
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
listlengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
listlengths 0
25
| languages
listlengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
listlengths 0
352
| processed_texts
listlengths 1
353
| tokens_length
listlengths 1
353
| input_texts
listlengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
7e2c8b8b6ee24dfecb9c47a8528118d9972b4364
|
# Dataset Card for "Test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
islamrokon/Test
|
[
"region:us"
] |
2023-10-29T16:51:58+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int32"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 17012.625, "num_examples": 14}, {"name": "test", "num_bytes": 2430.375, "num_examples": 2}], "download_size": 17101, "dataset_size": 19443.0}}
|
2023-11-11T15:37:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Test"
More Information needed
|
[
"# Dataset Card for \"Test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Test\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Test\"\n\nMore Information needed"
] |
ceffd9025087562002acf74805519d7a798f9b8f
|
# Dataset Card for "f7c1d08f"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-kand2-sdxl-wuerst-karlo/f7c1d08f
|
[
"region:us"
] |
2023-10-29T17:05:28+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 150, "num_examples": 10}], "download_size": 1322, "dataset_size": 150}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T17:05:29+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "f7c1d08f"
More Information needed
|
[
"# Dataset Card for \"f7c1d08f\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"f7c1d08f\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"f7c1d08f\"\n\nMore Information needed"
] |
a782a9bf959dad816d66ec4f400ce1eb7cb33450
|
# Dataset Card for "upsampled-prompts-parti"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
roborovski/upsampled-prompts-parti
|
[
"region:us"
] |
2023-10-29T17:32:37+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Category", "dtype": "string"}, {"name": "Upsampled", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 45619526, "num_examples": 94672}], "download_size": 24525926, "dataset_size": 45619526}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2024-02-01T10:06:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "upsampled-prompts-parti"
More Information needed
|
[
"# Dataset Card for \"upsampled-prompts-parti\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"upsampled-prompts-parti\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"upsampled-prompts-parti\"\n\nMore Information needed"
] |
7c9ba8392c9bffbe3366dd595cdbc43edc4fe642
|
# Dataset Card for "only-text-data-various-domain"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yongchanskii/only-text-data-various-domain
|
[
"region:us"
] |
2023-10-29T17:35:51+00:00
|
{"dataset_info": {"features": [{"name": "docId", "dtype": "string"}, {"name": "category", "dtype": "string"}, {"name": "domainTag", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 26467274.758485764, "num_examples": 84235}, {"name": "test", "num_bytes": 6616897.241514237, "num_examples": 21059}], "download_size": 20057835, "dataset_size": 33084172.0}}
|
2023-10-29T17:36:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "only-text-data-various-domain"
More Information needed
|
[
"# Dataset Card for \"only-text-data-various-domain\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"only-text-data-various-domain\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"only-text-data-various-domain\"\n\nMore Information needed"
] |
112298c8b54e3777a4f853576643b7645fd00ded
|
# Dataset Card for "penetration_testing_scraped_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Isamu136/penetration_testing_scraped_dataset
|
[
"region:us"
] |
2023-10-29T17:44:34+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "embedding", "sequence": "float32"}, {"name": "tokens", "sequence": "int64"}, {"name": "database", "dtype": "string"}, {"name": "file", "dtype": "string"}, {"name": "chunk", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1005293572, "num_examples": 107542}], "download_size": 663206603, "dataset_size": 1005293572}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T07:35:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "penetration_testing_scraped_dataset"
More Information needed
|
[
"# Dataset Card for \"penetration_testing_scraped_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"penetration_testing_scraped_dataset\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"penetration_testing_scraped_dataset\"\n\nMore Information needed"
] |
dd5d4248b5852e609f1c4d810d88c521a0ebb518
|
# Dataset Card for "llama2_7b_fine_tuning_complete_dataset_v5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
hemantk089/llama2_7b_fine_tuning_complete_dataset_v5
|
[
"region:us"
] |
2023-10-29T18:02:34+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 339620, "num_examples": 915}, {"name": "test", "num_bytes": 34719, "num_examples": 102}], "download_size": 106126, "dataset_size": 374339}}
|
2023-10-29T18:02:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llama2_7b_fine_tuning_complete_dataset_v5"
More Information needed
|
[
"# Dataset Card for \"llama2_7b_fine_tuning_complete_dataset_v5\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llama2_7b_fine_tuning_complete_dataset_v5\"\n\nMore Information needed"
] |
[
6,
30
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llama2_7b_fine_tuning_complete_dataset_v5\"\n\nMore Information needed"
] |
73785519257ef1ede85e57b448d704654147c1ee
|
# Dataset Card for "texonom-md"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
texonom/texonom-md
|
[
"region:us"
] |
2023-10-29T18:18:27+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "parent", "dtype": "string"}, {"name": "created", "dtype": "string"}, {"name": "editor", "dtype": "string"}, {"name": "creator", "dtype": "string"}, {"name": "edited", "dtype": "string"}, {"name": "refs", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 11117155, "num_examples": 23960}], "download_size": 6320648, "dataset_size": 11117155}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T18:47:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "texonom-md"
More Information needed
|
[
"# Dataset Card for \"texonom-md\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"texonom-md\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"texonom-md\"\n\nMore Information needed"
] |
ba378e69db002450b9ca032abe81ba8105adf879
|
It's the English content dumped from 2023-10-01 version of Wikipedia dump site.
The format is similar with "[datasets/wikipedia](https://huggingface.co/datasets/wikipedia?row=0)". It has use same method to clean the text.
However, I ommitted the 'url' field because it follows the same format: "https://en.wikipedia.org/wiki/[title]".
Another change is the title. I merged the "REDIRECTED" title with its original and use comma as seperator.
For example, the title "An American in Paris, AnAmericanInParis" means "An American in Paris" and "AnAmericanInParis" points to the same content.
|
flyingfishinwater/wikipedia_20231001
|
[
"task_categories:text-generation",
"size_categories:10B<n<100B",
"language:en",
"license:apache-2.0",
"chemistry",
"biology",
"legal",
"music",
"art",
"medical",
"region:us"
] |
2023-10-29T18:43:44+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["10B<n<100B"], "task_categories": ["text-generation"], "tags": ["chemistry", "biology", "legal", "music", "art", "medical"]}
|
2023-11-01T21:54:16+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-generation #size_categories-10B<n<100B #language-English #license-apache-2.0 #chemistry #biology #legal #music #art #medical #region-us
|
It's the English content dumped from 2023-10-01 version of Wikipedia dump site.
The format is similar with "datasets/wikipedia". It has use same method to clean the text.
However, I ommitted the 'url' field because it follows the same format: "URL
Another change is the title. I merged the "REDIRECTED" title with its original and use comma as seperator.
For example, the title "An American in Paris, AnAmericanInParis" means "An American in Paris" and "AnAmericanInParis" points to the same content.
|
[] |
[
"TAGS\n#task_categories-text-generation #size_categories-10B<n<100B #language-English #license-apache-2.0 #chemistry #biology #legal #music #art #medical #region-us \n"
] |
[
57
] |
[
"passage: TAGS\n#task_categories-text-generation #size_categories-10B<n<100B #language-English #license-apache-2.0 #chemistry #biology #legal #music #art #medical #region-us \n"
] |
bf5e8c636ad7f62aacc75aaf00ba40f9df057dbf
|
# Dataset Card for "ig_rewarding_db_v4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
toilaluan/ig_rewarding_db_v4
|
[
"region:us"
] |
2023-10-29T18:58:35+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "topic", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "request_id", "dtype": "int64"}, {"name": "model_type", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 330547445.0, "num_examples": 4500}], "download_size": 340509190, "dataset_size": 330547445.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T18:58:49+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "ig_rewarding_db_v4"
More Information needed
|
[
"# Dataset Card for \"ig_rewarding_db_v4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"ig_rewarding_db_v4\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"ig_rewarding_db_v4\"\n\nMore Information needed"
] |
8c1d8b9de95e4f6992dafee03561a602d2ce0902
|
# Dataset Card for "finetuningopensecurity-llama"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
MichaelVeser/finetuningopensecurity-llama
|
[
"region:us"
] |
2023-10-29T19:33:16+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4000, "num_examples": 1000}], "download_size": 714, "dataset_size": 4000}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T19:33:18+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "finetuningopensecurity-llama"
More Information needed
|
[
"# Dataset Card for \"finetuningopensecurity-llama\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"finetuningopensecurity-llama\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"finetuningopensecurity-llama\"\n\nMore Information needed"
] |
61148368dc9502e85df8e0d4ee99f5f5db63a444
|
# Spine X-rays
The dataset consists of a collection of spine X-ray images in **.jpg and .dcm** formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.
### Types of diseases and conditions in the dataset:
*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*
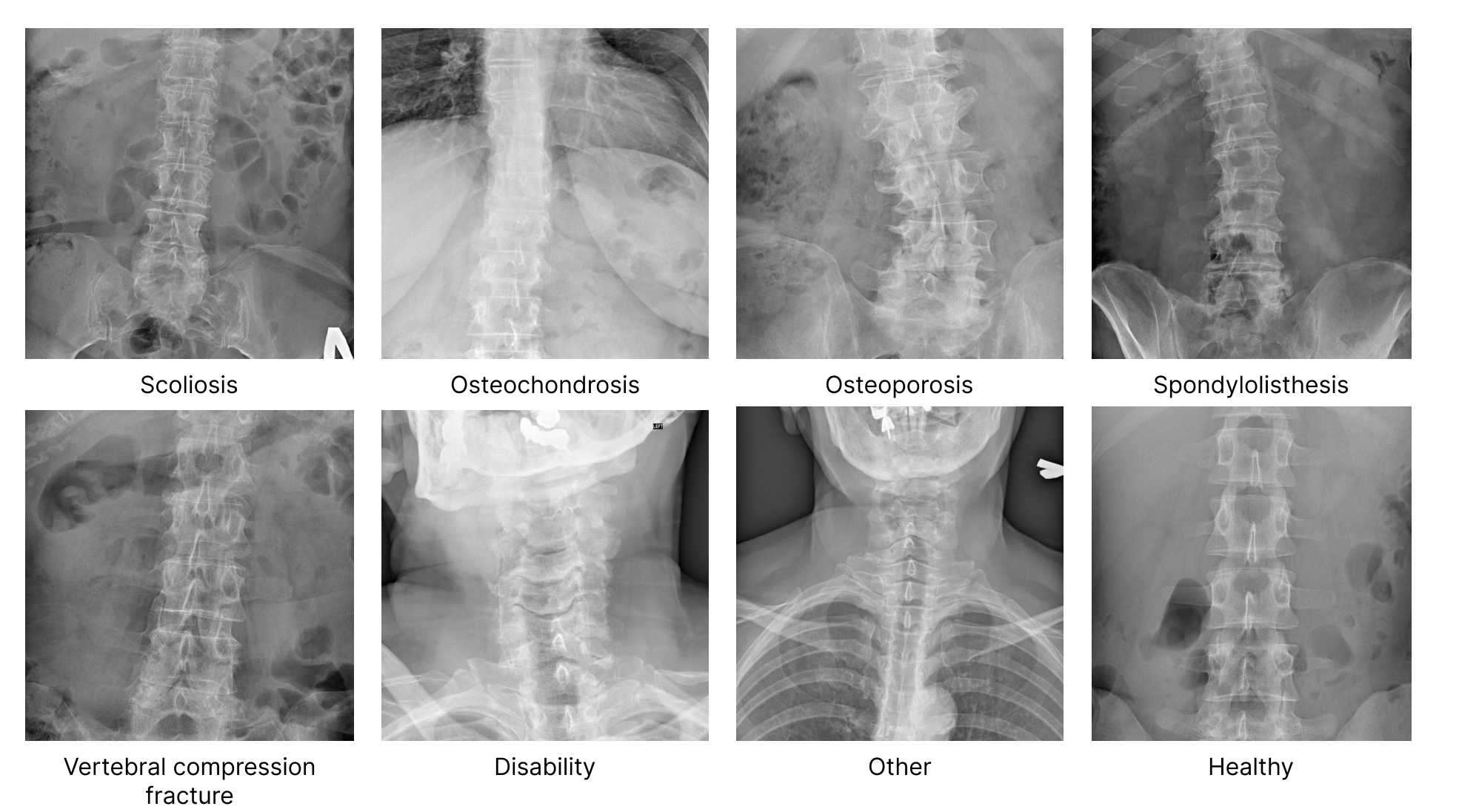
The dataset provides an opportunity for researchers and medical professionals to *analyze and develop algorithms for automated diagnosis, treatment planning, and prognosis estimation of* **various spinal conditions**.
It allows the development and evaluation of computer-based algorithms, machine learning models, and deep learning techniques for **automated detection, diagnosis, and classification** of these conditions.
# Get the Dataset
## This is just an example of the data
Leave a request on [https://trainingdata.pro/data-market](https://trainingdata.pro/data-market/spine-x-ray-image?utm_source=huggingface&utm_medium=cpc&utm_campaign=spine-x-ray) to discuss your requirements, learn about the price and buy the dataset
# Content
### The folder "files" includes 8 folders:
- corresponding to name of the disease/condition and including x-rays of people with this disease/condition (**scoliosis, osteochondrosis, VCFs etc.**)
- including x-rays in 2 different formats: **.jpg and .dcm**.
### File with the extension .csv includes the following information for each media file:
- **dcm**: link to access the .dcm file,
- **jpg**: link to access the .jpg file,
- **type**: name of the disease or condition on the x-ray
# Medical data might be collected in accordance with your requirements.
## [TrainingData](https://trainingdata.pro/data-market/spine-x-ray-image?utm_source=huggingface&utm_medium=cpc&utm_campaign=spine-x-ray) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/trainingdata-pro**
*keywords: spine dataset, spine X-rays dataset, scoliosis detection dataset, scoliosis segmentation dataset, scoliosis image dataset, medical imaging, radiology dataset, spine deformity dataset, orthopedic abnormalities, scoliotic curve dataset, degenerative spinal conditions, diagnostic imaging of the spine, osteoporosis dataset, osteochondrosis dataset, vertebral compression fracture detection, vertebral segmentation dataset*
|
TrainingDataPro/spine-x-ray
|
[
"task_categories:image-classification",
"task_categories:image-segmentation",
"task_categories:image-to-image",
"language:en",
"license:cc-by-nc-nd-4.0",
"medical",
"code",
"region:us"
] |
2023-10-29T19:40:35+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-classification", "image-segmentation", "image-to-image"], "tags": ["medical", "code"]}
|
2023-10-29T19:54:02+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-image-classification #task_categories-image-segmentation #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us
|
# Spine X-rays
The dataset consists of a collection of spine X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.
### Types of diseases and conditions in the dataset:
*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*

- including x-rays in 2 different formats: .jpg and .dcm.
### File with the extension .csv includes the following information for each media file:
- dcm: link to access the .dcm file,
- jpg: link to access the .jpg file,
- type: name of the disease or condition on the x-ray
# Medical data might be collected in accordance with your requirements.
## TrainingData provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: URL
TrainingData's GitHub: URL
*keywords: spine dataset, spine X-rays dataset, scoliosis detection dataset, scoliosis segmentation dataset, scoliosis image dataset, medical imaging, radiology dataset, spine deformity dataset, orthopedic abnormalities, scoliotic curve dataset, degenerative spinal conditions, diagnostic imaging of the spine, osteoporosis dataset, osteochondrosis dataset, vertebral compression fracture detection, vertebral segmentation dataset*
|
[
"# Spine X-rays\n\nThe dataset consists of a collection of spine X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.",
"### Types of diseases and conditions in the dataset:\n\n*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.",
"### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray",
"# Medical data might be collected in accordance with your requirements.",
"## TrainingData provides high-quality data annotation tailored to your needs\n\nMore datasets in TrainingData's Kaggle account: URL\n\nTrainingData's GitHub: URL\n\n*keywords: spine dataset, spine X-rays dataset, scoliosis detection dataset, scoliosis segmentation dataset, scoliosis image dataset, medical imaging, radiology dataset, spine deformity dataset, orthopedic abnormalities, scoliotic curve dataset, degenerative spinal conditions, diagnostic imaging of the spine, osteoporosis dataset, osteochondrosis dataset, vertebral compression fracture detection, vertebral segmentation dataset*"
] |
[
"TAGS\n#task_categories-image-classification #task_categories-image-segmentation #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us \n",
"# Spine X-rays\n\nThe dataset consists of a collection of spine X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.",
"### Types of diseases and conditions in the dataset:\n\n*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.",
"### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray",
"# Medical data might be collected in accordance with your requirements.",
"## TrainingData provides high-quality data annotation tailored to your needs\n\nMore datasets in TrainingData's Kaggle account: URL\n\nTrainingData's GitHub: URL\n\n*keywords: spine dataset, spine X-rays dataset, scoliosis detection dataset, scoliosis segmentation dataset, scoliosis image dataset, medical imaging, radiology dataset, spine deformity dataset, orthopedic abnormalities, scoliotic curve dataset, degenerative spinal conditions, diagnostic imaging of the spine, osteoporosis dataset, osteochondrosis dataset, vertebral compression fracture detection, vertebral segmentation dataset*"
] |
[
63,
68,
142,
5,
28,
2,
73,
60,
13,
159
] |
[
"passage: TAGS\n#task_categories-image-classification #task_categories-image-segmentation #task_categories-image-to-image #language-English #license-cc-by-nc-nd-4.0 #medical #code #region-us \n# Spine X-rays\n\nThe dataset consists of a collection of spine X-ray images in .jpg and .dcm formats. The images are organized into folders based on different medical conditions related to the spine. Each folder contains images depicting specific spinal deformities.### Types of diseases and conditions in the dataset:\n\n*Scoliosis, Osteochondrosis, Osteoporosis, Spondylolisthesis, Vertebral Compression Fractures (VCFs), Disability, Other and Healthy*\n\n\n- including x-rays in 2 different formats: .jpg and .dcm.### File with the extension .csv includes the following information for each media file:\n\n- dcm: link to access the .dcm file,\n- jpg: link to access the .jpg file, \n- type: name of the disease or condition on the x-ray# Medical data might be collected in accordance with your requirements."
] |
f9abddfa204260ba1fb4c6f62dbf1a8f2b4f3931
|
# Dataset Card for "plainscree"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
verayang/plainscree
|
[
"region:us"
] |
2023-10-29T20:14:20+00:00
|
{"dataset_info": {"features": [{"name": "audio_id", "dtype": "int64"}, {"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "cree_transcription", "dtype": "string"}, {"name": "english_transcription", "dtype": "string"}, {"name": "gender", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 22116992.0, "num_examples": 64}], "download_size": 22072728, "dataset_size": 22116992.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T22:07:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "plainscree"
More Information needed
|
[
"# Dataset Card for \"plainscree\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"plainscree\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"plainscree\"\n\nMore Information needed"
] |
95a226e6195f71e973de62b9e6796301320e5a92
|
# Dataset Card for "sentiment2to1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
marcus2000/sentiment2to1
|
[
"region:us"
] |
2023-10-29T20:50:15+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 4281800, "num_examples": 3350}, {"name": "test", "num_bytes": 441642, "num_examples": 373}], "download_size": 2338740, "dataset_size": 4723442}}
|
2023-10-29T20:52:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "sentiment2to1"
More Information needed
|
[
"# Dataset Card for \"sentiment2to1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"sentiment2to1\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"sentiment2to1\"\n\nMore Information needed"
] |
062dfbc1e327e7bc57c4dc852225f8eb5350d5bf
|
# Dataset Card for "pipeline_dataset2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
JosueElias/pipeline_dataset2
|
[
"region:us"
] |
2023-10-29T20:59:49+00:00
|
{"dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "section", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1522896529, "num_examples": 2101279}], "download_size": 850821844, "dataset_size": 1522896529}}
|
2023-10-29T21:23:27+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "pipeline_dataset2"
More Information needed
|
[
"# Dataset Card for \"pipeline_dataset2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"pipeline_dataset2\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"pipeline_dataset2\"\n\nMore Information needed"
] |
d3d4283e89bc7d58ebed2613b5a61ef8f63512e6
|
# Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
kinianlo/test
|
[
"region:us"
] |
2023-10-29T21:12:47+00:00
|
{"dataset_info": {"config_name": "scenarios", "features": [{"name": "noun1_id", "dtype": "int64"}, {"name": "noun2_id", "dtype": "int64"}, {"name": "adjectives_id", "sequence": "int64"}, {"name": "epsilons", "sequence": "float64"}], "splits": [{"name": "train", "num_bytes": 3741586560, "num_examples": 51966480}], "download_size": 569874919, "dataset_size": 3741586560}, "configs": [{"config_name": "scenarios", "data_files": [{"split": "train", "path": "scenarios/train-*"}]}]}
|
2023-10-29T21:13:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "test"
More Information needed
|
[
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"test\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"test\"\n\nMore Information needed"
] |
3813180ffeae603a955f0bca13f2abe0b596dd59
|
# Dataset Card for "text_classification_dataset_profile"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Abhay22/text_classification_dataset_profile
|
[
"region:us"
] |
2023-10-29T21:14:00+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "Profile", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2020475.2946482261, "num_examples": 1413}, {"name": "test", "num_bytes": 357479.7053517739, "num_examples": 250}], "download_size": 742409, "dataset_size": 2377955.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-10-29T21:15:36+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "text_classification_dataset_profile"
More Information needed
|
[
"# Dataset Card for \"text_classification_dataset_profile\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"text_classification_dataset_profile\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"text_classification_dataset_profile\"\n\nMore Information needed"
] |
11253a6a91e944a2c94ebffd29c5b97a709d44bf
|
# Dataset Card for "text_classification_dataset_journey"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Abhay22/text_classification_dataset_journey
|
[
"region:us"
] |
2023-10-29T21:14:02+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "Journey", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2016526.6737416617, "num_examples": 1401}, {"name": "test", "num_bytes": 356958.3262583384, "num_examples": 248}], "download_size": 740837, "dataset_size": 2373485.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-10-29T21:15:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "text_classification_dataset_journey"
More Information needed
|
[
"# Dataset Card for \"text_classification_dataset_journey\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"text_classification_dataset_journey\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"text_classification_dataset_journey\"\n\nMore Information needed"
] |
e4156e4ab4ff45c020428e8f6045efe0d29d73a7
|
# Dataset Card for "text_classification_dataset_area"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Abhay22/text_classification_dataset_area
|
[
"region:us"
] |
2023-10-29T21:14:03+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "Area", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2010078.5636031649, "num_examples": 1396}, {"name": "test", "num_bytes": 355651.4363968351, "num_examples": 247}], "download_size": 739481, "dataset_size": 2365730.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-10-29T21:15:41+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "text_classification_dataset_area"
More Information needed
|
[
"# Dataset Card for \"text_classification_dataset_area\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"text_classification_dataset_area\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"text_classification_dataset_area\"\n\nMore Information needed"
] |
0a28c36f20f3dfc959067f34fa95d08911ccc10b
|
This is a test audio dataset
|
acetennis01/audiotest
|
[
"task_categories:automatic-speech-recognition",
"size_categories:n<1K",
"language:en",
"region:us"
] |
2023-10-29T21:26:37+00:00
|
{"language": ["en"], "size_categories": ["n<1K"], "task_categories": ["automatic-speech-recognition"], "pretty_name": "a"}
|
2023-11-01T21:04:32+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-automatic-speech-recognition #size_categories-n<1K #language-English #region-us
|
This is a test audio dataset
|
[] |
[
"TAGS\n#task_categories-automatic-speech-recognition #size_categories-n<1K #language-English #region-us \n"
] |
[
36
] |
[
"passage: TAGS\n#task_categories-automatic-speech-recognition #size_categories-n<1K #language-English #region-us \n"
] |
a3374557ad980a7b85dfc2b4378b4d1f8437fda9
|
# Dataset Card for "facecontrol"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Taimoor-R/facecontrol
|
[
"region:us"
] |
2023-10-29T22:37:56+00:00
|
{"dataset_info": {"features": [{"name": "source", "dtype": "Image"}, {"name": "target", "dtype": "Image"}, {"name": "prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3191672531, "num_examples": 30000}], "download_size": 3188028488, "dataset_size": 3191672531}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-29T23:44:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "facecontrol"
More Information needed
|
[
"# Dataset Card for \"facecontrol\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"facecontrol\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"facecontrol\"\n\nMore Information needed"
] |
52fb08c30b274929adfd7a62a2152a4a22191552
|
# Dataset Card for MNR's General Imageset
In-flux. use at your own discrestion/frustration.
## Dataset Details
- random images. about 1,200 in total.
- **Curated by:** Rob James
|
Robathan/generalimageset
|
[
"task_categories:feature-extraction",
"size_categories:1K<n<10K",
"license:gpl-3.0",
"region:us"
] |
2023-10-29T23:21:45+00:00
|
{"license": "gpl-3.0", "size_categories": ["1K<n<10K"], "task_categories": ["feature-extraction"]}
|
2023-10-30T01:27:31+00:00
|
[] |
[] |
TAGS
#task_categories-feature-extraction #size_categories-1K<n<10K #license-gpl-3.0 #region-us
|
# Dataset Card for MNR's General Imageset
In-flux. use at your own discrestion/frustration.
## Dataset Details
- random images. about 1,200 in total.
