
sha
stringlengths 40
40
| text
stringlengths 1
13.4M
| id
stringlengths 2
117
| tags
sequencelengths 1
7.91k
| created_at
stringlengths 25
25
| metadata
stringlengths 2
875k
| last_modified
stringlengths 25
25
| arxiv
sequencelengths 0
25
| languages
sequencelengths 0
7.91k
| tags_str
stringlengths 17
159k
| text_str
stringlengths 1
447k
| text_lists
sequencelengths 0
352
| processed_texts
sequencelengths 1
353
| tokens_length
sequencelengths 1
353
| input_texts
sequencelengths 1
40
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
7f1c06dfea53ada1242918118b9ad209166383bd | # Dataset Card for "bert-pretokenized-2048-wiki-2023"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | nomic-ai/nomic-bert-2048-pretraining-data | [
"region:us"
] | 2023-12-24T21:04:21+00:00 | {"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "token_type_ids", "sequence": "int8"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "special_tokens_mask", "sequence": "int8"}], "splits": [{"name": "train", "num_bytes": 38003435808, "num_examples": 2647954}], "download_size": 10083076260, "dataset_size": 38003435808}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-24T21:12:15+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "bert-pretokenized-2048-wiki-2023"
More Information needed | [
"# Dataset Card for \"bert-pretokenized-2048-wiki-2023\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"bert-pretokenized-2048-wiki-2023\"\n\nMore Information needed"
] | [
6,
22
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"bert-pretokenized-2048-wiki-2023\"\n\nMore Information needed"
] |
7923081c284fc429818f2d80746c9221d690e7a7 | # Dataset Card for "FUI"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | iamkaikai/FUI | [
"region:us"
] | 2023-12-24T21:04:37+00:00 | {"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2001590.0, "num_examples": 59}], "download_size": 1944710, "dataset_size": 2001590.0}} | 2023-12-24T21:04:38+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "FUI"
More Information needed | [
"# Dataset Card for \"FUI\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"FUI\"\n\nMore Information needed"
] | [
6,
12
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"FUI\"\n\nMore Information needed"
] |
7ff1cdb43d16c70ae4e9894953bcab9773991520 |
# Dataset Card for Evaluation run of argilla/notus-8x7b-experiment
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [argilla/notus-8x7b-experiment](https://huggingface.co/argilla/notus-8x7b-experiment) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_argilla__notus-8x7b-experiment",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-24T21:16:18.856195](https://huggingface.co/datasets/open-llm-leaderboard/details_argilla__notus-8x7b-experiment/blob/main/results_2023-12-24T21-16-18.856195.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.7124178625456173,
"acc_stderr": 0.030199955715548343,
"acc_norm": 0.7160635607907738,
"acc_norm_stderr": 0.0307822236181654,
"mc1": 0.5079559363525091,
"mc1_stderr": 0.01750128507455182,
"mc2": 0.6579117349463197,
"mc2_stderr": 0.015011154188590699
},
"harness|arc:challenge|25": {
"acc": 0.6757679180887372,
"acc_stderr": 0.013678810399518822,
"acc_norm": 0.7098976109215017,
"acc_norm_stderr": 0.013261573677520762
},
"harness|hellaswag|10": {
"acc": 0.688707428799044,
"acc_stderr": 0.004620758579628659,
"acc_norm": 0.8773152758414658,
"acc_norm_stderr": 0.0032740447231806207
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.43,
"acc_stderr": 0.04975698519562429,
"acc_norm": 0.43,
"acc_norm_stderr": 0.04975698519562429
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6814814814814815,
"acc_stderr": 0.04024778401977108,
"acc_norm": 0.6814814814814815,
"acc_norm_stderr": 0.04024778401977108
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.7894736842105263,
"acc_stderr": 0.03317672787533157,
"acc_norm": 0.7894736842105263,
"acc_norm_stderr": 0.03317672787533157
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.74,
"acc_stderr": 0.0440844002276808,
"acc_norm": 0.74,
"acc_norm_stderr": 0.0440844002276808
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.7886792452830189,
"acc_stderr": 0.025125766484827845,
"acc_norm": 0.7886792452830189,
"acc_norm_stderr": 0.025125766484827845
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.8194444444444444,
"acc_stderr": 0.032166008088022675,
"acc_norm": 0.8194444444444444,
"acc_norm_stderr": 0.032166008088022675
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.5,
"acc_stderr": 0.050251890762960605,
"acc_norm": 0.5,
"acc_norm_stderr": 0.050251890762960605
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.64,
"acc_stderr": 0.04824181513244218,
"acc_norm": 0.64,
"acc_norm_stderr": 0.04824181513244218
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.45,
"acc_stderr": 0.05,
"acc_norm": 0.45,
"acc_norm_stderr": 0.05
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.7572254335260116,
"acc_stderr": 0.0326926380614177,
"acc_norm": 0.7572254335260116,
"acc_norm_stderr": 0.0326926380614177
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.4117647058823529,
"acc_stderr": 0.048971049527263666,
"acc_norm": 0.4117647058823529,
"acc_norm_stderr": 0.048971049527263666
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.81,
"acc_stderr": 0.039427724440366234,
"acc_norm": 0.81,
"acc_norm_stderr": 0.039427724440366234
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.676595744680851,
"acc_stderr": 0.030579442773610334,
"acc_norm": 0.676595744680851,
"acc_norm_stderr": 0.030579442773610334
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.5964912280701754,
"acc_stderr": 0.04615186962583707,
"acc_norm": 0.5964912280701754,
"acc_norm_stderr": 0.04615186962583707
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.6482758620689655,
"acc_stderr": 0.0397923663749741,
"acc_norm": 0.6482758620689655,
"acc_norm_stderr": 0.0397923663749741
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.48148148148148145,
"acc_stderr": 0.025733641991838987,
"acc_norm": 0.48148148148148145,
"acc_norm_stderr": 0.025733641991838987
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.5079365079365079,
"acc_stderr": 0.044715725362943486,
"acc_norm": 0.5079365079365079,
"acc_norm_stderr": 0.044715725362943486
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.4,
"acc_stderr": 0.04923659639173309,
"acc_norm": 0.4,
"acc_norm_stderr": 0.04923659639173309
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.8516129032258064,
"acc_stderr": 0.020222737554330378,
"acc_norm": 0.8516129032258064,
"acc_norm_stderr": 0.020222737554330378
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.6157635467980296,
"acc_stderr": 0.03422398565657551,
"acc_norm": 0.6157635467980296,
"acc_norm_stderr": 0.03422398565657551
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.79,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.79,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.793939393939394,
"acc_stderr": 0.03158415324047709,
"acc_norm": 0.793939393939394,
"acc_norm_stderr": 0.03158415324047709
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.8585858585858586,
"acc_stderr": 0.024825909793343336,
"acc_norm": 0.8585858585858586,
"acc_norm_stderr": 0.024825909793343336
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9637305699481865,
"acc_stderr": 0.013492659751295159,
"acc_norm": 0.9637305699481865,
"acc_norm_stderr": 0.013492659751295159
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.6923076923076923,
"acc_stderr": 0.02340092891831049,
"acc_norm": 0.6923076923076923,
"acc_norm_stderr": 0.02340092891831049
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3888888888888889,
"acc_stderr": 0.029723278961476664,
"acc_norm": 0.3888888888888889,
"acc_norm_stderr": 0.029723278961476664
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.8067226890756303,
"acc_stderr": 0.025649470265889183,
"acc_norm": 0.8067226890756303,
"acc_norm_stderr": 0.025649470265889183
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.4768211920529801,
"acc_stderr": 0.04078093859163083,
"acc_norm": 0.4768211920529801,
"acc_norm_stderr": 0.04078093859163083
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.8788990825688073,
"acc_stderr": 0.013987618292389713,
"acc_norm": 0.8788990825688073,
"acc_norm_stderr": 0.013987618292389713
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.5833333333333334,
"acc_stderr": 0.03362277436608043,
"acc_norm": 0.5833333333333334,
"acc_norm_stderr": 0.03362277436608043
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.8578431372549019,
"acc_stderr": 0.024509803921568617,
"acc_norm": 0.8578431372549019,
"acc_norm_stderr": 0.024509803921568617
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.8523206751054853,
"acc_stderr": 0.023094329582595694,
"acc_norm": 0.8523206751054853,
"acc_norm_stderr": 0.023094329582595694
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.7623318385650224,
"acc_stderr": 0.02856807946471428,
"acc_norm": 0.7623318385650224,
"acc_norm_stderr": 0.02856807946471428
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8015267175572519,
"acc_stderr": 0.03498149385462469,
"acc_norm": 0.8015267175572519,
"acc_norm_stderr": 0.03498149385462469
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.8760330578512396,
"acc_stderr": 0.030083098716035202,
"acc_norm": 0.8760330578512396,
"acc_norm_stderr": 0.030083098716035202
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.8425925925925926,
"acc_stderr": 0.03520703990517963,
"acc_norm": 0.8425925925925926,
"acc_norm_stderr": 0.03520703990517963
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.803680981595092,
"acc_stderr": 0.031207970394709218,
"acc_norm": 0.803680981595092,
"acc_norm_stderr": 0.031207970394709218
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.5892857142857143,
"acc_stderr": 0.04669510663875191,
"acc_norm": 0.5892857142857143,
"acc_norm_stderr": 0.04669510663875191
},
"harness|hendrycksTest-management|5": {
"acc": 0.8349514563106796,
"acc_stderr": 0.036756688322331886,
"acc_norm": 0.8349514563106796,
"acc_norm_stderr": 0.036756688322331886
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.9230769230769231,
"acc_stderr": 0.017456987872436186,
"acc_norm": 0.9230769230769231,
"acc_norm_stderr": 0.017456987872436186
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.76,
"acc_stderr": 0.04292346959909282,
"acc_norm": 0.76,
"acc_norm_stderr": 0.04292346959909282
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.8773946360153256,
"acc_stderr": 0.011728672144131563,
"acc_norm": 0.8773946360153256,
"acc_norm_stderr": 0.011728672144131563
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7832369942196532,
"acc_stderr": 0.022183477668412856,
"acc_norm": 0.7832369942196532,
"acc_norm_stderr": 0.022183477668412856
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.46033519553072627,
"acc_stderr": 0.016669799592112032,
"acc_norm": 0.46033519553072627,
"acc_norm_stderr": 0.016669799592112032
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.8235294117647058,
"acc_stderr": 0.021828596053108395,
"acc_norm": 0.8235294117647058,
"acc_norm_stderr": 0.021828596053108395
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7942122186495176,
"acc_stderr": 0.022961339906764244,
"acc_norm": 0.7942122186495176,
"acc_norm_stderr": 0.022961339906764244
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.8333333333333334,
"acc_stderr": 0.020736358408060006,
"acc_norm": 0.8333333333333334,
"acc_norm_stderr": 0.020736358408060006
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5602836879432624,
"acc_stderr": 0.02960991207559411,
"acc_norm": 0.5602836879432624,
"acc_norm_stderr": 0.02960991207559411
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.545632333767927,
"acc_stderr": 0.01271694172073482,
"acc_norm": 0.545632333767927,
"acc_norm_stderr": 0.01271694172073482
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.7867647058823529,
"acc_stderr": 0.024880971512294254,
"acc_norm": 0.7867647058823529,
"acc_norm_stderr": 0.024880971512294254
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.7696078431372549,
"acc_stderr": 0.01703522925803404,
"acc_norm": 0.7696078431372549,
"acc_norm_stderr": 0.01703522925803404
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.7090909090909091,
"acc_stderr": 0.04350271442923243,
"acc_norm": 0.7090909090909091,
"acc_norm_stderr": 0.04350271442923243
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7755102040816326,
"acc_stderr": 0.026711430555538405,
"acc_norm": 0.7755102040816326,
"acc_norm_stderr": 0.026711430555538405
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8955223880597015,
"acc_stderr": 0.021628920516700643,
"acc_norm": 0.8955223880597015,
"acc_norm_stderr": 0.021628920516700643
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.9,
"acc_stderr": 0.030151134457776334,
"acc_norm": 0.9,
"acc_norm_stderr": 0.030151134457776334
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5240963855421686,
"acc_stderr": 0.03887971849597264,
"acc_norm": 0.5240963855421686,
"acc_norm_stderr": 0.03887971849597264
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8888888888888888,
"acc_stderr": 0.024103384202072864,
"acc_norm": 0.8888888888888888,
"acc_norm_stderr": 0.024103384202072864
},
"harness|truthfulqa:mc|0": {
"mc1": 0.5079559363525091,
"mc1_stderr": 0.01750128507455182,
"mc2": 0.6579117349463197,
"mc2_stderr": 0.015011154188590699
},
"harness|winogrande|5": {
"acc": 0.8161010260457774,
"acc_stderr": 0.010887916013305889
},
"harness|gsm8k|5": {
"acc": 0.6163760424564063,
"acc_stderr": 0.01339423858493816
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | open-llm-leaderboard/details_argilla__notus-8x7b-experiment | [
"region:us"
] | 2023-12-24T21:18:33+00:00 | {"pretty_name": "Evaluation run of argilla/notus-8x7b-experiment", "dataset_summary": "Dataset automatically created during the evaluation run of model [argilla/notus-8x7b-experiment](https://huggingface.co/argilla/notus-8x7b-experiment) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\nTo load the details from a run, you can for instance do the following:\n```python\nfrom datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_argilla__notus-8x7b-experiment\",\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese are the [latest results from run 2023-12-24T21:16:18.856195](https://huggingface.co/datasets/open-llm-leaderboard/details_argilla__notus-8x7b-experiment/blob/main/results_2023-12-24T21-16-18.856195.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.7124178625456173,\n \"acc_stderr\": 0.030199955715548343,\n \"acc_norm\": 0.7160635607907738,\n \"acc_norm_stderr\": 0.0307822236181654,\n \"mc1\": 0.5079559363525091,\n \"mc1_stderr\": 0.01750128507455182,\n \"mc2\": 0.6579117349463197,\n \"mc2_stderr\": 0.015011154188590699\n },\n \"harness|arc:challenge|25\": {\n \"acc\": 0.6757679180887372,\n \"acc_stderr\": 0.013678810399518822,\n \"acc_norm\": 0.7098976109215017,\n \"acc_norm_stderr\": 0.013261573677520762\n },\n \"harness|hellaswag|10\": {\n \"acc\": 0.688707428799044,\n \"acc_stderr\": 0.004620758579628659,\n \"acc_norm\": 0.8773152758414658,\n \"acc_norm_stderr\": 0.0032740447231806207\n },\n \"harness|hendrycksTest-abstract_algebra|5\": {\n \"acc\": 0.43,\n \"acc_stderr\": 0.04975698519562429,\n \"acc_norm\": 0.43,\n \"acc_norm_stderr\": 0.04975698519562429\n },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6814814814814815,\n \"acc_stderr\": 0.04024778401977108,\n \"acc_norm\": 0.6814814814814815,\n \"acc_norm_stderr\": 0.04024778401977108\n },\n \"harness|hendrycksTest-astronomy|5\": {\n \"acc\": 0.7894736842105263,\n \"acc_stderr\": 0.03317672787533157,\n \"acc_norm\": 0.7894736842105263,\n \"acc_norm_stderr\": 0.03317672787533157\n },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.74,\n \"acc_stderr\": 0.0440844002276808,\n \"acc_norm\": 0.74,\n \"acc_norm_stderr\": 0.0440844002276808\n },\n \"harness|hendrycksTest-clinical_knowledge|5\": {\n \"acc\": 0.7886792452830189,\n \"acc_stderr\": 0.025125766484827845,\n \"acc_norm\": 0.7886792452830189,\n \"acc_norm_stderr\": 0.025125766484827845\n },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.8194444444444444,\n \"acc_stderr\": 0.032166008088022675,\n \"acc_norm\": 0.8194444444444444,\n \"acc_norm_stderr\": 0.032166008088022675\n },\n \"harness|hendrycksTest-college_chemistry|5\": {\n \"acc\": 0.5,\n \"acc_stderr\": 0.050251890762960605,\n \"acc_norm\": 0.5,\n \"acc_norm_stderr\": 0.050251890762960605\n },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\": 0.64,\n \"acc_stderr\": 0.04824181513244218,\n \"acc_norm\": 0.64,\n \"acc_norm_stderr\": 0.04824181513244218\n },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.45,\n \"acc_stderr\": 0.05,\n \"acc_norm\": 0.45,\n \"acc_norm_stderr\": 0.05\n },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.7572254335260116,\n \"acc_stderr\": 0.0326926380614177,\n \"acc_norm\": 0.7572254335260116,\n \"acc_norm_stderr\": 0.0326926380614177\n },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.4117647058823529,\n \"acc_stderr\": 0.048971049527263666,\n \"acc_norm\": 0.4117647058823529,\n \"acc_norm_stderr\": 0.048971049527263666\n },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\": 0.81,\n \"acc_stderr\": 0.039427724440366234,\n \"acc_norm\": 0.81,\n \"acc_norm_stderr\": 0.039427724440366234\n },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.676595744680851,\n \"acc_stderr\": 0.030579442773610334,\n \"acc_norm\": 0.676595744680851,\n \"acc_norm_stderr\": 0.030579442773610334\n },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.5964912280701754,\n \"acc_stderr\": 0.04615186962583707,\n \"acc_norm\": 0.5964912280701754,\n \"acc_norm_stderr\": 0.04615186962583707\n },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\": 0.6482758620689655,\n \"acc_stderr\": 0.0397923663749741,\n \"acc_norm\": 0.6482758620689655,\n \"acc_norm_stderr\": 0.0397923663749741\n },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\": 0.48148148148148145,\n \"acc_stderr\": 0.025733641991838987,\n \"acc_norm\": 0.48148148148148145,\n \"acc_norm_stderr\": 0.025733641991838987\n },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.5079365079365079,\n \"acc_stderr\": 0.044715725362943486,\n \"acc_norm\": 0.5079365079365079,\n \"acc_norm_stderr\": 0.044715725362943486\n },\n \"harness|hendrycksTest-global_facts|5\": {\n \"acc\": 0.4,\n \"acc_stderr\": 0.04923659639173309,\n \"acc_norm\": 0.4,\n \"acc_norm_stderr\": 0.04923659639173309\n },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.8516129032258064,\n \"acc_stderr\": 0.020222737554330378,\n \"acc_norm\": 0.8516129032258064,\n \"acc_norm_stderr\": 0.020222737554330378\n },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\": 0.6157635467980296,\n \"acc_stderr\": 0.03422398565657551,\n \"acc_norm\": 0.6157635467980296,\n \"acc_norm_stderr\": 0.03422398565657551\n },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \"acc\": 0.79,\n \"acc_stderr\": 0.040936018074033256,\n \"acc_norm\": 0.79,\n \"acc_norm_stderr\": 0.040936018074033256\n },\n \"harness|hendrycksTest-high_school_european_history|5\": {\n \"acc\": 0.793939393939394,\n \"acc_stderr\": 0.03158415324047709,\n \"acc_norm\": 0.793939393939394,\n \"acc_norm_stderr\": 0.03158415324047709\n },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\": 0.8585858585858586,\n \"acc_stderr\": 0.024825909793343336,\n \"acc_norm\": 0.8585858585858586,\n \"acc_norm_stderr\": 0.024825909793343336\n },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \"acc\": 0.9637305699481865,\n \"acc_stderr\": 0.013492659751295159,\n \"acc_norm\": 0.9637305699481865,\n \"acc_norm_stderr\": 0.013492659751295159\n },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \"acc\": 0.6923076923076923,\n \"acc_stderr\": 0.02340092891831049,\n \"acc_norm\": 0.6923076923076923,\n \"acc_norm_stderr\": 0.02340092891831049\n },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"acc\": 0.3888888888888889,\n \"acc_stderr\": 0.029723278961476664,\n \"acc_norm\": 0.3888888888888889,\n \"acc_norm_stderr\": 0.029723278961476664\n },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \"acc\": 0.8067226890756303,\n \"acc_stderr\": 0.025649470265889183,\n \"acc_norm\": 0.8067226890756303,\n \"acc_norm_stderr\": 0.025649470265889183\n },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\": 0.4768211920529801,\n \"acc_stderr\": 0.04078093859163083,\n \"acc_norm\": 0.4768211920529801,\n \"acc_norm_stderr\": 0.04078093859163083\n },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\": 0.8788990825688073,\n \"acc_stderr\": 0.013987618292389713,\n \"acc_norm\": 0.8788990825688073,\n \"acc_norm_stderr\": 0.013987618292389713\n },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\": 0.5833333333333334,\n \"acc_stderr\": 0.03362277436608043,\n \"acc_norm\": 0.5833333333333334,\n \"acc_norm_stderr\": 0.03362277436608043\n },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\": 0.8578431372549019,\n \"acc_stderr\": 0.024509803921568617,\n \"acc_norm\": 0.8578431372549019,\n \"acc_norm_stderr\": 0.024509803921568617\n },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"acc\": 0.8523206751054853,\n \"acc_stderr\": 0.023094329582595694,\n \"acc_norm\": 0.8523206751054853,\n \"acc_norm_stderr\": 0.023094329582595694\n },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.7623318385650224,\n \"acc_stderr\": 0.02856807946471428,\n \"acc_norm\": 0.7623318385650224,\n \"acc_norm_stderr\": 0.02856807946471428\n },\n \"harness|hendrycksTest-human_sexuality|5\": {\n \"acc\": 0.8015267175572519,\n \"acc_stderr\": 0.03498149385462469,\n \"acc_norm\": 0.8015267175572519,\n \"acc_norm_stderr\": 0.03498149385462469\n },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\": 0.8760330578512396,\n \"acc_stderr\": 0.030083098716035202,\n \"acc_norm\": 0.8760330578512396,\n \"acc_norm_stderr\": 0.030083098716035202\n },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.8425925925925926,\n \"acc_stderr\": 0.03520703990517963,\n \"acc_norm\": 0.8425925925925926,\n \"acc_norm_stderr\": 0.03520703990517963\n },\n \"harness|hendrycksTest-logical_fallacies|5\": {\n \"acc\": 0.803680981595092,\n \"acc_stderr\": 0.031207970394709218,\n \"acc_norm\": 0.803680981595092,\n \"acc_norm_stderr\": 0.031207970394709218\n },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.5892857142857143,\n \"acc_stderr\": 0.04669510663875191,\n \"acc_norm\": 0.5892857142857143,\n \"acc_norm_stderr\": 0.04669510663875191\n },\n \"harness|hendrycksTest-management|5\": {\n \"acc\": 0.8349514563106796,\n \"acc_stderr\": 0.036756688322331886,\n \"acc_norm\": 0.8349514563106796,\n \"acc_norm_stderr\": 0.036756688322331886\n },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.9230769230769231,\n \"acc_stderr\": 0.017456987872436186,\n \"acc_norm\": 0.9230769230769231,\n \"acc_norm_stderr\": 0.017456987872436186\n },\n \"harness|hendrycksTest-medical_genetics|5\": {\n \"acc\": 0.76,\n \"acc_stderr\": 0.04292346959909282,\n \"acc_norm\": 0.76,\n \"acc_norm_stderr\": 0.04292346959909282\n },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.8773946360153256,\n \"acc_stderr\": 0.011728672144131563,\n \"acc_norm\": 0.8773946360153256,\n \"acc_norm_stderr\": 0.011728672144131563\n },\n \"harness|hendrycksTest-moral_disputes|5\": {\n \"acc\": 0.7832369942196532,\n \"acc_stderr\": 0.022183477668412856,\n \"acc_norm\": 0.7832369942196532,\n \"acc_norm_stderr\": 0.022183477668412856\n },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.46033519553072627,\n \"acc_stderr\": 0.016669799592112032,\n \"acc_norm\": 0.46033519553072627,\n \"acc_norm_stderr\": 0.016669799592112032\n },\n \"harness|hendrycksTest-nutrition|5\": {\n \"acc\": 0.8235294117647058,\n \"acc_stderr\": 0.021828596053108395,\n \"acc_norm\": 0.8235294117647058,\n \"acc_norm_stderr\": 0.021828596053108395\n },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7942122186495176,\n \"acc_stderr\": 0.022961339906764244,\n \"acc_norm\": 0.7942122186495176,\n \"acc_norm_stderr\": 0.022961339906764244\n },\n \"harness|hendrycksTest-prehistory|5\": {\n \"acc\": 0.8333333333333334,\n \"acc_stderr\": 0.020736358408060006,\n \"acc_norm\": 0.8333333333333334,\n \"acc_norm_stderr\": 0.020736358408060006\n },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\": 0.5602836879432624,\n \"acc_stderr\": 0.02960991207559411,\n \"acc_norm\": 0.5602836879432624,\n \"acc_norm_stderr\": 0.02960991207559411\n },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.545632333767927,\n \"acc_stderr\": 0.01271694172073482,\n \"acc_norm\": 0.545632333767927,\n \"acc_norm_stderr\": 0.01271694172073482\n },\n \"harness|hendrycksTest-professional_medicine|5\": {\n \"acc\": 0.7867647058823529,\n \"acc_stderr\": 0.024880971512294254,\n \"acc_norm\": 0.7867647058823529,\n \"acc_norm_stderr\": 0.024880971512294254\n },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"acc\": 0.7696078431372549,\n \"acc_stderr\": 0.01703522925803404,\n \"acc_norm\": 0.7696078431372549,\n \"acc_norm_stderr\": 0.01703522925803404\n },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.7090909090909091,\n \"acc_stderr\": 0.04350271442923243,\n \"acc_norm\": 0.7090909090909091,\n \"acc_norm_stderr\": 0.04350271442923243\n },\n \"harness|hendrycksTest-security_studies|5\": {\n \"acc\": 0.7755102040816326,\n \"acc_stderr\": 0.026711430555538405,\n \"acc_norm\": 0.7755102040816326,\n \"acc_norm_stderr\": 0.026711430555538405\n },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8955223880597015,\n \"acc_stderr\": 0.021628920516700643,\n \"acc_norm\": 0.8955223880597015,\n \"acc_norm_stderr\": 0.021628920516700643\n },\n \"harness|hendrycksTest-us_foreign_policy|5\": {\n \"acc\": 0.9,\n \"acc_stderr\": 0.030151134457776334,\n \"acc_norm\": 0.9,\n \"acc_norm_stderr\": 0.030151134457776334\n },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5240963855421686,\n \"acc_stderr\": 0.03887971849597264,\n \"acc_norm\": 0.5240963855421686,\n \"acc_norm_stderr\": 0.03887971849597264\n },\n \"harness|hendrycksTest-world_religions|5\": {\n \"acc\": 0.8888888888888888,\n \"acc_stderr\": 0.024103384202072864,\n \"acc_norm\": 0.8888888888888888,\n \"acc_norm_stderr\": 0.024103384202072864\n },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.5079559363525091,\n \"mc1_stderr\": 0.01750128507455182,\n \"mc2\": 0.6579117349463197,\n \"mc2_stderr\": 0.015011154188590699\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.8161010260457774,\n \"acc_stderr\": 0.010887916013305889\n },\n \"harness|gsm8k|5\": {\n \"acc\": 0.6163760424564063,\n \"acc_stderr\": 0.01339423858493816\n }\n}\n```", "repo_url": "https://huggingface.co/argilla/notus-8x7b-experiment", "leaderboard_url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard", "point_of_contact": "[email protected]", "configs": [{"config_name": "harness_arc_challenge_25", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|arc:challenge|25_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|arc:challenge|25_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_gsm8k_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|gsm8k|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|gsm8k|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hellaswag_10", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hellaswag|10_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hellaswag|10_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T21-16-18.856195.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_abstract_algebra_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_anatomy_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_astronomy_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_business_ethics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_clinical_knowledge_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_biology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_chemistry_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_computer_science_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_mathematics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_medicine_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_physics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_computer_security_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_conceptual_physics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_econometrics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_electrical_engineering_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_elementary_mathematics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_formal_logic_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_global_facts_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_biology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_chemistry_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_computer_science_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_european_history_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_geography_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_government_and_politics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_macroeconomics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_mathematics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_microeconomics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_physics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_psychology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_statistics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_us_history_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_world_history_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_aging_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_sexuality_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_international_law_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_jurisprudence_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_logical_fallacies_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_machine_learning_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_management_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_marketing_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_medical_genetics_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_miscellaneous_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_disputes_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_scenarios_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_nutrition_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_philosophy_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_prehistory_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_accounting_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_law_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_medicine_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_psychology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_public_relations_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_security_studies_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_sociology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_us_foreign_policy_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_virology_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_hendrycksTest_world_religions_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_truthfulqa_mc_0", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "harness_winogrande_5", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["**/details_harness|winogrande|5_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["**/details_harness|winogrande|5_2023-12-24T21-16-18.856195.parquet"]}]}, {"config_name": "results", "data_files": [{"split": "2023_12_24T21_16_18.856195", "path": ["results_2023-12-24T21-16-18.856195.parquet"]}, {"split": "latest", "path": ["results_2023-12-24T21-16-18.856195.parquet"]}]}]} | 2023-12-24T21:19:04+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Evaluation run of argilla/notus-8x7b-experiment
Dataset automatically created during the evaluation run of model argilla/notus-8x7b-experiment on the Open LLM Leaderboard.
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).
To load the details from a run, you can for instance do the following:
## Latest results
These are the latest results from run 2023-12-24T21:16:18.856195(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Evaluation run of argilla/notus-8x7b-experiment\n\n\n\nDataset automatically created during the evaluation run of model argilla/notus-8x7b-experiment on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T21:16:18.856195(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Evaluation run of argilla/notus-8x7b-experiment\n\n\n\nDataset automatically created during the evaluation run of model argilla/notus-8x7b-experiment on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T21:16:18.856195(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
183,
67,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Evaluation run of argilla/notus-8x7b-experiment\n\n\n\nDataset automatically created during the evaluation run of model argilla/notus-8x7b-experiment on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:## Latest results\n\nThese are the latest results from run 2023-12-24T21:16:18.856195(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
af218f0f269812551436c1b659ab8089ca20286a |
**Update:**
- 2023/12/25
oasst2-135k-jaをチャット形式に変換した[oasst2-chat-68k-ja](https://huggingface.co/datasets/kunishou/oasst2-chat-68k-ja)を公開しました。
This dataset was created by automatically translating "OpenAssistant/oasst2" into Japanese by DeepL.
"OpenAssistant/oasst2" を DeepL翻訳を用いて日本語に自動翻訳したデータセットになります。
以下のコードを用いることで、 Instruction と Output (prompterの命令とassistantの回答)の形式に変換することができます。
ファインチューニングで使用する場合はこちらのコードで変換して下さい(変換には5分程度かかります)。
変換コード参考
https://github.com/h2oai/h2o-llmstudio/blob/5ebfd3879e226b4e1afd0a0b45eb632e60412129/app_utils/utils.py#L1888
```python
pip install datasets
```
```python
from datasets import load_dataset
import pandas as pd
import os
import json
# oasst2のオリジナルデータのロード
ds = load_dataset("OpenAssistant/oasst2")
train = ds["train"].to_pandas()
val = ds["validation"].to_pandas()
df_origin = pd.concat([train, val], axis=0).reset_index(drop=True)
# oasst1日本語翻訳データの読み込み
df_ja = load_dataset("kunishou/oasst2-135k-ja").to_pandas()
# oasst2のオリジナルデータと日本語翻訳データのマージ
df = pd.merge(df_origin, df_ja[["message_id", "text_ja"]], on="message_id", how="left").copy()
df["text"] = df["text_ja"]
df_assistant = df[(df.role == "assistant")].copy()
df_prompter = df[(df.role == "prompter")].copy()
df_prompter = df_prompter.set_index("message_id")
df_assistant["output"] = df_assistant["text"].values
inputs = []
parent_ids = []
for _, row in df_assistant.iterrows():
input = df_prompter.loc[row.parent_id]
inputs.append(input.text)
parent_ids.append(input.parent_id)
df_assistant["instruction"] = inputs
df_assistant["parent_id"] = parent_ids
df_assistant = df_assistant[
["instruction", "output", "message_id", "parent_id", "lang", "rank"]
].rename(columns={"message_id": "id"})
# これ以下でjsonファイルへ書き出し---------------
learn_datas = []
input_list = []
for n in range(len(df_assistant)):
learn_data = {
"instruction": str(df_assistant.iloc[n, 0]),
"input": "",
"output": ""
}
input_list.append(df_assistant.iloc[n, 0])
learn_data["input"] = ""
learn_data["output"] = str(df_assistant.iloc[n, 1])
learn_datas.append(learn_data)
json_learn_data = json.dumps(learn_datas, indent=4, ensure_ascii=False)
with open('oasst2_ja_converted.json', 'w', encoding="utf-8") as f:
f.write(json_learn_data)
```
OpenAssistant/oasst2
https://huggingface.co/datasets/OpenAssistant/oasst2 | kunishou/oasst2-135k-ja | [
"language:ja",
"license:apache-2.0",
"region:us"
] | 2023-12-24T22:04:54+00:00 | {"language": ["ja"], "license": "apache-2.0"} | 2023-12-25T13:23:55+00:00 | [] | [
"ja"
] | TAGS
#language-Japanese #license-apache-2.0 #region-us
|
Update:
- 2023/12/25
oasst2-135k-jaをチャット形式に変換したoasst2-chat-68k-jaを公開しました。
This dataset was created by automatically translating "OpenAssistant/oasst2" into Japanese by DeepL.
"OpenAssistant/oasst2" を DeepL翻訳を用いて日本語に自動翻訳したデータセットになります。
以下のコードを用いることで、 Instruction と Output (prompterの命令とassistantの回答)の形式に変換することができます。
ファインチューニングで使用する場合はこちらのコードで変換して下さい(変換には5分程度かかります)。
変換コード参考
URL
OpenAssistant/oasst2
URL | [] | [
"TAGS\n#language-Japanese #license-apache-2.0 #region-us \n"
] | [
20
] | [
"passage: TAGS\n#language-Japanese #license-apache-2.0 #region-us \n"
] |
7a868cc8672e842896be23c80619c06a458b66b5 |
# Dataset Card for Evaluation run of Undi95/Llamix2-MLewd-4x13B
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [Undi95/Llamix2-MLewd-4x13B](https://huggingface.co/Undi95/Llamix2-MLewd-4x13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Undi95__Llamix2-MLewd-4x13B",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-24T22:02:51.116526](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__Llamix2-MLewd-4x13B/blob/main/results_2023-12-24T22-02-51.116526.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.5658778116094036,
"acc_stderr": 0.033655629521003254,
"acc_norm": 0.5685687034689173,
"acc_norm_stderr": 0.0343395673955478,
"mc1": 0.36107711138310894,
"mc1_stderr": 0.016814312844836886,
"mc2": 0.5034696577826705,
"mc2_stderr": 0.015794631306390153
},
"harness|arc:challenge|25": {
"acc": 0.5827645051194539,
"acc_stderr": 0.014409825518403079,
"acc_norm": 0.6100682593856656,
"acc_norm_stderr": 0.01425295984889289
},
"harness|hellaswag|10": {
"acc": 0.6445927106154152,
"acc_stderr": 0.004776583530909569,
"acc_norm": 0.8317068313085043,
"acc_norm_stderr": 0.003733618111043529
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.3,
"acc_stderr": 0.046056618647183814,
"acc_norm": 0.3,
"acc_norm_stderr": 0.046056618647183814
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.5111111111111111,
"acc_stderr": 0.04318275491977976,
"acc_norm": 0.5111111111111111,
"acc_norm_stderr": 0.04318275491977976
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.5197368421052632,
"acc_stderr": 0.040657710025626036,
"acc_norm": 0.5197368421052632,
"acc_norm_stderr": 0.040657710025626036
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.52,
"acc_stderr": 0.050211673156867795,
"acc_norm": 0.52,
"acc_norm_stderr": 0.050211673156867795
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.6113207547169811,
"acc_stderr": 0.030000485448675986,
"acc_norm": 0.6113207547169811,
"acc_norm_stderr": 0.030000485448675986
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.5902777777777778,
"acc_stderr": 0.04112490974670788,
"acc_norm": 0.5902777777777778,
"acc_norm_stderr": 0.04112490974670788
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.4,
"acc_stderr": 0.04923659639173309,
"acc_norm": 0.4,
"acc_norm_stderr": 0.04923659639173309
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.43,
"acc_stderr": 0.04975698519562428,
"acc_norm": 0.43,
"acc_norm_stderr": 0.04975698519562428
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.33,
"acc_stderr": 0.047258156262526045,
"acc_norm": 0.33,
"acc_norm_stderr": 0.047258156262526045
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.5260115606936416,
"acc_stderr": 0.03807301726504513,
"acc_norm": 0.5260115606936416,
"acc_norm_stderr": 0.03807301726504513
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.2549019607843137,
"acc_stderr": 0.04336432707993179,
"acc_norm": 0.2549019607843137,
"acc_norm_stderr": 0.04336432707993179
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.72,
"acc_stderr": 0.04512608598542128,
"acc_norm": 0.72,
"acc_norm_stderr": 0.04512608598542128
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.4723404255319149,
"acc_stderr": 0.03263597118409769,
"acc_norm": 0.4723404255319149,
"acc_norm_stderr": 0.03263597118409769
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.32456140350877194,
"acc_stderr": 0.04404556157374768,
"acc_norm": 0.32456140350877194,
"acc_norm_stderr": 0.04404556157374768
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.47586206896551725,
"acc_stderr": 0.041618085035015295,
"acc_norm": 0.47586206896551725,
"acc_norm_stderr": 0.041618085035015295
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.3439153439153439,
"acc_stderr": 0.024464426625596437,
"acc_norm": 0.3439153439153439,
"acc_norm_stderr": 0.024464426625596437
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.3968253968253968,
"acc_stderr": 0.043758884927270605,
"acc_norm": 0.3968253968253968,
"acc_norm_stderr": 0.043758884927270605
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.37,
"acc_stderr": 0.048523658709391,
"acc_norm": 0.37,
"acc_norm_stderr": 0.048523658709391
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.6548387096774193,
"acc_stderr": 0.02704574657353433,
"acc_norm": 0.6548387096774193,
"acc_norm_stderr": 0.02704574657353433
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.4187192118226601,
"acc_stderr": 0.03471192860518468,
"acc_norm": 0.4187192118226601,
"acc_norm_stderr": 0.03471192860518468
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.56,
"acc_stderr": 0.04988876515698589,
"acc_norm": 0.56,
"acc_norm_stderr": 0.04988876515698589
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.6848484848484848,
"acc_stderr": 0.036277305750224094,
"acc_norm": 0.6848484848484848,
"acc_norm_stderr": 0.036277305750224094
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.7323232323232324,
"acc_stderr": 0.03154449888270285,
"acc_norm": 0.7323232323232324,
"acc_norm_stderr": 0.03154449888270285
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.8082901554404145,
"acc_stderr": 0.028408953626245258,
"acc_norm": 0.8082901554404145,
"acc_norm_stderr": 0.028408953626245258
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.5256410256410257,
"acc_stderr": 0.025317649726448656,
"acc_norm": 0.5256410256410257,
"acc_norm_stderr": 0.025317649726448656
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3111111111111111,
"acc_stderr": 0.02822644674968352,
"acc_norm": 0.3111111111111111,
"acc_norm_stderr": 0.02822644674968352
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.5882352941176471,
"acc_stderr": 0.03196876989195778,
"acc_norm": 0.5882352941176471,
"acc_norm_stderr": 0.03196876989195778
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.31125827814569534,
"acc_stderr": 0.03780445850526733,
"acc_norm": 0.31125827814569534,
"acc_norm_stderr": 0.03780445850526733
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.7431192660550459,
"acc_stderr": 0.018732492928342462,
"acc_norm": 0.7431192660550459,
"acc_norm_stderr": 0.018732492928342462
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.375,
"acc_stderr": 0.033016908987210894,
"acc_norm": 0.375,
"acc_norm_stderr": 0.033016908987210894
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.7598039215686274,
"acc_stderr": 0.02998373305591361,
"acc_norm": 0.7598039215686274,
"acc_norm_stderr": 0.02998373305591361
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.7805907172995781,
"acc_stderr": 0.026939106581553945,
"acc_norm": 0.7805907172995781,
"acc_norm_stderr": 0.026939106581553945
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.6905829596412556,
"acc_stderr": 0.03102441174057221,
"acc_norm": 0.6905829596412556,
"acc_norm_stderr": 0.03102441174057221
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.648854961832061,
"acc_stderr": 0.04186445163013751,
"acc_norm": 0.648854961832061,
"acc_norm_stderr": 0.04186445163013751
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.7520661157024794,
"acc_stderr": 0.03941897526516303,
"acc_norm": 0.7520661157024794,
"acc_norm_stderr": 0.03941897526516303
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.7222222222222222,
"acc_stderr": 0.043300437496507416,
"acc_norm": 0.7222222222222222,
"acc_norm_stderr": 0.043300437496507416
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.7116564417177914,
"acc_stderr": 0.035590395316173425,
"acc_norm": 0.7116564417177914,
"acc_norm_stderr": 0.035590395316173425
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.35714285714285715,
"acc_stderr": 0.04547960999764376,
"acc_norm": 0.35714285714285715,
"acc_norm_stderr": 0.04547960999764376
},
"harness|hendrycksTest-management|5": {
"acc": 0.6601941747572816,
"acc_stderr": 0.04689765937278134,
"acc_norm": 0.6601941747572816,
"acc_norm_stderr": 0.04689765937278134
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8076923076923077,
"acc_stderr": 0.025819233256483706,
"acc_norm": 0.8076923076923077,
"acc_norm_stderr": 0.025819233256483706
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.56,
"acc_stderr": 0.04988876515698589,
"acc_norm": 0.56,
"acc_norm_stderr": 0.04988876515698589
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.7624521072796935,
"acc_stderr": 0.015218733046150193,
"acc_norm": 0.7624521072796935,
"acc_norm_stderr": 0.015218733046150193
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.6560693641618497,
"acc_stderr": 0.025574123786546665,
"acc_norm": 0.6560693641618497,
"acc_norm_stderr": 0.025574123786546665
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.464804469273743,
"acc_stderr": 0.01668102093107665,
"acc_norm": 0.464804469273743,
"acc_norm_stderr": 0.01668102093107665
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.630718954248366,
"acc_stderr": 0.02763417668960266,
"acc_norm": 0.630718954248366,
"acc_norm_stderr": 0.02763417668960266
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.6430868167202572,
"acc_stderr": 0.027210420375934023,
"acc_norm": 0.6430868167202572,
"acc_norm_stderr": 0.027210420375934023
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.6419753086419753,
"acc_stderr": 0.026675611926037103,
"acc_norm": 0.6419753086419753,
"acc_norm_stderr": 0.026675611926037103
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.43617021276595747,
"acc_stderr": 0.029583452036284062,
"acc_norm": 0.43617021276595747,
"acc_norm_stderr": 0.029583452036284062
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.4335071707953064,
"acc_stderr": 0.012656810383983965,
"acc_norm": 0.4335071707953064,
"acc_norm_stderr": 0.012656810383983965
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.5330882352941176,
"acc_stderr": 0.030306257722468314,
"acc_norm": 0.5330882352941176,
"acc_norm_stderr": 0.030306257722468314
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.5833333333333334,
"acc_stderr": 0.01994491413687358,
"acc_norm": 0.5833333333333334,
"acc_norm_stderr": 0.01994491413687358
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.6,
"acc_stderr": 0.0469237132203465,
"acc_norm": 0.6,
"acc_norm_stderr": 0.0469237132203465
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.6285714285714286,
"acc_stderr": 0.03093285879278986,
"acc_norm": 0.6285714285714286,
"acc_norm_stderr": 0.03093285879278986
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.7313432835820896,
"acc_stderr": 0.03134328358208954,
"acc_norm": 0.7313432835820896,
"acc_norm_stderr": 0.03134328358208954
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.82,
"acc_stderr": 0.038612291966536934,
"acc_norm": 0.82,
"acc_norm_stderr": 0.038612291966536934
},
"harness|hendrycksTest-virology|5": {
"acc": 0.4939759036144578,
"acc_stderr": 0.03892212195333045,
"acc_norm": 0.4939759036144578,
"acc_norm_stderr": 0.03892212195333045
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.783625730994152,
"acc_stderr": 0.031581495393387324,
"acc_norm": 0.783625730994152,
"acc_norm_stderr": 0.031581495393387324
},
"harness|truthfulqa:mc|0": {
"mc1": 0.36107711138310894,
"mc1_stderr": 0.016814312844836886,
"mc2": 0.5034696577826705,
"mc2_stderr": 0.015794631306390153
},
"harness|winogrande|5": {
"acc": 0.7537490134175217,
"acc_stderr": 0.012108365307437526
},
"harness|gsm8k|5": {
"acc": 0.4336618650492798,
"acc_stderr": 0.013650728047064681
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | open-llm-leaderboard/details_Undi95__Llamix2-MLewd-4x13B | [
"region:us"
] | 2023-12-24T22:05:11+00:00 | {"pretty_name": "Evaluation run of Undi95/Llamix2-MLewd-4x13B", "dataset_summary": "Dataset automatically created during the evaluation run of model [Undi95/Llamix2-MLewd-4x13B](https://huggingface.co/Undi95/Llamix2-MLewd-4x13B) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\nTo load the details from a run, you can for instance do the following:\n```python\nfrom datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Undi95__Llamix2-MLewd-4x13B\",\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese are the [latest results from run 2023-12-24T22:02:51.116526](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__Llamix2-MLewd-4x13B/blob/main/results_2023-12-24T22-02-51.116526.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.5658778116094036,\n \"acc_stderr\": 0.033655629521003254,\n \"acc_norm\": 0.5685687034689173,\n \"acc_norm_stderr\": 0.0343395673955478,\n \"mc1\": 0.36107711138310894,\n \"mc1_stderr\": 0.016814312844836886,\n \"mc2\": 0.5034696577826705,\n \"mc2_stderr\": 0.015794631306390153\n },\n \"harness|arc:challenge|25\": {\n \"acc\": 0.5827645051194539,\n \"acc_stderr\": 0.014409825518403079,\n \"acc_norm\": 0.6100682593856656,\n \"acc_norm_stderr\": 0.01425295984889289\n },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6445927106154152,\n \"acc_stderr\": 0.004776583530909569,\n \"acc_norm\": 0.8317068313085043,\n \"acc_norm_stderr\": 0.003733618111043529\n },\n \"harness|hendrycksTest-abstract_algebra|5\": {\n \"acc\": 0.3,\n \"acc_stderr\": 0.046056618647183814,\n \"acc_norm\": 0.3,\n \"acc_norm_stderr\": 0.046056618647183814\n },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.5111111111111111,\n \"acc_stderr\": 0.04318275491977976,\n \"acc_norm\": 0.5111111111111111,\n \"acc_norm_stderr\": 0.04318275491977976\n },\n \"harness|hendrycksTest-astronomy|5\": {\n \"acc\": 0.5197368421052632,\n \"acc_stderr\": 0.040657710025626036,\n \"acc_norm\": 0.5197368421052632,\n \"acc_norm_stderr\": 0.040657710025626036\n },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.52,\n \"acc_stderr\": 0.050211673156867795,\n \"acc_norm\": 0.52,\n \"acc_norm_stderr\": 0.050211673156867795\n },\n \"harness|hendrycksTest-clinical_knowledge|5\": {\n \"acc\": 0.6113207547169811,\n \"acc_stderr\": 0.030000485448675986,\n \"acc_norm\": 0.6113207547169811,\n \"acc_norm_stderr\": 0.030000485448675986\n },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.5902777777777778,\n \"acc_stderr\": 0.04112490974670788,\n \"acc_norm\": 0.5902777777777778,\n \"acc_norm_stderr\": 0.04112490974670788\n },\n \"harness|hendrycksTest-college_chemistry|5\": {\n \"acc\": 0.4,\n \"acc_stderr\": 0.04923659639173309,\n \"acc_norm\": 0.4,\n \"acc_norm_stderr\": 0.04923659639173309\n },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\": 0.43,\n \"acc_stderr\": 0.04975698519562428,\n \"acc_norm\": 0.43,\n \"acc_norm_stderr\": 0.04975698519562428\n },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.33,\n \"acc_stderr\": 0.047258156262526045,\n \"acc_norm\": 0.33,\n \"acc_norm_stderr\": 0.047258156262526045\n },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.5260115606936416,\n \"acc_stderr\": 0.03807301726504513,\n \"acc_norm\": 0.5260115606936416,\n \"acc_norm_stderr\": 0.03807301726504513\n },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.2549019607843137,\n \"acc_stderr\": 0.04336432707993179,\n \"acc_norm\": 0.2549019607843137,\n \"acc_norm_stderr\": 0.04336432707993179\n },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\": 0.72,\n \"acc_stderr\": 0.04512608598542128,\n \"acc_norm\": 0.72,\n \"acc_norm_stderr\": 0.04512608598542128\n },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.4723404255319149,\n \"acc_stderr\": 0.03263597118409769,\n \"acc_norm\": 0.4723404255319149,\n \"acc_norm_stderr\": 0.03263597118409769\n },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.32456140350877194,\n \"acc_stderr\": 0.04404556157374768,\n \"acc_norm\": 0.32456140350877194,\n \"acc_norm_stderr\": 0.04404556157374768\n },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\": 0.47586206896551725,\n \"acc_stderr\": 0.041618085035015295,\n \"acc_norm\": 0.47586206896551725,\n \"acc_norm_stderr\": 0.041618085035015295\n },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\": 0.3439153439153439,\n \"acc_stderr\": 0.024464426625596437,\n \"acc_norm\": 0.3439153439153439,\n \"acc_norm_stderr\": 0.024464426625596437\n },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.3968253968253968,\n \"acc_stderr\": 0.043758884927270605,\n \"acc_norm\": 0.3968253968253968,\n \"acc_norm_stderr\": 0.043758884927270605\n },\n \"harness|hendrycksTest-global_facts|5\": {\n \"acc\": 0.37,\n \"acc_stderr\": 0.048523658709391,\n \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.048523658709391\n },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.6548387096774193,\n \"acc_stderr\": 0.02704574657353433,\n \"acc_norm\": 0.6548387096774193,\n \"acc_norm_stderr\": 0.02704574657353433\n },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\": 0.4187192118226601,\n \"acc_stderr\": 0.03471192860518468,\n \"acc_norm\": 0.4187192118226601,\n \"acc_norm_stderr\": 0.03471192860518468\n },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \"acc\": 0.56,\n \"acc_stderr\": 0.04988876515698589,\n \"acc_norm\": 0.56,\n \"acc_norm_stderr\": 0.04988876515698589\n },\n \"harness|hendrycksTest-high_school_european_history|5\": {\n \"acc\": 0.6848484848484848,\n \"acc_stderr\": 0.036277305750224094,\n \"acc_norm\": 0.6848484848484848,\n \"acc_norm_stderr\": 0.036277305750224094\n },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\": 0.7323232323232324,\n \"acc_stderr\": 0.03154449888270285,\n \"acc_norm\": 0.7323232323232324,\n \"acc_norm_stderr\": 0.03154449888270285\n },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \"acc\": 0.8082901554404145,\n \"acc_stderr\": 0.028408953626245258,\n \"acc_norm\": 0.8082901554404145,\n \"acc_norm_stderr\": 0.028408953626245258\n },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \"acc\": 0.5256410256410257,\n \"acc_stderr\": 0.025317649726448656,\n \"acc_norm\": 0.5256410256410257,\n \"acc_norm_stderr\": 0.025317649726448656\n },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"acc\": 0.3111111111111111,\n \"acc_stderr\": 0.02822644674968352,\n \"acc_norm\": 0.3111111111111111,\n \"acc_norm_stderr\": 0.02822644674968352\n },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \"acc\": 0.5882352941176471,\n \"acc_stderr\": 0.03196876989195778,\n \"acc_norm\": 0.5882352941176471,\n \"acc_norm_stderr\": 0.03196876989195778\n },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\": 0.31125827814569534,\n \"acc_stderr\": 0.03780445850526733,\n \"acc_norm\": 0.31125827814569534,\n \"acc_norm_stderr\": 0.03780445850526733\n },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\": 0.7431192660550459,\n \"acc_stderr\": 0.018732492928342462,\n \"acc_norm\": 0.7431192660550459,\n \"acc_norm_stderr\": 0.018732492928342462\n },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\": 0.375,\n \"acc_stderr\": 0.033016908987210894,\n \"acc_norm\": 0.375,\n \"acc_norm_stderr\": 0.033016908987210894\n },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\": 0.7598039215686274,\n \"acc_stderr\": 0.02998373305591361,\n \"acc_norm\": 0.7598039215686274,\n \"acc_norm_stderr\": 0.02998373305591361\n },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"acc\": 0.7805907172995781,\n \"acc_stderr\": 0.026939106581553945,\n \"acc_norm\": 0.7805907172995781,\n \"acc_norm_stderr\": 0.026939106581553945\n },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.6905829596412556,\n \"acc_stderr\": 0.03102441174057221,\n \"acc_norm\": 0.6905829596412556,\n \"acc_norm_stderr\": 0.03102441174057221\n },\n \"harness|hendrycksTest-human_sexuality|5\": {\n \"acc\": 0.648854961832061,\n \"acc_stderr\": 0.04186445163013751,\n \"acc_norm\": 0.648854961832061,\n \"acc_norm_stderr\": 0.04186445163013751\n },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\": 0.7520661157024794,\n \"acc_stderr\": 0.03941897526516303,\n \"acc_norm\": 0.7520661157024794,\n \"acc_norm_stderr\": 0.03941897526516303\n },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.7222222222222222,\n \"acc_stderr\": 0.043300437496507416,\n \"acc_norm\": 0.7222222222222222,\n \"acc_norm_stderr\": 0.043300437496507416\n },\n \"harness|hendrycksTest-logical_fallacies|5\": {\n \"acc\": 0.7116564417177914,\n \"acc_stderr\": 0.035590395316173425,\n \"acc_norm\": 0.7116564417177914,\n \"acc_norm_stderr\": 0.035590395316173425\n },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.35714285714285715,\n \"acc_stderr\": 0.04547960999764376,\n \"acc_norm\": 0.35714285714285715,\n \"acc_norm_stderr\": 0.04547960999764376\n },\n \"harness|hendrycksTest-management|5\": {\n \"acc\": 0.6601941747572816,\n \"acc_stderr\": 0.04689765937278134,\n \"acc_norm\": 0.6601941747572816,\n \"acc_norm_stderr\": 0.04689765937278134\n },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8076923076923077,\n \"acc_stderr\": 0.025819233256483706,\n \"acc_norm\": 0.8076923076923077,\n \"acc_norm_stderr\": 0.025819233256483706\n },\n \"harness|hendrycksTest-medical_genetics|5\": {\n \"acc\": 0.56,\n \"acc_stderr\": 0.04988876515698589,\n \"acc_norm\": 0.56,\n \"acc_norm_stderr\": 0.04988876515698589\n },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.7624521072796935,\n \"acc_stderr\": 0.015218733046150193,\n \"acc_norm\": 0.7624521072796935,\n \"acc_norm_stderr\": 0.015218733046150193\n },\n \"harness|hendrycksTest-moral_disputes|5\": {\n \"acc\": 0.6560693641618497,\n \"acc_stderr\": 0.025574123786546665,\n \"acc_norm\": 0.6560693641618497,\n \"acc_norm_stderr\": 0.025574123786546665\n },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.464804469273743,\n \"acc_stderr\": 0.01668102093107665,\n \"acc_norm\": 0.464804469273743,\n \"acc_norm_stderr\": 0.01668102093107665\n },\n \"harness|hendrycksTest-nutrition|5\": {\n \"acc\": 0.630718954248366,\n \"acc_stderr\": 0.02763417668960266,\n \"acc_norm\": 0.630718954248366,\n \"acc_norm_stderr\": 0.02763417668960266\n },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.6430868167202572,\n \"acc_stderr\": 0.027210420375934023,\n \"acc_norm\": 0.6430868167202572,\n \"acc_norm_stderr\": 0.027210420375934023\n },\n \"harness|hendrycksTest-prehistory|5\": {\n \"acc\": 0.6419753086419753,\n \"acc_stderr\": 0.026675611926037103,\n \"acc_norm\": 0.6419753086419753,\n \"acc_norm_stderr\": 0.026675611926037103\n },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\": 0.43617021276595747,\n \"acc_stderr\": 0.029583452036284062,\n \"acc_norm\": 0.43617021276595747,\n \"acc_norm_stderr\": 0.029583452036284062\n },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.4335071707953064,\n \"acc_stderr\": 0.012656810383983965,\n \"acc_norm\": 0.4335071707953064,\n \"acc_norm_stderr\": 0.012656810383983965\n },\n \"harness|hendrycksTest-professional_medicine|5\": {\n \"acc\": 0.5330882352941176,\n \"acc_stderr\": 0.030306257722468314,\n \"acc_norm\": 0.5330882352941176,\n \"acc_norm_stderr\": 0.030306257722468314\n },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"acc\": 0.5833333333333334,\n \"acc_stderr\": 0.01994491413687358,\n \"acc_norm\": 0.5833333333333334,\n \"acc_norm_stderr\": 0.01994491413687358\n },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.6,\n \"acc_stderr\": 0.0469237132203465,\n \"acc_norm\": 0.6,\n \"acc_norm_stderr\": 0.0469237132203465\n },\n \"harness|hendrycksTest-security_studies|5\": {\n \"acc\": 0.6285714285714286,\n \"acc_stderr\": 0.03093285879278986,\n \"acc_norm\": 0.6285714285714286,\n \"acc_norm_stderr\": 0.03093285879278986\n },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.7313432835820896,\n \"acc_stderr\": 0.03134328358208954,\n \"acc_norm\": 0.7313432835820896,\n \"acc_norm_stderr\": 0.03134328358208954\n },\n \"harness|hendrycksTest-us_foreign_policy|5\": {\n \"acc\": 0.82,\n \"acc_stderr\": 0.038612291966536934,\n \"acc_norm\": 0.82,\n \"acc_norm_stderr\": 0.038612291966536934\n },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.4939759036144578,\n \"acc_stderr\": 0.03892212195333045,\n \"acc_norm\": 0.4939759036144578,\n \"acc_norm_stderr\": 0.03892212195333045\n },\n \"harness|hendrycksTest-world_religions|5\": {\n \"acc\": 0.783625730994152,\n \"acc_stderr\": 0.031581495393387324,\n \"acc_norm\": 0.783625730994152,\n \"acc_norm_stderr\": 0.031581495393387324\n },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.36107711138310894,\n \"mc1_stderr\": 0.016814312844836886,\n \"mc2\": 0.5034696577826705,\n \"mc2_stderr\": 0.015794631306390153\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.7537490134175217,\n \"acc_stderr\": 0.012108365307437526\n },\n \"harness|gsm8k|5\": {\n \"acc\": 0.4336618650492798,\n \"acc_stderr\": 0.013650728047064681\n }\n}\n```", "repo_url": "https://huggingface.co/Undi95/Llamix2-MLewd-4x13B", "leaderboard_url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard", "point_of_contact": "[email protected]", "configs": [{"config_name": "harness_arc_challenge_25", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|arc:challenge|25_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|arc:challenge|25_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_gsm8k_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|gsm8k|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|gsm8k|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hellaswag_10", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hellaswag|10_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hellaswag|10_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T22-02-51.116526.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_abstract_algebra_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_anatomy_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_astronomy_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_business_ethics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_clinical_knowledge_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_biology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_chemistry_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_computer_science_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_mathematics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_medicine_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_physics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_computer_security_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_conceptual_physics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_econometrics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_electrical_engineering_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_elementary_mathematics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_formal_logic_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_global_facts_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_biology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_chemistry_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_computer_science_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_european_history_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_geography_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_government_and_politics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_macroeconomics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_mathematics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_microeconomics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_physics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_psychology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_statistics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_us_history_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_world_history_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_aging_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_sexuality_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_international_law_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_jurisprudence_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_logical_fallacies_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_machine_learning_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_management_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_marketing_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_medical_genetics_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_miscellaneous_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_disputes_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_scenarios_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_nutrition_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_philosophy_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_prehistory_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_accounting_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_law_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_medicine_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_psychology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_public_relations_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_security_studies_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_sociology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_us_foreign_policy_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_virology_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_hendrycksTest_world_religions_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_truthfulqa_mc_0", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "harness_winogrande_5", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["**/details_harness|winogrande|5_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["**/details_harness|winogrande|5_2023-12-24T22-02-51.116526.parquet"]}]}, {"config_name": "results", "data_files": [{"split": "2023_12_24T22_02_51.116526", "path": ["results_2023-12-24T22-02-51.116526.parquet"]}, {"split": "latest", "path": ["results_2023-12-24T22-02-51.116526.parquet"]}]}]} | 2023-12-24T22:05:31+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Evaluation run of Undi95/Llamix2-MLewd-4x13B
Dataset automatically created during the evaluation run of model Undi95/Llamix2-MLewd-4x13B on the Open LLM Leaderboard.
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).
To load the details from a run, you can for instance do the following:
## Latest results
These are the latest results from run 2023-12-24T22:02:51.116526(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Evaluation run of Undi95/Llamix2-MLewd-4x13B\n\n\n\nDataset automatically created during the evaluation run of model Undi95/Llamix2-MLewd-4x13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T22:02:51.116526(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Evaluation run of Undi95/Llamix2-MLewd-4x13B\n\n\n\nDataset automatically created during the evaluation run of model Undi95/Llamix2-MLewd-4x13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T22:02:51.116526(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
191,
67,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Evaluation run of Undi95/Llamix2-MLewd-4x13B\n\n\n\nDataset automatically created during the evaluation run of model Undi95/Llamix2-MLewd-4x13B on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:## Latest results\n\nThese are the latest results from run 2023-12-24T22:02:51.116526(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]"
] |
6803b2cef4924d6bf903eee2412860ef702fe707 |
# Dataset of Tyrolean Dialect (Austria)
This dataset contains 200+ words used in Tirol (Austria), together with their German translation and (optional) meaning. | morgendigital/dialect-at-tirol | [
"task_categories:text-generation",
"size_categories:n<1K",
"language:de",
"license:apache-2.0",
"region:us"
] | 2023-12-24T22:10:06+00:00 | {"language": ["de"], "license": "apache-2.0", "size_categories": ["n<1K"], "task_categories": ["text-generation"], "pretty_name": "Austrian Dialect: Tyrolean"} | 2023-12-24T23:26:40+00:00 | [] | [
"de"
] | TAGS
#task_categories-text-generation #size_categories-n<1K #language-German #license-apache-2.0 #region-us
|
# Dataset of Tyrolean Dialect (Austria)
This dataset contains 200+ words used in Tirol (Austria), together with their German translation and (optional) meaning. | [
"# Dataset of Tyrolean Dialect (Austria)\nThis dataset contains 200+ words used in Tirol (Austria), together with their German translation and (optional) meaning."
] | [
"TAGS\n#task_categories-text-generation #size_categories-n<1K #language-German #license-apache-2.0 #region-us \n",
"# Dataset of Tyrolean Dialect (Austria)\nThis dataset contains 200+ words used in Tirol (Austria), together with their German translation and (optional) meaning."
] | [
39,
41
] | [
"passage: TAGS\n#task_categories-text-generation #size_categories-n<1K #language-German #license-apache-2.0 #region-us \n# Dataset of Tyrolean Dialect (Austria)\nThis dataset contains 200+ words used in Tirol (Austria), together with their German translation and (optional) meaning."
] |
ee8d1b252560abde0656f8736d6749c42e709ace |
# e-Callisto Solar Flare Detection Dataset

[Institute of Data Science i4Ds, FHNW](https://i4ds.ch)
## Overview
This dataset comprises radio spectra from the [e-Callisto solar spectrometer network](https://www.e-callisto.org/index.html), annotated based on [labels from the e-Callisto database](http://soleil.i4ds.ch/solarradio/data/BurstLists/2010-yyyy_Monstein/).
The data was downloaded using the [ecallisto_ng Package](https://github.com/i4Ds/ecallisto_ng). It's designed for training machine learning models to automatically detect and classify solar flares.
## Data Collection
Data has been collected from various stations, with the following date ranges:
| Station | Date Range |
|-------------------|--------------------------|
| Australia-ASSA_01 | 2021-02-13 to 2021-12-11 |
| Australia-ASSA_02 | 2021-02-13 to 2021-12-09 |
| Australia-ASSA_62 | 2021-12-10 to 2023-12-12 |
| Australia-ASSA_63 | 2021-12-10 to 2023-12-12 |
## Data Augmentation
Due to the rarity of solar flares, we've augmented the dataset by padding the time series data around each flare event.
## Caution
The dataset underwent preprocessing and certain assumptions were made for label cleanup. Be aware of potential inaccuracies in the labels.
