
question_slug
stringlengths 3
77
| title
stringlengths 1
183
| slug
stringlengths 12
45
| summary
stringlengths 1
160
⌀ | author
stringlengths 2
30
| certification
stringclasses 2
values | created_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| updated_at
stringdate 2013-10-25 17:32:12
2025-04-12 09:38:24
| hit_count
int64 0
10.6M
| has_video
bool 2
classes | content
stringlengths 4
576k
| upvotes
int64 0
11.5k
| downvotes
int64 0
358
| tags
stringlengths 2
193
| comments
int64 0
2.56k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
department-highest-salary | SIMPLE LOGIC NO ADVANCE FUNCTION USED | simple-logic-no-advance-function-used-by-x3z7 | \nSELECT D.name AS DEPARTMENT , \n E.name AS EMPLOYEE , \n\t\t E.salary\n FROM EMPLOYEE AS E \n\t JOIN \n\t\t\t\t DEPARTMENT AS | recursive_coder | NORMAL | 2022-10-18T09:27:25.017522+00:00 | 2022-10-22T13:00:53.266168+00:00 | 1,921 | false | ```\nSELECT D.name AS DEPARTMENT , \n E.name AS EMPLOYEE , \n\t\t E.salary\n FROM EMPLOYEE AS E \n\t JOIN \n\t\t\t\t DEPARTMENT AS D \n\t\t\t\t ON E.departmentId = D.id\n WHERE E.salary = ( SELECT MAX(salary) # this subquery gives max salary of an department so that we can generate all employees who have max salary in that department.\n FROM EMPLOYEE\n WHERE departmentID = E.departmentID);\n``` | 7 | 0 | [] | 1 |
department-highest-salary | simplest solution | simplest-solution-by-invincible2511-qyab | \nselect d.name as Department ,e.name as Employee ,e.salary \nfrom Employee e, Department d \nwhere e.DepartmentId = d.id and (DepartmentId,Salary) in \n(select | Invincible2511 | NORMAL | 2022-09-03T17:55:49.653021+00:00 | 2022-09-03T17:55:49.653064+00:00 | 3,665 | false | ```\nselect d.name as Department ,e.name as Employee ,e.salary \nfrom Employee e, Department d \nwhere e.DepartmentId = d.id and (DepartmentId,Salary) in \n(select DepartmentId,max(Salary) as max from Employee group by DepartmentId)\n``` | 7 | 0 | ['MySQL'] | 3 |
department-highest-salary | clean code, I was upset about the discussion, none was clear. | clean-code-i-was-upset-about-the-discuss-8ktp | Upvote if you like the cleanliness!! \n\nwith cte as(\nselect d.Name as Department, \n e.Name as Employee, \n e.Salary as Salary,\n rank() over(partiti | shuvokamal | NORMAL | 2021-02-16T23:52:12.602151+00:00 | 2021-02-16T23:52:12.602193+00:00 | 403 | false | Upvote if you like the cleanliness!! \n\nwith cte as(\nselect d.Name as Department, \n e.Name as Employee, \n e.Salary as Salary,\n rank() over(partition by d.Name Order by Salary desc) as ranks\n from Employee e inner join Department d on d.Id = e.Departmentid)\n \nselect \nDepartment,\nEmployee, \nSalary\nfrom cte\nWhere ranks = 1 | 7 | 0 | [] | 1 |
department-highest-salary | MYSQL- Easy Solution - Window Function and CTE | mysql-easy-solution-window-function-and-dpnx5 | \n# Code\n\nwith new as\n(select *, dense_rank() over(partition by departmentId order by salary desc) as rn from employee)\n\nselect d.name as department, new.n | KG-Profile | NORMAL | 2024-04-14T14:59:07.348241+00:00 | 2024-06-12T16:49:16.006078+00:00 | 746 | false | \n# Code\n```\nwith new as\n(select *, dense_rank() over(partition by departmentId order by salary desc) as rn from employee)\n\nselect d.name as department, new.name as employee , salary from new\njoin department d on d.id=new.departmentId\nwhere rn=1\n``` | 6 | 0 | ['MySQL'] | 0 |
department-highest-salary | ✅ Pandas Beginner Friendly Solution 🔥 | pandas-beginner-friendly-solution-by-pni-oo7p | \uD83D\uDD3C IF YOU FIND THIS POST HELPFUL PLEASE UPVOTE \uD83D\uDC4D\n\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department | pniraj657 | NORMAL | 2023-08-18T15:04:52.314472+00:00 | 2023-08-18T15:04:52.314503+00:00 | 508 | false | **\uD83D\uDD3C IF YOU FIND THIS POST HELPFUL PLEASE UPVOTE \uD83D\uDC4D**\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n \n merged_df = employee.merge(department, left_on = \'departmentId\', right_on = \'id\')\n \n merged_df = merged_df.rename(columns = {\'name_x\': \'Employee\', \'name_y\': \'Department\', \'salary\': \'Salary\'})[[\'Department\', \'Employee\', \'Salary\']]\n \n return merged_df[merged_df[\'Salary\'] == merged_df.groupby(\'Department\')[\'Salary\'].transform(max)]\n```\n**Thank you for reading! \uD83D\uDE04 Comment if you have any questions or feedback.** | 6 | 0 | ['Python'] | 0 |
department-highest-salary | MS SQL| two approach | subquery| group by | join | ms-sql-two-approach-subquery-group-by-jo-u4jr | Approach 1\n\nselect d.name as Department, e.name as Employee, e.salary as Salary \nfrom Employee e join Department d on e.departmentId = d.id\nwhere 1 > (selec | kenechi03 | NORMAL | 2022-03-23T07:47:52.076726+00:00 | 2023-09-10T21:49:26.449904+00:00 | 1,077 | false | Approach 1\n```\nselect d.name as Department, e.name as Employee, e.salary as Salary \nfrom Employee e join Department d on e.departmentId = d.id\nwhere 1 > (select count(salary) \n from Employee e1 \n where e1.salary > e.salary and e1.departmentId = e.departmentId);\n\n```\n\nApproach 2\n\n```\nselect d.name as Department, e.name as Employee, e.salary as Salary \nfrom Employee e join Department d on e.departmentId = d.id\nwhere e.salary = (select max(salary) \n from Employee e1 group by e1.departmentId having e1.departmentId = e.departmentId);\n``` | 6 | 0 | ['MS SQL Server'] | 1 |
department-highest-salary | Simple Using RANK() function🌻 | simple-using-rank-function-by-ravithemor-jj7r | Intuition\nThe query selects the Department name, Employee name, and Salary from a derived table (t1) that includes the Department name, Employee name, Salary, | ravithemore | NORMAL | 2023-11-17T06:27:24.770799+00:00 | 2023-11-17T06:27:24.770829+00:00 | 849 | false | # Intuition\nThe query selects the Department name, Employee name, and Salary from a derived table (t1) that includes the Department name, Employee name, Salary, and the rank of each employee within their department based on salary in descending order. The outer query then filters the results to only include rows where the rank is 1, indicating the highest salary in each department.\n\n# Approach\nThe approach involves creating a derived table (t1) using a JOIN operation between the Department and Employee tables. The RANK() function is applied within each department partition to assign a rank to each employee based on their salary. The outer query then filters the results to only include rows with a rank of 1.\n\n# Complexity\n- Time complexity:\nThe time complexity is determined by the JOIN operation, the RANK() window function, and the final WHERE clause. Assuming appropriate indexing, the JOIN operation and RANK() function would have a time complexity of O(n log n), where n is the number of rows in the combined Department and Employee tables. The final WHERE clause does not significantly impact the time complexity.\n\n- Space complexity:\nThe space complexity is influenced by the temporary storage required for the derived table (t1), which includes the Department name, Employee name, Salary, and RANK(). Assuming m is the number of rows in the derived table, the space complexity is O(m). The RANK() function requires additional storage for the ranking information within each partition.\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT t1.Department, t1.Employee, t1.Salary\nFROM(SELECT d.name AS Department, e.name AS Employee, e.salary AS Salary\n,RANK()OVER(PARTITION BY d.id ORDER BY salary DESC) AS rk\nFROM Department AS d\nJOIN Employee AS e ON E.departmentId = d.id) AS t1\nWHERE rk = 1\n``` | 5 | 0 | ['MySQL'] | 1 |
department-highest-salary | Easy-Peasy Solution | easy-peasy-solution-by-priyanka8d19-sk45 | Code\n\n# Write your MySQL query statement below\n\nselect d.name as department,e.name as employee ,e.salary from employee as e \njoin \ndepartment as d on e.de | priyanka8d19 | NORMAL | 2023-05-07T10:07:03.377465+00:00 | 2023-05-07T10:07:03.377499+00:00 | 3,779 | false | # Code\n```\n# Write your MySQL query statement below\n\nselect d.name as department,e.name as employee ,e.salary from employee as e \njoin \ndepartment as d on e.departmentId=d.id \n where (e.departmentId,e.salary) in (\n select departmentId , max(salary) from employee\n group by departmentId\n);\n``` | 5 | 0 | ['MySQL'] | 1 |
department-highest-salary | EASY MySQL QUERY💯👌 | easy-mysql-query-by-dipesh_12-810u | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | dipesh_12 | NORMAL | 2023-03-21T06:34:23.120755+00:00 | 2023-03-21T06:34:23.120789+00:00 | 3,315 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT D.name AS Department, E.name AS Employee,E.salary AS Salary from Employee E,Department D\nwhere D.id=E.departmentId and E.salary=(SELECT max(salary) from Employee E where E.departmentId=D.id);\n``` | 5 | 0 | ['MySQL'] | 0 |
department-highest-salary | Simple MySQL Querry | simple-mysql-querry-by-user6774u-w9ss | \nSELECT \n dep.Name as Department,\n emp.Name as Employee,\n emp.Salary \nfrom \n Department dep,\n Employee emp \nwhere \n emp.DepartmentId | user6774u | NORMAL | 2022-03-21T05:08:27.773532+00:00 | 2022-03-21T05:08:27.773570+00:00 | 311 | false | ```\nSELECT \n dep.Name as Department,\n emp.Name as Employee,\n emp.Salary \nfrom \n Department dep,\n Employee emp \nwhere \n emp.DepartmentId = dep.Id \nand \n emp.Salary=\n (Select \n max(Salary) \n from \n Employee emp2 \n where \n emp2.DepartmentId=dep.Id)\n```\n\nPlease comment if there is any doubt in the above querry.\n\nPlease **Upvote** if you like the solution. | 5 | 0 | ['MySQL'] | 0 |
department-highest-salary | group by and having || oracle | group-by-and-having-oracle-by-abhinavred-ppfa | \n/* Write your PL/SQL query statement below */\nselect d.name department,e.name employee ,e.salary salary from employee e,department d where e.departmentid=d.i | abhinavreddy19 | NORMAL | 2021-07-18T13:43:53.108969+00:00 | 2021-07-18T13:43:53.109012+00:00 | 935 | false | ```\n/* Write your PL/SQL query statement below */\nselect d.name department,e.name employee ,e.salary salary from employee e,department d where e.departmentid=d.id and\ne.salary=(select max(distinct salary) from employee group by departmentid having departmentid=e.departmentid);\n``` | 5 | 0 | ['Oracle'] | 0 |
department-highest-salary | simple MYSQL query | simple-mysql-query-by-samarthtandon97-sp3s | \nSELECT \n d.Name AS Department, e.Name AS Employee, e.Salary AS Salary\nFROM \n Employee AS e, Department AS d\nWHERE \n e.DepartmentID = d.Id\n A | samarthtandon97 | NORMAL | 2019-12-02T10:08:09.133171+00:00 | 2019-12-02T10:08:09.133208+00:00 | 465 | false | ```\nSELECT \n d.Name AS Department, e.Name AS Employee, e.Salary AS Salary\nFROM \n Employee AS e, Department AS d\nWHERE \n e.DepartmentID = d.Id\n AND\n e.Salary = (SELECT \n MAX(Salary) \n FROM \n Employee\n WHERE\n DepartmentId = d.Id)\n``` | 5 | 0 | [] | 0 |
department-highest-salary | MSSQL Window function | mssql-window-function-by-pogodin-032m | \nSELECT\n d.Name AS Department,\n Sel.Name AS Employee,\n Sel.Salary AS Salary\nFROM\n(\n SELECT\n Name,\n Salary,\n Departmen | pogodin | NORMAL | 2019-07-31T19:28:51.141055+00:00 | 2019-07-31T19:28:51.141125+00:00 | 845 | false | ```\nSELECT\n d.Name AS Department,\n Sel.Name AS Employee,\n Sel.Salary AS Salary\nFROM\n(\n SELECT\n Name,\n Salary,\n DepartmentId,\n DENSE_RANK() OVER (PARTITION BY DepartmentId ORDER BY Salary DESC) AS dr\n FROM Employee \n) AS Sel\nINNER JOIN Department d ON d.Id = Sel.DepartmentId\nWHERE Sel.dr = 1\n``` | 5 | 0 | [] | 2 |
department-highest-salary | SIMPLEST PANDAS SOLUTION WITH EXPLANTION ❤ | simplest-pandas-solution-with-explantion-zosf | IntuitionApproach
Merge DataFrames: Combine the employee and department DataFrames using departmentId (from employee) and id (from department) to include depar | Y4heW1qDC3 | NORMAL | 2025-01-14T16:12:00.496599+00:00 | 2025-01-14T16:12:00.496599+00:00 | 908 | false | # Intuition
<!-- Describe your first thoughts on how to solve this problem. -->
# Approach
<!-- Describe your approach to solving the problem. -->Here’s a explanation of the code:
1. Merge DataFrames: Combine the employee and department DataFrames using departmentId (from employee) and id (from department) to include department names.
merged = employee.merge(department, left_on='departmentId', right_on='id')
2. Group and Transform: Use groupby on department names to find the maximum salary in each department and assign it to all rows in the group.
merged['max_salary'] = merged.groupby('name_y')['salary'].transform(max)