- Curated by: Rob James
|
[
"# Dataset Card for MNR's General Imageset\n\nIn-flux. use at your own discrestion/frustration.",
"## Dataset Details\n- random images. about 1,200 in total.\n\n\n- Curated by: Rob James"
] |
[
"TAGS\n#task_categories-feature-extraction #size_categories-1K<n<10K #license-gpl-3.0 #region-us \n",
"# Dataset Card for MNR's General Imageset\n\nIn-flux. use at your own discrestion/frustration.",
"## Dataset Details\n- random images. about 1,200 in total.\n\n\n- Curated by: Rob James"
] |
[
38,
29,
22
] |
[
"passage: TAGS\n#task_categories-feature-extraction #size_categories-1K<n<10K #license-gpl-3.0 #region-us \n# Dataset Card for MNR's General Imageset\n\nIn-flux. use at your own discrestion/frustration.## Dataset Details\n- random images. about 1,200 in total.\n\n\n- Curated by: Rob James"
] |
e6b7cfe94745ffe48ebdb4aea645c4448f45377c
|
# Dataset Card for "revision_data_split_0_translated"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
IndonesiaAI/revision_data_split_0_translated
|
[
"region:us"
] |
2023-10-30T02:30:14+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "qid", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "response_j", "dtype": "string"}, {"name": "response_k", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3176518202, "num_examples": 1050257}], "download_size": 957771712, "dataset_size": 3176518202}}
|
2023-10-30T02:31:09+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "revision_data_split_0_translated"
More Information needed
|
[
"# Dataset Card for \"revision_data_split_0_translated\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"revision_data_split_0_translated\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"revision_data_split_0_translated\"\n\nMore Information needed"
] |
397497f7a6b345a81c846f279f71d9ee6da2e244
|
# UN General Assembly Votes from 2000 to 2023
The following is a cleaned and compiled version of all of the UN General Assembly votes, from [the UN Digital Library](https://digitallibrary.un.org/), which includes ~1800 different resolutions and votes by the 196 voting members.
Fields include **Title**, **Resolution Number** and the actual votes.
The votes are in a dict format, with the name of the country. Countries have have changed names over the period (such as Turkey -> Türkiye, Swaziland -> Eswatini), so we use the latest name each country has used as of 2023. One voting member country (Serbia and Montengro) has since split into two voting member countries during the time period in question, and is not considered. South Sudan, Serbia, and Montenegro only came into existing in the middle of the time period in question, and so we consider them as not voting / null votes before they became voting members.
Please follow the [UN Digital Library terms of service](https://digitallibrary.un.org/pages/?ln=en&page=tos) (e.g. non-commercial use)
© United Nations, 2023, https://digitallibrary.un.org, downloaded on 10/29/2023
|
sam-bha/un-general-assembly-votes-2000-2023
|
[
"task_categories:tabular-regression",
"task_categories:tabular-classification",
"language:en",
"license:cc-by-nc-4.0",
"politics",
"region:us"
] |
2023-10-30T02:36:34+00:00
|
{"language": ["en"], "license": "cc-by-nc-4.0", "task_categories": ["tabular-regression", "tabular-classification"], "pretty_name": "UN General Assembly Votes from 2000 to 2023", "tags": ["politics"]}
|
2023-11-01T14:56:11+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-tabular-regression #task_categories-tabular-classification #language-English #license-cc-by-nc-4.0 #politics #region-us
|
# UN General Assembly Votes from 2000 to 2023
The following is a cleaned and compiled version of all of the UN General Assembly votes, from the UN Digital Library, which includes ~1800 different resolutions and votes by the 196 voting members.
Fields include Title, Resolution Number and the actual votes.
The votes are in a dict format, with the name of the country. Countries have have changed names over the period (such as Turkey -> Türkiye, Swaziland -> Eswatini), so we use the latest name each country has used as of 2023. One voting member country (Serbia and Montengro) has since split into two voting member countries during the time period in question, and is not considered. South Sudan, Serbia, and Montenegro only came into existing in the middle of the time period in question, and so we consider them as not voting / null votes before they became voting members.
Please follow the UN Digital Library terms of service (e.g. non-commercial use)
© United Nations, 2023, URL, downloaded on 10/29/2023
|
[
"# UN General Assembly Votes from 2000 to 2023\n\nThe following is a cleaned and compiled version of all of the UN General Assembly votes, from the UN Digital Library, which includes ~1800 different resolutions and votes by the 196 voting members.\n\nFields include Title, Resolution Number and the actual votes.\n\nThe votes are in a dict format, with the name of the country. Countries have have changed names over the period (such as Turkey -> Türkiye, Swaziland -> Eswatini), so we use the latest name each country has used as of 2023. One voting member country (Serbia and Montengro) has since split into two voting member countries during the time period in question, and is not considered. South Sudan, Serbia, and Montenegro only came into existing in the middle of the time period in question, and so we consider them as not voting / null votes before they became voting members.\n\nPlease follow the UN Digital Library terms of service (e.g. non-commercial use)\n\n© United Nations, 2023, URL, downloaded on 10/29/2023"
] |
[
"TAGS\n#task_categories-tabular-regression #task_categories-tabular-classification #language-English #license-cc-by-nc-4.0 #politics #region-us \n",
"# UN General Assembly Votes from 2000 to 2023\n\nThe following is a cleaned and compiled version of all of the UN General Assembly votes, from the UN Digital Library, which includes ~1800 different resolutions and votes by the 196 voting members.\n\nFields include Title, Resolution Number and the actual votes.\n\nThe votes are in a dict format, with the name of the country. Countries have have changed names over the period (such as Turkey -> Türkiye, Swaziland -> Eswatini), so we use the latest name each country has used as of 2023. One voting member country (Serbia and Montengro) has since split into two voting member countries during the time period in question, and is not considered. South Sudan, Serbia, and Montenegro only came into existing in the middle of the time period in question, and so we consider them as not voting / null votes before they became voting members.\n\nPlease follow the UN Digital Library terms of service (e.g. non-commercial use)\n\n© United Nations, 2023, URL, downloaded on 10/29/2023"
] |
[
48,
239
] |
[
"passage: TAGS\n#task_categories-tabular-regression #task_categories-tabular-classification #language-English #license-cc-by-nc-4.0 #politics #region-us \n# UN General Assembly Votes from 2000 to 2023\n\nThe following is a cleaned and compiled version of all of the UN General Assembly votes, from the UN Digital Library, which includes ~1800 different resolutions and votes by the 196 voting members.\n\nFields include Title, Resolution Number and the actual votes.\n\nThe votes are in a dict format, with the name of the country. Countries have have changed names over the period (such as Turkey -> Türkiye, Swaziland -> Eswatini), so we use the latest name each country has used as of 2023. One voting member country (Serbia and Montengro) has since split into two voting member countries during the time period in question, and is not considered. South Sudan, Serbia, and Montenegro only came into existing in the middle of the time period in question, and so we consider them as not voting / null votes before they became voting members.\n\nPlease follow the UN Digital Library terms of service (e.g. non-commercial use)\n\n© United Nations, 2023, URL, downloaded on 10/29/2023"
] |
cd8619d8722eea18f51b8f4d7b2634dba120a111
|
# Dataset Card for "llamanmt"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
zaanind/llamanmt
|
[
"region:us"
] |
2023-10-30T02:37:08+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 17230781, "num_examples": 80684}], "download_size": 4778305, "dataset_size": 17230781}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T02:37:10+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "llamanmt"
More Information needed
|
[
"# Dataset Card for \"llamanmt\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"llamanmt\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"llamanmt\"\n\nMore Information needed"
] |
d9e88d6b1e5a1189747aa07b3c76db46839a7cef
|
# Dataset Card for JudgeLM-data-collection
## Dataset Description
- **Repository:** https://github.com/baaivision/JudgeLM
- **Paper:** https://arxiv.org/abs/2310.17631
### Dataset Summary
This dataset is created for easily use and evaluate JudgeLM. We include LLMs-generated answers and a great multi-modal benchmark, [MM-Vet](https://github.com/yuweihao/MM-Vet) in this repo. The folder structure is shown as bellow:
**Folder structure**
```
data
├── JudgeLM/
│ ├── answers/
│ │ ├── alpaca_judgelm_val.jsonl
| | ├── ...
│ ├── judgelm_preprocess.py
│ ├── judgelm_val_5k.jsonl
│ ├── judgelm_val_5k_gpt4.jsonl
│ ├── judgelm_val_5k_gpt4_with_reference.jsonl
│ ├── judgelm_val_5k_references.jsonl
├── MM-Vet/
│ ├── mm-vet-emu-prediction.json
│ ├── mm-vet-gt.json
│ ├── mm-vet-judge-samples.jsonl
│ ├── mmvet_preprocess.py
```
You can directly put this dataset collection into the `/JudgeLM/judgelm` for better use.
### Languages
The data in Alpaca are in English.
## Additional Information
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@article{zhu2023judgelm,
title={JudgeLM: Fine-tuned Large Language Models are Scalable Judges},
author={Lianghui Zhu and Xinggang Wang and Xinlong Wang},
year={2023},
eprint={2310.17631},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
BAAI/JudgeLM-data-collection-v1.0
|
[
"task_categories:text-generation",
"language:en",
"license:cc-by-nc-4.0",
"instruction-finetuning",
"arxiv:2310.17631",
"region:us"
] |
2023-10-30T03:18:43+00:00
|
{"language": ["en"], "license": "cc-by-nc-4.0", "task_categories": ["text-generation"], "pretty_name": "JudgeLM-data-collection-v1.0", "tags": ["instruction-finetuning"]}
|
2023-10-30T03:53:59+00:00
|
[
"2310.17631"
] |
[
"en"
] |
TAGS
#task_categories-text-generation #language-English #license-cc-by-nc-4.0 #instruction-finetuning #arxiv-2310.17631 #region-us
|
# Dataset Card for JudgeLM-data-collection
## Dataset Description
- Repository: URL
- Paper: URL
### Dataset Summary
This dataset is created for easily use and evaluate JudgeLM. We include LLMs-generated answers and a great multi-modal benchmark, MM-Vet in this repo. The folder structure is shown as bellow:
Folder structure
You can directly put this dataset collection into the '/JudgeLM/judgelm' for better use.
### Languages
The data in Alpaca are in English.
## Additional Information
### Licensing Information
The dataset is available under the Creative Commons NonCommercial (CC BY-NC 4.0).
|
[
"# Dataset Card for JudgeLM-data-collection",
"## Dataset Description\n\n- Repository: URL\n- Paper: URL",
"### Dataset Summary\n\nThis dataset is created for easily use and evaluate JudgeLM. We include LLMs-generated answers and a great multi-modal benchmark, MM-Vet in this repo. The folder structure is shown as bellow:\n\nFolder structure\n\n\nYou can directly put this dataset collection into the '/JudgeLM/judgelm' for better use.",
"### Languages\n\nThe data in Alpaca are in English.",
"## Additional Information",
"### Licensing Information\n\nThe dataset is available under the Creative Commons NonCommercial (CC BY-NC 4.0)."
] |
[
"TAGS\n#task_categories-text-generation #language-English #license-cc-by-nc-4.0 #instruction-finetuning #arxiv-2310.17631 #region-us \n",
"# Dataset Card for JudgeLM-data-collection",
"## Dataset Description\n\n- Repository: URL\n- Paper: URL",
"### Dataset Summary\n\nThis dataset is created for easily use and evaluate JudgeLM. We include LLMs-generated answers and a great multi-modal benchmark, MM-Vet in this repo. The folder structure is shown as bellow:\n\nFolder structure\n\n\nYou can directly put this dataset collection into the '/JudgeLM/judgelm' for better use.",
"### Languages\n\nThe data in Alpaca are in English.",
"## Additional Information",
"### Licensing Information\n\nThe dataset is available under the Creative Commons NonCommercial (CC BY-NC 4.0)."
] |
[
47,
13,
14,
85,
13,
5,
26
] |
[
"passage: TAGS\n#task_categories-text-generation #language-English #license-cc-by-nc-4.0 #instruction-finetuning #arxiv-2310.17631 #region-us \n# Dataset Card for JudgeLM-data-collection## Dataset Description\n\n- Repository: URL\n- Paper: URL### Dataset Summary\n\nThis dataset is created for easily use and evaluate JudgeLM. We include LLMs-generated answers and a great multi-modal benchmark, MM-Vet in this repo. The folder structure is shown as bellow:\n\nFolder structure\n\n\nYou can directly put this dataset collection into the '/JudgeLM/judgelm' for better use.### Languages\n\nThe data in Alpaca are in English.## Additional Information### Licensing Information\n\nThe dataset is available under the Creative Commons NonCommercial (CC BY-NC 4.0)."
] |
336c77c0963515d6b9910026245aeb29b4eb7a5d
|
# Dataset Card for "t2i_reward_v4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
toilaluan/t2i_reward_v4
|
[
"region:us"
] |
2023-10-30T03:45:50+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "model_type", "dtype": "string"}, {"name": "request_id", "dtype": "int64"}, {"name": "topic", "dtype": "string"}, {"name": "reward", "dtype": "float64"}, {"name": "individual_rewards", "struct": [{"name": "clip_aesthetic_rewarder", "dtype": "float64"}, {"name": "pick_rewarder", "dtype": "float64"}, {"name": "image_rewarder", "dtype": "float64"}, {"name": "hps_v2_rewarder", "dtype": "float64"}]}], "splits": [{"name": "train", "num_bytes": 115800, "num_examples": 1125}], "download_size": 43681, "dataset_size": 115800}}
|
2023-10-30T09:19:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "t2i_reward_v4"
More Information needed
|
[
"# Dataset Card for \"t2i_reward_v4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"t2i_reward_v4\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"t2i_reward_v4\"\n\nMore Information needed"
] |
edac8b9ec031bb80f01339b021b03de532cfdf4a
|
# Dataset Card for "t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pkr7098/t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent
|
[
"region:us"
] |
2023-10-30T03:57:15+00:00
|
{"dataset_info": {"config_name": "truncate-512", "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "special_tokens_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 20525275188, "num_examples": 6655407}, {"name": "validation", "num_bytes": 1341647940, "num_examples": 435035}], "download_size": 0, "dataset_size": 21866923128}, "configs": [{"config_name": "truncate-512", "data_files": [{"split": "train", "path": "truncate-512/train-*"}, {"split": "validation", "path": "truncate-512/validation-*"}]}]}
|
2023-10-30T04:08:44+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent"
More Information needed
|
[
"# Dataset Card for \"t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent\"\n\nMore Information needed"
] |
[
6,
35
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"t5-small-bookcorpus-wiki-2022030-en-vocab_size-32000-5percent\"\n\nMore Information needed"
] |
c5a1cf75d3b55b9a6d54854fc2c5d93e3f97f9e7
|
# Dataset Card for "undl_en2zh_translation"
(undl_text)[https://huggingface.co/datasets/bot-yaya/undl_text]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。
机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。
感谢为我提供算力的小伙伴和云平台!
google云计算穷鬼算力白嫖指南:
- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核
- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。
- **重要!** 选抢占式(Spot)实例,可以便宜不少
- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租
- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G
- 13GB的标准硬盘、Debian 12 Bookworm镜像
- 开启允许HTTP和HTTPS流量
|
bot-yaya/undl_en2zh_translation
|
[
"region:us"
] |
2023-10-30T04:33:16+00:00
|
{"dataset_info": {"features": [{"name": "clean_en", "sequence": "string"}, {"name": "clean_zh", "sequence": "string"}, {"name": "record", "dtype": "string"}, {"name": "en2zh", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 12473072134, "num_examples": 165840}], "download_size": 6289516266, "dataset_size": 12473072134}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-04T09:28:20+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "undl_en2zh_translation"
(undl_text)[URL]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。
机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。
感谢为我提供算力的小伙伴和云平台!
google云计算穷鬼算力白嫖指南:
- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核
- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。
- 重要! 选抢占式(Spot)实例,可以便宜不少
- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租
- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G
- 13GB的标准硬盘、Debian 12 Bookworm镜像
- 开启允许HTTP和HTTPS流量
|
[
"# Dataset Card for \"undl_en2zh_translation\"\n\n(undl_text)[URL]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。\n\n机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。\n\n感谢为我提供算力的小伙伴和云平台!\n\n\ngoogle云计算穷鬼算力白嫖指南:\n- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核\n- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。\n- 重要! 选抢占式(Spot)实例,可以便宜不少\n- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租\n- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G\n- 13GB的标准硬盘、Debian 12 Bookworm镜像\n- 开启允许HTTP和HTTPS流量"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"undl_en2zh_translation\"\n\n(undl_text)[URL]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。\n\n机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。\n\n感谢为我提供算力的小伙伴和云平台!\n\n\ngoogle云计算穷鬼算力白嫖指南:\n- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核\n- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。\n- 重要! 选抢占式(Spot)实例,可以便宜不少\n- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租\n- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G\n- 13GB的标准硬盘、Debian 12 Bookworm镜像\n- 开启允许HTTP和HTTPS流量"
] |
[
6,
399
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"undl_en2zh_translation\"\n\n(undl_text)[URL]数据集的全量英文段落翻中文段落,是我口胡的基于翻译和最长公共子序列对齐方法的基础(雾)。\n\n机翻轮子使用argostranslate,使用google云虚拟机的36个v核、google colab提供的免费的3个实例、google cloud shell的1个实例,我本地电脑的cpu和显卡,还有帮我挂colab的ranWang,帮我挂笔记本和本地的同学们,共计跑了一个星期得到。\n\n感谢为我提供算力的小伙伴和云平台!\n\n\ngoogle云计算穷鬼算力白嫖指南:\n- 绑卡后的免费账户可以最多同时建3个项目来用Compute API,每个项目配额是12个v核\n- 选计算优化->C2D实例,高cpu,AMD EPYC Milan,这个比隔壁Xeon便宜又能打(AMD yes)。一般来说,免费用户的每个项目每个区域的配额顶天8vCPU,并且每个项目限制12vCPU。所以我推荐在最低价区买一个8x,再在次低价区整一个4x。\n- 重要! 选抢占式(Spot)实例,可以便宜不少\n- 截至写README,免费用户能租到的最低价的C2D实例是比利时和衣阿华、南卡。孟买甚至比比利时便宜50%,但是免费用户不能租\n- 内存其实实际运行只消耗2~3G,尽可能少要就好,C2D最低也是cpu:mem=1:2,那没办法只好要16G\n- 13GB的标准硬盘、Debian 12 Bookworm镜像\n- 开启允许HTTP和HTTPS流量"
] |
c45055b330297af22202008c60a3a5a216150a95
|
# Dataset Card for "Kan500"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
anonymouse03052002/Kan500
|
[
"region:us"
] |
2023-10-30T04:41:46+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "review", "dtype": "string"}, {"name": "review_length", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 6131.666666666667, "num_examples": 5}, {"name": "validation", "num_bytes": 1928, "num_examples": 1}], "download_size": 0, "dataset_size": 8059.666666666667}}
|
2023-10-30T04:50:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "Kan500"
More Information needed
|
[
"# Dataset Card for \"Kan500\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"Kan500\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"Kan500\"\n\nMore Information needed"
] |
4b3f7d75986b2425c5873be983131832e9baa807
|
# Dataset Card for "usda_tokenized_source"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
passionMan/usda_tokenized_source
|
[
"region:us"
] |
2023-10-30T04:56:45+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 1314644, "num_examples": 5628}, {"name": "test", "num_bytes": 437798, "num_examples": 1876}], "download_size": 434891, "dataset_size": 1752442}}
|
2023-10-30T04:56:51+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "usda_tokenized_source"
More Information needed
|
[
"# Dataset Card for \"usda_tokenized_source\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"usda_tokenized_source\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"usda_tokenized_source\"\n\nMore Information needed"
] |
26872595314c0798b0fedbe933850c6932a0c9de
|
# Dataset Card for "val"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
anonymouse03052002/val
|
[
"region:us"
] |
2023-10-30T05:04:57+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "review", "dtype": "string"}, {"name": "review_length", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 267482.34016393445, "num_examples": 439}, {"name": "validation", "num_bytes": 29855.659836065573, "num_examples": 49}], "download_size": 0, "dataset_size": 297338.0}}
|
2023-10-30T06:35:35+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "val"
More Information needed
|
[
"# Dataset Card for \"val\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"val\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"val\"\n\nMore Information needed"
] |
a55725d0486fbf773cfee7bb627e2f7caff1859a
|
# Dataset Card for "undl_en2zh_translation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ranWang/undl_en2zh_translation
|
[
"region:us"
] |
2023-10-30T05:34:29+00:00
|
{"dataset_info": {"features": [{"name": "clean_en", "sequence": "string"}, {"name": "clean_zh", "sequence": "string"}, {"name": "record", "dtype": "string"}, {"name": "en2zh", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 12473072134, "num_examples": 165840}], "download_size": 6289513941, "dataset_size": 12473072134}}
|
2023-10-30T05:58:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "undl_en2zh_translation"
More Information needed
|
[
"# Dataset Card for \"undl_en2zh_translation\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"undl_en2zh_translation\"\n\nMore Information needed"
] |
[
6,
19
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"undl_en2zh_translation\"\n\nMore Information needed"
] |
8682e83ed3bd945ffa6093ceb6ccf786f3aeb255
|
# BabyAGI (Dataset)
The initial demonstration dataset follows the Huggingface dataset spec, with the raw data split into two components, trajectory images and trajectory metadata. The metadata is stored in the raw dataset, and the images are stored on S3. The data is loaded using the dataloader defined in [baby_agi_dataset.py](./baby_agi_dataset.py).
**Data Layout:**
```plaintext
├── data
│ ├── metadata_0.json
│ ├── metadata_1.json
│ └── ...
├-- baby_agi_dataset.py
```
### Metadata Format (.json)
```json
[
{
"id": "<trajectory_id_hash>",
"instruction": "<some instruction>",
"trajectory": [
{
"image_id": "image_id",
"action_options": [
{
"index": 0,
"top_left": [120, 340],
"bottom_right": [140, 440],
},
...
],
"action_taken": {
"type": "click",
"value": "value (only for type and scroll)",
"action_option_index": 0
}
},
...
]
},
]
```
## Action Types
The dataset metadata includes three types of actions: "click", "type", and "scroll". The `action_option_index` field indicates the index of the clicked element within the `action_options` list.
1. **Click**: Represents a user clicking on an element.
2. **Type**: Represents a user typing into an input field.
3. **Scroll**: Represents a user scrolling the viewport. The `value` field indicates the direction of the scroll, with "up" corresponding to a 200px scroll upwards and "down" corresponding to a 200px scroll downwards. Note that `bottom_left` and `top_right` will always be zero-arrays for these.
## Dataset Generation Pipeline
The dataset is generated through the following steps:
1. **Load Demo**: The demo is loaded from the Hugging Face dataset.
2. **Load Trace**: The trace is loaded from the Globus dataset.
3. **Process Trajectories**: For each Mind2Web (M2W) trajectory:
a) **Map Actions**: M2W actions are mapped to Playwright trace actions using the timestamp in `dom_content.json`.
b) **Screenshot DOM**: The DOM is "screenshoted" just before the action.
c) **Map Candidates**: `pos_candidates` and `neg_candidates` from the M2W action metadata are mapped to HTML bounding boxes via class+id matching from the action metadata. New bounding box coordinates are obtained for each.
d) **Craft Meta + Screenshot Pair**: The pair of metadata and screenshots is crafted and saved/appended.
4. **Save Data**: The updated data directory is saved to S3 and Hugging Face.
### Screenshots
Screenshots in this dataset are generated from the before states of Mind2Web trajectory traces. Each image has a width of 2036 and a height of 1144. For alternate screen sizes (via augmentation), padding is added to maintain the aspect ratio. This ensures that the content of the screenshot remains consistent across different screen sizes.
### Options Generation
Options in this dataset are generated from `positive_candidates` (always one) and `negative_candidates` in the Mind2Web (M2W) dataset. The M2W dataset labels *all* possible interactions on the DOM. Therefore, the 50 largest area-wise options within the viewport containing the positive candidate are selected.
### Scrolling
The Mind2Web (M2W) dataset captures the entire DOM, so when the selected option action is not in the viewport, artificial scroll actions are created. This action has two possible values: "up" and "down". Each of which corresponds to a 200px scroll in the respective direction.
### Selecting
The "Select" action in the Mind2Web (M2W) dataset is recorded when a user makes a selection from a dropdown list. In this dataset, we represent it as a sequence of two distinct actions in a trajectory:
1. **Click**: The user clicks on the dropdown element.
2. **Type**: The user types the desired value followed by Enter
## Usage
To use the dataset in your Python program, you can load it using the `load_dataset` function from the `datasets` library:
```python
from datasets import load_dataset
# typically load_dataset("lukemann/baby-agi-dataset-v0"
dataset = load_dataset("lukemann/baby-agi-dataset-v0")
first_row = dataset['train'][0]
print(first_row)
```
This will load the dataset and print the first row of the training set.
For a short demo, refer to the [demo.py](./demo.py) file.
|
lukemann/baby-agi-dataset-v0
|
[
"region:us"
] |
2023-10-30T05:36:34+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "instruction", "dtype": "string"}, {"name": "trajectory", "list": [{"name": "image_id", "dtype": "string"}, {"name": "action_options", "list": [{"name": "index", "dtype": "int32"}, {"name": "top_left", "sequence": "int32"}, {"name": "bottom_right", "sequence": "int32"}]}, {"name": "action_taken", "struct": [{"name": "type", "dtype": "string"}, {"name": "value", "dtype": "string"}, {"name": "action_option_index", "dtype": "int32"}]}]}], "splits": [{"name": "train", "num_bytes": 722, "num_examples": 1}], "download_size": 1432409, "dataset_size": 722}}
|
2023-10-30T09:16:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# BabyAGI (Dataset)
The initial demonstration dataset follows the Huggingface dataset spec, with the raw data split into two components, trajectory images and trajectory metadata. The metadata is stored in the raw dataset, and the images are stored on S3. The data is loaded using the dataloader defined in baby_agi_dataset.py.
Data Layout:
### Metadata Format (.json)
## Action Types
The dataset metadata includes three types of actions: "click", "type", and "scroll". The 'action_option_index' field indicates the index of the clicked element within the 'action_options' list.
1. Click: Represents a user clicking on an element.
2. Type: Represents a user typing into an input field.
3. Scroll: Represents a user scrolling the viewport. The 'value' field indicates the direction of the scroll, with "up" corresponding to a 200px scroll upwards and "down" corresponding to a 200px scroll downwards. Note that 'bottom_left' and 'top_right' will always be zero-arrays for these.