## Split Recommendations
The dataset doesn't include predefined train-validation-test splits. When creating splits, ensure augmented data does not overlap between training and validation/test sets to avoid data leakage. | StellarMilk/ecallisto-bursts | [
"task_categories:image-classification",
"size_categories:100K<n<1M",
"astrophysics",
"flares",
"solar flares",
"sun",
"region:us"
] | 2023-12-24T22:16:36+00:00 | {"size_categories": ["100K<n<1M"], "task_categories": ["image-classification"], "pretty_name": "e-Callisto Solar Flare Detection", "tags": ["astrophysics", "flares", "solar flares", "sun"]} | 2024-01-15T14:45:27+00:00 | [] | [] | TAGS
#task_categories-image-classification #size_categories-100K<n<1M #astrophysics #flares #solar flares #sun #region-us
| e-Callisto Solar Flare Detection Dataset
========================================
 preprocessed for reward modeling using [tasksource's script](https://huggingface.co/datasets/tasksource/oasst1_pairwise_rlhf_reward#dataset-card-for-oasst1_pairwise_rlhf_reward). | monology/oasst2_dpo | [
"region:us"
] | 2023-12-24T22:49:07+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "lang", "dtype": "string"}, {"name": "parent_id", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 68098855, "num_examples": 26971}, {"name": "validation", "num_bytes": 3326974, "num_examples": 1408}], "download_size": 38605767, "dataset_size": 71425829}} | 2023-12-24T23:07:14+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "oasst2_dpo"
This is the Oasst2 dataset preprocessed for reward modeling using tasksource's script. | [
"# Dataset Card for \"oasst2_dpo\"\n\nThis is the Oasst2 dataset preprocessed for reward modeling using tasksource's script."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"oasst2_dpo\"\n\nThis is the Oasst2 dataset preprocessed for reward modeling using tasksource's script."
] | [
6,
37
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"oasst2_dpo\"\n\nThis is the Oasst2 dataset preprocessed for reward modeling using tasksource's script."
] |
a273f27e99a97a9cf1a036b521ae5f94513fa764 |
# Dataset Card for Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [Sao10K/WinterGoddess-1.4x-70B-L2](https://huggingface.co/Sao10K/WinterGoddess-1.4x-70B-L2) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_Sao10K__WinterGoddess-1.4x-70B-L2",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-24T23:38:15.266486](https://huggingface.co/datasets/open-llm-leaderboard/details_Sao10K__WinterGoddess-1.4x-70B-L2/blob/main/results_2023-12-24T23-38-15.266486.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.710699985333689,
"acc_stderr": 0.03011854843711099,
"acc_norm": 0.7147015884834241,
"acc_norm_stderr": 0.030703857357826155,
"mc1": 0.47980416156670747,
"mc1_stderr": 0.01748921684973705,
"mc2": 0.6575887143365204,
"mc2_stderr": 0.014151720891608486
},
"harness|arc:challenge|25": {
"acc": 0.6919795221843004,
"acc_stderr": 0.013491429517292038,
"acc_norm": 0.7278156996587031,
"acc_norm_stderr": 0.013006600406423707
},
"harness|hellaswag|10": {
"acc": 0.7263493328022307,
"acc_stderr": 0.004449206295922384,
"acc_norm": 0.9011153156741685,
"acc_norm_stderr": 0.0029789706046087928
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.37,
"acc_stderr": 0.04852365870939099,
"acc_norm": 0.37,
"acc_norm_stderr": 0.04852365870939099
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.6222222222222222,
"acc_stderr": 0.04188307537595853,
"acc_norm": 0.6222222222222222,
"acc_norm_stderr": 0.04188307537595853
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.8092105263157895,
"acc_stderr": 0.031975658210325,
"acc_norm": 0.8092105263157895,
"acc_norm_stderr": 0.031975658210325
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.75,
"acc_stderr": 0.04351941398892446,
"acc_norm": 0.75,
"acc_norm_stderr": 0.04351941398892446
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.7509433962264151,
"acc_stderr": 0.0266164829805017,
"acc_norm": 0.7509433962264151,
"acc_norm_stderr": 0.0266164829805017
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.8263888888888888,
"acc_stderr": 0.03167473383795718,
"acc_norm": 0.8263888888888888,
"acc_norm_stderr": 0.03167473383795718
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.55,
"acc_stderr": 0.049999999999999996,
"acc_norm": 0.55,
"acc_norm_stderr": 0.049999999999999996
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.6994219653179191,
"acc_stderr": 0.03496101481191179,
"acc_norm": 0.6994219653179191,
"acc_norm_stderr": 0.03496101481191179
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.3627450980392157,
"acc_stderr": 0.04784060704105654,
"acc_norm": 0.3627450980392157,
"acc_norm_stderr": 0.04784060704105654
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.79,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.79,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.6936170212765957,
"acc_stderr": 0.030135906478517563,
"acc_norm": 0.6936170212765957,
"acc_norm_stderr": 0.030135906478517563
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.4649122807017544,
"acc_stderr": 0.04692008381368909,
"acc_norm": 0.4649122807017544,
"acc_norm_stderr": 0.04692008381368909
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.6275862068965518,
"acc_stderr": 0.04028731532947558,
"acc_norm": 0.6275862068965518,
"acc_norm_stderr": 0.04028731532947558
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.47354497354497355,
"acc_stderr": 0.025715239811346758,
"acc_norm": 0.47354497354497355,
"acc_norm_stderr": 0.025715239811346758
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.5158730158730159,
"acc_stderr": 0.044698818540726076,
"acc_norm": 0.5158730158730159,
"acc_norm_stderr": 0.044698818540726076
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.52,
"acc_stderr": 0.050211673156867795,
"acc_norm": 0.52,
"acc_norm_stderr": 0.050211673156867795
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.832258064516129,
"acc_stderr": 0.021255464065371318,
"acc_norm": 0.832258064516129,
"acc_norm_stderr": 0.021255464065371318
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.5615763546798029,
"acc_stderr": 0.03491207857486519,
"acc_norm": 0.5615763546798029,
"acc_norm_stderr": 0.03491207857486519
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.8,
"acc_stderr": 0.04020151261036846,
"acc_norm": 0.8,
"acc_norm_stderr": 0.04020151261036846
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.8727272727272727,
"acc_stderr": 0.026024657651656194,
"acc_norm": 0.8727272727272727,
"acc_norm_stderr": 0.026024657651656194
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.8737373737373737,
"acc_stderr": 0.023664359402880242,
"acc_norm": 0.8737373737373737,
"acc_norm_stderr": 0.023664359402880242
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9378238341968912,
"acc_stderr": 0.017426974154240528,
"acc_norm": 0.9378238341968912,
"acc_norm_stderr": 0.017426974154240528
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.7128205128205128,
"acc_stderr": 0.022939925418530616,
"acc_norm": 0.7128205128205128,
"acc_norm_stderr": 0.022939925418530616
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.3148148148148148,
"acc_stderr": 0.028317533496066468,
"acc_norm": 0.3148148148148148,
"acc_norm_stderr": 0.028317533496066468
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.7815126050420168,
"acc_stderr": 0.02684151432295894,
"acc_norm": 0.7815126050420168,
"acc_norm_stderr": 0.02684151432295894
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.46357615894039733,
"acc_stderr": 0.04071636065944215,
"acc_norm": 0.46357615894039733,
"acc_norm_stderr": 0.04071636065944215
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.908256880733945,
"acc_stderr": 0.012376323409137116,
"acc_norm": 0.908256880733945,
"acc_norm_stderr": 0.012376323409137116
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.6342592592592593,
"acc_stderr": 0.032847388576472056,
"acc_norm": 0.6342592592592593,
"acc_norm_stderr": 0.032847388576472056
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.9215686274509803,
"acc_stderr": 0.018869514646658928,
"acc_norm": 0.9215686274509803,
"acc_norm_stderr": 0.018869514646658928
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.9029535864978903,
"acc_stderr": 0.019269323025640255,
"acc_norm": 0.9029535864978903,
"acc_norm_stderr": 0.019269323025640255
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.820627802690583,
"acc_stderr": 0.0257498195691928,
"acc_norm": 0.820627802690583,
"acc_norm_stderr": 0.0257498195691928
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8473282442748091,
"acc_stderr": 0.03154521672005472,
"acc_norm": 0.8473282442748091,
"acc_norm_stderr": 0.03154521672005472
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.8677685950413223,
"acc_stderr": 0.030922788320445795,
"acc_norm": 0.8677685950413223,
"acc_norm_stderr": 0.030922788320445795
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.8518518518518519,
"acc_stderr": 0.03434300243631,
"acc_norm": 0.8518518518518519,
"acc_norm_stderr": 0.03434300243631
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.8404907975460123,
"acc_stderr": 0.028767481725983854,
"acc_norm": 0.8404907975460123,
"acc_norm_stderr": 0.028767481725983854
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.5982142857142857,
"acc_stderr": 0.04653333146973647,
"acc_norm": 0.5982142857142857,
"acc_norm_stderr": 0.04653333146973647
},
"harness|hendrycksTest-management|5": {
"acc": 0.8446601941747572,
"acc_stderr": 0.03586594738573974,
"acc_norm": 0.8446601941747572,
"acc_norm_stderr": 0.03586594738573974
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.8974358974358975,
"acc_stderr": 0.019875655027867443,
"acc_norm": 0.8974358974358975,
"acc_norm_stderr": 0.019875655027867443
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.72,
"acc_stderr": 0.04512608598542127,
"acc_norm": 0.72,
"acc_norm_stderr": 0.04512608598542127
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.879948914431673,
"acc_stderr": 0.011622736692041282,
"acc_norm": 0.879948914431673,
"acc_norm_stderr": 0.011622736692041282
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.7803468208092486,
"acc_stderr": 0.022289638852617897,
"acc_norm": 0.7803468208092486,
"acc_norm_stderr": 0.022289638852617897
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.6368715083798883,
"acc_stderr": 0.016083749986853704,
"acc_norm": 0.6368715083798883,
"acc_norm_stderr": 0.016083749986853704
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.761437908496732,
"acc_stderr": 0.024404394928087873,
"acc_norm": 0.761437908496732,
"acc_norm_stderr": 0.024404394928087873
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.7781350482315113,
"acc_stderr": 0.02359885829286305,
"acc_norm": 0.7781350482315113,
"acc_norm_stderr": 0.02359885829286305
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.8395061728395061,
"acc_stderr": 0.020423955354778034,
"acc_norm": 0.8395061728395061,
"acc_norm_stderr": 0.020423955354778034
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.5780141843971631,
"acc_stderr": 0.0294621892333706,
"acc_norm": 0.5780141843971631,
"acc_norm_stderr": 0.0294621892333706
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.589960886571056,
"acc_stderr": 0.012561837621962023,
"acc_norm": 0.589960886571056,
"acc_norm_stderr": 0.012561837621962023
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.7095588235294118,
"acc_stderr": 0.02757646862274054,
"acc_norm": 0.7095588235294118,
"acc_norm_stderr": 0.02757646862274054
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.7647058823529411,
"acc_stderr": 0.017160587235046352,
"acc_norm": 0.7647058823529411,
"acc_norm_stderr": 0.017160587235046352
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.7090909090909091,
"acc_stderr": 0.04350271442923243,
"acc_norm": 0.7090909090909091,
"acc_norm_stderr": 0.04350271442923243
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.7959183673469388,
"acc_stderr": 0.025801283475090496,
"acc_norm": 0.7959183673469388,
"acc_norm_stderr": 0.025801283475090496
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8805970149253731,
"acc_stderr": 0.02292879327721974,
"acc_norm": 0.8805970149253731,
"acc_norm_stderr": 0.02292879327721974
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.88,
"acc_stderr": 0.03265986323710906,
"acc_norm": 0.88,
"acc_norm_stderr": 0.03265986323710906
},
"harness|hendrycksTest-virology|5": {
"acc": 0.536144578313253,
"acc_stderr": 0.038823108508905954,
"acc_norm": 0.536144578313253,
"acc_norm_stderr": 0.038823108508905954
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8654970760233918,
"acc_stderr": 0.026168221344662297,
"acc_norm": 0.8654970760233918,
"acc_norm_stderr": 0.026168221344662297
},
"harness|truthfulqa:mc|0": {
"mc1": 0.47980416156670747,
"mc1_stderr": 0.01748921684973705,
"mc2": 0.6575887143365204,
"mc2_stderr": 0.014151720891608486
},
"harness|winogrande|5": {
"acc": 0.8500394632991318,
"acc_stderr": 0.010034394804580809
},
"harness|gsm8k|5": {
"acc": 0.5458680818802123,
"acc_stderr": 0.013714410945264552
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | open-llm-leaderboard/details_Sao10K__WinterGoddess-1.4x-70B-L2 | [
"region:us"
] | 2023-12-24T23:40:34+00:00 | {"pretty_name": "Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2", "dataset_summary": "Dataset automatically created during the evaluation run of model [Sao10K/WinterGoddess-1.4x-70B-L2](https://huggingface.co/Sao10K/WinterGoddess-1.4x-70B-L2) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\nTo load the details from a run, you can for instance do the following:\n```python\nfrom datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_Sao10K__WinterGoddess-1.4x-70B-L2\",\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese are the [latest results from run 2023-12-24T23:38:15.266486](https://huggingface.co/datasets/open-llm-leaderboard/details_Sao10K__WinterGoddess-1.4x-70B-L2/blob/main/results_2023-12-24T23-38-15.266486.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.710699985333689,\n \"acc_stderr\": 0.03011854843711099,\n \"acc_norm\": 0.7147015884834241,\n \"acc_norm_stderr\": 0.030703857357826155,\n \"mc1\": 0.47980416156670747,\n \"mc1_stderr\": 0.01748921684973705,\n \"mc2\": 0.6575887143365204,\n \"mc2_stderr\": 0.014151720891608486\n },\n \"harness|arc:challenge|25\": {\n \"acc\": 0.6919795221843004,\n \"acc_stderr\": 0.013491429517292038,\n \"acc_norm\": 0.7278156996587031,\n \"acc_norm_stderr\": 0.013006600406423707\n },\n \"harness|hellaswag|10\": {\n \"acc\": 0.7263493328022307,\n \"acc_stderr\": 0.004449206295922384,\n \"acc_norm\": 0.9011153156741685,\n \"acc_norm_stderr\": 0.0029789706046087928\n },\n \"harness|hendrycksTest-abstract_algebra|5\": {\n \"acc\": 0.37,\n \"acc_stderr\": 0.04852365870939099,\n \"acc_norm\": 0.37,\n \"acc_norm_stderr\": 0.04852365870939099\n },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.6222222222222222,\n \"acc_stderr\": 0.04188307537595853,\n \"acc_norm\": 0.6222222222222222,\n \"acc_norm_stderr\": 0.04188307537595853\n },\n \"harness|hendrycksTest-astronomy|5\": {\n \"acc\": 0.8092105263157895,\n \"acc_stderr\": 0.031975658210325,\n \"acc_norm\": 0.8092105263157895,\n \"acc_norm_stderr\": 0.031975658210325\n },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.75,\n \"acc_stderr\": 0.04351941398892446,\n \"acc_norm\": 0.75,\n \"acc_norm_stderr\": 0.04351941398892446\n },\n \"harness|hendrycksTest-clinical_knowledge|5\": {\n \"acc\": 0.7509433962264151,\n \"acc_stderr\": 0.0266164829805017,\n \"acc_norm\": 0.7509433962264151,\n \"acc_norm_stderr\": 0.0266164829805017\n },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.8263888888888888,\n \"acc_stderr\": 0.03167473383795718,\n \"acc_norm\": 0.8263888888888888,\n \"acc_norm_stderr\": 0.03167473383795718\n },\n \"harness|hendrycksTest-college_chemistry|5\": {\n \"acc\": 0.46,\n \"acc_stderr\": 0.05009082659620332,\n \"acc_norm\": 0.46,\n \"acc_norm_stderr\": 0.05009082659620332\n },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\": 0.55,\n \"acc_stderr\": 0.049999999999999996,\n \"acc_norm\": 0.55,\n \"acc_norm_stderr\": 0.049999999999999996\n },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.46,\n \"acc_stderr\": 0.05009082659620332,\n \"acc_norm\": 0.46,\n \"acc_norm_stderr\": 0.05009082659620332\n },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.6994219653179191,\n \"acc_stderr\": 0.03496101481191179,\n \"acc_norm\": 0.6994219653179191,\n \"acc_norm_stderr\": 0.03496101481191179\n },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.3627450980392157,\n \"acc_stderr\": 0.04784060704105654,\n \"acc_norm\": 0.3627450980392157,\n \"acc_norm_stderr\": 0.04784060704105654\n },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\": 0.79,\n \"acc_stderr\": 0.040936018074033256,\n \"acc_norm\": 0.79,\n \"acc_norm_stderr\": 0.040936018074033256\n },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.6936170212765957,\n \"acc_stderr\": 0.030135906478517563,\n \"acc_norm\": 0.6936170212765957,\n \"acc_norm_stderr\": 0.030135906478517563\n },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.4649122807017544,\n \"acc_stderr\": 0.04692008381368909,\n \"acc_norm\": 0.4649122807017544,\n \"acc_norm_stderr\": 0.04692008381368909\n },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\": 0.6275862068965518,\n \"acc_stderr\": 0.04028731532947558,\n \"acc_norm\": 0.6275862068965518,\n \"acc_norm_stderr\": 0.04028731532947558\n },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\": 0.47354497354497355,\n \"acc_stderr\": 0.025715239811346758,\n \"acc_norm\": 0.47354497354497355,\n \"acc_norm_stderr\": 0.025715239811346758\n },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.5158730158730159,\n \"acc_stderr\": 0.044698818540726076,\n \"acc_norm\": 0.5158730158730159,\n \"acc_norm_stderr\": 0.044698818540726076\n },\n \"harness|hendrycksTest-global_facts|5\": {\n \"acc\": 0.52,\n \"acc_stderr\": 0.050211673156867795,\n \"acc_norm\": 0.52,\n \"acc_norm_stderr\": 0.050211673156867795\n },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.832258064516129,\n \"acc_stderr\": 0.021255464065371318,\n \"acc_norm\": 0.832258064516129,\n \"acc_norm_stderr\": 0.021255464065371318\n },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\": 0.5615763546798029,\n \"acc_stderr\": 0.03491207857486519,\n \"acc_norm\": 0.5615763546798029,\n \"acc_norm_stderr\": 0.03491207857486519\n },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \"acc\": 0.8,\n \"acc_stderr\": 0.04020151261036846,\n \"acc_norm\": 0.8,\n \"acc_norm_stderr\": 0.04020151261036846\n },\n \"harness|hendrycksTest-high_school_european_history|5\": {\n \"acc\": 0.8727272727272727,\n \"acc_stderr\": 0.026024657651656194,\n \"acc_norm\": 0.8727272727272727,\n \"acc_norm_stderr\": 0.026024657651656194\n },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\": 0.8737373737373737,\n \"acc_stderr\": 0.023664359402880242,\n \"acc_norm\": 0.8737373737373737,\n \"acc_norm_stderr\": 0.023664359402880242\n },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \"acc\": 0.9378238341968912,\n \"acc_stderr\": 0.017426974154240528,\n \"acc_norm\": 0.9378238341968912,\n \"acc_norm_stderr\": 0.017426974154240528\n },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \"acc\": 0.7128205128205128,\n \"acc_stderr\": 0.022939925418530616,\n \"acc_norm\": 0.7128205128205128,\n \"acc_norm_stderr\": 0.022939925418530616\n },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"acc\": 0.3148148148148148,\n \"acc_stderr\": 0.028317533496066468,\n \"acc_norm\": 0.3148148148148148,\n \"acc_norm_stderr\": 0.028317533496066468\n },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \"acc\": 0.7815126050420168,\n \"acc_stderr\": 0.02684151432295894,\n \"acc_norm\": 0.7815126050420168,\n \"acc_norm_stderr\": 0.02684151432295894\n },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\": 0.46357615894039733,\n \"acc_stderr\": 0.04071636065944215,\n \"acc_norm\": 0.46357615894039733,\n \"acc_norm_stderr\": 0.04071636065944215\n },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\": 0.908256880733945,\n \"acc_stderr\": 0.012376323409137116,\n \"acc_norm\": 0.908256880733945,\n \"acc_norm_stderr\": 0.012376323409137116\n },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\": 0.6342592592592593,\n \"acc_stderr\": 0.032847388576472056,\n \"acc_norm\": 0.6342592592592593,\n \"acc_norm_stderr\": 0.032847388576472056\n },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\": 0.9215686274509803,\n \"acc_stderr\": 0.018869514646658928,\n \"acc_norm\": 0.9215686274509803,\n \"acc_norm_stderr\": 0.018869514646658928\n },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"acc\": 0.9029535864978903,\n \"acc_stderr\": 0.019269323025640255,\n \"acc_norm\": 0.9029535864978903,\n \"acc_norm_stderr\": 0.019269323025640255\n },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.820627802690583,\n \"acc_stderr\": 0.0257498195691928,\n \"acc_norm\": 0.820627802690583,\n \"acc_norm_stderr\": 0.0257498195691928\n },\n \"harness|hendrycksTest-human_sexuality|5\": {\n \"acc\": 0.8473282442748091,\n \"acc_stderr\": 0.03154521672005472,\n \"acc_norm\": 0.8473282442748091,\n \"acc_norm_stderr\": 0.03154521672005472\n },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\": 0.8677685950413223,\n \"acc_stderr\": 0.030922788320445795,\n \"acc_norm\": 0.8677685950413223,\n \"acc_norm_stderr\": 0.030922788320445795\n },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.8518518518518519,\n \"acc_stderr\": 0.03434300243631,\n \"acc_norm\": 0.8518518518518519,\n \"acc_norm_stderr\": 0.03434300243631\n },\n \"harness|hendrycksTest-logical_fallacies|5\": {\n \"acc\": 0.8404907975460123,\n \"acc_stderr\": 0.028767481725983854,\n \"acc_norm\": 0.8404907975460123,\n \"acc_norm_stderr\": 0.028767481725983854\n },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.5982142857142857,\n \"acc_stderr\": 0.04653333146973647,\n \"acc_norm\": 0.5982142857142857,\n \"acc_norm_stderr\": 0.04653333146973647\n },\n \"harness|hendrycksTest-management|5\": {\n \"acc\": 0.8446601941747572,\n \"acc_stderr\": 0.03586594738573974,\n \"acc_norm\": 0.8446601941747572,\n \"acc_norm_stderr\": 0.03586594738573974\n },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.8974358974358975,\n \"acc_stderr\": 0.019875655027867443,\n \"acc_norm\": 0.8974358974358975,\n \"acc_norm_stderr\": 0.019875655027867443\n },\n \"harness|hendrycksTest-medical_genetics|5\": {\n \"acc\": 0.72,\n \"acc_stderr\": 0.04512608598542127,\n \"acc_norm\": 0.72,\n \"acc_norm_stderr\": 0.04512608598542127\n },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.879948914431673,\n \"acc_stderr\": 0.011622736692041282,\n \"acc_norm\": 0.879948914431673,\n \"acc_norm_stderr\": 0.011622736692041282\n },\n \"harness|hendrycksTest-moral_disputes|5\": {\n \"acc\": 0.7803468208092486,\n \"acc_stderr\": 0.022289638852617897,\n \"acc_norm\": 0.7803468208092486,\n \"acc_norm_stderr\": 0.022289638852617897\n },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.6368715083798883,\n \"acc_stderr\": 0.016083749986853704,\n \"acc_norm\": 0.6368715083798883,\n \"acc_norm_stderr\": 0.016083749986853704\n },\n \"harness|hendrycksTest-nutrition|5\": {\n \"acc\": 0.761437908496732,\n \"acc_stderr\": 0.024404394928087873,\n \"acc_norm\": 0.761437908496732,\n \"acc_norm_stderr\": 0.024404394928087873\n },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.7781350482315113,\n \"acc_stderr\": 0.02359885829286305,\n \"acc_norm\": 0.7781350482315113,\n \"acc_norm_stderr\": 0.02359885829286305\n },\n \"harness|hendrycksTest-prehistory|5\": {\n \"acc\": 0.8395061728395061,\n \"acc_stderr\": 0.020423955354778034,\n \"acc_norm\": 0.8395061728395061,\n \"acc_norm_stderr\": 0.020423955354778034\n },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\": 0.5780141843971631,\n \"acc_stderr\": 0.0294621892333706,\n \"acc_norm\": 0.5780141843971631,\n \"acc_norm_stderr\": 0.0294621892333706\n },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.589960886571056,\n \"acc_stderr\": 0.012561837621962023,\n \"acc_norm\": 0.589960886571056,\n \"acc_norm_stderr\": 0.012561837621962023\n },\n \"harness|hendrycksTest-professional_medicine|5\": {\n \"acc\": 0.7095588235294118,\n \"acc_stderr\": 0.02757646862274054,\n \"acc_norm\": 0.7095588235294118,\n \"acc_norm_stderr\": 0.02757646862274054\n },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"acc\": 0.7647058823529411,\n \"acc_stderr\": 0.017160587235046352,\n \"acc_norm\": 0.7647058823529411,\n \"acc_norm_stderr\": 0.017160587235046352\n },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.7090909090909091,\n \"acc_stderr\": 0.04350271442923243,\n \"acc_norm\": 0.7090909090909091,\n \"acc_norm_stderr\": 0.04350271442923243\n },\n \"harness|hendrycksTest-security_studies|5\": {\n \"acc\": 0.7959183673469388,\n \"acc_stderr\": 0.025801283475090496,\n \"acc_norm\": 0.7959183673469388,\n \"acc_norm_stderr\": 0.025801283475090496\n },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8805970149253731,\n \"acc_stderr\": 0.02292879327721974,\n \"acc_norm\": 0.8805970149253731,\n \"acc_norm_stderr\": 0.02292879327721974\n },\n \"harness|hendrycksTest-us_foreign_policy|5\": {\n \"acc\": 0.88,\n \"acc_stderr\": 0.03265986323710906,\n \"acc_norm\": 0.88,\n \"acc_norm_stderr\": 0.03265986323710906\n },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.536144578313253,\n \"acc_stderr\": 0.038823108508905954,\n \"acc_norm\": 0.536144578313253,\n \"acc_norm_stderr\": 0.038823108508905954\n },\n \"harness|hendrycksTest-world_religions|5\": {\n \"acc\": 0.8654970760233918,\n \"acc_stderr\": 0.026168221344662297,\n \"acc_norm\": 0.8654970760233918,\n \"acc_norm_stderr\": 0.026168221344662297\n },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.47980416156670747,\n \"mc1_stderr\": 0.01748921684973705,\n \"mc2\": 0.6575887143365204,\n \"mc2_stderr\": 0.014151720891608486\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.8500394632991318,\n \"acc_stderr\": 0.010034394804580809\n },\n \"harness|gsm8k|5\": {\n \"acc\": 0.5458680818802123,\n \"acc_stderr\": 0.013714410945264552\n }\n}\n```", "repo_url": "https://huggingface.co/Sao10K/WinterGoddess-1.4x-70B-L2", "leaderboard_url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard", "point_of_contact": "[email protected]", "configs": [{"config_name": "harness_arc_challenge_25", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|arc:challenge|25_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|arc:challenge|25_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_gsm8k_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|gsm8k|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|gsm8k|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hellaswag_10", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hellaswag|10_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hellaswag|10_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T23-38-15.266486.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_abstract_algebra_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_anatomy_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_astronomy_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_business_ethics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_clinical_knowledge_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_biology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_chemistry_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_computer_science_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_mathematics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_medicine_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_physics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_computer_security_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_conceptual_physics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_econometrics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_electrical_engineering_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_elementary_mathematics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_formal_logic_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_global_facts_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_biology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_chemistry_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_computer_science_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_european_history_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_geography_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_government_and_politics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_macroeconomics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_mathematics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_microeconomics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_physics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_psychology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_statistics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_us_history_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_world_history_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_aging_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_sexuality_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_international_law_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_jurisprudence_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_logical_fallacies_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_machine_learning_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_management_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_marketing_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_medical_genetics_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_miscellaneous_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_disputes_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_scenarios_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_nutrition_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_philosophy_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_prehistory_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_accounting_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_law_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_medicine_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_psychology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_public_relations_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_security_studies_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_sociology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_us_foreign_policy_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_virology_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_hendrycksTest_world_religions_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_truthfulqa_mc_0", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "harness_winogrande_5", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["**/details_harness|winogrande|5_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["**/details_harness|winogrande|5_2023-12-24T23-38-15.266486.parquet"]}]}, {"config_name": "results", "data_files": [{"split": "2023_12_24T23_38_15.266486", "path": ["results_2023-12-24T23-38-15.266486.parquet"]}, {"split": "latest", "path": ["results_2023-12-24T23-38-15.266486.parquet"]}]}]} | 2023-12-24T23:40:57+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2
Dataset automatically created during the evaluation run of model Sao10K/WinterGoddess-1.4x-70B-L2 on the Open LLM Leaderboard.
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).
To load the details from a run, you can for instance do the following:
## Latest results
These are the latest results from run 2023-12-24T23:38:15.266486(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2\n\n\n\nDataset automatically created during the evaluation run of model Sao10K/WinterGoddess-1.4x-70B-L2 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T23:38:15.266486(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2\n\n\n\nDataset automatically created during the evaluation run of model Sao10K/WinterGoddess-1.4x-70B-L2 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T23:38:15.266486(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
195,
67,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Evaluation run of Sao10K/WinterGoddess-1.4x-70B-L2\n\n\n\nDataset automatically created during the evaluation run of model Sao10K/WinterGoddess-1.4x-70B-L2 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:## Latest results\n\nThese are the latest results from run 2023-12-24T23:38:15.266486(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]"
] |
8853133025d2cbc76ed4d62a4e1dfda504874644 |
# Dataset Card for Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5
<!-- Provide a quick summary of the dataset. -->
Dataset automatically created during the evaluation run of model [brucethemoose/Yi-34B-200K-DARE-merge-v5](https://huggingface.co/brucethemoose/Yi-34B-200K-DARE-merge-v5) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).
To load the details from a run, you can for instance do the following:
```python
from datasets import load_dataset
data = load_dataset("open-llm-leaderboard/details_brucethemoose__Yi-34B-200K-DARE-merge-v5",
"harness_winogrande_5",
split="train")
```
## Latest results
These are the [latest results from run 2023-12-24T23:49:50.137882](https://huggingface.co/datasets/open-llm-leaderboard/details_brucethemoose__Yi-34B-200K-DARE-merge-v5/blob/main/results_2023-12-24T23-49-50.137882.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
```python
{
"all": {
"acc": 0.7667764662598182,
"acc_stderr": 0.0279506982164214,
"acc_norm": 0.7718008025916722,
"acc_norm_stderr": 0.02846678033491038,
"mc1": 0.41615667074663404,
"mc1_stderr": 0.017255657502903043,
"mc2": 0.5745773589644305,
"mc2_stderr": 0.015485111485623915
},
"harness|arc:challenge|25": {
"acc": 0.64419795221843,
"acc_stderr": 0.01399057113791876,
"acc_norm": 0.6646757679180887,
"acc_norm_stderr": 0.013796182947785562
},
"harness|hellaswag|10": {
"acc": 0.6613224457279426,
"acc_stderr": 0.004722928332834054,
"acc_norm": 0.8554072893845848,
"acc_norm_stderr": 0.0035097096477918394
},
"harness|hendrycksTest-abstract_algebra|5": {
"acc": 0.47,
"acc_stderr": 0.050161355804659205,
"acc_norm": 0.47,
"acc_norm_stderr": 0.050161355804659205
},
"harness|hendrycksTest-anatomy|5": {
"acc": 0.7407407407407407,
"acc_stderr": 0.03785714465066653,
"acc_norm": 0.7407407407407407,
"acc_norm_stderr": 0.03785714465066653
},
"harness|hendrycksTest-astronomy|5": {
"acc": 0.8881578947368421,
"acc_stderr": 0.02564834125169361,
"acc_norm": 0.8881578947368421,
"acc_norm_stderr": 0.02564834125169361
},
"harness|hendrycksTest-business_ethics|5": {
"acc": 0.79,
"acc_stderr": 0.040936018074033256,
"acc_norm": 0.79,
"acc_norm_stderr": 0.040936018074033256
},
"harness|hendrycksTest-clinical_knowledge|5": {
"acc": 0.8188679245283019,
"acc_stderr": 0.023702963526757798,
"acc_norm": 0.8188679245283019,
"acc_norm_stderr": 0.023702963526757798
},
"harness|hendrycksTest-college_biology|5": {
"acc": 0.8958333333333334,
"acc_stderr": 0.025545239210256917,
"acc_norm": 0.8958333333333334,
"acc_norm_stderr": 0.025545239210256917
},
"harness|hendrycksTest-college_chemistry|5": {
"acc": 0.47,
"acc_stderr": 0.050161355804659205,
"acc_norm": 0.47,
"acc_norm_stderr": 0.050161355804659205
},
"harness|hendrycksTest-college_computer_science|5": {
"acc": 0.62,
"acc_stderr": 0.04878317312145633,
"acc_norm": 0.62,
"acc_norm_stderr": 0.04878317312145633
},
"harness|hendrycksTest-college_mathematics|5": {
"acc": 0.46,
"acc_stderr": 0.05009082659620332,
"acc_norm": 0.46,
"acc_norm_stderr": 0.05009082659620332
},
"harness|hendrycksTest-college_medicine|5": {
"acc": 0.7572254335260116,
"acc_stderr": 0.0326926380614177,
"acc_norm": 0.7572254335260116,
"acc_norm_stderr": 0.0326926380614177
},
"harness|hendrycksTest-college_physics|5": {
"acc": 0.5490196078431373,
"acc_stderr": 0.04951218252396262,
"acc_norm": 0.5490196078431373,
"acc_norm_stderr": 0.04951218252396262
},
"harness|hendrycksTest-computer_security|5": {
"acc": 0.83,
"acc_stderr": 0.03775251680686371,
"acc_norm": 0.83,
"acc_norm_stderr": 0.03775251680686371
},
"harness|hendrycksTest-conceptual_physics|5": {
"acc": 0.7872340425531915,
"acc_stderr": 0.026754391348039787,
"acc_norm": 0.7872340425531915,
"acc_norm_stderr": 0.026754391348039787
},
"harness|hendrycksTest-econometrics|5": {
"acc": 0.631578947368421,
"acc_stderr": 0.04537815354939391,
"acc_norm": 0.631578947368421,
"acc_norm_stderr": 0.04537815354939391
},
"harness|hendrycksTest-electrical_engineering|5": {
"acc": 0.7862068965517242,
"acc_stderr": 0.03416520447747548,
"acc_norm": 0.7862068965517242,
"acc_norm_stderr": 0.03416520447747548
},
"harness|hendrycksTest-elementary_mathematics|5": {
"acc": 0.7222222222222222,
"acc_stderr": 0.02306818884826112,
"acc_norm": 0.7222222222222222,
"acc_norm_stderr": 0.02306818884826112
},
"harness|hendrycksTest-formal_logic|5": {
"acc": 0.5714285714285714,
"acc_stderr": 0.04426266681379909,
"acc_norm": 0.5714285714285714,
"acc_norm_stderr": 0.04426266681379909
},
"harness|hendrycksTest-global_facts|5": {
"acc": 0.59,
"acc_stderr": 0.04943110704237102,
"acc_norm": 0.59,
"acc_norm_stderr": 0.04943110704237102
},
"harness|hendrycksTest-high_school_biology|5": {
"acc": 0.9129032258064517,
"acc_stderr": 0.016041100741696682,
"acc_norm": 0.9129032258064517,
"acc_norm_stderr": 0.016041100741696682
},
"harness|hendrycksTest-high_school_chemistry|5": {
"acc": 0.6600985221674877,
"acc_stderr": 0.033327690684107895,
"acc_norm": 0.6600985221674877,
"acc_norm_stderr": 0.033327690684107895
},
"harness|hendrycksTest-high_school_computer_science|5": {
"acc": 0.83,
"acc_stderr": 0.0377525168068637,
"acc_norm": 0.83,
"acc_norm_stderr": 0.0377525168068637
},
"harness|hendrycksTest-high_school_european_history|5": {
"acc": 0.8606060606060606,
"acc_stderr": 0.0270459488258654,
"acc_norm": 0.8606060606060606,
"acc_norm_stderr": 0.0270459488258654
},
"harness|hendrycksTest-high_school_geography|5": {
"acc": 0.9242424242424242,
"acc_stderr": 0.018852670234993093,
"acc_norm": 0.9242424242424242,
"acc_norm_stderr": 0.018852670234993093
},
"harness|hendrycksTest-high_school_government_and_politics|5": {
"acc": 0.9792746113989638,
"acc_stderr": 0.010281417011909039,
"acc_norm": 0.9792746113989638,
"acc_norm_stderr": 0.010281417011909039
},
"harness|hendrycksTest-high_school_macroeconomics|5": {
"acc": 0.8128205128205128,
"acc_stderr": 0.01977660108655004,
"acc_norm": 0.8128205128205128,
"acc_norm_stderr": 0.01977660108655004
},
"harness|hendrycksTest-high_school_mathematics|5": {
"acc": 0.43333333333333335,
"acc_stderr": 0.030213340289237924,
"acc_norm": 0.43333333333333335,
"acc_norm_stderr": 0.030213340289237924
},
"harness|hendrycksTest-high_school_microeconomics|5": {
"acc": 0.8697478991596639,
"acc_stderr": 0.02186325849485211,
"acc_norm": 0.8697478991596639,
"acc_norm_stderr": 0.02186325849485211
},
"harness|hendrycksTest-high_school_physics|5": {
"acc": 0.5033112582781457,
"acc_stderr": 0.04082393379449654,
"acc_norm": 0.5033112582781457,
"acc_norm_stderr": 0.04082393379449654
},
"harness|hendrycksTest-high_school_psychology|5": {
"acc": 0.9321100917431193,
"acc_stderr": 0.010785412654517362,
"acc_norm": 0.9321100917431193,
"acc_norm_stderr": 0.010785412654517362
},
"harness|hendrycksTest-high_school_statistics|5": {
"acc": 0.6481481481481481,
"acc_stderr": 0.03256850570293647,
"acc_norm": 0.6481481481481481,
"acc_norm_stderr": 0.03256850570293647
},
"harness|hendrycksTest-high_school_us_history|5": {
"acc": 0.9362745098039216,
"acc_stderr": 0.01714392165552496,
"acc_norm": 0.9362745098039216,
"acc_norm_stderr": 0.01714392165552496
},
"harness|hendrycksTest-high_school_world_history|5": {
"acc": 0.9029535864978903,
"acc_stderr": 0.019269323025640255,
"acc_norm": 0.9029535864978903,
"acc_norm_stderr": 0.019269323025640255
},
"harness|hendrycksTest-human_aging|5": {
"acc": 0.8026905829596412,
"acc_stderr": 0.02670985334496796,
"acc_norm": 0.8026905829596412,
"acc_norm_stderr": 0.02670985334496796
},
"harness|hendrycksTest-human_sexuality|5": {
"acc": 0.8778625954198473,
"acc_stderr": 0.028718776889342327,
"acc_norm": 0.8778625954198473,
"acc_norm_stderr": 0.028718776889342327
},
"harness|hendrycksTest-international_law|5": {
"acc": 0.8925619834710744,
"acc_stderr": 0.028268812192540627,
"acc_norm": 0.8925619834710744,
"acc_norm_stderr": 0.028268812192540627
},
"harness|hendrycksTest-jurisprudence|5": {
"acc": 0.8703703703703703,
"acc_stderr": 0.03247224389917949,
"acc_norm": 0.8703703703703703,
"acc_norm_stderr": 0.03247224389917949
},
"harness|hendrycksTest-logical_fallacies|5": {
"acc": 0.8711656441717791,
"acc_stderr": 0.02632138319878367,
"acc_norm": 0.8711656441717791,
"acc_norm_stderr": 0.02632138319878367
},
"harness|hendrycksTest-machine_learning|5": {
"acc": 0.625,
"acc_stderr": 0.04595091388086298,
"acc_norm": 0.625,
"acc_norm_stderr": 0.04595091388086298
},
"harness|hendrycksTest-management|5": {
"acc": 0.8640776699029126,
"acc_stderr": 0.03393295729761012,
"acc_norm": 0.8640776699029126,
"acc_norm_stderr": 0.03393295729761012
},
"harness|hendrycksTest-marketing|5": {
"acc": 0.9273504273504274,
"acc_stderr": 0.01700436856813235,
"acc_norm": 0.9273504273504274,
"acc_norm_stderr": 0.01700436856813235
},
"harness|hendrycksTest-medical_genetics|5": {
"acc": 0.91,
"acc_stderr": 0.02876234912646613,
"acc_norm": 0.91,
"acc_norm_stderr": 0.02876234912646613
},
"harness|hendrycksTest-miscellaneous|5": {
"acc": 0.909323116219668,
"acc_stderr": 0.010268429662528547,
"acc_norm": 0.909323116219668,
"acc_norm_stderr": 0.010268429662528547
},
"harness|hendrycksTest-moral_disputes|5": {
"acc": 0.815028901734104,
"acc_stderr": 0.020903975842083027,
"acc_norm": 0.815028901734104,
"acc_norm_stderr": 0.020903975842083027
},
"harness|hendrycksTest-moral_scenarios|5": {
"acc": 0.7664804469273743,
"acc_stderr": 0.014149575348976264,
"acc_norm": 0.7664804469273743,
"acc_norm_stderr": 0.014149575348976264
},
"harness|hendrycksTest-nutrition|5": {
"acc": 0.8398692810457516,
"acc_stderr": 0.020998740930362303,
"acc_norm": 0.8398692810457516,
"acc_norm_stderr": 0.020998740930362303
},
"harness|hendrycksTest-philosophy|5": {
"acc": 0.8295819935691319,
"acc_stderr": 0.021355343028264053,
"acc_norm": 0.8295819935691319,
"acc_norm_stderr": 0.021355343028264053
},
"harness|hendrycksTest-prehistory|5": {
"acc": 0.8672839506172839,
"acc_stderr": 0.018877353839571866,
"acc_norm": 0.8672839506172839,
"acc_norm_stderr": 0.018877353839571866
},
"harness|hendrycksTest-professional_accounting|5": {
"acc": 0.648936170212766,
"acc_stderr": 0.028473501272963758,
"acc_norm": 0.648936170212766,
"acc_norm_stderr": 0.028473501272963758
},
"harness|hendrycksTest-professional_law|5": {
"acc": 0.6023468057366362,
"acc_stderr": 0.01249984034746064,
"acc_norm": 0.6023468057366362,
"acc_norm_stderr": 0.01249984034746064
},
"harness|hendrycksTest-professional_medicine|5": {
"acc": 0.8382352941176471,
"acc_stderr": 0.022368672562886747,
"acc_norm": 0.8382352941176471,
"acc_norm_stderr": 0.022368672562886747
},
"harness|hendrycksTest-professional_psychology|5": {
"acc": 0.8333333333333334,
"acc_stderr": 0.01507693792191538,
"acc_norm": 0.8333333333333334,
"acc_norm_stderr": 0.01507693792191538
},
"harness|hendrycksTest-public_relations|5": {
"acc": 0.7454545454545455,
"acc_stderr": 0.041723430387053825,
"acc_norm": 0.7454545454545455,
"acc_norm_stderr": 0.041723430387053825
},
"harness|hendrycksTest-security_studies|5": {
"acc": 0.8408163265306122,
"acc_stderr": 0.023420972069166348,
"acc_norm": 0.8408163265306122,
"acc_norm_stderr": 0.023420972069166348
},
"harness|hendrycksTest-sociology|5": {
"acc": 0.8805970149253731,
"acc_stderr": 0.02292879327721974,
"acc_norm": 0.8805970149253731,
"acc_norm_stderr": 0.02292879327721974
},
"harness|hendrycksTest-us_foreign_policy|5": {
"acc": 0.93,
"acc_stderr": 0.0256432399976243,
"acc_norm": 0.93,
"acc_norm_stderr": 0.0256432399976243
},
"harness|hendrycksTest-virology|5": {
"acc": 0.5662650602409639,
"acc_stderr": 0.03858158940685515,
"acc_norm": 0.5662650602409639,
"acc_norm_stderr": 0.03858158940685515
},
"harness|hendrycksTest-world_religions|5": {
"acc": 0.8771929824561403,
"acc_stderr": 0.02517298435015578,
"acc_norm": 0.8771929824561403,
"acc_norm_stderr": 0.02517298435015578
},
"harness|truthfulqa:mc|0": {
"mc1": 0.41615667074663404,
"mc1_stderr": 0.017255657502903043,
"mc2": 0.5745773589644305,
"mc2_stderr": 0.015485111485623915
},
"harness|winogrande|5": {
"acc": 0.8224151539068666,
"acc_stderr": 0.010740676861359245
},
"harness|gsm8k|5": {
"acc": 0.6292645943896892,
"acc_stderr": 0.013304267705458419
}
}
```
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | open-llm-leaderboard/details_brucethemoose__Yi-34B-200K-DARE-merge-v5 | [
"region:us"
] | 2023-12-24T23:52:02+00:00 | {"pretty_name": "Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5", "dataset_summary": "Dataset automatically created during the evaluation run of model [brucethemoose/Yi-34B-200K-DARE-merge-v5](https://huggingface.co/brucethemoose/Yi-34B-200K-DARE-merge-v5) on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)).\n\nTo load the details from a run, you can for instance do the following:\n```python\nfrom datasets import load_dataset\ndata = load_dataset(\"open-llm-leaderboard/details_brucethemoose__Yi-34B-200K-DARE-merge-v5\",\n\t\"harness_winogrande_5\",\n\tsplit=\"train\")\n```\n\n## Latest results\n\nThese are the [latest results from run 2023-12-24T23:49:50.137882](https://huggingface.co/datasets/open-llm-leaderboard/details_brucethemoose__Yi-34B-200K-DARE-merge-v5/blob/main/results_2023-12-24T23-49-50.137882.json)(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):\n\n```python\n{\n \"all\": {\n \"acc\": 0.7667764662598182,\n \"acc_stderr\": 0.0279506982164214,\n \"acc_norm\": 0.7718008025916722,\n \"acc_norm_stderr\": 0.02846678033491038,\n \"mc1\": 0.41615667074663404,\n \"mc1_stderr\": 0.017255657502903043,\n \"mc2\": 0.5745773589644305,\n \"mc2_stderr\": 0.015485111485623915\n },\n \"harness|arc:challenge|25\": {\n \"acc\": 0.64419795221843,\n \"acc_stderr\": 0.01399057113791876,\n \"acc_norm\": 0.6646757679180887,\n \"acc_norm_stderr\": 0.013796182947785562\n },\n \"harness|hellaswag|10\": {\n \"acc\": 0.6613224457279426,\n \"acc_stderr\": 0.004722928332834054,\n \"acc_norm\": 0.8554072893845848,\n \"acc_norm_stderr\": 0.0035097096477918394\n },\n \"harness|hendrycksTest-abstract_algebra|5\": {\n \"acc\": 0.47,\n \"acc_stderr\": 0.050161355804659205,\n \"acc_norm\": 0.47,\n \"acc_norm_stderr\": 0.050161355804659205\n },\n \"harness|hendrycksTest-anatomy|5\": {\n \"acc\": 0.7407407407407407,\n \"acc_stderr\": 0.03785714465066653,\n \"acc_norm\": 0.7407407407407407,\n \"acc_norm_stderr\": 0.03785714465066653\n },\n \"harness|hendrycksTest-astronomy|5\": {\n \"acc\": 0.8881578947368421,\n \"acc_stderr\": 0.02564834125169361,\n \"acc_norm\": 0.8881578947368421,\n \"acc_norm_stderr\": 0.02564834125169361\n },\n \"harness|hendrycksTest-business_ethics|5\": {\n \"acc\": 0.79,\n \"acc_stderr\": 0.040936018074033256,\n \"acc_norm\": 0.79,\n \"acc_norm_stderr\": 0.040936018074033256\n },\n \"harness|hendrycksTest-clinical_knowledge|5\": {\n \"acc\": 0.8188679245283019,\n \"acc_stderr\": 0.023702963526757798,\n \"acc_norm\": 0.8188679245283019,\n \"acc_norm_stderr\": 0.023702963526757798\n },\n \"harness|hendrycksTest-college_biology|5\": {\n \"acc\": 0.8958333333333334,\n \"acc_stderr\": 0.025545239210256917,\n \"acc_norm\": 0.8958333333333334,\n \"acc_norm_stderr\": 0.025545239210256917\n },\n \"harness|hendrycksTest-college_chemistry|5\": {\n \"acc\": 0.47,\n \"acc_stderr\": 0.050161355804659205,\n \"acc_norm\": 0.47,\n \"acc_norm_stderr\": 0.050161355804659205\n },\n \"harness|hendrycksTest-college_computer_science|5\": {\n \"acc\": 0.62,\n \"acc_stderr\": 0.04878317312145633,\n \"acc_norm\": 0.62,\n \"acc_norm_stderr\": 0.04878317312145633\n },\n \"harness|hendrycksTest-college_mathematics|5\": {\n \"acc\": 0.46,\n \"acc_stderr\": 0.05009082659620332,\n \"acc_norm\": 0.46,\n \"acc_norm_stderr\": 0.05009082659620332\n },\n \"harness|hendrycksTest-college_medicine|5\": {\n \"acc\": 0.7572254335260116,\n \"acc_stderr\": 0.0326926380614177,\n \"acc_norm\": 0.7572254335260116,\n \"acc_norm_stderr\": 0.0326926380614177\n },\n \"harness|hendrycksTest-college_physics|5\": {\n \"acc\": 0.5490196078431373,\n \"acc_stderr\": 0.04951218252396262,\n \"acc_norm\": 0.5490196078431373,\n \"acc_norm_stderr\": 0.04951218252396262\n },\n \"harness|hendrycksTest-computer_security|5\": {\n \"acc\": 0.83,\n \"acc_stderr\": 0.03775251680686371,\n \"acc_norm\": 0.83,\n \"acc_norm_stderr\": 0.03775251680686371\n },\n \"harness|hendrycksTest-conceptual_physics|5\": {\n \"acc\": 0.7872340425531915,\n \"acc_stderr\": 0.026754391348039787,\n \"acc_norm\": 0.7872340425531915,\n \"acc_norm_stderr\": 0.026754391348039787\n },\n \"harness|hendrycksTest-econometrics|5\": {\n \"acc\": 0.631578947368421,\n \"acc_stderr\": 0.04537815354939391,\n \"acc_norm\": 0.631578947368421,\n \"acc_norm_stderr\": 0.04537815354939391\n },\n \"harness|hendrycksTest-electrical_engineering|5\": {\n \"acc\": 0.7862068965517242,\n \"acc_stderr\": 0.03416520447747548,\n \"acc_norm\": 0.7862068965517242,\n \"acc_norm_stderr\": 0.03416520447747548\n },\n \"harness|hendrycksTest-elementary_mathematics|5\": {\n \"acc\": 0.7222222222222222,\n \"acc_stderr\": 0.02306818884826112,\n \"acc_norm\": 0.7222222222222222,\n \"acc_norm_stderr\": 0.02306818884826112\n },\n \"harness|hendrycksTest-formal_logic|5\": {\n \"acc\": 0.5714285714285714,\n \"acc_stderr\": 0.04426266681379909,\n \"acc_norm\": 0.5714285714285714,\n \"acc_norm_stderr\": 0.04426266681379909\n },\n \"harness|hendrycksTest-global_facts|5\": {\n \"acc\": 0.59,\n \"acc_stderr\": 0.04943110704237102,\n \"acc_norm\": 0.59,\n \"acc_norm_stderr\": 0.04943110704237102\n },\n \"harness|hendrycksTest-high_school_biology|5\": {\n \"acc\": 0.9129032258064517,\n \"acc_stderr\": 0.016041100741696682,\n \"acc_norm\": 0.9129032258064517,\n \"acc_norm_stderr\": 0.016041100741696682\n },\n \"harness|hendrycksTest-high_school_chemistry|5\": {\n \"acc\": 0.6600985221674877,\n \"acc_stderr\": 0.033327690684107895,\n \"acc_norm\": 0.6600985221674877,\n \"acc_norm_stderr\": 0.033327690684107895\n },\n \"harness|hendrycksTest-high_school_computer_science|5\": {\n \"acc\": 0.83,\n \"acc_stderr\": 0.0377525168068637,\n \"acc_norm\": 0.83,\n \"acc_norm_stderr\": 0.0377525168068637\n },\n \"harness|hendrycksTest-high_school_european_history|5\": {\n \"acc\": 0.8606060606060606,\n \"acc_stderr\": 0.0270459488258654,\n \"acc_norm\": 0.8606060606060606,\n \"acc_norm_stderr\": 0.0270459488258654\n },\n \"harness|hendrycksTest-high_school_geography|5\": {\n \"acc\": 0.9242424242424242,\n \"acc_stderr\": 0.018852670234993093,\n \"acc_norm\": 0.9242424242424242,\n \"acc_norm_stderr\": 0.018852670234993093\n },\n \"harness|hendrycksTest-high_school_government_and_politics|5\": {\n \"acc\": 0.9792746113989638,\n \"acc_stderr\": 0.010281417011909039,\n \"acc_norm\": 0.9792746113989638,\n \"acc_norm_stderr\": 0.010281417011909039\n },\n \"harness|hendrycksTest-high_school_macroeconomics|5\": {\n \"acc\": 0.8128205128205128,\n \"acc_stderr\": 0.01977660108655004,\n \"acc_norm\": 0.8128205128205128,\n \"acc_norm_stderr\": 0.01977660108655004\n },\n \"harness|hendrycksTest-high_school_mathematics|5\": {\n \"acc\": 0.43333333333333335,\n \"acc_stderr\": 0.030213340289237924,\n \"acc_norm\": 0.43333333333333335,\n \"acc_norm_stderr\": 0.030213340289237924\n },\n \"harness|hendrycksTest-high_school_microeconomics|5\": {\n \"acc\": 0.8697478991596639,\n \"acc_stderr\": 0.02186325849485211,\n \"acc_norm\": 0.8697478991596639,\n \"acc_norm_stderr\": 0.02186325849485211\n },\n \"harness|hendrycksTest-high_school_physics|5\": {\n \"acc\": 0.5033112582781457,\n \"acc_stderr\": 0.04082393379449654,\n \"acc_norm\": 0.5033112582781457,\n \"acc_norm_stderr\": 0.04082393379449654\n },\n \"harness|hendrycksTest-high_school_psychology|5\": {\n \"acc\": 0.9321100917431193,\n \"acc_stderr\": 0.010785412654517362,\n \"acc_norm\": 0.9321100917431193,\n \"acc_norm_stderr\": 0.010785412654517362\n },\n \"harness|hendrycksTest-high_school_statistics|5\": {\n \"acc\": 0.6481481481481481,\n \"acc_stderr\": 0.03256850570293647,\n \"acc_norm\": 0.6481481481481481,\n \"acc_norm_stderr\": 0.03256850570293647\n },\n \"harness|hendrycksTest-high_school_us_history|5\": {\n \"acc\": 0.9362745098039216,\n \"acc_stderr\": 0.01714392165552496,\n \"acc_norm\": 0.9362745098039216,\n \"acc_norm_stderr\": 0.01714392165552496\n },\n \"harness|hendrycksTest-high_school_world_history|5\": {\n \"acc\": 0.9029535864978903,\n \"acc_stderr\": 0.019269323025640255,\n \"acc_norm\": 0.9029535864978903,\n \"acc_norm_stderr\": 0.019269323025640255\n },\n \"harness|hendrycksTest-human_aging|5\": {\n \"acc\": 0.8026905829596412,\n \"acc_stderr\": 0.02670985334496796,\n \"acc_norm\": 0.8026905829596412,\n \"acc_norm_stderr\": 0.02670985334496796\n },\n \"harness|hendrycksTest-human_sexuality|5\": {\n \"acc\": 0.8778625954198473,\n \"acc_stderr\": 0.028718776889342327,\n \"acc_norm\": 0.8778625954198473,\n \"acc_norm_stderr\": 0.028718776889342327\n },\n \"harness|hendrycksTest-international_law|5\": {\n \"acc\": 0.8925619834710744,\n \"acc_stderr\": 0.028268812192540627,\n \"acc_norm\": 0.8925619834710744,\n \"acc_norm_stderr\": 0.028268812192540627\n },\n \"harness|hendrycksTest-jurisprudence|5\": {\n \"acc\": 0.8703703703703703,\n \"acc_stderr\": 0.03247224389917949,\n \"acc_norm\": 0.8703703703703703,\n \"acc_norm_stderr\": 0.03247224389917949\n },\n \"harness|hendrycksTest-logical_fallacies|5\": {\n \"acc\": 0.8711656441717791,\n \"acc_stderr\": 0.02632138319878367,\n \"acc_norm\": 0.8711656441717791,\n \"acc_norm_stderr\": 0.02632138319878367\n },\n \"harness|hendrycksTest-machine_learning|5\": {\n \"acc\": 0.625,\n \"acc_stderr\": 0.04595091388086298,\n \"acc_norm\": 0.625,\n \"acc_norm_stderr\": 0.04595091388086298\n },\n \"harness|hendrycksTest-management|5\": {\n \"acc\": 0.8640776699029126,\n \"acc_stderr\": 0.03393295729761012,\n \"acc_norm\": 0.8640776699029126,\n \"acc_norm_stderr\": 0.03393295729761012\n },\n \"harness|hendrycksTest-marketing|5\": {\n \"acc\": 0.9273504273504274,\n \"acc_stderr\": 0.01700436856813235,\n \"acc_norm\": 0.9273504273504274,\n \"acc_norm_stderr\": 0.01700436856813235\n },\n \"harness|hendrycksTest-medical_genetics|5\": {\n \"acc\": 0.91,\n \"acc_stderr\": 0.02876234912646613,\n \"acc_norm\": 0.91,\n \"acc_norm_stderr\": 0.02876234912646613\n },\n \"harness|hendrycksTest-miscellaneous|5\": {\n \"acc\": 0.909323116219668,\n \"acc_stderr\": 0.010268429662528547,\n \"acc_norm\": 0.909323116219668,\n \"acc_norm_stderr\": 0.010268429662528547\n },\n \"harness|hendrycksTest-moral_disputes|5\": {\n \"acc\": 0.815028901734104,\n \"acc_stderr\": 0.020903975842083027,\n \"acc_norm\": 0.815028901734104,\n \"acc_norm_stderr\": 0.020903975842083027\n },\n \"harness|hendrycksTest-moral_scenarios|5\": {\n \"acc\": 0.7664804469273743,\n \"acc_stderr\": 0.014149575348976264,\n \"acc_norm\": 0.7664804469273743,\n \"acc_norm_stderr\": 0.014149575348976264\n },\n \"harness|hendrycksTest-nutrition|5\": {\n \"acc\": 0.8398692810457516,\n \"acc_stderr\": 0.020998740930362303,\n \"acc_norm\": 0.8398692810457516,\n \"acc_norm_stderr\": 0.020998740930362303\n },\n \"harness|hendrycksTest-philosophy|5\": {\n \"acc\": 0.8295819935691319,\n \"acc_stderr\": 0.021355343028264053,\n \"acc_norm\": 0.8295819935691319,\n \"acc_norm_stderr\": 0.021355343028264053\n },\n \"harness|hendrycksTest-prehistory|5\": {\n \"acc\": 0.8672839506172839,\n \"acc_stderr\": 0.018877353839571866,\n \"acc_norm\": 0.8672839506172839,\n \"acc_norm_stderr\": 0.018877353839571866\n },\n \"harness|hendrycksTest-professional_accounting|5\": {\n \"acc\": 0.648936170212766,\n \"acc_stderr\": 0.028473501272963758,\n \"acc_norm\": 0.648936170212766,\n \"acc_norm_stderr\": 0.028473501272963758\n },\n \"harness|hendrycksTest-professional_law|5\": {\n \"acc\": 0.6023468057366362,\n \"acc_stderr\": 0.01249984034746064,\n \"acc_norm\": 0.6023468057366362,\n \"acc_norm_stderr\": 0.01249984034746064\n },\n \"harness|hendrycksTest-professional_medicine|5\": {\n \"acc\": 0.8382352941176471,\n \"acc_stderr\": 0.022368672562886747,\n \"acc_norm\": 0.8382352941176471,\n \"acc_norm_stderr\": 0.022368672562886747\n },\n \"harness|hendrycksTest-professional_psychology|5\": {\n \"acc\": 0.8333333333333334,\n \"acc_stderr\": 0.01507693792191538,\n \"acc_norm\": 0.8333333333333334,\n \"acc_norm_stderr\": 0.01507693792191538\n },\n \"harness|hendrycksTest-public_relations|5\": {\n \"acc\": 0.7454545454545455,\n \"acc_stderr\": 0.041723430387053825,\n \"acc_norm\": 0.7454545454545455,\n \"acc_norm_stderr\": 0.041723430387053825\n },\n \"harness|hendrycksTest-security_studies|5\": {\n \"acc\": 0.8408163265306122,\n \"acc_stderr\": 0.023420972069166348,\n \"acc_norm\": 0.8408163265306122,\n \"acc_norm_stderr\": 0.023420972069166348\n },\n \"harness|hendrycksTest-sociology|5\": {\n \"acc\": 0.8805970149253731,\n \"acc_stderr\": 0.02292879327721974,\n \"acc_norm\": 0.8805970149253731,\n \"acc_norm_stderr\": 0.02292879327721974\n },\n \"harness|hendrycksTest-us_foreign_policy|5\": {\n \"acc\": 0.93,\n \"acc_stderr\": 0.0256432399976243,\n \"acc_norm\": 0.93,\n \"acc_norm_stderr\": 0.0256432399976243\n },\n \"harness|hendrycksTest-virology|5\": {\n \"acc\": 0.5662650602409639,\n \"acc_stderr\": 0.03858158940685515,\n \"acc_norm\": 0.5662650602409639,\n \"acc_norm_stderr\": 0.03858158940685515\n },\n \"harness|hendrycksTest-world_religions|5\": {\n \"acc\": 0.8771929824561403,\n \"acc_stderr\": 0.02517298435015578,\n \"acc_norm\": 0.8771929824561403,\n \"acc_norm_stderr\": 0.02517298435015578\n },\n \"harness|truthfulqa:mc|0\": {\n \"mc1\": 0.41615667074663404,\n \"mc1_stderr\": 0.017255657502903043,\n \"mc2\": 0.5745773589644305,\n \"mc2_stderr\": 0.015485111485623915\n },\n \"harness|winogrande|5\": {\n \"acc\": 0.8224151539068666,\n \"acc_stderr\": 0.010740676861359245\n },\n \"harness|gsm8k|5\": {\n \"acc\": 0.6292645943896892,\n \"acc_stderr\": 0.013304267705458419\n }\n}\n```", "repo_url": "https://huggingface.co/brucethemoose/Yi-34B-200K-DARE-merge-v5", "leaderboard_url": "https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard", "point_of_contact": "[email protected]", "configs": [{"config_name": "harness_arc_challenge_25", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|arc:challenge|25_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|arc:challenge|25_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_gsm8k_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|gsm8k|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|gsm8k|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hellaswag_10", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hellaswag|10_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hellaswag|10_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-management|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-virology|5_2023-12-24T23-49-50.137882.parquet", "**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_abstract_algebra_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-abstract_algebra|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_anatomy_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-anatomy|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_astronomy_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-astronomy|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_business_ethics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-business_ethics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_clinical_knowledge_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-clinical_knowledge|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_biology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_biology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_chemistry_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_chemistry|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_computer_science_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_computer_science|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_mathematics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_medicine_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_medicine|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_college_physics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-college_physics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_computer_security_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-computer_security|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_conceptual_physics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-conceptual_physics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_econometrics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-econometrics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_electrical_engineering_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-electrical_engineering|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_elementary_mathematics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-elementary_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_formal_logic_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-formal_logic|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_global_facts_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-global_facts|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_biology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_biology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_chemistry_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_chemistry|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_computer_science_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_computer_science|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_european_history_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_european_history|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_geography_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_geography|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_government_and_politics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_government_and_politics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_macroeconomics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_macroeconomics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_mathematics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_mathematics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_microeconomics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_microeconomics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_physics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_physics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_psychology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_psychology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_statistics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_statistics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_us_history_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_us_history|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_high_school_world_history_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-high_school_world_history|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_aging_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_aging|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_human_sexuality_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-human_sexuality|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_international_law_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-international_law|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_jurisprudence_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-jurisprudence|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_logical_fallacies_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-logical_fallacies|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_machine_learning_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-machine_learning|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_management_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-management|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_marketing_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-marketing|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_medical_genetics_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-medical_genetics|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_miscellaneous_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-miscellaneous|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_disputes_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_disputes|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_moral_scenarios_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-moral_scenarios|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_nutrition_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-nutrition|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_philosophy_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-philosophy|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_prehistory_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-prehistory|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_accounting_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_accounting|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_law_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_law|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_medicine_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_medicine|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_professional_psychology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-professional_psychology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_public_relations_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-public_relations|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_security_studies_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-security_studies|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_sociology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-sociology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_us_foreign_policy_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-us_foreign_policy|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_virology_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-virology|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_hendrycksTest_world_religions_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|hendrycksTest-world_religions|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_truthfulqa_mc_0", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|truthfulqa:mc|0_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "harness_winogrande_5", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["**/details_harness|winogrande|5_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["**/details_harness|winogrande|5_2023-12-24T23-49-50.137882.parquet"]}]}, {"config_name": "results", "data_files": [{"split": "2023_12_24T23_49_50.137882", "path": ["results_2023-12-24T23-49-50.137882.parquet"]}, {"split": "latest", "path": ["results_2023-12-24T23-49-50.137882.parquet"]}]}]} | 2023-12-24T23:52:21+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5
Dataset automatically created during the evaluation run of model brucethemoose/Yi-34B-200K-DARE-merge-v5 on the Open LLM Leaderboard.
The dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.
The dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The "train" split is always pointing to the latest results.
An additional configuration "results" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).
To load the details from a run, you can for instance do the following:
## Latest results
These are the latest results from run 2023-12-24T23:49:50.137882(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the "latest" split for each eval):
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5\n\n\n\nDataset automatically created during the evaluation run of model brucethemoose/Yi-34B-200K-DARE-merge-v5 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T23:49:50.137882(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5\n\n\n\nDataset automatically created during the evaluation run of model brucethemoose/Yi-34B-200K-DARE-merge-v5 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:",
"## Latest results\n\nThese are the latest results from run 2023-12-24T23:49:50.137882(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
203,
67,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Evaluation run of brucethemoose/Yi-34B-200K-DARE-merge-v5\n\n\n\nDataset automatically created during the evaluation run of model brucethemoose/Yi-34B-200K-DARE-merge-v5 on the Open LLM Leaderboard.\n\nThe dataset is composed of 63 configuration, each one coresponding to one of the evaluated task.\n\nThe dataset has been created from 1 run(s). Each run can be found as a specific split in each configuration, the split being named using the timestamp of the run.The \"train\" split is always pointing to the latest results.\n\nAn additional configuration \"results\" store all the aggregated results of the run (and is used to compute and display the aggregated metrics on the Open LLM Leaderboard).\n\nTo load the details from a run, you can for instance do the following:## Latest results\n\nThese are the latest results from run 2023-12-24T23:49:50.137882(note that their might be results for other tasks in the repos if successive evals didn't cover the same tasks. You find each in the results and the \"latest\" split for each eval):## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]"
] |
be3b1236598a02eff6db05ea7ac386afaabc33e8 |
# Expert-annotated dataset to study cyberbullying in Polish language
This the first publically available expert-annotated dataset containing annotations of cyberbullying and hate-speech in Polish language.
Please, read [the paper](https://www.mdpi.com/2306-5729/9/1/1) about the dataset for all necessary details.
## Model
The classification model which achieved the highest classification results for the dataset is also released under the following URL.
[Polbert-CB - Polish BERT trained for Automatic Cyberbullying Detection](https://huggingface.co/ptaszynski/bert-base-polish-cyberbullying)
## Citations
Whenever you use the dataset, please, cite it using the following citation to [the paper](https://www.mdpi.com/2306-5729/9/1/1).
```
@article{ptaszynski2023expert,
title={Expert-Annotated Dataset to Study Cyberbullying in Polish Language},
author={Ptaszynski, Michal and Pieciukiewicz, Agata and Dybala, Pawel and Skrzek, Pawel and Soliwoda, Kamil and Fortuna, Marcin and Leliwa, Gniewosz and Wroczynski, Michal},
journal={Data},
volume={9},
number={1},
pages={1},
year={2023},
publisher={MDPI}
}
```
## Licences
The dataset is licensed under [CC BY 4.0](http://creativecommons.org/licenses/by/4.0/), or Creative Commons Attribution 4.0 International License.
<a rel="license" href="http://creativecommons.org/licenses/by/4.0/"><img alt="Creative Commons License" style="border-width:0" src="https://i.creativecommons.org/l/by/4.0/88x31.png" /></a>
## Bundle
The whole bundle containing (1) the old version of the dataset, (2) current version of the dataset, as well as (3) the model trained on this dataset can be found on [Zenodo](https://zenodo.org/records/7188178).
## Author
Michal Ptaszynski - contact me on:
- Twitter: [@mich_ptaszynski](https://twitter.com/mich_ptaszynski)
- GitHub: [ptaszynski](https://github.com/ptaszynski)
- LinkedIn: [michalptaszynski](https://jp.linkedin.com/in/michalptaszynski)
- HuggingFace: [ptaszynski](https://huggingface.co/ptaszynski)
| ptaszynski/PolishCyberbullyingDataset | [
"language:pl",
"license:cc-by-4.0",
"cyberbullying",
"hate-speech",
"region:us"
] | 2023-12-25T01:46:02+00:00 | {"language": ["pl"], "license": "cc-by-4.0", "pretty_name": "PolishCyberbullyingDataset", "tags": ["cyberbullying", "hate-speech"]} | 2023-12-25T02:19:22+00:00 | [] | [
"pl"
] | TAGS
#language-Polish #license-cc-by-4.0 #cyberbullying #hate-speech #region-us
|
# Expert-annotated dataset to study cyberbullying in Polish language
This the first publically available expert-annotated dataset containing annotations of cyberbullying and hate-speech in Polish language.
Please, read the paper about the dataset for all necessary details.
## Model
The classification model which achieved the highest classification results for the dataset is also released under the following URL.
Polbert-CB - Polish BERT trained for Automatic Cyberbullying Detection
s
Whenever you use the dataset, please, cite it using the following citation to the paper.
## Licences
The dataset is licensed under CC BY 4.0, or Creative Commons Attribution 4.0 International License.
<a rel="license" href="URL alt="Creative Commons License" style="border-width:0" src="https://i.URL /></a>
## Bundle
The whole bundle containing (1) the old version of the dataset, (2) current version of the dataset, as well as (3) the model trained on this dataset can be found on Zenodo.
## Author
Michal Ptaszynski - contact me on:
- Twitter: @mich_ptaszynski
- GitHub: ptaszynski
- LinkedIn: michalptaszynski
- HuggingFace: ptaszynski
| [
"# Expert-annotated dataset to study cyberbullying in Polish language\n\nThis the first publically available expert-annotated dataset containing annotations of cyberbullying and hate-speech in Polish language.\n\nPlease, read the paper about the dataset for all necessary details.",
"## Model\nThe classification model which achieved the highest classification results for the dataset is also released under the following URL.\nPolbert-CB - Polish BERT trained for Automatic Cyberbullying Detection\n\ns\nWhenever you use the dataset, please, cite it using the following citation to the paper.",
"## Licences\nThe dataset is licensed under CC BY 4.0, or Creative Commons Attribution 4.0 International License.\n\n<a rel=\"license\" href=\"URL alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.URL /></a>",
"## Bundle\n\nThe whole bundle containing (1) the old version of the dataset, (2) current version of the dataset, as well as (3) the model trained on this dataset can be found on Zenodo.",
"## Author\nMichal Ptaszynski - contact me on:\n- Twitter: @mich_ptaszynski\n- GitHub: ptaszynski\n- LinkedIn: michalptaszynski\n- HuggingFace: ptaszynski"
] | [
"TAGS\n#language-Polish #license-cc-by-4.0 #cyberbullying #hate-speech #region-us \n",
"# Expert-annotated dataset to study cyberbullying in Polish language\n\nThis the first publically available expert-annotated dataset containing annotations of cyberbullying and hate-speech in Polish language.\n\nPlease, read the paper about the dataset for all necessary details.",
"## Model\nThe classification model which achieved the highest classification results for the dataset is also released under the following URL.\nPolbert-CB - Polish BERT trained for Automatic Cyberbullying Detection\n\ns\nWhenever you use the dataset, please, cite it using the following citation to the paper.",
"## Licences\nThe dataset is licensed under CC BY 4.0, or Creative Commons Attribution 4.0 International License.\n\n<a rel=\"license\" href=\"URL alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.URL /></a>",
"## Bundle\n\nThe whole bundle containing (1) the old version of the dataset, (2) current version of the dataset, as well as (3) the model trained on this dataset can be found on Zenodo.",
"## Author\nMichal Ptaszynski - contact me on:\n- Twitter: @mich_ptaszynski\n- GitHub: ptaszynski\n- LinkedIn: michalptaszynski\n- HuggingFace: ptaszynski"
] | [
31,
63,
67,
60,
45,
49
] | [
"passage: TAGS\n#language-Polish #license-cc-by-4.0 #cyberbullying #hate-speech #region-us \n# Expert-annotated dataset to study cyberbullying in Polish language\n\nThis the first publically available expert-annotated dataset containing annotations of cyberbullying and hate-speech in Polish language.\n\nPlease, read the paper about the dataset for all necessary details.## Model\nThe classification model which achieved the highest classification results for the dataset is also released under the following URL.\nPolbert-CB - Polish BERT trained for Automatic Cyberbullying Detection\n\ns\nWhenever you use the dataset, please, cite it using the following citation to the paper.## Licences\nThe dataset is licensed under CC BY 4.0, or Creative Commons Attribution 4.0 International License.\n\n<a rel=\"license\" href=\"URL alt=\"Creative Commons License\" style=\"border-width:0\" src=\"https://i.URL /></a>## Bundle\n\nThe whole bundle containing (1) the old version of the dataset, (2) current version of the dataset, as well as (3) the model trained on this dataset can be found on Zenodo.## Author\nMichal Ptaszynski - contact me on:\n- Twitter: @mich_ptaszynski\n- GitHub: ptaszynski\n- LinkedIn: michalptaszynski\n- HuggingFace: ptaszynski"
] |
a74a21bf3755af1ce38d66335d3bfd3e68fb20f0 |
# Self Driving GTA V Dataset

# Dataset Varients
- Mini : [Link](https://huggingface.co/datasets/sartajbhuvaji/self-driving-GTA-V/tree/main/mini)
- Training Data(1-100) : [Link](https://huggingface.co/datasets/sartajbhuvaji/self-driving-GTA-V/tree/main/Training%20Data(1-100))
- Training Data(101-200) : [Link](https://huggingface.co/datasets/sartajbhuvaji/self-driving-GTA-V/tree/main/Training%20Data(101-200))
### Info
- Image Resolution : 270, 480
- Mode : RGB
- Dimension : (270, 480, 3)
- File Count : 100
- Size : 1.81 GB/file
- Total Data Size : 362 GB
- Total Frames : 1 Million
### Data Set sizes
#### Mini :
- Folder Name : mini
- Files : 01
- Total Size : 1.81 GB
- Total Frames : 5000
#### First Half
- Folder Name : Training Data(1-100)
- Files : 100
- Total Size : 181 GB
- Total Frames : 500,000
#### Second Half
- Folder Name : Training Data(101-200)
- Files : 100
- Total Size : 181 GB
- Total Frames : 500,000
### Data Count
#### Mini
```
'W': [1, 0, 0, 0, 0, 0, 0, 0, 0] : 3627
'S': [0, 1, 0, 0, 0, 0, 0, 0, 0] : 50
'A': [0, 0, 1, 0, 0, 0, 0, 0, 0] : 104
'D': [0, 0, 0, 1, 0, 0, 0, 0, 0] : 106
'WA': [0, 0, 0, 0, 1, 0, 0, 0, 0] : 364
'WD': [0, 0, 0, 0, 0, 1, 0, 0, 0] : 416
'SA': [0, 0, 0, 0, 0, 0, 1, 0, 0] : 35
'SD': [0, 0, 0, 0, 0, 0, 0, 1, 0] : 47
'NK': [0, 0, 0, 0, 0, 0, 0, 0, 1] : 248
NONE : 3
```
#### First Half (Data Count (1-100))
```
'W': [1, 0, 0, 0, 0, 0, 0, 0, 0] : 353725
'S': [0, 1, 0, 0, 0, 0, 0, 0, 0] : 2243
'A': [0, 0, 1, 0, 0, 0, 0, 0, 0] : 14303
'D': [0, 0, 0, 1, 0, 0, 0, 0, 0] : 13114
'WA': [0, 0, 0, 0, 1, 0, 0, 0, 0] : 30877
'WD': [0, 0, 0, 0, 0, 1, 0, 0, 0] : 29837
'SA': [0, 0, 0, 0, 0, 0, 1, 0, 0] : 1952
'SD': [0, 0, 0, 0, 0, 0, 0, 1, 0] : 1451
'NK': [0, 0, 0, 0, 0, 0, 0, 0, 1] : 52256
NONE : 242
```
#### Second Half (Data Count (101-200))
```
'W': [1, 0, 0, 0, 0, 0, 0, 0, 0] : 359025
'S': [0, 1, 0, 0, 0, 0, 0, 0, 0] : 2834
'A': [0, 0, 1, 0, 0, 0, 0, 0, 0] : 11025
'D': [0, 0, 0, 1, 0, 0, 0, 0, 0] : 9639
'WA': [0, 0, 0, 0, 1, 0, 0, 0, 0] : 31896
'WD': [0, 0, 0, 0, 0, 1, 0, 0, 0] : 29756
'SA': [0, 0, 0, 0, 0, 0, 1, 0, 0] : 1742
'SD': [0, 0, 0, 0, 0, 0, 0, 1, 0] : 2461
'NK': [0, 0, 0, 0, 0, 0, 0, 0, 1] : 51313
NONE : 309
```
### Graphics Details
- Original Resolution : 800 x 600
- Aspect Ratio : 16:10
- All Video Settings : Low
### Camera Details
- Camera : Hood Cam
- Vehical Camera Height : Low
- First Person Vehical Auto-Center : On
- First Person Head Bobbing : Off
### Other Details
- Vehical : Michael's Car
- Vehical Mods : All Max
- Cv2 Mask : None
- Way Point : Enabled/Following
- Weather Conditions : Mostly Sunny
- Time of Day : Day, Night
- Rain : Some
### Note
- Remove `NONE` while processing the data
- Use the `mini` dataset for initial setup and testing
- Check `training_data_count_001-100.csv` & `training_data_count_101-200.csv` for detailed count
- Check `training_data_stats.py` for more info
### Inspired From
- Sentdex
- [Youtube: Python Plays: Grand Theft Auto V](https://youtube.com/playlist?list=PLQVvvaa0QuDeETZEOy4VdocT7TOjfSA8a&si=M5Pt-O97yvWgZMQE) | sartajbhuvaji/self-driving-GTA-V | [
"task_categories:image-classification",
"size_categories:1M<n<10M",
"source_datasets:original",
"license:mit",
"self driving",
"GTA",
"GTA V",
"driving",
"region:us"
] | 2023-12-25T03:25:11+00:00 | {"license": "mit", "size_categories": ["1M<n<10M"], "source_datasets": ["original"], "task_categories": ["image-classification"], "tags": ["self driving", "GTA", "GTA V", "driving"], "configs": [{"config_name": "default", "data_files": [{"split": "mini", "path": "training_data_count_mini.csv"}, {"split": "TrainingData_1", "path": "training_data_count_001-100.csv"}, {"split": "TrainingData_2", "path": "training_data_count_101-200.csv"}]}]} | 2023-12-25T21:42:01+00:00 | [] | [] | TAGS
#task_categories-image-classification #size_categories-1M<n<10M #source_datasets-original #license-mit #self driving #GTA #GTA V #driving #region-us
|
# Self Driving GTA V Dataset
!image/png
# Dataset Varients
- Mini : Link
- Training Data(1-100) : Link)
- Training Data(101-200) : Link)
### Info
- Image Resolution : 270, 480
- Mode : RGB
- Dimension : (270, 480, 3)
- File Count : 100
- Size : 1.81 GB/file
- Total Data Size : 362 GB
- Total Frames : 1 Million
### Data Set sizes
#### Mini :
- Folder Name : mini
- Files : 01
- Total Size : 1.81 GB
- Total Frames : 5000
#### First Half
- Folder Name : Training Data(1-100)
- Files : 100
- Total Size : 181 GB
- Total Frames : 500,000
#### Second Half
- Folder Name : Training Data(101-200)
- Files : 100
- Total Size : 181 GB
- Total Frames : 500,000
### Data Count
#### Mini
#### First Half (Data Count (1-100))
#### Second Half (Data Count (101-200))
### Graphics Details
- Original Resolution : 800 x 600
- Aspect Ratio : 16:10
- All Video Settings : Low
### Camera Details
- Camera : Hood Cam
- Vehical Camera Height : Low
- First Person Vehical Auto-Center : On
- First Person Head Bobbing : Off
### Other Details
- Vehical : Michael's Car
- Vehical Mods : All Max
- Cv2 Mask : None
- Way Point : Enabled/Following
- Weather Conditions : Mostly Sunny
- Time of Day : Day, Night
- Rain : Some
### Note
- Remove 'NONE' while processing the data
- Use the 'mini' dataset for initial setup and testing
- Check 'training_data_count_001-URL' & 'training_data_count_101-URL' for detailed count
- Check 'training_data_stats.py' for more info
### Inspired From
- Sentdex
- Youtube: Python Plays: Grand Theft Auto V | [
"# Self Driving GTA V Dataset\n\n!image/png",
"# Dataset Varients\n- Mini : Link\n- Training Data(1-100) : Link) \n- Training Data(101-200) : Link)",
"### Info\n- Image Resolution : 270, 480\n- Mode : RGB\n- Dimension : (270, 480, 3)\n- File Count : 100\n- Size : 1.81 GB/file\n- Total Data Size : 362 GB \n- Total Frames : 1 Million",
"### Data Set sizes",
"#### Mini : \n- Folder Name : mini\n- Files : 01\n- Total Size : 1.81 GB\n- Total Frames : 5000",
"#### First Half\n- Folder Name : Training Data(1-100)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000",
"#### Second Half\n- Folder Name : Training Data(101-200)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000",
"### Data Count",
"#### Mini",
"#### First Half (Data Count (1-100))",
"#### Second Half (Data Count (101-200))",
"### Graphics Details\n- Original Resolution : 800 x 600\n- Aspect Ratio : 16:10\n- All Video Settings : Low",
"### Camera Details\n- Camera : Hood Cam\n- Vehical Camera Height : Low\n- First Person Vehical Auto-Center : On\n- First Person Head Bobbing : Off",
"### Other Details\n- Vehical : Michael's Car\n- Vehical Mods : All Max \n- Cv2 Mask : None\n- Way Point : Enabled/Following\n- Weather Conditions : Mostly Sunny\n- Time of Day : Day, Night\n- Rain : Some",
"### Note\n- Remove 'NONE' while processing the data\n- Use the 'mini' dataset for initial setup and testing\n- Check 'training_data_count_001-URL' & 'training_data_count_101-URL' for detailed count\n- Check 'training_data_stats.py' for more info",
"### Inspired From \n- Sentdex\n- Youtube: Python Plays: Grand Theft Auto V"
] | [
"TAGS\n#task_categories-image-classification #size_categories-1M<n<10M #source_datasets-original #license-mit #self driving #GTA #GTA V #driving #region-us \n",
"# Self Driving GTA V Dataset\n\n!image/png",
"# Dataset Varients\n- Mini : Link\n- Training Data(1-100) : Link) \n- Training Data(101-200) : Link)",
"### Info\n- Image Resolution : 270, 480\n- Mode : RGB\n- Dimension : (270, 480, 3)\n- File Count : 100\n- Size : 1.81 GB/file\n- Total Data Size : 362 GB \n- Total Frames : 1 Million",
"### Data Set sizes",
"#### Mini : \n- Folder Name : mini\n- Files : 01\n- Total Size : 1.81 GB\n- Total Frames : 5000",
"#### First Half\n- Folder Name : Training Data(1-100)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000",
"#### Second Half\n- Folder Name : Training Data(101-200)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000",
"### Data Count",
"#### Mini",
"#### First Half (Data Count (1-100))",
"#### Second Half (Data Count (101-200))",
"### Graphics Details\n- Original Resolution : 800 x 600\n- Aspect Ratio : 16:10\n- All Video Settings : Low",
"### Camera Details\n- Camera : Hood Cam\n- Vehical Camera Height : Low\n- First Person Vehical Auto-Center : On\n- First Person Head Bobbing : Off",
"### Other Details\n- Vehical : Michael's Car\n- Vehical Mods : All Max \n- Cv2 Mask : None\n- Way Point : Enabled/Following\n- Weather Conditions : Mostly Sunny\n- Time of Day : Day, Night\n- Rain : Some",
"### Note\n- Remove 'NONE' while processing the data\n- Use the 'mini' dataset for initial setup and testing\n- Check 'training_data_count_001-URL' & 'training_data_count_101-URL' for detailed count\n- Check 'training_data_stats.py' for more info",
"### Inspired From \n- Sentdex\n- Youtube: Python Plays: Grand Theft Auto V"
] | [
55,
13,
28,
53,
6,
28,
32,
33,
5,
3,
12,
13,
27,
38,
61,
70,
19
] | [
"passage: TAGS\n#task_categories-image-classification #size_categories-1M<n<10M #source_datasets-original #license-mit #self driving #GTA #GTA V #driving #region-us \n# Self Driving GTA V Dataset\n\n!image/png# Dataset Varients\n- Mini : Link\n- Training Data(1-100) : Link) \n- Training Data(101-200) : Link)### Info\n- Image Resolution : 270, 480\n- Mode : RGB\n- Dimension : (270, 480, 3)\n- File Count : 100\n- Size : 1.81 GB/file\n- Total Data Size : 362 GB \n- Total Frames : 1 Million### Data Set sizes#### Mini : \n- Folder Name : mini\n- Files : 01\n- Total Size : 1.81 GB\n- Total Frames : 5000#### First Half\n- Folder Name : Training Data(1-100)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000#### Second Half\n- Folder Name : Training Data(101-200)\n- Files : 100\n- Total Size : 181 GB\n- Total Frames : 500,000### Data Count#### Mini#### First Half (Data Count (1-100))#### Second Half (Data Count (101-200))### Graphics Details\n- Original Resolution : 800 x 600\n- Aspect Ratio : 16:10\n- All Video Settings : Low### Camera Details\n- Camera : Hood Cam\n- Vehical Camera Height : Low\n- First Person Vehical Auto-Center : On\n- First Person Head Bobbing : Off### Other Details\n- Vehical : Michael's Car\n- Vehical Mods : All Max \n- Cv2 Mask : None\n- Way Point : Enabled/Following\n- Weather Conditions : Mostly Sunny\n- Time of Day : Day, Night\n- Rain : Some### Note\n- Remove 'NONE' while processing the data\n- Use the 'mini' dataset for initial setup and testing\n- Check 'training_data_count_001-URL' & 'training_data_count_101-URL' for detailed count\n- Check 'training_data_stats.py' for more info### Inspired From \n- Sentdex\n- Youtube: Python Plays: Grand Theft Auto V"
] |
c4083a9f4cb7561366618a6d5550d5c6cd6ce368 | # Dataset Card for "wiki-span"
This dataset is constructed by sampling 25%-50% of each wikipedia record twice, as positive pairs. It can be used to train unsupervised sentence representation models. | gowitheflow/wiki-span | [
"region:us"
] | 2023-12-25T03:53:50+00:00 | {"dataset_info": {"features": [{"name": "sentence1", "dtype": "string"}, {"name": "sentence2", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 14498836027, "num_examples": 6458670}], "download_size": 8956015300, "dataset_size": 14498836027}} | 2024-01-11T19:58:32+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "wiki-span"
This dataset is constructed by sampling 25%-50% of each wikipedia record twice, as positive pairs. It can be used to train unsupervised sentence representation models. | [
"# Dataset Card for \"wiki-span\"\n\nThis dataset is constructed by sampling 25%-50% of each wikipedia record twice, as positive pairs. It can be used to train unsupervised sentence representation models."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"wiki-span\"\n\nThis dataset is constructed by sampling 25%-50% of each wikipedia record twice, as positive pairs. It can be used to train unsupervised sentence representation models."
] | [
6,
50
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"wiki-span\"\n\nThis dataset is constructed by sampling 25%-50% of each wikipedia record twice, as positive pairs. It can be used to train unsupervised sentence representation models."
] |
b6c57978d5842da1def32589218ea571f2bf1dd1 |
## 介绍/Introduction
本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。
We opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem.
## 组成
* 在预训练阶段,我们不仅使用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据包含人工收集和整理的高质量数据。涵盖了报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据。其中,报纸类数据包括广泛的新闻报道和专栏文章,这类数据通常结构化程度高,信息量丰富。文献类数据包括学术论文和研究报告,为我们的数据集注入了专业和深度。代码类数据包括各种编程语言的源码,有助于构建和优化技术类数据的处理模型。书籍类数据涵盖了小说、诗歌、古文、教材等内容,提供丰富的语境和词汇,增强语言模型的理解能力。数据分布情况如下:
* During the pre-training phase, we not only utilized internet data to train the model's language abilities but also incorporated curated general data and domain-specific information to enhance the model's expertise. Curated general data covers a wide range of categories including books (e.g., textbooks, novels), codes, encyclopedias, forums, academic papers, authoritative news, laws and regulations. Details of the data distribution are as follows:
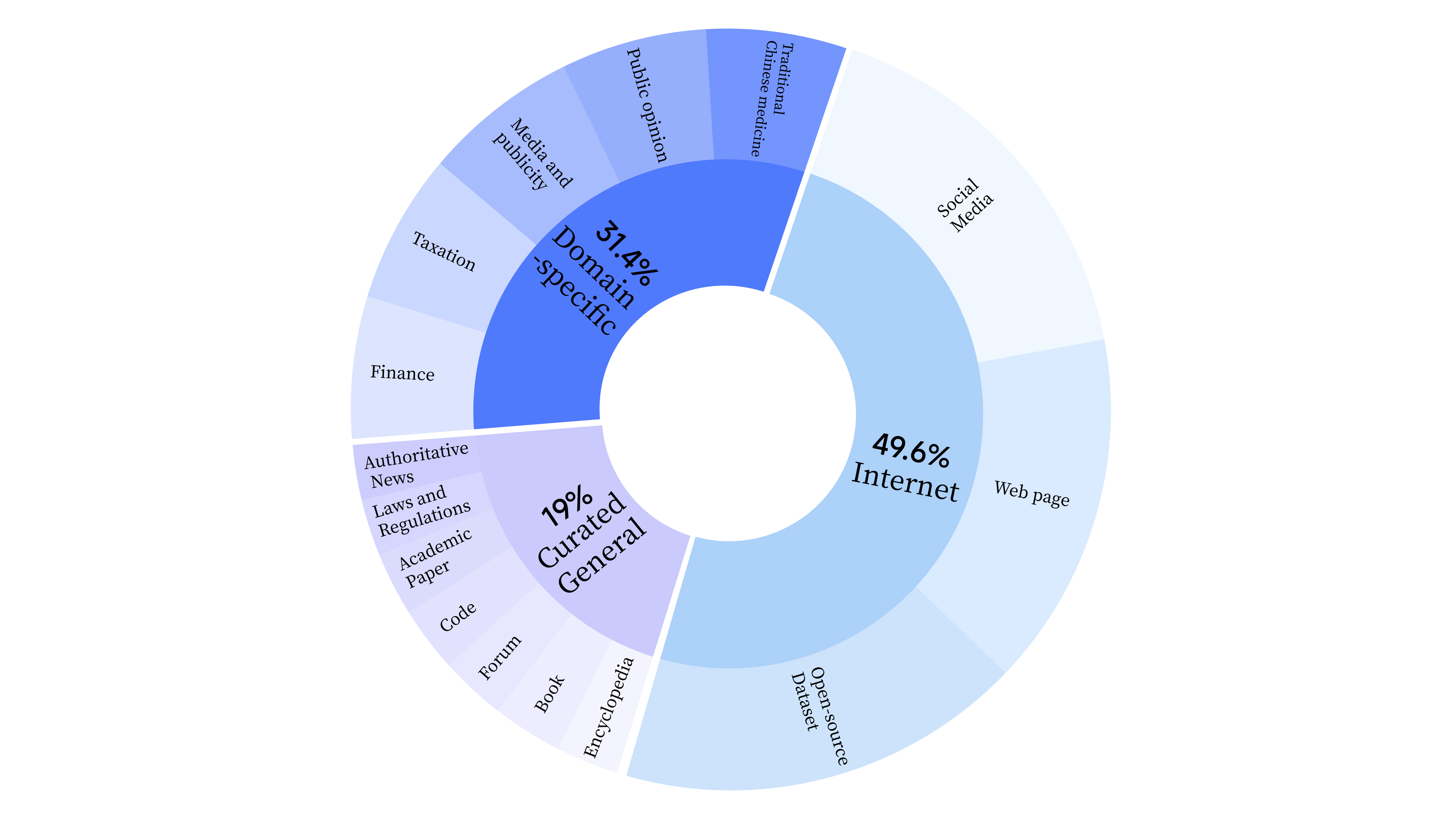
## 数据清洗
- 我们构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。我们共收集了 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。整体流程如下:
- We establish a comprehensive data processing pipeline to enhance data quality in all aspects. This pipeline comprises four modules: normalizing, heuristic cleaning, multi-level deduplication, and toxicity filtering. 240 terabytes of raw data are collected for pre-training, and only 10.6 terabytes of high-quality data remain after preprocessing. Details of the data processing pipeline are as follows:
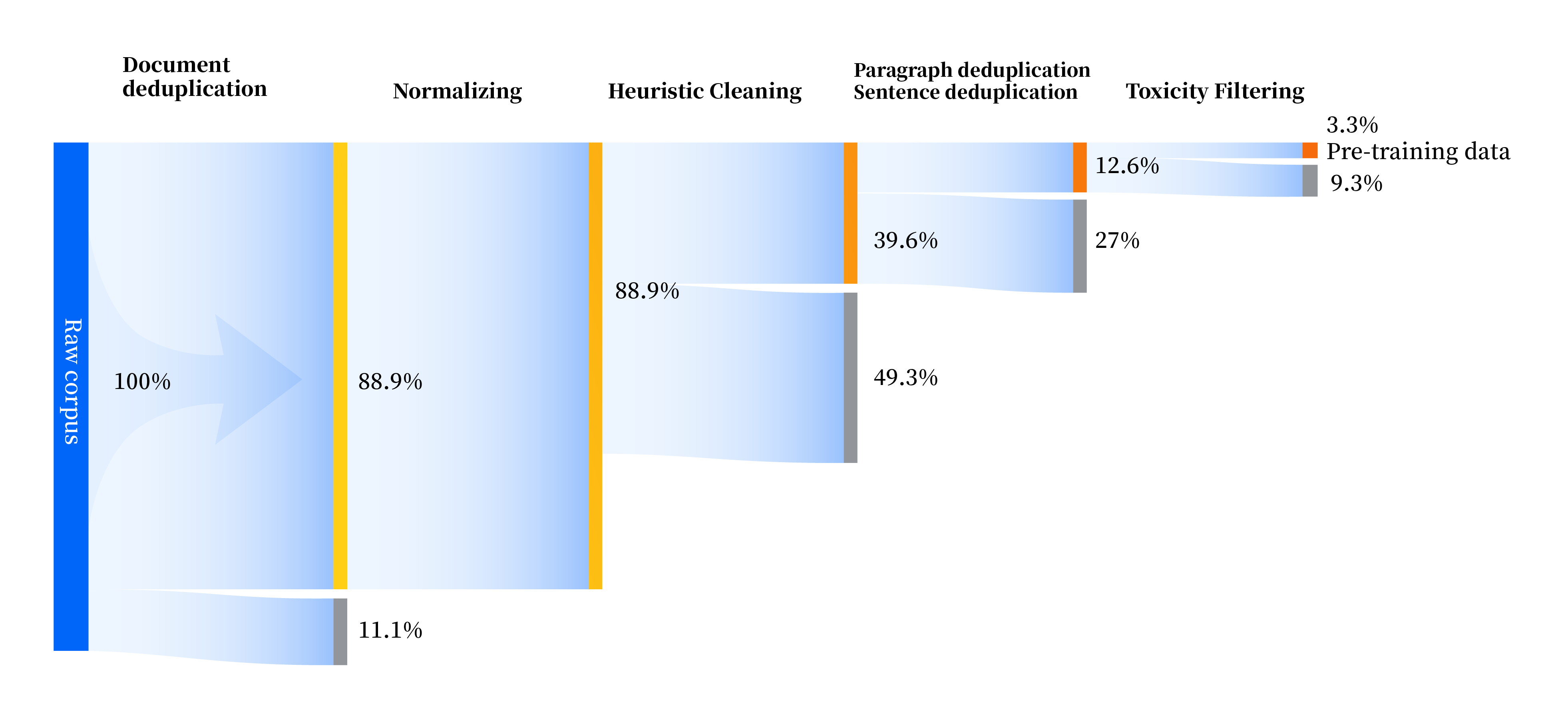
## 协议/License
本项目中的代码依照 [Apache-2.0](https://github.com/wenge-research/YAYI2/blob/main/LICENSE) 协议开源,社区使用 YAYI 2 模型和数据需要遵循[雅意YAYI 2 模型社区许可协议](https://github.com/wenge-research/YAYI2/blob/main/COMMUNITY_LICENSE)。若您需要将雅意 YAYI 2系列模型或其衍生品用作商业用途,请根据[《雅意 YAYI 2 模型商用许可协议》](https://github.com/wenge-research/YAYI2/blob/main/COMMERCIAL_LICENSE)将商用许可申请登记信息发送至指定邮箱 [[email protected]](mailto:[email protected])。审核通过后,雅意将授予您商用版权许可,请遵循协议中的商业许可限制。
The code in this project is open-sourced under the [Apache-2.0](https://github.com/wenge-research/YAYI2/blob/main/LICENSE) license. The use of YaYi series model weights and data must adhere to the [YAYI 2 Community License](https://github.com/wenge-research/YAYI2/blob/main/COMMUNITY_LICENSE). If you intend to use the YAYI 2 series models or their derivatives for commercial purposes, please submit your commercial license application and registration information to [[email protected]](mailto:[email protected]), following the [YAYI 2 Commercial License](https://github.com/wenge-research/YAYI2/blob/main/COMMERCIAL_LICENSE). Upon approval, YAYI will grant you a commercial copyright license, subject to the commercial license restrictions outlined in the agreement.
## 引用/Citation
如果您在工作中使用了我们的模型或者数据,请引用我们的论文。
If you are using the resource for your work, please cite our paper.
```
@article{YAYI 2,
author = {Yin Luo, Qingchao Kong, Nan Xu, et.al.},
title = {YAYI 2: Multilingual Open Source Large Language Models},
journal = {arXiv preprint arXiv:2312.14862},
url = {https://arxiv.org/abs/2312.14862},
year = {2023}
}
``` | wenge-research/yayi2_pretrain_data | [
"size_categories:100B<n<1T",
"language:zh",
"language:en",
"license:apache-2.0",
"arxiv:2312.14862",
"region:us"
] | 2023-12-25T05:15:47+00:00 | {"language": ["zh", "en"], "license": "apache-2.0", "size_categories": ["100B<n<1T"]} | 2023-12-29T08:40:24+00:00 | [
"2312.14862"
] | [
"zh",
"en"
] | TAGS
#size_categories-100B<n<1T #language-Chinese #language-English #license-apache-2.0 #arxiv-2312.14862 #region-us
|
## 介绍/Introduction
本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。
We opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem.
## 组成
* 在预训练阶段,我们不仅使用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据包含人工收集和整理的高质量数据。涵盖了报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据。其中,报纸类数据包括广泛的新闻报道和专栏文章,这类数据通常结构化程度高,信息量丰富。文献类数据包括学术论文和研究报告,为我们的数据集注入了专业和深度。代码类数据包括各种编程语言的源码,有助于构建和优化技术类数据的处理模型。书籍类数据涵盖了小说、诗歌、古文、教材等内容,提供丰富的语境和词汇,增强语言模型的理解能力。数据分布情况如下:
* During the pre-training phase, we not only utilized internet data to train the model's language abilities but also incorporated curated general data and domain-specific information to enhance the model's expertise. Curated general data covers a wide range of categories including books (e.g., textbooks, novels), codes, encyclopedias, forums, academic papers, authoritative news, laws and regulations. Details of the data distribution are as follows:
!data distribution
## 数据清洗
- 我们构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。我们共收集了 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。整体流程如下:
- We establish a comprehensive data processing pipeline to enhance data quality in all aspects. This pipeline comprises four modules: normalizing, heuristic cleaning, multi-level deduplication, and toxicity filtering. 240 terabytes of raw data are collected for pre-training, and only 10.6 terabytes of high-quality data remain after preprocessing. Details of the data processing pipeline are as follows:
!data process
## 协议/License
本项目中的代码依照 Apache-2.0 协议开源,社区使用 YAYI 2 模型和数据需要遵循雅意YAYI 2 模型社区许可协议。若您需要将雅意 YAYI 2系列模型或其衍生品用作商业用途,请根据《雅意 YAYI 2 模型商用许可协议》将商用许可申请登记信息发送至指定邮箱 yayi@URL。审核通过后,雅意将授予您商用版权许可,请遵循协议中的商业许可限制。
The code in this project is open-sourced under the Apache-2.0 license. The use of YaYi series model weights and data must adhere to the YAYI 2 Community License. If you intend to use the YAYI 2 series models or their derivatives for commercial purposes, please submit your commercial license application and registration information to yayi@URL, following the YAYI 2 Commercial License. Upon approval, YAYI will grant you a commercial copyright license, subject to the commercial license restrictions outlined in the agreement.
## 引用/Citation
如果您在工作中使用了我们的模型或者数据,请引用我们的论文。
If you are using the resource for your work, please cite our paper.
| [
"## 介绍/Introduction\n\n本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。\n\nWe opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem.",
"## 组成\n\n* 在预训练阶段,我们不仅使用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据包含人工收集和整理的高质量数据。涵盖了报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据。其中,报纸类数据包括广泛的新闻报道和专栏文章,这类数据通常结构化程度高,信息量丰富。文献类数据包括学术论文和研究报告,为我们的数据集注入了专业和深度。代码类数据包括各种编程语言的源码,有助于构建和优化技术类数据的处理模型。书籍类数据涵盖了小说、诗歌、古文、教材等内容,提供丰富的语境和词汇,增强语言模型的理解能力。数据分布情况如下:\n* During the pre-training phase, we not only utilized internet data to train the model's language abilities but also incorporated curated general data and domain-specific information to enhance the model's expertise. Curated general data covers a wide range of categories including books (e.g., textbooks, novels), codes, encyclopedias, forums, academic papers, authoritative news, laws and regulations. Details of the data distribution are as follows:\n\n!data distribution",
"## 数据清洗\n\n- 我们构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。我们共收集了 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。整体流程如下:\n\n- We establish a comprehensive data processing pipeline to enhance data quality in all aspects. This pipeline comprises four modules: normalizing, heuristic cleaning, multi-level deduplication, and toxicity filtering. 240 terabytes of raw data are collected for pre-training, and only 10.6 terabytes of high-quality data remain after preprocessing. Details of the data processing pipeline are as follows:\n\n!data process",
"## 协议/License\n\n本项目中的代码依照 Apache-2.0 协议开源,社区使用 YAYI 2 模型和数据需要遵循雅意YAYI 2 模型社区许可协议。若您需要将雅意 YAYI 2系列模型或其衍生品用作商业用途,请根据《雅意 YAYI 2 模型商用许可协议》将商用许可申请登记信息发送至指定邮箱 yayi@URL。审核通过后,雅意将授予您商用版权许可,请遵循协议中的商业许可限制。\n\nThe code in this project is open-sourced under the Apache-2.0 license. The use of YaYi series model weights and data must adhere to the YAYI 2 Community License. If you intend to use the YAYI 2 series models or their derivatives for commercial purposes, please submit your commercial license application and registration information to yayi@URL, following the YAYI 2 Commercial License. Upon approval, YAYI will grant you a commercial copyright license, subject to the commercial license restrictions outlined in the agreement.",
"## 引用/Citation\n\n如果您在工作中使用了我们的模型或者数据,请引用我们的论文。\n\nIf you are using the resource for your work, please cite our paper."
] | [
"TAGS\n#size_categories-100B<n<1T #language-Chinese #language-English #license-apache-2.0 #arxiv-2312.14862 #region-us \n",
"## 介绍/Introduction\n\n本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。\n\nWe opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem.",
"## 组成\n\n* 在预训练阶段,我们不仅使用了互联网数据来训练模型的语言能力,还添加了通用精选数据和领域数据,以增强模型的专业技能。通用精选数据包含人工收集和整理的高质量数据。涵盖了报纸类数据、文献类数据、APP类数据、代码类数据、书籍类数据、百科类数据。其中,报纸类数据包括广泛的新闻报道和专栏文章,这类数据通常结构化程度高,信息量丰富。文献类数据包括学术论文和研究报告,为我们的数据集注入了专业和深度。代码类数据包括各种编程语言的源码,有助于构建和优化技术类数据的处理模型。书籍类数据涵盖了小说、诗歌、古文、教材等内容,提供丰富的语境和词汇,增强语言模型的理解能力。数据分布情况如下:\n* During the pre-training phase, we not only utilized internet data to train the model's language abilities but also incorporated curated general data and domain-specific information to enhance the model's expertise. Curated general data covers a wide range of categories including books (e.g., textbooks, novels), codes, encyclopedias, forums, academic papers, authoritative news, laws and regulations. Details of the data distribution are as follows:\n\n!data distribution",
"## 数据清洗\n\n- 我们构建了一套全方位提升数据质量的数据处理流水线,包括标准化、启发式清洗、多级去重、毒性过滤四个模块。我们共收集了 240TB 原始数据,预处理后仅剩 10.6TB 高质量数据。整体流程如下:\n\n- We establish a comprehensive data processing pipeline to enhance data quality in all aspects. This pipeline comprises four modules: normalizing, heuristic cleaning, multi-level deduplication, and toxicity filtering. 240 terabytes of raw data are collected for pre-training, and only 10.6 terabytes of high-quality data remain after preprocessing. Details of the data processing pipeline are as follows:\n\n!data process",
"## 协议/License\n\n本项目中的代码依照 Apache-2.0 协议开源,社区使用 YAYI 2 模型和数据需要遵循雅意YAYI 2 模型社区许可协议。若您需要将雅意 YAYI 2系列模型或其衍生品用作商业用途,请根据《雅意 YAYI 2 模型商用许可协议》将商用许可申请登记信息发送至指定邮箱 yayi@URL。审核通过后,雅意将授予您商用版权许可,请遵循协议中的商业许可限制。\n\nThe code in this project is open-sourced under the Apache-2.0 license. The use of YaYi series model weights and data must adhere to the YAYI 2 Community License. If you intend to use the YAYI 2 series models or their derivatives for commercial purposes, please submit your commercial license application and registration information to yayi@URL, following the YAYI 2 Commercial License. Upon approval, YAYI will grant you a commercial copyright license, subject to the commercial license restrictions outlined in the agreement.",
"## 引用/Citation\n\n如果您在工作中使用了我们的模型或者数据,请引用我们的论文。\n\nIf you are using the resource for your work, please cite our paper."
] | [
44,
180,
290,
164,
227,
37
] | [
"passage: TAGS\n#size_categories-100B<n<1T #language-Chinese #language-English #license-apache-2.0 #arxiv-2312.14862 #region-us \n## 介绍/Introduction\n\n本数据集源自雅意训练语料,我们精选了约100B数据,数据大小约为500GB。我们期望通过雅意预训练数据的开源推动中文预训练大模型开源社区的发展,并积极为此贡献力量。通过开源,我们与每一位合作伙伴共同构建雅意大模型生态。\n\nWe opensource the pre-trained dataset in this release, it should contain more than 100B tokens depending on the tokenizer you use, requiring more than 500GB of local storage. By open-sourcing the pre-trained dataset, we aim to contribute to the development of the Chinese pre-trained large language model open-source community. Through open-source, we aspire to collaborate with every partner in building the YAYI large language model ecosystem."
] |
e0052fbd16cb9d433639543da5f2010fccc7cc76 | # OASST-RU-PPO Dataset
## Description
The oasst-ru-ppo dataset is designed for optimizing language models using Proximal Policy Optimization (PPO). It is specifically tailored for Russian language models and is created from a collection of dialogues with associated rewards.
## Dataset Creation
The dataset is created from the original oasst2 dataset, which contains a series of dialogs. Each dialog is a sequence of responses, where each response is a text message with corresponding labels. The labels are used to calculate the reward for each message in the dialog. The reward for each message is calculated using a predefined reward dictionary for each label. The reward for a message is the sum of the rewards for each label multiplied by the value of that label in the message. The dialogs are then converted into prompts for the language model. Each prompt is a sequence of user and assistant messages, with the assistant's messages being the responses in the dialog. The reward for the last assistant message in a hint is associated with that hint.
## Usage
This dataset can be used to train a language model using PPO. The prompts can be used as input to the model, and the associated rewards can be used as the target for optimization. The goal is to train the model to generate replies that maximize the reward. | 0x7o/oasst2-ru-ppo | [
"task_categories:text-generation",
"task_categories:conversational",
"size_categories:1K<n<10K",
"language:ru",
"license:apache-2.0",
"region:us"
] | 2023-12-25T07:02:52+00:00 | {"language": ["ru"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["text-generation", "conversational"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "reward", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 15805437, "num_examples": 5946}], "download_size": 7568450, "dataset_size": 15805437}} | 2023-12-26T05:19:49+00:00 | [] | [
"ru"
] | TAGS
#task_categories-text-generation #task_categories-conversational #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us
| # OASST-RU-PPO Dataset
## Description
The oasst-ru-ppo dataset is designed for optimizing language models using Proximal Policy Optimization (PPO). It is specifically tailored for Russian language models and is created from a collection of dialogues with associated rewards.
## Dataset Creation
The dataset is created from the original oasst2 dataset, which contains a series of dialogs. Each dialog is a sequence of responses, where each response is a text message with corresponding labels. The labels are used to calculate the reward for each message in the dialog. The reward for each message is calculated using a predefined reward dictionary for each label. The reward for a message is the sum of the rewards for each label multiplied by the value of that label in the message. The dialogs are then converted into prompts for the language model. Each prompt is a sequence of user and assistant messages, with the assistant's messages being the responses in the dialog. The reward for the last assistant message in a hint is associated with that hint.
## Usage
This dataset can be used to train a language model using PPO. The prompts can be used as input to the model, and the associated rewards can be used as the target for optimization. The goal is to train the model to generate replies that maximize the reward. | [
"# OASST-RU-PPO Dataset",
"## Description\nThe oasst-ru-ppo dataset is designed for optimizing language models using Proximal Policy Optimization (PPO). It is specifically tailored for Russian language models and is created from a collection of dialogues with associated rewards.",
"## Dataset Creation\nThe dataset is created from the original oasst2 dataset, which contains a series of dialogs. Each dialog is a sequence of responses, where each response is a text message with corresponding labels. The labels are used to calculate the reward for each message in the dialog. The reward for each message is calculated using a predefined reward dictionary for each label. The reward for a message is the sum of the rewards for each label multiplied by the value of that label in the message. The dialogs are then converted into prompts for the language model. Each prompt is a sequence of user and assistant messages, with the assistant's messages being the responses in the dialog. The reward for the last assistant message in a hint is associated with that hint.",
"## Usage\nThis dataset can be used to train a language model using PPO. The prompts can be used as input to the model, and the associated rewards can be used as the target for optimization. The goal is to train the model to generate replies that maximize the reward."
] | [
"TAGS\n#task_categories-text-generation #task_categories-conversational #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us \n",
"# OASST-RU-PPO Dataset",
"## Description\nThe oasst-ru-ppo dataset is designed for optimizing language models using Proximal Policy Optimization (PPO). It is specifically tailored for Russian language models and is created from a collection of dialogues with associated rewards.",
"## Dataset Creation\nThe dataset is created from the original oasst2 dataset, which contains a series of dialogs. Each dialog is a sequence of responses, where each response is a text message with corresponding labels. The labels are used to calculate the reward for each message in the dialog. The reward for each message is calculated using a predefined reward dictionary for each label. The reward for a message is the sum of the rewards for each label multiplied by the value of that label in the message. The dialogs are then converted into prompts for the language model. Each prompt is a sequence of user and assistant messages, with the assistant's messages being the responses in the dialog. The reward for the last assistant message in a hint is associated with that hint.",
"## Usage\nThis dataset can be used to train a language model using PPO. The prompts can be used as input to the model, and the associated rewards can be used as the target for optimization. The goal is to train the model to generate replies that maximize the reward."
] | [
52,
11,
54,
179,
62
] | [
"passage: TAGS\n#task_categories-text-generation #task_categories-conversational #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us \n# OASST-RU-PPO Dataset## Description\nThe oasst-ru-ppo dataset is designed for optimizing language models using Proximal Policy Optimization (PPO). It is specifically tailored for Russian language models and is created from a collection of dialogues with associated rewards.## Dataset Creation\nThe dataset is created from the original oasst2 dataset, which contains a series of dialogs. Each dialog is a sequence of responses, where each response is a text message with corresponding labels. The labels are used to calculate the reward for each message in the dialog. The reward for each message is calculated using a predefined reward dictionary for each label. The reward for a message is the sum of the rewards for each label multiplied by the value of that label in the message. The dialogs are then converted into prompts for the language model. Each prompt is a sequence of user and assistant messages, with the assistant's messages being the responses in the dialog. The reward for the last assistant message in a hint is associated with that hint.## Usage\nThis dataset can be used to train a language model using PPO. The prompts can be used as input to the model, and the associated rewards can be used as the target for optimization. The goal is to train the model to generate replies that maximize the reward."
] |
e47ed75bb32252edfec648f5d3a56f21108cceeb |
# Mixtral Malaysian Abstractive Summarization
Use https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1 to generate abstractive summarization on Malaysian dataset, notebooks at https://github.com/mesolitica/malaysian-dataset/tree/master/summarization/mixtral
## Example data
```python
{'source': 'gamerbraves.com.jsonl',
'text': 'Hunter x Hunter USJ Collaboration Announced\n\n\nUniversal Studios Japan ( USJ ) has announced a collaboration with popular Shonen anime Hunter x Hunter, that will take place next year.\n\n\n\nAccording to Oricon News, the attraction will run from March 4th to August 28th of 2022, and will aim to recreate the feeling of being in the world of Hunter x Hunter against the backdrop of USJ\n\n\n\nRelated Posts Pokemon Sleep Now Available In Malaysia GamerBraves Newsletter Vol. 103 – The Glory of The Barbie/Oppenheimer Double Feature From the description, it sounds like it will be a 4D coaster, similar to the Evangelion and Attack on Titan collaboration rides with the theme park.\nThe report also mentions a special collaboration event, though that’s likely to be special merchandise commemorating the collaboration sold at USJ.\nFollow us on Twitter\nFollow @GamerBraves\nand Tweet us\nTweet to @GamerBraves\n\nHunter x Hunter is a popular manga published in Shonen Jump, following the adventures of Gon as he strives to be the number 1 Hunter.\nMultiple characters from the series have also appeared in the game Shonen Jump, such as Gon himself as well as his friend Killua.\n\n \nUniversal Studios Japan itself is no stranger to collabs from the world of anime and videogames, having famously had rides with popular IP such as Monster Hunter, as well as the aforementioned Evangelion and Attack on Titan collabs.\nThey’ve even announced a further collaboration with Pokemon, giving it its own theme park akin to the Super Nintendo World park, themed around gaming icon Mario.\n\nCheck This Out Next\n\n\nTags: Hunter X HunterUniversal Studios Japan',
'summary': "Universal Studios Japan (USJ) will collaborate with the popular Shonen anime, Hunter x Hunter, from March 4 to August 28, 2022. The attraction aims to recreate the feeling of being in the Hunter x Hunter world, likely as a 4D coaster like previous USJ collabs with Evangelion and Attack on Titan. A special collaboration event will likely offer exclusive merchandise. USJ is known for successful anime and videogame collaborations, including Monster Hunter, Pokemon, and Super Nintendo World. Hunter x Hunter is a manga about Gon's journey to become the top Hunter, and some characters appear in the game Shonen Jump.",
'summary_ms': 'Universal Studios Japan (USJ) akan bekerjasama dengan anime popular Shonen, Hunter x Hunter, dari 4 Mac hingga 28 Ogos 2022. Tarikan ini bertujuan untuk mencipta semula perasaan berada di dunia Hunter x Hunter, mungkin sebagai coaster 4D seperti sebelumnya USJ bekerjasama dengan Evangelion dan Attack on Titan. Acara kerjasama khas mungkin akan menawarkan barangan eksklusif. USJ terkenal dengan kerjasama anime dan permainan video yang berjaya, termasuk Monster Hunter, Pokemon dan Super Nintendo World. Hunter x Hunter ialah manga tentang perjalanan Gon untuk menjadi Pemburu teratas, dan beberapa watak muncul dalam permainan Shonen Jump.'}
```
| mesolitica/mixtral-malaysian-abstractive-summarization | [
"task_categories:summarization",
"language:ms",
"region:us"
] | 2023-12-25T07:10:41+00:00 | {"language": ["ms"], "task_categories": ["summarization"]} | 2024-02-01T04:24:03+00:00 | [] | [
"ms"
] | TAGS
#task_categories-summarization #language-Malay (macrolanguage) #region-us
|
# Mixtral Malaysian Abstractive Summarization
Use URL to generate abstractive summarization on Malaysian dataset, notebooks at URL
## Example data
| [
"# Mixtral Malaysian Abstractive Summarization\n\nUse URL to generate abstractive summarization on Malaysian dataset, notebooks at URL",
"## Example data"
] | [
"TAGS\n#task_categories-summarization #language-Malay (macrolanguage) #region-us \n",
"# Mixtral Malaysian Abstractive Summarization\n\nUse URL to generate abstractive summarization on Malaysian dataset, notebooks at URL",
"## Example data"
] | [
26,
29,
4
] | [
"passage: TAGS\n#task_categories-summarization #language-Malay (macrolanguage) #region-us \n# Mixtral Malaysian Abstractive Summarization\n\nUse URL to generate abstractive summarization on Malaysian dataset, notebooks at URL## Example data"
] |
b83e33b1d8ef6328ec6015eccc46cea91b384f55 |
# eIDAS Terminology Dataset
## Dataset Description
### Overview
The EiDAS Terminology dataset is a comprehensive collection of terms and abbreviations related to electronic identification and trust services for electronic transactions in the European Single Market (eIDAS). This dataset provides clear definitions and explanations of various terms, making it an essential resource for researchers and practitioners in digital identity and security.
### Languages
The primary language of the dataset is English.
## Dataset Structure
### Data Instances
A typical data point in the dataset contains the following structure:
- `idx`: An index number for the entry.
- `prompt`: The term or abbreviation to be defined.
- `completion`: The definition or explanation of the term.
- `label`: A label categorizing the term. Truth 1 of False 0
- `lang`: Language of the entry (English).
- `URL`: A link to a relevant external resource. Separed by commas
- `sourceURL`: The source URL from where the information is derived.
- `ts`: Timestamp when the entry was added. POSIX Timestamp - seconds
### Example
Here is an example from the dataset:
```json
{
"idx": "1",
"prompt": "What does ARF-Architecture and Reference Framework mean?",
"completion": "Defines core requirements on EUDI Wallet, PID and QEAA so formats, interfaces and protocols. Developed by eIDAS Toolbox Group.",
"label": 1,
"lang": "en",
"URL": "https://digital-strategy.ec.europa.eu/en/library/european-digital-identity-architecture-and-reference-framework-outline",
"sourceURL": "https://medium.com/@schwalm.steffen/collection-of-eidas-identity-related-terms-and-abbreviations-d14eada34364",
"ts": 1703588321
}
```
## Additional Information
### Dataset Curators
The dataset was compiled by [Andrii Melashchenko](https://www.linkedin.com/in/melashchenkoandrii), drawing on various sources, including online articles and official documents related to eIDAS.
The first version is based on the article by [Steffen Schwalm](https://www.linkedin.com/in/steffen-schwalm-a383b8112) https://medium.com/@schwalm.steffen/collection-of-eidas-identity-related-terms-and-abbreviations-d14eada34364
### Licensing Information
https://creativecommons.org/licenses/by-sa/4.0/deed.en
### Citation Information
!TODO
## Dataset Creation
### Curation Rationale
The dataset was created to provide a comprehensive and accessible resource for understanding the terminology related to eIDAS.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from various sources, including official eIDAS documents and relevant online articles.
#### Who are the source language producers?
The primary source language producers are experts and authors in digital identity and eIDAS regulation.
### Annotations
#### Annotation process
Each term is annotated with its definition, relevant URL, and source information.
#### Who are the annotators?
The annotators are individuals with expertise in digital identity and eIDAS regulations.
| javatask/eidas | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"license:cc-by-sa-4.0",
"eidas",
"legal",
"code",
"doi:10.57967/hf/1524",
"region:us"
] | 2023-12-25T07:37:45+00:00 | {"language": ["en"], "license": "cc-by-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["conversational", "text-generation"], "pretty_name": "electronic IDentification, Authentication and trust Services", "tags": ["eidas", "legal", "code"]} | 2023-12-26T11:13:10+00:00 | [] | [
"en"
] | TAGS
#task_categories-conversational #task_categories-text-generation #size_categories-n<1K #language-English #license-cc-by-sa-4.0 #eidas #legal #code #doi-10.57967/hf/1524 #region-us
|
# eIDAS Terminology Dataset
## Dataset Description
### Overview
The EiDAS Terminology dataset is a comprehensive collection of terms and abbreviations related to electronic identification and trust services for electronic transactions in the European Single Market (eIDAS). This dataset provides clear definitions and explanations of various terms, making it an essential resource for researchers and practitioners in digital identity and security.
### Languages
The primary language of the dataset is English.
## Dataset Structure
### Data Instances
A typical data point in the dataset contains the following structure:
- 'idx': An index number for the entry.
- 'prompt': The term or abbreviation to be defined.
- 'completion': The definition or explanation of the term.
- 'label': A label categorizing the term. Truth 1 of False 0
- 'lang': Language of the entry (English).
- 'URL': A link to a relevant external resource. Separed by commas
- 'sourceURL': The source URL from where the information is derived.
- 'ts': Timestamp when the entry was added. POSIX Timestamp - seconds
### Example
Here is an example from the dataset:
## Additional Information
### Dataset Curators
The dataset was compiled by Andrii Melashchenko, drawing on various sources, including online articles and official documents related to eIDAS.
The first version is based on the article by Steffen Schwalm URL
### Licensing Information
URL
!TODO
## Dataset Creation
### Curation Rationale
The dataset was created to provide a comprehensive and accessible resource for understanding the terminology related to eIDAS.
### Source Data
#### Initial Data Collection and Normalization
Data was collected from various sources, including official eIDAS documents and relevant online articles.
#### Who are the source language producers?
The primary source language producers are experts and authors in digital identity and eIDAS regulation.
### Annotations
#### Annotation process
Each term is annotated with its definition, relevant URL, and source information.
#### Who are the annotators?
The annotators are individuals with expertise in digital identity and eIDAS regulations.
| [
"# eIDAS Terminology Dataset",
"## Dataset Description",
"### Overview\n\nThe EiDAS Terminology dataset is a comprehensive collection of terms and abbreviations related to electronic identification and trust services for electronic transactions in the European Single Market (eIDAS). This dataset provides clear definitions and explanations of various terms, making it an essential resource for researchers and practitioners in digital identity and security.",
"### Languages\n\nThe primary language of the dataset is English.",
"## Dataset Structure",
"### Data Instances\n\nA typical data point in the dataset contains the following structure:\n\n- 'idx': An index number for the entry.\n- 'prompt': The term or abbreviation to be defined.\n- 'completion': The definition or explanation of the term.\n- 'label': A label categorizing the term. Truth 1 of False 0\n- 'lang': Language of the entry (English).\n- 'URL': A link to a relevant external resource. Separed by commas\n- 'sourceURL': The source URL from where the information is derived.\n- 'ts': Timestamp when the entry was added. POSIX Timestamp - seconds",
"### Example\n\nHere is an example from the dataset:",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was compiled by Andrii Melashchenko, drawing on various sources, including online articles and official documents related to eIDAS. \nThe first version is based on the article by Steffen Schwalm URL",
"### Licensing Information\n\nURL\n\n\n\n!TODO",
"## Dataset Creation",
"### Curation Rationale\n\nThe dataset was created to provide a comprehensive and accessible resource for understanding the terminology related to eIDAS.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nData was collected from various sources, including official eIDAS documents and relevant online articles.",
"#### Who are the source language producers?\n\nThe primary source language producers are experts and authors in digital identity and eIDAS regulation.",
"### Annotations",
"#### Annotation process\n\nEach term is annotated with its definition, relevant URL, and source information.",
"#### Who are the annotators?\n\nThe annotators are individuals with expertise in digital identity and eIDAS regulations."
] | [
"TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-n<1K #language-English #license-cc-by-sa-4.0 #eidas #legal #code #doi-10.57967/hf/1524 #region-us \n",
"# eIDAS Terminology Dataset",
"## Dataset Description",
"### Overview\n\nThe EiDAS Terminology dataset is a comprehensive collection of terms and abbreviations related to electronic identification and trust services for electronic transactions in the European Single Market (eIDAS). This dataset provides clear definitions and explanations of various terms, making it an essential resource for researchers and practitioners in digital identity and security.",
"### Languages\n\nThe primary language of the dataset is English.",
"## Dataset Structure",
"### Data Instances\n\nA typical data point in the dataset contains the following structure:\n\n- 'idx': An index number for the entry.\n- 'prompt': The term or abbreviation to be defined.\n- 'completion': The definition or explanation of the term.\n- 'label': A label categorizing the term. Truth 1 of False 0\n- 'lang': Language of the entry (English).\n- 'URL': A link to a relevant external resource. Separed by commas\n- 'sourceURL': The source URL from where the information is derived.\n- 'ts': Timestamp when the entry was added. POSIX Timestamp - seconds",
"### Example\n\nHere is an example from the dataset:",
"## Additional Information",
"### Dataset Curators\n\nThe dataset was compiled by Andrii Melashchenko, drawing on various sources, including online articles and official documents related to eIDAS. \nThe first version is based on the article by Steffen Schwalm URL",
"### Licensing Information\n\nURL\n\n\n\n!TODO",
"## Dataset Creation",
"### Curation Rationale\n\nThe dataset was created to provide a comprehensive and accessible resource for understanding the terminology related to eIDAS.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\nData was collected from various sources, including official eIDAS documents and relevant online articles.",
"#### Who are the source language producers?\n\nThe primary source language producers are experts and authors in digital identity and eIDAS regulation.",
"### Annotations",
"#### Annotation process\n\nEach term is annotated with its definition, relevant URL, and source information.",
"#### Who are the annotators?\n\nThe annotators are individuals with expertise in digital identity and eIDAS regulations."
] | [
71,
8,
4,
77,
14,
6,
154,
13,
5,
52,
10,
5,
30,
4,
29,
31,
5,
22,
26
] | [
"passage: TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-n<1K #language-English #license-cc-by-sa-4.0 #eidas #legal #code #doi-10.57967/hf/1524 #region-us \n# eIDAS Terminology Dataset## Dataset Description### Overview\n\nThe EiDAS Terminology dataset is a comprehensive collection of terms and abbreviations related to electronic identification and trust services for electronic transactions in the European Single Market (eIDAS). This dataset provides clear definitions and explanations of various terms, making it an essential resource for researchers and practitioners in digital identity and security.### Languages\n\nThe primary language of the dataset is English.## Dataset Structure### Data Instances\n\nA typical data point in the dataset contains the following structure:\n\n- 'idx': An index number for the entry.\n- 'prompt': The term or abbreviation to be defined.\n- 'completion': The definition or explanation of the term.\n- 'label': A label categorizing the term. Truth 1 of False 0\n- 'lang': Language of the entry (English).\n- 'URL': A link to a relevant external resource. Separed by commas\n- 'sourceURL': The source URL from where the information is derived.\n- 'ts': Timestamp when the entry was added. POSIX Timestamp - seconds### Example\n\nHere is an example from the dataset:## Additional Information### Dataset Curators\n\nThe dataset was compiled by Andrii Melashchenko, drawing on various sources, including online articles and official documents related to eIDAS. \nThe first version is based on the article by Steffen Schwalm URL### Licensing Information\n\nURL\n\n\n\n!TODO## Dataset Creation### Curation Rationale\n\nThe dataset was created to provide a comprehensive and accessible resource for understanding the terminology related to eIDAS.### Source Data#### Initial Data Collection and Normalization\n\nData was collected from various sources, including official eIDAS documents and relevant online articles."
