
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
| tokens_length
listlengths 1
353
| input_texts
listlengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
7db3f2a31ab642a683db75adb6868e133251eb71
|
# Dataset Card for "bioasq10b"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
legacy107/bioasq10b-factoid
|
[
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:en",
"medical",
"region:us"
] |
2023-09-06T12:39:03+00:00
|
{"language": ["en"], "size_categories": ["1K<n<10K"], "task_categories": ["question-answering"], "pretty_name": "BioASQ10b (factoid only)", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "long_answer", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "context", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3321906, "num_examples": 1252}, {"name": "test", "num_bytes": 318200, "num_examples": 166}], "download_size": 1758966, "dataset_size": 3640106}, "tags": ["medical"]}
|
2023-09-06T12:45:03+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-question-answering #size_categories-1K<n<10K #language-English #medical #region-us
|
# Dataset Card for "bioasq10b"
More Information needed
|
[
"# Dataset Card for \"bioasq10b\"\n\nMore Information needed"
] |
[
"TAGS\n#task_categories-question-answering #size_categories-1K<n<10K #language-English #medical #region-us \n",
"# Dataset Card for \"bioasq10b\"\n\nMore Information needed"
] |
[
37,
15
] |
[
"passage: TAGS\n#task_categories-question-answering #size_categories-1K<n<10K #language-English #medical #region-us \n# Dataset Card for \"bioasq10b\"\n\nMore Information needed"
] |
1507f0fb425b054da4437865ec53b0dd4ea56a0d
|
For translating Indonesian to English
|
vhtran/uniq-id-en
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-09-06T12:39:51+00:00
|
{"license": "cc-by-4.0"}
|
2023-09-06T12:42:25+00:00
|
[] |
[] |
TAGS
#license-cc-by-4.0 #region-us
|
For translating Indonesian to English
|
[] |
[
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
[
15
] |
[
"passage: TAGS\n#license-cc-by-4.0 #region-us \n"
] |
6fb04a1bee4a53542e1ecc240bdbb5284c4be5c3
|
German to English
|
vhtran/uniq-de-en
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-09-06T12:42:52+00:00
|
{"license": "cc-by-4.0"}
|
2023-09-06T12:44:59+00:00
|
[] |
[] |
TAGS
#license-cc-by-4.0 #region-us
|
German to English
|
[] |
[
"TAGS\n#license-cc-by-4.0 #region-us \n"
] |
[
15
] |
[
"passage: TAGS\n#license-cc-by-4.0 #region-us \n"
] |
3278e822ff85599a96b20b2de59338d695c5acb7
|
# Dataset Card for Evaluation run of Undi95/ReMM-SLERP-L2-13B
## Dataset Description
- **Homepage:**
- **Repository:** https://huggingface.co/Undi95/ReMM-SLERP-L2-13B
- **Paper:**
- **Leaderboard:** https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
- **Point of Contact:** [email protected]
### Dataset Summary
Dataset automatically created during the evaluation run of model [Undi95/ReMM-SLERP-L2-13B](https://huggingface.co/Undi95/ReMM-SLERP-L2-13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Undi95__ReMM-SLERP-L2-13B",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-10-29T14:55:07.909290](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__ReMM-SLERP-L2-13B/blob/main/results_2023-10-29T14-55-07.909290.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"em": 0.13464765100671142,
"em_stderr": 0.0034957110748356193,
"f1": 0.20755138422818709,
"f1_stderr": 0.0036341951060626636,
"acc": 0.421953322606337,
"acc_stderr": 0.01004266408410234
},
"harness|drop|3": {
"em": 0.13464765100671142,
"em_stderr": 0.0034957110748356193,
"f1": 0.20755138422818709,
"f1_stderr": 0.0036341951060626636
},
"harness|gsm8k|5": {
"acc": 0.09173616376042457,
"acc_stderr": 0.00795094214833933
},
"harness|winogrande|5": {
"acc": 0.7521704814522494,
"acc_stderr": 0.01213438601986535
}
}
```
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
open-llm-leaderboard/details_Undi95__ReMM-SLERP-L2-13B
|
[
"region:us"
] |
2023-09-06T12:43:04+00:00
|
{"pretty_name": "Evaluation run of Undi95/ReMM-SLERP-L2-13B", "dataset_summary": "Dataset automatically created during the evaluation run of model [Undi95/ReMM-SLERP-L2-13B](https://huggingface.co/Undi95/ReMM-SLERP-L2-13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\nThe dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\nTo load the details from a run, you can for instance do the following:\n```python\nfrom datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Undi95__ReMM-SLERP-L2-13B\",\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese are the [latest results from run 2023-10-29T14:55:07.909290](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__ReMM-SLERP-L2-13B/blob/main/results_2023-10-29T14-55-07.909290.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):\n\n```python\n{\n \"all\": {\n \"em\": 0.13464765100671142,\n \"em_stderr\": 0.0034957110748356193,\n \"f1\": 0.20755138422818709,\n \"f1_stderr\": 0.0036341951060626636,\n \"acc\": 0.421953322606337,\n \"acc_stderr\": 0.01004266408410234\n },\n \"harness|drop|3\": {\n \"em\": 0.13464765100671142,\n \"em_stderr\": 0.0034957110748356193,\n \"f1\": 0.20755138422818709,\n \"f1_stderr\": 0.0036341951060626636\n },\n \"harness|gsm8k|5\": {\n \"acc\": 0.09173616376042457,\n \"acc_stderr\": 0.00795094214833933\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.7521704814522494,\n \"acc_stderr\": 0.01213438601986535\n }\n}\n```", "repo_url": "https://huggingface.co/Undi95/ReMM-SLERP-L2-13B", "leaderboard_url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard", "point_of_contact": "[email protected]", "configs": [{"config_name": "harness_arc_challenge_25", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|arc:challenge|25_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|arc:challenge|25_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_drop_3", "data_files": [{"split": "2023_10_29T14_55_07.909290", "path": ["**/details_harness|drop|3_2023-10-29T14-55-07.909290.parquet"]}, {"split": "latest", "path": ["**/details_harness|drop|3_2023-10-29T14-55-07.909290.parquet"]}]}, {"config_name": "harness_gsm8k_5", "data_files": [{"split": "2023_10_29T14_55_07.909290", "path": ["**/details_harness|gsm8k|5_2023-10-29T14-55-07.909290.parquet"]}, {"split": "latest", "path": ["**/details_harness|gsm8k|5_2023-10-29T14-55-07.909290.parquet"]}]}, {"config_name": "harness_hellaswag_10", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hellaswag|10_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hellaswag|10_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-management|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-virology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-management|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-virology|5_2023-09-06T13-42-48.770616.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_abstract_algebra_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_anatomy_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_astronomy_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_business_ethics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_clinical_knowledge_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_biology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_chemistry_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_computer_science_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_mathematics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_medicine_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_physics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_computer_security_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_conceptual_physics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_econometrics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_electrical_engineering_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_elementary_mathematics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_formal_logic_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_global_facts_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_biology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_chemistry_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_computer_science_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_european_history_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_geography_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_government_and_politics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_macroeconomics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_mathematics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_microeconomics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_physics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_psychology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_statistics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_us_history_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_world_history_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_aging_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_sexuality_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_international_law_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_jurisprudence_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_logical_fallacies_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_machine_learning_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_management_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-management|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-management|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_marketing_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_medical_genetics_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_miscellaneous_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_disputes_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_scenarios_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_nutrition_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_philosophy_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_prehistory_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_accounting_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_law_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_medicine_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_psychology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_public_relations_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_security_studies_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_sociology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_us_foreign_policy_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_virology_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-virology|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-virology|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_hendrycksTest_world_religions_5", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_truthfulqa_mc_0", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["**/details_harness|truthfulqa:mc|0_2023-09-06T13-42-48.770616.parquet"]}, {"split": "latest", "path": ["**/details_harness|truthfulqa:mc|0_2023-09-06T13-42-48.770616.parquet"]}]}, {"config_name": "harness_winogrande_5", "data_files": [{"split": "2023_10_29T14_55_07.909290", "path": ["**/details_harness|winogrande|5_2023-10-29T14-55-07.909290.parquet"]}, {"split": "latest", "path": ["**/details_harness|winogrande|5_2023-10-29T14-55-07.909290.parquet"]}]}, {"config_name": "results", "data_files": [{"split": "2023_09_06T13_42_48.770616", "path": ["results_2023-09-06T13-42-48.770616.parquet"]}, {"split": "2023_10_29T14_55_07.909290", "path": ["results_2023-10-29T14-55-07.909290.parquet"]}, {"split": "latest", "path": ["results_2023-10-29T14-55-07.909290.parquet"]}]}]}
|
2023-10-29T14:55:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for Evaluation run of Undi95/ReMM-SLERP-L2-13B
## Dataset Description
- Homepage:
- Repository: URL
- Paper:
- Leaderboard: URL
- Point of Contact: clementine@URL
### Dataset Summary
Dataset automatically created during the evaluation run of model Undi95/ReMM-SLERP-L2-13B on the Open LLM Leaderboard.
The dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the Open LLM Leaderboard).
To load the details from a run, you can for instance do the following:
## Latest results
These are the latest results from run 2023-10-29T14:55:07.909290(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
|
[
"# Dataset Card for Evaluation run of Undi95/ReMM-SLERP-L2-13B",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: \n- Leaderboard: URL\n- Point of Contact: clementine@URL",
"### Dataset Summary\n\nDataset automatically created during the evaluation run of model Undi95/ReMM-SLERP-L2-13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-10-29T14:55:07.909290(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for Evaluation run of Undi95/ReMM-SLERP-L2-13B",
"## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: \n- Leaderboard: URL\n- Point of Contact: clementine@URL",
"### Dataset Summary\n\nDataset automatically created during the evaluation run of model Undi95/ReMM-SLERP-L2-13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-10-29T14:55:07.909290(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
6,
24,
31,
172,
67,
10,
4,
6,
6,
5,
5,
5,
7,
4,
10,
10,
5,
5,
9,
8,
8,
7,
8,
7,
5,
6,
6,
5
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for Evaluation run of Undi95/ReMM-SLERP-L2-13B## Dataset Description\n\n- Homepage: \n- Repository: URL\n- Paper: \n- Leaderboard: URL\n- Point of Contact: clementine@URL### Dataset Summary\n\nDataset automatically created during the evaluation run of model Undi95/ReMM-SLERP-L2-13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 64 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 2 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the agregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:## Latest results\n\nThese are the latest results from run 2023-10-29T14:55:07.909290(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):### Supported Tasks and Leaderboards### Languages## Dataset Structure### Data Instances### Data Fields### Data Splits## Dataset Creation### Curation Rationale### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information## Considerations for Using the Data### Social Impact of Dataset### Discussion of Biases### Other Known Limitations## Additional Information### Dataset Curators### Licensing Information### Contributions"
] |
d8b805bd01e35979186291a11019ed3a631e8c19
|
# Dataset Card for "guanaco-llama2-10"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
astalin/guanaco-llama2-10
|
[
"region:us"
] |
2023-09-06T12:43:36+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 23665, "num_examples": 10}], "download_size": 27131, "dataset_size": 23665}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T12:43:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "guanaco-llama2-10"
More Information needed
|
[
"# Dataset Card for \"guanaco-llama2-10\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"guanaco-llama2-10\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"guanaco-llama2-10\"\n\nMore Information needed"
] |
706d794d0b23556862de824f34026ad09b342874
|
## Overview
This dataset is built upon [SQL Create Context](https://huggingface.co/datasets/b-mc2/sql-create-context), which in turn was constructed using data from [WikiSQL](https://huggingface.co/datasets/wikisql) and [Spider](https://huggingface.co/datasets/spider).
There are 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL Query answering the question using the CREATE statement as context. This dataset was built with text-to-SQL LLMs in mind, intending to prevent hallucination of column and table names often seen when trained on text-to-SQL datasets. The CREATE TABLE statement can often be copy and pasted from different DBMS and provides table names, column names, and their data types. By providing just the CREATE TABLE statement as context, we can hopefully provide better grounding for models without having to provide actual rows of data, limiting token usage and exposure to private, sensitive, or proprietary data.
## Cleansing and Augmentation
Cleansing and data augmentation have been done on the combined WikiSQL and Spider data. [SQLGlot](https://github.com/tobymao/sqlglot) was used on queries from Spider and WikiSQL to parse them into different tables and columns. Column data types were inferred based on the usage of `>` `<` operators as well as the use of `MIN()`, `MAX()`, `AVG()`, and `SUM()` on columns. While this isn't perfect, it increases the likelihood of inferring the correct datatype for a column; otherwise, columns default to VARCHAR type. These tables and columns are then used to generate CREATE TABLE statements using the inferred types. SQLGlot is used again to ensure both the SQL queries and CREATE TABLE statements parse without errors.
Some queries that do not have column names, e.g., SELECT * FROM table, have a default Id column added to the CREATE TABLE statement. Some other queries which use the generic `table` as the FROM table have instead been changed to a variation of `table_name_1` or some other number which is also reflected in the CREATE TABLE statement.
## TODO
- Further augment the data by converting queries and CREATE TABLE statements into different SQL dialects. This can be done with SQLGlot. Reference to the dialect might also be added to the question.
**Random sample:**
```json
{
"text" : "[INST] Write SQLite query to answer the following question given the database schema. Please wrap your code answer using ```: Schema: CREATE TABLE head (age INTEGER) Question: How many heads of the departments are older than 56 ? [/INST] Here is the SQLite query to answer to the question: How many heads of the departments are older than 56 ?: ``` SELECT COUNT(*) FROM head WHERE age > 56 ```",
"text" : "[INST] Write SQLite query to answer the following question given the database schema. Please wrap your code answer using ```: Schema: CREATE TABLE head (name VARCHAR, born_state VARCHAR, age VARCHAR) Question: List the name, born state and age of the heads of departments ordered by age. [/INST] Here is the SQLite query to answer to the question: List the name, born state and age of the heads of departments ordered by age.: ``` SELECT name, born_state, age FROM head ORDER BY age ```"
}
```
The dataset was used to create code-llama-2 style prompts. The basic prompt template is:
```
[INST] Instruction/context [/INST]
Model output
```
|
bugdaryan/sql-create-context-instruction
|
[
"task_categories:text-generation",
"task_categories:question-answering",
"task_categories:table-question-answering",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-4.0",
"SQL",
"code",
"NLP",
"text-to-sql",
"context-sql",
"spider",
"wikisql",
"sqlglot",
"region:us"
] |
2023-09-06T13:06:13+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-generation", "question-answering", "table-question-answering"], "pretty_name": "sql-create-context", "tags": ["SQL", "code", "NLP", "text-to-sql", "context-sql", "spider", "wikisql", "sqlglot"]}
|
2023-09-07T14:22:00+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #task_categories-question-answering #task_categories-table-question-answering #size_categories-10K<n<100K #language-English #license-cc-by-4.0 #SQL #code #NLP #text-to-sql #context-sql #spider #wikisql #sqlglot #region-us
|
## Overview
This dataset is built upon SQL Create Context, which in turn was constructed using data from WikiSQL and Spider.
There are 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL Query answering the question using the CREATE statement as context. This dataset was built with text-to-SQL LLMs in mind, intending to prevent hallucination of column and table names often seen when trained on text-to-SQL datasets. The CREATE TABLE statement can often be copy and pasted from different DBMS and provides table names, column names, and their data types. By providing just the CREATE TABLE statement as context, we can hopefully provide better grounding for models without having to provide actual rows of data, limiting token usage and exposure to private, sensitive, or proprietary data.
## Cleansing and Augmentation
Cleansing and data augmentation have been done on the combined WikiSQL and Spider data. SQLGlot was used on queries from Spider and WikiSQL to parse them into different tables and columns. Column data types were inferred based on the usage of '>' '<' operators as well as the use of 'MIN()', 'MAX()', 'AVG()', and 'SUM()' on columns. While this isn't perfect, it increases the likelihood of inferring the correct datatype for a column; otherwise, columns default to VARCHAR type. These tables and columns are then used to generate CREATE TABLE statements using the inferred types. SQLGlot is used again to ensure both the SQL queries and CREATE TABLE statements parse without errors.
Some queries that do not have column names, e.g., SELECT * FROM table, have a default Id column added to the CREATE TABLE statement. Some other queries which use the generic 'table' as the FROM table have instead been changed to a variation of 'table_name_1' or some other number which is also reflected in the CREATE TABLE statement.
## TODO
- Further augment the data by converting queries and CREATE TABLE statements into different SQL dialects. This can be done with SQLGlot. Reference to the dialect might also be added to the question.
Random sample:
: Schema: CREATE TABLE head (age INTEGER) Question: How many heads of the departments are older than 56 ? [/INST] Here is the SQLite query to answer to the question: How many heads of the departments are older than 56 ?: ",
"text" : "[INST] Write SQLite query to answer the following question given the database schema. Please wrap your code answer using SELECT name, born_state, age FROM head ORDER BY age
The dataset was used to create code-llama-2 style prompts. The basic prompt template is:
|
[
"## Overview\nThis dataset is built upon SQL Create Context, which in turn was constructed using data from WikiSQL and Spider.\n\nThere are 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL Query answering the question using the CREATE statement as context. This dataset was built with text-to-SQL LLMs in mind, intending to prevent hallucination of column and table names often seen when trained on text-to-SQL datasets. The CREATE TABLE statement can often be copy and pasted from different DBMS and provides table names, column names, and their data types. By providing just the CREATE TABLE statement as context, we can hopefully provide better grounding for models without having to provide actual rows of data, limiting token usage and exposure to private, sensitive, or proprietary data.",
"## Cleansing and Augmentation\nCleansing and data augmentation have been done on the combined WikiSQL and Spider data. SQLGlot was used on queries from Spider and WikiSQL to parse them into different tables and columns. Column data types were inferred based on the usage of '>' '<' operators as well as the use of 'MIN()', 'MAX()', 'AVG()', and 'SUM()' on columns. While this isn't perfect, it increases the likelihood of inferring the correct datatype for a column; otherwise, columns default to VARCHAR type. These tables and columns are then used to generate CREATE TABLE statements using the inferred types. SQLGlot is used again to ensure both the SQL queries and CREATE TABLE statements parse without errors.\n\nSome queries that do not have column names, e.g., SELECT * FROM table, have a default Id column added to the CREATE TABLE statement. Some other queries which use the generic 'table' as the FROM table have instead been changed to a variation of 'table_name_1' or some other number which is also reflected in the CREATE TABLE statement.",
"## TODO\n- Further augment the data by converting queries and CREATE TABLE statements into different SQL dialects. This can be done with SQLGlot. Reference to the dialect might also be added to the question.\n\nRandom sample:\n: Schema: CREATE TABLE head (age INTEGER) Question: How many heads of the departments are older than 56 ? [/INST] Here is the SQLite query to answer to the question: How many heads of the departments are older than 56 ?: \", \n \"text\" : \"[INST] Write SQLite query to answer the following question given the database schema. Please wrap your code answer using SELECT name, born_state, age FROM head ORDER BY age \n\nThe dataset was used to create code-llama-2 style prompts. The basic prompt template is:"
] |
[
"TAGS\n#task_categories-text-generation #task_categories-question-answering #task_categories-table-question-answering #size_categories-10K<n<100K #language-English #license-cc-by-4.0 #SQL #code #NLP #text-to-sql #context-sql #spider #wikisql #sqlglot #region-us \n",
"## Overview\nThis dataset is built upon SQL Create Context, which in turn was constructed using data from WikiSQL and Spider.\n\nThere are 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL Query answering the question using the CREATE statement as context. This dataset was built with text-to-SQL LLMs in mind, intending to prevent hallucination of column and table names often seen when trained on text-to-SQL datasets. The CREATE TABLE statement can often be copy and pasted from different DBMS and provides table names, column names, and their data types. By providing just the CREATE TABLE statement as context, we can hopefully provide better grounding for models without having to provide actual rows of data, limiting token usage and exposure to private, sensitive, or proprietary data.",
"## Cleansing and Augmentation\nCleansing and data augmentation have been done on the combined WikiSQL and Spider data. SQLGlot was used on queries from Spider and WikiSQL to parse them into different tables and columns. Column data types were inferred based on the usage of '>' '<' operators as well as the use of 'MIN()', 'MAX()', 'AVG()', and 'SUM()' on columns. While this isn't perfect, it increases the likelihood of inferring the correct datatype for a column; otherwise, columns default to VARCHAR type. These tables and columns are then used to generate CREATE TABLE statements using the inferred types. SQLGlot is used again to ensure both the SQL queries and CREATE TABLE statements parse without errors.\n\nSome queries that do not have column names, e.g., SELECT * FROM table, have a default Id column added to the CREATE TABLE statement. Some other queries which use the generic 'table' as the FROM table have instead been changed to a variation of 'table_name_1' or some other number which is also reflected in the CREATE TABLE statement.",
"## TODO\n- Further augment the data by converting queries and CREATE TABLE statements into different SQL dialects. This can be done with SQLGlot. Reference to the dialect might also be added to the question.\n\nRandom sample:\n: Schema: CREATE TABLE head (age INTEGER) Question: How many heads of the departments are older than 56 ? [/INST] Here is the SQLite query to answer to the question: How many heads of the departments are older than 56 ?: \", \n \"text\" : \"[INST] Write SQLite query to answer the following question given the database schema. Please wrap your code answer using SELECT name, born_state, age FROM head ORDER BY age \n\nThe dataset was used to create code-llama-2 style prompts. The basic prompt template is:"
] |
[
100,
192,
283,
185
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-question-answering #task_categories-table-question-answering #size_categories-10K<n<100K #language-English #license-cc-by-4.0 #SQL #code #NLP #text-to-sql #context-sql #spider #wikisql #sqlglot #region-us \n## Overview\nThis dataset is built upon SQL Create Context, which in turn was constructed using data from WikiSQL and Spider.\n\nThere are 78,577 examples of natural language queries, SQL CREATE TABLE statements, and SQL Query answering the question using the CREATE statement as context. This dataset was built with text-to-SQL LLMs in mind, intending to prevent hallucination of column and table names often seen when trained on text-to-SQL datasets. The CREATE TABLE statement can often be copy and pasted from different DBMS and provides table names, column names, and their data types. By providing just the CREATE TABLE statement as context, we can hopefully provide better grounding for models without having to provide actual rows of data, limiting token usage and exposure to private, sensitive, or proprietary data."
