
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
EdmilsonMLF/cnes-hospitais
|
https://github.com/EdmilsonMLF/cnes-hospitais
|
f8d5dc406820b26a20ae6399957c0fccbadf41da
|
7e98e75fa5ed0808b4de5257ec258441a8b93211
|
0e0b54c406245a1324e574b65225206bcf22d07d
|
refs/heads/main
| 2023-03-17T08:06:10.931640 | 2020-11-28T10:53:54 | 2020-11-28T10:53:54 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6618123054504395,
"alphanum_fraction": 0.6618123054504395,
"avg_line_length": 25.29787254333496,
"blob_id": "244da3b87014c418d1c1810fbe69396918a037d9",
"content_id": "5fc0e408e7667ba140344889ad46c7e070dec676",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1236,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 47,
"path": "/cnes-hospitais.py",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\n\nfrom extract.ftp import download_latest_cnes_dataset\nfrom transform.cnes import get_transformed_df\nfrom utils.logger import Logger\nfrom utils.unzip import unzip\n\nEXTRACTION_DIR = \"extracted\"\nTEMP_DIR = \"temp/\"\nOUTPUT_FILE_NAME = \"cnes-hospitais\"\n\n\ndef main():\n logger = Logger()\n err = run(logger)\n if err:\n logger.info(\"Terminated due to error\")\n logger.error(err)\n return\n\n logger.info(\"Finished without errors\")\n\n\ndef run(logger):\n try:\n os.mkdir(TEMP_DIR)\n\n logger.info(\"Downloading latest archived CNES dataset from FTP server...\")\n cnes_zip_file, version = download_latest_cnes_dataset(TEMP_DIR)\n\n logger.info(\"Extracting archived CNES dataset to {}...\".format(TEMP_DIR + EXTRACTION_DIR))\n unzip(cnes_zip_file, TEMP_DIR + EXTRACTION_DIR)\n\n logger.info(\"Applying transformations...\")\n df = get_transformed_df(TEMP_DIR + EXTRACTION_DIR, version)\n\n logger.info(\"Generating {}.csv...\".format(OUTPUT_FILE_NAME))\n df.to_csv(OUTPUT_FILE_NAME + \".csv\", index=False)\n\n logger.info(\"Cleaning temp files and directories...\")\n shutil.rmtree(TEMP_DIR)\n except Exception as e:\n return e\n\n\nmain()\n"
},
{
"alpha_fraction": 0.6584795117378235,
"alphanum_fraction": 0.7497075796127319,
"avg_line_length": 24.939393997192383,
"blob_id": "e6d8a23287a50cf92fd22decbebce4af2bcacf2d",
"content_id": "02fb8385dad2ce6011766696e12a3c076d3dd6f7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 879,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 33,
"path": "/README.md",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "# cnes-hospitais\n\n\n\nRotina em python para obtenção de dados relevantes dos hospitais brasileiros via **Cadastro Nacional de Estabelecimentos de Saúde (CNES)**.\n\nO script realiza um ETL para:\n\n* **E**xtract: base de dados mais recente do CNES via FTP\n* **T**ransform: cruzamentos, limpeza e organização dos dados relevantes\n* **L**oad: geração do arquivo `cnes-hospitais.csv` no diretório raiz do script, pronto para análise\n\n---\n\n#### Instruções\n\n```shell\npip install -r requirements.txt\npython cnes-hospitais.py\n```\n\n> python 3.8.6\n\n---\n\n\n\n---\nAutor: Fábio Tabalipa\n\nLicença: MIT\n\n> Fiquem à vontade para contribuir via *pull request* 🧑🏽💻"
},
{
"alpha_fraction": 0.6911764740943909,
"alphanum_fraction": 0.6911764740943909,
"avg_line_length": 21.66666603088379,
"blob_id": "eab5c39127bfb8e3137b31af14622e4ffa466322",
"content_id": "df0ad242ef273260bec9edb643828138f6197117",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 136,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 6,
"path": "/utils/unzip.py",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "from zipfile import ZipFile\n\n\ndef unzip(file, target_dir):\n with ZipFile(file, \"r\") as zipObj:\n zipObj.extractall(target_dir)\n"
},
{
"alpha_fraction": 0.5472155213356018,
"alphanum_fraction": 0.5609362125396729,
"avg_line_length": 31.605262756347656,
"blob_id": "a32fcc95865f041d5a07fd6b2556b6391285e7db",
"content_id": "5fe5b84a949d1a07fe9d8b4a5f3c572c6e5add89",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1239,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 38,
"path": "/extract/ftp.py",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "import re\n\nimport ftplib\n\nDATASUS_HOST = \"ftp.datasus.gov.br\"\nCNES_DIR = \"cnes\"\nFTP_CNES_FILE = r'(BASE_DE_DADOS_CNES_)(\\d{6})(\\.ZIP)'\n\n\ndef download_latest_cnes_dataset(temp_dir):\n with ftplib.FTP(DATASUS_HOST) as ftp:\n ftp.login()\n ftp.cwd(CNES_DIR)\n\n latest_file = [None, 0, None]\n file_list = ftp.nlst()\n for line in file_list:\n match = re.search(FTP_CNES_FILE, line)\n if match is not None:\n n = match.group(1)\n v = int(match.group(2))\n f = match.group(3)\n\n latest_file[0] = n if latest_file[0] is None else latest_file[0]\n latest_file[1] = v if v > latest_file[1] else latest_file[1]\n latest_file[2] = f if latest_file[2] is None else latest_file[2]\n\n latest_file[1] = str(latest_file[1])\n version = latest_file[1]\n latest_file_str = \"\".join(latest_file)\n\n handler_func = open(temp_dir + latest_file_str, 'wb').write\n try:\n ftp.retrbinary(\"RETR \" + latest_file_str, handler_func)\n except Exception as e:\n raise Exception(\"retrieving archived CNES dataset: \" + str(e))\n\n return temp_dir + latest_file_str, version\n"
},
{
"alpha_fraction": 0.5547576546669006,
"alphanum_fraction": 0.5583482980728149,
"avg_line_length": 30.191999435424805,
"blob_id": "5cd356edac1d114d5b0aa523cf7108509e56e861",
"content_id": "03abb0ea262e6bce92f5460b9f534b5e0a6fdc95",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3912,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 125,
"path": "/transform/cnes.py",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport warnings\n\nPREFIX_MAIN_TBL = \"tbEstabelecimento\"\nPREFIX_BEDS_TBL = \"rlEstabComplementar\"\nPREFIX_INSURANCE_TBL = \"rlEstabAtendPrestConv\"\nPREFIX_CITY_TBL = \"tbMunicipio\"\n\nCOD_GENERAL_HOSPITAL = 5\nCOD_SPECIALIZED_HOSPITAL = 7\n\nCOD_INSURANCE_OWN = 3\nCOD_INSURANCE_THIRD = 4\nCOD_INSURANCE_PRIVATE = 5\nCOD_INSURANCE_PUBLIC = 6\n\n\ndef get_transformed_df(files_dir, version):\n warnings.filterwarnings(\"ignore\")\n\n file_main = files_dir + \"/\" + PREFIX_MAIN_TBL + version + \".csv\"\n df_main = pd.read_csv(file_main, sep=\";\", dtype={\n \"CO_UNIDADE\": str,\n \"CO_CNES\": str,\n \"NU_CNPJ_MANTENEDORA\": str,\n \"CO_MUNICIPIO_GESTOR\": str,\n \"CO_CEP\": str,\n \"NU_TELEFONE\": str,\n })\n df_main = df_main.drop(df_main[\n (df_main['TP_UNIDADE'] != COD_GENERAL_HOSPITAL) &\n (df_main['TP_UNIDADE'] != COD_SPECIALIZED_HOSPITAL)\n ].index)\n df_main = df_main[[\n \"CO_UNIDADE\",\n \"CO_CNES\",\n \"NU_CNPJ_MANTENEDORA\",\n \"NO_RAZAO_SOCIAL\",\n \"NO_FANTASIA\",\n \"CO_MUNICIPIO_GESTOR\",\n \"CO_CEP\",\n \"NU_TELEFONE\",\n \"NO_EMAIL\",\n ]]\n df_main = df_main.rename({\"CO_MUNICIPIO_GESTOR\": \"CO_MUNICIPIO\"}, axis=1)\n df_main[\"NO_EMAIL\"] = df_main[\"NO_EMAIL\"].str.lower()\n\n file_city = files_dir + \"/\" + PREFIX_CITY_TBL + version + \".csv\"\n df_city = pd.read_csv(file_city, sep=\";\", dtype={\n \"CO_MUNICIPIO\": str,\n })\n df_city = df_city[[\n \"CO_MUNICIPIO\",\n \"NO_MUNICIPIO\",\n \"CO_SIGLA_ESTADO\",\n ]]\n df_city = df_city.groupby(by=\"CO_MUNICIPIO\").agg({\n \"NO_MUNICIPIO\": \"last\",\n \"CO_SIGLA_ESTADO\": \"last\",\n }).reset_index()\n\n file_beds = files_dir + \"/\" + PREFIX_BEDS_TBL + version + \".csv\"\n df_beds = pd.read_csv(file_beds, sep=\";\")\n df_beds = df_beds[[\n \"CO_UNIDADE\",\n \"QT_EXIST\",\n \"QT_SUS\",\n ]]\n df_beds[\"QT_SUS\"] = df_beds.apply(lambda row: 1 if row[\"QT_SUS\"] > 0 else 0, axis=1)\n df_beds = df_beds.groupby(by=\"CO_UNIDADE\").agg({\n \"QT_EXIST\": \"sum\",\n \"QT_SUS\": \"max\",\n }).reset_index()\n\n file_insurance = files_dir + \"/\" + PREFIX_INSURANCE_TBL + version + \".csv\"\n df_insurance = pd.read_csv(file_insurance, sep=\";\")\n df_insurance = df_insurance.drop(df_insurance[\n (df_insurance['CO_CONVENIO'] != COD_INSURANCE_OWN) &\n (df_insurance['CO_CONVENIO'] != COD_INSURANCE_THIRD) &\n (df_insurance['CO_CONVENIO'] != COD_INSURANCE_PRIVATE) &\n (df_insurance['CO_CONVENIO'] != COD_INSURANCE_PUBLIC)\n ].index)\n df_insurance = df_insurance[[\n \"CO_UNIDADE\",\n ]]\n df_insurance[\"Atende Convênio?\"] = 1\n df_insurance = df_insurance.groupby(by=\"CO_UNIDADE\").agg({\n \"Atende Convênio?\": \"max\",\n }).reset_index()\n\n df_merge = df_main.merge(df_beds, how=\"inner\", on=\"CO_UNIDADE\")\n df_merge = df_merge.merge(df_insurance, how=\"left\", on=\"CO_UNIDADE\")\n df_merge = df_merge.merge(df_city, how=\"left\", on=\"CO_MUNICIPIO\")\n df_merge[\"Atende Convênio?\"] = df_merge[\"Atende Convênio?\"].fillna(0)\n df_merge[\"Atende Convênio?\"] = df_merge[\"Atende Convênio?\"].astype(int)\n\n df_merge = df_merge.rename({\n \"CO_CNES\": \"Código CNES\",\n \"NU_CNPJ_MANTENEDORA\": \"CNPJ\",\n \"NO_RAZAO_SOCIAL\": \"Razão Social\",\n \"NO_FANTASIA\": \"Nome Fantasia\",\n \"CO_CEP\": \"CEP\",\n \"NU_TELEFONE\": \"Telefone\",\n \"NO_EMAIL\": \"Email\",\n \"QT_EXIST\": \"Leitos\",\n \"QT_SUS\": \"Atende SUS?\",\n \"NO_MUNICIPIO\": \"Município\",\n \"CO_SIGLA_ESTADO\": \"UF\",\n }, axis=1)\n\n df_merge = df_merge[[\n \"Nome Fantasia\",\n \"Razão Social\",\n \"CNPJ\",\n \"Código CNES\",\n \"Município\",\n \"UF\",\n \"CEP\",\n \"Telefone\",\n \"Email\",\n \"Leitos\",\n \"Atende SUS?\",\n \"Atende Convênio?\",\n ]]\n return df_merge.sort_values(by=[\"UF\"])\n"
},
{
"alpha_fraction": 0.607692301273346,
"alphanum_fraction": 0.607692301273346,
"avg_line_length": 19,
"blob_id": "2b05f7608aeba3664aeedf7b174f1077ae92993b",
"content_id": "b5bf160ec91a45541c46a7ea948404e454d8a736",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 26,
"path": "/utils/logger.py",
"repo_name": "EdmilsonMLF/cnes-hospitais",
"src_encoding": "UTF-8",
"text": "DEBUG_LEVEL = \"Debug\"\nERROR_LEVEL = \"Error\"\nINFO_LEVEL = \"Info\"\nWARNING_LEVEL = \"Warning\"\n\n\nclass Logger:\n @staticmethod\n def debug(msg):\n Logger.__output(DEBUG_LEVEL, msg)\n\n @staticmethod\n def error(error):\n Logger.__output(ERROR_LEVEL, str(error))\n\n @staticmethod\n def info(msg):\n Logger.__output(INFO_LEVEL, msg)\n\n @staticmethod\n def warning(msg):\n Logger.__output(WARNING_LEVEL, msg)\n\n @staticmethod\n def __output(level, msg):\n print(level, \"-\", msg)\n"
}
] | 6 |
SayedSibgath27/Data-Visualization
|
https://github.com/SayedSibgath27/Data-Visualization
|
43e3864c5936282937d49e1a54ed90d9a130902d
|
fd440dc469d9cf7e9dea884336ce53c971559a29
|
126f91c4b7f3caba260b81da476ec6eabde82c14
|
refs/heads/main
| 2023-08-20T07:57:04.490868 | 2021-10-18T15:10:03 | 2021-10-18T15:10:03 | 418,533,671 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6223776340484619,
"alphanum_fraction": 0.6573426723480225,
"avg_line_length": 17.066667556762695,
"blob_id": "477c74a10f1e2d3e4755dd5ef09a0166a106ed21",
"content_id": "09dfee35cab0a013b6a7dccedcd5f072d40cf4c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 15,
"path": "/Datarepreasent.py",
"repo_name": "SayedSibgath27/Data-Visualization",
"src_encoding": "UTF-8",
"text": "#Draw a scatterplot\r\nimport matplotlib.pyplot as plt\r\nimport random \r\n'''randomnumber=random.randint(1,10)\r\nprint(randomnumber)'''\r\n\r\n\r\n\r\nx=[]\r\ny=[]\r\nfor i in range(5):\r\n x.append(random.randint(1,10))\r\n y.append(random.randint(1,10))\r\nplt.scatter(x, y,color='blue')\r\nplt.show()\r\n"
}
] | 1 |
lnls-gam/Concrete-Instrum-Scripts
|
https://github.com/lnls-gam/Concrete-Instrum-Scripts
|
3d9a8bdbcba3f0e16f091a0aea8a6bfe35b7502b
|
dc93980e1a79435fd154fd7867987fa87a3b46a0
|
3efdef0e7cd14b03352aaa906302b2606ecff996
|
refs/heads/master
| 2023-04-13T18:54:45.786478 | 2021-07-27T14:50:05 | 2021-07-27T14:50:05 | 297,352,258 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5685821771621704,
"alphanum_fraction": 0.5818654298782349,
"avg_line_length": 34.517948150634766,
"blob_id": "03055e3215443e3a74a39c3b1ce3757a1de3f2ee",
"content_id": "91e0e02f19da5303212e11146956fff91454ce32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6926,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 195,
"path": "/buildMTI.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\n @author: Leonardo Rossi Leão / Rodrigo de Oliveira Neto\n @create: october, 1, 2020\n @title: File monitor\n\"\"\"\n\n# Libraries\nimport os\nimport csv\nimport time\nimport pandas\nimport threading\nfrom datetime import datetime\nfrom epicsConcrete import EpicsServer\nfrom calibration import Calibration as cal\nfrom PvProperties import PvProperties as pvp\n\n# Record the actions in monitor.txt\ndef recordAction(text):\n monitor = open(\"monitorRawData.txt\", \"a\")\n monitor.write(text + \"\\n\")\n print(text)\n monitor.close()\n \n# Get the file size\ndef fileSize(filename):\n fileStats = os.stat(filename)\n return fileStats.st_size\n\n# Get the current date and time\ndef getDateTime():\n now = datetime.now()\n return now.strftime(\"%d/%m/%Y %H:%M:%S\")\n\n# Update the Process Variables in Epics\ndef updateEpicsPV(muxId, channel, subChannel, value):\n pvName = pvp.pvName(muxId, channel, subChannel)\n if pvName != \"Dis.\":\n try:\n EpicsServer.driver.write(pvName, float(value))\n except:\n recordAction(\"[%s] Erro: value convertion in mux: %s, channel: %s, subchannel: %s\" \n % (getDateTime(), muxId, channel, subChannel))\n \n# Apply calibration curves in values\ndef convertValues(muxData):\n muxId = muxData[0]\n dataToConvert = muxData[4:]\n for i in range(len(dataToConvert)):\n sensor = cal.muxHeader[\"mux%d\" % muxId][i//2]\n if \"Dis\" not in dataToConvert[i]:\n # Convertion to subchannel A\n if i % 2 == 0:\n if sensor == \"PT100\":\n dataToConvert[i] = cal.convertPT100(dataToConvert[i])\n elif sensor == \"VWS2100\":\n dataToConvert[i] = cal.convertVWS2100((i//2) + 1, dataToConvert[i])\n else:\n dataToConvert[i] = cal.convertVWTS6000(muxId, (i//2) + 1, dataToConvert[i])\n updateEpicsPV(muxId, (i//2) + 1, \"A\", dataToConvert[i])\n # Convertion to subchannel B\n else:\n dataToConvert[i] = cal.convertChannelB(dataToConvert[i])\n updateEpicsPV(muxId, (i//2) + 1, \"B\", dataToConvert[i])\n \n \n return muxData[:4] + dataToConvert\n\n# Convert the data received in a list\ndef fileManipulation(directory, filename):\n rawData = pandas.read_csv(directory + filename)\n # Start the array of mux data with Mux ID\n muxData = [int(filename.replace(\"DT\", \"\").replace(\".CSV\", \"\").replace(\".csv\", \"\"))]\n lastData = rawData.tail(1).values[0][0].split(\";|;\")\n # Append the data in the muxData list\n for value in lastData:\n if \";\" in value:\n for subvalue in value.split(\";\"):\n muxData.append(subvalue)\n else:\n muxData.append(value)\n return (muxData, convertValues(muxData))\n\nmuxAtivo = cal.MUXactivated\n\n# Update MTI file with the data of acquisition\ndef updateMTI(acquisition, converted = False):\n listToSet = []\n muxIDs = list(acquisition.keys())\n muxIDs.sort()\n # Create a unique list from the dictionary\n for muxId in muxIDs:\n for value in acquisition[muxId][0]:\n listToSet.append(value)\n # Update the MTI file\n filename = \"mti.csv\"\n output = \"[%s] Action: MTI updated\" % getDateTime()\n if converted == True:\n filename = \"mti_conv.csv\"\n output = \"[%s] Action: MTI Converted updated\" % getDateTime()\n noHeader = False\n if os.path.exists(filename) == False:\n noHeader = True\n with open(filename, \"a\") as mtiFile:\n writer = csv.writer(mtiFile, dialect=\"excel\", lineterminator = '\\n')\n if noHeader == True:\n writer.writerow(cal.createHeader())\n writer.writerow(listToSet)\n recordAction(output)\n\nclass FileMonitor(threading.Thread):\n \n # Constructor Method \n def __init__(self):\n super(FileMonitor, self).__init__()\n self.kill = threading.Event()\n self.server = EpicsServer()\n self.server.start()\n self.muxIds = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29]\n self.directory = \"/usr/data/ftp-concrete/\"\n #self.directory = \"C:/Users/ASUS/Desktop/ftp-concrete/\"\n self.acquisition = {}\n self.acquisitionConverted = {}\n \n # \n def setDataToAcq(self, muxId, muxData, muxDataConverted):\n if muxId not in self.acquisition.keys():\n self.acquisition[muxId] = []\n self.acquisitionConverted[muxId] = []\n self.acquisition[muxId].append(muxData)\n self.acquisitionConverted[muxId].append(muxDataConverted)\n \n #\n def delFirstPosition(self):\n for muxId in self.muxIds:\n del self.acquisition[muxId][0]\n del self.acquisitionConverted[muxId][0]\n \n #\n def isComplete(self):\n for muxId in self.muxIds:\n if muxId in self.acquisition.keys():\n if len(self.acquisition[muxId]) == 0:\n return False\n else:\n return False\n return True\n \n # Set values to acquisition attribute\n def setAcquisition(self, muxData, muxDataConverted):\n muxId = muxData[0]\n if self.isComplete():\n updateMTI(self.acquisition)\n updateMTI(self.acquisitionConverted, True)\n self.delFirstPosition()\n self.setDataToAcq(muxId, muxData, muxDataConverted)\n \n # Observe the indicated file size\n def run(self):\n \n recordAction(\"[%s] Action: start file monitor\" % getDateTime())\n \n # Create a dictionary with the filenames e theirs sizes\n filesToWatch = {} \n for filename in os.listdir(self.directory):\n if \"DT\" in filename:\n filesToWatch[filename] = fileSize(self.directory + filename)\n \n while not self.kill.is_set():\n \n try:\n \n for filename in filesToWatch:\n actualSize = fileSize(self.directory + filename)\n if actualSize != filesToWatch[filename]:\n recordAction(\"[%s] Size changed in %s: %d kb -> %d kb\" % (getDateTime(), filename, filesToWatch[filename], actualSize))\n filesToWatch[filename] = actualSize\n muxData, muxDataConverted = fileManipulation(self.directory, filename)\n self.setAcquisition(muxData, muxDataConverted)\n \n except Exception as e:\n recordAction(\"[%s] ERRO: %s\" % (getDateTime(), str(e.__class__)))\n \n time.sleep(1)\n \n # Stop the thread FileMonitor \n def stop(self):\n recordAction(\"[%s] Action: stop file monitor\" % getDateTime())\n self.kill.set()\n \nif __name__ == \"__main__\":\n threadFM = FileMonitor()\n threadFM.start()\n"
},
{
"alpha_fraction": 0.5750091075897217,
"alphanum_fraction": 0.5771884918212891,
"avg_line_length": 33,
"blob_id": "68303e3e3d6ef668bb522e21436b9ed84b6ef494",
"content_id": "7780bc3a96e5ccd0bf405cd310f5a30dbc349ff9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2753,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 81,
"path": "/old/fileMonitor.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "\"\"\"\n @author: Leonardo Rossi Leão / Rodrigo de Oliveira Neto\n @create: october, 1, 2020\n @title: File monitor\n\"\"\"\n\n# Libraries\nimport time\nimport threading\nfrom ftplib import FTP\nfrom datetime import datetime\nfrom csvTreatment import CsvTreatment\n\nclass FileMonitor(threading.Thread):\n \n # Constructor Method \n def __init__(self, host, port, user, password, filename):\n super(FileMonitor, self).__init__()\n self.kill = threading.Event()\n self.host = host\n self.port = port\n self.user = user\n self.password = password\n self.filename = filename\n self.csvTreatment = CsvTreatment()\n \n try:\n self.ftp = FTP()\n self.ftp.connect(self.host, self.port)\n self.ftp.login(self.user, self.password)\n self.ftp.voidcmd('TYPE I')\n self.recordAction(\"[%s] Action: FTP connected\" % self.getDateTime())\n except:\n self.recordAction(\"[%s] Action: Error FTP not connected\" % self.getDateTime())\n \n # Get the current date and time\n def getDateTime(self):\n now = datetime.now()\n return now.strftime(\"%d/%m/%Y %H:%M:%S\")\n \n # Record the actions in monitor.txt\n def recordAction(self, text):\n monitor = open(\"monitor.txt\", \"a\")\n monitor.write(text + \"\\n\")\n monitor.close()\n \n # Get the file size\n def fileSize(self):\n try:\n return self.ftp.size(self.filename)\n except:\n self.recordAction(\"[%s] FTP error\" % self.getDateTime())\n self.ftp.close()\n self.ftp.connect(self.host, self.port)\n self.ftp.login(self.user, self.password)\n self.ftp.voidcmd('TYPE I')\n self.recordAction(\"[%s] FTP reconnected\" % self.getDateTime())\n return self.ftp.size(self.filename)\n \n # Realize the file manipulation\n def fileManipulation(self):\n rawData = self.csvTreatment.read(self.host, self.port, self.user, self.password, self.filename)\n self.csvTreatment.separateLastData(rawData)\n \n # Observe the indicated file size\n def run(self):\n self.recordAction(\"[%s] Action: start file monitor\" % self.getDateTime())\n lastSize = self.fileSize()\n while not self.kill.is_set():\n size = self.fileSize()\n if lastSize != size:\n self.recordAction(\"[%s] Size changed: %d kb -> %d kb\" % (self.getDateTime(), lastSize, size))\n lastSize = size\n self.fileManipulation()\n \n time.sleep(1)\n \n # Stop the thread FileMonitor \n def stop(self):\n self.recordAction(\"[%s] Action: stop file monitor\" % self.getDateTime())\n self.kill.set()"
},
{
"alpha_fraction": 0.5048505067825317,
"alphanum_fraction": 0.5103939771652222,
"avg_line_length": 40.74380111694336,
"blob_id": "0e011d92daedd7779f3cf1959e59f6b8361e1801",
"content_id": "f3e3a64897ffe914c0474920094d7a2308a4ff1e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5051,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 121,
"path": "/old/csvTreatment.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "\"\"\"\n @author Leonardo Rossi Leão / Rodrigo de Oliveira Neto\n @create october, 1, 2020\n @title: CSV functions\n\"\"\"\n# Libraries\nimport os\nimport csv\nimport pandas as pd\nfrom datetime import datetime\nfrom epicsConcrete import EpicsServer\nfrom calibration import Calibration as cal\nfrom PvProperties import PvProperties as pvp\n\nclass CsvTreatment():\n \n # Constructor Method\n def __init__(self):\n super(CsvTreatment, self).__init__()\n self.server = EpicsServer()\n self.server.start()\n\n # Read the csv file\n def read(self, host, port, user, password, filename):\n self.recordAction(\"[%s] Action: starting the file read\" % self.getDateTime())\n # Use pandas to read a csv file from an FTP server\n mti = pd.read_csv(\"ftp://%s:%s@%s:%d/%s\" %\n (user, password, host, port, filename), \n error_bad_lines=False, header=None)\n self.recordAction(\"[%s] Action: file imported\" % self.getDateTime())\n return(mti)\n \n # Get the current date and time\n def getDateTime(self):\n now = datetime.now()\n return now.strftime(\"%d/%m/%Y %H:%M:%S\")\n \n # Record the actions in monitor.txt\n def recordAction(self, text):\n self.monitor = open(\"monitor.txt\", \"a\")\n self.monitor.write(text + \"\\n\")\n self.monitor.close()\n \n # Separate data into a dictionary\n def newMux(self, mux):\n channel = 1 # Variable to control de number of channels\n # Initialize mux dictionary with basic informations\n muxDictionary = {\n \"Id\": mux[0],\n \"Datetime\": mux[1],\n \"Volt\": mux[2],\n \"Temperature\": mux[3]} \n # Scroll the channels and set the info into the dictionary\n for i in range(4, len(mux)):\n if str(mux[i]) != \"nan\":\n if i % 2 == 0:\n option = \"Ch%d%s\" % (channel, \"A\")\n try:\n muxDictionary[option] = cal.convertChannelA(mux[0], channel, mux[i])\n except:\n muxDictionary[option] = float(\"nan\")\n # Update the respective pv\n pvName = pvp.pvName(int(mux[0]), int(channel), \"A\")\n if pvName != \"Dis.\":\n if str(muxDictionary[option]) not in [\"Dis.\", \"error\"]:\n EpicsServer.driver.write(pvName, float(muxDictionary[option]))\n else:\n EpicsServer.driver.write(pvName, 0)\n else:\n # Add to dictionary with convertion to Celsius degrees\n try:\n muxDictionary[\"Ch%d%s\" % (channel, \"B\")] = cal.convertChannelB(mux[i])\n except:\n muxDictionary[\"Ch%d%s\" % (channel, \"B\")] = str(mux[i]) + \" (error)\"\n # Update the respective pv\n pvName = pvp.pvName(mux[0], channel, \"B\")\n if pvName != \"Dis.\":\n if str(muxDictionary[option]) not in [\"Dis.\", \"error\"]:\n EpicsServer.driver.write(pvName, float(muxDictionary[option]))\n else:\n EpicsServer.driver.write(pvName, 0)\n channel += 1\n muxDictionary[\"Number of channels\"] = channel - 1\n return muxDictionary\n \n # Get the last line of csv and separate data into a dictionary\n def separateLastData(self, rawData):\n setId = 0; mux = []; muxes = {}\n tableLine = rawData.tail(1).values[0]\n # Scroll the vector looking for a new mux\n for i in range(len(tableLine) - 1):\n if \":\" in str(tableLine[i]): # Identify a datetime cell\n if setId != 0:\n muxes[cal.MUXactivated[setId - 1]] = self.newMux(mux)\n mux = []; mux.append(cal.MUXactivated[setId])\n mux.append(tableLine[i])\n setId += 1\n elif tableLine[i] != \"\":\n mux.append(tableLine[i])\n self.updateCSV(muxes)\n \n # Generate a CSV file with the data read\n def updateCSV(self, muxes):\n with open(\"MTI_converted.csv\", \"a\", newline='') as csvfile:\n writer = csv.writer(csvfile, delimiter=';')\n header = []; data = []\n # Verify if the csv file is empty to set a header\n if os.path.getsize(\"MTI_converted.csv\") == 0:\n for mux in muxes.keys():\n for op in (muxes[mux]).keys():\n header.append(op)\n data.append(muxes[mux][op])\n writer.writerow(header)\n writer.writerow(data)\n else:\n for mux in muxes.keys():\n for op in (muxes[mux]).keys():\n data.append(muxes[mux][op])\n writer.writerow(data)\n csvfile.close()\n self.recordAction(\"[%s] CSV generate succesfully\" % self.getDateTime())\n"
},
{
"alpha_fraction": 0.47686687111854553,
"alphanum_fraction": 0.5012175440788269,
"avg_line_length": 42.24561309814453,
"blob_id": "3644eec369e19fad1b9ecca225962d8b894471ac",
"content_id": "d9845a1bfc2d20c2519718d6f1dff68cd5ed40e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2469,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 57,
"path": "/PvProperties.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Nov 17 08:44:26 2020\n\n@author: leona\n\"\"\"\n\nimport pandas as pd\nfrom calibration import Calibration as cal\n\nclass PvProperties():\n \n file = pd.read_excel(\"pvs.xlsx\")\n \n @staticmethod\n def pvName(mux, canal, ch):\n f = open(\"pvssss\", \"a\")\n file = PvProperties.file\n linha = file.loc[((file[\"Mux\"] == mux) & (file[\"Canal\"] == canal))]\n \n if not linha.empty:\n sensor = cal.muxHeader[\"mux%d\" % mux][canal-1]\n local = str(linha[\"Local\"].values[0])\n setor = int(linha[\"Setor\"].values[0])\n setor = (\"0\" + str(setor)) if setor < 10 else str(setor)\n posicao = (str(linha[\"Posição\"].values[0])).replace(\"L\", \"\").replace(\"P\", \"\")\n nivel = str(linha[\"Nível\"].values[0])\n nivel = \"\" if nivel == \"nan\" else nivel\n orientacao = str(linha[\"Orientação\"].values[0])\n orientacao = \"\" if orientacao == \"nan\" else orientacao\n \n if((sensor == \"PT100\" or sensor == \"VWTS6000\") and ch == \"A\"):\n return (f\"{setor}{local}:SS-Concrete-{posicao}{nivel}{sensor[0]}:Temp-Mon\")\n if(sensor == \"VWTS6000\" and ch == \"B\"):\n return (f\"{setor}{local}:SS-Concrete-{posicao}{nivel}N:Temp-Mon\")\n if(sensor == \"VWS2100\" and ch == \"A\"):\n return (f\"{setor}{local}:SS-Concrete-{posicao}{nivel}:Strain{orientacao}-Mon\")\n if(sensor == \"VWS2100\" and ch == \"B\"):\n return (f\"{setor}{local}:SS-Concrete-{posicao}{nivel}N:Temp-Mon\")\n\n @staticmethod\n def pvdb():\n pvdb = {}\n for index, row in PvProperties.file.iterrows():\n mux = row[\"Mux\"]\n canal = row[\"Canal\"]\n sensor = cal.muxHeader[\"mux%d\" % mux][canal-1]\n if(\"PT100\" in sensor):\n pvdb[PvProperties.pvName(mux, canal, \"A\")] = {'prec': 3, 'scan': 1, 'unit': 'C'}\n elif (\"VWTS6000\" in sensor):\n pvdb[PvProperties.pvName(mux, canal, \"A\")] = {'prec': 3, 'scan': 1, 'unit': 'C'}\n pvdb[PvProperties.pvName(mux, canal, \"B\")] = {'prec': 3, 'scan': 1, 'unit': 'C'}\n else:\n pvdb[PvProperties.pvName(mux, canal, \"A\")] = {'prec': 3, 'scan': 1, 'unit': 'uE'}\n pvdb[PvProperties.pvName(mux, canal, \"B\")] = {'prec': 3, 'scan': 1, 'unit': 'C'}\n\n return pvdb"
},
{
"alpha_fraction": 0.6161971688270569,
"alphanum_fraction": 0.6698943376541138,
"avg_line_length": 23.69565200805664,
"blob_id": "0a3f9138923ea11c5415469ca814838f93eb6e4d",
"content_id": "59be9a7bac794d50befdde11e9f83c7985de44a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1136,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 46,
"path": "/old/main.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "\"\"\"\n @author: Leonardo Rossi Leão / Rodrigo de Oliveira Neto\n @create: october, 1, 2020\n @title: main\n\"\"\"\n\n# Libraries\nimport time\nfrom fileMonitor import FileMonitor\nfrom cryptography.fernet import Fernet\n\n# Open the credentials\ncred = open(\"credentials.txt\").read()\ndecode = Fernet(cred[132:176])\n\n# Connection FTP attributes\nhost = \"13.94.133.22\"\nport = 21\nuser = decode.decrypt(str.encode(cred[264:364])).decode()\npassword = decode.decrypt(str.encode(cred[539:639])).decode()\nfilename = \"MTI.csv\"\nprint(password)\n\n# Start the software\nfile = open(\"start.txt\", \"r\");\nstart = bool(file.read())\nfile.close()\n\n#host = \"192.168.56.1\"\n#port = 8021\n#user = decode.decrypt(str.encode(cred[264:364])).decode()\n#password = decode.decrypt(str.encode(cred[539:639])).decode()\n#filename = \"MTI.csv\"\n\nif start == \"banana\":\n # Instantiates a monitoring object\n fileMonitor = FileMonitor(host, port, user, password, filename)\n fileMonitor.start() # Start the file monitoring\n while start == True:\n time.sleep(60)\n file = open(\"start.txt\", \"r\");\n start = bool(int(file.read()))\n file.close()\n\nprint(\"Finishing\")\nfileMonitor.stop()\n"
},
{
"alpha_fraction": 0.6047098636627197,
"alphanum_fraction": 0.6114381551742554,
"avg_line_length": 24.319149017333984,
"blob_id": "b8f4a4469241a0d432c5da1050e184b0193ee896",
"content_id": "81154e6a25626d792343acb25b864542e266f9c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1189,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 47,
"path": "/epicsConcrete.py",
"repo_name": "lnls-gam/Concrete-Instrum-Scripts",
"src_encoding": "UTF-8",
"text": "\"\"\"\n @author Leonardo Rossi Leão / Rodrigo de Oliveira Neto\n @create november, 09, 2020\n @title: EPICS\n\"\"\"\n\nimport threading\nfrom datetime import datetime\nfrom pcaspy import SimpleServer, Driver\nfrom PvProperties import PvProperties as pvp\n\n# Get the current date and time\ndef getDateTime():\n now = datetime.now()\n return now.strftime(\"%d/%m/%Y %H:%M:%S\")\n\n# Record the actions in monitor.txt\ndef recordAction(text):\n monitor = open(\"monitorRawData.txt\", \"a\")\n monitor.write(text + \"\\n\")\n print(text)\n monitor.close() \n\nclass EpicsDriver(Driver):\n def _init_(self):\n super(EpicsDriver, self)._init_()\n \n def write(self, reason, value):\n self.setParam(reason, value) \n \n def read(self, reason):\n return self.getParam(reason)\n \nclass EpicsServer(threading.Thread):\n \n driver = None\n \n def _init_(self):\n super(EpicsServer, self)._init_()\n \n def run(self):\n server = SimpleServer()\n server.createPV(\"TU-\", pvp.pvdb())\n EpicsServer.driver = EpicsDriver()\n recordAction(\"[%s] Action: EPICS server and driver started\" % getDateTime())\n while True:\n server.process(0.1)"
}
] | 6 |
muhal-git/IAM-592-project
|
https://github.com/muhal-git/IAM-592-project
|
14b9bd0f35a68f350bbe7963be6bc4d0fe9c2575
|
9aab1ac23f0d503470981501730003ba0f56ee50
|
5d9fc0eab8ea265e808abaa519da44b22bf9c34e
|
refs/heads/main
| 2023-05-31T23:46:37.974918 | 2021-06-29T21:00:04 | 2021-06-29T21:00:04 | 355,687,973 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5616341233253479,
"alphanum_fraction": 0.5847246646881104,
"avg_line_length": 22.65546226501465,
"blob_id": "efa295d2cf88cf2c40f48deb76fad9dfe6f5d64a",
"content_id": "cfecbba7673c87968c67404108ba01bf16679a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2815,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 119,
"path": "/math_tools.py",
"repo_name": "muhal-git/IAM-592-project",
"src_encoding": "UTF-8",
"text": "import secrets #for generating cryptographically! secure random integers\nimport random #for generating random numbers(not cryptographically secure)\n\n'''\negcd(..,..) recursively calculates greatest common divisor(gcd) of integers a and b\nAlso it caluculates x&y such that gcd(a,b) = x*a + y*b\nThis function also can be use for finding inverse of a in modulo b\n\ninput: a, b\noutput:gcd(a,b), x, y (such that gcd(a,b) = x*a + y*b)\n'''\ndef egcd(a, b):\n\n # handling base Case\n if a == 0 :\n return b, 0, 1\n\n gcd, x1, y1 = egcd(b%a, a)\n\n # updating x and y recursively\n x = y1 - (b//a) * x1\n y = x1\n\n return gcd, x, y\n\n'''\nUsing egcd(..,..),inverse_mod(..,..) calculates and returns inverse of a in mod b\n\ninput: a, b\noutput:inverse(say it is inv) of a in modulo b ( so that (a*inv)%b=1 )\n'''\ndef inverse_mod(a,b):\n\n #handles the case gcd(a,b)=1, since if not there is no inverse of a in mod b\n if egcd(a,b)[0]!=1:\n print(\"inverse of\",a,\"in modulo\",b,\"does not exist !\")\n return False\n\n inverse_of_a_in_mod_b = egcd(a,b)[1]\n\n if inverse_of_a_in_mod_b < 0:\n inverse_of_a_in_mod_b+=b\n return inverse_of_a_in_mod_b\n\n'''\nmiiller_rabin_test(d,n) makes Miller-Rabin primality test, it is a probabilistic\nprimality test, miillerTest(d,n) function looks for primality of integr n,\nsuch that n - 1 = (2^d)*k\n\ninput: d, n ( so that n-1 = 2^(d)*k for some odd k )\noutput:False(if n is not prime) or True(if n is (probably) prime)\n'''\ndef miiller_rabin_test(d, n):\n\n # take a random number from [2,...,n-2]\n a = 2 + secrets.randbelow(n-3)\n\n # applying Miller-Rabin primality test\n x = pow(a, d, n);\n if (x == 1 or x == n - 1):\n return True;\n\n while (d != n - 1):\n x = (x * x) % n;\n d *= 2;\n\n if (x == 1):\n return False;\n if (x == n - 1):\n return True;\n\n return False;\n\n\n\n'''\nisPrime(n,k) looks for primality of n using miiller_rabin_test() function k-times\ngreater k means greater accuracy of the test--->Error of this test is E(k)= 1/(4^k) \n\ninput: n, k(number of tests, equals to 64 as default)\noutput:False(if n is not prime) or True(if n is (probably) prime)\n'''\ndef isPrime( n, k=64):\n\t\n if (n <= 1 or n%2 == 0):\n return False;\n if (n <= 3):\n return True;\n\n # finding d such that n = n-1 = 2^(d)*k\n d = n - 1;\n while (d % 2 == 0):\n d //= 2;\n\t\n\t\n for i in range(k):\n if (miiller_rabin_test(d, n) == False):\n return False;\n return True;\n\n\n#generating 1024 bit primes and looking for primality of them\n'''\nk=7\ni=0\nwhile True:\n\tif k<=10:\n\t\t#print(\"number generated.\")\n\t\tp=secrets.randbits(1024)\n\t\tif(p%2==0):\n\t\t\tp=p-1\n\t\ti+=1\n\t\tif isPrime(p,10):\n\t\t\tprint(\"found at \",i,\"th try\",k,\"th prime:\",p)\n\t\t\tk=k+1\n\t\t\tif k==11:\n\t\t\t\tbreak\n\n'''\n"
},
{
"alpha_fraction": 0.4820420742034912,
"alphanum_fraction": 0.4976911246776581,
"avg_line_length": 26.645389556884766,
"blob_id": "98120d81da4848d62a6a0906695f39e7bd36702d",
"content_id": "1f2d3315e23529621a37863f0c6391202262b5ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3898,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 141,
"path": "/hill_cipher_matrix_tools.py",
"repo_name": "muhal-git/IAM-592-project",
"src_encoding": "UTF-8",
"text": "import secrets\nimport numpy as np\nimport math_tools\nfrom sympy import Matrix\nimport sympy\nimport time\n\ndef rand_matrix_gen(dimension):\n\n char_sequence=[]\n for i in range(255):\n char_sequence.append(i+1)\n\n\n flag=True\n k=0\n while flag:\n flag_1=False\n flag_2=False\n flag_3=True\n\n \"\"\"k+=1\n if k%20000==0:\n print(\"We are at\",k,\"th trying...\")\n \"\"\"\n\n rand_nums=[] #an array for keeping entries of matrix for encryption\n for i in range(dimension*dimension):\n # randomly generating entries of encryption matrix\n rand_nums.append(secrets.choice(char_sequence))\n\n A=np.zeros(shape=(dimension,dimension))\n pivot=0\n for i in range(dimension):\n for j in range(dimension):\n A[i][j]=int(rand_nums[pivot])\n pivot=pivot+1\n\n\n det=np.linalg.det(A)\n '''\n if int(det)!=det:\n continue'''\n if math_tools.egcd(det,256)[0]!=1:\n continue\n\n return A\n\ndef gen_key(A):\n k=10\n for i in range(k):\n k=k-1\n try:\n block_size=A.shape[1]\n dimension=block_size\n #A=rand_matrix_gen(dimension)\n A=np.round(A).astype(int)\n\n mod_matrix=Matrix()\n\n for i in range(dimension):\n mod_matrix=mod_matrix.row_insert(i,Matrix([A[i]]))\n try:\n A_inv=mod_matrix.inv_mod(256)\n except:\n continue\n k=10\n t=np.dot(mod_matrix,mod_matrix.inv_mod(256))%256\n\n\n except:\n print(\"sell\")\n continue\n return A_inv\n\ndef gen_hill_matrices(dimension):\n i=0\n while(True):\n i+=1\n try:\n A_1=rand_matrix_gen(dimension)\n B_1=gen_key(A_1)\n print(\"Hill Cipher Matrix Generation Completed !\",i)\n break\n except:\n #print(\"smthng gone wrong\")\n continue\n return A_1,B_1\n\ndef hill_cipher(A,A_inverse,mode,message,head_padding=0,tail_padding=0):\n\n block_size=A.shape[1]\n\n\n try:\n\n if mode==\"encrypt\":\n\n if ((len(message))%(block_size))!=0:\n message = \"\\n--------NEW MESSAGE--------\\n\\n\" + message + \"\\n\\n-----END OF THE MESSAGE-----\\n\"\n padding_size = block_size - len(message)%block_size\n for i in range(padding_size):\n padding = chr(secrets.randbits(8))\n message = message + padding\n\n cipher_text=\"\"\n pivot=0\n for i in range(int(len(message)/block_size)):\n B=Matrix()\n for j in range(block_size):\n B = B.row_insert(j,Matrix([ord(message[pivot])]))\n pivot+=1\n C = np.dot(A,B).astype(int)%256\n #print(C)\n for k in range(block_size):\n cipher_text = cipher_text + chr(C[k][0])\n try:\n return cipher_text\n except:\n return cipher_text\n\n elif mode==\"decrypt\":\n plain_text=\"\"\n pivot=0\n\n for i in range(int(len(message)/block_size)):\n cipher_matrix=Matrix()\n for j in range(block_size):\n cipher_matrix = cipher_matrix.row_insert(j,Matrix([ord(message[pivot])]))\n pivot+=1\n plain_matrix = np.dot(A_inverse,cipher_matrix).astype(int)%256\n for k in range(block_size):\n plain_text = plain_text + chr(plain_matrix[k][0])\n #print(\"inside function\",plain_text)\n return plain_text\n\n else:\n raise Exception(\"Cipher mode is not right!\")\n\n except:\n raise Exception(\"Something gone wrong while making encryption/decryption !\")\n"
},
{
"alpha_fraction": 0.7747252583503723,
"alphanum_fraction": 0.791208803653717,
"avg_line_length": 35.400001525878906,
"blob_id": "88990740105508c4e450f57fe06c8cc7a32da3e9",
"content_id": "272a1f59838df7f9ae7e0098750db7349d880a65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 5,
"path": "/README.md",
"repo_name": "muhal-git/IAM-592-project",
"src_encoding": "UTF-8",
"text": "# IAM-592-project\n\nFor now, I am planning to implement (textbook)RSA algorithm and Hill Cipher.\n\nAt the end I want to make a console application for encrypted instant communication.\n"
}
] | 3 |
ashwinvaidya17/Unity-Perception-annotation-converter
|
https://github.com/ashwinvaidya17/Unity-Perception-annotation-converter
|
cd7563408f5c9046f80620f511277417c29a6aa4
|
0922733328bb2730f78348c7609b4375138fb99a
|
4154f1053ad00e1438983bec252030a4405c105c
|
refs/heads/main
| 2023-04-29T09:15:14.302081 | 2022-03-25T01:12:10 | 2022-03-25T01:12:10 | 339,083,536 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6645326614379883,
"alphanum_fraction": 0.6645326614379883,
"avg_line_length": 38.04999923706055,
"blob_id": "23ec7575c07617494857c7dd6b27cbaa80d4445a",
"content_id": "b0ee669152bb55d96fd821806cc34eb523fd5866",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 20,
"path": "/run.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "import argparse\nfrom converters import convert\n\n\nif __name__ == \"__main__\":\n parser = argparse.ArgumentParser(\"Convert data from Unity annotation to selected annotation format.\")\n parser.add_argument(\"--input_dir\", type=str, help=\"Path to dataset\", required=True)\n parser.add_argument(\n \"--input_format\",\n type=str,\n help=\"Format of the input dataset. Supported Formats are ['egocentric_food', 'unity_perception']\",\n default=\"unity_perception\",\n )\n parser.add_argument(\n \"--output_format\", type=str, help=\"Select between [coco, voc, simplified_detection]\", required=True\n )\n parser.add_argument(\"--output_dir\", type=str, help=\"Folder to save the annotations.\", default=\"./\")\n\n args = parser.parse_args()\n convert(args)\n"
},
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.71875,
"avg_line_length": 20.33333396911621,
"blob_id": "5cf105ee242c1f53222d5bc144b87cafe410a6db",
"content_id": "e732b5a065dffec940e2908b98bad77c070b1018",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 3,
"path": "/converters/__init__.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "from converters.converter import convert\n\n__all__ = [\"convert\"]\n"
},
{
"alpha_fraction": 0.5901027321815491,
"alphanum_fraction": 0.601307213306427,
"avg_line_length": 30.5,
"blob_id": "e6b75ef489b9091b7e97823635c5439de08be216",
"content_id": "ab849782c982b1b792529dac4526ab3967357188",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2142,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 68,
"path": "/converters/unity_perception_converters/simplified_detection_writer.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "\"\"\"Generates a simple annotation format for detection\n\noutput:\n annotations:\n 001.txt\n 002.txt\n .\n\n images:\n 001.jpg\n 002.jpg\n .\n \n dataset.csv\n\nannotation format\nclass_id x1 y1 x2 y2\n\ndataset.csv\nimg_num.jpg, label_num.txt\n\"\"\"\n\n\nfrom converters.unity_perception_converters import unity_annotations\nimport os\nfrom tqdm import tqdm\nfrom PIL import Image\nfrom glob import glob\nimport math\n\n\nclass SimplifiedDetectionWriter:\n def __init__(self, input_dir: str, output_dir: str):\n \"\"\"\n\n Args:\n input_dir (str): path to input dir\n output_dir (str): path to output dir\n \"\"\"\n\n self.input_dir = input_dir\n self.output_dir = output_dir\n self.unity_annotations = unity_annotations.load_unity_annotations(self.input_dir)\n\n def write(self):\n \"\"\"Write the output dataset\n \"\"\"\n\n print(f\"Found dataset of size {len(self.unity_annotations)}\")\n precision = math.ceil(math.log(len(self.unity_annotations), 10))\n\n os.makedirs(os.path.join(self.output_dir, \"annotations\"), exist_ok=True)\n os.makedirs(os.path.join(self.output_dir, \"images\"), exist_ok=True)\n\n annotation_counter = 0\n with open(os.path.join(self.output_dir, \"dataset.csv\"), \"w\") as csv_file:\n for annotation in tqdm(self.unity_annotations):\n img = Image.open(os.path.join(self.input_dir, annotation[\"filename\"]))\n img.save(os.path.join(self.output_dir, \"images\", f\"{annotation_counter:0{precision}}.png\"), \"PNG\")\n with open(\n os.path.join(self.output_dir, \"annotations\", f\"{annotation_counter:0{precision}}.txt\"), \"w\"\n ) as ann_file:\n entries = unity_annotations.get_annotation_entry(annotation)\n for entry in entries:\n ann_file.write(f\"{entry['category_id']} {' '.join([str(num) for num in entry['bbox']])}\\n\")\n\n csv_file.write(f\"{annotation_counter:0{precision}}.png,{annotation_counter:0{precision}}.txt\\n\")\n annotation_counter += 1\n"
},
{
"alpha_fraction": 0.7491165995597839,
"alphanum_fraction": 0.7491165995597839,
"avg_line_length": 14.297297477722168,
"blob_id": "8363904c198cc03b2c54d068d77f8bd49f79dd8c",
"content_id": "c16e0a23101cd18b7b18d054246db33c83e466ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 566,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 37,
"path": "/README.md",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "# Annotation Converters\n\n## Supported source datasets\n\n- Egocentric Food\n\n- Unity Perception \n\n## Egocentric Food\n---\n\nConvert Egocentric Food dataset to common annotation formats.\n\n\n### Supported Formats:\n\n- [] VOC\n\n## Unity Perception annotation converter\n---\n\nConvert Unity Perception dataset format to common annotation formats.\n\nCurrently supports only single object detection.\n\n\n### Supported Formats:\n\n- [x] COCO\n\n- [x] VOC (supports multiple objects as well)\n\n- [x] Simplified Detection Annotation Format\n\n### Limitations\n\nDoes not support segmentation yet.\n"
},
{
"alpha_fraction": 0.5752608180046082,
"alphanum_fraction": 0.5838301181793213,
"avg_line_length": 38.47058868408203,
"blob_id": "962a8645f3c7daf89aedcde22ebd69d892260c5d",
"content_id": "84dd22e9968247699ff0191a67bd0c08fbccb0d9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2684,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 68,
"path": "/converters/unity_perception_converters/coco_writer.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nfrom datetime import datetime\nfrom typing import List, Tuple\n\nfrom converters.unity_perception_converters import unity_annotations\n\n\nclass COCOWriter:\n def __init__(self, input_dir: str, output_dir: str, splits: List = [0.8, 0.1, 0.1]) -> None:\n \"\"\"\n input_dir: path to unity dataset\n output_dir: directory in which to write\n splits: How to split the dataset. By default 80% is taken for training, 10 % for validation and 10% for testing\n \"\"\"\n self.input_dir = input_dir\n self.unity_annotations = unity_annotations.load_unity_annotations(self.input_dir)\n self.output_dir = output_dir\n self.splits = splits\n self.img_height, self.img_width, _ = unity_annotations.get_image_dims(self.input_dir, self.unity_annotations)\n\n def get_info_field(self):\n header = {}\n header[\"year\"] = datetime.now().year\n header[\"version\"] = \"1.0\"\n header[\"description\"] = \"Unity perception dataset\"\n header[\"Contributor\"] = \"contributor\"\n header[\"url\"] = \"\"\n header[\"date_created\"] = str(datetime.date(datetime.now()))\n return header\n\n def write(self):\n\n os.makedirs(os.path.join(self.output_dir, \"annotations\"), exist_ok=True)\n\n input_data_len = len(self.unity_annotations)\n # TODO add shuffle to splits\n train_split = self.unity_annotations[: int(self.splits[0] * input_data_len)]\n val_split = self.unity_annotations[\n int(self.splits[0] * input_data_len) : int(self.splits[0] * input_data_len)\n + int(self.splits[1] * input_data_len)\n ]\n test_split = self.unity_annotations[\n int((self.splits[0] + self.splits[1]) * input_data_len) : int(\n (self.splits[0] + self.splits[1]) * input_data_len\n )\n + int(self.splits[2] * input_data_len)\n ]\n\n for split in [\"train\", \"val\", \"test\"]:\n if split == \"train\":\n annotations = train_split\n elif split == \"val\":\n annotations = val_split\n else:\n annotations = test_split\n\n data = {}\n data[\"info\"] = self.get_info_field()\n data[\"images\"] = []\n data[\"annotations\"] = []\n\n for annotation in annotations:\n data[\"images\"].append(unity_annotations.get_image_entry(self.img_width, self.img_height, annotation))\n data[\"annotations\"].extend(unity_annotations.get_annotation_entry(annotation))\n\n with open(os.path.join(self.output_dir, \"annotations\", f\"{split}.json\"), \"w\") as f:\n json.dump(data, f)\n"
},
{
"alpha_fraction": 0.7050078511238098,
"alphanum_fraction": 0.7050078511238098,
"avg_line_length": 35.514286041259766,
"blob_id": "06d4ec86eea9f745d26bfa26085d59234df882b6",
"content_id": "deeb2c4ea5c97c170f6c3a826de0cf0f4a624276",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1278,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 35,
"path": "/converters/converter.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "from converters import unity_perception_converters, egocentric_food_converters\n\n\ndef unity_converter(args) -> None:\n\n output_format = args.output_format\n if output_format == \"coco\":\n writer = unity_perception_converters.COCOWriter(args.input_dir, args.output_dir)\n elif output_format == \"simplified_detection\":\n writer = unity_perception_converters.SimplifiedDetectionWriter(args.input_dir, args.output_dir)\n elif output_format == \"voc\":\n writer = unity_perception_converters.VOCWriter(args.input_dir, args.output_dir)\n else:\n raise NotImplementedError(f\"Output format {output_format} not supported yet.\")\n\n writer.write()\n\n\ndef egocentric_food_converter(args) -> None:\n output_format = args.output_format\n if output_format == \"voc\":\n writer = egocentric_food_converters.VOCWriter(args.input_dir, args.output_dir)\n else:\n raise NotImplementedError(f\"Output format {output_format} not supported yet.\")\n\n writer.write()\n\n\ndef convert(args):\n if args.input_format == \"unity_perception\":\n unity_converter(args)\n elif args.input_format == \"egocentric_food\":\n egocentric_food_converter(args)\n else:\n raise NotImplementedError(f\"Input format {args.input_format} not supported yet.\")\n"
},
{
"alpha_fraction": 0.846394956111908,
"alphanum_fraction": 0.846394956111908,
"avg_line_length": 62.79999923706055,
"blob_id": "b75e5a78b04549459da25d81151ab47ec6538fbc",
"content_id": "ff89a810657b716c84dc37a40e7c74b2d4c40b4e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 319,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 5,
"path": "/converters/unity_perception_converters/__init__.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "from converters.unity_perception_converters.coco_writer import COCOWriter\nfrom converters.unity_perception_converters.simplified_detection_writer import SimplifiedDetectionWriter\nfrom converters.unity_perception_converters.voc_writer import VOCWriter\n\n__all__ = [\"COCOWriter\", \"SimplifiedDetectionWriter\", \"VOCWriter\"]\n"
},
{
"alpha_fraction": 0.47819313406944275,
"alphanum_fraction": 0.48531374335289,
"avg_line_length": 44.39393997192383,
"blob_id": "4858710a541e30a6d28e44901ba31e8c2178f2a1",
"content_id": "a6a35c30dc66526ad74b074f9bf70f2fd00a313d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4494,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 99,
"path": "/converters/unity_perception_converters/voc_writer.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "import os\nfrom typing import List\n\nfrom PIL import Image\nfrom tqdm import tqdm\n\nfrom converters.unity_perception_converters import unity_annotations\n\n\nclass VOCWriter:\n def __init__(self, input_dir: str, output_dir: str, splits: List = [0.8, 0.1, 0.1]) -> None:\n \"\"\"\n input_dir: path to unity dataset\n output_dir: directory in which to write\n splits: How to split the dataset. By default 80% is taken for training, 10 % for validation and 10% for testing\n \"\"\"\n self.input_dir = input_dir\n self.unity_annotations = unity_annotations.load_unity_annotations(self.input_dir)\n self.output_dir = output_dir\n self.splits = splits\n self.img_height, self.img_width, _ = unity_annotations.get_image_dims(self.input_dir, self.unity_annotations)\n\n def write(self):\n \"\"\"write the output dataset\n \"\"\"\n\n print(f\"Found dataset of size {len(self.unity_annotations)}\")\n\n os.makedirs(os.path.join(self.output_dir, \"Annotations\"), exist_ok=True)\n os.makedirs(os.path.join(self.output_dir, \"JPEGImages\"), exist_ok=True)\n os.makedirs(os.path.join(self.output_dir, \"ImageSets\", \"Main\"), exist_ok=True)\n\n input_data_len = len(self.unity_annotations)\n # TODO add shuffle to splits\n train_split = self.unity_annotations[: int(self.splits[0] * input_data_len)]\n val_split = self.unity_annotations[\n int(self.splits[0] * input_data_len) : int(self.splits[0] * input_data_len)\n + int(self.splits[1] * input_data_len)\n ]\n test_split = self.unity_annotations[\n int((self.splits[0] + self.splits[1]) * input_data_len) : int(\n (self.splits[0] + self.splits[1]) * input_data_len\n )\n + int(self.splits[2] * input_data_len)\n ]\n\n for split in [\"train\", \"val\", \"test\"]:\n if split == \"train\":\n annotations = train_split\n elif split == \"val\":\n annotations = val_split\n else:\n annotations = test_split\n\n for annotation in tqdm(annotations):\n img = Image.open(os.path.join(self.input_dir, annotation[\"filename\"]))\n filename = os.path.split(annotation[\"filename\"])[-1].split(\".\")[0]\n img = img.convert(\"RGB\")\n # save image as jpeg. Not really necessary.\n img.save(os.path.join(self.output_dir, \"JPEGImages\", f\"{filename}.jpg\"), \"JPEG\")\n data = f\"\"\"<annotation>\n <floder>{os.path.split(self.output_dir)[-1]}</folder>\n <filename>{os.path.split(annotation['filename'])[-1]}\n <source>\n <database>Generated Data</database>\n <annotation>PASCAL VOC2007</annotation>\n <image>unity perception</image>\n </source>\n <size>\n <width>{self.img_width}</width>\n <height>{self.img_height}</height>\n <depth>3</depth>\n </size>\n \"\"\"\n categories = set()\n for obj in annotation[\"annotations\"][0][\"values\"]:\n categories.add(obj[\"label_name\"])\n data += f\"\"\"<object>\n <name>{obj['label_name']}</name>\n <bndbox>\n <xmin>{int(obj['x'])}</xmin>\n <ymin>{int(obj['y'])}</ymin>\n <xmax>{int(obj['x'] + obj['width'])}</xmax>\n <ymax>{int(obj['y'] + obj['height'])}</ymax>\n </bndbox>\n </object>\n \"\"\"\n\n data += \"</annotation>\"\n # write to annotation file\n with open(os.path.join(self.output_dir, \"Annotations\", filename + \".xml\"), \"w\") as annf:\n annf.write(data)\n\n # write to category file\n for category in categories:\n with open(\n os.path.join(self.output_dir, \"ImageSets\", \"Main\", f\"{category}_{split}.txt\"), \"a\"\n ) as imgsetf:\n imgsetf.write(f\"{filename} 1\\n\")\n"
},
{
"alpha_fraction": 0.7708333134651184,
"alphanum_fraction": 0.7708333134651184,
"avg_line_length": 31,
"blob_id": "7abc87d5f060ad87667abdeef2f6fc186c7176e7",
"content_id": "ac0ff533c992fa6c59776eaf52e8791fac33f534",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 96,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 3,
"path": "/converters/egocentric_food_converters/__init__.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "from converters.egocentric_food_converters.voc_writer import VOCWriter\n\n__all__ = [\"VOCWriter\"]\n"
},
{
"alpha_fraction": 0.49849268794059753,
"alphanum_fraction": 0.5017226338386536,
"avg_line_length": 45.439998626708984,
"blob_id": "2690029d890dcbb256d4edc01633db9c51a11925",
"content_id": "eaa9633e175c8bc390caaf1f5d5fa58c95d3da3a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4644,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 100,
"path": "/converters/egocentric_food_converters/voc_writer.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "from tqdm import tqdm\nfrom typing import Dict, List\nimport os\nfrom PIL import Image\nfrom converters.egocentric_food_converters.egocentric_food_annotation import get_categories, load_annotations\nfrom math import ceil\n\n\nclass VOCWriter:\n def __init__(self, input_dir: str, output_dir: str) -> None:\n \"\"\"\n input_dir: path to unity dataset\n output_dir: directory in which to write\n \"\"\"\n self.input_dir = input_dir\n self.output_dir = output_dir\n self.categories: Dict = get_categories(input_dir)\n\n def collect_annotations(self, split: str) -> Dict:\n \"\"\"Since a bounding box is in a single line, this function collects all the annotations in a single dict.\n The assumption is that there is only one category per image\"\"\"\n\n collected_annotations = {}\n annotations = load_annotations(self.input_dir, split)\n print(f\"Found {split} set of length {len(annotations)}\")\n print(\"Loading annotations\")\n for annotation in tqdm(annotations):\n orig_image_name = annotation[0].split(\"/\")[-1]\n category_id = annotation[1]\n img = Image.open(os.path.join(self.input_dir, category_id, orig_image_name))\n img = img.convert(\"RGB\")\n img_width, img_height = img.size\n filename = f\"{category_id}_{orig_image_name}\" # use this filename to save\n if filename not in collected_annotations.keys():\n collected_annotations[filename] = {\n \"img_width\": img_width,\n \"img_height\": img_height,\n \"original_filename\": orig_image_name,\n \"category\": category_id,\n \"bounding_boxes\": [],\n }\n\n collected_annotations[filename][\"bounding_boxes\"].append([ceil(float(x)) for x in annotation[2:]])\n\n return collected_annotations\n\n def write(self):\n \"\"\"write the output dataset\n \"\"\"\n os.makedirs(os.path.join(self.output_dir, \"Annotations\"), exist_ok=True)\n os.makedirs(os.path.join(self.output_dir, \"JPEGImages\"), exist_ok=True)\n os.makedirs(os.path.join(self.output_dir, \"ImageSets\", \"Main\"), exist_ok=True)\n\n for split in [\"val\", \"test\", \"train\"]:\n annotations = self.collect_annotations(split)\n\n print(\"Writing annotations\")\n for key, annotation in tqdm(annotations.items()):\n img = Image.open(\n os.path.join(self.input_dir, annotation[\"category\"], annotation[\"original_filename\"])\n )\n img = img.convert(\"RGB\")\n # add category id to filename so that images with the same name are not overwritten\n img.save(os.path.join(self.output_dir, \"JPEGImages\", key), \"JPEG\")\n data = f\"\"\"<annotation>\n <floder>{os.path.split(self.output_dir)[-1]}</folder>\n <filename>{key}</filename>\n <source>\n <database>Generated Data</database>\n <annotation>PASCAL VOC2007</annotation>\n <image>Egocentric Food</image>\n </source>\n <size>\n <width>{annotation['img_width']}</width>\n <height>{annotation['img_height']}</height>\n <depth>3</depth>\n </size>\n \"\"\"\n for obj in annotation[\"bounding_boxes\"]:\n data += f\"\"\"<object>\n <name>{self.categories[annotation['category']]}</name>\n <bndbox>\n <xmin>{int(obj[0])}</xmin>\n <ymin>{int(obj[1])}</ymin>\n <xmax>{int(obj[2])}</xmax>\n <ymax>{int(obj[3])}</ymax>\n </bndbox>\n </object>\n \"\"\"\n\n data += \"</annotation>\"\n # write to annotation file\n with open(os.path.join(self.output_dir, \"Annotations\", key + \".xml\"), \"w\") as annf:\n annf.write(data)\n\n # write to category file\n with open(\n os.path.join(self.output_dir, \"ImageSets\", \"Main\", f\"{self.categories[annotation['category']]}_{split}.txt\"), \"a\"\n ) as imgsetf:\n imgsetf.write(f\"{key} 1\\n\")\n"
},
{
"alpha_fraction": 0.6028767824172974,
"alphanum_fraction": 0.6078799366950989,
"avg_line_length": 26.568965911865234,
"blob_id": "1fb81f0d40c3a1a1fe39660a9997404b6b81196b",
"content_id": "8952d13ca68eeac64210e31281f4fd7f594257e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1599,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 58,
"path": "/converters/unity_perception_converters/unity_annotations.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "\"\"\"Common functions for handling Unity Annotations\"\"\"\n\nimport glob\nimport json\nimport os\nfrom typing import Dict, List, Tuple\n\nimport cv2\n\n\ndef load_unity_annotations(data_path) -> List:\n annotations = []\n\n annotation_files = glob.glob(os.path.join(data_path, \"Dataset*\", \"captures*.json\"))\n for annotation_file in annotation_files:\n with open(annotation_file, \"r\") as f:\n annotation = json.load(f)\n annotations.extend(annotation[\"captures\"])\n\n return annotations\n\n\ndef get_image_dims(input_dir: str, annotations: List[Dict]) -> Tuple:\n \"\"\"gets the size of the image. The assumption is that all the images are of the same size\n \n :return: Tuple(width, height, channels)\n \"\"\"\n img_path = annotations[0][\"filename\"]\n img = cv2.imread(os.path.join(input_dir, img_path))\n return img.shape\n\n\ndef get_image_entry(img_width: int, img_height: int, annotation: Dict):\n entry = {}\n entry[\"id\"] = annotation[\"id\"]\n entry[\"width\"] = img_width\n entry[\"height\"] = img_height\n entry[\"filename\"] = annotation[\"filename\"]\n\n return entry\n\n\ndef get_annotation_entry(annotation: Dict):\n entries = []\n for anns in annotation[\"annotations\"]:\n entry = {}\n entry[\"image_id\"] = annotation[\"id\"]\n entry[\"bbox\"] = [\n anns[\"values\"][0][\"x\"],\n anns[\"values\"][0][\"y\"],\n anns[\"values\"][0][\"width\"],\n anns[\"values\"][0][\"height\"],\n ]\n entry[\"id\"] = anns[\"id\"]\n entry[\"category_id\"] = anns[\"values\"][0][\"label_id\"]\n\n entries.append(entry)\n return entries\n"
},
{
"alpha_fraction": 0.6220858693122864,
"alphanum_fraction": 0.6233128905296326,
"avg_line_length": 29.185184478759766,
"blob_id": "878979413dcbcfe61ddadc4b5a4f8888a5d025f4",
"content_id": "69e705372a598d45e2a129d53a7f5ebaa61ad6dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 815,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 27,
"path": "/converters/egocentric_food_converters/egocentric_food_annotation.py",
"repo_name": "ashwinvaidya17/Unity-Perception-annotation-converter",
"src_encoding": "UTF-8",
"text": "\"\"\"Functions for loading egocentric food annotation\"\"\"\nfrom typing import Dict, List\nimport os\n\n\ndef load_annotations(data_path: str, split: str) -> List:\n annotations = []\n\n with open(os.path.join(data_path, f\"{split}_list.txt\"), \"r\") as f:\n data = f.readlines()\n # split each column in a line and store in a separate list\n annotations = [a.split() for a in data]\n\n # first line contains column names which we are not interested in\n return annotations[1:]\n\n\ndef get_categories(data_path: str) -> Dict:\n categories = {}\n with open(os.path.join(data_path, \"category.txt\"), \"r\") as f:\n data = f.readlines()\n for entry in data:\n k, v = entry.split()\n categories[k] = v\n\n categories.pop(\"id\") # remove the headers\n return categories\n"
}
] | 12 |
DisneyAladdin/Titanic
|
https://github.com/DisneyAladdin/Titanic
|
a0bc75833e3219173f001d17994a46c8a78966d5
|
ca4cc627e0cb36feebea5da2b9978cb1aecba7ad
|
0dd20161e584e6db6d3763814c861b49248adf6a
|
refs/heads/master
| 2022-02-10T18:31:00.624641 | 2019-08-15T05:37:06 | 2019-08-15T05:37:06 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6979591846466064,
"alphanum_fraction": 0.7088435292243958,
"avg_line_length": 28.399999618530273,
"blob_id": "01546a1e48ac18d9fec82838a38b3f017f0412fe",
"content_id": "45194c163436d7cfa046afbb6877b1aab621d973",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1504,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 50,
"path": "/test.py",
"repo_name": "DisneyAladdin/Titanic",
"src_encoding": "UTF-8",
"text": "#coding:utf-8\nimport pandas as pd\ndf = pd.read_csv('input/train.csv')\n#print (df)\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n\n\n#matplotlib inline\n#sns.countplot(data=df)\nfrom sklearn.model_selection import train_test_split\n#欠損値処理\ndf['Fare'] = df['Fare'].fillna(df['Fare'].median())\ndf['Age'] = df['Age'].fillna(df['Age'].median())\ndf['Embarked'] = df['Embarked'].fillna('S')\n\n#カテゴリ変数の変換\ndf['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0)\ndf['Embarked'] = df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int)\n\ndf = df.drop(['Cabin','Name','PassengerId','Ticket'],axis=1)\ntrain_X = df.drop('Survived', axis=1)\ntrain_y = df.Survived\n(train_X, test_X ,train_y, test_y) = train_test_split(train_X, train_y, test_size = 0.3, random_state = 666)\n\nfrom sklearn.tree import DecisionTreeClassifier\nclf = DecisionTreeClassifier(random_state=0)\nclf = clf.fit(train_X, train_y)\npred = clf.predict(test_X)\n\n\nfrom sklearn.metrics import (roc_curve, auc, accuracy_score)\n\npred = clf.predict(test_X)\nfpr, tpr, thresholds = roc_curve(test_y, pred, pos_label=1)\nauc(fpr, tpr)\naccuracy_score(pred, test_y)\n\n\n#可視化\nimport pydotplus\nfrom IPython.display import Image\nfrom graphviz import Digraph\nfrom sklearn.externals.six import StringIO\n\ndot_data = StringIO()\ntree.export_graphviz(clf, out_file=dot_data,feature_names=train_X.columns, max_depth=3)\ngraph = pydotplus.graph_from_dot_data(dot_data.getvalue())\ngraph.write_pdf(\"graph.pdf\")\nImage(graph.create_png())\n"
}
] | 1 |
SiddharthaAnand/competitive-programming-core-skills
|
https://github.com/SiddharthaAnand/competitive-programming-core-skills
|
f28623fa528e3cb8daa195511c0ded10bbd0f8ba
|
3728f6d19def3ee75ec9557b8f164cf75bb54c7a
|
4b603b90303d0f360009a92f93615158a048b148
|
refs/heads/master
| 2023-02-19T01:12:38.572413 | 2021-01-21T16:29:07 | 2021-01-21T16:29:07 | 331,335,718 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.48834627866744995,
"alphanum_fraction": 0.49611541628837585,
"avg_line_length": 15.703703880310059,
"blob_id": "f3504082a3cbf7aa2c7ad86f1eb9822877b5e168",
"content_id": "50c75f56a08e54acd42ae02baee52c955be6a771",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 901,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 54,
"path": "/1-b-erasing_maximum/erasing_maximum.py3",
"repo_name": "SiddharthaAnand/competitive-programming-core-skills",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport sys\n\n\ndef get_max(inp):\n if inp is None:\n return inp\n return max(inp)\n\n\ndef count_max(inp, _max):\n if inp is None or _max is None:\n return inp\n count = 0\n for i in inp:\n if i == _max:\n count += 1\n return count\n\n\ndef get_index(inp, _max, which_no):\n i = 0\n for x in range(len(inp)):\n if inp[x] == _max:\n i += 1\n if i == which_no:\n return x\n\n\ndef solution(inp):\n if inp is None:\n return inp\n count = count_max(inp, get_max(inp))\n idx = inp.index(get_max(inp))\n if count > 1:\n idx = get_index(inp, get_max(inp), 3)\n del inp[idx]\n return inp\n\n\ndef main():\n n = int(input())\n a = list(map(int, input().split()))\n\n result = solution(inp=a)\n\n # your code\n\n print(\" \".join(map(str,result)))\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.7425287365913391,
"alphanum_fraction": 0.7747126221656799,
"avg_line_length": 32.53845977783203,
"blob_id": "ca399428174bc36a65023ff3bb4a53f7f10296ae",
"content_id": "a77b4dcb04740c9b9fc82c3eabb4da6741ca1d0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 13,
"path": "/README.md",
"repo_name": "SiddharthaAnand/competitive-programming-core-skills",
"src_encoding": "UTF-8",
"text": "# Competitive Programming Core Skills\nhttps://www.coursera.org/learn/competitive-programming-core-skills\n\nFollowing the assignments and some commentary on the solutions.\n\n## Increment | Week 1\nGiven a large non-negative integer x, find the number of decimal digits in x + 1.\nInput\nA non-negative integer x (0 ≤ x ≤ 101 000 000) with no leading zeroes.\nOutput\nThe number of decimal digits in x + 1.\n\nSolution: 1-c-increment/increment.py"
},
{
"alpha_fraction": 0.5512820482254028,
"alphanum_fraction": 0.5759368538856506,
"avg_line_length": 20.14583396911621,
"blob_id": "fec9f812ab81fc44e60b6f029463fb77e5ccdd47",
"content_id": "b4ce6546d6eaca7c4eb9493f5a4cca28c8369f33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1018,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 48,
"path": "/1-c-increment/increment.py3",
"repo_name": "SiddharthaAnand/competitive-programming-core-skills",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nGiven a large non-negative integer x, find the number of decimal digits in x + 1.\nInput\nA non-negative integer x (0 ≤ x ≤ 101 000 000) with no leading zeroes.\nOutput\nThe number of decimal digits in x + 1.\n\"\"\"\n\ndef count_digit(number, digit=-1):\n if digit == -1 or number is None:\n return -1\n count = 0\n for i in str(number):\n if i == str(digit):\n count += 1\n return count\n\n\ndef total_digits(x):\n nines = count_digit(x, digit=9)\n if nines == len(x):\n return len(x) + 1\n return len(x)\n\n\ndef solution(x):\n \"\"\"\n Count the number of 9s present in x, if len(x) == number of nines, then (x+1) will have number of digits = len(x) +1\n else same as len(x)\n :param x: the input\n :return: total digits present in x + 1\n \"\"\"\n if x is None:\n return x\n return total_digits(x)\n\n\ndef main():\n x = map(str, input().split())\n\n result = solution(list(x)[0])\n\n print(result)\n\n\nif __name__ == '__main__':\n main()"
}
] | 3 |
abhinandam/time
|
https://github.com/abhinandam/time
|
0c4a12913467a77f7c6fd8515891fd85bd90b5c5
|
f586d1fcd2925680a8034f1ae82cb2caec836810
|
8e7814575d0a3e1a67410a8e96b84c00f10c7b32
|
refs/heads/master
| 2020-12-24T10:11:53.853364 | 2016-10-12T00:18:43 | 2016-10-12T00:18:43 | 73,095,219 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5898617506027222,
"alphanum_fraction": 0.6129032373428345,
"avg_line_length": 20.700000762939453,
"blob_id": "d3da9163e853e723193c61a591b3de1628e80cef",
"content_id": "ed5b1552753286afabadd3dc7de8f49cd9ea58ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 10,
"path": "/helloflask.py",
"repo_name": "abhinandam/time",
"src_encoding": "UTF-8",
"text": "import time\nfrom flask import Flask\napp = Flask(__name__)\n\[email protected](\"/\")\ndef hello():\n return \"The number of seconds since January 1st, 1970 is \" + str(int(time.time()))\n\nif __name__ == \"__main__\":\n app.run()\n"
}
] | 1 |
rogerhyam/shoreline
|
https://github.com/rogerhyam/shoreline
|
abe141d16d50aef183f6f3f1ca35d9c1522f26ed
|
002ba6092995cab4b427d35b4a8010eea195e581
|
99267cb6583453c1429d2be695f83bbb373ac9c0
|
refs/heads/master
| 2020-03-23T20:00:29.529055 | 2018-07-24T13:16:22 | 2018-07-24T13:16:22 | 142,015,401 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8040000200271606,
"avg_line_length": 26.66666603088379,
"blob_id": "d4d5469a4408f56433afe0b0e853e20074d707db",
"content_id": "92e17d46e07e5775b1716f2792b11a18d3ece707",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 9,
"path": "/README.md",
"repo_name": "rogerhyam/shoreline",
"src_encoding": "UTF-8",
"text": "# Shoreline Audio Player\n\nReally simple python script to play mp3 files in repsonse to button presses.\n\n## Make it into a service\n\nsudo cp shoreline_player.service /etc/systemd/system/shoreline_player.service\n\nsudo systemctl enable myscript.service\n\n"
},
{
"alpha_fraction": 0.6502793431282043,
"alphanum_fraction": 0.6581005454063416,
"avg_line_length": 26.9375,
"blob_id": "24a2e7afcbb22caca8bac6cb839b994d60f9e9de",
"content_id": "325488de4e22afd58a8350b7d92653018a4d89b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 32,
"path": "/player.py",
"repo_name": "rogerhyam/shoreline",
"src_encoding": "UTF-8",
"text": "import pygame\nimport os\n\nos.environ[\"SDL_VIDEODRIVER\"] = \"dummy\"\npygame.init()\n\npygame.joystick.init()\njs =pygame.joystick.Joystick(0)\njs.init()\n\npygame.mixer.init()\n\ndef playTrack(track_id):\n pygame.mixer.music.load('mp3/' + str(track_id) + '.mp3')\n pygame.mixer.music.set_volume(1.0)\n print('mp3/' + str(track_id) + '.mp3')\n print(pygame.mixer.music.get_volume())\n pygame.mixer.music.play()\n\n\ndone = False\n\nwhile done==False:\n # EVENT PROCESSING STEP\n for event in pygame.event.get(): # User did something \n # Possible joystick actions: JOYAXISMOTION JOYBALLMOTION JOYBUTTONDOWN JOYBUTTONUP JOYHATMOTION\n if event.type == pygame.JOYBUTTONDOWN:\n print(\"Joystick button pressed.\")\n if event.type == pygame.JOYBUTTONUP:\n print(\"Joystick button released.\")\n print(event.button)\n playTrack(event.button)\n\n"
}
] | 2 |
AbhishekKumarSingh07/Jarvis
|
https://github.com/AbhishekKumarSingh07/Jarvis
|
a623c811884935573e5b17f35a87554a9054a806
|
2cdc3dd1c35103388b01362a9736540a813f28a4
|
790235e74a2393b25ca8a2df2d58dd5d2a703d9f
|
refs/heads/main
| 2023-04-26T21:15:38.604923 | 2021-05-31T20:18:37 | 2021-05-31T20:18:37 | 372,168,783 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5429930686950684,
"alphanum_fraction": 0.548115611076355,
"avg_line_length": 25.606060028076172,
"blob_id": "2be3a66e80a760d1c446902b3c85de5aade066f8",
"content_id": "1dc52f61960f8228d01b638a4add06cb02c5ff11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2733,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 99,
"path": "/app.py",
"repo_name": "AbhishekKumarSingh07/Jarvis",
"src_encoding": "UTF-8",
"text": "import pyttsx3\r\nimport speech_recognition as sr\r\nimport time\r\nimport sys\r\nfrom flask import Flask, render_template, request, redirect\r\n\r\napp = Flask(__name__)\r\n\r\n\r\ndef activatejarvis():\r\n global command\r\n command = listen_jarvis()\r\n speak(command)\r\n\r\n\r\ndef callback(recognizer, audio): # this is called from the background thread\r\n global stop_it\r\n global statusJarvis\r\n global voice\r\n try:\r\n text = recognizer.recognize_google(audio)\r\n print(\"You said \" + text)\r\n if 'jarvis' in text.lower() or 'jarvis' == text.lower():\r\n statusJarvis = True\r\n activatejarvis()\r\n elif text.lower() == 'terminate':\r\n voice(wait_for_stop=False)\r\n\r\n except:\r\n pass\r\n\r\n\r\ndef listen_jarvis():\r\n listener = sr.Recognizer()\r\n op = \" \"\r\n try:\r\n with sr.Microphone() as source:\r\n listener.adjust_for_ambient_noise(source)\r\n print('Listening You: ')\r\n voice = listener.listen(source, timeout=3)\r\n op = listener.recognize_google(voice)\r\n except Exception as e:\r\n print(e)\r\n return 'error'\r\n return op\r\n\r\n\r\ndef speak(data):\r\n engine = pyttsx3.init('sapi5')\r\n voices = engine.getProperty('voices')\r\n engine.setProperty('voice', voices[0].id)\r\n engine.setProperty('rate', 170)\r\n if data == '0':\r\n engine.say(\"Yes Abhishek, How can I help you\")\r\n engine.runAndWait()\r\n else:\r\n engine.say(data)\r\n engine.runAndWait()\r\n\r\n\r\[email protected](\"/\", methods=[\"GET\", \"POST\"])\r\ndef index(name=\"\", data=\"\"):\r\n global stop_it\r\n global statusJarvis\r\n global command\r\n global voice\r\n if request.method == \"POST\" and name == \"\":\r\n print(\"listening now: \")\r\n voice = listener.listen_in_background(source, callback)\r\n while True:\r\n if statusJarvis:\r\n return render_template('index.html',\r\n name='activate',\r\n data=\"I can Listening Whole Day, I Am Captain Jarvis: \")\r\n\r\n time.sleep(0.1)\r\n\r\n return render_template('index.html', name=name)\r\n\r\n\r\nif __name__ == \"__main__\":\r\n stop_it = False\r\n statusJarvis = False\r\n command = \"\"\r\n listener = sr.Recognizer()\r\n source = sr.Microphone()\r\n app.run(debug=True, threaded=True)\r\n # print(\"listening now: \")\r\n # voice = listener.listen_in_background(source, callback)\r\n # while True:\r\n # if speakJarvis:\r\n # speakJarvis = False\r\n # speak('0')\r\n # k = listen_jarvis()\r\n # print(k)\r\n # if stop_it:\r\n # voice(wait_for_stop=False)\r\n # break\r\n # time.sleep(0.1)\r\n"
},
{
"alpha_fraction": 0.5745223164558411,
"alphanum_fraction": 0.7414012551307678,
"avg_line_length": 18.625,
"blob_id": "515494b3b24c3e90f665acdd9ced145549da1c2a",
"content_id": "a4229e8b2dc0004e76025cc68f7cb5fa0cff1719",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 40,
"path": "/requirements.txt",
"repo_name": "AbhishekKumarSingh07/Jarvis",
"src_encoding": "UTF-8",
"text": "Flask==2.0.1\ngunicorn==20.1.0\nheroku==0.1.4\npackaging==20.9\npipwin==0.5.1\npsutil==5.5.1\nPyAudio==0.2.11\npyinstaller==4.2\npyinstaller-hooks-contrib==2020.11\npySmartDL==1.3.4\npython-dateutil==1.5\npython-xlib==0.23\npyttsx3==2.71\npytz==2019.3\npyxdg==0.26\nPyYAML==5.3.1\nreportlab==3.5.34\nrequests==2.22.0\nrequests-oauthlib==1.0.0\nrequests-unixsocket==0.2.0\nscp==0.13.0\nSecretStorage==2.3.1\nsimplejson==3.16.0\nsix==1.14.0\nsnowballstemmer==2.1.0\nsoupsieve==2.2.1\nSpeechRecognition==3.8.1\nSphinx==4.0.2\nsphinxcontrib-applehelp==1.0.2\nsphinxcontrib-devhelp==1.0.2\nsphinxcontrib-htmlhelp==2.0.0\nsphinxcontrib-jsmath==1.0.1\nsphinxcontrib-qthelp==1.0.3\nsphinxcontrib-serializinghtml==1.1.5\nsshtunnel==0.1.4\nsystemd-python==234\ntabulate==0.8.6\ntzlocal==2.1\nwebsocket-client==0.53.0\nWerkzeug==2.0.1\n"
}
] | 2 |
solbi823/Artificial_intelligence
|
https://github.com/solbi823/Artificial_intelligence
|
6fa7f42f157faa7cb8d64515ec6a3312d29e35ee
|
ed130e846e62e7e779a7bef4af9bee19b75ce8ab
|
da43aa115dd99303cd2d2e8527dbe406bd05a87b
|
refs/heads/master
| 2020-04-01T10:40:04.337212 | 2018-11-25T02:46:17 | 2018-11-25T02:46:17 | 153,126,377 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6196268200874329,
"alphanum_fraction": 0.6339553594589233,
"avg_line_length": 20.35943031311035,
"blob_id": "58f39518e282c676993c9578beef994cf2662d0c",
"content_id": "7ae5a73b909f8b4383a0cecbed2c7228c1d1f683",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6612,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 281,
"path": "/assignment2/2016026026_assignment_2.py",
"repo_name": "solbi823/Artificial_intelligence",
"src_encoding": "UTF-8",
"text": "# 인공지능 assignment2\n# 2016026026 컴퓨터전공 최솔비\n\nfrom konlpy.tag import Mecab\nimport sys\nimport os\nimport string\nimport math\n\npos_cnt = 0\nneg_cnt = 0\npos_word_cnt = 0\nneg_word_cnt = 0\npos_words = {}\nneg_words = {}\n\n\n# 각 단어의 긍정빈도 혹은 부정빈도(확률)를 로그를 취한 값으로 리턴합니다. \ndef caculate_prob(bool, word):\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words\n\n\tif bool == 1:\n\t\ttotal = pos_word_cnt\n\t\tdic = pos_words\n\n\telse:\n\t\ttotal = neg_word_cnt\n\t\tdic = neg_words\n\n\t# test case 에서 처음 등장한 단어의 확률을 계산할때 0을 곱하게 되는 것을 방지하기 위해(혹은 로그0 계산)\n\t# 적당히 작은 상수 k를 분자와 분모에 더해줍니다. \n\tk = 0.5\n\n\tif dic.get(word) == None:\n\t\tv = 0\n\telse:\n\t\tv = dic[word]\n\n\n\treturn ( math.log(k + float(v)) - math.log(2.0 * k + float(total)) )\n\n\ndef dic_input(dic, word):\n\tif dic.get(word) == None:\n\t\tdic[word] = 1\n\n\telse:\n\t\tdic[word] += 1\n\n\n#train 파일을 읽어 단어의 개수를 세어 dictionary형태로 저장합니다. \ndef read_train_file(path):\n\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words, pos_cnt, neg_cnt\n\n\tmecab = Mecab()\n\tf = open(os.path.expanduser(path))\n\tline = f.readline()\n\n\tnumber = 0\n\n\twhile True :\n\n\t\tnumber += 1\n\t\tif number % 1000 == 0:\n\t\t\tprint(\"line: \", number)\n\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tbreak\n\t\tline = line.rstrip('\\n')\n\n\t\t# lineSplited[0]에는 id, [1]에는 text, [2]에는 긍정('1') 또는 부정('0')\n\t\tlineSplited = line.split('\\t')\n\n\t\t# 형태소 단위로 분석합니다.\n\t\tanalyzedLine = mecab.morphs(lineSplited[1])\n\t\t# print(analyzedLine)\n\n\t\t# 긍정적인 comment 일 경우, 긍정 딕셔너리에 input 하여 word counting 합니다. \n\t\tif lineSplited[2] == '1':\n\t\t\tpos_cnt += 1\n\t\t\tfor word in analyzedLine:\n\t\t\t\tpos_word_cnt += 1\n\t\t\t\tdic_input(pos_words, word)\n\n\t\t# 부정적인 comment 일 경우, 부정 딕셔너리에 input 하여 word counting 합니다.\n\t\telif lineSplited[2] == '0':\n\t\t\tneg_cnt += 1\n\t\t\tfor word in analyzedLine:\n\t\t\t\tneg_word_cnt += 1\n\t\t\t\tdic_input(neg_words, word)\n\n\t\telse:\n\t\t\tprint(\"parse error\")\n\t\t\tbreak\n\n\n\tprint(\"POS:\", pos_word_cnt)\n\t#print(pos_words)\n\tprint(\"NEG:\", neg_word_cnt)\n\t#print(neg_words)\n\n\tf.close()\n\n# 분석한 train file 의 결과를 텍스트 파일로 저장합니다. \ndef save_train_result(path):\n\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words, pos_cnt, neg_cnt\n\n\tf = open(os.path.expanduser(path), 'w')\n\n\tf.write(str(pos_cnt)+\" \"+str(neg_cnt)+\"\\n\")\n\tf.write(str(pos_word_cnt)+\" \"+str(neg_word_cnt)+\"\\n\")\n\tfor word in pos_words.keys():\n\t\tf.write(word+\" \"+str(pos_words[word])+\"\\t\")\n\tf.write(\"\\n\")\n\tfor word in neg_words.keys():\n\t\tf.write(word+\" \"+str(neg_words[word])+\"\\t\")\n\n\tf.close()\n\n# 텍스트 파일로 저장된 train 결과를 읽어 메모리에 올립니다. \ndef load_train_result(path):\n\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words, pos_cnt, neg_cnt\n\n\tf = open(os.path.expanduser(path), 'r')\n\n\tline = f.readline()\n\tline = line.rstrip('\\n')\n\tlineSplited = line.split(\" \")\n\tpos_cnt = int(lineSplited[0])\n\tneg_cnt = int(lineSplited[1])\n\n\tline = f.readline()\n\tline = line.rstrip('\\n')\n\tlineSplited = line.split(\" \")\n\tpos_word_cnt = int(lineSplited[0])\n\tneg_word_cnt = int(lineSplited[1])\n\n\tline = f.readline()\n\tline = line.rstrip('\\t\\n')\n\tlineSplited = line.split('\\t')\n\tfor string in lineSplited:\n\t\toneWord = string.split(\" \")\n\t\tpos_words[oneWord[0]] = int(oneWord[1])\n\n\tline = f.readline()\n\tline = line.rstrip('\\t\\n')\n\tlineSplited = line.split('\\t')\n\tfor string in lineSplited:\n\t\toneWord = string.split(\" \")\n\t\tneg_words[oneWord[0]] = int(oneWord[1])\n\n\tf.close()\n\n\tprint(pos_cnt, neg_cnt)\n\tprint(pos_word_cnt, neg_word_cnt)\n\t# print(pos_words)\n\t# print(neg_words)\n\n\ndef test_valid_file(path):\n\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words, pos_cnt, neg_cnt\n\n\ttrue_pos = 0\n\ttrue_neg = 0\n\tfalse_pos = 0\n\tfalse_neg = 0\n\n\tmecab = Mecab()\n\tf = open(os.path.expanduser(path))\n\tline = f.readline()\n\n\twhile True :\n\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tbreak\n\t\tline = line.rstrip('\\n')\n\n\t\t# lineSplited[0]에는 id, [1]에는 text\n\t\tlineSplited = line.split('\\t')\n\n\t\t# 형태소 단위로 분석합니다.\n\t\tanalyzedLine = mecab.morphs(lineSplited[1])\n\t\t# print(analyzedLine)\n\n\t\t#각각의 word에 대해 긍정과 부정의 확률을 계산합니다.\n\t\tlog_pos_prob = math.log(pos_cnt / (pos_cnt + neg_cnt) )\n\t\tlog_neg_prob = math.log(neg_cnt / (pos_cnt + neg_cnt) )\n\t\tfor word in analyzedLine:\n\t\t\tlog_pos_prob += caculate_prob(1, word)\n\t\t\tlog_neg_prob += caculate_prob(0, word)\n\n\t\t# print(\"POS:\", log_pos_prob)\n\t\t# print(\"NEG:\", log_neg_prob)\n\n\t\tif log_pos_prob >= log_neg_prob:\n\t\t\tif lineSplited[2] == '1':\n\t\t\t\ttrue_pos += 1\n\t\t\telse:\n\t\t\t\tfalse_pos += 1\n\t\t\t\t#print(lineSplited[1], lineSplited[2])\n\n\t\telse:\n\t\t\tif lineSplited[2] == '0':\n\t\t\t\ttrue_neg += 1\n\t\t\telse:\n\t\t\t\tfalse_neg += 1\n\t\t\t\t#print(lineSplited[1], lineSplited[2])\n\n\tf.close()\n\tprint(\"true positive: \", true_pos)\n\tprint(\"true negative: \", true_neg)\n\tprint(\"false positive: \", false_pos)\n\tprint(\"false negative: \", false_neg)\n\n\ndef classify(origin, result):\n\n\tglobal pos_word_cnt, neg_word_cnt, pos_words, neg_words, pos_cnt, neg_cnt\n\n\tfw = open(os.path.expanduser(result), 'w')\n\n\tmecab = Mecab()\n\tf = open(os.path.expanduser(origin),'r')\n\tline = f.readline()\n\tfw.write(line)\n\n\twhile True :\n\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tbreak\n\t\tline = line.rstrip('\\n')\n\n\t\t# lineSplited[0]에는 id, [1]에는 text\n\t\tlineSplited = line.split('\\t')\n\n\t\t# 형태소 단위로 분석합니다.\n\t\tanalyzedLine = mecab.morphs(lineSplited[1])\n\t\t# print(analyzedLine)\n\n\t\t#각각의 word에 대해 긍정과 부정의 확률을 계산합니다.\n\t\tlog_pos_prob = math.log(pos_cnt / (pos_cnt + neg_cnt) )\n\t\tlog_neg_prob = math.log(neg_cnt / (pos_cnt + neg_cnt) )\n\t\tfor word in analyzedLine:\n\t\t\tlog_pos_prob += caculate_prob(1, word)\n\t\t\tlog_neg_prob += caculate_prob(0, word)\n\n\t\t# print(\"POS:\", log_pos_prob)\n\t\t# print(\"NEG:\", log_neg_prob)\n\n\t\t# 결과 파일에 태그를 달아 기록합니다. \n\t\tif log_pos_prob >= log_neg_prob:\n\t\t\tfw.write(lineSplited[0]+'\\t'+lineSplited[1]+'\\t'+str(1)+'\\n')\n\n\t\telse:\n\t\t\tfw.write(lineSplited[0]+'\\t'+lineSplited[1]+'\\t'+str(0)+'\\n')\n\t\t\t\n\tf.close()\n\tfw.close()\n\n\ndef main():\n\n\t# read_train_file(\"./ratings_data/ratings_train.txt\")\n\t# save_train_result(\"./ratings_data/trained_data_save.txt\")\n\n\tload_train_result(\"./ratings_data/trained_data_save.txt\")\n\n\t#test_valid_file(\"./ratings_data/ratings_valid.txt\")\n\tclassify(\"./ratings_data/ratings_test.txt\", \"./ratings_data/ratings_result.txt\")\n\n\n\nif __name__ == \"__main__\":\n\tmain()\n"
},
{
"alpha_fraction": 0.6698432564735413,
"alphanum_fraction": 0.6780341863632202,
"avg_line_length": 22.471349716186523,
"blob_id": "80bab8566159c6080f0f6bf0a5d334dda5e3cf2f",
"content_id": "94bf234df1f4e60e1a9d7bcac6cf9ee32e76657d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15065,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 541,
"path": "/assignment1/2016026026_assignment_1.py",
"repo_name": "solbi823/Artificial_intelligence",
"src_encoding": "UTF-8",
"text": "import sys\nimport os\nimport string\nimport ctypes\n\n# double ended queue 를 import 한다: BFS와 IDS에 사용\nfrom collections import deque \n# prioirity queue 를 import 한다. a star algorithm에 사용\nimport heapq\n\n\n# 각각의 node 를 나타내는 자료구조입니다. 미로의 node들은 이중 배열로 저장합니다. \nclass Node():\n\n\tdef __init__(self, x, y, value):\n\n\t\tself.xpos = x\n\t\tself.ypos = y\n\t\tself.state = value\n\n\t\tself.parentNode = None\n\t\tself.childNodes =[]\n\n\t\t#key를 찾고 난 다음에 아래의 값들은 초기화 되어야합니다. \n\t\tself.heuristicValue = 1000\n\t\tself.movedDistance = 0\n\n\n\tdef __lt__(self, other):\n\t\treturn (self.heuristicValue + self.movedDistance < other.heuristicValue + other.movedDistance)\n\n\tdef printit(self):\n\t\tprint(\"x: \"+str(self.xpos)+\" y: \"+str(self.ypos) + \" state: \"+ str(self.state) + \" hValue: \"+str(self.heuristicValue))\n\n\n\t# 현재 거리로부터 목표 지점까지의 거리를 manhattan distance 로 구합니다.\n\tdef heuristic(self, goal): \n\t\tself.heuristicValue = abs(self.xpos - goal.xpos) + abs(self.ypos - goal.ypos)\n\n\t# 출발 지점에서 얼마나 이동했는지 계산합니다. \n\tdef setMovedDistance(self):\t\n\n\t\tif self.parentNode != None:\n\t\t\tself.movedDistance = self.parentNode.movedDistance + 1\n\n\n\t# 현재 노드에서 갈수 있는 node를 찾아서 parent - child 관계를 등록합니다. \n\tdef seekChildNodes(self, arrValue):\n\n\t\t# key를 찾은 이후에 다시 child node를 찾을 때에는 빈 리스트에서 시작해야합니다. \n\t\tself.childNodes = []\t\n\n\t\t# 출발지점이라면 아래 한칸이 유일한 child node.\n\t\tif self.state == 3:\t\t\t\n\t\t\tself.childNodes.append(arrValue[self.xpos+1][self.ypos])\n\t\t\tarrValue[self.xpos+1][self.ypos].parentNode = self\n\t\t\treturn\n\n\t\t# 도착지점이라면 child node 는 없습니다. \n\t\t# 키보다 목적지에 먼저 도달하였을 경우를 위한 예외처리\n\t\tif self.state == 4:\n\t\t\treturn\n\n\t\t# 상하좌우 중 벽이 아니고 parent node 가 아닌 것이 child node.\n\n\t\tif arrValue[self.xpos-1][self.ypos].state != 1 and arrValue[self.xpos-1][self.ypos] != self.parentNode:\n\t\t\tself.childNodes.append(arrValue[self.xpos-1][self.ypos])\n\t\t\tarrValue[self.xpos-1][self.ypos].parentNode = self\n\n\t\tif arrValue[self.xpos+1][self.ypos].state != 1 and arrValue[self.xpos+1][self.ypos]!= self.parentNode:\n\t\t\tself.childNodes.append(arrValue[self.xpos+1][self.ypos])\n\t\t\tarrValue[self.xpos+1][self.ypos].parentNode = self\n\n\t\tif arrValue[self.xpos][self.ypos-1].state != 1 and arrValue[self.xpos][self.ypos-1] != self.parentNode:\n\t\t\tself.childNodes.append(arrValue[self.xpos][self.ypos-1])\n\t\t\tarrValue[self.xpos][self.ypos-1].parentNode = self\n\n\t\tif arrValue[self.xpos][self.ypos+1].state != 1 and arrValue[self.xpos][self.ypos+1] != self.parentNode:\n\t\t\tself.childNodes.append(arrValue[self.xpos][self.ypos+1])\n\t\t\tarrValue[self.xpos][self.ypos+1].parentNode = self\n\n\n\t# 탐색을 종료하였을 때 백트래킹하여 경로를 파악합니다. 움직인 거리를 리턴합니다. \n\tdef backtrackPath(self):\n\t\tpath = self\n\t\tlength = self.movedDistance\n\t\tself.movedDistance = 0\n\n\t\t# 지나온 경로를 5로 바꿉니다. \n\t\twhile path.parentNode != None :\n\t\t\tpath.state = 5\n\t\t\tpath = path.parentNode\n\n\t\treturn length\n\n\n\n# 여기서부터 미로를 찾는 알고리즘입니다. \n# BFS 와 Iterative deepening search 는 uninformed search 입니다. \n# 키와 목적지의 위치를 알지 못하고 해당 값이 나올 때까지 search 해야합니다. \n\ndef BFS(arrInform, arrValue, start_point):\n\n\ttime = 0\n\tdq = deque()\n\t# 큐에 시작점을 넣어줍니다. \t\n\tdq.append(start_point)\n\n\twhile dq:\t# 큐가 비어있지 않은 동안\n\t\there = dq.popleft()\t\t# pop은 방문하는 것\n\t\there.setMovedDistance()\n\t\t# print(str(here.xpos)+\" \" + str(here.ypos)+\" \"+str(here.state) )\n\n\t\ttime += 1\n\n\t\t# 만일 키 값이라면, 탐색을 종료하고 다시 시작합니다. \n\t\tif here.state == 6:\n\t\t\tbreak\n\n\t\t# 갈수 있는 길을 탐색하여 자식 노드에 등록 후 큐에 넣도록 합니다.\n\t\there.seekChildNodes(arrValue)\t\t\n\t\tfor child in here.childNodes:\n\t\t\tdq.append(child)\n\n\tkey_length = here.backtrackPath()\n\there.parentNode = None\n\tdq = deque()\n\n\t# key에서부터 목적지까지의 탐색을 다시 시작합니다. \n\tdq.append(here)\n\n\twhile dq:\n\t\there = dq.popleft()\n\t\there.setMovedDistance()\n\t\ttime +=1 \n\n\t\t# 만일 goal 값이라면, 탐색을 종료합니다. \n\t\tif here.state == 4:\n\t\t\tbreak\n\n\t\there.seekChildNodes(arrValue)\n\t\tfor child in here.childNodes:\n\t\t\tdq.append(child)\n\n\tgoal_length = here.parentNode.backtrackPath() + 1\n\twhole_length = key_length + goal_length\n\t\n\tprint(\"length :\" + str(whole_length))\n\tprint(\"time: \" + str(time))\n\n\treturn arrValue, whole_length, time\n\n\n# Iterative Deepening Search\ndef IDS(arrInform, arrValue, start_point):\n\n\t# depth limit 은 DFS를 실시할 depth level을 제한합니다. \n\tdepth_limit = 0\n\ttime = 0\n\n\there = start_point\n\t\n\twhile here.state != 6 and depth_limit < 5000:\n\n\t\tdepth_limit += 1\n\n\t\t#double ended queue를 stack 으로 사용합니다. \n\t\tstk = deque()\n\t\tstk.append(start_point)\n\n\t\twhile stk:\n\n\t\t\there = stk.pop()\t\n\t\t\ttime += 1\n\n\t\t\tif here.state == 6:\n\t\t\t\tbreak\n\n\t\t\there.seekChildNodes(arrValue)\n\t\t\tfor child in here.childNodes:\n\t\t\t\tchild.setMovedDistance()\n\t\t\t\tif child.movedDistance > depth_limit:\n\t\t\t\t\tbreak\n\t\t\t\tstk.append(child)\n\n\n\tkey_length = here.backtrackPath()\n\there.parentNode = None\n\tkey_point = here\n\n\tdepth_limit = 0\t\n\n\twhile here.state != 4 and depth_limit < 5000:\n\n\t\tdepth_limit += 1\n\n\t\tstk = deque()\n\t\tstk.append(key_point)\n\n\t\twhile stk:\n\n\t\t\there = stk.pop()\t\n\t\t\ttime += 1\n\n\t\t\tif here.state == 4:\n\t\t\t\tbreak\n\n\t\t\there.seekChildNodes(arrValue)\n\t\t\tfor child in here.childNodes:\n\t\t\t\tchild.setMovedDistance()\n\t\t\t\tif child.movedDistance > depth_limit:\n\t\t\t\t\tbreak\n\t\t\t\tstk.append(child)\n\n\tgoal_length = here.parentNode.backtrackPath() + 1\n\twhole_length = key_length + goal_length\n\t\n\tprint(\"length :\" + str(whole_length))\n\tprint(\"time: \" + str(time))\n\n\treturn arrValue, whole_length, time\n\n\n\n# Greedy best first search , A* 알고리즘은 informed search 입니다. \n# 각각의 노드로부터 키와 목적지까지의 heuristic 값을 계산하여 이를 감소시키는 방향으로 search하도록 합니다.\n\n# Greedy best first search 는 휴리스틱 값만 고려합니다. \ndef greedyBestFirst(arrInform, arrValue, start_point, key_point, goal_point):\n\n\ttime = 0\n\tpq = []\n\n\t# 우선순위 큐에 시작점을 넣어줍니다. \n\t# 우선순위는 휴리스틱 값으로 설정합니다. \n\tstart_point.heuristic(key_point)\n\theapq.heappush(pq, (start_point.heuristicValue, start_point))\n\n\twhile pq: \t#priority queue 가 비어있지 않은 동안\n\n\t\t# 휴리스틱 값이 가장 작은 node 부터 pop 하게 됩니다. \n\t\tidle, here = heapq.heappop(pq)\t\n\t\ttime += 1\n\n\t\t# 만일 키 값이라면, 탐색을 종료하고 다시 시작합니다. \n\t\tif here.state == 6:\n\t\t\tbreak\n\n\t\t# 키 값이 아니라면, 갈수 있는 길을 탐색하여 자식 노드에 등록 후 큐에 넣도록 합니다. \n\t\there.seekChildNodes(arrValue)\n\t\tfor child in here.childNodes:\n\t\t\t# 모든 갈 수 있는 child node 에 대해서 휴리스틱 함수를 계산한 후에 우선순위 큐에 넣도록 합니다. \n\t\t\tchild.setMovedDistance()\n\t\t\tchild.heuristic(key_point)\n\t\t\theapq.heappush(pq, (child.heuristicValue, child))\n\n\t# 백트래킹하여 경로를 표시합니다. \n\tkey_length = here.backtrackPath()\n\there.parentNode = None\n\tpq = []\n\n\n\t# key에서부터 목적지까지의 탐색을 다시 시작합니다. \n\there.heuristic(goal_point)\n\theapq.heappush(pq, (here.heuristicValue, here))\n\n\twhile pq:\n\t\tidle, here = heapq.heappop(pq)\n\t\ttime += 1\n\n\t\t# 만일 goal 값이라면, 탐색을 종료합니다.\n\t\tif here.state == 4:\n\t\t\tbreak\n\n\t\there.seekChildNodes(arrValue)\n\t\tfor child in here.childNodes:\n\t\t\tchild.setMovedDistance()\n\t\t\tchild.heuristic(goal_point)\n\t\t\theapq.heappush(pq, (child.heuristicValue, child))\n\n\tgoal_length = here.parentNode.backtrackPath() + 1\n\twhole_length = key_length + goal_length\n\n\n\tprint(\"length :\" + str(whole_length))\n\tprint(\"time: \" + str(time))\n\n\treturn arrValue, whole_length, time\n\n\n# A* algorithm 은 휴리스틱 값 뿐만 아니라 지나온 거리와의 합도 고려합니다. \ndef aStarSearch(arrInform, arrValue, start_point, key_point, goal_point):\n\n\ttime = 0\n\tpq = []\n\n\t# 우선순위 큐에 시작점을 넣어줍니다. \n\t# 우선순위는 지나온 path cost와 휴리스틱 값의 합으로 설정합니다. \n\tstart_point.heuristic(key_point)\n\theapq.heappush(pq, (start_point.heuristicValue + start_point.movedDistance, start_point))\n\n\twhile pq: \t#priority queue 가 비어있지 않은 동안\n\n\t\t# 이동한 거리와 휴리스틱 값을 더한 값이 가장 작은 node 부터 pop 하게 됩니다. \n\t\tidle, here = heapq.heappop(pq)\t\n\t\ttime += 1\n\n\t\t# 만일 키 값이라면, 탐색을 종료하고 다시 시작합니다. \n\t\tif here.state == 6:\n\t\t\tbreak\n\n\t\t# 키 값이 아니라면, 갈수 있는 길을 탐색하여 자식 노드에 등록 후 큐에 넣도록 합니다. \n\t\there.seekChildNodes(arrValue)\n\t\tfor child in here.childNodes:\n\t\t\t# 모든 갈수 있는 child node 에 대해서 이동한 거리와 휴리스틱 함수를 계산한 후에 우선순위 큐에 넣도록 합니다. \n\t\t\tchild.setMovedDistance()\n\t\t\tchild.heuristic(key_point)\n\t\t\theapq.heappush(pq, (child.heuristicValue + child.movedDistance, child))\n\n\t# 백트래킹하여 경로를 표시합니다. \n\tkey_length = here.backtrackPath()\n\there.parentNode = None\n\tpq = []\n\n\n\t# key에서부터 목적지까지의 탐색을 다시 시작합니다. \n\there.heuristic(goal_point)\n\theapq.heappush(pq, (here.heuristicValue + here.movedDistance , here))\n\n\twhile pq:\n\t\tidle, here = heapq.heappop(pq)\n\t\ttime += 1\n\n\t\t# 만일 goal 값이라면, 탐색을 종료합니다.\n\t\tif here.state == 4:\n\t\t\tbreak\n\n\t\there.seekChildNodes(arrValue)\n\t\tfor child in here.childNodes:\n\t\t\tchild.setMovedDistance()\n\t\t\tchild.heuristic(goal_point)\n\t\t\theapq.heappush(pq, (child.heuristicValue + child.movedDistance , child))\n\n\tgoal_length = here.parentNode.backtrackPath() + 1\n\twhole_length = key_length + goal_length\n\n\n\tprint(\"length :\" + str(whole_length))\n\tprint(\"time: \" + str(time))\n\n\treturn arrValue, whole_length, time\n\n\n\n# 텍스트 파일을 입력받아 arrInform 리스트, arrValue 이중 리스트에 담아 리턴시키는 함수입니다. \ndef read_and_print_file(path):\n\n\tf = open(os.path.expanduser(path))\n\n\tline = f.readline()\n\tline.rstrip('\\n')\n\tarrInform = line.split(' ')\n\tarrInform = list(map(int, arrInform))\n\t# arrInform[0] == 층\n\t# arrInform[1] == 행의 개수\n\t# arrInform[2] == 열의 개수 \n\tprint(arrInform)\n\t\t\n\tarrValue = []\n\n\tfor i in range(0, arrInform[1]):\t\t#행의 수 만큼 line 을 읽습니다. \n\n\t\tline = f.readline()\n\t\tif not line:\n\t\t\tprint(\"제시된 행의 수보다 입력된 행의 수가 부족합니다.\")\n\t\t\tbreak\n\t\t# get a line\n\n\t\tline.rstrip('\\n')\n\t\tlineArr = line.split(' ')\n\t\tnodeArr = []\n\n\t\tfor j in range(0, arrInform[2]): \t#열의 수 만큼 node를 생성합니다. \n\t\t\ttmp = Node(i, j, int(lineArr[j]) )\n\t\t\t#tmp.printit()\n\t\t\tnodeArr.append(tmp)\n\n\t\tarrValue.append(nodeArr)\n\n\tf.close()\n\n\treturn arrInform, arrValue\n\n\n\n# arrInform, arrValue 를 받아서 시작, 키, 목적 지점을 리턴하는 함수입니다. \ndef find_points(arrInform, arrValue):\n\n\tstart_point = None \n\tkey_point = None \n\tgoal_point = None\n\n\tfor i in range(0, arrInform[2]):\n\t\tif arrValue[0][i].state == 3:\n\t\t\t#print(i)\n\t\t\tstart_point = arrValue[0][i]\n\t\t\tbreak\n\n\tfor i in range(1, arrInform[1]-1):\n\t\tfor j in range(0, arrInform[2]):\n\t\t\tif arrValue[i][j].state == 6:\n\t\t\t\t#print(str(i)+\" \"+str(j))\n\t\t\t\tkey_point = arrValue[i][j]\n\t\t\t\tbreak\n\t\tif key_point != None :\n\t\t\tbreak\n\t\t\t\n\n\tfor i in range(0, arrInform[2]):\n\t\tif arrValue[arrInform[1]-1][i].state == 4:\n\t\t\t#print(i)\n\t\t\tgoal_point = arrValue[arrInform[1]-1][i]\n\t\t\tbreak\n\n\tif start_point == None or key_point == None or goal_point == None:\n\t\tprint(\"포인트를 찾지 못했습니다.\")\n\n\telse:\n\t\tstart_point.printit()\n\t\tkey_point.printit()\n\t\tgoal_point.printit()\n\t\n\treturn start_point, key_point, goal_point\n\n\n# arrValue 이중 리스트를 출력하기 위하여 스트링 형식으로 바꾸어 리턴하는 함수입니다. \ndef arrToString(arrInform, arrValue):\n\tstring = \"\"\n\tfor i in range(arrInform[1]):\n\t\tfor j in range(arrInform[2]):\n\t\t\tstring+= str(arrValue[i][j].state)+\" \"\n\n\t\tstring+=\"\\n\"\n\n\treturn string\n\n\n\n\n# 여기서부터 각각의 층에 대해 적합한 알고리즘을 이용해 미로찾기를 수행하는 함수입니다.\n# 5개의 층 모두 greedy best first search 알고리즘이 최단시간 결과값이 나왔기에 이를 적용하였습니다. \n\ndef first_floor():\n\n\t#arrInform은 각 층의 미로에 대한 행과 열의 정보, \n\t#arrValue 는 각 층의 미로 구조에 대한 정보를 담고 있습니다.\n\n\tarrInform, arrValue = read_and_print_file(\"first_floor_input.txt\")\n\tstart, key, goal = find_points(arrInform, arrValue)\n\t\n\tchangedArr, length, time = greedyBestFirst(arrInform, arrValue, start, key, goal)\n\n\tf = open(os.path.expanduser(\"first_floor_output.txt\"), 'w', encoding='utf8')\n\n\tf.write( arrToString(arrInform, changedArr))\n\tf.write(\"---\\nlength=\"+str(length)+\"\\ntime=\"+str(time))\n\n\tf.close()\n\n\ndef second_floor():\n\n\tarrInform, arrValue = read_and_print_file(\"second_floor_input.txt\")\n\tstart, key, goal = find_points(arrInform, arrValue)\n\t\n\tchangedArr, length, time = greedyBestFirst(arrInform, arrValue, start, key, goal)\n\n\tf = open(os.path.expanduser(\"second_floor_output.txt\"), 'w', encoding='utf8')\n\n\tf.write( arrToString(arrInform, changedArr))\n\tf.write(\"---\\nlength=\"+str(length)+\"\\ntime=\"+str(time))\n\n\tf.close()\n\n\ndef third_floor():\n\n\tarrInform, arrValue = read_and_print_file(\"third_floor_input.txt\")\n\tstart, key, goal = find_points(arrInform, arrValue)\n\t\n\tchangedArr, length, time = greedyBestFirst(arrInform, arrValue, start, key, goal)\n\n\tf = open(os.path.expanduser(\"third_floor_output.txt\"), 'w', encoding='utf8')\n\n\tf.write( arrToString(arrInform, changedArr))\n\tf.write(\"---\\nlength=\"+str(length)+\"\\ntime=\"+str(time))\n\n\tf.close()\n\n\ndef fourth_floor():\n\n\tarrInform, arrValue = read_and_print_file(\"fourth_floor_input.txt\")\n\tstart, key, goal = find_points(arrInform, arrValue)\n\t\n\tchangedArr, length, time = greedyBestFirst(arrInform, arrValue, start, key, goal)\n\n\tf = open(os.path.expanduser(\"fourth_floor_output.txt\"), 'w', encoding='utf8')\n\n\tf.write( arrToString(arrInform, changedArr))\n\tf.write(\"---\\nlength=\"+str(length)+\"\\ntime=\"+str(time))\n\n\tf.close()\n\n\ndef fifth_floor():\n\n\tarrInform, arrValue = read_and_print_file(\"fifth_floor_input.txt\")\n\tstart, key, goal = find_points(arrInform, arrValue)\n\t\n\tchangedArr, length, time = greedyBestFirst(arrInform, arrValue, start, key, goal)\n\n\tf = open(os.path.expanduser(\"fifth_floor_output.txt\"), 'w', encoding='utf8')\n\n\tf.write( arrToString(arrInform, changedArr))\n\tf.write(\"---\\nlength=\"+str(length)+\"\\ntime=\"+str(time))\n\n\tf.close()\n\n\ndef main():\n\n\tfirst_floor()\n\tsecond_floor()\n\tthird_floor()\n\tfourth_floor()\n\tfifth_floor()\n\n\nif __name__ == \"__main__\":\n\tmain()"
}
] | 2 |
sammilward/Car-Dash
|
https://github.com/sammilward/Car-Dash
|
3accacc00c84a73c45f8d8c7fc4ea4164093e5b0
|
06cc73f297faa3d117371f2696f204d68df982d1
|
1ca56848dd9e63e25a2f0233781e8168da360430
|
refs/heads/master
| 2020-03-11T10:37:28.412821 | 2018-04-17T18:26:22 | 2018-04-17T18:26:22 | 129,947,559 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6347095966339111,
"alphanum_fraction": 0.6538372039794922,
"avg_line_length": 40.35369873046875,
"blob_id": "8e62d63fbeadf9b5e173ab38f494b1195686acde",
"content_id": "71450c53c929e96ba75f8404365bd6a4ff9825c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12861,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 311,
"path": "/Python Files and Images/OfficialProj.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "#Car Dash --- Programming Project 28/11/2016\n#Avoid all oncoming vehicles and collect coins to increase score.\n\n\n\n#Importing all the modules needed for the game to run\nimport pygame, random, time, os\n\n#Retrieving the players name through reading the text file the TKinter file created\nNameFile = open(\"PlayersNameFile.txt\" , \"r\")\nPlayersName = NameFile.read()\nNameFile.close()\n#Initialising PYGAME\npygame.init()\n#Setting the screen dimensions\nscreenWidth = 450\nscreenHight = 600\n#Initalising the first clock so that score can be calculated\nFirstTime = time.time()\n#Setting the colours\nBlack = (0,0,0)\n#Setting up the display\nGameScreen = pygame.display.set_mode((screenWidth, screenHight))\n#Setting the title of the game\npygame.display.set_caption(\"Car Dash\")\n#Loads images\nRedCar = pygame.image.load(\"RedCar.png\")\nYellowCar = pygame.image.load(\"YellowCar.png\")\nGreenCar = pygame.image.load(\"GreenCar.png\")\nBlueCar = pygame.image.load(\"BlueCar.png\")\nBackGround = pygame.image.load(\"Back.png\")\nRoadMarking = pygame.image.load(\"RoadMarkings.png\")\nBush = pygame.image.load(\"Bush.png\")\nCoin = pygame.image.load(\"Coin.png\")\nGameOver = pygame.image.load(\"GameOver.png\")\nGameScreen.blit(BackGround, (0,0))\npygame.display.update()\n\n#The movement of the lines in the road. Fixed X Val but Algorithm for Y (labeled z)\ndef DecorationMove(DecorationStartPoint):\n GameScreen.blit(RoadMarking, (114,DecorationStartPoint))\n GameScreen.blit(RoadMarking, (215,DecorationStartPoint))\n GameScreen.blit(RoadMarking, (321,DecorationStartPoint))\n GameScreen.blit(RoadMarking, (114,OtherMove))\n GameScreen.blit(RoadMarking, (215,OtherMove))\n GameScreen.blit(RoadMarking, (321,OtherMove))\n GameScreen.blit(Bush, (40,OtherMove))\n GameScreen.blit(Bush, (20,DecorationStartPoint))\n GameScreen.blit(Bush, (380,OtherMove))\n GameScreen.blit(Bush, (410,DecorationStartPoint)) \n\n#Function to calculate the players score. Finds difference between two times\n#Then puts the int value of the calculation in the top left hand of the screen\ndef Score(FirstTime, CoinCollected, AmountofCoins):\n ExtraPoints = 5\n if CoinCollected == True:\n AmountofCoins = AmountofCoins + 1 \n SecondTime = time.time()\n Score = ((SecondTime - FirstTime) + (AmountofCoins*ExtraPoints))\n font = pygame.font.SysFont(None, 25)\n text = font.render(\"Score: \"+str(int(Score)), True, Black)\n GameScreen.blit(text, (10,10))\n return int(Score)\n\ndef DisplayHighScore(FirstPlace, SecondPlace, ThirdPlace):\n font = pygame.font.SysFont(None, 20)\n Title = font.render(\"High Scores\", True, Black)\n FirstScore = font.render(str(FirstPlace), True, Black)\n SecondScore = font.render(str(SecondPlace), True, Black)\n ThirdScore = font.render(str(ThirdPlace), True, Black)\n\n GameScreen.blit(Title, (365,10))\n GameScreen.blit(FirstScore, (365,25))\n GameScreen.blit(SecondScore, (365,40))\n GameScreen.blit(ThirdScore, (365,55))\n\n#Function to Save the players name and score. First assigns a string to Textline\n#Then opens and appends the variable textline to the end of the text file.\ndef SaveScore(Name, Score):\n TextLine = str(Name) + \",\" + str(Score) + \"\\n\"\n HighScoresFile = open(\"HighScores.txt\", \"a\")\n HighScoresFile.write(TextLine) \n HighScoresFile.close()\n \n#A function that retrieves the high score from the textfile\ndef GetHighScores():\n #Open the file in read mode\n HighScoreFile = open(\"HighScores.txt\", \"r\")\n #Initalise the big list of all scores\n AllScores = []\n #loop through the file one line at a time \n for line in HighScoreFile:\n #initalise the name and score list\n NameAndScore = []\n #Assign a value to name and score, split the textline with a comma\n Name, Score = map(str, line.split(\",\"))\n #Add the name to the NameAndScore list\n NameAndScore.append(Name)\n #Add the interger of the score to NameandScore list\n NameAndScore.append(int(Score))\n #Add the NameAndScore list to the AllScores list\n AllScores.append(NameAndScore)\n #Assign the sorted version of AllScores to NewList\n Newlist = sorted(AllScores, key=lambda NameAndScore: NameAndScore[1], reverse=True)\n #Assign the first value of the new list to FirstList\n Firstlist = Newlist[0]\n #Assign second value of Newlist to Secondlist\n Secondlist = Newlist[1]\n #Assign the third value of newlist to ThirdList\n Thirdlist = Newlist[2]\n #Assign names and scores to set variables\n FirstName, FirstScore, SecondName, SecondScore, ThirdName, ThirdScore = Firstlist[0], Firstlist[1], Secondlist[0], Secondlist[1], Thirdlist[0], Thirdlist[1]\n #Create variables that contain the name and score of the high scores\n First = FirstName + \" \" + str(FirstScore)\n Second = SecondName + \" \" + str(SecondScore)\n Third = ThirdName + \" \" + str(ThirdScore)\n HighScoreFile.close()\n #Creates variables for the new sorted file. Uses , for split and \\n for newline\n sortFirst = FirstName + \",\" + str(FirstScore) +\"\\n\"\n sortSecond = SecondName + \",\" + str(SecondScore)+\"\\n\"\n sortThird = ThirdName + \",\" + str(ThirdScore)+\"\\n\"\n SortHighScores(sortFirst, sortSecond, sortThird)\n return First, Second, Third\n\n\ndef SortHighScores(First, Second, Third):\n #open file write mode to remove any information currently held in the file\n HighScoreFile = open(\"HighScores.txt\", \"w\")\n #Writes the top three high scores to the file\n HighScoreFile.write(First)\n HighScoreFile.write(Second)\n HighScoreFile.write(Third)\n #Closes the file\n HighScoreFile.close()\n \n#Increment of count, changes the speed of the y axis change \ndef SpeedIncrement(count):\n if count < 2:\n count = count + 0.01\n if count < 8: \n count = count + 0.0005\n else:\n count = count + 0.0000000000000001\n return count\n\ndef ResetHighScores():\n HighScoresFile = open(\"HighScores.txt\", \"w\")\n for i in range(0,3):\n HighScoresFile.write(\"N/A 0 \\n\")\n\n#Places the players red car on the screen\ndef FriendlyCar (LaneCoord,PlayersYval):\n GameScreen.blit(RedCar, (LaneCoord,PlayersYval))\n\n#This function chooses a random number that will later select the lane of the car\n#that has just spawned at the top of the window\ndef RandomLane():\n FirstCarLane = random.randint(0,2)\n CoinLane = random.randint(0,2)\n\n while FirstCarLane == CoinLane:\n CoinLane = random.randint(0,2)\n \n return FirstCarLane, CoinLane\n\n#This function produces a random number which will then determine the colour of\n#the new car being spawned\ndef WhichCar():\n CarType = random.randint(0,2)\n \n if CarType == 0:\n Car = YellowCar\n elif CarType == 1:\n Car = GreenCar\n elif CarType == 2:\n Car = BlueCar\n return Car\n\n#Sets the x coord of the car based on RandomLane value and then places the\n#car on to the window. Also returns OtherCarLane \ndef OtherCars(yAxis, LaneNo, Car):\n if LaneNo == 0:\n OtherCarLane = 97.5\n elif LaneNo == 1:\n OtherCarLane = 198.5\n elif LaneNo == 2:\n OtherCarLane = 305.5\n GameScreen.blit(Car, (OtherCarLane,yAxis))\n return OtherCarLane\n\ndef SpawnCoin(yaxis, LaneNo, Coin, AlreadyCollected):\n Adjustment = 10\n if LaneNo == 0:\n CoinLane = 97.5 + Adjustment\n elif LaneNo == 1:\n CoinLane = 198.5 + Adjustment\n elif LaneNo == 2:\n CoinLane = 305.5 + Adjustment\n\n if AlreadyCollected == False:\n GameScreen.blit(Coin, (CoinLane,yaxis+Adjustment-3))\n\n#This Function tests if the players car and the other car has collided\n#This is done by comparison of the lanes the cars are in and the height of the cars\ndef TestCrash(PlayersLane, OtherCarVertical, OtherCarLane):\n if PlayersLane == OtherCarLane and int(OtherCarVertical) < 525 and int(OtherCarVertical) > 442 :\n gameExit = True\n return gameExit\n \ndef CoinCollection(PlayersLane, CoinVertical, CoinLane):\n CoinXAxis = 0\n if CoinLane == 0:\n CoinXAxis = 97.5\n elif CoinLane == 1:\n CoinXAxis = 198.5\n elif CoinLane == 2:\n CoinXAxis = 305.5\n\n if AlreadyCollected == False:\n if PlayersLane == CoinXAxis and int(CoinVertical) < 525 and int(CoinVertical) > 480:\n Collected = True\n return Collected\n\n \n#Telling the game it has not crashed to start\ngameExit = False\n#Initalising Variables to start off\ncount = 0\nLaneNo, CoinLane = RandomLane()\nPlayersCarLane = 198.5\nPlayersVerticalVal = 500\nDecorationStartPoint = 300\nOtherMove = 0\nCar = YellowCar\nAmountofCoins = 0 \nAlreadyCollected = False\n#Call Function to get the high Scores\nFirstPlace, SecondPlace, ThirdPlace = GetHighScores() \nDisplayHighScore(FirstPlace, SecondPlace, ThirdPlace)\n\n#This is the main game loop and will continue to run untill player crashes\nwhile gameExit == False:\n #Lets user quit the game using the red cross in the top corner\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n pygame.quit()\n quit()\n #If a key is pressed down, left key move a lane to the left, right move a lane to the right\n if event.type == pygame.KEYDOWN:\n if PlayersCarLane == 198.5:\n if event.key == pygame.K_LEFT:\n PlayersCarLane = 97.5\n elif event.key == pygame.K_RIGHT:\n PlayersCarLane = 305.5\n\n elif PlayersCarLane == 97.5:\n if event.key == pygame.K_UP: \n PlayersCarLane = 198.5\n\n elif PlayersCarLane == 305.5:\n if event.key == pygame.K_UP:\n PlayersCarLane = 198.5\n \n #Count is calculated by the result of the function SpeedIncrement\n count = SpeedIncrement(count)\n #DecorationStartPoint is the y axis value of the decorations(Roadmarkings and the bushs)\n #When the Y value gets so high it is set to 0 to be increased again\n DecorationStartPoint = DecorationStartPoint + count\n if DecorationStartPoint > 590:\n DecorationStartPoint = 0\n #This is the algorithm to increment OtherMove. This variable is the y axis\n #For the other cars and some decoration. When it reaches 590 function LaneNo\n #and WhichCar are called\n OtherMove = OtherMove + count\n if OtherMove > 590:\n OtherMove =0\n LaneNo, CoinLane = RandomLane()\n AlreadyCollected = False\n Car = WhichCar()\n #Build and show the background to cover the previous frame \n GameScreen.blit(BackGround, (0,0))\n #Call DecorationMove with the parameter DecorationStartPoint\n DecorationMove(DecorationStartPoint)\n #Calls the FriendlyCar Function with parameters PlayersCarLane and PlayersVerticalVal\n FriendlyCar(PlayersCarLane,PlayersVerticalVal)\n #Assigns value to OtherCarLane from the return of OtherCars function\n OtherCarLane = OtherCars(OtherMove, LaneNo, Car)\n #Assigns a value to the varable PlayerScore whilst also running the function\n #score with FirstTime as a parameter\n PlayerScore = Score(FirstTime, CoinCollection(PlayersCarLane, OtherMove, OtherCarLane), AmountofCoins)\n SpawnCoin(OtherMove, CoinLane, Coin, AlreadyCollected)\n DisplayHighScore(FirstPlace, SecondPlace, ThirdPlace)\n #Updates the display\n pygame.display.update()\n #Call function to see if a coin has been collected\n if CoinCollection(PlayersCarLane, OtherMove, CoinLane) == True:\n AlreadyCollected = True\n AmountofCoins = AmountofCoins + 1\n Score(FirstTime, CoinCollection(PlayersCarLane, OtherMove, CoinLane), AmountofCoins)\n #If TestCrash returns True then stop the loop\n if TestCrash(PlayersCarLane, OtherMove, OtherCarLane) == True:\n SaveScore(PlayersName, PlayerScore)\n GetHighScores()\n GameScreen.blit(GameOver, (80,200))\n pygame.display.update()\n time.sleep(2)\n gameExit = True\n#Calls the function SaveScore to store PlayersName and PlayerScore to a textfile\npygame.quit()\nos.system('StartUp.py')\n#Save .pyw to stop console window from appearing\n"
},
{
"alpha_fraction": 0.6889632344245911,
"alphanum_fraction": 0.7023411393165588,
"avg_line_length": 18.29032325744629,
"blob_id": "f6598baf9cce43912fc10d09a1c9773c11c8e159",
"content_id": "dd7f9fcf17f10342757e8a060368b1dffc0765c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 31,
"path": "/Python Files and Images/Instructions.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nimport sys, os\nroot = Tk()\nroot.title(\"Instructions\")\napp = Frame(root)\napp.grid()\n\ndef MenuClick():\n root.withdraw()\n os.system('StartUp.py')\n\ntitle = Label(app, text = \"Instructions\")\n\ntitle.config(font=(\"Courier\", 30))\ntitle.grid()\n\nFile = open(\"Instructions.txt\", \"r\")\nInstructions = StringVar()\nInstructions.set(File.read())\n\n\nDisInst = Label(app, textvariable = Instructions, wraplength=200)\nDisInst.config(font=(\"Courier\", 10))\nDisInst.grid()\n\nMainButton = Button(app, text = \"Return to main menu\", command=MenuClick)\nMainButton.grid(pady = 5)\n\n\n\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.696012020111084,
"alphanum_fraction": 0.7080511450767517,
"avg_line_length": 21.525423049926758,
"blob_id": "8218922aa6431be9998fac5e2ea342cbc4d61bb7",
"content_id": "63ee8f0d89673c042398b266117ecb414bdbff31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1329,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 59,
"path": "/Python Files and Images/StartUp.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nimport sys\nimport os\n\nroot = Tk()\n#Setting the title of the frame\nroot.title(\"Car Dash Menu\")\n#Sets the size of the window\n#root.geometry(\"450x600\")\n\n\n#Creating a frame\napp = Frame(root)\napp.grid()\n\nlabel = Label(app, text=\"Welcome to Car Dash\")\nlabel.grid()\n\n#Learning Buttons\ndef PlayGameClick():\n root.withdraw()\n os.system('EnterName.py')\n quit()\n\ndef ViewHighScoresClick():\n root.withdraw()\n os.system('ViewHighScores.py')\n quit()\n\ndef ResetHighScoresClick():\n root.withdraw()\n os.system('ConfirmReset.py')\n quit()\n\ndef InstructionsClick():\n root.withdraw()\n os.system('Instructions.py')\n \ndef ExitClick():\n quit()\n sys.exit()\n\n \nPlayGameButton = Button(app, text = \"Play game\", command=PlayGameClick)\nPlayGameButton.grid(row = 1, pady = 5)\n\nViewHighScoresButton = Button(app, text = \"View High Scores\", command=ViewHighScoresClick)\nViewHighScoresButton.grid(row = 2, pady = 5)\n\nResetHighScoresButton = Button(app, text = \"Reset High Scores\", command=ResetHighScoresClick)\nResetHighScoresButton.grid(row = 3, pady = 5)\n\nInstructionsButton = Button(app, text= \"Instructions\", command=InstructionsClick)\nInstructionsButton.grid(row = 4, pady = 5)\n\nExitButton = Button(app, text = \"Exit\", command=ExitClick)\nExitButton.grid(row = 5, pady = 5)\n\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.5613515377044678,
"alphanum_fraction": 0.5820984244346619,
"avg_line_length": 27.116666793823242,
"blob_id": "4ecc95456e763479ab289ca681219deb49d9d701",
"content_id": "d5afb89f5a2e14698f805a9afebe1c99dc4ff5e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 60,
"path": "/Python Files and Images/EnterName.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nimport sys, os\nroot = Tk()\nroot.title(\"Play Game\")\napp = Frame(root)\napp.grid()\n\ndef PlayClick():\n PlayersName = str(InputBox.get())\n if len(PlayersName) == 3:\n for Char in PlayersName:\n if (ord(Char)>= 65 and ord(Char) <= 90) or (ord(Char) >=97 and ord(Char) <=122):\n Valid = True\n else:\n Valid = False\n break\n \n if Valid == True:\n WriteName(PlayersName.upper())\n root.withdraw()\n os.system('OfficialProj.py')\n quit()\n else:\n #Run error window explaining 3 letter required length\n Title = Label(app, text = \"Enter 3 letters as a name/initals\", fg = 'red')\n Title.grid(row = 0, columnspan = 2)\n else:\n #Run error window explaining 3 letter required length\n Title = Label(app, text = \"Enter 3 letters as a name/initals\", fg = 'red')\n Title.grid(row = 0, columnspan = 2)\n \n \ndef Back():\n root.withdraw()\n os.system('StartUp.py')\n quit()\n\ndef WriteName(Name):\n PlayersNameFile = open(\"PlayersNameFile.txt\", \"w\")\n PlayersNameFile.write(Name)\n PlayersNameFile.close()\n\nTitle = Label(app, text = \"Enter 3 letters as a name/initals\")\nTitle.grid(row = 0, columnspan = 2)\n\nInputBox = Entry(app)\nInputBox.grid(row = 1, column = 0)\n\nPlayButton = Button(app, text = \"Play Game!\", command = PlayClick)\nPlayButton.grid(row = 1, column = 1)\n\nmainButton = Button(app, text = \"Back to Main Menu\", command = Back)\nmainButton.grid(row = 2 , columnspan = 2, padx = 10)\n\nroot.mainloop()\n\n\n#row = 0, column = 0\n#row = 1, column = 0\n#row = 1, column = 1\n"
},
{
"alpha_fraction": 0.6867316365242004,
"alphanum_fraction": 0.690970778465271,
"avg_line_length": 33.69117736816406,
"blob_id": "48564ad5a773e46b3b80684deab8adb2c76fa3c3",
"content_id": "0d172511629c2c1336253d63ab5e18d72c74f725",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2359,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 68,
"path": "/Python Files and Images/ViewHighScores.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nimport sys, os\nroot = Tk()\n#root.title(\"View High Scores\") #Poss\napp = Frame(root)\napp.grid()\n\ndef MainMenuClick():\n root.withdraw()\n os.system('StartUp.py')\n \n\ndef GetHighScores():\n #Open the file in read mode\n HighScoreFile = open(\"HighScores.txt\", \"r\")\n #Initalise the big list of all scores\n AllScores = []\n #loop through the file one line at a time \n for line in HighScoreFile:\n #initalise the name and score list\n NameAndScore = []\n #Assign a value to name and score, split the textline with a comma\n Name, Score = map(str, line.split(\",\"))\n #Add the name to the NameAndScore list\n NameAndScore.append(Name)\n\n #Add the interger of the score to NameandScore list\n NameAndScore.append(int(Score))\n #Add the NameAndScore list to the AllScores list\n AllScores.append(NameAndScore)\n #Assign the sorted version of AllScores to NewList\n Newlist = sorted(AllScores, key=lambda NameAndScore: NameAndScore[1], reverse=True)\n #Assign the first value of the new list to FirstList\n Firstlist = Newlist[0]\n #Assign second value of Newlist to Secondlist\n Secondlist = Newlist[1]\n #Assign the third value of newlist to ThirdList\n Thirdlist = Newlist[2]\n #Assign names and scores to set variables\n FirstName, FirstScore, SecondName, SecondScore, ThirdName, ThirdScore = Firstlist[0], Firstlist[1], Secondlist[0], Secondlist[1], Thirdlist[0], Thirdlist[1]\n #Create variables that contain the name and score of the high scores\n First = FirstName + \" \" + str(FirstScore)\n Second = SecondName + \" \" + str(SecondScore)\n Third = ThirdName + \" \" + str(ThirdScore)\n return First, Second, Third\n HighScoresFile.close()\n\nFirst = StringVar()\nSecond = StringVar()\nThird = StringVar()\nFirstScore, SecondScore, ThirdScore = GetHighScores()\nFirst.set(FirstScore)\nSecond.set(SecondScore)\nThird.set(ThirdScore)\n\nTitleLabel = Label(app, text=\"HighScores\")\nTitleLabel.grid()\nFirstLabel = Label(app, textvariable = First)\nFirstLabel.grid()\nSecondLabel = Label(app, textvariable = Second)\nSecondLabel.grid()\nThirdLabel = Label(app, textvariable = Third)\nThirdLabel.grid()\n\nMainMenuButton = Button(app, text = \"Main Menu\", command=MainMenuClick)\nMainMenuButton.grid()\n\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.6365330815315247,
"alphanum_fraction": 0.658900260925293,
"avg_line_length": 23.386363983154297,
"blob_id": "a57430b1b87c808dd45480662655930209a9323f",
"content_id": "784dd60090a89109147931ad73560807450e3559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1073,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 44,