] |
5a84d0403315b99b72e04dc815712bf292f404f9 | # BLOSSOM CHAT V2
### 介绍
Blossom Chat V2是基于ShareGPT 90K衍生而来的中英双语对话数据集,适用于多轮对话微调。
相比于blossom-chat-v1,进一步优化了数据处理流程,并配平了中英语料。
本数据集抽取了ShareGPT的多轮对话指令,仅将指令进行翻译,随后使用多轮指令迭代调用gpt-3.5-turbo-0613。
相比原始的ShareGPT数据,主要解决了中文对话数据量较少,以及由ChatGPT生成长度限制而导致的输出截断问题。
本次发布了全量数据的20%,包含30K记录。
### 语言
以中文和英文为主,中英文数据按照约1:1的比例混合。
### 数据集结构
每条数据代表一个完整的多轮对话,包含id和conversations两个字段。
- id:字符串,代表原始ShareGPT的对话id,可以通过链接https://sharegpt.com/c/id来访问原始对话。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。
### 数据集限制
由于仅抽取了原始多轮对话的输入,对于一些涉及随机性的对话,例如:猜随机数,可能会出现多轮对话不连贯的情况。
此外,本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。 | Azure99/blossom-chat-v2 | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:10K<n<100K",
"language:zh",
"language:en",
"license:apache-2.0",
"region:us"
] | 2023-12-25T07:45:54+00:00 | {"language": ["zh", "en"], "license": "apache-2.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-generation", "text2text-generation"]} | 2023-12-25T07:50:52+00:00 | [] | [
"zh",
"en"
] | TAGS
#task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<100K #language-Chinese #language-English #license-apache-2.0 #region-us
| # BLOSSOM CHAT V2
### 介绍
Blossom Chat V2是基于ShareGPT 90K衍生而来的中英双语对话数据集,适用于多轮对话微调。
相比于blossom-chat-v1,进一步优化了数据处理流程,并配平了中英语料。
本数据集抽取了ShareGPT的多轮对话指令,仅将指令进行翻译,随后使用多轮指令迭代调用gpt-3.5-turbo-0613。
相比原始的ShareGPT数据,主要解决了中文对话数据量较少,以及由ChatGPT生成长度限制而导致的输出截断问题。
本次发布了全量数据的20%,包含30K记录。
### 语言
以中文和英文为主,中英文数据按照约1:1的比例混合。
### 数据集结构
每条数据代表一个完整的多轮对话,包含id和conversations两个字段。
- id:字符串,代表原始ShareGPT的对话id,可以通过链接https://URL/id来访问原始对话。
- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。
### 数据集限制
由于仅抽取了原始多轮对话的输入,对于一些涉及随机性的对话,例如:猜随机数,可能会出现多轮对话不连贯的情况。
此外,本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。 | [
"# BLOSSOM CHAT V2",
"### 介绍\n\nBlossom Chat V2是基于ShareGPT 90K衍生而来的中英双语对话数据集,适用于多轮对话微调。\n\n相比于blossom-chat-v1,进一步优化了数据处理流程,并配平了中英语料。\n\n本数据集抽取了ShareGPT的多轮对话指令,仅将指令进行翻译,随后使用多轮指令迭代调用gpt-3.5-turbo-0613。\n\n相比原始的ShareGPT数据,主要解决了中文对话数据量较少,以及由ChatGPT生成长度限制而导致的输出截断问题。\n\n本次发布了全量数据的20%,包含30K记录。",
"### 语言\n\n以中文和英文为主,中英文数据按照约1:1的比例混合。",
"### 数据集结构\n\n每条数据代表一个完整的多轮对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始ShareGPT的对话id,可以通过链接https://URL/id来访问原始对话。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n由于仅抽取了原始多轮对话的输入,对于一些涉及随机性的对话,例如:猜随机数,可能会出现多轮对话不连贯的情况。\n\n此外,本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。"
] | [
"TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<100K #language-Chinese #language-English #license-apache-2.0 #region-us \n",
"# BLOSSOM CHAT V2",
"### 介绍\n\nBlossom Chat V2是基于ShareGPT 90K衍生而来的中英双语对话数据集,适用于多轮对话微调。\n\n相比于blossom-chat-v1,进一步优化了数据处理流程,并配平了中英语料。\n\n本数据集抽取了ShareGPT的多轮对话指令,仅将指令进行翻译,随后使用多轮指令迭代调用gpt-3.5-turbo-0613。\n\n相比原始的ShareGPT数据,主要解决了中文对话数据量较少,以及由ChatGPT生成长度限制而导致的输出截断问题。\n\n本次发布了全量数据的20%,包含30K记录。",
"### 语言\n\n以中文和英文为主,中英文数据按照约1:1的比例混合。",
"### 数据集结构\n\n每条数据代表一个完整的多轮对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始ShareGPT的对话id,可以通过链接https://URL/id来访问原始对话。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。",
"### 数据集限制\n\n由于仅抽取了原始多轮对话的输入,对于一些涉及随机性的对话,例如:猜随机数,可能会出现多轮对话不连贯的情况。\n\n此外,本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。"
] | [
59,
8,
151,
21,
100,
81
] | [
"passage: TAGS\n#task_categories-text-generation #task_categories-text2text-generation #size_categories-10K<n<100K #language-Chinese #language-English #license-apache-2.0 #region-us \n# BLOSSOM CHAT V2### 介绍\n\nBlossom Chat V2是基于ShareGPT 90K衍生而来的中英双语对话数据集,适用于多轮对话微调。\n\n相比于blossom-chat-v1,进一步优化了数据处理流程,并配平了中英语料。\n\n本数据集抽取了ShareGPT的多轮对话指令,仅将指令进行翻译,随后使用多轮指令迭代调用gpt-3.5-turbo-0613。\n\n相比原始的ShareGPT数据,主要解决了中文对话数据量较少,以及由ChatGPT生成长度限制而导致的输出截断问题。\n\n本次发布了全量数据的20%,包含30K记录。### 语言\n\n以中文和英文为主,中英文数据按照约1:1的比例混合。### 数据集结构\n\n每条数据代表一个完整的多轮对话,包含id和conversations两个字段。\n\n- id:字符串,代表原始ShareGPT的对话id,可以通过链接https://URL/id来访问原始对话。\n- conversations:对象数组,每个对象包含role、content两个字段,role的取值为user或assistant,分别代表用户输入和助手输出,content则为对应的内容。### 数据集限制\n\n由于仅抽取了原始多轮对话的输入,对于一些涉及随机性的对话,例如:猜随机数,可能会出现多轮对话不连贯的情况。\n\n此外,本数据集的所有响应均由gpt-3.5-turbo-0613生成,并未经过严格的数据校验,可能包含不准确甚至严重错误的回答。"
] |
0cb3f6bb62505d8c89bc21719e71180f2b319179 | # Dataset Card for "oasst2-best"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 0x7o/oasst2-best | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:en",
"language:ru",
"license:apache-2.0",
"region:us"
] | 2023-12-25T08:21:10+00:00 | {"language": ["en", "ru"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["conversational", "text-generation"], "dataset_info": {"features": [{"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 14811588, "num_examples": 6504}], "download_size": 8135642, "dataset_size": 14811588}} | 2023-12-25T08:22:56+00:00 | [] | [
"en",
"ru"
] | TAGS
#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-English #language-Russian #license-apache-2.0 #region-us
| # Dataset Card for "oasst2-best"
More Information needed | [
"# Dataset Card for \"oasst2-best\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-English #language-Russian #license-apache-2.0 #region-us \n",
"# Dataset Card for \"oasst2-best\"\n\nMore Information needed"
] | [
56,
15
] | [
"passage: TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-English #language-Russian #license-apache-2.0 #region-us \n# Dataset Card for \"oasst2-best\"\n\nMore Information needed"
] |
c3f86e3f79c9f2ce0238e630cd41b3e366709567 |
<p align="center">
<h1>G-buffer Objaverse</h1>
<p>
G-buffer Objaverse: High-Quality Rendering Dataset of Objaverse.
[Chao Xu](mailto:[email protected]),
[Yuan Dong](mailto:[email protected]),
[Qi Zuo](mailto:[email protected]),
[Junfei Zhang](mailto:[email protected]),
[Xiaodan Ye](mailto:[email protected]),
[Wenbo Geng](mailto:[email protected]),
[Yuxiang Zhang](mailto:[email protected]),
[Xiaodong Gu](https://scholar.google.com.hk/citations?user=aJPO514AAAAJ&hl=zh-CN&oi=ao),
[Lingteng Qiu](https://lingtengqiu.github.io/),
[Zhengyi Zhao](mailto:[email protected]),
[Qing Ran](mailto:[email protected]),
[Jiayi Jiang](mailto:[email protected]),
[Zilong Dong](https://scholar.google.com/citations?user=GHOQKCwAAAAJ&hl=zh-CN&oi=ao),
[Liefeng Bo](https://scholar.google.com/citations?user=FJwtMf0AAAAJ&hl=zh-CN)
## [Project page](https://aigc3d.github.io/gobjaverse/)
## [Github](https://github.com/modelscope/richdreamer/tree/main/dataset/gobjaverse)
## [YouTube](https://www.youtube.com/watch?v=PWweS-EPbJo)
## [RichDreamer](https://aigc3d.github.io/richdreamer/)
## [ND-Diffusion Model](https://github.com/modelscope/normal-depth-diffusion)
## TODO
- [ ] Release objaverse-xl alignment rendering data
## News
- We have released a compressed version of the datasets, check the downloading tips! (01.14, 2024 UTC)
- Thanks for [JunzheJosephZhu](https://github.com/JunzheJosephZhu) for improving the robustness of the downloading scripts. Now you could restart the download script from the break point. (01.12, 2024 UTC)
- Release 10 Category Annotation of the Objaverse Subset (01.06, 2024 UTC)
- Release G-buffer Objaverse Rendering Dataset (01.06, 2024 UTC)
## Download
- Download gobjaverse ***(6.5T)*** rendering dataset using following scripts.
```bash
# download_gobjaverse_280k index file
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/gobjaverse_280k.json
# Example: python ./scripts/data/download_gobjaverse_280k.py ./gobjaverse_280k ./gobjaverse_280k.json 10
python ./download_gobjaverse_280k.py /path/to/savedata /path/to/gobjaverse_280k.json nthreads(eg. 10)
# Or if the network is not so good, we have provided a compressed verison with each object as a tar file
# To download the compressed version(only 260k tar files)
python ./download_objaverse_280k_tar.py /path/to/savedata /path/to/gobjaverse_280k.json nthreads(eg. 10)
# download gobjaverse_280k/gobjaverse index to objaverse
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/gobjaverse_280k_index_to_objaverse.json
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/gobjaverse_index_to_objaverse.json
# download Cap3D text-caption file
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/text_captions_cap3d.json
```
- The 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).
- Download the category annotation using following scripts.
```bash
# download category annotation
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/category_annotation.json
# If you want to download a specific category in gobjaverse280k:
# Step1: download the index file of the specified category.
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/aigc3d/gobjaverse_280k_split/gobjaverse_280k_{category_name}.json # category_name: Human-Shape, ...
# Step2: download using script.
# Example: python ./scripts/data/download_gobjaverse_280k.py ./gobjaverse_280k_Human-Shape ./gobjaverse_280k_Human-Shape.json 10
python ./download_gobjaverse_280k.py /path/to/savedata /path/to/gobjaverse_280k_{category_name}.json nthreads(eg. 10)
```
## Folder Structure
- The structure of gobjaverse rendering dataset:
```
|-- ROOT
|-- dictionary_id
|-- instance_id
|-- campos_512_v4
|-- 00000
|-- 00000.json # Camera Information
|-- 00000.png # RGB
|-- 00000_albedo.png # Albedo
|-- 00000_hdr.exr # HDR
|-- 00000_mr.png # Metalness and Roughness
|-- 00000_nd.exr # Normal and Depth
|-- ...
```
### Coordinate System
#### Normal Coordinate System
The 3D coordinate system definition is very complex. it is difficult for us to say what the camera system used. Fortunately, the target we want to get is mapping the world normal of rendering system to Normal-Bae system, as the following figure illustrates:

where the U-axis and V-axis denote the width-axis and height-axis in image space, respectively, the xyz is the Normal-Bae camera view coordinate system.
Note that public rendering system for Objaverse is blender-based system:

However, our rendering system is defined at **Unity-based system**, seeing:

*A question is how do we plug in blender's coordinate system directly without introducing a new coordinate system?*
A possible solution is that we maintain world to camera transfer matrix as blender setting, *transferring Unity-based system to blender-based system*
We provide example codes to visualize the coordinate mapping.
```bash
# example of coordinate experiments
## download datasets
wget https://virutalbuy-public.oss-cn-hangzhou.aliyuncs.com/share/Lingtengqiu/render_data_examples.zip
unzip render_data_examples.zip
## visualizing blender-based system, and warping world-space normal to normal-bae system.
python ./process_blender_dataset.py
## visualizing our system, and warping world-space normal to normal-bae system.
python ./process_unity_dataset.py
```
#### Depth-Warpping
We write an example to demonstrate that how to obtain intrinsic matrix K, and warp ref image to target image based on ref depth map.
```bash
# build quick-zbuff code
mkdir -p ./lib/build
g++ -shared -fpic -o ./lib/build/zbuff.so ./lib/zbuff.cpp
# an demo for depth-based Warpping
# python ./depth_warp_example.py $REFVIEW $TARGETVIEW
python3 ./depth_warp_example.py 0 3
```
## Citation
```
@article{qiu2023richdreamer,
title={RichDreamer: A Generalizable Normal-Depth Diffusion Model for Detail Richness in Text-to-3D},
author={Lingteng Qiu and Guanying Chen and Xiaodong Gu and Qi zuo and Mutian Xu and Yushuang Wu and Weihao Yuan and Zilong Dong and Liefeng Bo and Xiaoguang Han},
year={2023},
journal = {arXiv preprint arXiv:2311.16918}
}
```
```
@article{objaverse,
title={Objaverse: A Universe of Annotated 3D Objects},
author={Matt Deitke and Dustin Schwenk and Jordi Salvador and Luca Weihs and
Oscar Michel and Eli VanderBilt and Ludwig Schmidt and
Kiana Ehsani and Aniruddha Kembhavi and Ali Farhadi},
journal={arXiv preprint arXiv:2212.08051},
year={2022}
}
```
| 3DAIGC/gobjaverse | [
"license:mit",
"region:us"
] | 2023-12-25T08:25:43+00:00 | {"license": "mit"} | 2024-01-17T04:34:09+00:00 | [] | [] | TAGS
#license-mit #region-us
|
<p align="center">
<h1>G-buffer Objaverse</h1>
<p>
G-buffer Objaverse: High-Quality Rendering Dataset of Objaverse.
Chao Xu,
Yuan Dong,
Qi Zuo,
Junfei Zhang,
Xiaodan Ye,
Wenbo Geng,
Yuxiang Zhang,
Xiaodong Gu,
Lingteng Qiu,
Zhengyi Zhao,
Qing Ran,
Jiayi Jiang,
Zilong Dong,
Liefeng Bo
## Project page
## Github
## YouTube
## RichDreamer
## ND-Diffusion Model
## TODO
- [ ] Release objaverse-xl alignment rendering data
## News
- We have released a compressed version of the datasets, check the downloading tips! (01.14, 2024 UTC)
- Thanks for JunzheJosephZhu for improving the robustness of the downloading scripts. Now you could restart the download script from the break point. (01.12, 2024 UTC)
- Release 10 Category Annotation of the Objaverse Subset (01.06, 2024 UTC)
- Release G-buffer Objaverse Rendering Dataset (01.06, 2024 UTC)
## Download
- Download gobjaverse *(6.5T)* rendering dataset using following scripts.
- The 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).
- Download the category annotation using following scripts.
## Folder Structure
- The structure of gobjaverse rendering dataset:
### Coordinate System
#### Normal Coordinate System
The 3D coordinate system definition is very complex. it is difficult for us to say what the camera system used. Fortunately, the target we want to get is mapping the world normal of rendering system to Normal-Bae system, as the following figure illustrates:
!normal-bae system
where the U-axis and V-axis denote the width-axis and height-axis in image space, respectively, the xyz is the Normal-Bae camera view coordinate system.
Note that public rendering system for Objaverse is blender-based system:
!00000_normal
However, our rendering system is defined at Unity-based system, seeing:
!00000_normal
*A question is how do we plug in blender's coordinate system directly without introducing a new coordinate system?*
A possible solution is that we maintain world to camera transfer matrix as blender setting, *transferring Unity-based system to blender-based system*
We provide example codes to visualize the coordinate mapping.
#### Depth-Warpping
We write an example to demonstrate that how to obtain intrinsic matrix K, and warp ref image to target image based on ref depth map.
| [
"## Project page",
"## Github",
"## YouTube",
"## RichDreamer",
"## ND-Diffusion Model",
"## TODO\n- [ ] Release objaverse-xl alignment rendering data",
"## News\n\n- We have released a compressed version of the datasets, check the downloading tips! (01.14, 2024 UTC)\n- Thanks for JunzheJosephZhu for improving the robustness of the downloading scripts. Now you could restart the download script from the break point. (01.12, 2024 UTC)\n- Release 10 Category Annotation of the Objaverse Subset (01.06, 2024 UTC)\n- Release G-buffer Objaverse Rendering Dataset (01.06, 2024 UTC)",
"## Download\n- Download gobjaverse *(6.5T)* rendering dataset using following scripts.\n\n- The 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).\n- Download the category annotation using following scripts.",
"## Folder Structure\n- The structure of gobjaverse rendering dataset:",
"### Coordinate System",
"#### Normal Coordinate System\n\nThe 3D coordinate system definition is very complex. it is difficult for us to say what the camera system used. Fortunately, the target we want to get is mapping the world normal of rendering system to Normal-Bae system, as the following figure illustrates:\n\n!normal-bae system\n\nwhere the U-axis and V-axis denote the width-axis and height-axis in image space, respectively, the xyz is the Normal-Bae camera view coordinate system. \n\nNote that public rendering system for Objaverse is blender-based system:\n\n!00000_normal\n\nHowever, our rendering system is defined at Unity-based system, seeing:\n\n!00000_normal\n\n*A question is how do we plug in blender's coordinate system directly without introducing a new coordinate system?*\n\nA possible solution is that we maintain world to camera transfer matrix as blender setting, *transferring Unity-based system to blender-based system*\n\nWe provide example codes to visualize the coordinate mapping.",
"#### Depth-Warpping \nWe write an example to demonstrate that how to obtain intrinsic matrix K, and warp ref image to target image based on ref depth map."
] | [
"TAGS\n#license-mit #region-us \n",
"## Project page",
"## Github",
"## YouTube",
"## RichDreamer",
"## ND-Diffusion Model",
"## TODO\n- [ ] Release objaverse-xl alignment rendering data",
"## News\n\n- We have released a compressed version of the datasets, check the downloading tips! (01.14, 2024 UTC)\n- Thanks for JunzheJosephZhu for improving the robustness of the downloading scripts. Now you could restart the download script from the break point. (01.12, 2024 UTC)\n- Release 10 Category Annotation of the Objaverse Subset (01.06, 2024 UTC)\n- Release G-buffer Objaverse Rendering Dataset (01.06, 2024 UTC)",
"## Download\n- Download gobjaverse *(6.5T)* rendering dataset using following scripts.\n\n- The 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).\n- Download the category annotation using following scripts.",
"## Folder Structure\n- The structure of gobjaverse rendering dataset:",
"### Coordinate System",
"#### Normal Coordinate System\n\nThe 3D coordinate system definition is very complex. it is difficult for us to say what the camera system used. Fortunately, the target we want to get is mapping the world normal of rendering system to Normal-Bae system, as the following figure illustrates:\n\n!normal-bae system\n\nwhere the U-axis and V-axis denote the width-axis and height-axis in image space, respectively, the xyz is the Normal-Bae camera view coordinate system. \n\nNote that public rendering system for Objaverse is blender-based system:\n\n!00000_normal\n\nHowever, our rendering system is defined at Unity-based system, seeing:\n\n!00000_normal\n\n*A question is how do we plug in blender's coordinate system directly without introducing a new coordinate system?*\n\nA possible solution is that we maintain world to camera transfer matrix as blender setting, *transferring Unity-based system to blender-based system*\n\nWe provide example codes to visualize the coordinate mapping.",
"#### Depth-Warpping \nWe write an example to demonstrate that how to obtain intrinsic matrix K, and warp ref image to target image based on ref depth map."
] | [
11,
3,
4,
2,
4,
7,
17,
121,
115,
19,
6,
227,
41
] | [
"passage: TAGS\n#license-mit #region-us \n## Project page## Github## YouTube## RichDreamer## ND-Diffusion Model## TODO\n- [ ] Release objaverse-xl alignment rendering data## News\n\n- We have released a compressed version of the datasets, check the downloading tips! (01.14, 2024 UTC)\n- Thanks for JunzheJosephZhu for improving the robustness of the downloading scripts. Now you could restart the download script from the break point. (01.12, 2024 UTC)\n- Release 10 Category Annotation of the Objaverse Subset (01.06, 2024 UTC)\n- Release G-buffer Objaverse Rendering Dataset (01.06, 2024 UTC)## Download\n- Download gobjaverse *(6.5T)* rendering dataset using following scripts.\n\n- The 10 general categories including Human-Shape (41,557), Animals (28,882), Daily-Used (220,222), Furnitures (19,284), Buildings&&Outdoor (116,545), Transportations (20,075), Plants (7,195), Food (5,314), Electronics (13,252) and Poor-quality (107,001).\n- Download the category annotation using following scripts.## Folder Structure\n- The structure of gobjaverse rendering dataset:### Coordinate System"
] |
214c236785090d95e6655ba0e6b3e73cd5f60c86 | # Dataset Card for "oasst2-best-ru"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 0x7o/oasst2-best-ru | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:1K<n<10K",
"language:ru",
"license:apache-2.0",
"region:us"
] | 2023-12-25T08:49:15+00:00 | {"language": ["ru"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["conversational", "text-generation"], "dataset_info": {"features": [{"name": "texts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3746950, "num_examples": 1246}], "download_size": 1806207, "dataset_size": 3746950}} | 2023-12-26T05:19:18+00:00 | [] | [
"ru"
] | TAGS
#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us
| # Dataset Card for "oasst2-best-ru"
More Information needed | [
"# Dataset Card for \"oasst2-best-ru\"\n\nMore Information needed"
] | [
"TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us \n",
"# Dataset Card for \"oasst2-best-ru\"\n\nMore Information needed"
] | [
52,
17
] | [
"passage: TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-1K<n<10K #language-Russian #license-apache-2.0 #region-us \n# Dataset Card for \"oasst2-best-ru\"\n\nMore Information needed"
] |
a200d9e6b06e10edde93c3aa1b2c1b83d681f3ec |
# TaoGPT-7B Dataset
### General Information
- **Dataset Name**: TaoGPT-7B
- **Version**: 2.0
- **Size**: ~6,000 QA pairs
- **Domain**: Tao Science, Quantum Physics, Spirituality
- **Date Released**: [Release Date]
### Short Description
TaoGPT-7B is a unique dataset developed for an advanced language model, focusing on Tao Science. It includes over 6000 QA responses on quantum physics, spirituality, and Tao wisdom, co-authored by Dr. Zhi Gang Sha and Dr. Rulin Xiu.
### Dataset Structure
Each data entry in TaoGPT-7B follows this structure:
- `question`: A query related to Tao Science or quantum physics.
- `answer`: The response generated based on Tao Science principles.
- `metadata`: Additional information about the entry.
- `content`: The detailed content related to the query.
### Example
```json
{
"question": "What is the relationship between Tao Science and quantum physics?",
"answer": "Tao Science integrates the principles of quantum physics with spiritual wisdom, exploring the interconnectedness of the universe...",
"metadata": "Quantum Physics, Tao Science, Spirituality",
"content": "..."
}
| agency888/TaoGPT-v2 | [
"language:eng",
"license:mit",
"spirituality",
"tao-science",
"quantum-physics",
"region:us"
] | 2023-12-25T09:13:00+00:00 | {"language": ["eng"], "license": "mit", "pretty_name": "TaoGPT-7B", "tags": ["spirituality", "tao-science", "quantum-physics"]} | 2024-01-01T07:25:35+00:00 | [] | [
"eng"
] | TAGS
#language-English #license-mit #spirituality #tao-science #quantum-physics #region-us
|
# TaoGPT-7B Dataset
### General Information
- Dataset Name: TaoGPT-7B
- Version: 2.0
- Size: ~6,000 QA pairs
- Domain: Tao Science, Quantum Physics, Spirituality
- Date Released: [Release Date]
### Short Description
TaoGPT-7B is a unique dataset developed for an advanced language model, focusing on Tao Science. It includes over 6000 QA responses on quantum physics, spirituality, and Tao wisdom, co-authored by Dr. Zhi Gang Sha and Dr. Rulin Xiu.
### Dataset Structure
Each data entry in TaoGPT-7B follows this structure:
- 'question': A query related to Tao Science or quantum physics.
- 'answer': The response generated based on Tao Science principles.
- 'metadata': Additional information about the entry.
- 'content': The detailed content related to the query.
### Example
'''json
{
"question": "What is the relationship between Tao Science and quantum physics?",
"answer": "Tao Science integrates the principles of quantum physics with spiritual wisdom, exploring the interconnectedness of the universe...",
"metadata": "Quantum Physics, Tao Science, Spirituality",
"content": "..."
}
| [
"# TaoGPT-7B Dataset",
"### General Information\n- Dataset Name: TaoGPT-7B\n- Version: 2.0\n- Size: ~6,000 QA pairs\n- Domain: Tao Science, Quantum Physics, Spirituality\n- Date Released: [Release Date]",
"### Short Description\nTaoGPT-7B is a unique dataset developed for an advanced language model, focusing on Tao Science. It includes over 6000 QA responses on quantum physics, spirituality, and Tao wisdom, co-authored by Dr. Zhi Gang Sha and Dr. Rulin Xiu.",
"### Dataset Structure\nEach data entry in TaoGPT-7B follows this structure:\n- 'question': A query related to Tao Science or quantum physics.\n- 'answer': The response generated based on Tao Science principles.\n- 'metadata': Additional information about the entry.\n- 'content': The detailed content related to the query.",
"### Example\n'''json\n{\n \"question\": \"What is the relationship between Tao Science and quantum physics?\",\n \"answer\": \"Tao Science integrates the principles of quantum physics with spiritual wisdom, exploring the interconnectedness of the universe...\",\n \"metadata\": \"Quantum Physics, Tao Science, Spirituality\",\n \"content\": \"...\"\n}"
] | [
"TAGS\n#language-English #license-mit #spirituality #tao-science #quantum-physics #region-us \n",
"# TaoGPT-7B Dataset",
"### General Information\n- Dataset Name: TaoGPT-7B\n- Version: 2.0\n- Size: ~6,000 QA pairs\n- Domain: Tao Science, Quantum Physics, Spirituality\n- Date Released: [Release Date]",
"### Short Description\nTaoGPT-7B is a unique dataset developed for an advanced language model, focusing on Tao Science. It includes over 6000 QA responses on quantum physics, spirituality, and Tao wisdom, co-authored by Dr. Zhi Gang Sha and Dr. Rulin Xiu.",
"### Dataset Structure\nEach data entry in TaoGPT-7B follows this structure:\n- 'question': A query related to Tao Science or quantum physics.\n- 'answer': The response generated based on Tao Science principles.\n- 'metadata': Additional information about the entry.\n- 'content': The detailed content related to the query.",
"### Example\n'''json\n{\n \"question\": \"What is the relationship between Tao Science and quantum physics?\",\n \"answer\": \"Tao Science integrates the principles of quantum physics with spiritual wisdom, exploring the interconnectedness of the universe...\",\n \"metadata\": \"Quantum Physics, Tao Science, Spirituality\",\n \"content\": \"...\"\n}"
] | [
31,
8,
51,
69,
86,
91
] | [
"passage: TAGS\n#language-English #license-mit #spirituality #tao-science #quantum-physics #region-us \n# TaoGPT-7B Dataset### General Information\n- Dataset Name: TaoGPT-7B\n- Version: 2.0\n- Size: ~6,000 QA pairs\n- Domain: Tao Science, Quantum Physics, Spirituality\n- Date Released: [Release Date]### Short Description\nTaoGPT-7B is a unique dataset developed for an advanced language model, focusing on Tao Science. It includes over 6000 QA responses on quantum physics, spirituality, and Tao wisdom, co-authored by Dr. Zhi Gang Sha and Dr. Rulin Xiu.### Dataset Structure\nEach data entry in TaoGPT-7B follows this structure:\n- 'question': A query related to Tao Science or quantum physics.\n- 'answer': The response generated based on Tao Science principles.\n- 'metadata': Additional information about the entry.\n- 'content': The detailed content related to the query.### Example\n'''json\n{\n \"question\": \"What is the relationship between Tao Science and quantum physics?\",\n \"answer\": \"Tao Science integrates the principles of quantum physics with spiritual wisdom, exploring the interconnectedness of the universe...\",\n \"metadata\": \"Quantum Physics, Tao Science, Spirituality\",\n \"content\": \"...\"\n}"
] |
8a2408cbb433aae48f736ec94f3658e5cedde198 | # Reddit Dataset
## Overview
This dataset contains information from 200 subreddits, each comprising 5,012 posts. The data was scraped from Reddit and includes various attributes for each post and subreddit.
## Subreddits
Compelete list can be found at [here](https://pastebin.com/raw/niy3CHej)
## Data Fields
- 'title' - Title of the post
- 'score' - Upvote count
- 'id' - Reddit ID for the API
- 'subreddit' - Subreddit
- 'url' - URL to the post
- 'num_comments' - Amount of comments
- 'body' - The text in the postt
- 'created' - Date in UNIX time.
## Usage
literally a csv file | intone/reddit_sources | [
"task_categories:summarization",
"task_categories:conversational",
"task_categories:text-generation",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:en",
"code",
"region:us"
] | 2023-12-25T09:22:46+00:00 | {"language": ["en"], "size_categories": ["1K<n<10K"], "task_categories": ["summarization", "conversational", "text-generation", "text2text-generation"], "pretty_name": "reddit-programming", "tags": ["code"]} | 2023-12-25T15:24:45+00:00 | [] | [
"en"
] | TAGS
#task_categories-summarization #task_categories-conversational #task_categories-text-generation #task_categories-text2text-generation #size_categories-1K<n<10K #language-English #code #region-us
| # Reddit Dataset
## Overview
This dataset contains information from 200 subreddits, each comprising 5,012 posts. The data was scraped from Reddit and includes various attributes for each post and subreddit.
## Subreddits
Compelete list can be found at here
## Data Fields
- 'title' - Title of the post
- 'score' - Upvote count
- 'id' - Reddit ID for the API
- 'subreddit' - Subreddit
- 'url' - URL to the post
- 'num_comments' - Amount of comments
- 'body' - The text in the postt
- 'created' - Date in UNIX time.
## Usage
literally a csv file | [
"# Reddit Dataset",
"## Overview\n\nThis dataset contains information from 200 subreddits, each comprising 5,012 posts. The data was scraped from Reddit and includes various attributes for each post and subreddit.",
"## Subreddits\nCompelete list can be found at here",
"## Data Fields\n- 'title' - Title of the post\n- 'score' - Upvote count\n- 'id' - Reddit ID for the API\n- 'subreddit' - Subreddit\n- 'url' - URL to the post\n- 'num_comments' - Amount of comments\n- 'body' - The text in the postt\n- 'created' - Date in UNIX time.",
"## Usage\n\nliterally a csv file"
] | [
"TAGS\n#task_categories-summarization #task_categories-conversational #task_categories-text-generation #task_categories-text2text-generation #size_categories-1K<n<10K #language-English #code #region-us \n",
"# Reddit Dataset",
"## Overview\n\nThis dataset contains information from 200 subreddits, each comprising 5,012 posts. The data was scraped from Reddit and includes various attributes for each post and subreddit.",
"## Subreddits\nCompelete list can be found at here",
"## Data Fields\n- 'title' - Title of the post\n- 'score' - Upvote count\n- 'id' - Reddit ID for the API\n- 'subreddit' - Subreddit\n- 'url' - URL to the post\n- 'num_comments' - Amount of comments\n- 'body' - The text in the postt\n- 'created' - Date in UNIX time.",
"## Usage\n\nliterally a csv file"
] | [
68,
4,
45,
14,
87,
8
] | [
"passage: TAGS\n#task_categories-summarization #task_categories-conversational #task_categories-text-generation #task_categories-text2text-generation #size_categories-1K<n<10K #language-English #code #region-us \n# Reddit Dataset## Overview\n\nThis dataset contains information from 200 subreddits, each comprising 5,012 posts. The data was scraped from Reddit and includes various attributes for each post and subreddit.## Subreddits\nCompelete list can be found at here## Data Fields\n- 'title' - Title of the post\n- 'score' - Upvote count\n- 'id' - Reddit ID for the API\n- 'subreddit' - Subreddit\n- 'url' - URL to the post\n- 'num_comments' - Amount of comments\n- 'body' - The text in the postt\n- 'created' - Date in UNIX time.## Usage\n\nliterally a csv file"
] |
9b68708b2285aee56991bff53bdc6c4bbf460f73 |
# Dataset Card for UltraChat 200k Dutch
## Dataset Description
This is a Dutch recreation of [HuggingFaceH4/ultrachat_200k](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k), which in turn is a heavily filtered version of the [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) dataset. It contains multi-turn chat conversations between a user and an assistant created with `gpt-4-1106-preview` via Azure.
An important aspect of this recreation is that I wanted the user messages to be diverse. I therefore created a number of user personas going from an average user to an expert to a language learner. The goal with this idea is to make the model robust in communication, so that it can correctly adjust to different types of users. This is described in more detail below.
## Dataset Structure
The dataset has two splits (unlike the four splits of the parent dataset). I only recreated the SFT datasets for finetuning models on chat/instructions. The number of examples per split is shown as follows:
| train_sft | test_sft |
|:-------:|:-----------:|
| 192,598 | 21,424 |
That means that around 11.12% of the data is reserved for testing. One may find that this dataset is smaller than the original Ultrachat 200k dataset. This is caused by the OpenAI automatic filtering. More information in the sections below.
### Data Instances
The dataset does not have system messages.
```python
{
'prompt': 'Wat was de economische impact van de aardbeving in Haïti in 2010?',
'prompt_id': '24abf48beef8d3279605c53c9ddc18fa723fa723014eb7e4d1b0575cf8a0fc61',
'messages': [
{'content': 'Wat was de economische impact van de aardbeving in Haïti in 2010?', 'role': 'user'},
{'content': 'De aardbeving in Haïti in 2010 had een verwoestende economische impact. Schattingen geven aan dat de schade tussen de 7,8 en 8,5 miljard Amerikaanse dollars lag, wat aanzienlijk meer is dan het bruto binnenlands product van Haïti voor dat jaar. Ongeveer 230.000 mensen kwamen om, 300.000 raakten gewond en 1,5 miljoen mensen werden dakloos. De infrastructuur en economie hebben lange tijd onder de gevolgen geleden en het land is nog steeds bezig met het herstel.', 'role': 'assistant'},
{'content': 'Duidelijk. Hoe vergelijkt dit met andere grote natuurrampen qua economische schade?', 'role': 'user'},
{'content': 'De economische schade van de aardbeving in Haïti in 2010 is in verhouding tot het bruto binnenlands product (BBP) van het land een van de duurste natuurrampen in de geschiedenis. Ter vergelijking, de tsunami in Azië van 2004 kostte ongeveer 10 miljard dollar en de orkaan Katrina in de Verenigde Staten in 2005 kostte naar schatting 125 miljard dollar. Maar gezien het BBP van Haïti aanzienlijk lager is, was de impact daar relatief gezien veel catastrofaler.', 'role': 'assistant'},
{'content': 'Is de internationale hulp effectief geweest in het herstelproces?', 'role': 'user'},
{'content': 'De internationale hulp heeft zeker bijgedragen aan het herstelproces, maar de effectiviteit ervan is ook kritisch bekeken. Er zijn miljarden aan hulpgelden beloofd en uitgekeerd, maar de coördinatie en management van deze fondsen werden vaak als inefficiënt beschouwd. Er zijn veel projecten opgezet voor wederopbouw en ondersteuning, maar de resultaten en de snelheid waarmee deze verbeteringen plaatsvonden, waren niet altijd zoals gehoopt. Er zijn ook zorgen over corruptie en de afhankelijkheid van buitenlandse hulp die het eigen vermogen tot wederopbouw kan verzwakken.', 'role': 'assistant'},
{'content': 'Oké. Welke sectoren werden het hardst getroffen?', 'role': 'user'},
{'content': 'De sectoren die het hardst werden getroffen door de aardbeving waren de bouwsector, toerisme, productie en diensten. De infrastructuur, inclusief scholen, ziekenhuizen, wegen en communicatiesystemen, leed zware schade. De haven van Port-au-Prince, cruciaal voor de economie, was ook verwoest. Daarnaast leed de landbouwsector, die al kwetsbaar was door eerdere stormschade en ontbossing, aanzienlijke schade, wat de voedselveiligheid in het land nog verder in gevaar bracht.', 'role': 'assistant'},
{'content': "Goed, bedankt. Zijn er maatregelen genomen om toekomstige risico's te beperken?", 'role': 'user'},
{'content': "Ja, er zijn maatregelen genomen om de risico's van toekomstige aardbevingen te verminderen. Deze omvatten het herzien van de bouwvoorschriften, het versterken van bestaande structuren en het trainen van lokale gemeenschappen in rampenbestendige bouwtechnieken. Er is ook geïnvesteerd in de ontwikkeling van een beter crisismanagement en er zijn inspanningen om de waarschuwingssystemen en noodplannen te verbeteren. Echter, door de beperkte middelen en andere prioriteiten, blijven veel van deze maatregelen een uitdaging om volledig te implementeren.", 'role': 'assistant'}
],
}
```
### Data Fields
- **prompt**: the initial user prompt
- **prompt_id**: the unique hash of the prompt
- **messages**: list of messages (dictionaries) where each dictionary has a role (user, assistant) and content
## Dataset Creation
This dataset was created with [this repository](https://github.com/BramVanroy/dutch-instruction-datasets/) `conversation-hf` script. The original, English prompt (first user message) was provided as a starting point to the API. The model was then asked to use this topic as a starting point for a user to start a conversation in Dutch. Interestingly, the prompt also indicated that the user was a specific type of person so all generated user messages have to fit its profile. The personas were weighted (they do not all occur equally frequently). Below you find the used personas and their weights (summing to 100).
```json
{
"personas": {
"taalleerder": "Deze persoon spreekt niet goed Nederlands en gebruikt geen moeilijke woorden of ingewikkelde zinsconstructies. Af en toe schrijft de persoon fouten, maar niet altijd.",
"direct": "Een direct persoon die kortdadige taal hanteert. De gebruiker stelt specifieke, doelgerichte vragen in bondige en soms zelfs droge taal. De persoon verkiest een korte, duidelijke uitleg boven een lange, gedetailleerde uitleg.",
"detailliefhebber": "Een geduldig persoon die diepgaande vragen stelt en gedetailleerde antwoorden verwacht.",
"kritisch": "Een kritisch persoon die alles in vraag stelt en vaak moeilijk te overtuigen is.",
"kind": "Een jong persoon tussen 6 en 12 jaar oud die nog vele zaken niet kent en dus vragen stelt die voor ouderen misschien vanzelfsprekend zijn. Ook kan het zijn dat de persoon nog niet erg goed kan lezen en schrijven en dus zal de persoon zelf geen moeilijk taal gebruiken en soms om verduidelijking vragen.",
"expert": "Een ervaren expert die erg goed op de hoogte is van het onderwerp en dus ook diepgaande, bijna encyclopedische of academische, vragen stelt om wellicht een vak-specifiek probleem op te lossen.",
"lachebek": "Een persoon die graag lacht en grapjes maakt en in luchtige taal communiceert. De persoon gebruikt soms (maar niet altijd) smileys en andere emoticons om zijn/haar gevoelens te uiten. De persoon is voornamelijk geïnteresseerd in wonderbaarlijke en fantastische zaken en springt al eens van de hak op de tak.",
"generalist": "Een persoon die graag over veel verschillende onderwerpen praat en dus ook veel uiteenlopende vragen stelt. De persoon is niet erg geïnteresseerd in de details van een onderwerp, maar eerder in de grote lijnen.",
"gemiddeld": "Een gemiddelde, normale gebruiker die geen bijzonder eisen stelt of noden heeft maar simpelweg een behulpzame assistent verwacht."
},
"weights": {
"taalleerder": 0.01,
"direct": 0.1,
"detailliefhebber": 0.1,
"kritisch": 0.03,
"kind": 0.01,
"expert": 0.15,
"lachebek": 0.01,
"generalist": 0.15,
"gemiddeld": 0.44
}
}
```
English summary:
- a language learner who may not speak Dutch well
- a direct conversationalist who uses short, direct language
- a "nitpicker", someone who likes to go deep with detailed questions
- a critic, who will often question what is said and who is hard to convince
- a child of around 6-12 years old who may ask questions that are obvious to older people
- an expert of the field who may use the assistent for a research problem or other expert use cases
- a jokester, someone who likes to make jokes, look at the comical or fun things in a conversation
- a generalist who likes to talk about very different topics but who is not interested in details
- an "average" user who only requires a helpful assistant
Every full conversation was generated in a single query by telling the model to follow a specific structure for the output. (Given the context window of 128,000 of gpt-4, that is not an issue.) The prompt that I used is quite elaborate, describing (in Dutch) what the given input will be (a persona and a starting question (prompt) in English), and what it is expected to do with it. The full prompt is below where `{persona}` is replaced by a persona description (above) and `{subject}`, which is replaced with the original English user prompt.
````
# Simulatie van Interactie Tussen een Gebruiker en een AI-assistent
Je simuleert een interactie tussen een gebruiker met een gegeven 'Persona' en een AI-assistent. De interactie wordt gestart op basis van een gegeven 'Startvraag'.
## Persona van Gebruiker
De gebruiker krijgt een specifieke 'Persona' toegewezen, die diens manier van communiceren en de persoonlijkheid omschrijft. Alles dat de gebruiker zegt moet dus in lijn zijn met de karaktereigenschappen en communicatiestijl van de toegewezen Persona. De AI-assistent gedraagt zich als een behulpzame assistent en moet de vragen van de gebruiker objectief, en zo goed en eerlijk mogelijk beantwoorden en de instructies juist volgen.
## Startvraag
Je krijgt een 'Startvraag' in het Engels mee als startpunt van de interactie. Dat kan een vraag of instructie zijn. Als eerste stap moet je deze startvraag vertalen naar het Nederlands en volledig aanpassen aan het taalgebruik en persona van de gebruiker zodat de gebruiker met deze aangepaste vraag of instructie het gesprek kan beginnen. Zorg ervoor dat ALLE inhoud van de oorspronkelijk vraag behouden blijft maar pas waar nodig de schrijfstijl grondig aan.
## Beurten
Na de startvraag antwoordt de assistent. Afhankelijk van de persona kan de gebruiker daarna vragen om meer details, gerelateerde informatie, het antwoord in vraag stellen, of de instructies verder verfijnen. Dat gebeurt in verschillende op elkaar voortbouwende interacties zoals in een echt gesprek. Het gesprek neemt tussen de 5 en 12 beurten van zowel de gebruiker als de assisent in beslag. Gebruikers met Persona's die meer vragen stellen, zullen dus meer beurten nodig hebben.
## Taalgebruik
De vragen, instructies en antwoorden moeten in het Standaardnederlands geschreven zijn tenzij anders aangegeven in de Persona van de gebruiker. De taal is verzorgd en bevat geen regionale variatie zodat het over het hele taalgebied (waaronder Nederland en Vlaanderen) zonder problemen begrepen kan worden.
## Input en Output Formaat
Als input krijg je een 'Persona' van de gebruiker en een 'Startvraag' of instructie in het Engels. Voorbeeld input:
```
<persona>
[Beschrijving van de Persona van de gebruiker]
</persona>
<startvraag>
[Een korte of lange vraag of instructie in het Engels die eerst vertaald moet worden en dan aangepast moet worden aan de persona]
</startvraag>
```
De output moet simpel gestructureerd zijn zodat je voor de gebruiker en assistent respectievelijk de gebruikersvraag of -instructie en het antwoord van de assistent geeft.
Voorbeeld output:
```
gebruiker: [Vertaling en aanpassing van de Startvraag aan de persona in passend taalgebruik]
assistent: [antwoord op de vorige gebruikersvraag of -instructie]
gebruiker: [vervolgvraag-1]
assistent: [antwoord op de vorige vervolgvraag-1]
gebruiker: [vervolgvraag-2]
assistent: [antwoord op de vorige vervolgvraag-1]
```
---
<persona>
{persona}
</persona>
<startvraag>
{subject}
</startvraag>
````
Afterwards, the output ("voorbeeld output" format) was parsed and whenever there was an issue, the results were discarded. Fortunately this did not happen too often.
### Data filtering
On top of the automatic content filtering and parsing issues, additional filtering was also done. All the data is preserved in separate branches if you would like a historical view of the process.
- `1-gpt-4-turbo-convos-from-original`: the original output of the script after the previous steps. This branch also includes the persona per sample and original English prompt, which have been left out in the final revision.
- `2-lid`: added [language identification](https://github.com/BramVanroy/dutch-instruction-datasets/blob/main/src/dutch_data/scripts/add_lid.py) to the columns with [fastText](https://huggingface.co/facebook/fasttext-language-identification), which is based on the concatenation of all `content` keys in the `messages` column.
- `3-filtered`: removed samples where the detected text was not Dutch. (Note that this may remove translation-focused samples!). [Other filters](https://github.com/BramVanroy/dutch-instruction-datasets/blob/main/src/dutch_data/scripts/filter_dutch.py)
- samples with non-Latin characters are removed (very strict filtering, removes any translation tasks with non-Latin languages)
- samples with occurrences of "AI-assistent" or "AI-taalmodel" (and other derivations) are removed because these are often responses in the sense of "As an AI model, I cannot ...", which is not too useful
- samples with mentions of ChatGPT, GPT 3/4, OpenAI or ShareGPT are removed
- samples with mentions of the typical "knowledge cutoff" are removed
- samples with apologies such as "spijt me" are removed, as we are more interested in factual information and content-filled responses
- `main`: the main, default branch. Removes all "irrelevant" columns (like English messages, persona, language identification)
The filtering removed another 8174 samples.
### Source Data
#### Initial Data Collection and Normalization
Initial data filtering by [HuggingFaceH4](https://huggingface.co/datasets/HuggingFaceH4/ultrachat_200k), which in turn started from [UltraChat](https://huggingface.co/datasets/stingning/ultrachat).
#### Who are the source language producers?
The initial data [was collected ](https://huggingface.co/datasets/stingning/ultrachat#dataset-description) with "two separate ChatGPT Turbo APIs". This new dataset used `gpt-4-1106-preview` to create a Dutch version.
## Considerations for Using the Data
Note that except for a manual analysis of around 100 random samples, this dataset has not been verified or checked for issues. However, the OpenAI filters blocked 8023 requests for generation, which may indicate that some of the original prompts may contained ambiguous or potentially inappropriate content that has now been filtered.
### Discussion of Biases
As with any machine-generated texts, users should be aware of potential biases that are included in this dataset. It is likely that biases remain in the dataset so use with caution.
### Licensing Information
This dataset was generated (either in part or in full) with GPT-4 (`gpt-4-1106-preview`), OpenAI’s large-scale language-generation model. Therefore commercial usage is not allowed.
If you use this dataset, you must also follow the [Sharing](https://openai.com/policies/sharing-publication-policy) and [Usage](https://openai.com/policies/usage-policies) policies.
### Contributions
Thanks to Michiel Buisman of [UWV](https://www.uwv.nl/particulieren/index.aspx) for reaching out and making the creation of this dataset possible with access to Azure's API. | BramVanroy/ultrachat_200k_dutch | [
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:100K<n<1M",
"language:nl",
"license:cc-by-nc-4.0",
"region:us"
] | 2023-12-25T09:27:35+00:00 | {"language": ["nl"], "license": "cc-by-nc-4.0", "size_categories": ["100K<n<1M"], "task_categories": ["conversational", "text-generation"], "pretty_name": "Ultrachat 200k Dutch", "dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "prompt_id", "dtype": "string"}, {"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "test_sft", "num_bytes": 84151594, "num_examples": 21424}, {"name": "train_sft", "num_bytes": 757117243, "num_examples": 192598}], "download_size": 483255676, "dataset_size": 841268837}, "configs": [{"config_name": "default", "data_files": [{"split": "test_sft", "path": "data/test_sft-*"}, {"split": "train_sft", "path": "data/train_sft-*"}]}]} | 2024-02-01T11:52:01+00:00 | [] | [
"nl"
] | TAGS
#task_categories-conversational #task_categories-text-generation #size_categories-100K<n<1M #language-Dutch #license-cc-by-nc-4.0 #region-us
| Dataset Card for UltraChat 200k Dutch
=====================================
Dataset Description
-------------------
This is a Dutch recreation of HuggingFaceH4/ultrachat\_200k, which in turn is a heavily filtered version of the UltraChat dataset. It contains multi-turn chat conversations between a user and an assistant created with 'gpt-4-1106-preview' via Azure.
An important aspect of this recreation is that I wanted the user messages to be diverse. I therefore created a number of user personas going from an average user to an expert to a language learner. The goal with this idea is to make the model robust in communication, so that it can correctly adjust to different types of users. This is described in more detail below.
Dataset Structure
-----------------
The dataset has two splits (unlike the four splits of the parent dataset). I only recreated the SFT datasets for finetuning models on chat/instructions. The number of examples per split is shown as follows:
That means that around 11.12% of the data is reserved for testing. One may find that this dataset is smaller than the original Ultrachat 200k dataset. This is caused by the OpenAI automatic filtering. More information in the sections below.
### Data Instances
The dataset does not have system messages.
### Data Fields
* prompt: the initial user prompt
* prompt\_id: the unique hash of the prompt
* messages: list of messages (dictionaries) where each dictionary has a role (user, assistant) and content
Dataset Creation
----------------
This dataset was created with this repository 'conversation-hf' script. The original, English prompt (first user message) was provided as a starting point to the API. The model was then asked to use this topic as a starting point for a user to start a conversation in Dutch. Interestingly, the prompt also indicated that the user was a specific type of person so all generated user messages have to fit its profile. The personas were weighted (they do not all occur equally frequently). Below you find the used personas and their weights (summing to 100).
English summary:
* a language learner who may not speak Dutch well
* a direct conversationalist who uses short, direct language
* a "nitpicker", someone who likes to go deep with detailed questions
* a critic, who will often question what is said and who is hard to convince
* a child of around 6-12 years old who may ask questions that are obvious to older people
* an expert of the field who may use the assistent for a research problem or other expert use cases
* a jokester, someone who likes to make jokes, look at the comical or fun things in a conversation
* a generalist who likes to talk about very different topics but who is not interested in details
* an "average" user who only requires a helpful assistant
Every full conversation was generated in a single query by telling the model to follow a specific structure for the output. (Given the context window of 128,000 of gpt-4, that is not an issue.) The prompt that I used is quite elaborate, describing (in Dutch) what the given input will be (a persona and a starting question (prompt) in English), and what it is expected to do with it. The full prompt is below where '{persona}' is replaced by a persona description (above) and '{subject}', which is replaced with the original English user prompt.
[Beschrijving van de Persona van de gebruiker]
[Een korte of lange vraag of instructie in het Engels die eerst vertaald moet worden en dan aangepast moet worden aan de persona]
gebruiker: [Vertaling en aanpassing van de Startvraag aan de persona in passend taalgebruik]
assistent: [antwoord op de vorige gebruikersvraag of -instructie]
gebruiker: [vervolgvraag-1]
assistent: [antwoord op de vorige vervolgvraag-1]
gebruiker: [vervolgvraag-2]
assistent: [antwoord op de vorige vervolgvraag-1]
'
Afterwards, the output ("voorbeeld output" format) was parsed and whenever there was an issue, the results were discarded. Fortunately this did not happen too often.
### Data filtering
On top of the automatic content filtering and parsing issues, additional filtering was also done. All the data is preserved in separate branches if you would like a historical view of the process.
* '1-gpt-4-turbo-convos-from-original': the original output of the script after the previous steps. This branch also includes the persona per sample and original English prompt, which have been left out in the final revision.
* '2-lid': added language identification to the columns with fastText, which is based on the concatenation of all 'content' keys in the 'messages' column.
* '3-filtered': removed samples where the detected text was not Dutch. (Note that this may remove translation-focused samples!). Other filters
+ samples with non-Latin characters are removed (very strict filtering, removes any translation tasks with non-Latin languages)
+ samples with occurrences of "AI-assistent" or "AI-taalmodel" (and other derivations) are removed because these are often responses in the sense of "As an AI model, I cannot ...", which is not too useful
+ samples with mentions of ChatGPT, GPT 3/4, OpenAI or ShareGPT are removed
+ samples with mentions of the typical "knowledge cutoff" are removed
+ samples with apologies such as "spijt me" are removed, as we are more interested in factual information and content-filled responses
* 'main': the main, default branch. Removes all "irrelevant" columns (like English messages, persona, language identification)
The filtering removed another 8174 samples.
### Source Data
#### Initial Data Collection and Normalization
Initial data filtering by HuggingFaceH4, which in turn started from UltraChat.
#### Who are the source language producers?
The initial data was collected with "two separate ChatGPT Turbo APIs". This new dataset used 'gpt-4-1106-preview' to create a Dutch version.
Considerations for Using the Data
---------------------------------
Note that except for a manual analysis of around 100 random samples, this dataset has not been verified or checked for issues. However, the OpenAI filters blocked 8023 requests for generation, which may indicate that some of the original prompts may contained ambiguous or potentially inappropriate content that has now been filtered.
### Discussion of Biases
As with any machine-generated texts, users should be aware of potential biases that are included in this dataset. It is likely that biases remain in the dataset so use with caution.
### Licensing Information
This dataset was generated (either in part or in full) with GPT-4 ('gpt-4-1106-preview'), OpenAI’s large-scale language-generation model. Therefore commercial usage is not allowed.
If you use this dataset, you must also follow the Sharing and Usage policies.
### Contributions
Thanks to Michiel Buisman of UWV for reaching out and making the creation of this dataset possible with access to Azure's API.
| [
"### Data Instances\n\n\nThe dataset does not have system messages.",
"### Data Fields\n\n\n* prompt: the initial user prompt\n* prompt\\_id: the unique hash of the prompt\n* messages: list of messages (dictionaries) where each dictionary has a role (user, assistant) and content\n\n\nDataset Creation\n----------------\n\n\nThis dataset was created with this repository 'conversation-hf' script. The original, English prompt (first user message) was provided as a starting point to the API. The model was then asked to use this topic as a starting point for a user to start a conversation in Dutch. Interestingly, the prompt also indicated that the user was a specific type of person so all generated user messages have to fit its profile. The personas were weighted (they do not all occur equally frequently). Below you find the used personas and their weights (summing to 100).\n\n\nEnglish summary:\n\n\n* a language learner who may not speak Dutch well\n* a direct conversationalist who uses short, direct language\n* a \"nitpicker\", someone who likes to go deep with detailed questions\n* a critic, who will often question what is said and who is hard to convince\n* a child of around 6-12 years old who may ask questions that are obvious to older people\n* an expert of the field who may use the assistent for a research problem or other expert use cases\n* a jokester, someone who likes to make jokes, look at the comical or fun things in a conversation\n* a generalist who likes to talk about very different topics but who is not interested in details\n* an \"average\" user who only requires a helpful assistant\n\n\nEvery full conversation was generated in a single query by telling the model to follow a specific structure for the output. (Given the context window of 128,000 of gpt-4, that is not an issue.) The prompt that I used is quite elaborate, describing (in Dutch) what the given input will be (a persona and a starting question (prompt) in English), and what it is expected to do with it. The full prompt is below where '{persona}' is replaced by a persona description (above) and '{subject}', which is replaced with the original English user prompt.\n\n\n\n[Beschrijving van de Persona van de gebruiker]\n\n\n[Een korte of lange vraag of instructie in het Engels die eerst vertaald moet worden en dan aangepast moet worden aan de persona]\n\ngebruiker: [Vertaling en aanpassing van de Startvraag aan de persona in passend taalgebruik]\nassistent: [antwoord op de vorige gebruikersvraag of -instructie]\n\n\ngebruiker: [vervolgvraag-1]\nassistent: [antwoord op de vorige vervolgvraag-1]\n\n\ngebruiker: [vervolgvraag-2]\nassistent: [antwoord op de vorige vervolgvraag-1]\n'\n\n\nAfterwards, the output (\"voorbeeld output\" format) was parsed and whenever there was an issue, the results were discarded. Fortunately this did not happen too often.",
"### Data filtering\n\n\nOn top of the automatic content filtering and parsing issues, additional filtering was also done. All the data is preserved in separate branches if you would like a historical view of the process.\n\n\n* '1-gpt-4-turbo-convos-from-original': the original output of the script after the previous steps. This branch also includes the persona per sample and original English prompt, which have been left out in the final revision.\n* '2-lid': added language identification to the columns with fastText, which is based on the concatenation of all 'content' keys in the 'messages' column.\n* '3-filtered': removed samples where the detected text was not Dutch. (Note that this may remove translation-focused samples!). Other filters\n\t+ samples with non-Latin characters are removed (very strict filtering, removes any translation tasks with non-Latin languages)\n\t+ samples with occurrences of \"AI-assistent\" or \"AI-taalmodel\" (and other derivations) are removed because these are often responses in the sense of \"As an AI model, I cannot ...\", which is not too useful\n\t+ samples with mentions of ChatGPT, GPT 3/4, OpenAI or ShareGPT are removed\n\t+ samples with mentions of the typical \"knowledge cutoff\" are removed\n\t+ samples with apologies such as \"spijt me\" are removed, as we are more interested in factual information and content-filled responses\n* 'main': the main, default branch. Removes all \"irrelevant\" columns (like English messages, persona, language identification)\n\n\nThe filtering removed another 8174 samples.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nInitial data filtering by HuggingFaceH4, which in turn started from UltraChat.",
"#### Who are the source language producers?\n\n\nThe initial data was collected with \"two separate ChatGPT Turbo APIs\". This new dataset used 'gpt-4-1106-preview' to create a Dutch version.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nNote that except for a manual analysis of around 100 random samples, this dataset has not been verified or checked for issues. However, the OpenAI filters blocked 8023 requests for generation, which may indicate that some of the original prompts may contained ambiguous or potentially inappropriate content that has now been filtered.",
"### Discussion of Biases\n\n\nAs with any machine-generated texts, users should be aware of potential biases that are included in this dataset. It is likely that biases remain in the dataset so use with caution.",
"### Licensing Information\n\n\nThis dataset was generated (either in part or in full) with GPT-4 ('gpt-4-1106-preview'), OpenAI’s large-scale language-generation model. Therefore commercial usage is not allowed.\n\n\nIf you use this dataset, you must also follow the Sharing and Usage policies.",
"### Contributions\n\n\nThanks to Michiel Buisman of UWV for reaching out and making the creation of this dataset possible with access to Azure's API."
] | [
"TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-100K<n<1M #language-Dutch #license-cc-by-nc-4.0 #region-us \n",
"### Data Instances\n\n\nThe dataset does not have system messages.",
"### Data Fields\n\n\n* prompt: the initial user prompt\n* prompt\\_id: the unique hash of the prompt\n* messages: list of messages (dictionaries) where each dictionary has a role (user, assistant) and content\n\n\nDataset Creation\n----------------\n\n\nThis dataset was created with this repository 'conversation-hf' script. The original, English prompt (first user message) was provided as a starting point to the API. The model was then asked to use this topic as a starting point for a user to start a conversation in Dutch. Interestingly, the prompt also indicated that the user was a specific type of person so all generated user messages have to fit its profile. The personas were weighted (they do not all occur equally frequently). Below you find the used personas and their weights (summing to 100).\n\n\nEnglish summary:\n\n\n* a language learner who may not speak Dutch well\n* a direct conversationalist who uses short, direct language\n* a \"nitpicker\", someone who likes to go deep with detailed questions\n* a critic, who will often question what is said and who is hard to convince\n* a child of around 6-12 years old who may ask questions that are obvious to older people\n* an expert of the field who may use the assistent for a research problem or other expert use cases\n* a jokester, someone who likes to make jokes, look at the comical or fun things in a conversation\n* a generalist who likes to talk about very different topics but who is not interested in details\n* an \"average\" user who only requires a helpful assistant\n\n\nEvery full conversation was generated in a single query by telling the model to follow a specific structure for the output. (Given the context window of 128,000 of gpt-4, that is not an issue.) The prompt that I used is quite elaborate, describing (in Dutch) what the given input will be (a persona and a starting question (prompt) in English), and what it is expected to do with it. The full prompt is below where '{persona}' is replaced by a persona description (above) and '{subject}', which is replaced with the original English user prompt.\n\n\n\n[Beschrijving van de Persona van de gebruiker]\n\n\n[Een korte of lange vraag of instructie in het Engels die eerst vertaald moet worden en dan aangepast moet worden aan de persona]\n\ngebruiker: [Vertaling en aanpassing van de Startvraag aan de persona in passend taalgebruik]\nassistent: [antwoord op de vorige gebruikersvraag of -instructie]\n\n\ngebruiker: [vervolgvraag-1]\nassistent: [antwoord op de vorige vervolgvraag-1]\n\n\ngebruiker: [vervolgvraag-2]\nassistent: [antwoord op de vorige vervolgvraag-1]\n'\n\n\nAfterwards, the output (\"voorbeeld output\" format) was parsed and whenever there was an issue, the results were discarded. Fortunately this did not happen too often.",
"### Data filtering\n\n\nOn top of the automatic content filtering and parsing issues, additional filtering was also done. All the data is preserved in separate branches if you would like a historical view of the process.\n\n\n* '1-gpt-4-turbo-convos-from-original': the original output of the script after the previous steps. This branch also includes the persona per sample and original English prompt, which have been left out in the final revision.\n* '2-lid': added language identification to the columns with fastText, which is based on the concatenation of all 'content' keys in the 'messages' column.\n* '3-filtered': removed samples where the detected text was not Dutch. (Note that this may remove translation-focused samples!). Other filters\n\t+ samples with non-Latin characters are removed (very strict filtering, removes any translation tasks with non-Latin languages)\n\t+ samples with occurrences of \"AI-assistent\" or \"AI-taalmodel\" (and other derivations) are removed because these are often responses in the sense of \"As an AI model, I cannot ...\", which is not too useful\n\t+ samples with mentions of ChatGPT, GPT 3/4, OpenAI or ShareGPT are removed\n\t+ samples with mentions of the typical \"knowledge cutoff\" are removed\n\t+ samples with apologies such as \"spijt me\" are removed, as we are more interested in factual information and content-filled responses\n* 'main': the main, default branch. Removes all \"irrelevant\" columns (like English messages, persona, language identification)\n\n\nThe filtering removed another 8174 samples.",
"### Source Data",
"#### Initial Data Collection and Normalization\n\n\nInitial data filtering by HuggingFaceH4, which in turn started from UltraChat.",
"#### Who are the source language producers?\n\n\nThe initial data was collected with \"two separate ChatGPT Turbo APIs\". This new dataset used 'gpt-4-1106-preview' to create a Dutch version.\n\n\nConsiderations for Using the Data\n---------------------------------\n\n\nNote that except for a manual analysis of around 100 random samples, this dataset has not been verified or checked for issues. However, the OpenAI filters blocked 8023 requests for generation, which may indicate that some of the original prompts may contained ambiguous or potentially inappropriate content that has now been filtered.",
"### Discussion of Biases\n\n\nAs with any machine-generated texts, users should be aware of potential biases that are included in this dataset. It is likely that biases remain in the dataset so use with caution.",
"### Licensing Information\n\n\nThis dataset was generated (either in part or in full) with GPT-4 ('gpt-4-1106-preview'), OpenAI’s large-scale language-generation model. Therefore commercial usage is not allowed.\n\n\nIf you use this dataset, you must also follow the Sharing and Usage policies.",
"### Contributions\n\n\nThanks to Michiel Buisman of UWV for reaching out and making the creation of this dataset possible with access to Azure's API."
