
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
| tokens_length
listlengths 1
353
| input_texts
listlengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
67df84eb03d5c8072c9ae4e0016c54b958277c9b
|
# Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aminlouhichi/test
|
[
"region:us"
] |
2023-10-23T08:36:17+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 27904115.0, "num_examples": 128}, {"name": "validation", "num_bytes": 5016141.0, "num_examples": 22}, {"name": "test", "num_bytes": 5016141.0, "num_examples": 22}], "download_size": 35791518, "dataset_size": 37936397.0}}
|
2023-11-07T09:36:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test"
More Information needed
|
[
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test\"\n\nMore Information needed"
] |
1493e9e0395b0961f00498841a45ffb3838f1459
|
1000 images at 768x768 of 3 octaves of Perlin noise, at various brightness and contrast levels. eg:




|
damian0815/perlin-1k
|
[
"size_categories:n<1K",
"license:mit",
"region:us"
] |
2023-10-23T08:37:12+00:00
|
{"license": "mit", "size_categories": ["n<1K"]}
|
2023-10-23T08:52:31+00:00
|
[] |
[] |
TAGS
#size_categories-n<1K #license-mit #region-us
|
1000 images at 768x768 of 3 octaves of Perlin noise, at various brightness and contrast levels. eg:
!sample 1
!sample 2
!sample 3
!sample 4
|
[] |
[
"TAGS\n#size_categories-n<1K #license-mit #region-us \n"
] |
[
21
] |
[
"passage: TAGS\n#size_categories-n<1K #license-mit #region-us \n"
] |
9264b76e008f34f3207a6749f5cd44884cf1267b
|
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed]
|
Ahmed167/floor_plans_cleaned
|
[
"region:us"
] |
2023-10-23T08:37:46+00:00
|
{}
|
2023-10-23T08:39:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
|
[
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
6,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
a74505240dbd1b8fdd05e93d9bbadcc83b210774
|
# The Pile -- NIHExPorter (refined by Data-Juicer)
A refined version of NIHExPorter dataset in The Pile by [Data-Juicer](https://github.com/alibaba/data-juicer). Removing some "bad" samples from the original dataset to make it higher-quality.
This dataset is usually used to pretrain a Large Language Model.
**Notice**: Here is a small subset for previewing. The whole dataset is available [here](https://dail-wlcb.oss-cn-wulanchabu.aliyuncs.com/LLM_data/our_refined_datasets/pretraining/the-pile-hin-refine-result.jsonl) (About 2.0G).
## Dataset Information
- Number of samples: 858,492 (Keep ~91.36% from the original dataset)
## Refining Recipe
```yaml
# global parameters
project_name: 'Data-Juicer-recipes-Hin'
dataset_path: '/path/to/your/dataset' # path to your dataset directory or file
export_path: '/path/to/your/dataset.jsonl'
np: 50 # number of subprocess to process your dataset
open_tracer: true
# process schedule
# a list of several process operators with their arguments
process:
- clean_email_mapper:
- clean_links_mapper:
- fix_unicode_mapper:
- punctuation_normalization_mapper:
- whitespace_normalization_mapper:
- alphanumeric_filter:
tokenization: false
min_ratio: 0.75 # <3sigma (0.800)
max_ratio: 0.866
- average_line_length_filter:
max_len: 10000 # >3sigma (5425)
- character_repetition_filter:
rep_len: 10
max_ratio: 0.2 # >3sigma (0.127)
- flagged_words_filter:
lang: en
tokenization: true
max_ratio: 0.0003 # 3sigma
- language_id_score_filter:
min_score: 0.7
- perplexity_filter:
lang: en
max_ppl: 1669 #(3sigma)
- special_characters_filter:
max_ratio: 0.3 # > 3sigma (0.218)
- words_num_filter:
tokenization: true
min_num: 20
max_num: 2000
- word_repetition_filter:
lang: en
tokenization: true
rep_len: 10
max_ratio: 0.104 # 3sigma
- document_simhash_deduplicator:
tokenization: space
window_size: 6
lowercase: true
ignore_pattern: '\p{P}'
num_blocks: 6
hamming_distance: 4
```
|
datajuicer/the-pile-nih-refined-by-data-juicer
|
[
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:en",
"license:apache-2.0",
"data-juicer",
"pretraining",
"region:us"
] |
2023-10-23T08:38:24+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["100K<n<1M"], "task_categories": ["text-generation"], "tags": ["data-juicer", "pretraining"]}
|
2023-10-23T08:46:07+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-100K<n<1M #language-English #license-apache-2.0 #data-juicer #pretraining #region-us
|
# The Pile -- NIHExPorter (refined by Data-Juicer)
A refined version of NIHExPorter dataset in The Pile by Data-Juicer. Removing some "bad" samples from the original dataset to make it higher-quality.
This dataset is usually used to pretrain a Large Language Model.
Notice: Here is a small subset for previewing. The whole dataset is available here (About 2.0G).
## Dataset Information
- Number of samples: 858,492 (Keep ~91.36% from the original dataset)
## Refining Recipe
|
[
"# The Pile -- NIHExPorter (refined by Data-Juicer)\n\nA refined version of NIHExPorter dataset in The Pile by Data-Juicer. Removing some \"bad\" samples from the original dataset to make it higher-quality.\n\nThis dataset is usually used to pretrain a Large Language Model.\n\nNotice: Here is a small subset for previewing. The whole dataset is available here (About 2.0G).",
"## Dataset Information\n\n- Number of samples: 858,492 (Keep ~91.36% from the original dataset)",
"## Refining Recipe"
] |
[
"TAGS\n#task_categories-text-generation #size_categories-100K<n<1M #language-English #license-apache-2.0 #data-juicer #pretraining #region-us \n",
"# The Pile -- NIHExPorter (refined by Data-Juicer)\n\nA refined version of NIHExPorter dataset in The Pile by Data-Juicer. Removing some \"bad\" samples from the original dataset to make it higher-quality.\n\nThis dataset is usually used to pretrain a Large Language Model.\n\nNotice: Here is a small subset for previewing. The whole dataset is available here (About 2.0G).",
"## Dataset Information\n\n- Number of samples: 858,492 (Keep ~91.36% from the original dataset)",
"## Refining Recipe"
] |
[
49,
107,
27,
4
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-100K<n<1M #language-English #license-apache-2.0 #data-juicer #pretraining #region-us \n# The Pile -- NIHExPorter (refined by Data-Juicer)\n\nA refined version of NIHExPorter dataset in The Pile by Data-Juicer. Removing some \"bad\" samples from the original dataset to make it higher-quality.\n\nThis dataset is usually used to pretrain a Large Language Model.\n\nNotice: Here is a small subset for previewing. The whole dataset is available here (About 2.0G).## Dataset Information\n\n- Number of samples: 858,492 (Keep ~91.36% from the original dataset)## Refining Recipe"
] |
8d9706058425553c430d7e3f85d7df645d1d7a79
|
# Dataset Card for "vehicle-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
roupenminassian/vehicle-dataset
|
[
"region:us"
] |
2023-10-23T08:39:23+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "image_id", "dtype": "int64"}, {"name": "width", "dtype": "int64"}, {"name": "height", "dtype": "int64"}, {"name": "objects", "struct": [{"name": "id", "sequence": "int64"}, {"name": "area", "sequence": "float64"}, {"name": "bbox", "sequence": {"sequence": "float64"}}, {"name": "category", "sequence": "int64"}]}], "splits": [{"name": "train", "num_bytes": 74749784.0, "num_examples": 618}], "download_size": 74708626, "dataset_size": 74749784.0}}
|
2023-10-23T08:40:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "vehicle-dataset"
More Information needed
|
[
"# Dataset Card for \"vehicle-dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"vehicle-dataset\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"vehicle-dataset\"\n\nMore Information needed"
] |
f723e1f9bbce76ccc3a6a7ad88a38d0e66741b2b
|
This is a dataset that was created to re-train [REBEL](https://github.com/Babelscape/rebel) to work better for the Portuguese language.
This dataset was generated using [CROCODILE](https://github.com/Babelscape/crocodile), which was adapted to use a Portuguese specific model (pt_core_news_sm) instead of their default multi-language model (xx_ent_wiki_sm).
The dataset comes with a train, test, dev and train_dev splits. The train_dev split accounts for 80% of the dataset with the remaining 20% being the training data. The train and dev split was generated from the 80% train_dev data which was further split into an 80/20.
The split for the dataset ends up being:
* Train_dev -> 80% of the data
* Test -> 20% of the data
* Train -> 64% of the data
* Dev -> 16% of the data
|
grsilva/rebel_portuguese
|
[
"language:pt",
"license:mit",
"region:us"
] |
2023-10-23T08:40:44+00:00
|
{"language": ["pt"], "license": "mit", "pretty_name": "rebel_pt"}
|
2023-10-23T17:11:26+00:00
|
[] |
[
"pt"
] |
TAGS
#language-Portuguese #license-mit #region-us
|
This is a dataset that was created to re-train REBEL to work better for the Portuguese language.
This dataset was generated using CROCODILE, which was adapted to use a Portuguese specific model (pt_core_news_sm) instead of their default multi-language model (xx_ent_wiki_sm).
The dataset comes with a train, test, dev and train_dev splits. The train_dev split accounts for 80% of the dataset with the remaining 20% being the training data. The train and dev split was generated from the 80% train_dev data which was further split into an 80/20.
The split for the dataset ends up being:
* Train_dev -> 80% of the data
* Test -> 20% of the data
* Train -> 64% of the data
* Dev -> 16% of the data
|
[] |
[
"TAGS\n#language-Portuguese #license-mit #region-us \n"
] |
[
17
] |
[
"passage: TAGS\n#language-Portuguese #license-mit #region-us \n"
] |
bb5d871bf0e07e38eae95faa2b8a8dc2914fa946
|
# Dataset Card for "ideal-girlfriend"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Arsture/ideal-girlfriend
|
[
"region:us"
] |
2023-10-23T08:47:47+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 36234, "num_examples": 88}], "download_size": 10043, "dataset_size": 36234}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T09:30:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ideal-girlfriend"
More Information needed
|
[
"# Dataset Card for \"ideal-girlfriend\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ideal-girlfriend\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ideal-girlfriend\"\n\nMore Information needed"
] |
fe1f4f64f8bdec10c32895198d6fb5a42b227fab
|
# Dataset Card for "SECOND_RETRIEVE_PROCESSED_150"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jjonhwa/SECOND_RETRIEVE_PROCESSED_150
|
[
"region:us"
] |
2023-10-23T08:55:41+00:00
|
{"dataset_info": {"features": [{"name": "ctxs", "list": [{"name": "score", "dtype": "float64"}, {"name": "text", "dtype": "string"}]}, {"name": "summary", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 143544172, "num_examples": 30979}], "download_size": 69158772, "dataset_size": 143544172}}
|
2023-10-23T08:55:51+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "SECOND_RETRIEVE_PROCESSED_150"
More Information needed
|
[
"# Dataset Card for \"SECOND_RETRIEVE_PROCESSED_150\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"SECOND_RETRIEVE_PROCESSED_150\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"SECOND_RETRIEVE_PROCESSED_150\"\n\nMore Information needed"
] |
dbeaff0a001a316e485d592beb7a4b082e15185d
|
# Dataset Card for "embedded_ner_tokens"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
getawayfrommeXD/embedded_ner_tokens
|
[
"region:us"
] |
2023-10-23T09:03:08+00:00
|
{"dataset_info": {"features": [{"name": "word", "dtype": "string"}, {"name": "label", "dtype": "string"}, {"name": "OOV", "dtype": "bool"}, {"name": "embedding", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 248048533, "num_examples": 203621}, {"name": "validation", "num_bytes": 62568404, "num_examples": 51362}, {"name": "test", "num_bytes": 56564938, "num_examples": 46435}], "download_size": 130105515, "dataset_size": 367181875}}
|
2023-10-23T09:03:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "embedded_ner_tokens"
More Information needed
|
[
"# Dataset Card for \"embedded_ner_tokens\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"embedded_ner_tokens\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"embedded_ner_tokens\"\n\nMore Information needed"
] |
ec03cbb69686266ad7ef01d2298164c0ddcbcb28
|
Visuelle 2.0
https://arxiv.org/abs/2204.06972
|
qgyd2021/visuelle2
|
[
"size_categories:100M<n<1B",
"arxiv:2204.06972",
"region:us"
] |
2023-10-23T09:14:09+00:00
|
{"size_categories": ["100M<n<1B"]}
|
2023-10-23T09:15:16+00:00
|
[
"2204.06972"
] |
[] |
TAGS
#size_categories-100M<n<1B #arxiv-2204.06972 #region-us
|
Visuelle 2.0
URL
|
[] |
[
"TAGS\n#size_categories-100M<n<1B #arxiv-2204.06972 #region-us \n"
] |
[
27
] |
[
"passage: TAGS\n#size_categories-100M<n<1B #arxiv-2204.06972 #region-us \n"
] |
57906fbd3e2ec529a202a0d66ce1a01c7e7ecf84
|
# Dataset Card for "llava-pretrain"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
theblackcat102/llava-pretrain
|
[
"region:us"
] |
2023-10-23T09:14:11+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "conversations", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 32172470547.488, "num_examples": 558128}], "download_size": 27759109881, "dataset_size": 32172470547.488}}
|
2023-10-23T09:57:17+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llava-pretrain"
More Information needed
|
[
"# Dataset Card for \"llava-pretrain\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llava-pretrain\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llava-pretrain\"\n\nMore Information needed"
] |
94291402d3ef87df387a429767821451d69ae886
|
# Dataset Card for "pubchem_enamine_dedup"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
phanvancongthanh/pubchem_enamine_dedup
|
[
"region:us"
] |
2023-10-23T09:17:17+00:00
|
{"dataset_info": {"features": [{"name": "standardized_smiles", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 47338232, "num_examples": 906545}], "download_size": 24899243, "dataset_size": 47338232}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-24T07:56:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pubchem_enamine_dedup"
More Information needed
|
[
"# Dataset Card for \"pubchem_enamine_dedup\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pubchem_enamine_dedup\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pubchem_enamine_dedup\"\n\nMore Information needed"
] |
50fb35e5c54124e375972f291ed1fb7abc321967
|
# AmQA: Amharic Question Answering Dataset
Amharic question and answer dataset in a prompt and completion format.
## Dataset Details
In Amharic, interrogative sentences can be formulated using information-seeking pronouns like “ምን” (what), “መቼ” (when), “ማን” (who), “የት” (where), “የትኛው” (which), etc. and prepositional interrogative phrases like “ለምን” [ለ-ምን] (why), “በምን” [በ-ምን] (by what), etc. Besides, a verb phrase could be used to pose questions (Getahun 2013; Baye 2009). As shown bellow, the AmQA dataset contains context, question, and answer triplets. The contexts are articles collected from Amharic Wikipedia dump file. The question-answer pairs are created by crowdsourcing and annotated using the Haystack QA annotation tool. 2628 question and answer pairs are created from 378 documents. The whole AmQA dataset can be found here. We also split the datset into train, dev, and test with a size of 1728, 600, and 300 respectively.
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Repository:** [https://github.com/semantic-systems/amharic-qa]
- **Paper [optional]:** [https://arxiv.org/abs/2303.03290]
- **Curated by:** [Tilahun Abedissa, Ricardo Usbeck, Yaregal Assabie]
- **Language(s) (NLP):** [Amharic]
- **License:** [MIT]
## Dataset Structure
The dataset is classified into 70% train, 20% test, and 10% dev datasets.
The dataset is restructured in a new JSON format of the following:
```
formatted_json = {
"inputs": "ከዚህ በታች በተገለጸው አውድ ተከታዩን ጥያቄ ይመልሱ፡ {context} {question}",
"targets": "ከጥያቄው ጋር የሚስማማው ምላሽ {answer_text} ነው።",
"inputs": "ከዚህ በታች ያለውን ዝርዝር መረጃ በመጠቀም ለሚከተለው ጥያቄ መልስ ይስጡ፡ {context} {question}",
"targets": "ከጥያቄው አንጻር ትክክለኛው መልስ {answer_text} ነው።",
"inputs": "ከዚህ በታች ያለውን ጽሑፍ በማጣቀስ እባክዎን ለሚከተለው መልስ ይስጡ {context} {question}",
"targets": "ለጥያቄው መልስ {answer_text} ነው።",
"inputs": "የተሰጠውን ጥያቄ ለመመለስ ከዚህ በታች የቀረበውን መረጃ ይመልከቱ፡ {context} {question}",
"targets": "ለተጠቀሰው ጥያቄ ትክክለኛው ምላሽ {answer_text} ነው።",
"inputs": "ለሚከተለው ጥያቄ ምላሽ ለመስጠት ከዚህ በታች የቀረበውን አውድ ተጠቀም፡ {context} {question}",
"targets": "ለጥያቄው መልሱ {answer_text} ነው።",
"inputs": "የተሰጠውን ጥያቄ ከዚህ በታች በተሰጠው አውድ መሰረት መልሱ፡ {context} {question}",
"targets": "ለጥያቄው ትክክለኛው ምላሽ {answer_text} ነው።"
}
```
## Citation
**BibTeX:**
```
[@misc{abedissa2023amqa,
title={AmQA: Amharic Question Answering Dataset},
author={Tilahun Abedissa and Ricardo Usbeck and Yaregal Assabie},
year={2023},
eprint={2303.03290},
archivePrefix={arXiv},
primaryClass={cs.CL}
}]
```
|
Henok/amharic-qa
|
[
"task_categories:question-answering",
"size_categories:1K<n<10K",
"language:am",
"license:mit",
"arxiv:2303.03290",
"region:us"
] |
2023-10-23T09:25:52+00:00
|
{"language": ["am"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["question-answering"]}
|
2023-12-20T19:33:47+00:00
|
[
"2303.03290"
] |
[
"am"
] |
TAGS
#task_categories-question-answering #size_categories-1K<n<10K #language-Amharic #license-mit #arxiv-2303.03290 #region-us
|
# AmQA: Amharic Question Answering Dataset
Amharic question and answer dataset in a prompt and completion format.
## Dataset Details
In Amharic, interrogative sentences can be formulated using information-seeking pronouns like “ምን” (what), “መቼ” (when), “ማን” (who), “የት” (where), “የትኛው” (which), etc. and prepositional interrogative phrases like “ለምን” [ለ-ምን] (why), “በምን” [በ-ምን] (by what), etc. Besides, a verb phrase could be used to pose questions (Getahun 2013; Baye 2009). As shown bellow, the AmQA dataset contains context, question, and answer triplets. The contexts are articles collected from Amharic Wikipedia dump file. The question-answer pairs are created by crowdsourcing and annotated using the Haystack QA annotation tool. 2628 question and answer pairs are created from 378 documents. The whole AmQA dataset can be found here. We also split the datset into train, dev, and test with a size of 1728, 600, and 300 respectively.
### Dataset Sources
- Repository: [URL
- Paper [optional]: [URL
- Curated by: [Tilahun Abedissa, Ricardo Usbeck, Yaregal Assabie]
- Language(s) (NLP): [Amharic]
- License: [MIT]
## Dataset Structure
The dataset is classified into 70% train, 20% test, and 10% dev datasets.