3. Filter Rows: Keep only the rows where the employee's salary matches the maximum salary in their department.
result = merged[merged['salary'] == merged['max_salary']]

# Complexity
- Time complexity:
<!-- Add your time complexity here, e.g. $$O(n)$$ -->
- Space complexity:
<!-- Add your space complexity here, e.g. $$O(n)$$ -->68.18 MB✔
Beats 84.97%✔
# Code
```pythondata []
import pandas as pd
def department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:
merged = employee.merge(department , left_on = 'departmentId' , right_on = 'id')
rt = merged[merged['salary'] == merged.groupby('name_y')['salary'].transform(max)]
rt = rt[['name_y' , 'name_x' , 'salary']].rename(columns = {'name_y' : 'Department' , 'name_x': 'Employee' , 'salary' : 'Salary'})
return rt
``` | 4 | 0 | ['Pandas'] | 0 |
department-highest-salary | Department Highest Salary, simple pandas solution | department-highest-salary-simple-pandas-fgit3 | \n\n# Code\n\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n \n df = employee.m | Shariq20220 | NORMAL | 2024-07-23T10:50:39.831477+00:00 | 2024-07-23T10:50:39.831509+00:00 | 941 | false | \n\n# Code\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n \n df = employee.merge(department, left_on =\'departmentId\', right_on = \'id\', how =\'inner\')\n\n df[\'max_salary\'] = df.groupby(\'name_y\') [\'salary\'].transform(max)\n\n\n return df[df.salary == df.max_salary] [[\'name_y\',\'name_x\',\'max_salary\']].rename(columns = {\'name_y\': \'Department\', \'name_x\':\'Employee\', \'max_salary\': \'Salary\'})\n\n```\n\n\n | 4 | 0 | ['Database', 'Python', 'Python3', 'Pandas'] | 0 |
department-highest-salary | BEST solutions || MySQL || Pandas || Beats 100% !! | best-solutions-mysql-pandas-beats-100-by-zxfm | Code\n\n# Write your MySQL query statement below\nSELECT D.Name AS Department, E.Name AS Employee, E.Salary \nFROM Employee E, Department D \nWHERE E.Department | prathams29 | NORMAL | 2023-08-02T01:56:27.129309+00:00 | 2023-08-02T01:56:27.129327+00:00 | 1,536 | false | # Code\n```\n# Write your MySQL query statement below\nSELECT D.Name AS Department, E.Name AS Employee, E.Salary \nFROM Employee E, Department D \nWHERE E.DepartmentId = D.id AND (DepartmentId,Salary) in \n (SELECT DepartmentId,max(Salary) as max FROM Employee GROUP BY DepartmentId)\n```\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n data = pd.merge(employee, department, left_on = \'departmentId\', right_on = \'id\', how = \'left\')\n df = data.groupby(\'name_y\').apply(lambda x: x[x.salary == x.salary.max()])\n df = df.rename(columns={\'name_y\': \'Department\', \'name_x\': \'Employee\'})\n df = df.drop(columns=[\'id_x\', \'id_y\']).reset_index()\n return df[[\'Department\',\'Employee\',\'salary\']]\n``` | 4 | 0 | ['MySQL', 'Pandas'] | 0 |
department-highest-salary | MySQL Solution for Department Highest Salary Problem | mysql-solution-for-department-highest-sa-jcat | Intuition\n Describe your first thoughts on how to solve this problem. \nThe goal is to find employees who have the highest salary in each department. To achiev | Aman_Raj_Sinha | NORMAL | 2023-07-03T03:49:22.586331+00:00 | 2023-07-03T03:49:22.586350+00:00 | 2,517 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThe goal is to find employees who have the highest salary in each department. To achieve this, we need to compare the salary of each employee within their respective department and select the ones with the maximum salary.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nThe approach is to join the Employee and Department tables based on the departmentId foreign key. By performing this join, we can access the department name for each employee. Then, we use a subquery to calculate the maximum salary for each department. Finally, we filter the results by selecting only the employees whose department and salary match the maximum values.\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\nThe time complexity of this solution depends on the size of the Employee table. Let\'s denote m as the number of rows in the Employee table. The subquery that calculates the maximum salary for each department has a complexity of O(m). The join operation and filtering have a complexity of O(m) as well. Therefore, the overall time complexity is O(m).\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\nThe space complexity is determined by the number of rows returned in the result table. If there are k departments and each department has one employee with the highest salary, the result will have k rows. Therefore, the space complexity is O(k).\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT d.name AS Department, e.name AS Employee, e.Salary\nFROM Employee e\nINNER JOIN Department d ON e.departmentId = d.id\nWHERE (e.departmentId, e.salary) IN (\n SELECT departmentId, MAX(salary)\n FROM Employee\n GROUP BY departmentId\n);\n\n``` | 4 | 0 | ['MySQL'] | 0 |
department-highest-salary | SIMPLE and EASY TO UNDERSTAND SOLUTION || MySQL | simple-and-easy-to-understand-solution-m-0vtg | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Yashkumar_Sawarkar | NORMAL | 2023-03-09T11:33:59.267204+00:00 | 2023-03-09T11:33:59.267246+00:00 | 2,645 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT dept.name AS Department, emp.name AS Employee, emp.salary AS Salary\nFROM Department dept, Employee emp\nWHERE emp.departmentId = dept.id\nAND emp.salary = (SELECT MAX(Salary) FROM Employee emp WHERE emp.departmentId = dept.id)\n``` | 4 | 0 | ['MySQL'] | 0 |
department-highest-salary | Accepted simple oracle | accepted-simple-oracle-by-krystali-52h1 | oracle\n\nselect d.Name as Department, e.Name as Employee, e.Salary\nfrom Department d inner join Employee e on d.Id = e.DepartmentId\nwhere (e.Salary, e.Depart | krystali | NORMAL | 2020-12-19T16:15:32.927150+00:00 | 2020-12-19T16:15:32.927180+00:00 | 315 | false | oracle\n```\nselect d.Name as Department, e.Name as Employee, e.Salary\nfrom Department d inner join Employee e on d.Id = e.DepartmentId\nwhere (e.Salary, e.DepartmentId) in (select max(Salary), DepartmentId from Employee group by DepartmentId)\n``` | 4 | 0 | ['Oracle'] | 1 |
department-highest-salary | Accepted Solution without using Max() function | accepted-solution-without-using-max-func-4ecn | select b.Name Department, a.Name Employee, a.Salary from\n (\n select a.Name, a.Salary, a.DepartmentId \n from Employee a left outer join Emplo | baiji | NORMAL | 2015-02-07T19:57:14+00:00 | 2015-02-07T19:57:14+00:00 | 1,063 | false | select b.Name Department, a.Name Employee, a.Salary from\n (\n select a.Name, a.Salary, a.DepartmentId \n from Employee a left outer join Employee b\n on a.DepartmentId = b.DepartmentId \n and a.Salary < b.Salary\n where b.Id is null\n ) a join Department b\n on a.DepartmentId = b.Id; | 4 | 1 | [] | 1 |
department-highest-salary | 🏆🏆Beats 97%| 📈📈Easy Solution |Python Pandas | beats-97-easy-solution-python-pandas-by-waa3k | \n\n\n# Intuition\n Describe your first thoughts on how to solve this problem. \n\uD83E\uDD14When working with organizational data, it\'s common to analyze empl | u23cs159 | NORMAL | 2024-06-09T07:56:59.878554+00:00 | 2024-06-09T07:56:59.878573+00:00 | 1,219 | false | 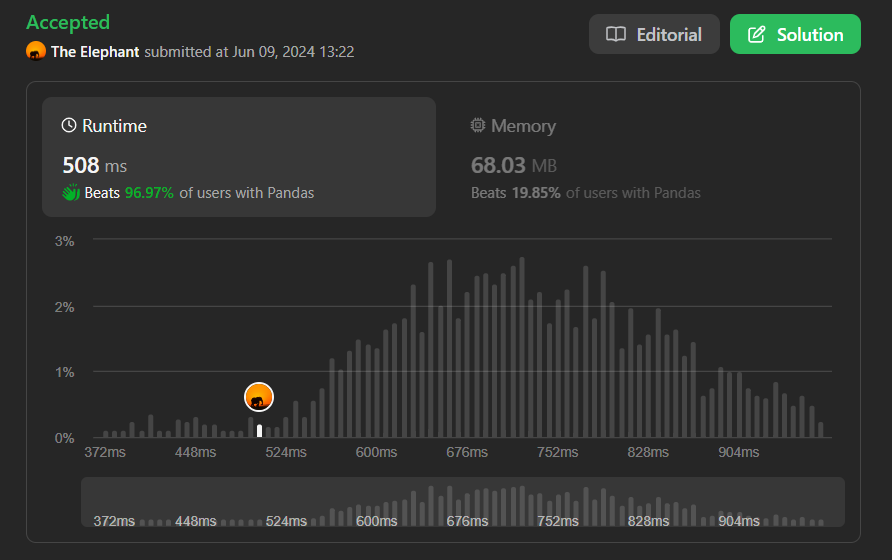\n\n\n# Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\uD83E\uDD14When working with organizational data, it\'s common to analyze employee salaries to identify the highest earners in each department. This task involves joining data from two related tables: one containing employee details and another containing department information. By merging these tables and using grouping and filtering techniques, we can extract the top earners for each department. \uD83D\uDCCA\uD83D\uDCBC\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1) **Data Merging** \uD83D\uDD17:\nCombine the Employee and Department tables using a join operation on the departmentId and id columns.\n2) **Grouping and Aggregation** \uD83D\uDCCA:\nGroup the merged data by departmentId and find the maximum salary within each group.\n3) **Filtering Top Earners** \uD83C\uDFC6:\nFilter the merged data to retain only the rows where the salary matches the highest salary in each department.\n4) **Result Formatting** \uD83D\uDCCB:\nSelect and rename the relevant columns to match the desired output format.\n\n\n# Code\n```\nimport pandas as pd\n\ndef department_highest_salary(df1: pd.DataFrame, df2: pd.DataFrame) -> pd.DataFrame:\n df = pd.merge(left=df1,right=df2,left_on=\'departmentId\',right_on=\'id\',how=\'left\')\n bf = df.groupby(\'departmentId\').max()\n pf = pd.merge(left=df,right=bf,on=[\'salary\',\'name_y\'])\n return pf[[\'name_y\',\'name_x_x\',\'salary\']].rename(columns={\'name_y\':\'Department\',\'name_x_x\':\'Employee\',\'salary\':\'Salary\'})\n``` | 3 | 0 | ['Python3', 'Pandas'] | 0 |
department-highest-salary | MS SQL SERVER - Subqueries - CTE | ms-sql-server-subqueries-cte-by-lshigami-fdvu | \n\n# Subqueries \n\n/* Write your T-SQL query statement below */\nselect d.name Department , e.name Employee ,salary Salary \nfrom employee e\njoin department | lshigami | NORMAL | 2024-05-01T16:43:05.956626+00:00 | 2024-05-01T16:44:43.704779+00:00 | 1,687 | false | \n\n# Subqueries \n```\n/* Write your T-SQL query statement below */\nselect d.name Department , e.name Employee ,salary Salary \nfrom employee e\njoin department d\non e.departmentId =d.id\nwhere salary = \n(select max(salary) from employee t where t.departmentId =e.departmentId )\n\n```\n# CTE \n```\nWITH emp as (\n select Max(salary) as maxSalary, departmentId from Employee\n group by\n departmentId\n)\n\nselect e.name as Employee, e.salary as Salary, d.name as Department from Employee e \ninner join Department d\non d.id = e.departmentId\ninner join emp\non emp.maxSalary = e.salary and emp.departmentId = d.id\n``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | ✅ 100% EASY || FAST 🔥|| CLEAN SOLUTION 🌟 | 100-easy-fast-clean-solution-by-vinay_ra-xow1 | \n Add your space complexity here, e.g. O(n) \n\n# Code\n\n# Write your MySQL query statement below\nselect department, Employee, salary from(\nselect d.name as | Vinay_Raju | NORMAL | 2023-10-14T21:25:24.174785+00:00 | 2023-10-14T21:25:24.174804+00:00 | 234 | false | \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\nselect department, Employee, salary from(\nselect d.name as department,e.name as Employee,e.salary, dense_rank() over(partition by d.name order by salary desc) as rank_\n from Employee e join department d on e.departmentId=d.id\n) as Table1\nwhere rank_=1\n``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | Pandas | SQL | Explained Step By Step | Department Highest Salary | pandas-sql-explained-step-by-step-depart-bs45 | \nsee the Successfully Accepted Submission\nPython\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd | Khosiyat | NORMAL | 2023-10-03T17:13:00.371193+00:00 | 2023-10-03T17:13:00.371221+00:00 | 946 | false | \n[see the Successfully Accepted Submission]( https://leetcode.com/submissions/detail/1056909975/)\n```Python\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n \n merged_employee = employee.merge(\n department, left_on=\'departmentId\', right_on=\'id\', suffixes=(\'_employee\', \'_department\')\n )\n \n grouped_department = merged_employee.groupby(\n \'departmentId\'\n )\n \n highest_salary = grouped_department.apply(\n lambda x: x[x[\'salary\'] == x[\'salary\'].max()]\n )\n \n structured_department = highest_salary.reset_index(drop=True)[\n [\'name_department\', \'name_employee\', \'salary\']\n ]\n department_highest_salary = structured_department.rename(columns={\n \'name_department\': \'Department\',\n \'name_employee\': \'Employee\',\n \'salary\': \'Salary\',\n })\n \n return department_highest_salary\n \n```\n\n**Intuituin**\n\nMerge the \'employee\' and \'department\' DataFrames on the \'departmentId\' and \'id\' columns, adding suffixes to identify columns from each DataFrame (\'_employee\' and \'_department\')\n```\n merged_employee = employee.merge(\n department, left_on=\'departmentId\', right_on=\'id\', suffixes=(\'_employee\', \'_department\')\n )\n```\n\nGroup the merged DataFrame by \'departmentId\'\n```\n grouped_department = merged_employee.groupby(\'departmentId\')\n```\n\nFor each group, find the rows where \'salary\' is equal to the maximum salary in that group\n```\n highest_salary = grouped_department.apply(\n lambda x: x[x[\'salary\'] == x[\'salary\'].max()]\n )\n```\n\nReset the index and keep only the specified columns: \'name_department\', \'name_employee\', and \'salary\'\n```\n structured_department = highest_salary.reset_index(drop=True)[\n [\'name_department\', \'name_employee\', \'salary\']\n ]\n```\n\nRename the columns to match the expected output format\n```\n department_highest_salary = structured_department.rename(columns={\n \'name_department\': \'Department\',\n \'name_employee\': \'Employee\',\n \'salary\': \'Salary\',\n })\n```\n\n**SQL**\n\n[see the Successfully Accepted Submission]( https://leetcode.com/submissions/detail/1062930265/)\n\n```SQL\nSELECT _Department.name \nAS \'Department\' , _Employee.name \nAS \'Employee\', _Employee.salary \nAS Salary\n\nFROM Employee _Employee\n\nLEFT JOIN Department _Department\nON _Employee.departmentId = _Department.id\n\nRIGHT JOIN (\n SELECT max(_Employee1.salary) \n AS _salary, _Employee1.departmentId AS _Employee_Department \n FROM Employee _Employee1\n GROUP BY _Employee1.departmentId\n ) _Employee2\n \n ON _Employee2._salary = _Employee.Salary\n WHERE _Employee2._Employee_Department = _Employee.departmentId;\n```\n\n\n\n\n# Pandas & SQL | SOLVED & EXPLAINED LIST\n\n**EASY**\n\n- [Combine Two Tables](https://leetcode.com/problems/combine-two-tables/solutions/4051076/pandas-sql-easy-combine-two-tables/)\n\n- [Employees Earning More Than Their Managers](https://leetcode.com/problems/employees-earning-more-than-their-managers/solutions/4051991/pandas-sql-easy-employees-earning-more-than-their-managers/)\n\n- [Duplicate Emails](https://leetcode.com/problems/duplicate-emails/solutions/4055225/pandas-easy-duplicate-emails/)\n\n- [Customers Who Never Order](https://leetcode.com/problems/customers-who-never-order/solutions/4055429/pandas-sql-easy-customers-who-never-order-easy-explained/)\n\n- [Delete Duplicate Emails](https://leetcode.com/problems/delete-duplicate-emails/solutions/4055572/pandas-sql-easy-delete-duplicate-emails-easy/)\n- [Rising Temperature](https://leetcode.com/problems/rising-temperature/solutions/4056328/pandas-sql-easy-rising-temperature-easy/)\n\n- [ Game Play Analysis I](https://leetcode.com/problems/game-play-analysis-i/solutions/4056422/pandas-sql-easy-game-play-analysis-i-easy/)\n\n- [Find Customer Referee](https://leetcode.com/problems/find-customer-referee/solutions/4056516/pandas-sql-easy-find-customer-referee-easy/)\n\n- [Classes More Than 5 Students](https://leetcode.com/problems/classes-more-than-5-students/solutions/4058381/pandas-sql-easy-classes-more-than-5-students-easy/)\n- [Employee Bonus](https://leetcode.com/problems/employee-bonus/solutions/4058430/pandas-sql-easy-employee-bonus/)\n\n- [Sales Person](https://leetcode.com/problems/sales-person/solutions/4058824/pandas-sql-easy-sales-person/)\n\n- [Biggest Single Number](https://leetcode.com/problems/biggest-single-number/solutions/4063950/pandas-sql-easy-biggest-single-number/)\n\n- [Not Boring Movies](https://leetcode.com/problems/not-boring-movies/solutions/4065350/pandas-sql-easy-not-boring-movies/)\n- [Swap Salary](https://leetcode.com/problems/swap-salary/solutions/4065423/pandas-sql-easy-swap-salary/)\n\n- [Actors & Directors Cooperated min Three Times](https://leetcode.com/problems/actors-and-directors-who-cooperated-at-least-three-times/solutions/4065511/pandas-sql-easy-explained-step-by-step-actors-directors-cooperated-min-three-times/)\n\n- [Product Sales Analysis I](https://leetcode.com/problems/product-sales-analysis-i/solutions/4065545/pandas-sql-easy-product-sales-analysis-i/)\n\n- [Project Employees I](https://leetcode.com/problems/project-employees-i/solutions/4065635/pandas-sql-easy-project-employees-i/)\n- [Sales Analysis III](https://leetcode.com/problems/sales-analysis-iii/solutions/4065755/sales-analysis-iii-pandas-easy/)\n\n- [Reformat Department Table](https://leetcode.com/problems/reformat-department-table/solutions/4066153/pandas-sql-easy-explained-step-by-step-reformat-department-table/)\n\n- [Top Travellers](https://leetcode.com/problems/top-travellers/solutions/4066252/top-travellers-pandas-easy-eaxplained-step-by-step/)\n\n- [Replace Employee ID With The Unique Identifier](https://leetcode.com/problems/replace-employee-id-with-the-unique-identifier/solutions/4066321/pandas-sql-easy-replace-employee-id-with-the-unique-identifier/)\n- [Group Sold Products By The Date](https://leetcode.com/problems/group-sold-products-by-the-date/solutions/4066344/pandas-sql-easy-explained-step-by-step-group-sold-products-by-the-date/)\n\n- [Customer Placing the Largest Number of Orders](https://leetcode.com/problems/customer-placing-the-largest-number-of-orders/solutions/4068822/pandas-sql-easy-explained-step-by-step-customer-placing-the-largest-number-of-orders/)\n\n- [Article Views I](https://leetcode.com/problems/article-views-i/solutions/4069777/pandas-sql-easy-article-views-i/)\n\n- [User Activity for the Past 30 Days I](https://leetcode.com/problems/user-activity-for-the-past-30-days-i/solutions/4069797/pandas-sql-easy-user-activity-for-the-past-30-days-i/)\n\n- [Find Users With Valid E-Mails](https://leetcode.com/problems/find-users-with-valid-e-mails/solutions/4069810/pandas-sql-easy-find-users-with-valid-e-mails/)\n\n- [Patients With a Condition](https://leetcode.com/problems/patients-with-a-condition/solutions/4069817/pandas-sql-easy-patients-with-a-condition/)\n\n- [Customer Who Visited but Did Not Make Any Transactions](https://leetcode.com/problems/customer-who-visited-but-did-not-make-any-transactions/solutions/4072542/pandas-sql-easy-customer-who-visited-but-did-not-make-any-transactions/)\n\n\n- [Bank Account Summary II](https://leetcode.com/problems/bank-account-summary-ii/solutions/4072569/pandas-sql-easy-bank-account-summary-ii/)\n\n- [Invalid