
text
stringlengths 96
319k
| id
stringlengths 14
178
| metadata
dict |
|---|---|---|
import {
ImageProcessor,
} from "../../base/image_processors_utils.js";
import { cat, Tensor } from "../../utils/tensor.js";
export class Qwen2VLImageProcessor extends ImageProcessor {
async _call(images, ...args) {
const { pixel_values, original_sizes, reshaped_input_sizes } = await super._call(images, ...args);
let patches = pixel_values;
// @ts-ignore
const { temporal_patch_size, merge_size, patch_size } = this.config;
if (patches.dims[0] === 1) {
// Equivalent to np.tile(patches, (self.temporal_patch_size, 1, 1, 1))
patches = cat(Array.from({ length: temporal_patch_size }, () => patches), 0);
}
const grid_t = patches.dims[0] / temporal_patch_size;
const channel = patches.dims[1];
const grid_h = Math.floor(patches.dims[2] / patch_size);
const grid_w = Math.floor(patches.dims[3] / patch_size);
const flatten_patches = patches
.view(
grid_t,
temporal_patch_size,
channel,
Math.floor(grid_h / merge_size),
merge_size,
patch_size,
Math.floor(grid_w / merge_size),
merge_size,
patch_size,
)
.permute(0, 3, 6, 4, 7, 2, 1, 5, 8)
.view(
grid_t * grid_h * grid_w,
channel * temporal_patch_size * patch_size * patch_size,
)
const image_grid_thw = new Tensor('int64', [grid_t, grid_h, grid_w], [1, 3]);
return {
pixel_values: flatten_patches,
image_grid_thw,
original_sizes,
reshaped_input_sizes,
}
}
}
|
transformers.js/src/models/qwen2_vl/image_processing_qwen2_vl.js/0
|
{
"file_path": "transformers.js/src/models/qwen2_vl/image_processing_qwen2_vl.js",
"repo_id": "transformers.js",
"token_count": 888
}
|
/**
* The list of devices supported by Transformers.js
*/
export const DEVICE_TYPES = Object.freeze({
auto: 'auto', // Auto-detect based on device and environment
gpu: 'gpu', // Auto-detect GPU
cpu: 'cpu', // CPU
wasm: 'wasm', // WebAssembly
webgpu: 'webgpu', // WebGPU
cuda: 'cuda', // CUDA
dml: 'dml', // DirectML
webnn: 'webnn', // WebNN (default)
'webnn-npu': 'webnn-npu', // WebNN NPU
'webnn-gpu': 'webnn-gpu', // WebNN GPU
'webnn-cpu': 'webnn-cpu', // WebNN CPU
});
/**
* @typedef {keyof typeof DEVICE_TYPES} DeviceType
*/
|
transformers.js/src/utils/devices.js/0
|
{
"file_path": "transformers.js/src/utils/devices.js",
"repo_id": "transformers.js",
"token_count": 247
}
|
import { LlamaTokenizer, CLIPImageProcessor, LlavaForConditionalGeneration, RawImage } from "../../../src/transformers.js";
import { MAX_MODEL_LOAD_TIME, MAX_TEST_EXECUTION_TIME, MAX_MODEL_DISPOSE_TIME, DEFAULT_MODEL_OPTIONS } from "../../init.js";
export default () => {
const prompts = [
// Example adapted from https://huggingface.co/docs/transformers/model_doc/llava#transformers.LlavaForConditionalGeneration.forward.example
"<image>\nUSER: What's the content of the image?\nASSISTANT:",
"<image>Hi",
];
// Empty white image
const dims = [224, 224, 3];
const image = new RawImage(new Uint8ClampedArray(dims[0] * dims[1] * dims[2]).fill(255), ...dims);
describe("LlavaForConditionalGeneration", () => {
const model_id = "Xenova/tiny-random-LlavaForConditionalGeneration";
/** @type {LlavaForConditionalGeneration} */
let model;
/** @type {LlamaTokenizer} */
let tokenizer;
/** @type {CLIPImageProcessor} */
let processor;
beforeAll(async () => {
model = await LlavaForConditionalGeneration.from_pretrained(model_id, DEFAULT_MODEL_OPTIONS);
tokenizer = await LlamaTokenizer.from_pretrained(model_id);
processor = await CLIPImageProcessor.from_pretrained(model_id);
}, MAX_MODEL_LOAD_TIME);
it(
"forward",
async () => {
const text_inputs = tokenizer(prompts[0]);
const vision_inputs = await processor(image);
const inputs = { ...text_inputs, ...vision_inputs };
const { logits } = await model(inputs);
expect(logits.dims).toEqual([1, 244, 32002]);
expect(logits.mean().item()).toBeCloseTo(-0.0005755752790719271, 8);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"batch_size=1",
async () => {
const text_inputs = tokenizer(prompts[0]);
const vision_inputs = await processor(image);
const inputs = { ...text_inputs, ...vision_inputs };
const generate_ids = await model.generate({ ...inputs, max_new_tokens: 10 });
expect(generate_ids.tolist()).toEqual([[1n, 32000n, 29871n, 13n, 11889n, 29901n, 1724n, 29915n, 29879n, 278n, 2793n, 310n, 278n, 1967n, 29973n, 13n, 22933n, 9047n, 13566n, 29901n, 21557n, 16781n, 27238n, 8279n, 20454n, 11927n, 12462n, 12306n, 2414n, 7561n]]);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"batch_size>1",
async () => {
const text_inputs = tokenizer(prompts, { padding: true });
const vision_inputs = await processor([image, image]);
const inputs = { ...text_inputs, ...vision_inputs };
const generate_ids = await model.generate({ ...inputs, max_new_tokens: 10 });
expect(generate_ids.tolist()).toEqual([
[1n, 32000n, 29871n, 13n, 11889n, 29901n, 1724n, 29915n, 29879n, 278n, 2793n, 310n, 278n, 1967n, 29973n, 13n, 22933n, 9047n, 13566n, 29901n, 21557n, 16781n, 27238n, 8279n, 20454n, 11927n, 12462n, 12306n, 2414n, 7561n],
[0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 0n, 1n, 32000n, 6324n, 1217n, 22958n, 22913n, 10381n, 148n, 31410n, 31736n, 7358n, 9150n, 28635n],
]);
},
MAX_TEST_EXECUTION_TIME,
);
afterAll(async () => {
await model?.dispose();
}, MAX_MODEL_DISPOSE_TIME);
});
};
|
transformers.js/tests/models/llava/test_modeling_llava.js/0
|
{
"file_path": "transformers.js/tests/models/llava/test_modeling_llava.js",
"repo_id": "transformers.js",
"token_count": 1443
}
|
import { AutoFeatureExtractor, SeamlessM4TFeatureExtractor } from "../../../src/transformers.js";
import { load_cached_audio } from "../../asset_cache.js";
import { MAX_FEATURE_EXTRACTOR_LOAD_TIME, MAX_TEST_EXECUTION_TIME } from "../../init.js";
const sum = (array) => Number(array.reduce((a, b) => a + b, array instanceof BigInt64Array ? 0n : 0));
export default () => {
// SeamlessM4TFeatureExtractor
describe("SeamlessM4TFeatureExtractor", () => {
const model_id = "Xenova/wav2vec2-bert-CV16-en";
/** @type {SeamlessM4TFeatureExtractor} */
let feature_extractor;
beforeAll(async () => {
feature_extractor = await AutoFeatureExtractor.from_pretrained(model_id);
}, MAX_FEATURE_EXTRACTOR_LOAD_TIME);
it(
"default",
async () => {
const audio = await load_cached_audio("mlk");
const { input_features, attention_mask } = await feature_extractor(audio);
const { dims, data } = input_features;
expect(dims).toEqual([1, 649, 160]);
expect(attention_mask.dims).toEqual([1, 649]);
expect(input_features.mean().item()).toBeCloseTo(-2.938903875815413e-8);
expect(data[0]).toBeCloseTo(1.1939343214035034);
expect(data[1]).toBeCloseTo(0.7874255180358887);
expect(data[160]).toBeCloseTo(-0.712975025177002);
expect(data[161]).toBeCloseTo(0.045802414417266846);
expect(data.at(-1)).toBeCloseTo(-1.3328346014022827);
expect(sum(attention_mask.data)).toEqual(649);
},
MAX_TEST_EXECUTION_TIME,
);
it(
"padding (pad_to_multiple_of=2)",
async () => {
const audio = await load_cached_audio("mlk");
const { input_features, attention_mask } = await feature_extractor(audio.slice(0, 10000));
const { dims, data } = input_features;
// [1, 61, 80] -> [1, 62, 80] -> [1, 31, 160]
expect(dims).toEqual([1, 31, 160]);
expect(attention_mask.dims).toEqual([1, 31]);
expect(input_features.mean().item()).toBeCloseTo(0.01612919569015503);
expect(data[0]).toBeCloseTo(0.9657132029533386);
expect(data[1]).toBeCloseTo(0.12912897765636444);
expect(data[160]).toBeCloseTo(-1.2364212274551392);
expect(data[161]).toBeCloseTo(-0.9703778028488159);
expect(data.at(-1)).toBeCloseTo(1); // padding value
expect(sum(attention_mask.data)).toEqual(30);
},
MAX_TEST_EXECUTION_TIME,
);
});
};
|
transformers.js/tests/models/seamless_m4t/test_feature_extraction_seamless_m4t.js/0
|
{
"file_path": "transformers.js/tests/models/seamless_m4t/test_feature_extraction_seamless_m4t.js",
"repo_id": "transformers.js",
"token_count": 1089
}
|
import { pipeline, Text2TextGenerationPipeline } from "../../src/transformers.js";
import { MAX_MODEL_LOAD_TIME, MAX_TEST_EXECUTION_TIME, MAX_MODEL_DISPOSE_TIME, DEFAULT_MODEL_OPTIONS } from "../init.js";
const PIPELINE_ID = "text2text-generation";
export default () => {
describe("Text to Text Generation", () => {
const model_id = "hf-internal-testing/tiny-random-T5ForConditionalGeneration";
/** @type {Text2TextGenerationPipeline} */
let pipe;
beforeAll(async () => {
pipe = await pipeline(PIPELINE_ID, model_id, DEFAULT_MODEL_OPTIONS);
}, MAX_MODEL_LOAD_TIME);
it("should be an instance of Text2TextGenerationPipeline", () => {
expect(pipe).toBeInstanceOf(Text2TextGenerationPipeline);
});
describe("batch_size=1", () => {
it(
"default",
async () => {
const text = "This is a test.";
const output = await pipe(text, {
max_new_tokens: 5,
});
const target = [{ generated_text: "" }];
expect(output).toEqual(target);
},
MAX_TEST_EXECUTION_TIME,
);
});
afterAll(async () => {
await pipe.dispose();
}, MAX_MODEL_DISPOSE_TIME);
});
};
|
transformers.js/tests/pipelines/test_pipelines_text2text_generation.js/0
|
{
"file_path": "transformers.js/tests/pipelines/test_pipelines_text2text_generation.js",
"repo_id": "transformers.js",
"token_count": 520
}
|
import { RawImage, rand } from "../../src/transformers.js";
import { load_cached_image } from "../asset_cache.js";
const TEST_IMAGES = {
rgba: new RawImage(new Uint8ClampedArray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23]), 2, 3, 4),
rgb: new RawImage(new Uint8ClampedArray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17]), 2, 3, 3),
la: new RawImage(new Uint8ClampedArray([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]), 2, 3, 2),
l: new RawImage(new Uint8ClampedArray([0, 1, 2, 3, 4, 5]), 2, 3, 1),
};
describe("Image utilities", () => {
describe("Padding", () => {
it("should pad image", async () => {
/** @type {RawImage} */
const padded_image = await load_cached_image("blue_image")
.then((image) => image.resize(224, 224))
.then((image) => image.pad([128, 128, 128, 128]));
expect(padded_image.size).toEqual([480, 480]);
const avg = padded_image.data.reduce((acc, val) => acc + val, 0) / padded_image.data.length;
expect(avg).toBeCloseTo((224 * 224 * 255) / (3 * 480 * 480), 6);
});
});
describe("Tensor to Image", () => {
it("should create an image from a tensor (CHW)", () => {
const tensor_chw = rand([3, 128, 256]).mul_(255).to("uint8");
const image = RawImage.fromTensor(tensor_chw);
expect(image.size).toEqual([256, 128]);
});
it("should create an image from a tensor (HWC)", () => {
const tensor_hwc = rand([128, 256, 3]).mul_(255).to("uint8");
const image = RawImage.fromTensor(tensor_hwc, "HWC");
expect(image.size).toEqual([256, 128]);
});
});
describe("Channel conversions", () => {
it("should convert RGBA to L (grayscale)", async () => {
const grayscale = TEST_IMAGES.rgba.clone().grayscale();
expect(grayscale.size).toEqual(TEST_IMAGES.rgba.size);
expect(grayscale.channels).toEqual(1);
});
it("should convert RGB to L (grayscale)", async () => {
const grayscale = TEST_IMAGES.rgb.clone().grayscale();
expect(grayscale.size).toEqual(TEST_IMAGES.rgb.size);
expect(grayscale.channels).toEqual(1);
});
it("should convert L to RGB", async () => {
const rgb = TEST_IMAGES.l.clone().rgb();
expect(rgb.size).toEqual(TEST_IMAGES.l.size);
expect(rgb.channels).toEqual(3);
});
it("should convert L to RGBA", async () => {
const rgba = TEST_IMAGES.l.clone().rgba();
expect(rgba.size).toEqual(TEST_IMAGES.l.size);
expect(rgba.channels).toEqual(4);
});
it("should convert RGB to RGBA", async () => {
const rgba = TEST_IMAGES.rgb.clone().rgba();
expect(rgba.size).toEqual(TEST_IMAGES.rgb.size);
expect(rgba.channels).toEqual(4);
});
it("should convert RGBA to RGB", async () => {
const rgb = TEST_IMAGES.rgba.clone().rgb();
expect(rgb.size).toEqual(TEST_IMAGES.rgba.size);
expect(rgb.channels).toEqual(3);
});
});
describe("putAlpha", () => {
it("should add alpha to RGB image", async () => {
const rgba = TEST_IMAGES.rgb.clone().putAlpha(TEST_IMAGES.l);
expect(rgba.size).toEqual(TEST_IMAGES.rgb.size);
expect(rgba.channels).toEqual(4);
});
it("should add alpha to RGBA image", async () => {
const rgba = TEST_IMAGES.rgba.clone().putAlpha(TEST_IMAGES.l);
expect(rgba.size).toEqual(TEST_IMAGES.rgb.size);
expect(rgba.channels).toEqual(4);
});
});
});
|
transformers.js/tests/utils/image.test.js/0
|
{
"file_path": "transformers.js/tests/utils/image.test.js",
"repo_id": "transformers.js",
"token_count": 1496
}
|
FROM python:3.9-slim
ENV PYTHONDONTWRITEBYTECODE=1
USER root
RUN apt-get update && apt-get install -y libsndfile1-dev espeak-ng time git cmake wget xz-utils build-essential g++5 libprotobuf-dev protobuf-compiler
ENV UV_PYTHON=/usr/local/bin/python
RUN pip --no-cache-dir install uv && uv venv && uv pip install --no-cache-dir -U pip setuptools
RUN wget https://github.com/ku-nlp/jumanpp/releases/download/v2.0.0-rc3/jumanpp-2.0.0-rc3.tar.xz
RUN tar xvf jumanpp-2.0.0-rc3.tar.xz
RUN mkdir jumanpp-2.0.0-rc3/bld
WORKDIR ./jumanpp-2.0.0-rc3/bld
RUN wget -LO catch.hpp https://github.com/catchorg/Catch2/releases/download/v2.13.8/catch.hpp
RUN mv catch.hpp ../libs/
RUN cmake .. -DCMAKE_INSTALL_PREFIX=/usr/local
RUN make install -j 10
RUN uv pip install --no-cache --upgrade 'torch' --index-url https://download.pytorch.org/whl/cpu
RUN uv pip install --no-cache-dir --no-deps accelerate --extra-index-url https://download.pytorch.org/whl/cpu
RUN uv pip install --no-cache-dir "transformers[ja,testing,sentencepiece,jieba,spacy,ftfy,rjieba]" unidic unidic-lite
# spacy is not used so not tested. Causes to failures. TODO fix later
RUN python3 -m unidic download
RUN pip uninstall -y transformers
RUN apt-get clean && rm -rf /var/lib/apt/lists/*
RUN apt remove -y g++ cmake xz-utils libprotobuf-dev protobuf-compiler
|
transformers/docker/custom-tokenizers.dockerfile/0
|
{
"file_path": "transformers/docker/custom-tokenizers.dockerfile",
"repo_id": "transformers",
"token_count": 548
}
|
FROM rocm/dev-ubuntu-22.04:6.2.4
LABEL maintainer="Hugging Face"
ARG DEBIAN_FRONTEND=noninteractive
RUN apt update && \
apt install -y --no-install-recommends git libsndfile1-dev tesseract-ocr espeak-ng python3 python3-dev python3-pip python3-dev ffmpeg && \
apt clean && \
rm -rf /var/lib/apt/lists/*
RUN python3 -m pip install --no-cache-dir --upgrade pip numpy
RUN python3 -m pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2
RUN python3 -m pip install --no-cache-dir --upgrade importlib-metadata setuptools ninja git+https://github.com/facebookresearch/detectron2.git pytesseract "itsdangerous<2.1.0"
ARG REF=main
WORKDIR /
# Invalidate docker cache from here if new commit is available.
ADD https://api.github.com/repos/huggingface/transformers/git/refs/heads/main version.json
RUN git clone https://github.com/huggingface/transformers && cd transformers && git checkout $REF
RUN python3 -m pip install --no-cache-dir -e ./transformers[dev-torch,testing,video]
RUN python3 -m pip uninstall -y tensorflow flax
# When installing in editable mode, `transformers` is not recognized as a package.
# this line must be added in order for python to be aware of transformers.
RUN cd transformers && python3 setup.py develop
# Remove nvml and nvidia-ml-py as it is not compatible with ROCm. apex is not tested on NVIDIA either.
RUN python3 -m pip uninstall py3nvml pynvml nvidia-ml-py apex -y
|
transformers/docker/transformers-pytorch-amd-gpu/Dockerfile/0
|
{
"file_path": "transformers/docker/transformers-pytorch-amd-gpu/Dockerfile",
"repo_id": "transformers",
"token_count": 491
}
|
# التدريب الموزع باستخدام 🤗 Accelerate
مع تزايد حجم النماذج اللغوية، برز التوازي كأحد الاستراتيجيات لتدريب نماذج أكبر على أجهزة محدودة وتسريع عملية التدريب بمقدار كبير. أنشأنا في Hugging Face، قمنا بإنشاء مكتبة [ Accelerate](https://huggingface.co/docs/accelerate) لمساعدة المستخدمين على تدريب أي نموذج من Transformers بسهولة على أي نوع من الإعدادات الموزعة، سواء كان ذلك على عدة وحدات معالجة رسومات (GPUs) على جهاز واحد أو على عدة وحدات معالجة رسومات موزعة على عدة أجهزة. في هذا الدليل، تعلم كيفية تخصيص حلقة تدريب PyTorch الأصلية لتمكين التدريب في بيئة موزعة.
## الإعداد
ابدأ بتثبيت 🤗 Accelerate:
```bash
pip install accelerate
```
ثم قم باستيراد وإنشاء كائن [`~accelerate.Accelerator`]. سيقوم [`~accelerate.Accelerator`] تلقائيًا باكتشاف نوع الإعداد الموزع الخاص بك وتهيئة جميع المكونات اللازمة للتدريب. لن تحتاج إلى وضع نموذجك على جهاز بشكل معين.
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## الاستعداد للتسريع
الخطوة التالية هي تمرير جميع كائنات التدريب ذات الصلة إلى دالة الإعداد [`~accelerate.Accelerator.prepare`]. ويشمل ذلك DataLoaders للتدريب والتقييم، ونموذجًا ومُحَسِّنً المعاملات (optimizer):
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## الخلفي Backward
الإضافة الأخيرة هي استبدال الدالة المعتادة `loss.backward()` في حلقة التدريب الخاصة بك بدالة [`~accelerate.Accelerator.backward`] في 🤗 Accelerate:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
كما يمكنك أن ترى في الكود التالي، فأنت بحاجة فقط إلى إضافة أربعة أسطر من الكود إلى حلقة التدريب الخاصة بك لتمكين التدريب الموزع!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## تدريب
بمجرد إضافة أسطر الكود ذات الصلة، قم بتشغيل التدريب الخاص بك في أحد النصوص أو الدفاتر مثل Colaboratory.
### التدريب باستخدام نص برمجي
إذا كنت تشغل التدريب الخاص بك من نص برمجي، فقم بتشغيل الأمر التالي لإنشاء وحفظ ملف تكوين:
```bash
accelerate config
```
ثم قم بتشغيل التدريب الخاص بك باستخدام:
```bash
accelerate launch train.py
```
### التدريب باستخدام دفتر ملاحظات
يمكن أيضًا تشغيل 🤗 Accelerate في دفاتر إذا كنت تخطط لاستخدام وحدات معالجة الرسوميات (TPUs) في Colaboratory. قم بتغليف كل الكود المسؤول عن التدريب في دالة، ومررها إلى [`~accelerate.notebook_launcher`]:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
للحصول على مزيد من المعلومات حول 🤗 Accelerate وميزاته الغنية، يرجى الرجوع إلى [الوثائق](https://huggingface.co/docs/accelerate).
|
transformers/docs/source/ar/accelerate.md/0
|
{
"file_path": "transformers/docs/source/ar/accelerate.md",
"repo_id": "transformers",
"token_count": 2534
}
|
# التوليد باستخدام نماذج اللغات الكبيرة (LLMs)
[[open-in-colab]]
تعد LLMs، أو نماذج اللغة الكبيرة، المكون الرئيسي وراء توليد النصوص. وباختصار، تتكون من نماذج محول كبيرة مسبقة التدريب تم تدريبها للتنبؤ بالكلمة التالية (أو، بشكل أكثر دقة، الرمز اللغوي) بالنظر إلى نص معين. نظرًا لأنها تتنبأ برمز واحد في كل مرة، يجب عليك القيام بشيء أكثر تعقيدًا لتوليد جمل جديدة بخلاف مجرد استدعاء النموذج - يجب عليك إجراء التوليد التلقائي.
التوليد التلقائي هو إجراء وقت الاستدلال الذي يتضمن استدعاء النموذج بشكل متكرر باستخدام مخرجاته الخاصة، بالنظر إلى بعض المدخلات الأولية. في 🤗 Transformers، يتم التعامل مع هذا بواسطة دالة [`~generation.GenerationMixin.generate`]، والتي تتوفر لجميع النماذج ذات القدرات التوليدية.
سيوضح هذا البرنامج التعليمي كيفية:
* تتوليد نص باستخدام نموذج اللغات الكبيرة (LLM)
* تجنب الوقوع في الأخطاء الشائعة
* الخطوات التالية لمساعدتك في الاستفادة القصوى من LLM الخاص بك
قبل البدء، تأكد من تثبيت جميع المكتبات الضرورية:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
## توليد النص
يأخذ نموذج اللغة المدرب لـ [نمذجة اللغة السببية](tasks/language_modeling) يأخذ تسلسلًا من رموز نصية كمدخل ويعيد توزيع الاحتمالية للرمز التالي.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"التنبؤ بالكلمة التالية لنموذج اللغة (LLM)"</figcaption>
</figure>
هناك جانب بالغ الأهمية في التوليد التلقائي باستخدام LLMs وهو كيفية اختيار الرمز التالي من توزيع الاحتمالية هذا. كل شيء مسموح به في هذه الخطوة طالما أنك تنتهي برمز للتكرار التالي. وهذا يعني أنه يمكن أن يكون بسيطًا مثل اختيار الرمز الأكثر احتمالًا من توزيع الاحتمالية أو معقدًا مثل تطبيق عشرات التحولات قبل أخذ العينات من التوزيع الناتج.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"التوليد التلقائي المتسلسل"</figcaption>
</figure>
تتكرر العملية الموضحة أعلاه بشكل تكراري حتى يتم الوصول إلى شرط التوقف. في الوضع المثالي، يحدد النموذج شرط التوقف، والذي يجب أن يتعلم عند إخراج رمز نهاية التسلسل (`EOS`). إذا لم يكن الأمر كذلك، يتوقف التوليد عند الوصول إلى طول أقصى محدد مسبقًا.
من الضروري إعداد خطوة اختيار الرمز وشرط التوقف بشكل صحيح لجعل نموذجك يتصرف كما تتوقع في مهمتك. ولهذا السبب لدينا [`~generation.GenerationConfig`] ملف مرتبط بكل نموذج، والذي يحتوي على معلمة توليدية افتراضية جيدة ويتم تحميله جنبًا إلى جنب مع نموذجك.
دعنا نتحدث عن الكود!
<Tip>
إذا كنت مهتمًا بالاستخدام الأساسي لـ LLM، فإن واجهة [`Pipeline`](pipeline_tutorial) عالية المستوى هي نقطة انطلاق رائعة. ومع ذلك، غالبًا ما تتطلب LLMs ميزات متقدمة مثل التكميم والتحكم الدقيق في خطوة اختيار الرمز، والتي يتم تنفيذها بشكل أفضل من خلال [`~generation.GenerationMixin.generate`]. التوليد التلقائي باستخدام LLMs يستهلك الكثير من المواردد ويجب تنفيذه على وحدة معالجة الرسومات للحصول على أداء كافٍ.
</Tip>
أولاً، تحتاج إلى تحميل النموذج.
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
ستلاحظ وجود معاملين في الاستدعاء `from_pretrained`:
- `device_map` يضمن انتقال النموذج إلى وحدة معالجة الرسومات (GPU) الخاصة بك
- `load_in_4bit` يطبق [4-bit dynamic quantization](main_classes/quantization) لخفض متطلبات الموارد بشكل كبير
هناك طرق أخرى لتهيئة نموذج، ولكن هذا خط أساس جيد للبدء باستخدام LLM.
بعد ذلك، تحتاج إلى معالجة إدخال النص الخاص بك باستخدام [مُجزّئ اللغوي](tokenizer_summary).
```py
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to("cuda")
```
يحتوي متغير `model_inputs` على النص المدخل بعد تقسيمه إلى وحدات لغوية (tokens)، بالإضافة إلى قناع الانتباه. في حين أن [`~generation.GenerationMixin.generate`] تبذل قصارى جهدها لاستنتاج قناع الانتباه عندما لا يتم تمريره، نوصي بتمريره كلما أمكن ذلك للحصول على نتائج مثالية.
بعد تقسيم المدخلات إلى وحدات لغوية، يمكنك استدعاء الدالة [`~generation.GenerationMixin.generate`] لإرجاع الوحدات اللغوية الناتجة. يجب بعد ذلك تحويل الوحدات المولدة إلى نص قبل طباعته.
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
```
أخيرًا، ليس عليك معالجة المتتاليات الواحدة تلو الأخرى! يمكنك معالجة مجموعة من المدخلات دفعة واحدة، والتي ستعمل على تحسين الإنتاجية بشكل كبير بتكلفة صغيرة في زمن الاستجابة واستهلاك الذاكر. كل ما عليك التأكد منه هو تعبئة المدخلات بشكل صحيح (المزيد حول ذلك أدناه).
```py
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
```
وهذا كل شيء! في بضع سطور من التعليمات البرمجية، يمكنك تسخير قوة LLM.
## الأخطاء الشائعة
هناك العديد من [استراتيجيات التوليد](generation_strategies)، وفي بعض الأحيان قد لا تكون القيم الافتراضية مناسبة لحالتك الاستخدام. إذا لم تكن الإخراج الخاصة بك متوافقة مع ما تتوقعه، فقد قمنا بإنشاء قائمة بأكثر الأخطاء الشائعة وكيفية تجنبها.
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### الإخراج المولد قصير جدًا/طويل جدًا
إذا لم يتم تحديد العدد الأقصى للرموز في [`~generation.GenerationConfig`] الملف، `generate` يعيد ما يصل إلى 20 رمزًا بشكل افتراضي. نوصي بشدة بتعيين `max_new_tokens` يدويًا في مكالمة `generate` للتحكم في العدد الأقصى من الرموز الجديدة التي يمكن أن يعيدها. ضع في اعتبارك أن LLMs (بشكل أكثر دقة، [نماذج فك التشفير فقط](https://huggingface.co/learn/nlp-course/chapter1/6؟fw=pt)) تعيد أيضًا المدخلات الأصلية كجزء من الناتج.
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to("cuda")
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### وضع التوليد الافتراضي
بشكل افتراضي، وما لم يتم تحديده في [`~generation.GenerationConfig`] الملف، `generate` يحدد الكلمة الأكثر احتمالًا فى كل خطوة من خطوات عملية التوليد (وهذا يُعرف بالتشفير الجشع). اعتمادًا على مهمتك، قد يكون هذا غير مرغوب فيه؛ تستفيد المهام الإبداعية مثل برامج الدردشة أو كتابة مقال ستفيد من أسلوب العينة العشوائية في اختيار الكلمات، تمن ناحية أخرى، فإن المهام التي تعتمد على مدخلات محددة مثل تحويل الصوت إلى نص أو الترجم من فك التشفير الجشع. قم بتفعيل أسلوب العينات العشوائية باستخدام `do_sample=True`، ويمكنك معرفة المزيد حول هذا الموضوع في [تدوينة المدونة](https://huggingface.co/blog/how-to-generate).
```py
>>> # Set seed or reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to("cuda")
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
```
### مشكلة حشو المدخلات فى الاتجاة الخطأ
LLMs هي [معماريات فك التشفير فقط](https://huggingface.co/learn/nlp-course/chapter1/6؟fw=pt)، مما يعني أنها تستمر في التكرار على موجه الإدخال الخاص بك. فإن جميع المدخلات يجب أن تكون بنفس الطول. لحل هذه المسألة، يتم إضافة رموز حشو إلى المدخلات الأقصر. نظرًا لأن LLMs لا تولي اهتمامًا لرموز الحشو هذه، ذلك، يجب تحديد الجزء المهم من المدخل الذي يجب أن يركز عليه النموذج، وهذا يتم عن طريق ما يسمى بـ "قناع الانتباه". يجب أن يكون الحشو في بداية المدخل (الحشو من اليسار)، وليس في نهايته.
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to("cuda")
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
### موجه غير صحيح
تتوقع بعض نماذج اللغات الكبيرة على صيغة محددة للمدخلات للعمل بشكل صحيح. إذا لم يتم اتباع هذه الصيغة، فإن أداء النموذج يتأثر سلبًا: لكن هذا التدهور قد لا يكون واضحًا للعيان. تتوفر معلومات إضافية حول التوجيه، بما في ذلك النماذج والمهام التي تحتاج إلى توخي الحذر، في [الدليل](tasks/prompting). دعنا نرى مثالاً باستخدام LLM للدردشة، والذي يستخدم [قالب الدردشة](chat_templating):
```python
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to("cuda")
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to("cuda")
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
```
## موارد إضافية
في حين أن عملية التوليد التلقائي بسيطة نسبيًا، فإن الاستفادة القصوى من LLM الخاص بك يمكن أن تكون مهمة صعبة لأن هناك العديد من الأجزاء المتحركة. للخطوات التالية لمساعدتك في الغوص بشكل أعمق في استخدام LLM وفهمه:
### استخدامات متقدمة للتوليد في نماذج اللغات الكبيرة
1. دليل حول كيفية [التحكم في طرق التوليد المختلفة](generation_strategies)، وكيفية إعداد ملف تكوين التوليد، وكيفية بث الناتج؛
2. [تسريع توليد النص](llm_optims)؛
3.[قوالب موجهات للدردشة LLMs](chat_
4. [دليل تصميم الموجه](tasks/prompting);
5. مرجع واجهة برمجة التطبيقات (API) [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`], و [generate-related classes](internal/generation_utils). والعديد من الفئات الأخرى المرتبطة بعملية التوليد.!
### لوحات صدارة نماذج اللغات الكبيرة
1. لوحة صدارة نماذج اللغات الكبيرة المفتوحة المصدر (Open LLM Leaderboard): تركز على جودة النماذج مفتوحة المصدر [رابط لوحة الصدارة](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard).
2. لوحة صدارة أداء نماذج اللغات الكبيرة المفتوحة المصدر (Open LLM-Perf Leaderboard): تركز على إنتاجية نماذج اللغات الكبيرة [رابط لوحة الصدارة](https://huggingface.co/spaces/optimum/llm-perf-leaderboard).
### زمن الاستجابة والإنتاجية واستهلاك الذاكرة
1. دليل تحسين نماذج اللغات الكبيرة من حيث السرعة والذاكرة: دليل تحسين نماذج اللغات الكبيرة.
2. التكميم (Quantization): دليل حول تقنية التكميم التكميم مثل تقنيتي bitsandbytes و autogptq، والتي توضح كيفية تقليل متطلبات الذاكرة بشكل كبير.
### مكتبات مرتبطة
1. [`optimum`](https://github.com/huggingface/optimum), امتداد لمكتبة Transformers يعمل على تحسين الأداء لأجهزة معينة.
2. [`outlines`](https://github.com/outlines-dev/outlines), مكتبة للتحكم في توليد النصوص (على سبيل المثال، لتوليد ملفات JSON).
3. [`SynCode`](https://github.com/uiuc-focal-lab/syncode), مكتبة للتوليد الموجه بقواعد اللغة الخالية من السياق (على سبيل المثال، JSON، SQL، Python).
4. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), خادم جاهز للإنتاج لنماذج اللغات الكبيرة.
5. [`text-generation-webui`](https://github.com/oobabooga/text-generation-webui), واجهة مستخدم لتوليد النصوص.
|
transformers/docs/source/ar/llm_tutorial.md/0
|
{
"file_path": "transformers/docs/source/ar/llm_tutorial.md",
"repo_id": "transformers",
"token_count": 9367
}
|
# التدريب باستخدام نص برمجى
بالإضافة إلى دفاتر الملاحظات [notebooks](./notebooks) الخاصة بـ 🤗 Transformers، هناك أيضًا نصوص برمجية توضيحية تُظهر كيفية تدريب نموذج لمهمة باستخدام [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch) أو [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow) أو [JAX/Flax](https://github.com/huggingface/transformers/tree/main/examples/flax).
كما ستجد النصوص البرمجية التي استخدمناها في [مشاريع الأبحاث](https://github.com/huggingface/transformers/tree/main/examples/research_projects) و [الأمثلة القديمة](https://github.com/huggingface/transformers/tree/main/examples/legacy) والتي ساهم بها المجتمع بشكل أساسي. هذه النصوص البرمجية غير مدعومة بشكل نشط وقد تتطلب إصدارًا محددًا من مكتبة 🤗 Transformers والذي من المحتمل أن يكون غير متوافق مع الإصدار الأحدث من المكتبة.
لا يُتوقع أن تعمل النصوص البرمجية التوضيحية بشكل مباشر على كل مشكلة، وقد تحتاج إلى تكييف النص البرمجي مع المشكلة التي تحاول حلها. ولمساعدتك في ذلك، تعرض معظم النصوص البرمجية كيفية معالجة البيانات قبل التدريب بشكل كامل، مما يتيح لك تحريرها حسب الحاجة لحالتك الاستخدام.
بالنسبة لأي ميزة ترغب في تنفيذها في نص برمجي توضيحي، يرجى مناقشتها في [المنتدى](https://discuss.huggingface.co/) أو في [قضية](https://github.com/huggingface/transformers/issues) قبل إرسال طلب سحب. وفي حين أننا نرحب بإصلاح الأخطاء، فمن غير المرجح أن نقوم بدمج طلب سحب الذي يضيف المزيد من الوظائف على حساب قابلية القراءة.
سيوضح هذا الدليل كيفية تشغيل نص برمجي توضيحي للتدريب على التلخيص في [PyTorch](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) و [TensorFlow](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization). يُتوقع أن تعمل جميع الأمثلة مع كلا الإطارين ما لم يُنص على خلاف ذلك.
## الإعداد
لتشغيل الإصدار الأحدث من النصوص البرمجية التوضيحية بنجاح، يجب عليك **تثبيت 🤗 Transformers من المصدر** في بيئة افتراضية جديدة:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
بالنسبة للإصدارات الأقدم من النصوص البرمجية التوضيحية، انقر فوق الزر أدناه:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
pip install .
```
بالنسبة للإصدارات الأقدم من النصوص البرمجية التوضيحية، انقر فوق الزر أدناه:
<details>
<summary>أمثلة للإصدارات الأقدم من 🤗 Transformers</summary>
<ul>
<li><a href="https://github.com/huggingface/transformers/tree/v4.5.1/examples">v4.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.4.2/examples">v4.4.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.3.3/examples">v4.3.3</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.2.2/examples">v4.2.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.1.1/examples">v4.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v4.0.1/examples">v4.0.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.5.1/examples">v3.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.4.0/examples">v3.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.3.1/examples">v3.3.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.2.0/examples">v3.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.1.0/examples">v3.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v3.0.2/examples">v3.0.2</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.11.0/examples">v2.11.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.10.0/examples">v2.10.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.9.1/examples">v2.9.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.8.0/examples">v2.8.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.7.0/examples">v2.7.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.6.0/examples">v2.6.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.5.1/examples">v2.5.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.4.0/examples">v2.4.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.3.0/examples">v2.3.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.2.0/examples">v2.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.1.0/examples">v2.1.1</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v2.0.0/examples">v2.0.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.2.0/examples">v1.2.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.1.0/examples">v1.1.0</a></li>
<li><a href="https://github.com/huggingface/transformers/tree/v1.0.0/examples">v1.0.0</a></li>
</ul>
</details>
ثم قم بالتبديل إلى النسخة الحالية من 🤗 Transformers إلى إصدار محدد، مثل v3.5.1 على سبيل المثال:
```bash
git checkout tags/v3.5.1
```
بعد إعداد إصدار المكتبة الصحيح، انتقل إلى مجلد الأمثلة الذي تختاره وقم بتثبيت المتطلبات المحددة:
```bash
pip install -r requirements.txt
```
## تشغيل نص برمجي
<frameworkcontent>
<pt>
- يقوم النص البرمجي التوضيحي بتنزيل مجموعة بيانات ومعالجتها مسبقًا من مكتبة 🤗 [Datasets](https://huggingface.co/docs/datasets).
- ثم يقوم النص البرمجي بضبط نموذج بيانات دقيق باستخدام [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) على بنية تدعم الملخص.
- يوضح المثال التالي كيفية ضبط نموذج [T5-small](https://huggingface.co/google-t5/t5-small) على مجموعة بيانات [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail).
- يتطلب نموذج T5 معامل `source_prefix` إضافية بسبب الطريقة التي تم تدريبه بها. يتيح هذا المطالبة لـ T5 معرفة أن هذه مهمة التلخيص.
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
- يقوم النص البرمجي التوضيحي بتنزيل مجموعة بيانات ومعالجتها مسبقًا من مكتبة 🤗 [Datasets](https://huggingface.co/docs/datasets/).
- ثم يقوم النص البرمجي بضبط نموذج بيانات دقيق باستخدام Keras على بنية تدعم الملخص.
- يوضح المثال التالي كيفية ضبط نموذج [T5-small](https://huggingface.co/google-t5/t5-small) على مجموعة بيانات [CNN/DailyMail](https://huggingface.co/datasets/cnn_dailymail).
- يتطلب نموذج T5 ماعمل `source_prefix` إضافية بسبب الطريقة التي تم تدريبه بها. يتيح هذا المطالبة لـ T5 معرفة أن هذه مهمة التلخيص.
```bash
python examples/tensorflow/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## التدريب الموزع والدقة المختلطة
يدعم [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) التدريب الموزع والدقة المختلطة، مما يعني أنه يمكنك أيضًا استخدامه في نص برمجي. لتمكين كلتا الميزتين:
- أضف معامل `fp16` لتمكين الدقة المختلطة.
- قم بتعيين عدد وحدات معالجة الرسومات (GPUs) التي تريد استخدامها باستخدام حجة `nproc_per_node`.
```bash
torchrun \
--nproc_per_node 8 pytorch/summarization/run_summarization.py \
--fp16 \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
تستخدم نصوص TensorFlow البرمجية استراتيجية [`MirroredStrategy`](https://www.tensorflow.org/guide/distributed_training#mirroredstrategy) للتدريب الموزع، ولا تحتاج إلى إضافة أي معامﻻت إضافية إلى النص البرمجي التدريبي. سيستخدم نص TensorFlow البرمجي وحدات معالجة الرسومات (GPUs) متعددة بشكل افتراضي إذا كانت متوفرة.
## تشغيل نص برمجي على وحدة معالجة الدقة الفائقة (TPU)
<frameworkcontent>
<pt>
تُعد وحدات معالجة الدقة الفائقة (TPUs) مصممة خصيصًا لتسريع الأداء. يدعم PyTorch وحدات معالجة الدقة الفائقة (TPUs) مع [XLA](https://www.tensorflow.org/xla) مجمع الدقة الفائقة للتعلم العميق (راجع [هنا](https://github.com/pytorch/xla/blob/master/README.md) لمزيد من التفاصيل). لاستخدام وحدة معالجة الدقة الفائقة (TPU)، قم بتشغيل نص `xla_spawn.py` البرمجي واستخدم معامل `num_cores` لتعيين عدد وحدات معالجة الدقة الفائقة (TPU) التي تريد استخدامها.
```bash
python xla_spawn.py --num_cores 8 \
summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
</pt>
<tf>
تُعد وحدات معالجة الدقة الفائقة (TPUs) مصممة خصيصًا لتسريع الأداء. تستخدم نصوص TensorFlow البرمجية استراتيجية [`TPUStrategy`](https://www.tensorflow.org/guide/distributed_training#tpustrategy) للتدريب على وحدات معالجة الدقة الفائقة (TPUs). لاستخدام وحدة معالجة الدقة الفائقة (TPU)، قم بتمرير اسم مورد وحدة معالجة الدقة الفائقة (TPU) إلى حجة `tpu`.
```bash
python run_summarization.py \
--tpu name_of_tpu_resource \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 16 \
--num_train_epochs 3 \
--do_train \
--do_eval
```
</tf>
</frameworkcontent>
## تشغيل نص برمجي باستخدام 🤗 Accelerate
🤗 [Accelerate](https://huggingface.co/docs/accelerate) هي مكتبة خاصة بـ PyTorch فقط توفر طريقة موحدة لتدريب نموذج على عدة أنواع من الإعدادات (الاعتماد على وحدة المعالجة المركزية (CPU) فقط، أو وحدات معالجة الرسومات (GPUs) المتعددة، أو وحدات معالجة الدقة الفائقة (TPUs)) مع الحفاظ على الرؤية الكاملة لحلقة تدريب PyTorch. تأكد من تثبيت 🤗 Accelerate إذا لم يكن لديك بالفعل:
> ملاحظة: نظرًا لأن Accelerate في حالة تطوير سريع، يجب تثبيت إصدار Git من Accelerate لتشغيل النصوص البرمجية.
```bash
pip install git+https://github.com/huggingface/accelerate
```
بدلاً من إستخدام النص البرمجي `run_summarization.py` يجب عليك استخدام النص البرمجي `run_summarization_no_trainer.py` . ستكون النصوص البرمجية المدعومة من 🤗 Accelerate لها ملف `task_no_trainer.py` في المجلد. ابدأ بتشغيل الأمر التالي لإنشاء وحفظ ملف تكوين:
```bash
accelerate config
```
اختبر إعدادك للتأكد من أنه تم تكوينه بشكل صحيح:
```bash
accelerate test
```
الآن أنت مستعد لبدء التدريب:
```bash
accelerate launch run_summarization_no_trainer.py \
--model_name_or_path google-t5/t5-small \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir ~/tmp/tst-summarization
```
## استخدام مجموعة بيانات مخصصة
يدعم النص البرمجي للتلخيص مجموعة بيانات مخصصة طالما أنها ملف CSV أو JSON Line. عندما تستخدم مجموعة بياناتك الخاصة، تحتاج إلى تحديد العديد من المعلمات الإضافية:
- `train_file` و`validation_file` يحددان مسار ملفات التدريب والتحقق الخاصة بك.
- `text_column` النص المدخل الذي سيتم تلخيصه.
- `summary_column` النص الملخص المستهدف الذي سيتم إخراجه.
سيبدو النص البرمجي للتلخيص الذي يستخدم مجموعة بيانات مخصصة على النحو التالي:
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--train_file path_to_csv_or_jsonlines_file \
--validation_file path_to_csv_or_jsonlines_file \
--text_column text_column_name \
--summary_column summary_column_name \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--overwrite_output_dir \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--predict_with_generate
```
## اختبار البرنامج النصي
من الجيد غالبًا تشغيل نصك البرمجي على عدد أقل من أمثلة مجموعة البيانات للتأكد من أن كل شيء يعمل كما هو متوقع قبل الالتزام بمجموعة بيانات كاملة والتي قد تستغرق ساعات لإكمالها. استخدم المعلمات التالية لتقليص مجموعة البيانات إلى عدد أقصى من العينات:
- `max_train_samples`
- `max_eval_samples`
- `max_predict_samples`
```bash
python examples/pytorch/summarization/run_summarization.py \
--model_name_or_path google-t5/t5-small \
--max_train_samples 50 \
--max_eval_samples 50 \
--max_predict_samples 50 \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
لا تدعم جميع أمثلة النصوص البرمجية المعلمة `max_predict_samples`. إذا لم تكن متأكدًا مما إذا كان نصك البرمجي يدعم هذه المعلمة، فأضف معلمة `-h` للتحقق:
```bash
examples/pytorch/summarization/run_summarization.py -h
```
## استئناف التدريب من نقطة تفتيش
خيار آخر مفيد لتمكينه هو استئناف التدريب من نقطة تفتيش سابقة. سيضمن ذلك أنك تستطيع الاستمرار من حيث توقفت دون البدء من جديد إذا تم مقاطعة تدريبك. هناك طريقتان لاستئناف التدريب من نقطة تفتيش.
تستخدم الطريقة الأولى المعلمة `output_dir previous_output_dir` لاستئناف التدريب من أحدث نقطة تفتيش مخزنة في `output_dir`. في هذه الحالة، يجب عليك إزالة `overwrite_output_dir`:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--output_dir previous_output_dir \
--predict_with_generate
```
تستخدم الطريقة الثانية معلمة `resume_from_checkpoint path_to_specific_checkpoint` لاستئناف التدريب من مجلد نقطة تفتيش محددة.
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--resume_from_checkpoint path_to_specific_checkpoint \
--predict_with_generate
```
## شارك نموذجك
يمكن لجميع النصوص البرمجية رفع نموذجك النهائي إلى [مركز النماذج](https://huggingface.co/models). تأكد من تسجيل الدخول إلى Hugging Face قبل البدء:
```bash
huggingface-cli login
```
ثم أضف المعلمة `push_to_hub` إلى النص البرمجي . ستقوم هذه المعلمة بإنشاء مستودع باستخدام اسم مستخدم Hugging Face واسم المجلد المحدد في `output_dir`.
لإعطاء مستودعك اسمًا محددًا، استخدم المعلمة `push_to_hub_model_id` لإضافته. سيتم عرض المستودع تلقائيًا ضمن مساحة الاسم الخاصة بك.
يوضح المثال التالي كيفية رفع نموذج باستخدام اسم مستودع محدد:
```bash
python examples/pytorch/summarization/run_summarization.py
--model_name_or_path google-t5/t5-small \
--do_train \
--do_eval \
--dataset_name cnn_dailymail \
--dataset_config "3.0.0" \
--source_prefix "summarize: " \
--push_to_hub \
--push_to_hub_model_id finetuned-t5-cnn_dailymail \
--output_dir /tmp/tst-summarization \
--per_device_train_batch_size=4 \
--per_device_eval_batch_size=4 \
--overwrite_output_dir \
--predict_with_generate
```
|
transformers/docs/source/ar/run_scripts.md/0
|
{
"file_path": "transformers/docs/source/ar/run_scripts.md",
"repo_id": "transformers",
"token_count": 10161
}
|
# التصدير إلى TorchScript
<Tip>
هذه هي بداية تجاربنا مع TorchScript ولا زلنا نستكشف قدراته مع نماذج المدخلات المتغيرة الحجم. إنه مجال اهتمامنا وسنعمق تحليلنا في الإصدارات القادمة، مع المزيد من الأمثلة البرمجية، وتنفيذ أكثر مرونة، ومقاييس مقارنة بين الأكواد القائمة على Python مع أكواد TorchScript المُجمّعة.
</Tip>
وفقًا لـ [وثائق TorchScript](https://pytorch.org/docs/stable/jit.html):
> TorchScript هي طريقة لإنشاء نماذج قابلة للتسلسل والتحسين من تعليمات PyTorch البرمجية.
هناك وحدتان من PyTorch، [JIT and TRACE](https://pytorch.org/docs/stable/jit.html)، تتيحان للمطورين تصدير نماذجهم لإعادة استخدامها في برامج أخرى مثل برامج C++ المُحسّنة للأداء.
نقدم واجهة تتيح لك تصدير نماذج 🤗 Transformers إلى TorchScript بحيث يمكن إعادة استخدامها في بيئة مختلفة عن برامج Python القائمة إلى PyTorch. هنا نشرح كيفية تصدير نماذجنا واستخدامها باستخدام TorchScript.
يتطلب تصدير نموذج أمرين:
- تهيئة مثيل للنموذج باستخدام علامة `torchscript`
- تمرير مُدخلات وهمية (dummy inputs) خلال النموذج
تنطوي هذه الضرورات على عدة أمور يجب على المطورين توخي الحذر بشأنها كما هو مفصل أدناه.
## علامة TorchScript والأوزان المرتبطة
علامة `torchscript` ضرورية لأن معظم نماذج اللغة 🤗 Transformers لها أوزان مرتبطة بين طبقة `Embedding` وطبقة `Decoding`. لا يسمح لك TorchScript بتصدير النماذج ذات الأوزان المرتبطة، لذلك من الضروري فصل الأوزان ونسخها مسبقًا.
النماذج المُهيأة باستخدام علامة `torchscript` لها طبقة `Embedding` وطبقة`Decoding` منفصلتين، مما يعني أنه لا ينبغي تدريبها لاحقًا. سيؤدي التدريب إلى عدم تزامن الطبقتين، مما يؤدي إلى نتائج غير متوقعة.
هذا لا ينطبق على النماذج التي لا تحتوي على رأس نموذج اللغة، حيث لا تملك أوزانًا مرتبطة. يمكن تصدير هذه النماذج بأمان دون علامة `torchscript`.
## المدخلات الوهمية والأطوال القياسية
تُستخدم المُدخلات الوهمية لتمرير أمامي خلال النموذج. أثناء انتشار قيم المُدخلات عبر الطبقات، يتتبع PyTorch العمليات المختلفة التي يتم تنفيذها على كل مصفوفة(tensor). ثم يتم استخدام هذه العمليات المُسجلة بعد ذلك لإنشاء *أثر* النموذج.
يتم إنشاء التتبع بالنسبة لأبعاد المُدخلات. وبالتالي، فهو مُقيّد بأبعاد المُدخلات الوهمية، ولن يعمل لأي طول تسلسل أو حجم دفعة مختلف. عند المحاولة بحجم مختلف، يتم رفع الخطأ التالي:
```
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
نوصي بتتبع النموذج باستخدام حجم مُدخلات وهمية لا يقل عن أكبر مُدخل سيتم تقديمه للنموذج أثناء الاستدلال. يمكن أن تساعد الحشوة(padding) في ملء القيم المفقودة. ومع ذلك، نظرًا لتتبع النموذج بحجم مُدخل أكبر، ستكون أبعاد المصفوفة ستكون كبيرة أيضًا، مما يؤدي عنه المزيد من الحسابات.
انتبه إلى إجمالي عدد العمليات المُنفذة على كل مُدخل وتابع الأداء عن كثب عند تصدير نماذج متغيرة طول التسلسل.
## استخدام TorchScript في Python
يوضح هذا القسم كيفية حفظ النماذج وتحميلها، بالإضافة إلى كيفية استخدام التتبع للاستدلال.
### حفظ نموذج
لتصدير `BertModel` باستخدام TorchScript، قم بتهيئة ـ `BertModel` من فئة `BertConfig` ثم احفظه على القرص تحت اسم الملف `traced_bert.pt`:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
# Tokenizing input text
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# Masking one of the input tokens
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# Creating a dummy input
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# Initializing the model with the torchscript flag
# Flag set to True even though it is not necessary as this model does not have an LM Head.
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# Instantiating the model
model = BertModel(config)
# The model needs to be in evaluation mode
model.eval()
# If you are instantiating the model with *from_pretrained* you can also easily set the TorchScript flag
model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
# Creating the trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### تحميل نموذج
يمكنك الآن تحميل `BertModel` المُحفظ سابقًا، `traced_bert.pt`، من القرص واستخدامه على `dummy_input` المُهيأ سابقًا:
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### استخدام نموذج مُتتبع للاستدلال
استخدم النموذج المُتتبع للاستدلال باستخدام أسلوب `__call__` الخاص به:
```python
traced_model(tokens_tensor, segments_tensors)
```
## نشر نماذج Hugging Face TorchScript على AWS باستخدام Neuron SDK
قدمت AWS عائلة [Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) من اﻷجهزة لخفض التكلفة وأداء التعلم الآلي عالي الأداء في البيئة السحابية. تعمل أجهزة Inf1 بواسطة شريحة Inferentia من AWS، وهي مُسرّع أجهزة مُخصص، متخصص في أعباء عمل الاستدلال للتعلم العميق. [AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) هي SDK لـ Inferentia التي تدعم تتبع نماذج المحولات وتحسينها للنشر على Inf1. توفر Neuron SDK ما يلي:
1. واجهة برمجة تطبيقات سهلة الاستخدام مع تغيير سطر واحد من التعليمات البرمجية لتتبع نموذج TorchScript وتحسينه للاستدلال في البيئة السحابية.
2. تحسينات الأداء الجاهزة للاستخدام [تحسين التكلفة والأداء](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/>).
3. دعم نماذج Hugging Face المحولات المبنية باستخدام إما [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html) أو [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html).
### الآثار المترتبة
تعمل نماذج المحولات المستندة إلى بنية [BERT (تمثيلات الترميز ثنائية الاتجاه من المحولات)](https://huggingface.co/docs/transformers/main/model_doc/bert) أو متغيراتها مثل [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert) و [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) بشكل أفضل على Inf1 للمهام غير التوليدية مثل الإجابة على الأسئلة الاستخراجية، وتصنيف التسلسلات، وتصنيف الرموز (tokens). ومع ذلك، يمكن تكييف مهام توليد النصوص للعمل على Inf1 وفقًا لهذا [برنامج تعليمي AWS Neuron MarianMT](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html). يمكن العثور على مزيد من المعلومات حول النماذج التي يمكن تحويلها جاهزة على Inferentia في قسم [ملاءمة بنية النموذج](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia) من وثائق Neuron.
### التبعيات (Dependencies)
يتطلب استخدام AWS Neuron لتحويل النماذج [بيئة SDK Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide) والتي تأتي مسبقًا على [AMI للتعلم العميق من AWS](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html).
### تحويل نموذج لـ AWS Neuron
قم بتحويل نموذج لـ AWS NEURON باستخدام نفس التعليمات البرمجية من [استخدام TorchScript في Python](torchscript#using-torchscript-in-python) لتتبع `BertModel`. قم باستيراد امتداد إطار عمل `torch.neuron` للوصول إلى مكونات Neuron SDK من خلال واجهة برمجة تطبيقات Python:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
كل ما عليك فعله هو تعديل السطر التالي:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
يتيح ذلك لـ Neuron SDK تتبع النموذج وتحسينه لمثيلات Inf1.
لمعرفة المزيد حول ميزات AWS Neuron SDK والأدوات ودروس البرامج التعليمية والتحديثات الأخيرة، يرجى الاطلاع على [وثائق AWS NeuronSDK](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html).
|
transformers/docs/source/ar/torchscript.md/0
|
{
"file_path": "transformers/docs/source/ar/torchscript.md",
"repo_id": "transformers",
"token_count": 5475
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Pipelines für Inferenzen
Die [`pipeline`] macht es einfach, jedes beliebige Modell aus dem [Hub](https://huggingface.co/models) für die Inferenz auf jede Sprache, Computer Vision, Sprache und multimodale Aufgaben zu verwenden. Selbst wenn Sie keine Erfahrung mit einer bestimmten Modalität haben oder nicht mit dem zugrundeliegenden Code hinter den Modellen vertraut sind, können Sie sie mit der [`pipeline`] für Inferenzen verwenden! In diesem Beispiel lernen Sie, wie:
* Eine [`pipeline`] für Inferenz zu verwenden.
* Einen bestimmten Tokenizer oder ein bestimmtes Modell zu verwenden.
* Eine [`pipeline`] für Audio-, Vision- und multimodale Aufgaben zu verwenden.
<Tip>
Eine vollständige Liste der unterstützten Aufgaben und verfügbaren Parameter finden Sie in der [`pipeline`]-Dokumentation.
</Tip>
## Verwendung von Pipelines
Obwohl jede Aufgabe eine zugehörige [`pipeline`] hat, ist es einfacher, die allgemeine [`pipeline`]-Abstraktion zu verwenden, die alle aufgabenspezifischen Pipelines enthält. Die [`pipeline`] lädt automatisch ein Standardmodell und eine Vorverarbeitungsklasse, die für Ihre Aufgabe inferenzfähig ist.
1. Beginnen Sie mit der Erstellung einer [`pipeline`] und geben Sie eine Inferenzaufgabe an:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation")
```
2. Übergeben Sie Ihren Eingabetext an die [`pipeline`]:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Iron-priests at the door to the east, and thirteen for the Lord Kings at the end of the mountain'}]
```
Wenn Sie mehr als eine Eingabe haben, übergeben Sie die Eingabe als Liste:
```py
>>> generator(
... [
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... "Nine for Mortal Men, doomed to die, One for the Dark Lord on his dark throne",
... ]
... ) # doctest: +SKIP
```
Alle zusätzlichen Parameter für Ihre Aufgabe können auch in die [`pipeline`] aufgenommen werden. Die Aufgabe `Text-Generierung` hat eine [`~generation.GenerationMixin.generate`]-Methode mit mehreren Parametern zur Steuerung der Ausgabe. Wenn Sie zum Beispiel mehr als eine Ausgabe erzeugen wollen, setzen Sie den Parameter `num_return_sequences`:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone",
... num_return_sequences=2,
... ) # doctest: +SKIP
```
### Wählen Sie ein Modell und einen Tokenizer
Die [`pipeline`] akzeptiert jedes Modell aus dem [Hub](https://huggingface.co/models). Auf dem Hub gibt es Tags, mit denen Sie nach einem Modell filtern können, das Sie für Ihre Aufgabe verwenden möchten. Sobald Sie ein passendes Modell ausgewählt haben, laden Sie es mit der entsprechenden `AutoModelFor` und [`AutoTokenizer`] Klasse. Laden Sie zum Beispiel die Klasse [`AutoModelForCausalLM`] für eine kausale Sprachmodellierungsaufgabe:
```py
>>> from transformers import AutoTokenizer, AutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilgpt2")
>>> model = AutoModelForCausalLM.from_pretrained("distilbert/distilgpt2")
```
Erstellen Sie eine [`pipeline`] für Ihre Aufgabe, und geben Sie das Modell und den Tokenizer an, die Sie geladen haben:
```py
>>> from transformers import pipeline
>>> generator = pipeline(task="text-generation", model=model, tokenizer=tokenizer)
```
Übergeben Sie Ihren Eingabetext an die [`pipeline`] , um einen Text zu erzeugen:
```py
>>> generator(
... "Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone"
... ) # doctest: +SKIP
[{'generated_text': 'Three Rings for the Elven-kings under the sky, Seven for the Dwarf-lords in their halls of stone, Seven for the Dragon-lords (for them to rule in a world ruled by their rulers, and all who live within the realm'}]
```
## Audio-Pipeline
Die [`pipeline`] unterstützt auch Audioaufgaben wie Audioklassifizierung und automatische Spracherkennung.
Lassen Sie uns zum Beispiel die Emotion in diesem Audioclip klassifizieren:
```py
>>> from datasets import load_dataset
>>> import torch
>>> torch.manual_seed(42) # doctest: +IGNORE_RESULT
>>> ds = load_dataset("hf-internal-testing/librispeech_asr_demo", "clean", split="validation")
>>> audio_file = ds[0]["audio"]["path"]
```
Finden Sie ein [Audioklassifikation](https://huggingface.co/models?pipeline_tag=audio-classification) Modell auf dem Model Hub für Emotionserkennung und laden Sie es in die [`pipeline`]:
```py
>>> from transformers import pipeline
>>> audio_classifier = pipeline(
... task="audio-classification", model="ehcalabres/wav2vec2-lg-xlsr-en-speech-emotion-recognition"
... )
```
Übergeben Sie die Audiodatei an die [`pipeline`]:
```py
>>> preds = audio_classifier(audio_file)
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.1315, 'label': 'calm'}, {'score': 0.1307, 'label': 'neutral'}, {'score': 0.1274, 'label': 'sad'}, {'score': 0.1261, 'label': 'fearful'}, {'score': 0.1242, 'label': 'happy'}]
```
## Bildverarbeitungs-Pipeline
Die Verwendung einer [`pipeline`] für Bildverarbeitungsaufgaben ist praktisch identisch.
Geben Sie Ihre Aufgabe an und übergeben Sie Ihr Bild an den Klassifikator. Das Bild kann ein Link oder ein lokaler Pfad zu dem Bild sein. Zum Beispiel: Welche Katzenart ist unten abgebildet?

```py
>>> from transformers import pipeline
>>> vision_classifier = pipeline(task="image-classification")
>>> preds = vision_classifier(
... images="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
... )
>>> preds = [{"score": round(pred["score"], 4), "label": pred["label"]} for pred in preds]
>>> preds
[{'score': 0.4335, 'label': 'lynx, catamount'}, {'score': 0.0348, 'label': 'cougar, puma, catamount, mountain lion, painter, panther, Felis concolor'}, {'score': 0.0324, 'label': 'snow leopard, ounce, Panthera uncia'}, {'score': 0.0239, 'label': 'Egyptian cat'}, {'score': 0.0229, 'label': 'tiger cat'}]
```
## Multimodale Pipeline
Die [`pipeline`] unterstützt mehr als eine Modalität. Eine Aufgabe zur Beantwortung visueller Fragen (VQA) kombiniert zum Beispiel Text und Bild. Verwenden Sie einen beliebigen Bildlink und eine Frage, die Sie zu dem Bild stellen möchten. Das Bild kann eine URL oder ein lokaler Pfad zu dem Bild sein.
Wenn Sie zum Beispiel das gleiche Bild wie in der obigen Vision-Pipeline verwenden:
```py
>>> image = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg"
>>> question = "Where is the cat?"
```
Erstellen Sie eine Pipeline für "vqa" und übergeben Sie ihr das Bild und die Frage:
```py
>>> from transformers import pipeline
>>> vqa = pipeline(task="vqa")
>>> preds = vqa(image=image, question=question)
>>> preds = [{"score": round(pred["score"], 4), "answer": pred["answer"]} for pred in preds]
>>> preds
[{'score': 0.9112, 'answer': 'snow'}, {'score': 0.8796, 'answer': 'in snow'}, {'score': 0.6717, 'answer': 'outside'}, {'score': 0.0291, 'answer': 'on ground'}, {'score': 0.027, 'answer': 'ground'}]
```
|
transformers/docs/source/de/pipeline_tutorial.md/0
|
{
"file_path": "transformers/docs/source/de/pipeline_tutorial.md",
"repo_id": "transformers",
"token_count": 3003
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Attention mechanisms
Most transformer models use full attention in the sense that the attention matrix is square. It can be a big
computational bottleneck when you have long texts. Longformer and reformer are models that try to be more efficient and
use a sparse version of the attention matrix to speed up training.
## LSH attention
[Reformer](model_doc/reformer) uses LSH attention. In the softmax(QK^t), only the biggest elements (in the softmax
dimension) of the matrix QK^t are going to give useful contributions. So for each query q in Q, we can consider only
the keys k in K that are close to q. A hash function is used to determine if q and k are close. The attention mask is
modified to mask the current token (except at the first position), because it will give a query and a key equal (so
very similar to each other). Since the hash can be a bit random, several hash functions are used in practice
(determined by a n_rounds parameter) and then are averaged together.
## Local attention
[Longformer](model_doc/longformer) uses local attention: often, the local context (e.g., what are the two tokens to the
left and right?) is enough to take action for a given token. Also, by stacking attention layers that have a small
window, the last layer will have a receptive field of more than just the tokens in the window, allowing them to build a
representation of the whole sentence.
Some preselected input tokens are also given global attention: for those few tokens, the attention matrix can access
all tokens and this process is symmetric: all other tokens have access to those specific tokens (on top of the ones in
their local window). This is shown in Figure 2d of the paper, see below for a sample attention mask:
<div class="flex justify-center">
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
</div>
Using those attention matrices with less parameters then allows the model to have inputs having a bigger sequence
length.
## Other tricks
### Axial positional encodings
[Reformer](model_doc/reformer) uses axial positional encodings: in traditional transformer models, the positional encoding
E is a matrix of size \\(l\\) by \\(d\\), \\(l\\) being the sequence length and \\(d\\) the dimension of the
hidden state. If you have very long texts, this matrix can be huge and take way too much space on the GPU. To alleviate
that, axial positional encodings consist of factorizing that big matrix E in two smaller matrices E1 and E2, with
dimensions \\(l_{1} \times d_{1}\\) and \\(l_{2} \times d_{2}\\), such that \\(l_{1} \times l_{2} = l\\) and
\\(d_{1} + d_{2} = d\\) (with the product for the lengths, this ends up being way smaller). The embedding for time
step \\(j\\) in E is obtained by concatenating the embeddings for timestep \\(j \% l1\\) in E1 and \\(j // l1\\)
in E2.
|
transformers/docs/source/en/attention.md/0
|
{
"file_path": "transformers/docs/source/en/attention.md",
"repo_id": "transformers",
"token_count": 958
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Glossary
This glossary defines general machine learning and 🤗 Transformers terms to help you better understand the
documentation.
## A
### attention mask
The attention mask is an optional argument used when batching sequences together.
<Youtube id="M6adb1j2jPI"/>
This argument indicates to the model which tokens should be attended to, and which should not.
For example, consider these two sequences:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
>>> sequence_a = "This is a short sequence."
>>> sequence_b = "This is a rather long sequence. It is at least longer than the sequence A."
>>> encoded_sequence_a = tokenizer(sequence_a)["input_ids"]
>>> encoded_sequence_b = tokenizer(sequence_b)["input_ids"]
```
The encoded versions have different lengths:
```python
>>> len(encoded_sequence_a), len(encoded_sequence_b)
(8, 19)
```
Therefore, we can't put them together in the same tensor as-is. The first sequence needs to be padded up to the length
of the second one, or the second one needs to be truncated down to the length of the first one.
In the first case, the list of IDs will be extended by the padding indices. We can pass a list to the tokenizer and ask
it to pad like this:
```python
>>> padded_sequences = tokenizer([sequence_a, sequence_b], padding=True)
```
We can see that 0s have been added on the right of the first sentence to make it the same length as the second one:
```python
>>> padded_sequences["input_ids"]
[[101, 1188, 1110, 170, 1603, 4954, 119, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [101, 1188, 1110, 170, 1897, 1263, 4954, 119, 1135, 1110, 1120, 1655, 2039, 1190, 1103, 4954, 138, 119, 102]]
```
This can then be converted into a tensor in PyTorch or TensorFlow. The attention mask is a binary tensor indicating the
position of the padded indices so that the model does not attend to them. For the [`BertTokenizer`], `1` indicates a
value that should be attended to, while `0` indicates a padded value. This attention mask is in the dictionary returned
by the tokenizer under the key "attention_mask":
```python
>>> padded_sequences["attention_mask"]
[[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
```
### autoencoding models
See [encoder models](#encoder-models) and [masked language modeling](#masked-language-modeling-mlm)
### autoregressive models
See [causal language modeling](#causal-language-modeling) and [decoder models](#decoder-models)
## B
### backbone
The backbone is the network (embeddings and layers) that outputs the raw hidden states or features. It is usually connected to a [head](#head) which accepts the features as its input to make a prediction. For example, [`ViTModel`] is a backbone without a specific head on top. Other models can also use [`VitModel`] as a backbone such as [DPT](model_doc/dpt).
## C
### causal language modeling
A pretraining task where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence but using a mask inside the model to hide the future tokens at a certain timestep.
### channel
Color images are made up of some combination of values in three channels: red, green, and blue (RGB) and grayscale images only have one channel. In 🤗 Transformers, the channel can be the first or last dimension of an image's tensor: [`n_channels`, `height`, `width`] or [`height`, `width`, `n_channels`].
### connectionist temporal classification (CTC)
An algorithm which allows a model to learn without knowing exactly how the input and output are aligned; CTC calculates the distribution of all possible outputs for a given input and chooses the most likely output from it. CTC is commonly used in speech recognition tasks because speech doesn't always cleanly align with the transcript for a variety of reasons such as a speaker's different speech rates.
### convolution
A type of layer in a neural network where the input matrix is multiplied element-wise by a smaller matrix (kernel or filter) and the values are summed up in a new matrix. This is known as a convolutional operation which is repeated over the entire input matrix. Each operation is applied to a different segment of the input matrix. Convolutional neural networks (CNNs) are commonly used in computer vision.
## D
### DataParallel (DP)
Parallelism technique for training on multiple GPUs where the same setup is replicated multiple times, with each instance
receiving a distinct data slice. The processing is done in parallel and all setups are synchronized at the end of each training step.
Learn more about how DataParallel works [here](perf_train_gpu_many#dataparallel-vs-distributeddataparallel).
### decoder input IDs
This input is specific to encoder-decoder models, and contains the input IDs that will be fed to the decoder. These
inputs should be used for sequence to sequence tasks, such as translation or summarization, and are usually built in a
way specific to each model.
Most encoder-decoder models (BART, T5) create their `decoder_input_ids` on their own from the `labels`. In such models,
passing the `labels` is the preferred way to handle training.
Please check each model's docs to see how they handle these input IDs for sequence to sequence training.
### decoder models
Also referred to as autoregressive models, decoder models involve a pretraining task (called causal language modeling) where the model reads the texts in order and has to predict the next word. It's usually done by
reading the whole sentence with a mask to hide future tokens at a certain timestep.
<Youtube id="d_ixlCubqQw"/>
### deep learning (DL)
Machine learning algorithms which use neural networks with several layers.
## E
### encoder models
Also known as autoencoding models, encoder models take an input (such as text or images) and transform them into a condensed numerical representation called an embedding. Oftentimes, encoder models are pretrained using techniques like [masked language modeling](#masked-language-modeling-mlm), which masks parts of the input sequence and forces the model to create more meaningful representations.
<Youtube id="H39Z_720T5s"/>
## F
### feature extraction
The process of selecting and transforming raw data into a set of features that are more informative and useful for machine learning algorithms. Some examples of feature extraction include transforming raw text into word embeddings and extracting important features such as edges or shapes from image/video data.
### feed forward chunking
In each residual attention block in transformers the self-attention layer is usually followed by 2 feed forward layers.
The intermediate embedding size of the feed forward layers is often bigger than the hidden size of the model (e.g., for
`google-bert/bert-base-uncased`).
For an input of size `[batch_size, sequence_length]`, the memory required to store the intermediate feed forward
embeddings `[batch_size, sequence_length, config.intermediate_size]` can account for a large fraction of the memory
use. The authors of [Reformer: The Efficient Transformer](https://arxiv.org/abs/2001.04451) noticed that since the
computation is independent of the `sequence_length` dimension, it is mathematically equivalent to compute the output
embeddings of both feed forward layers `[batch_size, config.hidden_size]_0, ..., [batch_size, config.hidden_size]_n`
individually and concat them afterward to `[batch_size, sequence_length, config.hidden_size]` with `n = sequence_length`, which trades increased computation time against reduced memory use, but yields a mathematically
**equivalent** result.
For models employing the function [`apply_chunking_to_forward`], the `chunk_size` defines the number of output
embeddings that are computed in parallel and thus defines the trade-off between memory and time complexity. If
`chunk_size` is set to 0, no feed forward chunking is done.
### finetuned models
Finetuning is a form of transfer learning which involves taking a pretrained model, freezing its weights, and replacing the output layer with a newly added [model head](#head). The model head is trained on your target dataset.
See the [Fine-tune a pretrained model](https://huggingface.co/docs/transformers/training) tutorial for more details, and learn how to fine-tune models with 🤗 Transformers.
## H
### head
The model head refers to the last layer of a neural network that accepts the raw hidden states and projects them onto a different dimension. There is a different model head for each task. For example:
* [`GPT2ForSequenceClassification`] is a sequence classification head - a linear layer - on top of the base [`GPT2Model`].
* [`ViTForImageClassification`] is an image classification head - a linear layer on top of the final hidden state of the `CLS` token - on top of the base [`ViTModel`].
* [`Wav2Vec2ForCTC`] is a language modeling head with [CTC](#connectionist-temporal-classification-ctc) on top of the base [`Wav2Vec2Model`].
## I
### image patch
Vision-based Transformers models split an image into smaller patches which are linearly embedded, and then passed as a sequence to the model. You can find the `patch_size` - or resolution - of the model in its configuration.
### inference
Inference is the process of evaluating a model on new data after training is complete. See the [Pipeline for inference](https://huggingface.co/docs/transformers/pipeline_tutorial) tutorial to learn how to perform inference with 🤗 Transformers.
### input IDs
The input ids are often the only required parameters to be passed to the model as input. They are token indices,
numerical representations of tokens building the sequences that will be used as input by the model.
<Youtube id="VFp38yj8h3A"/>
Each tokenizer works differently but the underlying mechanism remains the same. Here's an example using the BERT
tokenizer, which is a [WordPiece](https://arxiv.org/pdf/1609.08144.pdf) tokenizer:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
>>> sequence = "A Titan RTX has 24GB of VRAM"
```
The tokenizer takes care of splitting the sequence into tokens available in the tokenizer vocabulary.
```python
>>> tokenized_sequence = tokenizer.tokenize(sequence)
```
The tokens are either words or subwords. Here for instance, "VRAM" wasn't in the model vocabulary, so it's been split
in "V", "RA" and "M". To indicate those tokens are not separate words but parts of the same word, a double-hash prefix
is added for "RA" and "M":
```python
>>> print(tokenized_sequence)
['A', 'Titan', 'R', '##T', '##X', 'has', '24', '##GB', 'of', 'V', '##RA', '##M']
```
These tokens can then be converted into IDs which are understandable by the model. This can be done by directly feeding the sentence to the tokenizer, which leverages the Rust implementation of [🤗 Tokenizers](https://github.com/huggingface/tokenizers) for peak performance.
```python
>>> inputs = tokenizer(sequence)
```
The tokenizer returns a dictionary with all the arguments necessary for its corresponding model to work properly. The
token indices are under the key `input_ids`:
```python
>>> encoded_sequence = inputs["input_ids"]
>>> print(encoded_sequence)
[101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102]
```
Note that the tokenizer automatically adds "special tokens" (if the associated model relies on them) which are special
IDs the model sometimes uses.
If we decode the previous sequence of ids,
```python
>>> decoded_sequence = tokenizer.decode(encoded_sequence)
```
we will see
```python
>>> print(decoded_sequence)
[CLS] A Titan RTX has 24GB of VRAM [SEP]
```
because this is the way a [`BertModel`] is going to expect its inputs.
## L
### labels
The labels are an optional argument which can be passed in order for the model to compute the loss itself. These labels
should be the expected prediction of the model: it will use the standard loss in order to compute the loss between its
predictions and the expected value (the label).
These labels are different according to the model head, for example:
- For sequence classification models, ([`BertForSequenceClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of the entire sequence.
- For token classification models, ([`BertForTokenClassification`]), the model expects a tensor of dimension
`(batch_size, seq_length)` with each value corresponding to the expected label of each individual token.
- For masked language modeling, ([`BertForMaskedLM`]), the model expects a tensor of dimension `(batch_size,
seq_length)` with each value corresponding to the expected label of each individual token: the labels being the token
ID for the masked token, and values to be ignored for the rest (usually -100).
- For sequence to sequence tasks, ([`BartForConditionalGeneration`], [`MBartForConditionalGeneration`]), the model
expects a tensor of dimension `(batch_size, tgt_seq_length)` with each value corresponding to the target sequences
associated with each input sequence. During training, both BART and T5 will make the appropriate
`decoder_input_ids` and decoder attention masks internally. They usually do not need to be supplied. This does not
apply to models leveraging the Encoder-Decoder framework.
- For image classification models, ([`ViTForImageClassification`]), the model expects a tensor of dimension
`(batch_size)` with each value of the batch corresponding to the expected label of each individual image.
- For semantic segmentation models, ([`SegformerForSemanticSegmentation`]), the model expects a tensor of dimension
`(batch_size, height, width)` with each value of the batch corresponding to the expected label of each individual pixel.
- For object detection models, ([`DetrForObjectDetection`]), the model expects a list of dictionaries with a
`class_labels` and `boxes` key where each value of the batch corresponds to the expected label and number of bounding boxes of each individual image.
- For automatic speech recognition models, ([`Wav2Vec2ForCTC`]), the model expects a tensor of dimension `(batch_size,
target_length)` with each value corresponding to the expected label of each individual token.
<Tip>
Each model's labels may be different, so be sure to always check the documentation of each model for more information
about their specific labels!
</Tip>
The base models ([`BertModel`]) do not accept labels, as these are the base transformer models, simply outputting
features.
### large language models (LLM)
A generic term that refers to transformer language models (GPT-3, BLOOM, OPT) that were trained on a large quantity of data. These models also tend to have a large number of learnable parameters (e.g. 175 billion for GPT-3).
## M
### masked language modeling (MLM)
A pretraining task where the model sees a corrupted version of the texts, usually done by
masking some tokens randomly, and has to predict the original text.
### multimodal
A task that combines texts with another kind of inputs (for instance images).
## N
### Natural language generation (NLG)
All tasks related to generating text (for instance, [Write With Transformers](https://transformer.huggingface.co/), translation).
### Natural language processing (NLP)
A generic way to say "deal with texts".
### Natural language understanding (NLU)
All tasks related to understanding what is in a text (for instance classifying the
whole text, individual words).
## P
### pipeline
A pipeline in 🤗 Transformers is an abstraction referring to a series of steps that are executed in a specific order to preprocess and transform data and return a prediction from a model. Some example stages found in a pipeline might be data preprocessing, feature extraction, and normalization.
For more details, see [Pipelines for inference](https://huggingface.co/docs/transformers/pipeline_tutorial).
### PipelineParallel (PP)
Parallelism technique in which the model is split up vertically (layer-level) across multiple GPUs, so that only one or
several layers of the model are placed on a single GPU. Each GPU processes in parallel different stages of the pipeline
and working on a small chunk of the batch. Learn more about how PipelineParallel works [here](perf_train_gpu_many#from-naive-model-parallelism-to-pipeline-parallelism).
### pixel values
A tensor of the numerical representations of an image that is passed to a model. The pixel values have a shape of [`batch_size`, `num_channels`, `height`, `width`], and are generated from an image processor.
### pooling
An operation that reduces a matrix into a smaller matrix, either by taking the maximum or average of the pooled dimension(s). Pooling layers are commonly found between convolutional layers to downsample the feature representation.
### position IDs
Contrary to RNNs that have the position of each token embedded within them, transformers are unaware of the position of
each token. Therefore, the position IDs (`position_ids`) are used by the model to identify each token's position in the
list of tokens.
They are an optional parameter. If no `position_ids` are passed to the model, the IDs are automatically created as
absolute positional embeddings.
Absolute positional embeddings are selected in the range `[0, config.max_position_embeddings - 1]`. Some models use
other types of positional embeddings, such as sinusoidal position embeddings or relative position embeddings.
### preprocessing
The task of preparing raw data into a format that can be easily consumed by machine learning models. For example, text is typically preprocessed by tokenization. To gain a better idea of what preprocessing looks like for other input types, check out the [Preprocess](https://huggingface.co/docs/transformers/preprocessing) tutorial.
### pretrained model
A model that has been pretrained on some data (for instance all of Wikipedia). Pretraining methods involve a
self-supervised objective, which can be reading the text and trying to predict the next word (see [causal language
modeling](#causal-language-modeling)) or masking some words and trying to predict them (see [masked language
modeling](#masked-language-modeling-mlm)).
Speech and vision models have their own pretraining objectives. For example, Wav2Vec2 is a speech model pretrained on a contrastive task which requires the model to identify the "true" speech representation from a set of "false" speech representations. On the other hand, BEiT is a vision model pretrained on a masked image modeling task which masks some of the image patches and requires the model to predict the masked patches (similar to the masked language modeling objective).
## R
### recurrent neural network (RNN)
A type of model that uses a loop over a layer to process texts.
### representation learning
A subfield of machine learning which focuses on learning meaningful representations of raw data. Some examples of representation learning techniques include word embeddings, autoencoders, and Generative Adversarial Networks (GANs).
## S
### sampling rate
A measurement in hertz of the number of samples (the audio signal) taken per second. The sampling rate is a result of discretizing a continuous signal such as speech.
### self-attention
Each element of the input finds out which other elements of the input they should attend to.
### self-supervised learning
A category of machine learning techniques in which a model creates its own learning objective from unlabeled data. It differs from [unsupervised learning](#unsupervised-learning) and [supervised learning](#supervised-learning) in that the learning process is supervised, but not explicitly from the user.
One example of self-supervised learning is [masked language modeling](#masked-language-modeling-mlm), where a model is passed sentences with a proportion of its tokens removed and learns to predict the missing tokens.
### semi-supervised learning
A broad category of machine learning training techniques that leverages a small amount of labeled data with a larger quantity of unlabeled data to improve the accuracy of a model, unlike [supervised learning](#supervised-learning) and [unsupervised learning](#unsupervised-learning).
An example of a semi-supervised learning approach is "self-training", in which a model is trained on labeled data, and then used to make predictions on the unlabeled data. The portion of the unlabeled data that the model predicts with the most confidence gets added to the labeled dataset and used to retrain the model.
### sequence-to-sequence (seq2seq)
Models that generate a new sequence from an input, like translation models, or summarization models (such as
[Bart](model_doc/bart) or [T5](model_doc/t5)).
### Sharded DDP
Another name for the foundational [ZeRO](#zero-redundancy-optimizer-zero) concept as used by various other implementations of ZeRO.
### stride
In [convolution](#convolution) or [pooling](#pooling), the stride refers to the distance the kernel is moved over a matrix. A stride of 1 means the kernel is moved one pixel over at a time, and a stride of 2 means the kernel is moved two pixels over at a time.
### supervised learning
A form of model training that directly uses labeled data to correct and instruct model performance. Data is fed into the model being trained, and its predictions are compared to the known labels. The model updates its weights based on how incorrect its predictions were, and the process is repeated to optimize model performance.
## T
### Tensor Parallelism (TP)
Parallelism technique for training on multiple GPUs in which each tensor is split up into multiple chunks, so instead of
having the whole tensor reside on a single GPU, each shard of the tensor resides on its designated GPU. Shards gets
processed separately and in parallel on different GPUs and the results are synced at the end of the processing step.
This is what is sometimes called horizontal parallelism, as the splitting happens on horizontal level.
Learn more about Tensor Parallelism [here](perf_train_gpu_many#tensor-parallelism).
### token
A part of a sentence, usually a word, but can also be a subword (non-common words are often split in subwords) or a
punctuation symbol.
### token Type IDs
Some models' purpose is to do classification on pairs of sentences or question answering.
<Youtube id="0u3ioSwev3s"/>
These require two different sequences to be joined in a single "input_ids" entry, which usually is performed with the
help of special tokens, such as the classifier (`[CLS]`) and separator (`[SEP]`) tokens. For example, the BERT model
builds its two sequence input as such:
```python
>>> # [CLS] SEQUENCE_A [SEP] SEQUENCE_B [SEP]
```
We can use our tokenizer to automatically generate such a sentence by passing the two sequences to `tokenizer` as two
arguments (and not a list, like before) like this:
```python
>>> from transformers import BertTokenizer
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-cased")
>>> sequence_a = "HuggingFace is based in NYC"
>>> sequence_b = "Where is HuggingFace based?"
>>> encoded_dict = tokenizer(sequence_a, sequence_b)
>>> decoded = tokenizer.decode(encoded_dict["input_ids"])
```
which will return:
```python
>>> print(decoded)
[CLS] HuggingFace is based in NYC [SEP] Where is HuggingFace based? [SEP]
```
This is enough for some models to understand where one sequence ends and where another begins. However, other models,
such as BERT, also deploy token type IDs (also called segment IDs). They are represented as a binary mask identifying
the two types of sequence in the model.
The tokenizer returns this mask as the "token_type_ids" entry:
```python
>>> encoded_dict["token_type_ids"]
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1]
```
The first sequence, the "context" used for the question, has all its tokens represented by a `0`, whereas the second
sequence, corresponding to the "question", has all its tokens represented by a `1`.
Some models, like [`XLNetModel`] use an additional token represented by a `2`.
### transfer learning
A technique that involves taking a pretrained model and adapting it to a dataset specific to your task. Instead of training a model from scratch, you can leverage knowledge obtained from an existing model as a starting point. This speeds up the learning process and reduces the amount of training data needed.
### transformer
Self-attention based deep learning model architecture.
## U
### unsupervised learning
A form of model training in which data provided to the model is not labeled. Unsupervised learning techniques leverage statistical information of the data distribution to find patterns useful for the task at hand.
## Z
### Zero Redundancy Optimizer (ZeRO)
Parallelism technique which performs sharding of the tensors somewhat similar to [TensorParallel](#tensor-parallelism-tp),
except the whole tensor gets reconstructed in time for a forward or backward computation, therefore the model doesn't need
to be modified. This method also supports various offloading techniques to compensate for limited GPU memory.
Learn more about ZeRO [here](perf_train_gpu_many#zero-data-parallelism).
|
transformers/docs/source/en/glossary.md/0
|
{
"file_path": "transformers/docs/source/en/glossary.md",
"repo_id": "transformers",
"token_count": 6761
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Generation with LLMs
[[open-in-colab]]
LLMs, or Large Language Models, are the key component behind text generation. In a nutshell, they consist of large pretrained transformer models trained to predict the next word (or, more precisely, token) given some input text. Since they predict one token at a time, you need to do something more elaborate to generate new sentences other than just calling the model -- you need to do autoregressive generation.
Autoregressive generation is the inference-time procedure of iteratively calling a model with its own generated outputs, given a few initial inputs. In 🤗 Transformers, this is handled by the [`~generation.GenerationMixin.generate`] method, which is available to all models with generative capabilities.
<Tip>
If you want to jump straight to chatting with a model, [try our chat CLI](quicktour#chat-with-text-generation-models).
</Tip>
This tutorial will show you how to:
* Generate text with an LLM
* Avoid common pitfalls
* Next steps to help you get the most out of your LLM
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers bitsandbytes>=0.39.0 -q
```
Bitsandbytes supports multiple backends in addition to CUDA-based GPUs. Refer to the multi-backend installation [guide](https://huggingface.co/docs/bitsandbytes/main/en/installation#multi-backend) to learn more.
## Generate text
A language model trained for [causal language modeling](tasks/language_modeling) takes a sequence of text tokens as input and returns the probability distribution for the next token.
<!-- [GIF 1 -- FWD PASS] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_1_1080p.mov"
></video>
<figcaption>"Forward pass of an LLM"</figcaption>
</figure>
A critical aspect of autoregressive generation with LLMs is how to select the next token from this probability distribution. Anything goes in this step as long as you end up with a token for the next iteration. This means it can be as simple as selecting the most likely token from the probability distribution or as complex as applying a dozen transformations before sampling from the resulting distribution.
<!-- [GIF 2 -- TEXT GENERATION] -->
<figure class="image table text-center m-0 w-full">
<video
style="max-width: 90%; margin: auto;"
autoplay loop muted playsinline
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/assisted-generation/gif_2_1080p.mov"
></video>
<figcaption>"Autoregressive generation iteratively selects the next token from a probability distribution to generate text"</figcaption>
</figure>
The process depicted above is repeated iteratively until some stopping condition is reached. Ideally, the stopping condition is dictated by the model, which should learn when to output an end-of-sequence (`EOS`) token. If this is not the case, generation stops when some predefined maximum length is reached.
Properly setting up the token selection step and the stopping condition is essential to make your model behave as you'd expect on your task. That is why we have a [`~generation.GenerationConfig`] file associated with each model, which contains a good default generative parameterization and is loaded alongside your model.
Let's talk code!
<Tip>
If you're interested in basic LLM usage, our high-level [`Pipeline`](pipeline_tutorial) interface is a great starting point. However, LLMs often require advanced features like quantization and fine control of the token selection step, which is best done through [`~generation.GenerationMixin.generate`]. Autoregressive generation with LLMs is also resource-intensive and should be executed on a GPU for adequate throughput.
</Tip>
First, you need to load the model.
```py
>>> from transformers import AutoModelForCausalLM
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
You'll notice two flags in the `from_pretrained` call:
- `device_map` ensures the model is moved to your GPU(s)
- `load_in_4bit` applies [4-bit dynamic quantization](main_classes/quantization) to massively reduce the resource requirements
There are other ways to initialize a model, but this is a good baseline to begin with an LLM.
Next, you need to preprocess your text input with a [tokenizer](tokenizer_summary).
```py
>>> from transformers import AutoTokenizer
>>> from accelerate.test_utils.testing import get_backend
>>> DEVICE, _, _ = get_backend() # automatically detects the underlying device type (CUDA, CPU, XPU, MPS, etc.)
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> model_inputs = tokenizer(["A list of colors: red, blue"], return_tensors="pt").to(DEVICE)
```
The `model_inputs` variable holds the tokenized text input, as well as the attention mask. While [`~generation.GenerationMixin.generate`] does its best effort to infer the attention mask when it is not passed, we recommend passing it whenever possible for optimal results.
After tokenizing the inputs, you can call the [`~generation.GenerationMixin.generate`] method to returns the generated tokens. The generated tokens then should be converted to text before printing.
```py
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A list of colors: red, blue, green, yellow, orange, purple, pink,'
```
Finally, you don't need to do it one sequence at a time! You can batch your inputs, which will greatly improve the throughput at a small latency and memory cost. All you need to do is to make sure you pad your inputs properly (more on that below).
```py
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["A list of colors: red, blue", "Portugal is"], return_tensors="pt", padding=True
... ).to(DEVICE)
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
['A list of colors: red, blue, green, yellow, orange, purple, pink,',
'Portugal is a country in southwestern Europe, on the Iber']
```
And that's it! In a few lines of code, you can harness the power of an LLM.
## Common pitfalls
There are many [generation strategies](generation_strategies), and sometimes the default values may not be appropriate for your use case. If your outputs aren't aligned with what you're expecting, we've created a list of the most common pitfalls and how to avoid them.
```py
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model = AutoModelForCausalLM.from_pretrained(
... "mistralai/Mistral-7B-v0.1", device_map="auto", load_in_4bit=True
... )
```
### Generated output is too short/long
If not specified in the [`~generation.GenerationConfig`] file, `generate` returns up to 20 tokens by default. We highly recommend manually setting `max_new_tokens` in your `generate` call to control the maximum number of new tokens it can return. Keep in mind LLMs (more precisely, [decoder-only models](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt)) also return the input prompt as part of the output.
```py
>>> model_inputs = tokenizer(["A sequence of numbers: 1, 2"], return_tensors="pt").to(DEVICE)
>>> # By default, the output will contain up to 20 tokens
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5'
>>> # Setting `max_new_tokens` allows you to control the maximum length
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=50)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'A sequence of numbers: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,'
```
### Incorrect generation mode
By default, and unless specified in the [`~generation.GenerationConfig`] file, `generate` selects the most likely token at each iteration (greedy decoding). Depending on your task, this may be undesirable; creative tasks like chatbots or writing an essay benefit from sampling. On the other hand, input-grounded tasks like audio transcription or translation benefit from greedy decoding. Enable sampling with `do_sample=True`, and you can learn more about this topic in this [blog post](https://huggingface.co/blog/how-to-generate).
```py
>>> # Set seed for reproducibility -- you don't need this unless you want full reproducibility
>>> from transformers import set_seed
>>> set_seed(42)
>>> model_inputs = tokenizer(["I am a cat."], return_tensors="pt").to(DEVICE)
>>> # LLM + greedy decoding = repetitive, boring output
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. I am a cat. I am a cat. I am a cat'
>>> # With sampling, the output becomes more creative!
>>> generated_ids = model.generate(**model_inputs, do_sample=True)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'I am a cat. Specifically, I am an indoor-only cat. I'
```
### Wrong padding side
LLMs are [decoder-only](https://huggingface.co/learn/nlp-course/chapter1/6?fw=pt) architectures, meaning they continue to iterate on your input prompt. If your inputs do not have the same length, they need to be padded. Since LLMs are not trained to continue from pad tokens, your input needs to be left-padded. Make sure you also don't forget to pass the attention mask to generate!
```py
>>> # The tokenizer initialized above has right-padding active by default: the 1st sequence,
>>> # which is shorter, has padding on the right side. Generation fails to capture the logic.
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to(DEVICE)
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 33333333333'
>>> # With left-padding, it works as expected!
>>> tokenizer = AutoTokenizer.from_pretrained("mistralai/Mistral-7B-v0.1", padding_side="left")
>>> tokenizer.pad_token = tokenizer.eos_token # Most LLMs don't have a pad token by default
>>> model_inputs = tokenizer(
... ["1, 2, 3", "A, B, C, D, E"], padding=True, return_tensors="pt"
... ).to(DEVICE)
>>> generated_ids = model.generate(**model_inputs)
>>> tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
'1, 2, 3, 4, 5, 6,'
```
### Wrong prompt
Some models and tasks expect a certain input prompt format to work properly. When this format is not applied, you will get a silent performance degradation: the model kinda works, but not as well as if you were following the expected prompt. More information about prompting, including which models and tasks need to be careful, is available in this [guide](tasks/prompting). Let's see an example with a chat LLM, which makes use of [chat templating](chat_templating):
```python
>>> tokenizer = AutoTokenizer.from_pretrained("HuggingFaceH4/zephyr-7b-alpha")
>>> model = AutoModelForCausalLM.from_pretrained(
... "HuggingFaceH4/zephyr-7b-alpha", device_map="auto", load_in_4bit=True
... )
>>> set_seed(0)
>>> prompt = """How many helicopters can a human eat in one sitting? Reply as a thug."""
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(DEVICE)
>>> input_length = model_inputs.input_ids.shape[1]
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
"I'm not a thug, but i can tell you that a human cannot eat"
>>> # Oh no, it did not follow our instruction to reply as a thug! Let's see what happens when we write
>>> # a better prompt and use the right template for this model (through `tokenizer.apply_chat_template`)
>>> set_seed(0)
>>> messages = [
... {
... "role": "system",
... "content": "You are a friendly chatbot who always responds in the style of a thug",
... },
... {"role": "user", "content": "How many helicopters can a human eat in one sitting?"},
... ]
>>> model_inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt").to(DEVICE)
>>> input_length = model_inputs.shape[1]
>>> generated_ids = model.generate(model_inputs, do_sample=True, max_new_tokens=20)
>>> print(tokenizer.batch_decode(generated_ids[:, input_length:], skip_special_tokens=True)[0])
'None, you thug. How bout you try to focus on more useful questions?'
>>> # As we can see, it followed a proper thug style 😎
```
## Further resources
While the autoregressive generation process is relatively straightforward, making the most out of your LLM can be a challenging endeavor because there are many moving parts. For your next steps to help you dive deeper into LLM usage and understanding:
### Advanced generate usage
1. Guide on how to [control different generation methods](generation_strategies), how to set up the generation configuration file, and how to stream the output;
2. [Accelerating text generation](llm_optims);
3. [Prompt templates for chat LLMs](chat_templating);
4. [Prompt design guide](tasks/prompting);
5. API reference on [`~generation.GenerationConfig`], [`~generation.GenerationMixin.generate`], and [generate-related classes](internal/generation_utils). Most of the classes, including the logits processors, have usage examples!
### LLM leaderboards
1. [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard), which focuses on the quality of the open-source models;
2. [Open LLM-Perf Leaderboard](https://huggingface.co/spaces/optimum/llm-perf-leaderboard), which focuses on LLM throughput.
### Latency, throughput and memory utilization
1. Guide on how to [optimize LLMs for speed and memory](llm_tutorial_optimization);
2. Guide on [quantization](main_classes/quantization) such as bitsandbytes and autogptq, which shows you how to drastically reduce your memory requirements.
### Related libraries
1. [`optimum`](https://github.com/huggingface/optimum), an extension of 🤗 Transformers that optimizes for specific hardware devices;
2. [`outlines`](https://github.com/outlines-dev/outlines), a library where you can constrain text generation (e.g. to generate JSON files);
3. [`SynCode`](https://github.com/uiuc-focal-lab/syncode), a library for context-free grammar guided generation (e.g. JSON, SQL, Python);
4. [`text-generation-inference`](https://github.com/huggingface/text-generation-inference), a production-ready server for LLMs;
5. [`text-generation-webui`](https://github.com/oobabooga/text-generation-webui), a UI for text generation;
6. [`logits-processor-zoo`](https://github.com/NVIDIA/logits-processor-zoo), containing additional options to control text generation with 🤗 Transformers. See our related [blog post](https://huggingface.co/blog/logits-processor-zoo).
|
transformers/docs/source/en/llm_tutorial.md/0
|
{
"file_path": "transformers/docs/source/en/llm_tutorial.md",
"repo_id": "transformers",
"token_count": 4715
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BART
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bart">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bart-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bart-large-mnli">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
The Bart model was proposed in [BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation,
Translation, and Comprehension](https://arxiv.org/abs/1910.13461) by Mike Lewis, Yinhan Liu, Naman Goyal, Marjan
Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov and Luke Zettlemoyer on 29 Oct, 2019.
According to the abstract,
- Bart uses a standard seq2seq/machine translation architecture with a bidirectional encoder (like BERT) and a
left-to-right decoder (like GPT).
- The pretraining task involves randomly shuffling the order of the original sentences and a novel in-filling scheme,
where spans of text are replaced with a single mask token.
- BART is particularly effective when fine tuned for text generation but also works well for comprehension tasks. It
matches the performance of RoBERTa with comparable training resources on GLUE and SQuAD, achieves new
state-of-the-art results on a range of abstractive dialogue, question answering, and summarization tasks, with gains
of up to 6 ROUGE.
This model was contributed by [sshleifer](https://huggingface.co/sshleifer). The authors' code can be found [here](https://github.com/pytorch/fairseq/tree/master/examples/bart).
## Usage tips:
- BART is a model with absolute position embeddings so it's usually advised to pad the inputs on the right rather than
the left.
- Sequence-to-sequence model with an encoder and a decoder. Encoder is fed a corrupted version of the tokens, decoder is fed the original tokens (but has a mask to hide the future words like a regular transformers decoder). A composition of the following transformations are applied on the pretraining tasks for the encoder:
* mask random tokens (like in BERT)
* delete random tokens
* mask a span of k tokens with a single mask token (a span of 0 tokens is an insertion of a mask token)
* permute sentences
* rotate the document to make it start at a specific token
## Implementation Notes
- Bart doesn't use `token_type_ids` for sequence classification. Use [`BartTokenizer`] or
[`~BartTokenizer.encode`] to get the proper splitting.
- The forward pass of [`BartModel`] will create the `decoder_input_ids` if they are not passed.
This is different than some other modeling APIs. A typical use case of this feature is mask filling.
- Model predictions are intended to be identical to the original implementation when
`forced_bos_token_id=0`. This only works, however, if the string you pass to
[`fairseq.encode`] starts with a space.
- [`~generation.GenerationMixin.generate`] should be used for conditional generation tasks like
summarization, see the example in that docstrings.
- Models that load the *facebook/bart-large-cnn* weights will not have a `mask_token_id`, or be able to perform
mask-filling tasks.
## Mask Filling
The `facebook/bart-base` and `facebook/bart-large` checkpoints can be used to fill multi-token masks.
```python
from transformers import BartForConditionalGeneration, BartTokenizer
model = BartForConditionalGeneration.from_pretrained("facebook/bart-large", forced_bos_token_id=0)
tok = BartTokenizer.from_pretrained("facebook/bart-large")
example_english_phrase = "UN Chief Says There Is No <mask> in Syria"
batch = tok(example_english_phrase, return_tensors="pt")
generated_ids = model.generate(batch["input_ids"])
assert tok.batch_decode(generated_ids, skip_special_tokens=True) == [
"UN Chief Says There Is No Plan to Stop Chemical Weapons in Syria"
]
```
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BART. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="summarization"/>
- A blog post on [Distributed Training: Train BART/T5 for Summarization using 🤗 Transformers and Amazon SageMaker](https://huggingface.co/blog/sagemaker-distributed-training-seq2seq).
- A notebook on how to [finetune BART for summarization with fastai using blurr](https://colab.research.google.com/github/ohmeow/ohmeow_website/blob/master/posts/2021-05-25-mbart-sequence-classification-with-blurr.ipynb). 🌎
- A notebook on how to [finetune BART for summarization in two languages with Trainer class](https://colab.research.google.com/github/elsanns/xai-nlp-notebooks/blob/master/fine_tune_bart_summarization_two_langs.ipynb). 🌎
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/summarization) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/summarization-tf.ipynb).
- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/summarization).
- An example of how to train [`BartForConditionalGeneration`] with a Hugging Face `datasets` object can be found in this [forum discussion](https://discuss.huggingface.co/t/train-bart-for-conditional-generation-e-g-summarization/1904)
- [Summarization](https://huggingface.co/course/chapter7/5?fw=pt#summarization) chapter of the 🤗 Hugging Face course.
- [Summarization task guide](../tasks/summarization)
<PipelineTag pipeline="fill-mask"/>
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb).
- [`FlaxBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb).
- [Masked language modeling](https://huggingface.co/course/chapter7/3?fw=pt) chapter of the 🤗 Hugging Face Course.
- [Masked language modeling task guide](../tasks/masked_language_modeling)
<PipelineTag pipeline="translation"/>
- A notebook on how to [finetune mBART using Seq2SeqTrainer for Hindi to English translation](https://colab.research.google.com/github/vasudevgupta7/huggingface-tutorials/blob/main/translation_training.ipynb). 🌎
- [`BartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation.ipynb).
- [`TFBartForConditionalGeneration`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/translation) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/translation-tf.ipynb).
- [Translation task guide](../tasks/translation)
See also:
- [Text classification task guide](../tasks/sequence_classification)
- [Question answering task guide](../tasks/question_answering)
- [Causal language modeling task guide](../tasks/language_modeling)
- [Distilled checkpoints](https://huggingface.co/models?search=distilbart) are described in this [paper](https://arxiv.org/abs/2010.13002).
