
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
4027c449a6f1cc95bbb0e96ca92e08b00c258abe
|
# Dataset Card for "hpqa-fid-input-wo-sp"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
carnival13/hpqa-fid-input-wo-sp
|
[
"region:us"
] |
2023-04-21T11:31:57+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": {"sequence": "int32"}}, {"name": "attention_mask", "sequence": {"sequence": "int8"}}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "validation", "num_bytes": 99256620, "num_examples": 7405}, {"name": "train", "num_bytes": 1212354164, "num_examples": 90447}], "download_size": 259132709, "dataset_size": 1311610784}}
|
2023-04-21T12:55:57+00:00
|
e27e1b0cd97d06c6981a4fd515eb84fe99cff7fd
|
# Dataset Card for "fr_crawler2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
factored/fr_crawler_class
|
[
"region:us"
] |
2023-04-21T11:45:54+00:00
|
{"dataset_info": {"features": [{"name": "labels", "dtype": {"class_label": {"names": {"0": "business analyst", "1": "data analyst", "2": "data engineer", "3": "full stack", "4": "data scientist", "5": "software engineer", "6": "devops engineer", "7": "front end", "8": "business intelligence analyst", "9": "machine learning engineer"}}}}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 393756835.62683624, "num_examples": 2250902}, {"name": "val", "num_bytes": 49219648.18658188, "num_examples": 281363}, {"name": "test", "num_bytes": 49219648.18658188, "num_examples": 281363}], "download_size": 284157951, "dataset_size": 492196132.0}}
|
2023-04-21T11:50:24+00:00
|
9f5c30ed5371dcb11608c71cc5e6efa44b38884d
|
## Dataset Summary
In [CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval](https://ai-muzic.github.io/clamp/), we introduce WikiMusicText (WikiMT), a new dataset for the evaluation of semantic search and music classification. It includes 1010 lead sheets in ABC notation sourced from Wikifonia.org, each accompanied by a title, artist, genre, and description. The title and artist information is extracted from the score, whereas the genre labels are obtained by matching keywords from the Wikipedia entries and assigned to one of the 8 classes (Jazz, Country, Folk, R&B, Pop, Rock, Dance, and Latin) that loosely mimic the GTZAN genres. The description is obtained by utilizing BART-large to summarize and clean the corresponding Wikipedia entry. Additionally, the natural language information within the ABC notation is removed.
WikiMT is a unique resource to support the evaluation of semantic search and music classification. However, it is important to acknowledge that the dataset was curated from publicly available sources, and there may be limitations concerning the accuracy and completeness of the genre and description information. Further research is needed to explore the potential biases and limitations of the dataset and to develop strategies to address them.
## How to Access Music Score Metadata for ABC Notation
To access metadata related to ABC notation music scores from the WikiMT dataset, follow these steps:
1. **Locate the Wikifonia MusicXML Data Link:** Start by visiting the discussion thread on the forum to find the download link for the Wikifonia dataset in MusicXML format (with a .mxl extension). You can find the discussion here: [Download for Wikifonia all 6,675 Lead Sheets](http://www.synthzone.com/forum/ubbthreads.php/topics/384909/Download_for_Wikifonia_all_6,6).
2. **Run the Provided Code:** Once you have found the Wikifonia MusicXML data link, execute the provided Python code below. This code will handle the following tasks:
- Automatically download the "wikimusictext.jsonl" dataset, which contains metadata associated with music scores.
- Automatically download the "xml2abc.py" conversion script, with special thanks to the author, Willem (Wim).
- Prompt you for the Wikifonia data URL, as follows:
```python
Enter the Wikifonia URL: [Paste your URL here]
```
Paste the URL pointing to the Wikifonia.zip file and press Enter.
The below code will take care of downloading, processing, and extracting the music score metadata, making it ready for your research or applications.
```python
import subprocess
import os
import json
import zipfile
import io
# Install the required packages if they are not installed
try:
from unidecode import unidecode
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'unidecode'])
from unidecode import unidecode
try:
from tqdm import tqdm
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'tqdm'])
from tqdm import tqdm
try:
import requests
except ImportError:
subprocess.check_call(["python", '-m', 'pip', 'install', 'requests'])
import requests
def filter(lines):
# Filter out all lines that include language information
music = ""
for line in lines:
if line[:2] in ['A:', 'B:', 'C:', 'D:', 'F:', 'G', 'H:', 'I:', 'N:', 'O:', 'R:', 'r:', 'S:', 'T:', 'W:', 'w:', 'X:', 'Z:'] \
or line=='\n' \
or (line.startswith('%') and not line.startswith('%%score')):
continue
else:
if "%" in line and not line.startswith('%%score'):
line = "%".join(line.split('%')[:-1])
music += line[:-1] + '\n'
else:
music += line + '\n'
return music
def load_music(filename):
# Convert the file to ABC notation
p = subprocess.Popen(
f'python xml2abc_145/xml2abc.py -m 2 -c 6 -x "{filename}"',
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
shell=True
)
out, err = p.communicate()
output = out.decode('utf-8').replace('\r', '') # Capture standard output
music = unidecode(output).split('\n')
music = filter(music).strip()
return music
def download_and_extract(url):
print(f"Downloading {url}")
# Send an HTTP GET request to the URL and get the response
response = requests.get(url, stream=True)
if response.status_code == 200:
# Create a BytesIO object and write the HTTP response content into it
zip_data = io.BytesIO()
total_size = int(response.headers.get('content-length', 0))
with tqdm(total=total_size, unit='B', unit_scale=True) as pbar:
for data in response.iter_content(chunk_size=1024):
pbar.update(len(data))
zip_data.write(data)
# Use the zipfile library to extract the file
print("Extracting the zip file...")
with zipfile.ZipFile(zip_data, "r") as zip_ref:
zip_ref.extractall("")
print("Done!")
else:
print("Failed to download the file. HTTP response code:", response.status_code)
# URL of the JSONL file
wikimt_url = "https://huggingface.co/datasets/sander-wood/wikimusictext/resolve/main/wikimusictext.jsonl"
# Local filename to save the downloaded file
local_filename = "wikimusictext.jsonl"
# Download the file and save it locally
response = requests.get(wikimt_url)
if response.status_code == 200:
with open(local_filename, 'wb') as file:
file.write(response.content)
print(f"Downloaded '{local_filename}' successfully.")
else:
print(f"Failed to download. Status code: {response.status_code}")
# Download the xml2abc.py script (special thanks to Wim Vree for creating this script)
download_and_extract("https://wim.vree.org/svgParse/xml2abc.py-145.zip")
# Download the Wikifonia dataset
wikifonia_url = input("Enter the Wikifonia URL: ")
download_and_extract(wikifonia_url)
wikimusictext = []
with open("wikimusictext.jsonl", "r", encoding="utf-8") as f:
for line in f.readlines():
wikimusictext.append(json.loads(line))
updated_wikimusictext = []
for song in tqdm(wikimusictext):
filename = song["artist"] + " - " + song["title"] + ".mxl"
filepath = os.path.join("Wikifonia", filename)
song["music"] = load_music(filepath)
updated_wikimusictext.append(song)
with open("wikimusictext.jsonl", "w", encoding="utf-8") as f:
for song in updated_wikimusictext:
f.write(json.dumps(song, ensure_ascii=False)+"\n")
```
By following these steps and running the provided code, you can efficiently access ABC notation music scores from the WikiMT dataset. Just ensure you have the metadata, the `xml2abc.py` script, and the correct download link before starting. Enjoy your musical journey!
## Copyright Disclaimer
WikiMT was curated from publicly available sources, and all rights to the original content and data remain with their respective copyright holders. The dataset is made available for research and educational purposes, and any use, distribution, or modification of the dataset should comply with the terms and conditions set forth by the original data providers.
## BibTeX entry and citation info
```
@misc{wu2023clamp,
title={CLaMP: Contrastive Language-Music Pre-training for Cross-Modal Symbolic Music Information Retrieval},
author={Shangda Wu and Dingyao Yu and Xu Tan and Maosong Sun},
year={2023},
eprint={2304.11029},
archivePrefix={arXiv},
primaryClass={cs.SD}
}
```
|
sander-wood/wikimusictext
|
[
"task_categories:text-classification",
"task_categories:text2text-generation",
"size_categories:1K<n<10K",
"language:en",
"license:mit",
"music",
"arxiv:2304.11029",
"region:us"
] |
2023-04-21T12:16:40+00:00
|
{"language": ["en"], "license": "mit", "size_categories": ["1K<n<10K"], "task_categories": ["text-classification", "text2text-generation"], "pretty_name": "wikimt", "tags": ["music"]}
|
2023-12-28T15:09:23+00:00
|
acaa4ca03d178b89704d7047ca2b9deab76464f8
|
This dataset can be used as a benchmark for clustering word embeddings for <b>German</b>.
The datasets contains news article titles and is based on the dataset of the [One Million Posts Corpus](https://ofai.github.io/million-post-corpus/) and [10kGNAD](https://github.com/tblock/10kGNAD). It contains 10'267 unique samples, 10 splits with 1'436 to 9'962 samples and 9 unique classes. Splits are built similarly to MTEB's [TwentyNewsgroupsClustering](https://huggingface.co/datasets/mteb/twentynewsgroups-clustering).
Have a look at German Text Embedding Clustering Benchmark ([Github](https://github.com/ClimSocAna/tecb-de), [Paper](https://arxiv.org/abs/2401.02709)) for more infos, datasets and evaluation results.
|
slvnwhrl/tenkgnad-clustering-s2s
|
[
"size_categories:10K<n<100K",
"language:de",
"license:cc-by-nc-sa-4.0",
"embeddings",
"clustering",
"benchmark",
"arxiv:2401.02709",
"region:us"
] |
2023-04-21T13:03:22+00:00
|
{"language": ["de"], "license": "cc-by-nc-sa-4.0", "size_categories": ["10K<n<100K"], "tags": ["embeddings", "clustering", "benchmark"]}
|
2024-01-08T08:32:02+00:00
|
c3a51bf9d41dfa3321575fdc40b40ae607eb77ce
|
This dataset can be used as a benchmark for clustering word embeddings for <b>German</b>.
The datasets contains news article titles and is based on the dataset of the [One Million Posts Corpus](https://ofai.github.io/million-post-corpus/) and [10kGNAD](https://github.com/tblock/10kGNAD). It contains 10'275 unique samples, 10 splits with 1'436 to 9'962 samples and 9 unique classes. Splits are built similarly to MTEB's [TwentyNewsgroupsClustering](https://huggingface.co/datasets/mteb/twentynewsgroups-clustering).
Have a look at German Text Embedding Clustering Benchmark ([Github](https://github.com/ClimSocAna/tecb-de), [Paper](https://arxiv.org/abs/2401.02709)) for more infos, datasets and evaluation results.
|
slvnwhrl/tenkgnad-clustering-p2p
|
[
"size_categories:10K<n<100K",
"language:de",
"license:cc-by-nc-sa-4.0",
"embeddings",
"clustering",
"benchmark",
"arxiv:2401.02709",
"region:us"
] |
2023-04-21T13:07:23+00:00
|
{"language": ["de"], "license": "cc-by-nc-sa-4.0", "size_categories": ["10K<n<100K"], "tags": ["embeddings", "clustering", "benchmark"]}
|
2024-01-08T08:36:14+00:00
|
03e513de547438a4baa00a173c0338274452a886
|
# Dataset Card for SpeechCommands
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=speech-commands-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [tensorflow.org/datasets](https://www.tensorflow.org/datasets/catalog/speech_commands)
- **Paper:** [Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition](https://arxiv.org/pdf/1804.03209.pdf)
- **Leaderboard:** [More Information Needed]
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=speech-commands-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [SpeechCommands Dataset](https://huggingface.co/datasets/speech_commands).
### Explore the Dataset

The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets[audio]
```
> **_Notice:_** On Linux, non-Python dependency on libsndfile package must be installed manually. See [Datasets - Installation](https://huggingface.co/docs/datasets/installation#audio) for more information.
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/speech_commands_enriched", "v0.01")
```
[//]: <> (TODO: Update this!)
Start exploring with a simple view:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['audio'])
spotlight.show(df_show, port=8000, dtype={"file": spotlight.Audio})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### SpeechCommands Dataset
This is a set of one-second .wav audio files, each containing a single spoken
English word or background noise. These words are from a small set of commands, and are spoken by a
variety of different speakers. This data set is designed to help train simple
machine learning models. It is covered in more detail at [https://arxiv.org/abs/1804.03209](https://arxiv.org/abs/1804.03209).
Version 0.01 of the data set (configuration `"v0.01"`) was released on August 3rd 2017 and contains
64,727 audio files.
Version 0.02 of the data set (configuration `"v0.02"`) was released on April 11th 2018 and
contains 105,829 audio files.
### Supported Tasks and Leaderboards
* `keyword-spotting`: the dataset can be used to train and evaluate keyword
spotting systems. The task is to detect preregistered keywords by classifying utterances
into a predefined set of words. The task is usually performed on-device for the
fast response time. Thus, accuracy, model size, and inference time are all crucial.
### Languages
The language data in SpeechCommands is in English (BCP-47 `en`).
## Dataset Structure
### Data Instances
Example of a core word (`"label"` is a word, `"is_unknown"` is `False`):
```python
{
"file": "no/7846fd85_nohash_0.wav",
"audio": {
"path": "no/7846fd85_nohash_0.wav",
"array": array([ -0.00021362, -0.00027466, -0.00036621, ..., 0.00079346,
0.00091553, 0.00079346]),
"sampling_rate": 16000
},
"label": 1, # "no"
"is_unknown": False,
"speaker_id": "7846fd85",
"utterance_id": 0
}
```
Example of an auxiliary word (`"label"` is a word, `"is_unknown"` is `True`)
```python
{
"file": "tree/8b775397_nohash_0.wav",
"audio": {
"path": "tree/8b775397_nohash_0.wav",
"array": array([ -0.00854492, -0.01339722, -0.02026367, ..., 0.00274658,
0.00335693, 0.0005188]),
"sampling_rate": 16000
},
"label": 28, # "tree"
"is_unknown": True,
"speaker_id": "1b88bf70",
"utterance_id": 0
}
```
Example of background noise (`_silence_`) class:
```python
{
"file": "_silence_/doing_the_dishes.wav",
"audio": {
"path": "_silence_/doing_the_dishes.wav",
"array": array([ 0. , 0. , 0. , ..., -0.00592041,
-0.00405884, -0.00253296]),
"sampling_rate": 16000
},
"label": 30, # "_silence_"
"is_unknown": False,
"speaker_id": "None",
"utterance_id": 0 # doesn't make sense here
}
```
### Data Fields
* `file`: relative audio filename inside the original archive.
* `audio`: dictionary containing a relative audio filename,
a decoded audio array, and the sampling rate. Note that when accessing
the audio column: `dataset[0]["audio"]` the audio is automatically decoded
and resampled to `dataset.features["audio"].sampling_rate`.
Decoding and resampling of a large number of audios might take a significant
amount of time. Thus, it is important to first query the sample index before
the `"audio"` column, i.e. `dataset[0]["audio"]` should always be preferred
over `dataset["audio"][0]`.
* `label`: either word pronounced in an audio sample or background noise (`_silence_`) class.
Note that it's an integer value corresponding to the class name.
* `is_unknown`: if a word is auxiliary. Equals to `False` if a word is a core word or `_silence_`,
`True` if a word is an auxiliary word.
* `speaker_id`: unique id of a speaker. Equals to `None` if label is `_silence_`.
* `utterance_id`: incremental id of a word utterance within the same speaker.
### Data Splits
The dataset has two versions (= configurations): `"v0.01"` and `"v0.02"`. `"v0.02"`
contains more words (see section [Source Data](#source-data) for more details).
| | train | validation | test |
|----- |------:|-----------:|-----:|
| v0.01 | 51093 | 6799 | 3081 |
| v0.02 | 84848 | 9982 | 4890 |
Note that in train and validation sets examples of `_silence_` class are longer than 1 second.
You can use the following code to sample 1-second examples from the longer ones:
```python
def sample_noise(example):
# Use this function to extract random 1 sec slices of each _silence_ utterance,
# e.g. inside `torch.utils.data.Dataset.__getitem__()`
from random import randint
if example["label"] == "_silence_":
random_offset = randint(0, len(example["speech"]) - example["sample_rate"] - 1)
example["speech"] = example["speech"][random_offset : random_offset + example["sample_rate"]]
return example
```
## Dataset Creation
### Curation Rationale
The primary goal of the dataset is to provide a way to build and test small
models that can detect a single word from a set of target words and differentiate it
from background noise or unrelated speech with as few false positives as possible.
### Source Data
#### Initial Data Collection and Normalization
The audio files were collected using crowdsourcing, see
[aiyprojects.withgoogle.com/open_speech_recording](https://github.com/petewarden/extract_loudest_section)
for some of the open source audio collection code that was used. The goal was to gather examples of
people speaking single-word commands, rather than conversational sentences, so
they were prompted for individual words over the course of a five minute
session.
In version 0.01 thirty different words were recoded: "Yes", "No", "Up", "Down", "Left",
"Right", "On", "Off", "Stop", "Go", "Zero", "One", "Two", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine",
"Bed", "Bird", "Cat", "Dog", "Happy", "House", "Marvin", "Sheila", "Tree", "Wow".
In version 0.02 more words were added: "Backward", "Forward", "Follow", "Learn", "Visual".
In both versions, ten of them are used as commands by convention: "Yes", "No", "Up", "Down", "Left",
"Right", "On", "Off", "Stop", "Go". Other words are considered to be auxiliary (in current implementation
it is marked by `True` value of `"is_unknown"` feature). Their function is to teach a model to distinguish core words
from unrecognized ones.
The `_silence_` label contains a set of longer audio clips that are either recordings or
a mathematical simulation of noise.
#### Who are the source language producers?
The audio files were collected using crowdsourcing.
### Annotations
#### Annotation process
Labels are the list of words prepared in advances.
Speakers were prompted for individual words over the course of a five minute
session.
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Creative Commons BY 4.0 License ((CC-BY-4.0)[https://creativecommons.org/licenses/by/4.0/legalcode]).
### Citation Information
```
@article{speechcommandsv2,
author = { {Warden}, P.},
title = "{Speech Commands: A Dataset for Limited-Vocabulary Speech Recognition}",
journal = {ArXiv e-prints},
archivePrefix = "arXiv",
eprint = {1804.03209},
primaryClass = "cs.CL",
keywords = {Computer Science - Computation and Language, Computer Science - Human-Computer Interaction},
year = 2018,
month = apr,
url = {https://arxiv.org/abs/1804.03209},
}
```
### Contributions
[More Information Needed]
|
renumics/speech_commands_enriched
|
[
"task_categories:audio-classification",
"task_ids:keyword-spotting",
"annotations_creators:other",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"size_categories:10K<n<100K",
"source_datasets:extended|speech_commands",
"language:en",
"license:cc-by-4.0",
"spotlight",
"enriched",
"renumics",
"enhanced",
"audio",
"classification",
"extended",
"arxiv:1804.03209",
"region:us"
] |
2023-04-21T13:11:59+00:00
|
{"annotations_creators": ["other"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M", "10K<n<100K"], "source_datasets": ["extended|speech_commands"], "task_categories": ["audio-classification"], "task_ids": ["keyword-spotting"], "pretty_name": "SpeechCommands", "config_names": ["v0.01", "v0.02"], "tags": ["spotlight", "enriched", "renumics", "enhanced", "audio", "classification", "extended"]}
|
2023-09-27T11:02:25+00:00
|
22793b6a6465bf00120ad525e38c51210858132c
|
This dataset can be used as a benchmark for clustering word embeddings for <b>German</b>.
The datasets contains book titles and is based on the dataset from the [GermEval 2019 Shared Task on Hierarchical Classification of Blurbs](https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/germeval-2019-hmc.html). It contains 17'726 unqiue samples, 28 splits with 177 to 16'425 samples and 4 to 93 unique classes. Splits are built similarly to [MTEB](https://github.com/embeddings-benchmark/mteb)'s [ArxivClusteringS2S](https://huggingface.co/datasets/mteb/arxiv-clustering-s2s).
Have a look at German Text Embedding Clustering Benchmark ([Github](https://github.com/ClimSocAna/tecb-de), [Paper](https://arxiv.org/abs/2401.02709)) for more infos, datasets and evaluation results.
|
slvnwhrl/blurbs-clustering-s2s
|
[
"size_categories:10K<n<100K",
"language:de",
"license:cc-by-nc-4.0",
"embeddings",
"clustering",
"benchmark",
"arxiv:2401.02709",
"region:us"
] |
2023-04-21T13:16:09+00:00
|
{"language": ["de"], "license": "cc-by-nc-4.0", "size_categories": ["10K<n<100K"], "tags": ["embeddings", "clustering", "benchmark"]}
|
2024-01-08T08:34:19+00:00
|
016ed8bb5a2d584c600b3370d95c7c44c9d96240
|
This dataset can be used as a benchmark for clustering word embeddings for <b>German</b>.
The datasets contains book titles and is based on the dataset from the [GermEval 2019 Shared Task on Hierarchical Classification of Blurbs](https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/germeval-2019-hmc.html). It contains 18'084 unqiue samples, 28 splits with 177 to 16'425 samples and 4 to 93 unique classes. Splits are built similarly to [MTEB](https://github.com/embeddings-benchmark/mteb)'s [ArxivClusteringP2P](https://huggingface.co/datasets/mteb/arxiv-clustering-p2p).
Have a look at German Text Embedding Clustering Benchmark ([Github](https://github.com/ClimSocAna/tecb-de), [Paper](https://arxiv.org/abs/2401.02709)) for more infos, datasets and evaluation results.
|
slvnwhrl/blurbs-clustering-p2p
|
[
"size_categories:10K<n<100K",
"language:de",
"license:cc-by-nc-4.0",
"embeddings",
"clustering",
"benchmark",
"arxiv:2401.02709",
"region:us"
] |
2023-04-21T13:17:32+00:00
|
{"language": ["de"], "license": "cc-by-nc-4.0", "size_categories": ["10K<n<100K"], "tags": ["embeddings", "clustering", "benchmark"]}
|
2024-01-08T08:27:34+00:00
|
0bd22791ee4d7d0e061e938a366d781ac82998cf
|
medhallou/medhallou
|
[
"license:openrail",
"region:us"
] |
2023-04-21T13:18:44+00:00
|
{"license": "openrail"}
|
2023-04-21T13:18:44+00:00
|
|
50b51af63354f51f3b58e22db5986ef817cee5a5
|
rishiraj/traffic-detection
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-21T14:06:16+00:00
|
{"license": "apache-2.0"}
|
2023-04-21T14:09:35+00:00
|
|
681f86bc1bf40b84d9f9ed006ae4af38e73ebfc1
|
# Dataset Card for CIFAR-100-Enriched (Enhanced by Renumics)
## Dataset Description
- **Homepage:** [Renumics Homepage](https://renumics.com/?hf-dataset-card=cifar100-enriched)
- **GitHub** [Spotlight](https://github.com/Renumics/spotlight)
- **Dataset Homepage** [CS Toronto Homepage](https://www.cs.toronto.edu/~kriz/cifar.html#:~:text=The%20CIFAR%2D100%20dataset)
- **Paper:** [Learning Multiple Layers of Features from Tiny Images](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf)
### Dataset Summary
📊 [Data-centric AI](https://datacentricai.org) principles have become increasingly important for real-world use cases.
At [Renumics](https://renumics.com/?hf-dataset-card=cifar100-enriched) we believe that classical benchmark datasets and competitions should be extended to reflect this development.
🔍 This is why we are publishing benchmark datasets with application-specific enrichments (e.g. embeddings, baseline results, uncertainties, label error scores). We hope this helps the ML community in the following ways:
1. Enable new researchers to quickly develop a profound understanding of the dataset.
2. Popularize data-centric AI principles and tooling in the ML community.
3. Encourage the sharing of meaningful qualitative insights in addition to traditional quantitative metrics.
📚 This dataset is an enriched version of the [CIFAR-100 Dataset](https://www.cs.toronto.edu/~kriz/cifar.html).
### Explore the Dataset
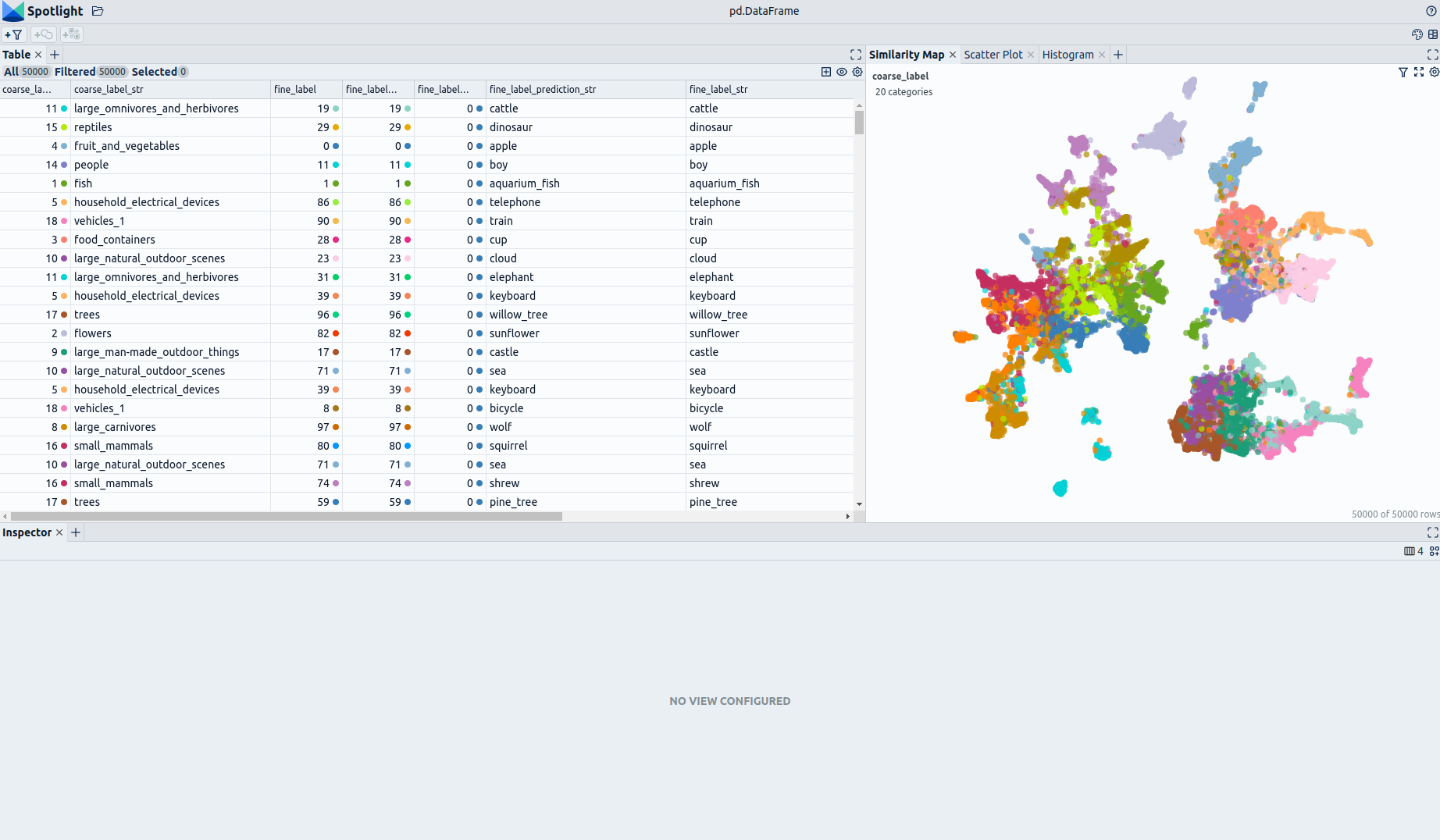
The enrichments allow you to quickly gain insights into the dataset. The open source data curation tool [Renumics Spotlight](https://github.com/Renumics/spotlight) enables that with just a few lines of code:
Install datasets and Spotlight via [pip](https://packaging.python.org/en/latest/key_projects/#pip):
```python
!pip install renumics-spotlight datasets
```
Load the dataset from huggingface in your notebook:
```python
import datasets
dataset = datasets.load_dataset("renumics/cifar100-enriched", split="train")
```
Start exploring with a simple view that leverages embeddings to identify relevant data segments:
```python
from renumics import spotlight
df = dataset.to_pandas()
df_show = df.drop(columns=['embedding', 'probabilities'])
spotlight.show(df_show, port=8000, dtype={"image": spotlight.Image, "embedding_reduced": spotlight.Embedding})
```
You can use the UI to interactively configure the view on the data. Depending on the concrete tasks (e.g. model comparison, debugging, outlier detection) you might want to leverage different enrichments and metadata.