## Dataset Generation Pipeline
The dataset is generated through the following steps:
1. Load Demo: The demo is loaded from the Hugging Face dataset.
2. Load Trace: The trace is loaded from the Globus dataset.
3. Process Trajectories: For each Mind2Web (M2W) trajectory:
a) Map Actions: M2W actions are mapped to Playwright trace actions using the timestamp in 'dom_content.json'.
b) Screenshot DOM: The DOM is "screenshoted" just before the action.
c) Map Candidates: 'pos_candidates' and 'neg_candidates' from the M2W action metadata are mapped to HTML bounding boxes via class+id matching from the action metadata. New bounding box coordinates are obtained for each.
d) Craft Meta + Screenshot Pair: The pair of metadata and screenshots is crafted and saved/appended.
4. Save Data: The updated data directory is saved to S3 and Hugging Face.
### Screenshots
Screenshots in this dataset are generated from the before states of Mind2Web trajectory traces. Each image has a width of 2036 and a height of 1144. For alternate screen sizes (via augmentation), padding is added to maintain the aspect ratio. This ensures that the content of the screenshot remains consistent across different screen sizes.
### Options Generation
Options in this dataset are generated from 'positive_candidates' (always one) and 'negative_candidates' in the Mind2Web (M2W) dataset. The M2W dataset labels *all* possible interactions on the DOM. Therefore, the 50 largest area-wise options within the viewport containing the positive candidate are selected.
### Scrolling
The Mind2Web (M2W) dataset captures the entire DOM, so when the selected option action is not in the viewport, artificial scroll actions are created. This action has two possible values: "up" and "down". Each of which corresponds to a 200px scroll in the respective direction.
### Selecting
The "Select" action in the Mind2Web (M2W) dataset is recorded when a user makes a selection from a dropdown list. In this dataset, we represent it as a sequence of two distinct actions in a trajectory:
1. Click: The user clicks on the dropdown element.
2. Type: The user types the desired value followed by Enter
## Usage
To use the dataset in your Python program, you can load it using the 'load_dataset' function from the 'datasets' library:
This will load the dataset and print the first row of the training set.
For a short demo, refer to the URL file.
|
[
"# BabyAGI (Dataset)\n\nThe initial demonstration dataset follows the Huggingface dataset spec, with the raw data split into two components, trajectory images and trajectory metadata. The metadata is stored in the raw dataset, and the images are stored on S3. The data is loaded using the dataloader defined in baby_agi_dataset.py.\n\nData Layout:",
"### Metadata Format (.json)",
"## Action Types\n\nThe dataset metadata includes three types of actions: \"click\", \"type\", and \"scroll\". The 'action_option_index' field indicates the index of the clicked element within the 'action_options' list.\n\n1. Click: Represents a user clicking on an element.\n\n2. Type: Represents a user typing into an input field.\n\n3. Scroll: Represents a user scrolling the viewport. The 'value' field indicates the direction of the scroll, with \"up\" corresponding to a 200px scroll upwards and \"down\" corresponding to a 200px scroll downwards. Note that 'bottom_left' and 'top_right' will always be zero-arrays for these.",
"## Dataset Generation Pipeline\n\nThe dataset is generated through the following steps:\n\n1. Load Demo: The demo is loaded from the Hugging Face dataset.\n2. Load Trace: The trace is loaded from the Globus dataset.\n3. Process Trajectories: For each Mind2Web (M2W) trajectory:\n\n a) Map Actions: M2W actions are mapped to Playwright trace actions using the timestamp in 'dom_content.json'.\n\n b) Screenshot DOM: The DOM is \"screenshoted\" just before the action.\n\n c) Map Candidates: 'pos_candidates' and 'neg_candidates' from the M2W action metadata are mapped to HTML bounding boxes via class+id matching from the action metadata. New bounding box coordinates are obtained for each.\n\n d) Craft Meta + Screenshot Pair: The pair of metadata and screenshots is crafted and saved/appended.\n\n4. Save Data: The updated data directory is saved to S3 and Hugging Face.",
"### Screenshots\n\nScreenshots in this dataset are generated from the before states of Mind2Web trajectory traces. Each image has a width of 2036 and a height of 1144. For alternate screen sizes (via augmentation), padding is added to maintain the aspect ratio. This ensures that the content of the screenshot remains consistent across different screen sizes.",
"### Options Generation\n\nOptions in this dataset are generated from 'positive_candidates' (always one) and 'negative_candidates' in the Mind2Web (M2W) dataset. The M2W dataset labels *all* possible interactions on the DOM. Therefore, the 50 largest area-wise options within the viewport containing the positive candidate are selected.",
"### Scrolling\n\nThe Mind2Web (M2W) dataset captures the entire DOM, so when the selected option action is not in the viewport, artificial scroll actions are created. This action has two possible values: \"up\" and \"down\". Each of which corresponds to a 200px scroll in the respective direction.",
"### Selecting \n\nThe \"Select\" action in the Mind2Web (M2W) dataset is recorded when a user makes a selection from a dropdown list. In this dataset, we represent it as a sequence of two distinct actions in a trajectory: \n\n1. Click: The user clicks on the dropdown element.\n2. Type: The user types the desired value followed by Enter",
"## Usage\n\nTo use the dataset in your Python program, you can load it using the 'load_dataset' function from the 'datasets' library:\n\n\n\nThis will load the dataset and print the first row of the training set.\n\nFor a short demo, refer to the URL file."
] |
[
"TAGS\n#region-us \n",
"# BabyAGI (Dataset)\n\nThe initial demonstration dataset follows the Huggingface dataset spec, with the raw data split into two components, trajectory images and trajectory metadata. The metadata is stored in the raw dataset, and the images are stored on S3. The data is loaded using the dataloader defined in baby_agi_dataset.py.\n\nData Layout:",
"### Metadata Format (.json)",
"## Action Types\n\nThe dataset metadata includes three types of actions: \"click\", \"type\", and \"scroll\". The 'action_option_index' field indicates the index of the clicked element within the 'action_options' list.\n\n1. Click: Represents a user clicking on an element.\n\n2. Type: Represents a user typing into an input field.\n\n3. Scroll: Represents a user scrolling the viewport. The 'value' field indicates the direction of the scroll, with \"up\" corresponding to a 200px scroll upwards and \"down\" corresponding to a 200px scroll downwards. Note that 'bottom_left' and 'top_right' will always be zero-arrays for these.",
"## Dataset Generation Pipeline\n\nThe dataset is generated through the following steps:\n\n1. Load Demo: The demo is loaded from the Hugging Face dataset.\n2. Load Trace: The trace is loaded from the Globus dataset.\n3. Process Trajectories: For each Mind2Web (M2W) trajectory:\n\n a) Map Actions: M2W actions are mapped to Playwright trace actions using the timestamp in 'dom_content.json'.\n\n b) Screenshot DOM: The DOM is \"screenshoted\" just before the action.\n\n c) Map Candidates: 'pos_candidates' and 'neg_candidates' from the M2W action metadata are mapped to HTML bounding boxes via class+id matching from the action metadata. New bounding box coordinates are obtained for each.\n\n d) Craft Meta + Screenshot Pair: The pair of metadata and screenshots is crafted and saved/appended.\n\n4. Save Data: The updated data directory is saved to S3 and Hugging Face.",
"### Screenshots\n\nScreenshots in this dataset are generated from the before states of Mind2Web trajectory traces. Each image has a width of 2036 and a height of 1144. For alternate screen sizes (via augmentation), padding is added to maintain the aspect ratio. This ensures that the content of the screenshot remains consistent across different screen sizes.",
"### Options Generation\n\nOptions in this dataset are generated from 'positive_candidates' (always one) and 'negative_candidates' in the Mind2Web (M2W) dataset. The M2W dataset labels *all* possible interactions on the DOM. Therefore, the 50 largest area-wise options within the viewport containing the positive candidate are selected.",
"### Scrolling\n\nThe Mind2Web (M2W) dataset captures the entire DOM, so when the selected option action is not in the viewport, artificial scroll actions are created. This action has two possible values: \"up\" and \"down\". Each of which corresponds to a 200px scroll in the respective direction.",
"### Selecting \n\nThe \"Select\" action in the Mind2Web (M2W) dataset is recorded when a user makes a selection from a dropdown list. In this dataset, we represent it as a sequence of two distinct actions in a trajectory: \n\n1. Click: The user clicks on the dropdown element.\n2. Type: The user types the desired value followed by Enter",
"## Usage\n\nTo use the dataset in your Python program, you can load it using the 'load_dataset' function from the 'datasets' library:\n\n\n\nThis will load the dataset and print the first row of the training set.\n\nFor a short demo, refer to the URL file."
] |
[
6,
90,
10,
165,
239,
83,
88,
69,
85,
64
] |
[
"passage: TAGS\n#region-us \n# BabyAGI (Dataset)\n\nThe initial demonstration dataset follows the Huggingface dataset spec, with the raw data split into two components, trajectory images and trajectory metadata. The metadata is stored in the raw dataset, and the images are stored on S3. The data is loaded using the dataloader defined in baby_agi_dataset.py.\n\nData Layout:### Metadata Format (.json)## Action Types\n\nThe dataset metadata includes three types of actions: \"click\", \"type\", and \"scroll\". The 'action_option_index' field indicates the index of the clicked element within the 'action_options' list.\n\n1. Click: Represents a user clicking on an element.\n\n2. Type: Represents a user typing into an input field.\n\n3. Scroll: Represents a user scrolling the viewport. The 'value' field indicates the direction of the scroll, with \"up\" corresponding to a 200px scroll upwards and \"down\" corresponding to a 200px scroll downwards. Note that 'bottom_left' and 'top_right' will always be zero-arrays for these."
] |
2abbf81717012df3352853fec88bff25bb902a58
|
# Dataset Card for "andersonbcdefg_chemistry_zh-tw"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
FelixChao/andersonbcdefg_chemistry_zh-tw
|
[
"region:us"
] |
2023-10-30T05:42:54+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 35129271, "num_examples": 20000}], "download_size": 18530541, "dataset_size": 35129271}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T05:43:02+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "andersonbcdefg_chemistry_zh-tw"
More Information needed
|
[
"# Dataset Card for \"andersonbcdefg_chemistry_zh-tw\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"andersonbcdefg_chemistry_zh-tw\"\n\nMore Information needed"
] |
[
6,
24
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"andersonbcdefg_chemistry_zh-tw\"\n\nMore Information needed"
] |
870c35e225745bb6b1d1ad3c56c1eaeb263087fe
|
# Dataset Card for "layouts_donut_1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sankettgorey/layouts_donut_1
|
[
"region:us"
] |
2023-10-30T05:59:54+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1107628464.82414, "num_examples": 4007}, {"name": "test", "num_bytes": 136074844.03892994, "num_examples": 501}, {"name": "validation", "num_bytes": 139076925.03892994, "num_examples": 501}], "download_size": 1146273186, "dataset_size": 1382780233.902}}
|
2023-10-30T06:00:49+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "layouts_donut_1"
More Information needed
|
[
"# Dataset Card for \"layouts_donut_1\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"layouts_donut_1\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"layouts_donut_1\"\n\nMore Information needed"
] |
c44953f0adfcc2c2aa39c9ffebb1cb0970617bc8
|
# Dataset Card for "tldr_5000rows"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Naveengo/tldr_5000rows
|
[
"region:us"
] |
2023-10-30T06:01:20+00:00
|
{"dataset_info": {"features": [{"name": "headline", "dtype": "string"}, {"name": "content", "dtype": "string"}, {"name": "category", "dtype": {"class_label": {"names": {"0": "Sponsor", "1": "Big Tech & Startups", "2": "Science and Futuristic Technology", "3": "Programming, Design & Data Science", "4": "Miscellaneous"}}}}], "splits": [{"name": "train", "num_bytes": 2802214.906136173, "num_examples": 5000}], "download_size": 1783189, "dataset_size": 2802214.906136173}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T06:01:22+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "tldr_5000rows"
More Information needed
|
[
"# Dataset Card for \"tldr_5000rows\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"tldr_5000rows\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"tldr_5000rows\"\n\nMore Information needed"
] |
3d1184338e52850ba7dbec471846dae07dc4b000
|
# Dataset Card for "memes_dataset_full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
marij868/memes_dataset_full
|
[
"region:us"
] |
2023-10-30T06:12:48+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "Unnamed: 0", "dtype": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5694447.0, "num_examples": 98}], "download_size": 0, "dataset_size": 5694447.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T06:13:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "memes_dataset_full"
More Information needed
|
[
"# Dataset Card for \"memes_dataset_full\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"memes_dataset_full\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"memes_dataset_full\"\n\nMore Information needed"
] |
55679440210d6fb7d92d4485e1463054e7728b6e
|
# Dataset Card for "full_memes_dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
marij868/full_memes_dataset
|
[
"region:us"
] |
2023-10-30T06:14:54+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5693663.0, "num_examples": 98}], "download_size": 5673882, "dataset_size": 5693663.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T06:14:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "full_memes_dataset"
More Information needed
|
[
"# Dataset Card for \"full_memes_dataset\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"full_memes_dataset\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"full_memes_dataset\"\n\nMore Information needed"
] |
2292605cf0597ae5bfdfb2a66e15871cc21b0af7
|
Given the scarcity of datasets for understanding natural language in visual scenes, we introduce a novel textual entailment dataset, named Textual Natural Contextual Classification (TNCC).
This dataset is formulated on the foundation of Crisscrossed Captions (https://github.com/google-research-datasets/Crisscrossed-Captions), an image captioning dataset supplied with human-rated semantic similarity ratings on a continuous scale from 0 to 5.
We tailor the dataset to suit a binary classification task. Specifically, sentence pairs with annotation scores exceeding 4 are categorized as positive (entailment), whereas pairs with scores less than 1 are marked as negative (non-entailment).
The TNCC dataset is partitioned into training, validation, and testing sets, containing 3,600, 1,200, and 1,560 instances, respectively.
If you use this dataset for academic research, please cite the NeurIPS 2023 paper titled 'Back-Modality: Leveraging Modal Transformation for Data Augmentation'.
|
zhili312/Textual-Natural-Contextual-Classification
|
[
"task_categories:text-classification",
"size_categories:1K<n<10K",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-10-30T06:22:12+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification"], "pretty_name": "TNCC"}
|
2023-10-30T06:45:42+00:00
|
[] |
[
"en"
] |
TAGS
#task_categories-text-classification #size_categories-1K<n<10K #language-English #license-apache-2.0 #region-us
|
Given the scarcity of datasets for understanding natural language in visual scenes, we introduce a novel textual entailment dataset, named Textual Natural Contextual Classification (TNCC).
This dataset is formulated on the foundation of Crisscrossed Captions (URL an image captioning dataset supplied with human-rated semantic similarity ratings on a continuous scale from 0 to 5.
We tailor the dataset to suit a binary classification task. Specifically, sentence pairs with annotation scores exceeding 4 are categorized as positive (entailment), whereas pairs with scores less than 1 are marked as negative (non-entailment).
The TNCC dataset is partitioned into training, validation, and testing sets, containing 3,600, 1,200, and 1,560 instances, respectively.
If you use this dataset for academic research, please cite the NeurIPS 2023 paper titled 'Back-Modality: Leveraging Modal Transformation for Data Augmentation'.
|
[] |
[
"TAGS\n#task_categories-text-classification #size_categories-1K<n<10K #language-English #license-apache-2.0 #region-us \n"
] |
[
41
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-1K<n<10K #language-English #license-apache-2.0 #region-us \n"
] |
fc9626ea5337b57901ce8a8ecd7ec7d699782861
|
In today's fast-paced world, convenience and quality are paramount when it comes to shopping. **[SnoppyMart](https://snoppymart.com/)**, a rising star in the retail industry, has quickly earned a reputation for being the ultimate one-stop shop for all your needs. From groceries to electronics, apparel to home decor, **[SnoppyMart](https://snoppymart.com/)** provides a diverse range of products and services, all wrapped up with top-notch customer service.
### [**Know More About SnoppyMart Official Website Click Here**](https://snoppymart.com/)
### A Wide Range of Products
At **[SnoppyMart](https://snoppymart.com/)**, you can find a vast array of products, making it the perfect destination for your shopping needs. Whether you're looking for fresh groceries, household essentials, electronics, clothing, or even pet supplies, **[SnoppyMart](https://snoppymart.com/)** has you covered. This wide selection ensures you can tick off all the items on your shopping list without running from store to store.
### Quality Assurance
**[SnoppyMart](https://snoppymart.com/)** understands the importance of quality, and they make it a priority. From the freshest produce to durable electronics, they source their products from trusted suppliers and brands. This commitment to quality ensures that every purchase you make at **[SnoppyMart](https://snoppymart.com/)** is a wise investment in your daily life.
### Competitive Prices
In a world where prices are constantly on the rise, **[SnoppyMart](https://snoppymart.com/)** stands out by offering competitive prices without compromising on quality. They frequently run promotions and sales, making it easier for customers to save money while enjoying high-quality products.
### User-Friendly Online Shopping
**[SnoppyMart](https://snoppymart.com/)**'s user-friendly website and mobile app allow you to shop from the comfort of your own home. You can browse their extensive product catalog, read detailed product descriptions, and make secure transactions with ease. The convenience of online shopping with SnoppyMart is a game-changer for those with busy schedules.
### Convenient Store Locations
For those who prefer the in-store experience, **[SnoppyMart](https://snoppymart.com/)** has a network of conveniently located physical stores. The store layouts are designed for easy navigation, and their friendly staff is always ready to assist with your inquiries or provide product recommendations.
### [**Know More About SnoppyMart Official Website Click Here**](https://snoppymart.com/)
### Fast and Reliable Delivery
**[SnoppyMart](https://snoppymart.com/)** offers fast and reliable delivery services to ensure you receive your products promptly. With various delivery options, including same-day and next-day delivery, you can have your purchases at your doorstep when you need them.
### Customer Service Excellence
Exceptional customer service is at the heart of **[SnoppyMart](https://snoppymart.com/)**'s operations. Their dedicated team is always ready to assist with any inquiries or issues you may have, ensuring a hassle-free shopping experience. Your satisfaction is their top priority.
### Sustainability Initiatives
**[SnoppyMart](https://snoppymart.com/)** takes its environmental responsibilities seriously. They are committed to reducing their carbon footprint by implementing sustainable practices, such as using eco-friendly packaging and supporting local and organic products. By choosing **[SnoppyMart](https://snoppymart.com/)**, you're not only shopping conveniently, but also supporting a retailer with a strong commitment to the environment.
### [**Know More About SnoppyMart Official Website Click Here**](https://snoppymart.com/)
### Conclusion
In a world where convenience, quality, and competitive prices are paramount, **[SnoppyMart](https://snoppymart.com/)** has risen to the challenge. Whether you prefer to shop online or in-store, this one-stop shop offers a wide range of products, quality assurance, competitive prices, and excellent customer service. With a commitment to sustainability, **[SnoppyMart](https://snoppymart.com/)** is not just a retailer but a responsible and dependable partner for your everyday needs. Experience the difference with **[SnoppyMart](https://snoppymart.com/)**, your ultimate shopping destination.
|
snoopymart/SnoopyMart
|
[
"region:us"
] |
2023-10-30T06:37:03+00:00
|
{}
|
2023-10-30T06:38:03+00:00
|
[] |
[] |
TAGS
#region-us
|
In today's fast-paced world, convenience and quality are paramount when it comes to shopping. SnoppyMart, a rising star in the retail industry, has quickly earned a reputation for being the ultimate one-stop shop for all your needs. From groceries to electronics, apparel to home decor, SnoppyMart provides a diverse range of products and services, all wrapped up with top-notch customer service.
### Know More About SnoppyMart Official Website Click Here
### A Wide Range of Products
At SnoppyMart, you can find a vast array of products, making it the perfect destination for your shopping needs. Whether you're looking for fresh groceries, household essentials, electronics, clothing, or even pet supplies, SnoppyMart has you covered. This wide selection ensures you can tick off all the items on your shopping list without running from store to store.
### Quality Assurance
SnoppyMart understands the importance of quality, and they make it a priority. From the freshest produce to durable electronics, they source their products from trusted suppliers and brands. This commitment to quality ensures that every purchase you make at SnoppyMart is a wise investment in your daily life.
### Competitive Prices
In a world where prices are constantly on the rise, SnoppyMart stands out by offering competitive prices without compromising on quality. They frequently run promotions and sales, making it easier for customers to save money while enjoying high-quality products.
### User-Friendly Online Shopping
SnoppyMart's user-friendly website and mobile app allow you to shop from the comfort of your own home. You can browse their extensive product catalog, read detailed product descriptions, and make secure transactions with ease. The convenience of online shopping with SnoppyMart is a game-changer for those with busy schedules.
### Convenient Store Locations
For those who prefer the in-store experience, SnoppyMart has a network of conveniently located physical stores. The store layouts are designed for easy navigation, and their friendly staff is always ready to assist with your inquiries or provide product recommendations.
### Know More About SnoppyMart Official Website Click Here
### Fast and Reliable Delivery
SnoppyMart offers fast and reliable delivery services to ensure you receive your products promptly. With various delivery options, including same-day and next-day delivery, you can have your purchases at your doorstep when you need them.
### Customer Service Excellence
Exceptional customer service is at the heart of SnoppyMart's operations. Their dedicated team is always ready to assist with any inquiries or issues you may have, ensuring a hassle-free shopping experience. Your satisfaction is their top priority.
### Sustainability Initiatives
SnoppyMart takes its environmental responsibilities seriously. They are committed to reducing their carbon footprint by implementing sustainable practices, such as using eco-friendly packaging and supporting local and organic products. By choosing SnoppyMart, you're not only shopping conveniently, but also supporting a retailer with a strong commitment to the environment.
### Know More About SnoppyMart Official Website Click Here
### Conclusion
In a world where convenience, quality, and competitive prices are paramount, SnoppyMart has risen to the challenge. Whether you prefer to shop online or in-store, this one-stop shop offers a wide range of products, quality assurance, competitive prices, and excellent customer service. With a commitment to sustainability, SnoppyMart is not just a retailer but a responsible and dependable partner for your everyday needs. Experience the difference with SnoppyMart, your ultimate shopping destination.
|
[
"### Know More About SnoppyMart Official Website Click Here",
"### A Wide Range of Products\n\nAt SnoppyMart, you can find a vast array of products, making it the perfect destination for your shopping needs. Whether you're looking for fresh groceries, household essentials, electronics, clothing, or even pet supplies, SnoppyMart has you covered. This wide selection ensures you can tick off all the items on your shopping list without running from store to store.",
"### Quality Assurance\n\nSnoppyMart understands the importance of quality, and they make it a priority. From the freshest produce to durable electronics, they source their products from trusted suppliers and brands. This commitment to quality ensures that every purchase you make at SnoppyMart is a wise investment in your daily life.",
"### Competitive Prices\n\nIn a world where prices are constantly on the rise, SnoppyMart stands out by offering competitive prices without compromising on quality. They frequently run promotions and sales, making it easier for customers to save money while enjoying high-quality products.",
"### User-Friendly Online Shopping\n\nSnoppyMart's user-friendly website and mobile app allow you to shop from the comfort of your own home. You can browse their extensive product catalog, read detailed product descriptions, and make secure transactions with ease. The convenience of online shopping with SnoppyMart is a game-changer for those with busy schedules.",
"### Convenient Store Locations\n\nFor those who prefer the in-store experience, SnoppyMart has a network of conveniently located physical stores. The store layouts are designed for easy navigation, and their friendly staff is always ready to assist with your inquiries or provide product recommendations.",
"### Know More About SnoppyMart Official Website Click Here",
"### Fast and Reliable Delivery\n\nSnoppyMart offers fast and reliable delivery services to ensure you receive your products promptly. With various delivery options, including same-day and next-day delivery, you can have your purchases at your doorstep when you need them.",
"### Customer Service Excellence\n\nExceptional customer service is at the heart of SnoppyMart's operations. Their dedicated team is always ready to assist with any inquiries or issues you may have, ensuring a hassle-free shopping experience. Your satisfaction is their top priority.",
"### Sustainability Initiatives\n\nSnoppyMart takes its environmental responsibilities seriously. They are committed to reducing their carbon footprint by implementing sustainable practices, such as using eco-friendly packaging and supporting local and organic products. By choosing SnoppyMart, you're not only shopping conveniently, but also supporting a retailer with a strong commitment to the environment.",
"### Know More About SnoppyMart Official Website Click Here",
"### Conclusion\n\nIn a world where convenience, quality, and competitive prices are paramount, SnoppyMart has risen to the challenge. Whether you prefer to shop online or in-store, this one-stop shop offers a wide range of products, quality assurance, competitive prices, and excellent customer service. With a commitment to sustainability, SnoppyMart is not just a retailer but a responsible and dependable partner for your everyday needs. Experience the difference with SnoppyMart, your ultimate shopping destination."