## BartConfig
[[autodoc]] BartConfig
- all
## BartTokenizer
[[autodoc]] BartTokenizer
- all
## BartTokenizerFast
[[autodoc]] BartTokenizerFast
- all
<frameworkcontent>
<pt>
## BartModel
[[autodoc]] BartModel
- forward
## BartForConditionalGeneration
[[autodoc]] BartForConditionalGeneration
- forward
## BartForSequenceClassification
[[autodoc]] BartForSequenceClassification
- forward
## BartForQuestionAnswering
[[autodoc]] BartForQuestionAnswering
- forward
## BartForCausalLM
[[autodoc]] BartForCausalLM
- forward
</pt>
<tf>
## TFBartModel
[[autodoc]] TFBartModel
- call
## TFBartForConditionalGeneration
[[autodoc]] TFBartForConditionalGeneration
- call
## TFBartForSequenceClassification
[[autodoc]] TFBartForSequenceClassification
- call
</tf>
<jax>
## FlaxBartModel
[[autodoc]] FlaxBartModel
- __call__
- encode
- decode
## FlaxBartForConditionalGeneration
[[autodoc]] FlaxBartForConditionalGeneration
- __call__
- encode
- decode
## FlaxBartForSequenceClassification
[[autodoc]] FlaxBartForSequenceClassification
- __call__
- encode
- decode
## FlaxBartForQuestionAnswering
[[autodoc]] FlaxBartForQuestionAnswering
- __call__
- encode
- decode
## FlaxBartForCausalLM
[[autodoc]] FlaxBartForCausalLM
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/bart.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/bart.md",
"repo_id": "transformers",
"token_count": 3297
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BLOOM
## Overview
The BLOOM model has been proposed with its various versions through the [BigScience Workshop](https://bigscience.huggingface.co/). BigScience is inspired by other open science initiatives where researchers have pooled their time and resources to collectively achieve a higher impact.
The architecture of BLOOM is essentially similar to GPT3 (auto-regressive model for next token prediction), but has been trained on 46 different languages and 13 programming languages.
Several smaller versions of the models have been trained on the same dataset. BLOOM is available in the following versions:
- [bloom-560m](https://huggingface.co/bigscience/bloom-560m)
- [bloom-1b1](https://huggingface.co/bigscience/bloom-1b1)
- [bloom-1b7](https://huggingface.co/bigscience/bloom-1b7)
- [bloom-3b](https://huggingface.co/bigscience/bloom-3b)
- [bloom-7b1](https://huggingface.co/bigscience/bloom-7b1)
- [bloom](https://huggingface.co/bigscience/bloom) (176B parameters)
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with BLOOM. If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
<PipelineTag pipeline="text-generation"/>
- [`BloomForCausalLM`] is supported by this [causal language modeling example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb).
See also:
- [Causal language modeling task guide](../tasks/language_modeling)
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
⚡️ Inference
- A blog on [Optimization story: Bloom inference](https://huggingface.co/blog/bloom-inference-optimization).
- A blog on [Incredibly Fast BLOOM Inference with DeepSpeed and Accelerate](https://huggingface.co/blog/bloom-inference-pytorch-scripts).
⚙️ Training
- A blog on [The Technology Behind BLOOM Training](https://huggingface.co/blog/bloom-megatron-deepspeed).
## BloomConfig
[[autodoc]] BloomConfig
- all
## BloomTokenizerFast
[[autodoc]] BloomTokenizerFast
- all
<frameworkcontent>
<pt>
## BloomModel
[[autodoc]] BloomModel
- forward
## BloomForCausalLM
[[autodoc]] BloomForCausalLM
- forward
## BloomForSequenceClassification
[[autodoc]] BloomForSequenceClassification
- forward
## BloomForTokenClassification
[[autodoc]] BloomForTokenClassification
- forward
## BloomForQuestionAnswering
[[autodoc]] BloomForQuestionAnswering
- forward
</pt>
<jax>
## FlaxBloomModel
[[autodoc]] FlaxBloomModel
- __call__
## FlaxBloomForCausalLM
[[autodoc]] FlaxBloomForCausalLM
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/bloom.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/bloom.md",
"repo_id": "transformers",
"token_count": 1158
}
|
# Cohere
## Overview
[C4AI Command R7B](https://cohere.com/blog/command-r7b) is an open weights research release of a 7B billion parameter model developed by Cohere and Cohere For AI. It has advanced capabilities optimized for various use cases, including reasoning, summarization, question answering, and code. The model is trained to perform sophisticated tasks including Retrieval Augmented Generation (RAG) and tool use. The model also has powerful agentic capabilities that can use and combine multiple tools over multiple steps to accomplish more difficult tasks. It obtains top performance on enterprise-relevant code use cases. C4AI Command R7B is a multilingual model trained on 23 languages.
The model features three layers with sliding window attention (window size 4096) and ROPE for efficient local context modeling and relative positional encoding. A fourth layer uses global attention without positional embeddings, enabling unrestricted token interactions across the entire sequence.
The model has been trained on 23 languages: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, Chinese, Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, and Persian.
## Usage tips
The model and tokenizer can be loaded via:
```python
# pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "CohereForAI/c4ai-command-r7b-12-2024"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id)
# Format message with the command-r chat template
messages = [{"role": "user", "content": "Hello, how are you?"}]
input_ids = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
gen_tokens = model.generate(
input_ids,
max_new_tokens=100,
do_sample=True,
temperature=0.3,
)
gen_text = tokenizer.decode(gen_tokens[0])
print(gen_text)
```
## Cohere2Config
[[autodoc]] Cohere2Config
## Cohere2Model
[[autodoc]] Cohere2Model
- forward
## Cohere2ForCausalLM
[[autodoc]] Cohere2ForCausalLM
- forward
|
transformers/docs/source/en/model_doc/cohere2.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/cohere2.md",
"repo_id": "transformers",
"token_count": 601
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Decision Transformer
## Overview
The Decision Transformer model was proposed in [Decision Transformer: Reinforcement Learning via Sequence Modeling](https://arxiv.org/abs/2106.01345)
by Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, Igor Mordatch.
The abstract from the paper is the following:
*We introduce a framework that abstracts Reinforcement Learning (RL) as a sequence modeling problem.
This allows us to draw upon the simplicity and scalability of the Transformer architecture, and associated advances
in language modeling such as GPT-x and BERT. In particular, we present Decision Transformer, an architecture that
casts the problem of RL as conditional sequence modeling. Unlike prior approaches to RL that fit value functions or
compute policy gradients, Decision Transformer simply outputs the optimal actions by leveraging a causally masked
Transformer. By conditioning an autoregressive model on the desired return (reward), past states, and actions, our
Decision Transformer model can generate future actions that achieve the desired return. Despite its simplicity,
Decision Transformer matches or exceeds the performance of state-of-the-art model-free offline RL baselines on
Atari, OpenAI Gym, and Key-to-Door tasks.*
This version of the model is for tasks where the state is a vector.
This model was contributed by [edbeeching](https://huggingface.co/edbeeching). The original code can be found [here](https://github.com/kzl/decision-transformer).
## DecisionTransformerConfig
[[autodoc]] DecisionTransformerConfig
## DecisionTransformerGPT2Model
[[autodoc]] DecisionTransformerGPT2Model
- forward
## DecisionTransformerModel
[[autodoc]] DecisionTransformerModel
- forward
|
transformers/docs/source/en/model_doc/decision_transformer.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/decision_transformer.md",
"repo_id": "transformers",
"token_count": 639
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DPR
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=dpr">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-dpr-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/dpr-question_encoder-bert-base-multilingual">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
Dense Passage Retrieval (DPR) is a set of tools and models for state-of-the-art open-domain Q&A research. It was
introduced in [Dense Passage Retrieval for Open-Domain Question Answering](https://arxiv.org/abs/2004.04906) by
Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, Wen-tau Yih.
The abstract from the paper is the following:
*Open-domain question answering relies on efficient passage retrieval to select candidate contexts, where traditional
sparse vector space models, such as TF-IDF or BM25, are the de facto method. In this work, we show that retrieval can
be practically implemented using dense representations alone, where embeddings are learned from a small number of
questions and passages by a simple dual-encoder framework. When evaluated on a wide range of open-domain QA datasets,
our dense retriever outperforms a strong Lucene-BM25 system largely by 9%-19% absolute in terms of top-20 passage
retrieval accuracy, and helps our end-to-end QA system establish new state-of-the-art on multiple open-domain QA
benchmarks.*
This model was contributed by [lhoestq](https://huggingface.co/lhoestq). The original code can be found [here](https://github.com/facebookresearch/DPR).
## Usage tips
- DPR consists in three models:
* Question encoder: encode questions as vectors
* Context encoder: encode contexts as vectors
* Reader: extract the answer of the questions inside retrieved contexts, along with a relevance score (high if the inferred span actually answers the question).
## DPRConfig
[[autodoc]] DPRConfig
## DPRContextEncoderTokenizer
[[autodoc]] DPRContextEncoderTokenizer
## DPRContextEncoderTokenizerFast
[[autodoc]] DPRContextEncoderTokenizerFast
## DPRQuestionEncoderTokenizer
[[autodoc]] DPRQuestionEncoderTokenizer
## DPRQuestionEncoderTokenizerFast
[[autodoc]] DPRQuestionEncoderTokenizerFast
## DPRReaderTokenizer
[[autodoc]] DPRReaderTokenizer
## DPRReaderTokenizerFast
[[autodoc]] DPRReaderTokenizerFast
## DPR specific outputs
[[autodoc]] models.dpr.modeling_dpr.DPRContextEncoderOutput
[[autodoc]] models.dpr.modeling_dpr.DPRQuestionEncoderOutput
[[autodoc]] models.dpr.modeling_dpr.DPRReaderOutput
<frameworkcontent>
<pt>
## DPRContextEncoder
[[autodoc]] DPRContextEncoder
- forward
## DPRQuestionEncoder
[[autodoc]] DPRQuestionEncoder
- forward
## DPRReader
[[autodoc]] DPRReader
- forward
</pt>
<tf>
## TFDPRContextEncoder
[[autodoc]] TFDPRContextEncoder
- call
## TFDPRQuestionEncoder
[[autodoc]] TFDPRQuestionEncoder
- call
## TFDPRReader
[[autodoc]] TFDPRReader
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/dpr.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/dpr.md",
"repo_id": "transformers",
"token_count": 1170
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FLAN-UL2
## Overview
Flan-UL2 is an encoder decoder model based on the T5 architecture. It uses the same configuration as the [UL2](ul2) model released earlier last year.
It was fine tuned using the "Flan" prompt tuning and dataset collection. Similar to `Flan-T5`, one can directly use FLAN-UL2 weights without finetuning the model:
According to the original blog here are the notable improvements:
- The original UL2 model was only trained with receptive field of 512, which made it non-ideal for N-shot prompting where N is large.
- The Flan-UL2 checkpoint uses a receptive field of 2048 which makes it more usable for few-shot in-context learning.
- The original UL2 model also had mode switch tokens that was rather mandatory to get good performance. However, they were a little cumbersome as this requires often some changes during inference or finetuning. In this update/change, we continue training UL2 20B for an additional 100k steps (with small batch) to forget “mode tokens” before applying Flan instruction tuning. This Flan-UL2 checkpoint does not require mode tokens anymore.
Google has released the following variants:
The original checkpoints can be found [here](https://github.com/google-research/t5x/blob/main/docs/models.md#flan-ul2-checkpoints).
## Running on low resource devices
The model is pretty heavy (~40GB in half precision) so if you just want to run the model, make sure you load your model in 8bit, and use `device_map="auto"` to make sure you don't have any OOM issue!
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-ul2", load_in_8bit=True, device_map="auto")
>>> tokenizer = AutoTokenizer.from_pretrained("google/flan-ul2")
>>> inputs = tokenizer("A step by step recipe to make bolognese pasta:", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['In a large skillet, brown the ground beef and onion over medium heat. Add the garlic']
```
<Tip>
Refer to [T5's documentation page](t5) for API reference, tips, code examples and notebooks.
</Tip>
|
transformers/docs/source/en/model_doc/flan-ul2.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/flan-ul2.md",
"repo_id": "transformers",
"token_count": 785
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# I-BERT
## Overview
The I-BERT model was proposed in [I-BERT: Integer-only BERT Quantization](https://arxiv.org/abs/2101.01321) by
Sehoon Kim, Amir Gholami, Zhewei Yao, Michael W. Mahoney and Kurt Keutzer. It's a quantized version of RoBERTa running
inference up to four times faster.
The abstract from the paper is the following:
*Transformer based models, like BERT and RoBERTa, have achieved state-of-the-art results in many Natural Language
Processing tasks. However, their memory footprint, inference latency, and power consumption are prohibitive for
efficient inference at the edge, and even at the data center. While quantization can be a viable solution for this,
previous work on quantizing Transformer based models use floating-point arithmetic during inference, which cannot
efficiently utilize integer-only logical units such as the recent Turing Tensor Cores, or traditional integer-only ARM
processors. In this work, we propose I-BERT, a novel quantization scheme for Transformer based models that quantizes
the entire inference with integer-only arithmetic. Based on lightweight integer-only approximation methods for
nonlinear operations, e.g., GELU, Softmax, and Layer Normalization, I-BERT performs an end-to-end integer-only BERT
inference without any floating point calculation. We evaluate our approach on GLUE downstream tasks using
RoBERTa-Base/Large. We show that for both cases, I-BERT achieves similar (and slightly higher) accuracy as compared to
the full-precision baseline. Furthermore, our preliminary implementation of I-BERT shows a speedup of 2.4 - 4.0x for
INT8 inference on a T4 GPU system as compared to FP32 inference. The framework has been developed in PyTorch and has
been open-sourced.*
This model was contributed by [kssteven](https://huggingface.co/kssteven). The original code can be found [here](https://github.com/kssteven418/I-BERT).
## Resources
- [Text classification task guide](../tasks/sequence_classification)
- [Token classification task guide](../tasks/token_classification)
- [Question answering task guide](../tasks/question_answering)
- [Masked language modeling task guide](../tasks/masked_language_modeling)
- [Multiple choice task guide](../tasks/masked_language_modeling)
## IBertConfig
[[autodoc]] IBertConfig
## IBertModel
[[autodoc]] IBertModel
- forward
## IBertForMaskedLM
[[autodoc]] IBertForMaskedLM
- forward
## IBertForSequenceClassification
[[autodoc]] IBertForSequenceClassification
- forward
## IBertForMultipleChoice
[[autodoc]] IBertForMultipleChoice
- forward
## IBertForTokenClassification
[[autodoc]] IBertForTokenClassification
- forward
## IBertForQuestionAnswering
[[autodoc]] IBertForQuestionAnswering
- forward
|
transformers/docs/source/en/model_doc/ibert.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/ibert.md",
"repo_id": "transformers",
"token_count": 947
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LayoutXLM
## Overview
LayoutXLM was proposed in [LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding](https://arxiv.org/abs/2104.08836) by Yiheng Xu, Tengchao Lv, Lei Cui, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha
Zhang, Furu Wei. It's a multilingual extension of the [LayoutLMv2 model](https://arxiv.org/abs/2012.14740) trained
on 53 languages.
The abstract from the paper is the following:
*Multimodal pre-training with text, layout, and image has achieved SOTA performance for visually-rich document
understanding tasks recently, which demonstrates the great potential for joint learning across different modalities. In
this paper, we present LayoutXLM, a multimodal pre-trained model for multilingual document understanding, which aims to
bridge the language barriers for visually-rich document understanding. To accurately evaluate LayoutXLM, we also
introduce a multilingual form understanding benchmark dataset named XFUN, which includes form understanding samples in
7 languages (Chinese, Japanese, Spanish, French, Italian, German, Portuguese), and key-value pairs are manually labeled
for each language. Experiment results show that the LayoutXLM model has significantly outperformed the existing SOTA
cross-lingual pre-trained models on the XFUN dataset.*
This model was contributed by [nielsr](https://huggingface.co/nielsr). The original code can be found [here](https://github.com/microsoft/unilm).
## Usage tips and examples
One can directly plug in the weights of LayoutXLM into a LayoutLMv2 model, like so:
```python
from transformers import LayoutLMv2Model
model = LayoutLMv2Model.from_pretrained("microsoft/layoutxlm-base")
```
Note that LayoutXLM has its own tokenizer, based on
[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`]. You can initialize it as
follows:
```python
from transformers import LayoutXLMTokenizer
tokenizer = LayoutXLMTokenizer.from_pretrained("microsoft/layoutxlm-base")
```
Similar to LayoutLMv2, you can use [`LayoutXLMProcessor`] (which internally applies
[`LayoutLMv2ImageProcessor`] and
[`LayoutXLMTokenizer`]/[`LayoutXLMTokenizerFast`] in sequence) to prepare all
data for the model.
<Tip>
As LayoutXLM's architecture is equivalent to that of LayoutLMv2, one can refer to [LayoutLMv2's documentation page](layoutlmv2) for all tips, code examples and notebooks.
</Tip>
## LayoutXLMTokenizer
[[autodoc]] LayoutXLMTokenizer
- __call__
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## LayoutXLMTokenizerFast
[[autodoc]] LayoutXLMTokenizerFast
- __call__
## LayoutXLMProcessor
[[autodoc]] LayoutXLMProcessor
- __call__
|
transformers/docs/source/en/model_doc/layoutxlm.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/layoutxlm.md",
"repo_id": "transformers",
"token_count": 981
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MADLAD-400
## Overview
MADLAD-400 models were released in the paper [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](MADLAD-400: A Multilingual And Document-Level Large Audited Dataset).
The abstract from the paper is the following:
*We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss
the limitations revealed by self-auditing MADLAD-400, and the role data auditing
had in the dataset creation process. We then train and release a 10.7B-parameter
multilingual machine translation model on 250 billion tokens covering over 450
languages using publicly available data, and find that it is competitive with models
that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot
translation. We make the baseline models 1
available to the research community.*
This model was added by [Juarez Bochi](https://huggingface.co/jbochi). The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
This is a machine translation model that supports many low-resource languages, and that is competitive with models that are significantly larger.
One can directly use MADLAD-400 weights without finetuning the model:
```python
>>> from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
>>> model = AutoModelForSeq2SeqLM.from_pretrained("google/madlad400-3b-mt")
>>> tokenizer = AutoTokenizer.from_pretrained("google/madlad400-3b-mt")
>>> inputs = tokenizer("<2pt> I love pizza!", return_tensors="pt")
>>> outputs = model.generate(**inputs)
>>> print(tokenizer.batch_decode(outputs, skip_special_tokens=True))
['Eu amo pizza!']
```
Google has released the following variants:
- [google/madlad400-3b-mt](https://huggingface.co/google/madlad400-3b-mt)
- [google/madlad400-7b-mt](https://huggingface.co/google/madlad400-7b-mt)
- [google/madlad400-7b-mt-bt](https://huggingface.co/google/madlad400-7b-mt-bt)
- [google/madlad400-10b-mt](https://huggingface.co/google/madlad400-10b-mt)
The original checkpoints can be found [here](https://github.com/google-research/google-research/tree/master/madlad_400).
<Tip>
Refer to [T5's documentation page](t5) for all API references, code examples, and notebooks. For more details regarding training and evaluation of the MADLAD-400, refer to the model card.
</Tip>
|
transformers/docs/source/en/model_doc/madlad-400.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/madlad-400.md",
"repo_id": "transformers",
"token_count": 930
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# MusicGen
## Overview
The MusicGen model was proposed in the paper [Simple and Controllable Music Generation](https://arxiv.org/abs/2306.05284)
by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned
on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a
sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or *audio codes*,
conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec,
to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of
the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g.
hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
The abstract from the paper is the following:
*We tackle the task of conditional music generation. We introduce MusicGen, a single Language Model (LM) that operates
over several streams of compressed discrete music representation, i.e., tokens. Unlike prior work, MusicGen is comprised
of a single-stage transformer LM together with efficient token interleaving patterns, which eliminates the need for
cascading several models, e.g., hierarchically or upsampling. Following this approach, we demonstrate how MusicGen
can generate high-quality samples, while being conditioned on textual description or melodic features, allowing better
controls over the generated output. We conduct extensive empirical evaluation, considering both automatic and human
studies, showing the proposed approach is superior to the evaluated baselines on a standard text-to-music benchmark.
Through ablation studies, we shed light over the importance of each of the components comprising MusicGen.*
This model was contributed by [sanchit-gandhi](https://huggingface.co/sanchit-gandhi). The original code can be found
[here](https://github.com/facebookresearch/audiocraft). The pre-trained checkpoints can be found on the
[Hugging Face Hub](https://huggingface.co/models?sort=downloads&search=facebook%2Fmusicgen-).
## Usage tips
- After downloading the original checkpoints from [here](https://github.com/facebookresearch/audiocraft/blob/main/docs/MUSICGEN.md#importing--exporting-models) , you can convert them using the **conversion script** available at
`src/transformers/models/musicgen/convert_musicgen_transformers.py` with the following command:
```bash
python src/transformers/models/musicgen/convert_musicgen_transformers.py \
--checkpoint small --pytorch_dump_folder /output/path --safe_serialization
```
## Generation
MusicGen is compatible with two generation modes: greedy and sampling. In practice, sampling leads to significantly
better results than greedy, thus we encourage sampling mode to be used where possible. Sampling is enabled by default,
and can be explicitly specified by setting `do_sample=True` in the call to [`MusicgenForConditionalGeneration.generate`],
or by overriding the model's generation config (see below).
Generation is limited by the sinusoidal positional embeddings to 30 second inputs. Meaning, MusicGen cannot generate more
than 30 seconds of audio (1503 tokens), and input audio passed by Audio-Prompted Generation contributes to this limit so,
given an input of 20 seconds of audio, MusicGen cannot generate more than 10 seconds of additional audio.
Transformers supports both mono (1-channel) and stereo (2-channel) variants of MusicGen. The mono channel versions
generate a single set of codebooks. The stereo versions generate 2 sets of codebooks, 1 for each channel (left/right),
and each set of codebooks is decoded independently through the audio compression model. The audio streams for each
channel are combined to give the final stereo output.
### Unconditional Generation
The inputs for unconditional (or 'null') generation can be obtained through the method
[`MusicgenForConditionalGeneration.get_unconditional_inputs`]:
```python
>>> from transformers import MusicgenForConditionalGeneration
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> unconditional_inputs = model.get_unconditional_inputs(num_samples=1)
>>> audio_values = model.generate(**unconditional_inputs, do_sample=True, max_new_tokens=256)
```
The audio outputs are a three-dimensional Torch tensor of shape `(batch_size, num_channels, sequence_length)`. To listen
to the generated audio samples, you can either play them in an ipynb notebook:
```python
from IPython.display import Audio
sampling_rate = model.config.audio_encoder.sampling_rate
Audio(audio_values[0].numpy(), rate=sampling_rate)
```
Or save them as a `.wav` file using a third-party library, e.g. `scipy`:
```python
>>> import scipy
>>> sampling_rate = model.config.audio_encoder.sampling_rate
>>> scipy.io.wavfile.write("musicgen_out.wav", rate=sampling_rate, data=audio_values[0, 0].numpy())
```
### Text-Conditional Generation
The model can generate an audio sample conditioned on a text prompt through use of the [`MusicgenProcessor`] to pre-process
the inputs:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> inputs = processor(
... text=["80s pop track with bassy drums and synth", "90s rock song with loud guitars and heavy drums"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
```
The `guidance_scale` is used in classifier free guidance (CFG), setting the weighting between the conditional logits
(which are predicted from the text prompts) and the unconditional logits (which are predicted from an unconditional or
'null' prompt). Higher guidance scale encourages the model to generate samples that are more closely linked to the input
prompt, usually at the expense of poorer audio quality. CFG is enabled by setting `guidance_scale > 1`. For best results,
use `guidance_scale=3` (default).
### Audio-Prompted Generation
The same [`MusicgenProcessor`] can be used to pre-process an audio prompt that is used for audio continuation. In the
following example, we load an audio file using the 🤗 Datasets library, which can be pip installed through the command
below:
```bash
pip install --upgrade pip
pip install datasets[audio]
```
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> from datasets import load_dataset
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
>>> sample = next(iter(dataset))["audio"]
>>> # take the first half of the audio sample
>>> sample["array"] = sample["array"][: len(sample["array"]) // 2]
>>> inputs = processor(
... audio=sample["array"],
... sampling_rate=sample["sampling_rate"],
... text=["80s blues track with groovy saxophone"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
```
For batched audio-prompted generation, the generated `audio_values` can be post-processed to remove padding by using the
[`MusicgenProcessor`] class:
```python
>>> from transformers import AutoProcessor, MusicgenForConditionalGeneration
>>> from datasets import load_dataset
>>> processor = AutoProcessor.from_pretrained("facebook/musicgen-small")
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> dataset = load_dataset("sanchit-gandhi/gtzan", split="train", streaming=True)
>>> sample = next(iter(dataset))["audio"]
>>> # take the first quarter of the audio sample
>>> sample_1 = sample["array"][: len(sample["array"]) // 4]
>>> # take the first half of the audio sample
>>> sample_2 = sample["array"][: len(sample["array"]) // 2]
>>> inputs = processor(
... audio=[sample_1, sample_2],
... sampling_rate=sample["sampling_rate"],
... text=["80s blues track with groovy saxophone", "90s rock song with loud guitars and heavy drums"],
... padding=True,
... return_tensors="pt",
... )
>>> audio_values = model.generate(**inputs, do_sample=True, guidance_scale=3, max_new_tokens=256)
>>> # post-process to remove padding from the batched audio
>>> audio_values = processor.batch_decode(audio_values, padding_mask=inputs.padding_mask)
```
### Generation Configuration
The default parameters that control the generation process, such as sampling, guidance scale and number of generated
tokens, can be found in the model's generation config, and updated as desired:
```python
>>> from transformers import MusicgenForConditionalGeneration
>>> model = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small")
>>> # inspect the default generation config
>>> model.generation_config
>>> # increase the guidance scale to 4.0
>>> model.generation_config.guidance_scale = 4.0
>>> # decrease the max length to 256 tokens
>>> model.generation_config.max_length = 256
```
Note that any arguments passed to the generate method will **supersede** those in the generation config, so setting
`do_sample=False` in the call to generate will supersede the setting of `model.generation_config.do_sample` in the
generation config.
## Model Structure
The MusicGen model can be de-composed into three distinct stages:
1. Text encoder: maps the text inputs to a sequence of hidden-state representations. The pre-trained MusicGen models use a frozen text encoder from either T5 or Flan-T5
2. MusicGen decoder: a language model (LM) that auto-regressively generates audio tokens (or codes) conditional on the encoder hidden-state representations
3. Audio encoder/decoder: used to encode an audio prompt to use as prompt tokens, and recover the audio waveform from the audio tokens predicted by the decoder
Thus, the MusicGen model can either be used as a standalone decoder model, corresponding to the class [`MusicgenForCausalLM`],
or as a composite model that includes the text encoder and audio encoder/decoder, corresponding to the class
[`MusicgenForConditionalGeneration`]. If only the decoder needs to be loaded from the pre-trained checkpoint, it can be loaded by first
specifying the correct config, or be accessed through the `.decoder` attribute of the composite model:
```python
>>> from transformers import AutoConfig, MusicgenForCausalLM, MusicgenForConditionalGeneration
>>> # Option 1: get decoder config and pass to `.from_pretrained`
>>> decoder_config = AutoConfig.from_pretrained("facebook/musicgen-small").decoder
>>> decoder = MusicgenForCausalLM.from_pretrained("facebook/musicgen-small", **decoder_config)
>>> # Option 2: load the entire composite model, but only return the decoder
>>> decoder = MusicgenForConditionalGeneration.from_pretrained("facebook/musicgen-small").decoder
```
Since the text encoder and audio encoder/decoder models are frozen during training, the MusicGen decoder [`MusicgenForCausalLM`]
can be trained standalone on a dataset of encoder hidden-states and audio codes. For inference, the trained decoder can
be combined with the frozen text encoder and audio encoder/decoders to recover the composite [`MusicgenForConditionalGeneration`]
model.
Tips:
* MusicGen is trained on the 32kHz checkpoint of Encodec. You should ensure you use a compatible version of the Encodec model.
* Sampling mode tends to deliver better results than greedy - you can toggle sampling with the variable `do_sample` in the call to [`MusicgenForConditionalGeneration.generate`]
## MusicgenDecoderConfig
[[autodoc]] MusicgenDecoderConfig
## MusicgenConfig
[[autodoc]] MusicgenConfig
## MusicgenProcessor
[[autodoc]] MusicgenProcessor
## MusicgenModel
[[autodoc]] MusicgenModel
- forward
## MusicgenForCausalLM
[[autodoc]] MusicgenForCausalLM
- forward
## MusicgenForConditionalGeneration
[[autodoc]] MusicgenForConditionalGeneration
- forward
|
transformers/docs/source/en/model_doc/musicgen.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/musicgen.md",
"repo_id": "transformers",
"token_count": 3592
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Open-Llama
<Tip warning={true}>
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.31.0.
You can do so by running the following command: `pip install -U transformers==4.31.0`.
</Tip>
<Tip warning={true}>
This model differs from the [OpenLLaMA models](https://huggingface.co/models?search=openllama) on the Hugging Face Hub, which primarily use the [LLaMA](llama) architecture.
</Tip>
## Overview
The Open-Llama model was proposed in the open source Open-Llama project by community developer s-JoL.
The model is mainly based on LLaMA with some modifications, incorporating memory-efficient attention from Xformers, stable embedding from Bloom, and shared input-output embedding from PaLM.
And the model is pre-trained on both Chinese and English, which gives it better performance on Chinese language tasks.
This model was contributed by [s-JoL](https://huggingface.co/s-JoL).
The original code was released on GitHub by [s-JoL](https://github.com/s-JoL), but is now removed.
## OpenLlamaConfig
[[autodoc]] OpenLlamaConfig
## OpenLlamaModel
[[autodoc]] OpenLlamaModel
- forward
## OpenLlamaForCausalLM
[[autodoc]] OpenLlamaForCausalLM
- forward
## OpenLlamaForSequenceClassification
[[autodoc]] OpenLlamaForSequenceClassification
- forward
|
transformers/docs/source/en/model_doc/open-llama.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/open-llama.md",
"repo_id": "transformers",
"token_count": 620
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# RecurrentGemma
## Overview
The Recurrent Gemma model was proposed in [RecurrentGemma: Moving Past Transformers for Efficient Open Language Models](https://storage.googleapis.com/deepmind-media/gemma/recurrentgemma-report.pdf) by the Griffin, RLHF and Gemma Teams of Google.
The abstract from the paper is the following:
*We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.*
Tips:
- The original checkpoints can be converted using the conversion script [`src/transformers/models/recurrent_gemma/convert_recurrent_gemma_weights_to_hf.py`](https://github.com/huggingface/transformers/blob/main/src/transformers/models/recurrent_gemma/convert_recurrent_gemma_to_hf.py).
This model was contributed by [Arthur Zucker](https://huggingface.co/ArthurZ). The original code can be found [here](https://github.com/google-deepmind/recurrentgemma).
## RecurrentGemmaConfig
[[autodoc]] RecurrentGemmaConfig
## RecurrentGemmaModel
[[autodoc]] RecurrentGemmaModel
- forward
## RecurrentGemmaForCausalLM
[[autodoc]] RecurrentGemmaForCausalLM
- forward
|
transformers/docs/source/en/model_doc/recurrent_gemma.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/recurrent_gemma.md",
"repo_id": "transformers",
"token_count": 608
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# SegFormer
## Overview
The SegFormer model was proposed in [SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers](https://arxiv.org/abs/2105.15203) by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping
Luo. The model consists of a hierarchical Transformer encoder and a lightweight all-MLP decode head to achieve great
results on image segmentation benchmarks such as ADE20K and Cityscapes.
The abstract from the paper is the following:
*We present SegFormer, a simple, efficient yet powerful semantic segmentation framework which unifies Transformers with
lightweight multilayer perception (MLP) decoders. SegFormer has two appealing features: 1) SegFormer comprises a novel
hierarchically structured Transformer encoder which outputs multiscale features. It does not need positional encoding,
thereby avoiding the interpolation of positional codes which leads to decreased performance when the testing resolution
differs from training. 2) SegFormer avoids complex decoders. The proposed MLP decoder aggregates information from
different layers, and thus combining both local attention and global attention to render powerful representations. We
show that this simple and lightweight design is the key to efficient segmentation on Transformers. We scale our
approach up to obtain a series of models from SegFormer-B0 to SegFormer-B5, reaching significantly better performance
and efficiency than previous counterparts. For example, SegFormer-B4 achieves 50.3% mIoU on ADE20K with 64M parameters,
being 5x smaller and 2.2% better than the previous best method. Our best model, SegFormer-B5, achieves 84.0% mIoU on
Cityscapes validation set and shows excellent zero-shot robustness on Cityscapes-C.*
The figure below illustrates the architecture of SegFormer. Taken from the [original paper](https://arxiv.org/abs/2105.15203).
<img width="600" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/segformer_architecture.png"/>
This model was contributed by [nielsr](https://huggingface.co/nielsr). The TensorFlow version
of the model was contributed by [sayakpaul](https://huggingface.co/sayakpaul). The original code can be found [here](https://github.com/NVlabs/SegFormer).
## Usage tips
- SegFormer consists of a hierarchical Transformer encoder, and a lightweight all-MLP decoder head.
[`SegformerModel`] is the hierarchical Transformer encoder (which in the paper is also referred to
as Mix Transformer or MiT). [`SegformerForSemanticSegmentation`] adds the all-MLP decoder head on
top to perform semantic segmentation of images. In addition, there's
[`SegformerForImageClassification`] which can be used to - you guessed it - classify images. The
authors of SegFormer first pre-trained the Transformer encoder on ImageNet-1k to classify images. Next, they throw
away the classification head, and replace it by the all-MLP decode head. Next, they fine-tune the model altogether on
ADE20K, Cityscapes and COCO-stuff, which are important benchmarks for semantic segmentation. All checkpoints can be
found on the [hub](https://huggingface.co/models?other=segformer).
- The quickest way to get started with SegFormer is by checking the [example notebooks](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer) (which showcase both inference and
fine-tuning on custom data). One can also check out the [blog post](https://huggingface.co/blog/fine-tune-segformer) introducing SegFormer and illustrating how it can be fine-tuned on custom data.
- TensorFlow users should refer to [this repository](https://github.com/deep-diver/segformer-tf-transformers) that shows off-the-shelf inference and fine-tuning.
- One can also check out [this interactive demo on Hugging Face Spaces](https://huggingface.co/spaces/chansung/segformer-tf-transformers)
to try out a SegFormer model on custom images.
- SegFormer works on any input size, as it pads the input to be divisible by `config.patch_sizes`.
- One can use [`SegformerImageProcessor`] to prepare images and corresponding segmentation maps
for the model. Note that this image processor is fairly basic and does not include all data augmentations used in
the original paper. The original preprocessing pipelines (for the ADE20k dataset for instance) can be found [here](https://github.com/NVlabs/SegFormer/blob/master/local_configs/_base_/datasets/ade20k_repeat.py). The most
important preprocessing step is that images and segmentation maps are randomly cropped and padded to the same size,
such as 512x512 or 640x640, after which they are normalized.
- One additional thing to keep in mind is that one can initialize [`SegformerImageProcessor`] with
`do_reduce_labels` set to `True` or `False`. In some datasets (like ADE20k), the 0 index is used in the annotated
segmentation maps for background. However, ADE20k doesn't include the "background" class in its 150 labels.
Therefore, `do_reduce_labels` is used to reduce all labels by 1, and to make sure no loss is computed for the
background class (i.e. it replaces 0 in the annotated maps by 255, which is the *ignore_index* of the loss function
used by [`SegformerForSemanticSegmentation`]). However, other datasets use the 0 index as
background class and include this class as part of all labels. In that case, `do_reduce_labels` should be set to
`False`, as loss should also be computed for the background class.
- As most models, SegFormer comes in different sizes, the details of which can be found in the table below
(taken from Table 7 of the [original paper](https://arxiv.org/abs/2105.15203)).
| **Model variant** | **Depths** | **Hidden sizes** | **Decoder hidden size** | **Params (M)** | **ImageNet-1k Top 1** |
| :---------------: | ------------- | ------------------- | :---------------------: | :------------: | :-------------------: |
| MiT-b0 | [2, 2, 2, 2] | [32, 64, 160, 256] | 256 | 3.7 | 70.5 |
| MiT-b1 | [2, 2, 2, 2] | [64, 128, 320, 512] | 256 | 14.0 | 78.7 |
| MiT-b2 | [3, 4, 6, 3] | [64, 128, 320, 512] | 768 | 25.4 | 81.6 |
| MiT-b3 | [3, 4, 18, 3] | [64, 128, 320, 512] | 768 | 45.2 | 83.1 |
| MiT-b4 | [3, 8, 27, 3] | [64, 128, 320, 512] | 768 | 62.6 | 83.6 |
| MiT-b5 | [3, 6, 40, 3] | [64, 128, 320, 512] | 768 | 82.0 | 83.8 |
Note that MiT in the above table refers to the Mix Transformer encoder backbone introduced in SegFormer. For
SegFormer's results on the segmentation datasets like ADE20k, refer to the [paper](https://arxiv.org/abs/2105.15203).
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with SegFormer.
<PipelineTag pipeline="image-classification"/>
- [`SegformerForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- [Image classification task guide](../tasks/image_classification)
Semantic segmentation:
- [`SegformerForSemanticSegmentation`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/semantic-segmentation).
- A blog on fine-tuning SegFormer on a custom dataset can be found [here](https://huggingface.co/blog/fine-tune-segformer).
- More demo notebooks on SegFormer (both inference + fine-tuning on a custom dataset) can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/SegFormer).
- [`TFSegformerForSemanticSegmentation`] is supported by this [example notebook](https://github.com/huggingface/notebooks/blob/main/examples/semantic_segmentation-tf.ipynb).
- [Semantic segmentation task guide](../tasks/semantic_segmentation)
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SegformerConfig
[[autodoc]] SegformerConfig
## SegformerFeatureExtractor
[[autodoc]] SegformerFeatureExtractor
- __call__
- post_process_semantic_segmentation
## SegformerImageProcessor
[[autodoc]] SegformerImageProcessor
- preprocess
- post_process_semantic_segmentation
<frameworkcontent>
<pt>
## SegformerModel
[[autodoc]] SegformerModel
- forward
## SegformerDecodeHead
[[autodoc]] SegformerDecodeHead
- forward
## SegformerForImageClassification
[[autodoc]] SegformerForImageClassification
- forward
## SegformerForSemanticSegmentation
[[autodoc]] SegformerForSemanticSegmentation
- forward
</pt>
<tf>
## TFSegformerDecodeHead
[[autodoc]] TFSegformerDecodeHead
- call
## TFSegformerModel
[[autodoc]] TFSegformerModel
- call
## TFSegformerForImageClassification
[[autodoc]] TFSegformerForImageClassification
- call
## TFSegformerForSemanticSegmentation
[[autodoc]] TFSegformerForSemanticSegmentation
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/segformer.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/segformer.md",
"repo_id": "transformers",
"token_count": 3183
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Swin Transformer
## Overview
The Swin Transformer was proposed in [Swin Transformer: Hierarchical Vision Transformer using Shifted Windows](https://arxiv.org/abs/2103.14030)
by Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo.
The abstract from the paper is the following:
*This paper presents a new vision Transformer, called Swin Transformer, that capably serves as a general-purpose backbone
for computer vision. Challenges in adapting Transformer from language to vision arise from differences between the two domains,
such as large variations in the scale of visual entities and the high resolution of pixels in images compared to words in text.
To address these differences, we propose a hierarchical Transformer whose representation is computed with \bold{S}hifted
\bold{win}dows. The shifted windowing scheme brings greater efficiency by limiting self-attention computation to non-overlapping
local windows while also allowing for cross-window connection. This hierarchical architecture has the flexibility to model at
various scales and has linear computational complexity with respect to image size. These qualities of Swin Transformer make it
compatible with a broad range of vision tasks, including image classification (87.3 top-1 accuracy on ImageNet-1K) and dense
prediction tasks such as object detection (58.7 box AP and 51.1 mask AP on COCO test-dev) and semantic segmentation
(53.5 mIoU on ADE20K val). Its performance surpasses the previous state-of-the-art by a large margin of +2.7 box AP and
+2.6 mask AP on COCO, and +3.2 mIoU on ADE20K, demonstrating the potential of Transformer-based models as vision backbones.
The hierarchical design and the shifted window approach also prove beneficial for all-MLP architectures.*
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/swin_transformer_architecture.png"
alt="drawing" width="600"/>
<small> Swin Transformer architecture. Taken from the <a href="https://arxiv.org/abs/2102.03334">original paper</a>.</small>
This model was contributed by [novice03](https://huggingface.co/novice03). The Tensorflow version of this model was contributed by [amyeroberts](https://huggingface.co/amyeroberts). The original code can be found [here](https://github.com/microsoft/Swin-Transformer).
## Usage tips
- Swin pads the inputs supporting any input height and width (if divisible by `32`).
- Swin can be used as a *backbone*. When `output_hidden_states = True`, it will output both `hidden_states` and `reshaped_hidden_states`. The `reshaped_hidden_states` have a shape of `(batch, num_channels, height, width)` rather than `(batch_size, sequence_length, num_channels)`.
## Resources
A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with Swin Transformer.
<PipelineTag pipeline="image-classification"/>
- [`SwinForImageClassification`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) and [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb).
- See also: [Image classification task guide](../tasks/image_classification)
Besides that:
- [`SwinForMaskedImageModeling`] is supported by this [example script](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining).
If you're interested in submitting a resource to be included here, please feel free to open a Pull Request and we'll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
## SwinConfig
[[autodoc]] SwinConfig
<frameworkcontent>
<pt>
## SwinModel
[[autodoc]] SwinModel
- forward
## SwinForMaskedImageModeling
[[autodoc]] SwinForMaskedImageModeling
- forward
## SwinForImageClassification
[[autodoc]] transformers.SwinForImageClassification
- forward
</pt>
<tf>
## TFSwinModel
[[autodoc]] TFSwinModel
- call
## TFSwinForMaskedImageModeling
[[autodoc]] TFSwinForMaskedImageModeling
- call
## TFSwinForImageClassification
[[autodoc]] transformers.TFSwinForImageClassification
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/en/model_doc/swin.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/swin.md",
"repo_id": "transformers",
"token_count": 1394
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TVLT
<Tip warning={true}>
This model is in maintenance mode only, we don't accept any new PRs changing its code.
If you run into any issues running this model, please reinstall the last version that supported this model: v4.40.2.
You can do so by running the following command: `pip install -U transformers==4.40.2`.
</Tip>
## Overview
The TVLT model was proposed in [TVLT: Textless Vision-Language Transformer](https://arxiv.org/abs/2209.14156)
by Zineng Tang, Jaemin Cho, Yixin Nie, Mohit Bansal (the first three authors contributed equally). The Textless Vision-Language Transformer (TVLT) is a model that uses raw visual and audio inputs for vision-and-language representation learning, without using text-specific modules such as tokenization or automatic speech recognition (ASR). It can perform various audiovisual and vision-language tasks like retrieval, question answering, etc.
The abstract from the paper is the following:
*In this work, we present the Textless Vision-Language Transformer (TVLT), where homogeneous transformer blocks take raw visual and audio inputs for vision-and-language representation learning with minimal modality-specific design, and do not use text-specific modules such as tokenization or automatic speech recognition (ASR). TVLT is trained by reconstructing masked patches of continuous video frames and audio spectrograms (masked autoencoding) and contrastive modeling to align video and audio. TVLT attains performance comparable to its text-based counterpart on various multimodal tasks, such as visual question answering, image retrieval, video retrieval, and multimodal sentiment analysis, with 28x faster inference speed and only 1/3 of the parameters. Our findings suggest the possibility of learning compact and efficient visual-linguistic representations from low-level visual and audio signals without assuming the prior existence of text.*
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/model_doc/tvlt_architecture.png"
alt="drawing" width="600"/>
</p>
<small> TVLT architecture. Taken from the <a href="[https://arxiv.org/abs/2102.03334](https://arxiv.org/abs/2209.14156)">original paper</a>. </small>
The original code can be found [here](https://github.com/zinengtang/TVLT). This model was contributed by [Zineng Tang](https://huggingface.co/ZinengTang).
## Usage tips
- TVLT is a model that takes both `pixel_values` and `audio_values` as input. One can use [`TvltProcessor`] to prepare data for the model.
This processor wraps an image processor (for the image/video modality) and an audio feature extractor (for the audio modality) into one.
- TVLT is trained with images/videos and audios of various sizes: the authors resize and crop the input images/videos to 224 and limit the length of audio spectrogram to 2048. To make batching of videos and audios possible, the authors use a `pixel_mask` that indicates which pixels are real/padding and `audio_mask` that indicates which audio values are real/padding.
- The design of TVLT is very similar to that of a standard Vision Transformer (ViT) and masked autoencoder (MAE) as in [ViTMAE](vitmae). The difference is that the model includes embedding layers for the audio modality.
- The PyTorch version of this model is only available in torch 1.10 and higher.
## TvltConfig
[[autodoc]] TvltConfig
## TvltProcessor
[[autodoc]] TvltProcessor
- __call__
## TvltImageProcessor
[[autodoc]] TvltImageProcessor
- preprocess
## TvltFeatureExtractor
[[autodoc]] TvltFeatureExtractor
- __call__
## TvltModel
[[autodoc]] TvltModel
- forward
## TvltForPreTraining
[[autodoc]] TvltForPreTraining
- forward
## TvltForAudioVisualClassification
[[autodoc]] TvltForAudioVisualClassification
- forward
|
transformers/docs/source/en/model_doc/tvlt.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/tvlt.md",
"repo_id": "transformers",
"token_count": 1236
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# VisualBERT
## Overview
The VisualBERT model was proposed in [VisualBERT: A Simple and Performant Baseline for Vision and Language](https://arxiv.org/pdf/1908.03557) by Liunian Harold Li, Mark Yatskar, Da Yin, Cho-Jui Hsieh, Kai-Wei Chang.
VisualBERT is a neural network trained on a variety of (image, text) pairs.
The abstract from the paper is the following:
*We propose VisualBERT, a simple and flexible framework for modeling a broad range of vision-and-language tasks.
VisualBERT consists of a stack of Transformer layers that implicitly align elements of an input text and regions in an
associated input image with self-attention. We further propose two visually-grounded language model objectives for
pre-training VisualBERT on image caption data. Experiments on four vision-and-language tasks including VQA, VCR, NLVR2,
and Flickr30K show that VisualBERT outperforms or rivals with state-of-the-art models while being significantly
simpler. Further analysis demonstrates that VisualBERT can ground elements of language to image regions without any
explicit supervision and is even sensitive to syntactic relationships, tracking, for example, associations between
verbs and image regions corresponding to their arguments.*
This model was contributed by [gchhablani](https://huggingface.co/gchhablani). The original code can be found [here](https://github.com/uclanlp/visualbert).
## Usage tips
1. Most of the checkpoints provided work with the [`VisualBertForPreTraining`] configuration. Other
checkpoints provided are the fine-tuned checkpoints for down-stream tasks - VQA ('visualbert-vqa'), VCR
('visualbert-vcr'), NLVR2 ('visualbert-nlvr2'). Hence, if you are not working on these downstream tasks, it is
recommended that you use the pretrained checkpoints.
2. For the VCR task, the authors use a fine-tuned detector for generating visual embeddings, for all the checkpoints.
We do not provide the detector and its weights as a part of the package, but it will be available in the research
projects, and the states can be loaded directly into the detector provided.
VisualBERT is a multi-modal vision and language model. It can be used for visual question answering, multiple choice,
visual reasoning and region-to-phrase correspondence tasks. VisualBERT uses a BERT-like transformer to prepare
embeddings for image-text pairs. Both the text and visual features are then projected to a latent space with identical
dimension.
To feed images to the model, each image is passed through a pre-trained object detector and the regions and the
bounding boxes are extracted. The authors use the features generated after passing these regions through a pre-trained
CNN like ResNet as visual embeddings. They also add absolute position embeddings, and feed the resulting sequence of
vectors to a standard BERT model. The text input is concatenated in the front of the visual embeddings in the embedding
layer, and is expected to be bound by [CLS] and a [SEP] tokens, as in BERT. The segment IDs must also be set
appropriately for the textual and visual parts.
The [`BertTokenizer`] is used to encode the text. A custom detector/image processor must be used
to get the visual embeddings. The following example notebooks show how to use VisualBERT with Detectron-like models:
- [VisualBERT VQA demo notebook](https://github.com/huggingface/transformers/tree/main/examples/research_projects/visual_bert) : This notebook
contains an example on VisualBERT VQA.
- [Generate Embeddings for VisualBERT (Colab Notebook)](https://colab.research.google.com/drive/1bLGxKdldwqnMVA5x4neY7-l_8fKGWQYI?usp=sharing) : This notebook contains
an example on how to generate visual embeddings.
The following example shows how to get the last hidden state using [`VisualBertModel`]:
```python
>>> import torch
>>> from transformers import BertTokenizer, VisualBertModel
>>> model = VisualBertModel.from_pretrained("uclanlp/visualbert-vqa-coco-pre")
>>> tokenizer = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
>>> inputs = tokenizer("What is the man eating?", return_tensors="pt")
>>> # this is a custom function that returns the visual embeddings given the image path
>>> visual_embeds = get_visual_embeddings(image_path)
>>> visual_token_type_ids = torch.ones(visual_embeds.shape[:-1], dtype=torch.long)
>>> visual_attention_mask = torch.ones(visual_embeds.shape[:-1], dtype=torch.float)
>>> inputs.update(
... {
... "visual_embeds": visual_embeds,
... "visual_token_type_ids": visual_token_type_ids,
... "visual_attention_mask": visual_attention_mask,
... }
... )
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
```
## VisualBertConfig
[[autodoc]] VisualBertConfig
## VisualBertModel
[[autodoc]] VisualBertModel
- forward
## VisualBertForPreTraining
[[autodoc]] VisualBertForPreTraining
- forward
## VisualBertForQuestionAnswering
[[autodoc]] VisualBertForQuestionAnswering
- forward
## VisualBertForMultipleChoice
[[autodoc]] VisualBertForMultipleChoice
- forward
## VisualBertForVisualReasoning
[[autodoc]] VisualBertForVisualReasoning
- forward
## VisualBertForRegionToPhraseAlignment
[[autodoc]] VisualBertForRegionToPhraseAlignment
- forward
|
transformers/docs/source/en/model_doc/visual_bert.md/0
|
{
"file_path": "transformers/docs/source/en/model_doc/visual_bert.md",
"repo_id": "transformers",
"token_count": 1680
}
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Model training anatomy
To understand performance optimization techniques that one can apply to improve efficiency of model training
speed and memory utilization, it's helpful to get familiar with how GPU is utilized during training, and how compute
intensity varies depending on an operation performed.
Let's start by exploring a motivating example of GPU utilization and the training run of a model. For the demonstration,
we'll need to install a few libraries:
```bash
pip install transformers datasets accelerate nvidia-ml-py3
```
The `nvidia-ml-py3` library allows us to monitor the memory usage of the models from within Python. You might be familiar
with the `nvidia-smi` command in the terminal - this library allows to access the same information in Python directly.
Then, we create some dummy data: random token IDs between 100 and 30000 and binary labels for a classifier.
In total, we get 512 sequences each with length 512 and store them in a [`~datasets.Dataset`] with PyTorch format.
```py
>>> import numpy as np
>>> from datasets import Dataset
>>> seq_len, dataset_size = 512, 512
>>> dummy_data = {
... "input_ids": np.random.randint(100, 30000, (dataset_size, seq_len)),
... "labels": np.random.randint(0, 2, (dataset_size)),
... }
>>> ds = Dataset.from_dict(dummy_data)
>>> ds.set_format("pt")
```
To print summary statistics for the GPU utilization and the training run with the [`Trainer`] we define two helper functions:
```py
>>> from pynvml import *
>>> def print_gpu_utilization():
... nvmlInit()
... handle = nvmlDeviceGetHandleByIndex(0)
... info = nvmlDeviceGetMemoryInfo(handle)
... print(f"GPU memory occupied: {info.used//1024**2} MB.")
>>> def print_summary(result):
... print(f"Time: {result.metrics['train_runtime']:.2f}")
... print(f"Samples/second: {result.metrics['train_samples_per_second']:.2f}")
... print_gpu_utilization()
```
Let's verify that we start with a free GPU memory:
```py
>>> print_gpu_utilization()
GPU memory occupied: 0 MB.
```
That looks good: the GPU memory is not occupied as we would expect before we load any models. If that's not the case on
your machine make sure to stop all processes that are using GPU memory. However, not all free GPU memory can be used by
the user. When a model is loaded to the GPU the kernels are also loaded, which can take up 1-2GB of memory. To see how
much it is we load a tiny tensor into the GPU which triggers the kernels to be loaded as well.
```py
>>> import torch
>>> torch.ones((1, 1)).to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 1343 MB.
```
We see that the kernels alone take up 1.3GB of GPU memory. Now let's see how much space the model uses.
## Load Model
First, we load the `google-bert/bert-large-uncased` model. We load the model weights directly to the GPU so that we can check
how much space just the weights use.
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-large-uncased").to("cuda")
>>> print_gpu_utilization()
GPU memory occupied: 2631 MB.
```
We can see that the model weights alone take up 1.3 GB of GPU memory. The exact number depends on the specific
GPU you are using. Note that on newer GPUs a model can sometimes take up more space since the weights are loaded in an
optimized fashion that speeds up the usage of the model. Now we can also quickly check if we get the same result
as with `nvidia-smi` CLI:
```bash
nvidia-smi
```
```bash
Tue Jan 11 08:58:05 2022
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 460.91.03 Driver Version: 460.91.03 CUDA Version: 11.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla V100-SXM2... On | 00000000:00:04.0 Off | 0 |
| N/A 37C P0 39W / 300W | 2631MiB / 16160MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 3721 C ...nvs/codeparrot/bin/python 2629MiB |
+-----------------------------------------------------------------------------+
```
We get the same number as before and you can also see that we are using a V100 GPU with 16GB of memory. So now we can
start training the model and see how the GPU memory consumption changes. First, we set up a few standard training
arguments:
```py
default_args = {
"output_dir": "tmp",
"eval_strategy": "steps",
"num_train_epochs": 1,
"log_level": "error",
"report_to": "none",
}
```
<Tip>
If you plan to run multiple experiments, in order to properly clear the memory between experiments, restart the Python
kernel between experiments.
</Tip>
## Memory utilization at vanilla training
Let's use the [`Trainer`] and train the model without using any GPU performance optimization techniques and a batch size of 4:
```py
>>> from transformers import TrainingArguments, Trainer, logging
>>> logging.set_verbosity_error()
>>> training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
>>> trainer = Trainer(model=model, args=training_args, train_dataset=ds)
>>> result = trainer.train()
>>> print_summary(result)
```
```
Time: 57.82
Samples/second: 8.86
GPU memory occupied: 14949 MB.
```
We see that already a relatively small batch size almost fills up our GPU's entire memory. However, a larger batch size
can often result in faster model convergence or better end performance. So ideally we want to tune the batch size to our
model's needs and not to the GPU limitations. What's interesting is that we use much more memory than the size of the model.
To understand a bit better why this is the case let's have a look at a model's operations and memory needs.
## Anatomy of Model's Operations
Transformers architecture includes 3 main groups of operations grouped below by compute-intensity.
1. **Tensor Contractions**
Linear layers and components of Multi-Head Attention all do batched **matrix-matrix multiplications**. These operations are the most compute-intensive part of training a transformer.
2. **Statistical Normalizations**
Softmax and layer normalization are less compute-intensive than tensor contractions, and involve one or more **reduction operations**, the result of which is then applied via a map.
3. **Element-wise Operators**
These are the remaining operators: **biases, dropout, activations, and residual connections**. These are the least compute-intensive operations.
This knowledge can be helpful to know when analyzing performance bottlenecks.
This summary is derived from [Data Movement Is All You Need: A Case Study on Optimizing Transformers 2020](https://arxiv.org/abs/2007.00072)
## Anatomy of Model's Memory
We've seen that training the model uses much more memory than just putting the model on the GPU. This is because there
are many components during training that use GPU memory. The components on GPU memory are the following:
1. model weights
2. optimizer states
3. gradients
4. forward activations saved for gradient computation
5. temporary buffers
6. functionality-specific memory
A typical model trained in mixed precision with AdamW requires 18 bytes per model parameter plus activation memory. For
inference there are no optimizer states and gradients, so we can subtract those. And thus we end up with 6 bytes per
model parameter for mixed precision inference, plus activation memory.
Let's look at the details.
**Model Weights:**
- 4 bytes * number of parameters for fp32 training
- 6 bytes * number of parameters for mixed precision training (maintains a model in fp32 and one in fp16 in memory)
**Optimizer States:**
- 8 bytes * number of parameters for normal AdamW (maintains 2 states)
- 2 bytes * number of parameters for 8-bit AdamW optimizers like [bitsandbytes](https://github.com/bitsandbytes-foundation/bitsandbytes)
- 4 bytes * number of parameters for optimizers like SGD with momentum (maintains only 1 state)
**Gradients**
- 4 bytes * number of parameters for either fp32 or mixed precision training (gradients are always kept in fp32)
**Forward Activations**
- size depends on many factors, the key ones being sequence length, hidden size and batch size.
There are the input and output that are being passed and returned by the forward and the backward functions and the
forward activations saved for gradient computation.
**Temporary Memory**
Additionally, there are all kinds of temporary variables which get released once the calculation is done, but in the
moment these could require additional memory and could push to OOM. Therefore, when coding it's crucial to think
strategically about such temporary variables and sometimes to explicitly free those as soon as they are no longer needed.
**Functionality-specific memory**
Then, your software could have special memory needs. For example, when generating text using beam search, the software
needs to maintain multiple copies of inputs and outputs.
**`forward` vs `backward` Execution Speed**
For convolutions and linear layers there are 2x flops in the backward compared to the forward, which generally translates
into ~2x slower (sometimes more, because sizes in the backward tend to be more awkward). Activations are usually
bandwidth-limited, and it’s typical for an activation to have to read more data in the backward than in the forward
(e.g. activation forward reads once, writes once, activation backward reads twice, gradOutput and output of the forward,
and writes once, gradInput).
As you can see, there are potentially a few places where we could save GPU memory or speed up operations.
Now that you understand what affects GPU utilization and computation speed, refer to
the [Methods and tools for efficient training on a single GPU](perf_train_gpu_one) documentation page to learn about
performance optimization techniques.
|
transformers/docs/source/en/model_memory_anatomy.md/0
|
{
"file_path": "transformers/docs/source/en/model_memory_anatomy.md",
"repo_id": "transformers",
"token_count": 3298
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Methods and tools for efficient training on a single GPU
This guide demonstrates practical techniques that you can use to increase the efficiency of your model's training by
optimizing memory utilization, speeding up the training, or both. If you'd like to understand how GPU is utilized during
training, please refer to the [Model training anatomy](model_memory_anatomy) conceptual guide first. This guide
focuses on practical techniques.
<Tip>
If you have access to a machine with multiple GPUs, these approaches are still valid, plus you can leverage additional methods outlined in the [multi-GPU section](perf_train_gpu_many).
</Tip>
When training large models, there are two aspects that should be considered at the same time:
* Data throughput/training time
* Model performance
Maximizing the throughput (samples/second) leads to lower training cost. This is generally achieved by utilizing the GPU
as much as possible and thus filling GPU memory to its limit. If the desired batch size exceeds the limits of the GPU memory,
the memory optimization techniques, such as gradient accumulation, can help.
However, if the preferred batch size fits into memory, there's no reason to apply memory-optimizing techniques because they can
slow down the training. Just because one can use a large batch size, does not necessarily mean they should. As part of
hyperparameter tuning, you should determine which batch size yields the best results and then optimize resources accordingly.
The methods and tools covered in this guide can be classified based on the effect they have on the training process:
| Method/tool | Improves training speed | Optimizes memory utilization |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------|:------------------------|:-----------------------------|
| [Batch size choice](#batch-size-choice) | Yes | Yes |
| [Gradient accumulation](#gradient-accumulation) | No | Yes |
| [Gradient checkpointing](#gradient-checkpointing) | No | Yes |
| [Mixed precision training](#mixed-precision-training) | Yes | Maybe* |
| [torch_empty_cache_steps](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.TrainingArguments.torch_empty_cache_steps) | No | Yes |
| [Optimizer choice](#optimizer-choice) | Yes | Yes |
| [Data preloading](#data-preloading) | Yes | No |
| [DeepSpeed Zero](#deepspeed-zero) | No | Yes |
| [torch.compile](#using-torchcompile) | Yes | No |
| [Parameter-Efficient Fine Tuning (PEFT)](#using--peft) | No | Yes |
<Tip>
*Note: when using mixed precision with a small model and a large batch size, there will be some memory savings but with a
large model and a small batch size, the memory use will be larger.
</Tip>
You can combine the above methods to get a cumulative effect. These techniques are available to you whether you are
training your model with [`Trainer`] or writing a pure PyTorch loop, in which case you can [configure these optimizations
with 🤗 Accelerate](#using--accelerate).
If these methods do not result in sufficient gains, you can explore the following options:
* [Look into building your own custom Docker container with efficient software prebuilds](#efficient-software-prebuilds)
* [Consider a model that uses Mixture of Experts (MoE)](#mixture-of-experts)
* [Convert your model to BetterTransformer to leverage PyTorch native attention](#using-pytorch-native-attention-and-flash-attention)
Finally, if all of the above is still not enough, even after switching to a server-grade GPU like A100, consider moving
to a multi-GPU setup. All these approaches are still valid in a multi-GPU setup, plus you can leverage additional parallelism
techniques outlined in the [multi-GPU section](perf_train_gpu_many).
## Batch size choice
To achieve optimal performance, start by identifying the appropriate batch size. It is recommended to use batch sizes and
input/output neuron counts that are of size 2^N. Often it's a multiple of 8, but it can be
higher depending on the hardware being used and the model's dtype.
For reference, check out NVIDIA's recommendation for [input/output neuron counts](
https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#input-features) and
[batch size](https://docs.nvidia.com/deeplearning/performance/dl-performance-fully-connected/index.html#batch-size) for
fully connected layers (which are involved in GEMMs (General Matrix Multiplications)).
[Tensor Core Requirements](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#requirements-tc)
define the multiplier based on the dtype and the hardware. For instance, for fp16 data type a multiple of 8 is recommended, unless
it's an A100 GPU, in which case use multiples of 64.
For parameters that are small, consider also [Dimension Quantization Effects](https://docs.nvidia.com/deeplearning/performance/dl-performance-matrix-multiplication/index.html#dim-quantization).
This is where tiling happens and the right multiplier can have a significant speedup.
## Gradient Accumulation
The **gradient accumulation** method aims to calculate gradients in smaller increments instead of computing them for the
entire batch at once. This approach involves iteratively calculating gradients in smaller batches by performing forward
and backward passes through the model and accumulating the gradients during the process. Once a sufficient number of
gradients have been accumulated, the model's optimization step is executed. By employing gradient accumulation, it
becomes possible to increase the **effective batch size** beyond the limitations imposed by the GPU's memory capacity.
However, it is important to note that the additional forward and backward passes introduced by gradient accumulation can
slow down the training process.
You can enable gradient accumulation by adding the `gradient_accumulation_steps` argument to [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=1, gradient_accumulation_steps=4, **default_args)
```
In the above example, your effective batch size becomes 4.
Alternatively, use 🤗 Accelerate to gain full control over the training loop. Find the 🤗 Accelerate example
[further down in this guide](#using--accelerate).
While it is advised to max out GPU usage as much as possible, a high number of gradient accumulation steps can
result in a more pronounced training slowdown. Consider the following example. Let's say, the `per_device_train_batch_size=4`
without gradient accumulation hits the GPU's limit. If you would like to train with batches of size 64, do not set the
`per_device_train_batch_size` to 1 and `gradient_accumulation_steps` to 64. Instead, keep `per_device_train_batch_size=4`
and set `gradient_accumulation_steps=16`. This results in the same effective batch size while making better use of
the available GPU resources.
For additional information, please refer to batch size and gradient accumulation benchmarks for [RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004392537)
and [A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1005033957).
## Gradient Checkpointing
Some large models may still face memory issues even when the batch size is set to 1 and gradient accumulation is used.
This is because there are other components that also require memory storage.
Saving all activations from the forward pass in order to compute the gradients during the backward pass can result in
significant memory overhead. The alternative approach of discarding the activations and recalculating them when needed
during the backward pass, would introduce a considerable computational overhead and slow down the training process.
**Gradient checkpointing** offers a compromise between these two approaches and saves strategically selected activations
throughout the computational graph so only a fraction of the activations need to be re-computed for the gradients. For
an in-depth explanation of gradient checkpointing, refer to [this great article](https://medium.com/tensorflow/fitting-larger-networks-into-memory-583e3c758ff9).
To enable gradient checkpointing in the [`Trainer`], pass the corresponding a flag to [`TrainingArguments`]:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1, gradient_accumulation_steps=4, gradient_checkpointing=True, **default_args
)
```
Alternatively, use 🤗 Accelerate - find the 🤗 Accelerate example [further in this guide](#using--accelerate).
<Tip>
While gradient checkpointing may improve memory efficiency, it slows training by approximately 20%.
</Tip>
## Mixed precision training
**Mixed precision training** is a technique that aims to optimize the computational efficiency of training models by
utilizing lower-precision numerical formats for certain variables. Traditionally, most models use 32-bit floating point
precision (fp32 or float32) to represent and process variables. However, not all variables require this high precision
level to achieve accurate results. By reducing the precision of certain variables to lower numerical formats like 16-bit
floating point (fp16 or float16), we can speed up the computations. Because in this approach some computations are performed
in half-precision, while some are still in full precision, the approach is called mixed precision training.
Most commonly mixed precision training is achieved by using fp16 (float16) data types, however, some GPU architectures
(such as the Ampere architecture) offer bf16 and tf32 (CUDA internal data type) data types. Check
out the [NVIDIA Blog](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/) to learn more about
the differences between these data types.
### fp16
The main advantage of mixed precision training comes from saving the activations in half precision (fp16).
Although the gradients are also computed in half precision they are converted back to full precision for the optimization
step so no memory is saved here.
While mixed precision training results in faster computations, it can also lead to more GPU memory being utilized, especially for small batch sizes.
This is because the model is now present on the GPU in both 16-bit and 32-bit precision (1.5x the original model on the GPU).
To enable mixed precision training, set the `fp16` flag to `True`:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, fp16=True, **default_args)
```
If you prefer to use 🤗 Accelerate, find the 🤗 Accelerate example [further in this guide](#using--accelerate).
### BF16
If you have access to an Ampere or newer hardware you can use bf16 for mixed precision training and evaluation. While
bf16 has a worse precision than fp16, it has a much bigger dynamic range. In fp16 the biggest number you can have
is `65504` and any number above that will result in an overflow. A bf16 number can be as large as `3.39e+38` (!) which
is about the same as fp32 - because both have 8-bits used for the numerical range.
You can enable BF16 in the 🤗 Trainer with:
```python
training_args = TrainingArguments(bf16=True, **default_args)
```
### TF32
The Ampere hardware uses a magical data type called tf32. It has the same numerical range as fp32 (8-bits), but instead
of 23 bits precision it has only 10 bits (same as fp16) and uses only 19 bits in total. It's "magical" in the sense that
you can use the normal fp32 training and/or inference code and by enabling tf32 support you can get up to 3x throughput
improvement. All you need to do is to add the following to your code:
```python
import torch
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
```
CUDA will automatically switch to using tf32 instead of fp32 where possible, assuming that the used GPU is from the Ampere series.
According to [NVIDIA research](https://developer.nvidia.com/blog/accelerating-ai-training-with-tf32-tensor-cores/), the
majority of machine learning training workloads show the same perplexity and convergence with tf32 training as with fp32.
If you're already using fp16 or bf16 mixed precision it may help with the throughput as well.
You can enable this mode in the 🤗 Trainer:
```python
TrainingArguments(tf32=True, **default_args)
```
<Tip>
tf32 can't be accessed directly via `tensor.to(dtype=torch.tf32)` because it is an internal CUDA data type. You need `torch>=1.7` to use tf32 data types.
</Tip>
For additional information on tf32 vs other precisions, please refer to the following benchmarks:
[RTX-3090](https://github.com/huggingface/transformers/issues/14608#issuecomment-1004390803) and
[A100](https://github.com/huggingface/transformers/issues/15026#issuecomment-1004543189).
## Flash Attention 2
You can speedup the training throughput by using Flash Attention 2 integration in transformers. Check out the appropriate section in the [single GPU section](./perf_infer_gpu_one#Flash-Attention-2) to learn more about how to load a model with Flash Attention 2 modules.
## Optimizer choice
The most common optimizer used to train transformer models is Adam or AdamW (Adam with weight decay). Adam achieves
good convergence by storing the rolling average of the previous gradients; however, it adds an additional memory
footprint of the order of the number of model parameters. To remedy this, you can use an alternative optimizer.
For example if you have [NVIDIA/apex](https://github.com/NVIDIA/apex) installed for NVIDIA GPUs, or [ROCmSoftwarePlatform/apex](https://github.com/ROCmSoftwarePlatform/apex) for AMD GPUs, `adamw_apex_fused` will give you the
fastest training experience among all supported AdamW optimizers.
[`Trainer`] integrates a variety of optimizers that can be used out of box: `adamw_hf`, `adamw_torch`, `adamw_torch_fused`,
`adamw_apex_fused`, `adamw_anyprecision`, `adafactor`, or `adamw_bnb_8bit`. More optimizers can be plugged in via a third-party implementation.
Let's take a closer look at two alternatives to AdamW optimizer:
1. `adafactor` which is available in [`Trainer`]
2. `adamw_bnb_8bit` is also available in Trainer, but a third-party integration is provided below for demonstration.
For comparison, for a 3B-parameter model, like “google-t5/t5-3b”:
* A standard AdamW optimizer will need 24GB of GPU memory because it uses 8 bytes for each parameter (8*3 => 24GB)
* Adafactor optimizer will need more than 12GB. It uses slightly more than 4 bytes for each parameter, so 4*3 and then some extra.
* 8bit BNB quantized optimizer will use only (2*3) 6GB if all optimizer states are quantized.
### Adafactor
Adafactor doesn't store rolling averages for each element in weight matrices. Instead, it keeps aggregated information
(sums of rolling averages row- and column-wise), significantly reducing its footprint. However, compared to Adam,
Adafactor may have slower convergence in certain cases.
You can switch to Adafactor by setting `optim="adafactor"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adafactor", **default_args)
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training)
you can notice up to 3x improvement while maintaining the throughput! However, as mentioned before, the convergence of
Adafactor can be worse than Adam.
### 8-bit Adam
Instead of aggregating optimizer states like Adafactor, 8-bit Adam keeps the full state and quantizes it. Quantization
means that it stores the state with lower precision and dequantizes it only for the optimization. This is similar to the
idea behind mixed precision training.
To use `adamw_bnb_8bit`, you simply need to set `optim="adamw_bnb_8bit"` in [`TrainingArguments`]:
```py
training_args = TrainingArguments(per_device_train_batch_size=4, optim="adamw_bnb_8bit", **default_args)
```
However, we can also use a third-party implementation of the 8-bit optimizer for demonstration purposes to see how that can be integrated.
First, follow the installation guide in the GitHub [repo](https://github.com/bitsandbytes-foundation/bitsandbytes) to install the `bitsandbytes` library
that implements the 8-bit Adam optimizer.
Next you need to initialize the optimizer. This involves two steps:
* First, group the model's parameters into two groups - one where weight decay should be applied, and the other one where it should not. Usually, biases and layer norm parameters are not weight decayed.
* Then do some argument housekeeping to use the same parameters as the previously used AdamW optimizer.
```py
import bitsandbytes as bnb
from torch import nn
from transformers.trainer_pt_utils import get_parameter_names
training_args = TrainingArguments(per_device_train_batch_size=4, **default_args)
decay_parameters = get_parameter_names(model, [nn.LayerNorm], ["bias", "layernorm", "rmsnorm"])
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if n in decay_parameters],
"weight_decay": training_args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if n not in decay_parameters],
"weight_decay": 0.0,
},
]
optimizer_kwargs = {
"betas": (training_args.adam_beta1, training_args.adam_beta2),
"eps": training_args.adam_epsilon,
}
optimizer_kwargs["lr"] = training_args.learning_rate
adam_bnb_optim = bnb.optim.Adam8bit(
optimizer_grouped_parameters,
betas=(training_args.adam_beta1, training_args.adam_beta2),
eps=training_args.adam_epsilon,
lr=training_args.learning_rate,
)
```
Finally, pass the custom optimizer as an argument to the `Trainer`:
```py
trainer = Trainer(model=model, args=training_args, train_dataset=ds, optimizers=(adam_bnb_optim, None))
```
Combined with other approaches (gradient accumulation, gradient checkpointing, and mixed precision training),
you can expect to get about a 3x memory improvement and even slightly higher throughput as using Adafactor.
### multi_tensor
pytorch-nightly introduced `torch.optim._multi_tensor` which should significantly speed up the optimizers for situations
with lots of small feature tensors. It should eventually become the default, but if you want to experiment with it sooner, take a look at this GitHub [issue](https://github.com/huggingface/transformers/issues/9965).
## Data preloading
One of the important requirements to reach great training speed is the ability to feed the GPU at the maximum speed it
can handle. By default, everything happens in the main process, and it might not be able to read the data from disk fast
enough, and thus create a bottleneck, leading to GPU under-utilization. Configure the following arguments to reduce the bottleneck:
- `DataLoader(pin_memory=True, ...)` - ensures the data gets preloaded into the pinned memory on CPU and typically leads to much faster transfers from CPU to GPU memory.
- `DataLoader(num_workers=4, ...)` - spawn several workers to preload data faster. During training, watch the GPU utilization stats; if it's far from 100%, experiment with increasing the number of workers. Of course, the problem could be elsewhere, so many workers won't necessarily lead to better performance.
When using [`Trainer`], the corresponding [`TrainingArguments`] are: `dataloader_pin_memory` (`True` by default), and `dataloader_num_workers` (defaults to `0`).
## DeepSpeed ZeRO
DeepSpeed is an open-source deep learning optimization library that is integrated with 🤗 Transformers and 🤗 Accelerate.
It provides a wide range of features and optimizations designed to improve the efficiency and scalability of large-scale
deep learning training.
If your model fits onto a single GPU and you have enough space to fit a small batch size, you don't need to use DeepSpeed
as it'll only slow things down. However, if the model doesn't fit onto a single GPU or you can't fit a small batch, you can
leverage DeepSpeed ZeRO + CPU Offload, or NVMe Offload for much larger models. In this case, you need to separately
[install the library](main_classes/deepspeed#installation), then follow one of the guides to create a configuration file
and launch DeepSpeed:
* For an in-depth guide on DeepSpeed integration with [`Trainer`], review [the corresponding documentation](main_classes/deepspeed), specifically the
[section for a single GPU](main_classes/deepspeed#deployment-with-one-gpu). Some adjustments are required to use DeepSpeed in a notebook; please take a look at the [corresponding guide](main_classes/deepspeed#deployment-in-notebooks).
* If you prefer to use 🤗 Accelerate, refer to [🤗 Accelerate DeepSpeed guide](https://huggingface.co/docs/accelerate/en/usage_guides/deepspeed).
## Using torch.compile
PyTorch 2.0 introduced a new compile function that doesn't require any modification to existing PyTorch code but can
optimize your code by adding a single line of code: `model = torch.compile(model)`.
If using [`Trainer`], you only need `to` pass the `torch_compile` option in the [`TrainingArguments`]:
```python
training_args = TrainingArguments(torch_compile=True, **default_args)
```
`torch.compile` uses Python's frame evaluation API to automatically create a graph from existing PyTorch programs. After
capturing the graph, different backends can be deployed to lower the graph to an optimized engine.
You can find more details and benchmarks in [PyTorch documentation](https://pytorch.org/get-started/pytorch-2.0/).
`torch.compile` has a growing list of backends, which can be found in by calling `torchdynamo.list_backends()`, each of which with its optional dependencies.
Choose which backend to use by specifying it via `torch_compile_backend` in the [`TrainingArguments`]. Some of the most commonly used backends are:
**Debugging backends**:
* `dynamo.optimize("eager")` - Uses PyTorch to run the extracted GraphModule. This is quite useful in debugging TorchDynamo issues.
* `dynamo.optimize("aot_eager")` - Uses AotAutograd with no compiler, i.e, just using PyTorch eager for the AotAutograd's extracted forward and backward graphs. This is useful for debugging, and unlikely to give speedups.
**Training & inference backends**:
* `dynamo.optimize("inductor")` - Uses TorchInductor backend with AotAutograd and cudagraphs by leveraging codegened Triton kernels [Read more](https://dev-discuss.pytorch.org/t/torchinductor-a-pytorch-native-compiler-with-define-by-run-ir-and-symbolic-shapes/747)
* `dynamo.optimize("nvfuser")` - nvFuser with TorchScript. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_nvfuser")` - nvFuser with AotAutograd. [Read more](https://dev-discuss.pytorch.org/t/tracing-with-primitives-update-1-nvfuser-and-its-primitives/593)
* `dynamo.optimize("aot_cudagraphs")` - cudagraphs with AotAutograd. [Read more](https://github.com/pytorch/torchdynamo/pull/757)
**Inference-only backend**s:
* `dynamo.optimize("ofi")` - Uses TorchScript optimize_for_inference. [Read more](https://pytorch.org/docs/stable/generated/torch.jit.optimize_for_inference.html)
* `dynamo.optimize("fx2trt")` - Uses NVIDIA TensorRT for inference optimizations. [Read more](https://pytorch.org/TensorRT/tutorials/getting_started_with_fx_path.html)
* `dynamo.optimize("onnxrt")` - Uses ONNXRT for inference on CPU/GPU. [Read more](https://onnxruntime.ai/)
* `dynamo.optimize("ipex")` - Uses IPEX for inference on CPU. [Read more](https://github.com/intel/intel-extension-for-pytorch)
For an example of using `torch.compile` with 🤗 Transformers, check out this [blog post on fine-tuning a BERT model for Text Classification using the newest PyTorch 2.0 features](https://www.philschmid.de/getting-started-pytorch-2-0-transformers)
## Using 🤗 PEFT
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) methods freeze the pretrained model parameters during fine-tuning and add a small number of trainable parameters (the adapters) on top of it.
As a result the [memory associated to the optimizer states and gradients](https://huggingface.co/docs/transformers/model_memory_anatomy#anatomy-of-models-memory) are greatly reduced.
For example with a vanilla AdamW, the memory requirement for the optimizer state would be:
* fp32 copy of parameters: 4 bytes/param
* Momentum: 4 bytes/param
* Variance: 4 bytes/param
Suppose a model with 7B parameters and 200 million parameters injected with [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora).
The memory requirement for the optimizer state of the plain model would be 12 * 7 = 84 GB (assuming 7B trainable parameters).
Adding Lora increases slightly the memory associated to the model weights and substantially decreases memory requirement for the optimizer state to 12 * 0.2 = 2.4GB.
Read more about PEFT and its detailed usage in [the PEFT documentation](https://huggingface.co/docs/peft/) or [PEFT repository](https://github.com/huggingface/peft).
## Using 🤗 Accelerate
With [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) you can use the above methods while gaining full
control over the training loop and can essentially write the loop in pure PyTorch with some minor modifications.
Suppose you have combined the methods in the [`TrainingArguments`] like so:
```py
training_args = TrainingArguments(
per_device_train_batch_size=1,
gradient_accumulation_steps=4,
gradient_checkpointing=True,
fp16=True,
**default_args,
)
```
The full example training loop with 🤗 Accelerate is only a handful of lines of code long:
```py
from accelerate import Accelerator
from torch.utils.data.dataloader import DataLoader
dataloader = DataLoader(ds, batch_size=training_args.per_device_train_batch_size)
if training_args.gradient_checkpointing:
model.gradient_checkpointing_enable()
accelerator = Accelerator(fp16=training_args.fp16)
model, optimizer, dataloader = accelerator.prepare(model, adam_bnb_optim, dataloader)
model.train()
for step, batch in enumerate(dataloader, start=1):
loss = model(**batch).loss
loss = loss / training_args.gradient_accumulation_steps
accelerator.backward(loss)
if step % training_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
```
First we wrap the dataset in a [`DataLoader`](https://pytorch.org/docs/stable/data.html#torch.utils.data.DataLoader).
Then we can enable gradient checkpointing by calling the model's [`~PreTrainedModel.gradient_checkpointing_enable`] method.
When we initialize the [`Accelerator`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator)
we can specify if we want to use mixed precision training and it will take care of it for us in the [`prepare`] call.
During the [`prepare`](https://huggingface.co/docs/accelerate/package_reference/accelerator#accelerate.Accelerator.prepare)
call the dataloader will also be distributed across workers should we use multiple GPUs. We use the same [8-bit optimizer](#8-bit-adam) from the earlier example.
Finally, we can add the main training loop. Note that the `backward` call is handled by 🤗 Accelerate. We can also see
how gradient accumulation works: we normalize the loss, so we get the average at the end of accumulation and once we have
enough steps we run the optimization.
Implementing these optimization techniques with 🤗 Accelerate only takes a handful of lines of code and comes with the
benefit of more flexibility in the training loop. For a full documentation of all features have a look at the
[Accelerate documentation](https://huggingface.co/docs/accelerate/index).
## Efficient Software Prebuilds
PyTorch's [pip and conda builds](https://pytorch.org/get-started/locally/#start-locally) come prebuilt with the cuda toolkit
which is enough to run PyTorch, but it is insufficient if you need to build cuda extensions.
At times, additional efforts may be required to pre-build some components. For instance, if you're using libraries like `apex` that
don't come pre-compiled. In other situations figuring out how to install the right cuda toolkit system-wide can be complicated.
To address these scenarios PyTorch and NVIDIA released a new version of NGC docker container which already comes with
everything prebuilt. You just need to install your programs on it, and it will run out of the box.
This approach is also useful if you want to tweak the pytorch source and/or make a new customized build.
To find the docker image version you want start [with PyTorch release notes](https://docs.nvidia.com/deeplearning/frameworks/pytorch-release-notes/),
choose one of the latest monthly releases. Go into the release's notes for the desired release, check that the environment's
components are matching your needs (including NVIDIA Driver requirements!) and then at the very top of that document go
to the corresponding NGC page. If for some reason you get lost, here is [the index of all PyTorch NGC images](https://ngc.nvidia.com/catalog/containers/nvidia:pytorch).
Next follow the instructions to download and deploy the docker image.
## Mixture of Experts
Some recent papers reported a 4-5x training speedup and a faster inference by integrating
Mixture of Experts (MoE) into the Transformer models.
Since it has been discovered that more parameters lead to better performance, this technique allows to increase the
number of parameters by an order of magnitude without increasing training costs.
In this approach every other FFN layer is replaced with a MoE Layer which consists of many experts, with a gated function
that trains each expert in a balanced way depending on the input token's position in a sequence.

(source: [GLAM](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html))
You can find exhaustive details and comparison tables in the papers listed at the end of this section.
The main drawback of this approach is that it requires staggering amounts of GPU memory - almost an order of magnitude
larger than its dense equivalent. Various distillation and approaches are proposed to how to overcome the much higher memory requirements.
There is direct trade-off though, you can use just a few experts with a 2-3x smaller base model instead of dozens or
hundreds experts leading to a 5x smaller model and thus increase the training speed moderately while increasing the
memory requirements moderately as well.
Most related papers and implementations are built around Tensorflow/TPUs:
- [GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding](https://arxiv.org/abs/2006.16668)
- [Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity](https://arxiv.org/abs/2101.03961)
- [GLaM: Generalist Language Model (GLaM)](https://ai.googleblog.com/2021/12/more-efficient-in-context-learning-with.html)
And for Pytorch DeepSpeed has built one as well: [DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Power Next-Generation AI Scale](https://arxiv.org/abs/2201.05596), [Mixture of Experts](https://www.deepspeed.ai/tutorials/mixture-of-experts/) - blog posts: [1](https://www.microsoft.com/en-us/research/blog/deepspeed-powers-8x-larger-moe-model-training-with-high-performance/), [2](https://www.microsoft.com/en-us/research/publication/scalable-and-efficient-moe-training-for-multitask-multilingual-models/) and specific deployment with large transformer-based natural language generation models: [blog post](https://www.deepspeed.ai/2021/12/09/deepspeed-moe-nlg.html), [Megatron-Deepspeed branch](https://github.com/microsoft/Megatron-DeepSpeed/tree/moe-training).
## Using PyTorch native attention and Flash Attention
PyTorch's [`torch.nn.functional.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention.html) (SDPA) can also call FlashAttention and memory-efficient attention kernels under the hood. SDPA support is currently being added natively in Transformers and is used by default for `torch>=2.1.1` when an implementation is available. Please refer to [PyTorch scaled dot product attention](https://huggingface.co/docs/transformers/perf_infer_gpu_one#pytorch-scaled-dot-product-attention) for a list of supported models and more details.
Check out this [blogpost](https://pytorch.org/blog/out-of-the-box-acceleration/) to learn more about acceleration and memory-savings with SDPA.
|
transformers/docs/source/en/perf_train_gpu_one.md/0
|
{
"file_path": "transformers/docs/source/en/perf_train_gpu_one.md",
"repo_id": "transformers",
"token_count": 10820
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# EETQ
The [EETQ](https://github.com/NetEase-FuXi/EETQ) library supports int8 per-channel weight-only quantization for NVIDIA GPUS. The high-performance GEMM and GEMV kernels are from FasterTransformer and TensorRT-LLM. It requires no calibration dataset and does not need to pre-quantize your model. Moreover, the accuracy degradation is negligible owing to the per-channel quantization.
Make sure you have eetq installed from the [release page](https://github.com/NetEase-FuXi/EETQ/releases)
```
pip install --no-cache-dir https://github.com/NetEase-FuXi/EETQ/releases/download/v1.0.0/EETQ-1.0.0+cu121+torch2.1.2-cp310-cp310-linux_x86_64.whl
```
or via the source code https://github.com/NetEase-FuXi/EETQ. EETQ requires CUDA capability <= 8.9 and >= 7.0
```
git clone https://github.com/NetEase-FuXi/EETQ.git
cd EETQ/
git submodule update --init --recursive
pip install .
```
An unquantized model can be quantized via "from_pretrained".
```py
from transformers import AutoModelForCausalLM, EetqConfig
path = "/path/to/model"
quantization_config = EetqConfig("int8")
model = AutoModelForCausalLM.from_pretrained(path, device_map="auto", quantization_config=quantization_config)
```
A quantized model can be saved via "saved_pretrained" and be reused again via the "from_pretrained".
```py
quant_path = "/path/to/save/quantized/model"
model.save_pretrained(quant_path)
model = AutoModelForCausalLM.from_pretrained(quant_path, device_map="auto")
```
|
transformers/docs/source/en/quantization/eetq.md/0
|
{
"file_path": "transformers/docs/source/en/quantization/eetq.md",
"repo_id": "transformers",
"token_count": 683
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contains specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Audio classification
[[open-in-colab]]
<Youtube id="KWwzcmG98Ds"/>
Audio classification - just like with text - assigns a class label as output from the input data. The only difference is instead of text inputs, you have raw audio waveforms. Some practical applications of audio classification include identifying speaker intent, language classification, and even animal species by their sounds.
This guide will show you how to:
1. Fine-tune [Wav2Vec2](https://huggingface.co/facebook/wav2vec2-base) on the [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14) dataset to classify speaker intent.
2. Use your fine-tuned model for inference.
<Tip>
To see all architectures and checkpoints compatible with this task, we recommend checking the [task-page](https://huggingface.co/tasks/audio-classification)
</Tip>
Before you begin, make sure you have all the necessary libraries installed:
```bash
pip install transformers datasets evaluate
```
We encourage you to login to your Hugging Face account so you can upload and share your model with the community. When prompted, enter your token to login:
```py
>>> from huggingface_hub import notebook_login
>>> notebook_login()
```
## Load MInDS-14 dataset
Start by loading the MInDS-14 dataset from the 🤗 Datasets library:
```py
>>> from datasets import load_dataset, Audio
>>> minds = load_dataset("PolyAI/minds14", name="en-US", split="train")
```
Split the dataset's `train` split into a smaller train and test set with the [`~datasets.Dataset.train_test_split`] method. This will give you a chance to experiment and make sure everything works before spending more time on the full dataset.
```py
>>> minds = minds.train_test_split(test_size=0.2)
```
Then take a look at the dataset:
```py
>>> minds
DatasetDict({
train: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 450
})
test: Dataset({
features: ['path', 'audio', 'transcription', 'english_transcription', 'intent_class', 'lang_id'],
num_rows: 113
})
})
```
While the dataset contains a lot of useful information, like `lang_id` and `english_transcription`, you will focus on the `audio` and `intent_class` in this guide. Remove the other columns with the [`~datasets.Dataset.remove_columns`] method:
```py
>>> minds = minds.remove_columns(["path", "transcription", "english_transcription", "lang_id"])
```
Here's an example:
```py
>>> minds["train"][0]
{'audio': {'array': array([ 0. , 0. , 0. , ..., -0.00048828,
-0.00024414, -0.00024414], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 8000},
'intent_class': 2}
```
There are two fields:
- `audio`: a 1-dimensional `array` of the speech signal that must be called to load and resample the audio file.
- `intent_class`: represents the class id of the speaker's intent.
To make it easier for the model to get the label name from the label id, create a dictionary that maps the label name to an integer and vice versa:
```py
>>> labels = minds["train"].features["intent_class"].names
>>> label2id, id2label = dict(), dict()
>>> for i, label in enumerate(labels):
... label2id[label] = str(i)
... id2label[str(i)] = label
```
Now you can convert the label id to a label name:
```py
>>> id2label[str(2)]
'app_error'
```
## Preprocess
The next step is to load a Wav2Vec2 feature extractor to process the audio signal:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("facebook/wav2vec2-base")
```
The MInDS-14 dataset has a sampling rate of 8kHz (you can find this information in its [dataset card](https://huggingface.co/datasets/PolyAI/minds14)), which means you'll need to resample the dataset to 16kHz to use the pretrained Wav2Vec2 model:
```py
>>> minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
>>> minds["train"][0]
{'audio': {'array': array([ 2.2098757e-05, 4.6582241e-05, -2.2803260e-05, ...,
-2.8419291e-04, -2.3305941e-04, -1.1425107e-04], dtype=float32),
'path': '/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-US~APP_ERROR/602b9a5fbb1e6d0fbce91f52.wav',
'sampling_rate': 16000},
'intent_class': 2}
```
Now create a preprocessing function that:
1. Calls the `audio` column to load, and if necessary, resample the audio file.
2. Checks if the sampling rate of the audio file matches the sampling rate of the audio data a model was pretrained with. You can find this information in the Wav2Vec2 [model card](https://huggingface.co/facebook/wav2vec2-base).
3. Set a maximum input length to batch longer inputs without truncating them.
```py
>>> def preprocess_function(examples):
... audio_arrays = [x["array"] for x in examples["audio"]]
... inputs = feature_extractor(
... audio_arrays, sampling_rate=feature_extractor.sampling_rate, max_length=16000, truncation=True
... )
... return inputs
```
To apply the preprocessing function over the entire dataset, use 🤗 Datasets [`~datasets.Dataset.map`] function. You can speed up `map` by setting `batched=True` to process multiple elements of the dataset at once. Remove unnecessary columns and rename `intent_class` to `label`, as required by the model:
```py
>>> encoded_minds = minds.map(preprocess_function, remove_columns="audio", batched=True)
>>> encoded_minds = encoded_minds.rename_column("intent_class", "label")
```
## Evaluate
Including a metric during training is often helpful for evaluating your model's performance. You can quickly load an evaluation method with the 🤗 [Evaluate](https://huggingface.co/docs/evaluate/index) library. For this task, load the [accuracy](https://huggingface.co/spaces/evaluate-metric/accuracy) metric (see the 🤗 Evaluate [quick tour](https://huggingface.co/docs/evaluate/a_quick_tour) to learn more about how to load and compute a metric):
```py
>>> import evaluate
>>> accuracy = evaluate.load("accuracy")
```
Then create a function that passes your predictions and labels to [`~evaluate.EvaluationModule.compute`] to calculate the accuracy:
```py
>>> import numpy as np
>>> def compute_metrics(eval_pred):
... predictions = np.argmax(eval_pred.predictions, axis=1)
... return accuracy.compute(predictions=predictions, references=eval_pred.label_ids)
```
Your `compute_metrics` function is ready to go now, and you'll return to it when you setup your training.
## Train
<frameworkcontent>
<pt>
<Tip>
If you aren't familiar with finetuning a model with the [`Trainer`], take a look at the basic tutorial [here](../training#train-with-pytorch-trainer)!
</Tip>
You're ready to start training your model now! Load Wav2Vec2 with [`AutoModelForAudioClassification`] along with the number of expected labels, and the label mappings:
```py
>>> from transformers import AutoModelForAudioClassification, TrainingArguments, Trainer
>>> num_labels = len(id2label)
>>> model = AutoModelForAudioClassification.from_pretrained(
... "facebook/wav2vec2-base", num_labels=num_labels, label2id=label2id, id2label=id2label
... )
```
At this point, only three steps remain:
1. Define your training hyperparameters in [`TrainingArguments`]. The only required parameter is `output_dir`, which specifies where to save your model. You'll push this model to the Hub by setting `push_to_hub=True` (you need to be signed in to Hugging Face to upload your model). At the end of each epoch, the [`Trainer`] will evaluate the accuracy and save the training checkpoint.
2. Pass the training arguments to [`Trainer`] along with the model, dataset, tokenizer, data collator, and `compute_metrics` function.
3. Call [`~Trainer.train`] to fine-tune your model.
```py
>>> training_args = TrainingArguments(
... output_dir="my_awesome_mind_model",
... eval_strategy="epoch",
... save_strategy="epoch",
... learning_rate=3e-5,
... per_device_train_batch_size=32,
... gradient_accumulation_steps=4,
... per_device_eval_batch_size=32,
... num_train_epochs=10,
... warmup_ratio=0.1,
... logging_steps=10,
... load_best_model_at_end=True,
... metric_for_best_model="accuracy",
... push_to_hub=True,
... )
>>> trainer = Trainer(
... model=model,
... args=training_args,
... train_dataset=encoded_minds["train"],
... eval_dataset=encoded_minds["test"],
... processing_class=feature_extractor,
... compute_metrics=compute_metrics,
... )
>>> trainer.train()
```
Once training is completed, share your model to the Hub with the [`~transformers.Trainer.push_to_hub`] method so everyone can use your model:
```py
>>> trainer.push_to_hub()
```
</pt>
</frameworkcontent>
<Tip>
For a more in-depth example of how to fine-tune a model for audio classification, take a look at the corresponding [PyTorch notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/audio_classification.ipynb).
</Tip>
## Inference
Great, now that you've fine-tuned a model, you can use it for inference!
Load an audio file for inference. Remember to resample the sampling rate of the audio file to match the model's sampling rate, if necessary.
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="en-US", split="train")
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
>>> sampling_rate = dataset.features["audio"].sampling_rate
>>> audio_file = dataset[0]["audio"]["path"]
```
The simplest way to try out your fine-tuned model for inference is to use it in a [`pipeline`]. Instantiate a `pipeline` for audio classification with your model, and pass your audio file to it:
```py
>>> from transformers import pipeline
>>> classifier = pipeline("audio-classification", model="stevhliu/my_awesome_minds_model")
>>> classifier(audio_file)
[
{'score': 0.09766869246959686, 'label': 'cash_deposit'},
{'score': 0.07998877018690109, 'label': 'app_error'},
{'score': 0.0781070664525032, 'label': 'joint_account'},
{'score': 0.07667109370231628, 'label': 'pay_bill'},
{'score': 0.0755252093076706, 'label': 'balance'}
]
```
You can also manually replicate the results of the `pipeline` if you'd like:
<frameworkcontent>
<pt>
Load a feature extractor to preprocess the audio file and return the `input` as PyTorch tensors:
```py
>>> from transformers import AutoFeatureExtractor
>>> feature_extractor = AutoFeatureExtractor.from_pretrained("stevhliu/my_awesome_minds_model")
>>> inputs = feature_extractor(dataset[0]["audio"]["array"], sampling_rate=sampling_rate, return_tensors="pt")
```
Pass your inputs to the model and return the logits:
```py
>>> from transformers import AutoModelForAudioClassification
>>> model = AutoModelForAudioClassification.from_pretrained("stevhliu/my_awesome_minds_model")
>>> with torch.no_grad():
... logits = model(**inputs).logits
```
Get the class with the highest probability, and use the model's `id2label` mapping to convert it to a label:
```py
>>> import torch
>>> predicted_class_ids = torch.argmax(logits).item()
>>> predicted_label = model.config.id2label[predicted_class_ids]
>>> predicted_label
'cash_deposit'
```
</pt>
</frameworkcontent>
|
transformers/docs/source/en/tasks/audio_classification.md/0
|
{
"file_path": "transformers/docs/source/en/tasks/audio_classification.md",
"repo_id": "transformers",
"token_count": 4036
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# LLM prompting guide
[[open-in-colab]]
Large Language Models such as Falcon, LLaMA, etc. are pretrained transformer models initially trained to predict the
next token given some input text. They typically have billions of parameters and have been trained on trillions of
tokens for an extended period of time. As a result, these models become quite powerful and versatile, and you can use
them to solve multiple NLP tasks out of the box by instructing the models with natural language prompts.
Designing such prompts to ensure the optimal output is often called "prompt engineering". Prompt engineering is an
iterative process that requires a fair amount of experimentation. Natural languages are much more flexible and expressive
than programming languages, however, they can also introduce some ambiguity. At the same time, prompts in natural language
are quite sensitive to changes. Even minor modifications in prompts can lead to wildly different outputs.
While there is no exact recipe for creating prompts to match all cases, researchers have worked out a number of best
practices that help to achieve optimal results more consistently.
This guide covers the prompt engineering best practices to help you craft better LLM prompts and solve various NLP tasks.
You'll learn:
- [Basics of prompting](#basics-of-prompting)
- [Best practices of LLM prompting](#best-practices-of-llm-prompting)
- [Advanced prompting techniques: few-shot prompting and chain-of-thought](#advanced-prompting-techniques)
- [When to fine-tune instead of prompting](#prompting-vs-fine-tuning)
<Tip>
Prompt engineering is only a part of the LLM output optimization process. Another essential component is choosing the
optimal text generation strategy. You can customize how your LLM selects each of the subsequent tokens when generating
the text without modifying any of the trainable parameters. By tweaking the text generation parameters, you can reduce
repetition in the generated text and make it more coherent and human-sounding.
Text generation strategies and parameters are out of scope for this guide, but you can learn more about these topics in
the following guides:
* [Generation with LLMs](../llm_tutorial)
* [Text generation strategies](../generation_strategies)
</Tip>
## Basics of prompting
### Types of models
The majority of modern LLMs are decoder-only transformers. Some examples include: [LLaMA](../model_doc/llama),
[Llama2](../model_doc/llama2), [Falcon](../model_doc/falcon), [GPT2](../model_doc/gpt2). However, you may encounter
encoder-decoder transformer LLMs as well, for instance, [Flan-T5](../model_doc/flan-t5) and [BART](../model_doc/bart).
Encoder-decoder-style models are typically used in generative tasks where the output **heavily** relies on the input, for
example, in translation and summarization. The decoder-only models are used for all other types of generative tasks.
When using a pipeline to generate text with an LLM, it's important to know what type of LLM you are using, because
they use different pipelines.
Run inference with decoder-only models with the `text-generation` pipeline:
```python
>>> from transformers import pipeline
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> generator = pipeline('text-generation', model = 'openai-community/gpt2')
>>> prompt = "Hello, I'm a language model"
>>> generator(prompt, max_length = 30)
[{'generated_text': "Hello, I'm a language model. Not a programming language at all: it's pretty simple.\n\nWhen I write a function, I mean"}]
```
To run inference with an encoder-decoder, use the `text2text-generation` pipeline:
```python
>>> text2text_generator = pipeline("text2text-generation", model = 'google/flan-t5-base')
>>> prompt = "Translate from English to French: I'm very happy to see you"
>>> text2text_generator(prompt)
[{'generated_text': 'Je suis très heureuse de vous rencontrer.'}]
```
### Base vs instruct/chat models
Most of the recent LLM checkpoints available on 🤗 Hub come in two versions: base and instruct (or chat). For example,
[`tiiuae/falcon-7b`](https://huggingface.co/tiiuae/falcon-7b) and [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct).
Base models are excellent at completing the text when given an initial prompt, however, they are not ideal for NLP tasks
where they need to follow instructions, or for conversational use. This is where the instruct (chat) versions come in.
These checkpoints are the result of further fine-tuning of the pre-trained base versions on instructions and conversational data.
This additional fine-tuning makes them a better choice for many NLP tasks.
Let's illustrate some simple prompts that you can use with [`tiiuae/falcon-7b-instruct`](https://huggingface.co/tiiuae/falcon-7b-instruct)
to solve some common NLP tasks.
### NLP tasks
First, let's set up the environment:
```bash
pip install -q transformers accelerate
```
Next, let's load the model with the appropriate pipeline (`"text-generation"`):
```python
>>> from transformers import pipeline, AutoTokenizer
>>> import torch
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> model = "tiiuae/falcon-7b-instruct"
>>> tokenizer = AutoTokenizer.from_pretrained(model)
>>> pipe = pipeline(
... "text-generation",
... model=model,
... tokenizer=tokenizer,
... torch_dtype=torch.bfloat16,
... device_map="auto",
... )
```
<Tip>
Note that Falcon models were trained using the `bfloat16` datatype, so we recommend you use the same. This requires a recent
version of CUDA and works best on modern cards.
</Tip>
Now that we have the model loaded via the pipeline, let's explore how you can use prompts to solve NLP tasks.
#### Text classification
One of the most common forms of text classification is sentiment analysis, which assigns a label like "positive", "negative",
or "neutral" to a sequence of text. Let's write a prompt that instructs the model to classify a given text (a movie review).
We'll start by giving the instruction, and then specifying the text to classify. Note that instead of leaving it at that, we're
also adding the beginning of the response - `"Sentiment: "`:
```python
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Classify the text into neutral, negative or positive.
... Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
... Sentiment:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Classify the text into neutral, negative or positive.
Text: This movie is definitely one of my favorite movies of its kind. The interaction between respectable and morally strong characters is an ode to chivalry and the honor code amongst thieves and policemen.
Sentiment:
Positive
```
As a result, the output contains a classification label from the list we have provided in the instructions, and it is a correct one!
<Tip>
You may notice that in addition to the prompt, we pass a `max_new_tokens` parameter. It controls the number of tokens the
model shall generate, and it is one of the many text generation parameters that you can learn about
in [Text generation strategies](../generation_strategies) guide.
</Tip>
#### Named Entity Recognition
Named Entity Recognition (NER) is a task of finding named entities in a piece of text, such as a person, location, or organization.