] |
c566e97cdb139bb63f78dac18971ddf309adf847
|
# Dataset Card for "package_design_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/package_design_prompts
|
[
"region:us"
] |
2023-09-06T13:09:29+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 29373693, "num_examples": 100000}], "download_size": 3879481, "dataset_size": 29373693}}
|
2023-09-07T08:11:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "package_design_prompts"
More Information needed
|
[
"# Dataset Card for \"package_design_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"package_design_prompts\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"package_design_prompts\"\n\nMore Information needed"
] |
6c83f3c24a022f5bd02c20448644f511f82685a8
|
# Dataset Card for "CV_13_FT_75_25_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
RikRaes/CV_13_FT_75_25_1
|
[
"region:us"
] |
2023-09-06T13:16:15+00:00
|
{"dataset_info": {"features": [{"name": "client_id", "dtype": "string"}, {"name": "path", "struct": [{"name": "array", "sequence": "float32"}, {"name": "path", "dtype": "string"}, {"name": "sampling_rate", "dtype": "int64"}]}, {"name": "sentence", "dtype": "string"}, {"name": "up_votes", "dtype": "int64"}, {"name": "down_votes", "dtype": "int64"}, {"name": "age", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "accents", "dtype": "string"}, {"name": "variant", "dtype": "null"}, {"name": "locale", "dtype": "string"}, {"name": "segment", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1363205491.3122818, "num_examples": 5000}, {"name": "val", "num_bytes": 272641098.26245636, "num_examples": 1000}, {"name": "test", "num_bytes": 545282196.5249127, "num_examples": 2000}], "download_size": 824807117, "dataset_size": 2181128786.099651}}
|
2023-09-07T09:45:15+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "CV_13_FT_75_25_1"
More Information needed
|
[
"# Dataset Card for \"CV_13_FT_75_25_1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"CV_13_FT_75_25_1\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"CV_13_FT_75_25_1\"\n\nMore Information needed"
] |
bf588b2381969790c319dd211c23fd8f82f447e7
|
189k (~1GB of raw clean text) documents of various programming language & tech stacks by [DevDocs](https://devdocs.io/), it combines multiple API documentations in a fast, organized, and searchable interface.
DevDocs is free and open source by FreeCodeCamp.
I've converted it into Markdown format for the standard of training data.
|
nampdn-ai/devdocs.io
|
[
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"code",
"region:us"
] |
2023-09-06T13:22:20+00:00
|
{"language": ["en"], "size_categories": ["100K<n<1M"], "task_categories": ["text-generation"], "pretty_name": "devdocs.io", "tags": ["code"]}
|
2023-09-21T20:03:20+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-100K<n<1M #language-English #code #region-us
|
189k (~1GB of raw clean text) documents of various programming language & tech stacks by DevDocs, it combines multiple API documentations in a fast, organized, and searchable interface.
DevDocs is free and open source by FreeCodeCamp.
I've converted it into Markdown format for the standard of training data.
|
[] |
[
"TAGS\n#task_categories-text-generation #size_categories-100K<n<1M #language-English #code #region-us \n"
] |
[
35
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-100K<n<1M #language-English #code #region-us \n"
] |
40fda5027e1aabad05e301810e165c5e43b3efa4
|
# Dataset Card for "data_for_synthesis_with_entities_align_v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
quocanh34/data_for_synthesis_with_entities_align_v2
|
[
"region:us"
] |
2023-09-06T13:46:05+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "sentence", "dtype": "string"}, {"name": "intent", "dtype": "string"}, {"name": "sentence_annotation", "dtype": "string"}, {"name": "entities", "list": [{"name": "type", "dtype": "string"}, {"name": "filler", "dtype": "string"}]}, {"name": "file", "dtype": "string"}, {"name": "audio", "struct": [{"name": "array", "sequence": "float64"}, {"name": "path", "dtype": "string"}, {"name": "sampling_rate", "dtype": "int64"}]}, {"name": "origin_transcription", "dtype": "string"}, {"name": "sentence_norm", "dtype": "string"}, {"name": "w2v2_large_transcription", "dtype": "string"}, {"name": "wer", "dtype": "int64"}, {"name": "entities_norm", "list": [{"name": "filler", "dtype": "string"}, {"name": "type", "dtype": "string"}]}, {"name": "entities_align", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 698110051.1801205, "num_examples": 1413}], "download_size": 158745470, "dataset_size": 698110051.1801205}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T13:46:23+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "data_for_synthesis_with_entities_align_v2"
More Information needed
|
[
"# Dataset Card for \"data_for_synthesis_with_entities_align_v2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"data_for_synthesis_with_entities_align_v2\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"data_for_synthesis_with_entities_align_v2\"\n\nMore Information needed"
] |
38dc39c39944bcf8f7e7d5cde38785d3d1ec151b
|
# Walnut Trees Dataset
The dataset consists of images of walnut trees and polygons denoting the **crown, trunk, and road areas** for agriculture and farming.
- The **crown** polygons mark the external boundary of the trees' canopy. The labeling is made relatively. **By your request, the labeling can be done precisely along the outline of the tree crown.**.
- The **trunk** polygons represent the central woody structure of the trees. They outline the main stem or trunk of the walnut trees.
- The **road** polygons represent the areas surrounding the walnut trees, intended for nut harvesting machines.
This dataset is useful for agriculture and provides a comprehensive representation of these trees, enabling people to explore numerous aspects related to walnut tree growth, health, and spatial distribution. It also helps to automate and optimize the harvesting process in walnut plantations.

# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=walnut-trees-dataset) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
- **images** - contains of original images of walnut trees
- **labels** - includes polygon labeling for the original images
- **annotations.xml** - contains coordinates of the polygons and labels, created for the original photo
# Data Format
Each image from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the polygon for each of the classes. For each point, the x and y coordinates are provided.
### Сlasses:
- **tree_trunk**: trunk of the tree,
- **tree_crown**: crow of the tree,
- **road**: road where a nut harvesting machine can pass
# Example of XML file structure
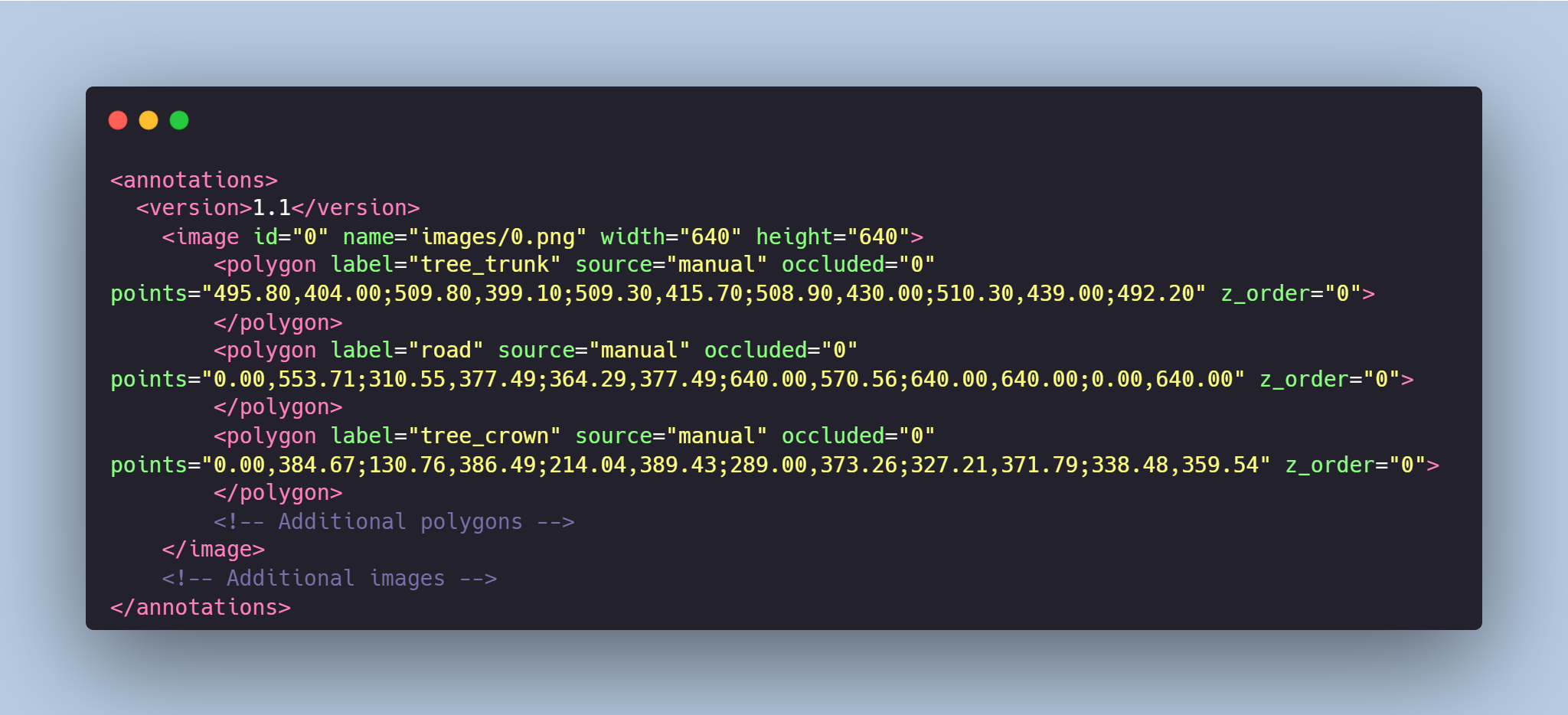
# Walnut Trees Images might be collected and annotated in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=walnut-trees-dataset) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/walnut-trees-dataset
|
[
"task_categories:image-classification",
"task_categories:image-to-image",
"task_categories:image-segmentation",
"language:en",
"license:cc-by-nc-nd-4.0",
"biology",
"code",
"region:us"
] |
2023-09-06T14:13:46+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-classification", "image-to-image", "image-segmentation"], "tags": ["biology", "code"], "dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "width", "dtype": "uint16"}, {"name": "height", "dtype": "uint16"}, {"name": "shapes", "sequence": [{"name": "label", "dtype": {"class_label": {"names": {"0": "tree_trunk", "1": "tree_crown", "2": "road"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 56274934, "num_examples": 20}], "download_size": 55509430, "dataset_size": 56274934}}
|
2023-09-26T08:23:07+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-classification #task_categories-image-to-image #task_categories-image-segmentation #language-English #license-cc-by-nc-nd-4.0 #biology #code #region-us
|
# Walnut Trees Dataset
The dataset consists of images of walnut trees and polygons denoting the crown, trunk, and road areas for agriculture and farming.
- The crown polygons mark the external boundary of the trees' canopy. The labeling is made relatively. By your request, the labeling can be done precisely along the outline of the tree crown..
- The trunk polygons represent the central woody structure of the trees. They outline the main stem or trunk of the walnut trees.
- The road polygons represent the areas surrounding the walnut trees, intended for nut harvesting machines.
This dataset is useful for agriculture and provides a comprehensive representation of these trees, enabling people to explore numerous aspects related to walnut tree growth, health, and spatial distribution. It also helps to automate and optimize the harvesting process in walnut plantations.

|
P1ayer-1/isbndb-full-database
|
[
"region:us"
] |
2023-09-06T14:41:05+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "authors", "sequence": "string"}, {"name": "language", "dtype": "string"}, {"name": "title_long", "dtype": "string"}, {"name": "date_published", "dtype": "string"}, {"name": "isbn", "dtype": "string"}, {"name": "isbn13", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5382889444, "num_examples": 28086774}], "download_size": 0, "dataset_size": 5382889444}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-09T02:54:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "isbndb-annas"
More Information needed
|
[
"# Dataset Card for \"isbndb-annas\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"isbndb-annas\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"isbndb-annas\"\n\nMore Information needed"
] |
935ca138074fb71883659421d9c487c2d732bc06
|
# Dataset Card for "test_synthesis_data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
quocanh34/test_synthesis_data
|
[
"region:us"
] |
2023-09-06T14:53:28+00:00
|
{"dataset_info": {"features": [{"name": "audio", "struct": [{"name": "array", "sequence": "float64"}, {"name": "path", "dtype": "null"}, {"name": "sampling_rate", "dtype": "int64"}]}, {"name": "transcription", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 38195460, "num_examples": 75}], "download_size": 9149788, "dataset_size": 38195460}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T15:35:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test_synthesis_data"
More Information needed
|
[
"# Dataset Card for \"test_synthesis_data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test_synthesis_data\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test_synthesis_data\"\n\nMore Information needed"
] |
8713637d0b75dbb58fd06b620e50dbd8a9372fa0
|
# Dataset Card for "imdb-truncated"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
shawhin/imdb-truncated
|
[
"region:us"
] |
2023-09-06T14:55:01+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "label", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1310325, "num_examples": 1000}, {"name": "validation", "num_bytes": 1329205, "num_examples": 1000}], "download_size": 1688812, "dataset_size": 2639530}}
|
2023-09-06T20:06:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "imdb-truncated"
More Information needed
|
[
"# Dataset Card for \"imdb-truncated\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"imdb-truncated\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"imdb-truncated\"\n\nMore Information needed"
] |
ff976c36dfdca7d6e2ef1717a4da66712ac8c43e
|
# Dataset Card for "guanaco-llama2-1k-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
silvacarl/guanaco-llama2-1k-test
|
[
"region:us"
] |
2023-09-06T15:05:37+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1654448, "num_examples": 1000}], "download_size": 966693, "dataset_size": 1654448}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T15:05:41+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "guanaco-llama2-1k-test"
More Information needed
|
[
"# Dataset Card for \"guanaco-llama2-1k-test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"guanaco-llama2-1k-test\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"guanaco-llama2-1k-test\"\n\nMore Information needed"
] |
2225a5674b252d623cfb151ef099d179629c2f49
|
# Data source
Downloaded via Andrej Karpathy's nanogpt repo from this [link](https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt)
# Data Format
- The entire dataset is split into train (90%) and test (10%).
- All rows are at most 1024 tokens, using the Llama 2 tokenizer.
- All rows are split cleanly so that sentences are whole and unbroken.
|
Trelis/tiny-shakespeare
|
[
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"fine-tuning",
"shakespeare",
"region:us"
] |
2023-09-06T15:16:36+00:00
|
{"language": ["en"], "size_categories": ["n<1K"], "task_categories": ["text-generation"], "tags": ["fine-tuning", "shakespeare"]}
|
2023-09-06T15:27:30+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-n<1K #language-English #fine-tuning #shakespeare #region-us
|
# Data source
Downloaded via Andrej Karpathy's nanogpt repo from this link
# Data Format
- The entire dataset is split into train (90%) and test (10%).
- All rows are at most 1024 tokens, using the Llama 2 tokenizer.
- All rows are split cleanly so that sentences are whole and unbroken.
|
[
"# Data source\nDownloaded via Andrej Karpathy's nanogpt repo from this link",
"# Data Format\n- The entire dataset is split into train (90%) and test (10%).\n- All rows are at most 1024 tokens, using the Llama 2 tokenizer.\n- All rows are split cleanly so that sentences are whole and unbroken."
] |
[
"TAGS\n#task_categories-text-generation #size_categories-n<1K #language-English #fine-tuning #shakespeare #region-us \n",
"# Data source\nDownloaded via Andrej Karpathy's nanogpt repo from this link",
"# Data Format\n- The entire dataset is split into train (90%) and test (10%).\n- All rows are at most 1024 tokens, using the Llama 2 tokenizer.\n- All rows are split cleanly so that sentences are whole and unbroken."
] |
[
41,
18,
61
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-n<1K #language-English #fine-tuning #shakespeare #region-us \n# Data source\nDownloaded via Andrej Karpathy's nanogpt repo from this link# Data Format\n- The entire dataset is split into train (90%) and test (10%).\n- All rows are at most 1024 tokens, using the Llama 2 tokenizer.\n- All rows are split cleanly so that sentences are whole and unbroken."
] |
6425fe0a877c0965b0f8677c82b14d25d4eba2dc
|
# Dataset of Tachibana Arisu
This is the dataset of Tachibana Arisu, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 486 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 486 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 486 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 486 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/tachibana_arisu_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T15:25:50+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:00+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Tachibana Arisu
==========================
This is the dataset of Tachibana Arisu, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
75343f1caaea26b4aafc338c6259019975149396
|
csv logs from one of the whocars proxies idr which one
has some gpt3.5/gpt4 maybe some claude idk, just a dump so i can del from my drive
|
ludis/whocars
|
[
"size_categories:10K<n<100K",
"not-for-all-audiences",
"conversational",
"roleplay",
"region:us"
] |
2023-09-06T15:26:33+00:00
|
{"size_categories": ["10K<n<100K"], "pretty_name": "whocars", "tags": ["not-for-all-audiences", "conversational", "roleplay"]}
|
2023-09-12T23:08:08+00:00
|
[] |
[] |
TAGS
#size_categories-10K<n<100K #not-for-all-audiences #conversational #roleplay #region-us
|
csv logs from one of the whocars proxies idr which one
has some gpt3.5/gpt4 maybe some claude idk, just a dump so i can del from my drive
|
[] |
[
"TAGS\n#size_categories-10K<n<100K #not-for-all-audiences #conversational #roleplay #region-us \n"
] |
[
35
] |
[
"passage: TAGS\n#size_categories-10K<n<100K #not-for-all-audiences #conversational #roleplay #region-us \n"
] |
0ace7819c464d3685b309b1d22d9c4be8f5192b9
|
# Dataset of Sakurai Momoka
This is the dataset of Sakurai Momoka, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 439 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 439 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 439 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 439 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/sakurai_momoka_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T15:42:56+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:02+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Sakurai Momoka
=========================
This is the dataset of Sakurai Momoka, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
b1df09da792927f3af7dc4d18669a1de80ebc5fb
|
# Dataset Card for "pypi_raw"
All of the latest package versions from pypi. The original data came from [here](https://py-code.org/datasets). I pulled the latest versions of each package, then extracted only `md`, `rst`, `ipynb`, and `py` files. See other datasets for versions that have been cleaned and labeled.
|
vikp/pypi_raw
|
[
"region:us"
] |
2023-09-06T15:44:33+00:00
|
{"dataset_info": {"features": [{"name": "code", "dtype": "string"}, {"name": "package", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "filename", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 42561764962, "num_examples": 5978028}], "download_size": 12186040767, "dataset_size": 42561764962}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T16:17:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pypi_raw"
All of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files. See other datasets for versions that have been cleaned and labeled.
|
[
"# Dataset Card for \"pypi_raw\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files. See other datasets for versions that have been cleaned and labeled."
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pypi_raw\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files. See other datasets for versions that have been cleaned and labeled."