The dataset is restructured in a new JSON format of the following:
BibTeX:
|
[
"# AmQA: Amharic Question Answering Dataset\n\n\nAmharic question and answer dataset in a prompt and completion format.",
"## Dataset Details\n\nIn Amharic, interrogative sentences can be formulated using information-seeking pronouns like “ምን” (what), “መቼ” (when), “ማን” (who), “የት” (where), “የትኛው” (which), etc. and prepositional interrogative phrases like “ለምን” [ለ-ምን] (why), “በምን” [በ-ምን] (by what), etc. Besides, a verb phrase could be used to pose questions (Getahun 2013; Baye 2009). As shown bellow, the AmQA dataset contains context, question, and answer triplets. The contexts are articles collected from Amharic Wikipedia dump file. The question-answer pairs are created by crowdsourcing and annotated using the Haystack QA annotation tool. 2628 question and answer pairs are created from 378 documents. The whole AmQA dataset can be found here. We also split the datset into train, dev, and test with a size of 1728, 600, and 300 respectively.",
"### Dataset Sources\n\n\n\n- Repository: [URL\n- Paper [optional]: [URL\n\n- Curated by: [Tilahun Abedissa, Ricardo Usbeck, Yaregal Assabie]\n- Language(s) (NLP): [Amharic]\n- License: [MIT]",
"## Dataset Structure\nThe dataset is classified into 70% train, 20% test, and 10% dev datasets.\n\nThe dataset is restructured in a new JSON format of the following: \n\n\nBibTeX:"
] |
[
"TAGS\n#task_categories-question-answering #size_categories-1K<n<10K #language-Amharic #license-mit #arxiv-2303.03290 #region-us \n",
"# AmQA: Amharic Question Answering Dataset\n\n\nAmharic question and answer dataset in a prompt and completion format.",
"## Dataset Details\n\nIn Amharic, interrogative sentences can be formulated using information-seeking pronouns like “ምን” (what), “መቼ” (when), “ማን” (who), “የት” (where), “የትኛው” (which), etc. and prepositional interrogative phrases like “ለምን” [ለ-ምን] (why), “በምን” [በ-ምን] (by what), etc. Besides, a verb phrase could be used to pose questions (Getahun 2013; Baye 2009). As shown bellow, the AmQA dataset contains context, question, and answer triplets. The contexts are articles collected from Amharic Wikipedia dump file. The question-answer pairs are created by crowdsourcing and annotated using the Haystack QA annotation tool. 2628 question and answer pairs are created from 378 documents. The whole AmQA dataset can be found here. We also split the datset into train, dev, and test with a size of 1728, 600, and 300 respectively.",
"### Dataset Sources\n\n\n\n- Repository: [URL\n- Paper [optional]: [URL\n\n- Curated by: [Tilahun Abedissa, Ricardo Usbeck, Yaregal Assabie]\n- Language(s) (NLP): [Amharic]\n- License: [MIT]",
"## Dataset Structure\nThe dataset is classified into 70% train, 20% test, and 10% dev datasets.\n\nThe dataset is restructured in a new JSON format of the following: \n\n\nBibTeX:"
] |
[
49,
24,
232,
66,
48
] |
[
"passage: TAGS\n#task_categories-question-answering #size_categories-1K<n<10K #language-Amharic #license-mit #arxiv-2303.03290 #region-us \n# AmQA: Amharic Question Answering Dataset\n\n\nAmharic question and answer dataset in a prompt and completion format.## Dataset Details\n\nIn Amharic, interrogative sentences can be formulated using information-seeking pronouns like “ምን” (what), “መቼ” (when), “ማን” (who), “የት” (where), “የትኛው” (which), etc. and prepositional interrogative phrases like “ለምን” [ለ-ምን] (why), “በምን” [በ-ምን] (by what), etc. Besides, a verb phrase could be used to pose questions (Getahun 2013; Baye 2009). As shown bellow, the AmQA dataset contains context, question, and answer triplets. The contexts are articles collected from Amharic Wikipedia dump file. The question-answer pairs are created by crowdsourcing and annotated using the Haystack QA annotation tool. 2628 question and answer pairs are created from 378 documents. The whole AmQA dataset can be found here. We also split the datset into train, dev, and test with a size of 1728, 600, and 300 respectively.### Dataset Sources\n\n\n\n- Repository: [URL\n- Paper [optional]: [URL\n\n- Curated by: [Tilahun Abedissa, Ricardo Usbeck, Yaregal Assabie]\n- Language(s) (NLP): [Amharic]\n- License: [MIT]## Dataset Structure\nThe dataset is classified into 70% train, 20% test, and 10% dev datasets.\n\nThe dataset is restructured in a new JSON format of the following: \n\n\nBibTeX:"
] |
1dea679d616dbfda540d57f2276f145efa18a3de
|
# Dataset Card for "ideal-girlfriend2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Arsture/ideal-girlfriend2
|
[
"region:us"
] |
2023-10-23T09:31:26+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 36234, "num_examples": 88}], "download_size": 10043, "dataset_size": 36234}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T09:31:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ideal-girlfriend2"
More Information needed
|
[
"# Dataset Card for \"ideal-girlfriend2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ideal-girlfriend2\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ideal-girlfriend2\"\n\nMore Information needed"
] |
25a4e2811a829d37ae4ddf7db4becf09d891800c
|
# Dataset Card for "car-driving-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
zhangyi617/car-driving-dataset
|
[
"region:us"
] |
2023-10-23T09:37:47+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1715614.0, "num_examples": 16}], "download_size": 1716794, "dataset_size": 1715614.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T11:46:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "car-driving-dataset"
More Information needed
|
[
"# Dataset Card for \"car-driving-dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"car-driving-dataset\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"car-driving-dataset\"\n\nMore Information needed"
] |
41924c35076d97f53450a9da73209df66f3cbff7
|
# Dataset Card for "celebrity_art_prompts"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Falah/celebrity_art_prompts
|
[
"region:us"
] |
2023-10-23T09:48:19+00:00
|
{"dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 163783, "num_examples": 1000}], "download_size": 32791, "dataset_size": 163783}}
|
2023-10-23T10:03:56+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "celebrity_art_prompts"
More Information needed
|
[
"# Dataset Card for \"celebrity_art_prompts\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"celebrity_art_prompts\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"celebrity_art_prompts\"\n\nMore Information needed"
] |
b83282ea0619ddcccc0fe05c6922a35fb80a6d23
|
# Dataset Card for "cvt2_GS3_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fun1021183/cvt2_GS3_1
|
[
"region:us"
] |
2023-10-23T09:49:33+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1131317391.0, "num_examples": 8100}, {"name": "test", "num_bytes": 2796623.0, "num_examples": 20}], "download_size": 1073448506, "dataset_size": 1134114014.0}}
|
2023-10-23T09:51:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cvt2_GS3_1"
More Information needed
|
[
"# Dataset Card for \"cvt2_GS3_1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cvt2_GS3_1\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cvt2_GS3_1\"\n\nMore Information needed"
] |
96f2c07ab15c7570cadbe4ef3cf660feb8c26c34
|
# Dataset Card for "cvt2_GS3_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fun1021183/cvt2_GS3_2
|
[
"region:us"
] |
2023-10-23T09:56:18+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 540743793.3, "num_examples": 3900}, {"name": "test", "num_bytes": 332492834.56, "num_examples": 2480}], "download_size": 787636091, "dataset_size": 873236627.8599999}}
|
2023-10-23T09:57:45+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cvt2_GS3_2"
More Information needed
|
[
"# Dataset Card for \"cvt2_GS3_2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cvt2_GS3_2\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cvt2_GS3_2\"\n\nMore Information needed"
] |
b7217539c85dcfa25962211cdc609f738ee50fea
|
# Dataset Card for "cvt2_GS3_3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fun1021183/cvt2_GS3_3
|
[
"region:us"
] |
2023-10-23T10:00:45+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 168383363.336, "num_examples": 1258}, {"name": "test", "num_bytes": 303296888.792, "num_examples": 2222}], "download_size": 471343711, "dataset_size": 471680252.128}}
|
2023-10-23T10:03:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cvt2_GS3_3"
More Information needed
|
[
"# Dataset Card for \"cvt2_GS3_3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cvt2_GS3_3\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cvt2_GS3_3\"\n\nMore Information needed"
] |
c4184398d0ae9bb4f2c317f7b2b92fd4a08d9ba4
|
# Dataset Card for "llama-2-clinc-test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Luciya/llama-2-clinc-test
|
[
"region:us"
] |
2023-10-23T10:11:31+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 10464310, "num_examples": 4468}], "download_size": 986893, "dataset_size": 10464310}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T10:11:34+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llama-2-clinc-test"
More Information needed
|
[
"# Dataset Card for \"llama-2-clinc-test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llama-2-clinc-test\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llama-2-clinc-test\"\n\nMore Information needed"
] |
d3323c7af6701dc2c2ccafc3b7916d8088061b76
|
# Dataset Card for "llama-2-clinc-train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Luciya/llama-2-clinc-train
|
[
"region:us"
] |
2023-10-23T10:12:26+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 10464310, "num_examples": 4468}], "download_size": 986893, "dataset_size": 10464310}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T10:12:30+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llama-2-clinc-train"
More Information needed
|
[
"# Dataset Card for \"llama-2-clinc-train\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llama-2-clinc-train\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llama-2-clinc-train\"\n\nMore Information needed"
] |
f5cc0b2c2418b7f74f2830af5b4d2944eaf59b96
|
# Dataset Card for "cvt2_GS3_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
fun1021183/cvt2_GS3_0
|
[
"region:us"
] |
2023-10-23T10:13:07+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1832280306.75, "num_examples": 13258}, {"name": "test", "num_bytes": 640923801.75, "num_examples": 4722}], "download_size": 2373732866, "dataset_size": 2473204108.5}}
|
2023-10-23T10:16:57+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cvt2_GS3_0"
More Information needed
|
[
"# Dataset Card for \"cvt2_GS3_0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cvt2_GS3_0\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cvt2_GS3_0\"\n\nMore Information needed"
] |
ee63e205347501981d94c1c4f1ffb3b3770816d1
|
# Dataset Card for "LLM5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Mihir1108/LLM5
|
[
"region:us"
] |
2023-10-23T10:14:11+00:00
|
{"dataset_info": {"features": [{"name": "index", "dtype": "float64"}, {"name": "input", "dtype": "string"}, {"name": "json", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1263320, "num_examples": 485}], "download_size": 480672, "dataset_size": 1263320}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T10:14:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "LLM5"
More Information needed
|
[
"# Dataset Card for \"LLM5\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"LLM5\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"LLM5\"\n\nMore Information needed"
] |
0e744d97c40907a757b4262aa0fc40cd684ff2ed
|
What sets PhytAge Labs MycoSoothe apart is its proactive approach—it doesn't just eliminate existing fungus; it strives to prevent its unwelcome return. This means enduring relief and newfound confidence in your daily life. Keep in mind that individual experiences may vary, but with MycoSoothe, you're taking a positive step towards healthier, fungus-free skin, hair, and nails.
[EXCLUSIVE PROMO OFFER: Click Here to Buy MycoSoothe Advance Nail Health Support Formula at the Best Price Available Online](https://snoppymart.com/us-mycosoothe)
MycoSoothe Reviews
------------------
Are you plagued by relentless fungal infections that simply refuse to go away? Well, fret no more, because MycoSoothe is here to offer you the ultimate solution. MycoSoothe stands as a revolutionary oral supplement designed specifically to combat fungi with its groundbreaking ingredients.
Nails, often overlooked, actually play a pivotal role in our daily lives. From intricate tasks like food preparation to simple actions like gripping objects, healthy nails are essential. When fungal growth disrupts the harmony of our nails, it not only affects their appearance but also poses potential health risks.
Nail-related issues are far more common than one might imagine, with thousands of individuals grappling with nail health concerns. In the quest for solutions, many have come across a plethora of products in the market, each claiming to address these issues uniquely.
Among these contenders, [MycoSoothe](https://snoppymart.com/mycosoothe/) emerges as a trailblazing nail health support product, offering a holistic approach to combat skin and nail fungus while nurturing long-term nail health.
Nail health goes beyond mere aesthetics; our nails are steadfast companions in our daily endeavors. Unhealthy nails can lead to significant inconveniences. Consider how frequently we use our hands for various activities, from opening doors to eating – all of which could potentially lead to health problems if our nails are not in optimal condition.
The global prevalence of nail health issues highlights the significance of this often overlooked aspect of well-being. The realm of supplements is filled with promises of quick fixes for nail health problems. Sadly, most of these products fall short of their claims, leaving consumers disillusioned and disheartened.
Now, bid farewell to those days of ineffective treatments and welcome a revolutionary approach to fungal defense with MycoSoothe. Our potent formula is meticulously crafted to strike at the very core of fungal issues, delivering results that are truly unparalleled. MycoSoothe empowers you to regain control over your health and finally wave goodbye to those persistent fungal problems.
PhytAge Labs MycoSoothe is an oral supplement armed with cutting-edge ingredients to combat fungus effectively. It serves as a beacon of hope, offering a way to address these concerns more efficiently. So, if you're weary of the endless struggle against fungal infections, it's high time to consider MycoSoothe as your trusted ally in the quest for better health and nail rejuvenation.
[.png)](https://snoppymart.com/us-mycosoothe)
What is [MycoSoothe](https://snoppymart.com/mycosoothe/)?
---------------------------------------------------------
Mycosoothe is a potent natural remedy designed to effectively combat fungal infections from within. This safe and efficient supplement is formulated with a unique blend of ingredients that work in tandem to target the root cause of fungal infections, providing long-lasting relief and preventing future outbreaks.
One of the key components of Mycosoothe is tea tree oil, renowned for its robust antifungal properties. Throughout history, tea tree oil has been used to treat various skin issues, including fungal infections. By incorporating this natural wonder, Mycosoothe offers a tried-and-true solution, instilling confidence in its effectiveness.
However, Mycosoothe doesn't stop at tea tree oil; it also harnesses the power of other potent ingredients such as grapefruit seed extract, garlic extract, and oregano extract. These carefully selected substances are chosen for their antifungal, antibacterial, and immune-boosting qualities, providing your body with the tools it needs to combat fungal infections effectively.
Unlike topical treatments that offer only temporary relief, Mycosoothe works internally to address the underlying harmful cause of fungal infections. It not only eliminates existing ailments but also plays a preventive role by bolstering your immune system and restoring your body's natural balance, reducing the likelihood of future infections.
[.png)](https://snoppymart.com/us-mycosoothe)
PhytAge Labs, the manufacturer of Mycosoothe, assures the safety of this medication and emphasizes that it contains the appropriate therapeutic dosages. All ingredients are sourced from reliable, natural sources, and this prescription-free antifungal remedy is readily available online, providing a convenient and accessible solution for those in need.
[BEST DEAL OFFER! Buy MycoSoothe Toenail Supplement Directly from the Manufacturer at the Lowest Price!](https://snoppymart.com/us-mycosoothe)
How Does MycoSoothe Work?
-------------------------
MycoSoothe is a revolutionary solution designed to combat chronic fungal attacks on your nails, scalp, or skin. This exceptional formula not only prioritizes your safety but also harnesses the power of nature to revitalize and enhance the strength and beauty of your nails. By incorporating MycoSoothe into your daily routine, you can bid farewell to issues like discoloration and persistent fungal attacks, experiencing a remarkable transformation in your nail health. Curious about how it works? Here’s how the magic behind this extraordinary formulation works:
* **Revitalization from Within:** MycoSoothe addresses the root causes of brittle and yellow nails, often linked to nutrient deficiencies. By providing a generous dose of essential vitamins and minerals with each intake, this supplement is meticulously designed to improve the texture, tone, strength, and overall appearance of your nails. Just two pills a day act as your armor against common nail issues, making them a robust and healthy part of your body.
* **Defense Against the Unwanted:** MycoSoothe is well blended with the best of the best antioxidants and anti-inflammatory compounds, precisely composed to target the core of fungal cell walls. It acts as a natural fortress against these harmful invaders, inhibiting their replication and preventing infections and swelling. This defense mechanism safeguards your nails with style and confidence.
* **Energizing Your Blood:** MycoSoothe's unique blend of vitamins and minerals promotes the production of robust red blood cells, optimizing blood flow beneath your nails. This enhanced circulation ensures your nails receive the nutrients and oxygen they need, resulting in healthier, more vibrant nail color and reduced risk of discoloration.
* **Transformation with Protein Power:** Brittle nails become a thing of the past with MycoSoothe. It fuels nail strength to boost and strengthen the keratin production, making your nails resilient and stunning. Additionally, this supplement contributes to elevated collagen levels, thanks to the inclusion of vitamin C. Collagen is a vital protein that enhances the structure and integrity of your nail tissues, further improving their shape and appearance.
[MycoSoothe](https://snoppymart.com/mycosoothe/) Ingredients
------------------------------------------------------------
MycoSoothe contains a powerful combination of ingredients, including a dynamic trio of active components: ascorbic acid (vitamin C), vitamin E, and Selenium. However, these are just the beginning. Each serving of MycoSoothe includes a proprietary blend with over 15 natural nutrients, creating a symphony of health benefits that can elevate your nail, hair, and skin care routine to new heights. Let's delve into the key ingredients that make MycoSoothe a passport to a healthier, more vibrant you:
* **Vitamin C (Ascorbic Acid)**
Vitamin C, also known as ascorbic acid, is a cornerstone ingredient in MycoSoothe, renowned for its exceptional benefits in nail, hair, and skin care. Its primary strength lies in its capacity to supercharge collagen levels, the fundamental protein that maintains the integrity and strength of your nails. Particularly important for toenails, where cell regeneration is rapid, vitamin C plays a pivotal role in ensuring nail health. When combined with MycoSoothe's array of nutrients, it forms a robust defense against nail plate deterioration and the development of unsightly white spots.
* **Vitamin E**
Vitamin E is another essential component of MycoSoothe, offering a wide range of benefits. This nutrient strengthens, hydrates, and rejuvenates damaged toenails, thanks to its rich alpha-tocopherol content. Alpha-tocopherol acts as a protective shield against oxidative damage to skin and nail cells. Furthermore, its moisturizing properties contribute to maintaining lustrous and well-hydrated skin and cuticles. Vitamin E plays a crucial role in nurturing nail health and preserving its natural beauty.
* **Selenium (20 mcg)**
MycoSoothe includes 20 mcg of Selenium, a pivotal mineral in the formula. Selenium takes on the role of an antioxidant, shielding rapidly growing nail cells from the potentially harmful impact of free radicals. It serves as a steadfast guardian, defending these delicate cells against oxidative harm and relentless fungal attacks. Beyond nail health, according to the official MycoSoothe website, it is suggested that Selenium may also enhance heart health by promoting healthy blood flow throughout the body, including your precious nails. In essence, it acts as a stalwart soldier in the battle against fungal nail invasions.
* **Turmeric**
Turmeric, a potent anti-inflammatory powerhouse, is a key component of MycoSoothe. It promotes healthy blood flow, providing protection against fungal intruders that could compromise the well-being of your nails.
* **Soursop**
Rich in antioxidants, soursop contributes to the elimination of free radicals and toxins from your system. Beyond nail health, it offers support for heart health and optimal gut function.
* **Green Tea**
Green tea is a source of bioactive nutrients that energize nail cells, strengthen and secure the immune system to act as a vigilant guardian against chronic fungal infections.
* **Raspberry**
This red gem is known for its defensive properties against various ailments, enhancing cell growth and division, and preventing nail discoloration.
* **Essiac Tea**
Rich in antioxidants and metabolism-boosting nutrients, Essiac tea takes on resilient toenail fungus, fortifying keratin and collagen formation to banish brittleness.
* **Burdock Leaf**
Renowned for its support of the urinary system, burdock leaf also contributes to expanding immunity and supporting blood purification, thereby bolstering liver and kidney functions.
* **Mushroom Complex (Maitake, Shiitake, and Reishi)**
Ancient mushrooms such as Maitake, Shiitake, and Reishi fortify the immune system, combat fungal infections, enhance sleep quality, and revitalize the body's metabolic processes.
* **Pomegranate**
Pomegranate, bursting with essential vitamins and minerals, enhances blood flow, minimizes inflammations, and effectively combats harmful nail fungus.
* **Olive Leaf**
Rich in antioxidants and anti-fungal components, olive leaf rejuvenates scalp, skin, and nail health, working harmoniously with other MycoSoothe nutrients to hydrate and strengthen your nails.
* **Panax Asian Ginseng**
Panax Asian Ginseng, a nutrient enriched with antioxidant, anti-inflammatory, and anti-fungal properties, energizes your body, supports cognitive functions, and contributes to overall well-being.
[MycoSoothe](https://snoppymart.com/mycosoothe/) For Sale: Pricing and Where to Buy?
------------------------------------------------------------------------------------
You can conveniently purchabuy se MycoSoothe from the official website, www.trymycosoothe.com. It's important to emphasize that the official website is the sole reliable source for authentic MycoSoothe supplements. To ensure the legitimacy of the product, it is strongly recommended to make your purchases exclusively through the official website.
Claims of MycoSoothe being available from local merchants, vendors, or franchisees should be disregarded, as they lack the necessary authorization. Bottles purchased from other sources may potentially be counterfeit. Here is the pricing information available on the official website:
* One bottle: Priced at $69.95, this package provides a one-month supply of MycoSoothe. It includes standard shipping fees, multiple payment methods, and is backed by a 90-day money-back guarantee.
* Two bottles: You can purchase two bottles for a total of $119.90, which equates to $59.95 per bottle. This package offers a two-month supply, with no shipping fees, multiple payment methods, 2 free e-books, and a 90-day money-back guarantee.
* Four bottles: The four-bottle package is available for $199.80, making each bottle $49.95. It provides a four-month supply, free shipping within the US, 2 free e-books, and a 90-day money-back guarantee.
Not Happy with MycoSoothe Results? - 90-Days Money Back Guarantee?
------------------------------------------------------------------
MycoSoothe takes customer satisfaction seriously and offers a 90-day return policy. If you are not satisfied with your purchase, you can request a refund within 90 days from the date of purchase. The refund process is straightforward and does not require you to provide explanations or reasons.
To initiate a refund, simply contact MycoSoothe's customer care team through the provided email or phone number, which are prominently displayed on the official website and supplement bottle. Once they receive your refund request, they will promptly review your order details and other relevant information to expedite the refund process.
Conclusion - MycoSoothe Reviews
-------------------------------
If you're in search of an effective and natural solution to combat fungal infections, MycoSoothe supplement is definitely worth considering. Its potent blend of natural ingredients is designed to work from the inside out, addressing fungal infections at their core and preventing their recurrence. With consistent use, you can finally bid farewell to those persistent fungal issues and enjoy the benefits of healthy, fungus-free skin.
Don't let fungal infections continue to impact your life and well-being. Empower yourself to take control and fight back with MycoSoothe, the groundbreaking oral supplement that delivers tangible results. Say goodbye to discomfort, irritation, and frustration, and say hello to healthier, happier skin.
[.png)](https://snoppymart.com/us-mycosoothe)
With MycoSoothe, your fungal infections won't stand a chance against the power of its revolutionary ingredients. It's time to seize control and reclaim your skin's health and vitality. Try MycoSoothe today and experience the transformation for yourself – because you deserve to live without the burden of fungal infections.
[Click Here to Buy MycoSoothe For Toenail Fungus From the Official Website Now at Discounted Price!](https://snoppymart.com/us-mycosoothe)
|
getphytagelabsmycosoothe/PhytAgeLabsMycoSoothe
|
[
"region:us"
] |
2023-10-23T10:17:49+00:00
|
{}
|
2023-10-23T10:21:36+00:00
|
[] |
[] |
TAGS
#region-us
|
What sets PhytAge Labs MycoSoothe apart is its proactive approach—it doesn't just eliminate existing fungus; it strives to prevent its unwelcome return. This means enduring relief and newfound confidence in your daily life. Keep in mind that individual experiences may vary, but with MycoSoothe, you're taking a positive step towards healthier, fungus-free skin, hair, and nails.
EXCLUSIVE PROMO OFFER: Click Here to Buy MycoSoothe Advance Nail Health Support Formula at the Best Price Available Online
MycoSoothe Reviews
------------------
Are you plagued by relentless fungal infections that simply refuse to go away? Well, fret no more, because MycoSoothe is here to offer you the ultimate solution. MycoSoothe stands as a revolutionary oral supplement designed specifically to combat fungi with its groundbreaking ingredients.
Nails, often overlooked, actually play a pivotal role in our daily lives. From intricate tasks like food preparation to simple actions like gripping objects, healthy nails are essential. When fungal growth disrupts the harmony of our nails, it not only affects their appearance but also poses potential health risks.
Nail-related issues are far more common than one might imagine, with thousands of individuals grappling with nail health concerns. In the quest for solutions, many have come across a plethora of products in the market, each claiming to address these issues uniquely.
Among these contenders, MycoSoothe emerges as a trailblazing nail health support product, offering a holistic approach to combat skin and nail fungus while nurturing long-term nail health.
Nail health goes beyond mere aesthetics; our nails are steadfast companions in our daily endeavors. Unhealthy nails can lead to significant inconveniences. Consider how frequently we use our hands for various activities, from opening doors to eating – all of which could potentially lead to health problems if our nails are not in optimal condition.
The global prevalence of nail health issues highlights the significance of this often overlooked aspect of well-being. The realm of supplements is filled with promises of quick fixes for nail health problems. Sadly, most of these products fall short of their claims, leaving consumers disillusioned and disheartened.
Now, bid farewell to those days of ineffective treatments and welcome a revolutionary approach to fungal defense with MycoSoothe. Our potent formula is meticulously crafted to strike at the very core of fungal issues, delivering results that are truly unparalleled. MycoSoothe empowers you to regain control over your health and finally wave goodbye to those persistent fungal problems.
PhytAge Labs MycoSoothe is an oral supplement armed with cutting-edge ingredients to combat fungus effectively. It serves as a beacon of hope, offering a way to address these concerns more efficiently. So, if you're weary of the endless struggle against fungal infections, it's high time to consider MycoSoothe as your trusted ally in the quest for better health and nail rejuvenation.
](URL
PhytAge Labs, the manufacturer of Mycosoothe, assures the safety of this medication and emphasizes that it contains the appropriate therapeutic dosages. All ingredients are sourced from reliable, natural sources, and this prescription-free antifungal remedy is readily available online, providing a convenient and accessible solution for those in need.
BEST DEAL OFFER! Buy MycoSoothe Toenail Supplement Directly from the Manufacturer at the Lowest Price!
How Does MycoSoothe Work?
-------------------------
MycoSoothe is a revolutionary solution designed to combat chronic fungal attacks on your nails, scalp, or skin. This exceptional formula not only prioritizes your safety but also harnesses the power of nature to revitalize and enhance the strength and beauty of your nails. By incorporating MycoSoothe into your daily routine, you can bid farewell to issues like discoloration and persistent fungal attacks, experiencing a remarkable transformation in your nail health. Curious about how it works? Here’s how the magic behind this extraordinary formulation works:
* Revitalization from Within: MycoSoothe addresses the root causes of brittle and yellow nails, often linked to nutrient deficiencies. By providing a generous dose of essential vitamins and minerals with each intake, this supplement is meticulously designed to improve the texture, tone, strength, and overall appearance of your nails. Just two pills a day act as your armor against common nail issues, making them a robust and healthy part of your body.
* Defense Against the Unwanted: MycoSoothe is well blended with the best of the best antioxidants and anti-inflammatory compounds, precisely composed to target the core of fungal cell walls. It acts as a natural fortress against these harmful invaders, inhibiting their replication and preventing infections and swelling. This defense mechanism safeguards your nails with style and confidence.
* Energizing Your Blood: MycoSoothe's unique blend of vitamins and minerals promotes the production of robust red blood cells, optimizing blood flow beneath your nails. This enhanced circulation ensures your nails receive the nutrients and oxygen they need, resulting in healthier, more vibrant nail color and reduced risk of discoloration.
