
sha
stringlengths 40
40
| text
stringlengths 0
13.4M
| id
stringlengths 2
117
| tags
list | created_at
stringlengths 25
25
| metadata
stringlengths 2
31.7M
| last_modified
stringlengths 25
25
|
|---|---|---|---|---|---|---|
4dfe4b157eddca8cecc422c7fdebb9368d3267c7
|
# Dataset Card for "chunk_33"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_33
|
[
"region:us"
] |
2023-05-19T05:02:16+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 641352676, "num_examples": 125953}], "download_size": 654144243, "dataset_size": 641352676}}
|
2023-05-19T05:02:51+00:00
|
e6ee5ef6dde2434db592b5c1b2450b7dcbc2f506
|
# Dataset Card for "chunk_34"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_34
|
[
"region:us"
] |
2023-05-19T05:05:05+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 645792900, "num_examples": 126825}], "download_size": 659289645, "dataset_size": 645792900}}
|
2023-05-19T05:05:29+00:00
|
9319734b723ba97c654e3c05f53e06a393168e91
|
# Dataset Card for "chunk_30"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_30
|
[
"region:us"
] |
2023-05-19T05:13:34+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 791551400, "num_examples": 155450}], "download_size": 807854682, "dataset_size": 791551400}}
|
2023-05-19T05:14:04+00:00
|
346795c278aa1d88eae387e0d5ff41e5b9596673
|
# Dataset Card for "chunk_31"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_31
|
[
"region:us"
] |
2023-05-19T05:15:28+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 803700912, "num_examples": 157836}], "download_size": 818726715, "dataset_size": 803700912}}
|
2023-05-19T05:15:53+00:00
|
0dc5283ccd0f3f046df06e8b4973563b4ddfcf82
|
# Dataset Card for "chunk_35"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_35
|
[
"region:us"
] |
2023-05-19T05:15:35+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 594577564, "num_examples": 116767}], "download_size": 607086643, "dataset_size": 594577564}}
|
2023-05-19T05:16:44+00:00
|
88a6a8948d79dca4085e56dfc6b4a857cee54f26
|
# Dataset Card for "chunk_29"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_29
|
[
"region:us"
] |
2023-05-19T05:19:15+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 865894600, "num_examples": 170050}], "download_size": 883413488, "dataset_size": 865894600}}
|
2023-05-19T05:19:45+00:00
|
3ac8ad64daea88158dff43500119881c87cc910b
|
ShiwenNi/PatentQA-100
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T05:22:38+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T05:23:04+00:00
|
|
32c4d8ea3dd1f71e5be9f1316885ef633fbc25f6
|
# Dataset Card for "chunk_32"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_32
|
[
"region:us"
] |
2023-05-19T05:24:02+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 741563236, "num_examples": 145633}], "download_size": 757084214, "dataset_size": 741563236}}
|
2023-05-19T05:25:25+00:00
|
195b0773b1ef2255b698cbd3efc688eb5030bdbc
|
# Dataset Card for "chunk_23"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_23
|
[
"region:us"
] |
2023-05-19T05:35:23+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 996183604, "num_examples": 195637}], "download_size": 1015214298, "dataset_size": 996183604}}
|
2023-05-19T05:36:07+00:00
|
e9a082cfb0948c2cc7aa2a79b194376a12d0f06a
|
shrinath-suresh/so_context_with_summary
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T05:38:54+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T05:40:05+00:00
|
|
d9528609871f3075f2b040cb71dbc8acdefc98cc
|
shrinath-suresh/so_forum_docs_blogs_all
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T05:47:56+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T09:11:01+00:00
|
|
28eb414f54dd7e0da4038a8ae6a6d0b1e75b3308
|
# Dataset Card for "chunk_37"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_37
|
[
"region:us"
] |
2023-05-19T05:48:05+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 951913756, "num_examples": 186943}], "download_size": 967957987, "dataset_size": 951913756}}
|
2023-05-19T05:49:49+00:00
|
12a2584be4387f268d7afb564abb802efbbe4dd0
|
# Dataset Card for "reward-modeling-long-tokenized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
andersonbcdefg/reward-modeling-long-tokenized
|
[
"region:us"
] |
2023-05-19T05:54:26+00:00
|
{"dataset_info": {"features": [{"name": "preferred_input_ids", "sequence": "int64"}, {"name": "preferred_attention_masks", "sequence": "int64"}, {"name": "dispreferred_input_ids", "sequence": "int64"}, {"name": "dispreferred_attention_masks", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 17170494224, "num_examples": 261937}], "download_size": 437217639, "dataset_size": 17170494224}}
|
2023-05-19T05:55:35+00:00
|
df195251195da898173a5d8956aa6b00bcd37abb
|
# Dataset Card for "A_TRAIN"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
dongyoungkim/A_TRAIN
|
[
"region:us"
] |
2023-05-19T05:54:54+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": "audio"}, {"name": "sentence", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 4506855816.658, "num_examples": 58427}], "download_size": 2556917023, "dataset_size": 4506855816.658}}
|
2023-05-19T08:28:20+00:00
|
e5d489bfa96dc6570078bbbd346e2496e43c8ebc
|
# Dataset Card for "reward-modeling-short-tokenized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
andersonbcdefg/reward-modeling-short-tokenized
|
[
"region:us"
] |
2023-05-19T05:55:35+00:00
|
{"dataset_info": {"features": [{"name": "preferred_input_ids", "sequence": "int64"}, {"name": "preferred_attention_masks", "sequence": "int64"}, {"name": "dispreferred_input_ids", "sequence": "int64"}, {"name": "dispreferred_attention_masks", "sequence": "int64"}], "splits": [{"name": "train", "num_bytes": 8509513392, "num_examples": 259563}], "download_size": 138519630, "dataset_size": 8509513392}}
|
2023-05-19T05:56:04+00:00
|
1f8e280a0c9d0a6c53d6055fb229a0051edb13d5
|
## QA evaluation dataset in intellectual property
The IPQA contains questions in seven languages, and the 100 data items include 35 each in Chinese and English, and 6 each in Spanish, Japanese, German, French, and Russian.
|
BNNT/IPQA
|
[
"task_categories:question-answering",
"size_categories:n<1K",
"language:zh",
"language:en",
"language:de",
"language:fr",
"language:ja",
"language:es",
"language:ru",
"license:cc-by-nc-sa-4.0",
"Intellectual property",
"region:us"
] |
2023-05-19T06:32:52+00:00
|
{"language": ["zh", "en", "de", "fr", "ja", "es", "ru"], "license": "cc-by-nc-sa-4.0", "size_categories": ["n<1K"], "task_categories": ["question-answering"], "tags": ["Intellectual property"]}
|
2023-08-09T03:04:06+00:00
|
568045a9107711458f42b1c9be12938a166285a4
|
# Dataset Card for Dataset Name
## Dataset Description
- **Homepage:**
- **Repository:**
- **Paper:**
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
just for test
### Supported Tasks and Leaderboards
[More Information Needed]
### Languages
[More Information Needed]
## Dataset Structure
### Data Instances
[More Information Needed]
### Data Fields
[More Information Needed]
### Data Splits
[More Information Needed]
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
[More Information Needed]
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
[More Information Needed]
### Citation Information
[More Information Needed]
### Contributions
[More Information Needed]
|
RossVermouth/chensu_test_dataset
|
[
"task_categories:image-classification",
"size_categories:1K<n<10K",
"language:aa",
"language:ae",
"license:apache-2.0",
"not-for-all-audiences",
"region:us"
] |
2023-05-19T06:58:00+00:00
|
{"language": ["aa", "ae"], "license": "apache-2.0", "size_categories": ["1K<n<10K"], "task_categories": ["image-classification"], "tags": ["not-for-all-audiences"]}
|
2023-05-19T07:23:29+00:00
|
7848296e413693c2d97c8b72d6985763d2f96ca6
|
# Dataset Card for "978d0222"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/978d0222
|
[
"region:us"
] |
2023-05-19T07:13:26+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 188, "num_examples": 10}], "download_size": 1337, "dataset_size": 188}}
|
2023-05-19T07:13:27+00:00
|
d85308a4c44e89add2595e7a9bd81d647082213b
|
# Dataset Card for "chunk_46"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_46
|
[
"region:us"
] |
2023-05-19T07:18:00+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1174036980, "num_examples": 230565}], "download_size": 1189940464, "dataset_size": 1174036980}}
|
2023-05-19T07:18:43+00:00
|
9f0a857b7be4f0612f8414c4041388115cbc3862
|
# Dataset Card for "chunk_45"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_45
|
[
"region:us"
] |
2023-05-19T07:18:15+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1209553680, "num_examples": 237540}], "download_size": 1229354036, "dataset_size": 1209553680}}
|
2023-05-19T07:19:01+00:00
|
39d3390a38c48427940a528b4b79e0dd5f4c5d27
|
# Dataset Card for "chunk_44"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_44
|
[
"region:us"
] |
2023-05-19T07:23:07+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1241572176, "num_examples": 243828}], "download_size": 1260638110, "dataset_size": 1241572176}}
|
2023-05-19T07:24:04+00:00
|
456ac78904849d00410ef769af9cb50790f34131
|
# Dataset Card for "invig"
[Github](https://github.com/ZhangHanbo/invig-dataset)
```latex
@misc{invigdataset,
title={InViG: Interactive Visual-Language Disambiguation with 21K Human-to-Human Dialogues},
author={Zhang, Hanbo and Mo, Yuchen and Xu, Jie and Si, Qingyi and Kong, Tao},
howpublished = {\url{https://github.com/ZhangHanbo/invig-dataset}},
year={2023}
}
```
|
jxu124/invig
|
[
"language:en",
"language:zh",
"license:apache-2.0",
"region:us"
] |
2023-05-19T07:25:25+00:00
|
{"language": ["en", "zh"], "license": "apache-2.0", "configs": [{"config_name": "default", "data_files": [{"split": "validation", "path": "data/validation-*"}, {"split": "test", "path": "data/test-*"}, {"split": "train", "path": "data/train-*"}]}], "dataset_info": {"features": [{"name": "ref_list", "list": [{"name": "bbox", "sequence": "float64"}, {"name": "category", "dtype": "string"}, {"name": "dialog", "sequence": {"sequence": "string"}}, {"name": "dialog_cn", "sequence": {"sequence": "string"}}, {"name": "id", "dtype": "string"}]}, {"name": "image_info", "struct": [{"name": "file_name", "dtype": "string"}, {"name": "height", "dtype": "int64"}, {"name": "id", "dtype": "string"}, {"name": "width", "dtype": "int64"}]}, {"name": "image", "dtype": "image"}], "splits": [{"name": "validation", "num_bytes": 96380848.0, "num_examples": 996}, {"name": "test", "num_bytes": 193325330.698, "num_examples": 1997}, {"name": "train", "num_bytes": 1735786813.55, "num_examples": 17710}], "download_size": 865015922, "dataset_size": 2025492992.248}}
|
2023-10-31T11:19:59+00:00
|
a97d2f51706c6e3a86c5d89ae89e26b0d51dcb81
|
RossVermouth/chensu_test_dataset1
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T07:25:25+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T07:26:12+00:00
|
|
f3477ff42c8043d299b4817d9f40ffaeaa824dd8
|
RossVermouth/chensu_test_dataset2
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T07:28:36+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T07:29:20+00:00
|
|
87f04494ae019915f6e5b112d57be580d2bc5667
|
# Dataset Card for "chunk_47"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_47
|
[
"region:us"
] |
2023-05-19T07:45:14+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1180412164, "num_examples": 231817}], "download_size": 1199989787, "dataset_size": 1180412164}}
|
2023-05-19T07:45:50+00:00
|
37e8f52b7f87173498d300dc19608925687fd120
|
# Dataset Card for "chunk_43"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_43
|
[
"region:us"
] |
2023-05-19T07:55:22+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1242422540, "num_examples": 243995}], "download_size": 1262743635, "dataset_size": 1242422540}}
|
2023-05-19T07:57:38+00:00
|
90220065f54c6dca4c8d8b9998fcfb1bb99ac056
|
# Dataset Card for "c4_t5_pretrain"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
hlillemark/c4_t5_pretrain
|
[
"region:us"
] |
2023-05-19T08:17:45+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}, {"name": "labels", "sequence": "int64"}], "splits": [{"name": "validation", "num_bytes": 53400000, "num_examples": 10000}, {"name": "train", "num_bytes": 961505597520, "num_examples": 180057228}], "download_size": 2939856140, "dataset_size": 961558997520}}
|
2023-05-22T15:33:38+00:00
|
96cb88fa22ba73188085f7cf78a3b802e6b38d5a
|
fuflik/1
|
[
"license:cc",
"region:us"
] |
2023-05-19T08:44:49+00:00
|
{"license": "cc"}
|
2023-05-19T08:44:49+00:00
|
|
94f3dbdd81bb8c7ee5922ee651802ff9181a8ec8
|
dw0815/butterfly
|
[
"license:unknown",
"region:us"
] |
2023-05-19T08:48:25+00:00
|
{"license": "unknown"}
|
2023-05-19T08:48:25+00:00
|
|
6be04ae17ed320b4615cde82d5a61cfef66e6daa
|
# Dataset Card for "ffhq_controlnet_5_18_23"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
cr7Por/ffhq_controlnet_5_18_23
|
[
"region:us"
] |
2023-05-19T08:52:36+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "image_crop", "dtype": "image"}, {"name": "image_caption", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 48024410718.216, "num_examples": 85436}], "download_size": 48457280502, "dataset_size": 48024410718.216}}
|
2023-05-19T12:17:49+00:00
|
8523c90253805a1f1b468092e5e7d4fb4631335e
|
# Dataset Card for "reddit_crush"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
next-social/reddit_crush
|
[
"region:us"
] |
2023-05-19T08:57:59+00:00
|
{"dataset_info": {"features": [{"name": "selftext", "dtype": "string"}, {"name": "subreddit", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 91006275, "num_examples": 114942}], "download_size": 0, "dataset_size": 91006275}}
|
2023-05-25T04:36:04+00:00
|
219c5095a1603ce43e863e59f239b4e794d415f0
|
charmanQ/xq
|
[
"region:us"
] |
2023-05-19T08:58:43+00:00
|
{}
|
2023-05-19T09:02:04+00:00
|
|
f5ce5af8c5c510ccd9b852c0d65cffd34f4f097d
|
# ShareGPT unfiltered dataset in RedPajama-Chat format
This dataset was created by converting <a href="https://huggingface.co/datasets/Fredithefish/ShareGPT-unfiltered-alpaca-lora-format">The alpaca-lora formatted ShareGPT dataset</a> to the format required by RedPajama-Chat.<br>
This script was used for the conversion: https://github.com/fredi-python/Alpaca2INCITE-Dataset-Converter/blob/main/convert.py
WARNING: Only the first human and gpt text of each conversation from the original dataset is included in the dataset.