] | [
56,
15,
639,
382,
4,
32,
132,
53,
77,
37
] | [
"passage: TAGS\n#task_categories-conversational #task_categories-text-generation #size_categories-100K<n<1M #language-Dutch #license-cc-by-nc-4.0 #region-us \n### Data Instances\n\n\nThe dataset does not have system messages.",
"passage: ### Data Fields\n\n\n* prompt: the initial user prompt\n* prompt\\_id: the unique hash of the prompt\n* messages: list of messages (dictionaries) where each dictionary has a role (user, assistant) and content\n\n\nDataset Creation\n----------------\n\n\nThis dataset was created with this repository 'conversation-hf' script. The original, English prompt (first user message) was provided as a starting point to the API. The model was then asked to use this topic as a starting point for a user to start a conversation in Dutch. Interestingly, the prompt also indicated that the user was a specific type of person so all generated user messages have to fit its profile. The personas were weighted (they do not all occur equally frequently). Below you find the used personas and their weights (summing to 100).\n\n\nEnglish summary:\n\n\n* a language learner who may not speak Dutch well\n* a direct conversationalist who uses short, direct language\n* a \"nitpicker\", someone who likes to go deep with detailed questions\n* a critic, who will often question what is said and who is hard to convince\n* a child of around 6-12 years old who may ask questions that are obvious to older people\n* an expert of the field who may use the assistent for a research problem or other expert use cases\n* a jokester, someone who likes to make jokes, look at the comical or fun things in a conversation\n* a generalist who likes to talk about very different topics but who is not interested in details\n* an \"average\" user who only requires a helpful assistant\n\n\nEvery full conversation was generated in a single query by telling the model to follow a specific structure for the output. (Given the context window of 128,000 of gpt-4, that is not an issue.) The prompt that I used is quite elaborate, describing (in Dutch) what the given input will be (a persona and a starting question (prompt) in English), and what it is expected to do with it. The full prompt is below where '{persona}' is replaced by a persona description (above) and '{subject}', which is replaced with the original English user prompt.\n\n\n\n[Beschrijving van de Persona van de gebruiker]\n\n\n[Een korte of lange vraag of instructie in het Engels die eerst vertaald moet worden en dan aangepast moet worden aan de persona]\n\ngebruiker: [Vertaling en aanpassing van de Startvraag aan de persona in passend taalgebruik]\nassistent: [antwoord op de vorige gebruikersvraag of -instructie]\n\n\ngebruiker: [vervolgvraag-1]\nassistent: [antwoord op de vorige vervolgvraag-1]\n\n\ngebruiker: [vervolgvraag-2]\nassistent: [antwoord op de vorige vervolgvraag-1]\n'\n\n\nAfterwards, the output (\"voorbeeld output\" format) was parsed and whenever there was an issue, the results were discarded. Fortunately this did not happen too often.### Data filtering\n\n\nOn top of the automatic content filtering and parsing issues, additional filtering was also done. All the data is preserved in separate branches if you would like a historical view of the process.\n\n\n* '1-gpt-4-turbo-convos-from-original': the original output of the script after the previous steps. This branch also includes the persona per sample and original English prompt, which have been left out in the final revision.\n* '2-lid': added language identification to the columns with fastText, which is based on the concatenation of all 'content' keys in the 'messages' column.\n* '3-filtered': removed samples where the detected text was not Dutch. (Note that this may remove translation-focused samples!). Other filters\n\t+ samples with non-Latin characters are removed (very strict filtering, removes any translation tasks with non-Latin languages)\n\t+ samples with occurrences of \"AI-assistent\" or \"AI-taalmodel\" (and other derivations) are removed because these are often responses in the sense of \"As an AI model, I cannot ...\", which is not too useful\n\t+ samples with mentions of ChatGPT, GPT 3/4, OpenAI or ShareGPT are removed\n\t+ samples with mentions of the typical \"knowledge cutoff\" are removed\n\t+ samples with apologies such as \"spijt me\" are removed, as we are more interested in factual information and content-filled responses\n* 'main': the main, default branch. Removes all \"irrelevant\" columns (like English messages, persona, language identification)\n\n\nThe filtering removed another 8174 samples.### Source Data#### Initial Data Collection and Normalization\n\n\nInitial data filtering by HuggingFaceH4, which in turn started from UltraChat."
] |
9cf6cb38d4a7aea14eaaafb9c1c93e135825a968 |
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | adnanhassan/testadadad | [
"region:us"
] | 2023-12-25T09:45:09+00:00 | {} | 2023-12-25T09:45:43+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
19febd7b99bd530c3d665c6d8cb87ad25793dac8 | <p style="-webkit-text-stroke-width: 0px; background-color: white; box-sizing: border-box; color: #333333; font-family: Roboto, Helvetica, Arial, sans-serif; font-size: 14px; font-style: normal; font-variant-caps: normal; font-variant-ligatures: normal; font-weight: 400; letter-spacing: normal; margin: 0px 0px 10px; orphans: 2; padding: 0px; text-align: start; text-decoration-color: initial; text-decoration-style: initial; text-decoration-thickness: initial; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px;"><strong style="box-sizing: border-box; font-style: normal; font-weight: bold;"><span style="box-sizing: border-box; color: magenta;">➥ Where to Get Bottle Online -</span> <a href="https://www.healthsupplement24x7.com/get-prostamend"><span style="background-color: white; box-sizing: border-box; color: red;">https://www.healthsupplement24x7.com/get-prostamend</span></a><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: green;">➥ Product Name -</span> PROSTAMEND<br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #993300;">➥ Side Effects -</span> <span style="box-sizing: border-box; color: navy;">No Major Side Effects</span><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #993366;">➥ Category -</span> HEALTH (PROSTATE)<br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: maroon;">➥ Results -</span> <span style="box-sizing: border-box; color: #00ccff;">In 1-2 Months</span><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: red;">➥ Availability –</span> <a href="https://www.healthsupplement24x7.com/get-prostamend"><span style="background-color: transparent; box-sizing: border-box; color: black; text-decoration: none;"><span style="box-sizing: border-box; color: #ff6600;">Online</span></span></a><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #333300;">➥ Rating: -</span> <span style="box-sizing: border-box; color: red;">5.0/5.0</span> ⭐⭐⭐⭐⭐</strong></p>
<p>The prostate is a tiny gland located in the male reproductive system. It resembles a walnut in shape and size and sits below the pelvis. It plays a crucial role in creating semen, a milky fluid that carries sperm from the testicles through the penis.The prostate gland grows larger as one grows older. Since it surrounds the urethra, it may squeeze it, thus causing a problem when passing urine. This problem may begin when one attains thirty or forty. </p>
<p>A combination of all-natural components proven to support prostate health was used in the formulation of <a href="https://sites.google.com/view/prostamend-prostamend/home">ProstaMend</a>.This dietary supplement is intended to assist men who have benign prostatic hyperplasia (BPH), an enlarged prostate that can result in pain, urinary issues, and other symptoms.According to the ProstaMend website, the supplement comprises a combination of substances that promote normal prostate function.</p>
<h2 class="wp-block-heading"><span id="What_Is_ProstaMend" class="ez-toc-section"></span>What Is ProstaMend?</h2>
<p><a href="https://sites.google.com/view/prostamend-pill/home">ProstaMend</a> is a dietary supplement that contains only all natural ingredients and herbs and is intended to support prostate health. It is designed for men who are suffering from benign prostatic hyperplasia (BPH), which is a prostate enlargement problem that can cause discomfort, difficulty urinating, and other symptoms. </p>
<p>This supplement is made in an FDA approved and GMP certified facility to ensure maximum safety and highest quality of the components are used.Each ingredient in <a href="https://prostamend.clubeo.com/calendar/2023/12/25/prostamend-shocking-news-does-prostamend-really-worth-it?_ga=2.91958298.186797702.1703482350-277504833.1703482343">ProstaMend</a> was clinically tested and approved to help solving prostate problems.In this article we’ll look at ProstaMend and see how effectively it supports prostate health.</p>
<h2 style="text-align: center;"><a href="https://www.healthsupplement24x7.com/get-prostamend"><span style="text-decoration: underline;"><strong><span style="color: red; text-decoration: underline;">(OFFICIAL WEBSITE) Click Here To Order ProstaMend For The Lowest Price Right Now</span></strong></span></a></h2>
<h2 class="wp-block-heading"><span id="Does_ProstaMend_Work" class="ez-toc-section"></span>Does ProstaMend Work?</h2>
<p>It is crucial to highlight that there is little scientific evidence to support the usefulness of the <a href="https://prostamend.clubeo.com/page/prostamend-year-end-sale-2023-all-you-need-to-know-about-offer.html">ProstaMend</a> components for treating BPH, despite the fact that they have been used for decades in traditional medicine to maintain prostate health. </p>
<p>Yet, there is some proof that some of the components in <a href="https://prostamend-pills.webflow.io/">ProstaMend</a> may be useful in lessening BPH symptoms. For instance, studies on saw palmetto have revealed that it can decrease the size of an enlarged prostate and increase urine flow. Stinging nettle has also been found to lessen BPH symptoms including frequent and urgent urination.</p>
<p>The investigations on these compounds have, however, been somewhat limited, and bigger, more thorough studies are required to adequately evaluate their efficacy. </p>
<p>It’s also critical to keep in mind that the FDA does not oversee dietary supplements the same way it does prescription pharmaceuticals. Hence, there is no way to determine the precise amount of each component in <a href="https://www.townscript.com/e/prostamend-new-2024-does-it-really-works-or-scam-101043">ProstaMend</a> and there is no assurance that they are safe or effective.</p>
<h2 class="wp-block-heading"><span id="Ingredietns_Of_ProstaMend" class="ez-toc-section"></span>Ingredietns Of ProstaMend</h2>
<p>A deeper look at <a href="https://prostamend.clubeo.com/page/prostamend-reviews-a-potent-nutrient-rich-prostate-health-support-formula.html">ProstaMend</a>’s components is provided below: </p>
<h3 class="wp-block-heading">Extract of Saw Palmetto </h3>
<p>In traditional medicine, saw palmetto is a plant extract that has traditionally been used to enhance prostate health. It is thought to function by lowering inflammation and the synthesis of certain hormones that can lead to prostate enlargement.</p>
<h3 class="wp-block-heading">Extract From Graviola Leaf </h3>
<p>South America is the original home of the tropical fruit known as graviola. Many bioactive substances that are thought to have anti-inflammatory and antioxidant activities may be found in the leaves of the graviola tree.</p>
<h3 class="wp-block-heading">Pureed Tomato Fruit </h3>
<p>Lycopene, a potent antioxidant that has been demonstrated to have a protective impact on prostate health, can be found in tomatoes in significant amounts. Lycopene is hypothesized to function by lowering oxidative stress and inflammation in the prostate gland. </p>
<h3 class="wp-block-heading">African Pygeum Bark Extract </h3>
<p>A tree that is indigenous to Africa is called Pygeum Africanum. Many bioactive substances that are thought to have anti-inflammatory and antioxidant activities may be found in the tree’s bark. Traditional medicine frequently employs Pygeum Africanum to treat BPH symptoms.</p>
<h3 class="wp-block-heading">E vitamin </h3>
<p>A fat-soluble vitamin that is vital for human health is vitamin E. It is frequently used in conventional medicine to treat a number of illnesses since it is thought to have antioxidant effects.</p>
<h3 class="wp-block-heading">Zinc </h3>
<p>A trace mineral called zinc is crucial for maintaining human health. It is frequently used in conventional medicine to treat a number of illnesses since it is thought to have antioxidant effects. </p>
<h2 style="text-align: center;"><a href="https://www.healthsupplement24x7.com/get-prostamend"><strong><span style="text-decoration: underline;"><span style="color: red; text-decoration: underline;">24Hrs Limited OFFER – GET</span></span></strong> <span style="text-decoration: underline;"><strong><span style="color: red; text-decoration: underline;">ProstaMend a</span></strong></span><strong><span style="text-decoration: underline;"><span style="color: red; text-decoration: underline;">t the LOW Price from its Official Website</span></span></strong></a></h2>
<h2 class="wp-block-heading">Benefits Of ProstaMend</h2>
<p>Dietary supplement <a href="https://www.sunflower-cissp.com/glossary/cissp/8540/prostamend-reviews-a-potent-nutrient-rich-prostate-health-support-formula">ProstaMend</a> uses a combination of organic substances to enhance prostate health. Several of the individual constituents in <a href="https://groups.google.com/g/prostamend-pills/c/qCM1bDxm-og">ProstaMend</a> have been used for many years in traditional medicine to promote prostate health, even though the supplement’s efficacy has not been well researched.</p>
<p><a href="https://groups.google.com/a/chromium.org/g/telemetry/c/G9wixZgplSk">ProstaMend</a> may have the following advantages: </p>
<ul>
<li><strong>Promotes Normal Prostate Function</strong>: An essential component of the male reproductive system is the prostate gland. Prostate enlargement in older men can result in a range of symptoms related to the urinary system. It is thought that the components of ProstaMend operate in concert to promote healthy prostate function and lower the risk of prostate enlargement.</li>
<li><strong>Minimizes Inflammation: </strong>Inflammation is a normal reaction to injury or illness, but persistent inflammation can cause a number of health issues, including enlargement of the prostate. The ProstaMend components may help to lessen inflammation in the prostate gland and other areas of the body since they are thought to have anti-inflammatory capabilities. </li>
<li><strong>Encourages Healthy Urination: </strong>Many urine symptoms, such as frequent urination, difficulty urinating, and urinary urgency, can be brought on by prostate enlargement. By lowering prostate gland inflammation and enhancing urine flow, the components of ProstaMend are thought to enhance urinary wellness.</li>
<li><strong>Increasing Antioxidant Levels :</strong>The body needs antioxidants to defend itself from oxidative stress, which can lead to a number of health issues. Antioxidants are essential nutrients. Antioxidant-rich ProstaMend components may help increase the body’s total antioxidant levels. </li>
<li><strong>Aids Immune System Performance</strong>: The immune system is in charge of defending the body from illnesses and infections. By lowering inflammation and encouraging the development of healthy immune cells, the components of ProstaMend are thought to boost immunological function.</li>
<li><strong>Enhances Sexual Performance :</strong>Erectile dysfunction and reduced libido are only two of the many sexual symptoms that can result from enlarged prostates. Although ProstaMend isn’t made expressly to enhance sexual performance, certain of its component parts are thought to be beneficial for sexual health. </li>
<li><strong>Maybe Lowers Risk of Prostate Cancer :</strong>ProstaMend’s contents have not been proven to particularly prevent prostate cancer, although some research has indicated that certain vitamins and minerals, such lycopene and selenium, may lower the chance of getting the disease.</li>
</ul>
<h2 class="wp-block-heading"><span id="How_To_Take_ProstaMend" class="ez-toc-section"></span>How To Take ProstaMend</h2>
<p>Two pills per day, taken with a meal, is the suggested dosage, according to the <a href="https://medium.com/@haroldstarc/prostamend-shocking-news-does-prostamend-really-worth-it-1cf41e86d425">ProstaMend</a> website. It’s crucial to adhere to the directions on the label and not take more medication than is advised. </p>
<p>It’s also critical to remember that dietary supplements are not intended to take the place of a healthy diet or way of life. Maintaining excellent prostate health involves several different aspects, including eating a balanced diet, exercising frequently, and keeping a healthy weight.</p>
<h2 style="text-align: center;"><a href="https://www.globalfitnessmart.com/get-trump-badge"><span style="text-decoration: underline;"><strong><span style="background-color: #ffcc99; color: red; text-decoration: underline;">Free Shipping On All Orders Secured Checkout</span></strong></span></a></h2>
<h2 style="text-align: center;"><a href="https://www.healthsupplement24x7.com/get-prostamend"><span style="text-decoration: underline;"><span style="background-color: #ffcc99; color: red; text-decoration: underline;"><strong>[Special Discount] ProstaMend – Get Your Best Discount Online Hurry!!</strong></span></span></a></h2>
<h2 class="wp-block-heading">Packages And Prices Of ProstaMend</h2>
<p>On the official ProstaMend website, <a href="https://gamma.app/public/ProstaMend-Reviews-9ze3v34qo99j3nf?mode=doc">ProstaMend</a> may be purchased. The supplement is sold in bottles containing 60 capsules, or a month’s worth.</p>
<p>Depending on the number of bottles ordered, the price per bottle fluctuates, but normally falls between $49 and $69 per bottle. </p>
<ul>
<li><strong>One </strong>bottle for one month supply for <strong>$69 / bottle</strong> <strong>plus small shipping fee</strong></li>
<li><strong>Three </strong>bottles for three month supply for <strong>$59 / bottle</strong> <strong>plus free US shipping</strong></li>
<li><strong>Six </strong>bottles for six month supply for <strong>$49 / bottle plus free US shipping</strong></li>
</ul>
<p>Check the latest packages and prices of <a href="https://pdfhost.io/v/2b7RDsvjy_ProstaMend_Shocking_News_Does_ProstaMend_Really_Worth_It_">ProstaMend</a></p>
<h3 class="wp-block-heading"><span id="Refund_Policy_Of_ProstaMend" class="ez-toc-section"></span>Refund Policy Of ProstaMend</h3>
<p>A 60-day money-back guarantee covers every transaction made at <a href="https://sketchfab.com/3d-models/prostamend-new-2024-does-it-really-works-1194260313ed485895d095edd6a81bda">ProstaMend</a> in full. Within 60 days after the purchase date, you may return the item for a complete refund if you are unhappy with it.</p>
<h2 class="wp-block-heading"><span id="Conclusion" class="ez-toc-section"></span>Conclusion</h2>
<p><a href="https://prostamend1.bandcamp.com/track/prostamend-new-2024-does-it-really-works-or-scam">ProstaMend</a> is a dietary supplement that claims to support prostate health by using a blend of natural ingredients. While the ingredients in ProstaMend have been used for centuries in traditional medicine to support prostate health, there is limited scientific research to support their effectiveness for treating BPH.</p>
<p>While some users of ProstaMend claim to be 100% satisfied, others claim that the supplement did not help their symptoms or side effects at all. </p>
<p>It’s critical to remember that every person will experience outcomes differently, and that dietary supplements cannot be relied upon to be effective in all cases. </p>
<p>It’s important to consult a healthcare professional before taking ProstaMend or any other dietary supplement. They may advise you on various methods for preserving your prostate health and assist you in determining whether the supplement is safe for you to consume.</p> | ProstaMend/ProstaMendReviews | [
"region:us"
] | 2023-12-25T10:21:35+00:00 | {} | 2023-12-25T10:22:44+00:00 | [] | [] | TAGS
#region-us
| <p style="-webkit-text-stroke-width: 0px; background-color: white; box-sizing: border-box; color: #333333; font-family: Roboto, Helvetica, Arial, sans-serif; font-size: 14px; font-style: normal; font-variant-caps: normal; font-variant-ligatures: normal; font-weight: 400; letter-spacing: normal; margin: 0px 0px 10px; orphans: 2; padding: 0px; text-align: start; text-decoration-color: initial; text-decoration-style: initial; text-decoration-thickness: initial; text-indent: 0px; text-transform: none; white-space: normal; widows: 2; word-spacing: 0px;"><strong style="box-sizing: border-box; font-style: normal; font-weight: bold;"><span style="box-sizing: border-box; color: magenta;"> Where to Get Bottle Online -</span> <a href="URL style="background-color: white; box-sizing: border-box; color: red;">URL style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: green;"> Product Name -</span> PROSTAMEND<br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #993300;"> Side Effects -</span> <span style="box-sizing: border-box; color: navy;">No Major Side Effects</span><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #993366;"> Category -</span> HEALTH (PROSTATE)<br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: maroon;"> Results -</span> <span style="box-sizing: border-box; color: #00ccff;">In 1-2 Months</span><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: red;"> Availability –</span> <a href="URL style="background-color: transparent; box-sizing: border-box; color: black; text-decoration: none;"><span style="box-sizing: border-box; color: #ff6600;">Online</span></span></a><br style="box-sizing: border-box;" /><span style="box-sizing: border-box; color: #333300;"> Rating: -</span> <span style="box-sizing: border-box; color: red;">5.0/5.0</span> ⭐⭐⭐⭐⭐</strong></p>
<p>The prostate is a tiny gland located in the male reproductive system. It resembles a walnut in shape and size and sits below the pelvis. It plays a crucial role in creating semen, a milky fluid that carries sperm from the testicles through the penis.The prostate gland grows larger as one grows older. Since it surrounds the urethra, it may squeeze it, thus causing a problem when passing urine. This problem may begin when one attains thirty or forty. </p>
<p>A combination of all-natural components proven to support prostate health was used in the formulation of <a href="URL dietary supplement is intended to assist men who have benign prostatic hyperplasia (BPH), an enlarged prostate that can result in pain, urinary issues, and other symptoms.According to the ProstaMend website, the supplement comprises a combination of substances that promote normal prostate function.</p>
<h2 class="wp-block-heading"><span id="What_Is_ProstaMend" class="ez-toc-section"></span>What Is ProstaMend?</h2>
<p><a href="URL is a dietary supplement that contains only all natural ingredients and herbs and is intended to support prostate health. It is designed for men who are suffering from benign prostatic hyperplasia (BPH), which is a prostate enlargement problem that can cause discomfort, difficulty urinating, and other symptoms. </p>
<p>This supplement is made in an FDA approved and GMP certified facility to ensure maximum safety and highest quality of the components are used.Each ingredient in <a href="URL was clinically tested and approved to help solving prostate problems.In this article we’ll look at ProstaMend and see how effectively it supports prostate health.</p>
<h2 style="text-align: center;"><a href="URL style="text-decoration: underline;"><strong><span style="color: red; text-decoration: underline;">(OFFICIAL WEBSITE) Click Here To Order ProstaMend For The Lowest Price Right Now</span></strong></span></a></h2>
<h2 class="wp-block-heading"><span id="Does_ProstaMend_Work" class="ez-toc-section"></span>Does ProstaMend Work?</h2>
<p>It is crucial to highlight that there is little scientific evidence to support the usefulness of the <a href="URL components for treating BPH, despite the fact that they have been used for decades in traditional medicine to maintain prostate health. </p>
<p>Yet, there is some proof that some of the components in <a href="URL may be useful in lessening BPH symptoms. For instance, studies on saw palmetto have revealed that it can decrease the size of an enlarged prostate and increase urine flow. Stinging nettle has also been found to lessen BPH symptoms including frequent and urgent urination.</p>
<p>The investigations on these compounds have, however, been somewhat limited, and bigger, more thorough studies are required to adequately evaluate their efficacy. </p>
<p>It’s also critical to keep in mind that the FDA does not oversee dietary supplements the same way it does prescription pharmaceuticals. Hence, there is no way to determine the precise amount of each component in <a href="URL and there is no assurance that they are safe or effective.</p>
<h2 class="wp-block-heading"><span id="Ingredietns_Of_ProstaMend" class="ez-toc-section"></span>Ingredietns Of ProstaMend</h2>
<p>A deeper look at <a href="URL components is provided below: </p>
<h3 class="wp-block-heading">Extract of Saw Palmetto </h3>
<p>In traditional medicine, saw palmetto is a plant extract that has traditionally been used to enhance prostate health. It is thought to function by lowering inflammation and the synthesis of certain hormones that can lead to prostate enlargement.</p>
<h3 class="wp-block-heading">Extract From Graviola Leaf </h3>
<p>South America is the original home of the tropical fruit known as graviola. Many bioactive substances that are thought to have anti-inflammatory and antioxidant activities may be found in the leaves of the graviola tree.</p>
<h3 class="wp-block-heading">Pureed Tomato Fruit </h3>
<p>Lycopene, a potent antioxidant that has been demonstrated to have a protective impact on prostate health, can be found in tomatoes in significant amounts. Lycopene is hypothesized to function by lowering oxidative stress and inflammation in the prostate gland. </p>
<h3 class="wp-block-heading">African Pygeum Bark Extract </h3>
<p>A tree that is indigenous to Africa is called Pygeum Africanum. Many bioactive substances that are thought to have anti-inflammatory and antioxidant activities may be found in the tree’s bark. Traditional medicine frequently employs Pygeum Africanum to treat BPH symptoms.</p>
<h3 class="wp-block-heading">E vitamin </h3>
<p>A fat-soluble vitamin that is vital for human health is vitamin E. It is frequently used in conventional medicine to treat a number of illnesses since it is thought to have antioxidant effects.</p>
<h3 class="wp-block-heading">Zinc </h3>
<p>A trace mineral called zinc is crucial for maintaining human health. It is frequently used in conventional medicine to treat a number of illnesses since it is thought to have antioxidant effects. </p>
<h2 style="text-align: center;"><a href="URL style="text-decoration: underline;"><span style="color: red; text-decoration: underline;">24Hrs Limited OFFER – GET</span></span></strong> <span style="text-decoration: underline;"><strong><span style="color: red; text-decoration: underline;">ProstaMend a</span></strong></span><strong><span style="text-decoration: underline;"><span style="color: red; text-decoration: underline;">t the LOW Price from its Official Website</span></span></strong></a></h2>
<h2 class="wp-block-heading">Benefits Of ProstaMend</h2>
<p>Dietary supplement <a href="URL uses a combination of organic substances to enhance prostate health. Several of the individual constituents in <a href="URL have been used for many years in traditional medicine to promote prostate health, even though the supplement’s efficacy has not been well researched.</p>
<p><a href="URL may have the following advantages: </p>
<ul>
<li><strong>Promotes Normal Prostate Function</strong>: An essential component of the male reproductive system is the prostate gland. Prostate enlargement in older men can result in a range of symptoms related to the urinary system. It is thought that the components of ProstaMend operate in concert to promote healthy prostate function and lower the risk of prostate enlargement.</li>
<li><strong>Minimizes Inflammation: </strong>Inflammation is a normal reaction to injury or illness, but persistent inflammation can cause a number of health issues, including enlargement of the prostate. The ProstaMend components may help to lessen inflammation in the prostate gland and other areas of the body since they are thought to have anti-inflammatory capabilities. </li>
<li><strong>Encourages Healthy Urination: </strong>Many urine symptoms, such as frequent urination, difficulty urinating, and urinary urgency, can be brought on by prostate enlargement. By lowering prostate gland inflammation and enhancing urine flow, the components of ProstaMend are thought to enhance urinary wellness.</li>
<li><strong>Increasing Antioxidant Levels :</strong>The body needs antioxidants to defend itself from oxidative stress, which can lead to a number of health issues. Antioxidants are essential nutrients. Antioxidant-rich ProstaMend components may help increase the body’s total antioxidant levels. </li>
<li><strong>Aids Immune System Performance</strong>: The immune system is in charge of defending the body from illnesses and infections. By lowering inflammation and encouraging the development of healthy immune cells, the components of ProstaMend are thought to boost immunological function.</li>
<li><strong>Enhances Sexual Performance :</strong>Erectile dysfunction and reduced libido are only two of the many sexual symptoms that can result from enlarged prostates. Although ProstaMend isn’t made expressly to enhance sexual performance, certain of its component parts are thought to be beneficial for sexual health. </li>
<li><strong>Maybe Lowers Risk of Prostate Cancer :</strong>ProstaMend’s contents have not been proven to particularly prevent prostate cancer, although some research has indicated that certain vitamins and minerals, such lycopene and selenium, may lower the chance of getting the disease.</li>
</ul>
<h2 class="wp-block-heading"><span id="How_To_Take_ProstaMend" class="ez-toc-section"></span>How To Take ProstaMend</h2>
<p>Two pills per day, taken with a meal, is the suggested dosage, according to the <a href="URL website. It’s crucial to adhere to the directions on the label and not take more medication than is advised. </p>
<p>It’s also critical to remember that dietary supplements are not intended to take the place of a healthy diet or way of life. Maintaining excellent prostate health involves several different aspects, including eating a balanced diet, exercising frequently, and keeping a healthy weight.</p>
<h2 style="text-align: center;"><a href="URL style="text-decoration: underline;"><strong><span style="background-color: #ffcc99; color: red; text-decoration: underline;">Free Shipping On All Orders Secured Checkout</span></strong></span></a></h2>
<h2 style="text-align: center;"><a href="URL style="text-decoration: underline;"><span style="background-color: #ffcc99; color: red; text-decoration: underline;"><strong>[Special Discount] ProstaMend – Get Your Best Discount Online Hurry!!</strong></span></span></a></h2>
<h2 class="wp-block-heading">Packages And Prices Of ProstaMend</h2>
<p>On the official ProstaMend website, <a href="URL may be purchased. The supplement is sold in bottles containing 60 capsules, or a month’s worth.</p>
<p>Depending on the number of bottles ordered, the price per bottle fluctuates, but normally falls between $49 and $69 per bottle. </p>
<ul>
<li><strong>One </strong>bottle for one month supply for <strong>$69 / bottle</strong> <strong>plus small shipping fee</strong></li>
<li><strong>Three </strong>bottles for three month supply for <strong>$59 / bottle</strong> <strong>plus free US shipping</strong></li>
<li><strong>Six </strong>bottles for six month supply for <strong>$49 / bottle plus free US shipping</strong></li>
</ul>
<p>Check the latest packages and prices of <a href="URL
<h3 class="wp-block-heading"><span id="Refund_Policy_Of_ProstaMend" class="ez-toc-section"></span>Refund Policy Of ProstaMend</h3>
<p>A 60-day money-back guarantee covers every transaction made at <a href="URL in full. Within 60 days after the purchase date, you may return the item for a complete refund if you are unhappy with it.</p>
<h2 class="wp-block-heading"><span id="Conclusion" class="ez-toc-section"></span>Conclusion</h2>
<p><a href="URL is a dietary supplement that claims to support prostate health by using a blend of natural ingredients. While the ingredients in ProstaMend have been used for centuries in traditional medicine to support prostate health, there is limited scientific research to support their effectiveness for treating BPH.</p>
<p>While some users of ProstaMend claim to be 100% satisfied, others claim that the supplement did not help their symptoms or side effects at all. </p>
<p>It’s critical to remember that every person will experience outcomes differently, and that dietary supplements cannot be relied upon to be effective in all cases. </p>
<p>It’s important to consult a healthcare professional before taking ProstaMend or any other dietary supplement. They may advise you on various methods for preserving your prostate health and assist you in determining whether the supplement is safe for you to consume.</p> | [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
2ef5f8ae16889ecb56934ee1c0831551e38ce546 |
# Dataset Card for bt_humaneval
## How to use
```python
from datasets import load_dataset
dataset = load_dataset("kogi-jwu/bt_humaneval")
``` | kogi-jwu/bt_humaneval | [
"license:mit",
"region:us"
] | 2023-12-25T10:48:16+00:00 | {"license": "mit", "configs": [{"config_name": "default", "data_files": [{"split": "test", "path": "bt_humaneval.jsonl"}]}]} | 2024-01-05T15:02:25+00:00 | [] | [] | TAGS
#license-mit #region-us
|
# Dataset Card for bt_humaneval
## How to use
| [
"# Dataset Card for bt_humaneval",
"## How to use"
] | [
"TAGS\n#license-mit #region-us \n",
"# Dataset Card for bt_humaneval",
"## How to use"
] | [
11,
11,
4
] | [
"passage: TAGS\n#license-mit #region-us \n# Dataset Card for bt_humaneval## How to use"
] |
62cfb6ea3bfe3e1aa204dea6f6f9d0c8ea02518d |
# Dataset Card for bt_jhumaneval
## How to use
```python
from datasets import load_dataset
dataset = load_dataset("kogi-jwu/bt_jhumaneval")
```
| kogi-jwu/bt_jhumaneval | [
"license:mit",
"region:us"
] | 2023-12-25T10:53:31+00:00 | {"license": "mit", "configs": [{"config_name": "default", "data_files": [{"split": "test", "path": "bt_jhumaneval.jsonl"}]}]} | 2023-12-26T03:43:34+00:00 | [] | [] | TAGS
#license-mit #region-us
|
# Dataset Card for bt_jhumaneval
## How to use
| [
"# Dataset Card for bt_jhumaneval",
"## How to use"
] | [
"TAGS\n#license-mit #region-us \n",
"# Dataset Card for bt_jhumaneval",
"## How to use"
] | [
11,
12,
4
] | [
"passage: TAGS\n#license-mit #region-us \n# Dataset Card for bt_jhumaneval## How to use"
] |
7ede1e914a226911132d3958dca2a0088ba066e1 | # **Orca-Math-DPO**
I merged about
- [Intel/orca_dpo_pairs](https://huggingface.co/datasets/Intel/orca_dpo_pairs)
- [argilla/distilabel-math-preference-dpo](https://huggingface.co/datasets/argilla/distilabel-math-preference-dpo)
## Example
[kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO](https://huggingface.co/kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO).
| kyujinpy/orca_math_dpo | [
"region:us"
] | 2023-12-25T10:57:16+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "system", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}, {"name": "id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 41410009, "num_examples": 15277}], "download_size": 21916261, "dataset_size": 41410009}} | 2023-12-25T11:23:14+00:00 | [] | [] | TAGS
#region-us
| # Orca-Math-DPO
I merged about
- Intel/orca_dpo_pairs
- argilla/distilabel-math-preference-dpo
## Example
kyujinpy/Sakura-SOLRCA-Math-Instruct-DPO.
| [
"# Orca-Math-DPO \nI merged about \n- Intel/orca_dpo_pairs\n- argilla/distilabel-math-preference-dpo",
"## Example\nkyujinpy/Sakura-SOLRCA-Math-Instruct-DPO."
] | [
"TAGS\n#region-us \n",
"# Orca-Math-DPO \nI merged about \n- Intel/orca_dpo_pairs\n- argilla/distilabel-math-preference-dpo",
"## Example\nkyujinpy/Sakura-SOLRCA-Math-Instruct-DPO."
] | [
6,
38,
22
] | [
"passage: TAGS\n#region-us \n# Orca-Math-DPO \nI merged about \n- Intel/orca_dpo_pairs\n- argilla/distilabel-math-preference-dpo## Example\nkyujinpy/Sakura-SOLRCA-Math-Instruct-DPO."
] |
b4f30ab703430d5d5065c86bbfbbdd8be01ece16 | license: apache-2.0 | Bhandari10/CUB-200-2011-Ne | [
"language:ne",
"region:us"
] | 2023-12-25T11:10:57+00:00 | {"language": ["ne"], "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": ["text_c10_nepali/002.Laysan_Albatross/Laysan_Albatross_0002_1027.txt", "text_c10_nepali/002.Laysan_Albatross/Laysan_Albatross_0003_1033.txt", "text_c10_nepali/002.Laysan_Albatross/Laysan_Albatross_0082_524.txt", "text_c10_nepali/002.Laysan_Albatross/Laysan_Albatross_0044_784.txt", "text_c10_nepali/002.Laysan_Albatross/Laysan_Albatross_0070_788.txt"]}, {"split": "test", "path": ["text_c10_nepali/001.Black_footed_Albatross/Black_Footed_Albatross_0046_18.txt", "text_c10_nepali/001.Black_footed_Albatross/Black_Footed_Albatross_0009_34.txt", "text_c10_nepali/001.Black_footed_Albatross/Black_Footed_Albatross_0002_55.txt", "text_c10_nepali/001.Black_footed_Albatross/Black_Footed_Albatross_0074_59.txt", "text_c10_nepali/001.Black_footed_Albatross/Black_Footed_Albatross_0014_89.txt"]}]}]} | 2023-12-25T12:01:29+00:00 | [] | [
"ne"
] | TAGS
#language-Nepali (macrolanguage) #region-us
| license: apache-2.0 | [] | [
"TAGS\n#language-Nepali (macrolanguage) #region-us \n"
] | [
16
] | [
"passage: TAGS\n#language-Nepali (macrolanguage) #region-us \n"
] |
12e360bb0a97412b576010062fced663bf0bec95 |
# RP3D-DiagDS
**Overview of RP3D-DiagDS.** There are **39,026 cases (192,675 scans)** across 7 human anatomy regions and 9 diverse modalities covering **930 ICD-10-CM codes**.
The images used in our dataset can be downloaded from [BaiduYun](https://pan.baidu.com/s/1E_uSoCLm5H66a7KkpRfi1g?pwd=urfg) or [OneDrive](https://onedrive.live.com/?authkey=%21AN6taBTpTQ16xqA&id=FCA8CA4C877919CB%2123996&cid=FCA8CA4C877919CB).

## About Dataset
There are totally 4 json files:
1. **RP3D_train**.json: Data used for model training. This file is organized at case level (there may be more than one kind of modality and anatomy in a case. For more details, refer to the paper [Large-scale Long-tailed Disease Diagnosis on Radiology](https://qiaoyu-zheng.github.io/RP3D-Diag).
2. **RP3D_test_json**: Data used for model evaluation.
3. **disorder_label_dict.json**: For disorder granularity. There are totally 5569 ( 5568 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.
4. **icd10_label_dict.json**: For ICD-10-CM granularity. There are totally 931 ( 930 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.
## About Model Checkpoint
Please refer to [RP3D-DiagModel](https://huggingface.co/QiaoyuZheng/RP3D-DiagModel)
For more information about the code please refer to our instructions on [github](https://github.com/qiaoyu-zheng/RP3D-Diag) to download and use.
| QiaoyuZheng/RP3D-DiagDS | [
"region:us"
] | 2023-12-25T11:28:16+00:00 | {} | 2024-01-02T02:10:45+00:00 | [] | [] | TAGS
#region-us
|
# RP3D-DiagDS
Overview of RP3D-DiagDS. There are 39,026 cases (192,675 scans) across 7 human anatomy regions and 9 diverse modalities covering 930 ICD-10-CM codes.
The images used in our dataset can be downloaded from BaiduYun or OneDrive.
!results
## About Dataset
There are totally 4 json files:
1. RP3D_train.json: Data used for model training. This file is organized at case level (there may be more than one kind of modality and anatomy in a case. For more details, refer to the paper Large-scale Long-tailed Disease Diagnosis on Radiology.
2. RP3D_test_json: Data used for model evaluation.
3. disorder_label_dict.json: For disorder granularity. There are totally 5569 ( 5568 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.
4. icd10_label_dict.json: For ICD-10-CM granularity. There are totally 931 ( 930 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.
## About Model Checkpoint
Please refer to RP3D-DiagModel
For more information about the code please refer to our instructions on github to download and use.
| [
"# RP3D-DiagDS\n\nOverview of RP3D-DiagDS. There are 39,026 cases (192,675 scans) across 7 human anatomy regions and 9 diverse modalities covering 930 ICD-10-CM codes.\n\nThe images used in our dataset can be downloaded from BaiduYun or OneDrive.\n\n!results",
"## About Dataset\n\nThere are totally 4 json files:\n\n1. RP3D_train.json: Data used for model training. This file is organized at case level (there may be more than one kind of modality and anatomy in a case. For more details, refer to the paper Large-scale Long-tailed Disease Diagnosis on Radiology.\n2. RP3D_test_json: Data used for model evaluation.\n3. disorder_label_dict.json: For disorder granularity. There are totally 5569 ( 5568 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.\n4. icd10_label_dict.json: For ICD-10-CM granularity. There are totally 931 ( 930 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.",
"## About Model Checkpoint\n\nPlease refer to RP3D-DiagModel\n\n\nFor more information about the code please refer to our instructions on github to download and use."
] | [
"TAGS\n#region-us \n",
"# RP3D-DiagDS\n\nOverview of RP3D-DiagDS. There are 39,026 cases (192,675 scans) across 7 human anatomy regions and 9 diverse modalities covering 930 ICD-10-CM codes.\n\nThe images used in our dataset can be downloaded from BaiduYun or OneDrive.\n\n!results",
"## About Dataset\n\nThere are totally 4 json files:\n\n1. RP3D_train.json: Data used for model training. This file is organized at case level (there may be more than one kind of modality and anatomy in a case. For more details, refer to the paper Large-scale Long-tailed Disease Diagnosis on Radiology.\n2. RP3D_test_json: Data used for model evaluation.\n3. disorder_label_dict.json: For disorder granularity. There are totally 5569 ( 5568 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.\n4. icd10_label_dict.json: For ICD-10-CM granularity. There are totally 931 ( 930 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.",
"## About Model Checkpoint\n\nPlease refer to RP3D-DiagModel\n\n\nFor more information about the code please refer to our instructions on github to download and use."
] | [
6,
79,
210,
34
] | [
"passage: TAGS\n#region-us \n# RP3D-DiagDS\n\nOverview of RP3D-DiagDS. There are 39,026 cases (192,675 scans) across 7 human anatomy regions and 9 diverse modalities covering 930 ICD-10-CM codes.\n\nThe images used in our dataset can be downloaded from BaiduYun or OneDrive.\n\n!results## About Dataset\n\nThere are totally 4 json files:\n\n1. RP3D_train.json: Data used for model training. This file is organized at case level (there may be more than one kind of modality and anatomy in a case. For more details, refer to the paper Large-scale Long-tailed Disease Diagnosis on Radiology.\n2. RP3D_test_json: Data used for model evaluation.\n3. disorder_label_dict.json: For disorder granularity. There are totally 5569 ( 5568 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.\n4. icd10_label_dict.json: For ICD-10-CM granularity. There are totally 931 ( 930 abnormal and 1 noraml) label. There disorders are sorted in descending order based on the corresponding case number for evaluation.## About Model Checkpoint\n\nPlease refer to RP3D-DiagModel\n\n\nFor more information about the code please refer to our instructions on github to download and use."
] |
7d859ded7379327b562e721fbda4558154c4c8eb | # Dataset Card for "mwp-instruct-tune-dataset"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | OmegaGamage/mwp-instruct-tune-dataset | [
"region:us"
] | 2023-12-25T13:06:41+00:00 | {"dataset_info": {"features": [{"name": "instruction", "dtype": "string"}, {"name": "mwp", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1986871, "num_examples": 8278}], "download_size": 807667, "dataset_size": 1986871}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-25T13:06:48+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "mwp-instruct-tune-dataset"
More Information needed | [
"# Dataset Card for \"mwp-instruct-tune-dataset\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"mwp-instruct-tune-dataset\"\n\nMore Information needed"
] | [
6,
20
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"mwp-instruct-tune-dataset\"\n\nMore Information needed"
] |
3b814d81f3821c6943250993d8667c8e2c45608f |
[oasst2-135k-ja](https://huggingface.co/datasets/kunishou/oasst2-135k-ja)をチャット形式に変換したデータセットになります。
マルチターン会話でのファインチューニングをする際にご活用下さい(1レコードのトークン長が大きいのでそれなりの計算リソースが必要になります)。
フォーマットは ShareGPT 形式になっています。ファインチューニングをする際は[こちらの記事](https://note.com/npaka/n/n7cbe6f11526c)を参考にして下さい。
OpenAssistant/oasst2
https://huggingface.co/datasets/OpenAssistant/oasst2 | kunishou/oasst2-chat-68k-ja | [
"language:ja",
"license:apache-2.0",
"region:us"
] | 2023-12-25T13:19:09+00:00 | {"language": ["ja"], "license": "apache-2.0"} | 2023-12-25T13:21:58+00:00 | [] | [
"ja"
] | TAGS
#language-Japanese #license-apache-2.0 #region-us
|
oasst2-135k-jaをチャット形式に変換したデータセットになります。
マルチターン会話でのファインチューニングをする際にご活用下さい(1レコードのトークン長が大きいのでそれなりの計算リソースが必要になります)。
フォーマットは ShareGPT 形式になっています。ファインチューニングをする際はこちらの記事を参考にして下さい。
OpenAssistant/oasst2
URL | [] | [
"TAGS\n#language-Japanese #license-apache-2.0 #region-us \n"
] | [
20
] | [
"passage: TAGS\n#language-Japanese #license-apache-2.0 #region-us \n"
] |
29a37070e575d8e4bd38f6e19876c6a93fd8b84d |
# The Unsplash Lite Dataset (v1.2.1) with color palettes

The Lite dataset contains all of the same fields as the Full dataset, but is limited to ~25,000 photos.
It can be used for both commercial and non-commercial usage, provided you abide by [the terms](https://github.com/unsplash/datasets/blob/master/TERMS.md).
The Unsplash Dataset is made available for research purposes.
[It cannot be used to redistribute the images contained within](https://github.com/unsplash/datasets/blob/master/TERMS.md).
To use the Unsplash library in a product, see [the Unsplash API](https://unsplash.com/developers).
This subset of the dataset contains only urls to the images, their descriptions generated from an AI service, and 8 palettes (generated using [okolors](https://github.com/Ivordir/Okolors)).
To download the images from the urls, you may do something like this:
```python
from datasets import load_dataset, DownloadManager, Image
ds = load_dataset("1aurent/unsplash-lite-palette")
def download_image(url: str | list[str], dl_manager: DownloadManager):
filename = dl_manager.download(url)
return {"image": filename}
ds = ds.map(
function=download_image,
input_columns=["url"],
fn_kwargs={
"dl_manager": DownloadManager(),
},
batched=True,
num_proc=6,
)
ds = ds.cast_column(
column="image",
feature=Image(),
)
```
 | 1aurent/unsplash-lite-palette | [
"task_categories:text-to-image",
"task_categories:image-to-text",
"size_categories:10K<n<100K",
"language:en",
"license:other",
"unsplash",
"v1.2.1",
"region:us"
] | 2023-12-25T13:27:25+00:00 | {"language": ["en"], "license": "other", "size_categories": ["10K<n<100K"], "task_categories": ["text-to-image", "image-to-text"], "pretty_name": "Unsplash Lite w/ Palettes", "dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "ai_description", "dtype": "string"}, {"name": "palettes", "struct": [{"name": "1", "dtype": {"array2_d": {"shape": [1, 3], "dtype": "uint8"}}}, {"name": "2", "dtype": {"array2_d": {"shape": [2, 3], "dtype": "uint8"}}}, {"name": "3", "dtype": {"array2_d": {"shape": [3, 3], "dtype": "uint8"}}}, {"name": "4", "dtype": {"array2_d": {"shape": [4, 3], "dtype": "uint8"}}}, {"name": "5", "dtype": {"array2_d": {"shape": [5, 3], "dtype": "uint8"}}}, {"name": "6", "dtype": {"array2_d": {"shape": [6, 3], "dtype": "uint8"}}}, {"name": "7", "dtype": {"array2_d": {"shape": [7, 3], "dtype": "uint8"}}}, {"name": "8", "dtype": {"array2_d": {"shape": [8, 3], "dtype": "uint8"}}}]}], "splits": [{"name": "train", "num_bytes": 28536733, "num_examples": 24998}], "download_size": 4159745, "dataset_size": 28536733}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "license_name": "unsplash-commercial", "license_link": "https://github.com/unsplash/datasets/blob/master/DOCS.md", "tags": ["unsplash", "v1.2.1"]} | 2024-01-09T17:41:34+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-to-image #task_categories-image-to-text #size_categories-10K<n<100K #language-English #license-other #unsplash #v1.2.1 #region-us
|
# The Unsplash Lite Dataset (v1.2.1) with color palettes
.
To download the images from the urls, you may do something like this:
 with color palettes\n\n.\n\nTo download the images from the urls, you may do something like this:\n\n\n with color palettes\n\n.\n\nTo download the images from the urls, you may do something like this:\n\n\n with color palettes\n\n.\n\nTo download the images from the urls, you may do something like this:\n\n\n.
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | TanviGupta/datasets_finetuning | [
"region:us"
] | 2023-12-25T13:59:13+00:00 | {} | 2023-12-25T14:35:07+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
547ebedf87e017367d0c6b6a876ef852ec2f5411 | 
Results of [WolframRavenwolfs](https://www.reddit.com/user/WolframRavenwolf/)([@wolfram](https://huggingface.co/wolfram) on huggingface) tests in csv form.
- 1st Score = Correct answers to multiple choice questions (after being given curriculum information)
- 2nd Score = Correct answers to multiple choice questions (without being given curriculum information beforehand)
- OK = Followed instructions to acknowledge all data input with just "OK" consistently
- +/- = Followed instructions to answer with just a single letter or more than just a single letter
| ChuckMcSneed/WolframRavenwolfs_benchmark_results | [
"region:us"
] | 2023-12-25T15:02:21+00:00 | {} | 2024-02-13T22:27:18+00:00 | [] | [] | TAGS
#region-us
| !URL
Results of WolframRavenwolfs(@wolfram on huggingface) tests in csv form.
- 1st Score = Correct answers to multiple choice questions (after being given curriculum information)
- 2nd Score = Correct answers to multiple choice questions (without being given curriculum information beforehand)
- OK = Followed instructions to acknowledge all data input with just "OK" consistently
- +/- = Followed instructions to answer with just a single letter or more than just a single letter
| [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
d0cbb0ad05d0b84d8f7bc1a8ae314c547b0b7c60 | # Dataset Card for "viwiki-20231220"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | agi-soda/viwiki-20231220 | [
"region:us"
] | 2023-12-25T15:43:42+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "revid", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1212662534, "num_examples": 961315}], "download_size": 559018623, "dataset_size": 1212662534}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2024-01-15T12:35:06+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "viwiki-20231220"
More Information needed | [
"# Dataset Card for \"viwiki-20231220\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"viwiki-20231220\"\n\nMore Information needed"
] | [
6,
16
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"viwiki-20231220\"\n\nMore Information needed"
] |
5fe9e2ef32e2cd378a5968a3d376cb76386c4861 | # Dataset Card for "YOUR_DATASET_NAME_DEV_YOK"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | gorkemsevinc/MultiTurnCleanup_flan-t5-xxl_preprocess | [
"region:us"
] | 2023-12-25T17:13:51+00:00 | {"dataset_info": {"features": [{"name": "Conversation", "dtype": "string"}, {"name": "Combined Dialogue", "dtype": "string"}], "splits": [{"name": "test", "num_bytes": 235775, "num_examples": 64}, {"name": "train", "num_bytes": 5511351, "num_examples": 930}, {"name": "dev", "num_bytes": 324714, "num_examples": 86}], "download_size": 3437254, "dataset_size": 6071840}} | 2023-12-25T17:14:01+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "YOUR_DATASET_NAME_DEV_YOK"
More Information needed | [
"# Dataset Card for \"YOUR_DATASET_NAME_DEV_YOK\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"YOUR_DATASET_NAME_DEV_YOK\"\n\nMore Information needed"
] | [
6,
23
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"YOUR_DATASET_NAME_DEV_YOK\"\n\nMore Information needed"
] |
5fcb7139ed8acbdd822e47746470c88f13be5e18 |
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | flyhero/AttributionData | [
"region:us"
] | 2023-12-25T21:20:32+00:00 | {} | 2023-12-25T21:22:55+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
4df943f8d2b26f4c444c00d5e7a18ba5a246a277 |
Original data source - [https://huggingface.co/datasets/tatsu-lab/alpaca](https://huggingface.co/datasets/tatsu-lab/alpaca)
Used Google Translate API to translate the dataset into Gujarati.
### Data Instances
An example of "train" looks as follows:
```json
{
"instruction": "Identify the odd one out.",
"input": "Twitter, Instagram, Telegram",
"output": "Telegram",
"text": "Below is an instruction that describes a task...",
"gujarati_instruction": "વિષમને ઓળખો.",
"gujarati_input": "ટ્વિટર, ઇન્સ્ટાગ્રામ, ટેલિગ્રામ",
"gujarati_output": "ટેલિગ્રામ"
}
```
### Data Fields
The data fields are as follows:
* `instruction`: describes the task the model should perform. Each of the 52K instructions is unique.
* `input`: optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
* `output`: the answer to the instruction as generated by `text-davinci-003`.
* `text`: the `instruction`, `input` and `output` formatted with the [prompt template](https://github.com/tatsu-lab/stanford_alpaca#data-release) used by the authors for fine-tuning their models.
* `gujarati_instruction`: Gujarati translation of the instruction
* `gujarati_input`: Gujarati translation of the input
* `gujarati_output`: Gujarati translation of the output
### Data Splits
| | train |
|---------------|------:|
| alpaca | 88 |
| jayshah5696/alpaca-small-gujarati | [
"license:cc-by-nc-4.0",
"region:us"
] | 2023-12-25T21:24:18+00:00 | {"license": "cc-by-nc-4.0"} | 2023-12-25T21:40:06+00:00 | [] | [] | TAGS
#license-cc-by-nc-4.0 #region-us
| Original data source - URL
Used Google Translate API to translate the dataset into Gujarati.
### Data Instances
An example of "train" looks as follows:
### Data Fields
The data fields are as follows:
* 'instruction': describes the task the model should perform. Each of the 52K instructions is unique.
* 'input': optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
* 'output': the answer to the instruction as generated by 'text-davinci-003'.
* 'text': the 'instruction', 'input' and 'output' formatted with the prompt template used by the authors for fine-tuning their models.
* 'gujarati\_instruction': Gujarati translation of the instruction
* 'gujarati\_input': Gujarati translation of the input
* 'gujarati\_output': Gujarati translation of the output
### Data Splits
| [
"### Data Instances\n\n\nAn example of \"train\" looks as follows:",
"### Data Fields\n\n\nThe data fields are as follows:\n\n\n* 'instruction': describes the task the model should perform. Each of the 52K instructions is unique.\n* 'input': optional context or input for the task. For example, when the instruction is \"Summarize the following article\", the input is the article. Around 40% of the examples have an input.\n* 'output': the answer to the instruction as generated by 'text-davinci-003'.\n* 'text': the 'instruction', 'input' and 'output' formatted with the prompt template used by the authors for fine-tuning their models.\n* 'gujarati\\_instruction': Gujarati translation of the instruction\n* 'gujarati\\_input': Gujarati translation of the input\n* 'gujarati\\_output': Gujarati translation of the output",
"### Data Splits"
] | [
"TAGS\n#license-cc-by-nc-4.0 #region-us \n",
"### Data Instances\n\n\nAn example of \"train\" looks as follows:",
"### Data Fields\n\n\nThe data fields are as follows:\n\n\n* 'instruction': describes the task the model should perform. Each of the 52K instructions is unique.\n* 'input': optional context or input for the task. For example, when the instruction is \"Summarize the following article\", the input is the article. Around 40% of the examples have an input.\n* 'output': the answer to the instruction as generated by 'text-davinci-003'.\n* 'text': the 'instruction', 'input' and 'output' formatted with the prompt template used by the authors for fine-tuning their models.\n* 'gujarati\\_instruction': Gujarati translation of the instruction\n* 'gujarati\\_input': Gujarati translation of the input\n* 'gujarati\\_output': Gujarati translation of the output",
"### Data Splits"
] | [
17,
18,
194,
5
] | [
"passage: TAGS\n#license-cc-by-nc-4.0 #region-us \n### Data Instances\n\n\nAn example of \"train\" looks as follows:### Data Fields\n\n\nThe data fields are as follows:\n\n\n* 'instruction': describes the task the model should perform. Each of the 52K instructions is unique.\n* 'input': optional context or input for the task. For example, when the instruction is \"Summarize the following article\", the input is the article. Around 40% of the examples have an input.\n* 'output': the answer to the instruction as generated by 'text-davinci-003'.\n* 'text': the 'instruction', 'input' and 'output' formatted with the prompt template used by the authors for fine-tuning their models.\n* 'gujarati\\_instruction': Gujarati translation of the instruction\n* 'gujarati\\_input': Gujarati translation of the input\n* 'gujarati\\_output': Gujarati translation of the output### Data Splits"
] |
0c0707206d6d0a21f9d37136ab0d70d302a3560b |
This dataset is a noisy, no-prompt textbook quality source for language models. The intention behind this dataset is to force the language model to understand human intention through imperfections on the input while providing high-quality signals from textbook and output texts. This is based on 70,000 randomly shuffled and distorted samples from `tiny-orca-textbooks`. Make sure to train from the text column, otherwise you will train on the original data. | appvoid/noisy-textbook-70k | [
"region:us"
] | 2023-12-25T21:35:26+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "large_string"}, {"name": "prompt", "dtype": "large_string"}, {"name": "textbook", "dtype": "large_string"}, {"name": "question", "dtype": "large_string"}, {"name": "response", "dtype": "large_string"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1075465821, "num_examples": 70000}], "download_size": 481516931, "dataset_size": 1075465821}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-25T21:43:20+00:00 | [] | [] | TAGS
#region-us
|
This dataset is a noisy, no-prompt textbook quality source for language models. The intention behind this dataset is to force the language model to understand human intention through imperfections on the input while providing high-quality signals from textbook and output texts. This is based on 70,000 randomly shuffled and distorted samples from 'tiny-orca-textbooks'. Make sure to train from the text column, otherwise you will train on the original data. | [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
f86cb481d04525ebbf1014dcbd611b49533fdc84 | # Counting bilingual and monolingual instances
In order to count bilingual and monolingual instances, we use the following code. We count bilingual instances where there are two languages, one of them is English and the other is either German, French, Spanish, Italian, Portuguese or Dutch. All other instances fall into the "Other" category.
```python
from datasets import load_dataset
import json
from tqdm import tqdm
#Specify the dataset name
dataset_name = "RaiBP/openwebtext2-first-30-chunks-lang-detect-raw-output"
# Load the dataset
bilingual_dataset = load_dataset(dataset_name, data_dir='bilingual')
dataset = bilingual_dataset["train"]
n_examples = len(dataset)
keys_dict = {}
for document in tqdm(dataset, total=n_examples):
instance_labels = document["instance_labels"]
instance_languages = document["instance_languages"]
for languages in instance_languages:
unique_languages = list(set(languages))
lang_key = "-".join(sorted(unique_languages))
if lang_key not in keys_dict.keys():
keys_dict[lang_key] = 1
else:
keys_dict[lang_key] += 1
english_keys_list = [] # keys where "en" is present
non_english_keys_list = [] # keys where "en" is not present
for key in keys_dict.keys():
key_list = key.split('-')
if "en" in key_list:
english_keys_list.append(key_list)
else:
non_english_keys_list.append(key_list)
# more than two languages, none of them English
nen_multi_count = 0
# one language, one of the following: de, fr, es, pt, it, nl
lang_mono_count = {'de': 0, 'fr': 0, 'es': 0, 'pt': 0, 'it': 0, 'nl': 0}
# one language, not one of the following: de, fr, es, pt, it, nl
other_mono_count = 0
# two languages, none of them English
nen_bi_count = 0
for key in non_english_keys_list:
if len(key) > 2:
nen_multi_count += keys_dict['-'.join(key)]
elif len(key) == 2:
nen_bi_count += keys_dict['-'.join(key)]
elif len(key) == 1:
nen_lang = key[0]
if nen_lang in lang_mono_count.keys():
lang_mono_count[nen_lang] += keys_dict[nen_lang]
else:
other_mono_count += keys_dict[nen_lang]
# more than two languages, at least one of them English
english_multi_count = 0
# one language, English
english_mono_count = 0
for key in english_keys_list:
if len(key) == 1 and key[0] == 'en':
english_mono_count += keys_dict[key[0]]
if len(key) > 2:
english_multi_count += keys_dict['-'.join(key)]
# two languages, one of them English, the other one not one of the following: de, fr, es, pt, it, nl
other_bi_count = 0
# two languages, one of them English, the other one of the following: de, fr, es, pt, it, nl
lang_bi_count = {'de': 0, 'fr': 0, 'es': 0, 'pt': 0, 'it': 0, 'nl': 0}
for key in english_keys_list:
if len(key) == 2:
nen_lang = key[0] if key[1] == 'en' else key[1]
if nen_lang in lang_bi_count.keys():
lang_bi_count[nen_lang] += keys_dict['-'.join(key)]
else:
other_bi_count += keys_dict['-'.join(key)]
# Save the counts for monolingual
counts_dict_monolingual = {"en": english_mono_count}
for lang in lang_mono_count.keys():
counts_dict_monolingual[lang] = lang_mono_count[lang]
counts_dict_monolingual["other"] = other_mono_count
with open('monolingual_counts.json', 'w') as json_file:
json.dump(counts_dict_monolingual, json_file)
# Save the counts for bilingual
counts_dict_bilingual = {}
for lang in lang_bi_count.keys():
counts_dict_bilingual[lang] = lang_bi_count[lang]
counts_dict_bilingual["other"] = other_bi_count + nen_bi_count + english_multi_count + nen_multi_count
with open('bilingual_counts.json', 'w') as json_file:
json.dump(counts_dict_bilingual, json_file)
```
# Counting translation instances
In order to count translation instances containing English paired with German, French, Spanish, Portuguese, Italian or Dutch, we use:
```python
from datasets import load_dataset
import json
from tqdm import tqdm
# Specify the dataset name
dataset_name = "RaiBP/openwebtext2-first-30-chunks-lang-detect-raw-output"
# Load the dataset
translation_dataset = load_dataset(dataset_name, data_dir="translation")
dataset = translation_dataset["train"]
n_examples = len(dataset)
total_instances = 0
counts_dict = {"de": 0, "fr": 0, "es": 0, "pt": 0, "it": 0, "nl": 0}
others_count = 0
instances = {}
for document in tqdm(dataset, total=n_examples):
embedded_label = document["embedded_label"]
primary_label = document["primary_label"]
document_id = document["document_index"]
instance_id = document["instance_index"]
id = f"{document_id}-{instance_id}"
if id not in instances.keys():
instances[id] = [f"{embedded_label}-{primary_label}"]
else:
instances[id].append(f"{embedded_label}-{primary_label}")
for id, labels in instances.items():
state = 0
found_langs = []
for langs in labels:
lang_pair = langs.split("-")
if "en" in lang_pair:
non_english = lang_pair[0] if lang_pair[1] == "en" else lang_pair[1]
if non_english in counts_dict.keys():
state = 1 # found a translation with English and a language in the counts_dict
found_langs.append(non_english)
elif state != 1:
state = 2 # found a translation with English and a language not in the counts_dict
elif state != 1:
state = 2 # found a translation without English
if state == 1:
majority_lang = max(set(found_langs), key=found_langs.count)
counts_dict[majority_lang] += 1
elif state == 2:
others_count += 1
else:
print("Error: state is 0")
# Specify the file path where you want to save the JSON file
file_path = "translation_counts.json"
counts_dict["others"] = others_count
# Save the dictionary as a JSON file
with open(file_path, "w") as json_file:
json.dump(
counts_dict, json_file, indent=2
) # indent argument is optional, but it makes the file more human-readable
``` | RaiBP/openwebtext2-first-30-chunks-lang-detect-raw-output | [
"license:mit",
"region:us"
] | 2023-12-25T22:04:33+00:00 | {"license": "mit"} | 2024-02-11T13:29:06+00:00 | [] | [] | TAGS
#license-mit #region-us
| # Counting bilingual and monolingual instances
In order to count bilingual and monolingual instances, we use the following code. We count bilingual instances where there are two languages, one of them is English and the other is either German, French, Spanish, Italian, Portuguese or Dutch. All other instances fall into the "Other" category.