Tweets](https://leetcode.com/problems/invalid-tweets/solutions/4072599/pandas-sql-easy-invalid-tweets/)\n\n- [Daily Leads and Partners](https://leetcode.com/problems/daily-leads-and-partners/solutions/4072981/pandas-sql-easy-daily-leads-and-partners/)\n\n- [Recyclable and Low Fat Products](https://leetcode.com/problems/recyclable-and-low-fat-products/solutions/4073003/pandas-sql-easy-recyclable-and-low-fat-products/)\n\n- [Rearrange Products Table](https://leetcode.com/problems/rearrange-products-table/solutions/4073028/pandas-sql-easy-rearrange-products-table/)\n- [Calculate Special Bonus](https://leetcode.com/problems/calculate-special-bonus/solutions/4073595/pandas-sql-easy-calculate-special-bonus/)\n\n- [Count Unique Subjects](https://leetcode.com/problems/number-of-unique-subjects-taught-by-each-teacher/solutions/4073666/pandas-sql-easy-count-unique-subjects/)\n\n- [Count Unique Subjects](https://leetcode.com/problems/number-of-unique-subjects-taught-by-each-teacher/solutions/4073666/pandas-sql-easy-count-unique-subjects/)\n\n- [Fix Names in a Table](https://leetcode.com/problems/fix-names-in-a-table/solutions/4073695/pandas-sql-easy-fix-names-in-a-table/)\n- [Primary Department for Each Employee](https://leetcode.com/problems/primary-department-for-each-employee/solutions/4076183/pandas-sql-easy-primary-department-for-each-employee/)\n\n- [The Latest Login in 2020](https://leetcode.com/problems/the-latest-login-in-2020/solutions/4076240/pandas-sql-easy-the-latest-login-in-2020/)\n\n- [Find Total Time Spent by Each Employee](https://leetcode.com/problems/find-total-time-spent-by-each-employee/solutions/4076313/pandas-sql-easy-find-total-time-spent-by-each-employee/)\n\n- [Find Followers Count](https://leetcode.com/problems/find-followers-count/solutions/4076342/pandas-sql-easy-find-followers-count/)\n- [Percentage of Users Attended a Contest](https://leetcode.com/problems/percentage-of-users-attended-a-contest/solutions/4077301/pandas-sql-easy-percentage-of-users-attended-a-contest/)\n\n- [Employees With Missing Information](https://leetcode.com/problems/employees-with-missing-information/solutions/4077308/pandas-sql-easy-employees-with-missing-information/)\n\n- [Average Time of Process per Machine](https://leetcode.com/problems/average-time-of-process-per-machine/solutions/4077402/pandas-sql-easy-average-time-of-process-per-machine/)\n | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | Pandas Simple Solution | pandas-simple-solution-by-hayyan_hajwani-nt38 | Intuition\n Describe your first thoughts on how to solve this problem. \nEasy Solution you will understand once you see the code\n\n# Approach\n Describe your a | Hayyan_Hajwani | NORMAL | 2023-08-07T18:20:28.362257+00:00 | 2023-08-07T18:20:28.362280+00:00 | 427 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nEasy Solution you will understand once you see the code\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n if employee.empty or department.empty:\n return pd.DataFrame(columns=[\'Department\', \'Employee\', \'Salary\'])\n\n # Merge the employee and department DataFrames on \'departmentId\' and \'id\' columns\n merged_df = employee.merge(department, left_on=\'departmentId\', right_on=\'id\', suffixes= (\'_employee\', \'_department\'))\n\n # Find the maximum salary in each department\n max_salaries = merged_df.groupby(\'departmentId\')[\'salary\'].transform(\'max\')\n\n # Filter for employees with maximum salary in each department\n highest_salary_df = merged_df[merged_df[\'salary\'] == max_salaries]\n\n # Select the required columns\n result_df = highest_salary_df[[\'name_department\', \'name_employee\', \'salary\']]\n\n # Rename the columns as specified\n result_df.columns = [\'Department\', \'Employee\', \'Salary\']\n\n return result_df\n\n\n``` | 3 | 0 | ['Pandas'] | 0 |
department-highest-salary | EASY MYSQL SOLUTION | easy-mysql-solution-by-2005115-60be | \n\n# Code\n\nSELECT D.Name AS Department ,E.Name AS Employee ,E.Salary \nfrom \n\tEmployee E,\n\tDepartment D \nWHERE E.DepartmentId = D.id \n AND (Department | 2005115 | NORMAL | 2023-07-13T14:25:31.236724+00:00 | 2023-07-13T14:25:31.236758+00:00 | 1,061 | false | \n\n# Code\n```\nSELECT D.Name AS Department ,E.Name AS Employee ,E.Salary \nfrom \n\tEmployee E,\n\tDepartment D \nWHERE E.DepartmentId = D.id \n AND (DepartmentId,Salary) in \n (SELECT DepartmentId,max(Salary) as max FROM Employee GROUP BY DepartmentId)\n``` | 3 | 0 | ['MySQL'] | 1 |
department-highest-salary | Solved via CTE | solved-via-cte-by-shnitsel666-fgqo | Code\n\n;WITH emp as (\n select Max(salary) as maxSalary, departmentId from Employee\n group by\n departmentId\n)\n\nselect e.name as Employee, e.salary as S | shnitsel666 | NORMAL | 2023-05-16T16:38:48.761242+00:00 | 2023-05-16T16:38:48.761280+00:00 | 1,987 | false | # Code\n```\n;WITH emp as (\n select Max(salary) as maxSalary, departmentId from Employee\n group by\n departmentId\n)\n\nselect e.name as Employee, e.salary as Salary, d.name as Department from Employee e \ninner join Department d\non d.id = e.departmentId\ninner join emp\non emp.maxSalary = e.salary and emp.departmentId = d.id\n\n\n\n\n\n``` | 3 | 0 | ['MS SQL Server'] | 1 |
department-highest-salary | ✅ SQL || Multiple Approaches || Easy to understand | sql-multiple-approaches-easy-to-understa-wbe5 | I just found this Blog and Github repository with solutions to Leetcode problems.\nhttps://leet-codes.blogspot.com/2022/10/department-highest-salary.html\nIt ha | pmistry_ | NORMAL | 2022-11-15T02:39:05.277240+00:00 | 2022-11-15T02:39:05.277287+00:00 | 1,351 | false | I just found this Blog and Github repository with solutions to Leetcode problems.\nhttps://leet-codes.blogspot.com/2022/10/department-highest-salary.html\nIt has solutions to almost every problem on Leetcode, and I recommend checking it out.\nNote: You can bookmark it as a resource, and approach. Other approaches are in above blog\n<br>\n\n```\nSELECT d.name AS Department, e.Employee, e.Salary\nFROM Department d\nLEFT JOIN (\n SELECT \n departmentId, \n salary AS Salary,\n name AS Employee,\n DENSE_RANK() OVER (PARTITION BY departmentId ORDER BY salary DESC) AS \'salary_rank\'\n FROM Employee) e\nON d.id = e.departmentId\nWHERE salary_rank = 1\n``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | 93% FASTER | 93-faster-by-rikam-nvdr | \n\n\n\nSELECT Department, Employee, Salary \nFROM ( \n SELECT *, rank() over(PARTITION BY Department ORDER BY Salary DESC) AS Highest_Salaries \n | rikam | NORMAL | 2022-11-14T10:41:59.933335+00:00 | 2022-11-14T10:41:59.933375+00:00 | 857 | false | 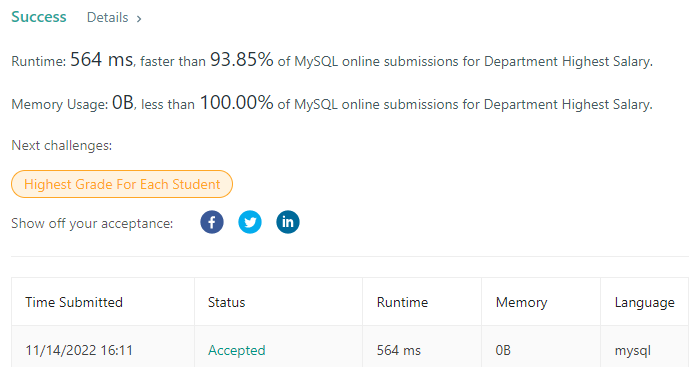\n\n\n```\nSELECT Department, Employee, Salary \nFROM ( \n SELECT *, rank() over(PARTITION BY Department ORDER BY Salary DESC) AS Highest_Salaries \n FROM (\n SELECT d.name AS Department, e.name AS Employee, e.salary AS Salary\n FROM Department d\n INNER JOIN Employee e\n ON d.id = e.departmentId\n ) AS x \n ) AS y\nWHERE Highest_Salaries < 2;\n``` | 3 | 0 | [] | 0 |
department-highest-salary | MYSQL subquery, easy to understand | mysql-subquery-easy-to-understand-by-wil-rgmf | \nselect d.name as department,e.name as employee,salary\nfrom department d\njoin employee e\non d.id = e.departmentid\nwhere (departmentid,salary ) in\n(select | william_26 | NORMAL | 2022-10-15T05:58:08.652759+00:00 | 2022-10-15T05:58:08.652785+00:00 | 351 | false | ```\nselect d.name as department,e.name as employee,salary\nfrom department d\njoin employee e\non d.id = e.departmentid\nwhere (departmentid,salary ) in\n(select departmentid,max(salary) from employee group by departmentid);\n```\nBreaking the code\n\n1 inside the subquerry, we can get the max salary for each department using the \n```\n(select departmentid,max(salary) from employee group by departmentid)\n```\n\n2 select the multiple condtion where clause to select the max salary by department using \n```\nwhere (departmentid,salary ) in\n(select departmentid,max(salary) from employee group by departmentid)\n```\n\n3 Rest of the code is to join the tables and select the required column\n\nupvote if helps, ping if need help. | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | Easy solution by JOIN & GROUP BY in MySQL beats 72.88% runtimes & 100% memory | easy-solution-by-join-group-by-in-mysql-z21vj | ```\nSELECT \n\te2.departmentname AS Department,\n e1.name AS Employee,\n e1.salary AS Salary \nFROM employee e1 JOIN \n(\n\tSELECT \t\n\t\te.departmentid | pritom5928 | NORMAL | 2022-09-18T16:39:15.347378+00:00 | 2022-09-18T16:39:15.347413+00:00 | 110 | false | ```\nSELECT \n\te2.departmentname AS Department,\n e1.name AS Employee,\n e1.salary AS Salary \nFROM employee e1 JOIN \n(\n\tSELECT \t\n\t\te.departmentid, \n d.name AS departmentname, \n max(e.salary) AS maxsalary \n FROM employee e JOIN department d ON e.departmentid = d.id \n\tGROUP BY e.departmentid\n) e2 ON e1.salary = e2.maxsalary AND e1.Departmentid = e2.departmentid; | 3 | 0 | ['MySQL'] | 1 |
department-highest-salary | Inner Join - where - group by | 70.20% time | inner-join-where-group-by-7020-time-by-p-k73k | \n# Write your MySQL query statement below\nselect Department.name as Department, Employee.name as Employee, Employee.salary as salary\nfrom Employee\ninner joi | photon_einstein | NORMAL | 2022-04-23T22:54:14.673074+00:00 | 2022-04-23T22:54:14.673105+00:00 | 167 | false | ```\n# Write your MySQL query statement below\nselect Department.name as Department, Employee.name as Employee, Employee.salary as salary\nfrom Employee\ninner join Department on\nemployee.departmentId = department.id\nwhere \n(employee.departmentId, salary) IN (\n select DepartmentId, max(salary)\n from Employee\n group by departmentId\n);\n\n``` | 3 | 0 | [] | 0 |
department-highest-salary | Correlated subqueries | correlated-subqueries-by-calvinliang-mj61 | SELECT d.name AS Department, e.name AS Employee, Salary\nFROM Employee e\nJOIN department d ON e.departmentId = d.id\nWHERE salary = (SELECT MAX(salary) FROM em | calvinliang | NORMAL | 2022-03-05T20:22:35.933368+00:00 | 2022-03-05T20:22:35.933411+00:00 | 166 | false | SELECT d.name AS Department, e.name AS Employee, Salary\nFROM Employee e\nJOIN department d ON e.departmentId = d.id\nWHERE salary = (SELECT MAX(salary) FROM employee WHERE departmentId = e.departmentId )\n\nI learned that from Mosh | 3 | 0 | ['MySQL'] | 1 |
department-highest-salary | Solution with explanation using RANK() in MySQL | solution-with-explanation-using-rank-in-mnc4r | This query can be written using INNER JOIN and/or Sub-query. This solution shows a way of writing it using RANK() function.\n\nStep 1\nWe need to rank the empl | iamrafiul | NORMAL | 2021-10-15T12:58:54.098383+00:00 | 2021-10-15T13:00:59.360899+00:00 | 356 | false | This query can be written using INNER JOIN and/or Sub-query. This solution shows a way of writing it using `RANK()` function.\n\n**`Step 1`**\nWe need to rank the employees based on their salaries for each department\n\n```\nSELECT\n\td.Name AS Department,\n\te.Name as Employee,\n\te.Salary,\n\t/* Ranking employee based on salary for each department(d.Name)*/\n\tRANK() OVER (PARTITION BY d.Name ORDER BY e.Salary DESC) AS emp_rank #\nFROM employee e\nJOIN department d ON d.Id = e.DepartmentId\n```\n\n**`Step 2`** \nThe ranking above is done in descending order of salary and partitioned by department so the highest salary for each department should always have `rank = 1`. All we need is to just select the ones whose `rank = 1`.\n\nWe can write a CTE(Common Table Expression) for the first step and simply select the necessary columns in second step from the CTE table. \n\nThe full query should look like this:\n```\nWITH employee_rank AS(\n SELECT\n d.Name AS Department,\n e.Name as Employee,\n e.Salary,\n RANK() OVER (PARTITION BY d.Name ORDER BY e.Salary DESC) AS emp_rank\n FROM employee e\n JOIN department d ON d.Id = e.DepartmentId\n)\n\nSELECT\n Department,\n Employee,\n Salary\nFROM employee_rank\nWHERE emp_rank = 1;\n```\n\n\n**N. B.:** We can also use `DENSE_RANK()` instead of `RANK()` here which will give us the exact same result for this problem as we are only considering the highest salary here.\n\nThis query gives the following runtime and memory usage after successful submission\n```\nRuntime: 505 ms, faster than 88.21% of MySQL online submissions for Department Highest Salary.\nMemory Usage: 0B, less than 100.00% of MySQL online submissions for Department Highest Salary.\n``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | Intuitive Solution | intuitive-solution-by-divyeshgarg-2lii | Approach/Steps:\n1. Calculate department wise highest salaries\n\t\n\tselect DepartmentId, max(Salary) from Employee group by DepartmentId\n\t\n2. Fetch all Emp | divyeshgarg | NORMAL | 2021-09-21T10:20:17.852527+00:00 | 2021-09-21T10:20:17.852558+00:00 | 205 | false | Approach/Steps:\n1. Calculate department wise highest salaries\n\t```\n\tselect DepartmentId, max(Salary) from Employee group by DepartmentId\n\t```\n2. Fetch all Employees which are getting highest salary in the department\n\t```\n\tselect * from Employee\n\twhere (DepartmentId, Salary) in \n\t(select DepartmentId, max(Salary) from Employee group by DepartmentId)\n\t```\n3. Join the Employee and Department tables to get the department name in the result (Final Solution)\n\t```\n\tselect d.Name as Department, e.Name as Employee, Salary from Employee e join Department d on\n\te.DepartmentId = d.Id\n\twhere (e.DepartmentId, e.Salary) in \n\t(select DepartmentId, max(Salary) from Employee group by DepartmentId)\n\t```\n\nRuntime: 506 ms, faster than 87.68% submissions | 3 | 0 | ['MySQL'] | 1 |
department-highest-salary | Using Subquery | using-subquery-by-sanjaychandak95-44uz | \nselect max(e2.salary) from employee e2 where e2.departmentid = e.departmentid\n\nthis query will give maximum salary for one departmentId\nand use this result | sanjaychandak95 | NORMAL | 2021-09-17T04:47:53.448615+00:00 | 2021-09-17T04:48:12.706476+00:00 | 250 | false | ```\nselect max(e2.salary) from employee e2 where e2.departmentid = e.departmentid\n```\nthis query will give maximum salary for one departmentId\nand use this result to our main query so the result will be like below:\n\n```\nselect d.name as Department, e.name as Employee, e.salary as Salary\nfrom department d , Employee e\nwhere e.departmentId = d.id\nand e.salary = (\n select max(e2.salary) from employee e2 where e2.departmentid = e.departmentid\n);\n```\nHit like if you find this helpful!\n | 3 | 0 | [] | 0 |
department-highest-salary | Using inner join, easy to understand | using-inner-join-easy-to-understand-by-5-71l5 | \nSELECT Department.Name AS Department, Employee.Name AS Employee, Employee.Salary AS Salary\nFROM Employee INNER JOIN Department\nON Employee.DepartmentId =Dep | 5899biswas | NORMAL | 2021-07-23T18:06:20.171961+00:00 | 2021-07-23T18:06:20.172029+00:00 | 428 | false | ```\nSELECT Department.Name AS Department, Employee.Name AS Employee, Employee.Salary AS Salary\nFROM Employee INNER JOIN Department\nON Employee.DepartmentId =Department.Id\nWHERE Employee.Salary=\n (\n SELECT MAX(Salary) FROM Employee \n WHERE Employee.DepartmentId=Department.Id\n );\n\t``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | 【MySQL】simple window function | mysql-simple-window-function-by-qiaochow-sux9 | \nselect b.Name as Department, a.Name as Employee, Salary\nfrom \n# rank Salary in department\n(select *, dense_rank () over (partition by DepartmentId order by | qiaochow | NORMAL | 2021-06-22T20:13:50.667651+00:00 | 2021-06-22T20:15:07.941043+00:00 | 298 | false | ```\nselect b.Name as Department, a.Name as Employee, Salary\nfrom \n# rank Salary in department\n(select *, dense_rank () over (partition by DepartmentId order by Salary desc) as salaryRank\nfrom Employee) a \njoin Department b \non a.DepartmentId = b.Id and a.salaryRank = 1\n``` | 3 | 0 | ['MySQL'] | 0 |
department-highest-salary | Simple solution using WHERE and AND | simple-solution-using-where-and-and-by-e-80ku | \nSELECT D.NAME AS Department, E.NAME AS Employee, E.SALARY AS Salary\nFROM EMPLOYEE AS E, DEPARTMENT AS D\nWHERE D.ID = E.DEPARTMENTID\nAND E.SALARY = \n (S | emiliahep | NORMAL | 2021-06-09T17:52:24.219008+00:00 | 2021-06-09T17:52:24.219058+00:00 | 343 | false | ```\nSELECT D.NAME AS Department, E.NAME AS Employee, E.SALARY AS Salary\nFROM EMPLOYEE AS E, DEPARTMENT AS D\nWHERE D.ID = E.DEPARTMENTID\nAND E.SALARY = \n (SELECT MAX(SALARY) \n FROM EMPLOYEE AS E2 \n WHERE E2.DEPARTMENTID = D.ID)\n```\n\n\n | 3 | 0 | [] | 1 |
department-highest-salary | use dense_rank() and inner join | use-dense_rank-and-inner-join-by-xunjuey-9mr3 | \nSELECT Department, Employee, Salary\nFROM (SELECT D.Name AS Department, E.Name AS Employee, E.Salary AS Salary , DENSE_RANK() OVER(PARTITION BY E.DepartmentId | xunjueyulin | NORMAL | 2020-10-03T02:40:46.595174+00:00 | 2020-10-03T02:42:36.988316+00:00 | 258 | false | ```\nSELECT Department, Employee, Salary\nFROM (SELECT D.Name AS Department, E.Name AS Employee, E.Salary AS Salary , DENSE_RANK() OVER(PARTITION BY E.DepartmentId ORDER BY E.Salary DESC) RN\n FROM Employee E\n INNER JOIN Department D\n ON E.DepartmentId = D.Id)\nWHERE RN=1\n```\n\u4E00\u5F00\u59CB\u60F3\u7528group by\u6765\u7740\uFF0C\u53D1\u73B0\u5206\u7EC4\u7684\u65F6\u5019\u8981\u4E48\u8003\u8651\u5B50\u67E5\u8BE2\u8981\u4E48\u4E0D\u597D\u7EC4\u5185\u6392\u5E8F\n\u7528\u4E86\u5206\u6790\u51FD\u6570\u6765\u5B9E\u73B0\u5206\u7EC4\u6392\u5E8F\u548C\u83B7\u53D6\u5206\u7EC4\u6392\u540D\u987A\u5E8F\n\u4E00\u5F00\u59CB\u7528\u4E86\u5DE6\u8FDE\u63A5\uFF0Csubmission\u7684\u65F6\u5019\u53D1\u73B0\u6709\u53EF\u80FD\u5B58\u5728\u7A7A\u503C\u7684\u60C5\u51B5\uFF0C\u6539\u6210\u4E86\u5185\u8FDE\u63A5\uFF0C\u6EE4\u6389\u5DE6\u8868\u53EF\u80FD\u5339\u914D\u4E0D\u5230departmentid\u7684\u60C5\u51B5\n\u6700\u540E\u8FD8\u662F\u7528\u4E86\u5B50\u67E5\u8BE2\u2026\u2026 | 3 | 0 | ['Oracle'] | 0 |
department-highest-salary | MySQL using inner join | mysql-using-inner-join-by-pallaviroy-16nn | \nselect d.Name as Department,\ne.Name as Employee,\ne.Salary\nfrom Employee e inner join Department d\non e.DepartmentId = d.Id\nwhere e.Salary = (select max(s | pallaviroy | NORMAL | 2020-05-21T01:55:08.679999+00:00 | 2020-05-21T01:55:08.680051+00:00 | 352 | false | ```\nselect d.Name as Department,\ne.Name as Employee,\ne.Salary\nfrom Employee e inner join Department d\non e.DepartmentId = d.Id\nwhere e.Salary = (select max(salary) from Employee where departmentId = d.Id);\n``` | 3 | 0 | [] | 0 |