"path": "/Python Files and Images/ConfirmReset.py",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nimport sys, os\n\nroot = Tk()\nroot.title(\"High Score Reset\")\n\napp = Frame(root)\napp.grid()\n\nlabel = Label(app, text = \"Are you sure you want to reset the high scores\", wraplength = 160)\nlabel.grid(columnspan = 2)\n\ndef YesClick():\n ResetHigh()\n DisplayExtra()\n\ndef NoClick():\n root.withdraw()\n os.system('StartUp.py')\n quit()\n\ndef ResetHigh():\n Highscores = open(\"Highscores.txt\", \"w\")\n for i in range (1, 4):\n Highscores.write(\"N/A,0 \\n\")\n Highscores.close()\n\ndef DisplayExtra():\n Message = Label(app, text = \"High Scores have been reset\", wraplength =150, fg = 'red') \n Message.grid(row=2,columnspan =2)\n MainButton = Button(app,text=\"MainMenu\",command = NoClick)\n MainButton.grid(row=3,columnspan=2)\n MainButton.config(width=22)\n\n \nNoButton = Button(app, text = \"NO\", command = NoClick)\nNoButton.grid(row = 1, column = 0)\nNoButton.config(width = 10 )\n\nYesButton = Button(app, text = \"YES\", command = YesClick, fg='red')\nYesButton.grid(row=1,column=1)\nYesButton.config(width = 10 )\n\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.7928571701049805,
"alphanum_fraction": 0.7928571701049805,
"avg_line_length": 69,
"blob_id": "0390bbad4583d6fe23d5acaca326c9154ea2feb7",
"content_id": "81fd0b0cab5ab419477c83b08fbef7594417c07b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 4,
"path": "/README.md",
"repo_name": "sammilward/Car-Dash",
"src_encoding": "UTF-8",
"text": "# Car-Dash\nMy first ever python project, started in the first term of university. A graphical game, using the PyGame module.\nTo start the project load the python file StartUp.py\nThis will load the menu, where you can start the game from, and view the instructions and highscores.\n"
}
] | 7 |
yunluo0921/examples
|
https://github.com/yunluo0921/examples
|
dca67d3060ed191816db1069c1048c42c9e43e85
|
73a2a13150cb06e6a8935933521ae9a0c9e09662
|
50e5058985f8c0ae2db49d543a302e1612655d55
|
refs/heads/master
| 2022-06-23T09:00:14.775174 | 2020-05-12T14:20:24 | 2020-05-12T14:20:24 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49167928099632263,
"alphanum_fraction": 0.57823646068573,
"avg_line_length": 39.94247817993164,
"blob_id": "3b67ff9a11184a0933ece6f5b55408c112782d65",
"content_id": "c487c89c580fdbf0a2e9c7cbd123ef6f420fed0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9254,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 226,
"path": "/Linac/Parmila_Benchmark/generator.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#--------------------------------------------------------\n# The script will generates bunches for Parmila and Impact\n# codes the by using gerenrators from bunch_generators.py\n#--------------------------------------------------------\n\nimport math\nimport sys\nimport os\nimport random\n\nfrom orbit.bunch_generators import TwissContainer\nfrom orbit.bunch_generators import KVDist2D, KVDist3D\nfrom orbit.bunch_generators import GaussDist2D, GaussDist3D\nfrom orbit.bunch_generators import WaterBagDist2D, WaterBagDist3D\nfrom orbit.bunch_generators import TwissAnalysis\n\nrandom.seed(1)\n\nn_particles = 20000 # number of particles\ne_kin = 2.5 # MeV - kinetic energy\nmass = 939.3014 # MeV - mass of H-\nc = 2.99792458e+10 # speed of light in cm/sec\nfreq = 402.5e+6 # cavity frequency in Hz\nbeam_current = 0.01 # beam current in mA , design = 38 mA \nlambd = c/freq # lambda in cm\ngamma = 1.0 + e_kin/mass\nbeta = math.sqrt(1.0 - 1.0/gamma**2)\n\n#=======INITIAL PHASE in DEG\nphase_init_deg = -45.0\n\n#-----------x plane ----------\n# for x and y axises: alpha - dimensionless, beta - [cm/radian], emitt - [cm*radian]\nalpha_x = -1.9619\nbeta_x = 18.3140\nemitt_x = 0.00002/(beta*gamma)\n\nalpha_x = -0.1149*25\nbeta_x = 55.8710*4\nemitt_x = (0.0000160/(beta*gamma))/1\n\nalpha_x = 4.\nbeta_x = 200.\nemitt_x = (0.000016/(beta*gamma))/1\n\n\n#-----------y plane ----------\n# for x and y axises: alpha - dimensionless, beta - [cm/radian], emitt - [cm*radian]\nalpha_y = -1.7681\nbeta_y = 16.1030\nemitt_y = 0.00002/(beta*gamma)\n\nalpha_y = -0.0933*25\nbeta_y = 13.4717*4\nemitt_y = (0.0000162/(beta*gamma))/1.\n\nalpha_y = -4.\nbeta_y = 200.\nemitt_y = (0.000016/(beta*gamma))/1\n\n#Distribution contains 20000 particles, current= 0.0100 mA, freq= 402.500 MHz\n#Beam distribution parameters: STRANGE\n# rms(n) 100% ellipse alfa beta(u)\n# (cm-mr) (cm-mr) (cm/rad),(deg/MeV)\n# 1 0.0225 0.4853 4.9469 209.1178\n# 2 0.0200 0.1574 -0.0504 10.8433\n# 3 0.1312 1.2519 0.1884 207.6669\n\n#----------z plane ----------\n# for z axis: alpha - dimensionless, beta - [degree/MeV], emitt - [MeV*degree]\n# The numbers are from the Parmila file: they are related to the output\n# lambda = c*T = c/freq\n# beta_z[Parmila_out in degrees/Mev] = beta_z[Parmila_input in cm/radian]*360/(m*c^2*(beta*gamma)^3*lambda)\n# emitt_z[Parmila_out, normalized, deg*MeV] = emitt_z[Parmila_in, cm*radian]*360*m*c^2*beta*gamma^3/lambda\nalpha_z = 0.0196\nbeta_z = 58.2172*360/(mass*(beta*gamma)**3*lambd)\nemitt_z = 0.1281\n\nalpha_z = 0.0665 \nbeta_z = 388.0340\nemitt_z = 0.1004\n\nalpha_z = 0.1884\nbeta_z = 207.6669\nemitt_z = 0.10\n\n#Beam distribution parameters:\n# rms(n) 100% ellipse alfa beta(u)\n# (cm-mr) (cm-mr) (cm/rad),(deg/MeV)\n# 1 0.0160 0.1269 -0.1149 55.8710\n# 2 0.0162 0.1240 -0.0933 13.4717\n# 3 0.1004 0.7741 0.0665 388.0340\n\n\n\"\"\"WaterBagDist3D\nParmila input\n;input -2 100000 -1.9619 18.3140 0.0021824 ! Toutatis 38 mA emittance to 7mm into MEBT\n; 1.7681 16.1030 0.0021856\n; 0.0196 58.2172 0.003088\n\n;input -2 100000 -1.9899 19.6360 0.0017573 ! exact match to rms properties of ReadDist distribution\n; 1.92893 17.778 0.0017572\n; 0.015682 67.0939 0.002420\n\"\"\"\n\n#---------------------------------------------\n# Set up Twiss for X,Y,Z\n#---------------------------------------------\ntwissX = TwissContainer(alpha = alpha_x, beta = beta_x, emittance = emitt_x)\ntwissY = TwissContainer(alpha = alpha_y, beta = beta_y, emittance = emitt_y)\ntwissZ = TwissContainer(alpha = alpha_z, beta = beta_z, emittance = emitt_z)\nprint \"-------------------input parameters----------------------------------------\"\nprint \"X alpha= %12.5g beta [cm/rad] =%12.5g emitt[cm*rad] = %12.5g \"%(alpha_x,beta_x,emitt_x)\nprint \"Y alpha= %12.5g beta [cm/rad] =%12.5g emitt[cm*rad] = %12.5g \"%(alpha_y,beta_y,emitt_y)\nprint \"Z alpha= %12.5g beta [deg/MeV] =%12.5g emitt[deg*MeV] = %12.5g \"%(alpha_z,beta_z,emitt_z)\n\n#distributor = GaussDist3D(twissX,twissY,twissZ,cut_off = 4.0)\ndistributor = WaterBagDist3D(twissX,twissY,twissZ)\n#distributor = KVDist3D(twissX,twissY,twissZ)\n\ntwiss_analysis = TwissAnalysis(3)\n\n#----------------------------------\n#open file for Parmila\n#----------------------------------\nparmila_out = open(\"parmila_bunch_tmp.txt\",\"w\")\nparmila_out.write(\"Parmila data from ***** Generated ex= %5.4f ey= %5.4f ez = %6.5f \\n\"%(emitt_x,emitt_y,emitt_z))\nparmila_out.write(\"Structure number = 1 \\n\")\nparmila_out.write(\"Cell or element number = 0 \\n\")\nparmila_out.write(\"Design particle energy =%11.6g MeV \\n\"%e_kin)\nparmila_out.write(\"Number of particles =%11d \\n\"%n_particles)\nparmila_out.write(\"Beam current =%11.7f \\n\"%beam_current)\nparmila_out.write(\"RF Frequency = 402.5000 MHz \\n\")\nparmila_out.write(\"Bunch Freq = 402.5000 MHz \\n\")\nparmila_out.write(\"Chopper fraction = 0.680000 \\n\") \nparmila_out.write(\"The input file particle coordinates were written in double precision. \\n\")\nparmila_out.write(\" x(cm) xpr(=dx/ds) y(cm) ypr(=dy/ds) phi(radian) W(MeV) \\n\")\n\t \n\t \n#----------------------------------\n#open file for Impact\n#----------------------------------\t \nimpact_out = open(\"impact.dat\",\"w\")\nimpact_coeff_x = 1/(c/(2*math.pi*freq))\nimpact_coeff_xp = gamma*beta\nimpact_coeff_phi = math.pi/180\nimpact_coeff_dE = 1./mass\nimpact_q_m = -1.0/(mass*1.0e+6)\nimpact_macrosize = (beam_current*1.0e-3/freq)/n_particles\n\t \ni = 0\nwhile(i < n_particles):\n\ti = i + 1\n\tif(i % 10000 == 0): print \"i=\",i\n\t#results are ([m],[rad],[m],[rad],[deg],[MeV])\n\t(x,xp,y,yp,phi,dE) = distributor.getCoordinates()\n\ttwiss_analysis.account((x,xp,y,yp,phi + phase_init_deg,dE))\n\tparmila_out.write(\"%18.11g%18.11g%18.11g%18.11g%18.11g%18.11g \\n\"%(x,xp,y,yp,(phi + phase_init_deg)*math.pi/180.,dE+e_kin))\n\t#---write impact line --------\n\ts = \"\"\n\ts = s + \" %14.7e\"%(x*impact_coeff_x)\n\ts = s + \" %14.7e\"%(xp*impact_coeff_xp)\n\ts = s + \" %14.7e\"%(y*impact_coeff_x)\n\ts = s + \" %14.7e\"%(yp*impact_coeff_xp)\n\ts = s + \" %14.7e\"%(phi*impact_coeff_phi)\n\ts = s + \" %14.7e\"%(dE*impact_coeff_dE)\n\ts = s + \" %14.7e\"%(impact_q_m)\n\ts = s + \" %14.7e\"%(impact_macrosize)\n\ts = s + \" %14.7e\"%(1.0*i)\n\timpact_out.write(s+\"\\n\")\n\t\nparmila_out.close()\nimpact_out.close()\n\nprint \"n total =\",n_particles\n\n#------------------------------\n# print the parameters of the generated distribution\n#------------------------------\nbg = gamma*beta\n(alpha_x,beta_x,gamma_x,emitt_x) = twiss_analysis.getTwiss(0)\n(alpha_y,beta_y,gamma_y,emitt_y) = twiss_analysis.getTwiss(1)\n(alpha_z,beta_z,gamma_z,emitt_z) = twiss_analysis.getTwiss(2)\nemitt_x = 1000.*emitt_x*bg\nemitt_y = 1000.*emitt_y*bg\nprint \"-------------------bunch's twiss parameters----------------------------------------\"\nprint \"X alpha= %12.5g beta [cm/rad] =%12.5g gamma = %12.5g norm. emitt[cm*mrad] = %12.5g \"%(alpha_x,beta_x,gamma_x,emitt_x)\nprint \"Y alpha= %12.5g beta [cm/rad] =%12.5g gamma = %12.5g norm. emitt[cm*mrad] = %12.5g \"%(alpha_y,beta_y,gamma_y,emitt_y)\nprint \"Z alpha= %12.5g beta [deg/MeV] =%12.5g gamma = %12.5g emitt[deg*MeV] = %12.5g \"%(alpha_z,beta_z,gamma_z,emitt_z)\n\nprint \"-------------------centroid params--------------------------------------\"\nprint \"X x_avg [cm] =%12.5g xp_avg [rad] =%12.5g \"%twiss_analysis.getAvgU_UP(0)\nprint \"Y y_avg [cm] =%12.5g yp_avg [rad] =%12.5g \"%twiss_analysis.getAvgU_UP(1)\nprint \"Z phi_avg [deg] =%12.5g Ek [Mev] =%12.5g \"%twiss_analysis.getAvgU_UP(2)\n\n(x_rms,xp_rms) = twiss_analysis.getRmsU_UP(0)\n(y_rms,yp_rms) = twiss_analysis.getRmsU_UP(1)\n(z_rms,zp_rms) = twiss_analysis.getRmsU_UP(2)\nprint \"-------------------Rms--------------------------------------\"\nprint \"X x_rms [cm] =%12.5g xp_rms [deg] =%12.5g \"%(x_rms,xp_rms*180./math.pi)\nprint \"Y y_rms [cm] =%12.5g yp_rms [deg] =%12.5g \"%(y_rms,yp_rms*180./math.pi)\nprint \"Z phi_rms [deg] =%12.5g Ek_rms [MeV] =%12.5g \"%(z_rms,zp_rms)\n\n(x_max,xp_max) = twiss_analysis.getMaxU_UP(0)\n(x_min,xp_min) = twiss_analysis.getMinU_UP(0)\n(y_max,yp_max) = twiss_analysis.getMaxU_UP(1)\n(y_min,yp_min) = twiss_analysis.getMinU_UP(1)\n(z_max,zp_max) = twiss_analysis.getMaxU_UP(2)\n(z_min,zp_min) = twiss_analysis.getMinU_UP(2)\nprint \"-------------------Min Max--------------------------------------\"\nprint \"X x_min_max [cm] =%12.5g %12.5g xp_min_max [rad] =%12.5g %12.5g \"%(x_min,x_max,xp_min,xp_max)\nprint \"Y y_min_max [cm] =%12.5g %12.5g yp_min_max [rad] =%12.5g %12.5g \"%(y_min,y_max,yp_min,yp_max)\nprint \"Z phi_min_max [deg] =%12.5g %12.5g Ek_min_max [MeV] =%12.5g %12.5g \"%(z_min,z_max,zp_min,zp_max)\n\nprint \"-------------------generate parmila binary dst file----------------------------------------\"\n\nos.system(\"del part_rfq.dst\")\nos.system(\"del part_rfq.txt\")\nos.system(\"PARMILA_TXT_2_DST.exe parmila_bunch_tmp.txt\")\nos.system(\"unfseq_lf95_to_lf90.exe part_rfq_lf95.dst part_rfq.dst\")\nos.system(\"readdst.exe part_rfq.dst part_rfq.txt\")\nos.system(\"del part_rfq_lf95.dst\")\nos.system(\"del parmila_bunch_tmp.txt\")\nprint \"Done! Stop.\"\n\n"
},
{
"alpha_fraction": 0.603090763092041,
"alphanum_fraction": 0.6408450603485107,
"avg_line_length": 33.775508880615234,
"blob_id": "8fbfe63b81e009c1c78bae347dbea88b6efc7aa2",
"content_id": "970e566d6ee7521bfe1ad1880f95f3ca21dd2e21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5112,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 147,
"path": "/Linac/SNS_Cavities_Fields/rf_3d_field_tracker_mebt_bunchers_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#-------------------------------------------------------------------------\n# This script reads the SuperFish file and creates the SuperFishFieldSource\n# and the Runge-Kutta 3D tracker. The tracker tracks the bunch of particles\n# through the RF cavity. This example is for 1.5 and 1.8 cm MEBT bunchers.\n# The focusing effect is calculated from the acceleration and compared with\n# the Runge-Kutta bunch tracking.\n# The maximal acceleration coincides with the zero focusing and separates \n# transition from de-focusing (xp/x > 0) to focusing(xp/x < 0).\n#--------------------------------------------------------------------------\n\nimport sys\nimport math\n\nfrom bunch import Bunch\nfrom spacecharge import Grid2D\nfrom orbit.sns_linac.rf_field_readers import SuperFish_3D_RF_FieldReader, RF_AxisFieldAnalysis\nfrom trackerrk4 import RungeKuttaTracker\n\n# from linac import the \nfrom linac import SuperFishFieldSource\n\nfReader = SuperFish_3D_RF_FieldReader()\n#fReader.readFile(\"data/mebt_1.8cm_field.dat\")\nfReader.readFile(\"data/mebt_1.5cm_field.dat\")\n(grid2D_Ez,grid2D_Er,grid2D_H) = fReader.makeGrid2DFileds_EzErH()\n\nfieldSource = SuperFishFieldSource()\nfieldSource.setGrid2D_Fields(grid2D_Ez,grid2D_Er,grid2D_H)\n\n#----------------------------------------------\n# RF field parameters \n#----------------------------------------------\nrf_freq = 402.50e+6 # in Hz\nzSimmetric = 1 # it is symmetric\nzOrientation = 1 # the cavity is oriented as in the input file\namplitude = 2.0e+6 # the initial amplitude. It is just a number.\nphase = 0.*math.pi/180. # the initial phase\ntime_init = 0. # initial time\n\nfieldSource = SuperFishFieldSource()\nfieldSource.setGrid2D_Fields(grid2D_Ez,grid2D_Er,grid2D_H)\nfieldSource.setFrequency(rf_freq)\nfieldSource.setAmplitude(amplitude)\nfieldSource.setPhase(phase)\nfieldSource.setDirectionZ(zOrientation)\nfieldSource.setSymmetry(zSimmetric)\nfieldSource.setTimeInit(time_init)\n\nprint \"frequnecy=\",fieldSource.getFrequency()\nprint \"amplitude=\",fieldSource.getAmplitude()\nprint \"phase=\",fieldSource.getPhase()*180./math.pi\nprint \"fieldCenterPos = \",fieldSource.getFieldCenterPos()\nprint \"directionZ=\",fieldSource.getDirectionZ()\nprint \"symmetry = \",fieldSource.getSymmetry()\nprint \"min max Z =\",(grid2D_Ez.getMinX(),grid2D_Ez.getMaxX())\nprint \"min max R =\",(grid2D_Ez.getMinY(),grid2D_Ez.getMaxY())\nprint \"length of Grid2D =\",(grid2D_Ez.getMaxX()-grid2D_Ez.getMinX())\nprint \"length of the filed =\",fieldSource.getLength()\nprint \"initial time [sec] =\",fieldSource.getTimeInit()\nprint \"average filed [MV/m] =\",fieldSource.getAvgField()/1.0e+6\nprint \"AvgField*Length [kV] =\",fieldSource.getAvgField()*fieldSource.getLength()/1000.\n\n#-------Bunch definition ------------------\nb = Bunch()\nprint \"Part. m=\",b.mass()\nprint \"Part. q=\",b.charge()\n\nTK = 0.0025 # in [GeV]\nE = b.mass() + TK\nP = math.sqrt(E*E - b.mass()*b.mass())\nc_light = 2.99792458e+8\nlmbd = c_light/fieldSource.getFrequency()\n\nsyncPart = b.getSyncParticle()\nsyncPart.kinEnergy(TK)\n\nprint \"TK[GeV] = \",TK\nprint \"P[GeV/c] = \",P\n\nb.addParticle(0.001,0.0,0.000,0.,0.,0.)\n\nb.compress()\n\nprint \"initial syncPart (px,py,pz) =\",(syncPart.px(),syncPart.py(),syncPart.pz())\n\nlength = grid2D_Ez.getMaxX()-grid2D_Ez.getMinX()\n\ntracker = RungeKuttaTracker(length)\n#--------------------------------------------------------------------------------\n# for the symmetric fields (if zSimmetric == +1) the grid2D has only z = 0,z_max\n#--------------------------------------------------------------------------------\nif(fieldSource.getSymmetry() == 1):\n\ttracker.entrancePlane(0,0,-1.,-grid2D_Ez.getMaxX())\nelse:\n\ttracker.entrancePlane(0,0,-1.,grid2D_Ez.getMinX())\ntracker.exitPlane(0,0,1.,-grid2D_Ez.getMaxX())\ntracker.spatialEps(0.0000001)\ntracker.stepsNumber(60)\n\nprint \"Entrance plane (a,b,c,d)=\",tracker.entrancePlane()\nprint \"Exit plane (a,b,c,d)=\",tracker.exitPlane()\nprint \"Length[m]=\",tracker.length()\n\neKin_min = 1.0e+40\neKin_max =-1.0e+40\n\nk_r_min = 1.0e+40\nk_r_max =-1.0e+40\n\nphase_start = 0.\nphase_step = 1.0\nn_steps = int(360./phase_step) + 1\nprint \"# phase[deg] Ek[MeV] k_x n_steps\" \nfor i in range(n_steps):\n\tphase_dgr = phase_start + i*phase_step\n\tphase =phase_dgr*math.pi/180.\n\tfieldSource.setPhase(phase)\n\n\tb1 = Bunch()\n\tb.copyBunchTo(b1)\n\ttracker.trackBunch(b1,fieldSource)\n\tn_rk4_steps = tracker.stepsNumber()\n\tk_r = b1.xp(0)/b1.x(0)\n\teKin_out = b1.getSyncParticle().kinEnergy()\n\tif(eKin_min > eKin_out):\n\t\teKin_min = eKin_out\n\tif(eKin_max < eKin_out):\n\t\teKin_max = eKin_out\n\tif(k_r_min > k_r):\n\t\tk_r_min = k_r\n\tif(k_r_max < k_r):\n\t\tk_r_max = k_r\n\tprint \" %3d \"%i,\" %5.1f \"%phase_dgr,\" %12.6f \"%(eKin_out*1000),\" %12.6f \"%k_r,\" %3d \"%n_rk4_steps\n\n\t\nE0TL = \t(eKin_max - eKin_min)/2.0\nbeta = syncPart.beta()\ngamma = syncPart.gamma() \nmass = syncPart.mass()\nprint \" E0TL [keV] = %12.6f \"%(E0TL*1000*1000)\nk_r_theory = math.pi*E0TL/(mass*gamma**3*beta**3*lmbd)\nprint \"focusing coef. theory xp/r = %12.5g \"%k_r_theory \nprint \"focusing coef. SuperFish xp/r = %12.5g \"%((k_r_max - k_r_min)/2.0)\n\n\t\nprint \"==========================================\"\nprint \"Done.\"\n"
},
{
"alpha_fraction": 0.4197802245616913,
"alphanum_fraction": 0.4475063383579254,
"avg_line_length": 38.16556167602539,
"blob_id": "8ad6c6aa4c73ca962aae46d903ebe311c12cf0db",
"content_id": "f37014bb13cfe652c431cac38668c2d8ff9100ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5915,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 151,
"path": "/Linac/RF_Gap_Models/rf_gap_three_point_ttf_model_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script is a test for RfGapThreePointTTF gap model. \nThis model uses T,T',S,S' transit time factors (TTF) \ncalculated for the second order of polynomial defined by three points \nof the electric field on the axis Em,E0,Ep for -dz,0.,+dz positions.\nThis class does not use the Polynomial class. Instead it uses\njust E(z) = E0*(1+a*z+b*z^2).\n\"\"\"\n\nimport sys\nimport math\nimport random\n\nfrom bunch import Bunch\n\n# from linac import the RF gap classes\nfrom linac import BaseRfGap, MatrixRfGap, RfGapTTF, RfGapThreePointTTF \nfrom orbit.sns_linac import Drift\n\n# The classes for the field on axis of the cavity\nfrom orbit.sns_linac.rf_field_readers import SuperFish_3D_RF_FieldReader, RF_AxisFieldAnalysis\n\ndef makePhaseNear(phase, phase0): \n\t\"\"\" It will add or substruct any amount of 360. from phase to get close to phase0 \"\"\" \n\tn = int(phase0/360.) \n\tphase = phase%360. \n\tmin_x = 1.0e+38 \n\tn_min = 0 \n\tfor i0 in range(5): \n\t\ti = i0 - 3 \n\t\td = math.fabs(phase + 360.*(i+n) - phase0) \n\t\tif(d < min_x): \n\t\t\tn_min = i \n\t\t\tmin_x = d \n\treturn (phase + 360.*(n_min+n)) \n\nrf_gap = RfGapThreePointTTF()\n\nrf_frequency = 400.0*1.0e+6 # in Hz\n\n#read the RF cavity field\nfReader = SuperFish_3D_RF_FieldReader()\nfReader.readFile(\"../SNS_Cavities_Fields/data/scl_medium_beta_rf_cav_field.dat\")\n\n#This particular cavity is not symmetric\nzSimmetric = 0\nspline = fReader.getAxisEz(zSimmetric)\n\nrf_analysis = RF_AxisFieldAnalysis(spline)\nroot_pos_arr = rf_analysis.rootAnalysis()\ncenter_pos_arr = rf_analysis.gapCentersAnalysis()\nprint \"roots=\",root_pos_arr\nprint \"centers=\",center_pos_arr\n\nspline = rf_analysis.getNormilizedSpline()\n\nn_gap_steps = 10\nz_min = spline.x(0)\nz_max = spline.x(spline.getSize() - 1)\nstep_size = (z_max - z_min)/(n_gap_steps - 1)\n\ndz = step_size/2.0\ndrift = Drift()\ndrift.setLength(dz)\n\ndef trackBunch(b,cavity_amp,phase_dgr):\n\tphase = phase_dgr*math.pi/180.\t\n\ttime_init = b.getSyncParticle().time()\n\tfor i in range(n_gap_steps-1):\n\t\tzm = z_min + i*step_size\n\t\tz0 = zm + dz\n\t\tzp = z0 + dz\n\t\tEm = cavity_amp*spline.getY(zm)\n\t\tE0 = cavity_amp*spline.getY(z0)\n\t\tEp = cavity_amp*spline.getY(zp)\n\t\tdrift.setLength(dz)\n\t\tdrift.trackBunch(b)\n\t\ttime_gap = b.getSyncParticle().time()\n\t\tdelta_phase = 2*math.pi*(time_gap - time_init)*rf_frequency\n\t\trf_gap.trackBunch(b,dz,Em,E0,Ep,rf_frequency,phase+delta_phase)\n\t\t#print \"====debug Python level=========\"\n\t\t#b.dumpBunch()\n\t\tdrift.setLength(dz)\n\t\tdrift.trackBunch(b)\n\t\t#b.dumpBunch()\n\treturn b\n\n#---------------------------------------\n#---- let's make bunch ---------\n#---------------------------------------\nb = Bunch()\nprint \"Part. m=\",b.mass()\nprint \"Part. q=\",b.charge()\nTK = 0.1856 # in [GeV]\nsyncPart = b.getSyncParticle()\nsyncPart.kinEnergy(TK)\nbeta = syncPart.beta()\ngamma = syncPart.gamma() \nmass = syncPart.mass()\n\nc_light = 2.99792458e+8\nlmbd = c_light/rf_frequency\n\n#---cavity field\nE0 = 20.0e+6 # average field in V/m\n\nb.addParticle(0.001,0.0,0.000,0.,0.,0.)\n\neKin_min = 1.0e+40\neKin_max =-1.0e+40\n\nk_r_min = 1.0e+40\nk_r_max =-1.0e+40\n\nphase_start = 0.\nphase_step = 1.0\nn_steps = int(360./phase_step) + 1\nphase_maxE = 0.\nprint \"# phase[deg] Ek[MeV] k_x \" \nfor i in range(n_steps):\n\tphase = phase_start + i*phase_step\n\tb1 = Bunch()\n\tb.copyBunchTo(b1)\n\tb1 = trackBunch(b1,E0,phase)\n\tk_r = b1.xp(0)/b1.x(0)\n\teKin_out = b1.getSyncParticle().kinEnergy()\n\tif(eKin_min > eKin_out):\n\t\teKin_min = eKin_out\n\tif(eKin_max < eKin_out):\n\t\teKin_max = eKin_out\n\t\tphase_maxE = phase\n\tif(k_r_min > k_r):\n\t\tk_r_min = k_r\n\tif(k_r_max < k_r):\n\t\tk_r_max = k_r\n\tprint \" %3d \"%i,\" %5.1f \"%phase,\" %12.6f \"%(eKin_out*1000),\" %12.6f \"%k_r\n\nE0TL = \t(eKin_max - eKin_min)/2.0\nbeta = syncPart.beta()\ngamma = syncPart.gamma() \nmass = syncPart.mass()\nprint \"maximal Ekin at RF phase=\",makePhaseNear(phase_maxE,0.)\nprint \" E0TL [MeV] = %12.6f \"%(E0TL*1000)\nk_r_theory = math.pi*E0TL/(mass*gamma**3*beta**3*lmbd)\nprint \"focusing coef. theory xp/r = %12.5g \"%k_r_theory \nprint \"focusing coef. RF TTF Gap xp/r = %12.5g \"%((k_r_max - k_r_min)/2.0)\n\nprint \"==========================================\"\nprint \"Stop.\"\n\n"
},
{
"alpha_fraction": 0.6794564127922058,
"alphanum_fraction": 0.704236626625061,
"avg_line_length": 32.36000061035156,
"blob_id": "a74db5543157deec0bf1c3ed695c1f92f47787ac",
"content_id": "5f1fc5f0b30c83976413f2c68e9c4250d07c3545",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2502,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 75,
"path": "/Linac/Parmila_Benchmark/pyorbit_sns_linac_energy_track.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch through the SNS linac in pyORBIT and \nwill generate the file with the energy after each RF gap\n\"\"\"\n\nimport sys\nimport math\nimport random\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\n\nfrom orbit.bunch_generators import TwissContainer, TwissAnalysis\nfrom orbit.bunch_generators import WaterBagDist3D, GaussDist3D, KVDist3D\n\n\nfrom bunch import Bunch\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\naccLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\n\nprint \"Acc Lattice is ready. \"\n#set H- mass\n#self.bunch.mass(0.9382723 + 2*0.000511)\nbunch = Bunch()\nbunch.mass(0.939294)\nbunch.charge(-1.0)\nbunch.getSyncParticle().kinEnergy(0.0025)\n\n#set up design\naccLattice.trackDesignBunch(bunch)\n\nprint \"Design tracking completed.\"\n\n#track through the lattice \nparamsDict = {\"test_pos\":0.,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\nprint \"N name position x xp y yp z dE eKin \"\nfile_out = open(\"pyorbit_pos_energy.dat\",\"w\")\nfile_out.write(\" N name position eKin \\n\")\n\t\ndef action_exit(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tbunch = paramsDict[\"bunch\"]\n\t#print \"debug ============= exit xp=\",bunch.xp(0), \" name=\",node.getName(),\" L=\",length\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice) and node.getName().find(\":Rg\") > 0 and node.getName().find(\"drift\") < 0):\t\n\t\tparamsDict[\"count\"]\t+= 1\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %10.5f %12.6f \"%(paramsDict[\"count\"],node.getName(),pos,eKin)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\nactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\naccLattice.trackBunch(bunch, paramsDict = paramsDict, actionContainer = actionContainer)\n\nfile_out.close()\n"
},
{
"alpha_fraction": 0.49253731966018677,
"alphanum_fraction": 0.5041459202766418,
"avg_line_length": 22.19230842590332,
"blob_id": "d26e09fb5525ae1d902fe605709844ae0de1d493",
"content_id": "cd21262412f92fc47119a8f53e975f429309abe1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 26,
"path": "/Linac/SNS_Linac/tracewin_scl_quad_lattice_reading.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#--------------------------------------------------------\n# The classes will read data file with lattice information\n#--------------------------------------------------------\n\nimport math\nimport sys\nimport os\n\nfl_in = open(\"trace_win_scl_structure.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\n\ncount = 0\nquads = []\nfor ind in range(len(lns)):\n\tln = lns[ind]\n\tln = ln.strip()\n\tif(len(ln) <= 0 or ln[0] == \";\"): continue\n\tif(ln.find(\"QUAD\") >= 0):\n\t\tcount += 1\n\t\tif(lns[ind-1].find(\"MATCH_FAM_GRAD\") >= 0):\n\t\t\tprint \"quad count=\",count,\" ln=\",ln\n\t\t\t\nprint \"total quads N=\",count\n"
},
{
"alpha_fraction": 0.6696468591690063,
"alphanum_fraction": 0.6928922533988953,
"avg_line_length": 31.39130401611328,
"blob_id": "b8ca993a8431ed397326e04656aa9462133cf49d",
"content_id": "36300f6608615d1c9f61d6ec3927a462aff6e6dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2237,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 69,
"path": "/Linac/Input_File_Parsing/linac_acc_lattice_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis is a test script to check the functionality of the \nlinac acc lattice. It will print out the table with the\npositions of RF gaps and energies after each gap.\nKeep in mind that phases in pyORBIT linac RF cavities are shifted by 180\nbecause we track the negative ions for SNS.\n\"\"\"\n\nimport sys\nimport math\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\n\nfrom bunch import Bunch\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\naccLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\n\nb = Bunch()\nsyncPart = b.getSyncParticle()\n#set H- mass\nb.mass(0.9382723 + 2*0.000511)\nb.charge(-1.0)\nsyncPart.kinEnergy(0.0025)\n\n#set up design\nparamsDict = {\"test_pos\":0.,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\noutF = open(\"sns_linac_energy.dat\",\"w\")\n\n\nprint \" N node position kinEnergy[MeV] \"\ndef test_action(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tbunch = paramsDict[\"bunch\"]\n\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\t\n\tif(node.getName().find(\":Rg\") >= 0):\n\t\tparamsDict[\"count\"]\t+= 1\n\t\ts = \" %5d %35s %4.5f %5.3f \"%(paramsDict[\"count\"],node.getName(),(pos - length/2),eKin)\n\t\t#outF.write(s+\"\\n\")\n\t\tprint s\n\nactionContainer.addAction(test_action, AccActionsContainer.EXIT)\n\naccLattice.trackDesignBunch(b, paramsDict = paramsDict, actionContainer = actionContainer)\n\noutF.close()\n\naccLattice.trackBunch(b, paramsDict = paramsDict, actionContainer = actionContainer)\n\n\n"
},
{
"alpha_fraction": 0.5194982290267944,
"alphanum_fraction": 0.5674938559532166,
"avg_line_length": 39.733333587646484,
"blob_id": "62cf133924f543f0f96d0ef33a8df4914a874f2e",
"content_id": "71e108579421ca1f86e08cc07a25448c708c4786",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3667,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 90,
"path": "/Linac/Parmila_Benchmark/parmila_bunch_analysis.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#--------------------------------------------------------\n# The script will calculate the Twiss parameters of the \n# Parmila particles' distribution that was dumped and \n# transformed to the text file by readdst.exe\n#--------------------------------------------------------\n\nimport math\nimport sys\n\nfrom orbit.bunch_generators import TwissAnalysis\n\nif(len(sys.argv) != 2): \n\tprint \"Usage: >python \",sys.argv[0],\" <name of Parmila bunch text file>\" \n\tsys.exit(1)\n\t\nparmila_bunch_in = open(sys.argv[1],\"r\")\n\ntwiss_analysis = TwissAnalysis(3)\n\n\ns = parmila_bunch_in.readline()\nwhile(s.find(\"x(cm) xpr(=dx/ds)\") < 0):\n\ts = parmila_bunch_in.readline()\n\ns = parmila_bunch_in.readline()\nn_parts = 0\nwhile(len(s) > 20):\n\ts_arr = s.split()\n\tif(len(s_arr) != 6):\n\t\tprint \"Structure of the Parmila dump file is wrong! file name =\",sys.argv[1]\n\t\tsys.exit(1)\n\tn_parts = n_parts + 1\n\tx = float(s_arr[0])\n\txp = float(s_arr[1])\n\ty = float(s_arr[2])\n\typ = float(s_arr[3])\n\tphi = float(s_arr[4])\n\tEk = float(s_arr[5])\n\ttwiss_analysis.account((x,xp,y,yp,phi*180/math.pi,Ek))\n\ts = parmila_bunch_in.readline()\n\t\nparmila_bunch_in.close()\n\nprint \"n particles =\",n_parts\nmass = 939.3014 # MeV - mass of H-\ne_kin = twiss_analysis.getAvgU_UP(2)[1]\ngamma = 1.0 + e_kin/mass\nbeta = math.sqrt(1.0 - 1.0/gamma**2)\nbg = gamma*beta\n\n#------------------------------\n# print the parameters of the distribution\n#------------------------------\nprint \"file =\",sys.argv[1]\n(alpha_x,beta_x,gamma_x,emitt_x) = twiss_analysis.getTwiss(0)\n(alpha_y,beta_y,gamma_y,emitt_y) = twiss_analysis.getTwiss(1)\n(alpha_z,beta_z,gamma_z,emitt_z) = twiss_analysis.getTwiss(2)\nemitt_x = 1000.*emitt_x*bg\nemitt_y = 1000.*emitt_y*bg\n\nprint \"-------------------bunch's twiss parameters----------------------------------------\"\nprint \"X alpha= %12.5g beta [cm/rad] =%12.5g gamma = %12.5g norm. emitt[cm*mrad] = %12.5g \"%(alpha_x,beta_x,gamma_x,emitt_x)\nprint \"Y alpha= %12.5g beta [cm/rad] =%12.5g gamma = %12.5g norm. emitt[cm*mrad] = %12.5g \"%(alpha_y,beta_y,gamma_y,emitt_y)\nprint \"Z alpha= %12.5g beta [deg/MeV] =%12.5g gamma = %12.5g emitt[deg*MeV] = %12.5g \"%(alpha_z,beta_z,gamma_z,emitt_z)\n\nprint \"-------------------centroid params--------------------------------------\"\nprint \"X x_avg [cm] =%12.5g xp_avg [rad] =%12.5g \"%twiss_analysis.getAvgU_UP(0)\nprint \"Y y_avg [cm] =%12.5g xp_avg [rad] =%12.5g \"%twiss_analysis.getAvgU_UP(1)\nprint \"Z phi_avg [deg] =%12.5g Ek [Mev] =%12.5g \"%twiss_analysis.getAvgU_UP(2)\n\n(x_rms,xp_rms) = twiss_analysis.getRmsU_UP(0)\n(y_rms,yp_rms) = twiss_analysis.getRmsU_UP(1)\n(z_rms,zp_rms) = twiss_analysis.getRmsU_UP(2)\nprint \"-------------------Rms--------------------------------------\"\nprint \"X x_rms [cm] =%12.5g xp_rms [deg] =%12.5g \"%(x_rms,xp_rms*180./math.pi)\nprint \"Y y_rms [cm] =%12.5g yp_rms [deg] =%12.5g \"%(y_rms,yp_rms*180./math.pi)\nprint \"Z phi_rms [deg] =%12.5g Ek_rms [MeV] =%12.5g \"%(z_rms,zp_rms)\n\n(x_max,xp_max) = twiss_analysis.getMaxU_UP(0)\n(x_min,xp_min) = twiss_analysis.getMinU_UP(0)\n(y_max,yp_max) = twiss_analysis.getMaxU_UP(1)\n(y_min,yp_min) = twiss_analysis.getMinU_UP(1)\n(z_max,zp_max) = twiss_analysis.getMaxU_UP(2)\n(z_min,zp_min) = twiss_analysis.getMinU_UP(2)\nprint \"-------------------Min Max--------------------------------------\"\nprint \"X x_min_max [cm] =%12.5g %12.5g xp_min_max [rad] =%12.5g %12.5g \"%(x_min,x_max,xp_min,xp_max)\nprint \"Y y_min_max [cm] =%12.5g %12.5g yp_min_max [rad] =%12.5g %12.5g \"%(y_min,y_max,yp_min,yp_max)\nprint \"Z phi_min_max [deg] =%12.5g %12.5g Ek_min_max [MeV] =%12.5g %12.5g \"%(z_min,z_max,zp_min,zp_max)\n\n"
},
{
"alpha_fraction": 0.4741773009300232,
"alphanum_fraction": 0.4967794716358185,
"avg_line_length": 37.63348388671875,
"blob_id": "337f4e161fceb8bf3a83805ce9c25f0c31ba4755",
"content_id": "9553a3b03c09c70934b30be402c0a28a5ed64920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8539,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 221,
"path": "/Linac/RF_Gap_Models/rf_gap_ttf_model_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script is a test for RfGapTTF gap model. \nThis model uses T,T',S,S' transit time factors (TTF).\nIt will read the TTF polynomials from the external file.\nThis file was created by \"SNS_Cavities_Fields/rf_ttf_generator.py\".\nAt this moment this script is not parallel.\n\"\"\"\n\nimport sys\nimport math\nimport random\n\nfrom bunch import Bunch\n\nfrom orbit_utils import Polynomial\n\n# from linac import the RF gap classes\nfrom linac import BaseRfGap, MatrixRfGap, RfGapTTF\nfrom orbit.sns_linac import Drift\n\ndef makePhaseNear(phase, phase0): \n\t\"\"\" It will add or substruct any amount of 360. from phase to get close to phase0 \"\"\" \n\tn = int(phase0/360.) \n\tphase = phase%360. \n\tmin_x = 1.0e+38 \n\tn_min = 0 \n\tfor i0 in range(5): \n\t\ti = i0 - 3 \n\t\td = math.fabs(phase + 360.*(i+n) - phase0) \n\t\tif(d < min_x): \n\t\t\tn_min = i \n\t\t\tmin_x = d \n\treturn (phase + 360.*(n_min+n)) \n\n#------read the parameters from the external file \nfl_in = open(\"../SNS_Cavities_Fields/data/scl_medium_beta_rf_cav_field_t_tp_s_sp.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\n\nrf_freq = float(lns[0].split()[1])\n(beta_min,beta_max) = (float(lns[1].split()[1]),float(lns[1].split()[2]))\nn_gaps = int(lns[2].split()[1])\n\ndef split_arr_func(ln):\n\tres_arr = ln.split()\n\tval_arr = []\n\tfor st in res_arr[1:]:\n\t\tval_arr.append(float(st)) \n\treturn val_arr\n\ngap_border_points = split_arr_func(lns[3])\ngap_positions = split_arr_func(lns[4])\ngap_lengths = split_arr_func(lns[5])\ngap_E0_amplitudes = split_arr_func(lns[6])\ngap_E0L_amplitudes = split_arr_func(lns[7])\n\ndef split_polynom_coeffs(ln):\n\tres_arr = ln.split()\n\tcoeff_arr = []\n\tcount = 0\n\tfor i in range(4,len(res_arr),3):\n\t\tval = float(res_arr[i])\n\t\tcoeff_arr.append(val)\n\t\t#print \"debug i=\",count,\" val=\",val\n\t\tcount += 1\n\tpoly = Polynomial(len(coeff_arr)-1)\n\tfor i in range(len(coeff_arr)):\n\t\tpoly.coefficient(i,coeff_arr[i])\n\treturn poly\n\n#---------------------------------------\n# We set T, T', S, and S'. The T'=dT/d(kappa) and S'=dS/d(kappa).\n# where kappa = 2*PI*frequency/(c*beta)\n# The T' and S' are set up as separate polynomials, because\n# the accuracy of calculating a derivative from the polynomial\n# fitting is very low.\n#---------------------------------------\t\t\n\t\t\nrf_gap_ttf_arr = []\nfor i_gap in range(n_gaps):\n\trf_gap_ttf = RfGapTTF()\n\tpolyT = split_polynom_coeffs(lns[8+i_gap])\n\tpolyTp = split_polynom_coeffs(lns[9+i_gap])\n\tpolyS = split_polynom_coeffs(lns[10+i_gap])\n\tpolySp = split_polynom_coeffs(lns[11+i_gap])\n\trf_gap_ttf.setT_TTF(polyT)\n\trf_gap_ttf.setTp_TTF(polyTp)\n\trf_gap_ttf.setS_TTF(polyS)\n\trf_gap_ttf.setSp_TTF(polySp)\n\tgap_length = gap_lengths[i_gap]\n\trelative_amplitude = gap_E0_amplitudes[i_gap]\n\trf_gap_ttf.setParameters(polyT,polyTp,polyS,polySp,beta_min,beta_max,rf_freq,gap_length,relative_amplitude)\n\trf_gap_ttf_arr.append(rf_gap_ttf)\n\n#--------directions of the cavity can be +1 or -1\ndirectionZ = +1\nif(directionZ < 0):\n\tfor i_gap in range(len(gap_border_points)):\n\t\tgap_border_points[i_gap] = - gap_border_points[i_gap]\n\tfor i_gap in range(len(gap_positions)):\n\t\tgap_positions[i_gap] = - gap_positions[i_gap]\n\tgap_border_points.reverse()\n\tgap_positions.reverse()\n\tgap_E0_amplitudes.reverse()\n\tgap_E0L_amplitudes.reverse()\n\tgap_lengths.reverse()\n\trf_gap_ttf_arr.reverse()\n\t\t\nprint \"debug ===========================================\"\nfor i_gap in range(n_gaps):\t\n\trf_gap_ttf = rf_gap_ttf_arr[i_gap]\n\tprint \"=============== RF Gap index=\",i_gap\n\tprint \"beta min/max= \",rf_gap_ttf.getBetaMinMax()\n\tprint \"rf_frequency= \",rf_gap_ttf.getFrequency()\n\tprint \"gap_length= \",rf_gap_ttf.getLength()\n\tprint \"relative_amplitude= \",rf_gap_ttf.getRelativeAmplitude()\t\n\t\n#----------------------------------------------------------\n# RF Cavity tracking through the set of RF gaps and drifts\n#----------------------------------------------------------\nrf_cavity_mode = 1\n\ndrift = Drift()\n\ndef RF_Cavity_Track(b,E0,phase_dgr):\n\tphase = phase_dgr*math.pi/180.\n\ttime_init = 0.\n\tfor i_gap in range(n_gaps):\n\t\trf_gap_ttf = rf_gap_ttf_arr[i_gap]\n\t\tdrfit_1_length = gap_positions[i_gap] - gap_border_points[i_gap]\n\t\tdrift_2_length = gap_border_points[i_gap+1] - gap_positions[i_gap]\n\t\tdrift.setLength(drfit_1_length)\n\t\tdrift.trackBunch(b)\n\t\tif(i_gap == 0): time_init = b.getSyncParticle().time()\n\t\ttime_gap = b.getSyncParticle().time()\n\t\tdelta_phase = 2*math.pi*(time_gap - time_init)*rf_gap_ttf.getFrequency()\n\t\tdelta_phase += rf_cavity_mode*math.pi*(i_gap%2)\n\t\trf_gap_ttf.trackBunch(b,E0,phase+delta_phase)\n\t\t#print \"debug rf_pahse =\", makePhaseNear((phase+delta_phase)*180.0/math.pi,0.),\" e_kin=\",b.getSyncParticle().kinEnergy()\n\t\tdrift.setLength(drift_2_length)\n\t\tdrift.trackBunch(b)\t\t\n\treturn b\n\n#---------------------------------------\n#---- let's make bunch ---------\n#---------------------------------------\nb = Bunch()\nprint \"Part. m=\",b.mass()\nprint \"Part. q=\",b.charge()\nTK = 0.1856 # in [GeV]\nsyncPart = b.getSyncParticle()\nsyncPart.kinEnergy(TK)\nbeta = syncPart.beta()\ngamma = syncPart.gamma() \nmass = syncPart.mass()\n\nc_light = 2.99792458e+8\nlmbd = c_light/rf_freq\n\n#---cavity field\nE0 = 20.0e+6 # average field in V/m\n\n#---let's calculate the approximate maximal energy gain\nenergy_gain = 0.\nfor i_gap in range(n_gaps):\n\trf_gap_ttf = rf_gap_ttf_arr[i_gap]\n\tamp = rf_gap_ttf.getRelativeAmplitude()\n\tlength = rf_gap_ttf.getLength()\n\tpolyT = rf_gap_ttf.getT_TTF()\n\tkappa = 2*math.pi*rf_gap_ttf.getFrequency()/(c_light*beta)\n\tttf_t = polyT.value(kappa)\n\tenergy_gain += E0*ttf_t*amp*length\n\nprint \"Approximate maximal energy gain [MeV] = \",energy_gain/1.0e+6\n\nb.addParticle(0.001,0.0,0.000,0.,0.,0.)\n\neKin_min = 1.0e+40\neKin_max =-1.0e+40\n\nk_r_min = 1.0e+40\nk_r_max =-1.0e+40\n\nphase_start = 0.\nphase_step = 1.0\nn_steps = int(360./phase_step) + 1\nphase_maxE = 0.\nprint \"# phase[deg] Ek[MeV] k_x \" \nfor i in range(n_steps):\n\tphase = phase_start + i*phase_step\n\tb1 = Bunch()\n\tb.copyBunchTo(b1)\n\tb1 = RF_Cavity_Track(b1,E0,phase)\n\tk_r = b1.xp(0)/b1.x(0)\n\teKin_out = b1.getSyncParticle().kinEnergy()\n\tif(eKin_min > eKin_out):\n\t\teKin_min = eKin_out\n\tif(eKin_max < eKin_out):\n\t\teKin_max = eKin_out\n\t\tphase_maxE = phase\n\tif(k_r_min > k_r):\n\t\tk_r_min = k_r\n\tif(k_r_max < k_r):\n\t\tk_r_max = k_r\n\tprint \" %3d \"%i,\" %5.1f \"%phase,\" %12.6f \"%(eKin_out*1000),\" %12.6f \"%k_r\n\n\t\nE0TL = \t(eKin_max - eKin_min)/2.0\nbeta = syncPart.beta()\ngamma = syncPart.gamma() \nmass = syncPart.mass()\nprint \"maximal Ekin at RF phase=\",makePhaseNear(phase_maxE,0.)\nprint \" E0TL [MeV] = %12.6f \"%(E0TL*1000)\nk_r_theory = math.pi*E0TL/(mass*gamma**3*beta**3*lmbd)\nprint \"focusing coef. theory xp/r = %12.5g \"%k_r_theory \nprint \"focusing coef. RF TTF Gap xp/r = %12.5g \"%((k_r_max - k_r_min)/2.0)\n\nprint \"==========================================\"\nprint \"Stop.\"\n\n"
},
{
"alpha_fraction": 0.5885167717933655,
"alphanum_fraction": 0.6089314222335815,
"avg_line_length": 24.892562866210938,
"blob_id": "6197f2d0f6941fbfef7e4dbea9f5a20510c9af5b",
"content_id": "66ea29332c62d69d8e48b4815bc3d9d3ad264fd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3135,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 121,
"path": "/Linac/RF_Gap_Models/rf_gap_ttf_interface_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script is a test for RfGapTTF gap model settings. \nThis model uses T,T',S,S' transit time factors (TTF)\nto calculate the 6D coordinates transformation in the RF gap. \nThis test includes the memory leak test.\n\"\"\"\n\nimport sys\nimport math\nimport random\n\nfrom bunch import Bunch\n\nfrom orbit_utils import Polynomial\n\n# from linac import the RF gap classes\nfrom linac import BaseRfGap, MatrixRfGap, RfGapTTF\n\nrf_gap_ttf = RfGapTTF()\nT_ttf = rf_gap_ttf.getT_TTF()\nS_ttf = rf_gap_ttf.getS_TTF()\n#---------------------------------------\n# We set T, T', S, and S'. The T'=dT/d(cappa) and S'=dS/d(cappa).\n# where cappa = 2*PI*frequency/(c*beta)\n# The T' and S' are set up as separate polynomials, because\n# the accuracy of calculating a derivative from the polynomial\n# fitting is very low.\n#---------------------------------------\n\npolyT = Polynomial(4)\npolyT.coefficient(2,2.0)\nrf_gap_ttf.setT_TTF(polyT)\n\npolyS = Polynomial(5)\npolyS.coefficient(3,3.0)\nrf_gap_ttf.setS_TTF(polyS)\n\npolyTp = Polynomial(4)\npolyTp.coefficient(3,2.0)\nrf_gap_ttf.setT_TTF(polyTp)\n\npolySp = Polynomial(5)\npolySp.coefficient(1,3.0)\nrf_gap_ttf.setS_TTF(polySp)\n\nbeta_min = 0.5\nbeta_max = 0.9\nrf_frequency = 805.0e+6\ngap_length = 0.22\nrelative_amplitude = 0.89\n\nprint \"===========second set=======================\"\nrf_gap_ttf.setParameters(polyT,polyTp,polyS,polySp,beta_min,beta_max,rf_frequency,gap_length,relative_amplitude)\n\nprint \"===========second get=======================\"\nT_ttf = rf_gap_ttf.getT_TTF()\nS_ttf = rf_gap_ttf.getS_TTF()\nTp_ttf = rf_gap_ttf.getTp_TTF()\nSp_ttf = rf_gap_ttf.getSp_TTF()\n\nprint \"========================================\"\norder = T_ttf.order()\nfor i in range(order+1):\n\tprint \"T_ttf i=\",i,\" coef=\",T_ttf.coefficient(i)\n\nprint \"========================================\"\norder = S_ttf.order()\nfor i in range(order+1):\n\tprint \"S_ttf i=\",i,\" coef=\",S_ttf.coefficient(i)\n\nprint \"========================================\"\norder = Tp_ttf.order()\nfor i in range(order+1):\n\tprint \"Tp_ttf i=\",i,\" coef=\",Tp_ttf.coefficient(i)\n\nprint \"========================================\"\norder = Sp_ttf.order()\nfor i in range(order+1):\n\tprint \"Sp_ttf i=\",i,\" coef=\",Sp_ttf.coefficient(i)\nprint \"========================================\"\n\nprint \"beta min/max= \",rf_gap_ttf.getBetaMinMax()\nprint \"rf_frequency= \",rf_gap_ttf.getFrequency()\nprint \"gap_length= \",rf_gap_ttf.getLength()\nprint \"relative_amplitude= \",rf_gap_ttf.getRelativeAmplitude()\n\nprint \"===========memory leak check======================\"\ncount = 0\n\nrf_gap_ttf = RfGapTTF()\n\nwhile(1 < 2):\n\tcount += 1\n\n\trf_gap_ttf = RfGapTTF()\n\t\n\tpolyT = Polynomial(4)\n\tpolyT.coefficient(2,2.0)\n\tT_ttf = rf_gap_ttf.setT_TTF(polyT)\n\t\n\tpolyS = Polynomial(5)\n\tpolyS.coefficient(3,3.0)\n\tS_ttf = rf_gap_ttf.setS_TTF(polyS)\n\t\n\tpolyT = Polynomial(4)\n\tpolyT.coefficient(2,2.0)\n\tT_ttf = rf_gap_ttf.setTp_TTF(polyT)\n\t\n\tpolyS = Polynomial(5)\n\tpolyS.coefficient(3,3.0)\n\tS_ttf = rf_gap_ttf.setSp_TTF(polyS)\t\n\t\n\t\n\tT_ttf = rf_gap_ttf.getT_TTF()\n\tS_ttf = rf_gap_ttf.getS_TTF()\n\tTp_ttf = rf_gap_ttf.getTp_TTF()\n\tSp_ttf = rf_gap_ttf.getSp_TTF()\n\n\tif(count % 100000 == 0): print \"count=\",count\n\n\n"
},
{
"alpha_fraction": 0.6274402141571045,
"alphanum_fraction": 0.6796810626983643,
"avg_line_length": 37.59574508666992,
"blob_id": "eba0407be86d4a96a80cfdcf7a3419bf554e4790",
"content_id": "1d7472a4dad2cc961a0cf7656f65f2d862d66771",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3637,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 94,
"path": "/Linac/Parmila_Benchmark/pyorbit_single_part_tracking.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch with one particle through the SNS Linac\nand print the coordinates into the file.\n\"\"\"\n\nimport sys\nimport math\nimport random\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\n\nfrom orbit.bunch_generators import TwissContainer, TwissAnalysis\nfrom orbit.bunch_generators import WaterBagDist3D, GaussDist3D, KVDist3D\n\n\nfrom bunch import Bunch\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\nlattFactory.setMaxDriftLength(0.05)\naccLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\n#accLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\"])\n\nprint \"Acc Lattice is ready. \"\n#set H- mass\n#self.bunch.mass(0.9382723 + 2*0.000511)\nbunch = Bunch()\nbunch.mass(0.939294)\nbunch.charge(-1.0)\nbunch.getSyncParticle().kinEnergy(0.0025)\nbunch.addParticle(0.000,0.0,0.000,0.0,0.001,0.0)\n\n#set up design\naccLattice.trackDesignBunch(bunch)\n\nprint \"Design tracking completed.\"\n\n#track through the lattice \nparamsDict = {\"test_pos\":0.,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\nprint \" N name position[m] x[mm] xp[mrad] y[mm] yp[mrad] z[mm] dE[keV] eKin[MeV] \"\nfile_out = open(\"pyorbit_trajectory_ekin.dat\",\"w\")\nfile_out.write(\" N name position[m] x[mm] xp[mrad] y[mm] yp[mrad] z[mm] dE[keV] eKin[MeV] \\n\")\n\ndef action_entrance(paramsDict):\n\tbunch = paramsDict[\"bunch\"]\n\tnode = paramsDict[\"node\"]\t\n\tlength = node.getLength()\n\t#print \"debug ============= entr xp=\",bunch.xp(0), \" name=\",node.getName(),\" L=\",length\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\n\t\tpos = paramsDict[\"test_pos\"]\n\t\t(x,xp,y,yp,z,dE) = (bunch.x(0)*1000.,bunch.xp(0)*1000.,bunch.y(0)*1000.,bunch.yp(0)*1000.,bunch.z(0)*1000.,bunch.dE(0)*1000.*1000.)\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %9.6f %9.6f %9.6f %9.3f %9.6f %9.5f %12.6f \"%(paramsDict[\"count\"],node.getName(),pos,x,xp,y,yp,z,dE,eKin)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\t\n\t\n\ndef action_exit(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tbunch = paramsDict[\"bunch\"]\n\t#print \"debug ============= exit xp=\",bunch.xp(0), \" name=\",node.getName(),\" L=\",length\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\t\n\t\tparamsDict[\"count\"]\t+= 1\n\t\t(x,xp,y,yp,z,dE) = (bunch.x(0)*1000.,bunch.xp(0)*1000.,bunch.y(0)*1000.,bunch.yp(0)*1000.,bunch.z(0)*1000.,bunch.dE(0)*1000.*1000.)\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %9.6f %9.6f %9.6f %9.3f %9.6f %9.5f %12.6f \"%(paramsDict[\"count\"],node.getName(),pos,x,xp,y,yp,z,dE,eKin)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\nactionContainer.addAction(action_entrance, AccActionsContainer.ENTRANCE)\nactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\naccLattice.trackBunch(bunch, paramsDict = paramsDict, actionContainer = actionContainer)\n\nfile_out.close()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5345167517662048,
"alphanum_fraction": 0.5641025900840759,
"avg_line_length": 23.658536911010742,
"blob_id": "e1e33e3af78dc558e88829807be4b0352e4410f4",
"content_id": "623970bd8ac119557849f422fb2499f6981cc84b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1014,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 41,
"path": "/Linac/SNS_Linac/TraceWin_Results_File_Transformation.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#--------------------------------------------------------\n# The classes will read data file with beam sizes and transform\n# it to another file with less elements (bigger position step)\n#--------------------------------------------------------\n\nimport math\nimport sys\nimport os\n\n\nmass = 0.939294*1000.\n\nfl_in = open(\"envelope.txt\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\n\nfl_out = open(\"trace_win_results.dat\",\"w\")\nst = \"pos[m] eKin rmsX rmsXp rmsY rmsYp rmsZ rmsdp_p rmsZp phase time eKin x xp y yp z dp_p zp phase0 time0 eKin0 \" \nfl_out.write(st+\"\\n\")\n\npos_step = 0.05\npos_old = 0.\ncount = 0\nfor i in range(1,len(lns)):\n\tln = lns[i]\n\tres_arr = ln.split()\n\tif(len(res_arr) < 1): continue \n\tpos = float(res_arr[0])\n\tif(pos > (pos_old + pos_step)):\n\t\tres_arr = res_arr[0:len(res_arr)-4]\n\t\tres_arr[1] = \" %12.6f \"%(float(res_arr[1])*mass)\n\t\tst = \"\"\n\t\tfor res in res_arr:\n\t\t\tst += res+\" \"\n\t\tfl_out.write(st+\"\\n\")\n\t\tpos_old = pos\n\t\tcount += 1\nfl_out.close()\nprint \"count new lines=\",count\n\t\n\n"
},
{
"alpha_fraction": 0.6307756900787354,
"alphanum_fraction": 0.6636002659797668,
"avg_line_length": 38.79999923706055,
"blob_id": "3e578d6d5eae8093d91123face08f8bca44c605a",
"content_id": "df91c03dc7a2fd1038c63db6015cb7b1453ef73b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4783,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 120,
"path": "/Linac/Parmila_Benchmark/sns_linac_bunch_generator.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n#--------------------------------------------------------\n# The classes will generates bunches for pyORBIT and Parmila \n# at the entrance of SNS MEBT accelerator line (by default)\n# It is not parallel !!!!!!!!!\n#--------------------------------------------------------\n\nimport math\nimport sys\nimport os\nimport random\n\nfrom orbit.bunch_generators import TwissContainer\nfrom orbit.bunch_generators import KVDist2D, KVDist3D\nfrom orbit.bunch_generators import GaussDist2D, GaussDist3D\nfrom orbit.bunch_generators import WaterBagDist2D, WaterBagDist3D\nfrom orbit.bunch_generators import TwissAnalysis\n\nfrom bunch import Bunch\n\nclass SNS_Linac_BunchGenerator:\n\t\"\"\"\n\tGenerates the pyORBIT and Parmila (dump into file) Bunches.\n\tTwiss prameters has the folowing units: x in [m], xp in [rad]\n\tand the X and Y emittances are normalized. The longitudinal emittance \n\tis in [GeV*m].\n\t\"\"\"\n\tdef __init__(self,twissX, twissY, twissZ,frequency = 402.5e+6):\n\t\tself.twiss = (twissX, twissY, twissZ)\n\t\tself.bunch_frequency = frequency\n\t\tself.bunch = Bunch()\n\t\tsyncPart = self.bunch.getSyncParticle()\n\t\t#set H- mass\n\t\t#self.bunch.mass(0.9382723 + 2*0.000511)\n\t\tself.bunch.mass(0.939294)\n\t\tself.bunch.charge(-1.0)\n\t\tsyncPart.kinEnergy(0.0025)\n\t\tself.c = 2.99792458e+8 # speed of light in m/sec\n\t\tself.beam_current = 0.01 # beam current in mA , design = 38 mA\n\t\tself.rf_wave_lenght = self.c/self.bunch_frequency\n\t\tself.si_e_charge = 1.6021773e-19\n\t\t\n\tdef getKinEnergy(self):\n\t\t\"\"\"\n\t\tReturns the kinetic energy in GeV\n\t\t\"\"\"\n\t\treturn self.bunch.getSyncParticle().kinEnergy()\n\t\t\n\tdef setKinEnergy(self, e_kin = 0.0025):\n\t\t\"\"\"\n\t\tSets the kinetic energy in GeV\n\t\t\"\"\"\n\t\tself.bunch.getSyncParticle().kinEnergy(e_kin)\n\t\t\n\tdef getZtoPhaseCoeff(self,bunch):\n\t\tbunch_lambda = bunch.getSyncParticle().beta()*self.rf_wave_lenght \n\t\tphase_coeff = 360./bunch_lambda\n\t\treturn phase_coeff\n\t\t\n\tdef getBeamCurrent(self):\n\t\t\"\"\"\n\t\tReturns the beam currect in mA\n\t\t\"\"\"\n\t\treturn self.beam_current\n\t\t\n\tdef setBeamCurrent(self, current):\n\t\t\"\"\"\n\t\tSets the beam currect in mA\n\t\t\"\"\"\n\t\tself.beam_current = current\n\t\n\tdef getBunch(self, nParticles = 0, distributorClass = WaterBagDist3D):\n\t\t\"\"\"\n\t\tReturns the pyORBIT bunch with particular number of particles.\n\t\t\"\"\"\n\t\tbunch = Bunch()\n\t\tself.bunch.copyEmptyBunchTo(bunch)\t\t\n\t\tmacrosize = (self.beam_current*1.0e-3/self.bunch_frequency)\n\t\tmacrosize /= (math.fabs(bunch.charge())*self.si_e_charge)\n\t\tdistributor = distributorClass(self.twiss[0],self.twiss[1],self.twiss[2])\n\t\tbunch.getSyncParticle().time(0.)\t\n\t\tfor i in range(nParticles):\n\t\t\t(x,xp,y,yp,z,dE) = distributor.getCoordinates()\n\t\t\tbunch.addParticle(x,xp,y,yp,z,dE)\n\t\tnParticlesGlobal = bunch.getSizeGlobal()\n\t\tbunch.macroSize(macrosize/nParticlesGlobal)\n\t\treturn bunch\n\t\n\tdef dumpParmilaFile(self, bunch, phase_init = -45.0, fileName = \t\"parmila_bunch.txt\"):\n\t\t\"\"\"\n\t\tDump the Parmila bunch into the file\n\t\t\"\"\"\n\t\te_kin = bunch.getSyncParticle().kinEnergy()\n\t\tn_particles = bunch.getSize()\n\t\tnParticlesGlobal = bunch.getSizeGlobal()\n\t\tbeam_current = (bunch.macroSize()*nParticlesGlobal*self.bunch_frequency*1.0e+3)*(math.fabs(bunch.charge())*self.si_e_charge)\n\t\tparmila_out = open(fileName,\"w\")\n\t\tparmila_out.write(\"Parmila data from ***** Generated by pyORBIT \\n\")\n\t\tparmila_out.write(\"Structure number = 1 \\n\")\n\t\tparmila_out.write(\"Cell or element number = 0 \\n\")\n\t\tparmila_out.write(\"Design particle energy =%11.6g MeV \\n\"%e_kin)\n\t\tparmila_out.write(\"Number of particles =%11d \\n\"%n_particles)\n\t\tparmila_out.write(\"Beam current =%11.7f \\n\"%beam_current)\n\t\tparmila_out.write(\"RF Frequency = 402.5000 MHz \\n\")\n\t\tparmila_out.write(\"Bunch Freq = 402.5000 MHz \\n\")\n\t\tparmila_out.write(\"Chopper fraction = 0.680000 \\n\") \n\t\tparmila_out.write(\"The input file particle coordinates were written in double precision. \\n\")\n\t\tparmila_out.write(\" x(cm) xpr(=dx/ds) y(cm) ypr(=dy/ds) phi(radian) W(MeV) \\n\")\n\t\tpart_wave_lenghth = self.rf_wave_lenght*bunch.getSyncParticle().beta()\n\t\tfor i in range(n_particles):\n\t\t\t(x,xp,y,yp,z,dE) = (bunch.x(i),bunch.xp(i),bunch.y(i),bunch.yp(i),bunch.z(i),bunch.dE(i))\n\t\t\tphi = 2*math.pi*(z/part_wave_lenghth + phase_init/360.)\n\t\t\tkinE = (dE+e_kin)*1.0e+3 # we need in [MeV], but pyORBIT is in [GeV]\n\t\t\tx = x*100. # pyORBIT in [m] and intermediate file for Parmila in [cm]\n\t\t\ty = y*100. # pyORBIT in [m] and intermediate file for Parmila in [cm]\n\t\t\txp = xp # pyORBIT in [rad] and intermediate file for Parmila in [rad]\n\t\t\typ = yp # pyORBIT in [rad] and Pintermediate file for armila in [rad]\n\t\t\tparmila_out.write(\"%18.11g%18.11g%18.11g%18.11g%18.11g%18.11g \\n\"%(x,xp,y,yp,phi,kinE))\n\t\tparmila_out.close()\n\t \n\n\n\n"
},
{
"alpha_fraction": 0.6586599349975586,
"alphanum_fraction": 0.7048040628433228,
"avg_line_length": 36.26886749267578,
"blob_id": "04a7b8272a5fbbecb6ecc737b127564ff7d85350",
"content_id": "0c1908b84452f2294c1a98181e10bca149aa02b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7910,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 212,
"path": "/Linac/Parmila_Benchmark/pyorbit_parmila_bechmark.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch through the SNS MEBT in pyORBIT and \nwill generate the intermediate file for PARMILA\n\"\"\"\n\nimport sys\nimport math\nimport random\nimport time\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\n\nfrom orbit.bunch_generators import TwissContainer\nfrom orbit.bunch_generators import WaterBagDist3D, GaussDist3D, KVDist3D\n\n\nfrom bunch import Bunch\nfrom bunch import BunchTwissAnalysis\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nfrom sns_linac_bunch_generator import SNS_Linac_BunchGenerator\n\nrandom.seed(100)\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\nlattFactory.setMaxDriftLength(0.02)\n#accLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\naccLattice = lattFactory.getLinacAccLattice([\"MEBT\",])\n\n#-----------------------------------------------------\n# Set up Space Charge Acc Nodes\n#-----------------------------------------------------\nfrom orbit.space_charge.sc2p5d import setSC2p5DrbAccNodes\nfrom orbit.space_charge.sc3d import setSC3DAccNodes, setUniformEllipsesSCAccNodes\nfrom spacecharge import SpaceChargeCalc2p5Drb, SpaceChargeCalcUnifEllipse, SpaceChargeCalc3D\nsc_path_length_min = 0.015\n\n\"\"\"\n#the 2p5rb Space Charge nodes\nsizeX = 64\nsizeY = 64\nsizeZ = 30\nlong_avg_n = 5\ncalc2p5d = SpaceChargeCalc2p5Drb(sizeX,sizeY,sizeZ)\ncalc2p5d.setLongAveragingPointsN(long_avg_n)\n\npipe_radius = 0.015\nspace_charge_nodes = setSC2p5DrbAccNodes(accLattice,sc_path_length_min,calc2p5d,pipe_radius)\n\"\"\"\n\n\"\"\"\n# set of uniformly charged ellipses Space Charge\nnEllipses = 1\ncalcUnifEllips = SpaceChargeCalcUnifEllipse(nEllipses)\nspace_charge_nodes = setUniformEllipsesSCAccNodes(accLattice,sc_path_length_min,calcUnifEllips)\n\"\"\"\n\n# set FFT 3D Space Charge\nsizeX = 32\nsizeY = 32\nsizeZ = 32\ncalc3d = SpaceChargeCalc3D(sizeX,sizeY,sizeZ)\nspace_charge_nodes = setSC3DAccNodes(accLattice,sc_path_length_min,calc3d)\n\nmax_sc_length = 0.\nmin_sc_length = accLattice.getLength()\nfor sc_node in space_charge_nodes:\n\tscL = sc_node.getLengthOfSC()\n\tif(scL > max_sc_length): max_sc_length = scL\n\tif(scL < min_sc_length): min_sc_length = scL\nprint \"maximal SC length =\",max_sc_length,\" min=\",min_sc_length\n\nprint \"Acc Lattice is ready. \"\n#-----TWISS Parameters at the entrance of the MEBT ---------------\n# transverse emittances are normalized and in pi*mm*mrad\n# longitudinal emittance is in pi*eV*sec\ne_kin_ini = 0.0025 # in [GeV]\nmass = 0.939294 # in [GeV]\ngamma = (mass + e_kin_ini)/mass\nbeta = math.sqrt(gamma*gamma - 1.0)/gamma\nprint \"relat. gamma=\",gamma\nprint \"relat. beta=\",beta\nfrequency = 402.5e+6\nv_light = 2.99792458e+8 # in [m/sec]\n\n\nemittX = 0.21\nemittY = 0.21\nemittZ = 7.6e-7\n\nemittX = (emittX/(beta*gamma))*1.0e-6\nemittY = (emittY/(beta*gamma))*1.0e-6\nemittZ = emittZ*1.0e-9*v_light*beta\n\nalphaX = -1.962\nbetaX = 0.0183*1.0e+3*1.0e-2\n\nalphaY = 1.768\nbetaY = 0.0161*1.0e+3*1.0e-2\n\n# Parmila betaZ in [deg/MeV] and we need [m/GeV]\nalphaZ = 0.0196\nbetaZ = (772.8/360.)*(v_light*beta/frequency)*1.0e+3\n\nprint \" aplha beta emitt X=\",alphaX,betaX,emittX\nprint \" aplha beta emitt Y=\",alphaY,betaY,emittY\nprint \" aplha beta emitt Z=\",alphaZ,betaZ,emittZ\n\ntwissX = TwissContainer(alphaX,betaX,emittX)\ntwissY = TwissContainer(alphaY,betaY,emittY)\ntwissZ = TwissContainer(alphaZ,betaZ,emittZ)\n\nxal_emittZ = emittZ/(gamma**3*beta**2*mass)\nxal_betaZ = betaZ*(gamma**3*beta**2*mass)\nprint \"XAL Twiss Longitudinal parameters alpha=\",alphaZ,\" beta=\", xal_betaZ,\" emittZ =\",xal_emittZ\nprint \"===============================================\"\n\nprint \"Start Bunch Generation.\"\nbunch_gen = SNS_Linac_BunchGenerator(twissX,twissY,twissZ)\n\n#set the beam peak current in mA\nbunch_gen.setBeamCurrent(38.0)\n\nbunch_in = bunch_gen.getBunch(nParticles = 200000, distributorClass = WaterBagDist3D)\n\nbunch_gen.dumpParmilaFile(bunch_in, phase_init = -45.0, fileName = \t\"parmila_bunch.txt\")\nprint \"Bunch Generation completed.\"\n#set up design\naccLattice.trackDesignBunch(bunch_in)\n\nprint \"Design tracking completed.\"\n\n#track through the lattice \nparamsDict = {\"test_pos\":0.,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\ntwiss_analysis = BunchTwissAnalysis()\n\nprint \" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP size_dE eKin Nparts\"\nfile_out = open(\"pyorbit_sizes_ekin.dat\",\"w\")\nfile_out.write(\" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP sizedE eKin Nparts \\n\")\n\ndef action_entrance(paramsDict):\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\n\t\tnode = paramsDict[\"node\"]\n\t\tpos = paramsDict[\"test_pos\"]\n\t\tbunch = paramsDict[\"bunch\"]\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*100.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*100.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos*100,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\t\n\t\n\ndef action_exit(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\t\n\t\tbunch = paramsDict[\"bunch\"]\n\t\tparamsDict[\"count\"]\t+= 1\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*100.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*100.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\t\t\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos*100,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\n\t\n#actionContainer.addAction(action_entrance, AccActionsContainer.ENTRANCE)\nactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\n\ntime_start = time.clock()\n\naccLattice.trackBunch(bunch_in, paramsDict = paramsDict, actionContainer = actionContainer)\n\ntime_exec = time.clock() - time_start\nprint \"time[sec]=\",time_exec\n\nfile_out.close()\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5997017621994019,
"alphanum_fraction": 0.6348530054092407,
"avg_line_length": 34.832061767578125,
"blob_id": "ce389eff32fc33018c8040efc4b0d2860d01e8f6",
"content_id": "e0cb7f55826fda2b91f580b747afe179da132b9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4694,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 131,
"path": "/Linac/SNS_Cavities_Fields/rf_3d_field_tracker_nparts_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#-------------------------------------------------------------------------\n# This script reads the SuperFish file and creates the SuperFishFieldSource\n# and the Runge-Kutta 3D tracker. The tracker tracks the bunch of particles\n# through the RF cavity. The tracker will be divided onto the Nparts parts.\n# The results should be the same no matter how many parts we use.\n#--------------------------------------------------------------------------\nimport sys\nimport math\n\nfrom bunch import Bunch\nfrom spacecharge import Grid2D\nfrom orbit.sns_linac.rf_field_readers import SuperFish_3D_RF_FieldReader, RF_AxisFieldAnalysis\nfrom trackerrk4 import RungeKuttaTracker\n\n# from linac import the \nfrom linac import SuperFishFieldSource\n\nfReader = SuperFish_3D_RF_FieldReader()\nfReader.readFile(\"data/scl_medium_beta_rf_cav_field.dat\")\n#fReader.readFile(\"data/scl_high_beta_rf_cav_field.dat\")\n(grid2D_Ez,grid2D_Er,grid2D_H) = fReader.makeGrid2DFileds_EzErH()\n\nfieldSource = SuperFishFieldSource()\nfieldSource.setGrid2D_Fields(grid2D_Ez,grid2D_Er,grid2D_H)\n\n#----------------------------------------------\n# RF field parameters \n#----------------------------------------------\nrf_freq = 805.0e+6 # in Hz\nzSimmetric = 0 # it is not symmetric\nzOrientation = -1 # the cavity is oriented as in the input file\namplitude = 20.0e+6 # the initial amplitude. It is just a number.\nphase = (270.-90.)*math.pi/180. # the initial phase\ntime_init = 0. # initial time\n\nfieldSource = SuperFishFieldSource()\nfieldSource.setGrid2D_Fields(grid2D_Ez,grid2D_Er,grid2D_H)\nfieldSource.setFrequency(rf_freq)\nfieldSource.setAmplitude(amplitude)\nfieldSource.setPhase(phase)\nfieldSource.setDirectionZ(zOrientation)\nfieldSource.setSymmetry(zSimmetric)\nfieldSource.setTimeInit(time_init)\n\nprint \"frequnecy=\",fieldSource.getFrequency()\nprint \"amplitude=\",fieldSource.getAmplitude()\nprint \"phase=\",fieldSource.getPhase()*180./math.pi\nprint \"fieldCenterPos = \",fieldSource.getFieldCenterPos()\nprint \"directionZ=\",fieldSource.getDirectionZ()\nprint \"symmetry = \",fieldSource.getSymmetry()\nprint \"min max Z =\",(grid2D_Ez.getMinX(),grid2D_Ez.getMaxX())\nprint \"min max R =\",(grid2D_Ez.getMinY(),grid2D_Ez.getMaxY())\nprint \"length =\",(grid2D_Ez.getMaxX()-grid2D_Ez.getMinX())\nprint \"length of the filed =\",fieldSource.getLength()\nprint \"average filed [MV/m] =\",fieldSource.getAvgField()/1.0e+6\nprint \"AvgField*Length [kV] =\",fieldSource.getAvgField()*fieldSource.getLength()/1000.\nprint \"initial time [sec] =\",fieldSource.getTimeInit()\n\n#-------Bunch definition ------------------\nb = Bunch()\nprint \"Part. m=\",b.mass()\nprint \"Part. q=\",b.charge()\nsyncPart = b.getSyncParticle()\n\nTK = 0.400 # in [GeV]\nE = b.mass() + TK\nP = math.sqrt(E*E - b.mass()*b.mass())\nc_light = 2.99792458e+8\nlmbd = c_light/fieldSource.getFrequency()\n\nsyncPart.kinEnergy(TK)\n\nprint \"TK[GeV] = \",TK\nprint \"P[GeV/c] = \",P\n\nprint \"lambda [mm] =\",lmbd*1000.\nprint \"beta*lambda/360 deg [mm/deg] =\",lmbd*syncPart.beta()*1000./360.\n\nb.addParticle(0.002,0.001,0.002,0.001,0.005,0.)\nb.addParticle(0.0,0.0,0.0,0.,-0.005,0.)\n\nb.compress()\n\nprint \"initial syncPart (px,py,pz) =\",(syncPart.px(),syncPart.py(),syncPart.pz())\n\nlength = grid2D_Ez.getMaxX()-grid2D_Ez.getMinX()\n\ntracker = RungeKuttaTracker(length)\n#-------------------------------------------------------------------------------\n# for the symmetric fields (if zSimmetric == +1) the grid2D has only z = 0,z_max\n#-------------------------------------------------------------------------------\nif(fieldSource.getSymmetry() == 1):\n\ttracker.entrancePlane(0,0,-1.,-grid2D_Ez.getMaxX())\nelse:\n\ttracker.entrancePlane(0,0,-1.,grid2D_Ez.getMinX())\ntracker.exitPlane(0,0,1.,-grid2D_Ez.getMaxX())\ntracker.spatialEps(0.0000001)\ntracker.stepsNumber(60)\n\nprint \"Entrance plane (a,b,c,d)=\",tracker.entrancePlane()\nprint \"Exit plane (a,b,c,d)=\",tracker.exitPlane()\nprint \"Length[m]=\",tracker.length()\n\t\nb1 = Bunch()\nb.copyBunchTo(b1)\n\nnParts = 10\ns_start = grid2D_Ez.getMinX()\nif(fieldSource.getSymmetry() == 1):\n\ts_start = - grid2D_Ez.getMaxX()\ns_end = grid2D_Ez.getMaxX()\ns_step = (s_end - s_start)/nParts\n\ntime_ini = 0.\nsyncPart = b1.getSyncParticle()\n\nfor i in range(nParts):\n\ts0 = s_start + i*s_step\n\ts1 = s0+s_step\n\ttracker.entrancePlane(0,0,-1.,s0)\n\ttracker.exitPlane(0,0,1.,-s1)\n\t#print \"============================================================ i=\",i\n\t#print \"Entrance plane (a,b,c,d)=\",tracker.entrancePlane()\n\t#print \"Exit plane (a,b,c,d)=\",tracker.exitPlane()\t\n\tfieldSource.setTimeInit(syncPart.time())\n\ttracker.trackBunch(b1,fieldSource)\n\nb1.dumpBunch()\n\t\nprint \"==========================================\"\nprint \"Done.\"\n"
},
{
"alpha_fraction": 0.638064980506897,
"alphanum_fraction": 0.6679614186286926,
"avg_line_length": 32.97200012207031,
"blob_id": "dddaaaef90c237a595875b55b0da3e8b1c253451",
"content_id": "331747863934a3ecb6e630aa48569a555091092f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8496,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 250,
"path": "/Linac/SNS_Linac/tracewin_scl_cav_vs_energy_reading.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch through the SNS Linac with an upgraded\nfor the second target station (STS) SCL linac \n\"\"\"\n\nimport sys\nimport math\nimport random\nimport time\n\nfrom orbit.sns_linac import SimplifiedLinacParser,BaseRF_Gap\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\nfrom linac import MatrixRfGap\n\nfrom bunch import Bunch\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\n\ndef makePhaseNear(phase, phase0):\n\t\"\"\" It will add or substruct any amount of 360. from phase to get close to phase0 \"\"\"\n\tn = int(phase0/360.)\n\tphase = phase%360.\n\tmin_x = 1.0e+38\n\tn_min = 0\n\tfor i0 in range(5):\n\t\ti = i0 - 3\n\t\td = math.fabs(phase + 360.*(i+n) - phase0)\n\t\tif(d < min_x):\n\t\t\tn_min = i\n\t\t\tmin_x = d\n\treturn (phase + 360.*(n_min+n))\n\n\n\nrandom.seed(100)\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac_sts.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\naccLattice = lattFactory.getLinacAccLattice([\"SCLMed\",\"SCLHigh\"])\n\nprint \"Acc Lattice is ready. \"\n\t\t\n#------- read the SCL cavities phases \nfl_in = open(\"./data/scl_cavs_phases_sts.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\ncav_phases_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\tcav_phases_dict[res_arr[0]] = float(res_arr[1])\t\n\t\t\n#------- read the SCL RF gaps E0TL parameters (E0TL in MeV) we want GeV \nfl_in = open(\"./data/scl_rf_gaps_e0tl_sts.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\nrf_gaps_e0tl_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\trf_gaps_e0tl_dict[res_arr[0]] = 0.001*float(res_arr[1])\t\n\n#-------correct cavities phases and amplitudes if necessary\nrf_cavs = accLattice.getRF_Cavities()\nfor rf_cav in rf_cavs:\n\t#print \"rf_cav=\",rf_cav.getName(),\" amp=\",rf_cav.getAmp(),\" phase=\",(rf_cav.getPhase()-math.pi)*180.0/math.pi\n\tif(cav_phases_dict.has_key(rf_cav.getName())):\n\t\trf_cav.setParam(\"\",cav_phases_dict[rf_cav.getName()]*math.pi/180.)\n\trf_gaps = rf_cav.getRF_GapNodes()\n\tfor rf_gap in rf_gaps:\n\t\t#print \" rf_gap=\",rf_gap.getName(),\" E0TL=\",rf_gap.getParam(\"E0TL\"),\" phase=\",rf_gap.getParam(\"gap_phase\")*180.0/math.pi\n\t\tif(rf_gaps_e0tl_dict.has_key(rf_gap.getName())):\n\t\t\trf_gap.setParam(\"E0TL\",rf_gaps_e0tl_dict[rf_gap.getName()])\n\ndef getRF_Cav(rf_cavs,rf_name):\n\tfor rf_cav in rf_cavs:\n\t\tif(rf_cav.getName() == rf_name): return rf_cav \n\treturn None \n\nrf_cavs_avg_phases_dict = {}\nfor rf_cav in rf_cavs:\n\trf_cavs_avg_phases_dict[rf_cav] = -20.0\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01a\")\nif(cav != None): rf_cavs_avg_phases_dict[cav] += -9.73136\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01c\")\nif(cav != None): rf_cavs_avg_phases_dict[cav] += 23.1382\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav02a\")\nif(cav != None): rf_cavs_avg_phases_dict[cav] += -1.11485\n\ntrace_win_fl_in = open(\"./data/trace_win_results.dat\",\"r\")\nlns = trace_win_fl_in.readlines()[1:]\ntrace_win_fl_in.close()\n\ntrace_win_pos_eKIn_arr = []\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) > 2):\n\t\tpos = float(res_arr[0])\n\t\tif(pos > 95.605984):\n\t\t\ttrace_win_pos_eKIn_arr.append([pos-95.605984,float(res_arr[1])])\n\t\t\t#print \"debug pos=\",pos,\" eKIn=\",float(res_arr[1])\n\t\t\ndef get_eKin(pos):\n\tfor pos_ind in range(len(trace_win_pos_eKIn_arr)-1):\n\t\tif(pos >= trace_win_pos_eKIn_arr[pos_ind][0] and trace_win_pos_eKIn_arr[pos_ind+1][0] >= pos):\n\t\t\treturn trace_win_pos_eKIn_arr[pos_ind][1]\n\neKin_in = trace_win_pos_eKIn_arr[0][1]\n\nnode_pos_dict = \taccLattice.getNodePositionsDict()\n#print \"debug dict=\",node_pos_dict\n\ncav_eKin_dict = {}\nfor rf_cav_ind in range(len(rf_cavs)-1):\n\trf_cav = rf_cavs[rf_cav_ind]\n\trf_gaps = rf_cav.getRF_GapNodes()\n\trf_cav1 = rf_cavs[rf_cav_ind+1]\n\trf_gaps1 = rf_cav.getRF_GapNodes()\n\t(posBefore, posAfter) = node_pos_dict[rf_gaps[len(rf_gaps)-1]]\n\t(posBefore1, posAfter1) = node_pos_dict[rf_gaps1[0]]\n\tpos = (posAfter+posBefore1)/2.0\n\teKin_out = get_eKin(pos)\n\tcav_eKin_dict[rf_cav] = [eKin_in,eKin_out]\n\teKin_in = eKin_out\ncav_eKin_dict[rf_cavs[len(rf_cavs)-1]]\t = [eKin_in,trace_win_pos_eKIn_arr[len(trace_win_pos_eKIn_arr)-1][1]]\n\nfor rf_cav in rf_cavs:\n\t[eKin_in,eKin_out] = cav_eKin_dict[rf_cav]\n\t#print \"debug cav=\",rf_cav.getName(),\" eKin_in=\",eKin_in,\" eKin_out=\",eKin_out\n\t\n\t\nbunch_init = Bunch()\nsyncPart = bunch_init.getSyncParticle()\n#set H- mass\n#self.bunch.mass(0.9382723 + 2*0.000511)\nbunch_init.mass(0.939294)\nbunch_init.charge(-1.0)\nsyncPart.kinEnergy(trace_win_pos_eKIn_arr[0][1]*0.001)\n\n\ndef getResultsDict():\n\tbunch = Bunch()\n\tbunch_init.copyEmptyBunchTo(bunch)\n\n\t#set up design\n\taccLattice.trackDesignBunch(bunch)\n\n\t#track through the lattice START SCL with 95.610 \n\trf_gaps_eKin_phases_dict = {}\n\tparamsDict = {\"test_pos\":95.605984,\"count\":0,\"rf_gap_dict\":rf_gaps_eKin_phases_dict}\n\tactionContainer = AccActionsContainer(\"Bunch Tracking\")\n\t\n\tdef action_exit(paramsDict):\n\t\tnode = paramsDict[\"node\"]\n\t\tlength = node.getLength()\n\t\tpos = paramsDict[\"test_pos\"] + length\n\t\tparamsDict[\"test_pos\"] = pos\t\n\t\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\n\t\t\tif(isinstance(node,BaseRF_Gap)):\n\t\t\t\tbunch_inner = paramsDict[\"bunch\"]\n\t\t\t\teKin_out = bunch_inner.getSyncParticle().kinEnergy()*1.0e+3\n\t\t\t\tphase = makePhaseNear(node.getGapPhase()*180./math.pi-180.,0.)\n\t\t\t\trf_gaps_eKin_phases_dict = paramsDict[\"rf_gap_dict\"]\n\t\t\t\trf_gaps_eKin_phases_dict[node] = [eKin_out,phase]\n\t\t\t\t#print \"debug eKin out=\",eKin_out\n\tactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\n\taccLattice.trackBunch(bunch, paramsDict = paramsDict, actionContainer = actionContainer)\n\treturn rf_gaps_eKin_phases_dict\n\t\nrf_gap_e0tl_dict = {}\nrf_cav_new_phases_dict = {}\nfor rf_cav in rf_cavs:\n\trf_gaps = rf_cav.getRF_GapNodes()\n\t[eKin_in,eKin_out] = cav_eKin_dict[rf_cav]\n\tdeltaE = 10.\n\tdeltaPhase = 10.\t\n\twhile(math.fabs(deltaE) > 0.01):\n\t\trf_gaps_eKin_phases_dict = getResultsDict()\n\t\teKin_out_new = rf_gaps_eKin_phases_dict[rf_gaps[len(rf_gaps)-1]][0]\n\t\tdeltaE = eKin_out - eKin_out_new\n\t\tcoeff = deltaE/50.\n\t\tfor rf_gap in rf_gaps:\n\t\t\tE0TL = rf_gap.getParam(\"E0TL\")\n\t\t\trf_gap.setParam(\"E0TL\",E0TL*(1.0+coeff))\n\t\t\t#print \"debug E0TL=\",E0TL,\" new E0TL=\",E0TL*(1.0+coeff),\" deltaE=\",deltaE,\" coeff=\",coeff\n\t\twhile(math.fabs(deltaPhase) > 0.1):\n\t\t\trf_gaps_eKin_phases_dict = getResultsDict()\n\t\t\tphase_gap_avg = 0.\n\t\t\tfor rf_gap in rf_gaps:\n\t\t\t\tphase_gap_avg += rf_gaps_eKin_phases_dict[rf_gap][1]\n\t\t\tphase_gap_avg /= len(rf_gaps)\n\t\t\tdeltaPhase = phase_gap_avg - rf_cavs_avg_phases_dict[rf_cav]\n\t\t\tphase = rf_cav.getPhase() - 0.3*deltaPhase*math.pi/180.\n\t\t\trf_cav.setPhase(phase)\n\t\t\t#print \"rf_cav=\",rf_cav.getName(),\" phase_gap_avg=\",phase_gap_avg\n\t\trf_gaps_eKin_phases_dict = getResultsDict()\n\t\teKin_out_new = rf_gaps_eKin_phases_dict[rf_gaps[len(rf_gaps)-1]][0]\n\t\tdeltaE = eKin_out - eKin_out_new\n\t\tphase_gap_avg = 0.\n\t\tfor rf_gap in rf_gaps:\n\t\t\tphase_gap_avg += rf_gaps_eKin_phases_dict[rf_gap][1]\n\t\tphase_gap_avg /= len(rf_gaps)\n\t\tdeltaPhase = phase_gap_avg - rf_cavs_avg_phases_dict[rf_cav]\n\t#----------------------------------------------\n\trf_gaps_eKin_phases_dict = getResultsDict()\n\teKin_out_new = rf_gaps_eKin_phases_dict[rf_gaps[len(rf_gaps)-1]][0]\n\tdeltaE = eKin_out - eKin_out_new\n\tphase_gap_avg = 0.\n\tfor rf_gap in rf_gaps:\n\t\tphase_gap_avg += rf_gaps_eKin_phases_dict[rf_gap][1]\n\tphase_gap_avg /= len(rf_gaps)\n\tdeltaPhase = phase_gap_avg - rf_cavs_avg_phases_dict[rf_cav]\t\n\tE0TL_avg = 0\n\tfor rf_gap in rf_gaps:\n\t\tE0TL_avg += rf_gap.getParam(\"E0TL\")\n\t\trf_gap_e0tl_dict[rf_gap] = rf_gap.getParam(\"E0TL\")\n\trf_cav_new_phases_dict[rf_cav] = rf_cav.getPhase()*180./math.pi\n\tE0TL_avg /= len(rf_gaps)\n\tprint \"debug cav=\",rf_cav.getName(),\" new phase=\",rf_cav.getPhase()*180/math.pi,\" deltaE=\",deltaE,\" E0TL_avg=\",E0TL_avg\n\n\t\nfl_out = open(\"scl_sts_pyorbit_cav_phase.dat\",\"w\")\nfor rf_cav in rf_cavs:\n\tif(rf_cav_new_phases_dict.has_key(rf_cav)):\n\t\tfl_out.write(rf_cav.getName()+\" %12.5f \"%rf_cav_new_phases_dict[rf_cav]+\"\\n\")\nfl_out.close()\n\nfl_out = open(\"scl_sts_pyorbit_rf_gaps_e0tl.dat\",\"w\")\nfor rf_cav in rf_cavs:\n\trf_gaps = rf_cav.getRF_GapNodes()\n\tfor rf_gap in rf_gaps:\n\t\tif(rf_gap_e0tl_dict.has_key(rf_gap)):\n\t\t\tfl_out.write(rf_gap.getName()+\" %12.10f \"%rf_gap_e0tl_dict[rf_gap]+\"\\n\")\nfl_out.close()\t\n\n\n"
},
{
"alpha_fraction": 0.597278892993927,
"alphanum_fraction": 0.5986394286155701,
"avg_line_length": 29.54166603088379,
"blob_id": "f958a7fbb24c08757bc2db5b208be48bc8caff6c",
"content_id": "3a5298af617c8f3c4ed5663a4fab8015309ad262",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 735,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 24,
"path": "/Linac/Input_File_Parsing/linac_parser_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis is a test script to check the functionality of the \nlinac parser.\n\"\"\"\n\nimport sys\n\nfrom orbit.sns_linac import SimplifiedLinacParser\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\nfor seq in sequences:\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength()\n\t\nprint \"=======================================\"\t\nnodes = sequences[0].getNodes()\nfor node in nodes:\n\tprint \"node=\",node.getName(),\" type=\",node.getType(),\" position=\",node.getParam(\"pos\"),\" L=\",node.getLength()\n\n\n"
},
{
"alpha_fraction": 0.6289402842521667,
"alphanum_fraction": 0.6610627174377441,
"avg_line_length": 29.009008407592773,
"blob_id": "2a8a64b6affa5535c719f9fba2c39e5ada8e6510",
"content_id": "46bf2f8385baff658b7a7dc7ca6b01694d8598f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3331,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 111,
"path": "/Linac/RF_Gap_Models/rf_gap_three_point_ttf_test.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script is a test for TTF of the RfGapThreePointTTF gap model. \nThis model uses T,T',S,S' transit time factors (TTF) \ncalculated for the second order of polynomial defined by three points \nof the electric field on the axis Em,E0,Ep for -dz,0.,+dz positions.\nThis class does not use the Polynomial class. Instead it uses\njust E(z) = E0*(1+a*z+b*z^2) representation.\nThe script will compare TTF from the C++ class with the direct integration\nof the TTF integrals.\n\"\"\"\nimport sys\nimport math\nimport random\n\nfrom bunch import Bunch\n\nfrom orbit_utils import GaussLegendreIntegrator\n\n# from linac import the RF gap classes\nfrom linac import BaseRfGap, MatrixRfGap, RfGapTTF, RfGapThreePointTTF \nfrom orbit.sns_linac import Drift\n\nrf_gap = RfGapThreePointTTF()\n\nrf_frequency = 400.0*1.0e+6 # in Hz\ndz = 0.01 # in m\nEm = 12.0e+6 # in V/m\nE0 = 13.2e+6 # in V/m\nEp = 14.0e+6 # in V/m\n\n#kappa = 2*PI*frequency/(c*beta)\nc_light = 2.99792458e+8\nbeta = 0.5\nkappa = 2*math.pi*rf_frequency/(c_light*beta)\nprint \"kappa =\",kappa\n\na_param = (Ep-Em)/(2*E0*dz)\nb_param = (Ep+Em-2*E0)/(2*E0*dz*dz)\n\ndef FieldFunction(z):\n\treturn E0*(1. + a_param*z + b_param*z*z)\n\nprint \"Em=\",Em,\" E_Func(-dz)= \",FieldFunction(-dz)\nprint \"E0=\",E0,\" E_Func( 0)= \",FieldFunction(0.)\nprint \"Ep=\",Ep,\" E_Func(+dz)= \",FieldFunction(+dz)\n\nE0L = E0*(2*dz+(2./3.)*b_param*dz*dz*dz)\n\ndef T_TTF(kappa, n = 32):\n\tintegrator = GaussLegendreIntegrator(n)\t\n\tintegrator.setLimits(-dz,+dz)\n\tpoint_weight_arr = integrator.getPointsAndWeights()\n\tres = 0.\n\tfor (z,w) in point_weight_arr:\n\t\tres += w*FieldFunction(z)*math.cos(kappa*z)\n\t#return integrator.integral(spline)/E0L\n\treturn res/E0L\n\ndef Tp_TTF(kappa, n = 32):\n\tintegrator = GaussLegendreIntegrator(n)\t\n\tintegrator.setLimits(-dz,+dz)\n\tpoint_weight_arr = integrator.getPointsAndWeights()\n\tres = 0.\n\tfor (z,w) in point_weight_arr:\n\t\tres += -z*w*FieldFunction(z)*math.sin(kappa*z)\n\t#return integrator.integral(spline)/E0L\n\treturn res/E0L\t\n\t\n\ndef S_TTF(kappa, n = 32):\n\tintegrator = GaussLegendreIntegrator(n)\t\n\tintegrator.setLimits(-dz,+dz)\n\tpoint_weight_arr = integrator.getPointsAndWeights()\n\tres = 0.\n\tfor (z,w) in point_weight_arr:\n\t\tres += w*FieldFunction(z)*math.sin(kappa*z)\n\t#return integrator.integral(spline)/E0L\n\treturn res/E0L\t\t\n\ndef Sp_TTF(kappa, n = 32):\n\tintegrator = GaussLegendreIntegrator(n)\t\n\tintegrator.setLimits(-dz,+dz)\n\tpoint_weight_arr = integrator.getPointsAndWeights()\n\tres = 0.\n\tfor (z,w) in point_weight_arr:\n\t\tres += w*z*FieldFunction(z)*math.cos(kappa*z)\n\t#return integrator.integral(spline)/E0L\n\treturn res/E0L\t\t\n\t\n\nprint \"===============================================\"\nres_T = T_TTF(kappa,3)\nres_T_test = rf_gap.getT_TTF(dz,a_param,b_param,kappa)\nprint \"T = %16.9g \"%res_T,\" cpp_model= %16.9g\"%res_T_test\n\nres_Tp = Tp_TTF(kappa,3)\nres_Tp_test = rf_gap.getTp_TTF(dz,a_param,b_param,kappa)\nprint \"Tp= %16.9g \"%res_Tp,\" cpp_model= %16.9g\"%res_Tp_test\n\nres_S = S_TTF(kappa,3)\nres_S_test = rf_gap.getS_TTF(dz,a_param,b_param,kappa)\nprint \"S = %16.9g \"%res_S,\" cpp_model= %16.9g\"%res_S_test\n\nres_Sp = Sp_TTF(kappa,3)\nres_Sp_test = rf_gap.getSp_TTF(dz,a_param,b_param,kappa)\nprint \"Sp= %16.9g \"%res_Sp,\" cpp_model= %16.9g\"%res_Sp_test\n\nprint \"==========================================\"\nprint \"Stop.\"\n"
},
{
"alpha_fraction": 0.6402415633201599,
"alphanum_fraction": 0.684427797794342,
"avg_line_length": 37.81305694580078,
"blob_id": "73a53b673439ef807a42498762034768c4e1286d",
"content_id": "390297ae7175e55c06cbe9c1ed5107d711b088c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13081,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 337,
"path": "/Linac/SNS_Linac/pyorbit_sns_linac_sts.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch through the SNS Linac with an upgraded\nfor the second target station (STS) SCL linac \n\"\"\"\n\nimport sys\nimport math\nimport random\nimport time\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\nfrom linac import BaseRfGap, MatrixRfGap\n\n\nfrom orbit.bunch_generators import TwissContainer\nfrom orbit.bunch_generators import WaterBagDist3D, GaussDist3D, KVDist3D\n\n\nfrom bunch import Bunch\nfrom bunch import BunchTwissAnalysis\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nfrom sns_linac_bunch_generator import SNS_Linac_BunchGenerator\n\nfrom orbit_utils import BunchExtremaCalculator\n\nrandom.seed(100)\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac_sts.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\nlattFactory.setMaxDriftLength(0.01)\n#accLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\n#accLattice = lattFactory.getLinacAccLattice([\"SCLMed\",\"SCLHigh\"])\naccLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\n\n#-----------------------------------------------------\n# Set up Space Charge Acc Nodes\n#-----------------------------------------------------\nfrom orbit.space_charge.sc3d import setSC3DAccNodes, setUniformEllipsesSCAccNodes\nfrom spacecharge import SpaceChargeCalcUnifEllipse, SpaceChargeCalc3D\nsc_path_length_min = 0.02\n\nprint \"Set up Space Charge nodes. \"\n\"\"\"\n# set of uniformly charged ellipses Space Charge\nnEllipses = 1\ncalcUnifEllips = SpaceChargeCalcUnifEllipse(nEllipses)\nspace_charge_nodes = setUniformEllipsesSCAccNodes(accLattice,sc_path_length_min,calcUnifEllips)\n\n\"\"\"\n# set FFT 3D Space Charge\nsizeX = 64\nsizeY = 64\nsizeZ = 64\ncalc3d = SpaceChargeCalc3D(sizeX,sizeY,sizeZ)\nspace_charge_nodes = setSC3DAccNodes(accLattice,sc_path_length_min,calc3d)\n\n\n\nmax_sc_length = 0.\nmin_sc_length = accLattice.getLength()\nfor sc_node in space_charge_nodes:\n\tscL = sc_node.getLengthOfSC()\n\tif(scL > max_sc_length): max_sc_length = scL\n\tif(scL < min_sc_length): min_sc_length = scL\nprint \"maximal SC length =\",max_sc_length,\" min=\",min_sc_length\n\n\nprint \"Acc Lattice is ready. \"\n\n#-------set up external fields to quads\nquads = accLattice.getQuads(accLattice.getSequence(\"SCLMed\"))\nquads = accLattice.getQuads()\n#for quad in quads:\n#\tprint \"quad=\",quad.getName(),\" G[T/m]=\",quad.getParam(\"dB/dr\")\n\t\nfl_in = open(\"./data/sns_linac_quad_fields_matched.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\nquad_name_field_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\tquad_name_field_dict[res_arr[0]] = float(res_arr[1])\n\t\t\nfor quad in quads:\n\tif(\tquad_name_field_dict.has_key(quad.getName())):\n\t\tfield = quad_name_field_dict[quad.getName()]\n\t\tquad.setParam(\"dB/dr\",field)\n\t\tprint \"debug quad=\",quad.getName(),\" new field=\",field\n\t\t\n#------- read the SCL cavities phases \nfl_in = open(\"./data/scl_cavs_phases_sts.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\ncav_phases_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\tcav_phases_dict[res_arr[0]] = float(res_arr[1])\t\n\t\t\n#------- read the SCL RF gaps E0TL parameters (E0TL in MeV) we want GeV \nfl_in = open(\"./data/scl_rf_gaps_e0tl_sts.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\nrf_gaps_e0tl_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\trf_gaps_e0tl_dict[res_arr[0]] = 0.001*float(res_arr[1])\t\n\n#-------correct cavities phases and amplitudes if necessary\n#cppGapModel = MatrixRfGap\ncppGapModel = BaseRfGap\n\nrf_cavs = accLattice.getRF_Cavities()\nfor rf_cav in rf_cavs:\n\t#print \"rf_cav=\",rf_cav.getName(),\" amp=\",rf_cav.getAmp(),\" phase=\",(rf_cav.getPhase()-math.pi)*180.0/math.pi\n\tif(cav_phases_dict.has_key(rf_cav.getName())):\n\t\trf_cav.setPhase(cav_phases_dict[rf_cav.getName()]*math.pi/180.)\n\trf_gaps = rf_cav.getRF_GapNodes()\n\tfor rf_gap in rf_gaps:\n\t\t#print \" rf_gap=\",rf_gap.getName(),\" E0TL=\",rf_gap.getParam(\"E0TL\"),\" phase=\",rf_gap.getParam(\"gap_phase\")*180.0/math.pi\n\t\trf_gap.setCppGapModel(cppGapModel())\n\t\tif(rf_gaps_e0tl_dict.has_key(rf_gap.getName())):\n\t\t\trf_gap.setParam(\"E0TL\",rf_gaps_e0tl_dict[rf_gap.getName()])\n\n\ndef getRF_Cav(rf_cavs,rf_name):\n\tfor rf_cav in rf_cavs:\n\t\tif(rf_cav.getName() == rf_name): return rf_cav \n\treturn None \n\ncav = getRF_Cav(rf_cavs,\"MEBT_RF:Bnch03\")\nif(cav != None):\n\tamp = cav.getRF_GapNodes()[0].getParam(\"E0TL\")*0.851389\n\tcav.getRF_GapNodes()[0].setParam(\"E0TL\",amp)\n\t\ncav = getRF_Cav(rf_cavs,\"MEBT_RF:Bnch04\")\nif(cav != None):\n\tamp = cav.getRF_GapNodes()[0].getParam(\"E0TL\")*1.01944\n\tcav.getRF_GapNodes()[0].setParam(\"E0TL\",amp)\n\n\t\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01a\")\nif(cav != None): cav.setPhase(cav.getPhase() -9.73136*math.pi/180.)\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01c\")\nif(cav != None): cav.setPhase(cav.getPhase() +23.1382*math.pi/180.)\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav02a\")\nif(cav != None): cav.setPhase(cav.getPhase() -1.11485*math.pi/180.)\n\n#-----TWISS Parameters at the entrance of MEBT ---------------\n# transverse emittances are unnormalized and in pi*mm*mrad\n# longitudinal emittance is in pi*eV*sec\ne_kin_ini = 0.0025 # in [GeV]\nmass = 0.939294 # in [GeV]\ngamma = (mass + e_kin_ini)/mass\nbeta = math.sqrt(gamma*gamma - 1.0)/gamma\nprint \"relat. gamma=\",gamma\nprint \"relat. beta=\",beta\nfrequency = 402.5e+6\nv_light = 2.99792458e+8 # in [m/sec]\n\n#------ emittances are normalized - transverse by gamma*beta and long. by gamma**3*beta \n(alphaX,betaX,emittX) = (-1.9620, 0.1831, 0.21)\n(alphaY,betaY,emittY) = ( 1.7681, 0.1620, 0.21)\n(alphaZ,betaZ,emittZ) = ( 0.0196, 0.5844, 0.24153)\n\nalphaZ = -alphaZ\n\n#---make emittances un-normalized XAL units [m*rad]\nemittX = 1.0e-6*emittX/(gamma*beta)\nemittY = 1.0e-6*emittY/(gamma*beta)\nemittZ = 1.0e-6*emittZ/(gamma**3*beta)\nprint \" ========= XAL Twiss ===========\"\nprint \" aplha beta emitt[mm*mrad] X= %6.4f %6.4f %6.4f \"%(alphaX,betaX,emittX*1.0e+6)\nprint \" aplha beta emitt[mm*mrad] Y= %6.4f %6.4f %6.4f \"%(alphaY,betaY,emittY*1.0e+6)\nprint \" aplha beta emitt[mm*mrad] Z= %6.4f %6.4f %6.4f \"%(alphaZ,betaZ,emittZ*1.0e+6)\n\n#---- long. size in mm\nsizeZ = math.sqrt(emittZ*betaZ)*1.0e+3\n\n#---- transform to pyORBIT emittance[GeV*m]\nemittZ = emittZ*gamma**3*beta**2*mass\nbetaZ = betaZ/(gamma**3*beta**2*mass)\n\nprint \" ========= PyORBIT Twiss ===========\"\nprint \" aplha beta emitt[mm*mrad] X= %6.4f %6.4f %6.4f \"%(alphaX,betaX,emittX*1.0e+6)\nprint \" aplha beta emitt[mm*mrad] Y= %6.4f %6.4f %6.4f \"%(alphaY,betaY,emittY*1.0e+6)\nprint \" aplha beta emitt[mm*MeV] Z= %6.4f %6.4f %6.4f \"%(alphaZ,betaZ,emittZ*1.0e+6)\n\ntwissX = TwissContainer(alphaX,betaX,emittX)\ntwissY = TwissContainer(alphaY,betaY,emittY)\ntwissZ = TwissContainer(alphaZ,betaZ,emittZ)\n\nprint \"Start Bunch Generation.\"\nbunch_gen = SNS_Linac_BunchGenerator(twissX,twissY,twissZ)\n\n#set the initial kinetic energy in GeV\nbunch_gen.setKinEnergy(e_kin_ini)\n\n#set the beam peak current in mA\nbunch_gen.setBeamCurrent(50.0)\n\n#bunch_in = bunch_gen.getBunch(nParticles = 20000, distributorClass = WaterBagDist3D)\nbunch_in = bunch_gen.getBunch(nParticles = 2000, distributorClass = GaussDist3D, cut_off = 3.0)\n#bunch_in = bunch_gen.getBunch(nParticles = 20000, distributorClass = KVDist3D)\n\nprint \"Bunch Generation completed.\"\nseq = accLattice.getSequence(\"MEBT\")\nseq_nodes = seq.getNodes()\nnode0 = seq_nodes[0]\nnode1 = seq_nodes[len(seq_nodes)-1]\nind_start = accLattice.getNodes().index(node0)\nind_stop = accLattice.getNodes().index(node1)\naccLattice = accLattice.getSubLattice(ind_start,ind_stop)\n\n#set up design\naccLattice.trackDesignBunch(bunch_in)\n\nprint \"Design tracking completed.\"\n\ncollimation_dict = {\"MEBT\":16.0,\"DTL\":12.5,\"CCL\":15.0,\"SCL\":38.0}\nloss_part_pos_arr = []\n\n#track through the lattice \nparamsDict = {\"test_pos\":0.,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\ntwiss_analysis = BunchTwissAnalysis()\n\nbunchExtremaCalculator = BunchExtremaCalculator()\n(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch_in)\n\nprint \" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP size_dE eKin Nparts xMax yMax zMax\"\nfile_out = open(\"pyorbit_scl_sizes_ekin.dat\",\"w\")\nfile_out.write(\" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP sizedE eKin Nparts xMax yMax zMax\\n\")\n\ndef action_entrance(paramsDict):\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\n\t\tnode = paramsDict[\"node\"]\n\t\tpos = paramsDict[\"test_pos\"]\n\t\tbunch = paramsDict[\"bunch\"]\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch)\n\t\tif(math.fabs(xMin) > xMax): xMax = math.fabs(xMin)\n\t\tif(math.fabs(yMin) > yMax): yMax = math.fabs(yMin)\n\t\tif(math.fabs(zMin) > zMax): zMax = math.fabs(zMin)\n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\ts +=\" %10.6f %10.6f \"%(xMax*1000.,yMax*1000.,zMax*1000.)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\t\ndef action_exit(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\t\n\t\tbunch = paramsDict[\"bunch\"]\n\t\tparamsDict[\"count\"]\t+= 1\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\t\t\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch)\n\t\tif(math.fabs(xMin) > xMax): xMax = math.fabs(xMin)\n\t\tif(math.fabs(yMin) > yMax): yMax = math.fabs(yMin)\t\n\t\tif(math.fabs(zMin) > zMax): zMax = math.fabs(zMin)\t\n\t\tr_max = 0.\n\t\tif(node.getName().find(\"MEBT\") >= 0): r_max = 0.001*collimation_dict[\"MEBT\"]\n\t\tif(node.getName().find(\"DTL\") >= 0): r_max = 0.001*collimation_dict[\"DTL\"]\n\t\tif(node.getName().find(\"CCL\") >= 0): r_max = 0.001*collimation_dict[\"CCL\"]\n\t\tif(node.getName().find(\"SCL\") >= 0): r_max = 0.001*collimation_dict[\"SCL\"]\n\t\tif(math.sqrt(xMax**2+yMax**2) > r_max):\n\t\t\tnParticles = bunch.getSize()\n\t\t\tfor ind in range(nParticles):\n\t\t\t\tx = bunch.x(ind)\n\t\t\t\ty = bunch.y(ind)\n\t\t\t\tr = math.sqrt(x**2+y**2)\n\t\t\t\tif(math.sqrt(x**2+y**2) > r_max):\n\t\t\t\t\tbunch.deleteParticleFast(ind)\n\t\t\t\t\tloss_part_pos_arr.append(pos)\n\t\t\tbunch.compress()\n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\ts +=\" %10.6f %10.6f %10.6f \"%(xMax*1000.,yMax*1000.,zMax*1000.)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\n\t\n#actionContainer.addAction(action_entrance, AccActionsContainer.ENTRANCE)\nactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\n\ntime_start = time.clock()\n\naccLattice.trackBunch(bunch_in, paramsDict, actionContainer)\n\ntime_exec = time.clock() - time_start\nprint \"time[sec]=\",time_exec\n\nfile_out.close()\n\nfl_loss_pos_out = open(\"loss_parts_pos.dat\",\"w\")\nfor pos in loss_part_pos_arr:\n\tfl_loss_pos_out.write(\" %13.6g \"%pos+\"\\n\")\nfl_loss_pos_out.close()\n\n"
},
{
"alpha_fraction": 0.6458683013916016,
"alphanum_fraction": 0.6899690628051758,
"avg_line_length": 37.74314880371094,
"blob_id": "f89f044a0abadad7dbc1caa2dcf9573053a28e2b",
"content_id": "c1f8041cb64b338a26bd5689f4b36520810d2e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11315,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 292,
"path": "/Linac/SNS_Linac/pyorbit_sns_linac_scl_sts.py",
"repo_name": "yunluo0921/examples",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\n\"\"\"\nThis script will track the bunch through the SNS Linac with an upgraded\nfor the second target station (STS) SCL linac \n\"\"\"\n\nimport sys\nimport math\nimport random\nimport time\n\nfrom orbit.sns_linac import SimplifiedLinacParser\nfrom orbit.sns_linac import LinacLatticeFactory, LinacAccLattice\nfrom linac import BaseRfGap, MatrixRfGap\n\n\nfrom orbit.bunch_generators import TwissContainer\nfrom orbit.bunch_generators import WaterBagDist3D, GaussDist3D, KVDist3D\n\n\nfrom bunch import Bunch\nfrom bunch import BunchTwissAnalysis\n\nfrom orbit.lattice import AccLattice, AccNode, AccActionsContainer\n\nfrom sns_linac_bunch_generator import SNS_Linac_BunchGenerator\n\nfrom orbit_utils import BunchExtremaCalculator\n\nrandom.seed(100)\n\nparser = SimplifiedLinacParser(\"../SNS_Linac_XML/sns_linac_sts.xml\")\nlinacTree = parser.getLinacStructureTree()\nprint \"=======================================\"\nprint \"Total length=\",linacTree.getLength()\nprint \"=======================================\"\nsequences = linacTree.getSeqs()\ntotalLength = 0.\nfor seq in sequences:\n\ttotalLength += seq.getLength()\t\n\tprint \"seq=\",seq.getName(),\" L=\",seq.getLength(),\" total length=\",totalLength\n\nlattFactory = \tLinacLatticeFactory(linacTree)\nlattFactory.setMaxDriftLength(0.01)\n#accLattice = lattFactory.getLinacAccLattice([\"MEBT\",\"DTL1\",\"DTL2\",\"DTL3\",\"DTL4\",\"DTL5\",\"DTL6\",\"CCL1\",\"CCL2\",\"CCL3\",\"CCL4\",\"SCLMed\",\"SCLHigh\"])\naccLattice = lattFactory.getLinacAccLattice([\"SCLMed\",\"SCLHigh\"])\n\n#-----------------------------------------------------\n# Set up Space Charge Acc Nodes\n#-----------------------------------------------------\nfrom orbit.space_charge.sc3d import setSC3DAccNodes, setUniformEllipsesSCAccNodes\nfrom spacecharge import SpaceChargeCalcUnifEllipse, SpaceChargeCalc3D\nsc_path_length_min = 0.03\n\nprint \"Set up Space Charge nodes. \"\n\"\"\"\n# set of uniformly charged ellipses Space Charge\nnEllipses = 1\ncalcUnifEllips = SpaceChargeCalcUnifEllipse(nEllipses)\nspace_charge_nodes = setUniformEllipsesSCAccNodes(accLattice,sc_path_length_min,calcUnifEllips)\n\n\"\"\"\n# set FFT 3D Space Charge\nsizeX = 64\nsizeY = 64\nsizeZ = 64\ncalc3d = SpaceChargeCalc3D(sizeX,sizeY,sizeZ)\nspace_charge_nodes = setSC3DAccNodes(accLattice,sc_path_length_min,calc3d)\n\n\n\nmax_sc_length = 0.\nmin_sc_length = accLattice.getLength()\nfor sc_node in space_charge_nodes:\n\tscL = sc_node.getLengthOfSC()\n\tif(scL > max_sc_length): max_sc_length = scL\n\tif(scL < min_sc_length): min_sc_length = scL\nprint \"maximal SC length =\",max_sc_length,\" min=\",min_sc_length\n\n\nprint \"Acc Lattice is ready. \"\n\n#-------set up external fields to quads\nquads = accLattice.getQuads(accLattice.getSequence(\"SCLMed\"))\nquads = accLattice.getQuads()\n#for quad in quads:\n#\tprint \"quad=\",quad.getName(),\" G[T/m]=\",quad.getParam(\"dB/dr\")\n\t\nfl_in = open(\"./data/sns_linac_quad_fields_matched.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\nquad_name_field_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\tquad_name_field_dict[res_arr[0]] = float(res_arr[1])\n\t\t\nfor quad in quads:\n\tif(\tquad_name_field_dict.has_key(quad.getName())):\n\t\tfield = quad_name_field_dict[quad.getName()]\n\t\tquad.setParam(\"dB/dr\",field)\n\t\tprint \"debug quad=\",quad.getName(),\" new field=\",field\n\t\t\n#------- read the SCL cavities phases \nfl_in = open(\"./data/scl_cavs_phases_sts.dat\",\"r\")\n#fl_in = open(\"./data/scl_sts_pyorbit_cav_phase.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\ncav_phases_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\tcav_phases_dict[res_arr[0]] = float(res_arr[1])\t\n\t\t\n#------- read the SCL RF gaps E0TL parameters (E0TL in MeV) we want GeV \nfl_in = open(\"./data/scl_rf_gaps_e0tl_sts.dat\",\"r\")\n#fl_in = open(\"./data/scl_sts_pyorbit_rf_gaps_e0tl.dat\",\"r\")\nlns = fl_in.readlines()\nfl_in.close()\nrf_gaps_e0tl_dict = {}\nfor ln in lns:\n\tres_arr = ln.split()\n\tif(len(res_arr) == 2):\n\t\trf_gaps_e0tl_dict[res_arr[0]] = 0.001*float(res_arr[1])\t\n\t\t#rf_gaps_e0tl_dict[res_arr[0]] = float(res_arr[1])\t\n#-------correct cavities phases and amplitudes if necessary\n#cppGapModel = MatrixRfGap\ncppGapModel = BaseRfGap\n\nrf_cavs = accLattice.getRF_Cavities()\nfor rf_cav in rf_cavs:\n\t#print \"rf_cav=\",rf_cav.getName(),\" amp=\",rf_cav.getAmp(),\" phase=\",(rf_cav.getPhase()-math.pi)*180.0/math.pi\n\tif(cav_phases_dict.has_key(rf_cav.getName())):\n\t\trf_cav.setPhase(cav_phases_dict[rf_cav.getName()]*math.pi/180.)\n\trf_gaps = rf_cav.getRF_GapNodes()\n\tfor rf_gap in rf_gaps:\n\t\t#print \" rf_gap=\",rf_gap.getName(),\" E0TL=\",rf_gap.getParam(\"E0TL\"),\" phase=\",rf_gap.getParam(\"gap_phase\")*180.0/math.pi\n\t\trf_gap.setCppGapModel(cppGapModel())\n\t\tif(rf_gaps_e0tl_dict.has_key(rf_gap.getName())):\n\t\t\trf_gap.setParam(\"E0TL\",rf_gaps_e0tl_dict[rf_gap.getName()])\n\n\ndef getRF_Cav(rf_cavs,rf_name):\n\tfor rf_cav in rf_cavs:\n\t\tif(rf_cav.getName() == rf_name): return rf_cav \n\treturn None \n\ncav = getRF_Cav(rf_cavs,\"MEBT_RF:Bnch03\")\nif(cav != None):\n\tamp = cav.getRF_GapNodes()[0].getParam(\"E0TL\")*0.851389\n\tcav.getRF_GapNodes()[0].setParam(\"E0TL\",amp)\n\t\ncav = getRF_Cav(rf_cavs,\"MEBT_RF:Bnch04\")\nif(cav != None):\n\tamp = cav.getRF_GapNodes()[0].getParam(\"E0TL\")*1.01944\n\tcav.getRF_GapNodes()[0].setParam(\"E0TL\",amp)\n\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01a\")\nif(cav != None): cav.setPhase(cav.getPhase() -9.73136*math.pi/180.)\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav01c\")\nif(cav != None): cav.setPhase(cav.getPhase() +23.1382*math.pi/180.)\n\ncav = getRF_Cav(rf_cavs,\"SCL_RF:Cav02a\")\nif(cav != None): cav.setPhase(cav.getPhase() -1.11485*math.pi/180.)\n\n\n#-----TWISS Parameters at the entrance of SCL ---------------\n# transverse emittances are unnormalized and in pi*mm*mrad\n# longitudinal emittance is in pi*mm*MeV\ne_kin_ini = 0.185611 # in [GeV]\nmass = 0.939294 # in [GeV]\ngamma = (mass + e_kin_ini)/mass\nbeta = math.sqrt(gamma*gamma - 1.0)/gamma\nprint \"relat. gamma=\",gamma\nprint \"relat. beta=\",beta\nfrequency = 402.5e+6\nv_light = 2.99792458e+8 # in [m/sec]\n\n#------ emittances are in 1e-6\n(alphaX,betaX,emittX) = ( -3.1105 , 10.1926 , 0.5469 )\n(alphaY,betaY,emittY) = ( 1.3880 , 6.2129 , 0.5353 ) \n(alphaZ,betaZ,emittZ) = ( 0.1691 , 12.5589 , 0.2149 ) \n \nprint \" ========= PyORBIT Twiss ===========\"\nprint \" aplha beta emitt[mm*mrad] X= %6.4f %6.4f %6.4f \"%(alphaX,betaX,emittX)\nprint \" aplha beta emitt[mm*mrad] Y= %6.4f %6.4f %6.4f \"%(alphaY,betaY,emittY)\nprint \" aplha beta emitt[mm*MeV] Z= %6.4f %6.4f %6.4f \"%(alphaZ,betaZ,emittZ)\n\ntwissX = TwissContainer(alphaX,betaX,emittX*1.0e-6)\ntwissY = TwissContainer(alphaY,betaY,emittY*1.0e-6)\ntwissZ = TwissContainer(alphaZ,betaZ,emittZ*1.0e-6)\n\nprint \"Start Bunch Generation.\"\nbunch_gen = SNS_Linac_BunchGenerator(twissX,twissY,twissZ)\n\n#set the initial kinetic energy in GeV\nbunch_gen.setKinEnergy(e_kin_ini)\n\n#set the beam peak current in mA\nbunch_gen.setBeamCurrent(50.0)\n\n#bunch_in = bunch_gen.getBunch(nParticles = 20000, distributorClass = WaterBagDist3D)\nbunch_in = bunch_gen.getBunch(nParticles = 20000, distributorClass = GaussDist3D)\n#bunch_in = bunch_gen.getBunch(nParticles = 20000, distributorClass = KVDist3D)\n\nprint \"Bunch Generation completed.\"\n\n#set up design\naccLattice.trackDesignBunch(bunch_in)\n\nprint \"Design tracking completed.\"\n\n#track through the lattice START SCL with 95.610 \nparamsDict = {\"test_pos\":95.605984,\"count\":0}\nactionContainer = AccActionsContainer(\"Test Design Bunch Tracking\")\n\ntwiss_analysis = BunchTwissAnalysis()\n\n\nbunchExtremaCalculator = BunchExtremaCalculator()\n(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch_in)\n\nprint \" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP size_dE eKin Nparts xMax yMax zMax\"\nfile_out = open(\"pyorbit_scl_sizes_ekin.dat\",\"w\")\nfile_out.write(\" N node position sizeX sizeY sizeZ sizeZdeg sizeXP sizeYP sizedE eKin Nparts xMax yMax zMax\\n\")\n\ndef action_entrance(paramsDict):\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\n\t\tnode = paramsDict[\"node\"]\n\t\tpos = paramsDict[\"test_pos\"]\n\t\tbunch = paramsDict[\"bunch\"]\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch)\n\t\tif(math.fabs(xMin) > xMax): xMax = math.fabs(xMin)\n\t\tif(math.fabs(yMin) > yMax): yMax = math.fabs(yMin)\n\t\tif(math.fabs(zMin) > zMax): zMax = math.fabs(zMin)\n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\ts +=\" %10.6f %10.6f \"%(xMax*1000.,yMax*1000.,zMax*1000.)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\t\ndef action_exit(paramsDict):\n\tnode = paramsDict[\"node\"]\n\tlength = node.getLength()\n\tpos = paramsDict[\"test_pos\"] + length\n\tparamsDict[\"test_pos\"] = pos\t\n\tif(isinstance(paramsDict[\"parentNode\"],AccLattice)):\t\n\t\tbunch = paramsDict[\"bunch\"]\n\t\tparamsDict[\"count\"]\t+= 1\n\t\ttwiss_analysis.analyzeBunch(bunch)\n\t\tx_rms = math.sqrt(twiss_analysis.getTwiss(0)[1]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\ty_rms = math.sqrt(twiss_analysis.getTwiss(1)[1]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tz_rms = math.sqrt(twiss_analysis.getTwiss(2)[1]*twiss_analysis.getTwiss(2)[3])*1000.\n\t\tz_rms_deg = bunch_gen.getZtoPhaseCoeff(bunch)*z_rms/1000.0\t\t\n\t\txp_rms = math.sqrt(twiss_analysis.getTwiss(0)[2]*twiss_analysis.getTwiss(0)[3])*1000.\n\t\typ_rms = math.sqrt(twiss_analysis.getTwiss(1)[2]*twiss_analysis.getTwiss(1)[3])*1000.\n\t\tdE_rms = math.sqrt(twiss_analysis.getTwiss(2)[2]*twiss_analysis.getTwiss(2)[3])*1000. \n\t\t(xMin, xMax, yMin, yMax, zMin, zMax) = bunchExtremaCalculator.extremaXYZ(bunch)\n\t\tif(math.fabs(xMin) > xMax): xMax = math.fabs(xMin)\n\t\tif(math.fabs(yMin) > yMax): yMax = math.fabs(yMin)\t\n\t\tif(math.fabs(zMin) > zMax): zMax = math.fabs(zMin)\t\t\n\t\t#emittX = twiss_analysis.getTwiss(0)[3]*1000.0*1000.0\t*bunch.getSyncParticle().gamma()*bunch.getSyncParticle().beta()\n\t\teKin = bunch.getSyncParticle().kinEnergy()*1.0e+3\n\t\ts = \" %5d %35s %4.5f %5.3f %5.3f %5.3f %5.3f %5.3f %5.3f %7.5f %10.6f %8d \"%(paramsDict[\"count\"],node.getName(),pos,x_rms,y_rms,z_rms,z_rms_deg,xp_rms,yp_rms,dE_rms,eKin,bunch.getSize())\n\t\ts +=\" %10.6f %10.6f %10.6f \"%(xMax*1000.,yMax*1000.,zMax*1000.)\n\t\tfile_out.write(s +\"\\n\")\n\t\tprint s\t\n\t\n\t\n#actionContainer.addAction(action_entrance, AccActionsContainer.ENTRANCE)\nactionContainer.addAction(action_exit, AccActionsContainer.EXIT)\n\ntime_start = time.clock()\n\naccLattice.trackBunch(bunch_in, paramsDict = paramsDict, actionContainer = actionContainer)\n\ntime_exec = time.clock() - time_start\nprint \"time[sec]=\",time_exec\n\nfile_out.close()\n\n\n"
}
] | 19 |
leelasetty/python_project
|
https://github.com/leelasetty/python_project
|
9da4007ab16be69fdfc7444ccd4c3cb6e1cacaaf
|
a19d41ea94dd55e6a199982c118016a1a1f09d6c
|
dbf4d379e25cd053e68b83d3426e212b5c8084f4
|
refs/heads/main
| 2023-02-02T15:41:15.010831 | 2020-12-18T18:16:40 | 2020-12-18T18:16:40 | 322,670,982 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 18.5,
"blob_id": "07cb88e3b2ed3a01fb64f2046a7303964a431ecd",
"content_id": "8c96bb1c0e80d1993759f54603ddb178c4f5b12e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/README.md",
"repo_name": "leelasetty/python_project",
"src_encoding": "UTF-8",
"text": "# python_project\npython files to test\n"
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.6333333253860474,
"avg_line_length": 14,
"blob_id": "8102367cfde119867d5a90783836b04e4e7942f4",
"content_id": "cf2e18db54087a43274d776e68bf6cebc9ed7eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/first1.py",
"repo_name": "leelasetty/python_project",
"src_encoding": "UTF-8",
"text": "def myfunction():\n print(\"Helloworld\")\n \nmyfunction()\n"
}
] | 2 |
SimJunSik/election0225-2
|
https://github.com/SimJunSik/election0225-2
|
431fe0d0e1f2f97fed39e52d3baa3ba54654901e
|
8670018ad84cd78f3136bc19f8217e08ff2c8635
|
4c439781921e30962bf35e74ef4cec140dd69553
|
refs/heads/master
| 2019-01-03T04:01:53.721268 | 2017-02-25T14:05:12 | 2017-02-25T14:05:12 | 83,135,713 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7637860178947449,
"alphanum_fraction": 0.767078161239624,
"avg_line_length": 29.399999618530273,
"blob_id": "15ff8ab27e7a7b1f5d8b2db412b66f271e8c592b",
"content_id": "2b8fe0bb1dd0c5540a08cf05c65f4483c6b801ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1215,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 40,
"path": "/electionsite-test4/elections/views.py",
"repo_name": "SimJunSik/election0225-2",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.http import HttpResponse\nfrom django.core import serializers\n\nfrom .models import Candidate\nfrom .models import Commitment\nfrom .models import Category\n# Create your views here.\n\ndef index(request) :\n\tcandidates = Candidate.objects.all()\n\tcommitments = Commitment.objects.all()\n\tcategory = Category.objects.all()\n\tcontext = {'commitments':commitments, 'categories':category}\n\n\treturn render(request, 'elections/index.html', context)\n\ndef index2(request) :\n\tjson_serializer = serializers.get_serializer(\"json\")()\n\tcandidates = Candidate.objects.all()\n\tcmts = json_serializer.serialize(Commitment.objects.all(), ensure_ascii=False)\n\tcommitments = Commitment.objects.all()\n\tcategory = Category.objects.all()\n\tcontext = {'commitments':commitments, 'categories':category, 'cmts':cmts}\n\n\n\treturn render(request, 'elections/index2.html', context)\n\ndef index3(request) :\n\tcandidates = Candidate.objects.all()\n\tcommitments = Commitment.objects.all()\n\tcategory = Category.objects.all()\n\tcontext = {'commitments':commitments, 'categories':category}\n\n\treturn render(request, 'elections/index3.html', context)\n\n\n\ndef areas(request) :\n\treturn render(request, 'elections/area.html')"
}
] | 1 |
JeromeParadis/django-mailing
|
https://github.com/JeromeParadis/django-mailing
|
3a9dd567bf7904568af9afe8da305dc8c50a0437
|
51ecda686e65eb7cc33983259679fbdd083a36aa
|
2dac83ed18ef7334253c01bb8215313e10ddd678
|
refs/heads/master
| 2023-05-14T01:48:28.764502 | 2023-05-05T15:54:23 | 2023-05-05T15:54:23 | 5,878,568 | 2 | 3 |
MIT
| 2012-09-19T21:51:51 | 2017-08-21T08:25:04 | 2016-09-06T19:29:44 |
HTML
|
[
{
"alpha_fraction": 0.5731593370437622,
"alphanum_fraction": 0.5806151032447815,
"avg_line_length": 31.53125,
"blob_id": "ec5b19011907995b59e43097c24bd05adf8c0bc8",
"content_id": "9fd1c832a86cfb1b92cd366e5d8b5730cdad512d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1073,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\r\n\r\nsetup(\r\n name=\"django-mailing\",\r\n version=__import__(\"mailing\").__version__,\r\n description=\"A flexible Django app for templated mailings with support for celery queuing, SendGrid and more.\",\r\n long_description=open(\"docs/usage.txt\").read(),\r\n author=\"Jerome Paradis\",\r\n author_email=\"[email protected]\",\r\n url=\"http://github.com/JeromeParadis/django-mailing\",\r\n license='LICENSE.txt',\r\n packages=[\r\n \"mailing\",\r\n ],\r\n package_dir={\"mailing\": \"mailing\"},\r\n classifiers=[\r\n \"Development Status :: 4 - Beta\",\r\n \"Environment :: Web Environment\",\r\n \"Intended Audience :: Developers\",\r\n \"License :: OSI Approved :: MIT License\",\r\n \"Operating System :: OS Independent\",\r\n \"Programming Language :: Python\",\r\n \"Framework :: Django\",\r\n ],\r\n install_requires=[\r\n \"Django >= 1.4.1\",\r\n \"redis >= 2.4.10\",\r\n \"celery\",\r\n \"django-celery\",\r\n ],\r\n package_data={'mailing': ['templates/mailing/base.html', 'templates/mailing/base.txt']},\r\n)\r\n"
},
{
"alpha_fraction": 0.7866666913032532,
"alphanum_fraction": 0.791372537612915,
"avg_line_length": 86.93103790283203,
"blob_id": "74dfd090bb60af3a7e89abdb14dbe4cd1ff2e765",
"content_id": "8a8205defc14a9443cadbbe2af78480c0564ec8f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2550,
"license_type": "permissive",
"max_line_length": 521,
"num_lines": 29,
"path": "/mailing/templates/mailing/email_boiletplate/README.markdown",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "# HOW TO USE: \nUse these code examples as a guideline for formatting your HTML email to avoid some of the major styling pitfalls in HTML email design. You may want to create your own template based on these snippets or just pick and choose the ones that fix your specific rendering issue(s). There are two main areas in the template: 1. The header (head) area of the document. You will find global styles, where indicated, to move inline. 2. The body section contains more specific fixes and guidance to use where needed in your design.\n\nDO NOT COPY OVER COMMENTS AND INSTRUCTIONS WITH THE CODE to your message or risk spam box banishment :).\n\nIt is important to note that sometimes the styles in the header area should not be or don't need to be brought inline. Those instances will be marked accordingly in the comments.\n\n## A few things to note: \n\n1. Not all of the styles in the header area should be brought inline. Those instances will be marked accordingly in the comments.\n2. Remember to test accordingly with your own code and styling. Although this code will help you get through a number of HTML email issues, it is no substitute for proper testing.\n\n### Subscribe\nReceive updates on the boilerplate here: http://tinyletter.com/ebp\n\n### License:\nMIT License\n[http://htmlemailboilerplate.com/license.html](http://htmlemailboilerplate.com/license.html)\n\nCopyright (c) 2010-2011 Sean Powell, The Engage Group\n\nPermission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the \"Software\"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.\n\n### Contributors\n[List Here >>](https://github.com/seanpowell/Email-Boilerplate/blob/master/contributors.txt)\n"
},
{
"alpha_fraction": 0.6743905544281006,
"alphanum_fraction": 0.6765629053115845,
"avg_line_length": 34.02608871459961,
"blob_id": "ffbf86ae2667e5947150df8753ab11be2576f5f1",
"content_id": "a9a6d4cc5c7bbb23941dd6f9dad62a68eb672ffb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8286,
"license_type": "permissive",
"max_line_length": 293,
"num_lines": 230,
"path": "/README.md",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "\r\n=====\r\nUsage\r\n=====\r\n\r\ndjango-mailing was developed to:\r\n * send emails in ASCII or HTML\r\n * support email templating with headers and footers\r\n * support multilingual environments\r\n * optionally use SendGrid to categorize email statistics and sync email lists\r\n * optionally support celery for queuing mail sending and/or processing in background processes\r\n\r\nInstallation\r\n============\r\n\r\nAvailable on PyPi:\r\n\r\n pip install django-mailing\r\n\r\nConfiguration\r\n=============\r\n\r\nAdd to your installed apps in your setting.py file:\r\n\r\n INSTALLED_APPS = (\r\n ...\r\n 'mailing',\r\n )\r\n\r\nsettings.DEFAULT_FROM_EMAIL\r\n---------------------------\r\n\r\nYou need to set your default from email:\r\n\r\n DEFAULT_FROM_EMAIL = '[email protected]'\r\n\r\n\r\nsettings.MAILING_USE_SENDGRID\r\n-----------------------------\r\n\r\nBoolean to indicate you have configured Django to use SendGrid:\r\n\r\n MAILING_USE_SENDGRID = True\r\n\r\nThe impact is you now have additional SendGrid capabilities such as the ability to:\r\n * categorize emails sent\r\n * manage/sync mailing lists (currently not implemented)\r\n * plus all the good stuff they do on their side.\r\n\r\nsettings.MAILING_MAILTO_HIJACK\r\n------------------------------\r\n\r\nYou can hijack email sent by your app to redirect to another email. Quite practical when developing or testing with external email addresses:\r\n\r\n MAILING_MAILTO_HIJACK = '[email protected]'\r\n\r\nIf defined, every outgoind email will be sent to [email protected]. For debugging/testing purposes, the following header is added to the email:\r\n\r\n X-MAILER-ORIGINAL-MAILTO: [email protected]\r\n\r\nIt will contain what would have been the original \"To\" header if we hadn't hijacked it\r\n\r\nsettings.MAILING_USE_CELERY\r\n---------------------------\r\n\r\nBoolean indicating celery is configured and you want to send/process email related stuff in background:\r\n\r\n MAILING_USE_CELERY = True\r\n\r\nFor example, you can configure your app to use celery by installing a redis server.\r\n\r\nYour settings would also need to include things like:\r\n\r\n INSTALLED_APPS = (\r\n #\r\n # ...\r\n #\r\n\r\n 'celery',\r\n 'djcelery',\r\n\r\n #\r\n # ...\r\n #\r\n\r\n 'mailing',\r\n\r\n #\r\n # ...\r\n #\r\n )\r\n \r\n # \r\n # ...\r\n #\r\n \r\n # Celery Configuration. Ref.: http://celery.github.com/celery/configuration.htm\r\n # -------------------------------------\r\n os.environ[\"CELERY_LOADER\"] = \"django\"\r\n djcelery.setup_loader()\r\n\r\n BROKER_TRANSPORT = \"redis\"\r\n BROKER_HOST = \"localhost\" # Maps to redis host.\r\n BROKER_PORT = 6379 # Maps to redis port.\r\n BROKER_VHOST = \"0\" # Maps to database number.\r\n\r\n CELERY_IGNORE_RESULT = False\r\n CELERY_RESULT_BACKEND = \"redis\"\r\n CELERY_REDIS_HOST = \"localhost\"\r\n CELERY_REDIS_PORT = 6379\r\n CELERY_REDIS_DB = 0\r\n\r\nWhen running the celery daemon, you need to include the ``mailing`` app in the tasks through the ``include`` parameter. Example:\r\n\r\n manage.py celeryd --verbosity=2 --beat --schedule=celery --events --loglevel=INFO -I mailing\r\n\r\nYou therefore could run a separate celery daemon to run your mailing tasks independently of other tasks if the need arises.\r\n\r\nsettings.MAILING_LANGUAGES\r\n--------------------------\r\n\r\nNot yet implemented.\r\n\r\nReplacing the core django send_mail function\r\n--------------------------------------------\r\n\r\nTo replace Django's core send_mail function to add support for email templates, SendGrid integration and background celery sending, add the following code to your settings file:\r\n\r\n import sys\r\n from mailing.mail import send_email_default\r\n try:\r\n from django.core import mail \r\n mail.send_mail = send_email_default\r\n sys.modules['django.core.mail'] = mail\r\n except ImportError:\r\n pass\r\n\r\n\r\nUsing django-mailing\r\n====================\r\n\r\nSimple multi-part send_mail replacement\r\n---------------------------------------\r\n\r\nYou can using mailing.send_email instead of Django's send_mail to send multi-part messages:\r\n\r\n send_email(recipients, subject, text_content=None, html_content=None, from_email=settings.DEFAULT_FROM_EMAIL, category=None, fail_silently=False, bypass_queue=False)\r\n\r\nParameters are:\r\n * ``recipients`` is a list of email addresses to send the email to\r\n * ``subject`` is the subject of your email\r\n * ``text_content`` is the ASCII content of the email\r\n * ``html_content`` is the HTML content of the email\r\n * ``from_email`` is a string and is the sender's address\r\n * ``category`` is a string and is used to define SendGrid's X-SMTPAPI's category header\r\n\r\nYou must supply at least text_content or html_content. If both aren't supplied, an exception will be raised. If only one of the two is supplied, the email will be sent in the corresponding format. If both content are supplied, a multi-part email will be sent.\r\n\r\nExample usage:\r\n\r\n from mailing import send_email\r\n \r\n send_email(['[email protected]', '[email protected]'], 'Testing 1,2,3...', 'Text Body', 'HTML Body', category='testing')\r\n\r\nRendering and sending emails using templates\r\n--------------------------------------------\r\n\r\nTo use Django templates to generate dynamic emails, similar to using ``render_with_context`` in a Django view, use the ``render_send_email`` shortcut:\r\n\r\n render_send_email(recipients, template, data, from_email=settings.DEFAULT_FROM_EMAIL, subject=None, category=None, fail_silently=False, language='en', bypass_queue=False)\r\n\r\nParameters are:\r\n * ``recipients`` is a list of email addresses to send the email to\r\n * ``template`` the path to your Django templates, without any extension\r\n * ``data`` data context dictionnary to render the template\r\n * ``from_email`` is a string and is the sender's address\r\n * ``subject`` is the subject of your email\r\n * ``category`` is a string and is used to define SendGrid's X-SMTPAPI's category header\r\n\r\nExample:\r\n\r\n def send_welcome_email(user):\r\n from mailing.shortcuts import render_send_email\r\n \r\n render_send_email(['[email protected]', '[email protected]'], 'users/welcome', {'user': user}, category='welcome')\r\n\r\nin your app, you would need the following template files with the right extensions:\r\n * ``templates/users/welcome.txt``\r\n * ``templates/users/welcome.html``\r\n * ``templates/users/welcome.subject``\r\n\r\nThe subject template file can be omitted but you then need to supply the ``subject`` parameter. If you do not create a template with a .txt or a .html extension, then the associated format won't be included in the email. So, if you want to only send ASCII messages, do not create a .html file.\r\n\r\nExample without using a subject template:\r\n\r\n render_send_email(['[email protected]', '[email protected]'], 'app/welcome', data, subject='Welcome new user', category='welcome')\r\n\r\nTemplates\r\n---------\r\n\r\nThe following templates are defined and used by django-mailing and should be overriten in your own templates:\r\n * ``templates/mailing/base.txt``\r\n * ``templates/mailing/base.html``\r\n\r\nThese are used to define your email overall look like the header and footer. The only requirement is to include the ``{{ content }}`` template variable. It is there than the supplied content of your email will be inserted in your base template.\r\n\r\nLICENSE\r\n=======\r\n\r\nCopyright (c) 2009 Jerome Paradis, Alain Carpentier and contributors\r\n\r\nPermission is hereby granted, free of charge, to any person\r\nobtaining a copy of this software and associated documentation\r\nfiles (the \"Software\"), to deal in the Software without\r\nrestriction, including without limitation the rights to use,\r\ncopy, modify, merge, publish, distribute, sublicense, and/or sell\r\ncopies of the Software, and to permit persons to whom the\r\nSoftware is furnished to do so, subject to the following\r\nconditions:\r\n\r\nThe above copyright notice and this permission notice shall be\r\nincluded in all copies or substantial portions of the Software.\r\n\r\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND,\r\nEXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES\r\nOF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND\r\nNONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\r\nHOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,\r\nWHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\r\nFROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR\r\nOTHER DEALINGS IN THE SOFTWARE."
