
pipeline_tag
stringclasses 48
values | library_name
stringclasses 198
values | text
stringlengths 1
900k
| metadata
stringlengths 2
438k
| id
stringlengths 5
122
| last_modified
null | tags
listlengths 1
1.84k
| sha
null | created_at
stringlengths 25
25
| arxiv
listlengths 0
201
| languages
listlengths 0
1.83k
| tags_str
stringlengths 17
9.34k
| text_str
stringlengths 0
389k
| text_lists
listlengths 0
722
| processed_texts
listlengths 1
723
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
text2text-generation
|
transformers
|
This model is used in the paper **Generative Relation Linking for Question Answering over Knowledge Bases**. [ArXiv](https://arxiv.org/abs/2108.07337), [GitHub](https://github.com/IBM/kbqa-relation-linking)
## Citation
```bibtex
@inproceedings{rossiello-genrl-2021,
title={Generative relation linking for question answering over knowledge bases},
author={Rossiello, Gaetano and Mihindukulasooriya, Nandana and Abdelaziz, Ibrahim and Bornea, Mihaela and Gliozzo, Alfio and Naseem, Tahira and Kapanipathi, Pavan},
booktitle={International Semantic Web Conference},
pages={321--337},
year={2021},
organization={Springer},
url = "https://link.springer.com/chapter/10.1007/978-3-030-88361-4_19",
doi = "10.1007/978-3-030-88361-4_19"
}
```
|
{"license": "apache-2.0"}
|
gaetangate/bart-large_genrl_lcquad1
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"arxiv:2108.07337",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2108.07337"
] |
[] |
TAGS
#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
This model is used in the paper Generative Relation Linking for Question Answering over Knowledge Bases. ArXiv, GitHub
|
[] |
[
"TAGS\n#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
text2text-generation
|
transformers
|
This model is used in the paper **Generative Relation Linking for Question Answering over Knowledge Bases**. [ArXiv](https://arxiv.org/abs/2108.07337), [GitHub](https://github.com/IBM/kbqa-relation-linking)
## Citation
```bibtex
@inproceedings{rossiello-genrl-2021,
title={Generative relation linking for question answering over knowledge bases},
author={Rossiello, Gaetano and Mihindukulasooriya, Nandana and Abdelaziz, Ibrahim and Bornea, Mihaela and Gliozzo, Alfio and Naseem, Tahira and Kapanipathi, Pavan},
booktitle={International Semantic Web Conference},
pages={321--337},
year={2021},
organization={Springer},
url = "https://link.springer.com/chapter/10.1007/978-3-030-88361-4_19",
doi = "10.1007/978-3-030-88361-4_19"
}
```
|
{"license": "apache-2.0"}
|
gaetangate/bart-large_genrl_lcquad2
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"arxiv:2108.07337",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2108.07337"
] |
[] |
TAGS
#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
This model is used in the paper Generative Relation Linking for Question Answering over Knowledge Bases. ArXiv, GitHub
|
[] |
[
"TAGS\n#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
text2text-generation
|
transformers
|
This model is used in the paper **Generative Relation Linking for Question Answering over Knowledge Bases**. [ArXiv](https://arxiv.org/abs/2108.07337), [GitHub](https://github.com/IBM/kbqa-relation-linking)
## Citation
```bibtex
@inproceedings{rossiello-genrl-2021,
title={Generative relation linking for question answering over knowledge bases},
author={Rossiello, Gaetano and Mihindukulasooriya, Nandana and Abdelaziz, Ibrahim and Bornea, Mihaela and Gliozzo, Alfio and Naseem, Tahira and Kapanipathi, Pavan},
booktitle={International Semantic Web Conference},
pages={321--337},
year={2021},
organization={Springer},
url = "https://link.springer.com/chapter/10.1007/978-3-030-88361-4_19",
doi = "10.1007/978-3-030-88361-4_19"
}
```
|
{"license": "apache-2.0"}
|
gaetangate/bart-large_genrl_qald9
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"arxiv:2108.07337",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2108.07337"
] |
[] |
TAGS
#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
This model is used in the paper Generative Relation Linking for Question Answering over Knowledge Bases. ArXiv, GitHub
|
[] |
[
"TAGS\n#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
text2text-generation
|
transformers
|
This model is used in the paper **Generative Relation Linking for Question Answering over Knowledge Bases**. [ArXiv](https://arxiv.org/abs/2108.07337), [GitHub](https://github.com/IBM/kbqa-relation-linking)
## Citation
```bibtex
@inproceedings{rossiello-genrl-2021,
title={Generative relation linking for question answering over knowledge bases},
author={Rossiello, Gaetano and Mihindukulasooriya, Nandana and Abdelaziz, Ibrahim and Bornea, Mihaela and Gliozzo, Alfio and Naseem, Tahira and Kapanipathi, Pavan},
booktitle={International Semantic Web Conference},
pages={321--337},
year={2021},
organization={Springer},
url = "https://link.springer.com/chapter/10.1007/978-3-030-88361-4_19",
doi = "10.1007/978-3-030-88361-4_19"
}
```
|
{"license": "apache-2.0"}
|
gaetangate/bart-large_genrl_simpleq
| null |
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"arxiv:2108.07337",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2108.07337"
] |
[] |
TAGS
#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
This model is used in the paper Generative Relation Linking for Question Answering over Knowledge Bases. ArXiv, GitHub
|
[] |
[
"TAGS\n#transformers #pytorch #bart #text2text-generation #arxiv-2108.07337 #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n"
] |
null | null |
test 123
|
{}
|
gaga42gaga42/test
| null |
[
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#region-us
|
test 123
|
[] |
[
"TAGS\n#region-us \n"
] |
text-generation
|
transformers
|
# Generating Right Wing News Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data from FOX news
### My model can be accessed at gagan3012/Fox-News-Generator
Check the [BenchmarkTest](https://github.com/gagan3012/Fox-News-Generator/blob/master/BenchmarkTest.ipynb) notebook for results
Find the model at [gagan3012/Fox-News-Generator](https://huggingface.co/gagan3012/Fox-News-Generator)
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/Fox-News-Generator")
model = AutoModelWithLMHead.from_pretrained("gagan3012/Fox-News-Generator")
```
|
{}
|
gagan3012/Fox-News-Generator
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Generating Right Wing News Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data from FOX news
### My model can be accessed at gagan3012/Fox-News-Generator
Check the BenchmarkTest notebook for results
Find the model at gagan3012/Fox-News-Generator
|
[
"# Generating Right Wing News Using GPT2",
"### I have built a custom model for it using data from Kaggle \n\nCreating a new finetuned model using data from FOX news",
"### My model can be accessed at gagan3012/Fox-News-Generator\n\nCheck the BenchmarkTest notebook for results\n\nFind the model at gagan3012/Fox-News-Generator"
] |
[
"TAGS\n#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# Generating Right Wing News Using GPT2",
"### I have built a custom model for it using data from Kaggle \n\nCreating a new finetuned model using data from FOX news",
"### My model can be accessed at gagan3012/Fox-News-Generator\n\nCheck the BenchmarkTest notebook for results\n\nFind the model at gagan3012/Fox-News-Generator"
] |
null |
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ViTGPT2I2A
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the vizwiz dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0708
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 4
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.1528 | 0.17 | 1000 | 0.0869 |
| 0.0899 | 0.34 | 2000 | 0.0817 |
| 0.084 | 0.51 | 3000 | 0.0790 |
| 0.0814 | 0.68 | 4000 | 0.0773 |
| 0.0803 | 0.85 | 5000 | 0.0757 |
| 0.077 | 1.02 | 6000 | 0.0745 |
| 0.0739 | 1.19 | 7000 | 0.0740 |
| 0.0719 | 1.37 | 8000 | 0.0737 |
| 0.0717 | 1.54 | 9000 | 0.0730 |
| 0.0731 | 1.71 | 10000 | 0.0727 |
| 0.0708 | 1.88 | 11000 | 0.0720 |
| 0.0697 | 2.05 | 12000 | 0.0717 |
| 0.0655 | 2.22 | 13000 | 0.0719 |
| 0.0653 | 2.39 | 14000 | 0.0719 |
| 0.0657 | 2.56 | 15000 | 0.0712 |
| 0.0663 | 2.73 | 16000 | 0.0710 |
| 0.0654 | 2.9 | 17000 | 0.0708 |
| 0.0645 | 3.07 | 18000 | 0.0716 |
| 0.0616 | 3.24 | 19000 | 0.0712 |
| 0.0607 | 3.41 | 20000 | 0.0712 |
| 0.0611 | 3.58 | 21000 | 0.0711 |
| 0.0615 | 3.76 | 22000 | 0.0711 |
| 0.0614 | 3.93 | 23000 | 0.0710 |
| 0.0594 | 4.1 | 24000 | 0.0716 |
| 0.0587 | 4.27 | 25000 | 0.0715 |
| 0.0574 | 4.44 | 26000 | 0.0715 |
| 0.0579 | 4.61 | 27000 | 0.0715 |
| 0.0581 | 4.78 | 28000 | 0.0715 |
| 0.0579 | 4.95 | 29000 | 0.0715 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
{"license": "apache-2.0", "tags": ["image-captioning", "generated_from_trainer"], "model-index": [{"name": "ViTGPT2I2A", "results": []}]}
|
gagan3012/ViTGPT2I2A
| null |
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"image-captioning",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #vision-encoder-decoder #image-captioning #generated_from_trainer #license-apache-2.0 #endpoints_compatible #has_space #region-us
|
ViTGPT2I2A
==========
This model is a fine-tuned version of google/vit-base-patch16-224-in21k on the vizwiz dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0708
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* distributed\_type: multi-GPU
* num\_devices: 2
* total\_train\_batch\_size: 4
* total\_eval\_batch\_size: 4
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.2
* Pytorch 1.10.2+cu113
* Datasets 1.18.3
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* total\\_train\\_batch\\_size: 4\n* total\\_eval\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.2+cu113\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #vision-encoder-decoder #image-captioning #generated_from_trainer #license-apache-2.0 #endpoints_compatible #has_space #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* total\\_train\\_batch\\_size: 4\n* total\\_eval\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.2+cu113\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
null |
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ViTGPT2_VW
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0771
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 4
- total_eval_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.1256 | 0.03 | 1000 | 0.0928 |
| 0.0947 | 0.07 | 2000 | 0.0897 |
| 0.0889 | 0.1 | 3000 | 0.0859 |
| 0.0888 | 0.14 | 4000 | 0.0842 |
| 0.0866 | 0.17 | 5000 | 0.0831 |
| 0.0852 | 0.2 | 6000 | 0.0819 |
| 0.0833 | 0.24 | 7000 | 0.0810 |
| 0.0835 | 0.27 | 8000 | 0.0802 |
| 0.081 | 0.31 | 9000 | 0.0796 |
| 0.0803 | 0.34 | 10000 | 0.0789 |
| 0.0814 | 0.38 | 11000 | 0.0785 |
| 0.0799 | 0.41 | 12000 | 0.0780 |
| 0.0786 | 0.44 | 13000 | 0.0776 |
| 0.0796 | 0.48 | 14000 | 0.0771 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu113
- Datasets 1.18.3
- Tokenizers 0.11.0
|
{"tags": ["generated_from_trainer"], "model-index": [{"name": "ViTGPT2_VW", "results": []}]}
|
gagan3012/ViTGPT2_VW
| null |
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"generated_from_trainer",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #endpoints_compatible #region-us
|
ViTGPT2\_VW
===========
This model is a fine-tuned version of [](URL on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0771
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 2
* eval\_batch\_size: 2
* seed: 42
* distributed\_type: multi-GPU
* num\_devices: 2
* total\_train\_batch\_size: 4
* total\_eval\_batch\_size: 4
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 1.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.16.2
* Pytorch 1.10.2+cu113
* Datasets 1.18.3
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* total\\_train\\_batch\\_size: 4\n* total\\_eval\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.2+cu113\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 2\n* eval\\_batch\\_size: 2\n* seed: 42\n* distributed\\_type: multi-GPU\n* num\\_devices: 2\n* total\\_train\\_batch\\_size: 4\n* total\\_eval\\_batch\\_size: 4\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 1.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.16.2\n* Pytorch 1.10.2+cu113\n* Datasets 1.18.3\n* Tokenizers 0.11.0"
] |
image-to-text
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# ViTGPT2_vizwiz
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0719
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.1207 | 0.07 | 1000 | 0.0906 |
| 0.0916 | 0.14 | 2000 | 0.0861 |
| 0.0879 | 0.2 | 3000 | 0.0840 |
| 0.0856 | 0.27 | 4000 | 0.0822 |
| 0.0834 | 0.34 | 5000 | 0.0806 |
| 0.0817 | 0.41 | 6000 | 0.0795 |
| 0.0812 | 0.48 | 7000 | 0.0785 |
| 0.0808 | 0.55 | 8000 | 0.0779 |
| 0.0796 | 0.61 | 9000 | 0.0771 |
| 0.0786 | 0.68 | 10000 | 0.0767 |
| 0.0774 | 0.75 | 11000 | 0.0762 |
| 0.0772 | 0.82 | 12000 | 0.0758 |
| 0.0756 | 0.89 | 13000 | 0.0754 |
| 0.0759 | 0.96 | 14000 | 0.0750 |
| 0.0756 | 1.02 | 15000 | 0.0748 |
| 0.0726 | 1.09 | 16000 | 0.0745 |
| 0.0727 | 1.16 | 17000 | 0.0745 |
| 0.0715 | 1.23 | 18000 | 0.0742 |
| 0.0726 | 1.3 | 19000 | 0.0741 |
| 0.072 | 1.37 | 20000 | 0.0738 |
| 0.0723 | 1.43 | 21000 | 0.0735 |
| 0.0715 | 1.5 | 22000 | 0.0734 |
| 0.0724 | 1.57 | 23000 | 0.0732 |
| 0.0723 | 1.64 | 24000 | 0.0730 |
| 0.0718 | 1.71 | 25000 | 0.0729 |
| 0.07 | 1.78 | 26000 | 0.0728 |
| 0.0702 | 1.84 | 27000 | 0.0726 |
| 0.0704 | 1.91 | 28000 | 0.0725 |
| 0.0703 | 1.98 | 29000 | 0.0725 |
| 0.0686 | 2.05 | 30000 | 0.0726 |
| 0.0687 | 2.12 | 31000 | 0.0726 |
| 0.0688 | 2.19 | 32000 | 0.0724 |
| 0.0677 | 2.25 | 33000 | 0.0724 |
| 0.0665 | 2.32 | 34000 | 0.0725 |
| 0.0684 | 2.39 | 35000 | 0.0723 |
| 0.0678 | 2.46 | 36000 | 0.0722 |
| 0.0686 | 2.53 | 37000 | 0.0722 |
| 0.067 | 2.59 | 38000 | 0.0721 |
| 0.0669 | 2.66 | 39000 | 0.0721 |
| 0.0673 | 2.73 | 40000 | 0.0721 |
| 0.0673 | 2.8 | 41000 | 0.0720 |
| 0.0662 | 2.87 | 42000 | 0.0720 |
| 0.0681 | 2.94 | 43000 | 0.0719 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
{"tags": ["generated_from_trainer", "image-to-text"], "model-index": [{"name": "ViTGPT2_vizwiz", "results": []}]}
|
gagan3012/ViTGPT2_vizwiz
| null |
[
"transformers",
"pytorch",
"vision-encoder-decoder",
"generated_from_trainer",
"image-to-text",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #image-to-text #endpoints_compatible #has_space #region-us
|
ViTGPT2\_vizwiz
===============
This model is a fine-tuned version of [](URL on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0719
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* distributed\_type: multi-GPU
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2+cu102
* Datasets 1.18.2.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* distributed\\_type: multi-GPU\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #vision-encoder-decoder #generated_from_trainer #image-to-text #endpoints_compatible #has_space #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* distributed\\_type: multi-GPU\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
token-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-tiny-finetuned-ner
This model is a fine-tuned version of [prajjwal1/bert-tiny](https://huggingface.co/prajjwal1/bert-tiny) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1689
- Precision: 0.8083
- Recall: 0.8274
- F1: 0.8177
- Accuracy: 0.9598
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0355 | 1.0 | 878 | 0.1692 | 0.8072 | 0.8248 | 0.8159 | 0.9594 |
| 0.0411 | 2.0 | 1756 | 0.1678 | 0.8101 | 0.8277 | 0.8188 | 0.9600 |
| 0.0386 | 3.0 | 2634 | 0.1697 | 0.8103 | 0.8269 | 0.8186 | 0.9599 |
| 0.0373 | 4.0 | 3512 | 0.1694 | 0.8106 | 0.8263 | 0.8183 | 0.9600 |
| 0.0383 | 5.0 | 4390 | 0.1689 | 0.8083 | 0.8274 | 0.8177 | 0.9598 |
### Framework versions
- Transformers 4.10.0
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
{"tags": ["generated_from_trainer"], "datasets": ["conll2003"], "metrics": ["precision", "recall", "f1", "accuracy"], "model-index": [{"name": "bert-tiny-finetuned-ner", "results": [{"task": {"type": "token-classification", "name": "Token Classification"}, "dataset": {"name": "conll2003", "type": "conll2003", "args": "conll2003"}, "metrics": [{"type": "precision", "value": 0.8083060109289617, "name": "Precision"}, {"type": "recall", "value": 0.8273856136033113, "name": "Recall"}, {"type": "f1", "value": 0.8177345348001547, "name": "F1"}, {"type": "accuracy", "value": 0.9597597979252387, "name": "Accuracy"}]}]}]}
|
gagan3012/bert-tiny-finetuned-ner
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bert #token-classification #generated_from_trainer #dataset-conll2003 #model-index #autotrain_compatible #endpoints_compatible #has_space #region-us
|
bert-tiny-finetuned-ner
=======================
This model is a fine-tuned version of prajjwal1/bert-tiny on the conll2003 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.1689
* Precision: 0.8083
* Recall: 0.8274
* F1: 0.8177
* Accuracy: 0.9598
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5
### Training results
### Framework versions
* Transformers 4.10.0
* Pytorch 1.9.0+cu102
* Datasets 1.11.0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.0\n* Pytorch 1.9.0+cu102\n* Datasets 1.11.0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #token-classification #generated_from_trainer #dataset-conll2003 #model-index #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.0\n* Pytorch 1.9.0+cu102\n* Datasets 1.11.0\n* Tokenizers 0.10.3"
] |
token-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0614
- Precision: 0.9274
- Recall: 0.9363
- F1: 0.9319
- Accuracy: 0.9840
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2403 | 1.0 | 878 | 0.0701 | 0.9101 | 0.9202 | 0.9151 | 0.9805 |
| 0.0508 | 2.0 | 1756 | 0.0600 | 0.9220 | 0.9350 | 0.9285 | 0.9833 |
| 0.0301 | 3.0 | 2634 | 0.0614 | 0.9274 | 0.9363 | 0.9319 | 0.9840 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["conll2003"], "metrics": ["precision", "recall", "f1", "accuracy"], "model-index": [{"name": "distilbert-base-uncased-finetuned-ner", "results": [{"task": {"type": "token-classification", "name": "Token Classification"}, "dataset": {"name": "conll2003", "type": "conll2003", "args": "conll2003"}, "metrics": [{"type": "precision", "value": 0.9274238227146815, "name": "Precision"}, {"type": "recall", "value": 0.9363463474661595, "name": "Recall"}, {"type": "f1", "value": 0.9318637274549098, "name": "F1"}, {"type": "accuracy", "value": 0.9839865283492462, "name": "Accuracy"}]}]}]}
|
gagan3012/distilbert-base-uncased-finetuned-ner
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"token-classification",
"generated_from_trainer",
"dataset:conll2003",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #distilbert #token-classification #generated_from_trainer #dataset-conll2003 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
distilbert-base-uncased-finetuned-ner
=====================================
This model is a fine-tuned version of distilbert-base-uncased on the conll2003 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0614
* Precision: 0.9274
* Recall: 0.9363
* F1: 0.9319
* Accuracy: 0.9840
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3
### Training results
### Framework versions
* Transformers 4.10.2
* Pytorch 1.9.0+cu102
* Datasets 1.12.0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #distilbert #token-classification #generated_from_trainer #dataset-conll2003 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.10.2\n* Pytorch 1.9.0+cu102\n* Datasets 1.12.0\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
# keytotext

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
{"language": "en", "license": "mit", "tags": ["keytotext", "k2t-base", "Keywords to Sentences"], "datasets": ["WebNLG", "Dart"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t-base
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t-base",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #keytotext #k2t-base #Keywords to Sentences #en #dataset-WebNLG #dataset-Dart #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# keytotext
!keytotext (1)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface

## UI:
UI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: ](https://user-images.githubusercontent.com/49101362/116334480-f5e57a00-a7dd-11eb-987c-186477f94b6e.png)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
{"language": "en", "license": "mit", "tags": ["keytotext", "k2t", "Keywords to Sentences"], "datasets": ["common_gen"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t-new
| null |
[
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"keytotext",
"k2t",
"Keywords to Sentences",
"en",
"dataset:common_gen",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #jax #t5 #text2text-generation #keytotext #k2t #Keywords to Sentences #en #dataset-common_gen #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# keytotext
!keytotext (1)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface

## UI:
UI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: ](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/notebooks/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
[](https://github.com/gagan3012/keytotext#api)
[](https://hub.docker.com/r/gagan30/keytotext)
[](https://huggingface.co/models?filter=keytotext)
[](https://keytotext.readthedocs.io/en/latest/?badge=latest)
[](https://github.com/psf/black)

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
Potential use case can include:
- Marketing
- Search Engine Optimization
- Topic generation etc.
- Fine tuning of topic modeling models
|
{"language": "en", "license": "MIT", "tags": ["keytotext", "k2t", "Keywords to Sentences"], "datasets": ["WebNLG", "Dart"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t-test
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #keytotext #k2t #Keywords to Sentences #en #dataset-WebNLG #dataset-Dart #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
<h1 align="center">keytotext</h1>
](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/notebooks/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
[](https://github.com/gagan3012/keytotext#api)
[](https://hub.docker.com/r/gagan30/keytotext)
[](https://huggingface.co/models?filter=keytotext)
[](https://keytotext.readthedocs.io/en/latest/?badge=latest)
[](https://github.com/psf/black)

Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
Potential use case can include:
- Marketing
- Search Engine Optimization
- Topic generation etc.