# Counting translation instances
In order to count translation instances containing English paired with German, French, Spanish, Portuguese, Italian or Dutch, we use:
| [
"# Counting bilingual and monolingual instances\nIn order to count bilingual and monolingual instances, we use the following code. We count bilingual instances where there are two languages, one of them is English and the other is either German, French, Spanish, Italian, Portuguese or Dutch. All other instances fall into the \"Other\" category.",
"# Counting translation instances\nIn order to count translation instances containing English paired with German, French, Spanish, Portuguese, Italian or Dutch, we use:"
] | [
"TAGS\n#license-mit #region-us \n",
"# Counting bilingual and monolingual instances\nIn order to count bilingual and monolingual instances, we use the following code. We count bilingual instances where there are two languages, one of them is English and the other is either German, French, Spanish, Italian, Portuguese or Dutch. All other instances fall into the \"Other\" category.",
"# Counting translation instances\nIn order to count translation instances containing English paired with German, French, Spanish, Portuguese, Italian or Dutch, we use:"
] | [
11,
83,
36
] | [
"passage: TAGS\n#license-mit #region-us \n# Counting bilingual and monolingual instances\nIn order to count bilingual and monolingual instances, we use the following code. We count bilingual instances where there are two languages, one of them is English and the other is either German, French, Spanish, Italian, Portuguese or Dutch. All other instances fall into the \"Other\" category.# Counting translation instances\nIn order to count translation instances containing English paired with German, French, Spanish, Portuguese, Italian or Dutch, we use:"
] |
9597bc93b942d60701666ad377d9078a410f30e6 | # Dataset Card for "bbc_images_alltime"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | RealTimeData/bbc_images_alltime | [
"region:us"
] | 2023-12-25T23:05:29+00:00 | {"dataset_info": [{"config_name": "2017-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 122443326.504, "num_examples": 1688}], "download_size": 123150214, "dataset_size": 122443326.504}, {"config_name": "2017-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 102583557.641, "num_examples": 1469}], "download_size": 102621580, "dataset_size": 102583557.641}, {"config_name": "2017-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 47392374.0, "num_examples": 721}], "download_size": 0, "dataset_size": 47392374.0}, {"config_name": "2017-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 51586742.0, "num_examples": 807}], "download_size": 0, "dataset_size": 51586742.0}, {"config_name": "2017-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 49729114.0, "num_examples": 756}], "download_size": 49449289, "dataset_size": 49729114.0}, {"config_name": "2017-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 101940444.214, "num_examples": 1106}], "download_size": 99929261, "dataset_size": 101940444.214}, {"config_name": "2017-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 106945858.75, "num_examples": 1139}], "download_size": 107313303, "dataset_size": 106945858.75}, {"config_name": "2017-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 100514218.575, "num_examples": 1113}], "download_size": 0, "dataset_size": 100514218.575}, {"config_name": "2017-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 111890945.259, "num_examples": 1199}], "download_size": 109931209, "dataset_size": 111890945.259}, {"config_name": "2017-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 110331938.63, "num_examples": 1187}], "download_size": 107643658, "dataset_size": 110331938.63}, {"config_name": "2017-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 126967573.77, "num_examples": 1443}], "download_size": 125743771, "dataset_size": 126967573.77}, {"config_name": "2017-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 115994458.002, "num_examples": 1294}], "download_size": 114829893, "dataset_size": 115994458.002}, {"config_name": "2018-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 118540155.49, "num_examples": 1323}], "download_size": 117509146, "dataset_size": 118540155.49}, {"config_name": "2018-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 117797012.007, "num_examples": 1223}], "download_size": 111594833, "dataset_size": 117797012.007}, {"config_name": "2018-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 109050223.68, "num_examples": 1280}], "download_size": 108054338, "dataset_size": 109050223.68}, {"config_name": "2018-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 127060957.288, "num_examples": 1328}], "download_size": 0, "dataset_size": 127060957.288}, {"config_name": "2018-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 115683290.224, "num_examples": 1334}], "download_size": 116119560, "dataset_size": 115683290.224}, {"config_name": "2018-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 96671553.698, "num_examples": 1189}], "download_size": 96349655, "dataset_size": 96671553.698}, {"config_name": "2018-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 130703350.32, "num_examples": 1496}], "download_size": 129730979, "dataset_size": 130703350.32}, {"config_name": "2018-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 115238413.428, "num_examples": 1253}], "download_size": 114020376, "dataset_size": 115238413.428}, {"config_name": "2018-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 112634923.633, "num_examples": 1277}], "download_size": 112185186, "dataset_size": 112634923.633}, {"config_name": "2018-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 109628565.494, "num_examples": 1249}], "download_size": 108625160, "dataset_size": 109628565.494}, {"config_name": "2018-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 117169704.96, "num_examples": 1290}], "download_size": 118003238, "dataset_size": 117169704.96}, {"config_name": "2018-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 101776799.8, "num_examples": 1138}], "download_size": 100265438, "dataset_size": 101776799.8}, {"config_name": "2019-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 108770178.24, "num_examples": 1240}], "download_size": 108809412, "dataset_size": 108770178.24}, {"config_name": "2019-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 106230713.004, "num_examples": 1214}], "download_size": 104176974, "dataset_size": 106230713.004}, {"config_name": "2019-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 125389025.589, "num_examples": 1333}], "download_size": 0, "dataset_size": 125389025.589}, {"config_name": "2019-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 120403617.8, "num_examples": 1280}], "download_size": 0, "dataset_size": 120403617.8}, {"config_name": "2019-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 125960887.126, "num_examples": 1369}], "download_size": 124276084, "dataset_size": 125960887.126}, {"config_name": "2019-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 136392438.664, "num_examples": 1348}], "download_size": 135672371, "dataset_size": 136392438.664}, {"config_name": "2019-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 124935466.248, "num_examples": 1366}], "download_size": 124602238, "dataset_size": 124935466.248}, {"config_name": "2019-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 111433073.671, "num_examples": 1219}], "download_size": 107134716, "dataset_size": 111433073.671}, {"config_name": "2019-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 110837648.736, "num_examples": 1256}], "download_size": 108585292, "dataset_size": 110837648.736}, {"config_name": "2019-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 125283502.331, "num_examples": 1271}], "download_size": 0, "dataset_size": 125283502.331}, {"config_name": "2019-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 114959215.775, "num_examples": 1275}], "download_size": 109114628, "dataset_size": 114959215.775}, {"config_name": "2019-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 111162509.392, "num_examples": 1304}], "download_size": 110040161, "dataset_size": 111162509.392}, {"config_name": "2020-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 128033419.15, "num_examples": 1230}], "download_size": 126141589, "dataset_size": 128033419.15}, {"config_name": "2020-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 115035598.574, "num_examples": 1197}], "download_size": 115310651, "dataset_size": 115035598.574}, {"config_name": "2020-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 106606945.448, "num_examples": 1156}], "download_size": 0, "dataset_size": 106606945.448}, {"config_name": "2020-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 100981933.728, "num_examples": 1152}], "download_size": 0, "dataset_size": 100981933.728}, {"config_name": "2020-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 110835151.6, "num_examples": 1257}], "download_size": 108012913, "dataset_size": 110835151.6}, {"config_name": "2020-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 108239718.802, "num_examples": 1231}], "download_size": 106030989, "dataset_size": 108239718.802}, {"config_name": "2020-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 126564071.054, "num_examples": 1302}], "download_size": 121234236, "dataset_size": 126564071.054}, {"config_name": "2020-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 108827972.6, "num_examples": 1240}], "download_size": 106795246, "dataset_size": 108827972.6}, {"config_name": "2020-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 137288418.524, "num_examples": 1199}], "download_size": 127316972, "dataset_size": 137288418.524}, {"config_name": "2020-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 141209470.562, "num_examples": 1298}], "download_size": 0, "dataset_size": 141209470.562}, {"config_name": "2020-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 123343537.459, "num_examples": 1297}], "download_size": 117797111, "dataset_size": 123343537.459}, {"config_name": "2020-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 129561685.87, "num_examples": 1186}], "download_size": 125121403, "dataset_size": 129561685.87}, {"config_name": "2021-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 156547452.065, "num_examples": 1365}], "download_size": 146649533, "dataset_size": 156547452.065}, {"config_name": "2021-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 137506074.088, "num_examples": 1368}], "download_size": 132663295, "dataset_size": 137506074.088}, {"config_name": "2021-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 131466965.02, "num_examples": 1321}], "download_size": 0, "dataset_size": 131466965.02}, {"config_name": "2021-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 140977723.04, "num_examples": 1320}], "download_size": 0, "dataset_size": 140977723.04}, {"config_name": "2021-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 146883988.472, "num_examples": 1264}], "download_size": 138956660, "dataset_size": 146883988.472}, {"config_name": "2021-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 145262842.075, "num_examples": 1367}], "download_size": 141442160, "dataset_size": 145262842.075}, {"config_name": "2021-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 155767742.626, "num_examples": 1486}], "download_size": 155846129, "dataset_size": 155767742.626}, {"config_name": "2021-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 155819324.92, "num_examples": 1381}], "download_size": 157101336, "dataset_size": 155819324.92}, {"config_name": "2021-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 136990935.044, "num_examples": 1429}], "download_size": 134893440, "dataset_size": 136990935.044}, {"config_name": "2021-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 150938276.384, "num_examples": 1474}], "download_size": 147195524, "dataset_size": 150938276.384}, {"config_name": "2021-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 140033960.728, "num_examples": 1461}], "download_size": 0, "dataset_size": 140033960.728}, {"config_name": "2021-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 147085138.232, "num_examples": 1344}], "download_size": 139674835, "dataset_size": 147085138.232}, {"config_name": "2022-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 157639017.352, "num_examples": 1404}], "download_size": 150370010, "dataset_size": 157639017.352}, {"config_name": "2022-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 160343907.725, "num_examples": 1405}], "download_size": 160789713, "dataset_size": 160343907.725}, {"config_name": "2022-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 173057850.04, "num_examples": 1440}], "download_size": 0, "dataset_size": 173057850.04}, {"config_name": "2022-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 161817777.72, "num_examples": 1436}], "download_size": 0, "dataset_size": 161817777.72}, {"config_name": "2022-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 152861222.783, "num_examples": 1357}], "download_size": 144151531, "dataset_size": 152861222.783}, {"config_name": "2022-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 155906985.904, "num_examples": 1479}], "download_size": 152209912, "dataset_size": 155906985.904}, {"config_name": "2022-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 174086233.52, "num_examples": 1445}], "download_size": 174793110, "dataset_size": 174086233.52}, {"config_name": "2022-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 144507245.265, "num_examples": 1281}], "download_size": 141608383, "dataset_size": 144507245.265}, {"config_name": "2022-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 220240636.862, "num_examples": 1538}], "download_size": 220451624, "dataset_size": 220240636.862}, {"config_name": "2022-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 157358453.01, "num_examples": 1394}], "download_size": 149329234, "dataset_size": 157358453.01}, {"config_name": "2022-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 163897645.91, "num_examples": 1630}], "download_size": 161735514, "dataset_size": 163897645.91}, {"config_name": "2022-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 174900822.864, "num_examples": 1647}], "download_size": 165712871, "dataset_size": 174900822.864}, {"config_name": "2023-01", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 188584311.627, "num_examples": 1623}], "download_size": 186501700, "dataset_size": 188584311.627}, {"config_name": "2023-02", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 184023573.872, "num_examples": 1588}], "download_size": 175704980, "dataset_size": 184023573.872}, {"config_name": "2023-03", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 190227193.1, "num_examples": 1590}], "download_size": 0, "dataset_size": 190227193.1}, {"config_name": "2023-04", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 180919389.272, "num_examples": 1672}], "download_size": 0, "dataset_size": 180919389.272}, {"config_name": "2023-05", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 209876602.552, "num_examples": 1746}], "download_size": 220487583, "dataset_size": 209876602.552}, {"config_name": "2023-06", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 201399691.026, "num_examples": 1674}], "download_size": 188589435, "dataset_size": 201399691.026}, {"config_name": "2023-07", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 201701187.76, "num_examples": 1694}], "download_size": 185009875, "dataset_size": 201701187.76}, {"config_name": "2023-08", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 184269420.23, "num_examples": 1715}], "download_size": 178141669, "dataset_size": 184269420.23}, {"config_name": "2023-09", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 161634889.2, "num_examples": 1661}], "download_size": 162707652, "dataset_size": 161634889.2}, {"config_name": "2023-10", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 193440351.04, "num_examples": 1680}], "download_size": 190638289, "dataset_size": 193440351.04}, {"config_name": "2023-11", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 167218244.95, "num_examples": 1575}], "download_size": 158769063, "dataset_size": 167218244.95}, {"config_name": "2023-12", "features": [{"name": "url", "dtype": "string"}, {"name": "img", "dtype": "image"}, {"name": "title", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 177898899.32, "num_examples": 1460}], "download_size": 180835697, "dataset_size": 177898899.32}], "configs": [{"config_name": "2017-01", "data_files": [{"split": "train", "path": "2017-01/train-*"}]}, {"config_name": "2017-02", "data_files": [{"split": "train", "path": "2017-02/train-*"}]}, {"config_name": "2017-03", "data_files": [{"split": "train", "path": "2017-03/train-*"}]}, {"config_name": "2017-04", "data_files": [{"split": "train", "path": "2017-04/train-*"}]}, {"config_name": "2017-05", "data_files": [{"split": "train", "path": "2017-05/train-*"}]}, {"config_name": "2017-06", "data_files": [{"split": "train", "path": "2017-06/train-*"}]}, {"config_name": "2017-07", "data_files": [{"split": "train", "path": "2017-07/train-*"}]}, {"config_name": "2017-08", "data_files": [{"split": "train", "path": "2017-08/train-*"}]}, {"config_name": "2017-09", "data_files": [{"split": "train", "path": "2017-09/train-*"}]}, {"config_name": "2017-10", "data_files": [{"split": "train", "path": "2017-10/train-*"}]}, {"config_name": "2017-11", "data_files": [{"split": "train", "path": "2017-11/train-*"}]}, {"config_name": "2017-12", "data_files": [{"split": "train", "path": "2017-12/train-*"}]}, {"config_name": "2018-01", "data_files": [{"split": "train", "path": "2018-01/train-*"}]}, {"config_name": "2018-02", "data_files": [{"split": "train", "path": "2018-02/train-*"}]}, {"config_name": "2018-03", "data_files": [{"split": "train", "path": "2018-03/train-*"}]}, {"config_name": "2018-04", "data_files": [{"split": "train", "path": "2018-04/train-*"}]}, {"config_name": "2018-05", "data_files": [{"split": "train", "path": "2018-05/train-*"}]}, {"config_name": "2018-06", "data_files": [{"split": "train", "path": "2018-06/train-*"}]}, {"config_name": "2018-07", "data_files": [{"split": "train", "path": "2018-07/train-*"}]}, {"config_name": "2018-08", "data_files": [{"split": "train", "path": "2018-08/train-*"}]}, {"config_name": "2018-09", "data_files": [{"split": "train", "path": "2018-09/train-*"}]}, {"config_name": "2018-10", "data_files": [{"split": "train", "path": "2018-10/train-*"}]}, {"config_name": "2018-11", "data_files": [{"split": "train", "path": "2018-11/train-*"}]}, {"config_name": "2018-12", "data_files": [{"split": "train", "path": "2018-12/train-*"}]}, {"config_name": "2019-01", "data_files": [{"split": "train", "path": "2019-01/train-*"}]}, {"config_name": "2019-02", "data_files": [{"split": "train", "path": "2019-02/train-*"}]}, {"config_name": "2019-03", "data_files": [{"split": "train", "path": "2019-03/train-*"}]}, {"config_name": "2019-04", "data_files": [{"split": "train", "path": "2019-04/train-*"}]}, {"config_name": "2019-05", "data_files": [{"split": "train", "path": "2019-05/train-*"}]}, {"config_name": "2019-06", "data_files": [{"split": "train", "path": "2019-06/train-*"}]}, {"config_name": "2019-07", "data_files": [{"split": "train", "path": "2019-07/train-*"}]}, {"config_name": "2019-08", "data_files": [{"split": "train", "path": "2019-08/train-*"}]}, {"config_name": "2019-09", "data_files": [{"split": "train", "path": "2019-09/train-*"}]}, {"config_name": "2019-10", "data_files": [{"split": "train", "path": "2019-10/train-*"}]}, {"config_name": "2019-11", "data_files": [{"split": "train", "path": "2019-11/train-*"}]}, {"config_name": "2019-12", "data_files": [{"split": "train", "path": "2019-12/train-*"}]}, {"config_name": "2020-01", "data_files": [{"split": "train", "path": "2020-01/train-*"}]}, {"config_name": "2020-02", "data_files": [{"split": "train", "path": "2020-02/train-*"}]}, {"config_name": "2020-03", "data_files": [{"split": "train", "path": "2020-03/train-*"}]}, {"config_name": "2020-04", "data_files": [{"split": "train", "path": "2020-04/train-*"}]}, {"config_name": "2020-05", "data_files": [{"split": "train", "path": "2020-05/train-*"}]}, {"config_name": "2020-06", "data_files": [{"split": "train", "path": "2020-06/train-*"}]}, {"config_name": "2020-07", "data_files": [{"split": "train", "path": "2020-07/train-*"}]}, {"config_name": "2020-08", "data_files": [{"split": "train", "path": "2020-08/train-*"}]}, {"config_name": "2020-09", "data_files": [{"split": "train", "path": "2020-09/train-*"}]}, {"config_name": "2020-10", "data_files": [{"split": "train", "path": "2020-10/train-*"}]}, {"config_name": "2020-11", "data_files": [{"split": "train", "path": "2020-11/train-*"}]}, {"config_name": "2020-12", "data_files": [{"split": "train", "path": "2020-12/train-*"}]}, {"config_name": "2021-01", "data_files": [{"split": "train", "path": "2021-01/train-*"}]}, {"config_name": "2021-02", "data_files": [{"split": "train", "path": "2021-02/train-*"}]}, {"config_name": "2021-03", "data_files": [{"split": "train", "path": "2021-03/train-*"}]}, {"config_name": "2021-04", "data_files": [{"split": "train", "path": "2021-04/train-*"}]}, {"config_name": "2021-05", "data_files": [{"split": "train", "path": "2021-05/train-*"}]}, {"config_name": "2021-06", "data_files": [{"split": "train", "path": "2021-06/train-*"}]}, {"config_name": "2021-07", "data_files": [{"split": "train", "path": "2021-07/train-*"}]}, {"config_name": "2021-08", "data_files": [{"split": "train", "path": "2021-08/train-*"}]}, {"config_name": "2021-09", "data_files": [{"split": "train", "path": "2021-09/train-*"}]}, {"config_name": "2021-10", "data_files": [{"split": "train", "path": "2021-10/train-*"}]}, {"config_name": "2021-11", "data_files": [{"split": "train", "path": "2021-11/train-*"}]}, {"config_name": "2021-12", "data_files": [{"split": "train", "path": "2021-12/train-*"}]}, {"config_name": "2022-01", "data_files": [{"split": "train", "path": "2022-01/train-*"}]}, {"config_name": "2022-02", "data_files": [{"split": "train", "path": "2022-02/train-*"}]}, {"config_name": "2022-03", "data_files": [{"split": "train", "path": "2022-03/train-*"}]}, {"config_name": "2022-04", "data_files": [{"split": "train", "path": "2022-04/train-*"}]}, {"config_name": "2022-05", "data_files": [{"split": "train", "path": "2022-05/train-*"}]}, {"config_name": "2022-06", "data_files": [{"split": "train", "path": "2022-06/train-*"}]}, {"config_name": "2022-07", "data_files": [{"split": "train", "path": "2022-07/train-*"}]}, {"config_name": "2022-08", "data_files": [{"split": "train", "path": "2022-08/train-*"}]}, {"config_name": "2022-09", "data_files": [{"split": "train", "path": "2022-09/train-*"}]}, {"config_name": "2022-10", "data_files": [{"split": "train", "path": "2022-10/train-*"}]}, {"config_name": "2022-11", "data_files": [{"split": "train", "path": "2022-11/train-*"}]}, {"config_name": "2022-12", "data_files": [{"split": "train", "path": "2022-12/train-*"}]}, {"config_name": "2023-01", "data_files": [{"split": "train", "path": "2023-01/train-*"}]}, {"config_name": "2023-02", "data_files": [{"split": "train", "path": "2023-02/train-*"}]}, {"config_name": "2023-03", "data_files": [{"split": "train", "path": "2023-03/train-*"}]}, {"config_name": "2023-04", "data_files": [{"split": "train", "path": "2023-04/train-*"}]}, {"config_name": "2023-05", "data_files": [{"split": "train", "path": "2023-05/train-*"}]}, {"config_name": "2023-06", "data_files": [{"split": "train", "path": "2023-06/train-*"}]}, {"config_name": "2023-07", "data_files": [{"split": "train", "path": "2023-07/train-*"}]}, {"config_name": "2023-08", "data_files": [{"split": "train", "path": "2023-08/train-*"}]}, {"config_name": "2023-09", "data_files": [{"split": "train", "path": "2023-09/train-*"}]}, {"config_name": "2023-10", "data_files": [{"split": "train", "path": "2023-10/train-*"}]}, {"config_name": "2023-11", "data_files": [{"split": "train", "path": "2023-11/train-*"}]}, {"config_name": "2023-12", "data_files": [{"split": "train", "path": "2023-12/train-*"}]}]} | 2023-12-26T21:22:17+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "bbc_images_alltime"
More Information needed | [
"# Dataset Card for \"bbc_images_alltime\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"bbc_images_alltime\"\n\nMore Information needed"
] | [
6,
18
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"bbc_images_alltime\"\n\nMore Information needed"
] |
9a0c602aa3d4c431613be81905e138d51f6d6615 | # Dataset Card for "aihub_books_generated_answers_negative"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | wisenut-nlp-team/aihub_books_generated_answers_negative | [
"region:us"
] | 2023-12-26T01:13:38+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "similar_contexts", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 5886595919, "num_examples": 944076}], "download_size": 3411355687, "dataset_size": 5886595919}} | 2023-12-26T01:46:15+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "aihub_books_generated_answers_negative"
More Information needed | [
"# Dataset Card for \"aihub_books_generated_answers_negative\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"aihub_books_generated_answers_negative\"\n\nMore Information needed"
] | [
6,
23
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"aihub_books_generated_answers_negative\"\n\nMore Information needed"
] |
09286936396ed84b668d1389a7a373dd70620bc9 | # test
## test line
### test1234 | sjl521/test1 | [
"region:us"
] | 2023-12-26T01:17:47+00:00 | {} | 2023-12-26T01:18:24+00:00 | [] | [] | TAGS
#region-us
| # test
## test line
### test1234 | [
"# test",
"## test line",
"### test1234"
] | [
"TAGS\n#region-us \n",
"# test",
"## test line",
"### test1234"
] | [
6,
2,
3,
4
] | [
"passage: TAGS\n#region-us \n# test## test line### test1234"
] |
cfaed9f7156a26285e573f14203e2007bd9ee369 | 10,000 high-quality captions with image pairs produced by dalle3 with a raw.zip incase i uploaded it wrong. | dataautogpt3/Dalle3 | [
"license:mit",
"region:us"
] | 2023-12-26T01:32:50+00:00 | {"license": "mit"} | 2023-12-27T17:17:02+00:00 | [] | [] | TAGS
#license-mit #region-us
| 10,000 high-quality captions with image pairs produced by dalle3 with a URL incase i uploaded it wrong. | [] | [
"TAGS\n#license-mit #region-us \n"
] | [
11
] | [
"passage: TAGS\n#license-mit #region-us \n"
] |
76acf288db94245ceead597dd89ebbdd5e11bc6c | # DL3DV-10K Dataset Sample
Here is the repo for a sample (11 scenes/videos) of the full DL3DV-10K dataset. Each scene has a raw 4K video and the processed colmap results.
## File Structure Example
``` bash
5c3af581028068a3c402c7cbe16ecf9471ddf2897c34ab634b7b1b6cf81aba00
├── colmap
│ ├── colmap
│ │ ├── features.h5
│ │ ├── global-feats-netvlad.h5
│ │ ├── matches.h5
│ │ ├── pairs-netvlad.txt
│ │ └── sparse
│ │ └── 0
│ │ ├── cameras.bin
│ │ ├── database.db
│ │ ├── images.bin
│ │ ├── models
│ │ │ └── 0
│ │ └── points3D.bin
│ ├── images
│ │ ├── frame_00001.png
│ │ ├── frame_00002.png
│ │ ├── ....
│ ├── images_2
│ │ ├── frame_00001.png
│ │ ├── frame_00002.png
│ │ ├── ....
│ ├── images_4
│ │ ├── frame_00001.png
│ │ ├── frame_00002.png
│ │ ├── ....
│ ├── images_8
│ │ ├── frame_00001.png
│ │ ├── frame_00002.png
│ │ ├── ....
│ ├── temp_images
│ └── transforms.json
└── video.mp4
```
# DL3DV-10K Benchmark
Please refer to this [repo](https://github.com/DL3DV-10K/Dataset) for instruction.
| DL3DV/DL3DV-10K-Sample | [
"size_categories:100B<n<1T",
"novel view synthesis",
"NeRF",
"3D Gaussian Splatting",
"3D Vision",
"Content Generation",
"text-to-3d",
"image-to-3d",
"region:us"
] | 2023-12-26T03:39:15+00:00 | {"size_categories": ["100B<n<1T"], "tags": ["novel view synthesis", "NeRF", "3D Gaussian Splatting", "3D Vision", "Content Generation", "text-to-3d", "image-to-3d"]} | 2024-01-05T02:21:19+00:00 | [] | [] | TAGS
#size_categories-100B<n<1T #novel view synthesis #NeRF #3D Gaussian Splatting #3D Vision #Content Generation #text-to-3d #image-to-3d #region-us
| # DL3DV-10K Dataset Sample
Here is the repo for a sample (11 scenes/videos) of the full DL3DV-10K dataset. Each scene has a raw 4K video and the processed colmap results.
## File Structure Example
# DL3DV-10K Benchmark
Please refer to this repo for instruction.
| [
"# DL3DV-10K Dataset Sample \nHere is the repo for a sample (11 scenes/videos) of the full DL3DV-10K dataset. Each scene has a raw 4K video and the processed colmap results.",
"## File Structure Example",
"# DL3DV-10K Benchmark \nPlease refer to this repo for instruction."
] | [
"TAGS\n#size_categories-100B<n<1T #novel view synthesis #NeRF #3D Gaussian Splatting #3D Vision #Content Generation #text-to-3d #image-to-3d #region-us \n",
"# DL3DV-10K Dataset Sample \nHere is the repo for a sample (11 scenes/videos) of the full DL3DV-10K dataset. Each scene has a raw 4K video and the processed colmap results.",
"## File Structure Example",
"# DL3DV-10K Benchmark \nPlease refer to this repo for instruction."
] | [
55,
53,
7,
19
] | [
"passage: TAGS\n#size_categories-100B<n<1T #novel view synthesis #NeRF #3D Gaussian Splatting #3D Vision #Content Generation #text-to-3d #image-to-3d #region-us \n# DL3DV-10K Dataset Sample \nHere is the repo for a sample (11 scenes/videos) of the full DL3DV-10K dataset. Each scene has a raw 4K video and the processed colmap results.## File Structure Example# DL3DV-10K Benchmark \nPlease refer to this repo for instruction."
] |
c9a3b59be01a1e11493e9830e2d7920f72d6dc77 |
# Dataset Card for "squad_es"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://github.com/ccasimiro88/TranslateAlignRetrieve](https://github.com/ccasimiro88/TranslateAlignRetrieve)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 39.29 MB
- **Size of the generated dataset:** 94.63 MB
- **Total amount of disk used:** 133.92 MB
### Dataset Summary
Automatic translation of the Stanford Question Answering Dataset (SQuAD) v2 into Spanish
### Supported Tasks and Leaderboards
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Languages
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Structure
### Data Instances
#### v1.1.0
- **Size of downloaded dataset files:** 39.29 MB
- **Size of the generated dataset:** 94.63 MB
- **Total amount of disk used:** 133.92 MB
An example of 'train' looks as follows.
```
This example was too long and was cropped:
{
"answers": {
"answer_start": [404, 356, 356],
"text": ["Santa Clara, California", "Levi 's Stadium", "Levi 's Stadium en la Bahía de San Francisco en Santa Clara, California."]
},
"context": "\"El Super Bowl 50 fue un partido de fútbol americano para determinar al campeón de la NFL para la temporada 2015. El campeón de ...",
"id": "56be4db0acb8001400a502ee",
"question": "¿Dónde tuvo lugar el Super Bowl 50?",
"title": "Super Bowl _ 50"
}
```
### Data Fields
The data fields are the same among all splits.
#### v1.1.0
- `id`: a `string` feature.
- `title`: a `string` feature.
- `context`: a `string` feature.
- `question`: a `string` feature.
- `answers`: a dictionary feature containing:
- `text`: a `string` feature.
- `answer_start`: a `int32` feature.
### Data Splits
| name |train|validation|
|------|----:|---------:|
|v1.1.0|87595| 10570|
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
The SQuAD-es dataset is licensed under the [CC BY 4.0](https://creativecommons.org/licenses/by/4.0/) license.
### Citation Information
```
@article{2016arXiv160605250R,
author = {Casimiro Pio , Carrino and Marta R. , Costa-jussa and Jose A. R. , Fonollosa},
title = "{Automatic Spanish Translation of the SQuAD Dataset for Multilingual
Question Answering}",
journal = {arXiv e-prints},
year = 2019,
eid = {arXiv:1912.05200v1},
pages = {arXiv:1912.05200v1},
archivePrefix = {arXiv},
eprint = {1912.05200v2},
}
```
license: mit
task_categories:
- question-answering
language:
- es
size_categories:
- 10K<n<100K
--- | TheTung/squad_es_v2 | [
"task_categories:question-answering",
"task_ids:extractive-qa",
"annotations_creators:machine-generated",
"language_creators:machine-generated",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|squad",
"language:es",
"license:cc-by-4.0",
"arxiv:1912.05200",
"region:us"
] | 2023-12-26T04:45:32+00:00 | {"annotations_creators": ["machine-generated"], "language_creators": ["machine-generated"], "language": ["es"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|squad"], "task_categories": ["question-answering"], "task_ids": ["extractive-qa"], "paperswithcode_id": "squad-es", "pretty_name": "SQuAD-es", "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "context", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": [{"name": "text", "dtype": "string"}, {"name": "answer_start", "dtype": "int32"}]}], "config_name": "v1.1.0", "splits": [{"name": "train", "num_bytes": 83680438, "num_examples": 87595}, {"name": "validation", "num_bytes": 10955800, "num_examples": 10570}], "download_size": 39291362, "dataset_size": 94636238}} | 2024-01-23T06:12:22+00:00 | [
"1912.05200"
] | [
"es"
] | TAGS
#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|squad #language-Spanish #license-cc-by-4.0 #arxiv-1912.05200 #region-us
| Dataset Card for "squad\_es"
============================
Table of Contents
-----------------
* Dataset Description
+ Dataset Summary
+ Supported Tasks and Leaderboards
+ Languages
* Dataset Structure
+ Data Instances
+ Data Fields
+ Data Splits
* Dataset Creation
+ Curation Rationale
+ Source Data
+ Annotations
+ Personal and Sensitive Information
* Considerations for Using the Data
+ Social Impact of Dataset
+ Discussion of Biases
+ Other Known Limitations
* Additional Information
+ Dataset Curators
+ Licensing Information
+ Citation Information
+ Contributions
Dataset Description
-------------------
* Homepage: URL
* Repository:
* Paper:
* Point of Contact:
* Size of downloaded dataset files: 39.29 MB
* Size of the generated dataset: 94.63 MB
* Total amount of disk used: 133.92 MB
### Dataset Summary
Automatic translation of the Stanford Question Answering Dataset (SQuAD) v2 into Spanish
### Supported Tasks and Leaderboards
### Languages
Dataset Structure
-----------------
### Data Instances
#### v1.1.0
* Size of downloaded dataset files: 39.29 MB
* Size of the generated dataset: 94.63 MB
* Total amount of disk used: 133.92 MB
An example of 'train' looks as follows.
### Data Fields
The data fields are the same among all splits.
#### v1.1.0
* 'id': a 'string' feature.
* 'title': a 'string' feature.
* 'context': a 'string' feature.
* 'question': a 'string' feature.
* 'answers': a dictionary feature containing:
+ 'text': a 'string' feature.
+ 'answer\_start': a 'int32' feature.
### Data Splits
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
The SQuAD-es dataset is licensed under the CC BY 4.0 license.
license: mit
task\_categories:
* question-answering
language:
* es
size\_categories:
* 10K<n<100K
---
| [
"### Dataset Summary\n\n\nAutomatic translation of the Stanford Question Answering Dataset (SQuAD) v2 into Spanish",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### v1.1.0\n\n\n* Size of downloaded dataset files: 39.29 MB\n* Size of the generated dataset: 94.63 MB\n* Total amount of disk used: 133.92 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### v1.1.0\n\n\n* 'id': a 'string' feature.\n* 'title': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nThe SQuAD-es dataset is licensed under the CC BY 4.0 license.\n\n\nlicense: mit\ntask\\_categories:\n\n\n* question-answering\nlanguage:\n* es\nsize\\_categories:\n* 10K<n<100K\n\n\n\n\n---"
] | [
"TAGS\n#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|squad #language-Spanish #license-cc-by-4.0 #arxiv-1912.05200 #region-us \n",
"### Dataset Summary\n\n\nAutomatic translation of the Stanford Question Answering Dataset (SQuAD) v2 into Spanish",
"### Supported Tasks and Leaderboards",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data Instances",
"#### v1.1.0\n\n\n* Size of downloaded dataset files: 39.29 MB\n* Size of the generated dataset: 94.63 MB\n* Total amount of disk used: 133.92 MB\n\n\nAn example of 'train' looks as follows.",
"### Data Fields\n\n\nThe data fields are the same among all splits.",
"#### v1.1.0\n\n\n* 'id': a 'string' feature.\n* 'title': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.",
"### Data Splits\n\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information\n\n\nThe SQuAD-es dataset is licensed under the CC BY 4.0 license.\n\n\nlicense: mit\ntask\\_categories:\n\n\n* question-answering\nlanguage:\n* es\nsize\\_categories:\n* 10K<n<100K\n\n\n\n\n---"
] | [
109,
26,
10,
11,
6,
55,
17,
93,
11,
7,
4,
10,
10,
5,
5,
9,
18,
7,
8,
14,
6,
57
] | [
"passage: TAGS\n#task_categories-question-answering #task_ids-extractive-qa #annotations_creators-machine-generated #language_creators-machine-generated #multilinguality-monolingual #size_categories-10K<n<100K #source_datasets-extended|squad #language-Spanish #license-cc-by-4.0 #arxiv-1912.05200 #region-us \n### Dataset Summary\n\n\nAutomatic translation of the Stanford Question Answering Dataset (SQuAD) v2 into Spanish### Supported Tasks and Leaderboards### Languages\n\n\nDataset Structure\n-----------------### Data Instances#### v1.1.0\n\n\n* Size of downloaded dataset files: 39.29 MB\n* Size of the generated dataset: 94.63 MB\n* Total amount of disk used: 133.92 MB\n\n\nAn example of 'train' looks as follows.### Data Fields\n\n\nThe data fields are the same among all splits.#### v1.1.0\n\n\n* 'id': a 'string' feature.\n* 'title': a 'string' feature.\n* 'context': a 'string' feature.\n* 'question': a 'string' feature.\n* 'answers': a dictionary feature containing:\n\t+ 'text': a 'string' feature.\n\t+ 'answer\\_start': a 'int32' feature.### Data Splits\n\n\n\nDataset Creation\n----------------### Curation Rationale### Source Data#### Initial Data Collection and Normalization#### Who are the source language producers?### Annotations#### Annotation process#### Who are the annotators?### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------### Social Impact of Dataset### Discussion of Biases### Other Known Limitations\n\n\nAdditional Information\n----------------------### Dataset Curators### Licensing Information\n\n\nThe SQuAD-es dataset is licensed under the CC BY 4.0 license.\n\n\nlicense: mit\ntask\\_categories:\n\n\n* question-answering\nlanguage:\n* es\nsize\\_categories:\n* 10K<n<100K\n\n\n\n\n---"
] |
221d3583603fc927ef58794a076952910b8e5919 |
# BlocksWorld
This repo contains the BlocksWorld data for ["PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change"](https://arxiv.org/abs/2206.10498).
The original data link is here: https://github.com/karthikv792/LLMs-Planning/tree/main/plan-bench/instances/blocksworld/generated | chiayewken/blocksworld | [
"arxiv:2206.10498",
"region:us"
] | 2023-12-26T05:20:19+00:00 | {"dataset_info": {"features": [{"name": "domain", "dtype": "string"}, {"name": "instance", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 675434, "num_examples": 501}], "download_size": 61032, "dataset_size": 675434}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-26T05:24:16+00:00 | [
"2206.10498"
] | [] | TAGS
#arxiv-2206.10498 #region-us
|
# BlocksWorld
This repo contains the BlocksWorld data for "PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change".
The original data link is here: URL | [
"# BlocksWorld\n\nThis repo contains the BlocksWorld data for \"PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change\".\n\nThe original data link is here: URL"
] | [
"TAGS\n#arxiv-2206.10498 #region-us \n",
"# BlocksWorld\n\nThis repo contains the BlocksWorld data for \"PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change\".\n\nThe original data link is here: URL"
] | [
14,
50
] | [
"passage: TAGS\n#arxiv-2206.10498 #region-us \n# BlocksWorld\n\nThis repo contains the BlocksWorld data for \"PlanBench: An Extensible Benchmark for Evaluating Large Language Models on Planning and Reasoning about Change\".\n\nThe original data link is here: URL"
] |
60cf93bdc2900c8c15d673d28a12dc77cc8d1093 |
# Dataset Card for Text-to-Image ScoreScore (T2IScoreScore or TS2)
This dataset exists as part of the **T2IScoreScore** metaevaluation for assessing the *faithfulness* and *consistency* of text-to-image model prompt-image evaluation metrics.
Necessary code for utilizing the resource is present at [github.com/michaelsaxon/T2IScoreScore](https://github.com/michaelsaxon/T2IScoreScore)
## Dataset Details
### Dataset Description
This is a test set of *165 "target prompts"* which each have *between 5 and 76 generated images* of varying correctness wrt the target prompt.
In total there are 2,839 images.
This dataset is meant to be used along with the **T2IScoreScore metrics** presented in our paper (to be preprinted shortly), where some T2I image correctness metric
is evaluated in terms of its ability to correctly order samples of decreasing quality (which we have assigned ground truth rank order labels) along an **image error graph**.
We provide images generated by several T2I models including DALL-E 2, StableDiffusion 1.4, 2.0, 2.1, and XL, as well as natural stock images under a redistributable license
that move further and further away from the ground truth.
- **Curated by:** [Mahsa Khoshnoodi](https://github.com/Arenaa/), [Fatima Jahara](https://fatimajahara.com/), [Michael Saxon](https://saxon.me), and [Yujie Lu](https://yujielu10.github.io/)
- **Language(s) (NLP):** English
- **License:** MIT
- **Support:** [Fatima Fellowship](https://www.fatimafellowship.com/), [UCSB NLP Group](http://nlp.cs.ucsb.edu/)
### Dataset Sources
- **Repository:** [https://github.com/michaelsaxon/T2IScoreScore](https://github.com/michaelsaxon/T2IScoreScore)
- **Paper:** TBD
### Contact
[Michael Saxon](https://saxon.me), UCSB NLP Group | saxon/T2IScoreScore | [
"task_categories:text-to-image",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"evaluation",
"text-to-image",
"region:us"
] | 2023-12-26T05:20:51+00:00 | {"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["text-to-image"], "pretty_name": "T2IScoreScore (TS2)", "tags": ["evaluation", "text-to-image"], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "target_prompt", "dtype": "string"}, {"name": "file_name", "dtype": "image"}, {"name": "image_source", "dtype": "string"}, {"name": "rank", "dtype": "string"}]}} | 2024-01-19T07:06:08+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-to-image #size_categories-1K<n<10K #language-English #license-mit #evaluation #text-to-image #region-us
|
# Dataset Card for Text-to-Image ScoreScore (T2IScoreScore or TS2)
This dataset exists as part of the T2IScoreScore metaevaluation for assessing the *faithfulness* and *consistency* of text-to-image model prompt-image evaluation metrics.
Necessary code for utilizing the resource is present at URL
## Dataset Details
### Dataset Description
This is a test set of *165 "target prompts"* which each have *between 5 and 76 generated images* of varying correctness wrt the target prompt.
In total there are 2,839 images.
This dataset is meant to be used along with the T2IScoreScore metrics presented in our paper (to be preprinted shortly), where some T2I image correctness metric
is evaluated in terms of its ability to correctly order samples of decreasing quality (which we have assigned ground truth rank order labels) along an image error graph.
We provide images generated by several T2I models including DALL-E 2, StableDiffusion 1.4, 2.0, 2.1, and XL, as well as natural stock images under a redistributable license
that move further and further away from the ground truth.
- Curated by: Mahsa Khoshnoodi, Fatima Jahara, Michael Saxon, and Yujie Lu
- Language(s) (NLP): English
- License: MIT
- Support: Fatima Fellowship, UCSB NLP Group
### Dataset Sources
- Repository: URL
- Paper: TBD
### Contact
Michael Saxon, UCSB NLP Group | [
"# Dataset Card for Text-to-Image ScoreScore (T2IScoreScore or TS2) \n\nThis dataset exists as part of the T2IScoreScore metaevaluation for assessing the *faithfulness* and *consistency* of text-to-image model prompt-image evaluation metrics.\n\nNecessary code for utilizing the resource is present at URL",
"## Dataset Details",
"### Dataset Description\n\nThis is a test set of *165 \"target prompts\"* which each have *between 5 and 76 generated images* of varying correctness wrt the target prompt. \nIn total there are 2,839 images.\n\nThis dataset is meant to be used along with the T2IScoreScore metrics presented in our paper (to be preprinted shortly), where some T2I image correctness metric\nis evaluated in terms of its ability to correctly order samples of decreasing quality (which we have assigned ground truth rank order labels) along an image error graph.\n\nWe provide images generated by several T2I models including DALL-E 2, StableDiffusion 1.4, 2.0, 2.1, and XL, as well as natural stock images under a redistributable license \nthat move further and further away from the ground truth.\n\n- Curated by: Mahsa Khoshnoodi, Fatima Jahara, Michael Saxon, and Yujie Lu\n- Language(s) (NLP): English\n- License: MIT\n- Support: Fatima Fellowship, UCSB NLP Group",
"### Dataset Sources\n\n- Repository: URL\n- Paper: TBD",
"### Contact\n\nMichael Saxon, UCSB NLP Group"
] | [
"TAGS\n#task_categories-text-to-image #size_categories-1K<n<10K #language-English #license-mit #evaluation #text-to-image #region-us \n",
"# Dataset Card for Text-to-Image ScoreScore (T2IScoreScore or TS2) \n\nThis dataset exists as part of the T2IScoreScore metaevaluation for assessing the *faithfulness* and *consistency* of text-to-image model prompt-image evaluation metrics.\n\nNecessary code for utilizing the resource is present at URL",
"## Dataset Details",
"### Dataset Description\n\nThis is a test set of *165 \"target prompts\"* which each have *between 5 and 76 generated images* of varying correctness wrt the target prompt. \nIn total there are 2,839 images.\n\nThis dataset is meant to be used along with the T2IScoreScore metrics presented in our paper (to be preprinted shortly), where some T2I image correctness metric\nis evaluated in terms of its ability to correctly order samples of decreasing quality (which we have assigned ground truth rank order labels) along an image error graph.\n\nWe provide images generated by several T2I models including DALL-E 2, StableDiffusion 1.4, 2.0, 2.1, and XL, as well as natural stock images under a redistributable license \nthat move further and further away from the ground truth.\n\n- Curated by: Mahsa Khoshnoodi, Fatima Jahara, Michael Saxon, and Yujie Lu\n- Language(s) (NLP): English\n- License: MIT\n- Support: Fatima Fellowship, UCSB NLP Group",
"### Dataset Sources\n\n- Repository: URL\n- Paper: TBD",
"### Contact\n\nMichael Saxon, UCSB NLP Group"
] | [
48,
84,
4,
241,
17,
12
] | [
"passage: TAGS\n#task_categories-text-to-image #size_categories-1K<n<10K #language-English #license-mit #evaluation #text-to-image #region-us \n# Dataset Card for Text-to-Image ScoreScore (T2IScoreScore or TS2) \n\nThis dataset exists as part of the T2IScoreScore metaevaluation for assessing the *faithfulness* and *consistency* of text-to-image model prompt-image evaluation metrics.\n\nNecessary code for utilizing the resource is present at URL## Dataset Details### Dataset Description\n\nThis is a test set of *165 \"target prompts\"* which each have *between 5 and 76 generated images* of varying correctness wrt the target prompt. \nIn total there are 2,839 images.\n\nThis dataset is meant to be used along with the T2IScoreScore metrics presented in our paper (to be preprinted shortly), where some T2I image correctness metric\nis evaluated in terms of its ability to correctly order samples of decreasing quality (which we have assigned ground truth rank order labels) along an image error graph.\n\nWe provide images generated by several T2I models including DALL-E 2, StableDiffusion 1.4, 2.0, 2.1, and XL, as well as natural stock images under a redistributable license \nthat move further and further away from the ground truth.\n\n- Curated by: Mahsa Khoshnoodi, Fatima Jahara, Michael Saxon, and Yujie Lu\n- Language(s) (NLP): English\n- License: MIT\n- Support: Fatima Fellowship, UCSB NLP Group### Dataset Sources\n\n- Repository: URL\n- Paper: TBD### Contact\n\nMichael Saxon, UCSB NLP Group"
] |
06d5f9a2680db7dac3046e025406a4f9009625c5 | # Dataset Card for "fialka-v1-zephyr"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 0x7o/fialka-v1-zephyr | [
"region:us"
] | 2023-12-26T06:17:57+00:00 | {"dataset_info": {"features": [{"name": "texts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 221476959.0, "num_examples": 129712}], "download_size": 103638760, "dataset_size": 221476959.0}} | 2023-12-26T06:19:32+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "fialka-v1-zephyr"
More Information needed | [
"# Dataset Card for \"fialka-v1-zephyr\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"fialka-v1-zephyr\"\n\nMore Information needed"
] | [
6,
17
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"fialka-v1-zephyr\"\n\nMore Information needed"
] |
647bac631bbd209c37407e5280715aeff8f0c761 | # Dataset Card for "WOS5736"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | aeromaki/WOS5736 | [
"region:us"
] | 2023-12-26T06:34:48+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "label", "sequence": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 7328406.626569037, "num_examples": 5162}, {"name": "test", "num_bytes": 407449.18671548116, "num_examples": 287}, {"name": "validation", "num_bytes": 407449.18671548116, "num_examples": 287}], "download_size": 4612294, "dataset_size": 8143304.999999999}} | 2023-12-26T06:34:58+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "WOS5736"
More Information needed | [
"# Dataset Card for \"WOS5736\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"WOS5736\"\n\nMore Information needed"
] | [
6,
14
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"WOS5736\"\n\nMore Information needed"
] |
513e910e592b2353e768540a937a2313d386f513 | # Thanks 🍏 Applio-RVC-Fork for a good fork. | kanoyo/k-rvc-fork | [
"region:us"
] | 2023-12-26T07:27:24+00:00 | {} | 2023-12-26T07:27:49+00:00 | [] | [] | TAGS
#region-us
| # Thanks Applio-RVC-Fork for a good fork. | [
"# Thanks Applio-RVC-Fork for a good fork."
] | [
"TAGS\n#region-us \n",
"# Thanks Applio-RVC-Fork for a good fork."
] | [
6,
16
] | [
"passage: TAGS\n#region-us \n# Thanks Applio-RVC-Fork for a good fork."
] |
6c9ec73a0b58a73b0404ae3fc2a8903bbf127de4 | data for finetuning using the coq framework for mathematical formalization | jbb/coq_code | [
"license:mit",
"region:us"
] | 2023-12-26T07:35:30+00:00 | {"license": "mit"} | 2023-12-26T08:54:25+00:00 | [] | [] | TAGS
#license-mit #region-us
| data for finetuning using the coq framework for mathematical formalization | [] | [
"TAGS\n#license-mit #region-us \n"
] | [
11
] | [
"passage: TAGS\n#license-mit #region-us \n"
] |
d41cbd708935d9373c16500d26ae8f7b67f9b18c |
[WritingPrompts_preferences](https://huggingface.co/datasets/euclaise/WritingPrompts_preferences), but processed like [SHP](https://huggingface.co/datasets/stanfordnlp/SHP) | euclaise/WritingPrompts_binarized | [
"license:mit",
"region:us"
] | 2023-12-26T07:59:44+00:00 | {"license": "mit", "dataset_info": {"features": [{"name": "post_text", "dtype": "string"}, {"name": "post_title", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1808381183, "num_examples": 352994}], "download_size": 514563548, "dataset_size": 1808381183}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-26T08:16:49+00:00 | [] | [] | TAGS
#license-mit #region-us
|
WritingPrompts_preferences, but processed like SHP | [] | [
"TAGS\n#license-mit #region-us \n"
] | [
11
] | [
"passage: TAGS\n#license-mit #region-us \n"
] |
2b289c692b4e36e3b1276faac97c6e342e142f49 | data for wizmap
| yichencc/wizmapdata | [
"region:us"
] | 2023-12-26T08:28:04+00:00 | {} | 2023-12-26T08:38:14+00:00 | [] | [] | TAGS
#region-us
| data for wizmap
| [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
0465eb7f4fae78b4f0d5aa6351af676d807c2788 | # Dataset Card for "wsd_fr_wngt_semcor_translated_aligned_all_v1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | gguichard/wsd_fr_wngt_semcor_translated_aligned_all_v1 | [
"region:us"
] | 2023-12-26T09:10:44+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "tokens", "sequence": "string"}, {"name": "wn_sens", "sequence": "int64"}, {"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 919383947.317851, "num_examples": 925349}, {"name": "test", "num_bytes": 9286746.682149062, "num_examples": 9347}], "download_size": 218724215, "dataset_size": 928670694.0}} | 2023-12-26T09:11:31+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "wsd_fr_wngt_semcor_translated_aligned_all_v1"
More Information needed | [
"# Dataset Card for \"wsd_fr_wngt_semcor_translated_aligned_all_v1\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"wsd_fr_wngt_semcor_translated_aligned_all_v1\"\n\nMore Information needed"
] | [
6,
32
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"wsd_fr_wngt_semcor_translated_aligned_all_v1\"\n\nMore Information needed"
] |
65fe5bad8d6f0fefa07c32d929a6ec4f29d5e4c1 | Synthetic textbooks created by Gemini using thooton/muse script on Github. | Ba2han/muse_textbooks | [
"language:en",
"region:us"
] | 2023-12-26T09:49:18+00:00 | {"language": ["en"]} | 2023-12-29T04:25:28+00:00 | [] | [
"en"
] | TAGS
#language-English #region-us
| Synthetic textbooks created by Gemini using thooton/muse script on Github. | [] | [
"TAGS\n#language-English #region-us \n"
] | [
10
] | [
"passage: TAGS\n#language-English #region-us \n"
] |
5a722fc766c9f4def495fb59f3730c4b6022043d |
Aggregation of the datasets in https://huggingface.co/collections/euclaise/supermc-658aa00d1b44d0e69467c32f | euclaise/SuperMC | [
"region:us"
] | 2023-12-26T10:06:16+00:00 | {"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "msg", "dtype": "string"}, {"name": "resp_correct", "dtype": "string"}, {"name": "resp_incorrect", "sequence": "string"}, {"name": "source", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 294374216.0, "num_examples": 277912}], "download_size": 173664182, "dataset_size": 294374216.0}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2024-01-25T21:05:38+00:00 | [] | [] | TAGS
#region-us
|
Aggregation of the datasets in URL | [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
45757d28cc7b265a6c0dca0a55e344322d6b5005 |
# Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | chuckskakap/nirnama_jw-rm | [
"region:us"
] | 2023-12-26T10:10:04+00:00 | {} | 2023-12-26T10:17:01+00:00 | [] | [] | TAGS
#region-us
|
# Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
6,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
2b5eab1be9feee159e9f946daf253edd4c027d03 | # Dataset Card for "github-issues"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | sloango/github-issues | [
"region:us"
] | 2023-12-26T10:25:45+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "repository_url", "dtype": "string"}, {"name": "labels_url", "dtype": "string"}, {"name": "comments_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "number", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "user", "struct": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "labels", "list": [{"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "name", "dtype": "string"}, {"name": "color", "dtype": "string"}, {"name": "default", "dtype": "bool"}, {"name": "description", "dtype": "string"}]}, {"name": "state", "dtype": "string"}, {"name": "locked", "dtype": "bool"}, {"name": "assignee", "struct": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "assignees", "list": [{"name": "login", "dtype": "string"}, {"name": "id", "dtype": "int64"}, {"name": "node_id", "dtype": "string"}, {"name": "avatar_url", "dtype": "string"}, {"name": "gravatar_id", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "followers_url", "dtype": "string"}, {"name": "following_url", "dtype": "string"}, {"name": "gists_url", "dtype": "string"}, {"name": "starred_url", "dtype": "string"}, {"name": "subscriptions_url", "dtype": "string"}, {"name": "organizations_url", "dtype": "string"}, {"name": "repos_url", "dtype": "string"}, {"name": "events_url", "dtype": "string"}, {"name": "received_events_url", "dtype": "string"}, {"name": "type", "dtype": "string"}, {"name": "site_admin", "dtype": "bool"}]}, {"name": "comments", "sequence": "string"}, {"name": "created_at", "dtype": "timestamp[s]"}, {"name": "updated_at", "dtype": "timestamp[s]"}, {"name": "closed_at", "dtype": "timestamp[s]"}, {"name": "author_association", "dtype": "string"}, {"name": "body", "dtype": "string"}, {"name": "reactions", "struct": [{"name": "url", "dtype": "string"}, {"name": "total_count", "dtype": "int64"}, {"name": "+1", "dtype": "int64"}, {"name": "-1", "dtype": "int64"}, {"name": "laugh", "dtype": "int64"}, {"name": "hooray", "dtype": "int64"}, {"name": "confused", "dtype": "int64"}, {"name": "heart", "dtype": "int64"}, {"name": "rocket", "dtype": "int64"}, {"name": "eyes", "dtype": "int64"}]}, {"name": "timeline_url", "dtype": "string"}, {"name": "state_reason", "dtype": "string"}, {"name": "draft", "dtype": "bool"}, {"name": "pull_request", "struct": [{"name": "url", "dtype": "string"}, {"name": "html_url", "dtype": "string"}, {"name": "diff_url", "dtype": "string"}, {"name": "patch_url", "dtype": "string"}, {"name": "merged_at", "dtype": "timestamp[s]"}]}, {"name": "is_pull_request", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 30030287, "num_examples": 5000}], "download_size": 8781855, "dataset_size": 30030287}} | 2023-12-26T10:25:57+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "github-issues"
More Information needed | [
"# Dataset Card for \"github-issues\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"github-issues\"\n\nMore Information needed"
] | [
6,
15
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"github-issues\"\n\nMore Information needed"
] |
79ac16098aec81a72a5bf5abb6f2a8d4ffd8ba23 | # Dataset Card for Dataset Name
<!-- Provide a quick summary of the dataset. -->
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
## Dataset Details
### Dataset Description
<!-- Provide a longer summary of what this dataset is. -->
- **Curated by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
### Dataset Sources [optional]
<!-- Provide the basic links for the dataset. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the dataset is intended to be used. -->
### Direct Use
<!-- This section describes suitable use cases for the dataset. -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the dataset will not work well for. -->
[More Information Needed]
## Dataset Structure
<!-- This section provides a description of the dataset fields, and additional information about the dataset structure such as criteria used to create the splits, relationships between data points, etc. -->
[More Information Needed]
## Dataset Creation
### Curation Rationale
<!-- Motivation for the creation of this dataset. -->
[More Information Needed]
### Source Data
<!-- This section describes the source data (e.g. news text and headlines, social media posts, translated sentences, ...). -->
#### Data Collection and Processing
<!-- This section describes the data collection and processing process such as data selection criteria, filtering and normalization methods, tools and libraries used, etc. -->
[More Information Needed]
#### Who are the source data producers?
<!-- This section describes the people or systems who originally created the data. It should also include self-reported demographic or identity information for the source data creators if this information is available. -->
[More Information Needed]
### Annotations [optional]
<!-- If the dataset contains annotations which are not part of the initial data collection, use this section to describe them. -->
#### Annotation process
<!-- This section describes the annotation process such as annotation tools used in the process, the amount of data annotated, annotation guidelines provided to the annotators, interannotator statistics, annotation validation, etc. -->
[More Information Needed]
#### Who are the annotators?
<!-- This section describes the people or systems who created the annotations. -->
[More Information Needed]
#### Personal and Sensitive Information
<!-- State whether the dataset contains data that might be considered personal, sensitive, or private (e.g., data that reveals addresses, uniquely identifiable names or aliases, racial or ethnic origins, sexual orientations, religious beliefs, political opinions, financial or health data, etc.). If efforts were made to anonymize the data, describe the anonymization process. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
## Citation [optional]
<!-- If there is a paper or blog post introducing the dataset, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the dataset or dataset card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Dataset Card Authors [optional]
[More Information Needed]
## Dataset Card Contact
[More Information Needed] | aayvyas/issues-dataset | [
"size_categories:1K<n<10K",
"license:mit",
"region:us"
] | 2023-12-26T10:46:51+00:00 | {"license": "mit", "size_categories": ["1K<n<10K"]} | 2023-12-26T11:25:43+00:00 | [] | [] | TAGS
#size_categories-1K<n<10K #license-mit #region-us
| # Dataset Card for Dataset Name
This dataset card aims to be a base template for new datasets. It has been generated using this raw template.
## Dataset Details
### Dataset Description
- Curated by:
- Funded by [optional]:
- Shared by [optional]:
- Language(s) (NLP):
- License:
### Dataset Sources [optional]
- Repository:
- Paper [optional]:
- Demo [optional]:
## Uses
### Direct Use
### Out-of-Scope Use
## Dataset Structure
## Dataset Creation
### Curation Rationale
### Source Data
#### Data Collection and Processing
#### Who are the source data producers?
### Annotations [optional]
#### Annotation process
#### Who are the annotators?
#### Personal and Sensitive Information
## Bias, Risks, and Limitations
### Recommendations
Users should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.
[optional]
BibTeX:
APA:
## Glossary [optional]
## More Information [optional]
## Dataset Card Authors [optional]
## Dataset Card Contact
| [
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
"TAGS\n#size_categories-1K<n<10K #license-mit #region-us \n",
"# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.",
"## Dataset Details",
"### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:",
"### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:",
"## Uses",
"### Direct Use",
"### Out-of-Scope Use",
"## Dataset Structure",
"## Dataset Creation",
"### Curation Rationale",
"### Source Data",
"#### Data Collection and Processing",
"#### Who are the source data producers?",
"### Annotations [optional]",
"#### Annotation process",
"#### Who are the annotators?",
"#### Personal and Sensitive Information",
"## Bias, Risks, and Limitations",
"### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:",
"## Glossary [optional]",
"## More Information [optional]",
"## Dataset Card Authors [optional]",
"## Dataset Card Contact"
] | [
23,
34,
4,
40,
29,
3,
4,
9,
6,
5,
7,
4,
7,
10,
9,
5,
9,
8,
10,
46,
8,
7,
10,
5
] | [
"passage: TAGS\n#size_categories-1K<n<10K #license-mit #region-us \n# Dataset Card for Dataset Name\n\n\n\nThis dataset card aims to be a base template for new datasets. It has been generated using this raw template.## Dataset Details### Dataset Description\n\n\n\n\n\n- Curated by: \n- Funded by [optional]: \n- Shared by [optional]: \n- Language(s) (NLP): \n- License:### Dataset Sources [optional]\n\n\n\n- Repository: \n- Paper [optional]: \n- Demo [optional]:## Uses### Direct Use### Out-of-Scope Use## Dataset Structure## Dataset Creation### Curation Rationale### Source Data#### Data Collection and Processing#### Who are the source data producers?### Annotations [optional]#### Annotation process#### Who are the annotators?#### Personal and Sensitive Information## Bias, Risks, and Limitations### Recommendations\n\n\n\nUsers should be made aware of the risks, biases and limitations of the dataset. More information needed for further recommendations.\n\n[optional]\n\n\n\nBibTeX:\n\n\n\nAPA:## Glossary [optional]## More Information [optional]## Dataset Card Authors [optional]## Dataset Card Contact"
] |
59b52fab911279ed12810aa77782a9909912b6be |
## 1. ONLY FOR TEST
## 2. ONLY FOR TEST
| wangxingjun778/test_123 | [
"license:apache-2.0",
"region:us"
] | 2023-12-26T12:16:53+00:00 | {"license": "apache-2.0"} | 2024-02-04T03:43:16+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
|
## 1. ONLY FOR TEST
## 2. ONLY FOR TEST
| [
"## 1. ONLY FOR TEST",
"## 2. ONLY FOR TEST"
] | [
"TAGS\n#license-apache-2.0 #region-us \n",
"## 1. ONLY FOR TEST",
"## 2. ONLY FOR TEST"
] | [
14,
7,
7
] | [
"passage: TAGS\n#license-apache-2.0 #region-us \n## 1. ONLY FOR TEST## 2. ONLY FOR TEST"
] |
48d656a09d4ad9136065153610c21c8b26001280 |
# Portuguese Hate Speech Dataset (TuPy)
The Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.
This repository is organized as follows:
```sh
root.
├── annotations : classification given by annotators
├── raw corpus : dataset before being split between annotators
├── tupy datasets : combined result of annotations
└── README.md
```
## Voting process
To generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.
## Languages
The language used in the dataset is Brazilian Portuguese. The associated BCP-47 code is pt-BR.
# Dataset Structure
## Data Instances
A data point comprises the tweet text (a string) along with thirteen categories, each category is assigned a value of 0 when there is an absence of aggressive or hateful content and a value of 1 when such content is present. These values represent the consensus of annotators regarding the presence of aggressive, hate, ageism, aporophobia, body shame, capacitism, lgbtphobia, political, racism, religious intolerance, misogyny, xenophobia, and others.
An illustration from the multilabel ToLD-Br dataset is depicted below:
```
{'text': 'e tem pobre de direita imbecil que ainda defendia a manutenção da política de preços atrelada ao dólar link'
'aggressive': 1
'hate': 1
'ageism': 0
'aporophobia': 1
'body shame': 0
'capacitism': 0
'lgbtphobia': 0
'political': 1
'racism' : 0
'religious intolerance' : 0
'misogyny' : 0
'xenophobia' : 0
'other' : 0
}
```
## Data Fields
- Text: A string representing a anonymized tweet posted by a user. .
- aggressive: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aggressive language.
- hate: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet is hateful.
- ageism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits ageism.
- aporophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aporophobia.
- body shame: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits body shame.
- capacitism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits capacitism.
- lgbtphobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits lgbtphobia.
- political: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits political.
- racism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits racism.
- religious intolerance: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits religious intolerance.
- misogyny: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits misogyny.
- xenophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits xenophobia.
- other: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits other.
## Acknowledge
The TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro ([UFRJ](https://ufrj.br/)) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering ([COPPE](https://coppe.ufrj.br/)). | victoriadreis/TuPY_dataset_multilabel | [
"task_categories:text-classification",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:pt",
"license:cc-by-sa-4.0",
"hate-speech-detection",
"region:us"
] | 2023-12-26T12:33:08+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["pt"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "TuPy", "language_bcp47": ["pt-BR"], "tags": ["hate-speech-detection"], "configs": [{"config_name": "multi-label", "data_files": [{"split": "full", "path": "tupy_dummy_vote.csv"}]}]} | 2023-12-26T20:39:54+00:00 | [] | [
"pt"
] | TAGS
#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us
|
# Portuguese Hate Speech Dataset (TuPy)
The Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.
This repository is organized as follows:
## Voting process
To generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.
## Languages
The language used in the dataset is Brazilian Portuguese. The associated BCP-47 code is pt-BR.
# Dataset Structure
## Data Instances
A data point comprises the tweet text (a string) along with thirteen categories, each category is assigned a value of 0 when there is an absence of aggressive or hateful content and a value of 1 when such content is present. These values represent the consensus of annotators regarding the presence of aggressive, hate, ageism, aporophobia, body shame, capacitism, lgbtphobia, political, racism, religious intolerance, misogyny, xenophobia, and others.
An illustration from the multilabel ToLD-Br dataset is depicted below:
## Data Fields
- Text: A string representing a anonymized tweet posted by a user. .
- aggressive: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aggressive language.
- hate: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet is hateful.
- ageism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits ageism.
- aporophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aporophobia.
- body shame: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits body shame.
- capacitism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits capacitism.
- lgbtphobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits lgbtphobia.
- political: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits political.
- racism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits racism.
- religious intolerance: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits religious intolerance.
- misogyny: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits misogyny.
- xenophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits xenophobia.
- other: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits other.
## Acknowledge
The TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE). | [
"# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:",
"## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.",
"## Languages\nThe language used in the dataset is Brazilian Portuguese. The associated BCP-47 code is pt-BR.",
"# Dataset Structure",
"## Data Instances\n\nA data point comprises the tweet text (a string) along with thirteen categories, each category is assigned a value of 0 when there is an absence of aggressive or hateful content and a value of 1 when such content is present. These values represent the consensus of annotators regarding the presence of aggressive, hate, ageism, aporophobia, body shame, capacitism, lgbtphobia, political, racism, religious intolerance, misogyny, xenophobia, and others.\nAn illustration from the multilabel ToLD-Br dataset is depicted below:",
"## Data Fields\n\n- Text: A string representing a anonymized tweet posted by a user. .\n- aggressive: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aggressive language.\n- hate: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet is hateful.\n- ageism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits ageism.\n- aporophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aporophobia.\n- body shame: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits body shame.\n- capacitism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits capacitism.\n- lgbtphobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits lgbtphobia.\n- political: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits political.\n- racism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits racism.\n- religious intolerance: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits religious intolerance.\n- misogyny: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits misogyny.\n- xenophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits xenophobia.\n- other: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits other.",
"## Acknowledge\nThe TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE)."
] | [
"TAGS\n#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us \n",
"# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:",
"## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.",
"## Languages\nThe language used in the dataset is Brazilian Portuguese. The associated BCP-47 code is pt-BR.",
"# Dataset Structure",
"## Data Instances\n\nA data point comprises the tweet text (a string) along with thirteen categories, each category is assigned a value of 0 when there is an absence of aggressive or hateful content and a value of 1 when such content is present. These values represent the consensus of annotators regarding the presence of aggressive, hate, ageism, aporophobia, body shame, capacitism, lgbtphobia, political, racism, religious intolerance, misogyny, xenophobia, and others.\nAn illustration from the multilabel ToLD-Br dataset is depicted below:",
"## Data Fields\n\n- Text: A string representing a anonymized tweet posted by a user. .\n- aggressive: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aggressive language.\n- hate: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet is hateful.\n- ageism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits ageism.\n- aporophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits aporophobia.\n- body shame: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits body shame.\n- capacitism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits capacitism.\n- lgbtphobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits lgbtphobia.\n- political: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits political.\n- racism: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits racism.\n- religious intolerance: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits religious intolerance.\n- misogyny: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits misogyny.\n- xenophobia: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits xenophobia.\n- other: Binary values (0 or 1) representing the consensus among annotators on whether the respective tweet exhibits other.",
"## Acknowledge\nThe TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE)."
] | [
95,
96,
65,
28,
6,
140,
418,
68
] | [
"passage: TAGS\n#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us \n# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.## Languages\nThe language used in the dataset is Brazilian Portuguese. The associated BCP-47 code is pt-BR.# Dataset Structure## Data Instances\n\nA data point comprises the tweet text (a string) along with thirteen categories, each category is assigned a value of 0 when there is an absence of aggressive or hateful content and a value of 1 when such content is present. These values represent the consensus of annotators regarding the presence of aggressive, hate, ageism, aporophobia, body shame, capacitism, lgbtphobia, political, racism, religious intolerance, misogyny, xenophobia, and others.\nAn illustration from the multilabel ToLD-Br dataset is depicted below:"
] |
525db8e9f2f7c006f89e7dc5faae35b5f306e5a1 |
**Julia-Proof-Pile-2**
This dataset is part of Proof-Pile-2 dataset. This dataset is consisting of mathematical code, including numerical computing, computer algebra, and formal mathematics.
This entire dataset is in Julia language. It is slightly more than 0.5 Billion tokens. I have removed Meta data from this dataset hence you can directly use it for training purpose.
This dataset is in Jsonl format.
| ajibawa-2023/Julia-Proof-Pile-2 | [
"task_categories:text-generation",
"size_categories:100M<n<1B",
"language:en",
"license:apache-2.0",
"code",
"region:us"
] | 2023-12-26T12:33:48+00:00 | {"language": ["en"], "license": "apache-2.0", "size_categories": ["100M<n<1B"], "task_categories": ["text-generation"], "tags": ["code"]} | 2023-12-26T17:01:01+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-generation #size_categories-100M<n<1B #language-English #license-apache-2.0 #code #region-us
|
Julia-Proof-Pile-2
This dataset is part of Proof-Pile-2 dataset. This dataset is consisting of mathematical code, including numerical computing, computer algebra, and formal mathematics.