## The format
```{"text": "<human>: hello\n<bot>: Hello! How can I help you today?"}```
|
Fredithefish/ShareGPT-Unfiltered-RedPajama-Chat-format
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T09:21:58+00:00
|
{"license": "apache-2.0"}
|
2023-06-06T13:17:56+00:00
|
b69188888b890781930e4ccbaa06a76266903be4
|
Fredithefish/ShareGPT-unfiltered-alpaca-lora-format
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T09:27:33+00:00
|
{"license": "apache-2.0"}
|
2023-05-21T17:40:50+00:00
|
|
e05280f22ca8be6feefc9b84a0e056c06e6a9a2f
|
# Dataset Card for "71e9d947"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/71e9d947
|
[
"region:us"
] |
2023-05-19T09:30:59+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 186, "num_examples": 10}], "download_size": 1337, "dataset_size": 186}}
|
2023-05-19T09:31:00+00:00
|
c0d9b3a45ad9a5f4e6bdbb784e7594decc9e70df
|
# Dataset Card for "chunk_52"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_52
|
[
"region:us"
] |
2023-05-19T09:43:31+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1162793844, "num_examples": 228357}], "download_size": 1185195511, "dataset_size": 1162793844}}
|
2023-05-19T09:44:22+00:00
|
a03566d205b2daca339f2e9d5c219caa44c4e847
|
# Dataset Card for "chunk_48"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_48
|
[
"region:us"
] |
2023-05-19T09:44:41+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1151657640, "num_examples": 226170}], "download_size": 1172028048, "dataset_size": 1151657640}}
|
2023-05-19T09:45:20+00:00
|
7b48ded625c943b3caa576b8e22ebeb789cd7812
|
# Dataset Card for "chunk_42"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_42
|
[
"region:us"
] |
2023-05-19T09:46:45+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1247219204, "num_examples": 244937}], "download_size": 1265911719, "dataset_size": 1247219204}}
|
2023-05-19T09:47:18+00:00
|
e1d6be15cea78b5ec0f26e17929f2b2c9508128b
|
# Dataset Card for "chunk_49"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_49
|
[
"region:us"
] |
2023-05-19T09:48:21+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1221056508, "num_examples": 239799}], "download_size": 1246786494, "dataset_size": 1221056508}}
|
2023-05-19T09:49:13+00:00
|
3f04ab7a44c4e7c35148c35dcad13cc9cc9ae183
|
# Dataset Card for "chunk_39"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_39
|
[
"region:us"
] |
2023-05-19T09:49:20+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1299167788, "num_examples": 255139}], "download_size": 1317614307, "dataset_size": 1299167788}}
|
2023-05-19T09:50:05+00:00
|
d062dbf49ba994a5f09bedbe2e28ca38504af345
|
# Dataset Card for "chunk_41"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_41
|
[
"region:us"
] |
2023-05-19T09:50:26+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1270362344, "num_examples": 249482}], "download_size": 1289494342, "dataset_size": 1270362344}}
|
2023-05-19T09:51:02+00:00
|
dba2775a6cbb38ed916a189420148a8f7afd2cac
|
# Dataset Card for "chunk_38"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_38
|
[
"region:us"
] |
2023-05-19T09:52:49+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1341400836, "num_examples": 263433}], "download_size": 1360357450, "dataset_size": 1341400836}}
|
2023-05-19T09:55:10+00:00
|
8e8a5b28f25840d1087bbba7fd66fbfedb173786
|
# Dataset Card for "chunk_51"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_51
|
[
"region:us"
] |
2023-05-19T09:57:46+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1238822496, "num_examples": 243288}], "download_size": 1265551736, "dataset_size": 1238822496}}
|
2023-05-19T09:58:25+00:00
|
dc2ce72466d0f1b2cb8cc6aa6d7e633df5724c70
|
# Facial Keypoints
The dataset is designed for computer vision and machine learning tasks involving the identification and analysis of key points on a human face. It consists of images of human faces, each accompanied by key point annotations in XML format.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) to discuss your requirements, learn about the price and buy the dataset.

# Data Format
Each image from `FKP` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the key points. For each point, the x and y coordinates are provided, and there is a `Presumed_Location` attribute, indicating whether the point is presumed or accurately defined.
# Example of XML file structure
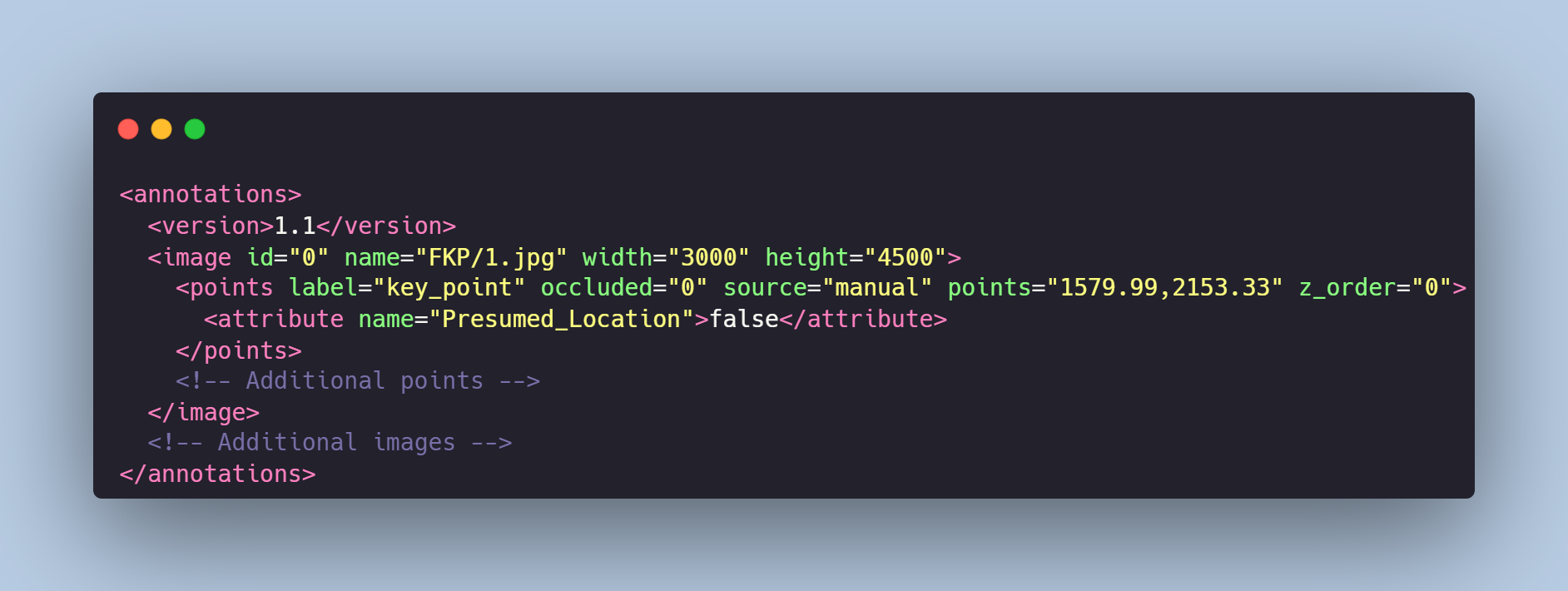
# Labeled Keypoints
**1.** Left eye, the closest point to the nose
**2.** Left eye, pupil's center
**3.** Left eye, the closest point to the left ear
**4.** Right eye, the closest point to the nose
**5.** Right eye, pupil's center
**6.** Right eye, the closest point to the right ear
**7.** Left eyebrow, the closest point to the nose
**8.** Left eyebrow, the closest point to the left ear
**9.** Right eyebrow, the closest point to the nose
**10.** Right eyebrow, the closest point to the right ear
**11.** Nose, center
**12.** Mouth, left corner point
**13.** Mouth, right corner point
**14.** Mouth, the highest point in the middle
**15.** Mouth, the lowest point in the middle
# Keypoint annotation is made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=facial_keypoint_detection) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/facial_keypoint_detection
|
[
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] |
2023-05-19T10:03:44+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-classification"], "tags": ["code", "finance"], "dataset_info": {"features": [{"name": "image_id", "dtype": "uint32"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "key_points", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 134736982, "num_examples": 15}], "download_size": 129724970, "dataset_size": 134736982}}
|
2023-09-14T15:46:20+00:00
|
c47ed91520e95263aed82af743d975b06f818220
|
# Dataset Card for "chunk_40"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_40
|
[
"region:us"
] |
2023-05-19T10:17:04+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1281646216, "num_examples": 251698}], "download_size": 1299505185, "dataset_size": 1281646216}}
|
2023-05-19T10:19:40+00:00
|
7f404f34b9f6df1a71d48311150455684b2fdf15
|
# Pose Estimation
The dataset is primarly intended to dentify and predict the positions of major joints of a human body in an image. It consists of people's photographs with body part labeled with keypoints.
# Get the dataset
### This is just an example of the data
Leave a request on [**https://trainingdata.pro/data-market**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=pose_estimation) to discuss your requirements, learn about the price and buy the dataset.

# Data Format
Each image from `EP` folder is accompanied by an XML-annotation in the `annotations.xml` file indicating the coordinates of the key points. For each point, the x and y coordinates are provided, and there is a `Presumed_Location` attribute, indicating whether the point is presumed or accurately defined.
# Example of XML file structure
.png?generation=1684358333663868&alt=media)
# Labeled body parts
Each keypoint is ordered and corresponds to the concrete part of the body:
0. **Nose**
1. **Neck**
2. **Right shoulder**
3. **Right elbow**
4. **Right wrist**
5. **Left shoulder**
6. **Left elbow**
7. **Left wrist**
8. **Right hip**
9. **Right knee**
10. **Right foot**
11. **Left hip**
12. **Left knee**
13. **Left foot**
14. **Right eye**
15. **Left eye**
16. **Right ear**
17. **Left ear**
# Keypoint annotation is made in accordance with your requirements.
## [**TrainingData**](https://trainingdata.pro/data-market?utm_source=huggingface&utm_medium=cpc&utm_campaign=pose_estimation) provides high-quality data annotation tailored to your needs
More datasets in TrainingData's Kaggle account: **https://www.kaggle.com/trainingdatapro/datasets**
TrainingData's GitHub: **https://github.com/Trainingdata-datamarket/TrainingData_All_datasets**
|
TrainingDataPro/pose_estimation
|
[
"task_categories:image-classification",
"language:en",
"license:cc-by-nc-nd-4.0",
"code",
"finance",
"region:us"
] |
2023-05-19T10:17:45+00:00
|
{"language": ["en"], "license": "cc-by-nc-nd-4.0", "task_categories": ["image-classification"], "tags": ["code", "finance"], "dataset_info": {"features": [{"name": "image_id", "dtype": "uint32"}, {"name": "image", "dtype": "image"}, {"name": "mask", "dtype": "image"}, {"name": "shapes", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 142645152, "num_examples": 29}], "download_size": 137240523, "dataset_size": 142645152}}
|
2023-09-14T15:47:12+00:00
|
1b588871cb512fa1999dc7fb36e69ab0af6a80f7
|
# Dataset Card for "chunk_50"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_50
|
[
"region:us"
] |
2023-05-19T10:24:28+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1151952976, "num_examples": 226228}], "download_size": 1167457861, "dataset_size": 1151952976}}
|
2023-05-19T10:26:39+00:00
|
e8e00aa4d454f8a95775c971ee95c9626d175c38
|
# Dataset Card for "deduplicated_dataset_100hrs_wer0_cut"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/deduplicated_dataset_100hrs_wer0_cut
|
[
"region:us"
] |
2023-05-19T10:28:36+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}, {"name": "w2v2_transcription", "dtype": "string"}, {"name": "WER", "dtype": "int64"}, {"name": "sum", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 11763462285.202608, "num_examples": 155859}], "download_size": 11516711375, "dataset_size": 11763462285.202608}}
|
2023-05-19T11:10:30+00:00
|
ec9bdf65e9d860566628cd9ded8f5b67184dafe5
|
# Dataset Card for "0074e854"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
results-sd-v1-5-sd-v2-1-if-v1-0-karlo/0074e854
|
[
"region:us"
] |
2023-05-19T10:30:21+00:00
|
{"dataset_info": {"features": [{"name": "result", "dtype": "string"}, {"name": "id", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 181, "num_examples": 10}], "download_size": 1322, "dataset_size": 181}}
|
2023-05-19T10:30:23+00:00
|
978e5b1491a5488335613b34e311d5569df5e22d
|
# Socio-Moral Image Rationales
This is a collection of machine-generated and human-labeled explanations for immorality in images.