- Fine tuning of topic modeling models
|
{"language": "en", "license": "MIT", "tags": ["keytotext", "k2t", "Keywords to Sentences"], "datasets": ["WebNLG", "Dart"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t-test3
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #keytotext #k2t #Keywords to Sentences #en #dataset-WebNLG #dataset-Dart #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
#keytotext
](https://user-images.githubusercontent.com/49101362/116334480-f5e57a00-a7dd-11eb-987c-186477f94b6e.png)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
{"language": "en", "license": "mit", "tags": ["keytotext", "k2t-tiny", "Keywords to Sentences"], "datasets": ["WebNLG", "Dart"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t-tiny
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t-tiny",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #keytotext #k2t-tiny #Keywords to Sentences #en #dataset-WebNLG #dataset-Dart #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# keytotext
!keytotext (1)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface

## UI:
UI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: ](https://user-images.githubusercontent.com/49101362/116334480-f5e57a00-a7dd-11eb-987c-186477f94b6e.png)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface 🤗
[](https://pypi.org/project/keytotext/)
[](https://pepy.tech/project/keytotext)
[](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
[](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
## Model:
Keytotext is based on the Amazing T5 Model:
- `k2t`: [Model](https://huggingface.co/gagan3012/k2t)
- `k2t-tiny`: [Model](https://huggingface.co/gagan3012/k2t-tiny)
- `k2t-base`: [Model](https://huggingface.co/gagan3012/k2t-base)
Training Notebooks can be found in the [`Training Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Training%20Notebooks) Folder
## Usage:
Example usage: [](https://colab.research.google.com/github/gagan3012/keytotext/blob/master/Examples/K2T.ipynb)
Example Notebooks can be found in the [`Notebooks`](https://github.com/gagan3012/keytotext/tree/master/Examples) Folder
```
pip install keytotext
```

## UI:
UI: [](https://share.streamlit.io/gagan3012/keytotext/UI/app.py)
```
pip install streamlit-tags
```
This uses a custom streamlit component built by me: [GitHub](https://github.com/gagan3012/streamlit-tags)

|
{"language": "en", "license": "mit", "tags": ["keytotext", "k2t", "Keywords to Sentences"], "datasets": ["WebNLG", "Dart"], "metrics": ["NLG"], "thumbnail": "Keywords to Sentences"}
|
gagan3012/k2t
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"keytotext",
"k2t",
"Keywords to Sentences",
"en",
"dataset:WebNLG",
"dataset:Dart",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #t5 #text2text-generation #keytotext #k2t #Keywords to Sentences #en #dataset-WebNLG #dataset-Dart #license-mit #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
# keytotext
!keytotext (1)
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Keytotext is powered by Huggingface

## UI:
UI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: \n\nIdea is to build a model which will take keywords as inputs and generate sentences as outputs.",
"### Keytotext is powered by Huggingface \n\n",
"## UI:\n\nUI: 
model = AutoModelWithLMHead.from_pretrained("gagan3012/keytotext-small")
```
### Demo:
[](https://share.streamlit.io/gagan3012/keytotext/app.py)
https://share.streamlit.io/gagan3012/keytotext/app.py

### Example:
['India', 'Wedding'] -> We are celebrating today in New Delhi with three wedding anniversary parties.
|
{}
|
gagan3012/keytotext-small
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #t5 #text2text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# keytotext
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Model:
Two Models have been built:
- Using T5-base size = 850 MB can be found here: URL
- Using T5-small size = 230 MB can be found here: URL
#### Usage:
### Demo:

model = AutoModelWithLMHead.from_pretrained("gagan3012/keytotext-small")
```
### Demo:
[](https://share.streamlit.io/gagan3012/keytotext/app.py)
https://share.streamlit.io/gagan3012/keytotext/app.py

### Example:
['India', 'Wedding'] -> We are celebrating today in New Delhi with three wedding anniversary parties.
|
{}
|
gagan3012/keytotext
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #t5 #text2text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# keytotext
Idea is to build a model which will take keywords as inputs and generate sentences as outputs.
### Model:
Two Models have been built:
- Using T5-base size = 850 MB can be found here: URL
- Using T5-small size = 230 MB can be found here: URL
#### Usage:
### Demo:
 on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "model", "results": []}]}
|
gagan3012/model
| null |
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #gpt2 #text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# model
This model is a fine-tuned version of distilgpt2 on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.6250
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
[
"# model\n\nThis model is a fine-tuned version of distilgpt2 on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 3.6250",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3.0",
"### Training results",
"### Framework versions\n\n- Transformers 4.12.0.dev0\n- Pytorch 1.9.0+cu111\n- Datasets 1.13.3\n- Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #gpt2 #text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# model\n\nThis model is a fine-tuned version of distilgpt2 on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 3.6250",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 3.0",
"### Training results",
"### Framework versions\n\n- Transformers 4.12.0.dev0\n- Pytorch 1.9.0+cu111\n- Datasets 1.13.3\n- Tokenizers 0.10.3"
] |
text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pickuplines
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.7873
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100.0
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
{"license": "mit", "tags": ["generated_from_trainer"], "model-index": [{"name": "pickuplines", "results": []}]}
|
gagan3012/pickuplines
| null |
[
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #gpt2 #text-generation #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# pickuplines
This model is a fine-tuned version of gpt2 on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 5.7873
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100.0
### Training results
### Framework versions
- Transformers 4.12.0.dev0
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
[
"# pickuplines\n\nThis model is a fine-tuned version of gpt2 on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 5.7873",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 100.0",
"### Training results",
"### Framework versions\n\n- Transformers 4.12.0.dev0\n- Pytorch 1.9.0+cu111\n- Datasets 1.13.3\n- Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #gpt2 #text-generation #generated_from_trainer #license-mit #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"# pickuplines\n\nThis model is a fine-tuned version of gpt2 on an unknown dataset.\nIt achieves the following results on the evaluation set:\n- Loss: 5.7873",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 5e-05\n- train_batch_size: 2\n- eval_batch_size: 8\n- seed: 42\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- num_epochs: 100.0",
"### Training results",
"### Framework versions\n\n- Transformers 4.12.0.dev0\n- Pytorch 1.9.0+cu111\n- Datasets 1.13.3\n- Tokenizers 0.10.3"
] |
text-generation
|
transformers
|
# Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
**Note**: the Answers might not make sense in some cases because of the bias in GPT-2
**Contribtuions:** If you would like to make the model better contributions are welcome Check out [CONTRIBUTIONS.md](https://github.com/gagan3012/project-code-py/blob/master/CONTRIBUTIONS.md)
### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py
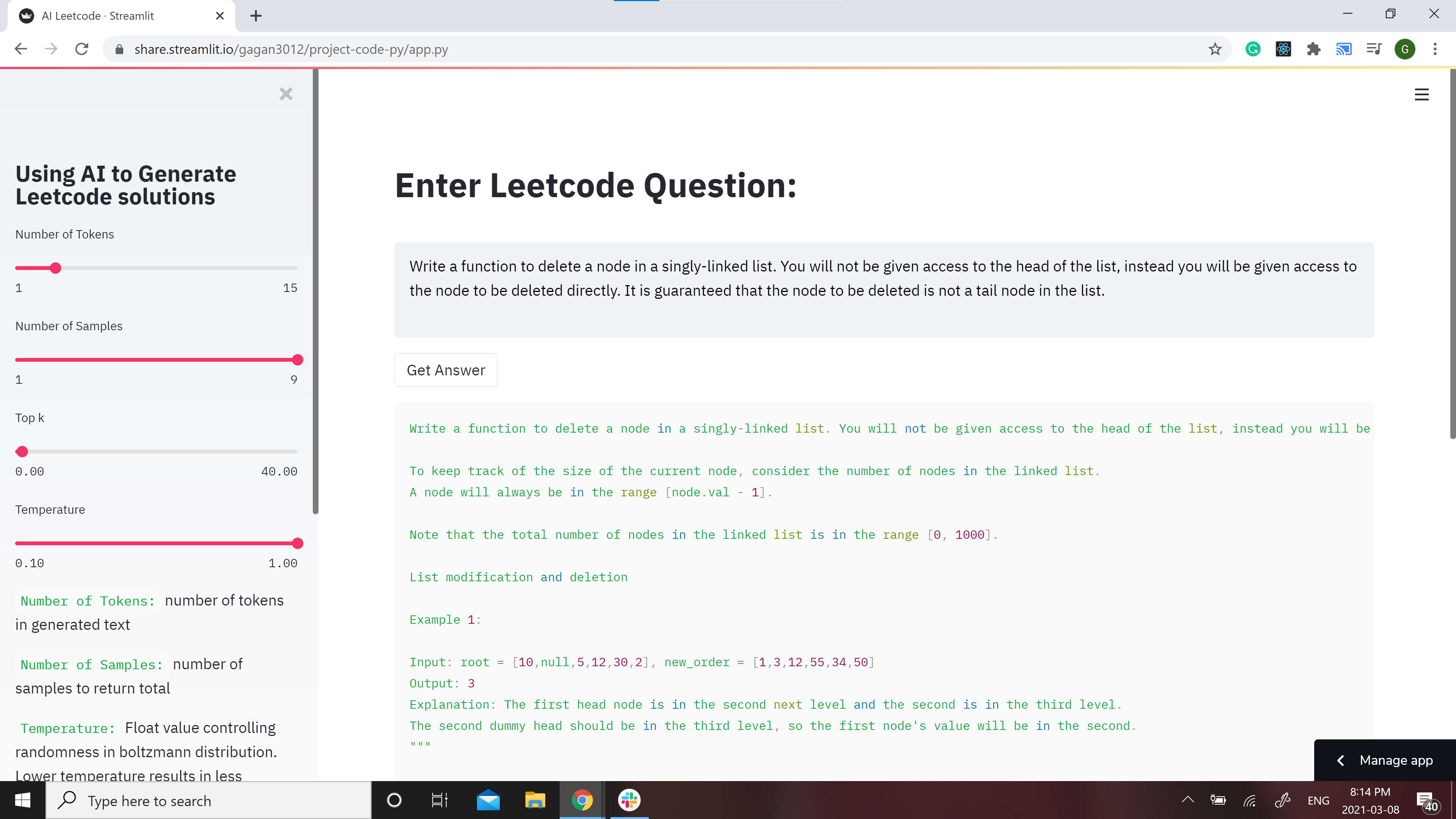
## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
{}
|
gagan3012/project-code-py-small
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
# Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
Note: the Answers might not make sense in some cases because of the bias in GPT-2
Contribtuions: If you would like to make the model better contributions are welcome Check out URL
### Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at URL
The model weights can be found here: GPT-2 and DistilGPT-2
### Example usage:
## Demo

### 📢 Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at https://huggingface.co/gagan3012
The model weights can be found here: [GPT-2](https://huggingface.co/gagan3012/project-code-py) and [DistilGPT-2](https://huggingface.co/gagan3012/project-code-py-small)
### Example usage:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("gagan3012/project-code-py")
model = AutoModelWithLMHead.from_pretrained("gagan3012/project-code-py")
```
## Demo
[](https://share.streamlit.io/gagan3012/project-code-py/app.py)
A streamlit webapp has been setup to use the model: https://share.streamlit.io/gagan3012/project-code-py/app.py

## Example results:
### Question:
```
Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
```
### Answer:
```python
""" Write a function to delete a node in a singly-linked list. You will not be given access to the head of the list, instead you will be given access to the node to be deleted directly. It is guaranteed that the node to be deleted is not a tail node in the list.
For example,
a = 1->2->3
b = 3->1->2
t = ListNode(-1, 1)
Note: The lexicographic ordering of the nodes in a tree matters. Do not assign values to nodes in a tree.
Example 1:
Input: [1,2,3]
Output: 1->2->5
Explanation: 1->2->3->3->4, then 1->2->5[2] and then 5->1->3->4.
Note:
The length of a linked list will be in the range [1, 1000].
Node.val must be a valid LinkedListNode type.
Both the length and the value of the nodes in a linked list will be in the range [-1000, 1000].
All nodes are distinct.
"""
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, x):
# self.val = x
# self.next = None
class Solution:
def deleteNode(self, head: ListNode, val: int) -> None:
"""
BFS
Linked List
:param head: ListNode
:param val: int
:return: ListNode
"""
if head is not None:
return head
dummy = ListNode(-1, 1)
dummy.next = head
dummy.next.val = val
dummy.next.next = head
dummy.val = ""
s1 = Solution()
print(s1.deleteNode(head))
print(s1.deleteNode(-1))
print(s1.deleteNode(-1))
```
|
{}
|
gagan3012/project-code-py
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
# Leetcode using AI :robot:
GPT-2 Model for Leetcode Questions in python
Note: the Answers might not make sense in some cases because of the bias in GPT-2
Contribtuions: If you would like to make the model better contributions are welcome Check out URL
### Favour:
It would be highly motivating, if you can STAR⭐ this repo if you find it helpful.
## Model
Two models have been developed for different use cases and they can be found at URL
The model weights can be found here: GPT-2 and DistilGPT-2
### Example usage:
## Demo

model = AutoModelWithLMHead.from_pretrained("gagan3012/rap-writer")
```
|
{}
|
gagan3012/rap-writer
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
# Generating Rap song Lyrics like Eminem Using GPT2
### I have built a custom model for it using data from Kaggle
Creating a new finetuned model using data lyrics from leading hip-hop stars
### My model can be accessed at: gagan3012/rap-writer
|
[
"# Generating Rap song Lyrics like Eminem Using GPT2",
"### I have built a custom model for it using data from Kaggle \n\nCreating a new finetuned model using data lyrics from leading hip-hop stars",
"### My model can be accessed at: gagan3012/rap-writer"
] |
[
"TAGS\n#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n",
"# Generating Rap song Lyrics like Eminem Using GPT2",
"### I have built a custom model for it using data from Kaggle \n\nCreating a new finetuned model using data lyrics from leading hip-hop stars",
"### My model can be accessed at: gagan3012/rap-writer"
] |
text2text-generation
|
transformers
|
---
Summarisation model summarsiation
|
{}
|
gagan3012/summarsiation
| null |
[
"transformers",
"pytorch",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #t5 #text2text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us
|
---
Summarisation model summarsiation
|
[] |
[
"TAGS\n#transformers #pytorch #t5 #text2text-generation #autotrain_compatible #endpoints_compatible #has_space #text-generation-inference #region-us \n"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-hindi
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "wav2vec2-large-xls-r-300m-hindi", "results": []}]}
|
gagan3012/wav2vec2-large-xls-r-300m-hindi
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us
|
# wav2vec2-large-xls-r-300m-hindi
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the common_voice dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
[
"# wav2vec2-large-xls-r-300m-hindi\n\nThis model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the common_voice dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0003\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 500\n- num_epochs: 30\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.17.0.dev0\n- Pytorch 1.10.2+cu102\n- Datasets 1.18.2.dev0\n- Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #generated_from_trainer #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us \n",
"# wav2vec2-large-xls-r-300m-hindi\n\nThis model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the common_voice dataset.",
"## Model description\n\nMore information needed",
"## Intended uses & limitations\n\nMore information needed",
"## Training and evaluation data\n\nMore information needed",
"## Training procedure",
"### Training hyperparameters\n\nThe following hyperparameters were used during training:\n- learning_rate: 0.0003\n- train_batch_size: 16\n- eval_batch_size: 8\n- seed: 42\n- gradient_accumulation_steps: 2\n- total_train_batch_size: 32\n- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n- lr_scheduler_type: linear\n- lr_scheduler_warmup_steps: 500\n- num_epochs: 30\n- mixed_precision_training: Native AMP",
"### Training results",
"### Framework versions\n\n- Transformers 4.17.0.dev0\n- Pytorch 1.10.2+cu102\n- Datasets 1.18.2.dev0\n- Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Chuvash
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Chuvash using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cv", split="test")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Results:
Prediction: ['проектпа килӗшӳллӗн тӗлӗ мероприяти иртермелле', 'твăра çак планета минтӗ пуяни калленнана']
Reference: ['Проектпа килӗшӳллӗн, тӗрлӗ мероприяти ирттермелле.', 'Çак планета питĕ пуян иккен.']
## Evaluation
The model can be evaluated as follows on the Chuvash test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
!mkdir cer
!wget -O cer/cer.py https://huggingface.co/ctl/wav2vec2-large-xlsr-cantonese/raw/main/cer.py
test_dataset = load_dataset("common_voice", "cv", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
cer = load_metric("cer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-chuvash")
model.to("cuda")
chars_to_ignore_regex = '[\\\\,\\\\?\\\\.\\\\!\\\\-\\\\;\\\\:\\\\"\\\\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\twith torch.no_grad():
\\t\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\tpred_ids = torch.argmax(logits, dim=-1)
\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 48.40 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1A7Y20c1QkSHfdOmLXPMiOEpwlTjDZ7m5?usp=sharing)
|
{"language": "cv", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "wav2vec2-xlsr-chuvash by Gagan Bhatia", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice cv", "type": "common_voice", "args": "cv"}, "metrics": [{"type": "wer", "value": 48.4, "name": "Test WER"}]}]}]}
|
gagan3012/wav2vec2-xlsr-chuvash
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"cv",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"cv"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #cv #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Chuvash
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Chuvash using the Common Voice
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
#### Results:
Prediction: ['проектпа килӗшӳллӗн тӗлӗ мероприяти иртермелле', 'твăра çак планета минтӗ пуяни калленнана']
Reference: ['Проектпа килӗшӳллӗн, тӗрлӗ мероприяти ирттермелле.', 'Çак планета питĕ пуян иккен.']
## Evaluation
The model can be evaluated as follows on the Chuvash test data of Common Voice.