### CIFAR-100 Dataset
The CIFAR-100 dataset consists of 60000 32x32 colour images in 100 classes, with 600 images per class. There are 50000 training images and 10000 test images.
The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
The classes are completely mutually exclusive.
We have enriched the dataset by adding **image embeddings** generated with a [Vision Transformer](https://huggingface.co/google/vit-base-patch16-224).
Here is the list of classes in the CIFAR-100:
| Superclass | Classes |
|---------------------------------|----------------------------------------------------|
| aquatic mammals | beaver, dolphin, otter, seal, whale |
| fish | aquarium fish, flatfish, ray, shark, trout |
| flowers | orchids, poppies, roses, sunflowers, tulips |
| food containers | bottles, bowls, cans, cups, plates |
| fruit and vegetables | apples, mushrooms, oranges, pears, sweet peppers |
| household electrical devices | clock, computer keyboard, lamp, telephone, television|
| household furniture | bed, chair, couch, table, wardrobe |
| insects | bee, beetle, butterfly, caterpillar, cockroach |
| large carnivores | bear, leopard, lion, tiger, wolf |
| large man-made outdoor things | bridge, castle, house, road, skyscraper |
| large natural outdoor scenes | cloud, forest, mountain, plain, sea |
| large omnivores and herbivores | camel, cattle, chimpanzee, elephant, kangaroo |
| medium-sized mammals | fox, porcupine, possum, raccoon, skunk |
| non-insect invertebrates | crab, lobster, snail, spider, worm |
| people | baby, boy, girl, man, woman |
| reptiles | crocodile, dinosaur, lizard, snake, turtle |
| small mammals | hamster, mouse, rabbit, shrew, squirrel |
| trees | maple, oak, palm, pine, willow |
| vehicles 1 | bicycle, bus, motorcycle, pickup truck, train |
| vehicles 2 | lawn-mower, rocket, streetcar, tank, tractor |
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image into one of 100 classes. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-cifar-100).
### Languages
English class labels.
## Dataset Structure
### Data Instances
A sample from the training set is provided below:
```python
{
'image': '/huggingface/datasets/downloads/extracted/f57c1a3fbca36f348d4549e820debf6cc2fe24f5f6b4ec1b0d1308a80f4d7ade/0/0.png',
'full_image': <PIL.PngImagePlugin.PngImageFile image mode=RGB size=32x32 at 0x7F15737C9C50>,
'fine_label': 19,
'coarse_label': 11,
'fine_label_str': 'cattle',
'coarse_label_str': 'large_omnivores_and_herbivores',
'fine_label_prediction': 19,
'fine_label_prediction_str': 'cattle',
'fine_label_prediction_error': 0,
'split': 'train',
'embedding': [-1.2482988834381104,
0.7280710339546204, ...,
0.5312759280204773],
'probabilities': [4.505949982558377e-05,
7.286163599928841e-05, ...,
6.577593012480065e-05],
'embedding_reduced': [1.9439491033554077, -5.35720682144165]
}
```
### Data Fields
| Feature | Data Type |
|---------------------------------|------------------------------------------------|
| image | Value(dtype='string', id=None) |
| full_image | Image(decode=True, id=None) |
| fine_label | ClassLabel(names=[...], id=None) |
| coarse_label | ClassLabel(names=[...], id=None) |
| fine_label_str | Value(dtype='string', id=None) |
| coarse_label_str | Value(dtype='string', id=None) |
| fine_label_prediction | ClassLabel(names=[...], id=None) |
| fine_label_prediction_str | Value(dtype='string', id=None) |
| fine_label_prediction_error | Value(dtype='int32', id=None) |
| split | Value(dtype='string', id=None) |
| embedding | Sequence(feature=Value(dtype='float32', id=None), length=768, id=None) |
| probabilities | Sequence(feature=Value(dtype='float32', id=None), length=100, id=None) |
| embedding_reduced | Sequence(feature=Value(dtype='float32', id=None), length=2, id=None) |
### Data Splits
| Dataset Split | Number of Images in Split | Samples per Class (fine) |
| ------------- |---------------------------| -------------------------|
| Train | 50000 | 500 |
| Test | 10000 | 100 |
## Dataset Creation
### Curation Rationale
The CIFAR-10 and CIFAR-100 are labeled subsets of the [80 million tiny images](http://people.csail.mit.edu/torralba/tinyimages/) dataset.
They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton.
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
If you use this dataset, please cite the following paper:
```
@article{krizhevsky2009learning,
added-at = {2021-01-21T03:01:11.000+0100},
author = {Krizhevsky, Alex},
biburl = {https://www.bibsonomy.org/bibtex/2fe5248afe57647d9c85c50a98a12145c/s364315},
interhash = {cc2d42f2b7ef6a4e76e47d1a50c8cd86},
intrahash = {fe5248afe57647d9c85c50a98a12145c},
keywords = {},
pages = {32--33},
timestamp = {2021-01-21T03:01:11.000+0100},
title = {Learning Multiple Layers of Features from Tiny Images},
url = {https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf},
year = 2009
}
```
### Contributions
Alex Krizhevsky, Vinod Nair, Geoffrey Hinton, and Renumics GmbH.
|
renumics/cifar100-enriched
|
[
"task_categories:image-classification",
"annotations_creators:crowdsourced",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-80-Million-Tiny-Images",
"language:en",
"license:mit",
"image classification",
"cifar-100",
"cifar-100-enriched",
"embeddings",
"enhanced",
"spotlight",
"renumics",
"region:us"
] |
2023-04-21T14:07:01+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["found"], "language": ["en"], "license": "mit", "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-80-Million-Tiny-Images"], "task_categories": ["image-classification"], "paperswithcode_id": "cifar-100", "pretty_name": "CIFAR-100", "tags": ["image classification", "cifar-100", "cifar-100-enriched", "embeddings", "enhanced", "spotlight", "renumics"]}
|
2023-06-06T11:23:33+00:00
|
693a60875f874a8f288c3fbf956aadf2724fa023
|
# Dataset Card for "voxelgym_3c_200"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Cubpaw/voxelgym_3c_200
|
[
"region:us"
] |
2023-04-21T14:21:32+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": "image"}, {"name": "rgb_label", "dtype": "image"}], "splits": [{"name": "train", "num_bytes": 342576.0, "num_examples": 200}, {"name": "validation", "num_bytes": 86676.0, "num_examples": 50}], "download_size": 277351, "dataset_size": 429252.0}}
|
2023-04-21T14:21:41+00:00
|
0f7e23e31b6f4a11cb0ddabba52341b0f5c35166
|
Bibr/miku_mx
|
[
"license:openrail",
"region:us"
] |
2023-04-21T14:33:58+00:00
|
{"license": "openrail"}
|
2023-04-21T14:51:35+00:00
|
|
2a3d01fea2f182be425f877a0f14b42fb3bfa24c
|
# Dataset Card for "laplacian_image_aesthetic_3M"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ioclab/laplacian_image_aesthetic_3M
|
[
"region:us"
] |
2023-04-21T14:35:24+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "conditioning_image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 359597047282.0, "num_examples": 3000000}], "download_size": 359170663793, "dataset_size": 359597047282.0}}
|
2023-04-21T21:30:16+00:00
|
d9742a2df969e345f68c411a1ecd378565a77e27
|
aashay96/indic_language_corpus
|
[
"license:cc",
"region:us"
] |
2023-04-21T14:35:30+00:00
|
{"license": "cc"}
|
2023-04-21T19:22:34+00:00
|
|
03515f557fe3585c4e3d400feda066b598d03f84
|
Chinar/asr_processed
|
[
"license:cc",
"region:us"
] |
2023-04-21T14:56:42+00:00
|
{"license": "cc"}
|
2023-04-21T15:30:11+00:00
|
|
0c97bfa853d0ff01ec138370f71bc0c38bda9120
|
# Dataset Card for DaCoref
## Dataset Description
- **Repository:** <https://gist.github.com/saattrupdan/3551300138e8668fbb8d32357e7b39f7>
- **Point of Contact:** [Dan Saattrup Nielsen](mailto:[email protected])
- **Size of downloaded dataset files:** 569 KB
- **Size of the generated dataset:** 1099 KB
- **Total amount of disk used:** 1668 KB
### Dataset Summary
This dataset contains coreference annotations of part of the [Copenhagen Dependency Treebank](https://github.com/mbkromann/copenhagen-dependency-treebank/wiki/CDT).
### Supported Tasks and Leaderboards
This dataset is meant to train coreference resolution models.
### Languages
The dataset is available in Danish (`da`).
## Dataset Structure
### Data Instances
- **Size of downloaded dataset files:** 569 KB
- **Size of the generated dataset:** 1099 KB
- **Total amount of disk used:** 1668 KB
| split | samples |
|---------|--------:|
| train | 2,686 |
| val | 332 |
| test | 385 |
An example from the dataset looks as follows.
```
{
'sent_id': 'train-v2-0',
'doc_id': 'nw/0442',
'text': 'På fredag har SID inviteret til reception i SID-huset i anledning af at formanden Kjeld Christensen går ind i de glade tressere.',
'tokens': ['På',
'fredag',
'har',
'SID',
'inviteret',
'til',
'reception',
'i',
'SID-huset',
'i',
'anledning',
'af',
'at',
'formanden',
'Kjeld',
'Christensen',
'går',
'ind',
'i',
'de',
'glade',
'tressere',
'.'
],
'clusters': [[13, 14, 15]]
}
```
### Data Fields
The data fields are the same among all splits.
- `sent_id` (`string`): The sentence ID from the [Universal Dependencies]().
- `doc_id` (`string`): The document ID from the [Copenhagen Dependency Treebank]().
- `text` (`string`): The document.
- `tokens` (`list[str]`): The tokens appearing in the document.
- `clusters` (`list[list[int]]`): The coreference clusters in the document, where the integers refer to the indices in `tokens`.
## Dataset Creation
This coreference dataset was originally annotated as part of the Copenhagen Dependency Treebank (CDT) project but never finished. The incomplete annotation can be downloaded from the [project github](https://github.com/mbkromann/copenhagen-dependency-treebank).
The [CDT documentation](https://github.com/mbkromann/copenhagen-dependency-treebank/blob/master/manual/cdt-manual.pdf) contains description of the coreference classes as well as inter-annotator agreement and confusion matrices.
For this resource, we used the annotation files from the annotator "Lotte" along with the UD syntax which is an automatic conversion of the CDT syntax annotation by Johansen et al. (2015). We provide the sentence ID from the UD resource as well as the document ID from CDT. The document ID has been prepended with a two letter domain code compatible with the domain codes of the Ontonotes corpus. This is a manually mapping of the sources listed in the CDT. Only nw (newswire), mz (magazine), and bn (broadcast news) were present:
- 299 nw documents
- 41 mz documents
- 1 bn
For the CDT, only the core node of each span was annotated and one annotator manually propagated the label to the entire span. A few systematic errors were corrected in this process, the most important being that plural pronouns "we" and "they" can be coreferent with company names if they refer to the employee group of this company.
For this resource we have merged the following labels to form uniquely numbered clusters: coref, coref-evol, coref-iden, coref-iden.sb, coref-var, and ref. Coref-res and coref-res.prg are also included as clusters but not merged with any other label, nor each other.
Some notes about the annotation, but see also the CDT documentation: If conjunctions of entities are only referred to as a group, they are marked as one span. (e.g. if "Lise, Lone og Birthe" are only referred to as a group, e.g. by the plural pronoun "de"), "Line, Lone og Birthe" is marked as one span. The spans are generally as long as possible. Example: Det sidste gik ud over politikerne, da de i sin tid præsenterede [det første forslag til den milliard-dyre vandmiljøplan].
Singletons are not annotated. The annotation does not label attributative noun phrases that are connected through copula verbs such as to be. Name-initual appositive constructions are part of the same mention as the name. Generic pronouns (mainly "man" and "du") are not clustered unless they are part of a cluster, e.g. with a reflexive or possesive pronoun.
## Additional Information
### Dataset Curators
The work was conducted by Maria Jung Barrett, and has been uploaded to the Hugging Face Hub by [Dan Saattrup Nielsen](https://saattrupdan.github.io/) from the [The Alexandra
Institute](https://alexandra.dk/).
### Licensing Information
The dataset is licensed under the [CC BY 4.0
license](https://creativecommons.org/licenses/by/4.0/).
|
alexandrainst/dacoref
|
[
"size_categories:1K<n<10K",
"language:da",
"license:cc-by-sa-4.0",
"coreference-resolution",
"region:us"
] |
2023-04-21T15:04:23+00:00
|
{"language": ["da"], "license": "cc-by-sa-4.0", "size_categories": ["1K<n<10K"], "pretty_name": "DaCoref", "dataset_info": {"features": [{"name": "sent_id", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "clusters", "sequence": {"sequence": "int64"}}], "splits": [{"name": "train", "num_bytes": 871763, "num_examples": 2686}, {"name": "val", "num_bytes": 103309, "num_examples": 332}, {"name": "test", "num_bytes": 123444, "num_examples": 385}], "download_size": 568857, "dataset_size": 1098516}, "tags": ["coreference-resolution"]}
|
2023-04-21T15:53:49+00:00
|
6eb1eb0e3fcc84c62a83ea962326d9dac2fd6d0e
|
ocky7/garbled_3000_20230421
|
[
"license:gpl",
"region:us"
] |
2023-04-21T15:23:57+00:00
|
{"license": "gpl"}
|
2023-04-21T15:23:57+00:00
|
|
8303b12f4a2406dea9f9f5896ef8fafcdba113bd
|
I mannually choose images from league of legends champions and skins.
I have to mention that some of painters may not be consent to the use of their art works in AI training.
|
ecccho/lol-splash-girl-aesthetics
|
[
"region:us"
] |
2023-04-21T15:29:41+00:00
|
{}
|
2023-04-21T15:32:21+00:00
|
0c6c7feb54a2b7dda6caf2cbd20f5abe9518b478
|
# **CloudSEN12 HIGH-QUALITY**
## **A Benchmark Dataset for Cloud Semantic Understanding**

CloudSEN12 is a LARGE dataset (~1 TB) for cloud semantic understanding that consists of 49,400 image patches (IP) that are
evenly spread throughout all continents except Antarctica. Each IP covers 5090 x 5090 meters and contains data from Sentinel-2
levels 1C and 2A, hand-crafted annotations of thick and thin clouds and cloud shadows, Sentinel-1 Synthetic Aperture Radar (SAR),
digital elevation model, surface water occurrence, land cover classes, and cloud mask results from six cutting-edge
cloud detection algorithms.
CloudSEN12 is designed to support both weakly and self-/semi-supervised learning strategies by including three distinct forms of
hand-crafted labeling data: high-quality, scribble and no-annotation. For more details on how we created the dataset see our
paper.
Ready to start using **[CloudSEN12](https://cloudsen12.github.io/)**?
**[Download Dataset](https://cloudsen12.github.io/download.html)**
**[Paper - Scientific Data](https://www.nature.com/articles/s41597-022-01878-2)**
**[Inference on a new S2 image](https://colab.research.google.com/github/cloudsen12/examples/blob/master/example02.ipynb)**
**[Enter to cloudApp](https://github.com/cloudsen12/CloudApp)**
**[CloudSEN12 in Google Earth Engine](https://gee-community-catalog.org/projects/cloudsen12/)**
<br>
### **General Description**
<br>
| File | Name | Scale | Wavelength | Description | Datatype |
|---------------|-----------------|--------|------------------------------|------------------------------------------------------------------------------------------------------|----------|
| L1C_ & L2A_ | B1 | 0.0001 | 443.9nm (S2A) / 442.3nm (S2B)| Aerosols. | np.int16 |
| | B2 | 0.0001 | 496.6nm (S2A) / 492.1nm (S2B)| Blue. | np.int16 |
| | B3 | 0.0001 | 560nm (S2A) / 559nm (S2B) | Green. | np.int16 |
| | B4 | 0.0001 | 664.5nm (S2A) / 665nm (S2B) | Red. | np.int16 |
| | B5 | 0.0001 | 703.9nm (S2A) / 703.8nm (S2B)| Red Edge 1. | np.int16 |
| | B6 | 0.0001 | 740.2nm (S2A) / 739.1nm (S2B)| Red Edge 2. | np.int16 |
| | B7 | 0.0001 | 782.5nm (S2A) / 779.7nm (S2B)| Red Edge 3. | np.int16 |
| | B8 | 0.0001 | 835.1nm (S2A) / 833nm (S2B) | NIR. | np.int16 |
| | B8A | 0.0001 | 864.8nm (S2A) / 864nm (S2B) | Red Edge 4. | np.int16 |
| | B9 | 0.0001 | 945nm (S2A) / 943.2nm (S2B) | Water vapor. | np.int16 |
| | B11 | 0.0001 | 1613.7nm (S2A) / 1610.4nm (S2B)| SWIR 1. | np.int16 |
| | B12 | 0.0001 | 2202.4nm (S2A) / 2185.7nm (S2B)| SWIR 2. | np.int16 |
| L1C_ | B10 | 0.0001 | 1373.5nm (S2A) / 1376.9nm (S2B)| Cirrus. | np.int16 |
| L2A_ | AOT | 0.001 | - | Aerosol Optical Thickness. | np.int16 |
| | WVP | 0.001 | - | Water Vapor Pressure. | np.int16 |
| | TCI_R | 1 | - | True Color Image, Red. | np.int16 |
| | TCI_G | 1 | - | True Color Image, Green. | np.int16 |
| | TCI_B | 1 | - | True Color Image, Blue. | np.int16 |
| S1_ | VV | 1 | 5.405GHz | Dual-band cross-polarization, vertical transmit/horizontal receive. |np.float32|
| | VH | 1 | 5.405GHz | Single co-polarization, vertical transmit/vertical receive. |np.float32|
| | angle | 1 | - | Incidence angle generated by interpolating the ‘incidenceAngle’ property. |np.float32|
| EXTRA_ | CDI | 0.0001 | - | Cloud Displacement Index. | np.int16 |
| | Shwdirection | 0.01 | - | Azimuth. Values range from 0°- 360°. | np.int16 |
| | elevation | 1 | - | Elevation in meters. Obtained from MERIT Hydro datasets. | np.int16 |
| | ocurrence | 1 | - | JRC Global Surface Water. The frequency with which water was present. | np.int16 |
| | LC100 | 1 | - | Copernicus land cover product. CGLS-LC100 Collection 3. | np.int16 |
| | LC10 | 1 | - | ESA WorldCover 10m v100 product. | np.int16 |
| LABEL_ | fmask | 1 | - | Fmask4.0 cloud masking. | np.int16 |
| | QA60 | 1 | - | SEN2 Level-1C cloud mask. | np.int8 |
| | s2cloudless | 1 | - | sen2cloudless results. | np.int8 |
| | sen2cor | 1 | - | Scene Classification band. Obtained from SEN2 level 2A. | np.int8 |
| | cd_fcnn_rgbi | 1 | - | López-Puigdollers et al. results based on RGBI bands. | np.int8 |
| |cd_fcnn_rgbi_swir| 1 | - | López-Puigdollers et al. results based on RGBISWIR bands. | np.int8 |
| | kappamask_L1C | 1 | - | KappaMask results using SEN2 level L1C as input. | np.int8 |
| | kappamask_L2A | 1 | - | KappaMask results using SEN2 level L2A as input. | np.int8 |
| | manual_hq | 1 | | High-quality pixel-wise manual annotation. | np.int8 |
| | manual_sc | 1 | | Scribble manual annotation. | np.int8 |
<br>
### **Label Description**
| **CloudSEN12** | **KappaMask** | **Sen2Cor** | **Fmask** | **s2cloudless** | **CD-FCNN** | **QA60** |
|------------------|------------------|-------------------------|-----------------|-----------------------|---------------------|--------------------|
| 0 Clear | 1 Clear | 4 Vegetation | 0 Clear land | 0 Clear | 0 Clear | 0 Clear |
| | | 2 Dark area pixels | 1 Clear water | | | |
| | | 5 Bare Soils | 3 Snow | | | |
| | | 6 Water | | | | |
| | | 11 Snow | | | | |
| 1 Thick cloud | 4 Cloud | 8 Cloud medium probability | 4 Cloud | 1 Cloud | 1 Cloud | 1024 Opaque cloud |
| | | 9 Cloud high probability | | | | |
| 2 Thin cloud | 3 Semi-transparent cloud | 10 Thin cirrus | | | | 2048 Cirrus cloud |
| 3 Cloud shadow | 2 Cloud shadow | 3 Cloud shadows | 2 Cloud shadow | | | |
<br>
<be>
# **Dataset information, working with np.memmap:**
Sentinel-1 and Sentinel-2 collect images that span an area of 5090 x 5090 meters at 10 meters per pixel.
This results in 509 x 509 pixel images, presenting a challenge.
**Given each layer is a two-dimensional matrix, true image data is held from pixel (1,1) to (509,509)**
The subsequent images have been padded with three pixels around the image to make the images 512 x 512, a size that most models accept.
To give a visual representation of where the padding has been added:
x marks blank pixels stored as black (255)
xxxxxxxxxxxxxx
x xx
x xx
x xx
x xx
x xx
xxxxxxxxxxxxxx
xxxxxxxxxxxxxx
The effects of the padding can be mitigated by adding a random crop within (1,1) to (509, 509)
or completing a center crop to the desired size for network architecture.
### The current split of image data is into three categories:
- Training: 84.90 % of total
- Validation: 5.35 % of total
- Testing: 9.75 % of total
For the recomposition of the data to take random samples of all 10,000 available images,
we can combine the np.memmap objects and take random selections at the beginning of each trial,
selecting random samples of the 10,000 images based on the desired percentage of the total data available.
This approach ensures the mitigation of training bias based on the original selection of images for each category.
<br>
### **Example**
**train shape: (8490, 512, 512)**
<br>
**val shape: (535, 512, 512)**
<br>
**test shape: (975, 512, 512)**
<br>
```py
import numpy as np
# Read high-quality train
train_shape = (8490, 512, 512)
B4X = np.memmap('train/L1C_B04.dat', dtype='int16', mode='r', shape=train_shape)
y = np.memmap('train/manual_hq.dat', dtype='int8', mode='r', shape=train_shape)
# Read high-quality val
val_shape = (535, 512, 512)
B4X = np.memmap('val/L1C_B04.dat', dtype='int16', mode='r', shape=val_shape)
y = np.memmap('val/manual_hq.dat', dtype='int8', mode='r', shape=val_shape)
# Read high-quality test
test_shape = (975, 512, 512)
B4X = np.memmap('test/L1C_B04.dat', dtype='int16', mode='r', shape=test_shape)
y = np.memmap('test/manual_hq.dat', dtype='int8', mode='r', shape=test_shape)
```
<br>
This work has been partially supported by the Spanish Ministry of Science and Innovation project
PID2019-109026RB-I00 (MINECO-ERDF) and the Austrian Space Applications Programme within the
**[SemantiX project](https://austria-in-space.at/en/projects/2019/semantix.php)**.
|
csaybar/CloudSEN12-high
|
[
"license:cc-by-nc-4.0",
"region:us"
] |
2023-04-21T15:39:53+00:00
|
{"license": "cc-by-nc-4.0"}
|
2023-10-04T17:24:35+00:00
|
895115d3eaa2acd5fe5659a626d4667828e5a668
|
source: https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/complex-word-identification-dataset.html
|
H-Huang/complex_word_identification
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-04-21T15:49:18+00:00
|
{"license": "cc-by-4.0"}
|
2023-04-22T02:06:55+00:00
|
e925ffc249cc6856019a98f684b92ee9d28a7b9c
|
# Dataset Card for "msra_ner_k_V3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
doushabao4766/msra_ner_k_V3
|
[
"region:us"
] |
2023-04-21T16:24:08+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "string"}, {"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": {"class_label": {"names": {"0": "O", "1": "B-PER", "2": "I-PER", "3": "B-ORG", "4": "I-ORG", "5": "B-LOC", "6": "I-LOC"}}}}, {"name": "knowledge", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 56718636, "num_examples": 45001}, {"name": "test", "num_bytes": 4320277, "num_examples": 3443}], "download_size": 0, "dataset_size": 61038913}}
|
2023-04-21T16:24:24+00:00
|
423ad9ea37d4fdb622875c540b6ae881058f5753
|
kyot/embeddings
|
[
"license:unknown",
"region:us"
] |
2023-04-21T16:39:19+00:00
|
{"license": "unknown"}
|
2023-05-13T04:38:15+00:00
|
|
b7f6ba7870cd3e98d7fd60a47889131bdb6ef68f
|
# Dataset Card for "ccks_2019_ner_k_v3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
doushabao4766/ccks_2019_ner_k_V3
|
[
"region:us"
] |
2023-04-21T16:58:55+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": "int64"}, {"name": "knowledge", "dtype": "string"}], "splits": [{"name": "validation", "num_bytes": 2100351, "num_examples": 2001}, {"name": "test", "num_bytes": 3255296, "num_examples": 2795}, {"name": "train", "num_bytes": 8310126, "num_examples": 7754}], "download_size": 0, "dataset_size": 13665773}}
|
2023-04-22T03:22:44+00:00
|
a15e016c0dd5b8bd64c4ed6ddd3b7181925ff829
|
ChangeMavens/OrgChange
|
[
"license:afl-3.0",
"region:us"
] |
2023-04-21T17:08:57+00:00
|
{"license": "afl-3.0"}
|
2023-04-21T17:08:57+00:00
|
|
8e0fb26870723172058d6b0c8b750c11320fd3ba
|
# **CloudSEN12 SCRIBBLE**
## **A Benchmark Dataset for Cloud Semantic Understanding**

CloudSEN12 is a LARGE dataset (~1 TB) for cloud semantic understanding that consists of 49,400 image patches (IP) that are
evenly spread throughout all continents except Antarctica. Each IP covers 5090 x 5090 meters and contains data from Sentinel-2
levels 1C and 2A, hand-crafted annotations of thick and thin clouds and cloud shadows, Sentinel-1 Synthetic Aperture Radar (SAR),
digital elevation model, surface water occurrence, land cover classes, and cloud mask results from six cutting-edge
cloud detection algorithms.
CloudSEN12 is designed to support both weakly and self-/semi-supervised learning strategies by including three distinct forms of
hand-crafted labeling data: high-quality, scribble and no-annotation. For more details on how we created the dataset see our
paper.
Ready to start using **[CloudSEN12](https://cloudsen12.github.io/)**?