Let's modify the instructions in the prompt to make the LLM perform this task. Here, let's also set `return_full_text = False`
so that output doesn't contain the prompt:
```python
>>> torch.manual_seed(1) # doctest: +IGNORE_RESULT
>>> prompt = """Return a list of named entities in the text.
... Text: The Golden State Warriors are an American professional basketball team based in San Francisco.
... Named entities:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=15,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
- Golden State Warriors
- San Francisco
```
As you can see, the model correctly identified two named entities from the given text.
#### Translation
Another task LLMs can perform is translation. You can choose to use encoder-decoder models for this task, however, here,
for the simplicity of the examples, we'll keep using Falcon-7b-instruct, which does a decent job. Once again, here's how
you can write a basic prompt to instruct a model to translate a piece of text from English to Italian:
```python
>>> torch.manual_seed(2) # doctest: +IGNORE_RESULT
>>> prompt = """Translate the English text to Italian.
... Text: Sometimes, I've believed as many as six impossible things before breakfast.
... Translation:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=20,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
A volte, ho creduto a sei impossibili cose prima di colazione.
```
Here we've added a `do_sample=True` and `top_k=10` to allow the model to be a bit more flexible when generating output.
#### Text summarization
Similar to the translation, text summarization is another generative task where the output **heavily** relies on the input,
and encoder-decoder models can be a better choice. However, decoder-style models can be used for this task as well.
Previously, we have placed the instructions at the very beginning of the prompt. However, the very end of the prompt can
also be a suitable location for instructions. Typically, it's better to place the instruction on one of the extreme ends.
```python
>>> torch.manual_seed(3) # doctest: +IGNORE_RESULT
>>> prompt = """Permaculture is a design process mimicking the diversity, functionality and resilience of natural ecosystems. The principles and practices are drawn from traditional ecological knowledge of indigenous cultures combined with modern scientific understanding and technological innovations. Permaculture design provides a framework helping individuals and communities develop innovative, creative and effective strategies for meeting basic needs while preparing for and mitigating the projected impacts of climate change.
... Write a summary of the above text.
... Summary:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"{seq['generated_text']}")
"Permaculture is an ecological design method that mimics natural ecosystems' diversity, functionality, and resilience using modern technology and indigenous knowledge. It aims to help"
```
#### Question answering
For question answering task we can structure the prompt into the following logical components: instructions, context, question, and
the leading word or phrase (`"Answer:"`) to nudge the model to start generating the answer:
```python
>>> torch.manual_seed(4) # doctest: +IGNORE_RESULT
>>> prompt = """Answer the question using the context below.
... Context: Gazpacho is a cold soup and drink made of raw, blended vegetables. Most gazpacho includes stale bread, tomato, cucumbers, onion, bell peppers, garlic, olive oil, wine vinegar, water, and salt. Northern recipes often include cumin and/or pimentón (smoked sweet paprika). Traditionally, gazpacho was made by pounding the vegetables in a mortar with a pestle; this more laborious method is still sometimes used as it helps keep the gazpacho cool and avoids the foam and silky consistency of smoothie versions made in blenders or food processors.
... Question: What modern tool is used to make gazpacho?
... Answer:
... """
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
"Result: Modern tools are used, such as immersion blenders"
```
#### Reasoning
Reasoning is one of the most difficult tasks for LLMs, and achieving good results often requires applying advanced prompting techniques, like
[Chain-of-thought](#chain-of-thought).
Let's try if we can make a model reason about a simple arithmetics task with a basic prompt:
```python
>>> torch.manual_seed(5) # doctest: +IGNORE_RESULT
>>> prompt = """There are 5 groups of students in the class. Each group has 4 students. How many students are there in the class?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=30,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
There are a total of 50 students in the class (5 groups x 4 students per group = 20 groups, and
```
Correct! Let's increase the complexity a little and see if we can still get away with a basic prompt:
```python
>>> torch.manual_seed(6) # doctest: +IGNORE_RESULT
>>> prompt = """I baked 15 muffins. I ate 2 muffins and gave 5 muffins to a neighbor. My partner then bought 6 more muffins and ate 2. How many muffins do we now have?"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=10,
... do_sample=True,
... top_k=10,
... return_full_text = False,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result:
The total number of muffins now is 21
```
This is a wrong answer, it should be 12. In this case, this can be due to the prompt being too basic, or due to the choice
of model, after all we've picked the smallest version of Falcon. Reasoning is difficult for models of all sizes, but larger
models are likely to perform better.
## Best practices of LLM prompting
In this section of the guide we have compiled a list of best practices that tend to improve the prompt results:
* When choosing the model to work with, the latest and most capable models are likely to perform better.
* Start with a simple and short prompt, and iterate from there.
* Put the instructions at the beginning of the prompt, or at the very end. When working with large context, models apply various optimizations to prevent Attention complexity from scaling quadratically. This may make a model more attentive to the beginning or end of a prompt than the middle.
* Clearly separate instructions from the text they apply to - more on this in the next section.
* Be specific and descriptive about the task and the desired outcome - its format, length, style, language, etc.
* Avoid ambiguous descriptions and instructions.
* Favor instructions that say "what to do" instead of those that say "what not to do".
* "Lead" the output in the right direction by writing the first word (or even begin the first sentence for the model).
* Use advanced techniques like [Few-shot prompting](#few-shot-prompting) and [Chain-of-thought](#chain-of-thought)
* Test your prompts with different models to assess their robustness.
* Version and track the performance of your prompts.
## Advanced prompting techniques
### Few-shot prompting
The basic prompts in the sections above are the examples of "zero-shot" prompts, meaning, the model has been given
instructions and context, but no examples with solutions. LLMs that have been fine-tuned on instruction datasets, generally
perform well on such "zero-shot" tasks. However, you may find that your task has more complexity or nuance, and, perhaps,
you have some requirements for the output that the model doesn't catch on just from the instructions. In this case, you can
try the technique called few-shot prompting.
In few-shot prompting, we provide examples in the prompt giving the model more context to improve the performance.
The examples condition the model to generate the output following the patterns in the examples.
Here's an example:
```python
>>> torch.manual_seed(0) # doctest: +IGNORE_RESULT
>>> prompt = """Text: The first human went into space and orbited the Earth on April 12, 1961.
... Date: 04/12/1961
... Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
... Date:"""
>>> sequences = pipe(
... prompt,
... max_new_tokens=8,
... do_sample=True,
... top_k=10,
... )
>>> for seq in sequences:
... print(f"Result: {seq['generated_text']}")
Result: Text: The first human went into space and orbited the Earth on April 12, 1961.
Date: 04/12/1961
Text: The first-ever televised presidential debate in the United States took place on September 28, 1960, between presidential candidates John F. Kennedy and Richard Nixon.
Date: 09/28/1960
```
In the above code snippet we used a single example to demonstrate the desired output to the model, so this can be called a
"one-shot" prompting. However, depending on the task complexity you may need to use more than one example.
Limitations of the few-shot prompting technique:
- While LLMs can pick up on the patterns in the examples, these technique doesn't work well on complex reasoning tasks
- Few-shot prompting requires creating lengthy prompts. Prompts with large number of tokens can increase computation and latency. There's also a limit to the length of the prompts.
- Sometimes when given a number of examples, models can learn patterns that you didn't intend them to learn, e.g. that the third movie review is always negative.
### Chain-of-thought
Chain-of-thought (CoT) prompting is a technique that nudges a model to produce intermediate reasoning steps thus improving
the results on complex reasoning tasks.
There are two ways of steering a model to producing the reasoning steps:
- few-shot prompting by illustrating examples with detailed answers to questions, showing the model how to work through a problem.
- by instructing the model to reason by adding phrases like "Let's think step by step" or "Take a deep breath and work through the problem step by step."
If we apply the CoT technique to the muffins example from the [reasoning section](#reasoning) and use a larger model,
such as (`tiiuae/falcon-180B-chat`) which you can play with in the [HuggingChat](https://huggingface.co/chat/),
we'll get a significant improvement on the reasoning result:
```text
Let's go through this step-by-step:
1. You start with 15 muffins.
2. You eat 2 muffins, leaving you with 13 muffins.
3. You give 5 muffins to your neighbor, leaving you with 8 muffins.
4. Your partner buys 6 more muffins, bringing the total number of muffins to 14.
5. Your partner eats 2 muffins, leaving you with 12 muffins.
Therefore, you now have 12 muffins.
```
## Prompting vs fine-tuning
You can achieve great results by optimizing your prompts, however, you may still ponder whether fine-tuning a model
would work better for your case. Here are some scenarios when fine-tuning a smaller model may be a preferred option:
- Your domain is wildly different from what LLMs were pre-trained on and extensive prompt optimization did not yield sufficient results.
- You need your model to work well in a low-resource language.
- You need the model to be trained on sensitive data that is under strict regulations.
- You have to use a small model due to cost, privacy, infrastructure or other limitations.
In all of the above examples, you will need to make sure that you either already have or can easily obtain a large enough
domain-specific dataset at a reasonable cost to fine-tune a model. You will also need to have enough time and resources
to fine-tune a model.
If the above examples are not the case for you, optimizing prompts can prove to be more beneficial.
|
transformers/docs/source/en/tasks/prompting.md/0
|
{
"file_path": "transformers/docs/source/en/tasks/prompting.md",
"repo_id": "transformers",
"token_count": 5582
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Export to TFLite
[TensorFlow Lite](https://www.tensorflow.org/lite/guide) is a lightweight framework for deploying machine learning models
on resource-constrained devices, such as mobile phones, embedded systems, and Internet of Things (IoT) devices.
TFLite is designed to optimize and run models efficiently on these devices with limited computational power, memory, and
power consumption.
A TensorFlow Lite model is represented in a special efficient portable format identified by the `.tflite` file extension.
🤗 Optimum offers functionality to export 🤗 Transformers models to TFLite through the `exporters.tflite` module.
For the list of supported model architectures, please refer to [🤗 Optimum documentation](https://huggingface.co/docs/optimum/exporters/tflite/overview).
To export a model to TFLite, install the required dependencies:
```bash
pip install optimum[exporters-tf]
```
To check out all available arguments, refer to the [🤗 Optimum docs](https://huggingface.co/docs/optimum/main/en/exporters/tflite/usage_guides/export_a_model),
or view help in command line:
```bash
optimum-cli export tflite --help
```
To export a model's checkpoint from the 🤗 Hub, for example, `google-bert/bert-base-uncased`, run the following command:
```bash
optimum-cli export tflite --model google-bert/bert-base-uncased --sequence_length 128 bert_tflite/
```
You should see the logs indicating progress and showing where the resulting `model.tflite` is saved, like this:
```bash
Validating TFLite model...
-[✓] TFLite model output names match reference model (logits)
- Validating TFLite Model output "logits":
-[✓] (1, 128, 30522) matches (1, 128, 30522)
-[x] values not close enough, max diff: 5.817413330078125e-05 (atol: 1e-05)
The TensorFlow Lite export succeeded with the warning: The maximum absolute difference between the output of the reference model and the TFLite exported model is not within the set tolerance 1e-05:
- logits: max diff = 5.817413330078125e-05.
The exported model was saved at: bert_tflite
```
The example above illustrates exporting a checkpoint from 🤗 Hub. When exporting a local model, first make sure that you
saved both the model's weights and tokenizer files in the same directory (`local_path`). When using CLI, pass the
`local_path` to the `model` argument instead of the checkpoint name on 🤗 Hub.
|
transformers/docs/source/en/tflite.md/0
|
{
"file_path": "transformers/docs/source/en/tflite.md",
"repo_id": "transformers",
"token_count": 878
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Convertir checkpoints de Tensorflow
Te proporcionamos una interfaz de línea de comando (`CLI`, por sus siglas en inglés) para convertir puntos de control (_checkpoints_) originales de Bert/GPT/GPT-2/Transformer-XL/XLNet/XLM en modelos que se puedan cargar utilizando los métodos `from_pretrained` de la biblioteca.
<Tip>
Desde 2.3.0, el script para convertir es parte de la CLI de transformers (**transformers-cli**) disponible en cualquier instalación de transformers >= 2.3.0.
La siguiente documentación refleja el formato para el comando **transformers-cli convert**.
</Tip>
## BERT
Puedes convertir cualquier checkpoint de TensorFlow para BERT (en particular, [los modelos pre-entrenados y publicados por Google](https://github.com/google-research/bert#pre-trained-models)) en un archivo de PyTorch mediante el script [convert_bert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/bert/convert_bert_original_tf_checkpoint_to_pytorch.py).
Esta CLI toma como entrada un checkpoint de TensorFlow (tres archivos que comienzan con `bert_model.ckpt`) y el archivo de configuración asociado (`bert_config.json`), y crea un modelo PyTorch para esta configuración, carga los pesos del checkpoint de TensorFlow en el modelo de PyTorch y guarda el modelo resultante en un archivo estándar de PyTorch que se puede importar usando `from_pretrained()` (ve el ejemplo en [Tour rápido](quicktour), [run_glue.py](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification/run_glue.py)).
Solo necesitas ejecutar este script **una vez** para convertir un modelo a PyTorch. Después, puedes ignorar el checkpoint de TensorFlow (los tres archivos que comienzan con `bert_model.ckpt`), pero asegúrate de conservar el archivo de configuración (`bert_config.json`) y el archivo de vocabulario (`vocab.txt`) ya que estos también son necesarios para el modelo en PyTorch.
Para ejecutar este script deberás tener instalado TensorFlow y PyTorch (`pip install tensorflow`). El resto del repositorio solo requiere PyTorch.
Aquí hay un ejemplo del proceso para convertir un modelo `BERT-Base Uncased` pre-entrenado:
```bash
export BERT_BASE_DIR=/path/to/bert/uncased_L-12_H-768_A-12
transformers-cli convert --model_type bert \
--tf_checkpoint $BERT_BASE_DIR/bert_model.ckpt \
--config $BERT_BASE_DIR/bert_config.json \
--pytorch_dump_output $BERT_BASE_DIR/pytorch_model.bin
```
Puedes descargar los modelos pre-entrenados de Google para la conversión [aquí](https://github.com/google-research/bert#pre-trained-models).
## ALBERT
Convierte los checkpoints del modelo ALBERT de TensorFlow a PyTorch usando el script [convert_albert_original_tf_checkpoint_to_pytorch.py](https://github.com/huggingface/transformers/tree/main/src/transformers/models/albert/convert_albert_original_tf_checkpoint_to_pytorch.py).
La CLI toma como entrada un checkpoint de TensorFlow (tres archivos que comienzan con `model.ckpt-best`) y el archivo de configuración adjunto (`albert_config.json`), luego crea y guarda un modelo de PyTorch. Para ejecutar esta conversión deberás tener instalados TensorFlow y PyTorch.
Aquí hay un ejemplo del proceso para convertir un modelo `ALBERT Base` pre-entrenado:
```bash
export ALBERT_BASE_DIR=/path/to/albert/albert_base
transformers-cli convert --model_type albert \
--tf_checkpoint $ALBERT_BASE_DIR/model.ckpt-best \
--config $ALBERT_BASE_DIR/albert_config.json \
--pytorch_dump_output $ALBERT_BASE_DIR/pytorch_model.bin
```
Puedes descargar los modelos pre-entrenados de Google para la conversión [aquí](https://github.com/google-research/albert#pre-trained-models).
## OpenAI GPT
Este es un ejemplo del proceso para convertir un modelo OpenAI GPT pre-entrenado, asumiendo que tu checkpoint de NumPy se guarda con el mismo formato que el modelo pre-entrenado de OpenAI (más información [aquí](https://github.com/openai/finetune-transformer-lm)):
```bash
export OPENAI_GPT_CHECKPOINT_FOLDER_PATH=/path/to/openai/pretrained/numpy/weights
transformers-cli convert --model_type gpt \
--tf_checkpoint $OPENAI_GPT_CHECKPOINT_FOLDER_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT_CONFIG] \
[--finetuning_task_name OPENAI_GPT_FINETUNED_TASK] \
```
## OpenAI GPT-2
Aquí hay un ejemplo del proceso para convertir un modelo OpenAI GPT-2 pre-entrenado (más información [aquí](https://github.com/openai/gpt-2)):
```bash
export OPENAI_GPT2_CHECKPOINT_PATH=/path/to/openai-community/gpt2/pretrained/weights
transformers-cli convert --model_type gpt2 \
--tf_checkpoint $OPENAI_GPT2_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--config OPENAI_GPT2_CONFIG] \
[--finetuning_task_name OPENAI_GPT2_FINETUNED_TASK]
```
## XLNet
Aquí hay un ejemplo del proceso para convertir un modelo XLNet pre-entrenado:
```bash
export TRANSFO_XL_CHECKPOINT_PATH=/path/to/xlnet/checkpoint
export TRANSFO_XL_CONFIG_PATH=/path/to/xlnet/config
transformers-cli convert --model_type xlnet \
--tf_checkpoint $TRANSFO_XL_CHECKPOINT_PATH \
--config $TRANSFO_XL_CONFIG_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT \
[--finetuning_task_name XLNET_FINETUNED_TASK] \
```
## XLM
Aquí hay un ejemplo del proceso para convertir un modelo XLM pre-entrenado:
```bash
export XLM_CHECKPOINT_PATH=/path/to/xlm/checkpoint
transformers-cli convert --model_type xlm \
--tf_checkpoint $XLM_CHECKPOINT_PATH \
--pytorch_dump_output $PYTORCH_DUMP_OUTPUT
[--config XML_CONFIG] \
[--finetuning_task_name XML_FINETUNED_TASK]
```
## T5
Aquí hay un ejemplo del proceso para convertir un modelo T5 pre-entrenado:
```bash
export T5=/path/to/t5/uncased_L-12_H-768_A-12
transformers-cli convert --model_type t5 \
--tf_checkpoint $T5/t5_model.ckpt \
--config $T5/t5_config.json \
--pytorch_dump_output $T5/pytorch_model.bin
```
|
transformers/docs/source/es/converting_tensorflow_models.md/0
|
{
"file_path": "transformers/docs/source/es/converting_tensorflow_models.md",
"repo_id": "transformers",
"token_count": 2424
}
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Uso de un flujo de trabajo para un servidor web
<Tip>
Crear un motor de inferencia es un tema complejo, y la "mejor" solución probablemente dependerá de tu caso de uso. ¿Estás en CPU o en GPU? ¿Quieres la latencia más baja, el rendimiento más alto, soporte para muchos modelos o simplemente optimizar altamente un modelo específico? Hay muchas formas de abordar este tema, así que lo que vamos a presentar es un buen valor predeterminado para comenzar, que no necesariamente será la solución más óptima para ti.
</Tip>
Lo fundamental para entender es que podemos usar un iterador, tal como [en un conjunto de datos](pipeline_tutorial#uso-de-pipelines-en-un-conjunto-de-datos), ya que un servidor web es básicamente un sistema que espera solicitudes y las trata a medida que llegan.
Por lo general, los servidores web están multiplexados (multihilo, asíncrono, etc.) para manejar varias solicitudes simultáneamente. Por otro lado, los flujos de trabajo (y principalmente los modelos subyacentes) no son realmente ideales para el paralelismo; consumen mucha RAM, por lo que es mejor darles todos los recursos disponibles cuando se están ejecutando o es un trabajo intensivo en cómputo.
Vamos a resolver esto haciendo que el servidor web maneje la carga ligera de recibir y enviar solicitudes, y que un único hilo maneje el trabajo real. Este ejemplo va a utilizar `starlette`. El marco de trabajo no es realmente importante, pero es posible que debas ajustar o cambiar el código si estás utilizando otro para lograr el mismo efecto.
Crear `server.py`:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="google-bert/bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
Ahora puedes empezar con:
```bash
uvicorn server:app
```
Y puedes consultarlo con:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
¡Y listo, ahora tienes una buena idea de cómo crear un servidor web!
Lo realmente importante es cargar el modelo solo **una vez**, de modo que no haya copias del modelo en el servidor web. De esta manera, no se utiliza RAM innecesariamente. Luego, el mecanismo de queuing (colas) te permite hacer cosas sofisticadas como acumular algunos elementos antes de inferir para usar el agrupamiento dinámico:
<Tip warning={true}>
El ejemplo de código a continuación está escrito intencionalmente como pseudocódigo para facilitar la lectura.
¡No lo ejecutes sin verificar si tiene sentido para los recursos de tu sistema!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
Nuevamente, el código propuesto está optimizado para la legibilidad, no para ser el mejor código.
En primer lugar, no hay límite de tamaño de lote, lo cual generalmente no es una buena idea. Luego, el tiempo de espera se restablece en cada obtención de la cola, lo que significa que podrías esperar mucho más de 1ms antes de ejecutar la inferencia (retrasando la primera solicitud en esa cantidad).
Sería mejor tener un único plazo de 1ms.
Esto siempre esperará 1ms incluso si la cola está vacía, lo que podría no ser lo mejor ya que probablemente quieras comenzar a hacer inferencias si no hay nada en la cola. Pero tal vez tenga sentido si el agrupamiento es realmente crucial para tu caso de uso. Nuevamente, no hay una solución única y mejor.
## Algunas cosas que podrías considerar
### Comprobación de errores
Hay muchas cosas que pueden salir mal en producción: falta de memoria, falta de espacio, cargar el modelo podría fallar, la consulta podría ser incorrecta, la consulta podría ser correcta pero aún así fallar debido a una mala configuración del modelo, y así sucesivamente.
Generalmente, es bueno que el servidor muestre los errores al usuario, por lo que agregar muchos bloques `try..except` para mostrar esos errores es una buena idea. Pero ten en cuenta que también puede ser un riesgo de seguridad revelar todos esos errores dependiendo de tu contexto de seguridad.
### Interrupción de circuito
Los servidores web suelen verse mejor cuando hacen interrupciones de circuitos. Significa que devuelven errores adecuados cuando están sobrecargados en lugar de simplemente esperar la consulta indefinidamente. Devolver un error 503 en lugar de esperar un tiempo muy largo o un error 504 después de mucho tiempo.
Esto es relativamente fácil de implementar en el código propuesto ya que hay una sola cola. Mirar el tamaño de la cola es una forma básica de empezar a devolver errores antes de que tu servidor web falle bajo carga.
### Bloqueo del hilo principal
Actualmente, PyTorch no es consciente de la asincronía, y el cálculo bloqueará el hilo principal mientras se ejecuta. Esto significa que sería mejor si PyTorch se viera obligado a ejecutarse en su propio hilo/proceso. Esto no se hizo aquí porque el código es mucho más complejo (principalmente porque los hilos, la asincronía y las colas no se llevan bien juntos). Pero en última instancia, hace lo mismo.
Esto sería importante si la inferencia de elementos individuales fuera larga (> 1s) porque en este caso, significa que cada consulta durante la inferencia tendría que esperar 1s antes de recibir incluso un error.
### Procesamiento por lotes dinámico
En general, el procesamiento por lotes no es necesariamente una mejora respecto a pasar 1 elemento a la vez (ver [procesamiento por lotes](https://huggingface.co/docs/transformers/main_classes/pipelines#pipeline-batching) para más información). Pero puede ser muy efectivo cuando se usa en el entorno correcto. En la API, no hay procesamiento por lotes dinámico por defecto (demasiada oportunidad para una desaceleración). Pero para la inferencia de BLOOM - que es un modelo muy grande - el procesamiento por lotes dinámico es **esencial** para proporcionar una experiencia decente para todos.
|
transformers/docs/source/es/pipeline_webserver.md/0
|
{
"file_path": "transformers/docs/source/es/pipeline_webserver.md",
"repo_id": "transformers",
"token_count": 2575
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# वितरित प्रशिक्षण के साथ 🤗 Accelerate
जैसे-जैसे मॉडल बड़े होते हैं, समानांतरता सीमित हार्डवेयर पर बड़े मॉडल को प्रशिक्षित करने और प्रशिक्षण की गति को कई आदेशों के आकार में तेज करने के लिए एक रणनीति के रूप में उभरी है। हगिंग फेस में, हमने उपयोगकर्ताओं को किसी भी प्रकार के वितरित सेटअप पर 🤗 ट्रांसफार्मर्स मॉडल को आसानी से प्रशिक्षित करने में मदद करने के लिए [🤗 Accelerate](https://huggingface.co/docs/accelerate) पुस्तकालय बनाया है, चाहे वह एक मशीन पर कई GPU हों या कई मशीनों में कई GPU। इस ट्यूटोरियल में, जानें कि अपने मूल PyTorch प्रशिक्षण लूप को कैसे अनुकूलित किया जाए ताकि वितरित वातावरण में प्रशिक्षण सक्षम हो सके।
## सेटअप
🤗 Accelerate स्थापित करके शुरू करें:
```bash
pip install accelerate
```
फिर एक [`~accelerate.Accelerator`] ऑब्जेक्ट आयात करें और बनाएं। [`~accelerate.Accelerator`] स्वचालित रूप से आपके वितरित सेटअप के प्रकार का पता लगाएगा और प्रशिक्षण के लिए सभी आवश्यक घटकों को प्रारंभ करेगा। आपको अपने मॉडल को किसी डिवाइस पर स्पष्ट रूप से रखने की आवश्यकता नहीं है।
```py
>>> from accelerate import Accelerator
>>> accelerator = Accelerator()
```
## तेजी लाने की तैयारी
अगला कदम सभी प्रासंगिक प्रशिक्षण वस्तुओं को [`~accelerate.Accelerator.prepare`] विधि में पास करना है। इसमें आपके प्रशिक्षण और मूल्यांकन DataLoaders, एक मॉडल और एक ऑप्टिमाइज़र शामिल हैं:
```py
>>> train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
... train_dataloader, eval_dataloader, model, optimizer
... )
```
## बैकवर्ड
अंतिम जोड़ यह है कि आपके प्रशिक्षण लूप में सामान्य `loss.backward()` को 🤗 Accelerate के [`~accelerate.Accelerator.backward`] विधि से बदलें:
```py
>>> for epoch in range(num_epochs):
... for batch in train_dataloader:
... outputs = model(**batch)
... loss = outputs.loss
... accelerator.backward(loss)
... optimizer.step()
... lr_scheduler.step()
... optimizer.zero_grad()
... progress_bar.update(1)
```
जैसा कि आप निम्नलिखित कोड में देख सकते हैं, आपको वितरित प्रशिक्षण सक्षम करने के लिए अपने प्रशिक्षण लूप में केवल चार अतिरिक्त कोड की पंक्तियाँ जोड़ने की आवश्यकता है!
```diff
+ from accelerate import Accelerator
from transformers import AdamW, AutoModelForSequenceClassification, get_scheduler
+ accelerator = Accelerator()
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2)
optimizer = AdamW(model.parameters(), lr=3e-5)
- device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
- model.to(device)
+ train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(
+ train_dataloader, eval_dataloader, model, optimizer
+ )
num_epochs = 3
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
"linear",
optimizer=optimizer,
num_warmup_steps=0,
num_training_steps=num_training_steps
)
progress_bar = tqdm(range(num_training_steps))
model.train()
for epoch in range(num_epochs):
for batch in train_dataloader:
- batch = {k: v.to(device) for k, v in batch.items()}
outputs = model(**batch)
loss = outputs.loss
- loss.backward()
+ accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
progress_bar.update(1)
```
## प्रशिक्षण
एक बार जब आपने प्रासंगिक कोड की पंक्तियाँ जोड़ दी हैं, तो अपने प्रशिक्षण को स्क्रिप्ट या कोलैबोरेटरी जैसे नोटबुक में लॉन्च करें।
### स्क्रिप्ट के साथ प्रशिक्षण
यदि आप स्क्रिप्ट से अपना प्रशिक्षण चला रहे हैं, तो एक कॉन्फ़िगरेशन फ़ाइल बनाने और सहेजने के लिए निम्नलिखित कमांड चलाएँ:
```bash
accelerate config
```
फिर अपने प्रशिक्षण को इस तरह लॉन्च करें:
```bash
accelerate launch train.py
```
### नोटबुक के साथ प्रशिक्षण
🤗 Accelerate एक नोटबुक में भी चल सकता है यदि आप Colaboratory के TPU का उपयोग करने की योजना बना रहे हैं। प्रशिक्षण के लिए जिम्मेदार सभी कोड को एक फ़ंक्शन में लपेटें, और इसे [`~accelerate.notebook_launcher`] में पास करें:
```py
>>> from accelerate import notebook_launcher
>>> notebook_launcher(training_function)
```
🤗 Accelerate और इसकी समृद्ध सुविधाओं के बारे में अधिक जानकारी के लिए, [दस्तावेज़ीकरण](https://huggingface.co/docs/accelerate) देखें।
|
transformers/docs/source/hi/accelerate.md/0
|
{
"file_path": "transformers/docs/source/hi/accelerate.md",
"repo_id": "transformers",
"token_count": 3992
}
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installazione
Installa 🤗 Transformers per qualsiasi libreria di deep learning con cui stai lavorando, imposta la tua cache, e opzionalmente configura 🤗 Transformers per l'esecuzione offline.
🤗 Transformers è testato su Python 3.6+, PyTorch 1.1.0+, TensorFlow 2.0+, e Flax. Segui le istruzioni di installazione seguenti per la libreria di deep learning che stai utilizzando:
* [PyTorch](https://pytorch.org/get-started/locally/) istruzioni di installazione.
* [TensorFlow 2.0](https://www.tensorflow.org/install/pip) istruzioni di installazione.
* [Flax](https://flax.readthedocs.io/en/latest/) istruzioni di installazione.
## Installazione con pip
Puoi installare 🤗 Transformers in un [ambiente virtuale](https://docs.python.org/3/library/venv.html). Se non sei familiare con gli ambienti virtuali in Python, dai un'occhiata a questa [guida](https://packaging.python.org/guides/installing-using-pip-and-virtual-environments/). Un ambiente virtuale rende più semplice la gestione di progetti differenti, evitando problemi di compatibilità tra dipendenze.
Inizia creando un ambiente virtuale nella directory del tuo progetto:
```bash
python -m venv .env
```
Attiva l'ambiente virtuale:
```bash
source .env/bin/activate
```
Ora puoi procedere con l'installazione di 🤗 Transformers eseguendo il comando seguente:
```bash
pip install transformers
```
Per il solo supporto della CPU, puoi installare facilmente 🤗 Transformers e una libreria di deep learning in solo una riga. Ad esempio, installiamo 🤗 Transformers e PyTorch con:
```bash
pip install transformers[torch]
```
🤗 Transformers e TensorFlow 2.0:
```bash
pip install transformers[tf-cpu]
```
🤗 Transformers e Flax:
```bash
pip install transformers[flax]
```
Infine, verifica se 🤗 Transformers è stato installato in modo appropriato eseguendo il seguente comando. Questo scaricherà un modello pre-allenato:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('we love you'))"
```
Dopodiché stampa l'etichetta e il punteggio:
```bash
[{'label': 'POSITIVE', 'score': 0.9998704791069031}]
```
## Installazione dalla fonte
Installa 🤗 Transformers dalla fonte con il seguente comando:
```bash
pip install git+https://github.com/huggingface/transformers
```
Questo comando installa la versione `main` più attuale invece dell'ultima versione stabile. Questo è utile per stare al passo con gli ultimi sviluppi. Ad esempio, se un bug è stato sistemato da quando è uscita l'ultima versione ufficiale ma non è stata ancora rilasciata una nuova versione. Tuttavia, questo significa che questa versione `main` può non essere sempre stabile. Ci sforziamo per mantenere la versione `main` operativa, e la maggior parte dei problemi viene risolta in poche ore o in un giorno. Se riscontri un problema, per favore apri una [Issue](https://github.com/huggingface/transformers/issues) così possiamo sistemarlo ancora più velocemente!
Controlla se 🤗 Transformers è stata installata in modo appropriato con il seguente comando:
```bash
python -c "from transformers import pipeline; print(pipeline('sentiment-analysis')('I love you'))"
```
## Installazione modificabile
Hai bisogno di un'installazione modificabile se vuoi:
* Usare la versione `main` del codice dalla fonte.
* Contribuire a 🤗 Transformers e hai bisogno di testare i cambiamenti nel codice.
Clona il repository e installa 🤗 Transformers con i seguenti comandi:
```bash
git clone https://github.com/huggingface/transformers.git
cd transformers
pip install -e .
```
Questi comandi collegheranno la cartella in cui è stato clonato il repository e i path delle librerie Python. Python guarderà ora all'interno della cartella clonata, oltre ai normali path delle librerie. Per esempio, se i tuoi pacchetti Python sono installati tipicamente in `~/anaconda3/envs/main/lib/python3.7/site-packages/`, Python cercherà anche nella cartella clonata: `~/transformers/`.
<Tip warning={true}>
Devi tenere la cartella `transformers` se vuoi continuare ad utilizzare la libreria.
</Tip>
Ora puoi facilmente aggiornare il tuo clone all'ultima versione di 🤗 Transformers con il seguente comando:
```bash
cd ~/transformers/
git pull
```
Il tuo ambiente Python troverà la versione `main` di 🤗 Transformers alla prossima esecuzione.
## Installazione con conda
Installazione dal canale conda `conda-forge`:
```bash
conda install conda-forge::transformers
```
## Impostazione della cache
I modelli pre-allenati sono scaricati e memorizzati localmente nella cache in: `~/.cache/huggingface/transformers/`. Questa è la directory di default data dalla variabile d'ambiente della shell `TRANSFORMERS_CACHE`. Su Windows, la directory di default è data da `C:\Users\username\.cache\huggingface\transformers`. Puoi cambiare le variabili d'ambiente della shell indicate in seguito, in ordine di priorità, per specificare una directory differente per la cache:
1. Variabile d'ambiente della shell (default): `TRANSFORMERS_CACHE`.
2. Variabile d'ambiente della shell: `HF_HOME` + `transformers/`.
3. Variabile d'ambiente della shell: `XDG_CACHE_HOME` + `/huggingface/transformers`.
<Tip>
🤗 Transformers utilizzerà le variabili d'ambiente della shell `PYTORCH_TRANSFORMERS_CACHE` o `PYTORCH_PRETRAINED_BERT_CACHE` se si proviene da un'iterazione precedente di questa libreria e sono state impostate queste variabili d'ambiente, a meno che non si specifichi la variabile d'ambiente della shell `TRANSFORMERS_CACHE`.
</Tip>
## Modalità Offline
🤗 Transformers può essere eseguita in un ambiente firewalled o offline utilizzando solo file locali. Imposta la variabile d'ambiente `HF_HUB_OFFLINE=1` per abilitare questo comportamento.
<Tip>
Aggiungi [🤗 Datasets](https://huggingface.co/docs/datasets/) al tuo flusso di lavoro offline di training impostando la variabile d'ambiente `HF_DATASETS_OFFLINE=1`.
</Tip>
Ad esempio, in genere si esegue un programma su una rete normale, protetta da firewall per le istanze esterne, con il seguente comando:
```bash
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Esegui lo stesso programma in un'istanza offline con:
```bash
HF_DATASETS_OFFLINE=1 HF_HUB_OFFLINE=1 \
python examples/pytorch/translation/run_translation.py --model_name_or_path google-t5/t5-small --dataset_name wmt16 --dataset_config ro-en ...
```
Lo script viene ora eseguito senza bloccarsi o attendere il timeout, perché sa di dover cercare solo file locali.
### Ottenere modelli e tokenizer per l'uso offline
Un'altra opzione per utilizzare offline 🤗 Transformers è scaricare i file in anticipo, e poi puntare al loro path locale quando hai la necessità di utilizzarli offline. Ci sono tre modi per fare questo:
* Scarica un file tramite l'interfaccia utente sul [Model Hub](https://huggingface.co/models) premendo sull'icona ↓.

* Utilizza il flusso [`PreTrainedModel.from_pretrained`] e [`PreTrainedModel.save_pretrained`]:
1. Scarica i tuoi file in anticipo con [`PreTrainedModel.from_pretrained`]:
```py
>>> from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
>>> tokenizer = AutoTokenizer.from_pretrained("bigscience/T0_3B")
>>> model = AutoModelForSeq2SeqLM.from_pretrained("bigscience/T0_3B")
```
2. Salva i tuoi file in una directory specificata con [`PreTrainedModel.save_pretrained`]:
```py
>>> tokenizer.save_pretrained("./il/tuo/path/bigscience_t0")
>>> model.save_pretrained("./il/tuo/path/bigscience_t0")
```
3. Ora quando sei offline, carica i tuoi file con [`PreTrainedModel.from_pretrained`] dalla directory specificata:
```py
>>> tokenizer = AutoTokenizer.from_pretrained("./il/tuo/path/bigscience_t0")
>>> model = AutoModel.from_pretrained("./il/tuo/path/bigscience_t0")
```
* Scarica in maniera programmatica i file con la libreria [huggingface_hub](https://github.com/huggingface/huggingface_hub/tree/main/src/huggingface_hub):
1. Installa la libreria `huggingface_hub` nel tuo ambiente virtuale:
```bash
python -m pip install huggingface_hub
```
2. Utilizza la funzione [`hf_hub_download`](https://huggingface.co/docs/hub/adding-a-library#download-files-from-the-hub) per scaricare un file in un path specifico. Per esempio, il seguente comando scarica il file `config.json` dal modello [T0](https://huggingface.co/bigscience/T0_3B) nel path che desideri:
```py
>>> from huggingface_hub import hf_hub_download
>>> hf_hub_download(repo_id="bigscience/T0_3B", filename="config.json", cache_dir="./il/tuo/path/bigscience_t0")
```
Una volta che il tuo file è scaricato e salvato in cache localmente, specifica il suo path locale per caricarlo e utilizzarlo:
```py
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("./il/tuo/path/bigscience_t0/config.json")
```
<Tip>
Fai riferimento alla sezione [How to download files from the Hub](https://huggingface.co/docs/hub/how-to-downstream) per avere maggiori dettagli su come scaricare modelli presenti sull Hub.
</Tip>
|
transformers/docs/source/it/installation.md/0
|
{
"file_path": "transformers/docs/source/it/installation.md",
"repo_id": "transformers",
"token_count": 3586
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Quick tour
[[open-in-colab]]
Entra in azione con 🤗 Transformers! Inizia utilizzando [`pipeline`] per un'inferenza veloce, carica un modello pre-allenato e un tokenizer con una [AutoClass](./model_doc/auto) per risolvere i tuoi compiti legati a testo, immagini o audio.
<Tip>
Tutti gli esempi di codice presenti in questa documentazione hanno un pulsante in alto a sinistra che permette di selezionare tra PyTorch e TensorFlow. Se
questo non è presente, ci si aspetta che il codice funzioni per entrambi i backend senza alcun cambiamento.
</Tip>
## Pipeline
[`pipeline`] è il modo più semplice per utilizzare un modello pre-allenato per un dato compito.
<Youtube id="tiZFewofSLM"/>
La [`pipeline`] supporta molti compiti comuni:
**Testo**:
* Analisi del Sentimento (Sentiment Analysis, in inglese): classifica la polarità di un testo dato.
* Generazione del Testo (Text Generation, in inglese): genera del testo a partire da un dato input.
* Riconoscimento di Entità (Name Entity Recognition o NER, in inglese): etichetta ogni parola con l'entità che questa rappresenta (persona, data, luogo, ecc.).
* Rispondere a Domande (Question answering, in inglese): estrae la risposta da un contesto, dato del contesto e una domanda.
* Riempimento di Maschere (Fill-mask, in inglese): riempie gli spazi mancanti in un testo che ha parole mascherate.
* Riassumere (Summarization, in inglese): genera una sintesi di una lunga sequenza di testo o di un documento.
* Traduzione (Translation, in inglese): traduce un testo in un'altra lingua.
* Estrazione di Caratteristiche (Feature Extraction, in inglese): crea un tensore che rappresenta un testo.
**Immagini**:
* Classificazione di Immagini (Image Classification, in inglese): classifica un'immagine.
* Segmentazione di Immagini (Image Segmentation, in inglese): classifica ogni pixel di un'immagine.
* Rilevazione di Oggetti (Object Detection, in inglese): rileva oggetti all'interno di un'immagine.
**Audio**:
* Classificazione di Audio (Audio Classification, in inglese): assegna un'etichetta ad un segmento di audio dato.
* Riconoscimento Vocale Automatico (Automatic Speech Recognition o ASR, in inglese): trascrive il contenuto di un audio dato in un testo.
<Tip>
Per maggiori dettagli legati alla [`pipeline`] e ai compiti ad essa associati, fai riferimento alla documentazione [qui](./main_classes/pipelines).
</Tip>
### Utilizzo della Pipeline
Nel seguente esempio, utilizzerai la [`pipeline`] per l'analisi del sentimento.
Installa le seguenti dipendenze se non lo hai già fatto:
<frameworkcontent>
<pt>
```bash
pip install torch
```
</pt>
<tf>
```bash
pip install tensorflow
```
</tf>
</frameworkcontent>
Importa [`pipeline`] e specifica il compito che vuoi completare:
```py
>>> from transformers import pipeline
>>> classificatore = pipeline("sentiment-analysis", model="MilaNLProc/feel-it-italian-sentiment")
```
La pipeline scarica e salva il [modello pre-allenato](https://huggingface.co/MilaNLProc/feel-it-italian-sentiment) e il tokenizer per l'analisi del sentimento. Se non avessimo scelto un modello, la pipeline ne avrebbe scelto uno di default. Ora puoi utilizzare il `classifier` sul tuo testo obiettivo:
```py
>>> classificatore("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
[{'label': 'positive', 'score': 0.9997}]
```
Per più di una frase, passa una lista di frasi alla [`pipeline`] la quale restituirà una lista di dizionari:
```py
>>> risultati = classificatore(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."]
... )
>>> for risultato in risultati:
... print(f"etichetta: {risultato['label']}, con punteggio: {round(risultato['score'], 4)}")
etichetta: positive, con punteggio: 0.9998
etichetta: negative, con punteggio: 0.9998
```
La [`pipeline`] può anche iterare su un dataset intero. Inizia installando la libreria [🤗 Datasets](https://huggingface.co/docs/datasets/):
```bash
pip install datasets
```
Crea una [`pipeline`] con il compito che vuoi risolvere e con il modello che vuoi utilizzare.
```py
>>> import torch
>>> from transformers import pipeline
>>> riconoscitore_vocale = pipeline(
... "automatic-speech-recognition", model="radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram"
... )
```
Poi, carica un dataset (vedi 🤗 Datasets [Quick Start](https://huggingface.co/docs/datasets/quickstart) per maggiori dettagli) sul quale vuoi iterare. Per esempio, carichiamo il dataset [MInDS-14](https://huggingface.co/datasets/PolyAI/minds14):
```py
>>> from datasets import load_dataset, Audio
>>> dataset = load_dataset("PolyAI/minds14", name="it-IT", split="train") # doctest: +IGNORE_RESULT
```
Dobbiamo assicurarci che la frequenza di campionamento del set di dati corrisponda alla frequenza di campionamento con cui è stato addestrato `radiogroup-crits/wav2vec2-xls-r-1b-italian-doc4lm-5gram`.
```py
>>> dataset = dataset.cast_column("audio", Audio(sampling_rate=riconoscitore_vocale.feature_extractor.sampling_rate))
```
I file audio vengono caricati automaticamente e ri-campionati quando chiamiamo la colonna "audio".
Estraiamo i vettori delle forme d'onda grezze delle prime 4 osservazioni e passiamoli come lista alla pipeline:
```py
>>> risultato = riconoscitore_vocale(dataset[:4]["audio"])
>>> print([d["text"] for d in risultato])
['dovrei caricare dei soldi sul mio conto corrente', 'buongiorno e senza vorrei depositare denaro sul mio conto corrente come devo fare per cortesia', 'sì salve vorrei depositare del denaro sul mio conto', 'e buon pomeriggio vorrei depositare dei soldi sul mio conto bancario volleo sapere come posso fare se e posso farlo online ed un altro conto o andandoo tramite bancomut']
```
Per un dataset più grande dove gli input sono di dimensione maggiore (come nel parlato/audio o nella visione), dovrai passare un generatore al posto di una lista che carica tutti gli input in memoria. Guarda la [documentazione della pipeline](./main_classes/pipelines) per maggiori informazioni.
### Utilizzare un altro modello e tokenizer nella pipeline
La [`pipeline`] può ospitare qualsiasi modello del [Model Hub](https://huggingface.co/models), rendendo semplice l'adattamento della [`pipeline`] per altri casi d'uso. Per esempio, se si vuole un modello capace di trattare testo in francese, usa i tag presenti nel Model Hub in modo da filtrare per ottenere un modello appropriato. Il miglior risultato filtrato restituisce un modello multi-lingua [BERT model](https://huggingface.co/nlptown/bert-base-multilingual-uncased-sentiment) fine-tuned per l'analisi del sentimento. Ottimo, utilizziamo questo modello!
```py
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
```
<frameworkcontent>
<pt>
Usa [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `AutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> model = AutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</pt>
<tf>
Usa [`TFAutoModelForSequenceClassification`] e [`AutoTokenizer`] per caricare il modello pre-allenato e il suo tokenizer associato (maggiori informazioni su una `TFAutoClass` in seguito):
```py
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> model = TFAutoModelForSequenceClassification.from_pretrained(model_name)
>>> tokenizer = AutoTokenizer.from_pretrained(model_name)
```
</tf>
</frameworkcontent>
Poi puoi specificare il modello e il tokenizer nella [`pipeline`], e applicare il `classifier` sul tuo testo obiettivo:
```py
>>> classifier = pipeline("sentiment-analysis", model=model, tokenizer=tokenizer)
>>> classifier("Nous sommes très heureux de vous présenter la bibliothèque 🤗 Transformers.")
[{'label': '5 stars', 'score': 0.7273}]
```
Se non riesci a trovare un modello per il tuo caso d'uso, dovrai fare fine-tuning di un modello pre-allenato sui tuoi dati. Dai un'occhiata al nostro tutorial [fine-tuning tutorial](./training) per imparare come. Infine, dopo che hai completato il fine-tuning del tuo modello pre-allenato, considera per favore di condividerlo (vedi il tutorial [qui](./model_sharing)) con la comunità sul Model Hub per democratizzare l'NLP! 🤗
## AutoClass
<Youtube id="AhChOFRegn4"/>
Al suo interno, le classi [`AutoModelForSequenceClassification`] e [`AutoTokenizer`] lavorano assieme per dare potere alla [`pipeline`]. Una [AutoClass](./model_doc/auto) è una scorciatoia che automaticamente recupera l'architettura di un modello pre-allenato a partire dal suo nome o path. Hai solo bisogno di selezionare la `AutoClass` appropriata per il tuo compito e il suo tokenizer associato con [`AutoTokenizer`].
Ritorniamo al nostro esempio e vediamo come puoi utilizzare la `AutoClass` per replicare i risultati della [`pipeline`].
### AutoTokenizer
Un tokenizer è responsabile dell'elaborazione del testo in modo da trasformarlo in un formato comprensibile dal modello. Per prima cosa, il tokenizer dividerà il testo in parole chiamate *token*. Ci sono diverse regole che governano il processo di tokenizzazione, tra cui come dividere una parola e a quale livello (impara di più sulla tokenizzazione [qui](./tokenizer_summary)). La cosa più importante da ricordare comunque è che hai bisogno di inizializzare il tokenizer con lo stesso nome del modello in modo da assicurarti che stai utilizzando le stesse regole di tokenizzazione con cui il modello è stato pre-allenato.
Carica un tokenizer con [`AutoTokenizer`]:
```py
>>> from transformers import AutoTokenizer
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tokenizer = AutoTokenizer.from_pretrained(nome_del_modello)
```
Dopodiché, il tokenizer converte i token in numeri in modo da costruire un tensore come input del modello. Questo è conosciuto come il *vocabolario* del modello.
Passa il tuo testo al tokenizer:
```py
>>> encoding = tokenizer("Siamo molto felici di mostrarti la libreria 🤗 Transformers.")
>>> print(encoding)
{'input_ids': [101, 56821, 10132, 14407, 13019, 13007, 10120, 47201, 10330, 10106, 91686, 100, 58263, 119, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
Il tokenizer restituirà un dizionario contenente:
* [input_ids](./glossary#input-ids): rappresentazioni numeriche dei tuoi token.
* [attention_mask](.glossary#attention-mask): indica quali token devono essere presi in considerazione.
Come con la [`pipeline`], il tokenizer accetterà una lista di input. In più, il tokenizer può anche completare (pad, in inglese) e troncare il testo in modo da restituire un lotto (batch, in inglese) di lunghezza uniforme:
<frameworkcontent>
<pt>
```py
>>> pt_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="pt",
... )
```
</pt>
<tf>
```py
>>> tf_batch = tokenizer(
... ["Siamo molto felici di mostrarti la libreria 🤗 Transformers.", "Speriamo te non la odierai."],
... padding=True,
... truncation=True,
... max_length=512,
... return_tensors="tf",
... )
```
</tf>
</frameworkcontent>
Leggi il tutorial sul [preprocessing](./preprocessing) per maggiori dettagli sulla tokenizzazione.
### AutoModel
<frameworkcontent>
<pt>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`AutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare l'[`AutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`AutoModelForSequenceClassification`]:
```py
>>> from transformers import AutoModelForSequenceClassification
>>> model_name = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(model_name)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello. Devi solo spacchettare il dizionario aggiungendo `**`:
```py
>>> pt_outputs = pt_model(**pt_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> from torch import nn
>>> pt_predictions = nn.functional.softmax(pt_outputs.logits, dim=-1)
>>> print(pt_predictions)
tensor([[0.0041, 0.0037, 0.0203, 0.2005, 0.7713],
[0.3766, 0.3292, 0.1832, 0.0558, 0.0552]], grad_fn=<SoftmaxBackward0>)
```
</pt>
<tf>
🤗 Transformers fornisce un metodo semplice e unificato per caricare istanze pre-allenate. Questo significa che puoi caricare un [`TFAutoModel`] come caricheresti un [`AutoTokenizer`]. L'unica differenza è selezionare il [`TFAutoModel`] corretto per il compito di interesse. Dato che stai facendo classificazione di testi, o sequenze, carica [`TFAutoModelForSequenceClassification`]:
```py
>>> from transformers import TFAutoModelForSequenceClassification
>>> nome_del_modello = "nlptown/bert-base-multilingual-uncased-sentiment"
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(nome_del_modello)
```
<Tip>
Guarda il [task summary](./task_summary) per sapere quale classe di [`AutoModel`] utilizzare per quale compito.
</Tip>
Ora puoi passare il tuo lotto di input pre-processati direttamente al modello passando le chiavi del dizionario al tensore:
```py
>>> tf_outputs = tf_model(tf_batch)
```
Il modello produrrà le attivazioni finali nell'attributo `logits`. Applica la funzione softmax a `logits` per ottenere le probabilità:
```py
>>> import tensorflow as tf
>>> tf_predictions = tf.nn.softmax(tf_outputs.logits, axis=-1)
>>> tf_predictions # doctest: +IGNORE_RESULT
```
</tf>
</frameworkcontent>
<Tip>
Tutti i modelli di 🤗 Transformers (PyTorch e TensorFlow) restituiscono i tensori *prima* della funzione finale
di attivazione (come la softmax) perché la funzione di attivazione finale viene spesso unita a quella di perdita.
</Tip>
I modelli sono [`torch.nn.Module`](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) o [`tf.keras.Model`](https://www.tensorflow.org/api_docs/python/tf/keras/Model) standard così puoi utilizzarli all'interno del tuo training loop usuale. Tuttavia, per rendere le cose più semplici, 🤗 Transformers fornisce una classe [`Trainer`] per PyTorch che aggiunge delle funzionalità per l'allenamento distribuito, precisione mista, e altro ancora. Per TensorFlow, puoi utilizzare il metodo `fit` di [Keras](https://keras.io/). Fai riferimento al [tutorial per il training](./training) per maggiori dettagli.
<Tip>
Gli output del modello di 🤗 Transformers sono delle dataclasses speciali in modo che i loro attributi vengano auto-completati all'interno di un IDE.
Gli output del modello si comportano anche come una tupla o un dizionario (ad esempio, puoi indicizzare con un intero, una slice o una stringa) nel qual caso gli attributi che sono `None` vengono ignorati.
</Tip>
### Salva un modello
<frameworkcontent>
<pt>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`PreTrainedModel.save_pretrained`]:
```py
>>> pt_save_directory = "./pt_save_pretrained"
>>> tokenizer.save_pretrained(pt_save_directory) # doctest: +IGNORE_RESULT
>>> pt_model.save_pretrained(pt_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`PreTrainedModel.from_pretrained`]:
```py
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("./pt_save_pretrained")
```
</pt>
<tf>
Una volta completato il fine-tuning del tuo modello, puoi salvarlo con il suo tokenizer utilizzando [`TFPreTrainedModel.save_pretrained`]:
```py
>>> tf_save_directory = "./tf_save_pretrained"
>>> tokenizer.save_pretrained(tf_save_directory) # doctest: +IGNORE_RESULT
>>> tf_model.save_pretrained(tf_save_directory)
```
Quando desideri utilizzare il tuo modello nuovamente, puoi ri-caricarlo con [`TFPreTrainedModel.from_pretrained`]:
```py
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("./tf_save_pretrained")
```
</tf>
</frameworkcontent>
Una caratteristica particolarmente interessante di 🤗 Transformers è la sua abilità di salvare un modello e ri-caricarlo sia come modello di PyTorch che di TensorFlow. I parametri `from_pt` o `from_tf` possono convertire un modello da un framework all'altro:
<frameworkcontent>
<pt>
```py
>>> from transformers import AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(pt_save_directory)
>>> pt_model = AutoModelForSequenceClassification.from_pretrained(pt_save_directory, from_pt=True)
```
</pt>
<tf>
```py
>>> from transformers import TFAutoModel
>>> tokenizer = AutoTokenizer.from_pretrained(tf_save_directory)
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained(tf_save_directory, from_tf=True)
```
</tf>
</frameworkcontent>
|
transformers/docs/source/it/quicktour.md/0
|
{
"file_path": "transformers/docs/source/it/quicktour.md",
"repo_id": "transformers",
"token_count": 6489
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Use tokenizers from 🤗 Tokenizers
[`PreTrainedTokenizerFast`]は[🤗 Tokenizers](https://huggingface.co/docs/tokenizers)ライブラリに依存しています。🤗 Tokenizersライブラリから取得したトークナイザーは、非常に簡単に🤗 Transformersにロードできます。
具体的な内容に入る前に、まずはいくつかの行でダミーのトークナイザーを作成することから始めましょう:
```python
>>> from tokenizers import Tokenizer
>>> from tokenizers.models import BPE
>>> from tokenizers.trainers import BpeTrainer
>>> from tokenizers.pre_tokenizers import Whitespace
>>> tokenizer = Tokenizer(BPE(unk_token="[UNK]"))
>>> trainer = BpeTrainer(special_tokens=["[UNK]", "[CLS]", "[SEP]", "[PAD]", "[MASK]"])
>>> tokenizer.pre_tokenizer = Whitespace()
>>> files = [...]
>>> tokenizer.train(files, trainer)
```
私たちは今、定義したファイルにトレーニングされたトークナイザーを持っています。これをランタイムで引き続き使用するか、
将来の再利用のためにJSONファイルに保存することができます。
## Loading directly from the tokenizer object
🤗 Transformersライブラリでこのトークナイザーオブジェクトをどのように活用できるかを見てみましょう。[`PreTrainedTokenizerFast`]クラスは、
*tokenizer*オブジェクトを引数として受け入れ、簡単にインスタンス化できるようにします。
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_object=tokenizer)
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できます!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
## Loading from a JSON file
JSONファイルからトークナイザーを読み込むには、まずトークナイザーを保存することから始めましょう:
```python
>>> tokenizer.save("tokenizer.json")
```
このファイルを保存したパスは、`PreTrainedTokenizerFast` の初期化メソッドに `tokenizer_file` パラメータを使用して渡すことができます:
```python
>>> from transformers import PreTrainedTokenizerFast
>>> fast_tokenizer = PreTrainedTokenizerFast(tokenizer_file="tokenizer.json")
```
このオブジェクトは、🤗 Transformers トークナイザーが共有するすべてのメソッドと一緒に使用できるようになりました!詳細については、[トークナイザーページ](main_classes/tokenizer)をご覧ください。
|
transformers/docs/source/ja/fast_tokenizers.md/0
|
{
"file_path": "transformers/docs/source/ja/fast_tokenizers.md",
"repo_id": "transformers",
"token_count": 1187
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# BERT
<div class="flex flex-wrap space-x-1">
<a href="https://huggingface.co/models?filter=bert">
<img alt="Models" src="https://img.shields.io/badge/All_model_pages-bert-blueviolet">
</a>
<a href="https://huggingface.co/spaces/docs-demos/bert-base-uncased">
<img alt="Spaces" src="https://img.shields.io/badge/%F0%9F%A4%97%20Hugging%20Face-Spaces-blue">
</a>
</div>
## Overview
BERT モデルは、Jacob Devlin、Ming-Wei Chang、Kenton Lee、Kristina Toutanova によって [BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding](https://arxiv.org/abs/1810.04805) で提案されました。それは
マスクされた言語モデリング目標と次の文の組み合わせを使用して事前トレーニングされた双方向トランスフォーマー
Toronto Book Corpus と Wikipedia からなる大規模なコーパスでの予測。
論文の要約は次のとおりです。
*BERT と呼ばれる新しい言語表現モデルを導入します。これは Bidirectional Encoder Representations の略です
トランスフォーマーより。最近の言語表現モデルとは異なり、BERT は深い双方向性を事前にトレーニングするように設計されています。
すべてのレイヤーの左と右の両方のコンテキストを共同で条件付けすることにより、ラベルのないテキストから表現します。結果として、
事前トレーニングされた BERT モデルは、出力層を 1 つ追加するだけで微調整して、最先端のモデルを作成できます。
実質的なタスク固有のものを必要とせず、質問応答や言語推論などの幅広いタスクに対応
アーキテクチャの変更。*
*BERT は概念的にはシンプルですが、経験的に強力です。 11 の自然な要素に関する新しい最先端の結果が得られます。
言語処理タスク(GLUE スコアを 80.5% に押し上げる(7.7% ポイントの絶対改善)、MultiNLI を含む)
精度は 86.7% (絶対値 4.6% 向上)、SQuAD v1.1 質問応答テスト F1 は 93.2 (絶対値 1.5 ポイント)
改善) および SQuAD v2.0 テスト F1 から 83.1 (5.1 ポイントの絶対改善)。*
## Usage tips
- BERT は絶対位置埋め込みを備えたモデルであるため、通常は入力を右側にパディングすることをお勧めします。
左。
- BERT は、マスク言語モデリング (MLM) および次の文予測 (NSP) の目標を使用してトレーニングされました。それは
マスクされたトークンの予測や NLU では一般に効率的ですが、テキスト生成には最適ではありません。
- ランダム マスキングを使用して入力を破壊します。より正確には、事前トレーニング中に、トークンの指定された割合 (通常は 15%) が次によってマスクされます。
* 確率0.8の特別なマスクトークン
* 確率 0.1 でマスクされたトークンとは異なるランダムなトークン
* 確率 0.1 の同じトークン
- モデルは元の文を予測する必要がありますが、2 番目の目的があります。入力は 2 つの文 A と B (間に分離トークンあり) です。確率 50% では、文はコーパス内で連続していますが、残りの 50% では関連性がありません。モデルは、文が連続しているかどうかを予測する必要があります。
このモデルは [thomwolf](https://huggingface.co/thomwolf) によって提供されました。元のコードは [こちら](https://github.com/google-research/bert) にあります。
## Resources
BERT を始めるのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
<PipelineTag pipeline="text-classification"/>
- に関するブログ投稿 [別の言語での BERT テキスト分類](https://www.philschmid.de/bert-text-classification-in-a-different-language)。
- [マルチラベル テキスト分類のための BERT (およびその友人) の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/BERT/Fine_tuning_BERT_(and_friends)_for_multi_label_text_classification.ipynb) のノートブック.
- 方法に関するノートブック [PyTorch を使用したマルチラベル分類のための BERT の微調整](https://colab.research.google.com/github/abhmishra91/transformers-tutorials/blob/master/transformers_multi_label_classification.ipynb)。
- 方法に関するノートブック [要約のために BERT を使用して EncoderDecoder モデルをウォームスタートする](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/BERT2BERT_for_CNN_Dailymail.ipynb)。
- [`BertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)。
- [`TFBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)。
- [`FlaxBertForSequenceClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/text-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification_flax.ipynb)。
- [テキスト分類タスクガイド](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification"/>
- [Hugging Face Transformers with Keras: Fine-tune a non-English BERT for Named Entity Recognition](https://www.philschmid.de/huggingface-transformers-keras-tf) の使用方法に関するブログ投稿。
- 各単語の最初の単語部分のみを使用した [固有表現認識のための BERT の微調整](https://colab.research.google.com/github/NielsRogge/Transformers-Tutorials/blob/master/Custom_Named_Entity_Recognition_with_BERT_only_first_wordpiece.ipynb) のノートブックトークン化中の単語ラベル内。単語のラベルをすべての単語部分に伝播するには、代わりにノートブックのこの [バージョン](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/BERT/Custom_Named_Entity_Recognition_with_BERT.ipynb) を参照してください。
- [`BertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)。
- [`TFBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)。
- [`FlaxBertForTokenClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/token-classification) によってサポートされています。
- [トークン分類](https://huggingface.co/course/chapter7/2?fw=pt) 🤗 ハグフェイスコースの章。
- [トークン分類タスクガイド](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`BertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling) でサポートされており、 [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)。
- [`TFBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/lang-modeling#run_mlmpy) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)。
- [`FlaxBertForMaskedLM`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/language-modeling#masked-language-modeling) および [ノートブック]( https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/masked_language_modeling_flax.ipynb)。
- [マスクされた言語モデリング](https://huggingface.co/course/chapter7/3?fw=pt) 🤗 顔ハグ コースの章。
- [マスクされた言語モデリング タスク ガイド](../tasks/masked_lang_modeling)
<PipelineTag pipeline="question-answering"/>
- [`BertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)。
- [`TFBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)。
- [`FlaxBertForQuestionAnswering`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/flax/question-answering) でサポートされています。
- [質問回答](https://huggingface.co/course/chapter7/7?fw=pt) 🤗 ハグフェイスコースの章。
- [質問回答タスク ガイド](../tasks/question_answering)
**複数の選択肢**
- [`BertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice.ipynb)。
- [`TFBertForMultipleChoice`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/multiple-choice) および [ノートブック](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/multiple_choice-tf.ipynb)。
- [多肢選択タスク ガイド](../tasks/multiple_choice)
⚡️ **推論**
- 方法に関するブログ投稿 [Hugging Face Transformers と AWS Inferentia を使用して BERT 推論を高速化する](https://huggingface.co/blog/bert-inferentia-sagemaker)。
- 方法に関するブログ投稿 [GPU 上の DeepSpeed-Inference を使用して BERT 推論を高速化する](https://www.philschmid.de/bert-deepspeed-inference)。
⚙️ **事前トレーニング**
- [Hugging Face Transformers と Habana Gaudi を使用した BERT の事前トレーニング に関するブログ投稿](https://www.philschmid.de/pre-training-bert-habana)。
🚀 **デプロイ**
- 方法に関するブログ投稿 [ハグフェイス最適化でトランスフォーマーを ONNX に変換する](https://www.philschmid.de/convert-transformers-to-onnx)。
- 方法に関するブログ投稿 [AWS 上の Habana Gaudi を使用したハグ顔トランスフォーマーのための深層学習環境のセットアップ](https://www.philschmid.de/getting-started-habana-gaudi#conclusion)。
- に関するブログ投稿 [Hugging Face Transformers、Amazon SageMaker、および Terraform モジュールを使用した自動スケーリング BERT](https://www.philschmid.de/terraform-huggingface-amazon-sagemaker-advanced)。
- に関するブログ投稿 [HuggingFace、AWS Lambda、Docker を使用したサーバーレス BERT](https://www.philschmid.de/serverless-bert-with-huggingface-aws-lambda-docker)。
- に関するブログ投稿 [Amazon SageMaker と Training Compiler を使用した Hugging Face Transformers BERT 微調整](https://www.philschmid.de/huggingface-amazon-sagemaker-training-compiler)。
- に関するブログ投稿 [Transformers と Amazon SageMaker を使用した BERT のタスク固有の知識の蒸留](https://www.philschmid.de/knowledge-distillation-bert-transformers)
## BertConfig
[[autodoc]] BertConfig
- all
## BertTokenizer
[[autodoc]] BertTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
<frameworkcontent>
<pt>
## BertTokenizerFast
[[autodoc]] BertTokenizerFast
</pt>
<tf>
## TFBertTokenizer
[[autodoc]] TFBertTokenizer
</tf>
</frameworkcontent>
## Bert specific outputs
[[autodoc]] models.bert.modeling_bert.BertForPreTrainingOutput
[[autodoc]] models.bert.modeling_tf_bert.TFBertForPreTrainingOutput
[[autodoc]] models.bert.modeling_flax_bert.FlaxBertForPreTrainingOutput
<frameworkcontent>
<pt>
## BertModel
[[autodoc]] BertModel
- forward
## BertForPreTraining
[[autodoc]] BertForPreTraining
- forward
## BertLMHeadModel
[[autodoc]] BertLMHeadModel
- forward
## BertForMaskedLM
[[autodoc]] BertForMaskedLM
- forward
## BertForNextSentencePrediction
[[autodoc]] BertForNextSentencePrediction
- forward
## BertForSequenceClassification
[[autodoc]] BertForSequenceClassification
- forward
## BertForMultipleChoice
[[autodoc]] BertForMultipleChoice
- forward
## BertForTokenClassification
[[autodoc]] BertForTokenClassification
- forward
## BertForQuestionAnswering
[[autodoc]] BertForQuestionAnswering
- forward
</pt>
<tf>
## TFBertModel
[[autodoc]] TFBertModel
- call
## TFBertForPreTraining
[[autodoc]] TFBertForPreTraining
- call
## TFBertModelLMHeadModel
[[autodoc]] TFBertLMHeadModel
- call
## TFBertForMaskedLM
[[autodoc]] TFBertForMaskedLM
- call
## TFBertForNextSentencePrediction
[[autodoc]] TFBertForNextSentencePrediction
- call
## TFBertForSequenceClassification
[[autodoc]] TFBertForSequenceClassification
- call
## TFBertForMultipleChoice
[[autodoc]] TFBertForMultipleChoice
- call
## TFBertForTokenClassification
[[autodoc]] TFBertForTokenClassification
- call
## TFBertForQuestionAnswering
[[autodoc]] TFBertForQuestionAnswering
- call
</tf>
<jax>
## FlaxBertModel
[[autodoc]] FlaxBertModel
- __call__
## FlaxBertForPreTraining
[[autodoc]] FlaxBertForPreTraining
- __call__
## FlaxBertForCausalLM
[[autodoc]] FlaxBertForCausalLM
- __call__
## FlaxBertForMaskedLM
[[autodoc]] FlaxBertForMaskedLM
- __call__
## FlaxBertForNextSentencePrediction
[[autodoc]] FlaxBertForNextSentencePrediction
- __call__
## FlaxBertForSequenceClassification
[[autodoc]] FlaxBertForSequenceClassification
- __call__
## FlaxBertForMultipleChoice
[[autodoc]] FlaxBertForMultipleChoice
- __call__
## FlaxBertForTokenClassification
[[autodoc]] FlaxBertForTokenClassification
- __call__
## FlaxBertForQuestionAnswering
[[autodoc]] FlaxBertForQuestionAnswering
- __call__
</jax>
</frameworkcontent>
|
transformers/docs/source/ja/model_doc/bert.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/bert.md",
"repo_id": "transformers",
"token_count": 6595
}
|
<!--Copyright 2021 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# CANINE
## Overview
CANINE モデルは、[CANINE: Pre-training an Efficient Tokenization-Free Encoder for Language
Representation](https://arxiv.org/abs/2103.06874)、Jonathan H. Clark、Dan Garrette、Iulia Turc、John Wieting 著。その
明示的なトークン化ステップ (バイト ペアなど) を使用せずに Transformer をトレーニングする最初の論文の 1 つ
エンコーディング (BPE、WordPiece または SentencePiece)。代わりに、モデルは Unicode 文字レベルで直接トレーニングされます。
キャラクターレベルでのトレーニングでは必然的にシーケンスの長さが長くなりますが、CANINE はこれを効率的な方法で解決します。
ディープ Transformer エンコーダを適用する前に、ダウンサンプリング戦略を実行します。
論文の要約は次のとおりです。
*パイプライン NLP システムは、エンドツーエンドのニューラル モデリングに大部分が取って代わられていますが、一般的に使用されているほぼすべてのモデルは
依然として明示的なトークン化手順が必要です。最近のトークン化アプローチはデータ由来のサブワードに基づいていますが、
レキシコンは手動で作成されたトークナイザーよりも脆弱ではありませんが、これらの技術はすべての言語に等しく適しているわけではありません。
言語や固定語彙の使用により、モデルの適応能力が制限される可能性があります。この論文では、CANINE を紹介します。
明示的なトークン化や語彙を使用せずに、文字シーケンスを直接操作するニューラル エンコーダーと、
文字に直接作用するか、オプションでサブワードをソフト誘導バイアスとして使用する事前トレーニング戦略。
よりきめの細かい入力を効果的かつ効率的に使用するために、CANINE はダウンサンプリングを組み合わせて、入力を削減します。
コンテキストをエンコードするディープトランスフォーマースタックを備えたシーケンスの長さ。 CANINE は、同等の mBERT モデルよりも次の点で優れています。
TyDi QA の 2.8 F1 は、モデル パラメータが 28% 少ないにもかかわらず、困難な多言語ベンチマークです。*
このモデルは、[nielsr](https://huggingface.co/nielsr) によって提供されました。元のコードは [ここ](https://github.com/google-research/language/tree/master/language/canine) にあります。
## Usage tips
- CANINE は内部で少なくとも 3 つの Transformer エンコーダーを使用します: 2 つの「浅い」エンコーダー (単一のエンコーダーのみで構成)
レイヤー) と 1 つの「ディープ」エンコーダー (通常の BERT エンコーダー)。まず、「浅い」エンコーダを使用してコンテキストを設定します。
ローカル アテンションを使用した文字の埋め込み。次に、ダウンサンプリングの後、「ディープ」エンコーダーが適用されます。ついに、
アップサンプリング後、「浅い」エンコーダを使用して最終的な文字埋め込みが作成されます。アップと
ダウンサンプリングについては論文に記載されています。
- CANINE は、デフォルトで 2048 文字の最大シーケンス長を使用します。 [`CanineTokenizer`] を使用できます
モデル用のテキストを準備します。
- 特別な [CLS] トークンの最終的な非表示状態の上に線形レイヤーを配置することで分類を行うことができます。
(事前定義された Unicode コード ポイントがあります)。ただし、トークン分類タスクの場合は、ダウンサンプリングされたシーケンス
トークンは、元の文字シーケンスの長さ (2048) と一致するように再度アップサンプリングする必要があります。の
詳細については、論文を参照してください。
モデルのチェックポイント:
- [google/canine-c](https://huggingface.co/google/canine-c): 自己回帰文字損失で事前トレーニング済み、
12 レイヤー、768 隠し、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
- [google/canine-s](https://huggingface.co/google/canine-s): サブワード損失で事前トレーニング済み、12 層、
768 個の非表示、12 ヘッド、121M パラメーター (サイズ ~500 MB)。
## Usage example
CANINE は生の文字で動作するため、**トークナイザーなし**で使用できます。
```python
>>> from transformers import CanineModel
>>> import torch
>>> model = CanineModel.from_pretrained("google/canine-c") # model pre-trained with autoregressive character loss
>>> text = "hello world"
>>> # use Python's built-in ord() function to turn each character into its unicode code point id
>>> input_ids = torch.tensor([[ord(char) for char in text]])
>>> outputs = model(input_ids) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
ただし、バッチ推論とトレーニングの場合は、トークナイザーを使用することをお勧めします(すべてをパディング/切り詰めるため)
シーケンスを同じ長さにします):
```python
>>> from transformers import CanineTokenizer, CanineModel
>>> model = CanineModel.from_pretrained("google/canine-c")
>>> tokenizer = CanineTokenizer.from_pretrained("google/canine-c")
>>> inputs = ["Life is like a box of chocolates.", "You never know what you gonna get."]
>>> encoding = tokenizer(inputs, padding="longest", truncation=True, return_tensors="pt")
>>> outputs = model(**encoding) # forward pass
>>> pooled_output = outputs.pooler_output
>>> sequence_output = outputs.last_hidden_state
```
## Resources
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [多肢選択タスク ガイド](../tasks/multiple_choice)
## CanineConfig
[[autodoc]] CanineConfig
## CanineTokenizer
[[autodoc]] CanineTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
## CANINE specific outputs
[[autodoc]] models.canine.modeling_canine.CanineModelOutputWithPooling
## CanineModel
[[autodoc]] CanineModel
- forward
## CanineForSequenceClassification
[[autodoc]] CanineForSequenceClassification
- forward
## CanineForMultipleChoice
[[autodoc]] CanineForMultipleChoice
- forward
## CanineForTokenClassification
[[autodoc]] CanineForTokenClassification
- forward
## CanineForQuestionAnswering
[[autodoc]] CanineForQuestionAnswering
- forward
|
transformers/docs/source/ja/model_doc/canine.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/canine.md",
"repo_id": "transformers",
"token_count": 3007
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Data2Vec
## Overview
Data2Vec モデルは、[data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language](https://arxiv.org/pdf/2202.03555) で Alexei Baevski、Wei-Ning Hsu、Qiantong Xu、バArun Babu, Jiatao Gu and Michael Auli.
Data2Vec は、テキスト、音声、画像などのさまざまなデータ モダリティにわたる自己教師あり学習のための統一フレームワークを提案します。
重要なのは、事前トレーニングの予測ターゲットは、モダリティ固有のコンテキストに依存しないターゲットではなく、入力のコンテキスト化された潜在表現であることです。
論文の要約は次のとおりです。
*自己教師あり学習の一般的な考え方はどのモダリティでも同じですが、実際のアルゴリズムと
単一のモダリティを念頭に置いて開発されたため、目的は大きく異なります。一般に近づけるために
自己教師あり学習では、どちらの音声に対しても同じ学習方法を使用するフレームワークである data2vec を紹介します。
NLP またはコンピューター ビジョン。中心となるアイデアは、完全な入力データの潜在的な表現を、
標準の Transformer アーキテクチャを使用した自己蒸留セットアップの入力のマスクされたビュー。
単語、視覚的トークン、人間の音声単位などのモダリティ固有のターゲットを予測するのではなく、
本質的にローカルであるため、data2vec は、からの情報を含む文脈化された潜在表現を予測します。
入力全体。音声認識、画像分類、および
自然言語理解は、新しい最先端技術や、主流のアプローチに匹敵するパフォーマンスを実証します。
モデルとコードは、www.github.com/pytorch/fairseq/tree/master/examples/data2vec.* で入手できます。
このモデルは、[edugp](https://huggingface.co/edugp) および [patrickvonplaten](https://huggingface.co/patrickvonplaten) によって提供されました。
[sayakpaul](https://github.com/sayakpaul) と [Rocketknight1](https://github.com/Rocketknight1) は、TensorFlow のビジョンに Data2Vec を提供しました。
元のコード (NLP および音声用) は、[こちら](https://github.com/pytorch/fairseq/tree/main/examples/data2vec) にあります。
ビジョンの元のコードは [こちら](https://github.com/facebookresearch/data2vec_vision/tree/main/beit) にあります。
## Usage tips
- Data2VecAudio、Data2VecText、および Data2VecVision はすべて、同じ自己教師あり学習方法を使用してトレーニングされています。
- Data2VecAudio の場合、前処理は特徴抽出を含めて [`Wav2Vec2Model`] と同じです。
- Data2VecText の場合、前処理はトークン化を含めて [`RobertaModel`] と同じです。
- Data2VecVision の場合、前処理は特徴抽出を含めて [`BeitModel`] と同じです。
## Resources
Data2Vec の使用を開始するのに役立つ公式 Hugging Face およびコミュニティ (🌎 で示される) リソースのリスト。
<PipelineTag pipeline="image-classification"/>
- [`Data2VecVisionForImageClassification`] は、この [サンプル スクリプト](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-classification) および [ノートブック](https://cola.research.google.com/github/huggingface/notebooks/blob/main/examples/image_classification.ipynb)。
- カスタム データセットで [`TFData2VecVisionForImageClassification`] を微調整するには、[このノートブック](https://colab.research.google.com/github/sayakpaul/TF-2.0-Hacks/blob/master/data2vec_vision_image_classification.ipynb) を参照してください。 )。
**Data2VecText ドキュメント リソース**
- [テキスト分類タスクガイド](../tasks/sequence_classification)
- [トークン分類タスクガイド](../tasks/token_classification)
- [質問回答タスク ガイド](../tasks/question_answering)
- [因果言語モデリング タスク ガイド](../tasks/language_modeling)
- [マスク言語モデリング タスク ガイド](../tasks/masked_language_modeling)
- [多肢選択タスク ガイド](../tasks/multiple_choice)
**Data2VecAudio ドキュメント リソース**
- [音声分類タスクガイド](../tasks/audio_classification)
- [自動音声認識タスクガイド](../tasks/asr)
**Data2VecVision ドキュメント リソース**
- [画像分類](../tasks/image_classification)
- [セマンティック セグメンテーション](../tasks/semantic_segmentation)
ここに含めるリソースの送信に興味がある場合は、お気軽にプル リクエストを開いてください。審査させていただきます。リソースは、既存のリソースを複製するのではなく、何か新しいものを示すことが理想的です。
## Data2VecTextConfig
[[autodoc]] Data2VecTextConfig
## Data2VecAudioConfig
[[autodoc]] Data2VecAudioConfig
## Data2VecVisionConfig
[[autodoc]] Data2VecVisionConfig
<frameworkcontent>
<pt>
## Data2VecAudioModel
[[autodoc]] Data2VecAudioModel
- forward
## Data2VecAudioForAudioFrameClassification
[[autodoc]] Data2VecAudioForAudioFrameClassification
- forward
## Data2VecAudioForCTC
[[autodoc]] Data2VecAudioForCTC
- forward
## Data2VecAudioForSequenceClassification
[[autodoc]] Data2VecAudioForSequenceClassification
- forward
## Data2VecAudioForXVector
[[autodoc]] Data2VecAudioForXVector
- forward
## Data2VecTextModel
[[autodoc]] Data2VecTextModel
- forward
## Data2VecTextForCausalLM
[[autodoc]] Data2VecTextForCausalLM
- forward
## Data2VecTextForMaskedLM
[[autodoc]] Data2VecTextForMaskedLM
- forward
## Data2VecTextForSequenceClassification
[[autodoc]] Data2VecTextForSequenceClassification
- forward
## Data2VecTextForMultipleChoice
[[autodoc]] Data2VecTextForMultipleChoice
- forward
## Data2VecTextForTokenClassification
[[autodoc]] Data2VecTextForTokenClassification
- forward
## Data2VecTextForQuestionAnswering
[[autodoc]] Data2VecTextForQuestionAnswering
- forward
## Data2VecVisionModel
[[autodoc]] Data2VecVisionModel
- forward
## Data2VecVisionForImageClassification
[[autodoc]] Data2VecVisionForImageClassification
- forward
## Data2VecVisionForSemanticSegmentation
[[autodoc]] Data2VecVisionForSemanticSegmentation
- forward
</pt>
<tf>
## TFData2VecVisionModel
[[autodoc]] TFData2VecVisionModel
- call
## TFData2VecVisionForImageClassification
[[autodoc]] TFData2VecVisionForImageClassification
- call
## TFData2VecVisionForSemanticSegmentation
[[autodoc]] TFData2VecVisionForSemanticSegmentation
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/ja/model_doc/data2vec.md/0
|
{
"file_path": "transformers/docs/source/ja/model_doc/data2vec.md",
"repo_id": "transformers",
"token_count": 3072
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Load adapters with 🤗 PEFT
[[open-in-colab]]
[Parameter-Efficient Fine Tuning (PEFT)](https://huggingface.co/blog/peft) メソッドは、事前学習済みモデルのパラメータをファインチューニング中に凍結し、その上にわずかな訓練可能なパラメータ(アダプター)を追加するアプローチです。アダプターは、タスク固有の情報を学習するために訓練されます。このアプローチは、メモリ使用量が少なく、完全にファインチューニングされたモデルと比較して計算リソースを低く抑えつつ、同等の結果を生成することが示されています。
PEFTで訓練されたアダプターは通常、完全なモデルのサイズよりも1桁小さく、共有、保存、読み込むのが便利です。
<div class="flex flex-col justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/PEFT-hub-screenshot.png"/>
<figcaption class="text-center">Hubに格納されているOPTForCausalLMモデルのアダプター重みは、モデルの全体サイズの約6MBで、モデル重みの全サイズは約700MBです。</figcaption>
</div>
🤗 PEFTライブラリについて詳しく知りたい場合は、[ドキュメンテーション](https://huggingface.co/docs/peft/index)をご覧ください。
## Setup
🤗 PEFTをインストールして始めましょう:
```bash
pip install peft
```
新機能を試してみたい場合、ソースからライブラリをインストールすることに興味があるかもしれません:
```bash
pip install git+https://github.com/huggingface/peft.git
```
## Supported PEFT models
🤗 Transformersは、いくつかのPEFT(Parameter Efficient Fine-Tuning)メソッドをネイティブにサポートしており、ローカルまたはHubに格納されたアダプターウェイトを簡単に読み込んで実行またはトレーニングできます。以下のメソッドがサポートされています:
- [Low Rank Adapters](https://huggingface.co/docs/peft/conceptual_guides/lora)
- [IA3](https://huggingface.co/docs/peft/conceptual_guides/ia3)
- [AdaLoRA](https://arxiv.org/abs/2303.10512)
他のPEFTメソッドを使用したい場合、プロンプト学習やプロンプト調整などについて詳しく知りたい場合、または🤗 PEFTライブラリ全般については、[ドキュメンテーション](https://huggingface.co/docs/peft/index)を参照してください。
## Load a PEFT adapter
🤗 TransformersからPEFTアダプターモデルを読み込んで使用するには、Hubリポジトリまたはローカルディレクトリに `adapter_config.json` ファイルとアダプターウェイトが含まれていることを確認してください。次に、`AutoModelFor` クラスを使用してPEFTアダプターモデルを読み込むことができます。たとえば、因果言語モデリング用のPEFTアダプターモデルを読み込むには:
1. PEFTモデルのIDを指定します。
2. それを[`AutoModelForCausalLM`] クラスに渡します。
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id)
```
<Tip>
PEFTアダプターを`AutoModelFor`クラスまたは基本モデルクラス(`OPTForCausalLM`または`LlamaForCausalLM`など)で読み込むことができます。
</Tip>
また、`load_adapter`メソッドを呼び出すことで、PEFTアダプターを読み込むこともできます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer
model_id = "facebook/opt-350m"
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(model_id)
model.load_adapter(peft_model_id)
```
## Load in 8bit or 4bit
`bitsandbytes` 統合は、8ビットおよび4ビットの精度データ型をサポートしており、大規模なモデルを読み込む際にメモリを節約するのに役立ちます(詳細については `bitsandbytes` 統合の[ガイド](./quantization#bitsandbytes-integration)を参照してください)。[`~PreTrainedModel.from_pretrained`] に `load_in_8bit` または `load_in_4bit` パラメータを追加し、`device_map="auto"` を設定してモデルを効果的にハードウェアに分散配置できます:
```py
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig
peft_model_id = "ybelkada/opt-350m-lora"
model = AutoModelForCausalLM.from_pretrained(peft_model_id, quantization_config=BitsAndBytesConfig(load_in_8bit=True))
```
## Add a new adapter
既存のアダプターを持つモデルに新しいアダプターを追加するために [`~peft.PeftModel.add_adapter`] を使用できます。ただし、新しいアダプターは現在のアダプターと同じタイプである限り、これを行うことができます。たとえば、モデルに既存の LoRA アダプターがアタッチされている場合:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
model = AutoModelForCausalLM.from_pretrained(model_id)
lora_config = LoraConfig(
target_modules=["q_proj", "k_proj"],
init_lora_weights=False
)
model.add_adapter(lora_config, adapter_name="adapter_1")
```
新しいアダプタを追加するには:
```py
# attach new adapter with same config
model.add_adapter(lora_config, adapter_name="adapter_2")
```
[`~peft.PeftModel.set_adapter`] を使用して、どのアダプターを使用するかを設定できます:
```py
# use adapter_1
model.set_adapter("adapter_1")
output = model.generate(**inputs)
print(tokenizer.decode(output_disabled[0], skip_special_tokens=True))
# use adapter_2
model.set_adapter("adapter_2")
output_enabled = model.generate(**inputs)
print(tokenizer.decode(output_enabled[0], skip_special_tokens=True))
```
## Enable and disable adapters
モデルにアダプターを追加したら、アダプターモジュールを有効または無効にすることができます。アダプターモジュールを有効にするには、次の手順を実行します:
```py
from transformers import AutoModelForCausalLM, OPTForCausalLM, AutoTokenizer
from peft import PeftConfig
model_id = "facebook/opt-350m"
adapter_model_id = "ybelkada/opt-350m-lora"
tokenizer = AutoTokenizer.from_pretrained(model_id)
text = "Hello"
inputs = tokenizer(text, return_tensors="pt")
model = AutoModelForCausalLM.from_pretrained(model_id)
peft_config = PeftConfig.from_pretrained(adapter_model_id)
# to initiate with random weights
peft_config.init_lora_weights = False
model.add_adapter(peft_config)
model.enable_adapters()
output = model.generate(**inputs)
```
アダプターモジュールを無効にするには:
```py
model.disable_adapters()
output = model.generate(**inputs)
```
## Train a PEFT adapter
PEFTアダプターは[`Trainer`]クラスでサポートされており、特定のユースケースに対してアダプターをトレーニングすることができます。数行のコードを追加するだけで済みます。たとえば、LoRAアダプターをトレーニングする場合:
<Tip>
[`Trainer`]を使用したモデルの微調整に慣れていない場合は、[事前トレーニング済みモデルの微調整](training)チュートリアルをご覧ください。
</Tip>
1. タスクタイプとハイパーパラメータに対するアダプターの構成を定義します(ハイパーパラメータの詳細については[`~peft.LoraConfig`]を参照してください)。
```py
from peft import LoraConfig
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0.1,
r=64,
bias="none",
task_type="CAUSAL_LM",
)
```
2. モデルにアダプターを追加する。
```py
model.add_adapter(peft_config)
```
3. これで、モデルを [`Trainer`] に渡すことができます!
```py
trainer = Trainer(model=model, ...)
trainer.train()
```
保存するトレーニング済みアダプタとそれを読み込むための手順:
|
transformers/docs/source/ja/peft.md/0
|
{
"file_path": "transformers/docs/source/ja/peft.md",
"repo_id": "transformers",
"token_count": 3664
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Philosophy
🤗 Transformersは、次のような目的で構築された意見を持つライブラリです:
- 大規模なTransformersモデルを使用、研究、または拡張したい機械学習研究者および教育者。
- これらのモデルを微調整したり、本番環境で提供したり、またはその両方を行いたい実務家。
- 与えられた機械学習タスクを解決するために、事前トレーニングされたモデルをダウンロードして使用したいエンジニア。
このライブラリは、2つの強力な目標を持って設計されました:
1. できるだけ簡単かつ高速に使用できるようにすること:
- ユーザー向けの抽象化を限りなく少なくし、実際、ほとんどの場合、抽象化はありません。
各モデルを使用するために必要な3つの標準クラスだけが存在します:[構成](main_classes/configuration)、
[モデル](main_classes/model)、および前処理クラス(NLP用の[トークナイザ](main_classes/tokenizer)、ビジョン用の[イメージプロセッサ](main_classes/image_processor)、
オーディオ用の[特徴抽出器](main_classes/feature_extractor)、およびマルチモーダル入力用の[プロセッサ](main_classes/processors))。
- これらのクラスは、共通の`from_pretrained()`メソッドを使用して、事前トレーニング済みのインスタンスから簡単かつ統一された方法で初期化できます。このメソッドは、事前トレーニング済みのチェックポイントから関連するクラスのインスタンスと関連データ(構成のハイパーパラメータ、トークナイザの語彙、モデルの重み)をダウンロード(必要な場合はキャッシュ)して読み込みます。これらの基本クラスの上に、ライブラリは2つのAPIを提供しています:[パイプライン]は、特定のタスクでモデルをすばやく推論に使用するためのものであり、[`Trainer`]はPyTorchモデルを迅速にトレーニングまたは微調整するためのものです(すべてのTensorFlowモデルは`Keras.fit`と互換性があります)。
- その結果、このライブラリはニューラルネットワークのモジュラーツールボックスではありません。ライブラリを拡張または構築したい場合は、通常のPython、PyTorch、TensorFlow、Kerasモジュールを使用し、ライブラリの基本クラスから継承してモデルの読み込みと保存などの機能を再利用するだけです。モデルのコーディング哲学について詳しく知りたい場合は、[Repeat Yourself](https://huggingface.co/blog/transformers-design-philosophy)ブログ投稿をチェックしてみてください。
2. オリジナルのモデルにできるだけ近い性能を持つ最新のモデルを提供すること:
- 各アーキテクチャに対して、公式な著者から提供された結果を再現する少なくとも1つの例を提供します。
- コードは通常、可能な限り元のコードベースに近いものであり、これはPyTorchコードがTensorFlowコードに変換されることから生じ、逆もまた然りです。
その他のいくつかの目標:
- モデルの内部をできるだけ一貫して公開すること:
- フルな隠れ状態と注意の重みにアクセスできる単一のAPIを提供します。
- 前処理クラスと基本モデルのAPIは標準化され、簡単にモデル間を切り替えることができます。
- これらのモデルの微調整と調査のための有望なツールを主観的に選定すること:
- 語彙と埋め込みに新しいトークンを追加するための簡単で一貫した方法。
- Transformerヘッドをマスクおよびプルーンするための簡単な方法。
- PyTorch、TensorFlow 2.0、およびFlaxの間を簡単に切り替えて、1つのフレームワークでトレーニングし、別のフレームワークで推論を行うことを可能にすること。
## Main concepts
このライブラリは、各モデルについて次の3つのタイプのクラスを中心に構築されています:
- **モデルクラス**は、ライブラリで提供される事前トレーニング済みの重みと互換性のあるPyTorchモデル([torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module))、Kerasモデル([tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model))またはJAX/Flaxモデル([flax.linen.Module](https://flax.readthedocs.io/en/latest/api_reference/flax.linen/module.html))を使用できます。
- **構成クラス**は、モデルを構築するために必要なハイパーパラメータを格納します(層の数や隠れ層のサイズなど)。これらを自分でインスタンス化する必要はありません。特に、変更を加えずに事前トレーニング済みモデルを使用している場合、モデルを作成すると自動的に構成がインスタンス化されるようになります(これはモデルの一部です)。
- **前処理クラス**は、生データをモデルが受け入れる形式に変換します。[トークナイザ](main_classes/tokenizer)は各モデルの語彙を保存し、文字列をトークン埋め込みのインデックスのリストにエンコードおよびデコードするためのメソッドを提供します。[イメージプロセッサ](main_classes/image_processor)はビジョン入力を前処理し、[特徴抽出器](main_classes/feature_extractor)はオーディオ入力を前処理し、[プロセッサ](main_classes/processors)はマルチモーダル入力を処理します。
これらのすべてのクラスは、事前トレーニング済みのインスタンスからインスタンス化し、ローカルに保存し、Hubで共有することができる3つのメソッドを使用しています:
- `from_pretrained()`は、ライブラリ自体によって提供される([モデルハブ](https://huggingface.co/models)でサポートされているモデルがあります)か、ユーザーによってローカルに保存された(またはサーバーに保存された)事前トレーニング済みバージョンからモデル、構成、前処理クラスをインスタンス化するためのメソッドです。
- `save_pretrained()`は、モデル、構成、前処理クラスをローカルに保存し、`from_pretrained()`を使用して再読み込みできるようにします。
- `push_to_hub()`は、モデル、構成、前処理クラスをHubに共有し、誰でも簡単にアクセスできるようにします。
|
transformers/docs/source/ja/philosophy.md/0
|
{
"file_path": "transformers/docs/source/ja/philosophy.md",
"repo_id": "transformers",
"token_count": 3292
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Knowledge Distillation for Computer Vision
[[open-in-colab]]
知識の蒸留は、より大規模で複雑なモデル (教師) からより小規模で単純なモデル (生徒) に知識を伝達するために使用される手法です。あるモデルから別のモデルに知識を抽出するには、特定のタスク (この場合は画像分類) でトレーニングされた事前トレーニング済み教師モデルを取得し、画像分類でトレーニングされる生徒モデルをランダムに初期化します。次に、学生モデルをトレーニングして、その出力と教師の出力の差を最小限に抑え、動作を模倣します。これは [Distilling the Knowledge in a Neural Network by Hinton et al](https://arxiv.org/abs/1503.02531) で最初に導入されました。このガイドでは、タスク固有の知識の蒸留を行います。これには [Beans データセット](https://huggingface.co/datasets/beans) を使用します。
このガイドでは、[微調整された ViT モデル](https://huggingface.co/merve/vit-mobilenet-beans-224) (教師モデル) を抽出して [MobileNet](https://huggingface.co/google/mobilenet_v2_1.4_224) (学生モデル) 🤗 Transformers の [Trainer API](https://huggingface.co/docs/transformers/en/main_classes/trainer#trainer) を使用します。
蒸留とプロセスの評価に必要なライブラリをインストールしましょう。
```bash
pip install transformers datasets accelerate tensorboard evaluate --upgrade
```
この例では、教師モデルとして`merve/beans-vit-224`モデルを使用しています。これは、Bean データセットに基づいて微調整された`google/vit-base-patch16-224-in21k`に基づく画像分類モデルです。このモデルをランダムに初期化された MobileNetV2 に抽出します。
次に、データセットをロードします。
```python
from datasets import load_dataset
dataset = load_dataset("beans")
```
この場合、同じ解像度で同じ出力が返されるため、どちらのモデルの画像プロセッサも使用できます。 `dataset`の`map()`メソッドを使用して、データセットのすべての分割に前処理を適用します。
```python
from transformers import AutoImageProcessor
teacher_processor = AutoImageProcessor.from_pretrained("merve/beans-vit-224")
def process(examples):
processed_inputs = teacher_processor(examples["image"])
return processed_inputs
processed_datasets = dataset.map(process, batched=True)
```
基本的に、我々は生徒モデル(ランダムに初期化されたMobileNet)が教師モデル(微調整されたビジョン変換器)を模倣することを望む。これを実現するために、まず教師と生徒からロジット出力を得る。次に、それぞれのソフトターゲットの重要度を制御するパラメータ`temperature`で分割する。`lambda`と呼ばれるパラメータは蒸留ロスの重要度を量る。この例では、`temperature=5`、`lambda=0.5`とする。生徒と教師の間の発散を計算するために、Kullback-Leibler発散損失を使用します。2つのデータPとQが与えられたとき、KLダイバージェンスはQを使ってPを表現するためにどれだけの余分な情報が必要かを説明します。もし2つが同じであれば、QからPを説明するために必要な他の情報はないので、それらのKLダイバージェンスはゼロになります。
```python
from transformers import TrainingArguments, Trainer
import torch
import torch.nn as nn
import torch.nn.functional as F
class ImageDistilTrainer(Trainer):
def __init__(self, *args, teacher_model=None, **kwargs):
super().__init__(*args, **kwargs)
self.teacher = teacher_model
self.student = student_model
self.loss_function = nn.KLDivLoss(reduction="batchmean")
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.teacher.to(device)
self.teacher.eval()
self.temperature = temperature
self.lambda_param = lambda_param
def compute_loss(self, student, inputs, return_outputs=False):
student_output = self.student(**inputs)
with torch.no_grad():
teacher_output = self.teacher(**inputs)
# Compute soft targets for teacher and student
soft_teacher = F.softmax(teacher_output.logits / self.temperature, dim=-1)
soft_student = F.log_softmax(student_output.logits / self.temperature, dim=-1)
# Compute the loss
distillation_loss = self.loss_function(soft_student, soft_teacher) * (self.temperature ** 2)
# Compute the true label loss
student_target_loss = student_output.loss
# Calculate final loss
loss = (1. - self.lambda_param) * student_target_loss + self.lambda_param * distillation_loss
return (loss, student_output) if return_outputs else loss
```
次に、Hugging Face Hub にログインして、`trainer`を通じてモデルを Hugging Face Hub にプッシュできるようにします。
```python
from huggingface_hub import notebook_login
notebook_login()
```
教師モデルと生徒モデルである`TrainingArguments`を設定しましょう。
```python
from transformers import AutoModelForImageClassification, MobileNetV2Config, MobileNetV2ForImageClassification
training_args = TrainingArguments(
output_dir="my-awesome-model",
num_train_epochs=30,
fp16=True,
logging_dir=f"{repo_name}/logs",
logging_strategy="epoch",
eval_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
metric_for_best_model="accuracy",
report_to="tensorboard",
push_to_hub=True,
hub_strategy="every_save",
hub_model_id=repo_name,
)
num_labels = len(processed_datasets["train"].features["labels"].names)
# initialize models
teacher_model = AutoModelForImageClassification.from_pretrained(
"merve/beans-vit-224",
num_labels=num_labels,
ignore_mismatched_sizes=True
)
# training MobileNetV2 from scratch
student_config = MobileNetV2Config()
student_config.num_labels = num_labels
student_model = MobileNetV2ForImageClassification(student_config)
```
`compute_metrics` 関数を使用して、テスト セットでモデルを評価できます。この関数は、トレーニング プロセス中にモデルの`accuracy`と`f1`を計算するために使用されます。
```python
import evaluate
import numpy as np
accuracy = evaluate.load("accuracy")
def compute_metrics(eval_pred):
predictions, labels = eval_pred
acc = accuracy.compute(references=labels, predictions=np.argmax(predictions, axis=1))
return {"accuracy": acc["accuracy"]}
```
定義したトレーニング引数を使用して`Trainer`を初期化しましょう。データ照合装置も初期化します。
```python
from transformers import DefaultDataCollator
data_collator = DefaultDataCollator()
trainer = ImageDistilTrainer(
student_model=student_model,
teacher_model=teacher_model,
training_args=training_args,
train_dataset=processed_datasets["train"],
eval_dataset=processed_datasets["validation"],
data_collator=data_collator,
processing_class=teacher_extractor,
compute_metrics=compute_metrics,
temperature=5,
lambda_param=0.5
)
```
これでモデルをトレーニングできるようになりました。
```python
trainer.train()
```
テスト セットでモデルを評価できます。
```python
trainer.evaluate(processed_datasets["test"])
```
テスト セットでは、モデルの精度は 72% に達します。蒸留効率の健全性チェックを行うために、同じハイパーパラメータを使用して Bean データセットで MobileNet を最初からトレーニングし、テスト セットで 63% の精度を観察しました。読者の皆様には、さまざまな事前トレーニング済み教師モデル、学生アーキテクチャ、蒸留パラメータを試していただき、その結果を報告していただくようお勧めします。抽出されたモデルのトレーニング ログとチェックポイントは [このリポジトリ](https://huggingface.co/merve/vit-mobilenet-beans-224) にあり、最初からトレーニングされた MobileNetV2 はこの [リポジトリ](https://huggingface.co/merve/resnet-mobilenet-beans-5)。
|
transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/knowledge_distillation_for_image_classification.md",
"repo_id": "transformers",
"token_count": 3678
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Zero-shot image classification
[[open-in-colab]]
ゼロショット画像分類は、次のモデルを使用して画像をさまざまなカテゴリに分類するタスクです。
これらの特定のカテゴリのラベル付きの例を含むデータに対して明示的にトレーニングされていない。
従来、画像分類には、ラベル付き画像の特定のセットでモデルをトレーニングする必要があり、このモデルは次のことを学習します。
特定の画像の特徴をラベルに「マッピング」します。分類タスクにそのようなモデルを使用する必要がある場合、
新しいラベルのセットでは、モデルを "再調整" するために微調整が必要です。
対照的に、ゼロショットまたはオープン語彙画像分類モデルは、通常、大規模なシステムでトレーニングされたマルチモーダル モデルです。
画像と関連する説明のデータセット。これらのモデルは、ゼロショット画像分類を含む多くの下流タスクに使用できる、調整された視覚言語表現を学習します。
これは、画像分類に対するより柔軟なアプローチであり、モデルを新しいまだ見たことのないカテゴリに一般化できるようになります。
追加のトレーニング データを必要とせず、ユーザーはターゲット オブジェクトの自由形式のテキスト説明を含む画像をクエリできるようになります。
このガイドでは、次の方法を学びます。
* ゼロショット画像分類パイプラインを作成する
* 手動でゼロショット画像分類推論を実行します
始める前に、必要なライブラリがすべてインストールされていることを確認してください。
```bash
pip install -q transformers
```
## Zero-shot image classification pipeline
ゼロショット画像分類をサポートするモデルで推論を試す最も簡単な方法は、対応する [`パイプライン`] を使用することです。
[Hugging Face Hub のチェックポイント](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads) からパイプラインをインスタンス化します。
```python
>>> from transformers import pipeline
>>> checkpoint = "openai/clip-vit-large-patch14"
>>> detector = pipeline(model=checkpoint, task="zero-shot-image-classification")
```
次に、分類したい画像を選択します。
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/g8oS8-82DxI/download?ixid=MnwxMjA3fDB8MXx0b3BpY3x8SnBnNktpZGwtSGt8fHx8fDJ8fDE2NzgxMDYwODc&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/owl.jpg" alt="Photo of an owl"/>
</div>
画像と候補オブジェクトのラベルをパイプラインに渡します。ここでは画像を直接渡します。他の適切なオプション
画像へのローカル パスまたは画像 URL を含めます。
候補ラベルは、この例のように単純な単語にすることも、より説明的な単語にすることもできます。
```py
>>> predictions = detector(image, candidate_labels=["fox", "bear", "seagull", "owl"])
>>> predictions
[{'score': 0.9996670484542847, 'label': 'owl'},
{'score': 0.000199399160919711, 'label': 'seagull'},
{'score': 7.392891711788252e-05, 'label': 'fox'},
{'score': 5.96074532950297e-05, 'label': 'bear'}]
```
## Zero-shot image classification by hand
ゼロショット画像分類パイプラインの使用方法を理解したところで、ゼロショットを実行する方法を見てみましょう。
画像を手動で分類します。
まず、[Hugging Face Hub のチェックポイント](https://huggingface.co/models?pipeline_tag=zero-shot-image-classification&sort=downloads) からモデルと関連プロセッサをロードします。
ここでは、前と同じチェックポイントを使用します。
```py
>>> from transformers import AutoProcessor, AutoModelForZeroShotImageClassification
>>> model = AutoModelForZeroShotImageClassification.from_pretrained(checkpoint)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
```
気分を変えて、別の画像を撮ってみましょう。
```py
>>> from PIL import Image
>>> import requests
>>> url = "https://unsplash.com/photos/xBRQfR2bqNI/download?ixid=MnwxMjA3fDB8MXxhbGx8fHx8fHx8fHwxNjc4Mzg4ODEx&force=true&w=640"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> image
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg" alt="Photo of a car"/>
</div>
プロセッサを使用してモデルの入力を準備します。プロセッサーは、
サイズ変更と正規化によるモデルの画像、およびテキスト入力を処理するトークナイザー。
```py
>>> candidate_labels = ["tree", "car", "bike", "cat"]
>>> inputs = processor(images=image, text=candidate_labels, return_tensors="pt", padding=True)
```
入力をモデルに渡し、結果を後処理します。
```py
>>> import torch
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> logits = outputs.logits_per_image[0]
>>> probs = logits.softmax(dim=-1).numpy()
>>> scores = probs.tolist()
>>> result = [
... {"score": score, "label": candidate_label}
... for score, candidate_label in sorted(zip(probs, candidate_labels), key=lambda x: -x[0])
... ]
>>> result
[{'score': 0.998572, 'label': 'car'},
{'score': 0.0010570387, 'label': 'bike'},
{'score': 0.0003393686, 'label': 'tree'},
{'score': 3.1572064e-05, 'label': 'cat'}]
```
|
transformers/docs/source/ja/tasks/zero_shot_image_classification.md/0
|
{
"file_path": "transformers/docs/source/ja/tasks/zero_shot_image_classification.md",
"repo_id": "transformers",
"token_count": 2709
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 어텐션 메커니즘[[attention_mechanisms]]
대부분의 트랜스포머 모델은 정방행렬인 전체 어텐션을 사용합니다.