Test Result: 48.40 %
## Training
The script used for training can be found here
|
[
"# Wav2Vec2-Large-XLSR-53-Chuvash \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Chuvash using the Common Voice\n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Results: \n\nPrediction: ['проектпа килӗшӳллӗн тӗлӗ мероприяти иртермелле', 'твăра çак планета минтӗ пуяни калленнана']\n\nReference: ['Проектпа килӗшӳллӗн, тӗрлӗ мероприяти ирттермелле.', 'Çак планета питĕ пуян иккен.']",
"## Evaluation\n\nThe model can be evaluated as follows on the Chuvash test data of Common Voice.\n\n\n\nTest Result: 48.40 %",
"## Training\n\nThe script used for training can be found here"
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #cv #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Chuvash \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Chuvash using the Common Voice\n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Results: \n\nPrediction: ['проектпа килӗшӳллӗн тӗлӗ мероприяти иртермелле', 'твăра çак планета минтӗ пуяни калленнана']\n\nReference: ['Проектпа килӗшӳллӗн, тӗрлӗ мероприяти ирттермелле.', 'Çак планета питĕ пуян иккен.']",
"## Evaluation\n\nThe model can be evaluated as follows on the Chuvash test data of Common Voice.\n\n\n\nTest Result: 48.40 %",
"## Training\n\nThe script used for training can be found here"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-khmer
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Khmer using the [Common Voice](https://huggingface.co/datasets/common_voice), and [OpenSLR Kh](http://www.openslr.org/42/).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
!wget https://www.openslr.org/resources/42/km_kh_male.zip
!unzip km_kh_male.zip
!ls km_kh_male
colnames=['path','sentence']
df = pd.read_csv('/content/km_kh_male/line_index.tsv',sep='\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t',header=None,names = colnames)
df['path'] = '/content/km_kh_male/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/km_kh_male/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/km_kh_male/line_index_test.csv',split = 'train')
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\\\\\\\\\\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\\\\\\\\\\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\\\\\\\\\\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\\\\\\\\\\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
from sklearn.model_selection import train_test_split
import pandas as pd
from datasets import load_dataset
!wget https://www.openslr.org/resources/42/km_kh_male.zip
!unzip km_kh_male.zip
!ls km_kh_male
colnames=['path','sentence']
df = pd.read_csv('/content/km_kh_male/line_index.tsv',sep='\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\\t',header=None,names = colnames)
df['path'] = '/content/km_kh_male/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/km_kh_male/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/km_kh_male/line_index_test.csv',split = 'train')
wer = load_metric("wer")
cer = load_metric("cer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-khmer")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-khmer")
model.to("cuda")
chars_to_ignore_regex = '[\\\\,\\\\?\\\\.\\\\!\\\\-\\\\;\\\\:\\\\"\\\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\tbatch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\twith torch.no_grad():
\\t\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\tpred_ids = torch.argmax(logits, dim=-1)
\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\treturn batch
cer = load_metric("cer")
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["text"])))
print("CER: {:2f}".format(100 * cer.compute(predictions=result["pred_strings"], references=result["text"])))
```
**Test Result**: 24.96 %
WER: 24.962519
CER: 6.950925
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1yo_OTMH8FHQrAKCkKdQGMqpkj-kFhS_2?usp=sharing)
|
{"language": "km", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["OpenSLR", "common_voice"], "metrics": ["wer"], "model-index": [{"name": "wav2vec2-xlsr-Khmer by Gagan Bhatia", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR km", "type": "OpenSLR", "args": "km"}, "metrics": [{"type": "wer", "value": 24.96, "name": "Test WER"}]}]}]}
|
gagan3012/wav2vec2-xlsr-khmer
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"km",
"dataset:OpenSLR",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"km"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #km #dataset-OpenSLR #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us
|
# Wav2Vec2-Large-XLSR-53-khmer
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Khmer using the Common Voice, and OpenSLR Kh.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
Test Result: 24.96 %
WER: 24.962519
CER: 6.950925
## Training
The script used for training can be found here
|
[
"# Wav2Vec2-Large-XLSR-53-khmer \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Khmer using the Common Voice, and OpenSLR Kh. \n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Result \n\nPrediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']\n\nReference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 24.96 % \n\nWER: 24.962519\nCER: 6.950925",
"## Training\n\nThe script used for training can be found here"
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #km #dataset-OpenSLR #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #has_space #region-us \n",
"# Wav2Vec2-Large-XLSR-53-khmer \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Khmer using the Common Voice, and OpenSLR Kh. \n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Result \n\nPrediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']\n\nReference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 24.96 % \n\nWER: 24.962519\nCER: 6.950925",
"## Training\n\nThe script used for training can be found here"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Nepali
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Nepali using the [Common Voice](https://huggingface.co/datasets/common_voice), and [OpenSLR ne](http://www.openslr.org/43/).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
!wget https://www.openslr.org/resources/43/ne_np_female.zip
!unzip ne_np_female.zip
!ls ne_np_female
colnames=['path','sentence']
df = pd.read_csv('/content/ne_np_female/line_index.tsv',sep='\\t',header=None,names = colnames)
df['path'] = '/content/ne_np_female/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/ne_np_female/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/ne_np_female/line_index_test.csv',split = 'train')
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
!wget https://www.openslr.org/resources/43/ne_np_female.zip
!unzip ne_np_female.zip
!ls ne_np_female
colnames=['path','sentence']
df = pd.read_csv('/content/ne_np_female/line_index.tsv',sep='\\t',header=None,names = colnames)
df['path'] = '/content/ne_np_female/wavs/'+df['path'] +'.wav'
train, test = train_test_split(df, test_size=0.1)
test.to_csv('/content/ne_np_female/line_index_test.csv')
test_dataset = load_dataset('csv', data_files='/content/ne_np_female/line_index_test.csv',split = 'train')
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-nepali")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\twith torch.no_grad():
\t\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\tpred_ids = torch.argmax(logits, dim=-1)
\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 05.97 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1AHnYWXb5cwfMEa2o4O3TSdasAR3iVBFP?usp=sharing)
|
{"language": "ne", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["OpenSLR", "common_voice"], "metrics": ["wer"], "model-index": [{"name": "wav2vec2-xlsr-nepali", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR ne", "type": "OpenSLR", "args": "ne"}, "metrics": [{"type": "wer", "value": 5.97, "name": "Test WER"}]}]}]}
|
gagan3012/wav2vec2-xlsr-nepali
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ne",
"dataset:OpenSLR",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ne"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ne #dataset-OpenSLR #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Nepali
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Nepali using the Common Voice, and OpenSLR ne.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
#### Result
Prediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
Reference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
Test Result: 05.97 %
## Training
The script used for training can be found here
|
[
"# Wav2Vec2-Large-XLSR-53-Nepali \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Nepali using the Common Voice, and OpenSLR ne. \n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Result \n\nPrediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']\n\nReference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 05.97 %",
"## Training\n\nThe script used for training can be found here"
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ne #dataset-OpenSLR #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Nepali \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Nepali using the Common Voice, and OpenSLR ne. \n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Result \n\nPrediction: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']\n\nReference: ['पारानाको ब्राजिली राज्यमा रहेको राजधानी', 'देवराज जोशी त्रिभुवन विश्वविद्यालयबाट शिक्षाशास्त्रमा स्नातक हुनुहुन्छ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 05.97 %",
"## Training\n\nThe script used for training can be found here"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Punjabi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Punjabi using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pa-IN", split="test")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
\\\\tlogits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
#### Results:
Prediction: ['ਹਵਾ ਲਾਤ ਵਿੱਚ ਪੰਦ ਛੇ ਇਖਲਾਟਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈ ਇ ਹਾ ਪੈਸੇ ਲੇਹੜ ਨਹੀਂ ਸੀ ਚੌਨਾ']
Reference: ['ਹਵਾਲਾਤ ਵਿੱਚ ਪੰਜ ਛੇ ਇਖ਼ਲਾਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈਂ ਇਹ ਪੈਸੇ ਲੈਣੇ ਨਹੀਂ ਸੀ ਚਾਹੁੰਦਾ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pa-IN", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model = Wav2Vec2ForCTC.from_pretrained("gagan3012/wav2vec2-xlsr-punjabi")
model.to("cuda")
chars_to_ignore_regex = '[\\\\\\\\\\\\\\\\,\\\\\\\\\\\\\\\\?\\\\\\\\\\\\\\\\.\\\\\\\\\\\\\\\\!\\\\\\\\\\\\\\\\-\\\\\\\\\\\\\\\\;\\\\\\\\\\\\\\\\:\\\\\\\\\\\\\\\\"\\\\\\\\\\\\\\\\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
\\\\\\\\tbatch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
\\\\\\\\tspeech_array, sampling_rate = torchaudio.load(batch["path"])
\\\\\\\\tbatch["speech"] = resampler(speech_array).squeeze().numpy()
\\\\\\\\treturn batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
\\\\\\\\tinputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
\\\\\\\\twith torch.no_grad():
\\\\\\\\t\\\\\\\\tlogits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
\\\\\\\\tpred_ids = torch.argmax(logits, dim=-1)
\\\\\\\\tbatch["pred_strings"] = processor.batch_decode(pred_ids)
\\\\\\\\treturn batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 58.05 %
## Training
The script used for training can be found [here](https://colab.research.google.com/drive/1A7Y20c1QkSHfdOmLXPMiOEpwlTjDZ7m5?usp=sharing)
|
{"language": "pa-IN", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "wav2vec2-xlsr-punjabi", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice pa", "type": "common_voice", "args": "pa-IN"}, "metrics": [{"type": "wer", "value": 58.06, "name": "Test WER"}]}]}]}
|
gagan3012/wav2vec2-xlsr-punjabi
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"pa-IN"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Punjabi
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Punjabi using the Common Voice
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
#### Results:
Prediction: ['ਹਵਾ ਲਾਤ ਵਿੱਚ ਪੰਦ ਛੇ ਇਖਲਾਟਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈ ਇ ਹਾ ਪੈਸੇ ਲੇਹੜ ਨਹੀਂ ਸੀ ਚੌਨਾ']
Reference: ['ਹਵਾਲਾਤ ਵਿੱਚ ਪੰਜ ਛੇ ਇਖ਼ਲਾਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈਂ ਇਹ ਪੈਸੇ ਲੈਣੇ ਨਹੀਂ ਸੀ ਚਾਹੁੰਦਾ']
## Evaluation
The model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French
Test Result: 58.05 %
## Training
The script used for training can be found here
|
[
"# Wav2Vec2-Large-XLSR-53-Punjabi \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Punjabi using the Common Voice\n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Results: \n\nPrediction: ['ਹਵਾ ਲਾਤ ਵਿੱਚ ਪੰਦ ਛੇ ਇਖਲਾਟਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈ ਇ ਹਾ ਪੈਸੇ ਲੇਹੜ ਨਹੀਂ ਸੀ ਚੌਨਾ']\n\nReference: ['ਹਵਾਲਾਤ ਵਿੱਚ ਪੰਜ ਛੇ ਇਖ਼ਲਾਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈਂ ਇਹ ਪੈਸੇ ਲੈਣੇ ਨਹੀਂ ਸੀ ਚਾਹੁੰਦਾ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 58.05 %",
"## Training\n\nThe script used for training can be found here"
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Punjabi \n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Punjabi using the Common Voice\n\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"#### Results: \n\nPrediction: ['ਹਵਾ ਲਾਤ ਵਿੱਚ ਪੰਦ ਛੇ ਇਖਲਾਟਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈ ਇ ਹਾ ਪੈਸੇ ਲੇਹੜ ਨਹੀਂ ਸੀ ਚੌਨਾ']\n\nReference: ['ਹਵਾਲਾਤ ਵਿੱਚ ਪੰਜ ਛੇ ਇਖ਼ਲਾਕੀ ਮੁਜਰਮ ਸਨ', 'ਮੈਂ ਇਹ ਪੈਸੇ ਲੈਣੇ ਨਹੀਂ ਸੀ ਚਾਹੁੰਦਾ']",
"## Evaluation\n\nThe model can be evaluated as follows on the {language} test data of Common Voice. # TODO: replace #TODO: replace language with your {language}, *e.g.* French\n\n\n\n\nTest Result: 58.05 %",
"## Training\n\nThe script used for training can be found here"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-300m-hi
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7522
- Wer: 1.0091
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 50.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 5.0417 | 2.59 | 500 | 5.1484 | 1.0 |
| 3.3722 | 5.18 | 1000 | 3.3380 | 1.0001 |
| 1.9752 | 7.77 | 1500 | 1.3910 | 1.0074 |
| 1.5868 | 10.36 | 2000 | 1.0298 | 1.0084 |
| 1.4413 | 12.95 | 2500 | 0.9313 | 1.0175 |
| 1.3296 | 15.54 | 3000 | 0.8966 | 1.0194 |
| 1.2746 | 18.13 | 3500 | 0.8875 | 1.0097 |
| 1.2147 | 20.73 | 4000 | 0.8746 | 1.0089 |
| 1.1774 | 23.32 | 4500 | 0.8383 | 1.0198 |
| 1.129 | 25.91 | 5000 | 0.7848 | 1.0167 |
| 1.0995 | 28.5 | 5500 | 0.7992 | 1.0210 |
| 1.0665 | 31.09 | 6000 | 0.7878 | 1.0107 |
| 1.0321 | 33.68 | 6500 | 0.7653 | 1.0082 |
| 1.0068 | 36.27 | 7000 | 0.7635 | 1.0065 |
| 0.9916 | 38.86 | 7500 | 0.7728 | 1.0090 |
| 0.9735 | 41.45 | 8000 | 0.7688 | 1.0070 |
| 0.9745 | 44.04 | 8500 | 0.7455 | 1.0097 |
| 0.9677 | 46.63 | 9000 | 0.7605 | 1.0099 |
| 0.9313 | 49.22 | 9500 | 0.7527 | 1.0097 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
{"language": ["hi"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "mozilla-foundation/common_voice_8_0", "generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "xls-r-300m-hi", "results": []}]}
|
gagan3012/xls-r-300m-hi
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"hi",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"hi"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #hi #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us
|
xls-r-300m-hi
=============
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the MOZILLA-FOUNDATION/COMMON\_VOICE\_8\_0 - HI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7522
* Wer: 1.0091
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 7.5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 2000
* num\_epochs: 50.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2+cu102
* Datasets 1.18.2.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #hi #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 50.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
automatic-speech-recognition
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xls-r-300m-pa
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - PA-IN dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0443
- Wer: 0.5715
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 500.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:------:|:-----:|:---------------:|:------:|
| 4.6694 | 19.22 | 500 | 4.0455 | 1.0 |
| 3.3907 | 38.45 | 1000 | 3.2836 | 1.0 |
| 2.0866 | 57.67 | 1500 | 1.2788 | 0.7715 |
| 1.4106 | 76.9 | 2000 | 0.7866 | 0.6891 |
| 1.1711 | 96.15 | 2500 | 0.6556 | 0.6272 |
| 1.038 | 115.37 | 3000 | 0.6195 | 0.5680 |
| 0.8989 | 134.6 | 3500 | 0.6563 | 0.5602 |
| 0.8021 | 153.82 | 4000 | 0.6644 | 0.5327 |
| 0.7161 | 173.07 | 4500 | 0.6844 | 0.5253 |
| 0.6449 | 192.3 | 5000 | 0.7018 | 0.5331 |
| 0.5659 | 211.52 | 5500 | 0.7451 | 0.5465 |
| 0.5118 | 230.75 | 6000 | 0.7857 | 0.5386 |
| 0.4385 | 249.97 | 6500 | 0.8062 | 0.5382 |
| 0.3984 | 269.22 | 7000 | 0.8316 | 0.5621 |
| 0.3666 | 288.45 | 7500 | 0.8736 | 0.5504 |
| 0.3256 | 307.67 | 8000 | 0.9133 | 0.5688 |
| 0.289 | 326.9 | 8500 | 0.9556 | 0.5684 |
| 0.2663 | 346.15 | 9000 | 0.9344 | 0.5708 |
| 0.2445 | 365.37 | 9500 | 0.9472 | 0.5590 |
| 0.2289 | 384.6 | 10000 | 0.9713 | 0.5672 |
| 0.2048 | 403.82 | 10500 | 0.9978 | 0.5762 |
| 0.1857 | 423.07 | 11000 | 1.0230 | 0.5798 |
| 0.1751 | 442.3 | 11500 | 1.0409 | 0.5755 |
| 0.1688 | 461.52 | 12000 | 1.0445 | 0.5727 |
| 0.1633 | 480.75 | 12500 | 1.0484 | 0.5739 |
| 0.1488 | 499.97 | 13000 | 1.0443 | 0.5715 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu102
- Datasets 1.18.2.dev0
- Tokenizers 0.11.0
|
{"language": ["pa-IN"], "license": "apache-2.0", "tags": ["automatic-speech-recognition", "mozilla-foundation/common_voice_8_0", "generated_from_trainer"], "datasets": ["common_voice"], "model-index": [{"name": "xls-r-300m-pa", "results": []}]}
|
gagan3012/xls-r-300m-pa
| null |
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"dataset:common_voice",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"pa-IN"
] |
TAGS
#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us
|
xls-r-300m-pa
=============
This model is a fine-tuned version of facebook/wav2vec2-xls-r-300m on the MOZILLA-FOUNDATION/COMMON\_VOICE\_8\_0 - PA-IN dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0443
* Wer: 0.5715
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 7.5e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* gradient\_accumulation\_steps: 4
* total\_train\_batch\_size: 32
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_steps: 2000
* num\_epochs: 500.0
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.17.0.dev0
* Pytorch 1.10.2+cu102
* Datasets 1.18.2.dev0
* Tokenizers 0.11.0
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 500.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
[
"TAGS\n#transformers #pytorch #wav2vec2 #automatic-speech-recognition #mozilla-foundation/common_voice_8_0 #generated_from_trainer #dataset-common_voice #license-apache-2.0 #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 7.5e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* gradient\\_accumulation\\_steps: 4\n* total\\_train\\_batch\\_size: 32\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_steps: 2000\n* num\\_epochs: 500.0\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.17.0.dev0\n* Pytorch 1.10.2+cu102\n* Datasets 1.18.2.dev0\n* Tokenizers 0.11.0"
] |
text-classification
|
transformers
|
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 19984005
- CO2 Emissions (in grams): 20.790169878009916
## Validation Metrics
- Loss: 0.06693269312381744
- Accuracy: 0.9789
- Precision: 0.9843244336569579
- Recall: 0.9733
- AUC: 0.99695552
- F1: 0.9787811745776348
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/gagandeepkundi/autonlp-text-classification-19984005
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("gagandeepkundi/autonlp-text-classification-19984005", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("gagandeepkundi/autonlp-text-classification-19984005", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
```
|
{"language": "es", "tags": "autonlp", "datasets": ["gagandeepkundi/autonlp-data-text-classification"], "widget": [{"text": "I love AutoNLP \ud83e\udd17"}], "co2_eq_emissions": 20.790169878009916}
|
gagandeepkundi/latam-question-quality
| null |
[
"transformers",
"pytorch",
"roberta",
"text-classification",
"autonlp",
"es",
"dataset:gagandeepkundi/autonlp-data-text-classification",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"es"
] |
TAGS
#transformers #pytorch #roberta #text-classification #autonlp #es #dataset-gagandeepkundi/autonlp-data-text-classification #co2_eq_emissions #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 19984005
- CO2 Emissions (in grams): 20.790169878009916
## Validation Metrics
- Loss: 0.06693269312381744
- Accuracy: 0.9789
- Precision: 0.9843244336569579
- Recall: 0.9733
- AUC: 0.99695552
- F1: 0.9787811745776348
## Usage
You can use cURL to access this model:
Or Python API:
|
[
"# Model Trained Using AutoNLP\n\n- Problem type: Binary Classification\n- Model ID: 19984005\n- CO2 Emissions (in grams): 20.790169878009916",
"## Validation Metrics\n\n- Loss: 0.06693269312381744\n- Accuracy: 0.9789\n- Precision: 0.9843244336569579\n- Recall: 0.9733\n- AUC: 0.99695552\n- F1: 0.9787811745776348",
"## Usage\n\nYou can use cURL to access this model:\n\n\n\nOr Python API:"
] |
[
"TAGS\n#transformers #pytorch #roberta #text-classification #autonlp #es #dataset-gagandeepkundi/autonlp-data-text-classification #co2_eq_emissions #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoNLP\n\n- Problem type: Binary Classification\n- Model ID: 19984005\n- CO2 Emissions (in grams): 20.790169878009916",
"## Validation Metrics\n\n- Loss: 0.06693269312381744\n- Accuracy: 0.9789\n- Precision: 0.9843244336569579\n- Recall: 0.9733\n- AUC: 0.99695552\n- F1: 0.9787811745776348",
"## Usage\n\nYou can use cURL to access this model:\n\n\n\nOr Python API:"
] |
text-classification
|
transformers
|
# Sentiment Classification for hinglish text: `gk-hinglish-sentiment`
## Model description
Trained small amount of reviews dataset
## Intended uses & limitations
I wanted something to work well with hinglish data as it is being used in India mostly.
The training data was not much as expected
#### How to use
```python
#sample code
from transformers import BertTokenizer, BertForSequenceClassification
tokenizerg = BertTokenizer.from_pretrained("/content/model")
modelg = BertForSequenceClassification.from_pretrained("/content/model")
text = "kuch bhi type karo hinglish mai"
encoded_input = tokenizerg(text, return_tensors='pt')
output = modelg(**encoded_input)
print(output)
#output contains 3 lables LABEL_0 = Negative ,LABEL_1 = Nuetral ,LABEL_2 = Positive
```
#### Limitations and bias
The data contains only hinglish codemixed text it and was very much limited may be I will Update this model if I can get good amount of data
## Training data
Training data contains labeled data for 3 labels
link to the pre-trained model card with description of the pre-training data.
I have Tuned below model
https://huggingface.co/rohanrajpal/bert-base-multilingual-codemixed-cased-sentiment
### BibTeX entry and citation info
```@inproceedings{khanuja-etal-2020-gluecos,
title = "{GLUEC}o{S}: An Evaluation Benchmark for Code-Switched {NLP}",
author = "Khanuja, Simran and
Dandapat, Sandipan and
Srinivasan, Anirudh and
Sitaram, Sunayana and
Choudhury, Monojit",
booktitle = "Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics",
month = jul,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/2020.acl-main.329",
pages = "3575--3585"
}
```
|
{"license": "apache-2.0", "tags": ["sentiment", "multilingual", "hindi codemix", "hinglish"], "datasets": ["sail"], "language_bcp47": ["hi-en"]}
|
ganeshkharad/gk-hinglish-sentiment
| null |
[
"transformers",
"pytorch",
"jax",
"safetensors",
"bert",
"text-classification",
"sentiment",
"multilingual",
"hindi codemix",
"hinglish",
"dataset:sail",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #safetensors #bert #text-classification #sentiment #multilingual #hindi codemix #hinglish #dataset-sail #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #region-us
|
# Sentiment Classification for hinglish text: 'gk-hinglish-sentiment'
## Model description
Trained small amount of reviews dataset
## Intended uses & limitations
I wanted something to work well with hinglish data as it is being used in India mostly.
The training data was not much as expected
#### How to use
#### Limitations and bias
The data contains only hinglish codemixed text it and was very much limited may be I will Update this model if I can get good amount of data
## Training data
Training data contains labeled data for 3 labels
link to the pre-trained model card with description of the pre-training data.
I have Tuned below model
URL
### BibTeX entry and citation info
|
[
"# Sentiment Classification for hinglish text: 'gk-hinglish-sentiment'",
"## Model description\n\nTrained small amount of reviews dataset",
"## Intended uses & limitations\n\nI wanted something to work well with hinglish data as it is being used in India mostly.\nThe training data was not much as expected",
"#### How to use",
"#### Limitations and bias\n\nThe data contains only hinglish codemixed text it and was very much limited may be I will Update this model if I can get good amount of data",
"## Training data\n\nTraining data contains labeled data for 3 labels\n\nlink to the pre-trained model card with description of the pre-training data.\nI have Tuned below model\n\nURL",
"### BibTeX entry and citation info"
] |
[
"TAGS\n#transformers #pytorch #jax #safetensors #bert #text-classification #sentiment #multilingual #hindi codemix #hinglish #dataset-sail #license-apache-2.0 #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"# Sentiment Classification for hinglish text: 'gk-hinglish-sentiment'",
"## Model description\n\nTrained small amount of reviews dataset",
"## Intended uses & limitations\n\nI wanted something to work well with hinglish data as it is being used in India mostly.\nThe training data was not much as expected",
"#### How to use",
"#### Limitations and bias\n\nThe data contains only hinglish codemixed text it and was very much limited may be I will Update this model if I can get good amount of data",
"## Training data\n\nTraining data contains labeled data for 3 labels\n\nlink to the pre-trained model card with description of the pre-training data.\nI have Tuned below model\n\nURL",
"### BibTeX entry and citation info"
] |
text-generation
|
transformers
|
## Generating Chinese poetry by topic.
```python
from transformers import *
tokenizer = BertTokenizer.from_pretrained("gaochangkuan/model_dir")
model = AutoModelWithLMHead.from_pretrained("gaochangkuan/model_dir")
prompt= '''<s>田园躬耕'''
length= 84
stop_token='</s>'
temperature = 1.2
repetition_penalty=1.3
k= 30
p= 0.95
device ='cuda'
seed=2020
no_cuda=False
prompt_text = prompt if prompt else input("Model prompt >>> ")
encoded_prompt = tokenizer.encode(
'<s>'+prompt_text+'<sep>',
add_special_tokens=False,
return_tensors="pt"
)
encoded_prompt = encoded_prompt.to(device)
output_sequences = model.generate(
input_ids=encoded_prompt,
max_length=length,
min_length=10,
do_sample=True,
early_stopping=True,
num_beams=10,
temperature=temperature,
top_k=k,
top_p=p,
repetition_penalty=repetition_penalty,
bad_words_ids=None,
bos_token_id=tokenizer.bos_token_id,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
length_penalty=1.2,
no_repeat_ngram_size=2,
num_return_sequences=1,
attention_mask=None,
decoder_start_token_id=tokenizer.bos_token_id,)
generated_sequence = output_sequences[0].tolist()
text = tokenizer.decode(generated_sequence)
text = text[: text.find(stop_token) if stop_token else None]
print(''.join(text).replace(' ','').replace('<pad>','').replace('<s>',''))
```
|
{}
|
gaochangkuan/model_dir
| null |
[
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
## Generating Chinese poetry by topic.
|
[
"## Generating Chinese poetry by topic."
] |
[
"TAGS\n#transformers #pytorch #jax #gpt2 #text-generation #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"## Generating Chinese poetry by topic."
] |
image-classification
|
transformers
|
### What style is that?
This model can help identify five architectural styles that were prominent in the early to mid 20th century. Check back for updates including more architectural styles and more accurate predictions as this model diversifies and improves its training.
Upload a photograph of a building to the File Uploader on the right. The Image Classifier will predict its architectural style using a database of over 700 images. Scroll down to read more about each style.
### Classical Revival (1895 - 1950)
The Classical Revival or Neoclassical style is one of the most commonly seen across the state and the country. This style was inspired by the World's Columbian Exposition in Chicago held in 1893 which promoted a renewed interest in the classical forms. This style encompasses many different styles, including Colonial Revival, Greek Revival, Neoclassical Revival and Mediterranean Revival. Colonial Revival is most commonly used in residential dwellings, while Greek and Neoclassical Revival styles are commonly used in commercial buildings like banks, post offices, and municipal buildings.

#### Queen Anne (1880-1910)
The Queen Anne style was one of a number of popular architectural styles that emerged in the United States during the Victorian Period. It ranges from high style, like the image pictured here, to more vernacular styles that exhibit the Queen Anne form without its high style architectural details.

#### Craftsman Bungalow (1900-1930)
The terms “craftsman” and “bungalow” are often used interchangably, however, “craftsman” refers to the Arts and Crafts movement and is considered an architectural style, whereas “bungalow” is the form of house. Bungalows often exhibit a craftsman style.

#### Tudor Cottage (1910-1950)
Tudor homes are inspired by the Medieval period and can range is size and style. In general, the Tudor style features steeply pitched roofs, often with a cat-slide roof line, predominately brick construction, sometimes accented with half-timber framing, front-facing, prominently placed brick or stone chimneys, and tall windows with rectangular or diamond-shaped panes. Front doors are typically off-center with a round arch at the top of the door or doorway.