},
{
"alpha_fraction": 0.7689008116722107,
"alphanum_fraction": 0.7689008116722107,
"avg_line_length": 65.60713958740234,
"blob_id": "74258bf80ca3510d6f99937bba151826b4db76a5",
"content_id": "cf238bd7389819e57391a44f9777437db3ff3f1c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1865,
"license_type": "permissive",
"max_line_length": 374,
"num_lines": 28,
"path": "/mailing/tasks.py",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom django.conf import settings\n\nfrom celery.task import task\n\nfrom .mail import send_email\nfrom .shortcuts import render_send_email\n\n@task(name=\"mailing.queue_send_email\")\ndef queue_send_email(recipients, subject, text_content=None, html_content=None, from_email=settings.DEFAULT_FROM_EMAIL, use_base_template=True, category=None, fail_silently=False, language=None, cc=None, bcc=None, attachments=None, headers=None, bypass_hijacking=False, attach_files=None): \n \n logger = queue_send_email.get_logger()\n logger.debug('Sending %s to %s' % (subject, ','.join(recipients), ))\n\n send_email(recipients=recipients, subject=subject, text_content=text_content, html_content=html_content, from_email=from_email, use_base_template=use_base_template, category=category, fail_silently=fail_silently, language=language, cc=cc, bcc=bcc, attachments=attachments, headers=headers, bypass_queue=True, bypass_hijacking=bypass_hijacking, attach_files=attach_files)\n\n return True\n\n@task(name=\"mailing.queue_render_send_email\")\ndef queue_render_send_email(recipients, template, data, from_email=settings.DEFAULT_FROM_EMAIL, subject=None, use_base_template=True, category=None, fail_silently=False, language=None, cc=None, bcc=None, attachments=None, headers=None, bypass_hijacking=False, attach_files=None):\n \n logger = queue_render_send_email.get_logger()\n\n logger.debug('Rendering and sending %s to %s' % (template, ','.join(recipients), ))\n\n render_send_email(recipients=recipients, template=template, data=data, from_email=from_email, subject=subject, use_base_template=use_base_template, category=category, fail_silently=fail_silently, language=language, cc=cc, bcc=bcc, attachments=attachments, headers=headers, bypass_queue=True, bypass_hijacking=bypass_hijacking, attach_files=attach_files)\n\n return True\n"
},
{
"alpha_fraction": 0.6685815453529358,
"alphanum_fraction": 0.6685815453529358,
"avg_line_length": 52.69047546386719,
"blob_id": "7b95cc9a0331c3e15f8b96d91639fa1087ccbeed",
"content_id": "02820a80708b4012c855a1db5c557c05642cbaef",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2263,
"license_type": "permissive",
"max_line_length": 298,
"num_lines": 42,
"path": "/mailing/shortcuts.py",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom django.conf import settings\nfrom django.template.loader import render_to_string\nfrom django.template import TemplateDoesNotExist\nfrom django.utils import translation\n\nfrom mailing.mail import send_email\n\ndef render_send_email(recipients, template, data, from_email=settings.DEFAULT_FROM_EMAIL, subject=None, use_base_template=True, category=None, fail_silently=False, language=None, cc=None, bcc=None, attachments=None, headers=None, bypass_queue=False, bypass_hijacking=False, attach_files=None):\n if not bypass_queue and hasattr(settings, 'MAILING_USE_CELERY') and settings.MAILING_USE_CELERY:\n from celery.execute import send_task\n return send_task('mailing.queue_render_send_email',[recipients, template, data, from_email, subject, use_base_template, category, fail_silently, language if language else translation.get_language(), cc, bcc, attachments, headers, bypass_hijacking, attach_files])\n else:\n # Set language\n # --------------------------------\n prev_language = translation.get_language()\n language and translation.activate(language)\n if subject:\n my_subject = subject\n else:\n try:\n my_subject = render_to_string('%s.subject' % template, data)\n except:\n my_subject = None\n if not data:\n data = dict()\n if use_base_template and my_subject and 'mailing_subject' not in data:\n data['mailing_subject'] = my_subject\n if 'settings' not in data:\n data['settings'] = settings\n try:\n text_content = render_to_string('%s.txt' % template, data)\n except TemplateDoesNotExist:\n text_content = None\n\n try:\n html_content = render_to_string('%s.html' % template, data)\n except TemplateDoesNotExist:\n html_content = None\n\n translation.activate(prev_language)\n send_email(recipients, my_subject, text_content, html_content, from_email, use_base_template, category, fail_silently=fail_silently, language=language, cc=cc, bcc=bcc, attachments=attachments, headers=headers, bypass_queue=True, bypass_hijacking=bypass_hijacking, attach_files=attach_files)\n "
},
{
"alpha_fraction": 0.673496425151825,
"alphanum_fraction": 0.6756659150123596,
"avg_line_length": 34.07391357421875,
"blob_id": "374dc59c9c63d4a0c90fe501de43e9b2542846cf",
"content_id": "25a831ac2bbe42c21a9c79e7f3d8aeaf56e3ff13",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 8297,
"license_type": "permissive",
"max_line_length": 293,
"num_lines": 230,
"path": "/README.txt",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "\r\n=====\r\nUsage\r\n=====\r\n\r\ndjango-mailing was developed to:\r\n * send emails in ASCII or HTML\r\n * support email templating with headers and footers\r\n * support multilingual environments\r\n * optionally use SendGrid to categorize email statistics and sync email lists\r\n * optionally support celery for queuing mail sending and/or processing in background processes\r\n\r\nInstallation\r\n============\r\n\r\nAvailable on PyPi::\r\n\r\n pip install django-mailing\r\n\r\nConfiguration\r\n=============\r\n\r\nAdd to your installed apps in your setting.py file::\r\n\r\n INSTALLED_APPS = (\r\n ...\r\n 'mailing',\r\n )\r\n\r\nsettings.DEFAULT_FROM_EMAIL\r\n---------------------------\r\n\r\nYou need to set your default from email::\r\n\r\n DEFAULT_FROM_EMAIL = '[email protected]'\r\n\r\n\r\nsettings.MAILING_USE_SENDGRID\r\n-----------------------------\r\n\r\nBoolean to indicate you have configured Django to use SendGrid::\r\n\r\n MAILING_USE_SENDGRID = True\r\n\r\nThe impact is you now have additional SendGrid capabilities such as the ability to:\r\n * categorize emails sent\r\n * manage/sync mailing lists (currently not implemented)\r\n * plus all the good stuff they do on their side.\r\n\r\nsettings.MAILING_MAILTO_HIJACK\r\n------------------------------\r\n\r\nYou can hijack email sent by your app to redirect to another email. Quite practical when developing or testing with external email addresses::\r\n\r\n MAILING_MAILTO_HIJACK = '[email protected]'\r\n\r\nIf defined, every outgoind email will be sent to [email protected]. For debugging/testing purposes, the following header is added to the email::\r\n\r\n X-MAILER-ORIGINAL-MAILTO: [email protected]\r\n\r\nIt will contain what would have been the original \"To\" header if we hadn't hijacked it\r\n\r\nsettings.MAILING_USE_CELERY\r\n---------------------------\r\n\r\nBoolean indicating celery is configured and you want to send/process email related stuff in background::\r\n\r\n MAILING_USE_CELERY = True\r\n\r\nFor example, you can configure your app to use celery by installing a redis server.\r\n\r\nYour settings would also need to include things like::\r\n\r\n INSTALLED_APPS = (\r\n #\r\n # ...\r\n #\r\n\r\n 'celery',\r\n 'djcelery',\r\n\r\n #\r\n # ...\r\n #\r\n\r\n 'mailing',\r\n\r\n #\r\n # ...\r\n #\r\n )\r\n \r\n # \r\n # ...\r\n #\r\n \r\n # Celery Configuration. Ref.: http://celery.github.com/celery/configuration.htm\r\n # -------------------------------------\r\n os.environ[\"CELERY_LOADER\"] = \"django\"\r\n djcelery.setup_loader()\r\n\r\n BROKER_TRANSPORT = \"redis\"\r\n BROKER_HOST = \"localhost\" # Maps to redis host.\r\n BROKER_PORT = 6379 # Maps to redis port.\r\n BROKER_VHOST = \"0\" # Maps to database number.\r\n\r\n CELERY_IGNORE_RESULT = False\r\n CELERY_RESULT_BACKEND = \"redis\"\r\n CELERY_REDIS_HOST = \"localhost\"\r\n CELERY_REDIS_PORT = 6379\r\n CELERY_REDIS_DB = 0\r\n\r\nWhen running the celery daemon, you need to include the ``mailing`` app in the tasks through the ``include`` parameter. Example::\r\n\r\n manage.py celeryd --verbosity=2 --beat --schedule=celery --events --loglevel=INFO -I mailing\r\n\r\nYou therefore could run a separate celery daemon to run your mailing tasks independently of other tasks if the need arises.\r\n\r\nsettings.MAILING_LANGUAGES\r\n--------------------------\r\n\r\nNot yet implemented.\r\n\r\nReplacing the core django send_mail function\r\n--------------------------------------------\r\n\r\nTo replace Django's core send_mail function to add support for email templates, SendGrid integration and background celery sending, add the following code to your settings file::\r\n\r\n import sys\r\n from mailing.mail import send_email_default\r\n try:\r\n from django.core import mail \r\n mail.send_mail = send_email_default\r\n sys.modules['django.core.mail'] = mail\r\n except ImportError:\r\n pass\r\n\r\n\r\nUsing django-mailing\r\n====================\r\n\r\nSimple multi-part send_mail replacement\r\n---------------------------------------\r\n\r\nYou can using mailing.send_email instead of Django's send_mail to send multi-part messages::\r\n\r\n send_email(recipients, subject, text_content=None, html_content=None, from_email=settings.DEFAULT_FROM_EMAIL, category=None, fail_silently=False, bypass_queue=False)\r\n\r\nParameters are:\r\n * ``recipients`` is a list of email addresses to send the email to\r\n * ``subject`` is the subject of your email\r\n * ``text_content`` is the ASCII content of the email\r\n * ``html_content`` is the HTML content of the email\r\n * ``from_email`` is a string and is the sender's address\r\n * ``category`` is a string and is used to define SendGrid's X-SMTPAPI's category header\r\n\r\nYou must supply at least text_content or html_content. If both aren't supplied, an exception will be raised. If only one of the two is supplied, the email will be sent in the corresponding format. If both content are supplied, a multi-part email will be sent.\r\n\r\nExample usage::\r\n\r\n from mailing import send_email\r\n\r\n send_email(['[email protected]', '[email protected]'], 'Testing 1,2,3...', 'Text Body', 'HTML Body', category='testing')\r\n\r\nRendering and sending emails using templates\r\n--------------------------------------------\r\n\r\nTo use Django templates to generate dynamic emails, similar to using ``render_with_context`` in a Django view, use the ``render_send_email`` shortcut::\r\n\r\n render_send_email(recipients, template, data, from_email=settings.DEFAULT_FROM_EMAIL, subject=None, category=None, fail_silently=False, language='en', bypass_queue=False)\r\n\r\nParameters are:\r\n * ``recipients`` is a list of email addresses to send the email to\r\n * ``template`` the path to your Django templates, without any extension\r\n * ``data`` data context dictionnary to render the template\r\n * ``from_email`` is a string and is the sender's address\r\n * ``subject`` is the subject of your email\r\n * ``category`` is a string and is used to define SendGrid's X-SMTPAPI's category header\r\n\r\nExample::\r\n\r\n def send_welcome_email(user):\r\n from mailing.shortcuts import render_send_email\r\n \r\n render_send_email(['[email protected]', '[email protected]'], 'users/welcome', {'user': user}, category='welcome')\r\n\r\nin your app, you would need the following template files with the right extensions:\r\n * ``templates/users/welcome.txt``\r\n * ``templates/users/welcome.html``\r\n * ``templates/users/welcome.subject``\r\n\r\nThe subject template file can be omitted but you then need to supply the ``subject`` parameter. If you do not create a template with a .txt or a .html extension, then the associated format won't be included in the email. So, if you want to only send ASCII messages, do not create a .html file.\r\n\r\nExample without using a subject template::\r\n\r\n render_send_email(['[email protected]', '[email protected]'], 'app/welcome', data, subject='Welcome new user', category='welcome')\r\n\r\nTemplates\r\n---------\r\n\r\nThe following templates are defined and used by django-mailing and should be overriten in your own templates:\r\n * ``templates/mailing/base.txt``\r\n * ``templates/mailing/base.html``\r\n\r\nThese are used to define your email overall look like the header and footer. The only requirement is to include the ``{{ content }}`` template variable. It is there than the supplied content of your email will be inserted in your base template.\r\n\r\nLICENSE\r\n=======\r\n\r\nCopyright (c) 2009 Jerome Paradis, Alain Carpentier and contributors\r\n\r\nPermission is hereby granted, free of charge, to any person\r\nobtaining a copy of this software and associated documentation\r\nfiles (the \"Software\"), to deal in the Software without\r\nrestriction, including without limitation the rights to use,\r\ncopy, modify, merge, publish, distribute, sublicense, and/or sell\r\ncopies of the Software, and to permit persons to whom the\r\nSoftware is furnished to do so, subject to the following\r\nconditions:\r\n\r\nThe above copyright notice and this permission notice shall be\r\nincluded in all copies or substantial portions of the Software.\r\n\r\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND,\r\nEXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES\r\nOF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND\r\nNONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT\r\nHOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY,\r\nWHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING\r\nFROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR\r\nOTHER DEALINGS IN THE SOFTWARE."
},
{
"alpha_fraction": 0.6049701571464539,
"alphanum_fraction": 0.6063618063926697,
"avg_line_length": 46.904762268066406,
"blob_id": "8b9ee1768e870b84e163011acdee7cab01cb804b",
"content_id": "2bea5628094eaa4674fa6ead7982fffb8b1e07a5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5030,
"license_type": "permissive",
"max_line_length": 280,
"num_lines": 105,
"path": "/mailing/mail.py",
"repo_name": "JeromeParadis/django-mailing",
"src_encoding": "UTF-8",
"text": "from __future__ import absolute_import\nfrom django.conf import settings\nfrom django.core.mail import EmailMultiAlternatives, EmailMessage\nfrom django.template.loader import render_to_string\nfrom django.utils import translation\nimport six\n\n# Define exception classes\n# --------------------------------\nclass MailerInvalidBodyError(Exception):\n def __init__(self, value):\n self.value = value\n def __str__(self):\n return repr(self.value)\n\nclass MailerMissingSubjectError(Exception):\n def __init__(self, value=None):\n self.value = value\n def __str__(self):\n return repr(self.value if value else '')\n\ndef send_email_default(*args, **kwargs):\n send_email(args[3],args[0],args[1], from_email=args[2], category='django core email')\n\ndef send_email(recipients, subject, text_content=None, html_content=None, from_email=None, use_base_template=True, category=None, fail_silently=False, language=None, cc=None, bcc=None, attachments=None, headers=None, bypass_queue=False, bypass_hijacking=False, attach_files=None):\n \"\"\"\n Will send a multi-format email to recipients. Email may be queued through celery\n \"\"\"\n from django.conf import settings\n if not bypass_queue and hasattr(settings, 'MAILING_USE_CELERY') and settings.MAILING_USE_CELERY:\n from celery.execute import send_task\n return send_task('mailing.queue_send_email',[recipients, subject, text_content, html_content, from_email, use_base_template, category, fail_silently, language if language else translation.get_language(), cc, bcc, attachments, headers, bypass_hijacking, attach_files])\n else:\n\n header_category_value = '%s%s' % (settings.MAILING_HEADER_CATEGORY_PREFIX if hasattr(settings, 'MAILING_HEADER_CATEGORY_PREFIX') else '', category)\n # Check for sendgrid support and add category header\n # --------------------------------\n if hasattr(settings, 'MAILING_USE_SENDGRID'):\n send_grid_support = settings.MAILING_USE_SENDGRID\n else:\n send_grid_support = False\n\n if not headers:\n headers = dict() \n if send_grid_support and category:\n headers['X-SMTPAPI'] = '{\"category\": \"%s\"}' % header_category_value\n\n # Check for Mailgun support and add label header\n # --------------------------------\n if hasattr(settings, 'MAILING_USE_MAILGUN'):\n mailgun_support = settings.MAILING_USE_MAILGUN\n else:\n mailgun_support = False\n\n if not headers:\n headers = dict() \n if mailgun_support and category:\n headers['X-Mailgun-Tag'] = header_category_value\n\n\n # Ensure recipients are in a list\n # --------------------------------\n if isinstance(recipients, six.string_types):\n recipients_list = [recipients]\n else:\n recipients_list = recipients\n\n # Check if we need to hijack the email\n # --------------------------------\n if hasattr(settings, 'MAILING_MAILTO_HIJACK') and not bypass_hijacking:\n headers['X-MAILER-ORIGINAL-MAILTO'] = ','.join(recipients_list)\n recipients_list = [settings.MAILING_MAILTO_HIJACK]\n\n if not subject:\n raise MailerMissingSubjectError('Subject not supplied')\n\n # Send ascii, html or multi-part email\n # --------------------------------\n if text_content or html_content:\n if use_base_template:\n prev_language = translation.get_language()\n language and translation.activate(language)\n text_content = render_to_string('mailing/base.txt', {'mailing_text_body': text_content, 'mailing_subject': subject, 'settings': settings}) if text_content else None\n html_content = render_to_string('mailing/base.html', {'mailing_html_body': html_content, 'mailing_subject': subject, 'settings': settings}) if html_content else None\n translation.activate(prev_language)\n msg = EmailMultiAlternatives(subject, text_content if text_content else html_content, from_email if from_email else settings.DEFAULT_FROM_EMAIL, recipients_list, cc=cc, bcc=bcc, attachments=attachments, headers = headers)\n if html_content and text_content:\n msg.attach_alternative(html_content, \"text/html\")\n elif html_content: # Only HTML\n msg.content_subtype = \"html\"\n\n # Attach files through attach_files helper\n # --------------------------------\n if attach_files:\n for att in attach_files: # attachments are tuples of (filepath, mimetype, filename)\n with open(att[0], 'rb') as f:\n content = f.read()\n msg.attach(att[2], content, att[1])\n\n # Send email\n # --------------------------------\n\n msg.send(fail_silently=fail_silently)\n else:\n raise MailerInvalidBodyError('No text or html body supplied.')\n"
}
] | 7 |
abiiranathan/drf-authtoken
|
https://github.com/abiiranathan/drf-authtoken
|
e87b2fba30b5c88c10c2c18b9635558c86ca1715
|
172b2ea082ad2b46555415d1d5ad5d51fa74dccb
|
7c7123d59c8dfa1f2d8d3d33a31d4121fc619d88
|
refs/heads/master
| 2023-05-07T11:17:18.867178 | 2021-05-29T00:28:36 | 2021-05-29T00:28:36 | 371,803,930 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6059610843658447,
"alphanum_fraction": 0.6125284433364868,
"avg_line_length": 33.42608642578125,
"blob_id": "4e9de8e25766c64eb5281173dddb42579c20ef43",
"content_id": "472a14bb3db812dc03a24f79dfc8eaf263f8d3d2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3959,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 115,
"path": "/drf_auth/tests.py",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "from rest_framework.test import APIClient\nfrom rest_framework.authtoken.models import Token\nfrom django.urls import reverse\nfrom rest_framework import status\nfrom rest_framework.test import APITestCase\n\nfrom django.contrib.auth import get_user_model\n\nUser = get_user_model()\n\n\nclass RegistrationTests(APITestCase):\n def setUp(self):\n self.superuser = User.objects.create_superuser(\n 'randomusername', '[email protected]', 'STRONGpassword')\n\n self.client.login(username='john', password='johnpassword')\n\n self.data = {\n 'username': 'mike',\n 'first_name': 'Mike',\n 'last_name': 'Tyson',\n 'email': \"[email protected]\",\n 'password': \"mikepassword\"\n }\n\n def test_can_register(self):\n \"\"\"\n Ensure we can create new users.\n \"\"\"\n\n url = reverse('drf_auth:register')\n\n response = self.client.post(url, self.data, format='json')\n self.assertEqual(response.status_code, status.HTTP_201_CREATED)\n self.assertEqual(response.data[\"user\"][\"first_name\"], 'Mike')\n self.assertEqual(response.data[\"user\"][\"last_name\"], 'Tyson')\n self.assertEqual(response.data[\"user\"][\"username\"], 'mike')\n self.assertTrue(\n \"token\" in response.data and response.data[\"token\"] is not None)\n\n\nclass LoginTests(APITestCase):\n def setUp(self):\n self.superuser = User.objects.create_superuser(\n 'john', '[email protected]', 'johnpassword')\n\n self.data = {\"username\": \"john\", \"password\": \"johnpassword\"}\n\n def test_can_login(self):\n \"\"\"\n Ensure we can users can log in.\n \"\"\"\n\n url = reverse('drf_auth:login')\n response = self.client.post(url, self.data, format='json')\n\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(response.data[\"user\"][\"username\"], \"john\")\n self.assertEqual(response.data[\"user\"][\"email\"], \"[email protected]\")\n\n\nclass UserTests(APITestCase):\n def setUp(self):\n self.superuser = User.objects.create_superuser(\n 'froid', '[email protected]', 'moneyTeAM')\n\n self.data = {\"username\": \"froid\", \"password\": \"moneyTeAM\"}\n token, _ = Token.objects.get_or_create(user=self.superuser)\n self.client.credentials(HTTP_AUTHORIZATION='Token ' + token.key)\n\n def test_can_retrieve_user(self):\n response = self.client.get(\n reverse('drf_auth:get_user'), format='json')\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n\n def test_can_retrieve_all_users(self):\n response1 = self.client.get(\n reverse(\"drf_auth:get_all_users\"), format='json')\n self.assertEqual(response1.status_code, status.HTTP_200_OK)\n\n def test_can_update_user(self):\n response = self.client.put(reverse(\"drf_auth:update_user\"), {\n \"first_name\": \"Froid\",\n \"last_name\": \"May Weather\",\n })\n\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n self.assertEqual(response.data[\"first_name\"], \"Froid\")\n\n def test_can_change_password(self):\n response = self.client.post(reverse(\"drf_auth:change_password\"), {\n \"old_password\": \"moneyTeAM\",\n \"new_password\": \"moneyTeAMUpdated\",\n })\n\n self.assertEqual(response.status_code, status.HTTP_200_OK)\n\n def test_password_change_fails_on_wrong_password(self):\n response = self.client.post(reverse(\"drf_auth:change_password\"), {\n \"old_password\": \"moneyTeAMWrong\",\n \"new_password\": \"moneyTeAMUpdated\",\n })\n\n self.assertEqual(response.status_code, status.HTTP_400_BAD_REQUEST)\n\n def test_send_password_reset_email(self):\n \"\"\"Tested with Gmail and passes tests\"\"\"\n url = reverse(\"drf_auth:reset_password\")\n\n self.assertEqual(url, \"/api/auth/reset-password/\")\n\n # response = self.client.post(url, {\"email\": \"[email protected]\"})\n\n # self.assertEqual(response.status_code, status.HTTP_200_OK)\n"
},
{
"alpha_fraction": 0.6795889735221863,
"alphanum_fraction": 0.6917328238487244,
"avg_line_length": 34.09836196899414,
"blob_id": "7d5327608c7413d93b2d4b0cbec014ea39f9373f",
"content_id": "bc606bd84ee3306c5d4746a55fdd3c72e8a79fed",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2141,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 61,
"path": "/drf_auth/mail.py",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "import json\nimport smtplib\nfrom email.header import Header\nfrom email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom email.utils import formataddr\n\nfrom django.conf import settings\nfrom django.contrib.auth.tokens import PasswordResetTokenGenerator\nfrom django.utils.encoding import force_bytes\nfrom django.utils.http import urlsafe_base64_encode\n\n\ndef send_reset_email(request, user, subject):\n message = MIMEMultipart(\"alternative\")\n message[\"Subject\"] = subject\n\n SITE_NAME = settings.DRF_AUTH_SETTINGS[\"SITE_NAME\"]\n EMAIL_HOST_USER = settings.DRF_AUTH_SETTINGS[\"EMAIL_HOST_USER\"]\n EMAIL_HOST_PASSWORD = settings.DRF_AUTH_SETTINGS[\"EMAIL_HOST_PASSWORD\"]\n\n EMAIL_HOST = settings.DRF_AUTH_SETTINGS[\"EMAIL_HOST\"]\n EMAIL_PORT = settings.DRF_AUTH_SETTINGS[\"EMAIL_PORT\"]\n\n if not EMAIL_HOST or not EMAIL_PORT or not EMAIL_HOST_USER or not SITE_NAME:\n print(\"settings.DRF_AUTH_SETTINGS Configuration incomplete.\")\n return False\n\n message[\"From\"] = formataddr(\n (str(Header(SITE_NAME, \"utf-8\")), EMAIL_HOST_USER))\n message[\"To\"] = user.email\n\n uidb64 = urlsafe_base64_encode(force_bytes(user.id))\n token = PasswordResetTokenGenerator().make_token(user)\n\n reset_url = request.build_absolute_uri(\n f\"/api/auth/reset_password_confirmation/{uidb64}/{token}/\")\n\n html = f\"\"\"\n <h2>Hi, {user}<h1>\n <p style=\"font-size: 12px; color:#333; line-height:1.6;\">\n You requested for a password reset for your {SITE_NAME} account.<br>\n Please follow the link below to set your new password.<br><br>\n\n <a href=\"{reset_url}\" style=\"background-color:teal;color: #fff;padding: 0.5rem 1rem; border-radius:8px;\">Reset My Password</a>\n </p>\n \"\"\"\n\n part1 = MIMEText(html, \"html\")\n message.attach(part1)\n\n try:\n with smtplib.SMTP_SSL(EMAIL_HOST, EMAIL_PORT, timeout=30) as server:\n server.ehlo()\n server.login(EMAIL_HOST_USER, EMAIL_HOST_PASSWORD)\n server.sendmail(EMAIL_HOST_USER, user.email, message.as_string())\n\n return True\n except Exception as e:\n print(e)\n return False\n"
},
{
"alpha_fraction": 0.578125,
"alphanum_fraction": 0.75,
"avg_line_length": 20.66666603088379,
"blob_id": "1f972ddc620b493eb4c3220e05849cb65bddd57c",
"content_id": "511ad3e5c1da6d771b3c2f915d29e0f462f358a0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 64,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "Django>= 3.2.3\ndjangorestframework>=3.12.4\npython-dotenv>=0.17.1"
},
{
"alpha_fraction": 0.662618100643158,
"alphanum_fraction": 0.6653171181678772,
"avg_line_length": 38,
"blob_id": "6537eaedf91f76f7ee4d93555d554da8ad882500",
"content_id": "aa70f7fa614d0e0c1759d7a7a3fb0e64c74b81ee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 741,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 19,
"path": "/drf_auth/urls.py",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom . import views\n\napp_name = \"drf_auth\"\n\nurlpatterns = [\n path(\"register/\", views.register, name=\"register\"),\n path(\"login/\", views.LoginAPIView.as_view(), name=\"login\"),\n path(\"logout/\", views.logout, name=\"logout\"),\n path(\"user/\", views.get_user, name=\"get_user\"),\n path(\"users/\", views.get_all_users, name=\"get_all_users\"),\n path(\"update-user/\", views.update_user, name=\"update_user\"),\n path(\"change-password/\", views.change_password, name=\"change_password\"),\n path(\"reset-password/\", views.reset_password, name=\"reset_password\"),\n path(\"reset_password_confirmation/<uidb64>/<token>/\",\n views.reset_password_confirmation,\n name=\"reset_password_confirmation\"),\n]\n"
},
{
"alpha_fraction": 0.6529914736747742,
"alphanum_fraction": 0.6629370450973511,
"avg_line_length": 31.33668327331543,
"blob_id": "392b496b296d308eb16de08e1171e3f535fca4a8",
"content_id": "6853ca3967195fa454eecc8cbc8a198ed28643b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6435,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 199,
"path": "/drf_auth/views.py",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "from django.conf import settings\nfrom django.contrib.auth import authenticate, get_user_model\nfrom django.contrib.auth.tokens import PasswordResetTokenGenerator\nfrom django.http.response import HttpResponse\nfrom django.shortcuts import get_object_or_404\nfrom rest_framework import permissions, serializers\nfrom rest_framework.authtoken.models import Token\nfrom rest_framework.authtoken.views import ObtainAuthToken\nfrom rest_framework.decorators import (api_view, authentication_classes,\n permission_classes)\nfrom rest_framework.response import Response\nfrom .mail import send_reset_email\nfrom .serializers import UserSerializer\nfrom django.utils import timezone\nfrom django.shortcuts import render\nfrom django.core.exceptions import ValidationError\nfrom django.utils.http import urlsafe_base64_decode\n\n\nUser = get_user_model()\n\n\n@api_view(http_method_names=[\"POST\"])\n@permission_classes([])\n@authentication_classes([])\ndef register(request):\n serializer = UserSerializer(data=request.data)\n\n if serializer.is_valid(raise_exception=True):\n user = serializer.save()\n user.set_password(request.data[\"password\"])\n user.save()\n\n token = Token.objects.create(user=user)\n\n data = {\n \"user\": UserSerializer(user).data,\n \"token\": token.key\n }\n\n return Response(status=201, data=data)\n\n\nclass LoginAPIView(ObtainAuthToken):\n def post(self, request, *args, **kwargs):\n serializer = self.serializer_class(data=request.data,\n context={'request': request})\n serializer.is_valid(raise_exception=True)\n user = serializer.validated_data['user']\n token, _ = Token.objects.get_or_create(user=user)\n\n return Response(status=200, data={\n 'token': token.key,\n 'user': UserSerializer(user).data\n })\n\n\n@api_view(http_method_names=[\"POST\"])\ndef logout(request):\n Token.objects.filter(user=request.user).delete()\n return Response(status=200, data={\"success\": True})\n\n\n@api_view(http_method_names=[\"GET\"])\n@permission_classes([permissions.IsAuthenticated])\ndef get_user(request):\n data = UserSerializer(request.user).data\n return Response(status=200, data=data)\n\n\n@api_view(http_method_names=[\"GET\"])\n@permission_classes([permissions.IsAuthenticated, permissions.IsAdminUser])\ndef get_all_users(request):\n data = UserSerializer(request.user).data\n return Response(status=200, data=data)\n\n\n@api_view(http_method_names=[\"PUT\", \"PATCH\"])\n@permission_classes([permissions.IsAuthenticated])\ndef update_user(request):\n \"\"\"Update user first_name, last_name, email\"\"\"\n user = request.user\n\n # Explicit is better than implicit\n if request.data.get(\"first_name\"):\n user.first_name = request.data.get(\"first_name\")\n\n if request.data.get(\"last_name\"):\n user.last_name = request.data.get(\"last_name\")\n\n if request.data.get(\"email\"):\n user.email = request.data.get(\"email\")\n\n user.save()\n\n serializer = UserSerializer(instance=user)\n return Response(status=200, data=serializer.data)\n\n\n@api_view(http_method_names=[\"POST\"])\n@permission_classes([permissions.IsAuthenticated])\ndef change_password(request):\n \"\"\"Change user password!\"\"\"\n old_password = request.data.get(\"old_password\")\n new_password = request.data.get(\"new_password\")\n\n if not old_password:\n raise serializers.ValidationError(\n {\"old_password\": [\"old_password is required\"]})\n\n if not new_password:\n raise serializers.ValidationError(\n {\"new_password\": [\"new_password is required\"]})\n\n user = authenticate(username=request.user.username, password=old_password)\n\n if not user:\n raise serializers.ValidationError(\n {\"old_password\": [\"old_password is invalid!\"]})\n\n user.set_password(new_password)\n user.save()\n\n return Response(status=200, data=UserSerializer(user).data)\n\n\n@api_view(http_method_names=[\"POST\"])\n@permission_classes([permissions.AllowAny])\ndef reset_password(request):\n \"\"\"\n Sends a password reset email that expires in 30 minutes.\n \"\"\"\n\n email = request.data.get(\"email\")\n user = get_object_or_404(User, email=email)\n subject = request.data.get(\"subject\", \"Password Reset email\")\n\n try:\n sent = send_reset_email(request, user, subject)\n if sent:\n return Response(status=200, data={\"message\": \"Password reset email sent successfully!\"})\n else:\n return Response(status=400, data={\"message\": \"Unable to send email!\"})\n except Exception as e:\n return Response(status=500, data={\"message\": \"Internal server error\"})\n\n\n@api_view(http_method_names=[\"POST\", \"GET\"])\n@permission_classes([permissions.AllowAny])\n@authentication_classes([])\ndef reset_password_confirmation(request, uidb64, token):\n user = get_user_from_base64(uidb64)\n\n if request.method == 'POST':\n # Post request to change password\n\n if not user:\n return Response(status=404, data={\"error\": \"Invalidate user token!\"})\n\n password = request.data.get(\"password\", \"\")\n\n if len(password) < 8:\n raise serializers.ValidationError(\n \"Password should be at least 8 characters\")\n\n if PasswordResetTokenGenerator().check_token(user, token):\n user.set_password(password)\n user.last_login = timezone.localtime()\n user.save()\n token, _ = Token.objects.get_or_create(user=user)\n\n return Response({\n \"user\": UserSerializer(user).data,\n \"token\": token.key,\n })\n\n return Response(status=403, data={\"message\": \"Password reset token has expired!\"})\n else:\n # GET Requests when user click email link\n if not user:\n return HttpResponse(\"Invalid password reset token!\")\n\n context = {\n \"user\": user,\n \"site_name\": settings.DRF_AUTH_SETTINGS[\"SITE_NAME\"]\n }\n\n return render(request, \"drf_auth/password_change_form.html\", context=context)\n\n\ndef get_user_from_base64(uidb64):\n try:\n # urlsafe_base64_decode() decodes to bytestring\n uid = urlsafe_base64_decode(uidb64).decode()\n user = User._default_manager.get(pk=uid)\n except (TypeError, ValueError, OverflowError, User.DoesNotExist, ValidationError):\n user = None\n\n return user\n"
},
{
"alpha_fraction": 0.640026330947876,
"alphanum_fraction": 0.6446307897567749,
"avg_line_length": 19.20265769958496,
"blob_id": "d44e91332c436cdd5913d721b8d53f250528d287",
"content_id": "7cbf5c815d5dca1ae0163de8e74ee4dd12e60fd0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6081,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 301,
"path": "/README.md",
"repo_name": "abiiranathan/drf-authtoken",
"src_encoding": "UTF-8",
"text": "# drf-auth\n\nPainless token authentication for django restframework. Built on top of rest_framework.auth_token. It's meant to provide a ready to use authentication for your **SPAs** and other **Mobile Apps**\n\n[](https://travis-ci.com/abiiranathan/drf-authtoken)\n\n\n## Installation\n```bash \n\npip install drf-restauth\n\n```\n\n## Homepage\nThe project homepage on: [Github](https://github.com/abiiranathan/drf-authtoken)\n\n\n### Usage\n```python\nINSTALLED_APPS=[\n 'rest_framework',\n 'rest_framework.authtoken',\n 'drf_auth'\n]\n```\n\nConfigure project urls.py:\n\nSubsequent examples assume, you are using \"/api/auth/ as the path prefix.\n\n```python\nurlpatterns = [\n path(\"api/auth/\", include(\"drf_auth.urls\"))\n]\n\n# settings.py\n\nREST_FRAMEWORK = {\n 'DEFAULT_RENDERER_CLASSES': [\n 'rest_framework.renderers.JSONRenderer',\n ],\n 'DEFAULT_AUTHENTICATION_CLASSES': [\n 'rest_framework.authentication.TokenAuthentication'\n ],\n 'DEFAULT_PERMISSION_CLASSES': [\n 'rest_framework.permissions.IsAuthenticated'\n ]\n}\n\n# drf-specific settings for password reset\n\nDRF_AUTH_SETTINGS = {\n \"SITE_NAME\": \"My Site Title\",\n \"PASSWORD_RESET_REDIRCT_URL\": \"/\",\n \"PASSWORD_CHANGE_TEMPLATE\": \"drf_auth/password_change_form.html\",\n \"EMAIL_HOST_USER\": \"[email protected]\",\n \"EMAIL_HOST_PASSWORD\": \"yourpassword\",\n \"EMAIL_HOST\": \"smtp.gmail.com\",\n \"EMAIL_PORT\": 587,\n}\n\n```\n\n**These settings can be ignored if you don't plan to do password reset by email!**\n\nEndpoints:\n\n1. ```/POST api/auth/register/```\n\n\n```json\n{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n}\n\nresponse:{\n \"token\": \"string\",\n \"user\":{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n }\n}\n```\n\n2. ```/POST api/auth/login/```\n \n```json\nbody:\n{\n \"username\": \"string\",\n \"password\":\"string\"\n}\n\nresponse:{\n \"token\": \"string\",\n \"user\":{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n }\n}\n```\n\n3. ```/POST api/auth/logout/```\n```\nbody: null\nresponse:{\n \"success\": true\n}\n```\n\n4. ```/GET api/auth/user/ (Protected Route)```\n\n```json\nresponse:\n{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n}\n```\n\n5. ```GET /api/auth/users (Protected route, must be admin)```\n- Retrieves a json array of all users unpaginated\n\n6. ```/api/auth/update-user/ (Protected route)```\n\n```json\n\nbody:{\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n}\n\nresponse:\n{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n}\n\n```\n\n7. ```POST /api/auth/change-password/ (Protected route)```\n\n```json\n\nbody:{\n \"old_password\":\"string\",\n \"new_password\": \"string\",\n}\n\nresponse:\n{\n \"username\": \"string\",\n \"password\":\"string\",\n \"email\":\"string\",\n \"first_name\": \"string\",\n \"last_name\":\"string\"\n}\n\n```\n\n8. ```POST /api/auth/reset-password/```\n\nFor restting forgotten passwords. An email will be sent\nusing the settings provided in settings.DRF_AUTH_SETTINGS\ndictionary.\n\n```json\n\nbody:{\n \"email\":\"string\",\n}\n\nstatus: 200 - OK(Email sent)\nstatus: 400 - Email not sent\nstatus: 500 - Internal server error\n\nresponse:\n{\n \"message\": \"string\"\n}\n\n```\n\n### Handle user email confirmation\n\n9. ```/GET /api/auth/reset_password_confirmation/<uidb64>/<token>/\"\n\nThis route handles navigations/get requests when the user clicks the password reset link.\n\nFor a complete workflow, provide a template to render in DRF_AUTH_SETTINGS(see above) and make sure that\nthe new password is **POSTED** to the same route.\n\nThe following variables are passed to you in the context for customization:\n - user\n - site_name\n\n\n1. ```/POST /api/auth/reset_password_confirmation/<uidb64>/<token>/```\n\n**Note that the token expires after 30 minutes after the email is sent**\n\n```json\n\nbody:\n{\n \"password\": \"string\"\n}\n\n```\n\n### Required Headers\n- Authorization: Token xxxxxxxx (required for protected routes)\n- Content-Type: application/json\n- X-Requested-With: XMLHttpRequest (Desirable)\n\n### Practical examples using typescript\n\n```ts\nimport axios from \"axios\";\n\n\n// Add content-type header on every request\naxios.interceptors.request.use(function (config) {\n const token = localStorage.getItem(\"token\");\n\n if (token) {\n config.headers.Authorization = `Token ${token}`;\n }\n\n config.headers[\"Content-Type\"] = \"application/json\";\n return config;\n});\n\nconst handleLogin = async (username:string, password:string)=>{\n const body = JSON.stringify({\n username,\n password\n });\n\n const res = await axios.post(\"/api/auth/login/\", body);\n const {user, token} = res.data;\n\n localStorage.setItem(\"token\", token);\n localStorage.setItem(\"user\", JSON.stringify(user));\n}\n\ninterface User{\n username:string,\n first_name:string,\n last_name:string,\n password:string,\n email:string\n}\n\nconst handleRegister = async (user:User):Promise<User> =>{\n const body = JSON.stringify(user);\n\n const res = await axios.post(\"/api/auth/login/\", body);\n const {user, token} = res.data;\n\n localStorage.setItem(\"token\", token);\n localStorage.setItem(\"user\", JSON.stringify(user));\n return user\n}\n\ntype LogoutResponse = {\n success: boolean\n}\n\nconst handleLogout = ():Promise<LogoutResponse>=>{\n const res = await axios.post(\"/api/auth/logout/\", null)\n return res.data\n}\n\nconst getLoggedInUser = ():Promise<User>=>{\n const res = await axios.get(\"/api/auth/user/\")\n return res.data\n}\n```\n\nSubmit an issue at [Github](https://github.com/abiiranathan/drf-authtoken/issues \"Click to submit an issue\")\n\nFeel free to add your voice but be gentle, this is my first open source Django package!\n"
}
] | 6 |
AdrianE92/DnD_Combat
|
https://github.com/AdrianE92/DnD_Combat
|
a7982f5608ee1c1160603db04bd2439d8dce84ed
|
b99d9b928126b315854a6acce4668fee61b3ea16
|
1479a3f35423c75df8f7d2e17bd1a97b5c4c4dcb
|
refs/heads/master
| 2021-01-02T10:33:32.702568 | 2020-02-10T18:19:17 | 2020-02-10T18:19:17 | 239,580,159 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4686567187309265,
"alphanum_fraction": 0.47940298914909363,
"avg_line_length": 29.472726821899414,
"blob_id": "889151a2bdc9a42e6a75ec28530bf0f9cd1881f6",
"content_id": "a4cf2783f86f97f50a9466492bc2ce7c3e6f2fc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1675,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 55,
"path": "/monster.py",
"repo_name": "AdrianE92/DnD_Combat",
"src_encoding": "UTF-8",
"text": "import os\n\ndef create_monster(name, hp, ac, stats, spells, spell_slots):\n \"\"\"\n Params:\n name(str)\n hp(int)\n ac(int)\n stats(dict of str:int)\n spells(dict of str:str)\n spell_slots(dict of str:int)\n \"\"\"\n if type(name) != str:\n print(\"Name must be a string\")\n return ValueError\n\n monster = {\"Name\": name,\n \"HP\": hp,\n \"AC\": ac,\n \"Stats\": stats,\n \"Spells\": spells,\n \"Spell_Slots\": spell_slots}\n path = \"C:\\\\DnD_Combat\\\\monster_list\"\n \n if (monster[\"Name\"] + \".mon\") in os.listdir(path):\n print(\"works\") \n return 0\n \n return monster\n\ndef update_monster(monster, values):\n \"\"\"\n Update values based on which is recieved\n \"\"\"\n return monster\n\nif __name__ == \"__main__\":\n values = {\"Name\", \"HP\", \"AC\", \"Stats\", \"Spells\", \"Spell_Slots\"}\n stats = {\"strength\": 1,\n \"dex\": 2,\n \"con\": 3,\n \"intelligence\": 4,\n \"wis\": 5,\n \"charisma\": 6}\n monster = create_monster(\"Hei\", 5, 25, stats, {\"One spell\": \"All spells\"}, 0)\n #print((stat, monster[\"Stats\"][stat]) for stat in monster[\"Stats\"])\n \"\"\"\n for stat in monster[\"Stats\"]:\n print(stat, monster[\"Stats\"][stat])\n monster2 = create_monster(\"Spellcaster\", 10, 10, {\"Fireball\": \"Fireball Description\",\n \"Wall of Fire\": \"Wall of Fire Description\",\n \"Blink\": \"Blink Description\"}, 0)\n print(monster2[\"Spells\"][\"Blink\"])\n print(monster[\"Spells\"])\n \"\"\""
},
{
"alpha_fraction": 0.5501205921173096,
"alphanum_fraction": 0.5521873831748962,
"avg_line_length": 26.657142639160156,
"blob_id": "b4835fb689dbb22c53e33b66406ca9625792c469",
"content_id": "611a47b7148d0f2ee230c0950d336203244633a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2903,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 105,
"path": "/combat_app.py",
"repo_name": "AdrianE92/DnD_Combat",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request\nfrom monster import create_monster, update_monster\nimport os\napp = Flask(__name__)\n\"\"\"\nTo implement:\n- Initiative:\n - Order\n- Monsters:\n - Create monster\n - Health\n - Skills\n- Function for saving default\n- ???\n- Profit!\n\"\"\"\npath = \"C:\\\\DnD_Combat\\\\monster_list\"\n\[email protected](\"/\")\ndef home():\n return render_template('home.html')\n\[email protected](\"/combat\", methods=['GET', 'POST'])\ndef combat():\n return render_template('combat.html')\n\[email protected](\"/monsters\", methods=['GET', 'POST'])\ndef monsters():\n \"Path to folder\"\n \"Create list of stored monsters\"\n\n return render_template('monsters.html', mon_list=os.listdir(path))\n\[email protected](\"/new_monster\", methods=['GET', 'POST'])\ndef new_monster():\n \"\"\"\n monster = create_monster(request.form['name'], request.form['hp'], \n request.form['ac'], request.form['stats'], \n request.form['spells'], request.form['spell_slots'])\n\n \"\"\"\n return render_template('new_monster.html')\n\[email protected](\"/cre_mon\", methods=['GET', 'POST'])\ndef cre_mon():\n\n name = request.form.get(\"name\")\n hp = request.form.get(\"hp\")\n ac = request.form.get(\"ac\")\n strength = request.form.get(\"str\")\n dex = request.form.get(\"dex\")\n con = request.form.get(\"con\")\n intelligence = request.form.get(\"int\")\n wis = request.form.get(\"wis\")\n charisma = request.form.get(\"char\")\n\n stats = {\"strength\": strength,\n \"dex\": dex,\n \"con\": con,\n \"intelligence\": intelligence,\n \"wis\": wis,\n \"charisma\": charisma}\n\n spells = {\"Fireball\": \"Fireball Description\",\n \"Wall of Fire\": \"Wall of Fire Description\",\n \"Blink\": \"Blink Description\"}\n\n spell_slots = 0\n monster = create_monster(name, hp, ac, stats, spells, spell_slots)\n if monster == 0:\n return render_template('monsters')\n else:\n #Create new monster\n f = open(os.path.join(path, (monster[\"Name\"] + \".mon\")), 'w')\n f.write(monster[\"Name\"])\n f.write('\\n')\n f.write(\"HP:\" + monster[\"HP\"])\n f.write('\\n')\n f.write(\"Armor Class:\" + str(monster[\"AC\"]))\n f.write('\\n')\n f.write(\"Stats: \")\n f.write('\\n')\n for stat in monster[\"Stats\"]:\n f.write(stat)\n f.write(str(monster[\"Stats\"][stat]))\n f.write('\\n')\n for spell in monster[\"Spells\"]:\n f.write(spell)\n f.write(\": \")\n f.write(monster[\"Spells\"][spell])\n f.write(\"\\n\")\n \n f.write('\\n')\n f.write(str(spell_slots)) \n f.close()\n \n return render_template('monsters.html', mon_list=os.listdir(path))\n\[email protected](\"/help\")\ndef help():\n return render_template('help.html')\n\n\nif __name__ == '__main__':\n app.run(port=5001, debug=True)"
},
{
"alpha_fraction": 0.5181236863136292,
"alphanum_fraction": 0.5287846326828003,
"avg_line_length": 26.647058486938477,
"blob_id": "0dcf73a559440595067d05b7a496fb05390aeb87",
"content_id": "cae39428fa5db94bde2d66a028a23ba1b91ee518",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 17,
"path": "/templates/help.html",
"repo_name": "AdrianE92/DnD_Combat",
"src_encoding": "UTF-8",
"text": "<!-- ./templates/help.html -->\n<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <meta charset=\"utf-8\"/>\n <h1>Diabetes correlation charts</h1>\n <a href=\"/\">Home</a>\n <a href=\"/default_chart\">Charts</a>\n <a href=\"/help\">Help</a>\n </head>\n <body>\n <h1>Want to look at the documentation?</h1>\n <a href=\"/data_help\">data.py</a>\n <a href=\"/fit_help\">fitting.py</a>\n <a href=\"/vis_help\">visualize.py</a>\n </body>\n</html>"
},
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.807692289352417,
"avg_line_length": 25,
"blob_id": "c770a40e95da4e39b6231eb96969bb5f0a3f2027",
"content_id": "cf7e870aeb0c190c8bfc1ff224bdac5b37fa22ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AdrianE92/DnD_Combat",
"src_encoding": "UTF-8",
"text": "# DnD_Combat\nCombat helper for Dungeons and Dragons\n"
}
] | 4 |
daftspaniel/pyweek27
|
https://github.com/daftspaniel/pyweek27
|
7ed40544da583dd7a49817c1fb64b268a0c72ef3
|
fa281cdbd70a2dd30b8d9d94565e04fc86e3e554
|
cb00a779e7e7f364eb287f932fc97fd4d7d1a3b9
|
refs/heads/master
| 2021-10-24T09:39:01.371031 | 2019-03-24T18:00:48 | 2019-03-24T18:00:48 | 177,335,268 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7213114500045776,
"alphanum_fraction": 0.7213114500045776,
"avg_line_length": 14.25,
"blob_id": "f8d9dcd8eab762d5104300c1223a12385535af76",
"content_id": "be28b15b1fdd76d6fde49240cf4abc8248f301b6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 4,
"path": "/run_game.py",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": " #! /usr/bin/env python\n\nfrom gamelib import main\nmain.main()"
},
{
"alpha_fraction": 0.6813880205154419,
"alphanum_fraction": 0.6908517479896545,
"avg_line_length": 21.64285659790039,
"blob_id": "3d38e414498d65d6d03854249fcbc508d3c398f8",
"content_id": "6dc2ca877843ca8a23c52103874b42d96d7973a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 317,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 14,
"path": "/gamelib/main.py",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": "from gamelib.lib.config import game_name, screen_size\nfrom gamelib.state.game import gameplay_main\nfrom gamelib.lib.util import init_pygame\n\n# Globals.\ngame_state = 1\nscreen = init_pygame(game_name, screen_size)\n\n\ndef main():\n while game_state != -1:\n\n if game_state == 1:\n gameplay_main(screen)\n"
},
{
"alpha_fraction": 0.5976676344871521,
"alphanum_fraction": 0.6107871532440186,
"avg_line_length": 28.826086044311523,
"blob_id": "d99f90d0424903e0de4d73f2aab3e8bc745a5fb5",
"content_id": "baa85b328476027ebb7756c8ddbbb57f865596c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 23,
"path": "/gamelib/lifeform/bug.py",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": "from gamelib.lib.cycle import loop_in_range, keep_in_range\nfrom gamelib.gfx.creatures import draw_bug\n\n\nclass Bug(object):\n def __init__(self, screen, x, y):\n self.screen = screen\n self.x = x\n self.y = y\n\n self.leg_up = 1\n self.eye_pos = 1\n\n def update(self):\n self.leg_up = loop_in_range(self.leg_up, 1, 6, 1)\n self.x = keep_in_range(self.x, self.contraints[0], self.contraints[1])\n self.y = keep_in_range(self.y, self.contraints[2], self.contraints[3])\n\n def draw(self):\n draw_bug(self.screen, self.x, self.y, self.leg_up, self.eye_pos)\n\n def constrain(self, constaints):\n self.contraints = constaints\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 9,
"blob_id": "81a52624cf3f24e6cb7e61b8d108c00f76beb5e0",
"content_id": "adf045bfa06a9453a1ab3a0affa0b158ecaa26e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20,
"license_type": "permissive",
"max_line_length": 10,
"num_lines": 2,
"path": "/README.md",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": "# pyweek27\npyweek27\n"
},
{
"alpha_fraction": 0.42456766963005066,
"alphanum_fraction": 0.4937388300895691,
"avg_line_length": 33.9375,
"blob_id": "fb6cd013d87bd4e817b400f9b2ab13a177a1187e",
"content_id": "bccabfacc906ec50dcd3da12877bbcece7267cf4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1677,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 48,
"path": "/gamelib/state/game.py",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": "import sys\nfrom gamelib.lifeform.bug import Bug\n\nfrom pygame.locals import *\nfrom gamelib.lib.util import *\n\nHORIZON = 100\n\n\ndef gameplay_main(screen):\n game_state = 1\n p1 = Bug(screen, 25, HORIZON + 15)\n p1.constrain((20, 780, HORIZON+15, 480))\n while game_state == 1:\n\n pygame.display.flip()\n\n for event in pygame.event.get():\n if event.type == pygame.QUIT:\n sys.exit()\n elif event.type == ANIMEVENT:\n screen.fill(pygame.Color(\"black\"))\n draw_background(screen)\n p1.draw()\n elif event.type == pygame.KEYDOWN:\n keystate = pygame.key.get_pressed()\n if keystate[K_d] == 1:\n p1.x += 1\n p1.eye_pos = 1\n p1.update()\n elif keystate[K_a] == 1:\n p1.x -= 1\n p1.eye_pos = 0\n p1.update()\n if keystate[K_w] == 1:\n p1.y -= 1\n p1.update()\n elif keystate[K_s] == 1:\n p1.y += 1\n p1.update()\n\n\ndef draw_background(screen):\n pygame.draw.polygon(screen, Color(2, 56, 2), [(0, HORIZON), (115, HORIZON - 15), (230, HORIZON)])\n pygame.draw.polygon(screen, Color(2, 50, 2), [(134, HORIZON), (215, HORIZON - 15), (630, HORIZON)])\n pygame.draw.polygon(screen, Color(2, 56, 2), [(534, HORIZON), (565, HORIZON - 15), (640, HORIZON)])\n pygame.draw.polygon(screen, Color(2, 56, 2), [(634, HORIZON), (666, HORIZON - 15), (796, HORIZON)])\n pygame.draw.line(screen, Color(2, 50, 44), (0, 500), (800, 500), 2)\n"
},
{
"alpha_fraction": 0.503367006778717,
"alphanum_fraction": 0.5774410963058472,
"avg_line_length": 33.94117736816406,
"blob_id": "4c3a34cf4e5f56d96d82fd652ac010b616de7ed9",
"content_id": "99876b9d61fb132b0c2f9b473d6e66290c24ad4f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 17,
"path": "/gamelib/gfx/creatures.py",
"repo_name": "daftspaniel/pyweek27",
"src_encoding": "UTF-8",
"text": "import pygame\nfrom pygame.locals import *\n\nbug_color = (25, 205, 25)\neye_color = (78, 219, 24)\n\n\ndef draw_bug(surface, x, y, short_leg, eye_pos):\n pygame.draw.rect(surface, bug_color, Rect(x, y, 18, 5), 0)\n\n for leg in range(6):\n leg_length = 6 if leg + 1 == short_leg else 8\n pygame.draw.line(surface, bug_color, (x + leg * 3, y + 5), (x + leg * 3, y + leg_length), 1)\n\n pygame.draw.rect(surface, eye_color, Rect(x + 15 * eye_pos, y - 2, 5, 5), 0)\n tail_pos = 1 if eye_pos == 0 else 0\n pygame.draw.rect(surface, (0, 0, 0), Rect(x + 15 * tail_pos, y - 2, 3, 3), 0)\n"
}
] | 6 |
neopostmodern/antiking-chess-statistics-tools
|
https://github.com/neopostmodern/antiking-chess-statistics-tools
|
6624f46cd810e997f3332177c83159f162b16e9d
|
68061757ad05bc491cb836d38a10c8a59ef288a2
|
f9bc897b9e6ccbf548026b99ed1c30d70cbecbef
|
refs/heads/master
| 2020-04-02T06:39:23.335487 | 2016-06-06T16:20:10 | 2016-06-06T16:20:10 | 60,480,901 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.660089910030365,
"alphanum_fraction": 0.6654595136642456,
"avg_line_length": 39.226131439208984,
"blob_id": "fafb77ea2dfad61c960ad567de9a5ddadd887b1b",
"content_id": "6b05d73fd1381d6f203725914c4b7e1d8e515db9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8008,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 199,
"path": "/statistics.py",
"repo_name": "neopostmodern/antiking-chess-statistics-tools",
"src_encoding": "UTF-8",
"text": "import argparse\nimport csv\nimport glob\nimport os\nimport numpy\nimport matplotlib.pyplot as plot\nimport shutil\n\n\ndef to_number(string):\n try:\n return float(string)\n except ValueError:\n return None\n\nfield_names = []\nOUTPUT_BASE_FOLDER = 'plots'\n\nparser = argparse.ArgumentParser(description='Analyze (and visualize) logs')\nparser.add_argument('directory', metavar='logs_directory', type=str, help='The folder containing the PlyMouth CSV logs')\nparser.add_argument('-v', '--verbose', action='store_true', help='Print verbose output')\nparser.add_argument('-i', '--interactive', action='store_true', help='Show figures in window before saving')\nparser.add_argument('-c', '--compact', action='store_true', help='Focus on significant part of figures (might exclude outliers)')\nparser.add_argument('unnamed_fields', metavar='unnamed_field', type=str, nargs='+', help='Names of unnamed fields (iteration-level)')\n\nargs = parser.parse_args()\n\nif not os.path.isdir(args.directory):\n print(\"Not a directory (or does not exist: %s\" % args.directory)\n exit(1)\n\nif not os.path.isdir(OUTPUT_BASE_FOLDER):\n os.mkdir(OUTPUT_BASE_FOLDER)\n\noutput_folder = OUTPUT_BASE_FOLDER\nif '/' in args.directory:\n output_folder = os.path.join(OUTPUT_BASE_FOLDER, args.directory.split('/')[-1])\n\nif os.path.isdir(output_folder):\n shutil.rmtree(output_folder)\nos.mkdir(output_folder)\n\nraw_data = []\ngame_lengths = []\nrow_lengths = []\n\nprint(\"Load data... \", end='')\nfor log_file_name in glob.glob(os.path.join(args.directory, '*.csv')):\n with open(log_file_name, newline='') as game_log_file:\n csv_reader = csv.reader(game_log_file, delimiter=';')\n\n header = True\n game_length = 0\n for row in csv_reader:\n if header:\n header = False\n if len(field_names) == 0:\n field_names = row\n else:\n assert field_names == row, \"Logs of differing format supplied, aborting.\"\n continue\n\n raw_data.append(row)\n row_lengths.append(len(row))\n game_length += 1\n\n game_lengths.append(game_length)\nprint(\"OK.\")\n\nmax_row_length = max(row_lengths)\nmaximum_game_length = max(game_lengths)\niteration_counts = numpy.bincount(row_lengths)[len(field_names)::len(args.unnamed_fields)][1:]\nmaximum_iterations = (max_row_length - len(field_names)) // len(args.unnamed_fields)\niteration_sizes = [sum(iteration_counts[iteration_index:]) for iteration_index in range(maximum_iterations)]\n\nif args.verbose:\n print(\"Read %d games (%d plies).\" % (len(game_lengths), len(raw_data)))\n print(\"> Game lengths:\", game_lengths)\n print(\"> Maximum game length:\", maximum_game_length)\n print(\"> Maximum row length: %d\" % max_row_length)\n print(\"> Number of named fields: %d\" % len(field_names), field_names)\n print(\"> Number of unnamed fields (per iteration): %d\" % len(args.unnamed_fields), args.unnamed_fields)\n print(\"> Maximum iterations: %d\" % maximum_iterations)\n print(\"> Iteration counts:\", list(iteration_counts), iteration_sizes)\n\nply_data = numpy.ndarray((len(raw_data), len(field_names) + 1), dtype=numpy.float)\n\nprint(\"Processing data... \", end='')\niteration_data = [numpy.zeros((iteration_size, len(args.unnamed_fields)), dtype=numpy.float) for iteration_size in iteration_sizes]\nrunning_iteration_indices = numpy.zeros(maximum_iterations)\nfor row_index, row in enumerate(raw_data):\n # copy all ply-level fields\n ply_data[row_index, :len(field_names)] = [to_number(value) for value in row[:len(field_names)]]\n # very good approximate of total used time is in the last field, add to ply-level data\n ply_data[row_index, len(field_names)] = row[len(row) - 1]\n\n # print(row, len(row))\n for iteration_index in range(maximum_iterations):\n base_index = len(field_names) + iteration_index * len(args.unnamed_fields)\n if len(row) > base_index:\n iteration_data[iteration_index][running_iteration_indices[iteration_index]] = [\n to_number(value) for value in row[base_index:base_index + len(args.unnamed_fields)]\n ]\n running_iteration_indices[iteration_index] += 1\nprint(\"OK.\")\n\nprint(\"Create histograms for iterations... \", end='')\nmean = numpy.mean(game_lengths)\n\nplot.hist(game_lengths, bins=10, label=\"Game lengths\")\nplot.axvline(mean)\n#\nplot.savefig(\"%s/game_lengths.png\" % output_folder)\nif args.interactive:\n plot.show()\nplot.close()\nprint(\"OK.\")\n\nprint(\"Create plots for plies... \", end='')\nply_data = [ply_data[numpy.where(ply_data[:, 0] == ply_index + 1)] for ply_index in range(maximum_game_length)]\nply_indices = numpy.concatenate([ply_data[ply_index][:, 0] for ply_index in range(maximum_game_length)])\nfor field_name_index, field_name in enumerate(field_names):\n if field_name_index == 0: # ply index itself\n continue\n\n points = numpy.concatenate([ply_data[ply_index][:, field_name_index] for ply_index in range(maximum_game_length)])\n\n plot.title(field_name)\n plot.xlim([0, maximum_game_length + 1]) # one before and after\n plot.ylim([0, numpy.mean(points) + 3 * numpy.std(points)])\n plot.scatter(\n ply_indices,\n points,\n alpha=.2,\n c='r',\n edgecolors=''\n )\n mean = numpy.array([numpy.mean(ply_data[ply_index][:, field_name_index], axis=0) for ply_index in range(maximum_game_length)])\n std = numpy.array([numpy.std(ply_data[ply_index][:, field_name_index], axis=0) for ply_index in range(maximum_game_length)])\n\n plot.plot(range(1, maximum_game_length + 1), mean, color='b')\n plot.plot(range(1, maximum_game_length + 1), mean + std, color='g', alpha=.5)\n plot.plot(range(1, maximum_game_length + 1), mean - std, color='g', alpha=.5)\n plot.savefig(\"%s/%s.png\" % (output_folder, field_name.replace(' ', '_').lower()))\n if args.interactive:\n plot.show()\n plot.close()\nprint(\"OK.\")\n\n\nprint(\"Create combined graphs for unnamed fields per iterations... \", end='')\nplot.title(\"Per iteration\")\nplot.ylim([0, 2000])\nmeans = numpy.zeros([maximum_iterations, len(args.unnamed_fields)])\ncolors = ['b', 'g', 'r']\nfor iteration_index, iteration in enumerate(iteration_data):\n means[iteration_index] = numpy.ma.masked_invalid(iteration_data[iteration_index]).mean(0)\n\n for unnamed_field_index, unnamed_field in enumerate(args.unnamed_fields):\n plot.scatter(\n [iteration_index] * iteration.shape[0], # a list of the same X value\n iteration[:, unnamed_field_index], # actual data\n c=colors[unnamed_field_index], # stable colors\n edgecolors='',\n alpha=.1\n )\n\nfor unnamed_field_index, unnamed_field in enumerate(args.unnamed_fields):\n plot.plot([mean[unnamed_field_index] for mean in means], label=unnamed_field, c=colors[unnamed_field_index])\n\nplot.legend()\nplot.savefig(\"%s/per-iteration.png\" % output_folder)\nif args.interactive:\n plot.show()\nplot.close()\nprint(\"OK.\")\n\nprint(\"Create histograms for iterations... \", end='')\nfor unnamed_field_index, unnamed_field in enumerate(args.unnamed_fields):\n plot.title(unnamed_field)\n bins = numpy.linspace(\n min([numpy.min(iteration_data[iteration_index][:, unnamed_field_index]) for iteration_index in range(maximum_iterations)]),\n max([numpy.max(iteration_data[iteration_index][:, unnamed_field_index]) for iteration_index in range(maximum_iterations)]),\n 100\n )\n for iteration_index in range(maximum_iterations):\n # print(numpy.mean(iteration_data[iteration_index], axis=0))\n mean = numpy.mean(iteration_data[iteration_index], axis=0)[unnamed_field_index]\n\n plot.hist(iteration_data[iteration_index][:, unnamed_field_index], bins, label=(\"Iteration %d\" % iteration_index))\n plot.axvline(mean)\n\n plot.savefig(\"%s/%s.png\" % (output_folder, unnamed_field.replace(' ', '_').lower()))\n if args.interactive:\n plot.show()\n plot.close()\nprint(\"OK.\")\n\nprint(\"Goodbye.\")\n\n\n\n"
},
{
"alpha_fraction": 0.6116207838058472,
"alphanum_fraction": 0.6116207838058472,
"avg_line_length": 37.411766052246094,
"blob_id": "229a0cf2207eec55aae51b5fe69d9b9f58f1a962",
"content_id": "e2e7f07c723c64818ee7130ccb31312089e93974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 17,
"path": "/README.md",
"repo_name": "neopostmodern/antiking-chess-statistics-tools",
"src_encoding": "UTF-8",
"text": "# antiking-chess-statistics-tools\n\n usage: statistics.py [-h] [-v] [-i] [-c]\n logs_directory unnamed_field [unnamed_field ...]\n\n Analyze (and visualize) logs\n\n positional arguments:\n logs_directory The folder containing the PlyMouth CSV logs\n unnamed_field Names of unnamed fields (iteration-level)\n\n optional arguments:\n -h, --help show this help message and exit\n -v, --verbose Print verbose output\n -i, --interactive Show figures in window before saving\n -c, --compact Focus on significant part of figures (might exclude\n outliers)\n\n"
}
] | 2 |
snauhaus/orm_sqlite
|
https://github.com/snauhaus/orm_sqlite
|
af50dff0d1e41c0a3c537c2514a1bf5488c1dec2
|
75d2df5050b790f8a5e635d07bd45b426859d7c5
|
a7957f11fca60d3fe66102341ade08d7dc07c472
|
refs/heads/main
| 2023-05-03T13:53:23.496667 | 2021-05-14T18:25:58 | 2021-05-14T18:25:58 | 366,502,790 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5541217923164368,
"alphanum_fraction": 0.5598774552345276,
"avg_line_length": 28.756906509399414,
"blob_id": "a67e79bdef048fb198a54b27dfc664900c27eb5f",
"content_id": "7c2962552c9a50ab94b9e0ea7460e76d028e12c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10772,
"license_type": "permissive",
"max_line_length": 185,
"num_lines": 362,
"path": "/orm_sqlite.py",
"repo_name": "snauhaus/orm_sqlite",
"src_encoding": "UTF-8",
"text": "import os\nimport sqlite3\nimport progressbar\nimport subprocess\nimport zipfile, zlib\nimport csv\nimport pandas as pd\nimport numpy\nimport glob\n\n\n\nclass orm_sqlite(object):\n \"\"\"\n An object for easy interaction with an SQLite database\n\n Primarily meant for a db holding text articles\n\n \"\"\"\n def __init__(self, file_name):\n super(dbORM, self).__init__()\n self.__name__ = file_name\n\n\n def connect(self, check_packed=True):\n \"\"\"Connect to a database.\n Creates connection object (con) and cursor (c)\n\n \"\"\"\n self.con = sqlite3.connect(self.__name__)\n self.c = self.con.cursor()\n\n def close(self):\n \"\"\"Close database connection\"\"\"\n self.c.close()\n\n def execute(self, command, commit=False):\n \"\"\"Execute a command\n\n \"\"\"\n self.c.execute(command)\n if commit:\n self.commit()\n\n def commit(self):\n \"\"\"Commit to database\n\n \"\"\"\n self.con.commit()\n\n def fetch(self, what = \"all\", size=None):\n \"\"\"Fetch data from database.\n What can be \"ALL\", \"MANY\", or \"ONE\". Defaults to ALL\n\n \"\"\"\n if what.upper() == \"ALL\":\n return self.c.fetchall()\n elif what.upper() == \"MANY\":\n if size is not None:\n return self.c.fetchmany(size)\n else:\n return self.c.fetchmany()\n elif what.upper() == \"ONE\":\n return self.c.fetchone()\n else:\n print(\"what must be element of 'all', 'many' or 'one'.\")\n\n def drop_table(self, table_name):\n \"\"\"\n Shorthand for dropping a table.\n Be careful with this.\n\n \"\"\"\n cmd=\"DROP TABLE {}\".format(table_name)\n self.execute(cmd)\n self.commit()\n\n\n \"\"\"\n Miscellaneous functions\n\n \"\"\"\n\n def read_text(self, file):\n \"\"\"\n Read a text file from disk\n\n \"\"\"\n file_con = open(file, 'r')\n text = file_con.read()\n return str(text)\n\n\n \"\"\"\n Adding new tables\n\n \"\"\"\n\n def create_table(self, table, col_names, col_types=None, col_constraints=None, other_args=None, overwrite=False):\n \"\"\"\n Create a table in the database\n\n table (name) must be provided\n col_names must be provided\n col_types defaults to TXT\n col_constraints defaults to \"\"\n other_args to add additional arguments\n\n Example usage:\n\n db.create_table('Sentiments', col_names = [\"File\", \"Paragraph\", \"Text\", \"Sentiment\"], col_types = [\"TXT\", \"INT\", \"TXT\", \"INT\"], other_args = \"PRIMARY KEY (File, Paragraph)\")\n\n \"\"\"\n if overwrite and table in self.list_tables():\n self.drop_table(table)\n ncols = len(col_names)\n if col_types is None:\n col_types = list(numpy.repeat(\"TXT\", ncols))\n if col_constraints is None:\n col_constraints = list(numpy.repeat(\"\", ncols))\n query = [' '.join([cn, cp, cc]) for cn, cp, cc in zip(col_names, col_types, col_constraints)]\n query = \"CREATE TABLE {} (\".format(table) + ', '.join(query)\n if other_args is not None:\n query = ', '.join([query, other_args])\n query = query + \")\"\n self.execute(query)\n self.commit()\n\n def insert_pandas(self, table, df, overwrite=False):\n \"\"\"Inserts Pandas DataFrame object to a new or existing table\n\n Use create_table() first if column flags or so need to be set.\n\n If overwrite is True, overwrites existing table\n \"\"\"\n if overwrite:\n try:\n self.drop_table(table)\n except:\n print(\"No existing table found\")\n df.to_sql(table, self.con, if_exists='append', index = False)\n\n def insert_text_files(self, table, files_path, overwrite=False):\n \"\"\"Adds all txt files in given directory into a new table\n in the database, using the file name as ID\n\n table = name of new table where to add the files\n files_path = directory with text files\n\n Returns nothing\n\n \"\"\"\n cols=[\"File\", \"Text\"]\n p=files_path\n if overwrite:\n try:\n self.drop_table(table)\n except:\n print(\"No existing table found\")\n prim_key=\"PRIMARY KEY (File)\"\n self.create_table(table=table, col_names=cols, other_args=prim_key)\n all_files=os.listdir(p)\n txt_files=[(f,os.path.join(p,f)) for f in all_files if \".TXT\" in f.upper()]\n df = pd.DataFrame([(f[0], self.read_text(f[1])) for f in txt_files], columns=cols)\n self.insert_pandas(table, df)\n\n\n def insert_csv(self, table, csv_file, overwrite=False):\n \"\"\"Add CSV file to a table in the database\n\n Use create_table() first if column flags or so need to be set.\n \"\"\"\n df = pd.read_csv(csv_file)\n self.insert_pandas(table, df, overwrite=overwrite)\n\n\n \"\"\"\n Selecting data\n\n \"\"\"\n\n def select(self, table, fetch=None, arguments=None):\n \"\"\"Select query to table\n\n What defaults to all ('*')\n\n Fetch is optional, can be either 'all', 'first' or 'many'\n\n Optional arguments can be passed via `arguments`\n\n Returns nothing if fetch is None (default)\n \"\"\"\n query = 'SELECT * FROM {}'.format(table)\n if arguments is not None:\n query = query + \" \" + arguments\n self.execute(query)\n if fetch is not None:\n res = self.fetch(fetch)\n return res\n\n def select_query(self, query):\n \"\"\"Send full select query to database and return results\"\"\"\n self.execute(query)\n result = self.fetch()\n return result\n\n def select_where(self, table, condition):\n \"\"\"Select * where condition is met\"\"\"\n query = 'SELECT * FROM {} WHERE {}'.format(table, condition)\n self.execute(query)\n result = self.fetch()\n return result\n\n def select_like(self, table, where, like):\n \"\"\"Select entire table where a specific column contains text\"\"\"\n cmd=\"SELECT * FROM {} WHERE {} LIKE '%{}%'\".format(table, where, like)\n self.execute(cmd)\n result = self.fetch()\n return result\n\n def select_articles(self, like):\n \"\"\"Get articles where text contains like\n Shorthand for select_like\n \"\"\"\n result = self.select_like(table='Documents', where='Text', like=like)\n return result\n\n def get_pandas(self, table, columns=\"*\", arguments=None, chunksize=None):\n \"\"\"Return a database table as pandas dataframe\n\n Optional arguments can be passed via `arguments`\n \"\"\"\n if type(columns) is list: columns=','.join(columns)\n query = \"SELECT {} FROM {}\".format(columns, table)\n if arguments is not None:\n query = query + \" \" + arguments\n df = pd.read_sql_query(query, self.con, chunksize=chunksize)\n return df\n\n \"\"\"\n Database info / statistics\n\n \"\"\"\n\n def list_tables(self):\n \"\"\"List tables in database\n\n Returns list\n \"\"\"\n query=\"SELECT name FROM sqlite_master WHERE type='table';\"\n self.execute(query)\n output = self.fetch()\n tables = [t[0] for t in output]\n return tables\n\n def list_columns(self, table):\n \"\"\"List columns in table\n\n \"\"\"\n query='PRAGMA TABLE_INFO({})'.format(table)\n self.execute(query)\n output = self.fetch()\n columns = [tup[1] for tup in output]\n return columns\n\n def pragma(self, table):\n \"\"\"Full pragma output for table\n\n Prints table with column information\n (id, name, type, notnull, default_value, primary_key)\n\n Returns nothing\n \"\"\"\n query='PRAGMA TABLE_INFO({})'.format(table)\n self.execute(query)\n output = self.fetch()\n info = [list(tup) for tup in output]\n print(\"\\nColumn Info:\\n{:10s}{:25s}{:10s}{:10s}{:12s}{:10s}\"\\\n .format(\"ID\", \"Name\", \"Type\", \"NotNull\", \"DefaultVal\", \"PrimaryKey\"))\n for col in info:\n print_text=tuple(str(t) for t in col)\n print('{:10s}{:25s}{:10s}{:10s}{:12s}{:10s}'.format(*print_text))\n\n def column_info(self, table):\n \"\"\"Summary information for columns in table\n\n Prints table with some pragma information plus actual not null count\n\n Returns nothing\n \"\"\"\n query = 'PRAGMA TABLE_INFO({})'.format(table)\n self.execute(query)\n info = self.fetch()\n info = [list(i)[0:3] for i in info] # Only ID, Name, Type\n columns = [i[1] for i in info] # Extract columns\n for i, col in enumerate(columns):\n count = self.count_notnull(col, table)\n info[i].append(count)\n print(\"\\nColumn Info:\\n{:10s}{:25s}{:10s}{:10s}\"\\\n .format(\"ID\", \"Name\", \"Type\", \"NotNull\"))\n for col in info:\n print_text=tuple(str(t) for t in col)\n print('{:10s}{:25s}{:10s}{:10s}'.format(*print_text))\n\n def count(self, column, table):\n \"\"\"Count number of rows\n\n returns int\n\n \"\"\"\n query = \"SELECT COUNT({}) FROM {}\".format(column, table)\n self.execute(query)\n count = self.fetch()\n return int(count[0][0])\n\n def count_where(self, column, table, condition):\n \"\"\"count rows where condition is met\"\"\"\n query = \"SELECT COUNT({}) FROM {} WHERE {}\".format(column, table, condition)\n self.execute(query)\n count = self.fetch()\n return int(count[0][0])\n\n def count_distinct(self, column, table):\n \"\"\"Count distinct entries\n\n Returns int\n \"\"\"\n query = \"SELECT COUNT(DISTINCT {}) FROM {}\".format(column, table)\n self.execute(query)\n count = self.fetch()\n return int(count[0][0])\n\n def count_notnull(self, what, where):\n \"\"\"Count non-null entries in column\n\n Returns int\n \"\"\"\n query='SELECT COUNT({0}) FROM {1} WHERE {0} IS NOT NULL'.format(what, where)\n self.execute(query)\n count = self.fetch()\n return int(count[0][0])\n\n def count_like(self, what, where, like):\n \"\"\"Count number of rows containing text (`like`)\n\n Returns int\n \"\"\"\n cmd=\"SELECT COUNT({}) FROM {} WHERE {} LIKE '%{}%'\".format(what, where, what, like)\n self.execute(cmd)\n count =self.fetch()\n return count[0][0]\n\n def count_articles(self, like):\n \"\"\"Count articles matching text (`like`)\n\n Shorthand function for count_like() with what='Text' and\n where='documents'\n\n Returns int\n \"\"\"\n result = self.count_like(like=like, what=\"Text\", where=\"Documents\")\n return result\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 31.5,
"blob_id": "65e82a76570642f5789a353c93bb638cf8af0b80",
"content_id": "751d212e32b2dc51bddc3308f1a8a5a703ad294c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 2,
"path": "/README.md",
"repo_name": "snauhaus/orm_sqlite",
"src_encoding": "UTF-8",
"text": "# orm_sqlite\nA basic ORM for interacting with an SQLite database\n"
}
] | 2 |
dayelu/c_learning
|
https://github.com/dayelu/c_learning
|
e8b03efc2a98fe222e8938230accb08fbc299886
|
643493d3cd708222ca4157a7797a307d1bb2408d
|
3557ef794b7d7fb5481a11a686dbbed4d4623c6a
|
refs/heads/master
| 2020-05-18T13:07:28.616894 | 2019-10-23T15:00:57 | 2019-10-23T15:07:28 | 184,429,093 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5577889680862427,
"alphanum_fraction": 0.5653266310691833,
"avg_line_length": 23,
"blob_id": "8a6fdef8629700e1df7f3088abe1dad81102d428",
"content_id": "18bb92ab10520e695060145a784ca4f28287860c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 16,
"path": "/c_basic/code/basic/strfuncs/sizeofstrlen.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar hi[] = {\"long time no see.\"};\r\n\tchar h[] = \"long time no see.\";\r\n\tprintf(\"%s\\n\", hi);\r\n\tprintf(\"%s\\n\", h);\r\n\tchar hello[10];\r\n\t// hello = \"good morning?\";\r\n\tchar *str;\r\n\tstr = \"how are you?\";\r\n\tprintf(\"The sizeof str is: %d\\n\", sizeof str); \r\n\tprintf(\"The strlen(str) is: %d\\n\", strlen(str)); \r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4869976341724396,
"alphanum_fraction": 0.4893617033958435,
"avg_line_length": 11.709677696228027,
"blob_id": "45432a663e58d6d0642e178246e1b922c633572c",
"content_id": "010d9fdb26cca2ba2b0fa5cea7c09305dc082435",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 441,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/c_basic/code/nbio/chari.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"demo.txt\";\r\n\tFILE *pfile = fopen(filename,\"r\");\r\n\tint ch;\r\n\r\n\twhile( (ch = fgetc(pfile)) != EOF )\r\n\t{\r\n\r\n\t\tprintf(\"%c\", ch);\r\n\t}\r\n\r\n\tprintf(\"\\n\");\r\n\r\n\tprintf(\"请输入一个字符串:\\n\");\r\n\r\n\tint chs;\r\n\twhile( (chs = getchar()) != EOF)\r\n\t{\r\n\t\tif (chs == '@')\r\n\t\t{\r\n\t\t\tbreak;\r\n\t\t}\r\n\t\tprintf(\"%c\", chs);\r\n\t}\r\n\tprintf(\"\\n\");\r\n\tfclose(pfile);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.554973840713501,
"alphanum_fraction": 0.5575916171073914,
"avg_line_length": 32.90909194946289,
"blob_id": "11d7fa5967647f57f8b4015bfdc5b85b77fe11b8",
"content_id": "8ffd511ba0836df5c070436d718f169226083c13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 11,
"path": "/c_basic/code/basic/strfuncs/strlen2.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tconst char greet[] = \"hello,world!\";\r\n\t/* assignment of read-only location 'greet' [enabled by default] */\r\n\t//greet = \"你好,世界!\";\r\n\tchar hello[] = {'h','e','l','l','o',',','w','o','r','l','d','!'};\r\n\tprintf(\"字符串 \\\"%s\\\"的大小是 %d\\n\",greet,sizeof greet );\r\n\tprintf(\"字符数组 \\\"%s\\\"的大小是 %d\\n\",hello,sizeof hello );\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6172248721122742,
"alphanum_fraction": 0.6267942786216736,
"avg_line_length": 17.18181800842285,
"blob_id": "442251e216768d844e48928c980c9ed1d266d138",
"content_id": "bbdd677cff2b9cc2be76c4ae1e8cd3f786255c60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 209,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 11,
"path": "/c_basic/code/nbio/stri.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"text1.txt\";\r\n\tFILE *pfile = fopen(filename,\"w\");\r\n\tputs(filename);\r\n\tfputs(filename, pfile);\r\n\tfclose(pfile);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4810126721858978,
"alphanum_fraction": 0.49367088079452515,
"avg_line_length": 12.058823585510254,
"blob_id": "2c2941ff3d397ef12f2961b267b141214cbc50f1",
"content_id": "a2d0c77dc3d0300473da8e08f1c0481565b93314",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 237,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 17,
"path": "/c_basic/code/bio/otherstdin.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n// #include <conio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar ch = NULL;\r\n\twhile(ch = getchar())\r\n\t{\r\n\t\tif (ch == '\\0')\r\n\t\t{\r\n\t\t\texit(1);\r\n\t\t}\r\n\t\tprintf(\"%c\", ch);\r\n\t}\r\n\t\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5901639461517334,
"alphanum_fraction": 0.6065573692321777,
"avg_line_length": 9.166666984558105,
"blob_id": "ebe02a25993c5d8b03f18c5f0e7bd097da5a4e58",
"content_id": "7dffe5906c659b8f1a5a0b665739c8bf78b1be4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 6,
"path": "/shell/second",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfor file in $(ls f*); do\n lpr $file\ndone\nexit 0\n"
},
{
"alpha_fraction": 0.5548780560493469,
"alphanum_fraction": 0.5579268336296082,
"avg_line_length": 18.625,
"blob_id": "57d3e2397649ed628e4ced7f88f91e159153df4d",
"content_id": "259e6b9febc894f7878f69b6790637dfbde5aab6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 328,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 16,
"path": "/c_basic/code/nbio/ungetchar.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\t// char *filename = \"test.txt\";\r\n\t// FILE *pfile = fopen(filename, \"r\");\r\n\t// char res = fgetc(pfile);\r\n\t// ungetc(res,pfile);\r\n\t// printf(\"%c\\n\", fgetc(pfile));\r\n\tchar ch = 'd';\r\n\tungetc(ch,stdin);\r\n\tchar res = getchar();\r\n\tprintf(\"%c\\n\", res);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4837758243083954,
"alphanum_fraction": 0.5103244781494141,
"avg_line_length": 24.230770111083984,
"blob_id": "94c641637d4cf85ac90075461405d6b33a0ce545",
"content_id": "b854133824cfbb3441ae3b2629d15ae96b843b32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/c_basic/code/bio/scanf5.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tfloat fno = 0.0f;\r\n\t// int num1, num2, num3;\r\n\tint num;\r\n\t// printf(\"\\n\");\r\n\tscanf(\"%f,%d\",&fno,&num);\r\n\t// scanf(\"%f,%o,%x,%X\",&fno,&num1,&num2,&num3);\r\n\tprintf(\"fno = %f.\\nfno(e) = %e.\\nnum(o) = %o.\\n\"\r\n\t\t\t\"num(x) = %x.\\nnum(X) = %X.\\n\",fno,fno,num,num,num);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5240641832351685,
"alphanum_fraction": 0.5614973306655884,
"avg_line_length": 19.653846740722656,
"blob_id": "4748e04edfd40f2448707c4c000207e78ac12f78",
"content_id": "84d193d13ff2de281689ee8c9f04773644eba740",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 571,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 26,
"path": "/c_basic/code/c_run.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tif (argv[1])\r\n\t{\r\n\t\t// char *pcmd = (char *)malloc(10 * sizeof(char));\r\n\t\tchar command1[50] = \"gcc \";\r\n\t\tstrcat(command1, argv[1]);\r\n\t\tchar command2[] = \".c -o ../../exectue/\";\r\n\t\tstrcat(command1, command2);\r\n\t\tstrcat(command1, argv[1]);\r\n\t\tchar command3[] = \" && ./../../exectue/\";\r\n\t\tstrcat(command1, command3);\r\n\t\tstrcat(command1, argv[1]);\r\n\t\t\r\n\t\tsystem(command1);\r\n\t\t// printf(\"%s\\n\", command1);\r\n\t}else{\r\n\t\tprintf(\"缺少参数!\\n\");\r\n\t}\r\n\t\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4950000047683716,
"alphanum_fraction": 0.57833331823349,
"avg_line_length": 29.6842098236084,
"blob_id": "cddd7aeaba67e54943eab3ecc58f53aee2495a60",
"content_id": "4f3c3cd816e8ca7c0f23bc13a58d463642c34eda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 742,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 19,
"path": "/c_basic/code/basic/arrays/arr_add.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint arr[10] = {1,2,3,4,5,6,7,8,9};\r\n\tprintf(\"%d\\n\", arr[8]);\r\n\tprintf(\"元素arr[2]的内存地址:%p\\n\", &arr[2]);\r\n\tprintf(\"元素arr[3]的内存地址:%p\\n\", &arr[3]);\r\n\tprintf(\"元素arr[6]的内存地址:%p\\n\", &arr[6]);\r\n\tprintf(\"元素arr[2]与元素arr[3]内存地址之间的距离:%p\\n\",&arr[3]-&arr[2]);\r\n\tprintf(\"元素arr[2]与元素arr6]内存地址之间的距离:%p\\n\", &arr[6]-&arr[2]);\r\n\tprintf(\"int 类型数据的长度:%ld\\n\", sizeof(int));\r\n\r\n\tprintf(\"元素arr[2]的内存地址:%d\\n\", &arr[2]);\r\n\tprintf(\"元素arr[3]的内存地址:%d\\n\", &arr[3]);\r\n\tprintf(\"%d\\n\",(&arr[3]-&arr[2]));\r\n\r\n\tprintf(\"%p\\n\",0x7ffc85489d0c - 0x7ffc85489d08);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5796661376953125,
"alphanum_fraction": 0.5963581204414368,
"avg_line_length": 24.440000534057617,
"blob_id": "28dbfd32f39e1b05fa16fdffab91fada175adfb6",
"content_id": "6870c85b83967cdc37972bade784155961e7be12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 25,
"path": "/c_basic/code/pointer/hipointer.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tlong num = 100L;\r\n\tconst long *pointer = NULL;\t//pointer initial\r\n\tpointer = #\r\n\tprintf(\"num = %ld\\n\", num);\r\n\tprintf(\"*pointer = %ld\\n\", *pointer);\r\n\tprintf(\"pointer = %p\\n\", pointer);\r\n\t\r\n\t// *pointer = 300L;\t\t//assignment of read-only location '*pointer'\r\n\tnum =200L;\r\n\tlong result = *pointer + 5;\r\n\tprintf(\"result = %ld\\n\", result);\r\n\tprintf(\"num = %ld\\n\", num);\r\n\tprintf(\"pointer = %p\\n\", pointer);\r\n\tprintf(\"pointer memorize size: %d\\n\", sizeof pointer);\r\n\r\n\tprintf(\"请输入一个整数:\");\r\n\tint number;\r\n\tint *add = &number;\r\n\tscanf(\"%d\",add);\r\n\tprintf(\"您输入的是:%d\\n\", number);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4855072498321533,
"alphanum_fraction": 0.5806159377098083,
"avg_line_length": 23.53333282470703,
"blob_id": "1c9994f08adf0d80ad55643ef5e92bf2ddf3086f",
"content_id": "d6b56e9b64e6fb3274fcfff91aa7cf741f4d56d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1104,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 45,
"path": "/exercises/code/wday.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n\nint which_day(unsigned int year, unsigned int month, unsigned int day)\n{\n\t\n\tint wday = 0;\n\tint count = 0;\n\tint offset = (year%100) ? !(year % 4) : !(year%400);\n\tint feb = 28 + offset;\n\tint days = 365 + offset;\n\n\tswitch (month)\n\t{\n\t\tcase 1:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 2:if(day == 0 || day > feb)return 0;count+=feb;\n\t\tcase 3:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 4:if(day == 0 || day > 30)return 0;count+=30;\n\t\tcase 5:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 6:if(day == 0 || day > 30)return 0;count+=30;\n\t\tcase 7:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 8:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 9:if(day == 0 || day > 30)return 0;count+=30;\n\t\tcase 10:if(day == 0 || day > 31)return 0;count+=31;\n\t\tcase 11:if(day == 0 || day > 30)return 0;count+=30;\n\t\tcase 12:if(day == 0 || day > 31)return 0;count+=31;\n\t\t\tbreak;\n\t\tdefault:return 0;\n\t}\n\n\twday = days - count + day;\n\n\treturn wday;\n}\n\n\nint main()\n{\n\tint res = which_day(2000, 2, 7);\n\n\tif(res)\n\t\tprintf(\"%dth day\\n\", res);\n\telse\n\t\tprintf(\"input error.\\n\");\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5709282159805298,
"alphanum_fraction": 0.5735551714897156,
"avg_line_length": 12.75903606414795,
"blob_id": "ad2dead2414c194525d8ab9ce3693e74122cbee9",
"content_id": "7d8c4bc608c7f9ca7e506b720b1d8828d5e3c932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1222,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 83,
"path": "/c_basic/code/basic/datatype/enum.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\nint main()\n{\n\tenum Weekday\n\t{\n\t\tMonday,\n\t\tTuesday,\n\t\tWednesday,\n\t\tThursday,\n\t\tFriday,\n\t\tStaturday,\n\t\tSunday\n\t};\n\n\t// enum Weekday\t\t\t//定义枚举类型时声明变量类型\n\t// {\n\t// \tMonday,\n\t// \tTuesday,\n\t// \tWednesday,\n\t// \tThursday,\n\t// \tFriday,\n\t// \tStaturday,\n\t// \tSunday\n\t// } today,\n\t// \ttomorrow;\n\t// enum Weekday\t\t\t//定义枚举类型时声明变量类型并初始化变量\n\t// {\n\t// \tMonday,\n\t// \tTuesday,\n\t// \tWednesday,\n\t// \tThursday,\n\t// \tFriday,\n\t// \tStaturday,\n\t// \tSunday\n\t// } today = Monday,\n\t// tomorrow = Thursday;\n\n\t// enum Weekday\n\t// {\n\t// \tMonday,\n\t// \tTuesday,\n\t// \tWednesday,\n\t// \tThursday,\n\t// \tFriday,\n\t// \tStaturday,\n\t// \tSunday\n\t// } today = Monday,\n\t// tomorrow = today + 1;\n\n\tenum Size\n\t{\n\t\tsmall = 1,\n\t\tmidium,\n\t\tlarge\n\t};\n\n\tenum FirstQuarter\n\t{\n\t\tJanuary,\n\t\tFebruary = 2,\n\t\tMarch\n\t};\n\n\tenum //未命名的枚举类型\n\t{\n\t\tred,\n\t\torange,\n\t\twhite,\n\t\tyellow,\n\t\tgreen\n\t} shirt_color;\n\n\tenum Weekday today = Tuesday;\n\tenum Size size = midium;\n\tenum FirstQuarter month = January;\n\tenum FirstQuarter month_d = March;\n\tshirt_color = green;\n\tprintf(\"%d\\n\", today);\n\tprintf(\"%d\\n\", size);\n\tprintf(\"%d\\n\", month);\n\tprintf(\"%d\\n\", month_d);\n\tprintf(\"%d\\n\", shirt_color);\n}\n"
},
{
"alpha_fraction": 0.5783132314682007,
"alphanum_fraction": 0.5903614163398743,
"avg_line_length": 10,
"blob_id": "c8e432f79eaf2119f570993ca2786ec107981406",
"content_id": "7f59d10337a8224f3ab5230a94aeb970203813e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 14,
"path": "/c_basic/code/preprocessor/functions.h",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#ifndef FUNCTIONS_H_\r\n#define FUNCTIONS_H_\r\n// #ifndef NAMES_H_\r\n// #define NAMES_H_\r\n\r\n#define LEN 8\r\n\r\nint greet()\r\n{\r\n\tprintf(\"hello!\\n\");\r\n\treturn 0;\r\n}\r\n\r\n#endif"
},
{
"alpha_fraction": 0.49307480454444885,
"alphanum_fraction": 0.5706371068954468,
"avg_line_length": 16.149999618530273,
"blob_id": "4df094e15488fffd43c3a46960a1b4aeda4a0d70",
"content_id": "c0f9b24ae2caea593cbbb527b9ac4997da63a8a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 20,
"path": "/c_basic/code/structiondata/union.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tunion u_example\r\n\t{\r\n\t\tfloat decval;\r\n\t\tint pnum;\r\n\t\tdouble my_value;\r\n\t}U1, U2;\r\n\t// U2 = 3.14f;\r\n\tunion u_example U3;\r\n\tU3 = 3.14;\r\n\tU1.my_value = 125.5;\r\n\tU1.pnum = 10;\r\n\tU1.decval = 100.5f;\r\n\r\n\tprintf(\"decval = %f pnum = %d my_value = %lf\\n\", U1.decval, U1.pnum, U1.my_value);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.31293705105781555,
"alphanum_fraction": 0.4877622425556183,
"avg_line_length": 16.516128540039062,
"blob_id": "0609cea41fc1d34e9ad16e26b532aba8c9a5a3e0",
"content_id": "06d024280a1efb0d9ce8ca5256b0ac04f8bb1fd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 31,
"path": "/c_basic/code/basic/arrays/arrays.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint num[3][4] = {\r\n\t\t{1,2,3,4},\r\n\t\t{11,12,13,14},\r\n\t\t{21,22,23,24},\t\t\t//最后一行后的逗号可写可不写,在gcc中\r\n\t};\r\n\r\n\r\n\tint numbers[2][3][4] = {\r\n\t\t{\r\n\t\t\t{1,2,3,4},\r\n\t\t\t{11,12,13,14},\r\n\t\t\t{21,22,23,24},\r\n\t\t},\r\n\r\n\t\t{\r\n\t\t\t{31,32,33,34},\r\n\t\t\t{111,112,113,114},\r\n\t\t\t{211,212,213,214},\r\n\t\t}\r\n\t};\r\n\r\n\tprintf(\"元素num[0][0]的值是:%d\\n\", num[0][0]);\r\n\r\n\tprintf(\"元素numbers[0][2][3]的值是:%d,内存地址是:%p\\n\", numbers[0][2][3],&numbers[0][2][3]);\r\n\tprintf(\"元素numbers[1][0][0]的值是:%d,内存地址是:%p\\n\", numbers[1][0][0],&numbers[1][0][0]);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6017897129058838,
"alphanum_fraction": 0.6152125000953674,
"avg_line_length": 21.63157844543457,
"blob_id": "792b963d90c58a53702659506e1c40e76b65df0b",
"content_id": "5b84966f408c08f756c57c362c796eca20dfaae6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 447,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 19,
"path": "/c_basic/code/file/inputstr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"test1.txt\";\r\n\tFILE *pfile = fopen(filename,\"w\");\r\n\tchar *instr = \"write something today.\";\r\n\tfputs(instr, pfile);\r\n\tfclose(pfile);\r\n\r\n\tFILE *pfiler = fopen(filename,\"r\");\r\n\tchar *pstr = (char *)malloc(10 * sizeof(char));\r\n\tchar *str = fgets(pstr, 18, pfiler);\r\n\tprintf(\"%s\\n\", str);\r\n\tfclose(pfiler);\r\n\tfree(pstr);\r\n\tpstr = NULL;\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.48394495248794556,
"alphanum_fraction": 0.5114678740501404,
"avg_line_length": 15.520000457763672,
"blob_id": "a02351c210fc4d883a303dd778345e04189c72c9",
"content_id": "5823c0f072d76f7258eb7b02cae7008358b352e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 25,
"path": "/c_basic/code/basic/strfuncs/sstrls.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tstruct data\r\n\t{\r\n\t\tint i;\r\n\t\tchar c;\t\r\n\t\tfloat a;\r\n\t}test;\r\n\r\n\tstruct data demo[10] = {\r\n\t\t3, 'i', 3.33,\r\n\t\t2, 't', \r\n\t};\r\n\r\n\tprintf(\"demo[0].c = %c\\n\", demo[0].c);\r\n\tprintf(\"demo[1].c = %c\\n\", demo[1].c);\r\n\r\n\tprintf(\"int = %d\\n\", sizeof(int));\r\n\tprintf(\"char = %d\\n\", sizeof(char));\r\n\tprintf(\"float = %d\\n\", sizeof(float));\r\n\tprintf(\"%d\\n\", sizeof test);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5430183410644531,
"alphanum_fraction": 0.5528913736343384,
"avg_line_length": 15.774999618530273,
"blob_id": "b58dbf95d6039b23a640a8587c862567b38444b1",
"content_id": "6ec6052dbb6e6f6ac4aac9e50403ebc66e655cc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 40,
"path": "/c_basic/code/function/sharval.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint shareint = 8;\r\n\r\nint increase(int *);\r\nint aincrease(int *);\r\nint sincrease(int);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tfor (int i = 0; i < 4; ++i)\r\n\t{\r\n\t\tprintf(\"the %d th time run increase(), value = %d\\n\", i, increase(&shareint));\r\n\t}\r\n\tprintf(\"\\n\");\r\n\tfor (int i = 0; i < 4; ++i)\r\n\t{\r\n\t\tprintf(\"the %d th time run aincrease(), value = %d\\n\", i, aincrease(&shareint));\r\n\t}\r\n\tprintf(\"\\n\");\r\n\tfor (int i = 0; i < 4; ++i)\r\n\t{\r\n\t\tprintf(\"the %d th time run sincrease(), value = %d\\n\", i, sincrease(shareint));\r\n\t}\r\n}\r\n\r\nint increase(int *value)\r\n{\r\n\treturn ++*value;\r\n}\r\n\r\nint aincrease(int *value)\r\n{\r\n\treturn ++*value;\r\n}\r\n\r\nint sincrease(int value)\r\n{\r\n\treturn ++value;\r\n}"
},
{
"alpha_fraction": 0.5514403581619263,
"alphanum_fraction": 0.5658436417579651,
"avg_line_length": 14.266666412353516,
"blob_id": "e8e4960a8c5d520bdc7e3cbbf907a74acc41baea",
"content_id": "7049583ef76d9e602a5fd201c31279291d7ce1c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 506,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 30,
"path": "/c_basic/code/structiondata/structParam.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\t\r\n\tstruct cat\r\n\t{\r\n\t\tint age;\r\n\t\tchar *name;\r\n\t\tfloat weight;\r\n\t} LuoCat= {2,\"Luo Cat\",2.5},*pblack;\r\n\r\n\tpblack = &LuoCat;\r\n\t// LuoCat = {2,\"Luo Cat\",2.5};\t// 错误的初始化格式格式\r\n\r\n\tint getAgeP(struct cat const *pcat)\r\n\t{\r\n\t\t// return (*pcat).age;\r\n\t\treturn pcat->age;\r\n\t}\r\n\r\n\tint getAge(struct cat Miao)\r\n\t{\r\n\t\treturn Miao.age;\r\n\t}\r\n\r\n\tprintf(\"age = %d\\n\",getAge(LuoCat));\r\n\tprintf(\"age = %d\\n\",getAgeP(pblack));\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5598027110099792,
"alphanum_fraction": 0.6128236651420593,
"avg_line_length": 29.269229888916016,
"blob_id": "64fbaf28ef2917f371761a69fb0d423fced833f5",
"content_id": "cde700bf854fc9e87f43dfbd776e8c69d28992a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 811,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 26,
"path": "/c_basic/code/basic/strfuncs/compare2.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\n#include <stdbool.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *str1 = \"abOut you\";\r\n\tchar *str2 = \"About\";\r\n\tbool result = (str1 == str2);\r\n\r\n\tint res = strcmp(str1,str2);\r\n\tint res1 = strncmp(str1,str2,0);\r\n\tint res2 = strncmp(str1,str2,1);\r\n\tint res3 = strncmp(str1,str2,2);\r\n\tint res4 = strncmp(str1,str2,3);\r\n\r\n\tprintf(\"The result of (str1 > str2) is: %f\\n\", result);\r\n\tprintf(\"The result of strcmp(str1,str2) is:%d\\n\", res);\r\n\tprintf(\"The result of strncmp(str1,str2,0); is:%d\\n\", res1);\r\n\tprintf(\"The result of strncmp(str1,str2,1); is:%d\\n\", res2);\r\n\tprintf(\"The result of strncmp(str1,str2,2); is:%d\\n\", res3);\r\n\tprintf(\"The result of strncmp(str1,str2,3); is:%d\\n\", res4);\r\n\tprintf(\"The result of ('a' - 'A') is: %d\\n\", ('a' - 'A'));\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.559077799320221,
"alphanum_fraction": 0.5706051588058472,
"avg_line_length": 13.863636016845703,
"blob_id": "b28b9478d184d01aa759c889d5b0e3f3c5a0cf4a",
"content_id": "4cb3d194400fa0220d0c8a5bd830f4eaa1a92fe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 347,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 22,
"path": "/c_basic/code/function/recur.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tprintf(\"Plese input a integer number:\");\r\n\tint num = 0; \r\n\tscanf(\"%d\",&num);\r\n\tint result = recursion(num);\r\n\tprintf(\"The result is: %d\\n\", result);\r\n\treturn 0;\r\n}\r\n\r\n\r\nint recursion(int num)\r\n{\r\n\tif (num == 1)\r\n\t{\r\n\t\treturn num;\r\n\t}else{\r\n\t\treturn num + recursion(num - 1);\r\n\t}\r\n}"
},
{
"alpha_fraction": 0.5132275223731995,
"alphanum_fraction": 0.5264550447463989,
"avg_line_length": 10.666666984558105,
"blob_id": "11701303d9ba791e15eb95706e46ef0b82574a46",
"content_id": "0af6a27c656e330364a8ac752fa8b6256c60375c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 30,
"path": "/c_basic/code/nbio/ungetc.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <ctype.h>\r\n\r\nint read_int()\r\n{\r\n\tint value;\r\n\tint ch;\r\n\tvalue = 0;\r\n\r\n\t/*\r\n\t\t转换从标准输入读入的数字,当我们得到一个非数字的字符时停止。\r\n\t*/\r\n\twhile( (ch = getchar()) != EOF && isdigit( ch ) )\r\n\t{\r\n\t\tvalue *= 10;\r\n\t\tvalue += ch - '0';\r\n\t}\r\n\t/*\r\n\t\t把数字字符退回到流中\r\n\t*/\r\n\tungetc(ch,stdin);\r\n\treturn value;\r\n}\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\r\n\tread_int();\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5743494629859924,
"alphanum_fraction": 0.5762081742286682,
"avg_line_length": 22.545454025268555,
"blob_id": "a802e6dc9db1140b4fdd1841f068d8b0df9c3fbb",
"content_id": "62c978c023778f9608d2215f8b5f5fa8436a6787",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 22,
"path": "/c_basic/code/basic/strfuncs/strsearch.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar str[] = \"You are beautiful.\";\r\n\t// char key = 'b';\r\n\tchar key_str[] = \"beaut\";\r\n\tint key = 'b';\r\n\tchar *pionter = NULL;\r\n\tpionter = strchr(str,key);\r\n\tchar *pkey = NULL;\r\n\tpkey = strrchr(str,key);\r\n\r\n\tprintf(\"char %c was found by function \\\"strchr()\\\": %c\\n\", key, *pionter);\r\n\tprintf(\"char %c was found by function \\\"strrchr()\\\": %c\\n\", key, *pkey);\r\n\r\n\tif(strstr(str,key_str)){\r\n\t\tprintf(\"str \\\"%s\\\" was found.\\n\", key_str);\r\n\t}\r\n\t\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5375375151634216,
"alphanum_fraction": 0.5540540814399719,
"avg_line_length": 29.023256301879883,
"blob_id": "86c7fcbf33a3e99c0b514e5d1499a75e4a81ba0f",
"content_id": "d882ff4e67187afcf68b3a5a0b2d0a8ada523845",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 43,
"path": "/c_basic/code/pointer/p7_12.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "/* Program 7.12 Arrays of Pointer to Strings */\r\n#include <stdio.h>\r\nconst size_t BUFFER_LEN = 512;\t/* Size of input buffer */\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar buffer[BUFFER_LEN];\t/* Store for strings */\r\n\tchar *pS[3] = { NULL }; \t/* Array of string pointers */\r\n\tchar *pbuffer = buffer;\t\t/* Poiinter to buffer */\r\n\tsize_t index = 0;\t\t\t/* Avaiable buffer position */\r\n\r\n\tprintf(\"\\nEnter 3 messages that total less than %u characters.\", BUFFER_LEN - 2);\r\n\t\r\n\t/* Read the strings from the keyboard */\r\n\tfor (int i = 0; i < 3; ++i)\r\n\t{\r\n\t\tprintf(\"\\nEnter %s message\\n\", i > 0 ? \"another\" : \"a\");\r\n\t\tpS[i] = &buffer[index];\t/* Save start of string */\r\n\t\t/* Read up to the end of buffer if necessary */\r\n\t\tfor ( ; index < BUFFER_LEN; ++index)\t/* If you read \\n ... */\r\n\t\t{\t\r\n\t\t\tif ((*(pbuffer+index) = getchar()) == '\\n')\r\n\t\t\t{\r\n\t\t\t\t*( pbuffer + index++ ) = '\\0';\t\t/* ...substitute \\0 */\r\n\t\t\t\tbreak;\r\n\t\t\t}\r\n\t\t}\r\n\t\t/* Check for buffer capacity exceeded */\r\n\t\tif ( ( index == BUFFER_LEN ) && ( (*(pbuffer+index-1) != '\\0' ) || (i < 2)))\r\n\t\t{\r\n\t\t\tprintf(\"\\nYou rann out of space in the buffer.\");\r\n\t\t\treturn 1;\r\n\t\t}\t\r\n\t}\r\n\t\r\n\tprintf(\"\\nThe strings you entered are:\\n\\n\");\r\n\tfor (int i = 0; i < 3; ++i)\r\n\t{\r\n\t\tprintf(\"%s\\n\", pS[i]);\r\n\t}\r\n\r\n\tprintf(\"\\nThe buffer has %d characters unused.\\n\",BUFFER_LEN-index);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4507042169570923,
"alphanum_fraction": 0.49295774102211,
"avg_line_length": 16.75,
"blob_id": "2f281b93462cbf3391f980f5ca949e1a8f97fc54",
"content_id": "49191fb9dcd921be74540ae586c9c528e6134a61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 12,
"path": "/c_basic/code/basic/datatype/type_switch.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\nint main(){\nint a = 189;\nfloat b = 89.391f;\nint c = a + (int)b;\nint d = a + b;\nprintf(\"c = %d\\n\",c);\nprintf(\"d = %d\\n\",d);\nprintf(\"a + b = %d\\n\",(a+b));\nprintf(\"a + b = %f\\n\",a+b);\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.5047318339347839,
"alphanum_fraction": 0.5205047130584717,
"avg_line_length": 16.61111068725586,
"blob_id": "98fd63281af5837ba643800d565b1ac533a6023d",
"content_id": "6bd20d5d7e46a938aeb65e1e400d33885b01696e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 359,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 18,
"path": "/c_basic/code/basic/datatype/bool.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#define TRUE 1 /*宏定义*/\n#define FALSE 0\n#include <stdio.h>\n#include <stdbool.h> /* 此头文件中将 _Bool 定义为 bool*/\nint main()\n{\n /* 利用枚举类型自定义 */\n enum Bool\n {\n False,\n True\n };\n _Bool is_right = 1;\n bool is_false = 0;\n printf(\"%d\\n\", is_right);\n printf(\"%d\\n\", is_false);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4504716992378235,
"alphanum_fraction": 0.4929245412349701,
"avg_line_length": 23.058822631835938,
"blob_id": "956a128de2dbad46ff9043897cead2d5664fb14b",
"content_id": "f899b96bfac1978665b690a44b12644bfdb37a08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 17,
"path": "/c_basic/code/pointer/mularrpointer.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar board[3][3] = {\r\n\t\t\t\t\t\t\t{'1','2','3'},\r\n\t\t\t\t\t\t\t{'4','5','6'},\r\n\t\t\t\t\t\t\t{'7','8','9'}\r\n\t\t\t\t\t\t};\r\n\tprintf(\"address of board : %p\\n\", board);\r\n\tprintf(\"address of board[0] : %p\\n\", board[0]);\r\n\tprintf(\"address of board[0][0] : %p\\n\", &board[0][0]);\r\n\r\n\tprintf(\"\\naddress of board : %p\\n\", board);\r\n\tprintf(\"address of *board : %p\\n\", *board);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5448275804519653,
"alphanum_fraction": 0.5737931132316589,
"avg_line_length": 24.925926208496094,
"blob_id": "39c91a7fc67d2799c5b6e4cd0fed00f1bf092082",
"content_id": "6bd7ba40b7e3e75ab2ea7aef127998515d12d724",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 727,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 27,
"path": "/c_basic/code/bio/scanf2.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n/*\r\n 12.44,12,46,nihofs ⇲\r\n*/\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *str = NULL;\r\n\tstr = (char *)malloc(10 * sizeof(char));\r\n\tint value = 0;\r\n\tint value2 = 0;\r\n\tdouble fnum = 0.0;\r\n\r\n\tprintf(\"Please input a float number,two integer numbers and a string.\\n\");\r\n\t// int count = scanf(\"%s %lf,%*d,%3d\",str,&fnum,&value);\r\n\t// int count = scanf(\"%lf,%s,%*d,%3d\",&fnum,str,&value);\r\n\tint count = scanf(\"%lf,%*d,%3d,%s\",&fnum,&value,str);\r\n\r\n\tprintf(\"fnum = %lf.\\n\", fnum);\r\n\tprintf(\"value = %d.\\n\", value);\r\n\tprintf(\"value2 = %d.\\n\", value2);\r\n\tprintf(\"str = %s.\\n\", str);\r\n\tprintf(\"There is %d numbers be inputed scanf().\\n\", count);\r\n\tfree(str);\r\n\tstr = NULL;\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5440000295639038,
"alphanum_fraction": 0.581333339214325,
"avg_line_length": 24.928571701049805,
"blob_id": "79e16dc1f1a0f2cf59862b74dad03df04e58a549",
"content_id": "cd4470eb0e579f654d358b4dce0b4dacefe6fa2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 14,
"path": "/c_basic/code/basic/operator/sizeof.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tdouble num = 10.0;\r\n\tdouble values[] = {1.6,2.5,3.6,5.5,9.3};\r\n\tprintf(\"%ld\\n\", sizeof num);\r\n\tprintf(\"%ld\\n\", sizeof(num));\r\n\tprintf(\"%ld\\n\", sizeof(double));\r\n\t// printf(\"%ld\\n\", sizeof double);\t\t//Error\r\n\tprintf(\"%ld\\n\", sizeof values);\r\n\tprintf(\"%ld\\n\", (sizeof values) / (sizeof(double)));\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.551886796951294,
"alphanum_fraction": 0.5566037893295288,
"avg_line_length": 13.285714149475098,
"blob_id": "e5b17dc9a8246906c18f7417b858e811100b022a",
"content_id": "f0c2a85aebc9f08ba8a38731b42a2c255fe5cc6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 14,
"path": "/c_basic/code/nbio/file.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tFILE *pfile = fopen(\"hh.txt\",\"r\");\r\n\tif (pfile == NULL)\r\n\t{\r\n\t\tperror(\"hh.txt\");\r\n\t\texit(EXIT_FAILURE);\r\n\t}\r\n\t\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5730336904525757,
"alphanum_fraction": 0.6029962301254272,
"avg_line_length": 31.375,
"blob_id": "18d55857db378466ba68ca95e43f899a14b830fb",
"content_id": "4bcb00b349c68e3a2405ee6affcd0aef58f798b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 8,
"path": "/c_basic/code/basic/datatype/complex.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\r\n#include<complex.h> /* 定义复数有关参数和方法 */\r\nint main(int argc, char const *argv[])\r\n{\r\n double complex z1 = 2.0 + 3.0*I; // <complex.h> 头文件把I定义为等价于_Complex_I\r\n printf(\"复数complex的实数部分:%f,虚数部分:%f\\n\",creal(z1),cimag(z1));\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5670731663703918,
"alphanum_fraction": 0.5731707215309143,
"avg_line_length": 12.909090995788574,
"blob_id": "b48d80583b3faf0c210af07a6c870c2aa08c2b46",
"content_id": "4d668db0dd9d2bad39f78cf9652120bde3de0c33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 11,
"path": "/c_basic/code/preprocessor/test.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include \"functions.h\"\r\n\r\n// extern int greet();\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tprintf(\"%d\\n\", LEN);\r\n\tgreet();\r\n\treturn 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5797101259231567,
"alphanum_fraction": 0.5869565010070801,
"avg_line_length": 17.433332443237305,
"blob_id": "057bfefe8df70aa4eb47a6189f8000a866eddb01",
"content_id": "70f42a0395dee84337600e4a146bdb137de90735",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 552,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 30,
"path": "/c_basic/code/bio/scanf.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n\nint main(int argc, char const *argv[])\n{\n\tstatic int count;\n\tint value = 0;\n\tchar *str = NULL;\n\tstr = (char *)malloc(10 * sizeof(char));\n\n\tint *pval = NULL;\n\tpval = &value;\n\tprintf(\"Please input a number and a string,divide by ',':\\n\");\n\t\n\tif (str)\n\t{\n\t\tcount = scanf(\"%d,%s\", pval,str);\n\t}else{\n\t\tprintf(\"memory is not enough.\\n\");\n\t}\n\n\tprintf(\"value = %d.\\n\", value);\n\tprintf(\"%d\\n\", 'L');\n\tprintf(\"There is %d data input scanf().\\n\", count);\n\tprintf(\"str = %s.\\n\", str);\n\n\tfree(str);\n\tstr = NULL;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5914221405982971,
"alphanum_fraction": 0.6049661636352539,
"avg_line_length": 20.25,
"blob_id": "82d7c49e2ca62d09f998bd91b734c5dc3f9e9ab5",
"content_id": "5419a7d57d50c1af48163225888e703087b777e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 20,
"path": "/c_basic/code/function/p8_5.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n// int change(int *pnumber);\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint number = 10;\r\n\tint result = 0;\r\n\tint *pnumber = &number;\r\n\tresult = change(pnumber);\r\n\tprintf(\"\\nIn main, result = %d\\tnubmer = %d\\n\", result, number);\r\n\tprintf(\"\\n%d\",*pnumber);\r\n\treturn 0;\r\n}\r\n\r\nint change(int *pnumber)\r\n{\r\n\t*pnumber = 2 * (*pnumber);\r\n\tprintf(\"\\nIn function change, number = %d\\n\", *pnumber);\r\n\tpnumber = NULL;\r\n\treturn 1;\r\n}"
},
{
"alpha_fraction": 0.5135802626609802,
"alphanum_fraction": 0.5234568119049072,
"avg_line_length": 23.4375,
"blob_id": "740b1d7487206e94a83f8c55244720cc2d17999b",
"content_id": "103bfdc3df5f411b56b7f713daa53a9fa24202f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 16,
"path": "/c_basic/code/pointer/arrpointer.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar multiple[] = \"a string\";\r\n\tchar *p = multiple;\r\n\r\n\tprintf(\"p = %p\\n\", p);\r\n\tprintf(\"&multiple[0] = %p\\n\", &multiple[0]);\r\n\tfor (int i = 0; i < strlen(multiple); ++i)\r\n\t{\r\n\t\tprintf(\"multiple[%d] = %c * (p+%d) = %c; &multiple[%d] = %p p+%d = %p\\n\",\r\n\t\t\ti,multiple[i],i,*(p+i),i,&multiple[i],i,p+i);\r\n\t}\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.46315789222717285,
"alphanum_fraction": 0.49473685026168823,
"avg_line_length": 5.785714149475098,
"blob_id": "c04e7dc36ee57b6f5d637772ba81cef7379b3705",
"content_id": "df3e5caecb78c46a9c2fe1f9a00cb3e41c804aa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 9,
"num_lines": 14,
"path": "/shell/args",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nIFS=\"\"\n\necho $0\necho $3\necho $#\necho $$\necho $*\necho \"$*\"\necho $@\necho \"$@\"\n\nexit 0\n"
},
{
"alpha_fraction": 0.3852140009403229,
"alphanum_fraction": 0.40856030583381653,
"avg_line_length": 18.769229888916016,
"blob_id": "1fecf737ab69061597aef3cd45f2bd2b22299af3",
"content_id": "2ab6da6ec84714253945cb7202bd0a2ce1cb6ead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 13,
"path": "/c_basic/code/basic/recycle/waitCall.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\nint main(){\n int i = 0; //运球次数\n for(i=1; i<=10; i++){\n printf(\"运球%d次\\n\", i);\n if(i == 5){\n printf(\"去接个电话\\n\");\n continue; //电话铃响了,去接电话\n }\n }\n printf(\"今天的训练到此结束。\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.541850209236145,
"alphanum_fraction": 0.5550661087036133,
"avg_line_length": 11.470588684082031,
"blob_id": "9ab880c987b9513f5a1ecc8b8e9cc99ba250bb67",
"content_id": "1199971884e4a4ea983a7f37ce8207582f697ad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 17,
"path": "/c_basic/code/function/poifunc.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint puls(int num);\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint (*pfunc) (int);\r\n\tint num = 99;\r\n\r\n\tpfunc = puls;\r\n\tprintf(\"%d\\n\", pfunc(num));\r\n\treturn 0;\r\n}\r\n\r\nint puls(int num)\r\n{\r\n\treturn ++num;\r\n}"
},
{
"alpha_fraction": 0.5871211886405945,
"alphanum_fraction": 0.6098484992980957,
"avg_line_length": 18.461538314819336,
"blob_id": "a8b770525fb52ce41d1beab24873ce81667dc671",
"content_id": "fee97442547075c286cc32fb75bccf8700ca68a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 13,
"path": "/c_basic/code/nbio/stro.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"text1.txt\";\r\n\tFILE *pfile = fopen(filename,\"r\");\r\n\tchar *buffer = NULL;\r\n\t// gets(filename);\r\n\tfgets(buffer,1024, pfile);\r\n\tprintf(\"%s\\n\", buffer);\r\n\tfclose(pfile);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5746753215789795,
"alphanum_fraction": 0.5844155550003052,
"avg_line_length": 12.7619047164917,
"blob_id": "0374d7a35f04a3dcb3aba692b23303a9daa2398d",
"content_id": "c8e16b38697bc8d660b44ebcc77e334cc613b3c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 308,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 21,
"path": "/c_basic/code/function/funcpoiparam.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint puls(int num);\r\nint content(int (*pfunc) (int),int num);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint num = 99;\r\n\tprintf(\"%d\\n\", content(puls,num));\r\n\treturn 0;\r\n}\r\n\r\nint content(int (*pfunc) (int),int num)\r\n{\r\n\treturn pfunc(num);\r\n}\r\n\r\nint puls(int num)\r\n{\r\n\treturn ++num;\r\n}"
},
{
"alpha_fraction": 0.5446428656578064,
"alphanum_fraction": 0.546875,
"avg_line_length": 18.454545974731445,
"blob_id": "445e627eccbac21647d8c58ed34202d1459d9ca4",
"content_id": "2c308ca8be9c805f9256998153b6d60a75a59fd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 22,
"path": "/c_basic/code/file/rewindemo.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"myfile.bin\";\r\n\tFILE *pfile = fopen(filename,\"wb\");\r\n\tchar pdata[] = \"how are you? are ok ?\";\r\n\tchar *instr = \"I'm fine, thanks.\";\r\n\r\n\tfprintf(pfile, \"%s\\n\", pdata);\r\n\trewind(pfile);\r\n\tif (fscanf(pfile, \"%s\", instr))\r\n\t{\r\n\t\tprintf(\"%s\\n\", instr);\r\n\t};\r\n\tprintf(\"%d\\n\", __LINE__);\r\n\tputs(__TIME__);\r\n\tputs(__FILE__);\r\n\tputs(__TIME__);\r\n\tfclose(pfile);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.580777108669281,
"alphanum_fraction": 0.5889570713043213,
"avg_line_length": 17.639999389648438,
"blob_id": "f2e1615ac48d63cb4eb9e4ebb7dd8ceabbdd5293",
"content_id": "2bf7e0b9e647c98df0e9dbccdd14065f60ed6b2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 25,
"path": "/c_basic/code/function/stval.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint increase();\r\nint aincrease();\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tfor (int i = 0; i < 4; ++i)\r\n\t{\r\n\t\tprintf(\"the %d th time run increase(), static value = %d\\n\", i, increase());\r\n\t\tprintf(\"the %d th time run aincrease(), auto value = %d\\n\", i, aincrease());\r\n\t}\r\n}\r\n\r\nint increase()\r\n{\r\n\tstatic int sinner = 8;\t/* static value only inital once when the function run */\r\n\treturn ++sinner;\r\n}\r\n\r\nint aincrease()\r\n{\r\n\tint ainner = 8;\r\n\treturn ++ainner;\r\n}"
},
{
"alpha_fraction": 0.6222910284996033,
"alphanum_fraction": 0.6222910284996033,
"avg_line_length": 17.117647171020508,
"blob_id": "6d11d22e11e4862a68592316edc8bc6cc12a555b",
"content_id": "b9ced7e4994d7d797a3e50ba5c16631470742dbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 375,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 17,
"path": "/c_basic/code/nbio/readline.py",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "filename = \"test.txt\"\r\n\r\nwith open(filename,\"r\") as f_obj:\r\n\tprint(f_obj.readline())\r\n\r\nf_obj = open(filename, \"r\")\r\n\r\nfor line in f_obj.readlines():\r\n\tprint(line,end='')\r\n\r\nwhile f_obj:\r\n\tline = f_obj.readline()\r\n\tprint(line,end='')\r\n\tif not line:\t#判断文件读取到末尾的方式,判断行内容是否为空, not line 等价于 line == ''\r\n\t\tbreak\r\n\r\nf_obj.close()"
},
{
"alpha_fraction": 0.6091954112052917,
"alphanum_fraction": 0.6168582439422607,
"avg_line_length": 12.166666984558105,
"blob_id": "fb6c4f2522772fb74fb6a98501371867b926ab4d",
"content_id": "20aed2a6e62ba3730a3a43e236d29ce797c24677",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 18,
"path": "/c_basic/code/preprocessor/names.h",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#ifndef NAME_H_\r\n#define NAME_H_\r\n\r\n#define SLEN 32\r\n\r\nstruct names_st\r\n{\r\n\tchar first[SLEN];\r\n\tchar last[SLEN];\r\n};\r\n\r\ntypedef struct names_st names;\r\n\r\nvoid get_names(names *);\r\nvoid show_names(const names *);\r\nchar *s_gets(char *st, int n);\r\n\r\n#endif\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5698198080062866,
"alphanum_fraction": 0.5855855941772461,
"avg_line_length": 18.30434799194336,
"blob_id": "28410916c0e0142d537a74513562a8a794a6dc1c",
"content_id": "81a4fd696d109346a99d476ec0299514d65da845",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 23,
"path": "/demowork/code/strdivide.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#define MAX_SIZE 100\n\nint main(int argc, char const *argv[])\n{\t\n\tchar *filename = \"test.txt\";\n\tFILE *pfile = fopen(filename,\"r\");\n\tchar *str = NULL;\n\tstr = (char *)malloc(50 * sizeof(char));\n\tif(str)\n\t{\n\t\twhile(fgets(str, MAX_SIZE - 1, pfile) != NULL){\n\t\t\tprintf(\"%s\", str);\n\t\t\tchar *p = strrchr(str,'.');\n\t\t\tprintf(\"%s\", p);\t\n\t\t\t}\n\t}else{\n\t\tprintf(\"memory is empty\");\n\t}\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.5950413346290588,
"avg_line_length": 18.33333396911621,
"blob_id": "e137ae758adced290d01d52620247787fccc0c22",
"content_id": "3bcac6b1e7e4bf09a525053c99b2b50d2f105fa4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 242,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 12,
"path": "/c_basic/code/file/fprintf.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"myfile.txt\";\r\n\tFILE *pfile = fopen(filename,\"w\");\r\n\tchar pdata[] = \"how are you? are ok ?\";\r\n\tfprintf(pfile, \"%s\\n\", pdata);\r\n\tfclose(pfile);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6744186282157898,
"alphanum_fraction": 0.6976743936538696,
"avg_line_length": 7.599999904632568,
"blob_id": "d58ade806714060fedfe1d28d4dfadbb2c891536",
"content_id": "ba973bbec54d8745c121c29e7e79673b1fa6d328",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 5,
"path": "/shell/input",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nread greet\necho $greet\n\nexit 0\n"
},
{
"alpha_fraction": 0.6192982196807861,
"alphanum_fraction": 0.6245614290237427,
"avg_line_length": 17.65517234802246,
"blob_id": "a5aa9cf2bf33d285fa95183a1c9cffa3c4e8a2fc",
"content_id": "2631fcadef7adad4f2cc821f5c3b261d455f610f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 29,
"path": "/c_basic/code/function/constPointer.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <stdbool.h>\r\n\r\nbool change(char *const pmessage);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *pmessage = NULL;\r\n\tpmessage = (char *)malloc( 10 * sizeof(char));\r\n\tif (pmessage)\r\n\t{\r\n\t\tpmessage = \"yipinyixiaozuiwoxin\";\r\n\t}else{\r\n\t\tprintf(\"memory is not enough.\\n\");\r\n\t}\r\n\r\n\tchange(pmessage);\r\n\r\n\treturn 0;\r\n}\r\n\r\nbool change(char *const pmessage)\r\n{\r\n\tprintf(\"%s\\n\", pmessage);\r\n\t// pmessage = \"jinxihexi\";\t\t\t// error: assignment of read-only parameter 'pmessage'\r\n\t// printf(\"%s\\n\",pmessage );\r\n\treturn true;\r\n}\r\n"
},
{
"alpha_fraction": 0.3894389569759369,
"alphanum_fraction": 0.4026402533054352,
"avg_line_length": 12.523809432983398,
"blob_id": "4a3016a81c7766ef0cddb798596dffaa645cbc76",
"content_id": "74abe4b11d86e3a77beef6bb082209db57b9f45e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 21,
"path": "/c_basic/code/function/main.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n \r\nint main(int argc, char const *argv[])\r\n{\r\n\tprintf(\"%d\\n\", argc);\r\n\tint i = 0;\r\n\r\n\twhile(argv[i++])\r\n\t{\r\n\t\tprintf(\"%s\\n\", argv[i-1]);\r\n\t}\r\n\r\n\tprintf(\"====================================\\n\");\r\n\t\r\n\tfor (int i = 0; i < argc; ++i)\r\n\t{\r\n\t\tprintf(\"%s\\n\", argv[i]);\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.556768536567688,
"alphanum_fraction": 0.5829694271087646,
"avg_line_length": 21,
"blob_id": "6d9c5167fa52c1103fcb3b911497d62bc7206575",
"content_id": "3c0b4b2f42e51351b7991695442264de22f68d6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 20,
"path": "/c_basic/code/basic/strfuncs/strlen.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar str1[] = \"To be or not to be\";\r\n\tchar str2[] = \",that is the question\";\r\n\tint count = 0;\r\n\r\n\twhile(str1[count] != '\\0'){\r\n\t\tcount++;\r\n\t}\r\n\tprintf(\"The length of the string \\\"%s\\\" is %d characters.\\n\",str1,count);\r\n\t\r\n\tcount = 0;\r\n\twhile(str2[count]){\t// '\\0'字符的ASCI码是 0,所以也可以这样判断\r\n\t\tcount++;\r\n\t}\r\n\tprintf(\"The length of the string \\\"%s\\\" is %d characters.\\n\",str2,count);\t\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5566878914833069,