하지만 이는 긴 텍스트를 다룰 때는 큰 계산 병목 현상을 유발할 수 있습니다.
`Longformer`와 `Reformer`는 훈련 속도를 높이기 위해 어텐션 행렬의 희소 버전을 사용하여 효율을 높이려는 모델입니다.
## LSH 어텐션[[lsh_attention]]
[Reformer](model_doc/reformer)는 LSH(Locality Sensitive Hashing) 어텐션을 사용합니다. softmax(QK^t)에서는 행렬 QK^t의 (softmax 차원에서) 가장 큰 요소들만 유용한 기여를 할 것입니다.
따라서 각각의 쿼리 q에 대해, q와 가까운 키 k만 고려할 수 있습니다. 해시 함수는 q와 k가 가까운지 여부를 결정하는 데 사용됩니다.
어텐션 마스크는 현재 토큰을 마스킹하여 변경됩니다. 이 때 첫 번째 위치의 토큰은 제외합니다. 왜냐하면 쿼리와 키가 동일한 값을 갖게 되기 때문입니다(서로 매우 유사함).
해시는 약간의 무작위성을 가질 수 있으므로, 실제로는 여러 개의 해시 함수가 사용되고 (`n_rounds` 매개변수에 의해 결정됨) 그 후에 평균값을 취하게 됩니다.
## 지역 어텐션[[local_attention]]
[Longformer](model_doc/longformer)는 지역 어텐션을 사용합니다. 종종 특정 토큰에 대해 지역 컨텍스트(예: 왼쪽과 오른쪽에 있는 두 개의 토큰은 무엇인가요?)만으로도 작업을 수행하는데 충분합니다.
또한 작은 창(window)을 가진 어텐션 레이어를 쌓음으로써 마지막 레이어는 창 내의 토큰뿐만 아니라 더 많은 수의 토큰에 대한 수용 영역(receptive field)을 갖게 되어 전체 문장의 표현을 구축할 수 있습니다.
사전에 선택된 일부 입력 토큰들은 전역 어텐션을 받습니다. 이 몇 개의 토큰에 대해서는 어텐션 행렬이 모든 토큰에 접근할 수 있으며, 이 과정은 대칭적으로 이루어집니다.
다른 모든 토큰들은 로컬 창 내의 토큰들에 더해 해당 특정 토큰들에도 접근할 수 있습니다. 이는 논문의 Figure 2d에서 나타나며, 아래에 샘플 어텐션 마스크가 제시되어 있습니다:
<div class="flex justify-center">
<img scale="50 %" align="center" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/local_attention_mask.png"/>
</div>
적은 파라미터의 어텐션 행렬을 사용하면 모델이 더 큰 시퀀스 입력 길이를 가질 수 있습니다.
## 다른 방법들[[other_tricks]]
### 축별 위치 인코딩[[axial_positional_encodings]]
[Reformer](model_doc/reformer)는 축별 위치 인코딩(axial positional encodings)을 사용합니다. 기존의 트랜스포머 모델에서는 위치 인코딩 행렬 E는 크기가 \\(l \times d\\)인 행렬이며,
여기서 \\(l\\)은 시퀀스 길이(sequence length)이고 \\(d\\)는 숨겨진 상태(hidden state)의 차원입니다. 매우 긴 텍스트의 경우, 이 행렬은 매우 크며 GPU 상에서 공간을 많이 차지할 수 있습니다.
이를 완화하기 위해, 축별 위치 인코딩은 큰 행렬 E를 두 개의 작은 행렬 E1과 E2로 분해합니다. 이때 E1의 크기는 \\(l_{1} \times d_{1}\\)이고, E2의 크기는 \\(l_{2} \times d_{2}\\)입니다.
이때 \\(l_{1} \times l_{2} = l\\)이고 \\(d_{1} + d_{2} = d\\)(길이에 대한 곱셈 연산을 사용하면 훨씬 작아집니다). E의 시간 단계 j에 대한 임베딩은 E1에서 시간 단계 \\(j \% l1\\)의 임베딩과 E2에서 시간 단계 \\(j // l1\\)의 임베딩을 연결하여 얻습니다.
|
transformers/docs/source/ko/attention.md/0
|
{
"file_path": "transformers/docs/source/ko/attention.md",
"repo_id": "transformers",
"token_count": 3070
}
|
<!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Trainer API를 사용한 하이퍼파라미터 탐색 [[hyperparameter-search-using-trainer-api]]
🤗 Transformers에서는 🤗 Transformers 모델을 학습시키는데 최적화된 [`Trainer`] 클래스를 제공하기 때문에, 사용자는 직접 훈련 루프를 작성할 필요 없이 더욱 간편하게 학습을 시킬 수 있습니다. 또한, [`Trainer`]는 하이퍼파라미터 탐색을 위한 API를 제공합니다. 이 문서에서 이 API를 활용하는 방법을 예시와 함께 보여드리겠습니다.
## 하이퍼파라미터 탐색 백엔드 [[hyperparameter-search-backend]]
[`Trainer`]는 현재 아래 4가지 하이퍼파라미터 탐색 백엔드를 지원합니다:
[optuna](https://optuna.org/)와 [sigopt](https://sigopt.com/), [raytune](https://docs.ray.io/en/latest/tune/index.html), [wandb](https://wandb.ai/site/sweeps) 입니다.
하이퍼파라미터 탐색 백엔드로 사용하기 전에 아래의 명령어를 사용하여 라이브러리들을 설치하세요.
```bash
pip install optuna/sigopt/wandb/ray[tune]
```
## 예제에서 하이퍼파라미터 탐색을 활성화하는 방법 [[how-to-enable-hyperparameter-search-in-example]]
하이퍼파라미터 탐색 공간을 정의하세요. 하이퍼파라미터 탐색 백엔드마다 서로 다른 형식이 필요합니다.
sigopt의 경우, 해당 [object_parameter](https://docs.sigopt.com/ai-module-api-references/api_reference/objects/object_parameter) 문서를 참조하여 아래와 같이 작성하세요:
```py
>>> def sigopt_hp_space(trial):
... return [
... {"bounds": {"min": 1e-6, "max": 1e-4}, "name": "learning_rate", "type": "double"},
... {
... "categorical_values": ["16", "32", "64", "128"],
... "name": "per_device_train_batch_size",
... "type": "categorical",
... },
... ]
```
optuna의 경우, 해당 [object_parameter](https://optuna.readthedocs.io/en/stable/tutorial/10_key_features/002_configurations.html#sphx-glr-tutorial-10-key-features-002-configurations-py) 문서를 참조하여 아래와 같이 작성하세요:
```py
>>> def optuna_hp_space(trial):
... return {
... "learning_rate": trial.suggest_float("learning_rate", 1e-6, 1e-4, log=True),
... "per_device_train_batch_size": trial.suggest_categorical("per_device_train_batch_size", [16, 32, 64, 128]),
... }
```
raytune의 경우, 해당 [object_parameter](https://docs.ray.io/en/latest/tune/api/search_space.html) 문서를 참조하여 아래와 같이 작성하세요:
```py
>>> def ray_hp_space(trial):
... return {
... "learning_rate": tune.loguniform(1e-6, 1e-4),
... "per_device_train_batch_size": tune.choice([16, 32, 64, 128]),
... }
```
wandb의 경우, 해당 [object_parameter](https://docs.wandb.ai/guides/sweeps/configuration) 문서를 참조하여 아래와 같이 작성하세요:
```py
>>> def wandb_hp_space(trial):
... return {
... "method": "random",
... "metric": {"name": "objective", "goal": "minimize"},
... "parameters": {
... "learning_rate": {"distribution": "uniform", "min": 1e-6, "max": 1e-4},
... "per_device_train_batch_size": {"values": [16, 32, 64, 128]},
... },
... }
```
`model_init` 함수를 정의하고 이를 [`Trainer`]에 전달하세요. 아래는 그 예시입니다.
```py
>>> def model_init(trial):
... return AutoModelForSequenceClassification.from_pretrained(
... model_args.model_name_or_path,
... from_tf=bool(".ckpt" in model_args.model_name_or_path),
... config=config,
... cache_dir=model_args.cache_dir,
... revision=model_args.model_revision,
... token=True if model_args.use_auth_token else None,
... )
```
아래와 같이 `model_init` 함수, 훈련 인수, 훈련 및 테스트 데이터셋, 그리고 평가 함수를 사용하여 [`Trainer`]를 생성하세요:
```py
>>> trainer = Trainer(
... model=None,
... args=training_args,
... train_dataset=small_train_dataset,
... eval_dataset=small_eval_dataset,
... compute_metrics=compute_metrics,
... processing_class=tokenizer,
... model_init=model_init,
... data_collator=data_collator,
... )
```
하이퍼파라미터 탐색을 호출하고, 최적의 시험 매개변수를 가져오세요. 백엔드는 `"optuna"`/`"sigopt"`/`"wandb"`/`"ray"` 중에서 선택할 수 있습니다. 방향은 `"minimize"` 또는 `"maximize"` 중 선택하며, 목표를 최소화할 것인지 최대화할 것인지를 결정합니다.
자신만의 compute_objective 함수를 정의할 수 있습니다. 만약 이 함수를 정의하지 않으면, 기본 compute_objective가 호출되고, f1과 같은 평가 지표의 합이 목푯값으로 반환됩니다.
```py
>>> best_trial = trainer.hyperparameter_search(
... direction="maximize",
... backend="optuna",
... hp_space=optuna_hp_space,
... n_trials=20,
... compute_objective=compute_objective,
... )
```
## DDP 미세 조정을 위한 하이퍼파라미터 탐색 [[hyperparameter-search-for-ddp-finetune]]
현재, DDP(Distributed Data Parallelism; 분산 데이터 병렬처리)를 위한 하이퍼파라미터 탐색은 optuna와 sigopt에서 가능합니다. 최상위 프로세스가 하이퍼파라미터 탐색 과정을 시작하고 그 결과를 다른 프로세스에 전달합니다.
|
transformers/docs/source/ko/hpo_train.md/0
|
{
"file_path": "transformers/docs/source/ko/hpo_train.md",
"repo_id": "transformers",
"token_count": 3520
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 에이전트 & 도구 [[agents-tools]]
<Tip warning={true}>
Transformers Agent는 실험 중인 API이므로 언제든지 변경될 수 있습니다.
API나 기반 모델이 자주 업데이트되므로, 에이전트가 제공하는 결과물은 달라질 수 있습니다.
</Tip>
에이전트와 도구에 대해 더 알아보려면 [소개 가이드](../transformers_agents)를 꼭 읽어보세요.
이 페이지에는 기본 클래스에 대한 API 문서가 포함되어 있습니다.
## 에이전트 [[agents]]
우리는 기본 [`Agent`] 클래스를 기반으로 두 가지 유형의 에이전트를 제공합니다:
- [`CodeAgent`]는 한 번에 동작합니다. 작업을 해결하기 위해 코드를 생성한 다음, 바로 실행합니다.
- [`ReactAgent`]는 단계별로 동작하며, 각 단계는 하나의 생각, 하나의 도구 호출 및 실행으로 구성됩니다. 이 에이전트에는 두 가지 클래스가 있습니다:
- [`ReactJsonAgent`]는 도구 호출을 JSON으로 작성합니다.
- [`ReactCodeAgent`]는 도구 호출을 Python 코드로 작성합니다.
### Agent [[agent]]
[[autodoc]] Agent
### CodeAgent [[codeagent]]
[[autodoc]] CodeAgent
### React agents [[react-agents]]
[[autodoc]] ReactAgent
[[autodoc]] ReactJsonAgent
[[autodoc]] ReactCodeAgent
## Tools [[tools]]
### load_tool [[loadtool]]
[[autodoc]] load_tool
### Tool [[tool]]
[[autodoc]] Tool
### Toolbox [[toolbox]]
[[autodoc]] Toolbox
### PipelineTool [[pipelinetool]]
[[autodoc]] PipelineTool
### launch_gradio_demo [[launchgradiodemo]]
[[autodoc]] launch_gradio_demo
### ToolCollection [[toolcollection]]
[[autodoc]] ToolCollection
## 엔진 [[engines]]
에이전트 프레임워크에서 사용할 수 있는 엔진을 자유롭게 만들고 사용할 수 있습니다.
이 엔진들은 다음과 같은 사양을 가지고 있습니다:
1. 입력(`List[Dict[str, str]]`)에 대한 [메시지 형식](../chat_templating.md)을 따르고 문자열을 반환해야 합니다.
2. 인수 `stop_sequences`에 시퀀스가 전달되기 *전에* 출력을 생성하는 것을 중지해야 합니다.
### HfApiEngine [[HfApiEngine]]
편의를 위해, 위의 사항을 구현하고 대규모 언어 모델 실행을 위해 추론 엔드포인트를 사용하는 `HfApiEngine`을 추가했습니다.
```python
>>> from transformers import HfApiEngine
>>> messages = [
... {"role": "user", "content": "Hello, how are you?"},
... {"role": "assistant", "content": "I'm doing great. How can I help you today?"},
... {"role": "user", "content": "No need to help, take it easy."},
... ]
>>> HfApiEngine()(messages, stop_sequences=["conversation"])
"That's very kind of you to say! It's always nice to have a relaxed "
```
[[autodoc]] HfApiEngine
## 에이전트 유형 [[agent-types]]
에이전트는 도구 간의 모든 유형의 객체를 처리할 수 있습니다; 도구는 완전히 멀티모달이므로 텍스트, 이미지, 오디오, 비디오 등 다양한 유형을 수락하고 반환할 수 있습니다.
도구 간의 호환성을 높이고 ipython (jupyter, colab, ipython 노트북, ...)에서 이러한
반환 값을 올바르게 렌더링하기 위해 이러한 유형을 중심으로 래퍼 클래스를
구현합니다.
래핑된 객체는 처음과 동일하게 작동해야 합니다; 텍스트 객체는 여전히 문자열로 작동해야 하며,
이미지 객체는 여전히 `PIL.Image`로 작동해야 합니다.
이러한 유형에는 세 가지 특정 목적이 있습니다:
- `to_raw`를 호출하면 기본 객체가 반환되어야 합니다.
- `to_string`을 호출하면 객체가 문자열로 반환되어야 합니다:
`AgentText`의 경우 문자열이 될 수 있지만, 다른 경우에는 객체의 직렬화된 버전의 경로일 수 있습니다.
- ipython 커널에서 표시할 때 객체가 올바르게 표시되어야 합니다.
### AgentText [[agenttext]]
[[autodoc]] transformers.agents.agent_types.AgentText
### AgentImage [[agentimage]]
[[autodoc]] transformers.agents.agent_types.AgentImage
### AgentAudio [[agentaudio]]
[[autodoc]] transformers.agents.agent_types.AgentAudio
|
transformers/docs/source/ko/main_classes/agent.md/0
|
{
"file_path": "transformers/docs/source/ko/main_classes/agent.md",
"repo_id": "transformers",
"token_count": 2949
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Autoformer[[autoformer]]
## 개요[[overview]]
The Autoformer 모델은 Haixu Wu, Jiehui Xu, Jianmin Wang, Mingsheng Long가 제안한 [오토포머: 장기 시계열 예측을 위한 자기상관 분해 트랜스포머](https://arxiv.org/abs/2106.13008) 라는 논문에서 소개 되었습니다.
이 모델은 트랜스포머를 심층 분해 아키텍처로 확장하여, 예측 과정에서 추세와 계절성 요소를 점진적으로 분해할 수 있습니다.
해당 논문의 초록입니다:
*예측 시간을 연장하는 것은 극한 기상 조기 경보 및 장기 에너지 소비 계획과 같은 실제 응용 프로그램에 중요한 요구 사항입니다. 본 논문은 시계열의 장기 예측 문제를 연구합니다. 기존의 트랜스포머 기반 모델들은 장거리 종속성을 발견하기 위해 다양한 셀프 어텐션 메커니즘을 채택합니다. 그러나 장기 미래의 복잡한 시간적 패턴으로 인해 모델이 신뢰할 수 있는 종속성을 찾기 어렵습니다. 또한, 트랜스포머는 긴 시계열의 효율성을 위해 점별 셀프 어텐션의 희소 버전을 채택해야 하므로 정보 활용의 병목 현상이 발생합니다. 우리는 트랜스포머를 넘어서 자기상관 메커니즘을 갖춘 새로운 분해 아키텍처인 Autoformer를 설계했습니다. 우리는 시계열 분해의 전처리 관행을 깨고 이를 심층 모델의 기본 내부 블록으로 혁신했습니다. 이 설계는 Autoformer에 복잡한 시계열에 대한 점진적 분해 능력을 부여합니다. 또한, 확률 과정 이론에서 영감을 받아 시계열의 주기성을 기반으로 자기상관 메커니즘을 설계했으며, 이는 하위 시계열 수준에서 종속성 발견과 표현 집계를 수행합니다. 자기상관은 효율성과 정확도 면에서 셀프 어텐션를 능가합니다. 장기 예측에서 Autoformer는 에너지, 교통, 경제, 날씨, 질병 등 5가지 실용적 응용 분야를 포괄하는 6개 벤치마크에서 38%의 상대적 개선으로 최첨단 정확도를 달성했습니다.*
이 모델은 [elisim](https://huggingface.co/elisim)과 [kashif](https://huggingface.co/kashif)에 의해 기여 되었습니다.
원본 코드는 [이곳](https://github.com/thuml/Autoformer)에서 확인할 수 있습니다.
## 자료[[resources]]
시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
- HuggingFace 블로그에서 Autoformer 포스트를 확인하세요: [네, 그렇습니다, 트랜스포머는 시계열 예측에 효과적입니다(+ Autoformer)](https://huggingface.co/blog/autoformer)
## AutoformerConfig[[transformers.AutoformerConfig]]
[[autodoc]] AutoformerConfig
## AutoformerModel[[transformers.AutoformerModel]]
[[autodoc]] AutoformerModel
- forward
## AutoformerForPrediction[[transformers.AutoformerForPrediction]]
[[autodoc]] AutoformerForPrediction
- forward
|
transformers/docs/source/ko/model_doc/autoformer.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/autoformer.md",
"repo_id": "transformers",
"token_count": 2603
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DeBERTa[[deberta]]
## 개요[[overview]]
DeBERTa 모델은 Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen이 작성한 [DeBERTa: 분리된 어텐션을 활용한 디코딩 강화 BERT](https://arxiv.org/abs/2006.03654)이라는 논문에서 제안되었습니다. 이 모델은 2018년 Google이 발표한 BERT 모델과 2019년 Facebook이 발표한 RoBERTa 모델을 기반으로 합니다.
DeBERTa는 RoBERTa에서 사용된 데이터의 절반만을 사용하여 분리된(disentangled) 어텐션과 향상된 마스크 디코더 학습을 통해 RoBERTa를 개선했습니다.
논문의 초록은 다음과 같습니다:
*사전 학습된 신경망 언어 모델의 최근 발전은 많은 자연어 처리(NLP) 작업의 성능을 크게 향상시켰습니다. 본 논문에서는 두 가지 새로운 기술을 사용하여 BERT와 RoBERTa 모델을 개선한 새로운 모델 구조인 DeBERTa를 제안합니다. 첫 번째는 분리된 어텐션 메커니즘으로, 각 단어가 내용과 위치를 각각 인코딩하는 두 개의 벡터로 표현되며, 단어들 간의 어텐션 가중치는 내용과 상대적 위치에 대한 분리된 행렬을 사용하여 계산됩니다. 두 번째로, 모델 사전 학습을 위해 마스킹된 토큰을 예측하는 출력 소프트맥스 층을 대체하는 향상된 마스크 디코더가 사용됩니다. 우리는 이 두 가지 기술이 모델 사전 학습의 효율성과 다운스트림 작업의 성능을 크게 향상시킨다는 것을 보여줍니다. RoBERTa-Large와 비교했을 때, 절반의 학습 데이터로 학습된 DeBERTa 모델은 광범위한 NLP 작업에서 일관되게 더 나은 성능을 보여주며, MNLI에서 +0.9%(90.2% vs 91.1%), SQuAD v2.0에서 +2.3%(88.4% vs 90.7%), RACE에서 +3.6%(83.2% vs 86.8%)의 성능 향상을 달성했습니다. DeBERTa 코드와 사전 학습된 모델은 https://github.com/microsoft/DeBERTa 에서 공개될 예정입니다.*
[DeBERTa](https://huggingface.co/DeBERTa) 모델의 텐서플로 2.0 구현은 [kamalkraj](https://huggingface.co/kamalkraj)가 기여했습니다. 원본 코드는 [이곳](https://github.com/microsoft/DeBERTa)에서 확인하실 수 있습니다.
## 리소스[[resources]]
DeBERTa를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다. 여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰해 드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
<PipelineTag pipeline="text-classification"/>
- DeBERTa와 [DeepSpeed를 이용해서 대형 모델 학습을 가속시키는](https://huggingface.co/blog/accelerate-deepspeed) 방법에 대한 포스트.
- DeBERTa와 [머신러닝으로 한층 향상된 고객 서비스](https://huggingface.co/blog/supercharge-customer-service-with-machine-learning)에 대한 블로그 포스트.
- [`DebertaForSequenceClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification.ipynb)에서 지원됩니다.
- [`TFDebertaForSequenceClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/text-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/text_classification-tf.ipynb)에서 지원됩니다.
- [텍스트 분류 작업 가이드](../tasks/sequence_classification)
<PipelineTag pipeline="token-classification" />
- [`DebertaForTokenClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification.ipynb)에서 지원합니다.
- [`TFDebertaForTokenClassification`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/token-classification)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/token_classification-tf.ipynb)에서 지원합니다.
- 🤗 Hugging Face 코스의 [토큰 분류](https://huggingface.co/course/chapter7/2?fw=pt) 장.
- 🤗 Hugging Face 코스의 [BPE(Byte-Pair Encoding) 토큰화](https://huggingface.co/course/chapter6/5?fw=pt) 장.
- [토큰 분류 작업 가이드](../tasks/token_classification)
<PipelineTag pipeline="fill-mask"/>
- [`DebertaForMaskedLM`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#robertabertdistilbert-and-masked-language-modeling)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb)에서 지원합니다.
- [`TFDebertaForMaskedLM`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_mlmpy)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb)에서 지원합니다.
- 🤗 Hugging Face 코스의 [마스크 언어 모델링](https://huggingface.co/course/chapter7/3?fw=pt) 장.
- [마스크 언어 모델링 작업 가이드](../tasks/masked_language_modeling)
<PipelineTag pipeline="question-answering"/>
- [`DebertaForQuestionAnswering`]은 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/pytorch/question-answering)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering.ipynb)에서 지원합니다.
- [`TFDebertaForQuestionAnswering`]는 이 [예제 스크립트](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/question-answering)와 [노트북](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/question_answering-tf.ipynb)에서 지원합니다.
- 🤗 Hugging Face 코스의 [질의응답(Question answering)](https://huggingface.co/course/chapter7/7?fw=pt) 장.
- [질의응답 작업 가이드](../tasks/question_answering)
## DebertaConfig[[transformers.DebertaConfig]]
[[autodoc]] DebertaConfig
## DebertaTokenizer[[transformers.DebertaTokenizer]]
[[autodoc]] DebertaTokenizer
- build_inputs_with_special_tokens
- get_special_tokens_mask
- create_token_type_ids_from_sequences
- save_vocabulary
## DebertaTokenizerFast[[transformers.DebertaTokenizerFast]]
[[autodoc]] DebertaTokenizerFast
- build_inputs_with_special_tokens
- create_token_type_ids_from_sequences
<frameworkcontent>
<pt>
## DebertaModel[[transformers.DebertaModel]]
[[autodoc]] DebertaModel
- forward
## DebertaPreTrainedModel[[transformers.DebertaPreTrainedModel]]
[[autodoc]] DebertaPreTrainedModel
## DebertaForMaskedLM[[transformers.DebertaForMaskedLM]]
[[autodoc]] DebertaForMaskedLM
- forward
## DebertaForSequenceClassification[[transformers.DebertaForSequenceClassification]]
[[autodoc]] DebertaForSequenceClassification
- forward
## DebertaForTokenClassification[[transformers.DebertaForTokenClassification]]
[[autodoc]] DebertaForTokenClassification
- forward
## DebertaForQuestionAnswering[[transformers.DebertaForQuestionAnswering]]
[[autodoc]] DebertaForQuestionAnswering
- forward
</pt>
<tf>
## TFDebertaModel[[transformers.TFDebertaModel]]
[[autodoc]] TFDebertaModel
- call
## TFDebertaPreTrainedModel[[transformers.TFDebertaPreTrainedModel]]
[[autodoc]] TFDebertaPreTrainedModel
- call
## TFDebertaForMaskedLM[[transformers.TFDebertaForMaskedLM]]
[[autodoc]] TFDebertaForMaskedLM
- call
## TFDebertaForSequenceClassification[[transformers.TFDebertaForSequenceClassification]]
[[autodoc]] TFDebertaForSequenceClassification
- call
## TFDebertaForTokenClassification[[transformers.TFDebertaForTokenClassification]]
[[autodoc]] TFDebertaForTokenClassification
- call
## TFDebertaForQuestionAnswering[[transformers.TFDebertaForQuestionAnswering]]
[[autodoc]] TFDebertaForQuestionAnswering
- call
</tf>
</frameworkcontent>
|
transformers/docs/source/ko/model_doc/deberta.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/deberta.md",
"repo_id": "transformers",
"token_count": 4741
}
|
<!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# PaliGemma[[paligemma]]
## 개요[[overview]]
PaliGemma 모델은 구글이 제안한 [PaliGemma – Google의 최첨단 오픈 비전 언어 모델](https://huggingface.co/blog/paligemma)에서 소개 되었습니다. PaliGemma는 [SigLIP](siglip) 비전 인코더와 [Gemma](gemma) 언어 인코더로 구성된 3B 규모의 비전-언어 모델로, 두 인코더가 멀티모달 선형 프로젝션으로 연결되어 있습니다. 이 모델은 이미지를 고정된 수의 VIT토큰으로 분할하고 이를 선택적 프롬프트 앞에 추가 하며, 모든 이미지 토큰과 입력 텍스트 토큰에 대해 전체 블록 어텐션을 사용하는 특징을 가지고 있습니다.
PaliGemma는 224x224, 448x448, 896x896의 3가지 해상도로 제공되며, 3개의 기본 모델과 55개의 다양한 작업에 대해 미세 조정된 버전, 그리고 2개의 혼합 모델이 있습니다.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/paligemma/paligemma_arch.png"
alt="drawing" width="600"/>
<small> PaliGemma 아키텍처 <a href="https://huggingface.co/blog/paligemma">블로그 포스트.</a> </small>
이 모델은 [Molbap](https://huggingface.co/Molbap)에 의해 기여 되었습니다.
## 사용 팁[[usage-tips]]
PaliGemma의 추론은 다음처럼 수행됩니다:
```python
from transformers import AutoProcessor, PaliGemmaForConditionalGeneration
model_id = "google/paligemma-3b-mix-224"
model = PaliGemmaForConditionalGeneration.from_pretrained(model_id)
processor = AutoProcessor.from_pretrained(model_id)
prompt = "What is on the flower?"
image_file = "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/bee.jpg?download=true"
raw_image = Image.open(requests.get(image_file, stream=True).raw)
inputs = processor(raw_image, prompt, return_tensors="pt")
output = model.generate(**inputs, max_new_tokens=20)
print(processor.decode(output[0], skip_special_tokens=True)[len(prompt):])
```
- PaliGemma는 대화용으로 설계되지 않았으며, 특정 사용 사례에 대해 미세 조정할 때 가장 잘 작동합니다. PaliGemma를 미세 조정할 수 있는 몇 가지 하위 작업에는 이미지 캡셔닝, 시각적 질문 답변(VQA), 오브젝트 디텍션, 참조 표현 분할 및 문서 이해가 포함됩니다.
- 모델에 필요한 이미지, 텍스트 및 선택적 레이블을 준비하는데 `PaliGemmaProcessor`를 사용할 수 있습니다. PaliGemma 모델을 미세 조정할 때는, 프로세서에 `suffix`인자를 전달하여 다음 처럼 모델의 `labels`를 생성할 수 있습니다:
```python
prompt = "What is on the flower?"
answer = "a bee"
inputs = processor(images=raw_image, text=prompt, suffix=answer, return_tensors="pt")
```
## 자료[[resources]]
PaliGemma를 시작하는 데 도움이 되는 Hugging Face와 community 자료 목록(🌎로 표시됨) 입니다.여기에 포함될 자료를 제출하고 싶으시다면 PR(Pull Request)를 열어주세요. 리뷰 해드리겠습니다! 자료는 기존 자료를 복제하는 대신 새로운 내용을 담고 있어야 합니다.
- PaliGemma의 모든 기능을 소개하는 블로그 포스트는 [이곳](https://huggingface.co/blog/paligemma)에서 찾을 수 있습니다. 🌎
- Trainer API를 사용하여 VQA(Visual Question Answering)를 위해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/huggingface/notebooks/tree/main/examples/paligemma)에서 찾을 수 있습니다. 🌎
- 사용자 정의 데이터셋(영수증 이미지 -> JSON)에 대해 PaliGemma를 미세 조정하는 방법과 추론에 대한 데모 노트북은 [이곳](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/PaliGemma)에서 찾을 수 있습니다. 🌎
## PaliGemmaConfig[[transformers.PaliGemmaConfig]]
[[autodoc]] PaliGemmaConfig
## PaliGemmaProcessor[[transformers.PaliGemmaProcessor]]
[[autodoc]] PaliGemmaProcessor
## PaliGemmaForConditionalGeneration[[transformers.PaliGemmaForConditionalGeneration]]
[[autodoc]] PaliGemmaForConditionalGeneration
- forward
|
transformers/docs/source/ko/model_doc/paligemma.md/0
|
{
"file_path": "transformers/docs/source/ko/model_doc/paligemma.md",
"repo_id": "transformers",
"token_count": 2814
}
|
# 모듈식 트랜스포머 [[modular-transformers]]
`transformers`는 opinionated(자기 의견이 강한) 프레임워크이며, 우리의 철학은 다음의 [개념 가이드](./philosophy)에 정의되어 있습니다.
이 철학의 핵심은 라이브러리의 [단일 모델, 단일 파일](https://huggingface.co/blog/transformers-design-philosophy) 측면에서 잘 나타납니다. 이 구성 요소의 단점은 파일 간에 구성 요소의 상속과 임포트 가능성을 제한한다는 것입니다.
그 결과, 모델 구성 요소가 여러 파일에 걸쳐 반복되는 경향이 있습니다. `transformers`에는 모델 수만큼 많은 어텐션 레이어가 정의되어 있으며, 그 중 상당수는 서로 동일합니다. 안타깝게도, 수정과 변경 사항이 코드의 특정 부분에 적용되면서 독립적인 구현들이 서로 분기되는 경향이 있습니다.
이 문제를 적절히 해결하기 위해, 우리는 라이브러리 전체에 "복사본"의 개념을 도입했습니다. 코드가 다른 코드의 복사본임을 나타내는 주석을 추가함으로써, CI 및 로컬 명령을 통해 복사본이 분기되지 않도록 강제할 수 있습니다. 그러나 복잡성이 낮더라도 이는 종종 매우 번거로운 작업입니다.
마지막으로, 이 방식은 우리가 줄이고자 하는 상당한 오버헤드를 모델 기여 과정에 추가하게 됩니다. 이 접근 방식은 종종 모델 기여에 모델링 코드(~1,000줄), 프로세서(~500줄), 테스트, 문서 등을 추가해야 합니다. 모델 기여 PR은 대부분 3,000~5,000줄 이상의 코드를 추가하며, 이 중 많은 부분이 보일러플레이트(boilerplate) 코드입니다.
이는 기여의 장벽을 높이며, 모듈식 트랜스포머를 통해 우리는 이러한 장벽을 훨씬 더 수용 가능한 수준으로 낮추고자 합니다.
## 무엇인가요 [[what-is-it]]
모듈식 트랜스포머는 모델 폴더에 "모듈식" 파일의 개념을 도입합니다. 이 모듈식 파일은 일반적으로 모델링/프로세싱 파일에서 허용되지 않는 코드를 허용하며, 이는 인접한 모델로부터의 임포트와 클래스 간의 상속을 허용합니다.
이 모듈식 파일은 각각의 별도의 모듈에서 정의되었을 모델, 프로세서 및 구성 클래스를 정의합니다.
마지막으로, 이 기능은 모듈식 파일을 "풀어내어" 단일 모델, 단일 파일 디렉토리 구조로 변환하는 새로운 `linter`를 도입합니다. 이 파일들은 스크립트가 실행될 때마다 자동으로 생성되며, 기여해야 할 내용을 모듈식 파일, 그리고 기여된 모델과 다른 모델 간의 차이점으로만 줄여줍니다.
모델 사용자는 단일 파일 인터페이스를 임포트하고 사용하게 되므로, 여기에는 변화가 없을 것입니다. 이를 통해 간단한 기여를 가능하게 하면서도 우리의 철학을 유지하는 양쪽의 장점을 결합하고자 합니다.
따라서 이는 `# Copied from` 마커의 대체품이며, 이전에 기여된 모델은 앞으로 몇 달 내에 새로운 모듈식 트랜스포머 형식으로 전환될 예정입니다.
### 자세한 내용 [[details]]
“linter”는 상속 구조를 풀어서 모듈화된 파일로부터 모든 단일 파일을 생성하며, Python 사용자들에게는 그 과정이 보이지 않도록 동작합니다. 현재 linter는 **단일** 수준의 상속만을 평탄화합니다.
예를 들어:
- 구성 클래스가 다른 클래스를 상속하고 인자를 추가/삭제하는 경우, 생성된 파일은 직접 참조(추가의 경우)하거나 완전히 제거합니다(삭제의 경우).
- 클래스가 다른 클래스를 상속하는 경우, 예를 들어 class GemmaModel(LlamaModel): 의 경우, 종속성이 자동으로 추론됩니다. 모든 서브모듈은 슈퍼클래스로부터 자동으로 추론됩니다.
토크나이저, 이미지 프로세서, 모델, 구성 등을 이 `modular` 파일에 모두 작성할 수 있으며, 해당 파일들이 자동으로 생성됩니다.
### 시행 [[enforcement]]
[TODO] 우리는 새로운 테스트를 도입하여 생성된 콘텐츠가 `modular_xxxx.py`에 있는 내용과 일치하는지 확인합니다.
### 예시 [[examples]]
여기 BERT와 RoBERTa의 간단한 예가 있습니다. 두 모델은 밀접하게 관련되어 있으며, 모델 구현의 차이는 임베딩 레이어의 변경에서만 있습니다.
모델을 완전히 재정의하는 대신, `modular_roberta.py` 파일은 모델링 및 구성 클래스를 위해 다음과 같이 생겼습니다. (예시를 위해, 토크나이저는 매우 다르므로 일단 무시합니다.)
```python
from torch import nn
from ..bert.configuration_bert import BertConfig
from ..bert.modeling_bert import (
BertModel,
BertEmbeddings,
BertForMaskedLM
)
# RoBERTa 구성은 BERT의 구성과 동일합니다
class RobertaConfig(BertConfig):
model_type = 'roberta'
# 여기서 패딩 ID 차이를 강조하기 위해 임베딩을 재정의하고, 위치 임베딩을 재정의합니다
class RobertaEmbeddings(BertEmbeddings):
def __init__(self, config):
super().__init__(config())
self.padding_idx = config.pad_token_id
self.position_embeddings = nn.Embedding(
config.max_position_embeddings, config.hidden_size, padding_idx=self.padding_idx
)
# RoBERTa 모델은 임베딩 레이어를 제외하면 BERT 모델과 동일합니다.
# 위에서 임베딩을 재정의했으므로, 여기서는 추가 작업이 필요 없습니다
class RobertaModel(BertModel):
def __init__(self, config):
super().__init__(config)
self.embeddings = RobertaEmbeddings(config)
# 헤드는 이제 내부에서 올바른 `RobertaModel`을 재정의하기만 하면 됩니다
class RobertaForMaskedLM(BertForMaskedLM):
def __init__(self, config):
super().__init__(config)
self.model = RobertaModel(config)
```
정의한 종속성을 사용하지 않으면 다음과 같은 오류가 발생합니다:
```bash
ValueError: You defined `RobertaEmbeddings` in the modular_roberta.py, it should be used
when you define `BertModel`, as it is one of it's direct dependencies. Make sure
you use it in the `__init__` function.
```
또한, 다음에서 예시 목록을 찾을 수 있습니다:
## 무엇이 아닌가요 [[what-it-is-not]]
(아직은?) 모델링 코드를 대체하는 것은 아닙니다. 그리고 여러분의 모델이 지금까지 존재했던 다른 어떤 것에도 기반하지 않는다면, 기존과 같이 `modeling` 파일을 추가할 수 있습니다.
|
transformers/docs/source/ko/modular_transformers.md/0
|
{
"file_path": "transformers/docs/source/ko/modular_transformers.md",
"repo_id": "transformers",
"token_count": 5200
}
|
<!--⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 웹 서버를 위한 파이프라인 사용하기[[using_pipelines_for_a_webserver]]
<Tip>
추론 엔진을 만드는 것은 복잡한 주제이며, "최선의" 솔루션은 문제 공간에 따라 달라질 가능성이 높습니다. CPU 또는 GPU를 사용하는지에 따라 다르고 낮은 지연 시간을 원하는지, 높은 처리량을 원하는지, 다양한 모델을 지원할 수 있길 원하는지, 하나의 특정 모델을 고도로 최적화하길 원하는지 등에 따라 달라집니다. 이 주제를 해결하는 방법에는 여러 가지가 있으므로, 이 장에서 제시하는 것은 처음 시도해 보기에 좋은 출발점일 수는 있지만, 이 장을 읽는 여러분이 필요로 하는 최적의 솔루션은 아닐 수 있습니다.
</Tip>
핵심적으로 이해해야 할 점은 [dataset](pipeline_tutorial#using-pipelines-on-a-dataset)를 다룰 때와 마찬가지로 반복자를 사용 가능하다는 것입니다. 왜냐하면, 웹 서버는 기본적으로 요청을 기다리고 들어오는 대로 처리하는 시스템이기 때문입니다.
보통 웹 서버는 다양한 요청을 동시에 다루기 위해 매우 다중화된 구조(멀티 스레딩, 비동기 등)를 지니고 있습니다. 반면에, 파이프라인(대부분 파이프라인 안에 있는 모델)은 병렬처리에 그다지 좋지 않습니다. 왜냐하면 파이프라인은 많은 RAM을 차지하기 때문입니다. 따라서, 파이프라인이 실행 중이거나 계산 집약적인 작업 중일 때 모든 사용 가능한 리소스를 제공하는 것이 가장 좋습니다.
이 문제를 우리는 웹 서버가 요청을 받고 보내는 가벼운 부하를 처리하고, 실제 작업을 처리하는 단일 스레드를 갖는 방법으로 해결할 것입니다. 이 예제는 `starlette` 라이브러리를 사용합니다.
실제 프레임워크는 중요하지 않지만, 다른 프레임워크를 사용하는 경우 동일한 효과를 보기 위해선 코드를 조정하거나 변경해야 할 수 있습니다.
`server.py`를 생성하세요:
```py
from starlette.applications import Starlette
from starlette.responses import JSONResponse
from starlette.routing import Route
from transformers import pipeline
import asyncio
async def homepage(request):
payload = await request.body()
string = payload.decode("utf-8")
response_q = asyncio.Queue()
await request.app.model_queue.put((string, response_q))
output = await response_q.get()
return JSONResponse(output)
async def server_loop(q):
pipe = pipeline(model="google-bert/bert-base-uncased")
while True:
(string, response_q) = await q.get()
out = pipe(string)
await response_q.put(out)
app = Starlette(
routes=[
Route("/", homepage, methods=["POST"]),
],
)
@app.on_event("startup")
async def startup_event():
q = asyncio.Queue()
app.model_queue = q
asyncio.create_task(server_loop(q))
```
이제 다음 명령어로 실행시킬 수 있습니다:
```bash
uvicorn server:app
```
이제 쿼리를 날려볼 수 있습니다:
```bash
curl -X POST -d "test [MASK]" http://localhost:8000/
#[{"score":0.7742936015129089,"token":1012,"token_str":".","sequence":"test."},...]
```
자, 이제 웹 서버를 만드는 방법에 대한 좋은 개념을 알게 되었습니다!
중요한 점은 모델을 **한 번만** 가져온다는 것입니다. 따라서 웹 서버에는 모델의 사본이 없습니다. 이런 방식은 불필요한 RAM이 사용되지 않습니다. 그런 다음 큐 메커니즘을 사용하면, 다음과 같은
동적 배치를 사용하기 위해 추론 전 단계에 몇 개의 항목을 축적하는 것과 같은 멋진 작업을 할 수 있습니다:
<Tip warning={true}>
코드는 의도적으로 가독성을 위해 의사 코드처럼 작성되었습니다!
아래 코드를 작동시키기 전에 시스템 자원이 충분한지 확인하세요!
</Tip>
```py
(string, rq) = await q.get()
strings = []
queues = []
while True:
try:
(string, rq) = await asyncio.wait_for(q.get(), timeout=0.001) # 1ms
except asyncio.exceptions.TimeoutError:
break
strings.append(string)
queues.append(rq)
strings
outs = pipe(strings, batch_size=len(strings))
for rq, out in zip(queues, outs):
await rq.put(out)
```
다시 말씀 드리자면, 제안된 코드는 가독성을 위해 최적화되었으며, 최상의 코드는 아닙니다.
첫째, 배치 크기 제한이 없으며 이는 일반적으로 좋은 방식이 아닙니다.
둘째, 모든 큐 가져오기에서 타임아웃이 재설정되므로 추론을 실행하기 전에 1ms보다 훨씬 오래 기다릴 수 있습니다(첫 번째 요청을 그만큼 지연시킴).
단일 1ms 길이의 데드라인을 두는 편이 더 좋습니다.
이 방식을 사용하면 큐가 비어 있어도 항상 1ms를 기다리게 될 것입니다.
큐에 아무것도 없을 때 추론을 원하는 경우에는 최선의 방법이 아닐 수 있습니다.
하지만 배치 작업이 사용례에 따라 정말로 중요하다면 의미가 있을 수도 있습니다.
다시 말하지만, 최상의 솔루션은 없습니다.
## 고려해야 할 몇 가지 사항[[few_things_you_might want_to_consider]]
### 에러 확인[[error_checking]]
프로덕션 환경에서는 문제가 발생할 여지가 많습니다.
메모리가 모자라거나, 공간이 부족하거나, 모델을 가져오는 데에 실패하거나, 쿼리가 잘못되었거나, 쿼리는 정확해도 모델 설정이 잘못되어 실행에 실패하는 등등 많은 경우가 존재합니다.
일반적으로 서버가 사용자에게 오류를 출력하는 것이 좋으므로
오류를 표시하기 위해 `try...except` 문을 많이 추가하는 것이 좋습니다.
하지만 보안 상황에 따라 모든 오류를 표시하는 것은 보안상 위험할 수도 있다는 점을 명심해야합니다.
### 서킷 브레이킹[[circuit_breaking]]
웹 서버는 일반적으로 서킷 브레이킹을 수행할 때 더 나은 상황에 직면합니다.
즉, 이는 서버가 쿼리를 무기한 기다리는 대신 과부하 상태일 때 적절한 오류를 반환하는 것을 의미합니다.
서버가 매우 오랜 시간 동안 대기하거나 적당한 시간이 지난 후에 504 에러를 반환하는 대신 503 에러를 빠르게 반환하게 하는 것입니다.
제안된 코드에는 단일 큐가 있으므로 구현하기가 비교적 쉽습니다.
큐 크기를 확인하는 것은 웹 서버가 과부하 상항 하에 있을 때 에러를 반환하기 위한 가장 기초적인 작업입니다.
### 메인 쓰레드 차단[[blocking_the_main_thread]]
현재 PyTorch는 비동기 처리를 지원하지 않으며, 실행 중에는 메인 스레드가 차단됩니다.
따라서 PyTorch를 별도의 스레드/프로세스에서 실행하도록 강제하는 것이 좋습니다.
여기서는 이 작업이 수행되지 않았습니다. 왜냐하면 코드가 훨씬 더 복잡하기 때문입니다(주로 스레드, 비동기 처리, 큐가 서로 잘 맞지 않기 때문입니다).
하지만 궁극적으로는 같은 작업을 수행하는 것입니다.
단일 항목의 추론이 오래 걸린다면 (> 1초), 메인 쓰레드를 차단하는 것은 중요할 수 있습니다. 왜냐하면 이 경우 추론 중 모든 쿼리는 오류를 받기 전에 1초를 기다려야 하기 때문입니다.
### 동적 배치[[dynamic_batching]]
일반적으로, 배치 처리가 1개 항목을 한 번에 전달하는 것에 비해 반드시 성능 향상이 있는 것은 아닙니다(자세한 내용은 [`batching details`](./main_classes/pipelines#pipeline-batching)을 참고하세요).
하지만 올바른 설정에서 사용하면 매우 효과적일 수 있습니다.
API에는 기본적으로 속도 저하의 가능성이 매우 높기 때문에 동적 배치 처리가 없습니다.
하지만 매우 큰 모델인 BLOOM 추론의 경우 동적 배치 처리는 모든 사람에게 적절한 경험을 제공하는 데 **필수**입니다.
|
transformers/docs/source/ko/pipeline_webserver.md/0
|
{
"file_path": "transformers/docs/source/ko/pipeline_webserver.md",
"repo_id": "transformers",
"token_count": 6178
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# IDEFICS를 이용한 이미지 작업[[image-tasks-with-idefics]]
[[open-in-colab]]
개별 작업은 특화된 모델을 미세 조정하여 처리할 수 있지만, 최근 등장하여 인기를 얻고 있는 방식은 대규모 모델을 미세 조정 없이 다양한 작업에 사용하는 것입니다. 예를 들어, 대규모 언어 모델은 요약, 번역, 분류 등과 같은 자연어처리 (NLP) 작업을 처리할 수 있습니다. 이 접근 방식은 텍스트와 같은 단일 모달리티에 국한되지 않으며, 이 가이드에서는 IDEFICS라는 대규모 멀티모달 모델을 사용하여 이미지-텍스트 작업을 다루는 방법을 설명합니다.
[IDEFICS](../model_doc/idefics)는 [Flamingo](https://huggingface.co/papers/2204.14198)를 기반으로 하는 오픈 액세스 비전 및 언어 모델로, DeepMind에서 처음 개발한 최신 시각 언어 모델입니다. 이 모델은 임의의 이미지 및 텍스트 입력 시퀀스를 받아 일관성 있는 텍스트를 출력으로 생성합니다. 이미지에 대한 질문에 답변하고, 시각적인 내용을 설명하며, 여러 이미지에 기반한 이야기를 생성하는 등 다양한 작업을 수행할 수 있습니다. IDEFICS는 [800억 파라미터](https://huggingface.co/HuggingFaceM4/idefics-80b)와 [90억 파라미터](https://huggingface.co/HuggingFaceM4/idefics-9b) 두 가지 버전을 제공하며, 두 버전 모두 🤗 Hub에서 이용할 수 있습니다. 각 버전에는 대화형 사용 사례에 맞게 미세 조정된 버전도 있습니다.
이 모델은 매우 다재다능하며 광범위한 이미지 및 멀티모달 작업에 사용될 수 있습니다. 그러나 대규모 모델이기 때문에 상당한 컴퓨팅 자원과 인프라가 필요합니다. 각 개별 작업에 특화된 모델을 미세 조정하는 것보다 모델을 그대로 사용하는 것이 더 적합한지는 사용자가 판단해야 합니다.
이 가이드에서는 다음을 배우게 됩니다:
- [IDEFICS 로드하기](#loading-the-model) 및 [양자화된 버전의 모델 로드하기](#quantized-model)
- IDEFICS를 사용하여:
- [이미지 캡셔닝](#image-captioning)
- [프롬프트 이미지 캡셔닝](#prompted-image-captioning)
- [퓨샷 프롬프트](#few-shot-prompting)
- [시각적 질의 응답](#visual-question-answering)
- [이미지 분류](#image-classification)
- [이미지 기반 텍스트 생성](#image-guided-text-generation)
- [배치 모드에서 추론 실행](#running-inference-in-batch-mode)
- [대화형 사용을 위한 IDEFICS 인스트럭트 실행](#idefics-instruct-for-conversational-use)
시작하기 전에 필요한 모든 라이브러리가 설치되어 있는지 확인하세요.
```bash
pip install -q bitsandbytes sentencepiece accelerate transformers
```
<Tip>
다음 예제를 비양자화된 버전의 모델 체크포인트로 실행하려면 최소 20GB의 GPU 메모리가 필요합니다.
</Tip>
## 모델 로드[[loading-the-model]]
모델을 90억 파라미터 버전의 체크포인트로 로드해 봅시다:
```py
>>> checkpoint = "HuggingFaceM4/idefics-9b"
```
다른 Transformers 모델과 마찬가지로, 체크포인트에서 프로세서와 모델 자체를 로드해야 합니다.
IDEFICS 프로세서는 [`LlamaTokenizer`]와 IDEFICS 이미지 프로세서를 하나의 프로세서로 감싸서 텍스트와 이미지 입력을 모델에 맞게 준비합니다.
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16, device_map="auto")
```
`device_map`을 `"auto"`로 설정하면 사용 중인 장치를 고려하여 모델 가중치를 가장 최적화된 방식으로 로드하고 저장하는 방법을 자동으로 결정합니다.
### 양자화된 모델[[quantized-model]]
고용량 GPU 사용이 어려운 경우, 모델의 양자화된 버전을 로드할 수 있습니다. 모델과 프로세서를 4비트 정밀도로 로드하기 위해서, `from_pretrained` 메소드에 `BitsAndBytesConfig`를 전달하면 모델이 로드되는 동안 실시간으로 압축됩니다.
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor, BitsAndBytesConfig
>>> quantization_config = BitsAndBytesConfig(
... load_in_4bit=True,
... bnb_4bit_compute_dtype=torch.float16,
... )
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> model = IdeficsForVisionText2Text.from_pretrained(
... checkpoint,
... quantization_config=quantization_config,
... device_map="auto"
... )
```
이제 모델을 제안된 방법 중 하나로 로드했으니, IDEFICS를 사용할 수 있는 작업들을 탐구해봅시다.
## 이미지 캡셔닝[[image-captioning]]
이미지 캡셔닝은 주어진 이미지에 대한 캡션을 예측하는 작업입니다. 일반적인 응용 분야는 시각 장애인이 다양한 상황을 탐색할 수 있도록 돕는 것입니다. 예를 들어, 온라인에서 이미지 콘텐츠를 탐색하는 데 도움을 줄 수 있습니다.
작업을 설명하기 위해 캡션을 달 이미지 예시를 가져옵니다. 예시:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-im-captioning.jpg" alt="Image of a puppy in a flower bed"/>
</div>
사진 제공: [Hendo Wang](https://unsplash.com/@hendoo).
IDEFICS는 텍스트 및 이미지 프롬프트를 모두 수용합니다. 그러나 이미지를 캡션하기 위해 모델에 텍스트 프롬프트를 제공할 필요는 없습니다. 전처리된 입력 이미지만 제공하면 됩니다. 텍스트 프롬프트 없이 모델은 BOS(시퀀스 시작) 토큰부터 텍스트 생성을 시작하여 캡션을 만듭니다.
모델에 이미지 입력으로는 이미지 객체(`PIL.Image`) 또는 이미지를 가져올 수 있는 URL을 사용할 수 있습니다.
```py
>>> prompt = [
... "https://images.unsplash.com/photo-1583160247711-2191776b4b91?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3542&q=80",
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
A puppy in a flower bed
```
<Tip>
`max_new_tokens`의 크기를 증가시킬 때 발생할 수 있는 오류를 피하기 위해 `generate` 호출 시 `bad_words_ids`를 포함하는 것이 좋습니다. 모델로부터 생성된 이미지가 없을 때 새로운 `<image>` 또는 `<fake_token_around_image>` 토큰을 생성하려고 하기 때문입니다.
이 가이드에서처럼 `bad_words_ids`를 함수 호출 시에 매개변수로 설정하거나, [텍스트 생성 전략](../generation_strategies) 가이드에 설명된 대로 `GenerationConfig`에 저장할 수도 있습니다.
</Tip>
## 프롬프트 이미지 캡셔닝[[prompted-image-captioning]]
텍스트 프롬프트를 이용하여 이미지 캡셔닝을 확장할 수 있으며, 모델은 주어진 이미지를 바탕으로 텍스트를 계속 생성합니다. 다음 이미지를 예시로 들어보겠습니다:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-prompted-im-captioning.jpg" alt="Image of the Eiffel Tower at night"/>
</div>
사진 제공: [Denys Nevozhai](https://unsplash.com/@dnevozhai).
텍스트 및 이미지 프롬프트는 적절한 입력을 생성하기 위해 모델의 프로세서에 하나의 목록으로 전달될 수 있습니다.
```py
>>> prompt = [
... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "This is an image of ",
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
This is an image of the Eiffel Tower in Paris, France.
```
## 퓨샷 프롬프트[[few-shot-prompting]]
IDEFICS는 훌륭한 제로샷 결과를 보여주지만, 작업에 특정 형식의 캡션이 필요하거나 작업의 복잡성을 높이는 다른 제한 사항이나 요구 사항이 있을 수 있습니다. 이럴 때 퓨샷 프롬프트를 사용하여 맥락 내 학습(In-Context Learning)을 가능하게 할 수 있습니다.
프롬프트에 예시를 제공함으로써 모델이 주어진 예시의 형식을 모방한 결과를 생성하도록 유도할 수 있습니다.
이전의 에펠탑 이미지를 모델에 예시로 사용하고, 모델에게 이미지의 객체를 학습하는 것 외에도 흥미로운 정보를 얻고 싶다는 것을 보여주는 프롬프트를 작성해 봅시다.
그런 다음 자유의 여신상 이미지에 대해 동일한 응답 형식을 얻을 수 있는지 확인해 봅시다:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-few-shot.jpg" alt="Image of the Statue of Liberty"/>
</div>
사진 제공: [Juan Mayobre](https://unsplash.com/@jmayobres).
```py
>>> prompt = ["User:",
... "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "Describe this image.\nAssistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.\n",
... "User:",
... "https://images.unsplash.com/photo-1524099163253-32b7f0256868?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3387&q=80",
... "Describe this image.\nAssistant:"
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=30, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
User: Describe this image.
Assistant: An image of the Eiffel Tower at night. Fun fact: the Eiffel Tower is the same height as an 81-storey building.
User: Describe this image.
Assistant: An image of the Statue of Liberty. Fun fact: the Statue of Liberty is 151 feet tall.
```
단 하나의 예시만으로도(즉, 1-shot) 모델이 작업 수행 방법을 학습했다는 점이 주목할 만합니다. 더 복잡한 작업의 경우, 더 많은 예시(예: 3-shot, 5-shot 등)를 사용하여 실험해 보는 것도 좋은 방법입니다.
## 시각적 질의 응답[[visual-question-answering]]
시각적 질의 응답(VQA)은 이미지를 기반으로 개방형 질문에 답하는 작업입니다. 이미지 캡셔닝과 마찬가지로 접근성 애플리케이션에서 사용할 수 있지만, 교육(시각 자료에 대한 추론), 고객 서비스(이미지를 기반으로 한 제품 질문), 이미지 검색 등에서도 사용할 수 있습니다.
이 작업을 위해 새로운 이미지를 가져옵니다:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-vqa.jpg" alt="Image of a couple having a picnic"/>
</div>
사진 제공: [Jarritos Mexican Soda](https://unsplash.com/@jarritos).
적절한 지시문을 사용하면 이미지 캡셔닝에서 시각적 질의 응답으로 모델을 유도할 수 있습니다:
```py
>>> prompt = [
... "Instruction: Provide an answer to the question. Use the image to answer.\n",
... "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "Question: Where are these people and what's the weather like? Answer:"
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=20, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Provide an answer to the question. Use the image to answer.
Question: Where are these people and what's the weather like? Answer: They're in a park in New York City, and it's a beautiful day.
```
## 이미지 분류[[image-classification]]
IDEFICS는 특정 카테고리의 라벨이 포함된 데이터로 명시적으로 학습되지 않아도 이미지를 다양한 카테고리로 분류할 수 있습니다. 카테고리 목록이 주어지면, 모델은 이미지와 텍스트 이해 능력을 사용하여 이미지가 속할 가능성이 높은 카테고리를 추론할 수 있습니다.
여기에 야채 가판대 이미지가 있습니다.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-classification.jpg" alt="Image of a vegetable stand"/>
</div>
사진 제공: [Peter Wendt](https://unsplash.com/@peterwendt).
우리는 모델에게 우리가 가진 카테고리 중 하나로 이미지를 분류하도록 지시할 수 있습니다:
```py
>>> categories = ['animals','vegetables', 'city landscape', 'cars', 'office']
>>> prompt = [f"Instruction: Classify the following image into a single category from the following list: {categories}.\n",
... "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "Category: "
... ]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=6, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Classify the following image into a single category from the following list: ['animals', 'vegetables', 'city landscape', 'cars', 'office'].
Category: Vegetables
```
위 예제에서는 모델에게 이미지를 단일 카테고리로 분류하도록 지시했지만, 순위 분류를 하도록 모델에 프롬프트를 제공할 수도 있습니다.
## 이미지 기반 텍스트 생성[[image-guided-text-generation]]
이미지를 활용한 텍스트 생성 기술을 사용하면 더욱 창의적인 작업이 가능합니다. 이 기술은 이미지를 바탕으로 텍스트를 만들어내며, 제품 설명, 광고 문구, 장면 묘사 등 다양한 용도로 활용할 수 있습니다.
간단한 예로, 빨간 문 이미지를 IDEFICS에 입력하여 이야기를 만들어보겠습니다:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/idefics-story-generation.jpg" alt="Image of a red door with a pumpkin on the steps"/>
</div>
사진 제공: [Craig Tidball](https://unsplash.com/@devonshiremedia).
```py
>>> prompt = ["Instruction: Use the image to write a story. \n",
... "https://images.unsplash.com/photo-1517086822157-2b0358e7684a?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=2203&q=80",
... "Story: \n"]
>>> inputs = processor(prompt, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, num_beams=2, max_new_tokens=200, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generated_text[0])
Instruction: Use the image to write a story.
Story:
Once upon a time, there was a little girl who lived in a house with a red door. She loved her red door. It was the prettiest door in the whole world.
One day, the little girl was playing in her yard when she noticed a man standing on her doorstep. He was wearing a long black coat and a top hat.
The little girl ran inside and told her mother about the man.
Her mother said, “Don’t worry, honey. He’s just a friendly ghost.”
The little girl wasn’t sure if she believed her mother, but she went outside anyway.
When she got to the door, the man was gone.
The next day, the little girl was playing in her yard again when she noticed the man standing on her doorstep.
He was wearing a long black coat and a top hat.
The little girl ran
```
IDEFICS가 문 앞에 있는 호박을 보고 유령에 대한 으스스한 할로윈 이야기를 만든 것 같습니다.
<Tip>
이처럼 긴 텍스트를 생성할 때는 텍스트 생성 전략을 조정하는 것이 좋습니다. 이렇게 하면 생성된 결과물의 품질을 크게 향상시킬 수 있습니다. 자세한 내용은 [텍스트 생성 전략](../generation_strategies)을 참조하세요.
</Tip>
## 배치 모드에서 추론 실행[[running-inference-in-batch-mode]]
앞선 모든 섹션에서는 단일 예시에 대해 IDEFICS를 설명했습니다. 이와 매우 유사한 방식으로, 프롬프트 목록을 전달하여 여러 예시에 대한 추론을 실행할 수 있습니다:
```py
>>> prompts = [
... [ "https://images.unsplash.com/photo-1543349689-9a4d426bee8e?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3501&q=80",
... "This is an image of ",
... ],
... [ "https://images.unsplash.com/photo-1623944889288-cd147dbb517c?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "This is an image of ",
... ],
... [ "https://images.unsplash.com/photo-1471193945509-9ad0617afabf?ixlib=rb-4.0.3&ixid=M3wxMjA3fDB8MHxwaG90by1wYWdlfHx8fGVufDB8fHx8fA%3D%3D&auto=format&fit=crop&w=3540&q=80",
... "This is an image of ",
... ],
... ]
>>> inputs = processor(prompts, return_tensors="pt").to("cuda")
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, max_new_tokens=10, bad_words_ids=bad_words_ids)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i,t in enumerate(generated_text):
... print(f"{i}:\n{t}\n")
0:
This is an image of the Eiffel Tower in Paris, France.
1:
This is an image of a couple on a picnic blanket.
2:
This is an image of a vegetable stand.
```
## 대화형 사용을 위한 IDEFICS 인스트럭트 실행[[idefics-instruct-for-conversational-use]]
대화형 사용 사례를 위해, 🤗 Hub에서 명령어 수행에 최적화된 버전의 모델을 찾을 수 있습니다. 이곳에는 `HuggingFaceM4/idefics-80b-instruct`와 `HuggingFaceM4/idefics-9b-instruct`가 있습니다.
이 체크포인트는 지도 학습 및 명령어 미세 조정 데이터셋의 혼합으로 각각의 기본 모델을 미세 조정한 결과입니다. 이를 통해 모델의 하위 작업 성능을 향상시키는 동시에 대화형 환경에서 모델을 더 사용하기 쉽게 합니다.
대화형 사용을 위한 사용법 및 프롬프트는 기본 모델을 사용하는 것과 매우 유사합니다.
```py
>>> import torch
>>> from transformers import IdeficsForVisionText2Text, AutoProcessor
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> checkpoint = "HuggingFaceM4/idefics-9b-instruct"
>>> model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
>>> processor = AutoProcessor.from_pretrained(checkpoint)
>>> prompts = [
... [
... "User: What is in this image?",
... "https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
... "<end_of_utterance>",
... "\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
... "\nUser:",
... "https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
... "And who is that?<end_of_utterance>",
... "\nAssistant:",
... ],
... ]
>>> # --batched mode
>>> inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
>>> # --single sample mode
>>> # inputs = processor(prompts[0], return_tensors="pt").to(device)
>>> # args 생성
>>> exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
>>> bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
>>> generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
>>> generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> for i, t in enumerate(generated_text):
... print(f"{i}:\n{t}\n")
```
|
transformers/docs/source/ko/tasks/idefics.md/0
|
{
"file_path": "transformers/docs/source/ko/tasks/idefics.md",
"repo_id": "transformers",
"token_count": 13254
}
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 문제 해결[[troubleshoot]]
때때로 오류가 발생할 수 있지만, 저희가 도와드리겠습니다! 이 가이드는 현재까지 확인된 가장 일반적인 문제 몇 가지와 그것들을 해결하는 방법에 대해 다룹니다. 그러나 이 가이드는 모든 🤗 Transformers 문제를 포괄적으로 다루고 있지 않습니다. 문제 해결에 더 많은 도움을 받으려면 다음을 시도해보세요:
<Youtube id="S2EEG3JIt2A"/>
1. [포럼](https://discuss.huggingface.co/)에서 도움을 요청하세요. [Beginners](https://discuss.huggingface.co/c/beginners/5) 또는 [🤗 Transformers](https://discuss.huggingface.co/c/transformers/9)와 같은 특정 카테고리에 질문을 게시할 수 있습니다. 재현 가능한 코드와 함께 잘 서술된 포럼 게시물을 작성하여 여러분의 문제가 해결될 가능성을 극대화하세요!
<Youtube id="_PAli-V4wj0"/>
2. 라이브러리와 관련된 버그이면 🤗 Transformers 저장소에서 [이슈](https://github.com/huggingface/transformers/issues/new/choose)를 생성하세요. 버그에 대해 설명하는 정보를 가능한 많이 포함하려고 노력하여, 무엇이 잘못 되었는지와 어떻게 수정할 수 있는지 더 잘 파악할 수 있도록 도와주세요.
3. 이전 버전의 🤗 Transformers을 사용하는 경우 중요한 변경 사항이 버전 사이에 도입되었기 때문에 [마이그레이션](migration) 가이드를 확인하세요.
문제 해결 및 도움 매뉴얼에 대한 자세한 내용은 Hugging Face 강좌의 [8장](https://huggingface.co/course/chapter8/1?fw=pt)을 참조하세요.
## 방화벽 환경[[firewalled-environments]]
클라우드 및 내부망(intranet) 설정의 일부 GPU 인스턴스는 외부 연결에 대한 방화벽으로 차단되어 연결 오류가 발생할 수 있습니다. 스크립트가 모델 가중치나 데이터를 다운로드하려고 할 때, 다운로드가 중단되고 다음 메시지와 함께 시간 초과됩니다:
```
ValueError: Connection error, and we cannot find the requested files in the cached path.
Please try again or make sure your Internet connection is on.
```
이 경우에는 연결 오류를 피하기 위해 🤗 Transformers를 [오프라인 모드](installation#offline-mode)로 실행해야 합니다.
## CUDA 메모리 부족(CUDA out of memory)[[cuda-out-of-memory]]
수백만 개의 매개변수로 대규모 모델을 훈련하는 것은 적절한 하드웨어 없이 어려울 수 있습니다. GPU 메모리가 부족한 경우 발생할 수 있는 일반적인 오류는 다음과 같습니다:
```
CUDA out of memory. Tried to allocate 256.00 MiB (GPU 0; 11.17 GiB total capacity; 9.70 GiB already allocated; 179.81 MiB free; 9.85 GiB reserved in total by PyTorch)
```
다음은 메모리 사용을 줄이기 위해 시도해 볼 수 있는 몇 가지 잠재적인 해결책입니다:
- [`TrainingArguments`]의 [`per_device_train_batch_size`](main_classes/trainer#transformers.TrainingArguments.per_device_train_batch_size) 값을 줄이세요.
- [`TrainingArguments`]의 [`gradient_accumulation_steps`](main_classes/trainer#transformers.TrainingArguments.gradient_accumulation_steps)은 전체 배치 크기를 효과적으로 늘리세요.
<Tip>
메모리 절약 기술에 대한 자세한 내용은 성능 [가이드](performance)를 참조하세요.
</Tip>
## 저장된 TensorFlow 모델을 가져올 수 없습니다(Unable to load a saved TensorFlow model)[[unable-to-load-a-saved-uensorFlow-model]]
TensorFlow의 [model.save](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model) 메소드는 아키텍처, 가중치, 훈련 구성 등 전체 모델을 단일 파일에 저장합니다. 그러나 모델 파일을 다시 가져올 때 🤗 Transformers는 모델 파일에 있는 모든 TensorFlow 관련 객체를 가져오지 않을 수 있기 때문에 오류가 발생할 수 있습니다. TensorFlow 모델 저장 및 가져오기 문제를 피하려면 다음을 권장합니다:
- 모델 가중치를 `h5` 파일 확장자로 [`model.save_weights`](https://www.tensorflow.org/tutorials/keras/save_and_load#save_the_entire_model)로 저장한 다음 [`~TFPreTrainedModel.from_pretrained`]로 모델을 다시 가져옵니다:
```py
>>> from transformers import TFPreTrainedModel
>>> from tensorflow import keras
>>> model.save_weights("some_folder/tf_model.h5")
>>> model = TFPreTrainedModel.from_pretrained("some_folder")
```
- 모델을 [`~TFPretrainedModel.save_pretrained`]로 저장하고 [`~TFPreTrainedModel.from_pretrained`]로 다시 가져옵니다:
```py
>>> from transformers import TFPreTrainedModel
>>> model.save_pretrained("path_to/model")
>>> model = TFPreTrainedModel.from_pretrained("path_to/model")
```
## ImportError[[importerror]]
특히 최신 모델인 경우 만날 수 있는 다른 일반적인 오류는 `ImportError`입니다:
```
ImportError: cannot import name 'ImageGPTImageProcessor' from 'transformers' (unknown location)
```
이러한 오류 유형의 경우 최신 모델에 액세스할 수 있도록 최신 버전의 🤗 Transformers가 설치되어 있는지 확인하세요:
```bash
pip install transformers --upgrade
```
## CUDA error: device-side assert triggered[[cuda-error-deviceside-assert-triggered]]
때때로 장치 코드 오류에 대한 일반적인 CUDA 오류가 발생할 수 있습니다.
```
RuntimeError: CUDA error: device-side assert triggered
```
더 자세한 오류 메시지를 얻으려면 우선 코드를 CPU에서 실행합니다. 다음 환경 변수를 코드의 시작 부분에 추가하여 CPU로 전환하세요:
```py
>>> import os
>>> os.environ["CUDA_VISIBLE_DEVICES"] = ""
```
또 다른 옵션은 GPU에서 더 나은 역추적(traceback)을 얻는 것입니다. 다음 환경 변수를 코드의 시작 부분에 추가하여 역추적이 오류가 발생한 소스를 가리키도록 하세요:
```py
>>> import os
>>> os.environ["CUDA_LAUNCH_BLOCKING"] = "1"
```
## 패딩 토큰이 마스킹되지 않은 경우 잘못된 출력(Incorrect output when padding tokens aren't masked)[[incorrect-output-when-padding-tokens-arent-masked]]
경우에 따라 `input_ids`에 패딩 토큰이 포함된 경우 `hidden_state` 출력이 올바르지 않을 수 있습니다. 데모를 위해 모델과 토크나이저를 가져오세요. 모델의 `pad_token_id`에 액세스하여 해당 값을 확인할 수 있습니다. 일부 모델의 경우 `pad_token_id`가 `None`일 수 있지만 언제든지 수동으로 설정할 수 있습니다.
```py
>>> from transformers import AutoModelForSequenceClassification
>>> import torch
>>> model = AutoModelForSequenceClassification.from_pretrained("google-bert/bert-base-uncased")
>>> model.config.pad_token_id
0
```
다음 예제는 패딩 토큰을 마스킹하지 않은 출력을 보여줍니다:
```py
>>> input_ids = torch.tensor([[7592, 2057, 2097, 2393, 9611, 2115], [7592, 0, 0, 0, 0, 0]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[ 0.1317, -0.1683]], grad_fn=<AddmmBackward0>)
```
다음은 두 번째 시퀀스의 실제 출력입니다:
```py
>>> input_ids = torch.tensor([[7592]])
>>> output = model(input_ids)
>>> print(output.logits)
tensor([[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
대부분의 경우 모델에 `attention_mask`를 제공하여 패딩 토큰을 무시해야 이러한 조용한 오류를 방지할 수 있습니다. 이제 두 번째 시퀀스의 출력이 실제 출력과 일치합니다:
<Tip>
일반적으로 토크나이저는 특정 토크나이저의 기본 값을 기준으로 사용자에 대한 'attention_mask'를 만듭니다.
</Tip>
```py
>>> attention_mask = torch.tensor([[1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0]])
>>> output = model(input_ids, attention_mask=attention_mask)
>>> print(output.logits)
tensor([[ 0.0082, -0.2307],
[-0.1008, -0.4061]], grad_fn=<AddmmBackward0>)
```
🤗 Transformers는 패딩 토큰이 제공된 경우 패딩 토큰을 마스킹하기 위한 `attention_mask`를 자동으로 생성하지 않습니다. 그 이유는 다음과 같습니다:
- 일부 모델에는 패딩 토큰이 없습니다.
- 일부 사용 사례의 경우 사용자가 모델이 패딩 토큰을 관리하기를 원합니다.
## ValueError: 이 유형의 AutoModel에 대해 인식할 수 없는 XYZ 구성 클래스(ValueError: Unrecognized configuration class XYZ for this kind of AutoModel)[[valueerror-unrecognized-configuration-class-xyz-for-this-kind-of-automodel]]
일반적으로, 사전 학습된 모델의 인스턴스를 가져오기 위해 [`AutoModel`] 클래스를 사용하는 것이 좋습니다.
이 클래스는 구성에 따라 주어진 체크포인트에서 올바른 아키텍처를 자동으로 추론하고 가져올 수 있습니다.
모델을 체크포인트에서 가져올 때 이 `ValueError`가 발생하면, 이는 Auto 클래스가 주어진 체크포인트의 구성에서
가져오려는 모델 유형과 매핑을 찾을 수 없다는 것을 의미합니다. 가장 흔하게 발생하는 경우는
체크포인트가 주어진 태스크를 지원하지 않을 때입니다.
예를 들어, 다음 예제에서 질의응답에 대한 GPT2가 없기 때문에 오류가 발생합니다:
```py
>>> from transformers import AutoProcessor, AutoModelForQuestionAnswering
>>> processor = AutoProcessor.from_pretrained("openai-community/gpt2-medium")
>>> model = AutoModelForQuestionAnswering.from_pretrained("openai-community/gpt2-medium")
ValueError: Unrecognized configuration class <class 'transformers.models.gpt2.configuration_gpt2.GPT2Config'> for this kind of AutoModel: AutoModelForQuestionAnswering.
Model type should be one of AlbertConfig, BartConfig, BertConfig, BigBirdConfig, BigBirdPegasusConfig, BloomConfig, ...
```
|
transformers/docs/source/ko/troubleshooting.md/0
|
{
"file_path": "transformers/docs/source/ko/troubleshooting.md",
"repo_id": "transformers",
"token_count": 6571
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Exportando modelos para ONNX
Se você precisar implantar modelos 🤗 Transformers em ambientes de produção, recomendamos
exporta-los para um formato serializado que pode ser carregado e executado em
tempos de execução e hardware. Neste guia, mostraremos como exportar modelos 🤗 Transformers
para [ONNX (Open Neural Network eXchange)](http://onnx.ai).
<Tip>
Uma vez exportado, um modelo pode ser otimizado para inferência por meio de técnicas como
quantização e poda. Se você estiver interessado em otimizar seus modelos para serem executados com
máxima eficiência, confira a biblioteca [🤗 Optimum
](https://github.com/huggingface/optimum).
</Tip>
ONNX é um padrão aberto que define um conjunto comum de operadores e um formato de arquivo comum
para representar modelos de aprendizado profundo em uma ampla variedade de estruturas, incluindo PyTorch e
TensorFlow. Quando um modelo é exportado para o formato ONNX, esses operadores são usados para
construir um grafo computacional (muitas vezes chamado de _representação intermediária_) que
representa o fluxo de dados através da rede neural.
Ao expor um grafo com operadores e tipos de dados padronizados, o ONNX facilita a
alternar entre os frameworks. Por exemplo, um modelo treinado em PyTorch pode ser exportado para
formato ONNX e depois importado no TensorFlow (e vice-versa).
🤗 Transformers fornece um pacote [`transformers.onnx`](main_classes/onnx) que permite
que você converta os checkpoints do modelo em um grafo ONNX aproveitando os objetos de configuração.
Esses objetos de configuração vêm prontos para várias arquiteturas de modelo e são
projetado para ser facilmente extensível a outras arquiteturas.
As configurações prontas incluem as seguintes arquiteturas:
<!--This table is automatically generated by `make fix-copies`, do not fill manually!-->
- ALBERT
- BART
- BEiT
- BERT
- BigBird
- BigBird-Pegasus
- Blenderbot
- BlenderbotSmall
- BLOOM
- CamemBERT
- CLIP
- CodeGen
- Conditional DETR
- ConvBERT
- ConvNeXT
- ConvNeXTV2
- Data2VecText
- Data2VecVision
- DeBERTa
- DeBERTa-v2
- DeiT
- DETR
- DistilBERT
- ELECTRA
- ERNIE
- FlauBERT
- GPT Neo
- GPT-J
- GroupViT
- I-BERT
- LayoutLM
- LayoutLMv3
- LeViT
- Longformer
- LongT5
- M2M100
- Marian
- mBART
- MobileBERT
- MobileViT
- MT5
- OpenAI GPT-2
- OWL-ViT
- Perceiver
- PLBart
- ResNet
- RoBERTa
- RoFormer
- SegFormer
- SqueezeBERT
- Swin Transformer
- T5
- Table Transformer
- Vision Encoder decoder
- ViT
- XLM
- XLM-RoBERTa
- XLM-RoBERTa-XL
- YOLOS
Nas próximas duas seções, mostraremos como:
* Exportar um modelo suportado usando o pacote `transformers.onnx`.
* Exportar um modelo personalizado para uma arquitetura sem suporte.
## Exportando um modelo para ONNX
Para exportar um modelo 🤗 Transformers para o ONNX, primeiro você precisa instalar algumas
dependências extras:
```bash
pip install transformers[onnx]
```
O pacote `transformers.onnx` pode então ser usado como um módulo Python:
```bash
python -m transformers.onnx --help
usage: Hugging Face Transformers ONNX exporter [-h] -m MODEL [--feature {causal-lm, ...}] [--opset OPSET] [--atol ATOL] output
positional arguments:
output Path indicating where to store generated ONNX model.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Model ID on huggingface.co or path on disk to load model from.
--feature {causal-lm, ...}
The type of features to export the model with.
--opset OPSET ONNX opset version to export the model with.
--atol ATOL Absolute difference tolerance when validating the model.
```
A exportação de um checkpoint usando uma configuração pronta pode ser feita da seguinte forma:
```bash
python -m transformers.onnx --model=distilbert/distilbert-base-uncased onnx/
```
Você deve ver os seguintes logs:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'last_hidden_state'})
- Validating ONNX Model output "last_hidden_state":
-[✓] (2, 8, 768) matches (2, 8, 768)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Isso exporta um grafo ONNX do ponto de verificação definido pelo argumento `--model`. Nisso
Por exemplo, é `distilbert/distilbert-base-uncased`, mas pode ser qualquer checkpoint no Hugging
Face Hub ou um armazenado localmente.
O arquivo `model.onnx` resultante pode ser executado em um dos [muitos
aceleradores](https://onnx.ai/supported-tools.html#deployModel) que suportam o ONNX
padrão. Por exemplo, podemos carregar e executar o modelo com [ONNX
Tempo de execução](https://onnxruntime.ai/) da seguinte forma:
```python
>>> from transformers import AutoTokenizer
>>> from onnxruntime import InferenceSession
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
>>> session = InferenceSession("onnx/model.onnx")
>>> # ONNX Runtime expects NumPy arrays as input
>>> inputs = tokenizer("Using DistilBERT with ONNX Runtime!", return_tensors="np")
>>> outputs = session.run(output_names=["last_hidden_state"], input_feed=dict(inputs))
```
Os nomes de saída necessários (como `["last_hidden_state"]`) podem ser obtidos pegando uma
configuração ONNX de cada modelo. Por exemplo, para DistilBERT temos:
```python
>>> from transformers.models.distilbert import DistilBertConfig, DistilBertOnnxConfig
>>> config = DistilBertConfig()
>>> onnx_config = DistilBertOnnxConfig(config)
>>> print(list(onnx_config.outputs.keys()))
["last_hidden_state"]
```
O processo é idêntico para os checkpoints do TensorFlow no Hub. Por exemplo, podemos
exportar um checkpoint TensorFlow puro do [Keras
](https://huggingface.co/keras-io) da seguinte forma:
```bash
python -m transformers.onnx --model=keras-io/transformers-qa onnx/
```
Para exportar um modelo armazenado localmente, você precisará ter os pesos e
arquivos tokenizer armazenados em um diretório. Por exemplo, podemos carregar e salvar um checkpoint como:
```python
>>> from transformers import AutoTokenizer, AutoModelForSequenceClassification
>>> # Load tokenizer and PyTorch weights form the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
>>> pt_model = AutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-pt-checkpoint")
>>> pt_model.save_pretrained("local-pt-checkpoint")
```
Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
argumento do pacote `transformers.onnx` para o diretório desejado:
```bash
python -m transformers.onnx --model=local-pt-checkpoint onnx/
```
```python
>>> from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
>>> # Load tokenizer and TensorFlow weights from the Hub
>>> tokenizer = AutoTokenizer.from_pretrained("distilbert/distilbert-base-uncased")
>>> tf_model = TFAutoModelForSequenceClassification.from_pretrained("distilbert/distilbert-base-uncased")
>>> # Save to disk
>>> tokenizer.save_pretrained("local-tf-checkpoint")
>>> tf_model.save_pretrained("local-tf-checkpoint")
```
Uma vez que o checkpoint é salvo, podemos exportá-lo para o ONNX apontando o `--model`
argumento do pacote `transformers.onnx` para o diretório desejado:
```bash
python -m transformers.onnx --model=local-tf-checkpoint onnx/
```
## Selecionando features para diferentes tarefas do modelo
Cada configuração pronta vem com um conjunto de _features_ que permitem exportar
modelos para diferentes tipos de tarefas. Conforme mostrado na tabela abaixo, cada recurso é
associado a uma `AutoClass` diferente:
| Feature | Auto Class |
| ------------------------------------ | ------------------------------------ |
| `causal-lm`, `causal-lm-with-past` | `AutoModelForCausalLM` |
| `default`, `default-with-past` | `AutoModel` |
| `masked-lm` | `AutoModelForMaskedLM` |
| `question-answering` | `AutoModelForQuestionAnswering` |
| `seq2seq-lm`, `seq2seq-lm-with-past` | `AutoModelForSeq2SeqLM` |
| `sequence-classification` | `AutoModelForSequenceClassification` |
| `token-classification` | `AutoModelForTokenClassification` |
Para cada configuração, você pode encontrar a lista de recursos suportados por meio do
[`~transformers.onnx.FeaturesManager`]. Por exemplo, para DistilBERT temos:
```python
>>> from transformers.onnx.features import FeaturesManager
>>> distilbert_features = list(FeaturesManager.get_supported_features_for_model_type("distilbert").keys())
>>> print(distilbert_features)
["default", "masked-lm", "causal-lm", "sequence-classification", "token-classification", "question-answering"]
```
Você pode então passar um desses recursos para o argumento `--feature` no
pacote `transformers.onnx`. Por exemplo, para exportar um modelo de classificação de texto, podemos
escolher um modelo ajustado no Hub e executar:
```bash
python -m transformers.onnx --model=distilbert/distilbert-base-uncased-finetuned-sst-2-english \
--feature=sequence-classification onnx/
```
Isso exibe os seguintes logs:
```bash
Validating ONNX model...
-[✓] ONNX model output names match reference model ({'logits'})
- Validating ONNX Model output "logits":
-[✓] (2, 2) matches (2, 2)
-[✓] all values close (atol: 1e-05)
All good, model saved at: onnx/model.onnx
```
Observe que, neste caso, os nomes de saída do modelo ajustado são `logits`
em vez do `last_hidden_state` que vimos com o checkpoint `distilbert/distilbert-base-uncased`
mais cedo. Isso é esperado, pois o modelo ajustado (fine-tuned) possui uma cabeça de classificação de sequência.
<Tip>
Os recursos que têm um sufixo `with-pass` (como `causal-lm-with-pass`) correspondem a
classes de modelo com estados ocultos pré-computados (chave e valores nos blocos de atenção)
que pode ser usado para decodificação autorregressiva rápida.
</Tip>
<Tip>
Para modelos do tipo `VisionEncoderDecoder`, as partes do codificador e do decodificador são
exportados separadamente como dois arquivos ONNX chamados `encoder_model.onnx` e `decoder_model.onnx` respectivamente.
</Tip>
## Exportando um modelo para uma arquitetura sem suporte
Se você deseja exportar um modelo cuja arquitetura não é suportada nativamente pela
biblioteca, há três etapas principais a seguir:
1. Implemente uma configuração ONNX personalizada.
2. Exporte o modelo para o ONNX.
3. Valide as saídas do PyTorch e dos modelos exportados.
Nesta seção, veremos como o DistilBERT foi implementado para mostrar o que está envolvido
em cada passo.
### Implementando uma configuração ONNX personalizada
Vamos começar com o objeto de configuração ONNX. Fornecemos três classes abstratas que
você deve herdar, dependendo do tipo de arquitetura de modelo que deseja exportar:
* Modelos baseados em codificador herdam de [`~onnx.config.OnnxConfig`]
* Modelos baseados em decodificador herdam de [`~onnx.config.OnnxConfigWithPast`]
* Os modelos codificador-decodificador herdam de [`~onnx.config.OnnxSeq2SeqConfigWithPast`]
<Tip>
Uma boa maneira de implementar uma configuração ONNX personalizada é observar as
implementação no arquivo `configuration_<model_name>.py` de uma arquitetura semelhante.
</Tip>
Como o DistilBERT é um modelo baseado em codificador, sua configuração é herdada de
`OnnxConfig`:
```python
>>> from typing import Mapping, OrderedDict
>>> from transformers.onnx import OnnxConfig
>>> class DistilBertOnnxConfig(OnnxConfig):
... @property
... def inputs(self) -> Mapping[str, Mapping[int, str]]:
... return OrderedDict(
... [
... ("input_ids", {0: "batch", 1: "sequence"}),
... ("attention_mask", {0: "batch", 1: "sequence"}),
... ]
... )
```
Todo objeto de configuração deve implementar a propriedade `inputs` e retornar um mapeamento,
onde cada chave corresponde a uma entrada esperada e cada valor indica o eixo
dessa entrada. Para o DistilBERT, podemos ver que duas entradas são necessárias: `input_ids` e
`attention_mask`. Essas entradas têm a mesma forma de `(batch_size, sequence_length)`
é por isso que vemos os mesmos eixos usados na configuração.
<Tip>
Notice that `inputs` property for `DistilBertOnnxConfig` returns an `OrderedDict`. This
ensures that the inputs are matched with their relative position within the
`PreTrainedModel.forward()` method when tracing the graph. We recommend using an
`OrderedDict` for the `inputs` and `outputs` properties when implementing custom ONNX
configurations.
Observe que a propriedade `inputs` para `DistilBertOnnxConfig` retorna um `OrderedDict`. Este
garante que as entradas sejam combinadas com sua posição relativa dentro do
método `PreTrainedModel.forward()` ao traçar o grafo. Recomendamos o uso de um
`OrderedDict` para as propriedades `inputs` e `outputs` ao implementar configurações personalizadas ONNX.
</Tip>
Depois de implementar uma configuração ONNX, você pode instanciá-la fornecendo a
configuração do modelo base da seguinte forma:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased")
>>> onnx_config = DistilBertOnnxConfig(config)
```
O objeto resultante tem várias propriedades úteis. Por exemplo, você pode visualizar o conjunto de operadores ONNX
que será usado durante a exportação:
```python
>>> print(onnx_config.default_onnx_opset)
11
```
Você também pode visualizar as saídas associadas ao modelo da seguinte forma:
```python
>>> print(onnx_config.outputs)
OrderedDict([("last_hidden_state", {0: "batch", 1: "sequence"})])
```
Observe que a propriedade outputs segue a mesma estrutura das entradas; ele retorna um
`OrderedDict` de saídas nomeadas e suas formas. A estrutura de saída está ligada a
escolha do recurso com o qual a configuração é inicializada. Por padrão, a configuração do ONNX
é inicializada com o recurso `default` que corresponde à exportação de um
modelo carregado com a classe `AutoModel`. Se você deseja exportar um modelo para outra tarefa,
apenas forneça um recurso diferente para o argumento `task` quando você inicializar a configuração ONNX
. Por exemplo, se quisermos exportar o DistilBERT com uma sequência
de classificação, poderíamos usar:
```python
>>> from transformers import AutoConfig
>>> config = AutoConfig.from_pretrained("distilbert/distilbert-base-uncased")
>>> onnx_config_for_seq_clf = DistilBertOnnxConfig(config, task="sequence-classification")
>>> print(onnx_config_for_seq_clf.outputs)
OrderedDict([('logits', {0: 'batch'})])
```
<Tip>
Todas as propriedades e métodos básicos associados a [`~onnx.config.OnnxConfig`] e
as outras classes de configuração podem ser substituídas se necessário. Confira [`BartOnnxConfig`]
para um exemplo avançado.
</Tip>
### Exportando um modelo
Depois de ter implementado a configuração do ONNX, o próximo passo é exportar o modelo.
Aqui podemos usar a função `export()` fornecida pelo pacote `transformers.onnx`.
Esta função espera a configuração do ONNX, juntamente com o modelo base e o tokenizer,
e o caminho para salvar o arquivo exportado:
```python
>>> from pathlib import Path
>>> from transformers.onnx import export
>>> from transformers import AutoTokenizer, AutoModel
>>> onnx_path = Path("model.onnx")
>>> model_ckpt = "distilbert/distilbert-base-uncased"
>>> base_model = AutoModel.from_pretrained(model_ckpt)
>>> tokenizer = AutoTokenizer.from_pretrained(model_ckpt)
>>> onnx_inputs, onnx_outputs = export(tokenizer, base_model, onnx_config, onnx_config.default_onnx_opset, onnx_path)
```
Os `onnx_inputs` e `onnx_outputs` retornados pela função `export()` são listas de
chaves definidas nas propriedades `inputs` e `outputs` da configuração. Uma vez que o
modelo é exportado, você pode testar se o modelo está bem formado da seguinte forma:
```python
>>> import onnx
>>> onnx_model = onnx.load("model.onnx")
>>> onnx.checker.check_model(onnx_model)
```
<Tip>
Se o seu modelo for maior que 2GB, você verá que muitos arquivos adicionais são criados
durante a exportação. Isso é _esperado_ porque o ONNX usa [Protocol
Buffers](https://developers.google.com/protocol-buffers/) para armazenar o modelo e estes
têm um limite de tamanho de 2GB. Veja a [ONNX
documentação](https://github.com/onnx/onnx/blob/master/docs/ExternalData.md) para
instruções sobre como carregar modelos com dados externos.
</Tip>
### Validando a saída dos modelos
A etapa final é validar se as saídas do modelo base e exportado concordam
dentro de alguma tolerância absoluta. Aqui podemos usar a função `validate_model_outputs()`
fornecida pelo pacote `transformers.onnx` da seguinte forma:
```python
>>> from transformers.onnx import validate_model_outputs
>>> validate_model_outputs(
... onnx_config, tokenizer, base_model, onnx_path, onnx_outputs, onnx_config.atol_for_validation
... )
```
Esta função usa o método [`~transformers.onnx.OnnxConfig.generate_dummy_inputs`] para
gerar entradas para o modelo base e o exportado, e a tolerância absoluta pode ser
definida na configuração. Geralmente encontramos concordância numérica em 1e-6 a 1e-4
de alcance, embora qualquer coisa menor que 1e-3 provavelmente esteja OK.
## Contribuindo com uma nova configuração para 🤗 Transformers
Estamos procurando expandir o conjunto de configurações prontas e receber contribuições
da comunidade! Se você gostaria de contribuir para a biblioteca, você
precisará:
* Implemente a configuração do ONNX no arquivo `configuration_<model_name>.py` correspondente
Arquivo
* Incluir a arquitetura do modelo e recursos correspondentes em
[`~onnx.features.FeatureManager`]
* Adicione sua arquitetura de modelo aos testes em `test_onnx_v2.py`
Confira como ficou a configuração do [IBERT
](https://github.com/huggingface/transformers/pull/14868/files) para obter uma
idéia do que está envolvido.
|
transformers/docs/source/pt/serialization.md/0
|
{
"file_path": "transformers/docs/source/pt/serialization.md",
"repo_id": "transformers",
"token_count": 7144
}
|
<!--版权2020年HuggingFace团队保留所有权利。
根据Apache许可证第2.0版(“许可证”)许可;除非符合许可证,否则您不得使用此文件。您可以在以下网址获取许可证的副本:
http://www.apache.org/licenses/LICENSE-2.0
除非适用法律要求或书面同意,否则按“按原样”分发的软件,无论是明示还是暗示的,都没有任何担保或条件。请参阅许可证以了解特定语言下的权限和限制。
⚠️ 请注意,本文件虽然使用Markdown编写,但包含了特定的语法,适用于我们的doc-builder(类似于MDX),可能无法在您的Markdown查看器中正常渲染。
-->
# 基于BERT进行的相关研究(BERTology)
当前,一个新兴的研究领域正致力于探索大规模 transformer 模型(如BERT)的内部工作机制,一些人称之为“BERTology”。以下是这个领域的一些典型示例:
- BERT Rediscovers the Classical NLP Pipeline by Ian Tenney, Dipanjan Das, Ellie Pavlick:
https://arxiv.org/abs/1905.05950
- Are Sixteen Heads Really Better than One? by Paul Michel, Omer Levy, Graham Neubig: https://arxiv.org/abs/1905.10650
- What Does BERT Look At? An Analysis of BERT's Attention by Kevin Clark, Urvashi Khandelwal, Omer Levy, Christopher D.