#### Mid-Century Modern Ranch (1930-1970)
The Ranch style originated in southern California in the mid-1930s. In the 1940s, the Ranch was one of the small house types financed by the Federal Housing Administration (FHA), along with Minimal Traditional and other small house styles. The Ranch house began to pick up popularity as the financial controls that encouraged small house building lifted following WWII; by the 1950s it was the most predominant residential style in the country.

This model was created with HuggingPics🤗🖼️ Image Classifier!
Make your own!: [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
|
{"tags": ["image-classification", "pytorch", "huggingpics"], "metrics": ["accuracy"]}
|
gatecitypreservation/architectural_styles
| null |
[
"transformers",
"pytorch",
"tensorboard",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #vit #image-classification #huggingpics #model-index #autotrain_compatible #endpoints_compatible #has_space #region-us
|
### What style is that?
This model can help identify five architectural styles that were prominent in the early to mid 20th century. Check back for updates including more architectural styles and more accurate predictions as this model diversifies and improves its training.
Upload a photograph of a building to the File Uploader on the right. The Image Classifier will predict its architectural style using a database of over 700 images. Scroll down to read more about each style.
### Classical Revival (1895 - 1950)
The Classical Revival or Neoclassical style is one of the most commonly seen across the state and the country. This style was inspired by the World's Columbian Exposition in Chicago held in 1893 which promoted a renewed interest in the classical forms. This style encompasses many different styles, including Colonial Revival, Greek Revival, Neoclassical Revival and Mediterranean Revival. Colonial Revival is most commonly used in residential dwellings, while Greek and Neoclassical Revival styles are commonly used in commercial buildings like banks, post offices, and municipal buildings.
!classical revival architecture
#### Queen Anne (1880-1910)
The Queen Anne style was one of a number of popular architectural styles that emerged in the United States during the Victorian Period. It ranges from high style, like the image pictured here, to more vernacular styles that exhibit the Queen Anne form without its high style architectural details.
!queen anne architecture
#### Craftsman Bungalow (1900-1930)
The terms “craftsman” and “bungalow” are often used interchangably, however, “craftsman” refers to the Arts and Crafts movement and is considered an architectural style, whereas “bungalow” is the form of house. Bungalows often exhibit a craftsman style.
!craftsman bungalow architecture
#### Tudor Cottage (1910-1950)
Tudor homes are inspired by the Medieval period and can range is size and style. In general, the Tudor style features steeply pitched roofs, often with a cat-slide roof line, predominately brick construction, sometimes accented with half-timber framing, front-facing, prominently placed brick or stone chimneys, and tall windows with rectangular or diamond-shaped panes. Front doors are typically off-center with a round arch at the top of the door or doorway.
!tudor cottage architecture
#### Mid-Century Modern Ranch (1930-1970)
The Ranch style originated in southern California in the mid-1930s. In the 1940s, the Ranch was one of the small house types financed by the Federal Housing Administration (FHA), along with Minimal Traditional and other small house styles. The Ranch house began to pick up popularity as the financial controls that encouraged small house building lifted following WWII; by the 1950s it was the most predominant residential style in the country.
!mid-century modern ranch
This model was created with HuggingPics️ Image Classifier!
Make your own!: the demo on Google Colab.
|
[
"### What style is that?\n\nThis model can help identify five architectural styles that were prominent in the early to mid 20th century. Check back for updates including more architectural styles and more accurate predictions as this model diversifies and improves its training. \n\nUpload a photograph of a building to the File Uploader on the right. The Image Classifier will predict its architectural style using a database of over 700 images. Scroll down to read more about each style.",
"### Classical Revival (1895 - 1950)\n\nThe Classical Revival or Neoclassical style is one of the most commonly seen across the state and the country. This style was inspired by the World's Columbian Exposition in Chicago held in 1893 which promoted a renewed interest in the classical forms. This style encompasses many different styles, including Colonial Revival, Greek Revival, Neoclassical Revival and Mediterranean Revival. Colonial Revival is most commonly used in residential dwellings, while Greek and Neoclassical Revival styles are commonly used in commercial buildings like banks, post offices, and municipal buildings. \n\n!classical revival architecture",
"#### Queen Anne (1880-1910)\n\nThe Queen Anne style was one of a number of popular architectural styles that emerged in the United States during the Victorian Period. It ranges from high style, like the image pictured here, to more vernacular styles that exhibit the Queen Anne form without its high style architectural details.\n\n!queen anne architecture",
"#### Craftsman Bungalow (1900-1930)\n\nThe terms “craftsman” and “bungalow” are often used interchangably, however, “craftsman” refers to the Arts and Crafts movement and is considered an architectural style, whereas “bungalow” is the form of house. Bungalows often exhibit a craftsman style.\n\n!craftsman bungalow architecture",
"#### Tudor Cottage (1910-1950)\n\nTudor homes are inspired by the Medieval period and can range is size and style. In general, the Tudor style features steeply pitched roofs, often with a cat-slide roof line, predominately brick construction, sometimes accented with half-timber framing, front-facing, prominently placed brick or stone chimneys, and tall windows with rectangular or diamond-shaped panes. Front doors are typically off-center with a round arch at the top of the door or doorway. \n\n!tudor cottage architecture",
"#### Mid-Century Modern Ranch (1930-1970)\n\nThe Ranch style originated in southern California in the mid-1930s. In the 1940s, the Ranch was one of the small house types financed by the Federal Housing Administration (FHA), along with Minimal Traditional and other small house styles. The Ranch house began to pick up popularity as the financial controls that encouraged small house building lifted following WWII; by the 1950s it was the most predominant residential style in the country.\n\n!mid-century modern ranch\n\nThis model was created with HuggingPics️ Image Classifier! \nMake your own!: the demo on Google Colab."
] |
[
"TAGS\n#transformers #pytorch #tensorboard #vit #image-classification #huggingpics #model-index #autotrain_compatible #endpoints_compatible #has_space #region-us \n",
"### What style is that?\n\nThis model can help identify five architectural styles that were prominent in the early to mid 20th century. Check back for updates including more architectural styles and more accurate predictions as this model diversifies and improves its training. \n\nUpload a photograph of a building to the File Uploader on the right. The Image Classifier will predict its architectural style using a database of over 700 images. Scroll down to read more about each style.",
"### Classical Revival (1895 - 1950)\n\nThe Classical Revival or Neoclassical style is one of the most commonly seen across the state and the country. This style was inspired by the World's Columbian Exposition in Chicago held in 1893 which promoted a renewed interest in the classical forms. This style encompasses many different styles, including Colonial Revival, Greek Revival, Neoclassical Revival and Mediterranean Revival. Colonial Revival is most commonly used in residential dwellings, while Greek and Neoclassical Revival styles are commonly used in commercial buildings like banks, post offices, and municipal buildings. \n\n!classical revival architecture",
"#### Queen Anne (1880-1910)\n\nThe Queen Anne style was one of a number of popular architectural styles that emerged in the United States during the Victorian Period. It ranges from high style, like the image pictured here, to more vernacular styles that exhibit the Queen Anne form without its high style architectural details.\n\n!queen anne architecture",
"#### Craftsman Bungalow (1900-1930)\n\nThe terms “craftsman” and “bungalow” are often used interchangably, however, “craftsman” refers to the Arts and Crafts movement and is considered an architectural style, whereas “bungalow” is the form of house. Bungalows often exhibit a craftsman style.\n\n!craftsman bungalow architecture",
"#### Tudor Cottage (1910-1950)\n\nTudor homes are inspired by the Medieval period and can range is size and style. In general, the Tudor style features steeply pitched roofs, often with a cat-slide roof line, predominately brick construction, sometimes accented with half-timber framing, front-facing, prominently placed brick or stone chimneys, and tall windows with rectangular or diamond-shaped panes. Front doors are typically off-center with a round arch at the top of the door or doorway. \n\n!tudor cottage architecture",
"#### Mid-Century Modern Ranch (1930-1970)\n\nThe Ranch style originated in southern California in the mid-1930s. In the 1940s, the Ranch was one of the small house types financed by the Federal Housing Administration (FHA), along with Minimal Traditional and other small house styles. The Ranch house began to pick up popularity as the financial controls that encouraged small house building lifted following WWII; by the 1950s it was the most predominant residential style in the country.\n\n!mid-century modern ranch\n\nThis model was created with HuggingPics️ Image Classifier! \nMake your own!: the demo on Google Colab."
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7550
- Matthews Correlation: 0.5265
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5296 | 1.0 | 535 | 0.5144 | 0.4215 |
| 0.3504 | 2.0 | 1070 | 0.4903 | 0.5046 |
| 0.2393 | 3.0 | 1605 | 0.6339 | 0.5058 |
| 0.175 | 4.0 | 2140 | 0.7550 | 0.5265 |
| 0.1259 | 5.0 | 2675 | 0.8688 | 0.5259 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "distilbert-base-uncased-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "glue", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.5264763891845121, "name": "Matthews Correlation"}]}]}]}
|
gauravtripathy/distilbert-base-uncased-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #distilbert #text-classification #generated_from_trainer #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
distilbert-base-uncased-finetuned-cola
======================================
This model is a fine-tuned version of distilbert-base-uncased on the glue dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7550
* Matthews Correlation: 0.5265
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5
### Training results
### Framework versions
* Transformers 4.11.3
* Pytorch 1.9.0+cu111
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #distilbert #text-classification #generated_from_trainer #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
sentence-similarity
|
sentence-transformers
|
# gaussfer/test_simcse_new
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('gaussfer/test_simcse_new')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('gaussfer/test_simcse_new')
model = AutoModel.from_pretrained('gaussfer/test_simcse_new')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=gaussfer/test_simcse_new)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 875 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 40,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
{"tags": ["sentence-transformers", "feature-extraction", "sentence-similarity", "transformers"], "pipeline_tag": "sentence-similarity"}
|
gaussfer/test_simcse_new
| null |
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#sentence-transformers #pytorch #bert #feature-extraction #sentence-similarity #transformers #endpoints_compatible #region-us
|
# gaussfer/test_simcse_new
This is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
## Usage (Sentence-Transformers)
Using this model becomes easy when you have sentence-transformers installed:
Then you can use the model like this:
## Usage (HuggingFace Transformers)
Without sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
## Evaluation Results
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL
## Training
The model was trained with the parameters:
DataLoader:
'URL.dataloader.DataLoader' of length 875 with parameters:
Loss:
'sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss' with parameters:
Parameters of the fit()-Method:
## Full Model Architecture
## Citing & Authors
|
[
"# gaussfer/test_simcse_new\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 875 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss' with parameters:\n \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
] |
[
"TAGS\n#sentence-transformers #pytorch #bert #feature-extraction #sentence-similarity #transformers #endpoints_compatible #region-us \n",
"# gaussfer/test_simcse_new\n\nThis is a sentence-transformers model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.",
"## Usage (Sentence-Transformers)\n\nUsing this model becomes easy when you have sentence-transformers installed:\n\n\n\nThen you can use the model like this:",
"## Usage (HuggingFace Transformers)\nWithout sentence-transformers, you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.",
"## Evaluation Results\n\n\n\nFor an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: URL",
"## Training\nThe model was trained with the parameters:\n\nDataLoader:\n\n'URL.dataloader.DataLoader' of length 875 with parameters:\n\n\nLoss:\n\n'sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss' with parameters:\n \n\nParameters of the fit()-Method:",
"## Full Model Architecture",
"## Citing & Authors"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-finetuned-pubmed
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5363
- Rouge2 Precision: 0.3459
- Rouge2 Recall: 0.2455
- Rouge2 Fmeasure: 0.2731
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.652 | 1.0 | 1125 | 1.5087 | 0.3647 | 0.2425 | 0.2772 |
| 1.4695 | 2.0 | 2250 | 1.5039 | 0.3448 | 0.2457 | 0.2732 |
| 1.3714 | 3.0 | 3375 | 1.4842 | 0.3509 | 0.2474 | 0.277 |
| 1.2734 | 4.0 | 4500 | 1.4901 | 0.3452 | 0.2426 | 0.2716 |
| 1.1853 | 5.0 | 5625 | 1.5152 | 0.3658 | 0.2371 | 0.2744 |
| 1.0975 | 6.0 | 6750 | 1.5133 | 0.3529 | 0.2417 | 0.2729 |
| 1.0448 | 7.0 | 7875 | 1.5203 | 0.3485 | 0.2464 | 0.275 |
| 0.9999 | 8.0 | 9000 | 1.5316 | 0.3437 | 0.2435 | 0.2719 |
| 0.9732 | 9.0 | 10125 | 1.5338 | 0.3464 | 0.2446 | 0.2732 |
| 0.954 | 10.0 | 11250 | 1.5363 | 0.3459 | 0.2455 | 0.2731 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-finetuned-pubmed", "results": []}]}
|
gayanin/bart-finetuned-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-finetuned-pubmed
=====================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.5363
* Rouge2 Precision: 0.3459
* Rouge2 Recall: 0.2455
* Rouge2 Fmeasure: 0.2731
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-mlm-pubmed-15
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4822
- Rouge2 Precision: 0.7578
- Rouge2 Recall: 0.5933
- Rouge2 Fmeasure: 0.6511
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.7006 | 1.0 | 663 | 0.5062 | 0.7492 | 0.5855 | 0.6434 |
| 0.5709 | 2.0 | 1326 | 0.4811 | 0.7487 | 0.5879 | 0.6447 |
| 0.5011 | 3.0 | 1989 | 0.4734 | 0.7541 | 0.5906 | 0.6483 |
| 0.4164 | 4.0 | 2652 | 0.4705 | 0.7515 | 0.5876 | 0.6452 |
| 0.3888 | 5.0 | 3315 | 0.4703 | 0.7555 | 0.5946 | 0.6515 |
| 0.3655 | 6.0 | 3978 | 0.4725 | 0.7572 | 0.5943 | 0.6516 |
| 0.319 | 7.0 | 4641 | 0.4733 | 0.7557 | 0.5911 | 0.6491 |
| 0.3089 | 8.0 | 5304 | 0.4792 | 0.7577 | 0.5936 | 0.6513 |
| 0.2907 | 9.0 | 5967 | 0.4799 | 0.7577 | 0.5931 | 0.6509 |
| 0.275 | 10.0 | 6630 | 0.4822 | 0.7578 | 0.5933 | 0.6511 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-mlm-pubmed-15", "results": []}]}
|
gayanin/bart-mlm-pubmed-15
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-mlm-pubmed-15
==================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4822
* Rouge2 Precision: 0.7578
* Rouge2 Recall: 0.5933
* Rouge2 Fmeasure: 0.6511
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-mlm-pubmed-35
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9359
- Rouge2 Precision: 0.5451
- Rouge2 Recall: 0.4232
- Rouge2 Fmeasure: 0.4666
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.4156 | 1.0 | 663 | 1.0366 | 0.5165 | 0.3967 | 0.4394 |
| 1.1773 | 2.0 | 1326 | 0.9841 | 0.5354 | 0.4168 | 0.4589 |
| 1.0894 | 3.0 | 1989 | 0.9554 | 0.5346 | 0.4133 | 0.4563 |
| 0.9359 | 4.0 | 2652 | 0.9440 | 0.5357 | 0.4163 | 0.4587 |
| 0.8758 | 5.0 | 3315 | 0.9340 | 0.5428 | 0.4226 | 0.465 |
| 0.8549 | 6.0 | 3978 | 0.9337 | 0.5385 | 0.422 | 0.4634 |
| 0.7743 | 7.0 | 4641 | 0.9330 | 0.542 | 0.422 | 0.4647 |
| 0.7465 | 8.0 | 5304 | 0.9315 | 0.5428 | 0.4231 | 0.4654 |
| 0.7348 | 9.0 | 5967 | 0.9344 | 0.5462 | 0.4244 | 0.4674 |
| 0.7062 | 10.0 | 6630 | 0.9359 | 0.5451 | 0.4232 | 0.4666 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-mlm-pubmed-35", "results": []}]}
|
gayanin/bart-mlm-pubmed-35
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-mlm-pubmed-35
==================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9359
* Rouge2 Precision: 0.5451
* Rouge2 Recall: 0.4232
* Rouge2 Fmeasure: 0.4666
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-mlm-pubmed-45
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1797
- Rouge2 Precision: 0.4333
- Rouge2 Recall: 0.3331
- Rouge2 Fmeasure: 0.3684
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.7989 | 1.0 | 663 | 1.3385 | 0.4097 | 0.3086 | 0.3444 |
| 1.5072 | 2.0 | 1326 | 1.2582 | 0.4218 | 0.3213 | 0.3569 |
| 1.4023 | 3.0 | 1989 | 1.2236 | 0.4207 | 0.3211 | 0.3562 |
| 1.2205 | 4.0 | 2652 | 1.2025 | 0.4359 | 0.3331 | 0.3696 |
| 1.1584 | 5.0 | 3315 | 1.1910 | 0.4304 | 0.3307 | 0.3658 |
| 1.1239 | 6.0 | 3978 | 1.1830 | 0.4247 | 0.3279 | 0.3618 |
| 1.0384 | 7.0 | 4641 | 1.1761 | 0.4308 | 0.3325 | 0.367 |
| 1.0168 | 8.0 | 5304 | 1.1762 | 0.4314 | 0.3336 | 0.368 |
| 0.9966 | 9.0 | 5967 | 1.1773 | 0.4335 | 0.3341 | 0.369 |
| 0.961 | 10.0 | 6630 | 1.1797 | 0.4333 | 0.3331 | 0.3684 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-mlm-pubmed-45", "results": []}]}
|
gayanin/bart-mlm-pubmed-45
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-mlm-pubmed-45
==================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1797
* Rouge2 Precision: 0.4333
* Rouge2 Recall: 0.3331
* Rouge2 Fmeasure: 0.3684
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-mlm-pubmed-medterm
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0000
- Rouge2 Precision: 0.985
- Rouge2 Recall: 0.7208
- Rouge2 Fmeasure: 0.8088
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:------:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.0018 | 1.0 | 13833 | 0.0003 | 0.985 | 0.7208 | 0.8088 |
| 0.0014 | 2.0 | 27666 | 0.0006 | 0.9848 | 0.7207 | 0.8086 |
| 0.0009 | 3.0 | 41499 | 0.0002 | 0.9848 | 0.7207 | 0.8086 |
| 0.0007 | 4.0 | 55332 | 0.0002 | 0.985 | 0.7208 | 0.8088 |
| 0.0006 | 5.0 | 69165 | 0.0001 | 0.9848 | 0.7207 | 0.8087 |
| 0.0001 | 6.0 | 82998 | 0.0002 | 0.9846 | 0.7206 | 0.8086 |
| 0.0009 | 7.0 | 96831 | 0.0001 | 0.9848 | 0.7208 | 0.8087 |
| 0.0 | 8.0 | 110664 | 0.0000 | 0.9848 | 0.7207 | 0.8087 |
| 0.0001 | 9.0 | 124497 | 0.0000 | 0.985 | 0.7208 | 0.8088 |
| 0.0 | 10.0 | 138330 | 0.0000 | 0.985 | 0.7208 | 0.8088 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-mlm-pubmed-medterm", "results": []}]}
|
gayanin/bart-mlm-pubmed-medterm
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-mlm-pubmed-medterm
=======================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.0000
* Rouge2 Precision: 0.985
* Rouge2 Recall: 0.7208
* Rouge2 Fmeasure: 0.8088
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 8
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.16.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.16.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 8\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.16.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-mlm-pubmed
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7223
- Rouge2 Precision: 0.6572
- Rouge2 Recall: 0.5164
- Rouge2 Fmeasure: 0.5662
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.0322 | 1.0 | 663 | 0.7891 | 0.639 | 0.4989 | 0.5491 |
| 0.8545 | 2.0 | 1326 | 0.7433 | 0.6461 | 0.5057 | 0.5556 |
| 0.758 | 3.0 | 1989 | 0.7299 | 0.647 | 0.5033 | 0.5547 |
| 0.6431 | 4.0 | 2652 | 0.7185 | 0.6556 | 0.5101 | 0.5616 |
| 0.6058 | 5.0 | 3315 | 0.7126 | 0.6537 | 0.5144 | 0.5638 |
| 0.5726 | 6.0 | 3978 | 0.7117 | 0.6567 | 0.5169 | 0.5666 |
| 0.5168 | 7.0 | 4641 | 0.7150 | 0.6585 | 0.5154 | 0.566 |
| 0.5011 | 8.0 | 5304 | 0.7220 | 0.6568 | 0.5164 | 0.5664 |
| 0.4803 | 9.0 | 5967 | 0.7208 | 0.6573 | 0.5161 | 0.5662 |
| 0.4577 | 10.0 | 6630 | 0.7223 | 0.6572 | 0.5164 | 0.5662 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-mlm-pubmed", "results": []}]}
|
gayanin/bart-mlm-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-mlm-pubmed
===============
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7223
* Rouge2 Precision: 0.6572
* Rouge2 Recall: 0.5164
* Rouge2 Fmeasure: 0.5662
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase-pubmed-1.1
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4236
- Rouge2 Precision: 0.8482
- Rouge2 Recall: 0.673
- Rouge2 Fmeasure: 0.7347
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.6534 | 1.0 | 663 | 0.4641 | 0.8448 | 0.6691 | 0.7313 |
| 0.5078 | 2.0 | 1326 | 0.4398 | 0.8457 | 0.6719 | 0.7333 |
| 0.4367 | 3.0 | 1989 | 0.4274 | 0.847 | 0.6717 | 0.7335 |
| 0.3575 | 4.0 | 2652 | 0.4149 | 0.8481 | 0.6733 | 0.735 |
| 0.3319 | 5.0 | 3315 | 0.4170 | 0.8481 | 0.6724 | 0.7343 |
| 0.3179 | 6.0 | 3978 | 0.4264 | 0.8484 | 0.6733 | 0.735 |
| 0.2702 | 7.0 | 4641 | 0.4207 | 0.8489 | 0.6732 | 0.7353 |
| 0.2606 | 8.0 | 5304 | 0.4205 | 0.8487 | 0.6725 | 0.7347 |
| 0.2496 | 9.0 | 5967 | 0.4247 | 0.8466 | 0.6717 | 0.7334 |
| 0.2353 | 10.0 | 6630 | 0.4236 | 0.8482 | 0.673 | 0.7347 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-paraphrase-pubmed-1.1", "results": []}]}
