toBeAdded = mutable.ListBuffer[Pair]()
var remaining = List[Pair]()
var result = mutable.ListBuffer[Pair](cur)
for(p <- remainingClauses) {
if (!(cur._2 & p._2).isEmpty) {
toBeAdded += p
}
else {
remaining = p::remaining
}
}
while (toBeAdded.size > 0) {
val p = toBeAdded.head
val (newToBeAdded, newRemaining) = separateEqClass(p, remaining)
assert(newToBeAdded.head == p)
remaining = newRemaining
toBeAdded ++= newToBeAdded.tail
toBeAdded.remove(0)
result += p
}
(result.toList, remaining)
}
var remaining = cnfVars
val result = mutable.ListBuffer[FixUnit]()
while(remaining.size > 0) {
val (eqClass, newRemaining) = separateEqClass(remaining.head, remaining.tail)
val rangeUnit = eqClass.map(p => new RangeUnit(p._2, clause2GExpr(p._1))).reduceLeft(_ ++ _)
val unit = ExpressionHelper.simplify(rangeUnit.constraint) match {
case Eq(v:IdentifierRef, c:Expression) if rangeUnit.vars.size == 1 => new AssignmentUnit(rangeUnit.vars.head, c)
case Eq(c:Expression, v:IdentifierRef) if rangeUnit.vars.size == 1 => new AssignmentUnit(rangeUnit.vars.head, c)
case Not(v:IdentifierRef) => new AssignmentUnit(v.id, BoolLiteral(false))
case v:IdentifierRef => new AssignmentUnit(v.id, BoolLiteral(true))
case x => new RangeUnit(rangeUnit.variables, x)
}
result += unit
remaining = newRemaining
}
new DataFix(result)
}
private def constraint2DataFix(z3:Z3, types:Expression.Types, constraints:Iterable[Expression]):DataFix={
val dataFix = constraint2DataFix(constraints)
if (SMTFixGenerator.divideUnits){
val replacedUnits = dataFix.units.map(
unit=>{
if (unit.variables().size <= 1)
Set(unit)
else{
val cons = unit.constraint
val translator = new Expression2SMT(Set(cons), Map[String, Literal](), types)
z3.push()
val (varNames, varTypes, varValues) = getVariableValue(z3:Z3, translator, types, cons)
val divideResult = temp_divideConstraint(z3:Z3, translator, cons, varNames, varTypes, varValues)
z3.pop()
constraint2DataFix(divideResult.map(_._2)).units // suppose the result doesn't need to be divided again
}
}
).flatten
new DataFix(replacedUnits)
}
else dataFix
}
}
|
matachi/rangeFix
|
src/main/scala/fixGeneration/SMTFixGenerator.scala
|
Scala
|
mit
| 43,227 |
package im.actor.server.messaging
import akka.actor.ActorSystem
import im.actor.api.rpc.messaging._
import im.actor.server.group.GroupExtension
import im.actor.server.model.{ Peer, PeerType }
import scala.concurrent.Future
trait PushText {
implicit val system: ActorSystem
import system.dispatcher
type PushText = String
type CensoredPushText = String
private val CensoredText = "New message"
protected def getPushText(peer: Peer, outUser: Int, clientName: String, message: ApiMessage): Future[(PushText, CensoredPushText)] = {
message match {
case ApiTextMessage(text, _, _) ⇒
formatAuthored(peer, outUser, clientName, text)
case dm: ApiDocumentMessage ⇒
dm.ext match {
case Some(_: ApiDocumentExPhoto) ⇒
formatAuthored(peer, outUser, clientName, "Photo")
case Some(_: ApiDocumentExVideo) ⇒
formatAuthored(peer, outUser, clientName, "Video")
case _ ⇒
formatAuthored(peer, outUser, clientName, dm.name)
}
case unsupported ⇒ Future.successful(("", ""))
}
}
private def formatAuthored(peer: Peer, userId: Int, authorName: String, message: String): Future[(PushText, CensoredPushText)] = {
peer match {
case Peer(PeerType.Group, groupId) ⇒
for {
group ← GroupExtension(system).getApiStruct(groupId, userId)
} yield (s"$authorName@${group.title}: $message", s"$authorName@${group.title}: $CensoredText")
case Peer(PeerType.Private, _) ⇒ Future.successful((s"$authorName: $message", s"$authorName: $CensoredText"))
}
}
}
|
ljshj/actor-platform
|
actor-server/actor-core/src/main/scala/im/actor/server/messaging/PushText.scala
|
Scala
|
mit
| 1,623 |
package com.github.kimutansk.akka.exercise.persistence
import akka.actor.ActorLogging
import akka.persistence.{SnapshotOffer, PersistentActor}
/**
* Akka-Persistenceの確認を行うサンプルActor
*/
class SamplePersistentActor(name: String) extends PersistentActor with ActorLogging {
override def persistenceId: String = "SamplePersistentActor" + name
var stateCount = 0
override def receiveCommand: SamplePersistentActor#Receive = {
case "path" => context.sender ! self.path
case "print" => println(self.path + ":" + stateCount)
case "snap" => saveSnapshot(stateCount)
case "view" => context.sender ! self.path + ":" + stateCount
case message: String => stateCount += message.length
}
override def receiveRecover: SamplePersistentActor#Receive = {
case SnapshotOffer(_, snapshot: Int) => stateCount = snapshot
case other:Any => println(self.path + "(" + stateCount + "):" + other)
}
}
|
togusafish/kimutansk-_-scala-exercise
|
akka-exercise/src/main/scala/com/github/kimutansk/akka/exercise/persistence/SamplePersistentActor.scala
|
Scala
|
mit
| 940 |
package avrohugger
package input
package reflectivecompilation
import schemagen._
import scala.collection.JavaConverters._
object PackageSplitter {
def getCompilationUnits(code: String): List[String] = {
def getCompilationUnits(
lines : List[String],
pkgResult: List[String]= List(),
compUnitResult: List[String]= List() ): List[String] = {
def getBody(code: List[String], bodyResult: List[String] = List()): List[String] = {
code match {
case head::tail if head.startsWith("package") => {
getCompilationUnits(code, List(), compUnitResult:+((pkgResult:::bodyResult).mkString("\\n")))
}
case head::tail => getBody(tail, bodyResult:+head)
case Nil => compUnitResult:+((pkgResult:::bodyResult).mkString("\\n"))
}
}
val compilationUnits = lines match {
case head::tail if head.startsWith("package") => getCompilationUnits(tail, pkgResult:+head, compUnitResult)
case ls => getBody(ls)
}
compilationUnits
}
// the parser can only parse packages if their contents are within explicit blocks
def wrapPackages(code: String): String = {
// match package definitions that don't already wrap their contents in { }
val nonWrappedRegEx = "(?!(package .*? \\\\{))(package ([a-zA-Z_$][a-zA-Z\\\\d_$]*\\\\.)*[a-zA-Z_$][a-zA-Z\\\\d_$]*)".r
nonWrappedRegEx.findFirstIn(code) match {
case Some(nonWrappedPackage) => {
val openPackage = nonWrappedPackage + " {"
val closePackage = "}"
val wrappedPackage = nonWrappedRegEx.replaceFirstIn(code, openPackage) + closePackage
wrapPackages(wrappedPackage)}
case None => code
}
}
val lines = code.split("\\n").toList
val compilationUnits = getCompilationUnits(lines)
// reversed so the most nested classes need to be expanded first
val formatted = compilationUnits.map(compUnit => wrapPackages(compUnit)).reverse
formatted
}
}
|
ppearcy/avrohugger
|
avrohugger-core/src/main/scala/input/reflectivecompilation/PackageSplitter.scala
|
Scala
|
apache-2.0
| 2,005 |
package infrastructure.actor
import akka.actor._
import scala.language.implicitConversions
trait CreationSupport {
def getChild(name: String): Option[ActorRef]
def createChild(props: Props, name: String): ActorRef
def getOrCreateChild(props: Props, name: String): ActorRef = getChild(name).getOrElse(createChild(props, name))
}
trait ActorContextCreationSupport extends CreationSupport {
this: ActorLogging =>
def context: ActorContext
def getChild(name: String): Option[ActorRef] = context.child(name)
def createChild(props: Props, name: String): ActorRef = {
val actor: ActorRef = context.actorOf(props, name)
log.info(s"Actor created $actor")
actor
}
}
|
pawelkaczor/ddd-leaven-akka
|
src/main/scala/infrastructure/actor/CreationSupport.scala
|
Scala
|
mit
| 688 |
/*
*************************************************************************************
* Copyright 2011 Normation SAS
*************************************************************************************
*
* This program is free software: you can redistribute it and/or modify
* it under the terms of the GNU Affero General Public License as
* published by the Free Software Foundation, either version 3 of the
* License, or (at your option) any later version.
*
* In accordance with the terms of section 7 (7. Additional Terms.) of
* the GNU Affero GPL v3, the copyright holders add the following
* Additional permissions:
* Notwithstanding to the terms of section 5 (5. Conveying Modified Source
* Versions) and 6 (6. Conveying Non-Source Forms.) of the GNU Affero GPL v3
* licence, when you create a Related Module, this Related Module is
* not considered as a part of the work and may be distributed under the
* license agreement of your choice.
* A "Related Module" means a set of sources files including their
* documentation that, without modification of the Source Code, enables
* supplementary functions or services in addition to those offered by
* the Software.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU Affero General Public License for more details.
*
* You should have received a copy of the GNU Affero General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/agpl.html>.
*
*************************************************************************************
*/
package com.normation.rudder.web.snippet.administration
import com.normation.rudder.web.model._
import com.normation.rudder.domain.policies._
import com.normation.cfclerk.domain._
import com.normation.rudder.web.model.JsTreeNode
import net.liftweb.common._
import net.liftweb.http.{SHtml,S}
import scala.xml._
import net.liftweb.http.DispatchSnippet
import net.liftweb.http.js._
import net.liftweb.http.js.JsCmds._
import com.normation.rudder.web.components.popup.CreateActiveTechniqueCategoryPopup
import net.liftweb.http.js.JE._
import net.liftweb.util.Helpers
import net.liftweb.util.Helpers._
import com.normation.rudder.repository._
import net.liftweb.http.LocalSnippet
import net.liftweb.json._
import net.liftweb.http.IdMemoizeTransform
import com.normation.rudder.web.components.popup.GiveReasonPopup
import com.normation.rudder.web.services.ReasonBehavior._
import com.normation.rudder.authorization.Write
import com.normation.eventlog.ModificationId
import com.normation.rudder.domain.eventlog.RudderEventActor
import bootstrap.liftweb.RudderConfig
import net.liftweb.common.Box.box2Option
import net.liftweb.common.Box.option2Box
import net.liftweb.http.NodeSeqFuncOrSeqNodeSeqFunc.promoteNodeSeq
import net.liftweb.http.SHtml.ElemAttr.pairToBasic
import scala.Option.option2Iterable
import scala.xml.NodeSeq.seqToNodeSeq
import com.normation.rudder.web.snippet.configuration._
import com.normation.rudder.web.components._
/**
* Snippet for managing the System and User Technique libraries.
*
* It allow to see what Techniques are available in the
* system library, choose and configure which one to use in
* the user private library.
*
* Techniques are classify by categories in a tree.
*
*/
class TechniqueLibraryManagement extends DispatchSnippet with Loggable {
import TechniqueLibraryManagement._
private[this] val techniqueRepository = RudderConfig.techniqueRepository
private[this] val updatePTLibService = RudderConfig.updateTechniqueLibrary
private[this] val roActiveTechniqueRepository = RudderConfig.roDirectiveRepository
private[this] val rwActiveTechniqueRepository = RudderConfig.woDirectiveRepository
private[this] val uuidGen = RudderConfig.stringUuidGenerator
//transform Technique variable to human viewable HTML fields
private[this] val directiveEditorService = RudderConfig.directiveEditorService
private[this] val treeUtilService = RudderConfig.jsTreeUtilService
private[this] val userPropertyService = RudderConfig.userPropertyService
private[this] val updateTecLibInterval = RudderConfig.RUDDER_BATCH_TECHNIQUELIBRARY_UPDATEINTERVAL
//the popup component to create user technique category
private[this] val creationPopup = new LocalSnippet[CreateActiveTechniqueCategoryPopup]
// the popup component to give reason when moving techniques from Reference
// Technique Library to Active Technique Library
private[this] val giveReasonPopup = new LocalSnippet[GiveReasonPopup]
def dispatch = {
case "head" => { _ => head }
case "systemLibrary" => { _ => systemLibrary }
case "userLibrary" => { _ => userLibrary }
case "bottomPanel" => { _ => showBottomPanel }
case "userLibraryAction" => { _ => userLibraryAction }
case "reloadTechniqueButton" => reloadTechniqueLibrary(false)
case "reloadTechniqueLibrary" => reloadTechniqueLibrary(true)
}
//current states for the page - they will be kept only for the duration
//of one request and its followng Ajax requests
private[this] val rootCategoryId = roActiveTechniqueRepository.getActiveTechniqueLibrary.map( _.id )
private[this] val currentTechniqueDetails = new LocalSnippet[TechniqueEditForm]
private[this] var currentTechniqueCategoryDetails = new LocalSnippet[TechniqueCategoryEditForm]
private[this] val techniqueId: Box[String] = S.param("techniqueId")
//create a new Technique edit form and update currentTechniqueDetails
private[this] def updateCurrentTechniqueDetails(technique:Technique) = {
currentTechniqueDetails.set(Full(new TechniqueEditForm(
htmlId_editForm,
technique,
currentTechniqueCategoryDetails.is.map( _.getCategory ),
{ () => Replace(htmlId_activeTechniquesTree, userLibrary) }
//we don't need/want an error callback here - the error is managed in the form.
)))
}
//create a new Technique edit form and update currentTechniqueDetails
private[this] def updateCurrentTechniqueCategoryDetails(category:ActiveTechniqueCategory) = {
currentTechniqueCategoryDetails.set(
rootCategoryId.map { rootCategoryId =>
new TechniqueCategoryEditForm(
htmlId_bottomPanel,
category,
rootCategoryId,
{ () => Replace(htmlId_activeTechniquesTree, userLibrary) }
)
}
)
}
/**
* Head information (JsTree dependencies,...)
*/
def head() : NodeSeq = {
TechniqueEditForm.staticInit
}
private[this] def setCreationPopup : Unit = {
creationPopup.set(Full(new CreateActiveTechniqueCategoryPopup(
onSuccessCallback = { () => refreshTree })))
}
private[this] def setGiveReasonPopup(s : ActiveTechniqueId, d : ActiveTechniqueCategoryId) : Unit = {
giveReasonPopup.set(Full(new GiveReasonPopup(
onSuccessCallback = { onSuccessReasonPopup }
, onFailureCallback = { onFailureReasonPopup }
, refreshActiveTreeLibrary = { refreshActiveTreeLibrary }
, sourceActiveTechniqueId = s
, destCatId = d)
))
}
/**
* Create the popup
*/
private[this] def createPopup : NodeSeq = {
creationPopup.is match {
case Failure(m,_,_) => <span class="error">Error: {m}</span>
case Empty => <div>The component is not set</div>
case Full(popup) => popup.popupContent(NodeSeq.Empty)
}
}
/**
* Create the reason popup
*/
private[this] def createReasonPopup : NodeSeq = {
giveReasonPopup.is match {
case Failure(m,_,_) => <span class="error">Error: {m}</span>
case Empty => <div>The component is not set</div>
case Full(popup) => popup.popupContent(NodeSeq.Empty)
}
}
////////////////////
/**
* Display the Technique system library, which is
* what Technique are known by the system.
* Technique are classified by category, one technique
* belonging at most to one category.
* Categories are ordered in trees of subcategories.
*/
def systemLibrary() : NodeSeq = {
<div id={htmlId_techniqueLibraryTree}>
<ul>{jsTreeNodeOf_ptCategory(techniqueRepository.getTechniqueLibrary).toXml}</ul>
{Script(OnLoad(buildReferenceLibraryJsTree))}
</div>
}
/**
* Display the actions bar of the user library
*/
def userLibraryAction() : NodeSeq = {
<div>{SHtml.ajaxButton("Create a new category", () => showCreateActiveTechniqueCategoryPopup(), ("class", "autoWidthButton"))}</div>
}
/**
* Display the Technique user library, which is
* what Technique are configurable as Directive.
* Technique are classified by category, one technique
* belonging at most to one category.
* Categories are ordered in trees of subcategories.
*/
def userLibrary() : NodeSeq = {
<div id={htmlId_activeTechniquesTree}>{
val xml = {
roActiveTechniqueRepository.getActiveTechniqueLibrary match {
case eb:EmptyBox =>
val f = eb ?~! "Error when trying to get the root category of Active Techniques"
logger.error(f.messageChain)
f.rootExceptionCause.foreach { ex =>
logger.error("Exception causing the error was:" , ex)
}
<span class="error">An error occured when trying to get information from the database. Please contact your administrator of retry latter.</span>
case Full(activeTechLib) =>
<ul>{ jsTreeNodeOf_uptCategory(activeTechLib).toXml }</ul>
}
}
xml ++ {
Script(OnLoad(
buildUserLibraryJsTree &
//init bind callback to move
JsRaw("""
// use global variables to store where the event come from to prevent infinite recursion
var fromUser = false;
var fromReference = false;
$('#%1$s').bind("move_node.jstree", function (e,data) {
var interTree = "%1$s" != data.rslt.ot.get_container().attr("id");
var sourceCatId = $(data.rslt.o).attr("catId");
var sourceactiveTechniqueId = $(data.rslt.o).attr("activeTechniqueId");
var destCatId = $(data.rslt.np).attr("catId");
if( destCatId ) {
if(sourceactiveTechniqueId) {
var arg = JSON.stringify({ 'sourceactiveTechniqueId' : sourceactiveTechniqueId, 'destCatId' : destCatId });
if(interTree) {
%2$s;
} else {
%3$s;
}
} else if( sourceCatId ) {
var arg = JSON.stringify({ 'sourceCatId' : sourceCatId, 'destCatId' : destCatId });
%4$s;
} else {
alert("Can not move that kind of object");
$.jstree.rollback(data.rlbk);
}
} else {
alert("Can not move to something else than a category");
$.jstree.rollback(data.rlbk);
}
});
$('#%1$s').bind("select_node.jstree", function (e,data) {
var sourceactiveTechniqueId = data.rslt.obj.attr("activeTechniqueId");
var target = $('#%5$s li[activeTechniqueId|="'+sourceactiveTechniqueId+'"]');
if (target.length>0) {
if (fromReference) {
fromReference = false;
return false;
}
fromUser = true;
$('#%5$s').jstree("select_node", target , true , null );
}
});
$('#%5$s').bind("select_node.jstree", function (e,data) {
var sourceactiveTechniqueId = data.rslt.obj.attr("activeTechniqueId");
var target = $('#%1$s li[activeTechniqueId|="'+sourceactiveTechniqueId+'"]');
if (target.length>0) {
if (fromUser) {
fromUser = false;
return false;
}
fromReference = true;
$('#%1$s').jstree("select_node", target , true , null );
}
});
""".format(
// %1$s
htmlId_activeTechniquesTree ,
// %2$s
SHtml.ajaxCall(JsVar("arg"), bindTechnique _ )._2.toJsCmd,
// %3$s
SHtml.ajaxCall(JsVar("arg"), moveTechnique _ )._2.toJsCmd,
// %4$s
SHtml.ajaxCall(JsVar("arg"), moveCategory _)._2.toJsCmd,
htmlId_techniqueLibraryTree
)))
)
}
}</div>
}
def showBottomPanel : NodeSeq = {
(for {
ptName <- techniqueId
technique <- techniqueRepository.getLastTechniqueByName(TechniqueName(ptName))
} yield {
technique
}) match {
case Full(technique) =>
updateCurrentTechniqueDetails(technique)
showTechniqueDetails()
case _ =>
<div id={htmlId_bottomPanel}>
<div class="centertext">
Click on a Technique or a category from user library to
display its details.</div>
</div>
}
}
/**
* Configure a Rudder internal Technique to be usable in the
* user Technique (private) library.
*/
def showTechniqueDetails() : NodeSeq = {
currentTechniqueDetails.is match {
case e:EmptyBox =>
<div id={htmlId_bottomPanel}>
<h3>Technique details</h3>
<p>Click on a Technique to display its details</p>
</div>
case Full(form) => form.showForm
}
}
def showUserCategoryDetails() : NodeSeq = {
currentTechniqueCategoryDetails.is match {
case e:EmptyBox => <div id={htmlId_bottomPanel}><p>Click on a category from the user library to display its details and edit its properties</p></div>
case Full(form) => form.showForm
}
}
///////////////////// Callback function for Drag'n'drop in the tree /////////////////////
private[this] def moveTechnique(arg: String) : JsCmd = {
//parse arg, which have to be json object with sourceactiveTechniqueId, destCatId
try {
(for {
JObject(child) <- JsonParser.parse(arg)
JField("sourceactiveTechniqueId", JString(sourceactiveTechniqueId)) <- child
JField("destCatId", JString(destCatId)) <- child
} yield {
(sourceactiveTechniqueId, destCatId)
}) match {
case (sourceactiveTechniqueId, destCatId) :: Nil =>
(for {
activeTechnique <- roActiveTechniqueRepository.getActiveTechnique(TechniqueName(sourceactiveTechniqueId)).flatMap(Box(_)) ?~! "Error while trying to find Active Technique with requested id %s".format(sourceactiveTechniqueId)
result <- rwActiveTechniqueRepository.move(activeTechnique.id, ActiveTechniqueCategoryId(destCatId), ModificationId(uuidGen.newUuid), CurrentUser.getActor, Some("User moved active technique from UI"))?~! "Error while trying to move Active Technique with requested id '%s' to category id '%s'".format(sourceactiveTechniqueId,destCatId)
} yield {
result
}) match {
case Full(res) =>
refreshTree() & JsRaw("""setTimeout(function() { $("[activeTechniqueId=%s]").effect("highlight", {}, 2000)}, 100)""".format(sourceactiveTechniqueId)) & refreshBottomPanel(res)
case f:Failure => Alert(f.messageChain + "\nPlease reload the page")
case Empty => Alert("Error while trying to move Active Technique with requested id '%s' to category id '%s'\nPlease reload the page.".format(sourceactiveTechniqueId,destCatId))
}
case _ => Alert("Error while trying to move Active Technique: bad client parameters")
}
} catch {
case e:Exception => Alert("Error while trying to move Active Technique")
}
}
private[this] def moveCategory(arg: String) : JsCmd = {
//parse arg, which have to be json object with sourceactiveTechniqueId, destCatId
try {
(for {
JObject(child) <- JsonParser.parse(arg)
JField("sourceCatId", JString(sourceCatId)) <- child
JField("destCatId", JString(destCatId)) <- child
} yield {
(sourceCatId, destCatId)
}) match {
case (sourceCatId, destCatId) :: Nil =>
(for {
result <- rwActiveTechniqueRepository.move(
ActiveTechniqueCategoryId(sourceCatId)
, ActiveTechniqueCategoryId(destCatId)
, ModificationId(uuidGen.newUuid)
, CurrentUser.getActor
, Some("User moved Active Technique Category from UI")) ?~! "Error while trying to move category with requested id %s into new parent: %s".format(sourceCatId,destCatId)
} yield {
result
}) match {
case Full(res) =>
refreshTree() &
OnLoad(JsRaw("""setTimeout(function() { $("[catid=%s]").effect("highlight", {}, 2000);}, 100)"""
.format(sourceCatId)))
case f:Failure => Alert(f.messageChain + "\nPlease reload the page")
case Empty => Alert("Error while trying to move category with requested id '%s' to category id '%s'\nPlease reload the page.".format(sourceCatId,destCatId))
}
case _ => Alert("Error while trying to move category: bad client parameters")
}
} catch {
case e:Exception => Alert("Error while trying to move category")
}
}
private[this] def bindTechnique(arg: String) : JsCmd = {
//parse arg, which have to be json object with sourceactiveTechniqueId, destCatId
try {
(for {
JObject(child) <- JsonParser.parse(arg)
JField("sourceactiveTechniqueId", JString(sourceactiveTechniqueId)) <- child
JField("destCatId", JString(destCatId)) <- child
} yield {
(sourceactiveTechniqueId, destCatId)
}) match {
case (sourceactiveTechniqueId, destCatId) :: Nil =>
if(userPropertyService.reasonsFieldBehavior != Disabled) {
showGiveReasonPopup(ActiveTechniqueId(sourceactiveTechniqueId),
ActiveTechniqueCategoryId(destCatId))
} else {
val ptName = TechniqueName(sourceactiveTechniqueId)
val errorMess= "Error while trying to add Rudder internal " +
"Technique with requested id '%s' in user library category '%s'"
(for {
result <- (rwActiveTechniqueRepository
.addTechniqueInUserLibrary(
ActiveTechniqueCategoryId(destCatId),
ptName,
techniqueRepository.getTechniqueVersions(ptName).toSeq,
ModificationId(uuidGen.newUuid),
CurrentUser.getActor,
Some("Active Technique added by user from UI")
)
?~! errorMess.format(sourceactiveTechniqueId,destCatId)
)
} yield {
result
}) match {
case Full(res) =>
val jsString = """setTimeout(function() { $("[activeTechniqueId=%s]")
.effect("highlight", {}, 2000)}, 100)"""
refreshTree() & JsRaw(jsString
.format(sourceactiveTechniqueId)) &
refreshBottomPanel(res.id)
case f:Failure => Alert(f.messageChain + "\nPlease reload the page")
case Empty =>
val errorMess = "Error while trying to move Active Technique with " +
"requested id '%s' to category id '%s'\nPlease reload the page."
Alert(errorMess.format(sourceactiveTechniqueId, destCatId))
}
}
case _ =>
Alert("Error while trying to move Active Technique: bad client parameters")
}
} catch {
case e:Exception => Alert("Error while trying to move Active Technique")
}
}
private[this] def onSuccessReasonPopup(id : ActiveTechniqueId) : JsCmd = {
val jsStr = """setTimeout(function() { $("[activeTechniqueId=%s]")
.effect("highlight", {}, 2000)}, 100)"""
refreshTree() &
JsRaw(jsStr) & refreshBottomPanel(id)
}
def onFailureReasonPopup(srcActiveTechId : String, destCatId : String) : JsCmd = {
val errorMessage = "Error while trying to move Active Technique with " +
"requested id '%s' to category id '%s'\nPlease reload the page."
Alert(errorMessage.format(srcActiveTechId, destCatId))
}
private[this] def refreshTree() : JsCmd = {
Replace(htmlId_techniqueLibraryTree, systemLibrary) &
Replace(htmlId_activeTechniquesTree, userLibrary) &
OnLoad(After(TimeSpan(100), JsRaw("""createTooltip();""")))
}
private[this] def refreshActiveTreeLibrary() : JsCmd = {
Replace(htmlId_activeTechniquesTree, userLibrary)
}
private[this] def refreshBottomPanel(id:ActiveTechniqueId) : JsCmd = {
for {
activeTechnique <- roActiveTechniqueRepository.getActiveTechnique(id).flatMap { Box(_) }
technique <- techniqueRepository.getLastTechniqueByName(activeTechnique.techniqueName)
} { //TODO : check errors
updateCurrentTechniqueDetails(technique)
}
SetHtml(htmlId_bottomPanel, showTechniqueDetails() )
}
//////////////// display trees ////////////////////////
/**
* Javascript to initialize the reference library tree
*/
private[this] def buildReferenceLibraryJsTree : JsExp = JsRaw(
"""buildReferenceTechniqueTree('#%s','%s','%s')""".format(htmlId_techniqueLibraryTree,{
techniqueId match {
case Full(activeTechniqueId) => "ref-technique-"+activeTechniqueId
case _ => ""
}
}, S.contextPath)
)
/**
* Javascript to initialize the user library tree
*/
private[this] def buildUserLibraryJsTree : JsExp = JsRaw(
"""buildActiveTechniqueTree('#%s', '%s', %s ,'%s')""".format(htmlId_activeTechniquesTree, htmlId_techniqueLibraryTree, CurrentUser.checkRights(Write("technique")), S.contextPath)
)
//ajax function that update the bottom of the page when a Technique is clicked
private[this] def onClickTemplateNode(technique : Technique): JsCmd = {
updateCurrentTechniqueDetails(technique)
//update UI
SetHtml(htmlId_bottomPanel, showTechniqueDetails() )
}
/**
* Transform a WBTechniqueCategory into category JsTree node in reference library:
* - contains:
* - other categories
* - Techniques
* - no action can be done with such node.
*/
private[this] def jsTreeNodeOf_ptCategory(category:TechniqueCategory) : JsTreeNode = {
def jsTreeNodeOf_pt(technique : Technique) : JsTreeNode = new JsTreeNode {
override def body = {
val tooltipid = Helpers.nextFuncName
SHtml.a(
{ () => onClickTemplateNode(technique) },
<span class="treeTechniqueName tooltipable" tooltipid={tooltipid} title={technique.description}>{technique.name}</span>
<div class="tooltipContent" id={tooltipid}><h3>{technique.name}</h3><div>{technique.description}</div></div>
)
}
override def children = Nil
override val attrs = ( "rel" -> "template") :: ( "id" -> ("ref-technique-"+technique.id.name.value) ) :: ( "activeTechniqueId" -> technique.id.name.value ) :: Nil
}
new JsTreeNode {
//actually transform a technique category to jsTree nodes:
override def body = {
val tooltipid = Helpers.nextFuncName
<a href="#">
<span class="treeActiveTechniqueCategoryName tooltipable" tooltipid={tooltipid} title={category.description}>{category.name}</span>
<div class="tooltipContent" id={tooltipid}>
<h3>{category.name}</h3>
<div>{category.description}</div>
</div>
</a>
}
override def children =
category.subCategoryIds.flatMap(x => treeUtilService.getPtCategory(x,logger) ).
toList.sortWith( treeUtilService.sortPtCategory( _ , _ ) ).
map(jsTreeNodeOf_ptCategory(_)
) ++
category.packageIds.map( _.name ).
flatMap(x => treeUtilService.getPt(x,logger)).toList.
sortWith((x,y) => treeUtilService.sortPt(x.id.name, y.id.name ) ).map(jsTreeNodeOf_pt( _ ) )
override val attrs = ( "rel" -> "category" ) :: Nil
}
}
/**
* Transform ActiveTechniqueCategory into category JsTree nodes in User Library:
* - contains
* - other user categories
* - Active Techniques
* - are clickable
* - on the left (triangle) : open contents
* - on the name : update zones
* - "add a subcategory here"
* - "add the current Technique which is not yet in the User Library here"
*
* @param category
* @return
*/
private[this] def jsTreeNodeOf_uptCategory(category:ActiveTechniqueCategory) : JsTreeNode = {
/*
* Transform a ActiveTechnique into a JsTree leaf
*/
def jsTreeNodeOf_upt(activeTechnique : ActiveTechnique, optTechnique: Option[Technique]) : JsTreeNode = {
//there is two case: the normal one, and the case where the technique is missing and
//we want to inform the user of the problem
optTechnique match {
case Some(technique) =>
new JsTreeNode {
override def body = {
val tooltipid = Helpers.nextFuncName
SHtml.a(
{ () => onClickTemplateNode(technique) },
<span class="treeTechniqueName tooltipable" tooltipid={tooltipid} title={technique.description}>{technique.name}</span>
<div class="tooltipContent" id={tooltipid}><h3>{technique.name}</h3><div>{technique.description}</div></div>
)
}
override def children = Nil
override val attrs = ( "rel" -> "template") :: ( "activeTechniqueId" -> technique.id.name.value ) :: Nil ::: (if(!activeTechnique.isEnabled) ("class" -> "disableTreeNode") :: Nil else Nil )
}
case None =>
if(activeTechnique.isEnabled) {
val msg = s"Disableling active technique '${activeTechnique.id.value}' because its Technique '${activeTechnique.techniqueName.value}' was not found in the repository"
rwActiveTechniqueRepository.changeStatus(
activeTechnique.id
, false, ModificationId(uuidGen.newUuid)
, RudderEventActor
, Some(msg)
) match {
case eb: EmptyBox =>
val e = eb ?~! s"Error when trying to disable active technique '${activeTechnique.id.value}'"
logger.debug(e.messageChain)
case Full(x) =>
logger.warn(msg)
}
}
new JsTreeNode {
override def body = {
val tooltipid = Helpers.nextFuncName
<a href="#">
<span class="error treeTechniqueName tooltipable" tooltipid={tooltipid} title={activeTechnique.techniqueName.value}>{activeTechnique.techniqueName.value}</span>
<div class="tooltipContent" id={tooltipid}>
<h3>Missing technique {activeTechnique.techniqueName.value}</h3>
<div>The technique is missing on the repository. Active technique based on it are disable until the technique is putted back on the repository</div>
</div>
</a>
}
override def children = Nil
override val attrs = ( "rel" -> "template") :: ( "activeTechniqueId" -> activeTechnique.techniqueName.value ) :: Nil ::: (if(!activeTechnique.isEnabled) ("class" -> "disableTreeNode") :: Nil else Nil )
}
}
}
def onClickUserCategory() : JsCmd = {
updateCurrentTechniqueCategoryDetails(category)
//update UI
//update template details only if it is open
(
currentTechniqueDetails.is match {
case Full(form) =>
updateCurrentTechniqueDetails(form.technique)
//update UI
SetHtml(htmlId_bottomPanel, showTechniqueDetails() )
case _ => Noop
}
) &
SetHtml(htmlId_bottomPanel, showUserCategoryDetails() )
}
//the actual mapping activeTechnique category to jsTree nodes:
new JsTreeNode {
override val attrs =
( "rel" -> { if(Full(category.id) == rootCategoryId) "root-category" else "category" } ) ::
( "catId" -> category.id.value ) ::
Nil
override def body = {
val tooltipid = Helpers.nextFuncName
SHtml.a(onClickUserCategory _,
<span class="treeActiveTechniqueCategoryName tooltipable" tooltipid={tooltipid} title={category.description}>{category.name}</span>
<div class="tooltipContent" id={tooltipid}><h3>{category.name}</h3><div>{category.description}</div></div>
)
}
override def children =
category.children.flatMap(x => treeUtilService.getActiveTechniqueCategory(x,logger)).
toList.sortWith { treeUtilService.sortActiveTechniqueCategory( _,_ ) }.
map(jsTreeNodeOf_uptCategory(_) ) ++
category.items.flatMap(x => treeUtilService.getActiveTechnique(x,logger)).
toList.sortWith( (x,y) => treeUtilService.sortPt( x._1.techniqueName, y._1.techniqueName) ).
map { case (activeTechnique,technique) => jsTreeNodeOf_upt(activeTechnique, technique) }
}
}
///////////// success pop-up ///////////////
private[this] def successPopup : JsCmd = {
JsRaw(""" callPopupWithTimeout(200, "successConfirmationDialog")
""")
}
private[this] def showCreateActiveTechniqueCategoryPopup() : JsCmd = {
setCreationPopup
//update UI
SetHtml("createActiveTechniquesCategoryContainer", createPopup) &
JsRaw( """createPopup("createActiveTechniqueCategoryPopup")
""")
}
private[this] def showGiveReasonPopup(
sourceActiveTechniqueId : ActiveTechniqueId, destCatId : ActiveTechniqueCategoryId) : JsCmd = {
setGiveReasonPopup(sourceActiveTechniqueId, destCatId)
//update UI
SetHtml("createActiveTechniquesContainer", createReasonPopup) &
JsRaw( """createPopup("createActiveTechniquePopup")
""")
}
private[this] def reloadTechniqueLibrary(isTechniqueLibraryPage : Boolean) : IdMemoizeTransform = SHtml.idMemoize { outerXml =>
def initJs = SetHtml("techniqueLibraryUpdateInterval" , <span>{updateTecLibInterval}</span>)
def process = {
updatePTLibService.update(ModificationId(uuidGen.newUuid), CurrentUser.getActor, Some("Technique library reloaded by user")) match {
case Full(x) =>
S.notice("updateLib", "The Technique library was successfully reloaded")
case e:EmptyBox =>
val error = e ?~! "An error occured when updating the Technique library from file system"
logger.debug(error.messageChain, e)
S.error("updateLib", error.msg)
}
Replace("reloadTechniqueLibForm",outerXml.applyAgain) &
(if (isTechniqueLibraryPage) {
refreshTree
} else {
Noop
} )
}
//fill the template
// Add a style to display correctly the button in both page : policyServer and technique library
":submit" #> ( SHtml.ajaxSubmit("Update Techniques now", process _, ("style","min-width:160px")) ++
Script(OnLoad(JsRaw(""" correctButtons(); """) & initJs))
)
}
}
object TechniqueLibraryManagement {
/*
* HTML id for zones with Ajax / snippet output
*/
val htmlId_techniqueLibraryTree = "techniqueLibraryTree"
val htmlId_activeTechniquesTree = "activeTechniquesTree"
val htmlId_addPopup = "addPopup"
val htmlId_addToActiveTechniques = "addToActiveTechniques"
val htmlId_bottomPanel = "bottomPanel"
val htmlId_editForm = "editForm"
}
|
Kegeruneku/rudder
|
rudder-web/src/main/scala/com/normation/rudder/web/snippet/administration/TechniqueLibraryManagement.scala
|
Scala
|
agpl-3.0
| 32,132 |
package spinoco.fs2.cassandra.internal
import shapeless.HList
import shapeless.ops.hlist.ToTraversable
import shapeless.ops.record.Keys
import spinoco.fs2.cassandra.internal
/**
* Created by adamchlupacek on 03/08/16.
*/
trait ColumnsKeys[C <: HList]{
def keys: Seq[String]
}
object ColumnsKeys {
implicit def instance[C <: HList, KL <: HList](
implicit K: Keys.Aux[C, KL]
, trav: ToTraversable.Aux[KL, List, Any]
):ColumnsKeys[C] = {
new ColumnsKeys[C] {
def keys: Seq[String] = K().toList.map(internal.asKeyName)
}
}
}
|
Spinoco/fs2-cassandra
|
core/src/main/scala/spinoco/fs2/cassandra/internal/ColumnsKeys.scala
|
Scala
|
mit
| 559 |
package tetravex.view
import scala.swing._
import scala.swing.event._
import tetravex.core.{Grid, Tile}
object View extends BorderPanel{
private var board: Board = null
private var menu: Menu = new Menu()
layout(menu) = BorderPanel.Position.North
def init(g: Grid) {
board = new Board(g)
layout(board) = BorderPanel.Position.Center
revalidate
}
def errorMsg(s: String) {
layout(new Label(s)) = BorderPanel.Position.Center
revalidate
}
def select(pos: (Int, Int), gridName: String) {
board.select(pos, gridName)
}
def unselect(pos: (Int, Int), gridName: String) {
board.unselect(pos, gridName)
}
def move(from: ((Int, Int), String), to: ((Int, Int), String), t: Tile) {
board.move(from, to, t)
}
def updateTime(s: String) {
board.updateTime(s)
}
}
|
antoineB/tetravex
|
src/main/scala/view/View.scala
|
Scala
|
bsd-3-clause
| 834 |
/**
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package kafka.tools
import joptsimple.OptionParser
import java.util.concurrent.{Executors, CountDownLatch}
import java.util.Properties
import kafka.producer.async.DefaultEventHandler
import kafka.serializer.DefaultEncoder
import kafka.producer.{ProducerData, DefaultPartitioner, ProducerConfig, Producer}
import kafka.consumer._
import kafka.utils.{ZKStringSerializer, Logging}
import kafka.api.OffsetRequest
import org.I0Itec.zkclient._
import kafka.message.{CompressionCodec, Message}
object ReplayLogProducer extends Logging {
private val GROUPID: String = "replay-log-producer"
def main(args: Array[String]) {
val config = new Config(args)
val executor = Executors.newFixedThreadPool(config.numThreads)
val allDone = new CountDownLatch(config.numThreads)
// if there is no group specified then avoid polluting zookeeper with persistent group data, this is a hack
tryCleanupZookeeper(config.zkConnect, GROUPID)
Thread.sleep(500)
// consumer properties
val consumerProps = new Properties
consumerProps.put("groupid", GROUPID)
consumerProps.put("zk.connect", config.zkConnect)
consumerProps.put("consumer.timeout.ms", "10000")
consumerProps.put("autooffset.reset", OffsetRequest.SmallestTimeString)
consumerProps.put("fetch.size", (1024*1024).toString)
consumerProps.put("socket.buffer.size", (2 * 1024 * 1024).toString)
val consumerConfig = new ConsumerConfig(consumerProps)
val consumerConnector: ConsumerConnector = Consumer.create(consumerConfig)
val topicMessageStreams = consumerConnector.createMessageStreams(Predef.Map(config.inputTopic -> config.numThreads))
var threadList = List[ZKConsumerThread]()
for ((topic, streamList) <- topicMessageStreams)
for (stream <- streamList)
threadList ::= new ZKConsumerThread(config, stream)
for (thread <- threadList)
thread.start
threadList.foreach(_.shutdown)
consumerConnector.shutdown
}
class Config(args: Array[String]) {
val parser = new OptionParser
val zkConnectOpt = parser.accepts("zookeeper", "REQUIRED: The connection string for the zookeeper connection in the form host:port. " +
"Multiple URLS can be given to allow fail-over.")
.withRequiredArg
.describedAs("zookeeper url")
.ofType(classOf[String])
.defaultsTo("127.0.0.1:2181")
val brokerInfoOpt = parser.accepts("brokerinfo", "REQUIRED: broker info (either from zookeeper or a list.")
.withRequiredArg
.describedAs("broker.list=brokerid:hostname:port or zk.connect=host:port")
.ofType(classOf[String])
val inputTopicOpt = parser.accepts("inputtopic", "REQUIRED: The topic to consume from.")
.withRequiredArg
.describedAs("input-topic")
.ofType(classOf[String])
val outputTopicOpt = parser.accepts("outputtopic", "REQUIRED: The topic to produce to")
.withRequiredArg
.describedAs("output-topic")
.ofType(classOf[String])
val numMessagesOpt = parser.accepts("messages", "The number of messages to send.")
.withRequiredArg
.describedAs("count")
.ofType(classOf[java.lang.Integer])
.defaultsTo(-1)
val asyncOpt = parser.accepts("async", "If set, messages are sent asynchronously.")
val delayMSBtwBatchOpt = parser.accepts("delay-btw-batch-ms", "Delay in ms between 2 batch sends.")
.withRequiredArg
.describedAs("ms")
.ofType(classOf[java.lang.Long])
.defaultsTo(0)
val batchSizeOpt = parser.accepts("batch-size", "Number of messages to send in a single batch.")
.withRequiredArg
.describedAs("batch size")
.ofType(classOf[java.lang.Integer])
.defaultsTo(200)
val numThreadsOpt = parser.accepts("threads", "Number of sending threads.")
.withRequiredArg
.describedAs("threads")
.ofType(classOf[java.lang.Integer])
.defaultsTo(1)
val reportingIntervalOpt = parser.accepts("reporting-interval", "Interval at which to print progress info.")
.withRequiredArg
.describedAs("size")
.ofType(classOf[java.lang.Integer])
.defaultsTo(5000)
val compressionCodecOption = parser.accepts("compression-codec", "If set, messages are sent compressed")
.withRequiredArg
.describedAs("compression codec ")
.ofType(classOf[java.lang.Integer])
.defaultsTo(0)
val options = parser.parse(args : _*)
for(arg <- List(brokerInfoOpt, inputTopicOpt)) {
if(!options.has(arg)) {
System.err.println("Missing required argument \"" + arg + "\"")
parser.printHelpOn(System.err)
System.exit(1)
}
}
val zkConnect = options.valueOf(zkConnectOpt)
val brokerInfo = options.valueOf(brokerInfoOpt)
val numMessages = options.valueOf(numMessagesOpt).intValue
val isAsync = options.has(asyncOpt)
val delayedMSBtwSend = options.valueOf(delayMSBtwBatchOpt).longValue
var batchSize = options.valueOf(batchSizeOpt).intValue
val numThreads = options.valueOf(numThreadsOpt).intValue
val inputTopic = options.valueOf(inputTopicOpt)
val outputTopic = options.valueOf(outputTopicOpt)
val reportingInterval = options.valueOf(reportingIntervalOpt).intValue
val compressionCodec = CompressionCodec.getCompressionCodec(options.valueOf(compressionCodecOption).intValue)
}
def tryCleanupZookeeper(zkUrl: String, groupId: String) {
try {
val dir = "/consumers/" + groupId
info("Cleaning up temporary zookeeper data under " + dir + ".")
val zk = new ZkClient(zkUrl, 30*1000, 30*1000, ZKStringSerializer)
zk.deleteRecursive(dir)
zk.close()
} catch {
case _ => // swallow
}
}
class ZKConsumerThread(config: Config, stream: KafkaStream[Message]) extends Thread with Logging {
val shutdownLatch = new CountDownLatch(1)
val props = new Properties()
val brokerInfoList = config.brokerInfo.split("=")
if (brokerInfoList(0) == "zk.connect")
props.put("zk.connect", brokerInfoList(1))
else
props.put("broker.list", brokerInfoList(1))
props.put("reconnect.interval", Integer.MAX_VALUE.toString)
props.put("buffer.size", (64*1024).toString)
props.put("compression.codec", config.compressionCodec.codec.toString)
props.put("batch.size", config.batchSize.toString)
props.put("queue.enqueueTimeout.ms", "-1")
if(config.isAsync)
props.put("producer.type", "async")
val producerConfig = new ProducerConfig(props)
val producer = new Producer[Message, Message](producerConfig, new DefaultEncoder,
new DefaultEventHandler[Message](producerConfig, null),
null, new DefaultPartitioner[Message])
override def run() {
info("Starting consumer thread..")
var messageCount: Int = 0
try {
val iter =
if(config.numMessages >= 0)
stream.slice(0, config.numMessages)
else
stream
for (messageAndMetadata <- iter) {
try {
producer.send(new ProducerData[Message, Message](config.outputTopic, messageAndMetadata.message))
if (config.delayedMSBtwSend > 0 && (messageCount + 1) % config.batchSize == 0)
Thread.sleep(config.delayedMSBtwSend)
messageCount += 1
}catch {
case ie: Exception => error("Skipping this message", ie)
}
}
}catch {
case e: ConsumerTimeoutException => error("consumer thread timing out", e)
}
info("Sent " + messageCount + " messages")
shutdownLatch.countDown
info("thread finished execution !" )
}
def shutdown() {
shutdownLatch.await
producer.close
}
}
}
|
piavlo/operations-debs-kafka
|
core/src/main/scala/kafka/tools/ReplayLogProducer.scala
|
Scala
|
apache-2.0
| 8,574 |
/***********************************************************************
* Copyright (c) 2013-2018 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.features
import java.util.{Collection => jCollection, List => jList, Map => jMap}
import com.vividsolutions.jts.geom.Geometry
import org.geotools.geometry.jts.ReferencedEnvelope
import org.geotools.process.vector.TransformProcess
import org.opengis.feature.`type`.Name
import org.opengis.feature.simple.{SimpleFeature, SimpleFeatureType}
import org.opengis.feature.{GeometryAttribute, Property}
import org.opengis.filter.expression.{Expression, PropertyName}
import org.opengis.filter.identity.FeatureId
import org.opengis.geometry.BoundingBox
/**
* Simple feature implementation that wraps another feature type and applies a transform/projection
*
* @param transformSchema transformed feature type
* @param attributes attribute evaluations, in order
*/
class TransformSimpleFeature(transformSchema: SimpleFeatureType,
attributes: Array[(SimpleFeature) => AnyRef],
private var underlying: SimpleFeature = null) extends SimpleFeature {
private lazy val geomIndex = transformSchema.indexOf(transformSchema.getGeometryDescriptor.getLocalName)
def setFeature(sf: SimpleFeature): TransformSimpleFeature = {
underlying = sf
this
}
override def getAttribute(index: Int): AnyRef = attributes(index).apply(underlying)
override def getIdentifier: FeatureId = underlying.getIdentifier
override def getID: String = underlying.getID
override def getUserData: jMap[AnyRef, AnyRef] = underlying.getUserData
override def getType: SimpleFeatureType = transformSchema
override def getFeatureType: SimpleFeatureType = transformSchema
override def getName: Name = transformSchema.getName
override def getAttribute(name: Name): AnyRef = getAttribute(name.getLocalPart)
override def getAttribute(name: String): Object = {
val index = transformSchema.indexOf(name)
if (index == -1) null else getAttribute(index)
}
override def getDefaultGeometry: AnyRef = getAttribute(geomIndex)
override def getAttributeCount: Int = transformSchema.getAttributeCount
override def getBounds: BoundingBox = getDefaultGeometry match {
case g: Geometry => new ReferencedEnvelope(g.getEnvelopeInternal, transformSchema.getCoordinateReferenceSystem)
case _ => new ReferencedEnvelope(transformSchema.getCoordinateReferenceSystem)
}
override def getAttributes: jList[AnyRef] = {
val attributes = new java.util.ArrayList[AnyRef](transformSchema.getAttributeCount)
var i = 0
while (i < transformSchema.getAttributeCount) {
attributes.add(getAttribute(i))
i += 1
}
attributes
}
override def getDefaultGeometryProperty = throw new NotImplementedError
override def getProperties: jCollection[Property] = throw new NotImplementedError
override def getProperties(name: Name) = throw new NotImplementedError
override def getProperties(name: String) = throw new NotImplementedError
override def getProperty(name: Name) = throw new NotImplementedError
override def getProperty(name: String) = throw new NotImplementedError
override def getValue = throw new NotImplementedError
override def getDescriptor = throw new NotImplementedError
override def setAttribute(name: Name, value: Object): Unit = throw new NotImplementedError
override def setAttribute(name: String, value: Object): Unit = throw new NotImplementedError
override def setAttribute(index: Int, value: Object): Unit = throw new NotImplementedError
override def setAttributes(vals: jList[Object]): Unit = throw new NotImplementedError
override def setAttributes(vals: Array[Object]): Unit = throw new NotImplementedError
override def setDefaultGeometry(geo: Object): Unit = throw new NotImplementedError
override def setDefaultGeometryProperty(geoAttr: GeometryAttribute): Unit = throw new NotImplementedError
override def setValue(newValue: Object): Unit = throw new NotImplementedError
override def setValue(values: jCollection[Property]): Unit = throw new NotImplementedError
override def isNillable: Boolean = true
override def validate(): Unit = throw new NotImplementedError
override def hashCode: Int = getID.hashCode()
override def equals(obj: scala.Any): Boolean = obj match {
case other: SimpleFeature =>
getID == other.getID && getName == other.getName && getAttributeCount == other.getAttributeCount && {
var i = 0
while (i < getAttributeCount) {
if (getAttribute(i) != other.getAttribute(i)) {
return false
}
i += 1
}
true
}
case _ => false
}
override def toString = s"TransformSimpleFeature:$getID"
}
object TransformSimpleFeature {
import scala.collection.JavaConversions._
def apply(sft: SimpleFeatureType, transformSchema: SimpleFeatureType, transforms: String): TransformSimpleFeature = {
val a = attributes(sft, transformSchema, transforms)
new TransformSimpleFeature(transformSchema, a)
}
def attributes(sft: SimpleFeatureType,
transformSchema: SimpleFeatureType,
transforms: String): Array[(SimpleFeature) => AnyRef] = {
TransformProcess.toDefinition(transforms).map(attribute(sft, _)).toArray
}
private def attribute(sft: SimpleFeatureType, d: TransformProcess.Definition): (SimpleFeature) => AnyRef = {
d.expression match {
case p: PropertyName => val i = sft.indexOf(p.getPropertyName); (sf) => sf.getAttribute(i)
case e: Expression => (sf) => e.evaluate(sf)
}
}
}
|
ddseapy/geomesa
|
geomesa-features/geomesa-feature-common/src/main/scala/org/locationtech/geomesa/features/TransformSimpleFeature.scala
|
Scala
|
apache-2.0
| 6,011 |
/**
* Copyright (C) 2009-2015 Typesafe Inc. <http://www.typesafe.com>
*/
package akka.actor
import akka.actor.Deploy.{ NoDispatcherGiven, NoMailboxGiven }
import akka.dispatch._
import akka.routing._
import scala.annotation.varargs
import scala.collection.immutable
import scala.language.existentials
import scala.reflect.ClassTag
/** TO BE FIXED...
* INTERNAL API
*
* (Not because it is so immensely complicated, only because we might remove it if no longer needed internally)
*/
/*private[akka]*/ class EmptyActor extends Actor {
def receive = Actor.emptyBehavior
}
/**
* Factory for Props instances.
*
* Props is a ActorRef configuration object, that is immutable, so it is thread safe and fully sharable.
*
* Used when creating new actors through <code>ActorSystem.actorOf</code> and <code>ActorContext.actorOf</code>.
*/
object Props extends AbstractProps {
/**
* The defaultCreator, simply throws an UnsupportedOperationException when applied, which is used when creating a Props
*/
final val defaultCreator: () ⇒ Actor = () ⇒ throw new UnsupportedOperationException("No actor creator specified!")
/**
* The defaultRoutedProps is NoRouter which is used when creating a Props
*/
final val defaultRoutedProps: RouterConfig = NoRouter
/**
* The default Deploy instance which is used when creating a Props
*/
final val defaultDeploy = Deploy()
/**
* A Props instance whose creator will create an actor that doesn't respond to any message
*/
final val empty = Props[EmptyActor]
/**
* The default Props instance, uses the settings from the Props object starting with default*.
*/
final val default = Props(defaultDeploy, classOf[CreatorFunctionConsumer], List(defaultCreator))
/**
* Scala API: Returns a Props that has default values except for "creator" which will be a function that creates an instance
* of the supplied type using the default constructor.
*/
def apply[T <: Actor: ClassTag](): Props = apply(defaultDeploy, implicitly[ClassTag[T]].runtimeClass, List.empty)
/**
* Scala API: Returns a Props that has default values except for "creator" which will be a function that creates an instance
* using the supplied thunk.
*
* CAVEAT: Required mailbox type cannot be detected when using anonymous mixin composition
* when creating the instance. For example, the following will not detect the need for
* `DequeBasedMessageQueueSemantics` as defined in `Stash`:
* {{{
* 'Props(new Actor with Stash { ... })
* }}}
* Instead you must create a named class that mixin the trait,
* e.g. `class MyActor extends Actor with Stash`.
*/
def apply[T <: Actor: ClassTag](creator: ⇒ T): Props =
mkProps(implicitly[ClassTag[T]].runtimeClass, () ⇒ creator)
private def mkProps(classOfActor: Class[_], ctor: () ⇒ Actor): Props =
Props(classOf[TypedCreatorFunctionConsumer], classOfActor, ctor)
/**
* Scala API: create a Props given a class and its constructor arguments.
*/
def apply(clazz: Class[_], args: Any*): Props = apply(defaultDeploy, clazz, args.toList)
}
/**
* Props is a configuration object using in creating an [[Actor]]; it is
* immutable, so it is thread-safe and fully shareable.
*
* Examples on Scala API:
* {{{
* val props = Props.empty
* val props = Props[MyActor]
* val props = Props(classOf[MyActor], arg1, arg2)
*
* val otherProps = props.withDispatcher("dispatcher-id")
* val otherProps = props.withDeploy(<deployment info>)
* }}}
*
* Examples on Java API:
* {{{
* final Props props = Props.empty();
* final Props props = Props.create(MyActor.class, arg1, arg2);
*
* final Props otherProps = props.withDispatcher("dispatcher-id");
* final Props otherProps = props.withDeploy(<deployment info>);
* }}}
*/
@SerialVersionUID(2L)
final case class Props(deploy: Deploy = Props.defaultDeploy, clazz: Class[_], args: immutable.Seq[Any]) {
Props.isAbstract(clazz)
// derived property, does not need to be serialized
@transient
private[this] var _producer: IndirectActorProducer = _
// derived property, does not need to be serialized
@transient
private[this] var _cachedActorClass: Class[_ <: Actor] = _
private[this] def producer: IndirectActorProducer = {
if (_producer eq null)
_producer = IndirectActorProducer(clazz, args)
_producer
}
private[this] def cachedActorClass: Class[_ <: Actor] = {
if (_cachedActorClass eq null)
_cachedActorClass = producer.actorClass
_cachedActorClass
}
// validate producer constructor signature; throws IllegalArgumentException if invalid
producer
/**
* Convenience method for extracting the dispatcher information from the
* contained [[Deploy]] instance.
*/
def dispatcher: String = deploy.dispatcher match {
case NoDispatcherGiven ⇒ Dispatchers.DefaultDispatcherId
case x ⇒ x
}
/**
* Convenience method for extracting the mailbox information from the
* contained [[Deploy]] instance.
*/
def mailbox: String = deploy.mailbox match {
case NoMailboxGiven ⇒ Mailboxes.DefaultMailboxId
case x ⇒ x
}
/**
* Convenience method for extracting the router configuration from the
* contained [[Deploy]] instance.
*/
def routerConfig: RouterConfig = deploy.routerConfig
/**
* Returns a new Props with the specified dispatcher set.
*/
def withDispatcher(d: String): Props = deploy.dispatcher match {
case NoDispatcherGiven ⇒ copy(deploy = deploy.copy(dispatcher = d))
case x ⇒ if (x == d) this else copy(deploy = deploy.copy(dispatcher = d))
}
/**
* Returns a new Props with the specified mailbox set.