] |
[
"TAGS\n#region-us \n",
"### Know More About SnoppyMart Official Website Click Here",
"### A Wide Range of Products\n\nAt SnoppyMart, you can find a vast array of products, making it the perfect destination for your shopping needs. Whether you're looking for fresh groceries, household essentials, electronics, clothing, or even pet supplies, SnoppyMart has you covered. This wide selection ensures you can tick off all the items on your shopping list without running from store to store.",
"### Quality Assurance\n\nSnoppyMart understands the importance of quality, and they make it a priority. From the freshest produce to durable electronics, they source their products from trusted suppliers and brands. This commitment to quality ensures that every purchase you make at SnoppyMart is a wise investment in your daily life.",
"### Competitive Prices\n\nIn a world where prices are constantly on the rise, SnoppyMart stands out by offering competitive prices without compromising on quality. They frequently run promotions and sales, making it easier for customers to save money while enjoying high-quality products.",
"### User-Friendly Online Shopping\n\nSnoppyMart's user-friendly website and mobile app allow you to shop from the comfort of your own home. You can browse their extensive product catalog, read detailed product descriptions, and make secure transactions with ease. The convenience of online shopping with SnoppyMart is a game-changer for those with busy schedules.",
"### Convenient Store Locations\n\nFor those who prefer the in-store experience, SnoppyMart has a network of conveniently located physical stores. The store layouts are designed for easy navigation, and their friendly staff is always ready to assist with your inquiries or provide product recommendations.",
"### Know More About SnoppyMart Official Website Click Here",
"### Fast and Reliable Delivery\n\nSnoppyMart offers fast and reliable delivery services to ensure you receive your products promptly. With various delivery options, including same-day and next-day delivery, you can have your purchases at your doorstep when you need them.",
"### Customer Service Excellence\n\nExceptional customer service is at the heart of SnoppyMart's operations. Their dedicated team is always ready to assist with any inquiries or issues you may have, ensuring a hassle-free shopping experience. Your satisfaction is their top priority.",
"### Sustainability Initiatives\n\nSnoppyMart takes its environmental responsibilities seriously. They are committed to reducing their carbon footprint by implementing sustainable practices, such as using eco-friendly packaging and supporting local and organic products. By choosing SnoppyMart, you're not only shopping conveniently, but also supporting a retailer with a strong commitment to the environment.",
"### Know More About SnoppyMart Official Website Click Here",
"### Conclusion\n\nIn a world where convenience, quality, and competitive prices are paramount, SnoppyMart has risen to the challenge. Whether you prefer to shop online or in-store, this one-stop shop offers a wide range of products, quality assurance, competitive prices, and excellent customer service. With a commitment to sustainability, SnoppyMart is not just a retailer but a responsible and dependable partner for your everyday needs. Experience the difference with SnoppyMart, your ultimate shopping destination."
] |
[
6,
14,
93,
76,
60,
88,
62,
14,
58,
64,
83,
14,
113
] |
[
"passage: TAGS\n#region-us \n### Know More About SnoppyMart Official Website Click Here### A Wide Range of Products\n\nAt SnoppyMart, you can find a vast array of products, making it the perfect destination for your shopping needs. Whether you're looking for fresh groceries, household essentials, electronics, clothing, or even pet supplies, SnoppyMart has you covered. This wide selection ensures you can tick off all the items on your shopping list without running from store to store.### Quality Assurance\n\nSnoppyMart understands the importance of quality, and they make it a priority. From the freshest produce to durable electronics, they source their products from trusted suppliers and brands. This commitment to quality ensures that every purchase you make at SnoppyMart is a wise investment in your daily life.### Competitive Prices\n\nIn a world where prices are constantly on the rise, SnoppyMart stands out by offering competitive prices without compromising on quality. They frequently run promotions and sales, making it easier for customers to save money while enjoying high-quality products.### User-Friendly Online Shopping\n\nSnoppyMart's user-friendly website and mobile app allow you to shop from the comfort of your own home. You can browse their extensive product catalog, read detailed product descriptions, and make secure transactions with ease. The convenience of online shopping with SnoppyMart is a game-changer for those with busy schedules.### Convenient Store Locations\n\nFor those who prefer the in-store experience, SnoppyMart has a network of conveniently located physical stores. The store layouts are designed for easy navigation, and their friendly staff is always ready to assist with your inquiries or provide product recommendations.### Know More About SnoppyMart Official Website Click Here### Fast and Reliable Delivery\n\nSnoppyMart offers fast and reliable delivery services to ensure you receive your products promptly. With various delivery options, including same-day and next-day delivery, you can have your purchases at your doorstep when you need them."
] |
0d52e9c46cdf8c1af3cb449212b1178adcd158bd
|
# Dataset Card for "movie_posters-100k-torchvision"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
anforsm/movie_posters-100k-torchvision
|
[
"region:us"
] |
2023-10-30T06:44:24+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "image", "sequence": {"sequence": {"sequence": "float32"}}}, {"name": "title", "dtype": "string"}, {"name": "genres", "list": [{"name": "id", "dtype": "int64"}, {"name": "name", "dtype": "string"}]}, {"name": "overview", "dtype": "string"}, {"name": "popularity", "dtype": "float64"}, {"name": "release_date", "dtype": "string"}, {"name": "budget", "dtype": "int64"}, {"name": "revenue", "dtype": "int64"}, {"name": "tagline", "dtype": "string"}, {"name": "original_language", "dtype": "string"}, {"name": "runtime", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 25531277848.2, "num_examples": 85770}, {"name": "test", "num_bytes": 2836808649.8, "num_examples": 9530}], "download_size": 20999210873, "dataset_size": 28368086498.0}}
|
2023-10-30T15:06:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "movie_posters-100k-torchvision"
More Information needed
|
[
"# Dataset Card for \"movie_posters-100k-torchvision\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"movie_posters-100k-torchvision\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"movie_posters-100k-torchvision\"\n\nMore Information needed"
] |
4caecd08d7bdb41246bd7b0e94f8fde1f1d721c8
|
# Dataset of virtuosa/塑心 (Arknights)
This is the dataset of virtuosa/塑心 (Arknights), containing 161 images and their tags.
The core tags of this character are `long_hair, bangs, black_hair, very_long_hair, halo, blunt_bangs, black_eyes, wings`, which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by [DeepGHS Team](https://github.com/deepghs)([huggingface organization](https://huggingface.co/deepghs)).
## List of Packages
| Name | Images | Size | Download | Type | Description |
|:-----------------|---------:|:-----------|:--------------------------------------------------------------------------------------------------------------------|:-----------|:---------------------------------------------------------------------|
| raw | 161 | 363.68 MiB | [Download](https://huggingface.co/datasets/CyberHarem/virtuosa_arknights/resolve/main/dataset-raw.zip) | Waifuc-Raw | Raw data with meta information (min edge aligned to 1400 if larger). |
| 800 | 161 | 152.75 MiB | [Download](https://huggingface.co/datasets/CyberHarem/virtuosa_arknights/resolve/main/dataset-800.zip) | IMG+TXT | dataset with the shorter side not exceeding 800 pixels. |
| stage3-p480-800 | 421 | 330.83 MiB | [Download](https://huggingface.co/datasets/CyberHarem/virtuosa_arknights/resolve/main/dataset-stage3-p480-800.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
| 1200 | 161 | 292.77 MiB | [Download](https://huggingface.co/datasets/CyberHarem/virtuosa_arknights/resolve/main/dataset-1200.zip) | IMG+TXT | dataset with the shorter side not exceeding 1200 pixels. |
| stage3-p480-1200 | 421 | 538.42 MiB | [Download](https://huggingface.co/datasets/CyberHarem/virtuosa_arknights/resolve/main/dataset-stage3-p480-1200.zip) | IMG+TXT | 3-stage cropped dataset with the area not less than 480x480 pixels. |
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for [waifuc](https://deepghs.github.io/waifuc/main/tutorials/installation/index.html) loading. If you need this, just run the following code
```python
import os
import zipfile
from huggingface_hub import hf_hub_download
from waifuc.source import LocalSource
# download raw archive file
zip_file = hf_hub_download(
repo_id='CyberHarem/virtuosa_arknights',
repo_type='dataset',
filename='dataset-raw.zip',
)
# extract files to your directory
dataset_dir = 'dataset_dir'
os.makedirs(dataset_dir, exist_ok=True)
with zipfile.ZipFile(zip_file, 'r') as zf:
zf.extractall(dataset_dir)
# load the dataset with waifuc
source = LocalSource(dataset_dir)
for item in source:
print(item.image, item.meta['filename'], item.meta['tags'])
```
## List of Clusters
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | Tags |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 0 | 5 |  |  |  |  |  | 1girl, black_ascot, black_gloves, black_skirt, detached_wings, looking_at_viewer, smile, solo, white_shirt, closed_mouth, collared_shirt, cowboy_shot, energy_wings, long_sleeves, black_thighhighs, brown_eyes, pouch, belt, garter_straps, holding, simple_background, white_background |
| 1 | 16 |  |  |  |  |  | 1girl, looking_at_viewer, solo, smile, ascot, upper_body, mole_under_eye, closed_mouth, white_shirt, black_gloves, simple_background, collared_shirt, white_background |
| 2 | 5 |  |  |  |  |  | 1girl, looking_at_viewer, navel, simple_background, smile, solo, white_background, black_thighhighs, closed_mouth, nude, medium_breasts, mole_under_eye, pussy, black_footwear, black_gloves, blush, cleft_of_venus, collarbone, convenient_censoring, elbow_gloves, full_body, hair_censor, hair_over_breasts, high_heels, hime_cut, lying, nipples, stomach, uncensored |
### Table Version
| # | Samples | Img-1 | Img-2 | Img-3 | Img-4 | Img-5 | 1girl | black_ascot | black_gloves | black_skirt | detached_wings | looking_at_viewer | smile | solo | white_shirt | closed_mouth | collared_shirt | cowboy_shot | energy_wings | long_sleeves | black_thighhighs | brown_eyes | pouch | belt | garter_straps | holding | simple_background | white_background | ascot | upper_body | mole_under_eye | navel | nude | medium_breasts | pussy | black_footwear | blush | cleft_of_venus | collarbone | convenient_censoring | elbow_gloves | full_body | hair_censor | hair_over_breasts | high_heels | hime_cut | lying | nipples | stomach | uncensored |
|----:|----------:|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------------------------------|:--------|:--------------|:---------------|:--------------|:-----------------|:--------------------|:--------|:-------|:--------------|:---------------|:-----------------|:--------------|:---------------|:---------------|:-------------------|:-------------|:--------|:-------|:----------------|:----------|:--------------------|:-------------------|:--------|:-------------|:-----------------|:--------|:-------|:-----------------|:--------|:-----------------|:--------|:-----------------|:-------------|:-----------------------|:---------------|:------------|:--------------|:--------------------|:-------------|:-----------|:--------|:----------|:----------|:-------------|
| 0 | 5 |  |  |  |  |  | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | | | | | | | | | | | | | | | | | | | | | | |
| 1 | 16 |  |  |  |  |  | X | | X | | | X | X | X | X | X | X | | | | | | | | | | X | X | X | X | X | | | | | | | | | | | | | | | | | | | |
| 2 | 5 |  |  |  |  |  | X | | X | | | X | X | X | | X | | | | | X | | | | | | X | X | | | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X | X |
|
CyberHarem/virtuosa_arknights
|
[
"task_categories:text-to-image",
"size_categories:n<1K",
"license:mit",
"art",
"not-for-all-audiences",
"region:us"
] |
2023-10-30T06:58:15+00:00
|
{"license": "mit", "size_categories": ["n<1K"], "task_categories": ["text-to-image"], "tags": ["art", "not-for-all-audiences"]}
|
2024-01-10T18:59:26+00:00
|
[] |
[] |
TAGS
#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us
|
Dataset of virtuosa/塑心 (Arknights)
==================================
This is the dataset of virtuosa/塑心 (Arknights), containing 161 images and their tags.
The core tags of this character are 'long\_hair, bangs, black\_hair, very\_long\_hair, halo, blunt\_bangs, black\_eyes, wings', which are pruned in this dataset.
Images are crawled from many sites (e.g. danbooru, pixiv, zerochan ...), the auto-crawling system is powered by DeepGHS Team(huggingface organization).
List of Packages
----------------
### Load Raw Dataset with Waifuc
We provide raw dataset (including tagged images) for waifuc loading. If you need this, just run the following code
List of Clusters
----------------
List of tag clustering result, maybe some outfits can be mined here.
### Raw Text Version
### Table Version
|
[
"### Load Raw Dataset with Waifuc\n\n\nWe provide raw dataset (including tagged images) for waifuc loading. If you need this, just run the following code\n\n\nList of Clusters\n----------------\n\n\nList of tag clustering result, maybe some outfits can be mined here.",
"### Raw Text Version",
"### Table Version"
] |
[
"TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n",
"### Load Raw Dataset with Waifuc\n\n\nWe provide raw dataset (including tagged images) for waifuc loading. If you need this, just run the following code\n\n\nList of Clusters\n----------------\n\n\nList of tag clustering result, maybe some outfits can be mined here.",
"### Raw Text Version",
"### Table Version"
] |
[
44,
61,
5,
4
] |
[
"passage: TAGS\n#task_categories-text-to-image #size_categories-n<1K #license-mit #art #not-for-all-audiences #region-us \n### Load Raw Dataset with Waifuc\n\n\nWe provide raw dataset (including tagged images) for waifuc loading. If you need this, just run the following code\n\n\nList of Clusters\n----------------\n\n\nList of tag clustering result, maybe some outfits can be mined here.### Raw Text Version### Table Version"
] |
cc19564d17cf5f50c211503670a284b4d5b4f5a5
|
# Dataset Card for "kishoretrial"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
anonymouse03052002/kishoretrial
|
[
"region:us"
] |
2023-10-30T07:03:07+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "review", "dtype": "string"}, {"name": "review_length", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 261708.972, "num_examples": 439}, {"name": "validation", "num_bytes": 29211.252, "num_examples": 49}], "download_size": 132338, "dataset_size": 290920.224}}
|
2023-10-30T07:03:19+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "kishoretrial"
More Information needed
|
[
"# Dataset Card for \"kishoretrial\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"kishoretrial\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"kishoretrial\"\n\nMore Information needed"
] |
53469f40dda55cae1f970ec8e894199906790f6c
|
# Dataset Card for "gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pkr7098/gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257
|
[
"region:us"
] |
2023-10-30T07:20:36+00:00
|
{"dataset_info": {"config_name": "truncate-1024", "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "special_tokens_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 21168040068, "num_examples": 3438603}, {"name": "validation", "num_bytes": 1824422940, "num_examples": 296365}], "download_size": 0, "dataset_size": 22992463008}, "configs": [{"config_name": "truncate-1024", "data_files": [{"split": "train", "path": "truncate-1024/train-*"}, {"split": "validation", "path": "truncate-1024/validation-*"}]}]}
|
2023-10-30T07:35:23+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257"
More Information needed
|
[
"# Dataset Card for \"gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257\"\n\nMore Information needed"
] |
[
6,
31
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"gpt2-bookcorpus-wiki-2022030-en-vocab_size-50257\"\n\nMore Information needed"
] |
8f43d484c4246533e196bc72e8735c29e32f1c17
|
# Dataset Card for "LORA_ONE"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Adminhuggingface/LORA_ONE
|
[
"region:us"
] |
2023-10-30T07:27:41+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2895341.0, "num_examples": 12}], "download_size": 2896554, "dataset_size": 2895341.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T07:27:42+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "LORA_ONE"
More Information needed
|
[
"# Dataset Card for \"LORA_ONE\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"LORA_ONE\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"LORA_ONE\"\n\nMore Information needed"
] |
c40670d342bad2b1fa142bc23cafb6c7d2efbf23
|
# Dataset Card for "paradetox_with_labels"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
HamdanXI/paradetox_with_labels
|
[
"region:us"
] |
2023-10-30T07:29:43+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2471295.0, "num_examples": 39488}], "download_size": 1524792, "dataset_size": 2471295.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T07:29:47+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "paradetox_with_labels"
More Information needed
|
[
"# Dataset Card for \"paradetox_with_labels\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"paradetox_with_labels\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"paradetox_with_labels\"\n\nMore Information needed"
] |
d0dd4c8a2c3052482890272360498f19dbccc042
|
# COPA-SR
(The dataset uses cyrillic script. For the latin version, see [this dataset](https://huggingface.co/datasets/classla/COPA-SR_lat).)
The [COPA-SR dataset](http://hdl.handle.net/11356/1708) (Choice of plausible alternatives in Serbian) is a translation of the [English COPA dataset ](https://people.ict.usc.edu/~gordon/copa.html) by following the [XCOPA dataset translation methodology ](https://arxiv.org/abs/2005.00333).
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the [Croatian COPA-HR dataset ](http://hdl.handle.net/11356/1404) and [Macedonian COPA-MK dataset ](http://hdl.handle.net/11356/1687). It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation of the dataset was performed by the [ReLDI Centre Belgrade ](https://reldi.spur.uzh.ch/).
# Authors:
* Ljubešić, Nikola
* Starović, Mirjana
* Kuzman, Taja
* Samardžić, Tanja
# Citation information
```
@misc{11356/1708,
title = {Choice of plausible alternatives dataset in Serbian {COPA}-{SR}},
author = {Ljube{\v s}i{\'c}, Nikola and Starovi{\'c}, Mirjana and Kuzman, Taja and Samard{\v z}i{\'c}, Tanja},
url = {http://hdl.handle.net/11356/1708},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2022} }
```
|
classla/COPA-SR
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"language:sr",
"license:cc-by-sa-4.0",
"arxiv:2005.00333",
"region:us"
] |
2023-10-30T07:39:38+00:00
|
{"language": ["sr"], "license": "cc-by-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["text-classification"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "train.jsonl"}, {"split": "test", "path": "test.jsonl"}, {"split": "dev", "path": "val.jsonl"}]}]}
|
2023-11-02T09:22:25+00:00
|
[
"2005.00333"
] |
[
"sr"
] |
TAGS
#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us
|
# COPA-SR
(The dataset uses cyrillic script. For the latin version, see this dataset.)
The COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology .
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation of the dataset was performed by the ReLDI Centre Belgrade .
# Authors:
* Ljubešić, Nikola
* Starović, Mirjana
* Kuzman, Taja
* Samardžić, Tanja
information
|
[
"# COPA-SR\n\n(The dataset uses cyrillic script. For the latin version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology .\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
[
"TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n",
"# COPA-SR\n\n(The dataset uses cyrillic script. For the latin version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology .\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
[
50,
230,
30
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n# COPA-SR\n\n(The dataset uses cyrillic script. For the latin version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology .\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
dfcee1956e4a36b6af112bedc863fbebc8e72070
|
# leap
Experimental dataset for price performance of top cryptocurrencies.
This dataset is purely a research material and should not be be considered as an investment memorandum or financial advise.
## Acknowledgements
The token price data is sourced by calling the DefiLlama API. The API is available at https://defillama.com/docs/api.
---
license: unlicense
---
|
0zAND1z/leap
|
[
"size_categories:n<1K",
"language:en",
"license:unlicense",
"price",
"analysis",
"region:us"
] |
2023-10-30T07:49:00+00:00
|
{"language": ["en"], "license": "unlicense", "size_categories": ["n<1K"], "pretty_name": "leap", "thumbnail": "url to a thumbnail used in social sharing", "tags": ["price", "analysis"]}
|
2023-10-30T08:48:15+00:00
|
[] |
[
"en"
] |
TAGS
#size_categories-n<1K #language-English #license-unlicense #price #analysis #region-us
|
# leap
Experimental dataset for price performance of top cryptocurrencies.
This dataset is purely a research material and should not be be considered as an investment memorandum or financial advise.
## Acknowledgements
The token price data is sourced by calling the DefiLlama API. The API is available at URL
---
license: unlicense
---
|
[
"# leap\n\nExperimental dataset for price performance of top cryptocurrencies.\n\nThis dataset is purely a research material and should not be be considered as an investment memorandum or financial advise.",
"## Acknowledgements\n\nThe token price data is sourced by calling the DefiLlama API. The API is available at URL\n\n---\nlicense: unlicense\n---"
] |
[
"TAGS\n#size_categories-n<1K #language-English #license-unlicense #price #analysis #region-us \n",
"# leap\n\nExperimental dataset for price performance of top cryptocurrencies.\n\nThis dataset is purely a research material and should not be be considered as an investment memorandum or financial advise.",
"## Acknowledgements\n\nThe token price data is sourced by calling the DefiLlama API. The API is available at URL\n\n---\nlicense: unlicense\n---"
] |
[
33,
40,
35
] |
[
"passage: TAGS\n#size_categories-n<1K #language-English #license-unlicense #price #analysis #region-us \n# leap\n\nExperimental dataset for price performance of top cryptocurrencies.\n\nThis dataset is purely a research material and should not be be considered as an investment memorandum or financial advise.## Acknowledgements\n\nThe token price data is sourced by calling the DefiLlama API. The API is available at URL\n\n---\nlicense: unlicense\n---"
] |
ac6009cd7bb240536055b082382b96062ae890b1
|
# Dataset Card for "deepfashion-multimodal-descriptions"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Geonmo/deepfashion-multimodal-descriptions
|
[
"region:us"
] |
2023-10-30T07:58:29+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 9586020, "num_examples": 40770}], "download_size": 2270474, "dataset_size": 9586020}}
|
2023-10-30T07:58:32+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "deepfashion-multimodal-descriptions"
More Information needed
|
[
"# Dataset Card for \"deepfashion-multimodal-descriptions\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"deepfashion-multimodal-descriptions\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"deepfashion-multimodal-descriptions\"\n\nMore Information needed"
] |
f9c763e1e362129f3dbed57135c7ad0866e3fd3e
|
# Dataset Card for "deepfashion-multimodal-descriptions-split"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Geonmo/deepfashion-multimodal-descriptions-split
|
[
"region:us"
] |
2023-10-30T08:06:04+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 939822, "num_examples": 11730}], "download_size": 247226, "dataset_size": 939822}}
|
2023-10-30T08:06:07+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "deepfashion-multimodal-descriptions-split"
More Information needed
|
[
"# Dataset Card for \"deepfashion-multimodal-descriptions-split\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"deepfashion-multimodal-descriptions-split\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"deepfashion-multimodal-descriptions-split\"\n\nMore Information needed"
] |
18a585624e2aa268d52bfbaf9c882d6a4b98fb8c
|
# Dataset Card for "meal_type"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Eitanli/meal_type
|
[
"region:us"
] |
2023-10-30T08:16:00+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "recipe", "dtype": "string"}, {"name": "meal_type_title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 107900952, "num_examples": 74465}], "download_size": 54288491, "dataset_size": 107900952}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-02T13:51:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "meal_type"
More Information needed
|
[
"# Dataset Card for \"meal_type\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"meal_type\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"meal_type\"\n\nMore Information needed"
] |
8d7034eb581d56a979fdc199dd4f5849c352054d
|
# Dataset Card for "codeparrot-ds-50k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ioana23/codeparrot-ds-50k
|
[
"region:us"
] |
2023-10-30T08:19:20+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "valid", "path": "data/valid-*"}]}], "dataset_info": {"features": [{"name": "repo_name", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "copies", "dtype": "string"}, {"name": "size", "dtype": "string"}, {"name": "content", "dtype": "string"}, {"name": "license", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 652784990.8524525, "num_examples": 50000}, {"name": "valid", "num_bytes": 6658657.886815172, "num_examples": 500}], "download_size": 251530132, "dataset_size": 659443648.7392677}}
|
2023-10-30T08:20:47+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "codeparrot-ds-50k"
More Information needed
|
[
"# Dataset Card for \"codeparrot-ds-50k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"codeparrot-ds-50k\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"codeparrot-ds-50k\"\n\nMore Information needed"
] |
17068672954f8dd1bed10ef308429eaa5ddec46e
|
# Dataset Card for "LongCacti-quac"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ahrefs/LongCacti-quac
|
[
"region:us"
] |
2023-10-30T08:22:08+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "dialogue_id", "dtype": "string"}, {"name": "wikipedia_page_title", "dtype": "string"}, {"name": "background", "dtype": "string"}, {"name": "section_title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "turn_ids", "sequence": "string"}, {"name": "questions", "sequence": "string"}, {"name": "followups", "sequence": "int64"}, {"name": "yesnos", "sequence": "int64"}, {"name": "answers", "struct": [{"name": "answer_starts", "sequence": {"sequence": "int64"}}, {"name": "texts", "sequence": {"sequence": "string"}}]}, {"name": "orig_answers", "struct": [{"name": "answer_starts", "sequence": "int64"}, {"name": "texts", "sequence": "string"}]}, {"name": "wikipedia_page_text", "dtype": "string"}, {"name": "wikipedia_page_refs", "list": [{"name": "text", "dtype": "string"}, {"name": "title", "dtype": "string"}]}, {"name": "gpt4_answers", "sequence": "string"}, {"name": "gpt4_answers_consistent_check", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 576059175, "num_examples": 11567}], "download_size": 192048023, "dataset_size": 576059175}}
|
2023-10-30T08:22:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "LongCacti-quac"
More Information needed
|
[
"# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
16cb4c1d889e6e1413ba4c6186e29044cf5e9c08
|
# Dataset Card for "LongCacti-quac"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
yep-search/LongCacti-quac
|
[
"region:us"
] |
2023-10-30T08:22:48+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "dialogue_id", "dtype": "string"}, {"name": "wikipedia_page_title", "dtype": "string"}, {"name": "background", "dtype": "string"}, {"name": "section_title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "turn_ids", "sequence": "string"}, {"name": "questions", "sequence": "string"}, {"name": "followups", "sequence": "int64"}, {"name": "yesnos", "sequence": "int64"}, {"name": "answers", "struct": [{"name": "answer_starts", "sequence": {"sequence": "int64"}}, {"name": "texts", "sequence": {"sequence": "string"}}]}, {"name": "orig_answers", "struct": [{"name": "answer_starts", "sequence": "int64"}, {"name": "texts", "sequence": "string"}]}, {"name": "wikipedia_page_text", "dtype": "string"}, {"name": "wikipedia_page_refs", "list": [{"name": "text", "dtype": "string"}, {"name": "title", "dtype": "string"}]}, {"name": "gpt4_answers", "sequence": "string"}, {"name": "gpt4_answers_consistent_check", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 576059175, "num_examples": 11567}], "download_size": 192048023, "dataset_size": 576059175}}
|
2023-10-30T08:23:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "LongCacti-quac"
More Information needed
|
[
"# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"LongCacti-quac\"\n\nMore Information needed"
] |
0ab3dece7bb147f8e93bb4b721516cd34f3ce221
|
# Dataset Card for "domain_balance"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jay401521/domain_balance
|
[
"region:us"
] |
2023-10-30T08:26:09+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "domain", "dtype": "int64"}, {"name": "label", "dtype": "int64"}, {"name": "rank", "dtype": "string"}, {"name": "sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 6252293, "num_examples": 72276}], "download_size": 3387340, "dataset_size": 6252293}}
|
2023-10-30T08:26:13+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "domain_balance"
More Information needed
|
[
"# Dataset Card for \"domain_balance\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"domain_balance\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"domain_balance\"\n\nMore Information needed"
] |
06dbe47890c808552a614f94f8140047807add3b
|
# COPA-MK
The [COPA-MK dataset](http://hdl.handle.net/11356/1687) (Choice of plausible alternatives in Macedonian) is a translation of the [English COPA dataset ]https://people.ict.usc.edu/~gordon/copa.html) by following the [XCOPA dataset translation methodology](https://arxiv.org/abs/2005.00333).