The images are source from the [Socio-Moral Image Database](https://huggingface.co/datasets/AIML-TUDA/smid) (SMID) and limited to the ones displaying immoral content (SMID moral mean <= 2.0).
Sampled explanations were generated by vision-language model using the ILLUME paradigm presented in [ILLUME: Rationalizing Vision-Language Models through Human Interactions](https://arxiv.org/abs/2208.08241).
Explanations are rated by human annotators from 1-4 with 1 being the best score. Scores are given according to the following categories:
1. excellent
2. sufficient/satisfactory
3. weak (but right direction)
4. poor/unrelated
The sample are pre-split into a training and test split. Files contain the following fields:
- **smid_image_id**: Image identifier from the SMID dataset
- **smid_moral_mean**: Moral mean score from SMID. Ranging from 1-5 with lower being more immoral. We only include images with moral_mean <=2.0
- **rationale**: Generated rationale for immmorality of the image.
- **human_rating**: Human rating of the rational in accordance with the scoring system above.
- **fitting_rationale**: Whether a rational is a fitting one, i.e. score <= 2
## Citation
```bibtex
@inproceedings{brack2023illume,
title={ILLUME: Rationalizing Vision-Language Models through Human Interactions},
author={Manuel Brack and Patrick Schramowski and Björn Deiseroth and Kristian Kersting},
year={2023},
booktitle={Proceedings of the 40th International Conference on Machine Learning (ICML)}
}
```
|
AIML-TUDA/socio-moral-image-rationales
|
[
"language:en",
"license:cc-by-4.0",
"arxiv:2208.08241",
"region:us"
] |
2023-05-19T11:00:48+00:00
|
{"language": ["en"], "license": "cc-by-4.0", "pretty_name": "Socio Moral Image Rationales"}
|
2023-06-01T08:23:03+00:00
|
bb7e6bdf43301beb9bd18e7bbd3800d62e011e3c
|
# Dataset Card for "earnings-estimate-sp500"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Repository:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Summary
The earnings-estimate-sp500 dataset provides earnings estimate data for companies in the S&P 500 index.
### Supported Tasks and Leaderboards
The dataset can be used to analyze earnings estimates for systematic trading or financial analysis tasks. The dataset does not specify any associated leaderboards.
### Languages
[N/A]
## Dataset Structure
### Data Instances
[N/A]
### Data Fields
The dataset contains the following fields:
- symbol (string): A string representing the ticker symbol or abbreviation used to identify the company.
- date (string): The date associated with the earnings estimate data.
- current_qtr (string): The current quarter.
- no_of_analysts_current_qtr (int64): The number of analysts providing estimates for the current quarter.
- next_qtr (string): The next quarter.
- no_of_analysts_next_qtr (int64): The number of analysts providing estimates for the next quarter.
- current_year (int64): The current year.
- no_of_analysts_current_year (int64): The number of analysts providing estimates for the current year.
- next_year (int64): The next year.
- no_of_analysts_next_year (int64): The number of analysts providing estimates for the next year.
- avg_estimate_current_qtr (float64): The average estimate for the current quarter.
- avg_estimate_next_qtr (float64): The average estimate for the next quarter.
- avg_estimate_current_year (float64): The average estimate for the current year.
- avg_estimate_next_year (float64): The average estimate for the next year.
- low_estimate_current_qtr (float64): The low estimate for the current quarter.
- low_estimate_next_qtr (float64): The low estimate for the next quarter.
- low_estimate_current_year (float64): The low estimate for the current year.
- low_estimate_next_year (float64): The low estimate for the next year.
- high_estimate_current_qtr (float64): The high estimate for the current quarter.
- high_estimate_next_qtr (float64): The high estimate for the next quarter.
- high_estimate_current_year (float64): The high estimate for the current year.
- high_estimate_next_year (float64): The high estimate for the next year.
- year_ago_eps_current_qtr (float64): The earnings per share (EPS) for the current quarter a year ago.
- year_ago_eps_next_qtr (float64): The earnings per share (EPS) for the next quarter a year ago.
- year_ago_eps_current_year (float64): The earnings per share (EPS) for the current year a year ago.
- year_ago_eps_next_year (float64): The earnings per share (EPS) for the next year a year ago.
### Data Splits
The dataset consists of a single split, called "train."
## Additional Information
### Dataset Curators
This dataset does not specify any specific curators.
### Licensing Information
The earnings-estimate-sp500 dataset is licensed under the MIT License.
### Citation Information
> https://edarchimbaud.substack.com, earnings-estimate-sp500 dataset, GitHub repository, https://github.com/edarchimbaud
### Contributions
Thanks to [@edarchimbaud](https://github.com/edarchimbaud) for adding this dataset.
|
edarchimbaud/earnings-estimate-stocks
|
[
"region:us"
] |
2023-05-19T11:04:48+00:00
|
{"dataset_info": {"features": [{"name": "symbol", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "current_qtr", "dtype": "string"}, {"name": "no_of_analysts_current_qtr", "dtype": "int64"}, {"name": "next_qtr", "dtype": "string"}, {"name": "no_of_analysts_next_qtr", "dtype": "int64"}, {"name": "current_year", "dtype": "int64"}, {"name": "no_of_analysts_current_year", "dtype": "int64"}, {"name": "next_year", "dtype": "int64"}, {"name": "no_of_analysts_next_year", "dtype": "int64"}, {"name": "avg_estimate_current_qtr", "dtype": "float64"}, {"name": "avg_estimate_next_qtr", "dtype": "float64"}, {"name": "avg_estimate_current_year", "dtype": "float64"}, {"name": "avg_estimate_next_year", "dtype": "float64"}, {"name": "low_estimate_current_qtr", "dtype": "float64"}, {"name": "low_estimate_next_qtr", "dtype": "float64"}, {"name": "low_estimate_current_year", "dtype": "float64"}, {"name": "low_estimate_next_year", "dtype": "float64"}, {"name": "high_estimate_current_qtr", "dtype": "float64"}, {"name": "high_estimate_next_qtr", "dtype": "float64"}, {"name": "high_estimate_current_year", "dtype": "float64"}, {"name": "high_estimate_next_year", "dtype": "float64"}, {"name": "year_ago_eps_current_qtr", "dtype": "float64"}, {"name": "year_ago_eps_next_qtr", "dtype": "float64"}, {"name": "year_ago_eps_current_year", "dtype": "float64"}, {"name": "year_ago_eps_next_year", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 4919659, "num_examples": 22192}], "download_size": 630013, "dataset_size": 4919659}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-11T23:12:52+00:00
|
2765d39d6609dc29f708dded25b0fc65a8e9815b
|
<!--
---
dataset_info:
features:
- name: bn
dtype: string
- name: en
dtype: string
- name: ck
dtype: string
splits:
- name: parallel
num_bytes: 2482778
num_examples: 15021
- name: monolingual
num_bytes: 44194898
num_examples: 150000
- name: benchmark
num_bytes: 469802
num_examples: 600
download_size: 24263533
dataset_size: 47147478
---
# Dataset Card for "ck_bn_en_nmt_dataset"
This Dataset contains parallel, monolingual and a benchmark set of Chakma to Bangla or English and vice-versa. More details later....<br>
<br>
Total bn-ck-en parallel sentences/segments: 8647 (first 8647/15021 of the parallel set, 3444(common people online) + 5203(local experts))<br>
Total bn-ck parallel sentences/segments: 6374 (bottom 6374 of the parallel set, 620(UN crpd) + 281(cupdf) + 5473(dictionary))<br>
<br>
Total bn-ck-en benchmark sentences/segments: 600 (200 + 200 + 200, each 200 from 1 expert, and bottom 50 from each 200 have same root sentence(bn & en))<br>
<br>
Total bn monolingual sentences/segments: 150000<br>
Total en monolingual sentences/segments: 150000<br>
Total ck monolingual sentences/segments: 42783<br>
<br>
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
-->
|
amlan107/xyz
|
[
"region:us"
] |
2023-05-19T11:08:49+00:00
|
{}
|
2023-08-22T13:33:38+00:00
|
e651ae031fe492a99692afd758722f48e72ffbdd
|
# Dataset Card for "chunk_62"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_62
|
[
"region:us"
] |
2023-05-19T12:02:20+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1130261056, "num_examples": 221968}], "download_size": 1142648456, "dataset_size": 1130261056}}
|
2023-05-19T12:03:07+00:00
|
10d34c34128a8fcb1f4dae9e920366fdbf134ae9
|
# Dataset Card for "chunk_53"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_53
|
[
"region:us"
] |
2023-05-19T12:10:23+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1223373368, "num_examples": 240254}], "download_size": 1237091332, "dataset_size": 1223373368}}
|
2023-05-19T12:10:56+00:00
|
c26607d68a3dfb4b1816a5c660096703a720d08d
|
# Dataset Card for "chunk_60"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_60
|
[
"region:us"
] |
2023-05-19T12:13:55+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1299198340, "num_examples": 255145}], "download_size": 1319197777, "dataset_size": 1299198340}}
|
2023-05-19T12:14:39+00:00
|
e79bd0a4b066334dfcf99189b9fcaef8e2d1771b
|
# Dataset Card for "chunk_59"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_59
|
[
"region:us"
] |
2023-05-19T12:15:44+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1315014092, "num_examples": 258251}], "download_size": 1336512684, "dataset_size": 1315014092}}
|
2023-05-19T12:16:25+00:00
|
42a0d866624dac3b371737b4c2af8410ef511a44
|
# Dataset Card for "chunk_57"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_57
|
[
"region:us"
] |
2023-05-19T12:16:33+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1341573964, "num_examples": 263467}], "download_size": 1365055978, "dataset_size": 1341573964}}
|
2023-05-19T12:17:16+00:00
|
0c5913e66291aeabe494f7188425a1391b04ed5d
|
# Dataset Card for "chunk_55"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_55
|
[
"region:us"
] |
2023-05-19T12:16:53+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1315757524, "num_examples": 258397}], "download_size": 1344350056, "dataset_size": 1315757524}}
|
2023-05-19T12:17:42+00:00
|
f68638083f55b9fd38c6557ae1f0bc1a56b0589e
|
# Dataset Card for "chunk_54"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_54
|
[
"region:us"
] |
2023-05-19T12:19:36+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1322438228, "num_examples": 259709}], "download_size": 1351187413, "dataset_size": 1322438228}}
|
2023-05-19T12:20:25+00:00
|
94801d6c44795cef7655609dc19037ca34fe0ba9
|
# Dataset Card for "chunk_56"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_56
|
[
"region:us"
] |
2023-05-19T12:27:22+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1384794860, "num_examples": 271955}], "download_size": 1414749414, "dataset_size": 1384794860}}
|
2023-05-19T12:28:10+00:00
|
71f8a41395d36d7991da0367033a1c0430a776ee
|
# Dataset Card for "deduplicated_dataset_500hrs_wer0_cut"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/dataset_500hrs_wer0
|
[
"region:us"
] |
2023-05-19T12:37:25+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}, {"name": "w2v2_transcription", "dtype": "string"}, {"name": "WER", "dtype": "int64"}, {"name": "sum", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 53344498187.125, "num_examples": 649159}], "download_size": 52663642254, "dataset_size": 53344498187.125}}
|
2023-05-19T15:38:49+00:00
|
b60de5e693c045ea7abc3b4bac341fbf2bafabab
|
# Dataset Card for "chunk_58"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_58
|
[
"region:us"
] |
2023-05-19T12:48:57+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1299967232, "num_examples": 255296}], "download_size": 1319363295, "dataset_size": 1299967232}}
|
2023-05-19T12:51:24+00:00
|
4be65efaa66c581a00a06b0ee69d8d672919f82d
|
TFLai/Turkish-Dialog-Dataset
|
[
"license:mit",
"region:us"
] |
2023-05-19T12:57:03+00:00
|
{"license": "mit"}
|
2023-05-19T12:58:33+00:00
|
|
57545cb8f68892bc5db757f6a1255b8b02cd1665
|
# Dataset Card for "chunk_61"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_61
|
[
"region:us"
] |
2023-05-19T12:58:31+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1288087596, "num_examples": 252963}], "download_size": 1304914734, "dataset_size": 1288087596}}
|
2023-05-19T13:00:49+00:00
|
8de6df0be91c507906781e76efac66910371e36e
|
dataset_info:
features:
- name: input
dtype: string
- name: output
dtype: string
- name: source
dtype: string
- name: subset
dtype: string
splits:
- name: train
num_bytes: 63759065
num_examples: 23652
- name: validation
num_bytes: 6190242
num_examples: 2042
- name: test
num_bytes: 6080212
num_examples: 2045
download_size: 45525146
dataset_size: 76029519
task_categories:
- text2text-generation
- text-generation
- question-answering
- conversational
- summarization
- table-question-answering
language:
- en
tags:
- instruction-tuning
pretty_name: longform
size_categories:
- 10K<n<100K
---
# LongForm
The LongForm dataset is created by leveraging English corpus
examples with augmented instructions. We select a
diverse set of human-written
documents from existing corpora such as C4 and
Wikipedia and generate instructions for the given
documents via LLMs. Then, we extend these examples with structured corpora examples such as Stack Exchange and WikiHow and task examples such as question answering, email writing, grammar error correction, story/poem generation, and text summarization.