"alphanum_fraction": 0.6050955653190613,
"avg_line_length": 17.19512176513672,
"blob_id": "6f9d4188b663e8ecd99844e8397e6de99768325c",
"content_id": "a78441fa0ec2bf21f809cb661b77f418a8209fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 41,
"path": "/c_basic/code/function/alterableParam.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdarg.h>\r\n\r\ndouble average(double num1, double num2,...);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tprintf(\"The length of int is: %ld, the length of double is: %ld\\n\", sizeof(int), sizeof(double));\r\n\r\n\tdouble num1 = 59.4;\r\n\tdouble num2 = 67.7;\r\n\tdouble num3 = 100.1;\r\n\t// double num3 = 100;\r\n\tdouble num4 = 89.1;\r\n\tdouble result = average(num1,num2,num3,num4);\r\n\r\n\tprintf(\"result is: %lf\\n\",result);\r\n\treturn 0;\r\n}\r\n\r\ndouble average(double num1, double num2,...)\r\n{\r\n\tdouble sum = num1 + num2;\r\n\tdouble count = 2;\r\n\tdouble value = 0.0;\r\n\tdouble result = sum / count;\r\n\r\n\tva_list parg;\r\n\r\n\tva_start(parg,num2);\r\n\r\n\twhile((value = va_arg(parg,double) )!= 0.0)\r\n\t{\r\n\t\tsum += value;\r\n\t\tresult = sum / ++count;\r\n\t}\r\n\r\n\tva_end(parg);\r\n\r\n\treturn result;\r\n}"
},
{
"alpha_fraction": 0.52304607629776,
"alphanum_fraction": 0.5290580987930298,
"avg_line_length": 13.65625,
"blob_id": "76b07f0ae3c4741c4c51b8cde913093a4e7eae16",
"content_id": "71bdc6375f3dc126ae8278a6a68dfd6ba3ff66e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 32,
"path": "/c_basic/code/nbio/charo.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"test.txt\";\r\n\tFILE *pfile = fopen(filename,\"a\");\r\n\tint input = 0;\r\n\t\r\n\twhile( (input = getchar()) != EOF )\r\n\t{\r\n\t\tif (input == '@')\r\n\t\t{\r\n\t\t\tbreak;\r\n\t\t}\r\n\t\tputchar(input);\r\n\t\tfputc(input, pfile);\r\n\t}\r\n\r\n\tfclose(pfile);\r\n\r\n\tFILE *pfiler = fopen(filename,\"r\");\r\n\t\r\n\tint chc = 0;\r\n\twhile( (chc = fgetc(pfiler)) != EOF )\r\n\t{\r\n\t\tprintf(\"%c\", chc);\r\n\t}\r\n\tprintf(\"\\n\");\r\n\tfclose(pfiler);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5457271337509155,
"alphanum_fraction": 0.5569714903831482,
"avg_line_length": 21.438596725463867,
"blob_id": "1b661b48170e0e083f3008cb9c18a5e17bcceb7d",
"content_id": "a64c7fbbad24a60901427254a9fe06af1fd2d937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1334,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 57,
"path": "/c_basic/code/structiondata/p11_3.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <ctype.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tstruct horse\r\n\t{\r\n\t\tint age;\r\n\t\tint height;\r\n\t\tchar name[20];\r\n\t\tchar father[20];\r\n\t\tchar mother[20];\t\r\n\t};\r\n\r\n\tstruct horse *phorse[50];\r\n\tint hcount = 0;\r\n\tchar test = '\\0';\r\n\r\n\tfor (int i = 0; i < 50; ++i)\r\n\t{\r\n\t\tprintf(\"\\nYou want to enter details of a%s horse (Y or N)? \",\r\n\t\t\t\thcount ? \"another \":\" \");\r\n\t\tscanf(\" %c\", &test);\r\n\t\tif (tolower(test) == '\\n')\r\n\t\t{\r\n\t\t\tbreak;\r\n\t\t}\r\n\r\n\t\tphorse[hcount] = (struct horse*)malloc(sizeof( struct horse ) );\r\n\t\tprintf(\"\\nEnter the name of the horse: \");\r\n\t\tscanf(\"%s\", phorse[hcount]->name );\r\n\r\n\t\tprintf(\"How old is %s? \",phorse[hcount]->name );\r\n\t\tscanf(\"%d\", &phorse[hcount]->age );\r\n\r\n\t\tprintf(\"\\nHow high is %s (in hands)? \", phorse[hcount]->name );\r\n\t\tscanf(\"%d\",&phorse[hcount]->height );\r\n\r\n\t\tprintf(\"\\nWho is %s's father? \",phorse[hcount]->name );\r\n\t\tscanf(\"%s\", &phorse[hcount]->father );\r\n\r\n\t\tprintf(\"\\nWho is %s's mother? \",phorse[hcount]->name );\r\n\t\tscanf(\"%s\",&phorse[hcount]->mother );\r\n\r\n\t}\r\n\r\n\r\n\tfor (int i = 0; i < hcount; ++i)\r\n\t{\r\n\t\tprintf(\"\\n\\n %s is %d years old, %d hands high,\", phorse[i]->name, phorse[i]->age, phorse[i]->height);\r\n\t\tprintf(\" and has %s and %s as parent.\\n\", phorse[i]->father, phorse[i]->mother);\r\n\t\tfree(phorse[i]);\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5411255359649658,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 14.399999618530273,
"blob_id": "2d9a4494bb77580adc0ebee8c1f92b61d7b163a8",
"content_id": "55312aa1b5a9b121e33892cf8e404e977fe73980",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 15,
"path": "/c_basic/code/basic/datatype/letter_switch.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\nint main(){\nchar ch;\nprintf(\"请输入一个大写字母:\");\nscanf(\"%c\",&ch);\nwhile(!(ch >= 'A' && ch <= 'Z')){\nprintf(\"您的输入有误,请重新输入:\");\nscanf(\"%c\",&ch);\n}\n\nchar big_letter = 'a' - 'A' + ch;\n\nprintf(\"%c\\n\",big_letter);\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.6108786463737488,
"alphanum_fraction": 0.625523030757904,
"avg_line_length": 22,
"blob_id": "b3561f2579c388d942619fb204c8988c9715d5b0",
"content_id": "d5c66c5e680ab5c5e495475aeecb7ba59a68b4ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 478,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 20,
"path": "/c_basic/code/function/p8_4.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "/* Program 8.4 The change taht doesn't */\r\n#include <stdio.h>\r\n// int change(int number);\t\t/* Function prototype */\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint number = 10;\r\n\tint result = 0;\r\n\tresult = change(number);\r\n\tprintf(\"\\nIn main, result = %d\\tnubmer = %d\\n\", result, number);\r\n\treturn 0;\r\n}\r\n\r\n/* Definition of the function change() */\r\nint change(int number)\r\n{\r\n\tnumber = 2 * number;\r\n\tprintf(\"\\nIn function change, number = %d\\n\", number);\r\n\treturn number;\r\n}"
},
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 11.520000457763672,
"blob_id": "25990ffe9132c3100546b327cb7b3f0a8a90a0af",
"content_id": "e2311d75ba2414e73684c50d512d45c8a42ba840",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 25,
"path": "/c_basic/code/function/poifuncarr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint puls(int num);\r\nint minus(int num);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint (*pfunc[5]) (int) = {puls,minus};;\r\n\tint num = 99;\r\n\r\n\tprintf(\"%d\\n\", pfunc[0](num));\r\n\tprintf(\"%d\\n\", pfunc[1](num));\r\n\r\n\treturn 0;\r\n}\r\n\r\nint puls(int num)\r\n{\r\n\treturn ++num;\r\n}\r\n\r\nint minus(int num)\r\n{\r\n\treturn --num;\r\n}"
},
{
"alpha_fraction": 0.5979021191596985,
"alphanum_fraction": 0.6101398468017578,
"avg_line_length": 16.516128540039062,
"blob_id": "cf59933ccd62d48ba3e35853cc2e77a78a117b9c",
"content_id": "ebf2a15be8e4bac66a2dde1368804651df3efddb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 31,
"path": "/c_basic/code/structiondata/visitind.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\t// int *p;\r\n\t// *p = 18;\r\n\ttypedef struct cat\r\n\t{\r\n\t\tchar *name;\r\n\t\tint age;\r\n\t\tchar sex;\r\n\t} Miao;\r\n\r\n\tMiao littleBlack, *orange;\r\n\tlittleBlack.name = \"little black\";\r\n\tlittleBlack.age = 4;\r\n\tlittleBlack.sex = 1;\r\n\r\n\tstruct cat littleWhite;\r\n\r\n\tlittleWhite.name = \"little white\";\r\n\tlittleWhite.age = 3;\r\n\tlittleWhite.sex = 0;\r\n\r\n\tprintf(\"%s\\n\", littleWhite.name);\r\n\tprintf(\"%d\\n\", littleBlack.age);\r\n\torange = &littleBlack;\r\n\torange->name = \"little orange\";\r\n\tprintf(\"%d\\n\", (*orange).age);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5493300557136536,
"alphanum_fraction": 0.5602923035621643,
"avg_line_length": 14.795918464660645,
"blob_id": "315ef04f207b3f24809dac620b29f8db212cb35d",
"content_id": "e73ed7e66a45e673ee1725b180d87b22f4c5282f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 49,
"path": "/c_basic/code/function/valueSend.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nfloat average(float,float);\r\nchar greet_morning(char *);\r\n\r\nfloat greet_night(char *name)\r\n{\r\n\tprintf(\"Hello,good night,%s\\n\",name);\r\n\treturn 0.3f;\r\n}\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\r\n\tchar name[] = \"dayelu\";\r\n\tgreet_morning(name);\r\n\tfloat x_r = 8.0f;\r\n\tfloat y_r = 14.0f;\r\n\r\n\tfloat ave = average(x_r,y_r);\r\n\r\n\tprintf(\"average = %f\\n\", ave);\r\n\tprintf(\"x_r = %f\\n\", x_r);\r\n\tprintf(\"y_r = %f\\n\", y_r);\r\n\tgreet_evening(name);\r\n\tgreet_night(name);\r\n\treturn;\r\n}\r\n\r\nchar greet_morning(char *name)\r\n{\r\n\tprintf(\"Hello,good morning,%s\\n\",name);\r\n\treturn '+';\r\n}\r\n\r\nint greet_evening(char *name)\r\n{\r\n\tprintf(\"Hello,good evening,%s\\n\",name);\r\n\treturn;\r\n}\r\n\r\nfloat average(float x,float y)\r\n{\r\n x++;\r\n ++y;\r\n printf(\"x = %f\\n\", x);\r\n\tprintf(\"y = %f\\n\", y);\r\n return (x + y) / 2.0f;\r\n}"
},
{
"alpha_fraction": 0.5828678011894226,
"alphanum_fraction": 0.5959031581878662,
"avg_line_length": 20.479999542236328,
"blob_id": "c121ae7f6a7d83fe2c1186aa36f9976e623b08ee",
"content_id": "64284fd40e3e3c60e31a822a5a1095c077ac7175",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 25,
"path": "/demowork/code/strdeal.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include <stdlib.h>\n#define MAX_SIZE 100\n\nint main(int argc, char const *argv[])\n{\t\n\tchar *filename = \"test.txt\";\n\tFILE *pfile = fopen(filename,\"r\");\n\t//char *str = {NULL};\n\tchar *str = NULL;\n\tstr = (char *)malloc(50 * sizeof(char));\n\tif(str)\n\t{\n\twhile(fgets(str, MAX_SIZE - 1, pfile) != NULL){\n\t//while(fgets(str, printf(\"%d\",strlen(str)), pfile) != NULL){\n\t\t//printf(\"strlenth is: %d\\n\",strlen(str));\n\t\tprintf(\"%s\", str);\n\t\t}\n\t}else{\n\t\tprintf(\"memory is empty\");\n\t}\n\t//printf(\"\\n\");\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.32523149251937866,
"alphanum_fraction": 0.36921295523643494,
"avg_line_length": 13.464285850524902,
"blob_id": "f1fe864c383e68f348f3211acbaa626e4480c6cb",
"content_id": "fc4a84a5536e14c309c6138e11d361022337e4f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 56,
"path": "/c_basic/code/pointer/arrdemo.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint a[2][2] = {\r\n\t\t\t\t{1,2},\r\n\t\t\t\t{3,4}\r\n\t\t\t\t};\r\n\r\n\tint b[2][2][2] = {\r\n\t\t\t\t\t{\r\n\t\t\t\t\t\t{1,2},\r\n\t\t\t\t\t\t{3,4}\t\t\t\t\t\t\r\n\t\t\t\t\t},\r\n\t\t\t\t\t{\r\n\t\t\t\t\t\t{5,6},\r\n\t\t\t\t\t\t{7,8}\t\t\t\t\t\t\r\n\t\t\t\t\t}\r\n\t\t\t\t};\r\n\r\n\tprintf(\"%d\\n\", b[1][1][1]);\r\n\tprintf(\"%d\\n\", *(*(*(b+1)+1)+1));\r\n\r\n\tprintf(\"%d\\n\", a[1][1]);\r\n\tprintf(\"%d\\n\", *(*(a+1)+1));\r\n\r\n\tprintf(\"%p\\n\", *(a+1));\r\n\tprintf(\"%p\\n\", &a[1]);\r\n\tprintf(\"%d\\n\", **(a+1));\r\n\r\n\tprintf(\"%d\\n\", *a[0]);\r\n\r\n\r\n\tprintf(\"%d\\n\",sizeof a);\r\n\tprintf(\"%d\\n\",sizeof a[0]);\r\n\tprintf(\"%d\\n\",sizeof a[0][0]);\r\n\r\n\tint *ptr = (int *)&a;\r\n\tint *paf = (int *)&a[0];\r\n\r\n\tprintf(\"%d\\n\", **(a));\r\n\tprintf(\"%p\\n\", paf);\r\n\r\n\tprintf(\"%d\\n\", *((int *)&a));\r\n\tprintf(\"%p\\n\\n\", ptr);\r\n\r\n\r\n\tchar *p = \"hello,world!\";\r\n\t\r\n\tprintf(\"%s\\n\", p);\r\n\r\n\tprintf(\"%d\\n\", *(ptr+3));\r\n\r\n\tprintf(\"%d\\n\", *(ptr+1));\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4307692348957062,
"alphanum_fraction": 0.45769229531288147,
"avg_line_length": 13.44444465637207,
"blob_id": "7cccd51c86ae0e79ff35e73ef40f62525ace004a",
"content_id": "e6a7bdfca41d3bd5bed7b1090c7ec72356c7ce3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 304,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 18,
"path": "/c_basic/code/basic/variable/locvar_c.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\n/* 定义全局变量x */\nint x = 1;\nint func(int x){\n /* 函数中的x,y均为局部变量 */\n int y,z;\n z = 2;\n y = x+z;\n printf(\"y=%d\\n\", y);\n return 0;\n}\n\nint main(){\n func(2);\n int y = 10; // 定义局部变量y\n printf(\"x+y=%d\\n\", y+x);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5783132314682007,
"alphanum_fraction": 0.5933734774589539,
"avg_line_length": 18.875,
"blob_id": "c0e412a00f8d8602a24b1f5fdb43c32f5e487937",
"content_id": "5a636e39eb80a9f8c9a74d17decc6ca616dc55cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 16,
"path": "/c_basic/code/nbio/byter.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\t\r\n\tchar *filename = \"myfile.bin\";\r\n\r\n\tlong *data = (long *)malloc(sizeof(long));\r\n\t// long data[10];\r\n\tFILE *ppfile = fopen(filename, \"rb\");\r\n\tfread(data, sizeof(long), 3, ppfile);\r\n\tprintf(\"%ld\\n\", *(data + 2));\r\n\tfclose(ppfile);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.49367088079452515,
"alphanum_fraction": 0.5147679448127747,
"avg_line_length": 12.9375,
"blob_id": "e40f76b4296921c4d8a65af7d51688e50b4ca693",
"content_id": "3072acfa565eff0ba68ebee0819b4a4138f90986",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 237,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 16,
"path": "/c_basic/code/basic/arrays/arrstr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar sayings[][32] = {\r\n\t\t\"good morning\",\r\n\t\t\"good afternoon\",\r\n\t\t\"good evening\"\r\n\t};\r\n\r\n\tfor (int i = 0; i < 3; ++i)\r\n\t{\r\n\t\tprintf(\"%s\\n\", sayings[i]);\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4457831382751465,
"alphanum_fraction": 0.5361445546150208,
"avg_line_length": 19,
"blob_id": "772a887b13588c7fe32f12c09cbb2d41ed0ead0b",
"content_id": "341e3d5d7e0852c44233994e5684aedf9667c98b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 8,
"path": "/c_basic/code/basic/arrays/arr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint arr[10] = {1,2,3,4,5,6,7,8,9};\r\n\tprintf(\"%d\\n\", arr[8]);\r\n\tprintf(\"%d\\n\", arr[40]);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.3741496503353119,
"alphanum_fraction": 0.3945578336715698,
"avg_line_length": 20,
"blob_id": "f19ef4289bf9099588a517418b05f73aab8bc190",
"content_id": "569e55264bcc7890b35338f3ce7197e8e27bcf85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 14,
"path": "/c_basic/code/basic/recycle/playBall.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\nint main(){\n int i = 0; //运球次数\n for(i=1; i<=10; i++){\n printf(\"运球%d次\\n\", i);\n if(i == 5){\n printf(\"哎呀!!坏了!肚子疼...\\n\");\n printf(\"停止训练...\");\n break; //使用break跳出循环\n }\n }\n printf(\"今天的训练到此结束。\");\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3237822353839874,
"alphanum_fraction": 0.4111747741699219,
"avg_line_length": 20.8125,
"blob_id": "4d2bf8b2d2b4ba30a605f16ba7728bc1e3e159a9",
"content_id": "c557de12ae2ebb9ea07268f581e66f3171e87599",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 788,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 32,
"path": "/c_basic/code/basic/condition/when.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\nint main()\n{\n /* 定义需要计算的日期 */\n int year = 2008;\n int month = 8;\n int day = 8;\n /*\n * 请使用switch语句,if...else语句完成本题\n * 计算2008年8月8日这一天,是该年中的第几天\n */\n switch(month-1){\n case 11: day +=30;\n case 10: day +=31;\n case 9: day +=30;\n case 8: day +=31;\n case 7: day +=31;\n case 6: day +=30;\n case 5: day +=31;\n case 4: day +=30;\n case 3: day +=31;\n case 2:\n if((year%4==0&&year%100!=0) || year%400==0){\n day += 29;\n }else{\n day += 28;\n }\n case 1: day +=31; break;\n }\n printf(\"是该年的第%d天。\\n\",day);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.3650793731212616,
"avg_line_length": 11.5,
"blob_id": "01f5bde3d6f00157e1a296ec5395c10a1563f6c6",
"content_id": "4e465721600ec637c3f96d404cb530dc57f4506d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 12,
"path": "/exercises/code/emmm.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n\nint main()\n{\n\tenum color {\n\t\tred,yellow,blue=4,green,white\n\t} c1,c2;\n\tc1=yellow;\n\tc2=white;\n\tprintf(\"%d,%d\\n\",c1,c2);\n\treturn 0;\n} \n"
},
{
"alpha_fraction": 0.4175257682800293,
"alphanum_fraction": 0.4364261031150818,
"avg_line_length": 18.13793182373047,
"blob_id": "a9d51fa41f385cd6044c616745fac655d434ac65",
"content_id": "38a0013aefb541813a6d00147c1d7165ffc97f70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 29,
"path": "/c_basic/code/bio/comma.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint a = (3,5);\r\n\tint b = (5,4);\r\n\tint c = (5,6);\r\n\r\n\tprintf(\"a = %d\\n\", a);\r\n\tprintf(\"b = %d\\n\", b);\r\n\tprintf(\"c = %d\\n\", c);\r\n\r\n\t// printf(\"%d %d %d\\n\", (a++,b++,c++));\r\n\t// printf(\"%d %d\\n\", (a++,b++,c++));\r\n printf(\"%d\\n\", (a++,b++,c++));\r\n\r\n\tprintf(\"a = %d\\n\", a);\r\n\tprintf(\"b = %d\\n\", b);\r\n\tprintf(\"c = %d\\n\", c);\r\n\tif (-3.5)\r\n\t{\r\n\t\tprintf(\"OK!\\n\");\r\n\t}\r\n\tint k=3,s[k];\r\n\t// int k=3;int s[k];\r\n\tprintf(\"The size of int is:%d\\n\", sizeof(int));\r\n\tprintf(\"The size of array s is:%d\\n\", sizeof s);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5722057223320007,
"alphanum_fraction": 0.5825914740562439,
"avg_line_length": 29.625,
"blob_id": "2e6eb798a273ffb760ae21436de77e1a4dcf424f",
"content_id": "2f76ef0e85a2041a61f8f2ff0bf9696ae5a6a41c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2022,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 64,
"path": "/c_basic/code/pointer/p7_13.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "/* Program 7.13 Arrays of Pointer to Strings */\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <string.h>\r\n\r\nconst size_t BUFFER_LEN = 128;\t/* Length of input buffer */\r\nconst size_t NUM_P = 100;\t\t/* maximum number of strings */\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar buffer[BUFFER_LEN];\t/* Input buffer */\r\n\t// char *pS[NUM_P] = {NULL};\t//error: variable-sized object may not be initialized \r\n\t// excess elements in array initializer \r\n\tchar *pS[NUM_P]; \t\t\t/* Array of string pointers */\r\n\tchar *pbuffer = buffer;\t\t/* Poiinter to buffer */\r\n\tint i = 0;\t\t\t\t\t/* Loop counter */\r\n\r\n\tprintf(\"\\nYou can nter up to %u messages each up to %u characters.\", NUM_P, BUFFER_LEN-1);\r\n\t\r\n\t/* Read the strings from the keyboard */\r\n\tfor (i = 0; i < NUM_P; ++i)\r\n\t{\r\n\t\tpbuffer = buffer; \t\t/* Set pointer to beginning of buffer. */\r\n\r\n\t\tprintf(\"\\nEnter %s message, or press Enter to end\\n\", i > 0 ? \"another\" : \"a\");\r\n\t\t/* Read a string of up to BUFFER_LEN characters */\r\n\t\twhile((pbuffer-buffer < BUFFER_LEN-1) && \r\n\t\t\t((*pbuffer++ = getchar()) != '\\n'));\r\n\t\t\r\n\t\t/* Check for empty line indicating end of input */\r\n\t\tif ((pbuffer-buffer) < 2)\r\n\t\t{\r\n\t\t\tbreak;\r\n\t\t}\r\n\r\n\t\t/* Check for string too long */\r\n\t\tif ( ( pbuffer - buffer ) == BUFFER_LEN && *(pbuffer-1) != '\\n')\r\n\t\t{\r\n\t\t\tprintf(\"\\nString too long - maximum %d characters allowed.\", BUFFER_LEN);\r\n\t\t\ti--;\r\n\t\t\tcontinue;\r\n\t\t}\r\n\t\t*(pbuffer - 1) = '\\0';\t\t/* Add terminator */\r\n\t\tpS[i] = (char*)malloc(pbuffer-buffer);\t/* Get memory for string */\r\n\t\tif (pS[i] == NULL)\r\n\t\t\t{\r\n\t\t\t\tprintf(\"\\nOut of memory - ending program\");\r\n\t\t\t\treturn 1;\t\t\t/* ...Exit if we didn't */\r\n\t\t\t}\r\n\t\t\t/* Copy string from buffer to new memory */\t\r\n\t\t\tstrcpy(pS[i],buffer);\r\n\t}\r\n\t\r\n\t/* Output all the strings */\r\n\tprintf(\"\\nIn reverse order, the strings you entered are :\\n\");\r\n\twhile(--i >= 0)\r\n\t{\r\n\t\tprintf(\"%s\\n\", pS[i]);\t/* Display strings last to first */\r\n\t\tfree(pS[i]);\t\t\t/* Release the memory we got */\r\n\t\tpS[i] = NULL;\t\t\t/* Set pointer back to NULL for safety */\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5204892754554749,
"alphanum_fraction": 0.538226306438446,
"avg_line_length": 15.052083015441895,
"blob_id": "7bff467b30d68dd7b8b7f37e630125f558514f41",
"content_id": "ef706974f9b65378f19cd59d3151d8cb630a1e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1635,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 96,
"path": "/c_basic/code/function/p8_6.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "/* Program 8.6 The functional approach to string sorting */\r\n#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <stdbool.h>\r\n#include <string.h>\r\n\r\nbool str_in(char **);\r\nvoid str_sort(const char *[],int);\r\nvoid swap(void **p1,void **p2);\r\nvoid str_out(char *[],int);\r\n\r\nconst size_t BUFFER_LEN = 256;\r\nconst size_t NUM_P = 50;\r\n\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *pS[NUM_P];\r\n\tint count = 0;\r\n\tprintf(\"\\nEnter successive lines,pressing Enter at the end of \"\r\n\t\t\t\" each line.\\nJust press Enter to end.\\n\");\r\n\r\n\tfor (count = 0; count < NUM_P; ++count)\r\n\t{\r\n\t\tif (!str_in(&pS[count]))\r\n\t\t{\r\n\t\t\tbreak;\r\n\t\t}\r\n\t}\r\n\t\r\n\tstr_sort(pS,count);\r\n\tstr_out(pS,count);\r\n\treturn 0;\r\n}\r\n\r\nbool str_in(char **pString)\r\n{\r\n\tchar buffer[BUFFER_LEN];\r\n\tif (gets(buffer) == NULL)\r\n\t{\r\n\t\tprintf(\"\\nEnter reading string.\\n\");\r\n\t\texit(1);\t/* Error on input so exit */\r\n\t}\r\n\r\n\tif (buffer[0] == '\\0')\r\n\t{\r\n\t\treturn false;\r\n\t}\r\n\r\n\t*pString = (char *)malloc(strlen(buffer) + 1);\r\n\r\n\tif(*pString == NULL){\r\n\t\tprintf(\"\\nOut of memory.\");\r\n\t\texit(1);\r\n\t}\r\n\r\n\tstrcpy(*pString, buffer);\r\n\treturn true;\r\n}\r\n\r\nvoid str_sort(const char *p[], int n)\r\n{\r\n\tchar *pTemp = NULL;\r\n\tbool sorted = false;\r\n\twhile(!sorted)\r\n\t{\r\n\t\tsorted = true;\r\n\t\tfor (int i = 0; i < n-1; ++i)\r\n\t\t{\r\n\t\t\tif (strcmp(p[i],p[i+1]) > 0)\r\n\t\t\t{\r\n\t\t\t\tsorted = false;\r\n\t\t\t\tswap(&p[i],&p[i+1]);\r\n\t\t\t}\r\n\t\t}\r\n\t}\r\n}\r\n\r\nvoid swap(void **p1,void **p2)\r\n{\r\n\tvoid *pt = *p1;\r\n\t*p1 = *p2;\r\n\t*p2 = pt;\r\n}\r\n\r\nvoid str_out(char *p[], int n)\r\n{\r\n\tprintf(\"\\nYour input sorted in order is:\\n\\n\");\r\n\tfor (int i = 0; i < n; ++i)\r\n\t{\r\n\t\tprintf(\"%s\\n\", p[i]);\r\n\t\tfree(p[i]);\r\n\t\tp[i] = NULL;\r\n\t}\r\n\treturn;\r\n}"
},
{
"alpha_fraction": 0.5578464865684509,
"alphanum_fraction": 0.5658648610115051,
"avg_line_length": 19.292682647705078,
"blob_id": "9c5f188e74d7685a75c2af47dd3f55babf4a1e96",
"content_id": "18abf43dbf112ae5799396d8dac7906fac3305ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 41,
"path": "/c_basic/code/nbio/strdeal.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\n#include <stdlib.h>\r\n#include <wchar.h>\r\n\r\n#define MAX_SIZE 100\r\n\r\n\r\nchar *read_line(char const *filename)\r\n{\r\n\t// char *filename = \"test.txt\";\r\n\tFILE *pfile = fopen(filename,\"r\");\r\n\t//char *str = {NULL};\r\n\tchar *str = NULL;\r\n\tstr = (char *)malloc(50 * sizeof(char));\r\n\tif(str)\r\n\t{\r\n\t\twhile(fgets(str, MAX_SIZE - 1, pfile) != NULL){\r\n\t\t//while(fgets(str, printf(\"%d\",strlen(str)), pfile) != NULL){\r\n\t\t\t//printf(\"strlenth is: %d\\n\",strlen(str));\r\n\t\t\t// wprintf(L\"%ls\", str);\r\n\t\t\tprintf(\"%s\", str);\r\n\t\t\t}\r\n\t}else{\r\n\t\tprintf(\"memory is empty\");\r\n\t}\r\n\t// perror(filename);\r\n\t// fclose(pfile);\t// 为什么一关闭就报错???????\r\n}\r\n\r\n\r\nint main(int argc, char const *argv[])\r\n{\t\r\n\tchar *filename = \"test.txt\";\r\n\tread_line(filename);\r\n\r\n\tprintf(\"%ld\\n\", sizeof(size_t));\r\n\tprintf(\"%ld\\n\", sizeof(int));\r\n\tprintf(\"%ld\\n\", sizeof(long));\r\n\treturn 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.39032813906669617,
"alphanum_fraction": 0.42487046122550964,
"avg_line_length": 23.173913955688477,
"blob_id": "259bc8d55cae88d43fbfff9c4926716a259e5a92",
"content_id": "810db814c302d62759b5336dab3df5e767efe555",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 23,
"path": "/c_basic/code/basic/operator/op.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n int num = 9;\r\n int ten = 10;\r\n num /= 3;\r\n printf(\"num /= 3 运算之后 = %d\\n\", num);\r\n num *= 3;\r\n printf(\"num *= 3 运算之后 = %d\\n\", num);\r\n num %= 3;\r\n printf(\"num %%= 3 运算之后 = %d\\n\", num);\r\n ten <<= 3;\r\n printf(\"ten <<= 3 运算之后 = %d\\n\", ten);\r\n ten >>= 3;\r\n printf(\"ten >>= 3 运算之后 = %d\\n\", ten);\r\n ten &= 3;\r\n printf(\"ten &= 3 运算之后 = %d\\n\", ten);\r\n ten ^= 3;\r\n printf(\"ten ^= 3 运算之后 = %d\\n\", ten);\r\n ten |= 3;\r\n printf(\"ten |= 3 运算之后 = %d\\n\", ten);\r\n return 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5595375895500183,
"alphanum_fraction": 0.5838150382041931,
"avg_line_length": 15,
"blob_id": "b6f07a6409f0560b28d3ae4016ec1b8031366893",
"content_id": "c1d534ab53d6fe5c580919047cb55e791c32a2ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 865,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 51,
"path": "/c_basic/code/structiondata/struct.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tstruct\r\n\t{\r\n\t\tint age;\r\n\t\tchar name[20];\r\n\t} Miao;\r\n\r\n\tstruct horse\r\n\t{\r\n\t\tint age;\r\n\t\tint height;\r\n\t} Sliver;\r\n\r\n\tstruct horse duantui[20]; \r\n\r\n\tstruct xuhanhorse\r\n\t{\r\n\t\tint age;\r\n\t\tint height;\r\n\t\tchar name[20];\r\n\t\tchar mother[20];\r\n\t\tchar father[20];\r\n\t} Dobbin = {\r\n\t\t\t\t24, 17, \"Dobbin\", \"Trigger\", \"Flossie\"\r\n\t\t\t\t};\r\n\r\n\tstruct xuhanhorse Piebald, Bandy;\r\n\r\n\tstruct xuhanhorse Trigger = {\r\n\t\t\t30, 15, \"Trigger\", \"Smith\", \"Wesson\"\r\n\t\t\t};\r\n\r\n\tDobbin.age = 12;\r\n\r\n\tstruct xuhanhorse *phorse;\r\n\r\n\tphorse = &Dobbin;\r\n\tint *p_age = &Dobbin.age;\r\n\r\n\tprintf(\"%p\\n\",phorse);\r\n\tprintf(\"%p\\n\",p_age);\r\n\t\r\n\tprintf(\"The size of xuhanhorse is: %d\\n\", sizeof(Piebald));\r\n\tprintf(\"The size of xuhanhorse is: %d\\n\", sizeof(struct xuhanhorse));\r\n\tprintf(\"The Dobbin's age is: %d.\\n\", Dobbin.age);\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.3756345212459564,
"alphanum_fraction": 0.46192893385887146,
"avg_line_length": 14.583333015441895,
"blob_id": "f49db831213f31e57a050b48fe48cfe4d9e1736d",
"content_id": "33bd50649ecf331a5cc4210172742bcd0f415ae3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 12,
"path": "/c_basic/code/basic/arrays/multi_arr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint arr[3][3] = {\r\n\t\t{1,3,4},\r\n\t\t{2,5,8},\r\n\t\t{12,6,9}\r\n\t};\r\n\tprintf(\"%p\\n\", &arr[0][2]);\r\n\tprintf(\"%p\\n\", &arr[1][0]);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.56623375415802,
"alphanum_fraction": 0.5948051810264587,
"avg_line_length": 15.590909004211426,
"blob_id": "eaa208f4987ba3efc46fbdaed8b8305ef07a5c2a",
"content_id": "e7abf68db3fadbac6bbf27552003e851d16ef777",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 22,
"path": "/c_basic/code/function/p8_8.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nlong *IncomePuls(long* pPay);\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tlong your_pay = 30000L;\r\n\tlong* pold_pay = &your_pay;\r\n\tlong* pnew_pay = NULL;\r\n\tpnew_pay = IncomePuls(pold_pay);\r\n\r\n\tprintf(\"Old pay = $%ld\\n\", *pold_pay);\r\n\tprintf(\"New pay = $%ld\\n\", *pnew_pay);\r\n\r\n\treturn 0;\r\n}\r\n\r\nlong* IncomePuls(long* pPay)\r\n{\r\n\t*pPay += 10000L;\r\n\treturn pPay;\r\n}"
},
{
"alpha_fraction": 0.41389432549476624,
"alphanum_fraction": 0.48532289266586304,
"avg_line_length": 23.33333396911621,
"blob_id": "1d2f8cedbe7494f3870427b52da68cf08bdf2ceb",
"content_id": "313d7ada8512e012cff955c1400d34b70e910088",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1256,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 42,
"path": "/c_basic/code/basic/condition/when_c.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\nint main(){\n // 需计算的年份\n int year = 2008;\n // 需计算的月份\n int month = 8;\n // 需计算的日\n int day= 8;\n // 定义总天数和判断是否是闰年的状态位\n int sum, flag;\n // 使用switch语句计算月数的天数\n switch(month){\n case 1 : sum = 0;break;\n case 2 : sum = 31; break;\n case 3 : sum = 59; break;\n case 4 : sum = 90; break;\n case 5 : sum = 120; break;\n case 6 : sum = 151; break;\n case 7 : sum = 181; break;\n case 8 : sum = 212; break;\n case 9 : sum = 243; break;\n case 10: sum = 273; break;\n case 11: sum = 304; break;\n case 12: sum = 334; break;\n default:\n printf(\"一年当中只有12个月!\");break;\n }\n //计算天数\n sum = sum + day;\n //当该年为瑞年时,将状态位设置为1,否则为0\n if(year%400 == 0 || (year%4 == 0 && year%100 != 0)){\n flag = 1;\n }else{\n flag = 1;\n }\n //当需计算的日期是闰年并且计算的月份大于2月时,计算的天数自动加1\n if(flag==1 && month>2){\n sum++;\n }\n printf(\"%d年%d月%d日时该年的第%d天。\\n\",year,month,day,sum);\n return 0;\n}\n"
},
{
"alpha_fraction": 0.49677419662475586,
"alphanum_fraction": 0.5435484051704407,
"avg_line_length": 21.037036895751953,
"blob_id": "738c921456859058d4ebb5d40479c5e6e90ec28d",
"content_id": "336808886a33a609ca4f870c80ebea57ebb18516",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 27,
"path": "/c_basic/code/basic/strfuncs/compare.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar str1[] = \"hello,world!\";\r\n\tchar str2[] = \"hello,moon!\";\r\n\t//strncmp(str1,str2,n)\r\n\tif (strcmp(str1,str2) < 0)\r\n\t{\t\r\n\t\tprintf(\"%s\\n\", str1);\r\n\t\tprintf(\"%s\\n\", str2);\r\n\t\tprintf(\"%d\\n\", strcmp(str1,str2));\r\n\t\tprintf(\"str1 < str2\\n\");\r\n\t}else if (strcmp(str1,str2) > 0)\r\n\t{\r\n\t\tprintf(\"%s\\n\", str1);\r\n\t\tprintf(\"%s\\n\", str2);\r\n\t\tprintf(\"%d\\n\", strcmp(str1,str2));\r\n\t\tprintf(\"str1 > str2\\n\");\r\n\t}else{\r\n\t\tprintf(\"%s\\n\", str1);\r\n\t\tprintf(\"%s\\n\", str2);\r\n\t\tprintf(\"%d\\n\", strcmp(str1,str2));\r\n\t\tprintf(\"str1 = str2\\n\");\r\n\t}\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.47756409645080566,
"alphanum_fraction": 0.49038460850715637,
"avg_line_length": 12.952381134033203,
"blob_id": "c77d55afbd2450f419b321e313160346a7ea706c",
"content_id": "7ec8e42e2c7c3a83616d600a32a870cd5f7cc3ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/c_basic/code/function/poiarr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar* str[] = {\"nibupei\",\"erpilian\"};\r\n\tint n = 5;\r\n\tstr_out(str, n);\r\n\treturn 0;\r\n}\r\n\r\nint str_out(char *p[], int n)\r\n{\r\n\tfor (int i = 0; i < n; ++i)\r\n\t{\r\n\t\tprintf(\"%s\\n\", *p);\r\n\t\tfree(*p);\r\n\t\t*p++ = NULL;\r\n\t}\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4839319586753845,
"alphanum_fraction": 0.48582231998443604,
"avg_line_length": 10.642857551574707,
"blob_id": "5f16d6dda85d78de25540746f02acc8cce4196d5",
"content_id": "755f95bae09280d91a6f99cd55f7d68a750cce7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 42,
"path": "/c_basic/code/nbio/open_cls.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const **argv)\r\n{\r\n\tint exit_status = EXIT_SUCCESS;\r\n\r\n\tFILE *input;\r\n\r\n\t/*\r\n\t** 当还更多文件名时...\r\n\t*/\r\n\twhile( *++argv != NULL )\r\n\t/*\r\n\t** 试图打开这个文件.\r\n\t*/\r\n\t{\r\n\t\tinput = fopen( *argv, \"r\");\r\n\r\n\t\tif ( input = NULL )\r\n\t\t{\r\n\t\t\tperror( *argv );\r\n\t\t\texit_status = EXIT_FAILURE;\r\n\t\t\tcontinue;\r\n\t\t}\r\n\r\n\t/*\r\n\t** 正在处理这个文件\r\n\t*/\r\n\r\n\t\t/*\r\n\t\t** 关闭这个文件(期望不出错).\r\n\t\t*/\t\t\r\n\t\tif (fclose(input) != 0)\r\n\t\t{\r\n\t\t\tperror(\"fclose\");\r\n\t\t\texit(EXIT_FAILURE);\r\n\t\t}\r\n\r\n\t}\r\n\treturn exit_status;\r\n}"
},
{
"alpha_fraction": 0.6359447240829468,
"alphanum_fraction": 0.6405529975891113,
"avg_line_length": 18.727272033691406,
"blob_id": "ed101f76ee5def5e73eb9af3631c567a269731bb",
"content_id": "d879033193140874e5fd6811874d8cd8d4cc9571",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 11,
"path": "/c_basic/code/basic/datatype/wchar_t.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\n#include<stddef.h>\t/*wchar_t类型定义在此头文件中 */\nint main(){\nwchar_t w_ch = L'A';\nprintf(\"%lc\\n\",w_ch);\nprintf(\"请输入一个wchar_t类型的字符:\");\nwchar_t wch;\nscanf(\"%lc\",&wch);\nprintf(\"您输入的字符为:%d\\n\",wch);\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6035714149475098,
"avg_line_length": 18.14285659790039,
"blob_id": "8d510518eae34ba697a2a09a6aae371b1115fdd7",
"content_id": "b1a848cc19861c5327dddc34ed0227594ed3805c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/c_basic/code/preprocessor/doubincl.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include \"names.h\"\r\n#include \"names.h\"\r\n#include \"functions.h\"\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tgreet();\r\n\tprintf(\"%d\\n\", SLEN);\r\n\tnames winner = {\"Less\", \"Ismoor\"};\r\n\tprintf(\"The winner is %s %s\\n\", winner.first, \r\n\t\twinner.last);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4787878692150116,
"alphanum_fraction": 0.5060606002807617,
"avg_line_length": 17.52941131591797,
"blob_id": "a1621b8065e47a3f86373262acf2620945d63a5a",
"content_id": "970116589be7c1527c294b39f2fd50f06e36a41e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 414,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/c_basic/code/pointer/point.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint a =100;\r\n\tint b = 101;\r\n\t// int *p = &a;\r\n\tint *const p = &a;\t\t\t//指针本身不可改变,但是指向指针的变量可改变\r\n\t// const int *p = &a;\t\t//指针锁指向的变量不可改变,但是指针可以改变\r\n\tprintf(\"%d\\n\", a);\r\n\tprintf(\"%d\\n\", *p);\r\n\t// p = &b;\r\n\t*p = 99;\r\n\tprintf(\"%d\\n\", a);\r\n\tprintf(\"%d\\n\", *p);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6627634763717651,
"alphanum_fraction": 0.6861826777458191,
"avg_line_length": 29.5,
"blob_id": "608c542f74c638ca7f861f396a03fcc3cfb48400",
"content_id": "b6c03fb7b3f20eb21b8fd4e670a52767c7142996",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 14,
"path": "/c_basic/code/basic/datatype/length.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include<stdio.h>\nint main(){\nprintf(\"char 的长度是:%ld\\n\",sizeof(char));\nprintf(\"short 的长度是:%ld\\n\",sizeof(short));\nprintf(\"int 的长度是:%ld\\n\",sizeof(int));\nprintf(\"long 的长度是:%ld\\n\",sizeof(long));\nprintf(\"long long 的长度是:%ld\\n\",sizeof(long long));\nprintf(\"float 的长度是:%ld\\n\",sizeof(float));\nprintf(\"double 的长度是:%ld\\n\",sizeof(double));\n\nprintf(\"一个随机整数的默认长度是:%ld\\n\",sizeof(1213));\nprintf(\"一个随机小数的默认长度是:%ld\\n\",sizeof(123.12));\nreturn 0;\n}\n"
},
{
"alpha_fraction": 0.4845360815525055,
"alphanum_fraction": 0.5429553389549255,
"avg_line_length": 18.928571701049805,
"blob_id": "3c41601206a966544d3eeb9663ac6c7797c5cc48",
"content_id": "4a372f09b9a3f33859d6d2536f6b17804f8f4c80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 14,
"path": "/c_basic/code/preprocessor/mline.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main()\r\n{\r\n\t#line 90 \"digitmap.y\"\r\n printf(\"current line number %d ,current file %s\\n\", __LINE__, __FILE__);\r\n\r\n printf(\"TIME is %s,DATE is %s\\n\", __TIME__, __DATE__);\r\n\r\n #if __STDC_VERSION__ != 201112111111L\r\n #error Not C11\r\n #endif\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5361111164093018,
"alphanum_fraction": 0.550000011920929,
"avg_line_length": 17.052631378173828,
"blob_id": "53ed9b8a7fdf5a75f424c39cded6dfafba200f1f",
"content_id": "794a0d4ed71ca10bc21dc89c26f474c0a1ba1fc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 19,
"path": "/c_basic/code/bio/scanf3.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\t\r\n\tchar *str = NULL;\r\n\tstr = (char *)malloc(5 * sizeof(char));\r\n\tif (str)\r\n\t{\r\n\t\tprintf(\"Please a serial characters.\\n\");\r\n\t\tscanf(\"%[2,3,5,r,t,A,h]\",str);\r\n\t\tprintf(\"str = %s\\n\", str);\r\n\t\tfree(str);\r\n\t\tstr = NULL;\r\n\t}else{\r\n\t\tprintf(\"memory is empty.\\n\");\r\n\t}\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6583333611488342,
"alphanum_fraction": 0.6833333373069763,
"avg_line_length": 9.909090995788574,
"blob_id": "7620a9fea46edee8e89c9f1d426551d09cda877e",
"content_id": "58d673253bbe49b3567076444ead276e4f294a63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 11,
"path": "/shell/eixsts",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nif [ -f input11 ]; then\n echo wozai\nelif test -f args; then\n echo args exists\nelse\n echo meiyou\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.608832836151123,
"alphanum_fraction": 0.6151419281959534,
"avg_line_length": 19.266666412353516,
"blob_id": "08b55d8d407c350c5424a2aac443dbf5c0dbf28f",
"content_id": "ffc278e2fcd85ae10b8d8e47dcb2b6fd15e8ddde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 15,
"path": "/c_basic/code/file/file.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"test1.txt\";\r\n\tFILE *pfile = fopen(filename,\"w\");\r\n\tfputc('c',pfile);\r\n\tfclose(pfile);\r\n\r\n\tFILE *pfiler = fopen(filename,\"r\");\r\n\tchar mchar = fgetc(pfiler);\r\n\tprintf(\"%c\\n\", mchar);\r\n\tfclose(pfiler);\r\n\t// remove(filename)\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.45838358998298645,
"alphanum_fraction": 0.477683961391449,
"avg_line_length": 18.268293380737305,
"blob_id": "ebe04a5f8d6e6e0cadecd8908147d55692cb0613",
"content_id": "edb72f5151c06f659d2a357242acd2001e83f830",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 851,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 41,
"path": "/c_basic/code/pointer/malloc.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\t//int *pNumber = (int *)malloc(10 * sizeof(int));\r\n\tint *pNumber = NULL;\r\n\tpNumber = (int *)realloc(pNumber ,10 * sizeof(int));\r\n\r\n\tint *pNum = NULL;\r\n\r\n\tpNumber = (int *)calloc(10 ,sizeof(int));\r\n\r\n\tif(pNumber == NULL){\r\n\t\tprintf(\"内存不足!\");\r\n\t}\r\n\r\n\tif(pNumber == NULL){\r\n\t\tprintf(\"内存不足!\");\r\n\t}\r\n\r\n\t// printf(\"%d\\n\", sizeof pNumber);\r\n\r\n\t*pNumber = 1;\r\n\t*(pNumber + 1) = 2;\r\n\tfor (int i = 0; i < 10; ++i)\r\n\t{\r\n\t\tprintf(\"%d\\n\", *(pNumber + i));\r\n\t}\r\n\t// printf(\"%x\\n\", pNumber);\r\n\t// printf(\"%d\\n\", *pNumber);\r\n\tfree(pNumber);\r\n\tprintf(\"===================================================\\n\");\r\n\t// printf(\"%x\\n\", pNumber);\r\n\t// printf(\"%d\\n\", *pNumber);\r\n\tfor (int i = 0; i < 10; ++i)\r\n\t{\r\n\t\tprintf(\"%d\\n\", *(pNumber + i));\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.4743589758872986,
"alphanum_fraction": 0.504273533821106,
"avg_line_length": 13.733333587646484,
"blob_id": "cb669a0a49804e36a667487eaa143a0c5d6ea541",
"content_id": "bc791389c155219e6577b163fd591ac4dfa502d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 15,
"path": "/c_basic/code/basic/random/random.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tint chosen = 0;\r\n\tint num[10];\r\n\tfor (int i = 0; i < 10; ++i)\r\n\t{\r\n\t\tnum[i] = rand();\r\n\t\tprintf(\"%d\\t\", num[i]);\r\n\t}\r\n\tprintf(\"\\n\");\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5189075469970703,
"alphanum_fraction": 0.5315126180648804,
"avg_line_length": 18.782608032226562,
"blob_id": "70fba9088fa46c854059c6fc060bab1bfa271aac",
"content_id": "b4bc24abcf306604cb2049f0c82832e8a0169b7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 23,
"path": "/c_basic/code/bio/scanf4.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\t\r\n\tchar *str = NULL;\r\n\tchar ch = NULL;\r\n\tchar ch1 = NULL;\r\n\tstr = (char *)malloc(5 * sizeof(char));\r\n\tif (str)\r\n\t{\r\n\t\tprintf(\"Please a serial characters and a char.\\n\");\r\n\t\tscanf(\" %c, %c, %[^,]\", &ch, &ch1, str);\r\n\t\tprintf(\"str = %s\\n\", str);\r\n\t\tprintf(\"ch = %c\\n\", ch);\r\n\t\tprintf(\"ch1 = %c\\n\", ch1);\r\n\t\tfree(str);\r\n\t\tstr = NULL;\r\n\t}else{\r\n\t\tprintf(\"memory is empty.\\n\");\r\n\t}\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.557692289352417,
"alphanum_fraction": 0.5730769038200378,
"avg_line_length": 18.153846740722656,
"blob_id": "15b680b45f8de9eebf8e5f02dc614f503f2cfc04",
"content_id": "db790d80b31a1e0a3733f0201e08eb2925143296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 13,
"path": "/c_basic/code/file/fscanf.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"test.txt\";\r\n\tint pnum = 0;\r\n\tchar *pstr = NULL;\r\n\tFILE *pfile = fopen(filename, \"r\");\r\n\r\n\tfscanf(pfile, \"%d %s\", &pnum, pstr);\r\n\tprintf(\"%d %10s\\n\", pnum, pstr);\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.5522222518920898,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 17.148935317993164,
"blob_id": "c73ec3ea3393c3aa9fbc3ccbf31ce1e2a9d17fba",
"content_id": "53b2dfceb235d3955014132b646cc3acf2d315cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1092,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 47,
"path": "/c_basic/code/nbio/fgets.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n#include <string.h>\r\n#define\tMAX_SIZE 100\r\n\r\n// char *gets_in(char *str)\r\n// {\r\n// \tprintf(\"%p\\n\", str);\r\n// \tputs(\"请输入一串字符:\");\r\n// \tfgets(str, 5, stdin);\r\n// \tprintf(\"%s\\n\", str);\r\n// \treturn str;\r\n// }\r\n\r\n\r\nchar *read_line(char const *filename)\r\n{\r\n\tFILE *pfile = fopen(filename,\"r\");\r\n\tchar *str = NULL;\r\n\tstr = (char *)malloc(50 * sizeof(char));\r\n\t\r\n\tif(str)\r\n\t{\r\n\t\tfgets(str, MAX_SIZE - 1, pfile);\r\n\t\treturn str;\r\n\r\n\t}else{\r\n\t\treturn NULL;\r\n\t}\r\n\t// fclose(pfile);\r\n}\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *filename = \"test2.txt\";\r\n\r\n\tchar *str = read_line(filename);\r\n\tprintf(\"%s\\n\", str);\r\n\t// char *s = \"nihao\";\r\n\t// printf(\"%p\\n\", s);\r\n\t// gets_in(s);\t\t\t//为什么使用调用函数就会出错呢?是不是跟 绝对不返回 函数 本地指针原则有关?\r\n\tputs(\"请输入一串字符:\");\r\n\tfgets(str, 1000, stdin);\t//读取第二个参数,即指定输出长度减一个,设为k个字符,若k大于给定字符串str的长度则输出整个字符串。\r\n\tprintf(\"%s\\n\", str);\r\n\t\r\n\treturn 0;\r\n}\r\n"
},
{
"alpha_fraction": 0.5646981000900269,
"alphanum_fraction": 0.6091572642326355,
"avg_line_length": 30.106382369995117,
"blob_id": "0c366b378a63caf07390f9f9e777e58b0e8cb40c",
"content_id": "e4e58f07e0577cb86185b81c41e2492f39ddf8fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1925,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 47,
"path": "/c_basic/code/basic/strfuncs/strlicfunc.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "GB18030",
"text": "#include <stdio.h>\r\n#include <string.h>\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar str1[] = \"To be or not to be,\";\r\n\tchar str2[] = \"this is a question.\";\r\n\t// char str3[] = strcpy(str1,str2);\r\n\r\n\tprintf(\"%s\\n\", strcat(str1,str2));\t//把str2添加到str2末尾,并且返回str1\r\n\r\n\tprintf(\"strcat(str1,str2)后str1的值:%s\\n\", str1);\r\n\tprintf(\"strcat(str1,str2)后str2的值:%s\\n\", str2);\r\n\t//printf(\"%s\\n\", strncat(str1,str2,10));\r\n\t//printf(\"strncat(str1,str2,10)后str1的值:%s\\n\", str1);\r\n\r\n\tprintf(\"str1 的大小:%d,str1的长度:%d\\n\", sizeof str1, strlen(str1));\r\n\tprintf(\"str2 的大小:%d,str2的长度:%d\\n\", sizeof str2, strlen(str2));\r\n\r\n\tif (sizeof str1 >= sizeof str2)\t\t//使用时需要判断被取代的数组长度是否大于取代数组的大小\r\n\t{\r\n\t\tprintf(\"%s\\n\", strcpy(str1,str2));\r\n\t\tprintf(\"strcpy(str1,str2)后str1的值:%s\\n\", str1);\r\n\t}else{\r\n\t\tprintf(\"被取代数组比替代数组小\\n\");\r\n\t}\r\n\t/* 第三个参数是一个整型,指定了要复制的字符数。 */\r\n\t/* 当源字符串(要取代的字符串)的长度大于要复制的字符串(被取代的字符串)数时, */\r\n\t/*strncpy()函数就不会在目标字符串中添加字符 '\\0' ,因此目标字符串没有终止字符就会出现以下情况 */\r\n\tprintf(\"%s\\n\", strncpy(str1,str2,5));\r\n\r\n\tchar str3[] = \"hello\";\r\n\tchar str4[] = \"very good\";\r\n\r\n\tprintf(\"%s\\n\", strncpy(str4,str3,5));\r\n\tprintf(\"strncpy(str4,str3,5)后str4的值:%s\\n\", str4 );\r\n\tprintf(\"%s\\n\", strncpy(str3,str4,3));\r\n\tprintf(\"strncpy(str3,str4,3)后str4的值:%s\\n\", str4 );\r\n\r\n\tconst char greet[] = \"hello,world!\";\r\n\r\n\tchar hello[] = {'h','e','l','l','o',',','w','o','r','l','d','!'};\r\n\tprintf(\"字符串 \\\"%s\\\"的大小是 %d\\n\",greet, sizeof greet );\r\n\tprintf(\"字符串 \\\"%s\\\"的长度是 %d\\n\",greet, strlen(greet) );\r\n\tprintf(\"字符数组 \\\"%s\\\"的大小是 %d\\n\",hello, sizeof hello );\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6113636493682861,
"alphanum_fraction": 0.6147727370262146,
"avg_line_length": 30.66666603088379,
"blob_id": "185d828a7e6def03c88f597ca5c0584ef789a32d",
"content_id": "44c23f46d45d8808d50f6805395391e0966bef2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 880,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 27,
"path": "/c_basic/code/basic/strfuncs/strrchr.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <string.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\tchar *str = \"How are you? Are you happy now?\";\r\n\tchar key = 'a';\t\t//the second param is int or char type, a single character.\r\n\tchar *key_str = \"happy\";\r\n\tprintf(\"The search string is:\\n%s\\n\", str);\r\n\tprintf(\"The key word is:\\n%c\\n\", key);\r\n\tprintf(\"The key string is:\\n%s\\n\", key_str);\r\n\tchar *result = NULL;\r\n\tresult = strchr(str, key);\r\n\tprintf(\"The result of strchr(str, key) is: %p\\n\", result);\r\n\tprintf(\"After exectuing strchr(str, key), the next letter of result is: %c\\n\", *(result + 1));\r\n\r\n\tchar *res = NULL;\r\n\tres = strrchr(str, key);\r\n\tprintf(\"The result of strrchr(str, key) is: %p\\n\", res);\r\n\tprintf(\"After exectuing strrchr(str, key), the next letter of res is: %c\\n\", *(res + 1));\r\n\r\n\tif(strstr(str,key_str)){\r\n\t\tprintf(\"str \\\"%s\\\" was found.\\n\", key_str);\r\n\t}\r\n\r\n\treturn 0;\r\n}"
},
{
"alpha_fraction": 0.6504064798355103,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 8.461538314819336,
"blob_id": "1c6ebb12227ada62def1d1d0035e3e57ae4ce221",
"content_id": "1f93bc6dd1bee10ae0891292c7f828130ba9ee62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 123,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 13,
"path": "/shell/recyc",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nfiles=`ls`\nfile=$(ls)\nset $file\necho $3\necho $files\necho $file\nfor foo in bar $file\ndo\n echo $foo\ndone\n\nexit 0\n"
},
{
"alpha_fraction": 0.4830508530139923,
"alphanum_fraction": 0.5112994313240051,
"avg_line_length": 10.0625,
"blob_id": "06c524b813c751619759a6c562ebd8212dd09af6",
"content_id": "a1e65d24f65c9b965a08906ff5cbe04882f21677",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 354,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 32,
"path": "/exercises/code/gdc.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\n\nint gdc(int m,int n);\n\nint main()\n{\n\tint c=gdc(27,9);\n\tprintf(\"The greatest factor is: %d\\n\",c);\n\tprintf(\"The zuixiao gongbeishu is: %d\\n\",27*9/c);\n\treturn 0;\n}\n\nint gdc(int m,int n)\n{\n\tint k = 0;\n\tint res = 0;\n\tif(m<=n)\n\t{\n\t\tk=m;\n\t}else{\n\t\tk=n;\n\t}\n\n\tfor(int i=1;i<=k;i++)\n\t{\n\t\tif(!(m%i) && !(n%i))\n\t\t{\n\t\t\tres=i;\n\t\t}\n\t}\n\treturn res;\n}\n"
},
{
"alpha_fraction": 0.5862069129943848,
"alphanum_fraction": 0.5862069129943848,
"avg_line_length": 12.833333015441895,
"blob_id": "7196f979ad8372f51537038c998c8a38c890ac3a",
"content_id": "d0b299632472b8826556330707988927ccbb48d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 6,
"path": "/linux_c/code/bill.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include<stdio.h>\r\n\r\nvoid bill(char *arg)\r\n{\r\n\tprintf(\" bill: we passed %s\\n\", arg);\r\n}"
},
{
"alpha_fraction": 0.5765765905380249,
"alphanum_fraction": 0.6126126050949097,
"avg_line_length": 23.31818199157715,
"blob_id": "1f3a4310ef0beb25bfad8e5383f8f72388b9d961",
"content_id": "17adb2f038e8e1b5483bdf86672efa985b9d60c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 22,
"path": "/c_basic/code/nbio/bytew.c",
"repo_name": "dayelu/c_learning",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\r\n#include <stdlib.h>\r\n\r\nint main(int argc, char const *argv[])\r\n{\r\n\t\r\n\tchar *filename = \"myfile.bin\";\r\n\r\n\tFILE *pfile = fopen(filename, \"wb\");\r\n\tlong pdata[] = {212323L,2123L,42435L};\r\n\tint num_items = sizeof(pdata) / sizeof(long);\r\n\tsize_t wcount = fwrite(pdata, sizeof(long), num_items, pfile);\r\n\tprintf(\"%ld\\n\", wcount);\r\n\r\n\tlong *data = (long *)malloc(sizeof(long));\r\n\t// long data[10];\r\n\tFILE *ppfile = fopen(filename, \"rb\");\r\n\tfread(data, sizeof(long), 3, ppfile);\r\n\tprintf(\"%ld\\n\", *(data + 2));\r\n\tfclose(ppfile);\r\n\treturn 0;\r\n}"
}
] | 99 |
georgepsarakis/pitch
|
https://github.com/georgepsarakis/pitch
|
b126732ce0bb6e743248c1ecb977392f31d024f2
|
bfc903d0be883ce1a989299a2b4835c02bdf00e1
|
c62230429940c39488a400724baf1f56a5210ff6
|
refs/heads/master
| 2020-06-02T12:50:35.693118 | 2018-07-23T15:20:35 | 2018-07-23T15:25:13 | 15,341,156 | 6 | 0 |
MIT
| 2013-12-20T15:09:21 | 2017-01-11T03:40:09 | 2018-05-20T15:03:30 |
Python
|
[
{
"alpha_fraction": 0.6120020747184753,
"alphanum_fraction": 0.6120020747184753,
"avg_line_length": 25.12162208557129,
"blob_id": "51759388072a99eff916d2ee2865e4ffc0949c64",
"content_id": "37a09fbe7eec6fec38c675046d1c523926bba918",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1933,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 74,
"path": "/pitch/plugins/common.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import logging\nimport time\n\n\nclass BasePlugin(object):\n _phase = None\n _name = None\n _result = None\n\n @property\n def name(self):\n return self._name\n\n @property\n def result(self):\n return self._result\n\n @classmethod\n def get_name(cls):\n return cls._name\n\n @classmethod\n def get_phase(cls):\n return cls._phase\n\n def execute(self, plugin_context):\n pass\n\n\nclass LoggerPlugin(BasePlugin):\n \"\"\"\n Setup a logger, attach a file handler and log a message.\n \"\"\"\n _name = 'logger'\n\n def __init__(self, logger_name=None, message=None, **kwargs):\n if logger_name is None:\n logger_name = 'logger.plugin'\n logger_name = 'pitch.{}'.format(logger_name)\n self.logger = logging.getLogger(logger_name)\n self.logger.setLevel(logging.INFO)\n handler = logging.FileHandler(**kwargs.get('handler', {}))\n formatter_kwargs = kwargs.get('formatter', {})\n formatter_kwargs['fmt'] = formatter_kwargs.get(\n 'fmt',\n '%(asctime)s\\t%(levelname)s\\t%(message)s'\n )\n formatter = logging.Formatter(**formatter_kwargs)\n handler.setFormatter(formatter)\n self.logger.addHandler(handler)\n self._message = message\n\n def execute(self, plugin_context):\n self.logger.info(\n plugin_context.step['rendering'].render(self._message)\n )\n\n\nclass DelayPlugin(BasePlugin):\n \"\"\" Pause execution for the specified delay interval. \"\"\"\n def __init__(self, seconds):\n self._delay_seconds = float(seconds)\n\n def execute(self, plugin_context):\n time.sleep(self._delay_seconds)\n\n\nclass UpdateContext(BasePlugin):\n \"\"\" Add variables to the template context. \"\"\"\n def __init__(self, **updates):\n self._updates = updates\n\n def execute(self, plugin_context):\n plugin_context.templating['variables'].update(self._updates)\n"
},
{
"alpha_fraction": 0.5563411116600037,
"alphanum_fraction": 0.5572249293327332,
"avg_line_length": 25.313953399658203,
"blob_id": "9a6c29d8ad2aa8031c4f7ff95be923d218545bae",
"content_id": "6956bfd08c52a75e068644dcaf07934c503350ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2263,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 86,
"path": "/pitch/common/structures.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from collections import namedtuple\n\nfrom requests.structures import CaseInsensitiveDict\nfrom boltons.typeutils import make_sentinel\n\n\nclass ReadOnlyContainer(object):\n \"\"\"\n Base class for read-only property containers.\n \"\"\"\n def __init__(self, **fields):\n \"\"\"\n Initialize the property container from the given field-value pairs.\n :param fields: container field-value pairs as keyworded arguments.\n \"\"\"\n self._factory = namedtuple(\n typename='read_only_container',\n field_names=fields.keys()\n )\n self._container = self._factory(**fields)\n\n def __getattr__(self, name):\n return getattr(self._container, name)\n\n\nclass InstanceInfo(ReadOnlyContainer):\n def __init__(self, process_id: int, loop_id: int, threads: int):\n \"\"\"\n Instance information\n\n :param process_id: Process identifier\n :param loop_id: Current loop zero-based index\n :param threads: Total number of available threads\n \"\"\"\n thread_id = loop_id % threads + 1\n loop_id += 1\n super(InstanceInfo, self).__init__(\n process_id=process_id,\n thread_id=thread_id,\n loop_id=loop_id\n )\n\n\nclass HierarchicalDict(CaseInsensitiveDict):\n _MISSING = make_sentinel()\n\n def __add__(self, other):\n new = self.copy()\n new.update(other)\n return new\n\n def __iadd__(self, other):\n self.update(other)\n return self\n\n def __repr__(self):\n return '{}({})'.format(\n self.__class__.__name__,\n self.items()\n )\n\n def remove(self, *keys):\n dictionary_copy = self.copy()\n for key in keys:\n try:\n del dictionary_copy[key]\n except KeyError:\n pass\n return dictionary_copy\n\n def get_any(self, *keys):\n for key in keys:\n try:\n return key, self[key]\n except KeyError:\n pass\n\n def find_first(self, key: str, others: list, default: object=_MISSING):\n if key in self:\n return self[key]\n\n for other in others:\n if key in other:\n return other[key]\n\n return default\n"
},
{
"alpha_fraction": 0.6734693646430969,
"alphanum_fraction": 0.6938775777816772,
"avg_line_length": 47,
"blob_id": "8934300fdba58354f97d9124cfc77f7520d63226",
"content_id": "5ad141af2be8aca2dab9cac555f2733b365c816f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 1,
"path": "/pitch/__init__.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from .version import __version__ # flake8: noqa\n\n"
},
{
"alpha_fraction": 0.5960725545883179,
"alphanum_fraction": 0.5960725545883179,
"avg_line_length": 23.83333396911621,
"blob_id": "bf25c4f34441acce0e1ab59a75e7f29d46fd95d6",
"content_id": "92d479a67baa95825e879be0daa13a29b178ac0b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4023,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 162,
"path": "/pitch/interpreter/command.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import itertools\n\nimport yaml\n\nfrom boltons.typeutils import get_all_subclasses\n\n\ndef get_loop_classes():\n return get_all_subclasses(Loop)\n\n\nclass Command(object):\n def __init__(self, fn):\n self._fn = fn\n\n def execute(self, *args, **kwargs):\n return self._fn(*args, **kwargs)\n\n\nclass ControlFlowStatement(object):\n __keyword__ = None\n __default__ = None\n\n def __init__(self, context_proxy):\n self._name = self.__class__.__name__.lower()\n self._context_proxy = context_proxy\n\n @property\n def context(self):\n return self._context_proxy.context\n\n @property\n def keyword(self):\n return self.__keyword__\n\n @property\n def default(self):\n return self.__default__\n\n @property\n def name(self):\n return self._name\n\n def is_defined(self, instruction):\n return instruction.get(self.keyword) is not None\n\n\nclass Conditional(ControlFlowStatement):\n __keyword__ = 'when'\n __default__ = 'true'\n\n def _parse(self, expression):\n return yaml.safe_load(\n self.context.step['rendering'].render(expression)\n )\n\n def evaluate(self, expression):\n if isinstance(expression, bool):\n return expression\n else:\n return self._parse(expression)\n\n\nclass Loop(ControlFlowStatement):\n def __init__(self, *args, **kwargs):\n self._keyword_prefix = 'with_'\n self._items = None\n super(Loop, self).__init__(*args, **kwargs)\n\n @property\n def items(self):\n return self._items\n\n @items.setter\n def items(self, iterable):\n self._items = iterable\n\n\nclass Simple(Loop):\n __keyword__ = 'items'\n\n @property\n def keyword(self):\n return '{}{}'.format(self._keyword_prefix, self.__keyword__)\n\n def iterate(self):\n for item in self.items:\n yield item\n\n\nclass Indexed(Simple):\n __keyword__ = 'indexed_items'\n\n @property\n def keyword(self):\n return '{}{}'.format(self._keyword_prefix, self.__keyword__)\n\n def iterate(self):\n return enumerate(super(Indexed, self).iterate())\n\n\nclass Nested(Loop):\n __keyword__ = 'nested'\n\n @property\n def keyword(self):\n return '{}{}'.format(self._keyword_prefix, self.__keyword__)\n\n def evaluate(self):\n for item in itertools.product(*self.items):\n yield item\n\n\nclass Client(object):\n def __init__(self, context_proxy):\n self._context_proxy = context_proxy\n\n @property\n def context(self):\n return self._context_proxy.context\n\n def run(self, instruction):\n results = []\n\n for item in self._generate_loop(instruction).iterate():\n self._set_loop_variable(item)\n if self._evaluate_conditional(instruction):\n result = Command(fn=instruction['_function']).execute(\n *instruction['_args'],\n **instruction['_kwargs']\n )\n results.append(result)\n\n return results\n\n def _generate_loop(self, instruction):\n for loop_class in get_loop_classes():\n loop = loop_class(self._context_proxy)\n if loop.is_defined(instruction):\n loop.items = self._read_loop_items(loop, instruction)\n return loop\n\n default = Simple(self._context_proxy)\n default.items = [None]\n return default\n\n def _read_loop_items(self, loop, instruction):\n loop_items = self.context.step['rendering'].get(\n instruction[loop.keyword]\n )\n loop_items = self.context.step['rendering'].get(loop_items)\n\n return loop_items\n\n def _evaluate_conditional(self, instruction) -> Conditional:\n conditional = Conditional(context_proxy=self._context_proxy)\n expression = instruction.get(conditional.keyword, conditional.default)\n return conditional.evaluate(expression)\n\n def _set_loop_variable(self, item):\n self.context.templating['item'] = item\n return item\n"
},
{
"alpha_fraction": 0.7250548601150513,
"alphanum_fraction": 0.7279508709907532,
"avg_line_length": 33.113773345947266,
"blob_id": "5a0dbbb67ea3edd57609db418d433ff1dce6abf4",
"content_id": "d16bdd04b509e81b38d5ecfc89caef5db08c9cee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11395,
"license_type": "permissive",
"max_line_length": 293,
"num_lines": 334,
"path": "/README.md",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "# pitch\n\n[](https://travis-ci.org/georgepsarakis/pitch)\n\nHTTP handling is very common in daily development and operations tasks alike. \nWriting small scripts using the Python library [requests](http://docs.python-requests.org/en/latest/) \nis already very easy, however a more structured and formalised way of composing a sequence of HTTP operations\nwould increase reusability, brevity, expandability and clarity.\n\n## Installation\n\n```bash\n$ git clone https://github.com/georgepsarakis/pitch.git\n$ pip install .\n```\n\n> `pitch` can be used from the command-line as well as a library.\n\n## Examples\n\n### GitHub Public API\n\nThe following Sequence file will:\n\n- Fetch the details of the first 10 users\n- Fetch the repositories for users with id in the range [2,4]\n\n```yaml\n# Single process\nprocesses: 1\n# Single-threaded\nthreads: 1\n# Execute only once per thread\nrepeat: 1\n# Stop execution immediately if an\n# unexpected HTTP status code is returned.\n# By default error codes are defined\n# as greater-equal to 400.\nfailfast: yes\nbase_url: https://api.github.com\nplugins:\n - plugin: request_delay\n seconds: 1.0\nrequests:\n headers:\n User-Agent: pitch-json-api-client-test\nvariables: {}\nsteps:\n -\n\t\t# The relative URL\n url: /users\n\t\t# HTTP method (always GET by default)\n method: get\n\t\t# Conditionals are specified using the `when` keyword.\n\t\t# Any valid Jinja expression is allowed.\n # The following example evaluates to true.\n when: >\n {{ 2 > 1 }}\n # Any non-reserved keywords will be passed directly to\n\t\t# `requests.Request` objects as parameters.\n # Here we specify GET parameters with `params`.\n params:\n per_page: 10\n # The list of request/response plugins\n # that should be executed.\n # If not specified the Sequence default plugins\n # list will be used.\n plugins:\n - plugin: post_register\n user_list: response.as_json\n # Fetch the list of repositories for each user\n\t# if the user id is in the range [2,4]\n\t-\n url: >\n /users/{{ item.login }}/repos\n # This iterable has been added to the context \n # by the post_register plugin in the previous step.\n with_items: user_list\n # Conditionals are dynamically evaluated at each loop cycle.\n when: item.id >= 2 and item.id <=4\n\n```\n\n## Concepts\n\n### Scheme Files\n\nInstructions files containing a list of `steps` which will dynamically generate\na series of HTTP requests.\n\n### Step\n\nA `step` will be translated dynamically to one or more HTTP requests. \n\nThe step definition also may include:\n\n- Conditional\n- Loops\n- Request parameters\n- List of Request/Response Plugins and their parameters\n\n### Phases\n\nA single step may generate multiple HTTP requests.\nEach sub-step execution is divided in two phases: `request` and `response` phase.\n\n## Main Features\n\n### Session\n\nEach Sequence execution runs using the same\n[requests.Session](http://docs.python-requests.org/en/latest/user/advanced/#session-objects).\nThis means that each request is not necessarily isolated but can be part of\na common browser HTTP flow.\n\n### Control Flow\n\nTo avoid reinventing the wheel, `pitch` borrows certain concepts from\nAnsible's\n[Loops](http://docs.ansible.com/ansible/playbooks_loops.html) & \n[Conditionals](http://docs.ansible.com/ansible/playbooks_conditionals.html)\nin order to enable more advanced logic & processing, while maintaining\nsimplicity.\n\n### Templating\n\nAs already discussed in [Concepts](#concepts), `pitch` reads instructions from\n`Sequence` files. `Jinja2` template expressions can be widely used to allow\ndynamic context during execution.\n\n### Plugins\n\nAdditional functionality or pre/post-processing operations on\n`Request`/`Response` objects with the use of plugins. Apart from the core\nplugins, custom plugins can be written and loaded separately. See the\n[Plugin Development Reference](#developing-plugins).\n\n## Scheme File Reference\n\n| Parameter | Definition | Type | Description |\n| --------- |----------- | ---- | ----------- |\n|`processes`|sequence|`int`|The total number of processes to spawn. Each process will initialize separate threads.|\n|`threads`|sequence|`int`|Total number of threads for simultaneous sequence executions. Each thread will execute all sequence steps in a separate context and session.|\n|`repeat`|sequence|`int`|sequence execution repetition count for each thread.|\n|`failfast`|sequence, step|`bool`|Instructs the `assert_http_status_code` plugin to stop execution if an unexpected HTTP status code is returned.|\n|`base_url`|sequence, step|`string`|The base URL which will be used to compose the absolute URL for each HTTP request.|\n|`plugins`|sequence, step|`list`|The list of plugins that will be executed at each step. If defined on sequence-level, this list will be prepended to the step-level defined plugin list, if one exists.|\n|`use_default_plugins`|sequence, step|`bool`|Whether to add the list of default plugins (see `plugins`) to the defined list of plugins for a step. If no plugins have been defined for a step and this parameter is set to `true`, only the default plugins will be executed.|\n|`use_sequence_plugins`|sequence, step|`bool`|Whether to add the list of sequence-level plugin definitions to this step.|\n|`requests`|sequence|`dict`|Parameters to be passed directly to `requests.Request` objects at each HTTP request.|\n|`variables`|sequence, step|`dict`|Mapping of predefined variables that will be added to the context for each request.|\n|`steps`|sequence|`list`|List of sequence steps.|\n|`when`|step|`string`|Conditional expression determining whether to run this step or not. If combined with a loop statement, will be evaluated in every loop cycle.|\n|`with_items`|step|`iterable`|Execute the step instructions by iterating over the given collection items. Each item will be available in the Jinja2 context as `item`.|\n|`with_indexed_items`|step|`iterable`|Same as `with_items`, but the `item` context variable is a tuple with the zero-based index in the iterable as the first element and the actual item as the second element.|\n|`with_nested`|step|`list of iterables`|Same as `with_items` but has a list of iterables as input and creates a nested loop. The context variable `item` will be a tuple containing the current item of the first iterable at index 0, the current item of the second iterable at index 1 and so on.|\n\n\n> On step-level definitions, any non-reserved keywords will be passed directly to `requests.Request` e.g. `params`.\n\n| Parameter | Default<sup>*</sup> |\n| --------- | ------------------- |\n|`processes`|`1`|\n|`threads`|`1`|\n|`repeat`|`1`|\n|`failfast`|`false`|\n|`base_url`||\n|`plugins`|`['response_as_json', 'assert_status_http_code']`|\n|`use_default_plugins`|`true`|\n|`use_sequence_plugins`|`true`|\n|`requests`|`{}`|\n|`variables`|`{}`|\n|`steps`||\n|`when`|`true`|\n|`with_items`|`[None]`|\n|`with_indexed_items`|`[None]`|\n|`with_nested`|`[None]`|\n\n\n\n<strong><sup>*</sup></strong> If no default value is specified, then the parameter is required.\n\n### Available Context Variables\n\n### Rules\n\n- Parameters defined on `step` level will override the same parameter given\n on `Sequence` level.\n- [Jinja2 template braces](http://jinja.pocoo.org/docs/dev/templates/#variables)\ncan be omitted in `when` command expressions, as they\nwill be automatically resolved from the current context.\n- Loop expression values must be iterables.\n- Plugins are given in a list, because some plugins may depend on others, so the execution sequence is important. Also, a plugin may be requested multiple times.\n- The plugin list must contain both request & response plugins. This was introduced for simplicity and less boilerplate syntax. At each phase, the appropriate subset of plugins will be selected and executed.\n\n## Using Plugins\n\nPlugins are divided in two major categories:\n\n- Request Plugins\n- Response Plugins\n\nThe plugin list is specified at step-level. Each entry is a dictionary specifying the plugin name, while the remaining\nkey-value pairs will be used for the plugin initialization.\n\n### Example\n\nA simple plugin case is the `request_delay` plugin; it adds a delay before sending the HTTP request.\n\nThe implementation of this plugin is the following:\n\n```python\n# Module: pitch.plugins.common\nclass DelayPlugin(BasePlugin):\n # Notice the constructor argument\n def __init__(self, seconds):\n self._delay_seconds = float(seconds)\n\n def execute(self, plugin_context):\n time.sleep(self._delay_seconds)\n\n# Module: pitch.plugins.request\nclass RequestDelayPlugin(DelayPlugin, BaseRequestPlugin):\n _name = 'request_delay'\n```\n\nThe Sequence file instructions for calling the plugin are:\n\n```yaml\nsteps:\n - url: /example\n plugins:\n - plugin: request_delay\n seconds: 1.0\n```\n\n## Developing Plugins\n\nNew custom plugins can be developed by creating additional modules with subclasses of:\n\n- `pitch.plugins.request.BaseRequestPlugin`\n- `pitch.plugins.request.BaseResponsePlugin`\n\n### Example\n\n```python\nfrom pitch.plugins.request import BaseRequestPlugin\nfrom pitch.lib.common.utils import get_exported_plugins\n\nclass TestRequestPlugin(BaseRequestPlugin):\n _name = 'request_test'\n def __init__(self, message):\n self._message = message\n\n def execute(self, plugin_context):\n plugin_context.progress.info(\n 'Plugin {} says: {}'.format(self.name, self._message)\n )\n\nexported_plugins = get_exported_plugins(BaseRequestPlugin)\n```\n\nCalling the above plugin from the step definition:\n\n```yaml\nsteps:\n - url: /example\n plugins:\n - plugin: request_test\n message: 'hello world'\n # The above will display during the\n # execution in the progress logs:\n # 'Plugin request_test says: hello world'\n```\n\nAvailable plugins and their parameters can be listed\nfrom the command-line by using the switch `--list-plugins`:\n\n```bash\n$ pitch --list-plugins\n# Or if additional plugin modules must be loaded:\n$ pitch --list-plugins --request-plugins-modules MODULE_NAME\n```\n\n### Core Plugins\n\n```\nREQUEST\n-------\nadd_header()\n Add a request header\n\nfile_input()\n Read file from the local filesystem and store in the `result` property\n\njson_post_data()\n JSON-serialize the request data property (POST body)\n\npre_register(**updates)\n Add variables to the request template context\n\nprofiler()\n Keep track of the time required for the HTTP request & processing\n\nrequest_delay()\n Pause execution for the specified delay interval\n\nrequest_logger(logger_name=None, message=None, **kwargs)\n Setup a logger, attach a file handler and log a message\n\n\nRESPONSE\n--------\nassert_http_status_code(expect=200)\n Examine the response HTTP status code and raise error/stop execution\n\njson_file_output(filename, create_dirs=True)\n Write a JSON-serializable response to a file\n\npost_register(**updates)\n Add variables to the template context after the response has completed\n\nprofiler()\n Keep track of the time required for the HTTP request & processing\n\nresponse_as_json()\n Serialize the response body as JSON and store in response.as_json\n\nresponse_logger(logger_name=None, message=None, **kwargs)\n Setup a logger, attach a file handler and log a message\n\nstdout_writer()\n Print a JSON-serializable response to STDOUT\n```\n\n"
},
{
"alpha_fraction": 0.6304445266723633,
"alphanum_fraction": 0.6304445266723633,
"avg_line_length": 24.022472381591797,
"blob_id": "24b8a732489dc897ba7953f98a183d877e4f474e",
"content_id": "f51b1cf4378120d851197002179434be766a0129",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2227,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 89,
"path": "/pitch/plugins/request.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import os\nfrom pitch.plugins.common import (\n BasePlugin,\n LoggerPlugin,\n DelayPlugin,\n UpdateContext\n)\n\n\nclass BaseRequestPlugin(BasePlugin):\n _phase = 'request'\n\n\nclass RequestLoggerPlugin(LoggerPlugin, BaseRequestPlugin):\n \"\"\"\n Setup a logger, attach a file handler and log a message.\n \"\"\"\n _name = 'request_logger'\n\n\nclass RequestDelayPlugin(DelayPlugin, BaseRequestPlugin):\n \"\"\" Pause execution for the specified delay interval. \"\"\"\n _name = 'request_delay'\n\n\nclass RequestUpdateContext(UpdateContext, BaseRequestPlugin):\n \"\"\" Add variables to the request template context\n \"\"\"\n _name = 'pre_register'\n\n\nclass FileInputPlugin(BaseRequestPlugin):\n \"\"\" Read file from the local filesystem and store in the `result` property\n \"\"\"\n _name = 'file_input'\n\n def __init__(self, filename):\n self._filename = os.path.expanduser(os.path.abspath(filename))\n self._directory = os.path.dirname(filename)\n if not os.path.isfile(self._filename):\n raise OSError(\n \"Directory {} does not exist\".format(\n self._directory\n )\n )\n\n def execute(self, plugin_context):\n with open(self._filename, 'r') as f:\n self._result = f.read()\n\n\nclass ProfilerPlugin(BaseRequestPlugin):\n \"\"\" Keep track of the time required for the HTTP request & processing\n \"\"\"\n _name = 'profiler'\n\n def __init__(self):\n import time\n self._start_time = time.clock()\n\n @property\n def start_time(self):\n return self._start_time\n\n\nclass JSONPostDataPlugin(BaseRequestPlugin):\n \"\"\" JSON-serialize the request data property (POST body)\n \"\"\"\n import json\n _name = 'json_post_data'\n _encoder = json.dumps\n\n def execute(self, plugin_context):\n plugin_context.request.data = self._encoder(\n plugin_context.request.data\n )\n\n\nclass AddHeaderPlugin(BaseRequestPlugin):\n \"\"\" Add a request header\n \"\"\"\n _name = 'add_header'\n\n def __init__(self, header, value):\n self._header = header\n self._value = value\n\n def execute(self, plugin_context):\n plugin_context.request.headers[self._header] = self._value\n"
},
{
"alpha_fraction": 0.6108540296554565,
"alphanum_fraction": 0.6121160984039307,
"avg_line_length": 33.95588302612305,
"blob_id": "d0669b5b1859d0ccc355a57ea5050f2e7a2240c0",
"content_id": "77c79eaf6c3c3119f6f910a12dccf501585e85ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2377,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 68,
"path": "/pitch/cli/main.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import click\n\nfrom pitch.runner.bootstrap import bootstrap\nfrom pitch.plugins.utils import list_plugins, loader\nfrom pitch.cli.logger import logger\n\n\[email protected]()\[email protected]_option()\ndef cli():\n pass\n\n\[email protected](help='Run a sequence file.')\[email protected]('-P', '--processes', type=int,\n help='Number of processes', default=1)\[email protected]('-R', '--request-plugins',\n multiple=True,\n help='Additional request plugins (in Python import notation)')\[email protected]('-S', '--response-plugins',\n multiple=True,\n help='Additional response plugins (in Python import notation)')\[email protected]('sequence_file',\n type=click.Path(exists=True, dir_okay=False, readable=True))\ndef run(processes, request_plugins, response_plugins, sequence_file):\n logger.info('Loading file: {}'.format(sequence_file))\n bootstrap(\n processes=processes,\n request_plugins=request_plugins,\n response_plugins=response_plugins,\n sequence_file=sequence_file,\n logger=logger\n )\n\n\[email protected](help='View available plugins.')\ndef plugins():\n pass\n\n\[email protected](name='list', help='Display available plugins and exit.')\[email protected]('-R', '--request-plugins',\n multiple=True,\n help='Additional request plugins (in Python import notation)')\[email protected]('-S', '--response-plugins',\n multiple=True,\n help='Additional response plugins (in Python import notation)')\ndef list_(request_plugins, response_plugins):\n loader(request_plugins, response_plugins)\n for plugin_type, phase_plugins in list_plugins().items():\n click.echo()\n click.secho(plugin_type.upper(), bold=True)\n click.echo('-' * len(plugin_type))\n for name, plugin_details in sorted(phase_plugins.items()):\n signature = []\n for argument in plugin_details['arguments']:\n signature.append(argument['name'])\n if 'default' in argument:\n signature[-1] += '={}'.format(argument['default'])\n click.secho('{}({})'.format(name, ', '.join(signature)),\n bold=True)\n click.echo(2 * ' ', nl=False)\n click.echo(plugin_details['docstring'].strip('.'))\n click.echo()\n\n\nif __name__ == \"__main__\":\n cli()\n"
},
{
"alpha_fraction": 0.6770310997962952,
"alphanum_fraction": 0.6790370941162109,
"avg_line_length": 17.462963104248047,
"blob_id": "41c145ca0cced0c035a8dfebe9bb50e64755f4ad",
"content_id": "6a7ff7f7aec72b4cd13819ec111420cd97f0debe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 997,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 54,
"path": "/pitch/templating/jinja_custom_extensions.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nfrom typing import Callable\n\n_FILTERS = {}\n_TESTS = {}\n\n\ndef _get_name(name):\n return name.split('_', 2)[-1]\n\n\ndef register_filter(func: Callable):\n name = _get_name(func.__name__)\n _FILTERS[name] = func\n\n\ndef register_test(func: Callable):\n name = _get_name(func.__name__)\n _TESTS[name] = func\n\n\ndef _core_filter_from_environment(value, default=None):\n return os.environ.get(value, default=default)\n\n\ndef _core_filter_to_json(value):\n return json.dumps(value)\n\n\ndef _core_filter_from_json(value):\n return json.loads(value)\n\n\ndef _core_test_json_serializable(value):\n try:\n json.loads(value)\n return True\n except ValueError:\n return False\n\n\nregister_filter(_core_filter_from_environment)\nregister_filter(_core_filter_to_json)\nregister_filter(_core_filter_from_json)\nregister_test(_core_test_json_serializable)\n\n\ndef get_registered_filters():\n return _FILTERS.copy()\n\n\ndef get_registered_tests():\n return _TESTS.copy()\n"
},
{
"alpha_fraction": 0.6524271965026855,
"alphanum_fraction": 0.6524271965026855,
"avg_line_length": 24.75,
"blob_id": "d59b9b4d33280cbbcdbfdfdbf4ba2c7e5062fe03",
"content_id": "446c517ff7cb7e2e4e2492b9571dea0970c1c723",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 20,
"path": "/pitch/runner/structures.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from pitch.sequence.executor import SequenceExecutor\n\n\nclass PitchRunner(object):\n def __init__(self, sequence_loader, logger):\n self._sequence_loader = sequence_loader\n self._logger = logger\n self._responses = []\n\n @property\n def logger(self):\n return self._logger\n\n @property\n def sequence_loader(self):\n return self._sequence_loader\n\n def run(self):\n executor = SequenceExecutor(self._sequence_loader, logger=self.logger)\n return executor.run()\n"
},
{
"alpha_fraction": 0.5855161547660828,
"alphanum_fraction": 0.5855161547660828,
"avg_line_length": 19.28125,
"blob_id": "ea38ab19f2173dfb7be7e14849d8917b8064f1ec",
"content_id": "280245a844568e597e82a4ec36438744332cdcff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 649,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 32,
"path": "/pitch/common/utils.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from boltons.iterutils import is_collection\nfrom boltons.urlutils import URL\n\n\ndef compose_url(base_url, url):\n base_url = URL(base_url)\n url = URL(url)\n if not url.scheme:\n absolute_url = base_url.navigate(url.to_text())\n else:\n absolute_url = url\n return absolute_url.to_text()\n\n\ndef identity(x):\n return x\n\n\ndef to_iterable(obj):\n if not is_collection(obj):\n return [obj]\n return obj\n\n\ndef merge_dictionaries(a, b):\n r = a.copy()\n for k, v in b.items():\n if k in r and isinstance(r[k], dict):\n r[k] = merge_dictionaries(r[k], v)\n else:\n r[k] = v\n return r\n"
},
{
"alpha_fraction": 0.7384615540504456,
"alphanum_fraction": 0.7538461685180664,
"avg_line_length": 25,
"blob_id": "d170338be01e00e7f3d4f245250c45d150c84807",
"content_id": "4f371a9dcac81e64996f327e25edf98534a14447",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 10,
"path": "/pitch/encoding.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import yaml\n\n\ndef construct_yaml_str(self, node):\n # Override the default string handling function\n # to always return unicode objects\n return self.construct_scalar(node)\n\n\nyaml.SafeLoader.add_constructor(u'tag:yaml.org,2002:str', construct_yaml_str)\n"
},
{
"alpha_fraction": 0.5864036083221436,
"alphanum_fraction": 0.5864036083221436,
"avg_line_length": 30.1629638671875,
"blob_id": "6bfeff215b127b2383a275bfc80246843d231fe6",
"content_id": "4b6ba2b996f1da86b7bb52eb26198d7a04c67254",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4207,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 135,
"path": "/pitch/sequence/executor.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nfrom itertools import chain\nimport logging\n\nfrom pitch.common.utils import compose_url\nimport requests\n\nfrom pitch.plugins.utils import execute_plugins\nfrom pitch.structures import Context, ContextProxy, JinjaEvaluator, \\\n HTTPRequest, KEYWORDS\nfrom pitch.interpreter.command import Client\nfrom pitch.encoding import yaml\n\n\nclass SequenceLoader(object):\n def __init__(self, filename: str):\n self._filename = filename\n with open(filename, 'r') as f:\n self._sequence = yaml.safe_load(f)\n\n def get(self, key):\n return self._sequence[key]\n\n def validate(self):\n \"\"\"\n TODO: add marshmallow validation\n \"\"\"\n return True\n\n\nclass SequenceExecutor(object):\n def __init__(\n self,\n sequence_loader: SequenceLoader,\n logger: logging.Logger):\n self._sequence_loader = sequence_loader\n self._context = self._initialize_context()\n self._context_proxy = ContextProxy(self._context)\n self._command_client = Client(context_proxy=self._context_proxy)\n self._logger = logger\n\n @property\n def logger(self):\n return self._logger\n\n def _initialize_context(self) -> Context:\n context = Context()\n context.step['http_session'] = requests.Session()\n context.templating['response'] = requests.Response()\n context.templating['variables'] = self._sequence_loader.get(\n 'variables'\n )\n context.step['rendering'] = JinjaEvaluator(\n context.templating\n )\n return context\n\n def _get_base_http_parameters(self):\n base_url = self._sequence_loader.get('base_url')\n step_definition = self.context.step['definition']\n url = compose_url(\n base_url,\n self.context.step['definition']['url']\n )\n method = self.context.step['rendering'].render(\n step_definition.get('method', 'GET').upper()\n )\n url = self.context.step['rendering'].render(url)\n return {\n 'url': url,\n 'method': method\n }\n\n @property\n def context(self) -> Context:\n return self._context\n\n def on_before_request(self):\n request = HTTPRequest()\n request.update(**self._get_request_parameters())\n self.context.templating['request'] = request.prepare()\n self.context.step['phase'] = 'request'\n execute_plugins(self.context)\n\n def on_before_response(self):\n response = self._send_request()\n self.context.templating['response'] = response\n\n def on_after_response(self):\n self.logger.info(\n '[response] Completed HTTP request to URL: {}'.format(\n self.context.templating['response'].url\n )\n )\n self.context.step['phase'] = 'response'\n execute_plugins(self.context)\n\n def run(self):\n steps = deepcopy(self._sequence_loader.get('steps'))\n for step in steps:\n self.context.step['definition'] = step\n step.update({\n '_function': self._step_execution,\n '_args': (),\n '_kwargs': {}\n })\n self._command_client.run(step)\n\n def _step_execution(self):\n self.on_before_request()\n self.on_before_response()\n self.on_after_response()\n\n def _get_request_parameters(self):\n request_definition = self._sequence_loader.get('requests')\n parameters = self.context.step['rendering'].render_nested({\n key: value\n for key, value in chain(\n request_definition.items(),\n self.context.step['definition'].items()\n )\n if key not in KEYWORDS\n })\n base_http_parameters = self._get_base_http_parameters()\n parameters.update(base_http_parameters)\n return parameters\n\n def _send_request(self):\n request = self.context.templating['request']\n self.logger.info(\n '[request] Sending HTTP request to URL: {}'.format(\n request.url\n )\n )\n return self.context.step['http_session'].send(request)\n"
},
{
"alpha_fraction": 0.7220216393470764,
"alphanum_fraction": 0.7220216393470764,
"avg_line_length": 26.700000762939453,
"blob_id": "ee32aed01baff8bd65a5ab02ec5e06dd451d3a76",
"content_id": "f5f4a612729b3bbdf9ab3a298a54106b98d03786",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 554,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 20,
"path": "/pitch/runner/bootstrap.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from pitch.sequence.executor import SequenceLoader\nfrom pitch.plugins.utils import loader as plugin_loader\nfrom pitch.runner.structures import PitchRunner\n\n\ndef start_process(sequence, logger):\n sequence_loader = SequenceLoader(sequence)\n runner = PitchRunner(sequence_loader, logger=logger)\n runner.run()\n\n\ndef bootstrap(**kwargs):\n scheme = kwargs['sequence_file']\n logger = kwargs['logger']\n plugin_loader(\n kwargs.get('request_plugins'),\n kwargs.get('response_plugins')\n )\n\n start_process(scheme, logger=logger)\n"
},
{
"alpha_fraction": 0.7614678740501404,
"alphanum_fraction": 0.7614678740501404,
"avg_line_length": 20.799999237060547,
"blob_id": "f73f79a8208478df70a90400c9d16ba2ead2037c",
"content_id": "f20bee6668fbf437cb0a166e9c020c0c1299bbe7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 5,
"path": "/.ci/run-integration-tests.sh",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "#!/bin/bash -x\nset -e\n\npitch run json_api_examples/stack-exchange.yml\npitch run json_api_examples/github.yml\n"
},
{
"alpha_fraction": 0.6158940196037292,
"alphanum_fraction": 0.6181015372276306,
"avg_line_length": 21.09756088256836,
"blob_id": "62dd4ecc2b5ac3e9ad64715efb3eba3543426a13",
"content_id": "aa7d7617757c9ab0d600b58e8deca9e5b77cd37c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 906,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 41,
"path": "/pitch/concurrency.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from abc import abstractmethod\n\nfrom concurrent import futures\n\n\nclass Pool(object):\n def __init__(self, loops=1, concurrency=1):\n self._concurrency = concurrency\n self._loops = loops\n\n @abstractmethod\n @property\n def executor_class(self) -> futures.Executor:\n pass\n\n def run(self, fn, *args, **kwargs):\n promises = []\n\n with self.executor_class(max_workers=self._concurrency) as pool:\n for loop in range(self._loops):\n promises.append(\n pool.submit(fn, *args, **kwargs)\n )\n\n return promises, [p.exception() for p in promises]\n\n\nclass ThreadPool(Pool):\n @property\n def executor_class(self):\n return futures.ThreadPoolExecutor\n\n\nclass ProcessPool(Pool):\n @property\n def executor_class(self):\n return futures.ProcessPoolExecutor\n\n\nclass AsyncIOPool(Pool):\n pass\n"
},
{
"alpha_fraction": 0.4431818127632141,
"alphanum_fraction": 0.47727271914482117,
"avg_line_length": 16.600000381469727,
"blob_id": "f1998e7822e41fd9a6c1b3e435503c2ae19a4e02",
"content_id": "8600e49794b567b3a1863e76c9f92e7a17ccc0b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/pitch/version.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "__version__ = (0, 2, 0)\n\n\ndef get_version():\n return '{}.{}.{}'.format(*__version__)\n"
},
{
"alpha_fraction": 0.5747303366661072,
"alphanum_fraction": 0.5747303366661072,
"avg_line_length": 22.178571701049805,
"blob_id": "d777243170d5a0ad39d562f5a58e514bd5dd2e9d",
"content_id": "2ddf953b75b002de675cedee97c64a65db2aa0b2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1298,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 56,
"path": "/pitch/plugins/structures.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from pitch.plugins.common import BasePlugin\n\n\nclass Registry(object):\n def __init__(self):\n self._request = {}\n self._response = {}\n\n def add_subclasses(self, base_plugin_class):\n return [self.add(cls) for cls in base_plugin_class.__subclasses__()]\n\n @property\n def request_plugins(self):\n return self._request\n\n @property\n def response_plugins(self):\n return self._response\n\n @property\n def phases(self) -> tuple:\n return 'request', 'response'\n\n def all(self):\n return {\n 'request': self.request_plugins,\n 'response': self.response_plugins\n }\n\n def by_phase(self, name):\n if name == 'request':\n return self.request_plugins\n elif name == 'response':\n return self.response_plugins\n else:\n raise NameError(name)\n\n def exists(self, cls):\n name = cls.get_name()\n phase = cls.get_phase()\n return self.by_phase(phase).get(name) is not None\n\n def add(self, cls):\n name = cls.get_name()\n phase = cls.get_phase()\n self.by_phase(phase)[name] = cls\n return cls\n\n\ndef register(cls: BasePlugin):\n if not registry.exists(cls):\n registry.add(cls)\n return cls\n\n\nregistry = Registry()\n"
},
{
"alpha_fraction": 0.4329896867275238,
"alphanum_fraction": 0.4639175236225128,
"avg_line_length": 26.714284896850586,
"blob_id": "9448033ef71a830e04b0332f37e64b33c63ce3b8",
"content_id": "432247d8c7b50ed1e09ead4d6cf54c10985ee5b9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 14,
"path": "/tests/unit/common/test_utils.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\nfrom pitch.common.utils import merge_dictionaries\n\n\nclass TestUtils(TestCase):\n def test_merge_dictionaries(self):\n self.assertDictEqual(\n merge_dictionaries(\n {'a': {'b': 1}, 'c': 3, 'e': 10},\n {'a': {'b': 2, 'd': 4}, 'c': 3},\n ),\n {'a': {'b': 2, 'd': 4}, 'c': 3, 'e': 10}\n )\n"
},
{
"alpha_fraction": 0.474053293466568,
"alphanum_fraction": 0.52173912525177,
"avg_line_length": 21.28125,
"blob_id": "67e0d61dd6395e498542d59b35034e65cc14599e",
"content_id": "acb21680c776518a26ac10eeee75521be0d6ecf1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 713,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 32,
"path": "/setup.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nfrom pitch.version import get_version\n\nsetup(\n name='pitch',\n version=get_version(),\n author='George Psarakis',\n author_email='[email protected]',\n install_requires=[\n 'PyYaml==3.12',\n 'boltons==18.0.0',\n 'click==6.7',\n 'colorama==0.3.9',\n 'jinja2==2.10',\n 'marshmallow==2.15.3',\n 'requests==2.18.4',\n 'structlog==18.1.0'\n ],\n tests_require=[\n 'responses==0.9.0'\n ],\n packages=list(\n filter(lambda pkg: pkg.startswith('pitch'), find_packages())\n ),\n pythons_requires='>=3.6.0',\n entry_points={\n 'console_scripts': [\n 'pitch=pitch.cli.main:cli',\n ]\n }\n)\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 15.5,
"blob_id": "ede62dc5a0b433f72fef9003b036ebd145260325",
"content_id": "4452fc548535ecd8d29aa17152413002f6b9548a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 6,
"path": "/pitch/exceptions.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "class InvalidPluginPhaseError(Exception):\n pass\n\n\nclass UnknownPluginError(Exception):\n pass\n"
},
{
"alpha_fraction": 0.5875259637832642,
"alphanum_fraction": 0.5912681818008423,
"avg_line_length": 33.35714340209961,
"blob_id": "a1bf1dd0c244f282776e969f1e0e5c3822c39392",
"content_id": "96846ccd5c4f9e21d8b91f1b20b8a4b1716b5c21",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4810,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 140,
"path": "/generate-documentation.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport re\nfrom subprocess import check_output\n\nfrom jinja2 import Template\n\n\nwith open('docs/README.md.tmpl') as f:\n readme_template = Template(f.read())\n\nwith open('docs/github_api_example.yml.tmpl') as f:\n github_api_example = f.read()\n\nreplace_whitespace = re.compile('\\s+')\n\nsequence_file_reference = [\n [\n 'processes', ['sequence'], 'int', '1',\n \"\"\"The total number of processes to spawn.\n Each process will initialize separate threads.\"\"\",\n ],\n [\n 'threads', ['sequence'], 'int', '1',\n \"\"\"Total number of threads for simultaneous sequence executions.\n Each thread will execute all sequence steps in a\n separate context and session.\"\"\"\n ],\n [\n 'repeat', ['sequence'], 'int', '1',\n \"\"\"sequence execution repetition count for each thread.\"\"\"\n ],\n [\n 'failfast', ['sequence', 'step'], 'bool', 'false',\n \"\"\"Instructs the `assert_http_status_code` plugin to stop execution\n if an unexpected HTTP status code is returned.\"\"\"\n ],\n [\n 'base_url', ['sequence', 'step'], 'string', '',\n \"\"\"The base URL which will be used to compose the\n absolute URL for each HTTP request.\"\"\"\n ],\n [\n 'plugins' , ['sequence', 'step'], 'list',\n \"['response_as_json', 'assert_status_http_code']\",\n \"\"\"The list of plugins that will be executed at each step.\n If defined on sequence-level, this list will be prepended\n to the step-level defined plugin list, if one exists.\"\"\"\n ],\n [\n 'use_default_plugins', ['sequence', 'step'], 'bool', 'true',\n \"\"\"Whether to add the list of default plugins (see `plugins`)\n to the defined list of plugins for a step. If no plugins have been\n defined for a step and this parameter is set to `true`, only\n the default plugins will be executed.\"\"\"\n ],\n [\n 'use_sequence_plugins', ['sequence', 'step'], 'bool', 'true',\n \"\"\"Whether to add the list of sequence-level plugin definitions to\n this step.\"\"\"\n ],\n [\n 'requests', ['sequence'], 'dict', '{}',\n \"\"\"Parameters to be passed directly to `requests.Request`\n objects at each HTTP request.\"\"\"\n ],\n [\n 'variables', ['sequence', 'step'], 'dict', '{}',\n \"\"\"Mapping of predefined variables\n that will be added to the context for each request.\"\"\"\n ],\n [\n 'steps', ['sequence'], 'list', '', \"List of sequence steps.\"\n ],\n [\n 'when', ['step'], 'string', 'true',\n \"\"\"Conditional expression determining whether to run this step or not.\n If combined with a loop statement,\n will be evaluated in every loop cycle.\"\"\"\n ],\n [\n 'with_items', ['step'], 'iterable', '[None]',\n \"\"\"Execute the step instructions by iterating over the\n given collection items. Each item will be available\n in the Jinja2 context as `item`.\"\"\"\n ],\n [\n 'with_indexed_items', ['step'], 'iterable', '[None]',\n \"\"\"Same as `with_items`, but the `item` context variable\n is a tuple with the zero-based index in the\n iterable as the first element and the actual item\n as the second element.\"\"\"\n ],\n [\n 'with_nested', ['step'], 'list of iterables', '[None]',\n \"\"\"Same as `with_items` but has a list of iterables as input\n and creates a nested loop. The context variable `item` will\n be a tuple containing the current item of the first iterable at\n index 0, the current item of the second iterable at\n index 1 and so on.\"\"\"\n ]\n]\n\nlist_item_wrap = '<li>{}</li>'.format\nlist_wrap = '<ul>{}</ul>'.format\ncode_wrap = '`{}`'.format\nfor parameter_details in sequence_file_reference:\n for index, detail in enumerate(parameter_details):\n if index in [0, 2, 3]:\n if detail != '':\n parameter_details[index] = code_wrap(detail)\n elif index == 1:\n parameter_details[index] = ', '.join(detail)\n elif index == 4:\n parameter_details[index] = replace_whitespace.sub(' ', detail)\n\nsequence_file_reference_desc = [\n [detail[0], detail[1], detail[2], detail[4]]\n for detail in sequence_file_reference\n]\n\nsequence_file_reference_defaults = [\n [detail[0], detail[3]]\n for detail in sequence_file_reference\n]\n\n\nplugins_list = check_output(\n ['pitch', 'plugins', 'list'],\n universal_newlines=True\n)\n\nwith open('README.md', 'w') as f:\n f.write(\n readme_template.render(\n plugins_list=plugins_list,\n github_api_example=github_api_example,\n sequence_file_reference_desc=sequence_file_reference_desc,\n sequence_file_reference_defaults=sequence_file_reference_defaults\n )\n )\n"
},
{
"alpha_fraction": 0.586482584476471,
"alphanum_fraction": 0.5867248177528381,
"avg_line_length": 25.980392456054688,
"blob_id": "a1e14c0b90a5b04227a4f40c6066aff8d6db53f4",
"content_id": "e225034bc431f37aed717e4ab059efa73e18b71c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4128,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 153,
"path": "/pitch/structures.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from jinja2 import Environment, Undefined\nfrom requests.structures import CaseInsensitiveDict\nfrom boltons.typeutils import make_sentinel\n\nfrom pitch.templating.jinja_custom_extensions import \\\n get_registered_filters, get_registered_tests\n\nfrom requests import Request\nfrom argparse import Namespace\n\n\nKEYWORDS = (\n 'plugins',\n 'base_url',\n 'when',\n 'with_items',\n 'with_indexed_items',\n 'with_nested',\n 'use_default_plugins',\n 'use_scheme_plugins'\n)\n\nDEFAULT_PLUGINS = (\n CaseInsensitiveDict(plugin='assert_http_status_code'),\n CaseInsensitiveDict(plugin='response_as_json')\n)\n\n\nclass HTTPRequest(Request):\n def __init__(self, *args, **kwargs):\n super(HTTPRequest, self).__init__(*args, **kwargs)\n self.__pitch_properties = Namespace()\n\n @property\n def pitch_properties(self):\n return self.__pitch_properties\n\n def update(self, **kwargs):\n for property_name, value in kwargs.items():\n setattr(self.__pitch_properties, property_name, value)\n setattr(self, property_name, value)\n\n\nclass Context(CaseInsensitiveDict):\n def __init__(self, *args, **kwargs):\n super(Context, self).__init__(*args, **kwargs)\n self.setdefault(\n 'globals',\n CaseInsensitiveDict(\n failfast=True\n )\n )\n self.setdefault(\n 'templating',\n CaseInsensitiveDict(\n variables=CaseInsensitiveDict(),\n response=None,\n request=None\n )\n )\n self.setdefault(\n 'step',\n CaseInsensitiveDict(\n rendering=None,\n http_session=None,\n definition=None\n )\n )\n\n @property\n def globals(self):\n return self['globals']\n\n @property\n def templating(self):\n return self['templating']\n\n @property\n def step(self):\n return self['step']\n\n\nclass ContextProxy(object):\n def __init__(self, context: Context):\n self._context = context\n\n @property\n def context(self):\n \"\"\"\n :rtype: Context\n \"\"\"\n return self._context\n\n @context.setter\n def context(self, value: Context):\n self._context = value\n\n\nclass JinjaEvaluator(object):\n _MISSING = make_sentinel()\n\n def __init__(self, context: Context):\n self._context = context\n self._environment = Environment()\n self._environment.filters.update(get_registered_filters())\n self._environment.tests.update(get_registered_tests())\n\n def get(self, expression: str, default=None):\n \"\"\"\n Evaluate a Jinja expression and return the corresponding\n Python object.\n \"\"\"\n expression = expression.strip().lstrip('{').rstrip('}').strip()\n environment = Environment()\n expression = environment.compile_expression(\n expression,\n undefined_to_none=False\n )\n value = expression(**self._context)\n\n if isinstance(value, Undefined):\n return default\n else:\n return value\n\n def render(self, expression, default=_MISSING):\n if isinstance(expression, str):\n expression = self._environment.from_string(expression)\n value = expression.render(**self._context)\n else:\n value = expression\n\n if isinstance(value, Undefined):\n if default is self._MISSING:\n # TODO: add custom exception\n raise RuntimeError('expression can not be rendered')\n else:\n return default\n else:\n return value\n\n def render_nested(self, structure, default=_MISSING):\n if isinstance(structure, (CaseInsensitiveDict, dict)):\n iterator = structure.items()\n elif isinstance(structure, (list, tuple)):\n iterator = enumerate(structure)\n else:\n return self.render(structure, default)\n\n for key, value in iterator:\n structure[key] = self.render_nested(value, default)\n\n return structure\n"
},
{
"alpha_fraction": 0.6848137378692627,
"alphanum_fraction": 0.6848137378692627,
"avg_line_length": 22.266666412353516,
"blob_id": "571fef01f053ec82ec6481ff209082afaa1fba61",
"content_id": "8e826bba9a75f6afdf51f424b70d3656bdd5754c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 349,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 15,
"path": "/pitch/cli/logger.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import logging\n\nlogger = logging.getLogger()\nlogger.setLevel(logging.INFO)\nhandler = logging.StreamHandler()\nhandler.setLevel(logging.INFO)\nlogger.addHandler(handler)\n\nhandler.setFormatter(\n logging.Formatter(\n '%(asctime)s process=%(process)d '\n 'thread=%(thread)d name=%(name)s '\n 'level=%(levelname)s %(message)s'\n )\n)\n"
},
{
"alpha_fraction": 0.6076266169548035,
"alphanum_fraction": 0.6080433130264282,
"avg_line_length": 31.869863510131836,
"blob_id": "51b36fed75c04356035a8f985359e71e8ab56238",
"content_id": "8a932c6204d44c184372f27d86f00b175ca82532",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4799,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 146,
"path": "/pitch/plugins/utils.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "from copy import deepcopy\nimport inspect\nimport importlib\nimport itertools\nimport logging\nimport re\n\nfrom pitch.exceptions import InvalidPluginPhaseError, UnknownPluginError\nfrom pitch.plugins.structures import registry\nfrom pitch.plugins.request import BaseRequestPlugin\nfrom pitch.plugins.response import BaseResponsePlugin\n\nlogger = logging.getLogger(__name__)\n\n\ndef loader(request_plugins_modules=None, response_plugins_modules=None):\n if request_plugins_modules is not None:\n for module_path in request_plugins_modules:\n _import_plugins(module_path)\n\n if response_plugins_modules is not None:\n for module_path in response_plugins_modules:\n _import_plugins(module_path)\n\n return {\n 'request': registry.add_subclasses(BaseRequestPlugin),\n 'response': registry.add_subclasses(BaseResponsePlugin)\n }\n\n\ndef _import_plugins(from_path):\n return importlib.import_module(\n from_path.replace('.', '_'),\n from_path\n )\n\n\ndef verify_plugins(given_plugins):\n registered_plugin_names = set()\n for phase in registry.phases:\n registered_plugin_names.union(set(\n itertools.chain.from_iterable([\n phase_plugins.keys()\n for phase_plugins in registry.by_phase(phase).values()\n ])\n ))\n\n requested_plugin_names = set(given_plugins)\n if not requested_plugin_names.issubset(registered_plugin_names):\n raise UnknownPluginError(\n 'Unregistered plugins: {}'.format(\n ','.join(requested_plugin_names - registered_plugin_names)\n )\n )\n\n\ndef list_plugins():\n plugins = {}\n for phase, available_plugins in sorted(registry.all().items()):\n phase_plugins = plugins.setdefault(phase, {})\n\n for name, plugin_class in available_plugins.items():\n plugin_specification = phase_plugins.setdefault(name, {})\n constructor_signature = inspect.getfullargspec(\n plugin_class.__init__\n )\n plugin_specification['arguments'] = []\n\n plugin_args = constructor_signature.args\n plugin_args.remove('self')\n if constructor_signature.defaults is not None:\n defaults = constructor_signature.defaults\n args_with_default = len(plugin_args) - len(defaults)\n for index, argument in enumerate(plugin_args):\n plugin_specification['arguments'].append(\n {'name': argument}\n )\n if index >= args_with_default:\n plugin_specification['arguments'][-1]['default'] = \\\n defaults[index - args_with_default]\n\n if constructor_signature.varkw is not None:\n plugin_specification['arguments'].append(\n {'name': '**{}'.format(constructor_signature.varkw)}\n )\n\n plugin_specification['docstring'] = re.sub(\n r'\\s+',\n ' ',\n str(plugin_class.__doc__).strip().split(\"\\n\")[0]\n )\n return plugins\n\n\ndef execute_plugins(context):\n step_plugins = context.step['definition'].get('plugins')\n phase_plugins = registry.by_phase(context.step['phase'])\n step_phase_plugins = filter(\n lambda plugin_details:\n plugin_details.get('plugin')\n in phase_plugins,\n step_plugins\n )\n _valid_phase_or_raise(context.step['phase'])\n\n phase_object = context.templating[context.step['phase']]\n\n phase_object.plugins = []\n for plugin_execution_args in step_phase_plugins:\n phase_object.plugins.append(\n _execute_plugin(\n context=context,\n plugin_args=plugin_execution_args\n )\n )\n\n\ndef _valid_phase_or_raise(name):\n if name not in registry.phases:\n raise InvalidPluginPhaseError('Invalid Phase: {}'.format(name))\n\n\ndef _execute_plugin(context, plugin_args):\n phase = context.step['phase']\n renderer = context.step['rendering'].render_nested\n plugin_execution_args = renderer(\n deepcopy(plugin_args)\n )\n plugin_name = renderer(plugin_execution_args['plugin'])\n current_plugin_display_info = \"plugin={}.plugins.{}\".format(\n phase,\n plugin_name\n )\n plugin_instance = registry.by_phase(phase)[plugin_name](\n **{key: value\n for key, value in plugin_execution_args.items()\n if key != 'plugin'}\n )\n logger.info(\n \"{} status={}\".format(current_plugin_display_info, 'running')\n )\n plugin_instance.execute(context)\n logger.info(\n \"{} status={}\".format(current_plugin_display_info, 'done')\n )\n return {'plugin': plugin_name, 'instance': plugin_instance}\n"
},
{
"alpha_fraction": 0.5798137187957764,
"alphanum_fraction": 0.5800303220748901,
"avg_line_length": 27.856250762939453,
"blob_id": "051e8a3e008089e51d59bbaf6f462ca7cc83522c",
"content_id": "333e59f9c1fc324ed3cde80dcd352196807e2790",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4617,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 160,
"path": "/pitch/plugins/response.py",
"repo_name": "georgepsarakis/pitch",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nimport logging\nimport sys\nimport time\n\nimport requests\n\nfrom pitch.plugins.common import BasePlugin, LoggerPlugin, UpdateContext\nfrom pitch.common.utils import to_iterable\n\nlogger = logging.getLogger()\n\n\nclass BaseResponsePlugin(BasePlugin):\n _phase = 'response'\n\n\nclass ResponseUpdateContext(UpdateContext, BaseResponsePlugin):\n \"\"\" Add variables to the template context after the response has completed\n \"\"\"\n _name = 'post_register'\n\n\nclass JSONResponsePlugin(BaseResponsePlugin):\n \"\"\"\n Serialize the response body as JSON and store in response.as_json\n \"\"\"\n _name = 'response_as_json'\n\n def execute(self, plugin_context):\n response = plugin_context.templating['response']\n response.as_json = None\n try:\n response.as_json = json.loads(response.text)\n self._result = (True, None)\n except ValueError as e:\n self._result = (False, e)\n\n\nclass ResponseLoggerPlugin(LoggerPlugin, BaseResponsePlugin):\n \"\"\"\n Setup a logger, attach a file handler and log a message.\n \"\"\"\n _name = 'response_logger'\n\n\nclass JSONFileOutputPlugin(BaseResponsePlugin):\n \"\"\"\n Write a JSON-serializable response to a file\n \"\"\"\n _name = 'json_file_output'\n\n def __init__(self, filename, create_dirs=True):\n\n self._filename = os.path.expanduser(os.path.abspath(filename))\n self._directory = os.path.dirname(filename)\n if not os.path.exists(self._directory):\n if create_dirs:\n os.makedirs(self._directory)\n else:\n raise OSError(\n \"Directory {} does not exist\".format(\n self._directory\n )\n )\n super(JSONFileOutputPlugin, self).__init__()\n\n def execute(self, plugin_context):\n with open(self._filename, 'w') as f:\n json.dump(plugin_context.templating['response'].json(), f)\n\n\nclass ProfilerPlugin(BaseResponsePlugin):\n \"\"\" Keep track of the time required for the HTTP request & processing\n \"\"\"\n _name = 'profiler'\n\n def __init__(self):\n self._end_time = time.clock()\n self._elapsed_time = self._end_time\n super(ProfilerPlugin, self).__init__()\n\n def execute(self, plugin_context):\n request_profiler_plugin = plugin_context.request.plugins.get(\n self._name\n )\n if request_profiler_plugin is None:\n self._result = None\n else:\n self._result -= request_profiler_plugin.start_time\n\n @property\n def end_time(self):\n return self._end_time\n\n @property\n def elapsed_time(self):\n return self._result\n\n\nclass StdOutWriterPlugin(BaseResponsePlugin):\n \"\"\"\n Print a JSON-serializable response to STDOUT\n \"\"\"\n _name = 'stdout_writer'\n\n def execute(self, plugin_context):\n sys.stdout.write(\n \"{}\\n\".format(\n json.dumps(\n plugin_context.response.as_json,\n sort_keys=True,\n indent=4\n )\n )\n )\n sys.stdout.flush()\n\n\nclass AssertHttpStatusCode(BaseResponsePlugin):\n \"\"\" Examine the response HTTP status code and raise error/stop execution\n \"\"\"\n _name = 'assert_http_status_code'\n\n def __init__(self, expect=requests.codes.ok):\n self.__expect = [int(code) for code in to_iterable(expect)]\n super(AssertHttpStatusCode, self).__init__()\n\n def execute(self, plugin_context):\n response = plugin_context.templating['response']\n failfast = plugin_context.step.get(\n 'failfast',\n plugin_context.globals['failfast']\n )\n if response.status_code not in self.__expect:\n message = 'Expected HTTP status code {}, received {} - ' \\\n 'Reason={} - URL = {}'\n message = message.format(\n self.__expect,\n response.status_code,\n response.text,\n response.request.url\n )\n if failfast:\n raise SystemExit(message)\n if response.status_code < requests.codes.bad_request:\n reporter = logger.info\n else:\n reporter = logger.error\n reporter(\n '[response] Received response (HTTP code={}) from '\n 'URL: {}'.format(\n response.status_code,\n response.url\n )\n )\n if response.status_code >= requests.codes.bad_request:\n if failfast:\n response.raise_for_status()\n"
}
] | 25 |
Krypticdator/Complete-Roguelike-Tutorial--using-python-3-libtcod-tdl-
|
https://github.com/Krypticdator/Complete-Roguelike-Tutorial--using-python-3-libtcod-tdl-
|
5567b62ab08e9e38870da0aedf615fabb3f4196a
|
fc0f4720ee4fb9b38eb5cd7f5053492490fc498f
|
f7ea56167054336274ef58579c82a101287d57a4
|
refs/heads/master
| 2016-08-12T18:50:29.227727 | 2015-06-09T17:44:41 | 2015-06-09T17:44:41 | 36,950,399 | 2 | 3 | null | 2015-06-05T19:05:40 | 2015-06-05T19:07:45 | 2015-06-06T13:34:02 |
Python
|
[
{
"alpha_fraction": 0.5691773295402527,
"alphanum_fraction": 0.5827609896659851,
"avg_line_length": 32.89909362792969,
"blob_id": "35458b78182d58f9e31036392fa9dd7e3fb14221",
"content_id": "65af0152e32a0842f50e45182089554db8160503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26208,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 773,
"path": "/Launcher.py",
"repo_name": "Krypticdator/Complete-Roguelike-Tutorial--using-python-3-libtcod-tdl-",
"src_encoding": "UTF-8",