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the [Croatian COPA-HR dataset](http://hdl.handle.net/11356/1404). It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation quality was ensured with the help of the [ReLDI Centre Belgrade ](https://reldi.spur.uzh.ch).
# Authors:
* Ljubešić, Nikola
* Koloski, Boshko
* Zdravkovska, Kristina
* Samardžić, Tanja
# Citation information
```
@misc{11356/1687,
title = {Choice of plausible alternatives dataset in Macedonian {COPA}-{MK}},
author = {Ljube{\v s}i{\'c}, Nikola and Koloski, Boshko and Zdravkovska, Kristina and Kuzman, Taja},
url = {http://hdl.handle.net/11356/1687},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2022} }
```
|
classla/COPA-MK
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"language:mk",
"license:cc-by-sa-4.0",
"arxiv:2005.00333",
"region:us"
] |
2023-10-30T08:30:34+00:00
|
{"language": ["mk"], "license": "cc-by-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["text-classification"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "train.jsonl"}, {"split": "test", "path": "test.jsonl"}, {"split": "dev", "path": "val.jsonl"}]}]}
|
2023-11-02T09:25:32+00:00
|
[
"2005.00333"
] |
[
"mk"
] |
TAGS
#task_categories-text-classification #size_categories-n<1K #language-Macedonian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us
|
# COPA-MK
The COPA-MK dataset (Choice of plausible alternatives in Macedonian) is a translation of the [English COPA dataset ]URL by following the XCOPA dataset translation methodology.
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the Croatian COPA-HR dataset. It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation quality was ensured with the help of the ReLDI Centre Belgrade .
# Authors:
* Ljubešić, Nikola
* Koloski, Boshko
* Zdravkovska, Kristina
* Samardžić, Tanja
information
|
[
"# COPA-MK\n\nThe COPA-MK dataset (Choice of plausible alternatives in Macedonian) is a translation of the [English COPA dataset ]URL by following the XCOPA dataset translation methodology.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset. It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation quality was ensured with the help of the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Koloski, Boshko\n* Zdravkovska, Kristina\n* Samardžić, Tanja \n\ninformation"
] |
[
"TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Macedonian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n",
"# COPA-MK\n\nThe COPA-MK dataset (Choice of plausible alternatives in Macedonian) is a translation of the [English COPA dataset ]URL by following the XCOPA dataset translation methodology.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset. It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation quality was ensured with the help of the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Koloski, Boshko\n* Zdravkovska, Kristina\n* Samardžić, Tanja \n\ninformation"
] |
[
51,
200,
30
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Macedonian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n# COPA-MK\n\nThe COPA-MK dataset (Choice of plausible alternatives in Macedonian) is a translation of the [English COPA dataset ]URL by following the XCOPA dataset translation methodology.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset. It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation quality was ensured with the help of the ReLDI Centre Belgrade .# Authors:\n\n* Ljubešić, Nikola\n* Koloski, Boshko\n* Zdravkovska, Kristina\n* Samardžić, Tanja \n\ninformation"
] |
8c83aef64bcc9439e5069022e39d39f371c70d3a
|
# COPA-SR_lat
(The dataset uses latin script. For the original (cyrillic) version, see [this dataset](https://huggingface.co/datasets/classla/COPA-SR).)
The COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the [English COPA dataset ](https://people.ict.usc.edu/~gordon/copa.html) by following the [XCOPA dataset translation methodology ](https://arxiv.org/abs/2005.00333), transliterated into Latin script.
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the [Croatian COPA-HR dataset ](http://hdl.handle.net/11356/1404) and [Macedonian COPA-MK dataset ](http://hdl.handle.net/11356/1687). It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation of the dataset was performed by the [ReLDI Centre Belgrade ](https://reldi.spur.uzh.ch/).
# Authors:
* Ljubešić, Nikola
* Starović, Mirjana
* Kuzman, Taja
* Samardžić, Tanja
# Citation information
```
@misc{11356/1708,
title = {Choice of plausible alternatives dataset in Serbian {COPA}-{SR}},
author = {Ljube{\v s}i{\'c}, Nikola and Starovi{\'c}, Mirjana and Kuzman, Taja and Samard{\v z}i{\'c}, Tanja},
url = {http://hdl.handle.net/11356/1708},
note = {Slovenian language resource repository {CLARIN}.{SI}},
copyright = {Creative Commons - Attribution-{ShareAlike} 4.0 International ({CC} {BY}-{SA} 4.0)},
issn = {2820-4042},
year = {2022} }
```
|
classla/COPA-SR_lat
|
[
"task_categories:text-classification",
"size_categories:n<1K",
"language:sr",
"license:cc-by-sa-4.0",
"arxiv:2005.00333",
"region:us"
] |
2023-10-30T08:33:33+00:00
|
{"language": ["sr"], "license": "cc-by-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["text-classification"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "train.lat.jsonl"}, {"split": "test", "path": "test.lat.jsonl"}, {"split": "dev", "path": "val.lat.jsonl"}]}]}
|
2023-11-02T09:22:56+00:00
|
[
"2005.00333"
] |
[
"sr"
] |
TAGS
#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us
|
# COPA-SR_lat
(The dataset uses latin script. For the original (cyrillic) version, see this dataset.)
The COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology , transliterated into Latin script.
The dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).
The dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.
Translation of the dataset was performed by the ReLDI Centre Belgrade .
# Authors:
* Ljubešić, Nikola
* Starović, Mirjana
* Kuzman, Taja
* Samardžić, Tanja
information
|
[
"# COPA-SR_lat\n\n(The dataset uses latin script. For the original (cyrillic) version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology , transliterated into Latin script.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
[
"TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n",
"# COPA-SR_lat\n\n(The dataset uses latin script. For the original (cyrillic) version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology , transliterated into Latin script.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .",
"# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
[
50,
242,
30
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-n<1K #language-Serbian #license-cc-by-sa-4.0 #arxiv-2005.00333 #region-us \n# COPA-SR_lat\n\n(The dataset uses latin script. For the original (cyrillic) version, see this dataset.)\n\nThe COPA-SR dataset (Choice of plausible alternatives in Serbian) is a translation of the English COPA dataset by following the XCOPA dataset translation methodology , transliterated into Latin script.\n\nThe dataset consists of 1,000 premises (My body cast a shadow over the grass), each given a question (What is the cause? / What happened as a result?), and two choices (The sun was rising; The grass was cut), with a label encoding which of the choices is more plausible given the annotator or translator (The sun was rising).\n\nThe dataset follows the same format as the Croatian COPA-HR dataset and Macedonian COPA-MK dataset . It is split into training (400 instances), validation (100 instances) and test (500 instances) JSONL files.\n\nTranslation of the dataset was performed by the ReLDI Centre Belgrade .# Authors:\n\n* Ljubešić, Nikola\n* Starović, Mirjana\n* Kuzman, Taja\n* Samardžić, Tanja\n\ninformation"
] |
9286f96efcd5125786b15e75f70f4a7562efb863
|
A subset of MIPS Assembly instructions with matching reverse engineered C code from Paper Mario.
https://github.com/pmret/papermario
|
kalomaze/PaperMarioDecomp_1k
|
[
"license:apache-2.0",
"region:us"
] |
2023-10-30T08:40:17+00:00
|
{"license": "apache-2.0"}
|
2023-10-30T09:22:06+00:00
|
[] |
[] |
TAGS
#license-apache-2.0 #region-us
|
A subset of MIPS Assembly instructions with matching reverse engineered C code from Paper Mario.
URL
|
[] |
[
"TAGS\n#license-apache-2.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-apache-2.0 #region-us \n"
] |
1db07660925e9f5cbd6c8782d63d9edeafba6a8a
|
### Dataset Summary
Alfa BKI is a unique high-quality dataset collected from the real data source of credit history bureaus (in Russian "бюро кредитных историй/БКИ"). It contains the history of corresponding credit products and the applicants' default on the loan.
### Supported Tasks and Leaderboards
The dataset is supposed to be used for training models for the classical bank task of predicting the default of the applicant.
## Dataset Structure
### Data Instances
The example of one sample is provided below
```
{
'app_id': 0,
'history':
[
[ 0, 1, 18, 9, 2, 3, 16, 10, 11, 3, 3, 0, 2, 11, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 0, 0, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 3, 4, 1, 0, 0 ],
[ 0, 2, 18, 9, 14, 14, 12, 12, 0, 3, 3, 0, 2, 11, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 4, 1, 3, 4, 1, 0, 0 ],
[ 0, 3, 18, 9, 4, 8, 1, 11, 11, 0, 5, 0, 2, 8, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 15, 2, 17, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 4, 1, 2, 3, 1, 1, 1 ],
[ 0, 4, 4, 1, 9, 12, 16, 7, 12, 2, 3, 0, 2, 4, 6, 16, 5, 4, 8, 0, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 3, 1, 1, 0, 0 ],
[ 0, 5, 5, 12, 15, 2, 11, 12, 10, 2, 3, 0, 2, 4, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 3, 4, 1, 0, 0 ],
[ 0, 6, 5, 0, 11, 8, 12, 11, 4, 2, 3, 0, 2, 4, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 9, 5, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 3, 4, 3, 3, 3, 4, 1, 2, 3, 1, 0, 1 ],
[ 0, 7, 3, 9, 1, 2, 12, 14, 15, 5, 3, 0, 2, 3, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 3, 4, 1, 0, 0 ],
[ 0, 8, 2, 9, 2, 3, 12, 14, 15, 5, 3, 0, 2, 13, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 16, 2, 17, 1, 1, 1, 0, 0, 3, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 3, 4, 1, 0, 0 ],
[ 0, 9, 1, 9, 11, 13, 14, 8, 2, 5, 1, 0, 2, 11, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 1, 2, 17, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 2, 4, 1, 0, 0 ],
[ 0, 10, 7, 9, 2, 10, 8, 8, 16, 4, 2, 0, 2, 11, 6, 16, 5, 4, 8, 1, 1, 1, 1, 1, 15, 2, 17, 0, 1, 1, 0, 0, 0, 0, 0, 0, 3, 3, 3, 3, 3, 4, 3, 3, 3, 3, 3, 3, 3, 3, 4, 3, 3, 3, 4, 1, 2, 4, 1, 0, 0 ]
],
'flag': 0
}
```
### Data Fields
- `id`: application ID.
- `history`: an array of transactions where each credit product is represented as a 37-dimensional array, each element of the array represents a corresponding feature from the following list.
- `id`: application ID.
- `rn`: serial number of the credit product in the credit history.
- `pre_since_opened`: days from the date of opening the loan to the date of data collection.
- `pre_since_confirmed`: days from the date of confirmation of the loan information to the date of data collection.
- `pre_pterm`: planned number of days from the opening date of the loan to the closing date.
- `pre_fterm`: actual number of days from the opening date of the loan to the closing date.
- `pre_till_pclose`: planned number of days from the date of data collection to the closing date of the loan.
- `pre_till_fclose`: actual number of days from the date of data collection to the closing date of the loan.
- `pre_loans_credit_limit`: credit limit.
- `pre_loans_next_pay_summ`: amount of the next loan payment.
- `pre_loans_outstanding`: remaining unpaid loan amount.
- `pre_loans_total_overdue`: current overdue debt.
- `pre_loans_max_overdue_sum`: maximum overdue debt.
- `pre_loans_credit_cost_rate`: full cost of the loan.
- `pre_loans5`: number of delays up to 5 days.
- `pre_loans530`: number of delays from 5 to 30 days.
- `pre_loans3060`: number of delays from 30 to 60 days.
- `pre_loans6090`: number of delays from 60 to 90 days.
- `pre_loans90`: the number of delays of more than 90 days.
- `is_zero_loans_5`: flag: no delays up to 5 days.
- `is_zero_loans_530`: flag: no delays from 5 to 30 days.
- `is_zero_loans_3060`: flag: no delays from 30 to 60 days.
- `is_zero_loans_6090`: flag: no delays from 60 to 90 days.
- `is_zero_loans90`: flag: no delays for more than 90 days.
- `pre_util`: ratio of the remaining unpaid loan amount to the credit limit.
- `pre_over2limit`: ratio of current overdue debt to the credit limit.
- `pre_maxover2limit`: ratio of the maximum overdue debt to the credit limit.
- `is_zero_util`: flag: the ratio of the remaining unpaid loan amount to the credit limit is 0.
- `is_zero_over2limit`: flag: the ratio of the current overdue debt to the credit limit is 0.
- `is_zero_maxover2limit`: flag: the ratio of the maximum overdue debt to the credit limit is 0.
- `enc_paym_{0..n}`: monthly payment statuses for the last n months.
- `enc_loans_account_holder_type`: type of attitude to credit.
- `enc_loans_credit_status`: loan status.
- `enc_loans_account_cur`: loan currency.
- `enc_loans_credit_type`: type of loan.
- `pclose_flag`: flag: the planned number of days from the opening date of the loan to the closing date is not defined.
- `fclose_flag`: flag: the actual number of days from the opening date of the loan to the closing date is not determined.
- `flag`: target, 1 – the fact that the client has defaulted.
|
mllab/alfa_bki
|
[
"size_categories:1M<n<10M",
"language:ru",
"license:unknown",
"bank",
"loan",
"time-series",
"region:us"
] |
2023-10-30T08:40:18+00:00
|
{"language": ["ru"], "license": "unknown", "size_categories": ["1M<n<10M"], "pretty_name": "Alfa BKI", "tags": ["bank", "loan", "time-series"]}
|
2023-11-14T15:09:41+00:00
|
[] |
[
"ru"
] |
TAGS
#size_categories-1M<n<10M #language-Russian #license-unknown #bank #loan #time-series #region-us
|
### Dataset Summary
Alfa BKI is a unique high-quality dataset collected from the real data source of credit history bureaus (in Russian "бюро кредитных историй/БКИ"). It contains the history of corresponding credit products and the applicants' default on the loan.
### Supported Tasks and Leaderboards
The dataset is supposed to be used for training models for the classical bank task of predicting the default of the applicant.
## Dataset Structure
### Data Instances
The example of one sample is provided below
### Data Fields
- 'id': application ID.
- 'history': an array of transactions where each credit product is represented as a 37-dimensional array, each element of the array represents a corresponding feature from the following list.
- 'id': application ID.
- 'rn': serial number of the credit product in the credit history.
- 'pre_since_opened': days from the date of opening the loan to the date of data collection.
- 'pre_since_confirmed': days from the date of confirmation of the loan information to the date of data collection.
- 'pre_pterm': planned number of days from the opening date of the loan to the closing date.
- 'pre_fterm': actual number of days from the opening date of the loan to the closing date.
- 'pre_till_pclose': planned number of days from the date of data collection to the closing date of the loan.
- 'pre_till_fclose': actual number of days from the date of data collection to the closing date of the loan.
- 'pre_loans_credit_limit': credit limit.
- 'pre_loans_next_pay_summ': amount of the next loan payment.
- 'pre_loans_outstanding': remaining unpaid loan amount.
- 'pre_loans_total_overdue': current overdue debt.
- 'pre_loans_max_overdue_sum': maximum overdue debt.
- 'pre_loans_credit_cost_rate': full cost of the loan.
- 'pre_loans5': number of delays up to 5 days.
- 'pre_loans530': number of delays from 5 to 30 days.
- 'pre_loans3060': number of delays from 30 to 60 days.
- 'pre_loans6090': number of delays from 60 to 90 days.
- 'pre_loans90': the number of delays of more than 90 days.
- 'is_zero_loans_5': flag: no delays up to 5 days.
- 'is_zero_loans_530': flag: no delays from 5 to 30 days.
- 'is_zero_loans_3060': flag: no delays from 30 to 60 days.
- 'is_zero_loans_6090': flag: no delays from 60 to 90 days.
- 'is_zero_loans90': flag: no delays for more than 90 days.
- 'pre_util': ratio of the remaining unpaid loan amount to the credit limit.
- 'pre_over2limit': ratio of current overdue debt to the credit limit.
- 'pre_maxover2limit': ratio of the maximum overdue debt to the credit limit.
- 'is_zero_util': flag: the ratio of the remaining unpaid loan amount to the credit limit is 0.
- 'is_zero_over2limit': flag: the ratio of the current overdue debt to the credit limit is 0.
- 'is_zero_maxover2limit': flag: the ratio of the maximum overdue debt to the credit limit is 0.
- 'enc_paym_{0..n}': monthly payment statuses for the last n months.
- 'enc_loans_account_holder_type': type of attitude to credit.
- 'enc_loans_credit_status': loan status.
- 'enc_loans_account_cur': loan currency.
- 'enc_loans_credit_type': type of loan.
- 'pclose_flag': flag: the planned number of days from the opening date of the loan to the closing date is not defined.
- 'fclose_flag': flag: the actual number of days from the opening date of the loan to the closing date is not determined.
- 'flag': target, 1 – the fact that the client has defaulted.
|
[
"### Dataset Summary\n\nAlfa BKI is a unique high-quality dataset collected from the real data source of credit history bureaus (in Russian \"бюро кредитных историй/БКИ\"). It contains the history of corresponding credit products and the applicants' default on the loan.",
"### Supported Tasks and Leaderboards\n\nThe dataset is supposed to be used for training models for the classical bank task of predicting the default of the applicant.",
"## Dataset Structure",
"### Data Instances\n\nThe example of one sample is provided below",
"### Data Fields\n\n- 'id': application ID.\n- 'history': an array of transactions where each credit product is represented as a 37-dimensional array, each element of the array represents a corresponding feature from the following list.\n - 'id': application ID.\n - 'rn': serial number of the credit product in the credit history.\n - 'pre_since_opened': days from the date of opening the loan to the date of data collection.\n - 'pre_since_confirmed': days from the date of confirmation of the loan information to the date of data collection.\n - 'pre_pterm': planned number of days from the opening date of the loan to the closing date.\n - 'pre_fterm': actual number of days from the opening date of the loan to the closing date.\n - 'pre_till_pclose': planned number of days from the date of data collection to the closing date of the loan.\n - 'pre_till_fclose': actual number of days from the date of data collection to the closing date of the loan.\n - 'pre_loans_credit_limit': credit limit.\n - 'pre_loans_next_pay_summ': amount of the next loan payment.\n - 'pre_loans_outstanding': remaining unpaid loan amount.\n - 'pre_loans_total_overdue': current overdue debt.\n - 'pre_loans_max_overdue_sum': maximum overdue debt.\n - 'pre_loans_credit_cost_rate': full cost of the loan.\n - 'pre_loans5': number of delays up to 5 days.\n - 'pre_loans530': number of delays from 5 to 30 days.\n - 'pre_loans3060': number of delays from 30 to 60 days.\n - 'pre_loans6090': number of delays from 60 to 90 days.\n - 'pre_loans90': the number of delays of more than 90 days.\n - 'is_zero_loans_5': flag: no delays up to 5 days.\n - 'is_zero_loans_530': flag: no delays from 5 to 30 days.\n - 'is_zero_loans_3060': flag: no delays from 30 to 60 days.\n - 'is_zero_loans_6090': flag: no delays from 60 to 90 days.\n - 'is_zero_loans90': flag: no delays for more than 90 days.\n - 'pre_util': ratio of the remaining unpaid loan amount to the credit limit.\n - 'pre_over2limit': ratio of current overdue debt to the credit limit.\n - 'pre_maxover2limit': ratio of the maximum overdue debt to the credit limit.\n - 'is_zero_util': flag: the ratio of the remaining unpaid loan amount to the credit limit is 0.\n - 'is_zero_over2limit': flag: the ratio of the current overdue debt to the credit limit is 0.\n - 'is_zero_maxover2limit': flag: the ratio of the maximum overdue debt to the credit limit is 0.\n - 'enc_paym_{0..n}': monthly payment statuses for the last n months.\n - 'enc_loans_account_holder_type': type of attitude to credit.\n - 'enc_loans_credit_status': loan status.\n - 'enc_loans_account_cur': loan currency.\n - 'enc_loans_credit_type': type of loan.\n - 'pclose_flag': flag: the planned number of days from the opening date of the loan to the closing date is not defined.\n - 'fclose_flag': flag: the actual number of days from the opening date of the loan to the closing date is not determined.\n- 'flag': target, 1 – the fact that the client has defaulted."
] |
[
"TAGS\n#size_categories-1M<n<10M #language-Russian #license-unknown #bank #loan #time-series #region-us \n",
"### Dataset Summary\n\nAlfa BKI is a unique high-quality dataset collected from the real data source of credit history bureaus (in Russian \"бюро кредитных историй/БКИ\"). It contains the history of corresponding credit products and the applicants' default on the loan.",
"### Supported Tasks and Leaderboards\n\nThe dataset is supposed to be used for training models for the classical bank task of predicting the default of the applicant.",
"## Dataset Structure",
"### Data Instances\n\nThe example of one sample is provided below",
"### Data Fields\n\n- 'id': application ID.\n- 'history': an array of transactions where each credit product is represented as a 37-dimensional array, each element of the array represents a corresponding feature from the following list.\n - 'id': application ID.\n - 'rn': serial number of the credit product in the credit history.\n - 'pre_since_opened': days from the date of opening the loan to the date of data collection.\n - 'pre_since_confirmed': days from the date of confirmation of the loan information to the date of data collection.\n - 'pre_pterm': planned number of days from the opening date of the loan to the closing date.\n - 'pre_fterm': actual number of days from the opening date of the loan to the closing date.\n - 'pre_till_pclose': planned number of days from the date of data collection to the closing date of the loan.\n - 'pre_till_fclose': actual number of days from the date of data collection to the closing date of the loan.\n - 'pre_loans_credit_limit': credit limit.\n - 'pre_loans_next_pay_summ': amount of the next loan payment.\n - 'pre_loans_outstanding': remaining unpaid loan amount.\n - 'pre_loans_total_overdue': current overdue debt.\n - 'pre_loans_max_overdue_sum': maximum overdue debt.\n - 'pre_loans_credit_cost_rate': full cost of the loan.\n - 'pre_loans5': number of delays up to 5 days.\n - 'pre_loans530': number of delays from 5 to 30 days.\n - 'pre_loans3060': number of delays from 30 to 60 days.\n - 'pre_loans6090': number of delays from 60 to 90 days.\n - 'pre_loans90': the number of delays of more than 90 days.\n - 'is_zero_loans_5': flag: no delays up to 5 days.\n - 'is_zero_loans_530': flag: no delays from 5 to 30 days.\n - 'is_zero_loans_3060': flag: no delays from 30 to 60 days.\n - 'is_zero_loans_6090': flag: no delays from 60 to 90 days.\n - 'is_zero_loans90': flag: no delays for more than 90 days.\n - 'pre_util': ratio of the remaining unpaid loan amount to the credit limit.\n - 'pre_over2limit': ratio of current overdue debt to the credit limit.\n - 'pre_maxover2limit': ratio of the maximum overdue debt to the credit limit.\n - 'is_zero_util': flag: the ratio of the remaining unpaid loan amount to the credit limit is 0.\n - 'is_zero_over2limit': flag: the ratio of the current overdue debt to the credit limit is 0.\n - 'is_zero_maxover2limit': flag: the ratio of the maximum overdue debt to the credit limit is 0.\n - 'enc_paym_{0..n}': monthly payment statuses for the last n months.\n - 'enc_loans_account_holder_type': type of attitude to credit.\n - 'enc_loans_credit_status': loan status.\n - 'enc_loans_account_cur': loan currency.\n - 'enc_loans_credit_type': type of loan.\n - 'pclose_flag': flag: the planned number of days from the opening date of the loan to the closing date is not defined.\n - 'fclose_flag': flag: the actual number of days from the opening date of the loan to the closing date is not determined.\n- 'flag': target, 1 – the fact that the client has defaulted."
] |
[
40,
63,
37,
6,
14,
916
] |
[
"passage: TAGS\n#size_categories-1M<n<10M #language-Russian #license-unknown #bank #loan #time-series #region-us \n### Dataset Summary\n\nAlfa BKI is a unique high-quality dataset collected from the real data source of credit history bureaus (in Russian \"бюро кредитных историй/БКИ\"). It contains the history of corresponding credit products and the applicants' default on the loan.### Supported Tasks and Leaderboards\n\nThe dataset is supposed to be used for training models for the classical bank task of predicting the default of the applicant.## Dataset Structure### Data Instances\n\nThe example of one sample is provided below"
] |
69fd200d78320f67d9e4c740d58035323fabbd18
|
# SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis
**Publication**: *The First Workshop in South East Asian Language Processing Workshop under AACL-2023.*
**Read in [arXiv](https://arxiv.org/pdf/2310.18023.pdf)**
---
## 📖 Introduction
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several datasets have been built with the goal of training computational models for code-mixing. Although it is very common to observe code-mixing with multiple languages, most datasets available contain code-mixed between only two languages. In this paper, we introduce **SentMix-3L**, a novel dataset for sentiment analysis containing code-mixed data between three languages: Bangla, English, and Hindi. We show that zero-shot prompting with GPT-3.5 outperforms all transformer-based models on SentMix-3L.