**[Download Dataset](https://cloudsen12.github.io/download.html)**
**[Paper - Scientific Data](https://www.nature.com/articles/s41597-022-01878-2)**
**[Inference on a new S2 image](https://colab.research.google.com/github/cloudsen12/examples/blob/master/example02.ipynb)**
**[Enter to cloudApp](https://github.com/cloudsen12/CloudApp)**
**[CloudSEN12 in Google Earth Engine](https://gee-community-catalog.org/projects/cloudsen12/)**
<br>
### **Description**
<br>
| File | Name | Scale | Wavelength | Description | Datatype |
|---------------|-----------------|--------|------------------------------|------------------------------------------------------------------------------------------------------|----------|
| L1C_ & L2A_ | B1 | 0.0001 | 443.9nm (S2A) / 442.3nm (S2B)| Aerosols. | np.int16 |
| | B2 | 0.0001 | 496.6nm (S2A) / 492.1nm (S2B)| Blue. | np.int16 |
| | B3 | 0.0001 | 560nm (S2A) / 559nm (S2B) | Green. | np.int16 |
| | B4 | 0.0001 | 664.5nm (S2A) / 665nm (S2B) | Red. | np.int16 |
| | B5 | 0.0001 | 703.9nm (S2A) / 703.8nm (S2B)| Red Edge 1. | np.int16 |
| | B6 | 0.0001 | 740.2nm (S2A) / 739.1nm (S2B)| Red Edge 2. | np.int16 |
| | B7 | 0.0001 | 782.5nm (S2A) / 779.7nm (S2B)| Red Edge 3. | np.int16 |
| | B8 | 0.0001 | 835.1nm (S2A) / 833nm (S2B) | NIR. | np.int16 |
| | B8A | 0.0001 | 864.8nm (S2A) / 864nm (S2B) | Red Edge 4. | np.int16 |
| | B9 | 0.0001 | 945nm (S2A) / 943.2nm (S2B) | Water vapor. | np.int16 |
| | B11 | 0.0001 | 1613.7nm (S2A) / 1610.4nm (S2B)| SWIR 1. | np.int16 |
| | B12 | 0.0001 | 2202.4nm (S2A) / 2185.7nm (S2B)| SWIR 2. | np.int16 |
| L1C_ | B10 | 0.0001 | 1373.5nm (S2A) / 1376.9nm (S2B)| Cirrus. | np.int16 |
| L2A_ | AOT | 0.001 | - | Aerosol Optical Thickness. | np.int16 |
| | WVP | 0.001 | - | Water Vapor Pressure. | np.int16 |
| | TCI_R | 1 | - | True Color Image, Red. | np.int16 |
| | TCI_G | 1 | - | True Color Image, Green. | np.int16 |
| | TCI_B | 1 | - | True Color Image, Blue. | np.int16 |
| S1_ | VV | 1 | 5.405GHz | Dual-band cross-polarization, vertical transmit/horizontal receive. |np.float32|
| | VH | 1 | 5.405GHz | Single co-polarization, vertical transmit/vertical receive. |np.float32|
| | angle | 1 | - | Incidence angle generated by interpolating the ‘incidenceAngle’ property. |np.float32|
| EXTRA_ | CDI | 0.0001 | - | Cloud Displacement Index. | np.int16 |
| | Shwdirection | 0.01 | - | Azimuth. Values range from 0°- 360°. | np.int16 |
| | elevation | 1 | - | Elevation in meters. Obtained from MERIT Hydro datasets. | np.int16 |
| | ocurrence | 1 | - | JRC Global Surface Water. The frequency with which water was present. | np.int16 |
| | LC100 | 1 | - | Copernicus land cover product. CGLS-LC100 Collection 3. | np.int16 |
| | LC10 | 1 | - | ESA WorldCover 10m v100 product. | np.int16 |
| LABEL_ | fmask | 1 | - | Fmask4.0 cloud masking. | np.int16 |
| | QA60 | 1 | - | SEN2 Level-1C cloud mask. | np.int8 |
| | s2cloudless | 1 | - | sen2cloudless results. | np.int8 |
| | sen2cor | 1 | - | Scene Classification band. Obtained from SEN2 level 2A. | np.int8 |
| | cd_fcnn_rgbi | 1 | - | López-Puigdollers et al. results based on RGBI bands. | np.int8 |
| |cd_fcnn_rgbi_swir| 1 | - | López-Puigdollers et al. results based on RGBISWIR bands. | np.int8 |
| | kappamask_L1C | 1 | - | KappaMask results using SEN2 level L1C as input. | np.int8 |
| | kappamask_L2A | 1 | - | KappaMask results using SEN2 level L2A as input. | np.int8 |
| | manual_hq | 1 | | High-quality pixel-wise manual annotation. | np.int8 |
| | manual_sc | 1 | | Scribble manual annotation. | np.int8 |
<br>
### **Label Description**
| **CloudSEN12** | **KappaMask** | **Sen2Cor** | **Fmask** | **s2cloudless** | **CD-FCNN** | **QA60** |
|------------------|------------------|-------------------------|-----------------|-----------------------|---------------------|--------------------|
| 0 Clear | 1 Clear | 4 Vegetation | 0 Clear land | 0 Clear | 0 Clear | 0 Clear |
| | | 2 Dark area pixels | 1 Clear water | | | |
| | | 5 Bare Soils | 3 Snow | | | |
| | | 6 Water | | | | |
| | | 11 Snow | | | | |
| 1 Thick cloud | 4 Cloud | 8 Cloud medium probability | 4 Cloud | 1 Cloud | 1 Cloud | 1024 Opaque cloud |
| | | 9 Cloud high probability | | | | |
| 2 Thin cloud | 3 Semi-transparent cloud | 10 Thin cirrus | | | | 2048 Cirrus cloud |
| 3 Cloud shadow | 2 Cloud shadow | 3 Cloud shadows | 2 Cloud shadow | | | |
<br>
### **np.memmap shape information**
<br>
**train shape: (8785, 512, 512)**
<br>
**val shape: (560, 512, 512)**
<br>
**test shape: (655, 512, 512)**
<br>
### **Example**
<br>
```py
import numpy as np
# Read high-quality train
train_shape = (8785, 512, 512)
B4X = np.memmap('train/L1C_B04.dat', dtype='int16', mode='r', shape=train_shape)
y = np.memmap('train/manual_hq.dat', dtype='int8', mode='r', shape=train_shape)
# Read high-quality val
val_shape = (560, 512, 512)
B4X = np.memmap('val/L1C_B04.dat', dtype='int16', mode='r', shape=val_shape)
y = np.memmap('val/manual_hq.dat', dtype='int8', mode='r', shape=val_shape)
# Read high-quality test
test_shape = (655, 512, 512)
B4X = np.memmap('test/L1C_B04.dat', dtype='int16', mode='r', shape=test_shape)
y = np.memmap('test/manual_hq.dat', dtype='int8', mode='r', shape=test_shape)
```
<br>
This work has been partially supported by the Spanish Ministry of Science and Innovation project
PID2019-109026RB-I00 (MINECO-ERDF) and the Austrian Space Applications Programme within the
**[SemantiX project](https://austria-in-space.at/en/projects/2019/semantix.php)**.
|
csaybar/CloudSEN12-scribble
|
[
"license:cc-by-nc-4.0",
"region:us"
] |
2023-04-21T17:28:11+00:00
|
{"license": "cc-by-nc-4.0"}
|
2023-04-24T21:59:00+00:00
|
29e767219962376db0e1429b3819d125db3fb670
|
Norway/Iam
|
[
"task_categories:table-question-answering",
"task_categories:conversational",
"task_categories:text-generation",
"size_categories:n<1K",
"language:en",
"license:apache-2.0",
"region:us"
] |
2023-04-21T18:20:49+00:00
|
{"language": ["en"], "license": "apache-2.0", "size_categories": ["n<1K"], "task_categories": ["table-question-answering", "conversational", "text-generation"], "pretty_name": "Iam AI"}
|
2023-04-21T18:33:18+00:00
|
|
4ece76e784069def59ce663fa55305907d823ffc
|
RESPutin/RESPUTINTest1
|
[
"license:openrail",
"region:us"
] |
2023-04-21T19:23:23+00:00
|
{"license": "openrail"}
|
2023-04-21T21:11:33+00:00
|
|
0989b9f35ea6167426be9a5e9c1aadea4261ac2a
|
# h2oGPT Data Card
## Summary
H2O.ai's `openassistant_oasst1_h2ogpt` is an open-source instruct-type dataset for fine-tuning of large language models, licensed for commercial use.
- Number of rows: `48307`
- Number of columns: `3`
- Column names: `['input', 'prompt_type', 'source']`
## Source
- [Original Open Assistant data in tree structure](https://huggingface.co/datasets/OpenAssistant/oasst1)
- [This flattened dataset created by script in h2oGPT repository](https://github.com/h2oai/h2ogpt/blob/83857fcf7d3b712aad5db32207e6db0ab0f780f9/create_data.py#L1252)
|
h2oai/openassistant_oasst1_h2ogpt
|
[
"language:en",
"license:apache-2.0",
"gpt",
"llm",
"large language model",
"open-source",
"region:us"
] |
2023-04-21T20:02:50+00:00
|
{"language": ["en"], "license": "apache-2.0", "thumbnail": "https://h2o.ai/etc.clientlibs/h2o/clientlibs/clientlib-site/resources/images/favicon.ico", "tags": ["gpt", "llm", "large language model", "open-source"]}
|
2023-04-24T17:07:44+00:00
|
8e291f275f467a00f01099783ea5e2407b11772c
|
This data accompanies the WebUI project (https://dl.acm.org/doi/abs/10.1145/3544548.3581158)
For more information, check out the project website: https://uimodeling.github.io/
To download this dataset, you need to install the huggingface-hub package
```
pip install huggingface-hub
```
Use snapshot_download
```
from huggingface_hub import snapshot_download
snapshot_download(repo_id="biglab/webui-70k", repo_type="dataset")
```
IMPORTANT
* Before downloading and using, please review the copyright info here: https://github.com/js0nwu/webui/blob/main/COPYRIGHT.txt
* Not all data samples have the same number of files (e.g., same number of device screenshots) due to the fact that the crawler used a timeout during collection
* The dataset released on HuggingFace was filtered using a list of explicit words and therefore contains fewer samples than the experiments originally used in the paper. The raw dataset is currently available (https://drive.google.com/drive/folders/1hcO75W2FjsZoibsj2TIbKz67hy9JkOBz?usp=share_link) but may be removed in the future.
|
biglab/webui-70k
|
[
"license:other",
"region:us"
] |
2023-04-21T20:18:07+00:00
|
{"license": "other"}
|
2023-05-05T01:26:12+00:00
|
037b0277d99b90b1bd844e5429b0129aafafb763
|
Dolly and alpaca dataset merged into one
Converted to data format of Baize Project
|
couchpotato888/dolpaca_chat
|
[
"region:us"
] |
2023-04-21T20:28:13+00:00
|
{}
|
2023-04-29T02:57:45+00:00
|
cba9b3b747020b41123bc042fcca6f518c5aa928
|
# Dataset Card for "cohere-wiki-embedding-100k"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
ashraq/cohere-wiki-embedding-100k
|
[
"region:us"
] |
2023-04-21T21:12:39+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "title", "dtype": "string"}, {"name": "text", "dtype": "string"}, {"name": "url", "dtype": "string"}, {"name": "wiki_id", "dtype": "int64"}, {"name": "views", "dtype": "float64"}, {"name": "paragraph_id", "dtype": "int64"}, {"name": "langs", "dtype": "int64"}, {"name": "emb", "sequence": "float64"}], "splits": [{"name": "train", "num_bytes": 686289530, "num_examples": 100000}], "download_size": 538433661, "dataset_size": 686289530}}
|
2023-04-21T21:12:57+00:00
|
a5c9ef90d8bdf81d31bee0185e0e408368869b7d
|
# Dataset Card for "VQAv2Validation_ViT_H_14_A_T_C_D-PNP-FILTER_benchmarks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/VQAv2Validation_ViT_H_14_A_T_C_D-PNP-FILTER_benchmarks
|
[
"region:us"
] |
2023-04-21T21:50:55+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 3207928399, "num_examples": 214354}], "download_size": 869829383, "dataset_size": 3207928399}}
|
2023-04-21T21:52:17+00:00
|
66018b699fbb92896d5b475fe710236a4195cb57
|
# Dataset Card for "VQAv2Validation_ViT_L_14_A_T_C_D-PNP-FILTER_benchmarks"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Multimodal-Fatima/VQAv2Validation_ViT_L_14_A_T_C_D-PNP-FILTER_benchmarks
|
[
"region:us"
] |
2023-04-21T21:53:50+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int64"}, {"name": "prompts", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 398963044, "num_examples": 25994}], "download_size": 103241179, "dataset_size": 398963044}}
|
2023-06-07T19:02:43+00:00
|
b2f2a6939da233fa075ecc1135d0c2238019b7ae
|
Mutugi/housing
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-21T22:26:04+00:00
|
{"license": "apache-2.0"}
|
2023-04-21T22:27:03+00:00
|
|
a1c66e915149e8cd0a549d802b5cb18922fa10c7
|
**Asaka Yashima from the Konbini Shoujo Z eroge**
- *Trained with Anime (full-final-pruned) model.*
- *5 versions; **9-1:0** (9 epochs), **10-1:0** (epochs), **6-1:2** (6 epochs, activation tag with 1:2 weights), **7-1:2** (7 epochs, 1:2 weights), **10-1:2** (10 epochs, 1:2 weights).*
- *gives good results with **0.5-0.7** weights*
|
Cheetor1996/Asaka-Yashima_Konbini-Shoujo-Z
|
[
"language:en",
"license:cc-by-2.0",
"art",
"region:us"
] |
2023-04-21T22:26:13+00:00
|
{"language": ["en"], "license": "cc-by-2.0", "pretty_name": "Asaka Yashima - Konbini Shoujo Z", "tags": ["art"]}
|
2023-04-21T23:14:34+00:00
|
4f57008cd25fece4d12ed8d119906e7014fbdc42
|
The dataset is stored at the OSF [here](https://osf.io/ksdnm/)
MLRegTest is a benchmark for sequence classification, containing training, development, and test sets from 1,800 regular languages.
Regular languages are formal languages, which are sets of sequences definable with certain kinds of formal grammars, including
regular expressions, finite-state acceptors, and monadic second-order logic with either the successor or precedence relation in the
model signature for words. This benchmark was designed to help identify those factors, specifically the kinds of long-distance
dependencies, that can make it difficult for ML systems to generalize successfully in learning patterns over sequences. MLRegTest
organizes its languages according to their logical complexity (monadic second-order, first-order, propositional, or monomial
expressions) and the kind of logical literals (string, tier-string, subsequence, or combinations thereof). The logical complexity
and choice of literal provides a systematic way to understand different kinds of long-distance dependencies in regular languages,
and therefore to understand the capabilities of different ML systems to learn such long-distance dependencies. The authors think it
will be an important milestone if other researchers are able to find an ML system that succeeds across the board on MLRegTest.
|
samvdp/MLRegTest
|
[
"task_categories:text-classification",
"size_categories:10K<n<100K",
"license:cc-by-4.0",
"sequence classification",
"formal languages",
"regular languages",
"long-distance dependencies",
"logical complexity",
"generalization",
"region:us"
] |
2023-04-21T22:28:48+00:00
|
{"license": "cc-by-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-classification"], "pretty_name": "MLRegTest", "tags": ["sequence classification", "formal languages", "regular languages", "long-distance dependencies", "logical complexity", "generalization"]}
|
2023-04-21T22:36:09+00:00
|
419f243c64268ffde49c2b05a1607f959498ecff
|
noxneural/synthetic_hairstyles_dataset
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-04-21T23:18:52+00:00
|
{"license": "cc-by-4.0"}
|
2023-04-21T23:18:52+00:00
|
|
145e7bac20dce8a0800546eecb62e97ba6b128ba
|
noxneural/synthetic_beard_styles
|
[
"license:cc-by-4.0",
"region:us"
] |
2023-04-21T23:23:01+00:00
|
{"license": "cc-by-4.0"}
|
2023-04-21T23:23:01+00:00
|
|
4b3ef582aea9abfb6b1ae5734ea9afb22539790c
|
# Dataset Card for "MIIW-Depth-ControlNet"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Nahrawy/MIIW-Depth-ControlNet
|
[
"region:us"
] |
2023-04-21T23:38:36+00:00
|
{"dataset_info": {"features": [{"name": "image_path", "dtype": "image"}, {"name": "depth_path", "dtype": "image"}, {"name": "scene", "dtype": "string"}, {"name": "caption", "dtype": "string"}, {"name": "direction", "dtype": "int8"}], "splits": [{"name": "train", "num_bytes": 12475221926.5, "num_examples": 24625}], "download_size": 6659246738, "dataset_size": 12475221926.5}}
|
2023-04-21T23:52:51+00:00
|
8153959a4cab0b777161e68debb8ea3d890a98b4
|
houck2040/satire
|
[
"license:mit",
"region:us"
] |
2023-04-21T23:51:49+00:00
|
{"license": "mit"}
|
2023-04-21T23:52:23+00:00
|
|
b8d08eca80f339f48ae533f3626dc382d89d7aa2
|
alvations/esci-data-task1
|
[
"license:other",
"region:us"
] |
2023-04-21T23:53:35+00:00
|
{"license": "other", "dataset_info": {"features": [{"name": "example_id", "dtype": "int64"}, {"name": "query", "dtype": "string"}, {"name": "query_id", "dtype": "int64"}, {"name": "product_id", "dtype": "string"}, {"name": "product_locale", "dtype": "string"}, {"name": "esci_label", "dtype": "string"}, {"name": "small_version", "dtype": "int64"}, {"name": "large_version", "dtype": "int64"}, {"name": "split", "dtype": "string"}, {"name": "product_title", "dtype": "string"}, {"name": "product_description", "dtype": "string"}, {"name": "product_bullet_point", "dtype": "string"}, {"name": "product_brand", "dtype": "string"}, {"name": "product_color", "dtype": "string"}, {"name": "gain", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 1030417721, "num_examples": 777248}, {"name": "dev", "num_bytes": 5890341, "num_examples": 4390}, {"name": "test", "num_bytes": 445424864, "num_examples": 336373}], "download_size": 726913948, "dataset_size": 1481732926}}
|
2023-04-22T01:29:03+00:00
|
|
61116d801891cba285dee672efd1d92581f07844
|
# Dataset Card for "codexglue_codetrans"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_codetrans
|
[
"region:us"
] |
2023-04-22T00:07:30+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "java", "dtype": "string"}, {"name": "cs", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4372641, "num_examples": 10300}, {"name": "validation", "num_bytes": 226407, "num_examples": 500}, {"name": "test", "num_bytes": 418587, "num_examples": 1000}], "download_size": 0, "dataset_size": 5017635}}
|
2023-04-27T22:09:43+00:00
|
5c377eb66102297209e87096ca2cb50609e21a14
|
# Dataset Card for "sanskrit-monolingual-pretraining"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
chronbmm/sanskrit-monolingual-pretraining
|
[
"region:us"
] |
2023-04-22T00:13:49+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 1577362939, "num_examples": 21371582}, {"name": "validation", "num_bytes": 8601369, "num_examples": 26247}, {"name": "test", "num_bytes": 8601369, "num_examples": 26247}], "download_size": 850823877, "dataset_size": 1594565677}}
|
2023-04-22T00:16:55+00:00
|
413b3f636344fe26e9548feaeaf1290c009d4ddc
|
# Dataset Card for "spider"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/spider
|
[
"region:us"
] |
2023-04-22T00:15:44+00:00
|
{"dataset_info": {"features": [{"name": "db_id", "dtype": "string"}, {"name": "query", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "schema", "dtype": "string"}, {"name": "query_res", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 10008824322, "num_examples": 7672}, {"name": "test", "num_bytes": 6559891, "num_examples": 665}], "download_size": 1644782747, "dataset_size": 10015384213}}
|
2023-04-22T00:19:01+00:00
|
5385ce3fe4f032dd59c59739f4343976e2c79469
|
# Dataset Card for "esci-data-task2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
alvations/esci-data-task2
|
[
"region:us"
] |
2023-04-22T00:31:08+00:00
|
{"dataset_info": {"features": [{"name": "example_id", "dtype": "int64"}, {"name": "query", "dtype": "string"}, {"name": "query_id", "dtype": "int64"}, {"name": "product_id", "dtype": "string"}, {"name": "product_locale", "dtype": "string"}, {"name": "esci_label", "dtype": "string"}, {"name": "small_version", "dtype": "int64"}, {"name": "large_version", "dtype": "int64"}, {"name": "split", "dtype": "string"}, {"name": "product_title", "dtype": "string"}, {"name": "product_description", "dtype": "string"}, {"name": "product_bullet_point", "dtype": "string"}, {"name": "product_brand", "dtype": "string"}, {"name": "product_color", "dtype": "string"}, {"name": "gain", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2603008323, "num_examples": 1977767}, {"name": "dev", "num_bytes": 7386427, "num_examples": 5505}, {"name": "test", "num_bytes": 843102586, "num_examples": 638016}], "download_size": 2214316591, "dataset_size": 3453497336}}
|
2023-04-22T01:40:09+00:00
|
1a7bc840eff3f7706b83142a3925965a83e53a54
|
# Dataset Card for "esci-data-task3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
alvations/esci-data-task3
|
[
"region:us"
] |
2023-04-22T00:37:51+00:00
|
{"dataset_info": {"features": [{"name": "example_id", "dtype": "int64"}, {"name": "query", "dtype": "string"}, {"name": "query_id", "dtype": "int64"}, {"name": "product_id", "dtype": "string"}, {"name": "product_locale", "dtype": "string"}, {"name": "esci_label", "dtype": "string"}, {"name": "small_version", "dtype": "int64"}, {"name": "large_version", "dtype": "int64"}, {"name": "split", "dtype": "string"}, {"name": "product_title", "dtype": "string"}, {"name": "product_description", "dtype": "string"}, {"name": "product_bullet_point", "dtype": "string"}, {"name": "product_brand", "dtype": "string"}, {"name": "product_color", "dtype": "string"}, {"name": "subtitute_label", "dtype": "int64"}, {"name": "gain", "dtype": "float64"}, {"name": "__index_level_0__", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2618830459, "num_examples": 1977767}, {"name": "dev", "num_bytes": 7430467, "num_examples": 5505}, {"name": "test", "num_bytes": 848206714, "num_examples": 638016}], "download_size": 2215587905, "dataset_size": 3474467640}}
|
2023-04-22T01:51:34+00:00
|
008079061b9d575eeecaba3e49fbc82a03a060d5
|
# Dataset Card for "cancer_test_data3"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
SHS/cancer_test_data3
|
[
"region:us"
] |
2023-04-22T00:42:20+00:00
|
{"dataset_info": {"features": [{"name": "passage", "dtype": "string"}, {"name": "passage_token", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 16571, "num_examples": 1}], "download_size": 10583, "dataset_size": 16571}}
|
2023-04-22T00:42:23+00:00
|
6b2b159c164d09fad72449501600627cbaa42796
|
# Dataset Card for "codexglue_code2text_go"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_go
|
[
"region:us"
] |
2023-04-22T00:50:51+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 342243143, "num_examples": 167288}, {"name": "validation", "num_bytes": 13721860, "num_examples": 7325}, {"name": "test", "num_bytes": 16328406, "num_examples": 8122}], "download_size": 121340474, "dataset_size": 372293409}}
|
2023-04-22T00:51:07+00:00
|
3f47dc680e243ea2fb9e587298237eae6ff9ee4c
|
# Dataset Card for "codexglue_code2text_java"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_java
|
[
"region:us"
] |
2023-04-22T00:51:09+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 452553835, "num_examples": 164923}, {"name": "validation", "num_bytes": 13366344, "num_examples": 5183}, {"name": "test", "num_bytes": 29080753, "num_examples": 10955}], "download_size": 154860056, "dataset_size": 495000932}}
|
2023-04-22T00:51:28+00:00
|
16fb665bbad2501b87469f02d000718883dcf9fd
|
# Dataset Card for "codexglue_code2text_javascript"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_javascript
|
[
"region:us"
] |
2023-04-22T00:51:30+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 160860431, "num_examples": 58025}, {"name": "validation", "num_bytes": 10337344, "num_examples": 3885}, {"name": "test", "num_bytes": 10190713, "num_examples": 3291}], "download_size": 65795549, "dataset_size": 181388488}}
|
2023-04-22T00:51:42+00:00
|
2fcd9292b3f73870fd27ff2e3d9af47501c3fc9f
|
# Dataset Card for "codexglue_code2text_php"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_php
|
[
"region:us"
] |
2023-04-22T00:51:43+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 614654499, "num_examples": 241241}, {"name": "validation", "num_bytes": 33283045, "num_examples": 12982}, {"name": "test", "num_bytes": 35374993, "num_examples": 14014}], "download_size": 219734595, "dataset_size": 683312537}}
|
2023-04-22T00:52:10+00:00
|
7bccd264f93b53bd85b20ca84891f987d78245b4
|
# Dataset Card for "codexglue_code2text_python"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_python
|
[
"region:us"
] |
2023-04-22T00:52:12+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 813663148, "num_examples": 251820}, {"name": "validation", "num_bytes": 46888564, "num_examples": 13914}, {"name": "test", "num_bytes": 50659688, "num_examples": 14918}], "download_size": 325303743, "dataset_size": 911211400}}
|
2023-04-22T00:52:50+00:00
|
e51835c2fbe959bb2e6a84c80a9003947e71974d
|
# Dataset Card for "codexglue_code2text_ruby"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
CM/codexglue_code2text_ruby
|
[
"region:us"
] |
2023-04-22T00:52:51+00:00
|
{"dataset_info": {"features": [{"name": "id", "dtype": "int32"}, {"name": "repo", "dtype": "string"}, {"name": "path", "dtype": "string"}, {"name": "func_name", "dtype": "string"}, {"name": "original_string", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "code", "dtype": "string"}, {"name": "code_tokens", "sequence": "string"}, {"name": "docstring", "dtype": "string"}, {"name": "docstring_tokens", "sequence": "string"}, {"name": "sha", "dtype": "string"}, {"name": "url", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 51956439, "num_examples": 24927}, {"name": "validation", "num_bytes": 2821037, "num_examples": 1400}, {"name": "test", "num_bytes": 2671551, "num_examples": 1261}], "download_size": 21921316, "dataset_size": 57449027}}
|
2023-04-22T00:52:59+00:00
|
01af94dedfc5df4e0d407ef31b00c6d3bb1f0056
|
Hibari from the **Senran Kagura** franchise
- *Trained with Anime (full-final pruned) model.*
- 4 variants; **8 epochs**, **9 epochs**, **10 epochs**, **Exp- 10** (10 epochs, trained with increased-weight tags)
- Good results with 0.7+ weights.
- Activation tags; hibari_sk for general info (add short hair and twintails to the prompt just to make sure.), hibari_uniform for her school uniform (add sefuruku, sailor collar, and pleated skirt in case of items disappearing.), hibari_dot_bikini for her polka dot bikini (add pink bikini, polka dot bikini, striped bikini, and frilled bikini to the prompt in case of this outfit not coming out right.)
|
Cheetor1996/Hibari_SK
|
[
"language:en",
"license:cc-by-nc-2.0",
"art",
"region:us"
] |
2023-04-22T01:09:00+00:00
|
{"language": ["en"], "license": "cc-by-nc-2.0", "pretty_name": "Hibari - Senran Kagura", "tags": ["art"]}
|
2023-04-22T01:28:06+00:00
|
7844cb80b3c7f9ab0ed7a3946490ae4a337a8d5e
|
4가지 한국어 챗봇 학습용 데이터셋을 합쳐놓았습니다. 이중 ShareGPT 데이터는 멀티턴으로 되어있습니다.
데이터 생성 및 합치는 코드는 https://github.com/HeegyuKim/open-korean-instructions 여기를 참고하세요
| 이름 | # | 타입 |
|---|---|---|
| [KoAlpaca v1.0](https://huggingface.co/datasets/Bingsu/ko_alpaca_data) | 52K | 싱글턴 |
| [KoAlpaca v1.1](https://raw.githubusercontent.com/Beomi/KoAlpaca/main/KoAlpaca_v1.1.jsonl) | 21K | 싱글턴 |
| [ShareGPT DeepL 번역](https://huggingface.co/datasets/junelee/sharegpt_deepl_ko) | 620K(싱글턴), 84K(멀티턴) | 멀티턴, 싱글턴 |
| [OIG-small-chip2-ko](https://huggingface.co/datasets/heegyu/OIG-small-chip2-ko) | 210K | 싱글턴 |
| [Korquad-Chat](https://huggingface.co/datasets/heegyu/korquad-chat-v1) | 9.6K | 멀티턴, 지식기반 |
모든 데이터는 포멧이 통일되어 있습니다. `<sys>`, `<usr>`, `<bot>` 세가지 토큰과 줄넘김으로 화자를 구분합니다.
korquad-chat 데이터의 경우, 유저와 봇이 서로를 호칭할 때는 `<|bot|>`, `<|user|>`로 되어있습니다.