department-highest-salary | 248ms Ans beats 99% and illustration | 248ms-ans-beats-99-and-illustration-by-y-k3yo | The most tricky part is to get the actual name of each department. Otherwise it is a simple question\nFirst we find the max price from the employee table of eac | ycchou | NORMAL | 2018-12-03T02:08:19.550259+00:00 | 2018-12-03T02:08:19.550305+00:00 | 513 | false | The most tricky part is to get the actual name of each department. Otherwise it is a simple question\nFirst we find the max price from the employee table of each departmentID\nSecond, join the filtered employee table and department table and get the name of department\n```\nselect Department.Name as Department, a.Name as Employee, a.Salary as Salary\nfrom Department\njoin (select Name, Salary, DepartmentId from Employee \n where (DepartmentId, Salary) in (\n select DepartmentId, max(Salary) # find the max price of each departmentID\n from Employee\n group by DepartmentId)) as a \n on Department.Id = a.DepartmentId\n``` | 3 | 0 | [] | 2 |
department-highest-salary | What's wrong with my code? | whats-wrong-with-my-code-by-neverlate-le-6n36 | select Department.Name Department ,Employee.Name Employee, max(Salary) Salary\nfrom Employee join Department on Employee.DepartmentId = Department.ID \ngroup b | neverlate-leetcode | NORMAL | 2017-09-25T07:43:04.410000+00:00 | 2017-09-25T07:43:04.410000+00:00 | 558 | false | select Department.Name Department ,Employee.Name Employee, max(Salary) Salary\nfrom Employee join Department on Employee.DepartmentId = Department.ID \ngroup by Department.ID\norder by Department.ID\n\n{"headers": {"Employee": ["Id", "Name", "Salary", "DepartmentId"], "Department": ["Id", "Name"]}, "rows": {"Employee": [[1, "Joe", 70000, 1], [2, "Henry", 80000, 2], [3, "Sam", 60000, 2], [4, "Max", 90000, 1]], "Department": [[1, "IT"], [2, "Sales"]]}}\n\nmy output: \n{"headers": ["Department", "Employee", "Salary"], "values": [["IT", "Joe", 90000], ["Sales", "Henry", 80000]]}\n\nExpected:\n{"headers": ["Department", "Employee", "Salary"], "values": [["Sales", "Henry", 80000], ["IT", "Max", 90000]]} | 3 | 0 | [] | 3 |
department-highest-salary | 📚 Easy and Simple Four Solutions With Explanation 🚀 | Beginner-Friendly 🎓 | Beats 98.88% ⚡ | easy-and-simple-four-solutions-with-expl-dwmm | 🎯 Approach 1: Using WITH Clause and DENSE_RANK📌🖥️Code🧠Complexity Analysis
CTE Execution (WITH Clause):
The MaxSalaryCTE computes a DENSE_RANK() for each empl | bulbul_rahman | NORMAL | 2025-03-28T12:11:30.341302+00:00 | 2025-03-28T12:11:30.341302+00:00 | 549 | false | # 🎯 Approach 1: Using WITH Clause and DENSE_RANK📌
# 🖥️Code
```mysql []
With MaxSalaryCTE AS
(
select *,
dense_rank() Over(Partition By DepartmentId order by Salary Desc) RN
from employee
)
Select
d.name Department,
m.name Employee,
m.salary Salary
From MaxSalaryCTE as m
Join Department as d
On m.DepartmentId =d.id
Where rn =1
```
# 🧠Complexity Analysis
- **CTE Execution (WITH Clause):**
- The MaxSalaryCTE computes a DENSE_RANK() for each employee within their department, sorted by salary in descending order.
- The CTE scans the entire employee table, which is **O(N)**, where N is the number of employees.
- The DENSE_RANK() function assigns a rank to each row, ensuring that employees with the same salary receive the same rank.
- **Join Operation:**
- After the CTE, a JOIN operation between MaxSalaryCTE (aliased as m) and Department (d) is performed based on DepartmentId.
- This join requires scanning through **MaxSalaryCTE** and **Department** tables, with a time complexity of **O(N + M)**, where N is the number of rows in the CTE, and M is the number of rows in the Department table.
- **Filtering on RN = 1:**
- After the join, the query filters only the rows where RN = 1 (i.e., the employee with the highest salary in each department).
- The filtering is efficient, as it only involves a direct comparison of the RN value.
# 📈Overall
- **Time Complexity**:
- **Worst Case: O(N + M)**(due to the scan of both MaxSalaryCTE and Department tables and the join operation)
- **Best Case: O(N)** (if an index on DepartmentId or Salary is available, reducing the scan time)
time)
- **Space Complexity**: O(N)
# 🎯 Approach 2: Using WITH Clause and MAX() Aggregation📌
# 🖥️Code
```mysql []
WITH MaxSalaryCTE AS
(
SELECT
DepartmentId,
MAX(Salary) AS Salary
FROM employee
GROUP BY DepartmentId
)
SELECT
d.name AS Department,
e.name AS Employee,
e.salary AS Salary
FROM MaxSalaryCTE AS m
JOIN employee AS e
ON m.Salary = e.salary AND m.DepartmentId = e.DepartmentId
JOIN Department AS d
ON m.DepartmentId = d.id;
```
# 🧠Complexity Analysis
- **CTE Execution (WITH Clause):**
- The MaxSalaryCTE calculates the highest salary (MAX(Salary)) for each department by grouping rows based on DepartmentId.
- This involves scanning the employee table and performing a group-by operation. The time complexity for this is O(N), where N is the number of employees.
- **Join Operations:**
- After the CTE, the query performs **two joins**:
- **Employee Join:** It joins MaxSalaryCTE with the employee table, matching both Salary and DepartmentId.
- The join compares each row in the CTE with employees having the same department and highest salary.
- The time complexity of this join is O(N + M), where N is the number of rows in the employee table and M is the number of rows in the CTE.
- **Department Join:** The second join connects the MaxSalaryCTE with the Department table based on DepartmentId.
- This is a straightforward join that requires scanning the Department table.
- The time complexity of this join is **O(M)**, where M is the number of departments.
- **Filtering and Output:**
- The filtering occurs implicitly through the join conditions. There's no additional filtering step after the joins, so it doesn't add to the time complexity.
# 📈Overall
- **Time Complexity**:
- **Worst Case: O(N + M)** (due to scanning the employee and Department tables and performing the join operations)
- **Best Case: O(N)** (if an index on DepartmentId or Salary is available, reducing lookup time)
- **Space Complexity**: O(N)
# 🎯 Approach 3: Using a co-related Subquery with MAX() to Find the Highest Salary📌
# 🖥️Code
```mysql []
SELECT
d.name AS Department,
e.name AS Employee,
e.salary AS Salary
FROM employee e
JOIN Department d
ON e.DepartmentId = d.id
WHERE e.salary = (
SELECT MAX(Salary)
FROM employee
WHERE DepartmentId = e.DepartmentId
);
```
# 🧠Complexity Analysis
- **Subquery Execution:**
- The subquery inside the WHERE clause calculates the maximum salary for each department.
- For each employee in the employee table, the subquery runs once to get the maximum salary of the corresponding department.
- This results in a nested loop structure, where for each employee, the subquery executes, scanning the employee table for matching DepartmentId.
- The time complexity of the subquery is O(N) for each row in employee, leading to a total worst-case time complexity of O(N²) if no optimizations are in place.
- **Join Operation:**
- After retrieving the maximum salary for each department, the query performs a join between the employee table (e) and the Department table (d) based on DepartmentId.
- This join operation has a time complexity of O(N + M), where N is the number of employees, and M is the number of departments.
- **Filtering on MAX(Salary):**
- The WHERE clause filters out only those employees whose salary matches the maximum salary for their respective department.
- The filtering is efficient since it happens after the join and subquery evaluation, but it still requires checking each employee’s salary against the subquery result.
# 📈Overall
- **Time Complexity**:
- **Worst Case: O(N²)** (if no index optimization is present, due to the subquery for each employee)
- **Best Case: O(N log N)** (if an index on DepartmentId and Salary exists, reducing the subquery lookup time)
- **Space Complexity**: O(1) (the subquery only holds the result of MAX(Salary) for the current department, with no additional large data structures used)
# 🎯 Approach 4: Using EXISTS and HAVING to Find Employees with Maximum Salary📌
# 🖥️Code
```mysql []
SELECT
d.name AS Department,
e.name AS Employee,
e.salary AS Salary
FROM employee e
JOIN Department d
ON e.DepartmentId = d.id
WHERE Exists
(
Select
1
from employee e1
where e1.departmentId=e.departmentId
Having Max(e1.Salary)=e.Salary
)
```
# 🧠Complexity Analysis
- **Subquery Execution (EXISTS Clause):**
- The EXISTS clause checks whether there is any row in the subquery where the maximum salary for the department (MAX(e1.Salary)) matches the salary of the current employee.
- The EXISTS clause only returns TRUE or FALSE based on the existence of such rows, making it more efficient than returning actual results.
- The subquery evaluates for each employee, checking if their salary is the highest in their department.
- **HAVING Clause:**
- The HAVING clause filters groups by the maximum salary in the subquery, ensuring that only employees with the highest salary in their department are considered.
- The use of HAVING after the aggregation (MAX(e1.Salary)) avoids unnecessary grouping in the outer query.
- **Join Operation:**
- After filtering the employees through the EXISTS clause, the query performs a join between employee (e) and Department (d) based on DepartmentId.
- This join operation has a time complexity of O(N + M), where N is the number of rows in the employee table and M is the number of rows in the Department table.
- **EXISTS Optimization:**
- The EXISTS clause stops scanning once a matching row is found, which can optimize the execution compared to the subquery without EXISTS, especially when the number of employees in each department is small.
- However, without an index on DepartmentId or Salary, the subquery can still require a full scan of the employee table for each employee in the outer query.
# 📈Overall
- **Time Complexity**:
- **Worst Case: O(N²)** (if no index optimization is present, due to the nested subquery for each employee)
- **Best Case: O(N + M)** (if an index exists on DepartmentId and Salary, the subquery is more efficient and only requires looking up the department for each employee)
- **Space Complexity**: O(1) | 2 | 0 | ['MySQL'] | 0 |
department-highest-salary | Easy Way To Resolve | easy-way-to-resolve-by-daniel_charle_j-9jqp | \n\n# Approach\n Describe your approach to solving the problem. \nCreated a temporary table first and got the Unique department_id and salaey, Then did a join w | Daniel_Charles_J | NORMAL | 2024-09-03T11:10:35.746985+00:00 | 2024-09-03T11:10:35.747016+00:00 | 649 | false | \n\n# Approach\n<!-- Describe your approach to solving the problem. -->\nCreated a temporary table first and got the Unique department_id and salaey, Then did a join with two tables, used the temp table in the where condition.\n\n\n# Code\n```postgresql []\n-- Write your PostgreSQL query statement below\nWITH temp as (SELECT e.departmentId as "department_id",MAX(e.salary) as "salary" FROM Employee e GROUP BY 1)\n\nSELECT d.name as "Department",e.name as "Employee",e.salary as "Salary" FROM Employee \ne LEFT JOIN Department d ON e.departmentId = d.id\nWHERE (d.id,e.salary) IN (SELECT department_id, salary FROM temp)\n``` | 2 | 0 | ['PostgreSQL'] | 0 |
department-highest-salary | Simple solution that beats 81% of Postgres users | simple-solution-that-beats-81-of-postgre-9lwp | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | pp0787 | NORMAL | 2024-04-08T22:30:46.817995+00:00 | 2024-04-08T22:30:46.818040+00:00 | 222 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n-- Write your PostgreSQL query statement below\nSELECT d.name AS Department, e.name AS Employee, e.salary AS Salary\nFROM Employee e\nJOIN Department d ON e.departmentId = d.id\nWHERE (e.salary, e.departmentId) IN (\n SELECT MAX(salary) AS max_salary, departmentId\n FROM Employee\n GROUP BY departmentId\n);\n\n``` | 2 | 0 | ['PostgreSQL'] | 1 |
department-highest-salary | PostGreSQL easy solution | postgresql-easy-solution-by-rdaaraujo-ymgu | Intuition\nThink on previous problems and used then to solve this one.\n\n# Approach\nEasy using the WHERE clause.\n\n# Complexity\n- Time complexity:\nNone\n\n | rdaaraujo | NORMAL | 2024-04-01T12:52:10.967003+00:00 | 2024-04-01T12:52:10.967029+00:00 | 403 | false | # Intuition\nThink on previous problems and used then to solve this one.\n\n# Approach\nEasy using the WHERE clause.\n\n# Complexity\n- Time complexity:\nNone\n\n- Space complexity:\nNone\n\n# Code\n```\n-- Write your PostgreSQL query statement below\nSELECT d.Name AS Department, e.Name As Employee, e.Salary AS Salary\nFROM Employee e\nLEFT JOIN Department d ON e.DepartmentId = d.Id\nWHERE (d.Id, e.Salary) in (SELECT DepartmentId, max(Salary) FROM Employee GROUP BY DepartmentId)\n``` | 2 | 0 | ['PostgreSQL'] | 0 |
department-highest-salary | MySQL Clean Solution | mysql-clean-solution-by-shree_govind_jee-h15j | Code\n\n# Write your MySQL query statement below\nSELECT d.name AS Department, e.name AS Employee, e.salary AS Salary\nFROM Department d, Employee e\nWHERE e.de | Shree_Govind_Jee | NORMAL | 2024-03-08T04:55:43.990391+00:00 | 2024-03-08T04:55:43.990420+00:00 | 1,689 | false | # Code\n```\n# Write your MySQL query statement below\nSELECT d.name AS Department, e.name AS Employee, e.salary AS Salary\nFROM Department d, Employee e\nWHERE e.departmentId = d.id AND (e.departmentId, salary) IN (\n SELECT departmentId, MAX(salary)\n FROM Employee \n GROUP BY departmentId\n);\n``` | 2 | 0 | ['Database', 'MySQL'] | 0 |
department-highest-salary | Easy | Sub Query | easy-sub-query-by-cold_ice-g9yk | \n# Code\n\n# Write your MySQL query statement below\n\nwith cte as(\nselect e.name as Employee, e.salary, d.name as Department \nfrom Employee e join Departmen | Cold_Ice | NORMAL | 2024-02-13T14:08:52.126730+00:00 | 2024-02-13T14:08:52.126762+00:00 | 684 | false | \n# Code\n```\n# Write your MySQL query statement below\n\nwith cte as(\nselect e.name as Employee, e.salary, d.name as Department \nfrom Employee e join Department d\non e.departmentId = d.id \n)\nselect Employee, salary,Department from cte having (Department,salary) in \n(select Department,max(salary) as salary from cte group by Department)\n``` | 2 | 0 | ['MySQL'] | 0 |
department-highest-salary | Fast and Simple Solution by using window func with description | fast-and-simple-solution-by-using-window-quj8 | Problem Statement\nGiven two tables Employee and Department with columns id, name, and salary in the Employee table, and id and name in the Department table, th | OnDecember | NORMAL | 2023-12-24T09:26:14.574227+00:00 | 2023-12-24T09:26:14.574259+00:00 | 2,112 | false | # Problem Statement\nGiven two tables `Employee` and `Department` with columns `id`, `name`, and `salary` in the `Employee` table, and `id` and `name` in the `Department` table, the task is to retrieve the top salaried employee from each department.\n\n## Intuition\nThe problem involves selecting the top salaried employee from each department based on the salary.\n\n## Approach\n1. **Use of Window Function (`DENSE_RANK`):**\n - Utilize the window function `DENSE_RANK` along with the `OVER` clause to rank employees within each department based on their salary.\n - Partition the data by `department.id` and order it by `employee.salary` in descending order.\n - The resulting column, named `rnk`, will represent the dense ranking of employees within each department based on salary.\n\n2. **Filtering Top Salaried Employees:**\n - Create a subquery (`t`) to represent the combined result set.\n - Use the outer query to filter out rows where `rnk` is equal to 1, indicating the top-salaried employee in each department.\n\n3. **Result Output:**\n - Select the columns `Department`, `Employee`, and `Salary` for the final result.\n\n## Complexity\n- **Time complexity:**\n - The time complexity is primarily determined by the use of the window function `DENSE_RANK` and the sorting operation specified by the `ORDER BY` clause. It is generally efficient and can be considered as $$O(n \\log n)$$, where $$n$$ is the total number of rows in the `Employee` table.\n\n- **Space complexity:**\n - The space complexity is $$O(n)$$, where $$n$$ is the total number of rows in the `Employee` table. This accounts for the storage of intermediate results during the calculation of the dense rank.\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT \n Department,\n Employee,\n Salary\nFROM (SELECT \n d.name AS Department,\n e.name AS Employee,\n e.salary AS Salary,\n DENSE_RANK() OVER (PARTITION BY d.id ORDER BY e.salary DESC) AS rnk\nFROM Employee e\nJOIN Department d\nON e.departmentId = d.id) AS t\nWHERE rnk = 1;\n```\n\n\n | 2 | 0 | ['MySQL'] | 0 |
department-highest-salary | Not fast, but simple | not-fast-but-simple-by-badsenseavail-7k8p | Code\n\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n#Find max salary in every depar | BadSenseAvail | NORMAL | 2023-12-04T14:09:10.519436+00:00 | 2023-12-04T14:12:38.135717+00:00 | 589 | false | # Code\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n#Find max salary in every department\n high_dep = employee.groupby([\'departmentId\']).agg(max).reset_index()\n# Add employees who have these salaries in each department\n employee = employee.merge(high_dep, left_on=[\'departmentId\',\'salary\'], right_on=[\'departmentId\',\'salary\'], how=\'left\').dropna()[[\'name_x\',\'salary\',\'departmentId\']]\n#connect the necessary columns with the department name, rename them, output the necessary columns\n res = employee.merge(department, left_on=\'departmentId\', right_on=\'id\', how=\'inner\').rename({\'name\': \'Department\', \'name_x\' : \'Employee\', \'salary\' : \'Salary\'}, axis=1)[[\'Department\',\'Employee\',\'Salary\']]\n return res\n```\nMe while writing solution:\n\n | 2 | 0 | ['Pandas'] | 2 |