*/
def withMailbox(m: String): Props = deploy.mailbox match {
case NoMailboxGiven ⇒ copy(deploy = deploy.copy(mailbox = m))
case x ⇒ if (x == m) this else copy(deploy = deploy.copy(mailbox = m))
}
/**
* Returns a new Props with the specified router config set.
*/
def withRouter(r: RouterConfig): Props = copy(deploy = deploy.copy(routerConfig = r))
/**
* Returns a new Props with the specified deployment configuration.
*/
def withDeploy(d: Deploy): Props = copy(deploy = d withFallback deploy)
/**
* Obtain an upper-bound approximation of the actor class which is going to
* be created by these Props. In other words, the actor factory method will
* produce an instance of this class or a subclass thereof. This is used by
* the actor system to select special dispatchers or mailboxes in case
* dependencies are encoded in the actor type.
*/
def actorClass(): Class[_ <: Actor] = cachedActorClass
/**
* INTERNAL API
*
* Create a new actor instance. This method is only useful when called during
* actor creation by the ActorSystem, i.e. for user-level code it can only be
* used within the implementation of [[IndirectActorProducer#produce]].
*/
private[akka] def newActor(): Actor = {
producer.produce()
}
}
|
jmnarloch/akka.js
|
akka-js-actor/shared/src/main/scala/akka/actor/Props.scala
|
Scala
|
bsd-3-clause
| 7,053 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package com.datastax.killrweather
import org.joda.time.{DateTimeZone, DateTime}
import akka.actor._
/** This test requires that you have already run these in the cql shell:
* cqlsh> source 'create-timeseries.cql';
* cqlsh> source 'load-timeseries.cql';
*
* See: https://github.com/killrweather/killrweather/wiki/2.%20Code%20and%20Data%20Setup#data-setup
*/
class WeatherStationActorSpec extends ActorSparkSpec {
import WeatherEvent._
import Weather._
start(clean = false)
val weatherStations = system.actorOf(Props(new WeatherStationActor(sc, settings)), "weather-station")
"WeatherStationActor" must {
"return a weather station" in {
weatherStations ! GetWeatherStation(sample.wsid)
expectMsgPF() {
case e: WeatherStation =>
e.id should be(sample.wsid)
}
}
"get the current weather for a given weather station, based on UTC" in {
val timstamp = new DateTime(DateTimeZone.UTC).withYear(sample.year).withMonthOfYear(sample.month).withDayOfMonth(sample.day)
weatherStations ! GetCurrentWeather(sample.wsid, Some(timstamp))
expectMsgPF() {
case Some(e) =>
e.asInstanceOf[RawWeatherData].wsid should be(sample.wsid)
}
}
}
}
|
chbatey/killrweather
|
killrweather-app/src/it/scala/com/datastax/killrweather/WeatherStationActorSpec.scala
|
Scala
|
apache-2.0
| 2,039 |
package org.jetbrains.plugins.scala.codeInspection.typeChecking
import com.intellij.codeInspection.LocalInspectionTool
import org.jetbrains.plugins.scala.codeInspection.{ScalaInspectionBundle, ScalaInspectionTestBase}
import org.jetbrains.plugins.scala.util.runners.{MultipleScalaVersionsRunner, RunWithScalaVersions, TestScalaVersion}
import org.junit.runner.RunWith
@RunWith(classOf[MultipleScalaVersionsRunner])
@RunWithScalaVersions(Array(
TestScalaVersion.Scala_2_11,
TestScalaVersion.Scala_2_12,
TestScalaVersion.Scala_2_13,
TestScalaVersion.Scala_3_0,
TestScalaVersion.Scala_3_1
))
class IsInstanceOfInspectionTest extends ScalaInspectionTestBase {
override protected val classOfInspection: Class[_ <: LocalInspectionTool] =
classOf[IsInstanceOfInspection]
override protected val description: String =
ScalaInspectionBundle.message("missing.explicit.type.in.isinstanceof.call")
def testIsInstanceOfWithoutExplicitType(): Unit = checkTextHasError(
s"""
|def test(x: AnyRef): Boolean = ${START}x.isInstanceOf${END}
|""".stripMargin
)
def testIsInstanceOfWithoutExplicitTypeIf(): Unit = checkTextHasError(
s"""
|val x = "123"
|if (${START}x.isInstanceOf${END}) x.toInt else x.toLong""".stripMargin
)
def testIsInstanceOfWithoutExplicitTypeParens(): Unit = checkTextHasError(
s"""
|val bool = false || ((${START}x.isInstanceOf${END}) && true) ^^ false""".stripMargin
)
def testIsInstanceOfAsValueName(): Unit = checkTextHasNoErrors(
s"""
|val isInstanceOf: String = "abc"
|val list = List(isInstanceOf)
|""".stripMargin
)
def testIsInstanceOfAsVariable(): Unit = checkTextHasNoErrors(
s"""
|var isInstanceOf: String = "abc"
|isInstanceOf = "def"
|println(isInstanceOf.length())
|""".stripMargin
)
}
|
JetBrains/intellij-scala
|
scala/scala-impl/test/org/jetbrains/plugins/scala/codeInspection/typeChecking/IsInstanceOfInspectionTest.scala
|
Scala
|
apache-2.0
| 1,857 |
/***********************************************************************
* Copyright (c) 2013-2018 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.utils.geotools
import java.util.{Date, UUID}
import org.locationtech.geomesa.utils.geotools.SftBuilder._
import org.locationtech.geomesa.utils.geotools.SimpleFeatureTypes.AttributeOptions._
import org.locationtech.geomesa.utils.geotools.SimpleFeatureTypes.Configs._
import org.locationtech.geomesa.utils.stats.Cardinality
import org.locationtech.geomesa.utils.stats.Cardinality.Cardinality
import org.opengis.feature.`type`.AttributeDescriptor
import org.opengis.feature.simple.SimpleFeatureType
import scala.collection.mutable.ListBuffer
import scala.reflect.runtime.universe.{Type => UType, _}
abstract class InitBuilder[T] {
import org.locationtech.geomesa.utils.geotools.RichSimpleFeatureType.RichSimpleFeatureType
private val entries = new ListBuffer[String]
private val options = new ListBuffer[String]
private var dtgFieldOpt: Option[String] = None
// Primitives - back compatible
def stringType(name: String, index: Boolean): T =
stringType(name, Opts(index = index))
def stringType(name: String, index: Boolean, stIndex: Boolean): T =
stringType(name, Opts(index = index, stIndex = stIndex))
def intType(name: String, index: Boolean): T =
intType(name, Opts(index = index))
def intType(name: String, index: Boolean, stIndex: Boolean): T =
intType(name, Opts(index = index, stIndex = stIndex))
def longType(name: String, index: Boolean): T =
longType(name, Opts(index = index))
def longType(name: String, index: Boolean, stIndex: Boolean): T =
longType(name, Opts(index = index, stIndex = stIndex))
def floatType(name: String, index: Boolean): T =
floatType(name, Opts(index = index))
def floatType(name: String, index: Boolean, stIndex: Boolean): T =
floatType(name, Opts(index = index, stIndex = stIndex))
def doubleType(name: String, index: Boolean): T =
doubleType(name, Opts(index = index))
def doubleType(name: String, index: Boolean, stIndex: Boolean): T =
doubleType(name, Opts(index = index, stIndex = stIndex))
def booleanType(name: String, index: Boolean): T =
booleanType(name, Opts(index = index))
def booleanType(name: String, index: Boolean, stIndex: Boolean): T =
booleanType(name, Opts(index = index, stIndex = stIndex))
// Primitives
def stringType (name: String, opts: Opts = Opts()): T = append(name, opts, "String")
def intType (name: String, opts: Opts = Opts()): T = append(name, opts, "Integer")
def longType (name: String, opts: Opts = Opts()): T = append(name, opts, "Long")
def floatType (name: String, opts: Opts = Opts()): T = append(name, opts, "Float")
def doubleType (name: String, opts: Opts = Opts()): T = append(name, opts, "Double")
def booleanType(name: String, opts: Opts = Opts()): T = append(name, opts, "Boolean")
// Helpful Types - back compatible
def date(name: String, default: Boolean): T =
date(name, Opts(default = default))
def date(name: String, index: Boolean, default: Boolean): T =
date(name, Opts(index = index, default = default))
def date(name: String, index: Boolean, stIndex: Boolean, default: Boolean): T =
date(name, Opts(index = index, stIndex = stIndex, default = default))
def uuid(name: String, index: Boolean): T =
uuid(name, Opts(index = index))
def uuid(name: String, index: Boolean, stIndex: Boolean): T =
uuid(name, Opts(index = index, stIndex = stIndex))
// Helpful Types
def date(name: String, opts: Opts = Opts()): T = {
if (opts.default) {
withDefaultDtg(name)
}
append(name, opts, "Date")
}
def uuid(name: String, opts: Opts = Opts()): T = append(name, opts, "UUID")
def bytes(name: String, opts: Opts = Opts()): T = append(name, opts, "Bytes")
// Single Geometries
def point (name: String, default: Boolean = false): T = appendGeom(name, default, "Point")
def lineString(name: String, default: Boolean = false): T = appendGeom(name, default, "LineString")
def polygon (name: String, default: Boolean = false): T = appendGeom(name, default, "Polygon")
def geometry (name: String, default: Boolean = false): T = appendGeom(name, default, "Geometry")
// Multi Geometries
def multiPoint (name: String, default: Boolean = false): T = appendGeom(name, default, "MultiPoint")
def multiLineString(name: String, default: Boolean = false): T = appendGeom(name, default, "MultiLineString")
def multiPolygon (name: String, default: Boolean = false): T = appendGeom(name, default, "MultiPolygon")
def geometryCollection(name: String, default: Boolean = false): T =
appendGeom(name, default, "GeometryCollection")
// List and Map Types - back compatible
def mapType[K: TypeTag, V: TypeTag](name: String, index: Boolean): T =
mapType[K, V](name, Opts(index = index))
def listType[Type: TypeTag](name: String, index: Boolean): T =
listType[Type](name, Opts(index = index))
// List and Map Types
def mapType[K: TypeTag, V: TypeTag](name: String, opts: Opts = Opts()): T =
append(name, opts.copy(stIndex = false), s"Map[${resolve(typeOf[K])},${resolve(typeOf[V])}]")
def listType[Type: TypeTag](name: String, opts: Opts = Opts()): T =
append(name, opts.copy(stIndex = false), s"List[${resolve(typeOf[Type])}]")
// Convenience method to add columns via Attribute Descriptors
def attributeDescriptor(ad: AttributeDescriptor): T =
append(ad.getLocalName, Opts(), ad.getType.getBinding.getCanonicalName)
def withIndexes(indexSuffixes: List[String]): T = userData(ENABLED_INDICES, indexSuffixes.mkString(","))
def userData(key: String, value: String): T = {
options.append(s"$key='$value'")
this.asInstanceOf[T]
}
def withDefaultDtg(field: String): T = {
dtgFieldOpt = Some(field)
this.asInstanceOf[T]
}
def defaultDtg(): T = withDefaultDtg("dtg")
// Internal helper methods
private def resolve(tt: UType): String =
tt match {
case t if primitiveTypes.contains(tt) => simpleClassName(tt.toString)
case t if tt == typeOf[Date] => "Date"
case t if tt == typeOf[UUID] => "UUID"
case t if tt == typeOf[Array[Byte]] => "Bytes"
}
private def append(name: String, opts: Opts, typeStr: String) = {
val parts = List(name, typeStr) ++ indexPart(opts.index) ++ stIndexPart(opts.stIndex) ++
cardinalityPart(opts.cardinality)
entries += parts.mkString(SepPart)
this.asInstanceOf[T]
}
private def appendGeom(name: String, default: Boolean, typeStr: String) = {
val namePart = if (default) "*" + name else name
val parts = List(namePart, typeStr, SridPart) ++
indexPart(default) ++ //force index on default geom
stIndexPart(default)
entries += parts.mkString(SepPart)
this.asInstanceOf[T]
}
private def indexPart(index: Boolean) = if (index) Seq(s"$OPT_INDEX=true") else Seq.empty
private def stIndexPart(index: Boolean) = if (index) Seq(s"$OPT_INDEX_VALUE=true") else Seq.empty
private def cardinalityPart(cardinality: Cardinality) = cardinality match {
case Cardinality.LOW | Cardinality.HIGH => Seq(s"$OPT_CARDINALITY=${cardinality.toString}")
case _ => Seq.empty
}
// public accessors
/** Get the type spec string associated with this builder...doesn't include dtg info */
def getSpec: String = {
if (options.isEmpty) {
entries.mkString(SepEntry)
} else {
s"${entries.mkString(SepEntry)};${options.mkString(SepEntry)}"
}
}
/** builds a SimpleFeatureType object from this builder */
def build(nameSpec: String): SimpleFeatureType = {
val sft = SimpleFeatureTypes.createType(nameSpec, getSpec)
dtgFieldOpt.foreach(sft.setDtgField)
sft
}
}
class SftBuilder extends InitBuilder[SftBuilder] {}
object SftBuilder {
case class Opts(index: Boolean = false,
stIndex: Boolean = false,
default: Boolean = false,
cardinality: Cardinality = Cardinality.UNKNOWN)
// Note: not for general use - only for use with SimpleFeatureTypes parsing (doesn't escape separator characters)
def encodeMap(opts: Map[String,String], kvSep: String, entrySep: String): String =
opts.map { case (k, v) => k + kvSep + v }.mkString(entrySep)
val SridPart = "srid=4326"
val SepPart = ":"
val SepEntry = ","
val primitiveTypes =
List(
typeOf[java.lang.String],
typeOf[String],
typeOf[java.lang.Integer],
typeOf[Int],
typeOf[java.lang.Long],
typeOf[Long],
typeOf[java.lang.Double],
typeOf[Double],
typeOf[java.lang.Float],
typeOf[Float],
typeOf[java.lang.Boolean],
typeOf[Boolean]
)
def simpleClassName(clazz: String): String = clazz.split("[.]").last
}
|
jahhulbert-ccri/geomesa
|
geomesa-utils/src/main/scala/org/locationtech/geomesa/utils/geotools/SftBuilder.scala
|
Scala
|
apache-2.0
| 9,195 |
package breeze.math
/*
Copyright 2012 David Hall
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
import breeze.linalg.norm
import org.scalacheck.Prop
/**
*
* @author dlwh
*/
trait TensorSpaceTestBase[V, I, S] extends MutableModuleTestBase[V, S] {
implicit val space: MutableEnumeratedCoordinateField[V, I, S]
import space._
// norm
test("norm positive homogeneity") {
check(Prop.forAll{ (trip: (V, V, V), s: S) =>
val (a, b, c) = trip
(norm(a * s) - norm(s) * norm(a)) <= TOL * norm(a * s)
})
}
test("norm triangle inequality") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
((1.0 - TOL) * norm(a + b) <= norm(b) + norm(a))
})
}
test("norm(v) == 0 iff v == 0") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
val z = zeroLike(a)
norm(z) == 0.0 && ( (z == a) || norm(a) != 0.0)
})
}
// dot product distributes
test("dot product distributes") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
val res = scalars.close(scalars.+(a dot b,a dot c),(a dot (b + c)), 1E-3 )
if(!res)
println(scalars.+(a dot b,a dot c) + " " + (a dot (b + c)))
res
})
check(Prop.forAll{ (trip: (V, V, V), s: S) =>
val (a, b, c) = trip
scalars.close(scalars.*(a dot b,s),(a dot (b :* s)) )
scalars.close(scalars.*(s, a dot b),( (a :* s) dot (b)) )
})
}
// zip map values
test("zip map of + is the same as +") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, _) = trip
zipMapValues.map(a,b,{scalars.+(_:S,_:S)}) == (a + b)
})
}
test("Elementwise mult of vectors distributes over vector addition") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
val ab = copy(a)
ab += b
ab :*= c
val ba = copy(a) :* c
ba :+= (b :* c)
close(ab, ba, TOL)
})
}
test("Vector element-wise mult distributes over vector addition") {
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
close( (a + b) :* c, (b :* c) + (a :* c), TOL)
})
// check(Prop.forAll{ (trip: (V, V, V), s: S) =>
// val (a, b, _) = trip
// s == 0 || close( (a + b)/ s, (b / s +a / s), TOL)
// })
check(Prop.forAll{ (trip: (V, V, V)) =>
val (a, b, c) = trip
val ab = copy(a)
ab += b
ab :*= c
val ba = copy(a) :* c
ba += (b :* c)
close(ab, ba, TOL)
})
}
}
trait DoubleValuedTensorSpaceTestBase[V <: breeze.linalg.Vector[Double], I] extends TensorSpaceTestBase[V, I, Double] {
// normalization
import space._
test("normalization sets appropriate norm to 1") {
check(Prop.forAll{ (trip: (V, V, V), n: Double) =>
val (a, b, c) = trip
val nn = n.abs % 100 + 1.0
val normalized = breeze.linalg.normalize(a, nn)
val v = breeze.linalg.norm(normalized, nn)
(v - 1.0).abs <= TOL || norm(normalized) == 0.0
})
}
}
|
wstcpyt/breeze
|
math/src/test/scala/breeze/math/TensorSpaceTestBase.scala
|
Scala
|
apache-2.0
| 3,477 |
package com.github.vladminzatu.surfer
import scala.math._
class Score(val value: Double) extends Serializable {
def +(time: Long): Score = {
val u = max(value, Score.rate * time)
val v = min(value, Score.rate * time)
Score(u + log1p(exp(v - u)))
}
override def toString(): String = value.toString;
}
object Score{
def apply(value: Double) = new Score(value)
/**
* @param time milliseconds since the epoch
*/
def apply(time: Long) = new Score(rate * time)
def rate = 1.0 / 60000 /*(24 * 3.6e6)*/ // one day
}
|
VladMinzatu/surfer
|
src/main/scala/com/github/vladminzatu/surfer/Score.scala
|
Scala
|
mit
| 549 |
package lila.setup
import chess.format.Forsyth
import chess.{ Game => ChessGame, Board, Situation, Clock, Speed }
import lila.game.Game
import lila.lobby.Color
import lila.tournament.{ System => TournamentSystem }
private[setup] trait Config {
// Whether or not to use a clock
val timeMode: TimeMode
// Clock time in minutes
val time: Double
// Clock increment in seconds
val increment: Int
// Correspondence days per turn
val days: Int
// Game variant code
val variant: chess.variant.Variant
// Creator player color
val color: Color
def hasClock = timeMode == TimeMode.RealTime
lazy val creatorColor = color.resolve
def makeGame(v: chess.variant.Variant): ChessGame =
ChessGame(board = Board init v, clock = makeClock)
def makeGame: ChessGame = makeGame(variant)
def validClock = hasClock.fold(clockHasTime, true)
def clockHasTime = time + increment > 0
def makeClock = hasClock option justMakeClock
protected def justMakeClock =
Clock((time * 60).toInt, clockHasTime.fold(increment, 1))
def makeDaysPerTurn: Option[Int] = (timeMode == TimeMode.Correspondence) option days
}
trait GameGenerator { self: Config =>
def game: Game
}
trait Positional { self: Config =>
import chess.format.Forsyth, Forsyth.SituationPlus
def fen: Option[String]
def strictFen: Boolean
lazy val validFen = variant != chess.variant.FromPosition || {
fen ?? { f => ~(Forsyth <<< f).map(_.situation playable strictFen) }
}
def fenGame(builder: ChessGame => Game): Game = {
val baseState = fen ifTrue (variant == chess.variant.FromPosition) flatMap Forsyth.<<<
val (chessGame, state) = baseState.fold(makeGame -> none[SituationPlus]) {
case sit@SituationPlus(Situation(board, color), turns) =>
val game = ChessGame(
board = board,
player = color,
turns = turns,
startedAtTurn = turns,
clock = makeClock)
if (Forsyth.>>(game) == Forsyth.initial) makeGame(chess.variant.Standard) -> none
else game -> baseState
}
val game = builder(chessGame)
state.fold(game) {
case sit@SituationPlus(Situation(board, _), _) => game.copy(
variant = chess.variant.FromPosition,
castleLastMoveTime = game.castleLastMoveTime.copy(
lastMove = board.history.lastMove.map(_.origDest),
castles = board.history.castles
),
turns = sit.turns)
}
}
}
object Config extends BaseConfig
trait BaseConfig {
val systems = List(TournamentSystem.Arena.id)
val systemDefault = TournamentSystem.default
val variants = List(chess.variant.Standard.id, chess.variant.Chess960.id)
val variantDefault = chess.variant.Standard
val variantsWithFen = variants :+ chess.variant.FromPosition.id
val aiVariants = variants :+
chess.variant.KingOfTheHill.id :+
chess.variant.ThreeCheck.id :+
chess.variant.FromPosition.id
val variantsWithVariants =
variants :+ chess.variant.KingOfTheHill.id :+ chess.variant.ThreeCheck.id :+ chess.variant.Antichess.id :+ chess.variant.Atomic.id :+ chess.variant.Horde.id
val variantsWithFenAndVariants =
variants :+ chess.variant.KingOfTheHill.id :+ chess.variant.ThreeCheck.id :+ chess.variant.Antichess.id :+ chess.variant.Atomic.id :+ chess.variant.Horde.id :+ chess.variant.FromPosition.id
val speeds = Speed.all map (_.id)
private val timeMin = 0
private val timeMax = 180
private val acceptableFractions = Set(1/2d, 3/4d, 3/2d)
def validateTime(t: Double) =
t >= timeMin && t <= timeMax && (t.isWhole || acceptableFractions(t))
private val incrementMin = 0
private val incrementMax = 180
def validateIncrement(i: Int) = i >= incrementMin && i <= incrementMax
}
|
samuel-soubeyran/lila
|
modules/setup/src/main/Config.scala
|
Scala
|
mit
| 3,745 |
package lila.perfStat
import akka.actor._
import com.typesafe.config.Config
import scala.concurrent.duration._
import akka.actor._
import lila.common.PimpedConfig._
final class Env(
config: Config,
system: ActorSystem,
lightUser: String => Option[lila.common.LightUser],
db: lila.db.Env) {
private val settings = new {
val CollectionPerfStat = config getString "collection.perf_stat"
}
import settings._
lazy val storage = new PerfStatStorage(
coll = db(CollectionPerfStat))
lazy val indexer = new PerfStatIndexer(
storage = storage,
sequencer = system.actorOf(Props(
classOf[lila.hub.Sequencer],
None, None, lila.log("perfStat")
)))
lazy val jsonView = new JsonView(lightUser)
def get(user: lila.user.User, perfType: lila.rating.PerfType): Fu[PerfStat] =
storage.find(user.id, perfType) orElse {
indexer.userPerf(user, perfType) >> storage.find(user.id, perfType)
} map (_ | PerfStat.init(user.id, perfType))
system.lilaBus.subscribe(system.actorOf(Props(new Actor {
def receive = {
case lila.game.actorApi.FinishGame(game, _, _) if !game.aborted =>
indexer addGame game addFailureEffect { e =>
lila.log("perfStat").error(s"index game ${game.id}", e)
}
}
})), 'finishGame)
}
object Env {
lazy val current: Env = "perfStat" boot new Env(
config = lila.common.PlayApp loadConfig "perfStat",
system = lila.common.PlayApp.system,
lightUser = lila.user.Env.current.lightUser,
db = lila.db.Env.current)
}
|
clarkerubber/lila
|
modules/perfStat/src/main/Env.scala
|
Scala
|
agpl-3.0
| 1,549 |
///////////////////////////////////////////////////////////////////////////////
// argparser.scala
//
// Copyright (C) 2011-2014 Ben Wing, The University of Texas at Austin
//
// Licensed under the Apache License, Version 2.0 (the "License");
// you may not use this file except in compliance with the License.
// You may obtain a copy of the License at
//
// http://www.apache.org/licenses/LICENSE-2.0
//
// Unless required by applicable law or agreed to in writing, software
// distributed under the License is distributed on an "AS IS" BASIS,
// WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
// See the License for the specific language governing permissions and
// limitations under the License.
///////////////////////////////////////////////////////////////////////////////
package opennlp.textgrounder
package util
import scala.util.control.Breaks._
import scala.collection.mutable
import com.benwing.argot._
/**
This module implements an argument parser for Scala, which handles
both options (e.g. --output-file foo.txt) and positional arguments.
It is built on top of Argot and has an interface that is designed to
be quite similar to the argument-parsing mechanisms in Python.
The parser tries to be easy to use, and in particular to emulate the
field-based method of accessing values used in Python. This leads to
the need to be very slightly tricky in the way that arguments are
declared; see below.
The basic features here that Argot doesn't have are:
(1) Argument specification is simplified through the use of optional
parameters to the argument-creation functions.
(2) A simpler and easier-to-use interface is provided for accessing
argument values given on the command line, so that the values can be
accessed as simple field references (re-assignable if needed).
(3) Default values can be given.
(4) "Choice"-type arguments can be specified (only one of a fixed number
of choices allowed). This can include multiple aliases for a given
choice.
(5) The "flag" type is simplified to just handle boolean flags, which is
the most common usage. (FIXME: Eventually perhaps we should consider
also allowing more general Argot-type flags.)
(6) The help text can be split across multiple lines using multi-line
strings, and extra whitespace/carriage returns will be absorbed
appropriately. In addition, directives can be given, such as %default
for the default value, %choices for the list of choices, %metavar
for the meta-variable (see below), %prog for the name of the program,
%% for a literal percent sign, etc.
(7) A reasonable default value is provided for the "meta-variable"
parameter for options (which specifies the type of the argument).
(8) Conversion functions are easier to specify, since one function suffices
for all types of arguments.
(9) A conversion function is provided for type Boolean for handling
valueful boolean options, where the value can be any of "yes, no,
y, n, true, false, t, f, on, off".
(10) There is no need to manually catch exceptions (e.g. from usage errors)
if you don't want to. By default, exceptions are caught
automatically and printed out nicely, and then the program exits
with return code 1. You can turn this off if you want to handle
exceptions yourself.
In general, to parse arguments, you first create an object of type
ArgParser (call it `ap`), and then add options to it by calling
functions, typically:
-- ap.option[T]() for a single-valued option of type T
-- ap.multiOption[T]() for a multi-valued option of type T (i.e. the option
can be specified multiple times on the command line, and all such
values will be accumulated into a List)
-- ap.flag() for a boolean flag
-- ap.positional[T]() for a positional argument (coming after all options)
-- ap.multiPositional[T]() for a multi-valued positional argument (i.e.
eating up any remaining positional argument given)
There are two styles for accessing the values of arguments specified on the
command line. One possibility is to simply declare arguments by calling the
above functions, then parse a command line using `ap.parse()`, then retrieve
values using `ap.get[T]()` to get the value of a particular argument.
However, this style is not as convenient as we'd like, especially since
the type must be specified. In the original Python API, once the
equivalent calls have been made to specify arguments and a command line
parsed, the argument values can be directly retrieved from the ArgParser
object as if they were fields; e.g. if an option `--outfile` were
declared using a call like `ap.option[String]("outfile", ...)`, then
after parsing, the value could simply be fetched using `ap.outfile`,
and assignment to `ap.outfile` would be possible, e.g. if the value
is to be defaulted from another argument.
This functionality depends on the ability to dynamically intercept
field references and assignments, which doesn't currently exist in
Scala. However, it is possible to achieve a near-equivalent. It works
like this:
1) Functions like `ap.option[T]()` are set up so that the first time they
are called for a given ArgParser object and argument, they will note
the argument, and return the default value of this argument. If called
again after parsing, however, they will return the value specified in
the command line (or the default if no value was specified). (If called
again *before* parsing, they simply return the default value, as before.)
2) A class, e.g. ProgParams, is created to hold the values returned from
the command line. This class typically looks like this:
class ProgParams(ap: ArgParser) {
var outfile = ap.option[String]("outfile", "o", ...)
var verbose = ap.flag("verbose", "v", ...)
...
}
3) To parse a command line, we proceed as follows:
a) Create an ArgParser object.
b) Create an instance of ProgParams, passing in the ArgParser object.
c) Call `parse()` on the ArgParser object, to parse a command line.
d) Create *another* instance of ProgParams, passing in the *same*
ArgParser object.
e) Now, the argument values specified on the command line can be
retrieved from this new instance of ProgParams simply using field
accesses, and new values can likewise be set using field accesses.
Note how this actually works. When the first instance of ProgParams is
created, the initialization of the variables causes the arguments to be
specified on the ArgParser -- and the variables have the default values
of the arguments. When the second instance is created, after parsing, and
given the *same* ArgParser object, the respective calls to "initialize"
the arguments have no effect, but now return the values specified on the
command line. Because these are declared as `var`, they can be freely
re-assigned. Furthermore, because no actual reflection or any such thing
is done, the above scheme will work completely fine if e.g. ProgParams
subclasses another class that also declares some arguments (e.g. to
abstract out common arguments for multiple applications). In addition,
there is no problem mixing and matching the scheme described here with the
conceptually simpler scheme where argument values are retrieved using
`ap.get[T]()`.
Work being considered:
(1) Perhaps most important: Allow grouping of options. Groups would be
kept together in the usage message, displayed under the group name.
(2) Add constructor parameters to allow for specification of the other
things allowed in Argot, e.g. pre-usage, post-usage, whether to sort
arguments in the usage message or leave as-is.
(3) Provide an option to control how meta-variable generation works.
Normally, an unspecified meta-variable is derived from the
canonical argument name in all uppercase (e.g. FOO or STRATEGY),
but some people e.g. might instead want it derived from the argument
type (e.g. NUM or STRING). This would be controlled with a
constructor parameter to ArgParser.
(4) Add converters for other basic types, e.g. Float, Char, Byte, Short.
(5) Allow for something similar to Argot's typed flags (and related
generalizations). I'd call it `ap.typedFlag[T]()` or something
similar. But rather than use Argot's interface of "on" and "off"
flags, I'd prefer to follow the lead of Python's argparse, allowing
the "destination" argument name to be specified independently of
the argument name as it appears on the command line, so that
multiple arguments could write to the same place. I'd also add a
"const" parameter that stores an arbitrary constant value if a
flag is tripped, so that you could simulate the equivalent of a
limited-choice option using multiple flag options. In addition,
I'd add an optional "action" parameter that is passed in the old
and new values and returns the actual value to be stored; that
way, incrementing/decrementing or whatever could be implemented.
Note that I believe it's better to separate the conversion and
action routines, unlike what Argot does -- that way, the action
routine can work with properly-typed values and doesn't have to
worry about how to convert them to/from strings. This also makes
it possible to supply action routines for all the various categories
of arguments (e.g. flags, options, multi-options), while keeping
the conversion routines simple -- the action routines necessarily
need to be differently-typed at least for single vs. multi-options,
but the conversion routines shouldn't have to worry about this.
In fact, to truly implement all the generality of Python's 'argparse'
routine, we'd want expanded versions of option[], multiOption[],
etc. that take both a source type (to which the raw values are
initially converted) and a destination type (final type of the
value stored), so that e.g. a multiOption can sum values into a
single 'accumulator' destination argument, or a single String
option can parse a classpath into a List of File objects, or
whatever. (In fact, however, I think it's better to dispense
with such complexity in the ArgParser and require instead that the
calling routine deal with it on its own. E.g. there's absolutely
nothing preventing a calling routine using field-style argument
values from declaring extra vars to hold destination values and
then e.g. simply fetching the classpath value, parsing it and
storing it, or fetching all values of a multiOption and summing
them. The minimal support for the Argot example of increment and
decrement flags would be something like a call `ap.multiFlag`
that accumulates a list of Boolean "true" values, one per
invocation. Then we just count the number of increment flags and
number of decrement flags given. If we cared about the relative
way that these two flags were interleaved, we'd need a bit more
support -- (1) a 'destination' argument to allow two options to
store into the same place; (2) a typed `ap.multiFlag[T]`; (3)
a 'const' argument to specify what value to store. Then our
destination gets a list of exactly which flags were invoked and
in what order. On the other hand, it's easily arguable that no
program should have such intricate option processing that requires
this -- it's unlikely the user will have a good understanding
of what these interleaved flags end up doing.
*/
package object argparser {
/*
NOTE: At one point, in place of the second scheme described above, there
was a scheme involving reflection. This didn't work as well, and ran
into various problems. One such problem is described here, because it
shows some potential limitations/bugs in Scala. In particular, in that
scheme, calls to `ap.option[T]()` and similar were declared using `def`
instead of `var`, and the first call to them was made using reflection.
Underlyingly, all defs, vars and vals look like functions, and fields
declared as `def` simply look like no-argument functions. Because the
return type can vary and generally is a simple type like Int or String,
there was no way to reliably recognize defs of this sort from other
variables, functions, etc. in the object. To make this recognition
reliable, I tried wrapping the return value in some other object, with
bidirectional implicit conversions to/from the wrapped value, something
like this:
class ArgWrap[T](vall: T) extends ArgAny[T] {
def value = vall
def specified = true
}
implicit def extractValue[T](arg: ArgAny[T]): T = arg.value
implicit def wrapValue[T](vall: T): ArgAny[T] = new ArgWrap(vall)
Unfortunately, this didn't work, for somewhat non-obvious reasons.
Specifically, the problems were:
(1) Type unification between wrapped and unwrapped values fails. This is
a problem e.g. if I try to access a field value in an if-then-else
statements like this, I run into problems:
val files =
if (use_val)
Params.files
else
Seq[String]()
This unifies to AnyRef, not Seq[String], even if Params.files wraps
a Seq[String].
(2) Calls to methods on the wrapped values (e.g. strings) can fail in
weird ways. For example, the following fails:
def words = ap.option[String]("words")
...
val split_words = ap.words.split(',')
However, it doesn't fail if the argument passed in is a string rather
than a character. In this case, if I have a string, I *can* call
split with a character as an argument - perhaps this fails in the case
of an implicit conversion because there is a split() implemented on
java.lang.String that takes only strings, whereas split() that takes
a character is stored in StringOps, which itself is handled using an
implicit conversion.
*/
/**
* Implicit conversion function for Ints. Automatically selected
* for Int-type arguments.
*/
implicit def convertInt(rawval: String, name: String, ap: ArgParser) = {
val canonval = rawval.replace("_","").replace(",","")
try { canonval.toInt }
catch {
case e: NumberFormatException =>
throw new ArgParserConversionException(
"""Argument '%s': Cannot convert value '%s' to an integer"""
format (name, rawval))
}
}
/**
* Implicit conversion function for Doubles. Automatically selected
* for Double-type arguments.
*/
implicit def convertDouble(rawval: String, name: String, ap: ArgParser) = {
val canonval = rawval.replace("_","").replace(",","")
try { canonval.toDouble }
catch {
case e: NumberFormatException =>
throw new ArgParserConversionException(
"""Argument '%s': Cannot convert value '%s' to a floating-point number"""
format (name, rawval))
}
}
/**
* Implicit conversion function for Strings. Automatically selected
* for String-type arguments.
*/
implicit def convertString(rawval: String, name: String, ap: ArgParser) = {
rawval
}
/**
* Implicit conversion function for Boolean arguments, used for options
* that take a value (rather than flags).
*/
implicit def convertBoolean(rawval: String, name: String, ap: ArgParser) = {
rawval.toLowerCase match {
case "yes" => true
case "no" => false
case "y" => true
case "n" => false
case "true" => true
case "false" => false
case "t" => true
case "f" => false
case "on" => true
case "off" => false
case _ => throw new ArgParserConversionException(
("""Argument '%s': Cannot convert value '%s' to a boolean. """ +
"""Recognized values (case-insensitive) are """ +
"""yes, no, y, n, true, false, t, f, on, off""") format
(name, rawval))
}
}
/**
* Check that the value is < a given integer. Used with argument `must`.
*/
def be_<(num: Int) =
Must[Int]( { x => x < num }, s"value %s must be < $num")
/**
* Check that the value is < a given double. Used with argument `must`.
*/
def be_<(num: Double) =
Must[Double]( { x => x < num }, s"value %s must be < $num")
/**
* Check that the value is > a given integer. Used with argument `must`.
*/
def be_>(num: Int) =
Must[Int]( { x => x > num }, s"value %s must be > $num")
/**
* Check that the value is > a given double. Used with argument `must`.
*/
def be_>(num: Double) =
Must[Double]( { x => x > num }, s"value %s must be > $num")
/**
* Check that the value is <= a given integer. Used with argument `must`.
*/
def be_<=(num: Int) =
Must[Int]( { x => x <= num }, s"value %s must be <= $num")
/**
* Check that the value is <= a given double. Used with argument `must`.
*/
def be_<=(num: Double) =
Must[Double]( { x => x <= num }, s"value %s must be <= $num")
/**
* Check that the value is >= a given integer. Used with argument `must`.
*/
def be_>=(num: Int) =
Must[Int]( { x => x >= num }, s"value %s must be >= $num")
/**
* Check that the value is >= a given double. Used with argument `must`.
*/
def be_>=(num: Double) =
Must[Double]( { x => x >= num }, s"value %s must be >= $num")
/**
* Check that the value is a given value. Used with argument `must`.
*/
def be_==[T](value: T) =
Must[T]( { x => x == value}, s"value %s must be = $value")
/**
* Check that the value is not a given value. Used with argument `must`.
*/
def be_!=[T](value: T) =
Must[T]( { x => x != value}, s"value %s must not be = $value")
/**
* Check that the size of a string or iterable is > a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_>[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size > num},
s"size of value %s must be > $num")
/**
* Check that the size of a string or iterable is >= a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_>=[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size >= num},
s"size of value %s must be >= $num")
/**
* Check that the size of a string or iterable is < a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_<[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size < num},
s"size of value %s must be < $num")
/**
* Check that the size of a string or iterable is <= a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_<=[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size <= num},
s"size of value %s must be <= $num")
/**
* Check that the size of a string or iterable is a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_==[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size == num},
s"size of value %s must be == $num")
/**
* Check that the size of a string or iterable is not a given value.
* Used with argument `must`. Also allows for the argument to be null, i.e.
* unspecified. */
def be_size_!=[T <% Iterable[_]](num: Int) =
Must[T]( { x => x == null || x.size != num},
s"size of value %s must be != $num")
/**
* Check that the value is within a given integer range. Used with
* argument `must`.
*/
def be_within(lower: Int, upper: Int) =
Must[Int]( { x => x >= lower && x <= upper },
s"value %s must be within range [$lower, $upper]")
/**
* Check that the value is within a given double range. Used with
* argument `must`.
*/
def be_within(lower: Double, upper: Double) =
Must[Double]( { x => x >= lower && x <= upper },
s"value %s must be within range [$lower, $upper]")
/**
* Check that the value is specified. Used with argument `must`.
*/
def be_specified[T] =
Must[T]( { x => x != null.asInstanceOf[T] },
"value must be specified")
/**
* Check that the value satisfies all of the given restrictions.
* Used with argument `must`.
*/
def be_and[T](musts: Must[T]*) =
Must[T]( { x => musts.forall { y => y.fn(x) } },
musts.map { y =>
val errmess = y.errmess
if (errmess == null) "unknown restriction"
else errmess
}.mkString(" and "))
/**
* Check that the value satisfies at least one of the given restrictions.
* Used with argument `must`.
*/
def be_or[T](musts: Must[T]*) =
Must[T]( { x => musts.exists { y => y.fn(x) } },
musts.map { y =>
val errmess = y.errmess
if (errmess == null) "unknown restriction"
else errmess
}.mkString(" or "))
/**
* Check that the value does not satisfy of the given restriction.
* Used with argument `must`.
*/
def be_not[T](must: Must[T]) =
Must[T]( { x => !must.fn(x) },
if (must.errmess == null) null else
"must not be the case: " + must.errmess)
/**
* Check that the value is one of the given choices.
* Used with argument `must`.
*
* FIXME: Implement `aliasedChoices` as well.
*/
def choices[T](values: T*) =
Must[T]( { x => values contains x },
"choice '%%s' not one of the recognized choices: %s" format
(values mkString ","))
/**
* Execute the given body and catch parser errors. When they occur,
* output the message and exit with exit code 1, rather than outputting
* a stack trace.
*/
def catch_parser_errors[T](body: => T): T = {
try {
body
} catch {
case e: ArgParserException => {
System.err.println(e.message)
System.exit(1)
??? // Should never get here!
}
}
}
}
package argparser {
/* Class specifying a restriction on a possible value and possible
* transformation of the value. Applying the argument name and the
* converted value will either return a possibly transformed value
* or throw an error if the value does not pass the restriction.
*
* @param fn Function specifying a restriction. If null, no restriction.
* @param errmess Error message to be displayed when restriction fails,
* optionally containing a %s in it indicating where to display the
* value.
* @param transform Function to transform the value. If null,
* no transformation.
*/
case class Must[T](fn: T => Boolean, errmess: String = null,
transform: (String, T) => T = null) {
def apply(canon_name: String, converted: T): T = {
if (fn != null && !fn(converted)) {
val the_errmess =
if (errmess != null) errmess
else "value '%s' not one of the allowed values"
val msg =
if (the_errmess contains "%s") the_errmess format converted
else the_errmess
throw new ArgParserRestrictionException(
"Argument '%s': %s" format (canon_name, msg))
}
if (transform != null)
transform(canon_name, converted)
else
converted
}
}
/**
* Superclass of all exceptions related to `argparser`. These exceptions
* are generally thrown during argument parsing. Normally, the exceptions
* are automatically caught, their message displayed, and then the
* program exited with code 1, indicating a problem. However, this
* behavior can be suppressed by setting the constructor parameter
* `catchErrors` on `ArgParser` to false. In such a case, the exceptions
* will be propagated to the caller, which should catch them and handle
* appropriately; otherwise, the program will be terminated with a stack
* trace.
*
* @param message Message of the exception
* @param cause If not None, an exception, used for exception chaining
* (when one exception is caught, wrapped in another exception and
* rethrown)
*/
class ArgParserException(val message: String,
val cause: Option[Throwable] = None) extends Exception(message) {
if (cause != None)
initCause(cause.get)
/**
* Alternate constructor.
*
* @param message exception message
*/
def this(msg: String) = this(msg, None)
/**
* Alternate constructor.
*
* @param message exception message
* @param cause wrapped, or nested, exception
*/
def this(msg: String, cause: Throwable) = this(msg, Some(cause))
}
/**
* Thrown to indicate usage errors.
*
* @param message fully fleshed-out usage string.
* @param cause exception, if propagating an exception
*/
class ArgParserUsageException(
message: String,
cause: Option[Throwable] = None
) extends ArgParserException(message, cause)
/**
* Thrown to indicate that ArgParser could not convert a command line
* argument to the desired type.
*
* @param message exception message
* @param cause exception, if propagating an exception
*/
class ArgParserConversionException(
message: String,
cause: Option[Throwable] = None
) extends ArgParserException(message, cause)
/**
* Thrown to indicate that a command line argument failed to be one of
* the allowed values.
*
* @param message exception message
* @param cause exception, if propagating an exception
*/
class ArgParserRestrictionException(
message: String,
cause: Option[Throwable] = None
) extends ArgParserException(message, cause)
/**
* Thrown to indicate that ArgParser encountered a problem in the caller's
* argument specification, or something else indicating invalid coding.
* This indicates a bug in the caller's code. These exceptions are not
* automatically caught.
*
* @param message exception message
*/
class ArgParserCodingError(message: String,
cause: Option[Throwable] = None
) extends ArgParserException("(CALLER BUG) " + message, cause)
/**
* Thrown to indicate that ArgParser encountered a problem that should
* never occur under any circumstances, indicating a bug in the ArgParser
* code itself. These exceptions are not automatically caught.
*
* @param message exception message
*/
class ArgParserInternalError(message: String,
cause: Option[Throwable] = None
) extends ArgParserException("(INTERNAL BUG) " + message, cause)
/* Some static functions related to ArgParser; all are for internal use */
protected object ArgParser {
// Given a list of aliases for an argument, return the canonical one
// (first one that's more than a single letter).
def canonName(name: Seq[String]): String = {
assert(name.length > 0)
for (n <- name) {
if (n.length > 1) return n
}
return name(0)
}
// Compute the metavar for an argument. If the metavar has already
// been given, use it; else, use the upper case version of the
// canonical name of the argument.
def computeMetavar(metavar: String, name: Seq[String]) = {
if (metavar != null) metavar
else canonName(name).toUpperCase
}
// Return a sequence of all the given strings that aren't null.
def nonNullVals(val1: String, val2: String, val3: String, val4: String,
val5: String, val6: String, val7: String, val8: String,
val9: String) = {
val retval =
Seq(val1, val2, val3, val4, val5, val6, val7, val8, val9) filter
(_ != null)
if (retval.length == 0)
throw new ArgParserCodingError(
"Need to specify at least one name for each argument")
retval
}
// Combine `choices` and `aliasedChoices` into a larger list of the
// format of `aliasedChoices`. Note that before calling this, a special
// check must be done for the case where `choices` and `aliasedChoices`
// are both null, which includes that no limited-choice restrictions
// apply at all (and is actually the most common situation).
def canonicalizeChoicesAliases[T](choices: Seq[T],
aliasedChoices: Seq[Seq[T]]) = {
val newchoices = if (choices != null) choices else Seq[T]()
val newaliased =
if (aliasedChoices != null) aliasedChoices else Seq[Seq[T]]()
for (spellings <- newaliased) {
if (spellings.length == 0)
throw new ArgParserCodingError(
"Zero-length list of spellings not allowed in `aliasedChoices`:\n%s"
format newaliased)
}
newchoices.map(x => Seq(x)) ++ newaliased
}
// Convert a list of choices in the format of `aliasedChoices`
// (a sequence of sequences, first item is the canonical spelling)
// into a mapping that canonicalizes choices.
def getCanonMap[T](aliasedChoices: Seq[Seq[T]]) = {
(for {spellings <- aliasedChoices
canon = spellings.head
spelling <- spellings}
yield (spelling, canon)).toMap
}
// Return a human-readable list of all choices, based on the specifications
// of `choices` and `aliasedChoices`. If 'includeAliases' is true, include
// the aliases in the list of choices, in parens after the canonical name.
def choicesList[T](choices: Seq[T], aliasedChoices: Seq[Seq[T]],
includeAliases: Boolean) = {
val fullaliased =
canonicalizeChoicesAliases(choices, aliasedChoices)
if (!includeAliases)
fullaliased.map(_.head) mkString ", "
else
(
for { spellings <- fullaliased
canon = spellings.head
altspellings = spellings.tail
}
yield {
if (altspellings.length > 0)
"%s (%s)" format (canon, altspellings mkString "/")
else canon.toString
}
) mkString ", "
}
// Check that the given value passes any restrictions imposed by
// `must`, `choices` and/or `aliasedChoices`.
// If not, throw an exception.
def checkRestriction[T](canon_name: String, converted: T,
must: Must[T], choices: Seq[T], aliasedChoices: Seq[Seq[T]]) = {
val new_converted =
if (must == null) converted else must(canon_name, converted)
if (choices == null && aliasedChoices == null) converted
else {
val fullaliased =
canonicalizeChoicesAliases(choices, aliasedChoices)
val canonmap = getCanonMap(fullaliased)
if (canonmap contains converted)
canonmap(converted)
else
throw new ArgParserRestrictionException(
"Argument '%s': choice '%s' not one of the recognized choices: %s"
format (canon_name, converted, choicesList(choices, aliasedChoices,
includeAliases = true)))
}
}
}
/**
* Base class of all argument-wrapping classes. These are used to
* wrap the appropriate argument-category class from Argot, and return
* values by querying Argot for the value, returning the default value
* if Argot doesn't have a value recorded.
*
* NOTE that these classes are not meant to leak out to the user. They
* should be considered implementation detail only and subject to change.
*
* @param parser ArgParser for which this argument exists.
* @param name Name of the argument.
* @param default Default value of the argument, used when the argument
* wasn't specified on the command line.
* @tparam T Type of the argument (e.g. Int, Double, String, Boolean).
*/
abstract protected class ArgAny[T](
val parser: ArgParser,
val name: String,
val default: T,
checkres: T => T
) {
/**
* Return the value of the argument, if specified; else, the default
* value. */
def value = {
if (overridden)
overriddenValue
else if (specified)
wrappedValue
else
checkres(default)
}
def setValue(newval: T) {
overriddenValue = newval
overridden = true
}
/**
* When dereferenced as a function, also return the value.
*/
def apply() = value
/**
* Whether the argument's value was specified. If not, the default
* value applies.
*/
def specified: Boolean
/**
* Clear out any stored values so that future queries return the default.
*/
def clear() {
clearWrapped()
overridden = false
}
/**
* Return the value of the underlying Argot object, assuming it exists
* (possibly error thrown if not).
*/
protected def wrappedValue: T
/**
* Clear away the wrapped value.
*/
protected def clearWrapped()
/**
* Value if the user explicitly set a value.
*/
protected var overriddenValue: T = _
/**
* Whether the user explicit set a value.
*/
protected var overridden: Boolean = false
}
/**
* Class for wrapping simple Boolean flags.
*
* @param parser ArgParser for which this argument exists.
* @param name Name of the argument.
*/
protected class ArgFlag(
parser: ArgParser,
name: String
) extends ArgAny[Boolean](parser, name, default = false,
checkres = { x: Boolean => x }) {
var wrap: FlagOption[Boolean] = null
def wrappedValue = wrap.value.get
def specified = (wrap != null && wrap.value != None)
def clearWrapped() { if (wrap != null) wrap.reset() }
}
/**
* Class for wrapping a single (non-multi) argument (either option or
* positional param).
*
* @param parser ArgParser for which this argument exists.
* @param name Name of the argument.
* @param default Default value of the argument, used when the argument
* wasn't specified on the command line.
* @param is_positional Whether this is a positional argument rather than
* option (default false).
* @tparam T Type of the argument (e.g. Int, Double, String, Boolean).
*/
protected class ArgSingle[T](
parser: ArgParser,
name: String,
default: T,
checkres: T => T,
val is_positional: Boolean = false
) extends ArgAny[T](parser, name, default, checkres) {
var wrap: SingleValueArg[T] = null
def wrappedValue = wrap.value.get
def specified = (wrap != null && wrap.value != None)
def clearWrapped() { if (wrap != null) wrap.reset() }
}
/**
* Class for wrapping a multi argument (either option or positional param).
*
* @param parser ArgParser for which this argument exists.
* @param name Name of the argument.
* @param default Default value of the argument, used when the argument
* wasn't specified on the command line even once.
* @param is_positional Whether this is a positional argument rather than
* option (default false).
* @tparam T Type of the argument (e.g. Int, Double, String, Boolean).
*/
protected class ArgMulti[T](
parser: ArgParser,
name: String,
default: Seq[T],
checkres: T => T,
val is_positional: Boolean = false
) extends ArgAny[Seq[T]](parser, name, default,
{ x => x.map(checkres) }) {
var wrap: MultiValueArg[T] = null
val wrapSingle = new ArgSingle[T](parser, name, null.asInstanceOf[T],
checkres)
def wrappedValue = wrap.value
def specified = (wrap != null && wrap.value.length > 0)
def clearWrapped() { if (wrap != null) wrap.reset() }
}
/**
* Main class for parsing arguments from a command line.
*
* @param prog Name of program being run, for the usage message.
* @param description Text describing the operation of the program. It is
* placed between the line "Usage: ..." and the text describing the
* options and positional arguments; hence, it should not include either
* of these, just a description.
* @param preUsage Optional text placed before the usage message (e.g.
* a copyright and/or version string).
* @param postUsage Optional text placed after the usage message.
* @param return_defaults If true, field values in field-based value
* access always return the default value, even after parsing.
*/
class ArgParser(prog: String,
description: String = "",
preUsage: String = "",
postUsage: String = "",
return_defaults: Boolean = false) {
import ArgParser._
import ArgotConverters._
/* The underlying ArgotParser object. */
protected val argot = new ArgotParser(prog,
description = if (description.length > 0) Some(description) else None,
preUsage = if (preUsage.length > 0) Some(preUsage) else None,
postUsage = if (postUsage.length > 0) Some(postUsage) else None)
/* A map from the argument's canonical name to the subclass of ArgAny
describing the argument and holding its value. The canonical name
of options comes from the first non-single-letter name. The
canonical name of positional arguments is simply the name of the
argument. Iteration over the map yields keys in the order they
were added rather than random. */
protected val argmap = mutable.LinkedHashMap[String, ArgAny[_]]()
/* The type of each argument. For multi options and multi positional
arguments this will be of type Seq. Because of type erasure, the
type of sequence must be stored separately, using argtype_multi. */
protected val argtype = mutable.Map[String, Class[_]]()
/* For multi arguments, the type of each individual argument. */
protected val argtype_multi = mutable.Map[String, Class[_]]()
/* Set specifying arguments that are positional arguments. */
protected val argpositional = mutable.Set[String]()
/* Set specifying arguments that are flag options. */
protected val argflag = mutable.Set[String]()
/* Map from argument aliases to canonical argument name. Note that
* currently this isn't actually used when looking up an argument name;
* that lookup is handled internally to Argot, which has its own
* tables. */
protected val arg_to_canon = mutable.Map[String, String]()
protected var parsed = false
/* NOTE NOTE NOTE: Currently we don't provide any programmatic way of
accessing the ArgAny-subclass object by name. This is probably
a good thing -- these objects can be viewed as internal
*/
/**
* Return whether we've already parsed the command line.
*/
def isParsed = parsed
/**
* Return whether variables holding the return value of parameters
* hold the parsed values. Otherwise they hold the default values,
* which happens either when we haven't parsed the command line or
* when class parameter `return_defaults` was specified.
*/
def parsedValues = isParsed && !return_defaults
/**
* Return the canonical name of an argument. If the name is already
* canonical, the same value will be returned. Return value is an
* `Option`; if the argument name doesn't exist, `None` will be returned.
*
* @param arg The name of the argument.
*/
def argToCanon(arg: String): Option[String] = arg_to_canon.get(arg)
// Look the argument up in `argmap`, converting to canonical as needed.
protected def get_arg(arg: String) = argmap(arg_to_canon(arg))
/**
* Return the value of an argument, or the default if not specified.
*
* @param arg The name of the argument.
* @return The value, of type Any. It must be cast to the appropriate
* type.
* @see #get[T]
*/
def apply(arg: String) = get_arg(arg).value
/**
* Return the value of an argument, or the default if not specified.
*
* @param arg The name of the argument.
* @tparam T The type of the argument, which must match the type given
* in its definition
*
* @return The value, of type T.
*/
def get[T](arg: String) = get_arg(arg).asInstanceOf[ArgAny[T]].value
/**
* Explicitly set the value of an argument.
*
* @param arg The name of the argument.
* @param value The new value of the argument.
* @tparam T The type of the argument, which must match the type given
* in its definition
*
* @return The value, of type T.
*/
def set[T](arg: String, value: T) {
get_arg(arg).asInstanceOf[ArgAny[T]].setValue(value)
}
/**
* Return the default value of an argument.
*
* @param arg The name of the argument.
* @tparam T The type of the argument, which must match the type given
* in its definition
*
* @return The value, of type T.
*/
def defaultValue[T](arg: String) =
get_arg(arg).asInstanceOf[ArgAny[T]].default
/**
* Return whether an argument (either option or positional argument)
* exists with the given name.
*/
def exists(arg: String) = arg_to_canon contains arg
/**
* Return whether an argument (either option or positional argument)
* exists with the given canonical name.
*/
def existsCanon(arg: String) = argmap contains arg
/**
* Return whether an argument exists with the given name.
*/
def isOption(arg: String) = exists(arg) && !isPositional(arg)
/**
* Return whether a positional argument exists with the given name.
*/
def isPositional(arg: String) =
argToCanon(arg).map(argpositional contains _) getOrElse false
/**
* Return whether a flag option exists with the given name.
*/
def isFlag(arg: String) =
argToCanon(arg).map(argflag contains _) getOrElse false
/**
* Return whether a multi argument (either option or positional argument)
* exists with the given canonical name.
*/
def isMulti(arg: String) =
argToCanon(arg).map(argtype_multi contains _) getOrElse false
/**
* Return whether the given argument's value was specified. If not,
* fetching the argument's value returns its default value instead.
*/
def specified(arg: String) = get_arg(arg).specified
/**
* Return the type of the given argument. For multi arguments, the
* type will be Seq, and the type of the individual arguments can only
* be retrieved using `getMultiType`, due to type erasure.
*/
def getType(arg: String) = argtype(arg_to_canon(arg))
/**
* Return the type of an individual argument value of a multi argument.
* The actual type of the multi argument is a Seq of the returned type.
*/
def getMultiType(arg: String) = argtype_multi(arg_to_canon(arg))
/**
* Return an Iterable over the canonical names of all defined arguments.
* Values of the arguments can be retrieved using `apply` or `get[T]`.
* Properties of the arguments can be retrieved using `getType`,
* `specified`, `defaultValue`, `isFlag`, etc.
*/
def argNames: Iterable[String] = {
for ((name, argobj) <- argmap) yield name
}
/**
* Return an Iterable over pairs of canonically-named arguments and values
* (of type Any). The values need to be cast as appropriate.