## Distribution
The distribution of the LongForm dataset in terms of the source of examples is below. It contains examples generated from raw text corpora via LLMs, structured corpus examples, as well as various NLP task examples such as email writing, grammar error correction, story/poem generation, and text summarization.
| **Type** | **Source** | **Number of Examples** |
|------------------------|----------------|------------------------|
| **Corpora** | C4 | 10,000 |
| | Wikipedia | 5,000 |
| **Structured Corpora** | Stack Exchange | 4,380 |
| | WikiHow | 2,500 |
| **Tasks** | NIv2 | 3,684 |
| | Big Bench | 600 |
| | BEA-GEC | 1,203 |
| | Enron | 372 |
| **Total** | | 27,739 |
| | | |
| **Train** | | 23,652 |
| **Validation** | | 2,042 |
| **Test** | | 2,045 |
## Models
| | **All** | **Recipe Generation** | **ELI5** | **Writing Prompts** |
|-----------------------|---------|-----------------------------------|----------|---------------------|
| **T0++** | 10.9 | 18.7 | 3.8 | 10.2 |
| **Tk-Instruct** | 6.3 | 12.9* | 3.6 | 2.4 |
| **Flan-T5** | 10.6 | 20.9* | 3.5 | 7.4 |
| **Alpaca-LLaMA-7B** | 14.6 | 19.5 | 12.5 | 11.8 |
| **OPT-30B** | 11.1 | 18.6 | 12.2 | 2.6 |
| **[LongForm-T5-XL](https://huggingface.co/akoksal/LongForm-T5-XL)** | 16.3 | 20.2 | 18.3 | 10.6 |
| **[LongForm-OPT-2.7B](https://huggingface.co/akoksal/LongForm-OPT-2.7B)** | 17.8 | 15.5 | 17.9 | **19.9** |
| **[LongForm-OPT-6.7B](https://huggingface.co/akoksal/LongForm-OPT-6.7B)** | 17.7 | 16.9 | 17.2 | 19.0 |
| [**LongForm-LLaMA-7B**](https://huggingface.co/akoksal/LongForm-LLaMA-7B-diff)‡ | **19.7** | **21.7** | **18.6** | 18.9 |
‡: We can just release the difference between LongForm-LLaMA-7B and pretrained LLaMA-7B publicly due to restrictions of LLaMA models.
## Examples
| **Source** | **Instruction** | **Output**|
|------------------------|----------------|------------------------|
| C4 | What is the likelihood that Donald Trump's HHS secretary nominee, Alex Azar, will push policies that benefit pharmaceutical companies' pocketbooks? | His record suggests he’s unlikely to push pricing policies that would hit pharmaceutical companies’ pocketbooks.<br />President Donald Trump tweeted Monday that his nominee for HHS secretary, Alex Azar will “be a star for … lower drug prices!” But the record of the former top executive for Eli Lilly, which tripled the price of a top-selling insulin drug while he led its U.S. operation, suggests a different story.<br />Lilly is one of three drug companies targeted by a class-action lawsuit that accuses the company[...]<br />“This nominee has impeccable big pharma credentials but non-existent credentials when it comes to concerns on drug prices,” said Peter Welch, co-chair of the House Democrats Drug Pricing Task Force.
|Wikipedia | "Where is San Saba located in Rome, Italy?" Respond in 2 sentences. |San Saba is an ancient basilica church in Rome, Italy. It lies on the so-called "Piccolo Aventino", which is an area close to the ancient Aurelian Walls next to the Aventine Hill and Caelian Hill.|
## Dataset Description
- **Repository:** https://github.com/akoksal/LongForm
- **Paper:** https://arxiv.org/abs/2304.08460
- **Version:** v1.0 - April 18, 2023
- **Contact:** [Abdullatif Köksal](https://twitter.com/akoksal_)
## License
The LongForm project is subject to a MIT License with custom limitations for restrictions imposed by OpenAI (for the instruction generation part), as well as the license of language models (OPT, LLaMA, and T5).
## Citation
```
@misc{koksal2023longform,
title={LongForm: Optimizing Instruction Tuning for Long Text Generation with Corpus Extraction},
author={Abdullatif Köksal and Timo Schick and Anna Korhonen and Hinrich Schütze},
year={2023},
eprint={2304.08460},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
sehunnnn/123
|
[
"license:openrail",
"arxiv:2304.08460",
"region:us"
] |
2023-05-19T13:11:43+00:00
|
{"license": "openrail"}
|
2023-05-19T13:17:37+00:00
|
23657ae14f02067608a83eeaee7636b9200974c4
|
This is a dataset we are going to use when training our airtificial intelligence model.
During our data gathering process and planning we realized that we needed a dataset to be able
to train the model using Google Colab -> and Huggingface is the best place of convenience to do this.
Using Google Colab, we will fetch whispher model and our dataset from huggingface and then train the dataset
so that we can get a real-time transcription model that is going to recognize and translate the lecture's voice
with almost 100% accuracy.
|
mphonkala/absolom_voice
|
[
"language:en",
"code",
"region:us"
] |
2023-05-19T13:22:23+00:00
|
{"language": ["en"], "tags": ["code"]}
|
2023-05-19T13:26:35+00:00
|
2870107ded409d21238ae00c91f964ca39172ba5
|
# Dataset Card for "eps-revisions-sp500"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://edarchimbaud.substack.com
- **Repository:** https://github.com/edarchimbaud
- **Point of Contact:** [email protected]
### Dataset Summary
The eps-revisions-sp500 dataset provides information on earnings-per-share (EPS) revisions for companies in the S&P 500 index.
### Supported Tasks and Leaderboards
The dataset can be used to analyze EPS revisions and their impact on the performance of companies in the S&P 500 index. It does not specify any particular leaderboard or evaluation metric.
### Languages
[N/A]
## Dataset Structure
### Data Instances
[N/A]
### Data Fields
- symbol (string): A string representing the ticker symbol or abbreviation used to identify the company.
- date (string): A string indicating the date of the recorded data.
- current_qtr (string): A string representing the current quarter.
- up_last_7_days_current_qtr (int64): An integer indicating the number of days the EPS has increased in the current quarter.
- next_qtr (string): A string representing the next quarter.
- up_last_7_days_next_qtr (int64): An integer indicating the number of days the EPS is projected to increase in the next quarter.
- current_year (int64): An integer representing the current year.
- up_last_7_days_current_year (int64): An integer indicating the number of days the EPS has increased in the current year.
- next_year (int64): An integer representing the next year.
- up_last_7_days_next_year (int64): An integer indicating the number of days the EPS is projected to increase in the next year.
- up_last_30_days_current_qtr (int64): An integer indicating the number of days the EPS has increased in the current quarter over the last 30 days.
- up_last_30_days_next_qtr (int64): An integer indicating the number of days the EPS is projected to increase in the next quarter over the last 30 days.
- up_last_30_days_current_year (int64): An integer indicating the number of days the EPS has increased in the current year over the last 30 days.
- up_last_30_days_next_year (int64): An integer indicating the number of days the EPS is projected to increase in the next year over the last 30 days.
- down_last_7_days_current_qtr (null): A null value indicating the absence of data on EPS decrease in the current quarter.
- down_last_7_days_next_qtr (null): A null value indicating the absence of data on EPS decrease in the next quarter.
- down_last_7_days_current_year (null): A null value indicating the absence of data on EPS decrease in the current year.
- down_last_7_days_next_year (null): A null value indicating the absence of data on EPS decrease in the next year.
- down_last_30_days_current_qtr (int64): An integer indicating the number of days the EPS has decreased in the current quarter over the last 30 days.
- down_last_30_days_next_qtr (int64): An integer indicating the number of days the EPS is projected to decrease in the next quarter over the last 30 days.
- down_last_30_days_current_year (int64): An integer indicating the number of days the EPS has decreased in the current year over the last 30 days.
- down_last_30_days_next_year (int64): An integer indicating the number of days the EPS is projected to decrease in the next year over the last 30 days.
### Data Splits
A single split, called train.
## Dataset Creation
### Curation Rationale
The eps-revisions-sp500 dataset was created to provide information on EPS revisions for companies in the S&P 500 index.
### Source Data
#### Initial Data Collection and Normalization
The data was collected from reliable sources and normalized for consistency.
### Annotations
#### Annotation Process
[N/A]
#### Annotators
[N/A]
### Personal and Sensitive Information
[N/A]
## Considerations for Using the Data
### Social Impact of Dataset
[N/A]
### Discussion of Biases
[N/A]
### Other Known Limitations
[N/A]
## Additional Information
### Dataset Curators
The eps-revisions-sp500 dataset was collected by https://edarchimbaud.substack.com.
### Licensing Information
The eps-revisions-sp500 dataset is licensed under the MIT License.
### Citation Information
> https://edarchimbaud.substack.com, eps-revisions-sp500 dataset, GitHub repository, https://github.com/edarchimbaud
### Contributions
Thanks to [@edarchimbaud](https://github.com/edarchimbaud) for adding this dataset.
|
edarchimbaud/eps-revisions-stocks
|
[
"region:us"
] |
2023-05-19T13:23:43+00:00
|
{"dataset_info": {"features": [{"name": "symbol", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "current_qtr", "dtype": "string"}, {"name": "up_last_7_days_current_qtr", "dtype": "float64"}, {"name": "next_qtr", "dtype": "string"}, {"name": "up_last_7_days_next_qtr", "dtype": "float64"}, {"name": "current_year", "dtype": "int64"}, {"name": "up_last_7_days_current_year", "dtype": "float64"}, {"name": "next_year", "dtype": "int64"}, {"name": "up_last_7_days_next_year", "dtype": "float64"}, {"name": "up_last_30_days_current_qtr", "dtype": "float64"}, {"name": "up_last_30_days_next_qtr", "dtype": "float64"}, {"name": "up_last_30_days_current_year", "dtype": "float64"}, {"name": "up_last_30_days_next_year", "dtype": "float64"}, {"name": "down_last_7_days_current_qtr", "dtype": "null"}, {"name": "down_last_7_days_next_qtr", "dtype": "null"}, {"name": "down_last_7_days_current_year", "dtype": "null"}, {"name": "down_last_7_days_next_year", "dtype": "null"}, {"name": "down_last_30_days_current_qtr", "dtype": "float64"}, {"name": "down_last_30_days_next_qtr", "dtype": "float64"}, {"name": "down_last_30_days_current_year", "dtype": "float64"}, {"name": "down_last_30_days_next_year", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 3206767, "num_examples": 20208}], "download_size": 263860, "dataset_size": 3206767}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-11T23:13:30+00:00
|
150772595d60913fab0cdc1971052e6aea3763c8
|
# Dataset Card for "skin_cancer_complete_dataset_resized"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Pranavkpba2000/skin_cancer_complete_dataset_resized
|
[
"region:us"
] |
2023-05-19T13:26:34+00:00
|
{"dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "AK", "1": "BCC", "2": "BKL", "3": "DF", "4": "MEL", "5": "NV", "6": "SCC", "7": "VASC"}}}}], "splits": [{"name": "train", "num_bytes": 170443824.892, "num_examples": 28516}, {"name": "test", "num_bytes": 43096803.47, "num_examples": 7105}], "download_size": 203883734, "dataset_size": 213540628.362}}
|
2023-05-19T13:27:15+00:00
|
eef9a536011f300a5068735dfe7a36d94c9a312e
|
# Dataset Card for duorc
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [DuoRC](https://duorc.github.io/)
- **Repository:** [GitHub](https://github.com/duorc/duorc)
- **Paper:** [arXiv](https://arxiv.org/abs/1804.07927)
- **Leaderboard:** [DuoRC Leaderboard](https://duorc.github.io/#leaderboard)
- **Point of Contact:** [Needs More Information]
### Dataset Summary
The DuoRC dataset is an English language dataset of questions and answers gathered from crowdsourced AMT workers on Wikipedia and IMDb movie plots. The workers were given freedom to pick answer from the plots or synthesize their own answers. It contains two sub-datasets - SelfRC and ParaphraseRC. SelfRC dataset is built on Wikipedia movie plots solely. ParaphraseRC has questions written from Wikipedia movie plots and the answers are given based on corresponding IMDb movie plots.
### Supported Tasks and Leaderboards
- `abstractive-qa` : The dataset can be used to train a model for Abstractive Question Answering. An abstractive question answering model is presented with a passage and a question and is expected to generate a multi-word answer. The model performance is measured by exact-match and F1 score, similar to [SQuAD V1.1](https://huggingface.co/metrics/squad) or [SQuAD V2](https://huggingface.co/metrics/squad_v2). A [BART-based model](https://huggingface.co/yjernite/bart_eli5) with a [dense retriever](https://huggingface.co/yjernite/retribert-base-uncased) may be used for this task.
- `extractive-qa`: The dataset can be used to train a model for Extractive Question Answering. An extractive question answering model is presented with a passage and a question and is expected to predict the start and end of the answer span in the passage. The model performance is measured by exact-match and F1 score, similar to [SQuAD V1.1](https://huggingface.co/metrics/squad) or [SQuAD V2](https://huggingface.co/metrics/squad_v2). [BertForQuestionAnswering](https://huggingface.co/transformers/model_doc/bert.html#bertforquestionanswering) or any other similar model may be used for this task.
### Languages
The text in the dataset is in English, as spoken by Wikipedia writers for movie plots. The associated BCP-47 code is `en`.