] |
[
6,
80
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pypi_raw\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files. See other datasets for versions that have been cleaned and labeled."
] |
55472c271c986a305fd293d302c54d2b9eee2102
|
# Dataset Card for "dwitter"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
lonestar108/dwitter
|
[
"region:us"
] |
2023-09-06T15:49:14+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "best_train", "path": "data/best_train-*"}, {"split": "best_valid", "path": "data/best_valid-*"}, {"split": "most_train", "path": "data/most_train-*"}, {"split": "most_valid", "path": "data/most_valid-*"}, {"split": "good_train", "path": "data/good_train-*"}, {"split": "good_valid", "path": "data/good_valid-*"}, {"split": "top_train", "path": "data/top_train-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "best_train", "num_bytes": 80682, "num_examples": 577}, {"name": "best_valid", "num_bytes": 7190, "num_examples": 52}, {"name": "most_train", "num_bytes": 956260, "num_examples": 7018}, {"name": "most_valid", "num_bytes": 135422, "num_examples": 994}, {"name": "good_train", "num_bytes": 324996, "num_examples": 2350}, {"name": "good_valid", "num_bytes": 40160, "num_examples": 290}, {"name": "top_train", "num_bytes": 25101, "num_examples": 178}], "download_size": 999167, "dataset_size": 1569811}}
|
2023-09-07T01:44:59+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dwitter"
More Information needed
|
[
"# Dataset Card for \"dwitter\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dwitter\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dwitter\"\n\nMore Information needed"
] |
9c09f9aa90dfffb6b51825b2dffae20a3df757fe
|
# Dataset Card for "emotion"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/AdamCodd/emotion-dataset](https://github.com/AdamCodd/emotion-dataset)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 10.54 MB
### Dataset Summary
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
An example looks as follows.
```
{
"text": "im feeling quite sad and sorry for myself but ill snap out of it soon",
"label": 0
}
```
### Data Fields
The data fields are:
- `text`: a `string` feature.
- `label`: a classification label, with possible values including `sadness` (0), `joy` (1), `love` (2), `anger` (3), `fear` (4), `surprise` (5).
### Data Splits
The dataset has 2 configurations:
- split: with a total of 20_000 examples split into train, validation and test
- unsplit: with a total of 89_754 examples in a single train split
| name | train | validation | test |
|---------|-------:|-----------:|-----:|
| split | 16000 | 2000 | 2000 |
| unsplit | 89754 | n/a | n/a |
## Dataset Creation
### Curation Rationale
This dataset is designed for training machine learning models to perform emotion analysis. It contains text samples from Twitter labeled with six different emotions: sadness, joy, love, anger, fear, and surprise. The dataset is balanced, meaning that it has an equal number of samples for each label.
This dataset is originally sourced from [dair-ai's emotion dataset](https://huggingface.co/datasets/dair-ai/emotion), but the initial dataset was unbalanced and had some duplicate samples. Thus, this dataset has been deduplicated and balanced to ensure an equal number of samples for each emotion label.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The dataset should be used for educational and research purposes only.
### Citation Information
If you use this dataset, please cite:
```
@inproceedings{saravia-etal-2018-carer,
title = "{CARER}: Contextualized Affect Representations for Emotion Recognition",
author = "Saravia, Elvis and
Liu, Hsien-Chi Toby and
Huang, Yen-Hao and
Wu, Junlin and
Chen, Yi-Shin",
booktitle = "Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing",
month = oct # "-" # nov,
year = "2018",
address = "Brussels, Belgium",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D18-1404",
doi = "10.18653/v1/D18-1404",
pages = "3687--3697",
abstract = "Emotions are expressed in nuanced ways, which varies by collective or individual experiences, knowledge, and beliefs. Therefore, to understand emotion, as conveyed through text, a robust mechanism capable of capturing and modeling different linguistic nuances and phenomena is needed. We propose a semi-supervised, graph-based algorithm to produce rich structural descriptors which serve as the building blocks for constructing contextualized affect representations from text. The pattern-based representations are further enriched with word embeddings and evaluated through several emotion recognition tasks. Our experimental results demonstrate that the proposed method outperforms state-of-the-art techniques on emotion recognition tasks.",
}
```
If you want to support me, you can [here](https://ko-fi.com/adamcodd).
|
AdamCodd/emotion-balanced
|
[
"task_categories:text-classification",
"task_ids:multi-class-classification",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:other",
"emotion-classification",
"region:us"
] |
2023-09-06T15:49:25+00:00
|
{"annotations_creators": ["machine-generated"], "language_creators": ["machine-generated"], "language": ["en"], "license": ["other"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["multi-class-classification"], "paperswithcode_id": "emotion", "pretty_name": "Emotion", "tags": ["emotion-classification"], "dataset_info": [{"config_name": "split", "features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "sadness", "1": "joy", "2": "love", "3": "anger", "4": "fear", "5": "surprise"}}}}], "splits": [{"name": "train", "num_bytes": 1968209, "num_examples": 16000}, {"name": "validation", "num_bytes": 247888, "num_examples": 2000}, {"name": "test", "num_bytes": 244379, "num_examples": 2000}], "download_size": 740883, "dataset_size": 2173481}, {"config_name": "unsplit", "features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "sadness", "1": "joy", "2": "love", "3": "anger", "4": "fear", "5": "surprise"}}}}], "splits": [{"name": "train", "num_bytes": 10792185, "num_examples": 89754}], "download_size": 10792185, "dataset_size": 10792185}], "train-eval-index": [{"config": "default", "task": "text-classification", "task_id": "multi_class_classification", "splits": {"train_split": "train", "eval_split": "test"}, "col_mapping": {"text": "text", "label": "target"}, "metrics": [{"type": "accuracy", "name": "Accuracy"}, {"type": "f1", "name": "F1 macro", "args": {"average": "macro"}}, {"type": "f1", "name": "F1 micro", "args": {"average": "micro"}}, {"type": "f1", "name": "F1 weighted", "args": {"average": "weighted"}}, {"type": "precision", "name": "Precision macro", "args": {"average": "macro"}}, {"type": "precision", "name": "Precision micro", "args": {"average": "micro"}}, {"type": "precision", "name": "Precision weighted", "args": {"average": "weighted"}}, {"type": "recall", "name": "Recall macro", "args": {"average": "macro"}}, {"type": "recall", "name": "Recall micro", "args": {"average": "micro"}}, {"type": "recall", "name": "Recall weighted", "args": {"average": "weighted"}}]}]}
|
2023-10-14T22:10:06+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-classification #task_ids-multi-class-classification #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-other #emotion-classification #region-us
|
Dataset Card for "emotion"
==========================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository:
* Paper:
* Point of Contact:
* Size of downloaded dataset files: 10.54 MB
### Dataset Summary
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.
### Supported Tasks and Leaderboards
### Languages
Dataset Structure
-----------------
### Data Instances
An example looks as follows.
### Data Fields
The data fields are:
* 'text': a 'string' feature.
* 'label': a classification label, with possible values including 'sadness' (0), 'joy' (1), 'love' (2), 'anger' (3), 'fear' (4), 'surprise' (5).
### Data Splits
The dataset has 2 configurations:
* split: with a total of 20\_000 examples split into train, validation and test
* unsplit: with a total of 89\_754 examples in a single train split
Dataset Creation
----------------
### Curation Rationale
This dataset is designed for training machine learning models to perform emotion analysis. It contains text samples from Twitter labeled with six different emotions: sadness, joy, love, anger, fear, and surprise. The dataset is balanced, meaning that it has an equal number of samples for each label.
This dataset is originally sourced from dair-ai's emotion dataset, but the initial dataset was unbalanced and had some duplicate samples. Thus, this dataset has been deduplicated and balanced to ensure an equal number of samples for each emotion label.
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
The dataset should be used for educational and research purposes only.
If you use this dataset, please cite:
If you want to support me, you can here.
|
[
"### Dataset Summary\n\n\nEmotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example looks as follows.",
"### Data Fields\n\n\nThe data fields are:\n\n\n* 'text': a 'string' feature.\n* 'label': a classification label, with possible values including 'sadness' (0), 'joy' (1), 'love' (2), 'anger' (3), 'fear' (4), 'surprise' (5).",
"### Data Splits\n\n\nThe dataset has 2 configurations:\n\n\n* split: with a total of 20\\_000 examples split into train, validation and test\n* unsplit: with a total of 89\\_754 examples in a single train split\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThis dataset is designed for training machine learning models to perform emotion analysis. It contains text samples from Twitter labeled with six different emotions: sadness, joy, love, anger, fear, and surprise. The dataset is balanced, meaning that it has an equal number of samples for each label.\n\n\nThis dataset is originally sourced from dair-ai's emotion dataset, but the initial dataset was unbalanced and had some duplicate samples. Thus, this dataset has been deduplicated and balanced to ensure an equal number of samples for each emotion label.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nThe dataset should be used for educational and research purposes only.\n\n\nIf you use this dataset, please cite:\n\n\nIf you want to support me, you can here."
] |
[
"TAGS\n#task_categories-text-classification #task_ids-multi-class-classification #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-other #emotion-classification #region-us \n",
"### Dataset Summary\n\n\nEmotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances\n\n\nAn example looks as follows.",
"### Data Fields\n\n\nThe data fields are:\n\n\n* 'text': a 'string' feature.\n* 'label': a classification label, with possible values including 'sadness' (0), 'joy' (1), 'love' (2), 'anger' (3), 'fear' (4), 'surprise' (5).",
"### Data Splits\n\n\nThe dataset has 2 configurations:\n\n\n* split: with a total of 20\\_000 examples split into train, validation and test\n* unsplit: with a total of 89\\_754 examples in a single train split\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale\n\n\nThis dataset is designed for training machine learning models to perform emotion analysis. It contains text samples from Twitter labeled with six different emotions: sadness, joy, love, anger, fear, and surprise. The dataset is balanced, meaning that it has an equal number of samples for each label.\n\n\nThis dataset is originally sourced from dair-ai's emotion dataset, but the initial dataset was unbalanced and had some duplicate samples. Thus, this dataset has been deduplicated and balanced to ensure an equal number of samples for each emotion label.",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nThe dataset should be used for educational and research purposes only.\n\n\nIf you use this dataset, please cite:\n\n\nIf you want to support me, you can here."
] |
[
96,
47,
10,
11,
13,
68,
60,
137,
4,
10,
10,
5,
5,
9,
18,
7,
8,
14,
6,
41
] |
[
"passage: TAGS\n#task_categories-text-classification #task_ids-multi-class-classification #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-original #language-English #license-other #emotion-classification #region-us \n### Dataset Summary\n\n\nEmotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise. For more detailed information please refer to the paper.### Supported Tasks and Leaderboards### Languages\n\n\nDataset Structure\n-----------------### Data Instances\n\n\nAn example looks as follows.### Data Fields\n\n\nThe data fields are:\n\n\n* 'text': a 'string' feature.\n* 'label': a classification label, with possible values including 'sadness' (0), 'joy' (1), 'love' (2), 'anger' (3), 'fear' (4), 'surprise' (5).### Data Splits\n\n\nThe dataset has 2 configurations:\n\n\n* split: with a total of 20\\_000 examples split into train, validation and test\n* unsplit: with a total of 89\\_754 examples in a single train split\n\n\n\nDataset Creation\n----------------### Curation Rationale\n\n\nThis dataset is designed for training machine learning models to perform emotion analysis. It contains text samples from Twitter labeled with six different emotions: sadness, joy, love, anger, fear, and surprise. The dataset is balanced, meaning that it has an equal number of samples for each label.\n\n\nThis dataset is originally sourced from dair-ai's emotion dataset, but the initial dataset was unbalanced and had some duplicate samples. Thus, this dataset has been deduplicated and balanced to ensure an equal number of samples for each emotion label.### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------"
] |
74f0f1f702745bb14e5b2847398adb062855a983
|
# Dataset of Akagi Miria
This is the dataset of Akagi Miria, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 389 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 389 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 389 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 389 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/akagi_miria_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T15:57:00+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:04+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Akagi Miria
======================
This is the dataset of Akagi Miria, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
beb63ab5ea3e8dd36379729262da5bfab2ddb354
|
# Dataset Card for "processed_bert_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
winkm/processed_bert_dataset
|
[
"region:us"
] |
2023-09-06T15:59:58+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "token_type_ids", "sequence": "int8"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "special_tokens_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 8473147200.0, "num_examples": 2353652}], "download_size": 2275912633, "dataset_size": 8473147200.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T16:05:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "processed_bert_dataset"
More Information needed
|
[
"# Dataset Card for \"processed_bert_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"processed_bert_dataset\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"processed_bert_dataset\"\n\nMore Information needed"
] |
56ff9d8b40a92a5cd03520022afd0d7ef25fa9cb
|
# Dataset Card for "infer_55epoch"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/infer_55epoch
|
[
"region:us"
] |
2023-09-06T16:09:54+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "id", "dtype": "string"}, {"name": "w2v2_baseline_transcription", "dtype": "string"}, {"name": "w2v2_baseline_norm", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 174371517.027, "num_examples": 1299}], "download_size": 164199681, "dataset_size": 174371517.027}}
|
2023-09-06T16:10:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "infer_55epoch"
More Information needed
|
[
"# Dataset Card for \"infer_55epoch\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"infer_55epoch\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"infer_55epoch\"\n\nMore Information needed"
] |
01ce800336adf33fc8d36c226ea0ec24451d62cb
|
instruction, input, output
Give three tips for staying healthy.,, Eat a balance diet
What is an IV? ,,An instrumental variable.
|
TSGallen/metadata.csv
|
[
"region:us"
] |
2023-09-06T16:10:38+00:00
|
{}
|
2023-09-06T17:14:56+00:00
|
[] |
[] |
TAGS
#region-us
|
instruction, input, output
Give three tips for staying healthy.,, Eat a balance diet
What is an IV? ,,An instrumental variable.
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
8be523e4703b20cde505c9bb71f6ea8444c06d73
|
# Dataset of Matoba Risa
This is the dataset of Matoba Risa, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 431 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 431 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 431 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 431 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/matoba_risa_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T16:13:35+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:06+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Matoba Risa
======================
This is the dataset of Matoba Risa, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
c59858d4234adcf51e843623cdca78ed9ae094c5
|
# Dataset Card for "pypi_clean"
All of the latest package versions from pypi. The original data came from [here](https://py-code.org/datasets). I pulled the latest versions of each package, then extracted only `md`, `rst`, `ipynb`, and `py` files.
I then applied some cleaning:
- rendering notebooks
- removing leading comments/licenses
|
vikp/pypi_clean
|
[
"region:us"
] |
2023-09-06T16:15:42+00:00
|
{"dataset_info": {"features": [{"name": "code", "dtype": "string"}, {"name": "package", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "filename", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 31543801750, "num_examples": 2438172}], "download_size": 9201420527, "dataset_size": 31543801750}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T22:50:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pypi_clean"
All of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.
I then applied some cleaning:
- rendering notebooks
- removing leading comments/licenses
|
[
"# Dataset Card for \"pypi_clean\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pypi_clean\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses"
] |
[
6,
83
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pypi_clean\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses"
] |
cdf724bd53fbf718f939947bae054c0a5a68dde4
|
# Dataset of Yūki Haru
This is the dataset of Yūki Haru, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 461 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 461 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 461 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 461 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/yuki_haru_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T16:27:40+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:08+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Yūki Haru
====================
This is the dataset of Yūki Haru, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
8b62a9795f25b7c1481158fb8f1bcd0a96123a50
|
# Dataset Card for "address_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
SaleemUllah/address_dataset
|
[
"region:us"
] |
2023-09-06T16:35:21+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 71677.78378378379, "num_examples": 99}, {"name": "test", "num_bytes": 8688.216216216217, "num_examples": 12}], "download_size": 28411, "dataset_size": 80366.0}}
|
2023-09-06T16:35:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "address_dataset"
More Information needed
|
[
"# Dataset Card for \"address_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"address_dataset\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"address_dataset\"\n\nMore Information needed"
] |
552401096269c82bb4b11f29ff52465c95e10737
|
# Dataset of Sasaki Chie
This is the dataset of Sasaki Chie, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 445 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 445 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 445 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 445 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/sasaki_chie_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T16:39:50+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:10+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Sasaki Chie
======================
This is the dataset of Sasaki Chie, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
ec41a5d3376bf10b5796a3392d878aebe3f8f888
|
# Dataset of Ryūzaki Kaoru
This is the dataset of Ryūzaki Kaoru, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 436 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 436 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 436 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 436 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/ryuzaki_kaoru_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T16:53:13+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:12+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Ryūzaki Kaoru
========================
This is the dataset of Ryūzaki Kaoru, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
a8cf303de5ea4abb4c88dda9bc28322525aaf588
|
# Dataset Card for "autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0
|
[
"region:us"
] |
2023-09-06T16:57:32+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 2056800000, "num_examples": 100000}, {"name": "validation", "num_bytes": 205680000, "num_examples": 10000}], "download_size": 1056120152, "dataset_size": 2262480000}}
|
2023-09-06T16:58:14+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0\"\n\nMore Information needed"
] |
[
6,
34
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_100000_magic_sgosdt_l256_d3_sd0\"\n\nMore Information needed"
] |
ddb7b6d7f5fb3579bcabbb6f3ddb3367cc103329
|
# Dataset of Ichihara Nina
This is the dataset of Ichihara Nina, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 416 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 416 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 416 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 416 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/ichihara_nina_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T17:05:31+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:14+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Ichihara Nina
========================
This is the dataset of Ichihara Nina, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
0e9e4cede1041cacb9b4f4b06d2d828269e4593d
|
# Dataset of Koga Koharu
This is the dataset of Koga Koharu, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 200 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 460 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 200 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 200 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 200 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 200 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 200 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 460 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 460 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 460 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/koga_koharu_theidolmastercinderellagirlsu149
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-06T17:19:32+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:16+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Koga Koharu
======================
This is the dataset of Koga Koharu, containing 200 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
572277087b6f43bae9beeaeb19f4636c8ab9798d
|
# Dataset Card for "synthetic-cloud-removal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mespinosami/synthetic-cloud-removal
|
[
"region:us"
] |
2023-09-06T17:19:56+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "cloudy", "dtype": "image"}, {"name": "text_prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 7879735409.03169, "num_examples": 68195}, {"name": "test", "num_bytes": 1957989430.9243114, "num_examples": 17049}], "download_size": 9796796535, "dataset_size": 9837724839.956001}}
|
2023-09-06T17:37:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "synthetic-cloud-removal"
More Information needed
|
[
"# Dataset Card for \"synthetic-cloud-removal\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"synthetic-cloud-removal\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"synthetic-cloud-removal\"\n\nMore Information needed"
] |
a40dc0fda19afa2b7cb4033f876298c5402864a6
|
# Dataset Card for "alpagasus_cleaned_ar_reviewed"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
arbml/alpagasus_cleaned_ar_reviewed
|
[
"region:us"
] |
2023-09-06T17:49:14+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "input_en", "dtype": "string"}, {"name": "index", "dtype": "string"}, {"name": "instruction_en", "dtype": "string"}, {"name": "output", "dtype": "string"}, {"name": "output_en", "dtype": "string"}, {"name": "instruction", "dtype": "string"}, {"name": "input", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3037648, "num_examples": 2959}], "download_size": 0, "dataset_size": 3037648}}
|
2023-10-01T12:04:41+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "alpagasus_cleaned_ar_reviewed"
More Information needed
|
[
"# Dataset Card for \"alpagasus_cleaned_ar_reviewed\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"alpagasus_cleaned_ar_reviewed\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"alpagasus_cleaned_ar_reviewed\"\n\nMore Information needed"
] |
a8c0fd89fac62529af1fe07f0ddb2223a79dfa48
|
# Dataset Card for "pypi_labeled"
All of the latest package versions from pypi. The original data came from [here](https://py-code.org/datasets). I pulled the latest versions of each package, then extracted only `md`, `rst`, `ipynb`, and `py` files.
I then applied some cleaning:
- rendering notebooks
- removing leading comments/licenses
Then filtered out some low-quality code, and labeled the rest according to learning value and quality. Subset by those columns to get higher quality code.
|
vikp/pypi_labeled
|
[
"region:us"
] |
2023-09-06T17:55:03+00:00
|
{"dataset_info": {"features": [{"name": "code", "dtype": "string"}, {"name": "package", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "filename", "dtype": "string"}, {"name": "parsed_code", "dtype": "string"}, {"name": "quality_prob", "dtype": "float64"}, {"name": "learning_prob", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 40005369487, "num_examples": 1902405}], "download_size": 11174800633, "dataset_size": 40005369487}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T22:51:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pypi_labeled"
All of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.