"text": "__author__ = 'Toni'\n\nimport tdl\nfrom random import randint\nimport math\nimport textwrap\n\nSCREEN_WIDTH = 80\nSCREEN_HEIGHT = 65\n\nMAX_ROOM_MONSTERS = 3\n\n#size of the map\nMAP_WIDTH = 80\nMAP_HEIGHT = 50\n\n#sizes and coordinates relevant for the GUI\nBAR_WIDTH = 20\nPANEL_HEIGHT = 7\nPANEL_Y = SCREEN_HEIGHT - PANEL_HEIGHT\nMSG_X = BAR_WIDTH + 2\nMSG_WIDTH = SCREEN_WIDTH - BAR_WIDTH - 2\nMSG_HEIGHT = PANEL_HEIGHT - 1\n\nINVENTORY_WIDTH = 50\n\nLIMIT_FPS = 20\nplayerX = SCREEN_WIDTH/2\nplayerY = SCREEN_HEIGHT/2\n\nMOUSE_COORD = {'x':0, 'y':0}\n\nconsole = tdl.init(SCREEN_WIDTH, SCREEN_HEIGHT, title = \"Roguelike\")\npanel = tdl.Console(SCREEN_WIDTH, PANEL_HEIGHT)\ncon = tdl.Console(MAP_WIDTH, MAP_HEIGHT)\ntdl.setFPS(LIMIT_FPS)\n\nROOM_MAX_SIZE = 10\nROOM_MIN_SIZE = 6\nMAX_ROOMS = 30\nMAX_ROOM_ITEMS = 2\n\nfov_recompute = False\n\nFOV_ALGO = 0 #default FOV algorithm\nFOV_LIGHT_WALLS = True\nTORCH_RADIUS = 10\nHEAL_AMOUNT = 4\n\ncolor_dark_wall = [0, 0, 100]\ncolor_light_wall = [130, 110, 50]\ncolor_dark_ground = [50, 50, 150]\ncolor_light_ground = [200, 180, 50]\ncolor_yellow = [255, 255, 0]\ncolor_green = [0, 255, 0]\ncolor_dark_green = [0, 153, 0]\ncolor_dark_red = [204, 0, 0]\ncolor_violet = [255, 0, 255]\n\ngame_state = 'playing'\nplayer_action = None\n\nclass Tile:\n #a tile of the map and its properties\n def __init__(self, blocked, block_sight = None):\n self.blocked = blocked\n\n #all tiles start unexplored\n self.explored = False\n\n #by default, if a tile is blocked, it also blocks sight\n if block_sight is None: block_sight = blocked\n self.block_sight = block_sight\n\nclass Rect:\n #a rectangle on the map. used to characterize a room.\n def __init__(self, x, y, w, h):\n self.x1 = x\n self.y1 = y\n self.x2 = x + w\n self.y2 = y + h\n\n def center(self):\n center_x = int((self.x1 + self.x2) / 2)\n center_y = int((self.y1 + self.y2) / 2)\n return (center_x, center_y)\n\n def intersect(self, other):\n #returns true if this rectangle intersects with another one\n return (self.x1 <= other.x2 and self.x2 >= other.x1 and\n self.y1 <= other.y2 and self.y2 >= other.y1)\n\n\nclass Fighter:\n #combat-related properties and methods (monster, player, NPC).\n def __init__(self, hp, defense, power, death_function=None):\n self.max_hp = hp\n self.hp = hp\n self.defense = defense\n self.power = power\n self.death_function = death_function\n\n def take_damage(self, damage):\n #apply damage if possible\n if damage > 0:\n self.hp -= damage\n if self.hp <= 0:\n function = self.death_function\n if function is not None:\n function(self.owner)\n\n def attack(self, target):\n #a simple formula for attack damage\n damage = self.power - target.fighter.defense\n\n if damage > 0:\n #make the target take some damage\n print (self.owner.name.capitalize() + ' attacks ' + target.name + ' for ' + str(damage) + ' hit points.')\n target.fighter.take_damage(damage)\n else:\n print (self.owner.name.capitalize() + ' attacks ' + target.name + ' but it has no effect!')\n\n def heal(self, amount):\n #heal by the given amount, without going over the maximum\n self.hp += amount\n if self.hp > self.max_hp:\n self.hp = self.max_hp\n\nclass BasicMonster:\n #AI for a basic monster.\n def take_turn(self):\n global visible_tiles\n #a basic monster takes its turn. If you can see it, it can see you\n monster = self.owner\n #if libtcod.map_is_in_fov(fov_map, monster.x, monster.y):\n coord = (monster.x, monster.y)\n if coord in visible_tiles:\n\n #move towards player if far away\n if monster.distance_to(player) >= 2:\n monster.move_towards(player.x, player.y)\n\n #close enough, attack! (if the player is still alive.)\n elif player.fighter.hp > 0:\n monster.fighter.attack(player)\n\nclass GameObject:\n # this is a generic object: the player, a monster, an item, the stairs...\n # it's always represented by a character on screen.\n def __init__(self, x, y, char, name, color, blocks=False, fighter=None, ai=None, item=None):\n self.name = name\n self.blocks = blocks\n self.x = x\n self.y = y\n self.char = char\n self.color = color\n\n self.fighter = fighter\n if self.fighter: #let the fighter component know who owns it\n self.fighter.owner = self\n\n self.ai = ai\n if self.ai: #let the AI component know who owns it\n self.ai.owner = self\n\n self.item = item\n if self.item: #let the Item component know who owns it\n self.item.owner = self\n\n def move(self, dx, dy):\n #move by the given amount, if the destination is not blocked\n if not is_blocked(self.x + dx, self.y + dy):\n self.x += dx\n self.y += dy\n #print(str(self.x) + \" \" + str(self.y))\n\n def move_towards(self, target_x, target_y):\n #vector from this object to the target, and distance\n dx = target_x - self.x\n dy = target_y - self.y\n distance = math.sqrt(dx ** 2 + dy ** 2)\n\n #normalize it to length 1 (preserving direction), then round it and\n #convert to integer so the movement is restricted to the map grid\n dx = int(round(dx / distance))\n dy = int(round(dy / distance))\n self.move(dx, dy)\n\n def distance_to(self, other):\n #return the distance to another object\n dx = other.x - self.x\n dy = other.y - self.y\n return math.sqrt(dx ** 2 + dy ** 2)\n\n def draw(self):\n global visible_tiles\n coord = (self.x, self.y)\n if coord in visible_tiles:\n con.drawChar(self.x, self.y, self.char, self.color)\n\n def clear(self):\n con.drawChar(self.x, self.y, ' ')\n\n def send_to_back(self):\n #make this object be drawn first, so all others appear above it if they're in the same tile.\n global objects\n objects.remove(self)\n objects.insert(0, self)\n\nclass Item:\n #an item that can be picked up and used.\n def __init__(self, use_function=None):\n self.use_function = use_function\n\n def pick_up(self):\n #add to the player's inventory and remove from the map\n if len(inventory) >= 26:\n message('Your inventory is full, cannot pick up ' + self.owner.name + '.', color_dark_red)\n else:\n inventory.append(self.owner)\n objects.remove(self.owner)\n message('You picked up a ' + self.owner.name + '!', color_green)\n def use(self):\n #just call the \"use_function\" if it is defined\n if self.use_function is None:\n message('The ' + self.owner.name + ' cannot be used.')\n else:\n if self.use_function() != 'cancelled':\n inventory.remove(self.owner) #destroy after use, unless it was cancelled for some reason\n\n\n\ndef create_room(room):\n global map\n #go through the tiles in the rectangle and make them passable\n for x in range(room.x1 + 1, room.x2):\n for y in range(room.y1 + 1, room.y2):\n map[x][y].blocked = False\n map[x][y].block_sight = False\n\ndef is_blocked(x, y):\n global map\n #first test the map tile\n if map[x][y].blocked:\n return True\n\n #now check for any blocking objects\n for object in objects:\n if object.blocks and object.x == x and object.y == y:\n return True\n\n return False\n\ndef place_objects(room):\n num_monsters = randint(0, MAX_ROOM_MONSTERS)\n\n for i in range(num_monsters):\n #choose random spot for this monster\n x = randint(room.x1+1, room.x2-1)\n y = randint(room.y1+1, room.y2-1)\n\n #only place it if the tile is not blocked\n if not is_blocked(x, y):\n if randint(0, 100) < 80:\n fighter_component = Fighter(hp=10, defense=0, power=3, death_function=monster_death)\n ai_component = BasicMonster()\n monster = GameObject(x, y, 'o', 'orc', color_green, blocks=True, fighter=fighter_component, ai=ai_component)\n else:\n fighter_component = Fighter(hp=16, defense=1, power=4, death_function=monster_death)\n ai_component = BasicMonster()\n monster = GameObject(x, y, 'I', 'troll', color_dark_green, blocks=True, fighter=fighter_component, ai=ai_component)\n\n objects.append(monster)\n #choose random number of items\n #num_items = libtcod.random_get_int(0, 0, MAX_ROOM_ITEMS)\n num_items = randint(0, MAX_ROOM_ITEMS)\n\n for i in range(num_items):\n #choose random spot for this item\n #x = libtcod.random_get_int(0, room.x1+1, room.x2-1)\n #y = libtcod.random_get_int(0, room.y1+1, room.y2-1)\n x = randint(room.x1+1, room.x2-1)\n y = randint(room.y1+1, room.y2-1)\n\n #only place it if the tile is not blocked\n if not is_blocked(x, y):\n #create a healing potion\n item_component = Item(use_function=cast_heal)\n item = GameObject(x, y, '!', 'healing potion', color_violet, item=item_component)\n\n objects.append(item)\n item.send_to_back() #items appear below other objects\n\ndef create_h_tunnel(x1, x2, y):\n global map\n x1 = int(x1)\n x2 = int(x2)\n y = int(y)\n for x in range(min(x1, x2), max(x1, x2) + 1):\n map[x][y].blocked = False\n map[x][y].block_sight = False\n\ndef create_v_tunnel(y1, y2, x):\n global map\n y1 = int(y1)\n y2 = int(y2)\n x = int(x)\n #vertical tunnel\n for y in range(min(y1, y2), max(y1, y2) + 1):\n map[x][y].blocked = False\n map[x][y].block_sight = False\n\ndef is_visible_tile(x, y):\n global map\n x = int(x)\n y = int(y)\n #print(str(map))\n if x >= MAP_WIDTH or x < 0:\n return False\n elif y >= MAP_HEIGHT or y < 0:\n return False\n elif map[x][y].blocked == True:\n return False\n elif map[x][y].block_sight == True:\n return False\n else:\n return True\n\ndef make_map():\n global map, player, visible_tiles\n\n #fill map with \"unblocked\" tiles\n map = [[ Tile(True)\n for y in range(MAP_HEIGHT) ]\n for x in range(MAP_WIDTH) ]\n\n\n\n rooms = []\n num_rooms = 0\n\n for r in range(MAX_ROOMS):\n #random width and height\n w = randint(ROOM_MIN_SIZE, ROOM_MAX_SIZE)\n h = randint(ROOM_MIN_SIZE, ROOM_MAX_SIZE)\n #random position without going out of the boundaries of the map\n x = randint(0, MAP_WIDTH - w -1)\n y = randint(0, MAP_HEIGHT - h -1)\n x = int(x)\n y = int(y)\n #\"Rect\" class makes rectangles easier to work with\n new_room = Rect(x, y, w, h)\n\n #run through the other rooms and see if they intersect with this one\n failed = False\n for other_room in rooms:\n if new_room.intersect(other_room):\n failed = True\n break\n\n if not failed:\n #this means there are no intersections, so this room is valid\n\n #\"paint\" it to the map's tiles\n create_room(new_room)\n\n #add some contents to this room, such as monsters\n place_objects(new_room)\n\n #center coordinates of new room, will be useful later\n (new_x, new_y) = new_room.center()\n\n if num_rooms == 0:\n #this is the first room, where the player starts at\n player.x = new_x\n player.y = new_y\n visible_tiles = tdl.map.quickFOV(new_x, new_y, is_visible_tile)\n #print(visible_tiles)\n else:\n #all rooms after the first:\n #connect it to the previous room with a tunnel\n\n #center coordinates of previous room\n (prev_x, prev_y) = rooms[num_rooms-1].center()\n\n #draw a coin (random number that is either 0 or 1)\n if randint(0, 1) == 1:\n #first move horizontally, then vertically\n create_h_tunnel(prev_x, new_x, prev_y)\n create_v_tunnel(prev_y, new_y, new_x)\n else:\n #first move vertically, then horizontally\n create_v_tunnel(prev_y, new_y, prev_x)\n create_h_tunnel(prev_x, new_x, new_y)\n\n #finally, append the new room to the list\n rooms.append(new_room)\n num_rooms += 1\n\ndef player_death(player):\n #the game ended!\n global game_state\n print ('You died!')\n game_state = 'dead'\n\n #for added effect, transform the player into a corpse!\n player.char = '%'\n player.color = color_dark_red\n\ndef monster_death(monster):\n #transform it into a nasty corpse! it doesn't block, can't be\n #attacked and doesn't move\n print (monster.name.capitalize() + ' is dead!')\n monster.char = '%'\n monster.color = color_dark_red\n monster.blocks = False\n monster.fighter = None\n monster.ai = None\n monster.name = 'remains of ' + monster.name\n monster.send_to_back()\n\n\n\ndef cast_heal():\n #heal the player\n if player.fighter.hp == player.fighter.max_hp:\n message('You are already at full health.', color_dark_red)\n return 'cancelled'\n\n message('Your wounds start to feel better!', color_violet)\n player.fighter.heal(HEAL_AMOUNT)\n\nglobal visible_tiles\nfighter_component = Fighter(hp=30, defense=2, power=5, death_function=player_death)\nplayer = GameObject(0, 0, '@', 'player', [255, 255, 255], blocks=True, fighter=fighter_component)\n\n#create the list of game messages and their colors, starts empty\ngame_msgs = []\n\n\nobjects = [player]\ninventory = []\n\n#generate map (at this point it's not drawn to the screen)\nmake_map()\n\ndef render_all():\n global color_dark_wall, color_light_wall\n global color_dark_ground, color_light_ground\n global fov_recompute, visible_tiles, player, map\n\n if fov_recompute:\n fov_recompute = False\n #print(\"fov_recompute\")\n visible_tiles = tdl.map.quickFOV(player.x, player.y, is_visible_tile)\n #print(len(visible_tiles))\n #print(str(visible_tiles))\n #go through all tiles, and set their background color\n for y in range(MAP_HEIGHT):\n for x in range(MAP_WIDTH):\n visible = False\n coord = (x, y)\n #print(coord)\n if coord in visible_tiles:\n #print(\"visible\")\n visible = True\n wall = map[x][y].block_sight\n if not visible:\n if map[x][y].explored:\n if wall:\n # libtcod.console_set_char_background(con, x, y, color_dark_wall, libtcod.BKGND_SET )\n con.drawChar(x, y, None, bgcolor = color_dark_wall)\n else:\n #libtcod.console_set_char_background(con, x, y, color_dark_ground, libtcod.BKGND_SET )\n con.drawChar(x, y, None, bgcolor = color_dark_ground)\n else:\n if wall:\n con.drawChar(x, y, None, bgcolor = color_light_wall)\n\n else:\n con.drawChar(x, y, None, bgcolor = color_light_ground)\n #print(\"yellow\")\n map[x][y].explored = True\n\n #draw all objects in the list, except the player. we want it to\n #always appear over all other objects! so it's drawn later.\n for object in objects:\n if object != player:\n object.draw()\n player.draw()\n console.blit(con, 0, 0, MAP_WIDTH, MAP_HEIGHT,0,0)\n #prepare to render the GUI panel\n #libtcod.console_set_default_background(panel, libtcod.black)\n #libtcod.console_clear(panel)\n panel.clear()\n\n #print the game messages, one line at a time\n y = 1\n for (line, color) in game_msgs:\n #libtcod.console_set_default_foreground(panel, color)\n #libtcod.console_print_ex(panel, MSG_X, y, libtcod.BKGND_NONE, libtcod.LEFT, line)\n\n text = \"%s\" % (line)\n # then get a string spanning the entire bar with the text centered\n text = text.center(MSG_X)\n # render this text over the bar while preserving the background color\n panel.drawStr(MSG_X, y, text, [255,255,255], None)\n\n y += 1\n\n #show the player's stats\n render_bar(1, 1, BAR_WIDTH, 'HP', player.fighter.hp, player.fighter.max_hp,\n color_dark_red, color_yellow)\n\n #libtcod.console_print_ex(panel, 1, 0, libtcod.BKGND_NONE, libtcod.LEFT, get_names_under_mouse())\n mouse_message = get_names_under_mouse()\n mouse_message = \"%s\" % (mouse_message)\n mouse_message = mouse_message.center(1)\n panel.drawStr(1, 0, mouse_message, [255, 255, 255], None)\n\n #blit the contents of \"panel\" to the root console\n #libtcod.console_blit(panel, 0, 0, SCREEN_WIDTH, PANEL_HEIGHT, 0, 0, PANEL_Y)\n panel.move(0, 0)\n console.blit(panel, 0, 0, SCREEN_WIDTH, PANEL_HEIGHT)\n\ndef render_bar(x, y, total_width, name, value, maximum, bar_color, back_color):\n #render a bar (HP, experience, etc). first calculate the width of the bar\n bar_width = int(float(value) / maximum * total_width)\n\n #render the background first\n #libtcod.console_set_default_background(panel, back_color)\n #panel.setColors(bg=back_color) # not used if there's no printStr call\n #libtcod.console_rect(panel, x, y, total_width, 1, False, libtcod.BKGND_SCREEN)\n panel.drawRect(x, y, total_width, 1, None, None, back_color)\n\n #now render the bar on top\n #libtcod.console_set_default_background(panel, bar_color)\n #panel.setColors(bg=bar_color)\n if bar_width > 0:\n #libtcod.console_rect(panel, x, y, bar_width, 1, False, libtcod.BKGND_SCREEN)\n panel.drawRect(x, y, bar_width, 1, None, None, bar_color)\n\n #finally, some centered text with the values\n #libtcod.console_set_default_foreground(panel, libtcod.white)\n #panel.setColors(fg=[255,255,255])\n #libtcod.console_print_ex(panel, x + total_width / 2, y, libtcod.BKGND_NONE, libtcod.CENTER,\n # name + ': ' + str(value) + '/' + str(maximum))\n #panel.printStr(name + \": \" + str(value) + '/' + str(maximum))\n\n # prepare the text using old-style Python string formatting\n text = \"%s: %i/%i\" % (name, value, maximum)\n # then get a string spanning the entire bar with the text centered\n text = text.center(total_width)\n\n # render this text over the bar while preserving the background color\n panel.drawStr(x, y, text, [255,255,255], None)\n\ndef get_names_under_mouse():\n\n #return a string with the names of all objects under the mouse\n (x, y) = (MOUSE_COORD['x'], MOUSE_COORD['y'])\n\n #create a list with the names of all objects at the mouse's coordinates and in FOV\n names = [obj.name for obj in objects\n if obj.x == x and obj.y == y and (x, y) in visible_tiles]\n\n names = ', '.join(names) #join the names, separated by commas\n return names.capitalize()\n\ndef message(new_msg, color = [255, 255, 255]):\n #split the message if necessary, among multiple lines\n new_msg_lines = textwrap.wrap(new_msg, MSG_WIDTH)\n\n for line in new_msg_lines:\n #if the buffer is full, remove the first line to make room for the new one\n if len(game_msgs) == MSG_HEIGHT:\n del game_msgs[0]\n\n #add the new line as a tuple, with the text and the color\n game_msgs.append( (line, color) )\n\ndef menu(header, options, width):\n if len(options) > 26: raise ValueError('Cannot have a menu with more than 26 options.')\n #calculate total height for the header (after auto-wrap) and one line per option\n #header_height = libtcod.console_get_height_rect(con, 0, 0, width, SCREEN_HEIGHT, header)\n\n header_height = 1\n\n height = len(options) + header_height\n\n #create an off-screen console that represents the menu's window\n window = tdl.Console(width, height)\n\n #print the header, with auto-wrap\n #libtcod.console_set_default_foreground(window, libtcod.white)\n window.setColors(fg = [255, 255, 255])\n #libtcod.console_print_rect_ex(window, 0, 0, width, height, libtcod.BKGND_NONE, libtcod.LEFT, header)\n\n text = '%s' % (header)\n text = text.ljust(height)\n window.drawStr(0, 0, text)\n\n #print all the options\n y = header_height\n letter_index = ord('a')\n for option_text in options:\n text = '(' + chr(letter_index) + ') ' + option_text\n #libtcod.console_print_ex(window, 0, y, libtcod.BKGND_NONE, libtcod.LEFT, text)\n text = '%s' % (text)\n text = text.ljust(height)\n window.drawStr(0, y, text)\n\n y += 1\n letter_index += 1\n #blit the contents of \"window\" to the root console\n x = SCREEN_WIDTH/2 - width/2\n y = SCREEN_HEIGHT/2 - height/2\n #libtcod.console_blit(window, 0, 0, width, height, 0, x, y, 1.0, 0.7)\n #console.blit(window, 0, 0, width, height,x, y)\n console.blit(window, x, y, width, height, 0, 0)\n #present the root console to the player and wait for a key-press\n tdl.flush()\n #key = libtcod.console_wait_for_keypress(True)\n key = tdl.event.keyWait()\n\n #convert the ASCII code to an index; if it corresponds to an option, return it\n index = ord(key.char) - ord('a')\n if index >= 0 and index < len(options): return index\n return None\n\ndef inventory_menu(header):\n #show a menu with each item of the inventory as an option\n if len(inventory) == 0:\n options = ['Inventory is empty.']\n else:\n options = [item.name for item in inventory]\n\n index = menu(header, options, INVENTORY_WIDTH)\n\n #if an item was chosen, return it\n if index is None or len(inventory) == 0: return None\n return inventory[index].item\n\ndef player_move_or_attack(dx, dy):\n global fov_recompute\n\n #the coordinates the player is moving to/attacking\n x = player.x + dx\n y = player.y + dy\n\n #try to find an attackable object there\n target = None\n for object in objects:\n if object.fighter and object.x == x and object.y == y:\n target = object\n break\n\n #attack if target found, move otherwise\n if target is not None:\n player.fighter.attack(target)\n else:\n player.move(dx, dy)\n fov_recompute = True\n\ndef handle_keys():\n global fov_recompute\n user_input = tdl.event.get()\n\n #if user_input.key == 'ESCAPE':\n for event in user_input:\n #print(str(event))\n if event.type == 'KEYDOWN':\n if event.key == 'ESCAPE':\n return 'exit'\n if game_state == 'playing':\n if event.type == 'KEYDOWN':\n if event.key == 'UP':\n player_move_or_attack(0, -1)\n fov_recompute = True\n return 'took-turn'\n elif event.key == 'DOWN':\n player_move_or_attack(0, 1)\n fov_recompute = True\n return 'took-turn'\n elif event.key == 'LEFT':\n player_move_or_attack(-1, 0)\n fov_recompute = True\n return 'took-turn'\n elif event.key == 'RIGHT':\n player_move_or_attack(1, 0)\n fov_recompute = True\n return 'took-turn'\n else:\n key_char = event.keychar\n if key_char == 'g':\n #pick up an item\n for object in objects: #look for an item in the player's tile\n if object.x == player.x and object.y == player.y and object.item:\n object.item.pick_up()\n break\n return 'took_turn'\n if key_char == 'i':\n #show the inventory\n chosen_item = inventory_menu('Inventory')\n if chosen_item is not None:\n chosen_item.use()\n\n elif event.type == 'MOUSEMOTION':\n coord = event.cell\n MOUSE_COORD['x'] = coord[0]\n MOUSE_COORD['y'] = coord[1]\n #create a list with the names of all objects at the mouse's coordinates and in FOV\n\n\n else:\n return 'didnt-take-turn'\n else:\n return 'didnt-take-turn'\n\n return 'didnt-take-turn'\n #if user_input.contains('ESCAPE'):\n #return 'exit'\n '''if game_state == 'playing':\n if user_input.key == 'UP':\n player_move_or_attack(0, -1)\n fov_recompute = True\n elif user_input.key == 'DOWN':\n player_move_or_attack(0, 1)\n fov_recompute = True\n elif user_input.key == 'LEFT':\n player_move_or_attack(-1, 0)\n fov_recompute = True\n elif user_input.key == 'RIGHT':\n player_move_or_attack(1, 0)\n fov_recompute = True\n else:\n return 'didnt-take-turn'''''\n\n\n\n#fov_map = libtcod.map_new(MAP_WIDTH, MAP_HEIGHT)\nfor y in range(MAP_HEIGHT):\n for x in range(MAP_WIDTH):\n # libtcod.map_set_properties(fov_map, x, y, not map[x][y].block_sight, not map[x][y].blocked)\n #tdl.map.quickFOV(x, y, map[x][y].block_sight )\n pass\n\nfov_recompute = True\ntdl.setFPS(LIMIT_FPS)\n\n#a warm welcoming message!\nmessage('Welcome stranger! Prepare to perish in the Tombs of the Ancient Kings.', color_dark_red)\n\nwhile not tdl.event.isWindowClosed():\n #render the screen\n #all_events = tdl.event.get()\n render_all()\n\n tdl.flush()\n\n for obj in objects:\n obj.clear()\n\n player_action = handle_keys()\n #print(player_action)\n if player_action == 'exit':\n break;\n\n #let monsters take their turn\n if game_state == 'playing' and player_action != 'didnt-take-turn':\n for object in objects:\n if object.ai:\n object.ai.take_turn()\n\n\n\n\n"
}
] | 1 |
sugar-activities/4564-activity
|
https://github.com/sugar-activities/4564-activity
|
225b7f9cf81a406caa6f4a720a09974fc40c35b2
|
c711f93807ffdf3188eb63d25c57e448be81ce05
|
249fd90acd826d243aa72f4ee28641b31e5bbeae
|
refs/heads/master
| 2019-07-08T13:12:35.656646 | 2017-04-21T04:57:41 | 2017-04-21T04:57:41 | 88,937,248 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6586830019950867,
"alphanum_fraction": 0.6712652444839478,
"avg_line_length": 34.90825653076172,
"blob_id": "dd278d45755dce5888170677c9e736a3c8e75996",
"content_id": "0fafeffbf73759cb39b6a3acf9bc330e7f385b12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15662,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 436,
"path": "/CeibalNotifica.py",
"repo_name": "sugar-activities/4564-activity",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# Plan Ceibal - Uruguay\n# Flavio Danesse - [email protected]\n\n# This program is free software; you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program; if not, write to the Free Software\n# Foundation, Inc., 51 Franklin St, Fifth Floor, Boston, MA 02110-1301 USA\n\nimport shelve\nimport os\nimport gtk\nimport sys\nimport gobject\n#from store import *\nfrom ceibal.notifier.store import *\nfrom sugar.activity import activity\nfrom sugar.activity.widgets import StopButton\nBASE = os.path.dirname(__file__)\npixbuf1 = gtk.gdk.pixbuf_new_from_file_at_size(os.path.join(BASE, \"Iconos\", \"ceibal-gris.png\"), 32,32)\npixbuf2 = gtk.gdk.pixbuf_new_from_file_at_size(os.path.join(BASE, \"Iconos\", \"ceibal.png\"), 32,32)\n\nclass CeibalNotifica(activity.Activity):\n\tdef __init__(self, handle):\n\t\tactivity.Activity.__init__(self, handle, False)\n\t\tself.set_title(\"Ceibal Notifica\")\n\t\tself.set_border_width(2)\n\t\tself.text_buffer = None\n\t\tself.text_view = None\n\t\tself.store = None\n\t\tself.listore_model = None\n\t\tself.modelsort = None\n\t\tself.notify_store = None\n\t\tself.info_toolbar = None\n\t\tself.control_toolbar = None\n\t\tself.filter = None\n\t\tself.set_layout()\n\t\tself.show_all()\n\t\tself.connect(\"delete_event\", self.delete_event)\n\t\tself.notify_store.connect(\"show_notify\", self.show_notify)\n\t\tself.notify_store.connect(\"delete_notify\", self.delete_notify)\n\t\tself.notify_store.connect(\"marcar_notify\", self.marcar_notify)\n\t\tself.control_toolbar.connect(\"get_filter\", self.get_filter)\n\t\tself.control_toolbar.connect(\"make_filter\", self.make_filter)\n\t\tself.control_toolbar.connect(\"show_filter\", self.show_filter)\n\t\tself.control_toolbar.connect(\"exit\", self.salir)\n\t\tself.load_notify()\n\t\tself.notify_store.columns_autosize()\n\n\tdef set_layout(self):\n\t\tself.listore_model = ListoreModel()\n\t\tself.modelsort = gtk.TreeModelSort(self.listore_model)\n\t\tself.notify_store = Notify_Store(self.modelsort)\n\t\tself.text_buffer = gtk.TextBuffer()\n\t\tself.text_view = gtk.TextView(buffer=self.text_buffer)\n\t\tself.text_view.set_editable(False)\n\t\tself.text_view.set_justification(gtk.JUSTIFY_LEFT)\n\t\thpanel = gtk.HPaned()\n\t\t#self.store = Store(db_filename=\"prueba.db\")\n self.store = Store()\n\t\tscroll = gtk.ScrolledWindow()\n\t\tscroll.set_policy(gtk.POLICY_AUTOMATIC, gtk.POLICY_AUTOMATIC)\n\t\tscroll.add_with_viewport(self.notify_store)\n\t\thpanel.pack1(scroll, resize = False, shrink = True)\n\t\tscroll = gtk.ScrolledWindow()\n\t\tscroll.set_policy(gtk.POLICY_AUTOMATIC, gtk.POLICY_AUTOMATIC)\n\t\tscroll.add_with_viewport(self.text_view)\n\t\thpanel.pack2(scroll, resize = False, shrink = True)\n\t\tvbox = gtk.VBox()\n\t\tself.info_toolbar = ToolbarInfo()\n\t\tself.control_toolbar = ToolbarControl()\n\t\tvbox.pack_start(self.control_toolbar, False, False, 0)\n\t\tvbox.pack_start(hpanel, True, True, 0)\n\t\tvbox.pack_start(self.info_toolbar, False, False, 0)\n\t\thpanel.show_all()\n\t\tself.set_canvas(vbox)\n\n\tdef get_filter(self, widget, value):\n\t\tfiltro_nivel2 = self.store.db.get_categories(value=value)\n\t\twidget.set_filter(filtro_nivel2)\n\n\tdef make_filter(self, widget, value):\n\t\tself.filter = value\n\t\tself.load_notify()\n\t\twidget.make_filter(self.filter)\n\n\tdef show_notify(self, widget, text, info):\n\t\tself.text_buffer.set_text(text)\n\t\tself.info_toolbar.set_text(info)\n\n\tdef delete_notify(self, widget, path):\n\t\titer = widget.get_model().get_iter(path)\n\t\tid_registro = int(widget.get_model().get_value(iter, 1))\n\t\tself.store.db.remove_message(id_registro)\n\t\titer = self.listore_model.get_iter(path)\n\t\tself.listore_model.remove(iter)\n\t\tself.update_view()\n\n\tdef show_filter(self, widget):\n\t\tif self.filter[0] == 'Ninguno' and self.filter[1] == 'Ninguno': return\n\t\tvalor = 0\n\t\tif self.filter[0] == 'Prioridad': valor = 2\n\t\tif self.filter[0] == 'Lanzamiento': valor = 5\n\t\tif self.filter[0] == 'Expiración': valor = 6\n\t\tif self.filter[0] == 'Tipo': valor = 7\n\t\titer = self.listore_model.get_iter_first()\n\t\twhile iter:\n\t\t\tval = self.listore_model.get_value(iter, valor)\n\t\t\tpath = self.listore_model.get_path(iter)\n\t\t\titer = self.listore_model.iter_next(self.listore_model.get_iter(path))\n\t\t\tif val != self.filter[1]:\n\t\t\t\tself.listore_model.remove(self.listore_model.get_iter(path))\n\n\tdef marcar_notify(self, widget, path):\n\t\titer = widget.get_model().get_iter(path)\n\t\tid_registro = int(widget.get_model().get_value(iter, 1))\n\t\tmarca = not self.store.db.is_fav(id_registro)\n\t\tself.store.db.set_fav(id_registro, fav=marca)\n\t\titer = self.listore_model.get_iter(path)\n\t\tfav = self.store.db.is_fav(id_registro)\n\t\tself.listore_model.set_value(iter, 8, fav)\n\t\tself.update_view()\n\n\tdef update_view(self):\n\t\tpath = self.notify_store.get_path_selected()\n\t\tif path == None: path = 0\n\t\tself.notify_store.treeselection.select_path(path)\n\t\ttry:\n\t\t\titer = self.listore_model.get_iter(path)\n\t\t\tif self.listore_model.get_value(iter, 8):\n\t\t\t\tself.listore_model.set_value(iter, 0, pixbuf2)\n\t\t\telse:\n\t\t\t\tself.listore_model.set_value(iter, 0, pixbuf1)\n\t\texcept:\n\t\t\tself.text_buffer.set_text('')\n\t\t\tself.info_toolbar.set_text('')\n\n\tdef load_notify(self):\n\t\tnotificaciones = self.store.db.get_messages([])\n\t\tself.listore_model.clear()\n\t\tfor notif in notificaciones:\n\t\t\tself.add_notify(notif)\n\n\tdef add_notify(self, notify):\n\t\tmark = pixbuf1\n\t\tif bool(notify['fav']): mark = pixbuf2\n\t\tnotify = [mark, notify['id'], notify['priority'], notify['title'], notify['text'],\n\t\tnotify['launched'], notify['expires'], notify['type'], bool(notify['fav'])]\n\t\tio = self.modelsort.get_model().append(notify)\n\t\tsel = self.notify_store.get_selection()\n\t\til = self.modelsort.convert_child_iter_to_iter(None, io)\n\t\tsel.select_iter(il)\n\n\tdef delete_event(self, widget, event):\n\t\tself.salir()\n\t\treturn False\n\n\tdef salir(self, widget=None):\n\t\tsys.exit(0)\n\nclass ListoreModel(gtk.ListStore):\n\tdef __init__(self):\n\t\tgtk.ListStore.__init__(self, gtk.gdk.Pixbuf,\n gobject.TYPE_STRING, gobject.TYPE_STRING,\n gobject.TYPE_STRING, gobject.TYPE_STRING,\n gobject.TYPE_STRING, gobject.TYPE_STRING,\n gobject.TYPE_STRING, gobject.TYPE_BOOLEAN)\n\nclass Notify_Store(gtk.TreeView):\n __gsignals__ = {\"show_notify\": (gobject.SIGNAL_RUN_FIRST,\n gobject.TYPE_NONE, (gobject.TYPE_STRING, gobject.TYPE_STRING)),\n \"delete_notify\": (gobject.SIGNAL_RUN_FIRST,\n gobject.TYPE_NONE, (gobject.TYPE_PYOBJECT, )),\n \"marcar_notify\": (gobject.SIGNAL_RUN_FIRST,\n gobject.TYPE_NONE, (gobject.TYPE_PYOBJECT, ))}\n def __init__(self, model):\n gtk.TreeView.__init__(self, model)\n self.set_property(\"rules-hint\", True)\n self.add_events(gtk.gdk.BUTTON2_MASK)\n self.connect(\"button-press-event\", self.handle_click)\n self.set_headers_clickable(True)\n self.set_columns()\n self.show_all()\n self.treeselection = self.get_selection()\n self.treeselection.set_mode(gtk.SELECTION_SINGLE)\n self.treeselection.set_select_function(self.func_selections,\n self.get_model(), True)\n def set_columns(self):\n self.append_column(self.make_column_mark('', 0, True))\n self.append_column(self.make_column('id', 1, False))\n self.append_column(self.make_column('Prioridad', 2, True))\n self.append_column(self.make_column('Título', 3, True))\n self.append_column(self.make_column('Notificación', 4, False))\n self.append_column(self.make_column('Lanzamiento', 5, False))\n self.append_column(self.make_column('Expira', 6, True))\n self.append_column(self.make_column('Tipo', 7, True))\n self.append_column(self.make_column('Favorito', 8, False))\n def make_column_mark(self, text, index, visible):\n render = gtk.CellRendererPixbuf()\n column = gtk.TreeViewColumn(text, render, pixbuf = index)\n column.set_property(\"visible\", visible)\n return column\n def make_column(self, text, index, visible):\n render = gtk.CellRendererText()\n column = gtk.TreeViewColumn(text, render, text=index)\n column.set_sort_column_id(index)\n column.set_property('visible', visible)\n return column\n def func_selections(self, selection, model, path, is_selected, user_data):\n iter = self.get_model().get_iter(path)\n texto = self.get_model().get_value(iter, 4)\n nid = self.get_model().get_value(iter, 1)\n lanzamiento = self.get_model().get_value(iter, 5)\n fav = self.get_model().get_value(iter, 8)\n if fav:\n fav = \"Si\"\n else:\n fav = \"No\"\n info = \"id: %s Lanzamiento: %s Favorito: %s\" % (nid, lanzamiento, fav)\n self.emit(\"show_notify\", texto, info)\n return True\n def handle_click(self, widget, event):\n boton = event.button\n pos = (int(event.x), int(event.y))\n tiempo = event.time\n try:\n path, col, x, y = widget.get_path_at_pos(pos[0], pos[1])\n if boton == 1:\n return\n elif boton == 3:\n self.get_menu(boton, pos, tiempo, path)\n return\n elif boton == 2:\n return\n except:\n pass\n def get_menu(self, boton, pos, tiempo, path):\n menu = gtk.Menu()\n eliminar = gtk.MenuItem(\"Eliminar Notificación.\")\n menu.append(eliminar)\n eliminar.connect_object(\"activate\", self.emit_delete_notify, path)\n iter = self.get_model().get_iter(path)\n fav = self.get_model().get_value(iter, 8)\n marcar = gtk.MenuItem(\"Marcar Como Favorito.\")\n if fav: marcar = gtk.MenuItem(\"Desmarcar Como Favorito.\")\n menu.append(marcar)\n marcar.connect_object(\"activate\", self.emit_marcar_notify, path)\n menu.show_all()\n gtk.Menu.popup(menu, None, None, None, boton, tiempo)\n def get_path_selected(self):\n (model, iter) = self.get_selection().get_selected()\n path = None\n if iter:\n treemodelrow = model[iter]\n path = treemodelrow.path\n return path\n def emit_delete_notify(self, path):\n self.emit(\"delete_notify\", path)\n def emit_marcar_notify(self, path):\n self.emit(\"marcar_notify\", path)\n\nclass ToolbarInfo(gtk.Toolbar):\n def __init__(self):\n gtk.Toolbar.__init__(self)\n self.modify_bg(gtk.STATE_NORMAL,\n gtk.gdk.Color(0, 20000, 0, 1))\n separator = gtk.SeparatorToolItem()\n separator.props.draw = False\n separator.set_size_request(0, -1)\n separator.set_expand(True)\n self.insert(separator, -1)\n item = gtk.ToolItem()\n self.info_label = gtk.Label(\"\")\n self.info_label.modify_fg(gtk.STATE_NORMAL,\n gtk.gdk.Color(65535, 65535, 65535,1))\n self.info_label.show()\n item.add(self.info_label)\n self.insert(item, -1)\n separator = gtk.SeparatorToolItem()\n separator.props.draw = False\n separator.set_size_request(0, -1)\n separator.set_expand(True)\n self.insert(separator, -1)\n\n def set_text(self, text=\"\"):\n self.info_label.set_text(text)\n\nclass ToolbarControl(gtk.Toolbar):\n\t__gsignals__ = {\"get_filter\": (gobject.SIGNAL_RUN_FIRST,\n\tgobject.TYPE_NONE, (gobject.TYPE_STRING, )),\n\t\"make_filter\": (gobject.SIGNAL_RUN_FIRST,\n\tgobject.TYPE_NONE, (gobject.TYPE_PYOBJECT, )),\n\t\"show_filter\": (gobject.SIGNAL_RUN_FIRST,\n\tgobject.TYPE_NONE, []),\n\t\"exit\": (gobject.SIGNAL_RUN_FIRST,\n\tgobject.TYPE_NONE, [])}\n\tdef __init__(self):\n\t\tgtk.Toolbar.__init__(self)\n\t\tself.modify_bg(gtk.STATE_NORMAL, gtk.gdk.Color(0, 0, 0, 1))\n\t\tself.filter_combo1 = None\n\t\tself.filter_combo2 = None\n\t\tself.set_layout()\n\t\tself.show_all()\n\t\tself.filter_combo1.connect(\"change_selection\", self.emit_get_filter)\n\t\tself.filter_combo2.connect(\"change_selection\", self.emit_make_filter)\n\n\tdef set_layout(self):\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(10, -1)\n\t\tseparator.set_expand(False)\n\t\tself.insert(separator, -1)\n\t\titem = gtk.ToolItem()\n\t\tlabel = gtk.Label(\"Filtrar por:\")\n\t\tlabel.modify_fg(gtk.STATE_NORMAL,\n\t\t\tgtk.gdk.Color(65535, 65535, 65535,1))\n\t\tlabel.show()\n\t\titem.add(label)\n\t\tself.insert(item, -1)\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(10, -1)\n\t\tseparator.set_expand(False)\n\t\tself.insert(separator, -1)\n\t\titem = gtk.ToolItem()\n\t\tself.filter_combo1 = Combo()\n\t\tself.filter_combo1.set_items([\"Tipo\", \"Prioridad\",\n\t\t\t\"Lanzamiento\", \"Expiración\"])\n\t\tself.filter_combo1.show()\n\t\titem.add(self.filter_combo1)\n\t\tself.insert(item, -1)\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(10, -1)\n\t\tseparator.set_expand(False)\n\t\tself.insert(separator, -1)\n\t\titem = gtk.ToolItem()\n\t\tlabel = gtk.Label(\"Seleccionar:\")\n\t\tlabel.modify_fg(gtk.STATE_NORMAL,\n\t\t\tgtk.gdk.Color(65535, 65535, 65535,1))\n\t\tlabel.show()\n\t\titem.add(label)\n\t\tself.insert(item, -1)\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(10, -1)\n\t\tseparator.set_expand(False)\n\t\tself.insert(separator, -1)\n\t\titem = gtk.ToolItem()\n\t\tself.filter_combo2 = Combo()\n\t\tself.filter_combo2.set_items([])\n\t\tself.filter_combo2.get_model().clear()\n\t\tself.filter_combo2.show()\n\t\titem.add(self.filter_combo2)\n\t\tself.insert(item, -1)\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(0, -1)\n\t\tseparator.set_expand(True)\n\t\tself.insert(separator, -1)\n\t\t\n\t\tstopbutton = gtk.ToolButton()\n\t\timage = gtk.Image()\n\t\timage.set_from_stock(gtk.STOCK_STOP, 32)\t\t\t\n\t\tstopbutton.set_icon_widget(image)\n\t\timage.show()\n\t\tstopbutton.connect('clicked', self.emit_exit)\n\t\tself.insert(stopbutton, -1)\n\t\tstopbutton.show()\n\t\n\t\tseparator = gtk.SeparatorToolItem()\n\t\tseparator.props.draw = False\n\t\tseparator.set_size_request(10, -1)\n\t\tseparator.set_expand(False)\n\t\tself.insert(separator, -1)\n\n\tdef emit_get_filter(self, widget, value):\n\t\tself.emit(\"get_filter\", value)\n\n\tdef emit_make_filter(self, widget, value):\n\t\tval1 = self.filter_combo1.get_value_select()\n\t\tself.emit(\"make_filter\", [val1,value])\n\n\tdef set_filter(self, lista):\n\t\tself.filter_combo2.set_items(lista)\n\n\tdef make_filter(self, filter):\n\t\tif filter[0] == 'Ninguno':\n\t\t\tself.filter_combo2.get_model().clear()\n\t\tself.emit('show_filter')\n\n\tdef emit_exit(self, widget):\n\t\tself.emit('exit')\n\nclass Combo(gtk.ComboBox):\n\t__gsignals__ = {\"change_selection\": (gobject.SIGNAL_RUN_FIRST,\n\tgobject.TYPE_NONE, (gobject.TYPE_STRING, ))}\n\tdef __init__(self):\n\t\tgtk.ComboBox.__init__(self, gtk.ListStore(str))\n\t\tcell = gtk.CellRendererText()\n\t\tself.pack_start(cell, True)\n\t\tself.add_attribute(cell, 'text', 0)\n\t\tself.show_all()\n\t\tself.connect(\"changed\", self.emit_selection)\n\n\tdef set_items(self, items):\n\t\tself.get_model().clear()\n\t\tself.append_text(\"Ninguno\")\n\t\tfor item in items:\n\t\t\tself.append_text(str(item))\n\t\tself.set_active(0)\n\n\tdef emit_selection(self, widget):\n\t\tindice = widget.get_active()\n\t\tif indice < 0: return\n\t\titer = widget.get_model().get_iter(indice)\n\t\tvalue = widget.get_model().get_value(iter, 0)\n\t\tself.emit(\"change_selection\", value)\n\n\tdef get_value_select(self):\n\t\tindice = self.get_active()\n\t\tif indice < 0: return None\n\t\titer = self.get_model().get_iter(indice)\n\t\tvalue = self.get_model().get_value(iter, 0)\n\t\treturn value\n\n"
}
] | 1 |
820fans/iGEM-Code-Generator
|
https://github.com/820fans/iGEM-Code-Generator
|
4be431ec3fcc85611693ba3c1267b068357b8f3a
|
25335a6ef0456f5ffbe884503f6cad626955b11f
|
8891b8bc7581333e95624a516aded41a31d70fee
|
refs/heads/master
| 2020-04-11T22:19:59.435822 | 2018-12-18T08:10:45 | 2018-12-18T08:10:45 | 162,132,777 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8195488452911377,
"alphanum_fraction": 0.8203007578849792,
"avg_line_length": 34,
"blob_id": "bfec1de0d3ce1ff7c563c0a934749a4adcb8d961",
"content_id": "486ba4c2b8e4e8338e84da4c285857adcb7c0278",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1356,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 38,
"path": "/main.py",
"repo_name": "820fans/iGEM-Code-Generator",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\n# 想要生成哪个页面谁就引用谁\n# import Safety.SubGenerator\n# import Team.SubGenerators\n# import Attribution.SubGenerator\n# import Collabration.SubGenerator\n# import Notebook.SubGenerator\n# import Project.Background.SubGenerator\n# import InterLab.SubGenerator\n# import HP.SubGenerator\n# import Project.Design.SubGenerator\n# import Project.Description.SubGenerator\n# import Project.Experiment.SubGenerator\n# import HP.Overview.SubGenerator\n# import HP.Silver.SubGenerator\n# import HP.Gold.SubGenerator\n# import HP.Collabration.SubGenerator\n# import Notebook.Protocol.SubGenerator\n# import Project.Part.SubGenerator\n# import Achievements.Bronze.SubGenerator\n# import Results.SubGenerator\nimport Project.Model.SubGenerator\n\n# import _China.Safety.SubGenerator\n# import _China.Attribution.SubGenerator\n# import _China.Notebook.SubGenerator\n# import _China.Project.Background.SubGenerator\n# import _China.Project.Design.SubGenerator\n# import _China.Notebook.Protocol.SubGenerator\n# import _China.HP.OurStory.SubGenerator\n# import _China.HP.Silver.SubGenerator\n# import _China.HP.Gold.SubGenerator\n# import _China.Project.Future_Dir.SubGenerator\n# import _China.Project.Model.SubGenerator\n# import _China.Project.Result.SubGenerator\n# import _China.Project.Achievements.SubGenerator\n# import _China.Project.Parts.SubGenerator\n"
},
{
"alpha_fraction": 0.4101356565952301,
"alphanum_fraction": 0.4157416820526123,
"avg_line_length": 34.114173889160156,
"blob_id": "e7aa80d6a7b4bde941830228f61297d94e67fbd4",
"content_id": "0a071545e8ba331d9e4e1422b095fcccb198af5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9103,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 254,
"path": "/BasicGenerator.py",
"repo_name": "820fans/iGEM-Code-Generator",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\nimport codecs\nimport string\n\n\nclass BasicGenerator:\n \"\"\"基础的生成类\"\"\"\n id_count = 0\n anchor_count = 0\n\n def generateContent(self, i, lines):\n line = lines[i]\n # 所有的匹配规则都是自己定的\n # 不同规则给不同的class,然后给class样式\n if line.startswith(\"#### \"):\n \"\"\"四级标题\"\"\"\n return '<div class=\"forth-level\" >' + line.replace('#### ', '') + '</div>', i + 1\n elif line.startswith(\"### \"):\n \"\"\"三级标题\"\"\"\n return '<div class=\"third-level\" >' + line.replace('### ', '') + '</div>', i + 1\n elif line.startswith(\"## \"):\n \"\"\"二级标题\"\"\"\n self.id_count += 1\n return '<div class=\"second-level\" id=\"a' + str(self.id_count) + '\" >' + line.replace('## ',\n '') + '</div>', i + 1\n elif line.startswith(\"# \"):\n \"\"\"一级标题\"\"\"\n self.id_count += 1\n return '<div class=\"first-level\" id=\"a' + str(self.id_count) + '\" >' + line.replace('# ',\n '') + '</div>', i + 1\n elif line.startswith(\"-img|\"):\n \"\"\"图片\"\"\"\n item = line.split('|')\n # if len(item) == 2:\n return '<img class=\"my-img\" src=\"' + item[1] + '\" />', i + 1\n # else:\n # if str.strip(item[2]) == \"\":\n # return '<img class=\"my-img\" src=\"' + item[1] + '\" />', i + 1\n # return '<div class=\"my-formula-img\">' \\\n # '<img class=\"my-img\" src=\"' + item[1] + '\" />' \\\n # '<span>' + item[2] + '</span></div>', i + 1\n else:\n \"\"\"内容\"\"\"\n return '<p class=\"my-content\" >' + line + '</p>', i + 1\n\n def generateTeam(self, line):\n temp_arr = []\n target_html = []\n img_arr = []\n\n try:\n val = int(line)\n if len(temp_arr):\n temp_arr.append('</div>\\n</div>')\n target_html.append('\\n'.join(temp_arr))\n temp_arr.clear()\n\n except ValueError:\n if len(temp_arr) == 0:\n temp_arr.append('<div class=\"slider__item\">')\n\n if line.startswith(\"-img|\"):\n \"\"\"图片\"\"\"\n temp_arr.append('<img class=\"my-img\" src=\"' + line.replace('-img|', '') + '\" />')\n img_arr.append('<a href=\"#' + str(len(target_html)) +\n '\"><img src=\"' + line.replace('-img|', '') + '\" alt=\"\" /></a>')\n temp_arr.append('<div class=\"slider__caption\">')\n else:\n \"\"\"内容\"\"\"\n temp_arr.append('<p class=\"my-content\" >' + line + '</p>')\n\n # Teacher\n\n try:\n val = int(line)\n if len(temp_arr):\n temp_arr.append('</div>')\n target_html.append('\\n'.join(temp_arr))\n temp_arr.clear()\n\n except ValueError:\n if len(temp_arr) == 0:\n temp_arr.append('<div class=\"teacher-item\">')\n\n if line.startswith(\"-img|\"):\n \"\"\"图片\"\"\"\n temp_arr.append('<img class=\"my-img\" src=\"' + line.replace('-img|', '') + '\" />')\n elif line.startswith(\"# \"):\n \"\"\"一级标题\"\"\"\n temp_arr.append('<div class=\"first-level\" >' + line.replace('# ', '') + '</div>')\n else:\n \"\"\"内容\"\"\"\n temp_arr.append('<p class=\"my-content\" >' + line + '</p>')\n\n return '\\n'.join(target_html), '\\n'.join(img_arr)\n\n def generateTable(self, i, lines):\n target_html = []\n pos = i\n target_html.append('<table>')\n\n while not lines[pos].startswith(\"-table-end|\"):\n item = lines[pos]\n _tr = ['<tr>']\n if pos == i:\n # 页头\n words = item.split('#')\n for word in words:\n _tr.append('<td>' + word + '</td>')\n else:\n # 内容\n words = item.split('#')\n for word in words:\n _tr.append('<td>' + word + '</td>')\n _tr.append('</tr>')\n target_html.append('\\n'.join(_tr))\n pos += 1\n\n target_html.append('</table>')\n # 跳到下一行\n pos += 1\n return '\\n'.join(target_html), pos\n\n def generateRight(self, i, lines):\n target_html = []\n pos = i\n target_html.append('<div class=\"content-wrapper\">')\n\n left = ['<div class=\"content-left\">']\n right = ['<div class=\"content-right\">']\n while not lines[pos].startswith(\"-middle|\"):\n item = lines[pos]\n if item.startswith('-img|'):\n left.append('<img class=\"my-img\" src=\"' + item.replace('-img|', '') + '\" />')\n else:\n left.append('<p class=\"my-content\" >' + item + '</p>')\n pos += 1\n left.append('</div>')\n pos += 1\n\n while not lines[pos].startswith(\"-right-end|\"):\n item = lines[pos]\n if item.startswith('-img|'):\n right.append('<img class=\"my-img\" src=\"' + item.replace('-img|', '') + '\" />')\n else:\n right.append('<p class=\"my-content\" >' + item + '</p>')\n pos += 1\n right.append('</div>')\n\n target_html.append('\\n'.join(left))\n target_html.append('\\n'.join(right))\n target_html.append('</div>')\n pos += 1\n\n return '\\n'.join(target_html), pos\n\n def generateNav(self, lines):\n navs = ['<div id=\"my-sidebar\">',\n '<div class=\"sidebar__inner\">',\n '<div class=\"side-top\">',\n '<img src=\"http://2018.igem.org/wiki/images/5/53/T--CIEI-BJ--Team--logo.jpg\" alt=\"side_top\">',\n # '<img src=\"http://2017.igem.org/wiki/images/0/09/T--CIEI-China--Home--logo.jpg\" alt=\"side_top\">',\n '</div>',\n '<ul class=\"page-anchors\">']\n\n nav_lis = []\n first_level = False\n second_level = False\n for line in lines:\n if line.startswith(\"## \"):\n self.anchor_count += 1\n if first_level:\n nav_lis.append('<ul>')\n if second_level:\n nav_lis.append('</li>')\n\n second_level = True\n first_level = False\n nav_lis.append('<li><a href=\"#a' + str(self.anchor_count)\n + '\">' + line.replace(\"## \", '') + '</a>')\n\n elif line.startswith(\"# \"):\n self.anchor_count += 1\n if second_level:\n nav_lis.append('</li>')\n nav_lis.append('</ul></li>')\n\n second_level = False\n first_level = True\n nav_lis.append('<li><a href=\"#a' + str(self.anchor_count)\n + '\">' + line.replace(\"# \", '') + '</a>')\n\n if second_level:\n nav_lis.append('</li>')\n nav_lis.append('</ul>')\n if first_level:\n nav_lis.append('</li>')\n\n navs.append('\\n'.join(nav_lis))\n\n navs.append('</ul>')\n navs.append('</div>')\n navs.append('</div>')\n\n return '\\n'.join(navs)\n\n def loop_kinds(self, i, lines):\n target = []\n while i < len(lines):\n item = lines[i]\n if item.startswith(\"-table|\"):\n table, pos = self.generateTable(i + 1, lines)\n target.append(table)\n elif item.startswith(\"-right|\"):\n right, pos = self.generateRight(i + 1, lines)\n target.append(right)\n else:\n content, pos = self.generateContent(i, lines)\n target.append(content)\n i = pos\n\n # 生成左侧导航\n print('<div id=\"my-container\">')\n print(self.generateNav(lines))\n # print('<!--导航内容分割线-->')\n target.insert(0, '<div id=\"my-adjust-content\"><div id=\"adjust-padder\">')\n target.append('</div>')\n target.append('</div>')\n target.append('</div>')\n target.append('')\n target.append('<script type=\"text/javascript\">'\n \"var a = new StickySidebar('#my-sidebar', {\"\n \"\ttopSpacing: 50,\"\n \"\tcontainerSelector: '#my-container',\"\n \"\tinnerWrapperSelector: '.sidebar__inner'\"\n '});</script>')\n return '\\n'.join(target)\n\n def go(self, file):\n f_in = codecs.open(file, 'r', 'utf-8')\n lines = []\n\n for line in f_in:\n \"\"\"剔除无用行\"\"\"\n line = line.strip()\n if len(line) <= 0:\n continue\n\n lines.append(line)\n\n f_in.close()\n\n return lines\n"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.649350643157959,
"avg_line_length": 18.3125,
"blob_id": "cb4ee13a7dcc6a51baaeaf9c3714fc2ff2add2a0",
"content_id": "37d8a3d117ef82b3266cdca1e1e8ee5d8980b71f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 16,
"path": "/Project/Model/SubGenerator.py",
"repo_name": "820fans/iGEM-Code-Generator",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\nfrom BasicGenerator import BasicGenerator\n\n\nclass SubGenerator(BasicGenerator):\n \"\"\"子类,主要是为了传入文件路径\"\"\"\n\n def __init__(self):\n self.lines = self.go('Project/Model/data.txt')\n\n def generate(self):\n print(self.loop_kinds(0, self.lines))\n\n\nSubGenerator().generate()"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.7225725054740906,
"avg_line_length": 17.904762268066406,
"blob_id": "b79f1a5521ef0aa4a00a67600cfa2c1b396ce516",
"content_id": "cf531eed6836d1c66b9250ca7addfcf3d5edbf23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1373,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 42,
"path": "/README.md",
"repo_name": "820fans/iGEM-Code-Generator",
"src_encoding": "UTF-8",
"text": "# iGEM-Code-Generator\nHelper for igem, 对于参与`igem`网页之作的人员,希望能够帮上点小忙.\n\n---\n2016年参加了iGEM,之后陆陆续续各种原因又写了几次,发现使用Python将文本转化为网页十分好用,节省了非常多的时间.\n\n所以这个脚本的主要功能是生成iGEM网页代码.\n\nigem_2016_from_above_picture\n\n\n# Usage\n- `main.py`控制使用哪个目录下的脚本\n- `BasicGenerator.py`按照既定规则,生成网站元素\n- `SubGenerator.py`主要用于传入目录.读取该目录下的`data.txt`\n\n# 生成规则\n- 空行将被跳过.用多种标注识别不同元素.标注必须顶格,之前不能包含空格.\n- 以`-img|url`开头的元素,将被渲染成`<img>`标签,`url`对应图片的地址\n- 以`# `,`## `, `### `, `#### `开头的元素,将被渲染成一级\\二级\\三级\\四级标题.\n- 表格表示标注方法\n```\n-table|\ncell # cell # cell\n-table-end|\n```\n- 左右布局标注方法\n```\n-right|\n-img|url\n-middle|\n-img|url\n-right-end|\n```\n将被渲染成左右布局.\n\n# Css介绍\n- 整个`Css`下包含了多个css文件.\n- `sideCss`包含了生成导航栏的样式\n- `contentCss`对应脚本生成html标签的样式\n- `clear`用于清除igem网站默认样式,仅对2017,2018年网站有效,后续有效性尚未测试\n- `header.html`是一个导航栏示例."
}
] | 4 |
jesenator/MorseCodeFlasher
|
https://github.com/jesenator/MorseCodeFlasher
|
f55708c8b8c2ebe53e559e1ef61960e1ea9f79be
|
64bced3883f83b49241d6330a3ea4446c27ce0bd
|
5d3d0248a066e5b373bdf489e09ac2dffacdfc12
|
refs/heads/main
| 2023-07-11T06:00:49.743140 | 2021-08-16T14:25:45 | 2021-08-16T14:25:45 | 396,829,604 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.45984598994255066,
"alphanum_fraction": 0.4686468541622162,
"avg_line_length": 19.0930233001709,
"blob_id": "da9e4fcb20674a431f8f8c45783cea2c84fd6001",
"content_id": "78fc7505ebf22ecb814e291f418f0314c8146346",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 43,
"path": "/MorseCodeFlasher.py",
"repo_name": "jesenator/MorseCodeFlasher",
"src_encoding": "UTF-8",
"text": "import morse_talk as mtalk\r\n# from gpiozero import LED\r\nimport time\r\n\r\n# led = LED(4)\r\n\r\nphrase = 'Alpha Ranger 45 departed'\r\nencoded = mtalk.encode(phrase)\r\nprint(encoded)\r\n\r\nunit = .3\r\n\r\n# for char in encoded:\r\n# print(char)\r\n# if char == ' ':\r\n# time.sleep(unit)\r\n# else:\r\n# # led.on()\r\n# sleep = unit if char == '.' else unit*3\r\n# time.sleep(sleep)\r\n# # led.off()\r\n# time.sleep(unit)\r\n\r\n\r\nfor char in phrase:\r\n if char == ' ':\r\n print(\"*space*\")\r\n time.sleep(unit*6)\r\n else:\r\n print(char + \": \", end=\"\")\r\n\r\n charE = mtalk.encode(char)\r\n\r\n for elem in charE:\r\n print(elem, end=\"\")\r\n # led.on()\r\n sleep = unit if elem == '.' else unit*3\r\n time.sleep(sleep)\r\n # led.off()\r\n time.sleep(unit)\r\n print()\r\n\r\n time.sleep(unit*2)\r\n\r\n"
}
] | 1 |
RonLitman/Mathematical_foundations_of_machine_learning
|
https://github.com/RonLitman/Mathematical_foundations_of_machine_learning
|
1d77a5fcf7a8d40a13e8125a52f6221f2ca9e86d
|
6dfdbb07ee10868232982659ec0969faf7d014f5
|
c026b1d98baab2a557bc82d28504023816583d9e
|
refs/heads/master
| 2020-07-10T00:34:20.468576 | 2019-08-24T07:38:46 | 2019-08-24T07:38:46 | 204,121,110 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8441558480262756,
"alphanum_fraction": 0.8441558480262756,
"avg_line_length": 37.5,
"blob_id": "2d0a30a4de9f0a65951c2e08a6baac403473a0ed",
"content_id": "4da735579f5a614c115fe6db3942234cfa180130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 77,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/README.md",
"repo_name": "RonLitman/Mathematical_foundations_of_machine_learning",
"src_encoding": "UTF-8",
"text": "# Mathematical_foundations_ml\n# Mathematical_foundations_of_machine_learning\n"
},
{
"alpha_fraction": 0.613313615322113,
"alphanum_fraction": 0.6372780799865723,
"avg_line_length": 35.739131927490234,
"blob_id": "ecc28a9c45050ae5719e0af3debcb8d45afd0301",
"content_id": "9e3e1fce2b3711acc05042625dfaa3c0482db83f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3380,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 92,
"path": "/smothness_analysis/keras_mnist.py",
"repo_name": "RonLitman/Mathematical_foundations_of_machine_learning",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nimport keras\nfrom keras.datasets import mnist\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Dropout, Flatten\nfrom keras.layers import Conv2D, MaxPooling2D\nfrom keras import backend as k_backend\n\nbatch_size = 128\nnum_classes = 10\nepochs = 2\n\n\ndef read_data():\n # Define input image dimensions\n img_rows, img_cols = 28, 28\n\n # Load the data, split between train and test sets\n (data_train, labels_train), (data_test, labels_test) = mnist.load_data()\n # For the ease of debugging - take a small portion of the data. Take entire collection when running on VM\n data_train = data_train[0:6000, :, :]\n labels_train = labels_train[0:6000]\n data_test = data_test[0:1000, :, :]\n labels_test = labels_test[0:1000]\n\n if k_backend.image_data_format() == 'channels_first':\n data_train = data_train.reshape(data_train.shape[0], 1, img_rows, img_cols)\n data_test = data_test.reshape(data_test.shape[0], 1, img_rows, img_cols)\n data_shape = (1, img_rows, img_cols)\n else:\n data_train = data_train.reshape(data_train.shape[0], img_rows, img_cols, 1)\n data_test = data_test.reshape(data_test.shape[0], img_rows, img_cols, 1)\n data_shape = (img_rows, img_cols, 1)\n\n data_train = data_train.astype('float32')\n data_test = data_test.astype('float32')\n data_train /= 255\n data_test /= 255\n print('data_train shape:', data_train.shape)\n print(data_train.shape[0], 'train samples')\n print(data_test.shape[0], 'test samples')\n\n # convert class vectors to binary class matrices\n labels_train = keras.utils.to_categorical(labels_train, num_classes)\n labels_test = keras.utils.to_categorical(labels_test, num_classes)\n\n return data_train, data_test, labels_train, labels_test, data_shape\n\n\ndef main():\n x_train, x_test, y_train, y_test, input_shape = read_data()\n tb_callback = keras.callbacks.TensorBoard(log_dir='./TensorBoardLogs',\n histogram_freq=0, write_graph=True, write_images=True)\n\n model = Sequential()\n model.add(Conv2D(32, kernel_size=(3, 3),\n activation='relu',\n input_shape=input_shape))\n model.add(Conv2D(64, (3, 3), activation='relu'))\n model.add(MaxPooling2D(pool_size=(2, 2)))\n model.add(Dropout(0.25))\n model.add(Flatten())\n model.add(Dense(128, activation='relu'))\n model.add(Dropout(0.5))\n model.add(Dense(num_classes, activation='softmax'))\n\n model.compile(loss=keras.losses.categorical_crossentropy,\n optimizer=keras.optimizers.Adadelta(),\n metrics=['accuracy', keras.losses.binary_crossentropy])\n\n # Consider another loss function\n\n # model.compile(loss=keras.losses.binary_crossentropy,\n # optimizer=keras.optimizers.Adadelta(),\n # metrics=[keras.losses.categorical_crossentropy, 'accuracy'])\n\n model.fit(x_train, y_train,\n batch_size=batch_size,\n epochs=epochs,\n verbose=1,\n validation_data=(x_test, y_test),\n callbacks=[tb_callback])\n score = model.evaluate(x_test, y_test, verbose=1)\n print('Test loss:', score[0])\n print('Test accuracy:', score[1])\n\n model.summary()\n model.save('myModel.h5')\n\n\nif '__main__' == __name__:\n main()\n"
},
{
"alpha_fraction": 0.6325515508651733,
"alphanum_fraction": 0.6492537260055542,
"avg_line_length": 31.720930099487305,
"blob_id": "3a2464784409c481c25482909b644422e6a5974d",
"content_id": "46444603259a789354c17b31a69a7572cab233b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2814,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 86,
"path": "/smothness_analysis/calc_smothness_pytorch.py",
"repo_name": "RonLitman/Mathematical_foundations_of_machine_learning",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport keras\nfrom keras.models import load_model\nfrom keras.datasets import mnist\nfrom keras import backend as k_backend\nfrom random_forest import WaveletsForestRegressor\nfrom keras_mnist import read_data\nimport torch\nimport torchvision\nimport torchvision.transforms as transforms\nfrom torchsummary import summary\nfrom models import Generator, Discriminator, FeatureExtractor\n\nbatch_size = 20000\n# Load the data\ndef load_dataset():\n data_path = '/Users/nadav.nagel/Desktop/Studying/ShayDekel/PyTorch-SRGAN/output/'\n\n train_dataset = torchvision.datasets.ImageFolder(root=data_path, transform=torchvision.transforms.ToTensor())\n train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, num_workers=0, shuffle=True)\n\n return train_loader\n\n# x_train, x_test, y_train, y_test, input_shape = read_data()\n\n\ndef calc_smoothness(x, y):\n print('dim is :{}'.format(x.shape))\n wfr = WaveletsForestRegressor(regressor='random_forest', criterion='mse', depth=9, trees=5)\n wfr.fit(x, y)\n alpha, n_wavelets, errors = wfr.evaluate_smoothness(m=1000)\n return alpha\n\n\ndef plot_vec(x=0, y=None, title='', xaxis='', yaxis='', epoch=1):\n if x == 0:\n x = range(1, len(y) + 1)\n plt.plot(x, y)\n plt.title(title)\n plt.xlabel(xaxis)\n plt.ylabel(yaxis)\n plt.show()\n plt.savefig('smothness_epoch{}.png'.format(epoch))\n\n\n\ndef one_hot(x, class_count):\n return torch.eye(class_count)[x, :]\n\n\ndef main():\n\n model = Discriminator()\n model.load_state_dict(\n torch.load('/Users/nadav.nagel/Desktop/Studying/ShayDekel/from_vm/discriminator_epoch_98_after_dist_and_gen.pth',\n map_location='cpu'))\n\n normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])\n\n train_loader = load_dataset()\n alpha_vec = np.zeros((len(model._modules.items()), ))\n\n for i, data in enumerate(train_loader):\n x, y = data\n y = one_hot(y, 2)\n\n for j in range(batch_size):\n x[j] = normalize(x[j])\n\n for idx, layer in enumerate(model._modules.items()):\n layer_output = x\n print('Calculating smoothness parameters for layer '+str(idx)+'.')\n for idx_j, layer_j in enumerate(model._modules.items()):\n layer_output = layer_j[1](layer_output)\n if idx_j == idx:\n layer_output = layer_output.detach().numpy()\n break\n\n alpha_vec[idx] = calc_smoothness(layer_output.reshape(-1, layer_output.shape[0]).T, y.detach().numpy())\n print('For Layer {}, alpha is: {}'.format(idx, alpha_vec[idx]))\n plot_vec(y=alpha_vec, title='Smoothness over layers', xaxis='Alpha', yaxis='#Layer')\n\n\nif '__main__' == __name__:\n main()\n"
}
] | 3 |
AndySheHoi/Breast_Cancer_Classification
|
https://github.com/AndySheHoi/Breast_Cancer_Classification
|
2e89ca401b7caef98a43b2f3f8e0b0868e59878e
|
2486635a0e5653a3f8732755d01b24c3843517f1
|
8615913aafecac062b4dea1f66040da31f3bac25
|
refs/heads/master
| 2022-04-20T13:11:49.359738 | 2020-04-12T10:45:18 | 2020-04-12T10:45:18 | 255,060,896 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6338164210319519,
"alphanum_fraction": 0.6489533185958862,
"avg_line_length": 32.120880126953125,
"blob_id": "79a50eba11cf8cf51c9b04a4b3a0dbfefcbc3e59",
"content_id": "bf783a1678aa875277ab29941251a889e121bf4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3105,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 91,
"path": "/Breast_Cancer_Classification.py",
"repo_name": "AndySheHoi/Breast_Cancer_Classification",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport numpy as np\r\nimport seaborn as sns\r\nfrom sklearn.preprocessing import StandardScaler\r\nfrom sklearn.model_selection import train_test_split\r\nfrom sklearn.svm import SVC \r\nfrom sklearn.model_selection import cross_val_score, GridSearchCV\r\nfrom sklearn.metrics import classification_report, confusion_matrix\r\nfrom sklearn.datasets import load_breast_cancer\r\n\r\n# import the dataset\r\ncancer = load_breast_cancer()\r\n\r\n# np.c_[cancer['data'], cancer['target']], append 'target' to 'data' as a column\r\ndf_cancer = pd.DataFrame(np.c_[cancer['data'], cancer['target']], columns = np.append(cancer['feature_names'], ['target']))\r\n\r\n\r\n# =============================================================================\r\n# import matplotlib.pyplot as plt\r\n# # check the correlation between the variables \r\n# # Strong correlation between the mean radius and mean perimeter, mean area and mean primeter\r\n# plt.figure(figsize=(20,10)) \r\n# sns.heatmap(df_cancer.corr(), annot=True) \r\n# \r\n# # plot the correlations between different variables\r\n# sns.pairplot(df_cancer, hue = 'target', vars = ['mean radius', 'mean texture', 'mean area', 'mean perimeter', 'mean smoothness'])\r\n# \r\n# # plot one of the correlations\r\n# sns.scatterplot(x = 'mean area', y = 'mean smoothness', hue = 'target', data = df_cancer)\r\n# \r\n# # count the sample\r\n# sns.countplot(df_cancer['target'], label = \"Count\")\r\n# =============================================================================\r\n\r\n\r\n# split the dataset\r\nX = df_cancer.drop(['target'], axis = 1)\r\ny = df_cancer['target']\r\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=0)\r\n\r\n# feature scaling\r\nsc = StandardScaler()\r\nX_train = sc.fit_transform(X_train)\r\nX_test = sc.transform(X_test)\r\n\r\n# fit a Kernel SVM to the training set, default kernel = rbf\r\nsvc = SVC()\r\nsvc.fit(X_train, y_train)\r\n\r\n# predict the test set result\r\ny_predict = svc.predict(X_test)\r\n\r\n# confusion matrix\r\ncm = confusion_matrix(y_test, y_predict)\r\n\r\n# visualize the test set result\r\nsns.heatmap(cm, annot=True)\r\nprint(classification_report(y_test, y_predict))\r\n\r\n# K-fold cross validation\r\nacc = cross_val_score(svc, X_train, y_train, cv = 10)\r\nmean_acc = acc.mean() # 0.976\r\n\r\n# set parameters for GridSearchCV()\r\n# different combinations of C and gamma will lead to various results\r\n\r\n# default C = 1.0\r\nc_param = []\r\nfor i in range(101):\r\n c_param.append(0.1 + i*0.1)\r\n \r\n# default gamma = 1 / (n_features * X.var()) = 0.0353 \r\ngamma_param = []\r\nfor i in range(200):\r\n gamma_param.append(0.01 + i*0.002)\r\n \r\nparam = {'C': c_param, 'gamma': gamma_param, 'kernel': ['rbf']}\r\n\r\n# grid search with cross valiidation\r\n# n_jobs = -1 means using all processors\r\ngs = GridSearchCV(svc, param, scoring = 'accuracy', cv = 10, n_jobs = -1)\r\ngs = gs.fit(X_train, y_train)\r\n\r\nbest_acc = gs.best_score_ # 0.985\r\nbest_param = gs.best_params_\r\ngs_predict = gs.predict(X_test)\r\n\r\n# visualize the grid search result\r\ncm_gs = confusion_matrix(y_test, gs_predict)\r\nsns.heatmap(cm_gs, annot=True)\r\nprint(classification_report(y_test, gs_predict))\r\n"
}
] | 1 |
dholth/gdalinfo
|
https://github.com/dholth/gdalinfo
|
be5c2f954341a56538bcde0deea244cc0bbea0aa
|
acd48c6248e254d21767fd81faceea03aeb3f158
|
93e4d47802b425ca99c930c3c79ee0e05fc6030d
|
refs/heads/master
| 2023-04-30T11:29:15.748628 | 2021-05-11T21:16:22 | 2021-05-11T21:16:22 | 359,656,852 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7434554696083069,
"alphanum_fraction": 0.7513089179992676,
"avg_line_length": 33.818180084228516,
"blob_id": "6c1f1fda3f092e046b9871893fc76f45138d94d9",
"content_id": "4dde0b1f7a10545cd5d0172b13af9835475761a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 382,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 11,
"path": "/README.rst",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "gdalinfo\n========\n\nA cffi-based wrapper for just the GDALInfo() function from GDAL.\n\nReturns GIS metadata from a filename as JSON.\n\nOn pypy, ``import sqlite3`` may conflict with ``import gdalinfo``, \nthey both use a version of the sqlite library. Use ``pypy -m _sqlite3_build``\nto build the extension against system sqlite3, and replace the one that\ncame with the pypy distribution."
},
{
"alpha_fraction": 0.6882591247558594,
"alphanum_fraction": 0.7004048824310303,
"avg_line_length": 21.454545974731445,
"blob_id": "ca4ec54054f886a8aa6e1081becb9ce4756c44f5",
"content_id": "00ca0d830e0730e48fb4fc22748121039564e29c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 22,
"path": "/pyproject.toml",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "[tool]\n\n[tool.enscons]\nname=\"gdalinfo\"\nversion=\"0.0.3\"\npackages=['gdalinfo']\ninstall_requires=['cffi']\ndescription=\"PyPy-compatible wrapper for GDALINFO() to read GIS metadata\"\ndescription_file=\"README.rst\"\nlicense=\"MIT\"\nclassifiers=[\n \"Programming Language :: Python :: 3\",\n]\nkeywords=[\"gdal\", \"pypy\", \"cffi\"]\nauthor=\"Daniel Holth\"\nauthor_email=\"[email protected]\"\nurl=\"https://github.com/dholth/gdalinfo/\"\nsrc_root = \"src\"\n\n[build-system]\nrequires = [\"pytoml>=0.1\", \"enscons\"]\nbuild-backend = \"enscons.api\"\n"
},
{
"alpha_fraction": 0.6703296899795532,
"alphanum_fraction": 0.6739926934242249,
"avg_line_length": 29.44444465637207,
"blob_id": "4ecb1ac8f0029c0a0db17778d101d4f38cf33812",
"content_id": "8f7a99c496d31854d9b8dc2789ebb4599a0066c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 9,
"path": "/src/gdalinfo/__main__.py",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "if __name__ == \"__main__\":\n import sys\n import gdalinfo\n import pprint\n\n info = gdalinfo.info(sys.argv[1])\n pprint.pprint(info)\n wktVerbatim = info[\"coordinateSystem\"][\"wkt\"]\n assert isinstance(gdalinfo.SpatialReference(wktVerbatim).exportToWkt(), str)"
},
{
"alpha_fraction": 0.6887037754058838,
"alphanum_fraction": 0.7011972665786743,
"avg_line_length": 26.840579986572266,
"blob_id": "4aba933f9599d96bd18b565a5985971c8350a204",
"content_id": "2eb1893470409a3cfbb0d4f644e3f2f6aa313718",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1921,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 69,
"path": "/SConstruct",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "#\n# Build gdalinfo.\n# Install enscons, then run `scons`\n#\n\nimport sys, os, os.path\nimport distutils.sysconfig\nimport pytoml as toml\nimport enscons, enscons.cpyext\n\nmetadata = dict(toml.load(open(\"pyproject.toml\")))[\"tool\"][\"enscons\"]\n\nfull_tag = enscons.get_binary_tag()\n\nMSVC_VERSION = None\nSHLIBSUFFIX = None\nTARGET_ARCH = None # only set for win32\nif sys.platform == \"win32\":\n import distutils.msvccompiler\n\n MSVC_VERSION = str(distutils.msvccompiler.get_build_version()) # it is a float\n SHLIBSUFFIX = \".pyd\"\n TARGET_ARCH = \"x86_64\" if sys.maxsize.bit_length() == 63 else \"x86\"\n\nenv = Environment(\n tools=[\"default\", \"packaging\", enscons.generate, enscons.cpyext.generate],\n PACKAGE_METADATA=metadata,\n WHEEL_TAG=full_tag,\n MSVC_VERSION=MSVC_VERSION,\n TARGET_ARCH=TARGET_ARCH,\n)\n\nuse_py_limited = \"abi3\" in full_tag\n\next_filename = enscons.cpyext.extension_filename(\"_gdalinfo\", abi3=use_py_limited)\n\next_source = env.Command(\n \"__gdalinfo.c\",\n \"buildgdalinfo.py\",\n sys.executable\n + \" -c \\\"import buildgdalinfo; buildgdalinfo.ffibuilder.emit_c_code('$TARGET')\\\"\",\n)\n\nextension = env.SharedLibrary(\n target=\"src/\" + ext_filename,\n source=ext_source,\n LIBPREFIX=\"\",\n SHLIBSUFFIX=SHLIBSUFFIX,\n LIBS=[\"gdal\"],\n parse_flags=\"-DPy_LIMITED_API=0x03030000\" if use_py_limited else \"\",\n)\n\n# Only *.py is included automatically by setup2toml.\n# Add extra 'purelib' files or package_data here.\npy_source = Glob(\"src/gdalinfo/*.py\")\n\nplatlib = env.Whl(\"platlib\", py_source + extension, root=metadata[\"src_root\"])\nwhl = env.WhlFile(source=platlib)\n\n# Add automatic source files, plus any other needed files.\nsdist_source = list(set(FindSourceFiles() + [\"PKG-INFO\"]))\n\nsdist = env.SDist(source=sdist_source)\nenv.Alias(\"sdist\", sdist)\n\ndevelop = env.Command(\"#DEVELOP\", enscons.egg_info_targets(env), enscons.develop)\nenv.Alias(\"develop\", develop)\n\nenv.Default(whl, sdist)\n"
},
{
"alpha_fraction": 0.7576112151145935,
"alphanum_fraction": 0.7587822079658508,
"avg_line_length": 27.483333587646484,
"blob_id": "b370f54e24553002c4c834f8e9054dea315459d2",
"content_id": "6bc6dcc2d8d79fd9a3971d5ac8b826125e4cff10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1708,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 60,
"path": "/buildgdalinfo.py",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "from cffi import FFI\n\nffibuilder = FFI()\n\nffibuilder.cdef(\n \"\"\"\ntypedef void *GDALDatasetH;\n\ntypedef enum {\n GA_ReadOnly = 0,\n GA_Update = 1\n} GDALAccess;\n\nvoid GDALAllRegister (void);\n\nGDALDatasetH GDALOpen (const char *pszFilename, GDALAccess eAccess);\nvoid GDALClose (GDALDatasetH);\n\ntypedef struct GDALInfoOptions GDALInfoOptions;\ntypedef struct GDALInfoOptionsForBinary GDALInfoOptionsForBinary;\nGDALInfoOptions *GDALInfoOptionsNew (char** papszArgv, GDALInfoOptionsForBinary* psOptionsForBinary);\nvoid GDALInfoOptionsFree (GDALInfoOptions *psOptions);\n\nchar *GDALInfo (GDALDatasetH hDataset, const GDALInfoOptions *psOptions);\n\nvoid VSIFree (void *); // free gdalinfo string with vsifree\n\ntypedef int CPLErrorNum;\nCPLErrorNum CPLGetLastErrorNo (void);\nconst char* CPLGetLastErrorMsg (void);\n\n// Spatial Reference System\ntypedef void *OGRSpatialReferenceH;\n\ntypedef int OGRErr;\n\n// Accepts WKT\nOGRSpatialReferenceH OSRNewSpatialReference(const char*);\nvoid OSRDestroySpatialReference(OGRSpatialReferenceH);\nOGRErr OSRImportFromWkt(OGRSpatialReferenceH, char **);\nOGRErr OSRExportToWkt(OGRSpatialReferenceH, char**);\n// Caller must free returned string with CPLFree (VSIFree)\n\"\"\"\n)\n\n# set_source() gives the name of the python extension module to\n# produce, and some C source code as a string. This C code needs\n# to make the declarated functions, types and globals available,\n# so it is often just the \"#include\".\nffibuilder.set_source(\n \"_gdalinfo\",\n \"\"\"\n #include \"gdal/gdal_utils.h\" // the C header of the library\n #include \"gdal/ogr_srs_api.h\"\n\"\"\",\n libraries=[\"gdal\"],\n) # library name, for the linker\n\nif __name__ == \"__main__\":\n ffibuilder.compile(verbose=True)"
},
{
"alpha_fraction": 0.5336986184120178,
"alphanum_fraction": 0.5391780734062195,
"avg_line_length": 24.704225540161133,
"blob_id": "5622532d71565652a76cdc8ed1916a4a24dcd0de",
"content_id": "469b77a001965f3d099fca62b4b682951b8b3146",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1825,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 71,
"path": "/src/gdalinfo/__init__.py",
"repo_name": "dholth/gdalinfo",
"src_encoding": "UTF-8",
"text": "\"\"\"\nA cffi binding to gdalinfo.\n\"\"\"\n\nfrom _gdalinfo import ffi, lib\nimport json\n\nlib.GDALAllRegister()\n\n\nclass GDALException(Exception):\n def __init__(self):\n Exception.__init__(\n self,\n lib.CPLGetLastErrorNo(),\n ffi.string(lib.CPLGetLastErrorMsg()).decode(\"utf-8\"),\n )\n\n\ndef info(path):\n \"\"\"\n Return gdalinfo json for file at path.\n \"\"\"\n dataset = lib.GDALOpen(str(path).encode(\"utf-8\"), lib.GA_ReadOnly)\n if dataset == ffi.NULL:\n raise GDALException()\n\n try:\n with ffi.gc(\n lib.GDALInfoOptionsNew(\n [ffi.new(\"char[]\", arg) for arg in b\"-json -mdd all\".split()]\n + [ffi.NULL],\n ffi.NULL,\n ),\n lib.GDALInfoOptionsFree,\n ) as options:\n info = ffi.gc(lib.GDALInfo(dataset, options), lib.VSIFree)\n if info == ffi.NULL:\n raise GDALException()\n finally:\n lib.GDALClose(dataset)\n\n return json.loads(ffi.string(info).decode(\"utf-8\"))\n\n\nclass SpatialReference:\n def __init__(self, wkt=ffi.NULL):\n self._handle = ffi.gc(\n lib.OSRNewSpatialReference(ffi.NULL), lib.OSRDestroySpatialReference\n )\n if wkt:\n self.importFromWkt(wkt)\n\n def importFromWkt(self, wkt):\n err = lib.OSRImportFromWkt(\n self._handle, [ffi.new(\"char[]\", wkt.encode(\"utf-8\"))]\n )\n if err != 0:\n raise GDALException()\n\n def exportToWkt(self):\n \"\"\"\n Returned WKT can be simpler than imported WKT.\n \"\"\"\n rc = ffi.new(\"char*[1]\")\n err = lib.OSRExportToWkt(self._handle, rc)\n if err != 0:\n raise GDALException()\n wkt = ffi.string(rc[0]).decode(\"utf-8\")\n lib.VSIFree(rc[0])\n return wkt\n"
}
] | 6 |
hyowong/clustering_visualization
|
https://github.com/hyowong/clustering_visualization
|
2c8d231c25d31f7a49d03b1be66b99b05db4ebf7
|
05f6ff649ca1c331af5016ff12bfebe2795d7a45
|
9de874d88a9ca12b1d58a0c3f78cba2ffc2829b2
|
refs/heads/master
| 2020-06-16T14:58:11.655431 | 2017-09-30T17:43:51 | 2017-09-30T17:43:51 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8484848737716675,
"alphanum_fraction": 0.8484848737716675,
"avg_line_length": 33,
"blob_id": "4987246e0e3382b26e7b49ae86c5ffa56dfd0c8f",
"content_id": "33a546ea4aff72fd6a8ccae162c764ffe192f20b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 1,
"path": "/clustervis/__init__.py",
"repo_name": "hyowong/clustering_visualization",
"src_encoding": "UTF-8",
"text": "from ._scatter import scatterplot"
},
{
"alpha_fraction": 0.7138914465904236,
"alphanum_fraction": 0.731370747089386,
"avg_line_length": 42.47999954223633,
"blob_id": "963436809c7539e52a0a0ad5ac322167eeb0ef4f",
"content_id": "b88ac557893e49d4614676892cc715eeb62dac9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2117,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 25,
"path": "/README.md",
"repo_name": "hyowong/clustering_visualization",
"src_encoding": "UTF-8",
"text": "문서 군집화를 한 뒤, 이를 시각화 하는 튜토리얼입니다. \n\n시각화에는 t-SNE 알고리즘이 자주 이용이 되곤 합니다. 하지만, t-SNE는 학습 과정에서 만들어지는 **P의 품질에 따라** 임베딩 결과가 확연하게 달라집니다. 또한 이미 문서 군집화를 수행하였다면, **문서 군집화 결과를 모델에 반영**하고 싶지만, unsupervised로 진행되는 학습 과정에 이 정보를 반영하는건 쉽지 않습니다. \n\n이 튜토리얼에서는 172개 영화의 네이버영화 평점 리뷰를 바탕으로 Doc2Vec을 학습했던 document vectors를 군집화 한 뒤, 시각화 하는 방법을 소개합니다. \n\nPlot을 함께 봐야 하기 때문에 github의 [tutorial (click)][tutorial]을 살펴보시기 바랍니다. \n\n[tutorial]: https://github.com/lovit/clustering_visualization/blob/master/tutorial.ipynb\n\n172개 영화는 100차원으로 Doc2Vec을 이용하여 표현되었습니다. 하지만 이를 t-SNE로 그대로 임베딩할 경우, 하나의 군집에 속하는 영화들이 흩어지게 됩니다. \n\n\n\n우리는 문서 군집화까지 해뒀습니다. 이 결과를 시각화 과정에서 반영해야 문서 군집화 결과를 잘 설명하는 시각화가 될 것입니다. 하지만 t-SNE의 학습 과정에서 군집화의 결과를 이용하지 않았기 때문에 아래처럼 한 군집에 속하는 문서들이라 하더라도 흩어지게 됩니다. \n\n\n\n차라리, 군집화 결과의 centroids를 아래 그림처럼 임베딩해두고, 각 군집에 속한 문서들은 해당 centroid 주변에 뿌려두는 것이 군집화의 결과를 설명하기에 더 적절할 것입니다. \n\n\n\n이를 위해서 아래 그림처럼 각 군집의 centroids를 먼저 임베딩하고, 그 점들간의 voronoi 경계를 지키면서, 각 점과 군집중심과의 거리에 비레하도록 데이터 포인트를 뿌려둡니다. 그 과정은 위 링크의 튜토리얼에 적어뒀습니다. \n\n\n"
}
] | 2 |
MisterFischoeder/Text-Adventure-RPG-Python
|
https://github.com/MisterFischoeder/Text-Adventure-RPG-Python
|
7228dc60da66e96935e038fc88031281eebd0392
|
0c21aefd9ea6ef53ea23bb278b4635e6e68140e8
|
36bcfd150cb7d942b0d3a75cd07b5fccc80385cc
|
refs/heads/master
| 2022-03-27T18:33:54.029365 | 2019-10-14T14:09:05 | 2019-10-14T14:09:05 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6961326003074646,
"alphanum_fraction": 0.6961326003074646,
"avg_line_length": 34.20000076293945,
"blob_id": "d4a9653e49411cc6b6a21b133f5d22f269ec9b9f",
"content_id": "968a16b230761f2846b71a924a7e6418e19956fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 182,
"num_lines": 10,
"path": "/Text Adventure Game/Dictionary for the Text Based Adventure Game.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\ndictionary_for_adventure.py\r\n\r\nThis is going to be the dictionary that is going to be used when operating this text adventure game.\r\n\r\n\"\"\"\r\n\r\n#data setup\r\nareas = {'field': 'A field filled with various lengths of grasses, sprouting out the fertilized ground tended by the sweat of ones brow', 'east': 'pathway', 'north': 'Arcane Temple',\r\n 'text':\r\n"
},
{
"alpha_fraction": 0.5127198100090027,
"alphanum_fraction": 0.5394687652587891,
"avg_line_length": 34.114864349365234,
"blob_id": "4f3510e9b25e47c756c05fd5b35556bad9d60c1a",
"content_id": "9e8394187fa49da3fe577d6b0d2d2bc1e97bc5a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10692,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 296,
"path": "/Text Adventure Game/Enemies in Text Based Adventure.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "#-----------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nGeneral Code for the Enemies\r\n\"\"\"\r\n\r\nclass Enemy:\r\n def _init_(self, name, hp, damage,description):\r\n self.name = name\r\n self.hp = hp\r\n self.damage = damage\r\n self.description = description\r\n\r\n def is_alive(self):\r\n return self.hp > 0\r\n\r\n#-----------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nViking Enemies\r\n\"\"\"\r\n\r\nclass Viking_Soldier(Enemy):\r\n def _init_(self):\r\n super()._init_(name=\"Viking Soldier\", hp=30, damage=15, description=\" \")\r\nclass Viking_Archer(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Archer\", hp=20, damage=10, description='')\r\nclass Earl_Guard(Enemy):\r\n def _init(self):\r\n super()._init(name=\"Viking Earl Guard\", hp=300, damage=50, description='')\r\nclass Viking_Warlord(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Warlord\", hp=100, damage=35,description='')\r\nclass Viking_Raiders(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Raider\",hp=25, damage=15,description=\"\")\r\nclass Viking_Bomber(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Bomber\",hp=40, damage=45,description=\"\")\r\nclass Viking_Farmer(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Farmer\",hp=10, damage=5,description=\"\")\r\nclass Viking_Jarl_Guard(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Jarl Commando\",hp=100, damage=25,description=\"\")\r\nclass Hersir(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Hersir\",hp=500, damage=100,description=\"\")\r\nclass Aesir(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Aesir\",hp=100, damage=30,description=\"\")\r\nclass Huskarl(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Huskarl\",hp=60, damage=20, description=\"\")\r\nclass Himthiki(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Himthiki\",hp=45,damage=10,description=\"\")\r\nclass Viking_Marauder(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Marauder\",hp=50,damage=30,description=\"\")\r\nclass Herra(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Herra\",hp=15,damage=5,description=\"\")\r\nclass Thegn(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Thegn\",hp=20,damage=10,description=\"\")\r\nclass Merkismathr(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Merkismathr\",hp=250,damage=75,description=\"\")\r\nclass Radningar(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Viking Radningar\",hp=150,damage=45,description=\"\")\r\n\r\n\r\n#------------------------------------------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nTroll Enemies\r\n\"\"\"\r\n\r\nclass Troll(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll\",hp=10,damage=5,description=\"\")\r\nclass Troll_Archer(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Archer\",hp=15,damage=5,description=\"\")\r\nclass Troll_Soldier(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Soldier\",hp=20,damage=7,description=\"\")\r\nclass Troll_Brute(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Brute\",hp=30,damage=10,description=\"\")\r\nclass Troll_Giant(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Giant Troll\",hp=50,damage=20,description=\"\")\r\nclass Troll_Vanguard(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Vanguard\",hp=45,damage=35,description=\"\")\r\nclass Troll_General(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll General\",hp=60,damage=40,description=\"\")\r\nclass Troll_Berserker(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Berserker\",hp=25,damage=30,description=\"\")\r\nclass Troll_Chariot(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Chariot\",hp=75,damage=30,description=\"\")\r\nclass Troll_Knight(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Knight\",hp=40,damage=25,description=\"\")\r\nclass Troll_Pillager(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Pillager\",hp=20,damage=10,description=\"\")\r\nclass Troll_King(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll King\",hp=250,damage=100,description=\"\")\r\nclass Troll_Mage(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Mage\",hp=35,damage=20,description=\"\")\r\nclass Troll_Siege_Unit(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Siege Unit\",hp=55,damage=30,description=\"\")\r\nclass Troll_Marksman(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Marksman\",hp=35,damage=40,description=\"\")\r\nclass Troll_Guardian(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Troll Guardian\",hp=100,damage=45,description=\"\")\r\n\r\n#---------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nRaider Enemies\r\n\"\"\"\r\n\r\nclass Raider(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Raider\",hp=10,damage=5,description=\"\")\r\nclass Raider_Boss(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Raider Boss\",hp=25,damage=8,description=\"\")\r\nclass Raider_Scum(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Raider Scum\",hp=15,damage=6,description=\"\")\r\nclass Raider_Mech(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Raider Mech\",hp=20,damage=10,description=\"\")\r\n\r\n#----------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nThief Enemies\r\n\"\"\"\r\n\r\nclass Thief(Enemy):\r\n def _init(self):\r\n super()._init(name=\"Thief\",hp=15,damage=5,description=\"\")\r\nclass Thief_Brute(Enemy):\r\n def _init(self):\r\n super().init(name=\"Brute Thief\",hp=25,damage=15,description=\"\")\r\nclass Trickster(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Trickster\",hp=20,damage=5,description=\"\")\r\nclass Advanced_Thief(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Advanced Thief\",hp=35,damage=18,description=\"\")\r\nclass Advanced_Thief_Brute(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Advanced Brute Thief\",hp=60,damage=35,description=\"\")\r\nclass Rogue(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Rogue\",hp=35,damage=20,description=\"\")\r\nclass Specialist_Thief(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Specialist Thief\",hp=20,damage=10,description=\"\")\r\nclass King_Of_Thieves(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"King of Thieves\",hp=250,damage=100,description=\"\")\r\nclass Guild_Master(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Guild Master\",hp=50,damage=35,description=\"\")\r\nclass Guild_Memeber(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Guild Member\",hp=20,damage=10,description=\"\")\r\n\r\n#-----------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nGladiator Enemies\r\n\"\"\"\r\n\r\nclass Gladiator(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Gladiator\",hp=25,damage=15,description=\"\")\r\nclass Arena_Master(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Arena Master\",hp=30, damage=10, description=\"\")\r\nclass Gladiator_Champion(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Gladiator Champion\",hp=40, damage=20, description=\"\")\r\n\r\n#-----------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nNinja Enemies\r\n\"\"\"\r\n\r\nclass Ninja(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Ninja\",hp=30,damage=15,description=\"\")\r\nclass Sensei(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Sensei\",hp=50,damage=20,description=\"\")\r\nclass Genin(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Genin\",hp=25,damage=15,description=\"\")\r\nclass Chunin(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Chunin\",hp=35,damage=20,description=\"\")\r\nclass Jonin(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Jonin\",hp=45,damage=25,description=\"\")\r\nclass Shinobi(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Shinobi\",hp=55,damage=30,description=\"\")\r\nclass Kancho(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Kancho/Ninja Spy\",hp=30,damage=15,description=\"\")\r\nclass Teisatsu(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Teisatsua/Ninja Scout\",hp=20,damage=10,description=\"\")\r\nclass Kishu(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Kishu/Ninja Ambusher\",hp=25,damage=18,description=\"\")\r\nclass Konran(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Konran/Ninja Agitator\",hp=30,damage=20,description=\"\")\r\n\r\n#-------------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nPirate Enemies\r\n\"\"\"\r\n\r\nclass Pirate(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Pirate\",hp=20,damage=15,description=\"\")\r\nclass Captain_Pirate(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Pirate Captain\",hp=40,damage=20,description=\"\")\r\n#--------------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nGeneral Enemies\r\n\"\"\"\r\n\r\nclass Zombie(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Zombie\",hp=20,damage=5,description=\"\")\r\nclass Vampire(Enemy):\r\n def _init(self):\r\n super()._init(name=\"Vampire\",hp=30, damage=10,description=\"\")\r\nclass Skeleton(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Skeleton\",hp=20,damage=5,description=\"\")\r\nclass Spider(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Spider\",hp=15,damage=3,description=\"\")\r\nclass Witch(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Witch\",hp=25,damage=8,description=\"\")\r\n\r\n#--------------------------------------------------------------------------------------------------------------------\r\n\r\n\"\"\"\r\nBarbarian Enemies\r\n\"\"\"\r\n\r\nclass Barbarian(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Barbarian\",hp=20, damage=5,description=\"\")\r\nclass Barbarian_Brute(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Barbarian Brute\",hp=40, damage=15,description=\"\")\r\nclass Barbarian_Baron(Enemy):\r\n def _init_(self):\r\n super()._init(name=\"Barbarian Baron\",hp=50,damage=20,description=\"\")\r\nclass Barbarian_Warrior(Enemy):\r\n def _init_(self):\r\n super().init(name=\"Barbarian Warrior\",hp=35,damage=10,description=\"\")\r\nclass Barbarian_Archer(Enemy):\r\n def _init_(self):\r\n super().init(name=\"Barbarian Archer\",hp=25,damage=8,description=\"\")\r\n\r\n#--------------------------------------------------------------------------------------------------------------------\r\n\r\n"
},
{
"alpha_fraction": 0.5761272311210632,
"alphanum_fraction": 0.5852378010749817,
"avg_line_length": 56.8636360168457,
"blob_id": "42273e36aa5d8109729d2082a7731f47c0c10e85",
"content_id": "344eb3c02d805fa72bd84e53d58c9f912a762d36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6476,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 110,
"path": "/Text Adventure Game/Weapons/Items and Such.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "class Item():\r\n def _intit_(self, name, description, value):\r\n self.name = name\r\n self.description = description\r\n self.value = value\r\n def _str_(self):\r\n return \"{}\\n=====\\n{}\\nValue: {}\\n\".format(self.name, self.description, self.value)\r\nclass SilverEagles(Item):\r\n def _init_(self, amt):\r\n self.amt = amt\r\n super()._init_(name=\"Silver Eagles\",\r\n description=\"A round silver coin that is stamped with {} on the front of the coin.\".format(str(self.amt)),\r\n value=self.amt)\r\nclass Weapon(Item):\r\n def _init_(self, name, description, value):\r\n self.damage = damage\r\n super()._init_(name, description, value)\r\n def _str_(self):\r\n return \"{}\\=====\\n{}\\nValue: {}n\\Damage: {}\".format(self.name, self.description, self.value, self.damage)\r\nclass Dragon_Staff(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Staff of Anoss\",\r\n description=\"Descending from the might of the Mother Dragon, this staff that has a steel dragon head shaped on it breathes fire and various elements to deal damage to those whose hearts are tainted with greed and darkness.\",\r\n value=1500,\r\n damage=50)\r\nclass Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Iron Sword\",\r\n description=\"A typical iron sword with a steel handle wrapped in the finest leather of Dragondia. Its blade quite heavy and able to do a bit of damage.\",\r\n value=50,\r\n damage=25)\r\nclass Fang_Dagger(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Fang Dagger\",\r\n description=\"A dagger forged with the fang of a dragon serving as the blade. It does more damage than a regular stone sword and can pack a bit of a punch with a razor claw tooth of a dragon in your hand.\",\r\n value=65,\r\n damage=20)\r\nclass Stone_Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Stone Sword\",\r\n description=\"A sword forged with the rocks of the ground that the Eternal have made. This does a little more damage than a slingshot and a normal rock.\",\r\n value=20,\r\n damage=15)\r\nclass Slingshot(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Sling Shot\",\r\n description=\"A simple slingshot young ones use to throw stones at their targets. When utilized right, it can be a weapon for fighting off foes. It does one of the least amounts of damage.\",\r\n value=10,\r\n damage=5)\r\nclass Stick(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Wooden Stick\",\r\n description=\"A stick from one of the trees. Does the least amount of damage within the game.\",\r\n value=1,\r\n damage=2)\r\nclass Crossbow(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Crossbow\",\r\n description=\"A steel forged crossbow from the Western Borderlands where the Remains of Arcadia remain in turmoil. This shoot bolts made of iron that can cut the air in one push of the trigger.\",\r\n value=55,\r\n damage=30)\r\nclass Mace(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Mace\",\r\n description=\"A ball and chain with spikes within the ball that retract by a grip on the handle of the weapon. This weapon can be weilded with one or two hands as it requires the strength of the user to inflict the damage.\",\r\n value=45,\r\n damage=20)\r\nclass Pike(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Pike\",\r\n description=\"A weapon that is broad and long, capable of long range melee and packs a punch as it swings enemies flying. It does make up for its talent in its length. This weapon was originally used by the DragonGuarde of the Northern Providence during the days of the Viking Uprising.\",\r\n value=60,\r\n damage=30)\r\nclass LongBow(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Longbow\",\r\n description=\"A bow elongated to deliver deadly blows that can penetrate the armour of normal mortals. It is very wide and does more damage than that of the Crossbow but does not have its capable ability to pick off enemies.\",\r\n value=65,\r\n damage=35)\r\nclass Scimitar(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Scimitar\",\r\n description=\"A curved blade that is able to deal amounts of damage at a reasonable rate. Its curved blade serves as an advantage to that of normal blades.\",\r\n value=55,\r\n damage=30)\r\nclass Cutlass(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Cutlass\",\r\n description=\"A short and broad sword that has a blade slightly curved to deal more damage than that of a regular sword. This is fondly used by pirates such as the Sky Rats in the Southern Hemisphere.\",\r\n value=40,\r\n damage=28)\r\nclass Spear(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Spear\",\r\n description=\"A throwable staff with a blade on the edge that are used by the Throwers in the Western Quadrant of Dragondia. This can be used as a projectile and a melee weapon to use against enemies.\",\r\n value=35,\r\n damage=23)\r\nclass Lance(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Lance\",\r\n description=\"Within the Dragon Jousts of the Olde Days, the DragonGuarde would use these for ceremonial purposes. These ceremonial props have been improved to control riots within Dragondia.\",\r\n value=46,\r\n damage=30)\r\nclass Katana(Weapon):\r\n def_init(self):\r\n super()._init(name=\"Katana\",\r\n description=\"This Japanese Sword was plunged into the culture of Dragondia after the slaying of the Ancient Ones, a group of Demented Dragons trained by the Oni. The blade is curved into a single edge for a two handed grip.\",\r\n value=35,\r\n damage=35)\r\nclass \r\n"
},
{
"alpha_fraction": 0.5846441388130188,
"alphanum_fraction": 0.594611406326294,
"avg_line_length": 58,
"blob_id": "d560576d316d201c56201978066b521f276cb8b4",
"content_id": "99237fea1fb9d3381bdf7674005ece1e9d871833",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6421,
"license_type": "no_license",
"max_line_length": 427,
"num_lines": 107,
"path": "/Text Adventure Game/Weapons/Archer Weapons.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "class Item():\r\n def _intit_(self, name, description, value):\r\n self.name = name\r\n self.description = description\r\n self.value = value\r\n def _str_(self):\r\n return \"{}\\n=====\\n{}\\nValue: {}\\n\".format(self.name, self.description, self.value)\r\n\r\nclass Weapon(Item):\r\n def _init_(self, name, description, value):\r\n self.damage = damage\r\n super()._init_(name, description, value)\r\n def _str_(self):\r\n return \"{}\\=====\\n{}\\nValue: {}n\\Damage: {}\".format(self.name, self.description, self.value, self.damage)\r\n\r\nclass Pike(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Pike\",\r\n description=\"A weapon that is broad and long, capable of long range melee and packs a punch as it swings enemies flying. It does make up for its talent in its length. This weapon was originally used by the DragonGuarde of the Northern Providence during the days of the Viking Uprising.\",\r\n value=60,\r\n damage=30)\r\nclass Spear(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Spear\",\r\n description=\"A throwable staff with a blade on the edge that are used by the Throwers in the Western Quadrant of Dragondia. This can be used as a projectile and a melee weapon to use against enemies.\",\r\n value=45,\r\n damage=40)\r\nclass LongBow(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Longbow\",\r\n description=\"A bow elongated to deliver deadly blows that can penetrate the armour of normal mortals. It is very wide and does more damage than that of the Crossbow but does not have its capable ability to pick off enemies.\",\r\n value=65,\r\n damage=50)\r\nclass Crossbow(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Crossbow\",\r\n description=\"A steel forged crossbow from the Western Borderlands where the Remains of Arcadia remain in turmoil. This shoot bolts made of iron that can cut the air in one push of the trigger.\",\r\n value=55,\r\n damage=30)\r\nclass Slingshot(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Sling Shot\",\r\n description=\"A simple slingshot young ones use to throw stones at their targets. When utilized right, it can be a weapon for fighting off foes. It does one of the least amounts of damage.\",\r\n value=10,\r\n damage=5)\r\nclass Blowgun(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Blowgun\",\r\n description=\"A simple ranged weapon consiting of a long pipe tube designed for shooting projectiles such as darts or pellers. It is great for espionage and using ones breathe to fuel the launch of the dart.\",\r\n value=18,\r\n damage=15)\r\nclass Kpinga(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Kpinga\",\r\n description=\"A throwing knife that is 22 inches in length and has three different shaped blades to cut anything that is in one's way.\",\r\n value=21,\r\n damage=20)\r\nclass Shuriken(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Shuriken\",\r\n description=\"A concealed dagger or tool to distract, misdirect, or harm one's enemy of choice.\",\r\n value=35,\r\n damage=25)\r\nclass CompositeBow(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Composite Bow\",\r\n description=\"A regular bow with a set of arrows, its wood slightly carved to have the Dragondia symbol on it.\",\r\n value=25,\r\n damage=20)\r\nclass SelfBow(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Self Bow\",\r\n description=\"Perfect for an improvised situation, this fast bow is made of one piece of wood and attached with the hair of a Heavenly Dragon.\",\r\n value=22,\r\n damage=23)\r\nclass Musket(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Musket\",\r\n description=\"Rarely seen, due to Dragon armour being too strong for the bullet to pierce, Muskets can still be used against the likes of other enemies by penetrating their own armor.\",\r\n value=60,\r\n damage=45)\r\nclass Matchlock(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Matchlock\",\r\n description=\"An ancient like pistol used by the pirates roaming the skies of Dragondia, the Matchlock is a powerful pistol against the mortal creatures of this realm but cannot harm that of dragon armor.\",\r\n value=40,\r\n damage=40)\r\nclass TwinDaggers(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Twin Dragons\",\r\n description=\"Two daggers that have the markings and designs of dragons n their handles, each having the blade almost come out of their jaws. One of the daggers has the power of Ice from an ancient Glacier Dragon; the other has the brooding power of Fire from one of the Ashland's Molten Lava Dragons. These two powerful daggers can result in close quarters combat that will ensure victory in any battle\",\r\n value=100,\r\n damage=60)\r\nclass Quickfire(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Quickfire\",\r\n description=\"A SelfBow forged by the hands of Cog the Quick was used in the Dragon Wars against the likes of the Ancient Vikings. He used this weapon to stop the advancing forces of the Vikings who wanted to enslave the dragons for their needs. Before he died, legend has it that he hid his bow in an ancient crypt guarded by the Queen's Royal Guards within the Arcane Temple.\",\r\n value=500,\r\n damage=100)\r\n\r\nclass Dagger(Weapon):\r\n def _init_(self):\r\n super()._init(name=\"Dagger\",\r\n description=\"A small blade hilted with a curved to cut through the finest of materials. This would be good for close quarters and would be able to land a blow here and there.\",\r\n value=25,\r\n damage=20)\r\nclass \r\n"
},
{
"alpha_fraction": 0.7575757503509521,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 63.5,
"blob_id": "2ebb9d3d1e62a0c63737ab9572bdb43c3302aefc",
"content_id": "807c75be0e628840f0bd9dd4fe1271fb7f5a5a51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 2,
"path": "/README.md",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "# Text-Adventure-RPG-Python\nThis is a text adventure rpg that is written in Python as an alpha test for a game I want to create. \n\n\n"
},
{
"alpha_fraction": 0.5792059898376465,
"alphanum_fraction": 0.5890344977378845,
"avg_line_length": 58.33720779418945,
"blob_id": "375027ad12861282dd103b31e98f7df4fea36ffd",
"content_id": "c04dddc912f389239fe26c49c904606a23234c5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10378,
"license_type": "no_license",
"max_line_length": 427,
"num_lines": 172,
"path": "/Text Adventure Game/items.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "class Item():\r\n def _intit_(self, name, description, value):\r\n self.name = name\r\n self.description = description\r\n self.value = value\r\n def _str_(self):\r\n return \"{}\\n=====\\n{}\\nValue: {}\\n\".format(self.name, self.description, self.value)\r\nclass SilverEagles(Item):\r\n def _init_(self, amt):\r\n self.amt = amt\r\n super()._init_(name=\"Silver Eagles\",\r\n description=\"A round silver coin that is stamped with {} on the front of the coin.\".format(str(self.amt)),\r\n value=self.amt)\r\nclass Weapon(Item):\r\n def _init_(self, name, description, value):\r\n self.damage = damage\r\n super()._init_(name, description, value)\r\n def _str_(self):\r\n return \"{}\\=====\\n{}\\nValue: {}n\\Damage: {}\".format(self.name, self.description, self.value, self.damage)\r\n\r\nclass Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Iron Sword\",\r\n description=\"A typical iron sword with a steel handle wrapped in the finest leather of Dragondia. Its blade quite heavy and able to do a bit of damage.\",\r\n value=50,\r\n damage=25)\r\nclass Fang_Dagger(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Fang Dagger\",\r\n description=\"A dagger forged with the fang of a dragon serving as the blade. It does more damage than a regular stone sword and can pack a bit of a punch with a razor claw tooth of a dragon in your hand.\",\r\n value=65,\r\n damage=20)\r\nclass Stone_Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Stone Sword\",\r\n description=\"A sword forged with the rocks of the ground that the Eternal have made. This does a little more damage than a slingshot and a normal rock.\",\r\n value=20,\r\n damage=15)\r\nclass Stick(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Wooden Stick\",\r\n description=\"A stick from one of the trees. Does the least amount of damage within the game.\",\r\n value=1,\r\n damage=2)\r\nclass Mace(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Mace\",\r\n description=\"A ball and chain with spikes within the ball that retract by a grip on the handle of the weapon. This weapon can be weilded with one or two hands as it requires the strength of the user to inflict the damage.\",\r\n value=45,\r\n damage=20)\r\nclass Pike(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Pike\",\r\n description=\"A weapon that is broad and long, capable of long range melee and packs a punch as it swings enemies flying. It does make up for its talent in its length. This weapon was originally used by the DragonGuarde of the Northern Providence during the days of the Viking Uprising.\",\r\n value=60,\r\n damage=30)\r\nclass Scimitar(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Scimitar\",\r\n description=\"A curved blade that is able to deal amounts of damage at a reasonable rate. Its curved blade serves as an advantage to that of normal blades.\",\r\n value=55,\r\n damage=30)\r\nclass Cutlass(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Cutlass\",\r\n description=\"A short and broad sword that has a blade slightly curved to deal more damage than that of a regular sword. This is fondly used by pirates such as the Sky Rats in the Southern Hemisphere.\",\r\n value=40,\r\n damage=28)\r\nclass Lance(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Lance\",\r\n description=\"Within the Dragon Jousts of the Olde Days, the DragonGuarde would use these for ceremonial purposes. These ceremonial props have been improved to control riots within Dragondia.\",\r\n value=46,\r\n damage=30)\r\nclass Katana(Weapon):\r\n def_init(self):\r\n super()._init(name=\"Katana\",\r\n description=\"This Japanese Sword was plunged into the culture of Dragondia after the slaying of the Ancient Ones, a group of Demented Dragons trained by the Oni. The blade is curved into a single edge for a two handed grip.\",\r\n value=35,\r\n damage=35)\r\n\r\nclass Pike(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Pike\",\r\n description=\"A weapon that is broad and long, capable of long range melee and packs a punch as it swings enemies flying. It does make up for its talent in its length. This weapon was originally used by the DragonGuarde of the Northern Providence during the days of the Viking Uprising.\",\r\n value=60,\r\n damage=30)\r\nclass Spear(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Spear\",\r\n description=\"A throwable staff with a blade on the edge that are used by the Throwers in the Western Quadrant of Dragondia. This can be used as a projectile and a melee weapon to use against enemies.\",\r\n value=45,\r\n damage=40)\r\nclass LongBow(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Longbow\",\r\n description=\"A bow elongated to deliver deadly blows that can penetrate the armour of normal mortals. It is very wide and does more damage than that of the Crossbow but does not have its capable ability to pick off enemies.\",\r\n value=65,\r\n damage=50)\r\nclass Crossbow(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Crossbow\",\r\n description=\"A steel forged crossbow from the Western Borderlands where the Remains of Arcadia remain in turmoil. This shoot bolts made of iron that can cut the air in one push of the trigger.\",\r\n value=55,\r\n damage=30)\r\nclass Slingshot(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Sling Shot\",\r\n description=\"A simple slingshot young ones use to throw stones at their targets. When utilized right, it can be a weapon for fighting off foes. It does one of the least amounts of damage.\",\r\n value=10,\r\n damage=5)\r\nclass Blowgun(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Blowgun\",\r\n description=\"A simple ranged weapon consiting of a long pipe tube designed for shooting projectiles such as darts or pellers. It is great for espionage and using ones breathe to fuel the launch of the dart.\",\r\n value=18,\r\n damage=15)\r\nclass Kpinga(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Kpinga\",\r\n description=\"A throwing knife that is 22 inches in length and has three different shaped blades to cut anything that is in one's way.\",\r\n value=21,\r\n damage=20)\r\nclass Shuriken(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Shuriken\",\r\n description=\"A concealed dagger or tool to distract, misdirect, or harm one's enemy of choice.\",\r\n value=35,\r\n damage=25)\r\nclass CompositeBow(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Composite Bow\",\r\n description=\"A regular bow with a set of arrows, its wood slightly carved to have the Dragondia symbol on it.\",\r\n value=25,\r\n damage=20)\r\nclass SelfBow(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Self Bow\",\r\n description=\"Perfect for an improvised situation, this fast bow is made of one piece of wood and attached with the hair of a Heavenly Dragon.\",\r\n value=22,\r\n damage=23)\r\nclass Musket(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Musket\",\r\n description=\"Rarely seen, due to Dragon armour being too strong for the bullet to pierce, Muskets can still be used against the likes of other enemies by penetrating their own armor.\",\r\n value=60,\r\n damage=45)\r\nclass Matchlock(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Matchlock\",\r\n description=\"An ancient like pistol used by the pirates roaming the skies of Dragondia, the Matchlock is a powerful pistol against the mortal creatures of this realm but cannot harm that of dragon armor.\",\r\n value=40,\r\n damage=40)\r\nclass TwinDaggers(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Twin Dragons\",\r\n description=\"Two daggers that have the markings and designs of dragons n their handles, each having the blade almost come out of their jaws. One of the daggers has the power of Ice from an ancient Glacier Dragon; the other has the brooding power of Fire from one of the Ashland's Molten Lava Dragons. These two powerful daggers can result in close quarters combat that will ensure victory in any battle\",\r\n value=100,\r\n damage=60)\r\nclass Quickfire(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Quickfire\",\r\n description=\"A SelfBow forged by the hands of Cog the Quick was used in the Dragon Wars against the likes of the Ancient Vikings. He used this weapon to stop the advancing forces of the Vikings who wanted to enslave the dragons for their needs. Before he died, legend has it that he hid his bow in an ancient crypt guarded by the Queen's Royal Guards within the Arcane Temple.\",\r\n value=500,\r\n damage=100)\r\n\r\nclass Dagger(Weapon):\r\n def _init_(self):\r\n super()._init(name=\"Dagger\",\r\n description=\"A small blade hilted with a curved to cut through the finest of materials. This would be good for close quarters and would be able to land a blow here and there.\",\r\n value=25,\r\n damage=20)\r\n"
},
{
"alpha_fraction": 0.5729806423187256,
"alphanum_fraction": 0.58195561170578,
"avg_line_length": 54.45333480834961,
"blob_id": "5731311e0c3fd3e1174562087de4a616c059f509",
"content_id": "0c91ab6ec8743d16a2e916ea92b89c32348e73e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4234,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 75,
"path": "/Text Adventure Game/Weapons/Warrior Weapons.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "class Item():\r\n def _intit_(self, name, description, value):\r\n self.name = name\r\n self.description = description\r\n self.value = value\r\n def _str_(self):\r\n return \"{}\\n=====\\n{}\\nValue: {}\\n\".format(self.name, self.description, self.value)\r\n\r\nclass Weapon(Item):\r\n def _init_(self, name, description, value):\r\n self.damage = damage\r\n super()._init_(name, description, value)\r\n def _str_(self):\r\n return \"{}\\=====\\n{}\\nValue: {}n\\Damage: {}\".format(self.name, self.description, self.value, self.damage)\r\n\r\nclass Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Iron Sword\",\r\n description=\"A typical iron sword with a steel handle wrapped in the finest leather of Dragondia. Its blade quite heavy and able to do a bit of damage.\",\r\n value=50,\r\n damage=25)\r\nclass Fang_Dagger(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Fang Dagger\",\r\n description=\"A dagger forged with the fang of a dragon serving as the blade. It does more damage than a regular stone sword and can pack a bit of a punch with a razor claw tooth of a dragon in your hand.\",\r\n value=65,\r\n damage=20)\r\nclass Stone_Sword(Weapon):\r\n def _init_(self):\r\n super()._init_(name=\"Stone Sword\",\r\n description=\"A sword forged with the rocks of the ground that the Eternal have made. This does a little more damage than a slingshot and a normal rock.\",\r\n value=20,\r\n damage=15)\r\nclass Stick(Weapon):\r\n def _init(self):\r\n super()._init_(name=\"Wooden Stick\",\r\n description=\"A stick from one of the trees. Does the least amount of damage within the game.\",\r\n value=1,\r\n damage=2)\r\nclass Mace(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Mace\",\r\n description=\"A ball and chain with spikes within the ball that retract by a grip on the handle of the weapon. This weapon can be weilded with one or two hands as it requires the strength of the user to inflict the damage.\",\r\n value=45,\r\n damage=20)\r\nclass Pike(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Pike\",\r\n description=\"A weapon that is broad and long, capable of long range melee and packs a punch as it swings enemies flying. It does make up for its talent in its length. This weapon was originally used by the DragonGuarde of the Northern Providence during the days of the Viking Uprising.\",\r\n value=60,\r\n damage=30)\r\nclass Scimitar(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Scimitar\",\r\n description=\"A curved blade that is able to deal amounts of damage at a reasonable rate. Its curved blade serves as an advantage to that of normal blades.\",\r\n value=55,\r\n damage=30)\r\nclass Cutlass(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Cutlass\",\r\n description=\"A short and broad sword that has a blade slightly curved to deal more damage than that of a regular sword. This is fondly used by pirates such as the Sky Rats in the Southern Hemisphere.\",\r\n value=40,\r\n damage=28)\r\nclass Lance(Weapon):\r\n def _init(self):\r\n super()._init(name=\"Lance\",\r\n description=\"Within the Dragon Jousts of the Olde Days, the DragonGuarde would use these for ceremonial purposes. These ceremonial props have been improved to control riots within Dragondia.\",\r\n value=46,\r\n damage=30)\r\nclass Katana(Weapon):\r\n def_init(self):\r\n super()._init(name=\"Katana\",\r\n description=\"This Japanese Sword was plunged into the culture of Dragondia after the slaying of the Ancient Ones, a group of Demented Dragons trained by the Oni. The blade is curved into a single edge for a two handed grip.\",\r\n value=35,\r\n damage=35)\r\n"
},
{
"alpha_fraction": 0.49851658940315247,
"alphanum_fraction": 0.5129011869430542,
"avg_line_length": 25.391626358032227,
"blob_id": "6e431341530646ee66f3f399eef9197ff47f4dc3",
"content_id": "281e3eaebd0f805929482799e008ba741a55e41b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11123,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 406,
"path": "/Dragondia-Dawn of Desctruction.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "\r\nimport cmd\r\nimport textwrap\r\nimport sys\r\nimport os\r\nimport time\r\nimport random\r\n\r\nscreen_width = 100\r\n\r\n### Player Setup ###\r\nclass Player():\r\n def _int_(self):\r\n self.name = ''\r\n self.job = ''\r\n self.hp = 0\r\n self.mp = 0\r\n self.status_effects = []\r\n self.location = 'start'\r\n self.game_over = False\r\nmyPlayer = Player()\r\n\r\n### Title Screen ###\r\ndef title_screen_selection():\r\n option = input(\" -> \")\r\n if option.lower() == (\"play\"):\r\n setup_game()\r\n elif option.lower() == (\"help\"):\r\n help_menu()\r\n elif option.lower() == (\"quit\"):\r\n sys.exit()\r\n while option.lower() not in ['play', 'help', 'quit']:\r\n print(\"Please enter a valid command. \")\r\n option = input(\" -> \")\r\n if option.lower() == (\"play\"):\r\n setup_game()\r\n elif option.lower() == (\"help\"):\r\n help_menu()\r\n elif option.lower() == (\"quit\"):\r\n sys.exit()\r\n\r\ndef title_screen():\r\n os.system('clear')\r\n print('----------------------------')\r\n print(\"# Welcome to the Text RPG! #\")\r\n print('----------------------------')\r\n print(' -Play- ')\r\n print(' -Help- ')\r\n print(' -Quit- ')\r\n print(' Copyright 2019 Isaacgeddon ')\r\n title_screen_selection()\r\n\r\ndef help_menu():\r\n print('----------------------------')\r\n print(\"# Help Menu #\")\r\n print(\"- Use up, down, left, right to move\")\r\n print(\"- Type in your commands to excute them\")\r\n print(\"- Use 'look' to inspect something -\")\r\n print(\"'-Good luck and have fun! -\")\r\n title_screen_selection()\r\n\r\n### MAP ###\r\n\r\n\r\n\"\"\"\r\na1 a2... #player starts at b2\r\n---------\r\n| | | | | a4\r\n---------\r\n| | | | | b4\r\n---------\r\n| | | | |\r\n---------\r\n| | | | |\r\n---------\r\n\r\n\"\"\"\r\n\r\nZONE_NAME = ' '\r\nDESCRIPTION = 'description'\r\nEXAMINATION = 'examine'\r\nSOLVED = False\r\nUP = 'up', 'north'\r\nDOWN = 'down', 'south'\r\nLEFT = 'left', 'west'\r\nRIGHT = 'right', 'east'\r\n\r\n\r\nsolved_places = {'a1': False, 'a2': False, 'a3': False, 'a4': False,\r\n 'b1': False, 'b2': False, 'b3': False, 'b4': False,\r\n 'c1': False, 'c2': False, 'c3': False, 'c4': False,\r\n 'd1': False, 'd2': False, 'd3': False, 'd4': False,\r\n }\r\nzone_map ={\r\n 'a1': {\r\n ZONE_NAME: \"Dragondia Market \",\r\n DESCRIPTION: '',\r\n EXAMINATION: '',\r\n SOLVED: False,\r\n UP:'Bonk! You cannot go that way!',\r\n DOWN:'b1',\r\n LEFT: 'Bonk! You cannot go that way!',\r\n RIGHT: 'a2',\r\n },\r\n 'a2': {\r\n ZONE_NAME: \"Dragondia Town Enterance\",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'Bonk! You cannot go that way!',\r\n DOWN: 'b2',\r\n LEFT: 'a1',\r\n RIGHT: 'a3',\r\n },\r\n 'a3': {\r\n ZONE_NAME: \"Dragondia Square\",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'Bonk! You cannot go that way!',\r\n DOWN: 'b3',\r\n LEFT: 'a2',\r\n RIGHT: 'a4',\r\n },\r\n 'a4': {\r\n ZONE_NAME: \"Dragondia Hall\",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'Bonk! You cannot go that way!',\r\n DOWN: 'b4',\r\n LEFT: 'a3',\r\n RIGHT: 'Bonk! You cannot go that way!',\r\n },\r\n 'b1': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'a1',\r\n DOWN: 'c1',\r\n LEFT: 'Bonk! You cannot go that way!',\r\n RIGHT: 'b2',\r\n },\r\n 'b2': {\r\n ZONE_NAME: \"Home\",\r\n DESCRIPTION: 'This is your home!',\r\n EXAMINATION: 'Your home looks the same - nothing has changed.',\r\n SOLVED: False,\r\n UP: 'a2',\r\n DOWN: 'c2',\r\n LEFT: 'b1',\r\n RIGHT: 'b3'\r\n },\r\n 'b3': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'a3',\r\n DOWN: 'c3',\r\n LEFT: 'b2',\r\n RIGHT: 'b4'\r\n },\r\n 'b4': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'a4',\r\n DOWN: 'c4',\r\n LEFT: 'b3',\r\n RIGHT: 'Bonk! You cannot go that way!'\r\n },\r\n 'c1': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'b1',\r\n DOWN: 'd1',\r\n LEFT: 'Bonk! You cannot go that way!',\r\n RIGHT: 'c2'\r\n },\r\n 'c2': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'b2',\r\n DOWN: 'd2',\r\n LEFT: 'c1',\r\n RIGHT: 'c3'\r\n },\r\n 'c3': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'b3',\r\n DOWN: 'd3',\r\n LEFT: 'c2',\r\n RIGHT: 'c4'\r\n },\r\n 'c4': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'b4',\r\n DOWN: 'd4',\r\n LEFT: 'c3',\r\n RIGHT: 'Bonk! You cannot go that way!'\r\n },\r\n 'd1': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'c1',\r\n DOWN: 'Bonk! You cannot go that way!',\r\n LEFT: 'Bonk! You cannot go that way!',\r\n RIGHT: 'd2'\r\n },\r\n 'd2': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'c2',\r\n DOWN: 'Bonk! You cannot go that way!',\r\n LEFT: 'd1',\r\n RIGHT: 'd3',\r\n },\r\n 'd3': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'c3',\r\n DOWN: 'Bonk! You cannot go that way!',\r\n LEFT: 'd2',\r\n RIGHT: 'd4'\r\n },\r\n 'd4': {\r\n ZONE_NAME: \" \",\r\n DESCRIPTION: 'description',\r\n EXAMINATION: 'examine',\r\n SOLVED: False,\r\n UP: 'c4',\r\n DOWN: 'Bonk! You cannot go that way!',\r\n LEFT: 'd3',\r\n RIGHT: 'Bonk! You cannot go that way!'\r\n }\r\n\r\n\r\n }\r\n\r\n\r\n### GAME INTERACTIVITY ###\r\ndef print_location():\r\n print('\\n' + ('#' * (4 + len(myPlayer.location))))\r\n print('# ' + myPlayer.location.upper() + '#')\r\n print('# ' + zone_map[myPlayer.position][DESCRIPTION] + ' #')\r\n print('\\n' + ('#' * (4 + len(myPlayer.location))))\r\n\r\ndef prompt():\r\n print(\"\\n\" + \"=======================\")\r\n print(\"What would you like to do?\")\r\n action = input(\" -> \")\r\n acceptable_actions = ['move', 'go', 'travel', 'walk', 'quit', 'examine', 'inspect', 'interact', 'look']\r\n while action.lower() not in acceptable_actions:\r\n print(\"Unknown action, try again.\\n\")\r\n action = input(\" -> \")\r\n if action.lower() == 'quit':\r\n sys.exit\r\n elif action.lower() == ['move', 'go', 'travel', 'walk']:\r\n player_move(action.lower())\r\n elif action.lower() == ['examine', 'inspect', 'interact', 'look']:\r\n player_examine(action.lower())\r\n\r\ndef player_move(myAction):\r\n ask = \"where would you like to move to?\\n\"\r\n dest = input(ask)\r\n if dest in ['up', 'north']:\r\n destination = zone_map[myPlayer.location][UP]\r\n movement_handler(destination)\r\n elif dest in ['down', 'south']:\r\n destination = zone_map[myPlayer.location][DOWN]\r\n movement_handler(destination)\r\n elif dest in ['left', 'west']:\r\n destination = zone_map[myPlayer.location][LEFT]\r\n movement_handler(destination)\r\n elif dest in ['right', 'east']:\r\n destination = zone_map[myPlayer.location][RIGHT]\r\n movement_handler(destination)\r\n \r\ndef movement_handler(destination):\r\n print(\"\\n\" + \"You have moved to the\" + destination + \".\")\r\n myPlayer.location = destination\r\n print_location()\r\n\r\ndef player_examine(action):\r\n if zone_map[myPlayer.location][SOLVED]:\r\n print(\"You have already exhausted this zone.\")\r\n else:\r\n print(\"You can trigger puzzle here\")\r\n\r\n### GAME FUNCTIONALITY###\r\ndef main_game_loop():\r\n while myPlayer.game_over is False:\r\n prompt()\r\n if myPlayer.game_over is True:\r\n sys.exit\r\n # here handle if puzzles have been solved, boss defeated, explored everything\r\n\r\ndef setup_game():\r\n os.system(clear):\r\n\r\n### Name Collecting ###\r\n question1= \"Hello, what is you name?\\n\"\r\n for character in question1:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.05)\r\n player_name = input(\" -> \")\r\n myPlayer.name = player_name\r\n### Job Handling ###\r\n question2= \"What role do you want to play?\\n\"\r\n question2added = \"{You can only play as a warrior, mage, priest, archer, or worker.}\\n\"\r\n for character in question2:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.05)\r\n for character in question2added:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.01)\r\n player_job = input(\" -> \")\r\n myPlayer.job = player_job\r\n valid_jobs = ['warrior', 'mage', 'priest', 'archer','worker']\r\n while player_job.lower() not in valid_jobs:\r\n player_job = input(\" -> \")\r\n if player_job.lower() in valid_jobs:\r\n myPlayer.job = player_job\r\n print(\"You are now a \" + player_job + \"!\\n\")\r\n\r\n if myPlayer.job is 'warrior':\r\n self.hp = 120\r\n self.mp = 20\r\n print(\"You are now a Warrior!\\n\")\r\n elif myPlayer.job is 'mage':\r\n self.hp = 60\r\n self.mp = 120\r\n print(\"You are now a Mage!\\n\")\r\n elif myPlayer.job is 'priest':\r\n self.hp = 80\r\n self.mp = 80\r\n print(\"You are now a Priest!\\n\")\r\n elif myPlayer.job is 'archer':\r\n self.hp = 100\r\n self.mp = 40\r\n print(\"You are now an Archer!\\n\")\r\n elif myPlayer.job is 'worker':\r\n self.hp = 75\r\n self.mp = 15\r\n print(\"You are now a Worker!\\n\")\r\n ###Introduction###\r\n question3= \"Welcome, \" + player_name + \" the \" + player_job + \".\\n\"\r\n for character in question3:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.05)\r\n speech1 = \"Welcome to the enchanting land of Dragondia, where dragons are in control of floating continents made from the Mother Brood Dragon.\\n\"\r\n speech2 = \"Within this land, one can .\\n\"\r\n speech3 = \"Farthead Test 1. \\n \"\r\n speech4 = \"Farthead Test 2.\\n\"\r\n\r\n for character in speech1:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.03)\r\n myPlayer.name = player_name\r\n for character in speech2:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.03)\r\n myPlayer.name = player_name\r\n for character in speech3:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.01)\r\n myPlayer.name = player_name\r\n for character in speech4:\r\n sys.stdout.write(character)\r\n sys.stdout.flush()\r\n time.sleep(0.2)\r\n\r\n os.system(clear):\r\n print(\"######################\")\r\n print(\"# Let's start now! #\")\r\n print(\"######################\")\r\n main_game_loop()\r\n\r\ntitle_screen()\r\n\r\nmain_game_loop()\r\n"
},
{
"alpha_fraction": 0.6524389982223511,
"alphanum_fraction": 0.6524389982223511,
"avg_line_length": 39,
"blob_id": "fc7774a2c62aadc0414392898b4b00f29a1d201e",
"content_id": "1c7a9caa102ccbc7ee4a5e4c8a425c567a356b7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1804,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 44,
"path": "/Text Adventure Game/world_space.py",
"repo_name": "MisterFischoeder/Text-Adventure-RPG-Python",
"src_encoding": "UTF-8",
"text": "import items, enemies\r\n\r\nclass MapTile:\r\n def _init_(self, x,y):\r\n self.x = x\r\n self.y = y\r\n\r\ndef intro_text(self):\r\n raise NotImplementedError()\r\n\r\ndef modify_player(self,player):\r\n raise NotImplementedError()\r\n\r\nclass StartingLevel(Maptile):\r\n def intro_text(self):\r\n return \"\"\"\r\n You find yourself within an enchanting world up in the sky, the clouds slowly drifting through each island as Dragons fly throughout the land.\r\n You can make out exactly four paths from where you stand in front of the Arcan Temple, home to the Elemental Dragon Lords that govern the world you stand upon.\r\n These four paths all have different types of roads. The one north of you has an Arena made of Skeletons of the Mutant Spiders. The one south of you is what looks like a haunted sanctuary for the Red Ninja Clan.\r\n The one on the west seems to have rigid paths that lead to the Troll Kingdom; the east has the invading forces of the Earls of Swine Vikings.\r\n \"\"\"\r\n\r\n def modify_player(self,player):\r\n #This room does not have any action within it the player can enact upon\r\n pass\r\nclass Room_Of_Enemy(Maptile):\r\n def _init_(self, x,y, enemy):\r\n self.enemy = enemy\r\n super()._init_(x, y)\r\n\r\n def modify_player(self, the player):\r\n if self.enemy.is_alive():\r\n the_player.hp = the_player.hp - self.enemy.damage\r\n print(\"Enemy does {} damage. You have {} Health remaining.\".format(self.enemy.damage, the_player.hp))\r\nclass Room_Of_Loot(Maptile):\r\n def _init_(self,x, y, item):\r\n self.item = item\r\n super()._init_(x,y)\r\n\r\n def add_loot(self, player):\r\n player.inventory.append(self.item)\r\n\r\n def modify_player(self, player):\r\n self.add_loot(player)\r\n"