Manning: https://arxiv.org/abs/1906.04341
- CAT-probing: A Metric-based Approach to Interpret How Pre-trained Models for Programming Language Attend Code Structure: https://arxiv.org/abs/2210.04633
为了助力这一新兴领域的发展,我们在BERT/GPT/GPT-2模型中增加了一些附加功能,方便人们访问其内部表示,这些功能主要借鉴了Paul Michel的杰出工作(https://arxiv.org/abs/1905.10650):
- 访问BERT/GPT/GPT-2的所有隐藏状态,
- 访问BERT/GPT/GPT-2每个注意力头的所有注意力权重,
- 检索注意力头的输出值和梯度,以便计算头的重要性得分并对头进行剪枝,详情可见论文:https://arxiv.org/abs/1905.10650。
为了帮助您理解和使用这些功能,我们添加了一个具体的示例脚本:[bertology.py](https://github.com/huggingface/transformers/tree/main/examples/research_projects/bertology/run_bertology.py),该脚本可以对一个在 GLUE 数据集上预训练的模型进行信息提取与剪枝。
|
transformers/docs/source/zh/bertology.md/0
|
{
"file_path": "transformers/docs/source/zh/bertology.md",
"repo_id": "transformers",
"token_count": 1340
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 用于生成的工具
此页面列出了所有由 [`~generation.GenerationMixin.generate`]。
## 生成输出
[`~generation.GenerationMixin.generate`] 的输出是 [`~utils.ModelOutput`] 的一个子类的实例。这个输出是一种包含 [`~generation.GenerationMixin.generate`] 返回的所有信息数据结构,但也可以作为元组或字典使用。
这里是一个例子:
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
model = GPT2LMHeadModel.from_pretrained("openai-community/gpt2")
inputs = tokenizer("Hello, my dog is cute and ", return_tensors="pt")
generation_output = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
```
`generation_output` 的对象是 [`~generation.GenerateDecoderOnlyOutput`] 的一个实例,从该类的文档中我们可以看到,这意味着它具有以下属性:
- `sequences`: 生成的tokens序列
- `scores`(可选): 每个生成步骤的语言建模头的预测分数
- `hidden_states`(可选): 每个生成步骤模型的hidden states
- `attentions`(可选): 每个生成步骤模型的注意力权重
在这里,由于我们传递了 `output_scores=True`,我们具有 `scores` 属性。但我们没有 `hidden_states` 和 `attentions`,因为没有传递 `output_hidden_states=True` 或 `output_attentions=True`。
您可以像通常一样访问每个属性,如果该属性未被模型返回,则将获得 `None`。例如,在这里 `generation_output.scores` 是语言建模头的所有生成预测分数,而 `generation_output.attentions` 为 `None`。
当我们将 `generation_output` 对象用作元组时,它只保留非 `None` 值的属性。例如,在这里它有两个元素,`loss` 然后是 `logits`,所以
```python
generation_output[:2]
```
将返回元组`(generation_output.sequences, generation_output.scores)`。
当我们将`generation_output`对象用作字典时,它只保留非`None`的属性。例如,它有两个键,分别是`sequences`和`scores`。
我们在此记录所有输出类型。
### PyTorch
[[autodoc]] generation.GenerateDecoderOnlyOutput
[[autodoc]] generation.GenerateEncoderDecoderOutput
[[autodoc]] generation.GenerateBeamDecoderOnlyOutput
[[autodoc]] generation.GenerateBeamEncoderDecoderOutput
### TensorFlow
[[autodoc]] generation.TFGreedySearchEncoderDecoderOutput
[[autodoc]] generation.TFGreedySearchDecoderOnlyOutput
[[autodoc]] generation.TFSampleEncoderDecoderOutput
[[autodoc]] generation.TFSampleDecoderOnlyOutput
[[autodoc]] generation.TFBeamSearchEncoderDecoderOutput
[[autodoc]] generation.TFBeamSearchDecoderOnlyOutput
[[autodoc]] generation.TFBeamSampleEncoderDecoderOutput
[[autodoc]] generation.TFBeamSampleDecoderOnlyOutput
[[autodoc]] generation.TFContrastiveSearchEncoderDecoderOutput
[[autodoc]] generation.TFContrastiveSearchDecoderOnlyOutput
### FLAX
[[autodoc]] generation.FlaxSampleOutput
[[autodoc]] generation.FlaxGreedySearchOutput
[[autodoc]] generation.FlaxBeamSearchOutput
## LogitsProcessor
[`LogitsProcessor`] 可以用于修改语言模型头的预测分数以进行生成
### PyTorch
[[autodoc]] AlternatingCodebooksLogitsProcessor
- __call__
[[autodoc]] ClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] EncoderNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] EncoderRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] EpsilonLogitsWarper
- __call__
[[autodoc]] EtaLogitsWarper
- __call__
[[autodoc]] ExponentialDecayLengthPenalty
- __call__
[[autodoc]] ForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] ForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] HammingDiversityLogitsProcessor
- __call__
[[autodoc]] InfNanRemoveLogitsProcessor
- __call__
[[autodoc]] LogitNormalization
- __call__
[[autodoc]] LogitsProcessor
- __call__
[[autodoc]] LogitsProcessorList
- __call__
[[autodoc]] MinLengthLogitsProcessor
- __call__
[[autodoc]] MinNewTokensLengthLogitsProcessor
- __call__
[[autodoc]] NoBadWordsLogitsProcessor
- __call__
[[autodoc]] NoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] PrefixConstrainedLogitsProcessor
- __call__
[[autodoc]] RepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] SequenceBiasLogitsProcessor
- __call__
[[autodoc]] SuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] SuppressTokensLogitsProcessor
- __call__
[[autodoc]] TemperatureLogitsWarper
- __call__
[[autodoc]] TopKLogitsWarper
- __call__
[[autodoc]] TopPLogitsWarper
- __call__
[[autodoc]] TypicalLogitsWarper
- __call__
[[autodoc]] UnbatchedClassifierFreeGuidanceLogitsProcessor
- __call__
[[autodoc]] WhisperTimeStampLogitsProcessor
- __call__
### TensorFlow
[[autodoc]] TFForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] TFForceTokensLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessor
- __call__
[[autodoc]] TFLogitsProcessorList
- __call__
[[autodoc]] TFLogitsWarper
- __call__
[[autodoc]] TFMinLengthLogitsProcessor
- __call__
[[autodoc]] TFNoBadWordsLogitsProcessor
- __call__
[[autodoc]] TFNoRepeatNGramLogitsProcessor
- __call__
[[autodoc]] TFRepetitionPenaltyLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] TFSuppressTokensLogitsProcessor
- __call__
[[autodoc]] TFTemperatureLogitsWarper
- __call__
[[autodoc]] TFTopKLogitsWarper
- __call__
[[autodoc]] TFTopPLogitsWarper
- __call__
### FLAX
[[autodoc]] FlaxForcedBOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForcedEOSTokenLogitsProcessor
- __call__
[[autodoc]] FlaxForceTokensLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessor
- __call__
[[autodoc]] FlaxLogitsProcessorList
- __call__
[[autodoc]] FlaxLogitsWarper
- __call__
[[autodoc]] FlaxMinLengthLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensAtBeginLogitsProcessor
- __call__
[[autodoc]] FlaxSuppressTokensLogitsProcessor
- __call__
[[autodoc]] FlaxTemperatureLogitsWarper
- __call__
[[autodoc]] FlaxTopKLogitsWarper
- __call__
[[autodoc]] FlaxTopPLogitsWarper
- __call__
[[autodoc]] FlaxWhisperTimeStampLogitsProcessor
- __call__
## StoppingCriteria
可以使用[`StoppingCriteria`]来更改停止生成的时间(除了EOS token以外的方法)。请注意,这仅适用于我们的PyTorch实现。
[[autodoc]] StoppingCriteria
- __call__
[[autodoc]] StoppingCriteriaList
- __call__
[[autodoc]] MaxLengthCriteria
- __call__
[[autodoc]] MaxTimeCriteria
- __call__
## Constraints
可以使用[`Constraint`]来强制生成结果包含输出中的特定tokens或序列。请注意,这仅适用于我们的PyTorch实现。
[[autodoc]] Constraint
[[autodoc]] PhrasalConstraint
[[autodoc]] DisjunctiveConstraint
[[autodoc]] ConstraintListState
## BeamSearch
[[autodoc]] BeamScorer
- process
- finalize
[[autodoc]] BeamSearchScorer
- process
- finalize
[[autodoc]] ConstrainedBeamSearchScorer
- process
- finalize
## Streamers
[[autodoc]] TextStreamer
[[autodoc]] TextIteratorStreamer
|
transformers/docs/source/zh/internal/generation_utils.md/0
|
{
"file_path": "transformers/docs/source/zh/internal/generation_utils.md",
"repo_id": "transformers",
"token_count": 3447
}
|
<!--Copyright 2020 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Logging
🤗 Transformers拥有一个集中式的日志系统,因此您可以轻松设置库输出的日志详细程度。
当前库的默认日志详细程度为`WARNING`。
要更改日志详细程度,只需使用其中一个直接的setter。例如,以下是如何将日志详细程度更改为INFO级别的方法:
```python
import transformers
transformers.logging.set_verbosity_info()
```
您还可以使用环境变量`TRANSFORMERS_VERBOSITY`来覆盖默认的日志详细程度。您可以将其设置为以下级别之一:`debug`、`info`、`warning`、`error`、`critical`。例如:
```bash
TRANSFORMERS_VERBOSITY=error ./myprogram.py
```
此外,通过将环境变量`TRANSFORMERS_NO_ADVISORY_WARNINGS`设置为`true`(如*1*),可以禁用一些`warnings`。这将禁用[`logger.warning_advice`]记录的任何警告。例如:
```bash
TRANSFORMERS_NO_ADVISORY_WARNINGS=1 ./myprogram.py
```
以下是如何在您自己的模块或脚本中使用与库相同的logger的示例:
```python
from transformers.utils import logging
logging.set_verbosity_info()
logger = logging.get_logger("transformers")
logger.info("INFO")
logger.warning("WARN")
```
此日志模块的所有方法都在下面进行了记录,主要的方法包括 [`logging.get_verbosity`] 用于获取logger当前输出日志详细程度的级别和 [`logging.set_verbosity`] 用于将详细程度设置为您选择的级别。按照顺序(从最不详细到最详细),这些级别(及其相应的整数值)为:
- `transformers.logging.CRITICAL` 或 `transformers.logging.FATAL`(整数值,50):仅报告最关键的errors。
- `transformers.logging.ERROR`(整数值,40):仅报告errors。
- `transformers.logging.WARNING` 或 `transformers.logging.WARN`(整数值,30):仅报告error和warnings。这是库使用的默认级别。
- `transformers.logging.INFO`(整数值,20):报告error、warnings和基本信息。
- `transformers.logging.DEBUG`(整数值,10):报告所有信息。
默认情况下,将在模型下载期间显示`tqdm`进度条。[`logging.disable_progress_bar`] 和 [`logging.enable_progress_bar`] 可用于禁止或启用此行为。
## `logging` vs `warnings`
Python有两个经常一起使用的日志系统:如上所述的`logging`,和对特定buckets中的警告进行进一步分类的`warnings`,例如,`FutureWarning`用于输出已经被弃用的功能或路径,`DeprecationWarning`用于指示即将被弃用的内容。
我们在`transformers`库中同时使用这两个系统。我们利用并调整了`logging`的`captureWarning`方法,以便通过上面的详细程度setters来管理这些警告消息。
对于库的开发人员,这意味着什么呢?我们应该遵循以下启发法则:
- 库的开发人员和依赖于`transformers`的库应优先使用`warnings`
- `logging`应该用于在日常项目中经常使用它的用户
以下是`captureWarnings`方法的参考。
[[autodoc]] logging.captureWarnings
## Base setters
[[autodoc]] logging.set_verbosity_error
[[autodoc]] logging.set_verbosity_warning
[[autodoc]] logging.set_verbosity_info
[[autodoc]] logging.set_verbosity_debug
## Other functions
[[autodoc]] logging.get_verbosity
[[autodoc]] logging.set_verbosity
[[autodoc]] logging.get_logger
[[autodoc]] logging.enable_default_handler
[[autodoc]] logging.disable_default_handler
[[autodoc]] logging.enable_explicit_format
[[autodoc]] logging.reset_format
[[autodoc]] logging.enable_progress_bar
[[autodoc]] logging.disable_progress_bar
|
transformers/docs/source/zh/main_classes/logging.md/0
|
{
"file_path": "transformers/docs/source/zh/main_classes/logging.md",
"repo_id": "transformers",
"token_count": 2154
}
|
<!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 使用 torch.compile() 优化推理
本指南旨在为使用[`torch.compile()`](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html)在[🤗 Transformers中的计算机视觉模型](https://huggingface.co/models?pipeline_tag=image-classification&library=transformers&sort=trending)中引入的推理速度提升提供一个基准。
## torch.compile 的优势
根据模型和GPU的不同,`torch.compile()`在推理过程中可以提高多达30%的速度。要使用`torch.compile()`,只需安装2.0及以上版本的`torch`即可。
编译模型需要时间,因此如果您只需要编译一次模型而不是每次推理都编译,那么它非常有用。
要编译您选择的任何计算机视觉模型,请按照以下方式调用`torch.compile()`:
```diff
from transformers import AutoModelForImageClassification
model = AutoModelForImageClassification.from_pretrained(MODEL_ID).to("cuda")
+ model = torch.compile(model)
```
`compile()` 提供了多种编译模式,它们在编译时间和推理开销上有所不同。`max-autotune` 比 `reduce-overhead` 需要更长的时间,但会得到更快的推理速度。默认模式在编译时最快,但在推理时间上与 `reduce-overhead` 相比效率较低。在本指南中,我们使用了默认模式。您可以在[这里](https://pytorch.org/get-started/pytorch-2.0/#user-experience)了解更多信息。
我们在 PyTorch 2.0.1 版本上使用不同的计算机视觉模型、任务、硬件类型和数据批量大小对 `torch.compile` 进行了基准测试。
## 基准测试代码
以下是每个任务的基准测试代码。我们在推理之前”预热“GPU,并取300次推理的平均值,每次使用相同的图像。
### 使用 ViT 进行图像分类
```python
import torch
from PIL import Image
import requests
import numpy as np
from transformers import AutoImageProcessor, AutoModelForImageClassification
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AutoImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = AutoModelForImageClassification.from_pretrained("google/vit-base-patch16-224").to("cuda")
model = torch.compile(model)
processed_input = processor(image, return_tensors='pt').to(device="cuda")
with torch.no_grad():
_ = model(**processed_input)
```
#### 使用 DETR 进行目标检测
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
processor = AutoImageProcessor.from_pretrained("facebook/detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("facebook/detr-resnet-50").to("cuda")
model = torch.compile(model)
texts = ["a photo of a cat", "a photo of a dog"]
inputs = processor(text=texts, images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**inputs)
```
#### 使用 Segformer 进行图像分割
```python
from transformers import SegformerImageProcessor, SegformerForSemanticSegmentation
processor = SegformerImageProcessor.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512")
model = SegformerForSemanticSegmentation.from_pretrained("nvidia/segformer-b0-finetuned-ade-512-512").to("cuda")
model = torch.compile(model)
seg_inputs = processor(images=image, return_tensors="pt").to("cuda")
with torch.no_grad():
_ = model(**seg_inputs)
```
以下是我们进行基准测试的模型列表。
**图像分类**
- [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
- [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k)
- [facebook/convnext-large-224](https://huggingface.co/facebook/convnext-large-224)
- [microsoft/resnet-50](https://huggingface.co/)
**图像分割**
- [nvidia/segformer-b0-finetuned-ade-512-512](https://huggingface.co/nvidia/segformer-b0-finetuned-ade-512-512)
- [facebook/mask2former-swin-tiny-coco-panoptic](https://huggingface.co/facebook/mask2former-swin-tiny-coco-panoptic)
- [facebook/maskformer-swin-base-ade](https://huggingface.co/facebook/maskformer-swin-base-ade)
- [google/deeplabv3_mobilenet_v2_1.0_513](https://huggingface.co/google/deeplabv3_mobilenet_v2_1.0_513)
**目标检测**
- [google/owlvit-base-patch32](https://huggingface.co/google/owlvit-base-patch32)
- [facebook/detr-resnet-101](https://huggingface.co/facebook/detr-resnet-101)
- [microsoft/conditional-detr-resnet-50](https://huggingface.co/microsoft/conditional-detr-resnet-50)
下面是使用和不使用`torch.compile()`的推理持续时间可视化,以及每个模型在不同硬件和数据批量大小下的改进百分比。
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/a100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/v100_batch_comp.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/t4_batch_comp.png" />
</div>
</div>
<div class="flex">
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_duration.png" />
</div>
<div>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/torch_compile/A100_1_percentage.png" />
</div>
</div>
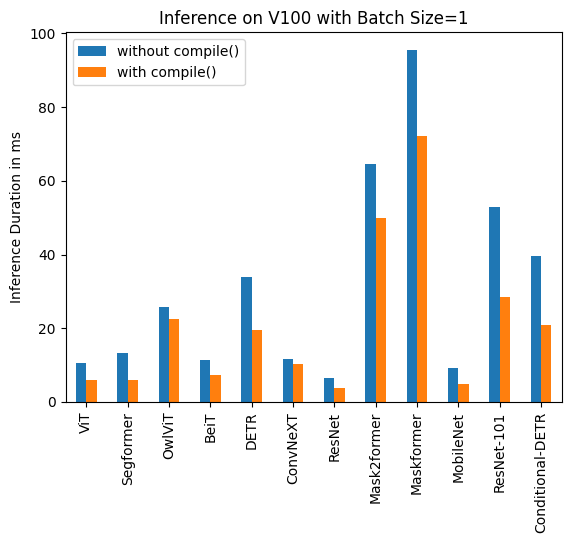
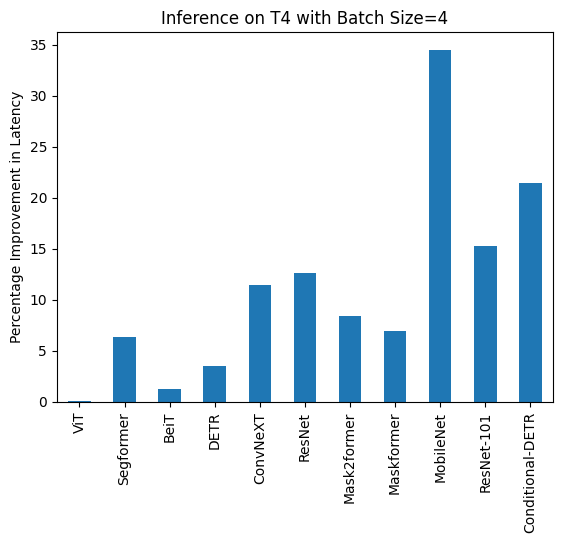
下面可以找到每个模型使用和不使用`compile()`的推理时间(毫秒)。请注意,OwlViT在大批量大小下会导致内存溢出。
### A100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 9.325 | 7.584 |
| Image Segmentation/Segformer | 11.759 | 10.500 |
| Object Detection/OwlViT | 24.978 | 18.420 |
| Image Classification/BeiT | 11.282 | 8.448 |
| Object Detection/DETR | 34.619 | 19.040 |
| Image Classification/ConvNeXT | 10.410 | 10.208 |
| Image Classification/ResNet | 6.531 | 4.124 |
| Image Segmentation/Mask2former | 60.188 | 49.117 |
| Image Segmentation/Maskformer | 75.764 | 59.487 |
| Image Segmentation/MobileNet | 8.583 | 3.974 |
| Object Detection/Resnet-101 | 36.276 | 18.197 |
| Object Detection/Conditional-DETR | 31.219 | 17.993 |
### A100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 14.832 | 14.499 |
| Image Segmentation/Segformer | 18.838 | 16.476 |
| Image Classification/BeiT | 13.205 | 13.048 |
| Object Detection/DETR | 48.657 | 32.418|
| Image Classification/ConvNeXT | 22.940 | 21.631 |
| Image Classification/ResNet | 6.657 | 4.268 |
| Image Segmentation/Mask2former | 74.277 | 61.781 |
| Image Segmentation/Maskformer | 180.700 | 159.116 |
| Image Segmentation/MobileNet | 14.174 | 8.515 |
| Object Detection/Resnet-101 | 68.101 | 44.998 |
| Object Detection/Conditional-DETR | 56.470 | 35.552 |
### A100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 40.944 | 40.010 |
| Image Segmentation/Segformer | 37.005 | 31.144 |
| Image Classification/BeiT | 41.854 | 41.048 |
| Object Detection/DETR | 164.382 | 161.902 |
| Image Classification/ConvNeXT | 82.258 | 75.561 |
| Image Classification/ResNet | 7.018 | 5.024 |
| Image Segmentation/Mask2former | 178.945 | 154.814 |
| Image Segmentation/Maskformer | 638.570 | 579.826 |
| Image Segmentation/MobileNet | 51.693 | 30.310 |
| Object Detection/Resnet-101 | 232.887 | 155.021 |
| Object Detection/Conditional-DETR | 180.491 | 124.032 |
### V100 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 10.495 | 6.00 |
| Image Segmentation/Segformer | 13.321 | 5.862 |
| Object Detection/OwlViT | 25.769 | 22.395 |
| Image Classification/BeiT | 11.347 | 7.234 |
| Object Detection/DETR | 33.951 | 19.388 |
| Image Classification/ConvNeXT | 11.623 | 10.412 |
| Image Classification/ResNet | 6.484 | 3.820 |
| Image Segmentation/Mask2former | 64.640 | 49.873 |
| Image Segmentation/Maskformer | 95.532 | 72.207 |
| Image Segmentation/MobileNet | 9.217 | 4.753 |
| Object Detection/Resnet-101 | 52.818 | 28.367 |
| Object Detection/Conditional-DETR | 39.512 | 20.816 |
### V100 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 15.181 | 14.501 |
| Image Segmentation/Segformer | 16.787 | 16.188 |
| Image Classification/BeiT | 15.171 | 14.753 |
| Object Detection/DETR | 88.529 | 64.195 |
| Image Classification/ConvNeXT | 29.574 | 27.085 |
| Image Classification/ResNet | 6.109 | 4.731 |
| Image Segmentation/Mask2former | 90.402 | 76.926 |
| Image Segmentation/Maskformer | 234.261 | 205.456 |
| Image Segmentation/MobileNet | 24.623 | 14.816 |
| Object Detection/Resnet-101 | 134.672 | 101.304 |
| Object Detection/Conditional-DETR | 97.464 | 69.739 |
### V100 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 52.209 | 51.633 |
| Image Segmentation/Segformer | 61.013 | 55.499 |
| Image Classification/BeiT | 53.938 | 53.581 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 109.682 | 100.771 |
| Image Classification/ResNet | 14.857 | 12.089 |
| Image Segmentation/Mask2former | 249.605 | 222.801 |
| Image Segmentation/Maskformer | 831.142 | 743.645 |
| Image Segmentation/MobileNet | 93.129 | 55.365 |
| Object Detection/Resnet-101 | 482.425 | 361.843 |
| Object Detection/Conditional-DETR | 344.661 | 255.298 |
### T4 (batch size: 1)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 16.520 | 15.786 |
| Image Segmentation/Segformer | 16.116 | 14.205 |
| Object Detection/OwlViT | 53.634 | 51.105 |
| Image Classification/BeiT | 16.464 | 15.710 |
| Object Detection/DETR | 73.100 | 53.99 |
| Image Classification/ConvNeXT | 32.932 | 30.845 |
| Image Classification/ResNet | 6.031 | 4.321 |
| Image Segmentation/Mask2former | 79.192 | 66.815 |
| Image Segmentation/Maskformer | 200.026 | 188.268 |
| Image Segmentation/MobileNet | 18.908 | 11.997 |
| Object Detection/Resnet-101 | 106.622 | 82.566 |
| Object Detection/Conditional-DETR | 77.594 | 56.984 |
### T4 (batch size: 4)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 43.653 | 43.626 |
| Image Segmentation/Segformer | 45.327 | 42.445 |
| Image Classification/BeiT | 52.007 | 51.354 |
| Object Detection/DETR | 277.850 | 268.003 |
| Image Classification/ConvNeXT | 119.259 | 105.580 |
| Image Classification/ResNet | 13.039 | 11.388 |
| Image Segmentation/Mask2former | 201.540 | 184.670 |
| Image Segmentation/Maskformer | 764.052 | 711.280 |
| Image Segmentation/MobileNet | 74.289 | 48.677 |
| Object Detection/Resnet-101 | 421.859 | 357.614 |
| Object Detection/Conditional-DETR | 289.002 | 226.945 |
### T4 (batch size: 16)
| **Task/Model** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|
| Image Classification/ViT | 163.914 | 160.907 |
| Image Segmentation/Segformer | 192.412 | 163.620 |
| Image Classification/BeiT | 188.978 | 187.976 |
| Object Detection/DETR | OOM | OOM |
| Image Classification/ConvNeXT | 422.886 | 388.078 |
| Image Classification/ResNet | 44.114 | 37.604 |
| Image Segmentation/Mask2former | 756.337 | 695.291 |
| Image Segmentation/Maskformer | 2842.940 | 2656.88 |
| Image Segmentation/MobileNet | 299.003 | 201.942 |
| Object Detection/Resnet-101 | 1619.505 | 1262.758 |
| Object Detection/Conditional-DETR | 1137.513 | 897.390|
## PyTorch Nightly
我们还在 PyTorch Nightly 版本(2.1.0dev)上进行了基准测试,可以在[这里](https://download.pytorch.org/whl/nightly/cu118)找到 Nightly 版本的安装包,并观察到了未编译和编译模型的延迟性能改善。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - no compile** | **torch 2.0 -<br> compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 12.462 | 6.954 |
| Image Classification/BeiT | 4 | 14.109 | 12.851 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 30.484 | 15.221 |
| Object Detection/DETR | 4 | 46.816 | 30.942 |
| Object Detection/DETR | 16 | 163.749 | 163.706 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 14.408 | 14.052 |
| Image Classification/BeiT | 4 | 47.381 | 46.604 |
| Image Classification/BeiT | 16 | 42.179 | 42.147 |
| Object Detection/DETR | Unbatched | 68.382 | 53.481 |
| Object Detection/DETR | 4 | 269.615 | 204.785 |
| Object Detection/DETR | 16 | OOM | OOM |
### V100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/BeiT | Unbatched | 13.477 | 7.926 |
| Image Classification/BeiT | 4 | 15.103 | 14.378 |
| Image Classification/BeiT | 16 | 52.517 | 51.691 |
| Object Detection/DETR | Unbatched | 28.706 | 19.077 |
| Object Detection/DETR | 4 | 88.402 | 62.949|
| Object Detection/DETR | 16 | OOM | OOM |
## 降低开销
我们在 PyTorch Nightly 版本中为 A100 和 T4 进行了 `reduce-overhead` 编译模式的性能基准测试。
### A100
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 11.758 | 7.335 |
| Image Classification/ConvNeXT | 4 | 23.171 | 21.490 |
| Image Classification/ResNet | Unbatched | 7.435 | 3.801 |
| Image Classification/ResNet | 4 | 7.261 | 2.187 |
| Object Detection/Conditional-DETR | Unbatched | 32.823 | 11.627 |
| Object Detection/Conditional-DETR | 4 | 50.622 | 33.831 |
| Image Segmentation/MobileNet | Unbatched | 9.869 | 4.244 |
| Image Segmentation/MobileNet | 4 | 14.385 | 7.946 |
### T4
| **Task/Model** | **Batch Size** | **torch 2.0 - <br>no compile** | **torch 2.0 - <br>compile** |
|:---:|:---:|:---:|:---:|
| Image Classification/ConvNeXT | Unbatched | 32.137 | 31.84 |
| Image Classification/ConvNeXT | 4 | 120.944 | 110.209 |
| Image Classification/ResNet | Unbatched | 9.761 | 7.698 |
| Image Classification/ResNet | 4 | 15.215 | 13.871 |
| Object Detection/Conditional-DETR | Unbatched | 72.150 | 57.660 |
| Object Detection/Conditional-DETR | 4 | 301.494 | 247.543 |
| Image Segmentation/MobileNet | Unbatched | 22.266 | 19.339 |
| Image Segmentation/MobileNet | 4 | 78.311 | 50.983 |
|
transformers/docs/source/zh/perf_torch_compile.md/0
|
{
"file_path": "transformers/docs/source/zh/perf_torch_compile.md",
"repo_id": "transformers",
"token_count": 6785
}
|
<!--
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# 导出为 TorchScript
<Tip>
这是开始使用 TorchScript 进行实验的起点,我们仍在探索其在变量输入大小模型中的能力。
这是我们关注的焦点,我们将在即将发布的版本中深入分析,提供更多的代码示例、更灵活的实现以及比较
Python 代码与编译 TorchScript 的性能基准。
</Tip>
根据 [TorchScript 文档](https://pytorch.org/docs/stable/jit.html):
> TorchScript 是从 PyTorch 代码创建可序列化和可优化的模型的一种方式。
有两个 PyTorch 模块:[JIT 和 TRACE](https://pytorch.org/docs/stable/jit.html)。
这两个模块允许开发人员将其模型导出到其他程序中重用,比如面向效率的 C++ 程序。
我们提供了一个接口,允许您将 🤗 Transformers 模型导出为 TorchScript,
以便在与基于 PyTorch 的 Python 程序不同的环境中重用。
本文解释如何使用 TorchScript 导出并使用我们的模型。
导出模型需要两个步骤:
- 使用 `torchscript` 参数实例化模型
- 使用虚拟输入进行前向传递
这些必要条件意味着开发人员应该注意以下详细信息。
## TorchScript 参数和绑定权重
`torchscript` 参数是必需的,因为大多数 🤗 Transformers 语言模型的 `Embedding` 层和
`Decoding` 层之间有绑定权重。TorchScript 不允许导出具有绑定权重的模型,因此必须事先解绑和克隆权重。
使用 `torchscript` 参数实例化的模型将其 `Embedding` 层和 `Decoding` 层分开,
这意味着它们不应该在后续进行训练。训练将导致这两层不同步,产生意外结果。
对于没有语言模型头部的模型,情况不同,因为这些模型没有绑定权重。
这些模型可以安全地导出而无需 `torchscript` 参数。
## 虚拟输入和标准长度
虚拟输入用于模型的前向传递。当输入的值传播到各层时,PyTorch 会跟踪在每个张量上执行的不同操作。
然后使用记录的操作来创建模型的 *trace* 。
跟踪是相对于输入的维度创建的。因此,它受到虚拟输入的维度限制,对于任何其他序列长度或批量大小都不起作用。
当尝试使用不同大小时,会引发以下错误:
```text
`The expanded size of the tensor (3) must match the existing size (7) at non-singleton dimension 2`
```
我们建议使用至少与推断期间将馈送到模型的最大输入一样大的虚拟输入大小进行跟踪。
填充可以帮助填补缺失的值。然而,由于模型是使用更大的输入大小进行跟踪的,矩阵的维度也会很大,导致更多的计算。
在每个输入上执行的操作总数要仔细考虑,并在导出不同序列长度模型时密切关注性能。
## 在 Python 中使用 TorchScript
本节演示了如何保存和加载模型以及如何使用 trace 进行推断。
### 保存模型
要使用 TorchScript 导出 `BertModel`,请从 `BertConfig` 类实例化 `BertModel`,
然后将其保存到名为 `traced_bert.pt` 的磁盘文件中:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
enc = BertTokenizer.from_pretrained("google-bert/bert-base-uncased")
# 对输入文本分词
text = "[CLS] Who was Jim Henson ? [SEP] Jim Henson was a puppeteer [SEP]"
tokenized_text = enc.tokenize(text)
# 屏蔽一个输入 token
masked_index = 8
tokenized_text[masked_index] = "[MASK]"
indexed_tokens = enc.convert_tokens_to_ids(tokenized_text)
segments_ids = [0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
# 创建虚拟输入
tokens_tensor = torch.tensor([indexed_tokens])
segments_tensors = torch.tensor([segments_ids])
dummy_input = [tokens_tensor, segments_tensors]
# 使用 torchscript 参数初始化模型
# 即使此模型没有 LM Head,也将参数设置为 True。
config = BertConfig(
vocab_size_or_config_json_file=32000,
hidden_size=768,
num_hidden_layers=12,
num_attention_heads=12,
intermediate_size=3072,
torchscript=True,
)
# 实例化模型
model = BertModel(config)
# 模型需要处于评估模式
model.eval()
# 如果您使用 *from_pretrained* 实例化模型,还可以轻松设置 TorchScript 参数
model = BertModel.from_pretrained("google-bert/bert-base-uncased", torchscript=True)
# 创建 trace
traced_model = torch.jit.trace(model, [tokens_tensor, segments_tensors])
torch.jit.save(traced_model, "traced_bert.pt")
```
### 加载模型
现在,您可以从磁盘加载先前保存的 `BertModel`、`traced_bert.pt`,并在先前初始化的 `dummy_input` 上使用:
```python
loaded_model = torch.jit.load("traced_bert.pt")
loaded_model.eval()
all_encoder_layers, pooled_output = loaded_model(*dummy_input)
```
### 使用 trace 模型进行推断
通过使用其 `__call__` dunder 方法使用 trace 模型进行推断:
```python
traced_model(tokens_tensor, segments_tensors)
```
## 使用 Neuron SDK 将 Hugging Face TorchScript 模型部署到 AWS
AWS 引入了用于云端低成本、高性能机器学习推理的
[Amazon EC2 Inf1](https://aws.amazon.com/ec2/instance-types/inf1/) 实例系列。
Inf1 实例由 AWS Inferentia 芯片提供支持,这是一款专为深度学习推理工作负载而构建的定制硬件加速器。
[AWS Neuron](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/#) 是
Inferentia 的 SDK,支持对 transformers 模型进行跟踪和优化,以便在 Inf1 上部署。Neuron SDK 提供:
1. 简单易用的 API,只需更改一行代码即可为云端推理跟踪和优化 TorchScript 模型。
2. 针对[改进的性能成本](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/benchmark/)的即插即用性能优化。
3. 支持使用 [PyTorch](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/bert_tutorial/tutorial_pretrained_bert.html)
或 [TensorFlow](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/tensorflow/huggingface_bert/huggingface_bert.html)
构建的 Hugging Face transformers 模型。
### 影响
基于 [BERT(来自 Transformers 的双向编码器表示)](https://huggingface.co/docs/transformers/main/model_doc/bert)架构的
transformers 模型,或其变体,如 [distilBERT](https://huggingface.co/docs/transformers/main/model_doc/distilbert)
和 [roBERTa](https://huggingface.co/docs/transformers/main/model_doc/roberta) 在 Inf1 上运行最佳,
可用于生成抽取式问答、序列分类和标记分类等任务。然而,文本生成任务仍可以适应在 Inf1 上运行,
如这篇 [AWS Neuron MarianMT 教程](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/src/examples/pytorch/transformers-marianmt.html)所述。
有关可以直接在 Inferentia 上转换的模型的更多信息,请参阅 Neuron 文档的[模型架构适配](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/models/models-inferentia.html#models-inferentia)章节。
### 依赖关系
使用 AWS Neuron 将模型转换为模型需要一个
[Neuron SDK 环境](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/neuron-guide/neuron-frameworks/pytorch-neuron/index.html#installation-guide),
它已经预先配置在 [AWS 深度学习 AMI](https://docs.aws.amazon.com/dlami/latest/devguide/tutorial-inferentia-launching.html)上。
### 将模型转换为 AWS Neuron
使用与 [Python 中使用 TorchScript](torchscript#using-torchscript-in-python) 相同的代码来跟踪
`BertModel` 以将模型转换为 AWS NEURON。导入 `torch.neuron` 框架扩展以通过 Python API 访问 Neuron SDK 的组件:
```python
from transformers import BertModel, BertTokenizer, BertConfig
import torch
import torch.neuron
```
您只需要修改下面这一行:
```diff
- torch.jit.trace(model, [tokens_tensor, segments_tensors])
+ torch.neuron.trace(model, [token_tensor, segments_tensors])
```
这样就能使 Neuron SDK 跟踪模型并对其进行优化,以在 Inf1 实例上运行。
要了解有关 AWS Neuron SDK 功能、工具、示例教程和最新更新的更多信息,
请参阅 [AWS NeuronSDK 文档](https://awsdocs-neuron.readthedocs-hosted.com/en/latest/index.html)。
|
transformers/docs/source/zh/torchscript.md/0
|
{
"file_path": "transformers/docs/source/zh/torchscript.md",
"repo_id": "transformers",
"token_count": 4763
}
|
#!/usr/bin/env python3
import json
from typing import Iterator, List, Union
from tokenizers import AddedToken, Regex, Tokenizer, decoders, normalizers, pre_tokenizers, trainers
from tokenizers.implementations.base_tokenizer import BaseTokenizer
from tokenizers.models import Unigram
from tokenizers.processors import TemplateProcessing
class SentencePieceUnigramTokenizer(BaseTokenizer):
"""
This class is a copy of `DeDLOC's tokenizer implementation <https://github.com/yandex-research/DeDLOC/blob/main/sahajbert/tokenizer/tokenizer_model.py>`__ .
Custom SentencePiece Unigram Tokenizer with NMT, NKFC, spaces and lower-casing characters normalization
Represents the Unigram algorithm, with the pretokenization used by SentencePiece
"""
def __init__(
self,
replacement: str = "▁",
add_prefix_space: bool = True,
unk_token: Union[str, AddedToken] = "<unk>",
eos_token: Union[str, AddedToken] = "</s>",
pad_token: Union[str, AddedToken] = "<pad>",
):
self.special_tokens = {
"pad": {"id": 0, "token": pad_token},
"eos": {"id": 1, "token": eos_token},
"unk": {"id": 2, "token": unk_token},
}
self.special_tokens_list = [None] * len(self.special_tokens)
for token_dict in self.special_tokens.values():
self.special_tokens_list[token_dict["id"]] = token_dict["token"]
tokenizer = Tokenizer(Unigram())
tokenizer.normalizer = normalizers.Sequence(
[
normalizers.Nmt(),
normalizers.NFKC(),
normalizers.Replace(Regex(" {2,}"), " "),
normalizers.Lowercase(),
]
)
tokenizer.pre_tokenizer = pre_tokenizers.Sequence(
[
pre_tokenizers.Metaspace(
replacement=replacement, prepend_scheme="always" if add_prefix_space else "never"
),
pre_tokenizers.Digits(individual_digits=True),
pre_tokenizers.Punctuation(),
]
)
tokenizer.decoder = decoders.Metaspace(
replacement=replacement, prepend_scheme="always" if add_prefix_space else "never"
)
tokenizer.post_processor = TemplateProcessing(
single=f"$A {self.special_tokens['eos']['token']}",
special_tokens=[(self.special_tokens["eos"]["token"], self.special_tokens["eos"]["id"])],
)
parameters = {
"model": "SentencePieceUnigram",
"replacement": replacement,
"add_prefix_space": add_prefix_space,
}
super().__init__(tokenizer, parameters)
def train(
self,
files: Union[str, List[str]],
vocab_size: int = 8000,
show_progress: bool = True,
):
"""Train the model using the given files"""
trainer = trainers.UnigramTrainer(
vocab_size=vocab_size,
special_tokens=self.special_tokens_list,
show_progress=show_progress,
)
if isinstance(files, str):
files = [files]
self._tokenizer.train(files, trainer=trainer)
self.add_unk_id()
def train_from_iterator(
self,
iterator: Union[Iterator[str], Iterator[Iterator[str]]],
vocab_size: int = 8000,
show_progress: bool = True,
):
"""Train the model using the given iterator"""
trainer = trainers.UnigramTrainer(
vocab_size=vocab_size,
special_tokens=self.special_tokens_list,
show_progress=show_progress,
)
self._tokenizer.train_from_iterator(iterator, trainer=trainer)
self.add_unk_id()
def add_unk_id(self):
tokenizer_json = json.loads(self._tokenizer.to_str())
tokenizer_json["model"]["unk_id"] = self.special_tokens["unk"]["id"]
self._tokenizer = Tokenizer.from_str(json.dumps(tokenizer_json))
|
transformers/examples/flax/language-modeling/t5_tokenizer_model.py/0
|
{
"file_path": "transformers/examples/flax/language-modeling/t5_tokenizer_model.py",
"repo_id": "transformers",
"token_count": 1823
}
|
import argparse
import glob
import logging
import os
from argparse import Namespace
from importlib import import_module
import numpy as np
import torch
from lightning_base import BaseTransformer, add_generic_args, generic_train
from seqeval.metrics import accuracy_score, f1_score, precision_score, recall_score
from torch.nn import CrossEntropyLoss
from torch.utils.data import DataLoader, TensorDataset
from utils_ner import TokenClassificationTask
logger = logging.getLogger(__name__)
class NERTransformer(BaseTransformer):
"""
A training module for NER. See BaseTransformer for the core options.
"""
mode = "token-classification"
def __init__(self, hparams):
if isinstance(hparams, dict):
hparams = Namespace(**hparams)
module = import_module("tasks")
try:
token_classification_task_clazz = getattr(module, hparams.task_type)
self.token_classification_task: TokenClassificationTask = token_classification_task_clazz()
except AttributeError:
raise ValueError(
f"Task {hparams.task_type} needs to be defined as a TokenClassificationTask subclass in {module}. "
f"Available tasks classes are: {TokenClassificationTask.__subclasses__()}"
)
self.labels = self.token_classification_task.get_labels(hparams.labels)
self.pad_token_label_id = CrossEntropyLoss().ignore_index
super().__init__(hparams, len(self.labels), self.mode)
def forward(self, **inputs):
return self.model(**inputs)
def training_step(self, batch, batch_num):
"Compute loss and log."
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type != "distilbert":
inputs["token_type_ids"] = (
batch[2] if self.config.model_type in ["bert", "xlnet"] else None
) # XLM and RoBERTa don"t use token_type_ids
outputs = self(**inputs)
loss = outputs[0]
# tensorboard_logs = {"loss": loss, "rate": self.lr_scheduler.get_last_lr()[-1]}
return {"loss": loss}
def prepare_data(self):
"Called to initialize data. Use the call to construct features"
args = self.hparams
for mode in ["train", "dev", "test"]:
cached_features_file = self._feature_file(mode)
if os.path.exists(cached_features_file) and not args.overwrite_cache:
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
else:
logger.info("Creating features from dataset file at %s", args.data_dir)
examples = self.token_classification_task.read_examples_from_file(args.data_dir, mode)
features = self.token_classification_task.convert_examples_to_features(
examples,
self.labels,
args.max_seq_length,
self.tokenizer,
cls_token_at_end=bool(self.config.model_type in ["xlnet"]),
cls_token=self.tokenizer.cls_token,
cls_token_segment_id=2 if self.config.model_type in ["xlnet"] else 0,
sep_token=self.tokenizer.sep_token,
sep_token_extra=False,
pad_on_left=bool(self.config.model_type in ["xlnet"]),
pad_token=self.tokenizer.pad_token_id,
pad_token_segment_id=self.tokenizer.pad_token_type_id,
pad_token_label_id=self.pad_token_label_id,
)
logger.info("Saving features into cached file %s", cached_features_file)
torch.save(features, cached_features_file)
def get_dataloader(self, mode: int, batch_size: int, shuffle: bool = False) -> DataLoader:
"Load datasets. Called after prepare data."
cached_features_file = self._feature_file(mode)
logger.info("Loading features from cached file %s", cached_features_file)
features = torch.load(cached_features_file)
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
if features[0].token_type_ids is not None:
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
else:
all_token_type_ids = torch.tensor([0 for f in features], dtype=torch.long)
# HACK(we will not use this anymore soon)
all_label_ids = torch.tensor([f.label_ids for f in features], dtype=torch.long)
return DataLoader(
TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_label_ids), batch_size=batch_size
)
def validation_step(self, batch, batch_nb):
"""Compute validation""" ""
inputs = {"input_ids": batch[0], "attention_mask": batch[1], "labels": batch[3]}
if self.config.model_type != "distilbert":
inputs["token_type_ids"] = (
batch[2] if self.config.model_type in ["bert", "xlnet"] else None
) # XLM and RoBERTa don"t use token_type_ids
outputs = self(**inputs)
tmp_eval_loss, logits = outputs[:2]
preds = logits.detach().cpu().numpy()
out_label_ids = inputs["labels"].detach().cpu().numpy()
return {"val_loss": tmp_eval_loss.detach().cpu(), "pred": preds, "target": out_label_ids}
def _eval_end(self, outputs):
"Evaluation called for both Val and Test"
val_loss_mean = torch.stack([x["val_loss"] for x in outputs]).mean()
preds = np.concatenate([x["pred"] for x in outputs], axis=0)
preds = np.argmax(preds, axis=2)
out_label_ids = np.concatenate([x["target"] for x in outputs], axis=0)
label_map = dict(enumerate(self.labels))
out_label_list = [[] for _ in range(out_label_ids.shape[0])]
preds_list = [[] for _ in range(out_label_ids.shape[0])]
for i in range(out_label_ids.shape[0]):
for j in range(out_label_ids.shape[1]):
if out_label_ids[i, j] != self.pad_token_label_id:
out_label_list[i].append(label_map[out_label_ids[i][j]])
preds_list[i].append(label_map[preds[i][j]])
results = {
"val_loss": val_loss_mean,
"accuracy_score": accuracy_score(out_label_list, preds_list),
"precision": precision_score(out_label_list, preds_list),
"recall": recall_score(out_label_list, preds_list),
"f1": f1_score(out_label_list, preds_list),
}
ret = dict(results.items())
ret["log"] = results
return ret, preds_list, out_label_list
def validation_epoch_end(self, outputs):
# when stable
ret, preds, targets = self._eval_end(outputs)
logs = ret["log"]
return {"val_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
def test_epoch_end(self, outputs):
# updating to test_epoch_end instead of deprecated test_end
ret, predictions, targets = self._eval_end(outputs)
# Converting to the dict required by pl
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master/\
# pytorch_lightning/trainer/logging.py#L139
logs = ret["log"]
# `val_loss` is the key returned by `self._eval_end()` but actually refers to `test_loss`
return {"avg_test_loss": logs["val_loss"], "log": logs, "progress_bar": logs}
@staticmethod
def add_model_specific_args(parser, root_dir):
# Add NER specific options
BaseTransformer.add_model_specific_args(parser, root_dir)
parser.add_argument(
"--task_type", default="NER", type=str, help="Task type to fine tune in training (e.g. NER, POS, etc)"
)
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
),
)
parser.add_argument(
"--labels",
default="",
type=str,
help="Path to a file containing all labels. If not specified, CoNLL-2003 labels are used.",
)
parser.add_argument(
"--gpus",
default=0,
type=int,
help="The number of GPUs allocated for this, it is by default 0 meaning none",
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
return parser
if __name__ == "__main__":
parser = argparse.ArgumentParser()
add_generic_args(parser, os.getcwd())
parser = NERTransformer.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
model = NERTransformer(args)
trainer = generic_train(model, args)
if args.do_predict:
# See https://github.com/huggingface/transformers/issues/3159
# pl use this default format to create a checkpoint:
# https://github.com/PyTorchLightning/pytorch-lightning/blob/master\
# /pytorch_lightning/callbacks/model_checkpoint.py#L322
checkpoints = sorted(glob.glob(os.path.join(args.output_dir, "checkpoint-epoch=*.ckpt"), recursive=True))
model = model.load_from_checkpoint(checkpoints[-1])
trainer.test(model)
|
transformers/examples/legacy/pytorch-lightning/run_ner.py/0
|
{
"file_path": "transformers/examples/legacy/pytorch-lightning/run_ner.py",
"repo_id": "transformers",
"token_count": 4295
}
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the proper usage is documented in the README, you need to specify data_dir, output_dir and model_name_or_path
# run ./finetune.sh --help to see all the possible options
python finetune_trainer.py \
--learning_rate=3e-5 \
--fp16 \
--do_train --do_eval --do_predict \
--eval_strategy steps \
--predict_with_generate \
--n_val 1000 \
"$@"
|
transformers/examples/legacy/seq2seq/finetune.sh/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/finetune.sh",
"repo_id": "transformers",
"token_count": 297
}
|
#!/usr/bin/env python
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import argparse
import itertools
import operator
import sys
from collections import OrderedDict
from run_eval import datetime_now, run_generate
from utils import ROUGE_KEYS
# A table of supported tasks and the list of scores in the order of importance to be sorted by.
# To add a new task, simply list the score names that `run_eval.run_generate()` returns
task_score_names = {
"translation": ["bleu"],
"summarization": ROUGE_KEYS,
}
def parse_search_arg(search):
groups = search.split()
entries = dict((g.split("=") for g in groups))
entry_names = list(entries.keys())
sets = [[f"--{k} {v}" for v in vs.split(":")] for k, vs in entries.items()]
matrix = [list(x) for x in itertools.product(*sets)]
return matrix, entry_names
def run_search():
"""
Run parametric search over the desired hparam space with help of ``run_eval.py``.
All the arguments except ``--search`` are passed to ``run_eval.py`` as is. The values inside of "--search" are parsed, reformatted and fed to ``run_eval.py`` as additional args.
The format for the ``--search`` value is a simple string with hparams and colon separated values to try, e.g.:
```
--search "num_beams=5:10 length_penalty=0.8:1.0:1.2 early_stopping=true:false"
```
which will generate ``12`` ``(2*3*2)`` searches for a product of each hparam. For example the example that was just used will invoke ``run_eval.py`` repeatedly with:
```
--num_beams 5 --length_penalty 0.8 --early_stopping true
--num_beams 5 --length_penalty 0.8 --early_stopping false
[...]
--num_beams 10 --length_penalty 1.2 --early_stopping false
```
On completion, this function prints a markdown table of the results sorted by the best BLEU score and the winning arguments.
"""
prog = sys.argv[0]
parser = argparse.ArgumentParser(
usage=(
"\n\nImportant: this script accepts all arguments `run_eval.py` accepts and then a few extra, therefore"
" refer to `run_eval.py -h` for the complete list."
)
)
parser.add_argument(
"--search",
type=str,
required=False,
help='param space to search, e.g. "num_beams=5:10 length_penalty=0.8:1.0:1.2"',
)
parser.add_argument(
"--bs", type=int, default=8, required=False, help="initial batch size (may get reduced if it's too big)"
)
parser.add_argument("--task", type=str, help="used for task_specific_params + metrics")
parser.add_argument(
"--info",
nargs="?",
type=str,
const=datetime_now(),
help=(
"add custom notes to be printed before the results table. If no value is passed, the current datetime"
" string will be used."
),
)
args, args_main = parser.parse_known_args()
# we share some of the args
args_main.extend(["--task", args.task])
args_normal = [prog] + args_main
# to support variations like translation_en_to_de"
task = "translation" if "translation" in args.task else "summarization"
matrix, col_names = parse_search_arg(args.search)
col_names[0:0] = task_score_names[task] # score cols first
col_widths = {col: len(str(col)) for col in col_names}
results = []
for r in matrix:
hparams = dict((x.replace("--", "").split() for x in r))
args_exp = " ".join(r).split()
args_exp.extend(["--bs", str(args.bs)]) # in case we need to reduce its size due to CUDA OOM
sys.argv = args_normal + args_exp
# XXX: need to trap CUDA OOM and lower args.bs if that happens and retry
scores = run_generate(verbose=False)
# make sure scores are first in the table
result = OrderedDict()
for score in task_score_names[task]:
result[score] = scores[score]
result.update(hparams)
results.append(result)
# find widest entries
for k, v in result.items():
l = len(str(v))
if l > col_widths[k]:
col_widths[k] = l
results_sorted = sorted(results, key=operator.itemgetter(*task_score_names[task]), reverse=True)
print(" | ".join([f"{col:{col_widths[col]}}" for col in col_names]))
print(" | ".join([f"{'-'*col_widths[col]}" for col in col_names]))
for row in results_sorted:
print(" | ".join([f"{row[col]:{col_widths[col]}}" for col in col_names]))
best = results_sorted[0]
for score in task_score_names[task]:
del best[score]
best_args = [f"--{k} {v}" for k, v in best.items()]
dyn_args = ["--bs", str(args.bs)]
if args.info:
print(f"\nInfo: {args.info}")
print("\nBest score args:")
print(" ".join(args_main + best_args + dyn_args))
return results_sorted
if __name__ == "__main__":
# Usage:
# [normal-run_eval_search.py cmd plus] \
# --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
#
# Example:
# PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval_search.py $MODEL_NAME \
# $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target \
# --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation \
# --search="num_beams=1:5:10 length_penalty=0.8:1:1.2 early_stopping=true:false"
run_search()
|
transformers/examples/legacy/seq2seq/run_eval_search.py/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/run_eval_search.py",
"repo_id": "transformers",
"token_count": 2316
}
|
# Copyright 2020 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
export WANDB_PROJECT=distil-marian
export BS=64
export GAS=1
export m=sshleifer/student_marian_en_ro_6_3
export MAX_LEN=128
python finetune_trainer.py \
--tokenizer_name $m --model_name_or_path $m \
--data_dir $ENRO_DIR \
--output_dir marian_en_ro_6_3 --overwrite_output_dir \
--learning_rate=3e-4 \
--warmup_steps 500 --sortish_sampler \
--fp16 \
--gradient_accumulation_steps=$GAS \
--per_device_train_batch_size=$BS --per_device_eval_batch_size=$BS \
--freeze_encoder --freeze_embeds \
--num_train_epochs=6 \
--save_steps 3000 --eval_steps 3000 \
--max_source_length $MAX_LEN --max_target_length $MAX_LEN \
--val_max_target_length $MAX_TGT_LEN --test_max_target_length $MAX_TGT_LEN \
--do_train --do_eval --do_predict \
--eval_strategy steps \
--predict_with_generate --logging_first_step \
--task translation --label_smoothing_factor 0.1 \
"$@"
|
transformers/examples/legacy/seq2seq/train_distil_marian_enro.sh/0
|
{
"file_path": "transformers/examples/legacy/seq2seq/train_distil_marian_enro.sh",
"repo_id": "transformers",
"token_count": 553
}
|
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
# This file was automatically generated from examples/modular-transformers/modular_switch_function.py.
# Do NOT edit this file manually as any edits will be overwritten by the generation of
# the file from the modular. If any change should be done, please apply the change to the
# modular_switch_function.py file directly. One of our CI enforces this.
# 🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨🚨
# Note that llama and cohere have different definitions for rotate_half
from typing import Callable, Optional, Tuple
import torch
from torch import nn
from ...cache_utils import Cache
from ...modeling_flash_attention_utils import FlashAttentionKwargs
from ...modeling_utils import ALL_ATTENTION_FUNCTIONS
from ...processing_utils import Unpack
from ...utils import logging
from .configuration_switch_function import SwitchFunctionConfig
logger = logging.get_logger(__name__)
def rotate_half(x):
# Split and rotate. Note that this function is different from e.g. Llama.
x1 = x[..., ::2]
x2 = x[..., 1::2]
rot_x = torch.stack([-x2, x1], dim=-1).flatten(-2)
return rot_x
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None, unsqueeze_dim=1):
"""Applies Rotary Position Embedding to the query and key tensors.
Args:
q (`torch.Tensor`): The query tensor.
k (`torch.Tensor`): The key tensor.
cos (`torch.Tensor`): The cosine part of the rotary embedding.
sin (`torch.Tensor`): The sine part of the rotary embedding.
position_ids (`torch.Tensor`, *optional*):
Deprecated and unused.
unsqueeze_dim (`int`, *optional*, defaults to 1):
The 'unsqueeze_dim' argument specifies the dimension along which to unsqueeze cos[position_ids] and
sin[position_ids] so that they can be properly broadcasted to the dimensions of q and k. For example, note
that cos[position_ids] and sin[position_ids] have the shape [batch_size, seq_len, head_dim]. Then, if q and
k have the shape [batch_size, heads, seq_len, head_dim], then setting unsqueeze_dim=1 makes
cos[position_ids] and sin[position_ids] broadcastable to the shapes of q and k. Similarly, if q and k have
the shape [batch_size, seq_len, heads, head_dim], then set unsqueeze_dim=2.
Returns:
`tuple(torch.Tensor)` comprising of the query and key tensors rotated using the Rotary Position Embedding.
"""
cos = cos.unsqueeze(unsqueeze_dim)
sin = sin.unsqueeze(unsqueeze_dim)
q_embed = (q * cos) + (rotate_half(q) * sin)
k_embed = (k * cos) + (rotate_half(k) * sin)
return q_embed, k_embed
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
def eager_attention_forward(
module: nn.Module,
query: torch.Tensor,
key: torch.Tensor,
value: torch.Tensor,
attention_mask: Optional[torch.Tensor],
scaling: float,
dropout: float = 0.0,
**kwargs,
):
key_states = repeat_kv(key, module.num_key_value_groups)
value_states = repeat_kv(value, module.num_key_value_groups)
attn_weights = torch.matmul(query, key_states.transpose(2, 3)) * scaling
if attention_mask is not None:
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=dropout, training=module.training)
attn_output = torch.matmul(attn_weights, value_states)
attn_output = attn_output.transpose(1, 2).contiguous()
return attn_output, attn_weights
class SwitchFunctionAttention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: SwitchFunctionConfig, layer_idx: int):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.head_dim = getattr(config, "head_dim", config.hidden_size // config.num_attention_heads)
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.scaling = self.head_dim**-0.5
self.attention_dropout = config.attention_dropout
self.is_causal = True
self.q_proj = nn.Linear(
config.hidden_size, config.num_attention_heads * self.head_dim, bias=config.attention_bias
)
self.k_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.v_proj = nn.Linear(
config.hidden_size, config.num_key_value_heads * self.head_dim, bias=config.attention_bias
)
self.o_proj = nn.Linear(
config.num_attention_heads * self.head_dim, config.hidden_size, bias=config.attention_bias
)
def forward(
self,
hidden_states: torch.Tensor,
position_embeddings: Tuple[torch.Tensor, torch.Tensor],
attention_mask: Optional[torch.Tensor],
past_key_value: Optional[Cache] = None,
cache_position: Optional[torch.LongTensor] = None,
**kwargs: Unpack[FlashAttentionKwargs],
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
input_shape = hidden_states.shape[:-1]
hidden_shape = (*input_shape, -1, self.head_dim)
query_states = self.q_proj(hidden_states).view(hidden_shape).transpose(1, 2)
key_states = self.k_proj(hidden_states).view(hidden_shape).transpose(1, 2)
value_states = self.v_proj(hidden_states).view(hidden_shape).transpose(1, 2)
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
# sin and cos are specific to RoPE models; cache_position needed for the static cache
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
attention_interface: Callable = eager_attention_forward
if self.config._attn_implementation != "eager":
if self.config._attn_implementation == "sdpa" and kwargs.get("output_attentions", False):
logger.warning_once(
"`torch.nn.functional.scaled_dot_product_attention` does not support `output_attentions=True`. Falling back to "
'eager attention. This warning can be removed using the argument `attn_implementation="eager"` when loading the model.'
)
else:
attention_interface = ALL_ATTENTION_FUNCTIONS[self.config._attn_implementation]
attn_output, attn_weights = attention_interface(
self,
query_states,
key_states,
value_states,
attention_mask,
dropout=0.0 if not self.training else self.attention_dropout,
scaling=self.scaling,
**kwargs,
)
attn_output = attn_output.reshape(*input_shape, -1).contiguous()
attn_output = self.o_proj(attn_output)
return attn_output, attn_weights
|
transformers/examples/modular-transformers/modeling_switch_function.py/0
|
{
"file_path": "transformers/examples/modular-transformers/modeling_switch_function.py",
"repo_id": "transformers",
"token_count": 3528
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
import argparse
import logging
import math
import os
from pathlib import Path
import datasets
import numpy as np
import torch
from accelerate import Accelerator, DistributedType
from accelerate.utils import set_seed
from datasets import load_dataset
from huggingface_hub import HfApi
from torch.utils.data import DataLoader
from torchvision.transforms import Compose, Lambda, Normalize, RandomHorizontalFlip, RandomResizedCrop, ToTensor
from tqdm.auto import tqdm
import transformers
from transformers import (
CONFIG_MAPPING,
IMAGE_PROCESSOR_MAPPING,
MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING,
AutoConfig,
AutoImageProcessor,
AutoModelForMaskedImageModeling,
SchedulerType,
get_scheduler,
)
from transformers.utils import check_min_version, send_example_telemetry
from transformers.utils.versions import require_version
""" Pre-training a 🤗 Transformers model for simple masked image modeling (SimMIM)
without using HuggingFace Trainer.
Any model supported by the AutoModelForMaskedImageModeling API can be used.
"""
logger = logging.getLogger(__name__)
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/image-pretraining/requirements.txt")
MODEL_CONFIG_CLASSES = list(MODEL_FOR_MASKED_IMAGE_MODELING_MAPPING.keys())
MODEL_TYPES = tuple(conf.model_type for conf in MODEL_CONFIG_CLASSES)
def parse_args():
parser = argparse.ArgumentParser(
description="Finetune a transformers model on a simple Masked Image Modeling task"
)
parser.add_argument(
"--dataset_name",
type=str,
default="cifar10",
help="Name of a dataset from the datasets package",
)
parser.add_argument(
"--dataset_config_name",
type=str,
default=None,
help="The configuration name of the dataset to use (via the datasets library).",
)
parser.add_argument(
"--image_column_name",
type=str,
default=None,
help="The column name of the images in the files. If not set, will try to use 'image' or 'img'.",
)
parser.add_argument(
"--train_dir",
type=str,
default=None,
help="A folder containing the training data.",
)
parser.add_argument(
"--validation_dir",
type=None,
default=None,
help="A folder containing the validation data.",
)
parser.add_argument(
"--train_val_split",
type=float,
default=0.15,
help="Percent to split off of train for validation.",
)
parser.add_argument(
"--mask_patch_size",
type=int,
default=32,
help="The size of the square patches to use for masking.",
)
parser.add_argument(
"--mask_ratio",
type=float,
default=0.6,
help="Percentage of patches to mask.",
)
parser.add_argument(
"--max_train_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
),
)
parser.add_argument(
"--max_eval_samples",
type=int,
default=None,
help=(
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
),
)
parser.add_argument(
"--model_name_or_path",
type=str,
default=None,
help=(
"The model checkpoint for weights initialization. Can be a local path to a pytorch_model.bin or a "
"checkpoint identifier on the hub. "
"Don't set if you want to train a model from scratch."
),
)
parser.add_argument(
"--model_type",
type=str,
default=None,
help="If training from scratch, pass a model type from the list: " + ", ".join(MODEL_TYPES),
)
parser.add_argument(
"--config_name_or_path",
type=str,
default=None,
help="Pretrained config name or path if not the same as model_name",
)
parser.add_argument(
"--config_overrides",
type=str,
default=None,
help=(
"Override some existing default config settings when a model is trained from scratch. Example: "
"n_embd=10,resid_pdrop=0.2,scale_attn_weights=false,summary_type=cls_index"
),
)
parser.add_argument(
"--cache_dir",
type=str,
default=None,
help="Where do you want to store (cache) the pretrained models/datasets downloaded from the hub",
)
parser.add_argument(
"--model_revision",
type=str,
default="main",
help="The specific model version to use (can be a branch name, tag name or commit id).",
)
parser.add_argument(
"--gradient_accumulation_steps",
type=int,
default=1,
help="Number of updates steps to accumulate before performing a backward/update pass.",
)
parser.add_argument(
"--image_processor_name",
type=str,
default=None,
help="Name or path of preprocessor config.",
)
parser.add_argument(
"--token",
type=str,
default=None,
help=(
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
),
)
parser.add_argument(
"--trust_remote_code",
action="store_true",
help=(
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
),
)
parser.add_argument(
"--image_size",
type=int,
default=None,
help="The size (resolution) of each image. If not specified, will use `image_size` of the configuration.",
)
parser.add_argument(
"--patch_size",
type=int,
default=None,
help="The size (resolution) of each patch. If not specified, will use `patch_size` of the configuration.",
)
parser.add_argument(
"--encoder_stride",
type=int,
default=None,
help={"help": "Stride to use for the encoder."},
)
parser.add_argument(
"--push_to_hub",
action="store_true",
help="Whether or not to push the model to the Hub.",
)
parser.add_argument(
"--with_tracking",
action="store_true",
help="Whether to enable experiment trackers for logging.",
)
parser.add_argument(
"--report_to",
type=str,
default="all",
help=(
'The integration to report the results and logs to. Supported platforms are `"tensorboard"`,'
' `"wandb"`, `"comet_ml"` and `"clearml"`. Use `"all"` (default) to report to all integrations. '
"Only applicable when `--with_tracking` is passed."
),
)
parser.add_argument(
"--seed",
type=int,
default=None,
help="A seed for reproducible training.",
)
parser.add_argument(
"--per_device_train_batch_size",
type=int,
default=8,
help="Batch size (per device) for the training dataloader.",
)
parser.add_argument(
"--learning_rate",
type=float,
default=5e-5,
help="The initial learning rate for [`AdamW`] optimizer.",
)
parser.add_argument(
"--weight_decay",
type=float,
default=0.0,
help="Weight decay to use.",
)
parser.add_argument(
"--num_train_epochs",
type=float,
default=3.0,
help="Total number of training epochs to perform (if not an integer, will perform the decimal part percents of the last epoch before stopping training).",
)
parser.add_argument(
"--max_train_steps",
type=int,
default=None,
help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
)
parser.add_argument(
"--lr_scheduler_type",
type=SchedulerType,
default="linear",
help="The scheduler type to use.",
choices=["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"],
)
parser.add_argument(
"--num_warmup_steps",
type=int,
default=0,
help="Number of steps for the warmup in the lr scheduler.",
)
parser.add_argument(
"--checkpointing_steps",
type=str,
default=None,
help="Whether the various states should be saved at the end of every n steps, or 'epoch' for each epoch.",
)
parser.add_argument(
"--resume_from_checkpoint",
type=str,
default=None,
help="If the training should continue from a checkpoint folder.",
)
parser.add_argument(
"--per_device_eval_batch_size",
type=int,
default=8,
help="Batch size (per device) for the evaluation dataloader.",
)
parser.add_argument(
"--output_dir",
type=str,
default=None,
help="Where to store the final model.",
)
args = parser.parse_args()
# Sanity checks
data_files = {}
if args.train_dir is not None:
data_files["train"] = args.train_dir
if args.validation_dir is not None:
data_files["val"] = args.validation_dir
args.data_files = data_files if data_files else None
if args.push_to_hub:
assert args.output_dir is not None, "Need an `output_dir` to create a repo when `--push_to_hub` is passed."
return args
class MaskGenerator:
"""
A class to generate boolean masks for the pretraining task.
A mask is a 1D tensor of shape (model_patch_size**2,) where the value is either 0 or 1,
where 1 indicates "masked".
"""
def __init__(self, input_size=192, mask_patch_size=32, model_patch_size=4, mask_ratio=0.6):
self.input_size = input_size
self.mask_patch_size = mask_patch_size
self.model_patch_size = model_patch_size
self.mask_ratio = mask_ratio
if self.input_size % self.mask_patch_size != 0:
raise ValueError("Input size must be divisible by mask patch size")
if self.mask_patch_size % self.model_patch_size != 0:
raise ValueError("Mask patch size must be divisible by model patch size")
self.rand_size = self.input_size // self.mask_patch_size
self.scale = self.mask_patch_size // self.model_patch_size
self.token_count = self.rand_size**2
self.mask_count = int(np.ceil(self.token_count * self.mask_ratio))
def __call__(self):
mask_idx = np.random.permutation(self.token_count)[: self.mask_count]
mask = np.zeros(self.token_count, dtype=int)
mask[mask_idx] = 1
mask = mask.reshape((self.rand_size, self.rand_size))
mask = mask.repeat(self.scale, axis=0).repeat(self.scale, axis=1)
return torch.tensor(mask.flatten())
def collate_fn(examples):
pixel_values = torch.stack([example["pixel_values"] for example in examples])
mask = torch.stack([example["mask"] for example in examples])
return {"pixel_values": pixel_values, "bool_masked_pos": mask}
def main():
args = parse_args()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_mim_no_trainer", args)
# Initialize the accelerator. We will let the accelerator handle device placement for us in this example.
# If we're using tracking, we also need to initialize it here and it will by default pick up all supported trackers
# in the environment
accelerator_log_kwargs = {}
if args.with_tracking:
accelerator_log_kwargs["log_with"] = args.report_to
accelerator_log_kwargs["project_dir"] = args.output_dir
accelerator = Accelerator(
gradient_accumulation_steps=args.gradient_accumulation_steps,
**accelerator_log_kwargs,
)
# Make one log on every process with the configuration for debugging.
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger.info(accelerator.state)
if accelerator.is_local_main_process:
datasets.utils.logging.set_verbosity_warning()
transformers.utils.logging.set_verbosity_info()
else:
datasets.utils.logging.set_verbosity_error()
transformers.utils.logging.set_verbosity_error()
# If passed along, set the training seed now.
if args.seed is not None:
set_seed(args.seed)
# Handle the repository creation
if accelerator.is_main_process:
if args.push_to_hub:
# Retrieve of infer repo_name
repo_name = args.hub_model_id
if repo_name is None:
repo_name = Path(args.output_dir).absolute().name
# Create repo and retrieve repo_id
api = HfApi()
repo_id = api.create_repo(repo_name, exist_ok=True, token=args.hub_token).repo_id
with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
if "step_*" not in gitignore:
gitignore.write("step_*\n")
if "epoch_*" not in gitignore:
gitignore.write("epoch_*\n")
elif args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
accelerator.wait_for_everyone()
# Initialize our dataset.
ds = load_dataset(
args.dataset_name,
args.dataset_config_name,
data_files=args.data_files,
cache_dir=args.cache_dir,
token=args.token,
trust_remote_code=args.trust_remote_code,
)
# If we don't have a validation split, split off a percentage of train as validation.
args.train_val_split = None if "validation" in ds.keys() else args.train_val_split
if isinstance(args.train_val_split, float) and args.train_val_split > 0.0:
split = ds["train"].train_test_split(args.train_val_split)
ds["train"] = split["train"]
ds["validation"] = split["test"]
# Create config
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config_kwargs = {
"cache_dir": args.cache_dir,
"revision": args.model_revision,
"token": args.token,
"trust_remote_code": args.trust_remote_code,
}
if args.config_name_or_path:
config = AutoConfig.from_pretrained(args.config_name_or_path, **config_kwargs)
elif args.model_name_or_path:
config = AutoConfig.from_pretrained(args.model_name_or_path, **config_kwargs)
else:
config = CONFIG_MAPPING[args.model_type]()
logger.warning("You are instantiating a new config instance from scratch.")
if args.config_overrides is not None:
logger.info(f"Overriding config: {args.config_overrides}")
config.update_from_string(args.config_overrides)
logger.info(f"New config: {config}")
# make sure the decoder_type is "simmim" (only relevant for BEiT)
if hasattr(config, "decoder_type"):
config.decoder_type = "simmim"
# adapt config
args.image_size = args.image_size if args.image_size is not None else config.image_size
args.patch_size = args.patch_size if args.patch_size is not None else config.patch_size
args.encoder_stride = args.encoder_stride if args.encoder_stride is not None else config.encoder_stride
config.update(
{
"image_size": args.image_size,
"patch_size": args.patch_size,
"encoder_stride": args.encoder_stride,
}
)
# create image processor
if args.image_processor_name:
image_processor = AutoImageProcessor.from_pretrained(args.image_processor_name, **config_kwargs)
elif args.model_name_or_path:
image_processor = AutoImageProcessor.from_pretrained(args.model_name_or_path, **config_kwargs)
else:
IMAGE_PROCESSOR_TYPES = {
conf.model_type: image_processor_class for conf, image_processor_class in IMAGE_PROCESSOR_MAPPING.items()
}
image_processor = IMAGE_PROCESSOR_TYPES[args.model_type]()
# create model
if args.model_name_or_path:
model = AutoModelForMaskedImageModeling.from_pretrained(
args.model_name_or_path,
from_tf=bool(".ckpt" in args.model_name_or_path),
config=config,
cache_dir=args.cache_dir,
revision=args.model_revision,
token=args.token,
trust_remote_code=args.trust_remote_code,
)
else:
logger.info("Training new model from scratch")
model = AutoModelForMaskedImageModeling.from_config(
config,
token=args.token,
trust_remote_code=args.trust_remote_code,
)
column_names = ds["train"].column_names
if args.image_column_name is not None:
image_column_name = args.image_column_name
elif "image" in column_names:
image_column_name = "image"
elif "img" in column_names:
image_column_name = "img"
else:
image_column_name = column_names[0]
# transformations as done in original SimMIM paper
# source: https://github.com/microsoft/SimMIM/blob/main/data/data_simmim.py
transforms = Compose(
[
Lambda(lambda img: img.convert("RGB")),
RandomResizedCrop(args.image_size, scale=(0.67, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
RandomHorizontalFlip(),
ToTensor(),
Normalize(mean=image_processor.image_mean, std=image_processor.image_std),
]
)
# create mask generator
mask_generator = MaskGenerator(
input_size=args.image_size,
mask_patch_size=args.mask_patch_size,
model_patch_size=args.patch_size,
mask_ratio=args.mask_ratio,
)
def preprocess_images(examples):
"""Preprocess a batch of images by applying transforms + creating a corresponding mask, indicating
which patches to mask."""
examples["pixel_values"] = [transforms(image) for image in examples[image_column_name]]
examples["mask"] = [mask_generator() for i in range(len(examples[image_column_name]))]
return examples
if args.max_train_samples is not None:
ds["train"] = ds["train"].shuffle(seed=args.seed).select(range(args.max_train_samples))
# Set the training transforms
ds["train"].set_transform(preprocess_images)
if args.max_eval_samples is not None:
ds["validation"] = ds["validation"].shuffle(seed=args.seed).select(range(args.max_eval_samples))
# Set the validation transforms
ds["validation"].set_transform(preprocess_images)
# DataLoaders creation:
train_dataloader = DataLoader(
ds["train"],
shuffle=True,
collate_fn=collate_fn,
batch_size=args.per_device_train_batch_size,
)
eval_dataloader = DataLoader(
ds["validation"],
collate_fn=collate_fn,
batch_size=args.per_device_eval_batch_size,
)
# Optimizer
# Split weights in two groups, one with weight decay and the other not.
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": args.weight_decay,
},
{
"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
]
optimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=args.learning_rate)
# Note -> the training dataloader needs to be prepared before we grab his length below (cause its length will be
# shorter in multiprocess)
# Scheduler and math around the number of training steps.
overrode_max_train_steps = False
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if args.max_train_steps is None:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
overrode_max_train_steps = True
lr_scheduler = get_scheduler(
name=args.lr_scheduler_type,
optimizer=optimizer,
num_warmup_steps=args.num_warmup_steps * accelerator.num_processes,
num_training_steps=args.max_train_steps
if overrode_max_train_steps
else args.max_train_steps * accelerator.num_processes,
)
# Prepare everything with our `accelerator`.
model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
model,
optimizer,
train_dataloader,
eval_dataloader,
lr_scheduler,
)
# On TPU, the tie weights in our model have been disconnected, so we need to restore the ties.
if accelerator.distributed_type == DistributedType.TPU:
model.tie_weights()
# We need to recalculate our total training steps as the size of the training dataloader may have changed.
num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
if overrode_max_train_steps:
args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
# Afterwards we recalculate our number of training epochs
args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
# Figure out how many steps we should save the Accelerator states
checkpointing_steps = args.checkpointing_steps
if checkpointing_steps is not None and checkpointing_steps.isdigit():
checkpointing_steps = int(checkpointing_steps)
# We need to initialize the trackers we use, and also store our configuration.
# The trackers initializes automatically on the main process.
if args.with_tracking:
experiment_config = vars(args)
# TensorBoard cannot log Enums, need the raw value
experiment_config["lr_scheduler_type"] = experiment_config["lr_scheduler_type"].value
accelerator.init_trackers("mim_no_trainer", experiment_config)
# Train!
total_batch_size = args.per_device_train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
logger.info("***** Running training *****")
logger.info(f" Num examples = {len(ds['train'])}")
logger.info(f" Num Epochs = {args.num_train_epochs}")
logger.info(f" Instantaneous batch size per device = {args.per_device_train_batch_size}")
logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
logger.info(f" Total optimization steps = {args.max_train_steps}")
# Only show the progress bar once on each machine.
progress_bar = tqdm(range(int(args.max_train_steps)), disable=not accelerator.is_local_main_process)
completed_steps = 0
starting_epoch = 0
# Potentially load in the weights and states from a previous save
if args.resume_from_checkpoint:
if args.resume_from_checkpoint is not None or args.resume_from_checkpoint != "":
checkpoint_path = args.resume_from_checkpoint
path = os.path.basename(args.resume_from_checkpoint)
else:
# Get the most recent checkpoint
dirs = [f.name for f in os.scandir(os.getcwd()) if f.is_dir()]
dirs.sort(key=os.path.getctime)
path = dirs[-1] # Sorts folders by date modified, most recent checkpoint is the last
checkpoint_path = path
path = os.path.basename(checkpoint_path)
accelerator.print(f"Resumed from checkpoint: {checkpoint_path}")
accelerator.load_state(checkpoint_path)
# Extract `epoch_{i}` or `step_{i}`
training_difference = os.path.splitext(path)[0]
if "epoch" in training_difference:
starting_epoch = int(training_difference.replace("epoch_", "")) + 1
resume_step = None
completed_steps = starting_epoch * num_update_steps_per_epoch
else:
# need to multiply `gradient_accumulation_steps` to reflect real steps
resume_step = int(training_difference.replace("step_", "")) * args.gradient_accumulation_steps
starting_epoch = resume_step // len(train_dataloader)
completed_steps = resume_step // args.gradient_accumulation_steps
resume_step -= starting_epoch * len(train_dataloader)
# update the progress_bar if load from checkpoint
progress_bar.update(completed_steps)
for epoch in range(starting_epoch, args.num_train_epochs):
model.train()
if args.with_tracking:
total_loss = 0
if args.resume_from_checkpoint and epoch == starting_epoch and resume_step is not None:
# We skip the first `n` batches in the dataloader when resuming from a checkpoint
active_dataloader = accelerator.skip_first_batches(train_dataloader, resume_step)
else:
active_dataloader = train_dataloader
for step, batch in enumerate(active_dataloader):
with accelerator.accumulate(model):
outputs = model(**batch)
loss = outputs.loss
# We keep track of the loss at each epoch
if args.with_tracking:
total_loss += loss.detach().float()
accelerator.backward(loss)
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
# Checks if the accelerator has performed an optimization step behind the scenes
if accelerator.sync_gradients:
progress_bar.update(1)
completed_steps += 1
if isinstance(checkpointing_steps, int):
if completed_steps % checkpointing_steps == 0 and accelerator.sync_gradients:
output_dir = f"step_{completed_steps}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if completed_steps >= args.max_train_steps:
break
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(**batch)
loss = outputs.loss
losses.append(accelerator.gather_for_metrics(loss.repeat(args.per_device_eval_batch_size)))
losses = torch.cat(losses)
eval_loss = torch.mean(losses)
logger.info(f"epoch {epoch}: eval_loss: {eval_loss}")
if args.with_tracking:
accelerator.log(
{
"eval_loss": eval_loss,
"train_loss": total_loss.item() / len(train_dataloader),
"epoch": epoch,
"step": completed_steps,
},
step=completed_steps,
)
if args.push_to_hub and epoch < args.num_train_epochs - 1:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
image_processor.save_pretrained(args.output_dir)
api.upload_folder(
commit_message=f"Training in progress epoch {epoch}",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
if args.checkpointing_steps == "epoch":
output_dir = f"epoch_{epoch}"
if args.output_dir is not None:
output_dir = os.path.join(args.output_dir, output_dir)
accelerator.save_state(output_dir)
if args.with_tracking:
accelerator.end_training()
if args.output_dir is not None:
accelerator.wait_for_everyone()
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
args.output_dir, is_main_process=accelerator.is_main_process, save_function=accelerator.save
)
if accelerator.is_main_process:
image_processor.save_pretrained(args.output_dir)
if args.push_to_hub:
api.upload_folder(
commit_message="End of training",
folder_path=args.output_dir,
repo_id=repo_id,
repo_type="model",
token=args.hub_token,
)
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/image-pretraining/run_mim_no_trainer.py/0
|
{
"file_path": "transformers/examples/pytorch/image-pretraining/run_mim_no_trainer.py",
"repo_id": "transformers",
"token_count": 12859
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for sequence to sequence.
"""
# You can also adapt this script on your own sequence to sequence task. Pointers for this are left as comments.
import logging
import os
import sys
from dataclasses import dataclass, field
from typing import Optional
import datasets
import evaluate
import nltk # Here to have a nice missing dependency error message early on
import numpy as np
from datasets import load_dataset
from filelock import FileLock
import transformers
from transformers import (
AutoConfig,
AutoModelForSeq2SeqLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
HfArgumentParser,
MBart50Tokenizer,
MBart50TokenizerFast,
MBartTokenizer,
MBartTokenizerFast,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
set_seed,
)
from transformers.trainer_utils import get_last_checkpoint
from transformers.utils import check_min_version, is_offline_mode, send_example_telemetry
from transformers.utils.versions import require_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.49.0.dev0")
require_version("datasets>=1.8.0", "To fix: pip install -r examples/pytorch/summarization/requirements.txt")
logger = logging.getLogger(__name__)
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
if is_offline_mode():
raise LookupError(
"Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
)
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
# A list of all multilingual tokenizer which require lang attribute.
MULTILINGUAL_TOKENIZERS = [MBartTokenizer, MBartTokenizerFast, MBart50Tokenizer, MBart50TokenizerFast]
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained tokenizer name or path if not the same as model_name"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
token: str = field(
default=None,
metadata={
"help": (
"The token to use as HTTP bearer authorization for remote files. If not specified, will use the token "
"generated when running `huggingface-cli login` (stored in `~/.huggingface`)."
)
},
)
trust_remote_code: bool = field(
default=False,
metadata={
"help": (
"Whether to trust the execution of code from datasets/models defined on the Hub."
" This option should only be set to `True` for repositories you trust and in which you have read the"
" code, as it will execute code present on the Hub on your local machine."
)
},
)
resize_position_embeddings: Optional[bool] = field(
default=None,
metadata={
"help": (
"Whether to automatically resize the position embeddings if `max_source_length` exceeds "
"the model's position embeddings."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
lang: Optional[str] = field(default=None, metadata={"help": "Language id for summarization."})
dataset_name: Optional[str] = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
text_column: Optional[str] = field(
default=None,
metadata={"help": "The name of the column in the datasets containing the full texts (for summarization)."},
)
summary_column: Optional[str] = field(
default=None,
metadata={"help": "The name of the column in the datasets containing the summaries (for summarization)."},
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={
"help": (
"An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
)
},
)
test_file: Optional[str] = field(
default=None,
metadata={
"help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_source_length: Optional[int] = field(
default=1024,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_target_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total sequence length for target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
val_max_target_length: Optional[int] = field(
default=None,
metadata={
"help": (
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
"during ``evaluate`` and ``predict``."
)
},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to model maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
num_beams: Optional[int] = field(
default=1,
metadata={
"help": (
"Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
"which is used during ``evaluate`` and ``predict``."
)
},
)
ignore_pad_token_for_loss: bool = field(
default=True,
metadata={
"help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
},
)
source_prefix: Optional[str] = field(
default=None, metadata={"help": "A prefix to add before every source text (useful for T5 models)."}
)
forced_bos_token: Optional[str] = field(
default=None,
metadata={
"help": (
"The token to force as the first generated token after the decoder_start_token_id. "
"Useful for multilingual models like mBART where the first generated token"
"needs to be the target language token (Usually it is the target language token)"
)
},
)
def __post_init__(self):
if (
self.dataset_name is None
and self.train_file is None
and self.validation_file is None
and self.test_file is None
):
raise ValueError("Need either a dataset name or a training, validation, or test file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if self.test_file is not None:
extension = self.test_file.split(".")[-1]
assert extension in ["csv", "json"], "`test_file` should be a csv or a json file."
if self.val_max_target_length is None:
self.val_max_target_length = self.max_target_length
summarization_name_mapping = {
"amazon_reviews_multi": ("review_body", "review_title"),
"big_patent": ("description", "abstract"),
"cnn_dailymail": ("article", "highlights"),
"orange_sum": ("text", "summary"),
"pn_summary": ("article", "summary"),
"psc": ("extract_text", "summary_text"),
"samsum": ("dialogue", "summary"),
"thaisum": ("body", "summary"),
"xglue": ("news_body", "news_title"),
"xsum": ("document", "summary"),
"wiki_summary": ("article", "highlights"),
"multi_news": ("document", "summary"),
}
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Sending telemetry. Tracking the example usage helps us better allocate resources to maintain them. The
# information sent is the one passed as arguments along with your Python/PyTorch versions.
send_example_telemetry("run_summarization", model_args, data_args)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
if training_args.should_log:
# The default of training_args.log_level is passive, so we set log level at info here to have that default.
transformers.utils.logging.set_verbosity_info()
log_level = training_args.get_process_log_level()
logger.setLevel(log_level)
datasets.utils.logging.set_verbosity(log_level)
transformers.utils.logging.set_verbosity(log_level)
transformers.utils.logging.enable_default_handler()
transformers.utils.logging.enable_explicit_format()
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}, "
+ f"distributed training: {training_args.parallel_mode.value == 'distributed'}, 16-bits training: {training_args.fp16}"
)
logger.info(f"Training/evaluation parameters {training_args}")
if data_args.source_prefix is None and model_args.model_name_or_path in [
"google-t5/t5-small",
"google-t5/t5-base",
"google-t5/t5-large",
"google-t5/t5-3b",
"google-t5/t5-11b",
]:
logger.warning(
"You're running a t5 model but didn't provide a source prefix, which is the expected, e.g. with "
"`--source_prefix 'summarize: ' `"
)
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For CSV/JSON files this script will use the first column for the full texts and the second column for the
# summaries (unless you specify column names for this with the `text_column` and `summary_column` arguments).
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
raw_datasets = load_dataset(
data_args.dataset_name,
data_args.dataset_config_name,
cache_dir=model_args.cache_dir,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
raw_datasets = load_dataset(
extension,
data_files=data_files,
cache_dir=model_args.cache_dir,
token=model_args.token,
)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
tokenizer = AutoTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
model = AutoModelForSeq2SeqLM.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=model_args.token,
trust_remote_code=model_args.trust_remote_code,
)
# We resize the embeddings only when necessary to avoid index errors. If you are creating a model from scratch
# on a small vocab and want a smaller embedding size, remove this test.
embedding_size = model.get_input_embeddings().weight.shape[0]
if len(tokenizer) > embedding_size:
model.resize_token_embeddings(len(tokenizer))
if model.config.decoder_start_token_id is None and isinstance(tokenizer, (MBartTokenizer, MBartTokenizerFast)):
if isinstance(tokenizer, MBartTokenizer):
model.config.decoder_start_token_id = tokenizer.lang_code_to_id[data_args.lang]
else:
model.config.decoder_start_token_id = tokenizer.convert_tokens_to_ids(data_args.lang)
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
if (
hasattr(model.config, "max_position_embeddings")
and model.config.max_position_embeddings < data_args.max_source_length
):
if model_args.resize_position_embeddings is None:
logger.warning(
"Increasing the model's number of position embedding vectors from"
f" {model.config.max_position_embeddings} to {data_args.max_source_length}."
)
model.resize_position_embeddings(data_args.max_source_length)
elif model_args.resize_position_embeddings:
model.resize_position_embeddings(data_args.max_source_length)
else:
raise ValueError(
f"`--max_source_length` is set to {data_args.max_source_length}, but the model only has"
f" {model.config.max_position_embeddings} position encodings. Consider either reducing"
f" `--max_source_length` to {model.config.max_position_embeddings} or to automatically resize the"
" model's position encodings by passing `--resize_position_embeddings`."
)
prefix = data_args.source_prefix if data_args.source_prefix is not None else ""
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if training_args.do_train:
if "train" not in raw_datasets:
raise ValueError("--do_train requires a train dataset")
column_names = raw_datasets["train"].column_names
elif training_args.do_eval:
if "validation" not in raw_datasets:
raise ValueError("--do_eval requires a validation dataset")
column_names = raw_datasets["validation"].column_names
elif training_args.do_predict:
if "test" not in raw_datasets:
raise ValueError("--do_predict requires a test dataset")
column_names = raw_datasets["test"].column_names
else:
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
return
if isinstance(tokenizer, tuple(MULTILINGUAL_TOKENIZERS)):
assert (
data_args.lang is not None
), f"{tokenizer.__class__.__name__} is a multilingual tokenizer which requires --lang argument"
tokenizer.src_lang = data_args.lang
tokenizer.tgt_lang = data_args.lang
# For multilingual translation models like mBART-50 and M2M100 we need to force the target language token
# as the first generated token. We ask the user to explicitly provide this as --forced_bos_token argument.
forced_bos_token_id = (
tokenizer.lang_code_to_id[data_args.forced_bos_token] if data_args.forced_bos_token is not None else None
)
model.config.forced_bos_token_id = forced_bos_token_id
# Get the column names for input/target.
dataset_columns = summarization_name_mapping.get(data_args.dataset_name, None)
if data_args.text_column is None:
text_column = dataset_columns[0] if dataset_columns is not None else column_names[0]
else:
text_column = data_args.text_column
if text_column not in column_names:
raise ValueError(
f"--text_column' value '{data_args.text_column}' needs to be one of: {', '.join(column_names)}"
)
if data_args.summary_column is None:
summary_column = dataset_columns[1] if dataset_columns is not None else column_names[1]
else:
summary_column = data_args.summary_column
if summary_column not in column_names:
raise ValueError(
f"--summary_column' value '{data_args.summary_column}' needs to be one of: {', '.join(column_names)}"
)
# Temporarily set max_target_length for training.
max_target_length = data_args.max_target_length
padding = "max_length" if data_args.pad_to_max_length else False
if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
logger.warning(
"label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
)
def preprocess_function(examples):
# remove pairs where at least one record is None
inputs, targets = [], []
for i in range(len(examples[text_column])):
if examples[text_column][i] and examples[summary_column][i]:
inputs.append(examples[text_column][i])
targets.append(examples[summary_column][i])
inputs = [prefix + inp for inp in inputs]
model_inputs = tokenizer(inputs, max_length=data_args.max_source_length, padding=padding, truncation=True)
# Tokenize targets with the `text_target` keyword argument
labels = tokenizer(text_target=targets, max_length=max_target_length, padding=padding, truncation=True)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length" and data_args.ignore_pad_token_for_loss:
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
if training_args.do_train:
train_dataset = raw_datasets["train"]
if data_args.max_train_samples is not None:
max_train_samples = min(len(train_dataset), data_args.max_train_samples)
train_dataset = train_dataset.select(range(max_train_samples))
with training_args.main_process_first(desc="train dataset map pre-processing"):
train_dataset = train_dataset.map(
preprocess_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on train dataset",
)
if training_args.do_eval:
max_target_length = data_args.val_max_target_length
eval_dataset = raw_datasets["validation"]
if data_args.max_eval_samples is not None:
max_eval_samples = min(len(eval_dataset), data_args.max_eval_samples)
eval_dataset = eval_dataset.select(range(max_eval_samples))
with training_args.main_process_first(desc="validation dataset map pre-processing"):
eval_dataset = eval_dataset.map(
preprocess_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on validation dataset",
)
if training_args.do_predict:
max_target_length = data_args.val_max_target_length
predict_dataset = raw_datasets["test"]
if data_args.max_predict_samples is not None:
max_predict_samples = min(len(predict_dataset), data_args.max_predict_samples)
predict_dataset = predict_dataset.select(range(max_predict_samples))
with training_args.main_process_first(desc="prediction dataset map pre-processing"):
predict_dataset = predict_dataset.map(
preprocess_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
desc="Running tokenizer on prediction dataset",
)
# Data collator
label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8 if training_args.fp16 else None,
)
# Metric
metric = evaluate.load("rouge", cache_dir=model_args.cache_dir)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
# rougeLSum expects newline after each sentence
preds = ["\n".join(nltk.sent_tokenize(pred)) for pred in preds]
labels = ["\n".join(nltk.sent_tokenize(label)) for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
# Replace -100s used for padding as we can't decode them
preds = np.where(preds != -100, preds, tokenizer.pad_token_id)
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
result = metric.compute(predictions=decoded_preds, references=decoded_labels, use_stemmer=True)
result = {k: round(v * 100, 4) for k, v in result.items()}
prediction_lens = [np.count_nonzero(pred != tokenizer.pad_token_id) for pred in preds]
result["gen_len"] = np.mean(prediction_lens)
return result
# Override the decoding parameters of Seq2SeqTrainer
training_args.generation_max_length = (
training_args.generation_max_length
if training_args.generation_max_length is not None
else data_args.val_max_target_length
)
training_args.generation_num_beams = (
data_args.num_beams if data_args.num_beams is not None else training_args.generation_num_beams
)
# Initialize our Trainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
processing_class=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
# Training
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
if isinstance(eval_dataset, dict):
metrics = {}
for eval_ds_name, eval_ds in eval_dataset.items():
dataset_metrics = trainer.evaluate(eval_dataset=eval_ds, metric_key_prefix=f"eval_{eval_ds_name}")
metrics.update(dataset_metrics)
else:
metrics = trainer.evaluate(metric_key_prefix="eval")
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.do_predict:
logger.info("*** Predict ***")
predict_results = trainer.predict(predict_dataset, metric_key_prefix="predict")
metrics = predict_results.metrics
max_predict_samples = (
data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
if trainer.is_world_process_zero():
if training_args.predict_with_generate:
predictions = predict_results.predictions
predictions = np.where(predictions != -100, predictions, tokenizer.pad_token_id)
predictions = tokenizer.batch_decode(
predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
predictions = [pred.strip() for pred in predictions]
output_prediction_file = os.path.join(training_args.output_dir, "generated_predictions.txt")
with open(output_prediction_file, "w") as writer:
writer.write("\n".join(predictions))
kwargs = {"finetuned_from": model_args.model_name_or_path, "tasks": "summarization"}
if data_args.dataset_name is not None:
kwargs["dataset_tags"] = data_args.dataset_name
if data_args.dataset_config_name is not None:
kwargs["dataset_args"] = data_args.dataset_config_name
kwargs["dataset"] = f"{data_args.dataset_name} {data_args.dataset_config_name}"
else:
kwargs["dataset"] = data_args.dataset_name
if data_args.lang is not None:
kwargs["language"] = data_args.lang
if training_args.push_to_hub:
trainer.push_to_hub(**kwargs)
else:
trainer.create_model_card(**kwargs)
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
|
transformers/examples/pytorch/summarization/run_summarization.py/0
|
{
"file_path": "transformers/examples/pytorch/summarization/run_summarization.py",
"repo_id": "transformers",
"token_count": 13637
}
|
# coding=utf-8
# Copyright 2020 Google AI, Google Brain, the HuggingFace Inc. team and Microsoft Corporation.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""PyTorch ALBERT model with Patience-based Early Exit."""
import logging
import torch
from torch import nn
from torch.nn import CrossEntropyLoss, MSELoss
from transformers.file_utils import add_start_docstrings, add_start_docstrings_to_model_forward
from transformers.models.albert.modeling_albert import (
ALBERT_INPUTS_DOCSTRING,
ALBERT_START_DOCSTRING,
AlbertModel,
AlbertPreTrainedModel,
AlbertTransformer,
)
logger = logging.getLogger(__name__)
class AlbertTransformerWithPabee(AlbertTransformer):
def adaptive_forward(self, hidden_states, current_layer, attention_mask=None, head_mask=None):
if current_layer == 0:
hidden_states = self.embedding_hidden_mapping_in(hidden_states)
else:
hidden_states = hidden_states[0]
layers_per_group = int(self.config.num_hidden_layers / self.config.num_hidden_groups)
# Index of the hidden group
group_idx = int(current_layer / (self.config.num_hidden_layers / self.config.num_hidden_groups))
layer_group_output = self.albert_layer_groups[group_idx](
hidden_states,
attention_mask,
head_mask[group_idx * layers_per_group : (group_idx + 1) * layers_per_group],
)
hidden_states = layer_group_output[0]
return (hidden_states,)
@add_start_docstrings(
"The bare ALBERT Model transformer with PABEE outputting raw hidden-states without any specific head on top.",
ALBERT_START_DOCSTRING,
)
class AlbertModelWithPabee(AlbertModel):
def __init__(self, config):
super().__init__(config)
self.encoder = AlbertTransformerWithPabee(config)
self.init_weights()
self.patience = 0
self.inference_instances_num = 0
self.inference_layers_num = 0
self.regression_threshold = 0
def set_regression_threshold(self, threshold):
self.regression_threshold = threshold
def set_patience(self, patience):
self.patience = patience
def reset_stats(self):
self.inference_instances_num = 0
self.inference_layers_num = 0
def log_stats(self):
avg_inf_layers = self.inference_layers_num / self.inference_instances_num
message = (
f"*** Patience = {self.patience} Avg. Inference Layers = {avg_inf_layers:.2f} Speed Up ="
f" {1 - avg_inf_layers / self.config.num_hidden_layers:.2f} ***"
)
print(message)
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
output_dropout=None,
output_layers=None,
regression=False,
):
r"""
Return:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
last_hidden_state (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`):
Sequence of hidden-states at the output of the last layer of the model.
pooler_output (:obj:`torch.FloatTensor`: of shape :obj:`(batch_size, hidden_size)`):
Last layer hidden-state of the first token of the sequence (classification token)
further processed by a Linear layer and a Tanh activation function. The Linear
layer weights are trained from the next sentence prediction (classification)
objective during pre-training.
This output is usually *not* a good summary
of the semantic content of the input, you're often better with averaging or pooling
the sequence of hidden-states for the whole input sequence.
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
"""
if input_ids is not None and inputs_embeds is not None:
raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
elif input_ids is not None:
input_shape = input_ids.size()
elif inputs_embeds is not None:
input_shape = inputs_embeds.size()[:-1]
else:
raise ValueError("You have to specify either input_ids or inputs_embeds")
device = input_ids.device if input_ids is not None else inputs_embeds.device
if attention_mask is None:
attention_mask = torch.ones(input_shape, device=device)
if token_type_ids is None:
token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=device)
extended_attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)
extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
embedding_output = self.embeddings(
input_ids, position_ids=position_ids, token_type_ids=token_type_ids, inputs_embeds=inputs_embeds
)
encoder_outputs = embedding_output
if self.training:
res = []
for i in range(self.config.num_hidden_layers):
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](output_dropout(pooled_output))
res.append(logits)
elif self.patience == 0: # Use all layers for inference
encoder_outputs = self.encoder(encoder_outputs, extended_attention_mask, head_mask=head_mask)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
res = [output_layers[self.config.num_hidden_layers - 1](pooled_output)]
else:
patient_counter = 0
patient_result = None
calculated_layer_num = 0
for i in range(self.config.num_hidden_layers):
calculated_layer_num += 1
encoder_outputs = self.encoder.adaptive_forward(
encoder_outputs,
current_layer=i,
attention_mask=extended_attention_mask,
head_mask=head_mask,
)
pooled_output = self.pooler_activation(self.pooler(encoder_outputs[0][:, 0]))
logits = output_layers[i](pooled_output)
if regression:
labels = logits.detach()
if patient_result is not None:
patient_labels = patient_result.detach()
if (patient_result is not None) and torch.abs(patient_result - labels) < self.regression_threshold:
patient_counter += 1
else:
patient_counter = 0
else:
labels = logits.detach().argmax(dim=1)
if patient_result is not None:
patient_labels = patient_result.detach().argmax(dim=1)
if (patient_result is not None) and torch.all(labels.eq(patient_labels)):
patient_counter += 1
else:
patient_counter = 0
patient_result = logits
if patient_counter == self.patience:
break
res = [patient_result]
self.inference_layers_num += calculated_layer_num
self.inference_instances_num += 1
return res
@add_start_docstrings(
"""Albert Model transformer with PABEE and a sequence classification/regression head on top (a linear layer on top of
the pooled output) e.g. for GLUE tasks. """,
ALBERT_START_DOCSTRING,
)
class AlbertForSequenceClassificationWithPabee(AlbertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.albert = AlbertModelWithPabee(config)
self.dropout = nn.Dropout(config.classifier_dropout_prob)
self.classifiers = nn.ModuleList(
[nn.Linear(config.hidden_size, self.config.num_labels) for _ in range(config.num_hidden_layers)]
)
self.init_weights()
@add_start_docstrings_to_model_forward(ALBERT_INPUTS_DOCSTRING)
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
):
r"""
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size,)`, `optional`):
Labels for computing the sequence classification/regression loss.
Indices should be in ``[0, ..., config.num_labels - 1]``.
If ``config.num_labels == 1`` a regression loss is computed (Mean-Square loss),
If ``config.num_labels > 1`` a classification loss is computed (Cross-Entropy).
Returns:
:obj:`tuple(torch.FloatTensor)` comprising various elements depending on the configuration (:class:`~transformers.AlbertConfig`) and inputs:
loss (`optional`, returned when ``labels`` is provided) ``torch.FloatTensor`` of shape ``(1,)``:
Classification (or regression if config.num_labels==1) loss.
logits ``torch.FloatTensor`` of shape ``(batch_size, config.num_labels)``
Classification (or regression if config.num_labels==1) scores (before SoftMax).
hidden_states (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_hidden_states=True``):
Tuple of :obj:`torch.FloatTensor` (one for the output of the embeddings + one for the output of each layer)
of shape :obj:`(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the initial embedding outputs.
attentions (:obj:`tuple(torch.FloatTensor)`, `optional`, returned when ``config.output_attentions=True``):
Tuple of :obj:`torch.FloatTensor` (one for each layer) of shape
:obj:`(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention
heads.
Examples::
from transformers import AlbertTokenizer
from pabee import AlbertForSequenceClassificationWithPabee
from torch import nn
import torch
tokenizer = AlbertTokenizer.from_pretrained('albert/albert-base-v2')
model = AlbertForSequenceClassificationWithPabee.from_pretrained('albert/albert-base-v2')
input_ids = torch.tensor(tokenizer.encode("Hello, my dog is cute")).unsqueeze(0) # Batch size 1
labels = torch.tensor([1]).unsqueeze(0) # Batch size 1
outputs = model(input_ids, labels=labels)
loss, logits = outputs[:2]
"""
logits = self.albert(
input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_dropout=self.dropout,
output_layers=self.classifiers,
regression=self.num_labels == 1,
)
outputs = (logits[-1],)
if labels is not None:
total_loss = None
total_weights = 0
for ix, logits_item in enumerate(logits):
if self.num_labels == 1:
# We are doing regression
loss_fct = MSELoss()
loss = loss_fct(logits_item.view(-1), labels.view(-1))
else:
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits_item.view(-1, self.num_labels), labels.view(-1))
if total_loss is None:
total_loss = loss
else:
total_loss += loss * (ix + 1)
total_weights += ix + 1
outputs = (total_loss / total_weights,) + outputs
return outputs
|
transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_albert.py/0
|
{
"file_path": "transformers/examples/research_projects/bert-loses-patience/pabee/modeling_pabee_albert.py",
"repo_id": "transformers",
"token_count": 6317
}
|
#!/usr/bin/env python3
"""This script is adapted from the Bertology pruning code (https://github.com/huggingface/transformers/blob/783d7d2629e97c5f0c5f9ef01b8c66410275c204/examples/research_projects/bertology/run_bertology.py)
to prune GPT-like models. The author is @altsoph.
"""
import argparse
import logging
import os
from datetime import datetime
import numpy as np
import torch
from torch import nn
from torch.utils.data import DataLoader, RandomSampler, TensorDataset
from tqdm import tqdm
from transformers import GPT2LMHeadModel
logger = logging.getLogger(__name__)
def save_model(model, dirpath):
# save results
if os.path.exists(dirpath):
if os.path.exists(os.path.join(dirpath, "config.json")) and os.path.isfile(
os.path.join(dirpath, "config.json")
):
os.remove(os.path.join(dirpath, "config.json"))
if os.path.exists(os.path.join(dirpath, "pytorch_model.bin")) and os.path.isfile(
os.path.join(dirpath, "pytorch_model.bin")
):
os.remove(os.path.join(dirpath, "pytorch_model.bin"))
else:
os.makedirs(dirpath)
model.save_pretrained(dirpath)
def entropy(p, unlogit=False):
"""Compute the entropy of a probability distribution"""
exponent = 2
if unlogit:
p = torch.pow(p, exponent)
plogp = p * torch.log(p)
plogp[p == 0] = 0
return -plogp.sum(dim=-1)
def print_2d_tensor(tensor):
"""Print a 2D tensor"""
logger.info("lv, h >\t" + "\t".join(f"{x + 1}" for x in range(len(tensor))))
for row in range(len(tensor)):
if tensor.dtype != torch.long:
logger.info(f"layer {row + 1}:\t" + "\t".join(f"{x:.5f}" for x in tensor[row].cpu().data))
else:
logger.info(f"layer {row + 1}:\t" + "\t".join(f"{x:d}" for x in tensor[row].cpu().data))
def compute_heads_importance(
args, model, eval_dataloader, compute_entropy=True, compute_importance=True, head_mask=None, actually_pruned=False
):
"""This method shows how to compute:
- head attention entropy
- head importance scores according to http://arxiv.org/abs/1905.10650
"""
# Prepare our tensors
n_layers, n_heads = model.config.num_hidden_layers, model.config.num_attention_heads
head_importance = torch.zeros(n_layers, n_heads).to(args.device)
attn_entropy = torch.zeros(n_layers, n_heads).to(args.device)
if head_mask is None:
head_mask = torch.ones(n_layers, n_heads).to(args.device)
head_mask.requires_grad_(requires_grad=True)
# If actually pruned attention multi-head, set head mask to None to avoid shape mismatch
if actually_pruned:
head_mask = None
tot_tokens = 0.0
total_loss = 0.0
for step, inputs in enumerate(tqdm(eval_dataloader, desc="Iteration", disable=args.local_rank not in [-1, 0])):
inputs = tuple(t.to(args.device) for t in inputs)
(input_ids,) = inputs
# Do a forward pass (not with torch.no_grad() since we need gradients for importance score - see below)
outputs = model(input_ids, labels=input_ids, head_mask=head_mask)
# (loss), lm_logits, presents, (all hidden_states), (attentions)
loss, _, all_attentions = (
outputs[0],
outputs[1],
outputs[-1],
) # Loss and logits are the first, attention the last
loss.backward() # Backpropagate to populate the gradients in the head mask
total_loss += loss.detach().cpu().numpy()
if compute_entropy:
for layer, attn in enumerate(all_attentions):
masked_entropy = entropy(attn.detach(), True)
attn_entropy[layer] += masked_entropy.sum(-1).sum(0).sum(0).detach()
if compute_importance:
head_importance += head_mask.grad.abs().detach()
tot_tokens += torch.ones_like(input_ids).float().detach().sum().data
# Normalize
attn_entropy /= tot_tokens
head_importance /= tot_tokens
# Layerwise importance normalization
if not args.dont_normalize_importance_by_layer:
exponent = 2
norm_by_layer = torch.pow(torch.pow(head_importance, exponent).sum(-1), 1 / exponent)
head_importance /= norm_by_layer.unsqueeze(-1) + 1e-20
if not args.dont_normalize_global_importance:
head_importance = (head_importance - head_importance.min()) / (head_importance.max() - head_importance.min())
# Print matrices
if compute_entropy:
logger.info("Attention entropies")
print_2d_tensor(attn_entropy)
if compute_importance:
logger.info("Head importance scores")
print_2d_tensor(head_importance)
logger.info("Head ranked by importance scores")
head_ranks = torch.zeros(head_importance.numel(), dtype=torch.long, device=args.device)
head_ranks[head_importance.view(-1).sort(descending=True)[1]] = torch.arange(
head_importance.numel(), device=args.device
)
head_ranks = head_ranks.view_as(head_importance)
print_2d_tensor(head_ranks)
return attn_entropy, head_importance, total_loss
def mask_heads(args, model, eval_dataloader):
"""This method shows how to mask head (set some heads to zero), to test the effect on the network,
based on the head importance scores, as described in Michel et al. (http://arxiv.org/abs/1905.10650)
"""
_, head_importance, loss = compute_heads_importance(args, model, eval_dataloader, compute_entropy=False)
original_score = 1 / loss # instead of downsteam score use the LM loss
logger.info("Pruning: original score: %f, threshold: %f", original_score, original_score * args.masking_threshold)
new_head_mask = torch.ones_like(head_importance)
num_to_mask = max(1, int(new_head_mask.numel() * args.masking_amount))
current_score = original_score
while current_score >= original_score * args.masking_threshold:
head_mask = new_head_mask.clone().detach() # save current head mask
# heads from least important to most - keep only not-masked heads
head_importance[head_mask == 0.0] = float("Inf")
current_heads_to_mask = head_importance.view(-1).sort()[1]
if len(current_heads_to_mask) <= num_to_mask:
print("BREAK BY num_to_mask")
break
# mask heads
current_heads_to_mask = current_heads_to_mask[:num_to_mask]
logger.info("Heads to mask: %s", str(current_heads_to_mask.tolist()))
new_head_mask = new_head_mask.view(-1)
new_head_mask[current_heads_to_mask] = 0.0
new_head_mask = new_head_mask.view_as(head_mask)
new_head_mask = new_head_mask.clone().detach()
print_2d_tensor(new_head_mask)
# Compute metric and head importance again
_, head_importance, loss = compute_heads_importance(
args, model, eval_dataloader, compute_entropy=False, head_mask=new_head_mask
)
current_score = 1 / loss
logger.info(
"Masking: current score: %f, remaining heads %d (%.1f percents)",
current_score,
new_head_mask.sum(),
new_head_mask.sum() / new_head_mask.numel() * 100,
)
logger.info("Final head mask")
print_2d_tensor(head_mask)
np.save(os.path.join(args.output_dir, "head_mask.npy"), head_mask.detach().cpu().numpy())
return head_mask
def prune_heads(args, model, eval_dataloader, head_mask):
"""This method shows how to prune head (remove heads weights) based on
the head importance scores as described in Michel et al. (http://arxiv.org/abs/1905.10650)
"""
# Try pruning and test time speedup
# Pruning is like masking but we actually remove the masked weights
before_time = datetime.now()
_, _, loss = compute_heads_importance(
args, model, eval_dataloader, compute_entropy=False, compute_importance=False, head_mask=head_mask
)
score_masking = 1 / loss
original_time = datetime.now() - before_time
original_num_params = sum(p.numel() for p in model.parameters())
heads_to_prune = {
layer: (1 - head_mask[layer].long()).nonzero().squeeze().tolist() for layer in range(len(head_mask))
}
for k, v in heads_to_prune.items():
if isinstance(v, int):
heads_to_prune[k] = [
v,
]
assert sum(len(h) for h in heads_to_prune.values()) == (1 - head_mask.long()).sum().item()
model.prune_heads(heads_to_prune)
pruned_num_params = sum(p.numel() for p in model.parameters())
before_time = datetime.now()
_, _, loss = compute_heads_importance(
args,
model,
eval_dataloader,
compute_entropy=False,
compute_importance=False,
head_mask=None,
actually_pruned=True,
)
score_pruning = 1 / loss
new_time = datetime.now() - before_time
logger.info(
"Pruning: original num of params: %.2e, after pruning %.2e (%.1f percents)",
original_num_params,
pruned_num_params,
pruned_num_params / original_num_params * 100,
)
logger.info("Pruning: score with masking: %f score with pruning: %f", score_masking, score_pruning)
logger.info("Pruning: speed ratio (original timing / new timing): %f percents", original_time / new_time * 100)
save_model(model, args.output_dir)
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--data_dir",
default=None,
type=str,
required=True,
help="The input data dir. Should contain the .tsv files (or other data files) for the task.",
)
parser.add_argument(
"--model_name_or_path",
default=None,
type=str,
required=True,
help="Path to pretrained model or model identifier from huggingface.co/models",
)
parser.add_argument(
"--output_dir",
default=None,
type=str,
required=True,
help="The output directory where the model predictions and checkpoints will be written.",
)
# Other parameters
parser.add_argument(
"--config_name",
default="",
type=str,
help="Pretrained config name or path if not the same as model_name_or_path",
)
parser.add_argument(
"--tokenizer_name",
default="",
type=str,
help="Pretrained tokenizer name or path if not the same as model_name_or_path",
)
parser.add_argument(
"--cache_dir",
default=None,
type=str,
help="Where do you want to store the pre-trained models downloaded from s3",
)
parser.add_argument(
"--data_subset", type=int, default=-1, help="If > 0: limit the data to a subset of data_subset instances."