```
{"source": "koalpaca-v1.0", "text": "<usr> 홀수 중 하나를 밝히세요.\n<sys> 트위터, 인스타그램, 텔레그램\n<bot> 텔레그램입니다."}
{"source": "korquad-chat", "text": "
<sys>1984년 9월부터 덴노지 역 ~ 히네노 역간에 운전을 개시한 '홈 라이너 이즈미'가 전신이다. 특급 구로시오의 381계 전동차의 히네노 전차구 입선 회송 열차를 좌석 정리권을 필요로 하는 정원제 열차로서 운행해온 것으로 간사이 지방 최초의 홈 라이너였다. 1986년 11월 개정에 따라 운전 구간이 와카야마 역까지 연장되어 한와 라이너로 개칭되어 현재에 이르게 되었다. 이전에는 평일에 상행 3편, 하행 6편이 운전되었지만 일부가 신오사카 역이나 교토 역 방면 발착 특급 구로시오로 변경되어 2002년 3월 이후에는 상행 2편, 하행 4편으로 축소되었다. 2009년 3월의 시간표 개정부터는 휴일 시간대의 운전이 중단되었으며 같은 해 6월 1일부터는 전면 금연화되었다.\n
<usr> 안녕하세요, <|bot|>. \"한와_선\"에 대해 알고 계시나요?\n
<bot> 네, 전체적으로 알고 있습니다. 1984년에 운전을 개시한 \"홈 라이너 이즈미\"가 전신이며, 간사이 지방 최초의 홈 라이너였습니다. 1986년에는 와카야마 역까지 연장된 후 \"한와 라이너\"로 개칭되었습니다.\n
<usr> 그렇군요. 이전에는 평일에 몇 편이 운행되었나요?\n
<bot> 평일에 상행 3편, 하행 6편이 운전되었습니다. 하지만 2002년 이후로는 상행 2편, 하행 4편으로 축소되었습니다.\n
<usr> 그렇군요. 혹시 특급 구로시오와 연관이 있을까요?\n
<bot> 네, \"한와 라이너\"는 특급 구로시오의 381계 전동차의 히네노 전차구 입선 회송 열차를 좌석 정리권을 필요로 하는 정원제 열차로서 운행되었습니다."
}
```
|
heegyu/open-korean-instructions
|
[
"license:mit",
"region:us"
] |
2023-04-22T01:10:17+00:00
|
{"license": "mit"}
|
2023-05-06T08:18:37+00:00
|
61848c32d05c0cfa77cc87931d2450d68689a298
|
# Dataset Card for "diffusers-testing"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
tsungtao/diffusers-testing
|
[
"region:us"
] |
2023-04-22T01:21:43+00:00
|
{"dataset_info": {"features": [{"name": "images", "dtype": "image"}, {"name": "conditions", "dtype": "image"}, {"name": "prompt", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5505979.0, "num_examples": 49}], "download_size": 5507558, "dataset_size": 5505979.0}}
|
2023-04-29T21:20:07+00:00
|
57f7d68c887501da37d11838237112cc879543c6
|
# Dataset Card for "sanskrit-monolingual-pretraining-corrupted"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
chronbmm/sanskrit-monolingual-pretraining-corrupted
|
[
"region:us"
] |
2023-04-22T01:42:29+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 7630102597, "num_examples": 21371582}, {"name": "val", "num_bytes": 17259654, "num_examples": 26247}, {"name": "test", "num_bytes": 17259654, "num_examples": 26247}], "download_size": 1093207625, "dataset_size": 7664621905}}
|
2023-04-22T01:47:21+00:00
|
8585e153a7b93b4a4d4dc5063cefd48302783a6a
|
# Dataset Card for "train_dataset_splitted_by_model1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
UchihaMadara/train_dataset_splitted_by_model1
|
[
"region:us"
] |
2023-04-22T02:06:04+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "sentiments", "sequence": "int64"}, {"name": "food", "sequence": "int64"}, {"name": "service", "sequence": "int64"}, {"name": "price", "sequence": "int64"}, {"name": "ambience", "sequence": "int64"}, {"name": "anecdotes/miscellaneous", "sequence": "int64"}, {"name": "aspect_sentences", "sequence": "string"}], "splits": [{"name": "train", "num_bytes": 2440714, "num_examples": 3043}], "download_size": 214931, "dataset_size": 2440714}}
|
2023-04-22T02:06:08+00:00
|
f98c5933c5c189e9435ce98fa6b3bb4d40cfba2d
|
19K Multilingual VQA Alignment Dataset, in the format of Mini-GPT4 dataset.
With 1.1K images from COCO-2017, resized.
|
JosephusCheung/GuanacoVQA-mini19K
|
[
"task_categories:visual-question-answering",
"language:zh",
"language:ja",
"language:de",
"license:gpl-3.0",
"llama",
"minigpt-4",
"region:us"
] |
2023-04-22T02:34:31+00:00
|
{"language": ["zh", "ja", "de"], "license": "gpl-3.0", "task_categories": ["visual-question-answering"], "tags": ["llama", "minigpt-4"]}
|
2023-04-22T02:46:39+00:00
|
aed052df6423c8a61d464690c405bebd36eb9bf5
|
theblackcat102/sharegpt-english
|
[
"task_categories:text-generation",
"size_categories:10K<n<100K",
"language:en",
"license:other",
"region:us"
] |
2023-04-22T02:40:58+00:00
|
{"language": ["en"], "license": "other", "size_categories": ["10K<n<100K"], "task_categories": ["text-generation"]}
|
2023-04-22T02:57:11+00:00
|
|
a2ebc4f6e23f37f569445558974aae6feb242637
|
hanpi2233/myself-models
|
[
"license:other",
"region:us"
] |
2023-04-22T03:22:56+00:00
|
{"license": "other"}
|
2023-07-19T03:10:48+00:00
|
|
2129c23ccec4ca6f84a70cbe0f238bc3a7720aca
|
theblackcat102/audio-alpaca
|
[
"task_categories:text-generation",
"task_categories:automatic-speech-recognition",
"size_categories:10K<n<100K",
"language:en",
"license:cc-by-nc-4.0",
"region:us"
] |
2023-04-22T03:23:19+00:00
|
{"language": ["en"], "license": "cc-by-nc-4.0", "size_categories": ["10K<n<100K"], "task_categories": ["text-generation", "automatic-speech-recognition"]}
|
2023-04-23T01:54:47+00:00
|
|
0835dced94eb65bd8cc77bff85d975aaec54627f
|
niaodtianatng/asdfghjkl
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-22T05:10:22+00:00
|
{"license": "apache-2.0"}
|
2023-04-22T05:10:22+00:00
|
|
09c0441ea1918dc4b3bdddf2441a4043549d2b72
|
phar/111
|
[
"license:odc-by",
"region:us"
] |
2023-04-22T05:12:52+00:00
|
{"license": "odc-by"}
|
2023-04-22T05:13:28+00:00
|
|
bcb0bd13c3b2d94059080bd4bcfdc9099f14776c
|
# Dataset Card for "gbsg"
A combination of the Rotterdam tumor bank and the German Breast Cancer Study Group.
This is the processed data set used in the DeepSurv paper (Katzman et al. 2018), and details
can be found at https://doi.org/10.1186/s12874-018-0482-1
See https://github.com/jaredleekatzman/DeepSurv/tree/master/experiments/data
for original data.
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jarrydmartinx/gbsg
|
[
"region:us"
] |
2023-04-22T05:45:48+00:00
|
{"dataset_info": {"features": [{"name": "horTh", "dtype": "float64"}, {"name": "tsize", "dtype": "float64"}, {"name": "menostat", "dtype": "float64"}, {"name": "age", "dtype": "float64"}, {"name": "pnodes", "dtype": "float64"}, {"name": "progrec", "dtype": "float64"}, {"name": "estrec", "dtype": "float64"}, {"name": "event_times", "dtype": "float64"}, {"name": "event_indicators", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 111312, "num_examples": 1546}, {"name": "test", "num_bytes": 49392, "num_examples": 686}], "download_size": 28144, "dataset_size": 160704}}
|
2023-04-27T04:51:04+00:00
|
55392a2c552da8bd91dd90e076bdbc71933e30d4
|
# Dataset Card for "support2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jarrydmartinx/support2
|
[
"region:us"
] |
2023-04-22T05:48:35+00:00
|
{"dataset_info": {"features": [{"name": "age", "dtype": "float64"}, {"name": "sex", "dtype": "string"}, {"name": "hospdead", "dtype": "int64"}, {"name": "slos", "dtype": "int64"}, {"name": "dzgroup", "dtype": "string"}, {"name": "dzclass", "dtype": "string"}, {"name": "num.co", "dtype": "int64"}, {"name": "edu", "dtype": "float64"}, {"name": "income", "dtype": "string"}, {"name": "scoma", "dtype": "float64"}, {"name": "charges", "dtype": "float64"}, {"name": "totcst", "dtype": "float64"}, {"name": "totmcst", "dtype": "float64"}, {"name": "avtisst", "dtype": "float64"}, {"name": "race", "dtype": "string"}, {"name": "sps", "dtype": "float64"}, {"name": "aps", "dtype": "float64"}, {"name": "surv2m", "dtype": "float64"}, {"name": "surv6m", "dtype": "float64"}, {"name": "hday", "dtype": "int64"}, {"name": "diabetes", "dtype": "int64"}, {"name": "dementia", "dtype": "int64"}, {"name": "ca", "dtype": "string"}, {"name": "prg2m", "dtype": "float64"}, {"name": "prg6m", "dtype": "float64"}, {"name": "dnr", "dtype": "string"}, {"name": "dnrday", "dtype": "float64"}, {"name": "meanbp", "dtype": "float64"}, {"name": "wblc", "dtype": "float64"}, {"name": "hrt", "dtype": "float64"}, {"name": "resp", "dtype": "float64"}, {"name": "temp", "dtype": "float64"}, {"name": "pafi", "dtype": "float64"}, {"name": "alb", "dtype": "float64"}, {"name": "bili", "dtype": "float64"}, {"name": "crea", "dtype": "float64"}, {"name": "sod", "dtype": "float64"}, {"name": "ph", "dtype": "float64"}, {"name": "glucose", "dtype": "float64"}, {"name": "bun", "dtype": "float64"}, {"name": "urine", "dtype": "float64"}, {"name": "adlp", "dtype": "float64"}, {"name": "adls", "dtype": "float64"}, {"name": "sfdm2", "dtype": "string"}, {"name": "adlsc", "dtype": "float64"}, {"name": "event_times", "dtype": "int64"}, {"name": "event_indicators", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 3753153, "num_examples": 9105}], "download_size": 827762, "dataset_size": 3753153}}
|
2023-04-22T05:48:40+00:00
|
ff634f1ff703723a3ab39894d673774a71c1c05b
|
# Dataset Card for "batch_indexing_machine_ViT_features"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Circularmachines/batch_indexing_machine_ViT_features
|
[
"region:us"
] |
2023-04-22T05:55:39+00:00
|
{"dataset_info": {"features": [{"name": "Unnamed: 0", "dtype": "int64"}, {"name": "0", "dtype": "float64"}, {"name": "1", "dtype": "float64"}, {"name": "2", "dtype": "float64"}, {"name": "3", "dtype": "float64"}, {"name": "4", "dtype": "float64"}, {"name": "5", "dtype": "float64"}, {"name": "6", "dtype": "float64"}, {"name": "7", "dtype": "float64"}, {"name": "8", "dtype": "float64"}, {"name": "9", "dtype": "float64"}, {"name": "10", "dtype": "float64"}, {"name": "11", "dtype": "float64"}, {"name": "12", "dtype": "float64"}, {"name": "13", "dtype": "float64"}, {"name": "14", "dtype": "float64"}, {"name": "15", "dtype": "float64"}, {"name": "16", "dtype": "float64"}, {"name": "17", "dtype": "float64"}, {"name": "18", "dtype": "float64"}, {"name": "19", "dtype": "float64"}, {"name": "20", "dtype": "float64"}, {"name": "21", "dtype": "float64"}, {"name": "22", "dtype": "float64"}, {"name": "23", "dtype": "float64"}, {"name": "24", "dtype": "float64"}, {"name": "25", "dtype": "float64"}, {"name": "26", "dtype": "float64"}, {"name": "27", "dtype": "float64"}, {"name": "28", "dtype": "float64"}, {"name": "29", "dtype": "float64"}, {"name": "30", "dtype": "float64"}, {"name": "31", "dtype": "float64"}, {"name": "32", "dtype": "float64"}, {"name": "33", "dtype": "float64"}, {"name": "34", "dtype": "float64"}, {"name": "35", "dtype": "float64"}, {"name": "36", "dtype": "float64"}, {"name": "37", "dtype": "float64"}, {"name": "38", "dtype": "float64"}, {"name": "39", "dtype": "float64"}, {"name": "40", "dtype": "float64"}, {"name": "41", "dtype": "float64"}, {"name": "42", "dtype": "float64"}, {"name": "43", "dtype": "float64"}, {"name": "44", "dtype": "float64"}, {"name": "45", "dtype": "float64"}, {"name": "46", "dtype": "float64"}, {"name": "47", "dtype": "float64"}, {"name": "48", "dtype": "float64"}, {"name": "49", "dtype": "float64"}, {"name": "50", "dtype": "float64"}, {"name": "51", "dtype": "float64"}, {"name": "52", "dtype": "float64"}, {"name": "53", "dtype": "float64"}, {"name": "54", "dtype": "float64"}, {"name": "55", "dtype": "float64"}, {"name": "56", "dtype": "float64"}, {"name": "57", "dtype": "float64"}, {"name": "58", "dtype": "float64"}, {"name": "59", "dtype": "float64"}, {"name": "60", "dtype": "float64"}, {"name": "61", "dtype": "float64"}, {"name": "62", "dtype": "float64"}, {"name": "63", "dtype": "float64"}, {"name": "64", "dtype": "float64"}, {"name": "65", "dtype": "float64"}, {"name": "66", "dtype": "float64"}, {"name": "67", "dtype": "float64"}, {"name": "68", "dtype": "float64"}, {"name": "69", "dtype": "float64"}, {"name": "70", "dtype": "float64"}, {"name": "71", "dtype": "float64"}, {"name": "72", "dtype": "float64"}, {"name": "73", "dtype": "float64"}, {"name": "74", "dtype": "float64"}, {"name": "75", "dtype": "float64"}, {"name": "76", "dtype": "float64"}, {"name": "77", "dtype": "float64"}, {"name": "78", "dtype": "float64"}, {"name": "79", "dtype": "float64"}, {"name": "80", "dtype": "float64"}, {"name": "81", "dtype": "float64"}, {"name": "82", "dtype": "float64"}, {"name": "83", "dtype": "float64"}, {"name": "84", "dtype": "float64"}, {"name": "85", "dtype": "float64"}, {"name": "86", "dtype": "float64"}, {"name": "87", "dtype": "float64"}, {"name": "88", "dtype": "float64"}, {"name": "89", "dtype": "float64"}, {"name": "90", "dtype": "float64"}, {"name": "91", "dtype": "float64"}, {"name": "92", "dtype": "float64"}, {"name": "93", "dtype": "float64"}, {"name": "94", "dtype": "float64"}, {"name": "95", "dtype": "float64"}, {"name": "96", "dtype": "float64"}, {"name": "97", "dtype": "float64"}, {"name": "98", "dtype": "float64"}, {"name": "99", "dtype": "float64"}, {"name": "100", "dtype": "float64"}, {"name": "101", "dtype": "float64"}, {"name": "102", "dtype": "float64"}, {"name": "103", "dtype": "float64"}, {"name": "104", "dtype": "float64"}, {"name": "105", "dtype": "float64"}, {"name": "106", "dtype": "float64"}, {"name": "107", "dtype": "float64"}, {"name": "108", "dtype": "float64"}, {"name": "109", "dtype": "float64"}, {"name": "110", "dtype": "float64"}, {"name": "111", "dtype": "float64"}, {"name": "112", "dtype": "float64"}, {"name": "113", "dtype": "float64"}, {"name": "114", "dtype": "float64"}, {"name": "115", "dtype": "float64"}, {"name": "116", "dtype": "float64"}, {"name": "117", "dtype": "float64"}, {"name": "118", "dtype": "float64"}, {"name": "119", "dtype": "float64"}, {"name": "120", "dtype": "float64"}, {"name": "121", "dtype": "float64"}, {"name": "122", "dtype": "float64"}, {"name": "123", "dtype": "float64"}, {"name": "124", "dtype": "float64"}, {"name": "125", "dtype": "float64"}, {"name": "126", "dtype": "float64"}, {"name": "127", "dtype": "float64"}, {"name": "128", "dtype": "float64"}, {"name": "129", "dtype": "float64"}, {"name": "130", "dtype": "float64"}, {"name": "131", "dtype": "float64"}, {"name": "132", "dtype": "float64"}, {"name": "133", "dtype": "float64"}, {"name": "134", "dtype": "float64"}, {"name": "135", "dtype": "float64"}, {"name": "136", "dtype": "float64"}, {"name": "137", "dtype": "float64"}, {"name": "138", "dtype": "float64"}, {"name": "139", "dtype": "float64"}, {"name": "140", "dtype": "float64"}, {"name": "141", "dtype": "float64"}, {"name": "142", "dtype": "float64"}, {"name": "143", "dtype": "float64"}, {"name": "144", "dtype": "float64"}, {"name": "145", "dtype": "float64"}, {"name": "146", "dtype": "float64"}, {"name": "147", "dtype": "float64"}, {"name": "148", "dtype": "float64"}, {"name": "149", "dtype": "float64"}, {"name": "150", "dtype": "float64"}, {"name": "151", "dtype": "float64"}, {"name": "152", "dtype": "float64"}, {"name": "153", "dtype": "float64"}, {"name": "154", "dtype": "float64"}, {"name": "155", "dtype": "float64"}, {"name": "156", "dtype": "float64"}, {"name": "157", "dtype": "float64"}, {"name": "158", "dtype": "float64"}, {"name": "159", "dtype": "float64"}, {"name": "160", "dtype": "float64"}, {"name": "161", "dtype": "float64"}, {"name": "162", "dtype": "float64"}, {"name": "163", "dtype": "float64"}, {"name": "164", "dtype": "float64"}, {"name": "165", "dtype": "float64"}, {"name": "166", "dtype": "float64"}, {"name": "167", "dtype": "float64"}, {"name": "168", "dtype": "float64"}, {"name": "169", "dtype": "float64"}, {"name": "170", "dtype": "float64"}, {"name": "171", "dtype": "float64"}, {"name": "172", "dtype": "float64"}, {"name": "173", "dtype": "float64"}, {"name": "174", "dtype": "float64"}, {"name": "175", "dtype": "float64"}, {"name": "176", "dtype": "float64"}, {"name": "177", "dtype": "float64"}, {"name": "178", "dtype": "float64"}, {"name": "179", "dtype": "float64"}, {"name": "180", "dtype": "float64"}, {"name": "181", "dtype": "float64"}, {"name": "182", "dtype": "float64"}, {"name": "183", "dtype": "float64"}, {"name": "184", "dtype": "float64"}, {"name": "185", "dtype": "float64"}, {"name": "186", "dtype": "float64"}, {"name": "187", "dtype": "float64"}, {"name": "188", "dtype": "float64"}, {"name": "189", "dtype": "float64"}, {"name": "190", "dtype": "float64"}, {"name": "191", "dtype": "float64"}, {"name": "192", "dtype": "float64"}, {"name": "193", "dtype": "float64"}, {"name": "194", "dtype": "float64"}, {"name": "195", "dtype": "float64"}, {"name": "196", "dtype": "float64"}, {"name": "197", "dtype": "float64"}, {"name": "198", "dtype": "float64"}, {"name": "199", "dtype": "float64"}, {"name": "200", "dtype": "float64"}, {"name": "201", "dtype": "float64"}, {"name": "202", "dtype": "float64"}, {"name": "203", "dtype": "float64"}, {"name": "204", "dtype": "float64"}, {"name": "205", "dtype": "float64"}, {"name": "206", "dtype": "float64"}, {"name": "207", "dtype": "float64"}, {"name": "208", "dtype": "float64"}, {"name": "209", "dtype": "float64"}, {"name": "210", "dtype": "float64"}, {"name": "211", "dtype": "float64"}, {"name": "212", "dtype": "float64"}, {"name": "213", "dtype": "float64"}, {"name": "214", "dtype": "float64"}, {"name": "215", "dtype": "float64"}, {"name": "216", "dtype": "float64"}, {"name": "217", "dtype": "float64"}, {"name": "218", "dtype": "float64"}, {"name": "219", "dtype": "float64"}, {"name": "220", "dtype": "float64"}, {"name": "221", "dtype": "float64"}, {"name": "222", "dtype": "float64"}, {"name": "223", "dtype": "float64"}, {"name": "224", "dtype": "float64"}, {"name": "225", "dtype": "float64"}, {"name": "226", "dtype": "float64"}, {"name": "227", "dtype": "float64"}, {"name": "228", "dtype": "float64"}, {"name": "229", "dtype": "float64"}, {"name": "230", "dtype": "float64"}, {"name": "231", "dtype": "float64"}, {"name": "232", "dtype": "float64"}, {"name": "233", "dtype": "float64"}, {"name": "234", "dtype": "float64"}, {"name": "235", "dtype": "float64"}, {"name": "236", "dtype": "float64"}, {"name": "237", "dtype": "float64"}, {"name": "238", "dtype": "float64"}, {"name": "239", "dtype": "float64"}, {"name": "240", "dtype": "float64"}, {"name": "241", "dtype": "float64"}, {"name": "242", "dtype": "float64"}, {"name": "243", "dtype": "float64"}, {"name": "244", "dtype": "float64"}, {"name": "245", "dtype": "float64"}, {"name": "246", "dtype": "float64"}, {"name": "247", "dtype": "float64"}, {"name": "248", "dtype": "float64"}, {"name": "249", "dtype": "float64"}, {"name": "250", "dtype": "float64"}, {"name": "251", "dtype": "float64"}, {"name": "252", "dtype": "float64"}, {"name": "253", "dtype": "float64"}, {"name": "254", "dtype": "float64"}, {"name": "255", "dtype": "float64"}, {"name": "256", "dtype": "float64"}, {"name": "257", "dtype": "float64"}, {"name": "258", "dtype": "float64"}, {"name": "259", "dtype": "float64"}, {"name": "260", "dtype": "float64"}, {"name": "261", "dtype": "float64"}, {"name": "262", "dtype": "float64"}, {"name": "263", "dtype": "float64"}, {"name": "264", "dtype": "float64"}, {"name": "265", "dtype": "float64"}, {"name": "266", "dtype": "float64"}, {"name": "267", "dtype": "float64"}, {"name": "268", "dtype": "float64"}, {"name": "269", "dtype": "float64"}, {"name": "270", "dtype": "float64"}, {"name": "271", "dtype": "float64"}, {"name": "272", "dtype": "float64"}, {"name": "273", "dtype": "float64"}, {"name": "274", "dtype": "float64"}, {"name": "275", "dtype": "float64"}, {"name": "276", "dtype": "float64"}, {"name": "277", "dtype": "float64"}, {"name": "278", "dtype": "float64"}, {"name": "279", "dtype": "float64"}, {"name": "280", "dtype": "float64"}, {"name": "281", "dtype": "float64"}, {"name": "282", "dtype": "float64"}, {"name": "283", "dtype": "float64"}, {"name": "284", "dtype": "float64"}, {"name": "285", "dtype": "float64"}, {"name": "286", "dtype": "float64"}, {"name": "287", "dtype": "float64"}, {"name": "288", "dtype": "float64"}, {"name": "289", "dtype": "float64"}, {"name": "290", "dtype": "float64"}, {"name": "291", "dtype": "float64"}, {"name": "292", "dtype": "float64"}, {"name": "293", "dtype": "float64"}, {"name": "294", "dtype": "float64"}, {"name": "295", "dtype": "float64"}, {"name": "296", "dtype": "float64"}, {"name": "297", "dtype": "float64"}, {"name": "298", "dtype": "float64"}, {"name": "299", "dtype": "float64"}, {"name": "300", "dtype": "float64"}, {"name": "301", "dtype": "float64"}, {"name": "302", "dtype": "float64"}, {"name": "303", "dtype": "float64"}, {"name": "304", "dtype": "float64"}, {"name": "305", "dtype": "float64"}, {"name": "306", "dtype": "float64"}, {"name": "307", "dtype": "float64"}, {"name": "308", "dtype": "float64"}, {"name": "309", "dtype": "float64"}, {"name": "310", "dtype": "float64"}, {"name": "311", "dtype": "float64"}, {"name": "312", "dtype": "float64"}, {"name": "313", "dtype": "float64"}, {"name": "314", "dtype": "float64"}, {"name": "315", "dtype": "float64"}, {"name": "316", "dtype": "float64"}, {"name": "317", "dtype": "float64"}, {"name": "318", "dtype": "float64"}, {"name": "319", "dtype": "float64"}, {"name": "320", "dtype": "float64"}, {"name": "321", "dtype": "float64"}, {"name": "322", "dtype": "float64"}, {"name": "323", "dtype": "float64"}, {"name": "324", "dtype": "float64"}, {"name": "325", "dtype": "float64"}, {"name": "326", "dtype": "float64"}, {"name": "327", "dtype": "float64"}, {"name": "328", "dtype": "float64"}, {"name": "329", "dtype": "float64"}, {"name": "330", "dtype": "float64"}, {"name": "331", "dtype": "float64"}, {"name": "332", "dtype": "float64"}, {"name": "333", "dtype": "float64"}, {"name": "334", "dtype": "float64"}, {"name": "335", "dtype": "float64"}, {"name": "336", "dtype": "float64"}, {"name": "337", "dtype": "float64"}, {"name": "338", "dtype": "float64"}, {"name": "339", "dtype": "float64"}, {"name": "340", "dtype": "float64"}, {"name": "341", "dtype": "float64"}, {"name": "342", "dtype": "float64"}, {"name": "343", "dtype": "float64"}, {"name": "344", "dtype": "float64"}, {"name": "345", "dtype": "float64"}, {"name": "346", "dtype": "float64"}, {"name": "347", "dtype": "float64"}, {"name": "348", "dtype": "float64"}, {"name": "349", "dtype": "float64"}, {"name": "350", "dtype": "float64"}, {"name": "351", "dtype": "float64"}, {"name": "352", "dtype": "float64"}, {"name": "353", "dtype": "float64"}, {"name": "354", "dtype": "float64"}, {"name": "355", "dtype": "float64"}, {"name": "356", "dtype": "float64"}, {"name": "357", "dtype": "float64"}, {"name": "358", "dtype": "float64"}, {"name": "359", "dtype": "float64"}, {"name": "360", "dtype": "float64"}, {"name": "361", "dtype": "float64"}, {"name": "362", "dtype": "float64"}, {"name": "363", "dtype": "float64"}, {"name": "364", "dtype": "float64"}, {"name": "365", "dtype": "float64"}, {"name": "366", "dtype": "float64"}, {"name": "367", "dtype": "float64"}, {"name": "368", "dtype": "float64"}, {"name": "369", "dtype": "float64"}, {"name": "370", "dtype": "float64"}, {"name": "371", "dtype": "float64"}, {"name": "372", "dtype": "float64"}, {"name": "373", "dtype": "float64"}, {"name": "374", "dtype": "float64"}, {"name": "375", "dtype": "float64"}, {"name": "376", "dtype": "float64"}, {"name": "377", "dtype": "float64"}, {"name": "378", "dtype": "float64"}, {"name": "379", "dtype": "float64"}, {"name": "380", "dtype": "float64"}, {"name": "381", "dtype": "float64"}, {"name": "382", "dtype": "float64"}, {"name": "383", "dtype": "float64"}, {"name": "384", "dtype": "float64"}, {"name": "385", "dtype": "float64"}, {"name": "386", "dtype": "float64"}, {"name": "387", "dtype": "float64"}, {"name": "388", "dtype": "float64"}, {"name": "389", "dtype": "float64"}, {"name": "390", "dtype": "float64"}, {"name": "391", "dtype": "float64"}, {"name": "392", "dtype": "float64"}, {"name": "393", "dtype": "float64"}, {"name": "394", "dtype": "float64"}, {"name": "395", "dtype": "float64"}, {"name": "396", "dtype": "float64"}, {"name": "397", "dtype": "float64"}, {"name": "398", "dtype": "float64"}, {"name": "399", "dtype": "float64"}, {"name": "400", "dtype": "float64"}, {"name": "401", "dtype": "float64"}, {"name": "402", "dtype": "float64"}, {"name": "403", "dtype": "float64"}, {"name": "404", "dtype": "float64"}, {"name": "405", "dtype": "float64"}, {"name": "406", "dtype": "float64"}, {"name": "407", "dtype": "float64"}, {"name": "408", "dtype": "float64"}, {"name": "409", "dtype": "float64"}, {"name": "410", "dtype": "float64"}, {"name": "411", "dtype": "float64"}, {"name": "412", "dtype": "float64"}, {"name": "413", "dtype": "float64"}, {"name": "414", "dtype": "float64"}, {"name": "415", "dtype": "float64"}, {"name": "416", "dtype": "float64"}, {"name": "417", "dtype": "float64"}, {"name": "418", "dtype": "float64"}, {"name": "419", "dtype": "float64"}, {"name": "420", "dtype": "float64"}, {"name": "421", "dtype": "float64"}, {"name": "422", "dtype": "float64"}, {"name": "423", "dtype": "float64"}, {"name": "424", "dtype": "float64"}, {"name": "425", "dtype": "float64"}, {"name": "426", "dtype": "float64"}, {"name": "427", "dtype": "float64"}, {"name": "428", "dtype": "float64"}, {"name": "429", "dtype": "float64"}, {"name": "430", "dtype": "float64"}, {"name": "431", "dtype": "float64"}, {"name": "432", "dtype": "float64"}, {"name": "433", "dtype": "float64"}, {"name": "434", "dtype": "float64"}, {"name": "435", "dtype": "float64"}, {"name": "436", "dtype": "float64"}, {"name": "437", "dtype": "float64"}, {"name": "438", "dtype": "float64"}, {"name": "439", "dtype": "float64"}, {"name": "440", "dtype": "float64"}, {"name": "441", "dtype": "float64"}, {"name": "442", "dtype": "float64"}, {"name": "443", "dtype": "float64"}, {"name": "444", "dtype": "float64"}, {"name": "445", "dtype": "float64"}, {"name": "446", "dtype": "float64"}, {"name": "447", "dtype": "float64"}, {"name": "448", "dtype": "float64"}, {"name": "449", "dtype": "float64"}, {"name": "450", "dtype": "float64"}, {"name": "451", "dtype": "float64"}, {"name": "452", "dtype": "float64"}, {"name": "453", "dtype": "float64"}, {"name": "454", "dtype": "float64"}, {"name": "455", "dtype": "float64"}, {"name": "456", "dtype": "float64"}, {"name": "457", "dtype": "float64"}, {"name": "458", "dtype": "float64"}, {"name": "459", "dtype": "float64"}, {"name": "460", "dtype": "float64"}, {"name": "461", "dtype": "float64"}, {"name": "462", "dtype": "float64"}, {"name": "463", "dtype": "float64"}, {"name": "464", "dtype": "float64"}, {"name": "465", "dtype": "float64"}, {"name": "466", "dtype": "float64"}, {"name": "467", "dtype": "float64"}, {"name": "468", "dtype": "float64"}, {"name": "469", "dtype": "float64"}, {"name": "470", "dtype": "float64"}, {"name": "471", "dtype": "float64"}, {"name": "472", "dtype": "float64"}, {"name": "473", "dtype": "float64"}, {"name": "474", "dtype": "float64"}, {"name": "475", "dtype": "float64"}, {"name": "476", "dtype": "float64"}, {"name": "477", "dtype": "float64"}, {"name": "478", "dtype": "float64"}, {"name": "479", "dtype": "float64"}, {"name": "480", "dtype": "float64"}, {"name": "481", "dtype": "float64"}, {"name": "482", "dtype": "float64"}, {"name": "483", "dtype": "float64"}, {"name": "484", "dtype": "float64"}, {"name": "485", "dtype": "float64"}, {"name": "486", "dtype": "float64"}, {"name": "487", "dtype": "float64"}, {"name": "488", "dtype": "float64"}, {"name": "489", "dtype": "float64"}, {"name": "490", "dtype": "float64"}, {"name": "491", "dtype": "float64"}, {"name": "492", "dtype": "float64"}, {"name": "493", "dtype": "float64"}, {"name": "494", "dtype": "float64"}, {"name": "495", "dtype": "float64"}, {"name": "496", "dtype": "float64"}, {"name": "497", "dtype": "float64"}, {"name": "498", "dtype": "float64"}, {"name": "499", "dtype": "float64"}, {"name": "500", "dtype": "float64"}, {"name": "501", "dtype": "float64"}, {"name": "502", "dtype": "float64"}, {"name": "503", "dtype": "float64"}, {"name": "504", "dtype": "float64"}, {"name": "505", "dtype": "float64"}, {"name": "506", "dtype": "float64"}, {"name": "507", "dtype": "float64"}, {"name": "508", "dtype": "float64"}, {"name": "509", "dtype": "float64"}, {"name": "510", "dtype": "float64"}, {"name": "511", "dtype": "float64"}, {"name": "512", "dtype": "float64"}, {"name": "513", "dtype": "float64"}, {"name": "514", "dtype": "float64"}, {"name": "515", "dtype": "float64"}, {"name": "516", "dtype": "float64"}, {"name": "517", "dtype": "float64"}, {"name": "518", "dtype": "float64"}, {"name": "519", "dtype": "float64"}, {"name": "520", "dtype": "float64"}, {"name": "521", "dtype": "float64"}, {"name": "522", "dtype": "float64"}, {"name": "523", "dtype": "float64"}, {"name": "524", "dtype": "float64"}, {"name": "525", "dtype": "float64"}, {"name": "526", "dtype": "float64"}, {"name": "527", "dtype": "float64"}, {"name": "528", "dtype": "float64"}, {"name": "529", "dtype": "float64"}, {"name": "530", "dtype": "float64"}, {"name": "531", "dtype": "float64"}, {"name": "532", "dtype": "float64"}, {"name": "533", "dtype": "float64"}, {"name": "534", "dtype": "float64"}, {"name": "535", "dtype": "float64"}, {"name": "536", "dtype": "float64"}, {"name": "537", "dtype": "float64"}, {"name": "538", "dtype": "float64"}, {"name": "539", "dtype": "float64"}, {"name": "540", "dtype": "float64"}, {"name": "541", "dtype": "float64"}, {"name": "542", "dtype": "float64"}, {"name": "543", "dtype": "float64"}, {"name": "544", "dtype": "float64"}, {"name": "545", "dtype": "float64"}, {"name": "546", "dtype": "float64"}, {"name": "547", "dtype": "float64"}, {"name": "548", "dtype": "float64"}, {"name": "549", "dtype": "float64"}, {"name": "550", "dtype": "float64"}, {"name": "551", "dtype": "float64"}, {"name": "552", "dtype": "float64"}, {"name": "553", "dtype": "float64"}, {"name": "554", "dtype": "float64"}, {"name": "555", "dtype": "float64"}, {"name": "556", "dtype": "float64"}, {"name": "557", "dtype": "float64"}, {"name": "558", "dtype": "float64"}, {"name": "559", "dtype": "float64"}, {"name": "560", "dtype": "float64"}, {"name": "561", "dtype": "float64"}, {"name": "562", "dtype": "float64"}, {"name": "563", "dtype": "float64"}, {"name": "564", "dtype": "float64"}, {"name": "565", "dtype": "float64"}, {"name": "566", "dtype": "float64"}, {"name": "567", "dtype": "float64"}, {"name": "568", "dtype": "float64"}, {"name": "569", "dtype": "float64"}, {"name": "570", "dtype": "float64"}, {"name": "571", "dtype": "float64"}, {"name": "572", "dtype": "float64"}, {"name": "573", "dtype": "float64"}, {"name": "574", "dtype": "float64"}, {"name": "575", "dtype": "float64"}, {"name": "576", "dtype": "float64"}, {"name": "577", "dtype": "float64"}, {"name": "578", "dtype": "float64"}, {"name": "579", "dtype": "float64"}, {"name": "580", "dtype": "float64"}, {"name": "581", "dtype": "float64"}, {"name": "582", "dtype": "float64"}, {"name": "583", "dtype": "float64"}, {"name": "584", "dtype": "float64"}, {"name": "585", "dtype": "float64"}, {"name": "586", "dtype": "float64"}, {"name": "587", "dtype": "float64"}, {"name": "588", "dtype": "float64"}, {"name": "589", "dtype": "float64"}, {"name": "590", "dtype": "float64"}, {"name": "591", "dtype": "float64"}, {"name": "592", "dtype": "float64"}, {"name": "593", "dtype": "float64"}, {"name": "594", "dtype": "float64"}, {"name": "595", "dtype": "float64"}, {"name": "596", "dtype": "float64"}, {"name": "597", "dtype": "float64"}, {"name": "598", "dtype": "float64"}, {"name": "599", "dtype": "float64"}, {"name": "600", "dtype": "float64"}, {"name": "601", "dtype": "float64"}, {"name": "602", "dtype": "float64"}, {"name": "603", "dtype": "float64"}, {"name": "604", "dtype": "float64"}, {"name": "605", "dtype": "float64"}, {"name": "606", "dtype": "float64"}, {"name": "607", "dtype": "float64"}, {"name": "608", "dtype": "float64"}, {"name": "609", "dtype": "float64"}, {"name": "610", "dtype": "float64"}, {"name": "611", "dtype": "float64"}, {"name": "612", "dtype": "float64"}, {"name": "613", "dtype": "float64"}, {"name": "614", "dtype": "float64"}, {"name": "615", "dtype": "float64"}, {"name": "616", "dtype": "float64"}, {"name": "617", "dtype": "float64"}, {"name": "618", "dtype": "float64"}, {"name": "619", "dtype": "float64"}, {"name": "620", "dtype": "float64"}, {"name": "621", "dtype": "float64"}, {"name": "622", "dtype": "float64"}, {"name": "623", "dtype": "float64"}, {"name": "624", "dtype": "float64"}, {"name": "625", "dtype": "float64"}, {"name": "626", "dtype": "float64"}, {"name": "627", "dtype": "float64"}, {"name": "628", "dtype": "float64"}, {"name": "629", "dtype": "float64"}, {"name": "630", "dtype": "float64"}, {"name": "631", "dtype": "float64"}, {"name": "632", "dtype": "float64"}, {"name": "633", "dtype": "float64"}, {"name": "634", "dtype": "float64"}, {"name": "635", "dtype": "float64"}, {"name": "636", "dtype": "float64"}, {"name": "637", "dtype": "float64"}, {"name": "638", "dtype": "float64"}, {"name": "639", "dtype": "float64"}, {"name": "640", "dtype": "float64"}, {"name": "641", "dtype": "float64"}, {"name": "642", "dtype": "float64"}, {"name": "643", "dtype": "float64"}, {"name": "644", "dtype": "float64"}, {"name": "645", "dtype": "float64"}, {"name": "646", "dtype": "float64"}, {"name": "647", "dtype": "float64"}, {"name": "648", "dtype": "float64"}, {"name": "649", "dtype": "float64"}, {"name": "650", "dtype": "float64"}, {"name": "651", "dtype": "float64"}, {"name": "652", "dtype": "float64"}, {"name": "653", "dtype": "float64"}, {"name": "654", "dtype": "float64"}, {"name": "655", "dtype": "float64"}, {"name": "656", "dtype": "float64"}, {"name": "657", "dtype": "float64"}, {"name": "658", "dtype": "float64"}, {"name": "659", "dtype": "float64"}, {"name": "660", "dtype": "float64"}, {"name": "661", "dtype": "float64"}, {"name": "662", "dtype": "float64"}, {"name": "663", "dtype": "float64"}, {"name": "664", "dtype": "float64"}, {"name": "665", "dtype": "float64"}, {"name": "666", "dtype": "float64"}, {"name": "667", "dtype": "float64"}, {"name": "668", "dtype": "float64"}, {"name": "669", "dtype": "float64"}, {"name": "670", "dtype": "float64"}, {"name": "671", "dtype": "float64"}, {"name": "672", "dtype": "float64"}, {"name": "673", "dtype": "float64"}, {"name": "674", "dtype": "float64"}, {"name": "675", "dtype": "float64"}, {"name": "676", "dtype": "float64"}, {"name": "677", "dtype": "float64"}, {"name": "678", "dtype": "float64"}, {"name": "679", "dtype": "float64"}, {"name": "680", "dtype": "float64"}, {"name": "681", "dtype": "float64"}, {"name": "682", "dtype": "float64"}, {"name": "683", "dtype": "float64"}, {"name": "684", "dtype": "float64"}, {"name": "685", "dtype": "float64"}, {"name": "686", "dtype": "float64"}, {"name": "687", "dtype": "float64"}, {"name": "688", "dtype": "float64"}, {"name": "689", "dtype": "float64"}, {"name": "690", "dtype": "float64"}, {"name": "691", "dtype": "float64"}, {"name": "692", "dtype": "float64"}, {"name": "693", "dtype": "float64"}, {"name": "694", "dtype": "float64"}, {"name": "695", "dtype": "float64"}, {"name": "696", "dtype": "float64"}, {"name": "697", "dtype": "float64"}, {"name": "698", "dtype": "float64"}, {"name": "699", "dtype": "float64"}, {"name": "700", "dtype": "float64"}, {"name": "701", "dtype": "float64"}, {"name": "702", "dtype": "float64"}, {"name": "703", "dtype": "float64"}, {"name": "704", "dtype": "float64"}, {"name": "705", "dtype": "float64"}, {"name": "706", "dtype": "float64"}, {"name": "707", "dtype": "float64"}, {"name": "708", "dtype": "float64"}, {"name": "709", "dtype": "float64"}, {"name": "710", "dtype": "float64"}, {"name": "711", "dtype": "float64"}, {"name": "712", "dtype": "float64"}, {"name": "713", "dtype": "float64"}, {"name": "714", "dtype": "float64"}, {"name": "715", "dtype": "float64"}, {"name": "716", "dtype": "float64"}, {"name": "717", "dtype": "float64"}, {"name": "718", "dtype": "float64"}, {"name": "719", "dtype": "float64"}, {"name": "720", "dtype": "float64"}, {"name": "721", "dtype": "float64"}, {"name": "722", "dtype": "float64"}, {"name": "723", "dtype": "float64"}, {"name": "724", "dtype": "float64"}, {"name": "725", "dtype": "float64"}, {"name": "726", "dtype": "float64"}, {"name": "727", "dtype": "float64"}, {"name": "728", "dtype": "float64"}, {"name": "729", "dtype": "float64"}, {"name": "730", "dtype": "float64"}, {"name": "731", "dtype": "float64"}, {"name": "732", "dtype": "float64"}, {"name": "733", "dtype": "float64"}, {"name": "734", "dtype": "float64"}, {"name": "735", "dtype": "float64"}, {"name": "736", "dtype": "float64"}, {"name": "737", "dtype": "float64"}, {"name": "738", "dtype": "float64"}, {"name": "739", "dtype": "float64"}, {"name": "740", "dtype": "float64"}, {"name": "741", "dtype": "float64"}, {"name": "742", "dtype": "float64"}, {"name": "743", "dtype": "float64"}, {"name": "744", "dtype": "float64"}, {"name": "745", "dtype": "float64"}, {"name": "746", "dtype": "float64"}, {"name": "747", "dtype": "float64"}, {"name": "748", "dtype": "float64"}, {"name": "749", "dtype": "float64"}, {"name": "750", "dtype": "float64"}, {"name": "751", "dtype": "float64"}, {"name": "752", "dtype": "float64"}, {"name": "753", "dtype": "float64"}, {"name": "754", "dtype": "float64"}, {"name": "755", "dtype": "float64"}, {"name": "756", "dtype": "float64"}, {"name": "757", "dtype": "float64"}, {"name": "758", "dtype": "float64"}, {"name": "759", "dtype": "float64"}, {"name": "760", "dtype": "float64"}, {"name": "761", "dtype": "float64"}, {"name": "762", "dtype": "float64"}, {"name": "763", "dtype": "float64"}, {"name": "764", "dtype": "float64"}, {"name": "765", "dtype": "float64"}, {"name": "766", "dtype": "float64"}, {"name": "767", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 2318073600, "num_examples": 376800}], "download_size": 2770805073, "dataset_size": 2318073600}}
|
2023-04-22T06:20:09+00:00
|
623592852707a5bc7d0e5d6e46dc5c8c6a15d11d
|
Bylts/byltnyc
|
[
"license:creativeml-openrail-m",
"region:us"
] |
2023-04-22T06:08:04+00:00
|
{"license": "creativeml-openrail-m"}
|
2023-04-22T06:08:04+00:00
|
|
1b45b72030868ceb502f21ddd6394884201b0126
|
# Dataset Card for "TaCCMatrix"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
livinNector/TaCCMatrix
|
[
"region:us"
] |
2023-04-22T06:17:38+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4161199748, "num_examples": 26617844}], "download_size": 1420194964, "dataset_size": 4161199748}}
|
2023-04-22T06:29:27+00:00
|
c0ac75072714a4c71fc1469d7538c2b523f3f3be
|
## Source:
https://huggingface.co/datasets/gozfarb/ShareGPT_Vicuna_unfiltered
ShareGPT_V4.1_unfiltered_cleaned_split.json (07f0cbc)
## Model Info:
https://huggingface.co/Neko-Institute-of-Science/LLaMA-7B-HF(d48acf8)
## Conversion:
practicaldreamer/fastchat-conversation-converter(9c642da)
which uses FastChat(5ccf842)'s "make_supervised_data_module"
and transformer's version 4.28.1
|
PKFKNK/vicuna.txt
|
[
"region:us"
] |
2023-04-22T06:28:28+00:00
|
{}
|
2023-04-26T01:37:56+00:00
|
f981e78ca20f9c99ef5ba3a811b5c7e82af43f6c
|
# Dataset Card for "recid"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jarrydmartinx/recid
|
[
"region:us"
] |
2023-04-22T06:30:34+00:00
|
{"dataset_info": {"features": [{"name": "black", "dtype": "int64"}, {"name": "alcohol", "dtype": "int64"}, {"name": "drugs", "dtype": "int64"}, {"name": "super", "dtype": "int64"}, {"name": "married", "dtype": "int64"}, {"name": "felon", "dtype": "int64"}, {"name": "workprg", "dtype": "int64"}, {"name": "property", "dtype": "int64"}, {"name": "person", "dtype": "int64"}, {"name": "priors", "dtype": "int64"}, {"name": "educ", "dtype": "int64"}, {"name": "rules", "dtype": "int64"}, {"name": "age", "dtype": "int64"}, {"name": "tserved", "dtype": "int64"}, {"name": "follow", "dtype": "int64"}, {"name": "event_time", "dtype": "int64"}, {"name": "event_indicator", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 196520, "num_examples": 1445}], "download_size": 27921, "dataset_size": 196520}}
|
2023-04-22T06:31:38+00:00
|
c1bfc36f0ca0811e6e454d846fc86cd66cd9cb4b
|
# AutoTrain Dataset for project: uta-ai-j-pop
## Dataset Description
This dataset has been automatically processed by AutoTrain for project uta-ai-j-pop.
### Languages
The BCP-47 code for the dataset's language is unk.
## Dataset Structure
### Data Instances
A sample from this dataset looks as follows:
```json
[
{
"text": "Drink dry tears love pain destiny enough half selfless love and said anyway crazy shadows",
"target": "Inexperienced and heartless, but be beautiful\nNo Destiny, unworthy\nI'm sure this is not enough\nIf you talk about it, it will go well\nThings, money, love, words, I'm tired of showing off\nD\u00e9j\u00e0 vu What's so frustrating?\nWhat more do you need than this?\nI don't hate places like that\n\"I'm tired of hearing that line\"\nI hate being half-hearted\nenough\nYou said like this\nlove how she I was told\nIf it's just for fun, it's easy, serious negotiations are unreasonable\nUnthinkable light words\nHow many times do you use it?\nAnyway\nI was expecting it, even if it was a good race\nPhrases full of quotes\nMake words that lift your heels taboo\nI read the air, don't let it rain\nI don't like boring stories\nPlease use the minimum required number of 2 characters or less\nCrimson Butterfly does not send any mail\nSpreading a fragile fan, she would be more attractive that way\nin confusion\nIf you can't respond, leave me alone\nIf you're at a loss, please leave\nThe most important thing is that you can just let go and feel at ease\nIf it rains sweet candy\nYou want an umbrella too, don't you?\nlike this\nI closed my eyes\nI wanted to change, pretending to be grown-up\nI lost it, I couldn't rewind it\nDon't stop raining now\ncopy paste delete repeat\ninhaled and exhaled\nthat's why\nI don't care, I want to stay here\nenough\nYou said like this\nlove how she I was told\nIf it's just for fun, it's easy, serious negotiations are incoherent\nThe unthinkable heavy truth\nShouldn't it be taboo?\nsurely\nI was expecting it, even if it was a good race\nOfficial phrases too\nStop the habit of raising your heels\nDon't let the sky clear when you read the air\nrain again today\nClose your umbrella and let's go home wet"
},
{
"text": "Without heart broken love tears kill mine lovely loneliness easier crying close and hug chose",
"target": "Hey, if everything is thrown away\nDoes laughing make life easier?\nMy chest hurts again\ndon't say anything anymore\nHey, if everything is forgotten\nWill it be easier to live without crying?\nBut I can't do that\ndon't show me anything anymore\nno matter how close i get to you\ni only have one heart\nIt's cruel, it's cruel, I'd rather take my body\nBreak it, tear it apart, do whatever you want\nEven if I scream and struggle and my eyelids swell\nYou still hug me and won't let go\nthat's enough\nHey, if my wish could come true\ni want the same thing as you\nBut I don't exist\nThen at least come here\nno matter how much i love you\ni only have one heart\nStop it, stop it, don't be nice\nI just can't understand\nIt hurts, it hurts, tell me in words\nI don't know this, don't leave me alone\nIt's cruel, it's cruel, I'd rather take my body\nBreak it, tear it apart, do whatever you want\nEven if I scream, scratch my eyes, and swell my eyelids\nYou still hug me and won't let go\nthat's enough\nHey, if I have a heart\nhow do i find it\nyou smile a little and say\nit's right here"
}
]
```
### Dataset Fields
The dataset has the following fields (also called "features"):
```json
{
"text": "Value(dtype='string', id=None)",
"target": "Value(dtype='string', id=None)"
}
```
### Dataset Splits
This dataset is split into a train and validation split. The split sizes are as follow:
| Split name | Num samples |
| ------------ | ------------------- |
| train | 5 |
| valid | 2 |
|
yukiarimo/Uta-AI
|
[
"task_categories:summarization",
"region:us"
] |
2023-04-22T06:53:18+00:00
|
{"task_categories": ["summarization"]}
|
2023-04-22T07:00:12+00:00
|
cfb7b20b74e12c536f8ea3fed2ae50336154a246
|
Phonecharger/1770
|
[
"license:openrail",
"region:us"
] |
2023-04-22T06:59:05+00:00
|
{"license": "openrail"}
|
2023-04-22T06:59:05+00:00
|
|
67b30436330d6980fdb8fa26f24d491ff464ddc4
|
# Dataset Card for "sst-sentiment-explainability"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Phonecharger/sst-sentiment-explainability
|
[
"region:us"
] |
2023-04-22T07:16:12+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "POSITIVE"}}}}], "splits": [{"name": "train", "num_bytes": 350.6666666666667, "num_examples": 4}, {"name": "test", "num_bytes": 175.33333333333334, "num_examples": 2}], "download_size": 3841, "dataset_size": 526.0}}
|
2023-04-22T07:16:55+00:00
|
8182c42b2e7f62d5f8d2c543d798ef0dc87bb481
|
# Dataset Card for "gutenberg_spacy-ner-monitoring"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Phonecharger/gutenberg_spacy-ner-monitoring
|
[
"region:us"
] |
2023-04-22T07:31:26+00:00
|
{"dataset_info": {"features": [{"name": "tokens", "sequence": "string"}, {"name": "ner_tags", "sequence": {"class_label": {"names": {"0": "O", "1": "B-CARDINAL", "2": "I-CARDINAL", "3": "B-PERSON", "4": "I-PERSON", "5": "B-TIME", "6": "I-TIME", "7": "B-WORK_OF_ART", "8": "I-WORK_OF_ART"}}}}], "splits": [{"name": "train", "num_bytes": 1531, "num_examples": 1}, {"name": "test", "num_bytes": 1697, "num_examples": 1}], "download_size": 5147, "dataset_size": 3228}}
|
2023-04-22T07:31:27+00:00
|
f6c3865bd0e14aa11733fad02346a99b6b5e1268
|
# Dataset Card for "final_training_set_v1_en_th"
Finetuning datasets for [WangChanGLM](https://github.com/pythainlp/wangchanglm) sourced from [LAION OIG chip2 and infill_dbpedia](https://huggingface.co/datasets/laion/OIG) ([Apache-2.0](https://github.com/pythainlp/wangchanglm/blob/main/LICENSE)), [DataBricks Dolly v2](https://github.com/databrickslabs/dolly) ([Apache-2.0](https://github.com/pythainlp/wangchanglm/blob/main/LICENSE)), [OpenAI TL;DR](https://github.com/openai/summarize-from-feedback) ([MIT](https://opensource.org/license/mit/)), and [Hello-SimpleAI HC3](https://huggingface.co/datasets/Hello-SimpleAI/HC3) ([CC-BY SA](https://creativecommons.org/licenses/by-sa/4.0/)).
The dataset is translated using Google Translate API by [Thu Ya Kyaw](https://github.com/iamthuya).
|
pythainlp/final_training_set_v1_enth
|
[
"task_categories:text-generation",
"task_categories:conversational",
"language:th",
"language:en",
"region:us"
] |
2023-04-22T07:56:14+00:00
|
{"language": ["th", "en"], "task_categories": ["text-generation", "conversational"], "dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "nb_token", "dtype": "int64"}, {"name": "metadata", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 665379914.0331497, "num_examples": 379520}, {"name": "test", "num_bytes": 899398.9668502472, "num_examples": 513}], "download_size": 258632318, "dataset_size": 666279313}}
|
2023-04-29T06:05:42+00:00
|
d0bac9989673bfa2a2832476e085850e00d4f09d
|
# Dataset Card for "test1"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
thanhduycao/test1
|
[
"region:us"
] |
2023-04-22T08:03:05+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}, {"name": "w2v2_transcription", "dtype": "string"}, {"name": "WER", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2119391056.375, "num_examples": 26453}], "download_size": 2104590081, "dataset_size": 2119391056.375}}
|
2023-04-22T08:04:15+00:00
|
c13653e0592f7baa8ff5864a85939c385a43077c
|
# Dataset Card for "test2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
thanhduycao/test2
|
[
"region:us"
] |
2023-04-22T08:03:13+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}, {"name": "w2v2_transcription", "dtype": "string"}, {"name": "WER", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2119391056.375, "num_examples": 26453}], "download_size": 0, "dataset_size": 2119391056.375}}
|
2023-04-22T08:07:06+00:00
|
5dbfea91130c45e5f2b0156404378cade2ee1447
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
This dataset card aims to be a base template for new datasets. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/datasetcard_template.md?plain=1).