department-highest-salary | INNER JOIN Solurion of department highest salary problem | inner-join-solurion-of-department-highes-zkzn | Approach\n- The INNER JOIN keyword selects records that have matching values in both tables.\n- The WHERE clause is used to filter records. \n- The MAX() functi | tiwafuj | NORMAL | 2023-11-20T19:46:18.021144+00:00 | 2023-11-20T19:46:18.021233+00:00 | 129 | false | # Approach\n- The `INNER JOIN` keyword selects records that have matching values in both tables.\n- The `WHERE` clause is used to filter records. \n- The `MAX()` function returns the largest value of the selected column.\n- The `GROUP B`Y statement groups rows that have the same values into summary rows.\n# Code\n```\nSELECT dep.name AS Department, emp.name AS Employee, salary AS Salary\nFROM Employee emp\nINNER JOIN Department dep ON emp.departmentId = dep.id\nWHERE (salary, emp.departmentId) IN (SELECT MAX(empdep.salary), empdep.departmentId\nFROM Employee empdep\nGROUP BY empdep.departmentId\n)\n``` | 2 | 0 | ['Database', 'MySQL'] | 0 |
department-highest-salary | RANK || DENSE_RANK || MySQL | rank-dense_rank-mysql-by-akanksha_23x07-p7ex | Intuition\n\n\n# Approach\n\n\n# Complexity\n- Time complexity:\nBeats 93.18% of users with MySQL\n\n- Space complexity:\n\n\n# Code\n\n# Write your MySQL query | akanksha_23x07 | NORMAL | 2023-10-29T08:31:40.488590+00:00 | 2023-10-29T08:31:40.488607+00:00 | 11 | false | # Intuition\n\n\n# Approach\n\n\n# Complexity\n- Time complexity:\nBeats 93.18% of users with MySQL\n\n- Space complexity:\n\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT Department, Employee, Salary \nFROM\n(SELECT e.name as Employee, d.name AS Department, e.salary AS Salary,\nDENSE_RANK() OVER(PARTITION BY departmentId ORDER BY Salary DESC) AS ranking\nFROM Employee AS e\nLEFT JOIN Department AS d\nON e.departmentId = d.id) AS r\nWHERE ranking = 1\n\n\n``` | 2 | 0 | ['MySQL'] | 0 |
department-highest-salary | ,✅ 100% EASY || Only in 3 lines🔥|| keep it simple and clean🌟 | 100-easy-only-in-3-lines-keep-it-simple-pfe2y | Intuition\nThink about the top employees that have highiest salaries, not the max\n\n\n# Code\n\nimport pandas as pd\n\ndef department_highest_salary(employee: | MehdiChellak | NORMAL | 2023-10-08T20:06:35.081233+00:00 | 2023-10-08T20:06:35.081261+00:00 | 217 | false | # Intuition\nThink about the top employees that have highiest salaries, not the max\n\n\n# Code\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n\n # Find the top 1 highest salaries in each department using nlargest,\n # keeping employees with the same salary using keep=\'all\'\n # Use apply and lambda to maintain the DataFrame\'s shape\n df_top1 = employee.groupby(\'departmentId\').apply(lambda x: x.nlargest(1, \'salary\', keep=\'all\')).reset_index(drop=True)\n\n # Merge the result with the department DataFrame to get department names\n df_joined = pd.merge(df_top1, department, left_on=\'departmentId\', right_on=\'id\', how=\'inner\', suffixes=(\'_employee\', \'_department\'))\n\n # Rename columns for clarity\n df_joined.rename(columns={"name_employee": "Employee", "name_department": "Department", "salary": "Salary"}, inplace=True)\n \n # Return a DataFrame with only the desired columns\n return df_joined[["Department", "Employee", "Salary"]]\n\n```\n\n\n\n\n\n\n | 2 | 0 | ['Pandas'] | 1 |
department-highest-salary | 184. Department Highest Salary💰 | 184-department-highest-salary-by-axatsac-8h29 | \n# Code\n\n# Write your MySQL query statement below\nSELECT DEPT.name AS Department, EMP.name AS Employee, EMP.salary AS Salary \nFROM Department DEPT, Employe | AxatSachani | NORMAL | 2023-08-29T16:44:32.898822+00:00 | 2023-08-29T16:44:32.898842+00:00 | 1,915 | false | \n# Code\n```\n# Write your MySQL query statement below\nSELECT DEPT.name AS Department, EMP.name AS Employee, EMP.salary AS Salary \nFROM Department DEPT, Employee EMP WHERE\nEMP.departmentId = DEPT.id AND (EMP.departmentId, salary) IN \n(SELECT departmentId, MAX(salary) FROM Employee GROUP BY departmentId)\n``` | 2 | 0 | ['Database', 'MySQL'] | 0 |
department-highest-salary | SQL and Pandas solution with explanation (SQL solution with Window function and nested inner join) | sql-and-pandas-solution-with-explanation-9b80 | Reflection on Complexity\nI would like to highlight the intricate nature of the SQL query I have developed, which I consider to be among the most intricate in m | luizasantos | NORMAL | 2023-08-12T13:14:12.379078+00:00 | 2023-08-12T13:14:12.379110+00:00 | 192 | false | # Reflection on Complexity\nI would like to highlight the intricate nature of the SQL query I have developed, which I consider to be among the most intricate in my repertoire. While I am fully cognizant of the potential avenues for enhancement, I take a sense of accomplishment in my achievement.\n\nCommencing with a nested inner join SQL query, I subsequently recognized the viability of accomplishing the same objective leveraging the RANK() window function. It is noteworthy that upon transcribing the code utilizing the pandas library, the solution conspicuously manifested a heightened level of accessibility and simplicity.\n\nThe complete code for each is at the bottom. \n\n\n# Approach SQL Nested Inner Join (least time efficient solution)\n1. Determined the maximum salary within each department of the `Employee` table by utilizing the MAX() function in conjunction with the GROUP BY operation.\n ```\n SELECT MAX(salary) AS max_salary, departmentId\n FROM Employee\n GROUP BY departmentId\n ```\n2. Performed an inner join between the outcomes of the initial step and the `Employee` table. This join is executed based on the criterion that an employee\'s salary corresponds to the highest salary within each department. This approach was undertaken to accurately account for scenarios where multiple individuals jointly held the top rank, ensuring their inclusion in the analysis.\n ```\n SELECT \n Employee.departmentId as departmentId,\n Employee.name as employee_name,\n Employee.salary as salary\n FROM Employee\n INNER JOIN (\n SELECT MAX(salary) AS max_salary, departmentId\n FROM Employee\n GROUP BY departmentId\n ) AS highest_salary \n ON highest_salary.departmentId = Employee.departmentId\n WHERE Employee.salary = highest_salary.max_salary\n ```\n3. Performed a subsequent inner join between the resultant table and the `Department` table, enabling the retrieval of the corresponding department names. Although it was feasible to execute this step initially, a strategic decision was made to defer it until later. This choice was driven by the anticipation that performing this join at the conclusion would be more time-efficient, owing to the comparatively reduced size of the intermediate table at that juncture.\n ```\n SELECT \n Department.name as Department,\n employees_highest_salary.employee_name as Employee,\n employees_highest_salary.salary as Salary\n FROM Department\n INNER JOIN (\n SELECT \n Employee.departmentId as departmentId,\n Employee.name as employee_name,\n Employee.salary as salary\n FROM Employee\n INNER JOIN (\n SELECT MAX(salary) AS max_salary, departmentId\n FROM Employee\n GROUP BY departmentId\n ) AS highest_salary \n ON highest_salary.departmentId = Employee.departmentId\n WHERE Employee.salary = highest_salary.max_salary\n ) as employees_highest_salary\n ON Department.id = employees_highest_salary.departmentId;\n ```\n\n# Approach SQL with Window Function\n1. Ranked the salary of every employee within each department of the `Employee` table by utilizing the RANK() Window function.\n ```\n RANK() OVER (PARTITION BY Employee.departmentId ORDER BY Employee.salary DESC) as salary_rank\n ```\n2. Performed an inner join between the `Employee` table and the `Department` table to get the Department name based on the Department ID. \n ```\n SELECT\n Department.name as department_name,\n Employee.name as employee_name,\n Employee.salary as employee_salary,\n RANK() OVER (PARTITION BY Employee.departmentId ORDER BY Employee.salary DESC) as salary_rank\n FROM Employee\n JOIN Department ON Employee.departmentId = Department.id\n ```\n3. Refined the results of step 2 to retain exclusively those instances where the rank was designated as 1, signifying the individuals with the highest remuneration.\n ```\n SELECT \n EmployeeRanked.department_name as Department,\n EmployeeRanked.employee_name as Employee,\n EmployeeRanked.employee_salary as Salary\n FROM (\n SELECT\n Department.name as department_name,\n Employee.name as employee_name,\n Employee.salary as employee_salary,\n RANK() OVER (PARTITION BY Employee.departmentId ORDER BY Employee.salary DESC) as salary_rank\n FROM Employee\n JOIN Department ON Employee.departmentId = Department.id\n ) as EmployeeRanked\n WHERE salary_rank = 1;\n ```\n# Approach Pandas (most optimized for time)\n1. Utilized pandas .merge() to merge the `Employee` table to the `Department` table \n ```\n employee.merge(department, left_on=\'departmentId\', right_on=\'id\')\n ```\n2. Added a new column using .assign() and employing a lambda function to assign ranks to salary values subsequent to their aggregation by department. A crucial observation prompted the adjustment of the ranking method to "dense," thereby ensuring that individuals with identical salaries were accorded the same ranking.\n ```\n .assign(salary_rank=lambda x: x.groupby(\'departmentId\')[\'salary\'].rank(method=\'dense\', ascending=False))\n ```\n3. Selected only the employees with highest remuneration.\n ```\n .query(\'salary_rank == 1\'\n ```\n4. Kept only the columns with department name, employee\'s name and salary\n ```\n .loc[:, [\'name_y\', \'name_x\', \'salary\']]\n ```\n5. An error consistently arose when attempting to rename the column "name_y" to "Department". However, the successful renaming of columns was achieved within the resultant DataFrame named "employee_ranked_df." The specific factor contributing to this disparity remains unclear.\n ```\n employee_ranked_df.rename(columns={\'name_y\': \'Department\', \'name_x\': \'Employee\', \'salary\': \'Salary\'})\n ```\n\n# Complete Code\n## SQL Query Nested Inner Join (least optimized for time)\n```\nSELECT \n Department.name as Department,\n employees_highest_salary.employee_name as Employee,\n employees_highest_salary.salary as Salary\nFROM Department\nINNER JOIN (\n SELECT \n Employee.departmentId as departmentId,\n Employee.name as employee_name,\n Employee.salary as salary\n FROM Employee\n INNER JOIN (\n SELECT MAX(salary) AS max_salary, departmentId\n FROM Employee\n GROUP BY departmentId\n ) AS highest_salary \n ON highest_salary.departmentId = Employee.departmentId\n WHERE Employee.salary = highest_salary.max_salary\n) as employees_highest_salary\nON Department.id = employees_highest_salary.departmentId;\n```\n\n## SQL Query with Window Function\n```\nSELECT \n EmployeeRanked.department_name as Department,\n EmployeeRanked.employee_name as Employee,\n EmployeeRanked.employee_salary as Salary\nFROM (\n SELECT\n Department.name as department_name,\n Employee.name as employee_name,\n Employee.salary as employee_salary,\n RANK() OVER (PARTITION BY Employee.departmentId ORDER BY Employee.salary DESC) as salary_rank\n FROM Employee\n JOIN Department ON Employee.departmentId = Department.id\n) as EmployeeRanked\nWHERE salary_rank = 1;\n```\n\n## Pandas Code (most optimized for time)\n```\nimport pandas as pd\n\ndef department_highest_salary(employee: pd.DataFrame, department: pd.DataFrame) -> pd.DataFrame:\n # group by department\n employee_ranked_df = (\n employee\n .merge(department, left_on=\'departmentId\', right_on=\'id\')\n .assign(salary_rank=lambda x: x.groupby(\'departmentId\')[\'salary\'].rank(method=\'dense\', ascending=False))\n .query(\'salary_rank == 1\')\n .loc[:, [\'name_y\', \'name_x\', \'salary\']]\n)\n return employee_ranked_df.rename(columns={\'name_y\': \'Department\', \'name_x\': \'Employee\', \'salary\': \'Salary\'})\n```\n | 2 | 0 | ['Python', 'Python3', 'MySQL', 'MS SQL Server', 'Pandas'] | 0 |
department-highest-salary | MySQL Eassy solution | mysql-eassy-solution-by-triyambkeshtiwar-eznf | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | triyambkeshtiwari | NORMAL | 2023-08-06T15:22:35.663797+00:00 | 2023-08-06T15:22:35.663819+00:00 | 1,638 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n# Write your MySQL query statement below\nSELECT Department.name AS Department ,Employee.name AS Employee, Employee.salary FROM Department JOIN Employee ON Employee.departmentId=Department.id WHERE(departmentId, salary) IN (SELECT departmentId,MAX(salary) FROM Employee GROUP BY departmentId) ;\n``` | 2 | 0 | ['MySQL'] | 2 |
department-highest-salary | CTE || FIRST_VAL | cte-first_val-by-amogh_n21-k21y | \nwith temporary_table(name,salary,departmentId,top_salary) as\n(select e.name,e.salary,e.departmentId,FIRST_VALUE(e.salary) over(partition by departmentId orde | Amogh_N21 | NORMAL | 2023-08-05T13:23:52.502919+00:00 | 2023-08-05T13:23:52.502943+00:00 | 1,464 | false | ```\nwith temporary_table(name,salary,departmentId,top_salary) as\n(select e.name,e.salary,e.departmentId,FIRST_VALUE(e.salary) over(partition by departmentId order by salary desc) as top_salary from Employee e)\n\n\nselect d.name as Department, t.name as Employee, t.salary as Salary \nfrom temporary_table t inner join Department d\non t.departmentId=d.id\nwhere t.salary=t.top_salary;\n``` | 2 | 0 | [] | 1 |
department-highest-salary | Clear Solution | clear-solution-by-mohit94596-jutv | -- We can write an inner query to get max salary department wise. \n-- After that we can use that result and join it with employee and department\n-- to get dep | mohit94596 | NORMAL | 2023-08-02T02:58:00.997730+00:00 | 2023-08-02T02:58:00.997752+00:00 | 34 | false | -- We can write an inner query to get max salary department wise. \n-- After that we can use that result and join it with employee and department\n-- to get department name, employee name and max salary. \n\n/* Write your T-SQL query statement below */\n```\nselect d.name Department, emp.name Employee, temp.salary Salary from \n(select dept.id as deptid, max(emp.salary) as salary\nfrom employee emp inner join department dept\non emp.departmentId = dept.id\ngroup by dept.id) temp\ninner join employee emp on emp.departmentId = temp.deptid\nand temp.salary = emp.salary\ninner join Department d on d.id = temp.deptid\n```\n\n-- --Other possible solutions\n```\n-- SELECT D.Name,A.Name,A.Salary \n-- FROM \n-- \tEmployee A,\n-- \tDepartment D \n-- WHERE A.DepartmentId = D.Id \n-- AND NOT EXISTS \n-- (SELECT 1 FROM Employee B WHERE B.Salary > A.Salary AND A.DepartmentId = B.DepartmentId) \n```\n-- -- \n```\n-- SELECT D.Name AS Department ,E.Name AS Employee ,E.Salary \n-- from \n-- \tEmployee E,\n-- \tDepartment D \n-- WHERE E.DepartmentId = D.id \n-- AND (DepartmentId,Salary) in \n-- (SELECT DepartmentId,max(Salary) as max FROM Employee GROUP BY DepartmentId)\n ``` | 2 | 0 | [] | 0 |
department-highest-salary | Easy to understand Solution for maximum Salary of each Department | easy-to-understand-solution-for-maximum-4fjb7 | Intuition\n Describe your first thoughts on how to solve this problem. \nFind MAX salary for each department\n# Approach\n Describe your approach to solving the | jitendervirmani | NORMAL | 2023-07-10T03:19:07.249503+00:00 | 2023-07-10T03:19:07.249531+00:00 | 265 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nFind MAX salary for each department\n# Approach\n<!-- Describe your approach to solving the problem. -->\nFirst find MAX salary for each department, that can be done only with employee table with departmentId & Salary. then filter that data using IN function to find the name of the person and his salary, use JOIN function with Department Table to identify the dept name\n\n# Complexity\n- Time complexity: 724 ms\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/* Write your PL/SQL query statement below */\nSELECT d.name AS Department, e.name AS Employee, Salary\nFROM Department d, Employee e\nWHERE d.id = e.departmentId\nAND (e.departmentId, Salary) IN (\n SELECT departmentId, MAX(Salary) FROM Employee\n GROUP BY departmentId)\n``` | 2 | 0 | ['MySQL', 'Oracle', 'MS SQL Server'] | 0 |
department-highest-salary | Easy solution SQL SERVER | easy-solution-sql-server-by-tmuhammadqod-gq36 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | TMuhammadqodir | NORMAL | 2023-06-20T17:18:28.331020+00:00 | 2023-06-20T17:18:28.331044+00:00 | 492 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/* Write your T-SQL query statement below */\nSELECT T2.name as \'Department\', T1.name as \'Employee\', T1.salary \'Salary\' FROM Employee T1 \nINNER JOIN Department T2 ON T1.departmentId = T2.Id\nWHERE T1.salary = (SELECT MAX(T3.salary) FROM Employee T3 \nWHERE T2.Id = T3.departmentId) \n\n``` | 2 | 0 | ['MS SQL Server'] | 1 |
department-highest-salary | SOLUTION WITH WINDOW FUNCTION ( SQL SERVER ) | solution-with-window-function-sql-server-w9bc | Intuition\r\n Describe your first thoughts on how to solve this problem. \r\n\r\n# Approach\r\n Describe your approach to solving the problem. \r\n\r\n# Complex | cooking_Guy_9ice | NORMAL | 2023-05-20T15:38:03.066515+00:00 | 2023-05-20T15:38:03.066538+00:00 | 4,791 | false | # Intuition\r\n<!-- Describe your first thoughts on how to solve this problem. -->\r\n\r\n# Approach\r\n<!-- Describe your approach to solving the problem. -->\r\n\r\n# Complexity\r\n- Time complexity:\r\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\r\n\r\n- Space complexity:\r\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\r\n\r\n# Code\r\n```\r\n/* Write your T-SQL query statement below */\r\n\r\n\r\nWITH CTE AS (SELECT\r\n *,\r\n DENSE_RANK() OVER(PARTITION BY DepartmentID ORDER BY salary DESC) RANKED\r\nFROM\r\n Employee\r\n)\r\nSELECT\r\n d.name Department ,\r\n c.name Employee,\r\n c.salary\r\nFROM\r\n CTE c\r\nINNER JOIN\r\n Department d on c.departmentid = d.id\r\nWHERE\r\n EXISTS (\r\n\r\n SELECT 1\r\n FROM\r\n CTE C1\r\n WHERE\r\n c.id = c1.id\r\n AND\r\n c.departmentid = c1.departmentid\r\n AND\r\n C1.RANKED = 1\r\n )\r\n``` | 2 | 0 | ['MS SQL Server'] | 2 |