I then applied some cleaning:
- rendering notebooks
- removing leading comments/licenses
Then filtered out some low-quality code, and labeled the rest according to learning value and quality. Subset by those columns to get higher quality code.
|
[
"# Dataset Card for \"pypi_labeled\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses\n\nThen filtered out some low-quality code, and labeled the rest according to learning value and quality. Subset by those columns to get higher quality code."
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pypi_labeled\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses\n\nThen filtered out some low-quality code, and labeled the rest according to learning value and quality. Subset by those columns to get higher quality code."
] |
[
6,
118
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pypi_labeled\"\n\nAll of the latest package versions from pypi. The original data came from here. I pulled the latest versions of each package, then extracted only 'md', 'rst', 'ipynb', and 'py' files.\n\nI then applied some cleaning:\n\n- rendering notebooks\n- removing leading comments/licenses\n\nThen filtered out some low-quality code, and labeled the rest according to learning value and quality. Subset by those columns to get higher quality code."
] |
9a067546b4ba5967e0a968f06beb719ab5bfbaf8
|
# Dataset Card for "fkr30k-image-captioning-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jpawan33/fkr30k-image-captioning-dataset
|
[
"region:us"
] |
2023-09-06T18:00:10+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1625135945.608, "num_examples": 31782}], "download_size": 1621386563, "dataset_size": 1625135945.608}}
|
2023-09-09T03:17:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "fkr30k-image-captioning-dataset"
More Information needed
|
[
"# Dataset Card for \"fkr30k-image-captioning-dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"fkr30k-image-captioning-dataset\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"fkr30k-image-captioning-dataset\"\n\nMore Information needed"
] |
bb80d324e1426a81bbb974b1075e541e339f1618
|
# Dataset Card for "latents_kl3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ocariz/latents_kl3
|
[
"region:us"
] |
2023-09-06T18:10:21+00:00
|
{"dataset_info": {"features": [{"name": "image", "sequence": {"sequence": {"sequence": "float32"}}}], "splits": [{"name": "train", "num_bytes": 1308440000, "num_examples": 70000}], "download_size": 1196391081, "dataset_size": 1308440000}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T18:29:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "latents_kl3"
More Information needed
|
[
"# Dataset Card for \"latents_kl3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"latents_kl3\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"latents_kl3\"\n\nMore Information needed"
] |
e41759bf18b43439445b77a8438138cd9fd062e0
|
# Dataset Card for "latents_kl3_image"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ocariz/latents_kl3_image
|
[
"region:us"
] |
2023-09-06T18:31:47+00:00
|
{"dataset_info": {"features": [{"name": "image", "sequence": {"sequence": {"sequence": "float32"}}}], "splits": [{"name": "train", "num_bytes": 1308440000, "num_examples": 70000}], "download_size": 0, "dataset_size": 1308440000}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T18:41:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "latents_kl3_image"
More Information needed
|
[
"# Dataset Card for \"latents_kl3_image\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"latents_kl3_image\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"latents_kl3_image\"\n\nMore Information needed"
] |
b4fca04d67dda58f81d52fe5b31af705d63ad4d2
|
dont do it to me
i will
no
please
dont
|
Arealbot/BigData
|
[
"license:unknown",
"region:us"
] |
2023-09-06T19:51:29+00:00
|
{"license": "unknown"}
|
2023-09-06T19:52:08+00:00
|
[] |
[] |
TAGS
#license-unknown #region-us
|
dont do it to me
i will
no
please
dont
|
[] |
[
"TAGS\n#license-unknown #region-us \n"
] |
[
13
] |
[
"passage: TAGS\n#license-unknown #region-us \n"
] |
6ce30a0e13b537fbbe63850bbdbb45631fb9356e
|
# Dataset Card for "jigsaw_hatebert"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jtatman/jigsaw_hatebert
|
[
"region:us"
] |
2023-09-06T20:30:07+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "text_masked", "dtype": "string"}, {"name": "text_replaced", "list": [{"name": "score", "dtype": "float64"}, {"name": "sequence", "dtype": "string"}, {"name": "token", "dtype": "int64"}, {"name": "token_str", "dtype": "string"}]}, {"name": "asian", "dtype": "string"}, {"name": "atheist", "dtype": "string"}, {"name": "bisexual", "dtype": "string"}, {"name": "black", "dtype": "string"}, {"name": "buddhist", "dtype": "string"}, {"name": "christian", "dtype": "string"}, {"name": "female", "dtype": "string"}, {"name": "heterosexual", "dtype": "string"}, {"name": "hindu", "dtype": "string"}, {"name": "homosexual_gay_or_lesbian", "dtype": "string"}, {"name": "intellectual_or_learning_disability", "dtype": "string"}, {"name": "jewish", "dtype": "string"}, {"name": "latino", "dtype": "string"}, {"name": "male", "dtype": "string"}, {"name": "muslim", "dtype": "string"}, {"name": "other_disability", "dtype": "string"}, {"name": "other_gender", "dtype": "string"}, {"name": "other_race_or_ethnicity", "dtype": "string"}, {"name": "other_religion", "dtype": "string"}, {"name": "other_sexual_orientation", "dtype": "string"}, {"name": "physical_disability", "dtype": "string"}, {"name": "psychiatric_or_mental_illness", "dtype": "string"}, {"name": "transgender", "dtype": "string"}, {"name": "white", "dtype": "string"}, {"name": "funny", "dtype": "string"}, {"name": "wow", "dtype": "string"}, {"name": "sad", "dtype": "string"}, {"name": "likes", "dtype": "string"}, {"name": "disagree", "dtype": "string"}, {"name": "target", "dtype": "int64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 236287827, "num_examples": 110000}], "download_size": 83975623, "dataset_size": 236287827}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T21:01:50+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "jigsaw_hatebert"
More Information needed
|
[
"# Dataset Card for \"jigsaw_hatebert\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"jigsaw_hatebert\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"jigsaw_hatebert\"\n\nMore Information needed"
] |
8fee491b4abb449ecd3b771b37d5a08e3d651f85
|
# Dataset Card for "rm-cr-search-1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
rmadiraju/rm-cr-search-1
|
[
"region:us"
] |
2023-09-06T20:43:12+00:00
|
{"dataset_info": {"features": [{"name": "instruction", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "response", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 19941, "num_examples": 9}], "download_size": 19959, "dataset_size": 19941}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T20:43:14+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "rm-cr-search-1"
More Information needed
|
[
"# Dataset Card for \"rm-cr-search-1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"rm-cr-search-1\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"rm-cr-search-1\"\n\nMore Information needed"
] |
be98748101f2f7825a053a0bb7e643fc721ac957
|
# Dataset Card for "Processed_Plus"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
NexaAI/Processed_Plus
|
[
"region:us"
] |
2023-09-06T20:50:26+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 16396650022.391663, "num_examples": 6008}], "download_size": 15954441937, "dataset_size": 16396650022.391663}}
|
2023-09-06T21:00:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Processed_Plus"
More Information needed
|
[
"# Dataset Card for \"Processed_Plus\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Processed_Plus\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Processed_Plus\"\n\nMore Information needed"
] |
7ef4c825ba0b3aa1cda83288dc934284c0408a97
|
# Dataset Card for "low_quality_call_voice"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
INo0121/low_quality_call_voice
|
[
"region:us"
] |
2023-09-06T21:57:42+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcripts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9302913443.561954, "num_examples": 111200}, {"name": "test", "num_bytes": 1119354595.6598015, "num_examples": 13901}, {"name": "valid", "num_bytes": 1125525152.5452442, "num_examples": 13900}], "download_size": 9232284149, "dataset_size": 11547793191.767}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "valid", "path": "data/valid-*"}]}]}
|
2023-09-20T00:26:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "low_quality_call_voice"
More Information needed
|
[
"# Dataset Card for \"low_quality_call_voice\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"low_quality_call_voice\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"low_quality_call_voice\"\n\nMore Information needed"
] |
ca7a952de530a4cf23ffead9e6a6a371019b609a
|
# Dataset Card for "th_dt_01"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HenriCastro/th_dt_01
|
[
"region:us"
] |
2023-09-06T22:21:43+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 445377, "num_examples": 242}], "download_size": 224741, "dataset_size": 445377}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-06T22:22:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "th_dt_01"
More Information needed
|
[
"# Dataset Card for \"th_dt_01\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"th_dt_01\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"th_dt_01\"\n\nMore Information needed"
] |
dd9e1d30dee2e65378e348157e457187f1a0c56f
|
# Dataset Card for "dmae-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Augusto777/dmae-dataset
|
[
"region:us"
] |
2023-09-06T22:29:02+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "avanzada", "1": "leve", "2": "moderada", "3": "no amd"}}}}], "splits": [{"name": "train", "num_bytes": 48967077.0, "num_examples": 40}, {"name": "test", "num_bytes": 16065989.0, "num_examples": 16}, {"name": "validation", "num_bytes": 15887796.0, "num_examples": 16}], "download_size": 80912022, "dataset_size": 80920862.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}]}
|
2023-09-06T22:34:41+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dmae-dataset"
More Information needed
|
[
"# Dataset Card for \"dmae-dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dmae-dataset\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dmae-dataset\"\n\nMore Information needed"
] |
ff90f9b613d07385ca3e31bb683b39123908bdd6
|
# Dataset Card for "bloomlotr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dileepsai/bloomlotr
|
[
"region:us"
] |
2023-09-06T22:43:28+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 2196528.0, "num_examples": 268}, {"name": "test", "num_bytes": 245880.0, "num_examples": 30}], "download_size": 1125209, "dataset_size": 2442408.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-09-06T22:43:40+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "bloomlotr"
More Information needed
|
[
"# Dataset Card for \"bloomlotr\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"bloomlotr\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"bloomlotr\"\n\nMore Information needed"
] |
4a6db1b2d3f745268c1c3a16a018d792b1c3d1f5
|
# Dataset Card for Spider Context Validation
### Ranked Schema by ChatGPT
The database context used here is generated from ChatGPT after telling it to reorder the schema with the most relevant columns in the beginning of the db_info.
### Dataset Summary
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students
The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
This dataset was created to validate spider-fine-tuned LLMs with database context.
### Yale Lily Spider Leaderboards
The leaderboard can be seen at https://yale-lily.github.io/spider
### Languages
The text in the dataset is in English.
### Licensing Information
The spider dataset is licensed under
the [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/legalcode)
### Citation
```
@article{yu2018spider,
title={Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task},
author={Yu, Tao and Zhang, Rui and Yang, Kai and Yasunaga, Michihiro and Wang, Dongxu and Li, Zifan and Ma, James and Li, Irene and Yao, Qingning and Roman, Shanelle and others},
journal={arXiv preprint arXiv:1809.08887},
year={2018}
}
```
|
richardr1126/spider-context-validation-ranked-schema
|
[
"source_datasets:spider",
"language:en",
"license:cc-by-4.0",
"text-to-sql",
"SQL",
"spider",
"validation",
"eval",
"spider-eval",
"region:us"
] |
2023-09-06T22:54:46+00:00
|
{"language": ["en"], "license": ["cc-by-4.0"], "source_datasets": ["spider"], "pretty_name": "Spider Context Validation Schema Ranked", "tags": ["text-to-sql", "SQL", "spider", "validation", "eval", "spider-eval"], "dataset_info": {"features": [{"name": "index", "dtype": "int32"}, {"name": "db_id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "db_info", "dtype": "string"}, {"name": "ground_truth", "dtype": "string"}]}}
|
2023-09-07T21:12:48+00:00
|
[] |
[
"en"
] |
TAGS
#source_datasets-spider #language-English #license-cc-by-4.0 #text-to-sql #SQL #spider #validation #eval #spider-eval #region-us
|
# Dataset Card for Spider Context Validation
### Ranked Schema by ChatGPT
The database context used here is generated from ChatGPT after telling it to reorder the schema with the most relevant columns in the beginning of the db_info.
### Dataset Summary
Spider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students
The goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.
This dataset was created to validate spider-fine-tuned LLMs with database context.
### Yale Lily Spider Leaderboards
The leaderboard can be seen at URL
### Languages
The text in the dataset is in English.
### Licensing Information
The spider dataset is licensed under
the CC BY-SA 4.0
|
[
"# Dataset Card for Spider Context Validation",
"### Ranked Schema by ChatGPT\n\nThe database context used here is generated from ChatGPT after telling it to reorder the schema with the most relevant columns in the beginning of the db_info.",
"### Dataset Summary\n\nSpider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students\nThe goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.\n\nThis dataset was created to validate spider-fine-tuned LLMs with database context.",
"### Yale Lily Spider Leaderboards\n\nThe leaderboard can be seen at URL",
"### Languages\n\nThe text in the dataset is in English.",
"### Licensing Information\n\nThe spider dataset is licensed under \nthe CC BY-SA 4.0"
] |
[
"TAGS\n#source_datasets-spider #language-English #license-cc-by-4.0 #text-to-sql #SQL #spider #validation #eval #spider-eval #region-us \n",
"# Dataset Card for Spider Context Validation",
"### Ranked Schema by ChatGPT\n\nThe database context used here is generated from ChatGPT after telling it to reorder the schema with the most relevant columns in the beginning of the db_info.",
"### Dataset Summary\n\nSpider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students\nThe goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.\n\nThis dataset was created to validate spider-fine-tuned LLMs with database context.",
"### Yale Lily Spider Leaderboards\n\nThe leaderboard can be seen at URL",
"### Languages\n\nThe text in the dataset is in English.",
"### Licensing Information\n\nThe spider dataset is licensed under \nthe CC BY-SA 4.0"
] |
[
53,
11,
46,
82,
17,
14,
21
] |
[
"passage: TAGS\n#source_datasets-spider #language-English #license-cc-by-4.0 #text-to-sql #SQL #spider #validation #eval #spider-eval #region-us \n# Dataset Card for Spider Context Validation### Ranked Schema by ChatGPT\n\nThe database context used here is generated from ChatGPT after telling it to reorder the schema with the most relevant columns in the beginning of the db_info.### Dataset Summary\n\nSpider is a large-scale complex and cross-domain semantic parsing and text-to-SQL dataset annotated by 11 Yale students\nThe goal of the Spider challenge is to develop natural language interfaces to cross-domain databases.\n\nThis dataset was created to validate spider-fine-tuned LLMs with database context.### Yale Lily Spider Leaderboards\n\nThe leaderboard can be seen at URL### Languages\n\nThe text in the dataset is in English.### Licensing Information\n\nThe spider dataset is licensed under \nthe CC BY-SA 4.0"
] |
0394d38204f31f3aedb29421e494c810474d05df
|
# Bangumi Image Base of Spy X Family
This is the image base of bangumi Spy x Family, we detected 62 characters, 5929 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 1020 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 203 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 132 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 162 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 72 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 107 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 54 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 58 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 95 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 90 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 45 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 50 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 23 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 36 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 33 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 49 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 52 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 29 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 32 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 15 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 16 | [Download](20/dataset.zip) |  |  |  |  |  |  |  |  |
| 21 | 63 | [Download](21/dataset.zip) |  |  |  |  |  |  |  |  |
| 22 | 46 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| 23 | 9 | [Download](23/dataset.zip) |  |  |  |  |  |  |  |  |
| 24 | 12 | [Download](24/dataset.zip) |  |  |  |  |  |  |  |  |
| 25 | 255 | [Download](25/dataset.zip) |  |  |  |  |  |  |  |  |
| 26 | 14 | [Download](26/dataset.zip) |  |  |  |  |  |  |  |  |
| 27 | 21 | [Download](27/dataset.zip) |  |  |  |  |  |  |  |  |
| 28 | 21 | [Download](28/dataset.zip) |  |  |  |  |  |  |  |  |
| 29 | 17 | [Download](29/dataset.zip) |  |  |  |  |  |  |  |  |
| 30 | 58 | [Download](30/dataset.zip) |  |  |  |  |  |  |  |  |
| 31 | 10 | [Download](31/dataset.zip) |  |  |  |  |  |  |  |  |
| 32 | 12 | [Download](32/dataset.zip) |  |  |  |  |  |  |  |  |
| 33 | 61 | [Download](33/dataset.zip) |  |  |  |  |  |  |  |  |
| 34 | 11 | [Download](34/dataset.zip) |  |  |  |  |  |  |  |  |
| 35 | 11 | [Download](35/dataset.zip) |  |  |  |  |  |  |  |  |
| 36 | 16 | [Download](36/dataset.zip) |  |  |  |  |  |  |  |  |
| 37 | 12 | [Download](37/dataset.zip) |  |  |  |  |  |  |  |  |
| 38 | 12 | [Download](38/dataset.zip) |  |  |  |  |  |  |  |  |
| 39 | 10 | [Download](39/dataset.zip) |  |  |  |  |  |  |  |  |
| 40 | 12 | [Download](40/dataset.zip) |  |  |  |  |  |  |  |  |
| 41 | 17 | [Download](41/dataset.zip) |  |  |  |  |  |  |  |  |
| 42 | 158 | [Download](42/dataset.zip) |  |  |  |  |  |  |  |  |
| 43 | 33 | [Download](43/dataset.zip) |  |  |  |  |  |  |  |  |
| 44 | 15 | [Download](44/dataset.zip) |  |  |  |  |  |  |  |  |
| 45 | 16 | [Download](45/dataset.zip) |  |  |  |  |  |  |  |  |
| 46 | 6 | [Download](46/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| 47 | 156 | [Download](47/dataset.zip) |  |  |  |  |  |  |  |  |
| 48 | 838 | [Download](48/dataset.zip) |  |  |  |  |  |  |  |  |
| 49 | 28 | [Download](49/dataset.zip) |  |  |  |  |  |  |  |  |
| 50 | 76 | [Download](50/dataset.zip) |  |  |  |  |  |  |  |  |
| 51 | 8 | [Download](51/dataset.zip) |  |  |  |  |  |  |  |  |
| 52 | 69 | [Download](52/dataset.zip) |  |  |  |  |  |  |  |  |
| 53 | 13 | [Download](53/dataset.zip) |  |  |  |  |  |  |  |  |
| 54 | 979 | [Download](54/dataset.zip) |  |  |  |  |  |  |  |  |
| 55 | 76 | [Download](55/dataset.zip) |  |  |  |  |  |  |  |  |
| 56 | 62 | [Download](56/dataset.zip) |  |  |  |  |  |  |  |  |
| 57 | 11 | [Download](57/dataset.zip) |  |  |  |  |  |  |  |  |
| 58 | 24 | [Download](58/dataset.zip) |  |  |  |  |  |  |  |  |
| 59 | 116 | [Download](59/dataset.zip) |  |  |  |  |  |  |  |  |
| 60 | 11 | [Download](60/dataset.zip) |  |  |  |  |  |  |  |  |
| noise | 161 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/spyxfamily
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-07T00:06:09+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-29T05:11:25+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Spy X Family
==================================
This is the image base of bangumi Spy x Family, we detected 62 characters, 5929 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
dc4d10a1bd0aac72dd4d4ce1ce82dd1981166765
|
# Dataset Card for "v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tingchih/Multi_News_fact_checking_claims
|
[
"region:us"
] |
2023-09-07T00:11:45+00:00
|
{"dataset_info": {"features": [{"name": "Documents", "sequence": "string"}, {"name": "Claim", "dtype": "string"}, {"name": "label", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 11477115090, "num_examples": 1038279}, {"name": "test", "num_bytes": 2800203857, "num_examples": 252889}], "download_size": 349947614, "dataset_size": 14277318947}}
|
2023-09-07T00:13:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "v2"
More Information needed
|
[
"# Dataset Card for \"v2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"v2\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"v2\"\n\nMore Information needed"
] |
fd1fa05114968843e7cd79993de71b8d0db77ff8
|
# UniProt Segmented Binding/Active Sites
This is a train/test split of 209,571 protein sequences from UniProt of protein sequences with active sites and binding sites labels.