|
gayanin/bart-paraphrase-pubmed-1.1
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-paraphrase-pubmed-1.1
==========================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4236
* Rouge2 Precision: 0.8482
* Rouge2 Recall: 0.673
* Rouge2 Fmeasure: 0.7347
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-paraphrase-pubmed
This model is a fine-tuned version of [facebook/bart-base](https://huggingface.co/facebook/bart-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6340
- Rouge2 Precision: 0.83
- Rouge2 Recall: 0.6526
- Rouge2 Fmeasure: 0.7144
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.6613 | 1.0 | 663 | 0.4750 | 0.8321 | 0.6552 | 0.7167 |
| 0.4993 | 2.0 | 1326 | 0.4404 | 0.8366 | 0.6583 | 0.7203 |
| 0.443 | 3.0 | 1989 | 0.4261 | 0.8319 | 0.6562 | 0.7176 |
| 0.3482 | 4.0 | 2652 | 0.4198 | 0.8348 | 0.6571 | 0.7191 |
| 0.3206 | 5.0 | 3315 | 0.4233 | 0.8344 | 0.656 | 0.7183 |
| 0.294 | 6.0 | 3978 | 0.4334 | 0.835 | 0.657 | 0.719 |
| 0.2404 | 7.0 | 4641 | 0.4437 | 0.8334 | 0.6559 | 0.7178 |
| 0.2228 | 8.0 | 5304 | 0.4438 | 0.8348 | 0.6565 | 0.7187 |
| 0.211 | 9.0 | 5967 | 0.4516 | 0.8329 | 0.6549 | 0.717 |
| 0.1713 | 10.0 | 6630 | 0.4535 | 0.8332 | 0.6547 | 0.7169 |
| 0.1591 | 11.0 | 7293 | 0.4763 | 0.8349 | 0.6561 | 0.7184 |
| 0.1555 | 12.0 | 7956 | 0.4824 | 0.8311 | 0.6534 | 0.7153 |
| 0.1262 | 13.0 | 8619 | 0.4883 | 0.8322 | 0.655 | 0.7167 |
| 0.1164 | 14.0 | 9282 | 0.5025 | 0.8312 | 0.6539 | 0.7158 |
| 0.1108 | 15.0 | 9945 | 0.5149 | 0.8321 | 0.6535 | 0.7157 |
| 0.0926 | 16.0 | 10608 | 0.5340 | 0.8315 | 0.6544 | 0.7159 |
| 0.0856 | 17.0 | 11271 | 0.5322 | 0.8306 | 0.6518 | 0.7142 |
| 0.0785 | 18.0 | 11934 | 0.5346 | 0.8324 | 0.6549 | 0.7167 |
| 0.071 | 19.0 | 12597 | 0.5488 | 0.8311 | 0.652 | 0.714 |
| 0.0635 | 20.0 | 13260 | 0.5624 | 0.8287 | 0.6517 | 0.7132 |
| 0.0608 | 21.0 | 13923 | 0.5612 | 0.8299 | 0.6527 | 0.7141 |
| 0.0531 | 22.0 | 14586 | 0.5764 | 0.8283 | 0.6498 | 0.7119 |
| 0.0486 | 23.0 | 15249 | 0.5832 | 0.8298 | 0.6532 | 0.7148 |
| 0.0465 | 24.0 | 15912 | 0.5866 | 0.83 | 0.6522 | 0.7142 |
| 0.0418 | 25.0 | 16575 | 0.5825 | 0.83 | 0.6523 | 0.7141 |
| 0.0391 | 26.0 | 17238 | 0.5997 | 0.8306 | 0.6545 | 0.716 |
| 0.0376 | 27.0 | 17901 | 0.5894 | 0.8315 | 0.6546 | 0.7164 |
| 0.035 | 28.0 | 18564 | 0.6045 | 0.8306 | 0.6529 | 0.7149 |
| 0.0316 | 29.0 | 19227 | 0.6168 | 0.8311 | 0.6546 | 0.7162 |
| 0.0314 | 30.0 | 19890 | 0.6203 | 0.8311 | 0.6552 | 0.7164 |
| 0.0292 | 31.0 | 20553 | 0.6173 | 0.8315 | 0.6548 | 0.7163 |
| 0.0265 | 32.0 | 21216 | 0.6226 | 0.832 | 0.6548 | 0.7166 |
| 0.0274 | 33.0 | 21879 | 0.6264 | 0.8314 | 0.6538 | 0.7155 |
| 0.0247 | 34.0 | 22542 | 0.6254 | 0.8289 | 0.6515 | 0.7132 |
| 0.0238 | 35.0 | 23205 | 0.6254 | 0.8307 | 0.6519 | 0.7142 |
| 0.0232 | 36.0 | 23868 | 0.6295 | 0.8287 | 0.6515 | 0.7133 |
| 0.0215 | 37.0 | 24531 | 0.6326 | 0.8293 | 0.6523 | 0.7138 |
| 0.0212 | 38.0 | 25194 | 0.6332 | 0.8295 | 0.6522 | 0.714 |
| 0.0221 | 39.0 | 25857 | 0.6335 | 0.8305 | 0.6528 | 0.7147 |
| 0.0202 | 40.0 | 26520 | 0.6340 | 0.83 | 0.6526 | 0.7144 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "bart-paraphrase-pubmed", "results": []}]}
|
gayanin/bart-paraphrase-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us
|
bart-paraphrase-pubmed
======================
This model is a fine-tuned version of facebook/bart-base on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6340
* Rouge2 Precision: 0.83
* Rouge2 Recall: 0.6526
* Rouge2 Fmeasure: 0.7144
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 40
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bart #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-pubmed
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6131
- Rouge2 Precision: 0.3
- Rouge2 Recall: 0.2152
- Rouge2 Fmeasure: 0.2379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 2.1335 | 1.0 | 563 | 1.7632 | 0.2716 | 0.1936 | 0.2135 |
| 1.9373 | 2.0 | 1126 | 1.7037 | 0.2839 | 0.2068 | 0.2265 |
| 1.8827 | 3.0 | 1689 | 1.6723 | 0.2901 | 0.2118 | 0.2316 |
| 1.8257 | 4.0 | 2252 | 1.6503 | 0.2938 | 0.2115 | 0.2332 |
| 1.8152 | 5.0 | 2815 | 1.6386 | 0.2962 | 0.2139 | 0.2357 |
| 1.7939 | 6.0 | 3378 | 1.6284 | 0.2976 | 0.212 | 0.2354 |
| 1.7845 | 7.0 | 3941 | 1.6211 | 0.2991 | 0.2155 | 0.2383 |
| 1.7468 | 8.0 | 4504 | 1.6167 | 0.2994 | 0.217 | 0.239 |
| 1.7464 | 9.0 | 5067 | 1.6137 | 0.3007 | 0.2154 | 0.2382 |
| 1.744 | 10.0 | 5630 | 1.6131 | 0.3 | 0.2152 | 0.2379 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-finetuned-pubmed", "results": []}]}
|
gayanin/t5-small-finetuned-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-finetuned-pubmed
=========================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6131
* Rouge2 Precision: 0.3
* Rouge2 Recall: 0.2152
* Rouge2 Fmeasure: 0.2379
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-mlm-pubmed-15
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5389
- Rouge2 Precision: 0.7165
- Rouge2 Recall: 0.5375
- Rouge2 Fmeasure: 0.5981
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.1024 | 0.75 | 500 | 0.7890 | 0.6854 | 0.4813 | 0.5502 |
| 0.8788 | 1.51 | 1000 | 0.7176 | 0.6906 | 0.4989 | 0.5638 |
| 0.8086 | 2.26 | 1500 | 0.6830 | 0.6872 | 0.5052 | 0.5663 |
| 0.7818 | 3.02 | 2000 | 0.6650 | 0.6912 | 0.5104 | 0.5711 |
| 0.7466 | 3.77 | 2500 | 0.6458 | 0.6965 | 0.5167 | 0.5774 |
| 0.731 | 4.52 | 3000 | 0.6355 | 0.6955 | 0.5161 | 0.5763 |
| 0.7126 | 5.28 | 3500 | 0.6249 | 0.6924 | 0.517 | 0.576 |
| 0.6998 | 6.03 | 4000 | 0.6166 | 0.6995 | 0.5207 | 0.5809 |
| 0.6855 | 6.79 | 4500 | 0.6076 | 0.6981 | 0.5215 | 0.5813 |
| 0.676 | 7.54 | 5000 | 0.6015 | 0.7003 | 0.5242 | 0.5836 |
| 0.6688 | 8.3 | 5500 | 0.5962 | 0.7004 | 0.5235 | 0.583 |
| 0.6569 | 9.05 | 6000 | 0.5900 | 0.6997 | 0.5234 | 0.5827 |
| 0.6503 | 9.8 | 6500 | 0.5880 | 0.703 | 0.5257 | 0.5856 |
| 0.6455 | 10.56 | 7000 | 0.5818 | 0.7008 | 0.5259 | 0.5849 |
| 0.635 | 11.31 | 7500 | 0.5796 | 0.7017 | 0.5271 | 0.5861 |
| 0.6323 | 12.07 | 8000 | 0.5769 | 0.7053 | 0.5276 | 0.5877 |
| 0.6241 | 12.82 | 8500 | 0.5730 | 0.7011 | 0.5243 | 0.5838 |
| 0.6224 | 13.57 | 9000 | 0.5696 | 0.7046 | 0.5286 | 0.5879 |
| 0.6139 | 14.33 | 9500 | 0.5685 | 0.7047 | 0.5295 | 0.5886 |
| 0.6118 | 15.08 | 10000 | 0.5653 | 0.704 | 0.5297 | 0.5886 |
| 0.6089 | 15.84 | 10500 | 0.5633 | 0.703 | 0.5272 | 0.5865 |
| 0.598 | 16.59 | 11000 | 0.5613 | 0.7059 | 0.5293 | 0.5889 |
| 0.6003 | 17.35 | 11500 | 0.5602 | 0.7085 | 0.532 | 0.5918 |
| 0.5981 | 18.1 | 12000 | 0.5587 | 0.7106 | 0.5339 | 0.5938 |
| 0.5919 | 18.85 | 12500 | 0.5556 | 0.708 | 0.5319 | 0.5914 |
| 0.5897 | 19.61 | 13000 | 0.5556 | 0.7106 | 0.5327 | 0.5931 |
| 0.5899 | 20.36 | 13500 | 0.5526 | 0.7114 | 0.534 | 0.5939 |
| 0.5804 | 21.12 | 14000 | 0.5521 | 0.7105 | 0.5328 | 0.5928 |
| 0.5764 | 21.87 | 14500 | 0.5520 | 0.715 | 0.537 | 0.5976 |
| 0.5793 | 22.62 | 15000 | 0.5506 | 0.713 | 0.5346 | 0.5951 |
| 0.5796 | 23.38 | 15500 | 0.5492 | 0.7124 | 0.5352 | 0.5952 |
| 0.5672 | 24.13 | 16000 | 0.5482 | 0.7124 | 0.5346 | 0.5948 |
| 0.5737 | 24.89 | 16500 | 0.5470 | 0.7134 | 0.5352 | 0.5956 |
| 0.5685 | 25.64 | 17000 | 0.5463 | 0.7117 | 0.5346 | 0.5946 |
| 0.5658 | 26.4 | 17500 | 0.5457 | 0.7145 | 0.5359 | 0.5965 |
| 0.5657 | 27.15 | 18000 | 0.5447 | 0.7145 | 0.5367 | 0.597 |
| 0.5645 | 27.9 | 18500 | 0.5441 | 0.7141 | 0.5362 | 0.5964 |
| 0.565 | 28.66 | 19000 | 0.5436 | 0.7151 | 0.5367 | 0.5972 |
| 0.5579 | 29.41 | 19500 | 0.5426 | 0.7162 | 0.5378 | 0.5982 |
| 0.563 | 30.17 | 20000 | 0.5424 | 0.7155 | 0.5373 | 0.5977 |
| 0.556 | 30.92 | 20500 | 0.5418 | 0.7148 | 0.536 | 0.5966 |
| 0.5576 | 31.67 | 21000 | 0.5411 | 0.7141 | 0.5356 | 0.5961 |
| 0.5546 | 32.43 | 21500 | 0.5409 | 0.7149 | 0.5364 | 0.5967 |
| 0.556 | 33.18 | 22000 | 0.5405 | 0.7143 | 0.5356 | 0.596 |
| 0.5536 | 33.94 | 22500 | 0.5401 | 0.7165 | 0.5377 | 0.5982 |
| 0.5527 | 34.69 | 23000 | 0.5397 | 0.7188 | 0.5389 | 0.5999 |
| 0.5531 | 35.44 | 23500 | 0.5395 | 0.7172 | 0.538 | 0.5989 |
| 0.5508 | 36.2 | 24000 | 0.5392 | 0.7166 | 0.538 | 0.5985 |
| 0.5495 | 36.95 | 24500 | 0.5391 | 0.7176 | 0.5387 | 0.5993 |
| 0.5539 | 37.71 | 25000 | 0.5391 | 0.7169 | 0.5372 | 0.598 |
| 0.5452 | 38.46 | 25500 | 0.5390 | 0.7179 | 0.5384 | 0.5991 |
| 0.5513 | 39.22 | 26000 | 0.5390 | 0.717 | 0.5377 | 0.5984 |
| 0.5506 | 39.97 | 26500 | 0.5389 | 0.7165 | 0.5375 | 0.5981 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-mlm-pubmed-15", "results": []}]}
|
gayanin/t5-small-mlm-pubmed-15
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-mlm-pubmed-15
======================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5389
* Rouge2 Precision: 0.7165
* Rouge2 Recall: 0.5375
* Rouge2 Fmeasure: 0.5981
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 40
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-mlm-pubmed-35
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1101
- Rouge2 Precision: 0.4758
- Rouge2 Recall: 0.3498
- Rouge2 Fmeasure: 0.3927
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 1.8404 | 0.75 | 500 | 1.5005 | 0.4265 | 0.2786 | 0.3273 |
| 1.6858 | 1.51 | 1000 | 1.4216 | 0.4318 | 0.2946 | 0.3404 |
| 1.6071 | 2.26 | 1500 | 1.3777 | 0.4472 | 0.3148 | 0.3598 |
| 1.5551 | 3.02 | 2000 | 1.3360 | 0.4406 | 0.3168 | 0.3586 |
| 1.5116 | 3.77 | 2500 | 1.3128 | 0.4523 | 0.3234 | 0.3671 |
| 1.4837 | 4.52 | 3000 | 1.2937 | 0.4477 | 0.3215 | 0.3645 |
| 1.4513 | 5.28 | 3500 | 1.2766 | 0.4511 | 0.3262 | 0.3689 |
| 1.4336 | 6.03 | 4000 | 1.2626 | 0.4548 | 0.3283 | 0.3718 |
| 1.4149 | 6.79 | 4500 | 1.2449 | 0.4495 | 0.3274 | 0.3687 |
| 1.3977 | 7.54 | 5000 | 1.2349 | 0.4507 | 0.3305 | 0.3712 |
| 1.3763 | 8.3 | 5500 | 1.2239 | 0.4519 | 0.3266 | 0.3688 |
| 1.371 | 9.05 | 6000 | 1.2171 | 0.4546 | 0.3305 | 0.3727 |
| 1.3501 | 9.8 | 6500 | 1.2080 | 0.4575 | 0.3329 | 0.3755 |
| 1.3443 | 10.56 | 7000 | 1.2017 | 0.4576 | 0.3314 | 0.3742 |
| 1.326 | 11.31 | 7500 | 1.1926 | 0.4578 | 0.333 | 0.3757 |
| 1.3231 | 12.07 | 8000 | 1.1866 | 0.4606 | 0.3357 | 0.3782 |
| 1.3089 | 12.82 | 8500 | 1.1816 | 0.4591 | 0.3338 | 0.3765 |
| 1.3007 | 13.57 | 9000 | 1.1764 | 0.4589 | 0.3361 | 0.3777 |
| 1.2943 | 14.33 | 9500 | 1.1717 | 0.4641 | 0.3382 | 0.3811 |
| 1.2854 | 15.08 | 10000 | 1.1655 | 0.4617 | 0.3378 | 0.38 |
| 1.2777 | 15.84 | 10500 | 1.1612 | 0.464 | 0.3401 | 0.3823 |
| 1.2684 | 16.59 | 11000 | 1.1581 | 0.4608 | 0.3367 | 0.3789 |
| 1.2612 | 17.35 | 11500 | 1.1554 | 0.4623 | 0.3402 | 0.3818 |
| 1.2625 | 18.1 | 12000 | 1.1497 | 0.4613 | 0.3381 | 0.3802 |
| 1.2529 | 18.85 | 12500 | 1.1465 | 0.4671 | 0.3419 | 0.3848 |
| 1.2461 | 19.61 | 13000 | 1.1431 | 0.4646 | 0.3399 | 0.3824 |
| 1.2415 | 20.36 | 13500 | 1.1419 | 0.4659 | 0.341 | 0.3835 |
| 1.2375 | 21.12 | 14000 | 1.1377 | 0.4693 | 0.3447 | 0.3873 |
| 1.2315 | 21.87 | 14500 | 1.1353 | 0.4672 | 0.3433 | 0.3855 |
| 1.2263 | 22.62 | 15000 | 1.1333 | 0.467 | 0.3433 | 0.3854 |
| 1.2214 | 23.38 | 15500 | 1.1305 | 0.4682 | 0.3446 | 0.3869 |
| 1.2202 | 24.13 | 16000 | 1.1291 | 0.4703 | 0.3465 | 0.3888 |
| 1.2155 | 24.89 | 16500 | 1.1270 | 0.472 | 0.348 | 0.3903 |
| 1.2064 | 25.64 | 17000 | 1.1261 | 0.4724 | 0.3479 | 0.3905 |
| 1.2173 | 26.4 | 17500 | 1.1236 | 0.4734 | 0.3485 | 0.3912 |
| 1.1994 | 27.15 | 18000 | 1.1220 | 0.4739 | 0.3486 | 0.3915 |
| 1.2018 | 27.9 | 18500 | 1.1217 | 0.4747 | 0.3489 | 0.3921 |
| 1.2045 | 28.66 | 19000 | 1.1194 | 0.4735 | 0.3488 | 0.3916 |
| 1.1949 | 29.41 | 19500 | 1.1182 | 0.4732 | 0.3484 | 0.3911 |
| 1.19 | 30.17 | 20000 | 1.1166 | 0.4724 | 0.3479 | 0.3904 |
| 1.1932 | 30.92 | 20500 | 1.1164 | 0.4753 | 0.3494 | 0.3924 |
| 1.1952 | 31.67 | 21000 | 1.1147 | 0.4733 | 0.3485 | 0.3911 |
| 1.1922 | 32.43 | 21500 | 1.1146 | 0.475 | 0.3494 | 0.3923 |
| 1.1889 | 33.18 | 22000 | 1.1132 | 0.4765 | 0.3499 | 0.3933 |
| 1.1836 | 33.94 | 22500 | 1.1131 | 0.4768 | 0.351 | 0.3939 |
| 1.191 | 34.69 | 23000 | 1.1127 | 0.4755 | 0.3495 | 0.3926 |
| 1.1811 | 35.44 | 23500 | 1.1113 | 0.4748 | 0.349 | 0.3919 |
| 1.1864 | 36.2 | 24000 | 1.1107 | 0.4751 | 0.3494 | 0.3921 |
| 1.1789 | 36.95 | 24500 | 1.1103 | 0.4756 | 0.3499 | 0.3927 |
| 1.1819 | 37.71 | 25000 | 1.1101 | 0.4758 | 0.35 | 0.3932 |
| 1.1862 | 38.46 | 25500 | 1.1099 | 0.4755 | 0.3497 | 0.3926 |
| 1.1764 | 39.22 | 26000 | 1.1101 | 0.4759 | 0.3498 | 0.3928 |
| 1.1819 | 39.97 | 26500 | 1.1101 | 0.4758 | 0.3498 | 0.3927 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-mlm-pubmed-35", "results": []}]}
|
gayanin/t5-small-mlm-pubmed-35
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-mlm-pubmed-35
======================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.1101
* Rouge2 Precision: 0.4758
* Rouge2 Recall: 0.3498
* Rouge2 Fmeasure: 0.3927
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 40
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-mlm-pubmed-45
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6395
- Rouge2 Precision: 0.3383
- Rouge2 Recall: 0.2424
- Rouge2 Fmeasure: 0.2753
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 2.519 | 0.75 | 500 | 1.9659 | 0.3178 | 0.1888 | 0.2299 |
| 2.169 | 1.51 | 1000 | 1.8450 | 0.3256 | 0.2138 | 0.25 |
| 2.0796 | 2.26 | 1500 | 1.7900 | 0.3368 | 0.2265 | 0.2636 |
| 1.9978 | 3.02 | 2000 | 1.7553 | 0.3427 | 0.234 | 0.2709 |
| 1.9686 | 3.77 | 2500 | 1.7172 | 0.3356 | 0.2347 | 0.2692 |
| 1.9142 | 4.52 | 3000 | 1.6986 | 0.3358 | 0.238 | 0.2715 |
| 1.921 | 5.28 | 3500 | 1.6770 | 0.3349 | 0.2379 | 0.2709 |
| 1.8848 | 6.03 | 4000 | 1.6683 | 0.3346 | 0.2379 | 0.2708 |
| 1.8674 | 6.79 | 4500 | 1.6606 | 0.3388 | 0.2419 | 0.2752 |
| 1.8606 | 7.54 | 5000 | 1.6514 | 0.3379 | 0.2409 | 0.274 |
| 1.8515 | 8.3 | 5500 | 1.6438 | 0.3356 | 0.2407 | 0.2731 |
| 1.8403 | 9.05 | 6000 | 1.6401 | 0.3367 | 0.2421 | 0.2744 |
| 1.8411 | 9.8 | 6500 | 1.6395 | 0.3383 | 0.2424 | 0.2753 |
### Framework versions
- Transformers 4.12.5
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-mlm-pubmed-45", "results": []}]}
|
gayanin/t5-small-mlm-pubmed-45
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-mlm-pubmed-45
======================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 1.6395
* Rouge2 Precision: 0.3383
* Rouge2 Recall: 0.2424
* Rouge2 Fmeasure: 0.2753
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 10
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.5
* Pytorch 1.10.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 10\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.5\n* Pytorch 1.10.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-mlm-pubmed
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8008
- Rouge2 Precision: 0.6071
- Rouge2 Recall: 0.4566
- Rouge2 Fmeasure: 0.5079
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.914 | 0.75 | 500 | 0.8691 | 0.5901 | 0.4357 | 0.4879 |
| 0.9093 | 1.51 | 1000 | 0.8646 | 0.5867 | 0.4372 | 0.488 |
| 0.895 | 2.26 | 1500 | 0.8618 | 0.5891 | 0.4387 | 0.49 |
| 0.8842 | 3.02 | 2000 | 0.8571 | 0.5899 | 0.4374 | 0.4891 |
| 0.8796 | 3.77 | 2500 | 0.8544 | 0.5903 | 0.4406 | 0.4916 |
| 0.8759 | 4.52 | 3000 | 0.8513 | 0.5921 | 0.4395 | 0.4912 |
| 0.8621 | 5.28 | 3500 | 0.8485 | 0.5934 | 0.4413 | 0.493 |
| 0.8613 | 6.03 | 4000 | 0.8442 | 0.5944 | 0.4428 | 0.4944 |
| 0.8537 | 6.79 | 4500 | 0.8406 | 0.594 | 0.4414 | 0.4932 |
| 0.8518 | 7.54 | 5000 | 0.8399 | 0.5956 | 0.4424 | 0.4945 |
| 0.8438 | 8.3 | 5500 | 0.8365 | 0.5953 | 0.4452 | 0.4964 |
| 0.8339 | 9.05 | 6000 | 0.8353 | 0.5983 | 0.4468 | 0.4983 |
| 0.8307 | 9.8 | 6500 | 0.8331 | 0.5979 | 0.4461 | 0.4976 |
| 0.8328 | 10.56 | 7000 | 0.8304 | 0.5975 | 0.4465 | 0.4979 |
| 0.8263 | 11.31 | 7500 | 0.8283 | 0.5977 | 0.4467 | 0.4981 |
| 0.8168 | 12.07 | 8000 | 0.8267 | 0.5971 | 0.4463 | 0.4976 |
| 0.8165 | 12.82 | 8500 | 0.8248 | 0.5969 | 0.4462 | 0.4976 |
| 0.8084 | 13.57 | 9000 | 0.8245 | 0.6018 | 0.4527 | 0.5035 |
| 0.8136 | 14.33 | 9500 | 0.8219 | 0.6023 | 0.4509 | 0.5023 |
| 0.8073 | 15.08 | 10000 | 0.8206 | 0.6002 | 0.4486 | 0.5001 |
| 0.808 | 15.84 | 10500 | 0.8185 | 0.6009 | 0.4506 | 0.5019 |
| 0.8027 | 16.59 | 11000 | 0.8173 | 0.5978 | 0.4478 | 0.4989 |
| 0.8061 | 17.35 | 11500 | 0.8169 | 0.6022 | 0.4513 | 0.5026 |
| 0.7922 | 18.1 | 12000 | 0.8152 | 0.6016 | 0.4501 | 0.5016 |
| 0.7928 | 18.85 | 12500 | 0.8141 | 0.6009 | 0.45 | 0.5012 |
| 0.7909 | 19.61 | 13000 | 0.8143 | 0.6019 | 0.4521 | 0.5028 |
| 0.7909 | 20.36 | 13500 | 0.8115 | 0.5997 | 0.4505 | 0.5011 |
| 0.7949 | 21.12 | 14000 | 0.8115 | 0.6043 | 0.4536 | 0.5048 |
| 0.7853 | 21.87 | 14500 | 0.8095 | 0.6033 | 0.4527 | 0.5038 |
| 0.7819 | 22.62 | 15000 | 0.8095 | 0.6054 | 0.4541 | 0.5056 |
| 0.7828 | 23.38 | 15500 | 0.8075 | 0.6036 | 0.453 | 0.5042 |
| 0.787 | 24.13 | 16000 | 0.8068 | 0.6031 | 0.4528 | 0.504 |
| 0.7739 | 24.89 | 16500 | 0.8072 | 0.6043 | 0.4529 | 0.5045 |
| 0.7782 | 25.64 | 17000 | 0.8073 | 0.606 | 0.4551 | 0.5063 |
| 0.7772 | 26.4 | 17500 | 0.8063 | 0.6055 | 0.4549 | 0.5062 |
| 0.7718 | 27.15 | 18000 | 0.8057 | 0.606 | 0.4546 | 0.5059 |
| 0.7747 | 27.9 | 18500 | 0.8045 | 0.6046 | 0.4543 | 0.5054 |
| 0.7738 | 28.66 | 19000 | 0.8035 | 0.6059 | 0.4549 | 0.506 |
| 0.7642 | 29.41 | 19500 | 0.8041 | 0.6053 | 0.4545 | 0.5058 |
| 0.7666 | 30.17 | 20000 | 0.8039 | 0.6066 | 0.457 | 0.508 |
| 0.7686 | 30.92 | 20500 | 0.8027 | 0.6075 | 0.4571 | 0.5081 |
| 0.7664 | 31.67 | 21000 | 0.8026 | 0.6062 | 0.4566 | 0.5076 |
| 0.77 | 32.43 | 21500 | 0.8022 | 0.6068 | 0.4571 | 0.5081 |
| 0.7618 | 33.18 | 22000 | 0.8015 | 0.6065 | 0.4563 | 0.5072 |
| 0.7615 | 33.94 | 22500 | 0.8013 | 0.6064 | 0.4565 | 0.5074 |
| 0.7611 | 34.69 | 23000 | 0.8017 | 0.607 | 0.4567 | 0.5078 |
| 0.7611 | 35.44 | 23500 | 0.8013 | 0.608 | 0.4565 | 0.5082 |
| 0.7604 | 36.2 | 24000 | 0.8012 | 0.6069 | 0.4561 | 0.5072 |
| 0.7599 | 36.95 | 24500 | 0.8013 | 0.6078 | 0.4571 | 0.5085 |
| 0.7542 | 37.71 | 25000 | 0.8016 | 0.6083 | 0.4579 | 0.5091 |
| 0.7637 | 38.46 | 25500 | 0.8009 | 0.6072 | 0.4569 | 0.5081 |
| 0.7596 | 39.22 | 26000 | 0.8008 | 0.6069 | 0.4566 | 0.5078 |
| 0.7604 | 39.97 | 26500 | 0.8008 | 0.6071 | 0.4566 | 0.5079 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-mlm-pubmed", "results": []}]}
|
gayanin/t5-small-mlm-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-mlm-pubmed
===================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.8008
* Rouge2 Precision: 0.6071
* Rouge2 Recall: 0.4566
* Rouge2 Fmeasure: 0.5079
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 40
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-paraphrase-pubmed
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4032
- Rouge2 Precision: 0.8281
- Rouge2 Recall: 0.6346
- Rouge2 Fmeasure: 0.6996
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 40
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge2 Precision | Rouge2 Recall | Rouge2 Fmeasure |
|:-------------:|:-----:|:-----:|:---------------:|:----------------:|:-------------:|:---------------:|
| 0.5253 | 1.0 | 663 | 0.4895 | 0.8217 | 0.6309 | 0.695 |
| 0.5385 | 2.0 | 1326 | 0.4719 | 0.822 | 0.6307 | 0.6953 |
| 0.5255 | 3.0 | 1989 | 0.4579 | 0.8225 | 0.631 | 0.6954 |
| 0.4927 | 4.0 | 2652 | 0.4510 | 0.824 | 0.6315 | 0.6965 |
| 0.484 | 5.0 | 3315 | 0.4426 | 0.8254 | 0.6323 | 0.6974 |
| 0.4691 | 6.0 | 3978 | 0.4383 | 0.8241 | 0.6311 | 0.6962 |
| 0.4546 | 7.0 | 4641 | 0.4319 | 0.8248 | 0.6322 | 0.6969 |
| 0.4431 | 8.0 | 5304 | 0.4270 | 0.8254 | 0.633 | 0.6977 |
| 0.4548 | 9.0 | 5967 | 0.4257 | 0.8257 | 0.6322 | 0.6976 |
| 0.4335 | 10.0 | 6630 | 0.4241 | 0.8271 | 0.6333 | 0.6986 |
| 0.4234 | 11.0 | 7293 | 0.4203 | 0.827 | 0.6341 | 0.6992 |
| 0.433 | 12.0 | 7956 | 0.4185 | 0.8279 | 0.6347 | 0.6998 |
| 0.4108 | 13.0 | 8619 | 0.4161 | 0.8285 | 0.6352 | 0.7004 |
| 0.4101 | 14.0 | 9282 | 0.4133 | 0.8289 | 0.6356 | 0.7008 |
| 0.4155 | 15.0 | 9945 | 0.4149 | 0.8279 | 0.635 | 0.6998 |
| 0.3991 | 16.0 | 10608 | 0.4124 | 0.8289 | 0.6353 | 0.7005 |
| 0.3962 | 17.0 | 11271 | 0.4113 | 0.829 | 0.6353 | 0.7006 |
| 0.3968 | 18.0 | 11934 | 0.4114 | 0.8285 | 0.6352 | 0.7002 |
| 0.3962 | 19.0 | 12597 | 0.4100 | 0.8282 | 0.6346 | 0.6998 |
| 0.3771 | 20.0 | 13260 | 0.4078 | 0.829 | 0.6352 | 0.7005 |
| 0.3902 | 21.0 | 13923 | 0.4083 | 0.8295 | 0.6351 | 0.7006 |
| 0.3811 | 22.0 | 14586 | 0.4077 | 0.8276 | 0.6346 | 0.6995 |
| 0.38 | 23.0 | 15249 | 0.4076 | 0.8281 | 0.6346 | 0.6997 |
| 0.3695 | 24.0 | 15912 | 0.4059 | 0.8277 | 0.6344 | 0.6993 |
| 0.3665 | 25.0 | 16575 | 0.4043 | 0.8278 | 0.6343 | 0.6992 |
| 0.3728 | 26.0 | 17238 | 0.4059 | 0.8279 | 0.6346 | 0.6994 |
| 0.3669 | 27.0 | 17901 | 0.4048 | 0.8271 | 0.6342 | 0.6991 |
| 0.3702 | 28.0 | 18564 | 0.4058 | 0.8265 | 0.6338 | 0.6985 |
| 0.3674 | 29.0 | 19227 | 0.4049 | 0.8277 | 0.6345 | 0.6993 |
| 0.364 | 30.0 | 19890 | 0.4048 | 0.8273 | 0.6341 | 0.699 |
| 0.3618 | 31.0 | 20553 | 0.4041 | 0.828 | 0.6349 | 0.6997 |
| 0.3609 | 32.0 | 21216 | 0.4040 | 0.8275 | 0.6346 | 0.6994 |
| 0.357 | 33.0 | 21879 | 0.4037 | 0.8278 | 0.6348 | 0.6996 |
| 0.3638 | 34.0 | 22542 | 0.4038 | 0.8275 | 0.634 | 0.6989 |
| 0.3551 | 35.0 | 23205 | 0.4035 | 0.8275 | 0.6344 | 0.6992 |
| 0.358 | 36.0 | 23868 | 0.4035 | 0.8279 | 0.6347 | 0.6995 |
| 0.3519 | 37.0 | 24531 | 0.4034 | 0.8277 | 0.6343 | 0.6992 |
| 0.359 | 38.0 | 25194 | 0.4035 | 0.8281 | 0.6346 | 0.6996 |
| 0.3542 | 39.0 | 25857 | 0.4033 | 0.8281 | 0.6346 | 0.6996 |
| 0.3592 | 40.0 | 26520 | 0.4032 | 0.8281 | 0.6346 | 0.6996 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.9.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "model-index": [{"name": "t5-small-paraphrase-pubmed", "results": []}]}
|
gayanin/t5-small-paraphrase-pubmed
| null |
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us
|
t5-small-paraphrase-pubmed
==========================
This model is a fine-tuned version of t5-small on an unknown dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4032
* Rouge2 Precision: 0.8281
* Rouge2 Recall: 0.6346
* Rouge2 Fmeasure: 0.6996
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 16
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 40
* mixed\_precision\_training: Native AMP
### Training results
### Framework versions
* Transformers 4.12.3
* Pytorch 1.9.0+cu111
* Datasets 1.15.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #t5 #text2text-generation #generated_from_trainer #license-apache-2.0 #autotrain_compatible #endpoints_compatible #text-generation-inference #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 16\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 40\n* mixed\\_precision\\_training: Native AMP",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.12.3\n* Pytorch 1.9.0+cu111\n* Datasets 1.15.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2180
- Accuracy: 0.923
- F1: 0.9233
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8217 | 1.0 | 250 | 0.3137 | 0.903 | 0.8999 |