*
* @see #argNames, #get[T], #apply
*/
def argValues: Iterable[(String, Any)] = {
for ((name, argobj) <- argmap) yield (name, argobj.value)
}
/**
* Return an Iterable over pairs of canonically-named arguments and values
* (of type Any), only including arguments whose values were specified on
* the command line. The values need to be cast as appropriate.
*
* @see #argNames, #argValues, #get[T], #apply
*/
def nonDefaultArgValues: Iterable[(String, Any)] = {
for ((name, argobj) <- argmap if argobj.specified)
yield (name, argobj.value)
}
/**
* Underlying function to implement the handling of all different types
* of arguments. Normally this will be called twice for each argument,
* once before and once after parsing. When before parsing, it records
* the argument and its properties. When after parsing, it returns the
* value of the argument as parsed from the command line.
*
* @tparam U Type of the argument. The variable holding an argument's
* value will always have this type.
* @tparam T Type of a single argument value. This will be different from
* `U` in the case of multi-arguments and arguments with parameters
* (in such case, `U` will consist of a tuple `(T, String)` or a
* sequence of such tuples). The elements in `choices` are of type `T`.
*
* @param Names of the argument.
* @param default Default value of argument.
* @param metavar User-visible argument type, in usage string. See
* `option` for more information.
* @param must Restriction on possible values for this option, as an
* object of type `Must`.
* @param choices Set of allowed choices, when an argument allows only
* a limited set of choices.
* @param aliasedChoices List of allowed aliases for the choices specified
* in `choices`.
* @param help Help string, to be displayed in the usage message.
* @param create_underlying Function to create the underlying object
* (of a subclass of `ArgAny`) that wraps the argument. The function
* arguments are the canonicalized name, metavar and help. The
* canonicalized help has %-sequences subsituted appropriately; the
* canonical name is the first non-single-letter name listed; the
* canonical metavar is computed from the canonical name, in all-caps,
* if not specified.
* @param is_multi Whether this is a multi-argument (allowing the argument
* to occur multiple times).
* @param is_positional Whether this is a positional argument rather than
* an option.
* @param is_flag Whether this is a flag (a Boolean option with no value
* specified).
*/
protected def handle_argument[T : Manifest, U : Manifest](
name: Seq[String],
default: U,
metavar: String,
must: Must[T],
choices: Seq[T],
aliasedChoices: Seq[Seq[T]],
help: String,
create_underlying: (String, String, String) => ArgAny[U],
is_multi: Boolean = false,
is_positional: Boolean = false,
is_flag: Boolean = false
) = {
val canon = canonName(name)
if (return_defaults)
default
else if (parsed) {
if (argmap contains canon)
argmap(canon).asInstanceOf[ArgAny[U]].value
else
throw new ArgParserCodingError("Can't define new arguments after parsing")
} else {
val canon_metavar = computeMetavar(metavar, name)
val helpsplit = """(%%|%default|%choices|%allchoices|%metavar|%prog|%|[^%]+)""".r.findAllIn(
help.replaceAll("""\s+""", " "))
val canon_help =
(for (s <- helpsplit) yield {
s match {
case "%default" => default.toString
case "%choices" => choicesList(choices, aliasedChoices,
includeAliases = false)
case "%allchoices" => choicesList(choices, aliasedChoices,
includeAliases = true)
case "%metavar" => canon_metavar
case "%%" => "%"
case "%prog" => this.prog
case _ => s
}
}) mkString ""
val underobj = create_underlying(canon, canon_metavar, canon_help)
for (nam <- name) {
if (arg_to_canon contains nam)
throw new ArgParserCodingError("Attempt to redefine existing argument '%s'" format nam)
arg_to_canon(nam) = canon
}
argmap(canon) = underobj
argtype(canon) = manifest[U].runtimeClass
if (is_multi)
argtype_multi(canon) = manifest[T].runtimeClass
if (is_positional)
argpositional += canon
if (is_flag)
argflag += canon
default
}
}
protected def argot_converter[T](
is_multi: Boolean, convert: (String, String, ArgParser) => T,
canon_name: String, checkres: T => T) = {
(rawval: String, argop: CommandLineArgument[T]) => {
val converted = convert(rawval, canon_name, this)
checkres(converted)
}
}
protected def argot_converter_with_params[T](
is_multi: Boolean, convert: (String, String, ArgParser) => T,
canon_name: String, checkres: ((T, String)) => (T, String)) = {
(rawval: String, argop: CommandLineArgument[(T, String)]) => {
val (raw, params) = rawval span (_ != ':')
val converted = (convert(raw, canon_name, this), params)
checkres(converted)
}
}
def optionSeq[T](name: Seq[String],
default: T = null.asInstanceOf[T],
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val checkres = { x: T => checkRestriction(canon_name, x,
must, choices, aliasedChoices) }
val arg = new ArgSingle(this, canon_name, default, checkres)
arg.wrap =
(argot.option[T](name.toList, canon_metavar, canon_help)
(argot_converter(is_multi = false, convert, canon_name,
checkres)))
arg
}
handle_argument[T,T](name, default, metavar, must,
choices, aliasedChoices, help, create_underlying _)
}
def optionSeqWithParams[T](name: Seq[String],
default: (T, String) = (null.asInstanceOf[T], ""),
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val checkres = { x: ((T, String)) =>
(checkRestriction(canon_name, x._1, must, choices, aliasedChoices),
x._2) }
val arg = new ArgSingle(this, canon_name, default, checkres)
arg.wrap =
(argot.option[(T, String)](name.toList, canon_metavar, canon_help)
(argot_converter_with_params(is_multi = false, convert, canon_name,
checkres)))
arg
}
handle_argument[T,(T, String)](name, default, metavar, must,
choices, aliasedChoices, help, create_underlying _)
}
/**
* Define a single-valued option of type T. Various standard types
* are recognized, e.g. String, Int, Double. (This is handled through
* the implicit `convert` argument.) Up to nine aliases for the
* option can be specified. Single-letter aliases are specified using
* a single dash, whereas longer aliases generally use two dashes.
* The "canonical" name of the option is the first non-single-letter
* alias given.
*
* @param name1
* @param name2
* @param name3
* @param name4
* @param name5
* @param name6
* @param name7
* @param name8
* @param name9
* Up to nine aliases for the option; see above.
*
* @param default Default value, if option not specified; if not given,
* it will end up as 0, 0.0 or false for value types, null for
* reference types.
* @param metavar "Type" of the option, as listed in the usage string.
* This is so that the relevant portion of the usage string will say
* e.g. "--counts-file FILE File containing word counts." (The
* value of `metavar` would be "FILE".) If not given, automatically
* computed from the canonical option name by capitalizing it.
* @param must Restriction on possible values for this option. This is
* a tuple of a function that must evaluate to true on the value
* and an error message to display otherwise, with a %s in it
* indicating where to display the value. There are a number of
* predefined functions to use, e.g. `be_<`, `be_within`, etc.
* @param choices List of possible choices for this option. If specified,
* it should be a sequence of possible choices that will be allowed,
* and only the choices that are either in this list of specified via
* `aliasedChoices` will be allowed. If neither `choices` nor
* `aliasedChoices` is given, all values will be allowed.
* @param aliasedChoices List of possible choices for this option,
* including alternative spellings (aliases). If specified, it should
* be a sequence of sequences, each of which specifies the possible
* alternative spellings for a given choice and where the first listed
* spelling is considered the "canonical" one. All choices that
* consist of any given spelling will be allowed, but any non-canonical
* spellings will be replaced by equivalent canonical spellings.
* For example, the choices of "dev", "devel" and "development" may
* all mean the same thing; regardless of how the user spells this
* choice, the same value will be passed to the program (whichever
* spelling comes first). Note that the value of `choices` lists
* additional choices, which are equivalent to choices listed in
* `aliasedChoices` without any alternative spellings. If both
* `choices` and `aliasedChoices` are omitted, all values will be
* allowed.
* @param help Help string for the option, shown in the usage string.
* @param convert Function to convert the raw option (a string) into
* a value of type `T`. The second and third parameters specify
* the name of the argument whose value is being converted, and the
* ArgParser object that the argument is defined on. Under normal
* circumstances, these parameters should not affect the result of
* the conversion function. For standard types, no conversion
* function needs to be specified, as the correct conversion function
* will be located automatically through Scala's 'implicit' mechanism.
* @tparam T The type of the option. For non-standard types, a
* converter must explicitly be given. (The standard types recognized
* are currently Int, Double, Boolean and String.)
*
* @return If class parameter `return_defaults` is true or if parsing
* has not yet happened, the default value. Otherwise, the value of
* the parameter.
*/
def option[T](
name1: String, name2: String = null, name3: String = null,
name4: String = null, name5: String = null, name6: String = null,
name7: String = null, name8: String = null, name9: String = null,
default: T = null.asInstanceOf[T],
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
optionSeq[T](nonNullVals(name1, name2, name3, name4, name5, name6,
name7, name8, name9),
metavar = metavar, default = default, must = must,
choices = choices, aliasedChoices = aliasedChoices, help = help
)(convert, m)
}
/**
* Define a single-valued option of type T, with parameters.
* This is like `option` but the value can include parameters, e.g.
* 'foo:2:3' in place of just 'foo'. The value is a tuple of
* (basicValue, params) where `basicValue` is whatever would be
* returned as the value of an `option` and `params` is a string,
* the raw value of the parameters (including any leading colon).
* The parameters themselves should be converted by
* `parseSubParams` or `parseSubParams2`. Any `choices` or
* `aliasedChoices` specified refer only to the `basicValue`
* part of the option value.
*/
def optionWithParams[T](
name1: String, name2: String = null, name3: String = null,
name4: String = null, name5: String = null, name6: String = null,
name7: String = null, name8: String = null, name9: String = null,
default: (T, String) = (null.asInstanceOf[T], ""),
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
optionSeqWithParams[T](nonNullVals(name1, name2, name3, name4, name5,
name6, name7, name8, name9),
metavar = metavar, default = default, must = must,
choices = choices, aliasedChoices = aliasedChoices, help = help
)(convert, m)
}
def flagSeq(name: Seq[String],
help: String = "") = {
import ArgotConverters._
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val arg = new ArgFlag(this, canon_name)
arg.wrap = argot.flag[Boolean](name.toList, canon_help)
arg
}
handle_argument[Boolean,Boolean](name, default = false,
metavar = null, must = null,
choices = Seq(true, false), aliasedChoices = null, help = help,
create_underlying = create_underlying _)
}
/**
* Define a boolean flag option. Unlike other options, flags have no
* associated value. Instead, their type is always Boolean, with the
* value 'true' if the flag is specified, 'false' if not.
*
* @param name1
* @param name2
* @param name3
* @param name4
* @param name5
* @param name6
* @param name7
* @param name8
* @param name9
* Up to nine aliases for the option; same as for `option[T]()`.
*
* @param help Help string for the option, shown in the usage string.
*/
def flag(name1: String, name2: String = null, name3: String = null,
name4: String = null, name5: String = null, name6: String = null,
name7: String = null, name8: String = null, name9: String = null,
help: String = "") = {
flagSeq(nonNullVals(name1, name2, name3, name4, name5, name6,
name7, name8, name9),
help = help)
}
def multiOptionSeq[T](name: Seq[String],
default: Seq[T] = Seq[T](),
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val checkres = { x: T => checkRestriction(canon_name, x,
must, choices, aliasedChoices) }
val arg = new ArgMulti[T](this, canon_name, default, checkres)
arg.wrap =
(argot.multiOption[T](name.toList, canon_metavar, canon_help)
(argot_converter(is_multi = true, convert, canon_name,
checkres)))
arg
}
handle_argument[T,Seq[T]](name, default, metavar, must,
choices, aliasedChoices, help, create_underlying _, is_multi = true)
}
/**
* Specify an option that can be repeated multiple times. The resulting
* option value will be a sequence (Seq) of all the values given on the
* command line (one value per occurrence of the option). If there are
* no occurrences of the option, the value will be an empty sequence.
* (NOTE: This is different from single-valued options, where the
* default value can be explicitly specified, and if not given, will be
* `null` for reference types. Here, `null` will never occur.)
*
* NOTE: The restrictions specified using `must`, `choices`,
* `aliasedChoices` apply individually to each value. There is no current
* way of specifying an overall restriction, e.g. that at least one
* item must be given. This should be handled separately by the caller.
*
* FIXME: There should be a way of allowing for specifying multiple values
* in a single argument, separated by spaces, commas, etc. We'd want the
* caller to be able to pass in a function to split the string. Currently
* Argot doesn't seem to have a way of allowing a converter function to
* take a single argument and stuff in multiple values, so we probably
* need to modify Argot. (At some point we should just incorporate the
* relevant parts of Argot directly.)
*/
def multiOption[T](
name1: String, name2: String = null, name3: String = null,
name4: String = null, name5: String = null, name6: String = null,
name7: String = null, name8: String = null, name9: String = null,
default: Seq[T] = Seq[T](),
metavar: String = null,
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "")
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
multiOptionSeq[T](nonNullVals(name1, name2, name3, name4, name5, name6,
name7, name8, name9),
metavar = metavar, default = default, must = must,
choices = choices, aliasedChoices = aliasedChoices, help = help
)(convert, m)
}
/**
* Specify a positional argument. Positional argument are processed
* in order. Optional argument must occur after all non-optional
* argument. The name of the argument is only used in the usage file
* and as the "name" parameter of the ArgSingle[T] object passed to
* the (implicit) conversion routine. Usually the name should be in
* all caps.
*
* @see #multiPositional[T]
*/
def positional[T](name: String,
default: T = null.asInstanceOf[T],
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "", optional: Boolean = false)
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val checkres = { x: T => checkRestriction(canon_name, x,
must, choices, aliasedChoices) }
val arg = new ArgSingle(this, canon_name, default, checkres,
is_positional = true)
arg.wrap =
(argot.parameter[T](canon_name, canon_help, optional)
(argot_converter(is_multi = false, convert, canon_name,
checkres)))
arg
}
handle_argument[T,T](Seq(name), default, null, must,
choices, aliasedChoices, help, create_underlying _,
is_positional = true)
}
/**
* Specify any number of positional arguments. These must come after
* all other arguments.
*
* @see #positional[T].
*/
def multiPositional[T](name: String,
default: Seq[T] = Seq[T](),
must: Must[T] = null,
choices: Seq[T] = null,
aliasedChoices: Seq[Seq[T]] = null,
help: String = "",
optional: Boolean = true)
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
def create_underlying(canon_name: String, canon_metavar: String,
canon_help: String) = {
val checkres = { x: T => checkRestriction(canon_name, x,
must, choices, aliasedChoices) }
val arg = new ArgMulti[T](this, canon_name, default,
checkres, is_positional = true)
arg.wrap =
(argot.multiParameter[T](canon_name, canon_help, optional)
(argot_converter(is_multi = true, convert, canon_name,
checkres)))
arg
}
handle_argument[T,Seq[T]](Seq(name), default, null, must,
choices, aliasedChoices, help, create_underlying _,
is_multi = true, is_positional = true)
}
/**
* Parse a sub-parameter specified with an argument's value,
* in an argument specified as with `optionWithParams`, when at most
* one such sub-parameter can be given.
*
* @param argtype Type of argument (usually the basic value of the
* argument or some variant); used only for error messages.
* @param spec The sub-parameter spec, i.e. the string in the second
* part of the tuple returned as the value of `optionWithParams` or
* the like.
* @param default Default value of sub-parameter, if not specified.
* @param convert Function to convert the raw value into a value of
* type `T`, as in `option` and the like.
*/
def parseSubParams[T](argtype: String, spec: String,
default: T = null.asInstanceOf[T])
(implicit convert: (String, String, ArgParser) => T, m: Manifest[T]) = {
val specs = spec.split(":", -1)
specs.tail.length match {
case 0 => default
case 1 =>
if (specs(1) == "") default
else convert(specs(1), argtype, this)
case _ => throw new ArgParserConversionException(
"""too many parameters for type "%s": %s seen, at most 1 allowed"""
format (argtype, specs.tail.length))
}
}
/**
* Parse a sub-parameter specified with an argument's value,
* in an argument specified as with `optionWithParams`, when at most
* two such sub-parameters can be given.
*
* @see #parseSubParams[T]
*/
def parseSubParams2[T,U](argtype: String, spec: String,
default: (T,U) = (null.asInstanceOf[T], null.asInstanceOf[U]))
(implicit convertT: (String, String, ArgParser) => T,
convertU: (String, String, ArgParser) => U,
m: Manifest[T]) = {
val specs = spec.split(":", -1)
val (deft, defu) = default
specs.tail.length match {
case 0 => default
case 1 => {
val t =
if (specs(1) == "") deft
else convertT(specs(1), argtype, this)
(t, defu)
}
case 2 => {
val t =
if (specs(1) == "") deft
else convertT(specs(1), argtype, this)
val u =
if (specs(2) == "") deft
else convertT(specs(2), argtype, this)
(t, u)
}
case _ => throw new ArgParserConversionException(
"""too many parameters for type "%s": %s seen, at most 2 allowed"""
format (argtype, specs.tail.length))
}
}
/**
* Parse the given command-line arguments. Extracted values of the
* arguments can subsequently be obtained either using the `#get[T]`
* function, by directly treating the ArgParser object as if it were
* a hash table and casting the result, or by using a separate class
* to hold the extracted values in fields, as described above. The
* last method is the recommended one and generally the easiest-to-
* use for the consumer of the values.
*
* @param args Command-line arguments, from main() or the like
* @param catchErrors If true (the default), usage errors will
* be caught, a message outputted (without a stack trace), and
* the program will exit. Otherwise, the errors will be allowed
* through, and the application should catch them.
*/
def parse(args: Seq[String], catchErrors: Boolean = true) = {
// FIXME: Should we allow this? Not sure if Argot can tolerate this.
if (parsed)
throw new ArgParserCodingError("Command-line arguments already parsed")
if (argmap.size == 0)
throw new ArgParserCodingError("No arguments initialized. If you thought you specified arguments, you might have defined the corresponding fields with 'def' instead of 'var' or 'val'.")
// Call the underlying Argot parsing function and wrap Argot usage
// errors in our own ArgParserUsageException.
def call_parse() {
// println(argmap)
try {
val retval = argot.parse(args.toList)
parsed = true
retval
} catch {
case e: ArgotUsageException => {
throw new ArgParserUsageException(e.message, Some(e))
}
}
}
// Reset everything, in case the user explicitly set some values
// (which otherwise override values retrieved from parsing)
clear()
if (catchErrors) catch_parser_errors { call_parse() }
else call_parse()
}
/**
* Clear all arguments back to their default values.
*/
def clear() {
for (obj <- argmap.values) {
obj.clear()
}
}
def error(msg: String) = {
throw new ArgParserConversionException(msg)
}
def usageError(msg: String) = {
throw new ArgParserUsageException(msg)
}
}
}
object TestArgParser extends App {
import argparser._
class MyParams(ap: ArgParser) {
/* An integer option named --foo, with a default value of 5. Can also
be specified using --spam or -f. */
var foo = ap.option[Int]("foo", "spam", "f", default = 5,
help="""An integer-valued option. Default %default.""")
/* A string option named --bar, with a default value of "chinga". Can
also be specified using -b. */
var bar = ap.option[String]("bar", "b", default = "chinga")
/* A string option named --baz, which can be given multiple times.
Default value is an empty sequence. */
var baz = ap.multiOption[String]("baz")
/* A floating-point option named --tick, which can be given multiple times.
Default value is the sequence Seq(2.5, 5.0, 9.0), which will obtain
when the option hasn't been given at all. */
var tick = ap.multiOption[Double]("tick", default = Seq(2.5, 5.0, 9.0),
help = """Option --tick, perhaps for specifying the position of
tick marks along the X axis. Multiple such options can be given. If
no marks are specified, the default is %default. Note that we can
freely insert
spaces and carriage
returns into the help text; whitespace is compressed
to a single space.""")
/* A flag --bezzaaf, alias -q. Value is true if given, false if not. */
var bezzaaf = ap.flag("bezzaaf", "q")
/* An integer option --blop, with only the values 1, 2, 4 or 7 are
allowed. Default is 1. Note, in this case, if the default is
not given, it will end up as 0, even though this isn't technically
a valid choice. This could be considered a bug -- perhaps instead
we should default to the first choice listed, or throw an error.
(It could also be considered a possibly-useful hack to allow
detection of when no choice is given; but this can be determined
in a more reliable way using `ap.specified("blop")`.)
*/
var blop = ap.option[Int]("blop", default = 1, choices = Seq(1, 2, 4, 7),
help = """An integral argument with limited choices. Default is %default,
possible choices are %choices.""")
/* A string option --daniel, with only the values "mene", "tekel", and
"upharsin" allowed, but where values can be repeated, e.g.
--daniel mene --daniel mene --daniel tekel --daniel upharsin
. */
var daniel = ap.multiOption[String]("daniel",
choices = Seq("mene", "tekel", "upharsin"))
var ranker =
ap.multiOption[String]("r", "ranker",
aliasedChoices = Seq(
Seq("baseline"),
Seq("none"),
Seq("full-kl-divergence", "full-kldiv", "full-kl"),
Seq("partial-kl-divergence", "partial-kldiv", "partial-kl", "part-kl"),
Seq("symmetric-full-kl-divergence", "symmetric-full-kldiv",
"symmetric-full-kl", "sym-full-kl"),
Seq("symmetric-partial-kl-divergence",
"symmetric-partial-kldiv", "symmetric-partial-kl", "sym-part-kl"),
Seq("cosine-similarity", "cossim"),
Seq("partial-cosine-similarity", "partial-cossim", "part-cossim"),
Seq("smoothed-cosine-similarity", "smoothed-cossim"),
Seq("smoothed-partial-cosine-similarity", "smoothed-partial-cossim",
"smoothed-part-cossim"),
Seq("average-cell-probability", "avg-cell-prob", "acp"),
Seq("naive-bayes-with-baseline", "nb-base"),
Seq("naive-bayes-no-baseline", "nb-nobase")),
help = """A multi-string option. This is an actual option in
one of my research programs. Possible choices are %choices; the full list
of choices, including all aliases, is %allchoices.""")
/* A required positional argument. */
var destfile = ap.positional[String]("DESTFILE",
help = "Destination file to store output in")
/* A multi-positional argument that sucks up all remaining arguments. */
var files = ap.multiPositional[String]("FILES", help = "Files to process")
}
val ap = new ArgParser("test")
// This first call is necessary, even though it doesn't appear to do
// anything. In particular, this ensures that all arguments have been
// defined on `ap` prior to parsing.
new MyParams(ap)
// ap.parse(List("--foo", "7"))
ap.parse(args)
val params = new MyParams(ap)
// Print out values of all arguments, whether options or positional.
// Also print out types and default values.
for (name <- ap.argNames)
println("%30s: %s (%s) (default=%s)" format (
name, ap(name), ap.getType(name), ap.defaultValue[Any](name)))
// Examples of how to retrieve individual arguments
for (file <- params.files)
println("Process file: %s" format file)
println("Maximum tick mark seen: %s" format (params.tick max))
// We can freely change the value of arguments if we want, since they're
// just vars.
if (params.daniel contains "upharsin")
params.bar = "chingamos"
}
|
utcompling/textgrounder
|
src/main/scala/opennlp/textgrounder/util/argparser.scala
|
Scala
|
apache-2.0
| 74,251 |
/***********************************************************************
* Copyright (c) 2013-2019 Commonwealth Computer Research, Inc.
* All rights reserved. This program and the accompanying materials
* are made available under the terms of the Apache License, Version 2.0
* which accompanies this distribution and is available at
* http://www.opensource.org/licenses/apache2.0.php.
***********************************************************************/
package org.locationtech.geomesa.utils.stats
import org.junit.runner.RunWith
import org.specs2.mutable.Specification
import org.specs2.runner.JUnitRunner
@RunWith(classOf[JUnitRunner])
class DescriptiveStatsTest extends Specification with StatTestHelper {
def newStat[T <: Number](attribute: String, observe: Boolean = true): DescriptiveStats = {
val stat = Stat(sft, s"DescriptiveStats($attribute)")
if (observe) {
features.foreach { stat.observe }
}
stat.asInstanceOf[DescriptiveStats]
}
// NOTE: This is pattern.
val JSON_0_to_100 =
"""\\{
| "count": 100,
| "minimum": \\[
| 0.0
| \\],
| "maximum": \\[
| 99.0
| \\],
| "mean": \\[
| 49.5
| \\],
| "population_variance": \\[
| 833.25
| \\],
| "population_standard_deviation": \\[
| 28.866070[0-9]+
| \\],
| "population_skewness": \\[
| 0.0
| \\],
| "population_kurtosis": \\[
| 1.799759[0-9]+
| \\],
| "population_excess_kurtosis": \\[
| -1.200240[0-9]+
| \\],
| "sample_variance": \\[
| 841.666666[0-9]+
| \\],
| "sample_standard_deviation": \\[
| 29.011491[0-9]+
| \\],
| "sample_skewness": \\[
| 0.0
| \\],
| "sample_kurtosis": \\[
| 1.889747[0-9]+
| \\],
| "sample_excess_kurtosis": \\[
| -1.110252[0-9]+
| \\],
| "population_covariance": \\[
| 833.25
| \\],
| "population_correlation": \\[
| 1.0
| \\],
| "sample_covariance": \\[
| 841.666666[0-9]+
| \\],
| "sample_correlation": \\[
| 1.0
| \\]
|\\}""".stripMargin('|').replaceAll("\\\\s+","")
val JSON_EMPTY="""{"count":0}"""
"Stats stat" should {
"work with ints" >> {
"be empty initiallly" >> {
val descStats = newStat[java.lang.Integer]("intAttr", observe = false)
descStats.properties(0) mustEqual "intAttr"
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"observe correct values" >> {
val descStats = newStat[java.lang.Integer]("intAttr")
descStats.bounds(0) mustEqual (0, 99)
descStats.count must beCloseTo(100L, 5)
}
"serialize to json" >> {
val descStats = newStat[java.lang.Integer]("intAttr")
descStats.toJson.replaceAll("\\\\s+","") must beMatching(JSON_0_to_100)
}
"serialize empty to json" >> {
val descStats = newStat[java.lang.Integer]("intAttr", observe = false)
descStats.toJson.replaceAll("\\\\s+","") mustEqual JSON_EMPTY
}
"serialize and deserialize" >> {
val descStats = newStat[java.lang.Integer]("intAttr")
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"serialize and deserialize empty descStats" >> {
val descStats = newStat[java.lang.Integer]("intAttr", observe = false)
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"combine two descStatses" >> {
val descStats = newStat[java.lang.Integer]("intAttr")
val descStats2 = newStat[java.lang.Integer]("intAttr", observe = false)
features2.foreach { descStats2.observe }
descStats2.bounds(0) mustEqual (100, 199)
descStats2.count must beCloseTo(100L, 5)
descStats += descStats2
descStats.bounds(0) mustEqual (0, 199)
descStats.count must beCloseTo(200L, 5)
descStats2.bounds(0) mustEqual (100, 199)
}
"clear" >> {
val descStats = newStat[java.lang.Integer]("intAttr")
descStats.isEmpty must beFalse
descStats.clear()
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"negatives" >> {
val descStats3 = newStat[java.lang.Integer]("intAttr", observe = false)
features3.foreach { descStats3.observe }
descStats3.bounds(0) mustEqual (-100, -1)
descStats3.count must beCloseTo(100L, 5)
}
}
"work with longs" >> {
"be empty initiallly" >> {
val descStats = newStat[java.lang.Long]("longAttr", observe = false)
descStats.properties(0) mustEqual "longAttr"
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"observe correct values" >> {
val descStats = newStat[java.lang.Long]("longAttr")
descStats.bounds(0) mustEqual (0L, 99L)
descStats.count must beCloseTo(100L, 5)
}
"serialize to json" >> {
val descStats = newStat[java.lang.Long]("longAttr")
descStats.toJson.replaceAll("\\\\s+","") must beMatching(JSON_0_to_100)
}
"serialize empty to json" >> {
val descStats = newStat[java.lang.Long]("longAttr", observe = false)
descStats.toJson.replaceAll("\\\\s+","") mustEqual JSON_EMPTY
}
"serialize and deserialize" >> {
val descStats = newStat[java.lang.Long]("longAttr")
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"serialize and deserialize empty descStats" >> {
val descStats = newStat[java.lang.Long]("longAttr", observe = false)
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"combine two descStatses" >> {
val descStats = newStat[java.lang.Long]("longAttr")
val descStats2 = newStat[java.lang.Long]("longAttr", observe = false)
features2.foreach { descStats2.observe }
descStats2.bounds(0) mustEqual (100L, 199L)
descStats2.count must beCloseTo(100L, 5)
descStats += descStats2
descStats.bounds(0) mustEqual (0L, 199L)
descStats.count must beCloseTo(200L, 5)
descStats2.bounds(0) mustEqual (100L, 199L)
}
"clear" >> {
val descStats = newStat[java.lang.Long]("longAttr")
descStats.isEmpty must beFalse
descStats.clear()
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"negatives" >> {
val descStats3 = newStat[java.lang.Integer]("longAttr", observe = false)
features3.foreach { descStats3.observe }
descStats3.bounds(0) mustEqual (-100L, -1L)
descStats3.count must beCloseTo(100L, 5)
}
}
"work with floats" >> {
"be empty initiallly" >> {
val descStats = newStat[java.lang.Float]("floatAttr", observe = false)
descStats.properties(0) mustEqual "floatAttr"
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"observe correct values" >> {
val descStats = newStat[java.lang.Float]("floatAttr")
descStats.bounds(0) mustEqual (0f, 99f)
descStats.count must beCloseTo(100L, 5)
}
"serialize to json" >> {
val descStats = newStat[java.lang.Float]("floatAttr")
descStats.toJson.replaceAll("\\\\s+","") must beMatching(JSON_0_to_100)
}
"serialize empty to json" >> {
val descStats = newStat[java.lang.Float]("floatAttr", observe = false)
descStats.toJson.replaceAll("\\\\s+","") mustEqual JSON_EMPTY
}
"serialize and deserialize" >> {
val descStats = newStat[java.lang.Float]("floatAttr")
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"serialize and deserialize empty descStats" >> {
val descStats = newStat[java.lang.Float]("floatAttr", observe = false)
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"combine two descStatses" >> {
val descStats = newStat[java.lang.Float]("floatAttr")
val descStats2 = newStat[java.lang.Float]("floatAttr", observe = false)
features2.foreach { descStats2.observe }
descStats2.bounds(0) mustEqual (100f, 199f)
descStats2.count must beCloseTo(100L, 5)
descStats += descStats2
descStats.bounds(0) mustEqual (0f, 199f)
descStats.count must beCloseTo(200L, 5)
descStats2.bounds(0) mustEqual (100f, 199f)
}
"clear" >> {
val descStats = newStat[java.lang.Float]("floatAttr")
descStats.isEmpty must beFalse
descStats.clear()
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"negatives" >> {
val descStats3 = newStat[java.lang.Integer]("floatAttr", observe = false)
features3.foreach { descStats3.observe }
descStats3.bounds(0) mustEqual (-100f, -1f)
descStats3.count must beCloseTo(100L, 5)
}
}
"work with doubles" >> {
"be empty initiallly" >> {
val descStats = newStat[java.lang.Double]("doubleAttr", observe = false)
descStats.properties(0) mustEqual "doubleAttr"
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"observe correct values" >> {
val descStats = newStat[java.lang.Double]("doubleAttr")
descStats.bounds(0) mustEqual (0d, 99d)
descStats.count must beCloseTo(100L, 5)
}
"serialize to json" >> {
val descStats = newStat[java.lang.Double]("doubleAttr")
descStats.toJson.replaceAll("\\\\s+","") must beMatching(JSON_0_to_100)
}
"serialize empty to json" >> {
val descStats = newStat[java.lang.Double]("doubleAttr", observe = false)
descStats.toJson.replaceAll("\\\\s+","") mustEqual JSON_EMPTY
}
"serialize and deserialize" >> {
val descStats = newStat[java.lang.Double]("doubleAttr")
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"serialize and deserialize empty descStats" >> {
val descStats = newStat[java.lang.Double]("doubleAttr", observe = false)
val packed = StatSerializer(sft).serialize(descStats)
val unpacked = StatSerializer(sft).deserialize(packed)
unpacked.toJson mustEqual descStats.toJson
}
"combine two descStatses" >> {
val descStats = newStat[java.lang.Double]("doubleAttr")
val descStats2 = newStat[java.lang.Double]("doubleAttr", observe = false)
features2.foreach { descStats2.observe }
descStats2.bounds(0) mustEqual (100d, 199d)
descStats2.count must beCloseTo(100L, 5)
descStats += descStats2
descStats.bounds(0) mustEqual (0d, 199d)
descStats.count must beCloseTo(200L, 10)
descStats2.bounds(0) mustEqual (100d, 199d)
}
"clear" >> {
val descStats = newStat[java.lang.Double]("doubleAttr")
descStats.isEmpty must beFalse
descStats.clear()
descStats.isEmpty must beTrue
descStats.count mustEqual 0
}
"negatives" >> {
val descStats3 = newStat[java.lang.Integer]("doubleAttr", observe = false)
features3.foreach { descStats3.observe }
descStats3.bounds(0) mustEqual (-100d, -1d)
descStats3.count must beCloseTo(100L, 5)
}
}
}
}
|
elahrvivaz/geomesa
|
geomesa-utils/src/test/scala/org/locationtech/geomesa/utils/stats/DescriptiveStatsTest.scala
|
Scala
|
apache-2.0
| 12,366 |
package com.tribbloids.spookystuff.parsing
import com.tribbloids.spookystuff.testutils.FunSpecx
import com.tribbloids.spookystuff.utils.{InterleavedIterator, Interpolation}
import fastparse.internal.Logger
import org.apache.spark.BenchmarkHelper
import org.scalatest.Ignore
import org.slf4j.LoggerFactory
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
@Ignore //TODO: enable!
class ParsersBenchmark extends FunSpecx {
import com.tribbloids.spookystuff.parsing.ParsersBenchmark._
def maxSectionLen = 100
def maxRepeat = 1000
lazy val seed: Long = Random.nextLong()
def getRandomStrs: Stream[String] = {
val gen = RandomStrGen(seed)
gen.toStream
}
it("replace N") {
val epochs: List[Epoch] = List(
Epoch(getRandomStrs, "speed reference", skipResultCheck = true)(_.speedRef()),
Epoch(getRandomStrs, "regex")(_.useRegex()),
Epoch(getRandomStrs, "fastParse")(_.useFastParse()),
Epoch(getRandomStrs, "FSM")(_.useFSM())
// Epoch(stream, "do nothing", skipResultCheck = true)(_.doNothing())
)
ParsersBenchmark.compare(epochs)
}
}
object ParsersBenchmark {
import scala.concurrent.duration._
val numVPerEpoch: Int = Math.pow(2, 16).toInt
val streamRange: Range = 1 to 2 ^ 10
object UseFastParse {
val blacklist: Set[Char] = "{}$/\\".toSet
case class Impl(log: ArrayBuffer[String] = ArrayBuffer.empty) {
import fastparse._
import NoWhitespace._
implicit val logger: Logger = Logger(v => log += v)
// val allKWs: String = "/\\\\$}"
case class UntilCharInclusive(kw: Char) {
// final val allKWs: String = "/\\\\" + kw
def predicate(c: Char): Boolean = c != kw && c != '\\'
def strChars[_: P]: P[Unit] = P(CharsWhile(predicate))
def escaped[_: P]: P[Unit] = P("\\" ~/ AnyChar)
def str[_: P]: P[String] = (strChars | escaped).rep.!
def result[_: P]: P[String] = P(str ~ kw.toString).log
}
val to_$ : UntilCharInclusive = UntilCharInclusive('$')
val `to_}`: UntilCharInclusive = UntilCharInclusive('}')
def once[_: P]: P[(String, String)] = P(to_$.result ~ "{" ~ `to_}`.result)
def nTimes[_: P]: P[(Seq[(String, String)], String)] =
P(once.rep ~/ AnyChar.rep.!) // last String should be ignored
def parser[_: P]: P[(Seq[(String, String)], String)] = nTimes.log
def parseStr(str: String, verbose: Boolean = false): (Seq[(String, String)], String) = {
parse(str, parser(_), verboseFailures = verbose) match {
case v: Parsed.Failure =>
throw new UnsupportedOperationException(
s"""
|Cannot parse:
|$str
|${if (verbose) v.longMsg else v.msg}
| === error breakdown ===
|${log.mkString("\n")}
""".stripMargin
)
case v @ _ =>
v.get.value
}
}
}
}
object UseFSM {
import FSMParserDSL._
def esc(v: Parser[_]): Operand[FSMParserGraph.Layout.GG] = {
val esc = ESC('\\')
esc :~> v
}
val first: Operand[FSMParserGraph.Layout.GG] = esc(P_*('$').!-)
val enclosed: Operand[FSMParserGraph.Layout.GG] = esc(P_*('}').!-.^^ { io =>
Some(io.outcome.`export`)
})
val fsmParser: Operand[FSMParserGraph.Layout.GG] = first :~> P('{').-- :~> enclosed :& first :~> EOS_* :~> FINISH
{
assert(
fsmParser.visualise().ASCIIArt() ==
"""
| ╔═══════════════╗ ╔═══════════════╗
| ║(TAIL>>-) [ ∅ ]║ ║(TAIL-<<) [ ∅ ]║
| ╚═══════╤═══════╝ ╚═══════╤═══════╝
| │ │
| └───────────┐ ┌──────────┘
| │ │
| v v
| ╔═══════════╗
| ║ ROOT ║
| ╚═╤═════╤═╤═╝
| │ ^^ │ │
| ┌────────────┘ ││┌─┘ └─────────┐
| │ ┌─┼┘│ │
| v │ │ │ │
| ╔══════════════╗ │ │ │ │
| ║[ '$' [0...] ]║ │ │ │ │
| ╚══╤═══════════╝ │ │ │ │
| │ │ │ │ │
| v │ │ │ │
| ╔═══╗ │ │ │ │
| ║---║ │ │ │ │
| ╚═╤═╝ │ │ │ │
| │ │ │ │ │
| v │ │ │ v
| ╔═══════════╗ │ │ │ ╔══════════════════╗
| ║[ '{' [0] ]║ │ │ │ ║[ '[EOS]' [0...] ]║
| ╚══════╤════╝ │ │ │ ╚══════════════╤═══╝
| │ │ │ │ │
| │ │ │ └────────────┐ │
| │ │ └─────────┐ │ │
| v │ │ │ v
| ╔═══════╗ │ │ │ ╔══════╗
| ║ --- ║ │ │ │ ║FINISH║
| ╚═╤═══╤═╝ │ │ │ ╚═══╤══╝
| │ ^ │ │ │ │ │
| │ │ └──────────┐ │ │ │ └───────┐
| │ │ │ │ │ │ │
| v │ v │ │ v v
| ╔═════════╧════╗ ╔═════════╧════╗ ╔════╧═════════╗ ╔════════════╗
| ║[ '\' [0...] ]║ ║[ '}' [0...] ]║ ║[ '\' [0...] ]║ ║(HEAD) [ ∅ ]║
| ╚══════════════╝ ╚══════════════╝ ╚══════════════╝ ╚════════════╝
|""".stripMargin
.split("\n")
.toList
.filterNot(_.replaceAllLiterally(" ", "").isEmpty)
.mkString("\n")
)
}
}
val interpolation: Interpolation = Interpolation("$")
case class RandomStrGen(
seed: Long,
override val size: Int = numVPerEpoch,
maxSectionLen: Int = 100,
maxRepeat: Int = 100
) extends Iterable[String] {
val random: Random = new Random()
import random._
def rndStr(len: Int): String = {
val charSeq = for (i <- 1 to len) yield {
nextPrintableChar()
}
charSeq
.filterNot(v => UseFastParse.blacklist.contains(v))
.mkString("")
}
def generate: String = {
// print("+")
def getSectionStr = rndStr(nextInt(maxSectionLen))
(0 to nextInt(maxRepeat)).map { _ =>
getSectionStr +
"${" +
getSectionStr +
"}" +
getSectionStr
}.mkString
}
lazy val base: Seq[Int] = 1 to size
override def iterator: Iterator[String] = {
random.setSeed(seed)
base.iterator.map { i =>
generate
}
}
}
class UTRunner(val str: String) extends AnyVal {
def replace: String => String = { str =>
(0 until str.length).map(_ => "X").mkString("[", "", "]")
}
def useFastParse(verbose: Boolean = false): String = {
val impl = UseFastParse.Impl()
val parsed = impl.parseStr(str, verbose)
val interpolated = parsed._1
.flatMap {
case (s1, s2) =>
Seq(s1, replace(s2))
}
val result = (interpolated :+ parsed._2)
.mkString("")
result
}
def useFSM(): String = {
import UseFSM._
val parsed: ParsingRun.ResultSeq = fsmParser.parse(str)
val interpolated: Seq[String] = parsed.outputs.map {
case v: String => v
case Some(vv: String) => replace(vv)
case v @ _ =>
sys.error(v.toString)
}
interpolated.mkString("")
}
def useRegex(): String = {
interpolation(str)(replace)
}
//measuring speed only, result is jibberish
def speedRef(): String = {
str.map(identity)
// str
}
def doNothing(): String = ""
}
case class Epoch(
strs: Stream[String],
name: String = "[UNKNOWN]",
skipResultCheck: Boolean = false
)(
fn: ParsersBenchmark.UTRunner => String
) {
val runners: Stream[UTRunner] = {
val runners = strs.zipWithIndex.map {
case (str, i) =>
new ParsersBenchmark.UTRunner(str)
}
runners
}
val converted: Stream[String] = {
runners.map { runner =>
fn(runner)
}
}
def run(i: Int): Unit = {
// System.gc()
converted.foreach(_ => {})
}
}
def compare(epochs: List[Epoch]): Unit = {
val benchmarkHelper = BenchmarkHelper(
this.getClass.getSimpleName.stripSuffix("$"),
valuesPerIteration = numVPerEpoch,
// minNumIters = 2,
warmupTime = 5.seconds,
minTime = 60.seconds
// outputPerIteration = true
// output = None,
)
epochs.foreach { epoch =>
benchmarkHelper.self.addCase(epoch.name)(epoch.run)
}
benchmarkHelper.self.run()
LoggerFactory.getLogger(this.getClass).info("=== Benchmark finished ===")
val _epochs = epochs.filterNot(_.skipResultCheck)
val zipped = new InterleavedIterator(
_epochs
.map { v =>
v.converted.iterator
}
)
val withOriginal = _epochs.head.converted.iterator.zip(zipped)
withOriginal.foreach {
case (original, seq) =>
Predef.assert(
seq.distinct.size == 1,
s"""
|result mismatch!
|original:
|$original
|${_epochs.map(_.name).zip(seq).map { case (k, v) => s"$k:\n$v" }.mkString("\n")}
""".stripMargin
)
}
}
}
|
tribbloid/spookystuff
|
benchmark/src/test/scala/com/tribbloids/spookystuff/parsing/ParsersBenchmark.scala
|
Scala
|
apache-2.0
| 12,023 |
/*
* Copyright 2011-2018 GatlingCorp (http://gatling.io)
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.gatling.core.action
import io.gatling.AkkaSpec
import io.gatling.core.session.Session
import io.gatling.core.stats.StatsEngine
class RendezVousSpec extends AkkaSpec {
"RendezVous" should "block the specified number of sessions until they have all reached it" in {
val rendezVous = RendezVous(3, system, mock[StatsEngine], new ActorDelegatingAction("next", self))
val session = Session("scenario", 0)
rendezVous ! session
expectNoMessage(remainingOrDefault)
rendezVous ! session
expectNoMessage(remainingOrDefault)
rendezVous ! session
expectMsgAllOf(session, session, session)
rendezVous ! session
expectMsg(session)
}
}
|
wiacekm/gatling
|
gatling-core/src/test/scala/io/gatling/core/action/RendezVousSpec.scala
|
Scala
|
apache-2.0
| 1,302 |
/*
* Copyright 2013 Maurício Linhares
*
* Maurício Linhares licenses this file to you under the Apache License,
* version 2.0 (the "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at:
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS, WITHOUT
* WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the
* License for the specific language governing permissions and limitations
* under the License.
*/
package com.github.mauricio.async.db.postgresql.column
import com.github.mauricio.async.db.column.ColumnEncoderDecoder
import com.github.mauricio.async.db.exceptions.DateEncoderNotAvailableException
import com.github.mauricio.async.db.general.ColumnData
import com.github.mauricio.async.db.postgresql.messages.backend.PostgreSQLColumnData
import com.github.mauricio.async.db.util.Log
import io.netty.buffer.ByteBuf
import java.nio.charset.Charset
import java.sql.Timestamp
import java.util.{Calendar, Date}
import org.joda.time._
import org.joda.time.format.DateTimeFormatterBuilder
object PostgreSQLTimestampEncoderDecoder extends ColumnEncoderDecoder {
private val log = Log.getByName(this.getClass.getName)
private val optionalTimeZone = new DateTimeFormatterBuilder()
.appendPattern("Z")
.toParser
private val internalFormatters = 1.until(6).inclusive.map { index =>
new DateTimeFormatterBuilder()
.appendPattern("yyyy-MM-dd HH:mm:ss")
.appendPattern("." + ("S" * index))
.appendOptional(optionalTimeZone)
.toFormatter
}
private val internalFormatterWithoutSeconds = new DateTimeFormatterBuilder()
.appendPattern("yyyy-MM-dd HH:mm:ss")
.appendOptional(optionalTimeZone)
.toFormatter
def formatter = internalFormatters(5)
override def decode(
kind: ColumnData,
value: ByteBuf,
charset: Charset
): Any = {
val bytes = new Array[Byte](value.readableBytes())
value.readBytes(bytes)
val text = new String(bytes, charset)
val columnType = kind.asInstanceOf[PostgreSQLColumnData]
columnType.dataType match {
case ColumnTypes.Timestamp | ColumnTypes.TimestampArray => {
selectFormatter(text).parseLocalDateTime(text)
}
case ColumnTypes.TimestampWithTimezoneArray => {
selectFormatter(text).parseDateTime(text)
}
case ColumnTypes.TimestampWithTimezone => {
if (columnType.dataTypeModifier > 0) {
internalFormatters(columnType.dataTypeModifier - 1)
.parseDateTime(text)
} else {
selectFormatter(text).parseDateTime(text)
}
}
}
}
private def selectFormatter(text: String) = {
if (text.contains(".")) {
internalFormatters(5)
} else {
internalFormatterWithoutSeconds
}
}
override def decode(value: String): Any =
throw new UnsupportedOperationException(
"this method should not have been called"
)
override def encode(value: Any): String = {
value match {
case t: Timestamp => this.formatter.print(new DateTime(t))
case t: Date => this.formatter.print(new DateTime(t))
case t: Calendar => this.formatter.print(new DateTime(t))
case t: LocalDateTime => this.formatter.print(t)
case t: ReadableDateTime => this.formatter.print(t)
case _ => throw new DateEncoderNotAvailableException(value)
}
}
override def supportsStringDecoding: Boolean = false
}
|
dripower/postgresql-async
|
postgresql-async/src/main/scala/com/github/mauricio/async/db/postgresql/column/PostgreSQLTimestampEncoderDecoder.scala
|
Scala
|
apache-2.0
| 3,644 |
/* *\\
** _____ __ _____ __ ____ **
** / ___/ / / /____/ / / / \\ FieldKit **
** / ___/ /_/ /____/ / /__ / / / (c) 2010, FIELD **
** /_/ /____/ /____/ /_____/ http://www.field.io **
\\* */
/* created March 24, 2009 */
package field.kit.math
/**
* Contains all math Package methods; deprecated since moving to 2.8 in favour of the
* new Package object. Instead of import field.kit.Math.Common._ use import field.kit._
* @deprecated
*/
object Common extends Package
/**
* Extensive Maths package for 2D/3D graphics and simulations.
*
* Provides trigonometry, interpolation and other helper methods.
*
* @author Marcus Wendt
*/
trait Package
extends Trigonometry
with Interpolation
with Intersection
with Randomness {
import java.lang.Math
final val EPSILON = 1e-6f
// Implicit conversions
implicit def doubleTofloat(d: Double) = d.toFloat
implicit def tuple2fToVec2(xy: (Float, Float)) = new Vec2(xy._1, xy._2)
implicit def tuple3fToVec3(xyz: (Float, Float, Float)) = new Vec3(xyz._1, xyz._2, xyz._3)
/** regular expression to detect a number within a string with optional minus and fractional part */
final val DECIMAL = """(-)?(\\d+)(\\.\\d*)?""".r
// -- Utilities --------------------------------------------------------------
final def abs(n:Int) = if(n < 0) -n else n
final def abs(n:Float) = if(n < 0) -n else n
final def sq(n:Float) = n*n
final def sqrt(a:Float) = Math.sqrt(a).toFloat
final def log(a:Float) = Math.log(a).toFloat
final def exp(a:Float) = Math.exp(a).toFloat
final def pow(a:Float, b:Float) = Math.pow(a,b).toFloat
final def max(a:Int, b:Int) = if(a > b) a else b
final def max(a:Float, b:Float) = if(a > b) a else b
final def max(a:Float, b:Float, c:Float) = if(a > b) if(a > c) a else c else if(b > c) b else c
final def min(a:Int, b:Int) = if(a > b) b else a
final def min(a:Float, b:Float) = if(a > b) b else a
final def min(a:Float, b:Float, c:Float) = if(a < b) if(a < c) a else c else if(b < c) b else c
final def floor(n:Float) = Math.floor(n).toFloat
final def ceil(n:Float) = Math.ceil(n).toFloat
/** @return Returns the signum function of the argument; zero if the argument is zero, 1.0f if the argument is greater than zero, -1.0f if the argument is less than zero.*/
final def signum(value:Float) = if(value > 1f) 1f else -1f
/** @return returns true when a and b are both positive or negative number */
final def same(a:Float, b:Float) = (a * b) >= 0
final def round(value:Float, precision:Int):Float = {
val _exp = Math.pow(10, precision).toFloat
Math.round(value * _exp) / _exp
}
final def clamp(value:Float):Float = clamp(value, 0f, 1f)
final def clamp(value:Float, min:Float, max:Float) = {
var result = value
if(result > max) result = max
if(result < min) result = min
if(result > max) result = max
result
}
}
|
field/FieldKit.scala
|
src/field/kit/math/Package.scala
|
Scala
|
lgpl-3.0
| 3,126 |
package org.jetbrains.plugins.scala
package codeInsight.intention
import com.intellij.codeInsight.intention.PsiElementBaseIntentionAction
import com.intellij.openapi.editor.Editor
import com.intellij.openapi.project.Project
import com.intellij.psi.PsiElement
import com.intellij.psi.impl.source.codeStyle.CodeEditUtil
import com.intellij.psi.util.PsiTreeUtil
import org.jetbrains.plugins.scala.extensions.PsiElementExt
import org.jetbrains.plugins.scala.lang.psi.api.expr._
import org.jetbrains.plugins.scala.lang.psi.api.statements.{ScFunctionDefinition, ScPatternDefinition}
import org.jetbrains.plugins.scala.lang.psi.impl.ScalaPsiElementFactory.createExpressionFromText
import org.jetbrains.plugins.scala.util.IntentionAvailabilityChecker
/**
* Jason Zaugg
*/
class AddBracesIntention extends PsiElementBaseIntentionAction {
def getFamilyName = "Add braces"
override def getText = "Add braces around single line expression"
def isAvailable(project: Project, editor: Editor, element: PsiElement): Boolean =
check(project, editor, element).isDefined && IntentionAvailabilityChecker.checkIntention(this, element)
override def invoke(project: Project, editor: Editor, element: PsiElement) {
if (element == null || !element.isValid) return
check(project, editor, element) match {
case Some(x) => x()
case None =>
}
}
private def check(project: Project, editor: Editor, element: PsiElement): Option[() => Unit] = {
val classes = Seq(classOf[ScPatternDefinition], classOf[ScIfStmt], classOf[ScFunctionDefinition], classOf[ScTryBlock],
classOf[ScFinallyBlock], classOf[ScWhileStmt], classOf[ScDoStmt])
def isAncestorOfElement(ancestor: PsiElement) = PsiTreeUtil.isContextAncestor(ancestor, element, false)
val expr: Option[ScExpression] = element.parentOfType(classes).flatMap {
case ScPatternDefinition.expr(e) if isAncestorOfElement(e) => Some(e)
case ifStmt: ScIfStmt =>
ifStmt.thenBranch.filter(isAncestorOfElement).orElse(ifStmt.elseBranch.filter(isAncestorOfElement))
case funDef: ScFunctionDefinition =>
funDef.body.filter(isAncestorOfElement)
case tryBlock: ScTryBlock if !tryBlock.hasRBrace =>
tryBlock.statements match {
case Seq(x: ScExpression) if isAncestorOfElement(x) => Some(x)
case _ => None
}
case finallyBlock: ScFinallyBlock =>
finallyBlock.expression.filter(isAncestorOfElement)
case whileStmt: ScWhileStmt =>
whileStmt.body.filter(isAncestorOfElement)
case doStmt: ScDoStmt =>
doStmt.getExprBody.filter(isAncestorOfElement)
case _ => None
}
val oneLinerExpr: Option[ScExpression] = expr.filter {
x =>
val startLine = editor.getDocument.getLineNumber(x.getTextRange.getStartOffset)
val endLine = editor.getDocument.getLineNumber(x.getTextRange.getEndOffset)
val isBlock = x match {
case _: ScBlockExpr => true
case _ => false
}
startLine == endLine && !isBlock
}
oneLinerExpr.map {
expr => () => {
CodeEditUtil.replaceChild(expr.getParent.getNode, expr.getNode,
createExpressionFromText("{\\n%s}".format(expr.getText))(expr.getManager).getNode)
}
}
}
}
|
triplequote/intellij-scala
|
scala/scala-impl/src/org/jetbrains/plugins/scala/codeInsight/intention/AddBracesIntention.scala
|
Scala
|
apache-2.0
| 3,280 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.predictionio.tools.commands
import org.apache.predictionio.core.BuildInfo
import org.apache.predictionio.data.storage
import org.apache.predictionio.data.api.EventServer
import org.apache.predictionio.data.api.EventServerConfig
import org.apache.predictionio.tools.EventServerArgs
import org.apache.predictionio.tools.EitherLogging
import org.apache.predictionio.tools.Common
import org.apache.predictionio.tools.ReturnTypes._
import org.apache.predictionio.tools.dashboard.Dashboard
import org.apache.predictionio.tools.dashboard.DashboardConfig
import org.apache.predictionio.tools.admin.AdminServer
import org.apache.predictionio.tools.admin.AdminServerConfig
import akka.actor.ActorSystem
import java.io.File
import scala.io.Source
import semverfi._
case class DashboardArgs(
ip: String = "127.0.0.1",
port: Int = 9000)
case class AdminServerArgs(
ip: String = "127.0.0.1",
port: Int = 7071)
case class PioStatus(
version: String = "",
pioHome: String = "",
sparkHome: String = "",
sparkVersion: String = "",
sparkMinVersion: String = "",
warnings: Seq[String] = Seq())
object Management extends EitherLogging {
def version(): String = BuildInfo.version
/** Starts a dashboard server and returns immediately
*
* @param da An instance of [[DashboardArgs]]
* @return An instance of [[ActorSystem]] in which the server is being executed
*/
def dashboard(da: DashboardArgs): ActorSystem = {
info(s"Creating dashboard at ${da.ip}:${da.port}")
Dashboard.createDashboard(DashboardConfig(
ip = da.ip,
port = da.port))
}
/** Starts an eventserver server and returns immediately
*
* @param ea An instance of [[EventServerArgs]]
* @return An instance of [[ActorSystem]] in which the server is being executed
*/
def eventserver(ea: EventServerArgs): ActorSystem = {
info(s"Creating Event Server at ${ea.ip}:${ea.port}")
EventServer.createEventServer(EventServerConfig(
ip = ea.ip,
port = ea.port,
stats = ea.stats))
}
/** Starts an adminserver server and returns immediately
*
* @param aa An instance of [[AdminServerArgs]]
* @return An instance of [[ActorSystem]] in which the server is being executed
*/
def adminserver(aa: AdminServerArgs): ActorSystem = {
info(s"Creating Admin Server at ${aa.ip}:${aa.port}")
AdminServer.createAdminServer(AdminServerConfig(
ip = aa.ip,
port = aa.port
))
}
private def stripMarginAndNewlines(string: String): String =
string.stripMargin.replaceAll("\\n", " ")
def status(pioHome: Option[String], sparkHome: Option[String]): Expected[PioStatus] = {
var pioStatus = PioStatus()
info("Inspecting PredictionIO...")
pioHome map { pioHome =>
info(s"PredictionIO ${BuildInfo.version} is installed at $pioHome")
pioStatus = pioStatus.copy(version = version(), pioHome = pioHome)
} getOrElse {
return logAndFail("Unable to locate PredictionIO installation. Aborting.")