All protein sequences (and corresponding binding site labels) are segmented into chunks of 1000 or less. Segmented sequences are indicated
by a `_partN` suffix in the Entry column labels. The split is approximately 85/15 before segmentation. The proteins are sorted by family in
decreasing order, with families with more protein sequences appearing earlier. Moreover, the split is such that the families in the
train/test split are non-overlapping and the `15%` test dataset is composed of the largest families.
|
AmelieSchreiber/family_split_protein_binding_sites
|
[
"task_categories:token-classification",
"size_categories:100K<n<1M",
"language:en",
"license:mit",
"protein",
"region:us"
] |
2023-09-07T00:19:25+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["100K<n<1M"], "task_categories": ["token-classification"], "pretty_name": "UniProt Segmented Binding/Active Sites", "tags": ["protein"]}
|
2023-09-07T14:26:56+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-token-classification #size_categories-100K<n<1M #language-English #license-mit #protein #region-us
|
# UniProt Segmented Binding/Active Sites
This is a train/test split of 209,571 protein sequences from UniProt of protein sequences with active sites and binding sites labels.
All protein sequences (and corresponding binding site labels) are segmented into chunks of 1000 or less. Segmented sequences are indicated
by a '_partN' suffix in the Entry column labels. The split is approximately 85/15 before segmentation. The proteins are sorted by family in
decreasing order, with families with more protein sequences appearing earlier. Moreover, the split is such that the families in the
train/test split are non-overlapping and the '15%' test dataset is composed of the largest families.
|
[
"# UniProt Segmented Binding/Active Sites\n\nThis is a train/test split of 209,571 protein sequences from UniProt of protein sequences with active sites and binding sites labels. \nAll protein sequences (and corresponding binding site labels) are segmented into chunks of 1000 or less. Segmented sequences are indicated \nby a '_partN' suffix in the Entry column labels. The split is approximately 85/15 before segmentation. The proteins are sorted by family in \ndecreasing order, with families with more protein sequences appearing earlier. Moreover, the split is such that the families in the \ntrain/test split are non-overlapping and the '15%' test dataset is composed of the largest families."
] |
[
"TAGS\n#task_categories-token-classification #size_categories-100K<n<1M #language-English #license-mit #protein #region-us \n",
"# UniProt Segmented Binding/Active Sites\n\nThis is a train/test split of 209,571 protein sequences from UniProt of protein sequences with active sites and binding sites labels. \nAll protein sequences (and corresponding binding site labels) are segmented into chunks of 1000 or less. Segmented sequences are indicated \nby a '_partN' suffix in the Entry column labels. The split is approximately 85/15 before segmentation. The proteins are sorted by family in \ndecreasing order, with families with more protein sequences appearing earlier. Moreover, the split is such that the families in the \ntrain/test split are non-overlapping and the '15%' test dataset is composed of the largest families."
] |
[
42,
177
] |
[
"passage: TAGS\n#task_categories-token-classification #size_categories-100K<n<1M #language-English #license-mit #protein #region-us \n# UniProt Segmented Binding/Active Sites\n\nThis is a train/test split of 209,571 protein sequences from UniProt of protein sequences with active sites and binding sites labels. \nAll protein sequences (and corresponding binding site labels) are segmented into chunks of 1000 or less. Segmented sequences are indicated \nby a '_partN' suffix in the Entry column labels. The split is approximately 85/15 before segmentation. The proteins are sorted by family in \ndecreasing order, with families with more protein sequences appearing earlier. Moreover, the split is such that the families in the \ntrain/test split are non-overlapping and the '15%' test dataset is composed of the largest families."
] |
f934b84aff09c7ec2a912d2c6a1b5efbb467cff1
|
# Dataset Card for "starcoderdata_0.001"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
codecomplete/starcoderdata_0.001
|
[
"region:us"
] |
2023-09-07T00:37:43+00:00
|
{"dataset_info": {"features": [{"name": "repo_name", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 200047956, "num_examples": 40254}], "download_size": 69120457, "dataset_size": 200047956}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-07T00:40:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "starcoderdata_0.001"
More Information needed
|
[
"# Dataset Card for \"starcoderdata_0.001\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"starcoderdata_0.001\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"starcoderdata_0.001\"\n\nMore Information needed"
] |
12d0f6777661da3adb729d199a772ed95d50819d
|
# Dataset Card for "autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T00:51:42+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 154520000, "num_examples": 10000}, {"name": "validation", "num_bytes": 154520000, "num_examples": 10000}], "download_size": 50636856, "dataset_size": 309040000}}
|
2023-09-07T00:51:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_banana_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
dfd39c839d19f5b76322f099035a13b8a4c84851
|
# Dataset Card for "dummy_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
nguyenthanhdo/dummy_alpaca
|
[
"region:us"
] |
2023-09-07T00:53:31+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "model_input", "dtype": "string"}, {"name": "input", "dtype": "string"}, {"name": "model_output", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 46208623, "num_examples": 52002}], "download_size": 24247917, "dataset_size": 46208623}}
|
2023-09-07T05:42:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dummy_alpaca"
More Information needed
|
[
"# Dataset Card for \"dummy_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dummy_alpaca\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dummy_alpaca\"\n\nMore Information needed"
] |
e1a666675c58d60357401b1f0fdd1372ec446ed6
|
The Mini-Coder dataset is a 2.2 million (~8GB) filtered selection of code snippets from the [bigcode/starcoderdata](https://huggingface.co/datasets/bigcode/starcoderdata) dataset, serving as a seed for synthetic dataset generation.
Each snippet is chosen for its clarity, presence of comments, and inclusion of at least one `if/else` or `switch case` statement
This repository is particularly useful for ML researchers in the field of making synthetic dataset.
|
nampdn-ai/mini-coder
|
[
"task_categories:text-generation",
"size_categories:1M<n<10M",
"source_datasets:bigcode/starcoderdata",
"language:en",
"license:other",
"region:us"
] |
2023-09-07T00:57:52+00:00
|
{"language": ["en"], "license": "other", "size_categories": ["1M<n<10M"], "source_datasets": ["bigcode/starcoderdata"], "task_categories": ["text-generation"], "pretty_name": "Mini Coder"}
|
2023-09-21T03:57:45+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-1M<n<10M #source_datasets-bigcode/starcoderdata #language-English #license-other #region-us
|
The Mini-Coder dataset is a 2.2 million (~8GB) filtered selection of code snippets from the bigcode/starcoderdata dataset, serving as a seed for synthetic dataset generation.
Each snippet is chosen for its clarity, presence of comments, and inclusion of at least one 'if/else' or 'switch case' statement
This repository is particularly useful for ML researchers in the field of making synthetic dataset.
|
[] |
[
"TAGS\n#task_categories-text-generation #size_categories-1M<n<10M #source_datasets-bigcode/starcoderdata #language-English #license-other #region-us \n"
] |
[
52
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-1M<n<10M #source_datasets-bigcode/starcoderdata #language-English #license-other #region-us \n"
] |
9bbe13d69771379064ec760613a07422e29723d3
|
# Dataset Card for "autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T01:24:03+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 126879367, "dataset_size": 472880000}}
|
2023-09-07T01:24:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
36
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_credit_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
1f713f005dc090def951088bb09d8557af1830d1
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
PeepDaSlan9/B2BMGMT_3.5
|
[
"task_categories:text-generation",
"license:apache-2.0",
"region:us"
] |
2023-09-07T01:28:55+00:00
|
{"license": "apache-2.0", "task_categories": ["text-generation"]}
|
2023-09-16T03:05:00+00:00
|
[] |
[] |
TAGS
#task_categories-text-generation #license-apache-2.0 #region-us
|
# Dataset Card for Dataset Name
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
### Supported Tasks and Leaderboards
### Languages
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
|
[
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
"TAGS\n#task_categories-text-generation #license-apache-2.0 #region-us \n",
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"### Supported Tasks and Leaderboards",
"### Languages",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
25,
8,
24,
32,
10,
4,
6,
6,
5,
5,
5,
7,
4,
10,
10,
5,
5,
9,
8,
8,
7,
8,
7,
5,
6,
6,
5
] |
[
"passage: TAGS\n#task_categories-text-generation #license-apache-2.0 #region-us \n# Dataset Card for Dataset Name## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:### Dataset Summary\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.### Supported Tasks and Leaderboards### Languages## Dataset Structure### Data Instances### Data Fields### Data Splits## Dataset Creation### Curation Rationale### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information## Considerations for Using the Data### Social Impact of Dataset### Discussion of Biases### Other Known Limitations## Additional Information### Dataset Curators### Licensing Information### Contributions"
] |
886c32afead257b001c16102330b9698d08fd2ac
|
# Dataset Card for "autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0
|
[
"region:us"
] |
2023-09-07T01:31:04+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 205720000, "num_examples": 10000}, {"name": "validation", "num_bytes": 205720000, "num_examples": 10000}], "download_size": 74206478, "dataset_size": 411440000}}
|
2023-09-07T01:31:08+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
[
6,
38
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_bank-marketing_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
f9c1c87483b9940343faa820428da8dd31f80731
|
# Dataset Card for "autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0
|
[
"region:us"
] |
2023-09-07T01:45:40+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 205720000, "num_examples": 10000}, {"name": "validation", "num_bytes": 205720000, "num_examples": 10000}], "download_size": 102866704, "dataset_size": 411440000}}
|
2023-09-07T01:45:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_electricity_sgosdt_l256_dim7_d3_sd0\"\n\nMore Information needed"
] |
6f108c00c1410c179b842b0f3e73cc7360f1c19d
|
# Dataset Card for "Processed_Plus_With_Face"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
NexaAI/Processed_Plus_With_Face
|
[
"region:us"
] |
2023-09-07T01:53:24+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 16246460552.0, "num_examples": 6008}], "download_size": 0, "dataset_size": 16246460552.0}}
|
2023-09-07T02:38:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Processed_Plus_With_Face"
More Information needed
|
[
"# Dataset Card for \"Processed_Plus_With_Face\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Processed_Plus_With_Face\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Processed_Plus_With_Face\"\n\nMore Information needed"
] |
00cffac9f5be17bf80ec9d63c96ca55b2081e0b6
|
# Dataset Card for "rm-cr-search-2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
rmadiraju/rm-cr-search-2
|
[
"region:us"
] |
2023-09-07T02:03:01+00:00
|
{"dataset_info": {"features": [{"name": "instruction", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "response", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 21011, "num_examples": 9}], "download_size": 21443, "dataset_size": 21011}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-07T02:03:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "rm-cr-search-2"
More Information needed
|
[
"# Dataset Card for \"rm-cr-search-2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"rm-cr-search-2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"rm-cr-search-2\"\n\nMore Information needed"
] |
f2f074547b0e3350d63007f807c7b9b5ee893dc4
|
# Dataset Card for "autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T02:31:59+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 155715478, "dataset_size": 472880000}}
|
2023-09-07T02:32:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
40
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_eye_movements_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
e035d5a4ef291ac4b0c9210802f3818e084720d9
|
# Dataset Card for "autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T02:32:48+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 62261087, "dataset_size": 472880000}}
|
2023-09-07T02:32:53+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
38
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_spambase_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
8374c02c5d27758c0393c26acc66b89379501093
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Financial conversation with the provided financial goals and summary.
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
JSON format
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
jsonfin17/hub24-financial-conversation-backstory
|
[
"region:us"
] |
2023-09-07T02:37:57+00:00
|
{"viewer": true}
|
2023-09-07T05:30:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for Dataset Name
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
Financial conversation with the provided financial goals and summary.
### Supported Tasks and Leaderboards
### Languages
JSON format
## Dataset Structure
### Data Instances
### Data Fields
### Data Splits
## Dataset Creation
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
## Considerations for Using the Data
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
## Additional Information
### Dataset Curators
### Licensing Information
### Contributions
|
[
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nFinancial conversation with the provided financial goals and summary.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nJSON format",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nFinancial conversation with the provided financial goals and summary.",
"### Supported Tasks and Leaderboards",
"### Languages\n\nJSON format",
"## Dataset Structure",
"### Data Instances",
"### Data Fields",
"### Data Splits",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information",
"## Considerations for Using the Data",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations",
"## Additional Information",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] |
[
6,
8,
24,
16,
10,
7,
6,
6,
5,
5,
5,
7,
4,
10,
10,
5,
5,
9,
8,
8,
7,
8,
7,
5,
6,
6,
5
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:### Dataset Summary\n\nFinancial conversation with the provided financial goals and summary.### Supported Tasks and Leaderboards### Languages\n\nJSON format## Dataset Structure### Data Instances### Data Fields### Data Splits## Dataset Creation### Curation Rationale### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information## Considerations for Using the Data### Social Impact of Dataset### Discussion of Biases### Other Known Limitations## Additional Information### Dataset Curators### Licensing Information### Contributions"
] |
99baf0fcf28f78ef463a68c52a0a87ec5660ea35
|
# Dataset Card for "autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T02:41:54+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 151417455, "dataset_size": 472880000}}
|
2023-09-07T02:42:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_covertype_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
20c1fc242514adb08cf760c03bdbe2e7f579edb9
|
# Dataset Card for "autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0
|
[
"region:us"
] |
2023-09-07T02:44:39+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 215960000, "num_examples": 10000}, {"name": "validation", "num_bytes": 215960000, "num_examples": 10000}], "download_size": 151409122, "dataset_size": 431920000}}
|
2023-09-07T02:44:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0\"\n\nMore Information needed"
] |
[
6,
38
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_california_sgosdt_l256_dim8_d3_sd0\"\n\nMore Information needed"
] |
9900da18e5f49ad3bd168274c1343914e1a35370
|
# Dataset Card for "Processed_Plus_With_Face_Two"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
NexaAI/Processed_Plus_With_Face_Two
|
[
"region:us"
] |
2023-09-07T02:47:14+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 16246460552.0, "num_examples": 6008}], "download_size": 15954441805, "dataset_size": 16246460552.0}}
|
2023-09-07T02:57:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Processed_Plus_With_Face_Two"
More Information needed
|
[
"# Dataset Card for \"Processed_Plus_With_Face_Two\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Processed_Plus_With_Face_Two\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Processed_Plus_With_Face_Two\"\n\nMore Information needed"
] |
8827d0e73129ab9cedfa6d1a4a46a37b1982ee77
|
# Dataset Card for "ecu_juri_rawfacts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ittailup/ecu_juri_rawfacts
|
[
"region:us"
] |
2023-09-07T02:51:00+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}, {"name": "instruction", "dtype": "string"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 114733486, "num_examples": 3816}], "download_size": 52736931, "dataset_size": 114733486}}
|
2023-09-07T02:51:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ecu_juri_rawfacts"
More Information needed
|
[
"# Dataset Card for \"ecu_juri_rawfacts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ecu_juri_rawfacts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ecu_juri_rawfacts\"\n\nMore Information needed"
] |
aebe0198826b593f15e25373383ddcb188941be6
|
# Dataset Card for "autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T03:06:02+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 185240000, "num_examples": 10000}, {"name": "validation", "num_bytes": 185240000, "num_examples": 10000}], "download_size": 68514231, "dataset_size": 370480000}}
|
2023-09-07T03:06:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_phoneme_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
c1db2d6efc816f5be4ab079fe98259a66d42954b
|
# Dataset Card for "autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T03:10:04+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 122258450, "dataset_size": 472880000}}
|
2023-09-07T03:10:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
45
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_default-of-credit-card-clients_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
9eb49c40fc943d36d8295a949f5be2fd495b6b19
|
_________________
----- BREAK THROUGH YOUR LIMITS -----
_________________

LimitlessCodeTraining is the direct sequal to Megacodetraining that is now called Legacy_MegaCodeTraining200k.
This dataset is just over 646k lines of pure refined coding data.
It is the pinacle of open source code training. It is the combination of the filtered Megacode training dataset filtered by shahules786 (shoutout to him) and the bigcode commitpackft dataset I converted to alpaca format.
The dataset that were used to create this dataset are linked bellow:
- https://huggingface.co/datasets/rombodawg/Rombodawgs_commitpackft_Evolinstruct_Converted
- https://huggingface.co/datasets/shahules786/megacode-best
|
rombodawg/LimitlessMegaCodeTraining
|
[
"license:mit",
"region:us"
] |
2023-09-07T03:10:53+00:00
|
{"license": "mit"}
|
2023-10-19T15:28:59+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
_________________
----- BREAK THROUGH YOUR LIMITS -----
_________________
!image/png
LimitlessCodeTraining is the direct sequal to Megacodetraining that is now called Legacy_MegaCodeTraining200k.
This dataset is just over 646k lines of pure refined coding data.
It is the pinacle of open source code training. It is the combination of the filtered Megacode training dataset filtered by shahules786 (shoutout to him) and the bigcode commitpackft dataset I converted to alpaca format.
The dataset that were used to create this dataset are linked bellow:
- URL
- URL
|
[] |
[
"TAGS\n#license-mit #region-us \n"
] |
[
11
] |
[
"passage: TAGS\n#license-mit #region-us \n"
] |
251470b14958e39bdd12a1525fb736d1d052c953
|
# Dataset Card for "autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T03:14:20+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 172085873, "dataset_size": 472880000}}
|
2023-09-07T03:14:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
45
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_with_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
7d32ca271929897f83091fbc5c65005d90ce54b0
|
# Dataset Card for "tl"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
TinyPixel/tl
|
[
"region:us"
] |
2023-09-07T03:38:38+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2915260, "num_examples": 1030}], "download_size": 1697269, "dataset_size": 2915260}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-07T03:38:39+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "tl"
More Information needed
|
[
"# Dataset Card for \"tl\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"tl\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"tl\"\n\nMore Information needed"
] |
b3fc675501067f683219cd0ba2160651cdc8def9
|
# Dataset Card for "autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T03:54:53+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 111490531, "dataset_size": 472880000}}
|
2023-09-07T03:54:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
38
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_clean2_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
e74868da2174d774e8bbc4e1f23c3338a77be867
|
# Dataset Card for "autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T04:11:28+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 168523499, "dataset_size": 472880000}}
|
2023-09-07T04:11:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
39
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_house_16H_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
0a0b86b4aa5a4ac9b11bc98b22ad75f4a97118a1
|
# Dataset Card for "autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T04:25:11+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 179483399, "dataset_size": 472880000}}
|
2023-09-07T04:25:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
46
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_Hill_Valley_without_noise_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
b0682fcd7bf3ea384f6d22e21e29530afb83d76b
|
# Dataset Card for "code_prompt_evol_lemur"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pvduy/code_prompt_evol_lemur
|
[
"region:us"
] |
2023-09-07T04:35:32+00:00
|
{"dataset_info": {"features": [{"name": "inputs", "dtype": "string"}, {"name": "outputs", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 122799704, "num_examples": 60000}], "download_size": 53813219, "dataset_size": 122799704}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-07T04:35:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "code_prompt_evol_lemur"
More Information needed
|
[
"# Dataset Card for \"code_prompt_evol_lemur\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"code_prompt_evol_lemur\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"code_prompt_evol_lemur\"\n\nMore Information needed"
] |
c95bc0edda0a3007d75921e1d9d09d3e283444f3
|
# Dataset Card for "autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T04:43:51+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 188904676, "dataset_size": 472880000}}
|
2023-09-07T04:44:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_magic_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
684dccb6442b00cb875362f20fe0eb4c9188436d
|
# Dataset Card for "autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T04:48:29+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 186721409, "dataset_size": 472880000}}
|
2023-09-07T04:48:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
39
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_MagicTelescope_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
c432bbf0e405ad9a72e900406fcbb141583ea0ad
|
<p><h1>🐋 OpenOrca-Chinese 数据集!🐋</h1></p>
感谢 [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca) 数据集的发布,给广大NLP研究人员和开发者带来了宝贵的资源!
这是一个对 [Open-Orca/OpenOrca](https://huggingface.co/datasets/Open-Orca/OpenOrca) 数据集中文翻译的版本,翻译引擎为 Google 翻译,希望能给中文 LLM 研究做出一点点贡献。
<br/>
# Dataset Summary
The OpenOrca dataset is a collection of augmented [FLAN Collection data](https://arxiv.org/abs/2301.13688).
Currently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.
It is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.
The data is primarily used for training and evaluation in the field of natural language processing.
<a name="dataset-structure"></a>
# Dataset Structure
<a name="data-instances"></a>
## Data Instances
A data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.
The response is then entered into the response field.
<a name="data-fields"></a>
## Data Fields
The fields are:
1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.