department-highest-salary | MSSQL solution with DENSE_RANK() | mssql-solution-with-dense_rank-by-yektao-f252 | \n# Code\n\n/* Write your T-SQL query statement below */\nSELECT\n Department, Employee, Salary\nFROM\n(SELECT\n D.NAME AS Department,\n E.NAME AS Empl | yektaozan | NORMAL | 2023-04-18T11:20:54.860055+00:00 | 2023-04-18T11:20:54.860100+00:00 | 775 | false | \n# Code\n```\n/* Write your T-SQL query statement below */\nSELECT\n Department, Employee, Salary\nFROM\n(SELECT\n D.NAME AS Department,\n E.NAME AS Employee,\n E.SALARY AS Salary,\n DENSE_RANK() OVER(PARTITION BY D.NAME ORDER BY E.SALARY DESC) AS rank\nFROM \n EMPLOYEE E\nJOIN \n DEPARTMENT D ON D.ID = E.DEPARTMENTID) AS R\nWHERE R.rank = 1;\n``` | 2 | 0 | ['MS SQL Server'] | 1 |
department-highest-salary | Easy to understand Step-by-step Explanation 😄 (Beats 80%) | easy-to-understand-step-by-step-explanat-yh67 | Intuition\n Describe your first thoughts on how to solve this problem. \n\nYou can solve this problem by using a combination of GROUP BY and MAX(salary). The tr | hankehly | NORMAL | 2023-04-18T03:48:31.242971+00:00 | 2023-04-18T03:51:47.174136+00:00 | 1,461 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\nYou can solve this problem by using a combination of `GROUP BY` and `MAX(salary)`. The tricky part is that more than one employee may have the maximum department salary. This means that we have to split the search process into several steps.\n\n1. Find the maximum salary for each department.\n2. Find the employees whose salary and department match the results from step 1.\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\nThis is your starting point. You can see that the highest salary for the IT department is 90000 and that Max and Jim both have this salary.\n\n```\nEmployee table:\n+----+-------+--------+--------------+\n| id | name | salary | departmentId |\n+----+-------+--------+--------------+\n| 1 | Joe | 70000 | 1 |\n| 2 | Jim | 90000 | 1 | <-- highest in IT\n| 3 | Henry | 80000 | 2 | <-- highest in Sales\n| 4 | Sam | 60000 | 2 |\n| 5 | Max | 90000 | 1 | <-- highest in IT\n+----+-------+--------+--------------+\n\nDepartment table:\n+----+-------+\n| id | name |\n+----+-------+\n| 1 | IT |\n| 2 | Sales |\n+----+-------+\n```\n\n### Step 1 - Find the maximum salary for each department\n\nYou can use `GROUP BY` in combination with `MAX(salary)` to find the highest salary per department.\n\n```\n| departmentId | maxSalary |\n| ------------ | --------- |\n| 1 | 90000 |\n| 2 | 80000 |\n```\n\n### Step 2 - Find the employees whose salary and department match the results from step 1\n\nJoin the Employee and Department tables with the MaxSalary table on the shared departmentId column, then filter out all rows where the employee\'s salary does not equal the maximum salary value. This is similar to asking for a list of employees who have the maximum salary for their department.\n\n(Rename the columns to get the correct answer.)\n\n```\n| departmentId | maxSalary | Department.name | Employee.name | Employee.salary |\n| ------------ | --------- | --------------- | ------------- | --------------- |\n| 1 | 90000 | IT | Jim | 90000 |\n| 2 | 80000 | Sales | Henry | 80000 |\n| 1 | 90000 | IT | Max | 90000 |\n```\n\n# Code\n```\n--\n-- Step 1 - Find the maximum salary for each department\n--\nWITH\n MaxSalary AS (\n SELECT\n Department.id departmentId,\n MAX(salary) maxSalary\n FROM\n Employee\n INNER JOIN\n Department\n ON\n Employee.departmentId = Department.id\n GROUP BY\n Department.id\n)\n--\n-- Step 2 - Find the employees whose salary and department match the results from step 1\n--\nSELECT\n Department.name Department,\n Employee.name Employee,\n Employee.salary Salary\nFROM\n Employee\nINNER JOIN\n MaxSalary\nON\n Employee.departmentId = MaxSalary.departmentId\nINNER JOIN\n Department\nON\n Employee.departmentId = Department.id\nWHERE\n Employee.salary = maxSalary\n\n``` | 2 | 0 | ['MySQL'] | 0 |
split-the-array | 【Video】Simple Hash solution - Python, JavaScript, Java and C++ | video-simple-hash-solution-python-javasc-q2ys | Intuition\nWe don\'t have to care about length of 2 arrays.\n\n# Solution Video\n\nhttps://youtu.be/YLZVibZ5RW8\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to | niits | NORMAL | 2024-02-25T15:28:35.217490+00:00 | 2024-02-25T15:28:35.217520+00:00 | 2,473 | false | # Intuition\nWe don\'t have to care about length of 2 arrays.\n\n# Solution Video\n\nhttps://youtu.be/YLZVibZ5RW8\n\n### \u2B50\uFE0F\u2B50\uFE0F Don\'t forget to subscribe to my channel! \u2B50\uFE0F\u2B50\uFE0F\n\n**\u25A0 Subscribe URL**\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\nSubscribers: 3,916\nThank you for your support!\n\n---\n\n# Approach\n\nIn this problem, the task is to determine the conditions under which it\'s not possible to create two arrays satisfying the given conditions, rather than focusing on the lengths of the two arrays, as implied by the description\'s mention of an even length input array.\n\n```\nInput: nums = [1,1,2,2,3,4]\n```\nBased on the description, we can create \n```\nnums1 = [1,2,3]\nnums2 = [1,2,4]\n```\nLet\'s think about when frequency of numbers is `1`. In this case, we have one `3` and `4`. Since above example is true case, if freqency of numbers is `1`, we can create two arrays with the condition the description says.\n\nHow about frequency of numbers is `2`. We have two `1` and `2`. Seems like that is also fine.\n```\nInput: nums = [1,1,2,2,3,4,1,5]\n```\nI added new numbers, `1` and `5`.\n\nLet\'s think about this case. we can create `[1,2,3]` and `[1,2,4]`. Let\'s add `5` at first. frequency of `5` is `1`, so we can put `5` into `nums1` or `nums2`. Let\'s put `5` into `nums1`\n\n```\nnums1 = [1,2,3,5]\nnums2 = [1,2,4]\n```\nLet\'s try to put `1` into `nums2`\n```\nnums1 = [1,2,3,5]\nnums2 = [1,2,4,1]\n```\nWe break the condition the description says, because `1` in `nums2` is duplicate number.\n\nHow about swtiching `1` and `5`. It\'s the same result. `1` is duplicate number in `nums1`.\n\nFrom this example,\n\n---\n\n\u2B50\uFE0F Points\n\nIf we have 3 same numbers or more, we should return `false`.\n\n---\n\nEasy!\uD83D\uDE06\nLet\'s see solution codes and step by step algorithm!\n\n---\n\n\u2B50\uFE0F I recently created a video on how I\'ve been using LeetCode to learn.\n\nhttps://youtu.be/bU_dXCOWHls\n\n\n---\n\n# Complexity\n- Time complexity: $$O(n)$$\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: $$O(n)$$\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n```python []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n count = {}\n\n for n in nums:\n count[n] = 1 + count.get(n, 0)\n \n for val in count.values():\n if val > 2:\n return False\n \n return True\n```\n```javascript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n let count = new Map();\n\n for (let n of nums) {\n count.set(n, (count.get(n) || 0) + 1);\n }\n \n for (let val of count.values()) {\n if (val > 2) {\n return false;\n }\n }\n \n return true; \n};\n```\n```java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer, Integer> count = new HashMap<>();\n\n for (int n : nums) {\n count.put(n, count.getOrDefault(n, 0) + 1);\n }\n \n for (int val : count.values()) {\n if (val > 2) {\n return false;\n }\n }\n \n return true; \n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n unordered_map<int, int> count;\n\n for (int n : nums) {\n count[n]++;\n }\n \n for (auto& pair : count) {\n if (pair.second > 2) {\n return false;\n }\n }\n \n return true; \n }\n};\n```\n\n## Step by step algorithm\n\n1. **Initialize a dictionary to count occurrences of each number:**\n\n```python\ncount = {}\n```\n\nThis dictionary will store the count of occurrences of each number in the `nums` array.\n\n2. **Count occurrences of each number in the array:**\n\n```python\nfor n in nums:\n count[n] = 1 + count.get(n, 0)\n```\n\nThis loop iterates through each number `n` in the `nums` array. It updates the count of `n` in the `count` dictionary by 1, adding 1 to the existing count if `n` is already a key in the dictionary, or initializing the count to 1 if `n` is encountered for the first time.\n\n3. **Check if any number appears more than twice:**\n\n```python\nfor val in count.values():\n if val > 2:\n return False\n```\n\nThis loop iterates through the values of the `count` dictionary, which represent the counts of each number in the `nums` array. If any count exceeds 2, it means that there are more than two occurrences of some number in the array. In such a case, the function returns `False`, indicating that it\'s not possible to split the array into two parts satisfying the conditions.\n\n4. **Return `True` if no number appears more than twice:**\n\n```python\nreturn True\n```\n\nIf the loop completes without finding any number appearing more than twice, it means that the `nums` array can be split into two parts where each part contains distinct elements and has equal lengths. Therefore, the function returns `True`.\n\nThis algorithm efficiently determines if it\'s possible to split the array according to the given conditions.\n\n---\n\nThank you for reading my post.\n\u2B50\uFE0F Please upvote it and don\'t forget to subscribe to my channel!\n\n\u25A0 Subscribe URL\nhttp://www.youtube.com/channel/UC9RMNwYTL3SXCP6ShLWVFww?sub_confirmation=1\n\n\u25A0 Twitter\nhttps://twitter.com/CodingNinjaAZ\n\n\u2B50\uFE0F My previous video\nhttps://youtu.be/0EHXLXz-Q5c\n | 25 | 2 | ['C++', 'Java', 'Python3', 'JavaScript'] | 4 |
split-the-array | [Python3] 1 line solution using Counter || 33ms | python3-1-line-solution-using-counter-33-vfx4 | python3 []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n return all(val <= 2 for val in Counter(nums).values())\n | yourick | NORMAL | 2024-02-25T05:26:00.104546+00:00 | 2024-02-25T07:39:12.681054+00:00 | 1,464 | false | ```python3 []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n return all(val <= 2 for val in Counter(nums).values())\n``` | 18 | 0 | ['Python', 'Python3'] | 2 |
split-the-array | Beats 100% | Detailed Solution | Java, C, C++, JavaScript, Python ✅✅ | beats-100-detailed-solution-java-c-c-jav-bw0d | Its Easy, Just read \n# You can do it\n# Approach\n Describe your approach to solving the problem. \n1. int[] data = new int[101]; creates an integer array name | Ikapoor123 | NORMAL | 2024-02-25T04:13:36.885917+00:00 | 2024-02-26T05:53:45.836142+00:00 | 1,759 | false | # Its Easy, Just read \n# You can do it\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. int[] data = new int[101]; creates an integer array named data with a size of 101. This array will be used to store the frequency of each number in the input array nums.\n2. for (int i : nums) iterates over each element i in the input array nums.\ndata[i]++; increments the count of the current element i in the data array. This effectively tracks how many times each number appears in nums.\n3. if (data[i] > 2) { return false; } checks if the count of any element in data becomes greater than 2. This condition ensures that no number appears more than twice in the input array. If this condition is violated, the method immediately returns false, indicating that splitting is not possible.\n4. If the loop completes without encountering any violations in the if condition, it means that no number appears more than twice in nums. Therefore, the method returns true, signifying that splitting the array is possible.\n\n# Complexity\n- Time complexity: O(N)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(N)\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Please Upvote !\u2705\u2705\n# Code\n``` java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int[] data = new int[101];\n \n for(int i : nums){\n data[i]++;\n if(data[i]>2) return false;\n }\n return true;\n }\n}\n```\n```C []\nbool isPossibleToSplit(int* nums, int numsSize) {\n int data[101] = {0};\n \n for(int i=0;i<numsSize;i++){\n data[nums[i]]++;\n if(data[nums[i]]>2) return false;\n }\n return true;\n}\n```\n```C++ []\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n int data[101] = {0};\n \n for(int i=0;i<nums.size();i++){\n data[nums[i]]++;\n if(data[nums[i]]>2) return false;\n }\n return true;\n }\n};\n```\n```JavaScript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n const data = new Array(101).fill(0); \n\n for (const i of nums) {\n data[i]++; \n if (data[i] > 2) return false; \n }\n\n return true; \n};\n```\n```Python []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n data = [0] * 101 \n\n for i in nums:\n data[i] += 1 \n if data[i] > 2: return False \n\n return True\n```\n | 9 | 2 | ['Hash Table', 'Stack', 'Ordered Map', 'C', 'Suffix Array', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 3 |
split-the-array | Python 3 || 1 line, Counter || T/S: 84% / 72% | python-3-1-line-counter-ts-84-72-by-spau-easv | \nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n \n return max(set(Counter(nums).values())) <= 2\n\nhttps://leetcode.com/p | Spaulding_ | NORMAL | 2024-02-25T04:49:28.257374+00:00 | 2024-06-12T04:02:00.293745+00:00 | 421 | false | ```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n \n return max(set(Counter(nums).values())) <= 2\n```\n[https://leetcode.com/problems/split-the-array/submissions/1185447945/](https://leetcode.com/problems/split-the-array/submissions/1185447945/)\n\n\nI could be wrong, but I think that time complexity is *O*(*N*) and space complexity is *O*(*N*), in which *N* ~ `len(nums)`. | 8 | 0 | ['Python3'] | 0 |
split-the-array | ✅☑ Easy Java Solution | HashMap | 1ms 🔥 | easy-java-solution-hashmap-1ms-by-yashma-0vye | \n\n# Code\n\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer,Integer> table = new HashMap<>();\n for(int i | yashmahajan270502 | NORMAL | 2024-03-02T17:43:13.179267+00:00 | 2024-03-02T17:55:32.328031+00:00 | 449 | false | \n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer,Integer> table = new HashMap<>();\n for(int i=0; i<nums.length; i++)\n {\n if(table.containsKey(nums[i]))\n {\n table.put(nums[i],table.get(nums[i])+1);\n if(table.get(nums[i])>2)\n {\n return false;\n }\n }\n\n else\n {\n table.put(nums[i],1);\n }\n }\n return true;\n \n }\n}\n``` | 7 | 0 | ['Java'] | 0 |
split-the-array | 👏Beats 98.75% of users with Java || Simple & Easy Array Approach 🔥💥 | beats-9875-of-users-with-java-simple-eas-lvfe | Intuition\nmake a array variable cnt and count the frequency of every element if any element\'s frequency is go to more than 2 simply return false.\n\n\n# I thi | Rutvik_Jasani | NORMAL | 2024-03-01T07:39:30.552716+00:00 | 2024-03-01T07:40:29.695887+00:00 | 288 | false | # Intuition\nmake a array variable cnt and count the frequency of every element if any element\'s frequency is go to more than 2 simply return false.\n\n\n# **I think This can Help you**\n\n\n# Approach\n1. make array variable as a cnt for storing frequency of every element.\n2. iterate over the array and add frequency in the cnt array variable & check if frequency is more than 2 then return false.\n3. if loop is finished & no one element has a frequency more than 2 then return true.\n\n# Complexity\n- Time complexity:\nO(n) --> iterating loop over the array.\n\n- Space complexity:\nO(n) --> for make array variable as cnt.\n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int[] cnt = new int[101]; // make array variable as a cnt for storing frequency of every element.\n for(int i=0;i<nums.length;i++){ // iterate over the array and add frequency in the cnt array variable & check if frequency is more than 2 then return false.\n cnt[nums[i]-1]++;\n if(cnt[nums[i]-1]>2){\n return false;\n }\n }\n return true; // if loop is finished & no one element has a frequency more than 2 then return true.\n }\n}\n```\n\n\n\n | 6 | 0 | ['Array', 'Counting', 'Java'] | 0 |
split-the-array | Easy Java Solution | easy-java-solution-by-1asthakhushi1-qmoc | \n\n# Code\n\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer, Integer> hm=new HashMap<>();\n for(int i=0;i | 1asthakhushi1 | NORMAL | 2024-02-25T04:01:55.575453+00:00 | 2024-02-25T04:29:36.285371+00:00 | 999 | false | \n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer, Integer> hm=new HashMap<>();\n for(int i=0;i<nums.length;i++){\n hm.put(nums[i],hm.getOrDefault(nums[i],0)+1);\n if(hm.get(nums[i])>2)\n return false;\n }\n return true;\n }\n}\n``` | 5 | 0 | ['Hash Table', 'Java'] | 1 |
split-the-array | split the array | split-the-array-by-jamiyat-wktd | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | Jamiyat | NORMAL | 2024-03-17T15:18:17.029900+00:00 | 2024-03-17T15:18:17.029930+00:00 | 203 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n counts = Counter(nums)\n return all(count <= 2 for count in counts.values())\n``` | 4 | 0 | ['Python3'] | 0 |
split-the-array | 3046. Split the Array | 3046-split-the-array-by-pgmreddy-bl8x | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | pgmreddy | NORMAL | 2024-02-25T04:56:19.439911+00:00 | 2024-02-25T04:56:19.439929+00:00 | 220 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n\n---\n\n```\nvar isPossibleToSplit = function (arr) {\n const freq = {};\n for (const ele of arr) {\n freq[ele] = (freq[ele] || 0) + 1;\n }\n for (const ele in freq) {\n if (freq[ele] > 2) {\n return false;\n }\n }\n return true;\n};\n```\n\n---\n | 4 | 0 | ['JavaScript'] | 3 |
split-the-array | ✅ Java Solution | Easy | java-solution-easy-by-harsh__005-oi8w | Code\nJava []\npublic boolean isPossibleToSplit(int[] nums) {\n\tMap<Integer, Integer> map = new HashMap<>();\n\tfor(int num : nums) map.put(num, map.getOrDefau | Harsh__005 | NORMAL | 2024-02-25T04:08:09.268301+00:00 | 2024-02-25T04:08:09.268326+00:00 | 442 | false | # Code\n```Java []\npublic boolean isPossibleToSplit(int[] nums) {\n\tMap<Integer, Integer> map = new HashMap<>();\n\tfor(int num : nums) map.put(num, map.getOrDefault(num, 0)+1);\n\n\tfor(int val : map.values()){\n\t\tif(val>2) return false;\n\t}\n\n\treturn true;\n}\n``` | 4 | 0 | ['Java'] | 1 |
split-the-array | 0ms 100% beat in java very easiest code 😊. | 0ms-100-beat-in-java-very-easiest-code-b-f5ok | Code | Galani_jenis | NORMAL | 2025-01-02T05:45:05.248689+00:00 | 2025-01-02T05:45:05.248689+00:00 | 396 | false | 
# Code
```java []
class Solution {
public boolean isPossibleToSplit(int[] nums) {
int[] numbers = new int[101];
// for (int i: nums) { It is also valid .