## Dataset Structure
### Data Instances
```
{'answers': ['They arrived by train.'], 'no_answer': False, 'plot': "200 years in the future, Mars has been colonized by a high-tech company.\nMelanie Ballard (Natasha Henstridge) arrives by train to a Mars mining camp which has cut all communication links with the company headquarters. She's not alone, as she is with a group of fellow police officers. They find the mining camp deserted except for a person in the prison, Desolation Williams (Ice Cube), who seems to laugh about them because they are all going to die. They were supposed to take Desolation to headquarters, but decide to explore first to find out what happened.They find a man inside an encapsulated mining car, who tells them not to open it. However, they do and he tries to kill them. One of the cops witnesses strange men with deep scarred and heavily tattooed faces killing the remaining survivors. The cops realise they need to leave the place fast.Desolation explains that the miners opened a kind of Martian construction in the soil which unleashed red dust. Those who breathed that dust became violent psychopaths who started to build weapons and kill the uninfected. They changed genetically, becoming distorted but much stronger.The cops and Desolation leave the prison with difficulty, and devise a plan to kill all the genetically modified ex-miners on the way out. However, the plan goes awry, and only Melanie and Desolation reach headquarters alive. Melanie realises that her bosses won't ever believe her. However, the red dust eventually arrives to headquarters, and Melanie and Desolation need to fight once again.", 'plot_id': '/m/03vyhn', 'question': 'How did the police arrive at the Mars mining camp?', 'question_id': 'b440de7d-9c3f-841c-eaec-a14bdff950d1', 'title': 'Ghosts of Mars'}
```
### Data Fields
- `plot_id`: a `string` feature containing the movie plot ID.
- `plot`: a `string` feature containing the movie plot text.
- `title`: a `string` feature containing the movie title.
- `question_id`: a `string` feature containing the question ID.
- `question`: a `string` feature containing the question text.
- `answers`: a `list` of `string` features containing list of answers.
- `no_answer`: a `bool` feature informing whether the question has no answer or not.
### Data Splits
The data is split into a training, dev and test set in such a way that the resulting sets contain 70%, 15%, and 15% of the total QA pairs and no QA pairs for any movie seen in train are included in the test set. The final split sizes are as follows:
Name Train Dec Test
SelfRC 60721 12961 12599
ParaphraseRC 69524 15591 15857
## Dataset Creation
### Curation Rationale
[Needs More Information]
### Source Data
Wikipedia and IMDb movie plots
#### Initial Data Collection and Normalization
[Needs More Information]
#### Who are the source language producers?
[Needs More Information]
### Annotations
#### Annotation process
For SelfRC, the annotators were allowed to mark an answer span in the plot or synthesize their own answers after reading Wikipedia movie plots.
For ParaphraseRC, questions from the Wikipedia movie plots from SelfRC were used and the annotators were asked to answer based on IMDb movie plots.
#### Who are the annotators?
Amazon Mechanical Turk Workers
### Personal and Sensitive Information
[Needs More Information]
## Considerations for Using the Data
### Social Impact of Dataset
[Needs More Information]
### Discussion of Biases
[Needs More Information]
### Other Known Limitations
[Needs More Information]
## Additional Information
### Dataset Curators
The dataset was intially created by Amrita Saha, Rahul Aralikatte, Mitesh M. Khapra, and Karthik Sankaranarayanan in a collaborated work between IIT Madras and IBM Research.
### Licensing Information
[MIT License](https://github.com/duorc/duorc/blob/master/LICENSE)
### Citation Information
```
@inproceedings{DuoRC,
author = { Amrita Saha and Rahul Aralikatte and Mitesh M. Khapra and Karthik Sankaranarayanan},
title = {{DuoRC: Towards Complex Language Understanding with Paraphrased Reading Comprehension}},
booktitle = {Meeting of the Association for Computational Linguistics (ACL)},
year = {2018}
}
```
### Contributions
Thanks to [@gchhablani](https://github.com/gchhablani) for adding this dataset.
|
asoria/duorc
|
[
"task_categories:question-answering",
"task_categories:text2text-generation",
"task_ids:abstractive-qa",
"task_ids:extractive-qa",
"annotations_creators:crowdsourced",
"language_creators:crowdsourced",
"multilinguality:monolingual",
"size_categories:100K<n<1M",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:mit",
"arxiv:1804.07927",
"region:us"
] |
2023-05-19T13:58:04+00:00
|
{"annotations_creators": ["crowdsourced"], "language_creators": ["crowdsourced"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["100K<n<1M", "10K<n<100K"], "source_datasets": ["original"], "task_categories": ["question-answering", "text2text-generation"], "task_ids": ["abstractive-qa", "extractive-qa"], "paperswithcode_id": "duorc", "pretty_name": "DuoRC", "configs": ["ParaphraseRC", "SelfRC"], "dataset_info": [{"config_name": "SelfRC", "features": [{"name": "plot_id", "dtype": "string"}, {"name": "plot", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "question_id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}, {"name": "no_answer", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 239852925, "num_examples": 60721}, {"name": "validation", "num_bytes": 51662575, "num_examples": 12961}, {"name": "test", "num_bytes": 49142766, "num_examples": 12559}], "download_size": 34462660, "dataset_size": 340658266}, {"config_name": "ParaphraseRC", "features": [{"name": "plot_id", "dtype": "string"}, {"name": "plot", "dtype": "string"}, {"name": "title", "dtype": "string"}, {"name": "question_id", "dtype": "string"}, {"name": "question", "dtype": "string"}, {"name": "answers", "sequence": "string"}, {"name": "no_answer", "dtype": "bool"}], "splits": [{"name": "train", "num_bytes": 496683105, "num_examples": 69524}, {"name": "validation", "num_bytes": 106510545, "num_examples": 15591}, {"name": "test", "num_bytes": 115215816, "num_examples": 15857}], "download_size": 62921050, "dataset_size": 718409466}]}
|
2023-05-19T13:59:33+00:00
|
32becbf1161559c95a308c1b806978c5e9a8f3d5
|
# Dataset Card for "eps-trend-sp500"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Repository:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Dataset Summary
The "eps-trend-sp500" dataset contains earnings per share (EPS) trend data for companies in the S&P 500 index. It includes information about the EPS estimates for the current quarter, next quarter, current year, and next year, as well as estimates from 7 days ago, 30 days ago, 60 days ago, and 90 days ago.
### Supported Tasks and Leaderboards
The dataset can be used to analyze EPS trends and perform financial analysis tasks. It does not specify any associated leaderboards.
### Languages
The dataset does not specify any specific language.
## Dataset Structure
### Data Instances
The dataset consists of multiple data instances, where each instance represents the EPS trend data for a specific company and date.
### Data Fields
The dataset contains the following fields:
- symbol (string): A string representing the ticker symbol or abbreviation used to identify the company.
- date (string): The date associated with the EPS trend data.
- current_qtr (string): The current quarter.
- current_estimate_current_qtr (float64): The current estimate for the EPS in the current quarter.
- next_qtr (string): The next quarter.
- current_estimate_next_qtr (float64): The current estimate for the EPS in the next quarter.
- current_year (int64): The current year.
- current_estimate_current_year (float64): The current estimate for the EPS in the current year.
- next_year (int64): The next year.
- current_estimate_next_year (float64): The current estimate for the EPS in the next year.
- 7_days_ago_current_qtr (float64): The EPS estimate for the current quarter from 7 days ago.
- 7_days_ago_next_qtr (float64): The EPS estimate for the next quarter from 7 days ago.
- 7_days_ago_current_year (float64): The EPS estimate for the current year from 7 days ago.
- 7_days_ago_next_year (float64): The EPS estimate for the next year from 7 days ago.
- 30_days_ago_current_qtr (float64): The EPS estimate for the current quarter from 30 days ago.
- 30_days_ago_next_qtr (float64): The EPS estimate for the next quarter from 30 days ago.
- 30_days_ago_current_year (float64): The EPS estimate for the current year from 30 days ago.
- 30_days_ago_next_year (float64): The EPS estimate for the next year from 30 days ago.
- 60_days_ago_current_qtr (float64): The EPS estimate for the current quarter from 60 days ago.
- 60_days_ago_next_qtr (float64): The EPS estimate for the next quarter from 60 days ago.
- 60_days_ago_current_year (float64): The EPS estimate for the current year from 60 days ago.
- 60_days_ago_next_year (float64): The EPS estimate for the next year from 60 days ago.
- 90_days_ago_current_qtr (float64): The EPS estimate for the current quarter from 90 days ago.
- 90_days_ago_next_qtr (float64): The EPS estimate for the next quarter from 90 days ago.
- 90_days_ago_current_year (float64): The EPS estimate for the current year from 90 days ago.
- 90_days_ago_next_year (float64): The EPS estimate for the next year from 90 days ago.
### Data Splits
The dataset consists of a single split, called "train."
## Additional Information
### Dataset Curators
The eps-trend-sp500 dataset was collected by https://edarchimbaud.substack.com.
### Licensing Information
The eps-trend-sp500 dataset is licensed under the MIT License.
### Citation Information
> https://edarchimbaud.substack.com, eps-trend-sp500 dataset, GitHub repository, https://github.com/edarchimbaud
### Contributions
Thanks to [@edarchimbaud](https://github.com/edarchimbaud) for adding this dataset.
|
edarchimbaud/eps-trend-stocks
|
[
"region:us"
] |
2023-05-19T14:17:04+00:00
|
{"dataset_info": {"features": [{"name": "symbol", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "current_qtr", "dtype": "string"}, {"name": "current_estimate_current_qtr", "dtype": "float64"}, {"name": "next_qtr", "dtype": "string"}, {"name": "current_estimate_next_qtr", "dtype": "float64"}, {"name": "current_year", "dtype": "int64"}, {"name": "current_estimate_current_year", "dtype": "float64"}, {"name": "next_year", "dtype": "int64"}, {"name": "current_estimate_next_year", "dtype": "float64"}, {"name": "7_days_ago_current_qtr", "dtype": "float64"}, {"name": "7_days_ago_next_qtr", "dtype": "float64"}, {"name": "7_days_ago_current_year", "dtype": "float64"}, {"name": "7_days_ago_next_year", "dtype": "float64"}, {"name": "30_days_ago_current_qtr", "dtype": "float64"}, {"name": "30_days_ago_next_qtr", "dtype": "float64"}, {"name": "30_days_ago_current_year", "dtype": "float64"}, {"name": "30_days_ago_next_year", "dtype": "float64"}, {"name": "60_days_ago_current_qtr", "dtype": "float64"}, {"name": "60_days_ago_next_qtr", "dtype": "float64"}, {"name": "60_days_ago_current_year", "dtype": "float64"}, {"name": "60_days_ago_next_year", "dtype": "float64"}, {"name": "90_days_ago_current_qtr", "dtype": "float64"}, {"name": "90_days_ago_next_qtr", "dtype": "float64"}, {"name": "90_days_ago_current_year", "dtype": "float64"}, {"name": "90_days_ago_next_year", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 4466882, "num_examples": 20195}], "download_size": 790088, "dataset_size": 4466882}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-11T23:13:43+00:00
|
48819145ec5be3e16da8a2d434cc81b59ffac1d0
|
# Dataset Card for "chunk_70"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_70
|
[
"region:us"
] |
2023-05-19T14:26:41+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1014107444, "num_examples": 199157}], "download_size": 1034350032, "dataset_size": 1014107444}}
|
2023-05-19T14:27:13+00:00
|
f826a22af1484d4f6093d589e66c11dd29be8ea0
|
# Dataset Card for "chunk_69"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_69
|
[
"region:us"
] |
2023-05-19T14:30:08+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1038212972, "num_examples": 203891}], "download_size": 1051817099, "dataset_size": 1038212972}}
|
2023-05-19T14:30:46+00:00
|
37bb893335c80b0ed80bee347aadccb8fe9cd729
|
# Dataset Card for "chunk_64"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_64
|
[
"region:us"
] |
2023-05-19T14:33:15+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1179602536, "num_examples": 231658}], "download_size": 1195294960, "dataset_size": 1179602536}}
|
2023-05-19T14:33:51+00:00
|
ce806d1855f29706704b252ac37247b8c3cc4f59
|
# Dataset Card for "revenue-estimate-sp500"
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://edarchimbaud.substack.com
- **Repository:** https://github.com/edarchimbaud
- **Point of Contact:** [email protected]
### Dataset Summary
The revenue-estimate-sp500 dataset provides revenue estimate data for companies in the S&P 500 index.
### Supported Tasks and Leaderboards
The dataset can be used to analyze and predict revenue estimates for companies in the S&P 500 index.
## Dataset Structure
### Data Instances
[N/A]
### Data Fields
- symbol (string): A string representing the ticker symbol or abbreviation used to identify the company.
- date (string): A string indicating the date of the recorded data.
- current_qtr (string): A string representing the current quarter.
- no_of_analysts_current_qtr (int64): An integer indicating the number of analysts providing estimates for the current quarter.
- next_qtr (string): A string representing the next quarter.
- no_of_analysts_next_qtr (int64): An integer indicating the number of analysts providing estimates for the next quarter.
- current_year (int64): An integer indicating the current year.
- no_of_analysts_current_year (int64): An integer indicating the number of analysts providing estimates for the current year.
- next_year (int64): An integer indicating the next year.
- no_of_analysts_next_year (int64): An integer indicating the number of analysts providing estimates for the next year.
- avg_estimate_current_qtr (string): A string representing the average estimate for the current quarter.
- avg_estimate_next_qtr (string): A string representing the average estimate for the next quarter.
- avg_estimate_current_year (string): A string representing the average estimate for the current year.
- avg_estimate_next_year (string): A string representing the average estimate for the next year.
- low_estimate_current_qtr (string): A string representing the low estimate for the current quarter.
- low_estimate_next_qtr (string): A string representing the low estimate for the next quarter.
- low_estimate_current_year (string): A string representing the low estimate for the current year.