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
Kartheesh/MLdataset
|
[
"task_categories:question-answering",
"size_categories:1M<n<10M",
"language:en",
"license:openrail",
"climate",
"region:us"
] |
2023-04-22T08:14:34+00:00
|
{"language": ["en"], "license": "openrail", "size_categories": ["1M<n<10M"], "task_categories": ["question-answering"], "pretty_name": "mountain", "tags": ["climate"]}
|
2023-04-22T08:23:11+00:00
|
7493b6281ddf30cf24442d7595e6175886173822
|
Shashashasha/audio
|
[
"license:other",
"region:us"
] |
2023-04-22T09:01:47+00:00
|
{"license": "other"}
|
2023-04-22T09:02:13+00:00
|
|
31cbe4a3d8d19da61ceb70f73cfcfd09ed67dc4a
|
dtadpole/sharegpt-20230401
|
[
"license:mit",
"region:us"
] |
2023-04-22T09:21:31+00:00
|
{"license": "mit"}
|
2023-04-22T10:19:14+00:00
|
|
0ae2c96b2a438b25a0ba76c49802502097914a08
|
13GP/newcsv
|
[
"license:mit",
"region:us"
] |
2023-04-22T09:23:20+00:00
|
{"license": "mit"}
|
2023-04-22T09:25:04+00:00
|
|
76c4e51574c3850b2a83ca5c70cf65b9bb76fb39
|
# Dataset Card for "metabric"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jarrydmartinx/metabric2
|
[
"region:us"
] |
2023-04-22T09:47:10+00:00
|
{"dataset_info": {"features": [{"name": "patient_id", "dtype": "int64"}, {"name": "age_at_diagnosis", "dtype": "float64"}, {"name": "type_of_breast_surgery", "dtype": "string"}, {"name": "cancer_type", "dtype": "string"}, {"name": "cancer_type_detailed", "dtype": "string"}, {"name": "cellularity", "dtype": "string"}, {"name": "chemotherapy", "dtype": "int64"}, {"name": "pam50_+_claudin-low_subtype", "dtype": "string"}, {"name": "cohort", "dtype": "float64"}, {"name": "er_status_measured_by_ihc", "dtype": "string"}, {"name": "er_status", "dtype": "string"}, {"name": "neoplasm_histologic_grade", "dtype": "float64"}, {"name": "her2_status_measured_by_snp6", "dtype": "string"}, {"name": "her2_status", "dtype": "string"}, {"name": "tumor_other_histologic_subtype", "dtype": "string"}, {"name": "hormone_therapy", "dtype": "int64"}, {"name": "inferred_menopausal_state", "dtype": "string"}, {"name": "integrative_cluster", "dtype": "string"}, {"name": "primary_tumor_laterality", "dtype": "string"}, {"name": "lymph_nodes_examined_positive", "dtype": "float64"}, {"name": "nottingham_prognostic_index", "dtype": "float64"}, {"name": "oncotree_code", "dtype": "string"}, {"name": "pr_status", "dtype": "string"}, {"name": "radio_therapy", "dtype": "int64"}, {"name": "3-gene_classifier_subtype", "dtype": "string"}, {"name": "tumor_size", "dtype": "float64"}, {"name": "tumor_stage", "dtype": "float64"}, {"name": "death_from_cancer", "dtype": "string"}, {"name": "brca1", "dtype": "float64"}, {"name": "brca2", "dtype": "float64"}, {"name": "palb2", "dtype": "float64"}, {"name": "pten", "dtype": "float64"}, {"name": "tp53", "dtype": "float64"}, {"name": "atm", "dtype": "float64"}, {"name": "cdh1", "dtype": "float64"}, {"name": "chek2", "dtype": "float64"}, {"name": "nbn", "dtype": "float64"}, {"name": "nf1", "dtype": "float64"}, {"name": "stk11", "dtype": "float64"}, {"name": "bard1", "dtype": "float64"}, {"name": "mlh1", "dtype": "float64"}, {"name": "msh2", "dtype": "float64"}, {"name": "msh6", "dtype": "float64"}, {"name": "pms2", "dtype": "float64"}, {"name": "epcam", "dtype": "float64"}, {"name": "rad51c", "dtype": "float64"}, {"name": "rad51d", "dtype": "float64"}, {"name": "rad50", "dtype": "float64"}, {"name": "rb1", "dtype": "float64"}, {"name": "rbl1", "dtype": "float64"}, {"name": "rbl2", "dtype": "float64"}, {"name": "ccna1", "dtype": "float64"}, {"name": "ccnb1", "dtype": "float64"}, {"name": "cdk1", "dtype": "float64"}, {"name": "ccne1", "dtype": "float64"}, {"name": "cdk2", "dtype": "float64"}, {"name": "cdc25a", "dtype": "float64"}, {"name": "ccnd1", "dtype": "float64"}, {"name": "cdk4", "dtype": "float64"}, {"name": "cdk6", "dtype": "float64"}, {"name": "ccnd2", "dtype": "float64"}, {"name": "cdkn2a", "dtype": "float64"}, {"name": "cdkn2b", "dtype": "float64"}, {"name": "myc", "dtype": "float64"}, {"name": "cdkn1a", "dtype": "float64"}, {"name": "cdkn1b", "dtype": "float64"}, {"name": "e2f1", "dtype": "float64"}, {"name": "e2f2", "dtype": "float64"}, {"name": "e2f3", "dtype": "float64"}, {"name": "e2f4", "dtype": "float64"}, {"name": "e2f5", "dtype": "float64"}, {"name": "e2f6", "dtype": "float64"}, {"name": "e2f7", "dtype": "float64"}, {"name": "e2f8", "dtype": "float64"}, {"name": "src", "dtype": "float64"}, {"name": "jak1", "dtype": "float64"}, {"name": "jak2", "dtype": "float64"}, {"name": "stat1", "dtype": "float64"}, {"name": "stat2", "dtype": "float64"}, {"name": "stat3", "dtype": "float64"}, {"name": "stat5a", "dtype": "float64"}, {"name": "stat5b", "dtype": "float64"}, {"name": "mdm2", "dtype": "float64"}, {"name": "tp53bp1", "dtype": "float64"}, {"name": "adam10", "dtype": "float64"}, {"name": "adam17", "dtype": "float64"}, {"name": "aph1a", "dtype": "float64"}, {"name": "aph1b", "dtype": "float64"}, {"name": "arrdc1", "dtype": "float64"}, {"name": "cir1", "dtype": "float64"}, {"name": "ctbp1", "dtype": "float64"}, {"name": "ctbp2", "dtype": "float64"}, {"name": "cul1", "dtype": "float64"}, {"name": "dll1", "dtype": "float64"}, {"name": "dll3", "dtype": "float64"}, {"name": "dll4", "dtype": "float64"}, {"name": "dtx1", "dtype": "float64"}, {"name": "dtx2", "dtype": "float64"}, {"name": "dtx3", "dtype": "float64"}, {"name": "dtx4", "dtype": "float64"}, {"name": "ep300", "dtype": "float64"}, {"name": "fbxw7", "dtype": "float64"}, {"name": "hdac1", "dtype": "float64"}, {"name": "hdac2", "dtype": "float64"}, {"name": "hes1", "dtype": "float64"}, {"name": "hes5", "dtype": "float64"}, {"name": "heyl", "dtype": "float64"}, {"name": "itch", "dtype": "float64"}, {"name": "jag1", "dtype": "float64"}, {"name": "jag2", "dtype": "float64"}, {"name": "kdm5a", "dtype": "float64"}, {"name": "lfng", "dtype": "float64"}, {"name": "maml1", "dtype": "float64"}, {"name": "maml2", "dtype": "float64"}, {"name": "maml3", "dtype": "float64"}, {"name": "ncor2", "dtype": "float64"}, {"name": "ncstn", "dtype": "float64"}, {"name": "notch1", "dtype": "float64"}, {"name": "notch2", "dtype": "float64"}, {"name": "notch3", "dtype": "float64"}, {"name": "nrarp", "dtype": "float64"}, {"name": "numb", "dtype": "float64"}, {"name": "numbl", "dtype": "float64"}, {"name": "psen1", "dtype": "float64"}, {"name": "psen2", "dtype": "float64"}, {"name": "psenen", "dtype": "float64"}, {"name": "rbpj", "dtype": "float64"}, {"name": "rbpjl", "dtype": "float64"}, {"name": "rfng", "dtype": "float64"}, {"name": "snw1", "dtype": "float64"}, {"name": "spen", "dtype": "float64"}, {"name": "hes2", "dtype": "float64"}, {"name": "hes4", "dtype": "float64"}, {"name": "hes7", "dtype": "float64"}, {"name": "hey1", "dtype": "float64"}, {"name": "hey2", "dtype": "float64"}, {"name": "acvr1", "dtype": "float64"}, {"name": "acvr1b", "dtype": "float64"}, {"name": "acvr1c", "dtype": "float64"}, {"name": "acvr2a", "dtype": "float64"}, {"name": "acvr2b", "dtype": "float64"}, {"name": "acvrl1", "dtype": "float64"}, {"name": "akt1", "dtype": "float64"}, {"name": "akt1s1", "dtype": "float64"}, {"name": "akt2", "dtype": "float64"}, {"name": "apaf1", "dtype": "float64"}, {"name": "arl11", "dtype": "float64"}, {"name": "atr", "dtype": "float64"}, {"name": "aurka", "dtype": "float64"}, {"name": "bad", "dtype": "float64"}, {"name": "bcl2", "dtype": "float64"}, {"name": "bcl2l1", "dtype": "float64"}, {"name": "bmp10", "dtype": "float64"}, {"name": "bmp15", "dtype": "float64"}, {"name": "bmp2", "dtype": "float64"}, {"name": "bmp3", "dtype": "float64"}, {"name": "bmp4", "dtype": "float64"}, {"name": "bmp5", "dtype": "float64"}, {"name": "bmp6", "dtype": "float64"}, {"name": "bmp7", "dtype": "float64"}, {"name": "bmpr1a", "dtype": "float64"}, {"name": "bmpr1b", "dtype": "float64"}, {"name": "bmpr2", "dtype": "float64"}, {"name": "braf", "dtype": "float64"}, {"name": "casp10", "dtype": "float64"}, {"name": "casp3", "dtype": "float64"}, {"name": "casp6", "dtype": "float64"}, {"name": "casp7", "dtype": "float64"}, {"name": "casp8", "dtype": "float64"}, {"name": "casp9", "dtype": "float64"}, {"name": "chek1", "dtype": "float64"}, {"name": "csf1", "dtype": "float64"}, {"name": "csf1r", "dtype": "float64"}, {"name": "cxcl8", "dtype": "float64"}, {"name": "cxcr1", "dtype": "float64"}, {"name": "cxcr2", "dtype": "float64"}, {"name": "dab2", "dtype": "float64"}, {"name": "diras3", "dtype": "float64"}, {"name": "dlec1", "dtype": "float64"}, {"name": "dph1", "dtype": "float64"}, {"name": "egfr", "dtype": "float64"}, {"name": "eif4e", "dtype": "float64"}, {"name": "eif4ebp1", "dtype": "float64"}, {"name": "eif5a2", "dtype": "float64"}, {"name": "erbb2", "dtype": "float64"}, {"name": "erbb3", "dtype": "float64"}, {"name": "erbb4", "dtype": "float64"}, {"name": "fas", "dtype": "float64"}, {"name": "fgf1", "dtype": "float64"}, {"name": "fgfr1", "dtype": "float64"}, {"name": "folr1", "dtype": "float64"}, {"name": "folr2", "dtype": "float64"}, {"name": "folr3", "dtype": "float64"}, {"name": "foxo1", "dtype": "float64"}, {"name": "foxo3", "dtype": "float64"}, {"name": "gdf11", "dtype": "float64"}, {"name": "gdf2", "dtype": "float64"}, {"name": "gsk3b", "dtype": "float64"}, {"name": "hif1a", "dtype": "float64"}, {"name": "hla-g", "dtype": "float64"}, {"name": "hras", "dtype": "float64"}, {"name": "igf1", "dtype": "float64"}, {"name": "igf1r", "dtype": "float64"}, {"name": "inha", "dtype": "float64"}, {"name": "inhba", "dtype": "float64"}, {"name": "inhbc", "dtype": "float64"}, {"name": "itgav", "dtype": "float64"}, {"name": "itgb3", "dtype": "float64"}, {"name": "izumo1r", "dtype": "float64"}, {"name": "kdr", "dtype": "float64"}, {"name": "kit", "dtype": "float64"}, {"name": "kras", "dtype": "float64"}, {"name": "map2k1", "dtype": "float64"}, {"name": "map2k2", "dtype": "float64"}, {"name": "map2k3", "dtype": "float64"}, {"name": "map2k4", "dtype": "float64"}, {"name": "map2k5", "dtype": "float64"}, {"name": "map3k1", "dtype": "float64"}, {"name": "map3k3", "dtype": "float64"}, {"name": "map3k4", "dtype": "float64"}, {"name": "map3k5", "dtype": "float64"}, {"name": "mapk1", "dtype": "float64"}, {"name": "mapk12", "dtype": "float64"}, {"name": "mapk14", "dtype": "float64"}, {"name": "mapk3", "dtype": "float64"}, {"name": "mapk4", "dtype": "float64"}, {"name": "mapk6", "dtype": "float64"}, {"name": "mapk7", "dtype": "float64"}, {"name": "mapk8", "dtype": "float64"}, {"name": "mapk9", "dtype": "float64"}, {"name": "mdc1", "dtype": "float64"}, {"name": "mlst8", "dtype": "float64"}, {"name": "mmp1", "dtype": "float64"}, {"name": "mmp10", "dtype": "float64"}, {"name": "mmp11", "dtype": "float64"}, {"name": "mmp12", "dtype": "float64"}, {"name": "mmp13", "dtype": "float64"}, {"name": "mmp14", "dtype": "float64"}, {"name": "mmp15", "dtype": "float64"}, {"name": "mmp16", "dtype": "float64"}, {"name": "mmp17", "dtype": "float64"}, {"name": "mmp19", "dtype": "float64"}, {"name": "mmp2", "dtype": "float64"}, {"name": "mmp21", "dtype": "float64"}, {"name": "mmp23b", "dtype": "float64"}, {"name": "mmp24", "dtype": "float64"}, {"name": "mmp25", "dtype": "float64"}, {"name": "mmp26", "dtype": "float64"}, {"name": "mmp27", "dtype": "float64"}, {"name": "mmp28", "dtype": "float64"}, {"name": "mmp3", "dtype": "float64"}, {"name": "mmp7", "dtype": "float64"}, {"name": "mmp9", "dtype": "float64"}, {"name": "mtor", "dtype": "float64"}, {"name": "nfkb1", "dtype": "float64"}, {"name": "nfkb2", "dtype": "float64"}, {"name": "opcml", "dtype": "float64"}, {"name": "pdgfa", "dtype": "float64"}, {"name": "pdgfb", "dtype": "float64"}, {"name": "pdgfra", "dtype": "float64"}, {"name": "pdgfrb", "dtype": "float64"}, {"name": "pdpk1", "dtype": "float64"}, {"name": "peg3", "dtype": "float64"}, {"name": "pik3ca", "dtype": "float64"}, {"name": "pik3r1", "dtype": "float64"}, {"name": "pik3r2", "dtype": "float64"}, {"name": "plagl1", "dtype": "float64"}, {"name": "ptk2", "dtype": "float64"}, {"name": "rab25", "dtype": "float64"}, {"name": "rad51", "dtype": "float64"}, {"name": "raf1", "dtype": "float64"}, {"name": "rassf1", "dtype": "float64"}, {"name": "rheb", "dtype": "float64"}, {"name": "rictor", "dtype": "float64"}, {"name": "rps6", "dtype": "float64"}, {"name": "rps6ka1", "dtype": "float64"}, {"name": "rps6ka2", "dtype": "float64"}, {"name": "rps6kb1", "dtype": "float64"}, {"name": "rps6kb2", "dtype": "float64"}, {"name": "rptor", "dtype": "float64"}, {"name": "slc19a1", "dtype": "float64"}, {"name": "smad1", "dtype": "float64"}, {"name": "smad2", "dtype": "float64"}, {"name": "smad3", "dtype": "float64"}, {"name": "smad4", "dtype": "float64"}, {"name": "smad5", "dtype": "float64"}, {"name": "smad6", "dtype": "float64"}, {"name": "smad7", "dtype": "float64"}, {"name": "smad9", "dtype": "float64"}, {"name": "sptbn1", "dtype": "float64"}, {"name": "terc", "dtype": "float64"}, {"name": "tert", "dtype": "float64"}, {"name": "tgfb1", "dtype": "float64"}, {"name": "tgfb2", "dtype": "float64"}, {"name": "tgfb3", "dtype": "float64"}, {"name": "tgfbr1", "dtype": "float64"}, {"name": "tgfbr2", "dtype": "float64"}, {"name": "tgfbr3", "dtype": "float64"}, {"name": "tsc1", "dtype": "float64"}, {"name": "tsc2", "dtype": "float64"}, {"name": "vegfa", "dtype": "float64"}, {"name": "vegfb", "dtype": "float64"}, {"name": "wfdc2", "dtype": "float64"}, {"name": "wwox", "dtype": "float64"}, {"name": "zfyve9", "dtype": "float64"}, {"name": "arid1a", "dtype": "float64"}, {"name": "arid1b", "dtype": "float64"}, {"name": "cbfb", "dtype": "float64"}, {"name": "gata3", "dtype": "float64"}, {"name": "kmt2c", "dtype": "float64"}, {"name": "kmt2d", "dtype": "float64"}, {"name": "myh9", "dtype": "float64"}, {"name": "ncor1", "dtype": "float64"}, {"name": "pde4dip", "dtype": "float64"}, {"name": "ptprd", "dtype": "float64"}, {"name": "ros1", "dtype": "float64"}, {"name": "runx1", "dtype": "float64"}, {"name": "tbx3", "dtype": "float64"}, {"name": "abcb1", "dtype": "float64"}, {"name": "abcb11", "dtype": "float64"}, {"name": "abcc1", "dtype": "float64"}, {"name": "abcc10", "dtype": "float64"}, {"name": "bbc3", "dtype": "float64"}, {"name": "bmf", "dtype": "float64"}, {"name": "cyp2c8", "dtype": "float64"}, {"name": "cyp3a4", "dtype": "float64"}, {"name": "fgf2", "dtype": "float64"}, {"name": "fn1", "dtype": "float64"}, {"name": "map2", "dtype": "float64"}, {"name": "map4", "dtype": "float64"}, {"name": "mapt", "dtype": "float64"}, {"name": "nr1i2", "dtype": "float64"}, {"name": "slco1b3", "dtype": "float64"}, {"name": "tubb1", "dtype": "float64"}, {"name": "tubb4a", "dtype": "float64"}, {"name": "tubb4b", "dtype": "float64"}, {"name": "twist1", "dtype": "float64"}, {"name": "adgra2", "dtype": "float64"}, {"name": "afdn", "dtype": "float64"}, {"name": "aff2", "dtype": "float64"}, {"name": "agmo", "dtype": "float64"}, {"name": "agtr2", "dtype": "float64"}, {"name": "ahnak", "dtype": "float64"}, {"name": "ahnak2", "dtype": "float64"}, {"name": "akap9", "dtype": "float64"}, {"name": "alk", "dtype": "float64"}, {"name": "apc", "dtype": "float64"}, {"name": "arid2", "dtype": "float64"}, {"name": "arid5b", "dtype": "float64"}, {"name": "asxl1", "dtype": "float64"}, {"name": "asxl2", "dtype": "float64"}, {"name": "bap1", "dtype": "float64"}, {"name": "bcas3", "dtype": "float64"}, {"name": "birc6", "dtype": "float64"}, {"name": "cacna2d3", "dtype": "float64"}, {"name": "ccnd3", "dtype": "float64"}, {"name": "chd1", "dtype": "float64"}, {"name": "clk3", "dtype": "float64"}, {"name": "clrn2", "dtype": "float64"}, {"name": "col12a1", "dtype": "float64"}, {"name": "col22a1", "dtype": "float64"}, {"name": "col6a3", "dtype": "float64"}, {"name": "ctcf", "dtype": "float64"}, {"name": "ctnna1", "dtype": "float64"}, {"name": "ctnna3", "dtype": "float64"}, {"name": "dnah11", "dtype": "float64"}, {"name": "dnah2", "dtype": "float64"}, {"name": "dnah5", "dtype": "float64"}, {"name": "dtwd2", "dtype": "float64"}, {"name": "fam20c", "dtype": "float64"}, {"name": "fanca", "dtype": "float64"}, {"name": "fancd2", "dtype": "float64"}, {"name": "flt3", "dtype": "float64"}, {"name": "foxp1", "dtype": "float64"}, {"name": "frmd3", "dtype": "float64"}, {"name": "gh1", "dtype": "float64"}, {"name": "gldc", "dtype": "float64"}, {"name": "gpr32", "dtype": "float64"}, {"name": "gps2", "dtype": "float64"}, {"name": "hdac9", "dtype": "float64"}, {"name": "herc2", "dtype": "float64"}, {"name": "hist1h2bc", "dtype": "float64"}, {"name": "kdm3a", "dtype": "float64"}, {"name": "kdm6a", "dtype": "float64"}, {"name": "klrg1", "dtype": "float64"}, {"name": "l1cam", "dtype": "float64"}, {"name": "lama2", "dtype": "float64"}, {"name": "lamb3", "dtype": "float64"}, {"name": "large1", "dtype": "float64"}, {"name": "ldlrap1", "dtype": "float64"}, {"name": "lifr", "dtype": "float64"}, {"name": "lipi", "dtype": "float64"}, {"name": "magea8", "dtype": "float64"}, {"name": "map3k10", "dtype": "float64"}, {"name": "map3k13", "dtype": "float64"}, {"name": "men1", "dtype": "float64"}, {"name": "mtap", "dtype": "float64"}, {"name": "muc16", "dtype": "float64"}, {"name": "myo1a", "dtype": "float64"}, {"name": "myo3a", "dtype": "float64"}, {"name": "ncoa3", "dtype": "float64"}, {"name": "nek1", "dtype": "float64"}, {"name": "nf2", "dtype": "float64"}, {"name": "npnt", "dtype": "float64"}, {"name": "nr2f1", "dtype": "float64"}, {"name": "nr3c1", "dtype": "float64"}, {"name": "nras", "dtype": "float64"}, {"name": "nrg3", "dtype": "float64"}, {"name": "nt5e", "dtype": "float64"}, {"name": "or6a2", "dtype": "float64"}, {"name": "palld", "dtype": "float64"}, {"name": "pbrm1", "dtype": "float64"}, {"name": "ppp2cb", "dtype": "float64"}, {"name": "ppp2r2a", "dtype": "float64"}, {"name": "prkacg", "dtype": "float64"}, {"name": "prkce", "dtype": "float64"}, {"name": "prkcq", "dtype": "float64"}, {"name": "prkcz", "dtype": "float64"}, {"name": "prkg1", "dtype": "float64"}, {"name": "prps2", "dtype": "float64"}, {"name": "prr16", "dtype": "float64"}, {"name": "ptpn22", "dtype": "float64"}, {"name": "ptprm", "dtype": "float64"}, {"name": "rasgef1b", "dtype": "float64"}, {"name": "rpgr", "dtype": "float64"}, {"name": "ryr2", "dtype": "float64"}, {"name": "sbno1", "dtype": "float64"}, {"name": "setd1a", "dtype": "float64"}, {"name": "setd2", "dtype": "float64"}, {"name": "setdb1", "dtype": "float64"}, {"name": "sf3b1", "dtype": "float64"}, {"name": "sgcd", "dtype": "float64"}, {"name": "shank2", "dtype": "float64"}, {"name": "siah1", "dtype": "float64"}, {"name": "sik1", "dtype": "float64"}, {"name": "sik2", "dtype": "float64"}, {"name": "smarcb1", "dtype": "float64"}, {"name": "smarcc1", "dtype": "float64"}, {"name": "smarcc2", "dtype": "float64"}, {"name": "smarcd1", "dtype": "float64"}, {"name": "spaca1", "dtype": "float64"}, {"name": "stab2", "dtype": "float64"}, {"name": "stmn2", "dtype": "float64"}, {"name": "syne1", "dtype": "float64"}, {"name": "taf1", "dtype": "float64"}, {"name": "taf4b", "dtype": "float64"}, {"name": "tbl1xr1", "dtype": "float64"}, {"name": "tg", "dtype": "float64"}, {"name": "thada", "dtype": "float64"}, {"name": "thsd7a", "dtype": "float64"}, {"name": "ttyh1", "dtype": "float64"}, {"name": "ubr5", "dtype": "float64"}, {"name": "ush2a", "dtype": "float64"}, {"name": "usp9x", "dtype": "float64"}, {"name": "utrn", "dtype": "float64"}, {"name": "zfp36l1", "dtype": "float64"}, {"name": "ackr3", "dtype": "float64"}, {"name": "akr1c1", "dtype": "float64"}, {"name": "akr1c2", "dtype": "float64"}, {"name": "akr1c3", "dtype": "float64"}, {"name": "akr1c4", "dtype": "float64"}, {"name": "akt3", "dtype": "float64"}, {"name": "ar", "dtype": "float64"}, {"name": "bche", "dtype": "float64"}, {"name": "cdk8", "dtype": "float64"}, {"name": "cdkn2c", "dtype": "float64"}, {"name": "cyb5a", "dtype": "float64"}, {"name": "cyp11a1", "dtype": "float64"}, {"name": "cyp11b2", "dtype": "float64"}, {"name": "cyp17a1", "dtype": "float64"}, {"name": "cyp19a1", "dtype": "float64"}, {"name": "cyp21a2", "dtype": "float64"}, {"name": "cyp3a43", "dtype": "float64"}, {"name": "cyp3a5", "dtype": "float64"}, {"name": "cyp3a7", "dtype": "float64"}, {"name": "ddc", "dtype": "float64"}, {"name": "hes6", "dtype": "float64"}, {"name": "hsd17b1", "dtype": "float64"}, {"name": "hsd17b10", "dtype": "float64"}, {"name": "hsd17b11", "dtype": "float64"}, {"name": "hsd17b12", "dtype": "float64"}, {"name": "hsd17b13", "dtype": "float64"}, {"name": "hsd17b14", "dtype": "float64"}, {"name": "hsd17b2", "dtype": "float64"}, {"name": "hsd17b3", "dtype": "float64"}, {"name": "hsd17b4", "dtype": "float64"}, {"name": "hsd17b6", "dtype": "float64"}, {"name": "hsd17b7", "dtype": "float64"}, {"name": "hsd17b8", "dtype": "float64"}, {"name": "hsd3b1", "dtype": "float64"}, {"name": "hsd3b2", "dtype": "float64"}, {"name": "hsd3b7", "dtype": "float64"}, {"name": "mecom", "dtype": "float64"}, {"name": "met", "dtype": "float64"}, {"name": "ncoa2", "dtype": "float64"}, {"name": "nrip1", "dtype": "float64"}, {"name": "pik3r3", "dtype": "float64"}, {"name": "prkci", "dtype": "float64"}, {"name": "prkd1", "dtype": "float64"}, {"name": "ran", "dtype": "float64"}, {"name": "rdh5", "dtype": "float64"}, {"name": "sdc4", "dtype": "float64"}, {"name": "serpini1", "dtype": "float64"}, {"name": "shbg", "dtype": "float64"}, {"name": "slc29a1", "dtype": "float64"}, {"name": "sox9", "dtype": "float64"}, {"name": "spry2", "dtype": "float64"}, {"name": "srd5a1", "dtype": "float64"}, {"name": "srd5a2", "dtype": "float64"}, {"name": "srd5a3", "dtype": "float64"}, {"name": "st7", "dtype": "float64"}, {"name": "star", "dtype": "float64"}, {"name": "tnk2", "dtype": "float64"}, {"name": "tulp4", "dtype": "float64"}, {"name": "ugt2b15", "dtype": "float64"}, {"name": "ugt2b17", "dtype": "float64"}, {"name": "ugt2b7", "dtype": "float64"}, {"name": "event_time", "dtype": "float64"}, {"name": "event_indicator", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 8074440, "num_examples": 1904}], "download_size": 7639518, "dataset_size": 8074440}}
|
2023-04-22T09:47:16+00:00
|
2fea0400681478921aaede873481ce12cfcc57f3
|
This is the dataset used in the paper "Readability Controllable Biomedical Document Summarization" by Zheheng Luo, Qianqian Xie, Sophia Ananiadou.
Every instance in the dataset contains a technical summary(abstract), a plain language summary, and the whole article text. All the data are from the PLOS journals.