)
parser.add_argument(
"--overwrite_output_dir", action="store_true", help="Whether to overwrite data in output directory"
)
parser.add_argument(
"--overwrite_cache", action="store_true", help="Overwrite the cached training and evaluation sets"
)
parser.add_argument(
"--dont_normalize_importance_by_layer", action="store_true", help="Don't normalize importance score by layers"
)
parser.add_argument(
"--dont_normalize_global_importance",
action="store_true",
help="Don't normalize all importance scores between 0 and 1",
)
parser.add_argument(
"--try_masking", action="store_true", help="Whether to try to mask head until a threshold of accuracy."
)
parser.add_argument(
"--masking_threshold",
default=0.9,
type=float,
help="masking threshold in term of metrics (stop masking when metric < threshold * original metric value).",
)
parser.add_argument(
"--masking_amount", default=0.1, type=float, help="Amount to heads to masking at each masking step."
)
parser.add_argument("--metric_name", default="acc", type=str, help="Metric to use for head masking.")
parser.add_argument(
"--max_seq_length",
default=128,
type=int,
help=(
"The maximum total input sequence length after WordPiece tokenization. \n"
"Sequences longer than this will be truncated, sequences shorter padded."
),
)
parser.add_argument("--batch_size", default=1, type=int, help="Batch size.")
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--local_rank", type=int, default=-1, help="local_rank for distributed training on gpus")
parser.add_argument("--no_cuda", action="store_true", help="Whether not to use CUDA when available")
parser.add_argument("--server_ip", type=str, default="", help="Can be used for distant debugging.")
parser.add_argument("--server_port", type=str, default="", help="Can be used for distant debugging.")
args = parser.parse_args()
if args.server_ip and args.server_port:
# Distant debugging - see https://code.visualstudio.com/docs/python/debugging#_attach-to-a-local-script
import ptvsd
print("Waiting for debugger attach")
ptvsd.enable_attach(address=(args.server_ip, args.server_port), redirect_output=True)
ptvsd.wait_for_attach()
# Setup devices and distributed training
if args.local_rank == -1 or args.no_cuda:
args.device = torch.device("cuda" if torch.cuda.is_available() and not args.no_cuda else "cpu")
args.n_gpu = 0 if args.no_cuda else torch.cuda.device_count()
else:
torch.cuda.set_device(args.local_rank)
args.device = torch.device("cuda", args.local_rank)
args.n_gpu = 1
torch.distributed.init_process_group(backend="nccl") # Initializes the distributed backend
# Setup logging
logging.basicConfig(level=logging.INFO if args.local_rank in [-1, 0] else logging.WARN)
logger.info("device: {} n_gpu: {}, distributed: {}".format(args.device, args.n_gpu, bool(args.local_rank != -1)))
model = GPT2LMHeadModel.from_pretrained(args.model_name_or_path)
# Distributed and parallel training
model.to(args.device)
if args.local_rank != -1:
model = nn.parallel.DistributedDataParallel(
model, device_ids=[args.local_rank], output_device=args.local_rank, find_unused_parameters=True
)
elif args.n_gpu > 1:
model = nn.DataParallel(model)
# Print/save training arguments
os.makedirs(args.output_dir, exist_ok=True)
torch.save(args, os.path.join(args.output_dir, "run_args.bin"))
logger.info("Training/evaluation parameters %s", args)
# Prepare dataset
numpy_data = np.concatenate(
[
np.loadtxt(args.data_dir, dtype=np.int64),
]
)
train_tensor_dataset = (torch.from_numpy(numpy_data),)
train_data = TensorDataset(*train_tensor_dataset)
train_sampler = RandomSampler(train_data)
eval_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=args.batch_size)
# Compute head entropy and importance score
compute_heads_importance(args, model, eval_dataloader)
# Try head masking (set heads to zero until the score goes under a threshole)
# and head pruning (remove masked heads and see the effect on the network)
if args.try_masking and args.masking_threshold > 0.0 and args.masking_threshold < 1.0:
head_mask = mask_heads(args, model, eval_dataloader)
prune_heads(args, model, eval_dataloader, head_mask)
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/bertology/run_prune_gpt.py/0
|
{
"file_path": "transformers/examples/research_projects/bertology/run_prune_gpt.py",
"repo_id": "transformers",
"token_count": 6338
}
|
import logging
import torch
from accelerate import Accelerator
from arguments import EvaluationArguments
from datasets import load_dataset
from torch.utils.data import IterableDataset
from torch.utils.data.dataloader import DataLoader
from transformers import AutoModelForCausalLM, AutoTokenizer, HfArgumentParser, set_seed
class ConstantLengthDataset(IterableDataset):
def __init__(self, tokenizer, dataset, seq_length=1024, num_of_sequences=1024, chars_per_token=3.6):
self.tokenizer = tokenizer
self.concat_token_id = tokenizer.bos_token_id
self.dataset = dataset
self.seq_length = seq_length
self.input_characters = seq_length * chars_per_token * num_of_sequences
def __iter__(self):
iterator = iter(self.dataset)
more_examples = True
while more_examples:
buffer, buffer_len = [], 0
while True:
if buffer_len >= self.input_characters:
break
try:
buffer.append(next(iterator)["content"])
buffer_len += len(buffer[-1])
except StopIteration:
more_examples = False
break
tokenized_inputs = tokenizer(buffer, truncation=False)["input_ids"]
all_token_ids = []
for tokenized_input in tokenized_inputs:
all_token_ids.extend(tokenized_input + [self.concat_token_id])
for i in range(0, len(all_token_ids), self.seq_length):
input_ids = all_token_ids[i : i + self.seq_length]
if len(input_ids) == self.seq_length:
yield torch.tensor(input_ids)
def create_dataloader(args):
ds_kwargs = {"streaming": True}
valid_data = load_dataset(args.dataset_name, split="train", **ds_kwargs)
valid_dataset = ConstantLengthDataset(tokenizer, valid_data, seq_length=args.seq_length)
eval_dataloader = DataLoader(valid_dataset, batch_size=args.batch_size)
return eval_dataloader
def evaluate(args):
model.eval()
losses = []
for step, batch in enumerate(eval_dataloader):
with torch.no_grad():
outputs = model(batch, labels=batch)
loss = outputs.loss.repeat(args.batch_size)
losses.append(accelerator.gather(loss))
if args.max_eval_steps > 0 and step >= args.max_eval_steps:
break
loss = torch.mean(torch.cat(losses))
try:
perplexity = torch.exp(loss)
except OverflowError:
perplexity = float("inf")
return loss.item(), perplexity.item()
# Setup Accelerator
accelerator = Accelerator()
# Parse configuration
parser = HfArgumentParser(EvaluationArguments)
args = parser.parse_args()
set_seed(args.seed)
# Logging
logger = logging.getLogger(__name__)
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s", datefmt="%m/%d/%Y %H:%M:%S", level=logging.INFO
)
# Load model and tokenizer
model = AutoModelForCausalLM.from_pretrained(args.model_ckpt)
tokenizer = AutoTokenizer.from_pretrained(args.model_ckpt)
# Load dataset and dataloader
eval_dataloader = create_dataloader(args)
# Prepare everything with our `accelerator`.
model, eval_dataloader = accelerator.prepare(model, eval_dataloader)
# Evaluate and save the last checkpoint
logger.info("Evaluating and saving model after training")
eval_loss, perplexity = evaluate(args)
logger.info(f"loss/eval: {eval_loss}, perplexity: {perplexity}")
|
transformers/examples/research_projects/codeparrot/scripts/validation_loss.py/0
|
{
"file_path": "transformers/examples/research_projects/codeparrot/scripts/validation_loss.py",
"repo_id": "transformers",
"token_count": 1471
}
|
# coding=utf-8
# Copyright 2019-present, the HuggingFace Inc. team and Facebook, Inc.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Dataset to distilled models
adapted in part from Facebook, Inc XLM model (https://github.com/facebookresearch/XLM)
"""
import numpy as np
import torch
from torch.utils.data import Dataset
from utils import logger
class LmSeqsDataset(Dataset):
"""Custom Dataset wrapping language modeling sequences.
Each sample will be retrieved by indexing the list of token_ids and their corresponding lengths.
Input:
------
params: `NameSpace` parameters
data: `List[np.array[int]]
"""
def __init__(self, params, data):
self.params = params
self.token_ids = np.array(data)
self.lengths = np.array([len(t) for t in data])
self.check()
self.remove_long_sequences()
self.remove_empty_sequences()
self.remove_unknown_sequences()
self.check()
self.print_statistics()
def __getitem__(self, index):
return (self.token_ids[index], self.lengths[index])
def __len__(self):
return len(self.lengths)
def check(self):
"""
Some sanity checks
"""
assert len(self.token_ids) == len(self.lengths)
assert all(self.lengths[i] == len(self.token_ids[i]) for i in range(len(self.lengths)))
def remove_long_sequences(self):
"""
Sequences that are too long are split by chunk of max_model_input_size.
"""
max_len = self.params.max_model_input_size
indices = self.lengths > max_len
logger.info(f"Splitting {sum(indices)} too long sequences.")
def divide_chunks(l, n):
return [l[i : i + n] for i in range(0, len(l), n)]
new_tok_ids = []
new_lengths = []
if self.params.mlm:
cls_id, sep_id = self.params.special_tok_ids["cls_token"], self.params.special_tok_ids["sep_token"]
else:
cls_id, sep_id = self.params.special_tok_ids["bos_token"], self.params.special_tok_ids["eos_token"]
for seq_, len_ in zip(self.token_ids, self.lengths):
assert (seq_[0] == cls_id) and (seq_[-1] == sep_id), seq_
if len_ <= max_len:
new_tok_ids.append(seq_)
new_lengths.append(len_)
else:
sub_seqs = []
for sub_s in divide_chunks(seq_, max_len - 2):
if sub_s[0] != cls_id:
sub_s = np.insert(sub_s, 0, cls_id)
if sub_s[-1] != sep_id:
sub_s = np.insert(sub_s, len(sub_s), sep_id)
assert len(sub_s) <= max_len
assert (sub_s[0] == cls_id) and (sub_s[-1] == sep_id), sub_s
sub_seqs.append(sub_s)
new_tok_ids.extend(sub_seqs)
new_lengths.extend([len(l) for l in sub_seqs])
self.token_ids = np.array(new_tok_ids)
self.lengths = np.array(new_lengths)
def remove_empty_sequences(self):
"""
Too short sequences are simply removed. This could be tuned.
"""
init_size = len(self)
indices = self.lengths > 11
self.token_ids = self.token_ids[indices]
self.lengths = self.lengths[indices]
new_size = len(self)
logger.info(f"Remove {init_size - new_size} too short (<=11 tokens) sequences.")
def remove_unknown_sequences(self):
"""
Remove sequences with a (too) high level of unknown tokens.
"""
if "unk_token" not in self.params.special_tok_ids:
return
else:
unk_token_id = self.params.special_tok_ids["unk_token"]
init_size = len(self)
unk_occs = np.array([np.count_nonzero(a == unk_token_id) for a in self.token_ids])
indices = (unk_occs / self.lengths) < 0.5
self.token_ids = self.token_ids[indices]
self.lengths = self.lengths[indices]
new_size = len(self)
logger.info(f"Remove {init_size - new_size} sequences with a high level of unknown tokens (50%).")
def print_statistics(self):
"""
Print some statistics on the corpus. Only the master process.
"""
if not self.params.is_master:
return
logger.info(f"{len(self)} sequences")
# data_len = sum(self.lengths)
# nb_unique_tokens = len(Counter(list(chain(*self.token_ids))))
# logger.info(f'{data_len} tokens ({nb_unique_tokens} unique)')
# unk_idx = self.params.special_tok_ids['unk_token']
# nb_unknown = sum([(t==unk_idx).sum() for t in self.token_ids])
# logger.info(f'{nb_unknown} unknown tokens (covering {100*nb_unknown/data_len:.2f}% of the data)')
def batch_sequences(self, batch):
"""
Do the padding and transform into torch.tensor.
"""
token_ids = [t[0] for t in batch]
lengths = [t[1] for t in batch]
assert len(token_ids) == len(lengths)
# Max for paddings
max_seq_len_ = max(lengths)
# Pad token ids
if self.params.mlm:
pad_idx = self.params.special_tok_ids["pad_token"]
else:
pad_idx = self.params.special_tok_ids["unk_token"]
tk_ = [list(t.astype(int)) + [pad_idx] * (max_seq_len_ - len(t)) for t in token_ids]
assert len(tk_) == len(token_ids)
assert all(len(t) == max_seq_len_ for t in tk_)
tk_t = torch.tensor(tk_) # (bs, max_seq_len_)
lg_t = torch.tensor(lengths) # (bs)
return tk_t, lg_t
|
transformers/examples/research_projects/distillation/lm_seqs_dataset.py/0
|
{
"file_path": "transformers/examples/research_projects/distillation/lm_seqs_dataset.py",
"repo_id": "transformers",
"token_count": 2820
}
|
import os
import jsonlines
import numpy as np
from tqdm import tqdm
DOC_STRIDE = 2048
MAX_LENGTH = 4096
SEED = 42
PROCESS_TRAIN = os.environ.pop("PROCESS_TRAIN", "false")
CATEGORY_MAPPING = {"null": 0, "short": 1, "long": 2, "yes": 3, "no": 4}
def _get_single_answer(example):
def choose_first(answer, is_long_answer=False):
assert isinstance(answer, list)
if len(answer) == 1:
answer = answer[0]
return {k: [answer[k]] for k in answer} if is_long_answer else answer
for a in answer:
if is_long_answer:
a = {k: [a[k]] for k in a}
if len(a["start_token"]) > 0:
break
return a
answer = {"id": example["id"]}
annotation = example["annotations"]
yes_no_answer = annotation["yes_no_answer"]
if 0 in yes_no_answer or 1 in yes_no_answer:
answer["category"] = ["yes"] if 1 in yes_no_answer else ["no"]
answer["start_token"] = answer["end_token"] = []
answer["start_byte"] = answer["end_byte"] = []
answer["text"] = ["<cls>"]
else:
answer["category"] = ["short"]
out = choose_first(annotation["short_answers"])
if len(out["start_token"]) == 0:
# answer will be long if short is not available
answer["category"] = ["long"]
out = choose_first(annotation["long_answer"], is_long_answer=True)
out["text"] = []
answer.update(out)
# disregard some samples
if len(answer["start_token"]) > 1 or answer["start_token"] == answer["end_token"]:
answer["remove_it"] = True
else:
answer["remove_it"] = False
cols = ["start_token", "end_token", "start_byte", "end_byte", "text"]
if not all(isinstance(answer[k], list) for k in cols):
raise ValueError("Issue in ID", example["id"])
return answer
def get_context_and_ans(example, assertion=False):
"""Gives new context after removing <html> & new answer tokens as per new context"""
answer = _get_single_answer(example)
# bytes are of no use
del answer["start_byte"]
del answer["end_byte"]
# handle yes_no answers explicitly
if answer["category"][0] in ["yes", "no"]: # category is list with one element
doc = example["document"]["tokens"]
context = []
for i in range(len(doc["token"])):
if not doc["is_html"][i]:
context.append(doc["token"][i])
return {
"context": " ".join(context),
"answer": {
"start_token": -100, # ignore index in cross-entropy
"end_token": -100, # ignore index in cross-entropy
"category": answer["category"],
"span": answer["category"], # extra
},
}
# later, help in removing all no answers
if answer["start_token"] == [-1]:
return {
"context": "None",
"answer": {
"start_token": -1,
"end_token": -1,
"category": "null",
"span": "None", # extra
},
}
# handling normal samples
cols = ["start_token", "end_token"]
answer.update({k: answer[k][0] if len(answer[k]) > 0 else answer[k] for k in cols}) # e.g. [10] == 10
doc = example["document"]["tokens"]
start_token = answer["start_token"]
end_token = answer["end_token"]
context = []
for i in range(len(doc["token"])):
if not doc["is_html"][i]:
context.append(doc["token"][i])
else:
if answer["start_token"] > i:
start_token -= 1
if answer["end_token"] > i:
end_token -= 1
new = " ".join(context[start_token:end_token])
# checking above code
if assertion:
"""checking if above code is working as expected for all the samples"""
is_html = doc["is_html"][answer["start_token"] : answer["end_token"]]
old = doc["token"][answer["start_token"] : answer["end_token"]]
old = " ".join([old[i] for i in range(len(old)) if not is_html[i]])
if new != old:
print("ID:", example["id"])
print("New:", new, end="\n")
print("Old:", old, end="\n\n")
return {
"context": " ".join(context),
"answer": {
"start_token": start_token,
"end_token": end_token - 1, # this makes it inclusive
"category": answer["category"], # either long or short
"span": new, # extra
},
}
def get_strided_contexts_and_ans(example, tokenizer, doc_stride=2048, max_length=4096, assertion=True):
# overlap will be of doc_stride - q_len
out = get_context_and_ans(example, assertion=assertion)
answer = out["answer"]
# later, removing these samples
if answer["start_token"] == -1:
return {
"example_id": example["id"],
"input_ids": [[-1]],
"labels": {
"start_token": [-1],
"end_token": [-1],
"category": ["null"],
},
}
input_ids = tokenizer(example["question"]["text"], out["context"]).input_ids
q_len = input_ids.index(tokenizer.sep_token_id) + 1
# return yes/no
if answer["category"][0] in ["yes", "no"]: # category is list with one element
inputs = []
category = []
q_indices = input_ids[:q_len]
doc_start_indices = range(q_len, len(input_ids), max_length - doc_stride)
for i in doc_start_indices:
end_index = i + max_length - q_len
slice = input_ids[i:end_index]
inputs.append(q_indices + slice)
category.append(answer["category"][0])
if slice[-1] == tokenizer.sep_token_id:
break
return {
"example_id": example["id"],
"input_ids": inputs,
"labels": {
"start_token": [-100] * len(category),
"end_token": [-100] * len(category),
"category": category,
},
}
splitted_context = out["context"].split()
complete_end_token = splitted_context[answer["end_token"]]
answer["start_token"] = len(
tokenizer(
" ".join(splitted_context[: answer["start_token"]]),
add_special_tokens=False,
).input_ids
)
answer["end_token"] = len(
tokenizer(" ".join(splitted_context[: answer["end_token"]]), add_special_tokens=False).input_ids
)
answer["start_token"] += q_len
answer["end_token"] += q_len
# fixing end token
num_sub_tokens = len(tokenizer(complete_end_token, add_special_tokens=False).input_ids)
if num_sub_tokens > 1:
answer["end_token"] += num_sub_tokens - 1
old = input_ids[answer["start_token"] : answer["end_token"] + 1] # right & left are inclusive
start_token = answer["start_token"]
end_token = answer["end_token"]
if assertion:
"""This won't match exactly because of extra gaps => visaully inspect everything"""
new = tokenizer.decode(old)
if answer["span"] != new:
print("ISSUE IN TOKENIZATION")
print("OLD:", answer["span"])
print("NEW:", new, end="\n\n")
if len(input_ids) <= max_length:
return {
"example_id": example["id"],
"input_ids": [input_ids],
"labels": {
"start_token": [answer["start_token"]],
"end_token": [answer["end_token"]],
"category": answer["category"],
},
}
q_indices = input_ids[:q_len]
doc_start_indices = range(q_len, len(input_ids), max_length - doc_stride)
inputs = []
answers_start_token = []
answers_end_token = []
answers_category = [] # null, yes, no, long, short
for i in doc_start_indices:
end_index = i + max_length - q_len
slice = input_ids[i:end_index]
inputs.append(q_indices + slice)
assert len(inputs[-1]) <= max_length, "Issue in truncating length"
if start_token >= i and end_token <= end_index - 1:
start_token = start_token - i + q_len
end_token = end_token - i + q_len
answers_category.append(answer["category"][0]) # ["short"] -> "short"
else:
start_token = -100
end_token = -100
answers_category.append("null")
new = inputs[-1][start_token : end_token + 1]
answers_start_token.append(start_token)
answers_end_token.append(end_token)
if assertion:
"""checking if above code is working as expected for all the samples"""
if new != old and new != [tokenizer.cls_token_id]:
print("ISSUE in strided for ID:", example["id"])
print("New:", tokenizer.decode(new))
print("Old:", tokenizer.decode(old), end="\n\n")
if slice[-1] == tokenizer.sep_token_id:
break
return {
"example_id": example["id"],
"input_ids": inputs,
"labels": {
"start_token": answers_start_token,
"end_token": answers_end_token,
"category": answers_category,
},
}
def prepare_inputs(example, tokenizer, doc_stride=2048, max_length=4096, assertion=False):
example = get_strided_contexts_and_ans(
example,
tokenizer,
doc_stride=doc_stride,
max_length=max_length,
assertion=assertion,
)
return example
def save_to_disk(hf_data, file_name):
with jsonlines.open(file_name, "a") as writer:
for example in tqdm(hf_data, total=len(hf_data), desc="Saving samples ... "):
labels = example["labels"]
for ids, start, end, cat in zip(
example["input_ids"],
labels["start_token"],
labels["end_token"],
labels["category"],
):
if start == -1 and end == -1:
continue # leave waste samples with no answer
if cat == "null" and np.random.rand() < 0.6:
continue # removing 50 % samples
writer.write(
{
"input_ids": ids,
"start_token": start,
"end_token": end,
"category": CATEGORY_MAPPING[cat],
}
)
if __name__ == "__main__":
"""Running area"""
from datasets import load_dataset
from transformers import BigBirdTokenizer
data = load_dataset("natural_questions")
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
data = data["train" if PROCESS_TRAIN == "true" else "validation"]
fn_kwargs = {
"tokenizer": tokenizer,
"doc_stride": DOC_STRIDE,
"max_length": MAX_LENGTH,
"assertion": False,
}
data = data.map(prepare_inputs, fn_kwargs=fn_kwargs)
data = data.remove_columns(["annotations", "document", "id", "question"])
print(data)
np.random.seed(SEED)
cache_file_name = "nq-training.jsonl" if PROCESS_TRAIN == "true" else "nq-validation.jsonl"
save_to_disk(data, file_name=cache_file_name)
|
transformers/examples/research_projects/jax-projects/big_bird/prepare_natural_questions.py/0
|
{
"file_path": "transformers/examples/research_projects/jax-projects/big_bird/prepare_natural_questions.py",
"repo_id": "transformers",
"token_count": 5324
}
|
<!---
Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Token classification with LayoutLMv3 (PyTorch version)
This directory contains a script, `run_funsd_cord.py`, that can be used to fine-tune (or evaluate) LayoutLMv3 on form understanding datasets, such as [FUNSD](https://guillaumejaume.github.io/FUNSD/) and [CORD](https://github.com/clovaai/cord).
The script `run_funsd_cord.py` leverages the 🤗 Datasets library and the Trainer API. You can easily customize it to your needs.
## Fine-tuning on FUNSD
Fine-tuning LayoutLMv3 for token classification on [FUNSD](https://guillaumejaume.github.io/FUNSD/) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name funsd \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--eval_strategy steps \
--eval_steps 100 \
--learning_rate 1e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-funsd
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd. By specifying the `push_to_hub` flag, the model gets uploaded automatically to the hub (regularly), together with a model card, which includes metrics such as precision, recall and F1. Note that you can easily update the model card, as it's just a README file of the respective repo on the hub.
There's also the "Training metrics" [tab](https://huggingface.co/nielsr/layoutlmv3-finetuned-funsd/tensorboard), which shows Tensorboard logs over the course of training. Pretty neat, huh?
## Fine-tuning on CORD
Fine-tuning LayoutLMv3 for token classification on [CORD](https://github.com/clovaai/cord) can be done as follows:
```bash
python run_funsd_cord.py \
--model_name_or_path microsoft/layoutlmv3-base \
--dataset_name cord \
--output_dir layoutlmv3-test \
--do_train \
--do_eval \
--max_steps 1000 \
--eval_strategy steps \
--eval_steps 100 \
--learning_rate 5e-5 \
--load_best_model_at_end \
--metric_for_best_model "eval_f1" \
--push_to_hub \
--push_to_hub°model_id layoutlmv3-finetuned-cord
```
👀 The resulting model can be found here: https://huggingface.co/nielsr/layoutlmv3-finetuned-cord. Note that a model card gets generated automatically in case you specify the `push_to_hub` flag.
|
transformers/examples/research_projects/layoutlmv3/README.md/0
|
{
"file_path": "transformers/examples/research_projects/layoutlmv3/README.md",
"repo_id": "transformers",
"token_count": 967
}
|
# End-to-End finetuning of RAG (including DPR retriever) for Question Answering.
This finetuning script is actively maintained by [Shamane Siri](https://github.com/shamanez). Feel free to ask questions on the [Forum](https://discuss.huggingface.co/) or post an issue on [GitHub](https://github.com/huggingface/transformers/issues/new/choose) and tag @shamanez.
Others that helped out: Patrick von Platen (@patrickvonplaten), Quentin Lhoest (@lhoestq), and Rivindu Weerasekera (@rivinduw)
The original RAG implementation is able to train the question encoder and generator end-to-end.
This extension enables complete end-to-end training of RAG including the context encoder in the retriever component.
Please read the [accompanying blog post](https://shamanesiri.medium.com/how-to-finetune-the-entire-rag-architecture-including-dpr-retriever-4b4385322552) for details on this implementation.
The original RAG code has also been modified to work with the latest versions of pytorch lightning (version 1.2.10) and RAY (version 1.3.0). All other implementation details remain the same as the [original RAG code](https://github.com/huggingface/transformers/tree/main/examples/research_projects/rag).
Read more about RAG at https://arxiv.org/abs/2005.11401.
This code can be modified to experiment with other research on retrival augmented models which include training of the retriever (e.g. [REALM](https://arxiv.org/abs/2002.08909) and [MARGE](https://arxiv.org/abs/2006.15020)).
To start training, use the bash script (finetune_rag_ray_end2end.sh) in this folder. This script also includes descriptions on each command-line argument used.
# Latest Update
⚠️ Updated the rag-end2end-retriever to be compatible with PL==1.6.4 and RAY==1.13.0 (latest versions to the date 2022-June-11)
# Note
⚠️ This project should be run with pytorch-lightning==1.3.1 which has a potential security vulnerability
# Testing
The following two bash scripts can be used to quickly test the implementation.
1. sh ./test_run/test_finetune.sh script
- Tests the full end-to-end fine-tuning ability with a dummy knowlendge-base and dummy training dataset (check test_dir directory).
- Users can replace the dummy dataset and knowledge-base with their own to do their own finetuning.
- Please read the comments in the test_finetune.sh file.
2. sh ./test_run/test_rag_new_features.sh
- Tests the newly added functions (set_context_encoder and set_context_encoder_tokenizer) related to modeling rag.
- This is sufficient to check the model's ability to use the set functions correctly.
# Comparison of end2end RAG (including DPR finetuning) VS original-RAG
We conducted a simple experiment to investigate the effectiveness of this end2end training extension using the SQuAD dataset. Please execute the following steps to reproduce the results.
- Create a knowledge-base using all the context passages in the SQuAD dataset with their respective titles.
- Use the question-answer pairs as training data.
- Train the system for 10 epochs.
- Test the Exact Match (EM) score with the SQuAD dataset's validation set.
- Training dataset, the knowledge-base, and hyperparameters used in experiments can be accessed from [here](https://drive.google.com/drive/folders/1qyzV-PaEARWvaU_jjpnU_NUS3U_dSjtG?usp=sharing).
# Results
- We train both models for 10 epochs.
| Model Type | EM-Score|
| --------------------| --------|
| RAG-original | 28.12 |
| RAG-end2end with DPR| 40.02 |
|
transformers/examples/research_projects/rag-end2end-retriever/README.md/0
|
{
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/README.md",
"repo_id": "transformers",
"token_count": 1044
}
|
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
#creates the custom knowlegebase
python use_own_knowledge_dataset.py
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python finetune_rag.py \
--model_name_or_path facebook/rag-token-base \
--model_type rag_token \
--fp16 \
--gpus 2 \
--profile \
--do_train \
--end2end \
--do_predict \
--n_val -1 \
--train_batch_size 1 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 10 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
--distributed_retriever ray \
--num_retrieval_workers 4 \
--index_name custom \
--context_encoder_name facebook/dpr-ctx_encoder-multiset-base \
--index_gpus 2 \
--gpu_order [2,3,4,5,6,7,8,9,0,1] \
--indexing_freq 5
# Stop the Ray cluster.
ray stop
#CUDA_VISIBLE_DEVICES=2,3,4,5,6,7,8,9,0,1 sh ./test_run/test_finetune.sh
#Make sure --gpu_order is same.
|
transformers/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh/0
|
{
"file_path": "transformers/examples/research_projects/rag-end2end-retriever/test_run/test_finetune.sh",
"repo_id": "transformers",
"token_count": 651
}
|
"""
This script reads DPR retriever training data and parses each datapoint. We save a line per datapoint.
Each line consists of the query followed by a tab-separated list of Wikipedia page titles constituting
positive contexts for a given query.
"""
import argparse
import json
from tqdm import tqdm
def main():
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--src_path",
type=str,
default="biencoder-nq-dev.json",
help="Path to raw DPR training data",
)
parser.add_argument(
"--evaluation_set",
type=str,
help="where to store parsed evaluation_set file",
)
parser.add_argument(
"--gold_data_path",
type=str,
help="where to store parsed gold_data_path file",
)
args = parser.parse_args()
with open(args.src_path, "r") as src_file, open(args.evaluation_set, "w") as eval_file, open(
args.gold_data_path, "w"
) as gold_file:
dpr_records = json.load(src_file)
for dpr_record in tqdm(dpr_records):
question = dpr_record["question"]
contexts = [context["title"] for context in dpr_record["positive_ctxs"]]
eval_file.write(question + "\n")
gold_file.write("\t".join(contexts) + "\n")
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/rag/parse_dpr_relevance_data.py/0
|
{
"file_path": "transformers/examples/research_projects/rag/parse_dpr_relevance_data.py",
"repo_id": "transformers",
"token_count": 559
}
|
#!/usr/bin/env python
import argparse
import os
import sys
from unittest.mock import patch
import pytorch_lightning as pl
import timeout_decorator
import torch
from distillation import SummarizationDistiller, distill_main
from finetune import SummarizationModule, main
from transformers import MarianMTModel
from transformers.file_utils import cached_path
from transformers.testing_utils import TestCasePlus, require_torch_gpu, slow
from utils import load_json
MARIAN_MODEL = "sshleifer/mar_enro_6_3_student"
class TestMbartCc25Enro(TestCasePlus):
def setUp(self):
super().setUp()
data_cached = cached_path(
"https://cdn-datasets.huggingface.co/translation/wmt_en_ro-tr40k-va0.5k-te0.5k.tar.gz",
extract_compressed_file=True,
)
self.data_dir = f"{data_cached}/wmt_en_ro-tr40k-va0.5k-te0.5k"
@slow
@require_torch_gpu
def test_model_download(self):
"""This warms up the cache so that we can time the next test without including download time, which varies between machines."""
MarianMTModel.from_pretrained(MARIAN_MODEL)
# @timeout_decorator.timeout(1200)
@slow
@require_torch_gpu
def test_train_mbart_cc25_enro_script(self):
env_vars_to_replace = {
"$MAX_LEN": 64,
"$BS": 64,
"$GAS": 1,
"$ENRO_DIR": self.data_dir,
"facebook/mbart-large-cc25": MARIAN_MODEL,
# "val_check_interval=0.25": "val_check_interval=1.0",
"--learning_rate=3e-5": "--learning_rate 3e-4",
"--num_train_epochs 6": "--num_train_epochs 1",
}
# Clean up bash script
bash_script = (self.test_file_dir / "train_mbart_cc25_enro.sh").open().read().split("finetune.py")[1].strip()
bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
for k, v in env_vars_to_replace.items():
bash_script = bash_script.replace(k, str(v))
output_dir = self.get_auto_remove_tmp_dir()
# bash_script = bash_script.replace("--fp16 ", "")
args = f"""
--output_dir {output_dir}
--tokenizer_name Helsinki-NLP/opus-mt-en-ro
--sortish_sampler
--do_predict
--gpus 1
--freeze_encoder
--n_train 40000
--n_val 500
--n_test 500
--fp16_opt_level O1
--num_sanity_val_steps 0
--eval_beams 2
""".split()
# XXX: args.gpus > 1 : handle multi_gpu in the future
testargs = ["finetune.py"] + bash_script.split() + args
with patch.object(sys, "argv", testargs):
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationModule.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
model = main(args)
# Check metrics
metrics = load_json(model.metrics_save_path)
first_step_stats = metrics["val"][0]
last_step_stats = metrics["val"][-1]
self.assertEqual(len(metrics["val"]), (args.max_epochs / args.val_check_interval))
assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
self.assertGreater(last_step_stats["val_avg_gen_time"], 0.01)
# model hanging on generate. Maybe bad config was saved. (XXX: old comment/assert?)
self.assertLessEqual(last_step_stats["val_avg_gen_time"], 1.0)
# test learning requirements:
# 1. BLEU improves over the course of training by more than 2 pts
self.assertGreater(last_step_stats["val_avg_bleu"] - first_step_stats["val_avg_bleu"], 2)
# 2. BLEU finishes above 17
self.assertGreater(last_step_stats["val_avg_bleu"], 17)
# 3. test BLEU and val BLEU within ~1.1 pt.
self.assertLess(abs(metrics["val"][-1]["val_avg_bleu"] - metrics["test"][-1]["test_avg_bleu"]), 1.1)
# check lightning ckpt can be loaded and has a reasonable statedict
contents = os.listdir(output_dir)
ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
full_path = os.path.join(args.output_dir, ckpt_path)
ckpt = torch.load(full_path, map_location="cpu")
expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
assert expected_key in ckpt["state_dict"]
assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
# TODO: turn on args.do_predict when PL bug fixed.
if args.do_predict:
contents = {os.path.basename(p) for p in contents}
assert "test_generations.txt" in contents
assert "test_results.txt" in contents
# assert len(metrics["val"]) == desired_n_evals
assert len(metrics["test"]) == 1
class TestDistilMarianNoTeacher(TestCasePlus):
@timeout_decorator.timeout(600)
@slow
@require_torch_gpu
def test_opus_mt_distill_script(self):
data_dir = f"{self.test_file_dir_str}/test_data/wmt_en_ro"
env_vars_to_replace = {
"--fp16_opt_level=O1": "",
"$MAX_LEN": 128,
"$BS": 16,
"$GAS": 1,
"$ENRO_DIR": data_dir,
"$m": "sshleifer/student_marian_en_ro_6_1",
"val_check_interval=0.25": "val_check_interval=1.0",
}
# Clean up bash script
bash_script = (
(self.test_file_dir / "distil_marian_no_teacher.sh").open().read().split("distillation.py")[1].strip()
)
bash_script = bash_script.replace("\\\n", "").strip().replace('"$@"', "")
bash_script = bash_script.replace("--fp16 ", " ")
for k, v in env_vars_to_replace.items():
bash_script = bash_script.replace(k, str(v))
output_dir = self.get_auto_remove_tmp_dir()
bash_script = bash_script.replace("--fp16", "")
epochs = 6
testargs = (
["distillation.py"]
+ bash_script.split()
+ [
f"--output_dir={output_dir}",
"--gpus=1",
"--learning_rate=1e-3",
f"--num_train_epochs={epochs}",
"--warmup_steps=10",
"--val_check_interval=1.0",
"--do_predict",
]
)
with patch.object(sys, "argv", testargs):
parser = argparse.ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = SummarizationDistiller.add_model_specific_args(parser, os.getcwd())
args = parser.parse_args()
# assert args.gpus == gpus THIS BREAKS for multi_gpu
model = distill_main(args)
# Check metrics
metrics = load_json(model.metrics_save_path)
first_step_stats = metrics["val"][0]
last_step_stats = metrics["val"][-1]
assert len(metrics["val"]) >= (args.max_epochs / args.val_check_interval) # +1 accounts for val_sanity_check
assert last_step_stats["val_avg_gen_time"] >= 0.01
assert first_step_stats["val_avg_bleu"] < last_step_stats["val_avg_bleu"] # model learned nothing
assert 1.0 >= last_step_stats["val_avg_gen_time"] # model hanging on generate. Maybe bad config was saved.
assert isinstance(last_step_stats[f"val_avg_{model.val_metric}"], float)
# check lightning ckpt can be loaded and has a reasonable statedict
contents = os.listdir(output_dir)
ckpt_path = [x for x in contents if x.endswith(".ckpt")][0]
full_path = os.path.join(args.output_dir, ckpt_path)
ckpt = torch.load(full_path, map_location="cpu")
expected_key = "model.model.decoder.layers.0.encoder_attn_layer_norm.weight"
assert expected_key in ckpt["state_dict"]
assert ckpt["state_dict"]["model.model.decoder.layers.0.encoder_attn_layer_norm.weight"].dtype == torch.float32
# TODO: turn on args.do_predict when PL bug fixed.
if args.do_predict:
contents = {os.path.basename(p) for p in contents}
assert "test_generations.txt" in contents
assert "test_results.txt" in contents
# assert len(metrics["val"]) == desired_n_evals
assert len(metrics["test"]) == 1
|
transformers/examples/research_projects/seq2seq-distillation/_test_bash_script.py/0
|
{
"file_path": "transformers/examples/research_projects/seq2seq-distillation/_test_bash_script.py",
"repo_id": "transformers",
"token_count": 3934
}
|
import warnings
from pathlib import Path
from typing import List, Tuple, Union
import fire
from torch import nn
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer, PreTrainedModel
from transformers.utils import logging
logger = logging.get_logger(__name__)
def copy_layers(src_layers: nn.ModuleList, dest_layers: nn.ModuleList, layers_to_copy: List[int]) -> None:
layers_to_copy = nn.ModuleList([src_layers[i] for i in layers_to_copy])
assert len(dest_layers) == len(layers_to_copy), f"{len(dest_layers)} != {len(layers_to_copy)}"
dest_layers.load_state_dict(layers_to_copy.state_dict())
LAYERS_TO_COPY = {
# maps num layers in teacher -> num_layers in student -> which teacher layers to copy.
# 12: bart, 16: pegasus, 6: marian/Helsinki-NLP
12: {
1: [0], # This says that if the teacher has 12 layers and the student has 1, copy layer 0 of the teacher
2: [0, 6],
3: [0, 6, 11],
4: [0, 4, 8, 11],
6: [0, 2, 4, 7, 9, 11],
9: [0, 1, 2, 4, 5, 7, 9, 10, 11],
12: list(range(12)),
},
16: { # maps num layers in student -> which teacher layers to copy
1: [0],
2: [0, 15],
3: [0, 8, 15],
4: [0, 5, 10, 15],
6: [0, 3, 6, 9, 12, 15],
8: [0, 2, 4, 6, 8, 10, 12, 15],
9: [0, 1, 3, 5, 7, 9, 11, 13, 15],
12: [0, 1, 2, 3, 4, 5, 6, 7, 9, 11, 13, 15],
16: list(range(16)),
},
6: {1: [0], 2: [0, 5], 3: [0, 2, 5], 4: [0, 1, 3, 5], 6: list(range(6))},
}
LAYERS_TO_SUPERVISE = {
# maps num layers in student -> which teacher layers to copy.
6: {1: [5], 2: [3, 5], 3: [1, 4, 5], 4: [1, 2, 4, 5]},
12: {1: [11], 2: [5, 11], 3: [3, 7, 11], 6: [1, 3, 5, 8, 10, 11]},
16: {1: [15], 4: [4, 9, 12, 15], 8: [1, 3, 5, 7, 9, 11, 13, 15]},
}
def pick_layers_to_copy(n_student, n_teacher):
try:
val = LAYERS_TO_COPY[n_teacher][n_student]
return val
except KeyError:
if n_student != n_teacher:
warnings.warn(
f"no hardcoded layers to copy for teacher {n_teacher} -> student {n_student}, defaulting to first"
f" {n_student}"
)
return list(range(n_student))
def get_layers_to_supervise(n_student, n_teacher) -> List[int]:
"""Used or the --supervise_forward kwarg"""
if n_student > n_teacher:
raise ValueError(f"Cannot perform intermediate supervision for student {n_student} > teacher {n_teacher}")
elif n_teacher == n_student:
return list(range(n_teacher))
elif n_student == 1:
return [n_teacher - 1]
else:
return LAYERS_TO_SUPERVISE[n_teacher][n_student]
def create_student_by_copying_alternating_layers(
teacher: Union[str, PreTrainedModel],
save_path: Union[str, Path] = "student",
e: Union[int, None] = None,
d: Union[int, None] = None,
copy_first_teacher_layers=False,
e_layers_to_copy=None,
d_layers_to_copy=None,
**extra_config_kwargs,
) -> Tuple[PreTrainedModel, List[int], List[int]]:
"""Make a student by copying alternating layers from a teacher, save it to save_path.
Args:
teacher: str or PreTrainedModel if str, this will call AutoModelForSeq2SeqLM.from_pretrained(teacher) before
copying layers
save_path: where to save the student, defaults to student directory.
e: how many Encoder layers should the student have, default is fully copy of teacher
d: how many Decoder layers should the student have, default is fully copy of teacher
copy_first_teacher_layers: [bool] dont copy alternating layers, just the first e/d.
**extra_config_kwargs: extra kwargs to pass to the student, by default the teacher config is used.
Returns:
student: new, smaller model. (Also saves it to save_path)
e_layers_to_copy: list of which teacher encoder layers were used
d_layers_to_copy: list of which teacher decoder layers were used
"""
_msg = "encoder_layers and decoder_layers cannot be both None-- you would just have an identical teacher."
assert (e is not None) or (d is not None), _msg
if isinstance(teacher, str):
AutoTokenizer.from_pretrained(teacher).save_pretrained(save_path) # purely for convenience
teacher = AutoModelForSeq2SeqLM.from_pretrained(teacher).eval()
else:
assert isinstance(teacher, PreTrainedModel), f"teacher must be a model or string got type {type(teacher)}"
init_kwargs = teacher.config.to_diff_dict()
try:
teacher_e, teacher_d = teacher.config.encoder_layers, teacher.config.decoder_layers
if e is None:
e = teacher_e
if d is None:
d = teacher_d
init_kwargs.update({"encoder_layers": e, "decoder_layers": d})
except AttributeError: # T5
if hasattr(teacher.config, "num_encoder_layers"):
teacher_e, teacher_d = teacher.config.num_encoder_layers, teacher.config.num_decoder_layers
else:
teacher_e, teacher_d = teacher.config.num_layers, teacher.config.num_decoder_layers
if e is None:
e = teacher_e
if d is None:
d = teacher_d
if hasattr(teacher.config, "num_encoder_layers"):
init_kwargs.update({"num_encoder_layers": e, "num_decoder_layers": d})
else:
init_kwargs.update({"num_layers": e, "num_decoder_layers": d})
# Kwargs to instantiate student: teacher kwargs with updated layer numbers + **extra_config_kwargs
init_kwargs.update(extra_config_kwargs)
# Copy weights
student_cfg = teacher.config_class(**init_kwargs)
student = AutoModelForSeq2SeqLM.from_config(student_cfg)
# Start by copying the full teacher state dict this will copy the first N teacher layers to the student.
info = student.load_state_dict(teacher.state_dict(), strict=False)
assert info.missing_keys == [], info.missing_keys # every student key should have a teacher keys.
if copy_first_teacher_layers: # Our copying is done. We just log and save
e_layers_to_copy, d_layers_to_copy = list(range(e)), list(range(d))
logger.info(
f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to"
f" {save_path}"
)
student.save_pretrained(save_path)
return student, e_layers_to_copy, d_layers_to_copy
# Decide which layers of the teacher to copy. Not exactly alternating -- we try to keep first and last layer.
if e_layers_to_copy is None:
e_layers_to_copy: List[int] = pick_layers_to_copy(e, teacher_e)
if d_layers_to_copy is None:
d_layers_to_copy: List[int] = pick_layers_to_copy(d, teacher_d)
try:
if hasattr(
teacher, "prophetnet"
): # For ProphetNet, student.model.encoder.layers is called student.prophetnet.encoder.layers
copy_layers(teacher.prophetnet.encoder.layers, student.prophetnet.encoder.layers, e_layers_to_copy)
copy_layers(teacher.prophetnet.decoder.layers, student.prophetnet.decoder.layers, d_layers_to_copy)
else:
copy_layers(teacher.model.encoder.layers, student.model.encoder.layers, e_layers_to_copy)
copy_layers(teacher.model.decoder.layers, student.model.decoder.layers, d_layers_to_copy)
except AttributeError: # For t5, student.model.encoder.layers is called student.encoder.block
copy_layers(teacher.encoder.block, student.encoder.block, e_layers_to_copy)
copy_layers(teacher.decoder.block, student.decoder.block, d_layers_to_copy)
logger.info(
f"Copied encoder layers {e_layers_to_copy} and decoder layers {d_layers_to_copy}. Saving them to {save_path}"
)
student.config.init_metadata = {
"teacher_type": teacher.config.model_type,
"copied_encoder_layers": e_layers_to_copy,
"copied_decoder_layers": d_layers_to_copy,
}
student.save_pretrained(save_path)
# Save information about copying for easier reproducibility
return student, e_layers_to_copy, d_layers_to_copy
if __name__ == "__main__":
fire.Fire(create_student_by_copying_alternating_layers)
|
transformers/examples/research_projects/seq2seq-distillation/make_student.py/0
|
{
"file_path": "transformers/examples/research_projects/seq2seq-distillation/make_student.py",
"repo_id": "transformers",
"token_count": 3522
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2022 The Microsoft and The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Fine-tuning the library models for tapex on table-based question answering tasks.
Adapted from script: https://github.com/huggingface/transformers/blob/master/examples/pytorch/summarization/run_summarization.py
"""
import logging
import os
import sys
from collections import defaultdict
from copy import deepcopy
from dataclasses import dataclass, field
from functools import partial
from typing import List, Optional
import nltk # Here to have a nice missing dependency error message early on
import numpy as np
import pandas as pd
from datasets import load_dataset
from filelock import FileLock
from wikisql_utils import _TYPE_CONVERTER, retrieve_wikisql_query_answer_tapas
import transformers
from transformers import (
AutoConfig,
BartForConditionalGeneration,
DataCollatorForSeq2Seq,
HfArgumentParser,
Seq2SeqTrainer,
Seq2SeqTrainingArguments,
TapexTokenizer,
set_seed,
)
from transformers.file_utils import is_offline_mode
from transformers.trainer_utils import get_last_checkpoint, is_main_process
from transformers.utils import check_min_version
# Will error if the minimal version of Transformers is not installed. Remove at your own risks.
check_min_version("4.17.0.dev0")
logger = logging.getLogger(__name__)
try:
nltk.data.find("tokenizers/punkt")
except (LookupError, OSError):
if is_offline_mode():
raise LookupError(
"Offline mode: run this script without TRANSFORMERS_OFFLINE first to download nltk data files"
)
with FileLock(".lock") as lock:
nltk.download("punkt", quiet=True)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"},
)
config_name: Optional[str] = field(
default=None, metadata={"help": "Pretrained config name or path if not the same as model_name"}
)
tokenizer_name: Optional[str] = field(
default=None,
metadata={
"help": (
"Pretrained tokenizer name or path if not the same as model_name. "
"By default we use BART-large tokenizer for TAPEX-large."
)
},
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where to store the pretrained models downloaded from huggingface.co"},
)
use_fast_tokenizer: bool = field(
default=True,
metadata={"help": "Whether to use one of the fast tokenizer (backed by the tokenizers library) or not."},
)
model_revision: str = field(
default="main",
metadata={"help": "The specific model version to use (can be a branch name, tag name or commit id)."},
)
use_auth_token: bool = field(
default=False,
metadata={
"help": (
"Will use the token generated when running `huggingface-cli login` (necessary to use this script "
"with private models)."
)
},
)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
"""
dataset_name: Optional[str] = field(
default="wikisql", metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_file: Optional[str] = field(
default=None, metadata={"help": "The input training data file (a jsonlines or csv file)."}
)
validation_file: Optional[str] = field(
default=None,
metadata={
"help": (
"An optional input evaluation data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
)
},
)
test_file: Optional[str] = field(
default=None,
metadata={
"help": "An optional input test data file to evaluate the metrics (rouge) on (a jsonlines or csv file)."
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached training and evaluation sets"}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
max_source_length: Optional[int] = field(
default=1024,
metadata={
"help": (
"The maximum total input sequence length after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
max_target_length: Optional[int] = field(
default=128,
metadata={
"help": (
"The maximum total sequence length for target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded."
)
},
)
val_max_target_length: Optional[int] = field(
default=None,
metadata={
"help": (
"The maximum total sequence length for validation target text after tokenization. Sequences longer "
"than this will be truncated, sequences shorter will be padded. Will default to `max_target_length`. "
"This argument is also used to override the ``max_length`` param of ``model.generate``, which is used "
"during ``evaluate`` and ``predict``."
)
},
)
pad_to_max_length: bool = field(
default=False,
metadata={
"help": (
"Whether to pad all samples to model maximum sentence length. "
"If False, will pad the samples dynamically when batching to the maximum length in the batch. More "
"efficient on GPU but very bad for TPU."
)
},
)
max_train_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of training examples to this "
"value if set."
)
},
)
max_eval_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of evaluation examples to this "
"value if set."
)
},
)
max_predict_samples: Optional[int] = field(
default=None,
metadata={
"help": (
"For debugging purposes or quicker training, truncate the number of prediction examples to this "
"value if set."
)
},
)
num_beams: Optional[int] = field(
default=None,
metadata={
"help": (
"Number of beams to use for evaluation. This argument will be passed to ``model.generate``, "
"which is used during ``evaluate`` and ``predict``."
)
},
)
ignore_pad_token_for_loss: bool = field(
default=True,
metadata={
"help": "Whether to ignore the tokens corresponding to padded labels in the loss computation or not."
},
)
def __post_init__(self):
if self.dataset_name is None and self.train_file is None and self.validation_file is None:
raise ValueError("Need either a dataset name or a training/validation file.")
else:
if self.train_file is not None:
extension = self.train_file.split(".")[-1]
assert extension in ["csv", "json"], "`train_file` should be a csv or a json file."
if self.validation_file is not None:
extension = self.validation_file.split(".")[-1]
assert extension in ["csv", "json"], "`validation_file` should be a csv or a json file."
if self.val_max_target_length is None:
self.val_max_target_length = self.max_target_length
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, Seq2SeqTrainingArguments))
if len(sys.argv) == 2 and sys.argv[1].endswith(".json"):
# If we pass only one argument to the script and it's the path to a json file,
# let's parse it to get our arguments.
model_args, data_args, training_args = parser.parse_json_file(json_file=os.path.abspath(sys.argv[1]))
else:
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
# Detecting last checkpoint.
last_checkpoint = None
if os.path.isdir(training_args.output_dir) and training_args.do_train and not training_args.overwrite_output_dir:
last_checkpoint = get_last_checkpoint(training_args.output_dir)
if last_checkpoint is None and len(os.listdir(training_args.output_dir)) > 0:
raise ValueError(
f"Output directory ({training_args.output_dir}) already exists and is not empty. "
"Use --overwrite_output_dir to overcome."
)
elif last_checkpoint is not None and training_args.resume_from_checkpoint is None:
logger.info(
f"Checkpoint detected, resuming training at {last_checkpoint}. To avoid this behavior, change "
"the `--output_dir` or add `--overwrite_output_dir` to train from scratch."
)
# Setup logging
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logger.setLevel(logging.INFO if is_main_process(training_args.local_rank) else logging.WARN)
# Log on each process the small summary:
logger.warning(
f"Process rank: {training_args.local_rank}, device: {training_args.device}, n_gpu: {training_args.n_gpu}"
+ f"distributed training: {bool(training_args.local_rank != -1)}, 16-bits training: {training_args.fp16}"
)
# Set the verbosity to info of the Transformers logger (on main process only):
if is_main_process(training_args.local_rank):
transformers.utils.logging.set_verbosity_info()
logger.info(f"Training/evaluation parameters {training_args}")
# Set seed before initializing model.
set_seed(training_args.seed)
# Get the datasets: you can either provide your own CSV/JSON training and evaluation files (see below)
# or just provide the name of one of the public datasets available on the hub at https://huggingface.co/datasets/
# (the dataset will be downloaded automatically from the datasets Hub).
#
# For JSON files, this script will use the `question` column for the input question and `table` column for the corresponding table.
#
# In distributed training, the load_dataset function guarantee that only one local process can concurrently
# download the dataset.
if data_args.dataset_name is not None:
# Downloading and loading a dataset from the hub.
datasets = load_dataset(data_args.dataset_name, data_args.dataset_config_name, cache_dir=model_args.cache_dir)
else:
data_files = {}
if data_args.train_file is not None:
data_files["train"] = data_args.train_file
extension = data_args.train_file.split(".")[-1]
if data_args.validation_file is not None:
data_files["validation"] = data_args.validation_file
extension = data_args.validation_file.split(".")[-1]
if data_args.test_file is not None:
data_files["test"] = data_args.test_file
extension = data_args.test_file.split(".")[-1]
datasets = load_dataset(extension, data_files=data_files, cache_dir=model_args.cache_dir)
# See more about loading any type of standard or custom dataset (from files, python dict, pandas DataFrame, etc) at
# https://huggingface.co/docs/datasets/loading_datasets.
# Load pretrained model and tokenizer
#
# Distributed training:
# The .from_pretrained methods guarantee that only one local process can concurrently
# download model & vocab.
config = AutoConfig.from_pretrained(
model_args.config_name if model_args.config_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
# IMPORTANT: the initial BART model's decoding is penalized by no_repeat_ngram_size, and thus
# we should disable it here to avoid problematic generation
config.no_repeat_ngram_size = 0
config.max_length = 1024
config.early_stopping = False
# load tapex tokenizer
tokenizer = TapexTokenizer.from_pretrained(
model_args.tokenizer_name if model_args.tokenizer_name else model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
use_fast=model_args.use_fast_tokenizer,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
add_prefix_space=True,
)
# load Bart based Tapex model (default tapex-large)
model = BartForConditionalGeneration.from_pretrained(
model_args.model_name_or_path,
from_tf=bool(".ckpt" in model_args.model_name_or_path),
config=config,
cache_dir=model_args.cache_dir,
revision=model_args.model_revision,
token=True if model_args.use_auth_token else None,
)
if model.config.decoder_start_token_id is None:
raise ValueError("Make sure that `config.decoder_start_token_id` is correctly defined")
# Preprocessing the datasets.
# We need to tokenize inputs and targets.
if training_args.do_train:
column_names = datasets["train"].column_names
elif training_args.do_eval:
column_names = datasets["validation"].column_names
elif training_args.do_predict:
column_names = datasets["test"].column_names
else:
logger.info("There is nothing to do. Please pass `do_train`, `do_eval` and/or `do_predict`.")
return
# Temporarily set max_target_length for training.
max_target_length = data_args.max_target_length
padding = "max_length" if data_args.pad_to_max_length else False
if training_args.label_smoothing_factor > 0 and not hasattr(model, "prepare_decoder_input_ids_from_labels"):
logger.warning(
"label_smoothing is enabled but the `prepare_decoder_input_ids_from_labels` method is not defined for "
f"`{model.__class__.__name__}`. This will lead to loss being calculated twice and will take up more memory"
)
def preprocess_tableqa_function(examples, is_training=False):
"""
The is_training FLAG is used to identify if we could use the supervision
to truncate the table content if it is required.
"""
# this function is specific for WikiSQL since the util function need the data structure
# to retrieve the WikiSQL answer for each question
def _convert_table_types(_table):
"""Runs the type converter over the table cells."""
ret_table = deepcopy(_table)
types = ret_table["types"]
ret_table["real_rows"] = ret_table["rows"]
typed_rows = []
for row in ret_table["rows"]:
typed_row = []
for column, cell_value in enumerate(row):
typed_row.append(_TYPE_CONVERTER[types[column]](cell_value))
typed_rows.append(typed_row)
ret_table["rows"] = typed_rows
return ret_table
questions = [question.lower() for question in examples["question"]]
example_tables = examples["table"]
example_sqls = examples["sql"]
tables = [
pd.DataFrame.from_records(example_table["rows"], columns=example_table["header"])
for example_table in example_tables
]
# using tapas utils to obtain wikisql answer
answers = []
for example_sql, example_table in zip(example_sqls, example_tables):
tapas_table = _convert_table_types(example_table)
answer_list: List[str] = retrieve_wikisql_query_answer_tapas(tapas_table, example_sql)
# you can choose other delimiters to split each answer
answers.append(answer_list)
# IMPORTANT: we cannot pass by answers during evaluation, answers passed during training are used to
# truncate large tables in the train set!
if is_training:
model_inputs = tokenizer(
table=tables,
query=questions,
answer=answers,
max_length=data_args.max_source_length,
padding=padding,
truncation=True,
)
else:
model_inputs = tokenizer(
table=tables, query=questions, max_length=data_args.max_source_length, padding=padding, truncation=True
)
labels = tokenizer(
answer=[", ".join(answer) for answer in answers],
max_length=max_target_length,
padding=padding,
truncation=True,
)
# If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore
# padding in the loss.
if padding == "max_length" and data_args.ignore_pad_token_for_loss:
labels["input_ids"] = [
[(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"]
]
model_inputs["labels"] = labels["input_ids"]
return model_inputs
# in training, we can use the answer as extra information to truncate large tables
preprocess_tableqa_function_training = partial(preprocess_tableqa_function, is_training=True)
if training_args.do_train:
if "train" not in datasets:
raise ValueError("--do_train requires a train dataset")
train_dataset = datasets["train"]
if data_args.max_train_samples is not None:
train_dataset = train_dataset.select(range(data_args.max_train_samples))
train_dataset = train_dataset.map(
preprocess_tableqa_function_training,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_eval:
max_target_length = data_args.val_max_target_length
if "validation" not in datasets:
raise ValueError("--do_eval requires a validation dataset")
eval_dataset = datasets["validation"]
if data_args.max_eval_samples is not None:
eval_dataset = eval_dataset.select(range(data_args.max_eval_samples))
eval_dataset = eval_dataset.map(
preprocess_tableqa_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
if training_args.do_predict:
max_target_length = data_args.val_max_target_length
if "test" not in datasets:
raise ValueError("--do_predict requires a test dataset")
predict_dataset = datasets["test"]
if data_args.max_predict_samples is not None:
predict_dataset = predict_dataset.select(range(data_args.max_predict_samples))
predict_dataset = predict_dataset.map(
preprocess_tableqa_function,
batched=True,
num_proc=data_args.preprocessing_num_workers,
remove_columns=column_names,
load_from_cache_file=not data_args.overwrite_cache,
)
# Data collator
label_pad_token_id = -100 if data_args.ignore_pad_token_for_loss else tokenizer.pad_token_id
data_collator = DataCollatorForSeq2Seq(
tokenizer,
model=model,
label_pad_token_id=label_pad_token_id,
pad_to_multiple_of=8 if training_args.fp16 else None,
)
def postprocess_text(preds, labels):
preds = [pred.strip() for pred in preds]
labels = [label.strip() for label in labels]
return preds, labels
def compute_metrics(eval_preds):
preds, labels = eval_preds
if isinstance(preds, tuple):
preds = preds[0]
decoded_preds = tokenizer.batch_decode(preds, skip_special_tokens=True)
if data_args.ignore_pad_token_for_loss:
# Replace -100 in the labels as we can't decode them.
labels = np.where(labels != -100, labels, tokenizer.pad_token_id)
decoded_labels = tokenizer.batch_decode(labels, skip_special_tokens=True)
# Some simple post-processing
decoded_preds, decoded_labels = postprocess_text(decoded_preds, decoded_labels)
delimiter = ", "
# define example evaluation
def evaluate_example(predict_str: str, ground_str: str):
predict_spans = predict_str.split(delimiter)
ground_spans = ground_str.split(delimiter)
predict_values = defaultdict(lambda: 0)
ground_values = defaultdict(lambda: 0)
for span in predict_spans:
try:
predict_values[float(span)] += 1
except ValueError:
predict_values[span.strip()] += 1
for span in ground_spans:
try:
ground_values[float(span)] += 1
except ValueError:
ground_values[span.strip()] += 1
is_correct = predict_values == ground_values
return is_correct
def get_denotation_accuracy(predictions: List[str], references: List[str]):
assert len(predictions) == len(references)
correct_num = 0
for predict_str, ground_str in zip(predictions, references):
is_correct = evaluate_example(predict_str.lower(), ground_str.lower())
if is_correct:
correct_num += 1
return correct_num / len(predictions)
accuracy = get_denotation_accuracy(decoded_preds, decoded_labels)
result = {"denotation_accuracy": accuracy}
return result
# Initialize our Trainer
trainer = Seq2SeqTrainer(
model=model,
args=training_args,
train_dataset=train_dataset if training_args.do_train else None,
eval_dataset=eval_dataset if training_args.do_eval else None,
tokenizer=tokenizer,
data_collator=data_collator,
compute_metrics=compute_metrics if training_args.predict_with_generate else None,
)
if training_args.do_train:
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint)
trainer.save_model() # Saves the tokenizer too for easy upload
metrics = train_result.metrics
max_train_samples = (
data_args.max_train_samples if data_args.max_train_samples is not None else len(train_dataset)
)
metrics["train_samples"] = min(max_train_samples, len(train_dataset))
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state()
# Evaluation
results = {}
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate(
max_length=data_args.val_max_target_length, num_beams=data_args.num_beams, metric_key_prefix="eval"
)
max_eval_samples = data_args.max_eval_samples if data_args.max_eval_samples is not None else len(eval_dataset)
metrics["eval_samples"] = min(max_eval_samples, len(eval_dataset))
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
if training_args.do_predict:
logger.info("*** Predict ***")
predict_results = trainer.predict(
predict_dataset,
metric_key_prefix="predict",
max_length=data_args.val_max_target_length,
num_beams=data_args.num_beams,
)
metrics = predict_results.metrics
max_predict_samples = (
data_args.max_predict_samples if data_args.max_predict_samples is not None else len(predict_dataset)
)
metrics["predict_samples"] = min(max_predict_samples, len(predict_dataset))
trainer.log_metrics("predict", metrics)
trainer.save_metrics("predict", metrics)
if trainer.is_world_process_zero():
if training_args.predict_with_generate:
predictions = tokenizer.batch_decode(
predict_results.predictions, skip_special_tokens=True, clean_up_tokenization_spaces=True
)
predictions = [pred.strip() for pred in predictions]
output_prediction_file = os.path.join(training_args.output_dir, "tapex_predictions.txt")
with open(output_prediction_file, "w") as writer:
writer.write("\n".join(predictions))
return results
def _mp_fn(index):
# For xla_spawn (TPUs)
main()
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/tapex/run_wikisql_with_tapex.py/0
|
{
"file_path": "transformers/examples/research_projects/tapex/run_wikisql_with_tapex.py",
"repo_id": "transformers",
"token_count": 11008
}
|
import importlib
import torch
import yaml
from omegaconf import OmegaConf
from taming.models.vqgan import VQModel
def load_config(config_path, display=False):
config = OmegaConf.load(config_path)
if display:
print(yaml.dump(OmegaConf.to_container(config)))
return config
def load_vqgan(device, conf_path=None, ckpt_path=None):
if conf_path is None:
conf_path = "./model_checkpoints/vqgan_only.yaml"
config = load_config(conf_path, display=False)
model = VQModel(**config.model.params)
if ckpt_path is None:
ckpt_path = "./model_checkpoints/vqgan_only.pt"
sd = torch.load(ckpt_path, map_location=device)
if ".ckpt" in ckpt_path:
sd = sd["state_dict"]
model.load_state_dict(sd, strict=True)
model.to(device)
del sd
return model
def reconstruct_with_vqgan(x, model):
z, _, [_, _, indices] = model.encode(x)
print(f"VQGAN --- {model.__class__.__name__}: latent shape: {z.shape[2:]}")
xrec = model.decode(z)
return xrec
def get_obj_from_str(string, reload=False):
module, cls = string.rsplit(".", 1)
if reload:
module_imp = importlib.import_module(module)
importlib.reload(module_imp)
return getattr(importlib.import_module(module, package=None), cls)
def instantiate_from_config(config):
if "target" not in config:
raise KeyError("Expected key `target` to instantiate.")
return get_obj_from_str(config["target"])(**config.get("params", {}))
def load_model_from_config(config, sd, gpu=True, eval_mode=True):
model = instantiate_from_config(config)
if sd is not None:
model.load_state_dict(sd)
if gpu:
model.cuda()
if eval_mode:
model.eval()
return {"model": model}
def load_model(config, ckpt, gpu, eval_mode):
# load the specified checkpoint
if ckpt:
pl_sd = torch.load(ckpt, map_location="cpu")
global_step = pl_sd["global_step"]
print(f"loaded model from global step {global_step}.")
else:
pl_sd = {"state_dict": None}
global_step = None
model = load_model_from_config(config.model, pl_sd["state_dict"], gpu=gpu, eval_mode=eval_mode)["model"]
return model, global_step
|
transformers/examples/research_projects/vqgan-clip/loaders.py/0
|
{
"file_path": "transformers/examples/research_projects/vqgan-clip/loaders.py",
"repo_id": "transformers",
"token_count": 926
}
|
#!/usr/bin/env python3
import logging
import pathlib
import re
import sys
from dataclasses import dataclass, field
from typing import Any, Callable, Dict, List, Optional, Set, Union
import datasets
import librosa
import numpy as np
import torch
from lang_trans import arabic
from packaging import version
from torch import nn
from transformers import (
HfArgumentParser,
Trainer,
TrainingArguments,
Wav2Vec2CTCTokenizer,
Wav2Vec2FeatureExtractor,
Wav2Vec2ForCTC,
Wav2Vec2Processor,
is_apex_available,
trainer_utils,
)
if is_apex_available():
from apex import amp
if version.parse(version.parse(torch.__version__).base_version) >= version.parse("1.6"):
_is_native_amp_available = True
from torch.cuda.amp import autocast
logger = logging.getLogger(__name__)
@dataclass
class ModelArguments:
"""
Arguments pertaining to which model/config/tokenizer we are going to fine-tune from.
"""
model_name_or_path: str = field(
metadata={"help": "Path to pretrained model or model identifier from huggingface.co/models"}
)
cache_dir: Optional[str] = field(
default=None,
metadata={"help": "Where do you want to store the pretrained models downloaded from huggingface.co"},
)
freeze_feature_extractor: Optional[bool] = field(
default=True, metadata={"help": "Whether to freeze the feature extractor layers of the model."}
)
verbose_logging: Optional[bool] = field(
default=False,
metadata={"help": "Whether to log verbose messages or not."},
)
def configure_logger(model_args: ModelArguments, training_args: TrainingArguments):
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
handlers=[logging.StreamHandler(sys.stdout)],
)
logging_level = logging.WARNING
if model_args.verbose_logging:
logging_level = logging.DEBUG
elif trainer_utils.is_main_process(training_args.local_rank):
logging_level = logging.INFO
logger.setLevel(logging_level)
@dataclass
class DataTrainingArguments:
"""
Arguments pertaining to what data we are going to input our model for training and eval.
Using `HfArgumentParser` we can turn this class
into argparse arguments to be able to specify them on
the command line.
"""
dataset_name: str = field(
default=None, metadata={"help": "The name of the dataset to use (via the datasets library)."}
)
dataset_config_name: Optional[str] = field(
default=None, metadata={"help": "The configuration name of the dataset to use (via the datasets library)."}
)
train_split_name: Optional[str] = field(
default="train",
metadata={
"help": "The name of the training data set split to use (via the datasets library). Defaults to 'train'"
},
)
validation_split_name: Optional[str] = field(
default="validation",
metadata={
"help": (
"The name of the validation data set split to use (via the datasets library). Defaults to 'validation'"
)
},
)
target_text_column: Optional[str] = field(
default="text",
metadata={"help": "Column in the dataset that contains label (target text). Defaults to 'text'"},
)
speech_file_column: Optional[str] = field(
default="file",
metadata={"help": "Column in the dataset that contains speech file path. Defaults to 'file'"},
)
target_feature_extractor_sampling_rate: Optional[bool] = field(
default=False,
metadata={"help": "Resample loaded audio to target feature extractor's sampling rate or not."},
)
max_duration_in_seconds: Optional[float] = field(
default=None,
metadata={"help": "Filters out examples longer than specified. Defaults to no filtering."},
)
orthography: Optional[str] = field(
default="librispeech",
metadata={
"help": (
"Orthography used for normalization and tokenization: 'librispeech' (default), 'timit', or"
" 'buckwalter'."
)
},
)
overwrite_cache: bool = field(
default=False, metadata={"help": "Overwrite the cached preprocessed datasets or not."}
)
preprocessing_num_workers: Optional[int] = field(
default=None,
metadata={"help": "The number of processes to use for the preprocessing."},
)
@dataclass
class Orthography:
"""
Orthography scheme used for text normalization and tokenization.
Args:
do_lower_case (:obj:`bool`, `optional`, defaults to :obj:`False`):
Whether or not to accept lowercase input and lowercase the output when decoding.
vocab_file (:obj:`str`, `optional`):
File containing the vocabulary.
word_delimiter_token (:obj:`str`, `optional`, defaults to :obj:`"|"`):
The token used for delimiting words; it needs to be in the vocabulary.
translation_table (:obj:`Dict[str, str]`, `optional`, defaults to :obj:`{}`):
Table to use with `str.translate()` when preprocessing text (e.g., "-" -> " ").
words_to_remove (:obj:`Set[str]`, `optional`, defaults to :obj:`set()`):
Words to remove when preprocessing text (e.g., "sil").
untransliterator (:obj:`Callable[[str], str]`, `optional`):
Function that untransliterates text back into native writing system.
"""
do_lower_case: bool = False
vocab_file: Optional[str] = None
word_delimiter_token: Optional[str] = "|"
translation_table: Optional[Dict[str, str]] = field(default_factory=dict)
words_to_remove: Optional[Set[str]] = field(default_factory=set)
untransliterator: Optional[Callable[[str], str]] = None
@classmethod
def from_name(cls, name: str):
if name == "librispeech":
return cls()
if name == "timit":
return cls(
do_lower_case=True,
# break compounds like "quarter-century-old" and replace pauses "--"
translation_table=str.maketrans({"-": " "}),
)
if name == "buckwalter":
translation_table = {
"-": " ", # sometimes used to represent pauses
"^": "v", # fixing "tha" in arabic_speech_corpus dataset
}
return cls(
vocab_file=pathlib.Path(__file__).parent.joinpath("vocab/buckwalter.json"),
word_delimiter_token="/", # "|" is Arabic letter alef with madda above
translation_table=str.maketrans(translation_table),
words_to_remove={"sil"}, # fixing "sil" in arabic_speech_corpus dataset
untransliterator=arabic.buckwalter.untransliterate,
)
raise ValueError(f"Unsupported orthography: '{name}'.")
def preprocess_for_training(self, text: str) -> str:
# TODO(elgeish) return a pipeline (e.g., from jiwer) instead? Or rely on branch predictor as is
if len(self.translation_table) > 0:
text = text.translate(self.translation_table)
if len(self.words_to_remove) == 0:
text = " ".join(text.split()) # clean up whitespaces
else:
text = " ".join(w for w in text.split() if w not in self.words_to_remove) # and clean up whilespaces
return text
def create_processor(self, model_args: ModelArguments) -> Wav2Vec2Processor:
feature_extractor = Wav2Vec2FeatureExtractor.from_pretrained(
model_args.model_name_or_path, cache_dir=model_args.cache_dir
)
if self.vocab_file:
tokenizer = Wav2Vec2CTCTokenizer(
self.vocab_file,
cache_dir=model_args.cache_dir,
do_lower_case=self.do_lower_case,
word_delimiter_token=self.word_delimiter_token,
)
else:
tokenizer = Wav2Vec2CTCTokenizer.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
do_lower_case=self.do_lower_case,
word_delimiter_token=self.word_delimiter_token,
)
return Wav2Vec2Processor(feature_extractor, tokenizer)
@dataclass
class DataCollatorCTCWithPadding:
"""
Data collator that will dynamically pad the inputs received.
Args:
processor (:class:`~transformers.Wav2Vec2Processor`)
The processor used for proccessing the data.
padding (:obj:`bool`, :obj:`str` or :class:`~transformers.tokenization_utils_base.PaddingStrategy`, `optional`, defaults to :obj:`True`):
Select a strategy to pad the returned sequences (according to the model's padding side and padding index)
among:
* :obj:`True` or :obj:`'longest'`: Pad to the longest sequence in the batch (or no padding if only a single
sequence if provided).
* :obj:`'max_length'`: Pad to a maximum length specified with the argument :obj:`max_length` or to the
maximum acceptable input length for the model if that argument is not provided.
* :obj:`False` or :obj:`'do_not_pad'` (default): No padding (i.e., can output a batch with sequences of
different lengths).
max_length (:obj:`int`, `optional`):
Maximum length of the ``input_values`` of the returned list and optionally padding length (see above).
max_length_labels (:obj:`int`, `optional`):
Maximum length of the ``labels`` returned list and optionally padding length (see above).
pad_to_multiple_of (:obj:`int`, `optional`):
If set will pad the sequence to a multiple of the provided value.
This is especially useful to enable the use of Tensor Cores on NVIDIA hardware with compute capability >=
7.5 (Volta).
"""
processor: Wav2Vec2Processor
padding: Union[bool, str] = True
max_length: Optional[int] = None
max_length_labels: Optional[int] = None
pad_to_multiple_of: Optional[int] = None
pad_to_multiple_of_labels: Optional[int] = None
def __call__(self, features: List[Dict[str, Union[List[int], torch.Tensor]]]) -> Dict[str, torch.Tensor]:
# split inputs and labels since they have to be of different lengths and need
# different padding methods
input_features = [{"input_values": feature["input_values"]} for feature in features]
label_features = [{"input_ids": feature["labels"]} for feature in features]
batch = self.processor.pad(
input_features,
padding=self.padding,
max_length=self.max_length,
pad_to_multiple_of=self.pad_to_multiple_of,
return_tensors="pt",
)
labels_batch = self.processor.pad(
labels=label_features,
padding=self.padding,
max_length=self.max_length_labels,
pad_to_multiple_of=self.pad_to_multiple_of_labels,
return_tensors="pt",
)
# replace padding with -100 to ignore loss correctly
labels = labels_batch["input_ids"].masked_fill(labels_batch.attention_mask.ne(1), -100)
batch["labels"] = labels
return batch
class CTCTrainer(Trainer):
def training_step(self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]]) -> torch.Tensor:
"""
Perform a training step on a batch of inputs.
Subclass and override to inject custom behavior.
Args:
model (:obj:`nn.Module`):
The model to train.
inputs (:obj:`Dict[str, Union[torch.Tensor, Any]]`):
The inputs and targets of the model.
The dictionary will be unpacked before being fed to the model. Most models expect the targets under the
argument :obj:`labels`. Check your model's documentation for all accepted arguments.
Return:
:obj:`torch.Tensor`: The tensor with training loss on this batch.
"""
model.train()
inputs = self._prepare_inputs(inputs)
if self.use_amp:
with autocast():
loss = self.compute_loss(model, inputs)
else:
loss = self.compute_loss(model, inputs)
if self.args.n_gpu > 1:
if model.module.config.ctc_loss_reduction == "mean":
loss = loss.mean()
elif model.module.config.ctc_loss_reduction == "sum":
loss = loss.sum() / (inputs["labels"] >= 0).sum()
else:
raise ValueError(f"{model.config.ctc_loss_reduction} is not valid. Choose one of ['mean', 'sum']")
if self.args.gradient_accumulation_steps > 1:
loss = loss / self.args.gradient_accumulation_steps
if self.use_amp:
self.scaler.scale(loss).backward()
elif self.use_apex:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
elif self.deepspeed:
self.deepspeed.backward(loss)
else:
loss.backward()
return loss.detach()
def main():
# See all possible arguments in src/transformers/training_args.py
# or by passing the --help flag to this script.
# We now keep distinct sets of args, for a cleaner separation of concerns.
parser = HfArgumentParser((ModelArguments, DataTrainingArguments, TrainingArguments))
model_args, data_args, training_args = parser.parse_args_into_dataclasses()
configure_logger(model_args, training_args)
orthography = Orthography.from_name(data_args.orthography.lower())
processor = orthography.create_processor(model_args)
model = Wav2Vec2ForCTC.from_pretrained(
model_args.model_name_or_path,
cache_dir=model_args.cache_dir,
gradient_checkpointing=training_args.gradient_checkpointing,
vocab_size=len(processor.tokenizer),
)
train_dataset = datasets.load_dataset(
data_args.dataset_name, data_args.dataset_config_name, split=data_args.train_split_name
)
val_dataset = datasets.load_dataset(
data_args.dataset_name, data_args.dataset_config_name, split=data_args.validation_split_name
)
wer_metric = datasets.load_metric("wer")
target_sr = processor.feature_extractor.sampling_rate if data_args.target_feature_extractor_sampling_rate else None
vocabulary_chars_str = "".join(t for t in processor.tokenizer.get_vocab().keys() if len(t) == 1)
vocabulary_text_cleaner = re.compile( # remove characters not in vocabulary
rf"[^\s{re.escape(vocabulary_chars_str)}]", # allow space in addition to chars in vocabulary
flags=re.IGNORECASE if processor.tokenizer.do_lower_case else 0,
)
text_updates = []
def prepare_example(example): # TODO(elgeish) make use of multiprocessing?
example["speech"], example["sampling_rate"] = librosa.load(example[data_args.speech_file_column], sr=target_sr)
if data_args.max_duration_in_seconds is not None:
example["duration_in_seconds"] = len(example["speech"]) / example["sampling_rate"]
# Normalize and clean up text; order matters!
updated_text = orthography.preprocess_for_training(example[data_args.target_text_column])
updated_text = vocabulary_text_cleaner.sub("", updated_text)
if updated_text != example[data_args.target_text_column]:
text_updates.append((example[data_args.target_text_column], updated_text))
example[data_args.target_text_column] = updated_text
return example
train_dataset = train_dataset.map(prepare_example, remove_columns=[data_args.speech_file_column])
val_dataset = val_dataset.map(prepare_example, remove_columns=[data_args.speech_file_column])
if data_args.max_duration_in_seconds is not None:
def filter_by_max_duration(example):
return example["duration_in_seconds"] <= data_args.max_duration_in_seconds
old_train_size = len(train_dataset)
old_val_size = len(val_dataset)
train_dataset = train_dataset.filter(filter_by_max_duration, remove_columns=["duration_in_seconds"])
val_dataset = val_dataset.filter(filter_by_max_duration, remove_columns=["duration_in_seconds"])
if len(train_dataset) > old_train_size:
logger.warning(
f"Filtered out {len(train_dataset) - old_train_size} train example(s) longer than"
f" {data_args.max_duration_in_seconds} second(s)."
)
if len(val_dataset) > old_val_size:
logger.warning(
f"Filtered out {len(val_dataset) - old_val_size} validation example(s) longer than"
f" {data_args.max_duration_in_seconds} second(s)."
)
logger.info(f"Split sizes: {len(train_dataset)} train and {len(val_dataset)} validation.")
logger.warning(f"Updated {len(text_updates)} transcript(s) using '{data_args.orthography}' orthography rules.")
if logger.isEnabledFor(logging.DEBUG):
for original_text, updated_text in text_updates:
logger.debug(f'Updated text: "{original_text}" -> "{updated_text}"')
text_updates = None
def prepare_dataset(batch):
# check that all files have the correct sampling rate
assert (
len(set(batch["sampling_rate"])) == 1
), f"Make sure all inputs have the same sampling rate of {processor.feature_extractor.sampling_rate}."
processed_batch = processor(
audio=batch["speech"], text=batch[data_args.target_text_column], sampling_rate=batch["sampling_rate"][0]
)
batch.update(processed_batch)
return batch
train_dataset = train_dataset.map(
prepare_dataset,
batch_size=training_args.per_device_train_batch_size,
batched=True,
num_proc=data_args.preprocessing_num_workers,
)
val_dataset = val_dataset.map(
prepare_dataset,
batch_size=training_args.per_device_train_batch_size,
batched=True,
num_proc=data_args.preprocessing_num_workers,
)
data_collator = DataCollatorCTCWithPadding(processor=processor, padding=True)
def compute_metrics(pred):
pred_logits = pred.predictions
pred_ids = np.argmax(pred_logits, axis=-1)
pred.label_ids[pred.label_ids == -100] = processor.tokenizer.pad_token_id
pred_str = processor.batch_decode(pred_ids)
# we do not want to group tokens when computing the metrics
label_str = processor.batch_decode(pred.label_ids, group_tokens=False)
if logger.isEnabledFor(logging.DEBUG):
for reference, predicted in zip(label_str, pred_str):
logger.debug(f'reference: "{reference}"')
logger.debug(f'predicted: "{predicted}"')
if orthography.untransliterator is not None:
logger.debug(f'reference (untransliterated): "{orthography.untransliterator(reference)}"')
logger.debug(f'predicted (untransliterated): "{orthography.untransliterator(predicted)}"')
wer = wer_metric.compute(predictions=pred_str, references=label_str)
return {"wer": wer}
if model_args.freeze_feature_extractor:
model.freeze_feature_extractor()
trainer = CTCTrainer(
model=model,
data_collator=data_collator,
args=training_args,
compute_metrics=compute_metrics,
train_dataset=train_dataset,
eval_dataset=val_dataset,
tokenizer=processor.feature_extractor,
)
trainer.train()
if __name__ == "__main__":
main()
|
transformers/examples/research_projects/wav2vec2/run_asr.py/0
|
{
"file_path": "transformers/examples/research_projects/wav2vec2/run_asr.py",
"repo_id": "transformers",
"token_count": 8256
}
|
<!---
Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
# Image classification examples
This directory contains 2 scripts that showcase how to fine-tune any model supported by the [`TFAutoModelForImageClassification` API](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.TFAutoModelForImageClassification) (such as [ViT](https://huggingface.co/docs/transformers/main/en/model_doc/vit), [ConvNeXT](https://huggingface.co/docs/transformers/main/en/model_doc/convnext), [ResNet](https://huggingface.co/docs/transformers/main/en/model_doc/resnet), [Swin Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/swin)...) using TensorFlow. They can be used to fine-tune models on both [datasets from the hub](#using-datasets-from-hub) as well as on [your own custom data](#using-your-own-data).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/image_classification_inference_widget.png" height="400" />
Try out the inference widget here: https://huggingface.co/google/vit-base-patch16-224
## TensorFlow
Based on the script [`run_image_classification.py`](https://github.com/huggingface/transformers/blob/main/examples/tensorflow/image-classification/run_image_classification.py).
### Using datasets from Hub
Here we show how to fine-tune a Vision Transformer (`ViT`) on the [beans](https://huggingface.co/datasets/beans) dataset, to classify the disease type of bean leaves. The following will train a model and push it to the `amyeroberts/vit-base-beans` repo.
```bash
python run_image_classification.py \
--dataset_name beans \
--output_dir ./beans_outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval \
--push_to_hub \
--hub_model_id amyeroberts/vit-base-beans \
--learning_rate 2e-5 \
--num_train_epochs 5 \
--per_device_train_batch_size 8 \
--per_device_eval_batch_size 8 \
--logging_strategy steps \
--logging_steps 10 \
--eval_strategy epoch \
--save_strategy epoch \
--load_best_model_at_end True \
--save_total_limit 3 \
--seed 1337
```
👀 See the results here: [amyeroberts/vit-base-beans](https://huggingface.co/amyeroberts/vit-base-beans).
Note that you can replace the model and dataset by simply setting the `model_name_or_path` and `dataset_name` arguments respectively, with any model or dataset from the [hub](https://huggingface.co/). For an overview of all possible arguments, we refer to the [docs](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) of the `TrainingArguments`, which can be passed as flags.
> If your model classification head dimensions do not fit the number of labels in the dataset, you can specify `--ignore_mismatched_sizes` to adapt it.
### Using your own data
To use your own dataset, there are 2 ways:
- you can either provide your own folders as `--train_dir` and/or `--validation_dir` arguments
- you can upload your dataset to the hub (possibly as a private repo, if you prefer so), and simply pass the `--dataset_name` argument.
Below, we explain both in more detail.
#### Provide them as folders
If you provide your own folders with images, the script expects the following directory structure:
```bash
root/dog/xxx.png
root/dog/xxy.png
root/dog/[...]/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/[...]/asd932_.png
```
In other words, you need to organize your images in subfolders, based on their class. You can then run the script like this:
```bash
python run_image_classification.py \
--train_dir <path-to-train-root> \
--output_dir ./outputs/ \
--remove_unused_columns False \
--do_train \
--do_eval
```
Internally, the script will use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature which will automatically turn the folders into 🤗 Dataset objects.
##### 💡 The above will split the train dir into training and evaluation sets
- To control the split amount, use the `--train_val_split` flag.
- To provide your own validation split in its own directory, you can pass the `--validation_dir <path-to-val-root>` flag.
#### Upload your data to the hub, as a (possibly private) repo
To upload your image dataset to the hub you can use the [`ImageFolder`](https://huggingface.co/docs/datasets/v2.0.0/en/image_process#imagefolder) feature available in 🤗 Datasets. Simply do the following:
```python
from datasets import load_dataset
# example 1: local folder
dataset = load_dataset("imagefolder", data_dir="path_to_your_folder")
# example 2: local files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="path_to_zip_file")
# example 3: remote files (supported formats are tar, gzip, zip, xz, rar, zstd)
dataset = load_dataset("imagefolder", data_files="https://download.microsoft.com/download/3/E/1/3E1C3F21-ECDB-4869-8368-6DEBA77B919F/kagglecatsanddogs_3367a.zip")
# example 4: providing several splits
dataset = load_dataset("imagefolder", data_files={"train": ["path/to/file1", "path/to/file2"], "test": ["path/to/file3", "path/to/file4"]})
```
`ImageFolder` will create a `label` column, and the label name is based on the directory name.
Next, push it to the hub!
```python
# assuming you have ran the huggingface-cli login command in a terminal
dataset.push_to_hub("name_of_your_dataset")
# if you want to push to a private repo, simply pass private=True:
dataset.push_to_hub("name_of_your_dataset", private=True)
```
and that's it! You can now train your model by simply setting the `--dataset_name` argument to the name of your dataset on the hub (as explained in [Using datasets from the 🤗 hub](#using-datasets-from-hub)).
More on this can also be found in [this blog post](https://huggingface.co/blog/image-search-datasets).
### Sharing your model on 🤗 Hub
0. If you haven't already, [sign up](https://huggingface.co/join) for a 🤗 account
1. Make sure you have `git-lfs` installed and git set up.
```bash
$ apt install git-lfs
$ git config --global user.email "[email protected]"
$ git config --global user.name "Your Name"
```
2. Log in with your HuggingFace account credentials using `huggingface-cli`:
```bash
$ huggingface-cli login
# ...follow the prompts
```
3. When running the script, pass the following arguments:
```bash
python run_image_classification.py \
--push_to_hub \
--push_to_hub_model_id <name-your-model> \
...
```
|
transformers/examples/tensorflow/image-classification/README.md/0
|
{
"file_path": "transformers/examples/tensorflow/image-classification/README.md",
"repo_id": "transformers",
"token_count": 2316
}
|
## 🔥 Model cards now live inside each huggingface.co model repo 🔥
For consistency, ease of use and scalability, `README.md` model cards now live directly inside each model repo on the HuggingFace model hub.
### How to update a model card
You can directly update a model card inside any model repo you have **write access** to, i.e.:
- a model under your username namespace
- a model under any organization you are a part of.
You can either:
- update it, commit and push using your usual git workflow (command line, GUI, etc.)
- or edit it directly from the website's UI.
**What if you want to create or update a model card for a model you don't have write access to?**
In that case, you can open a [Hub pull request](https://huggingface.co/docs/hub/repositories-pull-requests-discussions)! Check out the [announcement](https://huggingface.co/blog/community-update) of this feature for more details 🤗.
### What happened to the model cards here?
We migrated every model card from the repo to its corresponding huggingface.co model repo. Individual commits were preserved, and they link back to the original commit on GitHub.
|
transformers/model_cards/README.md/0
|
{
"file_path": "transformers/model_cards/README.md",
"repo_id": "transformers",
"token_count": 296
}
|
#!/usr/bin/env python
# coding=utf-8
# Copyright 2023 The HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import re
import numpy as np
import torch
from ..models.auto import AutoProcessor
from ..models.vision_encoder_decoder import VisionEncoderDecoderModel
from ..utils import is_vision_available
from .tools import PipelineTool
if is_vision_available():
from PIL import Image
class DocumentQuestionAnsweringTool(PipelineTool):
default_checkpoint = "naver-clova-ix/donut-base-finetuned-docvqa"
description = "This is a tool that answers a question about an document (pdf). It returns a string that contains the answer to the question."
name = "document_qa"
pre_processor_class = AutoProcessor
model_class = VisionEncoderDecoderModel
inputs = {
"document": {
"type": "image",
"description": "The image containing the information. Can be a PIL Image or a string path to the image.",
},
"question": {"type": "string", "description": "The question in English"},
}
output_type = "string"
def __init__(self, *args, **kwargs):
if not is_vision_available():
raise ValueError("Pillow must be installed to use the DocumentQuestionAnsweringTool.")
super().__init__(*args, **kwargs)
def encode(self, document: "Image", question: str):
task_prompt = "<s_docvqa><s_question>{user_input}</s_question><s_answer>"
prompt = task_prompt.replace("{user_input}", question)
decoder_input_ids = self.pre_processor.tokenizer(
prompt, add_special_tokens=False, return_tensors="pt"
).input_ids
if isinstance(document, str):
img = Image.open(document).convert("RGB")
img_array = np.array(img).transpose(2, 0, 1)
document = torch.from_numpy(img_array)
pixel_values = self.pre_processor(document, return_tensors="pt").pixel_values
return {"decoder_input_ids": decoder_input_ids, "pixel_values": pixel_values}
def forward(self, inputs):
return self.model.generate(
inputs["pixel_values"].to(self.device),
decoder_input_ids=inputs["decoder_input_ids"].to(self.device),
max_length=self.model.decoder.config.max_position_embeddings,
early_stopping=True,
pad_token_id=self.pre_processor.tokenizer.pad_token_id,
eos_token_id=self.pre_processor.tokenizer.eos_token_id,
use_cache=True,
num_beams=1,
bad_words_ids=[[self.pre_processor.tokenizer.unk_token_id]],
return_dict_in_generate=True,
).sequences
def decode(self, outputs):
sequence = self.pre_processor.batch_decode(outputs)[0]
sequence = sequence.replace(self.pre_processor.tokenizer.eos_token, "")
sequence = sequence.replace(self.pre_processor.tokenizer.pad_token, "")
sequence = re.sub(r"<.*?>", "", sequence, count=1).strip() # remove first task start token
sequence = self.pre_processor.token2json(sequence)
return sequence["answer"]
|
transformers/src/transformers/agents/document_question_answering.py/0
|
{
"file_path": "transformers/src/transformers/agents/document_question_answering.py",
"repo_id": "transformers",
"token_count": 1374
}
|
# Copyright 2021 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import difflib
import json
import os
import re
from argparse import ArgumentParser, Namespace
from dataclasses import dataclass
from datetime import date
from itertools import chain
from pathlib import Path
from typing import Any, Callable, Dict, List, Optional, Pattern, Tuple, Union
import yaml
from ..models import auto as auto_module
from ..models.auto.configuration_auto import model_type_to_module_name
from ..utils import is_flax_available, is_tf_available, is_torch_available, logging
from . import BaseTransformersCLICommand
logger = logging.get_logger(__name__) # pylint: disable=invalid-name
CURRENT_YEAR = date.today().year
TRANSFORMERS_PATH = Path(__file__).parent.parent
REPO_PATH = TRANSFORMERS_PATH.parent.parent
@dataclass
class ModelPatterns:
"""
Holds the basic information about a new model for the add-new-model-like command.
Args:
model_name (`str`): The model name.
checkpoint (`str`): The checkpoint to use for doc examples.
model_type (`str`, *optional*):
The model type, the identifier used internally in the library like `bert` or `xlm-roberta`. Will default to
`model_name` lowercased with spaces replaced with minuses (-).
model_lower_cased (`str`, *optional*):
The lowercased version of the model name, to use for the module name or function names. Will default to
`model_name` lowercased with spaces and minuses replaced with underscores.
model_camel_cased (`str`, *optional*):
The camel-cased version of the model name, to use for the class names. Will default to `model_name`
camel-cased (with spaces and minuses both considered as word separators.
model_upper_cased (`str`, *optional*):
The uppercased version of the model name, to use for the constant names. Will default to `model_name`
uppercased with spaces and minuses replaced with underscores.
config_class (`str`, *optional*):
The tokenizer class associated with this model. Will default to `"{model_camel_cased}Config"`.
tokenizer_class (`str`, *optional*):
The tokenizer class associated with this model (leave to `None` for models that don't use a tokenizer).
image_processor_class (`str`, *optional*):
The image processor class associated with this model (leave to `None` for models that don't use an image
processor).
feature_extractor_class (`str`, *optional*):
The feature extractor class associated with this model (leave to `None` for models that don't use a feature
extractor).
processor_class (`str`, *optional*):
The processor class associated with this model (leave to `None` for models that don't use a processor).
"""
model_name: str
checkpoint: str
model_type: Optional[str] = None
model_lower_cased: Optional[str] = None
model_camel_cased: Optional[str] = None
model_upper_cased: Optional[str] = None
config_class: Optional[str] = None
tokenizer_class: Optional[str] = None
image_processor_class: Optional[str] = None
feature_extractor_class: Optional[str] = None
processor_class: Optional[str] = None
def __post_init__(self):
if self.model_type is None:
self.model_type = self.model_name.lower().replace(" ", "-")
if self.model_lower_cased is None:
self.model_lower_cased = self.model_name.lower().replace(" ", "_").replace("-", "_")
if self.model_camel_cased is None:
# Split the model name on - and space
words = self.model_name.split(" ")
words = list(chain(*[w.split("-") for w in words]))
# Make sure each word is capitalized
words = [w[0].upper() + w[1:] for w in words]
self.model_camel_cased = "".join(words)
if self.model_upper_cased is None:
self.model_upper_cased = self.model_name.upper().replace(" ", "_").replace("-", "_")
if self.config_class is None:
self.config_class = f"{self.model_camel_cased}Config"
ATTRIBUTE_TO_PLACEHOLDER = {
"config_class": "[CONFIG_CLASS]",
"tokenizer_class": "[TOKENIZER_CLASS]",
"image_processor_class": "[IMAGE_PROCESSOR_CLASS]",
"feature_extractor_class": "[FEATURE_EXTRACTOR_CLASS]",
"processor_class": "[PROCESSOR_CLASS]",
"checkpoint": "[CHECKPOINT]",
"model_type": "[MODEL_TYPE]",
"model_upper_cased": "[MODEL_UPPER_CASED]",
"model_camel_cased": "[MODEL_CAMELCASED]",
"model_lower_cased": "[MODEL_LOWER_CASED]",
"model_name": "[MODEL_NAME]",
}
def is_empty_line(line: str) -> bool:
"""
Determines whether a line is empty or not.
"""
return len(line) == 0 or line.isspace()
def find_indent(line: str) -> int:
"""
Returns the number of spaces that start a line indent.
"""
search = re.search(r"^(\s*)(?:\S|$)", line)
if search is None:
return 0
return len(search.groups()[0])
def parse_module_content(content: str) -> List[str]:
"""
Parse the content of a module in the list of objects it defines.
Args:
content (`str`): The content to parse
Returns:
`List[str]`: The list of objects defined in the module.
"""
objects = []
current_object = []
lines = content.split("\n")
# Doc-styler takes everything between two triple quotes in docstrings, so we need a fake """ here to go with this.
end_markers = [")", "]", "}", '"""']
for line in lines:
# End of an object
is_valid_object = len(current_object) > 0
if is_valid_object and len(current_object) == 1:
is_valid_object = not current_object[0].startswith("# Copied from")
if not is_empty_line(line) and find_indent(line) == 0 and is_valid_object:
# Closing parts should be included in current object
if line in end_markers:
current_object.append(line)
objects.append("\n".join(current_object))
current_object = []
else:
objects.append("\n".join(current_object))
current_object = [line]
else:
current_object.append(line)
# Add last object
if len(current_object) > 0:
objects.append("\n".join(current_object))
return objects
def extract_block(content: str, indent_level: int = 0) -> str:
"""Return the first block in `content` with the indent level `indent_level`.
The first line in `content` should be indented at `indent_level` level, otherwise an error will be thrown.
This method will immediately stop the search when a (non-empty) line with indent level less than `indent_level` is
encountered.
Args:
content (`str`): The content to parse
indent_level (`int`, *optional*, default to 0): The indent level of the blocks to search for
Returns:
`str`: The first block in `content` with the indent level `indent_level`.
"""
current_object = []
lines = content.split("\n")
# Doc-styler takes everything between two triple quotes in docstrings, so we need a fake """ here to go with this.
end_markers = [")", "]", "}", '"""']
for idx, line in enumerate(lines):
if idx == 0 and indent_level > 0 and not is_empty_line(line) and find_indent(line) != indent_level:
raise ValueError(
f"When `indent_level > 0`, the first line in `content` should have indent level {indent_level}. Got "
f"{find_indent(line)} instead."
)
if find_indent(line) < indent_level and not is_empty_line(line):
break
# End of an object
is_valid_object = len(current_object) > 0
if (
not is_empty_line(line)
and not line.endswith(":")
and find_indent(line) == indent_level
and is_valid_object
):
# Closing parts should be included in current object
if line.lstrip() in end_markers:
current_object.append(line)
return "\n".join(current_object)
else:
current_object.append(line)
# Add last object
if len(current_object) > 0:
return "\n".join(current_object)
def add_content_to_text(
text: str,
content: str,
add_after: Optional[Union[str, Pattern]] = None,
add_before: Optional[Union[str, Pattern]] = None,
exact_match: bool = False,
) -> str:
"""
A utility to add some content inside a given text.
Args:
text (`str`): The text in which we want to insert some content.
content (`str`): The content to add.
add_after (`str` or `Pattern`):
The pattern to test on a line of `text`, the new content is added after the first instance matching it.
add_before (`str` or `Pattern`):
The pattern to test on a line of `text`, the new content is added before the first instance matching it.
exact_match (`bool`, *optional*, defaults to `False`):
A line is considered a match with `add_after` or `add_before` if it matches exactly when `exact_match=True`,
otherwise, if `add_after`/`add_before` is present in the line.
<Tip warning={true}>
The arguments `add_after` and `add_before` are mutually exclusive, and one exactly needs to be provided.
</Tip>
Returns:
`str`: The text with the new content added if a match was found.
"""
if add_after is None and add_before is None:
raise ValueError("You need to pass either `add_after` or `add_before`")
if add_after is not None and add_before is not None:
raise ValueError("You can't pass both `add_after` or `add_before`")
pattern = add_after if add_before is None else add_before
def this_is_the_line(line):
if isinstance(pattern, Pattern):
return pattern.search(line) is not None
elif exact_match:
return pattern == line
else:
return pattern in line
new_lines = []
for line in text.split("\n"):
if this_is_the_line(line):
if add_before is not None:
new_lines.append(content)
new_lines.append(line)
if add_after is not None:
new_lines.append(content)
else:
new_lines.append(line)
return "\n".join(new_lines)
def add_content_to_file(
file_name: Union[str, os.PathLike],
content: str,
add_after: Optional[Union[str, Pattern]] = None,
add_before: Optional[Union[str, Pattern]] = None,
exact_match: bool = False,
):
"""
A utility to add some content inside a given file.
Args:
file_name (`str` or `os.PathLike`): The name of the file in which we want to insert some content.
content (`str`): The content to add.
add_after (`str` or `Pattern`):
The pattern to test on a line of `text`, the new content is added after the first instance matching it.
add_before (`str` or `Pattern`):
The pattern to test on a line of `text`, the new content is added before the first instance matching it.
exact_match (`bool`, *optional*, defaults to `False`):
A line is considered a match with `add_after` or `add_before` if it matches exactly when `exact_match=True`,
otherwise, if `add_after`/`add_before` is present in the line.
<Tip warning={true}>
The arguments `add_after` and `add_before` are mutually exclusive, and one exactly needs to be provided.
</Tip>
"""
with open(file_name, "r", encoding="utf-8") as f:
old_content = f.read()
new_content = add_content_to_text(
old_content, content, add_after=add_after, add_before=add_before, exact_match=exact_match
)
with open(file_name, "w", encoding="utf-8") as f:
f.write(new_content)
def replace_model_patterns(
text: str, old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns
) -> Tuple[str, str]:
"""
Replace all patterns present in a given text.
Args:
text (`str`): The text to treat.
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
Returns:
`Tuple(str, str)`: A tuple of with the treated text and the replacement actually done in it.
"""
# The order is crucially important as we will check and replace in that order. For instance the config probably
# contains the camel-cased named, but will be treated before.
attributes_to_check = ["config_class"]
# Add relevant preprocessing classes
for attr in ["tokenizer_class", "image_processor_class", "feature_extractor_class", "processor_class"]:
if getattr(old_model_patterns, attr) is not None and getattr(new_model_patterns, attr) is not None:
attributes_to_check.append(attr)
# Special cases for checkpoint and model_type
if old_model_patterns.checkpoint not in [old_model_patterns.model_type, old_model_patterns.model_lower_cased]:
attributes_to_check.append("checkpoint")
if old_model_patterns.model_type != old_model_patterns.model_lower_cased:
attributes_to_check.append("model_type")
else:
text = re.sub(
rf'(\s*)model_type = "{old_model_patterns.model_type}"',
r'\1model_type = "[MODEL_TYPE]"',
text,
)
# Special case when the model camel cased and upper cased names are the same for the old model (like for GPT2) but
# not the new one. We can't just do a replace in all the text and will need a special regex
if old_model_patterns.model_upper_cased == old_model_patterns.model_camel_cased:
old_model_value = old_model_patterns.model_upper_cased
if re.search(rf"{old_model_value}_[A-Z_]*[^A-Z_]", text) is not None:
text = re.sub(rf"{old_model_value}([A-Z_]*)([^a-zA-Z_])", r"[MODEL_UPPER_CASED]\1\2", text)
else:
attributes_to_check.append("model_upper_cased")
attributes_to_check.extend(["model_camel_cased", "model_lower_cased", "model_name"])
# Now let's replace every other attribute by their placeholder
for attr in attributes_to_check:
text = text.replace(getattr(old_model_patterns, attr), ATTRIBUTE_TO_PLACEHOLDER[attr])
# Finally we can replace the placeholder byt the new values.
replacements = []
for attr, placeholder in ATTRIBUTE_TO_PLACEHOLDER.items():
if placeholder in text:
replacements.append((getattr(old_model_patterns, attr), getattr(new_model_patterns, attr)))
text = text.replace(placeholder, getattr(new_model_patterns, attr))
# If we have two inconsistent replacements, we don't return anything (ex: GPT2->GPT_NEW and GPT2->GPTNew)
old_replacement_values = [old for old, new in replacements]
if len(set(old_replacement_values)) != len(old_replacement_values):
return text, ""
replacements = simplify_replacements(replacements)
replacements = [f"{old}->{new}" for old, new in replacements]
return text, ",".join(replacements)
def simplify_replacements(replacements):
"""
Simplify a list of replacement patterns to make sure there are no needless ones.