* Transformation with Protein Power: Brittle nails become a thing of the past with MycoSoothe. It fuels nail strength to boost and strengthen the keratin production, making your nails resilient and stunning. Additionally, this supplement contributes to elevated collagen levels, thanks to the inclusion of vitamin C. Collagen is a vital protein that enhances the structure and integrity of your nail tissues, further improving their shape and appearance.
MycoSoothe Ingredients
------------------------------------------------------------
MycoSoothe contains a powerful combination of ingredients, including a dynamic trio of active components: ascorbic acid (vitamin C), vitamin E, and Selenium. However, these are just the beginning. Each serving of MycoSoothe includes a proprietary blend with over 15 natural nutrients, creating a symphony of health benefits that can elevate your nail, hair, and skin care routine to new heights. Let's delve into the key ingredients that make MycoSoothe a passport to a healthier, more vibrant you:
* Vitamin C (Ascorbic Acid)
Vitamin C, also known as ascorbic acid, is a cornerstone ingredient in MycoSoothe, renowned for its exceptional benefits in nail, hair, and skin care. Its primary strength lies in its capacity to supercharge collagen levels, the fundamental protein that maintains the integrity and strength of your nails. Particularly important for toenails, where cell regeneration is rapid, vitamin C plays a pivotal role in ensuring nail health. When combined with MycoSoothe's array of nutrients, it forms a robust defense against nail plate deterioration and the development of unsightly white spots.
* Vitamin E
Vitamin E is another essential component of MycoSoothe, offering a wide range of benefits. This nutrient strengthens, hydrates, and rejuvenates damaged toenails, thanks to its rich alpha-tocopherol content. Alpha-tocopherol acts as a protective shield against oxidative damage to skin and nail cells. Furthermore, its moisturizing properties contribute to maintaining lustrous and well-hydrated skin and cuticles. Vitamin E plays a crucial role in nurturing nail health and preserving its natural beauty.
* Selenium (20 mcg)
MycoSoothe includes 20 mcg of Selenium, a pivotal mineral in the formula. Selenium takes on the role of an antioxidant, shielding rapidly growing nail cells from the potentially harmful impact of free radicals. It serves as a steadfast guardian, defending these delicate cells against oxidative harm and relentless fungal attacks. Beyond nail health, according to the official MycoSoothe website, it is suggested that Selenium may also enhance heart health by promoting healthy blood flow throughout the body, including your precious nails. In essence, it acts as a stalwart soldier in the battle against fungal nail invasions.
* Turmeric
Turmeric, a potent anti-inflammatory powerhouse, is a key component of MycoSoothe. It promotes healthy blood flow, providing protection against fungal intruders that could compromise the well-being of your nails.
* Soursop
Rich in antioxidants, soursop contributes to the elimination of free radicals and toxins from your system. Beyond nail health, it offers support for heart health and optimal gut function.
* Green Tea
Green tea is a source of bioactive nutrients that energize nail cells, strengthen and secure the immune system to act as a vigilant guardian against chronic fungal infections.
* Raspberry
This red gem is known for its defensive properties against various ailments, enhancing cell growth and division, and preventing nail discoloration.
* Essiac Tea
Rich in antioxidants and metabolism-boosting nutrients, Essiac tea takes on resilient toenail fungus, fortifying keratin and collagen formation to banish brittleness.
* Burdock Leaf
Renowned for its support of the urinary system, burdock leaf also contributes to expanding immunity and supporting blood purification, thereby bolstering liver and kidney functions.
* Mushroom Complex (Maitake, Shiitake, and Reishi)
Ancient mushrooms such as Maitake, Shiitake, and Reishi fortify the immune system, combat fungal infections, enhance sleep quality, and revitalize the body's metabolic processes.
* Pomegranate
Pomegranate, bursting with essential vitamins and minerals, enhances blood flow, minimizes inflammations, and effectively combats harmful nail fungus.
* Olive Leaf
Rich in antioxidants and anti-fungal components, olive leaf rejuvenates scalp, skin, and nail health, working harmoniously with other MycoSoothe nutrients to hydrate and strengthen your nails.
* Panax Asian Ginseng
Panax Asian Ginseng, a nutrient enriched with antioxidant, anti-inflammatory, and anti-fungal properties, energizes your body, supports cognitive functions, and contributes to overall well-being.
MycoSoothe For Sale: Pricing and Where to Buy?
------------------------------------------------------------------------------------
You can conveniently purchabuy se MycoSoothe from the official website, URL. It's important to emphasize that the official website is the sole reliable source for authentic MycoSoothe supplements. To ensure the legitimacy of the product, it is strongly recommended to make your purchases exclusively through the official website.
Claims of MycoSoothe being available from local merchants, vendors, or franchisees should be disregarded, as they lack the necessary authorization. Bottles purchased from other sources may potentially be counterfeit. Here is the pricing information available on the official website:
* One bottle: Priced at $69.95, this package provides a one-month supply of MycoSoothe. It includes standard shipping fees, multiple payment methods, and is backed by a 90-day money-back guarantee.
* Two bottles: You can purchase two bottles for a total of $119.90, which equates to $59.95 per bottle. This package offers a two-month supply, with no shipping fees, multiple payment methods, 2 free e-books, and a 90-day money-back guarantee.
* Four bottles: The four-bottle package is available for $199.80, making each bottle $49.95. It provides a four-month supply, free shipping within the US, 2 free e-books, and a 90-day money-back guarantee.
Not Happy with MycoSoothe Results? - 90-Days Money Back Guarantee?
------------------------------------------------------------------
MycoSoothe takes customer satisfaction seriously and offers a 90-day return policy. If you are not satisfied with your purchase, you can request a refund within 90 days from the date of purchase. The refund process is straightforward and does not require you to provide explanations or reasons.
To initiate a refund, simply contact MycoSoothe's customer care team through the provided email or phone number, which are prominently displayed on the official website and supplement bottle. Once they receive your refund request, they will promptly review your order details and other relevant information to expedite the refund process.
Conclusion - MycoSoothe Reviews
-------------------------------
If you're in search of an effective and natural solution to combat fungal infections, MycoSoothe supplement is definitely worth considering. Its potent blend of natural ingredients is designed to work from the inside out, addressing fungal infections at their core and preventing their recurrence. With consistent use, you can finally bid farewell to those persistent fungal issues and enjoy the benefits of healthy, fungus-free skin.
Don't let fungal infections continue to impact your life and well-being. Empower yourself to take control and fight back with MycoSoothe, the groundbreaking oral supplement that delivers tangible results. Say goodbye to discomfort, irritation, and frustration, and say hello to healthier, happier skin.

|
mb23/cvt2_GS3_1
|
[
"region:us"
] |
2023-10-23T10:20:15+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1832280306.75, "num_examples": 13258}, {"name": "test", "num_bytes": 640923801.75, "num_examples": 4722}], "download_size": 2373732866, "dataset_size": 2473204108.5}}
|
2023-10-25T04:55:59+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "cvt2_GS3_1"
* 適応的ヒストグラム平坦化を、GraySpectrogram3に適用
More Information needed
|
[
"# Dataset Card for \"cvt2_GS3_1\"\n\n* 適応的ヒストグラム平坦化を、GraySpectrogram3に適用\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"cvt2_GS3_1\"\n\n* 適応的ヒストグラム平坦化を、GraySpectrogram3に適用\n\nMore Information needed"
] |
[
6,
40
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"cvt2_GS3_1\"\n\n* 適応的ヒストグラム平坦化を、GraySpectrogram3に適用\n\nMore Information needed"
] |
8864bd4a0af01533368729344f51ec5039f61334
|
# BLOSSOM WIZARD V1
### 介绍
[Blossom Wizard V2](https://huggingface.co/datasets/Azure99/blossom-wizard-v2)版本已发布!🤗
Blossom Wizard V1是一个基于WizardLM_evol_instruct_V2衍生而来的中英双语指令数据集,适用于指令微调。
本数据集从WizardLM_evol_instruct_V2中抽取了指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。
相比直接对原始Wizard进行翻译的中文数据集,Blossom Wizard的一致性及质量更高。
本次发布了全量数据的30%,包含中英双语各50K,共计100K记录。
### 语言
以中文和英文为主。
### 数据集结构
数据集包含两个文件:blossom-wizard-v1-chinese-50k.json和blossom-wizard-v1-english-50k.json,分别对应中文和英文的数据。
每条数据代表一个完整的对话,包含id和conversations两个字段。
- id:字符串,代表原始WizardLM_evol_instruct_V2的指令id。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。
### 数据集限制
本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。
|
Azure99/blossom-wizard-v1
|
[
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:100K<n<1M",
"language:zh",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-10-23T10:24:14+00:00
|
{"language": ["zh", "en"], "license": "apache-2.0", "size_categories": ["100K<n<1M"], "task_categories": ["text-generation", "text2text-generation"]}
|
2023-12-20T15:54:02+00:00
|
[] |
[
"zh",
"en"
] |
TAGS
#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us
|
# BLOSSOM WIZARD V1
### 介绍
Blossom Wizard V2版本已发布!
Blossom Wizard V1是一个基于WizardLM_evol_instruct_V2衍生而来的中英双语指令数据集,适用于指令微调。
本数据集从WizardLM_evol_instruct_V2中抽取了指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。
相比直接对原始Wizard进行翻译的中文数据集,Blossom Wizard的一致性及质量更高。
本次发布了全量数据的30%,包含中英双语各50K,共计100K记录。
### 语言
以中文和英文为主。
### 数据集结构
数据集包含两个文件:blossom-wizard-v1-chinese-50k.json和blossom-URL,分别对应中文和英文的数据。
每条数据代表一个完整的对话,包含id和conversations两个字段。
- id:字符串,代表原始WizardLM_evol_instruct_V2的指令id。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。
### 数据集限制
本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。
|
[
"# BLOSSOM WIZARD V1",
"### 介绍\n\nBlossom Wizard V2版本已发布!\n\nBlossom Wizard V1是一个基于WizardLM_evol_instruct_V2衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从WizardLM_evol_instruct_V2中抽取了指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始Wizard进行翻译的中文数据集,Blossom Wizard的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各50K,共计100K记录。",
"### 语言\n\n以中文和英文为主。",
"### 数据集结构\n\n数据集包含两个文件:blossom-wizard-v1-chinese-50k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始WizardLM_evol_instruct_V2的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
[
"TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us \n",
"# BLOSSOM WIZARD V1",
"### 介绍\n\nBlossom Wizard V2版本已发布!\n\nBlossom Wizard V1是一个基于WizardLM_evol_instruct_V2衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从WizardLM_evol_instruct_V2中抽取了指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始Wizard进行翻译的中文数据集,Blossom Wizard的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各50K,共计100K记录。",
"### 语言\n\n以中文和英文为主。",
"### 数据集结构\n\n数据集包含两个文件:blossom-wizard-v1-chinese-50k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始WizardLM_evol_instruct_V2的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
[
59,
9,
212,
11,
134,
67
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us \n# BLOSSOM WIZARD V1### 介绍\n\nBlossom Wizard V2版本已发布!\n\nBlossom Wizard V1是一个基于WizardLM_evol_instruct_V2衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从WizardLM_evol_instruct_V2中抽取了指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始Wizard进行翻译的中文数据集,Blossom Wizard的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各50K,共计100K记录。### 语言\n\n以中文和英文为主。### 数据集结构\n\n数据集包含两个文件:blossom-wizard-v1-chinese-50k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始WizardLM_evol_instruct_V2的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
3ef7f596a61def6977e775f8f4ada38226c982ea
|
# Open X-Embodiment Dataset (unofficial)
This is an unofficial Dataset Repo. This Repo is set up to make **Open X-Embodiment Dataset (55 in 1)** more accessible for people who love huggingface🤗.
**Open X-Embodiment Dataset** is the largest open-source real robot dataset to date. It contains 1M+ real robot trajectories spanning 22 robot embodiments, from single robot arms to bi-manual robots and quadrupeds.
More information is located on RT-X website (https://robotics-transformer-x.github.io/) .
### Usage Example
```python
import datasets
ds = datasets.load_dataset("jxu124/OpenX-Embodiment", "fractal20220817_data", streaming=True, split='train') # IterDataset
```
Optional subdatasets:
```
fractal20220817_data
kuka
bridge
taco_play
jaco_play
berkeley_cable_routing
roboturk
nyu_door_opening_surprising_effectiveness
viola
berkeley_autolab_ur5
toto
language_table
columbia_cairlab_pusht_real
stanford_kuka_multimodal_dataset_converted_externally_to_rlds
nyu_rot_dataset_converted_externally_to_rlds
stanford_hydra_dataset_converted_externally_to_rlds
austin_buds_dataset_converted_externally_to_rlds
nyu_franka_play_dataset_converted_externally_to_rlds
maniskill_dataset_converted_externally_to_rlds
furniture_bench_dataset_converted_externally_to_rlds
cmu_franka_exploration_dataset_converted_externally_to_rlds
ucsd_kitchen_dataset_converted_externally_to_rlds
ucsd_pick_and_place_dataset_converted_externally_to_rlds
austin_sailor_dataset_converted_externally_to_rlds
austin_sirius_dataset_converted_externally_to_rlds
bc_z
usc_cloth_sim_converted_externally_to_rlds
utokyo_pr2_opening_fridge_converted_externally_to_rlds
utokyo_pr2_tabletop_manipulation_converted_externally_to_rlds
utokyo_saytap_converted_externally_to_rlds
utokyo_xarm_pick_and_place_converted_externally_to_rlds
utokyo_xarm_bimanual_converted_externally_to_rlds
robo_net
berkeley_mvp_converted_externally_to_rlds
berkeley_rpt_converted_externally_to_rlds
kaist_nonprehensile_converted_externally_to_rlds
stanford_mask_vit_converted_externally_to_rlds
tokyo_u_lsmo_converted_externally_to_rlds
dlr_sara_pour_converted_externally_to_rlds
dlr_sara_grid_clamp_converted_externally_to_rlds
dlr_edan_shared_control_converted_externally_to_rlds
asu_table_top_converted_externally_to_rlds
stanford_robocook_converted_externally_to_rlds
eth_agent_affordances
imperialcollege_sawyer_wrist_cam
iamlab_cmu_pickup_insert_converted_externally_to_rlds
uiuc_d3field
utaustin_mutex
berkeley_fanuc_manipulation
cmu_playing_with_food
cmu_play_fusion
cmu_stretch
berkeley_gnm_recon
berkeley_gnm_cory_hall
berkeley_gnm_sac_son
```
Optional subdatasets (Full Name):
```
RT-1 Robot Action
QT-Opt
Berkeley Bridge
Freiburg Franka Play
USC Jaco Play
Berkeley Cable Routing
Roboturk
NYU VINN
Austin VIOLA
Berkeley Autolab UR5
TOTO Benchmark
Language Table
Columbia PushT Dataset
Stanford Kuka Multimodal
NYU ROT
Stanford HYDRA
Austin BUDS
NYU Franka Play
Maniskill
Furniture Bench
CMU Franka Exploration
UCSD Kitchen
UCSD Pick Place
Austin Sailor
Austin Sirius
BC-Z
USC Cloth Sim
Tokyo PR2 Fridge Opening
Tokyo PR2 Tabletop Manipulation
Saytap
UTokyo xArm PickPlace
UTokyo xArm Bimanual
Robonet
Berkeley MVP Data
Berkeley RPT Data
KAIST Nonprehensile Objects
QUT Dynamic Grasping
Stanford MaskVIT Data
LSMO Dataset
DLR Sara Pour Dataset
DLR Sara Grid Clamp Dataset
DLR Wheelchair Shared Control
ASU TableTop Manipulation
Stanford Robocook
ETH Agent Affordances
Imperial Wrist Cam
CMU Franka Pick-Insert Data
QUT Dexterous Manpulation
MPI Muscular Proprioception
UIUC D3Field
Austin Mutex
Berkeley Fanuc Manipulation
CMU Food Manipulation
CMU Play Fusion
CMU Stretch
RECON
CoryHall
SACSoN
RoboVQA
ALOHA
```
## Copyright Notice
- This is an unofficial Dataset Repo.
- Copyright 2023 DeepMind Technologies Limited
- All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may
not use this file except in compliance with the Apache 2.0 license. You may obtain a
copy of the Apache 2.0 license at: https://www.apache.org/licenses/LICENSE-2.0
- All other materials are licensed under the Creative Commons Attribution 4.0
International License (CC-BY). You may obtain a copy of the CC-BY license at:
https://creativecommons.org/licenses/by/4.0/legalcode
- Unless required by applicable law or agreed to in writing, all software and materials
distributed here under the Apache 2.0 or CC-BY licenses are distributed on an "AS IS"
BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied. See the licenses for the specific language governing permissions and
limitations under those licenses.
|
jxu124/OpenX-Embodiment
|
[
"task_categories:robotics",
"task_categories:reinforcement-learning",
"size_categories:1M<n<10M",
"language:en",
"license:cc-by-4.0",
"Robotics",
"region:us"
] |
2023-10-23T10:24:16+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "size_categories": ["1M<n<10M"], "task_categories": ["robotics", "reinforcement-learning"], "pretty_name": "Open X-Embodiment Dataset", "tags": ["Robotics"]}
|
2023-11-01T11:46:34+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-robotics #task_categories-reinforcement-learning #size_categories-1M<n<10M #language-English #license-cc-by-4.0 #Robotics #region-us
|
# Open X-Embodiment Dataset (unofficial)
This is an unofficial Dataset Repo. This Repo is set up to make Open X-Embodiment Dataset (55 in 1) more accessible for people who love huggingface.
Open X-Embodiment Dataset is the largest open-source real robot dataset to date. It contains 1M+ real robot trajectories spanning 22 robot embodiments, from single robot arms to bi-manual robots and quadrupeds.
More information is located on RT-X website (URL .
### Usage Example
Optional subdatasets:
Optional subdatasets (Full Name):
## Copyright Notice
- This is an unofficial Dataset Repo.
- Copyright 2023 DeepMind Technologies Limited
- All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may
not use this file except in compliance with the Apache 2.0 license. You may obtain a
copy of the Apache 2.0 license at: URL
- All other materials are licensed under the Creative Commons Attribution 4.0
International License (CC-BY). You may obtain a copy of the CC-BY license at:
URL
- Unless required by applicable law or agreed to in writing, all software and materials
distributed here under the Apache 2.0 or CC-BY licenses are distributed on an "AS IS"
BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied. See the licenses for the specific language governing permissions and
limitations under those licenses.
|
[
"# Open X-Embodiment Dataset (unofficial)\n\nThis is an unofficial Dataset Repo. This Repo is set up to make Open X-Embodiment Dataset (55 in 1) more accessible for people who love huggingface.\n\nOpen X-Embodiment Dataset is the largest open-source real robot dataset to date. It contains 1M+ real robot trajectories spanning 22 robot embodiments, from single robot arms to bi-manual robots and quadrupeds.\nMore information is located on RT-X website (URL .",
"### Usage Example\n\n\nOptional subdatasets:\n\n\nOptional subdatasets (Full Name):",
"## Copyright Notice\n- This is an unofficial Dataset Repo.\n- Copyright 2023 DeepMind Technologies Limited\n- All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may\nnot use this file except in compliance with the Apache 2.0 license. You may obtain a\ncopy of the Apache 2.0 license at: URL\n- All other materials are licensed under the Creative Commons Attribution 4.0\nInternational License (CC-BY). You may obtain a copy of the CC-BY license at:\nURL\n- Unless required by applicable law or agreed to in writing, all software and materials\ndistributed here under the Apache 2.0 or CC-BY licenses are distributed on an \"AS IS\"\nBASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\nimplied. See the licenses for the specific language governing permissions and\nlimitations under those licenses."
] |
[
"TAGS\n#task_categories-robotics #task_categories-reinforcement-learning #size_categories-1M<n<10M #language-English #license-cc-by-4.0 #Robotics #region-us \n",
"# Open X-Embodiment Dataset (unofficial)\n\nThis is an unofficial Dataset Repo. This Repo is set up to make Open X-Embodiment Dataset (55 in 1) more accessible for people who love huggingface.\n\nOpen X-Embodiment Dataset is the largest open-source real robot dataset to date. It contains 1M+ real robot trajectories spanning 22 robot embodiments, from single robot arms to bi-manual robots and quadrupeds.\nMore information is located on RT-X website (URL .",
"### Usage Example\n\n\nOptional subdatasets:\n\n\nOptional subdatasets (Full Name):",
"## Copyright Notice\n- This is an unofficial Dataset Repo.\n- Copyright 2023 DeepMind Technologies Limited\n- All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may\nnot use this file except in compliance with the Apache 2.0 license. You may obtain a\ncopy of the Apache 2.0 license at: URL\n- All other materials are licensed under the Creative Commons Attribution 4.0\nInternational License (CC-BY). You may obtain a copy of the CC-BY license at:\nURL\n- Unless required by applicable law or agreed to in writing, all software and materials\ndistributed here under the Apache 2.0 or CC-BY licenses are distributed on an \"AS IS\"\nBASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\nimplied. See the licenses for the specific language governing permissions and\nlimitations under those licenses."
] |
[
56,
125,
23,
192
] |
[
"passage: TAGS\n#task_categories-robotics #task_categories-reinforcement-learning #size_categories-1M<n<10M #language-English #license-cc-by-4.0 #Robotics #region-us \n# Open X-Embodiment Dataset (unofficial)\n\nThis is an unofficial Dataset Repo. This Repo is set up to make Open X-Embodiment Dataset (55 in 1) more accessible for people who love huggingface.\n\nOpen X-Embodiment Dataset is the largest open-source real robot dataset to date. It contains 1M+ real robot trajectories spanning 22 robot embodiments, from single robot arms to bi-manual robots and quadrupeds.\nMore information is located on RT-X website (URL .### Usage Example\n\n\nOptional subdatasets:\n\n\nOptional subdatasets (Full Name):## Copyright Notice\n- This is an unofficial Dataset Repo.\n- Copyright 2023 DeepMind Technologies Limited\n- All software is licensed under the Apache License, Version 2.0 (Apache 2.0); you may\nnot use this file except in compliance with the Apache 2.0 license. You may obtain a\ncopy of the Apache 2.0 license at: URL\n- All other materials are licensed under the Creative Commons Attribution 4.0\nInternational License (CC-BY). You may obtain a copy of the CC-BY license at:\nURL\n- Unless required by applicable law or agreed to in writing, all software and materials\ndistributed here under the Apache 2.0 or CC-BY licenses are distributed on an \"AS IS\"\nBASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\nimplied. See the licenses for the specific language governing permissions and\nlimitations under those licenses."
] |
c76cdc059fa83762ad8ca875fea8c02311899418
|
# BLOSSOM ORCA V1
### 介绍
[Blossom Orca V2](https://huggingface.co/datasets/Azure99/blossom-orca-v2)版本已发布!🤗
Blossom Orca V1是一个基于OpenOrca衍生而来的中英双语指令数据集,适用于指令微调。
本数据集从OpenOrca中抽取了系统提示和指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。
相比直接对原始OpenOrca进行翻译的中文数据集,Blossom Orca的一致性及质量更高。
本次发布了全量数据的30%,包含中英双语各100K,共计200K记录。
### 语言
以中文和英文为主。
### 数据集结构
数据集包含两个文件:blossom-orca-v1-chinese-100k.json和blossom-orca-v1-english-100k.json,分别对应中文和英文的数据。
每条数据代表一个完整的对话,包含id和conversations两个字段。
- id:字符串,代表原始OpenOrca的指令id。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为system、user或assistant,分别代表系统提示、用户输入和助手输出,content则为对应的内容。
### 数据集限制
本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。
|
Azure99/blossom-orca-v1
|
[
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:100K<n<1M",
"language:zh",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-10-23T10:26:57+00:00
|
{"language": ["zh", "en"], "license": "apache-2.0", "size_categories": ["100K<n<1M"], "task_categories": ["text-generation", "text2text-generation"]}
|
2023-12-20T15:53:40+00:00
|
[] |
[
"zh",
"en"
] |
TAGS
#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us
|
# BLOSSOM ORCA V1
### 介绍
Blossom Orca V2版本已发布!