}
] | 9 |
Lovezhe4ever/dev_task
|
https://github.com/Lovezhe4ever/dev_task
|
a4e74f715135c6a1e452abcff06bed5e350f3a20
|
f0c90a19bcbb660bf531d229c276137603a75a36
|
c74e5eaec08c5d70b33f041d916efdccfab46636
|
refs/heads/master
| 2020-09-11T16:36:33.940973 | 2019-08-14T16:44:25 | 2019-08-14T16:44:25 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7156916260719299,
"alphanum_fraction": 0.722252607345581,
"avg_line_length": 37.9361686706543,
"blob_id": "d501f6254055a1cfd226e77d17aac4282d6ebe7a",
"content_id": "50eba9676a1094f8ad6f8cdc4aa42e2d0146f23c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1829,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 47,
"path": "/dev_task/celery.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom __future__ import absolute_import, unicode_literals\nfrom kombu import Queue, Exchange\nfrom celery import Celery\nimport os\nimport ConfigParser\n\n# set the default Django settings module for the 'celery' program.\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'dev_task.settings')\napp = Celery('dev_task')\n\n# rabbitmq connect code\nBASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))\nconfig = ConfigParser.ConfigParser()\nconfig.read(os.path.join(BASE_DIR, 'dev_task.conf'))\nrabbitmq_host = config.get('rabbitmq', 'rabbitmq_host')\nrabbitmq_port = config.get('rabbitmq', 'rabbitmq_port')\nrabbitmq_user = config.get('rabbitmq', 'rabbitmq_user')\nrabbitmq_password = config.get('rabbitmq', 'rabbitmq_password')\nrabbitmq_vhost = config.get('rabbitmq', 'rabbitmq_vhost')\nrabbitmq_exchange = config.get('rabbitmq', 'rabbitmq_exchange')\nrabbitmq_queue = config.get('rabbitmq', 'rabbitmq_queue')\nrabbitmq_routing_key = config.get('rabbitmq', 'rabbitmq_routing_key')\n\napp.conf.broker_url = 'amqp://{0}:{1}@{2}:{3}/{4}'.format(rabbitmq_user, rabbitmq_password, rabbitmq_host, rabbitmq_port, rabbitmq_vhost)\nmedia_exchange = Exchange('{0}'.format(rabbitmq_exchange), type='topic')\nqueue = (\n Queue('{0}'.format(rabbitmq_queue), media_exchange, routing_key='{0}'.format(rabbitmq_routing_key)),\n)\nroute = {\n 'work.notify.email.send_mail': {\n 'queue': '{0}'.format(rabbitmq_queue),\n 'routing_key': '{0}'.format(rabbitmq_routing_key)\n }\n}\napp.conf.update(CELERY_QUEUES=queue, CELERY_ROUTES=route)\napp.config_from_object('django.conf:settings', namespace='CELERY')\n\n# Load task modules from all registered Django app configs.\napp.autodiscover_tasks()\n# lambda: settings.INSTALLED_APPS\n\n\[email protected](bind=True)\ndef debug_task(self):\n print('Request: {0!r}'.format(self.request))"
},
{
"alpha_fraction": 0.7506963610649109,
"alphanum_fraction": 0.7701950073242188,
"avg_line_length": 34.900001525878906,
"blob_id": "f41f31fdf0120e1f85a8f5376df0b8d0a272ba77",
"content_id": "b9aaaeb3887bdadbdb8c8074837dcc09305dcb65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 20,
"path": "/Dockerfile",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "FROM centos7-nginx\nMAINTAINER jeaner\nUSER root\n\nRUN yum install -y epel-release\nRUN yum -y update\nRUN yum install -y python python-dev python-devel python-pip gcc msgpack-python openssl openssl-devel mysql-devel git wget supervisor mysql\nWORKDIR /opt\nRUN git clone https://github.com/caiqing0204/dev_task.git\nWORKDIR dev_task/\nRUN pip install --upgrade pip\nRUN pip install -r requirements\nRUN pip install uwsgi==2.0.17.1\nWORKDIR /opt/dev_task/supply/django-celery-results-master/\nRUN python setup.py install\nEXPOSE 8070\nWORKDIR /opt/dev_task\nRUN chmod +x /opt/dev_task/init.sh\nRUN chmod +x /opt/dev_task/start_server.sh\nENTRYPOINT [\"/bin/bash\",\"-c\",\"/opt/dev_task/init.sh && /opt/dev_task/start_server.sh start\"]\n"
},
{
"alpha_fraction": 0.6430034041404724,
"alphanum_fraction": 0.6546075344085693,
"avg_line_length": 24.6842098236084,
"blob_id": "b2ecbeb785744c22d4a1862ee8c93a80bde7b2c2",
"content_id": "d8a90a5a954a73b4f85b16ddd02522be7ad7062e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 57,
"path": "/dev_task/templatetags/mytags.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n\nimport json\nfrom django import template\nfrom django_celery_beat.models import IntervalSchedule, CrontabSchedule\n\nregister = template.Library()\n'''\[email protected](name='groups2str')\ndef groups2str(group_list):\n \"\"\"\n 将用户组列表转换为str\n \"\"\"\n\n return ' '.join([group[\"groupname\"] for group in group_list])\n\n'''\n\n\[email protected](name='intervals2str')\ndef intervals2str(interval_id):\n interval_obj = IntervalSchedule.objects.get(id=interval_id)\n return 'every %s %s' % (interval_obj.every, interval_obj.period)\n\n\[email protected](name='crontab2str')\ndef crontab2str(crontab_id):\n crontab_obj = CrontabSchedule.objects.get(id=crontab_id)\n return '%s %s %s %s %s (m/h/dM/MY/d)' % (\n crontab_obj.minute, crontab_obj.hour, crontab_obj.day_of_month, crontab_obj.month_of_year, crontab_obj.day_of_week)\n\n\[email protected](name='host2str')\ndef host2str(obj):\n _list = obj.values_list(\"host\", flat=True)\n return list(set(list(_list)))\n\n\[email protected](name='kwargs2str')\ndef kwargs2str(obj):\n list_1 = []\n _list = obj.values_list(\"kwargs\", flat=True)\n for v in list(list(_list)):\n if isinstance(v, unicode):\n _v = json.loads(v)\n list_1.append(_v['cmd'])\n else:\n list_1.append(v['cmd'])\n return list(set(list_1))\n\n\[email protected](name='cmd2str')\ndef cmd2str(obj):\n try:\n return json.loads(obj)['cmd']\n except ValueError:\n return eval(obj)[u'cmd']\n\n"
},
{
"alpha_fraction": 0.659217894077301,
"alphanum_fraction": 0.659217894077301,
"avg_line_length": 61.260868072509766,
"blob_id": "d43160fcdc214872e6dd1defbeb514585cf20f28",
"content_id": "370f1d19504d2a754a2b1c6c7a14640afd2622d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1432,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 23,
"path": "/task/taskurls.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url\nfrom django.views.generic import TemplateView\nimport views\n\n\nurlpatterns = [\n url(r'^$', views.Dashboard.as_view(), name=\"index\"),\n url(r'^job/list/$', views.JobList.as_view(), name=\"job_list\"),\n url(r'^job/add/$', views.JobAdd.as_view(), name=\"job_add\"),\n url(r'^job/edit/(?P<id>\\d+)/$', views.JobEdit.as_view(), name=\"job_edit\"),\n url(r'^job/del/$', views.JobDel.as_view(), name=\"job_del\"),\n url(r'^job/interval/list/$', views.JobIntervalList.as_view(), name=\"job_interval_list\"),\n url(r'^job/interval/add/$', views.JobIntervalAdd.as_view(), name=\"job_interval_add\"),\n url(r'^job/interval/edit/(?P<id>\\d+)/$', views.JobIntervalEdit.as_view(), name=\"job_interval_edit\"),\n url(r'^job/interval/del/$', views.JobIntervalDel.as_view(), name=\"job_interval_del\"),\n url(r'^job/crontab/list/$', views.JobCronatbList.as_view(), name=\"job_crontab_list\"),\n url(r'^job/crontab/add/$', views.JobCrontabAdd.as_view(), name=\"job_crontab_add\"),\n url(r'^job/crontab/edit/(?P<id>\\d+)/$', views.JobCrontabEdit.as_view(), name=\"job_crontab_edit\"),\n url(r'^job/crontab/del/$', views.JobCrontabDel.as_view(), name=\"job_crontab_del\"),\n url(r'^job/result/list', views.JobResultList.as_view(), name=\"job_result_list\"),\n url(r'^api/flower/celeryworker', views.CeleryWorker.as_view(), name=\"api_flower\"),\n url(r'^api/rabbitmq', views.Rabbitmq.as_view(), name=\"api_rabbitmq\")\n]\n"
},
{
"alpha_fraction": 0.644859790802002,
"alphanum_fraction": 0.644859790802002,
"avg_line_length": 31,
"blob_id": "deab69c8df5f61fdc3ce5367306a7e2d31e640b2",
"content_id": "dd0801bb11f858b1e3a5063da2627ee05759cc02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 10,
"path": "/dev_task/urls.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import url, include\nfrom task import taskurls, views\n\n\nurlpatterns = [\n url(r'^$', views.Dashboard.as_view(), name=\"index\"),\n url(r'^task/', include(taskurls)),\n url(r'^login/$', views.LoginView.as_view(), name='login'),\n url(r'^logout/$', views.LogoutView.as_view(), name='logout'),\n]\n\n"
},
{
"alpha_fraction": 0.7231329679489136,
"alphanum_fraction": 0.7395263910293579,
"avg_line_length": 41.230770111083984,
"blob_id": "9a2635ef8f16dea1e6f1bffe85dfa814db1a0615",
"content_id": "5d6f49992e563aa501458d0480ed77d565d1613c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 13,
"path": "/task/models.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n\nfrom __future__ import unicode_literals\nfrom django.db import models\nfrom django_celery_beat.models import PeriodicTask\n\n\nclass TimedTask(PeriodicTask):\n nice_name = models.CharField(max_length=255, default='', blank=True)\n host = models.CharField(max_length=255, blank=True, null=True)\n email = models.EmailField(max_length=50, verbose_name=u\"邮箱\")\n is_send_email = models.BooleanField(default=True, db_index=True, editable=False)\n run_status = models.BooleanField(default=True, db_index=True, editable=False)\n"
},
{
"alpha_fraction": 0.5937916040420532,
"alphanum_fraction": 0.5970928072929382,
"avg_line_length": 36.94141387939453,
"blob_id": "1d42c02f49d10a6a104152ef46121f431d4142d9",
"content_id": "25f73b9667ce2429d261e00b957a627caad94283",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18919,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 495,
"path": "/task/views.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n\nfrom django_celery_beat.models import IntervalSchedule, CrontabSchedule, PeriodicTask\nfrom dev_task.celery import (rabbitmq_exchange, rabbitmq_routing_key, rabbitmq_queue,\n rabbitmq_host, rabbitmq_password, rabbitmq_user,rabbitmq_vhost)\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger\nfrom django.db.models.signals import pre_save, pre_delete\nfrom django_celery_results.models import TaskResult\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth import authenticate, login\nfrom django.contrib.messages.views import SuccessMessageMixin\nfrom django.contrib.auth.mixins import AccessMixin\nfrom django.contrib import auth\nfrom django.shortcuts import HttpResponseRedirect, HttpResponse\nfrom django.shortcuts import render as my_render\nfrom django.urls import reverse, reverse_lazy\nfrom django.views.decorators.debug import sensitive_post_parameters\nfrom django.views.decorators.cache import never_cache\nfrom django.views.decorators.csrf import csrf_protect\nfrom django.views.generic import TemplateView, ListView, CreateView, UpdateView\nfrom django.views.generic.edit import FormView\nfrom django.views.generic.base import View\nfrom django.utils.decorators import method_decorator\nfrom django.utils.translation import ugettext as _\nfrom dev_task.settings import default_email_users\nfrom datetime import datetime\nfrom celery import current_app\nfrom models import TimedTask\nfrom forms import LoginForm\nfrom supply.rabbitmq_api import MQManage\nimport json\nimport urllib, urllib2, base64\n\n\nclass LoginRequiredMixin(AccessMixin):\n\n @method_decorator(login_required(redirect_field_name='next', login_url='/login/'))\n def dispatch(self, request, *args, **kwargs):\n return super(LoginRequiredMixin, self).dispatch(request, *args, **kwargs)\n\n\n@method_decorator(sensitive_post_parameters(), name='dispatch')\n@method_decorator(csrf_protect, name='dispatch')\n@method_decorator(never_cache, name='dispatch')\nclass LoginView(FormView):\n template_name = 'login.html'\n form_class = LoginForm\n redirect_field_name = 'next'\n\n def get_context_data(self, **kwargs):\n kwargs = super(LoginView, self).get_context_data(**kwargs)\n kwargs.update({\n 'next': self.request.GET.get('next', '')\n })\n return kwargs\n\n def get(self, request, *args, **kwargs):\n if request.user.is_authenticated():\n return HttpResponseRedirect(reverse('index'))\n else:\n return super(LoginView, self).get(request, *args, **kwargs)\n\n def post(self, request, *args, **kwargs):\n login_form = self.get_form()\n if login_form.is_valid():\n user_name = login_form.cleaned_data['username']\n pass_word = login_form.cleaned_data['password']\n next = request.POST.get('next', '')\n user = authenticate(username=user_name, password=pass_word)\n if user is not None:\n if user.is_active:\n login(request, user)\n if next:\n return HttpResponseRedirect(next)\n else:\n return HttpResponseRedirect(reverse('index'))\n else:\n return my_render(request, \"login.html\", {\"msq\": _(u\"用户未激活,请联系管理!\")})\n else:\n return my_render(request, \"login.html\", {\"msq\": _(u\"用户验证失败,请联系管理员!\")})\n else:\n return my_render(request, \"login.html\", {\"msq\": _(u\"用户验证失败,请联系管理员!\"), \"login_form\": login_form})\n\n\nclass LogoutView(View):\n def get(self, request):\n auth.logout(request)\n return HttpResponseRedirect(\"/login/\")\n\n\n# dashboard\nclass Dashboard(LoginRequiredMixin, View):\n def get(self, request):\n return my_render(request, \"index.html\", locals())\n\n\n# api celery worker\nclass CeleryWorker(LoginRequiredMixin, View):\n def get(self, request):\n requests = urllib2.Request('http://127.0.0.1:5555/dashboard?json=1')\n response = urllib2.urlopen(requests).read()\n return HttpResponse(response)\n\n\n# api rabbitmq\nclass Rabbitmq(LoginRequiredMixin, View):\n def get(self, request):\n mq = MQManage()\n mq.create_connection(rabbitmq_host, rabbitmq_user, rabbitmq_password)\n queuelist = json.dumps({\"data\": [x for x in json.loads(mq.list_queues()) if not x[\"name\"].startswith('celery')]})\n return HttpResponse(queuelist)\n\n\n# job list\nclass JobList(LoginRequiredMixin, ListView):\n model = TimedTask\n template_name = \"task/job_list.html\"\n context_object_name = \"jobs_info\"\n\n\n# job add\nclass JobAdd(LoginRequiredMixin, SuccessMessageMixin, CreateView):\n model = TimedTask\n fields = '__all__'\n template_name = \"task/job_add.html\"\n celery_app = current_app\n celery_app.loader.import_default_modules()\n interval_info = IntervalSchedule.objects.all()\n crontab_info = CrontabSchedule.objects.all()\n\n def get_context_data(self, **kwargs):\n context = {\n \"interval_info\": IntervalSchedule.objects.all(),\n \"crontab_info\": CrontabSchedule.objects.all(),\n \"tasks\": list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.'))),\n \"default_email_user\": default_email_users\n }\n kwargs.update(context)\n return super(JobAdd, self).get_context_data(**kwargs)\n\n def post(self, request, *args, **kwargs):\n post_data = request.POST\n enabled_value = str(post_data.get(\"enabled\")) == str(True)\n is_send_email_value = str(post_data.get(\"is_send_email\")) == str(True)\n\n job_data = {\n \"nice_name\": post_data.get(\"nice_name\", ''),\n \"host\": post_data.get(\"host\", ''),\n \"name\": post_data.get(\"name\", ''),\n \"task\": post_data.get(\"regtask\", ''),\n \"interval_id\": post_data.get(\"interval\", ''),\n \"crontab_id\": post_data.get(\"crontab\", ''),\n \"args\": post_data.get(\"args\", ''),\n \"kwargs\": post_data.get(\"kwargs\", ''),\n \"queue\": str(rabbitmq_queue),\n \"exchange\": rabbitmq_exchange,\n \"routing_key\": str(rabbitmq_routing_key),\n \"expires\": None,\n \"enabled\": enabled_value,\n \"run_status\": True if enabled_value else False,\n \"description\": post_data.get(\"description\", ''),\n \"email\": post_data.get(\"email\"),\n \"is_send_email\": is_send_email_value\n }\n print job_data\n if job_data['interval_id'] and job_data['crontab_id']:\n error = u\"you can only choices one of interval or crontab!\"\n interval_info = self.interval_info\n crontab_info = self.crontab_info\n self.celery_app.loader.import_default_modules()\n tasks = list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.')))\n return my_render(request, \"task/job_add.html\", locals())\n value = job_data[\"kwargs\"]\n try:\n json.loads(value)\n except ValueError as exc:\n error = u\"Unable to parse JSON: %s\" % exc\n interval_info = self.interval_info\n crontab_info = self.crontab_info\n self.celery_app.loader.import_default_modules()\n tasks = list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.')))\n return my_render(request, \"task/job_add.html\", locals())\n if job_data['args']:\n try:\n json.loads(job_data['args'])\n except Exception as exc:\n error = u\"Unable to parse JSON: %s\" % exc\n interval_info = self.interval_info\n crontab_info = self.crontab_info\n self.celery_app.loader.import_default_modules()\n tasks = list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.')))\n try:\n pre_save.send(sender=PeriodicTask, instance=TimedTask)\n TimedTask.objects.create(**job_data)\n msg = u\"添加任务成功!\"\n except Exception as e:\n error = u\"添加任务失败!,{0}\".format(e)\n interval_info = self.interval_info\n crontab_info = self.crontab_info\n self.celery_app.loader.import_default_modules()\n tasks = list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.')))\n return my_render(request, \"task/job_add.html\", locals())\n\n\n# job edit\nclass JobEdit(LoginRequiredMixin, UpdateView):\n model = TimedTask\n pk_url_kwarg = 'id'\n context_object_name = 'job_info'\n template_name = 'task/job_edit.html'\n fields = '__all__'\n celery_app = current_app\n celery_app.loader.import_default_modules()\n interval_info = IntervalSchedule.objects.all()\n crontab_info = CrontabSchedule.objects.all()\n\n def get_context_data(self, **kwargs):\n kwargs = super(JobEdit, self).get_context_data(**kwargs)\n kwargs.update({\n \"interval_info\": self.interval_info,\n \"crontab_info\": self.crontab_info,\n \"tasks\": list(sorted(name for name in self.celery_app.tasks if not name.startswith('celery.'))),\n \"status\": 0\n })\n return kwargs\n\n def get_queryset(self):\n qs = super(JobEdit, self).get_queryset()\n return qs.filter(pk=self.kwargs.get(self.pk_url_kwarg))\n\n def post(self, request, *args, **kwargs):\n post_data = request.POST\n enabled_value = str(post_data.get(\"enabled\")) == str(True)\n is_send_email_value = str(post_data.get(\"is_send_email\")) == str(True)\n job_data = {\n \"nice_name\": post_data.get(\"nice_name\", ''),\n \"host\": post_data.get(\"host\", ''),\n \"name\": post_data.get(\"name\", ''),\n \"interval_id\": post_data.get(\"interval\", ''),\n \"crontab_id\": post_data.get(\"crontab\", ''),\n \"args\": post_data.get(\"args\", ''),\n \"kwargs\": post_data.get(\"kwargs\", ''),\n \"queue\": post_data.get(\"queue\", ''),\n \"enabled\": enabled_value,\n \"run_status\": True if enabled_value else False,\n \"exchange\": post_data.get(\"exchange\", ''),\n \"routing_key\": post_data.get(\"routing_key\", ''),\n \"expires\": None,\n \"description\": post_data.get(\"description\", ''),\n \"date_changed\": datetime.now(),\n \"email\": post_data.get(\"email\"),\n \"is_send_email\": is_send_email_value\n }\n if job_data['interval_id'] and job_data['crontab_id']:\n status = 2\n return my_render(request, \"task/job_edit.html\", locals())\n task_value = post_data.get(\"regtask\")\n if task_value:\n job_data[\"task\"] = task_value\n kwargs_vaule = job_data[\"kwargs\"]\n args_value = job_data[\"args\"]\n try:\n json.loads(kwargs_vaule)\n except:\n status = 2\n return my_render(request, \"task/job_edit.html\", locals())\n if args_value:\n try:\n json.loads(args_value)\n except:\n status = 2\n return my_render(request, \"task/job_edit.html\", locals())\n try:\n pre_save.send(sender=PeriodicTask, instance=TimedTask)\n self.get_queryset().update(**job_data)\n status = 1\n except Exception as e:\n print e\n status = 2\n return my_render(request, \"task/job_edit.html\", locals())\n\n\n# job del\nclass JobDel(LoginRequiredMixin, View):\n\n def post(self, request):\n pre_delete.send(sender=PeriodicTask, instance=TimedTask)\n jobs = request.POST.getlist(\"job_check\", [])\n if jobs:\n for v in jobs:\n TimedTask.objects.filter(pk=v).delete()\n return HttpResponseRedirect(reverse('job_list'))\n\n\n# job interval list\nclass JobIntervalList(LoginRequiredMixin, ListView):\n model = IntervalSchedule\n context_object_name = 'interval_info'\n template_name = \"task/interval_list.html\"\n\n\n# job interval add\nclass JobIntervalAdd(LoginRequiredMixin, SuccessMessageMixin, CreateView):\n model = IntervalSchedule\n template_name = 'task/interval_add.html'\n fields = '__all__'\n success_url = reverse_lazy('job_interval_add')\n success_message = _(\"<b>interval</b> was created successfully\")\n\n\n# job interval del\nclass JobIntervalDel(LoginRequiredMixin, View):\n\n def post(self, request):\n pre_delete.send(sender=PeriodicTask, instance=TimedTask)\n intervals = request.POST.getlist(\"interval_check\", [])\n if intervals:\n for v in intervals:\n IntervalSchedule.objects.filter(pk=v).delete()\n return HttpResponseRedirect(reverse('job_interval_list'))\n\n\n# job interval edit\nclass JobIntervalEdit(LoginRequiredMixin, UpdateView):\n model = IntervalSchedule\n fields = '__all__'\n template_name = 'task/interval_edit.html'\n pk_url_kwarg = 'id'\n context_object_name = 'interval_info'\n\n def get_context_data(self, **kwargs):\n kwargs = super(JobIntervalEdit, self).get_context_data(**kwargs)\n kwargs.update({\n \"status\": 0\n })\n return kwargs\n\n def get_queryset(self):\n qs = super(JobIntervalEdit, self).get_queryset()\n return qs.filter(pk=self.kwargs.get(self.pk_url_kwarg))\n\n def post(self, request, *args, **kwargs):\n post_data = request.POST\n interval_data = {\n \"every\": post_data.get(\"every\"),\n \"period\": post_data.get(\"period\")\n }\n try:\n pre_save.send(sender=PeriodicTask, instance=TimedTask)\n self.get_queryset().update(**interval_data)\n status = 1\n except:\n status = 2\n return my_render(request, \"task/interval_edit.html\", locals())\n\n\n# job crontab list\nclass JobCronatbList(LoginRequiredMixin, ListView):\n model = CrontabSchedule\n template_name = 'task/crontab_list.html'\n context_object_name = 'crontab_info'\n\n\n# job crontab add\nclass JobCrontabAdd(LoginRequiredMixin, View):\n def get(self, request):\n return my_render(request, \"task/crontab_add.html\", locals())\n\n def post(self, request):\n crontab_data = {\n \"minute\": request.POST.get(\"minute\", ''),\n \"hour\": request.POST.get(\"hour\", ''),\n \"day_of_week\": request.POST.get(\"day_of_week\", ''),\n \"day_of_month\": request.POST.get(\"day_of_month\", ''),\n \"month_of_year\": request.POST.get(\"month_of_year\", '')\n }\n try:\n CrontabSchedule.objects.create(**crontab_data)\n msg = u\"添加crontab成功!\"\n except:\n error = u\"添加crontab失败!\"\n return my_render(request, \"task/crontab_add.html\", locals())\n\n\n# job crontab del\nclass JobCrontabDel(LoginRequiredMixin, View):\n def post(self, request):\n pre_delete.send(sender=PeriodicTask, instance=TimedTask)\n crontabs = request.POST.getlist(\"crontab_check\", [])\n if crontabs:\n for v in crontabs:\n CrontabSchedule.objects.filter(pk=v).delete()\n return HttpResponseRedirect(reverse('job_crontab_list'))\n\n\n# job crontab edit\nclass JobCrontabEdit(LoginRequiredMixin, View):\n def get(self, request, id):\n status = 0\n crontab_info = CrontabSchedule.objects.get(pk=id)\n return my_render(request, \"task/crontab_edit.html\", locals())\n\n def post(self, request, id):\n crontab_data = {\n \"minute\": request.POST.get(\"minute\", ''),\n \"hour\": request.POST.get(\"hour\", ''),\n \"day_of_week\": request.POST.get(\"day_of_week\", ''),\n \"day_of_month\": request.POST.get(\"day_of_month\", ''),\n \"month_of_year\": request.POST.get(\"month_of_year\", '')\n }\n try:\n pre_save.send(sender=PeriodicTask, instance=TimedTask)\n CrontabSchedule.objects.filter(pk=id).update(**crontab_data)\n status = 1\n except:\n status = 2\n return my_render(request, \"task/crontab_edit.html\", locals())\n\n\n# job result list\nclass JobResultList(LoginRequiredMixin, View):\n\n def get(self, request):\n result_dict = {}\n left = []\n right = []\n first = False\n last = False\n left_has_more = False\n right_has_more = False\n is_paginated = True\n\n host_ip = request.GET.get('host', '')\n status = request.GET.get('status', '')\n kwargs = request.GET.get('kwargs', '')\n page = request.GET.get('page', 1)\n timedtask_obj = TimedTask.objects.all()\n result_list = TaskResult.objects.all()\n\n if host_ip and kwargs:\n result_dict['task_kwargs__contains'] = host_ip and kwargs\n elif host_ip:\n result_dict['task_kwargs__contains'] = host_ip\n elif kwargs:\n result_dict['task_kwargs__contains'] = kwargs\n if status:\n result_dict['status__contains'] = status\n if result_dict:\n result_list = TaskResult.objects.filter(**result_dict)\n total_result = result_list.count()\n page_number = int(page)\n paginator = Paginator(result_list, 10)\n # 获得分页后的总页数\n total_pages = paginator.num_pages\n page_range = list(paginator.page_range)\n currentPage = int(page_number)\n\n\n try:\n result_list = paginator.page(page)\n except PageNotAnInteger:\n result_list = paginator.page(1)\n except EmptyPage:\n result_list = paginator.page(total_pages)\n\n if result_list and total_pages > 1:\n if page_number == 1:\n right = page_range[page_number:page_number + 2]\n if right[-1] < total_pages - 1:\n right_has_more = True\n\n if right[-1] < total_pages:\n last = True\n\n elif page_number == total_pages:\n left = page_range[(page_number - 3) if (page_number - 3) > 0 else 0:page_number - 1]\n if left[0] > 2:\n left_has_more = True\n if left[0] > 1:\n first = True\n else:\n left = page_range[(page_number - 3) if (page_number - 3) > 0 else 0:page_number - 1]\n right = page_range[page_number:page_number + 2]\n if right[-1] < total_pages - 1:\n right_has_more = True\n if right[-1] < total_pages:\n last = True\n if left[0] > 2:\n left_has_more = True\n if left[0] > 1:\n first = True\n else:\n is_paginated = False\n\n return my_render(request, \"task/result_list.html\", locals())\n"
},
{
"alpha_fraction": 0.634854793548584,
"alphanum_fraction": 0.726141095161438,
"avg_line_length": 9.52173900604248,
"blob_id": "fc202cf4053e0e94eec0e7f05fd83bed63cb82ea",
"content_id": "d614ce066cc9dda78923f0f3d0d0a30ac0e776f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 23,
"path": "/uwsgi.ini",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "[uwsgi]\n\nsocket=127.0.0.1:3400\n\n;http=0.0.0.0:8070\n\nchdir=/opt/dev_task/\n\nmodule=dev_task.wsgi\n\nprocesses=4\n\nthreads=2\n\nmaster=True\n\nreload-mercy = 10\n\nvacuum=True\n\npidfile=/opt/dev_task/pid/uwsgi.pid\n\n;daemonize=/opt/dev_task/logs/uwsgi.log"
},
{
"alpha_fraction": 0.716156005859375,
"alphanum_fraction": 0.7487465143203735,
"avg_line_length": 22.61842155456543,
"blob_id": "0e5d48dd50b1a2932504ef2bdeb671b9c73b6bac",
"content_id": "99933ac919e0a8d2e4054962407f72d5b272ff5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4824,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 152,
"path": "/README.md",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# dev_task\ndev_task是一款基于django-celery-beat调度执行的任务管理平台,平台基于celery4.1.1开发,实现了类似crontab定时执行任务的功能。(后期将作为运维平台dev_system的任务编排组件)<br>\n### 当前版本:v1.0\n1. 修复了邮件告警相关的bug\n2. 修复了任务结果分页\n3. 修复了任务显示状态\n4. 添加了client端celery状态监控\n5. 添加了rabbitmq部分状态监控\n## 环境:\n建议大家在centos7.0系统安装此项目<br>\nPython2.7,暂不支持python3.x<br>\n项目部署目录 /opt<br>\n关闭防火墙<br>\nsetenforce 0<br>\nservice iptables stop<br>\n安装mysql5.6,rabbitmq,并且启动服务<br>\n安装supervisor,必须是3.0以上的版本,centos6.5yum安装默认是2.+的版本,这里需要手动安装。<br>\n\n## dev_task内部架构图\n\n\n\n## 以Docker方式运行\n\n> 建议大家使用docker方式运行项目,使用docker方式运行项目,需要注意的是\n\n> mysql和rabbitmq都是安装在宿主机上的,也就是说,容器中并没有包含mysql和rabbitmq的服务\n\n> 这也是提高了数据安全性和扩展性,所以安装好了mysql和rabbitmq服务以后,需要对容器的访问授权,然后利用启动容器的方式,把相关信息带入容器内部。\n\n```\nMYSQL_HOST:mysql主机ip\nMYSQL_PORT:mysql端口号\nRA_HOST:rabbitmq主机\nLO_HOST:本机ip\nRA_Q:rabbitmq queue\nRA_ROUTING_KEY:rabbitmq routing_key\nEM_HOST:发送服务器\nEM_PORT:邮件端口号\nEM_SEND_USER:发件人邮箱地址\nEM_PASS:发件人邮箱密码\nDEFAULT_EM_ADDR:默认收件人地址,多个地址以英文逗号区分\n```\n\n```\ndocker run -itd -p 80:8070\n -e \"MYSQL_HOST=192.168.100.10\"\n -e \"MYSQL_PORT=3306\"\n -e \"MYSQL_USER=root\"\n -e \"MYSQL_PASS=123456\"\n -e \"MYSQL_DB=dev_task\"\n -e \"RA_HOST=192.168.100.10\"\n -e \"LO_HOST=192.168.100.10\"\n -e \"RA_Q=192.168.100.10\"\n -e \"RA_ROUTING_KEY=192.168.100.10\"\n -e \"EM_HOST=smtp.exmail.qq.com\"\n -e \"EM_PORT=25\"\n -e \"[email protected]\"\n -e \"EM_PASS=123456\"\n -e \"[email protected],[email protected],[email protected]\"\n --name dev_task\n caiqing0204/dev_task\n```\n\n## 安装文档\n## 依赖\n```\nyum install -y epel-release\nyum clean all\nyum install -y python python-dev python-devel python-pip gcc msgpack-python openssl openssl-devel mysql-devel\n```\n## server端和client节点都需要安装的模块,并且git clone代码到server和client上\n```\ncd /opt\ngit clone https://github.com/caiqing0204/dev_task.git\npip install -r requirements\n```\n\n## server端安装\n关于rabbitmq日志文件等信息的配置,大家可以查官网,自行配置<br>\n###### 创建用户,添加user_tags,创建vhost,用户授权\n```\nrabbitmqctl add_user rabbitmqadmin 1234qwer\nrabbitmqctl set_user_tags rabbitmqadmin administrator\nrabbitmqctl add_vhost dev_task\nrabbitmqctl set_permissions -p dev_task rabbitmqadmin \".*\" \".*\" \".*\"\n# 安装rabbitmq的管理页面\nrabbitmq-plugins enable rabbitmq_management\n```\n\n### 安装uwsgi\n```\npip install uwsgi==2.0.17.1\n```\n### 配置dev_task.conf\n配置好相应的mysql,rabbitmq信息\n\n### 安装django-celery-result和项目\n```\ncd /opt/dev_task/supply/django-celery-results-master/\npython setup.py install\ncd /opt/dev_task/\npython manage.py makemigrations\npython manage.py migrate\n```\n### 创建登录用户\n```\npython /opt/dev_task/createsuperuser.py\n```\n### 部署supervisord\n```\ncp /opt/dev_task/server_supervisord.conf /etc/supervisord.conf\nsupervisord -c /etc/supervisord.conf\n```\n### 静态文件目录授权\n```\nchmod 777 /opt/dev_task/static/ -R\n```\n### 启动nginx,关于nginx配置和修改,可以自己随意定制,不必按照本文档进行,可参考文档部分进行部署配置。\n```\ncp /opt/dev_task/nginx.conf /usr/local/nginx/conf/\n```\n### 登录\nhttp://ip:port<br>\nadmin<br>\npassword!23456\n\n## client端安装\n### 配置dev_task.conf\n配置好相应的mysql,rabbitmq信息\n\n### 安装django-celery-result\n```\ncd /opt/dev_task/supply/django-celery-results-master/\npython setup.py install\n```\n### 部署supervisord\n```\ncp /opt/dev_task/client_supervisord.conf /etc/supervisord.conf\nsupervisord -c /etc/supervisord.conf\n```\n## 注意\n### server端和client端一样\n升级完python版本以后,需要重新安装一下pip,下载pip的tar包,解压安装。重新制定软连接,就可以使用了。\n我这里是手动安装supervisord 3版本的,安装supervisord之前,需要安装setuptools,centos6.5 yum安装supervisord,版本是2.1,\n有问题,欢迎随时提交issues!\n\n## screenshots\n\n\n\n\n"
},
{
"alpha_fraction": 0.5778947472572327,
"alphanum_fraction": 0.582105278968811,
"avg_line_length": 39.425533294677734,
"blob_id": "af9725b7b056d59d35fc7ca352d6669b6d02ce87",
"content_id": "2bc9c5fd920eddad460728c0d0aae0c9d22333a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1900,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 47,
"path": "/task/tasks.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\nfrom __future__ import absolute_import, unicode_literals\nfrom supply.email_send import send_monitor_email\nfrom task.models import TimedTask\nfrom celery import shared_task\nfrom dev_task import settings\nimport subprocess\n\n\n@shared_task\ndef exec_command_or_script(task_name, host, cmd):\n timetask_obj = TimedTask.objects.get(name=task_name)\n\n if str(host) == str(settings.host_ip):\n\n try:\n p = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.STDOUT)\n data = p.communicate()\n if str(p.wait()) != '0':\n if timetask_obj.run_status:\n timetask_obj.run_status = False\n timetask_obj.save()\n if timetask_obj.is_send_email:\n send_monitor_email(str(timetask_obj.email).split(','), str(host), str(cmd).split()[-1], str(cmd), task_name, str(p.wait()))\n elif str(p.wait()) == '0' and not timetask_obj.run_status:\n timetask_obj.run_status = True\n timetask_obj.save()\n if data[0]:\n return ' '.join(data[0].split('\\n'))\n else:\n return u\"scripts normal running.\"\n except Exception as e:\n if timetask_obj.run_status:\n timetask_obj.run_status = False\n timetask_obj.save()\n send_monitor_email(str(timetask_obj.email).split(','), str(host), str(cmd).split()[-1], str(cmd), task_name, e)\n return e\n\n else:\n if timetask_obj.run_status:\n timetask_obj.run_status = False\n timetask_obj.save()\n send_monitor_email(str(timetask_obj.email).split(','), str(host), str(cmd).split()[-1], str(cmd), task_name, u\"config error!\")\n return \"localhost:%s The choice of your target machine is a problem!\" % settings.host_ip\n"
},
{
"alpha_fraction": 0.5341190099716187,
"alphanum_fraction": 0.547504723072052,
"avg_line_length": 35.173683166503906,
"blob_id": "aec34a9641b92856cff16e44433c839fc9a3f9a9",
"content_id": "34c9a5700d1203c69059f7002a3fac455800192d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6879,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 190,
"path": "/supply/rabbitmq_api.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\n\nimport urllib,urllib2\nimport simplejson\nimport base64\nfrom dev_task.celery import rabbitmq_password, rabbitmq_user,rabbitmq_host\n\n\nclass MQManage(object):\n def __init__(self):\n self._conn = None\n self._host = None\n self._username = None\n self._password = None\n self._vhost = '/'\n\n def create_connection(self,host,username,password):\n try:\n self._username = username\n self._password = password\n url = \"http://\"+host + \":15672/api/whoami\"\n self._host = \"http://\"+host\n userInfo = \"%s:%s\" % (username, password)\n userInfo = base64.b64encode(userInfo.encode('UTF-8'))\n auth = 'Basic ' + userInfo#必须的\n request = urllib2.Request(url)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', auth)\n response = urllib2.urlopen(request)\n self._conn = auth\n except Exception, e:\n return None\n\n def set_user_vhost(self, vhost='/', configure='.*', write='.*', read='.*'):\n try:\n url = self._host + ':15672/api/permissions/%2F/'\n url += self._username\n body = {}\n body['username'] = self._username\n body['vhost'] = vhost\n body['configure'] = configure\n body['write'] = write\n body['read'] = read\n data = simplejson.dumps(body)\n request = urllib2.Request(url, data)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n request.get_method = lambda: \"PUT\"\n opener = urllib2.build_opener(urllib2.HTTPHandler)\n response = urllib2.urlopen(request)\n res = response.read()\n return res\n except Exception, e:\n # print str(e)\n return None\n\n def list_users(self):\n try:\n url = self._host + \":15672/api/users\"\n request = urllib2.Request(url)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n response = urllib2.urlopen(request)\n return response.read()\n except Exception, e:\n return None\n\n def list_queues(self):\n try:\n url = self._host + \":15672/api/queues\"\n request = urllib2.Request(url)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n response = urllib2.urlopen(request)\n return response.read()\n except Exception, e:\n return None\n\n def list_exchanges(self):\n try:\n url = self._host + \":15672/api/exchanges\"\n request = urllib2.Request(url)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n response = urllib2.urlopen(request)\n exchanges = response.read()\n return exchanges\n except Exception, e:\n return None\n\n def list_connections(self):\n try:\n url = self._host + \":15672/api/connections\"\n request = urllib2.Request(url)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n response = urllib2.urlopen(request)\n exchanges = response.read()\n return exchanges\n except Exception, e:\n return None\n\n def show_connection_detail(self,connection):\n try:\n con = urllib.quote_plus( connection,safe='(,),' )\n url = self._host + ':15672/api/channels/'+ con\n url = url.replace('+','%20')\n request = urllib2.Request( url )\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n response = urllib2.urlopen(request)\n detail = response.read()\n return detail\n except Exception, e:\n print str(e)\n return None\n\n def clear_exchanges(self):\n exchanges = self.list_exchanges()\n for exchange in exchanges:\n self.del_exchange(exchange_name=exchange['name'])\n\n def clear_queues(self):\n queues = self.list_queues()\n for queue in queues:\n self.del_queue(queue_name=queue['name'])\n\n def del_exchange(self, exchange_name):\n try:\n url = self._host + ':15672/api/exchanges/%2F/'\n url += exchange_name\n body = {}\n body['vhost'] = self._vhost\n body['name'] = exchange_name\n data = simplejson.dumps(body)\n request = urllib2.Request(url, data)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n request.get_method = lambda: \"PUT\"\n opener = urllib2.build_opener(urllib2.HTTPHandler)\n response = urllib2.urlopen(request)\n res = response.read()\n return res\n except Exception, e:\n return None\n\n def del_queue(self, queue_name ):\n try:\n url = self._host + ':15672/api/queues/%2F/'\n url += queue_name\n body = {}\n body['vhost'] = self._vhost\n body['name'] = queue_name\n data = simplejson.dumps(body)\n request = urllib2.Request(url, data)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n request.get_method = lambda: \"DELETE\"\n opener = urllib2.build_opener(urllib2.HTTPHandler)\n response = urllib2.urlopen(request)\n res = response.read()\n return res\n except Exception, e:\n return None\n\n def add_vhost(self, vhost_name):\n try:\n url = self._host + \":15672/api/vhosts/\"\n url = url + vhost_name\n body = {}\n body['name'] = vhost_name\n data = simplejson.dumps(body)\n request = urllib2.Request(url, data)\n request.add_header('content-type', 'application/json')\n request.add_header('authorization', self._conn)\n request.get_method = lambda: \"PUT\"\n urllib2.build_opener(urllib2.HTTPHandler)\n response = urllib2.urlopen(request)\n res = response.read()\n return None\n except Exception, e:\n print str(e)\n return None\n\n\nif __name__ == '__main__':\n mq = MQManage()\n mq.create_connection(rabbitmq_host,rabbitmq_user, rabbitmq_password)\n queuelist = mq.list_queues()\n print queuelist\n"
},
{
"alpha_fraction": 0.5986038446426392,
"alphanum_fraction": 0.6108202338218689,
"avg_line_length": 26.549999237060547,
"blob_id": "714ba2f8a46395c10f75bddbeaad99f0b2bdb7a2",
"content_id": "69ad7cbbe50374f4579eb13626a6d1e076c56cfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 20,
"path": "/supply/email_send.py",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "# -*- coding:utf-8 -*-\r\n\r\nfrom django.core.mail import send_mail\r\nfrom datetime import datetime\r\nfrom dev_task.settings import DEFAULT_FROM_EMAIL\r\n\r\n\r\ndef send_monitor_email(email, host, scripts_name, detail, taskname, abnormal):\r\n\r\n email_title = u\"dev_task任务管理平台告警\"\r\n email_body = u\"\"\"\r\n 告警内容如下:\r\n 脚本主机:{0}\r\n 任务名称:{4}\r\n 脚本名称:{1}\r\n 详情:{2}\r\n 当前时间:{5}\r\n 异常:exit status {3}\r\n \"\"\".format(host, scripts_name, detail, abnormal, taskname, datetime.now())\r\n send_mail(email_title, email_body, DEFAULT_FROM_EMAIL, email)\r\n\r\n"
},
{
"alpha_fraction": 0.316798597574234,
"alphanum_fraction": 0.32612136006355286,
"avg_line_length": 43.421875,
"blob_id": "893d78eb3df44215fc16905209ce72d4c26b3da3",
"content_id": "4cd6fd0cab76d1993b4920c3205a5e968901933e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 5905,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 128,
"path": "/templates/task/job_list.html",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "{% extends \"base.html\" %}\n{% load mytags %}\n{% block content %}\n <div class=\"row\">\n <div class=\"col-md-12\">\n <!-- Horizontal Form -->\n <form action=\"{% url 'job_del' %}\" method=\"post\">\n {% csrf_token %}\n <div class=\"box box-info\">\n <div class=\"box-header with-border\">\n <h3 class=\"box-title\">任务列表</h3>\n </div>\n <div class=\"box-body\">\n <table id=\"job_table\" class=\"table table-bordered table-striped\">\n <div style=\"padding-left: 0;bottom: 5px;\" class=\"col-sm-12\">\n <div class=\"btn-group\">\n <button id=\"btn_add\" type=\"button\" class=\"btn btn-success\" onclick=\"window.location.href='{% url 'job_add' %}'\">添加任务\n </button>\n </div>\n </div>\n <thead>\n <tr>\n <th>\n <input type=\"checkbox\" onclick=\"checkAll(this, 'item1');\" />\n </th>\n <th>主机名称</th>\n <th>主机ip</th>\n <th>任务名称</th>\n <th>任务指令</th>\n <th>Crontab</th>\n <th>interval</th>\n <th>上次运行</th>\n <th>上次修改</th>\n <th>运行状态</th>\n <th>是否启用</th>\n{# <th>过期时间</th>#}\n <th>操作</th>\n </tr>\n </thead>\n <tbody>\n {% for job in jobs_info %}\n <tr class=\"even geade\">\n <td><input type=\"checkbox\" id=\"u_id\" class=\"item1\" value=\"{{ job.id }}\" name=\"job_check\" /></td>\n <td>{{ job.nice_name }}</td>\n <td>{{ job.host }}</td>\n <td><a href=\"#\"><li style=\"list-style-type:none\"> {{ job.name }}</li></a></td>\n <td>{{ job.kwargs|cmd2str }}</td>\n <td>{% if job.crontab_id %}{{ job.crontab_id|crontab2str }}{% endif %}</td>\n <td>{% if job.interval_id %}{{ job.interval_id|intervals2str }}{% endif %}</td>\n <td>{{ job.last_run_at|date:\"Y-m-d H:i:s\" }}</td>\n <td>{{ job.date_changed|date:\"Y-m-d H:i:s\" }}</td>\n{# <td>{{ job.expires|date:\"Y-m-d H:i:s\" }}</td>#}\n <td>\n {% ifequal job.run_status 1 %}\n <span class=\"label label-success\">计时中</span>\n {% else %}\n <span class=\"label label-default\">已停止</span>\n {% endifequal %}\n </td>\n <td>\n {% ifequal job.enabled 1 %}\n <span class=\"label label-success\">启用</span>\n {% else %}\n <span class=\"label label-default\">禁用</span>\n {% endifequal %}\n </td>\n <td class=\"text-center\">\n <a class=\"btn btn-sm btn-info\" onclick=\"return job_edit({{ job.id }})\">编辑</a>\n </td>\n </tr>\n {% endfor %}\n </tbody>\n </table>\n <div class=\"btn-group\">\n <button class=\"btn btn-danger\" style=\"width: 60pt;font-size: medium\" onclick=\"return checkSubmit()\"><b>删除</b></button>\n </div>\n </div>\n </div>\n </form>\n </div>\n </div>\n <input id=\"handle_status\" value=\"\" hidden=\"hidden\">\n{% endblock %}\n{% block scripts-files %}\n<script>\n $(function () {\n $('#job_table').DataTable({\n \"paging\": true,\n \"lengthChange\": true,\n \"searching\": true,\n \"ordering\": false,\n \"info\": true,\n \"autoWidth\": true\n });\n });\n</script>\n<script>\nfunction job_edit(n){\n layer.open({\n type: 2,\n title: ['修改任务信息','background-color:#408EBA;color:#FFFFFF;'],\n closeBtn: 1,\n area: ['700px', '550px'],\n //shade: [0.8,'#393D49'],\n shadeClose: true, //点击遮罩关闭\n content: ['/task/job/edit/' + n],\n end:function(){\n var handle_status = $(\"#handle_status\").val();\n if ( handle_status == '1' ) {\n layer.msg('保存成功!',{\n icon: 1,\n time: 2000 //2秒关闭(如果不配置,默认是3秒)\n },function(){\n history.go(0);\n });\n } else if ( handle_status == '2' ) {\n layer.msg('修改失败!',{\n icon: 2,\n time: 2000 //2秒关闭(如果不配置,默认是3秒)\n },function(){\n history.go(0);\n });\n }\n }\n });\n}\n</script>\n{% endblock %}"
},
{
"alpha_fraction": 0.6213592290878296,
"alphanum_fraction": 0.6407766938209534,
"avg_line_length": 16.25,
"blob_id": "6f1be5ccd6a12cf63bba042293af323b096f6ff0",
"content_id": "970c35d35d6fa17324f6057703ccfd05b21748ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 12,
"path": "/start_server.sh",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nset -e\n\ntrap \"kill -15 -1 && echo all proc killed\" TERM KILL INT\n\nif [ \"$1\" = \"start\" ]; then\n\t/usr/sbin/nginx\n\t/usr/bin/supervisord -c /etc/supervisord.conf\n\tsleep inf & wait\nelse\n\texec \"$@\"\nfi"
},
{
"alpha_fraction": 0.6805304288864136,
"alphanum_fraction": 0.7040385603904724,
"avg_line_length": 56.24137878417969,
"blob_id": "1a9d37a1b8e929f397d411adf4bb52a8163e7b16",
"content_id": "584ba10312b8c06aa11cc701e477646dbb056c30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1659,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 29,
"path": "/init.sh",
"repo_name": "Lovezhe4ever/dev_task",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ncd /opt/dev_task/\n\nsed -i \"s/host = 127.0.0.1/host = $MYSQL_HOST/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/port = 3306/port = $MYSQL_PORT/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/user = root/user = $MYSQL_USER/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/password = 123456/password = $MYSQL_PASS/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/database = dev_task/database = $MYSQL_DB/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/rabbitmq_host = 127.0.0.1/rabbitmq_host = $RA_HOST/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/rabbitmq_queue = 127.0.0.1/rabbitmq_queue = $RA_Q/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/rabbitmq_routing_key = 127.0.0.1/rabbitmq_routing_key = $RA_ROUTING_KEY/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/email_host = smtp.exmail.qq.com/email_host = $EM_HOST/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/email_port = 25/email_port = $EM_PORT/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/email_host_user = [email protected]/email_host_user = $EM_SEND_USER/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/email_host_password = 123456/email_host_password = $EM_PASS/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/default_email_user = [email protected],[email protected]/default_email_user = $DEFAULT_EM_ADDR/g\" /opt/dev_task/dev_task.conf\nsed -i \"s/host_ip = 127.0.0.1/host_ip = $LO_HOST/g\" /opt/dev_task/dev_task.conf\nsed -i \"s@command=/usr/local/bin/uwsgi@command=/usr/bin/uwsgi@\" /opt/dev_task/server_supervisord.conf\n\npython manage.py makemigrations\npython manage.py migrate\npython createsuperuser.py\n\n\\cp server_supervisord.conf /etc/supervisord.conf\nchmod 777 /opt/dev_task/static/ -R\ncp nginx.conf /etc/nginx/\nchmod +x /opt/dev_task/init.sh\nchmod +x /opt/dev_task/start_server.sh"
}
] | 15 |
norbert-grothe/Serial-Receiver
|
https://github.com/norbert-grothe/Serial-Receiver
|
04a21af4128e86a68e7c735e6a55a53f4cfec73e
|
3777efa2e7545b7276526147ebded964ddfb9ba4
|
9635166b1ae7cd5ba97d1aacd0d0e5304297727a
|
refs/heads/master
| 2020-03-30T01:54:27.164131 | 2018-09-27T14:34:01 | 2018-09-27T14:34:01 | 150,601,303 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5448079705238342,
"alphanum_fraction": 0.5647225975990295,
"avg_line_length": 23.241378784179688,
"blob_id": "cf27b00224e5f97b9ebe5cf58d617d05ef91decb",
"content_id": "781eb18ffd0b740cf1d6d9df80c3ba8df8bc0418",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 703,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 29,
"path": "/receiver.py",
"repo_name": "norbert-grothe/Serial-Receiver",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\nimport serial\nimport time\nimport threading\n\nSERIAL_PORT = '/dev/ttyAMA0'\nSERIAL_BAUDRATE = 9600\n\n\nclass UART_Receiver(threading.Thread):\n def __init__(self):\n threading.Thread.__init__(self)\n self.sp = serial.Serial(SERIAL_PORT, SERIAL_BAUDRATE, timeout=1)\n\n def readSerial(self):\n return self.sp.readline().replace(\"\\n\", str(0x17))\n\n def run(self):\n self.sp.reset_input_buffer()\n while True: \n if (self.sp.in_waiting > 0): \n data = self.readSerial()\n print(data)\n time.sleep(.500)\n \nif __name__ == '__main__':\n sp = UART_Receiver()\n #sp.daemon = True\n sp.start()\n"
}
] | 1 |
jacoduplessis/regex
|
https://github.com/jacoduplessis/regex
|
e79490e962862fb27f6f333ad5da96daab7c750e
|
142f57fab9504f5ec14b594f8579ab8eb0c9ffaa
|
e569bee0ae4de0a59bcb87014f69b4c33a55c7a7
|
refs/heads/master
| 2021-06-30T10:00:52.428093 | 2017-09-23T00:51:17 | 2017-09-23T00:51:17 | 104,530,215 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7233009934425354,
"alphanum_fraction": 0.7572815418243408,
"avg_line_length": 24.875,
"blob_id": "595a19b9dc39bc33f917027d2de0633ca68b1346",
"content_id": "6b89bda086eab2ebe9abeab55f953d5084eab4f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 8,
"path": "/readme.md",
"repo_name": "jacoduplessis/regex",
"src_encoding": "UTF-8",
"text": "# Regex Python\n\nSimple app to test python regular expressions, inspired by regex101.com, with\nthe difference that the regexes are actually run on python.\n\n```\npython app.py # open http://localhost:8000\n```"
},
{
"alpha_fraction": 0.5629470944404602,
"alphanum_fraction": 0.5772532224655151,
"avg_line_length": 29.39130401611328,
"blob_id": "0f6026223eb74ff9c48b8dd5c47b56555166a9b4",
"content_id": "e76d5716058006a454125c836bbf7203f37c96da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1398,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 46,
"path": "/app.py",
"repo_name": "jacoduplessis/regex",
"src_encoding": "UTF-8",
"text": "from wsgiref.simple_server import make_server\nfrom string import Template\nimport json\nimport re\n\nwith open('templates/index.html', 'r') as html:\n template = Template(html.read())\n\n\ndef regex_app(environ, start_response):\n method = environ.get('REQUEST_METHOD')\n if method == \"GET\":\n status = '200 OK'\n headers = [('Content-type', 'text/html; charset=utf-8')]\n start_response(status, headers)\n\n context = {\n \"name\": \"Python Regex\",\n }\n\n return [template.substitute(context).encode('utf-8')]\n\n if method == \"POST\":\n\n request_body_size = int(environ.get('CONTENT_LENGTH', 0))\n data = json.loads(environ.get('wsgi.input').read(request_body_size))\n regex = eval(\"r\\\"\" + data.get('regex', '') + \"\\\"\")\n test = data.get('test', '')\n sub = eval(\"r\\\"\" + data.get('replace', '') + \"\\\"\")\n\n matches = re.findall(regex, test, re.MULTILINE)\n replaced = re.sub(regex, sub, test, 0, re.MULTILINE)\n\n status = '200 OK'\n headers = [('Content-type', 'application/json; charset=utf-8')]\n start_response(status, headers)\n result = {\n \"matches\": matches,\n \"replaced\": replaced,\n }\n return [json.dumps(result).encode('utf-8')]\n\n\nwith make_server('', 8000, regex_app) as httpd:\n print(\"Serving HTTP on port 8000...\")\n httpd.serve_forever()\n"
}
] | 2 |
SE-gmentation/yumyumgood_subgroup3
|
https://github.com/SE-gmentation/yumyumgood_subgroup3
|
418c4bb15f84e91b26ed31b9177dc93529564c85
|
2250ffcd8b0d6d352327f0885160366dbdf31fd3
|
52b774a2e3790243ec31f31e10c06b6ba1419dac
|
refs/heads/main
| 2023-05-11T05:51:58.528810 | 2021-05-31T13:16:28 | 2021-05-31T13:16:28 | 371,071,612 | 0 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5922330021858215,
"alphanum_fraction": 0.5922330021858215,
"avg_line_length": 9.8421049118042,
"blob_id": "a2ef8a37721757e5d02bdbc03bda5f7dcc930d7d",
"content_id": "91546e404d3f78f024fce20902016a161cb4e078",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "Markdown",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 19,
"path": "/.github/ISSUE_TEMPLATE/todo-issue-template.md",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "---\nname: todo issue template\nabout: for todo task\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n## todo 내용\n- [x] ex. \n- [x] ex.\n- [x] ex.\n\n## 해당 스크린샷\n\n## related issue\n\n## things to consider, personal feedback\n"
},
{
"alpha_fraction": 0.6030927896499634,
"alphanum_fraction": 0.617367148399353,
"avg_line_length": 30.936708450317383,
"blob_id": "d0d5fb9f9c499f7c0b6ccd239d191d64822c6dce",
"content_id": "93deaddba9cbf88665dbedd4f629089a85d2a4ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Kotlin",
"length_bytes": 2786,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 79,
"path": "/YumyumgoodApp/app/src/main/java/com/example/yumyumgoodapp/OrderHistory.kt",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "package com.example.yumyumgoodapp\n\nimport android.content.Intent\nimport android.os.Bundle\nimport android.widget.TextView\nimport android.widget.Toast\nimport androidx.appcompat.app.AppCompatActivity\nimport kotlinx.android.synthetic.main.order_history.*\n\nclass OrderHistory : AppCompatActivity() {\n\n override fun onCreate(savedInstanceState: Bundle?) {\n super.onCreate(savedInstanceState)\n setContentView(R.layout.order_history)\n\n val ddays : TextView = findViewById(R.id.days)\n val ddays2 : TextView = findViewById(R.id.days2)\n val ddays3 : TextView = findViewById(R.id.days3)\n val ddays4 : TextView = findViewById(R.id.days4)\n\n val passDays1 = ddays.text.toString().toInt()\n val passDays2 = ddays2.text.toString().toInt()\n val passDays3 = ddays3.text.toString().toInt()\n val passDays4 = ddays4.text.toString().toInt()\n\n btnWriteReview.setOnClickListener{\n val intent = Intent(this, WriteReview::class.java)\n startActivity(intent)\n }\n\n\n /**Domain Model 의 Concept : 카운터, 리뷰 작성 가능 여부 확인을 위해 경과일 체크*/\n\n if (passDays1 > 3){\n msg_pass.text = \"리뷰 작성 가능 기간이 지났습니다.\"\n btnWriteReview.isEnabled = false\n }\n else\n btnWriteReview.isEnabled = true\n\n if (passDays2 > 3){\n msg_pass2.text = \"리뷰 작성 가능 기간이 지났습니다.\"\n btnWriteReview2.isEnabled = false\n }\n else\n btnWriteReview2.isEnabled = true\n\n if (passDays3 > 3){\n msg_pass3.text = \"리뷰 작성 가능 기간이 지났습니다.\"\n btnWriteReview3.isEnabled = false\n }\n else\n btnWriteReview3.isEnabled = true\n\n if (passDays4 > 3){\n msg_pass4.text = \"리뷰 작성 가능 기간이 지났습니다.\"\n btnWriteReview4.isEnabled = false\n }\n else\n btnWriteReview4.isEnabled = true\n\n btnViewBuilding.setOnClickListener{\n val intent = Intent(this, ViewBuilding::class.java)\n startActivity(intent)\n }\n\n btnWriteReview2.setOnClickListener {\n Toast.makeText(this@OrderHistory, \"주문 후 3일 이내만 리뷰를 작성할 수 있습니다.\", Toast.LENGTH_LONG).show()\n }\n btnWriteReview3.setOnClickListener {\n Toast.makeText(this@OrderHistory, \"주문 후 3일 이내만 리뷰를 작성할 수 있습니다.\", Toast.LENGTH_LONG).show()\n }\n btnWriteReview4.setOnClickListener {\n Toast.makeText(this@OrderHistory, \"주문 후 3일 이내만 리뷰를 작성할 수 있습니다.\", Toast.LENGTH_LONG).show()\n }\n\n\n }\n}"
},
{
"alpha_fraction": 0.6073041558265686,
"alphanum_fraction": 0.6868250370025635,
"avg_line_length": 43.66666793823242,
"blob_id": "56ddb2827ba344e65bcb36ccd8bde542b810d229",
"content_id": "90cb0af084011fa11bce5c9ee638d766539fc35b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8480,
"license_type": "no_license",
"max_line_length": 530,
"num_lines": 114,
"path": "/README.md",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "## 📢 SubGroup 3\n\n- 주제 소개 \n - 식당 이용자의 리뷰 관련 기능 주제를 맡은 SUBGROUP3 박지수[jisoo-o](https://github.com/jisoo-o/)/이주연[2JooYeon](https://github.com/2JooYeon) 입니다. \n - 총 5가지의 USE-CASE 중 UC-2, UC-4의 기능을 구현하였고, UC-3, UC-5는 부분적으로 구현하였습니다. \n - UC-2 : 학식 건물 별 평점 확인\n - UC-4 : 리뷰 작성\n - (UC-3 : 리뷰 확인, UC-5 : 주문 내역 )\n\n\n- 개발한 기능 \n - 식당 이용자의 주문 내역 열람, 리뷰 작성 기능 구현\n - opinion mining을 이용한 리뷰의 긍정 또는 부정 확률 계산 기능 구현 \n\n<br/>\n\n## 🔨 Tech stacks & Language\n\n\n- Kotlin, Java, Python3\n- Android Studio\n- Tensorflow, Mecab\n\n<br/>\n\n## 🔎 Getting Started\n\nDefault. Clone this repository\n\n ```bash\n $ git clone https://github.com/SE-gmentation/yumyumgood_subgroup3\n ```\n \n- Android App 실행 방법\n\n1. Change the directory \n\n ```bash\n $ cd YumyumgoodApp\n ```\n\n2. Open with Android studio and run AVD emulator\n<br/>\n\n- 리뷰 감정 분석 실행 방법\n\n1. Change the directory\n\n ```bash\n $ cd Review_SentimentAnalysis\n ```\n2. Open **Sentiment_analysis.ipynb** with Google Colab\n<br/>\n\n\n## 📸 Features & Demo Screenshot\n \n\n- **( UC-5 ) 주문 내역 열람**\n - 식당 이용자의 주문 내역을 시간 순으로 정렬하여 보여준다. 주문 내역은 학식당, 주문한 메뉴, 결제 금액, 경과일을 포함한다. \n각 내역 별 3개의 버튼, 1.리뷰 작성 2.주문 상세 3.식당 보기 가 존재한다. 리뷰 작성 버튼은 *Domain Model 의 concept \"카운터\"* 가 작용한다. \n주문한지 3일이 지나면 버튼이 비활성화되어 리뷰를 작성할 수 없고 작성 기간을 경과하였음을 알린다.</br> \n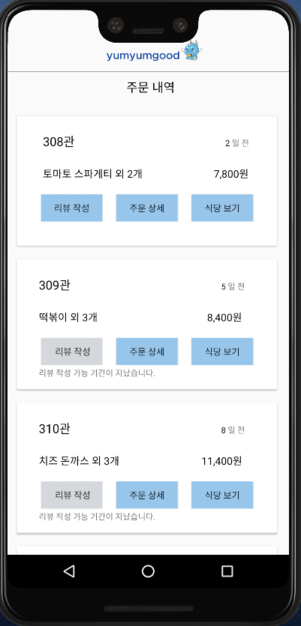 \n \n---\n\n- **( UC-4 ) 리뷰 작성**\n - 식당 이용자는 주문한 각 메뉴에 대하여 추천 여부를 버튼을 통해 남기고, 메뉴와 식당 시설에 대한 전반적인 리뷰를 최소 5자 최대 300자 내로 남길 수 있다. *Domain Model 의 concept \"리뷰 당위성 확인\"* 이 모든 메뉴에 대한 추천 여부를 선택하였는지와 글자수 조건을 만족하였는지 확인하여 리뷰 제출을 가능하게 해준다. 글자수는 changeListener를 이용하여 실시간으로 반영된다. \n조건을 만족하지 못하면 case 1. 추천 여부 미선택 시 dialog 안내, case 2. 최소 5자 이상 작성하지 않았을 시 dialog 안내, case 3. 300자 초과 시 입력 불가로 조건 만족을 유도한다.</br> \n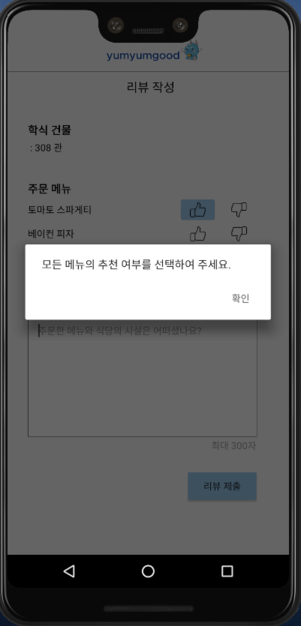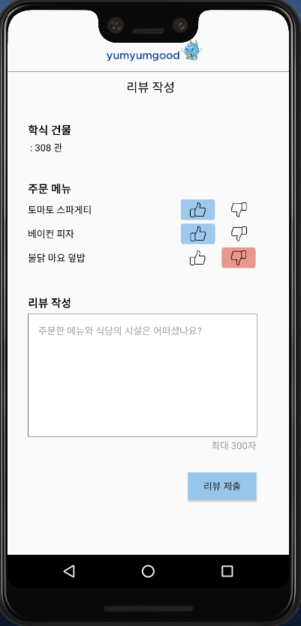 \n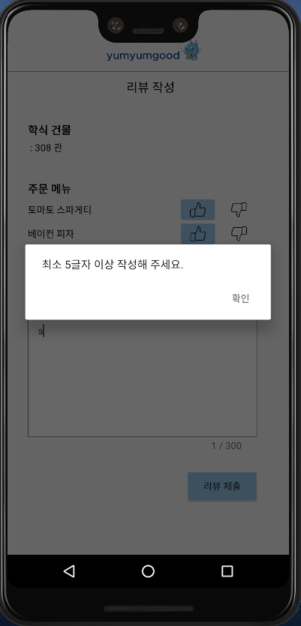\n\n\n---\n\n- **( UC-2, 3 ) 식당 보기 : 식당 평점 및 다른 이용자의 리뷰**\n - 식당 이용자는 다른 이용자들이 해당 학식당에 남긴 리뷰들과 그로부터 계산된 총점을 한눈에 확인할 수 있다. 리뷰 평점 계산은 opinion mining을 통해 이루어진다. 사용자가 남긴 리뷰는 긍정 또는 부정의 리뷰로 구분지어진다. 이때 구분의 정확도로 확률이 함께 계산되는데 해당 확률을 가중치로 리뷰는 수치화 된다. 예를 들어 확률의 10퍼센트 단위로 단계를 나누어 단계별로 부여하는 점수를 다르게 줄 수도 있을 것이다. 긍정 리뷰의 90퍼센트 이상은 10점으로, 80-90퍼센트는 9점.. 또는 부정 리뷰의 90퍼센트 이상은 1점으로, 80-90퍼센트는 2점.. 등의 방식으로 치환하는 과정을 거칠 수 있을 것이다. 특정 학식 건물의 모든 리뷰가 수치화되면 전체 리뷰의 수치화된 점수의 총합을 전체 리뷰 개수로 나눈 평균을 계산할 수 있을 것이다. 해당 평균점수의 구간에 따라 \"최고에요\", \"맛있어요\", \"아쉬워요\" 등의 문구로 식당의 평점을 나타낼 수 있고, 해당 문구는 사용자가 보는 앱 페이지에 뜨게 된다.</br> \n \n\n---\n\n- **( UC-2 ) 학식 건물별 평점 확인**\n - 사용자가 작성한 리뷰는 opinion mining을 이용하여 몇 퍼센트의 확률로 긍정 또는 부정의 리뷰인지 구분된다. 리뷰 감정분석을 위한 데이터를 얻기 위해 네이버의 맛집 리뷰를 selenium을 이용해서 동적으로 크롤링 했다. 총 14군데의 식당의 리뷰를 크롤링한 결과로 대략 9500개의 데이터가 생성되었다. 네이버 리뷰에서 리뷰 텍스트 뿐만 아니라 작성자가 남긴 평점도 크롤링하였는데, 평점이 4, 5인 리뷰들에 긍정을 의미하는 레이블 1을 부여하고, 평점이 1, 2인 리뷰들에 부정을 의미하는 레이블 0을 부여하여 감성 분류를 수행하는 모델을 만들었다. 참고로 3점인 리뷰는 긍정과 부정을 확고히 나누기 애매하다고 생각하여 제외했다. \n - 형태소 분석기로는 Mecab을 사용하였고, 본인의 노트북에 설치하는데에 오류가 있어서 편리하게 사용하기 위해 Google Colab을 이용해서 설치했다.\n - 리뷰 기반의 감정 분석을 하기 위해 GRU 모델을 이용했다. \n - 아래 사진은 사용자가 리뷰를 입력했다고 가정하고, 감정 분석의 결과를 테스트한 결과이다. </br> \n\n\n - 아래 사진은 selenium을 이용해서 평점과 리뷰텍스트를 크롤링한 결과의 일부이다. </br> \n\n\n---\n\n## 📍 SSD(Class Diagram) 대조표\n\n> | 클래스명(함수명) | SSD 내 컨셉(클래스)이름 |\n> | --- | --- |\n> |**Sentiment_analysis.ipynb** | 리뷰수치화 (UC-2 학식 건물 별 평점확인)|\n> |**class OrderHistory - btnWriteReview.isEnabled** | 카운터 (UC-4 리뷰 작성)|\n> |**class WriteReview - submit_button.setOnClickListener, write_review.addTextChangedListener** | 리뷰 당위성 확인 (UC-4 리뷰 작성)|\n> |**class WriteReview - showDialog()** | 디스플레이 (UC-4 리뷰 작성)|\n> |**class WriteReview - showErrorDialog(), showSelectLike()** | 예외페이지 생성 (UC-4 리뷰 작성)|\n> |**class ViewBuilding** | (UC-3 리뷰 확인)|\n> |**class OrderHistory** | (UC-5 주문내역 확인)|\n \n<br/>\n\n## 💻 참고사항\n- 코드 작업 위치 : yumyumgood_subgroup3 respository\n- 추후 안드로이드 앱 식당보기 뷰에서 리뷰 감정분석 알고리즘의 결과값을 확인할 수 있도록 연동하여 구현할 예정 \n<br/>\n\n## 🤣 개선사항\n- 사용자가 작성한 리뷰를 감정분석하기 위한 opinion mining에서 기계학습을 위한 데이터로 네이버 맛집 리뷰를 크롤링 해서 이용했는데, 긍정 레이블인 1에 대응하는 리뷰의 수와 부정 레이블인 0에 대응하는 리뷰의 수 차이의 불균형이 심했기 때문에 이를 해결하기 위해 수가 더 적은 부정 레이블에 해당하는 리뷰의 수를 기준으로 샘플링을 진행해서 데이터의 수가 줄어드는 결과가 발생했다. 데이터의 수가 줄어들다 보니 학습에 충분한 데이터가 돌아가지 못했고 그에 따라 정확도가 떨어지는 결과를 가져왔다. 따라서 추후에 긍정과 부정의 리뷰가 균형적으로 존재하는 대량의 데이터를 기반으로 학습시킨다면, 알고리즘의 정확도를 높일 수 있을 것이라고 기대한다. \n"
},
{
"alpha_fraction": 0.7599999904632568,
"alphanum_fraction": 0.7599999904632568,
"avg_line_length": 24.5,
"blob_id": "bf031456110acb3388e188d135472e972ad378e6",
"content_id": "d02e104fdaecf1ebef568bc597e4a1a55d929020",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Gradle",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 2,
"path": "/YumyumgoodApp/settings.gradle",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "include ':app'\nrootProject.name = \"Yumyumgood App\""
},
{
"alpha_fraction": 0.5522664189338684,
"alphanum_fraction": 0.6632747650146484,
"avg_line_length": 28.243244171142578,
"blob_id": "d22bb3544f5e456f96b89e1a71c2d98a1ac51741",
"content_id": "fd9ca6070ac4ed82b4824d801f682d9fb64d6312",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1081,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 37,
"path": "/Review_SentimentAnalysis/review_crawler.py",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport time\n\nfile_name = 'restaurant_review'\n\nurl_front = \"https://pcmap.place.naver.com/restaurant/\"\nurl_back = \"/review/visitor\"\n\nrestaurant_list = [13575119, 36406716, 13574931, 18714649, 1728322688, 19769179, 1003725520, 36208511, 36183674, 12890044, 11819292, 36813148, 37221619, 11679660]\ncontents = []\ndriver = webdriver.Chrome('./chromedriver')\n\nf = open(f'{file_name}.txt', 'w')\n\nfor restaurant in restaurant_list:\n driver.implicitly_wait(5)\n driver.get(url_front + str(restaurant) + url_back)\n while True:\n try:\n more = driver.find_element_by_class_name(\"_3iTUo\")\n more.click()\n time.sleep(2)\n except:\n break\n\n scores = driver.find_elements_by_class_name(\"_2tObC\")\n reviews = driver.find_elements_by_class_name(\"WoYOw\")\n scores = map(lambda x: x.text, scores)\n reviews = map(lambda x: x.text, reviews)\n contents.append(list(zip(scores, reviews)))\n\n\nfor content in contents:\n for score, review in content:\n f.write(f\"{score}\\t{review}\\n\")\n\nf.close()"
},
{
"alpha_fraction": 0.5523721575737,
"alphanum_fraction": 0.5599198937416077,
"avg_line_length": 33.721923828125,
"blob_id": "50ff686e7bfdf313f57c069f649879d137b26d6b",
"content_id": "8b96f63a380d0b3df2044265af511c87f65669e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6792,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 187,
"path": "/YumyumgoodApp/app/src/main/java/com/example/yumyumgoodapp/WriteReview.java",
"repo_name": "SE-gmentation/yumyumgood_subgroup3",
"src_encoding": "UTF-8",
"text": "package com.example.yumyumgoodapp;\n\nimport android.content.Context;\nimport android.content.DialogInterface;\nimport android.os.Bundle;\nimport android.text.Editable;\nimport android.text.TextWatcher;\nimport android.view.View;\nimport android.view.inputmethod.InputMethodManager;\nimport android.widget.Button;\nimport android.widget.EditText;\nimport android.widget.ImageButton;\nimport android.widget.TextView;\nimport android.widget.Toast;\n\nimport androidx.appcompat.app.AlertDialog;\nimport androidx.appcompat.app.AppCompatActivity;\n\n\npublic class WriteReview extends AppCompatActivity {\n\n EditText write_review;\n TextView count_letter;\n Button submit_button;\n ImageButton btnLike1;\n ImageButton btnDislike1;\n ImageButton btnLike2;\n ImageButton btnDislike2;\n ImageButton btnLike3;\n ImageButton btnDislike3;\n\n int like = 0;\n int dislike = 0;\n\n @Override\n protected void onCreate(Bundle savedInstanceState) {\n super.onCreate(savedInstanceState);\n setContentView(R.layout.write_review);\n\n write_review = (EditText) findViewById(R.id.writer);\n count_letter = (TextView) findViewById(R.id.counter);\n submit_button= (Button) findViewById(R.id.submit_review);\n\n btnLike1 = (ImageButton) findViewById(R.id.like1);\n btnDislike1 = (ImageButton) findViewById(R.id.dislike1);\n btnLike2 = (ImageButton) findViewById(R.id.like2);\n btnDislike2 = (ImageButton) findViewById(R.id.dislike2);\n btnLike3 = (ImageButton) findViewById(R.id.like3);\n btnDislike3 = (ImageButton) findViewById(R.id.dislike3);\n\n btnLike1.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike1.setSelected(true);\n btnDislike1.setSelected(false);\n like ++;\n }\n });\n\n btnDislike1.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike1.setSelected(false);\n btnDislike1.setSelected(true);\n dislike ++;\n }\n });\n btnLike2.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike2.setSelected(true);\n btnDislike2.setSelected(false);\n like ++;\n }\n });\n\n btnDislike2.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike2.setSelected(false);\n btnDislike2.setSelected(true);\n dislike ++;\n }\n });\n btnLike3.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike3.setSelected(true);\n btnDislike3.setSelected(false);\n like ++;\n }\n });\n\n btnDislike3.setOnClickListener(new View.OnClickListener() {\n @Override\n public void onClick(View view) {\n btnLike3.setSelected(false);\n btnDislike3.setSelected(true);\n dislike ++;\n }\n });\n\n\n /**Domain Model 의 Concept : 리뷰 당위성 확인*/\n submit_button.setOnClickListener(new View.OnClickListener(){\n @Override\n public void onClick(View v) {\n String input = write_review.getText().toString();\n if (input.length() < 6) /**case 2. 최소 5자 이상 작성하지 않았을 시 dialog 안내*/\n showErrorDialog() ;\n if (like + dislike < 3) /**case 1. 추천 여부 미선택 시 dialog 안내*/\n showSelectLike();\n if (input.length() > 5 && like + dislike > 2) /**모두 만족하였을 경우 당위성 테스트 통과 -> 리뷰 제출 가능*/\n showDialog() ;\n }\n });\n\n\n /** 리뷰 당위성 확인 컨셉이 사용하는 글자수 체크 함수*/\n write_review.addTextChangedListener(new TextWatcher() {\n @Override\n public void beforeTextChanged(CharSequence s, int start, int count, int after) {\n\n }\n\n @Override\n public void onTextChanged(CharSequence s, int start, int before, int count) {\n String input = write_review.getText().toString();\n count_letter.setText(input.length()+\" / 300 \");\n }\n\n @Override\n public void afterTextChanged(Editable s) {\n\n }\n });\n }\n\n\n void showDialog() {\n AlertDialog.Builder msgBuilder = new AlertDialog.Builder(WriteReview.this)\n .setMessage(\"리뷰를 제출 하시겠습니까? 소중한 의견 감사합니다.\")\n .setPositiveButton(\"제출\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n Toast.makeText(WriteReview.this, \"리뷰가 성공적으로 제출되었습니다.\", Toast.LENGTH_LONG).show();\n finish();\n }\n })\n .setNegativeButton(\"취소\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n\n }\n });\n AlertDialog msgDlg = msgBuilder.create();\n msgDlg.show();\n }\n\n void showErrorDialog() {\n AlertDialog.Builder msgBuilder = new AlertDialog.Builder(WriteReview.this)\n .setTitle(\"\")\n .setMessage(\"최소 5글자 이상 작성해 주세요.\")\n .setNegativeButton(\"확인\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n\n }\n });\n AlertDialog msgErrDlg = msgBuilder.create();\n msgErrDlg.show();\n }\n\n void showSelectLike() {\n AlertDialog.Builder msgBuilder = new AlertDialog.Builder(WriteReview.this)\n .setTitle(\"\")\n .setMessage(\"모든 메뉴의 추천 여부를 선택하여 주세요.\")\n .setNegativeButton(\"확인\", new DialogInterface.OnClickListener() {\n @Override\n public void onClick(DialogInterface dialogInterface, int i) {\n\n }\n });\n AlertDialog msgErrDlg = msgBuilder.create();\n msgErrDlg.show();\n }\n}"
}
] | 6 |
Mattaru/Signals-cache-django
|
https://github.com/Mattaru/Signals-cache-django
|
49ac5a7ff17edcd536269f845806accf14469f27
|
ec99e02094215631f29002413ec4903971f281fb
|
e457b25af36c5daaa55c4491bae09c89bdb4d195
|
refs/heads/main
| 2023-01-11T12:43:14.905724 | 2020-11-19T12:28:37 | 2020-11-19T12:28:37 | 314,233,155 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.8131868243217468,
"avg_line_length": 59.66666793823242,
"blob_id": "93f60effedd1108c82e1d4b54ff14558e4b00f06",
"content_id": "45ae46866f494ea81f27b84a835321707b9dd202",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 584,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Mattaru/Signals-cache-django",
"src_encoding": "UTF-8",
"text": "Проект выложен на Heroku и синхронизирован с GitHub репозиторием\n#### http://django-signals.herokuapp.com/\n\nДля того что бы просмотреть закэшированную страничку:\n1. Можете перейти по основной ссылке проекта и оттуда, при нажатии соответсвующего пункта, попасть на страничку с кэшированием.\n1. Перейти по следующему адресу http://django-signals.herokuapp.com/home/\n"
},
{
"alpha_fraction": 0.5709571242332458,
"alphanum_fraction": 0.6083608269691467,
"avg_line_length": 32.66666793823242,
"blob_id": "016cff5579d3a25eab14b2f3e08f0d672f69f21e",
"content_id": "5b087e6608acfe907c368935c3d7e6039a806a3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 27,
"path": "/tasks/migrations/0003_auto_20201113_1723.py",
"repo_name": "Mattaru/Signals-cache-django",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.10 on 2020-11-13 17:23\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tasks', '0002_auto_20201113_1257'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='PriorityCounter',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('priority', models.PositiveIntegerField(default=0)),\n ('counter', models.PositiveIntegerField(default=0)),\n ],\n ),\n migrations.AddField(\n model_name='todoitem',\n name='priority_counter',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, related_name='prior_counter', to='tasks.PriorityCounter'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.4563106894493103,
"alphanum_fraction": 0.4805825352668762,
"avg_line_length": 17.81818199157715,
"blob_id": "0952bd2e1a000526b214659bb34156e99bf28a40",
"content_id": "64a11c2fc13e960b0275ab5d53c7007c1d950853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 11,
"path": "/tasks/templates/tasks/home.html",
"repo_name": "Mattaru/Signals-cache-django",
"src_encoding": "UTF-8",
"text": "{% extends 'base.html' %}\n\n{% block title %}{% endblock %}\n\n{% block main_content %}\n <div>\n <h2>Дата с кэшем на 5 минут</h2>\n <br>\n <h4>{{ datetime }}</h4>\n </div>\n{% endblock %}"
},
{
"alpha_fraction": 0.6877880096435547,
"alphanum_fraction": 0.6927803158760071,
"avg_line_length": 29.26744270324707,
"blob_id": "41bf0e2c24355e13caa821ca73a036307d1213ff",
"content_id": "4f30fc6eaf567b3ecfa5be583f0620a99527ec0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2604,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 86,
"path": "/tasks/signals.py",
"repo_name": "Mattaru/Signals-cache-django",
"src_encoding": "UTF-8",
"text": "from django.db.models.signals import (\n m2m_changed,\n pre_save,\n post_save,\n pre_delete,\n post_delete,\n)\nfrom django.dispatch import receiver\n\nfrom tasks.models import (\n TodoItem,\n Category,\n PriorityCounter,\n)\n\n\n@receiver(m2m_changed, sender=TodoItem.category.through)\ndef task_cats_preadded(sender, instance, action, model, **kwargs):\n if action != \"pre_add\":\n return\n\n for cat in instance.category.all():\n new_count = cat.todos_count - 1\n Category.objects.filter(slug=cat.slug).update(todos_count=new_count)\n\n\n@receiver(m2m_changed, sender=TodoItem.category.through)\ndef task_cats_added(sender, instance, action, model, **kwargs):\n if action != \"post_add\":\n return\n\n for cat in instance.category.all():\n new_count = cat.todos_count + 1\n Category.objects.filter(slug=cat.slug).update(todos_count=new_count)\n\n\n@receiver(m2m_changed, sender=TodoItem.category.through)\ndef task_cats_preremoved(sender, instance, action, model, **kwargs):\n if action != \"pre_remove\":\n return\n\n for cat in instance.category.all():\n new_count = cat.todos_count - 1\n Category.objects.filter(slug=cat.slug).update(todos_count=new_count)\n\n\n@receiver(m2m_changed, sender=TodoItem.category.through)\ndef task_cats_removed(sender, instance, action, model, **kwargs):\n if action != \"post_remove\":\n return\n\n for cat in instance.category.all():\n new_count = cat.todos_count + 1\n Category.objects.filter(slug=cat.slug).update(todos_count=new_count)\n\n\n@receiver(pre_delete, sender=TodoItem)\ndef task_cats_delete(sender, instance, **kwargs):\n for cat in instance.category.all():\n cat.todos_count -= 1\n cat.save()\n\n\n@receiver(pre_save, sender=TodoItem)\ndef priority_counter_preadded(sender, instance, **kwargs):\n if instance.id is None:\n pass\n else:\n previous = TodoItem.objects.get(id=instance.id)\n previous_counter = PriorityCounter.objects.filter(priority=previous.priority).first()\n previous_counter.counter -= 1\n previous_counter.save()\n\n\n@receiver(post_save, sender=TodoItem)\ndef priority_counter_added(sender, instance, **kwargs):\n instance.priority_counter, created = PriorityCounter.objects.get_or_create(priority=instance.priority)\n instance.priority_counter.counter += 1\n instance.priority_counter.save()\n\n\n@receiver(post_delete, sender=TodoItem)\ndef priority_counter_deleted(sender, instance, **kwargs):\n active = PriorityCounter.objects.filter(priority=instance.priority).first()\n active.counter -= 1\n active.save()\n\n"
}
] | 4 |
TRomijn/MBDM-project
|
https://github.com/TRomijn/MBDM-project
|
27b4076940db731d84eda9ea4ad66e1034863780
|
3d1583317c75e749f3c4c912f06b899570418c37
|
f59c9ca68a1065215f7c4fe59ee604c264cc1c1f
|
refs/heads/master
| 2020-12-30T16:02:58.833427 | 2017-06-16T09:26:07 | 2017-06-16T09:26:07 | 90,959,174 | 0 | 2 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5689558982849121,
"alphanum_fraction": 0.5752372741699219,
"avg_line_length": 18.84487533569336,
"blob_id": "e0dfebc36483fd687657201a9e87c3c35bea2c5a",
"content_id": "5a8f41f37c054e0d37da64295158a93ad6b69314",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7164,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 361,
"path": "/final assignment/model/SEIR or SIR 20170501.py",
"repo_name": "TRomijn/MBDM-project",
"src_encoding": "UTF-8",
"text": "\"\"\"\nPython model model/SEIR or SIR 20170501.py\nTranslated using PySD version 0.7.4\n\"\"\"\nfrom __future__ import division\nimport numpy as np\nfrom pysd import utils\nimport xarray as xr\n\nfrom pysd.functions import cache\nfrom pysd import functions\n\n_subscript_dict = {}\n\n_namespace = {\n 'TIME': 'time',\n 'Time': 'time',\n 'Average incubation time': 'average_incubation_time',\n 'Average infectious period': 'average_infectious_period',\n 'Basic reproduction number': 'basic_reproduction_number',\n 'Case fatality rate': 'case_fatality_rate',\n 'Deceased population': 'deceased_population',\n 'Dying': 'dying',\n 'Exposed population': 'exposed_population',\n 'Fraction susceptible population': 'fraction_susceptible_population',\n 'Incubation': 'incubation',\n 'Infecting': 'infecting',\n 'Infectious population': 'infectious_population',\n 'Initial deceased population': 'initial_deceased_population',\n 'Initial exposed population': 'initial_exposed_population',\n 'Initial infectious population': 'initial_infectious_population',\n 'Initial recovered population': 'initial_recovered_population',\n 'Initial susceptible population': 'initial_susceptible_population',\n 'Recovered population': 'recovered_population',\n 'Surviving': 'surviving',\n 'Susceptible population': 'susceptible_population',\n 'Switch SEIR or SIR': 'switch_seir_or_sir',\n 'Total population': 'total_population',\n 'FINAL TIME': 'final_time',\n 'INITIAL TIME': 'initial_time',\n 'SAVEPER': 'saveper',\n 'TIME STEP': 'time_step'\n}\n\n\n@cache('run')\ndef average_incubation_time():\n \"\"\"\n Average incubation time\n -----------------------\n (average_incubation_time)\n Day\n\n \"\"\"\n return 2\n\n\n@cache('run')\ndef average_infectious_period():\n \"\"\"\n Average infectious period\n -------------------------\n (average_infectious_period)\n Day\n\n \"\"\"\n return 14\n\n\n@cache('run')\ndef basic_reproduction_number():\n \"\"\"\n Basic reproduction number\n -------------------------\n (basic_reproduction_number)\n Dmnl\n\n \"\"\"\n return 2\n\n\n@cache('run')\ndef case_fatality_rate():\n \"\"\"\n Case fatality rate\n ------------------\n (case_fatality_rate)\n Dmnl\n\n \"\"\"\n return 0.01\n\n\n@cache('step')\ndef deceased_population():\n \"\"\"\n Deceased population\n -------------------\n (deceased_population)\n Person\n\n \"\"\"\n return integ_deceased_population()\n\n\n@cache('step')\ndef dying():\n \"\"\"\n Dying\n -----\n (dying)\n Person/Day\n\n \"\"\"\n return case_fatality_rate() * infectious_population() / average_infectious_period()\n\n\n@cache('step')\ndef exposed_population():\n \"\"\"\n Exposed population\n ------------------\n (exposed_population)\n Person\n\n \"\"\"\n return integ_exposed_population()\n\n\n@cache('step')\ndef fraction_susceptible_population():\n \"\"\"\n Fraction susceptible population\n -------------------------------\n (fraction_susceptible_population)\n Dmnl\n\n \"\"\"\n return susceptible_population() / total_population()\n\n\n@cache('step')\ndef incubation():\n \"\"\"\n Incubation\n ----------\n (incubation)\n Person/Day\n\n \"\"\"\n return functions.if_then_else(switch_seir_or_sir() == 1,\n exposed_population() / average_incubation_time(), infecting())\n\n\n@cache('step')\ndef infecting():\n \"\"\"\n Infecting\n ---------\n (infecting)\n Person/Day\n\n \"\"\"\n return infectious_population() * basic_reproduction_number() * fraction_susceptible_population(\n ) / average_infectious_period()\n\n\n@cache('step')\ndef infectious_population():\n \"\"\"\n Infectious population\n ---------------------\n (infectious_population)\n Person\n\n \"\"\"\n return integ_infectious_population()\n\n\n@cache('run')\ndef initial_deceased_population():\n \"\"\"\n Initial deceased population\n ---------------------------\n (initial_deceased_population)\n Person\n\n \"\"\"\n return 0\n\n\n@cache('run')\ndef initial_exposed_population():\n \"\"\"\n Initial exposed population\n --------------------------\n (initial_exposed_population)\n Person\n\n \"\"\"\n return 0\n\n\n@cache('run')\ndef initial_infectious_population():\n \"\"\"\n Initial infectious population\n -----------------------------\n (initial_infectious_population)\n Person\n\n \"\"\"\n return 1\n\n\n@cache('run')\ndef initial_recovered_population():\n \"\"\"\n Initial recovered population\n ----------------------------\n (initial_recovered_population)\n Person\n\n \"\"\"\n return 0\n\n\n@cache('run')\ndef initial_susceptible_population():\n \"\"\"\n Initial susceptible population\n ------------------------------\n (initial_susceptible_population)\n Person\n\n \"\"\"\n return 100000\n\n\n@cache('step')\ndef recovered_population():\n \"\"\"\n Recovered population\n --------------------\n (recovered_population)\n Person\n\n \"\"\"\n return integ_recovered_population()\n\n\n@cache('step')\ndef surviving():\n \"\"\"\n Surviving\n ---------\n (surviving)\n Person/Day\n\n \"\"\"\n return (1 - case_fatality_rate()) * infectious_population() / average_infectious_period()\n\n\n@cache('step')\ndef susceptible_population():\n \"\"\"\n Susceptible population\n ----------------------\n (susceptible_population)\n Person\n\n \"\"\"\n return integ_susceptible_population()\n\n\n@cache('run')\ndef switch_seir_or_sir():\n \"\"\"\n Switch SEIR or SIR\n ------------------\n (switch_seir_or_sir)\n Dmnl [1,1,2]\n 1 = SEIR, ELSE = SIR\n \"\"\"\n return 0\n\n\n@cache('step')\ndef total_population():\n \"\"\"\n Total population\n ----------------\n (total_population)\n Person\n\n \"\"\"\n return susceptible_population() + exposed_population() + infectious_population(\n ) + recovered_population()\n\n\n@cache('run')\ndef final_time():\n \"\"\"\n FINAL TIME\n ----------\n (final_time)\n Day\n The final time for the simulation.\n \"\"\"\n return 360\n\n\n@cache('run')\ndef initial_time():\n \"\"\"\n INITIAL TIME\n ------------\n (initial_time)\n Day\n The initial time for the simulation.\n \"\"\"\n return 0\n\n\n@cache('step')\ndef saveper():\n \"\"\"\n SAVEPER\n -------\n (saveper)\n Day [0,?]\n The frequency with which output is stored.\n \"\"\"\n return time_step()\n\n\n@cache('run')\ndef time_step():\n \"\"\"\n TIME STEP\n ---------\n (time_step)\n Day [0,?]\n The time step for the simulation.\n \"\"\"\n return 0.125\n\n\ninteg_deceased_population = functions.Integ(lambda: dying(), lambda: initial_deceased_population())\n\ninteg_exposed_population = functions.Integ(lambda: infecting() - incubation(),\n lambda: initial_exposed_population())\n\ninteg_infectious_population = functions.Integ(lambda: incubation() - dying() - surviving(),\n lambda: initial_infectious_population())\n\ninteg_recovered_population = functions.Integ(lambda: surviving(),\n lambda: initial_recovered_population())\n\ninteg_susceptible_population = functions.Integ(lambda: -infecting(),\n lambda: initial_susceptible_population())\n"
},
{
"alpha_fraction": 0.5108225345611572,
"alphanum_fraction": 0.5381739735603333,
"avg_line_length": 67.6891860961914,
"blob_id": "395bbd8608817c2142df303ed1ed0d6f6bb75037",
"content_id": "59a125d39faacec0b7f85c3b480cbf35ab378d6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5082,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 74,
"path": "/Poster Assignment/Original Files/generate_data.py",
"repo_name": "TRomijn/MBDM-project",
"src_encoding": "UTF-8",
"text": "'''\n\n\n'''\nfrom __future__ import (unicode_literals, print_function, absolute_import,\n division)\n\nfrom ema_workbench import (RealParameter, IntegerParameter, ema_logging,\n ScalarOutcome, CategoricalParameter)\n\nfrom model_interface import WaasModel, SMALL, LARGE, XLARGE # @UnresolvedImport\nfrom ema_workbench.em_framework.parameters import Policy\nfrom ema_workbench.em_framework.evaluators import (MultiprocessingEvaluator, SequentialEvaluator,\n perform_experiments, PFF)\nfrom ema_workbench.util.utilities import save_results\n# Created on 1 Apr 2017\n#\n# .. codeauthor::jhkwakkel <j.h.kwakkel (at) tudelft (dot) nl>\n\npolicies = [{'params': {'RvR': '1', 'LandUseRvR': 'rundir\\\\landuservrsmall.pcr'}, 'name': 'RfR Small Scale'}, \n {'params': {'RvR': '2', 'LandUseRvR': 'rundir\\\\landuservrmed.pcr'}, 'name': 'RfR Medium Scale'}, \n {'params': {'RvR': '3', 'LandUseRvR': 'rundir\\\\landuservrlarge.pcr'}, 'name': 'RfR Large Scale'}, \n {'params': {'RvR': '4', 'LandUseRvR': 'rundir\\\\landuservrnev.pcr'}, 'name': 'RfR Side channel'}, \n {'params': {'MHW': 'rundir\\\\MHW500new.txt', 'MHWFactor': '1', 'DEMdijk': 'rundir\\\\dem7.pcr', 'OphoogMHW': '0.5'}, 'name': 'Dike 1:500 +0.5m'}, \n {'params': {'MHW': 'rundir\\\\MHW00new.txt', 'MHWFactor': '1', 'DEMdijk': 'rundir\\\\demlijn.pcr', 'OphoogMHW': '0'}, 'name': 'Dike 1:500 extr.'}, \n {'params': {'MHW': 'rundir\\\\MHW1000new.txt', 'MHWFactor': '1', 'DEMdijk': 'rundir\\\\dem7.pcr', 'OphoogMHW': '0.5'}, 'name': 'Dike 1:1000'}, \n {'params': {'MHW': 'rundir\\\\MHW00new.txt', 'MHWFactor': '1', 'DEMdijk': 'rundir\\\\demq20000.pcr', 'OphoogMHW': '0'}, 'name': 'Dike 1:1000 extr.'}, \n {'params': {'MHW': 'rundir\\\\MHW500jnew.txt', 'MHWFactor': '1.5', 'DEMdijk': 'rundir\\\\dem7.pcr', 'OphoogMHW': '0.5'}, 'name': 'Dike 2nd Q x 1.5'}, \n {'params': {'FragTbl': 'rundir\\\\FragTab50lsmSD.tbl'}, 'name': 'Dike Climate dikes'}, \n {'params': {'FragTbl': 'rundir\\\\FragTab50lsm.tbl'}, 'name': 'Dike Wave resistant'}, \n {'params': {'maxQLob': '20000'}, 'name': 'Coop Small'}, \n {'params': {'maxQLob': '18000'}, 'name': 'Coop Medium'}, \n {'params': {'maxQLob': '14000'}, 'name': 'Coop Large'}, \n {'params': {'DamFunctTbl': 'rundir\\\\damfunctionpalen.tbl', 'DEMterp': 'rundir\\\\dem7.pcr', 'StHouse': '0', 'FltHouse': '0', 'Terp': '0'}, 'name': 'DC Elevated'}, \n {'params': {'DamFunctTbl': 'rundir\\\\damfunction.tbl', 'DEMterp': 'rundir\\\\demdikelcity.pcr', 'StHouse': '0', 'FltHouse': '0', 'Terp': '0'}, 'name': 'DC Dikes'}, \n {'params': {'DamFunctTbl': 'rundir\\\\damfunction.tbl', 'DEMterp': 'rundir\\\\demterpini.pcr', 'StHouse': '0', 'FltHouse': '0', 'Terp': '1'}, 'name': 'DC Mounts'}, \n {'params': {'DamFunctTbl': 'rundir\\\\damfunctiondrijf.tbl', 'DEMterp': 'rundir\\\\dem7.pcr', 'StHouse': '0', 'FltHouse': '0', 'Terp': '0'}, 'name': 'DC Floating'},\n {'params': {'AlarmValue': 20}, 'name': 'Alarm Early'},\n {'params': {}, 'name': 'no policy'},\n {'params': {'AlarmEdu': 1}, 'name': 'Alarm Education'}\n ]\n\nif __name__ == '__main__':\n ema_logging.log_to_stderr(ema_logging.INFO)\n \n waas_model = WaasModel(\"waasmodel\", wd='./model')\n waas_model.uncertainties = [IntegerParameter(\"climate scenarios\", 1, 30, \n pff=True, resolution=[x for x in range(1, 31)]),\n RealParameter(\"fragility dikes\", -0.1, 0.1),\n RealParameter(\"DamFunctTbl\", -0.1, 0.1),\n RealParameter(\"ShipTbl1\", -0.1, 0.1),\n RealParameter(\"ShipTbl2\", -0.1, 0.1),\n RealParameter(\"ShipTbl3\", -0.1, 0.1),\n RealParameter(\"collaboration\",1, 1.6),\n CategoricalParameter(\"land use scenarios\", \n [\"NoChange\", \"moreNature\", \"Deurbanization\",\n \"sustainableGrowth\", \"urbanizationDeurbanization\",\n \"urbanizationLargeAndFast\", \"urbanizationLargeSteady\"],\n pff=True)]\n \n waas_model.outcomes = [ScalarOutcome(\"Flood damage (Milj. Euro)\"),\n ScalarOutcome(\"Number of casualties\"),\n ScalarOutcome(\"Costs\"),\n ScalarOutcome(\"Timing\")]\n \n n_scenarios = 500\n policies = [Policy(kwargs['name'], **kwargs['params']) for kwargs in policies]\n \n with MultiprocessingEvaluator(waas_model) as evaluator:\n # with SequentialEvaluator(waas_model) as evaluator:\n results = perform_experiments(waas_model, n_scenarios, policies, \n evaluator=evaluator)\n \n save_results(results, './data/partial factorial over pathways.tar.gz')"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 11,
"blob_id": "ba16052041352eae80461eda1aaaac7ecef881a0",
"content_id": "e9679d4e6eee96319e9942471032195a19319a47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 3,
"path": "/README.md",
"repo_name": "TRomijn/MBDM-project",
"src_encoding": "UTF-8",
"text": "Welcome to the project folder.\n\nTim\n"
}
] | 3 |
J-Wendl/API-Call-GUI
|
https://github.com/J-Wendl/API-Call-GUI
|
dbefca34df0cf432907a19b3dcf2c7b87fcfd17f
|
e4849782a4c2492a5898de6acc5fd450a2817795
|
fdd3c3290a4b2b9260bca4c97dd52ac3a9403ebe
|
refs/heads/master
| 2020-03-29T10:38:16.910830 | 2018-09-25T14:06:48 | 2018-09-25T14:06:48 | 149,815,780 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6267232298851013,
"alphanum_fraction": 0.6352067589759827,
"avg_line_length": 42.53845977783203,
"blob_id": "499e5c48cbf2e250a3139a2e24e084e57b3cc284",
"content_id": "b3efea306e8b010f3543f319710b58710b2261d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2829,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 65,
"path": "/api_call.py",
"repo_name": "J-Wendl/API-Call-GUI",
"src_encoding": "UTF-8",
"text": "#Import the relevant packages\nimport requests, json\nimport sys\n\na=\"\"\"+-------------------------------------------------------------------------------------------------------------------+\n| Visit the Dynatrace API Documentation at |\n| https://www.dynatrace.com/support/help/dynatrace-api/timeseries/how-do-i-fetch-the-metrics-of-monitored-entities/ |\n+-------------------------------------------------------------------------------------------------------------------+\"\"\"\n\n#Print the API doc banner\nprint(a+\"\\n\")\n\n#Give users the options to choose an endpoint\nprint(\"Please choose which endpoint you wish to query:\" + \"\\n\" + \"-\"*47 + \"\\n\" + \"1. Prod API Endpoint\\n2. QA API Endpoint\\n\\n\")\n\n#Define your tenant/environment information here to determine the endpoint. This should be a string object.\nenvOne = \"\"\nenvTwo = \"\" \n\n#Set up the while loop to ensure users can only enter number 1 or 2\nurl = 0\n\nwhile url != 1 or 2:\n\ttry:\n\t\turl = int(input(\"Please choose either 1 or 2: \"))\n\t\tif url == 1:\n\t\t\turl = envOne + \"/api/v1/timeseries\"\n\t\t\tapiToken = input(\"\\nPaste your PROD API Token here: \")\n\t\t\tbreak\n\t\telif url == 2:\n\t\t\turl = envTwo + \"/api/v1/timeseries\"\n\t\t\tapiToken = input(\"\\nPaste your QA API Token here: \")\n\t\t\tbreak\n\texcept ValueError:\n\t\tprint(\"Please try again!\")\n\n\t\n#Give the user the option to input relevant information for the API query\t\nrelativeTime = input(\"Input your desired relativeTime [hour, day, month]: \")\naggregationType = input(\"Input your desired aggregationType [avg, sum, min, max, count, median, percentile]: \")\nqueryMode = input(\"Input your desired queryMode [series, total]: \")\ntimeseriesId = input(\"Input your desired timeseriesId: \")\n\t\n#Format the JSON POST body\ndata = json.dumps({'relativeTime': relativeTime, 'aggregationType': aggregationType, 'queryMode': queryMode, 'timeseriesId': timeseriesId})\n\n\n#Set the request headers \nheaders = {'Content-Type': 'application/json', 'Authorization': 'Api-Token '+ apiToken}\n\n#Make the post request to the API endpoint. Pass in the url chosen in the beginning plus the body and headers.\nr = requests.post(url, data=data, headers=headers, verify=False) #verify=False is to circumvent any SSL cert issues.\n\n#Check if the status code returns 200, and if it does prompt the user to save a file for the payload.\nif r.status_code == 200:\n\tprint(\"\\nSuccess!\\n\")\n\tanswer=input(\"Would you like to save the payload to a file? [y/n]: \")\n#If the user chooses to save the payload, offer a format for the file to be saved in.\t\n\tif answer == \"y\":\n\t\textension = input(\"\\nWhat format would you like to output? (txt, json, csv, etc.): \")\n\t\tsys.stdout = open('api_output.'+extension, 'w')\n\t\tprint(r.text)\n#If the status code is not http 200, print the error to the terminal.\nelse:\n\tprint(\"\\n\" + r.text)"
},
{
"alpha_fraction": 0.7194533944129944,
"alphanum_fraction": 0.7781350612640381,
"avg_line_length": 48.7599983215332,
"blob_id": "883d0f50f8d7d15f981a0e7cfdf1b74df0fcc606",
"content_id": "8dca1456b1852096f9c6bf0375a6685e798dd3a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1244,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 25,
"path": "/README.md",
"repo_name": "J-Wendl/API-Call-GUI",
"src_encoding": "UTF-8",
"text": "# API-Call-GUI \n\nThis Python 3 script can be converted to a standalone .exe that can be distributed to team members. The script makes use of Requests and Pyinstaller modules but can also be used through the console as well.\n\nThe standalone .exe was created to be a lightweight command line option to query the Dynatrace API of your Managed cluster or SaaS instance to retrieve timeseries information that can be used for a multitude of use cases.\n\n\n### Getting started:\n\nFirst, install the requests and pyinstaller libraries\n\n ```pip install requests```\n\n ```pip install pyinstaller```\n\nEdit the variables \"envOne\" and \"envTwo\" to match your necessary endpoints. The code can be refactored to include more or less for your needs.\n\nOnce the source code is ready to go and you're ready to distribute the .exe, navigate to the folder where api_call.py is located and run:\n\n```pyinstaller --onefile api_call.py```\n\nA new \"dist\" folder will be created and you will find the .exe file.\n\n### Finalized standalone\n\n"
}
] | 2 |
gustavodebiasi/Python-Packet-Sniffer
|
https://github.com/gustavodebiasi/Python-Packet-Sniffer
|
b5545c6eaae448943e1071d805459e2aa6ce424b
|
0cb938d88235e036f03a8fe99377687af7481fc0
|
ea00eddd5956b48b92ba3d033953f1c4c369cd80
|
refs/heads/master
| 2020-06-12T00:31:43.510495 | 2019-06-27T17:30:52 | 2019-06-27T17:30:52 | 194,136,537 | 1 | 1 | null | 2019-06-27T17:25:36 | 2019-06-10T17:05:19 | 2015-12-30T01:05:49 | null |
[
{
"alpha_fraction": 0.4925491213798523,
"alphanum_fraction": 0.512531042098999,
"avg_line_length": 43.290000915527344,
"blob_id": "7939fb570969dbc862f671218b8e12db7b3355c0",
"content_id": "61c9ce6f2ddb953496fef701e8fc6abc41f5599d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8858,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 200,
"path": "/sniffer.py",
"repo_name": "gustavodebiasi/Python-Packet-Sniffer",
"src_encoding": "UTF-8",
"text": "import socket\n\nfrom struct import *\nfrom general import *\nfrom networking import *\n\nETH_HEADER_LEN = 14\nIPv4 = '0x800' \nIPv6 = '0x86dd'\nARP = '0x806'\n\nHOP_BY_HOP = 0\nDESTINATION_OPTIONS = 60\nROUTING = 43\nFRAGMENT = 44\nAH = 51\nESP = 50\nMOBILITIY = 135\nHOST_IDENTITY = 139\nSHIM6 = 140\n\nICMP_IPv6 = 58\nUDP = 17\nTCP = 6\nICMP_IPv4 = 1\nIGMP = 2\n\nTAB_1 = '\\t - '\nTAB_2 = '\\t\\t - '\nTAB_3 = '\\t\\t\\t - '\nTAB_4 = '\\t\\t\\t\\t - '\n\nDATA_TAB_1 = '\\t '\nDATA_TAB_2 = '\\t\\t '\nDATA_TAB_3 = '\\t\\t\\t '\nDATA_TAB_4 = '\\t\\t\\t\\t '\n\ndef mac_format (mac) :\n formatted_mac = \"%.2x:%.2x:%.2x:%.2x:%.2x:%.2x\" % (ord(mac[0]) , ord(mac[1]) , ord(mac[2]), ord(mac[3]), ord(mac[4]) , ord(mac[5]))\n return formatted_mac\n\n\ndef main():\n conn = socket.socket(socket.AF_PACKET, socket.SOCK_RAW, socket.ntohs(3)) \n\n while True:\n packet = conn.recvfrom(65535)\n packet = packet[0]\n\n eth_header = packet[:ETH_HEADER_LEN]\n eth_data = packet[ETH_HEADER_LEN:]\n eth = unpack('!6s6sH' , eth_header)\n eth_protocol = hex(eth[2])\n print '\\nEthernet Frame:'\n print TAB_1 + 'Destination: ' + mac_format(eth[0]) + ' Source: ' + mac_format(eth[1]) + ' Protocol: ' + eth_protocol\n \n if eth_protocol == IPv6:\n ipv6_packet = ipv6(eth_data)\n\n print(TAB_1 + 'IPv6 Packet:')\n print(TAB_2 + 'Version: {}, Trafic Class: {}, Hop Limit: {},'.format(ipv6_packet.version, ipv6_packet.trafic, ipv6_packet.hop_limit))\n print(TAB_2 + 'Next Header: {}, Flow Label: {}, Payload: {}'.format(ipv6_packet.next_header, ipv6_packet.flow_label, ipv6_packet.payload))\n print(TAB_2 + 'Source: {}, Target: {}'.format(ipv6_packet.src, ipv6_packet.target))\n flag = True\n next = ipv6_packet.next_header\n next_packet = ipv6_packet.data\n\n while flag: \n if next == TCP:\n tcp_packet = tcp(next_packet)\n print(TAB_2 + 'TCP Segment:')\n print(TAB_3 + 'Source Port: {}, Destination Port: {}'.format(tcp_packet.src_port, tcp_packet.dest_port))\n print(TAB_3 + 'Sequence: {}, Acknowledgment: {}'.format(tcp_packet.sequence, tcp_packet.acknowledgment))\n print(TAB_3 + 'Flags:')\n print(TAB_4 + 'URG: {}, ACK: {}, PSH: {}'.format(tcp_packet.flag_urg, tcp_packet.flag_ack, tcp_packet.flag_psh))\n print(TAB_4 + 'RST: {}, SYN: {}, FIN: {}'.format(tcp_packet.flag_rst, tcp_packet.flag_syn, tcp_packet.flag_fin))\n\n if len(tcp_packet.data) > 0:\n if tcp_packet.src_port == 80 or tcp_packet.dest_port == 80:\n print(TAB_3 + 'HTTP Data')\n else:\n print(TAB_3 + 'TCP Data')\n\n flag = False\n\n elif next == UDP:\n udp_packet = udp(next_packet)\n print(TAB_2 + 'UDP Segment:')\n print(TAB_3 + 'Source Port: {}, Destination Port: {}, Length: {}'.format(udp_packet.src_port, udp_packet.dest_port, udp_packet.lenght))\n\n flag = False\n\n elif next == ICMP_IPv6:\n imcp_packet = icmp(next_packet)\n print(TAB_2 + 'ICMP Packet:')\n print(TAB_3 + 'Type: {}, Code: {}, Checksum: {},'.format(imcp_packet.type, imcp_packet.code, imcp_packet.checksum))\n\n flag = False\n\n elif next == HOP_BY_HOP:\n hbp_packet = hopbyhop(next_packet)\n print(TAB_2 + 'Hop-by-Hop Segment:')\n print(TAB_3 + 'Next Header: {}, Header Extention Lenght: {}'.format(hbp_packet.next_header, hbp_packet.hdr_ext_len))\n next_packet = hbp_packet.data\n next = hbp_packet.next_header\n\n elif next == DESTINATION_OPTIONS:\n destination_packet = destination(next_packet)\n print(TAB_2 + 'Destination Segment:')\n print(TAB_3 + 'Next Header: {}, Header Extention Lenght: {}'.format(destination_packet.next_header, destination_packet.hdr_ext_len))\n next_packet = destination_packet.data\n next = destination_packet.next_header\n\n elif next == ROUTING:\n routing_packet = routing(next_packet)\n print(TAB_2 + 'Routing Segment:')\n print(TAB_3 + 'Next Header: {}, Header Extention Lenght: {}'.format(routing_packet.next_header, routing_packet.hdr_ext_len))\n print(TAB_3 + 'Routing Type: {}, Segments Left: {}'.format(routing_packet.routing_type, routing_packet.seg_left)) \n next_packet = routing_packet.data\n next = routing_packet.next_header\n\n elif next == FRAGMENT:\n fragment_packet = routing(next_packet)\n print(TAB_2 + 'Fragment Segment:')\n print(TAB_3 + 'Next Header: {}, Fragment Offset: {}'.format(fragment_packet.next_header, fragment_packet.frag_offset))\n print(TAB_3 + 'M Flag: {}, Identification: {}'.format(fragment_packet.m_flag, fragment_packet.identification)) \n next_packet = fragment_packet.data\n next = fragment_packet.next_header\n\n elif next == AH:\n ah_packet = authentication(next_packet)\n print(TAB_2 + 'Authentication Segment:')\n print(TAB_3 + 'Next Header: {}, Payload Lenght: {}'.format(ah_packet.next_header, ah_packet.payload_len))\n print(TAB_3 + 'Security Parameters Index: {}, Sequence Number: {}'.format(ah_packet.spi, ah_packet.sequence)) \n next_packet = ah_packet.data\n next = ah_packet.next_header\n break\n\n elif next == ESP:\n print(TAB_2 + 'ESP Segment')\n flag = False\n\n elif next == MOBILITIY:\n print(TAB_2 + 'Mobility Segment')\n flag = False\n\n elif next == HOST_IDENTITY:\n print(TAB_2 + 'Host Identity Segment')\n flag = False\n\n elif next == SHIM6:\n print(TAB_2 + 'SHIM6 Segment')\n flag = False\n\n else:\n print(TAB_2 + 'Other IPv6 Next Header Type: {}'.format(next))\n flag = False \n\n elif eth_protocol == ARP:\n print(TAB_1 + 'ARP Packet')\n\n elif eth_protocol == IPv4:\n ipv4_packet = ipv4(eth_data)\n\n print(TAB_1 + 'IPv4 Packet:')\n print(TAB_2 + 'Version: {}, Header Length: {}, TTL: {},'.format(ipv4_packet.version, ipv4_packet.length, ipv4_packet.ttl))\n print(TAB_2 + 'Next Header: {}, Source: {}, Target: {}'.format(ipv4_packet.next_header, ipv4_packet.src, ipv4_packet.target))\n\n if ipv4_packet.next_header == ICMP_IPv4:\n icmp_header = icmp(ipv4_packet.data)\n print(TAB_1 + 'ICMP Packet:')\n print(TAB_2 + 'Type: {}, Code: {}, Checksum: {},'.format(icmp_header.type, icmp_header.code, icmp_header.checksum))\n\n elif ipv4_packet.next_header == IGMP:\n print(TAB_2 + 'IGMP Segment')\n\n elif ipv4_packet.next_header == TCP: \n tcp_header = tcp(ipv4_packet.data)\n print(TAB_2 + 'TCP Segment:')\n print(TAB_3 + 'Source Port: {}, Destination Port: {}'.format(tcp_header.src_port, tcp_header.dest_port))\n print(TAB_3 + 'Sequence: {}, Acknowledgment: {}'.format(tcp_header.sequence, tcp_header.acknowledgment))\n print(TAB_3 + 'Flags:')\n print(TAB_4 + 'URG: {}, ACK: {}, PSH: {}'.format(tcp_header.flag_urg, tcp_header.flag_ack, tcp_header.flag_psh))\n print(TAB_4 + 'RST: {}, SYN: {}, FIN: {}'.format(tcp_header.flag_rst, tcp_header.flag_syn, tcp_header.flag_fin))\n\n if len(tcp_header.data) > 0:\n if tcp_header.src_port == 80 or tcp_header.dest_port == 80:\n print(TAB_3 + 'HTTP Data')\n else:\n print(TAB_3 + 'TCP Data')\n\n elif ipv4_packet.next_header == UDP: \n udp_header = udp(ipv4_packet.data)\n print(TAB_2 + 'UDP Segment:')\n print(TAB_3 + 'Source Port: {}, Destination Port: {}, Length: {}'.format(udp_header.src_port, udp_header.dest_port, udp_header.lenght))\n\n else:\n print('Other IPv4 protocol {}'.format(ipv4_packet.next_header))\n \nmain()\n"
},
{
"alpha_fraction": 0.4845717251300812,
"alphanum_fraction": 0.5280177593231201,
"avg_line_length": 29.65151596069336,
"blob_id": "5f8763303c5c48c582dc50c5285ba05a2003f3bc",
"content_id": "4fd7ede15662cd3bab0a2082dce4259289bd6863",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4051,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 132,
"path": "/networking.py",
"repo_name": "gustavodebiasi/Python-Packet-Sniffer",
"src_encoding": "UTF-8",
"text": "from struct import *\nimport socket\n\nclass ipv4:\n def __init__(self, packet):\n iph = packet[:20]\n iph = unpack('!BBHHHBBH4s4s' , iph)\n\n self.version = iph[0] >> 4\n self.length = (iph[0] & 0xF) * 4\n self.ttl = iph[5]\n self.next_header = iph[6]\n self.src = socket.inet_ntoa(iph[8])\n self.target = socket.inet_ntoa(iph[9])\n self.data = packet[20:]\n\nclass ipv6:\n def __init__(self, packet):\n iph = packet[:40]\n iph = unpack('!IHBB16H', iph)\n\n self.version = iph[0] >> 28 \n self.trafic = (iph[0] >> 20) & 0x00FF\n self.flow_label = iph[0] & 0xFFFF\n self.payload = iph[1]\n self.next_header = iph[2]\n self.hop_limit = iph[3]\n self.src = 'Source: ' + ipv6_to_string(iph, 4, 12)\n self.target = 'Target: ' + ipv6_to_string(iph, 12, 20)\n self.data = packet[40:]\ndef ipv6_to_string(iph, start, end):\n ipv6_string = ''\n for x in range(start, end):\n if iph[x] != 0:\n ipv6_string += str(hex(iph[x]))[2:]\n if x != end-1:\n ipv6_string += ':'\n\n return ipv6_string\n\nclass udp:\n def __init__(self, packet):\n header = unpack(\"!4H\",packet[:8])\n self.src_port = header[0]\n self.dest_port = header[1]\n self.lenght = header[2]\n self.check_sum = header[3]\n self.data = packet[8:]\n\nclass tcp:\n def __init__(self, packet):\n tcph = packet[:20]\n tcph = unpack('!2H2I4H', tcph)\n \n self.src_port = tcph[0]\n self.dest_port = tcph[1]\n self.sequence = tcph[2]\n self.acknowledgment = tcph[3]\n self.length = tcph[4] >> 12\n self.reserved = (tcph[4] >> 6) & 0x003F \n self.flag_urg = (tcph[4] & 0x0020) >> 5 \n self.flag_ack = (tcph[4] & 0x0010) >> 4\n self.flag_psh = (tcph[4] & 0x0008) >> 3\n self.flag_rst = (tcph[4] & 0x0004) >> 2\n self.flag_syn = (tcph[4] & 0x0002) >> 1\n self.flag_fin = (tcph[4] & 0x0001)\n self.window = packet[5]\n self.checkSum = packet[6]\n self.urgPntr = packet[7]\n\n h_size = self.length * 4\n data_size = len(packet) - h_size\n self.data = packet[h_size:]\n\nclass routing:\n def __init__(self, packet):\n header = unpack(\"!4B\", packet[:4])\n self.next_header = header[0]\n self.hdr_ext_len = int(header[1] * 8 + 8)\n self.routing_type = header[2]\n self.seg_left = header[3]\n self.data = packet[self.hdr_ext_len:]\n\nclass icmpv6:\n def __init__(self, packet):\n header = unpack(\"!BBH\",packet[:4])\n self.type = header[0]\n self.code = header[1]\n self.checksum = header[2]\n self.data = packet[4:]\n\nclass icmp:\n def __init__(self, packet):\n header = unpack(\"!BBH\", packet[:4])\n self.type = header[0]\n self.code = header[1]\n self.checksum = header[2]\n self.data = packet[4:]\n\nclass hopbyhop:\n def __init__(self, packet):\n header = unpack(\"!2B\", packet[:2])\n self.next_header = header[0]\n self.hdr_ext_len = int(header[1] * 8 + 8)\n self.data = packet[self.hdr_ext_len:]\n\nclass fragment:\n def __init__(self, packet):\n header = unpack(\"!2BHI\", packet[:8])\n self.next_header = header[0]\n self.reserved = header[1]\n self.frag_offset = packet[2] >> 3\n self.m_flag = packet[2] & 1\n self.identification = packet[3]\n self.data = packet[8:]\n\nclass destination:\n def __init__(self, packet):\n header = unpack(\"!2B\", packet[:2])\n self.next_header = header[0]\n self.hdr_ext_len = int(header[1] * 8 + 8)\n self.data = packet[self.hdr_ext_len:]\n \nclass authentication:\n def __init__(self, packet):\n header = unpack(\"!2BH2I\", packet[:12])\n self.next_header = header[0]\n self.payload_len = int(header[1] * 4 + 8)\n self.reserved = header[2]\n self.spi = header[3]\n self.sequence = header[4]\n self.data = packet[self.payload_len:]\n\n\n\n\n\n"
}
] | 2 |
aska912/ExcelAPI
|
https://github.com/aska912/ExcelAPI
|
5ce1f3bf3eaccbf0947412aeea20867a9b7515a2
|
5ddc6acac566e1f458059d20afafbb5141ae95ac
|
37ec40a60a982dfb1f66d41bb7cc142dbf9039a4
|
refs/heads/master
| 2021-05-08T05:29:12.406122 | 2017-10-11T07:10:56 | 2017-10-11T07:10:56 | 106,490,937 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5333831906318665,
"alphanum_fraction": 0.5343183279037476,
"avg_line_length": 27.08465576171875,
"blob_id": "5eba96bf1d6d2646eb61c47079a9313f7d2792f7",
"content_id": "dcff0db36068382c2f646237025786ca28e37b22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5347,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 189,
"path": "/OpenPyExcel.py",
"repo_name": "aska912/ExcelAPI",
"src_encoding": "UTF-8",
"text": "\nimport os, sys\nimport openpyxl\nfrom openpyxl.chart import (\n LineChart,\n Reference,\n)\nfrom openpyxl.chart.axis import DateAxis\n\nclass OpenPyExcel(object):\n \"\"\"\n Read/Write Excel\n The API just can read/write xlsx file. \n \"\"\"\n def __init__(self, filename, **args):\n super(OpenPyExcel, self).__init__()\n self.filename = filename\n self._workbook = None\n self._active_sheet = None\n \n \n def load_workbook(self, readonly=False):\n if not os.path.isfile(self.filename):\n if readonly is True:\n sys.stderr.write( \"OpenPyExcel Error: \\\"%s\\\" No such file.\\n\"%(self.filename) )\n self._workbook = None\n return False\n else:\n try:\n self._workbook = openpyxl.Workbook()\n return True\n except:\n return False\n try:\n self._workbook = openpyxl.load_workbook(self.filename, readonly)\n return True\n except:\n sys.stderr.write( \"OpenPyExcel Error: Load \\\"%s\\\" failure.\\n\"%(self.filename) )\n self._workbook = None\n return False\n \n \n @property\n def is_opened(self):\n if self._workbook is not None:\n return True\n else:\n return False\n \n \n #@property \n #def active_sheet(self):\n # return self._active_sheet\n \n \n #@active_sheet.setter\n #def active_sheet(self, sheet_name):\n # self.open_sheet(sheet_name)\n\n \n @property\n def rows(self):\n return self._active_sheet.max_row\n\n\n @property\n def columns(self):\n return self._active_sheet.max_column\n \n \n def open_sheet(self, sheet_name):\n if self._workbook is None:\n self._active_sheet = None\n return False\n try:\n ws = self._workbook.get_sheet_by_name(sheet_name)\n except:\n self._active_sheet = None\n return False\n self._workbook.active = self._workbook.get_index(ws)\n self._active_sheet = self._workbook.active\n return True\n \n \n def add_sheet(self, sheet_name, option='w'):\n \"\"\"\n option: r, w\n r - read only\n w - delete the original data & sheet, then add a blank sheet\n \"\"\"\n if option == 'w':\n if not self.del_sheet(sheet_name):\n return False\n if self._is_sheet_in_workbook(sheet_name) is False:\n new_sheet = self._workbook.create_sheet(title = sheet_name)\n if new_sheet is not None:\n return True\n return False\n\n \n def del_sheet(self, sheet_name):\n if self._is_sheet_in_workbook(sheet_name) is True:\n ws = self._workbook.get_sheet_by_name(sheet_name)\n #self._workbook.remove_sheet(ws)\n self._workbook.remove(ws)\n if self._is_sheet_in_workbook(sheet_name):\n return False\n return True\n \n \n def rename_sheet(self, old_sheet_name, new_sheet_name):\n if self._is_sheet_in_workbook(old_sheet_name) is True:\n ws = self._workbook.get_sheet_by_name(old_sheet_name)\n ws.title = new_sheet_name\n if self._is_sheet_in_workbook(new_sheet_name) is True: \n return True\n return False\n \n\n def get_rows(self):\n return self._active_sheet.max_row\n \n \n def get_columns(self):\n return self._active_sheet.max_column\n \n \n def get_sheet_names(self):\n \"\"\"\n return list of the sheet names\n \"\"\"\n return self._workbook.get_sheet_names()\n \n \n def get_cell_value(self, row, col):\n return self._active_sheet.cell(row=row, column=col).value\n\n\n def get_cell_value_by_coordinate(self, coordinate):\n \"\"\"\n :param coordinate: coordinates of the cell (e.g. 'B12')\n :type coordinate: string\n \"\"\"\n return self._active_sheet.cell(coordinate=coordinate).value\n \n \n def write_cell(self, row, col, data):\n return self._active_sheet.cell(row=row, column=col, value=data)\n \n \n def write_cell_by_coordinate(self, coordinate, data):\n \"\"\"\n :param coordinate: coordinates of the cell (e.g. 'B12')\n :type coordinate: string\n \"\"\"\n #return self._active_sheet.cell(coordinate=coordinate, value=data)\n self._active_sheet[coordinate].value = data \n \n \n def write_cell_string(self, row, col, str_data=\"\"):\n return self.write_cell(row, col, str_data)\n \n \n def write_cell_number(self, row, col, num=0):\n cell = self.write_cell(row, col, num)\n cell.number_format\n \n \n def close(self, save=False):\n if save:\n return self._save()\n else:\n return True\n \n def close_save(self):\n return self._save()\n \n def _save(self):\n try:\n self._workbook.save(filename = self.filename)\n return True\n except:\n return False\n \n \n def _is_sheet_in_workbook(self, ws_name):\n if ws_name in self.get_sheet_names():\n return True\n else:\n return False\n \n \n \n \n \n \n"
}
] | 1 |
felipemamedefranco/AO3-TEST
|
https://github.com/felipemamedefranco/AO3-TEST
|
946c299933f11b6b2b3fbc3a19e6bcb80cb71e2d
|
5ce45f13c3fe20b259bd2e38553966dede71904c
|
216c28d58c130977d99ec09638aa78150166bab9
|
refs/heads/main
| 2023-07-14T22:23:40.681457 | 2021-08-15T22:59:26 | 2021-08-15T22:59:26 | 395,148,660 | 0 | 0 | null | 2021-08-12T00:21:23 | 2021-08-15T05:18:12 | 2021-08-15T22:31:33 | null |
[
{
"alpha_fraction": 0.6080441474914551,
"alphanum_fraction": 0.6164563894271851,
"avg_line_length": 36.30392074584961,
"blob_id": "7a30af06002e9bd16d2da981b6d1b72025bac744",
"content_id": "62e9d65914b040b3079124a44dc8ef23e95ddbdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3820,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 102,
"path": "/teste_ao3_dataset_vacinacao_covid19.py",
"repo_name": "felipemamedefranco/AO3-TEST",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[1]:\n\n\n#Bibliotecas\nimport pandas as pd\nfrom sqlalchemy import create_engine\nfrom getpass import getpass\nimport pymongo as pym\n\n#----------------------------------------------\n#(1) Importa e Trata Dados:\n#----------------------------------------------\n#Importa Planilha\ndf = pd.read_excel(r'teste-ao3-dataset-vacinacao-covid19.xlsx')\n\n#Trata Ids Duplicados\ndf=df.drop_duplicates(['document_id','paciente_id'])\n\n#Trata valores faltantes na coluna 'vacina_fabricante_referencia' de acordo com a 'coluna vacina_fabricante_nome'\nfor x in df['vacina_fabricante_referencia'].drop_duplicates().dropna().index:\n for y in df.index:\n if df.loc[y]['vacina_fabricante_nome'] == df.loc[x]['vacina_fabricante_nome']:\n df.loc[y,['vacina_fabricante_referencia']] = df.loc[x]['vacina_fabricante_referencia']\n\n#Trata outros valores faltantes na coluna 'vacina_fabricante_referencia'\ndf['vacina_fabricante_referencia'].fillna('Sem Referência', inplace=True)\n\n#Trata valores faltantes de 'paciente_endereco_copais', igualando aos demais\ndf['paciente_endereco_copais'].fillna(10, inplace=True)\n\n#Transforma os valores de'vacina_lote' em string (Necessário para inserir dados no arquivo parquet)\ndf['vacina_lote']=df['vacina_lote'].astype(str)\n\n\n\n\n#----------------------------------------------\n#(2) Funçao Inserir Dados no MYSQL:\n#----------------------------------------------\ndef PutMYSQL(df):\n#Solicita dados de conexão com banco de dados MYSQL\n DB = input('Digite o nome do banco MYSQL:')\n SERVER = input('Digite o nome do servidor do banco MYSQL:')\n USER = input('Digite o nome do usuário do banco MYSQL:')\n PASS = getpass('Digite a senha do usuário do banco MYSQL:')\n \n#Conecta no banco MYSQL utilizando os dados de conexão digitados\n conn = create_engine(\"mysql+pymysql://\"+USER+\":\"+PASS+\"@\"+SERVER+\"/\"+DB)\n \n#Sobe a tabela com dados tratados para o banco MYSQL\n df.to_sql(con=conn, name='teste_ao3_tabela_vacinacao_covid19', if_exists='append',index=False)\n print('\\nDados inseridos em '+SERVER+\"/\"+DB+'\\n\\n\\n')\n\n \n \n#----------------------------------------------\n#(3) Funçao Inserir Dados no MongoDB:\n#----------------------------------------------\ndef PutMongo(df):\n#Solicita dados de conexão com o MongoDB\n DB = input('Digite o nome do banco MongoDB:')\n SERVER = input('Digite o nome do servidor MongoDB:')\n PORT = input('Digite a porta do serviço MongoDB:')\n COLLECTION = input('Digite o nome da coleção do MongoDB:')\n \n#Gera um dicionário a partir dos dados tratados\n df_dict = df.to_dict('records')\n\n#Insere o dicionário com dados tratados para o MongoDB\n pym.MongoClient('mongodb://'+SERVER+':'+PORT+'/')[DB][COLLECTION].insert_many(df_dict)\n print('\\nDados inseridos em mongodb://'+SERVER+':27017/\\n\\n\\n')\n\n\n \n \n#----------------------------------------------\n#(4) Funçao Inserir Dados no Arquivo Parquet:\n#----------------------------------------------\ndef PutParquet(df):\n#Insere tabela em um arquivo parquet\n df.to_parquet('teste_ao3_dataset_vacinacao_covid19.parquet', engine='fastparquet')\n print('\\nArquivo parquet criado\\n\\n\\n')\n\n \n \n\n#----------------------------------------------\n#(5) Main Loop:\n#----------------------------------------------\nwhile x != 'exit':\n#De acordo com o valor fornecido, o código faz input dos dados em um banco MySQL, MongoDB ou em um Parquet File\n print('Dataset teste-ao3-dataset-vacinacao-covid19.xlsx carregado!\\n\\nDigite 1 para transporta-lo para um banco MySQL\\nDigite 2 para transporta-lo para um banco MongoDB\\nDigite 3 para gerar um Parquet File')\n x=input('Ou digite \"exit\" para encerrar o programa:')\n if x=='1':\n PutMYSQL(df)\n elif x=='2':\n PutMongo(df)\n elif x=='3':\n PutParquet(df)"
}
] | 1 |
DANS-KNAW/dans-mvn-build-resources
|
https://github.com/DANS-KNAW/dans-mvn-build-resources
|
951fbe5658cddcef07166bed11bacb2eea87531c
|
51100953bf92c7bddf1e52f081fde2b5fc6acd68
|
0f665230b174c7b6c6e81b8be114629b73236c4a
|
refs/heads/master
| 2021-05-26T08:09:42.557770 | 2021-05-17T08:35:40 | 2021-05-17T08:35:40 | 128,027,786 | 0 | 2 |
Apache-2.0
| 2018-04-04T07:55:19 | 2019-11-21T12:45:41 | 2021-05-17T08:35:41 |
Shell
|
[
{
"alpha_fraction": 0.5668653249740601,
"alphanum_fraction": 0.5797377824783325,
"avg_line_length": 40.1274528503418,
"blob_id": "356ab1c0be792a381a37cfff879da72593d8c707",
"content_id": "0f64f23b0338b14ad0b3f0258903b2df58a2d398",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Maven POM",
"length_bytes": 4195,
"license_type": "permissive",
"max_line_length": 201,
"num_lines": 102,
"path": "/pom.xml",
"repo_name": "DANS-KNAW/dans-mvn-build-resources",
"src_encoding": "UTF-8",
"text": "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<!--\n\n Copyright (C) 2018 DANS - Data Archiving and Networked Services ([email protected])\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n you may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\n Unless required by applicable law or agreed to in writing, software\n distributed under the License is distributed on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n See the License for the specific language governing permissions and\n limitations under the License.\n\n-->\n<project xmlns=\"http://maven.apache.org/POM/4.0.0\" xmlns:xsi=\"http://www.w3.org/2001/XMLSchema-instance\" xsi:schemaLocation=\"http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd\">\n <modelVersion>4.0.0</modelVersion>\n <groupId>nl.knaw.dans.shared</groupId>\n <artifactId>dans-mvn-build-resources</artifactId>\n <version>4.0.2-SNAPSHOT</version>\n <scm>\n <developerConnection>scm:git:https://github.com/DANS-KNAW/${project.artifactId}</developerConnection>\n <tag>HEAD</tag>\n </scm>\n <packaging>jar</packaging>\n <name>DANS Build Resources</name>\n <inceptionYear>2018</inceptionYear>\n <properties>\n <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>\n <snapshot-repository>http://nexus.dans.knaw.nl/repository/maven-snapshots</snapshot-repository>\n <release-repository>http://nexus.dans.knaw.nl/repository/maven-releases</release-repository>\n </properties>\n <distributionManagement>\n <!-- Credentials for server are defined in ~/.m2/settings.xml -->\n <snapshotRepository>\n <id>nexus-snapshots</id>\n <!-- Final slash is important for Nexus ! -->\n <url>${snapshot-repository}/</url>\n </snapshotRepository>\n <repository>\n <id>nexus-releases</id>\n <!-- Final slash is important for Nexus ! -->\n <url>${release-repository}/</url>\n </repository>\n </distributionManagement>\n <dependencies>\n <dependency>\n <groupId>junit</groupId>\n <artifactId>junit</artifactId>\n <version>4.13.1</version>\n </dependency>\n </dependencies>\n <repositories>\n <repository>\n <id>DANS</id>\n <releases>\n <enabled>true</enabled>\n </releases>\n <url>http://maven.dans.knaw.nl/</url>\n </repository>\n </repositories>\n <build>\n <plugins>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-release-plugin</artifactId>\n <version>2.5.3</version>\n <configuration>\n <tagNameFormat>v@{project.version}</tagNameFormat>\n <pushChanges>true</pushChanges>\n </configuration>\n </plugin>\n <plugin>\n <groupId>org.apache.maven.plugins</groupId>\n <artifactId>maven-compiler-plugin</artifactId>\n <version>3.6.1</version>\n <configuration>\n <source>1.8</source>\n <target>1.8</target>\n </configuration>\n </plugin>\n <plugin>\n <groupId>com.mycila</groupId>\n <artifactId>license-maven-plugin</artifactId>\n <version>3.0</version>\n <configuration combine.children=\"override\">\n <header>src/main/resources/license/apache2.txt</header>\n <excludes>\n <exclude>LICENSE</exclude>\n <exclude>src/main/resources/license/**</exclude>\n <exclude>src/main/resources/rpm-includes/**</exclude>\n <exclude>src/main/resources/yworks-uml-doclet/**</exclude>\n <exclude>src/test/resources/**</exclude>\n </excludes>\n </configuration>\n </plugin>\n </plugins>\n </build>\n</project>\n"
},
{
"alpha_fraction": 0.7151514887809753,
"alphanum_fraction": 0.7151514887809753,
"avg_line_length": 32.099998474121094,
"blob_id": "8511297e76620a43a1e93e58ebf06916084764f8",
"content_id": "0558bce28dd2a5e08a20694ec961638833866f13",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 330,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 10,
"path": "/README.md",
"repo_name": "DANS-KNAW/dans-mvn-build-resources",
"src_encoding": "UTF-8",
"text": "dans-mvn-build-resources\n========================\n\nCommon resources for use during the build of a DANS project\n\n\nDescription\n-----------\nThese resources are used by the parent POMs defined in the https://github.com/DANS-KNAW/dans-parent-pom project.\nThey are extracted to the target folder and used from there by various plug-ins."