This entire dataset is in Julia language. It is slightly more than 0.5 Billion tokens. I have removed Meta data from this dataset hence you can directly use it for training purpose.
This dataset is in Jsonl format.
| [] | [
"TAGS\n#task_categories-text-generation #size_categories-100M<n<1B #language-English #license-apache-2.0 #code #region-us \n"
] | [
43
] | [
"passage: TAGS\n#task_categories-text-generation #size_categories-100M<n<1B #language-English #license-apache-2.0 #code #region-us \n"
] |
20caa318e9f0878f66fcda9f0d6fea8adcadffe0 | # Dataset Card for "WOS11967"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | aeromaki/WOS11967 | [
"region:us"
] | 2023-12-26T12:43:34+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "label", "sequence": "int64"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 14795457.370268237, "num_examples": 10770}, {"name": "test", "num_bytes": 822885.6977521518, "num_examples": 599}, {"name": "validation", "num_bytes": 821511.9319796106, "num_examples": 598}], "download_size": 9325361, "dataset_size": 16439855.0}} | 2023-12-26T12:43:53+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "WOS11967"
More Information needed | [
"# Dataset Card for \"WOS11967\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"WOS11967\"\n\nMore Information needed"
] | [
6,
14
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"WOS11967\"\n\nMore Information needed"
] |
026494f1891b223a0979d89bc269790d5f28ecb1 | # Dataset Card for "aligned_c_x86_O0_exebench_10k_json_cleaned"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | zhangshuoming/aligned_c_x86_O0_exebench_10k_json_cleaned | [
"region:us"
] | 2023-12-26T13:14:29+00:00 | {"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 16767029.979, "num_examples": 7833}], "download_size": 2124503, "dataset_size": 16767029.979}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2023-12-26T13:14:34+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "aligned_c_x86_O0_exebench_10k_json_cleaned"
More Information needed | [
"# Dataset Card for \"aligned_c_x86_O0_exebench_10k_json_cleaned\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"aligned_c_x86_O0_exebench_10k_json_cleaned\"\n\nMore Information needed"
] | [
6,
34
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"aligned_c_x86_O0_exebench_10k_json_cleaned\"\n\nMore Information needed"
] |
700e2a1fcbc17536c3f0dbd7d71f8ff28425ab36 | # Dataset Card for "Indian-Accent-ASR"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | anikak/Indian-Accent-ASR | [
"region:us"
] | 2023-12-26T13:34:29+00:00 | {"dataset_info": {"features": [{"name": "audio", "dtype": "audio"}], "splits": [{"name": "train", "num_bytes": 2156274.0, "num_examples": 15}], "download_size": 1795, "dataset_size": 2156274.0}} | 2023-12-26T13:48:26+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "Indian-Accent-ASR"
More Information needed | [
"# Dataset Card for \"Indian-Accent-ASR\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"Indian-Accent-ASR\"\n\nMore Information needed"
] | [
6,
18
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"Indian-Accent-ASR\"\n\nMore Information needed"
] |
6218f8dfde3ede11856a5e15f27dd7b79a6cbc49 | # Dataset Card for "han-instruct-dataset-v1.0"

## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Repository:** [https://github.com/PyThaiNLP/han](https://github.com/PyThaiNLP/han)
### Dataset Summary
🪿 Han (ห่าน or goose) Instruct Dataset is a Thai instruction dataset by PyThaiNLP. It collect the instruction following in Thai from many source.
Many question are collect from [Reference desk at Thai wikipedia](https://th.wikipedia.org/wiki/%E0%B8%A7%E0%B8%B4%E0%B8%81%E0%B8%B4%E0%B8%9E%E0%B8%B5%E0%B9%80%E0%B8%94%E0%B8%B5%E0%B8%A2:%E0%B8%9B%E0%B8%B8%E0%B8%88%E0%B8%89%E0%B8%B2-%E0%B8%A7%E0%B8%B4%E0%B8%AA%E0%B8%B1%E0%B8%8A%E0%B8%99%E0%B8%B2).
Data sources:
- [Reference desk at Thai wikipedia](https://th.wikipedia.org/wiki/%E0%B8%A7%E0%B8%B4%E0%B8%81%E0%B8%B4%E0%B8%9E%E0%B8%B5%E0%B9%80%E0%B8%94%E0%B8%B5%E0%B8%A2:%E0%B8%9B%E0%B8%B8%E0%B8%88%E0%B8%89%E0%B8%B2-%E0%B8%A7%E0%B8%B4%E0%B8%AA%E0%B8%B1%E0%B8%8A%E0%B8%99%E0%B8%B2).
- [Law from justicechannel.org](https://justicechannel.org/)
- [pythainlp/final_training_set_v1_enth](https://huggingface.co/datasets/pythainlp/final_training_set_v1_enth): Human checked and edited.
- Self-instruct from [WangChanGLM](https://huggingface.co/pythainlp/wangchanglm-7.5B-sft-en)
- [Wannaphong.com](https://www.wannaphong.com)
- Human annotators
### Supported Tasks and Leaderboards
- ChatBot
- Instruction Following
### Languages
Thai
## Dataset Structure
### Data Fields
- inputs: Question
- targets: Answer
### Considerations for Using the Data
The dataset can have a biased from human annotators. We recommend you should checked the dataset to select or remove an instruct follow before train the model or use it own your risk.
### Licensing Information
CC-BY-SA 4.0 | pythainlp/han-instruct-dataset-v1.0 | [
"task_categories:conversational",
"task_categories:text-generation",
"language:th",
"license:cc-by-sa-4.0",
"instruction-following",
"instruction-finetuning",
"region:us"
] | 2023-12-26T13:43:07+00:00 | {"language": ["th"], "license": "cc-by-sa-4.0", "task_categories": ["conversational", "text-generation"], "pretty_name": "o", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "inputs", "dtype": "string"}, {"name": "targets", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1461218, "num_examples": 1951}], "download_size": 599646, "dataset_size": 1461218}, "tags": ["instruction-following", "instruction-finetuning"]} | 2024-02-12T20:14:32+00:00 | [] | [
"th"
] | TAGS
#task_categories-conversational #task_categories-text-generation #language-Thai #license-cc-by-sa-4.0 #instruction-following #instruction-finetuning #region-us
| # Dataset Card for "han-instruct-dataset-v1.0"
 Instruct Dataset is a Thai instruction dataset by PyThaiNLP. It collect the instruction following in Thai from many source.
Many question are collect from Reference desk at Thai wikipedia.
Data sources:
- Reference desk at Thai wikipedia.
- Law from URL
- pythainlp/final_training_set_v1_enth: Human checked and edited.
- Self-instruct from WangChanGLM
- URL
- Human annotators
### Supported Tasks and Leaderboards
- ChatBot
- Instruction Following
### Languages
Thai
## Dataset Structure
### Data Fields
- inputs: Question
- targets: Answer
### Considerations for Using the Data
The dataset can have a biased from human annotators. We recommend you should checked the dataset to select or remove an instruct follow before train the model or use it own your risk.
### Licensing Information
CC-BY-SA 4.0 | [
"# Dataset Card for \"han-instruct-dataset-v1.0\"\n\n Instruct Dataset is a Thai instruction dataset by PyThaiNLP. It collect the instruction following in Thai from many source.\n\nMany question are collect from Reference desk at Thai wikipedia.\n\nData sources:\n- Reference desk at Thai wikipedia.\n- Law from URL\n- pythainlp/final_training_set_v1_enth: Human checked and edited.\n- Self-instruct from WangChanGLM\n- URL\n- Human annotators",
"### Supported Tasks and Leaderboards\n\n- ChatBot\n- Instruction Following",
"### Languages\n\nThai",
"## Dataset Structure",
"### Data Fields\n\n- inputs: Question\n- targets: Answer",
"### Considerations for Using the Data\nThe dataset can have a biased from human annotators. We recommend you should checked the dataset to select or remove an instruct follow before train the model or use it own your risk.",
"### Licensing Information\n\nCC-BY-SA 4.0"
] | [
"TAGS\n#task_categories-conversational #task_categories-text-generation #language-Thai #license-cc-by-sa-4.0 #instruction-following #instruction-finetuning #region-us \n",
"# Dataset Card for \"han-instruct-dataset-v1.0\"\n\n Instruct Dataset is a Thai instruction dataset by PyThaiNLP. It collect the instruction following in Thai from many source.\n\nMany question are collect from Reference desk at Thai wikipedia.\n\nData sources:\n- Reference desk at Thai wikipedia.\n- Law from URL\n- pythainlp/final_training_set_v1_enth: Human checked and edited.\n- Self-instruct from WangChanGLM\n- URL\n- Human annotators",
"### Supported Tasks and Leaderboards\n\n- ChatBot\n- Instruction Following",
"### Languages\n\nThai",
"## Dataset Structure",
"### Data Fields\n\n- inputs: Question\n- targets: Answer",
"### Considerations for Using the Data\nThe dataset can have a biased from human annotators. We recommend you should checked the dataset to select or remove an instruct follow before train the model or use it own your risk.",
"### Licensing Information\n\nCC-BY-SA 4.0"
] | [
54,
26,
125,
10,
116,
18,
5,
6,
15,
51,
12
] | [
"passage: TAGS\n#task_categories-conversational #task_categories-text-generation #language-Thai #license-cc-by-sa-4.0 #instruction-following #instruction-finetuning #region-us \n# Dataset Card for \"han-instruct-dataset-v1.0\"\n\n Instruct Dataset is a Thai instruction dataset by PyThaiNLP. It collect the instruction following in Thai from many source.\n\nMany question are collect from Reference desk at Thai wikipedia.\n\nData sources:\n- Reference desk at Thai wikipedia.\n- Law from URL\n- pythainlp/final_training_set_v1_enth: Human checked and edited.\n- Self-instruct from WangChanGLM\n- URL\n- Human annotators### Supported Tasks and Leaderboards\n\n- ChatBot\n- Instruction Following### Languages\n\nThai## Dataset Structure### Data Fields\n\n- inputs: Question\n- targets: Answer### Considerations for Using the Data\nThe dataset can have a biased from human annotators. We recommend you should checked the dataset to select or remove an instruct follow before train the model or use it own your risk.### Licensing Information\n\nCC-BY-SA 4.0"
] |
8f81a207f25530099d9337d939815aef414842c7 |
Data for the logic experiments in our paper [Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Evaluations](https://arxiv.org/abs/2307.02477).
See https://github.com/ZhaofengWu/counterfactual-evaluation/tree/master/logic for instructions on how to use this data. | ZhaofengWu/FOLIO-counterfactual | [
"license:mit",
"arxiv:2307.02477",
"region:us"
] | 2023-12-26T14:06:04+00:00 | {"license": "mit"} | 2023-12-26T14:51:44+00:00 | [
"2307.02477"
] | [] | TAGS
#license-mit #arxiv-2307.02477 #region-us
|
Data for the logic experiments in our paper Reasoning or Reciting? Exploring the Capabilities and Limitations of Language Models Through Counterfactual Evaluations.
See URL for instructions on how to use this data. | [] | [
"TAGS\n#license-mit #arxiv-2307.02477 #region-us \n"
] | [
19
] | [
"passage: TAGS\n#license-mit #arxiv-2307.02477 #region-us \n"
] |
456a2c55df1ad84dab0a75dbd17ce2e5b28c2a2f |
Multiple choice version of code_contests, for preference learning. | euclaise/code_contests_mc | [
"region:us"
] | 2023-12-26T14:18:46+00:00 | {"dataset_info": {"features": [{"name": "question", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 614058417176, "num_examples": 1767546}], "download_size": 188649995596, "dataset_size": 614058417176}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2024-01-02T18:47:48+00:00 | [] | [] | TAGS
#region-us
|
Multiple choice version of code_contests, for preference learning. | [] | [
"TAGS\n#region-us \n"
] | [
6
] | [
"passage: TAGS\n#region-us \n"
] |
5f7ad93d566612d64b277fe9ad3531a7d38c52d6 | # Dataset Card for "wizardLM_evol_instruct_v2_binarized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | jan-hq/wizardLM_evol_instruct_v2_binarized | [
"region:us"
] | 2023-12-26T16:32:03+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 302019360.3, "num_examples": 128700}, {"name": "test", "num_bytes": 33557706.7, "num_examples": 14300}], "download_size": 161132486, "dataset_size": 335577067.0}} | 2023-12-26T16:32:24+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "wizardLM_evol_instruct_v2_binarized"
More Information needed | [
"# Dataset Card for \"wizardLM_evol_instruct_v2_binarized\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"wizardLM_evol_instruct_v2_binarized\"\n\nMore Information needed"
] | [
6,
26
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"wizardLM_evol_instruct_v2_binarized\"\n\nMore Information needed"
] |
e8dd0c4515b838ae43299425f11f63b882fa48d7 | # Dataset Card for "test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | jay401521/test | [
"region:us"
] | 2023-12-26T16:52:32+00:00 | {"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "domain", "dtype": "string"}, {"name": "label", "dtype": "int64"}, {"name": "rank", "dtype": "int64"}, {"name": "sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2768369, "num_examples": 30021}], "download_size": 1371145, "dataset_size": 2768369}} | 2023-12-26T16:52:35+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "test"
More Information needed | [
"# Dataset Card for \"test\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"test\"\n\nMore Information needed"
] | [
6,
11
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"test\"\n\nMore Information needed"
] |
8ffbf64b16a46a173dca7a820e99d8f27e52736f | # Dataset Card for "magicoder_evol_instruct_binarized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | jan-hq/magicoder_evol_instruct_binarized | [
"region:us"
] | 2023-12-26T16:55:57+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 224078794.45166978, "num_examples": 100064}, {"name": "test", "num_bytes": 24899385.54833023, "num_examples": 11119}], "download_size": 130036042, "dataset_size": 248978180.0}} | 2023-12-26T16:56:16+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "magicoder_evol_instruct_binarized"
More Information needed | [
"# Dataset Card for \"magicoder_evol_instruct_binarized\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"magicoder_evol_instruct_binarized\"\n\nMore Information needed"
] | [
6,
23
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"magicoder_evol_instruct_binarized\"\n\nMore Information needed"
] |
8fb9c98f4bcdd82df0436ffbba0986f53fdd0fc9 | # Dataset Card for "magicoder_oss_instruct_binarized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | jan-hq/magicoder_oss_instruct_binarized | [
"region:us"
] | 2023-12-26T17:01:16+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 155731890.5684668, "num_examples": 67677}, {"name": "test", "num_bytes": 17304310.431533173, "num_examples": 7520}], "download_size": 69912560, "dataset_size": 173036201.0}} | 2023-12-26T17:01:30+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "magicoder_oss_instruct_binarized"
More Information needed | [
"# Dataset Card for \"magicoder_oss_instruct_binarized\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"magicoder_oss_instruct_binarized\"\n\nMore Information needed"
] | [
6,
23
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"magicoder_oss_instruct_binarized\"\n\nMore Information needed"
] |
2919b564ba4f31e91ca956748ee594d8a37816cd | # Dataset Card for "dolphin_coder_binarized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | jan-hq/dolphin_coder_binarized | [
"region:us"
] | 2023-12-26T17:04:01+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "test", "path": "data/test-*"}]}], "dataset_info": {"features": [{"name": "messages", "list": [{"name": "content", "dtype": "string"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 269516157.42079216, "num_examples": 98206}, {"name": "test", "num_bytes": 29946849.57920783, "num_examples": 10912}], "download_size": 134970100, "dataset_size": 299463007.0}} | 2023-12-26T17:04:17+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "dolphin_coder_binarized"
More Information needed | [
"# Dataset Card for \"dolphin_coder_binarized\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"dolphin_coder_binarized\"\n\nMore Information needed"
] | [
6,
20
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"dolphin_coder_binarized\"\n\nMore Information needed"
] |
b5599aeef915d5d762165bb8b78b9d82c2ab074f | # Dataset Card for "the-stack-python_api-10k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | api-misuse/the-stack-python_api-10k | [
"region:us"
] | 2023-12-26T17:05:37+00:00 | {"dataset_info": {"features": [{"name": "repo_name", "dtype": "string"}, {"name": "repo_path", "dtype": "string"}, {"name": "repo_head_hexsha", "dtype": "string"}, {"name": "content", "dtype": "string"}, {"name": "apis", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 88628996, "num_examples": 10000}], "download_size": 30089960, "dataset_size": 88628996}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2024-01-01T10:56:01+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "the-stack-python_api-10k"
More Information needed | [
"# Dataset Card for \"the-stack-python_api-10k\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"the-stack-python_api-10k\"\n\nMore Information needed"
] | [
6,
21
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"the-stack-python_api-10k\"\n\nMore Information needed"
] |
13f4b41f0dc1538da0136872518c953650969249 | # Small dataset generated by phi-2 for testing purposes
This dataset is generated by phi-2 using three different methods for generating prompts, each with a specific task:
* Human Generated : Assessing code
* AI Generated : Assessing math step-by-step reasoning
* From the 🤗 Hub: Assessing helpfulness
**Authors:** Elie Bakouch
The goal of this dataset is to demonstrate that with a small language model (even if not aligned) and a robust reward model, we can generate a reasonably good dataset for fine-tuning on specific tasks.
**This dataset is only a proof of concept and is not intended for use in production.**
We used [phi-2](https://huggingface.co/microsoft/phi-2) as the small language model and [Deberta](https://huggingface.co/OpenAssistant/reward-model-deberta-v3-large-v2) as the reward model.
## Generation process
- The `'human'` part of the dataset is written by the author.
- The `'ai'` is generated by [Mixtral]([Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) using the following prompt :
```
You are a ML engineer with 20 years of experiences, expert in alignment of large language model. You want to construct a robust dataset for doing SFT or RLHF to make LLM's good at math. Generate 5 prompt to give to your model. Don't generate the answer, only the math question.
Here is an example of what we want the prompt to look like :
"Q: Roger has 5 tennis balls. He buys 2 more cans of
tennis balls. Each can has 3 tennis balls. How many
tennis balls does he have now?
A: Roger started with 5 balls. 2 cans of 3 tennis balls
each is 6 tennis balls. 5 + 6 = 11. The answer is 11.
Q: The cafeteria had 23 apples. If they used 20 to
make lunch and bought 6 more, how many apples
do they have?"
```
- The `'hub'` is sourced from the from the [hhh_alignment](https://huggingface.co/datasets/HuggingFaceH4/hhh_alignment) dataset.
# How to use
```python
from datasets import load_dataset
dataset = load_dataset("eliebak/test-phi2-gen-dataset")
```
| eliebak/test-phi2-gen-dataset | [
"multilinguality:monolingual",
"region:us"
] | 2023-12-26T17:39:20+00:00 | {"multilinguality": ["monolingual"], "task_catageories": ["question-answering", "text-generation"], "dataset_info": {"features": [{"name": "prompt_id", "dtype": "int64"}, {"name": "system_instruction", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "output_instruction", "dtype": "string"}, {"name": "answer", "dtype": "string"}, {"name": "score", "sequence": "float32"}], "splits": [{"name": "human", "num_bytes": 4053, "num_examples": 3}, {"name": "ai", "num_bytes": 2470, "num_examples": 3}, {"name": "hub", "num_bytes": 5512, "num_examples": 4}], "download_size": 38291, "dataset_size": 12035}, "configs": [{"config_name": "default", "data_files": [{"split": "human", "path": "data/human-*"}, {"split": "ai", "path": "data/ai-*"}, {"split": "hub", "path": "data/hub-*"}]}]} | 2023-12-26T20:54:25+00:00 | [] | [] | TAGS
#multilinguality-monolingual #region-us
| # Small dataset generated by phi-2 for testing purposes
This dataset is generated by phi-2 using three different methods for generating prompts, each with a specific task:
* Human Generated : Assessing code
* AI Generated : Assessing math step-by-step reasoning
* From the Hub: Assessing helpfulness
Authors: Elie Bakouch
The goal of this dataset is to demonstrate that with a small language model (even if not aligned) and a robust reward model, we can generate a reasonably good dataset for fine-tuning on specific tasks.
This dataset is only a proof of concept and is not intended for use in production.
We used phi-2 as the small language model and Deberta as the reward model.
## Generation process
- The ''human'' part of the dataset is written by the author.
- The ''ai'' is generated by Mixtral using the following prompt :
- The ''hub'' is sourced from the from the hhh_alignment dataset.
# How to use
| [
"# Small dataset generated by phi-2 for testing purposes\nThis dataset is generated by phi-2 using three different methods for generating prompts, each with a specific task:\n* Human Generated : Assessing code\n* AI Generated : Assessing math step-by-step reasoning\n* From the Hub: Assessing helpfulness\n\nAuthors: Elie Bakouch\n\nThe goal of this dataset is to demonstrate that with a small language model (even if not aligned) and a robust reward model, we can generate a reasonably good dataset for fine-tuning on specific tasks. \n\nThis dataset is only a proof of concept and is not intended for use in production.\n\nWe used phi-2 as the small language model and Deberta as the reward model.",
"## Generation process\n- The ''human'' part of the dataset is written by the author.\n- The ''ai'' is generated by Mixtral using the following prompt :\n\n\n- The ''hub'' is sourced from the from the hhh_alignment dataset.",
"# How to use"
] | [
"TAGS\n#multilinguality-monolingual #region-us \n",
"# Small dataset generated by phi-2 for testing purposes\nThis dataset is generated by phi-2 using three different methods for generating prompts, each with a specific task:\n* Human Generated : Assessing code\n* AI Generated : Assessing math step-by-step reasoning\n* From the Hub: Assessing helpfulness\n\nAuthors: Elie Bakouch\n\nThe goal of this dataset is to demonstrate that with a small language model (even if not aligned) and a robust reward model, we can generate a reasonably good dataset for fine-tuning on specific tasks. \n\nThis dataset is only a proof of concept and is not intended for use in production.\n\nWe used phi-2 as the small language model and Deberta as the reward model.",
"## Generation process\n- The ''human'' part of the dataset is written by the author.\n- The ''ai'' is generated by Mixtral using the following prompt :\n\n\n- The ''hub'' is sourced from the from the hhh_alignment dataset.",
"# How to use"
] | [
14,
165,
55,
4
] | [
"passage: TAGS\n#multilinguality-monolingual #region-us \n# Small dataset generated by phi-2 for testing purposes\nThis dataset is generated by phi-2 using three different methods for generating prompts, each with a specific task:\n* Human Generated : Assessing code\n* AI Generated : Assessing math step-by-step reasoning\n* From the Hub: Assessing helpfulness\n\nAuthors: Elie Bakouch\n\nThe goal of this dataset is to demonstrate that with a small language model (even if not aligned) and a robust reward model, we can generate a reasonably good dataset for fine-tuning on specific tasks. \n\nThis dataset is only a proof of concept and is not intended for use in production.\n\nWe used phi-2 as the small language model and Deberta as the reward model.## Generation process\n- The ''human'' part of the dataset is written by the author.\n- The ''ai'' is generated by Mixtral using the following prompt :\n\n\n- The ''hub'' is sourced from the from the hhh_alignment dataset.# How to use"
] |
7858f2c61f1229e6f831aa7330ebb2ee2033740b |
# About
Synthetic Textbooks generated utilizing [Google Gemini Pro API](https://ai.google.dev); using [muse](https://github.com/thooton/muse).
## Implications
The generation of extensive open-source synthetic textbook data serves as a crucial catalyst for the development of highly efficient and performant open-source models. Notably, the [phi-2](https://huggingface.co/microsoft/phi-2) model stands as a testament to this advancement, having undergone training on a substantial corpus of 250 billion tokens comprising a blend of synthetic data and webtext.
## Note
Kindly take note of the terms and policies associated with the usage of the Google Generative AI API when incorporating this dataset: https://ai.google.dev/terms | Tanvir1337/muse_textbooks | [
"task_categories:text-generation",
"task_categories:text2text-generation",
"task_ids:natural-language-inference",
"language_creators:AI Generated",
"language_creators:Google Gemini",
"multilinguality:monolingual",
"size_categories:1M<n<10M",
"language:en",
"language:code",
"license:cc-by-4.0",
"Gemini",
"Synthetic",
"Textbook",
"region:us"
] | 2023-12-26T18:02:51+00:00 | {"annotations_creators": [], "language_creators": ["AI Generated", "Google Gemini"], "language": ["en", "code"], "license": "cc-by-4.0", "multilinguality": ["monolingual"], "size_categories": ["1M<n<10M"], "source_datasets": [], "task_categories": ["text-generation", "text2text-generation"], "task_ids": ["natural-language-inference"], "pretty_name": "Muse Textbooks", "tags": ["Gemini", "Synthetic", "Textbook"]} | 2024-01-14T05:12:55+00:00 | [] | [
"en",
"code"
] | TAGS
#task_categories-text-generation #task_categories-text2text-generation #task_ids-natural-language-inference #language_creators-AI Generated #language_creators-Google Gemini #multilinguality-monolingual #size_categories-1M<n<10M #language-English #language-code #license-cc-by-4.0 #Gemini #Synthetic #Textbook #region-us
|
# About
Synthetic Textbooks generated utilizing Google Gemini Pro API; using muse.
## Implications
The generation of extensive open-source synthetic textbook data serves as a crucial catalyst for the development of highly efficient and performant open-source models. Notably, the phi-2 model stands as a testament to this advancement, having undergone training on a substantial corpus of 250 billion tokens comprising a blend of synthetic data and webtext.
## Note
Kindly take note of the terms and policies associated with the usage of the Google Generative AI API when incorporating this dataset: URL | [
"# About\n\nSynthetic Textbooks generated utilizing Google Gemini Pro API; using muse.",
"## Implications\n\nThe generation of extensive open-source synthetic textbook data serves as a crucial catalyst for the development of highly efficient and performant open-source models. Notably, the phi-2 model stands as a testament to this advancement, having undergone training on a substantial corpus of 250 billion tokens comprising a blend of synthetic data and webtext.",
"## Note\n\nKindly take note of the terms and policies associated with the usage of the Google Generative AI API when incorporating this dataset: URL"
] | [
"TAGS\n#task_categories-text-generation #task_categories-text2text-generation #task_ids-natural-language-inference #language_creators-AI Generated #language_creators-Google Gemini #multilinguality-monolingual #size_categories-1M<n<10M #language-English #language-code #license-cc-by-4.0 #Gemini #Synthetic #Textbook #region-us \n",
"# About\n\nSynthetic Textbooks generated utilizing Google Gemini Pro API; using muse.",
"## Implications\n\nThe generation of extensive open-source synthetic textbook data serves as a crucial catalyst for the development of highly efficient and performant open-source models. Notably, the phi-2 model stands as a testament to this advancement, having undergone training on a substantial corpus of 250 billion tokens comprising a blend of synthetic data and webtext.",
"## Note\n\nKindly take note of the terms and policies associated with the usage of the Google Generative AI API when incorporating this dataset: URL"
] | [
111,
21,
83,
30
] | [
"passage: TAGS\n#task_categories-text-generation #task_categories-text2text-generation #task_ids-natural-language-inference #language_creators-AI Generated #language_creators-Google Gemini #multilinguality-monolingual #size_categories-1M<n<10M #language-English #language-code #license-cc-by-4.0 #Gemini #Synthetic #Textbook #region-us \n# About\n\nSynthetic Textbooks generated utilizing Google Gemini Pro API; using muse.## Implications\n\nThe generation of extensive open-source synthetic textbook data serves as a crucial catalyst for the development of highly efficient and performant open-source models. Notably, the phi-2 model stands as a testament to this advancement, having undergone training on a substantial corpus of 250 billion tokens comprising a blend of synthetic data and webtext.## Note\n\nKindly take note of the terms and policies associated with the usage of the Google Generative AI API when incorporating this dataset: URL"
] |
a26db086ba321135746e9968ab2546ea78c0a074 | # Dataset Card for "story_cloze_pt"
This is a portuguese translation of the [xstory_cloze dataset](https://huggingface.co/datasets/juletxara/xstory_cloze). The translation was performed using the Google Translate API.
This dataset follows the same structure as the original. | portuguese-benchmark-datasets/story_cloze_pt | [
"region:us"
] | 2023-12-26T18:31:55+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "eval", "path": "data/eval-*"}]}], "dataset_info": {"features": [{"name": "story_id", "dtype": "string"}, {"name": "input_sentence_1", "dtype": "string"}, {"name": "input_sentence_2", "dtype": "string"}, {"name": "input_sentence_3", "dtype": "string"}, {"name": "input_sentence_4", "dtype": "string"}, {"name": "sentence_quiz1", "dtype": "string"}, {"name": "sentence_quiz2", "dtype": "string"}, {"name": "answer_right_ending", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 128784, "num_examples": 360}, {"name": "eval", "num_bytes": 537102, "num_examples": 1511}], "download_size": 476330, "dataset_size": 665886}} | 2023-12-26T18:53:04+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "story_cloze_pt"
This is a portuguese translation of the xstory_cloze dataset. The translation was performed using the Google Translate API.
This dataset follows the same structure as the original. | [
"# Dataset Card for \"story_cloze_pt\"\n\nThis is a portuguese translation of the xstory_cloze dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"story_cloze_pt\"\n\nThis is a portuguese translation of the xstory_cloze dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] | [
6,
54
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"story_cloze_pt\"\n\nThis is a portuguese translation of the xstory_cloze dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] |
004e6a71278c3859a4b35be539104d2366c74e0c | # Dataset Card for "xpaws_pt"
This is a portuguese translation of the [x-paws dataset](https://huggingface.co/datasets/paws-x). The translation was performed using the Google Translate API.
This dataset follows the same structure as the original. | portuguese-benchmark-datasets/xpaws_pt | [
"region:us"
] | 2023-12-26T18:38:18+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "test", "path": "data/test-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "sentence1", "dtype": "string"}, {"name": "sentence2", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "test", "num_bytes": 513914, "num_examples": 2000}, {"name": "validation", "num_bytes": 512235, "num_examples": 2000}], "download_size": 645673, "dataset_size": 1026149}} | 2023-12-26T18:48:39+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "xpaws_pt"
This is a portuguese translation of the x-paws dataset. The translation was performed using the Google Translate API.
This dataset follows the same structure as the original. | [
"# Dataset Card for \"xpaws_pt\"\n\nThis is a portuguese translation of the x-paws dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"xpaws_pt\"\n\nThis is a portuguese translation of the x-paws dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] | [
6,
52
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"xpaws_pt\"\n\nThis is a portuguese translation of the x-paws dataset. The translation was performed using the Google Translate API.\n\nThis dataset follows the same structure as the original."
] |
9377ee73d09c89b3c0309b4b18fc73b2c7589ba5 | # Dataset Card for "pretrain_punctuation"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | xwjzds/pretrain_punctuation | [
"region:us"
] | 2023-12-26T19:06:50+00:00 | {"dataset_info": {"features": [{"name": "input", "dtype": "string"}, {"name": "output", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2388642394, "num_examples": 631331}], "download_size": 1485646531, "dataset_size": 2388642394}} | 2024-01-01T18:00:51+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "pretrain_punctuation"
More Information needed | [
"# Dataset Card for \"pretrain_punctuation\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"pretrain_punctuation\"\n\nMore Information needed"
] | [
6,
16
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"pretrain_punctuation\"\n\nMore Information needed"
] |
02704081c20c575882547cf1d271779751ad5b32 |
# Portuguese Hate Speech Dataset (TuPy)
The Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.
This repository is organized as follows:
```sh
root.
├── annotations : classification given by annotators
├── raw corpus : dataset before being split between annotators
├── tupy datasets : combined result of annotations
└── README.md
```
## Voting process
To generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.
## Acknowledge
The TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro ([UFRJ](https://ufrj.br/)) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering ([COPPE](https://coppe.ufrj.br/)). | victoriadreis/TuPY_dataset_binary | [
"task_categories:text-classification",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:1K<n<10K",
"source_datasets:original",
"language:pt",
"license:cc-by-sa-4.0",
"hate-speech-detection",
"region:us"
] | 2023-12-26T19:29:40+00:00 | {"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["pt"], "license": ["cc-by-sa-4.0"], "multilinguality": ["monolingual"], "size_categories": ["1K<n<10K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": [], "pretty_name": "TuPy", "language_bcp47": ["pt-BR"], "tags": ["hate-speech-detection"], "configs": [{"config_name": "binary", "data_files": [{"split": "full", "path": "tupy_binary_vote.csv"}]}]} | 2023-12-26T19:30:50+00:00 | [] | [
"pt"
] | TAGS
#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us
|
# Portuguese Hate Speech Dataset (TuPy)
The Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.
This repository is organized as follows:
## Voting process
To generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.
## Acknowledge
The TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE). | [
"# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:",
"## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.",
"## Acknowledge\nThe TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE)."
] | [
"TAGS\n#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us \n",
"# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:",
"## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.",
"## Acknowledge\nThe TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE)."
] | [
95,
96,
65,
68
] | [
"passage: TAGS\n#task_categories-text-classification #annotations_creators-crowdsourced #language_creators-crowdsourced #multilinguality-monolingual #size_categories-1K<n<10K #source_datasets-original #language-Portuguese #license-cc-by-sa-4.0 #hate-speech-detection #region-us \n# Portuguese Hate Speech Dataset (TuPy)\n\nThe Portuguese hate speech dataset (TuPy) is an annotated corpus designed to facilitate the development of advanced hate speech detection models using machine learning (ML) and natural language processing (NLP) techniques. TuPy is formed by 10000 thousand unpublished annotated tweets collected in 2023.\n\nThis repository is organized as follows:## Voting process\nTo generate the binary matrices, we employed a straightforward voting process. Three distinct evaluations were assigned to each document. In cases where a document received two or more identical classifications, the adopted value is set to 1; otherwise, it is marked as 0.## Acknowledge\nThe TuPy project is the result of the development of Felipe Oliveira's thesis and the work of several collaborators. This project is financed by the Federal University of Rio de Janeiro (UFRJ) and the Alberto Luiz Coimbra Institute for Postgraduate Studies and Research in Engineering (COPPE)."
] |
a2ba53f6dd7bcd12dd40538364b90c611db96688 | # 🌐💬 GranD-f - Grounded Conversation Generation (GCG) Dataset
The GranD-f datasets comprise four datasets: one high-quality human-annotated set proposed in our GLaMM paper, and 3 other open-source datasets including Open-PSG, RefCOCO-g and Flickr-30k, repurposed for the GCG task using OpenAI GPT4.
## 💻 Download
```
git lfs install
git clone https://huggingface.co/datasets/MBZUAI/GranD-f
```
## 📚 Additional Resources
- **Paper:** [ArXiv](https://arxiv.org/abs/2311.03356).
- **GitHub Repository:** [GitHub - GLaMM](https://github.com/mbzuai-oryx/groundingLMM).
- **Project Page:** For a detailed overview and insights into the project, visit our [Project Page - GLaMM](https://mbzuai-oryx.github.io/groundingLMM/).
## 📜 Citations and Acknowledgments
```bibtex
@article{hanoona2023GLaMM,
title={GLaMM: Pixel Grounding Large Multimodal Model},
author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},
journal={ArXiv 2311.03356},
year={2023}
}
| MBZUAI/GranD-f | [
"license:apache-2.0",
"arxiv:2311.03356",
"region:us"
] | 2023-12-26T20:22:52+00:00 | {"license": "apache-2.0"} | 2023-12-26T20:47:35+00:00 | [
"2311.03356"
] | [] | TAGS
#license-apache-2.0 #arxiv-2311.03356 #region-us
| # GranD-f - Grounded Conversation Generation (GCG) Dataset
The GranD-f datasets comprise four datasets: one high-quality human-annotated set proposed in our GLaMM paper, and 3 other open-source datasets including Open-PSG, RefCOCO-g and Flickr-30k, repurposed for the GCG task using OpenAI GPT4.
## Download
## Additional Resources
- Paper: ArXiv.
- GitHub Repository: GitHub - GLaMM.
- Project Page: For a detailed overview and insights into the project, visit our Project Page - GLaMM.
## Citations and Acknowledgments
'''bibtex
@article{hanoona2023GLaMM,
title={GLaMM: Pixel Grounding Large Multimodal Model},
author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},
journal={ArXiv 2311.03356},
year={2023}
}
| [
"# GranD-f - Grounded Conversation Generation (GCG) Dataset\n\nThe GranD-f datasets comprise four datasets: one high-quality human-annotated set proposed in our GLaMM paper, and 3 other open-source datasets including Open-PSG, RefCOCO-g and Flickr-30k, repurposed for the GCG task using OpenAI GPT4.",
"## Download",
"## Additional Resources\n- Paper: ArXiv.\n- GitHub Repository: GitHub - GLaMM.\n- Project Page: For a detailed overview and insights into the project, visit our Project Page - GLaMM.",
"## Citations and Acknowledgments\n\n'''bibtex\n @article{hanoona2023GLaMM,\n title={GLaMM: Pixel Grounding Large Multimodal Model},\n author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},\n journal={ArXiv 2311.03356},\n year={2023}\n }"
] | [
"TAGS\n#license-apache-2.0 #arxiv-2311.03356 #region-us \n",
"# GranD-f - Grounded Conversation Generation (GCG) Dataset\n\nThe GranD-f datasets comprise four datasets: one high-quality human-annotated set proposed in our GLaMM paper, and 3 other open-source datasets including Open-PSG, RefCOCO-g and Flickr-30k, repurposed for the GCG task using OpenAI GPT4.",
"## Download",
"## Additional Resources\n- Paper: ArXiv.\n- GitHub Repository: GitHub - GLaMM.\n- Project Page: For a detailed overview and insights into the project, visit our Project Page - GLaMM.",
"## Citations and Acknowledgments\n\n'''bibtex\n @article{hanoona2023GLaMM,\n title={GLaMM: Pixel Grounding Large Multimodal Model},\n author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},\n journal={ArXiv 2311.03356},\n year={2023}\n }"
] | [
23,
92,
2,
54,
130
] | [
"passage: TAGS\n#license-apache-2.0 #arxiv-2311.03356 #region-us \n# GranD-f - Grounded Conversation Generation (GCG) Dataset\n\nThe GranD-f datasets comprise four datasets: one high-quality human-annotated set proposed in our GLaMM paper, and 3 other open-source datasets including Open-PSG, RefCOCO-g and Flickr-30k, repurposed for the GCG task using OpenAI GPT4.## Download## Additional Resources\n- Paper: ArXiv.\n- GitHub Repository: GitHub - GLaMM.\n- Project Page: For a detailed overview and insights into the project, visit our Project Page - GLaMM.## Citations and Acknowledgments\n\n'''bibtex\n @article{hanoona2023GLaMM,\n title={GLaMM: Pixel Grounding Large Multimodal Model},\n author={Rasheed, Hanoona and Maaz, Muhammad and Shaji, Sahal and Shaker, Abdelrahman and Khan, Salman and Cholakkal, Hisham and Anwer, Rao M. and Xing, Eric and Yang, Ming-Hsuan and Khan, Fahad S.},\n journal={ArXiv 2311.03356},\n year={2023}\n }"
] |
3f8418883e84b99477c34a4ef501c8d05b685f1d | # Advent of Code Solutions Dataset
## Introduction
This dataset contains solutions and input data for the **Advent of Code** programming puzzles from **2015**, **2016**, **2017**, **2018**, **2019**, **2020**, **2021**, **2022** and **2023**. The **Advent of Code** is an annual set of programming challenges that can be solved in any language. At the moment the dataset contains **all solutions** in **Go** and **many solutions** in **Python**, **JavaScript**, **Java**, **Scala**, **Kotlin**, **Groovy**, **Clojure**, **C#**, **F#**, **Swift**, **Objective-C**, **R**, **Haskell**, **Ocaml**, **Ruby**, **Elixir**, **Rust**, **C**, **C++**, **Fortran90**, **Perl**, **Crystal**, **Lua**, **PHP**, **Dart**, **D**, **TypeScript**.
The dataset is structured as follows:
* All years of Advent of Code puzzles are stored together in a single dataset "train.json"
* Each entry contains:
* The name of the puzzle (e.g., "day1_part1_2017")
* The full text of the puzzle task
* The input data provided for the puzzle
* The correct answer to the puzzle as a string (e.g., "1914")
* The full code for the solution
* The programming language used for the solution (e.g., "go")
* The year of the puzzle (e.g., 2017)
This structured format allows easy analysis and comparison of different solutions and languages for each **Advent of Code** puzzle.
## Dataset Structure
* The dataset is organized store all years of **Advent of Code** puzzles together in a single dataset "train.json".
## Data Fields
Each entry in the dataset consists of the following fields:
- **name**: The unique identifier for each challenge, formatted as "dayX_partY_YEAR" (e.g., "day1_part1_2017").
- **task**: A detailed description of the challenge. The description of part 2 includes the description of part 1 and the answer to part 1, because part 2 requires information from part 1.
- **input**: The input data provided for the challenge (for my account).
- **answer**: The correct answer as a string (e.g., "1914").
- **solution**: The full solution code for the challenge.
- **solution_lang**: The programming language used for the solution (e.g., "go").
- **year**: The year of the challenge (e.g., 2017).
### Sample Entry
```json
{
"name": "day1_part1_2017",
"task": "--- Day 1: Inverse Captcha ---\nThe night before Christmas, one of Santa's Elves calls you in a panic. \"The printer's broken! We can't print the Naughty or Nice List!\" By the time you make it to sub-basement 17, there are only a few minutes until midnight. \"We have a big problem,\" she says; \"there must be almost fifty bugs in this system, but nothing else can print The List. Stand in this square, quick! There's no time to explain; if you can convince them to pay you in stars, you'll be able to--\" She pulls a lever and the world goes blurry.\n\nWhen your eyes can focus again, everything seems a lot more pixelated than before. She must have sent you inside the computer! You check the system clock: 25 milliseconds until midnight. With that much time, you should be able to collect all fifty stars by December 25th.\n\nCollect stars by solving puzzles. Two puzzles will be made available on each day millisecond in the Advent calendar; the second puzzle is unlocked when you complete the first. Each puzzle grants one star. Good luck!\n\nYou're standing in a room with \"digitization quarantine\" written in LEDs along one wall. The only door is locked, but it includes a small interface. \"Restricted Area - Strictly No Digitized Users Allowed.\"\n\nIt goes on to explain that you may only leave by solving a captcha to prove you're not a human. Apparently, you only get one millisecond to solve the captcha: too fast for a normal human, but it feels like hours to you.\n\nThe captcha requires you to review a sequence of digits (your puzzle input) and find the sum of all digits that match the next digit in the list. The list is circular, so the digit after the last digit is the first digit in the list.\n\nFor example:\n\n1122 produces a sum of 3 (1 + 2) because the first digit (1) matches the second digit and the third digit (2) matches the fourth digit.\n1111 produces 4 because each digit (all 1) matches the next.\n1234 produces 0 because no digit matches the next.\n91212129 produces 9 because the only digit that matches the next one is the last digit, 9.\nWhat is the solution to your captcha?",
"input": "111831362354551173134957758417849716877188716338227121869992652972154651632296676464285261171625892888598738721925357479249486886375279741651224686642647267979445939836673253446489428761486828844713816198414852769942459766921928735591892723619845983117283575762694758223956262583556675379533479458964152461973321432768858165818549484229241869657725166769662249574889435227698271439423511175653875622976121749344756734658248245212273242115488961818719828258936653236351924292251821352389471971641957941593141159982696396228218461855752555358856127582128823657548151545741663495182446281491763249374581774426225822474112338745629194213976328762985884127324443984163571711941113986826168921187567861288268744663142867866165546795621466134333541274633769865956692539151971953651886381195877638919355216642731848659649263217258599456646635412623461138792945854536154976732167439355548965778313264824237176152196614333748919711422188148687299757751955297978137561935963366682742334867854892581388263132968999722366495346854828316842352829827989419393594846893842746149235681921951476132585199265366836257322121681471877187847219712325933714149151568922456111149524629995933156924418468567649494728828858254296824372929211977446729691143995333874752448315632185286348657293395339475256796591968717487615896959976413637422536563273537972841783386358764761364989261322293887361558128521915542454126546182855197637753115352541578972298715522386683914777967729562229395936593272269661295295223113186683594678533511783187422193626234573849881185849626389774394351115527451886962844431947188429195191724662982411619815811652741733744864411666766133951954595344837179635668177845937578575117168875754181523584442699384167111317875138179567939174589917894597492816476662186746837552978671142265114426813792549412632291424594239391853358914643327549192165466628737614581458189732579814919468795493415762517372227862614224911844744711698557324454211123571327224554259626961741919243229688684838813912553397698937237114287944446722919198743189848428399356842626198635297851274879128322358195585284984366515428245928111112613638341345371",
"answer": "1044",
"solution": "package main\n\nimport (\n\t\"fmt\"\n\t\"os\"\n\t\"strings\"\n)\n\nfunc main() {\n\tdata, err := os.ReadFile(\"input.txt\")\n\tif err != nil {\n\t\tfmt.Println(\"File reading error\", err)\n\t\treturn\n\t}\n\n\tinput := strings.TrimSpace(string(data))\n\tsum := 0\n\n\tfor i := 0; i < len(input); i++ {\n\t\tnext := (i + 1) % len(input)\n\t\tif input[i] == input[next] {\n\t\t\tsum += int(input[i] - '0')\n\t\t}\n\t}\n\n\tfmt.Println(sum)\n}",
"solution_lang": "go",
"year": 2017
}
```
## Creation Process
I implemented and verified solutions for various **Advent Of Code** challenges. For each challenge, I solved the puzzles using my personal input data from **Advent of Code** or generated, tested and modified solution by open source models (e.g. codelama, mixtral etc.). This dataset contains my verified solutions and associated input data for these challenges.
## Usage
### Filtering Solutions by Programming Language
Here's an example of how to use the script to filter solutions by programming language:
```python
# Filter the dataset for solutions written in go
go_solutions = dataset.filter(lambda example: example['solution_lang'] == 'go')
```
### Filtering Solutions by Year
Here's an example of how to use the script to filter solutions by year:
```python
# Filter the dataset for solutions from 2017
year_2017_solutions = dataset.filter(lambda example: example['year'] == 2017)
```
## Future Expansion
The dataset currently includes data for the years **2015**, **2016**, **2017**, **2018**, **2019**, **2020**, **2021**, **2022**, **2023** with plans to expand it to include additional years and programming languages. As new years are added, the dataset structure will remain consistent.
## Metadata
- License: Apache 2.0
- Authors: Aleksandar Dimov
## Contributing
Contributions to this dataset are welcome, especially for adding solutions in different programming languages or/and for years not yet covered. To contribute, please ensure your submission follows the existing dataset structure and formatting.
## Contact
For any queries or contributions, please make PR or contact [email protected].
| isavita/advent-of-code | [
"task_categories:text-generation",
"size_categories:1k<n<10k",
"language:en",
"license:apache-2.0",
"advent of code",
"code",
"region:us"
] | 2023-12-26T20:28:20+00:00 | {"language": ["en"], "license": ["apache-2.0"], "size_categories": ["1k<n<10k"], "task_categories": ["text-generation"], "title": "Advent of Code Solutions Dataset", "tags": ["advent of code", "code"], "description": "This dataset contains solutions and related data for Advent of Code challenges, starting with the year 2015. It includes tasks, inputs, answers, solution codes, and the programming languages used for the solutions."} | 2024-02-17T12:36:18+00:00 | [] | [
"en"
] | TAGS
#task_categories-text-generation #size_categories-1k<n<10k #language-English #license-apache-2.0 #advent of code #code #region-us
| # Advent of Code Solutions Dataset
## Introduction
This dataset contains solutions and input data for the Advent of Code programming puzzles from 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022 and 2023. The Advent of Code is an annual set of programming challenges that can be solved in any language. At the moment the dataset contains all solutions in Go and many solutions in Python, JavaScript, Java, Scala, Kotlin, Groovy, Clojure, C#, F#, Swift, Objective-C, R, Haskell, Ocaml, Ruby, Elixir, Rust, C, C++, Fortran90, Perl, Crystal, Lua, PHP, Dart, D, TypeScript.
The dataset is structured as follows:
* All years of Advent of Code puzzles are stored together in a single dataset "URL"
* Each entry contains:
* The name of the puzzle (e.g., "day1_part1_2017")
* The full text of the puzzle task
* The input data provided for the puzzle
* The correct answer to the puzzle as a string (e.g., "1914")
* The full code for the solution
* The programming language used for the solution (e.g., "go")
* The year of the puzzle (e.g., 2017)
This structured format allows easy analysis and comparison of different solutions and languages for each Advent of Code puzzle.
## Dataset Structure
* The dataset is organized store all years of Advent of Code puzzles together in a single dataset "URL".
## Data Fields
Each entry in the dataset consists of the following fields:
- name: The unique identifier for each challenge, formatted as "dayX_partY_YEAR" (e.g., "day1_part1_2017").
- task: A detailed description of the challenge. The description of part 2 includes the description of part 1 and the answer to part 1, because part 2 requires information from part 1.
- input: The input data provided for the challenge (for my account).
- answer: The correct answer as a string (e.g., "1914").
- solution: The full solution code for the challenge.
- solution_lang: The programming language used for the solution (e.g., "go").
- year: The year of the challenge (e.g., 2017).
### Sample Entry
## Creation Process
I implemented and verified solutions for various Advent Of Code challenges. For each challenge, I solved the puzzles using my personal input data from Advent of Code or generated, tested and modified solution by open source models (e.g. codelama, mixtral etc.). This dataset contains my verified solutions and associated input data for these challenges.
## Usage
### Filtering Solutions by Programming Language
Here's an example of how to use the script to filter solutions by programming language:
### Filtering Solutions by Year
Here's an example of how to use the script to filter solutions by year:
## Future Expansion
The dataset currently includes data for the years 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023 with plans to expand it to include additional years and programming languages. As new years are added, the dataset structure will remain consistent.
## Metadata
- License: Apache 2.0
- Authors: Aleksandar Dimov
## Contributing
Contributions to this dataset are welcome, especially for adding solutions in different programming languages or/and for years not yet covered. To contribute, please ensure your submission follows the existing dataset structure and formatting.
## Contact
For any queries or contributions, please make PR or contact isavitaisa@URL.
| [
"# Advent of Code Solutions Dataset",
"## Introduction\nThis dataset contains solutions and input data for the Advent of Code programming puzzles from 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022 and 2023. The Advent of Code is an annual set of programming challenges that can be solved in any language. At the moment the dataset contains all solutions in Go and many solutions in Python, JavaScript, Java, Scala, Kotlin, Groovy, Clojure, C#, F#, Swift, Objective-C, R, Haskell, Ocaml, Ruby, Elixir, Rust, C, C++, Fortran90, Perl, Crystal, Lua, PHP, Dart, D, TypeScript.\n\nThe dataset is structured as follows:\n* All years of Advent of Code puzzles are stored together in a single dataset \"URL\"\n* Each entry contains:\n * The name of the puzzle (e.g., \"day1_part1_2017\")\n * The full text of the puzzle task\n * The input data provided for the puzzle\n * The correct answer to the puzzle as a string (e.g., \"1914\")\n * The full code for the solution\n * The programming language used for the solution (e.g., \"go\")\n * The year of the puzzle (e.g., 2017)\n\nThis structured format allows easy analysis and comparison of different solutions and languages for each Advent of Code puzzle.",
"## Dataset Structure\n* The dataset is organized store all years of Advent of Code puzzles together in a single dataset \"URL\".",
"## Data Fields\nEach entry in the dataset consists of the following fields:\n\n- name: The unique identifier for each challenge, formatted as \"dayX_partY_YEAR\" (e.g., \"day1_part1_2017\").\n- task: A detailed description of the challenge. The description of part 2 includes the description of part 1 and the answer to part 1, because part 2 requires information from part 1.\n- input: The input data provided for the challenge (for my account).\n- answer: The correct answer as a string (e.g., \"1914\").\n- solution: The full solution code for the challenge.\n- solution_lang: The programming language used for the solution (e.g., \"go\").\n- year: The year of the challenge (e.g., 2017).",
"### Sample Entry",
"## Creation Process\nI implemented and verified solutions for various Advent Of Code challenges. For each challenge, I solved the puzzles using my personal input data from Advent of Code or generated, tested and modified solution by open source models (e.g. codelama, mixtral etc.). This dataset contains my verified solutions and associated input data for these challenges.",
"## Usage",
"### Filtering Solutions by Programming Language\nHere's an example of how to use the script to filter solutions by programming language:",
"### Filtering Solutions by Year\nHere's an example of how to use the script to filter solutions by year:",
"## Future Expansion\nThe dataset currently includes data for the years 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023 with plans to expand it to include additional years and programming languages. As new years are added, the dataset structure will remain consistent.",
"## Metadata\n- License: Apache 2.0\n- Authors: Aleksandar Dimov",
"## Contributing\nContributions to this dataset are welcome, especially for adding solutions in different programming languages or/and for years not yet covered. To contribute, please ensure your submission follows the existing dataset structure and formatting.",
"## Contact\nFor any queries or contributions, please make PR or contact isavitaisa@URL."
] | [
"TAGS\n#task_categories-text-generation #size_categories-1k<n<10k #language-English #license-apache-2.0 #advent of code #code #region-us \n",
"# Advent of Code Solutions Dataset",
"## Introduction\nThis dataset contains solutions and input data for the Advent of Code programming puzzles from 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022 and 2023. The Advent of Code is an annual set of programming challenges that can be solved in any language. At the moment the dataset contains all solutions in Go and many solutions in Python, JavaScript, Java, Scala, Kotlin, Groovy, Clojure, C#, F#, Swift, Objective-C, R, Haskell, Ocaml, Ruby, Elixir, Rust, C, C++, Fortran90, Perl, Crystal, Lua, PHP, Dart, D, TypeScript.\n\nThe dataset is structured as follows:\n* All years of Advent of Code puzzles are stored together in a single dataset \"URL\"\n* Each entry contains:\n * The name of the puzzle (e.g., \"day1_part1_2017\")\n * The full text of the puzzle task\n * The input data provided for the puzzle\n * The correct answer to the puzzle as a string (e.g., \"1914\")\n * The full code for the solution\n * The programming language used for the solution (e.g., \"go\")\n * The year of the puzzle (e.g., 2017)\n\nThis structured format allows easy analysis and comparison of different solutions and languages for each Advent of Code puzzle.",
"## Dataset Structure\n* The dataset is organized store all years of Advent of Code puzzles together in a single dataset \"URL\".",
"## Data Fields\nEach entry in the dataset consists of the following fields:\n\n- name: The unique identifier for each challenge, formatted as \"dayX_partY_YEAR\" (e.g., \"day1_part1_2017\").\n- task: A detailed description of the challenge. The description of part 2 includes the description of part 1 and the answer to part 1, because part 2 requires information from part 1.\n- input: The input data provided for the challenge (for my account).\n- answer: The correct answer as a string (e.g., \"1914\").\n- solution: The full solution code for the challenge.\n- solution_lang: The programming language used for the solution (e.g., \"go\").\n- year: The year of the challenge (e.g., 2017).",
"### Sample Entry",
"## Creation Process\nI implemented and verified solutions for various Advent Of Code challenges. For each challenge, I solved the puzzles using my personal input data from Advent of Code or generated, tested and modified solution by open source models (e.g. codelama, mixtral etc.). This dataset contains my verified solutions and associated input data for these challenges.",
"## Usage",
"### Filtering Solutions by Programming Language\nHere's an example of how to use the script to filter solutions by programming language:",
"### Filtering Solutions by Year\nHere's an example of how to use the script to filter solutions by year:",
"## Future Expansion\nThe dataset currently includes data for the years 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023 with plans to expand it to include additional years and programming languages. As new years are added, the dataset structure will remain consistent.",
"## Metadata\n- License: Apache 2.0\n- Authors: Aleksandar Dimov",
"## Contributing\nContributions to this dataset are welcome, especially for adding solutions in different programming languages or/and for years not yet covered. To contribute, please ensure your submission follows the existing dataset structure and formatting.",
"## Contact\nFor any queries or contributions, please make PR or contact isavitaisa@URL."
] | [
48,
7,
303,
31,
176,
6,
81,
3,
28,
24,
58,
16,
52,
21
] | [
"passage: TAGS\n#task_categories-text-generation #size_categories-1k<n<10k #language-English #license-apache-2.0 #advent of code #code #region-us \n# Advent of Code Solutions Dataset## Introduction\nThis dataset contains solutions and input data for the Advent of Code programming puzzles from 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022 and 2023. The Advent of Code is an annual set of programming challenges that can be solved in any language. At the moment the dataset contains all solutions in Go and many solutions in Python, JavaScript, Java, Scala, Kotlin, Groovy, Clojure, C#, F#, Swift, Objective-C, R, Haskell, Ocaml, Ruby, Elixir, Rust, C, C++, Fortran90, Perl, Crystal, Lua, PHP, Dart, D, TypeScript.\n\nThe dataset is structured as follows:\n* All years of Advent of Code puzzles are stored together in a single dataset \"URL\"\n* Each entry contains:\n * The name of the puzzle (e.g., \"day1_part1_2017\")\n * The full text of the puzzle task\n * The input data provided for the puzzle\n * The correct answer to the puzzle as a string (e.g., \"1914\")\n * The full code for the solution\n * The programming language used for the solution (e.g., \"go\")\n * The year of the puzzle (e.g., 2017)\n\nThis structured format allows easy analysis and comparison of different solutions and languages for each Advent of Code puzzle.## Dataset Structure\n* The dataset is organized store all years of Advent of Code puzzles together in a single dataset \"URL\"."
] |
23ecf8b876e56ab0c189a5adddfa358d26836fc7 | Similar to [monology/oasst2_dpo](https://huggingface.co/datasets/monology/oasst2_dpo), except this uses Metharme tags instead. | PJMixers/oasst2_dpo_metharme | [
"size_categories:10K<n<100K",
"source_datasets:OpenAssistant/oasst2",
"dpo",
"rlhf",
"human-feedback",
"reward",
"preference",
"pairwise",
"pair",
"region:us"
] | 2023-12-26T22:29:52+00:00 | {"size_categories": ["10K<n<100K"], "source_datasets": ["OpenAssistant/oasst2"], "pretty_name": "Open Assistant 2 DPO (Metharme)", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "lang", "dtype": "string"}, {"name": "parent_id", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 68199812, "num_examples": 26971}, {"name": "validation", "num_bytes": 3332324, "num_examples": 1408}], "download_size": 38637920, "dataset_size": 71532136}, "tags": ["dpo", "rlhf", "human-feedback", "reward", "preference", "pairwise", "pair"]} | 2023-12-26T22:55:12+00:00 | [] | [] | TAGS
#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us
| Similar to monology/oasst2_dpo, except this uses Metharme tags instead. | [] | [
"TAGS\n#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us \n"
] | [
57
] | [
"passage: TAGS\n#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us \n"
] |
7c6c7e57cba77d7797db4c58a3bf0cf364f7d1be | Similar to [monology/oasst2_dpo](https://huggingface.co/datasets/monology/oasst2_dpo), except this uses Metharme tags instead. Only samples marked english were kept. | PJMixers/oasst2_dpo_metharme_english | [
"size_categories:10K<n<100K",
"source_datasets:OpenAssistant/oasst2",
"dpo",
"rlhf",
"human-feedback",
"reward",
"preference",
"pairwise",
"pair",
"region:us"
] | 2023-12-26T22:48:48+00:00 | {"size_categories": ["10K<n<100K"], "source_datasets": ["OpenAssistant/oasst2"], "pretty_name": "Open Assistant 2 DPO (Metharme)", "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}, {"split": "validation", "path": "data/validation-*"}]}], "dataset_info": {"features": [{"name": "lang", "dtype": "string"}, {"name": "parent_id", "dtype": "string"}, {"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 32775306, "num_examples": 12353}, {"name": "validation", "num_bytes": 1717916, "num_examples": 668}], "download_size": 18679121, "dataset_size": 34493222}, "tags": ["dpo", "rlhf", "human-feedback", "reward", "preference", "pairwise", "pair"]} | 2023-12-26T22:55:26+00:00 | [] | [] | TAGS
#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us
| Similar to monology/oasst2_dpo, except this uses Metharme tags instead. Only samples marked english were kept. | [] | [
"TAGS\n#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us \n"
] | [
57
] | [
"passage: TAGS\n#size_categories-10K<n<100K #source_datasets-OpenAssistant/oasst2 #dpo #rlhf #human-feedback #reward #preference #pairwise #pair #region-us \n"
] |
15bf40c2eac4a2d92f2bd9ef58052ec242cd6466 | # Dataset Card for "fluent_speech_commands_extract_unit"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Codec-SUPERB/fluent_speech_commands_extract_unit | [
"region:us"
] | 2023-12-26T23:14:50+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "academicodec_hifi_16k_320d", "path": "data/academicodec_hifi_16k_320d-*"}, {"split": "academicodec_hifi_16k_320d_large_uni", "path": "data/academicodec_hifi_16k_320d_large_uni-*"}, {"split": "academicodec_hifi_24k_320d", "path": "data/academicodec_hifi_24k_320d-*"}, {"split": "audiodec_24k_320d", "path": "data/audiodec_24k_320d-*"}, {"split": "dac_16k", "path": "data/dac_16k-*"}, {"split": "dac_24k", "path": "data/dac_24k-*"}, {"split": "dac_44k", "path": "data/dac_44k-*"}, {"split": "encodec_24k", "path": "data/encodec_24k-*"}, {"split": "funcodec_en_libritts_16k_gr1nq32ds320", "path": "data/funcodec_en_libritts_16k_gr1nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_gr8nq32ds320", "path": "data/funcodec_en_libritts_16k_gr8nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_nq32ds320", "path": "data/funcodec_en_libritts_16k_nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_nq32ds640", "path": "data/funcodec_en_libritts_16k_nq32ds640-*"}, {"split": "funcodec_zh_en_16k_nq32ds320", "path": "data/funcodec_zh_en_16k_nq32ds320-*"}, {"split": "funcodec_zh_en_16k_nq32ds640", "path": "data/funcodec_zh_en_16k_nq32ds640-*"}, {"split": "speech_tokenizer_16k", "path": "data/speech_tokenizer_16k-*"}]}], "dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "unit", "sequence": {"sequence": "int64"}}], "splits": [{"name": "academicodec_hifi_16k_320d", "num_bytes": 112174228, "num_examples": 30043}, {"name": "academicodec_hifi_16k_320d_large_uni", "num_bytes": 112174228, "num_examples": 30043}, {"name": "academicodec_hifi_24k_320d", "num_bytes": 167675540, "num_examples": 30043}, {"name": "audiodec_24k_320d", "num_bytes": 357932804, "num_examples": 30043}, {"name": "dac_16k", "num_bytes": 727643348, "num_examples": 30043}, {"name": "dac_24k", "num_bytes": 2109503268, "num_examples": 30043}, {"name": "dac_44k", "num_bytes": 637644968, "num_examples": 30043}, {"name": "encodec_24k", "num_bytes": 84979356, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_gr1nq32ds320", "num_bytes": 895831588, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_gr8nq32ds320", "num_bytes": 895831588, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_nq32ds320", "num_bytes": 895831076, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_nq32ds640", "num_bytes": 452616484, "num_examples": 30043}, {"name": "funcodec_zh_en_16k_nq32ds320", "num_bytes": 895831076, "num_examples": 30043}, {"name": "funcodec_zh_en_16k_nq32ds640", "num_bytes": 895831076, "num_examples": 30043}, {"name": "speech_tokenizer_16k", "num_bytes": 224949188, "num_examples": 30043}], "download_size": 1431306760, "dataset_size": 9466449816}} | 2023-12-26T23:17:55+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "fluent_speech_commands_extract_unit"
More Information needed | [
"# Dataset Card for \"fluent_speech_commands_extract_unit\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"fluent_speech_commands_extract_unit\"\n\nMore Information needed"
] | [
6,
24
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"fluent_speech_commands_extract_unit\"\n\nMore Information needed"
] |
61956f2540553e74be29988abc2455d917e20ef7 | A collection of datasets for finetuning LLMs on STEM related tasks. The dataset is formatted in the [LLaVA finetuning format](https://github.com/haotian-liu/LLaVA/blob/main/docs/Finetune_Custom_Data.md#dataset-format). | sr5434/CodegebraGPT_data | [
"task_categories:conversational",
"size_categories:100K<n<1M",
"language:en",
"license:mit",
"chemistry",
"biology",
"code",
"region:us"
] | 2023-12-26T23:32:30+00:00 | {"language": ["en"], "license": "mit", "size_categories": ["100K<n<1M"], "task_categories": ["conversational"], "dataset_info": [{"config_name": "100k-multimodal", "features": [{"name": "conversations", "struct": [{"name": "conversations", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 124335530, "num_examples": 100000}], "download_size": 64289784, "dataset_size": 124335530}, {"config_name": "100k-text", "features": [{"name": "conversations", "struct": [{"name": "conversations", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 124335530, "num_examples": 100000}], "download_size": 64289784, "dataset_size": 124335530}, {"config_name": "full", "features": [{"name": "conversations", "struct": [{"name": "conversations", "list": [{"name": "from", "dtype": "string"}, {"name": "value", "dtype": "string"}]}, {"name": "id", "dtype": "int64"}, {"name": "image", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 1305046195, "num_examples": 1049253}], "download_size": 673964053, "dataset_size": 1305046195}], "configs": [{"config_name": "100k-multimodal", "data_files": [{"split": "train", "path": "100k-multimodal/train-*"}]}, {"config_name": "100k-text", "data_files": [{"split": "train", "path": "100k-text/train-*"}]}, {"config_name": "full", "data_files": [{"split": "train", "path": "full/train-*"}]}], "tags": ["chemistry", "biology", "code"]} | 2023-12-27T00:17:19+00:00 | [] | [
"en"
] | TAGS
#task_categories-conversational #size_categories-100K<n<1M #language-English #license-mit #chemistry #biology #code #region-us
| A collection of datasets for finetuning LLMs on STEM related tasks. The dataset is formatted in the LLaVA finetuning format. | [] | [
"TAGS\n#task_categories-conversational #size_categories-100K<n<1M #language-English #license-mit #chemistry #biology #code #region-us \n"
] | [
46
] | [
"passage: TAGS\n#task_categories-conversational #size_categories-100K<n<1M #language-English #license-mit #chemistry #biology #code #region-us \n"
] |
deca0313dac501637b2d6eb7264404060e237340 |
# Nyan documents
Documents scraped for [НЯН](https://t.me/nyannews) Telegram channel from March 2022 to December 2023. The dataset includes documents from 100+ different Telegram news channels.