}
info("Inspecting Apache Spark...")
val sparkHomePath = Common.getSparkHome(sparkHome)
if (new File(s"$sparkHomePath/bin/spark-submit").exists) {
info(s"Apache Spark is installed at $sparkHomePath")
val sparkMinVersion = "1.3.0"
pioStatus = pioStatus.copy(
sparkHome = sparkHomePath,
sparkMinVersion = sparkMinVersion)
val sparkReleaseFile = new File(s"$sparkHomePath/RELEASE")
if (sparkReleaseFile.exists) {
val sparkReleaseStrings =
Source.fromFile(sparkReleaseFile).mkString.split(' ')
if (sparkReleaseStrings.length < 2) {
val warning = (stripMarginAndNewlines(
s"""|Apache Spark version information cannot be found (RELEASE file
|is empty). This is a known issue for certain vendors (e.g.
|Cloudera). Please make sure you are using a version of at least
|$sparkMinVersion."""))
warn(warning)
pioStatus = pioStatus.copy(warnings = pioStatus.warnings :+ warning)
} else {
val sparkReleaseVersion = sparkReleaseStrings(1)
val parsedMinVersion = Version.apply(sparkMinVersion)
val parsedCurrentVersion = Version.apply(sparkReleaseVersion)
if (parsedCurrentVersion >= parsedMinVersion) {
info(stripMarginAndNewlines(
s"""|Apache Spark $sparkReleaseVersion detected (meets minimum
|requirement of $sparkMinVersion)"""))
pioStatus = pioStatus.copy(sparkVersion = sparkReleaseVersion)
} else {
return logAndFail(stripMarginAndNewlines(
s"""|Apache Spark $sparkReleaseVersion detected (does not meet
|minimum requirement. Aborting."""))
}
}
} else {
val warning = (stripMarginAndNewlines(
s"""|Apache Spark version information cannot be found. If you are
|using a developmental tree, please make sure you are using a
|version of at least $sparkMinVersion."""))
warn(warning)
pioStatus = pioStatus.copy(warnings = pioStatus.warnings :+ warning)
}
} else {
return logAndFail("Unable to locate a proper Apache Spark installation. Aborting.")
}
info("Inspecting storage backend connections...")
try {
storage.Storage.verifyAllDataObjects()
} catch {
case e: Throwable =>
val errStr = s"""Unable to connect to all storage backends successfully.
|The following shows the error message from the storage backend.
|
|${e.getMessage} (${e.getClass.getName})
|
|Dumping configuration of initialized storage backend sources.
|Please make sure they are correct.
|
|""".stripMargin
val sources = storage.Storage.config.get("sources") map { src =>
src map { case (s, p) =>
s"Source Name: $s; Type: ${p.getOrElse("type", "(error)")}; " +
s"Configuration: ${p.getOrElse("config", "(error)")}"
} mkString("\\n")
} getOrElse {
"No properly configured storage backend sources."
}
return logOnFail(errStr + sources, e)
}
info("Your system is all ready to go.")
Right(pioStatus)
}
}
|
himanshudhami/PredictionIO
|
tools/src/main/scala/org/apache/predictionio/tools/commands/Management.scala
|
Scala
|
apache-2.0
| 7,151 |
/**
* Copyright 2016, deepsense.io
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.deepsense.workflowexecutor.communication.mq.json
import spray.json.{JsObject, JsonReader}
class DefaultJsonMessageDeserializer[T : JsonReader](handledName: String)
extends JsonMessageDeserializer {
val deserialize: PartialFunction[(String, JsObject), Any] = {
case (name, body) if isHandled(name) => handle(body)
}
private def isHandled(name: String): Boolean = name == handledName
private def handle(body: JsObject): Any = body.convertTo[T]
}
|
deepsense-io/seahorse-workflow-executor
|
workflowexecutormqprotocol/src/main/scala/io/deepsense/workflowexecutor/communication/mq/json/DefaultJsonMessageDeserializer.scala
|
Scala
|
apache-2.0
| 1,074 |
package org.jetbrains.plugins.scala.testingSupport.scalatest.scala2_13.scalatest3_1_1
import org.jetbrains.plugins.scala.testingSupport.scalatest.ScalaTestWholeSuiteTest
class Scalatest2_13_3_1_1_WholeSuiteTest extends Scalatest2_13_3_1_1_Base
with ScalaTestWholeSuiteTest
|
JetBrains/intellij-scala
|
scala/scala-impl/test/org/jetbrains/plugins/scala/testingSupport/scalatest/scala2_13/scalatest3_1_1/Scalatest2_13_3_1_1_WholeSuiteTest.scala
|
Scala
|
apache-2.0
| 277 |
/*
* Copyright (c) 2013 David Soergel <[email protected]>
* Licensed under the Apache License, Version 2.0
* http://www.apache.org/licenses/LICENSE-2.0
*/
package worldmake.storage.casbah
import collection.mutable
import com.mongodb.casbah.commons.Imports
import com.mongodb.casbah.Imports._
import com.mongodb.casbah.commons.conversions._
import com.mongodb.casbah.commons.conversions.scala._
import org.bson.{BSON, Transformer}
import java.net.URL
/**
* @author <a href="mailto:[email protected]">David Soergel</a>
*/
private[casbah] trait MongoWrapper {
def dbo: MongoDBObject
def rawString = dbo.toString()
}
class IntegrityException(s: String) extends RuntimeException(s)
private[casbah] object SerializationHelpers {
RegisterJodaTimeConversionHelpers()
RegisterURLHelpers()
/*
implicit def uuidToEventProcessor(uuid : UUID): EventProcessor = eventProcessorStore.get(uuid)
.getOrElse(throw new IntegrityException("Event Processor not found: " + uuid))
def uuidToMutableMailingList(uuid : UUID): MutableMailingList = uuidToEventProcessor(uuid) match {
case mml : MutableMailingList => mml
case _ => throw new IntegrityException("EventProcessor is not mutable mailing list: " + uuid)
}
implicit def uuidToEvent(uuid : UUID): Event = eventStore.get(uuid)
.getOrElse(throw new IntegrityException("Event not found: " + uuid))
def uuidToPrimaryEvent(uuid : UUID): PrimaryEvent = uuidToEvent(uuid) match {
case pe : PrimaryEvent => pe
case _ => throw new IntegrityException("Event is not primary: " + uuid)
}
implicit def uuidToDocument(uuid : UUID): Document = documentStore.get(uuid)
.getOrElse(throw new IntegrityException("Document not found: " + uuid))
implicit def uuidToVenue(uuid : UUID): Venue = venueStore.get(uuid)
.getOrElse(throw new IntegrityException("Venue not found: " + uuid))
implicit def uuidToMessageGenerator(uuid : UUID): MessageGenerator = messageGeneratorStore.get(uuid)
.getOrElse(throw new IntegrityException("Message generator not found: " + uuid))
*/
}
abstract class MongoSerializer[E, D](val typehint: String, constructor: MongoDBObject => D) {
def toDb(e: E): D = {
val builder = MongoDBObject.newBuilder
builder += "type" -> typehint
addFields(e, builder)
val dbo = builder.result()
constructor(dbo)
}
def addFields(e: E, builder: mutable.Builder[(String, Any), Imports.DBObject])
}
object RegisterURLHelpers extends URLSerializer with URLDeserializer {
def apply() = {
log.debug("Registering URL Serializers.")
super.register()
}
}
trait URLSerializer extends MongoConversionHelper {
private val encodeType = classOf[URL]
/** Encoding hook for MongoDB To be able to persist URL to MongoDB */
private val transformer = new Transformer {
def transform(o: AnyRef): AnyRef = {
log.trace("Encoding a java.net.URL")
o match {
// TODO There has to be a better way to marshall a URL than string munging like this...
case url: java.net.URL => "URL~%s".format(url.toExternalForm)
case _ => o
}
}
}
override def register() = {
log.trace("Hooking up java.net.URL serializer.")
BSON.addEncodingHook(encodeType, transformer)
super.register()
}
override def unregister() = {
log.trace("De-registering java.net.URL serializer.")
BSON.removeEncodingHooks(encodeType)
super.unregister()
}
}
trait URLDeserializer extends MongoConversionHelper {
private val encodeType = classOf[String]
private val transformer = new Transformer {
def transform(o: AnyRef): AnyRef = {
log.trace("Decoding java.net.URL")
o match {
case s: String if s.startsWith("URL~") && s.split("~").size == 2 => {
log.trace("DECODING: %s", s)
new java.net.URL(s.split("~")(1))
}
case _ => o
}
}
}
override def register() = {
log.trace("Hooking up java.net.URL deserializer")
BSON.addDecodingHook(encodeType, transformer)
super.register()
}
override def unregister() = {
log.trace("De-registering java.net.URL deserializer.")
BSON.removeDecodingHooks(encodeType)
super.unregister()
}
}
|
davidsoergel/worldmake
|
src/main/scala/worldmake/storage/casbah/CasbahHelpers.scala
|
Scala
|
apache-2.0
| 4,278 |
/*
* Copyright 2014 Frugal Mechanic (http://frugalmechanic.com)
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package fm.sbt
import java.util.{Collections, List}
import sbt.{RawRepository, Resolver}
final class S3RawRepository(val name: String) extends AnyVal {
def atS3(location: String): Resolver = {
require(null != location && location != "", "Empty Location!")
val pattern: List[String] = Collections.singletonList(resolvePattern(location, Resolver.mavenStyleBasePattern))
new RawRepository(new S3URLResolver(name, location, pattern))
}
private def resolvePattern(base: String, pattern: String): String = {
val normBase = base.replace('\\\\', '/')
if(normBase.endsWith("/") || pattern.startsWith("/")) normBase + pattern else normBase + "/" + pattern
}
}
|
AlwaysEncrypted/fm-sbt-s3-resolver
|
src/main/scala/fm/sbt/S3RawRepository.scala
|
Scala
|
apache-2.0
| 1,307 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql
import java.sql.{Date, Timestamp}
import scala.collection.mutable
import org.apache.spark.TestUtils.{assertNotSpilled, assertSpilled}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction, Window}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.test.SharedSQLContext
import org.apache.spark.sql.types._
import org.apache.spark.unsafe.types.CalendarInterval
/**
* Window function testing for DataFrame API.
*/
class DataFrameWindowFunctionsSuite extends QueryTest with SharedSQLContext {
import testImplicits._
test("reuse window partitionBy") {
val df = Seq((1, "1"), (2, "2"), (1, "1"), (2, "2")).toDF("key", "value")
val w = Window.partitionBy("key").orderBy("value")
checkAnswer(
df.select(
lead("key", 1).over(w),
lead("value", 1).over(w)),
Row(1, "1") :: Row(2, "2") :: Row(null, null) :: Row(null, null) :: Nil)
}
test("reuse window orderBy") {
val df = Seq((1, "1"), (2, "2"), (1, "1"), (2, "2")).toDF("key", "value")
val w = Window.orderBy("value").partitionBy("key")
checkAnswer(
df.select(
lead("key", 1).over(w),
lead("value", 1).over(w)),
Row(1, "1") :: Row(2, "2") :: Row(null, null) :: Row(null, null) :: Nil)
}
test("rank functions in unspecific window") {
val df = Seq((1, "1"), (2, "2"), (1, "2"), (2, "2")).toDF("key", "value")
df.createOrReplaceTempView("window_table")
checkAnswer(
df.select(
$"key",
max("key").over(Window.partitionBy("value").orderBy("key")),
min("key").over(Window.partitionBy("value").orderBy("key")),
mean("key").over(Window.partitionBy("value").orderBy("key")),
count("key").over(Window.partitionBy("value").orderBy("key")),
sum("key").over(Window.partitionBy("value").orderBy("key")),
ntile(2).over(Window.partitionBy("value").orderBy("key")),
row_number().over(Window.partitionBy("value").orderBy("key")),
dense_rank().over(Window.partitionBy("value").orderBy("key")),
rank().over(Window.partitionBy("value").orderBy("key")),
cume_dist().over(Window.partitionBy("value").orderBy("key")),
percent_rank().over(Window.partitionBy("value").orderBy("key"))),
Row(1, 1, 1, 1.0d, 1, 1, 1, 1, 1, 1, 1.0d, 0.0d) ::
Row(1, 1, 1, 1.0d, 1, 1, 1, 1, 1, 1, 1.0d / 3.0d, 0.0d) ::
Row(2, 2, 1, 5.0d / 3.0d, 3, 5, 1, 2, 2, 2, 1.0d, 0.5d) ::
Row(2, 2, 1, 5.0d / 3.0d, 3, 5, 2, 3, 2, 2, 1.0d, 0.5d) :: Nil)
}
test("window function should fail if order by clause is not specified") {
val df = Seq((1, "1"), (2, "2"), (1, "2"), (2, "2")).toDF("key", "value")
val e = intercept[AnalysisException](
// Here we missed .orderBy("key")!
df.select(row_number().over(Window.partitionBy("value"))).collect())
assert(e.message.contains("requires window to be ordered"))
}
test("corr, covar_pop, stddev_pop functions in specific window") {
val df = Seq(
("a", "p1", 10.0, 20.0),
("b", "p1", 20.0, 10.0),
("c", "p2", 20.0, 20.0),
("d", "p2", 20.0, 20.0),
("e", "p3", 0.0, 0.0),
("f", "p3", 6.0, 12.0),
("g", "p3", 6.0, 12.0),
("h", "p3", 8.0, 16.0),
("i", "p4", 5.0, 5.0)).toDF("key", "partitionId", "value1", "value2")
checkAnswer(
df.select(
$"key",
corr("value1", "value2").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
covar_pop("value1", "value2")
.over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
var_pop("value1")
.over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
stddev_pop("value1")
.over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
var_pop("value2")
.over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
stddev_pop("value2")
.over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing))),
// As stddev_pop(expr) = sqrt(var_pop(expr))
// the "stddev_pop" column can be calculated from the "var_pop" column.
//
// As corr(expr1, expr2) = covar_pop(expr1, expr2) / (stddev_pop(expr1) * stddev_pop(expr2))
// the "corr" column can be calculated from the "covar_pop" and the two "stddev_pop" columns.
Seq(
Row("a", -1.0, -25.0, 25.0, 5.0, 25.0, 5.0),
Row("b", -1.0, -25.0, 25.0, 5.0, 25.0, 5.0),
Row("c", null, 0.0, 0.0, 0.0, 0.0, 0.0),
Row("d", null, 0.0, 0.0, 0.0, 0.0, 0.0),
Row("e", 1.0, 18.0, 9.0, 3.0, 36.0, 6.0),
Row("f", 1.0, 18.0, 9.0, 3.0, 36.0, 6.0),
Row("g", 1.0, 18.0, 9.0, 3.0, 36.0, 6.0),
Row("h", 1.0, 18.0, 9.0, 3.0, 36.0, 6.0),
Row("i", Double.NaN, 0.0, 0.0, 0.0, 0.0, 0.0)))
}
test("covar_samp, var_samp (variance), stddev_samp (stddev) functions in specific window") {
val df = Seq(
("a", "p1", 10.0, 20.0),
("b", "p1", 20.0, 10.0),
("c", "p2", 20.0, 20.0),
("d", "p2", 20.0, 20.0),
("e", "p3", 0.0, 0.0),
("f", "p3", 6.0, 12.0),
("g", "p3", 6.0, 12.0),
("h", "p3", 8.0, 16.0),
("i", "p4", 5.0, 5.0)).toDF("key", "partitionId", "value1", "value2")
checkAnswer(
df.select(
$"key",
covar_samp("value1", "value2").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
var_samp("value1").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
variance("value1").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
stddev_samp("value1").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
stddev("value1").over(Window.partitionBy("partitionId")
.orderBy("key").rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing))
),
Seq(
Row("a", -50.0, 50.0, 50.0, 7.0710678118654755, 7.0710678118654755),
Row("b", -50.0, 50.0, 50.0, 7.0710678118654755, 7.0710678118654755),
Row("c", 0.0, 0.0, 0.0, 0.0, 0.0 ),
Row("d", 0.0, 0.0, 0.0, 0.0, 0.0 ),
Row("e", 24.0, 12.0, 12.0, 3.4641016151377544, 3.4641016151377544 ),
Row("f", 24.0, 12.0, 12.0, 3.4641016151377544, 3.4641016151377544 ),
Row("g", 24.0, 12.0, 12.0, 3.4641016151377544, 3.4641016151377544 ),
Row("h", 24.0, 12.0, 12.0, 3.4641016151377544, 3.4641016151377544 ),
Row("i", Double.NaN, Double.NaN, Double.NaN, Double.NaN, Double.NaN)))
}
test("collect_list in ascending ordered window") {
val df = Seq(
("a", "p1", "1"),
("b", "p1", "2"),
("c", "p1", "2"),
("d", "p1", null),
("e", "p1", "3"),
("f", "p2", "10"),
("g", "p2", "11"),
("h", "p3", "20"),
("i", "p4", null)).toDF("key", "partition", "value")
checkAnswer(
df.select(
$"key",
sort_array(
collect_list("value").over(Window.partitionBy($"partition").orderBy($"value")
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)))),
Seq(
Row("a", Array("1", "2", "2", "3")),
Row("b", Array("1", "2", "2", "3")),
Row("c", Array("1", "2", "2", "3")),
Row("d", Array("1", "2", "2", "3")),
Row("e", Array("1", "2", "2", "3")),
Row("f", Array("10", "11")),
Row("g", Array("10", "11")),
Row("h", Array("20")),
Row("i", Array())))
}
test("collect_list in descending ordered window") {
val df = Seq(
("a", "p1", "1"),
("b", "p1", "2"),
("c", "p1", "2"),
("d", "p1", null),
("e", "p1", "3"),
("f", "p2", "10"),
("g", "p2", "11"),
("h", "p3", "20"),
("i", "p4", null)).toDF("key", "partition", "value")
checkAnswer(
df.select(
$"key",
sort_array(
collect_list("value").over(Window.partitionBy($"partition").orderBy($"value".desc)
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)))),
Seq(
Row("a", Array("1", "2", "2", "3")),
Row("b", Array("1", "2", "2", "3")),
Row("c", Array("1", "2", "2", "3")),
Row("d", Array("1", "2", "2", "3")),
Row("e", Array("1", "2", "2", "3")),
Row("f", Array("10", "11")),
Row("g", Array("10", "11")),
Row("h", Array("20")),
Row("i", Array())))
}
test("collect_set in window") {
val df = Seq(
("a", "p1", "1"),
("b", "p1", "2"),
("c", "p1", "2"),
("d", "p1", "3"),
("e", "p1", "3"),
("f", "p2", "10"),
("g", "p2", "11"),
("h", "p3", "20")).toDF("key", "partition", "value")
checkAnswer(
df.select(
$"key",
sort_array(
collect_set("value").over(Window.partitionBy($"partition").orderBy($"value")
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)))),
Seq(
Row("a", Array("1", "2", "3")),
Row("b", Array("1", "2", "3")),
Row("c", Array("1", "2", "3")),
Row("d", Array("1", "2", "3")),
Row("e", Array("1", "2", "3")),
Row("f", Array("10", "11")),
Row("g", Array("10", "11")),
Row("h", Array("20"))))
}
test("skewness and kurtosis functions in window") {
val df = Seq(
("a", "p1", 1.0),
("b", "p1", 1.0),
("c", "p1", 2.0),
("d", "p1", 2.0),
("e", "p1", 3.0),
("f", "p1", 3.0),
("g", "p1", 3.0),
("h", "p2", 1.0),
("i", "p2", 2.0),
("j", "p2", 5.0)).toDF("key", "partition", "value")
checkAnswer(
df.select(
$"key",
skewness("value").over(Window.partitionBy("partition").orderBy($"key")
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing)),
kurtosis("value").over(Window.partitionBy("partition").orderBy($"key")
.rowsBetween(Window.unboundedPreceding, Window.unboundedFollowing))),
// results are checked by scipy.stats.skew() and scipy.stats.kurtosis()
Seq(
Row("a", -0.27238010581457267, -1.506920415224914),
Row("b", -0.27238010581457267, -1.506920415224914),
Row("c", -0.27238010581457267, -1.506920415224914),
Row("d", -0.27238010581457267, -1.506920415224914),
Row("e", -0.27238010581457267, -1.506920415224914),
Row("f", -0.27238010581457267, -1.506920415224914),
Row("g", -0.27238010581457267, -1.506920415224914),
Row("h", 0.5280049792181881, -1.5000000000000013),
Row("i", 0.5280049792181881, -1.5000000000000013),
Row("j", 0.5280049792181881, -1.5000000000000013)))
}
test("aggregation function on invalid column") {
val df = Seq((1, "1")).toDF("key", "value")
val e = intercept[AnalysisException](
df.select($"key", count("invalid").over()))
assert(e.message.contains("cannot resolve '`invalid`' given input columns: [key, value]"))
}
test("numerical aggregate functions on string column") {
val df = Seq((1, "a", "b")).toDF("key", "value1", "value2")
checkAnswer(
df.select($"key",
var_pop("value1").over(),
variance("value1").over(),
stddev_pop("value1").over(),
stddev("value1").over(),
sum("value1").over(),
mean("value1").over(),
avg("value1").over(),
corr("value1", "value2").over(),
covar_pop("value1", "value2").over(),
covar_samp("value1", "value2").over(),
skewness("value1").over(),
kurtosis("value1").over()),
Seq(Row(1, null, null, null, null, null, null, null, null, null, null, null, null)))
}
test("statistical functions") {
val df = Seq(("a", 1), ("a", 1), ("a", 2), ("a", 2), ("b", 4), ("b", 3), ("b", 2)).
toDF("key", "value")
val window = Window.partitionBy($"key")
checkAnswer(
df.select(
$"key",
var_pop($"value").over(window),
var_samp($"value").over(window),
approx_count_distinct($"value").over(window)),
Seq.fill(4)(Row("a", 1.0d / 4.0d, 1.0d / 3.0d, 2))
++ Seq.fill(3)(Row("b", 2.0d / 3.0d, 1.0d, 3)))
}
test("window function with aggregates") {
val df = Seq(("a", 1), ("a", 1), ("a", 2), ("a", 2), ("b", 4), ("b", 3), ("b", 2)).
toDF("key", "value")
val window = Window.orderBy()
checkAnswer(
df.groupBy($"key")
.agg(
sum($"value"),
sum(sum($"value")).over(window) - sum($"value")),
Seq(Row("a", 6, 9), Row("b", 9, 6)))
}
test("SPARK-16195 empty over spec") {
val df = Seq(("a", 1), ("a", 1), ("a", 2), ("b", 2)).
toDF("key", "value")
df.createOrReplaceTempView("window_table")
checkAnswer(
df.select($"key", $"value", sum($"value").over(), avg($"value").over()),
Seq(Row("a", 1, 6, 1.5), Row("a", 1, 6, 1.5), Row("a", 2, 6, 1.5), Row("b", 2, 6, 1.5)))
checkAnswer(
sql("select key, value, sum(value) over(), avg(value) over() from window_table"),
Seq(Row("a", 1, 6, 1.5), Row("a", 1, 6, 1.5), Row("a", 2, 6, 1.5), Row("b", 2, 6, 1.5)))
}
test("window function with udaf") {
val udaf = new UserDefinedAggregateFunction {
def inputSchema: StructType = new StructType()
.add("a", LongType)
.add("b", LongType)
def bufferSchema: StructType = new StructType()
.add("product", LongType)
def dataType: DataType = LongType
def deterministic: Boolean = true
def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = 0L
}
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
if (!(input.isNullAt(0) || input.isNullAt(1))) {
buffer(0) = buffer.getLong(0) + input.getLong(0) * input.getLong(1)
}
}
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0) = buffer1.getLong(0) + buffer2.getLong(0)
}
def evaluate(buffer: Row): Any =
buffer.getLong(0)
}
val df = Seq(
("a", 1, 1),
("a", 1, 5),
("a", 2, 10),
("a", 2, -1),
("b", 4, 7),
("b", 3, 8),
("b", 2, 4))
.toDF("key", "a", "b")
val window = Window.partitionBy($"key").orderBy($"a").rangeBetween(Long.MinValue, 0L)
checkAnswer(
df.select(
$"key",
$"a",
$"b",
udaf($"a", $"b").over(window)),
Seq(
Row("a", 1, 1, 6),
Row("a", 1, 5, 6),
Row("a", 2, 10, 24),
Row("a", 2, -1, 24),
Row("b", 4, 7, 60),
Row("b", 3, 8, 32),
Row("b", 2, 4, 8)))
}
test("null inputs") {
val df = Seq(("a", 1), ("a", 1), ("a", 2), ("a", 2), ("b", 4), ("b", 3), ("b", 2))
.toDF("key", "value")
val window = Window.orderBy()
checkAnswer(
df.select(
$"key",
$"value",
avg(lit(null)).over(window),
sum(lit(null)).over(window)),
Seq(
Row("a", 1, null, null),
Row("a", 1, null, null),
Row("a", 2, null, null),
Row("a", 2, null, null),
Row("b", 4, null, null),
Row("b", 3, null, null),
Row("b", 2, null, null)))
}
test("last/first with ignoreNulls") {
val nullStr: String = null
val df = Seq(
("a", 0, nullStr),
("a", 1, "x"),
("a", 2, "y"),
("a", 3, "z"),
("a", 4, nullStr),
("b", 1, nullStr),
("b", 2, nullStr)).
toDF("key", "order", "value")
val window = Window.partitionBy($"key").orderBy($"order")
checkAnswer(
df.select(
$"key",
$"order",
first($"value").over(window),
first($"value", ignoreNulls = false).over(window),
first($"value", ignoreNulls = true).over(window),
last($"value").over(window),
last($"value", ignoreNulls = false).over(window),
last($"value", ignoreNulls = true).over(window)),
Seq(
Row("a", 0, null, null, null, null, null, null),
Row("a", 1, null, null, "x", "x", "x", "x"),
Row("a", 2, null, null, "x", "y", "y", "y"),
Row("a", 3, null, null, "x", "z", "z", "z"),
Row("a", 4, null, null, "x", null, null, "z"),
Row("b", 1, null, null, null, null, null, null),
Row("b", 2, null, null, null, null, null, null)))
}
test("last/first on descending ordered window") {
val nullStr: String = null
val df = Seq(
("a", 0, nullStr),
("a", 1, "x"),
("a", 2, "y"),
("a", 3, "z"),
("a", 4, "v"),
("b", 1, "k"),
("b", 2, "l"),
("b", 3, nullStr)).
toDF("key", "order", "value")
val window = Window.partitionBy($"key").orderBy($"order".desc)
checkAnswer(
df.select(
$"key",
$"order",
first($"value").over(window),
first($"value", ignoreNulls = false).over(window),
first($"value", ignoreNulls = true).over(window),
last($"value").over(window),
last($"value", ignoreNulls = false).over(window),
last($"value", ignoreNulls = true).over(window)),
Seq(
Row("a", 0, "v", "v", "v", null, null, "x"),
Row("a", 1, "v", "v", "v", "x", "x", "x"),
Row("a", 2, "v", "v", "v", "y", "y", "y"),
Row("a", 3, "v", "v", "v", "z", "z", "z"),
Row("a", 4, "v", "v", "v", "v", "v", "v"),
Row("b", 1, null, null, "l", "k", "k", "k"),
Row("b", 2, null, null, "l", "l", "l", "l"),
Row("b", 3, null, null, null, null, null, null)))
}
test("SPARK-12989 ExtractWindowExpressions treats alias as regular attribute") {
val src = Seq((0, 3, 5)).toDF("a", "b", "c")
.withColumn("Data", struct("a", "b"))
.drop("a")
.drop("b")
val winSpec = Window.partitionBy("Data.a", "Data.b").orderBy($"c".desc)
val df = src.select($"*", max("c").over(winSpec) as "max")
checkAnswer(df, Row(5, Row(0, 3), 5))
}
test("aggregation and rows between with unbounded + predicate pushdown") {
val df = Seq((1, "1"), (2, "2"), (2, "3"), (1, "3"), (3, "2"), (4, "3")).toDF("key", "value")
df.createOrReplaceTempView("window_table")
val selectList = Seq($"key", $"value",
last("key").over(
Window.partitionBy($"value").orderBy($"key").rowsBetween(0, Long.MaxValue)),
last("key").over(
Window.partitionBy($"value").orderBy($"key").rowsBetween(Long.MinValue, 0)),
last("key").over(Window.partitionBy($"value").orderBy($"key").rowsBetween(-1, 1)))
checkAnswer(
df.select(selectList: _*).where($"value" < "3"),
Seq(Row(1, "1", 1, 1, 1), Row(2, "2", 3, 2, 3), Row(3, "2", 3, 3, 3)))
}
test("aggregation and range between with unbounded + predicate pushdown") {
val df = Seq((5, "1"), (5, "2"), (4, "2"), (6, "2"), (3, "1"), (2, "2")).toDF("key", "value")
df.createOrReplaceTempView("window_table")
val selectList = Seq($"key", $"value",
last("value").over(
Window.partitionBy($"value").orderBy($"key").rangeBetween(-2, -1)).equalTo("2")
.as("last_v"),
avg("key").over(Window.partitionBy("value").orderBy("key").rangeBetween(Long.MinValue, 1))
.as("avg_key1"),
avg("key").over(Window.partitionBy("value").orderBy("key").rangeBetween(0, Long.MaxValue))
.as("avg_key2"),
avg("key").over(Window.partitionBy("value").orderBy("key").rangeBetween(-1, 1))
.as("avg_key3"))
checkAnswer(
df.select(selectList: _*).where($"value" < 2),
Seq(Row(3, "1", null, 3.0, 4.0, 3.0), Row(5, "1", false, 4.0, 5.0, 5.0)))
}
test("Window spill with less than the inMemoryThreshold") {
val df = Seq((1, "1"), (2, "2"), (1, "3"), (2, "4")).toDF("key", "value")
val window = Window.partitionBy($"key").orderBy($"value")
withSQLConf(SQLConf.WINDOW_EXEC_BUFFER_IN_MEMORY_THRESHOLD.key -> "2",
SQLConf.WINDOW_EXEC_BUFFER_SPILL_THRESHOLD.key -> "2") {
assertNotSpilled(sparkContext, "select") {
df.select($"key", sum("value").over(window)).collect()
}
}
}
test("Window spill with more than the inMemoryThreshold but less than the spillThreshold") {
val df = Seq((1, "1"), (2, "2"), (1, "3"), (2, "4")).toDF("key", "value")
val window = Window.partitionBy($"key").orderBy($"value")
withSQLConf(SQLConf.WINDOW_EXEC_BUFFER_IN_MEMORY_THRESHOLD.key -> "1",
SQLConf.WINDOW_EXEC_BUFFER_SPILL_THRESHOLD.key -> "2") {
assertNotSpilled(sparkContext, "select") {
df.select($"key", sum("value").over(window)).collect()
}
}
}
test("Window spill with more than the inMemoryThreshold and spillThreshold") {
val df = Seq((1, "1"), (2, "2"), (1, "3"), (2, "4")).toDF("key", "value")
val window = Window.partitionBy($"key").orderBy($"value")
withSQLConf(SQLConf.WINDOW_EXEC_BUFFER_IN_MEMORY_THRESHOLD.key -> "1",
SQLConf.WINDOW_EXEC_BUFFER_SPILL_THRESHOLD.key -> "1") {
assertSpilled(sparkContext, "select") {
df.select($"key", sum("value").over(window)).collect()
}
}
}
test("SPARK-21258: complex object in combination with spilling") {
// Make sure we trigger the spilling path.
withSQLConf(SQLConf.WINDOW_EXEC_BUFFER_IN_MEMORY_THRESHOLD.key -> "1",
SQLConf.WINDOW_EXEC_BUFFER_SPILL_THRESHOLD.key -> "17") {
val sampleSchema = new StructType().
add("f0", StringType).
add("f1", LongType).
add("f2", ArrayType(new StructType().
add("f20", StringType))).
add("f3", ArrayType(new StructType().
add("f30", StringType)))
val w0 = Window.partitionBy("f0").orderBy("f1")
val w1 = w0.rowsBetween(Long.MinValue, Long.MaxValue)
val c0 = first(struct($"f2", $"f3")).over(w0) as "c0"
val c1 = last(struct($"f2", $"f3")).over(w1) as "c1"
val input =
"""{"f1":1497820153720,"f2":[{"f20":"x","f21":0}],"f3":[{"f30":"x","f31":0}]}
|{"f1":1497802179638}
|{"f1":1497802189347}
|{"f1":1497802189593}
|{"f1":1497802189597}
|{"f1":1497802189599}
|{"f1":1497802192103}
|{"f1":1497802193414}
|{"f1":1497802193577}
|{"f1":1497802193709}
|{"f1":1497802202883}
|{"f1":1497802203006}
|{"f1":1497802203743}
|{"f1":1497802203834}
|{"f1":1497802203887}
|{"f1":1497802203893}
|{"f1":1497802203976}
|{"f1":1497820168098}
|""".stripMargin.split("\\n").toSeq
import testImplicits._
assertSpilled(sparkContext, "select") {
spark.read.schema(sampleSchema).json(input.toDS()).select(c0, c1).foreach { _ => () }
}
}
}
}
|
ddna1021/spark
|
sql/core/src/test/scala/org/apache/spark/sql/DataFrameWindowFunctionsSuite.scala
|
Scala
|
apache-2.0
| 24,169 |
package exercise
import org.scalatest.{BeforeAndAfterAll, Matchers, WordSpecLike}
import akka.actor.{ActorSystem, Props}
import akka.testkit.{ImplicitSender, TestKit}
/**
* Created by guisil on 18/01/2017.
*/
class ExpressionManagerSpec extends TestKit(ActorSystem("ExpressionManagerIntegrationSpec")) with ImplicitSender with WordSpecLike with Matchers with BeforeAndAfterAll {
private val expressionManagerRef = system.actorOf(Props(classOf[ExpressionManager]), "expression-manager")
override def afterAll() {
TestKit.shutdownActorSystem(system)
}
"An ExpressionManager" should {
"Reply with the result of an expression containing parenthesis" in {
expectExpressionResultMessage("(1)", 1)
expectExpressionResultMessage("(1-1)*2", 0)
expectExpressionResultMessage("(1-1)*(2+4)", 0)
expectExpressionResultMessage("(1-1)*2+3*(1-3+4)+10/2", 11)
expectExpressionResultMessage("(1-1)*(2-4*9)+3*(3*5+4)+10/(3+2)", 59)
expectExpressionResultMessage("(1-2)*(2-4*9)+3*(3*5+4)+10/(3+2)", 93)
}
"Reply with the result of an expression not containing parenthesis" in {
expectExpressionResultMessage("1", 1)
expectExpressionResultMessage("1-1", 0)
expectExpressionResultMessage("1+4*2-3", 6)
expectExpressionResultMessage("1-1*2-4*9+3*1-3+4+10/2", -28)
}
"Reply with an exception when the expression is invalid" in {
expressionManagerRef ! StartEvaluation("1-")
expectMsgClass[IllegalArgumentException](classOf[IllegalArgumentException])
expressionManagerRef ! StartEvaluation("(1-2")
expectMsgClass[IllegalArgumentException](classOf[IllegalArgumentException])
expressionManagerRef ! StartEvaluation("(1-2+")
expectMsgClass[IllegalArgumentException](classOf[IllegalArgumentException])
expressionManagerRef ! StartEvaluation("1/0")
expectMsgClass[IllegalArgumentException](classOf[IllegalArgumentException])
}
}
private def expectExpressionResultMessage(expression: String, expectedResult: Double): Unit = {
expressionManagerRef ! StartEvaluation(expression)
expectMsg(EvaluationResult(expression, expectedResult))
}
}
|
guisil/scala-akka-http-calculator
|
src/test/scala/exercise/ExpressionManagerSpec.scala
|
Scala
|
mit
| 2,180 |
package com.github.gigurra.glasciia
import com.badlogic.gdx.Gdx
import com.badlogic.gdx.graphics.{Pixmap, Texture}
import com.badlogic.gdx.graphics.g2d.TextureRegion
import com.badlogic.gdx.graphics.glutils.FrameBuffer
import com.github.gigurra.glasciia.Glasciia._
/**
* Created by johan on 2017-01-14.
*/
case class TextureRegionFrameBuffer(region: TextureRegion,
useDepth: Boolean,
useStencil: Boolean)
extends FrameBuffer(
region.getTexture.getTextureData.getFormat,
region.width,
region.height,
useDepth,
useStencil
) {
def glFormat: Int = {
Pixmap.Format.toGlFormat(format)
}
def glType: Int = {
Pixmap.Format.toGlType(format)
}
def use(content: => Unit): Unit = {
begin()
content
end()
}
override protected def createColorTexture: Texture = {
region.getTexture
}
override protected def disposeColorTexture(colorTexture: Texture): Unit = {
// Don't dispose anything
}
override protected def setFrameBufferViewport(): Unit = {
Gdx.gl20.glViewport(region.x, region.y, region.width, region.height)
}
}
|
GiGurra/glasciia
|
glasciia-core/src/main/scala/com/github/gigurra/glasciia/TextureRegionFrameBuffer.scala
|
Scala
|
mit
| 1,168 |
package net.fehmicansaglam.tepkin.examples
import akka.stream.ActorMaterializer
import akka.util.Timeout
import net.fehmicansaglam.bson.BsonDocument
import net.fehmicansaglam.tepkin.MongoClient
import scala.concurrent.duration._
object TailableCursorExample extends App {
val client = MongoClient("mongodb://localhost")
import client.{context, ec}
implicit val timeout: Timeout = 5.seconds
implicit val mat = ActorMaterializer()
val db = client("tepkin")
val messages = db("messages")
db.createCollection("messages", capped = Some(true), size = Some(100000000))
messages
.find(query = BsonDocument.empty, tailable = true)
.runForeach(println)
}
|
cancobanoglu/tepkin
|
examples/src/main/scala/net/fehmicansaglam/tepkin/examples/TailableCursorExample.scala
|
Scala
|
apache-2.0
| 678 |
package chandu0101.scalajs.react.components
import japgolly.scalajs.react.vdom.html_<^._
import japgolly.scalajs.react.Callback
import japgolly.scalajs.react.BackendScope
import japgolly.scalajs.react.ScalaComponent
import scala.collection.immutable
import scalacss.ProdDefaults._
import scalacss.ScalaCssReact.scalacssStyleaToTagMod
/**
* Companion object of ReactTable, with tons of little utilities
*/
object ReactTable {
/**
* The direction of the sort
*/
object SortDirection extends Enumeration {
type SortDirection = Value
val asc, dsc = Value
}
/*
* Pass this to the ColumnConfig to sort using an ordering
*/
// def Sort[T, B](fn: T => B)(implicit ordering: Ordering[B]): (T, T) => Boolean = {
// (m1: T, m2: T) =>
// ordering.compare(fn(m1), fn(m2)) > 0
// }
// /*
// * Pass this to the ColumnConfig to sort a string ignoring case using an ordering
// */
// def IgnoreCaseStringSort[T](fn: T => String): (T, T) => Boolean =
// (m1: T, m2: T) => fn(m1).compareToIgnoreCase(fn(m2)) > 0
def DefaultOrdering[T, B](fn: T => B)(implicit ordering: Ordering[B]) = new Ordering[T] {
def compare(a: T, b: T) = ordering.compare(fn(a), fn(b))
}
def ignoreCaseStringOrdering[T](fn: T => String) = new Ordering[T] {
def compare(a: T, b: T) = fn(a).compareToIgnoreCase(fn(b))
}
class Style extends StyleSheet.Inline {
import dsl._
val reactTableContainer = style(display.flex, flexDirection.column)
val table = style(
display.flex,
flexDirection.column,
boxShadow := "0 1px 3px 0 rgba(0, 0, 0, 0.12), 0 1px 2px 0 rgba(0, 0, 0, 0.24)",
media.maxWidth(740 px)(boxShadow := "none")
)
val tableRow = style(padding :=! "0.8rem",
&.hover(backgroundColor :=! "rgba(244, 244, 244, 0.77)"),
media.maxWidth(740 px)(boxShadow := "0 1px 3px grey", margin(5 px)))
val tableHeader = style(fontWeight.bold, borderBottom :=! "1px solid #e0e0e0", tableRow)
val settingsBar = style(display.flex, margin :=! "15px 0", justifyContent.spaceBetween)
val sortIcon = styleF.bool(
ascending =>
styleS(
&.after(fontSize(9 px), marginLeft(5 px), if (ascending) { content := "'\\\\25B2'" } else {
content := "'\\\\25BC'"
})))
}
object DefaultStyle extends Style
type CellRenderer[T] = T => VdomNode
def DefaultCellRenderer[T]: CellRenderer[T] = { model =>
<.span(model.toString)
}
def EmailRenderer[T](fn: T => String): CellRenderer[T] = { t =>
val str = fn(t)
<.a(^.whiteSpace.nowrap, ^.href := s"mailto:${str}", str)
}
def OptionRenderer[T, B](defaultValue: VdomNode = "", bRenderer: CellRenderer[B])(
fn: T => Option[B]): CellRenderer[T] =
t => fn(t).fold(defaultValue)(bRenderer)
case class ColumnConfig[T](name: String,
cellRenderer: CellRenderer[T],
//sortBy: Option[(T, T) => Boolean] = None,
width: Option[String] = None,
nowrap: Boolean = false)(implicit val ordering: Ordering[T])
def SimpleStringConfig[T](name: String,
stringRetriever: T => String,
width: Option[String] = None,
nowrap: Boolean = false): ReactTable.ColumnConfig[T] = {
val renderer: CellRenderer[T] = if (nowrap) { t =>
<.span(stringRetriever(t))
} else { t =>
stringRetriever(t)
}
ColumnConfig(name, renderer, width, nowrap)(ignoreCaseStringOrdering(stringRetriever))
}
}
/**
* A relatively simple html/react table with a pager.
* You should pass in the data as a sequence of items of type T
* But you should also pass a list of Column Configurations, each of which describes how to get to each column for a given item in the data, how to display it, how to sort it, etc.
*/
case class ReactTable[T](data: Seq[T],
configs: List[ReactTable.ColumnConfig[T]] = List(),
rowsPerPage: Int = 5,
style: ReactTable.Style = ReactTable.DefaultStyle,
enableSearch: Boolean = true,
searchBoxStyle: ReactSearchBox.Style = ReactSearchBox.DefaultStyle,
onRowClick: (Int) => Callback = { _ =>
Callback {}
},
searchStringRetriever: T => String = { t: T =>
t.toString
}) {
import ReactTable._
import SortDirection._
case class State(filterText: String,
offset: Int,
rowsPerPage: Int,
filteredData: Seq[T],
sortedState: Map[Int, SortDirection])
class Backend(t: BackendScope[Props, State]) {
def onTextChange(props: Props)(value: String): Callback =
t.modState(_.copy(filteredData = getFilteredData(value, props.data), offset = 0))
def onPreviousClick: Callback =
t.modState(s => s.copy(offset = s.offset - s.rowsPerPage))
def onNextClick: Callback =
t.modState(s => s.copy(offset = s.offset + s.rowsPerPage))
def getFilteredData(text: String, data: Seq[T]): Seq[T] = {
if (text.isEmpty) {
data
} else {
data.filter(searchStringRetriever(_).toLowerCase.contains(text.toLowerCase))
}
}
def sort(ordering: Ordering[T], columnIndex: Int): Callback =
t.modState { state =>
val rows = state.filteredData
state.sortedState.get(columnIndex) match {
case Some(asc) =>
state.copy(filteredData = rows.sorted(ordering.reverse),
sortedState = Map(columnIndex -> dsc),
offset = 0)
case _ =>
state.copy(filteredData = rows.sorted(ordering),
sortedState = Map(columnIndex -> asc),
offset = 0)
}
}
def onPageSizeChange(value: String): Callback =
t.modState(_.copy(rowsPerPage = value.toInt))
def render(props: Props, state: State): VdomElement = {
def settingsBar = {
var value = ""
var options: List[String] = Nil
val total = state.filteredData.length
if (total > props.rowsPerPage) {
value = state.rowsPerPage.toString
options = immutable.Range
.inclusive(props.rowsPerPage, total, 10 * (total / 100 + 1))
.:+(total)
.toList
.map(_.toString)
}
<.div(props.style.settingsBar)(<.div(<.strong("Total: " + state.filteredData.size)),
DefaultSelect(label = "Page Size: ",
options = options,
value = value,
onChange = onPageSizeChange))
}
def renderHeader: TagMod =
<.tr(
props.style.tableHeader,
props.configs.zipWithIndex.map {
case (config, columnIndex) =>
val cell = getHeaderDiv(config)
// config.sortBy.fold(cell(config.name.capitalize))(sortByFn =>
cell(
^.cursor := "pointer",
^.onClick --> sort(config.ordering, columnIndex),
config.name.capitalize,
props.style
.sortIcon(state.sortedState.isDefinedAt(columnIndex) && state.sortedState(
columnIndex) == asc)
.when(state.sortedState.isDefinedAt(columnIndex))
)
//)
}.toTagMod
)
def renderRow(model: T): TagMod =
<.tr(
props.style.tableRow,
props.configs
.map(
config =>
<.td(^.whiteSpace.nowrap.when(config.nowrap),
^.verticalAlign.middle,
config.cellRenderer(model)))
.toTagMod
)
val rows = state.filteredData
.slice(state.offset, state.offset + state.rowsPerPage)
.zipWithIndex
.map {
case (row, i) => renderRow(row) //tableRow.withKey(i)((row, props))
}
.toTagMod
<.div(
props.style.reactTableContainer,
ReactSearchBox(onTextChange = onTextChange(props) _, style = props.searchBoxStyle)
.when(props.enableSearch),
settingsBar,
<.div(props.style.table, <.table(<.thead(renderHeader()), <.tbody(rows))),
Pager(state.rowsPerPage,
state.filteredData.length,
state.offset,
onNextClick,
onPreviousClick)
)
}
}
def getHeaderDiv(config: ColumnConfig[T]): TagMod = {
config.width.fold(<.th())(width => <.th(^.width := width))
}
def arrowUp: TagMod =
TagMod(^.width := 0.px,
^.height := 0.px,
^.borderLeft := "5px solid transparent",
^.borderRight := "5px solid transparent",
^.borderBottom := "5px solid black")
def arrowDown: TagMod =
TagMod(^.width := 0.px,
^.height := 0.px,
^.borderLeft := "5px solid transparent",
^.borderRight := "5px solid transparent",
^.borderTop := "5px solid black")
def emptyClass: TagMod =
TagMod(^.padding := "1px")
val component = ScalaComponent
.builder[Props]("ReactTable")
.initialStateFromProps(props =>
State(filterText = "", offset = 0, props.rowsPerPage, props.data, Map()))
.renderBackend[Backend]
.componentWillReceiveProps(e =>
Callback.when(e.currentProps.data != e.nextProps.data)(
e.backend.onTextChange(e.nextProps)(e.state.filterText)))
.build
case class Props(data: Seq[T],
configs: List[ColumnConfig[T]],
rowsPerPage: Int,
style: Style,
enableSearch: Boolean,
searchBoxStyle: ReactSearchBox.Style)
def apply() = component(Props(data, configs, rowsPerPage, style, enableSearch, searchBoxStyle))
}
|
chandu0101/scalajs-react-components
|
core/src/main/scala/chandu0101/scalajs/react/components/ReactTable.scala
|
Scala
|
apache-2.0
| 10,282 |
package org.scaladebugger.api.profiles.swappable
import org.scaladebugger.api.profiles.ProfileManager
import org.scaladebugger.api.profiles.traits.DebugProfile
/**
* Represents the management functionality of swapping debug profiles.
*/
trait SwappableDebugProfileManagement { this: DebugProfile =>
protected val profileManager: ProfileManager
@volatile private var currentProfileName = ""
/**
* Sets the current profile to the one with the provided name.
*
* @param name The name of the profile
* @return The updated profile
*/
def use(name: String): DebugProfile = {
currentProfileName = name
this
}
/**
* Retrieves the current underlying profile.
*
* @return The active underlying profile
*/
def withCurrentProfile: DebugProfile = withProfile(currentProfileName)
/**
* Retrieves the profile with the provided name.
*
* @param name The name of the profile
* @throws AssertionError If the profile is not found
* @return The debug profile
*/
@throws[AssertionError]
def withProfile(name: String): DebugProfile = {
val profile = profileManager.retrieve(name)
assert(profile.nonEmpty, s"Profile $name does not exist!")
profile.get
}
}
|
chipsenkbeil/scala-debugger
|
scala-debugger-api/src/main/scala/org/scaladebugger/api/profiles/swappable/SwappableDebugProfileManagement.scala
|
Scala
|
apache-2.0
| 1,230 |
package com.twitter.algebird
import java.util.PriorityQueue
import scala.collection.generic.CanBuildFrom
/**
* Aggregators compose well.
*
* To create a parallel aggregator that operates on a single
* input in parallel, use:
* GeneratedTupleAggregator.from2((agg1, agg2))
*/
object Aggregator extends java.io.Serializable {
implicit def applicative[I]: Applicative[({ type L[O] = Aggregator[I, _, O] })#L] = new AggregatorApplicative[I]
/**
* This is a trivial aggregator that always returns a single value
*/
def const[T](t: T): MonoidAggregator[Any, Unit, T] =
prepareMonoid { _: Any => () }
.andThenPresent(_ => t)
/**
* Using Aggregator.prepare,present you can add to this aggregator
*/
def fromReduce[T](red: (T, T) => T): Aggregator[T, T, T] = fromSemigroup(Semigroup.from(red))
def fromSemigroup[T](implicit sg: Semigroup[T]): Aggregator[T, T, T] = new Aggregator[T, T, T] {
def prepare(input: T) = input
def semigroup = sg
def present(reduction: T) = reduction
}
def fromMonoid[T](implicit mon: Monoid[T]): MonoidAggregator[T, T, T] = prepareMonoid(identity[T])
// Uses the product from the ring
def fromRing[T](implicit rng: Ring[T]): RingAggregator[T, T, T] = fromRing[T, T](rng, identity[T])
def fromMonoid[F, T](implicit mon: Monoid[T], prep: F => T): MonoidAggregator[F, T, T] =
prepareMonoid(prep)(mon)
def prepareMonoid[F, T](prep: F => T)(implicit m: Monoid[T]): MonoidAggregator[F, T, T] = new MonoidAggregator[F, T, T] {
def prepare(input: F) = prep(input)
def monoid = m
def present(reduction: T) = reduction
}
// Uses the product from the ring
def fromRing[F, T](implicit rng: Ring[T], prep: F => T): RingAggregator[F, T, T] = new RingAggregator[F, T, T] {
def prepare(input: F) = prep(input)
def ring = rng
def present(reduction: T) = reduction
}
/**
* How many items satisfy a predicate
*/
def count[T](pred: T => Boolean): MonoidAggregator[T, Long, Long] =
prepareMonoid { t: T => if (pred(t)) 1L else 0L }
/**
* Do any items satisfy some predicate
*/
def exists[T](pred: T => Boolean): MonoidAggregator[T, Boolean, Boolean] =
prepareMonoid(pred)(OrVal.unboxedMonoid)
/**
* Do all items satisfy a predicate
*/
def forall[T](pred: T => Boolean): MonoidAggregator[T, Boolean, Boolean] =
prepareMonoid(pred)(AndVal.unboxedMonoid)
/**
* Take the first (left most in reduce order) item found
*/
def head[T]: Aggregator[T, T, T] = fromReduce[T] { (l, r) => l }
/**
* Take the last (right most in reduce order) item found
*/
def last[T]: Aggregator[T, T, T] = fromReduce[T] { (l, r) => r }
/**
* Get the maximum item
*/
def max[T: Ordering]: Aggregator[T, T, T] = new MaxAggregator[T]
def maxBy[U, T: Ordering](fn: U => T): Aggregator[U, U, U] = {
implicit val ordU = Ordering.by(fn)
max[U]
}
/**
* Get the minimum item
*/
def min[T: Ordering]: Aggregator[T, T, T] = new MinAggregator[T]
def minBy[U, T: Ordering](fn: U => T): Aggregator[U, U, U] = {
implicit val ordU = Ordering.by(fn)
min[U]
}
/**
* This returns the number of items we find
*/
def size: MonoidAggregator[Any, Long, Long] =
prepareMonoid { (_: Any) => 1L }
/**
* Take the smallest `count` items using a heap
*/
def sortedTake[T: Ordering](count: Int): MonoidAggregator[T, PriorityQueue[T], Seq[T]] =
new mutable.PriorityQueueToListAggregator[T](count)
/**
* Take the largest `count` items using a heap
*/
def sortedReverseTake[T: Ordering](count: Int): MonoidAggregator[T, PriorityQueue[T], Seq[T]] =
new mutable.PriorityQueueToListAggregator[T](count)(implicitly[Ordering[T]].reverse)
/**
* Put everything in a List. Note, this could fill the memory if the List is very large.
*/
def toList[T]: MonoidAggregator[T, List[T], List[T]] =
prepareMonoid { t: T => List(t) }
/**
* Put everything in a Set. Note, this could fill the memory if the Set is very large.
*/
def toSet[T]: MonoidAggregator[T, Set[T], Set[T]] =
prepareMonoid { t: T => Set(t) }
/**
* This builds an in-memory Set, and then finally gets the size of that set.
* This may not be scalable if the Uniques are very large. You might check the
* HyperLogLog Aggregator to get an approximate version of this that is scalable.
*/
def uniqueCount[T]: MonoidAggregator[T, Set[T], Int] =
toSet[T].andThenPresent(_.size)
}
/**
* This is a type that models map/reduce(map). First each item is mapped,
* then we reduce with a semigroup, then finally we present the results.
*
* Unlike Fold, Aggregator keeps it's middle aggregation type externally visible.
* This is because Aggregators are useful in parallel map/reduce systems where
* there may be some additional types needed to cross the map/reduce boundary
* (such a serialization and intermediate storage). If you don't care about the
* middle type, an _ may be used and the main utility of the instance is still
* preserved (e.g. def operate[T](ag: Aggregator[T, _, Int]): Int)
*
* Note, join is very useful to combine multiple aggregations with one pass.
* Also GeneratedTupleAggregator.fromN((agg1, agg2, ... aggN)) can glue these
* together well.
*
* This type is the the Fold.M from Haskell's fold package:
* https://hackage.haskell.org/package/folds-0.6.2/docs/Data-Fold-M.html
*/
trait Aggregator[-A, B, +C] extends java.io.Serializable { self =>
def prepare(input: A): B
def semigroup: Semigroup[B]
def present(reduction: B): C
/* *****
* All the following are in terms of the above
*/
/**
* combine two inner values
*/
def reduce(l: B, r: B): B = semigroup.plus(l, r)
/**
* This may error if items is empty. To be safe you might use reduceOption
* if you don't know that items is non-empty
*/
def reduce(items: TraversableOnce[B]): B = semigroup.sumOption(items).get
/**
* This is the safe version of the above. If the input in empty, return None,
* else reduce the items
*/
def reduceOption(items: TraversableOnce[B]): Option[B] = semigroup.sumOption(items)
/**
* This may error if inputs are empty (for Monoid Aggregators it never will, instead
* you see present(Monoid.zero[B])
*/
def apply(inputs: TraversableOnce[A]): C = present(reduce(inputs.map(prepare)))
/**
* This returns None if the inputs are empty
*/
def applyOption(inputs: TraversableOnce[A]): Option[C] =
reduceOption(inputs.map(prepare))
.map(present)
/**
* This returns the cumulative sum of its inputs, in the same order.
* If the inputs are empty, the result will be empty too.
*/
def cumulativeIterator(inputs: Iterator[A]): Iterator[C] =
inputs
.scanLeft(None: Option[B]) {
case (None, a) => Some(prepare(a))
case (Some(b), a) => Some(append(b, a))
}
.collect { case Some(b) => present(b) }
/**
* This returns the cumulative sum of its inputs, in the same order.
* If the inputs are empty, the result will be empty too.
*/
def applyCumulatively[In <: TraversableOnce[A], Out](inputs: In)(implicit bf: CanBuildFrom[In, C, Out]): Out = {
val builder = bf()
builder ++= cumulativeIterator(inputs.toIterator)
builder.result
}
def append(l: B, r: A): B = reduce(l, prepare(r))
def appendAll(old: B, items: TraversableOnce[A]): B =
if (items.isEmpty) old else reduce(old, reduce(items.map(prepare)))
/** Like calling andThen on the present function */
def andThenPresent[D](present2: C => D): Aggregator[A, B, D] =
new Aggregator[A, B, D] {
def prepare(input: A) = self.prepare(input)
def semigroup = self.semigroup
def present(reduction: B) = present2(self.present(reduction))
}
/** Like calling compose on the prepare function */
def composePrepare[A1](prepare2: A1 => A): Aggregator[A1, B, C] =
new Aggregator[A1, B, C] {
def prepare(input: A1) = self.prepare(prepare2(input))
def semigroup = self.semigroup
def present(reduction: B) = self.present(reduction)
}
/**
* This allows you to run two aggregators on the same data with a single pass
*/
def join[A2 <: A, B2, C2](that: Aggregator[A2, B2, C2]): Aggregator[A2, (B, B2), (C, C2)] =
GeneratedTupleAggregator.from2((this, that))
/**
* This allows you to join two aggregators into one that takes a tuple input,
* which in turn allows you to chain .composePrepare onto the result if you have
* an initial input that has to be prepared differently for each of the joined aggregators.