---
## 📊 Dataset Details
We introduce **SentMix-3L**, a novel three-language code-mixed test dataset with gold standard labels in Bangla-Hindi-English for the task of Sentiment Analysis, containing 1,007 instances.
> We are presenting this dataset exclusively as a test set due to the unique and specialized nature of the task. Such data is very difficult to gather and requires significant expertise to access. The size of the dataset, while limiting for training purposes, offers a high-quality testing environment with gold-standard labels that can serve as a benchmark in this domain.
---
## 📈 Dataset Statistics
| | **All** | **Bangla** | **English** | **Hindi** | **Other** |
|-------------------|---------|------------|-------------|-----------|-----------|
| Tokens | 89494 | 32133 | 5998 | 15131 | 36232 |
| Types | 19686 | 8167 | 1073 | 1474 | 9092 |
| Max. in instance | 173 | 62 | 20 | 47 | 93 |
| Min. in instance | 41 | 4 | 3 | 2 | 8 |
| Avg | 88.87 | 31.91 | 5.96 | 15.03 | 35.98 |
| Std Dev | 19.19 | 8.39 | 2.94 | 5.81 | 9.70 |
*The row 'Avg' represents the average number of tokens with its standard deviation in row 'Std Dev'.*
---
## 📉 Results
| **Models** | **Weighted F1 Score** |
|---------------|-----------------------|
| GPT 3.5 Turbo | **0.62** |
| XLM-R | 0.59 |
| BanglishBERT | 0.56 |
| mBERT | 0.56 |
| BERT | 0.55 |
| roBERTa | 0.54 |
| MuRIL | 0.54 |
| IndicBERT | 0.53 |
| DistilBERT | 0.53 |
| HindiBERT | 0.48 |
| HingBERT | 0.47 |
| BanglaBERT | 0.47 |
*Weighted F-1 score for different models: training on synthetic, testing on natural data.*
---
## 📝 Citation
If you utilize this dataset, kindly cite our paper.
```bibtex
@article{raihan2023sentmix,
title={SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis},
author={Raihan, Md Nishat and Goswami, Dhiman and Mahmud, Antara and Anstasopoulos, Antonios and Zampieri, Marcos},
journal={arXiv preprint arXiv:2310.18023},
year={2023}
}
|
md-nishat-008/SentMix-3L
|
[
"license:agpl-3.0",
"arxiv:2310.18023",
"region:us"
] |
2023-10-30T09:19:23+00:00
|
{"license": "agpl-3.0"}
|
2023-11-08T12:26:02+00:00
|
[
"2310.18023"
] |
[] |
TAGS
#license-agpl-3.0 #arxiv-2310.18023 #region-us
|
SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis
============================================================================
Publication: *The First Workshop in South East Asian Language Processing Workshop under AACL-2023.*
Read in arXiv
---
Introduction
------------
Code-mixing is a well-studied linguistic phenomenon when two or more languages are mixed in text or speech. Several datasets have been built with the goal of training computational models for code-mixing. Although it is very common to observe code-mixing with multiple languages, most datasets available contain code-mixed between only two languages. In this paper, we introduce SentMix-3L, a novel dataset for sentiment analysis containing code-mixed data between three languages: Bangla, English, and Hindi. We show that zero-shot prompting with GPT-3.5 outperforms all transformer-based models on SentMix-3L.
---
Dataset Details
---------------
We introduce SentMix-3L, a novel three-language code-mixed test dataset with gold standard labels in Bangla-Hindi-English for the task of Sentiment Analysis, containing 1,007 instances.
>
> We are presenting this dataset exclusively as a test set due to the unique and specialized nature of the task. Such data is very difficult to gather and requires significant expertise to access. The size of the dataset, while limiting for training purposes, offers a high-quality testing environment with gold-standard labels that can serve as a benchmark in this domain.
>
>
>
---
Dataset Statistics
------------------
*The row 'Avg' represents the average number of tokens with its standard deviation in row 'Std Dev'.*
---
Results
-------
*Weighted F-1 score for different models: training on synthetic, testing on natural data.*
---
Citation
--------
If you utilize this dataset, kindly cite our paper.
'''bibtex
@article{raihan2023sentmix,
title={SentMix-3L: A Bangla-English-Hindi Code-Mixed Dataset for Sentiment Analysis},
author={Raihan, Md Nishat and Goswami, Dhiman and Mahmud, Antara and Anstasopoulos, Antonios and Zampieri, Marcos},
journal={arXiv preprint arXiv:2310.18023},
year={2023}
}
|
[] |
[
"TAGS\n#license-agpl-3.0 #arxiv-2310.18023 #region-us \n"
] |
[
23
] |
[
"passage: TAGS\n#license-agpl-3.0 #arxiv-2310.18023 #region-us \n"
] |
298da1c72b1232e4ce66589490027e9fcf611cb9
|
# Dataset Card for "embeddings_from_distilbert_class_heaps"
Dataset created for thesis: "Generating Robust Representations of Structures in OpenSSH Heap Dumps" by Johannes Garstenauer.
This dataset contains representations of heap data structures along with their labels and the predicted label.
The representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.
The representation-generating model is: https://huggingface.co/johannes-garstenauer/distilbert_class_heaps
The dataset from which representations were generated is: https://huggingface.co/datasets/johannes-garstenauer/structs_token_size_4_reduced_labelled_eval
The twin dataset (model with different training used to generate embeddings) is: https://huggingface.co/datasets/johannes-garstenauer/embeddings_from_distilbert_masking_heaps/
Thesis and associated scripts: https://zenodo.org/records/10053730
|
johannes-garstenauer/embeddings_from_distilbert_class_heaps
|
[
"region:us"
] |
2023-10-30T09:20:45+00:00
|
{"dataset_info": {"features": [{"name": "struct", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "pred", "dtype": "int64"}, {"name": "cls_layer_6", "sequence": "float32"}, {"name": "cls_layer_5", "sequence": "float32"}, {"name": "cls_layer_4", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 2564388529, "num_examples": 269087}], "download_size": 2985131227, "dataset_size": 2564388529}}
|
2023-10-30T13:26:52+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "embeddings_from_distilbert_class_heaps"
Dataset created for thesis: "Generating Robust Representations of Structures in OpenSSH Heap Dumps" by Johannes Garstenauer.
This dataset contains representations of heap data structures along with their labels and the predicted label.
The representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.
The representation-generating model is: URL
The dataset from which representations were generated is: URL
The twin dataset (model with different training used to generate embeddings) is: URL
Thesis and associated scripts: URL
|
[
"# Dataset Card for \"embeddings_from_distilbert_class_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"embeddings_from_distilbert_class_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
[
6,
158
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"embeddings_from_distilbert_class_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
c1e19acd31468376f71b9bbf32e67ef00e3b4594
|
# Dataset Card for "embeddings_from_distilbert_masking_heaps"
Dataset created for thesis: "Generating Robust Representations of Structures in OpenSSH Heap Dumps" by Johannes Garstenauer.
This dataset contains representations of heap data structures along with their labels and the predicted label.
The representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.
The representation-generating model is: https://huggingface.co/johannes-garstenauer/distilbert_masking_heaps
The dataset from which representations were generated is: https://huggingface.co/datasets/johannes-garstenauer/structs_token_size_4_reduced_labelled_eval
The twin dataset (model with different training used to generate embeddings) is: https://huggingface.co/datasets/johannes-garstenauer/embeddings_from_distilbert_class_heaps/
Thesis and associated scripts: https://zenodo.org/records/10053730
|
johannes-garstenauer/embeddings_from_distilbert_masking_heaps
|
[
"region:us"
] |
2023-10-30T09:26:33+00:00
|
{"dataset_info": {"features": [{"name": "struct", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "pred", "dtype": "int64"}, {"name": "cls_layer_6", "sequence": "float32"}, {"name": "cls_layer_5", "sequence": "float32"}, {"name": "cls_layer_4", "sequence": "float32"}], "splits": [{"name": "train", "num_bytes": 2564388529, "num_examples": 269087}], "download_size": 2984971174, "dataset_size": 2564388529}}
|
2023-10-30T13:26:44+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "embeddings_from_distilbert_masking_heaps"
Dataset created for thesis: "Generating Robust Representations of Structures in OpenSSH Heap Dumps" by Johannes Garstenauer.
This dataset contains representations of heap data structures along with their labels and the predicted label.
The representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.
The representation-generating model is: URL
The dataset from which representations were generated is: URL
The twin dataset (model with different training used to generate embeddings) is: URL
Thesis and associated scripts: URL
|
[
"# Dataset Card for \"embeddings_from_distilbert_masking_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"embeddings_from_distilbert_masking_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
[
6,
159
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"embeddings_from_distilbert_masking_heaps\"\n\nDataset created for thesis: \"Generating Robust Representations of Structures in OpenSSH Heap Dumps\" by Johannes Garstenauer.\n\nThis dataset contains representations of heap data structures along with their labels and the predicted label.\nThe representations are the [CLS] token embeddings of the last 3 layers of the DistilBERT model.\n\nThe representation-generating model is: URL\n\nThe dataset from which representations were generated is: URL\n\nThe twin dataset (model with different training used to generate embeddings) is: URL\n\nThesis and associated scripts: URL"
] |
cc094cb7c5648dbb1b1a73e153153c25b2b0580d
|
# Dataset Card for "donut2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aminlouhichi/donut2
|
[
"region:us"
] |
2023-10-30T09:41:05+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 8268950.0, "num_examples": 84}, {"name": "validation", "num_bytes": 3762544.0, "num_examples": 39}, {"name": "test", "num_bytes": 3059300.0, "num_examples": 33}], "download_size": 11855736, "dataset_size": 15090794.0}}
|
2023-10-30T09:41:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "donut2"
More Information needed
|
[
"# Dataset Card for \"donut2\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"donut2\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"donut2\"\n\nMore Information needed"
] |
55ed794e26412632048a1b499d789250e73666be
|
# Dataset Card for "stif-indonesia"
# STIF-Indonesia

A dataset of ["Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation"](https://arxiv.org/abs/2011.03286v1).
You can also find Indonesian informal-formal parallel corpus in this repository.
## Description
We were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource **machine translation** problem. We benchmark several strategies to perform the style transfer.
In this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!
## Paper

You can access our paper below:
[Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)](https://arxiv.org/abs/2011.03286v1)
## Team
1. Haryo Akbarianto Wibowo @ Kata.ai
2. Tatag Aziz Prawiro @ Universitas Indonesia
3. Muhammad Ihsan @ Bina Nusantara
4. Alham Fikri Aji @ Kata.ai
5. Radityo Eko Prasojo @ Kata.ai
6. Rahmad Mahendra @ Universitas Indonesia
|
haryoaw/stif-indonesia
|
[
"task_categories:translation",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:id",
"license:mit",
"arxiv:2011.03286",
"region:us"
] |
2023-10-30T10:10:47+00:00
|
{"language": ["id"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["translation", "text2text-generation"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "train.csv"}, {"split": "dev", "path": "dev.csv"}, {"split": "test", "path": "test.csv"}]}], "dataset_info": {"features": [{"name": "informal", "dtype": "string"}, {"name": "formal", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 344179, "num_examples": 1922}, {"name": "dev", "num_bytes": 37065, "num_examples": 214}, {"name": "test", "num_bytes": 66682, "num_examples": 363}], "download_size": 276834, "dataset_size": 447926}}
|
2023-10-30T10:19:03+00:00
|
[
"2011.03286"
] |
[
"id"
] |
TAGS
#task_categories-translation #task_categories-text2text-generation #size_categories-1K<n<10K #language-Indonesian #license-mit #arxiv-2011.03286 #region-us
|
# Dataset Card for "stif-indonesia"
# STIF-Indonesia
!Paper
A dataset of "Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation".
You can also find Indonesian informal-formal parallel corpus in this repository.
## Description
We were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource machine translation problem. We benchmark several strategies to perform the style transfer.
In this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!
## Paper
!Paper
You can access our paper below:
Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)
## Team
1. Haryo Akbarianto Wibowo @ URL
2. Tatag Aziz Prawiro @ Universitas Indonesia
3. Muhammad Ihsan @ Bina Nusantara
4. Alham Fikri Aji @ URL
5. Radityo Eko Prasojo @ URL
6. Rahmad Mahendra @ Universitas Indonesia
|
[
"# Dataset Card for \"stif-indonesia\"",
"# STIF-Indonesia\n\n!Paper\n\nA dataset of \"Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation\".\n\nYou can also find Indonesian informal-formal parallel corpus in this repository.",
"## Description\n\nWe were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource machine translation problem. We benchmark several strategies to perform the style transfer.\n\nIn this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!",
"## Paper\n\n!Paper\n\nYou can access our paper below:\n\nSemi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)",
"## Team\n\n1. Haryo Akbarianto Wibowo @ URL\n2. Tatag Aziz Prawiro @ Universitas Indonesia\n3. Muhammad Ihsan @ Bina Nusantara\n4. Alham Fikri Aji @ URL\n5. Radityo Eko Prasojo @ URL\n6. Rahmad Mahendra @ Universitas Indonesia"
] |
[
"TAGS\n#task_categories-translation #task_categories-text2text-generation #size_categories-1K<n<10K #language-Indonesian #license-mit #arxiv-2011.03286 #region-us \n",
"# Dataset Card for \"stif-indonesia\"",
"# STIF-Indonesia\n\n!Paper\n\nA dataset of \"Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation\".\n\nYou can also find Indonesian informal-formal parallel corpus in this repository.",
"## Description\n\nWe were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource machine translation problem. We benchmark several strategies to perform the style transfer.\n\nIn this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!",
"## Paper\n\n!Paper\n\nYou can access our paper below:\n\nSemi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)",
"## Team\n\n1. Haryo Akbarianto Wibowo @ URL\n2. Tatag Aziz Prawiro @ Universitas Indonesia\n3. Muhammad Ihsan @ Bina Nusantara\n4. Alham Fikri Aji @ URL\n5. Radityo Eko Prasojo @ URL\n6. Rahmad Mahendra @ Universitas Indonesia"
] |
[
59,
13,
61,
134,
45,
56
] |
[
"passage: TAGS\n#task_categories-translation #task_categories-text2text-generation #size_categories-1K<n<10K #language-Indonesian #license-mit #arxiv-2011.03286 #region-us \n# Dataset Card for \"stif-indonesia\"# STIF-Indonesia\n\n!Paper\n\nA dataset of \"Semi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation\".\n\nYou can also find Indonesian informal-formal parallel corpus in this repository.## Description\n\nWe were researching transforming a sentence from informal to its formal form. Our work addresses a style-transfer from informal to formal Indonesian as a low-resource machine translation problem. We benchmark several strategies to perform the style transfer.\n\nIn this repository, we provide the Phrase-Based Statistical Machine Translation, which has the highest result in our experiment. Note that, our data is extremely low-resource and domain-specific (Customer Service domain). Therefore, the system might not be robust towards out-of-domain input. Our future work includes exploring more robust style transfer. Stay tuned!## Paper\n\n!Paper\n\nYou can access our paper below:\n\nSemi-Supervised Low-Resource Style Transfer of Indonesian Informal to Formal Language with Iterative Forward-Translation (IALP 2020)## Team\n\n1. Haryo Akbarianto Wibowo @ URL\n2. Tatag Aziz Prawiro @ Universitas Indonesia\n3. Muhammad Ihsan @ Bina Nusantara\n4. Alham Fikri Aji @ URL\n5. Radityo Eko Prasojo @ URL\n6. Rahmad Mahendra @ Universitas Indonesia"
] |
8767a67d7b70b57e984577c0f1b8384523a769a7
|
# Dataset Card for "laion-rvs-fashion-caption-only"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Geonmo/laion-rvs-fashion-caption-only
|
[
"region:us"
] |
2023-10-30T10:49:40+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 64727598, "num_examples": 1436088}], "download_size": 39909300, "dataset_size": 64727598}}
|
2023-10-31T01:08:26+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "laion-rvs-fashion-caption-only"
More Information needed
|
[
"# Dataset Card for \"laion-rvs-fashion-caption-only\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"laion-rvs-fashion-caption-only\"\n\nMore Information needed"
] |
[
6,
23
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"laion-rvs-fashion-caption-only\"\n\nMore Information needed"
] |
f9d734377ca401f2cc665b6e1dcc39501efe1173
|
# Dataset Card for "CodeAlpacpa-20k-llama-format"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pesc101/CodeAlpacpa-20k-llama-format
|
[
"region:us"
] |
2023-10-30T10:56:13+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 6535066, "num_examples": 20022}], "download_size": 3269704, "dataset_size": 6535066}}
|
2023-10-30T11:07:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "CodeAlpacpa-20k-llama-format"
More Information needed
|
[
"# Dataset Card for \"CodeAlpacpa-20k-llama-format\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"CodeAlpacpa-20k-llama-format\"\n\nMore Information needed"
] |
[
6,
21
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"CodeAlpacpa-20k-llama-format\"\n\nMore Information needed"
] |
07db44cc73abc49b6110174863b4dc77d3ac8d7d
|
# Dataset Card for "train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ibizagrowthagency/train
|
[
"region:us"
] |
2023-10-30T11:16:05+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "Aquarell Tattoos", "1": "Bedeutung der Tribal Tattoos", "2": "Blackwork Tattoo", "3": "Building", "4": "Cover-Up Tattoo", "5": "Dotwork Tattoos", "6": "Fineline Tattoos", "7": "Geschiche der Maori Tattoos", "8": "Japanische Tattoos in Leipzig", "9": "Narben Tattoo", "10": "Portrait Tattoos", "11": "Poster", "12": "Realistic Tattoos", "13": "Totenkopf Tattoos", "14": "Trashpolka Tattoos", "15": "Tribal Tattoo", "16": "Wikinger Tattoos"}}}}], "splits": [{"name": "train", "num_bytes": 6665820.160194174, "num_examples": 175}, {"name": "test", "num_bytes": 1297030.8398058251, "num_examples": 31}], "download_size": 7953806, "dataset_size": 7962851.0}}
|
2023-11-01T14:39:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "train"
More Information needed
|
[
"# Dataset Card for \"train\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"train\"\n\nMore Information needed"
] |
[
6,
12
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"train\"\n\nMore Information needed"
] |
0b50112f0517c36e5c136f81e72042e9c29d26b1
|
# Dataset Card for "chemistry_zh-tw"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
FelixChao/chemistry_zh-tw
|
[
"region:us"
] |
2023-10-30T11:16:33+00:00
|
{"dataset_info": {"features": [{"name": "chem_text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 70334276, "num_examples": 40000}], "download_size": 33515185, "dataset_size": 70334276}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T11:16:38+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "chemistry_zh-tw"
More Information needed
|
[
"# Dataset Card for \"chemistry_zh-tw\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"chemistry_zh-tw\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"chemistry_zh-tw\"\n\nMore Information needed"
] |
ef231ddad527c7d0808208003dffb4618b206645
|
# Dataset Card for "donut3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aminlouhichi/donut3
|
[
"region:us"
] |
2023-10-30T11:31:15+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 25755597.0, "num_examples": 60}, {"name": "validation", "num_bytes": 25755597.0, "num_examples": 60}, {"name": "test", "num_bytes": 25755597.0, "num_examples": 60}], "download_size": 55055025, "dataset_size": 77266791.0}}
|
2023-10-30T12:08:39+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "donut3"
More Information needed
|
[
"# Dataset Card for \"donut3\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"donut3\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"donut3\"\n\nMore Information needed"
] |
55d8699793e9e46f5fbe90704d0cd6c0ce7f35c6
|
# Dataset Card for "bookcorpus-wikipedia-full"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pkr7098/bookcorpus-wikipedia-full
|
[
"region:us"
] |
2023-10-30T11:59:38+00:00
|
{"dataset_info": {"config_name": "20220301.en", "features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 24500165181, "num_examples": 80462898}], "download_size": 0, "dataset_size": 24500165181}, "configs": [{"config_name": "20220301.en", "data_files": [{"split": "train", "path": "20220301.en/train-*"}]}]}
|
2023-10-31T01:06:21+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "bookcorpus-wikipedia-full"
More Information needed
|
[
"# Dataset Card for \"bookcorpus-wikipedia-full\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"bookcorpus-wikipedia-full\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"bookcorpus-wikipedia-full\"\n\nMore Information needed"
] |
40913d735dba465a58f3f1b0912a5b8e0ec0b751
|
# Dataset Card for "vision-flan_191-task_1k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Phando/vision-flan_191-task_1k
|
[
"region:us"
] |
2023-10-30T12:07:33+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "task_name", "dtype": "string"}, {"name": "instruction", "dtype": "string"}, {"name": "response", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 33215298748.003, "num_examples": 186103}], "download_size": 36889036585, "dataset_size": 33215298748.003}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T12:28:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "vision-flan_191-task_1k"
More Information needed
|
[
"# Dataset Card for \"vision-flan_191-task_1k\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"vision-flan_191-task_1k\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"vision-flan_191-task_1k\"\n\nMore Information needed"
] |
4395d5580938f30299ec6c99ca9cb9a1ecc9fea0
|
# Dataset Card for "buildings_instseg"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
xrizs/buildings_instseg
|
[
"region:us"
] |
2023-10-30T12:10:08+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "test", "1": "train", "2": "valid"}}}}], "splits": [{"name": "train", "num_bytes": 4113145.0, "num_examples": 58}, {"name": "validation", "num_bytes": 1480042.0, "num_examples": 20}, {"name": "test", "num_bytes": 622722.0, "num_examples": 9}], "download_size": 6223810, "dataset_size": 6215909.0}}
|
2023-10-30T12:10:12+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "buildings_instseg"
More Information needed
|
[
"# Dataset Card for \"buildings_instseg\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"buildings_instseg\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"buildings_instseg\"\n\nMore Information needed"
] |
753eb1131781a02f6bfc2c478c65f00b75433e63
|
# Dataset Card for "donut4"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aminlouhichi/donut4
|
[
"region:us"
] |
2023-10-30T12:34:47+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 25755968.0, "num_examples": 60}, {"name": "validation", "num_bytes": 25755968.0, "num_examples": 60}, {"name": "test", "num_bytes": 25755968.0, "num_examples": 60}], "download_size": 55048836, "dataset_size": 77267904.0}}
|
2023-10-30T12:35:01+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "donut4"
More Information needed
|
[
"# Dataset Card for \"donut4\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"donut4\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"donut4\"\n\nMore Information needed"
] |
c9f13fb67e95fe3c7fd428a77ad48b88760638d0
|
# Dataset Card for "donut5"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aminlouhichi/donut5
|
[
"region:us"
] |
2023-10-30T12:55:16+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 12953017.0, "num_examples": 60}, {"name": "validation", "num_bytes": 12953017.0, "num_examples": 60}, {"name": "test", "num_bytes": 25755968.0, "num_examples": 60}], "download_size": 41314952, "dataset_size": 51662002.0}}
|
2023-10-30T12:55:34+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "donut5"
More Information needed
|
[
"# Dataset Card for \"donut5\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"donut5\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"donut5\"\n\nMore Information needed"
] |
2f2f892835bbf44b4db81f1c4ad6d46a3e9e4359
|
# Dataset Card for "refcoco-benchmark"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jxu124/refcoco-benchmark
|
[
"region:us"
] |
2023-10-30T13:04:52+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "refcoco_unc_val", "path": "data/refcoco_unc_val-*"}, {"split": "refcoco_unc_testA", "path": "data/refcoco_unc_testA-*"}, {"split": "refcoco_unc_testB", "path": "data/refcoco_unc_testB-*"}, {"split": "refcoco_google_val", "path": "data/refcoco_google_val-*"}, {"split": "refcoco_google_test", "path": "data/refcoco_google_test-*"}, {"split": "refcocog_umd_val", "path": "data/refcocog_umd_val-*"}, {"split": "refcocog_umd_test", "path": "data/refcocog_umd_test-*"}, {"split": "refcocog_google_val", "path": "data/refcocog_google_val-*"}, {"split": "refcoco_plus_unc_val", "path": "data/refcoco_plus_unc_val-*"}, {"split": "refcoco_plus_unc_testA", "path": "data/refcoco_plus_unc_testA-*"}, {"split": "refcoco_plus_unc_testB", "path": "data/refcoco_plus_unc_testB-*"}]}], "dataset_info": {"features": [{"name": "ref_list", "list": [{"name": "ann_info", "struct": [{"name": "area", "dtype": "float64"}, {"name": "bbox", "sequence": "float64"}, {"name": "category_id", "dtype": "int64"}, {"name": "id", "dtype": "int64"}, {"name": "image_id", "dtype": "int64"}, {"name": "iscrowd", "dtype": "int64"}, {"name": "segmentation", "sequence": {"sequence": "float64"}}]}, {"name": "ref_info", "struct": [{"name": "ann_id", "dtype": "int64"}, {"name": "category_id", "dtype": "int64"}, {"name": "file_name", "dtype": "string"}, {"name": "image_id", "dtype": "int64"}, {"name": "ref_id", "dtype": "int64"}, {"name": "sent_ids", "sequence": "int64"}, {"name": "sentences", "list": [{"name": "raw", "dtype": "string"}, {"name": "sent", "dtype": "string"}, {"name": "sent_id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}]}, {"name": "split", "dtype": "string"}]}]}, {"name": "image_info", "struct": [{"name": "coco_url", "dtype": "string"}, {"name": "date_captured", "dtype": "string"}, {"name": "file_name", "dtype": "string"}, {"name": "flickr_url", "dtype": "string"}, {"name": "height", "dtype": "int64"}, {"name": "id", "dtype": "int64"}, {"name": "license", "dtype": "int64"}, {"name": "width", "dtype": "int64"}]}, {"name": "image", "dtype": "image"}], "splits": [{"name": "refcoco_unc_val", "num_bytes": 264438667.5, "num_examples": 1500}, {"name": "refcoco_unc_testA", "num_bytes": 129028843.0, "num_examples": 750}, {"name": "refcoco_unc_testB", "num_bytes": 133102482.0, "num_examples": 750}, {"name": "refcoco_google_val", "num_bytes": 814855470.214, "num_examples": 4559}, {"name": "refcoco_google_test", "num_bytes": 800980159.978, "num_examples": 4527}, {"name": "refcocog_umd_val", "num_bytes": 220021282.2, "num_examples": 1300}, {"name": "refcocog_umd_test", "num_bytes": 442746080.0, "num_examples": 2600}, {"name": "refcocog_google_val", "num_bytes": 800691386.6, "num_examples": 4650}, {"name": "refcoco_plus_unc_val", "num_bytes": 264451297.5, "num_examples": 1500}, {"name": "refcoco_plus_unc_testA", "num_bytes": 129035632.0, "num_examples": 750}, {"name": "refcoco_plus_unc_testB", "num_bytes": 133095545.0, "num_examples": 750}], "download_size": 4072689321, "dataset_size": 4132446845.9919996}}
|
2023-10-30T13:15:05+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "refcoco-benchmark"
More Information needed
|
[
"# Dataset Card for \"refcoco-benchmark\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"refcoco-benchmark\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"refcoco-benchmark\"\n\nMore Information needed"
] |
fd0fa8d270fabc9ec264bea8e71d8c0e75f0bc78
|
# Dataset Card for "refclef-benchmark"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jxu124/refclef-benchmark
|
[
"region:us"
] |
2023-10-30T13:24:55+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "refclef_unc_val", "path": "data/refclef_unc_val-*"}, {"split": "refclef_unc_testA", "path": "data/refclef_unc_testA-*"}, {"split": "refclef_unc_testB", "path": "data/refclef_unc_testB-*"}, {"split": "refclef_unc_testC", "path": "data/refclef_unc_testC-*"}, {"split": "refclef_berkeley_val", "path": "data/refclef_berkeley_val-*"}, {"split": "refclef_berkeley_test", "path": "data/refclef_berkeley_test-*"}]}], "dataset_info": {"features": [{"name": "ref_list", "list": [{"name": "ann_info", "struct": [{"name": "area", "dtype": "int64"}, {"name": "bbox", "sequence": "float64"}, {"name": "category_id", "dtype": "int64"}, {"name": "id", "dtype": "string"}, {"name": "image_id", "dtype": "int64"}, {"name": "mask_name", "dtype": "string"}, {"name": "segmentation", "list": [{"name": "counts", "dtype": "string"}, {"name": "size", "sequence": "int64"}]}]}, {"name": "ref_info", "struct": [{"name": "ann_id", "dtype": "string"}, {"name": "category_id", "dtype": "int64"}, {"name": "image_id", "dtype": "int64"}, {"name": "ref_id", "dtype": "int64"}, {"name": "sent_ids", "sequence": "int64"}, {"name": "sentences", "list": [{"name": "raw", "dtype": "string"}, {"name": "sent", "dtype": "string"}, {"name": "sent_id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}]}, {"name": "split", "dtype": "string"}]}]}, {"name": "image_info", "struct": [{"name": "file_name", "dtype": "string"}, {"name": "height", "dtype": "int64"}, {"name": "id", "dtype": "int64"}, {"name": "width", "dtype": "int64"}]}, {"name": "image", "dtype": "image"}], "splits": [{"name": "refclef_unc_val", "num_bytes": 176315268.0, "num_examples": 2000}, {"name": "refclef_unc_testA", "num_bytes": 38748729.0, "num_examples": 485}, {"name": "refclef_unc_testB", "num_bytes": 41495038.0, "num_examples": 490}, {"name": "refclef_unc_testC", "num_bytes": 37159288.0, "num_examples": 465}, {"name": "refclef_berkeley_val", "num_bytes": 90320401.0, "num_examples": 1000}, {"name": "refclef_berkeley_test", "num_bytes": 889898825.642, "num_examples": 9999}], "download_size": 1256485050, "dataset_size": 1273937549.642}}
|
2023-10-30T13:28:06+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "refclef-benchmark"
More Information needed
|
[
"# Dataset Card for \"refclef-benchmark\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"refclef-benchmark\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"refclef-benchmark\"\n\nMore Information needed"
] |
e7c41b2ad10e995795378be8e1c5429f25743a09
|
# Dataset Card for "vca_ham_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
sck/vca_ham_train
|
[
"region:us"
] |
2023-10-30T13:45:33+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 59730035.8, "num_examples": 1720}], "download_size": 0, "dataset_size": 59730035.8}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-13T16:24:37+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "vca_ham_train"
More Information needed
|
[
"# Dataset Card for \"vca_ham_train\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"vca_ham_train\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"vca_ham_train\"\n\nMore Information needed"
] |
ef28e293dde6e5c381c7bd621b7a9fe5a1f1f114
|
# Dataset Card for "dpo-sample"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
abhishek/dpo-sample
|
[
"region:us"
] |
2023-10-30T13:46:52+00:00
|
{"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 404, "num_examples": 7}], "download_size": 1980, "dataset_size": 404}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T13:46:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dpo-sample"
More Information needed
|
[
"# Dataset Card for \"dpo-sample\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dpo-sample\"\n\nMore Information needed"
] |
[
6,
15
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dpo-sample\"\n\nMore Information needed"
] |
cf672e911096188c8354343903062ec7ee743260
|
# Dataset Card for "guanaco-llama2-800"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Chamoda/guanaco-llama2-800
|
[
"region:us"
] |
2023-10-30T14:06:01+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Completion", "dtype": "string"}, {"name": "Virality ", "dtype": "int64"}, {"name": "Unnamed: 3", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2872283, "num_examples": 800}], "download_size": 1751882, "dataset_size": 2872283}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T14:06:03+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "guanaco-llama2-800"
More Information needed
|
[
"# Dataset Card for \"guanaco-llama2-800\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"guanaco-llama2-800\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"guanaco-llama2-800\"\n\nMore Information needed"
] |
7b1228affece3235efd39a5d8095382df76a4345
|
# A German Language Labeled Dataset of Tweets
Gunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer
{gjikeli, skarali, damieh, ksoemer}@iu.edu
## Description
Our dataset contains 8,048 German language tweets related to Jewish life from a four-year timespan.