// if (++numbers[i] > 2) return false;
// }
for (int i: nums) {
if (numbers[i]++ >= 2)
return false;
}
return true;
}
}
``` | 3 | 0 | ['Java'] | 0 |
split-the-array | Just Understandin seconds | just-understandin-seconds-by-vansh0123-74i5 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | vansh0123 | NORMAL | 2024-08-28T14:09:34.831342+00:00 | 2024-08-28T14:09:34.831379+00:00 | 372 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int max=Integer.MIN_VALUE;\n for(int i=0; i<nums.length; i++)\n {\n max = Math.max(nums[i], max);\n } \n\n int[] countArray = new int[max+1];\n\n for(int i=0; i<nums.length; i++)\n { \n countArray[nums[i]]++;\n } \n\n for(int i=0; i<countArray.length; i++)\n {\n if(countArray[i]>2)\n {\n return false;\n }\n }\n return true;\n \n }\n}\n``` | 3 | 0 | ['Java'] | 0 |
split-the-array | Don't Use Hashmap. Use Arrays Instead of Hashmaps for O(1) Space. Achieves 100% Efficiency. | dont-use-hashmap-use-arrays-instead-of-h-73z2 | Intuition\nOur approach will be to use an index array to keep track of the frequency of each element in the input array. If any element appears more than twice, | muhammadfarhankt | NORMAL | 2024-03-27T06:29:09.922254+00:00 | 2024-03-27T06:40:22.662594+00:00 | 415 | false | # Intuition\nOur approach will be to use an index array to keep track of the frequency of each element in the input array. If any element appears more than twice, it is not possible to split the array as required.\n\n# Approach\nWe initialize an index array of size 100, as the elements in the input array are within the range [1, 100]. We iterate through the input array and update the corresponding index in the index array. If any element appears more than twice, we return false, indicating that it is not possible to split the array. Otherwise, we return true.\n\n# Complexity\n- Time complexity: O(n), where n is the size of the input array. We iterate through the input array once.\n\n- Space complexity: O(1), as we are using a fixed-size index array of size 100, which is independent of the input size.\n\n# Comparision Hashmap vs Array\n\n- When considering whether to use a hashmap or an index array of size 100 to solve this problem, we need to consider both the time and space complexities of each approach.\n\n## 1. Using Hashmap:\n\n- Time Complexity: O(n)\n- Space Complexity: O(n)\n## 2. Using Index Array of Size 100:\n\n- Time Complexity: O(n)\n- Space Complexity: O(1)\n- Given that the maximum size of the input array is 100 and each element in the array is bounded by the range [1, 100], using an index array of size 100 would provide a more space-efficient solution. This approach ensures that we have constant space complexity, as the space required does not depend on the size of the input array.\n- On the other hand, using a hashmap would still provide a valid solution with a space complexity of O(n), where n is the size of the input array. While this approach may be slightly more flexible, it is not necessary given the constraints of the problem.\n- Therefore, in this particular scenario, the index array approach is preferable due to its constant space complexity and simplicity.\n\n\n```javascript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n let idxArr = new Array(100).fill(0);\n for (let i = 0; i < nums.length; i++) {\n idxArr[nums[i] - 1]++;\n if (idxArr[nums[i] - 1] > 2) {\n return false;\n }\n }\n return true;\n};\n```\n```python []\nclass Solution(object):\n def isPossibleToSplit(self, nums):\n idxArr = [0] * 100\n for num in nums:\n idxArr[num - 1] += 1\n if idxArr[num - 1] > 2:\n return False\n return True\n\n```\n```python3 []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n idxArr = [0] * 100\n for num in nums:\n idxArr[num - 1] += 1\n if idxArr[num - 1] > 2:\n return False\n return True\n```\n```Java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int[] idxArr = new int[100];\n for (int num : nums) {\n idxArr[num - 1]++;\n if (idxArr[num - 1] > 2) {\n return false;\n }\n }\n return true;\n }\n}\n```\n```C++ []\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n vector<int> idxArr(100, 0);\n for (int i = 0; i < nums.size(); i++) {\n idxArr[nums[i] - 1]++;\n if (idxArr[nums[i] - 1] > 2) {\n return false;\n }\n }\n return true;\n }\n};\n\n```\n``` Go []\nfunc isPossibleToSplit(nums []int) bool {\n size := len(nums)\n idxArr := make([]int, 100)\n for i:=0; i<size; i++ {\n idxArr[(nums[i]-1)]++\n if idxArr[nums[i]-1] > 2 {\n return false\n }\n }\n return true\n}\n``` | 3 | 0 | ['Array', 'Hash Table', 'Math', 'Counting', 'Python', 'C++', 'Java', 'Go', 'Python3', 'JavaScript'] | 0 |
split-the-array | Easy one line Solution | easy-one-line-solution-by-demonsword09-oiu6 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | DemonSword09 | NORMAL | 2024-03-05T06:01:23.625279+00:00 | 2024-03-05T06:01:23.625315+00:00 | 410 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n return True if all([i<3 for i in Counter(nums).values()]) else False \n``` | 3 | 0 | ['Python3'] | 0 |
split-the-array | Python3 ✅✅✅ || Tiub-Recommended | python3-tiub-recommended-by-blackhole_ti-c0f3 | \n\n# Code\n\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n turn = 1\n half1 = []\n half2 = []\n for | Little_Tiub | NORMAL | 2024-03-03T05:21:39.618353+00:00 | 2024-03-03T05:21:39.618388+00:00 | 67 | false | \n\n# Code\n```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n turn = 1\n half1 = []\n half2 = []\n for n in nums:\n if turn == 1:\n if n in half1:\n if n in half2: return False\n else: half2.append(n)\n else: half1.append(n)\n if turn == 2:\n if n in half2:\n if n in half1: return False\n else: half1.append(n)\n else: half2.append(n)\n return True\n``` | 3 | 0 | ['Python3'] | 0 |
split-the-array | Frequency of each item should be less than 2 | frequency-of-each-item-should-be-less-th-alxk | \n# Code\n\nbool isPossibleToSplit(vector<int>& nums) {\n vector<int> freq(101, 0);\n for(auto n: nums) freq[n]++;\n for(auto f: freq) if(f > 2) return | kreakEmp | NORMAL | 2024-02-25T08:13:05.834685+00:00 | 2024-02-25T08:14:23.386643+00:00 | 871 | false | \n# Code\n```\nbool isPossibleToSplit(vector<int>& nums) {\n vector<int> freq(101, 0);\n for(auto n: nums) freq[n]++;\n for(auto f: freq) if(f > 2) return false;\n return true;\n}\n\n```\n\n---\n\n<b>Here is an article of my interview experience at Amazon, taht may be helpful for you: https://leetcode.com/discuss/interview-experience/3171859/Journey-to-a-FAANG-Company-Amazon-or-SDE2-(L5)-or-Bangalore-or-Oct-2022-Accepted\n\n--- | 3 | 0 | ['C++'] | 4 |
split-the-array | JS Solution | js-solution-by-bola-nabil-hrty | \n# Code\n\nvar isPossibleToSplit = function(nums) {\n if (nums.length % 2 !== 0) {\n return false;\n }\n\n const nums1 = new Set();\n const nums2 = new | bola-nabil | NORMAL | 2024-02-25T08:08:07.834794+00:00 | 2024-02-25T08:08:07.834813+00:00 | 149 | false | \n# Code\n```\nvar isPossibleToSplit = function(nums) {\n if (nums.length % 2 !== 0) {\n return false;\n }\n\n const nums1 = new Set();\n const nums2 = new Set();\n\n for (const num of nums) {\n if (!nums1.has(num)) {\n nums1.add(num);\n } else if (!nums2.has(num)) {\n nums2.add(num);\n } else {\n return false;\n }\n }\n\n return nums1.size + nums2.size === nums.length; \n};\n``` | 3 | 0 | ['JavaScript'] | 0 |
split-the-array | ✅Beats 100% Frequency Array || Split the Array || Simple solution in Java, C++, Python & javascript | beats-100-frequency-array-split-the-arra-bwrc | Intuition\nThe goal of the isPossibleToSplit function is to determine whether it is possible to split the given array nums into two parts (nums1 and nums2), eac | Mohit-P | NORMAL | 2024-02-25T04:28:53.352531+00:00 | 2024-02-25T04:28:53.352551+00:00 | 967 | false | # Intuition\nThe goal of the `isPossibleToSplit` function is to determine whether it is possible to split the given array `nums` into two parts (`nums1` and `nums2`), each containing distinct elements.\n\n# Approach\n1. **Frequency Array:**\n The code utilizes an array (`elementFrequency`) to store the frequency of each element in the given array `nums`. The array size is set to 101 to accommodate values in the range [1, 100].\n\n2. **Populating the Frequency Array:**\n It iterates through the array `nums` and increments the corresponding count in the `elementFrequency` array for each element encountered.\n\n3. **Checking Distinct Elements:**\n During the iteration, it checks if the frequency of any element becomes greater than 2. If so, it immediately returns `false` as it indicates non-distinct elements.\n\n4. **Result:**\n If no element exceeds a frequency of 2, the function returns `true`, indicating that it is possible to split the array into two parts with distinct elements.\n\n# Complexity\n- Time complexity:\n\n The function iterates through the entire `nums` array once, updating the frequency array. Therefore, the time complexity is O(nums.length).\n\n- Space complexity:\n\n The space complexity is O(1) as it uses a fixed-size array (`elementFrequency`) regardless of the input size.\n\n# Code\n```java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n // Array to store the frequency of each element in the range [1, 100]\n int[] elementFrequency = new int[101];\n \n // Populating the frequency array\n for (int num : nums) {\n elementFrequency[num]++;\n \n // If any element frequency exceeds 2, it\'s not possible to split\n if (elementFrequency[num] > 2) {\n return false;\n }\n }\n \n // If no element frequency exceeds 2, it\'s possible to split\n return true;\n }\n}\n\n```\n```python []\nclass Solution(object):\n def isPossibleToSplit(self, nums):\n element_frequency = [0] * 101\n \n for num in nums:\n element_frequency[num] += 1\n\n # If any element frequency exceeds 2, it\'s not possible to split\n if element_frequency[num] > 2:\n return False\n \n # If no element frequency exceeds 2, it\'s possible to split\n return True\n \n```\n```C++ []\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n // Array to store the frequency of each element in the range [1, 100]\n int elementFrequency[101] = {0};\n \n // Populating the frequency array\n for (int num : nums) {\n elementFrequency[num]++;\n \n // If any element frequency exceeds 2, it\'s not possible to split\n if (elementFrequency[num] > 2) {\n return false;\n }\n }\n```\n```javascript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n const elementFrequency = new Array(101).fill(0);\n \n // Populating the frequency array\n for (const num of nums) {\n elementFrequency[num]++;\n \n // If any element frequency exceeds 2, it\'s not possible to split\n if (elementFrequency[num] > 2) {\n return false;\n }\n }\n \n // If no element frequency exceeds 2, it\'s possible to split\n return true;\n\n return true;\n};\n```\n\nIf you found this content helpful, consider giving it an **upvote** and share your thoughts in the comments.\n | 3 | 0 | ['Array', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 0 |
split-the-array | Easy Python Solution | easy-python-solution-by-_suraj__007-4xmc | Code\n\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n for i in range(len(nums)):\n if nums.count(nums[i])>2:\n | _suraj__007 | NORMAL | 2024-02-25T04:10:29.211113+00:00 | 2024-02-25T04:10:29.211138+00:00 | 130 | false | # Code\n```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n for i in range(len(nums)):\n if nums.count(nums[i])>2:\n return False\n return True\n \n``` | 3 | 0 | ['Python3'] | 0 |
split-the-array | ✅HashMap solution || Split the array|| Simple solution in Java, C++, Python & javascript | hashmap-solution-split-the-array-simple-1jfpn | Intuition\nThe goal of the isPossibleToSplit function is to determine whether it is possible to split the given array nums into two distinct parts (nums1 and nu | Mohit-P | NORMAL | 2024-02-25T04:07:41.476198+00:00 | 2024-02-25T04:07:41.476223+00:00 | 841 | false | # Intuition\nThe goal of the `isPossibleToSplit` function is to determine whether it is possible to split the given array `nums` into two distinct parts (`nums1` and `nums2`), each containing distinct elements.\n\n# Approach\n1. **Frequency Map:**\n The code uses a HashMap (`map`) to keep track of the frequency of each element in the array.\n\n2. **Populating the Frequency Map:**\n It iterates through the array and updates the frequency of each element in the map.\n\n3. **Checking Distinct Elements:**\n After creating the frequency map, it iterates through the keys of the map and checks if any element has a frequency greater than 2. If so, it returns `false` since it is not possible to have two distinct arrays.\n\n4. **Result:**\n If no element has a frequency greater than 2, it returns `true`, indicating that it is possible to split the array into two parts with distinct elements.\n\n# Complexity\n- Time complexity:\n - The first loop to populate the frequency map runs in O(nums.length) time.\n - The second loop to check frequencies runs in O(unique elements) time.\n - Therefore, the overall time complexity is O(nums.length + unique elements).\n\n- Space complexity:\n The space complexity is O(unique elements) as it stores the frequency of each unique element in the map.\n\n```java []\nclass Solution {\n // Function to check if it\'s possible to split the array into two parts\n public boolean isPossibleToSplit(int[] nums) {\n // HashMap to store the frequency of each element in the array\n HashMap<Integer, Integer> map = new HashMap<>();\n \n // Populating the frequency map\n for (int i = 0; i < nums.length; i++) {\n map.put(nums[i], map.getOrDefault(nums[i], 0) + 1);\n }\n \n // Checking distinct elements in the frequency map\n for (int i : map.keySet()) {\n if (map.get(i) > 2)\n return false;\n }\n \n // If no element has a frequency greater than 2, return true\n return true;\n }\n}\n```\n```python []\nclass Solution(object):\n def isPossibleToSplit(self, nums):\n mapping = {}\n\n for num in nums:\n mapping[num] = mapping.get(num, 0) + 1\n\n for count in mapping.values():\n if count > 2:\n return False\n\n return True\n```\n```C++ []\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n unordered_map<int, int> map;\n\n for (int i = 0; i < nums.size(); i++) {\n map[nums[i]] = map[nums[i]] + 1;\n }\n\n for (auto& pair : map) {\n if (pair.second > 2) {\n return false;\n }\n }\n\n return true;\n }\n};\n```\n```javascript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n const map = new Map();\n\n for (const num of nums) {\n map.set(num, (map.get(num) || 0) + 1);\n }\n\n for (const count of map.values()) {\n if (count > 2) {\n return false;\n }\n }\n\n return true;\n};\n```\nIf you found this content helpful, consider giving it an **upvote** and share your thoughts in the comments. | 3 | 0 | ['Array', 'Hash Table', 'Python', 'C++', 'Java', 'Python3', 'JavaScript'] | 1 |
split-the-array | Easy JAVA Solution | easy-java-solution-by-mayur0106-pbyz | \n- Time complexity: O(n)\n- Space complexity: O(n)\n\n\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n \n int n=nums.leng | mayur0106 | NORMAL | 2024-02-25T04:03:43.641282+00:00 | 2024-02-25T04:03:43.641317+00:00 | 333 | false | \n- Time complexity: O(n)\n- Space complexity: O(n)\n\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n \n int n=nums.length;\n Map<Integer,Integer> map=new HashMap<>();\n for(int i=0;i<n;i++)\n {\n map.put(nums[i],map.getOrDefault(nums[i],0)+1);\n }\n int freq=0;\n for(Map.Entry<Integer,Integer> m:map.entrySet())\n {\n if(m.getValue()>2) return false;\n else if(m.getValue()==1) freq++; \n }\n \n return freq%2==0?true:false;\n \n }\n}\n``` | 3 | 0 | ['Java'] | 0 |
split-the-array | ✅Easy Java Solution✅ | easy-java-solution-by-anshchaudhary1-2m12 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | anshchaudhary1 | NORMAL | 2024-02-25T04:01:23.012601+00:00 | 2024-02-25T04:01:23.012624+00:00 | 230 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int arr[] = new int[101];\n for(int i=0;i<nums.length;i++){\n arr[nums[i]]++;\n }\n for(int i : arr){\n if(i>2){\n return false;\n }\n }\n return true;\n }\n}\n``` | 3 | 0 | ['Java'] | 1 |
split-the-array | O(n) python solution with explanation | on-python-solution-with-explanation-by-9-tpl0 | IntuitionSo, in this problem, we have to split the array into TWO parts. The splitting should be done in such a way that both parts should have distinct element | 9chaitanya11 | NORMAL | 2025-02-20T22:57:55.275643+00:00 | 2025-02-20T23:02:37.855034+00:00 | 183 | false | # Intuition
So, in this problem, we have to split the array into TWO parts. The splitting should be done in such a way that both parts should have distinct elements. We can solve this problem using hashmap.