*
* The law here is: ag1.zip(ag2).apply(as.zip(bs)) == (ag1(as), ag2(bs))
*/
def zip[A2, B2, C2](ag2: Aggregator[A2, B2, C2]): Aggregator[(A, A2), (B, B2), (C, C2)] = {
val ag1 = this
new Aggregator[(A, A2), (B, B2), (C, C2)] {
def prepare(a: (A, A2)) = (ag1.prepare(a._1), ag2.prepare(a._2))
val semigroup = new Tuple2Semigroup()(ag1.semigroup, ag2.semigroup)
def present(b: (B, B2)) = (ag1.present(b._1), ag2.present(b._2))
}
}
/**
* An Aggregator can be converted to a Fold, but not vice-versa
* Note, a Fold is more constrained so only do this if you require
* joining a Fold with an Aggregator to produce a Fold
*/
def toFold: Fold[A, Option[C]] = Fold.fold[Option[B], A, Option[C]](
{
case (None, a) => Some(self.prepare(a))
case (Some(b), a) => Some(self.append(b, a))
},
None,
{ _.map(self.present(_)) })
def lift: MonoidAggregator[A, Option[B], Option[C]] =
new MonoidAggregator[A, Option[B], Option[C]] {
def prepare(input: A): Option[B] = Some(self.prepare(input))
def present(reduction: Option[B]): Option[C] = reduction.map(self.present)
def monoid = new OptionMonoid[B]()(self.semigroup)
}
}
/**
* Aggregators are Applicatives, but this hides the middle type. If you need a join that
* does not hide the middle type use join on the trait, or GeneratedTupleAggregator.fromN
*/
class AggregatorApplicative[I] extends Applicative[({ type L[O] = Aggregator[I, _, O] })#L] {
override def map[T, U](mt: Aggregator[I, _, T])(fn: T => U): Aggregator[I, _, U] =
mt.andThenPresent(fn)
override def apply[T](v: T): Aggregator[I, _, T] =
Aggregator.const(v)
override def join[T, U](mt: Aggregator[I, _, T], mu: Aggregator[I, _, U]): Aggregator[I, _, (T, U)] =
mt.join(mu)
override def join[T1, T2, T3](m1: Aggregator[I, _, T1],
m2: Aggregator[I, _, T2],
m3: Aggregator[I, _, T3]): Aggregator[I, _, (T1, T2, T3)] =
GeneratedTupleAggregator.from3(m1, m2, m3)
override def join[T1, T2, T3, T4](m1: Aggregator[I, _, T1],
m2: Aggregator[I, _, T2],
m3: Aggregator[I, _, T3],
m4: Aggregator[I, _, T4]): Aggregator[I, _, (T1, T2, T3, T4)] =
GeneratedTupleAggregator.from4(m1, m2, m3, m4)
override def join[T1, T2, T3, T4, T5](m1: Aggregator[I, _, T1],
m2: Aggregator[I, _, T2],
m3: Aggregator[I, _, T3],
m4: Aggregator[I, _, T4],
m5: Aggregator[I, _, T5]): Aggregator[I, _, (T1, T2, T3, T4, T5)] =
GeneratedTupleAggregator.from5(m1, m2, m3, m4, m5)
}
trait MonoidAggregator[-A, B, +C] extends Aggregator[A, B, C] { self =>
def monoid: Monoid[B]
def semigroup = monoid
final override def reduce(items: TraversableOnce[B]): B =
monoid.sum(items)
def appendAll(items: TraversableOnce[A]): B = reduce(items.map(prepare))
override def andThenPresent[D](present2: C => D): MonoidAggregator[A, B, D] = {
val self = this
new MonoidAggregator[A, B, D] {
def prepare(a: A) = self.prepare(a)
def monoid = self.monoid
def present(b: B) = present2(self.present(b))
}
}
override def composePrepare[A2](prepare2: A2 => A): MonoidAggregator[A2, B, C] = {
val self = this
new MonoidAggregator[A2, B, C] {
def prepare(a: A2) = self.prepare(prepare2(a))
def monoid = self.monoid
def present(b: B) = self.present(b)
}
}
def sumBefore: MonoidAggregator[TraversableOnce[A], B, C] =
new MonoidAggregator[TraversableOnce[A], B, C] {
def monoid: Monoid[B] = self.monoid
def prepare(input: TraversableOnce[A]): B = monoid.sum(input.map(self.prepare))
def present(reduction: B): C = self.present(reduction)
}
}
trait RingAggregator[-A, B, +C] extends MonoidAggregator[A, B, C] {
def ring: Ring[B]
def monoid = Ring.asTimesMonoid(ring)
}
|
avibryant/algebird
|
algebird-core/src/main/scala/com/twitter/algebird/Aggregator.scala
|
Scala
|
apache-2.0
| 12,410 |
package walfie.gbf.raidfinder
import java.util.Date
import monix.execution.schedulers.TestScheduler
import monix.reactive.Observer
import monix.reactive.subjects._
import org.mockito.Mockito._
import org.scalatest._
import org.scalatest.concurrent.{Eventually, ScalaFutures}
import org.scalatest.Matchers._
import org.scalatest.mockito.MockitoSugar
import scala.concurrent.{ExecutionContext, Future}
import scala.util.Random
import walfie.gbf.raidfinder.domain._
class KnownBossesObserverSpec extends KnownBossesObserverSpecHelpers {
"Start with initial value" in new ObserverFixture {
val boss1 = mockRaidInfo("A").boss
val boss2 = mockRaidInfo("B").boss
override val initialBosses = Seq(boss1, boss2)
observer.get shouldBe Map("A" -> boss1, "B" -> boss2)
cancelable.cancel()
}
"Keep last known of each boss" in new ObserverFixture {
val bosses1 = (1 to 5).map(_ => mockRaidInfo("A"))
val bosses2 = (1 to 10).map(_ => mockRaidInfo("B"))
bosses1.foreach(raidInfos.onNext)
bosses2.foreach(raidInfos.onNext)
eventually {
scheduler.tick()
observer.get shouldBe Map(
"A" -> bosses1.last.boss,
"B" -> bosses2.last.boss
)
}
cancelable.cancel()
}
"purgeOldBosses" - {
"remove old bosses" in new ObserverFixture {
val bosses = (1 to 10).map { i =>
RaidBoss(name = i.toString, level = i, image = None, lastSeen = new Date(i), language = Language.Japanese)
}
override val initialBosses = bosses
scheduler.tick()
observer.get shouldBe bosses.map(boss => boss.name -> boss).toMap
val resultF = observer.purgeOldBosses(minDate = new Date(5), levelThreshold = 100)
scheduler.tick()
resultF.futureValue shouldBe
bosses.drop(5).map(boss => boss.name -> boss).toMap
}
"keep bosses that are above a certain level" in new ObserverFixture {
val bosses = Seq(10, 50, 100, 120, 150).map { i =>
RaidBoss(name = i.toString, level = i, image = None, lastSeen = new Date(0), language = Language.English)
}
override val initialBosses = bosses
scheduler.tick()
observer.get.values.toSet shouldBe bosses.toSet
val resultF = observer.purgeOldBosses(minDate = new Date(5), levelThreshold = 100)
scheduler.tick()
resultF.futureValue.values.toSet shouldBe
bosses.filter(_.level >= 100).toSet
}
}
}
trait KnownBossesObserverSpecHelpers extends FreeSpec
with MockitoSugar with Eventually with ScalaFutures {
trait ObserverFixture {
implicit val scheduler = TestScheduler()
val initialBosses: Seq[RaidBoss] = Seq.empty
val raidInfos = ConcurrentSubject.replay[RaidInfo]
lazy val (observer, cancelable) = KnownBossesObserver
.fromRaidInfoObservable(raidInfos, initialBosses)
}
def mockRaidInfo(bossName: String): RaidInfo = {
val tweet = mock[RaidTweet]
when(tweet.bossName) thenReturn bossName
when(tweet.createdAt) thenReturn (new Date(Random.nextLong.abs * 1000))
val boss = mock[RaidBoss]
when(boss.name) thenReturn bossName
RaidInfo(tweet, boss)
}
}
|
gnawnoraa/GBF-Raider-Copy
|
stream/src/test/scala/walfie/gbf/raidfinder/KnownBossesObserverSpec.scala
|
Scala
|
mit
| 3,131 |
package mesosphere.marathon.upgrade
import mesosphere.marathon.state.AppDefinition.VersionInfo
import mesosphere.marathon.state.AppDefinition.VersionInfo.FullVersionInfo
import mesosphere.marathon.state.PathId._
import mesosphere.marathon.state._
import mesosphere.marathon._
import mesosphere.marathon.test.Mockito
import org.apache.mesos.{ Protos => mesos }
import org.scalatest.{ GivenWhenThen, Matchers }
import com.wix.accord._
import scala.collection.immutable.Seq
class DeploymentPlanTest extends MarathonSpec with Matchers with GivenWhenThen with Mockito {
protected def actionsOf(plan: DeploymentPlan): Seq[DeploymentAction] =
plan.steps.flatMap(_.actions)
test("partition a simple group's apps into concurrently deployable subsets") {
Given("a group of four apps with some simple dependencies")
val aId = "/test/database/a".toPath
val bId = "/test/service/b".toPath
val cId = "/c".toPath
val dId = "/d".toPath
val a = AppDefinition(aId)
val b = AppDefinition(bId, dependencies = Set(aId))
val c = AppDefinition(cId, dependencies = Set(aId))
val d = AppDefinition(dId, dependencies = Set(bId))
val group = Group(
id = "/test".toPath,
apps = Set(c, d),
groups = Set(
Group("/test/database".toPath, Set(a)),
Group("/test/service".toPath, Set(b))
)
)
When("the group's apps are grouped by the longest outbound path")
val partitionedApps = DeploymentPlan.appsGroupedByLongestPath(group)
Then("three equivalence classes should be computed")
partitionedApps should have size (3)
partitionedApps.keySet should contain (1)
partitionedApps.keySet should contain (2)
partitionedApps.keySet should contain (3)
partitionedApps(2) should have size (2)
}
test("partition a complex group's apps into concurrently deployable subsets") {
Given("a group of four apps with some simple dependencies")
val aId = "/a".toPath
val bId = "/b".toPath
val cId = "/c".toPath
val dId = "/d".toPath
val eId = "/e".toPath
val fId = "/f".toPath
val a = AppDefinition(aId, dependencies = Set(bId, cId))
val b = AppDefinition(bId, dependencies = Set(cId))
val c = AppDefinition(cId, dependencies = Set(dId))
val d = AppDefinition(dId)
val e = AppDefinition(eId)
val group = Group(
id = "/".toPath,
apps = Set(a, b, c, d, e)
)
When("the group's apps are grouped by the longest outbound path")
val partitionedApps = DeploymentPlan.appsGroupedByLongestPath(group)
Then("three equivalence classes should be computed")
partitionedApps should have size (4)
partitionedApps.keySet should contain (1)
partitionedApps.keySet should contain (2)
partitionedApps.keySet should contain (3)
partitionedApps.keySet should contain (4)
partitionedApps(1) should have size (2)
}
test("start from empty group") {
val app = AppDefinition("/app".toPath, instances = 2)
val from = Group("/group".toPath, Set.empty)
val to = Group("/group".toPath, Set(app))
val plan = DeploymentPlan(from, to)
actionsOf(plan) should contain (StartApplication(app, 0))
actionsOf(plan) should contain (ScaleApplication(app, app.instances))
}
test("start from running group") {
val apps = Set(AppDefinition("/app".toPath, Some("sleep 10")), AppDefinition("/app2".toPath, Some("cmd2")), AppDefinition("/app3".toPath, Some("cmd3")))
val update = Set(AppDefinition("/app".toPath, Some("sleep 30")), AppDefinition("/app2".toPath, Some("cmd2"), instances = 10), AppDefinition("/app4".toPath, Some("cmd4")))
val from = Group("/group".toPath, apps)
val to = Group("/group".toPath, update)
val plan = DeploymentPlan(from, to)
/*
plan.toStart should have size 1
plan.toRestart should have size 1
plan.toScale should have size 1
plan.toStop should have size 1
*/
}
test("can compute affected app ids") {
val versionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10))
val app: AppDefinition = AppDefinition("/app".toPath, Some("sleep 10"), versionInfo = versionInfo)
val app2: AppDefinition = AppDefinition("/app2".toPath, Some("cmd2"), versionInfo = versionInfo)
val app3: AppDefinition = AppDefinition("/app3".toPath, Some("cmd3"), versionInfo = versionInfo)
val unchanged: AppDefinition = AppDefinition("/unchanged".toPath, Some("unchanged"), versionInfo = versionInfo)
val apps = Set(app, app2, app3, unchanged)
val update = Set(
app.copy(cmd = Some("sleep 30")),
app2.copy(instances = 10),
AppDefinition("/app4".toPath, Some("cmd4")),
unchanged
)
val from = Group("/group".toPath, apps)
val to = Group("/group".toPath, update)
val plan = DeploymentPlan(from, to)
plan.affectedApplicationIds should equal (Set("/app".toPath, "/app2".toPath, "/app3".toPath, "/app4".toPath))
plan.isAffectedBy(plan) should equal (right = true)
plan.isAffectedBy(DeploymentPlan(from, from)) should equal (right = false)
}
test("when updating a group with dependencies, the correct order is computed") {
Given("Two application updates with command and scale changes")
val mongoId = "/test/database/mongo".toPath
val serviceId = "/test/service/srv1".toPath
val strategy = UpgradeStrategy(0.75)
val versionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10))
val mongo: (AppDefinition, AppDefinition) =
AppDefinition(mongoId, Some("mng1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(mongoId, Some("mng2"), instances = 8, upgradeStrategy = strategy, versionInfo = versionInfo)
val service: (AppDefinition, AppDefinition) =
AppDefinition(serviceId, Some("srv1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(
serviceId, Some("srv2"), dependencies = Set(mongoId), instances = 10, upgradeStrategy = strategy,
versionInfo = versionInfo
)
val from = Group(
id = "/test".toPath,
groups = Set(
Group("/test/database".toPath, Set(mongo._1)),
Group("/test/service".toPath, Set(service._1))
)
)
val to = Group("/test".toPath, groups = Set(
Group("/test/database".toPath, Set(mongo._2)),
Group("/test/service".toPath, Set(service._2))
))
When("the deployment plan is computed")
val plan = DeploymentPlan(from, to)
Then("the deployment steps are correct")
plan.steps should have size 2
plan.steps(0).actions.toSet should equal (Set(RestartApplication(mongo._2)))
plan.steps(1).actions.toSet should equal (Set(RestartApplication(service._2)))
}
test("when starting apps without dependencies, they are first started and then scaled parallely") {
Given("an empty group and the same group but now including four independent apps")
val emptyGroup = Group(id = "/test".toPath)
val instances: Int = 10
val apps: Set[AppDefinition] = (1 to 4).map { i =>
AppDefinition(s"/test/$i".toPath, Some("cmd"), instances = instances)
}.toSet
val targetGroup = Group(
id = "/test".toPath,
apps = apps,
groups = Set()
)
When("the deployment plan is computed")
val plan = DeploymentPlan(emptyGroup, targetGroup)
Then("we get two deployment steps")
plan.steps should have size 2
Then("the first with all StartApplication actions")
plan.steps(0).actions.toSet should equal (apps.map(StartApplication(_, 0)))
Then("and the second with all ScaleApplication actions")
plan.steps(1).actions.toSet should equal (apps.map(ScaleApplication(_, instances)))
}
test("when updating apps without dependencies, the restarts are executed in the same step") {
Given("Two application updates with command and scale changes")
val mongoId = "/test/database/mongo".toPath
val serviceId = "/test/service/srv1".toPath
val strategy = UpgradeStrategy(0.75)
val versionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10))
val mongo =
AppDefinition(mongoId, Some("mng1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(mongoId, Some("mng2"), instances = 8, upgradeStrategy = strategy, versionInfo = versionInfo)
val service =
AppDefinition(serviceId, Some("srv1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(serviceId, Some("srv2"), instances = 10, upgradeStrategy = strategy, versionInfo = versionInfo)
val from: Group = Group("/test".toPath, groups = Set(
Group("/test/database".toPath, Set(mongo._1)),
Group("/test/service".toPath, Set(service._1))
))
val to: Group = Group("/test".toPath, groups = Set(
Group("/test/database".toPath, Set(mongo._2)),
Group("/test/service".toPath, Set(service._2))
))
When("the deployment plan is computed")
val plan = DeploymentPlan(from, to)
Then("the deployment steps are correct")
plan.steps should have size 1
plan.steps(0).actions.toSet should equal (Set(RestartApplication(mongo._2), RestartApplication(service._2)))
}
test("when updating a group with dependent and independent applications, the correct order is computed") {
Given("application updates with command and scale changes")
val mongoId = "/test/database/mongo".toPath
val serviceId = "/test/service/srv1".toPath
val appId = "/test/independent/app".toPath
val strategy = UpgradeStrategy(0.75)
val versionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10))
val mongo =
AppDefinition(mongoId, Some("mng1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(mongoId, Some("mng2"), instances = 8, upgradeStrategy = strategy, versionInfo = versionInfo)
val service =
AppDefinition(serviceId, Some("srv1"), instances = 4, upgradeStrategy = strategy, versionInfo = versionInfo) ->
AppDefinition(serviceId, Some("srv2"), dependencies = Set(mongoId), instances = 10, upgradeStrategy = strategy,
versionInfo = versionInfo)
val independent =
AppDefinition(appId, Some("app1"), instances = 1, upgradeStrategy = strategy) ->
AppDefinition(appId, Some("app2"), instances = 3, upgradeStrategy = strategy)
val toStop = AppDefinition("/test/service/toStop".toPath, instances = 1, dependencies = Set(mongoId))
val toStart = AppDefinition("/test/service/toStart".toPath, instances = 2, dependencies = Set(serviceId))
val from: Group = Group("/test".toPath, groups = Set(
Group("/test/database".toPath, Set(mongo._1)),
Group("/test/service".toPath, Set(service._1, toStop)),
Group("/test/independent".toPath, Set(independent._1))
))
val to: Group = Group("/test".toPath, groups = Set(
Group("/test/database".toPath, Set(mongo._2)),
Group("/test/service".toPath, Set(service._2, toStart)),
Group("/test/independent".toPath, Set(independent._2))
))
When("the deployment plan is computed")
val plan = DeploymentPlan(from, to)
Then("the deployment contains steps for dependent and independent applications")
plan.steps should have size (5)
actionsOf(plan) should have size (6)
plan.steps(0).actions.toSet should equal (Set(StopApplication(toStop)))
plan.steps(1).actions.toSet should equal (Set(StartApplication(toStart, 0)))
plan.steps(2).actions.toSet should equal (Set(RestartApplication(mongo._2), RestartApplication(independent._2)))
plan.steps(3).actions.toSet should equal (Set(RestartApplication(service._2)))
plan.steps(4).actions.toSet should equal (Set(ScaleApplication(toStart, 2)))
}
test("when the only action is to stop an application") {
Given("application updates with only the removal of an app")
val strategy = UpgradeStrategy(0.75)
val app = AppDefinition("/test/independent/app".toPath, Some("app2"), instances = 3, upgradeStrategy = strategy) -> None
val from: Group = Group("/test".toPath, groups = Set(
Group("/test/independent".toPath, Set(app._1))
))
val to: Group = Group("/test".toPath)
When("the deployment plan is computed")
val plan = DeploymentPlan(from, to)
Then("the deployment contains one step consisting of one stop action")
plan.steps should have size 1
plan.steps(0).actions.toSet should be(Set(StopApplication(app._1)))
}
// regression test for #765
test("Should create non-empty deployment plan when only args have changed") {
val versionInfo: FullVersionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10))
val app = AppDefinition(id = "/test".toPath, cmd = Some("sleep 5"), versionInfo = versionInfo)
val appNew = app.copy(args = Some(Seq("foo")))
val from = Group("/".toPath, apps = Set(app))
val to = from.copy(apps = Set(appNew))
val plan = DeploymentPlan(from, to)
plan.steps should not be empty
}
// regression test for #1007
test("Don't restart apps that have not changed") {
val app = AppDefinition(
id = "/test".toPath,
cmd = Some("sleep 5"),
instances = 1,
versionInfo = VersionInfo.forNewConfig(Timestamp(10))
)
val appNew = app.copy(instances = 1) // no change
val from = Group("/".toPath, apps = Set(app))
val to = from.copy(apps = Set(appNew))
DeploymentPlan(from, to) should be (empty)
}
test("Restart apps that have not changed but a new version") {
val app = AppDefinition(
id = "/test".toPath,
cmd = Some("sleep 5"),
versionInfo = VersionInfo.forNewConfig(Timestamp(10))
)
val appNew = app.markedForRestarting
val from = Group("/".toPath, apps = Set(app))
val to = from.copy(apps = Set(appNew))
DeploymentPlan(from, to).steps should have size (1)
DeploymentPlan(from, to).steps.head should be (DeploymentStep(Seq(RestartApplication(appNew))))
}
test("ScaleApplication step is created with TasksToKill") {
Given("a group with one app")
val aId = "/test/some/a".toPath
val oldApp = AppDefinition(aId, versionInfo = AppDefinition.VersionInfo.forNewConfig(Timestamp(10)))
When("A deployment plan is generated")
val originalGroup = Group(
id = "/test".toPath,
apps = Set(oldApp),
groups = Set(
Group("/test/some".toPath, Set(oldApp))
)
)
val newApp = oldApp.copy(instances = 5)
val targetGroup = Group(
id = "/test".toPath,
apps = Set(newApp),
groups = Set(
Group("/test/some".toPath, Set(newApp))
)
)
val taskToKill = MarathonTestHelper.stagedTaskForApp(aId)
val plan = DeploymentPlan(
original = originalGroup,
target = targetGroup,
resolveArtifacts = Seq.empty,
version = Timestamp.now(),
toKill = Map(aId -> Set(taskToKill)))
Then("DeploymentSteps should include ScaleApplication w/ tasksToKill")
plan.steps should not be empty
plan.steps.head.actions.head shouldEqual ScaleApplication(newApp, 5, Some(Set(taskToKill)))
}
test("Deployment plan allows valid updates for resident tasks") {
Given("All options are supplied and we have a valid group change")
AllConf.SuppliedOptionNames = Set("mesos_authentication_principal", "mesos_role", "mesos_authentication_secret_file")
val f = new Fixture()
When("We create a scale deployment")
val app = f.validResident.copy(instances = 123)
val group = f.group.copy(apps = Set(app))
val plan = DeploymentPlan(f.group, group)
Then("The deployment is valid")
validate(plan).isSuccess should be(true)
}
test("Deployment plan validation fails for invalid changes in resident tasks") {
Given("All options are supplied and we have a valid group change")
AllConf.SuppliedOptionNames = Set("mesos_authentication_principal", "mesos_role", "mesos_authentication_secret_file")
val f = new Fixture()
When("We update the upgrade strategy to the default strategy")
val app2 = f.validResident.copy(upgradeStrategy = AppDefinition.DefaultUpgradeStrategy)
val group2 = f.group.copy(apps = Set(app2))
val plan2 = DeploymentPlan(f.group, group2)
Then("The deployment is not valid")
validate(plan2).isSuccess should be(false)
}
class Fixture {
def persistentVolume(path: String) = PersistentVolume(path, PersistentVolumeInfo(123), mesos.Volume.Mode.RW)
val zero = UpgradeStrategy(0, 0)
def residentApp(id: String, volumes: Seq[PersistentVolume]): AppDefinition = {
AppDefinition(
id = PathId(id),
container = Some(Container(mesos.ContainerInfo.Type.MESOS, volumes)),
residency = Some(Residency(123, Protos.ResidencyDefinition.TaskLostBehavior.RELAUNCH_AFTER_TIMEOUT))
)
}
val vol1 = persistentVolume("foo")
val vol2 = persistentVolume("bla")
val vol3 = persistentVolume("test")
val validResident = residentApp("/app1", Seq(vol1, vol2)).copy(upgradeStrategy = zero)
val group = Group(PathId("/test"), apps = Set(validResident))
}
}
|
vivekjuneja/marathon
|
src/test/scala/mesosphere/marathon/upgrade/DeploymentPlanTest.scala
|
Scala
|
apache-2.0
| 17,139 |
/*
* Copyright (c) 2002-2018 "Neo Technology,"
* Network Engine for Objects in Lund AB [http://neotechnology.com]
*
* This file is part of Neo4j.
*
* Neo4j is free software: you can redistribute it and/or modify
* it under the terms of the GNU General Public License as published by
* the Free Software Foundation, either version 3 of the License, or
* (at your option) any later version.
*
* This program is distributed in the hope that it will be useful,
* but WITHOUT ANY WARRANTY; without even the implied warranty of
* MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
* GNU General Public License for more details.
*
* You should have received a copy of the GNU General Public License
* along with this program. If not, see <http://www.gnu.org/licenses/>.
*/
package org.neo4j.cypher.internal.compiler.v2_3.ast.rewriters
import org.neo4j.cypher.internal.compiler.v2_3.ast.rewriters.Namespacer.IdentifierRenamings
import org.neo4j.cypher.internal.frontend.v2_3.Foldable._
import org.neo4j.cypher.internal.frontend.v2_3.ast._
import org.neo4j.cypher.internal.frontend.v2_3.{Ref, Rewriter, SemanticTable, bottomUp, _}
object Namespacer {
type IdentifierRenamings = Map[Ref[Identifier], Identifier]
def apply(statement: Statement, scopeTree: Scope): Namespacer = {
val ambiguousNames = shadowedNames(scopeTree)
val identifierDefinitions: Map[SymbolUse, SymbolUse] = scopeTree.allIdentifierDefinitions
val protectedIdentifiers = returnAliases(statement)
val renamings = identifierRenamings(statement, identifierDefinitions, ambiguousNames, protectedIdentifiers)
Namespacer(renamings)
}
private def shadowedNames(scopeTree: Scope): Set[String] = {
val definitions = scopeTree.allSymbolDefinitions
definitions.collect {
case (name, symbolDefinitions) if symbolDefinitions.size > 1 => name
}.toSet
}
private def returnAliases(statement: Statement): Set[Ref[Identifier]] =
statement.treeFold(Set.empty[Ref[Identifier]]) {
// ignore identifier in StartItem that represents index names and key names
case Return(_, ReturnItems(_, items), _, _, _, _) =>
val identifiers = items.map(_.alias.map(Ref[Identifier]).get)
(acc, children) => children(acc ++ identifiers)
}
private def identifierRenamings(statement: Statement, identifierDefinitions: Map[SymbolUse, SymbolUse],
ambiguousNames: Set[String], protectedIdentifiers: Set[Ref[Identifier]]): IdentifierRenamings =
statement.treeFold(Map.empty[Ref[Identifier], Identifier]) {
case i: Identifier if ambiguousNames(i.name) && !protectedIdentifiers(Ref(i)) =>
val symbolDefinition = identifierDefinitions(i.toSymbolUse)
val newIdentifier = i.renameId(s" ${symbolDefinition.nameWithPosition}")
val renaming = Ref(i) -> newIdentifier
(acc, children) => children(acc + renaming)
}
}
case class Namespacer(renamings: IdentifierRenamings) {
val statementRewriter: Rewriter = bottomUp(Rewriter.lift {
case i: Identifier =>
renamings.get(Ref(i)) match {
case Some(newIdentifier) => newIdentifier
case None => i
}
})
val tableRewriter = (semanticTable: SemanticTable) => {
val replacements = renamings.toSeq.collect { case (old, newIdentifier) => old.value -> newIdentifier }
val newSemanticTable = semanticTable.replaceKeys(replacements: _*)
newSemanticTable
}
}
|
HuangLS/neo4j
|
community/cypher/cypher-compiler-2.3/src/main/scala/org/neo4j/cypher/internal/compiler/v2_3/ast/rewriters/Namespacer.scala
|
Scala
|
apache-2.0
| 3,476 |
package taczombie.client.view.gui
import scala.swing._
import taczombie.client.util.RegexHelper
import scala.swing.event.KeyPressed
import scala.swing.event.Key
import taczombie.client.util.Address
import taczombie.client.util.RegexHelper
class ConnectDialog extends Dialog {
var address: Option[Address] = None
val ip = new TextField {
listenTo(keys)
reactions += {
case KeyPressed(_, Key.Enter, _, _) =>
handleEvent(this)
}
}
val port = new TextField {
listenTo(keys)
reactions += {
case KeyPressed(_, Key.Enter, _, _) =>
handleEvent(this)
}
}
preferredSize = new Dimension(220, 150)
title = "Server Address"
modal = true
contents = new BorderPanel {
add(new BoxPanel(Orientation.Vertical) {
border = Swing.EmptyBorder(5, 5, 5, 5)
contents += new Label("IP:")
contents += ip
contents += new Label("Port:")
contents += port
}, BorderPanel.Position.North)
add(new FlowPanel(FlowPanel.Alignment.Center)(
new FlowPanel(FlowPanel.Alignment.Left)(Button("Connect") { handleEvent(this) }),
new FlowPanel(FlowPanel.Alignment.Right)(Button("Default") { close })), BorderPanel.Position.South)
}
centerOnScreen()
open()
def handleEvent(elem: Component) {
if (RegexHelper.checkPort(port.text)) {
address = Some(Address(ip.text, port.text))
close
} else {
Dialog.showMessage(elem, "Invalid Adress!", "Login Error", Dialog.Message.Error)
}
}
}
|
mahieke/TacZombie
|
gui/src/main/scala/taczombie/client/view/gui/ConnectDialog.scala
|
Scala
|
gpl-2.0
| 1,504 |
package monocle.internal.focus.features.each
import monocle.function.Each
import monocle.internal.focus.FocusBase
private[focus] trait EachGenerator {
this: FocusBase =>
import macroContext.reflect._
def generateEach(action: FocusAction.KeywordEach): Term = {
import action.{fromType, toType, eachInstance}
(fromType.asType, toType.asType) match {
case ('[f], '[t]) => '{ (${ eachInstance.asExprOf[Each[f, t]] }.each) }.asTerm
}
}
}
|
julien-truffaut/Monocle
|
core/shared/src/main/scala-3.x/monocle/internal/focus/features/each/EachGenerator.scala
|
Scala
|
mit
| 465 |
package org.gtri.util.scala.xsdbuilder.elements
import org.gtri.util.scala.statemachine._
import org.gtri.util.xsddatatypes._
import org.gtri.util.xsddatatypes.XsdConstants._
import org.gtri.util.scala.xsdbuilder.XmlParser._
import org.gtri.util.scala.xmlbuilder.{XmlNamespaceContext, XmlElement}
final case class XsdDocumentation(
optSource : Option[XsdAnyURI] = None,
optXmlLang : Option[XsdToken] = None,
optValue : Option[String] = None,
optMetadata : Option[XsdElement.Metadata] = None
) extends XsdElement {
def util = XsdDocumentation.util
def toAttributesMap(context: Seq[XmlNamespaceContext]) = {
{
optSource.map { (ATTRIBUTES.SOURCE.QNAME -> _.toString) } ::
optXmlLang.map { (ATTRIBUTES.FINALDEFAULT.QNAME -> _.toString )} ::
Nil
}.flatten.toMap
}
}
object XsdDocumentation {
implicit object util extends XsdElementUtil[XsdDocumentation] {
def qName = XsdConstants.ELEMENTS.DOCUMENTATION.QNAME
def parser[EE >: XsdDocumentation](context: Seq[XmlNamespaceContext]) : Parser[XmlElement,EE] = {
for {
element <- Parser.tell[XmlElement]
optSource <- optionalAttributeParser(ATTRIBUTES.SOURCE.QNAME, Try.parser(XsdAnyURI.parseString))
optXmlLang <- optionalAttributeParser(ATTRIBUTES.XML_LANG.QNAME, Try.parser(XsdToken.parseString))
} yield
XsdDocumentation(
optSource = optSource,
optXmlLang = optXmlLang,
optValue = element.optValue,
optMetadata = Some(XsdElement.Metadata(element))
)
}
def attributes = Set(
ATTRIBUTES.SOURCE.QNAME,
ATTRIBUTES.XML_LANG.QNAME,
ATTRIBUTES.VALUE.QNAME
)
def allowedChildElements(children: Seq[XsdElementUtil[XsdElement]]) = Seq.empty
}
}
|
gtri-iead/org.gtri.util.scala
|
xsdbuilder/src/main/scala/org/gtri/util/scala/xsdbuilder/elements/XsdDocumentation.scala
|
Scala
|
gpl-3.0
| 1,850 |
import scala.slick.driver.H2Driver.simple._
// The main application
object HelloSlick extends App {
// The query interface for the Suppliers table
val suppliers: TableQuery[Suppliers] = TableQuery[Suppliers]
// the query interface for the Coffees table
val coffees: TableQuery[Coffees] = TableQuery[Coffees]
// Create a connection (called a "session") to an in-memory H2 database
val db = Database.forURL("jdbc:h2:mem:hello", driver = "org.h2.Driver")
db.withSession { implicit session =>
// Create the schema by combining the DDLs for the Suppliers and Coffees
// tables using the query interfaces
(suppliers.ddl ++ coffees.ddl).create
/* Create / Insert */
// Insert some suppliers
suppliers += (101, "Acme, Inc.", "99 Market Street", "Groundsville", "CA", "95199")
suppliers += ( 49, "Superior Coffee", "1 Party Place", "Mendocino", "CA", "95460")
suppliers += (150, "The High Ground", "100 Coffee Lane", "Meadows", "CA", "93966")
// Insert some coffees (using JDBC's batch insert feature)
val coffeesInsertResult: Option[Int] = coffees ++= Seq (
("Colombian", 101, 7.99, 0, 0),
("French_Roast", 49, 8.99, 0, 0),
("Espresso", 150, 9.99, 0, 0),
("Colombian_Decaf", 101, 8.99, 0, 0),
("French_Roast_Decaf", 49, 9.99, 0, 0)
)
val allSuppliers: List[(Int, String, String, String, String, String)] =
suppliers.list
// Print the number of rows inserted
coffeesInsertResult foreach { numRows =>
println(s"Inserted $numRows rows into the Coffees table")
}
/* Read / Query / Select */
// Print the SQL for the Coffees query
println("Generated SQL for base Coffees query:\n" + coffees.selectStatement)
// Query the Coffees table using a foreach and print each row
coffees foreach { case (name, supID, price, sales, total) =>
println(" " + name + "\t" + supID + "\t" + price + "\t" + sales + "\t" + total)
}
/* Filtering / Where */
// Construct a query where the price of Coffees is > 9.0
val filterQuery: Query[Coffees, (String, Int, Double, Int, Int), Seq] =
coffees.filter(_.price > 9.0)
println("Generated SQL for filter query:\n" + filterQuery.selectStatement)
// Execute the query
println(filterQuery.list)
/* Update */
// Construct an update query with the sales column being the one to update
val updateQuery: Query[Column[Int], Int, Seq] = coffees.map(_.sales)
// Print the SQL for the Coffees update query
println("Generated SQL for Coffees update:\n" + updateQuery.updateStatement)
// Perform the update
val numUpdatedRows = updateQuery.update(1)
println(s"Updated $numUpdatedRows rows")
/* Delete */
// Construct a delete query that deletes coffees with a price less than 8.0
val deleteQuery: Query[Coffees,(String, Int, Double, Int, Int), Seq] =
coffees.filter(_.price < 8.0)
// Print the SQL for the Coffees delete query
println("Generated SQL for Coffees delete:\n" + deleteQuery.deleteStatement)
// Perform the delete
val numDeletedRows = deleteQuery.delete
println(s"Deleted $numDeletedRows rows")
/* Selecting Specific Columns */
// Construct a new coffees query that just selects the name
val justNameQuery: Query[Column[String], String, Seq] = coffees.map(_.name)
println("Generated SQL for query returning just the name:\n" +
justNameQuery.selectStatement)
// Execute the query
println(justNameQuery.list)
/* Sorting / Order By */
val sortByPriceQuery: Query[Coffees, (String, Int, Double, Int, Int), Seq] =
coffees.sortBy(_.price)
println("Generated SQL for query sorted by price:\n" +
sortByPriceQuery.selectStatement)
// Execute the query
println(sortByPriceQuery.list)
/* Query Composition */
val composedQuery: Query[Column[String], String, Seq] =
coffees.sortBy(_.name).take(3).filter(_.price > 9.0).map(_.name)
println("Generated SQL for composed query:\n" +
composedQuery.selectStatement)
// Execute the composed query
println(composedQuery.list)
/* Joins */
// Join the tables using the relationship defined in the Coffees table
val joinQuery: Query[(Column[String], Column[String]), (String, String), Seq] = for {
c <- coffees if c.price > 9.0
s <- c.supplier
} yield (c.name, s.name)
println("Generated SQL for the join query:\n" + joinQuery.selectStatement)
// Print the rows which contain the coffee name and the supplier name
println(joinQuery.list)
/* Computed Values */
// Create a new computed column that calculates the max price
val maxPriceColumn: Column[Option[Double]] = coffees.map(_.price).max
println("Generated SQL for max price column:\n" + maxPriceColumn.selectStatement)
// Execute the computed value query
println(maxPriceColumn.run)
/* Manual SQL / String Interpolation */
// Required import for the sql interpolator
import scala.slick.jdbc.StaticQuery.interpolation
// A value to insert into the statement
val state = "CA"
// Construct a SQL statement manually with an interpolated value
val plainQuery = sql"select SUP_NAME from SUPPLIERS where STATE = $state".as[String]
println("Generated SQL for plain query:\n" + plainQuery.getStatement)
// Execute the query
println(plainQuery.list)
}
}
|
sabau/valeriarossini
|
wp-content/plugins/activator-1.2.10/templates/42d77b2f-0e24-4a17-a285-2905405419e9/src/main/scala/HelloSlick.scala
|
Scala
|
apache-2.0
| 5,575 |
package im.actor.server.api.rpc.service.auth
import java.time.{ LocalDateTime, ZoneOffset }
import im.actor.api.rpc.misc.ApiExtension
import im.actor.server.acl.ACLUtils
import scala.concurrent.Future
import scala.concurrent.forkjoin.ThreadLocalRandom
import scalaz.{ -\\/, \\/, \\/- }
import akka.actor.ActorSystem
import akka.pattern.ask
import slick.dbio._
import im.actor.api.rpc.DBIOResult._
import im.actor.api.rpc._
import im.actor.api.rpc.users.ApiSex._
import im.actor.server.activation.Activation.{ CallCode, EmailCode, SmsCode }
import im.actor.server.activation._
import im.actor.server.models.{ AuthEmailTransaction, AuthPhoneTransaction, User }
import im.actor.server.persist.auth.AuthTransaction
import im.actor.server.session._
import im.actor.server.user.UserExtension
import im.actor.util.misc.IdUtils._
import im.actor.util.misc.PhoneNumberUtils._
import im.actor.util.misc.StringUtils.validName
import im.actor.server.{ models, persist }
trait AuthHelpers extends Helpers {
self: AuthServiceImpl ⇒
//expiration of code won't work
protected def newUserPhoneSignUp(transaction: models.AuthPhoneTransaction, name: String, sex: Option[ApiSex]): Result[(Int, String) \\/ User] = {
val phone = transaction.phoneNumber
for {
optPhone ← fromDBIO(persist.UserPhone.findByPhoneNumber(phone).headOption)
phoneAndCode ← fromOption(AuthErrors.PhoneNumberInvalid)(normalizeWithCountry(phone).headOption)
(_, countryCode) = phoneAndCode
result ← optPhone match {
case Some(userPhone) ⇒ point(-\\/((userPhone.userId, countryCode)))
case None ⇒ newUser(name, countryCode, sex)
}
} yield result
}
protected def newUserEmailSignUp(transaction: models.AuthEmailTransaction, name: String, sex: Option[ApiSex]): Result[(Int, String) \\/ User] = {
val email = transaction.email
for {
optEmail ← fromDBIO(persist.UserEmail.find(email))
result ← optEmail match {
case Some(existingEmail) ⇒ point(-\\/((existingEmail.userId, "")))
case None ⇒
val userResult: Result[(Int, String) \\/ User] =
for {
optToken ← fromDBIO(persist.OAuth2Token.findByUserId(email))
locale ← optToken.map { token ⇒
val locale = oauth2Service.fetchProfile(token.accessToken).map(_.flatMap(_.locale))
fromFuture(locale)
}.getOrElse(point(None))
user ← newUser(name, locale.getOrElse("").toUpperCase, sex)
} yield user
userResult
}
} yield result
}
def handleUserCreate(user: models.User, transaction: models.AuthTransactionChildren, authId: Long): Result[User] = {
for {
_ ← fromFuture(userExt.create(user.id, user.accessSalt, user.nickname, user.name, user.countryCode, im.actor.api.rpc.users.ApiSex(user.sex.toInt), isBot = false, Seq.empty[ApiExtension], None))
_ ← fromDBIO(persist.AvatarData.create(models.AvatarData.empty(models.AvatarData.OfUser, user.id.toLong)))
_ ← fromDBIO(AuthTransaction.delete(transaction.transactionHash))
_ ← transaction match {
case p: models.AuthPhoneTransaction ⇒
val phone = p.phoneNumber
for {
_ ← fromDBIO(activationContext.finish(p.transactionHash))
_ ← fromFuture(userExt.addPhone(user.id, phone))
} yield ()
case e: models.AuthEmailTransaction ⇒
fromFuture(userExt.addEmail(user.id, e.email))
}
} yield user
}
/**
* Validate phone code and remove `AuthCode` and `AuthTransaction`
* used for this sign action.
*/
protected def validateCode(transaction: models.AuthTransactionChildren, code: String): Result[(Int, String)] = {
val (codeExpired, codeInvalid) = transaction match {
case _: AuthPhoneTransaction ⇒ (AuthErrors.PhoneCodeExpired, AuthErrors.PhoneCodeInvalid)
case _: AuthEmailTransaction ⇒ (AuthErrors.EmailCodeExpired, AuthErrors.EmailCodeInvalid)
}
val transactionHash = transaction.transactionHash
for {
validationResponse ← fromDBIO(activationContext.validate(transactionHash, code))
_ ← validationResponse match {
case ExpiredCode ⇒ cleanupAndError(transactionHash, codeExpired)
case InvalidHash ⇒ cleanupAndError(transactionHash, AuthErrors.InvalidAuthCodeHash)
case InvalidCode ⇒ fromEither[Unit](-\\/(codeInvalid))
case InvalidResponse ⇒ cleanupAndError(transactionHash, AuthErrors.ActivationServiceError)
case Validated ⇒ point(())
}
_ ← fromDBIO(persist.auth.AuthTransaction.updateSetChecked(transactionHash))
userAndCountry ← transaction match {
case p: AuthPhoneTransaction ⇒
val phone = p.phoneNumber
for {
//if user is not registered - return error
phoneModel ← fromDBIOOption(AuthErrors.PhoneNumberUnoccupied)(persist.UserPhone.findByPhoneNumber(phone).headOption)
phoneAndCode ← fromOption(AuthErrors.PhoneNumberInvalid)(normalizeWithCountry(phone).headOption)
_ ← fromDBIO(activationContext.finish(transactionHash))
} yield (phoneModel.userId, phoneAndCode._2)
case e: AuthEmailTransaction ⇒
for {
//if user is not registered - return error
emailModel ← fromDBIOOption(AuthErrors.EmailUnoccupied)(persist.UserEmail.find(e.email))
_ ← fromDBIO(activationContext.finish(transactionHash))
} yield (emailModel.userId, "")
}
} yield userAndCountry
}
/**
* Terminate all sessions associated with given `deviceHash`
* and create new session
*/
protected def refreshAuthSession(deviceHash: Array[Byte], newSession: models.AuthSession): DBIO[Unit] =
for {
prevSessions ← persist.AuthSession.findByDeviceHash(deviceHash)
_ ← DBIO.from(Future.sequence(prevSessions map userExt.logout))
_ ← persist.AuthSession.create(newSession)
} yield ()
protected def authorize(userId: Int, clientData: ClientData)(implicit sessionRegion: SessionRegion): Future[AuthorizeUserAck] = {
for {
_ ← userExt.auth(userId, clientData.authId)
ack ← sessionRegion.ref
.ask(SessionEnvelope(clientData.authId, clientData.sessionId).withAuthorizeUser(AuthorizeUser(userId)))
.mapTo[AuthorizeUserAck]
} yield ack
}
//TODO: what country to use in case of email auth
protected def authorizeT(userId: Int, countryCode: String, clientData: ClientData): Result[User] = {
for {
user ← fromDBIOOption(CommonErrors.UserNotFound)(persist.User.find(userId).headOption)
_ ← fromFuture(userExt.changeCountryCode(userId, countryCode))
_ ← fromDBIO(persist.AuthId.setUserData(clientData.authId, userId))
} yield user
}
protected def sendSmsCode(phoneNumber: Long, code: String, transactionHash: Option[String])(implicit system: ActorSystem): DBIO[String \\/ Unit] = {
log.info("Sending sms code {} to {}", code, phoneNumber)
activationContext.send(transactionHash, SmsCode(phoneNumber, code))
}
protected def sendCallCode(phoneNumber: Long, code: String, transactionHash: Option[String], language: String)(implicit system: ActorSystem): DBIO[String \\/ Unit] = {
log.info("Sending call code {} to {}", code, phoneNumber)
activationContext.send(transactionHash, CallCode(phoneNumber, code, language))
}
protected def sendEmailCode(email: String, code: String, transactionHash: String)(implicit system: ActorSystem): DBIO[String \\/ Unit] = {
log.info("Sending email code {} to {}", code, email)
activationContext.send(Some(transactionHash), EmailCode(email, code))
}
protected def genCode() = ThreadLocalRandom.current.nextLong().toString.dropWhile(c ⇒ c == '0' || c == '-').take(5)
protected def genSmsHash() = ThreadLocalRandom.current.nextLong().toString
protected def genSmsCode(phone: Long): String = phone.toString match {
case strNumber if strNumber.startsWith("7555") ⇒ strNumber(4).toString * 4
case _ ⇒ genCode()
}
private def newUser(name: String, countryCode: String, optSex: Option[ApiSex]): Result[\\/-[User]] = {
val rng = ThreadLocalRandom.current()
val sex = optSex.map(s ⇒ models.Sex.fromInt(s.id)).getOrElse(models.NoSex)
for {
validName ← fromEither(validName(name).leftMap(validationFailed("NAME_INVALID", _)))
user = models.User(
id = nextIntId(rng),
accessSalt = ACLUtils.nextAccessSalt(rng),
name = validName,
countryCode = countryCode,
sex = sex,
state = models.UserState.Registered,
createdAt = LocalDateTime.now(ZoneOffset.UTC),
external = None
)
} yield \\/-(user)
}
private def cleanupAndError(transactionHash: String, error: RpcError): Result[Unit] = {
for {
_ ← fromDBIO(persist.auth.AuthTransaction.delete(transactionHash))
_ ← fromEither[Unit](Error(error))
} yield ()
}
}
|
lzpfmh/actor-platform
|
actor-server/actor-rpc-api/src/main/scala/im/actor/server/api/rpc/service/auth/AuthHelpers.scala
|
Scala
|
mit
| 9,108 |
/*
* Copyright (C) 2016-2019 Lightbend Inc. <https://www.lightbend.com>
*/
package docs.home.scaladsl.serialization.v2a
import com.lightbend.lagom.scaladsl.playjson.JsonMigration
import com.lightbend.lagom.scaladsl.playjson.JsonMigrations
import com.lightbend.lagom.scaladsl.playjson.JsonSerializerRegistry
import com.lightbend.lagom.scaladsl.playjson.JsonSerializer
//#rename-class
case class OrderPlaced(shoppingCartId: String)
//#rename-class
class ShopSerializerRegistry extends JsonSerializerRegistry {
override def serializers = Vector.empty[JsonSerializer[_]]
//#rename-class-migration
override def migrations: Map[String, JsonMigration] = Map(
JsonMigrations
.renamed(fromClassName = "com.lightbend.lagom.shop.OrderAdded", inVersion = 2, toClass = classOf[OrderPlaced])
)
//#rename-class-migration
}
|
ignasi35/lagom
|
docs/manual/scala/guide/cluster/code/docs/home/scaladsl/serialization/v2a/OrderPlaced.scala
|
Scala
|
apache-2.0
| 835 |
package org.openurp.edu.eams.teach.program.major.service.impl
import org.beangle.commons.dao.Operation
import org.beangle.commons.dao.impl.BaseServiceImpl
import org.beangle.data.jpa.dao.OqlBuilder
import com.ekingstar.eams.core.CommonAuditState
import org.openurp.edu.eams.teach.program.Program
import org.openurp.edu.eams.teach.program.major.MajorPlan
import org.openurp.edu.eams.teach.program.major.dao.MajorPlanAuditDao
import org.openurp.edu.eams.teach.program.major.service.MajorPlanAuditService
import org.openurp.edu.eams.teach.program.major.service.MajorPlanDuplicatedException
import org.openurp.edu.eams.teach.program.original.OriginalPlan
//remove if not needed
class MajorPlanAuditServiceImpl extends BaseServiceImpl with MajorPlanAuditService {
private var majorPlanAuditDao: MajorPlanAuditDao = _
def audit(plans: List[MajorPlan], auditState: CommonAuditState) {
for (plan <- plans if canTransferTo(plan.getProgram.getAuditState, auditState)) {
plan.getProgram.setAuditState(auditState)
if (auditState == CommonAuditState.ACCEPTED) {
majorPlanAuditDao.accepted(plan)
entityDao.saveOrUpdate(plan.getProgram)
} else {
entityDao.saveOrUpdate(plan.getProgram)
}
}
}
def revokeAccepted(plans: List[MajorPlan]) {
for (plan <- plans if canTransferTo(plan.getProgram.getAuditState, CommonAuditState.REJECTED) if plan.getProgram.getAuditState == CommonAuditState.ACCEPTED) {
plan.getProgram.setAuditState(CommonAuditState.REJECTED)
val originalPlans = entityDao.get(classOf[OriginalPlan], "program", plan.getProgram)
entityDao.execute(Operation.remove(originalPlans).saveOrUpdate(plan))
}
}
def submit(plans: List[MajorPlan]) {
for (plan <- plans if canTransferTo(plan.getProgram.getAuditState, CommonAuditState.SUBMITTED)) {
plan.getProgram.setAuditState(CommonAuditState.SUBMITTED)
}
entityDao.saveOrUpdate(plans)
}
def revokeSubmitted(plans: List[Program]) {
for (program <- plans if canTransferTo(program.getAuditState, CommonAuditState.UNSUBMITTED)) {
program.setAuditState(CommonAuditState.UNSUBMITTED)
}
entityDao.saveOrUpdate(plans)
}
private def canTransferTo(from: CommonAuditState, to: CommonAuditState): Boolean = from match {
case UNSUBMITTED => if (to == CommonAuditState.SUBMITTED) {
true
} else {
false
}
case SUBMITTED => if (to == CommonAuditState.ACCEPTED || to == CommonAuditState.REJECTED ||
to == CommonAuditState.UNSUBMITTED) {
true
} else {
false
}
case REJECTED => if (to == CommonAuditState.SUBMITTED) {
true
} else {
false
}
case ACCEPTED => if (to == CommonAuditState.REJECTED) {
true
} else {
false
}
case _ => false
}
def getOriginalMajorPlan(majorPlanId: java.lang.Long): OriginalPlan = {
val query = OqlBuilder.from(classOf[OriginalPlan], "plan")
query.where("plan.program.id=(select mp.program from org.openurp.edu.eams.teach.program.major.MajorPlan mp where mp.id = :mplanid)",
majorPlanId)
val originalPlans = entityDao.search(query)
if (originalPlans == null || originalPlans.size == 0) {
throw new RuntimeException("Cannot find Original Plan")
}
if (originalPlans.size > 1) {
throw new RuntimeException("Error More than one Original Plan found")
}
originalPlans.get(0)
}
def setMajorPlanAuditDao(majorPlanAuditDao: MajorPlanAuditDao) {
this.majorPlanAuditDao = majorPlanAuditDao
}
}
|
openurp/edu-eams-webapp
|
plan/src/main/scala/org/openurp/edu/eams/teach/program/major/service/impl/MajorPlanAuditServiceImpl.scala
|
Scala
|
gpl-3.0
| 3,548 |
/*
This file is part of Intake24.
Copyright 2015, 2016 Newcastle University.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package uk.ac.ncl.openlab.intake24.services.foodindex.russian
import uk.ac.ncl.openlab.intake24.services.foodindex.LocalSpecialFoodNames
class RussianSpecialFoodNames extends LocalSpecialFoodNames {
def buildMySandwichLabel = "Build my sandwich »"
def buildMySaladLabel = "Build my salad »"
def saladDescription = "salad"
def sandwichDescription = "sandwich"
}
|
digitalinteraction/intake24
|
FoodDataServices/src/main/scala/uk/ac/ncl/openlab/intake24/services/foodindex/russian/RussianSpecialFoodNames.scala
|
Scala
|
apache-2.0
| 980 |
/**
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package kafka.server
import java.net.SocketTimeoutException
import kafka.admin.AdminUtils
import kafka.cluster.BrokerEndPoint
import kafka.log.LogConfig
import kafka.message.ByteBufferMessageSet
import kafka.api.KAFKA_083
import kafka.common.{KafkaStorageException, TopicAndPartition}
import ReplicaFetcherThread._
import org.apache.kafka.clients.{ManualMetadataUpdater, NetworkClient, ClientRequest, ClientResponse}
import org.apache.kafka.common.network.{Selectable, ChannelBuilders, NetworkReceive, Selector}
import org.apache.kafka.common.requests.{ListOffsetResponse, FetchResponse, RequestSend, AbstractRequest, ListOffsetRequest}
import org.apache.kafka.common.requests.{FetchRequest => JFetchRequest}
import org.apache.kafka.common.{Node, TopicPartition}
import org.apache.kafka.common.metrics.Metrics
import org.apache.kafka.common.protocol.{Errors, ApiKeys}
import org.apache.kafka.common.security.ssl.SSLFactory
import org.apache.kafka.common.utils.Time
import scala.collection.{JavaConverters, Map, mutable}
import JavaConverters._
class ReplicaFetcherThread(name: String,
sourceBroker: BrokerEndPoint,
brokerConfig: KafkaConfig,
replicaMgr: ReplicaManager,
metrics: Metrics,
time: Time)
extends AbstractFetcherThread(name = name,
clientId = name,
sourceBroker = sourceBroker,
fetchBackOffMs = brokerConfig.replicaFetchBackoffMs,
isInterruptible = false) {
type REQ = FetchRequest
type PD = PartitionData
private val fetchRequestVersion: Short = if (brokerConfig.interBrokerProtocolVersion.onOrAfter(KAFKA_083)) 1 else 0
private val socketTimeout: Int = brokerConfig.replicaSocketTimeoutMs
private val replicaId = brokerConfig.brokerId
private val maxWait = brokerConfig.replicaFetchWaitMaxMs
private val minBytes = brokerConfig.replicaFetchMinBytes
private val fetchSize = brokerConfig.replicaFetchMaxBytes
private def clientId = name
private val sourceNode = new Node(sourceBroker.id, sourceBroker.host, sourceBroker.port)
private val networkClient = {
val selector = new Selector(
NetworkReceive.UNLIMITED,
brokerConfig.connectionsMaxIdleMs,
metrics,
time,
"replica-fetcher",
Map("broker-id" -> sourceBroker.id.toString).asJava,
false,
ChannelBuilders.create(brokerConfig.interBrokerSecurityProtocol, SSLFactory.Mode.CLIENT, brokerConfig.channelConfigs)
)
new NetworkClient(
selector,
new ManualMetadataUpdater(),
clientId,
1,
0,
Selectable.USE_DEFAULT_BUFFER_SIZE,
brokerConfig.replicaSocketReceiveBufferBytes,
brokerConfig.requestTimeoutMs
)
}
override def shutdown(): Unit = {
super.shutdown()
networkClient.close()
}
// process fetched data
def processPartitionData(topicAndPartition: TopicAndPartition, fetchOffset: Long, partitionData: PartitionData) {
try {
val TopicAndPartition(topic, partitionId) = topicAndPartition
val replica = replicaMgr.getReplica(topic, partitionId).get
val messageSet = partitionData.toByteBufferMessageSet
if (fetchOffset != replica.logEndOffset.messageOffset)
throw new RuntimeException("Offset mismatch: fetched offset = %d, log end offset = %d.".format(fetchOffset, replica.logEndOffset.messageOffset))
trace("Follower %d has replica log end offset %d for partition %s. Received %d messages and leader hw %d"
.format(replica.brokerId, replica.logEndOffset.messageOffset, topicAndPartition, messageSet.sizeInBytes, partitionData.highWatermark))
replica.log.get.append(messageSet, assignOffsets = false)
trace("Follower %d has replica log end offset %d after appending %d bytes of messages for partition %s"
.format(replica.brokerId, replica.logEndOffset.messageOffset, messageSet.sizeInBytes, topicAndPartition))
val followerHighWatermark = replica.logEndOffset.messageOffset.min(partitionData.highWatermark)
// for the follower replica, we do not need to keep
// its segment base offset the physical position,
// these values will be computed upon making the leader
replica.highWatermark = new LogOffsetMetadata(followerHighWatermark)
trace("Follower %d set replica high watermark for partition [%s,%d] to %s"
.format(replica.brokerId, topic, partitionId, followerHighWatermark))
} catch {
case e: KafkaStorageException =>
fatal("Disk error while replicating data.", e)
Runtime.getRuntime.halt(1)
}
}
/**
* Handle a partition whose offset is out of range and return a new fetch offset.