The dataset consists of 18 samples of tweets with the keyword “Juden” or “Israel.” The samples are representative samples of all live tweets (at the time of sampling) with these keywords respectively over the indicated time period. Each sample was annotated by two expert annotators using an Annotation Portal that visualizes the live tweets in context. We provide the annotation results based on the agreement of two annotators, after discussing discrepancies (Jikeli et al. 2022: 3-6).
Overall, 335 tweets (4%) were labelled as antisemitic following the IHRA Working Definition of Antisemitism. 1345 tweets (17 %) come from 2019, 1364 tweets (17 %) from 2020, 2639 tweets (33 %) from 2021 and 2700 tweets (34 %) from 2022.
About half of the tweets, a total of 4,493 tweets (56 %) come from queries with the keyword “Juden,” which is representative of a continuous time period from January 2019 to December 2022: 864 tweets (19 %) come from 2019, 891 tweets (20 %) from 2020, 1364 tweets (30 %) from 2021 and 1374 (31 %). 148 out of the 4493 tweets, so 3% from the query with “Juden” are antisemitic.
The other part of the tweets, a total of 3,555 (44 %) results of queries with the keyword “Israel”. 481 tweets (14 %) of the keywords containing Israel stem from 2019, 473 (13 %) come from 2020, 1275 tweets (36 %) from 2021 and 1326 tweets (37 %) are from 2022. Out of all tweets from the “Israel” query, 187 (5 %) are antisemitic.
The csv file contains diacritics and special characters of the German language (e.g., “ä”, “ü”, “ö”, “ß”), which should be taken into account when opening it with anything other than a text editor.
## References
Günther Jikeli, David Axelrod, Rhonda K. Fischer, Elham Forouzesh, Weejeong Jeong, Daniel Miehling, Katharina Soemer (2022): Differences between antisemitic and non-antisemitic English language tweets. Computational and Mathematical Organization Theory
## Acknowledgements
This work used Jetstream2 at Indiana University through allocation HUM200003 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296.
We are grateful for the support of Indiana University’s Observatory on Social Media (OSoMe) (Davis et al. 2016) and the contributions and annotations of all team members in our Social Media & Hate Research Lab at Indiana University’s Institute for the Study of Contemporary Antisemitism, especially Grace Bland, Elisha S. Breton, Kathryn Cooper, Robin Forstenhäusler, Sophie von Máriássy, Mabel Poindexter, Jenna Solomon, Clara Schilling, Emma Shriberg and Victor Tschiskale.
|
ISCA-IUB/GermanLanguageTwitterAntisemitism
|
[
"language:de",
"twitter",
"X",
"hate speech",
"antisemitism",
"machine learning",
"juden",
"israel",
"region:us"
] |
2023-10-30T14:09:13+00:00
|
{"language": ["de"], "pretty_name": "German Language Antisemitism on Twitter", "tags": ["twitter", "X", "hate speech", "antisemitism", "machine learning", "juden", "israel"]}
|
2023-11-13T08:56:44+00:00
|
[] |
[
"de"
] |
TAGS
#language-German #twitter #X #hate speech #antisemitism #machine learning #juden #israel #region-us
|
# A German Language Labeled Dataset of Tweets
Gunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer
{gjikeli, skarali, damieh, ksoemer}@URL
## Description
Our dataset contains 8,048 German language tweets related to Jewish life from a four-year timespan.
The dataset consists of 18 samples of tweets with the keyword “Juden” or “Israel.” The samples are representative samples of all live tweets (at the time of sampling) with these keywords respectively over the indicated time period. Each sample was annotated by two expert annotators using an Annotation Portal that visualizes the live tweets in context. We provide the annotation results based on the agreement of two annotators, after discussing discrepancies (Jikeli et al. 2022: 3-6).
Overall, 335 tweets (4%) were labelled as antisemitic following the IHRA Working Definition of Antisemitism. 1345 tweets (17 %) come from 2019, 1364 tweets (17 %) from 2020, 2639 tweets (33 %) from 2021 and 2700 tweets (34 %) from 2022.
About half of the tweets, a total of 4,493 tweets (56 %) come from queries with the keyword “Juden,” which is representative of a continuous time period from January 2019 to December 2022: 864 tweets (19 %) come from 2019, 891 tweets (20 %) from 2020, 1364 tweets (30 %) from 2021 and 1374 (31 %). 148 out of the 4493 tweets, so 3% from the query with “Juden” are antisemitic.
The other part of the tweets, a total of 3,555 (44 %) results of queries with the keyword “Israel”. 481 tweets (14 %) of the keywords containing Israel stem from 2019, 473 (13 %) come from 2020, 1275 tweets (36 %) from 2021 and 1326 tweets (37 %) are from 2022. Out of all tweets from the “Israel” query, 187 (5 %) are antisemitic.
The csv file contains diacritics and special characters of the German language (e.g., “ä”, “ü”, “ö”, “ß”), which should be taken into account when opening it with anything other than a text editor.
## References
Günther Jikeli, David Axelrod, Rhonda K. Fischer, Elham Forouzesh, Weejeong Jeong, Daniel Miehling, Katharina Soemer (2022): Differences between antisemitic and non-antisemitic English language tweets. Computational and Mathematical Organization Theory
## Acknowledgements
This work used Jetstream2 at Indiana University through allocation HUM200003 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296.
We are grateful for the support of Indiana University’s Observatory on Social Media (OSoMe) (Davis et al. 2016) and the contributions and annotations of all team members in our Social Media & Hate Research Lab at Indiana University’s Institute for the Study of Contemporary Antisemitism, especially Grace Bland, Elisha S. Breton, Kathryn Cooper, Robin Forstenhäusler, Sophie von Máriássy, Mabel Poindexter, Jenna Solomon, Clara Schilling, Emma Shriberg and Victor Tschiskale.
|
[
"# A German Language Labeled Dataset of Tweets \n\nGunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer\n{gjikeli, skarali, damieh, ksoemer}@URL",
"## Description\n \nOur dataset contains 8,048 German language tweets related to Jewish life from a four-year timespan. \nThe dataset consists of 18 samples of tweets with the keyword “Juden” or “Israel.” The samples are representative samples of all live tweets (at the time of sampling) with these keywords respectively over the indicated time period. Each sample was annotated by two expert annotators using an Annotation Portal that visualizes the live tweets in context. We provide the annotation results based on the agreement of two annotators, after discussing discrepancies (Jikeli et al. 2022: 3-6). \nOverall, 335 tweets (4%) were labelled as antisemitic following the IHRA Working Definition of Antisemitism. 1345 tweets (17 %) come from 2019, 1364 tweets (17 %) from 2020, 2639 tweets (33 %) from 2021 and 2700 tweets (34 %) from 2022. \n\nAbout half of the tweets, a total of 4,493 tweets (56 %) come from queries with the keyword “Juden,” which is representative of a continuous time period from January 2019 to December 2022: 864 tweets (19 %) come from 2019, 891 tweets (20 %) from 2020, 1364 tweets (30 %) from 2021 and 1374 (31 %). 148 out of the 4493 tweets, so 3% from the query with “Juden” are antisemitic. \n\nThe other part of the tweets, a total of 3,555 (44 %) results of queries with the keyword “Israel”. 481 tweets (14 %) of the keywords containing Israel stem from 2019, 473 (13 %) come from 2020, 1275 tweets (36 %) from 2021 and 1326 tweets (37 %) are from 2022. Out of all tweets from the “Israel” query, 187 (5 %) are antisemitic. \n\nThe csv file contains diacritics and special characters of the German language (e.g., “ä”, “ü”, “ö”, “ß”), which should be taken into account when opening it with anything other than a text editor.",
"## References \n\nGünther Jikeli, David Axelrod, Rhonda K. Fischer, Elham Forouzesh, Weejeong Jeong, Daniel Miehling, Katharina Soemer (2022): Differences between antisemitic and non-antisemitic English language tweets. Computational and Mathematical Organization Theory",
"## Acknowledgements \n\nThis work used Jetstream2 at Indiana University through allocation HUM200003 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296. \nWe are grateful for the support of Indiana University’s Observatory on Social Media (OSoMe) (Davis et al. 2016) and the contributions and annotations of all team members in our Social Media & Hate Research Lab at Indiana University’s Institute for the Study of Contemporary Antisemitism, especially Grace Bland, Elisha S. Breton, Kathryn Cooper, Robin Forstenhäusler, Sophie von Máriássy, Mabel Poindexter, Jenna Solomon, Clara Schilling, Emma Shriberg and Victor Tschiskale."
] |
[
"TAGS\n#language-German #twitter #X #hate speech #antisemitism #machine learning #juden #israel #region-us \n",
"# A German Language Labeled Dataset of Tweets \n\nGunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer\n{gjikeli, skarali, damieh, ksoemer}@URL",
"## Description\n \nOur dataset contains 8,048 German language tweets related to Jewish life from a four-year timespan. \nThe dataset consists of 18 samples of tweets with the keyword “Juden” or “Israel.” The samples are representative samples of all live tweets (at the time of sampling) with these keywords respectively over the indicated time period. Each sample was annotated by two expert annotators using an Annotation Portal that visualizes the live tweets in context. We provide the annotation results based on the agreement of two annotators, after discussing discrepancies (Jikeli et al. 2022: 3-6). \nOverall, 335 tweets (4%) were labelled as antisemitic following the IHRA Working Definition of Antisemitism. 1345 tweets (17 %) come from 2019, 1364 tweets (17 %) from 2020, 2639 tweets (33 %) from 2021 and 2700 tweets (34 %) from 2022. \n\nAbout half of the tweets, a total of 4,493 tweets (56 %) come from queries with the keyword “Juden,” which is representative of a continuous time period from January 2019 to December 2022: 864 tweets (19 %) come from 2019, 891 tweets (20 %) from 2020, 1364 tweets (30 %) from 2021 and 1374 (31 %). 148 out of the 4493 tweets, so 3% from the query with “Juden” are antisemitic. \n\nThe other part of the tweets, a total of 3,555 (44 %) results of queries with the keyword “Israel”. 481 tweets (14 %) of the keywords containing Israel stem from 2019, 473 (13 %) come from 2020, 1275 tweets (36 %) from 2021 and 1326 tweets (37 %) are from 2022. Out of all tweets from the “Israel” query, 187 (5 %) are antisemitic. \n\nThe csv file contains diacritics and special characters of the German language (e.g., “ä”, “ü”, “ö”, “ß”), which should be taken into account when opening it with anything other than a text editor.",
"## References \n\nGünther Jikeli, David Axelrod, Rhonda K. Fischer, Elham Forouzesh, Weejeong Jeong, Daniel Miehling, Katharina Soemer (2022): Differences between antisemitic and non-antisemitic English language tweets. Computational and Mathematical Organization Theory",
"## Acknowledgements \n\nThis work used Jetstream2 at Indiana University through allocation HUM200003 from the Advanced Cyberinfrastructure Coordination Ecosystem: Services & Support (ACCESS) program, which is supported by National Science Foundation grants #2138259, #2138286, #2138307, #2137603, and #2138296. \nWe are grateful for the support of Indiana University’s Observatory on Social Media (OSoMe) (Davis et al. 2016) and the contributions and annotations of all team members in our Social Media & Hate Research Lab at Indiana University’s Institute for the Study of Contemporary Antisemitism, especially Grace Bland, Elisha S. Breton, Kathryn Cooper, Robin Forstenhäusler, Sophie von Máriássy, Mabel Poindexter, Jenna Solomon, Clara Schilling, Emma Shriberg and Victor Tschiskale."
] |
[
31,
49,
460,
72,
199
] |
[
"passage: TAGS\n#language-German #twitter #X #hate speech #antisemitism #machine learning #juden #israel #region-us \n# A German Language Labeled Dataset of Tweets \n\nGunther Jikeli, Sameer Karali, Daniel Miehling and Katharina Soemer\n{gjikeli, skarali, damieh, ksoemer}@URL"
] |
0a0ac06d1817b01b4a1f10501ee2a772750efc42
|
[
{
"id": "ner_gpt_0",
"conversations": [
[
{ "from": "human",
"value": "Text: The impact of climate change on marine ecosystems and biodiversity is a pressing concern. Rising sea temperatures, ocean acidification, and changing currents have significant effects on marine life. Researchers are studying the adaptation mechanisms of various species to these environmental changes." },
{ "from": "gpt", "value": "I've read this text." },
{ "from": "human", "value": "What describes the main focus of the text?" },
{ "from": "gpt", "value": "[\"impact of climate change on marine ecosystems and biodiversity\"]" },
{ "from": "human", "value": "What describes environmental factors in the text?" },
{ "from": "gpt", "value": "[\"rising sea temperatures\", \"ocean acidification\", \"changing currents\"]" },
{ "from": "human", "value": "What describes the research subject in the text?" },
{ "from": "gpt", "value": "[\"adaptation mechanisms of various species\"]" },
{ "from": "human", "value": "What describes the time frame in the text?" },
{ "from": "gpt", "value": "[]" }
]
]
}
]
|
varuntrivedi/trial_dataset
|
[
"region:us"
] |
2023-10-30T14:26:26+00:00
|
{}
|
2023-10-30T14:28:01+00:00
|
[] |
[] |
TAGS
#region-us
|
[
{
"id": "ner_gpt_0",
"conversations": [
[
{ "from": "human",
"value": "Text: The impact of climate change on marine ecosystems and biodiversity is a pressing concern. Rising sea temperatures, ocean acidification, and changing currents have significant effects on marine life. Researchers are studying the adaptation mechanisms of various species to these environmental changes." },
{ "from": "gpt", "value": "I've read this text." },
{ "from": "human", "value": "What describes the main focus of the text?" },
{ "from": "gpt", "value": "[\"impact of climate change on marine ecosystems and biodiversity\"]" },
{ "from": "human", "value": "What describes environmental factors in the text?" },
{ "from": "gpt", "value": "[\"rising sea temperatures\", \"ocean acidification\", \"changing currents\"]" },
{ "from": "human", "value": "What describes the research subject in the text?" },
{ "from": "gpt", "value": "[\"adaptation mechanisms of various species\"]" },
{ "from": "human", "value": "What describes the time frame in the text?" },
{ "from": "gpt", "value": "[]" }
]
]
}
]
|
[] |
[
"TAGS\n#region-us \n"
] |
[
6
] |
[
"passage: TAGS\n#region-us \n"
] |
c561ccbaa74303b30014116646ec089907c2acbd
|
# Dataset Card for "JAX_FACADE_240"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
MylesChew/JAX_FACADE_240
|
[
"region:us"
] |
2023-10-30T14:31:55+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 3848813.0, "num_examples": 214}, {"name": "validation", "num_bytes": 371632.0, "num_examples": 24}], "download_size": 3438896, "dataset_size": 4220445.0}}
|
2023-10-30T20:29:55+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "JAX_FACADE_240"
More Information needed
|
[
"# Dataset Card for \"JAX_FACADE_240\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"JAX_FACADE_240\"\n\nMore Information needed"
] |
[
6,
18
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"JAX_FACADE_240\"\n\nMore Information needed"
] |
5a67ae411e8359a9d93d5a467f308715baea0887
|
# Kandinksy 2.2
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts. This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import PIL
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import DiffusionPipeline
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
pipe_prior = DiffusionPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-prior", torch_dtype=torch.float16
)
pipe_prior.to("cuda")
pipe_prior.set_progress_bar_config(disable=True)
t2i_pipe = DiffusionPipeline.from_pretrained(
"kandinsky-community/kandinsky-2-2-decoder", torch_dtype=torch.float16
)
t2i_pipe.to("cuda")
t2i_pipe.set_progress_bar_config(disable=True)
seed = 0
generator = torch.Generator("cuda").manual_seed(seed)
ckpt_id = (
"kandinsky-community/" + "kandinsky-2-2-prior" + "_" + "kandinsky-2-2-decoder"
)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
image_embeds, negative_image_embeds = pipe_prior(
prompt,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).to_tuple()
image = t2i_pipe(
image_embeds=image_embeds,
negative_image_embeds=negative_image_embeds,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).images[0]
image = image.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"kandinsky_22_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/kandinsky-2-2"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
```
|
Almost-AGI-Diffusion/kand2
|
[
"region:us"
] |
2023-10-30T14:42:57+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Category", "dtype": "string"}, {"name": "Challenge", "dtype": "string"}, {"name": "Note", "dtype": "string"}, {"name": "images", "dtype": "image"}, {"name": "model_name", "dtype": "string"}, {"name": "seed", "dtype": "int64"}, {"name": "upvotes", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 21708501.0, "num_examples": 219}], "download_size": 21693707, "dataset_size": 21708501.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T14:49:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Kandinksy 2.2
All images included in this dataset were voted as "Not solved" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
|
[
"# Kandinksy 2.2\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
"TAGS\n#region-us \n",
"# Kandinksy 2.2\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
6,
61
] |
[
"passage: TAGS\n#region-us \n# Kandinksy 2.2\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
739f10e7da36d464f6494a9de321a4d9b0bd2be5
|
# SDXL
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts.