Blossom Orca V1是一个基于OpenOrca衍生而来的中英双语指令数据集,适用于指令微调。
本数据集从OpenOrca中抽取了系统提示和指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。
相比直接对原始OpenOrca进行翻译的中文数据集,Blossom Orca的一致性及质量更高。
本次发布了全量数据的30%,包含中英双语各100K,共计200K记录。
### 语言
以中文和英文为主。
### 数据集结构
数据集包含两个文件:blossom-orca-v1-chinese-100k.json和blossom-URL,分别对应中文和英文的数据。
每条数据代表一个完整的对话,包含id和conversations两个字段。
- id:字符串,代表原始OpenOrca的指令id。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为system、user或assistant,分别代表系统提示、用户输入和助手输出,content则为对应的内容。
### 数据集限制
本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。
|
[
"# BLOSSOM ORCA V1",
"### 介绍\n\nBlossom Orca V2版本已发布!\n\nBlossom Orca V1是一个基于OpenOrca衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从OpenOrca中抽取了系统提示和指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始OpenOrca进行翻译的中文数据集,Blossom Orca的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各100K,共计200K记录。",
"### 语言\n\n以中文和英文为主。",
"### 数据集结构\n\n数据集包含两个文件:blossom-orca-v1-chinese-100k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始OpenOrca的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为system、user或assistant,分别代表系统提示、用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
[
"TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us \n",
"# BLOSSOM ORCA V1",
"### 介绍\n\nBlossom Orca V2版本已发布!\n\nBlossom Orca V1是一个基于OpenOrca衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从OpenOrca中抽取了系统提示和指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始OpenOrca进行翻译的中文数据集,Blossom Orca的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各100K,共计200K记录。",
"### 语言\n\n以中文和英文为主。",
"### 数据集结构\n\n数据集包含两个文件:blossom-orca-v1-chinese-100k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始OpenOrca的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为system、user或assistant,分别代表系统提示、用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
[
59,
8,
198,
11,
129,
67
] |
[
"passage: TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-100K<n<1M #language-Chinese #language-English #license-apache-2.0 #region-us \n# BLOSSOM ORCA V1### 介绍\n\nBlossom Orca V2版本已发布!\n\nBlossom Orca V1是一个基于OpenOrca衍生而来的中英双语指令数据集,适用于指令微调。\n\n本数据集从OpenOrca中抽取了系统提示和指令,首先将其翻译为中文并校验翻译结果,再使用指令调用gpt-3.5-turbo-0613模型生成响应,并过滤掉包含自我认知以及拒绝回答的响应,以便后续对齐。此外,为了确保响应风格的一致性以及中英数据配比,本数据集还对未翻译的原始指令也进行了相同的调用,最终得到了1:1的中英双语指令数据。\n\n相比直接对原始OpenOrca进行翻译的中文数据集,Blossom Orca的一致性及质量更高。\n\n本次发布了全量数据的30%,包含中英双语各100K,共计200K记录。### 语言\n\n以中文和英文为主。### 数据集结构\n\n数据集包含两个文件:blossom-orca-v1-chinese-100k.json和blossom-URL,分别对应中文和英文的数据。\n\n每条数据代表一个完整的对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始OpenOrca的指令id。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为system、user或assistant,分别代表系统提示、用户输入和助手输出,content则为对应的内容。### 数据集限制\n\n本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。此外,由于过滤了拒答响应,仅使用本数据集训练的模型,可能不会拒绝非法的请求。"
] |
e24034408d5c66aea5ec4e5f4ebb0c9a425df75e
|
# Dataset Card for "reward_test_custom_dataset_RLHF"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sayan1101/reward_test_custom_dataset_RLHF
|
[
"region:us"
] |
2023-10-23T10:45:02+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "valid1", "path": "data/valid1-*"}, {"split": "valid2", "path": "data/valid2-*"}]}], "dataset_info": {"features": [{"name": "chosen", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 27648, "num_examples": 41}, {"name": "test", "num_bytes": 27648, "num_examples": 41}, {"name": "valid1", "num_bytes": 27648, "num_examples": 41}, {"name": "valid2", "num_bytes": 27648, "num_examples": 41}], "download_size": 101852, "dataset_size": 110592}}
|
2023-10-23T10:55:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "reward_test_custom_dataset_RLHF"
More Information needed
|
[
"# Dataset Card for \"reward_test_custom_dataset_RLHF\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"reward_test_custom_dataset_RLHF\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"reward_test_custom_dataset_RLHF\"\n\nMore Information needed"
] |
23d8b7af6b5f377c4fce8d8a832782e7e6922017
|
# Knee X-rays
The dataset consists of a collection of knee X-ray images in **.jpg and .dcm** formats. The images are organized into folders based on different medical conditions. Each folder contains images depicting specific knee problems.
### Types of diseases and conditions in the dataset:
*Arthritis, Fracture, Stage 1 of Osteoarthritis, Stage 2 of Osteoarthritis, Stage 3 of Osteoarthritis and Stage 4 of Osteoarthritis*
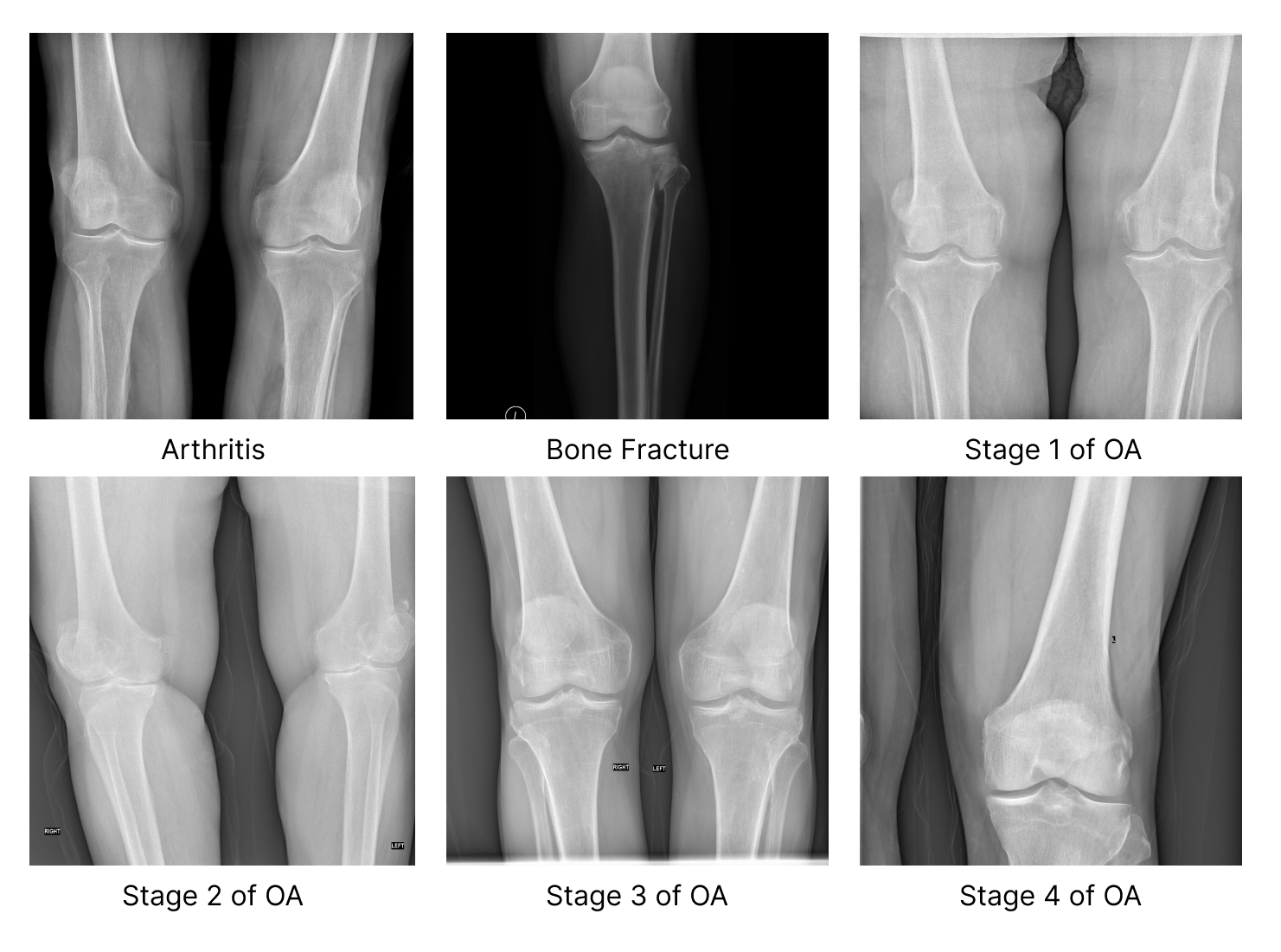
The dataset is a valuable resource for medical research and the field of **musculoskeletal disorders**. It allows the development and evaluation of computer-based algorithms, machine learning models, and deep learning techniques for **automated detection, diagnosis, and classification** of these conditions.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=knee-x-rays) to discuss your requirements, learn about the price and buy the dataset.
# Content
### The folder "files" includes 6 folders:
- corresponding to name of the disease/condition and including x-rays of people with this disease/condition (**arthritis, fracture, stage 1 of OA, stage 2 of OA, stage 3 of OA and stage 4 of OA**)
- including x-rays in 2 different formats: **.jpg and .dcm**.
### File with the extension .csv includes the following information for each media file:
- **dcm**: link to access the .dcm file,
- **jpg**: link to access the .jpg file,
- **type**: name of the disease or condition on the x-ray
# Medical data might be collected in accordance with your requirements.
## **[TrainingData](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=knee-x-rays)** provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
|
TrainingDataPro/knee-x-rays
|
[
"task_categories:image-classification",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"medical",
"code",
"region:us"
] |
2023-10-23T10:52:46+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-classification", "image-to-image"], "tags": ["medical", "code"], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "type", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 128352798.0, "num_examples": 50}], "download_size": 128350359, "dataset_size": 128352798.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-09T10:28:23+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-classification #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us
|
# Knee X-rays
The dataset consists of a collection of knee X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions. Each folder contains images depicting specific knee problems.
### Types of diseases and conditions in the dataset:
*Arthritis, Fracture, Stage 1 of Osteoarthritis, Stage 2 of Osteoarthritis, Stage 3 of Osteoarthritis and Stage 4 of Osteoarthritis*

- including x-rays in 2 different formats: .jpg and .dcm.
### File with the extension .csv includes the following information for each media file:
- dcm: link to access the .dcm file,
- jpg: link to access the .jpg file,
- type: name of the disease or condition on the x-ray
# Medical data might be collected in accordance with your requirements.
## TrainingData provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: URL
TrainingData's GitHub: URL
|
[
"# Knee X-rays\n\nThe dataset consists of a collection of knee X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions. Each folder contains images depicting specific knee problems.",
"### Types of diseases and conditions in the dataset:\n\n*Arthritis, Fracture, Stage 1 of Osteoarthritis, Stage 2 of Osteoarthritis, Stage 3 of Osteoarthritis and Stage 4 of Osteoarthritis*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.",
"### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray",
"# Medical data might be collected in accordance with your requirements.",
"## TrainingData provides high-quality data annotation tailored to your needs\n\nMore datasets in TrainingData's Kaggle account: URL\n\nTrainingData's GitHub: URL"
] |
[
"TAGS\n#task_categories-image-classification #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us \n",
"# Knee X-rays\n\nThe dataset consists of a collection of knee X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions. Each folder contains images depicting specific knee problems.",
"### Types of diseases and conditions in the dataset:\n\n*Arthritis, Fracture, Stage 1 of Osteoarthritis, Stage 2 of Osteoarthritis, Stage 3 of Osteoarthritis and Stage 4 of Osteoarthritis*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.",
"### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray",
"# Medical data might be collected in accordance with your requirements.",
"## TrainingData provides high-quality data annotation tailored to your needs\n\nMore datasets in TrainingData's Kaggle account: URL\n\nTrainingData's GitHub: URL"
] |
[
51,
64,
119,
5,
30,
2,
90,
60,
13,
39
] |
[
"passage: TAGS\n#task_categories-image-classification #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us \n# Knee X-rays\n\nThe dataset consists of a collection of knee X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions. Each folder contains images depicting specific knee problems.### Types of diseases and conditions in the dataset:\n\n*Arthritis, Fracture, Stage 1 of Osteoarthritis, Stage 2 of Osteoarthritis, Stage 3 of Osteoarthritis and Stage 4 of Osteoarthritis*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray# Medical data might be collected in accordance with your requirements.## TrainingData provides high-quality data annotation tailored to your needs\n\nMore datasets in TrainingData's Kaggle account: URL\n\nTrainingData's GitHub: URL"
] |
3e49f04a58c644035071317efa1c3d6e4a52e6e6
|
# Ner Fashion Brands
This dataset originally appear as part of
[this tutorial](https://github.com/explosion/projects/tree/v3/tutorials/ner_fashion_brands). The goal
of the dataset is to detect fashion brands in Reddit Comments.
For more details, be sure to read [this blogpost](https://explosion.ai/blog/sense2vec-reloaded#annotation).
|
explosion/ner-fashion-brands
|
[
"prodigy",
"region:us"
] |
2023-10-23T11:01:36+00:00
|
{"tags": ["prodigy"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "eval", "path": "data/eval-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "meta", "struct": [{"name": "section", "dtype": "string"}]}, {"name": "_input_hash", "dtype": "int64"}, {"name": "_task_hash", "dtype": "int64"}, {"name": "tokens", "list": [{"name": "end", "dtype": "int64"}, {"name": "id", "dtype": "int64"}, {"name": "start", "dtype": "int64"}, {"name": "text", "dtype": "string"}]}, {"name": "spans", "list": [{"name": "end", "dtype": "int64"}, {"name": "input_hash", "dtype": "int64"}, {"name": "label", "dtype": "string"}, {"name": "source", "dtype": "string"}, {"name": "start", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "token_end", "dtype": "int64"}, {"name": "token_start", "dtype": "int64"}]}, {"name": "_session_id", "dtype": "null"}, {"name": "_view_id", "dtype": "string"}, {"name": "answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2222165, "num_examples": 1235}, {"name": "eval", "num_bytes": 898819, "num_examples": 500}], "download_size": 839865, "dataset_size": 3120984}}
|
2023-10-23T11:04:31+00:00
|
[] |
[] |
TAGS
#prodigy #region-us
|
# Ner Fashion Brands
This dataset originally appear as part of
this tutorial. The goal
of the dataset is to detect fashion brands in Reddit Comments.
For more details, be sure to read this blogpost.
|
[
"# Ner Fashion Brands \n\nThis dataset originally appear as part of \nthis tutorial. The goal \nof the dataset is to detect fashion brands in Reddit Comments. \n\nFor more details, be sure to read this blogpost."
] |
[
"TAGS\n#prodigy #region-us \n",
"# Ner Fashion Brands \n\nThis dataset originally appear as part of \nthis tutorial. The goal \nof the dataset is to detect fashion brands in Reddit Comments. \n\nFor more details, be sure to read this blogpost."
] |
[
10,
45
] |
[
"passage: TAGS\n#prodigy #region-us \n# Ner Fashion Brands \n\nThis dataset originally appear as part of \nthis tutorial. The goal \nof the dataset is to detect fashion brands in Reddit Comments. \n\nFor more details, be sure to read this blogpost."
] |
e68a591508e5b5971fff2c272bbd772cd6f6395b
|
# arxiv-titles-instructorxl-embeddings
This dataset contains 768-dimensional embeddings generated from the [arxiv](https://arxiv.org/)
paper titles using [InstructorXL](https://huggingface.co/hkunlp/instructor-xl) model. Each
vector has an abstract used to create it, along with the DOI (Digital Object Identifier). The
dataset was created using precomputed embeddings exposed by the [Alexandria Index](https://alex.macrocosm.so/download).
## Generation process
The embeddings have been generated using the following instruction:
```text
Represent the Research Paper title for retrieval; Input:
```
The following code snippet shows how to generate embeddings using the InstructorXL model:
```python
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR('hkunlp/instructor-xl')
sentence = "3D ActionSLAM: wearable person tracking in multi-floor environments"
instruction = "Represent the Research Paper title for retrieval; Input:"
embeddings = model.encode([[instruction, sentence]])
```
|
Qdrant/arxiv-titles-instructorxl-embeddings
|
[
"task_categories:sentence-similarity",
"task_categories:feature-extraction",
"size_categories:1M<n<10M",
"language:en",
"region:us"
] |
2023-10-23T11:04:14+00:00
|
{"language": ["en"], "size_categories": ["1M<n<10M"], "task_categories": ["sentence-similarity", "feature-extraction"], "pretty_name": "InstructorXL embeddings of the Arxiv.org titles"}
|
2023-11-03T16:41:21+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-sentence-similarity #task_categories-feature-extraction #size_categories-1M<n<10M #language-English #region-us
|
# arxiv-titles-instructorxl-embeddings
This dataset contains 768-dimensional embeddings generated from the arxiv
paper titles using InstructorXL model. Each
vector has an abstract used to create it, along with the DOI (Digital Object Identifier). The
dataset was created using precomputed embeddings exposed by the Alexandria Index.
## Generation process
The embeddings have been generated using the following instruction:
The following code snippet shows how to generate embeddings using the InstructorXL model:
|
[
"# arxiv-titles-instructorxl-embeddings\n\nThis dataset contains 768-dimensional embeddings generated from the arxiv \npaper titles using InstructorXL model. Each \nvector has an abstract used to create it, along with the DOI (Digital Object Identifier). The \ndataset was created using precomputed embeddings exposed by the Alexandria Index.",
"## Generation process\n\nThe embeddings have been generated using the following instruction:\n\n\n\nThe following code snippet shows how to generate embeddings using the InstructorXL model:"
] |
[
"TAGS\n#task_categories-sentence-similarity #task_categories-feature-extraction #size_categories-1M<n<10M #language-English #region-us \n",
"# arxiv-titles-instructorxl-embeddings\n\nThis dataset contains 768-dimensional embeddings generated from the arxiv \npaper titles using InstructorXL model. Each \nvector has an abstract used to create it, along with the DOI (Digital Object Identifier). The \ndataset was created using precomputed embeddings exposed by the Alexandria Index.",
"## Generation process\n\nThe embeddings have been generated using the following instruction:\n\n\n\nThe following code snippet shows how to generate embeddings using the InstructorXL model:"
] |
[
47,
84,
39
] |
[
"passage: TAGS\n#task_categories-sentence-similarity #task_categories-feature-extraction #size_categories-1M<n<10M #language-English #region-us \n# arxiv-titles-instructorxl-embeddings\n\nThis dataset contains 768-dimensional embeddings generated from the arxiv \npaper titles using InstructorXL model. Each \nvector has an abstract used to create it, along with the DOI (Digital Object Identifier). The \ndataset was created using precomputed embeddings exposed by the Alexandria Index.## Generation process\n\nThe embeddings have been generated using the following instruction:\n\n\n\nThe following code snippet shows how to generate embeddings using the InstructorXL model:"
] |
41ebb7fba41f9356d6d38f794372829dfb3674e7
|
# Dataset Card for `ner-drugs`
This dataset was originally part of [this tutorial](https://github.com/explosion/projects/tree/v3/tutorials/ner_drugs). The goal of the
dataset is to find references to drugs in Reddit discussions.
|
explosion/ner-drugs
|
[
"prodigy",
"region:us"
] |
2023-10-23T11:10:43+00:00
|
{"tags": ["prodigy"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "eval", "path": "data/eval-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "meta", "struct": [{"name": "section", "dtype": "string"}]}, {"name": "_input_hash", "dtype": "int64"}, {"name": "_task_hash", "dtype": "int64"}, {"name": "tokens", "list": [{"name": "end", "dtype": "int64"}, {"name": "id", "dtype": "int64"}, {"name": "start", "dtype": "int64"}, {"name": "text", "dtype": "string"}]}, {"name": "answer", "dtype": "string"}, {"name": "spans", "list": [{"name": "end", "dtype": "int64"}, {"name": "label", "dtype": "string"}, {"name": "start", "dtype": "int64"}, {"name": "token_end", "dtype": "int64"}, {"name": "token_start", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 2486903, "num_examples": 1477}, {"name": "eval", "num_bytes": 849130, "num_examples": 500}], "download_size": 0, "dataset_size": 3336033}}
|
2023-10-23T11:22:59+00:00
|
[] |
[] |
TAGS
#prodigy #region-us
|
# Dataset Card for 'ner-drugs'
This dataset was originally part of this tutorial. The goal of the
dataset is to find references to drugs in Reddit discussions.
|
[
"# Dataset Card for 'ner-drugs'\n\nThis dataset was originally part of this tutorial. The goal of the \ndataset is to find references to drugs in Reddit discussions."
] |
[
"TAGS\n#prodigy #region-us \n",
"# Dataset Card for 'ner-drugs'\n\nThis dataset was originally part of this tutorial. The goal of the \ndataset is to find references to drugs in Reddit discussions."
] |
[
10,
40
] |
[
"passage: TAGS\n#prodigy #region-us \n# Dataset Card for 'ner-drugs'\n\nThis dataset was originally part of this tutorial. The goal of the \ndataset is to find references to drugs in Reddit discussions."
] |
bdec6901df865af2439ba3e40480a1cc8da520bf
|
**➥ ➣ Product Name – [MycoSoothe](https://snoppymart.com/mycosoothe/)**
➥ ➣ Rating - ⭐⭐⭐⭐⭐
➥ ➣ Price – Best Price
➥ ➣ Result - 1-2 Months/
➥ ➣ Benefits – Advanced Nail Health Supplement And Fights Against Skin
➥ ➣ Availability - [Online](https://www.facebook.com/people/MycoSoothe/61552691189275/)
#### **➥ ➣ Official Website -** [**➢➢ Visit The Official Website To Get Your Bottle Now ➢➢**](https://snoppymart.com/us-mycosoothe)
[.png)](https://snoppymart.com/mycosoothe/)
[**MycoSoothe**](https://www.facebook.com/people/MycoSoothe/61552691189275/) is an advanced nail fitness complement ideal for preventing skin, hair, and fungus. The proprietary formula is a made of PhytAge Labs and features a mixture of soursop, cat’s claw, and different evidently sourced substances.
### [**✅☍ Click Here To Buy Official Website Page ☍✅**](https://snoppymart.com/us-mycosoothe)
It claims to work for nail fungus through concentrated on its root cause, thereby assisting your body cleanse itself of all sorts of fungi on its very own. Its producer advertises it as an “extraordinary seven-2d ‘morning flush ritual’ \[that\] facilitates kill toenail fungus speedy.