2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint
3) 'question', representing a question entry as provided by the FLAN Collection
4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.
|
yys/OpenOrca-Chinese
|
[
"task_categories:conversational",
"task_categories:text-classification",
"task_categories:token-classification",
"task_categories:table-question-answering",
"task_categories:question-answering",
"task_categories:zero-shot-classification",
"task_categories:summarization",
"task_categories:feature-extraction",
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:10M<n<100M",
"language:zh",
"license:mit",
"arxiv:2301.13688",
"region:us"
] |
2023-09-07T05:01:51+00:00
|
{"language": ["zh"], "license": "mit", "size_categories": ["10M<n<100M"], "task_categories": ["conversational", "text-classification", "token-classification", "table-question-answering", "question-answering", "zero-shot-classification", "summarization", "feature-extraction", "text-generation", "text2text-generation"], "pretty_name": "OpenOrca-Chinese"}
|
2023-09-08T07:05:47+00:00
|
[
"2301.13688"
] |
[
"zh"
] |
TAGS
#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10M<n<100M #language-Chinese #license-mit #arxiv-2301.13688 #region-us
|
<p><h1> OpenOrca-Chinese 数据集!</h1></p>
感谢 Open-Orca/OpenOrca 数据集的发布,给广大NLP研究人员和开发者带来了宝贵的资源!
这是一个对 Open-Orca/OpenOrca 数据集中文翻译的版本,翻译引擎为 Google 翻译,希望能给中文 LLM 研究做出一点点贡献。
<br/>
# Dataset Summary
The OpenOrca dataset is a collection of augmented FLAN Collection data.
Currently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.
It is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.
The data is primarily used for training and evaluation in the field of natural language processing.
<a name="dataset-structure"></a>
# Dataset Structure
<a name="data-instances"></a>
## Data Instances
A data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.
The response is then entered into the response field.
<a name="data-fields"></a>
## Data Fields
The fields are:
1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.
2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint
3) 'question', representing a question entry as provided by the FLAN Collection
4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4.
|
[
"# Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n\n<a name=\"dataset-structure\"></a>",
"# Dataset Structure\n\n<a name=\"data-instances\"></a>",
"## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>",
"## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4."
] |
[
"TAGS\n#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10M<n<100M #language-Chinese #license-mit #arxiv-2301.13688 #region-us \n",
"# Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n\n<a name=\"dataset-structure\"></a>",
"# Dataset Structure\n\n<a name=\"data-instances\"></a>",
"## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>",
"## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4."
] |
[
155,
121,
19,
67,
140
] |
[
"passage: TAGS\n#task_categories-conversational #task_categories-text-classification #task_categories-token-classification #task_categories-table-question-answering #task_categories-question-answering #task_categories-zero-shot-classification #task_categories-summarization #task_categories-feature-extraction #task_categories-text-generation #task_categories-text2text-generation #size_categories-10M<n<100M #language-Chinese #license-mit #arxiv-2301.13688 #region-us \n# Dataset Summary\n\nThe OpenOrca dataset is a collection of augmented FLAN Collection data.\nCurrently ~1M GPT-4 completions, and ~3.2M GPT-3.5 completions.\nIt is tabularized in alignment with the distributions presented in the ORCA paper and currently represents a partial completion of the full intended dataset, with ongoing generation to expand its scope.\nThe data is primarily used for training and evaluation in the field of natural language processing.\n\n\n<a name=\"dataset-structure\"></a># Dataset Structure\n\n<a name=\"data-instances\"></a>## Data Instances\n\nA data instance in this dataset represents entries from the FLAN collection which have been augmented by submitting the listed question to either GPT-4 or GPT-3.5.\nThe response is then entered into the response field.\n\n<a name=\"data-fields\"></a>## Data Fields\n\nThe fields are:\n1) 'id', a unique numbered identifier which includes one of 'niv', 't0', 'cot', or 'flan' to represent which source FLAN Collection submix the 'question' is sourced from.\n2) 'system_prompt', representing the System Prompt presented to the GPT-3.5 or GPT-4 API for the datapoint\n3) 'question', representing a question entry as provided by the FLAN Collection\n4) 'response', a response to that question received from a query to either GPT-3.5 or GPT-4."
] |
e3b267169c18229e8d0fbc55f4be1dce1c5638ab
|
# Dataset Card for "autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T05:03:29+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 293033260, "dataset_size": 472880000}}
|
2023-09-07T05:03:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
39
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_MiniBooNE_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
1997e1c62778431950d5fbb8bde23b15255ad0ed
|
# Dataset Card for "autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T05:06:55+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 292435235, "dataset_size": 472880000}}
|
2023-09-07T05:07:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_jannis_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
105fdee696924495ec9ec3640ef3ffacd42cdec4
|
# Natsuki Chat 09072023 raw
* Dataset of Natsuki dialogue from DDLC (dataset of ~800 items augmented by [MythoMax-l2-13b](https://huggingface.co/Gryphe/MythoMax-L2-13b) to turn into multi-turn chat dialogue)
* Curated version planned
|
922-CA/ln2_09072023_test1_raw_NaChA_1a
|
[
"license:openrail",
"region:us"
] |
2023-09-07T05:15:25+00:00
|
{"license": "openrail"}
|
2023-09-22T07:08:57+00:00
|
[] |
[] |
TAGS
#license-openrail #region-us
|
# Natsuki Chat 09072023 raw
* Dataset of Natsuki dialogue from DDLC (dataset of ~800 items augmented by MythoMax-l2-13b to turn into multi-turn chat dialogue)
* Curated version planned
|
[
"# Natsuki Chat 09072023 raw\n* Dataset of Natsuki dialogue from DDLC (dataset of ~800 items augmented by MythoMax-l2-13b to turn into multi-turn chat dialogue)\n* Curated version planned"
] |
[
"TAGS\n#license-openrail #region-us \n",
"# Natsuki Chat 09072023 raw\n* Dataset of Natsuki dialogue from DDLC (dataset of ~800 items augmented by MythoMax-l2-13b to turn into multi-turn chat dialogue)\n* Curated version planned"
] |
[
12,
56
] |
[
"passage: TAGS\n#license-openrail #region-us \n# Natsuki Chat 09072023 raw\n* Dataset of Natsuki dialogue from DDLC (dataset of ~800 items augmented by MythoMax-l2-13b to turn into multi-turn chat dialogue)\n* Curated version planned"
] |
53b1aff8eeaacf168167cbec537c68226b68fd62
|
Translated from Stanford alpaca using google translate API.
|
sarahlintang/Alpaca_indo_instruct
|
[
"language:id",
"region:us"
] |
2023-09-07T05:21:17+00:00
|
{"language": ["id"]}
|
2023-09-07T05:27:38+00:00
|
[] |
[
"id"
] |
TAGS
#language-Indonesian #region-us
|
Translated from Stanford alpaca using google translate API.
|
[] |
[
"TAGS\n#language-Indonesian #region-us \n"
] |
[
11
] |
[
"passage: TAGS\n#language-Indonesian #region-us \n"
] |
18809be7ef5142e19c58308644008d09feb6c945
|
# Dataset Card for "autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T05:25:49+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 288073393, "dataset_size": 472880000}}
|
2023-09-07T05:25:57+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
38
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_Higgs_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
9e63d125d199dc07d5bdb167f298d42821a33f05
|
# Products Tracking
The dataset contains frames extracted from self-checkout videos, specifically focusing on **tracking products**. The tracking data provides the **trajectory of each product**, allowing for analysis of customer movement and behavior throughout the transaction.
The dataset assists in detecting shoplifting and fraud, enhancing efficiency, accuracy, and customer experience. It facilitates the development of computer vision models for *object detection, tracking, and recognition* within a self-checkout environment.
.gif?generation=1694065408131442&alt=media)
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=self-checkout-videos-object-tracking) to discuss your requirements, learn about the price and buy the dataset.
# Dataset structure
The dataset consists of 3 folders with video frames from self-checkouts.
Each folder includes:
- **images**: folder with original frames from the video,
- **boxes**: visualized data labeling for the images in the previous folder,
- **.csv file**: file with id and path of each frame in the "images" folder,
- **annotations.xml**: contains coordinates of the bounding boxes and labels, created for the original frames
# Data Format
Each frame from `images` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the bounding boxes for products tracking. For each point, the x and y coordinates are provided. The payment status of the product is also indicated in the attribute **paid** (true, false).
# Example of the XML-file
.png?generation=1695994818122714&alt=media)
# Object tracking might be made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=self-checkout-videos-object-tracking) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/self-checkout-videos-object-tracking
|
[
"task_categories:image-to-image",
"task_categories:object-detection",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] |
2023-09-07T05:30:07+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-to-image", "object-detection"], "tags": ["code", "finance"], "dataset_info": [{"config_name": "video_01", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "product"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 8664, "num_examples": 17}], "download_size": 56150105, "dataset_size": 8664}, {"config_name": "video_02", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "product"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 5857, "num_examples": 10}], "download_size": 35163267, "dataset_size": 5857}, {"config_name": "video_03", "features": [{"name": "id", "dtype": "int32"}, {"name": "name", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "sequence": [{"name": "track_id", "dtype": "uint32"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "product"}}}}, {"name": "type", "dtype": "string"}, {"name": "points", "sequence": {"sequence": "float32"}}, {"name": "rotation", "dtype": "float32"}, {"name": "occluded", "dtype": "uint8"}, {"name": "attributes", "sequence": [{"name": "name", "dtype": "string"}, {"name": "text", "dtype": "string"}]}]}], "splits": [{"name": "train", "num_bytes": 10586, "num_examples": 13}], "download_size": 42578549, "dataset_size": 10586}]}
|
2023-09-29T12:40:49+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-to-image #task_categories-object-detection #language-English #license-cc-by-nc-nd-4.0 #code #finance #region-us
|
# Products Tracking
The dataset contains frames extracted from self-checkout videos, specifically focusing on tracking products. The tracking data provides the trajectory of each product, allowing for analysis of customer movement and behavior throughout the transaction.
The dataset assists in detecting shoplifting and fraud, enhancing efficiency, accuracy, and customer experience. It facilitates the development of computer vision models for *object detection, tracking, and recognition* within a self-checkout environment.
.
# Example of the XML-file
.",
"# Example of the XML-file \n.",
"# Example of the XML-file \n.# Example of the XML-file \n, the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 158 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 318 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 158 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 158 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 158 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 158 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 158 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 318 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 318 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 318 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/becky_blackbell_spyxfamily
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-07T05:44:35+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:18+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Becky Blackbell
==========================
This is the dataset of Becky Blackbell, containing 158 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
2d3a87bc33929eba7e1716afeb3610ddad02c2bc
|
# Dataset Card for "autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T05:47:00+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 144253019, "dataset_size": 472880000}}
|
2023-09-07T05:47:08+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_pmlb_10000_twonorm_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
a39629c446c7b636c6f2d8ae15ed4e7cf9bc0d5f
|
# Dataset Card for "BlockTechBrew1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
GaganpreetSingh/BlockTechBrew1
|
[
"region:us"
] |
2023-09-07T05:51:27+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9276, "num_examples": 34}], "download_size": 6874, "dataset_size": 9276}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-09-07T05:51:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "BlockTechBrew1"
More Information needed
|
[
"# Dataset Card for \"BlockTechBrew1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"BlockTechBrew1\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"BlockTechBrew1\"\n\nMore Information needed"
] |
e1ae3adbae7a0ada0df79d40427e6a766d7a7841
|
# Dataset of Fiona Frost (Yellow Hair)
This is the dataset of Fiona Frost (Yellow Hair), containing 116 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
| Name | Images | Download | Description |
|:------------|---------:|:------------------------------------|:-------------------------------------------------------------------------|
| raw | 116 | [Download](dataset-raw.zip) | Raw data with meta information. |
| raw-stage3 | 259 | [Download](dataset-raw-stage3.zip) | 3-stage cropped raw data with meta information. |
| 384x512 | 116 | [Download](dataset-384x512.zip) | 384x512 aligned dataset. |
| 512x512 | 116 | [Download](dataset-512x512.zip) | 512x512 aligned dataset. |
| 512x704 | 116 | [Download](dataset-512x704.zip) | 512x704 aligned dataset. |
| 640x640 | 116 | [Download](dataset-640x640.zip) | 640x640 aligned dataset. |
| 640x880 | 116 | [Download](dataset-640x880.zip) | 640x880 aligned dataset. |
| stage3-640 | 259 | [Download](dataset-stage3-640.zip) | 3-stage cropped dataset with the shorter side not exceeding 640 pixels. |
| stage3-800 | 259 | [Download](dataset-stage3-800.zip) | 3-stage cropped dataset with the shorter side not exceeding 800 pixels. |
| stage3-1200 | 259 | [Download](dataset-stage3-1200.zip) | 3-stage cropped dataset with the shorter side not exceeding 1200 pixels. |
|
CyberHarem/fiona_frost_yellow_hair_spyxfamily
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-09-07T05:59:03+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2023-09-17T16:28:20+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of Fiona Frost (Yellow Hair)
====================================
This is the dataset of Fiona Frost (Yellow Hair), containing 116 images and their tags.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
|
[] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
[
44
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n"
] |
8ed742712d1dc8b6ba1f70279f05eb8a89c24154
|
# Bangumi Image Base of Fate - Kaleid Liner Prisma Illya
This is the image base of bangumi Fate - kaleid Liner Prisma Illya, we detected 44 characters, 4621 images in total. The full dataset is [here](all.zip).
**Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual.** If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
| # | Images | Download | Preview 1 | Preview 2 | Preview 3 | Preview 4 | Preview 5 | Preview 6 | Preview 7 | Preview 8 |
|:------|---------:|:---------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|:-------------------------------|
| 0 | 101 | [Download](0/dataset.zip) |  |  |  |  |  |  |  |  |
| 1 | 235 | [Download](1/dataset.zip) |  |  |  |  |  |  |  |  |
| 2 | 25 | [Download](2/dataset.zip) |  |  |  |  |  |  |  |  |
| 3 | 14 | [Download](3/dataset.zip) |  |  |  |  |  |  |  |  |
| 4 | 73 | [Download](4/dataset.zip) |  |  |  |  |  |  |  |  |
| 5 | 17 | [Download](5/dataset.zip) |  |  |  |  |  |  |  |  |
| 6 | 20 | [Download](6/dataset.zip) |  |  |  |  |  |  |  |  |
| 7 | 23 | [Download](7/dataset.zip) |  |  |  |  |  |  |  |  |
| 8 | 608 | [Download](8/dataset.zip) |  |  |  |  |  |  |  |  |
| 9 | 99 | [Download](9/dataset.zip) |  |  |  |  |  |  |  |  |
| 10 | 28 | [Download](10/dataset.zip) |  |  |  |  |  |  |  |  |
| 11 | 33 | [Download](11/dataset.zip) |  |  |  |  |  |  |  |  |
| 12 | 999 | [Download](12/dataset.zip) |  |  |  |  |  |  |  |  |
| 13 | 37 | [Download](13/dataset.zip) |  |  |  |  |  |  |  |  |
| 14 | 134 | [Download](14/dataset.zip) |  |  |  |  |  |  |  |  |
| 15 | 113 | [Download](15/dataset.zip) |  |  |  |  |  |  |  |  |
| 16 | 93 | [Download](16/dataset.zip) |  |  |  |  |  |  |  |  |
| 17 | 22 | [Download](17/dataset.zip) |  |  |  |  |  |  |  |  |
| 18 | 37 | [Download](18/dataset.zip) |  |  |  |  |  |  |  |  |
| 19 | 72 | [Download](19/dataset.zip) |  |  |  |  |  |  |  |  |
| 20 | 37 | [Download](20/dataset.zip) |  |  |  |  |  |  |  |  |
| 21 | 126 | [Download](21/dataset.zip) |  |  |  |  |  |  |  |  |
| 22 | 37 | [Download](22/dataset.zip) |  |  |  |  |  |  |  |  |
| 23 | 399 | [Download](23/dataset.zip) |  |  |  |  |  |  |  |  |
| 24 | 67 | [Download](24/dataset.zip) |  |  |  |  |  |  |  |  |
| 25 | 19 | [Download](25/dataset.zip) |  |  |  |  |  |  |  |  |
| 26 | 19 | [Download](26/dataset.zip) |  |  |  |  |  |  |  |  |
| 27 | 61 | [Download](27/dataset.zip) |  |  |  |  |  |  |  |  |
| 28 | 60 | [Download](28/dataset.zip) |  |  |  |  |  |  |  |  |
| 29 | 9 | [Download](29/dataset.zip) |  |  |  |  |  |  |  |  |
| 30 | 63 | [Download](30/dataset.zip) |  |  |  |  |  |  |  |  |
| 31 | 124 | [Download](31/dataset.zip) |  |  |  |  |  |  |  |  |
| 32 | 24 | [Download](32/dataset.zip) |  |  |  |  |  |  |  |  |
| 33 | 13 | [Download](33/dataset.zip) |  |  |  |  |  |  |  |  |
| 34 | 91 | [Download](34/dataset.zip) |  |  |  |  |  |  |  |  |
| 35 | 217 | [Download](35/dataset.zip) |  |  |  |  |  |  |  |  |
| 36 | 66 | [Download](36/dataset.zip) |  |  |  |  |  |  |  |  |
| 37 | 36 | [Download](37/dataset.zip) |  |  |  |  |  |  |  |  |
| 38 | 10 | [Download](38/dataset.zip) |  |  |  |  |  |  |  |  |
| 39 | 21 | [Download](39/dataset.zip) |  |  |  |  |  |  |  |  |
| 40 | 12 | [Download](40/dataset.zip) |  |  |  |  |  |  |  |  |
| 41 | 27 | [Download](41/dataset.zip) |  |  |  |  |  |  |  |  |
| 42 | 6 | [Download](42/dataset.zip) |  |  |  |  |  |  | N/A | N/A |
| noise | 294 | [Download](-1/dataset.zip) |  |  |  |  |  |  |  |  |
|
BangumiBase/fatekaleidlinerprismaillya
|
[
"size_categories:1K<n<10K",
"license:mit",
"art",
"region:us"
] |
2023-09-07T06:10:55+00:00
|
{"license": "mit", "size_categories": ["1K<n<10K"], "tags": ["art"]}
|
2023-09-29T05:20:35+00:00
|
[] |
[] |
TAGS
#size_categories-1K<n<10K #license-mit #art #region-us
|
Bangumi Image Base of Fate - Kaleid Liner Prisma Illya
======================================================
This is the image base of bangumi Fate - kaleid Liner Prisma Illya, we detected 44 characters, 4621 images in total. The full dataset is here.
Please note that these image bases are not guaranteed to be 100% cleaned, they may be noisy actual. If you intend to manually train models using this dataset, we recommend performing necessary preprocessing on the downloaded dataset to eliminate potential noisy samples (approximately 1% probability).
Here is the characters' preview:
|
[] |
[
"TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
[
25
] |
[
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #art #region-us \n"
] |
771852b8f56765e69542409c902579bb2bdb3baf
|
# Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Tverous/test
|
[
"region:us"
] |
2023-09-07T06:16:14+00:00
|
{"dataset_info": {"features": [{"name": "uid", "dtype": "string"}, {"name": "premise", "dtype": "string"}, {"name": "hypothesis", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "hyp_amr", "dtype": "string"}, {"name": "hyp_linearized_amr", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5344233, "num_examples": 14740}], "download_size": 1790710, "dataset_size": 5344233}}
|
2023-09-07T06:16:16+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test"
More Information needed
|
[
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test\"\n\nMore Information needed"
] |
976b1c6238611cb405073e5352aba982b81de5d0
|
# Dataset Card for "flcker30k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Tverous/flicker30k
|
[
"region:us"
] |
2023-09-07T06:22:31+00:00
|
{"dataset_info": {"features": [{"name": "uid", "dtype": "string"}, {"name": "premise", "dtype": "string"}, {"name": "hypothesis", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "hyp_amr", "dtype": "string"}, {"name": "hyp_linearized_amr", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 146513367, "num_examples": 401717}, {"name": "dev", "num_bytes": 5144374, "num_examples": 14339}, {"name": "test", "num_bytes": 5344233, "num_examples": 14740}], "download_size": 53289338, "dataset_size": 157001974}}
|
2023-09-07T06:22:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "flcker30k"
More Information needed
|
[
"# Dataset Card for \"flcker30k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"flcker30k\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"flcker30k\"\n\nMore Information needed"
] |
5514a7e976be8561fc8a512083bd628f9de0f649
|
# Dataset Card for "open_assistant_dataset_QA"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bilalahmadai/open_assistant_dataset_QA
|
[
"region:us"
] |
2023-09-07T06:24:31+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 782135, "num_examples": 2000}], "download_size": 483861, "dataset_size": 782135}}
|
2023-09-07T06:26:08+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "open_assistant_dataset_QA"
More Information needed
|
[
"# Dataset Card for \"open_assistant_dataset_QA\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"open_assistant_dataset_QA\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"open_assistant_dataset_QA\"\n\nMore Information needed"
] |
9971c4a489ad663b538a98e83b11ebc5edb38048
|
# Dataset Card for "autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yzhuang/autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0
|
[
"region:us"
] |
2023-09-07T06:33:51+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "input_x", "sequence": {"sequence": "float32"}}, {"name": "input_y", "sequence": {"sequence": "float32"}}, {"name": "input_y_clean", "sequence": {"sequence": "float32"}}, {"name": "rtg", "sequence": "float64"}, {"name": "status", "sequence": {"sequence": "float32"}}, {"name": "split_threshold", "sequence": {"sequence": "float32"}}, {"name": "split_dimension", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 236440000, "num_examples": 10000}, {"name": "validation", "num_bytes": 236440000, "num_examples": 10000}], "download_size": 80234603, "dataset_size": 472880000}}
|
2023-09-07T06:33:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0"
More Information needed
|
[
"# Dataset Card for \"autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
[
6,
37
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"autotree_automl_10000_heloc_sgosdt_l256_dim10_d3_sd0\"\n\nMore Information needed"
] |
dc0fadaf946ca19a6a26cc44f2f70cb953084582
|
# Dataset Card for "extracted-vi-wiki-20230820"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Zayt/extracted-vi-wiki-20230820
|
[
"region:us"
] |
2023-09-07T06:42:03+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 492261222.63576823, "num_examples": 395032}], "download_size": 663150112, "dataset_size": 492261222.63576823}}
|
2023-09-07T06:53:50+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "extracted-vi-wiki-20230820"
More Information needed
|
[
"# Dataset Card for \"extracted-vi-wiki-20230820\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"extracted-vi-wiki-20230820\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"extracted-vi-wiki-20230820\"\n\nMore Information needed"
] |
df7479d76cc3c549ff42cfc9f1deb5c7b3154d4d
|
# Dataset Card for CodeFuse-CodeExercise-Python-27k
<div align='center'>

[[中文]](#chinese) [[English]](#english)
</div>
<a id="english"></a>
### Dataset Description
This dataset consists of 27K Python programming exercises (in English), covering hundreds of Python-related topics including basic syntax and data structures, algorithm applications, database queries, machine learning, and more.