},
{
"alpha_fraction": 0.6465433239936829,
"alphanum_fraction": 0.6562804579734802,
"avg_line_length": 32.129032135009766,
"blob_id": "8775af8e80b13386bb6501a8001db9a3d32414cb",
"content_id": "cf3b3a6f170ea1ffb224c9afac750a463e5b41d3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2054,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 62,
"path": "/src/main/resources/script/deploy-rpm.py",
"repo_name": "DANS-KNAW/dans-mvn-build-resources",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#\n# Copyright (C) 2018 DANS - Data Archiving and Networked Services ([email protected])\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n#\n\nimport glob\nimport os\nimport re\nimport requests\nimport sys\n\nfrom requests.auth import HTTPBasicAuth\n\nsnapshot_pattern = re.compile('^.*/[^/]+SNAPSHOT[^/]+\\.rpm$')\n\n\ndef is_snapshot(rpm):\n return snapshot_pattern.match(rpm) is not None\n\n\ndef deploy_rpm(nexus_account, nexus_password, repo_url, build_dir):\n rpms = glob.glob(\"%s/rpm/*/RPMS/*/*.rpm\" % build_dir)\n if len(rpms) == 1:\n rpm = rpms[0]\n with open(rpm, 'rb') as f:\n response = requests.put(repo_url + os.path.basename(rpm), data=f, auth=HTTPBasicAuth(nexus_account, nexus_password))\n if response.status_code != 200:\n raise Exception(\"RPM could not be deployed to repository \" + repo_url +\n \". Status: \" + str(response.status_code) + \" \" + response.reason)\n else:\n raise Exception(\"Expected 1 RPM found %s, paths: %s\" % (len(rpms), ','.join(rpms)))\n\n\ndef print_usage():\n print(\"Uploads a SNAPSHOT RPM to the Nexus Yum repository\")\n print(\"Usage: ./deploy-rpm.py <nexus_account> <nexus_password> <repo-url> <build_dir>\")\n\n\nif __name__ == '__main__':\n if len(sys.argv) < 4:\n print_usage()\n exit(1)\n\n nexus_account = sys.argv[1]\n nexus_password = sys.argv[2]\n repo_url = sys.argv[3]\n build_dir = sys.argv[4]\n\n deploy_rpm(nexus_account, nexus_password, repo_url, build_dir)\n print(\"Deployed RPM to %s\" % repo_url)\n"
}
] | 3 |
foxpass/foxpass-ipsec-vpn
|
https://github.com/foxpass/foxpass-ipsec-vpn
|
a04082e1fb57a07c7bdc428fc78a4b7a6be301d4
|
79202fa1d0c4e1e86034378ea84a762528f9ca95
|
5b71e8a5d6203eb712785290ac3bc1259c622148
|
refs/heads/master
| 2023-06-16T01:21:29.466846 | 2023-05-25T04:45:12 | 2023-05-25T04:45:12 | 55,736,566 | 51 | 20 | null | 2016-04-08T00:11:44 | 2022-06-09T16:13:36 | 2023-05-25T04:45:13 |
Python
|
[
{
"alpha_fraction": 0.7151328921318054,
"alphanum_fraction": 0.7307270169258118,
"avg_line_length": 53.85542297363281,
"blob_id": "01e9d2c6b01846a69969735a16ad6a8259fa1f35",
"content_id": "ec5afa11dcc5671f74a009d8de090abc782e11ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4553,
"license_type": "no_license",
"max_line_length": 808,
"num_lines": 83,
"path": "/README.md",
"repo_name": "foxpass/foxpass-ipsec-vpn",
"src_encoding": "UTF-8",
"text": "### What it does\n\nThis repo helps you create an AMI image that offers a simple IPSEC/L2TP VPN server. Username and password will be checked against [Foxpass](https://www.foxpass.com) (which in-turn syncs with Google Apps) and optionally against [Duo](https://www.duo.com) or [Okta](https://www.okta.com) for two-factor authentication (HIGHLY RECOMMENDED). NOTE: If you use emails for your Duo requests instead of usernames, you must enable username normalization. You can find more info about that setting [here](https://duo.com/docs/creating_applications#username-normalization). If you use Okta instead, Foxpass requires credentials with at least [Group Admin](https://help.okta.com/en/prod/Content/Topics/Security/The_User_Admin_Role.htm?Highlight=group%20admin) privileges in order to check the 2FA API endpoint with Okta.\n\nNote that you don't have to build it. We have ready-to-go, free-of-charge AMIs on the [AWS Marketplace](https://aws.amazon.com/marketplace/pp/B01HMLVKPS).\n\n### How to build it\n\n* Clone this repo\n* init and update the submodules:\n * `git submodule init`\n * `git submodule update`\n* Download and install Hashicorp's Packer (http://packer.io)\n* Put your AWS access key and secret key someplace that Packer [can find them](https://www.packer.io/docs/builders/amazon.html#specifying-amazon-credentials).\n* set your region and base AMI (currently designed for Ubuntu 20.04 base images) in foxpass_vpn.json\n* run `packer build foxpass_vpn.json`\n\nfor Google Cloud Platform :\n\n* Get account file JSON if not building on a GCE instance as [described here](https://www.packer.io/docs/builders/googlecompute.html)\n* populate config variables via command line or variable file ([docs](https://www.packer.io/docs/templates/user-variables.html))\n* run `packer build gcp_foxpass_vpn.json`\n\n### How to run it\n\n* Instantiate an image with the resulting AMI\n * Make sure it has a public IP address\n * Make sure it is in a security group with the following inbound rules:\n * UDP 500\n * UDP 4500\n * TCP 22 to your IP (for SSH management)\n * (optional, see below) for AWS: setup script can pull config from S3. Set role and user-data as described below.\n\n* When the instance comes up\n\n ```\n ssh ubuntu@<hostname-or-ip>\n sudo /opt/bin/config.py\n ```\n\n* To automatically pull config from S3 (optional)\n * Set EC2 user-data to\n\n ```\n #!/bin/bash\n sudo /opt/bin/config.py s3://bucket-name/path/to/config.json\n ```\n This will run the config script on startup, you will not need to run the config script manually.\n\n * Set EC2 role to a role in IAM that has `ListBucket` and `GetObject` permissions (`GetObjectVersion`, too, if your bucket has versioning enabled) to the above-mentioned bucket and path in S3. (Only required if you choose to automatically pull your config from S3.)\n * Upload the config file with the following format (mfa_type, duo_config, okta_config, and require_groups are optional):\n\n ```\n {\n \"psk\": \"MAKE_UP_A_SECURE_SHARED_KEY\",\n \"dns_primary\": \"8.8.8.8\",\n \"dns_secondary\": \"8.8.4.4\",\n \"l2tp_cidr\": \"10.11.12.0/24\",\n \"xauth_cidr\": \"10.11.13.0/24\",\n \"foxpass_api_key\": \"PUT_YOUR_FOXPASS_API_KEY_HERE\",\n \"mfa_type\": \"duo_OR_okta\",\n \"duo_config\": {\"api_host\": \"API_HOST_FROM_DUO\", \"skey\": \"SKEY_FROM_DUO\", \"ikey\": \"IKEY_FROM_DUO\"},\n \"okta_config\": {\"hostname\": \"OKTA_HOSTNAME\", \"apikey\": \"OKTA_APIKEY\"},\n \"require_groups\": [\"group_1\", \"group_2\"] <- optionally requires user to be a member of one of the listed groups\n }\n ```\n\n### How to set up your clients\n\n* [Mac OSX](https://foxpass.readme.io/docs/foxpass-ipsec-vpn-macosx)\n* [Windows](https://foxpass.readme.io/docs/foxpass-windows-8-l2tpipsec-setup)\n\n### How to make changes\n\nPull requests welcome!\n\n* templates/ are the configuration templates that will be updated by the config.py script.\n* scripts/ include the config.py script and the static configuration files that need to be installed.\n* foxpass-radius-agent/ is a submodule [(See here)](https://github.com/foxpass/foxpass-radius-agent) that contains a radius agent that connects L2TP to Foxpass and Duo authentication APIs.\n\n### Thank you\n* Huge thank-you to [Travis Theune](https://github.com/ttheune) who was an instrumental collaborator throughout the design, implementation, and testing.\n* Based on the [work](https://github.com/hwdsl2/setup-ipsec-vpn/blob/master/vpnsetup.sh) of Lin Song (Copyright 2014-2016), which was based on the [work](https://github.com/sarfata/voodooprivacy/blob/master/voodoo-vpn.sh) of Thomas Sarlandie (Copyright 2012)\n"
},
{
"alpha_fraction": 0.42957746982574463,
"alphanum_fraction": 0.6830986142158508,
"avg_line_length": 14.88888931274414,
"blob_id": "9d649af72371c03fef739cd5ed3ba2b87ded7187",
"content_id": "d23b3904b3ed1343de7caa3ae81f1d38fdd6fa7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 9,
"path": "/requirements.txt",
"repo_name": "foxpass/foxpass-ipsec-vpn",
"src_encoding": "UTF-8",
"text": "boto3==1.13.0\nifaddr==0.1.6\niptools==0.7.0\njinja2==2.11.3\npyasn1==0.4.8\npython-hosts==1.0.0\npyOpenSSL==19.1.0\nrequests==2.31.0\nurllib3==1.26.5"
},
{
"alpha_fraction": 0.5868444442749023,
"alphanum_fraction": 0.5996072888374329,
"avg_line_length": 33.142459869384766,
"blob_id": "853d51bc5ec8f7a23ad28a09627277e8388192a3",
"content_id": "f622d4327dadeeab258e06173655cebfa1a0d378",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12223,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 358,
"path": "/scripts/config.py",
"repo_name": "foxpass/foxpass-ipsec-vpn",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\n# Copyright (c) 2015-present, Foxpass, Inc.\n# All rights reserved.\n#\n#\n# Redistribution and use in source and binary forms, with or without\n# modification, are permitted provided that the following conditions are met:\n#\n# 1. Redistributions of source code must retain the above copyright notice, this\n# list of conditions and the following disclaimer.\n# 2. Redistributions in binary form must reproduce the above copyright notice,\n# this list of conditions and the following disclaimer in the documentation\n# and/or other materials provided with the distribution.\n#\n# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\n# ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n# WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n# DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR\n# ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n# (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\n# LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND\n# ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n# (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\n# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\n# system libs\nimport json\nimport os\nimport random\nimport requests\nimport socket\nimport string\nimport sys\nfrom os import chown, chmod, geteuid, urandom\nfrom re import match\nfrom shutil import copyfile\nfrom subprocess import call\nfrom urllib.parse import urlparse\n\n# third party libs\nimport ifaddr\nfrom iptools import IpRange\nfrom iptools.ipv4 import validate_cidr\nfrom jinja2 import Environment, FileSystemLoader\nfrom python_hosts import Hosts, HostsEntry\n\n# require running as root\nif geteuid() != 0:\n exit(\"Not running as root.\\nconfig.py requires root privileges, please run again using sudo\")\n\nMETADATA_BASE_URL = \"http://169.254.169.254/\"\n\n\ndef check_ip(target, default=None):\n while True:\n try:\n ip = prompt('Enter {}: '.format(target), default)\n str(IpRange(ip))\n except TypeError:\n print('{} is not a valid IP.'.format(ip))\n else:\n return ip\n\n\ndef check_cidr(target, default=None):\n while True:\n try:\n cidr = prompt('Enter {}: '.format(target), default)\n if validate_cidr(cidr):\n pass\n else:\n print('{} is not a valid CIDR.'.format(cidr))\n if int(cidr.split('/')[1]) > 27:\n print('{} is too small, use a larger network size.'.format(cidr))\n else:\n return cidr\n except Exception:\n pass\n\n\ndef prompt(message, default=None):\n if default:\n return input('{} [{}]: '.format(message, default)) or default\n else:\n return input('{}: '.format(message))\n\n\ndef random_string(len):\n system_random = random.SystemRandom()\n chars = string.ascii_uppercase + string.digits + string.ascii_lowercase\n arr = [system_random.choice(chars) for i in range(len)]\n return ''.join(arr)\n\n\ndef get_mfa_type():\n while True:\n mfa_resp = prompt('Will you be using MFA: (y/N) ', default='N')\n if (mfa_resp == 'y' or mfa_resp == 'Y'):\n while True:\n mfa_type = prompt('What MFA provider: (duo/okta/Cancel) ', default='Cancel')\n mfa_type = mfa_type.lower()\n if (mfa_type == 'duo' or mfa_type == 'okta'):\n return mfa_type\n elif (mfa_type == 'cancel'):\n return ''\n else:\n print('Please enter `duo`, `okta`, or `Cancel`')\n elif (mfa_resp == 'n' or mfa_resp == 'N'):\n return ''\n else:\n print('Please enter `y` or `n`')\n\n\ndef get_duo_data():\n host = prompt('DUO api host, e.g. api-XXXXXXXX.duosecurity.com')\n ikey = prompt('DUO integration key')\n skey = prompt('DUO secret key')\n return {'api_host': host, 'ikey': ikey, 'skey': skey}\n\n\ndef get_okta_data():\n hostname = prompt('OKTA api hostname, e.g. XXXXXXXX.okta.com')\n apikey = prompt('OKTA api key')\n return {'hostname': hostname, 'apikey': apikey}\n\n\ndef is_gce():\n try:\n response = requests.get(METADATA_BASE_URL, timeout=.1)\n try:\n return response.headers['Metadata-Flavor'] == 'Google'\n finally:\n response.close()\n except Exception:\n return False\n\n\ndef gather_user_data_prompt():\n data = {}\n\n data['psk'] = prompt('Enter PSK', default=random_string(32))\n data['dns_primary'] = check_ip('Primary DNS', '1.1.1.1')\n data['dns_secondary'] = check_ip('Secondary DNS', '1.0.0.1')\n data['l2tp_cidr'] = check_cidr('L2TP IPv4 range (CIDR)', '10.11.12.0/24')\n data['xauth_cidr'] = check_cidr('XAUTH IPv4 range (CIDR)', '10.11.13.0/24')\n\n mfa_type = get_mfa_type()\n data['mfa_type'] = mfa_type\n if mfa_type == 'duo':\n data['duo_config'] = get_duo_data()\n elif mfa_type == 'okta':\n data['okta_config'] = get_okta_data()\n\n data['foxpass_api_key'] = prompt('Foxpass API Key')\n\n require_groups = prompt('Limit to groups (comma-separated)')\n\n if require_groups:\n data['require_groups'] = require_groups.split(',')\n\n return data\n\n\ndef gather_user_data_s3(s3_url):\n import boto3\n\n parts = urlparse(s3_url)\n\n if parts.scheme != 's3':\n raise Exception('Must use s3 url scheme')\n\n bucket_name = parts.netloc\n path = parts.path.lstrip('/')\n\n s3 = boto3.resource('s3')\n obj = s3.Object(bucket_name, path)\n data = obj.get()['Body'].read().decode('utf-8')\n\n config = json.loads(data)\n\n # if it has 'local_cidr', then use that value for l2tp_cidr\n local_cidr = config.pop('local_cidr', None)\n if local_cidr:\n config['l2tp_cidr'] = local_cidr\n\n return config\n\n\ndef gather_user_data_file(filename):\n config = json.load(open(filename))\n\n # if it has 'local_cidr', then use that value for l2tp_cidr\n local_cidr = config.pop('local_cidr', None)\n if local_cidr:\n config['l2tp_cidr'] = local_cidr\n\n return config\n\n\ndef get_machine_data():\n data = {}\n\n data['radius_secret'] = random_string(16)\n\n data['is_gce'] = is_gce()\n\n if data['is_gce']:\n headers = {'Metadata-Flavor': 'Google'}\n google_path = 'computeMetadata/v1/instance/network-interfaces/0/'\n data['public_ip'] = requests.get(METADATA_BASE_URL + google_path + 'access-configs/0/external-ip', headers=headers, timeout=.1).text\n data['private_ip'] = requests.get(METADATA_BASE_URL + google_path + 'ip', headers=headers, timeout=.1).text\n else:\n token_headers = None\n http_headers = { 'X-aws-ec2-metadata-token-ttl-seconds': '600', 'content-type': 'application/json'}\n token = requests.put(METADATA_BASE_URL + 'latest/api/token', timeout=.1, headers=http_headers).text\n if token:\n token_headers = {'X-aws-ec2-metadata-token': token, \"content-type\": 'application/json'}\n data['public_ip'] = requests.get(METADATA_BASE_URL + 'latest/meta-data/public-ipv4', timeout=.1, headers=token_headers).text\n data['private_ip'] = requests.get(METADATA_BASE_URL + 'latest/meta-data/local-ipv4', timeout=.1, headers=token_headers).text\n\n data['interface'] = get_adapter(data['private_ip'])\n\n return data\n\ndef get_adapter(private_ip):\n adapters = ifaddr.get_adapters()\n for adapter in adapters:\n for ip in adapter.ips:\n if ip.ip == private_ip:\n return adapter.nice_name\n\n\ndef modify_etc_hosts(data):\n private_ip = data['private_ip']\n hostname = socket.gethostname()\n\n hosts = Hosts()\n new_entry = HostsEntry(entry_type='ipv4',\n address=private_ip,\n names=[hostname])\n hosts.add([new_entry])\n hosts.write()\n\n\ndef config_vpn(data):\n context = {'PSK': data['psk'],\n 'DNS_PRIMARY': data['dns_primary'],\n 'DNS_SECONDARY': data['dns_secondary'],\n 'PUBLIC_IP': data['public_ip'],\n 'PRIVATE_IP': data['private_ip'],\n 'INTERFACE': data['interface'],\n 'RADIUS_SECRET': data['radius_secret'],\n 'API_KEY': data['foxpass_api_key'],\n 'API_HOST': data.get('foxpass_api_url', 'https://api.foxpass.com')\n }\n\n if 'require_groups' in data:\n context['REQUIRE_GROUPS'] = ','.join(data['require_groups'])\n\n if 'mfa_type' in data:\n context['MFA_TYPE'] = data.get('mfa_type')\n\n if 'duo_config' in data:\n context.update({'DUO_API_HOST': data['duo_config'].get('api_host'),\n 'DUO_IKEY': data['duo_config'].get('ikey'),\n 'DUO_SKEY': data['duo_config'].get('skey')})\n\n if 'okta_config' in data:\n context.update({'OKTA_HOSTNAME': data['okta_config'].get('hostname'),\n 'OKTA_APIKEY': data['okta_config'].get('apikey')})\n\n l2tp_cidr = data.get('l2tp_cidr')\n if l2tp_cidr:\n l2tp_ip_range_obj = IpRange(data['l2tp_cidr'])\n l2tp_ip_range = \"{}-{}\".format(l2tp_ip_range_obj[10],\n l2tp_ip_range_obj[-6])\n l2tp_local_ip = l2tp_ip_range_obj[1]\n context.update({\n 'L2TP_IP_RANGE': l2tp_ip_range,\n 'L2TP_LOCAL_IP': l2tp_local_ip,\n 'L2TP_CIDR': l2tp_cidr,\n })\n\n xauth_cidr = data.get('xauth_cidr')\n if xauth_cidr:\n xauth_ip_range_obj = IpRange(data['xauth_cidr'])\n xauth_ip_range = \"{}-{}\".format(xauth_ip_range_obj[10],\n xauth_ip_range_obj[-6])\n xauth_local_ip = xauth_ip_range_obj[1]\n\n context.update({\n 'XAUTH_IP_RANGE': xauth_ip_range,\n 'XAUTH_CIDR': xauth_cidr,\n })\n\n file_list = {'ipsec.secrets': '/etc/',\n 'iptables.rules': '/etc/',\n 'options.xl2tpd': '/etc/ppp/',\n 'xl2tpd.conf': '/etc/xl2tpd/',\n 'ipsec.conf': '/etc/',\n 'foxpass-radius-agent.conf': '/etc/',\n 'servers': '/etc/radiusclient/',\n 'pam_radius_auth.conf': '/etc/'}\n\n # initialize jinja to process conf files\n env = Environment(\n loader=FileSystemLoader('/opt/templates'),\n keep_trailing_newline=True\n )\n\n files = {}\n for (filename, dir) in file_list.items():\n path = os.path.join(dir, filename)\n template = env.get_template(filename)\n with open(path, \"w\") as f:\n rendered = template.render(**context)\n f.write(rendered)\n\n commands = ['xl2tpd', 'ipsec', 'foxpass-radius-agent']\n call(['/sbin/sysctl', '-p'])\n # set /etc/ipsec.secrets and foxpass-radius-agent.conf to be owned and only accessible by root\n # chmod 0o600 is r/w owner\n # chown 0 is set user to root\n # chown 65534 is set user to nobody:nogroup\n chmod('/etc/ipsec.secrets', 0o600)\n chown('/etc/ipsec.secrets', 0, 0)\n chmod('/etc/foxpass-radius-agent.conf', 0o600)\n chown('/etc/foxpass-radius-agent.conf', 65534, 65534)\n call('/sbin/iptables-restore < /etc/iptables.rules', shell=True)\n call('/usr/sbin/netfilter-persistent save', shell=True)\n call(['/usr/bin/systemctl', 'enable', 'ipsec.service'], shell=False)\n for command in commands:\n call(['/usr/bin/systemctl', 'stop', command], shell=False)\n call(['/usr/bin/systemctl', 'start', command], shell=False)\n\n\ndef main():\n # only allowed argument is pointer to json file on-disk or in s3\n if len(sys.argv) > 1:\n if sys.argv[1].startswith('s3:'):\n data = gather_user_data_s3(sys.argv[1])\n else:\n data = gather_user_data_file(sys.argv[1])\n else:\n data = gather_user_data_prompt()\n\n # update with machine data\n machine_data = get_machine_data()\n data.update(machine_data)\n\n # ppp won't work if the hostname can't resolve, so make sure it's in /etc/hosts\n modify_etc_hosts(data)\n config_vpn(data)\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6939040422439575,
"alphanum_fraction": 0.7055771946907043,
"avg_line_length": 21.676469802856445,
"blob_id": "fac8bd28d97c97689b7e773d7f7d15e8c4026c7e",
"content_id": "167ef4147a761f071700bfb7a8f3c6153cab7cb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 771,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 34,
"path": "/scripts/setup.sh",
"repo_name": "foxpass/foxpass-ipsec-vpn",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# quit if any command fails\nset -e\n\nmkdir -p /opt/src\ncd /opt/src\nSWAN_VER=3.31\nSWAN_FILE=\"libreswan-${SWAN_VER}.tar.gz\"\nSWAN_URL=\"https://download.libreswan.org/$SWAN_FILE\"\nwget -t 3 -T 30 -nv -O \"$SWAN_FILE\" \"$SWAN_URL\"\n/bin/rm -rf \"/opt/src/libreswan-$SWAN_VER\"\ntar xzf \"$SWAN_FILE\" && rm -f \"$SWAN_FILE\"\ncd \"libreswan-$SWAN_VER\"\n\ncat > Makefile.inc.local <<EOF\nWERROR_CFLAGS =\nEOF\n\nmake programs && make install\n\n# delete libreswan source\ncd /opt/src\nrm -rf \"libreswan-$SWAN_VER\"\n\necho > /var/tmp/libreswan-nss-pwd\n/usr/bin/certutil -N -f /var/tmp/libreswan-nss-pwd -d /etc/ipsec.d\n/bin/rm -f /var/tmp/libreswan-nss-pwd\n\ntouch /etc/ipsec.conf\ntouch /etc/iptables.rules\ntouch /etc/ipsec.secrets\ntouch /etc/ppp/options.xl2tpd\ntouch /etc/xl2tpd/xl2tpd.conf\n"
},
{
"alpha_fraction": 0.7830591201782227,
"alphanum_fraction": 0.792809247970581,
"avg_line_length": 41.07692337036133,
"blob_id": "82034a5bde534c490af323e0faf828c4f2b2bd71",
"content_id": "b3c75afae2f9c8f067cab0658576a62031b72e4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1641,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 39,
"path": "/Dockerfile",
"repo_name": "foxpass/foxpass-ipsec-vpn",
"src_encoding": "UTF-8",
"text": "FROM ubuntu:20.04\n\n#RUN mkdir /app\n#WORKDIR /app\n\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y libnss3-dev libnspr4-dev pkg-config libpam-dev \\\n libcap-ng-dev libcap-ng-utils libselinux-dev libpam-radius-auth \\\n libcurl3-nss-dev flex bison gcc make libldns-dev \\\n libunbound-dev libnss3-tools libevent-dev \\\n libsystemd-dev git devscripts build-essential fakeroot libsystemd-dev python3-pip wget xl2tpd xmlto\nRUN mkdir /tmp/foxpass-vpn\n\nCOPY scripts /tmp/foxpass-vpn/scripts\nCOPY templates /tmp/foxpass-vpn/templates\nCOPY static /tmp/foxpass-vpn/static\nCOPY foxpass-radius-agent /tmp/foxpass-vpn/foxpass-radius-agent\nCOPY requirements.txt /tmp/foxpass-vpn/requirements.txt\n\nRUN pip3 install -r /tmp/foxpass-vpn/requirements.txt\nRUN pip3 install -r /tmp/foxpass-vpn/foxpass-radius-agent/requirements.txt\n\nRUN /tmp/foxpass-vpn/scripts/setup.sh\n\nRUN mkdir /opt/bin\n\nRUN mv /tmp/foxpass-vpn/templates /opt/\nRUN mv /tmp/foxpass-vpn/scripts/config.py /opt/bin/config.py\nRUN mv /tmp/foxpass-vpn/scripts/sshd_config /etc/ssh/sshd_config\nRUN mv /tmp/foxpass-vpn/scripts/sysctl.conf /etc/sysctl.conf\n# docker does not have this directory\n# RUN mv /tmp/foxpass-vpn/scripts/iptablesload /etc/network/if-pre-up.d/iptablesload\nRUN mv /tmp/foxpass-vpn/static/radiusclient /etc\nRUN mv /tmp/foxpass-vpn/static/pluto /etc/pam.d/\nRUN mv /tmp/foxpass-vpn/foxpass-radius-agent/foxpass-radius-agent.py /usr/local/bin\nRUN mv /tmp/foxpass-vpn/foxpass-radius-agent/systemd/foxpass-radius-agent.service /lib/systemd/system/\nRUN systemctl enable foxpass-radius-agent.service\nRUN chmod 744 /opt/bin/config.py\"\n\nCMD python3 /opt/bin/config.py\n"
}
] | 5 |
duffym4/solving_minesweeper
|
https://github.com/duffym4/solving_minesweeper
|
400421f510f96248a2e82fa3aa07231eb1e088b9
|
33630a3440e042eecced5ccf7fde2ce41eb51d1c
|
96e77a4007d79e5b176aab59c00e30718851a6f8
|
refs/heads/master
| 2021-08-15T10:57:34.422990 | 2017-11-12T15:17:10 | 2017-11-12T15:17:10 | 110,366,297 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6345276832580566,
"alphanum_fraction": 0.6534202098846436,
"avg_line_length": 26.909090042114258,
"blob_id": "88b774a95fbe619ce8842b1742bbda853370eab6",
"content_id": "75c5f798b97044cfafa66c32e1f194d789b4ca73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1535,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 55,
"path": "/Board.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "import random as rand\n\nclass Board(object):\n\t\"\"\"\n\tInternal representation of the board,\n\tgrid is a list of board rows, where\n\t'True' represents a mine \n\t\"\"\"\n\n\tdef __init__(self,_ncols,_nrows,_mines):\n\t\tself.nrows = _nrows\n\t\tself.ncols = _ncols\n\t\tself.mines = _mines\n\t\tself.createBoard()\n\n\t#create a grid to represent all of the tiles\n\t#randomly place mines throughout the grid\n\tdef createBoard(self):\n\t\t#Initialize grid as a 2d list of lists\n\t\tself.grid = []\n\t\tfor y in range(0, self.nrows):\n\t\t\tself.grid.append([])\n\t\t\t#initialize all values as false\n\t\t\tfor x in range(0, self.ncols):\n\t\t\t\tself.grid[y].append(False)\n\n\t\t#randomly place self.mines number of mines throughout the grid\n\t\tfor i in range(self.mines):\n\t\t\trowPlacement = rand.randint(0,self.nrows-1)\n\t\t\tcolPlacement = rand.randint(0,self.ncols-1)\n\t\t\tplaced = False\n\t\t\twhile (not placed):\n\t\t\t\tif (not self.grid[rowPlacement][colPlacement]):\n\t\t\t\t\tself.grid[rowPlacement][colPlacement] = True\n\t\t\t\t\tplaced = True\n\t\t\t\telse:\n\t\t\t\t\t# if there is already a mine, move it\n\t\t\t\t\tif (colPlacement >= self.ncols-1):\n\t\t\t\t\t\trowPlacement += 1\n\t\t\t\t\t\tif (rowPlacement > self.nrows-1):\n\t\t\t\t\t\t\trowPlacement = 0\n\t\t\t\t\t\tcolPlacement = -1\n\t\t\t\t\tcolPlacement += 1\n\n\t#return the number of adjacent mines to this tile or 9 if it is a mine\n\tdef getCell(self, x, y):\n\t\tif self.grid[y][x]:\n\t\t\treturn 9\n\t\tmines = 0\n\t\tfor x0 in range(-1, 2):\n\t\t\tfor y0 in range (-1, 2):\n\t\t\t\tif (y + y0) in range (0, self.nrows) and (x + x0) in range(0, self.ncols):\n\t\t\t\t\tif self.grid[y+y0][x+x0]:\n\t\t\t\t\t\tmines+=1\n\t\treturn mines\n"
},
{
"alpha_fraction": 0.785977840423584,
"alphanum_fraction": 0.7970479726791382,
"avg_line_length": 32.875,
"blob_id": "111e52c565d5452786c249e47fdb1f81b85fffe7",
"content_id": "c8ecb4ef7dcecacc163fe114fa1d8479c5f2c15f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 542,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 16,
"path": "/ReadMe.txt",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "Martin Duffy\nAidan Anselmi\nAndy Soszynski\nTony Zheng\n\nNovember 12, 2017 rpi hackathon\n\nThis program simulates a fully functional game of minesweeper. The program \nalso has a help and solve buttons, the help button flagging/revealing a single \ntile and the solve button systematically flagging/revealing the entire board.\nUnfortunately due to the nature of minesweeper the helping functions can not always \nguarantee a solution, however, it does come very close to a full solution. \n\nInstallation/Running:\n-install pyglet (pip install pyglet)\n-run with python Main.py"
},
{
"alpha_fraction": 0.6312433481216431,
"alphanum_fraction": 0.6408076286315918,
"avg_line_length": 24.37837791442871,
"blob_id": "e417af7438182e3bcf71ccd5e655c0af97ab6d35",
"content_id": "f772aafef74b16731c84851abcecd372c9785551",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 941,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 37,
"path": "/Button.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "\n#class to represent \nclass Button(object): \n\tdef __init__(self, x, y, name):\n\t\t#state is 0 when pressed in, and 1 otherwise\n\t\tself.state = 1\n\t\tself.x = x\n\t\tself.y = y\n\t\tself.name = name\n\n\t\t#set to true when the button is pressed\n\t\tself.bang = False\n\n\n\tdef draw(self,images):\n\t\timages[self.name+\"-\"+str(self.state)].blit(self.x,self.y)\n\n\t#checks to see if this button was clicked on\n\tdef pressed(self, x, y, button, mouse, f):\n\t\tif self.overlap(x, y, f):\n\t\t\tself.state = 0\n\n\t#function is called when the mouse clicks as releases on this button\n\tdef released(self, x, y, button, mouse, f):\n\t\tif self.overlap(x, y, f):\n\t\t\tself.bang = True\n\t\t\tif self.name==\"play\":\n\t\t\t\tself.name = \"pause\"\n\t\t\telif self.name==\"pause\":\n\t\t\t\tself.name = \"play\"\n\n\t\tself.state = 1\n\n\t#returns if the mouse is over the button or not\n\tdef overlap(self, x, y, f):\n\t\tif x > self.x and x < self.x + 26*f and y > self.y and y < self.y + 26*f:\n\t\t\treturn True\n\t\treturn False\n\n"
},
{
"alpha_fraction": 0.49554896354675293,
"alphanum_fraction": 0.5267062187194824,
"avg_line_length": 30.428571701049805,
"blob_id": "882c34a9444ed4e437ffe8e1fd109e9a3bf15ec6",
"content_id": "ec343ab5420214384af4a88a554c338f88f6a672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 674,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 21,
"path": "/Number.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "class Number(object): \n\n def __init__(self, value, x, y):\n self.value = value\n self.x = x\n self.y = y\n\n def draw(self,images,scale):\n\n ''' determine the absolute value, integer value of the game timing '''\n i = abs(int(self.value))\n\n ''' print the two LSBs '''\n images[\"timer-\"+str(int(i%10))].blit(self.x, self.y)\n images[\"timer-\"+str(int(i/10%10))].blit(self.x-13*scale,self.y)\n\n ''' negative sign or MSB '''\n if self.value < 0:\n images[\"timer-10\"].blit(self.x-26*scale,self.y) \n else:\n images[\"timer-\"+str(int(i/100%100))].blit(self.x-26*scale,self.y) \n "
},
{
"alpha_fraction": 0.5332522392272949,
"alphanum_fraction": 0.5681264996528625,
"avg_line_length": 22.056074142456055,
"blob_id": "183c489d73a70aea5ed3961f55db04b4d017c1f9",
"content_id": "ffc77f5ea0a08899e6829ed1c22c613bd24f5ad8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2466,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 107,
"path": "/Solver.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "''' Unused File, was an attempt at using matrices as a method of solving, ended up less efficient than other methods '''\n\n\ndef findSolvableRegion(playerBoard):\n\tequation = []\n\tvariables = []\n\tfor row in range(len(playerBoard)):\n\t\tfor col in range(len(playerBoard[0])):\n\t\t\tif (playerBoard[row][col] == -1):\n\t\t\t\tvariables.append([row,col])\n\n\tpoints = []\n\tfor var in variables:\n\t\tfor x in range(var[1]-1, var[1]+2):\n\t\t\tfor y in range(var[0]-1, var[0]+2):\n\t\t\t\tif x in range(0, len(playerBoard[0])) and y in range(0, len(playerBoard)):\n\t\t\t\t\tif playerBoard[y][x] in range(1, 9):\n\t\t\t\t\t\tif not [x, y] in points:\n\t\t\t\t\t\t\tpoints.append([x, y])\n\t\t\t\t\t\t\tequation.append([])\n\t\t\t\t\t\t\tfor var2 in variables:\n\t\t\t\t\t\t\t\tif isTouching(var2[1], var2[0], x, y):\n\t\t\t\t\t\t\t\t\tequation[-1].append(1)\n\t\t\t\t\t\t\t\telse:\n\t\t\t\t\t\t\t\t\tequation[-1].append(0)\n\n\t\t\t\t\t\t\tequation[-1].append(playerBoard[y][x])\n\n\n\tprint(points)\n\n\treturn equation\n\n\ndef Gaussian(matrix):\n\n\trows = len(matrix)\n\tcols = len(matrix[0])\n\n\tfor i in range(0,min(rows, cols)):\n\n\t\t#calculate iMax\n\t\tiMax = i\n\t\tmax_val = matrix[i][i]\n\t\tfor j in range(i+1, rows):\n\t\t\tif(abs(matrix[j][i]) > max_val):\n\t\t\t\tmax_val = abs(matrix[j][i])\n\t\t\t\tiMax = j\n\n\t\t#swap rows\n\t\tfor j in range(i, rows+1):\n\t\t\tif(j>= cols):\n\t\t\t\tcontinue\n\t\t\ttmp = matrix[iMax][j]\n\t\t\tmatrix[iMax][j] = matrix[i][j]\n\t\t\tmatrix[i][j] = tmp\n\n\t\t# Make all rows below this one 0 in current column\n\t\tfor j in range(i+1, rows):\n\t\t\t#c = -matrix[j][i]/matrix[i][i]\n\t\t\tfor k in range(i, rows+1):\n\t\t\t\tif i == k:\n\t\t\t\t\tmatrix[j][k] = 0\n\t\t\t\telse:\n\t\t\t\t\tif(k >= cols):\n\t\t\t\t\t\tcontinue\n\t\t\t\t\tmatrix[j][k] += matrix[i][k] #*c\n\n\treturn matrix\n\ndef binarySolve(matrix):\n\t\"\"\"\n\tAugmented Row Reduced matrix as input\n\treturns the vector answer to Ax=b\n\tx_i=-1 if the result is underdetermined \n\t\"\"\"\n\tsolution = [-1]*(len(matrix[0])-1)\n\tfor row in matrix:\n\t\tupper, lower = (0,0)\n\t\tfor element in row[:len(matrix[0])-1]:\n\t\t\tif element == 1:\n\t\t\t\tupper += 1\n\t\t\telif element == -1:\n\t\t\t\tlower -= 1\n\t\tif (row[-1] == upper):\n\t\t\tfor i in range(len(matrix[0])-1):\n\t\t\t\tif row[i] == 1:\n\t\t\t\t\tsolution[i] = 1\n\t\t\t\telif row[i] == -1:\n\t\t\t\t\tsolution[i] = 0\n\t\tif (row[-1] == lower):\n\t\t\tfor i in range(len(matrix[0])-1):\n\t\t\t\tif row[i] == 1:\n\t\t\t\t\tsolution[i] = 0\n\t\t\t\telif row[i] == -1:\n\t\t\t\t\tsolution[i] = 1\n\treturn solution\n\nA = [[-1, 1, 0], [-1, 1, 0], [1, 1, 0]]\nA = [[-1, 2, 0], [-1, 2, 0], [1, 1, 0]]\nA = [[2, -1, 2], [3, -1, 3], [2, -1, 2]]\nQ = findSolvableRegion(A)\nprint(Q)\nGaussian(Q)\nprint(Q)\nS = binarySolve(Q)\nprint(S)"
},
{
"alpha_fraction": 0.5467255115509033,
"alphanum_fraction": 0.5621780753135681,
"avg_line_length": 29.795454025268555,
"blob_id": "7a9dc5d084c1a1806dd46d4cd84caf97028facc9",
"content_id": "b7faa59ce3c83c1727c8f07171d3a2dd04039961",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1359,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 44,
"path": "/Tile.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "\n#Representation of a single tile on the board\nclass Tile(object):\n def __init__ (self, x_, y_, flagCounter_):\n self.x = x_\n self.y = y_\n self.flagCounter = flagCounter_\n\n self.value = -1\n self.imageKey = \"blank\"\n \n #changes a tile's value and as a result its imageKey\n def activate(self, value):\n self.value = value\n self.updateImages()\n\n #change the imageKey to its corisponding value\n def updateImages(self):\n if self.imageKey == 'flag':\n self.flagCounter.value+=1\n\n if self.value in range(0,9):\n self.imageKey = 'number-' + str(self.value)\n elif self.value == 9:\n self.imageKey = 'mine-0'\n elif self.value == -2:\n self.imageKey = 'flag'\n elif self.value == -3:\n self.imageKey = 'unknown'\n elif self.value == -1:\n self.imageKey = 'blank'\n\n if self.imageKey == 'flag':\n self.flagCounter.value-=1\n\n #cycle value between unmarked, flag and question mark\n def rotateMarking(self):\n self.value -= 1\n if self.value == -4:\n self.value = -1\n self.updateImages()\n\n #draw the tile according to its imageKey\n def draw(self, x0, y0, images, scale):\n images[self.imageKey].blit(x0 + self.x*16*scale, y0 + 16*scale*self.y)\n\n\n\n"
},
{
"alpha_fraction": 0.6340621113777161,
"alphanum_fraction": 0.6498849391937256,
"avg_line_length": 30.04464340209961,
"blob_id": "b6227d14b5be7f0e100504a4045ce0ec9e1a61fa",
"content_id": "792c5357504f9e29eb981839a2a12e81ee6c5907",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3476,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 112,
"path": "/PlayerBoard.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "from Tile import *\n\nclass PlayerBoard(object):\n\t\"\"\"\n\tDisplay available to the player\n\t\"\"\"\n\tdef __init__(self, board_, x0_, y0_, timer_, smile_, flagCounter_):\n\t\tself.grid = []\n\t\tself.board = board_\n\t\tself.nrows = self.board.nrows\n\t\tself.ncols = self.board.ncols\n\t\tself.mines=self.board.mines\n\t\tself.x0 = x0_\n\t\tself.y0 = y0_\n\t\tself.timer = timer_\n\t\tself.smile = smile_\n\t\tself.flagCounter = flagCounter_\n\t\tself.createBoard()\n\n\t''' reset all values for starting the game, and create a blank board '''\n\tdef createBoard(self):\n\t\tself.boardCounter=0\n\t\tself.gameOver = False\n\t\tself.gameWon = False\n\t\tself.grid = []\n\t\tfor y in range(0, self.nrows):\n\t\t\tself.grid.append([])\n\t\t\tfor x in range(0, self.ncols):\n\t\t\t\tself.grid[y].append(Tile(x, y, self.flagCounter))\n\t\t\n\t''' called when a tile is overturned, either by clicking, a hint, or by the recursive unfolding of tiles which touch no bombs '''\n\tdef activate(self, x, y, userClicked=False):\n\n\t\t''' ensure the tile is one which may be pressed '''\n\t\tif self.grid[y][x].value >= 0:\n\t\t\treturn\n\n\t\t''' activate the individual tile object '''\n\t\tself.grid[y][x].activate(self.board.getCell(x,y))\n\n\t\t''' increase the board counter (used to check whether the board is complete) '''\n\t\tself.boardCounter+=1\n\n\t\t''' if this function was called directly, not recursively, check win/loss conditions '''\n\t\tif userClicked:\n\t\t\tself.checkwin()\n\t\t\tif self.grid[y][x].value==9:\n\t\t\t\tself.loseGame(x, y)\n\n\t\t''' if this reveals a tile touching no bombs, recursively unfold the surrounding tiles '''\n\t\tif self.grid[y][x].value == 0:\n\t\t\tfor x0 in range(-1, 2):\n\t\t\t\tfor y0 in range (-1, 2):\n\t\t\t\t\tif (y + y0) in range (0, self.nrows) and (x + x0) in range(0, self.ncols):\n\t\t\t\t\t\tif self.grid[y+y0][x+x0].value == -1:\n\t\t\t\t\t\t\tself.activate(x+x0, y+y0)\n\n\t''' check win conditions '''\n\tdef checkwin(self):\n\t\tif self.boardCounter==self.nrows*self.ncols-self.mines:\n\t\t\tself.smile.win()\n\t\t\tself.gameWon = True\n\t\t\tself.timer.stop()\n\t\t\t\n\t''' draw each tile object '''\n\tdef draw(self, images, scale):\n\t\tfor y in range(0, self.nrows):\n\t\t\tfor x in range(0, self.ncols):\n\t\t\t\tself.grid[y][x].draw(self.x0, self.y0, images, scale)\n\n\t''' set marking to 1=blank, 2=flag, 3=unkown '''\n\tdef setMarking(self, x, y, mark):\n\t\tif self.grid[y][x].value < 0:\n\t\t\tself.grid[y][x].value = -2\n\t\t\tself.grid[y][x].updateImages()\n\n\t''' attempt to reveal a bomb (called after the player loses, used to show remaining bombs) '''\n\tdef revealBomb(self, x, y, flag):\n\t\tself.grid[y][x].value = 9\n\t\tself.grid[y][x].updateImages()\n\t\tif flag:\n\t\t\tself.grid[y][x].imageKey = \"mine-1\"\n\n\t''' called when mouse is released '''\n\tdef mouse(self, x, y, button, mouse, f):\n\n\t\tif self.gameOver or self.gameWon:\n\t\t\treturn\n\n\t\t''' get the tile that the mouse is hovering '''\n\t\tgridX = int((x-self.x0)/(16*f))\n\t\tgridY = int((y-self.y0)/(16*f))\n\n\t\tif not (gridX in range(0, self.ncols) and gridY in range(0, self.nrows)):\n\t\t\treturn\n\n\t\tif button == mouse.LEFT:\n\t\t\tself.activate(gridX, gridY, userClicked=True)\n\n\t\telif button == mouse.RIGHT and self.grid[gridY][gridX].value < 0:\n\t\t\tself.grid[gridY][gridX].rotateMarking()\n\t\t\n\t''' react to a loss by revealing bombs and setting states / stopping timers '''\n\tdef loseGame(self, x, y):\n\t\tself.gameOver = True\n\t\tself.smile.state = 3\n\t\tself.grid[y][x].imageKey = \"mine-2\"\n\t\tself.timer.stop()\n\t\tfor i in range(0,self.nrows):\n\t\t\tfor j in range(0,self.ncols):\n\t\t\t\tif self.board.getCell(j,i)==9 and self.grid[i][j].value < 0:\n\t\t\t\t\tself.revealBomb(j, i, self.grid[i][j].value < -1)"
},
{
"alpha_fraction": 0.5753353834152222,
"alphanum_fraction": 0.5804953575134277,
"avg_line_length": 30.57377052307129,
"blob_id": "dc2877e8d47a2ad4b66f72f6f65102d6a8157546",
"content_id": "15f45e0f1ac63dcc2341252899ba9156e4ab0321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1938,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 61,
"path": "/Timer.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "import datetime\nimport time\nfrom Number import *\nfrom SingleStepSolver import *\nfrom Button import *\n\n\nclass Timer(object): \n def __init__(self, x, y, f):\n self.x = x\n self.y = y\n self.f = f\n self.runButton = Button(self.x - 26*self.f, self.y, \"play\")\n self.helpButton = Button(self.x + 2*26*self.f, self.y, \"help\")\n self.automatic = False\n self.start()\n\n ''' reset timer and set running to true '''\n def start(self):\n self.time = Number(0, self.x, self.y)\n self.running=True\n return self.time.value\n\n ''' only update when timer should be running .. '''\n def update(self,dt):\n if self.running:\n\n ''' if the runbutton was pressed, toggle automatic '''\n if self.runButton.bang:\n self.automatic = not self.automatic\n self.runButton.bang = False\n\n\n ''' if the helpbutton was pressed, display hint '''\n if self.helpButton.bang:\n SingleStepSolver(self.playerBoard)\n self.helpButton.bang = False\n\n ''' increment timer, call a new hint if automatic mode is on '''\n self.time.value = min(999,self.time.value+.1)\n if self.automatic:\n if SingleStepSolver(self.playerBoard) == \"stop\":\n self.automatic = False\n\n def stop(self):\n self.running=False\n\n ''' pass mouse queues to buttons '''\n def pressed(self, x, y, button, mouse, f):\n self.runButton.pressed(x, y, button, mouse, f)\n self.helpButton.pressed(x, y, button, mouse, f)\n\n def released(self, x, y, button, mouse, f):\n self.runButton.released(x, y, button, mouse, f)\n self.helpButton.released(x, y, button, mouse, f)\n\n ''' draw all included objects '''\n def draw(self,images):\n self.time.draw(images, self.f)\n self.runButton.draw(images)\n self.helpButton.draw(images)\n "
},
{
"alpha_fraction": 0.5909926295280457,
"alphanum_fraction": 0.6084558963775635,
"avg_line_length": 24.255813598632812,
"blob_id": "632bf2e3deb29b3e4de0408dcb2ab0a8db030636",
"content_id": "ad413ff8aef890da56b7efd66c1054621ea9c554",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1088,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 43,
"path": "/Smile.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "\nclass Smile(object): \n\n\tdef __init__(self, x, y):\n\t\tself.state = 1\n\t\tself.x = x\n\t\tself.y = y\n\t\tself.reset = False\n\n\t''' draws the appropriate smile image '''\n\tdef draw(self,images):\n\t\timages['smile-'+str(self.state)].blit(self.x,self.y)\n\n\t''' show the button pressed down when clicked '''\n\tdef mouse(self, x, y, button, mouse, f):\n\t\tif x > self.x and x < self.x + 26*f and y > self.y and y < self.y + 26*f:\n\t\t\tself.state = 0\n\n\t''' mouse pressed '''\n\tdef pressed(self, x, y, button, mouse, f):\n\t\tif self.overlap(x, y, f):\n\t\t\tself.state = 0\n\t\telif self.state == 1:\n\t\t\tself.state = 2\n\n\t''' mouse released '''\n\tdef released(self, x, y, button, mouse, f):\n\t\tif self.state == 0 and self.overlap(x, y, f):\n\t\t\tself.reset = True\n\t\tif self.state == 2 or self.state == 0:\n\t\t\tself.state = 1\n\n\t''' win/lose functions for readability when setting smile state '''\n\tdef win(self):\n\t\tself.state=4\n\n\tdef lose(self):\n\t\tself.state=3\n\n\t''' checks for mouse over smile '''\n\tdef overlap(self, x, y, f):\n\t\tif x > self.x and x < self.x + 26*f and y > self.y and y < self.y + 26*f:\n\t\t\treturn True\n\t\treturn False\n\n"
},
{
"alpha_fraction": 0.6548869609832764,
"alphanum_fraction": 0.6905444264411926,
"avg_line_length": 37.77777862548828,
"blob_id": "9da7d65839b2f92d11c02c0f4c8a97f630f8335f",
"content_id": "4b03378e6dc1d57c76466c97698a467599874183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3141,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 81,
"path": "/Main.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "import pyglet\nfrom Board import *\nfrom PlayerBoard import *\nfrom Timer import *\nfrom Smile import *\nfrom SingleStepSolver import *\n\n''' Board Initialization '''\nboard = Board(30, 16, 99)\n\n''' Window and Scaling '''\nspriteSheet = pyglet.image.load('images/sprites.png')\nf = int(spriteSheet.width/235) # The factor by which sprites are scaled up\ns = f*16\t\t\t\t\t # The size of a tile, given the scaling factor\nwindow = pyglet.window.Window(caption=\"Solving Minesweeper\", width=s*(2+board.ncols), height=s*(4+board.nrows))\n\n''' Initializing Classes '''\ntimer = Timer(window.width-s-13*f, window.height - 3*s + 13*f, f)\nsmile = Smile((window.width-26*f)/2, window.height - 3*s + 13*f)\ntimer.runButton.x = (window.width-26*f)/2 - 39*f\ntimer.helpButton.x = (window.width-26*f)/2 + 39*f\nflagCounter = Number(board.mines, s + 2*13*f, window.height - 3*s + 13*f)\nplayerBoard = PlayerBoard(board, s, s, timer, smile, flagCounter)\ntimer.playerBoard = playerBoard\n\n''' Image Initialization '''\nimages = {}\nimages['flag'] = pyglet.image.load('images/sprites.png').get_region(x=4*s, y=s*3+f, width=s, height=s)\nimages['unknown'] = pyglet.image.load('images/sprites.png').get_region(x=3*s, y=s*3+f, width=s, height=s)\nimages['blank'] = pyglet.image.load('images/sprites.png').get_region(x=5*s, y=s*3+f, width=s, height=s)\n\nfor i in range(0, 3):\n\timages['mine-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=s*i, y=s*3+f, width=s, height=s)\nfor i in range(0, 9):\n\timages['number-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=s*i, y=s*4+1, width=s, height=s)\nfor i in range(0, 11):\n\timages['timer-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=13*i*f, y=26*f, width=13*f, height=23*f)\nfor i in range(0, 5):\n\timages['smile-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=26*f*i,y=0,width=26*f,height=26*f)\nfor i in range(0, 2):\n\timages['pause-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=26*f*5+26*f*i,y=0,width=26*f,height=26*f)\nfor i in range(0, 2):\n\timages['play-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=26*f*7+26*f*i,y=0,width=26*f,height=26*f)\nfor i in range(0, 2):\n\timages['help-'+str(i)] = pyglet.image.load('images/sprites.png').get_region(x=26*f*7+26*f*i,y=26*f,width=26*f,height=26*f)\n\n\n''' Events '''\[email protected]\ndef on_draw():\n\twindow.clear()\n\tplayerBoard.draw(images, f)\n\ttimer.draw(images)\n\tsmile.draw(images)\n\tflagCounter.draw(images, f)\n\[email protected]\ndef on_mouse_release(x, y, button, modifiers):\n\tplayerBoard.mouse(x, y, button, pyglet.window.mouse, f)\n\tsmile.released(x, y, button, pyglet.window.mouse, f)\n\ttimer.released(x, y, button, pyglet.window.mouse, f)\n\tif smile.reset:\n\t\tresetGame()\n\[email protected]\ndef on_mouse_press(x, y, button, modifiers):\n\tsmile.pressed(x, y, button, pyglet.window.mouse, f)\n\ttimer.pressed(x, y, button, pyglet.window.mouse, f)\n\n''' Reset Game '''\ndef resetGame():\n\tsmile.reset = False\n\tboard.createBoard()\n\tplayerBoard.createBoard()\n\ttimer.time.value = 0\n\ttimer.running = True\n\tflagCounter.value = board.mines\n\n''' Startup '''\npyglet.clock.schedule_interval(timer.update, .1)\npyglet.app.run() "
},
{
"alpha_fraction": 0.679154634475708,
"alphanum_fraction": 0.6978866457939148,
"avg_line_length": 34.589744567871094,
"blob_id": "7c30c77bca67c138106dffe70f393e45563adc9b",
"content_id": "f1d5ede236aeef64041ae8f6752fb934a32967f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4164,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 117,
"path": "/SingleStepSolver.py",
"repo_name": "duffym4/solving_minesweeper",
"src_encoding": "UTF-8",
"text": "\n#count how many of an unmarked tiles and flags are adjacent tiles to the \n#input x and y value\ndef getBombOptions(x0, y0, board):\n\trows = board.nrows\n\tcols = board.ncols\n\tvalue = -1\n\n\toptions = []\n\tflagCount = 0\n\n\tfor x in range(x0-1, x0+2):\n\t\tfor y in range(y0-1, y0+2):\n\t\t\t#do not count self\n\t\t\tif x != x0 or y != y0:\n\t\t\t\t#make sure we are in range of the board\n\t\t\t\tif x in range(0, cols) and y in range(0, rows):\n\t\t\t\t\tif board.grid[y][x].value == value:\n\t\t\t\t\t\toptions.append([x, y])\n\t\t\t\t\telif board.grid[y][x].value == -2:\n\t\t\t\t\t\tflagCount += 1\n\n\treturn options, flagCount\n\n\n#mark tiles with flags next to x, y input if trivial solution possible\n#also build the ranges list\ndef MarkFlags(x, y, board, ranges):\n\toptions, count = getBombOptions(x, y, board)\n\tif len(options) > 0:\n\t\tranges.append([[x, y], options, count])\n\t\t#mark a tile from options list if the tile value = num unmarked tiles + num flags\n\t\tif(board.grid[y][x].value == count+len(options)):\n\t\t\tboard.setMarking(options[0][0], options[0][1], 2)\n\t\t\treturn True\n\treturn False\n\n\n#reveal tiles next to x, y input if trivial solution possible\ndef ActivateTiles(x, y, board):\n\toptions, count = getBombOptions(x, y, board)\n\t#reveal an adjacent unmarked tile if the tile value equals the number of adjacent flags\n\tif(board.grid[y][x].value == count and len(options) > 0):\n\t\tboard.activate(options[0][0], options[0][1], userClicked=True)\n\t\treturn True\n\treturn False\n\n\n#return true if the two positions are adjacent\ndef isTouching(x1, y1, x2, y2):\n\treturn abs(x1-x2)<2 and abs(y1-y2)<2\n\n#returns the number of adjacent unmarked flags for a tile\ndef minesLeft(x, y, playerBoard, flags):\n\treturn playerBoard.grid[y][x].value - flags\n\n#places a single flag or reveals a single tile\ndef SingleStepSolver(playerBoard):\n\n\trows = len(playerBoard.grid)\n\tcols = len(playerBoard.grid[0])\n\n\t#ranges stores a list of ranges that mines could be placed in\n\t#ranges[i][0] returns a tuple of ranges[i] position\n\t#ranges[i][1] returns all possible positions for mines adjacent to ranges[i][0]\n\t#ranges[i][2] returns the number of flags adjacent to ranges[i][0]\n\tranges = []\n\n\t#look for trivial solutions\n\tfor i in range(0, rows):\n\t\tfor j in range(0, cols):\n\t\t\t#skip tile if it is not yet revealed\n\t\t\tif (playerBoard.grid[i][j].value in range(-3, 1)):\n\t\t\t\tcontinue\n\t\t\tif(MarkFlags(j, i, playerBoard, ranges)):\n\t\t\t\treturn\n\t\t\tif(ActivateTiles(j, i, playerBoard)):\n\t\t\t\treturn\n\n\t#use ranges that mines can be in to calculate solutions\n\tfor i in range(0, len(ranges)):\n\t\tiPosition = ranges[i][0]\n\t\tiOptions = ranges[i][1]\n\t\tiFlags = ranges[i][2]\n\t\t#compare the ranges[i] to all elements in ranges\n\t\tfor j in range(len(ranges)):\n\t\t\t#skip self\n\t\t\tif(i == j):\n\t\t\t\tcontinue\n\n\t\t\tjPosition = ranges[j][0]\n\t\t\tjOptions = ranges[j][1]\n\t\t\tjFlags = ranges[j][2]\n\n\t\t\t#count the number of ranges that ranges[i] and ranges[j] share all values of\n\t\t\tshared = 0\n\t\t\tnotSharedRange = iOptions.copy()\n\t\t\tfor space in jOptions:\n\t\t\t\tif isTouching(space[0], space[1], iPosition[0], iPosition[1]):\n\t\t\t\t\tshared+=1\n\t\t\t\t\tnotSharedRange.remove(space)\n\n\t\t\t#the minimum number of mines that ranges[i] and ranges[j] share = NumSharedAdjacentPositions - NumPossibleJMinePositions + NumMinesUnrevieled \n\t\t\tmineCount = shared - len(jOptions) + minesLeft(jPosition[0], jPosition[1], playerBoard, jFlags)\n\n\t\t\t#if we know the ranges where all adjacent remaining mines are, reveal an adjacent tile\n\t\t\tif(mineCount == minesLeft(iPosition[0], iPosition[1], playerBoard, iFlags)):\n\t\t\t\tfor space in notSharedRange:\n\t\t\t\t\tplayerBoard.activate(space[0], space[1], userClicked=True)\n\t\t\t\t\treturn\n\n\t\t\t#if we know the minimum number of mines is in an overlap and that \n\t\t\t#the number of tiles out of the overlap is equal to the number of mines out of the overlap flag one of the tiles out of the overlap\n\t\t\tif min(min(minesLeft(jPosition[0], jPosition[1], playerBoard, jFlags), minesLeft(iPosition[0], iPosition[1], playerBoard, iFlags)), shared) == mineCount:\n\t\t\t\tif(mineCount == minesLeft(iPosition[0], iPosition[1], playerBoard, iFlags) - len(notSharedRange) and mineCount>0):\n\t\t\t\t\tfor space in notSharedRange:\n\t\t\t\t\t\tplayerBoard.setMarking(space[0], space[1], 2)\n\t\t\t\t\t\treturn"
}
] | 11 |
codezerro/Django-Dev-To-Development-2
|
https://github.com/codezerro/Django-Dev-To-Development-2
|
fc727d72fea3af19e15bc42429a50e159760252b
|
5e0780d2bdd8d3c5526a7cf813b14216336ed5f2
|
4f2dd2feb3d7a62c382534a563e4d823a324e5d9
|
refs/heads/master
| 2022-12-21T23:29:35.655252 | 2020-09-22T02:31:49 | 2020-09-22T02:31:49 | 296,371,171 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6033898591995239,
"alphanum_fraction": 0.6033898591995239,
"avg_line_length": 17.66666603088379,
"blob_id": "14eebb9b487823d61c7e6a72f937d574b20da31f",
"content_id": "a6afbfbbc3cc50e4220356d4e6d56975404911eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 295,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 15,
"path": "/src/listings/urls.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.urls import path\r\n\r\nfrom listings.views import (\r\n search,\r\n listings,\r\n listing\r\n)\r\n\r\napp_name = \"listings\"\r\n\r\nurlpatterns = [\r\n path('', listings, name=\"listings\"),\r\n path('<int:listing_id>', listing, name=\"listing\"),\r\n path('search/', search, name='search')\r\n]\r\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.625,
"avg_line_length": 20.22222137451172,
"blob_id": "e11834a5e63cf4ee0c84b3614efd3cc7b4639fa3",
"content_id": "4160d63f9029555d1c20388717584e59f3dfecda",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 9,
"path": "/src/pages/urls.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.urls import include, path\r\nfrom pages.views import (index, about)\r\n\r\napp_name = \"pages\"\r\n\r\nurlpatterns = [\r\n path('', index, name=\"index\"),\r\n path('about/', about, name=\"about\")\r\n]\r\n"
},
{
"alpha_fraction": 0.5129151344299316,
"alphanum_fraction": 0.5479704737663269,
"avg_line_length": 22.636363983154297,
"blob_id": "f38da88c813469862ed5f234f807c517d84ab467",
"content_id": "a4e3cc3c1ffd6b099cf4a006f1398c0bf45d190e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 22,
"path": "/src/imgUpload/migrations/0002_auto_20200922_0803.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.1.1 on 2020-09-22 02:03\r\n\r\nfrom django.db import migrations, models\r\n\r\n\r\nclass Migration(migrations.Migration):\r\n\r\n dependencies = [\r\n ('imgUpload', '0001_initial'),\r\n ]\r\n\r\n operations = [\r\n migrations.RemoveField(\r\n model_name='imgcompress',\r\n name='photo_main',\r\n ),\r\n migrations.AddField(\r\n model_name='imgcompress',\r\n name='img',\r\n field=models.ImageField(blank=True, upload_to='imgupload/compress/'),\r\n ),\r\n ]\r\n"
},
{
"alpha_fraction": 0.6815286874771118,
"alphanum_fraction": 0.6815286874771118,
"avg_line_length": 20.428571701049805,
"blob_id": "99f183b5e6d57a673171292c57682635bd293c82",
"content_id": "5abc7127bfb4e68d1553198f6718548d565172ab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 157,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 7,
"path": "/src/imgUpload/urls.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.urls import path\r\nfrom .views import (imgCompress)\r\n\r\napp_name = \"imgupload\"\r\nurlpatterns = [\r\n path('', imgCompress, name=\"imgcompress\")\r\n]\r\n"
},
{
"alpha_fraction": 0.8015267252922058,
"alphanum_fraction": 0.8015267252922058,
"avg_line_length": 30.75,
"blob_id": "2912b71a3a6a4a4dac09f69f580dc83d05546f5e",
"content_id": "59e5b8930f717fb5b0691fedd91449c635035179",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 4,
"path": "/src/imgUpload/admin.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom .models import Imgcompress\r\n# Register your models here.\r\nadmin.site.register(Imgcompress)\r\n"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7931034564971924,
"avg_line_length": 28,
"blob_id": "10c9f2c684c6779aab134b886c7e94281d8ec451",
"content_id": "164b06edf299d7e81a5812e58a7fa8ced2931f76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 2,
"path": "/README.md",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "# Django-Dev-To-Development-2\nDjango-Dev-To-Development-2\n"
},
{
"alpha_fraction": 0.8015267252922058,
"alphanum_fraction": 0.8015267252922058,
"avg_line_length": 30.75,
"blob_id": "123a1d622a1c143fa0d895652627b1def5f46a59",
"content_id": "e37c25b7797f7b6c0b2c4c75bef54d019bd3c532",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 4,
"path": "/src/listings/admin.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom listings.models import Listing\r\n# Register your models here.\r\nadmin.site.register(Listing)\r\n"
},
{
"alpha_fraction": 0.572549045085907,
"alphanum_fraction": 0.5960784554481506,
"avg_line_length": 24.842105865478516,
"blob_id": "28e734f972085a5c4543ec848173f9271520ceb5",
"content_id": "bb7f72f33a6dc494490481d84bfb378cfca5789b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 510,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 19,
"path": "/src/imgUpload/models.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.db import models\r\nfrom PIL import Image\r\n\r\n# Create your models here.\r\n\r\n\r\nclass Imgcompress(models.Model):\r\n img = models.ImageField(\r\n upload_to=\"imgupload/compress/\", blank=True)\r\n\r\n def save(self):\r\n super().save() # saving image first\r\n\r\n image = Image.open(self.img.path) # Open image using self\r\n\r\n if image.height > 300 or image.width > 300:\r\n new_img = (300, 300)\r\n image.thumbnail(new_img)\r\n image.save(self.img.path)\r\n"
},
{
"alpha_fraction": 0.7127659320831299,
"alphanum_fraction": 0.7127659320831299,
"avg_line_length": 16.799999237060547,
"blob_id": "677e18b1e15c0710d11f03dc07d481b7a7c856a7",
"content_id": "fc62448f95f612ab5729d82efb636f5001697854",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 94,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 5,
"path": "/src/basmoti/apps.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\r\n\r\n\r\nclass BasmotiConfig(AppConfig):\r\n name = 'basmoti'\r\n"
},
{
"alpha_fraction": 0.8015267252922058,
"alphanum_fraction": 0.8015267252922058,
"avg_line_length": 30.75,
"blob_id": "43c27be09113b6f867a98258b33c4c2afdab5243",
"content_id": "32b55fbde5543367ad3a76ed87a0f1765dcb86f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 4,
"path": "/src/realtors/admin.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom realtors.models import Realtor\r\n# Register your models here.\r\nadmin.site.register(Realtor)\r\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 23.14285659790039,
"blob_id": "370540b7d3680418b76aaaba6858a1277ff465ca",
"content_id": "9211fa1cfe5748232894a08bdd38f27b2e505111",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 176,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 7,
"path": "/src/basmoti/views.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\r\n# fromm django.http import h\r\n# Create your views here.\r\n\r\n\r\ndef basmoti_home(request):\r\n return render(request, 'basmoti/index.html')\r\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 20.714284896850586,
"blob_id": "0cbab0808b47ac5088a8680c6a6e80d3a1c759d8",
"content_id": "7a950c98ad0a1cbca752ef76b9be0a2e172d4e35",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 159,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 7,
"path": "/src/basmoti/urls.py",
"repo_name": "codezerro/Django-Dev-To-Development-2",
"src_encoding": "UTF-8",
"text": "from django.urls import path\r\nfrom basmoti.views import (basmoti_home)\r\napp_name = \"basmoti\"\r\n\r\nurlpatterns = [\r\n path('', basmoti_home, name=\"b_home\")\r\n]\r\n"
}
] | 12 |
zhunk/hrns_landing
|
https://github.com/zhunk/hrns_landing
|
925707a42a21c00eb3e8e5cfbd4acbb1dcb9376e
|
72aa65d750738ec24c7572374536d2457c978b53
|
e31e6ca2fd62d34ef0a7be02b268a213c0f90f94
|
refs/heads/master
| 2022-12-17T20:08:53.791712 | 2020-09-26T08:52:53 | 2020-09-26T08:52:53 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5722213387489319,
"alphanum_fraction": 0.629279375076294,
"avg_line_length": 32.828041076660156,
"blob_id": "219010ccc58b208efc09b69aa3d3cc145774f6dd",
"content_id": "c7b764bdfa887901a37d6d606adfda92d486c761",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13058,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 378,
"path": "/tools/drawTraj.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport systems as sys\nfrom matplotlib import rcParams\n\n# matplotlib.use(\"pgf\")\n# pgf_config = {\n# \"font.family\":'serif',\n# \"font.size\": 10,\n# \"pgf.rcfonts\": False,\n# \"text.usetex\": True,\n# \"pgf.preamble\": [\n# r\"\\usepackage{unicode-math}\",\n# #r\"\\setmathfont{XITS Math}\", \n# # 这里注释掉了公式的XITS字体,可以自行修改\n# r\"\\setmainfont{Times New Roman}\",\n# r\"\\usepackage{xeCJK}\",\n# r\"\\xeCJKsetup{CJKmath=true}\",\n# r\"\\setCJKmainfont{SimSun}\",\n# ],\n# }\n# # rcParams.update(pgf_config)\n######################## 自定义函数 ######################\ndef quat2euler(quat):\n q0 = quat[0]\n q1 = quat[1]\n q2 = quat[2]\n q3 = quat[3]\n yaw = math.atan(round(2.0 * (q1 * q2 - q0 * q3) / (q0 * q0 + q1 * q1 - q2 * q2 - q3 * q3), 6))\n pitch = math.asin(round(-2.0 * (q0 * q2 + q1 * q3), 6))\n roll = math.atan(2.0 * (q2 * q3 - q0 * q1) / (q0 * q0 + q3 * q3 - q2 * q2 - q1 * q1))\n return [roll, pitch, yaw]\n###################### 读取标称轨迹数据(csv格式) ########################\ntraj_data = pd.read_csv('../data/stdTraj/caGeo.csv').values\n# imu_data = pd.read_csv('../data/stdTraj/caGeoImu.csv').values\nimu_data = pd.read_csv('../data/sensorSimData/imuData.csv').values\nned_data = pd.read_csv('../data/stdTraj/posNED.csv').values\nned_data_imu = pd.read_csv('../data/sensorSimData/posNED.csv').values\n# beacon_location = pd.read_csv('/home/yuntian/dataset/simulator/lander/beacon_location.csv').values\n###################### 提取各数据序列(注意python切片不包括尾部) ####################\ntime_series = traj_data[:,0]\npos = traj_data[:,1:4]\nquat = traj_data[:,4:8] \neuler = traj_data[:,8:11]\nvel = traj_data[:,11:14]\ngyr = traj_data[:,14:17]\nacc = traj_data[:,17:20]\n\ntime_imu = imu_data[:,0]\npos_imu = imu_data[:,1:4]\nquat_imu = imu_data[:,4:8]\neuler_imu = imu_data[:,8:11]\nvel_imu = imu_data[:,11:14]\ngyr_imu = imu_data[:,14:17]\nacc_imu = imu_data[:,17:20]\n\nned_data = ned_data / 1000.\nned_data_imu = ned_data_imu / 1000.\n\nN = len(ned_data[:,0])\ndownRange = np.zeros(N)\ndownRangeImu = np.zeros(N)\nfor i in range(0, N): \n downRange[i] = math.sqrt(ned_data[i,0] * ned_data[i,0] + ned_data[i,1] * ned_data[i,1])\n downRangeImu[i] = math.sqrt(ned_data_imu[i,0] * ned_data_imu[i,0] + ned_data_imu[i,1] * ned_data_imu[i,1])\n######################### 画图 #########################\n# 图注使用$$开启数学环境\nlabels = ['trajectory','IMU']\n# labels = ['标称轨迹','IMU轨迹']\ncolors = ['tab:blue','tab:red']\n###### figure1 #####\nfig1, axes = plt.subplots(3, 1,figsize=(7,5))\nfig1.subplots_adjust(hspace=0.5)\n## 子图1\n# axes[0].plot(time_series, acc[:,0], color=colors[0], lw=2)\n# axes[0].plot(time_series, acc_imu[:,0], color=colors[1])\naxes[0].plot(time_series, acc[:,2] - acc_imu[:,2], color=colors[0], lw=2)\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-3, 3)\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('$a_x$($m/s^2$)')\n# axes[0].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\n# axes[1].plot(time_series, acc[:,1], color=colors[0], lw=2)\n# axes[1].plot(time_series, acc_imu[:,1], color=colors[1])\naxes[1].plot(time_series, acc[:,2] - acc_imu[:,2], color=colors[0], lw=2)\n# axes[1].set_xlim(0, 220)\naxes[1].set_ylim(-3, 3)\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('$a_y$($m/s^2$)')\n# axes[1].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\n# axes[2].plot(time_series, acc[:,2], color=colors[0], lw=2)\n# axes[2].plot(time_series, acc_imu[:,2], color=colors[1])\naxes[2].plot(time_series, acc[:,2] - acc_imu[:,2], color=colors[0], lw=2)\n# axes[2].set_xlim(0, 220)\naxes[2].set_ylim(-3, 3)\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('$a_z$($m/s^2$)')\n# axes[2].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig1.savefig('acc.pdf', format='pdf')\n# ##### figure2 #####\nfig2, axes = plt.subplots(3, 1,figsize=(7,5))\nfig2.subplots_adjust(hspace=0.5)\n## 子图1\n# axes[0].plot(time_series, gyr[:,0], color=colors[0], lw=2)\n# axes[0].plot(time_series, gyr_imu[:,0], color=colors[1])\naxes[0].plot(time_series, gyr[:,0] - gyr_imu[:,0], color=colors[0], lw=2)\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.075, 0.075)\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('$\\omega_x$(rad/s)')\n# axes[0].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\n# axes[1].plot(time_series, gyr[:,1], color=colors[0], lw=2)\n# axes[1].plot(time_series, gyr_imu[:,1], color=colors[1])\naxes[1].plot(time_series, gyr[:,1] - gyr_imu[:,1], color=colors[0], lw=2)\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.075, 0.075)\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('$\\omega_y$(rad/s)$')\n# axes[1].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\n# axes[2].plot(time_series, gyr[:,2], color=colors[0], lw=2)\n# axes[2].plot(time_series, gyr_imu[:,2], color=colors[1])\naxes[2].plot(time_series, gyr[:,2] - gyr_imu[:,2], color=colors[0], lw=2)\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.075, 0.075)\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('$\\omega_z$(rad/s)')\n# axes[2].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig2.savefig('gyr.pdf', format='pdf')\n##### figure3 #####\nfig3, axes = plt.subplots(3, 1,figsize=(7,5))\nfig3.subplots_adjust(hspace=0.5)\npos[:,0] = pos[:,0] / math.pi * 180. # latitude\npos[:,1] = pos[:,1] / 1000. # altitude\npos[:,2] = pos[:,2] / math.pi * 180. # longitude\n\npos_imu[:,0] = pos_imu[:,0] / math.pi * 180.\npos_imu[:,1] = pos_imu[:,1] / 1000.\npos_imu[:,2] = pos_imu[:,2] / math.pi * 180\n## 子图1\naxes[0].plot(time_series, pos[:,0], color=colors[0], lw=2)\naxes[0].plot(time_series, pos_imu[:,0], color=colors[1], lw=2)\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('t(s)')\n# axes[0].set_ylabel('纬度(deg)')\naxes[0].set_ylabel('lat(deg)')\naxes[0].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, pos[:,2], color=colors[0], lw=2)\naxes[1].plot(time_series, pos_imu[:,2], color=colors[1], lw=2)\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('lon(deg)')\n# axes[1].set_ylabel('经度(deg)')\naxes[1].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, pos[:,1], color=colors[0], lw=2)\naxes[2].plot(time_series, pos_imu[:,1], color=colors[1], lw=2)\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('alt(km)')\n# axes[2].set_ylabel('高程(km)')\naxes[2].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig3.savefig('pos.pdf', format='pdf')\n\n##### figure4 #####\nfig4, axes = plt.subplots(3, 1,figsize=(7,5))\nfig4.subplots_adjust(hspace=0.5)\n\n## 子图1\naxes[0].plot(time_series, vel[:,0], color=colors[0], lw=2)\naxes[0].plot(time_series, vel_imu[:,0], color=colors[1], lw=2)\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('$v_N$(m/s)')\naxes[0].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, vel[:,1], color=colors[0], lw=2)\naxes[1].plot(time_series, vel_imu[:,1], color=colors[1], lw=2)\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('$v_U$(m/s)')\naxes[1].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, vel[:,2], color=colors[0], lw=2)\naxes[2].plot(time_series, vel_imu[:,2], color=colors[1], lw=2)\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('$v_E$(m/s)')\naxes[2].legend(labels)\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig4.savefig('vel.pdf', format='pdf')\n##### figure5 #####\nfig5, axes = plt.subplots(3, 1,figsize=(7,5))\nfig5.subplots_adjust(hspace=0.5)\n## 子图1\naxes[0].plot(time_series, euler[:,0], color=colors[0], lw=2)\naxes[0].plot(time_imu, euler_imu[:,0], color=colors[1], lw=2)\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('pitch(deg)')\n# axes[0].set_ylabel('俯仰角(deg)')\naxes[0].legend(labels)\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, euler[:,1], color=colors[0], lw=2)\naxes[1].plot(time_series, euler_imu[:,1], color=colors[1], lw=2)\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('yaw(deg)')\n# axes[1].set_ylabel('偏航角(deg)')\naxes[1].legend(labels)\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, euler[:,2], color=colors[0], lw=2)\naxes[2].plot(time_series, euler_imu[:,2], color=colors[1], lw=2)\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('roll(deg)')\n# axes[2].set_ylabel('滚转角(deg)')\naxes[2].legend(labels)\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig5.savefig('att.pdf', format='pdf')\n# ##### figure6 #####\nfig6, axis = plt.subplots(1,1,figsize=(7,5))\n\naxis.plot(ned_data[:,3], ned_data[:,1], color=colors[0], lw=2)\naxis.plot(ned_data_imu[:,3], ned_data_imu[:,1], color=colors[1])\naxis.grid()\n# axis.set_xlabel(\"东向(km)\")\n# axis.set_ylabel(\"北向(km)\")\n# axis.legend(labels)\naxis.set_xlabel(\"East(km)\")\naxis.set_ylabel(\"North(km)\")\n\n# fig6.savefig('ne.pdf', format='pdf')\n# ##### figure7 ######\nfig7, axis = plt.subplots(1,1, figsize=(7,5))\naxis.plot(downRange, pos[:,1], color=colors[0], lw=2)\naxis.plot(downRangeImu, pos_imu[:,1], color=colors[1])\n# axis.set_xlabel(\"航向(km)\")\n# axis.set_ylabel(\"高程(km)\")\n# axis.legend(labels)\naxis.set_xlabel(\"downrange(km)\")\naxis.set_ylabel(\"alt(km)\")\naxis.grid()\n\n# fig7.savefig('da.pdf', format='pdf')\n# plt.axis('equal')\n# # ###### figure 8 #######\n# fig8, axes = plt.subplots(3,1)\n\n# axes[0].plot(time_series, ned_data[:,1] - ned_data_imu[:,1]);\n\n# axes[1].plot(time_series, ned_data[:,2] - ned_data_imu[:,2]);\n\n# axes[2].plot(time_series, pos[:,2] - pos_imu[:,2]);\n\n# ######### figure 9 #######\n# fig9, axes = plt.subplots(4,1)\n# axes[0].plot(time_series, quat[:,0])\n# axes[0].plot(time_series, quat_imu[:,0])\n\n# axes[1].plot(time_series, quat[:,1])\n# axes[1].plot(time_series, quat_imu[:,1])\n\n# axes[2].plot(time_series, quat[:,2])\n# axes[2].plot(time_series, quat_imu[:,2])\n\n# axes[3].plot(time_series, quat[:,3])\n# axes[3].plot(time_series, quat_imu[:,3])\n##显示绘图\nplt.show()\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.511675238609314,
"alphanum_fraction": 0.5339397192001343,
"avg_line_length": 31.444934844970703,
"blob_id": "feddb6e70ccc551295ec7bb55791a5d5a07e7189",
"content_id": "83fe6d4f15fe76ef563d399dd9ff9618388a1bb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7366,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 227,
"path": "/examples/scspkfDemo.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"commonHeaders.h\"\n#include \"backend/sckf/scspkf.h\"\n#include <matplotlibcpp.h>\n#include \"utilities/tic_toc.h\"\n#include \"simulator/sensorNoise.hpp\"\n\nusing namespace std;\nusing namespace MyFusion;\n\nnamespace plt = matplotlibcpp; // matplotlib-cpp\n/**\n * @brief convert data from Eigen to vector for matplotlib\n * \n * @param Mu \n * @param Sigma \n * @param idx : idx of state needed to be convert \n * @param allX : converted state\n * @param allP : converted covariance (3sigma)\n */\nvoid getForPlot(vector<vector<VecXd>> &Mu, vector<vector<MatXd>> &Sigma, int idx,\n vector<vector<double>> &allX, vector<vector<double>> &allP);\n\nvoid getForPlot(vector<vector<VecXd>> &Mu, int idx, vector<vector<double>> &allX);\n\nint main(int argc, char ** argv){\n // -------- data generation -------- // \n int N = 500;\n vector<Vec3d> x(N);\n vector<VecXd> y(N);\n\n int mCnt = 0;\n for(int i = 0; i < N; i++){\n x[i] = Vec3d::Ones() * 5.0;\n if(mCnt % 20 == 0){\n // relative plus absolute\n VecXd noiseY = VecXd::Zero(8);\n noiseY.segment(4, 4) = Vec4d(0.61548, M_PI_4, 0.61548, 3. * M_PI_4);\n SensorNoise::addGlintNoise(noiseY, 0.1, 0.6, GAUSSIAN, 0.0);\n y[i] = noiseY;\n }\n else{\n // relative\n VecXd noiseY = VecXd::Zero(4);\n SensorNoise::addGlintNoise(noiseY, 0.1, 0.6, GAUSSIAN, 0.0);\n y[i] = noiseY; \n }\n }\n // cout << x.transpose() << endl;\n // cout << y.transpose() << endl;\n\n // -------- filter -------- //\n if(argc != 2){\n cout << \"Usage: cnsFusion [errScale]\\n\"; \n return -1;\n }\n int errScale = atoi(argv[1]);\n\n Eigen::VectorXd Mu0 = Vec3d::Ones() * 5.0 + (double)errScale * Vec3d(0.1,0.1,0.1);\n Eigen::MatrixXd Sigma0 = Eigen::MatrixXd::Identity(3, 3) * 1;\n Eigen::MatrixXd Q0 = Eigen::MatrixXd::Identity(3, 3) * 0.001;\n Eigen::MatrixXd R0 = Eigen::MatrixXd::Identity(8, 8) * 0.01;\n // cout << Mu0 << endl << Sigma0 << endl << Q0 << endl << R0 << endl;\n \n SCSPKF mySCHCKF(Mu0, Sigma0, Q0, R0, SP_HCKF);\n SCSPKF mySCCKF(Mu0, Sigma0, Q0, R0, SP_CKF);\n SCSPKF mySCUKF(Mu0, Sigma0, Q0, R0, 0.001, 2, 0, SP_UKF);\n\n vector<vector<VecXd>> all_err;\n vector<vector<VecXd>> all_mu;\n vector<vector<MatXd>> all_sigma;\n \n double filterCost[3] = {0., 0., 0.};\n vector<VecXd> tmpMu;\n vector<VecXd> tmpErr;\n vector<MatXd> tmpSigma; \n\n TicToc filterTimer;\n // ============ SC-HCKF ============= //\n for (int i = 0; i < N; i++){\n Eigen::VectorXd Zk = y[i];\n Eigen::VectorXd Uk = VecXd::Zero(3);\n\n filterTimer.tic();\n mySCHCKF.oneStepPrediction(Uk);\n mySCHCKF.oneStepUpdate(Zk);\n filterCost[0] += filterTimer.toc();\n\n VecXd mu = mySCHCKF.getMu();\n MatXd Sigma = mySCHCKF.getSigma();\n \n tmpMu.emplace_back(mu);\n tmpErr.emplace_back((mu - x[i]).cwiseAbs());\n tmpSigma.emplace_back(Sigma);\n }\n cout << \"SC-HCKF total cost: \" << filterCost[0] << endl;\n\n all_mu.emplace_back(tmpMu);\n all_err.emplace_back(tmpErr);\n all_sigma.emplace_back(tmpSigma); \n \n tmpMu.clear(); tmpErr.clear(); tmpSigma.clear();\n\n // ============= SC-CKF =============== //\n for (int i = 0; i < N; i++){\n Eigen::VectorXd Zk = y[i];\n Eigen::VectorXd Uk = VecXd::Zero(3);\n // ------ SC-HCKF ------- //\n filterTimer.tic();\n mySCCKF.oneStepPrediction(Uk);\n mySCCKF.oneStepUpdate(Zk);\n filterCost[1] += filterTimer.toc();\n\n VecXd mu = mySCCKF.getMu();\n MatXd Sigma = mySCCKF.getSigma();\n \n tmpMu.emplace_back(mu);\n tmpErr.emplace_back((mu - x[i]).cwiseAbs());\n tmpSigma.emplace_back(Sigma);\n }\n cout << \"SC-CKF total cost: \" << filterCost[1] << endl;\n\n all_mu.emplace_back(tmpMu);\n all_err.emplace_back(tmpErr);\n all_sigma.emplace_back(tmpSigma); \n tmpMu.clear(); tmpErr.clear(); tmpSigma.clear();\n\n // ============ SC-UKF ================ //\n for (int i = 0; i < N; i++){\n Eigen::VectorXd Zk = y[i];\n Eigen::VectorXd Uk = VecXd::Zero(3);\n\n filterTimer.tic();\n mySCUKF.oneStepPrediction(Uk);\n mySCUKF.oneStepUpdate(Zk);\n filterCost[2] += filterTimer.toc();\n\n VecXd mu = mySCUKF.getMu();\n MatXd Sigma = mySCUKF.getSigma();\n \n tmpMu.emplace_back(mu);\n tmpErr.emplace_back((mu - x[i]).cwiseAbs());\n tmpSigma.emplace_back(Sigma);\n }\n cout << \"SC-UKF total cost: \" << filterCost[2] << endl;\n\n all_mu.emplace_back(tmpMu);\n all_err.emplace_back(tmpErr);\n all_sigma.emplace_back(tmpSigma); \n tmpMu.clear(); tmpErr.clear(); tmpSigma.clear();\n\n // ====================== matplotlib-cpp ================================= //\n vector<vector<double>> xTrue; // true value\n vector<vector<double>> xHCKF, xCKF, xUKF; // mean\n vector<vector<double>> pHCKF, pCKF, pUKF; // covariance\n vector<vector<double>> eHCKF, eCKF, eUKF; // error\n\n getForPlot(all_mu, all_sigma, 0, xHCKF, pHCKF);\n getForPlot(all_mu, all_sigma, 1, xCKF, pCKF);\n getForPlot(all_mu, all_sigma, 2, xUKF, pUKF);\n\n getForPlot(all_err, 0, eHCKF);\n getForPlot(all_err, 1, eCKF);\n getForPlot(all_err, 2, eUKF);\n\n // -------------------------------\n plt::figure();\n plt::subplot(3, 1, 1);\n plt::named_plot(\"HCKF\", eHCKF[0], \"--c\"); \n plt::named_plot(\"CKF\", eCKF[0], \"--r\"); \n plt::named_plot(\"UKF\", eUKF[0], \"--b\"); \n plt::named_plot(\"3sigma\", pHCKF[0], \"--k\"); \n \n plt::subplot(3, 1, 2);\n plt::named_plot(\"HCKF\", eHCKF[1], \"--c\"); \n plt::named_plot(\"CKF\", eCKF[1], \"--r\"); \n plt::named_plot(\"UKF\", eUKF[1], \"--b\"); \n plt::named_plot(\"3sigma\", pHCKF[1], \"--k\"); \n \n plt::subplot(3, 1, 3);\n plt::named_plot(\"HCKF\", eHCKF[2], \"--c\"); \n plt::named_plot(\"CKF\", eCKF[2], \"--r\"); \n plt::named_plot(\"UKF\", eUKF[2], \"--b\"); \n plt::named_plot(\"3sigma\", pHCKF[2], \"--k\"); \n \n plt::show();\n // ============================================================ //\n\n return 0;\n\n}\n\nvoid getForPlot(vector<vector<VecXd>> &Mu, vector<vector<MatXd>> &Sigma, int idx,\n vector<vector<double>> &allX, vector<vector<double>> &allP)\n{\n int N = Mu[0].size();\n vector<double> tmpX(N), tmpY(N), tmpZ(N);\n vector<double> tmpPx(N), tmpPy(N), tmpPz(N);\n\n for(size_t i = 0; i < N; i++){\n tmpX.at(i) = Mu[idx][i](0);\n tmpY.at(i) = Mu[idx][i](1);\n tmpZ.at(i) = Mu[idx][i](2);\n\n tmpPx.at(i) = 3. * sqrt(Sigma[idx][i](0, 0));\n tmpPy.at(i) = 3. * sqrt(Sigma[idx][i](1, 1));\n tmpPz.at(i) = 3. * sqrt(Sigma[idx][i](2, 2));\n }\n\n allX.clear(); allP.clear();\n allX.emplace_back(tmpX); allX.emplace_back(tmpY); allX.emplace_back(tmpZ);\n allP.emplace_back(tmpPx); allP.emplace_back(tmpPy); allP.emplace_back(tmpPz);\n}\n\nvoid getForPlot(vector<vector<VecXd>> &Mu, int idx, vector<vector<double>> &allX)\n{\n int N = Mu[0].size();\n \n vector<double> tmpX(N), tmpY(N), tmpZ(N);\n for(size_t i = 0; i < N; i++){\n tmpX.at(i) = Mu[idx][i](0);\n tmpY.at(i) = Mu[idx][i](1);\n tmpZ.at(i) = Mu[idx][i](2);\n }\n\n allX.clear();\n allX.emplace_back(tmpX); allX.emplace_back(tmpY); allX.emplace_back(tmpZ);\n}\n\n"
},
{
"alpha_fraction": 0.6376146674156189,
"alphanum_fraction": 0.642201840877533,
"avg_line_length": 19.46875,
"blob_id": "8006936d1067b9d0ec606ef9c338f66491a2ef6b",
"content_id": "fa59d47136ef4656f1c5a9044fa8024aabd3e5b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 32,
"path": "/include/simulator/sensors/imu_g.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef IMU_G_H_\n#define IMU_G_H_\n\n#include \"./imu_base.h\"\n\nnamespace MyFusion{\n\nclass IMU_G:public IMU_BASE{\npublic:\n IMU_G(ImuParam params);\n // ~IMU_G(){};\n\n void oneStepIntegration();\n\n /**\n * @brief generate trajectory date \n * \n * @param initPose : initiate pose\n * @param a_b_all : all accelerations in B frame \n * @param omega_gb_all : all angular rates with respect to G frame in B frame\n * @return ImuMotionData \n */\n vector<ImuMotionData> trajGenerator(ImuMotionData initPose, vector<Vec3d> a_b_all, vector<Vec3d> omega_gb_all);\n\n Eigen::Vector3d pos_n_; // pos in navigation frame\n\n};\n\n}\n\n\n#endif"
},
{
"alpha_fraction": 0.6749556064605713,
"alphanum_fraction": 0.6749556064605713,
"avg_line_length": 15.114285469055176,
"blob_id": "85199c35fb2fc4dc45b7e9a1d6e4076e18426e8e",
"content_id": "d356429385e478e01d2cf95022f260742846c485",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 563,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 35,
"path": "/include/simulator/sensors/altimeter.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef ALTIMETER_H_\n#define ALTIMETER_H_\n#include \"commonHeaders.h\"\n#include \"simulator/sensors/imu_base.h\"\n\nnamespace MyFusion\n{\nstruct AltData{\n double timeStamp_;\n double range_;\n};\n\nclass Altimeter{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n Altimeter(double bias, double sigma){\n setParam(bias, sigma);\n }\n\n ~Altimeter(){}\n\n void setParam(double bias, double sigma);\n\n AltData getMeasurement(ImuMotionData currMotion);\n\n double bias_;\n double sigma_;\n bool flagInit_ = false; \n};\n\n} // namespace MyFusion\n\n\n\n#endif"
},
{
"alpha_fraction": 0.540199339389801,
"alphanum_fraction": 0.5514950156211853,
"avg_line_length": 24.965517044067383,
"blob_id": "813216491e96263949c4ccd153afd011a216a3d7",
"content_id": "982ab67c815431a190a5175abf48132d2454715f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1505,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 58,
"path": "/examples/scFusion.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/sckf/pdSCSPKF.h\"\n#include \"backend/estimator.h\"\n#include \"utilities/io_function.h\"\n#include <matplotlibcpp.h>\n\nusing namespace std;\nusing namespace MyFusion;\nnamespace plt = matplotlibcpp;\n\nvector<ImuMotionData> trajData; \n\nint main(int argc, char** argv){\n printf(\"\\n#################### SC-Fusion Start ###################\\n\");\n \n readImuMotionData(\"../data/stdTraj/caGeo.csv\", trajData);\n\n float simTime(0);\n int sigmaType(1);\n int updateType;\n string fileName;\n if(argc == 3){\n sigmaType = atoi(argv[1]);\n fileName = argv[2]; \n }\n else if(argc == 4){\n simTime = atof(argv[1]);\n sigmaType = atoi(argv[2]);\n fileName = argv[3];\n }\n else if(argc == 5){\n simTime = atof(argv[1]);\n sigmaType = atoi(argv[2]);\n updateType = atoi(argv[3]);\n fileName = argv[4];\n }\n else{\n cerr << \"Wrong parameters number.\\n\";\n return -1;\n }\n // ---------- simulation ---------- //\n Estimator myEstimator(\"../config/fusion/backParam.yaml\", updateType); \n myEstimator.setSigmaType(sigmaType);\n myEstimator.setOutFile(fileName);\n // myEstimator.setUpdateType(updateType);\n\n if(simTime == 0){\n myEstimator.processBackend();\n }\n else{\n myEstimator.processBackend(simTime);\n }\n\n // myEstimator.showResults(); \n\n printf(\"#################### SC-Fusion Start ###################\\n\");\n // ---------- plot figure ---------- //\n return 0;\n}"
},
{
"alpha_fraction": 0.5873016119003296,
"alphanum_fraction": 0.5968254208564758,
"avg_line_length": 23.894737243652344,
"blob_id": "efd0556d22b98e834eead5b67d966808f0f49d03",
"content_id": "52016a6dc421d811e648ee6ba93b2576cc0e6c94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 945,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 38,
"path": "/src/simulator/sensors/virns.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/virns.h\"\n\nnamespace MyFusion{\n\nvoid VIRNS::setParams(double bias, double sigma){\n bias_ = bias;\n sigma_ = sigma;\n flagInit_ = true;\n}\n\nVirnsData VIRNS::getRelativeMeasurement(ImuMotionData currMotion){\n if(!flagInit_){\n cout << \"WARNING: Noise parameters unset !\\n\";\n }\n\n VirnsData tmp;\n std::random_device rd;\n std::default_random_engine rg(rd());\n std::normal_distribution<double> stdGau(0., 1.);\n\n if(flagFirst){\n tmp.timeStamp_ = currMotion.time_stamp_;\n curP_ = FrameConvert::geo2mcmf(currMotion.tnb_);\n\n tmp.dPos_ = Vec3d(0., 0., 0.);\n flagFirst = false; \n }\n else{\n tmp.timeStamp_ = currMotion.time_stamp_;\n curP_ = FrameConvert::geo2mcmf(currMotion.tnb_);\n tmp.dPos_ = curP_ - lastP_ + Vec3d::Ones() * sigma_ * stdGau(rg);\n }\n \n lastP_ = curP_; // reset lastP\n return tmp; // return result\n}\n\n}"
},
{
"alpha_fraction": 0.6051040887832642,
"alphanum_fraction": 0.607790470123291,
"avg_line_length": 24.689655303955078,
"blob_id": "19187c154b455e981dd1f05b809ddbe3c004fbe5",
"content_id": "4c8647d9a888b017ec87c82339fb8d18e23d9e2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1489,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 58,
"path": "/include/backend/spkf.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SPKF_H_\n#define SPKF_H_\n#include \"commonHeaders.h\"\n\nusing namespace std;\n\nnamespace MyFusion\n{\n\n/**\n * @brief base class for all sigma-points based Kalman filter\n * \n */\nclass SPKF{\npublic:\n SPKF(){}\n virtual ~SPKF(){}\n\n void initSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R);\n\n // ======================= //\n virtual void genSigmaPoints(vector<VecXd> &sPoints) = 0;\n \n virtual void computeWeight() = 0;\n\n virtual void propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY) = 0;\n\n virtual void updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY) = 0;\n // ====================== //\n void oneStepPrediction();\n void oneStepUpdate(VecXd &Z);\n VecXd calcWeightedMean(vector<VecXd> &sPointsX);\n MatXd calcWeightedCov(vector<VecXd> &sPointsX);\n MatXd calcWeightedCrossCov(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY);\n // ====================== //\n VecXd getMu(){return curMu_;}\n MatXd getSigma(){return curSigma_;}\n\nprotected:\n VecXd curMu_; // current mean\n MatXd curSigma_; // current covariance\n VecXd curResidual_;\n\n vector<VecXd> sPointsX_; // sigma points before propagation\n vector<VecXd> sPointsY_; // sigma point after propagation\n\n int xDim_, mDim_;\n MatXd Q_, R_; // noise matrice\n\n vector<double> weightMu_;\n vector<double> weightSigma_;\n\n bool flagInitiated_ = false; \n};\n\n} // namespace MyFusion\n\n#endif"
},
{
"alpha_fraction": 0.5274151563644409,
"alphanum_fraction": 0.5313315987586975,
"avg_line_length": 26.39285659790039,
"blob_id": "3bb4e5d9303900cf4dd1b5b96c32db892be2dfcd",
"content_id": "23db1383bfb3abbd9037eb9cb1b64954c90bcf9c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 816,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 28,
"path": "/tools/drawResults.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport systems as sys\nfrom matplotlib import rcParams\n\n# matplotlib.use(\"pgf\")\n# pgf_config = {\n# \"font.family\":'serif',\n# \"font.size\": 10,\n# \"pgf.rcfonts\": False,\n# \"text.usetex\": True,\n# \"pgf.preamble\": [\n# r\"\\usepackage{unicode-math}\",\n# #r\"\\setmathfont{XITS Math}\", \n# # 这里注释掉了公式的XITS字体,可以自行修改\n# r\"\\setmainfont{Times New Roman}\",\n# r\"\\usepackage{xeCJK}\",\n# r\"\\xeCJKsetup{CJKmath=true}\",\n# r\"\\setCJKmainfont{SimSun}\",\n# ],\n# }\n# # rcParams.update(pgf_config\n######################## 主函数 ###########################"
},
{
"alpha_fraction": 0.49229177832603455,
"alphanum_fraction": 0.5090000629425049,
"avg_line_length": 33.97590255737305,
"blob_id": "c1f8670198f9513d2e591bc8667246a98be8d34b",
"content_id": "033ad98e56b4e1b5a8c840c90470d97504e0f87e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 11611,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 332,
"path": "/src/backend/estimator.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/estimator.h\"\n\nnamespace MyFusion{\n\nEstimator::Estimator(string configFile, int updateType){\n updateType_ = updateType;\n initEstimator(configFile);\n}\nEstimator::~Estimator(){\n if(filterPtr_!=nullptr){\n delete filterPtr_;\n filterPtr_ = nullptr;\n }\n}\n\nvoid Estimator::initEstimator(string configFile){\n // load parameters\n loadBackParam(configFile);\n // ---------- read simulation data ------------- //\n vector<ImuMotionData> imuData;\n // vector<CnsData> cnsData;\n vector<VirnsData> virnsData;\n vector<CmnsData> cmnsData;\n vector<AltData> altData;\n \n readImuMotionData(\"../data/stdTraj/caGeo.csv\", trajData_);\n readImuMotionData(IMU_FILE, imuData);\n readVirnsData(VIRNS_FILE, virnsData);\n readCmnsData(CMNS_FILE, cmnsData);\n readAltData(ALT_FILE, altData);\n\n \n // extract U and Z\n extractU(allU_, imuData);\n extractZ(allZ_, virnsData, cmnsData, altData);\n lastZA_ = FrameConvert::geo2mcmf(imuData[0].tnb_);\n // allZ_.pop(); // pop first measurement as it is zero\n // ---------- initiate other parameters ---------- //\n dataSize_ = allU_.size();\n\n Mu0_ = VecXd::Zero(6);\n Mu0_(0) = imuData[0].tnb_(0) + INIT_ERR_P / R_m;\n Mu0_(1) = imuData[0].tnb_(1) + INIT_ERR_P;\n Mu0_(2) = imuData[0].tnb_(2) + INIT_ERR_P / R_m;\n Mu0_.segment(3, 3) = imuData[0].vel_ + INIT_ERR_V * Vec3d::Ones();\n allMu_.emplace_back(make_pair(0., Mu0_));\n\n Sigma0_ = INIT_SQRT_P * INIT_SQRT_P;\n allSigma_.emplace_back(make_pair(0., Sigma0_));\n\n Q0_ = INIT_SQRT_Q * INIT_SQRT_Q;\n R0_ = INIT_SQRT_R * INIT_SQRT_R;\n\n sigmaType_ = SampleType(SIGMA_TYPE);\n \n // output for debug\n cout << \"[2] Mu: \" << Mu0_.transpose()\n << \"\\n[2] P0: \\n\" << Sigma0_.diagonal().transpose()\n << \"\\n[2] Q0: \\n\" << Q0_.diagonal().transpose()\n << \"\\n[2] R0: \\n\" << R0_.diagonal().transpose() << endl;\n // set initiation flag\n dataInitiated_ = true;\n}\n\nvoid Estimator::extractU(queue<VecXd> &allU, const vector<ImuMotionData> & imuData){\n if(!allU.empty())\n clearQueue(allU);\n \n for(auto it : imuData){\n VecXd tmp = VecXd::Zero(7); // [t, ax, ay, az, gx, gy, gz]\n\n tmp(0) = it.time_stamp_;\n tmp.segment(1, 3) = it.acc_; // accB\n tmp.segment(4, 3) = it.gyr_; // gyrB\n\n allU.push(tmp);\n } \n}\n\nvoid Estimator::extractZ(queue<VecXd> &allZ, const vector<VirnsData> &virnsData, const vector<CmnsData> &cmnsData, const vector<AltData> &altData){\n if(!allZ.empty())\n clearQueue(allZ);\n\n \n if(updateType_ == 0){\n for(size_t i = 0; i < cmnsData.size(); i++){\n VecXd tmp = VecXd::Zero(4); // [L, l, h]\n tmp(0) = cmnsData[i].timeStamp_;\n tmp(1) = cmnsData[i].pos_.x();\n tmp(2) = cmnsData[i].pos_.y();\n tmp(3) = altData[i].range_;\n\n allZ.push(tmp);\n }\n }\n else{\n int cnt = 0;\n double t2 = cmnsData[cnt].timeStamp_;\n for(auto it : virnsData){\n VecXd tmp;\n double t1 = it.timeStamp_;\n if(abs(t1 - t2) < 1e-5){\n tmp = VecXd::Zero(7); // [t, dx, dy, dz, L, l, h]\n tmp(0) = it.timeStamp_;\n tmp.segment(1, 3) = it.dPos_;\n tmp.segment(4, 2) = cmnsData[cnt].pos_; \n tmp(6) = altData[cnt].range_;\n cnt++;\n\n t2 = cmnsData[cnt].timeStamp_;\n }\n else{\n tmp = VecXd::Zero(4); // [t, dx, dy, dz]\n tmp(0) = it.timeStamp_;\n tmp.segment(1, 3) = it.dPos_;\n }\n allZ.push(tmp);\n }\n }\n}\n\nvoid Estimator::processBackend(double time){\n if(!dataInitiated_){\n cerr << \"Please call member function initEstimator(configFile) first !\\n\";\n return;\n }\n if(time == 0)\n time = trajData_[dataSize_ - 2].time_stamp_;\n\n // initiate filter\n if(sigmaType_ == SP_UKF){\n filterPtr_ = new PdSCSPKF(Mu0_, Sigma0_, Q0_, R0_, UKF_A, UKF_B, UKF_K); // create SCSPKF pointer\n }\n else{\n filterPtr_ = new PdSCSPKF(Mu0_, Sigma0_, Q0_, R0_, sigmaType_); // create SCSPKF pointer\n }\n filterPtr_->setUpdateType(updateType_);\n filterPtr_->setQnb(trajData_[0].qnb_);\n cout << \"Sigma Type: \" << filterPtr_->getSigmaType() << endl;\n // start estimation\n for (size_t i = 0; i < dataSize_ - 1; i++){\n // ------------ prediction ------------//\n VecXd tmp = allU_.front();\n // onestep prediction\n filterPtr_->oneStepPrediction(tmp);\n // pop data\n allU_.pop();\n // ----------- update -------------//\n double timeStamp = allU_.front()(0);\n if(abs(allZ_.front()(0) - timeStamp) < 1e-5){\n int tmpSize = allZ_.front().size() - 1;\n\n if(updateType_ == 1){\n // A + A\n tmp = VecXd::Zero(tmpSize);\n lastZA_ += allZ_.front().segment(1, sizeMr_);\n if(tmpSize == sizeMr_){\n tmp = lastZA_;\n }\n else{\n tmp.segment(0, sizeMr_) = lastZA_;\n tmp.segment(sizeMr_, sizeMa_) = allZ_.front().tail(sizeMa_);\n }\n }\n else{\n // A + R\n tmp = allZ_.front().segment(1, tmpSize);\n }\n\n filterPtr_->oneStepUpdate(tmp);\n allZ_.pop();\n\n if(tmpSize != sizeMr_)\n lastZA_ = FrameConvert::geo2mcmf(filterPtr_->getMu().head(3));\n }\n // ---------- save results ----------//\n allMu_.emplace_back(make_pair(timeStamp, filterPtr_->getMu())); \n allSigma_.emplace_back(make_pair(timeStamp, filterPtr_->getSigma())); \n // print percentage\n int per = timeStamp * 100 / time;\n printPer(\"Backend Estimation\", per);\n \n // stop\n if(timeStamp >= time)\n break;\n if(allU_.empty() || allZ_.empty())\n break;\n }\n\n writeResults(\"../output/\" + outFile_ + \".csv\", allMu_, allSigma_);\n // writeResults(\"../output/results.csv\", allMu_, allSigma_, allQnb_);\n}\n\n// ======================================================================================== //\n\ntemplate <typename T>\nvoid Estimator::clearQueue(queue<T> &Q){\n queue<T> emptyQ;\n swap(emptyQ, Q);\n}\n\nvoid Estimator::writeResults(string fileName, const vector<pair<double, VecXd>> allMu, \n const vector<pair<double,MatXd>> allSigma,\n const vector<pair<double, Qd>> allQnb)\n{\n FILE *fp;\n struct stat buffer;\n if(stat(fileName.c_str(), &buffer) == 0)\n system((\"rm \" + fileName).c_str()); \n fp = fopen(fileName.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], lat[rad], alt[m], lon[rad], Vn[m/s], Vu[m/s], Ve[m/s], \"); \n fprintf(fp, \"CovX[], CovY[], CovZ[], CovVx[], CovVy[], CovVz[], q_w, q_x, q_y, q_z\\n\"); \n for(size_t i = 0; i < allMu.size(); i++){\n fprintf(fp, \"%lf,%le,%lf,%le,%lf,%lf,%lf,%le,%lf,%le,%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\",\n allMu[i].first, \n allMu[i].second(0), allMu[i].second(1), allMu[i].second(2),\n allMu[i].second(3), allMu[i].second(4), allMu[i].second(5), \n allSigma[i].second(0), allSigma[i].second(1), allSigma[i].second(2),\n allSigma[i].second(3), allSigma[i].second(4), allSigma[i].second(5),\n allQnb[i].second.w(), allQnb[i].second.x(), allQnb[i].second.y(), allQnb[i].second.z());\n }\n}\n\nvoid Estimator::writeResults(string fileName, const vector<pair<double, VecXd>> allMu, const vector<pair<double,MatXd>> allSigma)\n{\n FILE *fp;\n struct stat buffer;\n if(stat(fileName.c_str(), &buffer) == 0)\n system((\"rm \" + fileName).c_str()); \n fp = fopen(fileName.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], lat[rad], alt[m], lon[rad], Vn[m/s], Vu[m/s], Ve[m/s], \"); \n fprintf(fp, \"CovX[], CovY[], CovZ[], CovVx[], CovVy[], CovVz[]\\n\"); \n for(size_t i = 0; i < allMu.size(); i++){\n fprintf(fp, \"%lf,%le,%lf,%le,%lf,%lf,%lf,%le,%le,%le,%le,%le,%le\\n\",\n allMu[i].first, \n allMu[i].second(0), allMu[i].second(1), allMu[i].second(2),\n allMu[i].second(3), allMu[i].second(4), allMu[i].second(5), \n sqrt(allSigma[i].second(0, 0)), sqrt(allSigma[i].second(1, 1)), sqrt(allSigma[i].second(2, 2)),\n sqrt(allSigma[i].second(3, 3)), sqrt(allSigma[i].second(4, 4)), sqrt(allSigma[i].second(5, 5)));\n }\n}\n\nvoid Estimator::showResults(){\n int N = allMu_.size();\n vector<double> time(N);\n vector<double> err_lat(N), err_alt(N), err_lon(N);\n vector<double> err_px(N), err_pz(N);\n vector<double> err_vx(N), err_vy(N), err_vz(N);\n vector<double> PLat(N), PAlt(N), PLon(N);\n vector<double> Px(N), Pz(N);\n vector<double> Pvx(N), Pvy(N), Pvz(N);\n for(size_t i = 0; i < N; i++){\n time.at(i) = allMu_[i].first;\n double curLat = allMu_[i].second(0); \n double curAlt = allMu_[i].second(1); \n double curLon = allMu_[i].second(2); \n\n VecXd errP = allMu_[i].second.segment(0, 3) - trajData_[i].tnb_;\n VecXd errV = allMu_[i].second.segment(3, 3) - trajData_[i].vel_;\n err_lat.at(i) = errP.x(); err_alt.at(i) = errP.y(); err_lon.at(i) = errP.z();\n err_px.at(i) = errP.x() * (R_m + curAlt);\n err_pz.at(i) = errP.z() * (R_m + curAlt) * cos(curLat);\n err_vx.at(i) = errV.x(); err_vy.at(i) = errV.y(); err_vz.at(i) = errV.z();\n \n PLat.at(i) = 3. * sqrt(allSigma_[i].second(0, 0)); \n PAlt.at(i) = 3. * sqrt(allSigma_[i].second(1, 1)); \n PLon.at(i) = 3. * sqrt(allSigma_[i].second(2, 2));\n \n Px.at(i) = PLat[i] * (R_m + curAlt);\n Pz.at(i) = PLon[i] * (R_m + curAlt) * cos(curLat);\n\n Pvx.at(i) = 3. * sqrt(allSigma_[i].second(3, 3)); \n Pvy.at(i) = 3. * sqrt(allSigma_[i].second(4, 4)); \n Pvz.at(i) = 3. * sqrt(allSigma_[i].second(5, 5));\n }\n // position\n // plt::figure();\n // plt::subplot(3,1,1);\n // plt::named_plot(\"SCHCKF\", time, err_lat, \"-b\");\n // plt::named_plot(\"3sigma\", time, PLat, \"--k\");\n \n // plt::subplot(3,1,2);\n // plt::named_plot(\"SCHCKF\", time, err_alt, \"-b\");\n // plt::named_plot(\"3sigma\", time, PAlt, \"--k\");\n \n // plt::subplot(3,1,3);\n // plt::named_plot(\"SCHCKF\", time, err_lon, \"-b\");\n // plt::named_plot(\"3sigma\", time, PLon, \"--k\");\n // velocity\n plt::figure();\n plt::subplot(3,1,1);\n plt::named_plot(\"SCHCKF\", time, err_vx, \"-b\");\n plt::named_plot(\"3sigma\", time, Pvx, \"--k\");\n \n plt::subplot(3,1,2);\n plt::named_plot(\"SCHCKF\", time, err_vy, \"-b\");\n plt::named_plot(\"3sigma\", time, Pvy, \"--k\");\n \n plt::subplot(3,1,3);\n plt::named_plot(\"SCHCKF\", time, err_vz, \"-b\");\n plt::named_plot(\"3sigma\", time, Pvz, \"--k\");\n\n // \n plt::figure();\n plt::subplot(3,1,1);\n plt::named_plot(\"SCHCKF\", time, err_px, \"-b\");\n plt::named_plot(\"3sigma\", time, Px, \"--k\");\n \n plt::subplot(3,1,2);\n plt::named_plot(\"SCHCKF\", time, err_alt, \"-b\");\n plt::named_plot(\"3sigma\", time, PAlt, \"--k\");\n \n plt::subplot(3,1,3);\n plt::named_plot(\"SCHCKF\", time, err_pz, \"-b\");\n plt::named_plot(\"3sigma\", time, Pz, \"--k\");\n \n \n plt::show();\n}\n}"
},
{
"alpha_fraction": 0.6132354736328125,
"alphanum_fraction": 0.6219838857650757,
"avg_line_length": 34.59296417236328,
"blob_id": "4e77a93a0b011670e20c65439881d4597e7a1970",
"content_id": "fbe24a9f5a806dfb7bdb42f9819cbd2befe3a9a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7087,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 199,
"path": "/src/simulator/sensorSimulator.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensorSimulator.h\"\n\nnamespace MyFusion{\n\nSensorSimulator::SensorSimulator(string configFile){\n readSensorParameters(configFile);\n}\n\nSensorSimulator::~SensorSimulator(){}\n\nvoid SensorSimulator::readSensorParameters(string configFile){\n cv::FileStorage fsParams(configFile, cv::FileStorage::READ);\n\n if(!fsParams.isOpened()){\n cout << \"ERROR: failed to open config file. Please reset parameters!\\n\";\n return;\n }\n else{\n // imu parameters\n sensorParams_.acc_b_ = fsParams[\"acc_b\"];\n sensorParams_.acc_n_ = fsParams[\"acc_n\"];\n sensorParams_.acc_w_ = fsParams[\"acc_w\"]; \n sensorParams_.gyr_b_ = fsParams[\"gyr_b\"];\n sensorParams_.gyr_n_ = fsParams[\"gyr_n\"];\n sensorParams_.gyr_w_ = fsParams[\"gyr_w\"];\n sensorParams_.imu_step_ = fsParams[\"imu_step\"];\n // cns parameters\n sensorParams_.cns_step_ = fsParams[\"cns_step\"];\n sensorParams_.cns_sigma_ = fsParams[\"cns_n\"];\n // virns parameters\n sensorParams_.virns_step_ = fsParams[\"virns_step\"];\n sensorParams_.virns_bias_ = fsParams[\"virns_b\"];\n sensorParams_.virns_sigma_ = fsParams[\"virns_n\"];\n // cmns parameters\n sensorParams_.cmns_step_ = fsParams[\"cmns_step\"];\n sensorParams_.cmns_sigma_ = fsParams[\"cmns_n\"];\n // altimeter parameters\n sensorParams_.alt_step_ = fsParams[\"alt_step\"];\n sensorParams_.alt_sigma_ = fsParams[\"alt_n\"];\n\n paramInitialized_ = true;\n\n showParameters(sensorParams_);\n }\n}\n\nvoid SensorSimulator::showParameters(SensorParams params){\n printf(\"[0] IMU Parameters(%lf):\\n\", params.imu_step_);\n printf(\" ACC_B:%e, ACC_N:%e, ACC_W:%e.\\n\", params.acc_b_, params.acc_n_, params.acc_w_);\n printf(\" GYR_B:%e, GYR_N:%e, GYR_W:%e.\\n\", params.gyr_b_, params.gyr_n_, params.gyr_w_);\n\n // printf(\"[0] CNS Parameters(%lf):\\n\", params.cns_step_);\n // printf(\" Noise:%lf.\\n\", params.cns_sigma_);\n\n // printf(\"[0] VIRNS Parameters(%lf):\\n\", params.virns_step_);\n // printf(\" Bias:%lf, Noise:%lf.\\n\", params.virns_bias_, params.virns_sigma_);\n\n // printf(\"[0] CMNS Parameters(%lf):\\n\", params.cmns_step_);\n // printf(\" Noise:%lf.\\n\", params.cmns_sigma_);\n}\n\nvoid SensorSimulator::simIMU(const vector<ImuMotionData> &trajData, vector<ImuMotionData> &imuData){\n ImuParam tmpParam;\n tmpParam.time_step_ = sensorParams_.imu_step_;\n tmpParam.acc_b_ = sensorParams_.acc_b_; tmpParam.gyr_b_ = sensorParams_.gyr_b_;\n tmpParam.acc_n_ = sensorParams_.acc_n_; tmpParam.gyr_n_ = sensorParams_.gyr_n_;\n tmpParam.acc_w_ = sensorParams_.acc_w_; tmpParam.gyr_w_ = sensorParams_.gyr_w_;\n\n IMU_G imuSimulator(tmpParam);\n\n imuData.clear();\n int totalSize = trajData.size();\n for(size_t i = 0; i < totalSize; i++){\n ImuMotionData tmp = trajData[i];\n imuSimulator.oneStepPropagate(tmp);\n imuData.emplace_back(tmp);\n \n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating IMU measurements in GEO\", per);\n }\n // change line\n printf(\"\\n\");\n}\n\nvoid SensorSimulator::simCNS(const vector<ImuMotionData> &trajData, vector<CnsData> &cnsData){\n CNS cnsSimulator(0., sensorParams_.cns_sigma_);\n \n cnsData.clear();\n double lastTime = 0.0;\n int totalSize = trajData.size();\n for(size_t i = 0; i < totalSize; i++){\n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating CNS measurements in MCI\", per);\n \n if(abs(trajData[i].time_stamp_ - lastTime - sensorParams_.cns_step_) > 1e-5)\n continue;\n \n CnsData tmp = cnsSimulator.getMeasurements(trajData[i]);\n cnsData.emplace_back(tmp);\n lastTime = trajData[i].time_stamp_; \n } \n // change line\n printf(\"\\n\");\n}\n\nvoid SensorSimulator::simVIRNSRelative(const vector<ImuMotionData> &trajData, vector<VirnsData> &virnsData){\n VIRNS virnsSimulator(0., sensorParams_.virns_sigma_);\n \n virnsData.clear();\n double lastTime = 0.0;\n int totalSize = trajData.size();\n VirnsData tmp = virnsSimulator.getRelativeMeasurement(trajData[0]);\n for(size_t i = 0; i < totalSize; i++){\n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating VIRNS relative measurements in MCMF\", per);\n \n if (abs(trajData[i].time_stamp_ - lastTime - sensorParams_.virns_step_) > 1e-5)\n continue;\n \n tmp = virnsSimulator.getRelativeMeasurement(trajData[i]);\n virnsData.emplace_back(tmp);\n lastTime = trajData[i].time_stamp_;\n }\n // change line\n printf(\"\\n\");\n}\n\nvoid SensorSimulator::simVIRNS(const vector<ImuMotionData> &trajData, vector<VirnsData> &virnsData){\n printf(\"[0] VIRNS Parameters(%lf):\\n\", sensorParams_.virns_step_);\n printf(\" Bias:%lf, Noise:%lf.\\n\", sensorParams_.virns_bias_, sensorParams_.virns_sigma_);\n // generate relative measurements\n simVIRNSRelative(trajData, virnsData);\n // generate absolute measurements\n Vec3d lastPos = Vec3d::Ones() * sensorParams_.virns_bias_ + FrameConvert::geo2mcmf(trajData[0].tnb_);\n\n int totalSize = virnsData.size();\n for(size_t i = 0; i < totalSize; i++){\n\n lastPos += virnsData[i].dPos_;\n virnsData[i].pos_ = lastPos;\n \n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating VIRNS absolute measurements in MCMF\", per);\n }\n // change line\n printf(\"\\n\");\n}\n\nvoid SensorSimulator::simCMNS(const vector<ImuMotionData> &trajData, vector<CmnsData> &cmnsData){\n printf(\"[0] CMNS Parameters(%lf):\\n\", sensorParams_.cmns_step_);\n printf(\" Noise:%lf.\\n\", sensorParams_.cmns_sigma_);\n\n CMNS cmnsSimulator(0., sensorParams_.cmns_sigma_);\n\n cmnsData.clear();\n double lastTime = 0.0;\n int totalSize = trajData.size();\n \n // CmnsData tmp = cmnsSimulator.getMeasurement(trajData[0]);\n // cmnsData.emplace_back(tmp);\n for(size_t i = 0; i < totalSize; i++){\n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating CMNS measurements in MCMF\", per);\n \n if (abs(trajData[i].time_stamp_ - lastTime - sensorParams_.cmns_step_) > 1e-5)\n continue;\n\n CmnsData tmp = cmnsSimulator.getMeasurement(trajData[i]);\n cmnsData.emplace_back(tmp);\n lastTime = trajData[i].time_stamp_;\n }\n // change line\n printf(\"\\n\");\n}\n\nvoid SensorSimulator::simAltimeter(const vector<ImuMotionData> &trajData, vector<AltData> &altData){\n Altimeter altSimulator(0, sensorParams_.alt_sigma_);\n\n altData.clear();\n double lastTime = 0.0;\n int totalSize = trajData.size();\n\n for(size_t i = 0; i < totalSize; i++){\n int per = (i + 1) * 100 / totalSize;\n printPer(\"Generating Altimeter measurements in GEO\", per);\n \n if (abs(trajData[i].time_stamp_ - lastTime -sensorParams_.alt_step_) > 1e-5)\n continue;\n\n AltData tmp = altSimulator.getMeasurement(trajData[i]);\n altData.emplace_back(tmp);\n lastTime = trajData[i].time_stamp_;\n }\n \n // change line\n printf(\"\\n\");\n}\n\n} //namespace \n\n\n\n"