Its marketing typically targets individuals stricken by nail fungus, especially people who need to avoid taking prescription medicine. Our review today will take you via what **[MycoSoothe](https://snoppymart.com/mycosoothe/)** is, its composition, and in which to buy it.
### [MycoSoothe](https://snoppymart.com/mycosoothe/) Benefits and Why You Should Take It
The PhytAge Labs team claims that **[MycoSoothe](https://snoppymart.com/mycosoothe/)** gives numerous advantages, some of which consist of:
* Assists the frame to fight lower back in opposition to nail, pores and skin, and hair fungus
* Eliminate toenail fungus speedy
* Formulated the usage of evidently sourced substances known to fight fungal infections
* Works through focused on the foundation reason of nail and skin fungus
* It helps protect towards the deadly outcomes of fungal infections
* Promotes typical fitness and boosts a extra younger appearance
### [**✅☍ Click Here To Buy Official Website Page ☍✅**](https://snoppymart.com/us-mycosoothe)
### How [MycoSoothe](https://www.facebook.com/people/MycoSoothe/61552691189275/) Works to Eliminate Nail, Skin, and Hair fungus
**[MycoSoothe](https://snoppymart.com/mycosoothe/)** is predicated on its proprietary combo of clearly sourced substances to supply the above stated blessings. Each element (greater in this in a chunk) works uniquely to fight the fungus targeting your nail, pores and skin, and hair health.
According to PhytAge Labs, some of those substances comprise homes that can “attack the fungal cell walls,” helping prevent it from replicating. The fungi consequently turn out to be incapable of causing any greater health complications.
Ingredients no longer concerned in attacking the “fungi cell wall” paintings in other methods, consisting of selling healthful irritation with the aid of neutralizing the unfastened radicals roaming during the frame. The natural antioxidants involved in such acts make it simpler for the immune system to work.
Thanks to their presence, it’s able to cleanse the frame of pollution and other dangerous fungi.
Besides the natural antioxidants, other elements incorporate mighty antibacterial and antifungal houses which can assist slow down infections, reduce swelling, and combat micro organism. Many of these have a protracted records in conventional medicine, assisting show their efficacy.
#### [**✅☍ Click Here To Buy Official Website Page ☍✅**](https://snoppymart.com/us-mycosoothe)
### MycoSoothe Pricing and Where to Buy
MycoSoothe may be purchased from the respectable PhytAge Labs internet site, where you could select your desired package relying on the severity of your nail fungi contamination. Please notice that the **[MycoSoothe](https://snoppymart.com/mycosoothe/)** expenses cited underneath are legitimate as of the time of writing:
[](https://snoppymart.com/mycosoothe/)
Order one **[MycoSoothe](https://snoppymart.com/mycosoothe/)** bottle for $sixty nine.Ninety five
Order two **[MycoSoothe](https://snoppymart.com/mycosoothe/)** bottles for $119.90 + Free Bonus eBooks
Order 4 **[MycoSoothe](https://snoppymart.com/mycosoothe/)** bottles for $199.80 + two Free Bonus eBooks
### Conclusion
[**MycoSoothe**](https://www.facebook.com/people/MycoSoothe/61552691189275/) offers a comprehensive and unique combo of components that paintings synergistically to sell nail and pores and skin health. With its capability to fight nail and skin fungus, enhance nail strength, shield towards oxidative stress, help the immune gadget, and improve universal skin health, [**MycoSoothe**](https://snoppymart.com/mycosoothe/) provides a holistic technique to preserving healthy nails and skin.
### [**✅☍ Click Here To Buy Official Website Page ☍✅**](https://snoppymart.com/us-mycosoothe)
|
mycosoothereviewshere/mycosoothereviewshere
|
[
"region:us"
] |
2023-10-23T11:20:30+00:00
|
{}
|
2023-10-23T11:20:59+00:00
|
[] |
[] |
TAGS
#region-us
|
Product Name – MycoSoothe
Rating - ⭐⭐⭐⭐⭐
Price – Best Price
Result - 1-2 Months/
Benefits – Advanced Nail Health Supplement And Fights Against Skin
Availability - Online
#### Official Website - Visit The Official Website To Get Your Bottle Now
 works uniquely to fight the fungus targeting your nail, pores and skin, and hair health.
According to PhytAge Labs, some of those substances comprise homes that can “attack the fungal cell walls,” helping prevent it from replicating. The fungi consequently turn out to be incapable of causing any greater health complications.
Ingredients no longer concerned in attacking the “fungi cell wall” paintings in other methods, consisting of selling healthful irritation with the aid of neutralizing the unfastened radicals roaming during the frame. The natural antioxidants involved in such acts make it simpler for the immune system to work.
Thanks to their presence, it’s able to cleanse the frame of pollution and other dangerous fungi.
Besides the natural antioxidants, other elements incorporate mighty antibacterial and antifungal houses which can assist slow down infections, reduce swelling, and combat micro organism. Many of these have a protracted records in conventional medicine, assisting show their efficacy.
#### Click Here To Buy Official Website Page
### MycoSoothe Pricing and Where to Buy
MycoSoothe may be purchased from the respectable PhytAge Labs internet site, where you could select your desired package relying on the severity of your nail fungi contamination. Please notice that the MycoSoothe expenses cited underneath are legitimate as of the time of writing:
](URL\n\nMycoSoothe is an advanced nail fitness complement ideal for preventing skin, hair, and fungus. The proprietary formula is a made of PhytAge Labs and features a mixture of soursop, cat’s claw, and different evidently sourced substances.",
"### Click Here To Buy Official Website Page \n\nIt claims to work for nail fungus through concentrated on its root cause, thereby assisting your body cleanse itself of all sorts of fungi on its very own. Its producer advertises it as an “extraordinary seven-2d ‘morning flush ritual’ \\[that\\] facilitates kill toenail fungus speedy.\n\nIts marketing typically targets individuals stricken by nail fungus, especially people who need to avoid taking prescription medicine. Our review today will take you via what MycoSoothe is, its composition, and in which to buy it.",
"### MycoSoothe Benefits and Why You Should Take It\n\nThe PhytAge Labs team claims that MycoSoothe gives numerous advantages, some of which consist of:\n\n* Assists the frame to fight lower back in opposition to nail, pores and skin, and hair fungus\n\n* Eliminate toenail fungus speedy\n\n* Formulated the usage of evidently sourced substances known to fight fungal infections\n\n* Works through focused on the foundation reason of nail and skin fungus\n\n* It helps protect towards the deadly outcomes of fungal infections\n\n* Promotes typical fitness and boosts a extra younger appearance",
"### Click Here To Buy Official Website Page",
"### How MycoSoothe Works to Eliminate Nail, Skin, and Hair fungus\n\nMycoSoothe is predicated on its proprietary combo of clearly sourced substances to supply the above stated blessings. Each element (greater in this in a chunk) works uniquely to fight the fungus targeting your nail, pores and skin, and hair health.\n\nAccording to PhytAge Labs, some of those substances comprise homes that can “attack the fungal cell walls,” helping prevent it from replicating. The fungi consequently turn out to be incapable of causing any greater health complications.\n\nIngredients no longer concerned in attacking the “fungi cell wall” paintings in other methods, consisting of selling healthful irritation with the aid of neutralizing the unfastened radicals roaming during the frame. The natural antioxidants involved in such acts make it simpler for the immune system to work.\n\nThanks to their presence, it’s able to cleanse the frame of pollution and other dangerous fungi.\n\nBesides the natural antioxidants, other elements incorporate mighty antibacterial and antifungal houses which can assist slow down infections, reduce swelling, and combat micro organism. Many of these have a protracted records in conventional medicine, assisting show their efficacy.",
"#### Click Here To Buy Official Website Page",
"### MycoSoothe Pricing and Where to Buy\n\nMycoSoothe may be purchased from the respectable PhytAge Labs internet site, where you could select your desired package relying on the severity of your nail fungi contamination. Please notice that the MycoSoothe expenses cited underneath are legitimate as of the time of writing:\n\n](URL\n\nMycoSoothe is an advanced nail fitness complement ideal for preventing skin, hair, and fungus. The proprietary formula is a made of PhytAge Labs and features a mixture of soursop, cat’s claw, and different evidently sourced substances.",
"### Click Here To Buy Official Website Page \n\nIt claims to work for nail fungus through concentrated on its root cause, thereby assisting your body cleanse itself of all sorts of fungi on its very own. Its producer advertises it as an “extraordinary seven-2d ‘morning flush ritual’ \\[that\\] facilitates kill toenail fungus speedy.\n\nIts marketing typically targets individuals stricken by nail fungus, especially people who need to avoid taking prescription medicine. Our review today will take you via what MycoSoothe is, its composition, and in which to buy it.",
"### MycoSoothe Benefits and Why You Should Take It\n\nThe PhytAge Labs team claims that MycoSoothe gives numerous advantages, some of which consist of:\n\n* Assists the frame to fight lower back in opposition to nail, pores and skin, and hair fungus\n\n* Eliminate toenail fungus speedy\n\n* Formulated the usage of evidently sourced substances known to fight fungal infections\n\n* Works through focused on the foundation reason of nail and skin fungus\n\n* It helps protect towards the deadly outcomes of fungal infections\n\n* Promotes typical fitness and boosts a extra younger appearance",
"### Click Here To Buy Official Website Page",
"### How MycoSoothe Works to Eliminate Nail, Skin, and Hair fungus\n\nMycoSoothe is predicated on its proprietary combo of clearly sourced substances to supply the above stated blessings. Each element (greater in this in a chunk) works uniquely to fight the fungus targeting your nail, pores and skin, and hair health.\n\nAccording to PhytAge Labs, some of those substances comprise homes that can “attack the fungal cell walls,” helping prevent it from replicating. The fungi consequently turn out to be incapable of causing any greater health complications.\n\nIngredients no longer concerned in attacking the “fungi cell wall” paintings in other methods, consisting of selling healthful irritation with the aid of neutralizing the unfastened radicals roaming during the frame. The natural antioxidants involved in such acts make it simpler for the immune system to work.\n\nThanks to their presence, it’s able to cleanse the frame of pollution and other dangerous fungi.\n\nBesides the natural antioxidants, other elements incorporate mighty antibacterial and antifungal houses which can assist slow down infections, reduce swelling, and combat micro organism. Many of these have a protracted records in conventional medicine, assisting show their efficacy.",
"#### Click Here To Buy Official Website Page",
"### MycoSoothe Pricing and Where to Buy\n\nMycoSoothe may be purchased from the respectable PhytAge Labs internet site, where you could select your desired package relying on the severity of your nail fungi contamination. Please notice that the MycoSoothe expenses cited underneath are legitimate as of the time of writing:\n\n](URL\n\nMycoSoothe is an advanced nail fitness complement ideal for preventing skin, hair, and fungus. The proprietary formula is a made of PhytAge Labs and features a mixture of soursop, cat’s claw, and different evidently sourced substances.### Click Here To Buy Official Website Page \n\nIt claims to work for nail fungus through concentrated on its root cause, thereby assisting your body cleanse itself of all sorts of fungi on its very own. Its producer advertises it as an “extraordinary seven-2d ‘morning flush ritual’ \\[that\\] facilitates kill toenail fungus speedy.\n\nIts marketing typically targets individuals stricken by nail fungus, especially people who need to avoid taking prescription medicine. Our review today will take you via what MycoSoothe is, its composition, and in which to buy it.### MycoSoothe Benefits and Why You Should Take It\n\nThe PhytAge Labs team claims that MycoSoothe gives numerous advantages, some of which consist of:\n\n* Assists the frame to fight lower back in opposition to nail, pores and skin, and hair fungus\n\n* Eliminate toenail fungus speedy\n\n* Formulated the usage of evidently sourced substances known to fight fungal infections\n\n* Works through focused on the foundation reason of nail and skin fungus\n\n* It helps protect towards the deadly outcomes of fungal infections\n\n* Promotes typical fitness and boosts a extra younger appearance### Click Here To Buy Official Website Page"
] |
289611d25d9878133ea9c17eec97246b27268111
|
# Victorian authorship
The [Victorian authorship dataset](https://scholarworks.iupui.edu/server/api/core/bitstreams/708a9870-915e-4d59-b54d-938af563c196/content).
Which Victorian author wrote the given text?
# Configurations and tasks
| **Configuration** | **Task** | Description |
|-------------------|---------------------------|---------------------------------------------------------------|
| authorship | Classification | Which Victorian author wrote the given text?|
# Usage
```python
from datasets import load_dataset
dataset = load_dataset("mstz/victorian_authorship", "authorship")["train"]
```
# Features
|**Feature** |**Type** |
|-------------------|---------------|
| text | `[string]` |
# Citation
Cite this dataset as
```
@phdthesis{gungor2018benchmarking,
title={Benchmarking authorship attribution techniques using over a thousand books by fifty victorian era novelists},
author={Gungor, Abdulmecit},
year={2018},
school={Purdue University}
}
```
|
mstz/victorian_authorship
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:en",
"license:cc",
"victorian",
"text-classification",
"region:us"
] |
2023-10-23T11:27:28+00:00
|
{"language": ["en"], "license": "cc", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "pretty_name": "Victorian authorship", "tags": ["victorian", "text-classification"]}
|
2023-10-26T13:10:56+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-cc #victorian #text-classification #region-us
|
Victorian authorship
====================
The Victorian authorship dataset.
Which Victorian author wrote the given text?
Configurations and tasks
========================
Configuration: authorship, Task: Classification, Description: Which Victorian author wrote the given text?
Usage
=====
Features
========
Cite this dataset as
|
[] |
[
"TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-cc #victorian #text-classification #region-us \n"
] |
[
47
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-English #license-cc #victorian #text-classification #region-us \n"
] |
6ec87f6f1b1c6564818b4154d0850f0184eb4bf0
|
The Corpus Buscapé is a large corpus of Portuguese product reviews crawled in 2013 with more than 80,000 samples from the Buscapé, a product and price search website. Unlike the datasets above, the range of the labels is in the 0 to 5 interval.
Thus, the comments with a rate of zero were remmoved.
|
evelinamorim/buscape-reviews
|
[
"language:pt",
"license:unknown",
"region:us"
] |
2023-10-23T11:27:44+00:00
|
{"language": ["pt"], "license": "unknown"}
|
2023-10-23T11:31:35+00:00
|
[] |
[
"pt"
] |
TAGS
#language-Portuguese #license-unknown #region-us
|
The Corpus Buscapé is a large corpus of Portuguese product reviews crawled in 2013 with more than 80,000 samples from the Buscapé, a product and price search website. Unlike the datasets above, the range of the labels is in the 0 to 5 interval.
Thus, the comments with a rate of zero were remmoved.
|
[] |
[
"TAGS\n#language-Portuguese #license-unknown #region-us \n"
] |
[
19
] |
[
"passage: TAGS\n#language-Portuguese #license-unknown #region-us \n"
] |
d6395caa3005bcbf21dd80585c15f60004f77ccb
|
# SkyPile-150B
## Dataset Summary
SkyPile-150B is a comprehensive, large-scale Chinese dataset specifically designed for the pre-training of large language models. It is derived from a broad array of publicly accessible Chinese Internet web pages. Rigorous filtering, extensive deduplication, and thorough sensitive data filtering have been employed to ensure its quality. Furthermore, we have utilized advanced tools such as fastText and BERT to filter out low-quality data.
The publicly accessible portion of the SkyPile-150B dataset encompasses approximately 233 million unique web pages, each containing an average of over 1,000 Chinese characters. In total, the dataset includes approximately 150 billion tokens and 620 gigabytes of plain text data.
## Language
The SkyPile-150B dataset is exclusively composed of Chinese data.
## Data Field Explanation
- text: the processed and cleaned text extracted from each page.
## Dataset Safety
We utilized more than 200w rules and the BERT-base model to determine the sensitive data present in the dataset, and subsequently removed any harmful entries we detect.
## Sensitive Information and Bias
Despite our best efforts, SkyPile-150B, given its construction from publicly available web pages, might contain sensitive information such as email addresses, phone numbers, or IP addresses. We have endeavored to minimize this through deduplication and low-quality filtering, but users of SkyPile-150B should remain vigilant.
The Internet is rife with potentially toxic or biased data. We have attempted to mitigate this with specific URL filtering methods, but we encourage users to remain conscious of this potential issue.
## Social Impact of the Dataset
The open-source release of the SkyPile-150B dataset represents our commitment to enhancing access to high-quality web data, which has traditionally been a closely guarded resource among model developers. We believe that this release will foster greater accessibility and the proliferation of high-performance large language models, thereby contributing significantly to the advancement of the field.
## License Agreement
The community usage of SkyPile dataset requires Skywork Community License. The SkyPile dataset supports commercial use. If you plan to use the Skywork model or its derivatives for commercial purposes, you must abide by terms and conditions within Skywork Community License as well as Apache2.0.
## Contact Us and Citation
If you find our work helpful, please feel free to cite our paper~
```
@misc{wei2023skywork,
title={Skywork: A More Open Bilingual Foundation Model},
author={Tianwen Wei and Liang Zhao and Lichang Zhang and Bo Zhu and Lijie Wang and Haihua Yang and Biye Li and Cheng Cheng and Weiwei Lü and Rui Hu and Chenxia Li and Liu Yang and Xilin Luo and Xuejie Wu and Lunan Liu and Wenjun Cheng and Peng Cheng and Jianhao Zhang and Xiaoyu Zhang and Lei Lin and Xiaokun Wang and Yutuan Ma and Chuanhai Dong and Yanqi Sun and Yifu Chen and Yongyi Peng and Xiaojuan Liang and Shuicheng Yan and Han Fang and Yahui Zhou},
year={2023},
eprint={2310.19341},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Skywork/SkyPile-150B
|
[
"task_categories:text-generation",
"size_categories:100B<n<1T",
"language:zh",
"llm ",
"casual-lm",
"language-modeling",
"arxiv:2310.19341",
"region:us"
] |
2023-10-23T11:55:10+00:00
|
{"language": ["zh"], "size_categories": ["100B<n<1T"], "task_categories": ["text-generation"], "pretty_name": "SkyPile-150B", "tags": ["llm ", "casual-lm", "language-modeling"]}
|
2023-12-07T06:11:28+00:00
|
[
"2310.19341"
] |
[
"zh"
] |
TAGS
#task_categories-text-generation #size_categories-100B<n<1T #language-Chinese #llm #casual-lm #language-modeling #arxiv-2310.19341 #region-us
|
# SkyPile-150B
## Dataset Summary
SkyPile-150B is a comprehensive, large-scale Chinese dataset specifically designed for the pre-training of large language models. It is derived from a broad array of publicly accessible Chinese Internet web pages. Rigorous filtering, extensive deduplication, and thorough sensitive data filtering have been employed to ensure its quality. Furthermore, we have utilized advanced tools such as fastText and BERT to filter out low-quality data.
The publicly accessible portion of the SkyPile-150B dataset encompasses approximately 233 million unique web pages, each containing an average of over 1,000 Chinese characters. In total, the dataset includes approximately 150 billion tokens and 620 gigabytes of plain text data.
## Language
The SkyPile-150B dataset is exclusively composed of Chinese data.
## Data Field Explanation
- text: the processed and cleaned text extracted from each page.
## Dataset Safety
We utilized more than 200w rules and the BERT-base model to determine the sensitive data present in the dataset, and subsequently removed any harmful entries we detect.
## Sensitive Information and Bias
Despite our best efforts, SkyPile-150B, given its construction from publicly available web pages, might contain sensitive information such as email addresses, phone numbers, or IP addresses. We have endeavored to minimize this through deduplication and low-quality filtering, but users of SkyPile-150B should remain vigilant.
The Internet is rife with potentially toxic or biased data. We have attempted to mitigate this with specific URL filtering methods, but we encourage users to remain conscious of this potential issue.
## Social Impact of the Dataset
The open-source release of the SkyPile-150B dataset represents our commitment to enhancing access to high-quality web data, which has traditionally been a closely guarded resource among model developers. We believe that this release will foster greater accessibility and the proliferation of high-performance large language models, thereby contributing significantly to the advancement of the field.
## License Agreement
The community usage of SkyPile dataset requires Skywork Community License. The SkyPile dataset supports commercial use. If you plan to use the Skywork model or its derivatives for commercial purposes, you must abide by terms and conditions within Skywork Community License as well as Apache2.0.
## Contact Us and Citation
If you find our work helpful, please feel free to cite our paper~
|
[
"# SkyPile-150B",
"## Dataset Summary\nSkyPile-150B is a comprehensive, large-scale Chinese dataset specifically designed for the pre-training of large language models. It is derived from a broad array of publicly accessible Chinese Internet web pages. Rigorous filtering, extensive deduplication, and thorough sensitive data filtering have been employed to ensure its quality. Furthermore, we have utilized advanced tools such as fastText and BERT to filter out low-quality data.\n\nThe publicly accessible portion of the SkyPile-150B dataset encompasses approximately 233 million unique web pages, each containing an average of over 1,000 Chinese characters. In total, the dataset includes approximately 150 billion tokens and 620 gigabytes of plain text data.",
"## Language\nThe SkyPile-150B dataset is exclusively composed of Chinese data.",
"## Data Field Explanation\n- text: the processed and cleaned text extracted from each page.",
"## Dataset Safety\nWe utilized more than 200w rules and the BERT-base model to determine the sensitive data present in the dataset, and subsequently removed any harmful entries we detect.",
"## Sensitive Information and Bias\nDespite our best efforts, SkyPile-150B, given its construction from publicly available web pages, might contain sensitive information such as email addresses, phone numbers, or IP addresses. We have endeavored to minimize this through deduplication and low-quality filtering, but users of SkyPile-150B should remain vigilant.\n\nThe Internet is rife with potentially toxic or biased data. We have attempted to mitigate this with specific URL filtering methods, but we encourage users to remain conscious of this potential issue.",
"## Social Impact of the Dataset\nThe open-source release of the SkyPile-150B dataset represents our commitment to enhancing access to high-quality web data, which has traditionally been a closely guarded resource among model developers. We believe that this release will foster greater accessibility and the proliferation of high-performance large language models, thereby contributing significantly to the advancement of the field.",
"## License Agreement\nThe community usage of SkyPile dataset requires Skywork Community License. The SkyPile dataset supports commercial use. If you plan to use the Skywork model or its derivatives for commercial purposes, you must abide by terms and conditions within Skywork Community License as well as Apache2.0.",
"## Contact Us and Citation\nIf you find our work helpful, please feel free to cite our paper~"
] |
[
"TAGS\n#task_categories-text-generation #size_categories-100B<n<1T #language-Chinese #llm #casual-lm #language-modeling #arxiv-2310.19341 #region-us \n",
"# SkyPile-150B",
"## Dataset Summary\nSkyPile-150B is a comprehensive, large-scale Chinese dataset specifically designed for the pre-training of large language models. It is derived from a broad array of publicly accessible Chinese Internet web pages. Rigorous filtering, extensive deduplication, and thorough sensitive data filtering have been employed to ensure its quality. Furthermore, we have utilized advanced tools such as fastText and BERT to filter out low-quality data.\n\nThe publicly accessible portion of the SkyPile-150B dataset encompasses approximately 233 million unique web pages, each containing an average of over 1,000 Chinese characters. In total, the dataset includes approximately 150 billion tokens and 620 gigabytes of plain text data.",
"## Language\nThe SkyPile-150B dataset is exclusively composed of Chinese data.",
"## Data Field Explanation\n- text: the processed and cleaned text extracted from each page.",
"## Dataset Safety\nWe utilized more than 200w rules and the BERT-base model to determine the sensitive data present in the dataset, and subsequently removed any harmful entries we detect.",
"## Sensitive Information and Bias\nDespite our best efforts, SkyPile-150B, given its construction from publicly available web pages, might contain sensitive information such as email addresses, phone numbers, or IP addresses. We have endeavored to minimize this through deduplication and low-quality filtering, but users of SkyPile-150B should remain vigilant.\n\nThe Internet is rife with potentially toxic or biased data. We have attempted to mitigate this with specific URL filtering methods, but we encourage users to remain conscious of this potential issue.",
"## Social Impact of the Dataset\nThe open-source release of the SkyPile-150B dataset represents our commitment to enhancing access to high-quality web data, which has traditionally been a closely guarded resource among model developers. We believe that this release will foster greater accessibility and the proliferation of high-performance large language models, thereby contributing significantly to the advancement of the field.",
"## License Agreement\nThe community usage of SkyPile dataset requires Skywork Community License. The SkyPile dataset supports commercial use. If you plan to use the Skywork model or its derivatives for commercial purposes, you must abide by terms and conditions within Skywork Community License as well as Apache2.0.",
"## Contact Us and Citation\nIf you find our work helpful, please feel free to cite our paper~"
] |
[
57,
6,
164,
19,
22,
43,
125,
92,
67,
21
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-100B<n<1T #language-Chinese #llm #casual-lm #language-modeling #arxiv-2310.19341 #region-us \n# SkyPile-150B## Dataset Summary\nSkyPile-150B is a comprehensive, large-scale Chinese dataset specifically designed for the pre-training of large language models. It is derived from a broad array of publicly accessible Chinese Internet web pages. Rigorous filtering, extensive deduplication, and thorough sensitive data filtering have been employed to ensure its quality. Furthermore, we have utilized advanced tools such as fastText and BERT to filter out low-quality data.\n\nThe publicly accessible portion of the SkyPile-150B dataset encompasses approximately 233 million unique web pages, each containing an average of over 1,000 Chinese characters. In total, the dataset includes approximately 150 billion tokens and 620 gigabytes of plain text data.## Language\nThe SkyPile-150B dataset is exclusively composed of Chinese data.## Data Field Explanation\n- text: the processed and cleaned text extracted from each page.## Dataset Safety\nWe utilized more than 200w rules and the BERT-base model to determine the sensitive data present in the dataset, and subsequently removed any harmful entries we detect.## Sensitive Information and Bias\nDespite our best efforts, SkyPile-150B, given its construction from publicly available web pages, might contain sensitive information such as email addresses, phone numbers, or IP addresses. We have endeavored to minimize this through deduplication and low-quality filtering, but users of SkyPile-150B should remain vigilant.\n\nThe Internet is rife with potentially toxic or biased data. We have attempted to mitigate this with specific URL filtering methods, but we encourage users to remain conscious of this potential issue."