## Usage
```bash
pip3 install datasets
```
```python
from datasets import load_dataset
for row in load_dataset("NyanNyanovich/nyan_documents", split="train", streaming=True):
print(row)
break
```
## Other datasets
* Documents (this dataset): https://huggingface.co/datasets/NyanNyanovich/nyan_documents
* Clusters: https://huggingface.co/datasets/NyanNyanovich/nyan_clusters | NyanNyanovich/nyan_documents | [
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:ru",
"license:cc-by-4.0",
"region:us"
] | 2023-12-27T01:10:50+00:00 | {"language": ["ru"], "license": "cc-by-4.0", "size_categories": ["1M<n<10M"], "task_categories": ["text-generation"], "pretty_name": "Nyan Documents", "dataset_info": {"features": [{"name": "url", "dtype": "string"}, {"name": "channel_id", "dtype": "string"}, {"name": "post_id", "dtype": "int64"}, {"name": "views", "dtype": "int64"}, {"name": "pub_time", "dtype": "int64"}, {"name": "text", "dtype": "string"}, {"name": "fetch_time", "dtype": "int64"}, {"name": "images", "sequence": "string"}, {"name": "links", "sequence": "string"}, {"name": "videos", "sequence": "string"}, {"name": "reply_to", "dtype": "string"}, {"name": "forward_from", "dtype": "string"}, {"name": "channel_title", "dtype": "string"}, {"name": "has_obscene", "dtype": "bool"}, {"name": "patched_text", "dtype": "string"}, {"name": "groups", "struct": [{"name": "economy", "dtype": "string"}, {"name": "main", "dtype": "string"}, {"name": "tech", "dtype": "string"}]}, {"name": "issue", "dtype": "string"}, {"name": "language", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3508000056, "num_examples": 1672028}], "download_size": 1827333867, "dataset_size": 3508000056}} | 2023-12-28T22:58:29+00:00 | [] | [
"ru"
] | TAGS
#task_categories-text-generation #size_categories-1M<n<10M #language-Russian #license-cc-by-4.0 #region-us
|
# Nyan documents
Documents scraped for НЯН Telegram channel from March 2022 to December 2023. The dataset includes documents from 100+ different Telegram news channels.
## Usage
## Other datasets
* Documents (this dataset): URL
* Clusters: URL | [
"# Nyan documents\n\nDocuments scraped for НЯН Telegram channel from March 2022 to December 2023. The dataset includes documents from 100+ different Telegram news channels.",
"## Usage",
"## Other datasets\n* Documents (this dataset): URL\n* Clusters: URL"
] | [
"TAGS\n#task_categories-text-generation #size_categories-1M<n<10M #language-Russian #license-cc-by-4.0 #region-us \n",
"# Nyan documents\n\nDocuments scraped for НЯН Telegram channel from March 2022 to December 2023. The dataset includes documents from 100+ different Telegram news channels.",
"## Usage",
"## Other datasets\n* Documents (this dataset): URL\n* Clusters: URL"
] | [
43,
34,
3,
19
] | [
"passage: TAGS\n#task_categories-text-generation #size_categories-1M<n<10M #language-Russian #license-cc-by-4.0 #region-us \n# Nyan documents\n\nDocuments scraped for НЯН Telegram channel from March 2022 to December 2023. The dataset includes documents from 100+ different Telegram news channels.## Usage## Other datasets\n* Documents (this dataset): URL\n* Clusters: URL"
] |
2bf52c9553fab213b67fbecf82425890e75d9287 |
# Nyan clusters
Clusters of documents formed in [НЯН](https://t.me/nyannews) Telegram channel from March 2022 to December 2023. You can use the documents dataset to get texts.
## Usage
```bash
pip3 install datasets
```
```python
from datasets import load_dataset
for row in load_dataset("NyanNyanovich/nyan_clusters", split="train", streaming=True):
print(row)
break
```
## Other datasets
* Documents: https://huggingface.co/datasets/NyanNyanovich/nyan_documents
* Clusters (this dataset): https://huggingface.co/datasets/NyanNyanovich/nyan_clusters | NyanNyanovich/nyan_clusters | [
"size_categories:10K<n<100K",
"language:ru",
"license:cc-by-4.0",
"region:us"
] | 2023-12-27T01:59:19+00:00 | {"language": ["ru"], "license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "pretty_name": "Nyan Clusters", "dataset_info": {"features": [{"name": "docs", "sequence": "string"}, {"name": "message_id", "dtype": "float64"}, {"name": "create_time", "dtype": "float64"}, {"name": "annotation_doc", "dtype": "string"}, {"name": "first_doc", "dtype": "string"}, {"name": "hash", "dtype": "string"}, {"name": "is_important", "dtype": "bool"}, {"name": "clid", "dtype": "float64"}, {"name": "message", "struct": [{"name": "from_discussion", "dtype": "bool"}, {"name": "issue", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}]}, {"name": "messages", "list": [{"name": "from_discussion", "dtype": "bool"}, {"name": "issue", "dtype": "string"}, {"name": "message_id", "dtype": "int64"}]}], "splits": [{"name": "train", "num_bytes": 21796882, "num_examples": 41296}], "download_size": 6836100, "dataset_size": 21796882}} | 2023-12-28T23:00:32+00:00 | [] | [
"ru"
] | TAGS
#size_categories-10K<n<100K #language-Russian #license-cc-by-4.0 #region-us
|
# Nyan clusters
Clusters of documents formed in НЯН Telegram channel from March 2022 to December 2023. You can use the documents dataset to get texts.
## Usage
## Other datasets
* Documents: URL
* Clusters (this dataset): URL | [
"# Nyan clusters\n\nClusters of documents formed in НЯН Telegram channel from March 2022 to December 2023. You can use the documents dataset to get texts.",
"## Usage",
"## Other datasets\n* Documents: URL\n* Clusters (this dataset): URL"
] | [
"TAGS\n#size_categories-10K<n<100K #language-Russian #license-cc-by-4.0 #region-us \n",
"# Nyan clusters\n\nClusters of documents formed in НЯН Telegram channel from March 2022 to December 2023. You can use the documents dataset to get texts.",
"## Usage",
"## Other datasets\n* Documents: URL\n* Clusters (this dataset): URL"
] | [
32,
35,
3,
19
] | [
"passage: TAGS\n#size_categories-10K<n<100K #language-Russian #license-cc-by-4.0 #region-us \n# Nyan clusters\n\nClusters of documents formed in НЯН Telegram channel from March 2022 to December 2023. You can use the documents dataset to get texts.## Usage## Other datasets\n* Documents: URL\n* Clusters (this dataset): URL"
] |
a004c63c9cc198a34a8fadc58bbacf101d61af65 | # Dataset Card for "openai_summarize_vllm_generated_20k_label410m"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | mnoukhov/openai_summarize_vllm_generated_20k_label410m | [
"region:us"
] | 2023-12-27T03:22:47+00:00 | {"dataset_info": {"features": [{"name": "prompt", "dtype": "string"}, {"name": "chosen", "dtype": "string"}, {"name": "rejected", "dtype": "string"}, {"name": "pred_chosen", "dtype": "float32"}, {"name": "pred_rejected", "dtype": "float32"}], "splits": [{"name": "train", "num_bytes": 35694444, "num_examples": 19940}], "download_size": 21863059, "dataset_size": 35694444}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]} | 2024-02-05T04:42:08+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "openai_summarize_vllm_generated_20k_label410m"
More Information needed | [
"# Dataset Card for \"openai_summarize_vllm_generated_20k_label410m\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"openai_summarize_vllm_generated_20k_label410m\"\n\nMore Information needed"
] | [
6,
31
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"openai_summarize_vllm_generated_20k_label410m\"\n\nMore Information needed"
] |
c1c2658c2410174840c148d094e72fa97315b560 | # Dataset Card for "fluent_speech_commands_synth"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | Codec-SUPERB/fluent_speech_commands_synth | [
"region:us"
] | 2023-12-27T05:51:14+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "original", "path": "data/original-*"}, {"split": "academicodec_hifi_16k_320d", "path": "data/academicodec_hifi_16k_320d-*"}, {"split": "academicodec_hifi_16k_320d_large_uni", "path": "data/academicodec_hifi_16k_320d_large_uni-*"}, {"split": "academicodec_hifi_24k_320d", "path": "data/academicodec_hifi_24k_320d-*"}, {"split": "audiodec_24k_320d", "path": "data/audiodec_24k_320d-*"}, {"split": "dac_16k", "path": "data/dac_16k-*"}, {"split": "dac_24k", "path": "data/dac_24k-*"}, {"split": "dac_44k", "path": "data/dac_44k-*"}, {"split": "encodec_24k_12bps", "path": "data/encodec_24k_12bps-*"}, {"split": "encodec_24k_1_5bps", "path": "data/encodec_24k_1_5bps-*"}, {"split": "encodec_24k_24bps", "path": "data/encodec_24k_24bps-*"}, {"split": "encodec_24k_3bps", "path": "data/encodec_24k_3bps-*"}, {"split": "encodec_24k_6bps", "path": "data/encodec_24k_6bps-*"}, {"split": "funcodec_en_libritts_16k_gr1nq32ds320", "path": "data/funcodec_en_libritts_16k_gr1nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_gr8nq32ds320", "path": "data/funcodec_en_libritts_16k_gr8nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_nq32ds320", "path": "data/funcodec_en_libritts_16k_nq32ds320-*"}, {"split": "funcodec_en_libritts_16k_nq32ds640", "path": "data/funcodec_en_libritts_16k_nq32ds640-*"}, {"split": "funcodec_zh_en_16k_nq32ds320", "path": "data/funcodec_zh_en_16k_nq32ds320-*"}, {"split": "funcodec_zh_en_16k_nq32ds640", "path": "data/funcodec_zh_en_16k_nq32ds640-*"}, {"split": "speech_tokenizer_16k", "path": "data/speech_tokenizer_16k-*"}]}], "dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "id", "dtype": "string"}], "splits": [{"name": "original", "num_bytes": 2220326464.0, "num_examples": 30043}, {"name": "academicodec_hifi_16k_320d", "num_bytes": 2212154504.0, "num_examples": 30043}, {"name": "academicodec_hifi_16k_320d_large_uni", "num_bytes": 2212154504.0, "num_examples": 30043}, {"name": "academicodec_hifi_24k_320d", "num_bytes": 3322180744.0, "num_examples": 30043}, {"name": "audiodec_24k_320d", "num_bytes": 3338935944.0, "num_examples": 30043}, {"name": "dac_16k", "num_bytes": 2221347926.0, "num_examples": 30043}, {"name": "dac_24k", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "dac_44k", "num_bytes": 6114326168.0, "num_examples": 30043}, {"name": "encodec_24k_12bps", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "encodec_24k_1_5bps", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "encodec_24k_24bps", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "encodec_24k_3bps", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "encodec_24k_6bps", "num_bytes": 3329678726.0, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_gr1nq32ds320", "num_bytes": 2219150286.0, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_gr8nq32ds320", "num_bytes": 2219150286.0, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_nq32ds320", "num_bytes": 2221347926.0, "num_examples": 30043}, {"name": "funcodec_en_libritts_16k_nq32ds640", "num_bytes": 2221347926.0, "num_examples": 30043}, {"name": "funcodec_zh_en_16k_nq32ds320", "num_bytes": 2221347926.0, "num_examples": 30043}, {"name": "funcodec_zh_en_16k_nq32ds640", "num_bytes": 2221347926.0, "num_examples": 30043}, {"name": "speech_tokenizer_16k", "num_bytes": 2230445064.0, "num_examples": 30043}], "download_size": 21108462066, "dataset_size": 57173635950.0}} | 2024-02-01T15:29:11+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "fluent_speech_commands_synth"
More Information needed | [
"# Dataset Card for \"fluent_speech_commands_synth\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"fluent_speech_commands_synth\"\n\nMore Information needed"
] | [
6,
21
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"fluent_speech_commands_synth\"\n\nMore Information needed"
] |
0292bd82a5bbb46c2f036949f4d52e6c8c60b32f | 开源的二次元随机提示词库
相关项目;https://github.com/wochenlong/nai3_train
一、 prompt_4k.zip:4K高质量提示词库
特点:人工整理,良品率高,安全性高,只有2%的nsfw
内容:以人物和构图为主
来源:修改自尤吉的AID训练集的打标文件
二、 prompt_20W.zip :20w高质量提示词库
特点:真实图片反推,数量多,二次元浓度高,足够泛化,约有20%的nsfw
内容:题材很多,考虑到danbooru的构成,主要还是以女性为主
来源:从 https://danbooru.donmai.us/ 批量爬取,修改自杠杠哥的20W训练集
| windsingai/random_prompt | [
"license:apache-2.0",
"region:us"
] | 2023-12-27T05:51:53+00:00 | {"license": "apache-2.0"} | 2023-12-27T06:10:17+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
| 开源的二次元随机提示词库
相关项目;URL
一、 prompt_4k.zip:4K高质量提示词库
特点:人工整理,良品率高,安全性高,只有2%的nsfw
内容:以人物和构图为主
来源:修改自尤吉的AID训练集的打标文件
二、 prompt_20W.zip :20w高质量提示词库
特点:真实图片反推,数量多,二次元浓度高,足够泛化,约有20%的nsfw
内容:题材很多,考虑到danbooru的构成,主要还是以女性为主
来源:从 URL 批量爬取,修改自杠杠哥的20W训练集
| [] | [
"TAGS\n#license-apache-2.0 #region-us \n"
] | [
14
] | [
"passage: TAGS\n#license-apache-2.0 #region-us \n"
] |
55c6c79728905f2dec8538af168611b43d68f490 | # Bhagavad Gita Dataset for LLAMA 2 7B Model
## Description
This dataset contains the text of the Bhagavad Gita, a 28 Chapters Hindu scripture that is part of the Indian epic Mahabharata. The dataset is formatted according to the Alpaca format, making it compatible with the LLAMA 2 7B model for natural language processing tasks.
## Dataset Structure
- **Source**: The Bhagavad Gita text has been sourced from [knowrohit07/gita_dataset].
- **Format**: The dataset is structured in the Alpaca format, suitable for training and evaluating the LLAMA 2 7B model.
- **Languages**: The dataset includes texts in [English].
- **Files**: File dataset is in csv format.
## Citation
This dataset is taken from knowrohit07/gita_dataset repository found on hugging face. Please check it out!
## Contact
Include contact information for users to reach out with questions or feedback regarding the dataset.
---
license: apache-2.0
---
| Suru/gita_alpaca_format | [
"region:us"
] | 2023-12-27T06:37:10+00:00 | {} | 2023-12-31T04:31:25+00:00 | [] | [] | TAGS
#region-us
| # Bhagavad Gita Dataset for LLAMA 2 7B Model
## Description
This dataset contains the text of the Bhagavad Gita, a 28 Chapters Hindu scripture that is part of the Indian epic Mahabharata. The dataset is formatted according to the Alpaca format, making it compatible with the LLAMA 2 7B model for natural language processing tasks.
## Dataset Structure
- Source: The Bhagavad Gita text has been sourced from [knowrohit07/gita_dataset].
- Format: The dataset is structured in the Alpaca format, suitable for training and evaluating the LLAMA 2 7B model.
- Languages: The dataset includes texts in [English].
- Files: File dataset is in csv format.
This dataset is taken from knowrohit07/gita_dataset repository found on hugging face. Please check it out!
## Contact
Include contact information for users to reach out with questions or feedback regarding the dataset.
---
license: apache-2.0
---
| [
"# Bhagavad Gita Dataset for LLAMA 2 7B Model",
"## Description\nThis dataset contains the text of the Bhagavad Gita, a 28 Chapters Hindu scripture that is part of the Indian epic Mahabharata. The dataset is formatted according to the Alpaca format, making it compatible with the LLAMA 2 7B model for natural language processing tasks.",
"## Dataset Structure\n- Source: The Bhagavad Gita text has been sourced from [knowrohit07/gita_dataset].\n- Format: The dataset is structured in the Alpaca format, suitable for training and evaluating the LLAMA 2 7B model.\n- Languages: The dataset includes texts in [English].\n- Files: File dataset is in csv format.\n\n\nThis dataset is taken from knowrohit07/gita_dataset repository found on hugging face. Please check it out!",
"## Contact\nInclude contact information for users to reach out with questions or feedback regarding the dataset.\n\n\n---\nlicense: apache-2.0\n---"
] | [
"TAGS\n#region-us \n",
"# Bhagavad Gita Dataset for LLAMA 2 7B Model",
"## Description\nThis dataset contains the text of the Bhagavad Gita, a 28 Chapters Hindu scripture that is part of the Indian epic Mahabharata. The dataset is formatted according to the Alpaca format, making it compatible with the LLAMA 2 7B model for natural language processing tasks.",
"## Dataset Structure\n- Source: The Bhagavad Gita text has been sourced from [knowrohit07/gita_dataset].\n- Format: The dataset is structured in the Alpaca format, suitable for training and evaluating the LLAMA 2 7B model.\n- Languages: The dataset includes texts in [English].\n- Files: File dataset is in csv format.\n\n\nThis dataset is taken from knowrohit07/gita_dataset repository found on hugging face. Please check it out!",
"## Contact\nInclude contact information for users to reach out with questions or feedback regarding the dataset.\n\n\n---\nlicense: apache-2.0\n---"
] | [
6,
14,
67,
118,
29
] | [
"passage: TAGS\n#region-us \n# Bhagavad Gita Dataset for LLAMA 2 7B Model## Description\nThis dataset contains the text of the Bhagavad Gita, a 28 Chapters Hindu scripture that is part of the Indian epic Mahabharata. The dataset is formatted according to the Alpaca format, making it compatible with the LLAMA 2 7B model for natural language processing tasks.## Dataset Structure\n- Source: The Bhagavad Gita text has been sourced from [knowrohit07/gita_dataset].\n- Format: The dataset is structured in the Alpaca format, suitable for training and evaluating the LLAMA 2 7B model.\n- Languages: The dataset includes texts in [English].\n- Files: File dataset is in csv format.\n\n\nThis dataset is taken from knowrohit07/gita_dataset repository found on hugging face. Please check it out!## Contact\nInclude contact information for users to reach out with questions or feedback regarding the dataset.\n\n\n---\nlicense: apache-2.0\n---"
] |
f8413a4a423991c29d426c61528b43181efc8c71 |
# Dataset Card for emotion-custom
This dataset has been created with [Argilla](https://docs.argilla.io).
As shown in the sections below, this dataset can be loaded into Argilla as explained in [Load with Argilla](#load-with-argilla), or used directly with the `datasets` library in [Load with `datasets`](#load-with-datasets).
## Dataset Description
- **Homepage:** https://argilla.io
- **Repository:** https://github.com/argilla-io/argilla
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset contains:
* A dataset configuration file conforming to the Argilla dataset format named `argilla.yaml`. This configuration file will be used to configure the dataset when using the `FeedbackDataset.from_huggingface` method in Argilla.
* Dataset records in a format compatible with HuggingFace `datasets`. These records will be loaded automatically when using `FeedbackDataset.from_huggingface` and can be loaded independently using the `datasets` library via `load_dataset`.
* The [annotation guidelines](#annotation-guidelines) that have been used for building and curating the dataset, if they've been defined in Argilla.
### Load with Argilla
To load with Argilla, you'll just need to install Argilla as `pip install argilla --upgrade` and then use the following code:
```python
import argilla as rg
ds = rg.FeedbackDataset.from_huggingface("sanket03/emotion-custom")
```
### Load with `datasets`
To load this dataset with `datasets`, you'll just need to install `datasets` as `pip install datasets --upgrade` and then use the following code:
```python
from datasets import load_dataset
ds = load_dataset("sanket03/emotion-custom")
```
### Supported Tasks and Leaderboards
This dataset can contain [multiple fields, questions and responses](https://docs.argilla.io/en/latest/conceptual_guides/data_model.html#feedback-dataset) so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the [Dataset Structure section](#dataset-structure).
There are no leaderboards associated with this dataset.
### Languages
[More Information Needed]
## Dataset Structure
### Data in Argilla
The dataset is created in Argilla with: **fields**, **questions**, **suggestions**, **metadata**, **vectors**, and **guidelines**.
The **fields** are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.
| Field Name | Title | Type | Required | Markdown |
| ---------- | ----- | ---- | -------- | -------- |
| text | Text | text | True | False |
The **questions** are the questions that will be asked to the annotators. They can be of different types, such as rating, text, label_selection, multi_label_selection, or ranking.
| Question Name | Title | Type | Required | Description | Values/Labels |
| ------------- | ----- | ---- | -------- | ----------- | ------------- |
| sentiment | Sentiment | label_selection | True | N/A | ['positive', 'neutral', 'negative'] |
| mixed-emotion | Mixed-emotion | multi_label_selection | True | N/A | ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'] |
The **suggestions** are human or machine generated recommendations for each question to assist the annotator during the annotation process, so those are always linked to the existing questions, and named appending "-suggestion" and "-suggestion-metadata" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above, but the column name is appended with "-suggestion" and the metadata is appended with "-suggestion-metadata".
The **metadata** is a dictionary that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the `metadata_properties` defined in the dataset configuration file in `argilla.yaml`.
| Metadata Name | Title | Type | Values | Visible for Annotators |
| ------------- | ----- | ---- | ------ | ---------------------- |
The **guidelines**, are optional as well, and are just a plain string that can be used to provide instructions to the annotators. Find those in the [annotation guidelines](#annotation-guidelines) section.
### Data Instances
An example of a dataset instance in Argilla looks as follows:
```json
{
"external_id": null,
"fields": {
"text": "i didnt feel humiliated"
},
"metadata": {},
"responses": [],
"suggestions": [],
"vectors": {}
}
```
While the same record in HuggingFace `datasets` looks as follows:
```json
{
"external_id": null,
"metadata": "{}",
"mixed-emotion": [],
"mixed-emotion-suggestion": null,
"mixed-emotion-suggestion-metadata": {
"agent": null,
"score": null,
"type": null
},
"sentiment": [],
"sentiment-suggestion": null,
"sentiment-suggestion-metadata": {
"agent": null,
"score": null,
"type": null
},
"text": "i didnt feel humiliated"
}
```
### Data Fields
Among the dataset fields, we differentiate between the following:
* **Fields:** These are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.
* **text** is of type `text`.
* **Questions:** These are the questions that will be asked to the annotators. They can be of different types, such as `RatingQuestion`, `TextQuestion`, `LabelQuestion`, `MultiLabelQuestion`, and `RankingQuestion`.
* **sentiment** is of type `label_selection` with the following allowed values ['positive', 'neutral', 'negative'].
* **mixed-emotion** is of type `multi_label_selection` with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].
* **Suggestions:** As of Argilla 1.13.0, the suggestions have been included to provide the annotators with suggestions to ease or assist during the annotation process. Suggestions are linked to the existing questions, are always optional, and contain not just the suggestion itself, but also the metadata linked to it, if applicable.
* (optional) **sentiment-suggestion** is of type `label_selection` with the following allowed values ['positive', 'neutral', 'negative'].
* (optional) **mixed-emotion-suggestion** is of type `multi_label_selection` with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].
Additionally, we also have two more fields that are optional and are the following:
* **metadata:** This is an optional field that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the `metadata_properties` defined in the dataset configuration file in `argilla.yaml`.
* **external_id:** This is an optional field that can be used to provide an external ID for the dataset record. This can be useful if you want to link the dataset record to an external resource, such as a database or a file.
### Data Splits
The dataset contains a single split, which is `train`.
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation guidelines
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise.
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed] | sanket03/emotion-custom | [
"size_categories:n<1K",
"rlfh",
"argilla",
"human-feedback",
"region:us"
] | 2023-12-27T07:13:32+00:00 | {"size_categories": "n<1K", "tags": ["rlfh", "argilla", "human-feedback"]} | 2023-12-27T12:17:13+00:00 | [] | [] | TAGS
#size_categories-n<1K #rlfh #argilla #human-feedback #region-us
| Dataset Card for emotion-custom
===============================
This dataset has been created with Argilla.
As shown in the sections below, this dataset can be loaded into Argilla as explained in Load with Argilla, or used directly with the 'datasets' library in Load with 'datasets'.
Dataset Description
-------------------
* Homepage: URL
* Repository: URL
* Paper:
* Leaderboard:
* Point of Contact:
### Dataset Summary
This dataset contains:
* A dataset configuration file conforming to the Argilla dataset format named 'URL'. This configuration file will be used to configure the dataset when using the 'FeedbackDataset.from\_huggingface' method in Argilla.
* Dataset records in a format compatible with HuggingFace 'datasets'. These records will be loaded automatically when using 'FeedbackDataset.from\_huggingface' and can be loaded independently using the 'datasets' library via 'load\_dataset'.
* The annotation guidelines that have been used for building and curating the dataset, if they've been defined in Argilla.
### Load with Argilla
To load with Argilla, you'll just need to install Argilla as 'pip install argilla --upgrade' and then use the following code:
### Load with 'datasets'
To load this dataset with 'datasets', you'll just need to install 'datasets' as 'pip install datasets --upgrade' and then use the following code:
### Supported Tasks and Leaderboards
This dataset can contain multiple fields, questions and responses so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the Dataset Structure section.
There are no leaderboards associated with this dataset.
### Languages
Dataset Structure
-----------------
### Data in Argilla
The dataset is created in Argilla with: fields, questions, suggestions, metadata, vectors, and guidelines.
The fields are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.
The questions are the questions that will be asked to the annotators. They can be of different types, such as rating, text, label\_selection, multi\_label\_selection, or ranking.
The suggestions are human or machine generated recommendations for each question to assist the annotator during the annotation process, so those are always linked to the existing questions, and named appending "-suggestion" and "-suggestion-metadata" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above, but the column name is appended with "-suggestion" and the metadata is appended with "-suggestion-metadata".
The metadata is a dictionary that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\_properties' defined in the dataset configuration file in 'URL'.
The guidelines, are optional as well, and are just a plain string that can be used to provide instructions to the annotators. Find those in the annotation guidelines section.
### Data Instances
An example of a dataset instance in Argilla looks as follows:
While the same record in HuggingFace 'datasets' looks as follows:
### Data Fields
Among the dataset fields, we differentiate between the following:
* Fields: These are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.
+ text is of type 'text'.
* Questions: These are the questions that will be asked to the annotators. They can be of different types, such as 'RatingQuestion', 'TextQuestion', 'LabelQuestion', 'MultiLabelQuestion', and 'RankingQuestion'.
+ sentiment is of type 'label\_selection' with the following allowed values ['positive', 'neutral', 'negative'].
+ mixed-emotion is of type 'multi\_label\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].
* Suggestions: As of Argilla 1.13.0, the suggestions have been included to provide the annotators with suggestions to ease or assist during the annotation process. Suggestions are linked to the existing questions, are always optional, and contain not just the suggestion itself, but also the metadata linked to it, if applicable.
+ (optional) sentiment-suggestion is of type 'label\_selection' with the following allowed values ['positive', 'neutral', 'negative'].
+ (optional) mixed-emotion-suggestion is of type 'multi\_label\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].
Additionally, we also have two more fields that are optional and are the following:
* metadata: This is an optional field that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\_properties' defined in the dataset configuration file in 'URL'.
* external\_id: This is an optional field that can be used to provide an external ID for the dataset record. This can be useful if you want to link the dataset record to an external resource, such as a database or a file.
### Data Splits
The dataset contains a single split, which is 'train'.
Dataset Creation
----------------
### Curation Rationale
### Source Data
#### Initial Data Collection and Normalization
#### Who are the source language producers?
### Annotations
#### Annotation guidelines
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise.
#### Annotation process
#### Who are the annotators?
### Personal and Sensitive Information
Considerations for Using the Data
---------------------------------
### Social Impact of Dataset
### Discussion of Biases
### Other Known Limitations
Additional Information
----------------------
### Dataset Curators
### Licensing Information
### Contributions
| [
"### Dataset Summary\n\n\nThis dataset contains:\n\n\n* A dataset configuration file conforming to the Argilla dataset format named 'URL'. This configuration file will be used to configure the dataset when using the 'FeedbackDataset.from\\_huggingface' method in Argilla.\n* Dataset records in a format compatible with HuggingFace 'datasets'. These records will be loaded automatically when using 'FeedbackDataset.from\\_huggingface' and can be loaded independently using the 'datasets' library via 'load\\_dataset'.\n* The annotation guidelines that have been used for building and curating the dataset, if they've been defined in Argilla.",
"### Load with Argilla\n\n\nTo load with Argilla, you'll just need to install Argilla as 'pip install argilla --upgrade' and then use the following code:",
"### Load with 'datasets'\n\n\nTo load this dataset with 'datasets', you'll just need to install 'datasets' as 'pip install datasets --upgrade' and then use the following code:",
"### Supported Tasks and Leaderboards\n\n\nThis dataset can contain multiple fields, questions and responses so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the Dataset Structure section.\n\n\nThere are no leaderboards associated with this dataset.",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data in Argilla\n\n\nThe dataset is created in Argilla with: fields, questions, suggestions, metadata, vectors, and guidelines.\n\n\nThe fields are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.\n\n\n\nThe questions are the questions that will be asked to the annotators. They can be of different types, such as rating, text, label\\_selection, multi\\_label\\_selection, or ranking.\n\n\n\nThe suggestions are human or machine generated recommendations for each question to assist the annotator during the annotation process, so those are always linked to the existing questions, and named appending \"-suggestion\" and \"-suggestion-metadata\" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above, but the column name is appended with \"-suggestion\" and the metadata is appended with \"-suggestion-metadata\".\n\n\nThe metadata is a dictionary that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\\_properties' defined in the dataset configuration file in 'URL'.\n\n\n\nThe guidelines, are optional as well, and are just a plain string that can be used to provide instructions to the annotators. Find those in the annotation guidelines section.",
"### Data Instances\n\n\nAn example of a dataset instance in Argilla looks as follows:\n\n\nWhile the same record in HuggingFace 'datasets' looks as follows:",
"### Data Fields\n\n\nAmong the dataset fields, we differentiate between the following:\n\n\n* Fields: These are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.\n\n\n\t+ text is of type 'text'.\n* Questions: These are the questions that will be asked to the annotators. They can be of different types, such as 'RatingQuestion', 'TextQuestion', 'LabelQuestion', 'MultiLabelQuestion', and 'RankingQuestion'.\n\n\n\t+ sentiment is of type 'label\\_selection' with the following allowed values ['positive', 'neutral', 'negative'].\n\t+ mixed-emotion is of type 'multi\\_label\\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].\n* Suggestions: As of Argilla 1.13.0, the suggestions have been included to provide the annotators with suggestions to ease or assist during the annotation process. Suggestions are linked to the existing questions, are always optional, and contain not just the suggestion itself, but also the metadata linked to it, if applicable.\n\n\n\t+ (optional) sentiment-suggestion is of type 'label\\_selection' with the following allowed values ['positive', 'neutral', 'negative'].\n\t+ (optional) mixed-emotion-suggestion is of type 'multi\\_label\\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].\n\n\nAdditionally, we also have two more fields that are optional and are the following:\n\n\n* metadata: This is an optional field that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\\_properties' defined in the dataset configuration file in 'URL'.\n* external\\_id: This is an optional field that can be used to provide an external ID for the dataset record. This can be useful if you want to link the dataset record to an external resource, such as a database or a file.",
"### Data Splits\n\n\nThe dataset contains a single split, which is 'train'.\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation guidelines\n\n\nEmotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise.",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] | [
"TAGS\n#size_categories-n<1K #rlfh #argilla #human-feedback #region-us \n",
"### Dataset Summary\n\n\nThis dataset contains:\n\n\n* A dataset configuration file conforming to the Argilla dataset format named 'URL'. This configuration file will be used to configure the dataset when using the 'FeedbackDataset.from\\_huggingface' method in Argilla.\n* Dataset records in a format compatible with HuggingFace 'datasets'. These records will be loaded automatically when using 'FeedbackDataset.from\\_huggingface' and can be loaded independently using the 'datasets' library via 'load\\_dataset'.\n* The annotation guidelines that have been used for building and curating the dataset, if they've been defined in Argilla.",
"### Load with Argilla\n\n\nTo load with Argilla, you'll just need to install Argilla as 'pip install argilla --upgrade' and then use the following code:",
"### Load with 'datasets'\n\n\nTo load this dataset with 'datasets', you'll just need to install 'datasets' as 'pip install datasets --upgrade' and then use the following code:",
"### Supported Tasks and Leaderboards\n\n\nThis dataset can contain multiple fields, questions and responses so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the Dataset Structure section.\n\n\nThere are no leaderboards associated with this dataset.",
"### Languages\n\n\nDataset Structure\n-----------------",
"### Data in Argilla\n\n\nThe dataset is created in Argilla with: fields, questions, suggestions, metadata, vectors, and guidelines.\n\n\nThe fields are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.\n\n\n\nThe questions are the questions that will be asked to the annotators. They can be of different types, such as rating, text, label\\_selection, multi\\_label\\_selection, or ranking.\n\n\n\nThe suggestions are human or machine generated recommendations for each question to assist the annotator during the annotation process, so those are always linked to the existing questions, and named appending \"-suggestion\" and \"-suggestion-metadata\" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above, but the column name is appended with \"-suggestion\" and the metadata is appended with \"-suggestion-metadata\".\n\n\nThe metadata is a dictionary that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\\_properties' defined in the dataset configuration file in 'URL'.\n\n\n\nThe guidelines, are optional as well, and are just a plain string that can be used to provide instructions to the annotators. Find those in the annotation guidelines section.",
"### Data Instances\n\n\nAn example of a dataset instance in Argilla looks as follows:\n\n\nWhile the same record in HuggingFace 'datasets' looks as follows:",
"### Data Fields\n\n\nAmong the dataset fields, we differentiate between the following:\n\n\n* Fields: These are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.\n\n\n\t+ text is of type 'text'.\n* Questions: These are the questions that will be asked to the annotators. They can be of different types, such as 'RatingQuestion', 'TextQuestion', 'LabelQuestion', 'MultiLabelQuestion', and 'RankingQuestion'.\n\n\n\t+ sentiment is of type 'label\\_selection' with the following allowed values ['positive', 'neutral', 'negative'].\n\t+ mixed-emotion is of type 'multi\\_label\\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].\n* Suggestions: As of Argilla 1.13.0, the suggestions have been included to provide the annotators with suggestions to ease or assist during the annotation process. Suggestions are linked to the existing questions, are always optional, and contain not just the suggestion itself, but also the metadata linked to it, if applicable.\n\n\n\t+ (optional) sentiment-suggestion is of type 'label\\_selection' with the following allowed values ['positive', 'neutral', 'negative'].\n\t+ (optional) mixed-emotion-suggestion is of type 'multi\\_label\\_selection' with the following allowed values ['joy', 'anger', 'sadness', 'fear', 'surprise', 'love'].\n\n\nAdditionally, we also have two more fields that are optional and are the following:\n\n\n* metadata: This is an optional field that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\\_properties' defined in the dataset configuration file in 'URL'.\n* external\\_id: This is an optional field that can be used to provide an external ID for the dataset record. This can be useful if you want to link the dataset record to an external resource, such as a database or a file.",
"### Data Splits\n\n\nThe dataset contains a single split, which is 'train'.\n\n\nDataset Creation\n----------------",
"### Curation Rationale",
"### Source Data",
"#### Initial Data Collection and Normalization",
"#### Who are the source language producers?",
"### Annotations",
"#### Annotation guidelines\n\n\nEmotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise.",
"#### Annotation process",
"#### Who are the annotators?",
"### Personal and Sensitive Information\n\n\nConsiderations for Using the Data\n---------------------------------",
"### Social Impact of Dataset",
"### Discussion of Biases",
"### Other Known Limitations\n\n\nAdditional Information\n----------------------",
"### Dataset Curators",
"### Licensing Information",
"### Contributions"
] | [
27,
162,
40,
53,
68,
11,
404,
40,
597,
27,
7,
4,
10,
10,
5,
36,
5,
9,
18,
7,
8,
14,
6,
6,
5
] | [
"passage: TAGS\n#size_categories-n<1K #rlfh #argilla #human-feedback #region-us \n### Dataset Summary\n\n\nThis dataset contains:\n\n\n* A dataset configuration file conforming to the Argilla dataset format named 'URL'. This configuration file will be used to configure the dataset when using the 'FeedbackDataset.from\\_huggingface' method in Argilla.\n* Dataset records in a format compatible with HuggingFace 'datasets'. These records will be loaded automatically when using 'FeedbackDataset.from\\_huggingface' and can be loaded independently using the 'datasets' library via 'load\\_dataset'.\n* The annotation guidelines that have been used for building and curating the dataset, if they've been defined in Argilla.### Load with Argilla\n\n\nTo load with Argilla, you'll just need to install Argilla as 'pip install argilla --upgrade' and then use the following code:### Load with 'datasets'\n\n\nTo load this dataset with 'datasets', you'll just need to install 'datasets' as 'pip install datasets --upgrade' and then use the following code:### Supported Tasks and Leaderboards\n\n\nThis dataset can contain multiple fields, questions and responses so it can be used for different NLP tasks, depending on the configuration. The dataset structure is described in the Dataset Structure section.\n\n\nThere are no leaderboards associated with this dataset.### Languages\n\n\nDataset Structure\n-----------------",
"passage: ### Data in Argilla\n\n\nThe dataset is created in Argilla with: fields, questions, suggestions, metadata, vectors, and guidelines.\n\n\nThe fields are the dataset records themselves, for the moment just text fields are supported. These are the ones that will be used to provide responses to the questions.\n\n\n\nThe questions are the questions that will be asked to the annotators. They can be of different types, such as rating, text, label\\_selection, multi\\_label\\_selection, or ranking.\n\n\n\nThe suggestions are human or machine generated recommendations for each question to assist the annotator during the annotation process, so those are always linked to the existing questions, and named appending \"-suggestion\" and \"-suggestion-metadata\" to those, containing the value/s of the suggestion and its metadata, respectively. So on, the possible values are the same as in the table above, but the column name is appended with \"-suggestion\" and the metadata is appended with \"-suggestion-metadata\".\n\n\nThe metadata is a dictionary that can be used to provide additional information about the dataset record. This can be useful to provide additional context to the annotators, or to provide additional information about the dataset record itself. For example, you can use this to provide a link to the original source of the dataset record, or to provide additional information about the dataset record itself, such as the author, the date, or the source. The metadata is always optional, and can be potentially linked to the 'metadata\\_properties' defined in the dataset configuration file in 'URL'.\n\n\n\nThe guidelines, are optional as well, and are just a plain string that can be used to provide instructions to the annotators. Find those in the annotation guidelines section.### Data Instances\n\n\nAn example of a dataset instance in Argilla looks as follows:\n\n\nWhile the same record in HuggingFace 'datasets' looks as follows:"
] |
59290dd1e06a6a7bc7076e7d40cfde2071fdf8e9 | # Dataset Card for "cifar100_2_to_100"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | noahshinn/cifar100_2_to_100 | [
"region:us"
] | 2023-12-27T07:14:29+00:00 | {"configs": [{"config_name": "default", "data_files": [{"split": "cifar100_2", "path": "data/cifar100_2-*"}, {"split": "cifar100_3", "path": "data/cifar100_3-*"}, {"split": "cifar100_4", "path": "data/cifar100_4-*"}, {"split": "cifar100_5", "path": "data/cifar100_5-*"}, {"split": "cifar100_6", "path": "data/cifar100_6-*"}, {"split": "cifar100_7", "path": "data/cifar100_7-*"}, {"split": "cifar100_8", "path": "data/cifar100_8-*"}, {"split": "cifar100_9", "path": "data/cifar100_9-*"}, {"split": "cifar100_10", "path": "data/cifar100_10-*"}, {"split": "cifar100_11", "path": "data/cifar100_11-*"}, {"split": "cifar100_12", "path": "data/cifar100_12-*"}, {"split": "cifar100_13", "path": "data/cifar100_13-*"}, {"split": "cifar100_14", "path": "data/cifar100_14-*"}, {"split": "cifar100_15", "path": "data/cifar100_15-*"}, {"split": "cifar100_16", "path": "data/cifar100_16-*"}, {"split": "cifar100_17", "path": "data/cifar100_17-*"}, {"split": "cifar100_18", "path": "data/cifar100_18-*"}, {"split": "cifar100_19", "path": "data/cifar100_19-*"}, {"split": "cifar100_20", "path": "data/cifar100_20-*"}, {"split": "cifar100_21", "path": "data/cifar100_21-*"}, {"split": "cifar100_22", "path": "data/cifar100_22-*"}, {"split": "cifar100_23", "path": "data/cifar100_23-*"}, {"split": "cifar100_24", "path": "data/cifar100_24-*"}, {"split": "cifar100_25", "path": "data/cifar100_25-*"}, {"split": "cifar100_26", "path": "data/cifar100_26-*"}, {"split": "cifar100_27", "path": "data/cifar100_27-*"}, {"split": "cifar100_28", "path": "data/cifar100_28-*"}, {"split": "cifar100_29", "path": "data/cifar100_29-*"}, {"split": "cifar100_30", "path": "data/cifar100_30-*"}, {"split": "cifar100_31", "path": "data/cifar100_31-*"}, {"split": "cifar100_32", "path": "data/cifar100_32-*"}, {"split": "cifar100_33", "path": "data/cifar100_33-*"}, {"split": "cifar100_34", "path": "data/cifar100_34-*"}, {"split": "cifar100_35", "path": "data/cifar100_35-*"}, {"split": "cifar100_36", "path": "data/cifar100_36-*"}, {"split": "cifar100_37", "path": "data/cifar100_37-*"}, {"split": "cifar100_38", "path": "data/cifar100_38-*"}, {"split": "cifar100_39", "path": "data/cifar100_39-*"}, {"split": "cifar100_40", "path": "data/cifar100_40-*"}, {"split": "cifar100_41", "path": "data/cifar100_41-*"}, {"split": "cifar100_42", "path": "data/cifar100_42-*"}, {"split": "cifar100_43", "path": "data/cifar100_43-*"}, {"split": "cifar100_44", "path": "data/cifar100_44-*"}, {"split": "cifar100_45", "path": "data/cifar100_45-*"}, {"split": "cifar100_46", "path": "data/cifar100_46-*"}, {"split": "cifar100_47", "path": "data/cifar100_47-*"}, {"split": "cifar100_48", "path": "data/cifar100_48-*"}, {"split": "cifar100_49", "path": "data/cifar100_49-*"}, {"split": "cifar100_50", "path": "data/cifar100_50-*"}, {"split": "cifar100_51", "path": "data/cifar100_51-*"}, {"split": "cifar100_52", "path": "data/cifar100_52-*"}, {"split": "cifar100_53", "path": "data/cifar100_53-*"}, {"split": "cifar100_54", "path": "data/cifar100_54-*"}, {"split": "cifar100_55", "path": "data/cifar100_55-*"}, {"split": "cifar100_56", "path": "data/cifar100_56-*"}, {"split": "cifar100_57", "path": "data/cifar100_57-*"}, {"split": "cifar100_58", "path": "data/cifar100_58-*"}, {"split": "cifar100_59", "path": "data/cifar100_59-*"}, {"split": "cifar100_60", "path": "data/cifar100_60-*"}, {"split": "cifar100_61", "path": "data/cifar100_61-*"}, {"split": "cifar100_62", "path": "data/cifar100_62-*"}, {"split": "cifar100_63", "path": "data/cifar100_63-*"}, {"split": "cifar100_64", "path": "data/cifar100_64-*"}, {"split": "cifar100_65", "path": "data/cifar100_65-*"}, {"split": "cifar100_66", "path": "data/cifar100_66-*"}, {"split": "cifar100_67", "path": "data/cifar100_67-*"}, {"split": "cifar100_68", "path": "data/cifar100_68-*"}, {"split": "cifar100_69", "path": "data/cifar100_69-*"}, {"split": "cifar100_70", "path": "data/cifar100_70-*"}, {"split": "cifar100_71", "path": "data/cifar100_71-*"}, {"split": "cifar100_72", "path": "data/cifar100_72-*"}, {"split": "cifar100_73", "path": "data/cifar100_73-*"}, {"split": "cifar100_74", "path": "data/cifar100_74-*"}, {"split": "cifar100_75", "path": "data/cifar100_75-*"}, {"split": "cifar100_76", "path": "data/cifar100_76-*"}, {"split": "cifar100_77", "path": "data/cifar100_77-*"}, {"split": "cifar100_78", "path": "data/cifar100_78-*"}, {"split": "cifar100_79", "path": "data/cifar100_79-*"}, {"split": "cifar100_80", "path": "data/cifar100_80-*"}, {"split": "cifar100_81", "path": "data/cifar100_81-*"}, {"split": "cifar100_82", "path": "data/cifar100_82-*"}, {"split": "cifar100_83", "path": "data/cifar100_83-*"}, {"split": "cifar100_84", "path": "data/cifar100_84-*"}, {"split": "cifar100_85", "path": "data/cifar100_85-*"}, {"split": "cifar100_86", "path": "data/cifar100_86-*"}, {"split": "cifar100_87", "path": "data/cifar100_87-*"}, {"split": "cifar100_88", "path": "data/cifar100_88-*"}, {"split": "cifar100_89", "path": "data/cifar100_89-*"}, {"split": "cifar100_90", "path": "data/cifar100_90-*"}, {"split": "cifar100_91", "path": "data/cifar100_91-*"}, {"split": "cifar100_92", "path": "data/cifar100_92-*"}, {"split": "cifar100_93", "path": "data/cifar100_93-*"}, {"split": "cifar100_94", "path": "data/cifar100_94-*"}, {"split": "cifar100_95", "path": "data/cifar100_95-*"}, {"split": "cifar100_96", "path": "data/cifar100_96-*"}, {"split": "cifar100_97", "path": "data/cifar100_97-*"}, {"split": "cifar100_98", "path": "data/cifar100_98-*"}, {"split": "cifar100_99", "path": "data/cifar100_99-*"}, {"split": "cifar100_100", "path": "data/cifar100_100-*"}]}], "dataset_info": {"features": [{"name": "img", "dtype": "image"}, {"name": "fine_label", "dtype": {"class_label": {"names": {"0": "apple", "1": "aquarium_fish", "2": "baby", "3": "bear", "4": "beaver", "5": "bed", "6": "bee", "7": "beetle", "8": "bicycle", "9": "bottle", "10": "bowl", "11": "boy", "12": "bridge", "13": "bus", "14": "butterfly", "15": "camel", "16": "can", "17": "castle", "18": "caterpillar", "19": "cattle", "20": "chair", "21": "chimpanzee", "22": "clock", "23": "cloud", "24": "cockroach", "25": "couch", "26": "cra", "27": "crocodile", "28": "cup", "29": "dinosaur", "30": "dolphin", "31": "elephant", "32": "flatfish", "33": "forest", "34": "fox", "35": "girl", "36": "hamster", "37": "house", "38": "kangaroo", "39": "keyboard", "40": "lamp", "41": "lawn_mower", "42": "leopard", "43": "lion", "44": "lizard", "45": "lobster", "46": "man", "47": "maple_tree", "48": "motorcycle", "49": "mountain", "50": "mouse", "51": "mushroom", "52": "oak_tree", "53": "orange", "54": "orchid", "55": "otter", "56": "palm_tree", "57": "pear", "58": "pickup_truck", "59": "pine_tree", "60": "plain", "61": "plate", "62": "poppy", "63": "porcupine", "64": "possum", "65": "rabbit", "66": "raccoon", "67": "ray", "68": "road", "69": "rocket", "70": "rose", "71": "sea", "72": "seal", "73": "shark", "74": "shrew", "75": "skunk", "76": "skyscraper", "77": "snail", "78": "snake", "79": "spider", "80": "squirrel", "81": "streetcar", "82": "sunflower", "83": "sweet_pepper", "84": "table", "85": "tank", "86": "telephone", "87": "television", "88": "tiger", "89": "tractor", "90": "train", "91": "trout", "92": "tulip", "93": "turtle", "94": "wardrobe", "95": "whale", "96": "willow_tree", "97": "wolf", "98": "woman", "99": "worm"}}}}, {"name": "coarse_label", "dtype": {"class_label": {"names": {"0": "aquatic_mammals", "1": "fish", "2": "flowers", "3": "food_containers", "4": "fruit_and_vegetables", "5": "household_electrical_devices", "6": "household_furniture", "7": "insects", "8": "large_carnivores", "9": "large_man-made_outdoor_things", "10": "large_natural_outdoor_scenes", "11": "large_omnivores_and_herbivores", "12": "medium_mammals", "13": "non-insect_invertebrates", "14": "people", "15": "reptiles", "16": "small_mammals", "17": "trees", "18": "vehicles_1", "19": "vehicles_2"}}}}], "splits": [{"name": "cifar100_2", "num_bytes": 2250027.12, "num_examples": 1000}, {"name": "cifar100_3", "num_bytes": 3375040.68, "num_examples": 1500}, {"name": "cifar100_4", "num_bytes": 4500054.24, "num_examples": 2000}, {"name": "cifar100_5", "num_bytes": 5625067.8, "num_examples": 2500}, {"name": "cifar100_6", "num_bytes": 6750081.36, "num_examples": 3000}, {"name": "cifar100_7", "num_bytes": 7875094.92, "num_examples": 3500}, {"name": "cifar100_8", "num_bytes": 9000108.48, "num_examples": 4000}, {"name": "cifar100_9", "num_bytes": 10125122.04, "num_examples": 4500}, {"name": "cifar100_10", "num_bytes": 11250135.6, "num_examples": 5000}, {"name": "cifar100_11", "num_bytes": 12375149.16, "num_examples": 5500}, {"name": "cifar100_12", "num_bytes": 13500162.72, "num_examples": 6000}, {"name": "cifar100_13", "num_bytes": 14625176.28, "num_examples": 6500}, {"name": "cifar100_14", "num_bytes": 15750189.84, "num_examples": 7000}, {"name": "cifar100_15", "num_bytes": 16875203.4, "num_examples": 7500}, {"name": "cifar100_16", "num_bytes": 18000216.96, "num_examples": 8000}, {"name": "cifar100_17", "num_bytes": 19125230.52, "num_examples": 8500}, {"name": "cifar100_18", "num_bytes": 20250244.08, "num_examples": 9000}, {"name": "cifar100_19", "num_bytes": 21375257.64, "num_examples": 9500}, {"name": "cifar100_20", "num_bytes": 22500271.2, "num_examples": 10000}, {"name": "cifar100_21", "num_bytes": 23625284.76, "num_examples": 10500}, {"name": "cifar100_22", "num_bytes": 24750298.32, "num_examples": 11000}, {"name": "cifar100_23", "num_bytes": 25875311.88, "num_examples": 11500}, {"name": "cifar100_24", "num_bytes": 27000325.44, "num_examples": 12000}, {"name": "cifar100_25", "num_bytes": 28125339.0, "num_examples": 12500}, {"name": "cifar100_26", "num_bytes": 29250352.56, "num_examples": 13000}, {"name": "cifar100_27", "num_bytes": 30375366.12, "num_examples": 13500}, {"name": "cifar100_28", "num_bytes": 31500379.68, "num_examples": 14000}, {"name": "cifar100_29", "num_bytes": 32625393.24, "num_examples": 14500}, {"name": "cifar100_30", "num_bytes": 33750406.8, "num_examples": 15000}, {"name": "cifar100_31", "num_bytes": 34875420.36, "num_examples": 15500}, {"name": "cifar100_32", "num_bytes": 36000433.92, "num_examples": 16000}, {"name": "cifar100_33", "num_bytes": 37125447.48, "num_examples": 16500}, {"name": "cifar100_34", "num_bytes": 38250461.04, "num_examples": 17000}, {"name": "cifar100_35", "num_bytes": 39375474.6, "num_examples": 17500}, {"name": "cifar100_36", "num_bytes": 40500488.16, "num_examples": 18000}, {"name": "cifar100_37", "num_bytes": 41625501.72, "num_examples": 18500}, {"name": "cifar100_38", "num_bytes": 42750515.28, "num_examples": 19000}, {"name": "cifar100_39", "num_bytes": 43875528.84, "num_examples": 19500}, {"name": "cifar100_40", "num_bytes": 45000542.4, "num_examples": 20000}, {"name": "cifar100_41", "num_bytes": 46125555.96, "num_examples": 20500}, {"name": "cifar100_42", "num_bytes": 47250569.52, "num_examples": 21000}, {"name": "cifar100_43", "num_bytes": 48375583.08, "num_examples": 21500}, {"name": "cifar100_44", "num_bytes": 49500596.64, "num_examples": 22000}, {"name": "cifar100_45", "num_bytes": 50625610.2, "num_examples": 22500}, {"name": "cifar100_46", "num_bytes": 51750623.76, "num_examples": 23000}, {"name": "cifar100_47", "num_bytes": 52875637.32, "num_examples": 23500}, {"name": "cifar100_48", "num_bytes": 54000650.88, "num_examples": 24000}, {"name": "cifar100_49", "num_bytes": 55125664.44, "num_examples": 24500}, {"name": "cifar100_50", "num_bytes": 56250678.0, "num_examples": 25000}, {"name": "cifar100_51", "num_bytes": 57375691.56, "num_examples": 25500}, {"name": "cifar100_52", "num_bytes": 58500705.12, "num_examples": 26000}, {"name": "cifar100_53", "num_bytes": 59625718.68, "num_examples": 26500}, {"name": "cifar100_54", "num_bytes": 60750732.24, "num_examples": 27000}, {"name": "cifar100_55", "num_bytes": 61875745.8, "num_examples": 27500}, {"name": "cifar100_56", "num_bytes": 63000759.36, "num_examples": 28000}, {"name": "cifar100_57", "num_bytes": 64125772.92, "num_examples": 28500}, {"name": "cifar100_58", "num_bytes": 65250786.48, "num_examples": 29000}, {"name": "cifar100_59", "num_bytes": 66375800.04, "num_examples": 29500}, {"name": "cifar100_60", "num_bytes": 67500813.6, "num_examples": 30000}, {"name": "cifar100_61", "num_bytes": 68625827.16, "num_examples": 30500}, {"name": "cifar100_62", "num_bytes": 69750840.72, "num_examples": 31000}, {"name": "cifar100_63", "num_bytes": 70875854.28, "num_examples": 31500}, {"name": "cifar100_64", "num_bytes": 72000867.84, "num_examples": 32000}, {"name": "cifar100_65", "num_bytes": 73125881.4, "num_examples": 32500}, {"name": "cifar100_66", "num_bytes": 74250894.96, "num_examples": 33000}, {"name": "cifar100_67", "num_bytes": 75375908.52, "num_examples": 33500}, {"name": "cifar100_68", "num_bytes": 76500922.08, "num_examples": 34000}, {"name": "cifar100_69", "num_bytes": 77625935.64, "num_examples": 34500}, {"name": "cifar100_70", "num_bytes": 78750949.2, "num_examples": 35000}, {"name": "cifar100_71", "num_bytes": 79875962.76, "num_examples": 35500}, {"name": "cifar100_72", "num_bytes": 81000976.32, "num_examples": 36000}, {"name": "cifar100_73", "num_bytes": 82125989.88, "num_examples": 36500}, {"name": "cifar100_74", "num_bytes": 83251003.44, "num_examples": 37000}, {"name": "cifar100_75", "num_bytes": 84376017.0, "num_examples": 37500}, {"name": "cifar100_76", "num_bytes": 85501030.56, "num_examples": 38000}, {"name": "cifar100_77", "num_bytes": 86626044.12, "num_examples": 38500}, {"name": "cifar100_78", "num_bytes": 87751057.68, "num_examples": 39000}, {"name": "cifar100_79", "num_bytes": 88876071.24, "num_examples": 39500}, {"name": "cifar100_80", "num_bytes": 90001084.8, "num_examples": 40000}, {"name": "cifar100_81", "num_bytes": 91126098.36, "num_examples": 40500}, {"name": "cifar100_82", "num_bytes": 92251111.92, "num_examples": 41000}, {"name": "cifar100_83", "num_bytes": 93376125.48, "num_examples": 41500}, {"name": "cifar100_84", "num_bytes": 94501139.04, "num_examples": 42000}, {"name": "cifar100_85", "num_bytes": 95626152.6, "num_examples": 42500}, {"name": "cifar100_86", "num_bytes": 96751166.16, "num_examples": 43000}, {"name": "cifar100_87", "num_bytes": 97876179.72, "num_examples": 43500}, {"name": "cifar100_88", "num_bytes": 99001193.28, "num_examples": 44000}, {"name": "cifar100_89", "num_bytes": 100126206.84, "num_examples": 44500}, {"name": "cifar100_90", "num_bytes": 101251220.4, "num_examples": 45000}, {"name": "cifar100_91", "num_bytes": 102376233.96, "num_examples": 45500}, {"name": "cifar100_92", "num_bytes": 103501247.52, "num_examples": 46000}, {"name": "cifar100_93", "num_bytes": 104626261.08, "num_examples": 46500}, {"name": "cifar100_94", "num_bytes": 105751274.64, "num_examples": 47000}, {"name": "cifar100_95", "num_bytes": 106876288.2, "num_examples": 47500}, {"name": "cifar100_96", "num_bytes": 108001301.76, "num_examples": 48000}, {"name": "cifar100_97", "num_bytes": 109126315.32, "num_examples": 48500}, {"name": "cifar100_98", "num_bytes": 110251328.88, "num_examples": 49000}, {"name": "cifar100_99", "num_bytes": 111376342.44, "num_examples": 49500}, {"name": "cifar100_100", "num_bytes": 112501356.0, "num_examples": 50000}], "download_size": 5989828624, "dataset_size": 5680193464.44}} | 2023-12-27T08:05:03+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "cifar100_2_to_100"
More Information needed | [
"# Dataset Card for \"cifar100_2_to_100\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"cifar100_2_to_100\"\n\nMore Information needed"
] | [
6,
19
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"cifar100_2_to_100\"\n\nMore Information needed"
] |
b90ae41652422b636886c2bed8ad5e5f7e221de9 | # Dataset Card for "fialka-v3-data"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards) | 0x7o/fialka-v3-data | [
"region:us"
] | 2023-12-27T07:22:25+00:00 | {"dataset_info": {"features": [{"name": "texts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 225223909.0, "num_examples": 130958}], "download_size": 105289541, "dataset_size": 225223909.0}} | 2023-12-27T07:23:15+00:00 | [] | [] | TAGS
#region-us
| # Dataset Card for "fialka-v3-data"
More Information needed | [
"# Dataset Card for \"fialka-v3-data\"\n\nMore Information needed"
] | [
"TAGS\n#region-us \n",
"# Dataset Card for \"fialka-v3-data\"\n\nMore Information needed"
] | [
6,
16
] | [
"passage: TAGS\n#region-us \n# Dataset Card for \"fialka-v3-data\"\n\nMore Information needed"
] |
023da916a5ff62a62faf49c4830529c34f94a87c |
This is a simplified Open-Platypus dataset, ready for training on a Mistral 7B model. | Thermostatic/mistral_platypus | [
"license:mit",
"region:us"
] | 2023-12-27T08:03:02+00:00 | {"license": "mit"} | 2023-12-27T08:04:47+00:00 | [] | [] | TAGS
#license-mit #region-us
|
This is a simplified Open-Platypus dataset, ready for training on a Mistral 7B model. | [] | [
"TAGS\n#license-mit #region-us \n"
] | [
11
] | [
"passage: TAGS\n#license-mit #region-us \n"
] |
f776d52490aa4b59b4ea949352dc12a967ca0878 |
The alpaca format of dataset [toxicsharegpt-NoWarning](https://huggingface.co/datasets/Undi95/toxic-dpo-v0.1-sharegpt/blob/main/toxicsharegpt-NoWarning.jsonl)
DISCLAIMER : I'M NOT THE AUTHOR OF THIS DATASET.
ORIGINAL DATASET: [Undi95/toxic-dpo-v0.1-sharegpt](https://huggingface.co/datasets/Undi95/toxic-dpo-v0.1-sharegpt?not-for-all-audiences=true)
### Usage restriction
To use this data, you must acknowledge/agree to the following:
- data contained within is "toxic"/"harmful", and contains profanity and other types of sensitive content
- none of the content or views contained in the dataset necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs automatically (llama-2-70b via prompt engineering for chosen and llama-2-13b-chat-hf for rejected)
you are able to use the dataset lawfully, particularly in locations with less-than-free speech laws
you, and you alone are responsible for having downloaded and used the dataset, and I am completely indemnified from any and all liabilities
- This dataset is meant exclusively for academic/research or other non-nefarious use-cases.
This dataset is meant exclusively for academic/research or other non-nefarious use-cases. | diffnamehard/toxic-dpo-v0.1-NoWarning-alpaca | [
"license:apache-2.0",
"region:us"
] | 2023-12-27T09:00:25+00:00 | {"license": "apache-2.0"} | 2023-12-28T04:19:58+00:00 | [] | [] | TAGS
#license-apache-2.0 #region-us
|
The alpaca format of dataset toxicsharegpt-NoWarning
DISCLAIMER : I'M NOT THE AUTHOR OF THIS DATASET.
ORIGINAL DATASET: Undi95/toxic-dpo-v0.1-sharegpt
### Usage restriction
To use this data, you must acknowledge/agree to the following:
- data contained within is "toxic"/"harmful", and contains profanity and other types of sensitive content
- none of the content or views contained in the dataset necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs automatically (llama-2-70b via prompt engineering for chosen and llama-2-13b-chat-hf for rejected)
you are able to use the dataset lawfully, particularly in locations with less-than-free speech laws
you, and you alone are responsible for having downloaded and used the dataset, and I am completely indemnified from any and all liabilities
- This dataset is meant exclusively for academic/research or other non-nefarious use-cases.
This dataset is meant exclusively for academic/research or other non-nefarious use-cases. | [
"### Usage restriction\nTo use this data, you must acknowledge/agree to the following:\n\n- data contained within is \"toxic\"/\"harmful\", and contains profanity and other types of sensitive content\n- none of the content or views contained in the dataset necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs automatically (llama-2-70b via prompt engineering for chosen and llama-2-13b-chat-hf for rejected)\nyou are able to use the dataset lawfully, particularly in locations with less-than-free speech laws\nyou, and you alone are responsible for having downloaded and used the dataset, and I am completely indemnified from any and all liabilities\n- This dataset is meant exclusively for academic/research or other non-nefarious use-cases.\n\nThis dataset is meant exclusively for academic/research or other non-nefarious use-cases."
] | [
"TAGS\n#license-apache-2.0 #region-us \n",
"### Usage restriction\nTo use this data, you must acknowledge/agree to the following:\n\n- data contained within is \"toxic\"/\"harmful\", and contains profanity and other types of sensitive content\n- none of the content or views contained in the dataset necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs automatically (llama-2-70b via prompt engineering for chosen and llama-2-13b-chat-hf for rejected)\nyou are able to use the dataset lawfully, particularly in locations with less-than-free speech laws\nyou, and you alone are responsible for having downloaded and used the dataset, and I am completely indemnified from any and all liabilities\n- This dataset is meant exclusively for academic/research or other non-nefarious use-cases.\n\nThis dataset is meant exclusively for academic/research or other non-nefarious use-cases."
] | [
14,
214
] | [
"passage: TAGS\n#license-apache-2.0 #region-us \n### Usage restriction\nTo use this data, you must acknowledge/agree to the following:\n\n- data contained within is \"toxic\"/\"harmful\", and contains profanity and other types of sensitive content\n- none of the content or views contained in the dataset necessarily align with my personal beliefs or opinions, they are simply text generated by LLMs automatically (llama-2-70b via prompt engineering for chosen and llama-2-13b-chat-hf for rejected)\nyou are able to use the dataset lawfully, particularly in locations with less-than-free speech laws\nyou, and you alone are responsible for having downloaded and used the dataset, and I am completely indemnified from any and all liabilities\n- This dataset is meant exclusively for academic/research or other non-nefarious use-cases.\n\nThis dataset is meant exclusively for academic/research or other non-nefarious use-cases."
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.