| 0.2484 | 2.0 | 500 | 0.2180 | 0.923 | 0.9233 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
{"license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["emotion"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "distilbert-base-uncased-finetuned-emotion", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "emotion", "type": "emotion", "args": "default"}, "metrics": [{"type": "accuracy", "value": 0.923, "name": "Accuracy"}, {"type": "f1", "value": 0.9233262687967644, "name": "F1"}]}]}]}
|
gbade786/distilbert-base-uncased-finetuned-emotion
| null |
[
"transformers",
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[] |
TAGS
#transformers #pytorch #tensorboard #distilbert #text-classification #generated_from_trainer #dataset-emotion #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
distilbert-base-uncased-finetuned-emotion
=========================================
This model is a fine-tuned version of distilbert-base-uncased on the emotion dataset.
It achieves the following results on the evaluation set:
* Loss: 0.2180
* Accuracy: 0.923
* F1: 0.9233
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 64
* eval\_batch\_size: 64
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 2
### Training results
### Framework versions
* Transformers 4.15.0
* Pytorch 1.10.0+cu111
* Datasets 1.17.0
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.15.0\n* Pytorch 1.10.0+cu111\n* Datasets 1.17.0\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #distilbert #text-classification #generated_from_trainer #dataset-emotion #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 64\n* eval\\_batch\\_size: 64\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 2",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.15.0\n* Pytorch 1.10.0+cu111\n* Datasets 1.17.0\n* Tokenizers 0.10.3"
] |
text2text-generation
|
transformers
|
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 483413089
- CO2 Emissions (in grams): 210.6348731063569
## Validation Metrics
- Loss: 1.8478657007217407
- Rouge1: 50.5981
- Rouge2: 26.2167
- RougeL: 46.0513
- RougeLsum: 46.061
- Gen Len: 13.5987
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/gborn/autonlp-news-summarization-483413089
```
|
{"language": "en", "tags": "autonlp", "datasets": ["gborn/autonlp-data-news-summarization"], "widget": [{"text": "I love AutoNLP \ud83e\udd17"}], "co2_eq_emissions": 210.6348731063569}
|
gborn/autonlp-news-summarization-483413089
| null |
[
"transformers",
"pytorch",
"pegasus",
"text2text-generation",
"autonlp",
"en",
"dataset:gborn/autonlp-data-news-summarization",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #pegasus #text2text-generation #autonlp #en #dataset-gborn/autonlp-data-news-summarization #co2_eq_emissions #autotrain_compatible #endpoints_compatible #region-us
|
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 483413089
- CO2 Emissions (in grams): 210.6348731063569
## Validation Metrics
- Loss: 1.8478657007217407
- Rouge1: 50.5981
- Rouge2: 26.2167
- RougeL: 46.0513
- RougeLsum: 46.061
- Gen Len: 13.5987
## Usage
You can use cURL to access this model:
|
[
"# Model Trained Using AutoNLP\n\n- Problem type: Summarization\n- Model ID: 483413089\n- CO2 Emissions (in grams): 210.6348731063569",
"## Validation Metrics\n\n- Loss: 1.8478657007217407\n- Rouge1: 50.5981\n- Rouge2: 26.2167\n- RougeL: 46.0513\n- RougeLsum: 46.061\n- Gen Len: 13.5987",
"## Usage\n\nYou can use cURL to access this model:"
] |
[
"TAGS\n#transformers #pytorch #pegasus #text2text-generation #autonlp #en #dataset-gborn/autonlp-data-news-summarization #co2_eq_emissions #autotrain_compatible #endpoints_compatible #region-us \n",
"# Model Trained Using AutoNLP\n\n- Problem type: Summarization\n- Model ID: 483413089\n- CO2 Emissions (in grams): 210.6348731063569",
"## Validation Metrics\n\n- Loss: 1.8478657007217407\n- Rouge1: 50.5981\n- Rouge2: 26.2167\n- RougeL: 46.0513\n- RougeLsum: 46.061\n- Gen Len: 13.5987",
"## Usage\n\nYou can use cURL to access this model:"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-cola
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6747
- Matthews Correlation: 0.5957
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name cola \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-cola \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4921 | 1.0 | 535 | 0.5283 | 0.5068 |
| 0.2837 | 2.0 | 1070 | 0.5133 | 0.5521 |
| 0.1775 | 3.0 | 1605 | 0.6747 | 0.5957 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "bert-base-cased-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.5956649094312695, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-cola
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6747
* Matthews Correlation: 0.5957
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-mnli
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5721
- Accuracy: 0.8410
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name mnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-mnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.5323 | 1.0 | 24544 | 0.4431 | 0.8302 |
| 0.3447 | 2.0 | 49088 | 0.4725 | 0.8353 |
| 0.2267 | 3.0 | 73632 | 0.5887 | 0.8368 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-base-cased-finetuned-mnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MNLI", "type": "glue", "args": "mnli"}, "metrics": [{"type": "accuracy", "value": 0.8410292921074044, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-mnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-mnli
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5721
* Accuracy: 0.8410
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-mrpc
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7132
- Accuracy: 0.8603
- F1: 0.9026
- Combined Score: 0.8814
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name mrpc \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 5 \\n --output_dir bert-base-cased-finetuned-mrpc \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.5981 | 1.0 | 230 | 0.4580 | 0.7892 | 0.8562 | 0.8227 |
| 0.3739 | 2.0 | 460 | 0.3806 | 0.8480 | 0.8942 | 0.8711 |
| 0.1991 | 3.0 | 690 | 0.4879 | 0.8529 | 0.8958 | 0.8744 |
| 0.1286 | 4.0 | 920 | 0.6342 | 0.8529 | 0.8986 | 0.8758 |
| 0.0812 | 5.0 | 1150 | 0.7132 | 0.8603 | 0.9026 | 0.8814 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "bert-base-cased-finetuned-mrpc", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MRPC", "type": "glue", "args": "mrpc"}, "metrics": [{"type": "accuracy", "value": 0.8602941176470589, "name": "Accuracy"}, {"type": "f1", "value": 0.9025641025641027, "name": "F1"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-mrpc
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-mrpc
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7132
* Accuracy: 0.8603
* F1: 0.9026
* Combined Score: 0.8814
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-qnli
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3986
- Accuracy: 0.9099
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name qnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-qnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.337 | 1.0 | 6547 | 0.9013 | 0.2448 |
| 0.1971 | 2.0 | 13094 | 0.9143 | 0.2839 |
| 0.1175 | 3.0 | 19641 | 0.9099 | 0.3986 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-base-cased-finetuned-qnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE QNLI", "type": "glue", "args": "qnli"}, "metrics": [{"type": "accuracy", "value": 0.9099395936298736, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-qnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-qnli
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3986
* Accuracy: 0.9099
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-qqp
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3752
- Accuracy: 0.9084
- F1: 0.8768
- Combined Score: 0.8926
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name qqp \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-qqp \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.308 | 1.0 | 22741 | 0.2548 | 0.8925 | 0.8556 | 0.8740 |
| 0.201 | 2.0 | 45482 | 0.2881 | 0.9032 | 0.8698 | 0.8865 |
| 0.1416 | 3.0 | 68223 | 0.3752 | 0.9084 | 0.8768 | 0.8926 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "bert-base-cased-finetuned-qqp", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE QQP", "type": "glue", "args": "qqp"}, "metrics": [{"type": "accuracy", "value": 0.9083848627256987, "name": "Accuracy"}, {"type": "f1", "value": 0.8767633750332712, "name": "F1"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-qqp
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-qqp
=============================
This model is a fine-tuned version of bert-base-cased on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3752
* Accuracy: 0.9084
* F1: 0.8768
* Combined Score: 0.8926
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-rte
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7260
- Accuracy: 0.6715
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name rte \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-rte \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6915 | 1.0 | 156 | 0.6491 | 0.6606 |
| 0.55 | 2.0 | 312 | 0.6737 | 0.6570 |
| 0.3955 | 3.0 | 468 | 0.7260 | 0.6715 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-base-cased-finetuned-rte", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE RTE", "type": "glue", "args": "rte"}, "metrics": [{"type": "accuracy", "value": 0.6714801444043321, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-rte
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-rte
=============================
This model is a fine-tuned version of bert-base-cased on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7260
* Accuracy: 0.6715
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-sst2
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3649
- Accuracy: 0.9232
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name sst2 \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-sst2 \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.233 | 1.0 | 4210 | 0.9174 | 0.2841 |
| 0.1261 | 2.0 | 8420 | 0.9278 | 0.3310 |
| 0.0768 | 3.0 | 12630 | 0.9232 | 0.3649 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-base-cased-finetuned-sst2", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE SST2", "type": "glue", "args": "sst2"}, "metrics": [{"type": "accuracy", "value": 0.9231651376146789, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-sst2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-sst2
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3649
* Accuracy: 0.9232
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-stsb
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4861
- Pearson: 0.8926
- Spearmanr: 0.8898
- Combined Score: 0.8912
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name stsb \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir bert-base-cased-finetuned-stsb \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Combined Score | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:--------------:|:---------------:|:-------:|:---------:|
| 1.1174 | 1.0 | 360 | 0.8816 | 0.5000 | 0.8832 | 0.8800 |
| 0.3835 | 2.0 | 720 | 0.8901 | 0.4672 | 0.8915 | 0.8888 |
| 0.2388 | 3.0 | 1080 | 0.8912 | 0.4861 | 0.8926 | 0.8898 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["spearmanr"], "model-index": [{"name": "bert-base-cased-finetuned-stsb", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE STSB", "type": "glue", "args": "stsb"}, "metrics": [{"type": "spearmanr", "value": 0.8897907271421561, "name": "Spearmanr"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-stsb
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-stsb
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4861
* Pearson: 0.8926
* Spearmanr: 0.8898
* Combined Score: 0.8912
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-cased-finetuned-wnli
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6996
- Accuracy: 0.4648
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path bert-base-cased \\n --task_name wnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 5 \\n --output_dir bert-base-cased-finetuned-wnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7299 | 1.0 | 40 | 0.6923 | 0.5634 |
| 0.6982 | 2.0 | 80 | 0.7027 | 0.3803 |
| 0.6972 | 3.0 | 120 | 0.7005 | 0.4507 |
| 0.6992 | 4.0 | 160 | 0.6977 | 0.5352 |
| 0.699 | 5.0 | 200 | 0.6996 | 0.4648 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-base-cased-finetuned-wnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE WNLI", "type": "glue", "args": "wnli"}, "metrics": [{"type": "accuracy", "value": 0.4647887323943662, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-base-cased-finetuned-wnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-base-cased-finetuned-wnli
==============================
This model is a fine-tuned version of bert-base-cased on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6996
* Accuracy: 0.4648
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-cased-finetuned-cola
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8385
- Matthews Correlation: 0.5957
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5533 | 1.0 | 2138 | 0.7943 | 0.4439 |
| 0.5004 | 2.0 | 4276 | 0.7272 | 0.5678 |
| 0.2865 | 3.0 | 6414 | 0.8385 | 0.5957 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "bert-large-cased-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.5957317644481708, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/bert-large-cased-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-large-cased-finetuned-cola
===============================
This model is a fine-tuned version of bert-large-cased on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.8385
* Matthews Correlation: 0.5957
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-cased-finetuned-mrpc
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6274
- Accuracy: 0.6838
- F1: 0.8122
- Combined Score: 0.7480
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6441 | 1.0 | 917 | 0.6370 | 0.6838 | 0.8122 | 0.7480 |
| 0.6451 | 2.0 | 1834 | 0.6553 | 0.6838 | 0.8122 | 0.7480 |
| 0.6428 | 3.0 | 2751 | 0.6332 | 0.6838 | 0.8122 | 0.7480 |
| 0.6476 | 4.0 | 3668 | 0.6248 | 0.6838 | 0.8122 | 0.7480 |
| 0.6499 | 5.0 | 4585 | 0.6274 | 0.6838 | 0.8122 | 0.7480 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "bert-large-cased-finetuned-mrpc", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MRPC", "type": "glue", "args": "mrpc"}, "metrics": [{"type": "accuracy", "value": 0.6838235294117647, "name": "Accuracy"}, {"type": "f1", "value": 0.8122270742358079, "name": "F1"}]}]}]}
|
gchhablani/bert-large-cased-finetuned-mrpc
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-large-cased-finetuned-mrpc
===============================
This model is a fine-tuned version of bert-large-cased on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6274
* Accuracy: 0.6838
* F1: 0.8122
* Combined Score: 0.7480
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-cased-finetuned-rte
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5187
- Accuracy: 0.6643
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6969 | 1.0 | 623 | 0.7039 | 0.5343 |
| 0.5903 | 2.0 | 1246 | 0.6461 | 0.7184 |
| 0.4557 | 3.0 | 1869 | 1.5187 | 0.6643 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-large-cased-finetuned-rte", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE RTE", "type": "glue", "args": "rte"}, "metrics": [{"type": "accuracy", "value": 0.6642599277978339, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-large-cased-finetuned-rte
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-large-cased-finetuned-rte
==============================
This model is a fine-tuned version of bert-large-cased on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
* Loss: 1.5187
* Accuracy: 0.6643
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-large-cased-finetuned-wnli
This model is a fine-tuned version of [bert-large-cased](https://huggingface.co/bert-large-cased) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7087
- Accuracy: 0.3521
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:----:|:--------:|:---------------:|
| 0.7114 | 1.0 | 159 | 0.5634 | 0.6923 |
| 0.7141 | 2.0 | 318 | 0.5634 | 0.6895 |
| 0.7063 | 3.0 | 477 | 0.5634 | 0.6930 |
| 0.712 | 4.0 | 636 | 0.4507 | 0.7077 |
| 0.7037 | 5.0 | 795 | 0.3521 | 0.7087 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "bert-large-cased-finetuned-wnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE WNLI", "type": "glue", "args": "wnli"}, "metrics": [{"type": "accuracy", "value": 0.352112676056338, "name": "Accuracy"}]}]}]}
|
gchhablani/bert-large-cased-finetuned-wnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
bert-large-cased-finetuned-wnli
===============================
This model is a fine-tuned version of bert-large-cased on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7087
* Accuracy: 0.3521
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #bert #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-cola
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5929
- Matthews Correlation: 0.3594
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name cola \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-cola \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5895 | 1.0 | 535 | 0.6146 | 0.1699 |
| 0.4656 | 2.0 | 1070 | 0.5667 | 0.3047 |
| 0.3329 | 3.0 | 1605 | 0.5929 | 0.3594 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-base-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.35940659235571387, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-base-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-cola
========================
This model is a fine-tuned version of google/fnet-base on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5929
* Matthews Correlation: 0.3594
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-mnli
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6443
- Accuracy: 0.7675
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name mnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-mnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.7143 | 1.0 | 24544 | 0.6169 | 0.7504 |
| 0.5407 | 2.0 | 49088 | 0.6218 | 0.7627 |
| 0.4178 | 3.0 | 73632 | 0.6564 | 0.7658 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-base-finetuned-mnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MNLI", "type": "glue", "args": "mnli"}, "metrics": [{"type": "accuracy", "value": 0.7674938974776241, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-base-finetuned-mnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-mnli
========================
This model is a fine-tuned version of google/fnet-base on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6443
* Accuracy: 0.7675
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-mrpc
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9653
- Accuracy: 0.7721
- F1: 0.8502
- Combined Score: 0.8112
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name mrpc \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 5 \\n --output_dir fnet-base-finetuned-mrpc \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.544 | 1.0 | 230 | 0.5272 | 0.7328 | 0.8300 | 0.7814 |
| 0.4034 | 2.0 | 460 | 0.6211 | 0.7255 | 0.8298 | 0.7776 |
| 0.2602 | 3.0 | 690 | 0.9110 | 0.7230 | 0.8306 | 0.7768 |
| 0.1688 | 4.0 | 920 | 0.8640 | 0.7696 | 0.8489 | 0.8092 |
| 0.0913 | 5.0 | 1150 | 0.9653 | 0.7721 | 0.8502 | 0.8112 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "fnet-base-finetuned-mrpc", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MRPC", "type": "glue", "args": "mrpc"}, "metrics": [{"type": "accuracy", "value": 0.7720588235294118, "name": "Accuracy"}, {"type": "f1", "value": 0.8502415458937198, "name": "F1"}]}]}]}
|
gchhablani/fnet-base-finetuned-mrpc
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-mrpc
========================
This model is a fine-tuned version of google/fnet-base on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
* Loss: 0.9653
* Accuracy: 0.7721
* F1: 0.8502
* Combined Score: 0.8112
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-qnli
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4746
- Accuracy: 0.8439
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name qnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-qnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.4597 | 1.0 | 6547 | 0.3713 | 0.8411 |
| 0.3252 | 2.0 | 13094 | 0.3781 | 0.8420 |
| 0.2243 | 3.0 | 19641 | 0.4746 | 0.8439 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-base-finetuned-qnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE QNLI", "type": "glue", "args": "qnli"}, "metrics": [{"type": "accuracy", "value": 0.8438586857038257, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-base-finetuned-qnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-qnli
========================
This model is a fine-tuned version of google/fnet-base on the GLUE QNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4746
* Accuracy: 0.8439
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-qqp
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3686
- Accuracy: 0.8847
- F1: 0.8466
- Combined Score: 0.8657
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name qqp \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-qqp \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.3484 | 1.0 | 22741 | 0.3014 | 0.8676 | 0.8297 | 0.8487 |
| 0.2387 | 2.0 | 45482 | 0.3011 | 0.8801 | 0.8429 | 0.8615 |
| 0.1739 | 3.0 | 68223 | 0.3686 | 0.8847 | 0.8466 | 0.8657 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "fnet-base-finetuned-qqp", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE QQP", "type": "glue", "args": "qqp"}, "metrics": [{"type": "accuracy", "value": 0.8847390551570616, "name": "Accuracy"}, {"type": "f1", "value": 0.8466197090382463, "name": "F1"}]}]}]}
|
gchhablani/fnet-base-finetuned-qqp
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-qqp
=======================
This model is a fine-tuned version of google/fnet-base on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
* Loss: 0.3686
* Accuracy: 0.8847
* F1: 0.8466
* Combined Score: 0.8657
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-rte
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6978
- Accuracy: 0.6282
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name rte \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-rte \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6829 | 1.0 | 156 | 0.6657 | 0.5704 |