] |
c00e1214c9571bb9bf4431e32d0044e217ef9344
|
# Dataset Card for Spider Dev
This dataset aims to provide an easy reference to the [Spider](https://github.com/taoyds/spider) [Dev](https://drive.google.com/uc?export=download&id=1TqleXec_OykOYFREKKtschzY29dUcVAQ) set.
## Dataset Details
```
dataset_info:
features:
- name: db_id
dtype: string
description: maps to the database id of the underlying table
- name: query
dtype: string
description: the gold query for the question & database
- name: question
dtype: string
description: the relevant question for the gold & database
- name: create_w_keys
dtype: string
description: the create statment for the database including primary & foreign keys
- name: create_wo_keys
dtype: string
description: the create statement for the database (not inlcuding primary & foreign keys)
```
The `db_id` references the spider database found [here](https://drive.google.com/uc?export=download&id=1TqleXec_OykOYFREKKtschzY29dUcVAQ).
|
alagaesia/spider_dev
|
[
"license:mit",
"region:us"
] |
2023-10-23T12:27:04+00:00
|
{"license": "mit", "dataset_info": {"features": [{"name": "db_id", "dtype": "string"}, {"name": "query", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "create_w_keys", "dtype": "string"}, {"name": "create_wo_keys", "dtype": "string"}, {"name": "difficulty", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1967349, "num_examples": 1034}], "download_size": 82238, "dataset_size": 1967349}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-24T18:12:03+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
# Dataset Card for Spider Dev
This dataset aims to provide an easy reference to the Spider Dev set.
## Dataset Details
The 'db_id' references the spider database found here.
|
[
"# Dataset Card for Spider Dev\n\nThis dataset aims to provide an easy reference to the Spider Dev set.",
"## Dataset Details\n\n\n\nThe 'db_id' references the spider database found here."
] |
[
"TAGS\n#license-mit #region-us \n",
"# Dataset Card for Spider Dev\n\nThis dataset aims to provide an easy reference to the Spider Dev set.",
"## Dataset Details\n\n\n\nThe 'db_id' references the spider database found here."
] |
[
11,
22,
19
] |
[
"passage: TAGS\n#license-mit #region-us \n# Dataset Card for Spider Dev\n\nThis dataset aims to provide an easy reference to the Spider Dev set.## Dataset Details\n\n\n\nThe 'db_id' references the spider database found here."
] |
9fb4c3663d0614464a800d08ab5c177d89588a60
|
# Hestenet Question-Answer
The dataset is based on data from Hestenettet in the Danish Gigaword corpus.
Question-answer pairs are purely extracted on the basis of heuristics, and have not been manually evaluated.
The dataset was created for aiding the training of sentence transformer models in the Danish Foundation Models project.
The dataset is currently not production-ready.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
kardosdrur/hestenet-qa
|
[
"license:mit",
"region:us"
] |
2023-10-23T12:37:15+00:00
|
{"license": "mit", "dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1144206.5903728174, "num_examples": 1695}, {"name": "test", "num_bytes": 286220.40962718264, "num_examples": 424}], "download_size": 936129, "dataset_size": 1430427.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-10-23T13:16:16+00:00
|
[] |
[] |
TAGS
#license-mit #region-us
|
# Hestenet Question-Answer
The dataset is based on data from Hestenettet in the Danish Gigaword corpus.
Question-answer pairs are purely extracted on the basis of heuristics, and have not been manually evaluated.
The dataset was created for aiding the training of sentence transformer models in the Danish Foundation Models project.
The dataset is currently not production-ready.
More Information needed
|
[
"# Hestenet Question-Answer\nThe dataset is based on data from Hestenettet in the Danish Gigaword corpus.\nQuestion-answer pairs are purely extracted on the basis of heuristics, and have not been manually evaluated.\n\nThe dataset was created for aiding the training of sentence transformer models in the Danish Foundation Models project.\nThe dataset is currently not production-ready.\n\nMore Information needed"
] |
[
"TAGS\n#license-mit #region-us \n",
"# Hestenet Question-Answer\nThe dataset is based on data from Hestenettet in the Danish Gigaword corpus.\nQuestion-answer pairs are purely extracted on the basis of heuristics, and have not been manually evaluated.\n\nThe dataset was created for aiding the training of sentence transformer models in the Danish Foundation Models project.\nThe dataset is currently not production-ready.\n\nMore Information needed"
] |
[
11,
94
] |
[
"passage: TAGS\n#license-mit #region-us \n# Hestenet Question-Answer\nThe dataset is based on data from Hestenettet in the Danish Gigaword corpus.\nQuestion-answer pairs are purely extracted on the basis of heuristics, and have not been manually evaluated.\n\nThe dataset was created for aiding the training of sentence transformer models in the Danish Foundation Models project.\nThe dataset is currently not production-ready.\n\nMore Information needed"
] |
792f4886c26f740f3dfca93f115928718fa69306
|
This dataset is a subset of the Open Assistant dataset, which you can find here: https://huggingface.co/datasets/OpenAssistant/oasst1/tree/main
This subset of the data only contains the highest-rated paths in the conversation tree, with a total of 9,846 samples.
This dataset was used to train Guanaco with QLoRA.
For further information, please see the original dataset.
License: Apache 2.0
|
am96149/first
|
[
"region:us"
] |
2023-10-23T12:39:20+00:00
|
{}
|
2023-11-01T10:21:47+00:00
|
[] |
[] |
TAGS
#region-us
|
This dataset is a subset of the Open Assistant dataset, which you can find here: URL
This subset of the data only contains the highest-rated paths in the conversation tree, with a total of 9,846 samples.
This dataset was used to train Guanaco with QLoRA.
For further information, please see the original dataset.
License: Apache 2.0
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
1bbc3fd9f0d71bf49d6dc175729f7893713ee476
|
# Dataset Card for "child-100K"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
haseong8012/child-100K
|
[
"region:us"
] |
2023-10-23T12:55:13+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "audio", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 19504038988, "num_examples": 100000}], "download_size": 17224747032, "dataset_size": 19504038988}}
|
2023-10-23T15:26:49+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "child-100K"
More Information needed
|
[
"# Dataset Card for \"child-100K\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"child-100K\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"child-100K\"\n\nMore Information needed"
] |
66aa81ddac58a66a0b35251fb5e0cdf39bb17a9f
|
# Dataset Card for "datasci-standardized_unified"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_unified
|
[
"region:us"
] |
2023-10-23T12:57:17+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 4474152, "num_examples": 1982}], "download_size": 2284059, "dataset_size": 4474152}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:57:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_unified"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_unified\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_unified\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_unified\"\n\nMore Information needed"
] |
d51045efaab64b8b1e6cec120eca8fcb4200d61e
|
# Dataset Card for "datasci-standardized_embedded"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_embedded
|
[
"region:us"
] |
2023-10-23T12:57:30+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 12600352, "num_examples": 1982}], "download_size": 6271462, "dataset_size": 12600352}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:57:33+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_embedded"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_embedded\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_embedded\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_embedded\"\n\nMore Information needed"
] |
8a66d1df973d30f10bd001675e0f8189e5ba28e8
|
# Dataset Card for "datasci-standardized_cluster_0_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_0_std
|
[
"region:us"
] |
2023-10-23T12:57:48+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2931034, "num_examples": 2588}], "download_size": 1480621, "dataset_size": 2931034}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:57:51+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_0_std"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_0_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_0_std\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_0_std\"\n\nMore Information needed"
] |
097eb4fac6c28d902e76ddb21cc412b07a2fd184
|
# Dataset Card for "datasci-standardized_cluster_0_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_0_alpaca
|
[
"region:us"
] |
2023-10-23T12:57:52+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2856195, "num_examples": 1293}], "download_size": 1502648, "dataset_size": 2856195}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:57:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_0_alpaca"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
a62397adf8c2cab46239e4935990598a2e3830d3
|
# Dataset Card for "datasci-standardized_cluster_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_0
|
[
"region:us"
] |
2023-10-23T12:57:55+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 13439608, "num_examples": 1294}], "download_size": 4112832, "dataset_size": 13439608}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:57:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_0"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_0\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_0\"\n\nMore Information needed"
] |
049ca68868bd2f89ca1a59262389211ee9c1f068
|
# Dataset Card for "datasci-standardized_cluster_1_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_1_std
|
[
"region:us"
] |
2023-10-23T12:58:20+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1707624, "num_examples": 1376}], "download_size": 840372, "dataset_size": 1707624}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:58:22+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_1_std"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_1_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_1_std\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_1_std\"\n\nMore Information needed"
] |
d86a4cd5bb484143bcbca24063fce03980b2ff12
|
# Dataset Card for "datasci-standardized_cluster_1_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_1_alpaca
|
[
"region:us"
] |
2023-10-23T12:58:23+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1665954, "num_examples": 687}], "download_size": 847238, "dataset_size": 1665954}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:58:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_1_alpaca"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
d25e61d7d670d94fae201ed983b018c19000e55c
|
# Dataset Card for "datasci-standardized_cluster_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/datasci-standardized_cluster_1
|
[
"region:us"
] |
2023-10-23T12:58:26+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 7294872, "num_examples": 688}], "download_size": 2235819, "dataset_size": 7294872}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T12:58:28+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "datasci-standardized_cluster_1"
More Information needed
|
[
"# Dataset Card for \"datasci-standardized_cluster_1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"datasci-standardized_cluster_1\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"datasci-standardized_cluster_1\"\n\nMore Information needed"
] |
88efa251db4cea84ff1d25743288c9eae484edee
|
# Dataset Card for "QA-En-General"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Back-up/QA-En-General
|
[
"region:us"
] |
2023-10-23T13:01:57+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "system_prompt", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "response", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 34111625.1145805, "num_examples": 20000}], "download_size": 19538064, "dataset_size": 34111625.1145805}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:02:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "QA-En-General"
More Information needed
|
[
"# Dataset Card for \"QA-En-General\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"QA-En-General\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"QA-En-General\"\n\nMore Information needed"
] |
aa428cfa7e25a565b503950e9233ba40166d54e1
|
# Dataset Card for "e1cc4189"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-kand2-sdxl-wuerst-karlo/e1cc4189
|
[
"region:us"
] |
2023-10-23T13:05:25+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 211, "num_examples": 10}], "download_size": 1374, "dataset_size": 211}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:05:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "e1cc4189"
More Information needed
|
[
"# Dataset Card for \"e1cc4189\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"e1cc4189\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"e1cc4189\"\n\nMore Information needed"
] |
b677225fba4a914eca11b9981b59488c06a7a5b9
|
# Dataset Card for Testingdatasetcards
Very Simple Multiple Linear Regression Dataset
## Dataset Details
### Dataset Description
<!-- This is a very simple multiple linear regression dataset for beginners.
This dataset has only three columns and twenty rows.
There are only two independent variables and one dependent variable. The independent variables are 'age' and 'experience'.
The dependent variable is 'income'. -->
- **Curated by:** HUSSAIN NASIR KHAN (Kaggle)
- **Shared by [optional]:** Maria Murphy
- **Language(s) (NLP):** English
- **License:** CC0: Public Domain
## Uses
Intended for practice with linear regression.
## Dataset Structure
Contains three columns (age, experience, income) and twenty observations.
|
mariakmurphy55/testingdatasetcards
|
[
"size_categories:n<1K",
"language:en",
"license:cc0-1.0",
"region:us"
] |
2023-10-23T13:07:20+00:00
|
{"language": ["en"], "license": "cc0-1.0", "size_categories": ["n<1K"], "pretty_name": "linregdata"}
|
2023-10-23T13:23:13+00:00
|
[] |
[
"en"
] |
TAGS
#size_categories-n<1K #language-English #license-cc0-1.0 #region-us
|
# Dataset Card for Testingdatasetcards
Very Simple Multiple Linear Regression Dataset
## Dataset Details
### Dataset Description
- Curated by: HUSSAIN NASIR KHAN (Kaggle)
- Shared by [optional]: Maria Murphy
- Language(s) (NLP): English
- License: CC0: Public Domain
## Uses
Intended for practice with linear regression.
## Dataset Structure
Contains three columns (age, experience, income) and twenty observations.
|
[
"# Dataset Card for Testingdatasetcards\n\nVery Simple Multiple Linear Regression Dataset",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: HUSSAIN NASIR KHAN (Kaggle)\n- Shared by [optional]: Maria Murphy\n- Language(s) (NLP): English\n- License: CC0: Public Domain",
"## Uses\n\nIntended for practice with linear regression.",
"## Dataset Structure\n\nContains three columns (age, experience, income) and twenty observations."
] |
[
"TAGS\n#size_categories-n<1K #language-English #license-cc0-1.0 #region-us \n",
"# Dataset Card for Testingdatasetcards\n\nVery Simple Multiple Linear Regression Dataset",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: HUSSAIN NASIR KHAN (Kaggle)\n- Shared by [optional]: Maria Murphy\n- Language(s) (NLP): English\n- License: CC0: Public Domain",
"## Uses\n\nIntended for practice with linear regression.",
"## Dataset Structure\n\nContains three columns (age, experience, income) and twenty observations."
] |
[
28,
21,
4,
49,
13,
24
] |
[
"passage: TAGS\n#size_categories-n<1K #language-English #license-cc0-1.0 #region-us \n# Dataset Card for Testingdatasetcards\n\nVery Simple Multiple Linear Regression Dataset## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: HUSSAIN NASIR KHAN (Kaggle)\n- Shared by [optional]: Maria Murphy\n- Language(s) (NLP): English\n- License: CC0: Public Domain## Uses\n\nIntended for practice with linear regression.## Dataset Structure\n\nContains three columns (age, experience, income) and twenty observations."
] |
c1ffc02fb7559691c298cf2ca92676df2d727074
|
# Dataset Card for "test-dataset-bug"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vwxyzjn/test-dataset-bug
|
[
"region:us"
] |
2023-10-23T13:10:53+00:00
|
{"dataset_info": {"features": [{"name": "data", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 40, "num_examples": 2}, {"name": "remove_CritiqueRequest_10_18_2023_1697667530", "num_bytes": 40, "num_examples": 2}], "download_size": 2130, "dataset_size": 80}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "remove_CritiqueRequest_10_18_2023_1697667530", "path": "data/remove_CritiqueRequest_10_18_2023_1697667530-*"}]}]}
|
2023-10-23T13:12:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test-dataset-bug"
More Information needed
|
[
"# Dataset Card for \"test-dataset-bug\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test-dataset-bug\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test-dataset-bug\"\n\nMore Information needed"
] |
ca11eecd9e1b6eec90916a72d2f9432196be39aa
|
# Dataset Card for "test-dataset-bug2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vwxyzjn/test-dataset-bug2
|
[
"region:us"
] |
2023-10-23T13:11:18+00:00
|
{"dataset_info": {"features": [{"name": "data", "sequence": "int64"}], "splits": [{"name": "remove_CritiqueRequest_10_18_2023_1697667530", "num_bytes": 40, "num_examples": 2}], "download_size": 1065, "dataset_size": 40}, "configs": [{"config_name": "default", "data_files": [{"split": "remove_CritiqueRequest_10_18_2023_1697667530", "path": "data/remove_CritiqueRequest_10_18_2023_1697667530-*"}]}]}
|
2023-10-23T13:11:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test-dataset-bug2"
More Information needed
|
[
"# Dataset Card for \"test-dataset-bug2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test-dataset-bug2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test-dataset-bug2\"\n\nMore Information needed"
] |
4e7156f179f281567dd307340e3170db41e2ecb1
|
# Dataset Card for "test-dataset-bug3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vwxyzjn/test-dataset-bug3
|
[
"region:us"
] |
2023-10-23T13:13:08+00:00
|
{"dataset_info": {"features": [{"name": "data", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 40, "num_examples": 2}, {"name": "remove_CritiqueRequest_10_18_2023_1697667530", "num_bytes": 40, "num_examples": 2}], "download_size": 2130, "dataset_size": 80}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "remove_CritiqueRequest_10_18_2023_1697667530", "path": "data/remove_CritiqueRequest_10_18_2023_1697667530-*"}]}]}
|
2023-10-23T13:13:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test-dataset-bug3"
More Information needed
|
[
"# Dataset Card for \"test-dataset-bug3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test-dataset-bug3\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test-dataset-bug3\"\n\nMore Information needed"
] |
c790b472e4a51d5886da993ae4424a62ca77fe4f
|
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
Contains text pairs from https://www.aminer.org/citation v14. Similairty socres calculated with Jaccard index.
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed]
|
ppxscal/aminer-citation-graphv14-jaccard
|
[
"region:us"
] |
2023-10-23T13:13:25+00:00
|
{}
|
2023-10-24T00:56:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
Contains text pairs from URL v14. Similairty socres calculated with Jaccard index.