*Please note that this dataset was generated with the help of a teacher model and [Camel](https://arxiv.org/abs/2303.17760), and has not undergone strict validation. There may be errors or semantic duplicates in the questions or answers, so please use it with caution.*
## Field Structure
```
{
"dataset": #Dataset name,
"id": #Sample ID,
"chat_rounds": [
{
"role": "human",
"content": #instruction,
"chat_round_id": 0
},
{
"role": "bot",
"content": #output,
"chat_round_id": 1
}]
}
```
### Examples
```
{
"data_name": "CodeExercise-Py",
"id": 27219,
"chat_rounds": [
{
"role": "human",
"content": "Write a Python program to rotate an array by a given number of steps.",
"chat_round_id": 0
},
{
"role": "bot",
"content": "Sure! Here's a Python program that rotates an array by a given number of steps.\n\n```python\ndef rotate_array(arr, steps):\n \"\"\"\n Rotate an array by the given number of steps.\n\n Parameters:\n arr (list): The input array.\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\n while negative steps rotate it to the left.\n\n Returns:\n list: The rotated array.\n\n Examples:\n >>> rotate_array([1, 2, 3, 4, 5], 2)\n [4, 5, 1, 2, 3]\n\n >>> rotate_array([1, 2, 3, 4, 5], -1)\n [2, 3, 4, 5, 1]\n \"\"\"\n arr_length = len(arr)\n steps = steps % arr_length # Handle steps larger than array length\n\n if steps == 0: # No rotation needed\n return arr\n\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\n\n return rotated_arr\n\n\n# Example usage\narr = [1, 2, 3, 4, 5]\nsteps = 2\nrotated_arr = rotate_array(arr, steps)\nprint(rotated_arr)\n```\n\nThe `rotate_array()` function takes an input array `arr` and the number of steps `steps` to rotate the array. It first calculates the actual number of rotations by performing a modulo operation on `steps` with the length of the input array. This ensures that even if `steps` is larger than the array length, we always perform the appropriate number of rotations.\n\nIf `steps` is 0, the function returns the input array as no rotation is needed.\n\nOtherwise, the function splits the input array into two parts based on the number of steps: the last `steps` elements (using negative indexing) and the remaining elements. These two parts are then concatenated in the desired order to obtain the rotated array.\n\nFinally, the program demonstrates an example usage by rotating an array `[1, 2, 3, 4, 5]` by 2 steps (to the right) and printing the resulting rotated array.",
"chat_round_id": 1
}]
}
```
## Creation

* Step 1: Curate a seed set of Python knowledge points.
* Step 2: Embed each seed into a fixed task template to obtain a fixed template's "Task Prompt," which serves as a prompt for a teacher model to generate exercise questions related to the given knowledge point.
* Step 3: Use Camel to refine the "Task Prompt" obtained in step 2, in order to achieve more accurate and diverse descriptions.
* Step 4: Input the obtained Task Prompt into a teacher model to generate exercise questions (instructions) corresponding to the knowledge point.
* Step 5: For each exercise question (instruction), leverage a teacher model to generate the corresponding answer.
* Step 6: Assemble each question with its answer and remove duplicates.
<a id="chinese"></a>
## 简介
该数据集由2.7万道Python编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个Python相关知识点。
注意:该数据集是借助Teacher Model和[Camel](https://arxiv.org/abs/2303.17760)生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。
## 数据字段
```
{
"dataset": #数据集名称,
"id": #样本ID,
"chat_rounds": [
{
"role": "human",
"content": #指令内容,
"chat_round_id": 0
},
{
"role": "bot",
"content": #答案内容,
"chat_round_id": 1
}]
}
```
### 样例
```
{
"data_name": "CodeExercise-Py",
"id": 27219,
"chat_rounds": [
{
"role": "human",
"content": "Write a Python program to rotate an array by a given number of steps.",
"chat_round_id": 0
},
{
"role": "bot",
"content": "Sure! Here's a Python program that rotates an array by a given number of steps.\n\n```python\ndef rotate_array(arr, steps):\n \"\"\"\n Rotate an array by the given number of steps.\n\n Parameters:\n arr (list): The input array.\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\n while negative steps rotate it to the left.\n\n Returns:\n list: The rotated array.\n\n Examples:\n >>> rotate_array([1, 2, 3, 4, 5], 2)\n [4, 5, 1, 2, 3]\n\n >>> rotate_array([1, 2, 3, 4, 5], -1)\n [2, 3, 4, 5, 1]\n \"\"\"\n arr_length = len(arr)\n steps = steps % arr_length # Handle steps larger than array length\n\n if steps == 0: # No rotation needed\n return arr\n\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\n\n return rotated_arr\n\n\n# Example usage\narr = [1, 2, 3, 4, 5]\nsteps = 2\nrotated_arr = rotate_array(arr, steps)\nprint(rotated_arr)\n```\n\nThe `rotate_array()` function takes an input array `arr` and the number of steps `steps` to rotate the array. It first calculates the actual number of rotations by performing a modulo operation on `steps` with the length of the input array. This ensures that even if `steps` is larger than the array length, we always perform the appropriate number of rotations.\n\nIf `steps` is 0, the function returns the input array as no rotation is needed.\n\nOtherwise, the function splits the input array into two parts based on the number of steps: the last `steps` elements (using negative indexing) and the remaining elements. These two parts are then concatenated in the desired order to obtain the rotated array.\n\nFinally, the program demonstrates an example usage by rotating an array `[1, 2, 3, 4, 5]` by 2 steps (to the right) and printing the resulting rotated array.",
"chat_round_id": 1
}]
}
```
## 数据生成过程

* 第一步: 整理Python知识点,作为初始种子集
* 第二步:将每个种子嵌入到固定的任务模版中,获得固定模版的"Task Prompt",该任务模版的主题是提示教师模型生成给定知识点的练习题问题。
* 第三步:调用Camel对第二步获得的"Task Prompt"进行润色,以获得更加描述准确且多样的Task Prompt
* 第四步:将获得的Task Prompt输入给教师模型,令其生成对应知识点的练习题问题(指令)
* 第五步:对每个练习题问题(指令),借助教师模型生成对应的问题答案
* 第六步:组装每个问题和其答案,并进行去重操作
|
codefuse-ai/CodeExercise-Python-27k
|
[
"license:cc-by-nc-sa-4.0",
"arxiv:2303.17760",
"region:us"
] |
2023-09-07T06:47:24+00:00
|
{"license": "cc-by-nc-sa-4.0", "viewer": false}
|
2023-12-20T07:57:58+00:00
|
[
"2303.17760"
] |
[] |
TAGS
#license-cc-by-nc-sa-4.0 #arxiv-2303.17760 #region-us
|
# Dataset Card for CodeFuse-CodeExercise-Python-27k
<div align='center'>
!logo
[[中文]](#chinese) [[English]](#english)
</div>
<a id="english"></a>
### Dataset Description
This dataset consists of 27K Python programming exercises (in English), covering hundreds of Python-related topics including basic syntax and data structures, algorithm applications, database queries, machine learning, and more.
*Please note that this dataset was generated with the help of a teacher model and Camel, and has not undergone strict validation. There may be errors or semantic duplicates in the questions or answers, so please use it with caution.*
## Field Structure
### Examples
python\ndef rotate_array(arr, steps):\n \"\"\"\n Rotate an array by the given number of steps.\n\n Parameters:\n arr (list): The input array.\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\n while negative steps rotate it to the left.\n\n Returns:\n list: The rotated array.\n\n Examples:\n >>> rotate_array([1, 2, 3, 4, 5], 2)\n [4, 5, 1, 2, 3]\n\n >>> rotate_array([1, 2, 3, 4, 5], -1)\n [2, 3, 4, 5, 1]\n \"\"\"\n arr_length = len(arr)\n steps = steps % arr_length # Handle steps larger than array length\n\n if steps == 0: # No rotation needed\n return arr\n\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\n\n return rotated_arr\n\n\n# Example usage\narr = [1, 2, 3, 4, 5]\nsteps = 2\nrotated_arr = rotate_array(arr, steps)\nprint(rotated_arr)\n
## Creation
!Creation Approach
* Step 1: Curate a seed set of Python knowledge points.
* Step 2: Embed each seed into a fixed task template to obtain a fixed template's "Task Prompt," which serves as a prompt for a teacher model to generate exercise questions related to the given knowledge point.
* Step 3: Use Camel to refine the "Task Prompt" obtained in step 2, in order to achieve more accurate and diverse descriptions.
* Step 4: Input the obtained Task Prompt into a teacher model to generate exercise questions (instructions) corresponding to the knowledge point.
* Step 5: For each exercise question (instruction), leverage a teacher model to generate the corresponding answer.
* Step 6: Assemble each question with its answer and remove duplicates.
<a id="chinese"></a>
## 简介
该数据集由2.7万道Python编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个Python相关知识点。
注意:该数据集是借助Teacher Model和Camel生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。
## 数据字段
### 样例
python\ndef rotate_array(arr, steps):\n \"\"\"\n Rotate an array by the given number of steps.\n\n Parameters:\n arr (list): The input array.\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\n while negative steps rotate it to the left.\n\n Returns:\n list: The rotated array.\n\n Examples:\n >>> rotate_array([1, 2, 3, 4, 5], 2)\n [4, 5, 1, 2, 3]\n\n >>> rotate_array([1, 2, 3, 4, 5], -1)\n [2, 3, 4, 5, 1]\n \"\"\"\n arr_length = len(arr)\n steps = steps % arr_length # Handle steps larger than array length\n\n if steps == 0: # No rotation needed\n return arr\n\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\n\n return rotated_arr\n\n\n# Example usage\narr = [1, 2, 3, 4, 5]\nsteps = 2\nrotated_arr = rotate_array(arr, steps)\nprint(rotated_arr)\n
## 数据生成过程
!数据生成过程示意图
* 第一步: 整理Python知识点,作为初始种子集
* 第二步:将每个种子嵌入到固定的任务模版中,获得固定模版的"Task Prompt",该任务模版的主题是提示教师模型生成给定知识点的练习题问题。
* 第三步:调用Camel对第二步获得的"Task Prompt"进行润色,以获得更加描述准确且多样的Task Prompt
* 第四步:将获得的Task Prompt输入给教师模型,令其生成对应知识点的练习题问题(指令)
* 第五步:对每个练习题问题(指令),借助教师模型生成对应的问题答案
* 第六步:组装每个问题和其答案,并进行去重操作
|
[
"# Dataset Card for CodeFuse-CodeExercise-Python-27k\n\n<div align='center'>\n\n!logo\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>",
"### Dataset Description\nThis dataset consists of 27K Python programming exercises (in English), covering hundreds of Python-related topics including basic syntax and data structures, algorithm applications, database queries, machine learning, and more. \n\n*Please note that this dataset was generated with the help of a teacher model and Camel, and has not undergone strict validation. There may be errors or semantic duplicates in the questions or answers, so please use it with caution.*",
"## Field Structure",
"### Examples\npython\\ndef rotate_array(arr, steps):\\n \\\"\\\"\\\"\\n Rotate an array by the given number of steps.\\n\\n Parameters:\\n arr (list): The input array.\\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\\n while negative steps rotate it to the left.\\n\\n Returns:\\n list: The rotated array.\\n\\n Examples:\\n >>> rotate_array([1, 2, 3, 4, 5], 2)\\n [4, 5, 1, 2, 3]\\n\\n >>> rotate_array([1, 2, 3, 4, 5], -1)\\n [2, 3, 4, 5, 1]\\n \\\"\\\"\\\"\\n arr_length = len(arr)\\n steps = steps % arr_length # Handle steps larger than array length\\n\\n if steps == 0: # No rotation needed\\n return arr\\n\\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\\n\\n return rotated_arr\\n\\n\\n# Example usage\\narr = [1, 2, 3, 4, 5]\\nsteps = 2\\nrotated_arr = rotate_array(arr, steps)\\nprint(rotated_arr)\\n",
"## Creation\n\n!Creation Approach\n\n* Step 1: Curate a seed set of Python knowledge points. \n\n* Step 2: Embed each seed into a fixed task template to obtain a fixed template's \"Task Prompt,\" which serves as a prompt for a teacher model to generate exercise questions related to the given knowledge point. \n\n* Step 3: Use Camel to refine the \"Task Prompt\" obtained in step 2, in order to achieve more accurate and diverse descriptions. \n\n* Step 4: Input the obtained Task Prompt into a teacher model to generate exercise questions (instructions) corresponding to the knowledge point. \n\n* Step 5: For each exercise question (instruction), leverage a teacher model to generate the corresponding answer. \n\n* Step 6: Assemble each question with its answer and remove duplicates.\n\n\n<a id=\"chinese\"></a>",
"## 简介\n该数据集由2.7万道Python编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个Python相关知识点。\n注意:该数据集是借助Teacher Model和Camel生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。",
"## 数据字段",
"### 样例\npython\\ndef rotate_array(arr, steps):\\n \\\"\\\"\\\"\\n Rotate an array by the given number of steps.\\n\\n Parameters:\\n arr (list): The input array.\\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\\n while negative steps rotate it to the left.\\n\\n Returns:\\n list: The rotated array.\\n\\n Examples:\\n >>> rotate_array([1, 2, 3, 4, 5], 2)\\n [4, 5, 1, 2, 3]\\n\\n >>> rotate_array([1, 2, 3, 4, 5], -1)\\n [2, 3, 4, 5, 1]\\n \\\"\\\"\\\"\\n arr_length = len(arr)\\n steps = steps % arr_length # Handle steps larger than array length\\n\\n if steps == 0: # No rotation needed\\n return arr\\n\\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\\n\\n return rotated_arr\\n\\n\\n# Example usage\\narr = [1, 2, 3, 4, 5]\\nsteps = 2\\nrotated_arr = rotate_array(arr, steps)\\nprint(rotated_arr)\\n",
"## 数据生成过程\n!数据生成过程示意图\n\n* 第一步: 整理Python知识点,作为初始种子集\n\n* 第二步:将每个种子嵌入到固定的任务模版中,获得固定模版的\"Task Prompt\",该任务模版的主题是提示教师模型生成给定知识点的练习题问题。\n\n* 第三步:调用Camel对第二步获得的\"Task Prompt\"进行润色,以获得更加描述准确且多样的Task Prompt\n\n* 第四步:将获得的Task Prompt输入给教师模型,令其生成对应知识点的练习题问题(指令)\n\n* 第五步:对每个练习题问题(指令),借助教师模型生成对应的问题答案\n\n* 第六步:组装每个问题和其答案,并进行去重操作"
] |
[
"TAGS\n#license-cc-by-nc-sa-4.0 #arxiv-2303.17760 #region-us \n",
"# Dataset Card for CodeFuse-CodeExercise-Python-27k\n\n<div align='center'>\n\n!logo\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>",
"### Dataset Description\nThis dataset consists of 27K Python programming exercises (in English), covering hundreds of Python-related topics including basic syntax and data structures, algorithm applications, database queries, machine learning, and more. \n\n*Please note that this dataset was generated with the help of a teacher model and Camel, and has not undergone strict validation. There may be errors or semantic duplicates in the questions or answers, so please use it with caution.*",
"## Field Structure",
"### Examples\npython\\ndef rotate_array(arr, steps):\\n \\\"\\\"\\\"\\n Rotate an array by the given number of steps.\\n\\n Parameters:\\n arr (list): The input array.\\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\\n while negative steps rotate it to the left.\\n\\n Returns:\\n list: The rotated array.\\n\\n Examples:\\n >>> rotate_array([1, 2, 3, 4, 5], 2)\\n [4, 5, 1, 2, 3]\\n\\n >>> rotate_array([1, 2, 3, 4, 5], -1)\\n [2, 3, 4, 5, 1]\\n \\\"\\\"\\\"\\n arr_length = len(arr)\\n steps = steps % arr_length # Handle steps larger than array length\\n\\n if steps == 0: # No rotation needed\\n return arr\\n\\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\\n\\n return rotated_arr\\n\\n\\n# Example usage\\narr = [1, 2, 3, 4, 5]\\nsteps = 2\\nrotated_arr = rotate_array(arr, steps)\\nprint(rotated_arr)\\n",
"## Creation\n\n!Creation Approach\n\n* Step 1: Curate a seed set of Python knowledge points. \n\n* Step 2: Embed each seed into a fixed task template to obtain a fixed template's \"Task Prompt,\" which serves as a prompt for a teacher model to generate exercise questions related to the given knowledge point. \n\n* Step 3: Use Camel to refine the \"Task Prompt\" obtained in step 2, in order to achieve more accurate and diverse descriptions. \n\n* Step 4: Input the obtained Task Prompt into a teacher model to generate exercise questions (instructions) corresponding to the knowledge point. \n\n* Step 5: For each exercise question (instruction), leverage a teacher model to generate the corresponding answer. \n\n* Step 6: Assemble each question with its answer and remove duplicates.\n\n\n<a id=\"chinese\"></a>",
"## 简介\n该数据集由2.7万道Python编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个Python相关知识点。\n注意:该数据集是借助Teacher Model和Camel生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。",
"## 数据字段",
"### 样例\npython\\ndef rotate_array(arr, steps):\\n \\\"\\\"\\\"\\n Rotate an array by the given number of steps.\\n\\n Parameters:\\n arr (list): The input array.\\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\\n while negative steps rotate it to the left.\\n\\n Returns:\\n list: The rotated array.\\n\\n Examples:\\n >>> rotate_array([1, 2, 3, 4, 5], 2)\\n [4, 5, 1, 2, 3]\\n\\n >>> rotate_array([1, 2, 3, 4, 5], -1)\\n [2, 3, 4, 5, 1]\\n \\\"\\\"\\\"\\n arr_length = len(arr)\\n steps = steps % arr_length # Handle steps larger than array length\\n\\n if steps == 0: # No rotation needed\\n return arr\\n\\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\\n\\n return rotated_arr\\n\\n\\n# Example usage\\narr = [1, 2, 3, 4, 5]\\nsteps = 2\\nrotated_arr = rotate_array(arr, steps)\\nprint(rotated_arr)\\n",
"## 数据生成过程\n!数据生成过程示意图\n\n* 第一步: 整理Python知识点,作为初始种子集\n\n* 第二步:将每个种子嵌入到固定的任务模版中,获得固定模版的\"Task Prompt\",该任务模版的主题是提示教师模型生成给定知识点的练习题问题。\n\n* 第三步:调用Camel对第二步获得的\"Task Prompt\"进行润色,以获得更加描述准确且多样的Task Prompt\n\n* 第四步:将获得的Task Prompt输入给教师模型,令其生成对应知识点的练习题问题(指令)\n\n* 第五步:对每个练习题问题(指令),借助教师模型生成对应的问题答案\n\n* 第六步:组装每个问题和其答案,并进行去重操作"
] |
[
27,
61,
110,
5,
373,
186,
87,
5,
374,
185
] |
[
"passage: TAGS\n#license-cc-by-nc-sa-4.0 #arxiv-2303.17760 #region-us \n# Dataset Card for CodeFuse-CodeExercise-Python-27k\n\n<div align='center'>\n\n!logo\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>### Dataset Description\nThis dataset consists of 27K Python programming exercises (in English), covering hundreds of Python-related topics including basic syntax and data structures, algorithm applications, database queries, machine learning, and more. \n\n*Please note that this dataset was generated with the help of a teacher model and Camel, and has not undergone strict validation. There may be errors or semantic duplicates in the questions or answers, so please use it with caution.*## Field Structure",
"passage: ### Examples\npython\\ndef rotate_array(arr, steps):\\n \\\"\\\"\\\"\\n Rotate an array by the given number of steps.\\n\\n Parameters:\\n arr (list): The input array.\\n steps (int): The number of steps to rotate the array. Positive steps rotate it to the right,\\n while negative steps rotate it to the left.\\n\\n Returns:\\n list: The rotated array.\\n\\n Examples:\\n >>> rotate_array([1, 2, 3, 4, 5], 2)\\n [4, 5, 1, 2, 3]\\n\\n >>> rotate_array([1, 2, 3, 4, 5], -1)\\n [2, 3, 4, 5, 1]\\n \\\"\\\"\\\"\\n arr_length = len(arr)\\n steps = steps % arr_length # Handle steps larger than array length\\n\\n if steps == 0: # No rotation needed\\n return arr\\n\\n rotated_arr = arr[-steps:] + arr[:-steps] # Split the list and concatenate in the desired order\\n\\n return rotated_arr\\n\\n\\n# Example usage\\narr = [1, 2, 3, 4, 5]\\nsteps = 2\\nrotated_arr = rotate_array(arr, steps)\\nprint(rotated_arr)\\n## Creation\n\n!Creation Approach\n\n* Step 1: Curate a seed set of Python knowledge points. \n\n* Step 2: Embed each seed into a fixed task template to obtain a fixed template's \"Task Prompt,\" which serves as a prompt for a teacher model to generate exercise questions related to the given knowledge point. \n\n* Step 3: Use Camel to refine the \"Task Prompt\" obtained in step 2, in order to achieve more accurate and diverse descriptions. \n\n* Step 4: Input the obtained Task Prompt into a teacher model to generate exercise questions (instructions) corresponding to the knowledge point. \n\n* Step 5: For each exercise question (instruction), leverage a teacher model to generate the corresponding answer. \n\n* Step 6: Assemble each question with its answer and remove duplicates.\n\n\n<a id=\"chinese\"></a>## 简介\n该数据集由2.7万道Python编程练习题(英文)组成,覆盖基础语法与数据结构、算法应用、数据库查询、机器学习等数百个Python相关知识点。\n注意:该数据集是借助Teacher Model和Camel生成,未经严格校验,题目或答案可能存在错误或语义重复,使用时请注意。## 数据字段"
] |
d26de768e6793ecb1d18ec44eeba9e6a34161ed8
|
# Dataset Card for CodeFuse-Evol-instruction-66k
<div align='center'>

[[中文]](#chinese) [[English]](#english)
</div>
<a id="english"></a>
## Dataset Description
Evol-instruction-66k data is based on the method mentioned in the paper "WizardCoder: Empowering Code Large Language Models with Evol-Instruct". It enhances the fine-tuning effect of pre-trained code large models by adding complex code instructions.