*/
def handleOffsetOutOfRange(topicAndPartition: TopicAndPartition): Long = {
val replica = replicaMgr.getReplica(topicAndPartition.topic, topicAndPartition.partition).get
/**
* Unclean leader election: A follower goes down, in the meanwhile the leader keeps appending messages. The follower comes back up
* and before it has completely caught up with the leader's logs, all replicas in the ISR go down. The follower is now uncleanly
* elected as the new leader, and it starts appending messages from the client. The old leader comes back up, becomes a follower
* and it may discover that the current leader's end offset is behind its own end offset.
*
* In such a case, truncate the current follower's log to the current leader's end offset and continue fetching.
*
* There is a potential for a mismatch between the logs of the two replicas here. We don't fix this mismatch as of now.
*/
val leaderEndOffset: Long = earliestOrLatestOffset(topicAndPartition, ListOffsetRequest.LATEST_TIMESTAMP,
brokerConfig.brokerId)
if (leaderEndOffset < replica.logEndOffset.messageOffset) {
// Prior to truncating the follower's log, ensure that doing so is not disallowed by the configuration for unclean leader election.
// This situation could only happen if the unclean election configuration for a topic changes while a replica is down. Otherwise,
// we should never encounter this situation since a non-ISR leader cannot be elected if disallowed by the broker configuration.
if (!LogConfig.fromProps(brokerConfig.originals, AdminUtils.fetchEntityConfig(replicaMgr.zkClient,
ConfigType.Topic, topicAndPartition.topic)).uncleanLeaderElectionEnable) {
// Log a fatal error and shutdown the broker to ensure that data loss does not unexpectedly occur.
fatal("Halting because log truncation is not allowed for topic %s,".format(topicAndPartition.topic) +
" Current leader %d's latest offset %d is less than replica %d's latest offset %d"
.format(sourceBroker.id, leaderEndOffset, brokerConfig.brokerId, replica.logEndOffset.messageOffset))
Runtime.getRuntime.halt(1)
}
replicaMgr.logManager.truncateTo(Map(topicAndPartition -> leaderEndOffset))
warn("Replica %d for partition %s reset its fetch offset from %d to current leader %d's latest offset %d"
.format(brokerConfig.brokerId, topicAndPartition, replica.logEndOffset.messageOffset, sourceBroker.id, leaderEndOffset))
leaderEndOffset
} else {
/**
* The follower could have been down for a long time and when it starts up, its end offset could be smaller than the leader's
* start offset because the leader has deleted old logs (log.logEndOffset < leaderStartOffset).
*
* Roll out a new log at the follower with the start offset equal to the current leader's start offset and continue fetching.
*/
val leaderStartOffset: Long = earliestOrLatestOffset(topicAndPartition, ListOffsetRequest.EARLIEST_TIMESTAMP,
brokerConfig.brokerId)
warn("Replica %d for partition %s reset its fetch offset from %d to current leader %d's start offset %d"
.format(brokerConfig.brokerId, topicAndPartition, replica.logEndOffset.messageOffset, sourceBroker.id, leaderStartOffset))
replicaMgr.logManager.truncateFullyAndStartAt(topicAndPartition, leaderStartOffset)
leaderStartOffset
}
}
// any logic for partitions whose leader has changed
def handlePartitionsWithErrors(partitions: Iterable[TopicAndPartition]) {
delayPartitions(partitions, brokerConfig.replicaFetchBackoffMs.toLong)
}
protected def fetch(fetchRequest: FetchRequest): Map[TopicAndPartition, PartitionData] = {
val clientResponse = sendRequest(ApiKeys.FETCH, Some(fetchRequestVersion), fetchRequest.underlying)
new FetchResponse(clientResponse.responseBody).responseData.asScala.map { case (key, value) =>
TopicAndPartition(key.topic, key.partition) -> new PartitionData(value)
}
}
private def sendRequest(apiKey: ApiKeys, apiVersion: Option[Short], request: AbstractRequest): ClientResponse = {
import kafka.utils.NetworkClientBlockingOps._
val header = apiVersion.fold(networkClient.nextRequestHeader(apiKey))(networkClient.nextRequestHeader(apiKey, _))
try {
if (!networkClient.blockingReady(sourceNode, socketTimeout)(time))
throw new SocketTimeoutException(s"Failed to connect within $socketTimeout ms")
else {
val send = new RequestSend(sourceBroker.id.toString, header, request.toStruct)
val clientRequest = new ClientRequest(time.milliseconds(), true, send, null)
networkClient.blockingSendAndReceive(clientRequest, socketTimeout)(time).getOrElse {
throw new SocketTimeoutException(s"No response received within $socketTimeout ms")
}
}
}
catch {
case e: Throwable =>
networkClient.close(sourceBroker.id.toString)
throw e
}
}
private def earliestOrLatestOffset(topicAndPartition: TopicAndPartition, earliestOrLatest: Long, consumerId: Int): Long = {
val topicPartition = new TopicPartition(topicAndPartition.topic, topicAndPartition.partition)
val partitions = Map(
topicPartition -> new ListOffsetRequest.PartitionData(earliestOrLatest, 1)
)
val request = new ListOffsetRequest(consumerId, partitions.asJava)
val clientResponse = sendRequest(ApiKeys.LIST_OFFSETS, None, request)
val response = new ListOffsetResponse(clientResponse.responseBody)
val partitionData = response.responseData.get(topicPartition)
Errors.forCode(partitionData.errorCode) match {
case Errors.NONE => partitionData.offsets.asScala.head
case errorCode => throw errorCode.exception
}
}
protected def buildFetchRequest(partitionMap: Map[TopicAndPartition, PartitionFetchState]): FetchRequest = {
val requestMap = mutable.Map.empty[TopicPartition, JFetchRequest.PartitionData]
partitionMap.foreach { case ((TopicAndPartition(topic, partition), partitionFetchState)) =>
if (partitionFetchState.isActive)
requestMap(new TopicPartition(topic, partition)) = new JFetchRequest.PartitionData(partitionFetchState.offset, fetchSize)
}
new FetchRequest(new JFetchRequest(replicaId, maxWait, minBytes, requestMap.asJava))
}
}
object ReplicaFetcherThread {
private[server] class FetchRequest(val underlying: JFetchRequest) extends AbstractFetcherThread.FetchRequest {
def isEmpty: Boolean = underlying.fetchData.isEmpty
def offset(topicAndPartition: TopicAndPartition): Long =
underlying.fetchData.asScala(new TopicPartition(topicAndPartition.topic, topicAndPartition.partition)).offset
}
private[server] class PartitionData(val underlying: FetchResponse.PartitionData) extends AbstractFetcherThread.PartitionData {
def errorCode: Short = underlying.errorCode
def toByteBufferMessageSet: ByteBufferMessageSet = new ByteBufferMessageSet(underlying.recordSet)
def highWatermark: Long = underlying.highWatermark
def exception: Option[Throwable] = Errors.forCode(errorCode) match {
case Errors.NONE => None
case e => Some(e.exception)
}
}
}
|
reiseburo/kafka
|
core/src/main/scala/kafka/server/ReplicaFetcherThread.scala
|
Scala
|
apache-2.0
| 12,914 |
package com.eclipsesource.schema.internal.refs
import java.net.{URL, URLDecoder, URLStreamHandler}
import com.eclipsesource.schema._
import com.eclipsesource.schema.internal._
import com.eclipsesource.schema.internal.constraints.Constraints.Constraint
import com.eclipsesource.schema.internal.url.UrlStreamResolverFactory
import com.osinka.i18n.{Lang, Messages}
import play.api.libs.json._
import scalaz.syntax.either._
import scalaz.{\\/, \\/-}
import scala.io.Source
import scala.util.{Success, Try}
case class ResolvedResult(resolved: SchemaType, scope: SchemaResolutionScope)
/**
* Schema reference resolver.
*
*/
case class SchemaRefResolver
(
version: SchemaVersion,
cache: DocumentCache = DocumentCache(),
resolverFactory: UrlStreamResolverFactory = UrlStreamResolverFactory()
) {
import version._
val MaxDepth: Int = 100
/**
* Update the resolution scope based on the current element.
*
* @param scope the current resolution scope
* @param a the value that might contain scope refinements
* @return the updated scope, if the given value contain a scope refinement, otherwise
* the not updated scope
*/
private[schema] def updateResolutionScope(scope: SchemaResolutionScope, a: SchemaType): SchemaResolutionScope = a match {
case _ if refinesScope(a) =>
val updatedId = findScopeRefinement(a).map(
id => Refs.mergeRefs(id, scope.id, Some(resolverFactory))
)
scope.copy(id = updatedId)
case _ => scope
}
/**
* Resolve the given ref against the current schema. The current
* schema must not contain
*
* @param current the current schema to resolve the ref against.
* @param ref the ref to be resolved
* @param scope the current resolution scope
* @param lang the language to be used
* @return the resolved schema together with the scope.
*/
private[schema] def resolve(current: SchemaType, ref: Ref, scope: SchemaResolutionScope)
(implicit lang: Lang): \\/[JsonValidationError, ResolvedResult] = {
// update resolution scope, if applicable
val updatedScope = updateResolutionScope(scope.copy(depth = scope.depth + 1), current)
if (scope.depth >= MaxDepth) {
JsonValidationError(Messages("err.max.depth")).left
} else {
val result: \\/[JsonValidationError, ResolvedResult] = ref match {
case l@LocalRef(_) =>
resolveLocal(splitFragment(l), scope, current)
case r if cache.contains(r) =>
val resolvedSchema: SchemaType = cache(r)
ResolvedResult(
resolvedSchema,
scope.copy(
id = Some(Refs.mergeRefs(r, updatedScope.id)),
documentRoot = resolvedSchema
)
).right[JsonValidationError]
// check if any prefix of ref matches current element
case a@AbsoluteRef(absoluteRef) =>
val currentResolutionScope = findScopeRefinement(current)
currentResolutionScope.collectFirst {
case id if absoluteRef.startsWith(id.value) => absoluteRef.drop(id.value.length)
}.map(remaining =>
resolve(
current,
Ref(if (remaining.startsWith("#")) remaining else "#" + remaining),
updatedScope
)
).getOrElse(resolveAbsolute(a, updatedScope))
case r@RelativeRef(_) =>
resolveRelative(r, updatedScope, current)
}
result match {
case \\/-(resolvedResult@ResolvedResult(resolved, _)) =>
// if resolved result is ref, keep on going
findRef(resolved)
.fold(result)(foundRef =>
resolve(resolvedResult.resolved, foundRef, resolvedResult.scope)
)
case _ => resolutionFailure(ref).left
}
}
}
private[schema] def resolutionFailure(ref: Ref)(implicit lang: Lang): JsonValidationError =
JsonValidationError(Messages("err.unresolved.ref", ref.value))
private def resolveRelative(ref: RelativeRef, scope: SchemaResolutionScope, instance: SchemaType)
(implicit lang: Lang): \\/[JsonValidationError, ResolvedResult] = {
Refs.mergeRefs(ref, scope.id) match {
case a@AbsoluteRef(_) =>
resolve(instance, a, scope)
case r@RelativeRef(relativeRef) =>
val (file, localRef) = relativeRef.splitAt(relativeRef.indexOf("#"))
val result = for {
schema <- cache.get(file)
} yield {
resolve(
schema,
LocalRef(localRef),
scope.copy(
documentRoot = schema,
id = updateResolutionScope(scope, schema).id orElse Some(Ref(file)),
referrer = scope.schemaJsPath
)
)
}
result.getOrElse(resolutionFailure(r).left)
}
}
private[schema] def resolveLocal(schemaPath: List[String], scope: SchemaResolutionScope, instance: SchemaType)
(implicit lang: Lang): \\/[JsonValidationError, ResolvedResult] =
(schemaPath, instance) match {
case (Nil, _) =>
\\/.fromEither(
resolveSchema(instance, "")
.map(resolved => ResolvedResult(resolved, scope))
) orElse ResolvedResult(instance, scope).right
case (_, SchemaRef(ref, _, _)) if !ref.isInstanceOf[LocalRef] =>
resolve(scope.documentRoot, ref, scope).flatMap(resolvedResult =>
resolveLocal(schemaPath, resolvedResult.scope, resolvedResult.resolved)
)
case (schemaProp :: rest, resolvable) =>
schemaProp match {
case "#" => resolveLocal(rest, scope.copy(schemaJsPath = Some(JsPath \\ "#")), scope.documentRoot)
case _ => \\/.fromEither(resolveSchema(resolvable, schemaProp)).flatMap { r =>
val newScope = updateResolutionScope(scope, r)
resolveLocal(
rest,
newScope.copy(
schemaJsPath =
if (resolutionScopeChanged(newScope.id, scope.id)) None
else scope.schemaJsPath.map(_.compose(JsPath \\ schemaProp))
),
r
)
}
}
}
private def resolutionScopeChanged(oldScope: Option[Ref], newScope: Option[Ref]) = {
val changed = for {
n <- newScope
o <- oldScope
} yield n != o
changed.getOrElse(false)
}
private def createUrl(ref: Ref)(implicit lang: Lang): \\/[JsonValidationError, URL] = {
// use handlers for protocol-ful absolute refs or fall back to default behaviour via null
val handler: URLStreamHandler = ref.scheme.map(resolverFactory.createURLStreamHandler).orNull
val triedUrl = Try { new URL(null, ref.value, handler) }
triedUrl match {
case Success(url) => url.right
case _ => resolutionFailure(ref).left
}
}
/**
* Fetch the instance located at the given URL and eventually cache it as well.
*
* @param ref the ref to fetch from
* @param scope the current resolution scope
* @return the fetched instance, if any
*/
private[schema] def fetch(ref: Ref, scope: SchemaResolutionScope)(implicit lang: Lang): \\/[JsonValidationError, SchemaType] = {
cache.get(ref.value) orElse cache.get(ref.value + "#") match {
case Some(a) => a.right
case _ => for {
url <- createUrl(ref)
source <- if (url.getProtocol == null || version.options.supportsExternalReferences) {
\\/.fromEither(Try { Source.fromURL(url) }.toJsonEither)
} else {
JsonValidationError(Messages("err.unresolved.ref")).left
}
read <- readSource(source)
} yield {
cache.add(Refs.mergeRefs(ref, scope.id, Some(resolverFactory)))(read)
read
}
}
}
private def parseJson(source: Source): \\/[JsonValidationError, JsValue] = \\/.fromEither(Try {
Json.parse(source.getLines().mkString)
}.toJsonEither)
private[schema] def readJson(json: JsValue)(implicit lang: Lang): \\/[JsonValidationError, SchemaType] = \\/.fromEither(Json.fromJson[SchemaType](json).asEither)
.leftMap(errors =>
JsonValidationError(Messages("err.parse.json"), JsError.toJson(errors))
)
private[schema] def readSource(source: Source)(implicit lang: Lang): \\/[JsonValidationError, SchemaType] = {
using(source) { src =>
for {
json <- parseJson(src)
resolvedSchema <- readJson(json)
} yield resolvedSchema
}
}
/**
* Resolve the given ref. The given ref may be relative or absolute.
* If is relative it will be normalized against the current resolution scope.
*
* @param ref the ref to be resolved
* @param scope the resolution scope that will be used for normalization
* @return the resolved schema
*/
private def resolveAbsolute(ref: AbsoluteRef, scope: SchemaResolutionScope)
(implicit lang: Lang): \\/[JsonValidationError, ResolvedResult] = {
for {
fetchedSchema <- fetch(ref.documentName, scope)
result <- resolve(fetchedSchema,
ref.pointer.getOrElse(Refs.`#`),
scope.copy(
id = Some(ref.documentName),
documentRoot = fetchedSchema,
referrer = scope.schemaJsPath
)
)
} yield result
}
/**
* Split the given ref into single segments.
* Only the fragments of the given ref will be considered.
*
* @param ref the reference that should be split up into single segments
* @return a list containing all the segments
*/
private def splitFragment(ref: Ref): List[String] = {
def escape(s: String): String =
URLDecoder.decode(s, "UTF-8")
.replace("~1", "/")
.replace("~0", "~")
ref.pointer.map(_.value)
.getOrElse(ref.value)
.split("/").toList
.map(escape)
}
def refinesScope(a: SchemaType): Boolean = findScopeRefinement(a).isDefined
def findRef(schema: SchemaType): Option[Ref] = schema match {
case SchemaRef(ref, _, _) => Some(ref)
case _ => None
}
def findScopeRefinement(schema: SchemaType): Option[Ref] = schema.constraints.id.map(Ref(_))
private def resolveConstraint[A <: Constraint](constraints: A, constraint: String)
(implicit lang: Lang): Either[JsonValidationError, SchemaType] = {
constraints.resolvePath(constraint).fold[Either[JsonValidationError, SchemaType]](
Left(JsonValidationError(Messages("err.unresolved.ref", constraint)))
)(schema => Right(schema))
}
private def findProp(props: Seq[SchemaProp], propName: String)
(implicit lang: Lang): Either[JsonValidationError, SchemaType] = {
props.collectFirst {
case SchemaProp(name, s) if name == propName => s
}.toRight(JsonValidationError(Messages("err.prop.not.found", propName)))
}
private def findOtherProp(props: Seq[(String, SchemaType)], propName: String)
(implicit lang: Lang): Either[JsonValidationError, SchemaType] = {
props.collectFirst {
case (name, s) if name == propName => s
}.toRight(JsonValidationError(Messages("err.prop.not.found", propName)))
}
def resolveSchema[A <: SchemaType](schema: A, fragmentPart: String)
(implicit lang: Lang = Lang.Default): Either[JsonValidationError, SchemaType] = {
def isValidIndex(size: Int, idx: String) = {
Try {
val n = idx.toInt
n <= size && n >= 0
}.toOption.getOrElse(false)
}
schema match {
case SchemaMap(name, members) =>
members.find(_.name == fragmentPart).map(_.schemaType).toRight(JsonValidationError(Messages(s"err.$name.not.found")))
case SchemaSeq(members) =>
fragmentPart match {
case idx if isValidIndex(members.size, idx) => Right(members(idx.toInt))
}
case obj@SchemaObject(props, _, otherProps) => fragmentPart match {
case Keywords.Object.Properties => Right(obj)
case _ =>
resolveConstraint(obj.constraints, fragmentPart) orElse
findProp(props, fragmentPart) orElse
findOtherProp(otherProps, fragmentPart)
}
case arr@SchemaArray(items, _, otherProps) => fragmentPart match {
case Keywords.Array.Items => Right(items)
case other =>
findOtherProp(otherProps, other)
.map(Right(_))
.getOrElse(resolveConstraint(arr.constraints, fragmentPart))
}
case tuple@SchemaTuple(items, _, _) =>
fragmentPart match {
case Keywords.Array.Items => Right(tuple)
case idx if isValidIndex(items.size, idx) => Right(items(idx.toInt))
case _ => resolveConstraint(tuple.constraints, fragmentPart)
}
case SchemaValue(value) => (value, fragmentPart) match {
case (arr: JsArray, index) if Try {
index.toInt
}.isSuccess =>
val idx = index.toInt
if (idx > 0 && idx < arr.value.size) {
Right(SchemaValue(arr.value(idx)))
} else {
Left(JsonValidationError(Messages("arr.out.of.bounds", index)))
}
case _ => Left(JsonValidationError(Messages("arr.invalid.index", fragmentPart)))
}
case CompoundSchemaType(alternatives) =>
val results = alternatives.map(
alternative => resolveSchema(alternative, fragmentPart)
)
results
.collectFirst { case r@Right(_) => r }
.getOrElse(Left(JsonValidationError(Messages("err.unresolved.ref", fragmentPart))))
case n: SchemaNumber => resolveConstraint(n.constraints, fragmentPart)
case n: SchemaInteger => resolveConstraint(n.constraints, fragmentPart)
case n: SchemaBoolean => resolveConstraint(n.constraints, fragmentPart)
case n: SchemaString =>
resolveConstraint(n.constraints, fragmentPart)
case r: SchemaRef =>
findOtherProp(r.otherProps, fragmentPart) orElse resolveConstraint(r.constraints, fragmentPart)
case SchemaRoot(_, s) => resolveSchema(s, fragmentPart)
}
}
}
|
edgarmueller/play-json-schema-validator
|
src/main/scala/com/eclipsesource/schema/internal/refs/SchemaRefResolver.scala
|
Scala
|
apache-2.0
| 14,131 |
/*
* Copyright 2011-2018 GatlingCorp (http://gatling.io)
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package io.gatling.recorder.ui.swing.component
import scala.swing._
import scala.swing.BorderPanel.Position._
import io.gatling.recorder.ui.swing.util.UIHelper._
import io.gatling.recorder.ui.swing.frame.ConfigurationFrame
private[swing] object DialogFileSelector {
val message = """|A Swing bug on Mac OS X prevents the Recorder from getting
|the correct path for file with some known extensions.
|Those files closely matches the file you selected, please select
|the correct one :
|""".stripMargin
}
private[swing] class DialogFileSelector(configurationFrame: ConfigurationFrame, possibleFiles: List[String]) extends Dialog(configurationFrame) {
var selectedFile: Option[String] = None
val radioButtons = possibleFiles.map(new RadioButton(_))
val radiosGroup = new ButtonGroup(radioButtons: _*)
val cancelButton = Button("Cancel")(close())
val okButton = Button("OK") { radiosGroup.selected.foreach(button => selectedFile = Some(button.text)); close() }
val defaultBackground = background
contents = new BorderPanel {
val messageLabel = new TextArea(DialogFileSelector.message) { background = defaultBackground }
val radiosPanel = new BoxPanel(Orientation.Vertical) { radioButtons.foreach(contents += _) }
val buttonsPanel = new CenterAlignedFlowPanel {
contents += okButton
contents += cancelButton
}
layout(messageLabel) = North
layout(radiosPanel) = Center
layout(buttonsPanel) = South
}
modal = true
setLocationRelativeTo(configurationFrame)
}
|
wiacekm/gatling
|
gatling-recorder/src/main/scala/io/gatling/recorder/ui/swing/component/DialogFileSelector.scala
|
Scala
|
apache-2.0
| 2,214 |
package ee.cone.c4gate
import com.typesafe.scalalogging.LazyLogging
import ee.cone.c4actor.Types.SrcId
import ee.cone.c4actor._
import ee.cone.c4assemble.Types.{Each, Values}
import ee.cone.c4assemble.{Assemble, assemble, c4assemble}
import ee.cone.c4di.c4multi
import ee.cone.c4gate.HttpProtocol.S_HttpRequest
@c4assemble("TestTxTransformApp") class TestDelayAssembleBase(
factory: TestDelayHttpHandlerFactory,
){
def joinTestHttpHandler(
key: SrcId,
req: Each[S_HttpRequest]
): Values[(SrcId, TxTransform)] =
List(WithPK(factory.create(req.srcId, req)))
}
@c4multi("TestTxTransformApp") final case class TestDelayHttpHandler(srcId: SrcId, req: S_HttpRequest)(
txAdd: LTxAdd,
) extends TxTransform with LazyLogging {
def transform(local: Context): Context = {
logger.info(s"start handling $srcId")
concurrent.blocking{
Thread.sleep(1000)
}
logger.info(s"finish handling $srcId")
txAdd.add(LEvent.delete(req))(local)
}
}
|
conecenter/c4proto
|
base_examples/src/main/scala/ee/cone/c4gate/TestTxTransform.scala
|
Scala
|
apache-2.0
| 974 |
package ar.com.pablitar
import ar.com.pablitar.point._
trait Positioned[P<:Point[P]] {
def space: Space[P]
var position: P = space.origin
}
trait Speedy[P <: Point[P]] <: Positioned[P]{
def bounds = space.infiniteBounds
def speed: P
def applySpeed(delta:Double) = position = bounds.bound(position + speed * delta)
}
trait Speedy3D extends Speedy[Point3D] {
def space = Space._3D
}
class Car(var speed: Point3D = Point3D(10, 10, 10)) extends Speedy3D {
}
|
pablitar/fun-spaces
|
fun-spaces-alt2/test/ar/com/pablitar/TestTraits.scala
|
Scala
|
mit
| 493 |
package scroll.examples
import scroll.internal.compartment.impl.Compartment
import scroll.internal.dispatch.DispatchQuery
import scroll.internal.dispatch.DispatchQuery.Bypassing
import scroll.internal.util.Many.*
object BankExample {
@main def runBankExample(): Unit = {
val stan = Person("Stan")
val brian = Person("Brian")
val accForStan = new Account(10)
val accForBrian = new Account(0)
val _ = new Bank {
val ca = new CheckingsAccount()
val sa = new SavingsAccount()
roleGroups.checked {
accForStan play ca
accForBrian play sa
}
stan play new Customer()
brian play new Customer()
(+stan).addCheckingsAccount(ca)
(+brian).addSavingsAccount(sa)
println("### Before transaction ###")
println("Balance for Stan:")
(+stan).listBalances()
println("Balance for Brian:")
(+brian).listBalances()
private val transaction = new Transaction(10) {
roleGroups.checked {
accForStan play new Source()
accForBrian play new Target()
}
}
transaction.compartmentRelations.partOf(this)
(transaction play new TransactionRole()).execute()
println("### After transaction ###")
println("Balance for Stan:")
(+stan).listBalances()
println("Balance for Brian:")
(+brian).listBalances()
}
}
case class Person(name: String)
class Account(var balance: Double = 0) {
def increase(amount: Double): Unit = balance = balance + amount
def decrease(amount: Double): Unit = balance = balance - amount
}
class Bank extends Compartment {
roleGroups.create("Accounts").containing[CheckingsAccount, SavingsAccount](1, 1)(0, *)
class Customer() {
private val checkingsAccounts = scala.collection.mutable.ArrayBuffer[CheckingsAccount]()
private val savingsAccounts = scala.collection.mutable.ArrayBuffer[SavingsAccount]()
def addCheckingsAccount(acc: CheckingsAccount): Unit = checkingsAccounts += acc
def addSavingsAccount(acc: SavingsAccount): Unit = savingsAccounts += acc
def listBalances(): Unit = {
checkingsAccounts.foreach { a =>
val account = a
val balance: Double = (+account).balance
println(s"CheckingsAccount '$account': $balance")
}
savingsAccounts.foreach { a =>
val account = a
val balance: Double = (+account).balance
println(s"SavingsAccount '$account': $balance")
}
}
}
class CheckingsAccount() {
def decrease(amount: Double): Unit = {
given DispatchQuery = Bypassing(_.isInstanceOf[CheckingsAccount])
val _ = (+this).decrease(amount)
}
}
class SavingsAccount() {
private val transactionFee = 0.1
def increase(amount: Double): Unit = {
println("Increasing with fee.")
given DispatchQuery = Bypassing(_.isInstanceOf[SavingsAccount])
val _ = (+this).increase(amount - calcTransactionFee(amount))
}
private def calcTransactionFee(amount: Double): Double = amount * transactionFee
}
class TransactionRole() {
def execute(): Unit = {
println("Executing from Role.")
given DispatchQuery = Bypassing(_.isInstanceOf[TransactionRole])
val _ = (+this).execute()
}
}
}
class Transaction(val amount: Double) extends Compartment {
roleGroups.create("Transaction").containing[Source, Target](1, 1)(2, 2)
private val transferRel = roleRelationships.create("transfer").from[Source](1).to[Target](1)
def execute(): Unit = {
println("Executing from Player.")
roleQueries.one[Source]().withDraw(amount)
roleQueries.one[Target]().deposit(amount)
val from = transferRel.left().head
val to = transferRel.right().head
println(s"Transferred '$amount' from '$from' to '$to'.")
}
class Source() {
def withDraw(m: Double): Unit = {
val _ = (+this).decrease(m)
}
}
class Target() {
def deposit(m: Double): Unit = {
val _ = (+this).increase(m)
}
}
}
}
|
max-leuthaeuser/SCROLL
|
examples/src/main/scala/scroll/examples/BankExample.scala
|
Scala
|
lgpl-3.0
| 4,232 |
object test {
def apply[a,b](f: a => b): a => b = { x: a => f(x) }
def twice[a](f: a => a): a => a = { x: a => f(f(x)) }
def main = apply[Int,Int](twice[Int]{x: Int => x})(1);
}
|
folone/dotty
|
tests/untried/pos/lambda.scala
|
Scala
|
bsd-3-clause
| 192 |
package org.jetbrains.plugins.scala
package lang
package references
import java.util
import java.util.Collections
import com.intellij.openapi.diagnostic.Logger
import com.intellij.openapi.module.{Module, ModuleUtilCore}
import com.intellij.openapi.roots.ModuleRootManager
import com.intellij.openapi.util.{Condition, TextRange}
import com.intellij.openapi.vfs.VirtualFile
import com.intellij.patterns.PlatformPatterns
import com.intellij.psi._
import com.intellij.psi.impl.source.resolve.reference.impl.providers.{FileReference, FileReferenceSet}
import com.intellij.util.ProcessingContext
import com.intellij.util.containers.ContainerUtil
import org.jetbrains.annotations.NotNull
import org.jetbrains.plugins.scala.extensions._
import org.jetbrains.plugins.scala.lang.psi.api.base.patterns.ScInterpolationPattern
import org.jetbrains.plugins.scala.lang.psi.api.base.{ScInterpolatedStringLiteral, ScLiteral}
import org.jetbrains.plugins.scala.lang.psi.api.expr.ScReferenceExpression
import org.jetbrains.plugins.scala.lang.psi.impl.ScalaPsiElementFactory
import org.jetbrains.plugins.scala.lang.psi.impl.expr.ScInterpolatedStringPartReference
import scala.collection.JavaConversions
class ScalaReferenceContributor extends PsiReferenceContributor {
def registerReferenceProviders(registrar: PsiReferenceRegistrar) {
registrar.registerReferenceProvider(PlatformPatterns.psiElement(classOf[ScLiteral]), new FilePathReferenceProvider())
registrar.registerReferenceProvider(PlatformPatterns.psiElement(classOf[ScLiteral]), new InterpolatedStringReferenceProvider())
}
}
class InterpolatedStringReferenceProvider extends PsiReferenceProvider {
override def getReferencesByElement(element: PsiElement, context: ProcessingContext): Array[PsiReference] = {
element match {
case l: ScLiteral if (l.isString || l.isMultiLineString) && l.getText.contains("$") =>
val interpolated = ScalaPsiElementFactory.createExpressionFromText("s" + l.getText, l.getContext)
interpolated.getChildren.filter {
case r: ScInterpolatedStringPartReference => false
case ref: ScReferenceExpression => true
case _ => false
}.map {
case ref: ScReferenceExpression =>
new PsiReference {
override def getVariants: Array[AnyRef] = Array.empty
override def getCanonicalText: String = ref.getCanonicalText
override def getElement: PsiElement = l
override def isReferenceTo(element: PsiElement): Boolean = ref.isReferenceTo(element)
override def bindToElement(element: PsiElement): PsiElement = ref
override def handleElementRename(newElementName: String): PsiElement = ref
override def isSoft: Boolean = true
override def getRangeInElement: TextRange = {
val range = ref.getTextRange
val startOffset = interpolated.getTextRange.getStartOffset + 1
new TextRange(range.getStartOffset - startOffset, range.getEndOffset - startOffset)
}
override def resolve(): PsiElement = null
}
}
case _ => Array.empty
}
}
}
// todo: Copy of the corresponding class from IDEA, changed to use ScLiteral rather than PsiLiteralExpr
class FilePathReferenceProvider extends PsiReferenceProvider {
private val LOG: Logger = Logger.getInstance("#org.jetbrains.plugins.scala.lang.references.FilePathReferenceProvider")
@NotNull def getRoots(thisModule: Module, includingClasses: Boolean): java.util.Collection[PsiFileSystemItem] = {
if (thisModule == null) return Collections.emptyList[PsiFileSystemItem]
val modules: java.util.List[Module] = new util.ArrayList[Module]
modules.add(thisModule)
var moduleRootManager: ModuleRootManager = ModuleRootManager.getInstance(thisModule)
ContainerUtil.addAll(modules, moduleRootManager.getDependencies: _*)
val result: java.util.List[PsiFileSystemItem] = new java.util.ArrayList[PsiFileSystemItem]
val psiManager: PsiManager = PsiManager.getInstance(thisModule.getProject)
if (includingClasses) {
val libraryUrls: Array[VirtualFile] = moduleRootManager.orderEntries.getAllLibrariesAndSdkClassesRoots
for (file <- libraryUrls) {
val directory: PsiDirectory = psiManager.findDirectory(file)
if (directory != null) {
result.add(directory)
}
}
}
for (module <- JavaConversions.iterableAsScalaIterable(modules)) {
moduleRootManager = ModuleRootManager.getInstance(module)
val sourceRoots: Array[VirtualFile] = moduleRootManager.getSourceRoots
for (root <- sourceRoots) {
val directory: PsiDirectory = psiManager.findDirectory(root)
if (directory != null) {
val aPackage: PsiPackage = JavaDirectoryService.getInstance.getPackage(directory)
if (aPackage != null && aPackage.name != null) {
try {
val createMethod = Class.forName("com.intellij.psi.impl.source.resolve.reference.impl.providers.PackagePrefixFileSystemItemImpl").getMethod("create", classOf[PsiDirectory])
createMethod.setAccessible(true)
createMethod.invoke(directory)
} catch {
case t: Exception => LOG.warn(t)
}
}
else {
result.add(directory)
}
}
}
}
result
}
@NotNull def getReferencesByElement(element: PsiElement, text: String, offset: Int, soft: Boolean): Array[PsiReference] = {
new FileReferenceSet(text, element, offset, this, true, myEndingSlashNotAllowed) {
protected override def isSoft: Boolean = soft
override def isAbsolutePathReference: Boolean = true
override def couldBeConvertedTo(relative: Boolean): Boolean = !relative
override def absoluteUrlNeedsStartSlash: Boolean = {
val s: String = getPathString
s != null && s.length > 0 && s.charAt(0) == '/'
}
@NotNull override def computeDefaultContexts: java.util.Collection[PsiFileSystemItem] = {
val module: Module = ModuleUtilCore.findModuleForPsiElement(getElement)
getRoots(module, includingClasses = true)
}
override def createFileReference(range: TextRange, index: Int, text: String): FileReference = {
FilePathReferenceProvider.this.createFileReference(this, range, index, text)
}
protected override def getReferenceCompletionFilter: Condition[PsiFileSystemItem] = {
new Condition[PsiFileSystemItem] {
def value(element: PsiFileSystemItem): Boolean = {
isPsiElementAccepted(element)
}
}
}
}.getAllReferences.map(identity)
}
override def acceptsTarget(@NotNull target: PsiElement): Boolean = {
target.isInstanceOf[PsiFileSystemItem]
}
protected def isPsiElementAccepted(element: PsiElement): Boolean = {
!(element.isInstanceOf[PsiJavaFile] && element.isInstanceOf[PsiCompiledElement])
}
protected def createFileReference(referenceSet: FileReferenceSet, range: TextRange, index: Int, text: String): FileReference = {
new FileReference(referenceSet, range, index, text)
}
def getReferencesByElement(element: PsiElement, context: ProcessingContext): Array[PsiReference] = {
element match {
case interpolated: ScInterpolationPattern =>
val refs = interpolated.getReferencesToStringParts
val start: Int = interpolated.getTextRange.getStartOffset
return refs.flatMap{ r =>
val offset = r.getElement.getTextRange.getStartOffset - start
getReferencesByElement(r.getElement, r.getCanonicalText, offset, soft = true)}
case interpolatedString: ScInterpolatedStringLiteral =>
val refs = interpolatedString.getReferencesToStringParts
val start: Int = interpolatedString.getTextRange.getStartOffset
return refs.flatMap{ r =>
val offset = r.getElement.getTextRange.getStartOffset - start
getReferencesByElement(r.getElement, r.getCanonicalText, offset, soft = true)
}
case literal: ScLiteral =>
literal.getValue match {
case text: String =>
if (text == null) return PsiReference.EMPTY_ARRAY
return getReferencesByElement(element, text, 1, soft = true)
case _ =>
}
case _ =>
}
PsiReference.EMPTY_ARRAY
}
private final val myEndingSlashNotAllowed: Boolean = false
}
|
triggerNZ/intellij-scala
|
src/org/jetbrains/plugins/scala/lang/references/ScalaReferenceContributor.scala
|
Scala
|
apache-2.0
| 8,500 |
/*
* Licensed to the Apache Software Foundation (ASF) under one or more
* contributor license agreements. See the NOTICE file distributed with
* this work for additional information regarding copyright ownership.
* The ASF licenses this file to You under the Apache License, Version 2.0
* (the "License"); you may not use this file except in compliance with
* the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package org.apache.spark.sql.catalyst.parser
import java.util.Locale
import javax.xml.bind.DatatypeConverter
import scala.collection.JavaConverters._
import scala.collection.mutable.ArrayBuffer
import org.antlr.v4.runtime.{ParserRuleContext, Token}
import org.antlr.v4.runtime.tree.{ParseTree, RuleNode, TerminalNode}
import org.apache.spark.internal.Logging
import org.apache.spark.sql.AnalysisException
import org.apache.spark.sql.catalyst.{FunctionIdentifier, TableIdentifier}
import org.apache.spark.sql.catalyst.analysis._
import org.apache.spark.sql.catalyst.catalog.{BucketSpec, CatalogStorageFormat}
import org.apache.spark.sql.catalyst.expressions._
import org.apache.spark.sql.catalyst.expressions.aggregate.{First, Last}
import org.apache.spark.sql.catalyst.parser.SqlBaseParser._
import org.apache.spark.sql.catalyst.plans._
import org.apache.spark.sql.catalyst.plans.logical._
import org.apache.spark.sql.catalyst.util.DateTimeUtils.{getZoneId, stringToDate, stringToTimestamp}
import org.apache.spark.sql.catalyst.util.IntervalUtils
import org.apache.spark.sql.catalyst.util.IntervalUtils.IntervalUnit
import org.apache.spark.sql.connector.expressions.{ApplyTransform, BucketTransform, DaysTransform, Expression => V2Expression, FieldReference, HoursTransform, IdentityTransform, LiteralValue, MonthsTransform, Transform, YearsTransform}
import org.apache.spark.sql.internal.SQLConf
import org.apache.spark.sql.types._
import org.apache.spark.unsafe.types.{CalendarInterval, UTF8String}
import org.apache.spark.util.random.RandomSampler
/**
* The AstBuilder converts an ANTLR4 ParseTree into a catalyst Expression, LogicalPlan or
* TableIdentifier.
*/
class AstBuilder(conf: SQLConf) extends SqlBaseBaseVisitor[AnyRef] with Logging {
import ParserUtils._
def this() = this(new SQLConf())
protected def typedVisit[T](ctx: ParseTree): T = {
ctx.accept(this).asInstanceOf[T]
}
/**
* Override the default behavior for all visit methods. This will only return a non-null result
* when the context has only one child. This is done because there is no generic method to
* combine the results of the context children. In all other cases null is returned.
*/
override def visitChildren(node: RuleNode): AnyRef = {
if (node.getChildCount == 1) {
node.getChild(0).accept(this)
} else {
null
}
}
override def visitSingleStatement(ctx: SingleStatementContext): LogicalPlan = withOrigin(ctx) {
visit(ctx.statement).asInstanceOf[LogicalPlan]
}
override def visitSingleExpression(ctx: SingleExpressionContext): Expression = withOrigin(ctx) {
visitNamedExpression(ctx.namedExpression)
}
override def visitSingleTableIdentifier(
ctx: SingleTableIdentifierContext): TableIdentifier = withOrigin(ctx) {
visitTableIdentifier(ctx.tableIdentifier)
}
override def visitSingleFunctionIdentifier(
ctx: SingleFunctionIdentifierContext): FunctionIdentifier = withOrigin(ctx) {
visitFunctionIdentifier(ctx.functionIdentifier)
}
override def visitSingleMultipartIdentifier(
ctx: SingleMultipartIdentifierContext): Seq[String] = withOrigin(ctx) {
visitMultipartIdentifier(ctx.multipartIdentifier)
}
override def visitSingleDataType(ctx: SingleDataTypeContext): DataType = withOrigin(ctx) {
visitSparkDataType(ctx.dataType)
}
override def visitSingleTableSchema(ctx: SingleTableSchemaContext): StructType = {
withOrigin(ctx)(StructType(visitColTypeList(ctx.colTypeList)))
}
override def visitSingleInterval(ctx: SingleIntervalContext): CalendarInterval = {
withOrigin(ctx)(visitMultiUnitsInterval(ctx.multiUnitsInterval))
}
/* ********************************************************************************************
* Plan parsing
* ******************************************************************************************** */
protected def plan(tree: ParserRuleContext): LogicalPlan = typedVisit(tree)
/**
* Create a top-level plan with Common Table Expressions.
*/
override def visitQuery(ctx: QueryContext): LogicalPlan = withOrigin(ctx) {
val query = plan(ctx.queryTerm).optionalMap(ctx.queryOrganization)(withQueryResultClauses)
// Apply CTEs
query.optionalMap(ctx.ctes)(withCTE)
}
override def visitDmlStatement(ctx: DmlStatementContext): AnyRef = withOrigin(ctx) {
val dmlStmt = plan(ctx.dmlStatementNoWith)
// Apply CTEs
dmlStmt.optionalMap(ctx.ctes)(withCTE)
}
private def withCTE(ctx: CtesContext, plan: LogicalPlan): LogicalPlan = {
val ctes = ctx.namedQuery.asScala.map { nCtx =>
val namedQuery = visitNamedQuery(nCtx)
(namedQuery.alias, namedQuery)
}
// Check for duplicate names.
val duplicates = ctes.groupBy(_._1).filter(_._2.size > 1).keys
if (duplicates.nonEmpty) {
throw new ParseException(
s"CTE definition can't have duplicate names: ${duplicates.mkString("'", "', '", "'")}.",
ctx)
}
With(plan, ctes)
}
/**
* Create a logical query plan for a hive-style FROM statement body.
*/
private def withFromStatementBody(
ctx: FromStatementBodyContext, plan: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// two cases for transforms and selects
if (ctx.transformClause != null) {
withTransformQuerySpecification(
ctx,
ctx.transformClause,
ctx.whereClause,
plan
)
} else {
withSelectQuerySpecification(
ctx,
ctx.selectClause,
ctx.lateralView,
ctx.whereClause,
ctx.aggregationClause,
ctx.havingClause,
ctx.windowClause,
plan
)
}
}
override def visitFromStatement(ctx: FromStatementContext): LogicalPlan = withOrigin(ctx) {
val from = visitFromClause(ctx.fromClause)
val selects = ctx.fromStatementBody.asScala.map { body =>
withFromStatementBody(body, from).
// Add organization statements.
optionalMap(body.queryOrganization)(withQueryResultClauses)
}
// If there are multiple SELECT just UNION them together into one query.
if (selects.length == 1) {
selects.head
} else {
Union(selects)
}
}
/**
* Create a named logical plan.
*
* This is only used for Common Table Expressions.
*/
override def visitNamedQuery(ctx: NamedQueryContext): SubqueryAlias = withOrigin(ctx) {
val subQuery: LogicalPlan = plan(ctx.query).optionalMap(ctx.columnAliases)(
(columnAliases, plan) =>
UnresolvedSubqueryColumnAliases(visitIdentifierList(columnAliases), plan)
)
SubqueryAlias(ctx.name.getText, subQuery)
}
/**
* Create a logical plan which allows for multiple inserts using one 'from' statement. These
* queries have the following SQL form:
* {{{
* [WITH cte...]?
* FROM src
* [INSERT INTO tbl1 SELECT *]+
* }}}
* For example:
* {{{
* FROM db.tbl1 A
* INSERT INTO dbo.tbl1 SELECT * WHERE A.value = 10 LIMIT 5
* INSERT INTO dbo.tbl2 SELECT * WHERE A.value = 12
* }}}
* This (Hive) feature cannot be combined with set-operators.
*/
override def visitMultiInsertQuery(ctx: MultiInsertQueryContext): LogicalPlan = withOrigin(ctx) {
val from = visitFromClause(ctx.fromClause)
// Build the insert clauses.
val inserts = ctx.multiInsertQueryBody.asScala.map { body =>
withInsertInto(body.insertInto,
withFromStatementBody(body.fromStatementBody, from).
optionalMap(body.fromStatementBody.queryOrganization)(withQueryResultClauses))
}
// If there are multiple INSERTS just UNION them together into one query.
if (inserts.length == 1) {
inserts.head
} else {
Union(inserts)
}
}
/**
* Create a logical plan for a regular (single-insert) query.
*/
override def visitSingleInsertQuery(
ctx: SingleInsertQueryContext): LogicalPlan = withOrigin(ctx) {
withInsertInto(
ctx.insertInto(),
plan(ctx.queryTerm).optionalMap(ctx.queryOrganization)(withQueryResultClauses))
}
/**
* Parameters used for writing query to a table:
* (multipartIdentifier, partitionKeys, ifPartitionNotExists).
*/
type InsertTableParams = (Seq[String], Map[String, Option[String]], Boolean)
/**
* Parameters used for writing query to a directory: (isLocal, CatalogStorageFormat, provider).
*/
type InsertDirParams = (Boolean, CatalogStorageFormat, Option[String])
/**
* Add an
* {{{
* INSERT OVERWRITE TABLE tableIdentifier [partitionSpec [IF NOT EXISTS]]?
* INSERT INTO [TABLE] tableIdentifier [partitionSpec]
* INSERT OVERWRITE [LOCAL] DIRECTORY STRING [rowFormat] [createFileFormat]
* INSERT OVERWRITE [LOCAL] DIRECTORY [STRING] tableProvider [OPTIONS tablePropertyList]
* }}}
* operation to logical plan
*/
private def withInsertInto(
ctx: InsertIntoContext,
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
ctx match {
case table: InsertIntoTableContext =>
val (tableIdent, partition, ifPartitionNotExists) = visitInsertIntoTable(table)
InsertIntoStatement(
UnresolvedRelation(tableIdent),
partition,
query,
overwrite = false,
ifPartitionNotExists)
case table: InsertOverwriteTableContext =>
val (tableIdent, partition, ifPartitionNotExists) = visitInsertOverwriteTable(table)
InsertIntoStatement(
UnresolvedRelation(tableIdent),
partition,
query,
overwrite = true,
ifPartitionNotExists)
case dir: InsertOverwriteDirContext =>
val (isLocal, storage, provider) = visitInsertOverwriteDir(dir)
InsertIntoDir(isLocal, storage, provider, query, overwrite = true)
case hiveDir: InsertOverwriteHiveDirContext =>
val (isLocal, storage, provider) = visitInsertOverwriteHiveDir(hiveDir)
InsertIntoDir(isLocal, storage, provider, query, overwrite = true)
case _ =>
throw new ParseException("Invalid InsertIntoContext", ctx)
}
}
/**
* Add an INSERT INTO TABLE operation to the logical plan.
*/
override def visitInsertIntoTable(
ctx: InsertIntoTableContext): InsertTableParams = withOrigin(ctx) {
val tableIdent = visitMultipartIdentifier(ctx.multipartIdentifier)
val partitionKeys = Option(ctx.partitionSpec).map(visitPartitionSpec).getOrElse(Map.empty)
if (ctx.EXISTS != null) {
operationNotAllowed("INSERT INTO ... IF NOT EXISTS", ctx)
}
(tableIdent, partitionKeys, false)
}
/**
* Add an INSERT OVERWRITE TABLE operation to the logical plan.
*/
override def visitInsertOverwriteTable(
ctx: InsertOverwriteTableContext): InsertTableParams = withOrigin(ctx) {
assert(ctx.OVERWRITE() != null)
val tableIdent = visitMultipartIdentifier(ctx.multipartIdentifier)
val partitionKeys = Option(ctx.partitionSpec).map(visitPartitionSpec).getOrElse(Map.empty)
val dynamicPartitionKeys: Map[String, Option[String]] = partitionKeys.filter(_._2.isEmpty)
if (ctx.EXISTS != null && dynamicPartitionKeys.nonEmpty) {
operationNotAllowed("IF NOT EXISTS with dynamic partitions: " +
dynamicPartitionKeys.keys.mkString(", "), ctx)
}
(tableIdent, partitionKeys, ctx.EXISTS() != null)
}
/**
* Write to a directory, returning a [[InsertIntoDir]] logical plan.
*/
override def visitInsertOverwriteDir(
ctx: InsertOverwriteDirContext): InsertDirParams = withOrigin(ctx) {
throw new ParseException("INSERT OVERWRITE DIRECTORY is not supported", ctx)
}
/**
* Write to a directory, returning a [[InsertIntoDir]] logical plan.
*/
override def visitInsertOverwriteHiveDir(
ctx: InsertOverwriteHiveDirContext): InsertDirParams = withOrigin(ctx) {
throw new ParseException("INSERT OVERWRITE DIRECTORY is not supported", ctx)
}
private def getTableAliasWithoutColumnAlias(
ctx: TableAliasContext, op: String): Option[String] = {
if (ctx == null) {
None
} else {
val ident = ctx.strictIdentifier()
if (ctx.identifierList() != null) {
throw new ParseException(s"Columns aliases are not allowed in $op.", ctx.identifierList())
}
if (ident != null) Some(ident.getText) else None
}
}
override def visitDeleteFromTable(
ctx: DeleteFromTableContext): LogicalPlan = withOrigin(ctx) {
val table = UnresolvedRelation(visitMultipartIdentifier(ctx.multipartIdentifier()))
val tableAlias = getTableAliasWithoutColumnAlias(ctx.tableAlias(), "DELETE")
val aliasedTable = tableAlias.map(SubqueryAlias(_, table)).getOrElse(table)
val predicate = if (ctx.whereClause() != null) {
Some(expression(ctx.whereClause().booleanExpression()))
} else {
None
}
DeleteFromTable(aliasedTable, predicate)
}
override def visitUpdateTable(ctx: UpdateTableContext): LogicalPlan = withOrigin(ctx) {
val table = UnresolvedRelation(visitMultipartIdentifier(ctx.multipartIdentifier()))
val tableAlias = getTableAliasWithoutColumnAlias(ctx.tableAlias(), "UPDATE")
val aliasedTable = tableAlias.map(SubqueryAlias(_, table)).getOrElse(table)
val assignments = withAssignments(ctx.setClause().assignmentList())
val predicate = if (ctx.whereClause() != null) {
Some(expression(ctx.whereClause().booleanExpression()))
} else {
None
}
UpdateTable(aliasedTable, assignments, predicate)
}
private def withAssignments(assignCtx: SqlBaseParser.AssignmentListContext): Seq[Assignment] =
withOrigin(assignCtx) {
assignCtx.assignment().asScala.map { assign =>
Assignment(UnresolvedAttribute(visitMultipartIdentifier(assign.key)),
expression(assign.value))
}
}
override def visitMergeIntoTable(ctx: MergeIntoTableContext): LogicalPlan = withOrigin(ctx) {
val targetTable = UnresolvedRelation(visitMultipartIdentifier(ctx.target))
val targetTableAlias = getTableAliasWithoutColumnAlias(ctx.targetAlias, "MERGE")
val aliasedTarget = targetTableAlias.map(SubqueryAlias(_, targetTable)).getOrElse(targetTable)
val sourceTableOrQuery = if (ctx.source != null) {
UnresolvedRelation(visitMultipartIdentifier(ctx.source))
} else if (ctx.sourceQuery != null) {
visitQuery(ctx.sourceQuery)
} else {
throw new ParseException("Empty source for merge: you should specify a source" +
" table/subquery in merge.", ctx.source)
}
val sourceTableAlias = getTableAliasWithoutColumnAlias(ctx.sourceAlias, "MERGE")
val aliasedSource =
sourceTableAlias.map(SubqueryAlias(_, sourceTableOrQuery)).getOrElse(sourceTableOrQuery)
val mergeCondition = expression(ctx.mergeCondition)
val matchedClauses = ctx.matchedClause()
if (matchedClauses.size() > 2) {
throw new ParseException("There should be at most 2 'WHEN MATCHED' clauses.",
matchedClauses.get(2))
}
val matchedActions = matchedClauses.asScala.map {
clause => {
if (clause.matchedAction().DELETE() != null) {
DeleteAction(Option(clause.matchedCond).map(expression))
} else if (clause.matchedAction().UPDATE() != null) {
val condition = Option(clause.matchedCond).map(expression)
if (clause.matchedAction().ASTERISK() != null) {
UpdateAction(condition, Seq())
} else {
UpdateAction(condition, withAssignments(clause.matchedAction().assignmentList()))
}
} else {
// It should not be here.
throw new ParseException(
s"Unrecognized matched action: ${clause.matchedAction().getText}",
clause.matchedAction())
}
}
}
val notMatchedClauses = ctx.notMatchedClause()
if (notMatchedClauses.size() > 1) {
throw new ParseException("There should be at most 1 'WHEN NOT MATCHED' clause.",
notMatchedClauses.get(1))
}
val notMatchedActions = notMatchedClauses.asScala.map {
clause => {
if (clause.notMatchedAction().INSERT() != null) {
val condition = Option(clause.notMatchedCond).map(expression)
if (clause.notMatchedAction().ASTERISK() != null) {
InsertAction(condition, Seq())
} else {
val columns = clause.notMatchedAction().columns.multipartIdentifier()
.asScala.map(attr => UnresolvedAttribute(visitMultipartIdentifier(attr)))
val values = clause.notMatchedAction().expression().asScala.map(expression)
if (columns.size != values.size) {
throw new ParseException("The number of inserted values cannot match the fields.",
clause.notMatchedAction())
}
InsertAction(condition, columns.zip(values).map(kv => Assignment(kv._1, kv._2)))
}
} else {
// It should not be here.
throw new ParseException(
s"Unrecognized not matched action: ${clause.notMatchedAction().getText}",
clause.notMatchedAction())
}
}
}
MergeIntoTable(
aliasedTarget,
aliasedSource,
mergeCondition,
matchedActions,
notMatchedActions)
}
/**
* Create a partition specification map.
*/
override def visitPartitionSpec(
ctx: PartitionSpecContext): Map[String, Option[String]] = withOrigin(ctx) {
val parts = ctx.partitionVal.asScala.map { pVal =>
val name = pVal.identifier.getText
val value = Option(pVal.constant).map(visitStringConstant)
name -> value
}
// Before calling `toMap`, we check duplicated keys to avoid silently ignore partition values
// in partition spec like PARTITION(a='1', b='2', a='3'). The real semantical check for
// partition columns will be done in analyzer.
checkDuplicateKeys(parts, ctx)
parts.toMap
}
/**
* Create a partition specification map without optional values.
*/
protected def visitNonOptionalPartitionSpec(
ctx: PartitionSpecContext): Map[String, String] = withOrigin(ctx) {
visitPartitionSpec(ctx).map {
case (key, None) => throw new ParseException(s"Found an empty partition key '$key'.", ctx)
case (key, Some(value)) => key -> value
}
}
/**
* Convert a constant of any type into a string. This is typically used in DDL commands, and its
* main purpose is to prevent slight differences due to back to back conversions i.e.:
* String -> Literal -> String.
*/
protected def visitStringConstant(ctx: ConstantContext): String = withOrigin(ctx) {
ctx match {
case s: StringLiteralContext => createString(s)
case o => o.getText
}
}
/**
* Add ORDER BY/SORT BY/CLUSTER BY/DISTRIBUTE BY/LIMIT/WINDOWS clauses to the logical plan. These
* clauses determine the shape (ordering/partitioning/rows) of the query result.
*/
private def withQueryResultClauses(
ctx: QueryOrganizationContext,
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
import ctx._
// Handle ORDER BY, SORT BY, DISTRIBUTE BY, and CLUSTER BY clause.
val withOrder = if (
!order.isEmpty && sort.isEmpty && distributeBy.isEmpty && clusterBy.isEmpty) {
// ORDER BY ...
Sort(order.asScala.map(visitSortItem), global = true, query)
} else if (order.isEmpty && !sort.isEmpty && distributeBy.isEmpty && clusterBy.isEmpty) {
// SORT BY ...
Sort(sort.asScala.map(visitSortItem), global = false, query)
} else if (order.isEmpty && sort.isEmpty && !distributeBy.isEmpty && clusterBy.isEmpty) {
// DISTRIBUTE BY ...
withRepartitionByExpression(ctx, expressionList(distributeBy), query)
} else if (order.isEmpty && !sort.isEmpty && !distributeBy.isEmpty && clusterBy.isEmpty) {
// SORT BY ... DISTRIBUTE BY ...