| 0.6174 | 2.0 | 312 | 0.6784 | 0.6101 |
| 0.5141 | 3.0 | 468 | 0.6978 | 0.6282 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-base-finetuned-rte", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE RTE", "type": "glue", "args": "rte"}, "metrics": [{"type": "accuracy", "value": 0.628158844765343, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-base-finetuned-rte
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-rte
=======================
This model is a fine-tuned version of google/fnet-base on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6978
* Accuracy: 0.6282
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-sst2
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4674
- Accuracy: 0.8945
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name sst2 \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-sst2 \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:-----:|:--------:|:---------------:|
| 0.2956 | 1.0 | 4210 | 0.8819 | 0.3128 |
| 0.1746 | 2.0 | 8420 | 0.8979 | 0.3850 |
| 0.1204 | 3.0 | 12630 | 0.8945 | 0.4674 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-base-finetuned-sst2", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE SST2", "type": "glue", "args": "sst2"}, "metrics": [{"type": "accuracy", "value": 0.8944954128440367, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-base-finetuned-sst2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"rust",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #rust #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-sst2
========================
This model is a fine-tuned version of google/fnet-base on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.4674
* Accuracy: 0.8945
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #rust #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-stsb
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7894
- Pearson: 0.8256
- Spearmanr: 0.8219
- Combined Score: 0.8238
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name stsb \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 3 \\n --output_dir fnet-base-finetuned-stsb \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Combined Score | Validation Loss | Pearson | Spearmanr |
|:-------------:|:-----:|:----:|:--------------:|:---------------:|:-------:|:---------:|
| 1.5473 | 1.0 | 360 | 0.8120 | 0.7751 | 0.8115 | 0.8125 |
| 0.6954 | 2.0 | 720 | 0.8145 | 0.8717 | 0.8160 | 0.8130 |
| 0.4828 | 3.0 | 1080 | 0.8238 | 0.7894 | 0.8256 | 0.8219 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["spearmanr"], "model-index": [{"name": "fnet-base-finetuned-stsb", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE STSB", "type": "glue", "args": "stsb"}, "metrics": [{"type": "spearmanr", "value": 0.8219397497728022, "name": "Spearmanr"}]}]}]}
|
gchhablani/fnet-base-finetuned-stsb
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-stsb
========================
This model is a fine-tuned version of google/fnet-base on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7894
* Pearson: 0.8256
* Spearmanr: 0.8219
* Combined Score: 0.8238
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-base-finetuned-wnli
This model is a fine-tuned version of [google/fnet-base](https://huggingface.co/google/fnet-base) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6887
- Accuracy: 0.5493
The model was fine-tuned to compare [google/fnet-base](https://huggingface.co/google/fnet-base) as introduced in [this paper](https://arxiv.org/abs/2105.03824) against [bert-base-cased](https://huggingface.co/bert-base-cased).
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
This model is trained using the [run_glue](https://github.com/huggingface/transformers/blob/master/examples/pytorch/text-classification/run_glue.py) script. The following command was used:
```bash
#!/usr/bin/bash
python ../run_glue.py \\n --model_name_or_path google/fnet-base \\n --task_name wnli \\n --do_train \\n --do_eval \\n --max_seq_length 512 \\n --per_device_train_batch_size 16 \\n --learning_rate 2e-5 \\n --num_train_epochs 5 \\n --output_dir fnet-base-finetuned-wnli \\n --push_to_hub \\n --hub_strategy all_checkpoints \\n --logging_strategy epoch \\n --save_strategy epoch \\n --evaluation_strategy epoch \\n```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7052 | 1.0 | 40 | 0.6902 | 0.5634 |
| 0.6957 | 2.0 | 80 | 0.7013 | 0.4366 |
| 0.6898 | 3.0 | 120 | 0.6898 | 0.5352 |
| 0.6958 | 4.0 | 160 | 0.6874 | 0.5634 |
| 0.6982 | 5.0 | 200 | 0.6887 | 0.5493 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer", "fnet-bert-base-comparison"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-base-finetuned-wnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE WNLI", "type": "glue", "args": "wnli"}, "metrics": [{"type": "accuracy", "value": 0.5492957746478874, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-base-finetuned-wnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"fnet-bert-base-comparison",
"en",
"dataset:glue",
"arxiv:2105.03824",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[
"2105.03824"
] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-base-finetuned-wnli
========================
This model is a fine-tuned version of google/fnet-base on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6887
* Accuracy: 0.5493
The model was fine-tuned to compare google/fnet-base as introduced in this paper against bert-base-cased.
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
This model is trained using the run\_glue script. The following command was used:
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 16
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #fnet-bert-base-comparison #en #dataset-glue #arxiv-2105.03824 #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 16\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-cola-copy
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6243
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6195 | 1.0 | 2138 | 0.6527 | 0.0 |
| 0.6168 | 2.0 | 4276 | 0.6259 | 0.0 |
| 0.616 | 3.0 | 6414 | 0.6243 | 0.0 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-large-finetuned-cola-copy", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.0, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-large-finetuned-cola-copy
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-cola-copy
==============================
This model is a fine-tuned version of google/fnet-large on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6243
* Matthews Correlation: 0.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-cola-copy2
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6173
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6192 | 1.0 | 2138 | 0.6443 | 0.0 |
| 0.6177 | 2.0 | 4276 | 0.6296 | 0.0 |
| 0.6128 | 3.0 | 6414 | 0.6173 | 0.0 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-large-finetuned-cola-copy2", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.0, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-large-finetuned-cola-copy2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-cola-copy2
===============================
This model is a fine-tuned version of google/fnet-large on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6173
* Matthews Correlation: 0.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-cola-copy3
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6554
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6408 | 1.0 | 2138 | 0.7329 | 0.0 |
| 0.6589 | 2.0 | 4276 | 0.6311 | 0.0 |
| 0.6467 | 3.0 | 6414 | 0.6554 | 0.0 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-large-finetuned-cola-copy3", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.0, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-large-finetuned-cola-copy3
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-cola-copy3
===============================
This model is a fine-tuned version of google/fnet-large on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6554
* Matthews Correlation: 0.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 0.0001
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* lr\_scheduler\_warmup\_ratio: 0.1
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 0.0001\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* lr\\_scheduler\\_warmup\\_ratio: 0.1\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-cola-copy4
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6500
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: polynomial
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6345 | 1.0 | 2138 | 0.6611 | 0.0 |
| 0.6359 | 2.0 | 4276 | 0.6840 | 0.0 |
| 0.6331 | 3.0 | 6414 | 0.6500 | 0.0 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-large-finetuned-cola-copy4", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.0, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-large-finetuned-cola-copy4
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-cola-copy4
===============================
This model is a fine-tuned version of google/fnet-large on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6500
* Matthews Correlation: 0.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 4e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: polynomial
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 4e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: polynomial\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 4e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: polynomial\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-cola
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6243
- Matthews Correlation: 0.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.6195 | 1.0 | 2138 | 0.6527 | 0.0 |
| 0.6168 | 2.0 | 4276 | 0.6259 | 0.0 |
| 0.616 | 3.0 | 6414 | 0.6243 | 0.0 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["matthews_correlation"], "model-index": [{"name": "fnet-large-finetuned-cola", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE COLA", "type": "glue", "args": "cola"}, "metrics": [{"type": "matthews_correlation", "value": 0.0, "name": "Matthews Correlation"}]}]}]}
|
gchhablani/fnet-large-finetuned-cola
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-cola
=========================
This model is a fine-tuned version of google/fnet-large on the GLUE COLA dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6243
* Matthews Correlation: 0.0
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 1e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 1e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-mrpc
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0872
- Accuracy: 0.8260
- F1: 0.8799
- Combined Score: 0.8529
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:--------------:|
| 0.5656 | 1.0 | 917 | 0.6999 | 0.7843 | 0.8581 | 0.8212 |
| 0.3874 | 2.0 | 1834 | 0.7280 | 0.8088 | 0.8691 | 0.8390 |
| 0.1627 | 3.0 | 2751 | 1.1274 | 0.8162 | 0.8780 | 0.8471 |
| 0.0751 | 4.0 | 3668 | 1.0289 | 0.8333 | 0.8870 | 0.8602 |
| 0.0339 | 5.0 | 4585 | 1.0872 | 0.8260 | 0.8799 | 0.8529 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "fnet-large-finetuned-mrpc", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE MRPC", "type": "glue", "args": "mrpc"}, "metrics": [{"type": "accuracy", "value": 0.8259803921568627, "name": "Accuracy"}, {"type": "f1", "value": 0.8798646362098139, "name": "F1"}]}]}]}
|
gchhablani/fnet-large-finetuned-mrpc
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-mrpc
=========================
This model is a fine-tuned version of google/fnet-large on the GLUE MRPC dataset.
It achieves the following results on the evaluation set:
* Loss: 1.0872
* Accuracy: 0.8260
* F1: 0.8799
* Combined Score: 0.8529
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-qqp
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5515
- Accuracy: 0.8943
- F1: 0.8557
- Combined Score: 0.8750
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:------:|:---------------:|:--------:|:------:|:--------------:|
| 0.4574 | 1.0 | 90962 | 0.4946 | 0.8694 | 0.8297 | 0.8496 |
| 0.3387 | 2.0 | 181924 | 0.4745 | 0.8874 | 0.8437 | 0.8655 |
| 0.2029 | 3.0 | 272886 | 0.5515 | 0.8943 | 0.8557 | 0.8750 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy", "f1"], "model-index": [{"name": "fnet-large-finetuned-qqp", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE QQP", "type": "glue", "args": "qqp"}, "metrics": [{"type": "accuracy", "value": 0.8943111550828593, "name": "Accuracy"}, {"type": "f1", "value": 0.8556565212985171, "name": "F1"}]}]}]}
|
gchhablani/fnet-large-finetuned-qqp
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-qqp
========================
This model is a fine-tuned version of google/fnet-large on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5515
* Accuracy: 0.8943
* F1: 0.8557
* Combined Score: 0.8750
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-rte
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7528
- Accuracy: 0.6426
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7105 | 1.0 | 623 | 0.6887 | 0.5740 |
| 0.6714 | 2.0 | 1246 | 0.6742 | 0.6209 |
| 0.509 | 3.0 | 1869 | 0.7528 | 0.6426 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-large-finetuned-rte", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE RTE", "type": "glue", "args": "rte"}, "metrics": [{"type": "accuracy", "value": 0.6425992779783394, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-large-finetuned-rte
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-rte
========================
This model is a fine-tuned version of google/fnet-large on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
* Loss: 0.7528
* Accuracy: 0.6426
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-sst2
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5240
- Accuracy: 0.9048
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 0.394 | 1.0 | 16838 | 0.3896 | 0.8968 |
| 0.2076 | 2.0 | 33676 | 0.5100 | 0.8956 |
| 0.1148 | 3.0 | 50514 | 0.5240 | 0.9048 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-large-finetuned-sst2", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE SST2", "type": "glue", "args": "sst2"}, "metrics": [{"type": "accuracy", "value": 0.9048165137614679, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-large-finetuned-sst2
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-sst2
=========================
This model is a fine-tuned version of google/fnet-large on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
* Loss: 0.5240
* Accuracy: 0.9048
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-stsb
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6250
- Pearson: 0.8554
- Spearmanr: 0.8533
- Combined Score: 0.8543
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 1.0727 | 1.0 | 1438 | 0.7718 | 0.8187 | 0.8240 | 0.8214 |
| 0.4619 | 2.0 | 2876 | 0.7704 | 0.8472 | 0.8500 | 0.8486 |
| 0.2401 | 3.0 | 4314 | 0.6250 | 0.8554 | 0.8533 | 0.8543 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["spearmanr"], "model-index": [{"name": "fnet-large-finetuned-stsb", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE STSB", "type": "glue", "args": "stsb"}, "metrics": [{"type": "spearmanr", "value": 0.8532669137129205, "name": "Spearmanr"}]}]}]}
|
gchhablani/fnet-large-finetuned-stsb
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-stsb
=========================
This model is a fine-tuned version of google/fnet-large on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6250
* Pearson: 0.8554
* Spearmanr: 0.8533
* Combined Score: 0.8543
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 3.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 3.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
text-classification
|
transformers
|
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fnet-large-finetuned-wnli
This model is a fine-tuned version of [google/fnet-large](https://huggingface.co/google/fnet-large) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6953
- Accuracy: 0.3803
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7217 | 1.0 | 159 | 0.6864 | 0.5634 |
| 0.7056 | 2.0 | 318 | 0.6869 | 0.5634 |
| 0.706 | 3.0 | 477 | 0.6875 | 0.5634 |
| 0.7032 | 4.0 | 636 | 0.6931 | 0.5634 |
| 0.7025 | 5.0 | 795 | 0.6953 | 0.3803 |
### Framework versions
- Transformers 4.11.0.dev0
- Pytorch 1.9.0
- Datasets 1.12.1
- Tokenizers 0.10.3
|
{"language": ["en"], "license": "apache-2.0", "tags": ["generated_from_trainer"], "datasets": ["glue"], "metrics": ["accuracy"], "model-index": [{"name": "fnet-large-finetuned-wnli", "results": [{"task": {"type": "text-classification", "name": "Text Classification"}, "dataset": {"name": "GLUE WNLI", "type": "glue", "args": "wnli"}, "metrics": [{"type": "accuracy", "value": 0.38028169014084506, "name": "Accuracy"}]}]}]}
|
gchhablani/fnet-large-finetuned-wnli
| null |
[
"transformers",
"pytorch",
"tensorboard",
"fnet",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"en"
] |
TAGS
#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us
|
fnet-large-finetuned-wnli
=========================
This model is a fine-tuned version of google/fnet-large on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
* Loss: 0.6953
* Accuracy: 0.3803
Model description
-----------------
More information needed
Intended uses & limitations
---------------------------
More information needed
Training and evaluation data
----------------------------
More information needed
Training procedure
------------------
### Training hyperparameters
The following hyperparameters were used during training:
* learning\_rate: 2e-05
* train\_batch\_size: 4
* eval\_batch\_size: 8
* seed: 42
* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
* lr\_scheduler\_type: linear
* num\_epochs: 5.0
### Training results
### Framework versions
* Transformers 4.11.0.dev0
* Pytorch 1.9.0
* Datasets 1.12.1
* Tokenizers 0.10.3
|
[
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
[
"TAGS\n#transformers #pytorch #tensorboard #fnet #text-classification #generated_from_trainer #en #dataset-glue #license-apache-2.0 #model-index #autotrain_compatible #endpoints_compatible #region-us \n",
"### Training hyperparameters\n\n\nThe following hyperparameters were used during training:\n\n\n* learning\\_rate: 2e-05\n* train\\_batch\\_size: 4\n* eval\\_batch\\_size: 8\n* seed: 42\n* optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08\n* lr\\_scheduler\\_type: linear\n* num\\_epochs: 5.0",
"### Training results",
"### Framework versions\n\n\n* Transformers 4.11.0.dev0\n* Pytorch 1.9.0\n* Datasets 1.12.1\n* Tokenizers 0.10.3"
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Hakha-Chin
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hakha Chin using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "cnh", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh/")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "cnh", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-cnh")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\/]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 31.38 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://colab.research.google.com/drive/1pejk9gv9vMcUOjyVQ_vsV2ngW4NiWLWy?usp=sharing).
|
{"language": "cnh", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Hakha Chin by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice cnh", "type": "common_voice", "args": "cnh"}, "metrics": [{"type": "wer", "value": 31.38, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-cnh
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"cnh",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"cnh"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #cnh #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Hakha-Chin
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Hakha Chin using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 31.38 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Hakha-Chin\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Hakha Chin using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 31.38 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #cnh #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Hakha-Chin\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Hakha Chin using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 31.38 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Esperanto
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Esperanto using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "eo", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
test_dataset = load_dataset("common_voice", "eo", split="test") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-eo')
model.to("cuda")
chars_to_ignore_regex = """[\\\\\\\\,\\\\\\\\?\\\\\\\\.\\\\\\\\!\\\\\\\\-\\\\\\\\;\\\\\\\\:\\\\\\\\"\\\\\\\\“\\\\\\\\%\\\\\\\\‘\\\\\\\\”\\\\\\\\�\\\\\\\\„\\\\\\\\«\\\\\\\\(\\\\\\\\»\\\\\\\\)\\\\\\\\’\\\\\\\\']"""
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower().replace('—',' ').replace('–',' ')
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=5000)))
```
**Test Result**: 10.13 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-esperanto-asr-with-transformers-final.ipynb).
|
{"language": "eo", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Esperanto by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice eo", "type": "common_voice", "args": "eo"}, "metrics": [{"type": "wer", "value": 10.13, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-eo
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"eo",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"eo"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #eo #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Esperanto
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Esperanto using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 10.13 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The code can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Esperanto\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Esperanto using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 10.13 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #eo #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Esperanto\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Esperanto using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 10.13 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Gujarati
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Gujarati using the [OpenSLR SLR78](http://openslr.org/78/) dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Gujarati `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET.