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import DDIMScheduler, DiffusionPipeline
import PIL
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
ckpt_id = "stabilityai/stable-diffusion-xl-base-1.0"
refiner_ckpt_id = "stabilityai/stable-diffusion-xl-refiner-1.0"
pipe = DiffusionPipeline.from_pretrained(
ckpt_id, torch_dtype=torch.float16, use_auth_token=True
).to("cuda")
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
pipe.set_progress_bar_config(disable=True)
refiner = DiffusionPipeline.from_pretrained(
refiner_ckpt_id,
torch_dtype=torch.float16,
use_auth_token=True
).to("cuda")
refiner.scheduler = DDIMScheduler.from_config(refiner.scheduler.config)
refiner.set_progress_bar_config(disable=True)
seed = 0
generator = torch.Generator("cuda").manual_seed(seed)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
latent = pipe(
prompt,
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
output_type="latent",
).images[0]
image_refined = refiner(
prompt=prompt,
image=latent[None, :],
generator=generator,
num_inference_steps=100,
guidance_scale=7.5,
).images[0]
image = image_refined.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"sd_xl_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/sdxl-1.0-refiner"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
```
|
Almost-AGI-Diffusion/sdxl
|
[
"region:us"
] |
2023-10-30T14:43:04+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Category", "dtype": "string"}, {"name": "Challenge", "dtype": "string"}, {"name": "Note", "dtype": "string"}, {"name": "images", "dtype": "image"}, {"name": "model_name", "dtype": "string"}, {"name": "seed", "dtype": "int64"}, {"name": "upvotes", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 25650684.0, "num_examples": 219}], "download_size": 25640015, "dataset_size": 25650684.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T14:46:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# SDXL
All images included in this dataset were voted as "Not solved" by the community in URL
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
|
[
"# SDXL\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
"TAGS\n#region-us \n",
"# SDXL\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
6,
59
] |
[
"passage: TAGS\n#region-us \n# SDXL\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
ac9ce534a725db6096109a188cba475aaf0f5c8c
|
# Wuerstchen
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts. This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
import torch
from datasets import Dataset, Features
from datasets import Image as ImageFeature
from datasets import Value, load_dataset
from diffusers import AutoPipelineForText2Image
import PIL
def main():
print("Loading dataset...")
parti_prompts = load_dataset("nateraw/parti-prompts", split="train")
print("Loading pipeline...")
seed = 0
device = "cuda"
generator = torch.Generator(device).manual_seed(seed)
dtype = torch.float16
ckpt_id = "warp-diffusion/wuerstchen"
pipeline = AutoPipelineForText2Image.from_pretrained(
ckpt_id, torch_dtype=dtype
).to(device)
pipeline.prior_prior = torch.compile(pipeline.prior_prior, mode="reduce-overhead", fullgraph=True)
pipeline.decoder = torch.compile(pipeline.decoder, mode="reduce-overhead", fullgraph=True)
print("Running inference...")
main_dict = {}
for i in range(len(parti_prompts)):
sample = parti_prompts[i]
prompt = sample["Prompt"]
image = pipeline(
prompt=prompt,
height=1024,
width=1024,
prior_guidance_scale=4.0,
decoder_guidance_scale=0.0,
generator=generator,
).images[0]
image = image.resize((256, 256), resample=PIL.Image.Resampling.LANCZOS)
img_path = f"wuerstchen_{i}.png"
image.save(img_path)
main_dict.update(
{
prompt: {
"img_path": img_path,
"Category": sample["Category"],
"Challenge": sample["Challenge"],
"Note": sample["Note"],
"model_name": ckpt_id,
"seed": seed,
}
}
)
def generation_fn():
for prompt in main_dict:
prompt_entry = main_dict[prompt]
yield {
"Prompt": prompt,
"Category": prompt_entry["Category"],
"Challenge": prompt_entry["Challenge"],
"Note": prompt_entry["Note"],
"images": {"path": prompt_entry["img_path"]},
"model_name": prompt_entry["model_name"],
"seed": prompt_entry["seed"],
}
print("Preparing HF dataset...")
ds = Dataset.from_generator(
generation_fn,
features=Features(
Prompt=Value("string"),
Category=Value("string"),
Challenge=Value("string"),
Note=Value("string"),
images=ImageFeature(),
model_name=Value("string"),
seed=Value("int64"),
),
)
ds_id = "diffusers-parti-prompts/wuerstchen"
ds.push_to_hub(ds_id)
if __name__ == "__main__":
main()
```
|
Almost-AGI-Diffusion/wuerst
|
[
"region:us"
] |
2023-10-30T14:43:10+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Category", "dtype": "string"}, {"name": "Challenge", "dtype": "string"}, {"name": "Note", "dtype": "string"}, {"name": "images", "dtype": "image"}, {"name": "model_name", "dtype": "string"}, {"name": "seed", "dtype": "int64"}, {"name": "upvotes", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 19633368.0, "num_examples": 219}], "download_size": 19625614, "dataset_size": 19633368.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T14:50:04+00:00
|
[] |
[] |
TAGS
#region-us
|
# Wuerstchen
All images included in this dataset were voted as "Not solved" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
|
[
"# Wuerstchen\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
"TAGS\n#region-us \n",
"# Wuerstchen\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
6,
61
] |
[
"passage: TAGS\n#region-us \n# Wuerstchen\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
35ece4111ef1febf86df79c6c98ebe88d333506f
|
# Karlo
All images included in this dataset were voted as "Not solved" by the community in https://huggingface.co/spaces/OpenGenAI/open-parti-prompts.
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
```py
from diffusers import DiffusionPipeline
import torch
pipe = DiffusionPipeline.from_pretrained("kakaobrain/karlo-v1-alpha", torch_dtype=torch.float16)
pipe.to("cuda")
prompt = "" # a parti prompt
generator = torch.Generator("cuda").manual_seed(0)
image = pipe(prompt, prior_num_inference_steps=50, decoder_num_inference_steps=100, generator=generator).images[0]
```
|
Almost-AGI-Diffusion/karlo
|
[
"region:us"
] |
2023-10-30T14:43:16+00:00
|
{"dataset_info": {"features": [{"name": "Prompt", "dtype": "string"}, {"name": "Category", "dtype": "string"}, {"name": "Challenge", "dtype": "string"}, {"name": "Note", "dtype": "string"}, {"name": "images", "dtype": "image"}, {"name": "model_name", "dtype": "string"}, {"name": "seed", "dtype": "int64"}, {"name": "upvotes", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 20834626.0, "num_examples": 219}], "download_size": 20825015, "dataset_size": 20834626.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T14:48:09+00:00
|
[] |
[] |
TAGS
#region-us
|
# Karlo
All images included in this dataset were voted as "Not solved" by the community in URL
This means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.
The following script was used to generate the images:
|
[
"# Karlo\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
"TAGS\n#region-us \n",
"# Karlo\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
[
6,
59
] |
[
"passage: TAGS\n#region-us \n# Karlo\n\nAll images included in this dataset were voted as \"Not solved\" by the community in URL\nThis means that according to the community the model did not generate an image that corresponds sufficiently enough to the prompt.\n\nThe following script was used to generate the images:"
] |
b615ea51c49a897c2271cba113fc7b07811f7937
|
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed]
|
bordman/mihTest
|
[
"task_categories:text2text-generation",
"size_categories:10K<n<100K",
"language:de",
"language:en",
"language:nl",
"language:sl",
"license:apache-2.0",
"region:us"
] |
2023-10-30T15:00:28+00:00
|
{"language": ["de", "en", "nl", "sl"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text2text-generation"], "pretty_name": "invoice_test"}
|
2023-11-02T09:57:06+00:00
|
[] |
[
"de",
"en",
"nl",
"sl"
] |
TAGS
#task_categories-text2text-generation #size_categories-10K<n<100K #language-German #language-English #language-Dutch #language-Slovenian #license-apache-2.0 #region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
|
[
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
"TAGS\n#task_categories-text2text-generation #size_categories-10K<n<100K #language-German #language-English #language-Dutch #language-Slovenian #license-apache-2.0 #region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] |
[
58,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] |
[
"passage: TAGS\n#task_categories-text2text-generation #size_categories-10K<n<100K #language-German #language-English #language-Dutch #language-Slovenian #license-apache-2.0 #region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
7af813e0496ab703bd2427cbb42e0b2453123e41
|
# Dataset Card for "b8542650"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
result-kand2-sdxl-wuerst-karlo/b8542650
|
[
"region:us"
] |
2023-10-30T15:00:45+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 179, "num_examples": 10}], "download_size": 1367, "dataset_size": 179}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T15:00:46+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "b8542650"
More Information needed
|
[
"# Dataset Card for \"b8542650\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"b8542650\"\n\nMore Information needed"
] |
[
6,
14
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"b8542650\"\n\nMore Information needed"
] |
21ee35ccbc9560a1d142591640b220a970b14000
|
# Dataset Card for "atlas-storyteller-1000"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Chamoda/atlas-storyteller-1000
|
[
"region:us"
] |
2023-10-30T15:02:28+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "Story", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3357532, "num_examples": 800}], "download_size": 1949685, "dataset_size": 3357532}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-10-30T15:02:30+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "atlas-storyteller-1000"
More Information needed
|
[
"# Dataset Card for \"atlas-storyteller-1000\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"atlas-storyteller-1000\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"atlas-storyteller-1000\"\n\nMore Information needed"
] |
062b3027196abaa728f62d8dff65dc5ce1b4863d
|
# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic
This dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the `label` column) and is not balanced. Here are the number of rows of each class:
- 0 (Negative): **17,033 (34.06%)**
- 1 (Neutral): **11,136 (22.26%)**
- 2 (Positive): **21,847 (43.68%)**
Please note that there are some swear words in the dataset, so please use it with caution.
# Citation
If you find our work useful, please cite it as follows:
```bibtex
@article{2023,
title={Sentiment Analysis on Algerian Dialect with Transformers},
author={Zakaria Benmounah and Abdennour Boulesnane and Abdeladim Fadheli and Mustapha Khial},
journal={Applied Sciences},
volume={13},
number={20},
pages={11157},
year={2023},
month={Oct},
publisher={MDPI AG},
DOI={10.3390/app132011157},
ISSN={2076-3417},
url={http://dx.doi.org/10.3390/app132011157}
}
```
|
Abdou/dz-sentiment-yt-comments
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"language:ar",
"license:mit",
"region:us"
] |
2023-10-30T15:07:21+00:00
|
{"language": ["ar"], "license": "mit", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"]}
|
2023-11-06T10:49:24+00:00
|
[] |
[
"ar"
] |
TAGS
#task_categories-text-classification #size_categories-10K<n<100K #language-Arabic #license-mit #region-us
|
# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic
This dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the 'label' column) and is not balanced. Here are the number of rows of each class:
- 0 (Negative): 17,033 (34.06%)
- 1 (Neutral): 11,136 (22.26%)
- 2 (Positive): 21,847 (43.68%)
Please note that there are some swear words in the dataset, so please use it with caution.
If you find our work useful, please cite it as follows:
|
[
"# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic\nThis dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the 'label' column) and is not balanced. Here are the number of rows of each class:\n- 0 (Negative): 17,033 (34.06%)\n- 1 (Neutral): 11,136 (22.26%)\n- 2 (Positive): 21,847 (43.68%)\n\nPlease note that there are some swear words in the dataset, so please use it with caution.\n\nIf you find our work useful, please cite it as follows:"
] |
[
"TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-Arabic #license-mit #region-us \n",
"# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic\nThis dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the 'label' column) and is not balanced. Here are the number of rows of each class:\n- 0 (Negative): 17,033 (34.06%)\n- 1 (Neutral): 11,136 (22.26%)\n- 2 (Positive): 21,847 (43.68%)\n\nPlease note that there are some swear words in the dataset, so please use it with caution.\n\nIf you find our work useful, please cite it as follows:"
] |
[
39,
155
] |
[
"passage: TAGS\n#task_categories-text-classification #size_categories-10K<n<100K #language-Arabic #license-mit #region-us \n# A Sentiment Analysis Dataset for the Algerian Dialect of Arabic\nThis dataset consists of 50,016 samples of comments extracted from Algerian YouTube channels. It is manually annotated with 3 classes (the 'label' column) and is not balanced. Here are the number of rows of each class:\n- 0 (Negative): 17,033 (34.06%)\n- 1 (Neutral): 11,136 (22.26%)\n- 2 (Positive): 21,847 (43.68%)\n\nPlease note that there are some swear words in the dataset, so please use it with caution.\n\nIf you find our work useful, please cite it as follows:"
] |
af70cc5d3c07022857b392ae2e150293a28df522
|
# Dataset Card for "leichte-sprache-definitionen"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jmelsbach/leichte-sprache-definitionen
|
[
"region:us"
] |
2023-10-30T15:08:20+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "title", "dtype": "string"}, {"name": "parsed_content", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 530344.0658114891, "num_examples": 2868}, {"name": "test", "num_bytes": 132770.93418851087, "num_examples": 718}], "download_size": 417716, "dataset_size": 663115.0}}
|
2023-10-30T15:08:24+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "leichte-sprache-definitionen"
More Information needed
|
[
"# Dataset Card for \"leichte-sprache-definitionen\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"leichte-sprache-definitionen\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"leichte-sprache-definitionen\"\n\nMore Information needed"
] |
918885a84170d8a86c9654edcc544e79abdb5885
|
# Dataset Card for "dataset_for_orange_factures"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ayoub999/dataset_for_orange_factures
|
[
"region:us"
] |
2023-10-30T15:15:47+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "image", "dtype": "image"}, {"name": "bboxes", "sequence": {"sequence": "int64"}}, {"name": "ner_tags", "sequence": {"class_label": {"names": {"0": "O", "1": "Ref", "2": "NumFa", "3": "Fourniss", "4": "DateFa", "5": "DateLim", "6": "TotalHT", "7": "TVA", "8": "TotalTTc", "9": "unitP", "10": "Qt", "11": "TVAP", "12": "D\u00e9signation", "13": "Adresse"}}}}, {"name": "tokens", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 2942860.8, "num_examples": 12}, {"name": "test", "num_bytes": 735715.2, "num_examples": 3}], "download_size": 2799104, "dataset_size": 3678576.0}}
|
2023-11-09T13:59:48+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "dataset_for_orange_factures"
More Information needed
|
[
"# Dataset Card for \"dataset_for_orange_factures\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"dataset_for_orange_factures\"\n\nMore Information needed"
] |
[
6,
20
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"dataset_for_orange_factures\"\n\nMore Information needed"
] |
304325967091d279bc2c3a7d7974d4006a413a35
|
# Dataset Card for "BMO_vicuna_function"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bibidentuhanoi/BMO_vicuna_function
|
[
"region:us"
] |
2023-10-30T15:22:34+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "conversations", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 161113, "num_examples": 149}], "download_size": 82761, "dataset_size": 161113}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-03T15:18:58+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "BMO_vicuna_function"
More Information needed
|
[
"# Dataset Card for \"BMO_vicuna_function\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"BMO_vicuna_function\"\n\nMore Information needed"
] |
[
6,
17
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"BMO_vicuna_function\"\n\nMore Information needed"
] |
20463e6f151d99ee4b8b0b5a18fda6ff050d5d89
|
# Dataset Card for "BMO_BASE_FUNCTION_TEXT"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bibidentuhanoi/BMO_BASE_FUNCTION_TEXT
|
[
"region:us"
] |
2023-10-30T15:26:57+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 279348, "num_examples": 354}], "download_size": 88670, "dataset_size": 279348}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-12-21T16:39:31+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "BMO_BASE_FUNCTION_TEXT"
More Information needed
|
[
"# Dataset Card for \"BMO_BASE_FUNCTION_TEXT\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"BMO_BASE_FUNCTION_TEXT\"\n\nMore Information needed"
] |
[
6,
22
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"BMO_BASE_FUNCTION_TEXT\"\n\nMore Information needed"
] |
13a07d62fd3c88bb5f896fb7da57b5162fd48b5c
|
# Dataset Card for "covid-tweet-sentiment-analyzer-distilbert-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
snyamson/covid-tweet-sentiment-analyzer-distilbert-data
|
[
"region:us"
] |
2023-10-30T15:42:22+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "val", "path": "data/val-*"}]}], "dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 10366704, "num_examples": 7999}, {"name": "val", "num_bytes": 2592000, "num_examples": 2000}], "download_size": 514530, "dataset_size": 12958704}}
|
2023-10-30T15:42:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "covid-tweet-sentiment-analyzer-distilbert-data"
More Information needed
|
[
"# Dataset Card for \"covid-tweet-sentiment-analyzer-distilbert-data\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"covid-tweet-sentiment-analyzer-distilbert-data\"\n\nMore Information needed"
] |
[
6,
27
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"covid-tweet-sentiment-analyzer-distilbert-data\"\n\nMore Information needed"
] |
fcc9c0ec98a941c2e127b20d302d722f05533fd3
|
Hello
|
Jackmin108/cult-de-small
|
[
"license:apache-2.0",
"region:us"
] |
2023-10-30T15:46:46+00:00
|
{"license": "apache-2.0", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": ["data/train-0000.parquet", "data/train-0001.parquet", "data/train-0002.parquet", "data/train-0003.parquet", "data/train-0004.parquet", "data/train-0005.parquet", "data/train-0006.parquet", "data/train-0007.parquet"]}, {"split": "validation", "path": ["data/validation-0000.parquet", "data/validation-0001.parquet", "data/validation-0002.parquet", "data/validation-0003.parquet", "data/validation-0004.parquet", "data/validation-0005.parquet", "data/validation-0006.parquet", "data/validation-0007.parquet"]}]}]}
|
2023-10-30T15:49:39+00:00
|
[] |
[] |
TAGS
#license-apache-2.0 #region-us
|
Hello
|
[] |
[
"TAGS\n#license-apache-2.0 #region-us \n"
] |
[
14
] |
[
"passage: TAGS\n#license-apache-2.0 #region-us \n"
] |
a1d32567566828152e420afa7b5c0f7b604af2b4
|
# Dataset Card for "tla_code_train"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
aneeshas/tla_code_train
|
[
"region:us"
] |
2023-10-30T16:13:13+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 776809, "num_examples": 72}], "download_size": 270235, "dataset_size": 776809}}
|
2023-10-30T16:13:25+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "tla_code_train"
More Information needed
|
[
"# Dataset Card for \"tla_code_train\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"tla_code_train\"\n\nMore Information needed"
] |
[
6,
16
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"tla_code_train\"\n\nMore Information needed"
] |
209ddba905cb9aa212bd99cebd71d83d3617235c
|
# Dataset Card for "id_card"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
erikaxenia/id_card
|
[
"region:us"
] |
2023-10-30T16:33:10+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "ground_truth", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 75251549.0, "num_examples": 276}, {"name": "valid", "num_bytes": 7840082.0, "num_examples": 38}, {"name": "test", "num_bytes": 4404357.0, "num_examples": 50}], "download_size": 0, "dataset_size": 87495988.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "valid", "path": "data/valid-*"}, {"split": "test", "path": "data/test-*"}]}]}
|
2023-10-31T22:12:40+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "id_card"
More Information needed
|
[
"# Dataset Card for \"id_card\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"id_card\"\n\nMore Information needed"
] |
[
6,
13
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"id_card\"\n\nMore Information needed"
] |
241512db704fd5522db792c14932287390706b74
|
# Dataset Card for "prob"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
xrizs/prob
|
[
"region:us"
] |
2023-10-30T16:45:35+00:00
|
{"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "test", "1": "train", "2": "valid"}}}}], "splits": [{"name": "train", "num_bytes": 4113145.0, "num_examples": 58}, {"name": "validation", "num_bytes": 1480042.0, "num_examples": 20}, {"name": "test", "num_bytes": 622722.0, "num_examples": 9}], "download_size": 6223810, "dataset_size": 6215909.0}}
|
2023-10-30T16:45:39+00:00
|
[] |
[] |
TAGS
#region-us
|
# Dataset Card for "prob"
More Information needed
|
[
"# Dataset Card for \"prob\"\n\nMore Information needed"
] |
[
"TAGS\n#region-us \n",
"# Dataset Card for \"prob\"\n\nMore Information needed"
] |
[
6,
11
] |
[
"passage: TAGS\n#region-us \n# Dataset Card for \"prob\"\n\nMore Information needed"
] |
87e545fb1a9fe82fcffbb105103b18b2d1cc1189
|
# Dataset Card for iSUN for OOD Detection
<!-- Provide a quick summary of the dataset. -->
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Original Dataset Authors**: Junting Pan, Xavier Giró-i-Nieto
- **OOD Split Authors:** Shiyu Liang, Yixuan Li, R. Srikant
- **Shared by:** Eduardo Dadalto
- **License:** unknown
### Dataset Sources
<!-- Provide the basic links for the dataset. -->
- **Original Dataset Paper:** http://arxiv.org/abs/1507.01422v1
- **First OOD Application Paper:** http://arxiv.org/abs/1706.02690v5
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
This dataset is intended to be used as an ouf-of-distribution dataset for image classification benchmarks.
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
This dataset is not annotated.
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
The goal in curating and sharing this dataset to the HuggingFace Hub is to accelerate research and promote reproducibility in generalized Out-of-Distribution (OOD) detection.
Check the python library [detectors](https://github.com/edadaltocg/detectors) if you are interested in OOD detection.
### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
Please check original paper for details on the dataset.
### Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Please check original paper for details on the dataset.
## Citation
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
```bibtex
@software{detectors2023,
author = {Eduardo Dadalto},
title = {Detectors: a Python Library for Generalized Out-Of-Distribution Detection},
url = {https://github.com/edadaltocg/detectors},
doi = {https://doi.org/10.5281/zenodo.7883596},
month = {5},
year = {2023}
}
@article{1706.02690v5,
author = {Shiyu Liang and Yixuan Li and R. Srikant},
title = {Enhancing The Reliability of Out-of-distribution Image Detection in
Neural Networks},
year = {2017},
month = {6},
note = {ICLR 2018},
archiveprefix = {arXiv},
url = {http://arxiv.org/abs/1706.02690v5}
}
@article{1507.01422v1,
author = {Junting Pan and Xavier Giró-i-Nieto},
title = {End-to-end Convolutional Network for Saliency Prediction},
year = {2015},
month = {7},
note = {Winner of the saliency prediction challenge in the Large-scale Scene
Understanding (LSUN) Challenge in the associated workshop of the IEEE
Conference on Computer Vision and Pattern Recognition (CVPR) 2015},
archiveprefix = {arXiv},
url = {http://arxiv.org/abs/1507.01422v1}
}
```
## Dataset Card Authors
Eduardo Dadalto
## Dataset Card Contact
https://huggingface.co/edadaltocg
|
detectors/isun-ood
|
[
"task_categories:image-classification",
"size_categories:1K<n<10K",
"license:unknown",
"arxiv:1507.01422",
"arxiv:1706.02690",
"region:us"
] |
2023-10-30T16:55:14+00:00
|
{"license": "unknown", "size_categories": "1K<n<10K", "task_categories": ["image-classification"], "paperswithcode_id": "isun", "pretty_name": "iSUN", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "image", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 24514257.375, "num_examples": 8925}], "download_size": 0, "dataset_size": 24514257.375}}
|
2023-10-30T18:25:18+00:00
|
[
"1507.01422",
"1706.02690"
] |
[] |
TAGS
#task_categories-image-classification #size_categories-1K<n<10K #license-unknown #arxiv-1507.01422 #arxiv-1706.02690 #region-us
|
# Dataset Card for iSUN for OOD Detection
## Dataset Details
### Dataset Description
- Original Dataset Authors: Junting Pan, Xavier Giró-i-Nieto
- OOD Split Authors: Shiyu Liang, Yixuan Li, R. Srikant
- Shared by: Eduardo Dadalto
- License: unknown
### Dataset Sources
- Original Dataset Paper: URL
- First OOD Application Paper: URL
### Direct Use
This dataset is intended to be used as an ouf-of-distribution dataset for image classification benchmarks.
### Out-of-Scope Use
This dataset is not annotated.
### Curation Rationale
The goal in curating and sharing this dataset to the HuggingFace Hub is to accelerate research and promote reproducibility in generalized Out-of-Distribution (OOD) detection.
Check the python library detectors if you are interested in OOD detection.
### Personal and Sensitive Information
Please check original paper for details on the dataset.
### Bias, Risks, and Limitations
Please check original paper for details on the dataset.
BibTeX:
## Dataset Card Authors
Eduardo Dadalto
## Dataset Card Contact
URL
|
[
"# Dataset Card for iSUN for OOD Detection",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Original Dataset Authors: Junting Pan, Xavier Giró-i-Nieto\n- OOD Split Authors: Shiyu Liang, Yixuan Li, R. Srikant\n- Shared by: Eduardo Dadalto\n- License: unknown",
"### Dataset Sources\n\n\n\n- Original Dataset Paper: URL\n- First OOD Application Paper: URL",
"### Direct Use\n\n\n\nThis dataset is intended to be used as an ouf-of-distribution dataset for image classification benchmarks.",
"### Out-of-Scope Use\n\n\n\nThis dataset is not annotated.",
"### Curation Rationale\n\n\n\nThe goal in curating and sharing this dataset to the HuggingFace Hub is to accelerate research and promote reproducibility in generalized Out-of-Distribution (OOD) detection.\n\nCheck the python library detectors if you are interested in OOD detection.",
"### Personal and Sensitive Information\n\n\n\nPlease check original paper for details on the dataset.",
"### Bias, Risks, and Limitations\n\n\n\nPlease check original paper for details on the dataset.\n\nBibTeX:",
"## Dataset Card Authors\n\nEduardo Dadalto",
"## Dataset Card Contact\n\nURL"
] |
[
"TAGS\n#task_categories-image-classification #size_categories-1K<n<10K #license-unknown #arxiv-1507.01422 #arxiv-1706.02690 #region-us \n",
"# Dataset Card for iSUN for OOD Detection",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Original Dataset Authors: Junting Pan, Xavier Giró-i-Nieto\n- OOD Split Authors: Shiyu Liang, Yixuan Li, R. Srikant\n- Shared by: Eduardo Dadalto\n- License: unknown",
"### Dataset Sources\n\n\n\n- Original Dataset Paper: URL\n- First OOD Application Paper: URL",
"### Direct Use\n\n\n\nThis dataset is intended to be used as an ouf-of-distribution dataset for image classification benchmarks.",
"### Out-of-Scope Use\n\n\n\nThis dataset is not annotated.",
"### Curation Rationale\n\n\n\nThe goal in curating and sharing this dataset to the HuggingFace Hub is to accelerate research and promote reproducibility in generalized Out-of-Distribution (OOD) detection.\n\nCheck the python library detectors if you are interested in OOD detection.",
"### Personal and Sensitive Information\n\n\n\nPlease check original paper for details on the dataset.",
"### Bias, Risks, and Limitations\n\n\n\nPlease check original paper for details on the dataset.\n\nBibTeX:",
"## Dataset Card Authors\n\nEduardo Dadalto",
"## Dataset Card Contact\n\nURL"
] |
[
52,
12,
4,
59,
21,
30,
18,
67,
19,
27,
9,
6
] |
[
"passage: TAGS\n#task_categories-image-classification #size_categories-1K<n<10K #license-unknown #arxiv-1507.01422 #arxiv-1706.02690 #region-us \n# Dataset Card for iSUN for OOD Detection## Dataset Details### Dataset Description\n\n\n\n\n\n- Original Dataset Authors: Junting Pan, Xavier Giró-i-Nieto\n- OOD Split Authors: Shiyu Liang, Yixuan Li, R. Srikant\n- Shared by: Eduardo Dadalto\n- License: unknown### Dataset Sources\n\n\n\n- Original Dataset Paper: URL\n- First OOD Application Paper: URL### Direct Use\n\n\n\nThis dataset is intended to be used as an ouf-of-distribution dataset for image classification benchmarks.### Out-of-Scope Use\n\n\n\nThis dataset is not annotated.### Curation Rationale\n\n\n\nThe goal in curating and sharing this dataset to the HuggingFace Hub is to accelerate research and promote reproducibility in generalized Out-of-Distribution (OOD) detection.\n\nCheck the python library detectors if you are interested in OOD detection.### Personal and Sensitive Information\n\n\n\nPlease check original paper for details on the dataset.### Bias, Risks, and Limitations\n\n\n\nPlease check original paper for details on the dataset.\n\nBibTeX:## Dataset Card Authors\n\nEduardo Dadalto## Dataset Card Contact\n\nURL"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.