# Approach
So, we will create a hashmap named count which will count the number of elements in the array. If they are greater than 2, we have to return False because as the question says that we can split the array into only two parts and should also contain distinct ie different elemnts.
But if, we get less than or equal to 2, we can return True that means we can split it easily.
Example of the operation:
-> nums = [1,1,2,2,3,4]
This is the input array we're given which we have to split into two and have distinct elements in it.
We will create a hashset in which we will store all the elements of the array named count using counter func:
-> count = [1:2, 2:2, 3:1, 4:1]
In the 1:2, where 1 is the key ie element and 2 is the value ie number of occurences.
Now, we will check if the count of any elemt from the hashset is greater than 2. If yes, we have to return false for the above stated reason. If less or equal to 2, we can return true.
So, our output would be :
-> [1, 2, 3]
-> [1, 2, 4]
# Complexity
- Time complexity:
O(n) where n denotes the number of elemts in the array as we're looping through it and storing them in a hashmap and it has 0(1) lookup through hashset.
- Space complexity:
O(n) where n denotes the length of the hashmap as it's dependent on the number of elemts in the input array.
# Code
```python3 []
class Solution:
def isPossibleToSplit(self, nums: List[int]) -> bool:
count = Counter(nums) #counting the number of elemnts in the array
for c in count.values():
if c > 2:
return False # return false if greater than 2
return True #if less than or equal to 2
``` | 2 | 0 | ['Python3'] | 0 |
split-the-array | Simple...Think Opposite | simplethink-opposite-by-hk_international-ouz3 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | HK_INTERNATIONAL | NORMAL | 2024-10-22T00:29:23.289826+00:00 | 2024-10-22T00:29:23.289863+00:00 | 115 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```javascript []\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n nums.sort((x,y)=>x-y)\n for(let i=0;i<nums.length-2;i++)\n {\n if(nums[i] == nums[i+2])\n {\n return false;\n }\n }\n return true;\n}\n``` | 2 | 0 | ['Array', 'Hash Table', 'Counting', 'JavaScript'] | 1 |
split-the-array | 👏Beats 98.75% of users with Java || Simple & Easy Array Approach 🔥💥 | beats-9875-of-users-with-java-simple-eas-xv4h | \n\n# Code\n\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int[] cnt = new int[101]; \n for(int i=0;i<nums.length;i++){ | Ankit1317 | NORMAL | 2024-07-31T06:10:34.094900+00:00 | 2024-07-31T06:10:34.094919+00:00 | 211 | false | \n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int[] cnt = new int[101]; \n for(int i=0;i<nums.length;i++){ \n cnt[nums[i]-1]++;\n if(cnt[nums[i]-1]>2){\n return false;\n }\n }\n return true; \n }\n}\n``` | 2 | 0 | ['Array', 'Hash Table', 'Counting', 'Java'] | 1 |
split-the-array | Efficient Solution: Beats 90% in Runtime | efficient-solution-beats-90-in-runtime-b-5a72 | Intuition\nThe first thought is to check if every integer in the array appears exactly twice. If any integer appears more than twice or if the total number of e | ShreekrushnaDongare | NORMAL | 2024-07-26T18:10:51.623758+00:00 | 2024-07-26T18:10:51.623787+00:00 | 32 | false | ## Intuition\nThe first thought is to check if every integer in the array appears exactly twice. If any integer appears more than twice or if the total number of elements is odd, it would be impossible to form pairs.\n\n## Approach\n1. **Check array length:** If the length of the array is odd, return `false` since an odd number of elements cannot form pairs.\n2. **Count occurrences:** Use a map (or hash table) to count the occurrences of each integer in the array.\n3. **Check counts:** Traverse the map to ensure that each integer appears exactly twice. If any integer appears more than twice, return `false`.\n4. **Return true:** If all checks pass, return `true` indicating that it is possible to split the array into pairs.\n\n## Complexity\n- **Time complexity:** \\(O(n)\\), where \\(n\\) is the number of elements in the array. This is because we traverse the array once to count the occurrences and then traverse the map to check the counts.\n- **Space complexity:** \\(O(n)\\), where \\(n\\) is the number of distinct elements in the array. This is because we store counts for each distinct element in the map.\n\n## Code\nHere is the complete implementation of the solution:\n\n```cpp\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n // Check if the number of elements is odd\n if (nums.size() % 2 != 0) {\n return false;\n }\n \n // Count occurrences of each integer\n std::map<int, int> my_map;\n for (int i: nums) {\n my_map[i]++;\n // If any integer appears more than twice, return false\n if (my_map[i] > 2) {\n return false;\n }\n }\n \n // If all integers appear exactly twice, return true\n return true;\n }\n};\n```\n\nThis code ensures that we can only split the array into pairs if every integer appears exactly twice. If the conditions are not met, it returns `false`. | 2 | 0 | ['C++'] | 0 |
split-the-array | using map, easy C++ code | using-map-easy-c-code-by-divyam45-e195 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\nAny element\'s count > 2 will cause repetition in the splitted array\n De | divyam72 | NORMAL | 2024-07-01T02:29:21.410551+00:00 | 2024-07-01T02:29:21.410582+00:00 | 164 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\nAny element\'s count > 2 will cause repetition in the splitted array\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& a) {\n int n=a.size();\n map<int,int> mp;\n for(int i:a)\n mp[i]++;\n for(auto &it:mp)\n if(it.second>2)return false;\n return true;\n }\n};\n``` | 2 | 0 | ['Array', 'Hash Table', 'Counting', 'C++'] | 0 |
split-the-array | Easy solution in cpp !! Beats 92% user runtime !!! | easy-solution-in-cpp-beats-92-user-runti-idjw | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | parijatb_03 | NORMAL | 2024-06-19T22:28:13.572416+00:00 | 2024-06-19T22:28:13.572442+00:00 | 47 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n int n = nums.size();\n if(n%2!=0) return false;\n\n unordered_map<int,int> freq;\n for(int num : nums){\n freq[num]++;\n if(freq[num]>2){\n return false;\n } \n }\n \n return true;\n }\n};\n``` | 2 | 0 | ['C++'] | 0 |
split-the-array | Easy Hash Solution || Beats 100% | easy-hash-solution-beats-100-by-shivamkh-h0sj | \n\n# C++\n\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n ios_base::sync_with_stdio(0);\n\n int freq[101] = {}; // | ShivamKhator | NORMAL | 2024-05-23T04:48:59.263924+00:00 | 2024-05-23T04:48:59.263955+00:00 | 69 | false | \n\n# C++\n```\nclass Solution {\npublic:\n bool isPossibleToSplit(vector<int>& nums) {\n ios_base::sync_with_stdio(0);\n\n int freq[101] = {}; // Initialize an array to store frequency of each number\n\n // Iterate through each element in the vector\n for (int num : nums)\n if (++freq[num] > 2) // If frequency exceeds 2, return false\n return false;\n\n // If no number appears more than twice, return true\n return true;\n }\n};\n```\n\n | 2 | 0 | ['Array', 'Hash Table', 'C++'] | 0 |
split-the-array | SIMPLE JAVA and PYTHON Solution || Beginner friendly || Without HashMap | simple-java-and-python-solution-beginner-bsg0 | Intuition\n Describe your first thoughts on how to solve this problem. \nThis function aims to determine whether it\'s possible to split an array into two non-e | Pushkar91949 | NORMAL | 2024-03-18T16:49:55.461726+00:00 | 2024-03-18T16:49:55.461755+00:00 | 120 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\nThis function aims to determine whether it\'s possible to split an array into two non-empty subsets, each having the same sum. Instead of using a dictionary to store the frequency of each number, it uses a list x of size 101, assuming the range of numbers in the input array is from 0 to 100 inclusive. The function checks if any number appears more than twice in the array. If so, it\'s not possible to split the array as required; otherwise, it is possible.\n# Approach\n<!-- Describe your approach to solving the problem. -->\n1. Initialize a list x of size 101, with all elements initialized to 0. This list is used to store the frequency of each number in the input array.\n2. Iterate through the input array.\n3. For each number encountered, increment the corresponding index in the list x by 1.\n4. Check if the count of any number becomes greater than 2 during the iteration. If so, return False, indicating it\'s not possible to split the array as required.\n5. If no number has a count greater than 2, return True, indicating it\'s possible to split the array into two subsets with equal sums.\n# Complexity\n- Time complexity:O(n)\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity: O(1) \n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```python []\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n x = [0]*101\n for num in nums:\n x[num] += 1\n if x[num] > 2:\n return False\n return True\n```\n```java []\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n int new_arr[] = new int[101];\n \n for(int i = 0;i<nums.length;i++){\n new_arr[nums[i]]++;\n if(new_arr[nums[i]]>2)\n return false;\n } \n return true;\n }\n}\n``` | 2 | 0 | ['Array', 'Java', 'Python3'] | 0 |
split-the-array | ✅ Beats 98% | Simple 5 lines of code | beats-98-simple-5-lines-of-code-by-escap-o2lc | \n\n# Code\n\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n counter = Counter(nums)\n for f in counter.values():\n | durvesh_danve | NORMAL | 2024-03-16T18:18:12.134057+00:00 | 2024-03-16T18:18:12.134087+00:00 | 92 | false | \n\n# Code\n```\nclass Solution:\n def isPossibleToSplit(self, nums: List[int]) -> bool:\n counter = Counter(nums)\n for f in counter.values():\n if f > 2:\n return False\n return True\n \n``` | 2 | 0 | ['Python3'] | 0 |
split-the-array | Easy JavaScript Solution Beginner Level. | easy-javascript-solution-beginner-level-onp75 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | abhinandkbabu | NORMAL | 2024-03-07T03:33:29.532359+00:00 | 2024-03-07T03:33:29.532417+00:00 | 152 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\n/**\n * @param {number[]} nums\n * @return {boolean}\n */\nvar isPossibleToSplit = function(nums) {\n nums.sort((a,b)=>a-b)\n for(let i=0;i<nums.length-2;i++){\n if(nums[i]==nums[i+2]) return false\n }\n return true\n};\n``` | 2 | 0 | ['JavaScript'] | 1 |
split-the-array | 👏Beats 73.67% of users with Java || Easy & Simple HashMap Approach 🔥💥 | beats-7367-of-users-with-java-easy-simpl-1wpw | Intuition\nMake a Hashmap as a hm and store the all element\'s frequency and check if any element\'s frequency is more than 2 then return false, else return tru | Rutvik_Jasani | NORMAL | 2024-03-01T07:51:28.827643+00:00 | 2024-03-01T07:51:28.827675+00:00 | 216 | false | # Intuition\nMake a Hashmap as a hm and store the all element\'s frequency and check if any element\'s frequency is more than 2 then return false, else return true.\n\n# **I Think This can Help You**\n\n\n\n# Approach\n1. Make Hashmap as a hm.\n2. Iterate over the array & check if element is exist in the hashmap just increase the frequency. if element is not exist just add element in hashmap & frequency as a 1.\n3. After that just check any element have a frequency more than 2 and if any element is have a frequency more than 2 then return false else return true.\n\n# Complexity\n- Time complexity:\nO(n)\n\n- Space complexity:\n- O(n)\n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer,Integer> hm = new HashMap<>(); // Make Hashmap as a hm.\n for(int i=0;i<nums.length;i++){ // Iterate over the array & check if element is exist in the hashmap just increase the frequency. if element is not exist just add element in hashmap & frequency as a 1.\n if(hm.containsKey(nums[i])){\n hm.put(nums[i],hm.get(nums[i])+1);\n }else{\n hm.put(nums[i],1);\n }\n }\n for(int i=0;i<nums.length;i++){ // After that just check any element have a frequency more than 2 and if any element is have a frequency more than 2 then return false else return true.\n if((hm.get(nums[i]))>2){\n return false;\n }\n }\n return true;\n }\n}\n```\n\n\n | 2 | 0 | ['Array', 'Hash Table', 'Counting', 'Java'] | 0 |
split-the-array | Easy Java Solution || HashMap | easy-java-solution-hashmap-by-ravikumar5-sjd3 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | ravikumar50 | NORMAL | 2024-02-26T13:08:41.303852+00:00 | 2024-02-26T13:08:41.303879+00:00 | 45 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nclass Solution {\n public boolean isPossibleToSplit(int[] arr) {\n HashMap<Integer,Integer> hp = new HashMap<>();\n int n = arr.length;\n \n for(int i=0; i<n; i++){\n hp.put(arr[i],hp.getOrDefault(arr[i],0)+1);\n }\n \n \n for(var a : hp.values()){\n if(a>2) return false;\n }\n return true;\n }\n}\n``` | 2 | 0 | ['Java'] | 0 |
split-the-array | ✅ 5 Variations | 5-variations-by-eleev-70uh | Solutions\nSwift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n nums.withUnsafeBufferPointer {\ | eleev | NORMAL | 2024-02-25T16:22:51.264934+00:00 | 2024-02-25T16:22:51.264972+00:00 | 14 | false | # Solutions\n```Swift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n nums.withUnsafeBufferPointer {\n var freqs = ContiguousArray<UInt8>(repeating:0, count: 101)\n for num in $0 {\n freqs[num] += 1\n if freqs[num] > 2 { return false } \n }\n return true\n }\n }\n}\n\n```\n```Swift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n var freqs = ContiguousArray<UInt8>(repeating:0, count: 101)\n \n for num in nums {\n freqs[num] += 1\n if freqs[num] > 2 { return false }\n }\n return true\n }\n}\n```\n```Swift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n var freqs = [Int: UInt8]()\n freqs.reserveCapacity(101)\n\n for num in nums {\n freqs[num, default: 0] += 1\n if freqs[num] > 2 { return false}\n }\n return true\n }\n}\n```\n```Swift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n nums.lazy\n .reduce(into: [Int: UInt8]()) { $0[$1, default: 0] += 1 }\n .values.first(where: { $0 > 2 }) ?? 0 == 0\n }\n}\n```\n```Swift []\nfinal class Solution {\n @_optimize(speed)\n func isPossibleToSplit(_ nums: [Int]) -> Bool {\n Dictionary(nums.map { ($0, 1) }, uniquingKeysWith: +)\n .values.first(where: { $0 > 2 }) ?? 0 == 0\n }\n}\n``` | 2 | 0 | ['Array', 'Hash Table', 'Swift'] | 0 |
split-the-array | more than 2 times occurence | more-than-2-times-occurence-by-ssmbforev-g6y1 | Intuition\n Describe your first thoughts on how to solve this problem. \n\n# Approach\n Describe your approach to solving the problem. \n\n# Complexity\n- Time | ssmbforever | NORMAL | 2024-02-25T10:31:53.343206+00:00 | 2024-02-25T10:31:53.343229+00:00 | 102 | false | # Intuition\n<!-- Describe your first thoughts on how to solve this problem. -->\n\n# Approach\n<!-- Describe your approach to solving the problem. -->\n\n# Complexity\n- Time complexity:\n<!-- Add your time complexity here, e.g. $$O(n)$$ -->\n\n- Space complexity:\n<!-- Add your space complexity here, e.g. $$O(n)$$ -->\n\n# Code\n```\nimport java.util.HashMap;\n\nclass Solution {\n public boolean isPossibleToSplit(int[] nums) {\n HashMap<Integer,Integer> mp=new HashMap<>();\n for(int it:nums){\n mp.put(it, mp.getOrDefault(it, 0) + 1);\n }\n for(int i=0;i<nums.length;i++){\n if(mp.get(nums[i])>2) return false;\n }\n return true;\n }\n}\n\n``` | 2 | 0 | ['Java'] | 0 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.