Sort(
sort.asScala.map(visitSortItem),
global = false,
withRepartitionByExpression(ctx, expressionList(distributeBy), query))
} else if (order.isEmpty && sort.isEmpty && distributeBy.isEmpty && !clusterBy.isEmpty) {
// CLUSTER BY ...
val expressions = expressionList(clusterBy)
Sort(
expressions.map(SortOrder(_, Ascending)),
global = false,
withRepartitionByExpression(ctx, expressions, query))
} else if (order.isEmpty && sort.isEmpty && distributeBy.isEmpty && clusterBy.isEmpty) {
// [EMPTY]
query
} else {
throw new ParseException(
"Combination of ORDER BY/SORT BY/DISTRIBUTE BY/CLUSTER BY is not supported", ctx)
}
// WINDOWS
val withWindow = withOrder.optionalMap(windowClause)(withWindowClause)
// LIMIT
// - LIMIT ALL is the same as omitting the LIMIT clause
withWindow.optional(limit) {
Limit(typedVisit(limit), withWindow)
}
}
/**
* Create a clause for DISTRIBUTE BY.
*/
protected def withRepartitionByExpression(
ctx: QueryOrganizationContext,
expressions: Seq[Expression],
query: LogicalPlan): LogicalPlan = {
throw new ParseException("DISTRIBUTE BY is not supported", ctx)
}
override def visitTransformQuerySpecification(
ctx: TransformQuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withTransformQuerySpecification(ctx, ctx.transformClause, ctx.whereClause, from)
}
override def visitRegularQuerySpecification(
ctx: RegularQuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) {
visitFromClause(ctx.fromClause)
}
withSelectQuerySpecification(
ctx,
ctx.selectClause,
ctx.lateralView,
ctx.whereClause,
ctx.aggregationClause,
ctx.havingClause,
ctx.windowClause,
from
)
}
override def visitNamedExpressionSeq(
ctx: NamedExpressionSeqContext): Seq[Expression] = {
Option(ctx).toSeq
.flatMap(_.namedExpression.asScala)
.map(typedVisit[Expression])
}
/**
* Create a logical plan using a having clause.
*/
private def withHavingClause(
ctx: HavingClauseContext, plan: LogicalPlan): LogicalPlan = {
// Note that we add a cast to non-predicate expressions. If the expression itself is
// already boolean, the optimizer will get rid of the unnecessary cast.
val predicate = expression(ctx.booleanExpression) match {
case p: Predicate => p
case e => Cast(e, BooleanType)
}
Filter(predicate, plan)
}
/**
* Create a logical plan using a where clause.
*/
private def withWhereClause(ctx: WhereClauseContext, plan: LogicalPlan): LogicalPlan = {
Filter(expression(ctx.booleanExpression), plan)
}
/**
* Add a hive-style transform (SELECT TRANSFORM/MAP/REDUCE) query specification to a logical plan.
*/
private def withTransformQuerySpecification(
ctx: ParserRuleContext,
transformClause: TransformClauseContext,
whereClause: WhereClauseContext,
relation: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// Add where.
val withFilter = relation.optionalMap(whereClause)(withWhereClause)
// Create the transform.
val expressions = visitNamedExpressionSeq(transformClause.namedExpressionSeq)
// Create the attributes.
val (attributes, schemaLess) = if (transformClause.colTypeList != null) {
// Typed return columns.
(createSchema(transformClause.colTypeList).toAttributes, false)
} else if (transformClause.identifierSeq != null) {
// Untyped return columns.
val attrs = visitIdentifierSeq(transformClause.identifierSeq).map { name =>
AttributeReference(name, StringType, nullable = true)()
}
(attrs, false)
} else {
(Seq(AttributeReference("key", StringType)(),
AttributeReference("value", StringType)()), true)
}
// Create the transform.
ScriptTransformation(
expressions,
string(transformClause.script),
attributes,
withFilter,
withScriptIOSchema(
ctx,
transformClause.inRowFormat,
transformClause.recordWriter,
transformClause.outRowFormat,
transformClause.recordReader,
schemaLess
)
)
}
/**
* Add a regular (SELECT) query specification to a logical plan. The query specification
* is the core of the logical plan, this is where sourcing (FROM clause), projection (SELECT),
* aggregation (GROUP BY ... HAVING ...) and filtering (WHERE) takes place.
*
* Note that query hints are ignored (both by the parser and the builder).
*/
private def withSelectQuerySpecification(
ctx: ParserRuleContext,
selectClause: SelectClauseContext,
lateralView: java.util.List[LateralViewContext],
whereClause: WhereClauseContext,
aggregationClause: AggregationClauseContext,
havingClause: HavingClauseContext,
windowClause: WindowClauseContext,
relation: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// Add lateral views.
val withLateralView = lateralView.asScala.foldLeft(relation)(withGenerate)
// Add where.
val withFilter = withLateralView.optionalMap(whereClause)(withWhereClause)
val expressions = visitNamedExpressionSeq(selectClause.namedExpressionSeq)
// Add aggregation or a project.
val namedExpressions = expressions.map {
case e: NamedExpression => e
case e: Expression => UnresolvedAlias(e)
}
def createProject() = if (namedExpressions.nonEmpty) {
Project(namedExpressions, withFilter)
} else {
withFilter
}
val withProject = if (aggregationClause == null && havingClause != null) {
if (conf.getConf(SQLConf.LEGACY_HAVING_WITHOUT_GROUP_BY_AS_WHERE)) {
// If the legacy conf is set, treat HAVING without GROUP BY as WHERE.
withHavingClause(havingClause, createProject())
} else {
// According to SQL standard, HAVING without GROUP BY means global aggregate.
withHavingClause(havingClause, Aggregate(Nil, namedExpressions, withFilter))
}
} else if (aggregationClause != null) {
val aggregate = withAggregationClause(aggregationClause, namedExpressions, withFilter)
aggregate.optionalMap(havingClause)(withHavingClause)
} else {
// When hitting this branch, `having` must be null.
createProject()
}
// Distinct
val withDistinct = if (
selectClause.setQuantifier() != null &&
selectClause.setQuantifier().DISTINCT() != null) {
Distinct(withProject)
} else {
withProject
}
// Window
val withWindow = withDistinct.optionalMap(windowClause)(withWindowClause)
// Hint
selectClause.hints.asScala.foldRight(withWindow)(withHints)
}
/**
* Create a (Hive based) [[ScriptInputOutputSchema]].
*/
protected def withScriptIOSchema(
ctx: ParserRuleContext,
inRowFormat: RowFormatContext,
recordWriter: Token,
outRowFormat: RowFormatContext,
recordReader: Token,
schemaLess: Boolean): ScriptInputOutputSchema = {
throw new ParseException("Script Transform is not supported", ctx)
}
/**
* Create a logical plan for a given 'FROM' clause. Note that we support multiple (comma
* separated) relations here, these get converted into a single plan by condition-less inner join.
*/
override def visitFromClause(ctx: FromClauseContext): LogicalPlan = withOrigin(ctx) {
val from = ctx.relation.asScala.foldLeft(null: LogicalPlan) { (left, relation) =>
val right = plan(relation.relationPrimary)
val join = right.optionalMap(left)(Join(_, _, Inner, None, JoinHint.NONE))
withJoinRelations(join, relation)
}
if (ctx.pivotClause() != null) {
if (!ctx.lateralView.isEmpty) {
throw new ParseException("LATERAL cannot be used together with PIVOT in FROM clause", ctx)
}
withPivot(ctx.pivotClause, from)
} else {
ctx.lateralView.asScala.foldLeft(from)(withGenerate)
}
}
/**
* Connect two queries by a Set operator.
*
* Supported Set operators are:
* - UNION [ DISTINCT | ALL ]
* - EXCEPT [ DISTINCT | ALL ]
* - MINUS [ DISTINCT | ALL ]
* - INTERSECT [DISTINCT | ALL]
*/
override def visitSetOperation(ctx: SetOperationContext): LogicalPlan = withOrigin(ctx) {
val left = plan(ctx.left)
val right = plan(ctx.right)
val all = Option(ctx.setQuantifier()).exists(_.ALL != null)
ctx.operator.getType match {
case SqlBaseParser.UNION if all =>
Union(left, right)
case SqlBaseParser.UNION =>
Distinct(Union(left, right))
case SqlBaseParser.INTERSECT if all =>
Intersect(left, right, isAll = true)
case SqlBaseParser.INTERSECT =>
Intersect(left, right, isAll = false)
case SqlBaseParser.EXCEPT if all =>
Except(left, right, isAll = true)
case SqlBaseParser.EXCEPT =>
Except(left, right, isAll = false)
case SqlBaseParser.SETMINUS if all =>
Except(left, right, isAll = true)
case SqlBaseParser.SETMINUS =>
Except(left, right, isAll = false)
}
}
/**
* Add a [[WithWindowDefinition]] operator to a logical plan.
*/
private def withWindowClause(
ctx: WindowClauseContext,
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// Collect all window specifications defined in the WINDOW clause.
val baseWindowMap = ctx.namedWindow.asScala.map {
wCtx =>
(wCtx.name.getText, typedVisit[WindowSpec](wCtx.windowSpec))
}.toMap
// Handle cases like
// window w1 as (partition by p_mfgr order by p_name
// range between 2 preceding and 2 following),
// w2 as w1
val windowMapView = baseWindowMap.mapValues {
case WindowSpecReference(name) =>
baseWindowMap.get(name) match {
case Some(spec: WindowSpecDefinition) =>
spec
case Some(ref) =>
throw new ParseException(s"Window reference '$name' is not a window specification", ctx)
case None =>
throw new ParseException(s"Cannot resolve window reference '$name'", ctx)
}
case spec: WindowSpecDefinition => spec
}
// Note that mapValues creates a view instead of materialized map. We force materialization by
// mapping over identity.
WithWindowDefinition(windowMapView.map(identity), query)
}
/**
* Add an [[Aggregate]] or [[GroupingSets]] to a logical plan.
*/
private def withAggregationClause(
ctx: AggregationClauseContext,
selectExpressions: Seq[NamedExpression],
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
val groupByExpressions = expressionList(ctx.groupingExpressions)
if (ctx.GROUPING != null) {
// GROUP BY .... GROUPING SETS (...)
val selectedGroupByExprs =
ctx.groupingSet.asScala.map(_.expression.asScala.map(e => expression(e)))
GroupingSets(selectedGroupByExprs, groupByExpressions, query, selectExpressions)
} else {
// GROUP BY .... (WITH CUBE | WITH ROLLUP)?
val mappedGroupByExpressions = if (ctx.CUBE != null) {
Seq(Cube(groupByExpressions))
} else if (ctx.ROLLUP != null) {
Seq(Rollup(groupByExpressions))
} else {
groupByExpressions
}
Aggregate(mappedGroupByExpressions, selectExpressions, query)
}
}
/**
* Add [[UnresolvedHint]]s to a logical plan.
*/
private def withHints(
ctx: HintContext,
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
var plan = query
ctx.hintStatements.asScala.reverse.foreach { case stmt =>
plan = UnresolvedHint(stmt.hintName.getText, stmt.parameters.asScala.map(expression), plan)
}
plan
}
/**
* Add a [[Pivot]] to a logical plan.
*/
private def withPivot(
ctx: PivotClauseContext,
query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
val aggregates = Option(ctx.aggregates).toSeq
.flatMap(_.namedExpression.asScala)
.map(typedVisit[Expression])
val pivotColumn = if (ctx.pivotColumn.identifiers.size == 1) {
UnresolvedAttribute.quoted(ctx.pivotColumn.identifier.getText)
} else {
CreateStruct(
ctx.pivotColumn.identifiers.asScala.map(
identifier => UnresolvedAttribute.quoted(identifier.getText)))
}
val pivotValues = ctx.pivotValues.asScala.map(visitPivotValue)
Pivot(None, pivotColumn, pivotValues, aggregates, query)
}
/**
* Create a Pivot column value with or without an alias.
*/
override def visitPivotValue(ctx: PivotValueContext): Expression = withOrigin(ctx) {
val e = expression(ctx.expression)
if (ctx.identifier != null) {
Alias(e, ctx.identifier.getText)()
} else {
e
}
}
/**
* Add a [[Generate]] (Lateral View) to a logical plan.
*/
private def withGenerate(
query: LogicalPlan,
ctx: LateralViewContext): LogicalPlan = withOrigin(ctx) {
val expressions = expressionList(ctx.expression)
Generate(
UnresolvedGenerator(visitFunctionName(ctx.qualifiedName), expressions),
unrequiredChildIndex = Nil,
outer = ctx.OUTER != null,
// scalastyle:off caselocale
Some(ctx.tblName.getText.toLowerCase),
// scalastyle:on caselocale
ctx.colName.asScala.map(_.getText).map(UnresolvedAttribute.apply),
query)
}
/**
* Create a single relation referenced in a FROM clause. This method is used when a part of the
* join condition is nested, for example:
* {{{
* select * from t1 join (t2 cross join t3) on col1 = col2
* }}}
*/
override def visitRelation(ctx: RelationContext): LogicalPlan = withOrigin(ctx) {
withJoinRelations(plan(ctx.relationPrimary), ctx)
}
/**
* Join one more [[LogicalPlan]]s to the current logical plan.
*/
private def withJoinRelations(base: LogicalPlan, ctx: RelationContext): LogicalPlan = {
ctx.joinRelation.asScala.foldLeft(base) { (left, join) =>
withOrigin(join) {
val baseJoinType = join.joinType match {
case null => Inner
case jt if jt.CROSS != null => Cross
case jt if jt.FULL != null => FullOuter
case jt if jt.SEMI != null => LeftSemi
case jt if jt.ANTI != null => LeftAnti
case jt if jt.LEFT != null => LeftOuter
case jt if jt.RIGHT != null => RightOuter
case _ => Inner
}
// Resolve the join type and join condition
val (joinType, condition) = Option(join.joinCriteria) match {
case Some(c) if c.USING != null =>
(UsingJoin(baseJoinType, visitIdentifierList(c.identifierList)), None)
case Some(c) if c.booleanExpression != null =>
(baseJoinType, Option(expression(c.booleanExpression)))
case None if join.NATURAL != null =>
if (baseJoinType == Cross) {
throw new ParseException("NATURAL CROSS JOIN is not supported", ctx)
}
(NaturalJoin(baseJoinType), None)
case None =>
(baseJoinType, None)
}
Join(left, plan(join.right), joinType, condition, JoinHint.NONE)
}
}
}
/**
* Add a [[Sample]] to a logical plan.
*
* This currently supports the following sampling methods:
* - TABLESAMPLE(x ROWS): Sample the table down to the given number of rows.
* - TABLESAMPLE(x PERCENT): Sample the table down to the given percentage. Note that percentages
* are defined as a number between 0 and 100.
* - TABLESAMPLE(BUCKET x OUT OF y): Sample the table down to a 'x' divided by 'y' fraction.
*/
private def withSample(ctx: SampleContext, query: LogicalPlan): LogicalPlan = withOrigin(ctx) {
// Create a sampled plan if we need one.
def sample(fraction: Double): Sample = {
// The range of fraction accepted by Sample is [0, 1]. Because Hive's block sampling
// function takes X PERCENT as the input and the range of X is [0, 100], we need to
// adjust the fraction.
val eps = RandomSampler.roundingEpsilon
validate(fraction >= 0.0 - eps && fraction <= 1.0 + eps,
s"Sampling fraction ($fraction) must be on interval [0, 1]",
ctx)
Sample(0.0, fraction, withReplacement = false, (math.random * 1000).toInt, query)
}
if (ctx.sampleMethod() == null) {
throw new ParseException("TABLESAMPLE does not accept empty inputs.", ctx)
}
ctx.sampleMethod() match {
case ctx: SampleByRowsContext =>
Limit(expression(ctx.expression), query)
case ctx: SampleByPercentileContext =>
val fraction = ctx.percentage.getText.toDouble
val sign = if (ctx.negativeSign == null) 1 else -1
sample(sign * fraction / 100.0d)
case ctx: SampleByBytesContext =>
val bytesStr = ctx.bytes.getText
if (bytesStr.matches("[0-9]+[bBkKmMgG]")) {
throw new ParseException("TABLESAMPLE(byteLengthLiteral) is not supported", ctx)
} else {
throw new ParseException(
bytesStr + " is not a valid byte length literal, " +
"expected syntax: DIGIT+ ('B' | 'K' | 'M' | 'G')", ctx)
}
case ctx: SampleByBucketContext if ctx.ON() != null =>
if (ctx.identifier != null) {
throw new ParseException(
"TABLESAMPLE(BUCKET x OUT OF y ON colname) is not supported", ctx)
} else {
throw new ParseException(
"TABLESAMPLE(BUCKET x OUT OF y ON function) is not supported", ctx)
}
case ctx: SampleByBucketContext =>
sample(ctx.numerator.getText.toDouble / ctx.denominator.getText.toDouble)
}
}
/**
* Create a logical plan for a sub-query.
*/
override def visitSubquery(ctx: SubqueryContext): LogicalPlan = withOrigin(ctx) {
plan(ctx.query)
}
/**
* Create an un-aliased table reference. This is typically used for top-level table references,
* for example:
* {{{
* INSERT INTO db.tbl2
* TABLE db.tbl1
* }}}
*/
override def visitTable(ctx: TableContext): LogicalPlan = withOrigin(ctx) {
UnresolvedRelation(visitMultipartIdentifier(ctx.multipartIdentifier))
}
/**
* Create an aliased table reference. This is typically used in FROM clauses.
*/
override def visitTableName(ctx: TableNameContext): LogicalPlan = withOrigin(ctx) {
val tableId = visitMultipartIdentifier(ctx.multipartIdentifier)
val table = mayApplyAliasPlan(ctx.tableAlias, UnresolvedRelation(tableId))
table.optionalMap(ctx.sample)(withSample)
}
/**
* Create a table-valued function call with arguments, e.g. range(1000)
*/
override def visitTableValuedFunction(ctx: TableValuedFunctionContext)
: LogicalPlan = withOrigin(ctx) {
val func = ctx.functionTable
val aliases = if (func.tableAlias.identifierList != null) {
visitIdentifierList(func.tableAlias.identifierList)
} else {
Seq.empty
}
val tvf = UnresolvedTableValuedFunction(
func.funcName.getText, func.expression.asScala.map(expression), aliases)
tvf.optionalMap(func.tableAlias.strictIdentifier)(aliasPlan)
}
/**
* Create an inline table (a virtual table in Hive parlance).
*/
override def visitInlineTable(ctx: InlineTableContext): LogicalPlan = withOrigin(ctx) {
// Get the backing expressions.
val rows = ctx.expression.asScala.map { e =>
expression(e) match {
// inline table comes in two styles:
// style 1: values (1), (2), (3) -- multiple columns are supported
// style 2: values 1, 2, 3 -- only a single column is supported here
case struct: CreateNamedStruct => struct.valExprs // style 1
case child => Seq(child) // style 2
}
}
val aliases = if (ctx.tableAlias.identifierList != null) {
visitIdentifierList(ctx.tableAlias.identifierList)
} else {
Seq.tabulate(rows.head.size)(i => s"col${i + 1}")
}
val table = UnresolvedInlineTable(aliases, rows)
table.optionalMap(ctx.tableAlias.strictIdentifier)(aliasPlan)
}
/**
* Create an alias (SubqueryAlias) for a join relation. This is practically the same as
* visitAliasedQuery and visitNamedExpression, ANTLR4 however requires us to use 3 different
* hooks. We could add alias names for output columns, for example:
* {{{
* SELECT a, b, c, d FROM (src1 s1 INNER JOIN src2 s2 ON s1.id = s2.id) dst(a, b, c, d)
* }}}
*/
override def visitAliasedRelation(ctx: AliasedRelationContext): LogicalPlan = withOrigin(ctx) {
val relation = plan(ctx.relation).optionalMap(ctx.sample)(withSample)
mayApplyAliasPlan(ctx.tableAlias, relation)
}
/**
* Create an alias (SubqueryAlias) for a sub-query. This is practically the same as
* visitAliasedRelation and visitNamedExpression, ANTLR4 however requires us to use 3 different
* hooks. We could add alias names for output columns, for example:
* {{{
* SELECT col1, col2 FROM testData AS t(col1, col2)
* }}}
*/
override def visitAliasedQuery(ctx: AliasedQueryContext): LogicalPlan = withOrigin(ctx) {
val relation = plan(ctx.query).optionalMap(ctx.sample)(withSample)
if (ctx.tableAlias.strictIdentifier == null) {
// For un-aliased subqueries, use a default alias name that is not likely to conflict with
// normal subquery names, so that parent operators can only access the columns in subquery by
// unqualified names. Users can still use this special qualifier to access columns if they
// know it, but that's not recommended.
SubqueryAlias("__auto_generated_subquery_name", relation)
} else {
mayApplyAliasPlan(ctx.tableAlias, relation)
}
}
/**
* Create an alias ([[SubqueryAlias]]) for a [[LogicalPlan]].
*/
private def aliasPlan(alias: ParserRuleContext, plan: LogicalPlan): LogicalPlan = {
SubqueryAlias(alias.getText, plan)
}
/**
* If aliases specified in a FROM clause, create a subquery alias ([[SubqueryAlias]]) and
* column aliases for a [[LogicalPlan]].
*/
private def mayApplyAliasPlan(tableAlias: TableAliasContext, plan: LogicalPlan): LogicalPlan = {
if (tableAlias.strictIdentifier != null) {
val subquery = SubqueryAlias(tableAlias.strictIdentifier.getText, plan)
if (tableAlias.identifierList != null) {
val columnNames = visitIdentifierList(tableAlias.identifierList)
UnresolvedSubqueryColumnAliases(columnNames, subquery)
} else {
subquery
}
} else {
plan
}
}
/**
* Create a Sequence of Strings for a parenthesis enclosed alias list.
*/
override def visitIdentifierList(ctx: IdentifierListContext): Seq[String] = withOrigin(ctx) {
visitIdentifierSeq(ctx.identifierSeq)
}
/**
* Create a Sequence of Strings for an identifier list.
*/
override def visitIdentifierSeq(ctx: IdentifierSeqContext): Seq[String] = withOrigin(ctx) {
ctx.ident.asScala.map(_.getText)
}
/* ********************************************************************************************
* Table Identifier parsing
* ******************************************************************************************** */
/**
* Create a [[TableIdentifier]] from a 'tableName' or 'databaseName'.'tableName' pattern.
*/
override def visitTableIdentifier(
ctx: TableIdentifierContext): TableIdentifier = withOrigin(ctx) {
TableIdentifier(ctx.table.getText, Option(ctx.db).map(_.getText))
}
/**
* Create a [[FunctionIdentifier]] from a 'functionName' or 'databaseName'.'functionName' pattern.
*/
override def visitFunctionIdentifier(
ctx: FunctionIdentifierContext): FunctionIdentifier = withOrigin(ctx) {
FunctionIdentifier(ctx.function.getText, Option(ctx.db).map(_.getText))
}
/**
* Create a multi-part identifier.
*/
override def visitMultipartIdentifier(
ctx: MultipartIdentifierContext): Seq[String] = withOrigin(ctx) {
ctx.parts.asScala.map(_.getText)
}
/* ********************************************************************************************
* Expression parsing
* ******************************************************************************************** */
/**
* Create an expression from the given context. This method just passes the context on to the
* visitor and only takes care of typing (We assume that the visitor returns an Expression here).
*/
protected def expression(ctx: ParserRuleContext): Expression = typedVisit(ctx)
/**
* Create sequence of expressions from the given sequence of contexts.
*/
private def expressionList(trees: java.util.List[ExpressionContext]): Seq[Expression] = {
trees.asScala.map(expression)
}
/**
* Create a star (i.e. all) expression; this selects all elements (in the specified object).
* Both un-targeted (global) and targeted aliases are supported.
*/
override def visitStar(ctx: StarContext): Expression = withOrigin(ctx) {
UnresolvedStar(Option(ctx.qualifiedName()).map(_.identifier.asScala.map(_.getText)))
}
/**
* Create an aliased expression if an alias is specified. Both single and multi-aliases are
* supported.
*/
override def visitNamedExpression(ctx: NamedExpressionContext): Expression = withOrigin(ctx) {
val e = expression(ctx.expression)
if (ctx.name != null) {
Alias(e, ctx.name.getText)()
} else if (ctx.identifierList != null) {
MultiAlias(e, visitIdentifierList(ctx.identifierList))
} else {
e
}
}
/**
* Combine a number of boolean expressions into a balanced expression tree. These expressions are
* either combined by a logical [[And]] or a logical [[Or]].
*
* A balanced binary tree is created because regular left recursive trees cause considerable
* performance degradations and can cause stack overflows.
*/
override def visitLogicalBinary(ctx: LogicalBinaryContext): Expression = withOrigin(ctx) {
val expressionType = ctx.operator.getType
val expressionCombiner = expressionType match {
case SqlBaseParser.AND => And.apply _
case SqlBaseParser.OR => Or.apply _
}
// Collect all similar left hand contexts.
val contexts = ArrayBuffer(ctx.right)
var current = ctx.left
def collectContexts: Boolean = current match {
case lbc: LogicalBinaryContext if lbc.operator.getType == expressionType =>
contexts += lbc.right
current = lbc.left
true
case _ =>
contexts += current
false
}
while (collectContexts) {
// No body - all updates take place in the collectContexts.
}
// Reverse the contexts to have them in the same sequence as in the SQL statement & turn them
// into expressions.
val expressions = contexts.reverseMap(expression)
// Create a balanced tree.
def reduceToExpressionTree(low: Int, high: Int): Expression = high - low match {
case 0 =>
expressions(low)
case 1 =>
expressionCombiner(expressions(low), expressions(high))
case x =>
val mid = low + x / 2
expressionCombiner(
reduceToExpressionTree(low, mid),
reduceToExpressionTree(mid + 1, high))
}
reduceToExpressionTree(0, expressions.size - 1)
}
/**
* Invert a boolean expression.
*/
override def visitLogicalNot(ctx: LogicalNotContext): Expression = withOrigin(ctx) {
Not(expression(ctx.booleanExpression()))
}
/**
* Create a filtering correlated sub-query (EXISTS).
*/
override def visitExists(ctx: ExistsContext): Expression = {
Exists(plan(ctx.query))
}
/**
* Create a comparison expression. This compares two expressions. The following comparison
* operators are supported:
* - Equal: '=' or '=='
* - Null-safe Equal: '<=>'
* - Not Equal: '<>' or '!='
* - Less than: '<'
* - Less then or Equal: '<='
* - Greater than: '>'
* - Greater then or Equal: '>='
*/
override def visitComparison(ctx: ComparisonContext): Expression = withOrigin(ctx) {
val left = expression(ctx.left)
val right = expression(ctx.right)
val operator = ctx.comparisonOperator().getChild(0).asInstanceOf[TerminalNode]
operator.getSymbol.getType match {
case SqlBaseParser.EQ =>
EqualTo(left, right)
case SqlBaseParser.NSEQ =>
EqualNullSafe(left, right)
case SqlBaseParser.NEQ | SqlBaseParser.NEQJ =>
Not(EqualTo(left, right))
case SqlBaseParser.LT =>
LessThan(left, right)
case SqlBaseParser.LTE =>
LessThanOrEqual(left, right)
case SqlBaseParser.GT =>
GreaterThan(left, right)
case SqlBaseParser.GTE =>
GreaterThanOrEqual(left, right)
}
}
/**
* Create a predicated expression. A predicated expression is a normal expression with a
* predicate attached to it, for example:
* {{{
* a + 1 IS NULL
* }}}
*/
override def visitPredicated(ctx: PredicatedContext): Expression = withOrigin(ctx) {
val e = expression(ctx.valueExpression)
if (ctx.predicate != null) {
withPredicate(e, ctx.predicate)
} else {
e
}
}
/**
* Add a predicate to the given expression. Supported expressions are:
* - (NOT) BETWEEN
* - (NOT) IN
* - (NOT) LIKE
* - (NOT) RLIKE
* - IS (NOT) NULL.
* - IS (NOT) (TRUE | FALSE | UNKNOWN)
* - IS (NOT) DISTINCT FROM
*/
private def withPredicate(e: Expression, ctx: PredicateContext): Expression = withOrigin(ctx) {
// Invert a predicate if it has a valid NOT clause.
def invertIfNotDefined(e: Expression): Expression = ctx.NOT match {
case null => e
case not => Not(e)
}
def getValueExpressions(e: Expression): Seq[Expression] = e match {
case c: CreateNamedStruct => c.valExprs
case other => Seq(other)
}
// Create the predicate.
ctx.kind.getType match {
case SqlBaseParser.BETWEEN =>
// BETWEEN is translated to lower <= e && e <= upper
invertIfNotDefined(And(
GreaterThanOrEqual(e, expression(ctx.lower)),
LessThanOrEqual(e, expression(ctx.upper))))
case SqlBaseParser.IN if ctx.query != null =>
invertIfNotDefined(InSubquery(getValueExpressions(e), ListQuery(plan(ctx.query))))
case SqlBaseParser.IN =>
invertIfNotDefined(In(e, ctx.expression.asScala.map(expression)))
case SqlBaseParser.LIKE =>
invertIfNotDefined(Like(e, expression(ctx.pattern)))
case SqlBaseParser.RLIKE =>
invertIfNotDefined(RLike(e, expression(ctx.pattern)))
case SqlBaseParser.NULL if ctx.NOT != null =>
IsNotNull(e)
case SqlBaseParser.NULL =>
IsNull(e)
case SqlBaseParser.TRUE => ctx.NOT match {
case null => IsTrue(e)
case _ => IsNotTrue(e)
}
case SqlBaseParser.FALSE => ctx.NOT match {
case null => IsFalse(e)
case _ => IsNotFalse(e)
}
case SqlBaseParser.UNKNOWN => ctx.NOT match {
case null => IsUnknown(e)
case _ => IsNotUnknown(e)
}
case SqlBaseParser.DISTINCT if ctx.NOT != null =>
EqualNullSafe(e, expression(ctx.right))
case SqlBaseParser.DISTINCT =>
Not(EqualNullSafe(e, expression(ctx.right)))
}
}
/**
* Create a binary arithmetic expression. The following arithmetic operators are supported:
* - Multiplication: '*'
* - Division: '/'
* - Hive Long Division: 'DIV'
* - Modulo: '%'
* - Addition: '+'
* - Subtraction: '-'
* - Binary AND: '&'
* - Binary XOR
* - Binary OR: '|'
*/
override def visitArithmeticBinary(ctx: ArithmeticBinaryContext): Expression = withOrigin(ctx) {
val left = expression(ctx.left)
val right = expression(ctx.right)
ctx.operator.getType match {
case SqlBaseParser.ASTERISK =>
Multiply(left, right)
case SqlBaseParser.SLASH =>
Divide(left, right)
case SqlBaseParser.PERCENT =>
Remainder(left, right)
case SqlBaseParser.DIV =>
IntegralDivide(left, right)
case SqlBaseParser.PLUS =>
Add(left, right)
case SqlBaseParser.MINUS =>
Subtract(left, right)
case SqlBaseParser.CONCAT_PIPE =>
Concat(left :: right :: Nil)
case SqlBaseParser.AMPERSAND =>
BitwiseAnd(left, right)
case SqlBaseParser.HAT =>
BitwiseXor(left, right)
case SqlBaseParser.PIPE =>
BitwiseOr(left, right)
}
}
/**
* Create a unary arithmetic expression. The following arithmetic operators are supported:
* - Plus: '+'
* - Minus: '-'
* - Bitwise Not: '~'
*/
override def visitArithmeticUnary(ctx: ArithmeticUnaryContext): Expression = withOrigin(ctx) {
val value = expression(ctx.valueExpression)
ctx.operator.getType match {
case SqlBaseParser.PLUS =>
value
case SqlBaseParser.MINUS =>
UnaryMinus(value)
case SqlBaseParser.TILDE =>
BitwiseNot(value)
}
}
override def visitCurrentDatetime(ctx: CurrentDatetimeContext): Expression = withOrigin(ctx) {
if (conf.ansiEnabled) {
ctx.name.getType match {
case SqlBaseParser.CURRENT_DATE =>
CurrentDate()
case SqlBaseParser.CURRENT_TIMESTAMP =>
CurrentTimestamp()
}
} else {
// If the parser is not in ansi mode, we should return `UnresolvedAttribute`, in case there
// are columns named `CURRENT_DATE` or `CURRENT_TIMESTAMP`.
UnresolvedAttribute.quoted(ctx.name.getText)
}
}
/**
* Create a [[Cast]] expression.
*/
override def visitCast(ctx: CastContext): Expression = withOrigin(ctx) {
Cast(expression(ctx.expression), visitSparkDataType(ctx.dataType))
}
/**
* Create a [[CreateStruct]] expression.
*/
override def visitStruct(ctx: StructContext): Expression = withOrigin(ctx) {
CreateStruct(ctx.argument.asScala.map(expression))
}
/**
* Create a [[First]] expression.
*/
override def visitFirst(ctx: FirstContext): Expression = withOrigin(ctx) {
val ignoreNullsExpr = ctx.IGNORE != null
First(expression(ctx.expression), Literal(ignoreNullsExpr)).toAggregateExpression()
}
/**
* Create a [[Last]] expression.
*/
override def visitLast(ctx: LastContext): Expression = withOrigin(ctx) {
val ignoreNullsExpr = ctx.IGNORE != null
Last(expression(ctx.expression), Literal(ignoreNullsExpr)).toAggregateExpression()
}
/**
* Create a Position expression.
*/
override def visitPosition(ctx: PositionContext): Expression = withOrigin(ctx) {
new StringLocate(expression(ctx.substr), expression(ctx.str))
}
/**
* Create a Extract expression.
*/
override def visitExtract(ctx: ExtractContext): Expression = withOrigin(ctx) {
val fieldStr = ctx.field.getText
val source = expression(ctx.source)
val extractField = DatePart.parseExtractField(fieldStr, source, {
throw new ParseException(s"Literals of type '$fieldStr' are currently not supported.", ctx)
})
new DatePart(Literal(fieldStr), expression(ctx.source), extractField)
}
/**
* Create a Substring/Substr expression.
*/
override def visitSubstring(ctx: SubstringContext): Expression = withOrigin(ctx) {
if (ctx.len != null) {
Substring(expression(ctx.str), expression(ctx.pos), expression(ctx.len))
} else {
new Substring(expression(ctx.str), expression(ctx.pos))
}
}
/**
* Create a Trim expression.
*/
override def visitTrim(ctx: TrimContext): Expression = withOrigin(ctx) {
val srcStr = expression(ctx.srcStr)
val trimStr = Option(ctx.trimStr).map(expression)
Option(ctx.trimOption).map(_.getType).getOrElse(SqlBaseParser.BOTH) match {
case SqlBaseParser.BOTH =>
StringTrim(srcStr, trimStr)
case SqlBaseParser.LEADING =>
StringTrimLeft(srcStr, trimStr)
case SqlBaseParser.TRAILING =>
StringTrimRight(srcStr, trimStr)
case other =>
throw new ParseException("Function trim doesn't support with " +
s"type $other. Please use BOTH, LEADING or TRAILING as trim type", ctx)
}
}
/**
* Create a Overlay expression.
*/
override def visitOverlay(ctx: OverlayContext): Expression = withOrigin(ctx) {
val input = expression(ctx.input)
val replace = expression(ctx.replace)
val position = expression(ctx.position)
val lengthOpt = Option(ctx.length).map(expression)
lengthOpt match {
case Some(length) => Overlay(input, replace, position, length)
case None => new Overlay(input, replace, position)
}
}
/**
* Create a (windowed) Function expression.
*/
override def visitFunctionCall(ctx: FunctionCallContext): Expression = withOrigin(ctx) {
// Create the function call.
val name = ctx.qualifiedName.getText
val isDistinct = Option(ctx.setQuantifier()).exists(_.DISTINCT != null)
val arguments = ctx.argument.asScala.map(expression) match {
case Seq(UnresolvedStar(None))
if name.toLowerCase(Locale.ROOT) == "count" && !isDistinct =>
// Transform COUNT(*) into COUNT(1).
Seq(Literal(1))
case expressions =>
expressions
}
val function = UnresolvedFunction(visitFunctionName(ctx.qualifiedName), arguments, isDistinct)
// Check if the function is evaluated in a windowed context.
ctx.windowSpec match {
case spec: WindowRefContext =>
UnresolvedWindowExpression(function, visitWindowRef(spec))
case spec: WindowDefContext =>
WindowExpression(function, visitWindowDef(spec))
case _ => function
}
}
/**
* Create a function database (optional) and name pair, for multipartIdentifier.
* This is used in CREATE FUNCTION, DROP FUNCTION, SHOWFUNCTIONS.
*/
protected def visitFunctionName(ctx: MultipartIdentifierContext): FunctionIdentifier = {
visitFunctionName(ctx, ctx.parts.asScala.map(_.getText))
}
/**
* Create a function database (optional) and name pair.
*/
protected def visitFunctionName(ctx: QualifiedNameContext): FunctionIdentifier = {
visitFunctionName(ctx, ctx.identifier().asScala.map(_.getText))
}
/**
* Create a function database (optional) and name pair.
*/
private def visitFunctionName(ctx: ParserRuleContext, texts: Seq[String]): FunctionIdentifier = {
texts match {
case Seq(db, fn) => FunctionIdentifier(fn, Option(db))
case Seq(fn) => FunctionIdentifier(fn, None)
case other =>
throw new ParseException(s"Unsupported function name '${texts.mkString(".")}'", ctx)
}
}
/**
* Create an [[LambdaFunction]].
*/
override def visitLambda(ctx: LambdaContext): Expression = withOrigin(ctx) {
val arguments = ctx.identifier().asScala.map { name =>
UnresolvedNamedLambdaVariable(UnresolvedAttribute.quoted(name.getText).nameParts)
}
val function = expression(ctx.expression).transformUp {
case a: UnresolvedAttribute => UnresolvedNamedLambdaVariable(a.nameParts)
}
LambdaFunction(function, arguments)
}
/**
* Create a reference to a window frame, i.e. [[WindowSpecReference]].
*/
override def visitWindowRef(ctx: WindowRefContext): WindowSpecReference = withOrigin(ctx) {
WindowSpecReference(ctx.name.getText)
}
/**
* Create a window definition, i.e. [[WindowSpecDefinition]].
*/
override def visitWindowDef(ctx: WindowDefContext): WindowSpecDefinition = withOrigin(ctx) {
// CLUSTER BY ... | PARTITION BY ... ORDER BY ...
val partition = ctx.partition.asScala.map(expression)
val order = ctx.sortItem.asScala.map(visitSortItem)
// RANGE/ROWS BETWEEN ...
val frameSpecOption = Option(ctx.windowFrame).map { frame =>
val frameType = frame.frameType.getType match {
case SqlBaseParser.RANGE => RangeFrame
case SqlBaseParser.ROWS => RowFrame
}
SpecifiedWindowFrame(
frameType,
visitFrameBound(frame.start),
Option(frame.end).map(visitFrameBound).getOrElse(CurrentRow))
}
WindowSpecDefinition(
partition,
order,
frameSpecOption.getOrElse(UnspecifiedFrame))
}
/**
* Create or resolve a frame boundary expressions.
*/
override def visitFrameBound(ctx: FrameBoundContext): Expression = withOrigin(ctx) {
def value: Expression = {
val e = expression(ctx.expression)
validate(e.resolved && e.foldable, "Frame bound value must be a literal.", ctx)
e
}
ctx.boundType.getType match {
case SqlBaseParser.PRECEDING if ctx.UNBOUNDED != null =>
UnboundedPreceding
case SqlBaseParser.PRECEDING =>
UnaryMinus(value)
case SqlBaseParser.CURRENT =>
CurrentRow
case SqlBaseParser.FOLLOWING if ctx.UNBOUNDED != null =>
UnboundedFollowing
case SqlBaseParser.FOLLOWING =>
value
}
}
/**
* Create a [[CreateStruct]] expression.
*/
override def visitRowConstructor(ctx: RowConstructorContext): Expression = withOrigin(ctx) {
CreateStruct(ctx.namedExpression().asScala.map(expression))
}
/**
* Create a [[ScalarSubquery]] expression.
*/
override def visitSubqueryExpression(
ctx: SubqueryExpressionContext): Expression = withOrigin(ctx) {
ScalarSubquery(plan(ctx.query))
}
/**
* Create a value based [[CaseWhen]] expression. This has the following SQL form:
* {{{
* CASE [expression]
* WHEN [value] THEN [expression]
* ...
* ELSE [expression]
* END
* }}}
*/
override def visitSimpleCase(ctx: SimpleCaseContext): Expression = withOrigin(ctx) {
val e = expression(ctx.value)
val branches = ctx.whenClause.asScala.map { wCtx =>
(EqualTo(e, expression(wCtx.condition)), expression(wCtx.result))
}
CaseWhen(branches, Option(ctx.elseExpression).map(expression))
}
/**
* Create a condition based [[CaseWhen]] expression. This has the following SQL syntax:
* {{{
* CASE
* WHEN [predicate] THEN [expression]
* ...
* ELSE [expression]
* END
* }}}
*
* @param ctx the parse tree
* */
override def visitSearchedCase(ctx: SearchedCaseContext): Expression = withOrigin(ctx) {
val branches = ctx.whenClause.asScala.map { wCtx =>
(expression(wCtx.condition), expression(wCtx.result))
}
CaseWhen(branches, Option(ctx.elseExpression).map(expression))
}
/**
* Currently only regex in expressions of SELECT statements are supported; in other
* places, e.g., where `(a)?+.+` = 2, regex are not meaningful.
*/
private def canApplyRegex(ctx: ParserRuleContext): Boolean = withOrigin(ctx) {
var parent = ctx.getParent
while (parent != null) {
if (parent.isInstanceOf[NamedExpressionContext]) return true
parent = parent.getParent
}
return false
}
/**
* Create a dereference expression. The return type depends on the type of the parent.
* If the parent is an [[UnresolvedAttribute]], it can be a [[UnresolvedAttribute]] or
* a [[UnresolvedRegex]] for regex quoted in ``; if the parent is some other expression,
* it can be [[UnresolvedExtractValue]].
*/
override def visitDereference(ctx: DereferenceContext): Expression = withOrigin(ctx) {
val attr = ctx.fieldName.getText
expression(ctx.base) match {
case unresolved_attr @ UnresolvedAttribute(nameParts) =>
ctx.fieldName.getStart.getText match {
case escapedIdentifier(columnNameRegex)
if conf.supportQuotedRegexColumnName && canApplyRegex(ctx) =>
UnresolvedRegex(columnNameRegex, Some(unresolved_attr.name),
conf.caseSensitiveAnalysis)
case _ =>
UnresolvedAttribute(nameParts :+ attr)
}
case e =>
UnresolvedExtractValue(e, Literal(attr))
}
}
/**
* Create an [[UnresolvedAttribute]] expression or a [[UnresolvedRegex]] if it is a regex
* quoted in ``
*/
override def visitColumnReference(ctx: ColumnReferenceContext): Expression = withOrigin(ctx) {
ctx.getStart.getText match {
case escapedIdentifier(columnNameRegex)
if conf.supportQuotedRegexColumnName && canApplyRegex(ctx) =>
UnresolvedRegex(columnNameRegex, None, conf.caseSensitiveAnalysis)
case _ =>
UnresolvedAttribute.quoted(ctx.getText)
}
}
/**
* Create an [[UnresolvedExtractValue]] expression, this is used for subscript access to an array.
*/
override def visitSubscript(ctx: SubscriptContext): Expression = withOrigin(ctx) {
UnresolvedExtractValue(expression(ctx.value), expression(ctx.index))
}
/**
* Create an expression for an expression between parentheses. This is need because the ANTLR
* visitor cannot automatically convert the nested context into an expression.
*/
override def visitParenthesizedExpression(
ctx: ParenthesizedExpressionContext): Expression = withOrigin(ctx) {
expression(ctx.expression)
}
/**
* Create a [[SortOrder]] expression.
*/
override def visitSortItem(ctx: SortItemContext): SortOrder = withOrigin(ctx) {
val direction = if (ctx.DESC != null) {
Descending
} else {
Ascending
}
val nullOrdering = if (ctx.FIRST != null) {
NullsFirst
} else if (ctx.LAST != null) {
NullsLast
} else {
direction.defaultNullOrdering
}
SortOrder(expression(ctx.expression), direction, nullOrdering, Set.empty)
}
/**
* Create a typed Literal expression. A typed literal has the following SQL syntax:
* {{{
* [TYPE] '[VALUE]'
* }}}
* Currently Date, Timestamp, Interval, Binary and INTEGER typed literals are supported.
*/
override def visitTypeConstructor(ctx: TypeConstructorContext): Literal = withOrigin(ctx) {
val value = string(ctx.STRING)
val valueType = ctx.identifier.getText.toUpperCase(Locale.ROOT)
val isNegative = ctx.negativeSign != null
def toLiteral[T](f: UTF8String => Option[T], t: DataType): Literal = {
f(UTF8String.fromString(value)).map(Literal(_, t)).getOrElse {
throw new ParseException(s"Cannot parse the $valueType value: $value", ctx)
}
}
try {
valueType match {
case "DATE" if !isNegative =>
toLiteral(stringToDate(_, getZoneId(SQLConf.get.sessionLocalTimeZone)), DateType)
case "TIMESTAMP" if !isNegative =>
val zoneId = getZoneId(SQLConf.get.sessionLocalTimeZone)
toLiteral(stringToTimestamp(_, zoneId), TimestampType)
case "INTERVAL" =>
val interval = try {
IntervalUtils.fromString(value)
} catch {
case e: IllegalArgumentException =>
val ex = new ParseException("Cannot parse the INTERVAL value: " + value, ctx)
ex.setStackTrace(e.getStackTrace)
throw ex
}
val signedInterval = if (isNegative) IntervalUtils.negate(interval) else interval
Literal(signedInterval, CalendarIntervalType)
case "X" if !isNegative =>
val padding = if (value.length % 2 != 0) "0" else ""
Literal(DatatypeConverter.parseHexBinary(padding + value))
case "INTEGER" =>
val i = try {
value.toInt
} catch {
case e: NumberFormatException =>
val ex = new ParseException(s"Cannot parse the Int value: $value, $e", ctx)
ex.setStackTrace(e.getStackTrace)
throw ex
}
Literal(if (isNegative) -i else i, IntegerType)
case other =>
val negativeSign: String = if (isNegative) "-" else ""
throw new ParseException(s"Literals of type '$negativeSign$other' are currently not" +
" supported.", ctx)
}
} catch {
case e: IllegalArgumentException =>
val message = Option(e.getMessage).getOrElse(s"Exception parsing $valueType")
throw new ParseException(message, ctx)
}
}
/**
* Create a NULL literal expression.
*/
override def visitNullLiteral(ctx: NullLiteralContext): Literal = withOrigin(ctx) {
Literal(null)
}
/**
* Create a Boolean literal expression.
*/
override def visitBooleanLiteral(ctx: BooleanLiteralContext): Literal = withOrigin(ctx) {
if (ctx.getText.toBoolean) {
Literal.TrueLiteral
} else {
Literal.FalseLiteral
}
}
/**
* Create an integral literal expression. The code selects the most narrow integral type
* possible, either a BigDecimal, a Long or an Integer is returned.
*/
override def visitIntegerLiteral(ctx: IntegerLiteralContext): Literal = withOrigin(ctx) {
BigDecimal(ctx.getText) match {
case v if v.isValidInt =>
Literal(v.intValue())
case v if v.isValidLong =>
Literal(v.longValue())
case v => Literal(v.underlying())
}
}
/**
* Create a decimal literal for a regular decimal number.
*/
override def visitDecimalLiteral(ctx: DecimalLiteralContext): Literal = withOrigin(ctx) {
Literal(BigDecimal(ctx.getText).underlying())
}
/** Create a numeric literal expression. */
private def numericLiteral
(ctx: NumberContext, minValue: BigDecimal, maxValue: BigDecimal, typeName: String)
(converter: String => Any): Literal = withOrigin(ctx) {
val rawStrippedQualifier = ctx.getText.substring(0, ctx.getText.length - 1)
try {
val rawBigDecimal = BigDecimal(rawStrippedQualifier)
if (rawBigDecimal < minValue || rawBigDecimal > maxValue) {
throw new ParseException(s"Numeric literal ${rawStrippedQualifier} does not " +
s"fit in range [${minValue}, ${maxValue}] for type ${typeName}", ctx)
}
Literal(converter(rawStrippedQualifier))
} catch {
case e: NumberFormatException =>
throw new ParseException(e.getMessage, ctx)
}
}
/**
* Create a Byte Literal expression.
*/
override def visitTinyIntLiteral(ctx: TinyIntLiteralContext): Literal = {
numericLiteral(ctx, Byte.MinValue, Byte.MaxValue, ByteType.simpleString)(_.toByte)
}
/**
* Create a Short Literal expression.
*/
override def visitSmallIntLiteral(ctx: SmallIntLiteralContext): Literal = {
numericLiteral(ctx, Short.MinValue, Short.MaxValue, ShortType.simpleString)(_.toShort)
}
/**
* Create a Long Literal expression.
*/
override def visitBigIntLiteral(ctx: BigIntLiteralContext): Literal = {
numericLiteral(ctx, Long.MinValue, Long.MaxValue, LongType.simpleString)(_.toLong)
}
/**
* Create a Double Literal expression.
*/
override def visitDoubleLiteral(ctx: DoubleLiteralContext): Literal = {
numericLiteral(ctx, Double.MinValue, Double.MaxValue, DoubleType.simpleString)(_.toDouble)
}
/**
* Create a BigDecimal Literal expression.
*/
override def visitBigDecimalLiteral(ctx: BigDecimalLiteralContext): Literal = {
val raw = ctx.getText.substring(0, ctx.getText.length - 2)
try {
Literal(BigDecimal(raw).underlying())
} catch {
case e: AnalysisException =>
throw new ParseException(e.message, ctx)
}
}
/**
* Create a String literal expression.
*/
override def visitStringLiteral(ctx: StringLiteralContext): Literal = withOrigin(ctx) {
Literal(createString(ctx))
}
/**
* Create a String from a string literal context. This supports multiple consecutive string
* literals, these are concatenated, for example this expression "'hello' 'world'" will be
* converted into "helloworld".
*
* Special characters can be escaped by using Hive/C-style escaping.
*/
private def createString(ctx: StringLiteralContext): String = {
if (conf.escapedStringLiterals) {
ctx.STRING().asScala.map(stringWithoutUnescape).mkString
} else {
ctx.STRING().asScala.map(string).mkString
}
}
private def applyNegativeSign(sign: Token, interval: CalendarInterval): CalendarInterval = {
if (sign != null) {
IntervalUtils.negate(interval)
} else {
interval
}
}
/**
* Create a [[CalendarInterval]] literal expression. Two syntaxes are supported:
* - multiple unit value pairs, for instance: interval 2 months 2 days.
* - from-to unit, for instance: interval '1-2' year to month.
*/
override def visitInterval(ctx: IntervalContext): Literal = withOrigin(ctx) {
if (ctx.errorCapturingMultiUnitsInterval != null) {
val innerCtx = ctx.errorCapturingMultiUnitsInterval
if (innerCtx.unitToUnitInterval != null) {
throw new ParseException(
"Can only have a single from-to unit in the interval literal syntax",
innerCtx.unitToUnitInterval)
}
val interval = applyNegativeSign(
ctx.negativeSign,
visitMultiUnitsInterval(innerCtx.multiUnitsInterval))
Literal(interval, CalendarIntervalType)
} else if (ctx.errorCapturingUnitToUnitInterval != null) {
val innerCtx = ctx.errorCapturingUnitToUnitInterval
if (innerCtx.error1 != null || innerCtx.error2 != null) {
val errorCtx = if (innerCtx.error1 != null) innerCtx.error1 else innerCtx.error2
throw new ParseException(
"Can only have a single from-to unit in the interval literal syntax",
errorCtx)
}
val interval = applyNegativeSign(ctx.negativeSign, visitUnitToUnitInterval(innerCtx.body))
Literal(interval, CalendarIntervalType)
} else {
throw new ParseException("at least one time unit should be given for interval literal", ctx)
}
}
/**
* Creates a [[CalendarInterval]] with multiple unit value pairs, e.g. 1 YEAR 2 DAYS.
*/
override def visitMultiUnitsInterval(ctx: MultiUnitsIntervalContext): CalendarInterval = {
withOrigin(ctx) {
val units = ctx.intervalUnit().asScala.map { unit =>
val u = unit.getText.toLowerCase(Locale.ROOT)
// Handle plural forms, e.g: yearS/monthS/weekS/dayS/hourS/minuteS/hourS/...
if (u.endsWith("s")) u.substring(0, u.length - 1) else u
}.map(IntervalUtils.IntervalUnit.withName).toArray
val values = ctx.intervalValue().asScala.map { value =>
if (value.STRING() != null) {
string(value.STRING())
} else {
value.getText
}
}.toArray
try {
IntervalUtils.fromUnitStrings(units, values)
} catch {
case i: IllegalArgumentException =>
val e = new ParseException(i.getMessage, ctx)
e.setStackTrace(i.getStackTrace)
throw e
}
}
}
/**
* Creates a [[CalendarInterval]] with from-to unit, e.g. '2-1' YEAR TO MONTH.
*/
override def visitUnitToUnitInterval(ctx: UnitToUnitIntervalContext): CalendarInterval = {
withOrigin(ctx) {
val value = Option(ctx.intervalValue.STRING).map(string).getOrElse {
throw new ParseException("The value of from-to unit must be a string", ctx.intervalValue)
}
try {
val from = ctx.from.getText.toLowerCase(Locale.ROOT)
val to = ctx.to.getText.toLowerCase(Locale.ROOT)
(from, to) match {
case ("year", "month") =>
IntervalUtils.fromYearMonthString(value)
case ("day", "hour") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.DAY, IntervalUnit.HOUR)
case ("day", "minute") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.DAY, IntervalUnit.MINUTE)
case ("day", "second") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.DAY, IntervalUnit.SECOND)
case ("hour", "minute") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.HOUR, IntervalUnit.MINUTE)
case ("hour", "second") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.HOUR, IntervalUnit.SECOND)
case ("minute", "second") =>
IntervalUtils.fromDayTimeString(value, IntervalUnit.MINUTE, IntervalUnit.SECOND)
case _ =>
throw new ParseException(s"Intervals FROM $from TO $to are not supported.", ctx)
}
} catch {
// Handle Exceptions thrown by CalendarInterval
case e: IllegalArgumentException =>
val pe = new ParseException(e.getMessage, ctx)
pe.setStackTrace(e.getStackTrace)
throw pe
}
}
}
/* ********************************************************************************************
* DataType parsing
* ******************************************************************************************** */
/**
* Create a Spark DataType.
*/
private def visitSparkDataType(ctx: DataTypeContext): DataType = {
HiveStringType.replaceCharType(typedVisit(ctx))
}
/**
* Resolve/create a primitive type.
*/
override def visitPrimitiveDataType(ctx: PrimitiveDataTypeContext): DataType = withOrigin(ctx) {
val dataType = ctx.identifier.getText.toLowerCase(Locale.ROOT)
(dataType, ctx.INTEGER_VALUE().asScala.toList) match {
case ("boolean", Nil) => BooleanType
case ("tinyint" | "byte", Nil) => ByteType
case ("smallint" | "short", Nil) => ShortType
case ("int" | "integer", Nil) => IntegerType
case ("bigint" | "long", Nil) => LongType
case ("float", Nil) => FloatType
case ("double", Nil) => DoubleType
case ("date", Nil) => DateType
case ("timestamp", Nil) => TimestampType
case ("string", Nil) => StringType
case ("char", length :: Nil) => CharType(length.getText.toInt)
case ("varchar", length :: Nil) => VarcharType(length.getText.toInt)
case ("binary", Nil) => BinaryType
case ("decimal", Nil) => DecimalType.USER_DEFAULT
case ("decimal", precision :: Nil) => DecimalType(precision.getText.toInt, 0)
case ("decimal", precision :: scale :: Nil) =>
DecimalType(precision.getText.toInt, scale.getText.toInt)
case ("interval", Nil) => CalendarIntervalType
case (dt, params) =>
val dtStr = if (params.nonEmpty) s"$dt(${params.mkString(",")})" else dt
throw new ParseException(s"DataType $dtStr is not supported.", ctx)
}
}
/**
* Create a complex DataType. Arrays, Maps and Structures are supported.
*/
override def visitComplexDataType(ctx: ComplexDataTypeContext): DataType = withOrigin(ctx) {
ctx.complex.getType match {
case SqlBaseParser.ARRAY =>
ArrayType(typedVisit(ctx.dataType(0)))
case SqlBaseParser.MAP =>
MapType(typedVisit(ctx.dataType(0)), typedVisit(ctx.dataType(1)))
case SqlBaseParser.STRUCT =>
StructType(Option(ctx.complexColTypeList).toSeq.flatMap(visitComplexColTypeList))
}
}
/**
* Create top level table schema.
*/
protected def createSchema(ctx: ColTypeListContext): StructType = {
StructType(Option(ctx).toSeq.flatMap(visitColTypeList))
}
/**
* Create a [[StructType]] from a number of column definitions.
*/
override def visitColTypeList(ctx: ColTypeListContext): Seq[StructField] = withOrigin(ctx) {
ctx.colType().asScala.map(visitColType)
}
/**
* Create a top level [[StructField]] from a column definition.