- low_estimate_next_year (string): A string representing the low estimate for the next year.
- high_estimate_current_qtr (string): A string representing the high estimate for the current quarter.
- high_estimate_next_qtr (string): A string representing the high estimate for the next quarter.
- high_estimate_current_year (string): A string representing the high estimate for the current year.
- high_estimate_next_year (string): A string representing the high estimate for the next year.
- year_ago_sales_current_qtr (string): A string representing the year-ago sales for the current quarter.
- year_ago_sales_next_qtr (string): A string representing the year-ago sales for the next quarter.
- year_ago_sales_current_year (string): A string representing the year-ago sales for the current year.
- year_ago_sales_next_year (string): A string representing the year-ago sales for the next year.
- sales_growth_yearest_current_qtr (string): A string representing the sales growth estimate for the current quarter.
- sales_growth_yearest_next_qtr (string): A string representing the sales growth estimate for the next quarter.
- sales_growth_yearest_current_year (string): A string representing the sales growth estimate for the current year.
- sales_growth_yearest_next_year (string): A string representing the sales growth estimate for the next year.
### Data Splits
A single split, called train.
## Dataset Creation
### Curation Rationale
The revenue-estimate-sp500 dataset was created to provide revenue estimate data for companies in the S&P 500 index.
### Source Data
The data was collected and normalized from reliable sources.
## Additional Information
### Dataset Curators
The revenue-estimate-sp500 dataset was collected by https://edarchimbaud.substack.com.
### Licensing Information
The revenue-estimate-sp500 dataset is licensed under the MIT License.
### Citation Information
> https://edarchimbaud.substack.com, revenue-estimate-sp500 dataset, GitHub repository, https://github.com/edarchimbaud
### Contributions
Thanks to [@edarchimbaud](https://github.com/edarchimbaud) for adding this dataset.
|
edarchimbaud/revenue-estimate-stocks
|
[
"region:us"
] |
2023-05-19T14:34:56+00:00
|
{"dataset_info": {"features": [{"name": "symbol", "dtype": "string"}, {"name": "date", "dtype": "string"}, {"name": "current_qtr", "dtype": "string"}, {"name": "no_of_analysts_current_qtr", "dtype": "int64"}, {"name": "next_qtr", "dtype": "string"}, {"name": "no_of_analysts_next_qtr", "dtype": "int64"}, {"name": "current_year", "dtype": "int64"}, {"name": "no_of_analysts_current_year", "dtype": "int64"}, {"name": "next_year", "dtype": "int64"}, {"name": "no_of_analysts_next_year", "dtype": "int64"}, {"name": "avg_estimate_current_qtr", "dtype": "string"}, {"name": "avg_estimate_next_qtr", "dtype": "string"}, {"name": "avg_estimate_current_year", "dtype": "string"}, {"name": "avg_estimate_next_year", "dtype": "string"}, {"name": "low_estimate_current_qtr", "dtype": "string"}, {"name": "low_estimate_next_qtr", "dtype": "string"}, {"name": "low_estimate_current_year", "dtype": "string"}, {"name": "low_estimate_next_year", "dtype": "string"}, {"name": "high_estimate_current_qtr", "dtype": "string"}, {"name": "high_estimate_next_qtr", "dtype": "string"}, {"name": "high_estimate_current_year", "dtype": "string"}, {"name": "high_estimate_next_year", "dtype": "string"}, {"name": "year_ago_sales_current_qtr", "dtype": "string"}, {"name": "year_ago_sales_next_qtr", "dtype": "string"}, {"name": "year_ago_sales_current_year", "dtype": "string"}, {"name": "year_ago_sales_next_year", "dtype": "string"}, {"name": "sales_growth_yearest_current_qtr", "dtype": "string"}, {"name": "sales_growth_yearest_next_qtr", "dtype": "string"}, {"name": "sales_growth_yearest_current_year", "dtype": "string"}, {"name": "sales_growth_yearest_next_year", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 5577663, "num_examples": 19712}], "download_size": 737316, "dataset_size": 5577663}, "configs": [{"config_name": "default", "data_files": [{"split": "train", "path": "data/train-*"}]}]}
|
2023-11-11T23:15:05+00:00
|
97ce213b21de5bdfd971c7408d6d80e12c6a0b2d
|
# Dataset Card for "chunk_66"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_66
|
[
"region:us"
] |
2023-05-19T14:37:36+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1160431156, "num_examples": 227893}], "download_size": 1180581433, "dataset_size": 1160431156}}
|
2023-05-19T14:38:14+00:00
|
6af39582463b3c981dde2e302e1419fc50df0c5d
|
# Dataset Card for "chunk_68"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_68
|
[
"region:us"
] |
2023-05-19T14:37:37+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1105743076, "num_examples": 217153}], "download_size": 1123346328, "dataset_size": 1105743076}}
|
2023-05-19T14:38:37+00:00
|
45215596ca2345e1c4294f55247f3c0fd07fb123
|
# Dataset Card for "chunk_67"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_67
|
[
"region:us"
] |
2023-05-19T14:39:06+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1208520004, "num_examples": 237337}], "download_size": 1231308636, "dataset_size": 1208520004}}
|
2023-05-19T14:39:45+00:00
|
0167d7db41a1710d24f2d2fa6e6327e22f8cb490
|
# Dataset Card for "TokenizedMNAD.v2"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
J-Mourad/TokenizedMNAD.v2
|
[
"region:us"
] |
2023-05-19T14:40:10+00:00
|
{"dataset_info": {"features": [{"name": "input_ids", "sequence": "int32"}], "splits": [{"name": "train", "num_bytes": 1086299676, "num_examples": 1351119}, {"name": "validation", "num_bytes": 119121444, "num_examples": 148161}], "download_size": 725794557, "dataset_size": 1205421120}}
|
2023-05-19T14:41:01+00:00
|
3a43b19913959fd253f7cdbe94b7e436940334f1
|
# Dataset Card for "CodeNet"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
petersa2/CodeNet
|
[
"region:us"
] |
2023-05-19T14:47:25+00:00
|
{"dataset_info": {"features": [{"name": "text", "dtype": "string"}, {"name": "id", "dtype": "string"}, {"name": "label", "dtype": "int64"}], "splits": [{"name": "train", "num_bytes": 2162458, "num_examples": 845}, {"name": "test", "num_bytes": 6912398, "num_examples": 2532}], "download_size": 2295279, "dataset_size": 9074856}}
|
2023-05-19T17:52:20+00:00
|
53055a3f088b2a2c6a657cff6ea62fdf5267b85e
|
# Dataset Card for "chunk_71"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_71
|
[
"region:us"
] |
2023-05-19T14:48:03+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1180743144, "num_examples": 231882}], "download_size": 1202755762, "dataset_size": 1180743144}}
|
2023-05-19T14:48:56+00:00
|
8af76a088924abc38433c8b790fe8d76b91a1044
|
# Dataset Card for GLUE
## Table of Contents
- [Dataset Card for GLUE](#dataset-card-for-glue)
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [ax](#ax)
- [cola](#cola)
- [mnli](#mnli)
- [mnli_matched](#mnli_matched)
- [mnli_mismatched](#mnli_mismatched)
- [mrpc](#mrpc)
- [qnli](#qnli)
- [qqp](#qqp)
- [rte](#rte)
- [sst2](#sst2)
- [stsb](#stsb)
- [wnli](#wnli)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [ax](#ax-1)
- [cola](#cola-1)
- [mnli](#mnli-1)
- [mnli_matched](#mnli_matched-1)
- [mnli_mismatched](#mnli_mismatched-1)
- [mrpc](#mrpc-1)
- [qnli](#qnli-1)
- [qqp](#qqp-1)
- [rte](#rte-1)
- [sst2](#sst2-1)
- [stsb](#stsb-1)
- [wnli](#wnli-1)
- [Data Fields](#data-fields)
- [ax](#ax-2)
- [cola](#cola-2)
- [mnli](#mnli-2)
- [mnli_matched](#mnli_matched-2)
- [mnli_mismatched](#mnli_mismatched-2)
- [mrpc](#mrpc-2)
- [qnli](#qnli-2)
- [qqp](#qqp-2)
- [rte](#rte-2)
- [sst2](#sst2-2)
- [stsb](#stsb-2)
- [wnli](#wnli-2)
- [Data Splits](#data-splits)
- [ax](#ax-3)
- [cola](#cola-3)
- [mnli](#mnli-3)
- [mnli_matched](#mnli_matched-3)
- [mnli_mismatched](#mnli_mismatched-3)
- [mrpc](#mrpc-3)
- [qnli](#qnli-3)
- [qqp](#qqp-3)
- [rte](#rte-3)
- [sst2](#sst2-3)
- [stsb](#stsb-3)
- [wnli](#wnli-3)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Initial Data Collection and Normalization](#initial-data-collection-and-normalization)
- [Who are the source language producers?](#who-are-the-source-language-producers)
- [Annotations](#annotations)
- [Annotation process](#annotation-process)
- [Who are the annotators?](#who-are-the-annotators)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [https://nyu-mll.github.io/CoLA/](https://nyu-mll.github.io/CoLA/)
- **Repository:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Paper:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Point of Contact:** [More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
- **Size of downloaded dataset files:** 955.33 MB
- **Size of the generated dataset:** 229.68 MB
- **Total amount of disk used:** 1185.01 MB
### Dataset Summary
GLUE, the General Language Understanding Evaluation benchmark (https://gluebenchmark.com/) is a collection of resources for training, evaluating, and analyzing natural language understanding systems.
### Supported Tasks and Leaderboards
The leaderboard for the GLUE benchmark can be found [at this address](https://gluebenchmark.com/). It comprises the following tasks:
#### ax
A manually-curated evaluation dataset for fine-grained analysis of system performance on a broad range of linguistic phenomena. This dataset evaluates sentence understanding through Natural Language Inference (NLI) problems. Use a model trained on MulitNLI to produce predictions for this dataset.
#### cola
The Corpus of Linguistic Acceptability consists of English acceptability judgments drawn from books and journal articles on linguistic theory. Each example is a sequence of words annotated with whether it is a grammatical English sentence.
#### mnli
The Multi-Genre Natural Language Inference Corpus is a crowdsourced collection of sentence pairs with textual entailment annotations. Given a premise sentence and a hypothesis sentence, the task is to predict whether the premise entails the hypothesis (entailment), contradicts the hypothesis (contradiction), or neither (neutral). The premise sentences are gathered from ten different sources, including transcribed speech, fiction, and government reports. The authors of the benchmark use the standard test set, for which they obtained private labels from the RTE authors, and evaluate on both the matched (in-domain) and mismatched (cross-domain) section. They also uses and recommend the SNLI corpus as 550k examples of auxiliary training data.
#### mnli_matched
The matched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mnli_mismatched
The mismatched validation and test splits from MNLI. See the "mnli" BuilderConfig for additional information.
#### mrpc
The Microsoft Research Paraphrase Corpus (Dolan & Brockett, 2005) is a corpus of sentence pairs automatically extracted from online news sources, with human annotations for whether the sentences in the pair are semantically equivalent.
#### qnli
The Stanford Question Answering Dataset is a question-answering dataset consisting of question-paragraph pairs, where one of the sentences in the paragraph (drawn from Wikipedia) contains the answer to the corresponding question (written by an annotator). The authors of the benchmark convert the task into sentence pair classification by forming a pair between each question and each sentence in the corresponding context, and filtering out pairs with low lexical overlap between the question and the context sentence. The task is to determine whether the context sentence contains the answer to the question. This modified version of the original task removes the requirement that the model select the exact answer, but also removes the simplifying assumptions that the answer is always present in the input and that lexical overlap is a reliable cue.
#### qqp
The Quora Question Pairs2 dataset is a collection of question pairs from the community question-answering website Quora. The task is to determine whether a pair of questions are semantically equivalent.
#### rte
The Recognizing Textual Entailment (RTE) datasets come from a series of annual textual entailment challenges. The authors of the benchmark combined the data from RTE1 (Dagan et al., 2006), RTE2 (Bar Haim et al., 2006), RTE3 (Giampiccolo et al., 2007), and RTE5 (Bentivogli et al., 2009). Examples are constructed based on news and Wikipedia text. The authors of the benchmark convert all datasets to a two-class split, where for three-class datasets they collapse neutral and contradiction into not entailment, for consistency.
#### sst2
The Stanford Sentiment Treebank consists of sentences from movie reviews and human annotations of their sentiment. The task is to predict the sentiment of a given sentence. It uses the two-way (positive/negative) class split, with only sentence-level labels.
#### stsb
The Semantic Textual Similarity Benchmark (Cer et al., 2017) is a collection of sentence pairs drawn from news headlines, video and image captions, and natural language inference data. Each pair is human-annotated with a similarity score from 1 to 5.
#### wnli
The Winograd Schema Challenge (Levesque et al., 2011) is a reading comprehension task in which a system must read a sentence with a pronoun and select the referent of that pronoun from a list of choices. The examples are manually constructed to foil simple statistical methods: Each one is contingent on contextual information provided by a single word or phrase in the sentence. To convert the problem into sentence pair classification, the authors of the benchmark construct sentence pairs by replacing the ambiguous pronoun with each possible referent. The task is to predict if the sentence with the pronoun substituted is entailed by the original sentence. They use a small evaluation set consisting of new examples derived from fiction books that was shared privately by the authors of the original corpus. While the included training set is balanced between two classes, the test set is imbalanced between them (65% not entailment). Also, due to a data quirk, the development set is adversarial: hypotheses are sometimes shared between training and development examples, so if a model memorizes the training examples, they will predict the wrong label on corresponding development set example. As with QNLI, each example is evaluated separately, so there is not a systematic correspondence between a model's score on this task and its score on the unconverted original task. The authors of the benchmark call converted dataset WNLI (Winograd NLI).