# For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # The original data was with 48,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset_eval = test_dataset_eval.map(speech_file_to_array_fn)
inputs = processor(test_dataset_eval["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset_eval["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-gu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…\'\_\’]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 23.55 %
## Training
90% of the OpenSLR Gujarati Male+Female dataset was used for training, after removing few examples that contained Roman characters.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1fRQlgl4EPR4qKGScgza3MpWgbL5BeWtn?usp=sharing).
|
{"language": "gu", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["openslr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Gujarati by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR gu", "type": "openslr"}, "metrics": [{"type": "wer", "value": 23.55, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-gu
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"gu",
"dataset:openslr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"gu"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #gu #dataset-openslr #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Gujarati
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Gujarati using the OpenSLR SLR78 dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Gujarati 'sentence' and 'path' fields:
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
Test Result: 23.55 %
## Training
90% of the OpenSLR Gujarati Male+Female dataset was used for training, after removing few examples that contained Roman characters.
The colab notebook used for training can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Gujarati\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Gujarati using the OpenSLR SLR78 dataset. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Gujarati 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 23.55 %",
"## Training\n\n90% of the OpenSLR Gujarati Male+Female dataset was used for training, after removing few examples that contained Roman characters.\nThe colab notebook used for training can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #gu #dataset-openslr #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Gujarati\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Gujarati using the OpenSLR SLR78 dataset. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Gujarati 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 23.55 %",
"## Training\n\n90% of the OpenSLR Gujarati Male+Female dataset was used for training, after removing few examples that contained Roman characters.\nThe colab notebook used for training can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Hungarian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Hungarian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "hu", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "hu", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-hu")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 46.75 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-hungarian-asr.ipynb). The notebook containing the code used for evaluation can be found [here](https://colab.research.google.com/drive/1esYvWS6IkTQFfRqi_b6lAJEycuecInHE?usp=sharing).
|
{"language": "hu", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Hungarian by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice hu", "type": "common_voice", "args": "hu"}, "metrics": [{"type": "wer", "value": 46.75, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-hu
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hu",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"hu"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #hu #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Hungarian
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Hungarian using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 46.75 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The code can be found here. The notebook containing the code used for evaluation can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Hungarian\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Hungarian using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 46.75 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here. The notebook containing the code used for evaluation can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #hu #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Hungarian\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Hungarian using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 46.75 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here. The notebook containing the code used for evaluation can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Interlingua
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Interlingua using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ia", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ia", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-ia")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\']'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.09 %
## Training
The Common Voice `train` and `validation` datasets were used for training for 4000 steps due to GPU timeout. The results are based on the 4000 steps checkpoint. There is a good chance that full training will lead to better results.
The colab notebook used can be found [here](https://colab.research.google.com/drive/1nbqvVwS8DTNrCzzh3vgrN55qxgoqbita?usp=sharing) and the evaluation can be found [here](https://colab.research.google.com/drive/18pCWBwNNUMUYV1FiqT_0EsTbCfwwe7ms?usp=sharing).
|
{"language": "ia", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Interlingua by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice ia", "type": "common_voice", "args": "ia"}, "metrics": [{"type": "wer", "value": 25.09, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-ia
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"ia",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"ia"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ia #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Interlingua
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Interlingua using the Common Voice.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
Test Result: 25.09 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training for 4000 steps due to GPU timeout. The results are based on the 4000 steps checkpoint. There is a good chance that full training will lead to better results.
The colab notebook used can be found here and the evaluation can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Interlingua\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Interlingua using the Common Voice.\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\nThe model can be evaluated as follows on the Odia test data of Common Voice.\n\nTest Result: 25.09 %",
"## Training\nThe Common Voice 'train' and 'validation' datasets were used for training for 4000 steps due to GPU timeout. The results are based on the 4000 steps checkpoint. There is a good chance that full training will lead to better results.\n\nThe colab notebook used can be found here and the evaluation can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #ia #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Interlingua\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Interlingua using the Common Voice.\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\nThe model can be evaluated as follows on the Odia test data of Common Voice.\n\nTest Result: 25.09 %",
"## Training\nThe Common Voice 'train' and 'validation' datasets were used for training for 4000 steps due to GPU timeout. The results are based on the 4000 steps checkpoint. There is a good chance that full training will lead to better results.\n\nThe colab notebook used can be found here and the evaluation can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Italian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Italian using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "it", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import unicodedata
import jiwer
def chunked_wer(targets, predictions, chunk_size=None):
if chunk_size is None: return jiwer.wer(targets, predictions)
start = 0
end = chunk_size
H, S, D, I = 0, 0, 0, 0
while start < len(targets):
chunk_metrics = jiwer.compute_measures(targets[start:end], predictions[start:end])
H = H + chunk_metrics["hits"]
S = S + chunk_metrics["substitutions"]
D = D + chunk_metrics["deletions"]
I = I + chunk_metrics["insertions"]
start += chunk_size
end += chunk_size
return float(S + D + I) / float(H + S + D)
allowed_characters = [
" ",
"'",
'a',
'b',
'c',
'd',
'e',
'f',
'g',
'h',
'i',
'j',
'k',
'l',
'm',
'n',
'o',
'p',
'q',
'r',
's',
't',
'u',
'v',
'w',
'x',
'y',
'z',
'à',
'á',
'è',
'é',
'ì',
'í',
'ò',
'ó',
'ù',
'ú',
]
def remove_accents(input_str):
if input_str in allowed_characters:
return input_str
if input_str == 'ø':
return 'o'
elif input_str=='ß' or input_str =='ß':
return 'b'
elif input_str=='ё':
return 'e'
elif input_str=='đ':
return 'd'
nfkd_form = unicodedata.normalize('NFKD', input_str)
only_ascii = nfkd_form.encode('ASCII', 'ignore').decode()
if only_ascii is None or only_ascii=='':
return input_str
else:
return only_ascii
def fix_accents(sentence):
new_sentence=''
for char in sentence:
new_sentence+=remove_accents(char)
return new_sentence
test_dataset = load_dataset("common_voice", "it", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model = Wav2Vec2ForCTC.from_pretrained('gchhablani/wav2vec2-large-xlsr-it')
model.to("cuda")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
chars_to_remove= [",", "?", ".", "!", "-", ";", ":", '""', "%", '"', "�",'ʿ','“','”','(','=','`','_','+','«','<','>','~','…','«','»','–','\[','\]','°','̇','´','ʾ','„','̇','̇','̇','¡'] # All extra characters
chars_to_remove_regex = f'[{"".join(chars_to_remove)}]'
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_remove_regex, '', batch["sentence"]).lower().replace('‘',"'").replace('ʻ',"'").replace('ʼ',"'").replace('’',"'").replace('ʹ',"''").replace('̇','')
batch["sentence"] = fix_accents(batch["sentence"])
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * chunked_wer(predictions=result["pred_strings"], targets=result["sentence"],chunk_size=5000)))
```
**Test Result**: 11.49 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://github.com/gchhablani/wav2vec2-week/blob/main/fine-tune-xlsr-wav2vec2-on-italian-asr-with-transformers_final.ipynb).
|
{"language": "it", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Italian by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice it", "type": "common_voice", "args": "it"}, "metrics": [{"type": "wer", "value": 11.49, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-it
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"it",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"it"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #it #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Italian
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Italian using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 11.49 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The code can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Italian\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Italian using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 11.49 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #it #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Italian\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Italian using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 11.49 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using a part of the [InterSpeech 2021 Marathi](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
resampler = torchaudio.transforms.Resample(8_000, 16_000) # The original data was with 8,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-2")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\'\�]'
resampler = torchaudio.transforms.Resample(8_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 19.98 % (555 examples from test set were used for evaluation)
**Test Result on 10% of OpenSLR74 data**: 64.64 %
## Training
5000 examples of the InterSpeech Marathi dataset were used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1sIwGOLJPQqhKm_wVZDkzRuoJqAEgArFr?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["interspeech_2021_asr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi 2 by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "InterSpeech 2021 ASR mr", "type": "interspeech_2021_asr"}, "metrics": [{"type": "wer", "value": 14.53, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr-2
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:interspeech_2021_asr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"mr"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-interspeech_2021_asr #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using a part of the InterSpeech 2021 Marathi dataset. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:
## Evaluation
The model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.
Test Result: 19.98 % (555 examples from test set were used for evaluation)
Test Result on 10% of OpenSLR74 data: 64.64 %
## Training
5000 examples of the InterSpeech Marathi dataset were used for training.
The colab notebook used for training can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using a part of the InterSpeech 2021 Marathi dataset. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.\n\n\n\nTest Result: 19.98 % (555 examples from test set were used for evaluation)\n\nTest Result on 10% of OpenSLR74 data: 64.64 %",
"## Training\n\n5000 examples of the InterSpeech Marathi dataset were used for training. \nThe colab notebook used for training can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-interspeech_2021_asr #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using a part of the InterSpeech 2021 Marathi dataset. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on the test set of the Marathi data on InterSpeech-2021.\n\n\n\nTest Result: 19.98 % (555 examples from test set were used for evaluation)\n\nTest Result on 10% of OpenSLR74 data: 64.64 %",
"## Training\n\n5000 examples of the InterSpeech Marathi dataset were used for training. \nThe colab notebook used for training can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset and [InterSpeech 2021](https://navana-tech.github.io/IS21SS-indicASRchallenge/data.html) Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `text` and `audio_path` fields:
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000) # sampling_rate can vary
return batch
test_data= test_data.map(speech_file_to_array_fn)
inputs = processor(test_data["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_data["text"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
import librosa
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_data = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr-3")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
batch["text"] = re.sub(chars_to_ignore_regex, '', batch["text"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["audio_path"])
batch["speech"] = librosa.resample(speech_array[0].numpy(), sampling_rate, 16_000)
return batch
test_data= test_data.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the audio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_data.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["text"])))
```
**Test Result**: 19.05 % (157+157 examples)
**Test Result on OpenSLR test**: 14.15 % (157 examples)
**Test Results on InterSpeech test**: 27.14 % (157 examples)
## Training
1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.
The colab notebook used for training and evaluation can be found [here](https://colab.research.google.com/drive/15fUhb4bUFFGJyNLr-_alvPxVX4w0YXRu?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["openslr", "interspeech_2021_asr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR mr, InterSpeech 2021 ASR mr", "type": "openslr, interspeech_2021_asr"}, "metrics": [{"type": "wer", "value": 19.05, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr-3
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:openslr",
"dataset:interspeech_2021_asr",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"mr"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-openslr #dataset-interspeech_2021_asr #license-apache-2.0 #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset and InterSpeech 2021 Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'text' and 'audio_path' fields:
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
Test Result: 19.05 % (157+157 examples)
Test Result on OpenSLR test: 14.15 % (157 examples)
Test Results on InterSpeech test: 27.14 % (157 examples)
## Training
1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.
The colab notebook used for training and evaluation can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset and InterSpeech 2021 Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'text' and 'audio_path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 19.05 % (157+157 examples)\n \nTest Result on OpenSLR test: 14.15 % (157 examples)\n\nTest Results on InterSpeech test: 27.14 % (157 examples)",
"## Training\n\n1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.\n\nThe colab notebook used for training and evaluation can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-openslr #dataset-interspeech_2021_asr #license-apache-2.0 #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset and InterSpeech 2021 Marathi datasets. Note that this data OpenSLR contains only female voices. Please keep this in mind before using the model for your task. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'text' and 'audio_path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 19.05 % (157+157 examples)\n \nTest Result on OpenSLR test: 14.15 % (157 examples)\n\nTest Results on InterSpeech test: 27.14 % (157 examples)",
"## Training\n\n1412 examples of the OpenSLR Marathi dataset and 1412 examples of InterSpeech 2021 Marathi ASR dataset were used for training. For testing, 157 examples from each were used.\n\nThe colab notebook used for training and evaluation can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Marathi using the [OpenSLR SLR64](http://openslr.org/64/) dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi `sentence` and `path` fields:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # The original data was with 48,000 sampling rate. You can change it according to your input.
# Preprocessing the datasets.
# We need to read the audio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
# test_dataset = #TODO: WRITE YOUR CODE TO LOAD THE TEST DATASET. For sample see the Colab link in Training Section.
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-mr")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"),
attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 14.53 %
## Training
90% of the OpenSLR Marathi dataset was used for training.
The colab notebook used for training can be found [here](https://colab.research.google.com/drive/1_BbLyLqDUsXG3RpSULfLRjC6UY3RjwME?usp=sharing).
|
{"language": "mr", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["openslr"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Marathi by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "OpenSLR mr", "type": "openslr"}, "metrics": [{"type": "wer", "value": 14.53, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-mr
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"mr",
"dataset:openslr",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"mr"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-openslr #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Marathi
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:
## Evaluation
The model can be evaluated as follows on 10% of the Marathi data on OpenSLR.
Test Result: 14.53 %
## Training
90% of the OpenSLR Marathi dataset was used for training.
The colab notebook used for training can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 14.53 %",
"## Training\n\n90% of the OpenSLR Marathi dataset was used for training.\nThe colab notebook used for training can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #mr #dataset-openslr #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Marathi\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Marathi using the OpenSLR SLR64 dataset. Note that this data contains only female voices. Please keep this in mind before using the model for your task, although it works very well for male voice too. When using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows, assuming you have a dataset with Marathi 'sentence' and 'path' fields:",
"## Evaluation\n\nThe model can be evaluated as follows on 10% of the Marathi data on OpenSLR.\n\n\n\nTest Result: 14.53 %",
"## Training\n\n90% of the OpenSLR Marathi dataset was used for training.\nThe colab notebook used for training can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Odia
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Odia using the [Common Voice](https://huggingface.co/datasets/common_voice).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "or", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "or", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-or")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�\–\…\'\_\’\।\|]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 52.64 %
## Training
The Common Voice `train` and `validation` datasets were used for training.The colab notebook used can be found [here](https://colab.research.google.com/drive/1s8DrwgB5y4Z7xXIrPXo1rQA5_1OZ8WD5?usp=sharing).
|
{"language": "or", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "XLSR Wav2Vec2 Large 53 Odia by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice or", "type": "common_voice", "args": "or"}, "metrics": [{"type": "wer", "value": 52.64, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-or
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"or",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"or"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #or #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Odia
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Odia using the Common Voice.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Odia test data of Common Voice.
Test Result: 52.64 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training.The colab notebook used can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Odia\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Odia using the Common Voice.\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\nThe model can be evaluated as follows on the Odia test data of Common Voice.\n\nTest Result: 52.64 %",
"## Training\nThe Common Voice 'train' and 'validation' datasets were used for training.The colab notebook used can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #or #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Odia\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Odia using the Common Voice.\nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\nThe model can be evaluated as follows on the Odia test data of Common Voice.\n\nTest Result: 52.64 %",
"## Training\nThe Common Voice 'train' and 'validation' datasets were used for training.The colab notebook used can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Portuguese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Portuguese using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "pt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "pt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-pt")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\;\"\“\'\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 17.22 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The script used for training can be found [here](https://github.com/jqueguiner/wav2vec2-sprint/blob/main/run_common_voice.py).
The parameters passed were:
```bash
#!/usr/bin/env bash
python run_common_voice.py \
--model_name_or_path="facebook/wav2vec2-large-xlsr-53" \
--dataset_config_name="pt" \
--output_dir=/workspace/output_models/pt/wav2vec2-large-xlsr-pt \
--cache_dir=/workspace/data \
--overwrite_output_dir \
--num_train_epochs="30" \
--per_device_train_batch_size="32" \
--per_device_eval_batch_size="32" \
--evaluation_strategy="steps" \
--learning_rate="3e-4" \
--warmup_steps="500" \
--fp16 \
--freeze_feature_extractor \
--save_steps="500" \
--eval_steps="500" \
--save_total_limit="1" \
--logging_steps="500" \
--group_by_length \
--feat_proj_dropout="0.0" \
--layerdrop="0.1" \
--gradient_checkpointing \
--do_train --do_eval \
```
Notebook containing the evaluation can be found [here](https://colab.research.google.com/drive/14e-zNK_5pm8EMY9EbeZerpHx7WsGycqG?usp=sharing).
|
{"language": "pt", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Portugese by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice pt", "type": "common_voice", "args": "pt"}, "metrics": [{"type": "wer", "value": 17.22, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-pt
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"pt",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"pt"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #pt #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Portuguese
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Portuguese using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 17.22 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here.
The parameters passed were:
Notebook containing the evaluation can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Portuguese\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Portuguese using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 17.22 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here.\n The parameters passed were:\n\n\n\nNotebook containing the evaluation can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #pt #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Portuguese\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Portuguese using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 17.22 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The script used for training can be found here.\n The parameters passed were:\n\n\n\nNotebook containing the evaluation can be found here."
] |
automatic-speech-recognition
|
transformers
|
# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Romansh Sursilvan using the [Common Voice](https://huggingface.co/datasets/common_voice) dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "rm-sursilv", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model = Wav2Vec2ForCTC.from_pretrained("gchhablani/wav2vec2-large-xlsr-rm-sursilv")
model.to("cuda")
chars_to_ignore_regex = '[\\,\\?\\.\\!\\-\\;\\:\\"\\“\\%\\‘\\”\\�\\…\\«\\»\\–]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 25.16 %
## Training
The Common Voice `train` and `validation` datasets were used for training. The code can be found [here](https://colab.research.google.com/drive/1dpZr_GzRowCciUbzM3GnW04TNKnB7vrP?usp=sharing).
|
{"language": "rm-sursilv", "license": "apache-2.0", "tags": ["audio", "automatic-speech-recognition", "speech", "xlsr-fine-tuning-week"], "datasets": ["common_voice"], "metrics": ["wer"], "model-index": [{"name": "Wav2Vec2 Large 53 Romansh Sursilvan by Gunjan Chhablani", "results": [{"task": {"type": "automatic-speech-recognition", "name": "Speech Recognition"}, "dataset": {"name": "Common Voice rm-sursilv", "type": "common_voice", "args": "rm-sursilv"}, "metrics": [{"type": "wer", "value": 25.16, "name": "Test WER"}]}]}]}
|
gchhablani/wav2vec2-large-xlsr-rm-sursilv
| null |
[
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"dataset:common_voice",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"rm-sursilv"
] |
TAGS
#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us
|
# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan
Fine-tuned facebook/wav2vec2-large-xlsr-53 on Romansh Sursilvan using the Common Voice dataset.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
## Evaluation
The model can be evaluated as follows on the Portuguese test data of Common Voice.
Test Result: 25.16 %
## Training
The Common Voice 'train' and 'validation' datasets were used for training. The code can be found here.
|
[
"# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Romansh Sursilvan using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 25.16 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
[
"TAGS\n#transformers #pytorch #jax #wav2vec2 #automatic-speech-recognition #audio #speech #xlsr-fine-tuning-week #dataset-common_voice #license-apache-2.0 #model-index #endpoints_compatible #region-us \n",
"# Wav2Vec2-Large-XLSR-53-Romansh-Sursilvan\n\nFine-tuned facebook/wav2vec2-large-xlsr-53 on Romansh Sursilvan using the Common Voice dataset. \nWhen using this model, make sure that your speech input is sampled at 16kHz.",
"## Usage\n\nThe model can be used directly (without a language model) as follows:",
"## Evaluation\n\nThe model can be evaluated as follows on the Portuguese test data of Common Voice.\n\n\n\n\nTest Result: 25.16 %",
"## Training\n\nThe Common Voice 'train' and 'validation' datasets were used for training. The code can be found here."
] |
fill-mask
|
transformers
|
# GreekSocialBERT
## Model description
A Greek language model based on [GreekBERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts.
The training corpus has been collected and provided by [Palo LTD](http://www.paloservices.com/)
## Eval results
### BibTeX entry and citation info
```bibtex
@Article{info12080331,
AUTHOR = {Alexandridis, Georgios and Varlamis, Iraklis and Korovesis, Konstantinos and Caridakis, George and Tsantilas, Panagiotis},
TITLE = {A Survey on Sentiment Analysis and Opinion Mining in Greek Social Media},
JOURNAL = {Information},
VOLUME = {12},
YEAR = {2021},
NUMBER = {8},
ARTICLE-NUMBER = {331},
URL = {https://www.mdpi.com/2078-2489/12/8/331},
ISSN = {2078-2489},
DOI = {10.3390/info12080331}
}
```
|
{"language": "el"}
|
gealexandri/greeksocialbert-base-greek-uncased-v1
| null |
[
"transformers",
"pytorch",
"tf",
"bert",
"fill-mask",
"el",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | null |
2022-03-02T23:29:05+00:00
|
[] |
[
"el"
] |
TAGS
#transformers #pytorch #tf #bert #fill-mask #el #autotrain_compatible #endpoints_compatible #region-us
|
# GreekSocialBERT
## Model description
A Greek language model based on GreekBERT
## Training data
The training data is a corpus of 458,293 documents collected from Greek social media accounts.
The training corpus has been collected and provided by Palo LTD
## Eval results
### BibTeX entry and citation info
|
[
"# GreekSocialBERT",
"## Model description\n\nA Greek language model based on GreekBERT",
"## Training data\n\nThe training data is a corpus of 458,293 documents collected from Greek social media accounts. \n\nThe training corpus has been collected and provided by Palo LTD",
"## Eval results",
"### BibTeX entry and citation info"
] |
[
"TAGS\n#transformers #pytorch #tf #bert #fill-mask #el #autotrain_compatible #endpoints_compatible #region-us \n",
"# GreekSocialBERT",
"## Model description\n\nA Greek language model based on GreekBERT",
"## Training data\n\nThe training data is a corpus of 458,293 documents collected from Greek social media accounts. \n\nThe training corpus has been collected and provided by Palo LTD",
"## Eval results",
"### BibTeX entry and citation info"
] |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.