Detailed format is as following:
```
{
"doi": str, # unique doi identifier
"title": str, # title
"abstract": str, # abstract
"plain language summary": str, # plain language summary
"article": str # whole text
}
```
|
KennyLuo/RC-Sum-PLOS
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-22T09:49:31+00:00
|
{"license": "apache-2.0"}
|
2023-04-22T10:53:40+00:00
|
9fba8200c5326e996f789191f095bd464ef1d09e
|
# Dataset Card for "refcoco"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
jxu124/refcoco
|
[
"region:us"
] |
2023-04-22T09:52:18+00:00
|
{"dataset_info": {"features": [{"name": "sent_ids", "sequence": "int64"}, {"name": "file_name", "dtype": "string"}, {"name": "ann_id", "dtype": "int64"}, {"name": "ref_id", "dtype": "int64"}, {"name": "image_id", "dtype": "int64"}, {"name": "split", "dtype": "string"}, {"name": "sentences", "list": [{"name": "raw", "dtype": "string"}, {"name": "sent", "dtype": "string"}, {"name": "sent_id", "dtype": "int64"}, {"name": "tokens", "sequence": "string"}]}, {"name": "category_id", "dtype": "int64"}, {"name": "raw_anns", "dtype": "string"}, {"name": "raw_image_info", "dtype": "string"}, {"name": "raw_sentences", "dtype": "string"}, {"name": "image_path", "dtype": "string"}, {"name": "bbox", "sequence": "float64"}, {"name": "captions", "sequence": "string"}, {"name": "global_image_id", "dtype": "string"}, {"name": "anns_id", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 81385755, "num_examples": 42404}, {"name": "testB", "num_bytes": 3284397, "num_examples": 1810}, {"name": "test", "num_bytes": 3943834, "num_examples": 1975}, {"name": "validation", "num_bytes": 7355626, "num_examples": 3811}], "download_size": 38895129, "dataset_size": 95969612}}
|
2023-05-20T17:58:37+00:00
|
f9663dc24a70b15fb8997991288b11694618bfa5
|
# THFOOD-50
Fine-Grained Thai Food Image Classification Datasets
THFOOD-50 containing 15,770 images of 50 famous Thai dishes.
## Download:
[THFOOD-50 v1 on Google Drive](https://drive.google.com/file/d/1CuNO2e77ZTk7mDfv3XujYXuUwiMwlUQI/view?usp=sharing)
## License
THFOOD-50 for **non-commercial research/educational** use.
## Citation
If you use THFOOD-50 dataset in your research, please cite our paper:
@article{termritthikun2017nu,
title="{NU-InNet: Thai food image recognition using convolutional neural networks on smartphone}",
author={Termritthikun, Chakkrit and Muneesawang, Paisarn and Kanprachar, Surachet},
journal={Journal of Telecommunication, Electronic and Computer Engineering (JTEC)},
volume={9},
number={2-6},
pages={63--67},
year={2017}
}
@inproceedings{termritthikun2017accuracy,
title="{Accuracy improvement of Thai food image recognition using deep convolutional neural networks}",
author={Termritthikun, Chakkrit and Kanprachar, Surachet},
booktitle={2017 international electrical engineering congress (IEECON)},
pages={1--4},
year={2017},
organization={IEEE}
}
@article{termritthikun2018nu,
title="{Nu-ResNet: Deep residual networks for Thai food image recognition}",
author={Termritthikun, Chakkrit and Kanprachar, Surachet},
journal={Journal of Telecommunication, Electronic and Computer Engineering (JTEC)},
volume={10},
number={1-4},
pages={29--33},
year={2018}
}
## Paper
1. NU-InNet: Thai food image recognition using convolutional neural networks on smartphone [Paper](https://journal.utem.edu.my/index.php/jtec/article/download/2436/1521) [Code](https://github.com/chakkritte/NU-InNet)
2. Accuracy improvement of Thai food image recognition using deep convolutional neural networks [Paper](https://ieeexplore.ieee.org/abstract/document/8075874/)
3. Nu-resnet: Deep residual networks for thai food image recognition [Paper](https://journal.utem.edu.my/index.php/jtec/article/download/3572/2467) [Code](https://github.com/chakkritte/NU-ResNet)
#### Examples of Thai food images in the THFOOD-50 dataset

**NOTE**: I do not own this, but I took the liberty to upload this dataset to the community.
|
thean/THFOOD-50
|
[
"size_categories:10K<n<100K",
"license:afl-3.0",
"region:us"
] |
2023-04-22T10:13:49+00:00
|
{"license": "afl-3.0", "size_categories": ["10K<n<100K"], "pretty_name": "Fine-Grained Thai Food Image Classification Datasets.", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "BitterMelonSoup", "1": "BooPadPongali", "2": "CurriedFishCake", "3": "Dumpling", "4": "EggsStewed", "5": "FriedChicken", "6": "FriedKale", "7": "FriedMusselPancakes", "8": "GaengJued", "9": "GaengKeawWan", "10": "GaiYang", "11": "GoongObWoonSen", "12": "GoongPao", "13": "GrilledQquid", "14": "HoyKraeng", "15": "HoyLaiPrikPao", "16": "Joke", "17": "KaiJeowMooSaap", "18": "KaiThoon", "19": "KaoManGai", "20": "KaoMooDang", "21": "KhanomJeenNamYaKati", "22": "KhaoMokGai", "23": "KhaoMooTodGratiem", "24": "KhaoNiewMaMuang", "25": "KkaoKlukKaphi", "26": "KorMooYang", "27": "KuaKling", "28": "KuayJab", "29": "KuayTeowReua", "30": "LarbMoo", "31": "MassamanGai", "32": "MooSatay", "33": "NamTokMoo", "34": "PadPakBung", "35": "PadPakRuamMit", "36": "PadThai", "37": "PadYordMala", "38": "PhatKaphrao", "39": "PorkStickyNoodles", "40": "Roast_duck", "41": "Roast_fish", "42": "Somtam", "43": "SonInLawEggs", "44": "StewedPorkLeg", "45": "Suki", "46": "TomKhaGai", "47": "TomYumGoong", "48": "YamWoonSen", "49": "Yentafo"}}}}], "splits": [{"name": "train", "num_bytes": 1790570028.695, "num_examples": 12065}, {"name": "test", "num_bytes": 394634675.44, "num_examples": 2105}, {"name": "val", "num_bytes": 295187724.2, "num_examples": 1600}], "download_size": 3125698089, "dataset_size": 2480392428.3349996}}
|
2023-04-22T11:28:07+00:00
|
0a7938b094c3979388687f76fe43c0d853e1d8e1
|
tqfang229/CKBP
|
[
"license:mit",
"region:us"
] |
2023-04-22T10:48:32+00:00
|
{"license": "mit"}
|
2023-04-22T10:54:17+00:00
|
|
312eff5b0e72fa7e0fee1cf42810482683dc03c8
|
# Dataset Card for "chunk_193"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
one-sec-cv12/chunk_193
|
[
"region:us"
] |
2023-04-22T11:04:54+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}], "splits": [{"name": "train", "num_bytes": 18549173952.5, "num_examples": 193124}], "download_size": 16649725885, "dataset_size": 18549173952.5}}
|
2023-04-22T11:14:29+00:00
|
d09e24d4dcebcafd3a681143c4fa30e2befd0e01
|
# Dataset Card for "clothing-ads"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
pangluo/clothing-ads
|
[
"region:us"
] |
2023-04-22T11:29:04+00:00
|
{"dataset_info": {"features": [{"name": "name", "dtype": "string"}, {"name": "description", "dtype": "string"}, {"name": "price", "dtype": "float64"}, {"name": "color", "dtype": "string"}, {"name": "size", "dtype": "string"}, {"name": "ad", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 2417, "num_examples": 5}], "download_size": 6928, "dataset_size": 2417}}
|
2023-04-22T11:29:06+00:00
|
3698480a001cb3f62c61c314d4acb181eb31e983
|
# Dataset Card for "Bactrian-X"
## Table of Contents
- [Dataset Description](#a-dataset-description)
- [Dataset Summary](#dataset-summary)
- [Languages](#languages)
- [Dataset Structure](#b-dataset-structure)
- [Data Fields](#data-fields)
- [Data Instances](#data-instances)
- [Data in 52 Languages](#data-in-52-languages)
- [Dataset Creation](#c-dataset-creation)
- [Considerations for Using the Data](#d-considerations-for-using-the-data)
- [Additional Information](#e-additional-information)
## A. Dataset Description
- **Homepage:** https://github.com/mbzuai-nlp/Bactrian-X
- **Repository:** https://huggingface.co/datasets/MBZUAI/Bactrian-X
- **Paper:** to-be-soon released
### Dataset Summary
<h3 align="center">
<img src="https://raw.githubusercontent.com/fajri91/eval_picts/master/BactrianX_dataset.jpg" width="950" align="center">
</h3>
The Bactrain-X dataset is a collection of 3.4M instruction-response pairs in 52 languages, that are obtained by translating 67K English instructions ([alpaca-52k](https://github.com/tatsu-lab/stanford_alpaca) + [dolly-15k](https://github.com/databrickslabs/dolly/tree/master/data)) into 51 languages using Google Translate API. The translated instructions are then fed to ChatGPT (`gpt-3.5-turbo`) to obtain its natural responses, resulting in 3.4M instruction-response pairs in 52 languages (52 languages x 67k instances = 3.4M instances).
### Languages
We follow 52 languages of [mBART-50](https://arxiv.org/abs/2008.00401), with details can be found [below](#data-in-52-languages).
## B. Dataset Structure
### Data Fields
The data fields are as follows:
* `instruction`: describes the task the model should perform. Each of the 67K instructions is unique.
* `input`: optional context or input for the task. For example, when the instruction is "Summarize the following article", the input is the article. Around 40% of the examples have an input.
* `output`: the answer to the instruction as generated by `gpt-3.5-turbo`.
* `id`: the unique index for each data piece in a specific language. The same `id` across splits corresponds to the same original English data.
### Data Instances
An example in `en` looks as follows.
```json
{
"instruction": "What is the main idea of this text?",
"input": "The robotics industry has become one of the fastest growing sectors in today’s economy. Robotics technology is being applied in various industries and applications, such as manufacturing, healthcare, and defense.",
"output": "The main idea of the text is that the robotics industry is rapidly growing and its technology is being used in many different industries and applications.",
"id": "alpaca-107"
}
```
An example in `ar` looks as follows.
```json
{
"instruction": "قم بالوصول إلى إعدادات المتصفح الافتراضية على جهاز الكمبيوتر.",
"input": "",
"output": "لا يمكن لي كمساعد افتراضي القيام بهذه المهمة كونها تحتاج إلى الوصول إلى الجهاز المادي. يرجى الرجوع إلى دليل المستخدم للكمبيوتر الخاص بك أو البحث على الإنترنت لمعرفة كيفية الوصول إلى إعدادات المتصفح الافتراضية على جهاز الكمبيوتر الخاص بك.",
"id": "alpaca-41997"
}
```
An example in `id` looks as follows.
```json
{
"instruction": "Berapa banyak angka penting yang harus digunakan untuk nilai 0,000187?",
"input": "",
"output": "Ada tiga angka penting dalam nilai 0,000187.",
"id": "alpaca-40382"
}
```
An example in `de` looks as follows.
```json
{
"instruction": "Komponieren Sie ein Musikstück mit einem Titel, der Trauer bezeichnet.",
"input": "",
"output": ""Schmerzendes Herz"\n\nDas Stück beginnt mit einer langsamen, traurigen Melodie, gespielt von einem Solo-Violoncello. Die Harmonien, die von einem Klavier begleitet werden, sind durcheinander und dissonant, um ein Gefühl von Schmerz und Trauer zu vermitteln.\n\nIm Laufe des Stücks treten andere Instrumente ein, wie Streicher, Flöte und Oboe, um die Melodie zu unterstützen und zu intensivieren. Der Rhythmus bleibt langsam und schwerfällig, um die Schwere des Schmerzes darzustellen.\n\nIn der Mitte des Stücks gibt es einen Höhepunkt, wo die Melodie und Harmonien sich verdichten und ein Gefühl von Überwältigung erzeugen. Der Solo-Violoncello spielt eine traurige und schnelle Phrase, die die Verzweiflung und Isolation des Protagonisten ausdrückt.\n\nDas Stück endet mit einer Wiederholung der ersten Melodie, gespielt von einem Solo-Klavier, während die anderen Instrumente auslaufen. Die Harmonien werden jedoch weicher und sanfter, um einen Hauch von Hoffnung zu vermitteln, dass der Schmerz langsam vergeht.",
"id": "alpaca-33619"
}
```
An example in `fr` looks as follows.
```json
{
"instruction": "Les Ceanothus ont-ils des racines peu profondes ?",
"input": "",
"output": "En tant qu'IA, je ne peux pas répondre avec une certitude absolue, mais voici des informations générales sur les racines de Ceanothus : \n\nLes Ceanothus ont tendance à avoir un système racinaire étendu et peu profond. Les racines peuvent s'étaler jusqu'à 4 à 6 fois la taille de la plante et s'étendre à environ 60 à 90 cm de profondeur. Cependant, cela peut varier en fonction du type de sol et de la variété de Ceanothus. Certaines variétés de Ceanothus pourraient avoir des racines plus profondes si les conditions s'y prêtent.",
"id": "dolly-10940"
}
```
### Data in 52 Languages
| No | Languages | Code | Train |
| ---|---------------- | ----- | ----- |
| 1 | [Afrikaans](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/af) | af_ZA | 67017 |
| 2 | [Arabic](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ar) | ar_AR | 67017 |
| 3 | [Azerbaijani](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/az) | az_AZ | 67017 |
| 4 | [Bengali](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/bn) | bn_IN | 67017 |
| 5 | [Czech](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/cs) | cs_CZ | 67017 |
| 6 | [German](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/de) | de_DE | 67017 |
| 7 | [English](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/en) | en_XX | 67017 |
| 8 | [Spanish](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/es) | es_XX | 67017 |
| 9 | [Estonian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/et) | et_EE | 67017 |
| 10 | [Persian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/fa) | fa_IR | 67017 |
| 11 | [Finnish](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/fi) | fi_FI | 67017 |
| 12 | [French](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/fr) | fr_XX | 67017 |
| 13 | [Galician](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/gl) | gl_ES | 67017 |
| 14 | [Gujarati](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/gu) | gu_IN | 67017 |
| 15 | [Hebrew](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/he) | he_IL | 67017 |
| 16 | [Hindi](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/hi) | hi_IN | 67017 |
| 17 | [Croatian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/hr) | hr_HR | 67017 |
| 18 | [Indonesian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/id) | id_ID | 67017 |
| 19 | [Italian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/it) | it_IT | 67017 |
| 20 | [Japanese](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ja) | ja_XX | 67017 |
| 21 | [Georgian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ka) | ka_GE | 67017 |
| 22 | [Kazakh](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/kk) | kk_KZ | 67017 |
| 23 | [Khmer](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/km) | km_KH | 67017 |
| 24 | [Korean](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ko) | ko_KR | 67017 |
| 25 | [Lithuanian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/lt) | lt_LT | 67017 |
| 26 | [Latvian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/lv) | lv_LV | 67017 |
| 27 | [Macedonian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/mk) | mk_MK | 67017 |
| 28 | [Malayalam](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ml) | ml_IN | 67017 |
| 29 | [Mongolian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/mn) | mn_MN | 67017 |
| 30 | [Marathi](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/mr) | mr_IN | 67017 |
| 31 | [Burmese](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/my) | my_MM | 67017 |
| 32 | [Nepali](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ne) | ne_NP | 67017 |
| 33 | [Dutch](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/nl) | nl_XX | 67017 |
| 34 | [Polish](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/pl) | pl_PL | 67017 |
| 35 | [Pashto](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ps) | ps_AF | 67017 |
| 36 | [Portuguese](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/pt) | pt_XX | 67017 |
| 37 | [Romanian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ro) | ro_RO | 67017 |
| 38 | [Russian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ru) | ru_RU | 67017 |
| 39 | [Sinhala](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/si) | si_LK | 67017 |
| 40 | [Slovene](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/sl) | sl_SI | 67017 |
| 41 | [Swedish](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/sv) | sv_SE | 67017 |
| 42 | [Swahili](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/sw) | sw_KE | 67017 |
| 43 | [Tamil](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ta) | ta_IN | 67017 |
| 44 | [Telugu](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/te) | te_IN | 67017 |
| 45 | [Thai](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/th) | th_TH | 67017 |
| 46 | [Tagalog](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/tl) | tl_XX | 67017 |
| 47 | [Turkish](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/tr) | tr_TR | 67017 |
| 48 | [Ukrainian](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/uk) | uk_UA | 67017 |
| 49 | [Urdu](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/ur) | ur_PK | 67017 |
| 50 | [Vietnamese](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/vi) | vi_VN | 67017 |
| 51 | [Xhosa](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/xh) | xh_ZA | 67017 |
| 52 | [Chinese](https://huggingface.co/datasets/MBZUAI/Bactrian-X/viewer/zh) | zh_CN | 67017 |
## C. Dataset Creation
1. English Instructions: The English instuctions are obtained from [alpaca-53k](https://github.com/tatsu-lab/stanford_alpaca), and [dolly-15k](https://github.com/databrickslabs/dolly/tree/master/data).
2. Instruction Translation: The instructions (and inputs) are translated into 51 languages using Google Translation API (conducted on April 2023).
3. Output Generation: We generate output from `gpt-3.5-turbo` for each language (conducted on April 2023).
## D. Considerations for Using the Data
### Social Impact of Dataset
NLP for everyone: this dataset helps to democratize the cutting-edge instruction-following models in 52 languages. This dataset also allows the first experiment on the multilingual LoRA-based LLaMA model.
### Discussion of Biases
(1) Translation bias; (2) Potential English-culture bias in the translated dataset.
### Other Known Limitations
The `Bactrian-X` data is generated by a language model (`gpt-3.5-turbo`) and inevitably contains some errors or biases. We encourage users to use this data with caution and propose new methods to filter or improve the imperfections.
## E. Additional Information
### Dataset Curators
[Haonan Li](https://haonan-li.github.io/) and [Fajri Koto](http://www.fajrikoto.com)
### Licensing Information
The dataset is available under the [Creative Commons NonCommercial (CC BY-NC 4.0)](https://creativecommons.org/licenses/by-nc/4.0/legalcode).
### Citation Information
```
@misc{li2023bactrianx,
title={Bactrian-X : A Multilingual Replicable Instruction-Following Model with Low-Rank Adaptation},
author={Haonan Li and Fajri Koto and Minghao Wu and Alham Fikri Aji and Timothy Baldwin},
year={2023},
eprint={2305.15011},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
### Contributions
Thanks to [@haonan-li](https://github.com/haonan-li), [@fajri91](https://github.com/fajri91) for adding this dataset.
|
MBZUAI/Bactrian-X
|
[
"task_categories:text-generation",
"language:af",
"language:ar",
"language:az",
"language:bn",
"language:cs",
"language:de",
"language:en",
"language:es",
"language:et",
"language:fi",
"language:fr",
"language:gl",
"language:gu",
"language:he",
"language:hi",
"language:hr",
"language:id",
"language:it",
"language:ja",
"language:ka",
"language:kk",
"language:km",
"language:ko",
"language:lt",
"language:lv",
"language:mk",
"language:ml",
"language:mn",
"language:mr",
"language:my",
"language:ne",
"language:nl",
"language:pl",
"language:ps",
"language:pt",
"language:ro",
"language:ru",
"language:si",
"language:sl",
"language:sv",
"language:sw",
"language:ta",
"language:te",
"language:th",
"language:tl",
"language:tr",
"language:uk",
"language:ur",
"language:vi",
"language:xh",
"language:zh",
"license:cc-by-nc-4.0",
"instruction-finetuning",
"multilingual",
"arxiv:2008.00401",
"arxiv:2305.15011",
"region:us"
] |
2023-04-22T11:42:39+00:00
|
{"language": ["af", "ar", "az", "bn", "cs", "de", "en", "es", "et", "fi", "fr", "gl", "gu", "he", "hi", "hr", "id", "it", "ja", "ka", "kk", "km", "ko", "lt", "lv", "mk", "ml", "mn", "mr", "my", "ne", "nl", "pl", "ps", "pt", "ro", "ru", "si", "sl", "sv", "sw", "ta", "te", "th", "tl", "tr", "uk", "ur", "vi", "xh", "zh"], "license": "cc-by-nc-4.0", "task_categories": ["text-generation"], "pretty_name": "Bactrian-X", "tags": ["instruction-finetuning", "multilingual"]}
|
2023-05-27T11:54:05+00:00
|
ca1ddc9af7fe770dca95d162cea3fcbe858a6df4
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
Prospectus text mining is very important for the investor community to identify major risks.
factors and evaluate the use of the amount to be raised during an IPO. For this dataset author
downloaded 100 prospectuses from the Indian Market Regulator website. The dataset contains the URL and OCR text for 100 prospectuses.
Further, the author released a Roberta LM and sentence transformer for usage.
### Supported Tasks and Leaderboards
N.A.
### Languages
ENGLISH
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
There are 4 columns:
title_prospectus: Title of the IPO prospectus
href_prospectus: Location of HTML
pdf_prospectus : Pdf of prospectus
content_whole_prospectus: OCR text for the whole prospectus
### Data Splits
N.A.
## Dataset Creation
### Curation Rationale
Prospectus text mining
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
This will help investors and the merchant bank community explore prospectuses in a more automated way, thus saving time.
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
```bibtex
@misc{ROBERTA GOES FOR IPO: PROSPECTUS ANALYSIS WITH LANGUAGE MODELS FOR INDIAN INITIAL PUBLIC OFFERINGS,
author = {Abhishek Mishra and Yogendra Sisodia},
title = {ROBERTA GOES FOR IPO: PROSPECTUS ANALYSIS WITH LANGUAGE MODELS FOR INDIAN INITIAL PUBLIC OFFERINGS},
year = {2022},
url = {https://aircconline.com/csit/papers/vol12/csit121905.pdf},
}
```
### Contributions
Made by Author [Scholarly360](https://github.com/Scholarly360).
|
scholarly360/indian_ipo_prospectus_data
|
[
"doi:10.57967/hf/0558",
"region:us"
] |
2023-04-22T12:23:25+00:00
|
{}
|
2023-08-15T12:26:41+00:00
|
8bd3961ce0a708e488a50f61ae8dfc07ad6968d7
|
# Dataset Card for "nerdy-ghibli"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
bizoffermark/nerdy-ghibli
|
[
"region:us"
] |
2023-04-22T12:59:43+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "text", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 26970782.0, "num_examples": 50}], "download_size": 26971507, "dataset_size": 26970782.0}}
|
2023-04-22T13:39:14+00:00
|
7373079e6dc0710cd9c0f2c00ba89865e68abcd2
|
# Raw Data from MultiPL-E
**Uploads are a work in progress. If you are interested in a split that is not yet available, please contact [email protected].**
This repository contains the raw data -- both completions and executions -- from MultiPL-E that was used to generate several experimental results from the
MultiPL-E, SantaCoder, and StarCoder papers.
The original MultiPL-E completions and executions are stored in JOSN files. We use [the following script](https://github.com/nuprl/MultiPL-E/blob/main/upload_completions.py-)
to turn each experiment directory into a dataset split and upload to this repository.
Every split is named `base_dataset`.`language`.`model`.`temperature`.`variation`
- `base_dataset` is either `humaneval` or `mbpp`.
- `language` is the file extension of the programming language. E.g., `py` for Python or `sh` for Bash.
- `model` is the name of the model. Some model names used by MultiPL-E:
- `bigcode_15b_1000m`: StarCoderBase
- `bigcode_15b_200m`, `bigcode_15b_400m`, `bigcode_15b_600m`, `bigcode_15b_800m`: the 20%, 40%, 60%, 80% checkpoints for StarCoderBase
- `pystarcoder2`: StarCoder
- there are others, just have a look :)
- `temperature`: this is either 0.2 or 0.8
- `variation`: the variation of the MultiPL-E prompt to use, which should be `reworded`. MultiPL-E has several prompt ablations and the `reworded` prompts are the canonical variation.