*/
override def visitColType(ctx: ColTypeContext): StructField = withOrigin(ctx) {
import ctx._
val builder = new MetadataBuilder
// Add comment to metadata
if (STRING != null) {
builder.putString("comment", string(STRING))
}
// Add Hive type string to metadata.
val rawDataType = typedVisit[DataType](ctx.dataType)
val cleanedDataType = HiveStringType.replaceCharType(rawDataType)
if (rawDataType != cleanedDataType) {
builder.putString(HIVE_TYPE_STRING, rawDataType.catalogString)
}
StructField(
colName.getText,
cleanedDataType,
nullable = true,
builder.build())
}
/**
* Create a [[StructType]] from a sequence of [[StructField]]s.
*/
protected def createStructType(ctx: ComplexColTypeListContext): StructType = {
StructType(Option(ctx).toSeq.flatMap(visitComplexColTypeList))
}
/**
* Create a [[StructType]] from a number of column definitions.
*/
override def visitComplexColTypeList(
ctx: ComplexColTypeListContext): Seq[StructField] = withOrigin(ctx) {
ctx.complexColType().asScala.map(visitComplexColType)
}
/**
* Create a [[StructField]] from a column definition.
*/
override def visitComplexColType(ctx: ComplexColTypeContext): StructField = withOrigin(ctx) {
import ctx._
val structField = StructField(identifier.getText, typedVisit(dataType), nullable = true)
if (STRING == null) structField else structField.withComment(string(STRING))
}
/**
* Create location string.
*/
override def visitLocationSpec(ctx: LocationSpecContext): String = withOrigin(ctx) {
string(ctx.STRING)
}
/**
* Create a [[BucketSpec]].
*/
override def visitBucketSpec(ctx: BucketSpecContext): BucketSpec = withOrigin(ctx) {
BucketSpec(
ctx.INTEGER_VALUE.getText.toInt,
visitIdentifierList(ctx.identifierList),
Option(ctx.orderedIdentifierList)
.toSeq
.flatMap(_.orderedIdentifier.asScala)
.map { orderedIdCtx =>
Option(orderedIdCtx.ordering).map(_.getText).foreach { dir =>
if (dir.toLowerCase(Locale.ROOT) != "asc") {
operationNotAllowed(s"Column ordering must be ASC, was '$dir'", ctx)
}
}
orderedIdCtx.ident.getText
})
}
/**
* Convert a table property list into a key-value map.
* This should be called through [[visitPropertyKeyValues]] or [[visitPropertyKeys]].
*/
override def visitTablePropertyList(
ctx: TablePropertyListContext): Map[String, String] = withOrigin(ctx) {
val properties = ctx.tableProperty.asScala.map { property =>
val key = visitTablePropertyKey(property.key)
val value = visitTablePropertyValue(property.value)
key -> value
}
// Check for duplicate property names.
checkDuplicateKeys(properties, ctx)
properties.toMap
}
/**
* Parse a key-value map from a [[TablePropertyListContext]], assuming all values are specified.
*/
def visitPropertyKeyValues(ctx: TablePropertyListContext): Map[String, String] = {
val props = visitTablePropertyList(ctx)
val badKeys = props.collect { case (key, null) => key }
if (badKeys.nonEmpty) {
operationNotAllowed(
s"Values must be specified for key(s): ${badKeys.mkString("[", ",", "]")}", ctx)
}
props
}
/**
* Parse a list of keys from a [[TablePropertyListContext]], assuming no values are specified.
*/
def visitPropertyKeys(ctx: TablePropertyListContext): Seq[String] = {
val props = visitTablePropertyList(ctx)
val badKeys = props.filter { case (_, v) => v != null }.keys
if (badKeys.nonEmpty) {
operationNotAllowed(
s"Values should not be specified for key(s): ${badKeys.mkString("[", ",", "]")}", ctx)
}
props.keys.toSeq
}
/**
* A table property key can either be String or a collection of dot separated elements. This
* function extracts the property key based on whether its a string literal or a table property
* identifier.
*/
override def visitTablePropertyKey(key: TablePropertyKeyContext): String = {
if (key.STRING != null) {
string(key.STRING)
} else {
key.getText
}
}
/**
* A table property value can be String, Integer, Boolean or Decimal. This function extracts
* the property value based on whether its a string, integer, boolean or decimal literal.
*/
override def visitTablePropertyValue(value: TablePropertyValueContext): String = {
if (value == null) {
null
} else if (value.STRING != null) {
string(value.STRING)
} else if (value.booleanValue != null) {
value.getText.toLowerCase(Locale.ROOT)
} else {
value.getText
}
}
/**
* Type to keep track of a table header: (identifier, isTemporary, ifNotExists, isExternal).
*/
type TableHeader = (Seq[String], Boolean, Boolean, Boolean)
/**
* Validate a create table statement and return the [[TableIdentifier]].
*/
override def visitCreateTableHeader(
ctx: CreateTableHeaderContext): TableHeader = withOrigin(ctx) {
val temporary = ctx.TEMPORARY != null
val ifNotExists = ctx.EXISTS != null
if (temporary && ifNotExists) {
operationNotAllowed("CREATE TEMPORARY TABLE ... IF NOT EXISTS", ctx)
}
val multipartIdentifier = ctx.multipartIdentifier.parts.asScala.map(_.getText)
(multipartIdentifier, temporary, ifNotExists, ctx.EXTERNAL != null)
}
/**
* Validate a replace table statement and return the [[TableIdentifier]].
*/
override def visitReplaceTableHeader(
ctx: ReplaceTableHeaderContext): TableHeader = withOrigin(ctx) {
val multipartIdentifier = ctx.multipartIdentifier.parts.asScala.map(_.getText)
(multipartIdentifier, false, false, false)
}
/**
* Parse a qualified name to a multipart name.
*/
override def visitQualifiedName(ctx: QualifiedNameContext): Seq[String] = withOrigin(ctx) {
ctx.identifier.asScala.map(_.getText)
}
/**
* Parse a list of transforms.
*/
override def visitTransformList(ctx: TransformListContext): Seq[Transform] = withOrigin(ctx) {
def getFieldReference(
ctx: ApplyTransformContext,
arg: V2Expression): FieldReference = {
lazy val name: String = ctx.identifier.getText
arg match {
case ref: FieldReference =>
ref
case nonRef =>
throw new ParseException(
s"Expected a column reference for transform $name: ${nonRef.describe}", ctx)
}
}
def getSingleFieldReference(
ctx: ApplyTransformContext,
arguments: Seq[V2Expression]): FieldReference = {
lazy val name: String = ctx.identifier.getText
if (arguments.size > 1) {
throw new ParseException(s"Too many arguments for transform $name", ctx)
} else if (arguments.isEmpty) {
throw new ParseException(s"Not enough arguments for transform $name", ctx)
} else {
getFieldReference(ctx, arguments.head)
}
}
ctx.transforms.asScala.map {
case identityCtx: IdentityTransformContext =>
IdentityTransform(FieldReference(typedVisit[Seq[String]](identityCtx.qualifiedName)))
case applyCtx: ApplyTransformContext =>
val arguments = applyCtx.argument.asScala.map(visitTransformArgument)
applyCtx.identifier.getText match {
case "bucket" =>
val numBuckets: Int = arguments.head match {
case LiteralValue(shortValue, ShortType) =>
shortValue.asInstanceOf[Short].toInt
case LiteralValue(intValue, IntegerType) =>
intValue.asInstanceOf[Int]
case LiteralValue(longValue, LongType) =>
longValue.asInstanceOf[Long].toInt
case lit =>
throw new ParseException(s"Invalid number of buckets: ${lit.describe}", applyCtx)
}
val fields = arguments.tail.map(arg => getFieldReference(applyCtx, arg))
BucketTransform(LiteralValue(numBuckets, IntegerType), fields)
case "years" =>
YearsTransform(getSingleFieldReference(applyCtx, arguments))
case "months" =>
MonthsTransform(getSingleFieldReference(applyCtx, arguments))
case "days" =>
DaysTransform(getSingleFieldReference(applyCtx, arguments))
case "hours" =>
HoursTransform(getSingleFieldReference(applyCtx, arguments))
case name =>
ApplyTransform(name, arguments)
}
}
}
/**
* Parse an argument to a transform. An argument may be a field reference (qualified name) or
* a value literal.
*/
override def visitTransformArgument(ctx: TransformArgumentContext): V2Expression = {
withOrigin(ctx) {
val reference = Option(ctx.qualifiedName)
.map(typedVisit[Seq[String]])
.map(FieldReference(_))
val literal = Option(ctx.constant)
.map(typedVisit[Literal])
.map(lit => LiteralValue(lit.value, lit.dataType))
reference.orElse(literal)
.getOrElse(throw new ParseException(s"Invalid transform argument", ctx))
}
}
/**
* Create a [[CreateNamespaceStatement]] command.
*
* For example:
* {{{
* CREATE NAMESPACE [IF NOT EXISTS] ns1.ns2.ns3
* create_namespace_clauses;
*
* create_namespace_clauses (order insensitive):
* [COMMENT namespace_comment]
* [LOCATION path]
* [WITH PROPERTIES (key1=val1, key2=val2, ...)]
* }}}
*/
override def visitCreateNamespace(ctx: CreateNamespaceContext): LogicalPlan = withOrigin(ctx) {
checkDuplicateClauses(ctx.COMMENT, "COMMENT", ctx)
checkDuplicateClauses(ctx.locationSpec, "LOCATION", ctx)
checkDuplicateClauses(ctx.PROPERTIES, "WITH PROPERTIES", ctx)
checkDuplicateClauses(ctx.DBPROPERTIES, "WITH DBPROPERTIES", ctx)
if (!ctx.PROPERTIES.isEmpty && !ctx.DBPROPERTIES.isEmpty) {
throw new ParseException(s"Either PROPERTIES or DBPROPERTIES is allowed.", ctx)
}
var properties = ctx.tablePropertyList.asScala.headOption
.map(visitPropertyKeyValues)
.getOrElse(Map.empty)
Option(ctx.comment).map(string).map {
properties += CreateNamespaceStatement.COMMENT_PROPERTY_KEY -> _
}
ctx.locationSpec.asScala.headOption.map(visitLocationSpec).map {
properties += CreateNamespaceStatement.LOCATION_PROPERTY_KEY -> _
}
CreateNamespaceStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
ctx.EXISTS != null,
properties)
}
/**
* Create a [[DropNamespaceStatement]] command.
*
* For example:
* {{{
* DROP (DATABASE|SCHEMA|NAMESPACE) [IF EXISTS] ns1.ns2 [RESTRICT|CASCADE];
* }}}
*/
override def visitDropNamespace(ctx: DropNamespaceContext): LogicalPlan = withOrigin(ctx) {
DropNamespaceStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
ctx.EXISTS != null,
ctx.CASCADE != null)
}
/**
* Create a [[ShowNamespacesStatement]] command.
*/
override def visitShowNamespaces(ctx: ShowNamespacesContext): LogicalPlan = withOrigin(ctx) {
if (ctx.DATABASES != null && ctx.multipartIdentifier != null) {
throw new ParseException(s"FROM/IN operator is not allowed in SHOW DATABASES", ctx)
}
ShowNamespacesStatement(
Option(ctx.multipartIdentifier).map(visitMultipartIdentifier),
Option(ctx.pattern).map(string))
}
/**
* Create a table, returning a [[CreateTableStatement]] logical plan.
*
* Expected format:
* {{{
* CREATE [TEMPORARY] TABLE [IF NOT EXISTS] [db_name.]table_name
* USING table_provider
* create_table_clauses
* [[AS] select_statement];
*
* create_table_clauses (order insensitive):
* [OPTIONS table_property_list]
* [PARTITIONED BY (col_name, transform(col_name), transform(constant, col_name), ...)]
* [CLUSTERED BY (col_name, col_name, ...)
* [SORTED BY (col_name [ASC|DESC], ...)]
* INTO num_buckets BUCKETS
* ]
* [LOCATION path]
* [COMMENT table_comment]
* [TBLPROPERTIES (property_name=property_value, ...)]
* }}}
*/
override def visitCreateTable(ctx: CreateTableContext): LogicalPlan = withOrigin(ctx) {
val (table, temp, ifNotExists, external) = visitCreateTableHeader(ctx.createTableHeader)
if (external) {
operationNotAllowed("CREATE EXTERNAL TABLE ... USING", ctx)
}
checkDuplicateClauses(ctx.TBLPROPERTIES, "TBLPROPERTIES", ctx)
checkDuplicateClauses(ctx.OPTIONS, "OPTIONS", ctx)
checkDuplicateClauses(ctx.PARTITIONED, "PARTITIONED BY", ctx)
checkDuplicateClauses(ctx.COMMENT, "COMMENT", ctx)
checkDuplicateClauses(ctx.bucketSpec(), "CLUSTERED BY", ctx)
checkDuplicateClauses(ctx.locationSpec, "LOCATION", ctx)
val schema = Option(ctx.colTypeList()).map(createSchema)
val partitioning: Seq[Transform] =
Option(ctx.partitioning).map(visitTransformList).getOrElse(Nil)
val bucketSpec = ctx.bucketSpec().asScala.headOption.map(visitBucketSpec)
val properties = Option(ctx.tableProps).map(visitPropertyKeyValues).getOrElse(Map.empty)
val options = Option(ctx.options).map(visitPropertyKeyValues).getOrElse(Map.empty)
val provider = ctx.tableProvider.multipartIdentifier.getText
val location = ctx.locationSpec.asScala.headOption.map(visitLocationSpec)
val comment = Option(ctx.comment).map(string)
Option(ctx.query).map(plan) match {
case Some(_) if temp =>
operationNotAllowed("CREATE TEMPORARY TABLE ... USING ... AS query", ctx)
case Some(_) if schema.isDefined =>
operationNotAllowed(
"Schema may not be specified in a Create Table As Select (CTAS) statement",
ctx)
case Some(query) =>
CreateTableAsSelectStatement(
table, query, partitioning, bucketSpec, properties, provider, options, location, comment,
ifNotExists = ifNotExists)
case None if temp =>
// CREATE TEMPORARY TABLE ... USING ... is not supported by the catalyst parser.
// Use CREATE TEMPORARY VIEW ... USING ... instead.
operationNotAllowed("CREATE TEMPORARY TABLE IF NOT EXISTS", ctx)
case _ =>
CreateTableStatement(table, schema.getOrElse(new StructType), partitioning, bucketSpec,
properties, provider, options, location, comment, ifNotExists = ifNotExists)
}
}
/**
* Replace a table, returning a [[ReplaceTableStatement]] logical plan.
*
* Expected format:
* {{{
* [CREATE OR] REPLACE TABLE [db_name.]table_name
* USING table_provider
* replace_table_clauses
* [[AS] select_statement];
*
* replace_table_clauses (order insensitive):
* [OPTIONS table_property_list]
* [PARTITIONED BY (col_name, transform(col_name), transform(constant, col_name), ...)]
* [CLUSTERED BY (col_name, col_name, ...)
* [SORTED BY (col_name [ASC|DESC], ...)]
* INTO num_buckets BUCKETS
* ]
* [LOCATION path]
* [COMMENT table_comment]
* [TBLPROPERTIES (property_name=property_value, ...)]
* }}}
*/
override def visitReplaceTable(ctx: ReplaceTableContext): LogicalPlan = withOrigin(ctx) {
val (table, _, ifNotExists, external) = visitReplaceTableHeader(ctx.replaceTableHeader)
if (external) {
operationNotAllowed("REPLACE EXTERNAL TABLE ... USING", ctx)
}
checkDuplicateClauses(ctx.TBLPROPERTIES, "TBLPROPERTIES", ctx)
checkDuplicateClauses(ctx.OPTIONS, "OPTIONS", ctx)
checkDuplicateClauses(ctx.PARTITIONED, "PARTITIONED BY", ctx)
checkDuplicateClauses(ctx.COMMENT, "COMMENT", ctx)
checkDuplicateClauses(ctx.bucketSpec(), "CLUSTERED BY", ctx)
checkDuplicateClauses(ctx.locationSpec, "LOCATION", ctx)
val schema = Option(ctx.colTypeList()).map(createSchema)
val partitioning: Seq[Transform] =
Option(ctx.partitioning).map(visitTransformList).getOrElse(Nil)
val bucketSpec = ctx.bucketSpec().asScala.headOption.map(visitBucketSpec)
val properties = Option(ctx.tableProps).map(visitPropertyKeyValues).getOrElse(Map.empty)
val options = Option(ctx.options).map(visitPropertyKeyValues).getOrElse(Map.empty)
val provider = ctx.tableProvider.multipartIdentifier.getText
val location = ctx.locationSpec.asScala.headOption.map(visitLocationSpec)
val comment = Option(ctx.comment).map(string)
val orCreate = ctx.replaceTableHeader().CREATE() != null
Option(ctx.query).map(plan) match {
case Some(_) if schema.isDefined =>
operationNotAllowed(
"Schema may not be specified in a Replace Table As Select (RTAS) statement",
ctx)
case Some(query) =>
ReplaceTableAsSelectStatement(table, query, partitioning, bucketSpec, properties,
provider, options, location, comment, orCreate = orCreate)
case _ =>
ReplaceTableStatement(table, schema.getOrElse(new StructType), partitioning,
bucketSpec, properties, provider, options, location, comment, orCreate = orCreate)
}
}
/**
* Create a [[DropTableStatement]] command.
*/
override def visitDropTable(ctx: DropTableContext): LogicalPlan = withOrigin(ctx) {
DropTableStatement(
visitMultipartIdentifier(ctx.multipartIdentifier()),
ctx.EXISTS != null,
ctx.PURGE != null)
}
/**
* Create a [[DropViewStatement]] command.
*/
override def visitDropView(ctx: DropViewContext): AnyRef = withOrigin(ctx) {
DropViewStatement(
visitMultipartIdentifier(ctx.multipartIdentifier()),
ctx.EXISTS != null)
}
/**
* Create a [[UseStatement]] logical plan.
*/
override def visitUse(ctx: UseContext): LogicalPlan = withOrigin(ctx) {
val nameParts = visitMultipartIdentifier(ctx.multipartIdentifier)
UseStatement(ctx.NAMESPACE != null, nameParts)
}
/**
* Create a [[ShowCurrentNamespaceStatement]].
*/
override def visitShowCurrentNamespace(
ctx: ShowCurrentNamespaceContext) : LogicalPlan = withOrigin(ctx) {
ShowCurrentNamespaceStatement()
}
/**
* Create a [[ShowTablesStatement]] command.
*/
override def visitShowTables(ctx: ShowTablesContext): LogicalPlan = withOrigin(ctx) {
ShowTablesStatement(
Option(ctx.multipartIdentifier).map(visitMultipartIdentifier),
Option(ctx.pattern).map(string))
}
/**
* Parse new column info from ADD COLUMN into a QualifiedColType.
*/
override def visitQualifiedColTypeWithPosition(
ctx: QualifiedColTypeWithPositionContext): QualifiedColType = withOrigin(ctx) {
if (ctx.colPosition != null) {
operationNotAllowed("ALTER TABLE table ADD COLUMN ... FIRST | AFTER otherCol", ctx)
}
QualifiedColType(
typedVisit[Seq[String]](ctx.name),
typedVisit[DataType](ctx.dataType),
Option(ctx.comment).map(string))
}
/**
* Parse a [[AlterTableAddColumnsStatement]] command.
*
* For example:
* {{{
* ALTER TABLE table1
* ADD COLUMNS (col_name data_type [COMMENT col_comment], ...);
* }}}
*/
override def visitAddTableColumns(ctx: AddTableColumnsContext): LogicalPlan = withOrigin(ctx) {
AlterTableAddColumnsStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
ctx.columns.qualifiedColTypeWithPosition.asScala.map(typedVisit[QualifiedColType])
)
}
/**
* Parse a [[AlterTableRenameColumnStatement]] command.
*
* For example:
* {{{
* ALTER TABLE table1 RENAME COLUMN a.b.c TO x
* }}}
*/
override def visitRenameTableColumn(
ctx: RenameTableColumnContext): LogicalPlan = withOrigin(ctx) {
AlterTableRenameColumnStatement(
visitMultipartIdentifier(ctx.table),
ctx.from.parts.asScala.map(_.getText),
ctx.to.getText)
}
/**
* Parse a [[AlterTableAlterColumnStatement]] command.
*
* For example:
* {{{
* ALTER TABLE table1 ALTER COLUMN a.b.c TYPE bigint
* ALTER TABLE table1 ALTER COLUMN a.b.c TYPE bigint COMMENT 'new comment'
* ALTER TABLE table1 ALTER COLUMN a.b.c COMMENT 'new comment'
* }}}
*/
override def visitAlterTableColumn(
ctx: AlterTableColumnContext): LogicalPlan = withOrigin(ctx) {
val verb = if (ctx.CHANGE != null) "CHANGE" else "ALTER"
if (ctx.colPosition != null) {
operationNotAllowed(s"ALTER TABLE table $verb COLUMN ... FIRST | AFTER otherCol", ctx)
}
if (ctx.dataType == null && ctx.comment == null) {
operationNotAllowed(s"ALTER TABLE table $verb COLUMN requires a TYPE or a COMMENT", ctx)
}
AlterTableAlterColumnStatement(
visitMultipartIdentifier(ctx.table),
typedVisit[Seq[String]](ctx.column),
Option(ctx.dataType).map(typedVisit[DataType]),
Option(ctx.comment).map(string))
}
/**
* Parse a [[AlterTableDropColumnsStatement]] command.
*
* For example:
* {{{
* ALTER TABLE table1 DROP COLUMN a.b.c
* ALTER TABLE table1 DROP COLUMNS a.b.c, x, y
* }}}
*/
override def visitDropTableColumns(
ctx: DropTableColumnsContext): LogicalPlan = withOrigin(ctx) {
val columnsToDrop = ctx.columns.multipartIdentifier.asScala.map(typedVisit[Seq[String]])
AlterTableDropColumnsStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
columnsToDrop)
}
/**
* Parse [[AlterViewSetPropertiesStatement]] or [[AlterTableSetPropertiesStatement]] commands.
*
* For example:
* {{{
* ALTER TABLE table SET TBLPROPERTIES ('comment' = new_comment);
* ALTER VIEW view SET TBLPROPERTIES ('comment' = new_comment);
* }}}
*/
override def visitSetTableProperties(
ctx: SetTablePropertiesContext): LogicalPlan = withOrigin(ctx) {
val identifier = visitMultipartIdentifier(ctx.multipartIdentifier)
val properties = visitPropertyKeyValues(ctx.tablePropertyList)
if (ctx.VIEW != null) {
AlterViewSetPropertiesStatement(identifier, properties)
} else {
AlterTableSetPropertiesStatement(identifier, properties)
}
}
/**
* Parse [[AlterViewUnsetPropertiesStatement]] or [[AlterTableUnsetPropertiesStatement]] commands.
*
* For example:
* {{{
* ALTER TABLE table UNSET TBLPROPERTIES [IF EXISTS] ('comment', 'key');
* ALTER VIEW view UNSET TBLPROPERTIES [IF EXISTS] ('comment', 'key');
* }}}
*/
override def visitUnsetTableProperties(
ctx: UnsetTablePropertiesContext): LogicalPlan = withOrigin(ctx) {
val identifier = visitMultipartIdentifier(ctx.multipartIdentifier)
val properties = visitPropertyKeys(ctx.tablePropertyList)
val ifExists = ctx.EXISTS != null
if (ctx.VIEW != null) {
AlterViewUnsetPropertiesStatement(identifier, properties, ifExists)
} else {
AlterTableUnsetPropertiesStatement(identifier, properties, ifExists)
}
}
/**
* Create an [[AlterTableSetLocationStatement]] command.
*
* For example:
* {{{
* ALTER TABLE table SET LOCATION "loc";
* }}}
*/
override def visitSetTableLocation(ctx: SetTableLocationContext): LogicalPlan = withOrigin(ctx) {
AlterTableSetLocationStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec),
visitLocationSpec(ctx.locationSpec))
}
/**
* Create a [[DescribeColumnStatement]] or [[DescribeTableStatement]] commands.
*/
override def visitDescribeTable(ctx: DescribeTableContext): LogicalPlan = withOrigin(ctx) {
val isExtended = ctx.EXTENDED != null || ctx.FORMATTED != null
if (ctx.describeColName != null) {
if (ctx.partitionSpec != null) {
throw new ParseException("DESC TABLE COLUMN for a specific partition is not supported", ctx)
} else {
DescribeColumnStatement(
visitMultipartIdentifier(ctx.multipartIdentifier()),
ctx.describeColName.nameParts.asScala.map(_.getText),
isExtended)
}
} else {
val partitionSpec = if (ctx.partitionSpec != null) {
// According to the syntax, visitPartitionSpec returns `Map[String, Option[String]]`.
visitPartitionSpec(ctx.partitionSpec).map {
case (key, Some(value)) => key -> value
case (key, _) =>
throw new ParseException(s"PARTITION specification is incomplete: `$key`", ctx)
}
} else {
Map.empty[String, String]
}
DescribeTableStatement(
visitMultipartIdentifier(ctx.multipartIdentifier()),
partitionSpec,
isExtended)
}
}
/**
* Create an [[AnalyzeTableStatement]], or an [[AnalyzeColumnStatement]].
* Example SQL for analyzing a table or a set of partitions :
* {{{
* ANALYZE TABLE multi_part_name [PARTITION (partcol1[=val1], partcol2[=val2], ...)]
* COMPUTE STATISTICS [NOSCAN];
* }}}
*
* Example SQL for analyzing columns :
* {{{
* ANALYZE TABLE multi_part_name COMPUTE STATISTICS FOR COLUMNS column1, column2;
* }}}
*
* Example SQL for analyzing all columns of a table:
* {{{
* ANALYZE TABLE multi_part_name COMPUTE STATISTICS FOR ALL COLUMNS;
* }}}
*/
override def visitAnalyze(ctx: AnalyzeContext): LogicalPlan = withOrigin(ctx) {
def checkPartitionSpec(): Unit = {
if (ctx.partitionSpec != null) {
logWarning("Partition specification is ignored when collecting column statistics: " +
ctx.partitionSpec.getText)
}
}
if (ctx.identifier != null &&
ctx.identifier.getText.toLowerCase(Locale.ROOT) != "noscan") {
throw new ParseException(s"Expected `NOSCAN` instead of `${ctx.identifier.getText}`", ctx)
}
val tableName = visitMultipartIdentifier(ctx.multipartIdentifier())
if (ctx.ALL() != null) {
checkPartitionSpec()
AnalyzeColumnStatement(tableName, None, allColumns = true)
} else if (ctx.identifierSeq() == null) {
val partitionSpec = if (ctx.partitionSpec != null) {
visitPartitionSpec(ctx.partitionSpec)
} else {
Map.empty[String, Option[String]]
}
AnalyzeTableStatement(tableName, partitionSpec, noScan = ctx.identifier != null)
} else {
checkPartitionSpec()
AnalyzeColumnStatement(
tableName, Option(visitIdentifierSeq(ctx.identifierSeq())), allColumns = false)
}
}
/**
* Create a [[RepairTableStatement]].
*
* For example:
* {{{
* MSCK REPAIR TABLE multi_part_name
* }}}
*/
override def visitRepairTable(ctx: RepairTableContext): LogicalPlan = withOrigin(ctx) {
RepairTableStatement(visitMultipartIdentifier(ctx.multipartIdentifier()))
}
/**
* Create a [[LoadDataStatement]].
*
* For example:
* {{{
* LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE multi_part_name
* [PARTITION (partcol1=val1, partcol2=val2 ...)]
* }}}
*/
override def visitLoadData(ctx: LoadDataContext): LogicalPlan = withOrigin(ctx) {
LoadDataStatement(
tableName = visitMultipartIdentifier(ctx.multipartIdentifier),
path = string(ctx.path),
isLocal = ctx.LOCAL != null,
isOverwrite = ctx.OVERWRITE != null,
partition = Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec)
)
}
/**
* Creates a [[ShowCreateTableStatement]]
*/
override def visitShowCreateTable(ctx: ShowCreateTableContext): LogicalPlan = withOrigin(ctx) {
ShowCreateTableStatement(visitMultipartIdentifier(ctx.multipartIdentifier()))
}
/**
* Create a [[CacheTableStatement]].
*
* For example:
* {{{
* CACHE [LAZY] TABLE multi_part_name
* [OPTIONS tablePropertyList] [[AS] query]
* }}}
*/
override def visitCacheTable(ctx: CacheTableContext): LogicalPlan = withOrigin(ctx) {
import org.apache.spark.sql.connector.catalog.CatalogV2Implicits._
val query = Option(ctx.query).map(plan)
val tableName = visitMultipartIdentifier(ctx.multipartIdentifier)
if (query.isDefined && tableName.length > 1) {
val catalogAndNamespace = tableName.init
throw new ParseException("It is not allowed to add catalog/namespace " +
s"prefix ${catalogAndNamespace.quoted} to " +
"the table name in CACHE TABLE AS SELECT", ctx)
}
val options = Option(ctx.options).map(visitPropertyKeyValues).getOrElse(Map.empty)
CacheTableStatement(tableName, query, ctx.LAZY != null, options)
}
/**
* Create an [[UncacheTableStatement]] logical plan.
*/
override def visitUncacheTable(ctx: UncacheTableContext): LogicalPlan = withOrigin(ctx) {
UncacheTableStatement(visitMultipartIdentifier(ctx.multipartIdentifier), ctx.EXISTS != null)
}
/**
* Create a [[TruncateTableStatement]] command.
*
* For example:
* {{{
* TRUNCATE TABLE multi_part_name [PARTITION (partcol1=val1, partcol2=val2 ...)]
* }}}
*/
override def visitTruncateTable(ctx: TruncateTableContext): LogicalPlan = withOrigin(ctx) {
TruncateTableStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec))
}
/**
* A command for users to list the partition names of a table. If partition spec is specified,
* partitions that match the spec are returned. Otherwise an empty result set is returned.
*
* This function creates a [[ShowPartitionsStatement]] logical plan
*
* The syntax of using this command in SQL is:
* {{{
* SHOW PARTITIONS multi_part_name [partition_spec];
* }}}
*/
override def visitShowPartitions(ctx: ShowPartitionsContext): LogicalPlan = withOrigin(ctx) {
val table = visitMultipartIdentifier(ctx.multipartIdentifier)
val partitionKeys = Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec)
ShowPartitionsStatement(table, partitionKeys)
}
/**
* Create a [[RefreshTableStatement]].
*
* For example:
* {{{
* REFRESH TABLE multi_part_name
* }}}
*/
override def visitRefreshTable(ctx: RefreshTableContext): LogicalPlan = withOrigin(ctx) {
RefreshTableStatement(visitMultipartIdentifier(ctx.multipartIdentifier()))
}
/**
* A command for users to list the column names for a table.
* This function creates a [[ShowColumnsStatement]] logical plan.
*
* The syntax of using this command in SQL is:
* {{{
* SHOW COLUMNS (FROM | IN) tableName=multipartIdentifier
* ((FROM | IN) namespace=multipartIdentifier)?
* }}}
*/
override def visitShowColumns(ctx: ShowColumnsContext): LogicalPlan = withOrigin(ctx) {
val table = visitMultipartIdentifier(ctx.table)
val namespace = Option(ctx.namespace).map(visitMultipartIdentifier)
ShowColumnsStatement(table, namespace)
}
/**
* Create an [[AlterTableRecoverPartitionsStatement]]
*
* For example:
* {{{
* ALTER TABLE multi_part_name RECOVER PARTITIONS;
* }}}
*/
override def visitRecoverPartitions(
ctx: RecoverPartitionsContext): LogicalPlan = withOrigin(ctx) {
AlterTableRecoverPartitionsStatement(visitMultipartIdentifier(ctx.multipartIdentifier))
}
/**
* Create an [[AlterTableAddPartitionStatement]].
*
* For example:
* {{{
* ALTER TABLE multi_part_name ADD [IF NOT EXISTS] PARTITION spec [LOCATION 'loc1']
* ALTER VIEW multi_part_name ADD [IF NOT EXISTS] PARTITION spec
* }}}
*
* ALTER VIEW ... ADD PARTITION ... is not supported because the concept of partitioning
* is associated with physical tables
*/
override def visitAddTablePartition(
ctx: AddTablePartitionContext): LogicalPlan = withOrigin(ctx) {
if (ctx.VIEW != null) {
operationNotAllowed("ALTER VIEW ... ADD PARTITION", ctx)
}
// Create partition spec to location mapping.
val specsAndLocs = ctx.partitionSpecLocation.asScala.map { splCtx =>
val spec = visitNonOptionalPartitionSpec(splCtx.partitionSpec)
val location = Option(splCtx.locationSpec).map(visitLocationSpec)
spec -> location
}
AlterTableAddPartitionStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
specsAndLocs,
ctx.EXISTS != null)
}
/**
* Create an [[AlterTableRenamePartitionStatement]]
*
* For example:
* {{{
* ALTER TABLE multi_part_name PARTITION spec1 RENAME TO PARTITION spec2;
* }}}
*/
override def visitRenameTablePartition(
ctx: RenameTablePartitionContext): LogicalPlan = withOrigin(ctx) {
AlterTableRenamePartitionStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
visitNonOptionalPartitionSpec(ctx.from),
visitNonOptionalPartitionSpec(ctx.to))
}
/**
* Create an [[AlterTableDropPartitionStatement]]
*
* For example:
* {{{
* ALTER TABLE multi_part_name DROP [IF EXISTS] PARTITION spec1[, PARTITION spec2, ...]
* [PURGE];
* ALTER VIEW view DROP [IF EXISTS] PARTITION spec1[, PARTITION spec2, ...];
* }}}
*
* ALTER VIEW ... DROP PARTITION ... is not supported because the concept of partitioning
* is associated with physical tables
*/
override def visitDropTablePartitions(
ctx: DropTablePartitionsContext): LogicalPlan = withOrigin(ctx) {
if (ctx.VIEW != null) {
operationNotAllowed("ALTER VIEW ... DROP PARTITION", ctx)
}
AlterTableDropPartitionStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
ctx.partitionSpec.asScala.map(visitNonOptionalPartitionSpec),
ifExists = ctx.EXISTS != null,
purge = ctx.PURGE != null,
retainData = false)
}
/**
* Create an [[AlterTableSerDePropertiesStatement]]
*
* For example:
* {{{
* ALTER TABLE multi_part_name [PARTITION spec] SET SERDE serde_name
* [WITH SERDEPROPERTIES props];
* ALTER TABLE multi_part_name [PARTITION spec] SET SERDEPROPERTIES serde_properties;
* }}}
*/
override def visitSetTableSerDe(ctx: SetTableSerDeContext): LogicalPlan = withOrigin(ctx) {
AlterTableSerDePropertiesStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
Option(ctx.STRING).map(string),
Option(ctx.tablePropertyList).map(visitPropertyKeyValues),
// TODO a partition spec is allowed to have optional values. This is currently violated.
Option(ctx.partitionSpec).map(visitNonOptionalPartitionSpec))
}
/**
* Alter the query of a view. This creates a [[AlterViewAsStatement]]
*
* For example:
* {{{
* ALTER VIEW multi_part_name AS SELECT ...;
* }}}
*/
override def visitAlterViewQuery(ctx: AlterViewQueryContext): LogicalPlan = withOrigin(ctx) {
AlterViewAsStatement(
visitMultipartIdentifier(ctx.multipartIdentifier),
originalText = source(ctx.query),
query = plan(ctx.query))
}
/**
* A command for users to list the properties for a table. If propertyKey is specified, the value
* for the propertyKey is returned. If propertyKey is not specified, all the keys and their
* corresponding values are returned.
* The syntax of using this command in SQL is:
* {{{
* SHOW TBLPROPERTIES multi_part_name[('propertyKey')];
* }}}
*/
override def visitShowTblProperties(
ctx: ShowTblPropertiesContext): LogicalPlan = withOrigin(ctx) {
ShowTablePropertiesStatement(
visitMultipartIdentifier(ctx.table),
Option(ctx.key).map(visitTablePropertyKey))
}
}
|
caneGuy/spark
|
sql/catalyst/src/main/scala/org/apache/spark/sql/catalyst/parser/AstBuilder.scala
|
Scala
|
apache-2.0
| 115,421 |
/**
* ConnectedComponents.scala
* Generic connected components finding algorithm.
*
* Overview, created November 2012
*
* @author Jonathan Stray
*
*/
package com.overviewdocs.clustering
import scala.collection.mutable.{Stack, Set}
object ConnectedComponents {
// Takes a node, and a set of unvisited nodes, and yields all nodes we an visit next
type EdgeEnumerationFn[T] = (T, Set[T]) => Iterable[T]
// Returns component containing startNode, plus all nodes not in component
def singleComponent[T](startNode: T, allNodes: Set[T], edgeEnumerator: EdgeEnumerationFn[T]): (Set[T], Set[T]) = {
var component = Set[T](startNode) // all nodes found to be in the component so far
val frontier = Stack[T](startNode) // nodes in the component that we have not checked the edges of
var remaining = allNodes - startNode // nodes not yet visited
// walk outward from each node in the frontier, until the frontier is empty or we run out of nodes
while (!frontier.isEmpty && !remaining.isEmpty) {
val a = frontier.pop
for (b <- edgeEnumerator(a, remaining)) { // for every remaining we can reach from a...
component += b
frontier.push(b)
remaining -= b
}
}
(component, remaining)
}
// Find all connected componetns and do something with each
def foreachComponent[T](allNodes: Iterable[T], edgeEnumerator: EdgeEnumerationFn[T])(fn: Set[T]=>Unit): Unit = {
var remaining = Set[T]() ++ allNodes // really just allNodes.toSet, but toSet does not create a mutable set, can't use it here
while (!remaining.isEmpty) {
val (newComponent, leftOvers) = singleComponent(remaining.head, remaining, edgeEnumerator)
fn(newComponent)
remaining = leftOvers
}
}
// Produce all connected components, as a set of sets
def allComponents[T](allNodes: Iterable[T], edgeEnumerator: EdgeEnumerationFn[T]): Set[Set[T]] = {
var components = Set[Set[T]]()
foreachComponent(allNodes, edgeEnumerator) {
components += _
}
components
}
}
|
overview/overview-server
|
worker/src/main/scala/com/overviewdocs/clustering/ConnectedComponents.scala
|
Scala
|
agpl-3.0
| 2,057 |
/*
* Copyright (c) 2014-2020 by The Monix Project Developers.
* See the project homepage at: https://monix.io
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/
package monix.reactive.internal.builders
import monix.execution.Cancelable
import scala.util.control.NonFatal
import monix.reactive.Observable
import monix.reactive.observers.Subscriber
/** An observable that evaluates the given by-name argument,
* and emits it.
*/
private[reactive] final class EvalAlwaysObservable[+A](f: () => A) extends Observable[A] {
def unsafeSubscribeFn(subscriber: Subscriber[A]): Cancelable = {
try {
subscriber.onNext(f())
// No need to do back-pressure
subscriber.onComplete()
} catch {
case ex if NonFatal(ex) =>
try subscriber.onError(ex)
catch {
case err if NonFatal(err) =>
val s = subscriber.scheduler
s.reportFailure(ex)
s.reportFailure(err)
}
}
Cancelable.empty
}
}
|
alexandru/monifu
|
monix-reactive/shared/src/main/scala/monix/reactive/internal/builders/EvalAlwaysObservable.scala
|
Scala
|
apache-2.0
| 1,499 |
// Databricks notebook source exported at Fri, 24 Jun 2016 23:55:05 UTC
// MAGIC %md
// MAGIC
// MAGIC # [Scalable Data Science](http://www.math.canterbury.ac.nz/~r.sainudiin/courses/ScalableDataScience/)
// MAGIC
// MAGIC
// MAGIC ### prepared by [Raazesh Sainudiin](https://nz.linkedin.com/in/raazesh-sainudiin-45955845) and [Sivanand Sivaram](https://www.linkedin.com/in/sivanand)
// MAGIC
// MAGIC *supported by* [](https://databricks.com/)
// MAGIC and
// MAGIC [](https://www.awseducate.com/microsite/CommunitiesEngageHome)
// COMMAND ----------
// MAGIC %md
// MAGIC The [html source url](https://raw.githubusercontent.com/raazesh-sainudiin/scalable-data-science/master/db/week6/12_SparkStreaming/021_SparkStreamingIntro.html) of this databricks notebook and its recorded Uji :
// MAGIC
// MAGIC [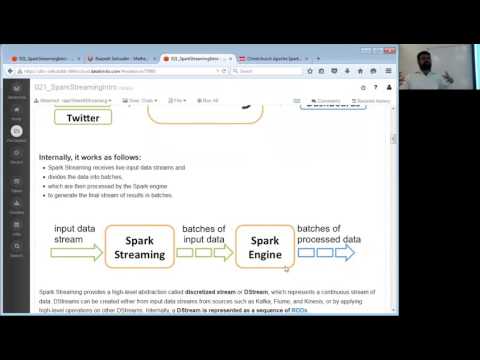](https://www.youtube.com/v/jqLcr2eS-Vs?rel=0&autoplay=1&modestbranding=1&start=0&end=2111)
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC # **Spark Streaming**
// MAGIC Spark Streaming is an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams.
// MAGIC
// MAGIC This is an augmentation of the following resources:
// MAGIC * the Databricks Guide [Workspace -> Databricks_Guide -> 08 Spark Streaming -> 00 Spark Streaming](/#workspace/databricks_guide/08 Spark Streaming/00 Spark Streaming) and
// MAGIC * [http://spark.apache.org/docs/latest/streaming-programming-guide.html](http://spark.apache.org/docs/latest/streaming-programming-guide.html)
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC Overview
// MAGIC ========
// MAGIC
// MAGIC Spark Streaming is an extension of the core Spark API that enables
// MAGIC scalable, high-throughput, fault-tolerant stream processing of live data
// MAGIC streams.
// MAGIC
// MAGIC Data can be ingested from many sources like
// MAGIC
// MAGIC * [Kafka](http://kafka.apache.org/documentation.html#introduction),
// MAGIC * [Flume](https://flume.apache.org/),
// MAGIC * [Twitter](https://twitter.com/) [Streaming](https://dev.twitter.com/streaming/overview) and [REST](https://dev.twitter.com/rest/public) APIs,
// MAGIC * [ZeroMQ](http://zeromq.org/),
// MAGIC * [Amazon Kinesis](https://aws.amazon.com/kinesis/streams/), or
// MAGIC * [TCP sockets](http://www.gnu.org/software/mit-scheme/documentation/mit-scheme-ref/TCP-Sockets.html),
// MAGIC
// MAGIC and can be processed using
// MAGIC complex algorithms expressed with high-level functions like `map`,
// MAGIC `reduce`, `join` and `window`.
// MAGIC
// MAGIC Finally, processed data can be pushed out
// MAGIC to filesystems, databases, and live dashboards. In fact, you can apply Spark's
// MAGIC * [machine learning](http://spark.apache.org/docs/latest/mllib-guide.html) and
// MAGIC * [graph processing](http://spark.apache.org/docs/latest/graphx-programming-guide.html) algorithms
// MAGIC on data streams.
// MAGIC
// MAGIC 
// MAGIC
// MAGIC #### Internally, it works as follows:
// MAGIC * Spark Streaming receives live input data streams and
// MAGIC * divides the data into batches,
// MAGIC * which are then processed by the Spark engine
// MAGIC * to generate the final stream of results in batches.
// MAGIC
// MAGIC 
// MAGIC
// MAGIC Spark Streaming provides a high-level abstraction called **discretized
// MAGIC stream** or **DStream**, which represents a continuous stream of data.
// MAGIC DStreams can be created either from input data streams from sources such
// MAGIC as Kafka, Flume, and Kinesis, or by applying high-level operations on
// MAGIC other DStreams. Internally, a **DStream is represented as a sequence of
// MAGIC [RDDs](http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.rdd.RDD)**.
// MAGIC
// MAGIC This guide shows you how to start writing Spark Streaming programs with
// MAGIC DStreams. You can write Spark Streaming programs in Scala, Java or
// MAGIC Python (introduced in Spark 1.2), all of which are presented in this
// MAGIC [guide](http://spark.apache.org/docs/latest/streaming-programming-guide.html).
// MAGIC
// MAGIC Here, we will focus on Streaming in Scala.
// MAGIC
// MAGIC * * * * *
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC #### Spark Streaming Resources
// MAGIC * [Spark Streaming Programming Guide](https://spark.apache.org/docs/latest/streaming-programming-guide.html) - The official Apache Spark Streaming programming guide.
// MAGIC * [Debugging Spark Streaming in Databricks](/#workspace/databricks_guide/08 Spark Streaming/02 Debugging Spark Streaming Application)
// MAGIC * [Streaming FAQs and Best Practices](/#workspace/databricks_guide/08 Spark Streaming/15 Streaming FAQs)
// COMMAND ----------
// MAGIC %md
// MAGIC Three Quick Examples
// MAGIC ===============
// MAGIC
// MAGIC Before we go into the details of how to write your own Spark Streaming
// MAGIC program, let?s take a quick look at what a simple Spark Streaming
// MAGIC program looks like.
// MAGIC
// MAGIC We will choose the first two examples in Databricks notebooks below.
// COMMAND ----------
// MAGIC %md #### Spark Streaming Hello World Examples in Databricks Notebooks
// MAGIC
// MAGIC 1. [Streaming Word Count (Scala)](/#workspace/databricks_guide/08 Spark Streaming/01 Streaming Word Count - Scala)
// MAGIC * Tweet Collector for Capturing Live Tweets
// MAGIC * [Twitter Hashtag Count (Scala)](/#workspace/databricks_guide/08 Spark Streaming/03 Twitter Hashtag Count - Scala)
// MAGIC
// MAGIC Other examples we won't try here:
// MAGIC * [Kinesis Word Count (Scala)](/#workspace/databricks_guide/08 Spark Streaming/04 Kinesis Word Count - Scala)
// MAGIC * [Kafka Word Count (Scala)](/#workspace/databricks_guide/08 Spark Streaming/05 Kafka Word Count - Scala)
// MAGIC * [FileStream Word Count (Python)](/#workspace/databricks_guide/08 Spark Streaming/06 FileStream Word Count - Python)
// COMMAND ----------
// MAGIC %md ## 1. Streaming Word Count
// MAGIC
// MAGIC This is a *hello world* example of Spark Streaming which counts words on 1 second batches of streaming data.
// MAGIC
// MAGIC It uses an in-memory string generator as a dummy source for streaming data.
// COMMAND ----------
// MAGIC %md
// MAGIC ## Configurations
// MAGIC
// MAGIC Configurations that control the streaming app in the notebook
// COMMAND ----------
// === Configuration to control the flow of the application ===
val stopActiveContext = true
// "true" = stop if any existing StreamingContext is running;
// "false" = dont stop, and let it run undisturbed, but your latest code may not be used
// === Configurations for Spark Streaming ===
val batchIntervalSeconds = 1
val eventsPerSecond = 1000 // For the dummy source
// Verify that the attached Spark cluster is 1.4.0+
require(sc.version.replace(".", "").toInt >= 140, "Spark 1.4.0+ is required to run this notebook. Please attach it to a Spark 1.4.0+ cluster.")
// COMMAND ----------
// MAGIC %md
// MAGIC ### Imports
// MAGIC
// MAGIC Import all the necessary libraries. If you see any error here, you have to make sure that you have attached the necessary libraries to the attached cluster.
// COMMAND ----------
import org.apache.spark._
import org.apache.spark.storage._
import org.apache.spark.streaming._
// COMMAND ----------
// MAGIC %md
// MAGIC Discretized Streams (DStreams)
// MAGIC ------------------------------
// MAGIC
// MAGIC **Discretized Stream** or **DStream** is the basic abstraction provided
// MAGIC by Spark Streaming. It represents a continuous stream of data, either
// MAGIC the input data stream received from source, or the processed data stream
// MAGIC generated by transforming the input stream. Internally, a DStream is
// MAGIC represented by a continuous series of RDDs, which is Spark?s abstraction
// MAGIC of an immutable, distributed dataset (see [Spark Programming
// MAGIC Guide](http://spark.apache.org/docs/latest/programming-guide.html#resilient-distributed-datasets-rdds)
// MAGIC for more details). Each RDD in a DStream contains data from a certain
// MAGIC interval, as shown in the following figure.
// MAGIC
// MAGIC 
// COMMAND ----------
// MAGIC %md
// MAGIC ### Setup: Define the function that sets up the StreamingContext
// MAGIC
// MAGIC In this we will do two things.
// MAGIC * Define a custom receiver as the dummy source (no need to understand this)
// MAGIC * this custom receiver will have lines that end with a random number between 0 and 9 and read:
// MAGIC ```
// MAGIC I am a dummy source 2
// MAGIC I am a dummy source 8
// MAGIC ...
// MAGIC ```
// COMMAND ----------
// MAGIC %md
// MAGIC This is the dummy source implemented as a custom receiver. **No need to understand this now.**
// COMMAND ----------
// This is the dummy source implemented as a custom receiver. No need to understand this.
import scala.util.Random
import org.apache.spark.streaming.receiver._
class DummySource(ratePerSec: Int) extends Receiver[String](StorageLevel.MEMORY_AND_DISK_2) {
def onStart() {
// Start the thread that receives data over a connection
new Thread("Dummy Source") {
override def run() { receive() }
}.start()
}
def onStop() {
// There is nothing much to do as the thread calling receive()
// is designed to stop by itself isStopped() returns false
}
/** Create a socket connection and receive data until receiver is stopped */
private def receive() {
while(!isStopped()) {
store("I am a dummy source " + Random.nextInt(10))
Thread.sleep((1000.toDouble / ratePerSec).toInt)
}
}
}
// COMMAND ----------
// MAGIC %md
// MAGIC Let's try to understand the following `creatingFunc` to create a new StreamingContext and setting it up for word count and registering it as temp table for each batch of 1000 lines per second in the stream.
// COMMAND ----------
var newContextCreated = false // Flag to detect whether new context was created or not
// Function to create a new StreamingContext and set it up
def creatingFunc(): StreamingContext = {
// Create a StreamingContext
val ssc = new StreamingContext(sc, Seconds(batchIntervalSeconds))
// Create a stream that generates 1000 lines per second
val stream = ssc.receiverStream(new DummySource(eventsPerSecond))
// Split the lines into words, and then do word count
val wordStream = stream.flatMap { _.split(" ") }
val wordCountStream = wordStream.map(word => (word, 1)).reduceByKey(_ + _)
// Create temp table at every batch interval
wordCountStream.foreachRDD { rdd =>
rdd.toDF("word", "count").registerTempTable("batch_word_count")
}
stream.foreachRDD { rdd =>
System.out.println("# events = " + rdd.count())
System.out.println("\\t " + rdd.take(10).mkString(", ") + ", ...")
}
ssc.remember(Minutes(1)) // To make sure data is not deleted by the time we query it interactively
println("Creating function called to create new StreamingContext")
newContextCreated = true
ssc
}
// COMMAND ----------
// MAGIC %md
// MAGIC ## Transforming and Acting on the DStream of lines
// MAGIC
// MAGIC Any operation applied on a DStream translates to operations on the
// MAGIC underlying RDDs. For converting
// MAGIC a stream of lines to words, the `flatMap` operation is applied on each
// MAGIC RDD in the `lines` DStream to generate the RDDs of the `wordStream` DStream.
// MAGIC This is shown in the following figure.
// MAGIC
// MAGIC 
// MAGIC
// MAGIC These underlying RDD transformations are computed by the Spark engine.
// MAGIC The DStream operations hide most of these details and provide the
// MAGIC developer with a higher-level API for convenience.
// MAGIC
// MAGIC Next `reduceByKey` is used to get `wordCountStream` that counts the words in `wordStream`.
// MAGIC
// MAGIC Finally, this is registered as a temporary table for each RDD in the DStream.
// COMMAND ----------
// MAGIC %md
// MAGIC ## Start Streaming Job: Stop existing StreamingContext if any and start/restart the new one
// MAGIC
// MAGIC Here we are going to use the configurations at the top of the notebook to decide whether to stop any existing StreamingContext, and start a new one, or recover one from existing checkpoints.
// COMMAND ----------
// Stop any existing StreamingContext
// The getActive function is proviced by Databricks to access active Streaming Contexts
if (stopActiveContext) {
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
}
// Get or create a streaming context
val ssc = StreamingContext.getActiveOrCreate(creatingFunc)
if (newContextCreated) {
println("New context created from currently defined creating function")
} else {
println("Existing context running or recovered from checkpoint, may not be running currently defined creating function")
}
// Start the streaming context in the background.
ssc.start()
// This is to ensure that we wait for some time before the background streaming job starts. This will put this cell on hold for 5 times the batchIntervalSeconds.
ssc.awaitTerminationOrTimeout(batchIntervalSeconds * 5 * 1000)
// COMMAND ----------
// MAGIC %md
// MAGIC ### Interactive Querying
// MAGIC
// MAGIC Now let's try querying the table. You can run this command again and again, you will find the numbers changing.
// COMMAND ----------
// MAGIC %sql select * from batch_word_count
// COMMAND ----------
// MAGIC %md
// MAGIC Try again for current table.
// COMMAND ----------
// MAGIC %sql select * from batch_word_count
// COMMAND ----------
// MAGIC %md ### Finally, if you want stop the StreamingContext, you can uncomment and execute the following
// MAGIC
// MAGIC `StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }`
// COMMAND ----------
StreamingContext.getActive.foreach { _.stop(stopSparkContext = false) }
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC ***
// COMMAND ----------
// MAGIC %md
// MAGIC # Let's do two more example applications of streaming involving live tweets.
// COMMAND ----------
// MAGIC %md
// MAGIC ***
// MAGIC ***
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC # More Pointers to Spark Streaming
// COMMAND ----------
// MAGIC %md
// MAGIC # Spark Streaming Common Sinks
// MAGIC
// MAGIC * [Writing data to Kinesis](/#workspace/databricks_guide/08 Spark Streaming/07 Write Output To Kinesis)
// MAGIC * [Writing data to S3](/#workspace/databricks_guide/08 Spark Streaming/08 Write Output To S3)
// MAGIC * [Writing data to Kafka](/#workspace/databricks_guide/08 Spark Streaming/09 Write Output To Kafka)
// COMMAND ----------
// MAGIC %md
// MAGIC ## Writing to S3
// MAGIC
// MAGIC We will be storing large amounts of data in s3, [Amazon's simple storage service](https://aws.amazon.com/s3/).
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC # Spark Streaming Tutorials
// MAGIC * [Window Aggregations in Streaming](/#workspace/databricks_guide/08 Spark Streaming/10 Window Aggregations) - Has examples for the different window aggregations available in spark streaming
// MAGIC * [Global Aggregations using updateStateByKey](/#workspace/databricks_guide/08 Spark Streaming/11 Global Aggregations - updateStateByKey) - Provides an example of how to do global aggregations
// MAGIC * [Global Aggregations using mapWithState](/#workspace/databricks_guide/08 Spark Streaming/12 Global Aggregations - mapWithState) - From Spark 1.6, you can use the `mapWithState` interface to do global aggregations more efficiently.
// MAGIC * [Joining DStreams](/#workspace/databricks_guide/08 Spark Streaming/13 Joining DStreams) - Has an example for joining 2 dstreams
// MAGIC * [Joining DStreams with static datasets](/#workspace/databricks_guide/08 Spark Streaming/14 Joining DStreams With Static Datasets) - Builds on the previous example and shows how to join DStreams with static dataframes or RDDs efficiently
// COMMAND ----------
// MAGIC %md
// MAGIC # Example Streaming Producers
// MAGIC * [Kinesis Word Producer](/#workspace/databricks_guide/08 Spark Streaming/Producers/1 Kinesis Word Producer)
// MAGIC * [Kafka Word Producer](/#workspace/databricks_guide/08 Spark Streaming/Producers/2 Kafka Word Producer)
// MAGIC * [Kafka Ads Data Producer](/#workspace/databricks_guide/08 Spark Streaming/Producers/3 Kafka Ads Data Producer)
// COMMAND ----------
// MAGIC %md
// MAGIC # Spark Streaming Applications
// MAGIC
// MAGIC * [Sessionization - Building Sessions from Streams](/#workspace/databricks_guide/08 Spark Streaming/Applications/01 Sessionization)
// COMMAND ----------
// MAGIC %md
// MAGIC
// MAGIC # [Scalable Data Science](http://www.math.canterbury.ac.nz/~r.sainudiin/courses/ScalableDataScience/)
// MAGIC
// MAGIC
// MAGIC ### prepared by [Raazesh Sainudiin](https://nz.linkedin.com/in/raazesh-sainudiin-45955845) and [Sivanand Sivaram](https://www.linkedin.com/in/sivanand)
// MAGIC
// MAGIC *supported by* [](https://databricks.com/)
// MAGIC and
// MAGIC [](https://www.awseducate.com/microsite/CommunitiesEngageHome)
|
raazesh-sainudiin/scalable-data-science
|
db/week6/12_SparkStreaming/021_SparkStreamingIntro.scala
|
Scala
|
unlicense
| 18,293 |
package org.template.recommendation
import org.apache.predictionio.controller.LServing
class Serving
extends LServing[Query, PredictedResult] {
override
def serve(query: Query,
predictedResults: Seq[PredictedResult]): PredictedResult = {
predictedResults.head
}
}
|
alex9311/PredictionIO
|
examples/scala-parallel-recommendation/filter-by-category/src/main/scala/Serving.scala
|
Scala
|
apache-2.0
| 282 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.