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
|
[
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\nContains text pairs from URL v14. Similairty socres calculated with Jaccard index. \n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\nContains text pairs from URL v14. Similairty socres calculated with Jaccard index. \n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
6,
34,
4,
64,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\nContains text pairs from URL v14. Similairty socres calculated with Jaccard index. \n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
849511e768e21604f92d7a0e1e8627429e157f18
|
# Dataset Card for "augmentatio-standardized_unified"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_unified
|
[
"region:us"
] |
2023-10-23T13:15:08+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 90820220, "num_examples": 43655}], "download_size": 45558933, "dataset_size": 90820220}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:15:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_unified"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_unified\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_unified\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_unified\"\n\nMore Information needed"
] |
2bfa2d81b59356536afa7546cbf1a6a0383abb37
|
# Dataset Card for "augmentatio-standardized_embedded"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_embedded
|
[
"region:us"
] |
2023-10-23T13:16:39+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 269805720, "num_examples": 43655}], "download_size": 133337025, "dataset_size": 269805720}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:16:51+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_embedded"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_embedded\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_embedded\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_embedded\"\n\nMore Information needed"
] |
8a02924771476e403f6ee261b3c7d123122de3c5
|
# Dataset Card for "paediatrics_abdominal_pain"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
BLACKBUN/paediatrics_abdominal_pain
|
[
"region:us"
] |
2023-10-23T13:18:30+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "Disease", "dtype": "string"}, {"name": "Explanation", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 393173, "num_examples": 143}], "download_size": 165813, "dataset_size": 393173}}
|
2023-10-23T13:18:33+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "paediatrics_abdominal_pain"
More Information needed
|
[
"# Dataset Card for \"paediatrics_abdominal_pain\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"paediatrics_abdominal_pain\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"paediatrics_abdominal_pain\"\n\nMore Information needed"
] |
7eba8a64f259ff208e4636d723fa22191ab02b65
|
# Dataset Card for "augmentatio-standardized_cluster_0_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_0_std
|
[
"region:us"
] |
2023-10-23T13:19:18+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 6065771, "num_examples": 4720}], "download_size": 2954709, "dataset_size": 6065771}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_0_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_0_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_0_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_0_std\"\n\nMore Information needed"
] |
abcbeea5a6ee85efbfdbf19670b09cea0113d18f
|
# Dataset Card for "augmentatio-standardized_cluster_0_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_0_alpaca
|
[
"region:us"
] |
2023-10-23T13:19:22+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5930091, "num_examples": 2359}], "download_size": 2668826, "dataset_size": 5930091}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_0_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_0_alpaca\"\n\nMore Information needed"
] |
8f1c09051ac3b1616e771a984267d39193ad3b56
|
# Dataset Card for "augmentatio-standardized_cluster_0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_0
|
[
"region:us"
] |
2023-10-23T13:19:25+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 25231331, "num_examples": 2360}], "download_size": 7470973, "dataset_size": 25231331}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_0"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_0\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_0\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_0\"\n\nMore Information needed"
] |
4d4244079ee95a9f88db2a0de1a7e8b47c997d17
|
# Dataset Card for "augmentatio-standardized_cluster_1_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_1_std
|
[
"region:us"
] |
2023-10-23T13:19:49+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 8931871, "num_examples": 6644}], "download_size": 4610102, "dataset_size": 8931871}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_1_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_1_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_1_std\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_1_std\"\n\nMore Information needed"
] |
59693eaa8035e79b710d7ef76d28f743fa8297cc
|
# Dataset Card for "augmentatio-standardized_cluster_1_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_1_alpaca
|
[
"region:us"
] |
2023-10-23T13:19:53+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8743989, "num_examples": 3321}], "download_size": 4269822, "dataset_size": 8743989}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_1_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_1_alpaca\"\n\nMore Information needed"
] |
1513ba6f95d2089aeffc3e537aa931d4c90121fc
|
# Dataset Card for "augmentatio-standardized_cluster_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_1
|
[
"region:us"
] |
2023-10-23T13:19:56+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 35909833, "num_examples": 3322}], "download_size": 10976861, "dataset_size": 35909833}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:19:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_1"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_1\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_1\"\n\nMore Information needed"
] |
f96e5a85f994a3431dbda5ae3229e0eb510bcce2
|
# Dataset Card for "augmentatio-standardized_cluster_2_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_2_std
|
[
"region:us"
] |
2023-10-23T13:20:20+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 14327656, "num_examples": 14670}], "download_size": 6277695, "dataset_size": 14327656}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:20:23+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_2_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_2_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_2_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_2_std\"\n\nMore Information needed"
] |
f9c44bb93660656db0a9b4641539639a1833c53f
|
# Dataset Card for "augmentatio-standardized_cluster_2_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_2_alpaca
|
[
"region:us"
] |
2023-10-23T13:20:24+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 13914510, "num_examples": 7334}], "download_size": 6033439, "dataset_size": 13914510}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:20:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_2_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_2_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_2_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_2_alpaca\"\n\nMore Information needed"
] |
2c5a41ac73e54e0298c015aea8b09905d1ea056a
|
# Dataset Card for "augmentatio-standardized_cluster_2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_2
|
[
"region:us"
] |
2023-10-23T13:20:27+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 73895191, "num_examples": 7335}], "download_size": 20782283, "dataset_size": 73895191}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:20:30+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_2"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_2\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_2\"\n\nMore Information needed"
] |
6563ebdcfaa4e2a994ebf3f9e6287dccd1bbc23f
|
# Dataset Card for "augmentatio-standardized_cluster_3_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_3_std
|
[
"region:us"
] |
2023-10-23T13:20:52+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 12918145, "num_examples": 12676}], "download_size": 5481927, "dataset_size": 12918145}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:20:54+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_3_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_3_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_3_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_3_std\"\n\nMore Information needed"
] |
1492cc81bf829fea1d58d5478da24cd766fffda8
|
# Dataset Card for "augmentatio-standardized_cluster_3_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_3_alpaca
|
[
"region:us"
] |
2023-10-23T13:20:55+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12560660, "num_examples": 6337}], "download_size": 5185004, "dataset_size": 12560660}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:20:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_3_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_3_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_3_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_3_alpaca\"\n\nMore Information needed"
] |
cd76a0301014a34cfc5e296a4ab204bd189d7082
|
# Dataset Card for "augmentatio-standardized_cluster_3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_3
|
[
"region:us"
] |
2023-10-23T13:20:58+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 64389043, "num_examples": 6338}], "download_size": 17963337, "dataset_size": 64389043}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:21:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_3"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_3\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_3\"\n\nMore Information needed"
] |
5e127d7d7c71d1dd6a267ddf2cb23427181703d5
|
# Dataset Card for "augmentatio-standardized_cluster_4_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_4_std
|
[
"region:us"
] |
2023-10-23T13:21:24+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 14341286, "num_examples": 13398}], "download_size": 6582669, "dataset_size": 14341286}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:21:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_4_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_4_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_4_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_4_std\"\n\nMore Information needed"
] |
7c2aec0a49a5d9adb4f96925cd75231800f06e8b
|
# Dataset Card for "augmentatio-standardized_cluster_4_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_4_alpaca
|
[
"region:us"
] |
2023-10-23T13:21:28+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 13964071, "num_examples": 6698}], "download_size": 6329527, "dataset_size": 13964071}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:21:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_4_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_4_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_4_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_4_alpaca\"\n\nMore Information needed"
] |
fb6703e92e2a4a859a9dc5ea3e1e025b42c8973d
|
# Dataset Card for "augmentatio-standardized_cluster_4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_4
|
[
"region:us"
] |
2023-10-23T13:21:31+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 68743865, "num_examples": 6699}], "download_size": 19780297, "dataset_size": 68743865}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:21:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_4"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_4\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_4\"\n\nMore Information needed"
] |
5c5c575d3744bf324421c9787456fba5a1bf72ec
|
# Dataset Card for "augmentatio-standardized_cluster_5_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_5_std
|
[
"region:us"
] |
2023-10-23T13:21:58+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 6032703, "num_examples": 5848}], "download_size": 2577283, "dataset_size": 6032703}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:00+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_5_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_5_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_5_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_5_std\"\n\nMore Information needed"
] |
66bf24403c6033cd2b4d2224d1e862a14491562d
|
# Dataset Card for "augmentatio-standardized_cluster_5_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_5_alpaca
|
[
"region:us"
] |
2023-10-23T13:22:01+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5866857, "num_examples": 2923}], "download_size": 2330511, "dataset_size": 5866857}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_5_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_5_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_5_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_5_alpaca\"\n\nMore Information needed"
] |
519436bd7472b61fd80431955b7246c0fa61c4fd
|
# Dataset Card for "augmentatio-standardized_cluster_5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_5
|
[
"region:us"
] |
2023-10-23T13:22:03+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 29778507, "num_examples": 2924}], "download_size": 8208591, "dataset_size": 29778507}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_5"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_5\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_5\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_5\"\n\nMore Information needed"
] |
9a971dfbad01480e51563215428549b86fd24372
|
# Dataset Card for "augmentatio-standardized_cluster_6_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_6_std
|
[
"region:us"
] |
2023-10-23T13:22:27+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 5554705, "num_examples": 5506}], "download_size": 2208702, "dataset_size": 5554705}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_6_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_6_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_6_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_6_std\"\n\nMore Information needed"
] |
a321a23fef7441829f325e5b851a1246e01d92fe
|
# Dataset Card for "augmentatio-standardized_cluster_6_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_6_alpaca
|
[
"region:us"
] |
2023-10-23T13:22:30+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5398233, "num_examples": 2752}], "download_size": 1995939, "dataset_size": 5398233}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_6_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_6_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_6_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_6_alpaca\"\n\nMore Information needed"
] |
00afab430137257516a10723a0affc29eeb0c9f6
|
# Dataset Card for "augmentatio-standardized_cluster_6"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_6
|
[
"region:us"
] |
2023-10-23T13:22:32+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 27911818, "num_examples": 2753}], "download_size": 7524422, "dataset_size": 27911818}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:22:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_6"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_6\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_6\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_6\"\n\nMore Information needed"
] |
d9cd68e4575a9ebf323f9438efcc2e654ed468c2
|
# Dataset Card for "augmentatio-standardized_cluster_7_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_7_std
|
[
"region:us"
] |
2023-10-23T13:22:57+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 13603534, "num_examples": 14342}], "download_size": 5857922, "dataset_size": 13603534}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:00+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_7_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_7_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_7_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_7_std\"\n\nMore Information needed"
] |
7659a98e8e97442d867d98812b40786d678e5404
|
# Dataset Card for "augmentatio-standardized_cluster_7_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_7_alpaca
|
[
"region:us"
] |
2023-10-23T13:23:01+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 13200216, "num_examples": 7170}], "download_size": 5579319, "dataset_size": 13200216}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_7_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_7_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_7_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_7_alpaca\"\n\nMore Information needed"
] |
54bc2dbebd68626191d7c5abd944f5a7c1c4ffb2
|
# Dataset Card for "augmentatio-standardized_cluster_7"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_7
|
[
"region:us"
] |
2023-10-23T13:23:04+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 71839225, "num_examples": 7171}], "download_size": 20017335, "dataset_size": 71839225}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:08+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_7"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_7\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_7\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_7\"\n\nMore Information needed"
] |
2af60be53b23e6b77adfc4ffee1a20e093b5d8f3
|
# Dataset Card for "augmentatio-standardized_cluster_8_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_8_std
|
[
"region:us"
] |
2023-10-23T13:23:30+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 9176034, "num_examples": 6540}], "download_size": 4302367, "dataset_size": 9176034}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_8_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_8_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_8_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_8_std\"\n\nMore Information needed"
] |
2612f87c0f449f03b4d725345b8a06ab9790a597
|
# Dataset Card for "augmentatio-standardized_cluster_8_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_8_alpaca
|
[
"region:us"
] |
2023-10-23T13:23:33+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8954341, "num_examples": 3269}], "download_size": 4011651, "dataset_size": 8954341}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_8_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_8_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_8_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_8_alpaca\"\n\nMore Information needed"
] |
62a8b9d83fb1004a54f946436208f5b692a94612
|
# Dataset Card for "augmentatio-standardized_cluster_8"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_8
|
[
"region:us"
] |
2023-10-23T13:23:35+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 35731704, "num_examples": 3270}], "download_size": 10632958, "dataset_size": 35731704}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:23:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_8"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_8\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_8\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_8\"\n\nMore Information needed"
] |
1b06fe22d5487275ddf013d90e569b78115d6414
|
# Dataset Card for "augmentatio-standardized_cluster_9_std"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_9_std
|
[
"region:us"
] |
2023-10-23T13:24:00+00:00
|
{"dataset_info": {"features": [{"name": "message", "dtype": "string"}, {"name": "message_type", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "cluster", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 3491880, "num_examples": 2966}], "download_size": 1567263, "dataset_size": 3491880}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:24:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_9_std"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_9_std\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_9_std\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_9_std\"\n\nMore Information needed"
] |
687eab9288b93a23a2f26e30a18176b9577d90f6
|
# Dataset Card for "augmentatio-standardized_cluster_9_alpaca"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_9_alpaca
|
[
"region:us"
] |
2023-10-23T13:24:03+00:00
|
{"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3406053, "num_examples": 1482}], "download_size": 1387156, "dataset_size": 3406053}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:24:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_9_alpaca"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_9_alpaca\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_9_alpaca\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_9_alpaca\"\n\nMore Information needed"
] |
33fa832d935a8e2ae1320104be8f31bc5c1e2781
|
# Dataset Card for "augmentatio-standardized_cluster_9"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/augmentatio-standardized_cluster_9
|
[
"region:us"
] |
2023-10-23T13:24:05+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}, {"name": "embedding", "sequence": "float64"}, {"name": "cluster", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 15535323, "num_examples": 1483}], "download_size": 4402938, "dataset_size": 15535323}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T13:24:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "augmentatio-standardized_cluster_9"
More Information needed
|
[
"# Dataset Card for \"augmentatio-standardized_cluster_9\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"augmentatio-standardized_cluster_9\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"augmentatio-standardized_cluster_9\"\n\nMore Information needed"
] |
55712e22068f2d0d961a8bc095a8d5dfdd0a1093
|
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
```
{
'image_id': 15,
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=640x640 at 0x2373B065C18>,
'width': 964043,
'height': 640,
'objects': {
'id': [114, 115, 116, 117],
'area': [3796, 1596, 152768, 81002],
'bbox': [
[302.0, 109.0, 73.0, 52.0],
[810.0, 100.0, 57.0, 28.0],
[160.0, 31.0, 248.0, 616.0],
[741.0, 68.0, 202.0, 401.0]
],
'category': [4, 4, 0, 0]
}
}
```
### Data Fields
- `image`: the image id
- `image`: `PIL.Image.Image` object containing the image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `width`: the image width
- `height`: the image height
- `objects`: a dictionary containing bounding box metadata for the objects present on the image
- `id`: the annotation id
- `area`: the area of the bounding box
- `bbox`: the object's bounding box (in the [coco](https://albumentations.ai/docs/getting_started/bounding_boxes_augmentation/#coco) format)
- `category`: the object's category.
## Licensing Information
See original homepage https://universe.roboflow.com/object-detection/bone-fracture-7fylg
### Citation Information
```
@misc{ bone-fracture-7fylg,
title = { bone fracture 7fylg Dataset },
type = { Open Source Dataset },
author = { Roboflow 100 },
howpublished = { \url{ https://universe.roboflow.com/object-detection/bone-fracture-7fylg } },
url = { https://universe.roboflow.com/object-detection/bone-fracture-7fylg },
journal = { Roboflow Universe },
publisher = { Roboflow },
year = { 2022 },
month = { nov },
note = { visited on 2023-03-29 },
contributions dataset = {[@mariosasko](https://github.com/mariosasko)}
}"
```
|
LosHuesitos9-9/Huesitos
|
[
"task_categories:object-detection",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:n<1K",
"source_datasets:original",
"language:en",
"language:es",
"license:cc",
"rf100",
"medical",
"code",
"region:us"
] |
2023-10-23T13:33:42+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["found"], "language": ["en", "es"], "license": ["cc"], "multilinguality": ["monolingual"], "size_categories": ["n<1K"], "source_datasets": ["original"], "task_categories": ["object-detection"], "task_ids": [], "pretty_name": "Huesitos", "dataset_info": {"features": [{"name": "image_id", "dtype": "int64"}, {"name": "image", "dtype": "image"}, {"name": "width", "dtype": "int32"}, {"name": "height", "dtype": "int32"}, {"name": "objects", "sequence": [{"name": "id", "dtype": "int64"}, {"name": "area", "dtype": "int64"}, {"name": "bbox", "sequence": "float32", "length": 4}, {"name": "category", "dtype": {"class_label": {"names": {"0": "bone-fracture", "1": "angle", "2": "fracture", "3": "line", "4": "messed_up_angle"}}}}]}], "splits": [{"name": "train", "num_bytes": 150839322.0, "num_examples": 626}, {"name": "validation", "num_bytes": 1278386.0, "num_examples": 44}, {"name": "test", "num_bytes": 2530151.0, "num_examples": 88}], "download_size": 71039842, "dataset_size": 154647859.0}, "tags": ["rf100", "medical", "code"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-11-04T19:08:54+00:00
|
[] |
[
"en",
"es"
] |
TAGS
#task_categories-object-detection #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-n<1K #source_datasets-original #language-English #language-Spanish #license-cc #rf100 #medical #code #region-us
|
## Dataset Structure
### Data Instances
A data point comprises an image and its object annotations.
### Data Fields
- 'image': the image id
- 'image': 'PIL.Image.Image' object containing the image. Note that when accessing the image column: 'dataset[0]["image"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '"image"' column, *i.e.* 'dataset[0]["image"]' should always be preferred over 'dataset["image"][0]'
- 'width': the image width
- 'height': the image height
- 'objects': a dictionary containing bounding box metadata for the objects present on the image
- 'id': the annotation id
- 'area': the area of the bounding box
- 'bbox': the object's bounding box (in the coco format)
- 'category': the object's category.
## Licensing Information
See original homepage URL
|
[
"## Dataset Structure",
"### Data Instances\n\nA data point comprises an image and its object annotations.",
"### Data Fields\n\n- 'image': the image id\n- 'image': 'PIL.Image.Image' object containing the image. Note that when accessing the image column: 'dataset[0][\"image\"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '\"image\"' column, *i.e.* 'dataset[0][\"image\"]' should always be preferred over 'dataset[\"image\"][0]'\n- 'width': the image width\n- 'height': the image height\n- 'objects': a dictionary containing bounding box metadata for the objects present on the image\n - 'id': the annotation id\n - 'area': the area of the bounding box\n - 'bbox': the object's bounding box (in the coco format)\n - 'category': the object's category.",
"## Licensing Information\n\nSee original homepage URL"
] |
[
"TAGS\n#task_categories-object-detection #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-n<1K #source_datasets-original #language-English #language-Spanish #license-cc #rf100 #medical #code #region-us \n",
"## Dataset Structure",
"### Data Instances\n\nA data point comprises an image and its object annotations.",
"### Data Fields\n\n- 'image': the image id\n- 'image': 'PIL.Image.Image' object containing the image. Note that when accessing the image column: 'dataset[0][\"image\"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '\"image\"' column, *i.e.* 'dataset[0][\"image\"]' should always be preferred over 'dataset[\"image\"][0]'\n- 'width': the image width\n- 'height': the image height\n- 'objects': a dictionary containing bounding box metadata for the objects present on the image\n - 'id': the annotation id\n - 'area': the area of the bounding box\n - 'bbox': the object's bounding box (in the coco format)\n - 'category': the object's category.",
"## Licensing Information\n\nSee original homepage URL"
] |
[
86,
6,
20,
233,
10
] |
[
"passage: TAGS\n#task_categories-object-detection #annotations_creators-crowdsourced #language_creators-found #multilinguality-monolingual #size_categories-n<1K #source_datasets-original #language-English #language-Spanish #license-cc #rf100 #medical #code #region-us \n## Dataset Structure### Data Instances\n\nA data point comprises an image and its object annotations.### Data Fields\n\n- 'image': the image id\n- 'image': 'PIL.Image.Image' object containing the image. Note that when accessing the image column: 'dataset[0][\"image\"]' the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the '\"image\"' column, *i.e.* 'dataset[0][\"image\"]' should always be preferred over 'dataset[\"image\"][0]'\n- 'width': the image width\n- 'height': the image height\n- 'objects': a dictionary containing bounding box metadata for the objects present on the image\n - 'id': the annotation id\n - 'area': the area of the bounding box\n - 'bbox': the object's bounding box (in the coco format)\n - 'category': the object's category.## Licensing Information\n\nSee original homepage URL"
] |
033513cc8669c2f08bd0eba3bf6c872479612fdd
|
# Some stats for random 10 WAT files from CC (see [GitHub](https://github.com/marianna13/PDF_extraction) for more info)
## Stats for the links
|Number of PDF links|
|------------------|
| 131379|
|Number of working PDF links from 10k sample|
|-------------------------|
| 3904|
|sum(num_words)|
|--------------|
| 384953|
|sum(num_tokens)|
|---------------|
| 715422|
| avg(num_words)|
|-----------------|
|6999.145454545454|
| avg(num_tokens)|
|------------------|
|13007.672727272728|
## Stats for extracted data (for 100 random URLs)
1 process:
| total_processing_time | No error | FSTimeoutError | FileDataError cannot open broken document | Empty doc | ValueError Protocol not known: "http | TypeError _request() got an unexpected keyword argument 'target_options' | FileNotFoundError |
|------------------------:|-----------:|------------------:|--------------------------------------------:|------------:|---------------------------------------:|---------------------------------------------------------------------------:|--------------------:|
| 147.385 | 54 | 17 | 11 | 8 | 2 | 1 | 7 |
5 processes:
| total_processing_time | No error | FSTimeoutError | FileDataError cannot open broken document | Empty doc | ValueError Protocol not known: "http | FileNotFoundError | TypeError _request() got an unexpected keyword argument 'target_options' |
|------------------------:|-----------:|------------------:|--------------------------------------------:|------------:|---------------------------------------:|--------------------:|---------------------------------------------------------------------------:|
| 28.9343 | 53 | 17 | 12 | 8 | 2 | 7 | 1 |
10 processes:
| total_processing_time | No error | FSTimeoutError | Empty doc | FileDataError cannot open broken document | FileNotFoundError | TypeError _request() got an unexpected keyword argument 'target_options' | ValueError Protocol not known: "http |
|------------------------:|-----------:|------------------:|------------:|--------------------------------------------:|--------------------:|---------------------------------------------------------------------------:|---------------------------------------:|
| 14.9258 | 55 | 17 | 8 | 12 | 5 | 1 | 2 |
|
marianna13/PDF_extraction_sample
|
[
"region:us"
] |
2023-10-23T13:36:37+00:00
|
{}
|
2023-10-23T14:19:39+00:00
|
[] |
[] |
TAGS
#region-us
|
Some stats for random 10 WAT files from CC (see GitHub for more info)
=====================================================================
Stats for the links
-------------------
Stats for extracted data (for 100 random URLs)
----------------------------------------------
1 process:
5 processes:
10 processes:
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
b2789e80c10a8052b657b4e96c8a1fed869401a7
|
# Dataset Card for "test-dataset-bug4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
vwxyzjn/test-dataset-bug4
|
[
"region:us"
] |
2023-10-23T13:37:54+00:00
|
{"dataset_info": {"features": [{"name": "init_prompt", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}, {"name": "init_response", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}, {"name": "critic_prompt", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}, {"name": "critic_response", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}, {"name": "revision_prompt", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}, {"name": "revision_response", "struct": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 129500, "num_examples": 100}, {"name": "remove_CritiqueRequest_10_18_2023_1697667530", "num_bytes": 129500, "num_examples": 100}, {"name": "remove_CritiqueRequest_10_18_2023_1697667550", "num_bytes": 129500, "num_examples": 100}], "download_size": 203079, "dataset_size": 388500}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "remove_CritiqueRequest_10_18_2023_1697667530", "path": "data/remove_CritiqueRequest_10_18_2023_1697667530-*"}, {"split": "remove_CritiqueRequest_10_18_2023_1697667550", "path": "data/remove_CritiqueRequest_10_18_2023_1697667550-*"}]}]}
|
2023-10-23T14:10:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test-dataset-bug4"
More Information needed
|
[
"# Dataset Card for \"test-dataset-bug4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test-dataset-bug4\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test-dataset-bug4\"\n\nMore Information needed"
] |
72f5340d3af5f08c279a1e5c1d0cf78402f95086
|
# Dataset Card for "vet_month_1d_all_text"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
james-burton/vet_month_1d_all_text
|
[
"region:us"
] |
2023-10-23T13:42:07+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "age_at_consult", "dtype": "string"}, {"name": "Ear_or_Mastoid", "dtype": "string"}, {"name": "Mental_Behavioral_or_Neuro", "dtype": "string"}, {"name": "Blood_or_Blood-forming", "dtype": "string"}, {"name": "Circulatory", "dtype": "string"}, {"name": "Dental", "dtype": "string"}, {"name": "Developmental", "dtype": "string"}, {"name": "Digestive", "dtype": "string"}, {"name": "Endocrine_Nutritional_or_Metabolic", "dtype": "string"}, {"name": "Immune", "dtype": "string"}, {"name": "Infectious_or_Parasitic", "dtype": "string"}, {"name": "Skin", "dtype": "string"}, {"name": "Musculoskeletal_or_Connective_Tissue", "dtype": "string"}, {"name": "Neoplasms", "dtype": "string"}, {"name": "Nervous", "dtype": "string"}, {"name": "Visual", "dtype": "string"}, {"name": "Perinatal", "dtype": "string"}, {"name": "Pregnancy_Childbirth_or_Puerperium", "dtype": "string"}, {"name": "Respiratory", "dtype": "string"}, {"name": "Injury_Poisoning_or_External_Causes", "dtype": "string"}, {"name": "Genitourinary", "dtype": "string"}, {"name": "gender", "dtype": "string"}, {"name": "neutered", "dtype": "string"}, {"name": "species", "dtype": "string"}, {"name": "insured", "dtype": "string"}, {"name": "practice_id", "dtype": "string"}, {"name": "premise_id", "dtype": "string"}, {"name": "breed", "dtype": "string"}, {"name": "region", "dtype": "string"}, {"name": "record", "dtype": "string"}, {"name": "labels", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 5353930, "num_examples": 8552}, {"name": "validation", "num_bytes": 946736, "num_examples": 1510}, {"name": "test", "num_bytes": 1635039, "num_examples": 2606}], "download_size": 4002909, "dataset_size": 7935705}}
|
2023-10-23T13:42:11+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "vet_month_1d_all_text"
More Information needed
|
[
"# Dataset Card for \"vet_month_1d_all_text\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"vet_month_1d_all_text\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"vet_month_1d_all_text\"\n\nMore Information needed"
] |
4ad75ad35b3a0ae5557fcd652356a9249ebfcd3e
|
# Dataset Card for "vet_month_1d_ordinal"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
james-burton/vet_month_1d_ordinal
|
[
"region:us"
] |
2023-10-23T13:42:11+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "age_at_consult", "dtype": "float64"}, {"name": "Ear_or_Mastoid", "dtype": "int64"}, {"name": "Mental_Behavioral_or_Neuro", "dtype": "int64"}, {"name": "Blood_or_Blood-forming", "dtype": "int64"}, {"name": "Circulatory", "dtype": "int64"}, {"name": "Dental", "dtype": "int64"}, {"name": "Developmental", "dtype": "int64"}, {"name": "Digestive", "dtype": "int64"}, {"name": "Endocrine_Nutritional_or_Metabolic", "dtype": "int64"}, {"name": "Immune", "dtype": "int64"}, {"name": "Infectious_or_Parasitic", "dtype": "int64"}, {"name": "Skin", "dtype": "int64"}, {"name": "Musculoskeletal_or_Connective_Tissue", "dtype": "int64"}, {"name": "Neoplasms", "dtype": "int64"}, {"name": "Nervous", "dtype": "int64"}, {"name": "Visual", "dtype": "int64"}, {"name": "Perinatal", "dtype": "int64"}, {"name": "Pregnancy_Childbirth_or_Puerperium", "dtype": "int64"}, {"name": "Respiratory", "dtype": "int64"}, {"name": "Injury_Poisoning_or_External_Causes", "dtype": "int64"}, {"name": "Genitourinary", "dtype": "int64"}, {"name": "gender", "dtype": "float64"}, {"name": "neutered", "dtype": "float64"}, {"name": "species", "dtype": "float64"}, {"name": "insured", "dtype": "float64"}, {"name": "practice_id", "dtype": "string"}, {"name": "premise_id", "dtype": "string"}, {"name": "breed", "dtype": "string"}, {"name": "region", "dtype": "string"}, {"name": "record", "dtype": "string"}, {"name": "labels", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 5867630, "num_examples": 8552}, {"name": "validation", "num_bytes": 1037398, "num_examples": 1510}, {"name": "test", "num_bytes": 1791540, "num_examples": 2606}], "download_size": 4036706, "dataset_size": 8696568}}
|
2023-10-23T13:42:15+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "vet_month_1d_ordinal"
More Information needed
|
[
"# Dataset Card for \"vet_month_1d_ordinal\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"vet_month_1d_ordinal\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"vet_month_1d_ordinal\"\n\nMore Information needed"
] |
5bc980b2538f4bd830967532932889499f3041a0
|
[](https://doi.org/10.5281/zenodo.7912264)
# A time-lapse embryo dataset for morphokinetic parameter prediction
**Homepage**: https://zenodo.org/record/7912264 \
**Publication Date**: 2022-03-28 \
**License**: [Creative Commons Attribution Non Commercial Share Alike 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/legalcode) \
**Citation**:
```bibtex
@dataset{gomez_tristan_2023_7912264,
author = {Gomez Tristan and Feyeux Magalie and Boulant Justine and Normand Nicolas and Paul-Gilloteaux Perrine and David Laurent and Fréour Thomas and Mouchère Harold},
title = {Human embryo time-lapse video dataset},
month = may,
year = 2023,
publisher = {Zenodo},
version = {v0.3},
doi = {10.5281/zenodo.7912264},
url = {https://doi.org/10.5281/zenodo.7912264}
}
```
|
1aurent/Human-Embryo-Timelapse
|
[
"task_categories:video-classification",
"task_categories:image-classification",
"size_categories:n<1K",
"license:cc-by-nc-sa-4.0",
"biology",
"embryo",
"region:us"
] |
2023-10-23T13:46:07+00:00
|
{"license": "cc-by-nc-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["video-classification", "image-classification"], "tags": ["biology", "embryo"]}
|
2023-10-27T12:46:11+00:00
|
[] |
[] |
TAGS
#task_categories-video-classification #task_categories-image-classification #size_categories-n<1K #license-cc-by-nc-sa-4.0 #biology #embryo #region-us
|
 dataset. Translated using Google Translate and rechecked (then modified if necessary) manually.