|
bigcode/MultiPL-E-completions
|
[
"code",
"region:us"
] |
2023-04-22T13:01:20+00:00
|
{"pretty_name": "MultiPL-E generated programs and execution results", "dataset_info": {"features": [{"name": "experiment", "dtype": "string"}, {"name": "problem", "dtype": "string"}, {"name": "language", "dtype": "string"}, {"name": "top_p", "dtype": "float64"}, {"name": "max_tokens", "dtype": "int64"}, {"name": "prompt", "dtype": "string"}, {"name": "tests", "dtype": "string"}, {"name": "stop_tokens", "sequence": "string"}, {"name": "completions", "sequence": "string"}, {"name": "programs", "sequence": "string"}, {"name": "stdouts", "sequence": "string"}, {"name": "stderrs", "sequence": "string"}, {"name": "exit_codes", "sequence": "int64"}, {"name": "statuses", "sequence": "string"}, {"name": "timestamps", "sequence": "int64"}], "splits": [{"name": "humaneval.py.bigcode_15b_800m.0.2.reworded", "num_bytes": 50941974, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_200m.0.2.reworded", "num_bytes": 57850786, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_400m.0.2.reworded", "num_bytes": 52404545, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_600m.0.2.reworded", "num_bytes": 55071293, "num_examples": 161}, {"name": "humaneval.rkt.bigcode_15b_800m.0.2.reworded", "num_bytes": 77194321, "num_examples": 161}, {"name": "humaneval.py.chatgpt.0.2.reworded", "num_bytes": 5473126, "num_examples": 161}, {"name": "humaneval.r.bigcode_15b_800m.0.2.reworded", "num_bytes": 73160389, "num_examples": 161}, {"name": "humaneval.r.bigcode_15b_1000m.0.2.reworded", "num_bytes": 63088872, "num_examples": 161}, {"name": "humaneval.r.bigcode_15b_200m.0.2.reworded", "num_bytes": 77532102, "num_examples": 161}, {"name": "humaneval.r.bigcode_15b_400m.0.2.reworded", "num_bytes": 80103073, "num_examples": 161}, {"name": "humaneval.r.bigcode_15b_600m.0.2.reworded", "num_bytes": 76123407, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_1000m.0.2.reworded", "num_bytes": 47282373, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_1000m.0.1.reworded", "num_bytes": 11724023, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_1000m.0.4.reworded", "num_bytes": 12167610, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_1000m.0.6.reworded", "num_bytes": 12344190, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_1000m.0.8.reworded", "num_bytes": 12825651, "num_examples": 161}, {"name": "humaneval.py.codegeex.0.2.reworded", "num_bytes": 49547494, "num_examples": 161}, {"name": "humaneval.py.codegen.0.2.reworded", "num_bytes": 55391634, "num_examples": 161}, {"name": "humaneval.py.Salesforce_codegen_16B_mono.0.2.reworded", "num_bytes": 54757013, "num_examples": 161}, {"name": "humaneval.py.cushman001.0.2.reworded", "num_bytes": 5081696, "num_examples": 161}, {"name": "humaneval.js.pystarcoder2.0.2.reworded", "num_bytes": 6784781, "num_examples": 161}, {"name": "humaneval.py.santacoder.0.2.reworded", "num_bytes": 57098223, "num_examples": 161}, {"name": "humaneval.py.santacoder_fim_prompt.0.2.reworded", "num_bytes": 5473782, "num_examples": 161}, {"name": "humaneval.lua.bigcode_15b_1000m.0.2.reworded", "num_bytes": 53170918, "num_examples": 161}, {"name": "mbpp.py.bigcode_15b_1000m.0.2.reworded", "num_bytes": 76438518, "num_examples": 397}, {"name": "mbpp.py.pystarcoder2.0.2.reworded", "num_bytes": 78424728, "num_examples": 397}, {"name": "mbpp.lua.davinci.0.2.reworded", "num_bytes": 82574073, "num_examples": 401}, {"name": "humaneval.js.davinci.0.2.transform", "num_bytes": 61113074, "num_examples": 161}, {"name": "humaneval.py.davinci.0.2.transform", "num_bytes": 46653237, "num_examples": 161}, {"name": "humaneval.ts.davinci.0.2.transform", "num_bytes": 60332695, "num_examples": 159}, {"name": "humaneval.ts.davinci.0.2.reworded", "num_bytes": 60256365, "num_examples": 159}, {"name": "humaneval.cpp.davinci.0.2.reworded", "num_bytes": 67044215, "num_examples": 159}, {"name": "humaneval.cs.davinci.0.2.reworded", "num_bytes": 103369582, "num_examples": 156}, {"name": "humaneval.d.davinci.0.2.reworded", "num_bytes": 66641398, "num_examples": 156}, {"name": "humaneval.go.davinci.0.2.reworded", "num_bytes": 71050586, "num_examples": 154}, {"name": "humaneval.java.davinci.0.2.reworded", "num_bytes": 71969268, "num_examples": 156}, {"name": "humaneval.jl.davinci.0.2.reworded", "num_bytes": 76515733, "num_examples": 159}, {"name": "humaneval.js.davinci.0.2.reworded", "num_bytes": 61674621, "num_examples": 161}, {"name": "humaneval.lua.davinci.0.2.reworded", "num_bytes": 54016568, "num_examples": 161}, {"name": "humaneval.php.davinci.0.2.reworded", "num_bytes": 61403511, "num_examples": 161}, {"name": "humaneval.pl.davinci.0.2.reworded", "num_bytes": 60281076, "num_examples": 161}, {"name": "humaneval.py.davinci.0.2.reworded", "num_bytes": 48223052, "num_examples": 161}, {"name": "humaneval.rb.davinci.0.2.reworded", "num_bytes": 65236003, "num_examples": 161}, {"name": "humaneval.r.davinci.0.2.reworded", "num_bytes": 48031115, "num_examples": 161}, {"name": "humaneval.rkt.davinci.0.2.reworded", "num_bytes": 66273931, "num_examples": 161}, {"name": "humaneval.rs.davinci.0.2.reworded", "num_bytes": 56522566, "num_examples": 156}, {"name": "humaneval.scala.davinci.0.2.reworded", "num_bytes": 84153007, "num_examples": 158}, {"name": "humaneval.sh.davinci.0.2.reworded", "num_bytes": 58089427, "num_examples": 158}, {"name": "humaneval.swift.davinci.0.2.reworded", "num_bytes": 61663115, "num_examples": 158}, {"name": "humaneval.java.bigcode_15b_1000m.0.2.reworded", "num_bytes": 75580922, "num_examples": 158}, {"name": "humaneval.java.bigcode_15b_200m.0.2.reworded", "num_bytes": 84307515, "num_examples": 158}, {"name": "humaneval.java.bigcode_15b_400m.0.2.reworded", "num_bytes": 85145220, "num_examples": 158}, {"name": "humaneval.java.bigcode_15b_600m.0.2.reworded", "num_bytes": 80223655, "num_examples": 158}, {"name": "humaneval.java.bigcode_15b_800m.0.2.reworded", "num_bytes": 78345454, "num_examples": 158}, {"name": "humaneval.java.codegeex.0.2.reworded", "num_bytes": 74859734, "num_examples": 158}, {"name": "humaneval.java.codegen.0.2.reworded", "num_bytes": 76705002, "num_examples": 158}, {"name": "humaneval.java.cushman001.0.2.reworded", "num_bytes": 7860926, "num_examples": 158}, {"name": "humaneval.java.replit_code.0.2.reworded", "num_bytes": 20396812, "num_examples": 158}, {"name": "humaneval.java.pystarcoder2.0.2.reworded", "num_bytes": 73528078, "num_examples": 158}, {"name": "humaneval.java.davinci.0.2.keep", "num_bytes": 71389774, "num_examples": 161}, {"name": "humaneval.java.davinci.0.2.remove", "num_bytes": 64493441, "num_examples": 157}, {"name": "humaneval.java.davinci.0.2.transform", "num_bytes": 72660740, "num_examples": 156}, {"name": "humaneval.java.davinci.0.8.keep", "num_bytes": 72358729, "num_examples": 161}, {"name": "humaneval.java.davinci.0.8.reworded", "num_bytes": 75043862, "num_examples": 156}, {"name": "humaneval.java.incoder.0.2.keep", "num_bytes": 110176353, "num_examples": 161}, {"name": "humaneval.java.incoder.0.2.remove", "num_bytes": 88903768, "num_examples": 157}, {"name": "humaneval.java.incoder.0.2.reworded", "num_bytes": 109021885, "num_examples": 156}, {"name": "humaneval.java.incoder.0.2.transform", "num_bytes": 107183302, "num_examples": 156}, {"name": "humaneval.java.incoder.0.8.keep", "num_bytes": 75299144, "num_examples": 139}, {"name": "humaneval.java.incoder.0.8.reworded", "num_bytes": 100533855, "num_examples": 158}, {"name": "mbpp.java.codegen.0.2.reworded", "num_bytes": 144592215, "num_examples": 373}, {"name": "mbpp.java.codegen.0.8.reworded", "num_bytes": 47521423, "num_examples": 120}, {"name": "mbpp.java.davinci.0.2.keep", "num_bytes": 135567713, "num_examples": 373}, {"name": "mbpp.java.davinci.0.2.reworded", "num_bytes": 136848151, "num_examples": 373}, {"name": "mbpp.java.incoder.0.2.reworded", "num_bytes": 225046095, "num_examples": 373}, {"name": "mbpp.java.incoder.0.8.reworded", "num_bytes": 167923488, "num_examples": 373}, {"name": "humaneval.cpp.davinci.0.2.keep", "num_bytes": 63794632, "num_examples": 161}, {"name": "humaneval.cpp.davinci.0.2.remove", "num_bytes": 58355394, "num_examples": 158}, {"name": "humaneval.cpp.davinci.0.2.transform", "num_bytes": 66852210, "num_examples": 159}, {"name": "humaneval.cpp.davinci.0.8.keep", "num_bytes": 61668425, "num_examples": 161}, {"name": "humaneval.cpp.bigcode_15b_1000m.0.2.reworded", "num_bytes": 67353068, "num_examples": 161}, {"name": "humaneval.cpp.bigcode_15b_200m.0.2.reworded", "num_bytes": 73914809, "num_examples": 161}, {"name": "humaneval.cpp.bigcode_15b_400m.0.2.reworded", "num_bytes": 68514672, "num_examples": 161}, {"name": "humaneval.cpp.bigcode_15b_600m.0.2.reworded", "num_bytes": 70059227, "num_examples": 161}, {"name": "humaneval.cpp.bigcode_15b_800m.0.2.reworded", "num_bytes": 69289473, "num_examples": 161}, {"name": "humaneval.cpp.codegeex.0.2.reworded", "num_bytes": 70250543, "num_examples": 161}, {"name": "humaneval.cpp.codegen.0.2.reworded", "num_bytes": 65355449, "num_examples": 161}, {"name": "humaneval.cpp.cushman001.0.2.reworded", "num_bytes": 6878097, "num_examples": 161}, {"name": "humaneval.cpp.replit_code.0.2.reworded", "num_bytes": 18647873, "num_examples": 161}, {"name": "humaneval.cs.bigcode_15b_1000m.0.2.reworded", "num_bytes": 115265463, "num_examples": 158}, {"name": "humaneval.cs.bigcode_15b_200m.0.2.reworded", "num_bytes": 128116325, "num_examples": 158}, {"name": "humaneval.cs.bigcode_15b_400m.0.2.reworded", "num_bytes": 116443233, "num_examples": 158}, {"name": "humaneval.cs.bigcode_15b_600m.0.2.reworded", "num_bytes": 110736924, "num_examples": 158}, {"name": "humaneval.cs.bigcode_15b_800m.0.2.reworded", "num_bytes": 116921504, "num_examples": 158}, {"name": "humaneval.cs.codegeex.0.2.reworded", "num_bytes": 108831398, "num_examples": 158}, {"name": "humaneval.cs.codegen.0.2.reworded", "num_bytes": 115085420, "num_examples": 158}, {"name": "humaneval.cs.cushman001.0.2.reworded", "num_bytes": 11455476, "num_examples": 158}, {"name": "humaneval.cs.replit_code.0.2.reworded", "num_bytes": 29978496, "num_examples": 158}, {"name": "humaneval.d.bigcode_15b_1000m.0.2.reworded", "num_bytes": 69856838, "num_examples": 156}, {"name": "humaneval.d.bigcode_15b_200m.0.2.reworded", "num_bytes": 69168908, "num_examples": 156}, {"name": "humaneval.d.bigcode_15b_400m.0.2.reworded", "num_bytes": 66130665, "num_examples": 156}, {"name": "humaneval.d.bigcode_15b_600m.0.2.reworded", "num_bytes": 60081870, "num_examples": 156}, {"name": "humaneval.d.bigcode_15b_800m.0.2.reworded", "num_bytes": 68285500, "num_examples": 156}, {"name": "humaneval.d.codegeex.0.2.reworded", "num_bytes": 67554723, "num_examples": 156}, {"name": "humaneval.d.codegen.0.2.reworded", "num_bytes": 69538065, "num_examples": 156}, {"name": "humaneval.d.cushman001.0.2.reworded", "num_bytes": 6543145, "num_examples": 156}, {"name": "humaneval.d.replit_code.0.2.reworded", "num_bytes": 19332975, "num_examples": 156}, {"name": "humaneval.go.bigcode_15b_1000m.0.2.reworded", "num_bytes": 75966586, "num_examples": 154}, {"name": "humaneval.go.bigcode_15b_200m.0.2.reworded", "num_bytes": 90496893, "num_examples": 154}, {"name": "humaneval.go.bigcode_15b_400m.0.2.reworded", "num_bytes": 80263304, "num_examples": 154}, {"name": "humaneval.go.bigcode_15b_600m.0.2.reworded", "num_bytes": 80653936, "num_examples": 154}, {"name": "humaneval.go.bigcode_15b_800m.0.2.reworded", "num_bytes": 79636433, "num_examples": 154}, {"name": "humaneval.go.codegeex.0.2.reworded", "num_bytes": 74466402, "num_examples": 154}, {"name": "humaneval.go.codegen.0.2.reworded", "num_bytes": 82565036, "num_examples": 154}, {"name": "humaneval.go.cushman001.0.2.reworded", "num_bytes": 7919252, "num_examples": 154}, {"name": "humaneval.go.replit_code.0.2.reworded", "num_bytes": 21740421, "num_examples": 154}, {"name": "humaneval.jl.bigcode_15b_1000m.0.2.reworded", "num_bytes": 64541752, "num_examples": 159}, {"name": "humaneval.jl.bigcode_15b_200m.0.2.reworded", "num_bytes": 64272523, "num_examples": 159}, {"name": "humaneval.jl.bigcode_15b_400m.0.2.reworded", "num_bytes": 84674386, "num_examples": 159}, {"name": "humaneval.jl.bigcode_15b_600m.0.2.reworded", "num_bytes": 83951098, "num_examples": 159}, {"name": "humaneval.jl.bigcode_15b_800m.0.2.reworded", "num_bytes": 71891875, "num_examples": 159}, {"name": "humaneval.jl.codegeex.0.2.reworded", "num_bytes": 49376484, "num_examples": 159}, {"name": "humaneval.jl.codegen.0.2.reworded", "num_bytes": 49686685, "num_examples": 159}, {"name": "humaneval.jl.cushman001.0.2.reworded", "num_bytes": 5594623, "num_examples": 159}, {"name": "humaneval.jl.replit_code.0.2.reworded", "num_bytes": 12432167, "num_examples": 159}, {"name": "humaneval.js.bigcode_15b_1000m.0.2.reworded", "num_bytes": 63930510, "num_examples": 161}, {"name": "humaneval.js.bigcode_15b_200m.0.2.reworded", "num_bytes": 71006276, "num_examples": 161}, {"name": "humaneval.js.bigcode_15b_400m.0.2.reworded", "num_bytes": 71141641, "num_examples": 161}, {"name": "humaneval.js.bigcode_15b_600m.0.2.reworded", "num_bytes": 66406645, "num_examples": 161}, {"name": "humaneval.js.bigcode_15b_800m.0.2.reworded", "num_bytes": 65906688, "num_examples": 161}, {"name": "humaneval.js.codegeex.0.2.reworded", "num_bytes": 68965171, "num_examples": 161}, {"name": "humaneval.js.codegen.0.2.reworded", "num_bytes": 71850674, "num_examples": 161}, {"name": "humaneval.js.cushman001.0.2.reworded", "num_bytes": 6756809, "num_examples": 161}, {"name": "humaneval.js.replit_code.0.2.reworded", "num_bytes": 20658701, "num_examples": 161}, {"name": "humaneval.lua.bigcode_15b_200m.0.2.reworded", "num_bytes": 56733662, "num_examples": 161}, {"name": "humaneval.lua.bigcode_15b_400m.0.2.reworded", "num_bytes": 57525953, "num_examples": 161}, {"name": "humaneval.lua.bigcode_15b_600m.0.2.reworded", "num_bytes": 53575875, "num_examples": 161}, {"name": "humaneval.lua.bigcode_15b_800m.0.2.reworded", "num_bytes": 54309789, "num_examples": 161}, {"name": "humaneval.lua.codegeex.0.2.reworded", "num_bytes": 53766400, "num_examples": 161}, {"name": "humaneval.lua.codegen.0.2.reworded", "num_bytes": 63642889, "num_examples": 161}, {"name": "humaneval.lua.cushman001.0.2.reworded", "num_bytes": 5726991, "num_examples": 161}, {"name": "humaneval.lua.replit_code.0.2.reworded", "num_bytes": 14458988, "num_examples": 161}, {"name": "humaneval.php.bigcode_15b_1000m.0.2.reworded", "num_bytes": 62087493, "num_examples": 161}, {"name": "humaneval.php.bigcode_15b_200m.0.2.reworded", "num_bytes": 67992787, "num_examples": 161}, {"name": "humaneval.php.bigcode_15b_400m.0.2.reworded", "num_bytes": 65415347, "num_examples": 161}, {"name": "humaneval.php.bigcode_15b_600m.0.2.reworded", "num_bytes": 64025429, "num_examples": 161}, {"name": "humaneval.php.bigcode_15b_800m.0.2.reworded", "num_bytes": 67914229, "num_examples": 161}, {"name": "humaneval.php.codegeex.0.2.reworded", "num_bytes": 63599818, "num_examples": 161}, {"name": "humaneval.php.codegen.0.2.reworded", "num_bytes": 71759630, "num_examples": 161}, {"name": "humaneval.php.cushman001.0.2.reworded", "num_bytes": 6680669, "num_examples": 161}, {"name": "humaneval.php.replit_code.0.2.reworded", "num_bytes": 18347062, "num_examples": 161}, {"name": "humaneval.pl.bigcode_15b_1000m.0.2.reworded", "num_bytes": 69839042, "num_examples": 161}, {"name": "humaneval.pl.bigcode_15b_200m.0.2.reworded", "num_bytes": 79671308, "num_examples": 161}, {"name": "humaneval.pl.bigcode_15b_400m.0.2.reworded", "num_bytes": 78788842, "num_examples": 161}, {"name": "humaneval.pl.bigcode_15b_600m.0.2.reworded", "num_bytes": 69916889, "num_examples": 161}, {"name": "humaneval.pl.bigcode_15b_800m.0.2.reworded", "num_bytes": 73552220, "num_examples": 161}, {"name": "humaneval.pl.codegeex.0.2.reworded", "num_bytes": 72617126, "num_examples": 161}, {"name": "humaneval.pl.codegen.0.2.reworded", "num_bytes": 74351768, "num_examples": 161}, {"name": "humaneval.pl.cushman001.0.2.reworded", "num_bytes": 7317844, "num_examples": 161}, {"name": "humaneval.pl.replit_code.0.2.reworded", "num_bytes": 23014112, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_200m.0.8.reworded", "num_bytes": 55679581, "num_examples": 161}, {"name": "humaneval.py.bigcode_15b_400m.0.8.reworded", "num_bytes": 49813429, "num_examples": 161}, {"name": "humaneval.py.replit_code.0.2.reworded", "num_bytes": 16222771, "num_examples": 161}, {"name": "humaneval.py.starcoder.0.8.reworded", "num_bytes": 50428866, "num_examples": 161}, {"name": "humaneval.py.starcoderprompted.0.1.reworded", "num_bytes": 53971758, "num_examples": 161}, {"name": "humaneval.rb.bigcode_15b_1000m.0.2.reworded", "num_bytes": 67446763, "num_examples": 161}, {"name": "humaneval.rb.bigcode_15b_200m.0.2.reworded", "num_bytes": 70571683, "num_examples": 161}, {"name": "humaneval.rb.bigcode_15b_400m.0.2.reworded", "num_bytes": 67565830, "num_examples": 161}, {"name": "humaneval.rb.bigcode_15b_600m.0.2.reworded", "num_bytes": 71419194, "num_examples": 161}, {"name": "humaneval.rb.bigcode_15b_800m.0.2.reworded", "num_bytes": 69995749, "num_examples": 161}, {"name": "humaneval.rb.codegeex.0.2.reworded", "num_bytes": 63388920, "num_examples": 161}, {"name": "humaneval.rb.codegen.0.2.reworded", "num_bytes": 68918022, "num_examples": 161}, {"name": "humaneval.rb.cushman001.0.2.reworded", "num_bytes": 7084615, "num_examples": 161}, {"name": "humaneval.rb.replit_code.0.2.reworded", "num_bytes": 17797810, "num_examples": 161}, {"name": "humaneval.r.codegeex.0.2.reworded", "num_bytes": 64172735, "num_examples": 161}, {"name": "humaneval.r.codegen.0.2.reworded", "num_bytes": 75777642, "num_examples": 161}, {"name": "humaneval.r.cushman001.0.2.reworded", "num_bytes": 6509329, "num_examples": 161}, {"name": "humaneval.rkt.bigcode_15b_1000m.0.2.reworded", "num_bytes": 71049799, "num_examples": 161}, {"name": "humaneval.rkt.bigcode_15b_200m.0.2.reworded", "num_bytes": 72642020, "num_examples": 161}, {"name": "humaneval.rkt.bigcode_15b_400m.0.2.reworded", "num_bytes": 73564249, "num_examples": 161}, {"name": "humaneval.rkt.bigcode_15b_600m.0.2.reworded", "num_bytes": 73730273, "num_examples": 161}, {"name": "humaneval.rkt.codegeex.0.2.reworded", "num_bytes": 70940774, "num_examples": 161}, {"name": "humaneval.rkt.codegen.0.2.reworded", "num_bytes": 90161741, "num_examples": 161}, {"name": "humaneval.rkt.cushman001.0.2.reworded", "num_bytes": 6030454, "num_examples": 161}, {"name": "humaneval.rkt.replit_code.0.2.reworded", "num_bytes": 18423402, "num_examples": 161}, {"name": "humaneval.r.replit_code.0.2.reworded", "num_bytes": 19677779, "num_examples": 161}, {"name": "humaneval.rs.bigcode_15b_1000m.0.2.reworded", "num_bytes": 59702550, "num_examples": 156}, {"name": "humaneval.rs.bigcode_15b_200m.0.2.reworded", "num_bytes": 67759741, "num_examples": 156}, {"name": "humaneval.rs.bigcode_15b_400m.0.2.reworded", "num_bytes": 68044357, "num_examples": 156}, {"name": "humaneval.rs.bigcode_15b_600m.0.2.reworded", "num_bytes": 54658037, "num_examples": 156}, {"name": "humaneval.rs.bigcode_15b_800m.0.2.reworded", "num_bytes": 62854949, "num_examples": 156}, {"name": "humaneval.rs.codegeex.0.2.reworded", "num_bytes": 67976569, "num_examples": 156}, {"name": "humaneval.rs.codegen.0.2.reworded", "num_bytes": 82843583, "num_examples": 156}, {"name": "humaneval.rs.cushman001.0.2.reworded", "num_bytes": 6310774, "num_examples": 156}, {"name": "humaneval.rs.replit_code.0.2.reworded", "num_bytes": 17624999, "num_examples": 156}, {"name": "humaneval.scala.bigcode_15b_1000m.0.2.reworded", "num_bytes": 84533532, "num_examples": 160}, {"name": "humaneval.scala.bigcode_15b_800m.0.2.reworded", "num_bytes": 87023720, "num_examples": 160}, {"name": "humaneval.scala.codegeex.0.2.reworded", "num_bytes": 79619828, "num_examples": 160}, {"name": "humaneval.scala.codegen.0.2.reworded", "num_bytes": 128885303, "num_examples": 160}, {"name": "humaneval.scala.cushman001.0.2.reworded", "num_bytes": 8500865, "num_examples": 160}, {"name": "humaneval.scala.replit_code.0.2.reworded", "num_bytes": 22458222, "num_examples": 160}, {"name": "humaneval.sh.bigcode_15b_1000m.0.2.reworded", "num_bytes": 62768941, "num_examples": 158}, {"name": "humaneval.sh.bigcode_15b_200m.0.2.reworded", "num_bytes": 75630478, "num_examples": 158}, {"name": "humaneval.sh.bigcode_15b_400m.0.2.reworded", "num_bytes": 77050658, "num_examples": 158}, {"name": "humaneval.sh.bigcode_15b_600m.0.2.reworded", "num_bytes": 65325746, "num_examples": 158}, {"name": "humaneval.swift.bigcode_15b_600m.0.2.reworded", "num_bytes": 70424335, "num_examples": 158}, {"name": "humaneval.scala.bigcode_15b_200m.0.2.reworded", "num_bytes": 89054581, "num_examples": 160}, {"name": "humaneval.scala.bigcode_15b_400m.0.2.reworded", "num_bytes": 83343360, "num_examples": 160}, {"name": "humaneval.scala.bigcode_15b_600m.0.2.reworded", "num_bytes": 89752223, "num_examples": 160}, {"name": "humaneval.sh.bigcode_15b_800m.0.2.reworded", "num_bytes": 66811937, "num_examples": 158}, {"name": "humaneval.sh.codegeex.0.2.reworded", "num_bytes": 65196768, "num_examples": 158}, {"name": "humaneval.sh.codegen.0.2.reworded", "num_bytes": 99280481, "num_examples": 158}, {"name": "humaneval.sh.cushman001.0.2.reworded", "num_bytes": 6237965, "num_examples": 158}, {"name": "humaneval.sh.replit_code.0.2.reworded", "num_bytes": 18134838, "num_examples": 158}, {"name": "humaneval.swift.bigcode_15b_1000m.0.2.reworded", "num_bytes": 68129948, "num_examples": 158}, {"name": "humaneval.swift.bigcode_15b_200m.0.2.reworded", "num_bytes": 76924134, "num_examples": 158}, {"name": "humaneval.swift.bigcode_15b_400m.0.2.reworded", "num_bytes": 72042977, "num_examples": 158}, {"name": "humaneval.swift.bigcode_15b_800m.0.2.reworded", "num_bytes": 70027106, "num_examples": 158}, {"name": "humaneval.swift.codegeex.0.2.reworded", "num_bytes": 73605273, "num_examples": 158}, {"name": "humaneval.swift.codegen.0.2.reworded", "num_bytes": 76081675, "num_examples": 158}, {"name": "humaneval.swift.cushman001.0.2.reworded", "num_bytes": 6766506, "num_examples": 158}, {"name": "humaneval.swift.replit_code.0.2.reworded", "num_bytes": 21605861, "num_examples": 158}, {"name": "humaneval.ts.bigcode_15b_1000m.0.2.reworded", "num_bytes": 61005831, "num_examples": 159}, {"name": "humaneval.ts.bigcode_15b_200m.0.2.reworded", "num_bytes": 68875546, "num_examples": 159}, {"name": "humaneval.ts.bigcode_15b_400m.0.2.reworded", "num_bytes": 62805583, "num_examples": 159}, {"name": "humaneval.ts.bigcode_15b_600m.0.2.reworded", "num_bytes": 53733690, "num_examples": 159}, {"name": "humaneval.ts.bigcode_15b_800m.0.2.reworded", "num_bytes": 64371975, "num_examples": 159}, {"name": "humaneval.ts.codegeex.0.2.reworded", "num_bytes": 58487751, "num_examples": 159}, {"name": "humaneval.ts.codegen.0.2.reworded", "num_bytes": 69981611, "num_examples": 159}, {"name": "humaneval.ts.cushman001.0.2.reworded", "num_bytes": 6768589, "num_examples": 159}, {"name": "humaneval.ts.replit_code.0.2.reworded", "num_bytes": 18208741, "num_examples": 159}, {"name": "mbpp.py.codegeex.0.2.reworded", "num_bytes": 86906502, "num_examples": 397}, {"name": "mbpp.py.codegen.0.2.reworded", "num_bytes": 92562493, "num_examples": 397}, {"name": "mbpp.py.cushman001.0.2.reworded", "num_bytes": 7629346, "num_examples": 397}, {"name": "mbpp.py.pystarcoder2.0.1.reworded", "num_bytes": 142442817, "num_examples": 397}, {"name": "mbpp.py.Salesforce_codegen_16B_mono.0.2.reworded", "num_bytes": 86067040, "num_examples": 397}, {"name": "humaneval.matlab.keep.gpt_35_turbo_0301.0.2.reworded", "num_bytes": 4837906, "num_examples": 161}], "download_size": 1286123094, "dataset_size": 14746371358}, "tags": ["code"]}
|
2023-07-12T13:03:29+00:00
|
7f229da7af57b1c15c2c7f125beda247ab54f070
|
WeiHai-haiyuan/666
|
[
"license:openrail",
"region:us"
] |
2023-04-22T13:11:49+00:00
|
{"license": "openrail"}
|
2023-04-22T13:11:49+00:00
|
|
1a68a58490c089556bc87f980433b19f654a4739
|
# Dataset Card for llm-book/ner-wikinews-dataset
書籍『大規模言語モデル入門』で使用する、[Wikinews](https://ja.wikinews.org/wiki/%E3%83%A1%E3%82%A4%E3%83%B3%E3%83%9A%E3%83%BC%E3%82%B8)の記事に固有表現ラベルを付与したデータセットです。
固有表現ラベルは[llm-book/ner-wikipedia-dataset](https://huggingface.co/datasets/llm-book/ner-wikipedia-dataset)と同様のものを採用しており、全部で8種類 (人名、法人名、地名、製品名、政治的組織名、施設名、その他の組織名、イベント名)あります。
テストセットのみのデータセットとなっています。
## Licence
ウィキニュース日本語版の記事を使用しているため、そのライセンスに従い、「クリエイティブ・コモンズ 表示 2.5 (CC BY 2.5)」とします。
|
llm-book/ner-wikinews-dataset
|
[
"task_categories:token-classification",
"size_categories:n<1K",
"language:ja",
"license:cc-by-2.5",
"news",
"region:us"
] |
2023-04-22T13:32:21+00:00
|
{"language": ["ja"], "license": ["cc-by-2.5"], "size_categories": ["n<1K"], "task_categories": ["token-classification"], "pretty_name": "ner-wikinews-dataset", "tags": ["news"]}
|
2023-12-12T02:22:26+00:00
|
a0cca0425468f94c84acd14479327b43c3c06084
|
Saads/xecanto_birds
|
[
"license:mit",
"region:us"
] |
2023-04-22T14:12:23+00:00
|
{"license": "mit"}
|
2023-04-23T04:59:40+00:00
|
|
3fb8ebf8e922c2ef49c842d28d90caaf0ae03d9d
|
houck2040/vet_news
|
[
"license:mit",
"region:us"
] |
2023-04-22T14:57:13+00:00
|
{"license": "mit"}
|
2023-04-22T14:58:01+00:00
|
|
62cbb99f7aedd9b87217535f752aaf45b11ac05b
|
thisisanshgupta/CodeAlpaca
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-22T15:08:54+00:00
|
{"license": "apache-2.0"}
|
2023-04-22T15:09:45+00:00
|
|
b7964fc5131516a0e1250a5f9b4e490b48fb5f38
|
thisisanshgupta/CodeAlpacaSmall
|
[
"license:apache-2.0",
"region:us"
] |
2023-04-22T15:10:24+00:00
|
{"license": "apache-2.0"}
|
2023-04-22T15:10:42+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.