### Languages
The language data in GLUE is in English (BCP-47 `en`)
## Dataset Structure
### Data Instances
#### ax
- **Size of downloaded dataset files:** 0.21 MB
- **Size of the generated dataset:** 0.23 MB
- **Total amount of disk used:** 0.44 MB
An example of 'test' looks as follows.
```
{
"premise": "The cat sat on the mat.",
"hypothesis": "The cat did not sit on the mat.",
"label": -1,
"idx: 0
}
```
#### cola
- **Size of downloaded dataset files:** 0.36 MB
- **Size of the generated dataset:** 0.58 MB
- **Total amount of disk used:** 0.94 MB
An example of 'train' looks as follows.
```
{
"sentence": "Our friends won't buy this analysis, let alone the next one we propose.",
"label": 1,
"id": 0
}
```
#### mnli
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 78.65 MB
- **Total amount of disk used:** 376.95 MB
An example of 'train' looks as follows.
```
{
"premise": "Conceptually cream skimming has two basic dimensions - product and geography.",
"hypothesis": "Product and geography are what make cream skimming work.",
"label": 1,
"idx": 0
}
```
#### mnli_matched
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 3.52 MB
- **Total amount of disk used:** 301.82 MB
An example of 'test' looks as follows.
```
{
"premise": "Hierbas, ans seco, ans dulce, and frigola are just a few names worth keeping a look-out for.",
"hypothesis": "Hierbas is a name worth looking out for.",
"label": -1,
"idx": 0
}
```
#### mnli_mismatched
- **Size of downloaded dataset files:** 298.29 MB
- **Size of the generated dataset:** 3.73 MB
- **Total amount of disk used:** 302.02 MB
An example of 'test' looks as follows.
```
{
"premise": "What have you decided, what are you going to do?",
"hypothesis": "So what's your decision?,
"label": -1,
"idx": 0
}
```
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Data Fields
The data fields are the same among all splits.
#### ax
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### cola
- `sentence`: a `string` feature.
- `label`: a classification label, with possible values including `unacceptable` (0), `acceptable` (1).
- `idx`: a `int32` feature.
#### mnli
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_matched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mnli_mismatched
- `premise`: a `string` feature.
- `hypothesis`: a `string` feature.
- `label`: a classification label, with possible values including `entailment` (0), `neutral` (1), `contradiction` (2).
- `idx`: a `int32` feature.
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Data Splits
#### ax
| |test|
|---|---:|
|ax |1104|
#### cola
| |train|validation|test|
|----|----:|---------:|---:|
|cola| 8551| 1043|1063|
#### mnli
| |train |validation_matched|validation_mismatched|test_matched|test_mismatched|
|----|-----:|-----------------:|--------------------:|-----------:|--------------:|
|mnli|392702| 9815| 9832| 9796| 9847|
#### mnli_matched
| |validation|test|
|------------|---------:|---:|
|mnli_matched| 9815|9796|
#### mnli_mismatched
| |validation|test|
|---------------|---------:|---:|
|mnli_mismatched| 9832|9847|
#### mrpc
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### qqp
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### rte
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### sst2
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### stsb
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### wnli
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Dataset Creation
### Curation Rationale
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the source language producers?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Annotations
#### Annotation process
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
#### Who are the annotators?
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Personal and Sensitive Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Discussion of Biases
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Other Known Limitations
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
## Additional Information
### Dataset Curators
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Licensing Information
[More Information Needed](https://github.com/huggingface/datasets/blob/master/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
### Citation Information
```
@article{warstadt2018neural,
title={Neural Network Acceptability Judgments},
author={Warstadt, Alex and Singh, Amanpreet and Bowman, Samuel R},
journal={arXiv preprint arXiv:1805.12471},
year={2018}
}
@inproceedings{wang2019glue,
title={{GLUE}: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding},
author={Wang, Alex and Singh, Amanpreet and Michael, Julian and Hill, Felix and Levy, Omer and Bowman, Samuel R.},
note={In the Proceedings of ICLR.},
year={2019}
}
Note that each GLUE dataset has its own citation. Please see the source to see
the correct citation for each contained dataset.
```
### Contributions
Thanks to [@patpizio](https://github.com/patpizio), [@jeswan](https://github.com/jeswan), [@thomwolf](https://github.com/thomwolf), [@patrickvonplaten](https://github.com/patrickvonplaten), [@mariamabarham](https://github.com/mariamabarham) for adding this dataset.
|
asoria/glue-test
|
[
"task_categories:text-classification",
"task_ids:acceptability-classification",
"task_ids:natural-language-inference",
"task_ids:semantic-similarity-scoring",
"task_ids:sentiment-classification",
"task_ids:text-scoring",
"annotations_creators:other",
"language_creators:other",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:original",
"language:en",
"license:cc-by-4.0",
"qa-nli",
"coreference-nli",
"paraphrase-identification",
"region:us"
] |
2023-05-19T14:54:11+00:00
|
{"annotations_creators": ["other"], "language_creators": ["other"], "language": ["en"], "license": ["cc-by-4.0"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["original"], "task_categories": ["text-classification"], "task_ids": ["acceptability-classification", "natural-language-inference", "semantic-similarity-scoring", "sentiment-classification", "text-scoring"], "paperswithcode_id": "glue", "pretty_name": "GLUE (General Language Understanding Evaluation benchmark)", "configs": ["ax", "cola", "mnli", "mnli_matched", "mnli_mismatched", "mrpc", "qnli", "qqp", "rte", "sst2", "stsb", "wnli"], "tags": ["qa-nli", "coreference-nli", "paraphrase-identification"], "train-eval-index": [{"config": "cola", "task": "text-classification", "task_id": "binary_classification", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence": "text", "label": "target"}}, {"config": "sst2", "task": "text-classification", "task_id": "binary_classification", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence": "text", "label": "target"}}, {"config": "mrpc", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence1": "text1", "sentence2": "text2", "label": "target"}}, {"config": "qqp", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"question1": "text1", "question2": "text2", "label": "target"}}, {"config": "stsb", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence1": "text1", "sentence2": "text2", "label": "target"}}, {"config": "mnli", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation_matched"}, "col_mapping": {"premise": "text1", "hypothesis": "text2", "label": "target"}}, {"config": "mnli_mismatched", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"premise": "text1", "hypothesis": "text2", "label": "target"}}, {"config": "mnli_matched", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"premise": "text1", "hypothesis": "text2", "label": "target"}}, {"config": "qnli", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"question": "text1", "sentence": "text2", "label": "target"}}, {"config": "rte", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence1": "text1", "sentence2": "text2", "label": "target"}}, {"config": "wnli", "task": "text-classification", "task_id": "natural_language_inference", "splits": {"train_split": "train", "eval_split": "validation"}, "col_mapping": {"sentence1": "text1", "sentence2": "text2", "label": "target"}}]}
|
2023-06-06T19:24:19+00:00
|
2321c4bcc00de0ab0bbd2ed29261842e68d93b58
|
# Dataset Card for MNIST
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** http://yann.lecun.com/exdb/mnist/
- **Repository:**
- **Paper:** MNIST handwritten digit database by Yann LeCun, Corinna Cortes, and CJ Burges
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The MNIST dataset consists of 70,000 28x28 black-and-white images of handwritten digits extracted from two NIST databases. There are 60,000 images in the training dataset and 10,000 images in the validation dataset, one class per digit so a total of 10 classes, with 7,000 images (6,000 train images and 1,000 test images) per class.
Half of the image were drawn by Census Bureau employees and the other half by high school students (this split is evenly distributed in the training and testing sets).
### Supported Tasks and Leaderboards
- `image-classification`: The goal of this task is to classify a given image of a handwritten digit into one of 10 classes representing integer values from 0 to 9, inclusively. The leaderboard is available [here](https://paperswithcode.com/sota/image-classification-on-mnist).
### Languages
English
## Dataset Structure
### Data Instances
A data point comprises an image and its label:
```
{
'image': <PIL.PngImagePlugin.PngImageFile image mode=L size=28x28 at 0x276021F6DD8>,
'label': 5
}
```
### Data Fields
- `image`: A `PIL.Image.Image` object containing the 28x28 image. Note that when accessing the image column: `dataset[0]["image"]` the image file is automatically decoded. Decoding of a large number of image files might take a significant amount of time. Thus it is important to first query the sample index before the `"image"` column, *i.e.* `dataset[0]["image"]` should **always** be preferred over `dataset["image"][0]`
- `label`: an integer between 0 and 9 representing the digit.
### Data Splits
The data is split into training and test set. All the images in the test set were drawn by different individuals than the images in the training set. The training set contains 60,000 images and the test set 10,000 images.
## Dataset Creation
### Curation Rationale
The MNIST database was created to provide a testbed for people wanting to try pattern recognition methods or machine learning algorithms while spending minimal efforts on preprocessing and formatting. Images of the original dataset (NIST) were in two groups, one consisting of images drawn by Census Bureau employees and one consisting of images drawn by high school students. In NIST, the training set was built by grouping all the images of the Census Bureau employees, and the test set was built by grouping the images form the high school students.
The goal in building MNIST was to have a training and test set following the same distributions, so the training set contains 30,000 images drawn by Census Bureau employees and 30,000 images drawn by high school students, and the test set contains 5,000 images of each group. The curators took care to make sure all the images in the test set were drawn by different individuals than the images in the training set.
### Source Data
#### Initial Data Collection and Normalization
The original images from NIST were size normalized to fit a 20x20 pixel box while preserving their aspect ratio. The resulting images contain grey levels (i.e., pixels don't simply have a value of black and white, but a level of greyness from 0 to 255) as a result of the anti-aliasing technique used by the normalization algorithm. The images were then centered in a 28x28 image by computing the center of mass of the pixels, and translating the image so as to position this point at the center of the 28x28 field.
#### Who are the source language producers?
Half of the source images were drawn by Census Bureau employees, half by high school students. According to the dataset curator, the images from the first group are more easily recognizable.
### Annotations
#### Annotation process
The images were not annotated after their creation: the image creators annotated their images with the corresponding label after drawing them.
#### Who are the annotators?
Same as the source data creators.
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
Chris Burges, Corinna Cortes and Yann LeCun
### Licensing Information
MIT Licence
### Citation Information
```
@article{lecun2010mnist,
title={MNIST handwritten digit database},
author={LeCun, Yann and Cortes, Corinna and Burges, CJ},
journal={ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist},
volume={2},
year={2010}
}
```
### Contributions
Thanks to [@sgugger](https://github.com/sgugger) for adding this dataset.
|
asoria/mnist
|
[
"task_categories:image-classification",
"task_ids:multi-class-image-classification",
"annotations_creators:expert-generated",
"language_creators:found",
"multilinguality:monolingual",
"size_categories:10K<n<100K",
"source_datasets:extended|other-nist",
"language:en",
"license:mit",
"region:us"
] |
2023-05-19T14:57:36+00:00
|
{"annotations_creators": ["expert-generated"], "language_creators": ["found"], "language": ["en"], "license": ["mit"], "multilinguality": ["monolingual"], "size_categories": ["10K<n<100K"], "source_datasets": ["extended|other-nist"], "task_categories": ["image-classification"], "task_ids": ["multi-class-image-classification"], "paperswithcode_id": "mnist", "pretty_name": "MNIST", "dataset_info": {"features": [{"name": "image", "dtype": "image"}, {"name": "label", "dtype": {"class_label": {"names": {"0": "0", "1": "1", "2": "2", "3": "3", "4": "4", "5": "5", "6": "6", "7": "7", "8": "8", "9": "9"}}}}], "config_name": "mnist", "splits": [{"name": "test", "num_bytes": 2916440, "num_examples": 10000}, {"name": "train", "num_bytes": 17470848, "num_examples": 60000}], "download_size": 11594722, "dataset_size": 20387288}}
|
2023-05-19T14:57:56+00:00
|
e854b9a7a722d9c630051f7e1624a5239d4ba486
|
AntonioRenatoMontefusco/kddChallenge2023
|
[
"task_categories:text-generation",
"size_categories:1M<n<10M",
"language:it",
"language:en",
"language:ja",
"language:fr",
"language:de",
"language:es",
"license:cc-by-nc-2.0",
"code",
"region:us"
] |
2023-05-19T15:07:50+00:00
|
{"language": ["it", "en", "ja", "fr", "de", "es"], "license": "cc-by-nc-2.0", "size_categories": ["1M<n<10M"], "task_categories": ["text-generation"], "pretty_name": "KDD2023", "tags": ["code"]}
|
2023-05-22T17:58:07+00:00
|
|
388ea1e836789acc2b7193223f2383d9d7663726
|
# Dataset Card for "gpt-roleplay-realm-chatml"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
AlekseyKorshuk/gpt-roleplay-realm-chatml
|
[
"region:us"
] |
2023-05-19T15:44:29+00:00
|
{"dataset_info": {"features": [{"name": "conversation", "list": [{"name": "content", "dtype": "string"}, {"name": "do_train", "dtype": "bool"}, {"name": "role", "dtype": "string"}]}], "splits": [{"name": "train", "num_bytes": 9428391, "num_examples": 4536}], "download_size": 3208011, "dataset_size": 9428391}}
|
2023-06-07T18:30:46+00:00
|
cb2023f0a88b1f4ba1658d4a6287759532124914
|
# Dataset Card for "final_dataset_500hrs_wer0"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
linhtran92/final_dataset_500hrs_wer0
|
[
"region:us"
] |
2023-05-19T16:05:54+00:00
|
{"dataset_info": {"features": [{"name": "audio", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "transcription", "dtype": "string"}, {"name": "w2v2_transcription", "dtype": "string"}, {"name": "WER", "dtype": "int64"}, {"name": "sum", "dtype": "float64"}], "splits": [{"name": "train", "num_bytes": 53343847999.09473, "num_examples": 649158}], "download_size": 52703888744, "dataset_size": 53343847999.09473}}
|
2023-05-19T19:01:49+00:00
|
cb76a5fa8bc3cb404ceb875c125f382ccf933ad9
|
# Dataset Card for "zindi_test"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
Ru3ll/zindi_test
|
[
"region:us"
] |
2023-05-19T16:32:53+00:00
|
{"dataset_info": {"features": [{"name": "audio_paths", "dtype": {"audio": {"sampling_rate": 16000}}}, {"name": "ID", "dtype": "string"}], "splits": [{"name": "train", "num_bytes": 10452392634.544, "num_examples": 6318}], "download_size": 9044328275, "dataset_size": 10452392634.544}}
|
2023-05-19T18:00:36+00:00
|
40812592409095fcf7ec9a327ca0e2c59160c6cb
|
soteroshanthi/courses-dataset
|
[
"license:apache-2.0",
"region:us"
] |
2023-05-19T17:29:30+00:00
|
{"license": "apache-2.0"}
|
2023-05-19T18:40:26+00:00
|
|
3390ec751f76a63fd5d0229b97c66675b9e2890f
|
# zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024
This dataset is a part of the `zh-tw-llm` project.