|
damand2061/id_cannot_12K
|
[
"task_categories:text-classification",
"language:id",
"license:cc-by-sa-4.0",
"region:us"
] |
2023-10-23T13:55:11+00:00
|
{"language": ["id"], "license": "cc-by-sa-4.0", "task_categories": ["text-classification"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "premise", "dtype": "string"}, {"name": "hypothesis", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1487375, "num_examples": 9600}, {"name": "validation", "num_bytes": 372708, "num_examples": 2400}], "download_size": 1214303, "dataset_size": 1860083}}
|
2023-10-23T14:31:38+00:00
|
[] |
[
"id"
] |
TAGS
#task_categories-text-classification #language-Indonesian #license-cc-by-sa-4.0 #region-us
|
This is Indonesia-translated version of the 12K top-rows of the cannot dataset. Translated using Google Translate and rechecked (then modified if necessary) manually.
|
[] |
[
"TAGS\n#task_categories-text-classification #language-Indonesian #license-cc-by-sa-4.0 #region-us \n"
] |
[
33
] |
[
"passage: TAGS\n#task_categories-text-classification #language-Indonesian #license-cc-by-sa-4.0 #region-us \n"
] |
91a988b513259c97b43d0279367b079f53f6454e
|
# Dataset Card for Seamless-Align (WIP). Inspired by https://huggingface.co/datasets/allenai/nllb
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [Needs More Information]
- **Repository:** [Needs More Information]
- **Paper:** [Needs More Information]
- **Leaderboard:** [Needs More Information]
- **Point of Contact:** [Needs More Information]
### Dataset Summary
This dataset was created based on [metadata](https://github.com/facebookresearch/seamless_communication/blob/main/docs/m4t/seamless_align_README.md) for mined Speech-to-Speech(S2S), Text-to-Speech(TTS) and Speech-to-Text(S2T) released by Meta AI. The S2S contains data for 35 language pairs. The S2S dataset is ~1000GB compressed.
#### How to use the data
There are two ways to access the data:
* Via the Hugging Face Python datasets library
```
Scripts coming soon
```
* Clone the git repo
```
git lfs install
git clone https://huggingface.co/datasets/jhu-clsp/seamless-align
```
### Supported Tasks and Leaderboards
N/A
### Languages
Language pairs can be found [here](https://github.com/facebookresearch/seamless_communication/blob/main/docs/m4t/seamless_align_README.md).
## Dataset Structure
The S2S dataset contains two gzipped files src.tar.gz annd tgt.tar.gz
### Data Instances
The number of instances for each language pair can be found in the [dataset_infos.json](https://huggingface.co/datasets/allenai/nllb/blob/main/dataset_infos.json) file.
### Data Fields
Data Field can be found [here](https://github.com/facebookresearch/seamless_communication/blob/main/docs/m4t/seamless_align_README.md).
### Data Splits
The data is not split.
## Dataset Creation
### Curation Rationale
### Source Data
Inspect links in metadata
#### Who are the source language producers?
Speech and Text was collected from the web many of which are web crawls.
### Annotations
#### Annotation process
Parallel sentences were identified using SONAR encoders. (Duquenne et al., 2023)
#### Who are the annotators?
The data was not human annotated.
### Personal and Sensitive Information
Data may contain personally identifiable information, sensitive content, or toxic content that was publicly shared on the Internet.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset provides data for training machine learning systems for many languages.
### Discussion of Biases
Biases in the data have not been specifically studied, however as the original source of data is World Wide Web it is likely that the data has biases similar to those prevalent in the Internet. The data may also exhibit biases introduced by language identification and data filtering techniques; lower resource languages generally have lower accuracy.
### Other Known Limitations
Some of the translations are in fact machine translations. While some website machine translation tools are identifiable from HTML source, these tools were not filtered out en mass because raw HTML was not available from some sources and CommonCrawl processing started from WET files.
## Additional Information
### Dataset Curators
The data was not curated.
### Licensing Information
The dataset is released under the terms of [MIT](https://opensource.org/license/mit/). **PLEASE, USE DATA RESPONSIBLY**
### Citation Information
Seamless Communication et al, SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv https://arxiv.org/abs/2308.11596, 2023. <br>
Duquenne et al, SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. arXiv https://arxiv.org/abs/2308.11466, 2023
### Contributions
We thank the Seamless Communication Meta AI team for open sourcing the meta data and instructions on how to use it with special thanks to Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang. We also thank the Center for Language and Speech Processing(CLSP) for hosting and releasing this data, including Bismarck Bamfo Odoom and Philipp Koehn (for engineering efforts to host the data, and releasing the huggingface dataset), and Alexandre Mourachko (for organizing the connection).
|
jhu-clsp/seamless-align
|
[
"license:mit",
"arxiv:2308.11596",
"arxiv:2308.11466",
"region:us"
] |
2023-10-23T13:58:29+00:00
|
{"license": "mit"}
|
2024-02-13T01:49:18+00:00
|
[
"2308.11596",
"2308.11466"
] |
[] |
TAGS
#license-mit #arxiv-2308.11596 #arxiv-2308.11466 #region-us
|
# Dataset Card for Seamless-Align (WIP). Inspired by URL
## Table of Contents
- Table of Contents
- Dataset Description
- Dataset Summary
- Supported Tasks and Leaderboards
- Languages
- Dataset Structure
- Data Instances
- Data Fields
- Data Splits
- Dataset Creation
- Curation Rationale
- Source Data
- Annotations
- Personal and Sensitive Information
- Considerations for Using the Data
- Social Impact of Dataset
- Discussion of Biases
- Other Known Limitations
- Additional Information
- Dataset Curators
- Licensing Information
- Citation Information
- Contributions
## Dataset Description
- Homepage:
- Repository:
- Paper:
- Leaderboard:
- Point of Contact:
### Dataset Summary
This dataset was created based on metadata for mined Speech-to-Speech(S2S), Text-to-Speech(TTS) and Speech-to-Text(S2T) released by Meta AI. The S2S contains data for 35 language pairs. The S2S dataset is ~1000GB compressed.
#### How to use the data
There are two ways to access the data:
* Via the Hugging Face Python datasets library
* Clone the git repo
### Supported Tasks and Leaderboards
N/A
### Languages
Language pairs can be found here.
## Dataset Structure
The S2S dataset contains two gzipped files URL annd URL
### Data Instances
The number of instances for each language pair can be found in the dataset_infos.json file.
### Data Fields
Data Field can be found here.
### Data Splits
The data is not split.
## Dataset Creation
### Curation Rationale
### Source Data
Inspect links in metadata
#### Who are the source language producers?
Speech and Text was collected from the web many of which are web crawls.
### Annotations
#### Annotation process
Parallel sentences were identified using SONAR encoders. (Duquenne et al., 2023)
#### Who are the annotators?
The data was not human annotated.
### Personal and Sensitive Information
Data may contain personally identifiable information, sensitive content, or toxic content that was publicly shared on the Internet.
## Considerations for Using the Data
### Social Impact of Dataset
This dataset provides data for training machine learning systems for many languages.
### Discussion of Biases
Biases in the data have not been specifically studied, however as the original source of data is World Wide Web it is likely that the data has biases similar to those prevalent in the Internet. The data may also exhibit biases introduced by language identification and data filtering techniques; lower resource languages generally have lower accuracy.
### Other Known Limitations
Some of the translations are in fact machine translations. While some website machine translation tools are identifiable from HTML source, these tools were not filtered out en mass because raw HTML was not available from some sources and CommonCrawl processing started from WET files.
## Additional Information
### Dataset Curators
The data was not curated.
### Licensing Information
The dataset is released under the terms of MIT. PLEASE, USE DATA RESPONSIBLY
Seamless Communication et al, SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv URL 2023. <br>
Duquenne et al, SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. arXiv URL 2023
### Contributions
We thank the Seamless Communication Meta AI team for open sourcing the meta data and instructions on how to use it with special thanks to Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang. We also thank the Center for Language and Speech Processing(CLSP) for hosting and releasing this data, including Bismarck Bamfo Odoom and Philipp Koehn (for engineering efforts to host the data, and releasing the huggingface dataset), and Alexandre Mourachko (for organizing the connection).
|
[
"# Dataset Card for Seamless-Align (WIP). Inspired by URL",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset was created based on metadata for mined Speech-to-Speech(S2S), Text-to-Speech(TTS) and Speech-to-Text(S2T) released by Meta AI. The S2S contains data for 35 language pairs. The S2S dataset is ~1000GB compressed.",
"#### How to use the data\nThere are two ways to access the data:\n* Via the Hugging Face Python datasets library \n\n\n\n* Clone the git repo",
"### Supported Tasks and Leaderboards\n\nN/A",
"### Languages\n\nLanguage pairs can be found here.",
"## Dataset Structure\n\nThe S2S dataset contains two gzipped files URL annd URL",
"### Data Instances\n\nThe number of instances for each language pair can be found in the dataset_infos.json file.",
"### Data Fields\n\nData Field can be found here.",
"### Data Splits\n\nThe data is not split.",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data\n\nInspect links in metadata",
"#### Who are the source language producers?\n\nSpeech and Text was collected from the web many of which are web crawls.",
"### Annotations",
"#### Annotation process\n\nParallel sentences were identified using SONAR encoders. (Duquenne et al., 2023)",
"#### Who are the annotators?\n\nThe data was not human annotated.",
"### Personal and Sensitive Information\n\nData may contain personally identifiable information, sensitive content, or toxic content that was publicly shared on the Internet.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThis dataset provides data for training machine learning systems for many languages.",
"### Discussion of Biases\n\nBiases in the data have not been specifically studied, however as the original source of data is World Wide Web it is likely that the data has biases similar to those prevalent in the Internet. The data may also exhibit biases introduced by language identification and data filtering techniques; lower resource languages generally have lower accuracy.",
"### Other Known Limitations\n\nSome of the translations are in fact machine translations. While some website machine translation tools are identifiable from HTML source, these tools were not filtered out en mass because raw HTML was not available from some sources and CommonCrawl processing started from WET files.",
"## Additional Information",
"### Dataset Curators\n\nThe data was not curated.",
"### Licensing Information\n\nThe dataset is released under the terms of MIT. PLEASE, USE DATA RESPONSIBLY\n\n\n\n\nSeamless Communication et al, SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv URL 2023. <br>\nDuquenne et al, SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. arXiv URL 2023",
"### Contributions\n\nWe thank the Seamless Communication Meta AI team for open sourcing the meta data and instructions on how to use it with special thanks to Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang. We also thank the Center for Language and Speech Processing(CLSP) for hosting and releasing this data, including Bismarck Bamfo Odoom and Philipp Koehn (for engineering efforts to host the data, and releasing the huggingface dataset), and Alexandre Mourachko (for organizing the connection)."
] |
[
"TAGS\n#license-mit #arxiv-2308.11596 #arxiv-2308.11466 #region-us \n",
"# Dataset Card for Seamless-Align (WIP). Inspired by URL",
"## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions",
"## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:",
"### Dataset Summary\n\nThis dataset was created based on metadata for mined Speech-to-Speech(S2S), Text-to-Speech(TTS) and Speech-to-Text(S2T) released by Meta AI. The S2S contains data for 35 language pairs. The S2S dataset is ~1000GB compressed.",
"#### How to use the data\nThere are two ways to access the data:\n* Via the Hugging Face Python datasets library \n\n\n\n* Clone the git repo",
"### Supported Tasks and Leaderboards\n\nN/A",
"### Languages\n\nLanguage pairs can be found here.",
"## Dataset Structure\n\nThe S2S dataset contains two gzipped files URL annd URL",
"### Data Instances\n\nThe number of instances for each language pair can be found in the dataset_infos.json file.",
"### Data Fields\n\nData Field can be found here.",
"### Data Splits\n\nThe data is not split.",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data\n\nInspect links in metadata",
"#### Who are the source language producers?\n\nSpeech and Text was collected from the web many of which are web crawls.",
"### Annotations",
"#### Annotation process\n\nParallel sentences were identified using SONAR encoders. (Duquenne et al., 2023)",
"#### Who are the annotators?\n\nThe data was not human annotated.",
"### Personal and Sensitive Information\n\nData may contain personally identifiable information, sensitive content, or toxic content that was publicly shared on the Internet.",
"## Considerations for Using the Data",
"### Social Impact of Dataset\n\nThis dataset provides data for training machine learning systems for many languages.",
"### Discussion of Biases\n\nBiases in the data have not been specifically studied, however as the original source of data is World Wide Web it is likely that the data has biases similar to those prevalent in the Internet. The data may also exhibit biases introduced by language identification and data filtering techniques; lower resource languages generally have lower accuracy.",
"### Other Known Limitations\n\nSome of the translations are in fact machine translations. While some website machine translation tools are identifiable from HTML source, these tools were not filtered out en mass because raw HTML was not available from some sources and CommonCrawl processing started from WET files.",
"## Additional Information",
"### Dataset Curators\n\nThe data was not curated.",
"### Licensing Information\n\nThe dataset is released under the terms of MIT. PLEASE, USE DATA RESPONSIBLY\n\n\n\n\nSeamless Communication et al, SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv URL 2023. <br>\nDuquenne et al, SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. arXiv URL 2023",
"### Contributions\n\nWe thank the Seamless Communication Meta AI team for open sourcing the meta data and instructions on how to use it with special thanks to Loïc Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-jussà, Onur Celebi, Maha Elbayad, Cynthia Gao, Francisco Guzmán, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang. We also thank the Center for Language and Speech Processing(CLSP) for hosting and releasing this data, including Bismarck Bamfo Odoom and Philipp Koehn (for engineering efforts to host the data, and releasing the huggingface dataset), and Alexandre Mourachko (for organizing the connection)."
] |
[
27,
19,
125,
24,
84,
34,
13,
12,
23,
30,
12,
11,
5,
7,
11,
27,
5,
27,
18,
33,
8,
22,
83,
64,
5,
13,
97,
431
] |
[
"passage: TAGS\n#license-mit #arxiv-2308.11596 #arxiv-2308.11466 #region-us \n# Dataset Card for Seamless-Align (WIP). Inspired by URL## Table of Contents\n- Table of Contents\n- Dataset Description\n - Dataset Summary\n - Supported Tasks and Leaderboards\n - Languages\n- Dataset Structure\n - Data Instances\n - Data Fields\n - Data Splits\n- Dataset Creation\n - Curation Rationale\n - Source Data\n - Annotations\n - Personal and Sensitive Information\n- Considerations for Using the Data\n - Social Impact of Dataset\n - Discussion of Biases\n - Other Known Limitations\n- Additional Information\n - Dataset Curators\n - Licensing Information\n - Citation Information\n - Contributions## Dataset Description\n\n- Homepage: \n- Repository: \n- Paper: \n- Leaderboard: \n- Point of Contact:### Dataset Summary\n\nThis dataset was created based on metadata for mined Speech-to-Speech(S2S), Text-to-Speech(TTS) and Speech-to-Text(S2T) released by Meta AI. The S2S contains data for 35 language pairs. The S2S dataset is ~1000GB compressed.#### How to use the data\nThere are two ways to access the data:\n* Via the Hugging Face Python datasets library \n\n\n\n* Clone the git repo### Supported Tasks and Leaderboards\n\nN/A### Languages\n\nLanguage pairs can be found here.## Dataset Structure\n\nThe S2S dataset contains two gzipped files URL annd URL### Data Instances\n\nThe number of instances for each language pair can be found in the dataset_infos.json file.### Data Fields\n\nData Field can be found here.### Data Splits\n\nThe data is not split.## Dataset Creation### Curation Rationale### Source Data\n\nInspect links in metadata#### Who are the source language producers?\n\nSpeech and Text was collected from the web many of which are web crawls.### Annotations#### Annotation process\n\nParallel sentences were identified using SONAR encoders. (Duquenne et al., 2023)",
"passage: #### Who are the annotators?\n\nThe data was not human annotated.### Personal and Sensitive Information\n\nData may contain personally identifiable information, sensitive content, or toxic content that was publicly shared on the Internet.## Considerations for Using the Data### Social Impact of Dataset\n\nThis dataset provides data for training machine learning systems for many languages.### Discussion of Biases\n\nBiases in the data have not been specifically studied, however as the original source of data is World Wide Web it is likely that the data has biases similar to those prevalent in the Internet. The data may also exhibit biases introduced by language identification and data filtering techniques; lower resource languages generally have lower accuracy.### Other Known Limitations\n\nSome of the translations are in fact machine translations. While some website machine translation tools are identifiable from HTML source, these tools were not filtered out en mass because raw HTML was not available from some sources and CommonCrawl processing started from WET files.## Additional Information### Dataset Curators\n\nThe data was not curated.### Licensing Information\n\nThe dataset is released under the terms of MIT. PLEASE, USE DATA RESPONSIBLY\n\n\n\n\nSeamless Communication et al, SeamlessM4T: Massively Multilingual & Multimodal Machine Translation. arXiv URL 2023. <br>\nDuquenne et al, SONAR: Sentence-Level Multimodal and Language-Agnostic Representations. arXiv URL 2023"
] |
9bf362d97c254c0f727bef58e0afa5e2babab80a
|
# Dataset Card for "fm_classifier_mutable-1-1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
coastalcph/fm_classifier_mutable-1-1
|
[
"region:us"
] |
2023-10-23T14:13:28+00:00
|
{"dataset_info": {"features": [{"name": "query", "dtype": "string"}, {"name": "answer", "list": [{"name": "wikidata_id", "dtype": "string"}, {"name": "name", "dtype": "string"}]}, {"name": "id", "dtype": "string"}, {"name": "relation", "dtype": "string"}, {"name": "date", "dtype": "int64"}, {"name": "type", "dtype": "string"}, {"name": "is_mutable", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1606940.087431288, "num_examples": 8967}, {"name": "all_fm", "num_bytes": 33865262.26303366, "num_examples": 177265}, {"name": "validation", "num_bytes": 996478.5738772711, "num_examples": 5800}, {"name": "test", "num_bytes": 1120775.194745333, "num_examples": 5698}], "download_size": 6684977, "dataset_size": 37589456.11908755}}
|
2023-10-24T12:24:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "fm_classifier_mutable-1-1"
More Information needed
|
[
"# Dataset Card for \"fm_classifier_mutable-1-1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"fm_classifier_mutable-1-1\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"fm_classifier_mutable-1-1\"\n\nMore Information needed"
] |
8ea35a9ce6a62365cc227faf73a9dc9ce267b4c0
|
# Dataset Card for "fm_classifier_mutable-1-n"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
coastalcph/fm_classifier_mutable-1-n
|
[
"region:us"
] |
2023-10-23T14:13:51+00:00
|
{"dataset_info": {"features": [{"name": "query", "dtype": "string"}, {"name": "answer", "list": [{"name": "wikidata_id", "dtype": "string"}, {"name": "name", "dtype": "string"}]}, {"name": "id", "dtype": "string"}, {"name": "relation", "dtype": "string"}, {"name": "date", "dtype": "int64"}, {"name": "type", "dtype": "string"}, {"name": "is_mutable", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1608732.147303521, "num_examples": 8977}, {"name": "all_fm", "num_bytes": 30017653.417646818, "num_examples": 157125}, {"name": "validation", "num_bytes": 1016408.1453548166, "num_examples": 5916}, {"name": "test", "num_bytes": 1125889.2970730583, "num_examples": 5724}], "download_size": 7539663, "dataset_size": 33768683.00737821}}
|
2023-10-24T12:24:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "fm_classifier_mutable-1-n"
More Information needed
|
[
"# Dataset Card for \"fm_classifier_mutable-1-n\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"fm_classifier_mutable-1-n\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"fm_classifier_mutable-1-n\"\n\nMore Information needed"
] |
1415e7ad04dce5dbbb227ae9531cc61e11a955b3
|
# Dataset Card for "gptindex-standardized_unified"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AdapterOcean/gptindex-standardized_unified
|
[
"region:us"
] |
2023-10-23T14:46:09+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "conversation_id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 807609, "num_examples": 1234}], "download_size": 395344, "dataset_size": 807609}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-23T14:46:12+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "gptindex-standardized_unified"
More Information needed
|
[
"# Dataset Card for \"gptindex-standardized_unified\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"gptindex-standardized_unified\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"gptindex-standardized_unified\"\n\nMore Information needed"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.