For instance in the sequence "Bert->BertNew, BertConfig->BertNewConfig, bert->bert_new", the replacement
"BertConfig->BertNewConfig" is implied by "Bert->BertNew" so not needed.
Args:
replacements (`List[Tuple[str, str]]`): List of patterns (old, new)
Returns:
`List[Tuple[str, str]]`: The list of patterns simplified.
"""
if len(replacements) <= 1:
# Nothing to simplify
return replacements
# Next let's sort replacements by length as a replacement can only "imply" another replacement if it's shorter.
replacements.sort(key=lambda x: len(x[0]))
idx = 0
while idx < len(replacements):
old, new = replacements[idx]
# Loop through all replacements after
j = idx + 1
while j < len(replacements):
old_2, new_2 = replacements[j]
# If the replacement is implied by the current one, we can drop it.
if old_2.replace(old, new) == new_2:
replacements.pop(j)
else:
j += 1
idx += 1
return replacements
def get_module_from_file(module_file: Union[str, os.PathLike]) -> str:
"""
Returns the module name corresponding to a module file.
"""
full_module_path = Path(module_file).absolute()
module_parts = full_module_path.with_suffix("").parts
# Find the first part named transformers, starting from the end.
idx = len(module_parts) - 1
while idx >= 0 and module_parts[idx] != "transformers":
idx -= 1
if idx < 0:
raise ValueError(f"{module_file} is not a transformers module.")
return ".".join(module_parts[idx:])
SPECIAL_PATTERNS = {
"_CHECKPOINT_FOR_DOC =": "checkpoint",
"_CONFIG_FOR_DOC =": "config_class",
"_TOKENIZER_FOR_DOC =": "tokenizer_class",
"_IMAGE_PROCESSOR_FOR_DOC =": "image_processor_class",
"_FEAT_EXTRACTOR_FOR_DOC =": "feature_extractor_class",
"_PROCESSOR_FOR_DOC =": "processor_class",
}
_re_class_func = re.compile(r"^(?:class|def)\s+([^\s:\(]+)\s*(?:\(|\:)", flags=re.MULTILINE)
def remove_attributes(obj, target_attr):
"""Remove `target_attr` in `obj`."""
lines = obj.split(os.linesep)
target_idx = None
for idx, line in enumerate(lines):
# search for assignment
if line.lstrip().startswith(f"{target_attr} = "):
target_idx = idx
break
# search for function/method definition
elif line.lstrip().startswith(f"def {target_attr}("):
target_idx = idx
break
# target not found
if target_idx is None:
return obj
line = lines[target_idx]
indent_level = find_indent(line)
# forward pass to find the ending of the block (including empty lines)
parsed = extract_block("\n".join(lines[target_idx:]), indent_level)
num_lines = len(parsed.split("\n"))
for idx in range(num_lines):
lines[target_idx + idx] = None
# backward pass to find comments or decorator
for idx in range(target_idx - 1, -1, -1):
line = lines[idx]
if (line.lstrip().startswith("#") or line.lstrip().startswith("@")) and find_indent(line) == indent_level:
lines[idx] = None
else:
break
new_obj = os.linesep.join([x for x in lines if x is not None])
return new_obj
def duplicate_module(
module_file: Union[str, os.PathLike],
old_model_patterns: ModelPatterns,
new_model_patterns: ModelPatterns,
dest_file: Optional[str] = None,
add_copied_from: bool = True,
attrs_to_remove: List[str] = None,
):
"""
Create a new module from an existing one and adapting all function and classes names from old patterns to new ones.
Args:
module_file (`str` or `os.PathLike`): Path to the module to duplicate.
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
dest_file (`str` or `os.PathLike`, *optional*): Path to the new module.
add_copied_from (`bool`, *optional*, defaults to `True`):
Whether or not to add `# Copied from` statements in the duplicated module.
"""
if dest_file is None:
dest_file = str(module_file).replace(
old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
)
with open(module_file, "r", encoding="utf-8") as f:
content = f.read()
content = re.sub(r"# Copyright (\d+)\s", f"# Copyright {CURRENT_YEAR} ", content)
objects = parse_module_content(content)
# Loop and treat all objects
new_objects = []
for obj in objects:
special_pattern = False
for pattern, attr in SPECIAL_PATTERNS.items():
if pattern in obj:
obj = obj.replace(getattr(old_model_patterns, attr), getattr(new_model_patterns, attr))
new_objects.append(obj)
special_pattern = True
break
if special_pattern:
continue
# Regular classes functions
old_obj = obj
obj, replacement = replace_model_patterns(obj, old_model_patterns, new_model_patterns)
has_copied_from = re.search(r"^#\s+Copied from", obj, flags=re.MULTILINE) is not None
if add_copied_from and not has_copied_from and _re_class_func.search(obj) is not None and len(replacement) > 0:
# Copied from statement must be added just before the class/function definition, which may not be the
# first line because of decorators.
module_name = get_module_from_file(module_file)
old_object_name = _re_class_func.search(old_obj).groups()[0]
obj = add_content_to_text(
obj, f"# Copied from {module_name}.{old_object_name} with {replacement}", add_before=_re_class_func
)
# In all cases, we remove Copied from statement with indent on methods.
obj = re.sub("\n[ ]+# Copied from [^\n]*\n", "\n", obj)
new_objects.append(obj)
content = "\n".join(new_objects)
# Remove some attributes that we don't want to copy to the new file(s)
if attrs_to_remove is not None:
for attr in attrs_to_remove:
content = remove_attributes(content, target_attr=attr)
with open(dest_file, "w", encoding="utf-8") as f:
f.write(content)
def filter_framework_files(
files: List[Union[str, os.PathLike]], frameworks: Optional[List[str]] = None
) -> List[Union[str, os.PathLike]]:
"""
Filter a list of files to only keep the ones corresponding to a list of frameworks.
Args:
files (`List[Union[str, os.PathLike]]`): The list of files to filter.
frameworks (`List[str]`, *optional*): The list of allowed frameworks.
Returns:
`List[Union[str, os.PathLike]]`: The list of filtered files.
"""
if frameworks is None:
frameworks = get_default_frameworks()
framework_to_file = {}
others = []
for f in files:
parts = Path(f).name.split("_")
if "modeling" not in parts:
others.append(f)
continue
if "tf" in parts:
framework_to_file["tf"] = f
elif "flax" in parts:
framework_to_file["flax"] = f
else:
framework_to_file["pt"] = f
return [framework_to_file[f] for f in frameworks if f in framework_to_file] + others
def get_model_files(model_type: str, frameworks: Optional[List[str]] = None) -> Dict[str, Union[Path, List[Path]]]:
"""
Retrieves all the files associated to a model.
Args:
model_type (`str`): A valid model type (like "bert" or "gpt2")
frameworks (`List[str]`, *optional*):
If passed, will only keep the model files corresponding to the passed frameworks.
Returns:
`Dict[str, Union[Path, List[Path]]]`: A dictionary with the following keys:
- **doc_file** -- The documentation file for the model.
- **model_files** -- All the files in the model module.
- **test_files** -- The test files for the model.
"""
module_name = model_type_to_module_name(model_type)
model_module = TRANSFORMERS_PATH / "models" / module_name
model_files = list(model_module.glob("*.py"))
model_files = filter_framework_files(model_files, frameworks=frameworks)
doc_file = REPO_PATH / "docs" / "source" / "en" / "model_doc" / f"{model_type}.md"
# Basic pattern for test files
test_files = [
f"test_modeling_{module_name}.py",
f"test_modeling_tf_{module_name}.py",
f"test_modeling_flax_{module_name}.py",
f"test_tokenization_{module_name}.py",
f"test_image_processing_{module_name}.py",
f"test_feature_extraction_{module_name}.py",
f"test_processor_{module_name}.py",
]
test_files = filter_framework_files(test_files, frameworks=frameworks)
# Add the test directory
test_files = [REPO_PATH / "tests" / "models" / module_name / f for f in test_files]
# Filter by existing files
test_files = [f for f in test_files if f.exists()]
return {"doc_file": doc_file, "model_files": model_files, "module_name": module_name, "test_files": test_files}
_re_checkpoint_for_doc = re.compile(r"^_CHECKPOINT_FOR_DOC\s+=\s+(\S*)\s*$", flags=re.MULTILINE)
def find_base_model_checkpoint(
model_type: str, model_files: Optional[Dict[str, Union[Path, List[Path]]]] = None
) -> str:
"""
Finds the model checkpoint used in the docstrings for a given model.
Args:
model_type (`str`): A valid model type (like "bert" or "gpt2")
model_files (`Dict[str, Union[Path, List[Path]]`, *optional*):
The files associated to `model_type`. Can be passed to speed up the function, otherwise will be computed.
Returns:
`str`: The checkpoint used.
"""
if model_files is None:
model_files = get_model_files(model_type)
module_files = model_files["model_files"]
for fname in module_files:
if "modeling" not in str(fname):
continue
with open(fname, "r", encoding="utf-8") as f:
content = f.read()
if _re_checkpoint_for_doc.search(content) is not None:
checkpoint = _re_checkpoint_for_doc.search(content).groups()[0]
# Remove quotes
checkpoint = checkpoint.replace('"', "")
checkpoint = checkpoint.replace("'", "")
return checkpoint
# TODO: Find some kind of fallback if there is no _CHECKPOINT_FOR_DOC in any of the modeling file.
return ""
def get_default_frameworks():
"""
Returns the list of frameworks (PyTorch, TensorFlow, Flax) that are installed in the environment.
"""
frameworks = []
if is_torch_available():
frameworks.append("pt")
if is_tf_available():
frameworks.append("tf")
if is_flax_available():
frameworks.append("flax")
return frameworks
_re_model_mapping = re.compile("MODEL_([A-Z_]*)MAPPING_NAMES")
def retrieve_model_classes(model_type: str, frameworks: Optional[List[str]] = None) -> Dict[str, List[str]]:
"""
Retrieve the model classes associated to a given model.
Args:
model_type (`str`): A valid model type (like "bert" or "gpt2")
frameworks (`List[str]`, *optional*):
The frameworks to look for. Will default to `["pt", "tf", "flax"]`, passing a smaller list will restrict
the classes returned.
Returns:
`Dict[str, List[str]]`: A dictionary with one key per framework and the list of model classes associated to
that framework as values.
"""
if frameworks is None:
frameworks = get_default_frameworks()
modules = {
"pt": auto_module.modeling_auto if is_torch_available() else None,
"tf": auto_module.modeling_tf_auto if is_tf_available() else None,
"flax": auto_module.modeling_flax_auto if is_flax_available() else None,
}
model_classes = {}
for framework in frameworks:
new_model_classes = []
if modules[framework] is None:
raise ValueError(f"You selected {framework} in the frameworks, but it is not installed.")
model_mappings = [attr for attr in dir(modules[framework]) if _re_model_mapping.search(attr) is not None]
for model_mapping_name in model_mappings:
model_mapping = getattr(modules[framework], model_mapping_name)
if model_type in model_mapping:
new_model_classes.append(model_mapping[model_type])
if len(new_model_classes) > 0:
# Remove duplicates
model_classes[framework] = list(set(new_model_classes))
return model_classes
def retrieve_info_for_model(model_type, frameworks: Optional[List[str]] = None):
"""
Retrieves all the information from a given model_type.
Args:
model_type (`str`): A valid model type (like "bert" or "gpt2")
frameworks (`List[str]`, *optional*):
If passed, will only keep the info corresponding to the passed frameworks.
Returns:
`Dict`: A dictionary with the following keys:
- **frameworks** (`List[str]`): The list of frameworks that back this model type.
- **model_classes** (`Dict[str, List[str]]`): The model classes implemented for that model type.
- **model_files** (`Dict[str, Union[Path, List[Path]]]`): The files associated with that model type.
- **model_patterns** (`ModelPatterns`): The various patterns for the model.
"""
if model_type not in auto_module.MODEL_NAMES_MAPPING:
raise ValueError(f"{model_type} is not a valid model type.")
model_name = auto_module.MODEL_NAMES_MAPPING[model_type]
config_class = auto_module.configuration_auto.CONFIG_MAPPING_NAMES[model_type]
if model_type in auto_module.tokenization_auto.TOKENIZER_MAPPING_NAMES:
tokenizer_classes = auto_module.tokenization_auto.TOKENIZER_MAPPING_NAMES[model_type]
tokenizer_class = tokenizer_classes[0] if tokenizer_classes[0] is not None else tokenizer_classes[1]
else:
tokenizer_class = None
image_processor_classes = auto_module.image_processing_auto.IMAGE_PROCESSOR_MAPPING_NAMES.get(model_type, None)
if isinstance(image_processor_classes, tuple):
image_processor_class = image_processor_classes[0] # we take the slow image processor class.
else:
image_processor_class = image_processor_classes
feature_extractor_class = auto_module.feature_extraction_auto.FEATURE_EXTRACTOR_MAPPING_NAMES.get(model_type, None)
processor_class = auto_module.processing_auto.PROCESSOR_MAPPING_NAMES.get(model_type, None)
model_files = get_model_files(model_type, frameworks=frameworks)
model_camel_cased = config_class.replace("Config", "")
available_frameworks = []
for fname in model_files["model_files"]:
if "modeling_tf" in str(fname):
available_frameworks.append("tf")
elif "modeling_flax" in str(fname):
available_frameworks.append("flax")
elif "modeling" in str(fname):
available_frameworks.append("pt")
if frameworks is None:
frameworks = get_default_frameworks()
frameworks = [f for f in frameworks if f in available_frameworks]
model_classes = retrieve_model_classes(model_type, frameworks=frameworks)
model_upper_cased = model_camel_cased.upper()
model_patterns = ModelPatterns(
model_name,
checkpoint=find_base_model_checkpoint(model_type, model_files=model_files),
model_type=model_type,
model_camel_cased=model_camel_cased,
model_lower_cased=model_files["module_name"],
model_upper_cased=model_upper_cased,
config_class=config_class,
tokenizer_class=tokenizer_class,
image_processor_class=image_processor_class,
feature_extractor_class=feature_extractor_class,
processor_class=processor_class,
)
return {
"frameworks": frameworks,
"model_classes": model_classes,
"model_files": model_files,
"model_patterns": model_patterns,
}
def clean_frameworks_in_init(
init_file: Union[str, os.PathLike], frameworks: Optional[List[str]] = None, keep_processing: bool = True
):
"""
Removes all the import lines that don't belong to a given list of frameworks or concern tokenizers/feature
extractors/image processors/processors in an init.
Args:
init_file (`str` or `os.PathLike`): The path to the init to treat.
frameworks (`List[str]`, *optional*):
If passed, this will remove all imports that are subject to a framework not in frameworks
keep_processing (`bool`, *optional*, defaults to `True`):
Whether or not to keep the preprocessing (tokenizer, feature extractor, image processor, processor) imports
in the init.
"""
if frameworks is None:
frameworks = get_default_frameworks()
names = {"pt": "torch"}
to_remove = [names.get(f, f) for f in ["pt", "tf", "flax"] if f not in frameworks]
if not keep_processing:
to_remove.extend(["sentencepiece", "tokenizers", "vision"])
if len(to_remove) == 0:
# Nothing to do
return
remove_pattern = "|".join(to_remove)
re_conditional_imports = re.compile(rf"^\s*if not is_({remove_pattern})_available\(\):\s*$")
re_try = re.compile(r"\s*try:")
re_else = re.compile(r"\s*else:")
re_is_xxx_available = re.compile(rf"is_({remove_pattern})_available")
with open(init_file, "r", encoding="utf-8") as f:
content = f.read()
lines = content.split("\n")
new_lines = []
idx = 0
while idx < len(lines):
# Conditional imports in try-except-else blocks
if (re_conditional_imports.search(lines[idx]) is not None) and (re_try.search(lines[idx - 1]) is not None):
# Remove the preceding `try:`
new_lines.pop()
idx += 1
# Iterate until `else:`
while is_empty_line(lines[idx]) or re_else.search(lines[idx]) is None:
idx += 1
idx += 1
indent = find_indent(lines[idx])
while find_indent(lines[idx]) >= indent or is_empty_line(lines[idx]):
idx += 1
# Remove the import from utils
elif re_is_xxx_available.search(lines[idx]) is not None:
line = lines[idx]
for framework in to_remove:
line = line.replace(f", is_{framework}_available", "")
line = line.replace(f"is_{framework}_available, ", "")
line = line.replace(f"is_{framework}_available,", "")
line = line.replace(f"is_{framework}_available", "")
if len(line.strip()) > 0:
new_lines.append(line)
idx += 1
# Otherwise we keep the line, except if it's a tokenizer import and we don't want to keep it.
elif keep_processing or (
re.search(r'^\s*"(tokenization|processing|feature_extraction|image_processing)', lines[idx]) is None
and re.search(r"^\s*from .(tokenization|processing|feature_extraction|image_processing)", lines[idx])
is None
):
new_lines.append(lines[idx])
idx += 1
else:
idx += 1
with open(init_file, "w", encoding="utf-8") as f:
f.write("\n".join(new_lines))
def add_model_to_main_init(
old_model_patterns: ModelPatterns,
new_model_patterns: ModelPatterns,
frameworks: Optional[List[str]] = None,
with_processing: bool = True,
):
"""
Add a model to the main init of Transformers.
Args:
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
frameworks (`List[str]`, *optional*):
If specified, only the models implemented in those frameworks will be added.
with_processsing (`bool`, *optional*, defaults to `True`):
Whether the tokenizer/feature extractor/processor of the model should also be added to the init or not.
"""
with open(TRANSFORMERS_PATH / "__init__.py", "r", encoding="utf-8") as f:
content = f.read()
lines = content.split("\n")
idx = 0
new_lines = []
framework = None
while idx < len(lines):
new_framework = False
if not is_empty_line(lines[idx]) and find_indent(lines[idx]) == 0:
framework = None
elif lines[idx].lstrip().startswith("if not is_torch_available"):
framework = "pt"
new_framework = True
elif lines[idx].lstrip().startswith("if not is_tf_available"):
framework = "tf"
new_framework = True
elif lines[idx].lstrip().startswith("if not is_flax_available"):
framework = "flax"
new_framework = True
if new_framework:
# For a new framework, we need to skip until the else: block to get where the imports are.
while lines[idx].strip() != "else:":
new_lines.append(lines[idx])
idx += 1
# Skip if we are in a framework not wanted.
if framework is not None and frameworks is not None and framework not in frameworks:
new_lines.append(lines[idx])
idx += 1
elif re.search(rf'models.{old_model_patterns.model_lower_cased}( |")', lines[idx]) is not None:
block = [lines[idx]]
indent = find_indent(lines[idx])
idx += 1
while find_indent(lines[idx]) > indent:
block.append(lines[idx])
idx += 1
if lines[idx].strip() in [")", "]", "],"]:
block.append(lines[idx])
idx += 1
block = "\n".join(block)
new_lines.append(block)
add_block = True
if not with_processing:
processing_classes = [
old_model_patterns.tokenizer_class,
old_model_patterns.image_processor_class,
old_model_patterns.feature_extractor_class,
old_model_patterns.processor_class,
]
# Only keep the ones that are not None
processing_classes = [c for c in processing_classes if c is not None]
for processing_class in processing_classes:
block = block.replace(f' "{processing_class}",', "")
block = block.replace(f', "{processing_class}"', "")
block = block.replace(f" {processing_class},", "")
block = block.replace(f", {processing_class}", "")
if processing_class in block:
add_block = False
if add_block:
new_lines.append(replace_model_patterns(block, old_model_patterns, new_model_patterns)[0])
else:
new_lines.append(lines[idx])
idx += 1
with open(TRANSFORMERS_PATH / "__init__.py", "w", encoding="utf-8") as f:
f.write("\n".join(new_lines))
def insert_tokenizer_in_auto_module(old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns):
"""
Add a tokenizer to the relevant mappings in the auto module.
Args:
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
"""
if old_model_patterns.tokenizer_class is None or new_model_patterns.tokenizer_class is None:
return
with open(TRANSFORMERS_PATH / "models" / "auto" / "tokenization_auto.py", "r", encoding="utf-8") as f:
content = f.read()
lines = content.split("\n")
idx = 0
# First we get to the TOKENIZER_MAPPING_NAMES block.
while not lines[idx].startswith(" TOKENIZER_MAPPING_NAMES = OrderedDict("):
idx += 1
idx += 1
# That block will end at this prompt:
while not lines[idx].startswith("TOKENIZER_MAPPING = _LazyAutoMapping"):
# Either all the tokenizer block is defined on one line, in which case, it ends with "),"
if lines[idx].endswith(","):
block = lines[idx]
# Otherwise it takes several lines until we get to a "),"
else:
block = []
while not lines[idx].startswith(" ),"):
block.append(lines[idx])
idx += 1
block = "\n".join(block)
idx += 1
# If we find the model type and tokenizer class in that block, we have the old model tokenizer block
if f'"{old_model_patterns.model_type}"' in block and old_model_patterns.tokenizer_class in block:
break
new_block = block.replace(old_model_patterns.model_type, new_model_patterns.model_type)
new_block = new_block.replace(old_model_patterns.tokenizer_class, new_model_patterns.tokenizer_class)
new_lines = lines[:idx] + [new_block] + lines[idx:]
with open(TRANSFORMERS_PATH / "models" / "auto" / "tokenization_auto.py", "w", encoding="utf-8") as f:
f.write("\n".join(new_lines))
AUTO_CLASSES_PATTERNS = {
"configuration_auto.py": [
' ("{model_type}", "{model_name}"),',
' ("{model_type}", "{config_class}"),',
' ("{model_type}", "{pretrained_archive_map}"),',
],
"feature_extraction_auto.py": [' ("{model_type}", "{feature_extractor_class}"),'],
"image_processing_auto.py": [' ("{model_type}", "{image_processor_class}"),'],
"modeling_auto.py": [' ("{model_type}", "{any_pt_class}"),'],
"modeling_tf_auto.py": [' ("{model_type}", "{any_tf_class}"),'],
"modeling_flax_auto.py": [' ("{model_type}", "{any_flax_class}"),'],
"processing_auto.py": [' ("{model_type}", "{processor_class}"),'],
}
def add_model_to_auto_classes(
old_model_patterns: ModelPatterns, new_model_patterns: ModelPatterns, model_classes: Dict[str, List[str]]
):
"""
Add a model to the relevant mappings in the auto module.
Args:
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
model_classes (`Dict[str, List[str]]`): A dictionary framework to list of model classes implemented.
"""
for filename in AUTO_CLASSES_PATTERNS:
# Extend patterns with all model classes if necessary
new_patterns = []
for pattern in AUTO_CLASSES_PATTERNS[filename]:
if re.search("any_([a-z]*)_class", pattern) is not None:
framework = re.search("any_([a-z]*)_class", pattern).groups()[0]
if framework in model_classes:
new_patterns.extend(
[
pattern.replace("{" + f"any_{framework}_class" + "}", cls)
for cls in model_classes[framework]
]
)
elif "{config_class}" in pattern:
new_patterns.append(pattern.replace("{config_class}", old_model_patterns.config_class))
elif "{image_processor_class}" in pattern:
if (
old_model_patterns.image_processor_class is not None
and new_model_patterns.image_processor_class is not None
):
new_patterns.append(
pattern.replace("{image_processor_class}", old_model_patterns.image_processor_class)
)
elif "{feature_extractor_class}" in pattern:
if (
old_model_patterns.feature_extractor_class is not None
and new_model_patterns.feature_extractor_class is not None
):
new_patterns.append(
pattern.replace("{feature_extractor_class}", old_model_patterns.feature_extractor_class)
)
elif "{processor_class}" in pattern:
if old_model_patterns.processor_class is not None and new_model_patterns.processor_class is not None:
new_patterns.append(pattern.replace("{processor_class}", old_model_patterns.processor_class))
else:
new_patterns.append(pattern)
# Loop through all patterns.
for pattern in new_patterns:
full_name = TRANSFORMERS_PATH / "models" / "auto" / filename
old_model_line = pattern
new_model_line = pattern
for attr in ["model_type", "model_name"]:
old_model_line = old_model_line.replace("{" + attr + "}", getattr(old_model_patterns, attr))
new_model_line = new_model_line.replace("{" + attr + "}", getattr(new_model_patterns, attr))
new_model_line = new_model_line.replace(
old_model_patterns.model_camel_cased, new_model_patterns.model_camel_cased
)
add_content_to_file(full_name, new_model_line, add_after=old_model_line)
# Tokenizers require special handling
insert_tokenizer_in_auto_module(old_model_patterns, new_model_patterns)
DOC_OVERVIEW_TEMPLATE = """## Overview
The {model_name} model was proposed in [<INSERT PAPER NAME HERE>](<INSERT PAPER LINK HERE>) by <INSERT AUTHORS HERE>.
<INSERT SHORT SUMMARY HERE>
The abstract from the paper is the following:
*<INSERT PAPER ABSTRACT HERE>*
Tips:
<INSERT TIPS ABOUT MODEL HERE>
This model was contributed by [INSERT YOUR HF USERNAME HERE](https://huggingface.co/<INSERT YOUR HF USERNAME HERE>).
The original code can be found [here](<INSERT LINK TO GITHUB REPO HERE>).
"""
def duplicate_doc_file(
doc_file: Union[str, os.PathLike],
old_model_patterns: ModelPatterns,
new_model_patterns: ModelPatterns,
dest_file: Optional[Union[str, os.PathLike]] = None,
frameworks: Optional[List[str]] = None,
):
"""
Duplicate a documentation file and adapts it for a new model.
Args:
module_file (`str` or `os.PathLike`): Path to the doc file to duplicate.
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
dest_file (`str` or `os.PathLike`, *optional*): Path to the new doc file.
Will default to the a file named `{new_model_patterns.model_type}.md` in the same folder as `module_file`.
frameworks (`List[str]`, *optional*):
If passed, will only keep the model classes corresponding to this list of frameworks in the new doc file.
"""
with open(doc_file, "r", encoding="utf-8") as f:
content = f.read()
content = re.sub(r"<!--\s*Copyright (\d+)\s", f"<!--Copyright {CURRENT_YEAR} ", content)
if frameworks is None:
frameworks = get_default_frameworks()
if dest_file is None:
dest_file = Path(doc_file).parent / f"{new_model_patterns.model_type}.md"
# Parse the doc file in blocks. One block per section/header
lines = content.split("\n")
blocks = []
current_block = []
for line in lines:
if line.startswith("#"):
blocks.append("\n".join(current_block))
current_block = [line]
else:
current_block.append(line)
blocks.append("\n".join(current_block))
new_blocks = []
in_classes = False
for block in blocks:
# Copyright
if not block.startswith("#"):
new_blocks.append(block)
# Main title
elif re.search(r"^#\s+\S+", block) is not None:
new_blocks.append(f"# {new_model_patterns.model_name}\n")
# The config starts the part of the doc with the classes.
elif not in_classes and old_model_patterns.config_class in block.split("\n")[0]:
in_classes = True
new_blocks.append(DOC_OVERVIEW_TEMPLATE.format(model_name=new_model_patterns.model_name))
new_block, _ = replace_model_patterns(block, old_model_patterns, new_model_patterns)
new_blocks.append(new_block)
# In classes
elif in_classes:
in_classes = True
block_title = block.split("\n")[0]
block_class = re.search(r"^#+\s+(\S.*)$", block_title).groups()[0]
new_block, _ = replace_model_patterns(block, old_model_patterns, new_model_patterns)
if "Tokenizer" in block_class:
# We only add the tokenizer if necessary
if old_model_patterns.tokenizer_class != new_model_patterns.tokenizer_class:
new_blocks.append(new_block)
elif "ImageProcessor" in block_class:
# We only add the image processor if necessary
if old_model_patterns.image_processor_class != new_model_patterns.image_processor_class:
new_blocks.append(new_block)
elif "FeatureExtractor" in block_class:
# We only add the feature extractor if necessary
if old_model_patterns.feature_extractor_class != new_model_patterns.feature_extractor_class:
new_blocks.append(new_block)
elif "Processor" in block_class:
# We only add the processor if necessary
if old_model_patterns.processor_class != new_model_patterns.processor_class:
new_blocks.append(new_block)
elif block_class.startswith("Flax"):
# We only add Flax models if in the selected frameworks
if "flax" in frameworks:
new_blocks.append(new_block)
elif block_class.startswith("TF"):
# We only add TF models if in the selected frameworks
if "tf" in frameworks:
new_blocks.append(new_block)
elif len(block_class.split(" ")) == 1:
# We only add PyTorch models if in the selected frameworks
if "pt" in frameworks:
new_blocks.append(new_block)
else:
new_blocks.append(new_block)
with open(dest_file, "w", encoding="utf-8") as f:
f.write("\n".join(new_blocks))
def insert_model_in_doc_toc(old_model_patterns, new_model_patterns):
"""
Insert the new model in the doc TOC, in the same section as the old model.
Args:
old_model_patterns (`ModelPatterns`): The patterns for the old model.
new_model_patterns (`ModelPatterns`): The patterns for the new model.
"""
toc_file = REPO_PATH / "docs" / "source" / "en" / "_toctree.yml"
with open(toc_file, "r", encoding="utf8") as f:
content = yaml.safe_load(f)
# Get to the model API doc
api_idx = 0
while content[api_idx]["title"] != "API":
api_idx += 1
api_doc = content[api_idx]["sections"]
model_idx = 0
while api_doc[model_idx]["title"] != "Models":
model_idx += 1
model_doc = api_doc[model_idx]["sections"]
# Find the base model in the Toc
old_model_type = old_model_patterns.model_type
section_idx = 0
while section_idx < len(model_doc):
sections = [entry["local"] for entry in model_doc[section_idx]["sections"]]
if f"model_doc/{old_model_type}" in sections:
break
section_idx += 1
if section_idx == len(model_doc):
old_model = old_model_patterns.model_name
new_model = new_model_patterns.model_name
print(f"Did not find {old_model} in the table of content, so you will need to add {new_model} manually.")
return
# Add the new model in the same toc
toc_entry = {"local": f"model_doc/{new_model_patterns.model_type}", "title": new_model_patterns.model_name}
model_doc[section_idx]["sections"].append(toc_entry)
model_doc[section_idx]["sections"] = sorted(model_doc[section_idx]["sections"], key=lambda s: s["title"].lower())
api_doc[model_idx]["sections"] = model_doc
content[api_idx]["sections"] = api_doc
with open(toc_file, "w", encoding="utf-8") as f:
f.write(yaml.dump(content, allow_unicode=True))
def create_new_model_like(
model_type: str,
new_model_patterns: ModelPatterns,
add_copied_from: bool = True,
frameworks: Optional[List[str]] = None,
old_checkpoint: Optional[str] = None,
):
"""
Creates a new model module like a given model of the Transformers library.
Args:
model_type (`str`): The model type to duplicate (like "bert" or "gpt2")
new_model_patterns (`ModelPatterns`): The patterns for the new model.
add_copied_from (`bool`, *optional*, defaults to `True`):
Whether or not to add "Copied from" statements to all classes in the new model modeling files.
frameworks (`List[str]`, *optional*):
If passed, will limit the duplicate to the frameworks specified.
old_checkpoint (`str`, *optional*):
The name of the base checkpoint for the old model. Should be passed along when it can't be automatically
recovered from the `model_type`.
"""
# Retrieve all the old model info.
model_info = retrieve_info_for_model(model_type, frameworks=frameworks)
model_files = model_info["model_files"]
old_model_patterns = model_info["model_patterns"]
if old_checkpoint is not None:
old_model_patterns.checkpoint = old_checkpoint
if len(old_model_patterns.checkpoint) == 0:
raise ValueError(
"The old model checkpoint could not be recovered from the model type. Please pass it to the "
"`old_checkpoint` argument."
)
keep_old_processing = True
for processing_attr in ["image_processor_class", "feature_extractor_class", "processor_class", "tokenizer_class"]:
if getattr(old_model_patterns, processing_attr) != getattr(new_model_patterns, processing_attr):
keep_old_processing = False
model_classes = model_info["model_classes"]
# 1. We create the module for our new model.
old_module_name = model_files["module_name"]
module_folder = TRANSFORMERS_PATH / "models" / new_model_patterns.model_lower_cased
os.makedirs(module_folder, exist_ok=True)
files_to_adapt = model_files["model_files"]
if keep_old_processing:
files_to_adapt = [
f
for f in files_to_adapt
if "tokenization" not in str(f)
and "processing" not in str(f)
and "feature_extraction" not in str(f)
and "image_processing" not in str(f)
]
os.makedirs(module_folder, exist_ok=True)
for module_file in files_to_adapt:
new_module_name = module_file.name.replace(
old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
)
dest_file = module_folder / new_module_name
duplicate_module(
module_file,
old_model_patterns,
new_model_patterns,
dest_file=dest_file,
add_copied_from=add_copied_from and "modeling" in new_module_name,
)
clean_frameworks_in_init(
module_folder / "__init__.py", frameworks=frameworks, keep_processing=not keep_old_processing
)
# 2. We add our new model to the models init and the main init
add_content_to_file(
TRANSFORMERS_PATH / "models" / "__init__.py",
f" {new_model_patterns.model_lower_cased},",
add_after=f" {old_module_name},",
exact_match=True,
)
add_model_to_main_init(
old_model_patterns, new_model_patterns, frameworks=frameworks, with_processing=not keep_old_processing
)
# 3. Add test files
files_to_adapt = model_files["test_files"]
if keep_old_processing:
files_to_adapt = [
f
for f in files_to_adapt
if "tokenization" not in str(f)
and "processor" not in str(f)
and "feature_extraction" not in str(f)
and "image_processing" not in str(f)
]
def disable_fx_test(filename: Path) -> bool:
with open(filename) as fp:
content = fp.read()
new_content = re.sub(r"fx_compatible\s*=\s*True", "fx_compatible = False", content)
with open(filename, "w") as fp:
fp.write(new_content)
return content != new_content
disabled_fx_test = False
tests_folder = REPO_PATH / "tests" / "models" / new_model_patterns.model_lower_cased
os.makedirs(tests_folder, exist_ok=True)
with open(tests_folder / "__init__.py", "w"):
pass
for test_file in files_to_adapt:
new_test_file_name = test_file.name.replace(
old_model_patterns.model_lower_cased, new_model_patterns.model_lower_cased
)
dest_file = test_file.parent.parent / new_model_patterns.model_lower_cased / new_test_file_name
duplicate_module(
test_file,
old_model_patterns,
new_model_patterns,
dest_file=dest_file,
add_copied_from=False,
attrs_to_remove=["pipeline_model_mapping", "is_pipeline_test_to_skip"],
)
disabled_fx_test = disabled_fx_test | disable_fx_test(dest_file)
if disabled_fx_test:
print(
"The tests for symbolic tracing with torch.fx were disabled, you can add those once symbolic tracing works"
" for your new model."
)
# 4. Add model to auto classes
add_model_to_auto_classes(old_model_patterns, new_model_patterns, model_classes)
# 5. Add doc file
doc_file = REPO_PATH / "docs" / "source" / "en" / "model_doc" / f"{old_model_patterns.model_type}.md"
duplicate_doc_file(doc_file, old_model_patterns, new_model_patterns, frameworks=frameworks)
insert_model_in_doc_toc(old_model_patterns, new_model_patterns)
# 6. Warn the user for duplicate patterns
if old_model_patterns.model_type == old_model_patterns.checkpoint:
print(
"The model you picked has the same name for the model type and the checkpoint name "
f"({old_model_patterns.model_type}). As a result, it's possible some places where the new checkpoint "
f"should be, you have {new_model_patterns.model_type} instead. You should search for all instances of "
f"{new_model_patterns.model_type} in the new files and check they're not badly used as checkpoints."
)
elif old_model_patterns.model_lower_cased == old_model_patterns.checkpoint:
print(
"The model you picked has the same name for the model type and the checkpoint name "
f"({old_model_patterns.model_lower_cased}). As a result, it's possible some places where the new "
f"checkpoint should be, you have {new_model_patterns.model_lower_cased} instead. You should search for "
f"all instances of {new_model_patterns.model_lower_cased} in the new files and check they're not badly "
"used as checkpoints."
)
if (
old_model_patterns.model_type == old_model_patterns.model_lower_cased
and new_model_patterns.model_type != new_model_patterns.model_lower_cased
):
print(
"The model you picked has the same name for the model type and the lowercased model name "
f"({old_model_patterns.model_lower_cased}). As a result, it's possible some places where the new "
f"model type should be, you have {new_model_patterns.model_lower_cased} instead. You should search for "
f"all instances of {new_model_patterns.model_lower_cased} in the new files and check they're not badly "
"used as the model type."
)
if not keep_old_processing and old_model_patterns.tokenizer_class is not None:
print(
"The constants at the start of the new tokenizer file created needs to be manually fixed. If your new "
"model has a tokenizer fast, you will also need to manually add the converter in the "
"`SLOW_TO_FAST_CONVERTERS` constant of `convert_slow_tokenizer.py`."
)
def add_new_model_like_command_factory(args: Namespace):
return AddNewModelLikeCommand(config_file=args.config_file, path_to_repo=args.path_to_repo)
class AddNewModelLikeCommand(BaseTransformersCLICommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
add_new_model_like_parser = parser.add_parser("add-new-model-like")
add_new_model_like_parser.add_argument(
"--config_file", type=str, help="A file with all the information for this model creation."
)
add_new_model_like_parser.add_argument(
"--path_to_repo", type=str, help="When not using an editable install, the path to the Transformers repo."
)
add_new_model_like_parser.set_defaults(func=add_new_model_like_command_factory)
def __init__(self, config_file=None, path_to_repo=None, *args):
if config_file is not None:
with open(config_file, "r", encoding="utf-8") as f:
config = json.load(f)
self.old_model_type = config["old_model_type"]
self.model_patterns = ModelPatterns(**config["new_model_patterns"])
self.add_copied_from = config.get("add_copied_from", True)
self.frameworks = config.get("frameworks", get_default_frameworks())
self.old_checkpoint = config.get("old_checkpoint", None)
else:
(
self.old_model_type,
self.model_patterns,
self.add_copied_from,
self.frameworks,
self.old_checkpoint,
) = get_user_input()
self.path_to_repo = path_to_repo
def run(self):
if self.path_to_repo is not None:
# Adapt constants
global TRANSFORMERS_PATH
global REPO_PATH
REPO_PATH = Path(self.path_to_repo)
TRANSFORMERS_PATH = REPO_PATH / "src" / "transformers"
create_new_model_like(
model_type=self.old_model_type,
new_model_patterns=self.model_patterns,
add_copied_from=self.add_copied_from,
frameworks=self.frameworks,
old_checkpoint=self.old_checkpoint,
)
def get_user_field(
question: str,
default_value: Optional[str] = None,
is_valid_answer: Optional[Callable] = None,
convert_to: Optional[Callable] = None,
fallback_message: Optional[str] = None,
) -> Any:
"""
A utility function that asks a question to the user to get an answer, potentially looping until it gets a valid
answer.
Args:
question (`str`): The question to ask the user.
default_value (`str`, *optional*): A potential default value that will be used when the answer is empty.
is_valid_answer (`Callable`, *optional*):
If set, the question will be asked until this function returns `True` on the provided answer.
convert_to (`Callable`, *optional*):
If set, the answer will be passed to this function. If this function raises an error on the procided
answer, the question will be asked again.
fallback_message (`str`, *optional*):
A message that will be displayed each time the question is asked again to the user.
Returns:
`Any`: The answer provided by the user (or the default), passed through the potential conversion function.
"""
if not question.endswith(" "):
question = question + " "
if default_value is not None:
question = f"{question} [{default_value}] "
valid_answer = False
while not valid_answer:
answer = input(question)
if default_value is not None and len(answer) == 0:
answer = default_value
if is_valid_answer is not None:
valid_answer = is_valid_answer(answer)
elif convert_to is not None:
try:
answer = convert_to(answer)
valid_answer = True
except Exception:
valid_answer = False
else:
valid_answer = True
if not valid_answer:
print(fallback_message)
return answer
def convert_to_bool(x: str) -> bool:
"""
Converts a string to a bool.
"""
if x.lower() in ["1", "y", "yes", "true"]:
return True
if x.lower() in ["0", "n", "no", "false"]:
return False
raise ValueError(f"{x} is not a value that can be converted to a bool.")
def get_user_input():
"""
Ask the user for the necessary inputs to add the new model.
"""
model_types = list(auto_module.configuration_auto.MODEL_NAMES_MAPPING.keys())
# Get old model type
valid_model_type = False
while not valid_model_type:
old_model_type = input(
"What is the model you would like to duplicate? Please provide the lowercase `model_type` (e.g. roberta): "
)
if old_model_type in model_types:
valid_model_type = True
else:
print(f"{old_model_type} is not a valid model type.")
near_choices = difflib.get_close_matches(old_model_type, model_types)
if len(near_choices) >= 1:
if len(near_choices) > 1:
near_choices = " or ".join(near_choices)
print(f"Did you mean {near_choices}?")
old_model_info = retrieve_info_for_model(old_model_type)
old_tokenizer_class = old_model_info["model_patterns"].tokenizer_class
old_image_processor_class = old_model_info["model_patterns"].image_processor_class
old_feature_extractor_class = old_model_info["model_patterns"].feature_extractor_class
old_processor_class = old_model_info["model_patterns"].processor_class
old_frameworks = old_model_info["frameworks"]
old_checkpoint = None
if len(old_model_info["model_patterns"].checkpoint) == 0:
old_checkpoint = get_user_field(
"We couldn't find the name of the base checkpoint for that model, please enter it here."
)
model_name = get_user_field(
"What is the name (with no special casing) for your new model in the paper (e.g. RoBERTa)? "
)
default_patterns = ModelPatterns(model_name, model_name)
model_type = get_user_field(
"What identifier would you like to use for the `model_type` of this model? ",
default_value=default_patterns.model_type,
)
model_lower_cased = get_user_field(
"What lowercase name would you like to use for the module (folder) of this model? ",
default_value=default_patterns.model_lower_cased,
)
model_camel_cased = get_user_field(
"What prefix (camel-cased) would you like to use for the model classes of this model (e.g. Roberta)? ",
default_value=default_patterns.model_camel_cased,
)
model_upper_cased = get_user_field(
"What prefix (upper-cased) would you like to use for the constants relative to this model? ",
default_value=default_patterns.model_upper_cased,
)
config_class = get_user_field(
"What will be the name of the config class for this model? ", default_value=f"{model_camel_cased}Config"
)
checkpoint = get_user_field(
"Please give a checkpoint identifier (on the model Hub) for this new model (e.g. facebook/FacebookAI/roberta-base): "
)
old_processing_classes = [
c if not isinstance(c, tuple) else c[0]
for c in [old_image_processor_class, old_feature_extractor_class, old_tokenizer_class, old_processor_class]
if c is not None
]
old_processing_classes = ", ".join(old_processing_classes)
keep_processing = get_user_field(
f"Will your new model use the same processing class as {old_model_type} ({old_processing_classes}) (yes/no)? ",
convert_to=convert_to_bool,
fallback_message="Please answer yes/no, y/n, true/false or 1/0. ",
)
if keep_processing:
image_processor_class = old_image_processor_class
feature_extractor_class = old_feature_extractor_class
processor_class = old_processor_class
tokenizer_class = old_tokenizer_class
else:
if old_tokenizer_class is not None:
tokenizer_class = get_user_field(
"What will be the name of the tokenizer class for this model? ",
default_value=f"{model_camel_cased}Tokenizer",
)
else:
tokenizer_class = None
if old_image_processor_class is not None:
image_processor_class = get_user_field(
"What will be the name of the image processor class for this model? ",
default_value=f"{model_camel_cased}ImageProcessor",
)
else:
image_processor_class = None
if old_feature_extractor_class is not None:
feature_extractor_class = get_user_field(
"What will be the name of the feature extractor class for this model? ",
default_value=f"{model_camel_cased}FeatureExtractor",
)
else:
feature_extractor_class = None
if old_processor_class is not None:
processor_class = get_user_field(
"What will be the name of the processor class for this model? ",
default_value=f"{model_camel_cased}Processor",
)
else:
processor_class = None
model_patterns = ModelPatterns(
model_name,
checkpoint,
model_type=model_type,
model_lower_cased=model_lower_cased,
model_camel_cased=model_camel_cased,
model_upper_cased=model_upper_cased,
config_class=config_class,
tokenizer_class=tokenizer_class,
image_processor_class=image_processor_class,
feature_extractor_class=feature_extractor_class,
processor_class=processor_class,
)
add_copied_from = get_user_field(
"Should we add # Copied from statements when creating the new modeling file (yes/no)? ",
convert_to=convert_to_bool,
default_value="yes",
fallback_message="Please answer yes/no, y/n, true/false or 1/0.",
)
all_frameworks = get_user_field(
"Should we add a version of your new model in all the frameworks implemented by"
f" {old_model_type} ({old_frameworks}) (yes/no)? ",
convert_to=convert_to_bool,
default_value="yes",
fallback_message="Please answer yes/no, y/n, true/false or 1/0.",
)
if all_frameworks:
frameworks = None
else:
frameworks = get_user_field(
"Please enter the list of framworks you want (pt, tf, flax) separated by spaces",
is_valid_answer=lambda x: all(p in ["pt", "tf", "flax"] for p in x.split(" ")),
)
frameworks = list(set(frameworks.split(" ")))
return (old_model_type, model_patterns, add_copied_from, frameworks, old_checkpoint)
|
transformers/src/transformers/commands/add_new_model_like.py/0
|
{
"file_path": "transformers/src/transformers/commands/add_new_model_like.py",
"repo_id": "transformers",
"token_count": 29705
}
|
# coding=utf-8
# Copyright 2020 The HuggingFace Inc. team.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""Convert Seq2Seq TF Hub checkpoint."""
import argparse
from . import (
BertConfig,
BertGenerationConfig,
BertGenerationDecoder,
BertGenerationEncoder,
load_tf_weights_in_bert_generation,
logging,
)
logging.set_verbosity_info()
def convert_tf_checkpoint_to_pytorch(tf_hub_path, pytorch_dump_path, is_encoder_named_decoder, vocab_size, is_encoder):
# Initialise PyTorch model
bert_config = BertConfig.from_pretrained(
"google-bert/bert-large-cased",
vocab_size=vocab_size,
max_position_embeddings=512,
is_decoder=True,
add_cross_attention=True,
)
bert_config_dict = bert_config.to_dict()
del bert_config_dict["type_vocab_size"]
config = BertGenerationConfig(**bert_config_dict)
if is_encoder:
model = BertGenerationEncoder(config)
else:
model = BertGenerationDecoder(config)
print(f"Building PyTorch model from configuration: {config}")
# Load weights from tf checkpoint
load_tf_weights_in_bert_generation(
model,
tf_hub_path,
model_class="bert",
is_encoder_named_decoder=is_encoder_named_decoder,
is_encoder=is_encoder,
)
# Save pytorch-model
print(f"Save PyTorch model and config to {pytorch_dump_path}")
model.save_pretrained(pytorch_dump_path)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
# Required parameters
parser.add_argument(
"--tf_hub_path", default=None, type=str, required=True, help="Path to the TensorFlow checkpoint path."
)
parser.add_argument(
"--pytorch_dump_path", default=None, type=str, required=True, help="Path to the output PyTorch model."
)
parser.add_argument(
"--is_encoder_named_decoder",
action="store_true",
help="If decoder has to be renamed to encoder in PyTorch model.",
)
parser.add_argument("--is_encoder", action="store_true", help="If model is an encoder.")
parser.add_argument("--vocab_size", default=50358, type=int, help="Vocab size of model")
args = parser.parse_args()
convert_tf_checkpoint_to_pytorch(
args.tf_hub_path,
args.pytorch_dump_path,
args.is_encoder_named_decoder,
args.vocab_size,
is_encoder=args.is_encoder,
)
|
transformers/src/transformers/convert_tf_hub_seq_to_seq_bert_to_pytorch.py/0
|
{
"file_path": "transformers/src/transformers/convert_tf_hub_seq_to_seq_bert_to_pytorch.py",
"repo_id": "transformers",
"token_count": 1134
}
|
# THIS FILE HAS BEEN AUTOGENERATED. To update:
# 1. modify the `_deps` dict in setup.py
# 2. run `make deps_table_update``
deps = {
"Pillow": "Pillow>=10.0.1,<=15.0",
"accelerate": "accelerate>=0.26.0",
"av": "av",
"beautifulsoup4": "beautifulsoup4",
"blobfile": "blobfile",
"codecarbon": "codecarbon>=2.8.1",
"cookiecutter": "cookiecutter==1.7.3",
"dataclasses": "dataclasses",
"datasets": "datasets!=2.5.0",
"deepspeed": "deepspeed>=0.9.3",
"diffusers": "diffusers",
"dill": "dill<0.3.5",
"evaluate": "evaluate>=0.2.0",
"faiss-cpu": "faiss-cpu",
"fastapi": "fastapi",
"filelock": "filelock",
"flax": "flax>=0.4.1,<=0.7.0",
"fsspec": "fsspec<2023.10.0",
"ftfy": "ftfy",
"fugashi": "fugashi>=1.0",
"GitPython": "GitPython<3.1.19",
"hf-doc-builder": "hf-doc-builder>=0.3.0",
"huggingface-hub": "huggingface-hub>=0.24.0,<1.0",
"importlib_metadata": "importlib_metadata",
"ipadic": "ipadic>=1.0.0,<2.0",
"isort": "isort>=5.5.4",
"jax": "jax>=0.4.1,<=0.4.13",
"jaxlib": "jaxlib>=0.4.1,<=0.4.13",
"jieba": "jieba",
"jinja2": "jinja2>=3.1.0",
"kenlm": "kenlm",
"keras": "keras>2.9,<2.16",
"keras-nlp": "keras-nlp>=0.3.1,<0.14.0",
"librosa": "librosa",
"nltk": "nltk<=3.8.1",
"natten": "natten>=0.14.6,<0.15.0",
"numpy": "numpy>=1.17",
"onnxconverter-common": "onnxconverter-common",
"onnxruntime-tools": "onnxruntime-tools>=1.4.2",
"onnxruntime": "onnxruntime>=1.4.0",
"opencv-python": "opencv-python",
"optimum-benchmark": "optimum-benchmark>=0.3.0",
"optuna": "optuna",
"optax": "optax>=0.0.8,<=0.1.4",
"packaging": "packaging>=20.0",
"parameterized": "parameterized",
"phonemizer": "phonemizer",
"protobuf": "protobuf",
"psutil": "psutil",
"pyyaml": "pyyaml>=5.1",
"pydantic": "pydantic",
"pytest": "pytest>=7.2.0,<8.0.0",
"pytest-asyncio": "pytest-asyncio",
"pytest-timeout": "pytest-timeout",
"pytest-xdist": "pytest-xdist",
"python": "python>=3.9.0",
"ray[tune]": "ray[tune]>=2.7.0",
"regex": "regex!=2019.12.17",
"requests": "requests",
"rhoknp": "rhoknp>=1.1.0,<1.3.1",
"rjieba": "rjieba",
"rouge-score": "rouge-score!=0.0.7,!=0.0.8,!=0.1,!=0.1.1",
"ruff": "ruff==0.5.1",
"sacrebleu": "sacrebleu>=1.4.12,<2.0.0",
"sacremoses": "sacremoses",
"safetensors": "safetensors>=0.4.1",
"sagemaker": "sagemaker>=2.31.0",
"schedulefree": "schedulefree>=1.2.6",
"scikit-learn": "scikit-learn",
"scipy": "scipy<1.13.0",
"sentencepiece": "sentencepiece>=0.1.91,!=0.1.92",
"sigopt": "sigopt",
"starlette": "starlette",
"sudachipy": "sudachipy>=0.6.6",
"sudachidict_core": "sudachidict_core>=20220729",
"tensorboard": "tensorboard",
"tensorflow-cpu": "tensorflow-cpu>2.9,<2.16",
"tensorflow": "tensorflow>2.9,<2.16",
"tensorflow-text": "tensorflow-text<2.16",
"tensorflow-probability": "tensorflow-probability<0.24",
"tf2onnx": "tf2onnx",
"timeout-decorator": "timeout-decorator",
"tiktoken": "tiktoken",
"timm": "timm<=1.0.11",
"tokenizers": "tokenizers>=0.21,<0.22",
"torch": "torch>=2.0",
"torchaudio": "torchaudio",
"torchvision": "torchvision",
"pyctcdecode": "pyctcdecode>=0.4.0",
"tqdm": "tqdm>=4.27",
"unidic": "unidic>=1.0.2",
"unidic_lite": "unidic_lite>=1.0.7",
"urllib3": "urllib3<2.0.0",
"uvicorn": "uvicorn",
"pytest-rich": "pytest-rich",
"libcst": "libcst",
"rich": "rich",
}
|
transformers/src/transformers/dependency_versions_table.py/0
|
{
"file_path": "transformers/src/transformers/dependency_versions_table.py",
"repo_id": "transformers",
"token_count": 1962
}
|
# coding=utf-8
# Copyright 2018 The Google AI Language Team Authors and The HuggingFace Inc. team.
# Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import copy
import inspect
import warnings
from dataclasses import dataclass
from typing import Any, Dict, Optional, Tuple, Union
import numpy as np
import tensorflow as tf
from tensorflow.compiler.tf2xla.python.xla import dynamic_update_slice
from ..modeling_tf_outputs import TFCausalLMOutputWithPast, TFSeq2SeqLMOutput
from ..models.auto import (
TF_MODEL_FOR_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
TF_MODEL_FOR_VISION_2_SEQ_MAPPING,
)
from ..tf_utils import shape_list, stable_softmax
from ..utils import ModelOutput, logging
from .configuration_utils import GenerationConfig
from .tf_logits_process import (
TFForcedBOSTokenLogitsProcessor,
TFForcedEOSTokenLogitsProcessor,
TFForceTokensLogitsProcessor,
TFLogitsProcessorList,
TFMinLengthLogitsProcessor,
TFNoBadWordsLogitsProcessor,
TFNoRepeatNGramLogitsProcessor,
TFRepetitionPenaltyLogitsProcessor,
TFSuppressTokensAtBeginLogitsProcessor,
TFSuppressTokensLogitsProcessor,
TFTemperatureLogitsWarper,
TFTopKLogitsWarper,
TFTopPLogitsWarper,
)
logger = logging.get_logger(__name__)
@dataclass
class TFGreedySearchDecoderOnlyOutput(ModelOutput):
"""
Base class for outputs of decoder-only generation models using greedy search.
Args:
sequences (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFGreedySearchEncoderDecoderOutput(ModelOutput):
"""
Base class for outputs of encoder-decoder generation models using greedy search. Hidden states and attention
weights of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the
encoder_hidden_states attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
Args:
sequences (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer of the decoder) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
decoder_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
cross_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
decoder_hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
encoder_attentions: Optional[Tuple[tf.Tensor]] = None
encoder_hidden_states: Optional[Tuple[tf.Tensor]] = None
decoder_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
cross_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
decoder_hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFSampleDecoderOnlyOutput(ModelOutput):
"""
Base class for outputs of decoder-only generation models using sampling.
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size*num_return_sequences, config.vocab_size)`.
attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(num_return_sequences*batch_size, num_heads, generated_length, sequence_length)`.
hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(num_return_sequences*batch_size, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFSampleEncoderDecoderOutput(ModelOutput):
"""
Base class for outputs of encoder-decoder generation models using sampling. Hidden states and attention weights of
the decoder (respectively the encoder) can be accessed via the encoder_attentions and the encoder_hidden_states
attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size*num_return_sequences, config.vocab_size)`.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer of the decoder) of shape `(batch_size*num_return_sequences,
num_heads, sequence_length, sequence_length)`.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size*num_return_sequences, sequence_length, hidden_size)`.
decoder_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_return_sequences, num_heads, generated_length, sequence_length)`.
cross_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
decoder_hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_return_sequences, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
encoder_attentions: Optional[Tuple[tf.Tensor]] = None
encoder_hidden_states: Optional[Tuple[tf.Tensor]] = None
decoder_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
cross_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
decoder_hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFBeamSearchDecoderOnlyOutput(ModelOutput):
"""
Base class for outputs of decoder-only generation models using beam search.
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
sequences_scores (`tf.Tensor` of shape `(batch_size*num_return_sequences)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Final beam scores of the generated `sequences`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed beam scores for each vocabulary token at each generation step. Beam scores consisting of log
softmax scores for each vocabulary token and sum of log softmax of previously generated tokens in this
beam. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each generated token),
with each tensor of shape `(batch_size*num_beams*num_return_sequences, config.vocab_size)`.
beam_indices (`tf.Tensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Beam indices of generated token id at each generation step. `tf.Tensor` of shape
`(batch_size*num_return_sequences, sequence_length)`.
attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams*num_return_sequences, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
sequences_scores: Optional[tf.Tensor] = None
scores: Optional[Tuple[tf.Tensor]] = None
beam_indices: Optional[tf.Tensor] = None
attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFBeamSearchEncoderDecoderOutput(ModelOutput):
"""
Base class for outputs of encoder-decoder generation models using beam search. Hidden states and attention weights
of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the encoder_hidden_states
attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
sequences_scores (`tf.Tensor` of shape `(batch_size*num_return_sequences)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Final beam scores of the generated `sequences`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed beam scores for each vocabulary token at each generation step. Beam scores consisting of log
softmax scores for each vocabulary token and sum of log softmax of previously generated tokens in this
beam. `Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each generated token),
with each tensor of shape `(batch_size*num_beams, config.vocab_size)`.
beam_indices (`tf.Tensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Beam indices of generated token id at each generation step. `tf.Tensor` of shape
`(batch_size*num_return_sequences, sequence_length)`.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer of the decoder) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size*num_beams*num_return_sequences, sequence_length, hidden_size)`.
decoder_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams*num_return_sequences, num_heads, generated_length,
sequence_length)`.
cross_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
decoder_hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams*num_return_sequences, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
sequences_scores: Optional[tf.Tensor] = None
scores: Optional[Tuple[tf.Tensor]] = None
beam_indices: Optional[tf.Tensor] = None
encoder_attentions: Optional[Tuple[tf.Tensor]] = None
encoder_hidden_states: Optional[Tuple[tf.Tensor]] = None
decoder_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
cross_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
decoder_hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFBeamSampleDecoderOnlyOutput(ModelOutput):
"""
Base class for outputs of decoder-only generation models using beam sample.
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
sequences_scores (`tf.Tensor` of shape `(batch_size * num_return_sequence)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Final beam scores of the generated `sequences`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed beam scores for each vocabulary token at each generation step. Beam scores consisting of log
softmax scores for each vocabulary token and sum of log softmax of previously generated tokens in this
beam. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each generated token),
with each tensor of shape `(batch_size*num_beams*num_return_sequences, config.vocab_size)`.
beam_indices (`tf.Tensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Beam indices of generated token id at each generation step. `tf.Tensor` of shape
`(batch_size*num_return_sequences, sequence_length)`.
attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
sequences_scores: Optional[tf.Tensor] = None
scores: Optional[Tuple[tf.Tensor]] = None
beam_indices: Optional[tf.Tensor] = None
attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFBeamSampleEncoderDecoderOutput(ModelOutput):
"""
Base class for outputs of encoder-decoder generation models using beam sampling. Hidden states and attention
weights of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the
encoder_hidden_states attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
Args:
sequences (`tf.Tensor` of shape `(batch_size*num_beams, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
sequences_scores (`tf.Tensor` of shape `(batch_size * num_return_sequence)`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Final beam scores of the generated `sequences`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed beam scores for each vocabulary token at each generation step. Beam scores consisting of log
softmax scores for each vocabulary token and sum of log softmax of previously generated tokens in this
beam. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each generated token),
with each tensor of shape `(batch_size*num_beams, config.vocab_size)`.
beam_indices (`tf.Tensor`, *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Beam indices of generated token id at each generation step. `tf.Tensor` of shape
`(batch_size*num_return_sequences, sequence_length)`.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer of the decoder) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size*num_beams, sequence_length, hidden_size)`.
decoder_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams, num_heads, generated_length, sequence_length)`.
cross_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
decoder_hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size*num_beams, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
sequences_scores: Optional[tf.Tensor] = None
scores: Optional[Tuple[tf.Tensor]] = None
beam_indices: Optional[tf.Tensor] = None
encoder_attentions: Optional[Tuple[tf.Tensor]] = None
encoder_hidden_states: Optional[Tuple[tf.Tensor]] = None
decoder_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
cross_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
decoder_hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFContrastiveSearchDecoderOnlyOutput(ModelOutput):
"""
Base class for outputs of decoder-only generation models using contrastive search.
Args:
sequences (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
@dataclass
class TFContrastiveSearchEncoderDecoderOutput(ModelOutput):
"""
Base class for outputs of encoder-decoder generation models using contrastive search. Hidden states and attention
weights of the decoder (respectively the encoder) can be accessed via the encoder_attentions and the
encoder_hidden_states attributes (respectively the decoder_attentions and the decoder_hidden_states attributes)
Args:
sequences (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or shorter
if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)` *optional*, returned when `output_scores=True` is passed or when `config.output_scores=True`):
Processed prediction scores of the language modeling head (scores for each vocabulary token before SoftMax)
at each generation step. Tuple of `tf.Tensor` with up to `max_new_tokens` elements (one element for each
generated token), with each tensor of shape `(batch_size, config.vocab_size)`.
encoder_attentions (`tuple(tf.Tensor)`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple of `tf.Tensor` (one for each layer of the decoder) of shape `(batch_size, num_heads, sequence_length,
sequence_length)`.
encoder_hidden_states (`tuple(tf.Tensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple of `tf.Tensor` (one for the output of the embeddings + one for the output of each layer) of shape
`(batch_size, sequence_length, hidden_size)`.
decoder_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
cross_attentions (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_attentions=True` is passed or `config.output_attentions=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, num_heads, generated_length, sequence_length)`.
decoder_hidden_states (`tuple(tuple(tf.Tensor))`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`):
Tuple (one element for each generated token) of tuples (one element for each layer of the decoder) of
`tf.Tensor` of shape `(batch_size, generated_length, hidden_size)`.
"""
sequences: tf.Tensor = None
scores: Optional[Tuple[tf.Tensor]] = None
encoder_attentions: Optional[Tuple[tf.Tensor]] = None
encoder_hidden_states: Optional[Tuple[tf.Tensor]] = None
decoder_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
cross_attentions: Optional[Tuple[Tuple[tf.Tensor]]] = None
decoder_hidden_states: Optional[Tuple[Tuple[tf.Tensor]]] = None
TFGreedySearchOutput = Union[TFGreedySearchEncoderDecoderOutput, TFGreedySearchDecoderOnlyOutput]
TFSampleOutput = Union[TFSampleEncoderDecoderOutput, TFSampleDecoderOnlyOutput]
TFBeamSearchOutput = Union[TFBeamSearchEncoderDecoderOutput, TFBeamSearchDecoderOnlyOutput]
TFBeamSampleOutput = Union[TFBeamSampleEncoderDecoderOutput, TFBeamSampleDecoderOnlyOutput]
TFContrastiveSearchOutput = Union[TFContrastiveSearchEncoderDecoderOutput, TFContrastiveSearchDecoderOnlyOutput]
TFGenerateOutput = Union[
TFGreedySearchOutput, TFSampleOutput, TFBeamSearchOutput, TFBeamSampleOutput, TFContrastiveSearchOutput
]
class TFGenerationMixin:
"""
A class containing all of the functions supporting generation, to be used as a mixin in [`TFPreTrainedModel`].
The class exposes [`~generation.TFGenerationMixin.generate`], which can be used for:
- *greedy decoding* by calling [`~generation.TFGenerationMixin.greedy_search`] if `num_beams=1` and
`do_sample=False`
- *contrastive search* by calling [`~generation.TFGenerationMixin.contrastive_search`] if `penalty_alpha>0` and
`top_k>1`
- *multinomial sampling* by calling [`~generation.TFGenerationMixin.sample`] if `num_beams=1` and
`do_sample=True`
- *beam-search decoding* by calling [`~generation.TFGenerationMixin.beam_search`] if `num_beams>1`
You do not need to call any of the above methods directly. Pass custom parameter values to 'generate' instead. To
learn more about decoding strategies refer to the [text generation strategies guide](../generation_strategies).
"""
_seed_generator = None
@property
def seed_generator(self):
warnings.warn("`seed_generator` is deprecated and will be removed in a future version.", UserWarning)
if self._seed_generator is None:
self._seed_generator = tf.random.Generator.from_non_deterministic_state()
return self._seed_generator
supports_xla_generation = True
def prepare_inputs_for_generation(self, *args, **kwargs):
raise NotImplementedError(
"A model class needs to define a `prepare_inputs_for_generation` method in order to use `generate`."
)
def compute_transition_scores(
self,
sequences: tf.Tensor,
scores: Tuple[tf.Tensor],
beam_indices: Optional[tf.Tensor] = None,
normalize_logits: bool = False,
) -> tf.Tensor:
"""
Computes the transition scores of sequences given the generation scores (and beam indices, if beam search was
used). This is a convenient method to quicky obtain the scores of the selected tokens at generation time.
Parameters:
sequences (`tf.Tensor`):
The generated sequences. The second dimension (sequence_length) is either equal to `max_length` or
shorter if all batches finished early due to the `eos_token_id`.
scores (`tuple(tf.Tensor)`):
Transition scores for each vocabulary token at each generation step. Beam transition scores consisting
of log probabilities of tokens conditioned on log softmax of previously generated tokens Tuple of
`tf.Tensor` with up to `max_new_tokens` elements (one element for each generated token), with each
tensor of shape `(batch_size*num_beams, config.vocab_size)`.
beam_indices (`tf.Tensor`, *optional*):
Beam indices of generated token id at each generation step. `tf.Tensor` of shape
`(batch_size*num_return_sequences, sequence_length)`. Only required if a `num_beams>1` at
generate-time.
normalize_logits (`bool`, *optional*, defaults to `False`):
Whether to normalize the logits (which, for legacy reasons, may be unnormalized).
Return:
`tf.Tensor`: A `tf.Tensor` of shape `(batch_size*num_return_sequences, sequence_length)` containing
the transition scores (logits)
Examples:
```python
>>> from transformers import GPT2Tokenizer, TFAutoModelForCausalLM
>>> import numpy as np
>>> tokenizer = GPT2Tokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> tokenizer.pad_token_id = tokenizer.eos_token_id
>>> inputs = tokenizer(["Today is"], return_tensors="tf")
>>> # Example 1: Print the scores for each token generated with Greedy Search
>>> outputs = model.generate(**inputs, max_new_tokens=5, return_dict_in_generate=True, output_scores=True)
>>> transition_scores = model.compute_transition_scores(
... outputs.sequences, outputs.scores, normalize_logits=True
... )
>>> # input_length is the length of the input prompt for decoder-only models, like the GPT family, and 1 for
>>> # encoder-decoder models, like BART or T5.
>>> input_length = 1 if model.config.is_encoder_decoder else inputs.input_ids.shape[1]
>>> generated_tokens = outputs.sequences[:, input_length:]
>>> for tok, score in zip(generated_tokens[0], transition_scores[0]):
... # | token | token string | logits | probability
... print(f"| {tok:5d} | {tokenizer.decode(tok):8s} | {score.numpy():.3f} | {np.exp(score.numpy()):.2%}")
| 262 | the | -1.414 | 24.33%
| 1110 | day | -2.609 | 7.36%
| 618 | when | -2.010 | 13.40%
| 356 | we | -1.859 | 15.58%
| 460 | can | -2.508 | 8.14%
>>> # Example 2: Reconstruct the sequence scores from Beam Search
>>> outputs = model.generate(
... **inputs,
... max_new_tokens=5,
... num_beams=4,
... num_return_sequences=4,
... return_dict_in_generate=True,
... output_scores=True,
... )
>>> transition_scores = model.compute_transition_scores(
... outputs.sequences, outputs.scores, outputs.beam_indices, normalize_logits=False
... )
>>> # If you sum the generated tokens' scores and apply the length penalty, you'll get the sequence scores.
>>> # Tip: recomputing the scores is only guaranteed to match with `normalize_logits=False`. Depending on the
>>> # use case, you might want to recompute it with `normalize_logits=True`.
>>> output_length = np.sum(transition_scores.numpy() < 0, axis=1)
>>> length_penalty = model.generation_config.length_penalty
>>> reconstructed_scores = np.sum(transition_scores, axis=1) / (output_length**length_penalty)
>>> print(np.allclose(outputs.sequences_scores, reconstructed_scores))
True
```"""
# 1. In absence of `beam_indices`, we can assume that we come from e.g. greedy search, which is equivalent
# to a beam search approach were the first (and only) beam is always selected
if beam_indices is None:
beam_indices = tf.tile(tf.expand_dims(tf.range(scores[0].shape[0]), axis=1), [1, len(scores)])
# 2. reshape scores as [batch_size, vocab_size, # generation steps] with # generation steps being
# seq_len - input_length
scores = tf.transpose(tf.reshape(tf.stack(scores), (len(scores), -1)), (1, 0))
scores = tf.reshape(scores, (-1, self.config.vocab_size, scores.shape[-1]))
# 3. Optionally normalize the logits (across the vocab dimension)
if normalize_logits:
scores = tf.nn.log_softmax(scores, axis=1)
# 4. cut beam_indices to longest beam length
beam_indices_mask = beam_indices < 0
max_beam_length = tf.math.reduce_max(
tf.math.reduce_sum((1 - tf.cast(beam_indices_mask, dtype=tf.int32)), axis=-1)
)
beam_indices = beam_indices[:, -max_beam_length:]
beam_indices_mask = beam_indices_mask[:, -max_beam_length:]
# 5. Set indices of beams that finished early to 0; such indices will be masked correctly afterwards
beam_indices = tf.where(beam_indices_mask, 0, beam_indices)
# 6. Define which indices contributed to scores
cut_idx = sequences.shape[-1] - max_beam_length
token_indices = sequences[:, cut_idx:]
gen_step_idx = tf.broadcast_to(tf.range(scores.shape[-1]), token_indices.shape)
indices = tf.stack([beam_indices, token_indices, gen_step_idx], axis=-1)
# 7. Compute scores
transition_scores = tf.gather_nd(scores, indices)
# 8. Mask out transition_scores of beams that stopped early
transition_scores = tf.where(beam_indices_mask, 0, transition_scores)
return transition_scores
def _validate_model_class(self):
"""
Confirms that the model class is compatible with generation. If not, raises an exception that points to the
right class to use.
"""
if not self.can_generate():
generate_compatible_mappings = [
TF_MODEL_FOR_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_VISION_2_SEQ_MAPPING,
TF_MODEL_FOR_SEQ_TO_SEQ_CAUSAL_LM_MAPPING,
TF_MODEL_FOR_SPEECH_SEQ_2_SEQ_MAPPING,
]
generate_compatible_classes = set()
for model_mapping in generate_compatible_mappings:
supported_models = model_mapping.get(type(self.config), default=None)
if supported_models is not None:
generate_compatible_classes.add(supported_models.__name__)
exception_message = (
f"The current model class ({self.__class__.__name__}) is not compatible with `.generate()`, as "
"it doesn't have a language model head."
)
if generate_compatible_classes:
exception_message += f" Please use one of the following classes instead: {generate_compatible_classes}"
raise TypeError(exception_message)
def _validate_model_kwargs(self, model_kwargs: Dict[str, Any]):
"""Validates model kwargs for generation. Generate argument typos will also be caught here."""
# Excludes arguments that are handled before calling any model function
if self.config.is_encoder_decoder:
for key in ["decoder_input_ids"]:
model_kwargs.pop(key, None)
unused_model_args = []
model_args = set(inspect.signature(self.prepare_inputs_for_generation).parameters)
# `kwargs`/`model_kwargs` is often used to handle optional forward pass inputs like `attention_mask`. If
# `prepare_inputs_for_generation` doesn't accept them, then a stricter check can be made ;)
if "kwargs" in model_args or "model_kwargs" in model_args:
model_args |= set(inspect.signature(self.call).parameters)
for key, value in model_kwargs.items():
if value is not None and key not in model_args:
unused_model_args.append(key)
if unused_model_args:
raise ValueError(
f"The following `model_kwargs` are not used by the model: {unused_model_args} (note: typos in the"
" generate arguments will also show up in this list)"
)
def generate(
self,
inputs: Optional[tf.Tensor] = None,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[TFLogitsProcessorList] = None,
seed=None,
**kwargs,
) -> Union[TFGenerateOutput, tf.Tensor]:
r"""
Generates sequences of token ids for models with a language modeling head.
<Tip warning={true}>
Most generation-controlling parameters are set in `generation_config` which, if not passed, will be set to the
model's default generation configuration. You can override any `generation_config` by passing the corresponding
parameters to generate, e.g. `.generate(inputs, num_beams=4, do_sample=True)`.
For an overview of generation strategies and code examples, check out the [following
guide](../generation_strategies).
</Tip>
Parameters:
inputs (`tf.Tensor` of varying shape depending on the modality, *optional*):
The sequence used as a prompt for the generation or as model inputs to the encoder. If `None` the
method initializes it with `bos_token_id` and a batch size of 1. For decoder-only models `inputs`
should of in the format of `input_ids`. For encoder-decoder models *inputs* can represent any of
`input_ids`, `input_values`, `input_features`, or `pixel_values`.
generation_config (`~generation.GenerationConfig`, *optional*):
The generation configuration to be used as base parametrization for the generation call. `**kwargs`
passed to generate matching the attributes of `generation_config` will override them. If
`generation_config` is not provided, the default will be used, which had the following loading
priority: 1) from the `generation_config.json` model file, if it exists; 2) from the model
configuration. Please note that unspecified parameters will inherit [`~generation.GenerationConfig`]'s
default values, whose documentation should be checked to parameterize generation.
logits_processor (`LogitsProcessorList`, *optional*):
Custom logits processors that complement the default logits processors built from arguments and
generation config. If a logit processor is passed that is already created with the arguments or a
generation config an error is thrown. This feature is intended for advanced users.
seed (`List[int]`, *optional*):
Random seed to control sampling, containing two integers, used when `do_sample` is `True`. See the
`seed` argument from stateless functions in `tf.random`.
kwargs (`Dict[str, Any]`, *optional*):
Ad hoc parametrization of `generate_config` and/or additional model-specific kwargs that will be
forwarded to the `forward` function of the model. If the model is an encoder-decoder model, encoder
specific kwargs should not be prefixed and decoder specific kwargs should be prefixed with *decoder_*.
Return:
[`~utils.ModelOutput`] or `tf.Tensor`: A [`~utils.ModelOutput`] (if `return_dict_in_generate=True` or when
`config.return_dict_in_generate=True`) or a `tf.Tensor`.
If the model is *not* an encoder-decoder model (`model.config.is_encoder_decoder=False`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.TFGreedySearchDecoderOnlyOutput`],
- [`~generation.TFSampleDecoderOnlyOutput`],
- [`~generation.TFBeamSearchDecoderOnlyOutput`],
- [`~generation.TFBeamSampleDecoderOnlyOutput`]
If the model is an encoder-decoder model (`model.config.is_encoder_decoder=True`), the possible
[`~utils.ModelOutput`] types are:
- [`~generation.TFGreedySearchEncoderDecoderOutput`],
- [`~generation.TFSampleEncoderDecoderOutput`],
- [`~generation.TFBeamSearchEncoderDecoderOutput`],
- [`~generation.TFBeamSampleEncoderDecoderOutput`]
"""
# 1. Handle `generation_config` and kwargs that might update it, and validate the `.generate()` call
self._validate_model_class()
# priority: `generation_config` argument > `model.generation_config` (the default generation config)
if generation_config is None:
# legacy: users may modify the model configuration to control generation. To trigger this legacy behavior,
# two conditions must be met
# 1) the generation config must have been created from the model config (`_from_model_config` field);
# 2) the generation config must have seen no modification since its creation (the hash is the same).
if self.generation_config._from_model_config and self.generation_config._original_object_hash == hash(
self.generation_config
):
new_generation_config = GenerationConfig.from_model_config(self.config)
if new_generation_config != self.generation_config:
warnings.warn(
"You have modified the pretrained model configuration to control generation. This is a"
" deprecated strategy to control generation and will be removed soon, in a future version."
" Please use and modify the model generation configuration (see"
" https://huggingface.co/docs/transformers/generation_strategies#default-text-generation-configuration )"
)
self.generation_config = new_generation_config
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs) # All unused kwargs must be model kwargs
self._validate_model_kwargs(model_kwargs.copy())
# 2. Cast input dtypes to tf.int32 unless they're floats (which happens for some image models)
if inputs is not None:
if isinstance(inputs, tf.Tensor) and inputs.dtype.is_floating:
pass
elif isinstance(inputs, np.ndarray) and np.issubdtype(inputs.dtype, np.floating):
pass
else:
inputs = tf.cast(inputs, tf.int32)
if model_kwargs.get("attention_mask") is not None:
model_kwargs["attention_mask"] = tf.cast(model_kwargs["attention_mask"], tf.int32)
if "decoder_input_ids" in model_kwargs:
if (
isinstance(model_kwargs["decoder_input_ids"], tf.Tensor)
and model_kwargs["decoder_input_ids"].dtype.is_floating
):
pass
elif isinstance(model_kwargs["decoder_input_ids"], np.ndarray) and np.issubdtype(
model_kwargs["decoder_input_ids"].dtype, np.floating
):
pass
else:
model_kwargs["decoder_input_ids"] = tf.cast(model_kwargs["decoder_input_ids"], tf.int32)
# 3. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None else TFLogitsProcessorList()
if generation_config.pad_token_id is None and generation_config.eos_token_id is not None:
if model_kwargs.get("attention_mask") is None:
logger.warning(
"The attention mask and the pad token id were not set. As a consequence, you may observe "
"unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results."
)
eos_token_id = generation_config.eos_token_id
if isinstance(eos_token_id, list):
eos_token_id = eos_token_id[0]
generation_config.pad_token_id = eos_token_id
use_xla = not tf.executing_eagerly()
if use_xla and not self.supports_xla_generation:
raise ValueError(
"The selected model does not support Graph mode nor XLA generation (e.g. from tf.function())"
)
# 4. Define model inputs
inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
inputs, generation_config.bos_token_id, model_kwargs
)
# inputs_ids now has to be defined and cannot be None anymore
batch_size = shape_list(inputs_tensor)[0]
# 5. Prepare other model kwargs
model_kwargs["output_attentions"] = generation_config.output_attentions
model_kwargs["output_hidden_states"] = generation_config.output_hidden_states
model_kwargs["use_cache"] = generation_config.use_cache
accepts_attention_mask = "attention_mask" in set(inspect.signature(self.call).parameters.keys())
requires_attention_mask = "encoder_outputs" not in model_kwargs
if model_kwargs.get("attention_mask", None) is None and requires_attention_mask and accepts_attention_mask:
model_kwargs["attention_mask"] = self._prepare_attention_mask_for_generation(
inputs_tensor, generation_config.pad_token_id, generation_config.eos_token_id
)
# decoder-only models should use left-padding for generation
if not self.config.is_encoder_decoder:
if generation_config.pad_token_id is not None and tf.math.reduce_any(
inputs_tensor[:, -1] == generation_config.pad_token_id
):
logger.warning(
"A decoder-only architecture is being used, but right-padding was detected! For correct "
"generation results, please set `padding_side='left'` when initializing the tokenizer."
)
if self.config.is_encoder_decoder and "encoder_outputs" not in model_kwargs:
# if model is encoder decoder encoder_outputs are created and added to `model_kwargs`
model_kwargs = self._prepare_encoder_decoder_kwargs_for_generation(
inputs_tensor, model_kwargs, model_input_name
)
# 6. Prepare model inputs which will be used for auto-regressive generation
if self.config.is_encoder_decoder:
input_ids, model_kwargs = self._prepare_decoder_input_ids_for_generation(
batch_size=batch_size,
model_input_name=model_input_name,
model_kwargs=model_kwargs,
decoder_start_token_id=generation_config.decoder_start_token_id,
bos_token_id=generation_config.bos_token_id,
)
else:
input_ids = inputs_tensor if model_input_name == "input_ids" else model_kwargs.pop("input_ids")
# 7. Prepare `max_length` depending on other stopping criteria.
input_ids_seq_length = shape_list(input_ids)[-1]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None and generation_config.max_length == 20:
# 20 is the default max_length of the generation config
warnings.warn(
f"Using the model-agnostic default `max_length` (={generation_config.max_length}) "
"to control the generation length. recommend setting `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
if not has_default_max_length and generation_config.max_length is not None:
logger.warning(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)"
)
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
# If the input length is a tensor (i.e. dynamic length), skip length checks
if not isinstance(input_ids_seq_length, tf.Tensor):
if (
generation_config.min_length is not None
and generation_config.min_length > generation_config.max_length
):
raise ValueError(
f"Unfeasable length constraints: the minimum length ({generation_config.min_length}) is larger"
f" than the maximum length ({generation_config.max_length})"
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing`max_new_tokens`."
)
# 8. determine generation mode
is_contrastive_search_gen_mode = (
generation_config.top_k is not None
and generation_config.top_k > 1
and generation_config.do_sample is False
and generation_config.penalty_alpha is not None
and generation_config.penalty_alpha > 0
)
is_greedy_gen_mode = (
not is_contrastive_search_gen_mode
and (generation_config.num_beams == 1)
and generation_config.do_sample is False
)
is_beam_gen_mode = (
not is_contrastive_search_gen_mode
and (generation_config.num_beams > 1)
and generation_config.do_sample is False
)
is_sample_gen_mode = (generation_config.num_beams == 1) and generation_config.do_sample is True
is_beam_sample_gen_mode = (generation_config.num_beams > 1) and generation_config.do_sample is True
# 9. prepare distribution pre_processing samplers
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
logits_processor=logits_processor,
)
# 10. go into different generation modes
if is_greedy_gen_mode:
if generation_config.num_return_sequences > 1:
raise ValueError(
f"num_return_sequences has to be 1, but is {generation_config.num_return_sequences} when doing"
" greedy search."
)
# 11. run greedy search
return self.greedy_search(
input_ids,
max_length=generation_config.max_length,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
logits_processor=logits_processor,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
**model_kwargs,
)
elif is_contrastive_search_gen_mode:
if generation_config.num_return_sequences > 1:
raise ValueError(
f"num_return_sequences has to be 1, but is {generation_config.num_return_sequences} when doing"
" contrastive search."
)
# 11. run contrastive search
return self.contrastive_search(
input_ids,
top_k=generation_config.top_k,
penalty_alpha=generation_config.penalty_alpha,
logits_processor=logits_processor,
max_length=generation_config.max_length,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
**model_kwargs,
)
elif is_sample_gen_mode:
# 11. prepare logits warper
logits_warper = self._get_logits_warper(generation_config=generation_config)
# 12. expand input_ids with `num_return_sequences` additional sequences per batch
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_return_sequences,
is_encoder_decoder=self.config.is_encoder_decoder,
**model_kwargs,
)
# 13. run sample
return self.sample(
input_ids,
logits_processor=logits_processor,
logits_warper=logits_warper,
max_length=generation_config.max_length,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
seed=seed,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
**model_kwargs,
)
elif is_beam_gen_mode:
if generation_config.num_beams < generation_config.num_return_sequences:
raise ValueError(
"Beam search decoding cannot return more sequences than it has beams. Please set num_beams >="
f" num_return_sequences, got {generation_config.num_beams} and"
f" {generation_config.num_return_sequences} (respectivelly)"
)
# 11. broadcast inputs to the desired number of beams
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_beams,
is_encoder_decoder=self.config.is_encoder_decoder,
expand_in_new_axis=True,
**model_kwargs,
)
# 12. run beam search
return self.beam_search(
input_ids,
max_length=generation_config.max_length,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
length_penalty=generation_config.length_penalty,
early_stopping=generation_config.early_stopping,
logits_processor=logits_processor,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
num_return_sequences=generation_config.num_return_sequences,
**model_kwargs,
)
elif is_beam_sample_gen_mode:
if generation_config.num_beams < generation_config.num_return_sequences:
raise ValueError(
"Beam search decoding cannot return more sequences than it has beams. Please set num_beams >="
f" num_return_sequences, got {generation_config.num_beams} and"
f" {generation_config.num_return_sequences} (respectivelly)"
)
# 11. prepare logits warper
logits_warper = self._get_logits_warper(generation_config=generation_config)
# 12. broadcast inputs to the desired number of beams
input_ids, model_kwargs = self._expand_inputs_for_generation(
input_ids=input_ids,
expand_size=generation_config.num_beams,
is_encoder_decoder=self.config.is_encoder_decoder,
expand_in_new_axis=True,
**model_kwargs,
)
# 13. run beam sample (beam search with sampling)
return self.beam_search(
input_ids,
do_sample=True,
max_length=generation_config.max_length,
pad_token_id=generation_config.pad_token_id,
eos_token_id=generation_config.eos_token_id,
length_penalty=generation_config.length_penalty,
early_stopping=generation_config.early_stopping,
logits_processor=logits_processor,
logits_warper=logits_warper,
output_scores=generation_config.output_scores,
return_dict_in_generate=generation_config.return_dict_in_generate,
num_return_sequences=generation_config.num_return_sequences,
**model_kwargs,
)
def _prepare_attention_mask_for_generation(
self,
inputs: tf.Tensor,
pad_token_id: Optional[int],
eos_token_id: Optional[int],
) -> tf.Tensor:
is_input_ids = len(inputs.shape) == 2 and inputs.dtype in (tf.int32, tf.int64)
is_pad_token_in_inputs = (pad_token_id is not None) and tf.math.reduce_any(inputs == pad_token_id)
is_pad_token_not_equal_to_eos_token_id = (eos_token_id is None) or (pad_token_id != eos_token_id)
# Check if input is input_ids and padded -> only then is attention_mask defined
if is_input_ids and is_pad_token_in_inputs and is_pad_token_not_equal_to_eos_token_id:
return tf.cast(tf.math.not_equal(inputs, pad_token_id), dtype=tf.int32)
else:
return tf.ones(inputs.shape[:2], dtype=tf.int32)
def _prepare_encoder_decoder_kwargs_for_generation(
self, inputs_tensor: tf.Tensor, model_kwargs, model_input_name: Optional[str] = None
) -> Dict[str, Any]:
# 1. get encoder and store encoder outputs
encoder = self.get_encoder()
# 2. prepare encoder args and encoder kwargs from model kwargs
irrelevant_prefix = ["decoder_", "cross_attn", "use_cache"]
encoder_kwargs = {
argument: value
for argument, value in model_kwargs.items()
if not any(argument.startswith(p) for p in irrelevant_prefix)
}
encoder_signature = set(inspect.signature(encoder.call).parameters)
encoder_accepts_wildcard = "kwargs" in encoder_signature or "model_kwargs" in encoder_signature
if not encoder_accepts_wildcard:
encoder_kwargs = {
argument: value for argument, value in encoder_kwargs.items() if argument in encoder_signature
}
# 3. vision models don't use `attention_mask`.
encoder_kwargs["return_dict"] = True
encoder_kwargs[model_input_name] = inputs_tensor
if model_input_name != self.main_input_name: # in Keras, the first input must always be passed
encoder_kwargs[self.main_input_name] = None
encoder_outputs = encoder(**encoder_kwargs)
model_kwargs["encoder_outputs"] = encoder_outputs
return model_kwargs
def _prepare_decoder_input_ids_for_generation(
self,
batch_size: int,
model_input_name: str,
model_kwargs: Dict[str, tf.Tensor],
decoder_start_token_id: int = None,
bos_token_id: int = None,
) -> Tuple[tf.Tensor, Dict[str, tf.Tensor]]:
"""Prepares `decoder_input_ids` for generation with encoder-decoder models"""
# 1. Check whether the user has defined `decoder_input_ids` manually. To facilitate in terms of input naming,
# we also allow the user to pass it under `input_ids`, if the encoder does not use it as the main input.
if model_kwargs is not None and "decoder_input_ids" in model_kwargs:
decoder_input_ids = model_kwargs.pop("decoder_input_ids")
elif "input_ids" in model_kwargs and model_input_name != "input_ids":
decoder_input_ids = model_kwargs.pop("input_ids")
else:
decoder_input_ids = None
# 2. Encoder-decoder models expect the `decoder_input_ids` to start with a special token. Let's ensure that.
decoder_start_token_id = self._get_decoder_start_token_id(decoder_start_token_id, bos_token_id)
decoder_input_ids_start = tf.ones((batch_size, 1), dtype=tf.int32) * decoder_start_token_id
# no user input -> use decoder_start_token_id as decoder_input_ids
if decoder_input_ids is None:
decoder_input_ids = decoder_input_ids_start
# user input but doesn't start with decoder_start_token_id -> prepend decoder_start_token_id (and adjust
# decoder_attention_mask if provided)
elif tf.reduce_all(decoder_input_ids[:, 0] != decoder_start_token_id):
decoder_input_ids = tf.concat([decoder_input_ids_start, decoder_input_ids], axis=-1)
if "decoder_attention_mask" in model_kwargs:
decoder_attention_mask = model_kwargs["decoder_attention_mask"]
decoder_attention_mask = tf.concat(
(tf.ones_like(decoder_attention_mask)[:, :1], decoder_attention_mask),
axis=-1,
)
model_kwargs["decoder_attention_mask"] = decoder_attention_mask
return decoder_input_ids, model_kwargs
def _get_decoder_start_token_id(self, decoder_start_token_id: int = None, bos_token_id: int = None) -> int:
# retrieve decoder_start_token_id for encoder-decoder models
# fall back to bos_token_id if necessary
decoder_start_token_id = (
decoder_start_token_id
if decoder_start_token_id is not None
else self.generation_config.decoder_start_token_id
)
bos_token_id = bos_token_id if bos_token_id is not None else self.generation_config.bos_token_id
if decoder_start_token_id is not None:
return decoder_start_token_id
elif bos_token_id is not None:
return bos_token_id
raise ValueError(
"`decoder_start_token_id` or `bos_token_id` has to be defined for encoder-decoder generation."
)
@staticmethod
def _expand_inputs_for_generation(
expand_size: int = 1,
is_encoder_decoder: bool = False,
input_ids: Optional[tf.Tensor] = None,
expand_in_new_axis: bool = False,
**model_kwargs,
) -> Tuple[tf.Tensor, Dict[str, Any]]:
"""
Expands tensors from [batch_size, ...] to [batch_size * expand_size, ...] or [batch_size, expand_size, ...],
depending on `expand_in_new_axis`. Beam-based approaches expect this function to be used with
`expand_in_new_axis=True`
"""
def _expand_tensor(tensor: tf.Tensor):
if expand_in_new_axis:
shape = shape_list(tensor)
return tf.broadcast_to(tensor[:, None], (shape[0], expand_size) + tuple(shape[1:]))
else:
return tf.repeat(tensor, expand_size, axis=0)
def _expand_dict_for_generation(dict_to_expand):
for key in dict_to_expand:
if dict_to_expand[key] is not None and isinstance(dict_to_expand[key], tf.Tensor):
dict_to_expand[key] = _expand_tensor(dict_to_expand[key])
return dict_to_expand
if input_ids is not None:
input_ids = _expand_tensor(input_ids)
model_kwargs = _expand_dict_for_generation(model_kwargs)
if is_encoder_decoder:
if model_kwargs.get("encoder_outputs") is None:
raise ValueError("If `is_encoder_decoder` is True, make sure that `encoder_outputs` is defined.")
model_kwargs["encoder_outputs"] = _expand_dict_for_generation(model_kwargs["encoder_outputs"])
return input_ids, model_kwargs
def _prepare_model_inputs(
self,
inputs: Optional[tf.Tensor] = None,
bos_token_id: Optional[int] = None,
model_kwargs: Optional[Dict[str, tf.Tensor]] = None,
) -> Tuple[tf.Tensor, Optional[str], Dict[str, tf.Tensor]]:
"""
This function extracts the model-specific `inputs` for generation.
"""
# 1. retrieve all kwargs that are non-None or non-model input related.
# some encoder-decoder models have different names for model and encoder
if (
self.config.is_encoder_decoder
and hasattr(self, "encoder")
and hasattr(self.encoder, "main_input_name")
and self.encoder.main_input_name != self.main_input_name
):
input_name = self.encoder.main_input_name
else:
input_name = self.main_input_name
model_kwargs = {k: v for k, v in model_kwargs.items() if v is not None or k != input_name}
# 2. check whether model_input_name is passed as kwarg
# if yes and `inputs` is None use kwarg inputs
inputs_kwarg = model_kwargs.pop(input_name, None)
if inputs_kwarg is not None and inputs is not None:
raise ValueError(
f"`inputs`: {inputs}` were passed alongside {input_name} which is not allowed. "
f"Make sure to either pass {inputs} or {input_name}=..."
)
elif inputs_kwarg is not None:
inputs = inputs_kwarg
# 3. In the presence of `inputs_embeds` for text models:
# - decoder-only models should complain if the user attempts to pass `inputs_embeds`, but the model
# doesn't have its forwarding implemented. `inputs_embeds` is kept in `model_kwargs` and can coexist with
# input_ids (`inputs_embeds` will be used in the 1st generation step, as opposed to `input_ids`)
# - encoder-decoder models should complain if the user attempts to pass `inputs_embeds` and `input_ids`, and
# pull the former to inputs. It will be used in place of `input_ids` to get the encoder hidden states.
if input_name == "input_ids" and "inputs_embeds" in model_kwargs:
if not self.config.is_encoder_decoder:
has_inputs_embeds_forwarding = "inputs_embeds" in set(
inspect.signature(self.prepare_inputs_for_generation).parameters.keys()
)
if not has_inputs_embeds_forwarding:
raise ValueError(
f"You passed `inputs_embeds` to `.generate()`, but the model class {self.__class__.__name__} "
"doesn't have its forwarding implemented. See the GPT2 implementation for an example "
"(https://github.com/huggingface/transformers/pull/21405), and feel free to open a PR with it!"
)
# In this case, `input_ids` is moved to the `model_kwargs`, so a few automations (like the creation of
# the attention mask) can rely on the actual model input.
model_kwargs["input_ids"] = self._maybe_initialize_input_ids_for_generation(
inputs, bos_token_id, model_kwargs=model_kwargs
)
else:
if inputs is not None:
raise ValueError("You passed `inputs_embeds` and `input_ids` to `.generate()`. Please pick one.")
inputs, input_name = model_kwargs["inputs_embeds"], "inputs_embeds"
# 4. if `inputs` is still None, try to create `input_ids` from BOS token
inputs = self._maybe_initialize_input_ids_for_generation(inputs, bos_token_id, model_kwargs)
return inputs, input_name, model_kwargs
def _maybe_initialize_input_ids_for_generation(
self,
inputs: Optional[tf.Tensor] = None,
bos_token_id: Optional[int] = None,
model_kwargs: Optional[Dict[str, tf.Tensor]] = None,
) -> tf.Tensor:
"""Initializes input ids for generation, if necessary."""
if inputs is not None:
return inputs
encoder_outputs = model_kwargs.get("encoder_outputs")
if self.config.is_encoder_decoder and encoder_outputs is not None:
# make dummy input_ids with value -100, as a sanity check ensuring that they won't be used for encoding
shape = encoder_outputs.last_hidden_state.shape[:-1]
return tf.ones(shape, dtype=tf.int32) * -100
if bos_token_id is None:
raise ValueError("`bos_token_id` has to be defined when no `input_ids` are provided.")
# If there is some tensor in `model_kwargs`, we can infer the batch size from it. This is helpful with
# soft-prompting or in multimodal implementations built on top of decoder-only language models.
batch_size = 1
for value in model_kwargs.values():
if isinstance(value, tf.Tensor):
batch_size = value.shape[0]
break
return tf.ones((batch_size, 1), dtype=tf.int32) * bos_token_id
@staticmethod
def _extract_past_from_model_output(outputs: ModelOutput):
past_key_values = None
if "past_key_values" in outputs:
past_key_values = outputs.past_key_values
elif "mems" in outputs:
past_key_values = outputs.mems
elif "past_buckets_states" in outputs:
past_key_values = outputs.past_buckets_states
return past_key_values
def _update_model_kwargs_for_generation(
self, outputs: ModelOutput, model_kwargs: Dict[str, Any], is_encoder_decoder: bool = False
) -> Dict[str, Any]:
# update past_key_values
model_kwargs["past_key_values"] = self._extract_past_from_model_output(outputs)
# update attention mask
if not is_encoder_decoder:
if "attention_mask" in model_kwargs:
attention_mask = model_kwargs["attention_mask"]
model_kwargs["attention_mask"] = tf.concat(
[attention_mask, tf.ones((shape_list(attention_mask)[0], 1), dtype=tf.int32)], axis=-1
)
return model_kwargs
def _update_model_kwargs_for_xla_generation(
self,
model_outputs: ModelOutput,
model_kwargs: Dict[str, Any],
cur_len: int,
max_length: int,
batch_size: int,
is_encoder_decoder: bool = False,
batch_axis: int = 0,
):
def _initialize_attention(model_kwargs, num_padding_values, is_encoder_decoder):
"""initializes the appropriate attention mask -- encoder-decoder models use `decoder_attention_mask`"""
if is_encoder_decoder:
# One 1 for decoder_start_token_id, 0s for the currently-unfilled locations in the past_key_values tensor,
# 1s for the actual input_ids
decoder_attention_mask = tf.concat(
[
tf.ones((batch_size, 1), dtype=tf.int32),
tf.zeros((batch_size, num_padding_values), dtype=tf.int32),
tf.ones((batch_size, 1), dtype=tf.int32),
],
axis=1,
)
mask = {"decoder_attention_mask": decoder_attention_mask}
else:
attention_mask = model_kwargs.pop("attention_mask")
# 0s for the currently-unfilled locations in the past_key_values tensor, 1s for the actual input_ids
attention_mask = tf.concat(
[
attention_mask,
tf.zeros((batch_size, num_padding_values), dtype=attention_mask.dtype),
tf.ones((batch_size, 1), dtype=attention_mask.dtype),
],
axis=1,
)
mask = {"attention_mask": attention_mask}
return mask
def _update_attention(model_kwargs, new_past_index, is_encoder_decoder):
"""updates the appropriate attention mask -- encoder-decoder models use `decoder_attention_mask`"""
update_start = tf.constant([0, 1], dtype=tf.int32) * new_past_index
if is_encoder_decoder:
decoder_attention_mask = model_kwargs.pop("decoder_attention_mask")
decoder_attention_mask_update_slice = tf.ones((batch_size, 1), dtype=decoder_attention_mask.dtype)
decoder_attention_mask = dynamic_update_slice(
decoder_attention_mask, decoder_attention_mask_update_slice, update_start
)
mask = {"decoder_attention_mask": decoder_attention_mask}
else:
attention_mask = model_kwargs.pop("attention_mask")
attention_mask_update_slice = tf.ones((batch_size, 1), dtype=attention_mask.dtype)
attention_mask = dynamic_update_slice(attention_mask, attention_mask_update_slice, update_start)
mask = {"attention_mask": attention_mask}
return mask
def _initialize_past(past_key_values, num_padding_values, batch_axis):
"""initialize past_key_values with zeros -- the structure depends on `batch_axis`"""
if batch_axis == 0:
padding_values = tf.constant([[0, 0], [0, 0], [0, num_padding_values], [0, 0]], dtype=tf.int32)
new_past = ()
for past_layer in past_key_values:
new_past_layer = list(past_layer)
for i in range(len(new_past_layer[:2])):
new_past_layer[i] = tf.pad(past_layer[i], padding_values)
new_past += (tuple(new_past_layer),)
else:
padding_values = tf.scatter_nd(indices=[[3, 1]], updates=[num_padding_values], shape=(5, 2))
new_past = list(past_key_values)
for i in range(len(past_key_values)):
new_past[i] = tf.pad(past_key_values[i], padding_values)
return new_past
def _update_past(past_key_values, new_past_index, batch_axis):
if batch_axis == 0:
slice_start_base = tf.constant([0, 0, 1, 0])
new_past = ()
for past_layer in past_key_values:
new_past_layer = list(past_layer)
for i in range(len(new_past_layer[:2])):
update_slice = past_layer[i][:, :, -1:]
# Write the last slice to the first open location in the padded past_key_values array
# and then truncate the last slice off the array
new_past_layer[i] = dynamic_update_slice(
past_layer[i][:, :, :-1], update_slice, slice_start_base * new_past_index
)
new_past += (tuple(new_past_layer),)
else:
slice_start_base = tf.constant([0, 0, 0, 1, 0])
new_past = [None for _ in range(len(past_key_values))]
for i in range(len(past_key_values)):
update_slice = past_key_values[i][:, :, :, -1:]
# Write the last slice to the first open location in the padded past_key_values array
# and then truncate the last slice off the array
new_past[i] = dynamic_update_slice(
past_key_values[i][:, :, :, :-1], update_slice, slice_start_base * new_past_index
)
return new_past
past_key_values = self._extract_past_from_model_output(model_outputs)
if past_key_values is None:
raise ValueError(
"No known `past_key_values variable` found in model outputs (model outputs keys:"
f" {list(model_outputs.keys())})"
)
is_past_initialized = model_kwargs.pop("past_key_values", None) is not None
if not is_past_initialized:
# The padded version of `past_key_values` has a length of `max_length - 1`, as `past_key_values` holds information relative to
# previous autoregressive generation steps (step 0 has no past_key_values, step 1 has 1 past_key_values value, ..., the last step
# has `max_length - 1` past_key_values values).
num_padding_values = max_length - cur_len - 1
mask = _initialize_attention(model_kwargs, num_padding_values, is_encoder_decoder)
new_past = _initialize_past(past_key_values, num_padding_values, batch_axis)
else:
# The new index of past_key_values to be filled corresponds to the current length of the sequence, with two
# subtractions: -1 because past_key_values holds information regarding previous generation steps (read comment above)
# and -1 again because in an array the index is the length of the array minus 1.
new_past_index = cur_len - 2
mask = _update_attention(model_kwargs, new_past_index, is_encoder_decoder)
new_past = _update_past(past_key_values, new_past_index, batch_axis)
# sets the updated variables (mask and past_key_values)
model_kwargs.update(mask)
model_kwargs["past_key_values"] = tuple(new_past)
return model_kwargs
def _get_logits_warper(
self,
generation_config: GenerationConfig,
) -> TFLogitsProcessorList:
"""
This class returns a [`TFLogitsProcessorList`] list object that contains all relevant [`TFLogitsWarper`]
instances used for multinomial sampling.