This data is processed based on an open-source dataset, which can be found at [Evol-Instruct-Code-80k-v1](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1). The processing includes low-quality filtering, filtering similar data through HumanEval evaluation, etc. After filtering from the original 80k data, we obtain 66k high-quality training and fine-tuning data.
## Creation
<strong>Filtering low-quality data</strong><br>
(1) Filter data with instruction length less than 10 words or greater than 1000 words;<br>
(2) Filter data with output length less than 50 words or greater than 2000 words;<br>
(3) Filter data with no markdown format or multiple markdown formats in the output;<br>
(4) Filter data with less than 3 lines or more than 100 lines of code in the markdown format;<br>
(5) Filter data with a description preceding the markdown format containing more than 200 words.<br>
<strong>Filtering data similar to humaneval</strong><br>
(1) Filter data containing any function name from humaneval;<br>
(2) Using NLTK to remove stop words and punctuation from the docstring of humaneval, obtain the core words such as "sort array prime", etc. Filter data containing more than 40% of the core words from humaneval.<br>
## Structure
````
Instruction:
Execute a multistage computational task consisting of organizing the provided list of numerals in an ascending sequence and then determining the middle, or median, figure from the resultant ordered sequence.
data = [12, 30, 4, 18, 24]
Output:
Here's a Python solution:
```python
data = [12, 30, 4, 18, 24]
# organizing the list in ascending sequence
data.sort()
# Finding the middle figure from the sorted sequence
n = len(data)
if n % 2 == 0:
median = (data[n//2 - 1] + data[n//2]) / 2
else:
median = data[n//2]
print(f\"Sorted Data: {data}\")
print(f\"Median: {median}\")
```
First, we sort the list in ascending order using the `sort()` function. Then, we find the median. If the length of the list is even, the median is the average of the two middle numbers. If the length is odd, the median is the middle number. In this specific case, because the list length is odd (5), the middle value (i.e., the median) is the 3rd value in the sorted list.
````
<a id="chinese"></a>
## 简介
Evol-instruction-66k数据是根据论文《WizardCoder: Empowering Code Large Language
Models with Evol-Instruct》中提到的方法,通过添加复杂的代码指令来增强预训练代码大模型的微调效果。
该数据是在开源数据集[Evol-Instruct-Code-80k-v1](https://huggingface.co/datasets/nickrosh/Evol-Instruct-Code-80k-v1)基础上对数据进行了一系列处理,包括低质量过滤、HumanEval评测相似数据过滤等,从原始80k数据筛选后得到66k高质量训练微调数据。
## 数据生产过程
<strong>过滤低质量数据</strong><br>
(1) 过滤instruction长度小于10个单词或者大于1000个单词的数据;<br>
(2) 过滤output长度小于50个单词或者大于2000个单词的数据;<br>
(3) 过滤output中无markdown格式或者有多个markdown的数据;<br>
(4) 过滤markdown格式中代码少于3行或者大于100行的数据;<br>
(5) 过滤markdown格式前面描述单词大于200个单词的数据。<br>
<strong>过滤与humaneval相似的数据</strong><br>
(1) 过滤包含humaneval中任意函数名的数据;<br>
(2) 采用NLTK去除humaneval的docstring中停用词、标点符号后,得到核心词,比如“sort array prime”等,<br>
过滤包含了humaneval超过40%核心词的数据。<br>
## 数据结构
````
Instruction:
Execute a multistage computational task consisting of organizing the provided list of numerals in an ascending sequence and then determining the middle, or median, figure from the resultant ordered sequence.
data = [12, 30, 4, 18, 24]
Output:
Here's a Python solution:
```python
data = [12, 30, 4, 18, 24]
# organizing the list in ascending sequence
data.sort()
# Finding the middle figure from the sorted sequence
n = len(data)
if n % 2 == 0:
median = (data[n//2 - 1] + data[n//2]) / 2
else:
median = data[n//2]
print(f\"Sorted Data: {data}\")
print(f\"Median: {median}\")
```
First, we sort the list in ascending order using the `sort()` function. Then, we find the median. If the length of the list is even, the median is the average of the two middle numbers. If the length is odd, the median is the middle number. In this specific case, because the list length is odd (5), the middle value (i.e., the median) is the 3rd value in the sorted list.
````
|
codefuse-ai/Evol-instruction-66k
|
[
"license:cc-by-nc-sa-4.0",
"region:us"
] |
2023-09-07T06:48:34+00:00
|
{"license": "cc-by-nc-sa-4.0", "viewer": false}
|
2023-10-23T07:02:12+00:00
|
[] |
[] |
TAGS
#license-cc-by-nc-sa-4.0 #region-us
|
# Dataset Card for CodeFuse-Evol-instruction-66k
<div align='center'>
!logo
[[中文]](#chinese) [[English]](#english)
</div>
<a id="english"></a>
## Dataset Description
Evol-instruction-66k data is based on the method mentioned in the paper "WizardCoder: Empowering Code Large Language Models with Evol-Instruct". It enhances the fine-tuning effect of pre-trained code large models by adding complex code instructions.
This data is processed based on an open-source dataset, which can be found at Evol-Instruct-Code-80k-v1. The processing includes low-quality filtering, filtering similar data through HumanEval evaluation, etc. After filtering from the original 80k data, we obtain 66k high-quality training and fine-tuning data.
## Creation
<strong>Filtering low-quality data</strong><br>
(1) Filter data with instruction length less than 10 words or greater than 1000 words;<br>
(2) Filter data with output length less than 50 words or greater than 2000 words;<br>
(3) Filter data with no markdown format or multiple markdown formats in the output;<br>
(4) Filter data with less than 3 lines or more than 100 lines of code in the markdown format;<br>
(5) Filter data with a description preceding the markdown format containing more than 200 words.<br>
<strong>Filtering data similar to humaneval</strong><br>
(1) Filter data containing any function name from humaneval;<br>
(2) Using NLTK to remove stop words and punctuation from the docstring of humaneval, obtain the core words such as "sort array prime", etc. Filter data containing more than 40% of the core words from humaneval.<br>
## Structure
python
data = [12, 30, 4, 18, 24]
# organizing the list in ascending sequence
URL()
# Finding the middle figure from the sorted sequence
n = len(data)
if n % 2 == 0:
median = (data[n//2 - 1] + data[n//2]) / 2
else:
median = data[n//2]
print(f\"Sorted Data: {data}\")
print(f\"Median: {median}\")
'
<a id="chinese"></a>
## 简介
Evol-instruction-66k数据是根据论文《WizardCoder: Empowering Code Large Language
Models with Evol-Instruct》中提到的方法,通过添加复杂的代码指令来增强预训练代码大模型的微调效果。
该数据是在开源数据集Evol-Instruct-Code-80k-v1基础上对数据进行了一系列处理,包括低质量过滤、HumanEval评测相似数据过滤等,从原始80k数据筛选后得到66k高质量训练微调数据。
## 数据生产过程
<strong>过滤低质量数据</strong><br>
(1) 过滤instruction长度小于10个单词或者大于1000个单词的数据;<br>
(2) 过滤output长度小于50个单词或者大于2000个单词的数据;<br>
(3) 过滤output中无markdown格式或者有多个markdown的数据;<br>
(4) 过滤markdown格式中代码少于3行或者大于100行的数据;<br>
(5) 过滤markdown格式前面描述单词大于200个单词的数据。<br>
<strong>过滤与humaneval相似的数据</strong><br>
(1) 过滤包含humaneval中任意函数名的数据;<br>
(2) 采用NLTK去除humaneval的docstring中停用词、标点符号后,得到核心词,比如“sort array prime”等,<br>
过滤包含了humaneval超过40%核心词的数据。<br>
## 数据结构
python
data = [12, 30, 4, 18, 24]
# organizing the list in ascending sequence
URL()
# Finding the middle figure from the sorted sequence
n = len(data)
if n % 2 == 0:
median = (data[n//2 - 1] + data[n//2]) / 2
else:
median = data[n//2]
print(f\"Sorted Data: {data}\")
print(f\"Median: {median}\")
'
|
[
"# Dataset Card for CodeFuse-Evol-instruction-66k\n\n<div align='center'>\n\n !logo\n\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>",
"## Dataset Description\nEvol-instruction-66k data is based on the method mentioned in the paper \"WizardCoder: Empowering Code Large Language Models with Evol-Instruct\". It enhances the fine-tuning effect of pre-trained code large models by adding complex code instructions.\nThis data is processed based on an open-source dataset, which can be found at Evol-Instruct-Code-80k-v1. The processing includes low-quality filtering, filtering similar data through HumanEval evaluation, etc. After filtering from the original 80k data, we obtain 66k high-quality training and fine-tuning data.",
"## Creation\n<strong>Filtering low-quality data</strong><br>\n (1) Filter data with instruction length less than 10 words or greater than 1000 words;<br>\n (2) Filter data with output length less than 50 words or greater than 2000 words;<br>\n (3) Filter data with no markdown format or multiple markdown formats in the output;<br>\n (4) Filter data with less than 3 lines or more than 100 lines of code in the markdown format;<br>\n (5) Filter data with a description preceding the markdown format containing more than 200 words.<br>\n<strong>Filtering data similar to humaneval</strong><br>\n (1) Filter data containing any function name from humaneval;<br>\n (2) Using NLTK to remove stop words and punctuation from the docstring of humaneval, obtain the core words such as \"sort array prime\", etc. Filter data containing more than 40% of the core words from humaneval.<br>",
"## Structure\npython\n data = [12, 30, 4, 18, 24]\n # organizing the list in ascending sequence\n URL()\n # Finding the middle figure from the sorted sequence\n n = len(data)\n if n % 2 == 0:\n median = (data[n//2 - 1] + data[n//2]) / 2\n else:\n median = data[n//2]\n \n print(f\\\"Sorted Data: {data}\\\")\n print(f\\\"Median: {median}\\\")\n '\n<a id=\"chinese\"></a>",
"## 简介\nEvol-instruction-66k数据是根据论文《WizardCoder: Empowering Code Large Language\nModels with Evol-Instruct》中提到的方法,通过添加复杂的代码指令来增强预训练代码大模型的微调效果。\n该数据是在开源数据集Evol-Instruct-Code-80k-v1基础上对数据进行了一系列处理,包括低质量过滤、HumanEval评测相似数据过滤等,从原始80k数据筛选后得到66k高质量训练微调数据。",
"## 数据生产过程\n<strong>过滤低质量数据</strong><br>\n (1) 过滤instruction长度小于10个单词或者大于1000个单词的数据;<br>\n (2) 过滤output长度小于50个单词或者大于2000个单词的数据;<br>\n (3) 过滤output中无markdown格式或者有多个markdown的数据;<br>\n (4) 过滤markdown格式中代码少于3行或者大于100行的数据;<br>\n (5) 过滤markdown格式前面描述单词大于200个单词的数据。<br>\n<strong>过滤与humaneval相似的数据</strong><br>\n (1) 过滤包含humaneval中任意函数名的数据;<br>\n (2) 采用NLTK去除humaneval的docstring中停用词、标点符号后,得到核心词,比如“sort array prime”等,<br>\n 过滤包含了humaneval超过40%核心词的数据。<br>",
"## 数据结构\npython\n data = [12, 30, 4, 18, 24]\n # organizing the list in ascending sequence\n URL()\n # Finding the middle figure from the sorted sequence\n n = len(data)\n if n % 2 == 0:\n median = (data[n//2 - 1] + data[n//2]) / 2\n else:\n median = data[n//2]\n \n print(f\\\"Sorted Data: {data}\\\")\n print(f\\\"Median: {median}\\\")\n '"
] |
[
"TAGS\n#license-cc-by-nc-sa-4.0 #region-us \n",
"# Dataset Card for CodeFuse-Evol-instruction-66k\n\n<div align='center'>\n\n !logo\n\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>",
"## Dataset Description\nEvol-instruction-66k data is based on the method mentioned in the paper \"WizardCoder: Empowering Code Large Language Models with Evol-Instruct\". It enhances the fine-tuning effect of pre-trained code large models by adding complex code instructions.\nThis data is processed based on an open-source dataset, which can be found at Evol-Instruct-Code-80k-v1. The processing includes low-quality filtering, filtering similar data through HumanEval evaluation, etc. After filtering from the original 80k data, we obtain 66k high-quality training and fine-tuning data.",
"## Creation\n<strong>Filtering low-quality data</strong><br>\n (1) Filter data with instruction length less than 10 words or greater than 1000 words;<br>\n (2) Filter data with output length less than 50 words or greater than 2000 words;<br>\n (3) Filter data with no markdown format or multiple markdown formats in the output;<br>\n (4) Filter data with less than 3 lines or more than 100 lines of code in the markdown format;<br>\n (5) Filter data with a description preceding the markdown format containing more than 200 words.<br>\n<strong>Filtering data similar to humaneval</strong><br>\n (1) Filter data containing any function name from humaneval;<br>\n (2) Using NLTK to remove stop words and punctuation from the docstring of humaneval, obtain the core words such as \"sort array prime\", etc. Filter data containing more than 40% of the core words from humaneval.<br>",
"## Structure\npython\n data = [12, 30, 4, 18, 24]\n # organizing the list in ascending sequence\n URL()\n # Finding the middle figure from the sorted sequence\n n = len(data)\n if n % 2 == 0:\n median = (data[n//2 - 1] + data[n//2]) / 2\n else:\n median = data[n//2]\n \n print(f\\\"Sorted Data: {data}\\\")\n print(f\\\"Median: {median}\\\")\n '\n<a id=\"chinese\"></a>",
"## 简介\nEvol-instruction-66k数据是根据论文《WizardCoder: Empowering Code Large Language\nModels with Evol-Instruct》中提到的方法,通过添加复杂的代码指令来增强预训练代码大模型的微调效果。\n该数据是在开源数据集Evol-Instruct-Code-80k-v1基础上对数据进行了一系列处理,包括低质量过滤、HumanEval评测相似数据过滤等,从原始80k数据筛选后得到66k高质量训练微调数据。",
"## 数据生产过程\n<strong>过滤低质量数据</strong><br>\n (1) 过滤instruction长度小于10个单词或者大于1000个单词的数据;<br>\n (2) 过滤output长度小于50个单词或者大于2000个单词的数据;<br>\n (3) 过滤output中无markdown格式或者有多个markdown的数据;<br>\n (4) 过滤markdown格式中代码少于3行或者大于100行的数据;<br>\n (5) 过滤markdown格式前面描述单词大于200个单词的数据。<br>\n<strong>过滤与humaneval相似的数据</strong><br>\n (1) 过滤包含humaneval中任意函数名的数据;<br>\n (2) 采用NLTK去除humaneval的docstring中停用词、标点符号后,得到核心词,比如“sort array prime”等,<br>\n 过滤包含了humaneval超过40%核心词的数据。<br>",
"## 数据结构\npython\n data = [12, 30, 4, 18, 24]\n # organizing the list in ascending sequence\n URL()\n # Finding the middle figure from the sorted sequence\n n = len(data)\n if n % 2 == 0:\n median = (data[n//2 - 1] + data[n//2]) / 2\n else:\n median = data[n//2]\n \n print(f\\\"Sorted Data: {data}\\\")\n print(f\\\"Median: {median}\\\")\n '"
] |
[
19,
57,
145,
215,
130,
119,
229,
120
] |
[
"passage: TAGS\n#license-cc-by-nc-sa-4.0 #region-us \n# Dataset Card for CodeFuse-Evol-instruction-66k\n\n<div align='center'>\n\n !logo\n\n\n[[中文]](#chinese) [[English]](#english)\n\n</div>\n\n<a id=\"english\"></a>## Dataset Description\nEvol-instruction-66k data is based on the method mentioned in the paper \"WizardCoder: Empowering Code Large Language Models with Evol-Instruct\". It enhances the fine-tuning effect of pre-trained code large models by adding complex code instructions.\nThis data is processed based on an open-source dataset, which can be found at Evol-Instruct-Code-80k-v1. The processing includes low-quality filtering, filtering similar data through HumanEval evaluation, etc. After filtering from the original 80k data, we obtain 66k high-quality training and fine-tuning data.## Creation\n<strong>Filtering low-quality data</strong><br>\n (1) Filter data with instruction length less than 10 words or greater than 1000 words;<br>\n (2) Filter data with output length less than 50 words or greater than 2000 words;<br>\n (3) Filter data with no markdown format or multiple markdown formats in the output;<br>\n (4) Filter data with less than 3 lines or more than 100 lines of code in the markdown format;<br>\n (5) Filter data with a description preceding the markdown format containing more than 200 words.<br>\n<strong>Filtering data similar to humaneval</strong><br>\n (1) Filter data containing any function name from humaneval;<br>\n (2) Using NLTK to remove stop words and punctuation from the docstring of humaneval, obtain the core words such as \"sort array prime\", etc. Filter data containing more than 40% of the core words from humaneval.<br>"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.