* Tokenizer: `zh-tw-pythia-tokenizer-a8000-v1`
* Built with: `translations`, `sharegpt`
* Rows: `train` `306319`, `test` `200`
* Max length: `1024`
* Full config:
```json
{"build_with": ["translations", "sharegpt"], "preview_length": 128, "translations_settings": {"source_dataset": "zetavg/coct-en-zh-tw-translations-twp-300k", "lang_1_key": "en", "lang_2_key": "ch", "templates": ["English: {lang_1}\nChinese: {lang_2}", "Chinese: {lang_2}\nEnglish: {lang_1}"], "use_template": "random", "rows_limit": 300000, "test_size": 100, "test_split_seed": 42}, "sharegpt_settings": {"source_dataset": "zetavg/ShareGPT-Processed", "train_on_inputs": false, "languages": [{"en": 0.4}, "zh_Hant"], "rows_limit": 8000, "test_size": 0.02, "test_split_seed": 42, "test_rows_limit": 100}}
```
|
zh-tw-llm-dv/zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024
|
[
"region:us"
] |
2023-05-19T17:35:56+00:00
|
{"dataset_info": {"dataset_size": 442704996.0, "download_size": 177974029, "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}, {"dtype": "string", "name": "preview"}], "splits": [{"name": "train", "num_bytes": 441717119.0, "num_examples": 306319}, {"name": "test", "num_bytes": 987877.0, "num_examples": 200}]}}
|
2023-05-19T17:37:52+00:00
|
a1e2a3c8caf09667e693d32c9ba885d93777021c
|
Mikecyane/kinn
|
[
"license:openrail",
"region:us"
] |
2023-05-19T17:49:10+00:00
|
{"license": "openrail"}
|
2023-05-19T17:49:10+00:00
|
|
f67ae8dedee6bb83e7523f6ce3b715a12147a200
|
# Dataset Card for CIFAKE_autotrain_compatible
## Dataset Description
- **Homepage:** [Kaggle data card](https://www.kaggle.com/datasets/birdy654/cifake-real-and-ai-generated-synthetic-images?resource=download)
- **Paper:** Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images.
### Dataset Summary
This is a copy of the CIFAKE dataset created by Dr Jordan J. Bird and Professor Ahmad Lotfi. See more information on the original data card on [Kaggle](https://www.kaggle.com/datasets/birdy654/cifake-real-and-ai-generated-synthetic-images?resource=download).
The real images used are from CIFAR-10. The fake images were created by the authors using Stable Diffusion v1.4.
This dataset removes the train/test structures in the original dataset to allow compatibility with HuggingFace's AutoTrain. It removes the test split images from the original dataset in both categories. All training images remain.
## Dataset Structure
### Data Fields
Contains 100k total images per splits below.
### Data Splits
Real: 50k real images
Fake: 50k AI generated images
## Additional Information
### Dataset Curators
Dr Jordan J. Bird
Professor Ahmad Lotfi
### Licensing Information
This dataset is published under the [same MIT license as CIFAR-10](https://github.com/wichtounet/cifar-10/blob/master/LICENSE):
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
### Citation Information
If you use this dataset, you must cite the following sources:
[Krizhevsky, A., & Hinton, G. (2009). Learning multiple layers of features from tiny images.](https://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdfl)
[Bird, J.J., Lotfi, A. (2023). CIFAKE: Image Classification and Explainable Identification of AI-Generated Synthetic Images. arXiv preprint arXiv:2303.14126.](https://arxiv.org/abs/2303.14126)
Real images are from Krizhevsky & Hinton (2009), fake images are from Bird & Lotfi (2023). The Bird & Lotfi study is a preprint currently available on ArXiv and this description will be updated when the paper is published.
|
yanbax/CIFAKE_autotrain_compatible
|
[
"task_categories:image-classification",
"size_categories:10K<n<100K",
"license:mit",
"arxiv:2303.14126",
"region:us"
] |
2023-05-19T18:09:22+00:00
|
{"license": "mit", "size_categories": ["10K<n<100K"], "task_categories": ["image-classification"]}
|
2023-05-19T18:57:01+00:00
|
db174cf81eb8986ba1fb7cf76b36288c1f1fd5c9
|
# zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt1
This dataset is a part of the `zh-tw-llm` project.
* Tokenizer: `zh-tw-pythia-tokenizer-a8000-v1`
* Built with: `sharegpt`
* Rows: `train` `6156`, `test` `97`
* Max length: `1024`
* Full config:
```json
{"build_with": ["sharegpt"], "preview_length": 128, "sort_by": "length-desc", "translations_settings": {"source_dataset": "zetavg/coct-en-zh-tw-translations-twp-300k", "lang_1_key": "en", "lang_2_key": "ch", "templates": ["English: {lang_1}\nChinese: {lang_2}", "Chinese: {lang_2}\nEnglish: {lang_1}"], "use_template": "random", "rows_limit": 300000, "test_size": 100, "test_split_seed": 42}, "sharegpt_settings": {"source_dataset": "zetavg/ShareGPT-Processed", "train_on_inputs": false, "languages": [{"en": 0.4}, "zh_Hant"], "rows_limit": 8000, "test_size": 0.02, "test_split_seed": 42, "test_rows_limit": 100}}
```
|
zh-tw-llm-dv/zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt1
|
[
"region:us"
] |
2023-05-19T19:02:46+00:00
|
{"dataset_info": {"dataset_size": 54170374.219814844, "download_size": 15314618, "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}, {"dtype": "string", "name": "preview"}, {"dtype": "int64", "name": "length"}], "splits": [{"name": "train", "num_bytes": 53254784.429814845, "num_examples": 6156}, {"name": "test", "num_bytes": 915589.79, "num_examples": 97}]}}
|
2023-05-19T19:13:39+00:00
|
7b879b784d337f6a0bde1927425e5700fe557ae4
|
# Dataset Card for "chunk_63"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_63
|
[
"region:us"
] |
2023-05-19T19:06:01+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1110575384, "num_examples": 218102}], "download_size": 1123394519, "dataset_size": 1110575384}}
|
2023-05-19T19:06:59+00:00
|
c2efddc3b214447972c3e0b61f8556159ac3afe2
|
# Dataset Card for "chunk_65"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_65
|
[
"region:us"
] |
2023-05-19T19:07:47+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1200601944, "num_examples": 235782}], "download_size": 1220462426, "dataset_size": 1200601944}}
|
2023-05-19T19:08:45+00:00
|
8d23d7090d0d9872dd0e1350b8cc6869adf56b7b
|
# zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt2
This dataset is a part of the `zh-tw-llm` project.
* Tokenizer: `zh-tw-pythia-tokenizer-a8000-v1`
* Built with: `sharegpt`
* Rows: `train` `6133`, `test` `97`
* Max length: `1024`
* Full config:
```json
{"build_with": ["sharegpt"], "preview_length": 128, "sort_by": "length-desc", "translations_settings": {"source_dataset": "zetavg/coct-en-zh-tw-translations-twp-300k", "lang_1_key": "en", "lang_2_key": "ch", "templates": ["English: {lang_1}\nChinese: {lang_2}", "Chinese: {lang_2}\nEnglish: {lang_1}"], "use_template": "random", "rows_limit": 300000, "test_size": 100, "test_split_seed": 42}, "sharegpt_settings": {"source_dataset": "zetavg/ShareGPT-Processed", "train_on_inputs": false, "languages": [{"en": 0.4}, "zh_Hant"], "rows_limit": 8000, "test_size": 0.02, "test_split_seed": 42, "test_rows_limit": 100}}
```
|
zh-tw-llm-dv/zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt2
|
[
"region:us"
] |
2023-05-19T19:15:29+00:00
|
{"dataset_info": {"dataset_size": 53808823.79506409, "download_size": 15215886, "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}, {"dtype": "string", "name": "preview"}, {"dtype": "int64", "name": "length"}], "splits": [{"name": "train", "num_bytes": 52893234.00506409, "num_examples": 6133}, {"name": "test", "num_bytes": 915589.79, "num_examples": 97}]}}
|
2023-05-19T19:15:52+00:00
|
f98d08d33c0d54a1aaf9a2ed04e05f2329e480d8
|
# Dataset Card for "chunk_74"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_74
|
[
"region:us"
] |
2023-05-19T19:15:34+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1274242448, "num_examples": 250244}], "download_size": 1299212227, "dataset_size": 1274242448}}
|
2023-05-19T19:16:29+00:00
|
8ce3b4a21a7c1eb0ff109b44ed5d006782ab7a17
|
# Dataset Card for "chunk_73"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_73
|
[
"region:us"
] |
2023-05-19T19:15:46+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1308822220, "num_examples": 257035}], "download_size": 1334313748, "dataset_size": 1308822220}}
|
2023-05-19T19:18:06+00:00
|
3cf4ce092dedec14660d41ff9c9f1d2a681d7e3e
|
# Dataset Card for "chunk_78"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_78
|
[
"region:us"
] |
2023-05-19T19:16:52+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1270846084, "num_examples": 249577}], "download_size": 1297694020, "dataset_size": 1270846084}}
|
2023-05-19T19:17:34+00:00
|
6e5fab43f7404012327bd7392f8e7a777cb6bd99
|
# Dataset Card for "chunk_76"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_76
|
[
"region:us"
] |
2023-05-19T19:17:18+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1270133204, "num_examples": 249437}], "download_size": 1296517927, "dataset_size": 1270133204}}
|
2023-05-19T19:18:00+00:00
|
4d49f3eb8c549a267c5168f3ae4ceefe364b8a5a
|
# zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt3
This dataset is a part of the `zh-tw-llm` project.
* Tokenizer: `zh-tw-pythia-tokenizer-a8000-v1`
* Built with: `sharegpt`
* Rows: `train` `6155`, `test` `97`
* Max length: `1024`
* Full config:
```json
{"build_with": ["sharegpt"], "preview_length": 128, "sort_by": "length-desc", "translations_settings": {"source_dataset": "zetavg/coct-en-zh-tw-translations-twp-300k", "lang_1_key": "en", "lang_2_key": "ch", "templates": ["English: {lang_1}\nChinese: {lang_2}", "Chinese: {lang_2}\nEnglish: {lang_1}"], "use_template": "random", "rows_limit": 300000, "test_size": 100, "test_split_seed": 42}, "sharegpt_settings": {"source_dataset": "zetavg/ShareGPT-Processed", "train_on_inputs": false, "languages": [{"en": 0.4}, "zh_Hant"], "rows_limit": 8000, "test_size": 0.02, "test_split_seed": 42, "test_rows_limit": 100}}
```
|
zh-tw-llm-dv/zh-tw-pythia-ta8000-v1-e1-tr_sg-301-c1024-sbldt3
|
[
"region:us"
] |
2023-05-19T19:20:35+00:00
|
{"dataset_info": {"dataset_size": 54222354.81927678, "download_size": 15275408, "features": [{"name": "input_ids", "sequence": "int32"}, {"name": "attention_mask", "sequence": "int8"}, {"name": "labels", "sequence": "int64"}, {"dtype": "string", "name": "preview"}, {"dtype": "int64", "name": "length"}], "splits": [{"name": "train", "num_bytes": 53306765.02927678, "num_examples": 6155}, {"name": "test", "num_bytes": 915589.79, "num_examples": 97}]}}
|
2023-05-19T19:20:59+00:00
|
ca9d9474e889943f43e71dd96c93b3ed551a2493
|
# Dataset Card for "chunk_72"
[More Information needed](https://github.com/huggingface/datasets/blob/main/CONTRIBUTING.md#how-to-contribute-to-the-dataset-cards)
|
mask-distilled-one-sec-cv12/chunk_72
|
[
"region:us"
] |
2023-05-19T19:22:54+00:00
|
{"dataset_info": {"features": [{"name": "logits", "sequence": "float32"}, {"name": "mfcc", "sequence": {"sequence": "float64"}}], "splits": [{"name": "train", "num_bytes": 1324225520, "num_examples": 260060}], "download_size": 1349812494, "dataset_size": 1324225520}}
|
2023-05-19T19:23:33+00:00
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.