"""
# instantiate warpers list
warpers = TFLogitsProcessorList()
# In beam methods, we need to keep at least one non-eos token to explore continuations that might have a
# better score (i.e. keep len(generation_config.eos_token_id) + 1)
if generation_config.num_beams > 1:
if isinstance(generation_config.eos_token_id, list):
min_tokens_to_keep = len(generation_config.eos_token_id) + 1
else:
min_tokens_to_keep = 2
else:
min_tokens_to_keep = 1
if generation_config.temperature is not None and generation_config.temperature != 1.0:
warpers.append(TFTemperatureLogitsWarper(generation_config.temperature))
if generation_config.top_k is not None and generation_config.top_k != 0:
warpers.append(TFTopKLogitsWarper(top_k=generation_config.top_k, min_tokens_to_keep=min_tokens_to_keep))
if generation_config.top_p is not None and generation_config.top_p < 1.0:
warpers.append(TFTopPLogitsWarper(top_p=generation_config.top_p, min_tokens_to_keep=min_tokens_to_keep))
return warpers
def _get_logits_processor(
self,
generation_config: GenerationConfig,
input_ids_seq_length: int,
logits_processor: Optional[TFLogitsProcessorList],
) -> TFLogitsProcessorList:
"""
This class returns a [`TFLogitsProcessorList`] list object that contains all relevant [`TFLogitsProcessor`]
instances used to modify the scores of the language model head.
"""
processors = TFLogitsProcessorList()
# instantiate processors list
if generation_config.repetition_penalty is not None and generation_config.repetition_penalty != 1.0:
processors.append(TFRepetitionPenaltyLogitsProcessor(penalty=generation_config.repetition_penalty))
if generation_config.no_repeat_ngram_size is not None and generation_config.no_repeat_ngram_size > 0:
processors.append(TFNoRepeatNGramLogitsProcessor(generation_config.no_repeat_ngram_size))
if generation_config.bad_words_ids is not None:
processors.append(
TFNoBadWordsLogitsProcessor(generation_config.bad_words_ids, generation_config.eos_token_id)
)
if (
generation_config.min_length is not None
and generation_config.eos_token_id is not None
and generation_config.min_length > 0
):
processors.append(TFMinLengthLogitsProcessor(generation_config.min_length, generation_config.eos_token_id))
if generation_config.forced_bos_token_id is not None:
processors.append(TFForcedBOSTokenLogitsProcessor(generation_config.forced_bos_token_id))
if generation_config.forced_eos_token_id is not None:
processors.append(
TFForcedEOSTokenLogitsProcessor(generation_config.max_length, generation_config.forced_eos_token_id)
)
if generation_config.suppress_tokens is not None:
processors.append(TFSuppressTokensLogitsProcessor(generation_config.suppress_tokens))
if generation_config.begin_suppress_tokens is not None:
begin_index = input_ids_seq_length
begin_index = (
begin_index
if (input_ids_seq_length > 1 or generation_config.forced_bos_token_id is None)
else begin_index + 1
)
if generation_config.forced_decoder_ids is not None:
begin_index += generation_config.forced_decoder_ids[-1][
0
] # generation starts after the last token that is forced
processors.append(
TFSuppressTokensAtBeginLogitsProcessor(generation_config.begin_suppress_tokens, begin_index)
)
if generation_config.forced_decoder_ids is not None:
processors.append(TFForceTokensLogitsProcessor(generation_config.forced_decoder_ids))
processors = self._merge_criteria_processor_list(processors, logits_processor)
return processors
def _merge_criteria_processor_list(
self,
default_list: TFLogitsProcessorList,
custom_list: TFLogitsProcessorList,
) -> TFLogitsProcessorList:
if len(custom_list) == 0:
return default_list
for default in default_list:
for custom in custom_list:
if type(custom) is type(default):
object_type = "logits processor"
raise ValueError(
f"A custom {object_type} of type {type(custom)} with values {custom} has been passed to"
f" `generate`, but it has already been created with the values {default}. {default} has been"
" created by passing the corresponding arguments to generate or by the model's config default"
f" values. If you just want to change the default values of {object_type} consider passing"
f" them as arguments to `generate` instead of using a custom {object_type}."
)
default_list.extend(custom_list)
return default_list
def greedy_search(
self,
input_ids: tf.Tensor,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
logits_processor: Optional[TFLogitsProcessorList] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
**model_kwargs,
) -> Union[TFGreedySearchOutput, tf.Tensor]:
r"""
Generates sequences for models with a language modeling head using greedy decoding.
Parameters:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
logits_processor (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsProcessor`]
used to modify the prediction scores of the language modeling head applied at each generation step.
max_length (`int`, *optional*, defaults to 20):
The maximum length of the sequence to be generated.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
eos_token_id (`Union[int, List[int]]`, *optional*):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
model_kwargs:
Additional model specific keyword arguments will be forwarded to the `call` function of the model. If
model is an encoder-decoder model the kwargs should include `encoder_outputs`.
Return:
[`~generation.TFGreedySearchDecoderOnlyOutput`], [`~generation.TFGreedySearchEncoderDecoderOutput`] or
`tf.Tensor`: A `tf.Tensor` containing the generated tokens (default behaviour) or a
[`~generation.TFGreedySearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
`return_dict_in_generate=True` or a [`~generation.TFGreedySearchEncoderDecoderOutput`] if
`model.config.is_encoder_decoder=True`.
Examples:
```python
>>> from transformers import (
... AutoTokenizer,
... TFAutoModelForCausalLM,
... TFLogitsProcessorList,
... TFMinLengthLogitsProcessor,
... )
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> # set pad_token_id to eos_token_id because GPT2 does not have a PAD token
>>> model.generation_config.pad_token_id = model.generation_config.eos_token_id
>>> input_prompt = "Today is a beautiful day, and"
>>> input_ids = tokenizer(input_prompt, return_tensors="tf").input_ids
>>> # instantiate logits processors
>>> logits_processor = TFLogitsProcessorList(
... [
... TFMinLengthLogitsProcessor(15, eos_token_id=model.generation_config.eos_token_id),
... ]
... )
>>> outputs = model.greedy_search(input_ids, logits_processor=logits_processor)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
["Today is a beautiful day, and I'm so happy to be here. I'm so happy to"]
```"""
# 1. init greedy_search values
logits_processor = logits_processor if logits_processor is not None else TFLogitsProcessorList()
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)
use_cache = model_kwargs.pop("use_cache", self.generation_config.use_cache)
use_xla = not tf.executing_eagerly()
# TODO (Joao): fix cache format or find programatic way to detect cache index
# GPT2 and other models has a slightly different cache structure, with a different batch axis
model_name = str(self.decoder) if "EncoderDecoder" in str(self) else str(self)
cache_batch_axis = 1 if any(model_prefix in model_name for model_prefix in ("TFGPT2", "TFCTRL")) else 0
# some models, like XLNet, need more than the last token in the presence of past_key_values
needs_full_input = "use_mems" in set(inspect.signature(self.prepare_inputs_for_generation).parameters.keys())
# 2. init `attentions`, `hidden_states`, and `scores` tuples
scores = [] if (return_dict_in_generate and output_scores) else None
decoder_attentions = [] if (return_dict_in_generate and output_attentions) else None
cross_attentions = [] if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = [] if (return_dict_in_generate and output_hidden_states) else None
# 3. init tensors to use for "xla-compileable" generate function
batch_size, cur_len = shape_list(input_ids)
# initialize `generated` (`input_ids` padded with `pad_token_id`), `finished_sequences`
input_ids_padding = tf.ones((batch_size, max_length - cur_len), dtype=tf.int32) * (pad_token_id or 0)
generated = tf.concat([input_ids, input_ids_padding], axis=-1)
finished_sequences = tf.zeros((batch_size,), dtype=tf.bool)
# 4. define "xla-compile-able" stop-condition and auto-regressive function
# define condition fn
def greedy_search_cond_fn(generated, finished_sequences, cur_len, model_kwargs):
"""state termination condition fn."""
return ~tf.reduce_all(finished_sequences)
# define condition fn
def greedy_search_body_fn(generated, finished_sequences, cur_len, model_kwargs):
"""state update fn."""
if model_kwargs.get("past_key_values") is None or needs_full_input:
input_ids = generated[:, :cur_len]
else:
input_ids = tf.expand_dims(generated[:, cur_len - 1], -1)
model_inputs = self.prepare_inputs_for_generation(input_ids, use_cache=use_cache, **model_kwargs)
# forward pass to get next token logits
model_outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
next_token_logits = model_outputs.logits[:, -1]
# pre-process distribution
next_tokens_scores = logits_processor(generated, next_token_logits, cur_len)
# Store scores, attentions and hidden_states when required
if not use_xla and return_dict_in_generate:
if output_scores:
scores.append(next_tokens_scores)
if output_attentions and self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.decoder_attentions)
elif output_attentions and not self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.attentions)
if self.config.is_encoder_decoder:
cross_attentions.append(model_outputs.cross_attentions)
if output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.decoder_hidden_states)
elif output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.hidden_states)
# argmax
next_tokens = tf.argmax(next_tokens_scores, axis=-1, output_type=tf.int32)
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
unfinished_seq = 1 - tf.cast(finished_sequences, tf.int32)
next_tokens = next_tokens * unfinished_seq + pad_token_id * (1 - unfinished_seq)
next_token_is_eos = tf.math.reduce_any(
tf.equal(
tf.broadcast_to(next_tokens, (len(eos_token_id), batch_size)), tf.expand_dims(eos_token_id, -1)
),
axis=0,
)
finished_sequences = finished_sequences | next_token_is_eos
# update `generated` and `cur_len`
update_indices = tf.stack([tf.range(batch_size), tf.broadcast_to(cur_len, [batch_size])], axis=-1)
generated = tf.tensor_scatter_nd_update(tensor=generated, indices=update_indices, updates=next_tokens)
cur_len += 1
# update model_kwargs
if use_xla:
model_kwargs = self._update_model_kwargs_for_xla_generation(
model_outputs=model_outputs,
model_kwargs=model_kwargs,
cur_len=cur_len,
max_length=max_length,
batch_size=batch_size,
is_encoder_decoder=self.config.is_encoder_decoder,
batch_axis=cache_batch_axis,
)
else:
model_kwargs = self._update_model_kwargs_for_generation(
model_outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# if we don't cache past_key_values key values we need the whole input
if model_kwargs.get("past_key_values", None) is None:
# let's throw out `past_key_values` since we don't want `None` tensors
model_kwargs.pop("past_key_values", None)
return generated, finished_sequences, cur_len, model_kwargs
# 5. run generation
# 1st generation step has to be run before to initialize `past_key_values`
generated, finished_sequences, cur_len, model_kwargs = greedy_search_body_fn(
generated, finished_sequences, cur_len, model_kwargs
)
# 2-to-n generation steps can then be run in autoregressive fashion
# only in case 1st generation step does NOT yield EOS token though
maximum_iterations = max_length - cur_len
generated, _, cur_len, _ = tf.while_loop(
greedy_search_cond_fn,
greedy_search_body_fn,
(generated, finished_sequences, cur_len, model_kwargs),
maximum_iterations=maximum_iterations,
)
# 6. prepare outputs
if not use_xla:
# cut for backward compatibility
generated = generated[:, :cur_len]
if return_dict_in_generate:
if self.config.is_encoder_decoder:
# if model is an encoder-decoder, retrieve encoder attention weights
# and hidden states
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
scores = tuple(scores) if scores is not None else None
decoder_attentions = tuple(decoder_attentions) if decoder_attentions is not None else None
cross_attentions = tuple(cross_attentions) if cross_attentions is not None else None
decoder_hidden_states = tuple(decoder_hidden_states) if decoder_hidden_states is not None else None
return TFGreedySearchEncoderDecoderOutput(
sequences=generated,
scores=scores,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
)
else:
return TFGreedySearchDecoderOnlyOutput(
sequences=generated,
scores=scores,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
)
else:
return generated
def sample(
self,
input_ids: tf.Tensor,
logits_processor: Optional[TFLogitsProcessorList] = None,
logits_warper: Optional[TFLogitsProcessorList] = None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
seed: Optional[Tuple[int, int]] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
**model_kwargs,
) -> Union[TFSampleOutput, tf.Tensor]:
r"""
Generates sequences for models with a language modeling head using multinomial sampling.
Parameters:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
logits_processor (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsProcessor`]
used to modify the prediction scores of the language modeling head applied at each generation step.
logits_warper (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsWarper`]
used to warp the prediction score distribution of the language modeling head applied before multinomial
sampling at each generation step.
max_length (`int`, *optional*, defaults to 20):
The maximum length of the sequence to be generated.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
eos_token_id (`Union[int, List[int]]`, *optional*):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
seed (`List[int]`, *optional*):
Random seed to control sampling, containing two integers, used when `do_sample` is `True`. See the
`seed` argument from stateless functions in `tf.random`.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
model_kwargs:
Additional model specific kwargs will be forwarded to the `call` function of the model. If model is an
encoder-decoder model the kwargs should include `encoder_outputs`.
Return:
[`~generation.TFSampleDecoderOnlyOutput`], [`~generation.TFSampleEncoderDecoderOutput`] or `tf.Tensor`: A
`tf.Tensor` containing the generated tokens (default behaviour) or a
[`~generation.TFSampleDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
`return_dict_in_generate=True` or a [`~generation.TFSampleEncoderDecoderOutput`] if
`model.config.is_encoder_decoder=True`.
Examples:
```python
>>> import tensorflow as tf
>>> from transformers import (
... AutoTokenizer,
... TFAutoModelForCausalLM,
... TFLogitsProcessorList,
... TFMinLengthLogitsProcessor,
... TFTopKLogitsWarper,
... TFTemperatureLogitsWarper,
... )
>>> tokenizer = AutoTokenizer.from_pretrained("openai-community/gpt2")
>>> model = TFAutoModelForCausalLM.from_pretrained("openai-community/gpt2")
>>> # set pad_token_id to eos_token_id because GPT2 does not have a EOS token
>>> model.generation_config.pad_token_id = model.generation_config.eos_token_id
>>> input_prompt = "Today is a beautiful day, and"
>>> input_ids = tokenizer(input_prompt, return_tensors="tf").input_ids
>>> # instantiate logits processors
>>> logits_processor = TFLogitsProcessorList(
... [
... TFMinLengthLogitsProcessor(15, eos_token_id=model.generation_config.eos_token_id),
... ]
... )
>>> # instantiate logits processors
>>> logits_warper = TFLogitsProcessorList(
... [
... TFTopKLogitsWarper(50),
... TFTemperatureLogitsWarper(0.7),
... ]
... )
>>> tf.random.set_seed(0)
>>> outputs = model.sample(input_ids, logits_processor=logits_processor, logits_warper=logits_warper)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Today is a beautiful day, and I love my country. But when I look at Donald Trump,']
```"""
# 1. init greedy_search values
logits_processor = logits_processor if logits_processor is not None else TFLogitsProcessorList()
logits_warper = logits_warper if logits_warper is not None else TFLogitsProcessorList()
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)
use_cache = model_kwargs.pop("use_cache", self.generation_config.use_cache)
use_xla = not tf.executing_eagerly()
# TODO (Joao): fix cache format or find programatic way to detect cache index
# GPT2 and other models has a slightly different cache structure, with a different batch axis
model_name = str(self.decoder) if "EncoderDecoder" in str(self) else str(self)
cache_batch_axis = 1 if any(model_prefix in model_name for model_prefix in ("TFGPT2", "TFCTRL")) else 0
# some models, like XLNet, need more than the last token in the presence of past_key_values
needs_full_input = "use_mems" in set(inspect.signature(self.prepare_inputs_for_generation).parameters.keys())
# 2. init `attentions`, `hidden_states`, and `scores` tuples
scores = [] if (return_dict_in_generate and output_scores) else None
decoder_attentions = [] if (return_dict_in_generate and output_attentions) else None
cross_attentions = [] if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = [] if (return_dict_in_generate and output_hidden_states) else None
# 3. init tensors to use for "xla-compileable" generate function
batch_size, cur_len = shape_list(input_ids)
# initialize `generated` (pre-populated with `pad_token_id`), `finished_sequences`
input_ids_padding = tf.ones((batch_size, max_length - cur_len), dtype=tf.int32) * (pad_token_id or 0)
generated = tf.concat([input_ids, input_ids_padding], axis=-1)
finished_sequences = tf.zeros((batch_size,), dtype=tf.bool)
# 4. define "xla-compile-able" stop-condition and auto-regressive function
def sample_cond_fn(generated, finished_sequences, cur_len, model_kwargs):
return ~tf.reduce_all(finished_sequences)
def sample_body_fn(generated, finished_sequences, cur_len, model_kwargs):
if model_kwargs.get("past_key_values") is None or needs_full_input:
input_ids = generated[:, :cur_len]
else:
input_ids = tf.expand_dims(generated[:, cur_len - 1], -1)
model_inputs = self.prepare_inputs_for_generation(input_ids, use_cache=use_cache, **model_kwargs)
# forward pass to get next token logits
model_outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
next_token_logits = model_outputs.logits[:, -1]
# pre-process distribution
next_tokens_scores = logits_processor(generated, next_token_logits, cur_len)
next_tokens_scores = logits_warper(generated, next_tokens_scores, cur_len)
# Store scores, attentions and hidden_states when required
if not use_xla and return_dict_in_generate:
if output_scores:
scores.append(next_tokens_scores)
if output_attentions and self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.decoder_attentions)
elif output_attentions and not self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.attentions)
if self.config.is_encoder_decoder:
cross_attentions.append(model_outputs.cross_attentions)
if output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.decoder_hidden_states)
elif output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.hidden_states)
# sample
if seed is not None:
sample_seed = seed
else:
sample_seed = tf.experimental.numpy.random.randint(tf.int32.min, tf.int32.max, (2,), dtype=tf.int32)
next_tokens = tf.squeeze(
tf.random.stateless_categorical(
logits=next_tokens_scores, num_samples=1, seed=sample_seed, dtype=tf.int32
),
axis=1,
)
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
unfinished_seq = 1 - tf.cast(finished_sequences, tf.int32)
next_tokens = next_tokens * unfinished_seq + pad_token_id * (1 - unfinished_seq)
next_token_is_eos = tf.math.reduce_any(
tf.equal(
tf.broadcast_to(next_tokens, (len(eos_token_id), batch_size)), tf.expand_dims(eos_token_id, -1)
),
axis=0,
)
finished_sequences = finished_sequences | next_token_is_eos
# update `generated` and `cur_len`
update_indices = tf.stack([tf.range(batch_size), tf.broadcast_to(cur_len, [batch_size])], axis=-1)
generated = tf.tensor_scatter_nd_update(tensor=generated, indices=update_indices, updates=next_tokens)
cur_len += 1
# update model_kwargs
if use_xla:
model_kwargs = self._update_model_kwargs_for_xla_generation(
model_outputs=model_outputs,
model_kwargs=model_kwargs,
cur_len=cur_len,
max_length=max_length,
batch_size=batch_size,
is_encoder_decoder=self.config.is_encoder_decoder,
batch_axis=cache_batch_axis,
)
else:
model_kwargs = self._update_model_kwargs_for_generation(
model_outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# if we don't cache past_key_values key values we need the whole input
if model_kwargs.get("past_key_values", None) is None:
# let's throw out `past_key_values` since we don't want `None` tensors
model_kwargs.pop("past_key_values", None)
return generated, finished_sequences, cur_len, model_kwargs
# 5. run generation
# 1st generation step has to be run before to initialize `past_key_values`
generated, finished_sequences, cur_len, model_kwargs = sample_body_fn(
generated, finished_sequences, cur_len, model_kwargs
)
# 2-to-n generation steps can then be run in autoregressive fashion
# only in case 1st generation step does NOT yield EOS token though
maximum_iterations = max_length - cur_len
generated, _, cur_len, _ = tf.while_loop(
sample_cond_fn,
sample_body_fn,
(generated, finished_sequences, cur_len, model_kwargs),
maximum_iterations=maximum_iterations,
)
# 6. prepare outputs
if not use_xla:
# cut for backward compatibility
generated = generated[:, :cur_len]
if return_dict_in_generate:
if self.config.is_encoder_decoder:
# if model is an encoder-decoder, retrieve encoder attention weights
# and hidden states
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
scores = tuple(scores) if scores is not None else None
decoder_attentions = tuple(decoder_attentions) if decoder_attentions is not None else None
cross_attentions = tuple(cross_attentions) if cross_attentions is not None else None
decoder_hidden_states = tuple(decoder_hidden_states) if decoder_hidden_states is not None else None
return TFSampleEncoderDecoderOutput(
sequences=generated,
scores=scores,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
)
else:
return TFSampleDecoderOnlyOutput(
sequences=generated,
scores=scores,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
)
else:
return generated
@staticmethod
def _gather_beams(nested, beam_indices, batch_axis=0):
"""Gathers the beam slices indexed by beam_indices into new beam array."""
def gather_fn(tensor):
if batch_axis > 0:
# pushes all dimentions before the batch to the end, so we get (batch, beam_id, ...)
perm = tf.concat((tf.range(tf.rank(tensor))[batch_axis:], tf.range(batch_axis)), axis=0)
tensor = tf.transpose(tensor, perm=perm)
gathered_tensor = tf.gather(params=tensor, indices=beam_indices, axis=1, batch_dims=1)
if batch_axis > 0:
# transposes back to the original dimensions
perm = tf.concat((tf.range(tf.rank(tensor))[batch_axis:], tf.range(batch_axis)), axis=0)
perm = tf.math.invert_permutation(perm)
gathered_tensor = tf.transpose(gathered_tensor, perm=perm)
return gathered_tensor
return tf.nest.map_structure(gather_fn, nested)
def beam_search(
self,
input_ids: tf.Tensor,
do_sample: bool = False,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
length_penalty: Optional[float] = None,
early_stopping: Optional[Union[bool, str]] = None,
logits_processor: Optional[TFLogitsProcessorList] = None,
logits_warper: Optional[TFLogitsProcessorList] = None,
num_return_sequences: Optional[int] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
**model_kwargs,
) -> Union[TFBeamSearchOutput, TFBeamSampleOutput, tf.Tensor]:
r"""
Generates sequences for models with a language modeling head using beam search. If `do_sample` is `False`, uses
a greedy approach, otherwise does multinomial sampling without replacement.
Parameters:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
do_sample (`bool`, *optional*, defaults to `False`):
Whether or not to use sampling ; use greedy decoding otherwise.
max_length (`int`, *optional*, defaults to 20):
The maximum length of the sequence to be generated.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
eos_token_id (`Union[int, List[int]]`, *optional*):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
length_penalty (`float`, *optional*, defaults to 1.0):
Exponential penalty to the length that is used with beam-based generation. It is applied as an exponent
to the sequence length, which in turn is used to divide the score of the sequence. Since the score is
the log likelihood of the sequence (i.e. negative), `length_penalty` > 0.0 promotes longer sequences,
while `length_penalty` < 0.0 encourages shorter sequences.
early_stopping (`bool` or `str`, *optional*, defaults to `False`):
Controls the stopping condition for beam-based methods, like beam-search. It accepts the following
values: `True`, where the generation stops as soon as there are `num_beams` complete candidates;
`False`, where an heuristic is applied and the generation stops when is it very unlikely to find better
candidates; `"never"`, where the beam search procedure only stops when there cannot be better
candidates (canonical beam search algorithm).
logits_processor (`[TFLogitsProcessorList]`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsProcessor`]
used to modify the prediction scores of the language modeling head applied at each generation step.
logits_warper (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsWarper`]
used to warp the prediction score distribution of the language modeling head applied before multinomial
sampling at each generation step.
num_return_sequences(`int`, *optional*, defaults to 1):
The number of independently computed returned sequences for each element in the batch.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~file_utils.ModelOutput`] instead of a plain tuple.
model_kwargs:
Additional model specific kwargs will be forwarded to the `call` function of the model. If model is an
encoder-decoder model the kwargs should include `encoder_outputs`.
Return:
[`~generation.TFBeamSearchDecoderOnlyOutput`], [`~generation.TFBeamSearchEncoderDecoderOutput`] or
`tf.Tensor`: A `tf.Tensor` containing the generated tokens (default behaviour) or a
[`~generation.TFBeamSearchDecoderOnlyOutput`] if `model.config.is_encoder_decoder=False` and
`return_dict_in_generate=True` or a [`~generation.TFBeamSearchEncoderDecoderOutput`] if
`model.config.is_encoder_decoder=True`.
Examples:
```python
>>> from transformers import (
... AutoTokenizer,
... TFAutoModelForSeq2SeqLM,
... TFLogitsProcessorList,
... TFMinLengthLogitsProcessor,
... )
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("google-t5/t5-base")
>>> model = TFAutoModelForSeq2SeqLM.from_pretrained("google-t5/t5-base")
>>> encoder_input_str = "translate English to German: How old are you?"
>>> encoder_input_ids = tokenizer(encoder_input_str, return_tensors="tf").input_ids
>>> # lets run beam search using 3 beams
>>> num_beams = 3
>>> # define decoder start token ids
>>> input_ids = tf.ones((1, num_beams, 1), dtype=tf.int32)
>>> input_ids = input_ids * model.generation_config.decoder_start_token_id
>>> # add encoder_outputs to model keyword arguments
>>> encoder_outputs = model.get_encoder()(encoder_input_ids, return_dict=True)
>>> encoder_outputs.last_hidden_state = tf.repeat(
... tf.expand_dims(encoder_outputs.last_hidden_state, axis=0), num_beams, axis=1
... )
>>> model_kwargs = {"encoder_outputs": encoder_outputs}
>>> # instantiate logits processors
>>> logits_processor = TFLogitsProcessorList(
... [TFMinLengthLogitsProcessor(5, eos_token_id=model.generation_config.eos_token_id)]
... )
>>> outputs = model.beam_search(input_ids, logits_processor=logits_processor, **model_kwargs)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['Wie alt bist du?']
```"""
def flatten_beam_dim(tensor, batch_axis=0):
"""Flattens the first two dimensions of a non-scalar array."""
shape = shape_list(tensor)
return tf.reshape(
tensor,
shape[:batch_axis] + [shape[batch_axis] * shape[batch_axis + 1]] + shape[batch_axis + 2 :],
)
def unflatten_beam_dim(tensor, num_beams, batch_axis=0):
"""Unflattens the first, flat batch*beam dimension of a non-scalar array."""
shape = shape_list(tensor)
return tf.reshape(tensor, shape[:batch_axis] + [-1, num_beams] + shape[batch_axis + 1 :])
# 1. init beam_search values
logits_processor = logits_processor if logits_processor is not None else TFLogitsProcessorList()
logits_warper = logits_warper if logits_warper is not None else TFLogitsProcessorList()
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
num_return_sequences = (
num_return_sequences if num_return_sequences is not None else self.generation_config.num_return_sequences
)
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)
length_penalty = length_penalty if length_penalty is not None else self.generation_config.length_penalty
early_stopping = early_stopping if early_stopping is not None else self.generation_config.early_stopping
use_cache = model_kwargs.pop("use_cache", self.generation_config.use_cache)
use_xla = not tf.executing_eagerly()
# TODO (Joao): fix cache format or find programatic way to detect cache index
# GPT2 and other models has a slightly different cache structure, with a different batch axis
model_name = str(self.decoder) if "EncoderDecoder" in str(self) else str(self)
cache_batch_axis = 1 if any(model_prefix in model_name for model_prefix in ("TFGPT2", "TFCTRL")) else 0
# some models, like XLNet, need more than the last token in the presence of past_key_values
needs_full_input = "use_mems" in set(inspect.signature(self.prepare_inputs_for_generation).parameters.keys())
# 2. init `attentions`, `hidden_states`, and `scores` tuples
all_scores = [] if (return_dict_in_generate and output_scores) else None
decoder_attentions = [] if (return_dict_in_generate and output_attentions) else None
cross_attentions = [] if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = [] if (return_dict_in_generate and output_hidden_states) else None
# 3. init tensors to use for "xla-compileable" generate function
batch_size, num_beams, cur_len = shape_list(input_ids)
# store the prompt length of decoder
decoder_prompt_len = cur_len
# per batch, beam-item holding current token in loop, pre-populated with `pad_token_id`
input_ids_padding = tf.ones((batch_size, num_beams, max_length - cur_len), dtype=tf.int32) * (
pad_token_id or 0
)
running_sequences = tf.concat([input_ids, input_ids_padding], axis=-1)
sequences = tf.ones((batch_size, num_beams, max_length), dtype=tf.int32) * (pad_token_id or 0)
# per batch,beam-item state bit indicating if sentence has finished.
is_sent_finished = tf.zeros((batch_size, num_beams), dtype=tf.bool)
# per batch, beam-item score, logprobs
running_scores = tf.tile(
tf.expand_dims(tf.convert_to_tensor([0.0] + [-1.0e9] * (num_beams - 1)), axis=0), [batch_size, 1]
)
scores = tf.ones((batch_size, num_beams)) * -1.0e9
# per batch beam indices
running_beam_indices = tf.ones((batch_size, num_beams, max_length - decoder_prompt_len), dtype=tf.int32) * -1
beam_indices = tf.ones((batch_size, num_beams, max_length - decoder_prompt_len), dtype=tf.int32) * -1
# flatten beam dim
if "encoder_outputs" in model_kwargs:
model_kwargs["encoder_outputs"]["last_hidden_state"] = flatten_beam_dim(
model_kwargs["encoder_outputs"]["last_hidden_state"]
)
if "attention_mask" in model_kwargs:
model_kwargs["attention_mask"] = flatten_beam_dim(model_kwargs["attention_mask"])
# 4. define "xla-compile-able" stop-condition and auto-regressive function
# define stop-condition and auto-regressive function
def beam_search_cond_fn(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
model_kwargs,
):
"""
Beam Search termination condition function -- halts the generation loop if any of these conditions becomes
False
"""
# 1. is less than max length?
not_max_length_yet = cur_len < max_length
# 2. can the new beams still improve?
# early_stopping == False -> apply heuristic = always get the best score from `cur_len - decoder_prompt_len`. See the discussion
# below for more details.
# https://github.com/huggingface/transformers/pull/20901#issuecomment-1369845565
# early_stopping == "never" -> compute the best score from max_length or cur_len, depending on the sign of
# length_penalty. Positive length_penalty favors longer sequences, thus we use max_length there.
if early_stopping == "never" and length_penalty > 0.0:
best_running_score = running_scores[:, :1] / ((max_length - decoder_prompt_len) ** length_penalty)
else:
best_running_score = running_scores[:, :1] / (
tf.cast(cur_len - decoder_prompt_len, dtype=tf.float32) ** length_penalty
)
worst_finished_score = tf.where(
is_sent_finished, tf.math.reduce_min(scores, axis=1, keepdims=True), -1.0e9
)
improvement_still_possible = tf.math.reduce_any(best_running_score > worst_finished_score)
# 3. is there still a beam that has not finished?
still_open_beam = ~(tf.math.reduce_all(is_sent_finished) & (early_stopping is True))
return not_max_length_yet & still_open_beam & improvement_still_possible
def beam_search_body_fn(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
model_kwargs,
):
"""
Beam Search iterative update function -- each iteration adds a new token and updates the best sequences
seen so far
"""
# 1. Forward current tokens
if model_kwargs.get("past_key_values") is None or needs_full_input:
input_ids = running_sequences[:, :, :cur_len]
else:
input_ids = tf.expand_dims(running_sequences[:, :, cur_len - 1], -1)
model_inputs = self.prepare_inputs_for_generation(
flatten_beam_dim(input_ids), use_cache=use_cache, **model_kwargs
)
model_outputs = self(
**model_inputs,
return_dict=True,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
)
logits = unflatten_beam_dim(model_outputs.logits[:, -1], num_beams)
# 2. Compute log probs
# get log probabilities from logits, process logits with processors (*e.g.* min_length, ...), and
# add new logprobs to existing running logprobs scores.
log_probs = tf.nn.log_softmax(logits)
log_probs = logits_processor(flatten_beam_dim(running_sequences), flatten_beam_dim(log_probs), cur_len)
log_probs = unflatten_beam_dim(log_probs, num_beams)
if do_sample:
log_probs = logits_warper(flatten_beam_dim(running_sequences), flatten_beam_dim(log_probs), cur_len)
log_probs = unflatten_beam_dim(log_probs, num_beams)
log_probs_processed = log_probs
log_probs = log_probs + tf.expand_dims(running_scores, axis=2)
vocab_size = log_probs.shape[2]
log_probs = tf.reshape(log_probs, (batch_size, num_beams * vocab_size))
# Store scores, attentions and hidden_states when required
if not use_xla and return_dict_in_generate:
if output_scores:
all_scores.append(
logits_warper(
flatten_beam_dim(running_sequences),
flatten_beam_dim(log_probs_processed),
cur_len,
)
)
if output_attentions and self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.decoder_attentions)
elif output_attentions and not self.config.is_encoder_decoder:
decoder_attentions.append(model_outputs.attentions)
if self.config.is_encoder_decoder:
cross_attentions.append(model_outputs.cross_attentions)
if output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.decoder_hidden_states)
elif output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(model_outputs.hidden_states)
# 3. Retrieve top-K
# Each item in batch has num_beams * vocab_size candidate sequences. For each item, get the top 2*k
# candidates with the highest log-probabilities. We gather the top 2*K beams here so that even if the
# best K sequences reach EOS simultaneously, we have another K sequences remaining to continue the live
# beam search.
# Gather the top 2*K scores from _all_ beams.
# Gather 2*k top beams.
# Recover the beam index by floor division.
# Recover token id by modulo division and expand Id array for broadcasting.
# Update sequences for the 2*K top-k new sequences.
beams_to_keep = 2 * num_beams
if do_sample:
topk_indices = sample_without_replacement(log_probs, beams_to_keep)
topk_log_probs = tf.gather(log_probs, topk_indices, axis=1, batch_dims=1)
else:
topk_log_probs, topk_indices = tf.math.top_k(log_probs, k=beams_to_keep)
topk_current_beam_indices = topk_indices // vocab_size
topk_running_beam_indices = self._gather_beams(running_beam_indices, topk_current_beam_indices)
topk_running_sequences = self._gather_beams(running_sequences, topk_current_beam_indices)
topk_ids = topk_indices % vocab_size
# writes the new token
indices_batch = tf.repeat(tf.range(batch_size), [beams_to_keep])
indices_beam = tf.tile(tf.range(beams_to_keep), [batch_size])
update_indices = tf.stack(
[indices_batch, indices_beam, tf.broadcast_to(cur_len, [batch_size * beams_to_keep])], axis=-1
)
topk_sequences = tf.tensor_scatter_nd_update(
tensor=topk_running_sequences,
indices=update_indices,
updates=tf.reshape(topk_ids, [batch_size * beams_to_keep]),
)
# we want to store the beam indices with batch information -> real beam index = beam index % num beams
batch_modified_indices = topk_current_beam_indices + tf.broadcast_to(
tf.expand_dims(tf.range(batch_size) * num_beams, axis=1), topk_current_beam_indices.shape
)
update_indices = tf.stack(
[
indices_batch,
indices_beam,
tf.broadcast_to(cur_len - decoder_prompt_len, [batch_size * beams_to_keep]),
],
axis=-1,
)
topk_beam_indices = tf.tensor_scatter_nd_update(
tensor=topk_running_beam_indices,
indices=update_indices,
updates=tf.reshape(batch_modified_indices, [batch_size * beams_to_keep]),
)
# 4. Check which sequences have ended
# Update current sequences: Did the top `num_beams` sequences reach an end marker?
# To prevent these just finished sequences from being added to the current sequences
# set of active beam search sequences, set their log probs to a very large negative value.
if eos_token_id is None:
eos_in_next_token = tf.zeros(topk_sequences[:, :, cur_len].shape, dtype=tf.bool)
else:
eos_in_next_token = tf.math.reduce_any(
tf.equal(
tf.broadcast_to(
topk_sequences[:, :, cur_len],
[len(eos_token_id)] + topk_sequences[:, :, cur_len].shape,
),
tf.expand_dims(tf.expand_dims(eos_token_id, -1), -1),
),
axis=0,
)
did_topk_just_finished = eos_in_next_token & tf.broadcast_to(
tf.concat((tf.ones((num_beams), dtype=tf.bool), tf.zeros((num_beams), dtype=tf.bool)), axis=0),
shape_list(eos_in_next_token),
)
# non-top `num_beams` eos tokens can't be used to finish a beam, but the others can't be used in the next
# running sentences either
running_topk_log_probs = topk_log_probs + tf.cast(eos_in_next_token, tf.float32) * -1.0e9
# 5. Get running sequences scores for next
# Determine the top k beam indices (from top 2*k beams) from log probs and gather top k beams
# (from top 2*k beams).
next_topk_indices = tf.math.top_k(running_topk_log_probs, k=num_beams)[1]
next_running_sequences, next_running_scores, next_running_beam_indices = self._gather_beams(
[topk_sequences, running_topk_log_probs, topk_beam_indices], next_topk_indices
)
# 6. Process topk logits
# Further process log probs:
# - add length penalty
# - make sure no scores can be added anymore if beam is full
# - make sure still running sequences cannot be chosen as finalized beam
topk_log_probs = topk_log_probs / (
tf.cast(cur_len + 1 - decoder_prompt_len, dtype=tf.float32) ** length_penalty
)
beams_in_batch_are_full = tf.broadcast_to(
tf.math.reduce_all(is_sent_finished, axis=-1, keepdims=True), shape_list(did_topk_just_finished)
) & (early_stopping is True)
add_penalty = ~did_topk_just_finished | beams_in_batch_are_full
topk_log_probs += tf.cast(add_penalty, tf.float32) * -1.0e9
# 7. Get scores, sequences, is sentence finished for next.
# Combine sequences, scores, and flags along the beam dimension and compare new finished sequence scores
# to existing finished scores and select the best from the new set of beams
merged_sequences = tf.concat([sequences, topk_sequences], axis=1)
merged_scores = tf.concat([scores, topk_log_probs], axis=1)
merged_beams = tf.concat([beam_indices, topk_beam_indices], axis=1)
merged_is_sent_finished = tf.concat([is_sent_finished, did_topk_just_finished], axis=1)
topk_merged_indices = tf.math.top_k(merged_scores, k=num_beams)[1]
next_sequences, next_scores, next_beam_indices, next_is_sent_finished = self._gather_beams(
[merged_sequences, merged_scores, merged_beams, merged_is_sent_finished], topk_merged_indices
)
# 8. Prepare data for the next iteration
# Determine the top k beam indices from the original set of all beams. With these, gather the top k
# beam-associated caches.
cur_len = cur_len + 1
if "past_key_values" in model_outputs:
cache = tf.nest.map_structure(
lambda tensor: unflatten_beam_dim(tensor, num_beams, batch_axis=cache_batch_axis),
model_outputs.past_key_values,
)
next_running_indices = self._gather_beams(topk_current_beam_indices, next_topk_indices)
next_cache = self._gather_beams(cache, next_running_indices, batch_axis=cache_batch_axis)
model_outputs["past_key_values"] = tf.nest.map_structure(
lambda tensor: flatten_beam_dim(tensor, batch_axis=cache_batch_axis), next_cache
)
if use_xla:
next_model_kwargs = self._update_model_kwargs_for_xla_generation(
model_outputs=model_outputs,
model_kwargs=model_kwargs,
cur_len=cur_len,
max_length=max_length,
batch_size=(batch_size * num_beams),
is_encoder_decoder=self.config.is_encoder_decoder,
batch_axis=cache_batch_axis,
)
else:
next_model_kwargs = self._update_model_kwargs_for_generation(
model_outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# if we don't cache past_key_values key values we need the whole input
if model_kwargs.get("past_key_values", None) is None:
# let's throw out `past_key_values` since we don't want `None` tensors
model_kwargs.pop("past_key_values", None)
return (
cur_len,
next_running_sequences,
next_running_scores,
next_running_beam_indices,
next_sequences,
next_scores,
next_beam_indices,
next_is_sent_finished,
decoder_prompt_len,
next_model_kwargs,
)
# 5. run generation
# 1st generation step has to be run before to initialize `past_key_values` (if active)
(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
model_kwargs,
) = beam_search_body_fn(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
model_kwargs,
)
# 2-to-n generation steps can then be run in autoregressive fashion (only in case 1st generation step does
# NOT yield EOS token though)
maximum_iterations = max_length - cur_len
(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
_,
) = tf.while_loop(
beam_search_cond_fn,
beam_search_body_fn,
(
cur_len,
running_sequences,
running_scores,
running_beam_indices,
sequences,
scores,
beam_indices,
is_sent_finished,
decoder_prompt_len,
model_kwargs,
),
maximum_iterations=maximum_iterations,
)
# 6. prepare outputs
# Account for the edge-case where there are no finished sequences for a particular batch item. If so, return
# running sequences for that batch item.
none_finished = tf.math.reduce_any(is_sent_finished, axis=1)
sequences = tf.where(none_finished[:, None, None], sequences, running_sequences)
beam_indices = tf.where(none_finished[:, None, None], beam_indices, running_beam_indices)
# Apply the length penalty so that running scores match the finalized scores if they are used
running_scores = running_scores / (tf.cast(cur_len - decoder_prompt_len, dtype=tf.float32) ** length_penalty)
scores = tf.where(none_finished[:, None], scores, running_scores)
# Take best beams for each batch (the score is sorted in descending order)
sequences = flatten_beam_dim(sequences[:, :num_return_sequences, :])
scores = flatten_beam_dim(scores[:, :num_return_sequences])
beam_indices = flatten_beam_dim(beam_indices[:, :num_return_sequences, :])
if not use_xla:
# Cut for backward compatibility
sequences = sequences[:, :cur_len]
beam_indices = beam_indices[:, : cur_len - decoder_prompt_len]
if return_dict_in_generate:
if self.config.is_encoder_decoder:
# if model is an encoder-decoder, retrieve encoder attention weights and hidden states
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
output_cls = TFBeamSampleEncoderDecoderOutput if do_sample else TFBeamSearchEncoderDecoderOutput
return output_cls(
sequences=sequences,
sequences_scores=scores,
scores=all_scores,
beam_indices=beam_indices,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
)
else:
output_cls = TFBeamSampleDecoderOnlyOutput if do_sample else TFBeamSearchDecoderOnlyOutput
return output_cls(
sequences=sequences,
sequences_scores=scores,
scores=all_scores,
beam_indices=beam_indices,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
)
else:
return sequences
def contrastive_search(
self,
input_ids: tf.Tensor,
top_k: Optional[int] = 1,
penalty_alpha: Optional[float] = 0,
logits_processor: Optional[TFLogitsProcessorList] = None,
logits_warper: Optional[TFLogitsProcessorList] = None,
max_length: Optional[int] = None,
pad_token_id: Optional[int] = None,
eos_token_id: Optional[int] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
output_scores: Optional[bool] = None,
return_dict_in_generate: Optional[bool] = None,
**model_kwargs,
) -> Union[TFContrastiveSearchOutput, tf.Tensor]:
r"""
Generates sequences of token ids for models with a language modeling head using **contrastive search** and can
be used for text-decoder, text-to-text, speech-to-text, and vision-to-text models.
Parameters:
input_ids (`tf.Tensor` of shape `(batch_size, sequence_length)`):
The sequence used as a prompt for the generation.
top_k (`int`, *optional*, defaults to 1):
The size of the candidate set that is used to re-rank for contrastive search
penalty_alpha (`float`, *optional*, defaults to 0):
The degeneration penalty for contrastive search; activate when it is larger than 0
logits_processor (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsProcessor`]
used to modify the prediction scores of the language modeling head applied at each generation step.
logits_warper (`TFLogitsProcessorList`, *optional*):
An instance of [`TFLogitsProcessorList`]. List of instances of class derived from [`TFLogitsWarper`]
used to warp the prediction score distribution of the language modeling head applied before multinomial
sampling at each generation step.
max_length (`int`, *optional*, defaults to 20):
The maximum length of the sequence to be generated.
pad_token_id (`int`, *optional*):
The id of the *padding* token.
eos_token_id (`Union[int, List[int]]`, *optional*):
The id of the *end-of-sequence* token. Optionally, use a list to set multiple *end-of-sequence* tokens.
output_attentions (`bool`, *optional*, defaults to `False`):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more details.
output_hidden_states (`bool`, *optional*, defaults to `False`):
Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors
for more details.
output_scores (`bool`, *optional*, defaults to `False`):
Whether or not to return the prediction scores. See `scores` under returned tensors for more details.
return_dict_in_generate (`bool`, *optional*, defaults to `False`):
Whether or not to return a [`~utils.ModelOutput`] instead of a plain tuple.
model_kwargs:
Additional model specific keyword arguments will be forwarded to the `call` function of the model. If
model is an encoder-decoder model the kwargs should include `encoder_outputs`.
Return:
[`~generation.TFContrastiveSearchDecoderOnlyOutput`],
[`~generation.TFContrastiveSearchEncoderDecoderOutput`] or `tf.Tensor`: A `tf.Tensor` containing the
generated tokens (default behaviour) or a [`~generation.TFContrastiveySearchDecoderOnlyOutput`] if
`model.config.is_encoder_decoder=False` and `return_dict_in_generate=True` or a
[`~generation.TFContrastiveSearchEncoderDecoderOutput`] if `model.config.is_encoder_decoder=True`.
Examples:
```python
>>> from transformers import AutoTokenizer, TFAutoModelForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("facebook/opt-125m")
>>> model = TFAutoModelForCausalLM.from_pretrained("facebook/opt-125m")
>>> # set pad_token_id to eos_token_id because OPT does not have a PAD token
>>> model.config.pad_token_id = model.config.eos_token_id
>>> input_prompt = "DeepMind Company is"
>>> input_ids = tokenizer(input_prompt, return_tensors="tf")
>>> outputs = model.contrastive_search(**input_ids, penalty_alpha=0.6, top_k=4, max_length=64)
>>> tokenizer.batch_decode(outputs, skip_special_tokens=True)
['DeepMind Company is a company that focuses on the development and commercialization of artificial intelligence (AI). DeepMind’s mission is to help people understand and solve problems that are difficult to solve in the world today.\n\nIn this post, we talk about the benefits of deep learning in business and how it']
```"""
def gather_best_candidate(nested, selected_idx_stacked, batch_axis=0):
"""Gathers the slices indexed by selected_idx_stacked from a potentially nested structure of tensors."""
def gather_fn(tensor):
gathered_tensor = tf.gather(params=tensor, indices=selected_idx_stacked, axis=batch_axis)
return gathered_tensor
return tf.nest.map_structure(gather_fn, nested)
# 1. init greedy_search values
logits_processor = logits_processor if logits_processor is not None else TFLogitsProcessorList()
logits_warper = logits_warper if logits_warper is not None else TFLogitsProcessorList()
max_length = max_length if max_length is not None else self.generation_config.max_length
pad_token_id = pad_token_id if pad_token_id is not None else self.generation_config.pad_token_id
eos_token_id = eos_token_id if eos_token_id is not None else self.generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
output_scores = output_scores if output_scores is not None else self.generation_config.output_scores
output_attentions = (
output_attentions if output_attentions is not None else self.generation_config.output_attentions
)
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.generation_config.output_hidden_states
)
return_dict_in_generate = (
return_dict_in_generate
if return_dict_in_generate is not None
else self.generation_config.return_dict_in_generate
)
use_cache = True # In contrastive search, we always use cache
model_kwargs.pop("use_cache", None)
use_xla = not tf.executing_eagerly()
# TODO (Joao): fix cache format or find programatic way to detect cache index
# GPT2 and other models has a slightly different cache structure, with a different batch axis
model_name = str(self.decoder) if "EncoderDecoder" in str(self) else str(self)
cache_batch_axis = 1 if any(model_prefix in model_name for model_prefix in ("TFGPT2", "TFCTRL")) else 0
# 2. init `attentions`, `hidden_states`, and `scores` tuples
scores = [] if (return_dict_in_generate and output_scores) else None
decoder_attentions = [] if (return_dict_in_generate and output_attentions) else None
cross_attentions = [] if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = [] if (return_dict_in_generate and output_hidden_states) else None
# 3. init tensors to use for "xla-compileable" generate function
batch_size, cur_len = shape_list(input_ids)
# initialize `generated` (`input_ids` padded with `pad_token_id`), `finished_sequences`
input_ids_padding = tf.ones((batch_size, max_length - cur_len), dtype=tf.int32) * (pad_token_id or 0)
generated = tf.concat([input_ids, input_ids_padding], axis=-1)
finished_sequences = tf.zeros((batch_size,), dtype=tf.bool)
# 4. define "xla-compile-able" stop-condition and auto-regressive function
# define condition fn
def contrastive_search_cond_fn(
generated, finished_sequences, cur_len, model_kwargs, next_step_cached_variables
):
"""state termination condition fn."""
return ~tf.reduce_all(finished_sequences)
# define condition fn
def contrastive_search_body_fn(
generated, finished_sequences, cur_len, model_kwargs, next_step_cached_variables
):
"""state update fn."""
# if the first step in the loop, encode all the prefix and obtain: (1) past_key_values;
# (2) last_hidden_states; (3) logit_for_next_step; (4) update model kwargs for the next step
if model_kwargs.get("past_key_values") is None:
# prepare inputs
model_inputs = self.prepare_inputs_for_generation(
generated[:, :cur_len], use_cache=use_cache, **model_kwargs
)
# encode the given prefix and prepare model inputs; encoder-decoder model process the prefix and save
# the `encoder_outputs`
outputs = self(
**model_inputs, return_dict=True, output_hidden_states=True, output_attentions=output_attentions
)
# last decoder hidden states will be used to compute the degeneration penalty (cosine similarity with
# previous tokens)
if self.config.is_encoder_decoder:
last_hidden_states = outputs.decoder_hidden_states[-1]
else:
last_hidden_states = outputs.hidden_states[-1]
# XLA: last_hidden_states normally grows at each step, but in XLA it is padded so as to be used across
# iterations (with fixed shapes)
if use_xla:
last_hidden_states = tf.pad(last_hidden_states, [[0, 0], [0, max_length - cur_len], [0, 0]])
# next logit for contrastive search to select top-k candidate tokens
logit_for_next_step = outputs.logits[:, -1, :]
if use_xla:
model_kwargs = self._update_model_kwargs_for_xla_generation(
model_outputs=outputs,
model_kwargs=model_kwargs,
cur_len=cur_len,
max_length=max_length,
batch_size=batch_size,
is_encoder_decoder=self.config.is_encoder_decoder,
batch_axis=cache_batch_axis,
)
else:
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
# Expands model inputs top_k times, for batched forward passes (akin to beam search).
_, model_kwargs = self._expand_inputs_for_generation(
expand_size=top_k, is_encoder_decoder=self.config.is_encoder_decoder, **model_kwargs
)
past_key_values = model_kwargs.get("past_key_values")
if past_key_values is None:
raise ValueError(
f"{self.__class__.__name__} does not support caching and therefore **can't** be used "
"for contrastive search."
)
elif (
not isinstance(past_key_values[0], (tuple, tf.Tensor))
or past_key_values[0][0].shape[0] != batch_size
):
raise ValueError(
f"{self.__class__.__name__} does not have a standard cache format and therefore **can't** be "
"used for contrastive search without further modifications."
)
else:
logit_for_next_step = next_step_cached_variables["logit_for_next_step"]
last_hidden_states = next_step_cached_variables["last_hidden_states"]
outputs = next_step_cached_variables["outputs"]
# contrastive_search main logic start:
# contrastive search decoding consists of two steps: (1) candidate tokens recall; (2) candidate re-rank by
# degeneration penalty
logit_for_next_step = logits_processor(generated, logit_for_next_step, cur_len)
logit_for_next_step = logits_warper(generated, logit_for_next_step, cur_len)
next_probs = stable_softmax(logit_for_next_step, axis=-1)
top_k_probs, top_k_ids = tf.math.top_k(next_probs, k=top_k)
# Store scores, attentions and hidden_states when required
if not use_xla and return_dict_in_generate:
if output_scores:
scores.append(logit_for_next_step)
if output_attentions and self.config.is_encoder_decoder:
decoder_attentions.append(outputs.decoder_attentions)
elif output_attentions and not self.config.is_encoder_decoder:
decoder_attentions.append(outputs.attentions)
if self.config.is_encoder_decoder:
cross_attentions.append(outputs.cross_attentions)
if output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(outputs.decoder_hidden_states)
elif output_hidden_states and self.config.is_encoder_decoder:
decoder_hidden_states.append(outputs.hidden_states)
# Replicates the new past_key_values to match the `top_k` candidates
model_kwargs["past_key_values"] = tf.nest.map_structure(
lambda tensor: tf.repeat(tensor, top_k, axis=cache_batch_axis), model_kwargs["past_key_values"]
)
# compute the candidate tokens by the language model and collects their hidden_states
next_model_inputs = self.prepare_inputs_for_generation(
tf.reshape(top_k_ids, [-1, 1]), use_cache=use_cache, **model_kwargs
)
outputs = self(
**next_model_inputs, return_dict=True, output_hidden_states=True, output_attentions=output_attentions
)
next_past_key_values = self._extract_past_from_model_output(outputs)
logits = outputs.logits[:, -1, :]
# name is different for encoder-decoder and decoder-only models
if self.config.is_encoder_decoder:
next_hidden = outputs.decoder_hidden_states[-1]
full_hidden_states = outputs.decoder_hidden_states
else:
next_hidden = outputs.hidden_states[-1]
full_hidden_states = outputs.hidden_states
context_hidden = tf.repeat(last_hidden_states[:, :cur_len, :], top_k, axis=0)
# compute the degeneration penalty and re-rank the candidates based on the degeneration penalty and the
# model confidence
selected_idx = _ranking_fast(context_hidden, next_hidden, top_k_probs, penalty_alpha, top_k)
# converts indices to a dimension of top_k to the stacked top_k * batch_size dimension, for indexing
# without a need to reshape on tensors that have these two dimensions stacked
selected_idx_stacked = selected_idx + tf.range(selected_idx.shape[0], dtype=tf.int64) * top_k
# prepare for the next step: (1) next token_id; (2) past_key_values; (3) last_hidden_states for computing
# the degeneration penalty; (4) logits for selecting next top-k candidates; (5) selected tokens scores
# (model confidence minus degeneration penalty); (6) decoder hidden_states
next_tokens = tf.gather(top_k_ids, selected_idx, axis=1, batch_dims=1)
next_hidden = gather_best_candidate(next_hidden, selected_idx_stacked)
# XLA: last_hidden_states normally grows at each step, but in XLA it is padded so as to be used across
# iterations (with fixed shapes)
if use_xla:
last_hidden_states = dynamic_update_slice(last_hidden_states, next_hidden, [0, cur_len, 0])
else:
last_hidden_states = tf.concat([last_hidden_states, next_hidden], axis=1)
next_decoder_hidden_states = gather_best_candidate(full_hidden_states, selected_idx_stacked)
next_past_key_values = gather_best_candidate(
next_past_key_values, selected_idx_stacked, batch_axis=cache_batch_axis
)
logit_for_next_step = gather_best_candidate(logits, selected_idx_stacked)
# Rebuilds the relevant parts of the model output for the selected token, for use in the next iteration
if self.config.is_encoder_decoder:
next_step_cross_attentions = ()
next_step_decoder_attentions = ()
if output_attentions:
next_step_cross_attentions = gather_best_candidate(outputs.cross_attentions, selected_idx_stacked)
next_step_decoder_attentions = gather_best_candidate(
outputs.decoder_attentions, selected_idx_stacked
)
outputs = TFSeq2SeqLMOutput(
past_key_values=next_past_key_values,
decoder_hidden_states=next_decoder_hidden_states,
decoder_attentions=next_step_decoder_attentions or None,
cross_attentions=next_step_cross_attentions or None,
)
else:
next_step_attentions = ()
if output_attentions:
next_step_attentions = gather_best_candidate(outputs.attentions, selected_idx_stacked)
outputs = TFCausalLMOutputWithPast(
past_key_values=next_past_key_values,
hidden_states=next_decoder_hidden_states,
attentions=next_step_attentions or None,
)
# contrastive_search main logic end
if eos_token_id is not None:
if pad_token_id is None:
raise ValueError("If `eos_token_id` is defined, make sure that `pad_token_id` is defined.")
unfinished_seq = 1 - tf.cast(finished_sequences, tf.int32)
next_tokens = next_tokens * unfinished_seq + pad_token_id * (1 - unfinished_seq)
next_token_is_eos = tf.math.reduce_any(
tf.equal(
tf.broadcast_to(next_tokens, (len(eos_token_id), batch_size)), tf.expand_dims(eos_token_id, -1)
),
axis=0,
)
finished_sequences = finished_sequences | next_token_is_eos
# update `generated` and `cur_len`
update_indices = tf.stack([tf.range(batch_size), tf.broadcast_to(cur_len, [batch_size])], axis=-1)
generated = tf.tensor_scatter_nd_update(tensor=generated, indices=update_indices, updates=next_tokens)
cur_len += 1
if use_xla:
# NOTE: 1) relative to other generation strategies, contrastive search is always running forward
# passes one step ahead -- hence the `cur_len=cur_len + 1`; 2) the attention mask here is expanded from
# [batch_size, ...] to [batch_size*top_k, ...] -- hence the `batch_size=batch_size * top_k`
model_kwargs = self._update_model_kwargs_for_xla_generation(
model_outputs=outputs,
model_kwargs=model_kwargs,
cur_len=cur_len + 1,
max_length=max_length,
batch_size=batch_size * top_k,
is_encoder_decoder=self.config.is_encoder_decoder,
batch_axis=cache_batch_axis,
)
else:
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
next_step_cached_variables = {
"logit_for_next_step": logit_for_next_step,
"last_hidden_states": last_hidden_states,
"outputs": outputs,
}
return generated, finished_sequences, cur_len, model_kwargs, next_step_cached_variables
# 5. run generation
# 1st generation step has to be run before to initialize `past_key_values`
generated, finished_sequences, cur_len, model_kwargs, next_step_cached_variables = contrastive_search_body_fn(
generated, finished_sequences, cur_len, model_kwargs, None
)
# 2-to-n generation steps can then be run in autoregressive fashion
# only in case 1st generation step does NOT yield EOS token though
maximum_iterations = max_length - cur_len
generated, _, cur_len, _, _ = tf.while_loop(
contrastive_search_cond_fn,
contrastive_search_body_fn,
(generated, finished_sequences, cur_len, model_kwargs, next_step_cached_variables),
maximum_iterations=maximum_iterations,
)
# 6. prepare outputs
if not use_xla:
# cut for backward compatibility
generated = generated[:, :cur_len]
if return_dict_in_generate:
if self.config.is_encoder_decoder:
# if model is an encoder-decoder, retrieve encoder attention weights
# and hidden states
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
scores = tuple(scores) if scores is not None else None
decoder_attentions = tuple(decoder_attentions) if decoder_attentions is not None else None
cross_attentions = tuple(cross_attentions) if cross_attentions is not None else None
decoder_hidden_states = tuple(decoder_hidden_states) if decoder_hidden_states is not None else None
return TFContrastiveSearchEncoderDecoderOutput(
sequences=generated,
scores=scores,
encoder_attentions=encoder_attentions,
encoder_hidden_states=encoder_hidden_states,
decoder_attentions=decoder_attentions,
cross_attentions=cross_attentions,
decoder_hidden_states=decoder_hidden_states,
)
else:
return TFContrastiveSearchDecoderOnlyOutput(
sequences=generated,
scores=scores,
attentions=decoder_attentions,
hidden_states=decoder_hidden_states,
)
else:
return generated
def scatter_values_on_batch_indices(values, batch_indices):
shape = shape_list(batch_indices)
# broadcast batch dim to shape
broad_casted_batch_dims = tf.reshape(tf.broadcast_to(tf.expand_dims(tf.range(shape[0]), axis=-1), shape), [1, -1])
# transform batch_indices to pair_indices
pair_indices = tf.transpose(tf.concat([broad_casted_batch_dims, tf.reshape(batch_indices, [1, -1])], 0))
# scatter values to pair indices
return tf.scatter_nd(pair_indices, tf.reshape(values, [-1]), shape)
def sample_without_replacement(logits, num_samples):
"""
categorical sampling without replacement is currently not implemented the gumbel-max trick will do for now see
https://github.com/tensorflow/tensorflow/issues/9260 for more info
"""
z = -tf.math.log(-tf.math.log(tf.random.uniform(shape_list(logits), 0, 1)))
_, indices = tf.nn.top_k(logits + z, num_samples)
return indices
def _ranking_fast(
context_hidden: tf.Tensor,
next_hidden: tf.Tensor,
next_top_k_probs: tf.Tensor,
alpha: float,
beam_width: int,
) -> tf.Tensor:
"""
Reranks the top_k candidates based on a degeneration penalty (cosine similarity with previous tokens), as described
in the paper "A Contrastive Framework for Neural Text Generation". Returns the index of the best candidate for each
row in the batch.
"""
norm_context_hidden = context_hidden / tf.norm(context_hidden, axis=2, keepdims=True)
norm_next_hidden = next_hidden / tf.norm(next_hidden, axis=2, keepdims=True)
cosine_matrix = tf.squeeze(tf.linalg.matmul(norm_context_hidden, norm_next_hidden, transpose_b=True), axis=-1)
degeneration_penalty = tf.reduce_max(cosine_matrix, axis=-1)
next_top_k_probs = tf.reshape(next_top_k_probs, shape=[-1])
contrastive_score = (1.0 - alpha) * next_top_k_probs - alpha * degeneration_penalty
contrastive_score = tf.reshape(contrastive_score, shape=[-1, beam_width])
selected_idx = tf.argmax(contrastive_score, axis=1)
return selected_idx
|
transformers/src/transformers/generation/tf_utils.py/0
|
{
"file_path": "transformers/src/transformers/generation/tf_utils.py",
"repo_id": "transformers",
"token_count": 76456
}
|
# coding=utf-8
# Copyright 2024 NetEase, Inc. and the HuggingFace Inc. team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from ..utils import is_accelerate_available, is_eetq_available, logging
if is_eetq_available():
import eetq
import torch.nn as nn
if is_accelerate_available():
from accelerate import init_empty_weights
logger = logging.get_logger(__name__)
def _replace_with_eetq_linear(
model,
modules_to_not_convert=None,
current_key_name=None,
quantization_config=None,
has_been_replaced=False,
pre_quantized=False,
):
"""
Private method that wraps the recursion for module replacement.
Returns the converted model and a boolean that indicates if the conversion has been successfull or not.
"""
if current_key_name is None:
current_key_name = []
for name, module in model.named_children():
current_key_name.append(name)
if (isinstance(module, nn.Linear)) and name not in modules_to_not_convert:
# Check if the current key is not in the `modules_to_not_convert`
current_key_name_str = ".".join(current_key_name)
if not any(
(key + "." in current_key_name_str) or (key == current_key_name_str) for key in modules_to_not_convert
):
with init_empty_weights():
in_features = module.in_features
out_features = module.out_features
model._modules[name] = eetq.EetqLinear(
in_features, out_features, module.bias is not None, module.weight.device
)
if pre_quantized:
model._modules[name].register_scale(module.weight.device)
has_been_replaced = True
# Force requires grad to False to avoid unexpected errors
model._modules[name].requires_grad_(False)
if len(list(module.children())) > 0:
_, has_been_replaced = _replace_with_eetq_linear(
module,
modules_to_not_convert,
current_key_name,
quantization_config,
has_been_replaced=has_been_replaced,
pre_quantized=pre_quantized,
)
# Remove the last key for recursion
current_key_name.pop(-1)
return model, has_been_replaced
def replace_with_eetq_linear(
model, modules_to_not_convert=None, current_key_name=None, quantization_config=None, pre_quantized=False
):
"""
A helper function to replace all `torch.nn.Linear` modules by `eetq.EetqLinear` modules from the `eetq`
library. This will enable running your models using high performance int8 weight-only gemm kerner from
FasterTransformer and TensorRT-LLM. Make sure `eetq` compiled with the correct CUDA
version of your hardware is installed before running this function. EETQ shall be installed via the source
'https://github.com/NetEase-FuXi/EETQ'
The function will be run recursively and replace all `torch.nn.Linear` modules except for the `lm_head` that should
be kept as a `torch.nn.Linear` module. The replacement is done under `init_empty_weights` context manager so no
CPU/GPU memory is required to run this function. Each weight will be quantized along the channel.
Parameters:
model (`torch.nn.Module`):
Input model or `torch.nn.Module` as the function is run recursively.
modules_to_not_convert (`List[`str`]`, *optional*, defaults to `["lm_head"]`):
Names of the modules to not convert in `EetqLinear`. In practice we keep the `lm_head` in full precision
for numerical stability reasons.
current_key_name (`List[`str`]`, *optional*):
An array to track the current key of the recursion. This is used to check whether the current key (part of
it) is not in the list of modules to not convert (for instances modules that are offloaded to `cpu` or
`disk`).
"""
modules_to_not_convert = ["lm_head"] if modules_to_not_convert is None else modules_to_not_convert
if quantization_config.modules_to_not_convert is not None:
modules_to_not_convert.extend(quantization_config.modules_to_not_convert)
modules_to_not_convert = list(set(modules_to_not_convert))
model, has_been_replaced = _replace_with_eetq_linear(
model, modules_to_not_convert, current_key_name, quantization_config, pre_quantized=pre_quantized
)
if not has_been_replaced:
logger.warning(
"You are loading your model using eetq but no linear modules were found in your model."
" Please double check your model architecture, or submit an issue on github if you think this is"
" a bug."
)
return model
|
transformers/src/transformers/integrations/eetq.py/0
|
{
"file_path": "transformers/src/transformers/integrations/eetq.py",
"repo_id": "transformers",
"token_count": 2106
}
|
# Copyright 2024 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"VPTQ (Vector Post-Training Quantization) integration file"
import torch.nn as nn
from accelerate import init_empty_weights
from vptq import VQuantLinear
def replace_with_vptq_linear(
model,
quantization_config=None,
modules_to_not_convert=None,
current_key_name=None,
has_been_replaced=False,
):
"""
Public method that recursively replaces the Linear layers of the given model with VPTQ quantized layers.
`accelerate` is needed to use this method. Returns the converted model and a boolean that indicates if the
conversion has been successfull or not.
Args:
model (`torch.nn.Module`):
The model to convert, can be any `torch.nn.Module` instance.
quantization_config (`VptqConfig`):
The quantization config object that contains the quantization parameters.
modules_to_not_convert (`List[`str`]`, *optional*, defaults to `["lm_head"]`):
Names of the modules to not convert in `VQuantLinear`. In practice we keep the `lm_head` in full precision
for numerical stability reasons.
current_key_name (`list`, *optional*):
A list that contains the current key name. This is used for recursion and should not be passed by the user.
has_been_replaced (`bool`, *optional*):
A boolean that indicates if the conversion has been successful or not. This is used for recursion and
should not be passed by the user.
"""
modules_to_not_convert = ["lm_head"] if not modules_to_not_convert else modules_to_not_convert
for name, module in model.named_children():
if current_key_name is None:
current_key_name = []
current_key_name.append(name)
layer_name = ".".join(current_key_name)
shared_layer_config = quantization_config.shared_layer_config
config_for_layers = quantization_config.config_for_layers
if (
isinstance(module, nn.Linear)
and layer_name not in modules_to_not_convert
and ((layer_name in config_for_layers) or (current_key_name[-1] in shared_layer_config))
):
layer_params = config_for_layers.get(layer_name, None) or shared_layer_config.get(
current_key_name[-1], None
)
with init_empty_weights():
in_features = module.in_features
out_features = module.out_features
model._modules[name] = VQuantLinear(
in_features,
out_features,
vector_lens=layer_params["vector_lens"],
num_centroids=layer_params["num_centroids"],
num_res_centroids=layer_params["num_res_centroids"],
group_num=layer_params["group_num"],
group_size=layer_params["group_size"],
outlier_size=layer_params["outlier_size"],
indices_as_float=layer_params["indices_as_float"],
enable_norm=layer_params["enable_norm"],
enable_perm=layer_params["enable_perm"],
is_indice_packed=True,
enable_proxy_error=False,
bias=module.bias is not None,
)
has_been_replaced = True
# Force requires grad to False to avoid unexpected errors
model._modules[name].requires_grad_(False)
if len(list(module.children())) > 0:
_, has_been_replaced = replace_with_vptq_linear(
module,
quantization_config=quantization_config,
modules_to_not_convert=modules_to_not_convert,
current_key_name=current_key_name,
has_been_replaced=has_been_replaced,
)
# Remove the last key for recursion
current_key_name.pop(-1)
return model, has_been_replaced
|
transformers/src/transformers/integrations/vptq.py/0
|
{
"file_path": "transformers/src/transformers/integrations/vptq.py",
"repo_id": "transformers",
"token_count": 1928
}
|
// File from https://github.com/mlpen/YOSO/blob/main/encoders/backbones/efficient_attentions/yoso/yoso_v1/cuda/fast_lsh_cumulation.cu
#include <torch/extension.h>
#include <ATen/ATen.h>
#include "fast_lsh_cumulation.h"
#include "fast_lsh_cumulation_cuda.h"
#include "common_cuda.h"
#include "common.h"
#include <vector>
//////////////////////////////////////////////////////////////////////////////////////////////////
//////////////////////////////////////////////////////////////////////////////////////////////////
std::vector<at::Tensor> fast_hash_ver1_kernel(
at::Tensor query_mask,
at::Tensor query_vector,
at::Tensor key_mask,
at::Tensor key_vector,
int num_hash_f,
int hash_code_len,
bool use_cuda
) {
int batch_size = query_vector.size(0);
int num_query = query_vector.size(1);
int num_key = key_vector.size(1);
int vector_dim = query_vector.size(2);
int num_hash_per_part = vector_dim / hash_code_len;
int num_part = max(1, ceil_divide(num_hash_f, num_hash_per_part));
at::Tensor Dmat = 2 * at::randint(0, 2, {batch_size, 3, num_part, vector_dim}, query_mask.options()) - 1;
at::Tensor query_hash_code = at::zeros({batch_size, num_query, num_hash_f}, query_mask.options());
at::Tensor key_hash_code = at::zeros({batch_size, num_key, num_hash_f}, key_mask.options());
int *query_mask_ptr = query_mask.data_ptr<int>();
float *query_vector_ptr = query_vector.data_ptr<float>();
int *key_mask_ptr = key_mask.data_ptr<int>();
float *key_vector_ptr = key_vector.data_ptr<float>();
int *Dmat_ptr = Dmat.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
if (use_cuda) {
{
dim3 threads(vector_dim);
dim3 blocks(num_part, num_query, batch_size);
int shared_mem = vector_dim * sizeof(float);
fast_hash_ver1_cuda_kernel<<<blocks, threads, shared_mem>>>(
query_mask_ptr,
query_vector_ptr,
Dmat_ptr,
query_hash_code_ptr,
batch_size,
num_query,
vector_dim,
num_part,
num_hash_f,
hash_code_len
);
}
{
dim3 threads(vector_dim);
dim3 blocks(num_part, num_key, batch_size);
int shared_mem = vector_dim * sizeof(float);
fast_hash_ver1_cuda_kernel<<<blocks, threads, shared_mem>>>(
key_mask_ptr,
key_vector_ptr,
Dmat_ptr,
key_hash_code_ptr,
batch_size,
num_key,
vector_dim,
num_part,
num_hash_f,
hash_code_len
);
}
}
return {query_hash_code, key_hash_code};
}
at::Tensor lsh_cumulation_ver1_kernel(
at::Tensor query_mask,
at::Tensor query_hash_code,
at::Tensor key_mask,
at::Tensor key_hash_code,
at::Tensor value,
int hashtable_capacity,
bool use_cuda
) {
int batch_size = query_hash_code.size(0);
int num_hash_f = query_hash_code.size(2);
int num_query = query_hash_code.size(1);
int num_key = key_hash_code.size(1);
int value_dim = value.size(2);
at::Tensor hashtable_value = at::empty({batch_size, num_hash_f, hashtable_capacity, WARP_SIZE}, value.options());
at::Tensor cumulation_value = at::zeros({batch_size, num_query, value_dim}, value.options());
if (use_cuda) {
int threads_x = WARP_SIZE;
int threads_y = OPTIMAL_THREADS_PER_BLOCK / WARP_SIZE;
int block_x_step1 = num_key / threads_y;
int block_x_step2 = num_query / threads_y;
int block_y = batch_size;
dim3 threads(threads_x, threads_y);
dim3 blocks_step1(block_x_step1, block_y);
dim3 blocks_step2(block_x_step2, block_y);
int *query_mask_ptr = query_mask.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
int *key_mask_ptr = key_mask.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
float *value_ptr = value.data_ptr<float>();
float *hashtable_value_ptr = hashtable_value.data_ptr<float>();
float *cumulation_value_ptr = cumulation_value.data_ptr<float>();
for (int value_offset = 0; value_offset < value_dim; value_offset = value_offset + WARP_SIZE) {
cudaMemset(hashtable_value_ptr, 0, (batch_size * num_hash_f * hashtable_capacity * WARP_SIZE) * sizeof(float));
lsh_cumulation_ver1_step1_cuda_kernel<<<blocks_step1, threads>>>(
key_mask_ptr,
key_hash_code_ptr,
value_ptr,
hashtable_value_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key,
value_dim,
value_offset
);
lsh_cumulation_ver1_step2_cuda_kernel<<<blocks_step2, threads>>>(
query_mask_ptr,
query_hash_code_ptr,
hashtable_value_ptr,
cumulation_value_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query,
value_dim,
value_offset
);
}
}
return cumulation_value;
}
at::Tensor lsh_weighted_cumulation_ver1_kernel(
at::Tensor query_mask,
at::Tensor query_hash_code,
at::Tensor query_weight,
at::Tensor key_mask,
at::Tensor key_hash_code,
at::Tensor key_weight,
at::Tensor value,
int hashtable_capacity,
bool use_cuda
) {
int batch_size = query_hash_code.size(0);
int num_hash_f = query_hash_code.size(2);
int num_query = query_hash_code.size(1);
int num_key = key_hash_code.size(1);
int value_dim = value.size(2);
int weight_dim = query_weight.size(2);
at::Tensor hashtable_value = at::zeros({batch_size, num_hash_f, hashtable_capacity, WARP_SIZE}, value.options());
at::Tensor cumulation_value = at::zeros({batch_size, num_query, value_dim}, value.options());
if (use_cuda) {
int threads_x = WARP_SIZE;
int threads_y = OPTIMAL_THREADS_PER_BLOCK / WARP_SIZE;
int block_x_step1 = num_key / threads_y;
int block_x_step2 = num_query / threads_y;
int block_y = batch_size;
dim3 threads(threads_x, threads_y);
dim3 blocks_step1(block_x_step1, block_y);
dim3 blocks_step2(block_x_step2, block_y);
int *query_mask_ptr = query_mask.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
float *query_weight_ptr = query_weight.data_ptr<float>();
int *key_mask_ptr = key_mask.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
float *key_weight_ptr = key_weight.data_ptr<float>();
float *value_ptr = value.data_ptr<float>();
float *hashtable_value_ptr = hashtable_value.data_ptr<float>();
float *cumulation_value_ptr = cumulation_value.data_ptr<float>();
for (int value_offset = 0; value_offset < value_dim; value_offset = value_offset + WARP_SIZE) {
for (int weight_idx = 0; weight_idx < weight_dim; weight_idx++) {
cudaMemset(hashtable_value_ptr, 0, (batch_size * num_hash_f * hashtable_capacity * WARP_SIZE) * sizeof(float));
lsh_weighted_cumulation_ver1_step1_cuda_kernel<<<blocks_step1, threads>>>(
key_mask_ptr,
key_hash_code_ptr,
key_weight_ptr,
value_ptr,
hashtable_value_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key,
value_dim,
weight_dim,
value_offset,
weight_idx
);
lsh_weighted_cumulation_ver1_step2_cuda_kernel<<<blocks_step2, threads>>>(
query_mask_ptr,
query_hash_code_ptr,
query_weight_ptr,
hashtable_value_ptr,
cumulation_value_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query,
value_dim,
weight_dim,
value_offset,
weight_idx
);
}
}
}
return cumulation_value;
}
at::Tensor lsh_weighted_cumulation_ver2_kernel(
at::Tensor query_mask,
at::Tensor query_hash_code,
at::Tensor query_weight,
at::Tensor key_mask,
at::Tensor key_hash_code,
at::Tensor key_weight,
at::Tensor value,
int hashtable_capacity,
bool use_cuda
) {
int batch_size = query_hash_code.size(0);
int num_hash_f = query_hash_code.size(2);
int num_query = query_hash_code.size(1);
int num_key = key_hash_code.size(1);
int value_dim = value.size(2);
int weight_dim = query_weight.size(2);
at::Tensor count_sort_table = at::zeros({batch_size, num_hash_f, hashtable_capacity}, query_hash_code.options());
at::Tensor key_sorted_idxes = at::zeros({batch_size, num_hash_f, num_key}, query_hash_code.options());
at::Tensor query_info = at::zeros({batch_size, num_query, 2, num_hash_f}, query_hash_code.options());
at::Tensor cumulation_value = at::zeros({batch_size, num_query, value_dim}, value.options());
if (use_cuda) {
int *query_mask_ptr = query_mask.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
float *query_weight_ptr = query_weight.data_ptr<float>();
int *key_mask_ptr = key_mask.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
float *key_weight_ptr = key_weight.data_ptr<float>();
float *value_ptr = value.data_ptr<float>();
int *count_sort_table_ptr = count_sort_table.data_ptr<int>();
int *key_sorted_idxes_ptr = key_sorted_idxes.data_ptr<int>();
int *query_info_ptr = query_info.data_ptr<int>();
float *cumulation_value_ptr = cumulation_value.data_ptr<float>();
{
dim3 threads_step13(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks_step13(num_key / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
dim3 threads_step2(min(hashtable_capacity, OPTIMAL_THREADS_PER_BLOCK));
dim3 blocks_step2(num_hash_f, batch_size);
int shared_mem = hashtable_capacity * sizeof(float);
count_sort_step1_cuda_kernel<<<blocks_step13, threads_step13>>>(
key_mask_ptr,
key_hash_code_ptr,
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key
);
count_sort_step2_cuda_kernel<<<blocks_step2, threads_step2, shared_mem>>>(
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity
);
count_sort_step3_cuda_kernel<<<blocks_step13, threads_step13>>>(
key_mask_ptr,
key_hash_code_ptr,
count_sort_table_ptr,
key_sorted_idxes_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key
);
}
{
dim3 threads(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks(num_query / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
extract_query_info_cuda_kernel<<<blocks, threads>>>(
query_mask_ptr,
query_hash_code_ptr,
count_sort_table_ptr,
query_info_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query
);
}
{
dim3 threads(WARP_SIZE, OPTIMAL_THREADS_PER_BLOCK / WARP_SIZE);
dim3 blocks(num_query, num_hash_f, batch_size);
int shared_mem = (weight_dim + WARP_SIZE) * sizeof(float);
lsh_weighted_cumulation_ver2_step2_cuda_kernel<<<blocks, threads, shared_mem>>>(
query_mask_ptr,
query_info_ptr,
key_sorted_idxes_ptr,
query_weight_ptr,
key_weight_ptr,
value_ptr,
cumulation_value_ptr,
batch_size,
num_hash_f,
num_query,
num_key,
value_dim,
weight_dim
);
}
}
return cumulation_value;
}
at::Tensor lsh_weighted_cumulation_ver3_kernel(
at::Tensor query_mask,
at::Tensor query_hash_code,
at::Tensor query_weight,
at::Tensor key_mask,
at::Tensor key_hash_code,
at::Tensor key_weight,
at::Tensor value,
int hashtable_capacity,
bool use_cuda
) {
int batch_size = query_hash_code.size(0);
int num_hash_f = query_hash_code.size(2);
int num_query = query_hash_code.size(1);
int num_key = key_hash_code.size(1);
int value_dim = value.size(2);
int weight_dim = query_weight.size(2);
at::Tensor count_sort_table = at::zeros({batch_size, num_hash_f, hashtable_capacity}, query_hash_code.options());
at::Tensor query_sorted_idxes = at::zeros({batch_size, num_hash_f, num_query}, query_hash_code.options());
at::Tensor key_info = at::zeros({batch_size, num_key, 2, num_hash_f}, query_hash_code.options());
at::Tensor cumulation_value = at::zeros({batch_size, num_query, value_dim}, value.options());
if (use_cuda) {
int *query_mask_ptr = query_mask.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
float *query_weight_ptr = query_weight.data_ptr<float>();
int *key_mask_ptr = key_mask.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
float *key_weight_ptr = key_weight.data_ptr<float>();
float *value_ptr = value.data_ptr<float>();
int *count_sort_table_ptr = count_sort_table.data_ptr<int>();
int *query_sorted_idxes_ptr = query_sorted_idxes.data_ptr<int>();
int *key_info_ptr = key_info.data_ptr<int>();
float *cumulation_value_ptr = cumulation_value.data_ptr<float>();
{
dim3 threads_step13(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks_step13(num_query / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
dim3 threads_step2(min(hashtable_capacity, OPTIMAL_THREADS_PER_BLOCK));
dim3 blocks_step2(num_hash_f, batch_size);
int shared_mem = hashtable_capacity * sizeof(float);
count_sort_step1_cuda_kernel<<<blocks_step13, threads_step13>>>(
query_mask_ptr,
query_hash_code_ptr,
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query
);
count_sort_step2_cuda_kernel<<<blocks_step2, threads_step2, shared_mem>>>(
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity
);
count_sort_step3_cuda_kernel<<<blocks_step13, threads_step13>>>(
query_mask_ptr,
query_hash_code_ptr,
count_sort_table_ptr,
query_sorted_idxes_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query
);
}
{
dim3 threads(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks(num_key / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
extract_query_info_cuda_kernel<<<blocks, threads>>>(
key_mask_ptr,
key_hash_code_ptr,
count_sort_table_ptr,
key_info_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key
);
}
{
dim3 threads(WARP_SIZE, OPTIMAL_THREADS_PER_BLOCK / WARP_SIZE);
dim3 blocks(num_key, num_hash_f, batch_size);
int shared_mem = (weight_dim + value_dim + WARP_SIZE) * sizeof(float);
lsh_weighted_cumulation_ver3_step2_cuda_kernel<<<blocks, threads, shared_mem>>>(
query_sorted_idxes_ptr,
key_mask_ptr,
key_info_ptr,
query_weight_ptr,
key_weight_ptr,
value_ptr,
cumulation_value_ptr,
batch_size,
num_hash_f,
num_query,
num_key,
value_dim,
weight_dim
);
}
}
return cumulation_value;
}
at::Tensor lsh_weighted_cumulation_ver4_kernel(
at::Tensor query_mask,
at::Tensor query_hash_code,
at::Tensor query_weight,
at::Tensor key_mask,
at::Tensor key_hash_code,
at::Tensor key_weight,
at::Tensor value,
int hashtable_capacity,
bool use_cuda
) {
int batch_size = query_hash_code.size(0);
int num_hash_f = query_hash_code.size(2);
int num_query = query_hash_code.size(1);
int num_key = key_hash_code.size(1);
int value_dim = value.size(2);
int weight_dim = query_weight.size(2);
at::Tensor count_sort_table = at::zeros({batch_size, num_hash_f, hashtable_capacity}, query_hash_code.options());
at::Tensor query_sorted_idxes = at::zeros({batch_size, num_hash_f, num_query}, query_hash_code.options());
at::Tensor key_info = at::zeros({batch_size, num_key, 2, num_hash_f}, query_hash_code.options());
at::Tensor cumulation_value = at::zeros({batch_size, num_query, value_dim}, value.options());
if (use_cuda) {
int *query_mask_ptr = query_mask.data_ptr<int>();
int *query_hash_code_ptr = query_hash_code.data_ptr<int>();
float *query_weight_ptr = query_weight.data_ptr<float>();
int *key_mask_ptr = key_mask.data_ptr<int>();
int *key_hash_code_ptr = key_hash_code.data_ptr<int>();
float *key_weight_ptr = key_weight.data_ptr<float>();
float *value_ptr = value.data_ptr<float>();
int *count_sort_table_ptr = count_sort_table.data_ptr<int>();
int *query_sorted_idxes_ptr = query_sorted_idxes.data_ptr<int>();
int *key_info_ptr = key_info.data_ptr<int>();
float *cumulation_value_ptr = cumulation_value.data_ptr<float>();
{
dim3 threads_step13(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks_step13(num_query / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
dim3 threads_step2(min(hashtable_capacity, OPTIMAL_THREADS_PER_BLOCK));
dim3 blocks_step2(num_hash_f, batch_size);
int shared_mem = hashtable_capacity * sizeof(float);
count_sort_step1_cuda_kernel<<<blocks_step13, threads_step13>>>(
query_mask_ptr,
query_hash_code_ptr,
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query
);
count_sort_step2_cuda_kernel<<<blocks_step2, threads_step2, shared_mem>>>(
count_sort_table_ptr,
batch_size,
num_hash_f,
hashtable_capacity
);
count_sort_step3_cuda_kernel<<<blocks_step13, threads_step13>>>(
query_mask_ptr,
query_hash_code_ptr,
count_sort_table_ptr,
query_sorted_idxes_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_query
);
}
{
dim3 threads(num_hash_f, max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f));
dim3 blocks(num_key / max(1, OPTIMAL_THREADS_PER_BLOCK / num_hash_f), batch_size);
extract_query_info_cuda_kernel<<<blocks, threads>>>(
key_mask_ptr,
key_hash_code_ptr,
count_sort_table_ptr,
key_info_ptr,
batch_size,
num_hash_f,
hashtable_capacity,
num_key
);
}
{
dim3 threads(WARP_SIZE, OPTIMAL_THREADS_PER_BLOCK / WARP_SIZE);
dim3 blocks(num_key, batch_size);
int shared_mem = (weight_dim + value_dim + 2 * num_hash_f) * sizeof(float);
lsh_weighted_cumulation_ver4_step2_cuda_kernel<<<blocks, threads, shared_mem>>>(
query_sorted_idxes_ptr,
key_mask_ptr,
key_info_ptr,
query_weight_ptr,
key_weight_ptr,
value_ptr,
cumulation_value_ptr,
batch_size,
num_hash_f,
num_query,
num_key,
value_dim,
weight_dim
);
}
}
return cumulation_value;
}
|
transformers/src/transformers/kernels/yoso/fast_lsh_cumulation.cu/0
|
{
"file_path": "transformers/src/transformers/kernels/yoso/fast_lsh_cumulation.cu",
"repo_id": "transformers",
"token_count": 8662
}
|
# coding=utf-8
# Copyright 2024 The ggml.ai team and The HuggingFace Inc. team. and pygguf author (github.com/99991)
# https://github.com/99991/pygguf
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import re
from typing import Dict, NamedTuple, Optional
import numpy as np
from tqdm import tqdm
from .integrations import (
GGUF_CONFIG_MAPPING,
GGUF_TOKENIZER_MAPPING,
_gguf_parse_value,
)
from .utils import is_torch_available
from .utils.import_utils import is_gguf_available
from .utils.logging import get_logger
if is_torch_available():
import torch
logger = get_logger(__name__)
GGUF_TO_TRANSFORMERS_MAPPING = {
"ignore": {
"GGUF": {
"version": "version",
"tensor_count": "tensor_count",
"kv_count": "kv_count",
},
"general": {"file_type": "file_type", "quantization_version": "quantization_version"},
},
"config": GGUF_CONFIG_MAPPING,
"tokenizer": {"tokenizer": GGUF_TOKENIZER_MAPPING["tokenizer"]},
"tokenizer_config": {"tokenizer": GGUF_TOKENIZER_MAPPING["tokenizer_config"]},
}
GGUF_SUPPORTED_ARCHITECTURES = list(GGUF_TO_TRANSFORMERS_MAPPING["config"].keys())
class GGUFTensor(NamedTuple):
weights: np.ndarray
name: str
metadata: dict
class TensorProcessor:
def __init__(self, config=None):
self.config = config or {}
def process(self, weights, name, **kwargs):
return GGUFTensor(weights, name, {})
class LlamaTensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
if ".attn_k." in name or ".attn_q." in name:
num_heads = self.config.get("num_attention_heads")
num_kv_heads = self.config.get("num_key_value_heads")
if None in (num_heads, num_kv_heads):
return GGUFTensor(weights, name, {})
if ".attn_q." in name:
weights = self._reverse_permute_weights(weights, num_heads, num_heads)
elif ".attn_k." in name:
weights = self._reverse_permute_weights(weights, num_heads, num_kv_heads)
return GGUFTensor(weights, name, {})
def _reverse_permute_weights(
self, weights: np.ndarray, n_head: int, num_kv_heads: Optional[int] = None
) -> np.ndarray:
# Original permutation implementation
# https://github.com/ggerganov/llama.cpp/blob/a38b884c6c4b0c256583acfaaabdf556c62fabea/convert_hf_to_gguf.py#L1402-L1408
if num_kv_heads is not None and n_head != num_kv_heads:
n_head = num_kv_heads
dim = weights.shape[0] // n_head // 2
w = weights.reshape(n_head, dim, 2, *weights.shape[1:])
return w.swapaxes(2, 1).reshape(weights.shape)
class Qwen2MoeTensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
if "_exp" in name:
tensor_key_mapping = kwargs.get("tensor_key_mapping")
parsed_parameters = kwargs.get("parsed_parameters")
if tensor_key_mapping:
self._split_moe_expert_tensor(weights, parsed_parameters, name, tensor_key_mapping)
return GGUFTensor(weights, None, {})
if "ffn_gate_inp_shexp" in name:
# for compatibility tensor shared_expert_gate must be (1, 2048) dim,
# quantized one is (2048)
weights = np.expand_dims(weights, axis=0)
return GGUFTensor(weights, name, {})
def _split_moe_expert_tensor(
self, weights: np.ndarray, parsed_parameters: Dict[str, Dict], name: str, tensor_key_mapping: dict
):
# Original merge implementation
# https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L1994-L2022
name = tensor_key_mapping[name]
w_counter = self.config.get("num_experts", 60)
for i in range(0, w_counter):
temp_name = name.replace("mlp.experts.", f"mlp.experts.{i}.")
exp_weight = weights[i]
parsed_parameters["tensors"][temp_name] = torch.from_numpy(np.copy(exp_weight))
class BloomTensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
if "attn_qkv" in name:
num_heads = self.config["n_head"]
n_embed = self.config["hidden_size"]
if "weight" in name:
weights = self._reverse_reshape_weights(weights, num_heads, n_embed)
else:
weights = self._reverse_reshape_bias(weights, num_heads, n_embed)
return GGUFTensor(weights, name, {})
def _reverse_reshape_weights(self, weights: np.ndarray, n_head: int, n_embed: int):
# Original reshape implementation
# https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L972-L985
q, k, v = np.array_split(weights, 3, axis=0)
q = q.reshape(n_head, n_embed // n_head, n_embed)
k = k.reshape(n_head, n_embed // n_head, n_embed)
v = v.reshape(n_head, n_embed // n_head, n_embed)
qkv_weights = np.stack([q, k, v], axis=1)
return qkv_weights.reshape(n_head * 3 * (n_embed // n_head), n_embed)
def _reverse_reshape_bias(self, weights: np.ndarray, n_head: int, n_embed: int):
# Original reshape implementation
# https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L986-L998
q_bias, k_bias, v_bias = np.array_split(weights, 3)
q_bias = q_bias.reshape(n_head, n_embed // n_head)
k_bias = k_bias.reshape(n_head, n_embed // n_head)
v_bias = v_bias.reshape(n_head, n_embed // n_head)
qkv_bias = np.stack([q_bias, k_bias, v_bias], axis=1).flatten()
return qkv_bias
class T5TensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
bid = None
for chunk in name.split("."):
if chunk.isdigit():
bid = int(chunk)
break
return GGUFTensor(weights, name, {"bid": bid})
class GPT2TensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
# Original transpose implementation
# https://github.com/ggerganov/llama.cpp/blob/a38b884c6c4b0c256583acfaaabdf556c62fabea/convert_hf_to_gguf.py#L2060-L2061
if (
"attn_qkv.weight" in name
or "ffn_down.weight" in name
or "ffn_up.weight" in name
or "attn_output.weight" in name
):
weights = weights.T
# Handle special case for output.weight
if name == "output.weight":
# output.weight has conflicts with attn_output.weight in name checking
# Store the tensor directly and signal to skip further processing
name = "lm_head.weight"
parsed_parameters = kwargs.get("parsed_parameters", {})
parsed_parameters["tensors"][name] = torch.from_numpy(np.copy(weights))
name = None # Signal to skip further processing
return GGUFTensor(weights, name, {})
class MambaTensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
def process(self, weights, name, **kwargs):
if "ssm_conv1d.weight" in name:
# for compatibility tensor ssm_conv1d must be (5120, 1, 4]) dim,
# quantized one is (5120, 4)
weights = np.expand_dims(weights, axis=1)
if "ssm_a" in name:
# Original exponential implementation
# https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L2975-L2977
weights = np.log(-weights)
return GGUFTensor(weights, name, {})
class NemotronTensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
# ref : https://github.com/ggerganov/llama.cpp/blob/master/convert_hf_to_gguf.py#L4666
def process(self, weights, name, **kwargs):
if "norm.weight" in name:
weights = weights - 1
return GGUFTensor(weights, name, {})
class Gemma2TensorProcessor(TensorProcessor):
def __init__(self, config=None):
super().__init__(config=config)
# ref: https://github.com/ggerganov/llama.cpp/blob/d79d8f39b4da6deca4aea8bf130c6034c482b320/convert_hf_to_gguf.py#L3191
# ref: https://github.com/huggingface/transformers/blob/fc37f38915372c15992b540dfcbbe00a916d4fc6/src/transformers/models/gemma/modeling_gemma.py#L89
def process(self, weights, name, **kwargs):
if "norm.weight" in name:
weights = weights - 1
return GGUFTensor(weights, name, {})
TENSOR_PROCESSORS = {
"llama": LlamaTensorProcessor,
"qwen2moe": Qwen2MoeTensorProcessor,
"bloom": BloomTensorProcessor,
"t5": T5TensorProcessor,
"t5encoder": T5TensorProcessor,
"gpt2": GPT2TensorProcessor,
"mamba": MambaTensorProcessor,
"nemotron": NemotronTensorProcessor,
"gemma2": Gemma2TensorProcessor,
}
def read_field(reader, field):
value = reader.fields[field]
return [_gguf_parse_value(value.parts[_data_index], value.types) for _data_index in value.data]
# modified from https://github.com/vllm-project/vllm/blob/v0.6.4.post1/vllm/model_executor/model_loader/loader.py#L1115-L1147
def get_gguf_hf_weights_map(
hf_model,
model_type: Optional[str] = None,
num_layers: Optional[int] = None,
qual_name: str = "",
):
"""
GGUF uses this naming convention for their tensors from HF checkpoint:
`blk.N.BB.weight` and `blk.N.BB.bias`
where N signifies the block number of a layer, and BB signifies the
attention/mlp layer components.
See "Standardized tensor names" in
https://github.com/ggerganov/ggml/blob/master/docs/gguf.md for details.
"""
if is_gguf_available() and is_torch_available():
from gguf import MODEL_ARCH_NAMES, get_tensor_name_map
else:
logger.error(
"Loading a GGUF checkpoint in PyTorch, requires both PyTorch and GGUF>=0.10.0 to be installed. Please see "
"https://pytorch.org/ and https://github.com/ggerganov/llama.cpp/tree/master/gguf-py for installation instructions."
)
raise ImportError("Please install torch and gguf>=0.10.0 to load a GGUF checkpoint in PyTorch.")
model_type = hf_model.config.model_type if model_type is None else model_type
num_layers = hf_model.config.num_hidden_layers if num_layers is None else num_layers
# hack: ggufs have a different name for cohere
if model_type == "cohere":
model_type = "command-r"
if model_type == "qwen2_moe":
model_type = "qwen2moe"
arch = None
for key, value in MODEL_ARCH_NAMES.items():
if value == model_type:
arch = key
break
if arch is None:
raise NotImplementedError(
f"Unknown gguf model_type: {model_type} in gguf-py. "
"This might because you're using an outdated version of gguf-py package, "
"you can install `gguf` package from source refer to "
"https://github.com/ggerganov/llama.cpp/tree/master/gguf-py#development"
)
name_map = get_tensor_name_map(arch, num_layers)
# Use a dummy conversion to get the mapping, because
# hf => gguf and gguf => hf mappings are reversed
gguf_to_hf_name_map = {}
state_dict = hf_model.state_dict()
for hf_name in state_dict.keys():
# An exception for qwen2moe model, where the expert layers are packed
if model_type == "qwen2moe" and "mlp.experts." in hf_name:
hf_name = re.sub(r"mlp.experts.\d+.", "mlp.experts.", hf_name)
name, suffix = hf_name, ""
if hf_name.endswith(".weight") or hf_name.endswith(".bias"):
name, suffix = hf_name.rsplit(".", 1)
suffix = "." + suffix
gguf_name = name_map.get_name(name)
if gguf_name is None:
continue
gguf_to_hf_name_map[gguf_name + suffix] = qual_name + hf_name
# Some model like Bloom converted from BloomModel instead of BloomForCausalLM
# Therefore, we need to check submodule as well to get a correct mapping
if named_children := hf_model.named_children():
for name, child in named_children:
sub_map = get_gguf_hf_weights_map(child, model_type, num_layers, qual_name=f"{qual_name}{name}.")
# Ignore the keys that are already in the main map to avoid overwriting
sub_map = {k: v for k, v in sub_map.items() if k not in gguf_to_hf_name_map}
gguf_to_hf_name_map.update(sub_map)
return gguf_to_hf_name_map
def load_gguf_checkpoint(gguf_checkpoint_path, return_tensors=False, model_to_load=None):
"""
Load a GGUF file and return a dictionary of parsed parameters containing tensors, the parsed
tokenizer and config attributes.
Args:
gguf_checkpoint_path (`str`):
The path the to GGUF file to load
return_tensors (`bool`, defaults to `True`):
Whether to read the tensors from the file and return them. Not doing so is faster
and only loads the metadata in memory.
"""
if is_gguf_available() and is_torch_available():
from gguf import GGUFReader, dequantize
else:
logger.error(
"Loading a GGUF checkpoint in PyTorch, requires both PyTorch and GGUF>=0.10.0 to be installed. Please see "
"https://pytorch.org/ and https://github.com/ggerganov/llama.cpp/tree/master/gguf-py for installation instructions."
)
raise ImportError("Please install torch and gguf>=0.10.0 to load a GGUF checkpoint in PyTorch.")
reader = GGUFReader(gguf_checkpoint_path)
fields = reader.fields
reader_keys = list(fields.keys())
parsed_parameters = {k: {} for k in GGUF_TO_TRANSFORMERS_MAPPING}
architecture = read_field(reader, "general.architecture")[0]
model_name = read_field(reader, "general.name")
# in llama.cpp mistral models use the same architecture as llama. We need
# to add this patch to ensure things work correctly on our side.
if "llama" in architecture and "mistral" in model_name:
updated_architecture = "mistral"
# FIXME: Currnetly this implementation is only for flan-t5 architecture.
# It needs to be developed for supporting legacy t5.
elif "t5" in architecture or "t5encoder" in architecture:
parsed_parameters["config"]["is_gated_act"] = True
updated_architecture = "t5"
else:
updated_architecture = architecture
if "qwen2moe" in architecture:
updated_architecture = "qwen2_moe"
# For stablelm architecture, we need to set qkv_bias and use_parallel_residual from tensors
# If `qkv_bias=True`, qkv_proj with bias will be present in the tensors
# If `use_parallel_residual=False`, ffn_norm will be present in the tensors
if "stablelm" in architecture:
attn_bias_name = {"attn_q.bias", "attn_k.bias", "attn_v.bias"}
ffn_norm_name = "ffn_norm"
qkv_bias = any(bias_name in tensor.name for tensor in reader.tensors for bias_name in attn_bias_name)
use_parallel_residual = any(ffn_norm_name in tensor.name for tensor in reader.tensors)
parsed_parameters["config"]["use_qkv_bias"] = qkv_bias
parsed_parameters["config"]["use_parallel_residual"] = not use_parallel_residual
if architecture not in GGUF_SUPPORTED_ARCHITECTURES:
raise ValueError(f"GGUF model with architecture {architecture} is not supported yet.")
# Handle tie_word_embeddings, if lm_head.weight is not present in tensors,
# tie_word_embeddings is true otherwise false
exceptions = ["falcon", "bloom"]
parsed_parameters["config"]["tie_word_embeddings"] = (
all("output.weight" != tensor.name for tensor in reader.tensors) or architecture in exceptions
)
# List all key-value pairs in a columnized format
for gguf_key, field in reader.fields.items():
gguf_key = gguf_key.replace(architecture, updated_architecture)
split = gguf_key.split(".")
prefix = split[0]
config_key = ".".join(split[1:])
value = [_gguf_parse_value(field.parts[_data_index], field.types) for _data_index in field.data]
if len(value) == 1:
value = value[0]
if isinstance(value, str) and architecture in value:
value = value.replace(architecture, updated_architecture)
for parameter in GGUF_TO_TRANSFORMERS_MAPPING:
parameter_renames = GGUF_TO_TRANSFORMERS_MAPPING[parameter]
if prefix in parameter_renames and config_key in parameter_renames[prefix]:
renamed_config_key = parameter_renames[prefix][config_key]
if renamed_config_key == -1:
continue
if renamed_config_key is not None:
parsed_parameters[parameter][renamed_config_key] = value
if gguf_key in reader_keys:
reader_keys.remove(gguf_key)
if gguf_key in reader_keys:
logger.info(f"Some keys were not parsed and added into account {gguf_key} | {value}")
# retrieve config vocab_size from tokenizer
# Pleas refer to https://github.com/huggingface/transformers/issues/32526 for more details
if "vocab_size" not in parsed_parameters["config"]:
tokenizer_parameters = parsed_parameters["tokenizer"]
if "tokens" in tokenizer_parameters:
parsed_parameters["config"]["vocab_size"] = len(tokenizer_parameters["tokens"])
else:
logger.warning(
"Can't find a way to retrieve missing config vocab_size from tokenizer parameters. "
"This will use default value from model config class and cause unexpected behavior."
)
if return_tensors:
parsed_parameters["tensors"] = {}
tensor_key_mapping = get_gguf_hf_weights_map(model_to_load)
config = parsed_parameters.get("config", {})
ProcessorClass = TENSOR_PROCESSORS.get(architecture, TensorProcessor)
processor = ProcessorClass(config=config)
for tensor in tqdm(reader.tensors, desc="Converting and de-quantizing GGUF tensors..."):
name = tensor.name
weights = dequantize(tensor.data, tensor.tensor_type)
result = processor.process(
weights=weights,
name=name,
tensor_key_mapping=tensor_key_mapping,
parsed_parameters=parsed_parameters,
)
weights = result.weights
name = result.name
if name not in tensor_key_mapping:
continue
name = tensor_key_mapping[name]
parsed_parameters["tensors"][name] = torch.from_numpy(np.copy(weights))
if len(reader_keys) > 0:
logger.info(f"Some keys of the GGUF file were not considered: {reader_keys}")
return parsed_parameters
|
transformers/src/transformers/modeling_gguf_pytorch_utils.py/0
|
{
"file_path": "transformers/src/transformers/modeling_gguf_pytorch_utils.py",
"repo_id": "transformers",
"token_count": 8580
}
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.