},
{
"alpha_fraction": 0.6379944682121277,
"alphanum_fraction": 0.6379944682121277,
"avg_line_length": 20.75,
"blob_id": "94a609bbdfeccfa0b45f564ef8f32404e3b0a1e5",
"content_id": "b558e41b52c0b20773f63c0d66bddbbceaa3d5c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2174,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 100,
"path": "/include/simulator/sensorSimulator.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SENSOR_SIMULATOR_H_\n#define SENSOR_SIMULATOR_H_\n#include \"commonHeaders.h\"\n#include \"utilities/utilities.hpp\"\n#include \"utilities/io_function.h\"\n#include \"simulator/sensors/imu_g.h\"\n#include \"simulator/sensors/cns.h\"\n#include \"simulator/sensors/cmns.h\"\n#include \"simulator/sensors/virns.h\"\n#include \"simulator/sensors/altimeter.h\"\n\nusing namespace std;\n\nnamespace MyFusion{\n\nstruct SensorParams\n{\n // imu parameters\n double acc_b_, gyr_b_;\n double acc_n_, acc_w_;\n double gyr_n_, gyr_w_;\n double imu_step_;\n // cns parameters\n double cns_sigma_;\n double cns_step_;\n // virns parameters\n double virns_bias_;\n double virns_sigma_;\n double virns_step_;\n // cmns parameters\n double cmns_sigma_;\n double cmns_step_;\n // altimeter parameters\n double alt_sigma_;\n double alt_step_;\n};\n\n\n\nclass SensorSimulator{\npublic:\n // must construct with config file\n SensorSimulator() = delete;\n SensorSimulator(string configFile);\n ~SensorSimulator();\n\n void readSensorParameters(string configFile);\n void showParameters(SensorParams params);\n\n /**\n * @brief \n * \n * @param trajData \n * @param imuData \n */\n void simIMU(const vector<ImuMotionData> &trajData, vector<ImuMotionData> &imuData);\n \n /**\n * @brief \n * \n * @param trajData \n * @param cnsData \n */\n void simCNS(const vector<ImuMotionData> &trajData, vector<CnsData> &cnsData);\n \n /**\n * @brief \n * \n * @param trajData \n * @param virnsData \n */\n void simVIRNSRelative(const vector<ImuMotionData> &trajData, vector<VirnsData> &virnsData);\n\n /**\n * @brief \n * \n * @param trajData \n * @param virnsData \n */\n void simVIRNS(const vector<ImuMotionData> &trajData, vector<VirnsData> &virnsData);\n \n /**\n * @brief \n * \n * @param trajData \n * @param cmnsData \n */\n void simCMNS(const vector<ImuMotionData> &trajData, vector<CmnsData> &cmnsData);\n\n void simAltimeter(const vector<ImuMotionData> &trajData, vector<AltData> &altData);\n\n SensorParams sensorParams_;\n \n bool paramInitialized_ = false;\n\n};\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.6700167655944824,
"alphanum_fraction": 0.6733668446540833,
"avg_line_length": 18.29032325744629,
"blob_id": "1fa9674ad44523d9212ef4a178ebfb70fdabcd10",
"content_id": "3ebcd3b55733c933d7f4e2c4fd5663245bd01afb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 597,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 31,
"path": "/include/backend/cnsHCKF.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef CNS_HCKF_H_\n#define CNS_HCKF_H_\n#include \"backend/spkf.h\"\n\nnamespace MyFusion{\n\nclass CnsHCKF : public SPKF{\npublic:\n CnsHCKF();\n ~CnsHCKF(){}\n\n void genSigmaPoints(vector<VecXd> &sPoints);\n void genSi(vector<VecXd> &allSi);\n void getScales(double &scale0, double &scale1, size_t k);\n\n void computeWeight();\n\n void propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY);\n\n void updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY);\n\nprotected:\n double beta_;\n vector<VecXd> allSi_;\n bool firstGen = true;\n\n}; // class\n\n} // namespace\n\n#endif"
},
{
"alpha_fraction": 0.6318840384483337,
"alphanum_fraction": 0.6340579986572266,
"avg_line_length": 25.55769157409668,
"blob_id": "c94b40ff6f1894a7bdb836d43cacc709b4b6cf2d",
"content_id": "173f8020b96b1cee1dd9cf7506ffee90c8f24867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1380,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 52,
"path": "/include/backend/sckf/sckf.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SCKF_H_\n#define SCKF_H_\n#include \"commonHeaders.h\"\n\nusing namespace std;\n\nnamespace MyFusion\n{\nclass SCKF{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n SCKF(){}\n SCKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R);\n void initSCKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R);\n // ------ filter functions ------ //\n /**\n * @brief one step prediction\n * \n * @param U : control vector \n */\n virtual void oneStepPrediction(VecXd &U) = 0;\n /**\n * @brief one step update\n * \n * @param Z : measurement vector \n */\n virtual void oneStepUpdate(VecXd &Z) = 0;\n // ------ io functions ------ //\n VecXd getMu(){return Mu_;}\n MatXd getSigma(){return Sigma_;}\n void setUpdateType(int updateType){updateType_ = updateType;}\n\n\nprotected:\n VecXd Mu_, lastMu_, augMu_; // current, clonal and augmented state\n MatXd Sigma_, lastSigma_, augSigma_; // current, clonal and augmented covariance\n MatXd Phi_; // multiplicative Jacobian\n MatXd Q_, R_;// process and measurement noise covariance matrix\n MatXd curR_; // current R of (relative) / (relative + absolute)\n VecXd residual_; // current measurement residual\n\n int xSize_, mSize_; // size of state and measurements\n int curMSize_; // current measurement size\n\n bool flagInitialized_ = false;\n int updateType_ = 2;\n};\n\n} // namespace MyFusion\n\n\n#endif"
},
{
"alpha_fraction": 0.6931106448173523,
"alphanum_fraction": 0.7035490870475769,
"avg_line_length": 24.263158798217773,
"blob_id": "fdc38b65dade708874d612b07b465a92fe1249f1",
"content_id": "730c54f57c42fe51235dad1aea46de23a0c2af93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 19,
"path": "/examples/allanData.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/imu_li.h\"\n#include \"utilities/io_function.h\"\n\nusing namespace std;\nusing namespace MyFusion;\n\nint main(int argc, char** argv){\n // generate trajectory\n ImuParam mtiParam;\n readImuParam(\"../config/simulator/mti_config.yaml\", mtiParam);\n IMU_LI mtiIMU(mtiParam);\n\n vector<ImuMotionData> imu_allan_data;\n mtiIMU.generateAllanData(7200, imu_allan_data);\n\n writeAllanData(\"../data/iMAR_allan.csv\", imu_allan_data);\n \n return 0;\n}"
},
{
"alpha_fraction": 0.6438356041908264,
"alphanum_fraction": 0.6438356041908264,
"avg_line_length": 11.941176414489746,
"blob_id": "834fa0151218d234f0796083061623c14f316df4",
"content_id": "a5f176b7d4226d3f617823adc04e57e0e68b6b4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 219,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 17,
"path": "/include/simulator/sensors/imu_mci.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef IMU_MCI_H_\n#define IMU_MCI_H_\n#include \"./imu_base.h\"\n\n\nnamespace MyFusion{\n\nclass IMU_MCI:public IMU_BASE{\npublic:\n IMU_MCI(ImuParam params);\n // ~IMU_MCI(){};\n void oneStepIntegration();\n\n};\n\n}\n#endif"
},
{
"alpha_fraction": 0.6239316463470459,
"alphanum_fraction": 0.6239316463470459,
"avg_line_length": 10.75,
"blob_id": "8e7d4ebfbeb7281555997df84ba485618d9cc8cd",
"content_id": "7dfa49b050ab6386883f460653e85707533b6163",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 20,
"path": "/include/simulator/sensors/imu_mcmf.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef IMU_MDMF_H_\n#define IMU_MCMF_H_\n\n#include \"./imu_base.h\"\n\nnamespace MyFusion{\n\nclass IMU_MCMF : public IMU_BASE{\npublic:\n IMU_MCMF(ImuParam params);\n // ~IMU_MCMF(){};\n \n void oneStepIntegration();\n\n}; \n\n}\n\n\n#endif"
},
{
"alpha_fraction": 0.5329086780548096,
"alphanum_fraction": 0.5583863854408264,
"avg_line_length": 27.57575798034668,
"blob_id": "f1cb0fc66217cd0e2741b35fd8c1fa579186cea3",
"content_id": "24096a5d0592c260d9769dffe432373b12759790",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 942,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 33,
"path": "/src/simulator/sensors/imu_mci.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/imu_mci.h\"\n\nnamespace MyFusion{\n\nIMU_MCI::IMU_MCI(ImuParam params):IMU_BASE(params){\n}\n\nvoid IMU_MCI::oneStepIntegration(){\n double h_m = tnb_.norm(); // distance to center\n double alt = h_m - R_m;\n double lon = atan2(tnb_.y(), tnb_.x()); \n double lat = atan2(tnb_.z(), tnb_.x());\n\n // update quaternion\n Eigen::Quaterniond dq(1., 0.5 * gyr_0_.x() * time_step_, 0.5 * gyr_0_.y() * time_step_, 0.5 * gyr_0_.z() * time_step_);\n dq.normalize();\n\n Eigen::Quaterniond qnb0 = qnb_;\n qnb_ = qnb0 * dq;\n qnb_.normalize();\n \n // calculate geavity\n Eigen::Vector3d g_n(0., 0., 0.); \n g_n.x() = -computeG(alt) * cos(lat);\n g_n.z() = -computeG(alt) * sin(lat);\n\n //update position and velocity \n Eigen::Vector3d acc_m = qnb0 * acc_0_ - gyr_0_.cross(vel_) + g_n;\n tnb_ += vel_ * time_step_ + 0.5 * acc_m * time_step_ * time_step_;\n vel_ += acc_m * time_step_;\n}\n\n}"
},
{
"alpha_fraction": 0.4473767876625061,
"alphanum_fraction": 0.49030205607414246,
"avg_line_length": 25.436975479125977,
"blob_id": "c62abee8a91dd75564fa1d45f859d8f42fdfc442",
"content_id": "cf7cc987a5c86d176aaf0aa8d3bc9c08b314ef45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3145,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 119,
"path": "/include/utilities/utilities.hpp",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef UTILITIES_H_\n#define UTILITIES_H_\n\n#include <cmath> \n#include <Eigen/Dense>\n\nclass AttUtility{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n\n \n /**\n * @brief return euler angle in [Yaw(z), Pitch(Y), Roll(X)], sequence Z-Y-X\n * \n * @param R \n * @return Eigen::Vector3d \n */\n static Eigen::Vector3d R2Euler(const Eigen::Matrix3d &R)\n {\n Eigen::Vector3d n = R.col(0);\n Eigen::Vector3d o = R.col(1);\n Eigen::Vector3d a = R.col(2);\n\n Eigen::Vector3d ypr(3);\n double y = atan2(n(1), n(0));\n double p = atan2(-n(2), n(0) * cos(y) + n(1) * sin(y));\n double r = atan2(a(0) * sin(y) - a(1) * cos(y), -o(0) * sin(y) + o(1) * cos(y));\n ypr(0) = y;\n ypr(1) = p;\n ypr(2) = r;\n\n return ypr / M_PI * 180.0;\n }\n\n /**\n * @brief \n * \n * @param R \n * @return Eigen::Vector3d \n */\n // static Eigen::Vector3d R2Euler(const Eigen::Matrix3d &R){\n // Eigen::Vector3d pyr;\n\n // if(R(2,0) > -0.99998f && R(2,0) < 0.99998f){\n // pyr(0) = atan2(R(1,0), R(0,0));\n // pyr(1) = asin(-R(2,0));\n // pyr(2) = atan2(R(2,1), R(2,2));\n // }\n // else\n // {\n // R(2,0) > 0.0f ? pyr(1) = -M_PI_2 : pyr(1) = M_PI_2;\n // pyr(0) = asin(-R(0,1));\n // pyr(2) = 0.;\n // }\n\n // return pyr;\n // }\n\n /**\n * @brief Get the rotation matrix Cge(e->g) \n * \n * @param lat : latitude \n * @param lon : longitude\n * @return Eigen::Matrix3d \n */\n static Eigen::Matrix3d getCge(double lat, double lon){\n Eigen::AngleAxisd rvec0(lat, Eigen::Vector3d(0., 0., 1.));\n Eigen::AngleAxisd rvec1(M_PI_2, Eigen::Vector3d(0., 1., 0.));\n Eigen::AngleAxisd rvec2((M_PI_2 - lon), Eigen::Vector3d(0., 0., 1.));\n\n Eigen::Quaterniond qgb(rvec0 * rvec1 * rvec2);\n return qgb.toRotationMatrix();\n }\n\n /**\n * @brief Get the rotation matrix Cge(e->g) \n * \n * @param lat : latitude \n * @param lon : longitude\n * @return Eigen::Matrix3d \n */\n static Eigen::Matrix3d getCge(Eigen::Vector3d &tnb){\n double scale = sqrt(tnb.x() * tnb.x() + tnb.y() * tnb.y());\n double lat = atan2(tnb.z(), scale);\n double lon = atan2(tnb.y(), tnb.x());\n\n Eigen::AngleAxisd rvec0(lat, Eigen::Vector3d(0., 0., 1.));\n Eigen::AngleAxisd rvec1(M_PI_2, Eigen::Vector3d(0., 1., 0.));\n Eigen::AngleAxisd rvec2((M_PI_2 - lon), Eigen::Vector3d(0., 0., 1.));\n\n Eigen::Quaterniond qgb(rvec0 * rvec1 * rvec2);\n return qgb.toRotationMatrix();\n }\n};\n\nclass FrameConvert{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n static Vec3d geo2mcmf(Vec3d geo){\n Vec3d tmp;\n double lat = geo.x();\n double alt = geo.y(); \n double lon = geo.z(); \n \n tmp.x() = (R_m + alt) * cos(lat) * cos(lon);\n tmp.y() = (R_m + alt) * cos(lat) * sin(lon);\n tmp.z() = (R_m + alt) * sin(lat);\n\n return tmp;\n }\n\n static Vec3d mcmf2geo(Vec3d mcmf){\n Vec3d tmp;\n\n return tmp;\n }\n};\n\n#endif"
},
{
"alpha_fraction": 0.49863573908805847,
"alphanum_fraction": 0.5466120839118958,
"avg_line_length": 25.660606384277344,
"blob_id": "4be1de2011c1497206025d4445c59b284b0da649",
"content_id": "6d3578e2a6328220bbf86378015c8a478609d75e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4398,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 165,
"path": "/examples/landerIMU.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "/**\n * @file cvIMU.cc\n * @author yuntian li ([email protected])\n * @brief const velocity circular trajectory around the Moon in G frame \n * @version 0.1\n * @date 2020-08-11\n * \n * @copyright Copyright (c) 2020\n * \n */\n#include \"commonHeaders.h\"\n#include \"utilities/io_function.h\"\n#include \"simulator/sensors/imu_g.h\"\n\nusing namespace std;\nusing namespace MyFusion;\n\n\nvector<ImuMotionData> traj_data;\nvector<ImuMotionData> imu_data;\n\nvoid cvModel(){\n ImuMotionData initPose;\n initPose.tnb_ = Vec3d(0., 0., 15000);\n initPose.vel_ = Vec3d(1672.9, 0., 0.);\n initPose.qnb_ = Eigen::Quaterniond(1., 0., 0., 0.);\n initPose.time_stamp_ = 0.;\n\n double a_max = 2.1825;\n double theta = 0. / 180. * M_PI;\n\n double time = 500;\n int N = 200 * time;\n\n vector<Vec3d> a_g_all, w_g_all; // all acc and gyr in G\n for (int i = 0; i < N; i++){\n a_g_all.emplace_back(Vec3d(-a_max * cos(theta), 0., -a_max * sin(theta)));\n w_g_all.emplace_back(Vec3d::Zero());\n }\n\n // vector<ImuMotionData> traj_data;\n\n ImuParam mtiParam;\n readImuParam(\"../config/simulator/mti_config.yaml\", mtiParam);\n IMU_G mtiIMU(mtiParam);\n\n mtiIMU.setIntType(0);\n traj_data.clear();\n traj_data = mtiIMU.trajGenerator(initPose, a_g_all, w_g_all);\n\n writeImuMotionData(\"../data/cvGeo.csv\", traj_data);\n writePos(\"../data/posNED.csv\", traj_data);\n}\n\nvoid landModel(){\n ImuMotionData initPose;\n initPose.tnb_ = Vec3d(0., 20000, 0.); // lat, alt, lon\n initPose.vel_ = Vec3d(1690, 0., 0.);\n initPose.time_stamp_ = 0.;\n\n double theta = -8.5 / 180. * M_PI;\n Eigen::AngleAxisd r_vec(theta, Vec3d(0., 0., 1.));\n initPose.qnb_ = Eigen::Quaterniond(r_vec);\n \n double cur_a = 2.6658;\n // main break\n double time = 405;\n int N = 200 * time;\n\n vector<Vec3d> a_b_all, w_g_all; // all acc in B and all gyr in G\n for (int i = 0; i < N; i++){\n cur_a += 3.5e-5;\n a_b_all.emplace_back(Vec3d(-cur_a, 0.,0.));\n w_g_all.emplace_back(Vec3d::Zero());\n }\n \n // fast adjustment\n time = 32.6;\n N = 200 * time;\n\n cur_a = 2.0;\n double w_ad = 2.5 / 180. * M_PI;\n for(int i = 0; i < N; i++){\n a_b_all.emplace_back(Vec3d( -cur_a, 0., 0.));\n w_g_all.emplace_back(Vec3d(0., 0., -w_ad));\n }\n\n // vertical approaching\n time = 74.4;\n N = 200 * time;\n\n for(int i = 0; i < N; i++){\n cur_a += 2.0e-4;\n a_b_all.emplace_back(Vec3d(-cur_a, 0.,0.));\n w_g_all.emplace_back(Vec3d(0., 0., 0.));\n }\n // hazard avoidance \n time = 15;\n N = 200 * time;\n\n for(int i = 0; i < N; i++){\n a_b_all.emplace_back(Vec3d(-1.622, 0.5, -0.6));\n w_g_all.emplace_back(Vec3d(0., 0., 0.));\n }\n \n time = 15;\n N = 200 * time;\n\n for(int i = 0; i < N; i++){\n a_b_all.emplace_back(Vec3d(-1.622, 0.5, 0.6));\n w_g_all.emplace_back(Vec3d(0., 0., 0.));\n }\n // finla approaching\n time = 11;\n N = 200 * time;\n for(int i = 0; i < N; i++){\n a_b_all.emplace_back(Vec3d(0., 0., 0.));\n w_g_all.emplace_back(Vec3d(0., 0., 0.)); \n }\n \n time = 10;\n N = 200 * time;\n for(int i = 0; i < N; i++){\n a_b_all.emplace_back(Vec3d(-3.5, 0., 0.));\n w_g_all.emplace_back(Vec3d(0., 0., 0.)); \n }\n // generate trajectory\n ImuParam mtiParam;\n readImuParam(\"../config/simulator/mti_config.yaml\", mtiParam);\n IMU_G mtiIMU(mtiParam);\n\n mtiIMU.setIntType(0);\n traj_data.clear();\n traj_data = mtiIMU.trajGenerator(initPose, a_b_all, w_g_all);\n\n writeImuMotionData(\"../data/stdTraj/caGeo.csv\", traj_data);\n writePos(\"../data/stdTraj/posNED.csv\", traj_data);\n\n // traj_data.clear();\n // readImuMotionData(\"../data/stdTraj/caGeo.csv\", traj_data);\n // cout << traj_data.size() << endl;\n // test imu integration \n // imu_data.clear();\n // int i = 0;\n // for(auto it: traj_data){\n // int per = (++i) * 100 / traj_data.size();\n // printf(\"[#][Generating IMU data...][%d%%]\\r\", per);\n // fflush(stdout);\n\n // ImuMotionData tmp_data = it;\n // mtiIMU.oneStepPropagate(tmp_data);\n // imu_data.emplace_back(tmp_data);\n // }\n // printf(\"\\n\");\n\n // writeImuMotionData(\"../data/stdTraj/caGeoImu.csv\", imu_data);\n // writePos(\"../data/stdTraj/posNEDImu.csv\", imu_data);\n}\n\nint main(int argc, char** argv){\n \n landModel(); \n\n return 0;\n}"
},
{
"alpha_fraction": 0.6409883499145508,
"alphanum_fraction": 0.6468023061752319,
"avg_line_length": 23.60714340209961,
"blob_id": "7e2b2675323b4d1229f28ba119183fafee820a0e",
"content_id": "62d2693463b4aac1bd502562515d705f8b7b3b33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 688,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 28,
"path": "/src/simulator/sensors/altimeter.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/altimeter.h\"\n\nnamespace MyFusion{\n\nvoid Altimeter::setParam(double bias, double sigma){\n bias_ = bias;\n sigma_ = sigma / R_m; // convert from m to rad\n flagInit_ = true;\n}\n\nAltData Altimeter::getMeasurement(ImuMotionData currMotion){\n if(!flagInit_){\n cout << \"WARNING: parameters untizlied! Please call setParam()\\n\";\n }\n \n AltData tmp;\n\n std::random_device rd;\n std::default_random_engine rg(rd());\n std::normal_distribution<double> noise(0., 1.); \n\n tmp.timeStamp_ = currMotion.time_stamp_;\n tmp.range_ = currMotion.tnb_.y() / currMotion.qnb_.toRotationMatrix()(1, 1) + sigma_ * noise(rg);\n\n return tmp;\n}\n\n}"
},
{
"alpha_fraction": 0.5112782120704651,
"alphanum_fraction": 0.5463659167289734,
"avg_line_length": 28.592592239379883,
"blob_id": "7ea21c0a24b67290bd95d5e31bd14018713c8b19",
"content_id": "2989c1fb357d32b176b56ba50f167eaa832c7eae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 27,
"path": "/src/simulator/sensors/imu_li.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"constParams.h\"\n#include \"simulator/sensors/imu_li.h\"\n\nnamespace MyFusion{\n\nvoid IMU_LI::oneStepIntegration()\n{\n // quaterniond update\n Eigen::Vector3d mid_gyr = 0.5 * (gyr_0_ + gyr_1_) - gyr_bias_;\n \n Eigen::Quaterniond qnb0 = qnb_;\n Eigen::Quaterniond dq(1., 0.5 * mid_gyr.x() * time_step_, 0.5 * mid_gyr.y() * time_step_, 0.5 * mid_gyr.z() * time_step_);\n dq.normalize();\n \n qnb_ = qnb0 * dq;\n // pos update\n Eigen::Vector3d gw = Vec3d::Zero(); // geavity vector\n gw.z() = -computeG(tnb_.z());\n // gw.z() = -1.622;\n\n Eigen::Vector3d acc_w = 0.5 * (qnb0 * (acc_0_ - acc_bias_) + qnb_ * (acc_1_ - acc_bias_)) + gw;\n tnb_ += vel_ * time_step_ + 0.5 * acc_w * time_step_ * time_step_; \n // vel update\n vel_ += acc_w * time_step_;\n}\n\n}"
},
{
"alpha_fraction": 0.6402438879013062,
"alphanum_fraction": 0.6451219320297241,
"avg_line_length": 19.024391174316406,
"blob_id": "36287cdf498b7e03cc5646646b146d6f7776581e",
"content_id": "7b180b32927b351d75cb6791d228495381da475f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 820,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 41,
"path": "/include/simulator/sensors/virns.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef VIRNS_H_\n#define VIRNS_H_\n#include \"commonHeaders.h\"\n#include \"simulator/sensors/imu_base.h\"\n#include \"utilities/utilities.hpp\"\n\nnamespace MyFusion{\n\nstruct VirnsData{\n double timeStamp_;\n Vec3d dPos_;\n Vec3d pos_;\n};\n\nclass VIRNS{\npublic:\n VIRNS(double bias, double sigma):bias_(bias), sigma_(sigma){\n flagInit_ = true;\n }\n ~VIRNS(){}\n\n\n void setParams(double bias, double sigma);\n /**\n * @brief Get the Relative Measurement dp\n * \n * @param currMotion \n * @return Vec3d \n */\n VirnsData getRelativeMeasurement(ImuMotionData currMotion);\n \n // ImuMotionData lastMotion_;\n Vec3d lastP_, curP_; // last position and current position\n double bias_, sigma_; // noise bias and sigma\n bool flagInit_ = false;\n bool flagFirst = true;\n};\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.6710280179977417,
"alphanum_fraction": 0.672897219657898,
"avg_line_length": 15.242424011230469,
"blob_id": "4c60dd2c6d405fa456811357e512da100c73eb0d",
"content_id": "8617264a72dc9fb8795cb8cf9137ea71bb9ef206",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 33,
"path": "/include/simulator/sensors/cmns.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef CMNS_H_\n#define CMNS_H_\n#include \"commonHeaders.h\"\n#include \"simulator/sensors/imu_base.h\"\n#include \"simulator/sensorNoise.hpp\"\n\nnamespace MyFusion{\n\nstruct CmnsData{\n double timeStamp_;\n Vec2d pos_; // latitude and longitude\n};\n\nclass CMNS{\npublic:\n CMNS(double bias, double sigma){\n setParam(bias, sigma);\n }\n\n ~CMNS(){}\n\n void setParam(double bias, double sigma);\n\n CmnsData getMeasurement(ImuMotionData currMotion);\n\n double bias_;\n double sigma_;\n bool flagInit_ = false;\n};\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.5350675582885742,
"alphanum_fraction": 0.5467993021011353,
"avg_line_length": 25.863014221191406,
"blob_id": "4942a7c7ef6d3e3f797bdc0a8651a34a961ef1e3",
"content_id": "d9b96ef627f2fd43fbd8824b39c40a7ab5e5db33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3921,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 146,
"path": "/src/simulator/sensors/imu_base.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/imu_base.h\"\n\nnamespace MyFusion{\n\nIMU_BASE::IMU_BASE(ImuParam params){\n setParams(params);\n}\n\nIMU_BASE::~IMU_BASE(){}\n\nvoid IMU_BASE::setParams(ImuParam param)\n{\n acc_bias_ = Vec3d::Ones() * param.acc_b_; \n gyr_bias_ = Vec3d::Ones() * param.gyr_b_;\n acc_n_ = param.acc_n_; gyr_n_ = param.gyr_n_;\n acc_w_ = param.acc_w_; gyr_w_ = param.gyr_w_;\n\n time_step_ = param.time_step_;\n \n init_flag_ = true; \n}\n\nvoid IMU_BASE::oneStepPropagate(ImuMotionData &data){\n // \n if(!init_flag_){\n std::cout << \"Please initiate imu parameters first !\\n\";\n return;\n }\n // extract imu measurements and states\n acc_1_ = data.acc_; gyr_1_ = data.gyr_;\n // add noise to trajectory data \n addNoise();\n // check if it's the first measurement\n if(first_flag_){\n tnb_ = data.tnb_; vel_ = data.vel_;\n qnb_ = data.qnb_;\n // pos_ = data.pos_;\n pos_ = Vec3d(0., tnb_.y(), 0.);\n // pos_ = FrameConvert::geo2mcmf(tnb_);\n // cout << \"\\nIntegration type: \" << intType << endl;\n first_flag_ = false;\n }\n else{\n oneStepIntegration();\n }\n // construct\n data.tnb_ = tnb_; data.vel_ = vel_; \n data.qnb_ = qnb_; data.Rnb_ = qnb_.toRotationMatrix();\n \n Vec3d tmp_euler;\n if(frameType_ == GEO){\n tmp_euler = AttUtility::R2Euler(data.Rnb_);\n }\n else if(frameType_ == MCMF){\n Eigen::Matrix3d Cgb = AttUtility::getCge(tnb_) * data.Rnb_;\n tmp_euler = AttUtility::R2Euler(Cgb);\n }\n else{\n cout << \"WARNING: Unknown frame type.\\n\"; \n }\n\n data.eulerAngles_ = tmp_euler;\n\n data.pos_ = pos_;\n\n data.acc_ = acc_1_; data.gyr_ = gyr_1_;\n data.acc_bias_ = acc_bias_; \n data.gyr_bias_ = gyr_bias_;\n // update\n acc_0_ = acc_1_; gyr_0_ = gyr_1_; \n}\n\nvoid IMU_BASE::addNoise(){\n if(!init_flag_){\n std::cout << \"Please initiate imu parameters first !\\n\";\n return;\n }\n // generate standard white noise\n std::random_device rd; // generate seed for random eigine \n std::default_random_engine rg(rd()); // create random eigine with seed rd();\n std::normal_distribution<double> noise(0.0, 1.0);\n\n // ================= add noise to measurements\n Eigen::Vector3d acc_noise(noise(rg), noise(rg), noise(rg));\n acc_noise *= acc_n_;\n // cout << \"acc_noise times deviation: \" << acc_noise << endl;\n acc_1_ += acc_noise / sqrt(time_step_) + acc_bias_;\n\n Eigen::Vector3d gyr_noise(noise(rg), noise(rg), noise(rg));\n gyr_noise *= gyr_n_;\n gyr_1_ += gyr_noise / sqrt(time_step_) + gyr_bias_;\n\n // ================= update bias with random walk\n Eigen::Vector3d acc_walk_noise(noise(rg), noise(rg), noise(rg));\n acc_walk_noise *= acc_w_;\n acc_bias_ += acc_walk_noise * sqrt(time_step_);\n\n Eigen::Vector3d gyr_walk_noise(noise(rg), noise(rg), noise(rg));\n gyr_walk_noise *= gyr_w_;\n gyr_bias_ += gyr_walk_noise * sqrt(time_step_);\n}\n\ndouble IMU_BASE::computeG(double h, CELESTIAL body){\n double scale = 0.0;\n \n switch (body)\n {\n case EARTH:\n scale = (1. + h / R_e);\n return (g0_e / (scale * scale));\n break;\n case MOON:\n scale = (1. + h / R_m);\n return (g0_m / (scale * scale));\n break;\n default:\n cout << \"Wrong celestial type!\\n\";\n break;\n }\n}\n\nvoid IMU_BASE::generateAllanData(double t, vector<ImuMotionData> & imu_data){\n double time_stamp = 0.0;\n\n imu_data.clear();\n while(time_stamp <= t){\n float per = time_stamp / t * 100.;\n printf(\"[#][Generating allan data...][%.2f%%]\\r\", per);\n fflush(stdout);\n\n acc_1_ = Eigen::Vector3d::Zero();\n gyr_1_ = Eigen::Vector3d::Zero();\n\n addNoise();\n\n ImuMotionData tmp_data;\n tmp_data.acc_ = acc_1_;\n tmp_data.gyr_ = gyr_1_;\n\n time_stamp += time_step_;\n }\n\n \n}\n\n}"
},
{
"alpha_fraction": 0.46839186549186707,
"alphanum_fraction": 0.5025877952575684,
"avg_line_length": 33.227848052978516,
"blob_id": "149852b9fbaa960a2c26c7581dac1829c93fdd23",
"content_id": "ad2190ec49423911cbb44f8cada19310930a0f68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5480,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 158,
"path": "/tools/drawRmse.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom sys import argv\nfrom matplotlib import rcParams\n\n# matplotlib.use(\"pgf\")\n# pgf_config = {\n# \"font.family\":'serif',\n# \"font.size\": 10,\n# \"pgf.rcfonts\": False,\n# \"text.usetex\": True,\n# \"pgf.preamble\": [\n# r\"\\usepackage{unicode-math}\",\n# #r\"\\setmathfont{XITS Math}\", \n# # 这里注释掉了公式的XITS字体,可以自行修改\n# r\"\\setmainfont{Times New Roman}\",\n# r\"\\usepackage{xeCJK}\",\n# r\"\\xeCJKsetup{CJKmath=true}\",\n# r\"\\setCJKmainfont{SimSun}\",\n# ],\n# }\n# # rcParams.update(pgf_config)\nR_M = 1.737e6\n######################## 自定义函数 ############################\ndef calcError(trajdata, filterdata):\n pos_0 = trajdata.iloc[:, 1:4].values\n pos_1 = filterdata.iloc[:, 1:4].values\n\n vel_0 = trajdata.iloc[:, 11:14].values\n vel_1 = filterdata.iloc[:, 4:7].values\n \n # sigmaP = filterdata.iloc[:, 7:10].values\n # sigmaV = filterdata.iloc[:, 10:13].values\n\n time_0 = trajdata.iloc[:,0].values\n time_1 = filterdata.iloc[:,0].values\n\n N = len(time_1)\n idx = 0\n # err = np.zeros([N, 13])\n err = np.zeros([N, 7])\n while idx < N:\n for i in range(0, len(time_0)):\n if time_0[i] == time_1[idx]:\n err[idx, 0] = time_1[idx]\n # err[idx, 1:4] = np.fabs(pos_1[idx, :] - pos_0[i, :])\n # err[idx, 4:7] = np.fabs(vel_1[idx, :] - vel_0[i, :])\n err[idx, 1:4] = pos_1[idx, :] - pos_0[i, :]\n err[idx, 1] = err[idx, 1] * (R_M + pos_1[idx, 1])\n err[idx, 3] = err[idx, 3] * (R_M + pos_1[idx, 1]) * math.cos(pos_1[idx,0])\n\n err[idx, 4:7] = vel_1[idx, :] - vel_0[i, :]\n \n # err[idx, 7] = sigmaP[idx, 0] * (R_M + pos_1[idx, 1])\n # err[idx, 8] = sigmaP[idx, 1]\n # err[idx, 9] = sigmaP[idx, 2] * (R_M + pos_1[idx, 1]) * math.cos(pos_1[idx,0])\n\n idx += 1\n if(idx >= N):\n break\n \n # err[:,10:13] = sigmaV\n\n return err \n\ndef calcRMSE(err, dim):\n N = len(err[:,0])\n M = round(len(err[0,:]) / 3) + 1\n \n rmse = np.zeros((N, M))\n rmse[:,0] = err[:,0]\n for i in range(0, N):\n for j in range(1, M):\n start_idx = -2 + 3 * j\n end_idx = start_idx + dim\n rmse[i, j] = math.sqrt(np.dot(err[i, start_idx:end_idx], err[i, start_idx:end_idx]) / dim)\n\n return rmse \n#################### 读取数据(csv格式) ########################\ndataset = argv[1]\nfolder = argv[2]\ncalc = True\nfilename = \"../output/\" + dataset + \"/rmse\" + folder +\".csv\"\nfilterNum = 2\n\ncolNames = ['time']\nfor i in range(0, filterNum):\n colNames.append('P_F' + str(i+1))\nfor i in range(0, filterNum):\n colNames.append('V_F' + str(i+1))\n\nif calc:\n datapath = \"../output/\" + dataset + \"/\" + folder + \"/\"\n trajData = pd.read_csv('../data/stdTraj/caGeo.csv')\n filterData = pd.read_csv(datapath + \"AA0.csv\");\n\n NN = filterData.shape[0]\n rmseAll = np.zeros([NN, 2 * filterNum + 1])\n\n start_idx = 0\n end_idx = 100\n for i in range(start_idx, end_idx):\n f1Data = pd.read_csv(datapath + \"AA\" + str(i) + \".csv\")\n f2Data = pd.read_csv(datapath + \"AR\" + str(i) + \".csv\")\n #calculate error\n f1Err = calcError(trajData, f1Data)\n f2Err = calcError(trajData, f2Data)\n # assign time\n if i == start_idx:\n rmseAll[:,0] = f1Err[:,0]\n # compute rmse\n f1Rmse = calcRMSE(f1Err, 3)\n f2Rmse = calcRMSE(f2Err, 3)\n # sum rmse\n rmseAll[:,1] += f1Rmse[:,1]\n rmseAll[:,2] += f2Rmse[:,1]\n \n rmseAll[:,3] += f1Rmse[:,2]\n rmseAll[:,4] += f2Rmse[:,2]\n\n rmseAll[:,1:] /= (end_idx - start_idx)\n\n rmseAllDf = pd.DataFrame(data=rmseAll, columns=colNames)\n rmseAllDf.to_csv(filename,index=None)\nelse: \n rmseAllDf = pd.read_csv(filename)\n\n#########################################################################\nrmseStatistic = np.zeros([2, 2 * filterNum])\nrmseStatistic[0,:] = rmseAllDf.mean()[1:,]\n\nfor i in range(0, 2 * filterNum):\n if(i != 0 and i != filterNum):\n rmseStatistic[1,i] = abs(rmseStatistic[0,i] - rmseStatistic[0,i-1]) / rmseStatistic[0,i-1] * 100\nfor i in range(0, 2):\n for j in range(0, 2 * filterNum):\n print('%7.3f '%rmseStatistic[i, j], end='')\n print()\n# #########################################################################\n# colors = ['royalblue', 'tomato']\n# labels = ['L2', 'Cauchy']\n# sep = 10\n# scaleSep = 10\n# ############### position rmse ############### \n# fig1, ax = plt.subplots(1, 1, figsize=(7,5))\n# ax.plot(rmseAllDf['time'].values[::scaleSep * sep], rmseAllDf['P_F1'].values[::scaleSep * sep], marker='d', color=colors[0])\n# ax.plot(rmseAllDf['time'].values[::scaleSep * sep], rmseAllDf['P_F2'].values[::scaleSep * sep], marker='X', color=colors[1])\n# ############### velocity rmse ############### \n# fig2, ax = plt.subplots(1, 1, figsize=(7,5))\n# ax.plot(rmseAllDf['time'].values[::scaleSep * sep], rmseAllDf['V_F1'].values[::scaleSep * sep], marker='d', color=colors[0])\n# ax.plot(rmseAllDf['time'].values[::scaleSep * sep], rmseAllDf['V_F2'].values[::scaleSep * sep], marker='X', color=colors[1])\n# ############### interaction ############### \n# plt.show()\n\n\n"
},
{
"alpha_fraction": 0.5830302834510803,
"alphanum_fraction": 0.6181818246841431,
"avg_line_length": 33.39583206176758,
"blob_id": "2d9c6bc6ec01bff7bd5a6c9b4d81f26a1078d9c4",
"content_id": "5dbd09eeae848a0419c0713b964323e60b1f6f23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1650,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 48,
"path": "/examples/insMoon.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"commonHeaders.h\"\n#include \"utilities/io_function.h\"\n#include \"simulator/sensors/imu_mci.h\"\n#include \"simulator/sensors/imu_mcmf.h\"\n#include \"simulator/sensors/imu_g.h\"\n\nusing namespace MyFusion;\n\nint main(int argc, char** argv){\n // read imu parmaeters\n ImuParam mtiParam;\n readImuParam(\"../config/simulator/mti_config.yaml\", mtiParam);\n // create two imu instance in MCI and MCMF\n IMU_MCMF mtiMCMF(mtiParam);\n\n // read designed imudata\n vector<ImuMotionData> traj_data;\n readImuMotionData(\"../data/standardTraj/caGeo.csv\", traj_data);\n\n // set initialization\n traj_data[0].tnb_ = Eigen::Vector3d(20000. + R_m, 0., 0.);\n traj_data[0].vel_ = Eigen::Vector3d(0., 0., 1690.);\n\n Eigen::AngleAxisd r_vec_1(-0.5 * M_PI, Eigen::Vector3d(0., 0., 1.)); // z(-pi/2)\n Eigen::AngleAxisd r_vec_2(-0.5 * M_PI, Eigen::Vector3d(0., 1., 0.)); // y(-pi/2)\n Eigen::AngleAxisd r_vec_3(-8.5 / 180 * M_PI, Eigen::Vector3d(0., 0., 1.)); // z(-8.5)\n\n traj_data[0].qnb_ = Eigen::Quaterniond(r_vec_1 * r_vec_2 * r_vec_3); // Z-Y-X (2,1,0)\n \n // integration\n vector<ImuMotionData> imu_data_mcmf;\n\n size_t N = traj_data.size();\n for(size_t i = 0; i < traj_data.size(); i++){\n int per = (i + 1) * 100 / N;\n printPer(\"IMU MCMF generating\", per);\n ImuMotionData tmp_data = traj_data[i];\n mtiMCMF.oneStepPropagate(tmp_data);\n imu_data_mcmf.emplace_back(tmp_data);\n }\n cout << endl;\n\n cout << \"Saving data...\\n\";\n writeImuMotionData(\"../data/standardTraj/imuMCMF.csv\", imu_data_mcmf);\n writePos(\"../data/standardTraj/posMCMF.csv\", imu_data_mcmf);\n\n return 0;\n}"
},
{
"alpha_fraction": 0.6001198887825012,
"alphanum_fraction": 0.6100119948387146,
"avg_line_length": 22.5,
"blob_id": "a1737ef6ce816c70147ca2f2ba53bfad3c75291f",
"content_id": "4c6364133aa72ebd5693c8879c6883deab610e4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3372,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 142,
"path": "/include/simulator/sensors/imu_base.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef IMU_BASE_H_\n#define IMU_BASE_H_\n\n#include \"commonHeaders.h\"\n#include \"utilities/utilities.hpp\"\n\nusing namespace std;\n\nenum FRAME{\n GEO = 0,\n MCMF,\n MCI,\n};\n\nenum CELESTIAL{\n EARTH = 0,\n MOON = 1,\n};\n\nnamespace MyFusion{\n\n/**\n * @brief Struct of IMU Parameters\n * \n */\nstruct ImuParam{\n double acc_b_, gyr_b_; // bias\n double acc_n_, gyr_n_; // noise\n double acc_w_, gyr_w_; // random walk\n double time_step_; // time_step of imu\n};\n\n/**\n * @brief Struct of IMU Data\n * \n */\nstruct ImuMotionData{\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW\n double time_stamp_; // current time stamp\n \n Eigen::Vector3d tnb_; // translation from b-frame to w-frame, e.g., posotion in w-frame;\n Eigen::Matrix3d Rnb_; // rotation transform from b-fram to w-frame\n Eigen::Quaterniond qnb_; // quaternion rotate w-frame to b-frame (q^w_b = R^w_b但前者表示w->q的旋转,后者表示b->w的坐标变换)\n Eigen::Vector3d eulerAngles_; // sequence 2-1-0\n\n Eigen::Vector3d acc_; // linear acceleration\n Eigen::Vector3d vel_; // linear velocity\n Eigen::Vector3d gyr_; // angular rate\n\n Eigen::Vector3d acc_bias_; // accelerometer bias\n Eigen::Vector3d gyr_bias_; // gyroscope bias\n\n // test variables\n Eigen::Vector3d pos_; // pos in local frame (used in geometric reference frame)\n Eigen::Vector3d acc_n_;\n // Eigen::Vector3d gyr_n_;\n};\n\nclass IMU_BASE{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n \n IMU_BASE(ImuParam params);\n\n virtual ~IMU_BASE();\n\n /**\n * @brief Set parameters of imu\n * \n * @param param struct of imu parameters \n */\n void setParams(ImuParam param);\n \n /**\n * @brief add noise to current measurement and update bias\n * \n * @param data \n */\n void addNoise();\n\n /**\n * @brief propagate for one step\n * \n * @param data io, received ImuMotionData from trajectory generator \n * and return ImuMotionData from IMU simulator. \n */\n void oneStepPropagate(ImuMotionData &data);\n\n double computeG(double h, CELESTIAL body=MOON);\n\n // /**\n // * @brief trajectory generator\n // * \n // * @param t \n // * @return IMUMotionData \n // */\n // virtual ImuMotionData motionModel(double t) = 0;\n\n virtual void oneStepIntegration() = 0;\n\n /**\n * @brief Set the Integration type\n * \n * @param type \n */\n void setIntType(int type){intType = type;}\n\n /**\n * @brief generate imu data for Allan derivation\n * \n * @param t : time in s \n * @param imu_data : vector of ImuMotionData\n */\n void generateAllanData(double t, vector<ImuMotionData> &imu_data);\n\nprotected:\n Vec3d acc_bias_, gyr_bias_; //bias \n double acc_n_, gyr_n_; // noise\n double acc_w_, gyr_w_; // random walk\n // init state\n // Vec3d init_twb_, init_vel_;\n // Mat3d init_Rwb_;\n // current state\n Vec3d tnb_, vel_;\n Qd qnb_;\n Vec3d pos_; // pos in local frame(used in geometric frame)\n // measurements for mid_integration\n Vec3d acc_0_, gyr_0_; // last measurements\n Vec3d acc_1_, gyr_1_; // current measurements\n\n double time_step_; // sample step of IMU\n\n bool init_flag_ = false; // flag of initialization\n bool first_flag_ = true; // flag of first measurement\n\n int intType = 0; // 0- euler; 1-mid\n FRAME frameType_;\n};\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.8444444537162781,
"alphanum_fraction": 0.8444444537162781,
"avg_line_length": 44,
"blob_id": "161e2db5e62b48b4dc3697d4dd4bced0ebd74ec3",
"content_id": "36bc276ee2e5a8d126109b2b4d6724fc2e3103ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 1,
"path": "/README.md",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "robust multi-sensor fusion for lunar landing\n"
},
{
"alpha_fraction": 0.7597535848617554,
"alphanum_fraction": 0.7597535848617554,
"avg_line_length": 23.779661178588867,
"blob_id": "042e8761feb210f13544b5dbcb2983687a14c550",
"content_id": "82486c2b228e60caad0f8915ad9899802a2497e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1461,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 59,
"path": "/include/utilities/io_function.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#pragma once\n// #ifndef IO_FUNCTION_H_\n// #define IO_FUNCTION_H_\n#include \"commonHeaders.h\"\n#include \"simulator/sensors/imu_base.h\"\n#include \"simulator/sensors/cns.h\"\n#include \"simulator/sensors/virns.h\"\n#include \"simulator/sensors/cmns.h\"\n#include \"simulator/sensors/altimeter.h\"\n\nusing namespace std;\n\nnamespace MyFusion{\n\nint readImuParam(string filename, ImuParam ¶m);\n\nvoid readImuMotionData(string filename, vector<ImuMotionData> &imu_data);\n\nvoid writeImuMotionData(string filename, vector<ImuMotionData> &imu_data);\n\nvoid writeCnsData(string filename, vector<CnsData> &cnsData);\n\nvoid writeVirnsData(string filename, vector<VirnsData> &virnsData);\n\nvoid writeCmnsData(string filename, vector<CmnsData> &cmnsData);\n\nvoid writeAltData(string filename, vector<AltData> &altData);\n\nvoid writePos(string filename, vector<ImuMotionData> &imu_data);\n\nvoid writeAllanData(string filename, vector<ImuMotionData> &imu_data);\n\nvoid readCnsData(string fileName, vector<CnsData> &cnsData);\n\nvoid readVirnsData(string fileName, vector<VirnsData> &virnsData);\n\nvoid readCmnsData(string fileName, vector<CmnsData> &cmnsData);\n\nvoid readAltData(string fileName, vector<AltData> &altData);\n\n/**\n * @brief print percentage of progress\n * \n * @param name \n * @param per \n */\nvoid printPer(string name, float per);\n/**\n * @brief print percentage of progress\n * \n * @param name \n * @param per \n */\nvoid printPer(string name, int per);\n\n} // namespace MyFusion\n\n\n// #endif"
},
{
"alpha_fraction": 0.7082228064537048,
"alphanum_fraction": 0.7096964120864868,
"avg_line_length": 46.13888931274414,
"blob_id": "d816c67f44d47a3f4fee04931e47db37d721b017",
"content_id": "e702846754bf91b79cbb56b034528be4fa1d761f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3393,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 72,
"path": "/include/backend/sckf/scspkf.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SCSPKF_H_\n#define SCSPKF_H_\n#include \"backend/sckf/sckf.h\"\n\n#define varName(x) #x //get variable name\n\n// type of sample points\nenum SampleType{\n SP_UKF = 0,\n SP_CKF,\n SP_HCKF\n};\n\nnamespace MyFusion{\n\nclass SCSPKF : public SCKF{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n SCSPKF(){} // default constructor\n SCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType=SP_HCKF);\n SCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, double alpha, double beta, double kappa, SampleType sigmaType=SP_UKF);\n void initSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType);\n // void setUKFParams(double alpha, double beta, double kappa);\n // ------ filter functions ------ //\n void genSigmaPoints(vector<VecXd> &sPoints, bool aug=0);\n // void genSigmaPointsCKF(vector<VecXd> &sPoints);\n void genSi(vector<VecXd> &allSi, int xSize);\n void genSiUKF(vector<VecXd> &allSi, int xSize); // generate UKF cubature points\n void genSiCKF(vector<VecXd> &allSi, int xSize); // generate CKF cubature points\n void genSiHCKF(vector<VecXd> &allSi, int xSize); // generate HCKF cubature points\n void getScaleHCKF(double &scale0, double &scale1, size_t k);\n\n void computeWeight(vector<double> &weightMu, vector<double> &weightSigma, int xSize);\n void computeWeightUKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize); // compute UKF weights\n void computeWeightCKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize); // compute CKF weights\n void computeWeightHCKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize); // compute HCKF weights\n \n void oneStepPrediction(VecXd &U) override;\n void oneStepUpdate(VecXd &Z) override;\n \n virtual void propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, VecXd &U);\n virtual void updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY);\n // ------ support functions ------ //\n VecXd calcWeightedMean(vector<VecXd> &sPointsX, const vector<double> &weightMu); // calculate weighted mean\n MatXd calcWeightedCov(vector<VecXd> &sPointsX, const vector<double> &weightMu, const vector<double> &weightSigma); // calculate weighted covariance\n MatXd calcWeightedCrossCov(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, const vector<double> &weightMu, const vector<double> &weightSigma); // calculate weighted corss-covariance\n // ------ io and debug functions ------ //\n void printSi(vector<VecXd> allSi, string name, int maxPerRow);\n void printWeight(vector<double> allWeight, string name, int maxPerRow);\n void setSigmaType(SampleType type){sigmaType_ = type;}\n SampleType getSigmaType(){return sigmaType_;}\n\nprotected:\n SampleType sigmaType_; // type of sigma points\n vector<VecXd> allSi_, allSiAug_; // cubature points for mu and augMu\n vector<VecXd> sPointsX_; // sigma points before propagation\n vector<VecXd> sPointsY_; // sigma point after propagation\n\n vector<double> weightMu_, weightMuAug_; // weight of mu and augMu\n vector<double> weightSigma_, weightSigmaAug_; // weight of sigma and augSigma\n\n double alpha_, beta_, kappa_, lambda_; // parameters of UKF \n double gamma_; // coefficient HCKF(sqrt(n+2)), CKF(sqrt(n)), UKF(sqrt(n+lambda)) \n // bool firstGen_ = true;\n bool ukfInit_ = false;\n bool siInit_ = false;\n};\n\n\n}// namespace MyFusion\n\n#endif"
},
{
"alpha_fraction": 0.7086834907531738,
"alphanum_fraction": 0.7086834907531738,
"avg_line_length": 27.600000381469727,
"blob_id": "79178a8a67ae825e2458624c7fa6cfdf1fc28706",
"content_id": "53d9479785c6cf706124c9060905dc9b1751cc09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 714,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 25,
"path": "/include/backend/sckf/pdSCSPKF.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef PD_SCSPKF_H_\n#define PD_SCSPKF_H_\n#include \"backend/sckf/scspkf.h\"\n#include \"backend/backParam.h\"\n\nnamespace MyFusion\n{\nclass PdSCSPKF : public SCSPKF{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n PdSCSPKF();\n PdSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType=SP_HCKF);\n PdSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, double alpha, double beta, double kappa);\n\n virtual void propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, VecXd &U);\n virtual void updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY);\n\n void setQnb(Qd qnb){qnb_ = qnb;}\n Qd getQnb(){return qnb_;}\nprotected:\n Eigen::Quaterniond qnb_;\n};\n\n} // namespace MyFusion\n#endif"
},
{
"alpha_fraction": 0.5645756721496582,
"alphanum_fraction": 0.5834358334541321,
"avg_line_length": 28.7560977935791,
"blob_id": "fcab419fe861212166eaa3bf76b516bdb60a731b",
"content_id": "8612ff8c3023ddec797f113f5895d568142cb231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2439,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 82,
"path": "/examples/glintDemo.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"commonHeaders.h\"\n#include \"simulator/sensorNoise.hpp\"\n#include <matplotlibcpp.h>\n#include \"utilities/tic_toc.h\"\n\nusing namespace std;\nusing namespace MyFusion;\nnamespace plt = matplotlibcpp; // matplotlib-cpp\n\nint main(int argc, char** argv){\n // generate noise sequence \n LaplacianDistribution<double> lap(0., 5.);\n default_random_engine rg;\n\n vector<double> laplacianSeq;\n \n vector<VecXd> noiseSeqGau;\n vector<VecXd> noiseSeqLap;\n \n vector<int> glintIdxGau;\n vector<int> glintIdxLap;\n for(size_t i = 0; i < 1000; i++){\n VecXd value = Vec3d(0., 0., 0.);\n int idx = SensorNoise::addGlintNoiseAll(value, 1., 5, GAUSSIAN, 0.2);\n noiseSeqGau.emplace_back(value);\n glintIdxGau.emplace_back(idx);\n \n value = Vec3d(0., 0., 0.);\n idx = SensorNoise::addGlintNoiseAll(value, 1., 5, LAPLACIAN, 0.2);\n noiseSeqLap.emplace_back(value);\n glintIdxLap.emplace_back(idx);\n\n laplacianSeq.emplace_back(lap(rg));\n }\n // check glint probability (for debug)\n int cnt = 0;\n for(auto it : glintIdxGau){\n if(it == 1)\n cnt++;\n }\n cout << \"Real Glint probability Gaussian: \" << (double)cnt / (double)glintIdxGau.size() << endl;\n \n cnt = 0;\n for(auto it : glintIdxLap){\n if(it == 1)\n cnt++;\n }\n cout << \"Real Glint probability Laplacian: \" << (double)cnt / (double)glintIdxLap.size() << endl;\n // convert for plt\n int M = noiseSeqGau.size();\n int N = noiseSeqGau[0].size();\n \n vector<vector<double>> noiseSeqGauPlt;\n vector<vector<double>> noiseSeqLapPlt;\n for(size_t i = 0; i < N; i++){\n vector<double> tmpGau, tmpLap;\n for(size_t j = 0; j < M; j++){\n tmpGau.emplace_back(noiseSeqGau[j](i));\n tmpLap.emplace_back(noiseSeqLap[j](i));\n }\n noiseSeqGauPlt.emplace_back(tmpGau);\n noiseSeqLapPlt.emplace_back(tmpLap);\n } \n // plt\n plt::figure(1); \n\n plt::subplot(3, 1, 1);\n plt::named_plot(\"GLMM\", noiseSeqLapPlt[0], \"-m\");\n plt::named_plot(\"DGMM\", noiseSeqGauPlt[0], \"-c\");\n plt::legend();\n plt::subplot(3, 1, 2);\n plt::named_plot(\"x\", noiseSeqLapPlt[1], \"-m\");\n plt::subplot(3, 1, 3);\n plt::named_plot(\"x\", noiseSeqLapPlt[2], \"-m\");\n\n // plt::figure(2);\n // plt::named_plot(\"x\", laplacianSeq, \"-b\");\n // plt::save(\"glintNoise.pdf\");\n plt::show();\n\n return 0;\n}"
},
{
"alpha_fraction": 0.5117558836936951,
"alphanum_fraction": 0.5287643671035767,
"avg_line_length": 24.64102554321289,
"blob_id": "694432f95735678b0660eb2b52cb17b28bddd41c",
"content_id": "924941ffd90653c0110be2a90dc874a1eb8660e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1999,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 78,
"path": "/src/backend/cnsUKF.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/cnsUKF.h\"\n\nnamespace MyFusion{\n\nCnsUKF::CnsUKF():SPKF(){\n}\n\nCnsUKF::CnsUKF(double alpha, double beta, double kappa):SPKF(){\n alpha_ = alpha;\n beta_ = beta;\n kappa_ = kappa;\n}\n\nvoid CnsUKF::genSigmaPoints(vector<VecXd> &points){\n if(points.size() != 0)\n points.clear();\n\n MatXd sqrtS = curSigma_.llt().matrixL();\n VecXd tmp = curMu_;\n\n points.emplace_back(tmp);\n // 1 ~ n\n for(size_t i = 0; i < xDim_; i++){\n tmp = curMu_ + sqrt(xDim_ + lambda_) * sqrtS.col(i);\n points.emplace_back(tmp);\n }\n // n+1 ~ 2n\n for(size_t i = 0; i < xDim_; i++){\n tmp = curMu_ - sqrt(xDim_ + lambda_) * sqrtS.col(i);\n points.emplace_back(tmp);\n }\n}\n\nvoid CnsUKF::computeWeight(){\n lambda_ = alpha_ * alpha_ * (xDim_ + kappa_) - xDim_;\n\n weightMu_.clear(); weightSigma_.clear();\n\n double W0 = lambda_ / (xDim_ + lambda_);\n double Wi = 0.5 / (xDim_ + lambda_);\n weightMu_.emplace_back(W0);\n weightMu_.insert(weightMu_.begin() + 1, 2 * xDim_, Wi);\n\n weightSigma_.assign(weightMu_.begin(), weightMu_.end());\n W0 += (1. - alpha_ * alpha_ + beta_);\n weightSigma_[0] = W0;\n}\n\nvoid CnsUKF::propagateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY){\n if(pointsY.size() != 0)\n pointsY.clear();\n \n // ---- test 3D const\n for(auto it : pointsX){\n pointsY.emplace_back(it); \n }\n}\n\nvoid CnsUKF::updateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY){\n if(pointsY.size() != 0)\n pointsY.clear();\n // ---- test 3D const\n VecXd tmp = VecXd::Zero(mDim_);\n for(auto it: pointsX){\n double scale = sqrt(it.x() * it.x() + it.y() * it.y());\n tmp(0) = atan2(it.z(), scale);\n tmp(1) = atan2(it.y(), it.x());\n\n scale = sqrt((it.x() - 10.) * (it.x() - 10.) + it.y() * it.y());\n tmp(2) = atan2(it.z(), scale);\n tmp(3) = atan2(it.y(), it.x() - 10.);\n // tmp = sqrt(it);\n pointsY.emplace_back(tmp);\n } \n}\n\n\n}"
},
{
"alpha_fraction": 0.4114982485771179,
"alphanum_fraction": 0.4536585509777069,
"avg_line_length": 31.625,
"blob_id": "2f3859e41b18dd98755d17852e286139d9e4d8a2",
"content_id": "6ca3d493dd186c1b51f29a464952190ebd217fad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2870,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 88,
"path": "/tools/drawRbustFunction.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n###################### Python Module ##########################\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport math\n##################### Custom Function #########################\n\n########################### Main ##############################\nsampleNum = 1000\nx = np.linspace(-5, 5, sampleNum)\n## ================ L2 ===================== ##\nrhoL2 = np.zeros((sampleNum, 2))\nfor i in range(0, sampleNum):\n rhoL2[i,0] = 0.5 * x[i] * x[i]\n rhoL2[i,1] = 1\n## ================ Huber ================== ##\nrhoHuber = np.zeros((sampleNum, 2))\nk = 1\nfor i in range(0, sampleNum):\n if(abs(x[i]) <= k):\n rhoHuber[i,0] = 0.5 * x[i] * x[i]\n rhoHuber[i,1] = 1\n else:\n rhoHuber[i,0] = k * (abs(x[i]) - 0.5 * k);\n rhoHuber[i,1] = k / abs(x[i])\n## ================ Cauchy ================= ##\nrhoCauchy = np.zeros((sampleNum, 2))\nk = 1\nfor i in range(0, sampleNum):\n rhoCauchy[i,0] = 0.5 * k * k * math.log(1. + x[i] * x[i] / k)\n rhoCauchy[i,1] = 1 / (1 + x[i] * x[i] / (k * k))\n## ================= G-M =================== ##\nrhoGM = np.zeros((sampleNum, 2))\nk = 1\nfor i in range(0, sampleNum):\n scale = (k + x[i] * x[i])\n rhoGM[i,0] = 0.5 * x[i] * x[i] / scale\n rhoGM[i,1] = k * k / (scale * scale) \n## ================= DCS =================== ##\nrhoDCS = np.zeros((sampleNum,2))\nk=1\nfor i in range(0, sampleNum):\n x2 = x[i] * x[i]\n if(x2 <= k):\n rhoDCS[i,0] = 0.5 * x2;\n rhoDCS[i,1] = 1\n else:\n scale = (k + x2)\n rhoDCS[i,0] = 2 * k * x2 / scale - 0.5 * k\n rhoDCS[i,1] = 4 * k * k / (scale * scale)\n## ================== MCC =================== ##\nrhoMCC = np.zeros((sampleNum, 2))\nk = 1\nfor i in range(0, sampleNum):\n rhoMCC[i,0] = - k * k * math.exp(-x[i] * x[i]/ (2 * k * k))\n rhoMCC[i,1] = math.exp(-x[i] * x[i]/ (2 * k * k))\n## ================== weight line ==================== ##\nhk = np.linspace(-0.05, 1.05, 100)\nkk = np.ones(100) * k\n########################### plot ##############################\nfig1, axes = plt.subplots(1,2,figsize=(10,4))\ncolors=['gold','royalblue', 'limegreen', 'violet', 'red', 'orange']\nlabels=['L2','Huber','Cauchy','GM', 'DCS', 'MCC']\n\nfor i in range(0, 2):\n axes[i].plot(x, rhoL2[:,i], color=colors[0])\n axes[i].plot(x, rhoHuber[:,i], color=colors[1])\n axes[i].plot(x, rhoCauchy[:,i], color=colors[2])\n axes[i].plot(x, rhoGM[:,i], color=colors[3])\n axes[i].plot(x, rhoDCS[:,i], color=colors[4])\n axes[i].plot(x, rhoMCC[:,i], color=colors[5])\n axes[i].grid()\n axes[i].set_xlabel('Error')\n\naxes[1].plot(kk,hk,'--k')\naxes[1].plot(-kk,hk,'--k')\n\naxes[0].legend(labels,loc=0)\naxes[1].legend(labels,loc=(0.7,0.5))\naxes[0].set_ylabel('Cost')\naxes[1].set_ylabel('Weight($k=1$)')\naxes[1].set_ylim([-0.05,1.05])\n\nfig1.savefig('kernel_function.pdf', format='pdf')\n\n\nplt.show()"
},
{
"alpha_fraction": 0.7516198754310608,
"alphanum_fraction": 0.7537797093391418,
"avg_line_length": 20.090909957885742,
"blob_id": "7348889f5ad216a91fcfe62a8bc5c838c176564f",
"content_id": "615692ea80940ededfc2e9ef3295abfe4933a9e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 22,
"path": "/include/backend/backParam.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef BACKPARAM_H_\n#define BACKPARAM_H_\n#include \"commonHeaders.h\"\n#include <opencv2/core/eigen.hpp>\n\nusing namespace std;\n\nnamespace MyFusion{\n\nextern double IMU_STEP;\nextern double INIT_ERR_P, INIT_ERR_V;\nextern MatXd INIT_SQRT_P, INIT_SQRT_Q, INIT_SQRT_R;\nextern string IMU_FILE, CNS_FILE, VIRNS_FILE, CMNS_FILE, ALT_FILE;\nextern int SIGMA_TYPE;\nextern double UKF_A, UKF_B, UKF_K;\n\n// load backend parameters\nvoid loadBackParam(string configFile);\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.6975806355476379,
"alphanum_fraction": 0.6975806355476379,
"avg_line_length": 18.115385055541992,
"blob_id": "79daa57011c0d95c70e99dc600555baa7e78163d",
"content_id": "c34bed35acb636abbd83eba6aa6ed98b524c8f6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 26,
"path": "/include/backend/sckf/scekf.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SCEKF_H_\n#define SCEKF_H_\n#include \"backend/sckf/sckf.h\"\n\nnamespace MyFusion{\n\nclass SCEKF : public SCKF{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n SCEKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R);\n\n void oneStepPrediction(VecXd &U) override;\n void oneStepUpdate(VecXd &Z) override;\n\n virtual void computeJacobianF();\n virtual void computeJacobianG();\n virtual void computeJacobianH();\n\nprotected:\n MatXd F_, G_, H_; // Jacobians\n\n};\n\n}// namespace MyFusion\n\n#endif"
},
{
"alpha_fraction": 0.610519289970398,
"alphanum_fraction": 0.6438082456588745,
"avg_line_length": 24.86206817626953,
"blob_id": "24c10c396e6c9160285ed91e091a58a3c0c9ecfc",
"content_id": "5c3bdd7441c3663357f874f6b18a2e3e07877ac1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1502,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 58,
"path": "/include/commonHeaders.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "/**\n * @file commonHeaders.h\n * @author yuntian li ([email protected])\n * @brief \n * @version 0.1\n * @date 2020-04-12\n * \n * @copyright Copyright (c) 2020. The source code is under GPL v3 license.\n * \n */\n#pragma once\n// ========= std lib ============= //\n#include <stdlib.h>\n#include <stdio.h>\n#include <unistd.h>\n// ========= io headers ========== //\n#include <iostream>\n#include <fstream>\n#include <sstream>\n#include <iomanip>\n#include <sys/stat.h>\n// ========== container ========== //\n#include <vector>\n#include <map>\n#include <queue>\n#include <iterator>\n#include <string>\n// ========== math ========== //\n#include <cmath>\n#include <random>\n// ========== multi thread == //\n#include <mutex>\n#include <thread>\n#include <condition_variable>\n// third_party headers\n#include <Eigen/Dense>\n#include <opencv2/opencv.hpp>\n// custom header\n#include \"constParams.h\"\n// ========== type def ======== //\ntypedef unsigned long ulong;\ntypedef Eigen::VectorXd VecXd;\ntypedef Eigen::MatrixXd MatXd;\ntypedef Eigen::Matrix<double, 1, 1> Vec1d;\ntypedef Eigen::Matrix<double, 1, 1> Mat1d;\ntypedef Eigen::Matrix<double, 2, 1> Vec2d;\ntypedef Eigen::Matrix<double, 2, 2> Mat2d;\ntypedef Eigen::Vector3d Vec3d;\ntypedef Eigen::Matrix3d Mat3d;\ntypedef Eigen::Matrix<double, 4, 1> Vec4d;\ntypedef Eigen::Matrix<double, 4, 4> Mat4d;\ntypedef Eigen::Matrix<double, 6, 1> Vec6d;\ntypedef Eigen::Matrix<double, 6, 6> Mat6d;\ntypedef Eigen::Matrix<double, 8, 1> Vec8d;\ntypedef Eigen::Matrix<double, 8, 8> Mat8d;\n\n\ntypedef Eigen::Quaterniond Qd; \n\n"
},
{
"alpha_fraction": 0.5644329786300659,
"alphanum_fraction": 0.5644329786300659,
"avg_line_length": 34.318180084228516,
"blob_id": "b531eaa18393fea7bee2ee90751240d804acea9d",
"content_id": "f3a95e484450844d8d76cb92b47311e92b1811a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 776,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 22,
"path": "/src/CMakeLists.txt",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "add_library(myFusion SHARED\n simulator/sensors/imu_base.cc\n simulator/sensors/imu_li.cc\n simulator/sensors/imu_g.cc\n simulator/sensors/imu_mcmf.cc\n simulator/sensors/imu_mci.cc\n simulator/sensors/cns.cc\n simulator/sensors/virns.cc\n simulator/sensors/cmns.cc\n simulator/sensors/altimeter.cc\n simulator/sensorSimulator.cc\n backend/backParam.cc\n backend/spkf.cc\n backend/cnsUKF.cc\n backend/cnsHCKF.cc\n backend/estimator.cc\n backend/sckf/sckf.cc\n # backend/sckf/scekf.cc\n backend/sckf/scspkf.cc\n backend/sckf/pdSCSPKF.cc\n utilities/io_function.cc\n )"
},
{
"alpha_fraction": 0.4906722903251648,
"alphanum_fraction": 0.5401267409324646,
"avg_line_length": 33.44242477416992,
"blob_id": "8075c476228e9b238b5e364e1474039fb6ee0da7",
"content_id": "dc10680708fead14d15553b43c9fbc90a0a625e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5764,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 165,
"path": "/tools/drawFilter.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib\nimport matplotlib.pyplot as plt\nimport systems as sys\nfrom matplotlib import rcParams\n\n# matplotlib.use(\"pgf\")\n# pgf_config = {\n# \"font.family\":'serif',\n# \"font.size\": 10,\n# \"pgf.rcfonts\": False,\n# \"text.usetex\": True,\n# \"pgf.preamble\": [\n# r\"\\usepackage{unicode-math}\",\n# #r\"\\setmathfont{XITS Math}\", \n# # 这里注释掉了公式的XITS字体,可以自行修改\n# r\"\\setmainfont{Times New Roman}\",\n# r\"\\usepackage{xeCJK}\",\n# r\"\\xeCJKsetup{CJKmath=true}\",\n# r\"\\setCJKmainfont{SimSun}\",\n# ],\n# }\n# # rcParams.update(pgf_config)\nR_M = 1.737e6\n######################## 自定义函数 ############################\ndef calcError(trajdata, filterdata):\n pos_0 = trajdata.iloc[:, 1:4].values\n pos_1 = filterdata.iloc[:, 1:4].values\n\n vel_0 = trajdata.iloc[:, 11:14].values\n vel_1 = filterdata.iloc[:, 4:7].values\n \n sigmaP = filterdata.iloc[:, 7:10].values\n sigmaV = filterdata.iloc[:, 10:13].values\n\n time_0 = trajdata.iloc[:,0].values\n time_1 = filterdata.iloc[:,0].values\n\n N = len(time_1)\n idx = 0\n err = np.zeros([N, 13])\n while idx < N:\n for i in range(0, len(time_0)):\n if time_0[i] == time_1[idx]:\n err[idx, 0] = time_1[idx]\n # err[idx, 1:4] = np.fabs(pos_1[idx, :] - pos_0[i, :])\n # err[idx, 4:7] = np.fabs(vel_1[idx, :] - vel_0[i, :])\n err[idx, 1:4] = pos_1[idx, :] - pos_0[i, :]\n err[idx, 1] = err[idx, 1] * (R_M + pos_1[idx, 1])\n err[idx, 3] = err[idx, 3] * (R_M + pos_1[idx, 1]) * math.cos(pos_1[idx,0])\n\n err[idx, 4:7] = vel_1[idx, :] - vel_0[i, :]\n \n err[idx, 7] = sigmaP[idx, 0] * (R_M + pos_1[idx, 1])\n err[idx, 8] = sigmaP[idx, 1]\n err[idx, 9] = sigmaP[idx, 2] * (R_M + pos_1[idx, 1]) * math.cos(pos_1[idx,0])\n\n idx += 1\n if(idx >= N):\n break\n \n err[:,10:13] = sigmaV\n\n return err \n\ndef calcRMSE(err, dim):\n N = len(err[:,0])\n M = round(len(err[0,:]) / 6) + 1\n \n rmse = np.zeros((N, M))\n rmse[:,0] = err[:,0]\n for i in range(0, N):\n for j in range(1, M):\n start_idx = -2 + 3 * j\n end_idx = start_idx + dim\n rmse[i, j] = math.sqrt(np.dot(err[i, start_idx:end_idx], err[i, start_idx:end_idx]) / dim)\n\n return rmse \n#################### 读取数据(csv格式) ########################\ntrajData = pd.read_csv('../data/stdTraj/caGeo.csv')\nimuData = pd.read_csv('../data/sensorSimData/imuData.csv')\nfilter1Data = pd.read_csv('../output/ckfAA.csv')\nfilter2Data = pd.read_csv('../output/ckfAR.csv')\n\nerrFilter1 = calcError(trajData, filter1Data)\nerrFilter2 = calcError(trajData, filter2Data)\n\n###################################################\ndrawSigma = True\nlabels = ['SC-SPKF','3$\\sigma$']\n# labels = ['标称轨迹','IMU轨迹']\ncolors = ['tab:blue','tab:red']\n\nfig1, axes = plt.subplots(3, 1, figsize=(7,5))\nfig1.subplots_adjust(hspace=0.5)\n\naxes[0].plot(errFilter1[:,0], abs(errFilter1[:,1]) , color=colors[0])\naxes[0].plot(errFilter2[:,0], abs(errFilter2[:,1]) , color=colors[1])\naxes[0].set_xlabel(\"time(s)\")\naxes[0].set_ylabel(\"$\\delta p_x$(m)\")\naxes[0].grid()\n\naxes[1].plot(errFilter1[:,0], abs(errFilter1[:,2]) , color=colors[0])\naxes[1].plot(errFilter2[:,0], abs(errFilter2[:,2]) , color=colors[1])\naxes[1].set_xlabel(\"time(s)\")\naxes[1].set_ylabel(\"$\\delta p_y$(m)\")\naxes[1].grid()\n\naxes[2].plot(errFilter1[:,0], abs(errFilter1[:,3]) , color=colors[0])\naxes[2].plot(errFilter2[:,0], abs(errFilter2[:,3]) , color=colors[1])\naxes[2].set_xlabel(\"time(s)\")\naxes[2].set_ylabel(\"$\\delta p_z$(m)\")\naxes[2].grid()\n\nif(drawSigma):\n axes[0].plot(errFilter1[:,0], errFilter1[:,7], '--k')\n axes[0].plot(errFilter1[:,0], -errFilter1[:,7], '--k')\n axes[1].plot(errFilter1[:,0], errFilter1[:,8], '--k')\n axes[1].plot(errFilter1[:,0], -errFilter1[:,8], '--k')\n axes[2].plot(errFilter1[:,0], errFilter1[:,9], '--k')\n axes[2].plot(errFilter1[:,0], -errFilter1[:,9], '--k')\n \naxes[0].legend(labels, loc='upper right')\naxes[1].legend(labels, loc='upper right')\naxes[2].legend(labels, loc='upper right')\n# ####################################################\nfig2, axes = plt.subplots(3, 1, figsize=(7,5))\nfig2.subplots_adjust(hspace=0.5)\n\naxes[0].plot(errFilter1[:,0], abs(errFilter1[:,4]) , color=colors[0])\naxes[0].plot(errFilter2[:,0], abs(errFilter2[:,4]) , color=colors[1])\naxes[0].set_xlabel(\"time(s)\")\naxes[0].set_ylabel(\"$\\delta v_x$(m/s)\")\naxes[0].grid()\n\naxes[1].plot(errFilter1[:,0], abs(errFilter1[:,5]) , color=colors[0])\naxes[1].plot(errFilter2[:,0], abs(errFilter2[:,5]) , color=colors[1])\naxes[1].set_xlabel(\"time(s)\")\naxes[1].set_ylabel(\"$\\delta v_y$(m/s)\")\naxes[1].grid()\n\naxes[2].plot(errFilter1[:,0], abs(errFilter1[:,6]) , color=colors[0])\naxes[2].plot(errFilter2[:,0], abs(errFilter2[:,6]) , color=colors[1])\naxes[2].set_xlabel(\"time(s)\")\naxes[2].set_ylabel(\"$\\delta v_z$(m/s)\")\naxes[2].grid()\n\nif(drawSigma):\n axes[0].plot(errFilter1[:,0], errFilter1[:,10], '--k')\n axes[0].plot(errFilter1[:,0], -errFilter1[:,10], '--k')\n axes[1].plot(errFilter1[:,0], errFilter1[:,11], '--k')\n axes[1].plot(errFilter1[:,0], -errFilter1[:,11], '--k')\n axes[2].plot(errFilter1[:,0], errFilter1[:,12], '--k')\n axes[2].plot(errFilter1[:,0], -errFilter1[:,12], '--k')\n \naxes[0].legend(labels, loc='upper right')\naxes[1].legend(labels, loc='upper right')\naxes[2].legend(labels, loc='upper right')\n####################################################\n\nplt.show()"
},
{
"alpha_fraction": 0.4483844041824341,
"alphanum_fraction": 0.46768778562545776,
"avg_line_length": 32.328670501708984,
"blob_id": "45bb43e776cafcb1340cbcb71019640eef6acef8",
"content_id": "d6a54764b6a9e798959cda74d6bab72e864dc39e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4766,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 143,
"path": "/src/backend/sckf/pdSCSPKF.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/sckf/pdSCSPKF.h\"\n\nnamespace MyFusion\n{\n \nPdSCSPKF::PdSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType):SCSPKF(Mu, Sigma, Q, R, sigmaType){\n}\n\n\nPdSCSPKF::PdSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R,\n double alpha, double beta, double kappa):SCSPKF(Mu, Sigma, Q, R, alpha, beta, kappa, SP_UKF)\n{\n \n}\n\nvoid PdSCSPKF::propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, VecXd &U){\n if(sPointsY.size() != 0)\n sPointsY.clear();\n // TODO : update quaternion \n Vec3d accG = qnb_ * U.segment(1,3);\n for (auto it: sPointsX){\n VecXd tmp = VecXd::Zero(xSize_);\n // [L h l Vn Vu Ve] \n double lat = it(0); double alt = it(1); double lon = it(2);\n double Vn = it(3); double Vu = it(4); double Ve = it(5);\n Vec3d vel0(Vn, Vu, Ve);\n double h_m = R_m + alt;\n // ------ update position ------ //\n tmp(0) = it(0) + IMU_STEP * Vn / h_m; //latitude\n tmp(1) = it(1) + IMU_STEP * Vu; // height\n tmp(2) = it(2) + IMU_STEP * Ve / (h_m * cos(lat)); //longitude\n // ------ update velocity ------ //\n // compute w^G_im = [W_im * cosL, W_m * sinL, 0]\n Vec3d w_im(W_im * cos(lat), W_im * sin(lat), 0.);\n // compute w^G_mg = [v_e / h_m, v_e * tanL / h_m, -v_n / h_m]\n Vec3d w_mg(Ve / h_m, Ve * tan(lat) / h_m, -Vn / h_m);\n // compute gravity\n Vec3d gn = Vec3d::Zero(); // gravity vector\n // gn.y() = -g0_m; // NUE\n gn.y() = -g0_m * (R_m * R_m) / (h_m * h_m); // NUE\n\n Vec3d acc_n = accG - (2. * w_im + w_mg).cross(vel0) + gn;\n\n tmp.segment(3, 3) = vel0 + acc_n * IMU_STEP;\n \n sPointsY.emplace_back(tmp);\n }\n // update quaternion\n double h_m = R_m + Mu_(1);\n Vec3d w_im(W_im * cos(Mu_(0)), W_im * sin(Mu_(0)), 0.);\n Vec3d w_mg(Mu_(5) / h_m, Mu_(5) * tan(Mu_(0)) / h_m, -Mu_(3) / h_m);\n \n Vec3d w_gb = U.segment(4, 3) - qnb_.conjugate() * (w_im + w_mg);\n Eigen::Quaterniond dq(1., 0.5 * w_gb.x() * IMU_STEP, 0.5 * w_gb.y() * IMU_STEP, 0.5 * w_gb.z() * IMU_STEP);\n dq.normalize();\n qnb_ *= dq;\n qnb_.normalize();\n}\n\nvoid PdSCSPKF::updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY){\n if(sPointsY.size() != 0)\n sPointsY.clear();\n \n VecXd curP = VecXd::Zero(3);\n double curLat, curAlt, curLon;\n\n switch (updateType_)\n {\n case 0:\n {\n for (auto it: sPointsX){\n // [L, l, h]\n curLat = it(0); curAlt = it(1); curLon = it(2);\n VecXd tmp = VecXd::Zero(curMSize_);\n tmp.segment(0, 2) = Vec2d(curLat, curLon);\n tmp(2) = curAlt / qnb_.toRotationMatrix()(1, 1);\n\n sPointsY_.emplace_back(tmp);\n }\n break;\n }\n case 1:\n {\n for (auto it: sPointsX){\n curLat = it(0); curAlt = it(1); curLon = it(2);\n \n curP.x() = (R_m + curAlt) * cos(curLat) * cos(curLon);\n curP.y() = (R_m + curAlt) * cos(curLat) * sin(curLon);\n curP.z() = (R_m + curAlt) * sin(curLat);\n\n VecXd tmp = VecXd::Zero(curMSize_);\n if(curMSize_ == mSize_){\n // [dx,dy,dz,L,l,h]\n tmp.segment(0, 3) = curP;\n tmp.segment(3, 2) = Vec2d(curLat, curLon);\n tmp(5) = curAlt / qnb_.toRotationMatrix()(1, 1);\n }\n else{\n // [dx dy dz]\n tmp = curP;\n }\n sPointsY_.emplace_back(tmp);\n }\n break;\n }\n case 2:\n {\n VecXd lastP = VecXd::Zero(3);\n double preLat, preAlt, preLon;\n for (auto it: sPointsX){\n preLat = it(0); preAlt = it(1); preLon = it(2);\n curLat = it(6); curAlt = it(7); curLon = it(8);\n\n lastP.x() = (R_m + preAlt) * cos(preLat) * cos(preLon);\n lastP.y() = (R_m + preAlt) * cos(preLat) * sin(preLon);\n lastP.z() = (R_m + preAlt) * sin(preLat);\n \n curP.x() = (R_m + curAlt) * cos(curLat) * cos(curLon);\n curP.y() = (R_m + curAlt) * cos(curLat) * sin(curLon);\n curP.z() = (R_m + curAlt) * sin(curLat);\n\n VecXd tmp = VecXd::Zero(curMSize_);\n if(curMSize_ == mSize_){\n // [dx,dy,dz,L,l,h]\n tmp.segment(0, 3) = curP - lastP;\n tmp.segment(3, 2) = Vec2d(curLat, curLon);\n tmp(5) = curAlt / qnb_.toRotationMatrix()(1, 1);\n }\n else{\n // [dx dy dz]\n tmp = curP - lastP;\n }\n sPointsY_.emplace_back(tmp);\n }\n break;\n }\n default:\n cout << \"[E] Error update type\\n.\";\n return;\n }\n}\n \n} // namespace MyFusion\n"
},
{
"alpha_fraction": 0.5145754218101501,
"alphanum_fraction": 0.5145754218101501,
"avg_line_length": 22.939393997192383,
"blob_id": "8865e82f6e68638fe40c7586647e26e3b6dccdc8",
"content_id": "f73b628cd2a8e38fec682d2af3d6395f60786cf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 33,
"path": "/src/backend/sckf/sckf.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/sckf/sckf.h\"\n\nnamespace MyFusion{\n\nSCKF::SCKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R){\n initSCKF(Mu, Sigma, Q, R);\n}\n\nvoid SCKF::initSCKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R){\n // ------ check size ------ //\n assert(Sigma.cols() == Sigma.rows());\n assert(Q.cols() == Q.rows());\n assert(R.cols() == R.rows());\n assert(Mu.size() == Sigma.rows());\n // ------ assigment ------ //\n xSize_ = Q.cols();\n mSize_ = R.cols();\n\n if(Mu.size() != xSize_ || Sigma.cols() != xSize_)\n cout << \"[E] Unequal state and covariance size.\\n\";\n \n Mu_ = Mu; Sigma_ = Sigma;\n Q_ = Q; R_ = R;\n // ------ clone ------ //\n lastMu_ = Mu_;\n lastSigma_ = Sigma_;\n Phi_ = MatXd::Identity(xSize_, xSize_);\n\n flagInitialized_ = true;\n}\n\n\n}"
},
{
"alpha_fraction": 0.3707983195781708,
"alphanum_fraction": 0.46139705181121826,
"avg_line_length": 38.67708206176758,
"blob_id": "3dc8386aa83b58c8cbbb35add33756dc91696e2d",
"content_id": "85e16029765bfa72d12cd60b968fd2d0ed32bc0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3808,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 96,
"path": "/tools/robustCompare.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n#####################################################################\n########################### Python Module ###########################\n#####################################################################\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nimport math\nfrom mpl_toolkits.axes_grid1.inset_locator import mark_inset\nimport seaborn as sns\nimport sys, os\nimport pylab as mpl\n\n# mpl.rcParams['font.sans-serif'] = ['STSong']\n#####################################################################\n######################### Custom Function ###########################\n#####################################################################\ndef autolabel(ax, rects, scale):\n \"\"\"Attach a text label above each bar in *rects*, displaying its height.\"\"\"\n for rect in rects:\n height = rect.get_height()\n ax.annotate('{}'.format(round(height/ scale, 2)),\n xy=(rect.get_x() + rect.get_width() / 2, height),\n xytext=(0, 3), # 3 points vertical offset\n textcoords=\"offset points\",\n ha='center', va='bottom')\n#####################################################################\n########################### Main Function ###########################\n#####################################################################\n\n#####################################################################\n########################### Plot Function ###########################\n#####################################################################\ncolors = ['royalblue', 'tomato', 'limegreen', 'violet', 'gold']\n# labels = ['filter1', 'filter2', 'filter3', 'filter4']\nlabels = ['Huber', 'Cauchy', 'SC-DCS', 'GM', 'L2']\n\n# colors = ['gold', 'tomato']\n# labels = ['L2', 'Cauchy', 'Improvement']\n#################### fig1 ####################\n# armes = np.zeros((3, 7))\n# idx = [0.,0.05,0.10,0.15,0.20,0.25,0.30]\n# armes[0,:] = [26.42,26.70,27.65,27.78,28.23,27.97,28.02]\n# armes[1,:] = [26.58,25.97,26.76,26.27,26.49,25.81,25.79]\n# armes[2,:] = [0.6,2.73,3.22,5.44,6.16,7.74,7.96]\n\narmes = np.zeros((3, 5))\nidx = [0.,0.05,0.10,0.15,0.20]\narmes = pd.read_csv('./rmsePg.csv').values\n# armes[0,:] = [26.42,26.70,27.65,27.78,28.23]\n# armes[1,:] = [26.58,25.97,26.76,26.27,26.49]\n# armes[2,:] = [0.6,2.73,3.22,5.44,6.16]\n\n\n\nfig3, ax1 = plt.subplots(1,1,figsize=(6,4.5))\n# ax2 = ax1.twinx()\n\nax1.plot(idx, armes[:,0], '--d', color=colors[0], label=labels[0])\nax1.plot(idx, armes[:,1], '--X', color=colors[1], label=labels[1])\nax1.plot(idx, armes[:,2], '--.', color=colors[2], label=labels[2])\nax1.plot(idx, armes[:,3], '--p', color=colors[3], label=labels[3])\nax1.plot(idx, armes[:,4], '--*', color=colors[4], label=labels[4])\nax1.set_ylabel('$P_{ARMSE}$(m)')\nax1.set_xlabel('$p_g$')\n# ax1.set_xlim([0,0.2])\nax1.set_ylim([25.5,28.5])\nax1.grid()\nax1.legend()\nfig3.savefig('pg.pdf',format='pdf')\n#################### fig2 ####################\narmes = np.zeros((3, 5))\nidx = [5,15,25,35,45]\n# armes[0,:] = [26.35,26.68,26.87,27.56,27.93]\n# armes[1,:] = [26.08,26.50,26.52,25.72,25.54]\n# armes[2,:] = [1.04,0.65,1.31,5.65,8.54]\n\n\nfig3, ax1 = plt.subplots(1,1,figsize=(6,4.5))\nax2 = ax1.twinx()\narmes = pd.read_csv('./rmseSigma.csv').values\n\nax1.plot(idx, armes[:,0], '--d', color=colors[0], label=labels[0])\nax1.plot(idx, armes[:,1], '--X', color=colors[1], label=labels[1])\nax1.plot(idx, armes[:,2], '--.', color=colors[2], label=labels[2])\nax1.plot(idx, armes[:,3], '--p', color=colors[3], label=labels[3])\nax1.plot(idx, armes[:,4], '--*', color=colors[4], label=labels[4])\nax1.set_ylabel('$P_{ARMSE}$(m)')\nax1.set_xlabel('$\\sigma_s(m)$')\n# ax1.set_xlim([0,25])\nax1.set_ylim([25,28.5])\nax1.grid()\nax1.legend()\nfig3.savefig('sigma.pdf',format='pdf')\n################# fig interaction ############\nplt.show()"
},
{
"alpha_fraction": 0.6309012770652771,
"alphanum_fraction": 0.642346203327179,
"avg_line_length": 17.421052932739258,
"blob_id": "7006304b299220cb4c490cdb99a876ce441427df",
"content_id": "e0abcc69539f457acca64087c88c08ffc2d85b79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 38,
"path": "/include/simulator/sensors/cns.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef CNS_H_\n#define CNS_H_\n#include \"commonHeaders.h\"\n#include \"utilities/utilities.hpp\"\n#include \"simulator/sensors/imu_base.h\"\nusing namespace std;\n\nnamespace MyFusion\n{\n\nstruct CnsData{\n double timeStamp_;\n Eigen::Quaterniond qnb_;\n Vec3d eulerAngle_;\n};\n\nclass CNS{\npublic:\n CNS(double bias, double sigma):bias_(bias){\n sigma_ = sigma / 3600.; // arcsec->deg\n sigma_ = sigma_ / 180. * M_PI; // deg->rad\n flag_init_ = true;\n }\n ~CNS(){};\n\n CnsData getMeasurements(ImuMotionData currMotion);\n\n double sigma_; // noise sigma of measurements\n double bias_; // bias of measurements\n\n bool flag_init_ = false;\n\n\n};\n\n} // namespace myFusion\n\n#endif"
},
{
"alpha_fraction": 0.45252081751823425,
"alphanum_fraction": 0.4752814471721649,
"avg_line_length": 25.53896141052246,
"blob_id": "01f7dbd94100640f9420a5118b549751d8095819",
"content_id": "260ffa80d0c57739fe79d1c7fbdbce45c033aeeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4086,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 154,
"path": "/src/backend/cnsHCKF.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/cnsHCKF.h\"\n\nnamespace MyFusion{\n\nCnsHCKF::CnsHCKF():SPKF(){\n}\n\nvoid CnsHCKF::genSigmaPoints(vector<VecXd> &sPoints){\n if(sPoints.size() != 0)\n sPoints.clear();\n\n if(firstGen){\n genSi(allSi_);\n firstGen = false;\n }\n\n MatXd sqrtS = curSigma_.llt().matrixL();\n \n for(size_t i = 0; i < allSi_.size(); i++){\n VecXd point = curMu_ + sqrtS * allSi_[i];\n sPoints.emplace_back(point);\n }\n // ------------- print sigma points for debug\n int totalSize = sPoints.size();\n MatXd outSPoints = MatXd::Zero(xDim_, totalSize);\n for(size_t i = 0; i < totalSize; i++){\n outSPoints.col(i) = sPoints[i].transpose();\n }\n // cout << \"Sigma Points:\\n\" << setprecision(3) << outSPoints << endl;\n}\n\nvoid CnsHCKF::genSi(vector<VecXd> &allSi){\n if(allSi.size() != 0)\n allSi.clear();\n \n VecXd si = VecXd::Zero(xDim_); \n // 0\n allSi.emplace_back(si);\n // 1 ~ 2n(n-1)\n for (size_t k = 0; k < 4; k++){\n for(size_t i = 0; i < xDim_ - 1; i++){\n for(size_t j = i + 1; j < xDim_; j++){\n VecXd tmp = VecXd::Zero(xDim_);\n \n double scale0, scale1;\n getScales(scale0, scale1, k); \n tmp(i) = scale0;\n tmp(j) = scale1;\n\n allSi.emplace_back(beta_ * tmp); \n }\n }\n }\n // 2n(n-1) + 1 ~ 2n^2 \n MatXd I = MatXd::Identity(xDim_, xDim_);\n for(size_t i = 0; i < xDim_; i++){\n allSi.emplace_back(beta_ * I.col(i));\n }\n\n for(size_t i = 0; i < xDim_; i++){\n allSi.emplace_back(-beta_ * I.col(i));\n } \n // check dims\n if(allSi.size() != 2 * xDim_ * xDim_ + 1)\n cout << \"Error size of Si !\\n\";\n // ------ for debug ------ //\n int siSize = allSi.size();\n MatXd outSi = MatXd::Zero(xDim_, siSize);\n for(size_t i = 0; i < siSize; i++){\n outSi.col(i) = allSi[i].transpose();\n }\n // cout << \"Si:\\n\" << setprecision(3) << outSi << endl;\n}\n\nvoid CnsHCKF::getScales(double &scale0, double &scale1, size_t k){\n double tmp = 0.5 * sqrt(2.0);\n \n switch (k)\n {\n case 0:\n scale0 = tmp;\n scale1 = tmp;\n break;\n case 1:\n scale0 = tmp;\n scale1 = -tmp;\n break;\n case 2:\n scale0 = -tmp;\n scale1 = tmp;\n break;\n case 3:\n scale0 = -tmp;\n scale1 = -tmp;\n break;\n default:\n cout << \"error k!\\n\";\n break;\n }\n}\n\nvoid CnsHCKF::computeWeight(){\n beta_ = sqrt(xDim_ + 2.);\n\n weightMu_.clear(); weightSigma_.clear();\n // ====== weight mu ====== //\n double scale = xDim_ + 2.;\n double W0 = 2. / scale;\n double W1 = 1. / (scale * scale);\n double W2 = (4. - xDim_) / (2. * scale * scale);\n // 0\n weightMu_.emplace_back(W0);\n // 1 ~ 2n(n-1)\n auto iter = weightMu_.begin() + 1;\n int cnt = 2 * xDim_ * (xDim_ - 1);\n weightMu_.insert(iter, cnt, W1);\n // 2n(n-1) + 1 ~ 2n^2\n iter = weightMu_.begin() + cnt + 1;\n cnt = 2 * xDim_;\n weightMu_.insert(iter, cnt, W2);\n // ====== weight sigma ====== //\n weightSigma_.assign(weightMu_.begin(), weightMu_.end());\n}\n\nvoid CnsHCKF::propagateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY){\n if(pointsY.size() != 0)\n pointsY.clear();\n \n // ---- test 3D const\n for(auto it : pointsX){\n pointsY.emplace_back(it); \n }\n}\n\nvoid CnsHCKF::updateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY){\n if(pointsY.size() != 0)\n pointsY.clear();\n // ---- test 3D const\n VecXd tmp = VecXd::Zero(mDim_);\n for(auto it: pointsX){\n double scale = sqrt(it.x() * it.x() + it.y() * it.y());\n tmp(0) = atan2(it.z(), scale);\n tmp(1) = atan2(it.y(), it.x());\n \n scale = sqrt((it.x() - 10.) * (it.x() - 10.) + it.y() * it.y());\n tmp(2) = atan2(it.z(), scale);\n tmp(3) = atan2(it.y(), it.x() - 10.);\n // tmp = sqrt(it);\n pointsY.emplace_back(tmp);\n } \n}\n\n\n}"
},
{
"alpha_fraction": 0.676447868347168,
"alphanum_fraction": 0.6795367002487183,
"avg_line_length": 33.078948974609375,
"blob_id": "7dc9ed8b2cd5c931c0f799d8eedba9384dbcdc37",
"content_id": "875aa6f05e2e16effa579c23524936bb8e2cf795",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2590,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 76,
"path": "/include/backend/estimator.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef ESTIMATOR_BACK_H_\n#define ESTIMATOR_BACK_H_\n#include \"backend/sckf/pdSCSPKF.h\"\n#include \"utilities/io_function.h\"\n#include \"utilities/utilities.hpp\"\n#include <matplotlibcpp.h>\n\nnamespace plt = matplotlibcpp;\nnamespace MyFusion\n{\n\nclass Estimator{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n Estimator(string configFile, int updateType);\n ~Estimator();\n void initEstimator(string configFile);\n\n /**\n * @brief extract control vectors consist of acc and gyt\n * \n * @param allU : queue of all control vectors \n * @param imuData : imu simulation data\n */\n void extractU(queue<VecXd> &allU, const vector<ImuMotionData> &imuData);\n /**\n * @brief extract measurement vectors consist of relative and absolute\n * \n * @param allZ : queue of all measurement vectors \n * @param virnsData : data of visual-inertial relative navigation system\n * @param cmnsData : data of crater matching navigation system\n * @param altData : data of altimeter\n */\n void extractZ(queue<VecXd> &allZ, const vector<VirnsData> &virnsData, const vector<CmnsData> &cmnsData, const vector<AltData> &altData);\n\n void processBackend(double time=0);\n\n // ========== other functions ========= //\n template <typename T>\n void clearQueue(queue<T> &Q);\n\n void writeResults(string fileName, const vector<pair<double, VecXd>> allMu, \n const vector<pair<double, MatXd>> allSigma, \n const vector<pair<double, Qd>> allQnb);\n void writeResults(string fileName, const vector<pair<double, VecXd>> allMu, const vector<pair<double, MatXd>> allSigma);\n\n void showResults();\n void setOutFile(string fileName){outFile_ = fileName;}\n void setSigmaType(int type){sigmaType_ = SampleType(type);}\n \nprotected:\n vector<ImuMotionData> trajData_; // traj data\n queue<VecXd> allU_, allZ_; // container of all control and measurement vectors\n vector<pair<double, VecXd>> allMu_; // estimated mean\n vector<pair<double, MatXd>> allSigma_; // estimated covariance\n vector<pair<double, Qd>> allQnb_;\n\n int dataSize_; // size of all control vector\n bool dataInitiated_ = false; // estimator has been initiated or not\n\n VecXd Mu0_;\n MatXd Sigma0_, Q0_, R0_;\n SampleType sigmaType_;\n PdSCSPKF *filterPtr_; // pointer of filter\n\n int updateType_ = 2; // type of update \n VecXd lastZA_ ; // Z for accumulative measurement\n int sizeMr_ = 3; // size of relative measurements\n int sizeMa_ = 3; // size of absolute measurements\n \n string outFile_;\n};\n \n} // namespace MyFusion\n\n#endif\n"
},
{
"alpha_fraction": 0.5024271607398987,
"alphanum_fraction": 0.557692289352417,
"avg_line_length": 35.442176818847656,
"blob_id": "493b78338fd255bc7ed3fd3fda001b2f390ac9a1",
"content_id": "cf304ee6c6bfb1a1e8618cc48ef11edf6aa3415d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5364,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 147,
"path": "/tools/sensorCompare.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\n#######################################################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nimport systems as sy\n#######################################################\ndef geo2mcmf(geo):\n R_m = 1.737e6\n mcmf = np.array([0.,0.,0.])\n mcmf[0] = (R_m + geo[1]) * math.cos(geo[0]) * math.cos(geo[2])\n mcmf[1] = (R_m + geo[1]) * math.cos(geo[0]) * math.sin(geo[2])\n mcmf[2] = (R_m + geo[1]) * math.sin(geo[0])\n return mcmf\n\ndef getDPos(trajData, virnsData):\n N1 = len(trajData[:,0])\n N2 = len(virnsData[:,0])\n\n dp = np.zeros((N2,4))\n cnt = 0\n lastPos = geo2mcmf(trajData[0,1:4])\n for i in range(0, N1):\n if(np.abs(trajData[i,0] - virnsData[cnt,0]) < 1e-5):\n curPos = geo2mcmf(trajData[i,1:4])\n dp[cnt,0] = virnsData[cnt,0]\n dp[cnt,1:4] = curPos - lastPos\n lastPos = curPos\n cnt = cnt + 1\n if(cnt == N2):\n break\n return dp\n\ndef getPos(trajData, virnsData):\n N1 = len(trajData[:,0])\n N2 = len(virnsData[:,0])\n\n Pos = np.zeros((N2,4))\n cnt = 0\n for i in range(0, N1):\n if(np.abs(trajData[i,0] - virnsData[cnt,0]) < 1e-5):\n Pos[cnt,0] = virnsData[cnt,0]\n Pos[cnt,1:4] =geo2mcmf(trajData[i,1:4])\n cnt = cnt + 1\n if(cnt == N2):\n break \n return Pos\n\n\ndef getError(trajData, cmnsData):\n N1 = len(trajData[:,0])\n N2 = len(cmnsData[:,0])\n\n errPos = np.zeros((N2,4))\n cnt = 0\n for i in range(0, N1):\n if(np.abs(trajData[i,0] - cmnsData[cnt,0]) < 1e-5):\n errPos[cnt,0] = cmnsData[cnt,0]\n errPos[cnt,1] = cmnsData[cnt,1] - trajData[i,1]\n errPos[cnt,2] = cmnsData[cnt,2] - trajData[i,3]\n cnt = cnt + 1\n if(cnt == N2):\n break \n return errPos\n\n#######################################################\ntrajData = pd.read_csv(\"../data/stdTraj/caGeo.csv\").values\nimuData = pd.read_csv(\"../data/sensorSimData/imuData.csv\").values\nvirnsData = pd.read_csv(\"../data/sensorSimData/virnsData.csv\").values\ncmnsData = pd.read_csv(\"../data/sensorSimData/cmnsData.csv\").values\n# cnsData = pd.read_csv(\"../data/sensorSimData/cnsData.csv\").values\n\ndPos = getDPos(trajData, virnsData)\ntrajPos = getPos(trajData, virnsData)\npErr = getError(trajData, cmnsData)\n\n# #####################################################\ncolors=['tab:blue', 'tab:red']\nlabels=['$\\Delta p$', 'virns']\nfig1, axes = plt.subplots(3,1,figsize=(8,6))\nfig1.subplots_adjust(hspace=0.7)\n\naxes[0].plot(dPos[1:,0], virnsData[1:,1], color=colors[1], label=labels[1])\naxes[0].plot(dPos[1:,0], dPos[1:,1], color=colors[0], label=labels[0])\n# axes[0].plot(dPos[1:,0], dPos[1:,1] - virnsData[1:,1], color=colors[0], label=labels[0])\naxes[0].legend(loc='upper right',fontsize='small')\naxes[0].grid()\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('$\\Delta p_x$(m)')\n\naxes[1].plot(dPos[1:,0], virnsData[1:,2], color=colors[1], label=labels[1])\naxes[1].plot(dPos[1:,0], dPos[1:,2], color=colors[0], label=labels[0])\n# axes[1].plot(dPos[1:,0], dPos[1:,2] - virnsData[1:,2], color=colors[0], label=labels[0])\naxes[1].legend(loc='upper right',fontsize='small')\naxes[1].grid()\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('$\\Delta p_y$(m)')\n\naxes[2].plot(dPos[1:,0], virnsData[1:,3], color=colors[1], label=labels[1])\naxes[2].plot(dPos[1:,0], dPos[1:,3], color=colors[0], label=labels[0])\n# axes[2].plot(dPos[1:,0], dPos[1:,3] - virnsData[1:,3], color=colors[0], label=labels[0])\naxes[2].legend(loc='upper right',fontsize='small')\naxes[2].grid()\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('$\\Delta p_z$(m)')\n\nfig1.savefig('virns_delta.pdf')\n#####################################################\ncolors=['tab:blue', 'tab:red']\nlabels=['$p$', 'virns']\nfig2, axes = plt.subplots(3,1,figsize=(8,6))\nfig2.subplots_adjust(hspace=0.7)\n\naxes[0].plot(trajPos[1:,0], (trajPos[1:,1] - virnsData[1:,4]) / 1000, color=colors[0], label=labels[0])\n# axes[0].plot(virnsData[1:,0], virnsData[1:,4] / 1000, color=colors[1], label=labels[1])\naxes[0].legend(loc='upper right',fontsize='small')\naxes[0].grid()\naxes[0].set_xlabel('t(s)')\naxes[0].set_ylabel('$p_x$(km)')\n\naxes[1].plot(trajPos[1:,0], (trajPos[1:,2] - virnsData[1:,5]) / 1000, color=colors[0], label=labels[0])\n# axes[1].plot(virnsData[1:,0], virnsData[1:,5] / 1000, color=colors[1], label=labels[1])\naxes[1].legend(loc='upper right',fontsize='small')\naxes[1].grid()\naxes[1].set_xlabel('t(s)')\naxes[1].set_ylabel('$p_y$(km)')\n\naxes[2].plot(trajPos[1:,0], (trajPos[1:,3] - virnsData[1:,6]) / 1000, color=colors[0], label=labels[0])\n# axes[2].plot(virnsData[1:,0], virnsData[1:,6] / 1000, color=colors[1], label=labels[1])\naxes[2].legend(loc='upper right',fontsize='small')\naxes[2].grid()\naxes[2].set_xlabel('t(s)')\naxes[2].set_ylabel('$p_z$(km)')\n\nfig2.savefig('virns.pdf')\n#####################################################\nfig3, axes = plt.subplots(2,1,figsize=(8,6))\nfig3.subplots_adjust(hspace=0.7)\n\naxes[0].plot(pErr[:,0], pErr[:,1], color=colors[0], label=labels[0])\naxes[1].plot(pErr[:,0], pErr[:,2], color=colors[1], label=labels[1])\nfig3.savefig('cmns.pdf')\n#####################################################\nplt.show()"
},
{
"alpha_fraction": 0.44171780347824097,
"alphanum_fraction": 0.4745836853981018,
"avg_line_length": 27.87974739074707,
"blob_id": "aa5cb7bafc46d73513aa041c90b225f816c431af",
"content_id": "ec9b687db75c6ee4341a854d5a93ec61669ee7a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4572,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 158,
"path": "/examples/spkfDemo.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"commonHeaders.h\"\n#include \"backend/cnsUKF.h\"\n#include \"backend/cnsHCKF.h\"\n#include <matplotlibcpp.h>\n#include \"utilities/tic_toc.h\"\n#include \"simulator/sensorNoise.hpp\"\n\nusing namespace std;\nusing namespace MyFusion;\n\nnamespace plt = matplotlibcpp; // matplotlib-cpp\n\nint main(int argc, char ** argv){\n\n // default_random_engine e;\n // normal_distribution<double> n(0, 0.1);\n // -------- data generation -------- // \n int N = 500;\n vector<Vec3d> x(N);\n vector<Vec4d> y(N);\n\n for(int i = 0; i < N; i++){\n x[i] = Vec3d::Ones() * 5.0;\n VecXd noiseY = Vec4d(0.61548, M_PI_4, 0.61548, 3. * M_PI_4);\n SensorNoise::addGlintNoise(noiseY, 0.1, 0.6, GAUSSIAN, 0.0);\n y[i] = noiseY;\n // y[i](0) = 0.61548 + n(e);\n // y[i](1) = M_PI_4 + n(e);\n // y[i](2) = 0.61548 + n(e);\n // y[i](3) = 3. * M_PI_4 + n(e);\n }\n // cout << x.transpose() << endl;\n // cout << y.transpose() << endl;\n\n // -------- filter -------- //\n CnsUKF myCns;\n CnsHCKF myHCKF;\n\n if(argc != 2){\n cout << \"Usage: cnsFusion [errScale]\\n\"; \n return -1;\n }\n int errScale = atoi(argv[1]);\n\n Eigen::VectorXd Mu0 = Vec3d::Ones() * 5.0 + (double)errScale * Vec3d(0.5,0.5,0.5);\n Eigen::MatrixXd Sigma0 = Eigen::MatrixXd::Identity(3, 3) * 9;\n Eigen::MatrixXd Q0 = Eigen::MatrixXd::Identity(3, 3) * 0.0001;\n Eigen::MatrixXd R0 = Eigen::MatrixXd::Identity(4, 4) * 0.01;\n // cout << Mu0 << endl << Sigma0 << endl << Q0 << endl << R0 << endl;\n \n myCns.initSPKF(Mu0, Sigma0, Q0, R0);\n myHCKF.initSPKF(Mu0, Sigma0, Q0, R0);\n\n vector<VecXd> all_mu;\n vector<VecXd> all_mu_h;\n vector<MatXd> all_sigma;\n\n double costUKF(0.), costHCKF(0.);\n TicToc filterTimer;\n for (int i = 0; i < N; i++){\n Eigen::VectorXd Zk = y[i];\n VecXd mu;\n MatXd Sigma;\n //-----------------------\n filterTimer.tic();\n myCns.oneStepPrediction();\n myCns.oneStepUpdate(Zk);\n costUKF += filterTimer.toc();\n\n mu = myCns.getMu();\n Sigma = myCns.getSigma();\n \n all_mu.emplace_back(mu);\n all_sigma.emplace_back(Sigma);\n //------------------------\n filterTimer.tic();\n myHCKF.oneStepPrediction();\n myHCKF.oneStepUpdate(Zk);\n costHCKF += filterTimer.toc();\n\n mu = myHCKF.getMu(); \n all_mu_h.emplace_back(mu);\n }\n cout << \"UKF total cost: \" << costUKF << endl;\n cout << \"HCKF total cost: \" << costHCKF << endl;\n\n // ====================== matplotlib-cpp ================================= //\n vector<double> x_est1(N), x_est2(N), x_est3(N);\n vector<double> x_est_h1(N), x_est_h2(N), x_est_h3(N);\n \n vector<double> p_est1(N), p_est2(N), p_est3(N);\n vector<double> x_true(N), y_true(N);\n\n\n\n for(int i = 0; i < N; i++){\n x_est1.at(i) = all_mu[i](0);\n x_est2.at(i) = all_mu[i](1);\n x_est3.at(i) = all_mu[i](2);\n\n x_est_h1.at(i) = all_mu_h[i](0);\n x_est_h2.at(i) = all_mu_h[i](1);\n x_est_h3.at(i) = all_mu_h[i](2);\n \n p_est1.at(i) = all_sigma[i](0, 0); \n p_est2.at(i) = all_sigma[i](1, 1); \n p_est3.at(i) = all_sigma[i](2, 2); \n\n x_true.at(i) = x[i](0);\n y_true.at(i) = y[i](0);\n }\n // -------------------------------\n plt::figure();\n \n plt::subplot(3, 1, 1);\n plt::named_plot(\"true\", x_true, \"-b\");\n // plt::named_plot(\"obs\", y_true, \"-g\");\n // 设置属性\n std::map<string, string> keywords;\n keywords.insert(make_pair(\"Color\",\"tomato\"));\n keywords.insert(make_pair(\"ls\",\"--\"));\n\n plt::named_plot(\"ukf\", x_est1, \"--r\");\n plt::named_plot(\"hckf\", x_est_h1, \"--c\");\n plt::grid(true);\n plt::legend();\n\n plt::subplot(3, 1, 2);\n plt::named_plot(\"true\", x_true, \"-b\");\n // plt::named_plot(\"obs\", y_true, \"-g\");\n\n plt::named_plot(\"est\", x_est2, \"--r\");\n plt::named_plot(\"hckf\", x_est_h2, \"--c\");\n plt::grid(true);\n plt::legend();\n\n plt::subplot(3, 1, 3);\n plt::named_plot(\"true\", x_true, \"-b\");\n // plt::named_plot(\"obs\", y_true, \"-g\");\n\n plt::named_plot(\"est\", x_est3, \"--r\");\n plt::named_plot(\"hckf\", x_est_h3, \"--c\");\n plt::grid(true);\n plt::legend();\n\n\n // -----------------------------\n // plt::figure();\n // plt::named_plot(\"P\", p_est1, \"-b\");\n // plt::legend();\n // plt::grid(true);\n // -----------------------------\n plt::show();\n // ============================================================ //\n\n return 0;\n\n}\n\n"
},
{
"alpha_fraction": 0.5594262480735779,
"alphanum_fraction": 0.6536885499954224,
"avg_line_length": 27.764705657958984,
"blob_id": "57e23d2ccfb63a02760069264e29d44d873fb526",
"content_id": "f9513944164769b5d86bd7507342caac25ad9d69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 17,
"path": "/include/constParams.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef CONST_PARAM_H_\n#define CONST_PARAM_H_\n\n\nconst double GM_m = 4.9037e12; // G * M_m\nconst double GM_e = 3.9802e14; // G * M_e\n\nconst double R_m = 1.737e6; // radius of moon (m)\nconst double R_e = 6.371e6; // radius of earth(m) \n\nconst double g0_m = 1.625; // gravity acceleration (m/s^2)\nconst double g0_e = 9.810; // gravity acceleration (m/s^2)\n\nconst double W_im = 2.662e-6; // rotation rate of moon (rad/s)\nconst double W_ie = 7.272e-5; // ratation rate of earth (rad/s)\n\n#endif"
},
{
"alpha_fraction": 0.5490180253982544,
"alphanum_fraction": 0.6065093278884888,
"avg_line_length": 30.9518985748291,
"blob_id": "e3e50399f1a6df8c92af80de1e786da70178d9ec",
"content_id": "10642a5d4289feb71b45826269e24ca8873e2595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12798,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 395,
"path": "/tools/drawTrajMCMF.py",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#coding=utf-8\n######################## 导入模块 #######################\nimport numpy as np\nimport pandas as pd\nimport math\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\nimport systems as sys\n######################## 自定义函数 ######################\ndef quat2euler(quat):\n q0 = quat[0]\n q1 = quat[1]\n q2 = quat[2]\n q3 = quat[3]\n yaw = math.atan(round(2.0 * (q1 * q2 - q0 * q3) / (q0 * q0 + q1 * q1 - q2 * q2 - q3 * q3), 6))\n pitch = math.asin(round(-2.0 * (q0 * q2 + q1 * q3), 6))\n roll = math.atan(2.0 * (q2 * q3 - q0 * q1) / (q0 * q0 + q3 * q3 - q2 * q2 - q1 * q1))\n return [roll, pitch, yaw]\n\ndef drawMoon(axis, radius, filled):\n # data\n center = [0., 0., 0.]\n u = np.linspace(-0.5 * np.pi, 0.5 * np.pi, 100)\n v = np.linspace(0, 0.5 * np.pi, 100)\n x = radius * np.outer(np.cos(u), np.sin(v)) + center[0]\n y = radius * np.outer(np.sin(u), np.sin(v)) + center[1]\n z = radius * np.outer(np.ones(np.size(u)), np.cos(v)) + center[2]\n\n if filled:\n axis.plot_surface(x, y, z, rstride=2, cstride=2, color='lightgrey', alpha=0.5)\n else:\n axis.plot_wireframe(x, y, z, rstride=5, cstride=5, color='silver')\n###################### 读取标称轨迹数据(csv格式) ########################\ntraj_data = pd.read_csv('../data/standardTraj/trajMCMF.csv').values\nimu_data = pd.read_csv('../data/sensorSimData/imuData.csv').values\n# ned_data = pd.read_csv('../data/posNED.csv').values\n# ned_data_imu = pd.read_csv('../data/posMCMF.csv').values\n# beacon_location = pd.read_csv('/home/yuntian/dataset/simulator/lander/beacon_location.csv').values\n###################### 提取各数据序列(注意python切片不包括尾部) ####################\ntime_series = traj_data[:,0]\npos = traj_data[:,1:4]\nquat = traj_data[:,4:8] \neuler = traj_data[:,8:11]\nvel = traj_data[:,11:14]\ngyr = traj_data[:,14:17]\nacc = traj_data[:,17:20]\n\ntime_imu = imu_data[:,0]\npos_imu = imu_data[:,1:4]\nquat_imu = imu_data[:,4:8]\neuler_imu = imu_data[:,8:11]\nvel_imu = imu_data[:,11:14]\ngyr_imu = imu_data[:,14:17]\nacc_imu = imu_data[:,17:20]\n\n# beacon_loc = beacon_location[:,4:7]\npos = pos / 1e3\npos_imu = pos_imu / 1e3\n\n# ned_data = ned_data / 1000.\n# ned_data_imu = ned_data_imu / 1000.\n\n# N = len(ned_data[:,0])\n# downRange = np.zeros(N)\n# downRangeImu = np.zeros(N)\n# for i in range(0, N): \n# downRange[i] = math.sqrt(ned_data[i,0] * ned_data[i,0] + ned_data[i,1] * ned_data[i,1])\n# downRangeImu[i] = math.sqrt(ned_data_imu[i,0] * ned_data_imu[i,0] + ned_data_imu[i,1] * ned_data_imu[i,1])\n\n######################### 画图 #########################\n# 图注使用$$开启数学环境\n###### figure1 #####\nfig1, axes = plt.subplots(3, 1)\nfig1.subplots_adjust(hspace=0.5)\n## 子图1\naxes[0].plot(time_series, acc[:,0], 'b-')\naxes[0].plot(time_series, acc_imu[:,0], 'r-')\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-3, 3)\naxes[0].set_xlabel('$Time (s)$')\naxes[0].set_ylabel('$a_x (m/s^2)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, acc[:,1], 'b-')\naxes[1].plot(time_series, acc_imu[:,1], 'r-')\n# axes[1].set_xlim(0, 220)\naxes[1].set_ylim(-3, 3)\naxes[1].set_xlabel('$Time (s)$')\naxes[1].set_ylabel('$a_y (m/s^2)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, acc[:,2], 'b-')\naxes[2].plot(time_series, acc_imu[:,2], 'r-')\n# axes[2].set_xlim(0, 220)\naxes[2].set_ylim(-3, 3)\naxes[2].set_xlabel('$Time (s)$')\naxes[2].set_ylabel('$a_z (m/s^2)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(1)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig1.savefig('acc.pdf', format='pdf')\n# ##### figure2 #####\nfig2, axes = plt.subplots(3, 1)\nfig2.subplots_adjust(hspace=0.5)\n## 子图1\naxes[0].plot(time_series, gyr[:,0], 'b-')\naxes[0].plot(time_series, gyr_imu[:,0], 'r-')\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.075, 0.075)\naxes[0].set_xlabel('$Time (s)$')\naxes[0].set_ylabel('$\\omega_x (rad/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, gyr[:,1], 'b-')\naxes[1].plot(time_series, gyr_imu[:,1], 'r-')\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.075, 0.075)\naxes[1].set_xlabel('$Time (s)$')\naxes[1].set_ylabel('$\\omega_y (rad/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, gyr[:,2], 'b-')\naxes[2].plot(time_series, gyr_imu[:,2], 'r-')\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.075, 0.075)\naxes[2].set_xlabel('$Time (s)$')\naxes[2].set_ylabel('$\\omega_z (rad/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig2.savefig('gyr.pdf', format='pdf')\n\n##### figure3 #####\nfig3, axes = plt.subplots(3, 1)\nfig3.subplots_adjust(hspace=0.5)\n\n## 子图1\naxes[0].plot(time_series, pos[:,0], 'b-')\naxes[0].plot(time_series, pos_imu[:,0], 'r-')\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('$time (s)$')\n# axes[0].set_ylabel('$Latitude(deg)$')\naxes[0].set_ylabel('$x(km)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, pos[:,1], 'b-')\naxes[1].plot(time_series, pos_imu[:,1], 'r-')\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('$time (s)$')\n# axes[1].set_ylabel('$Logitude (deg)$')\naxes[1].set_ylabel('$y(km)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, pos[:,2], 'b-')\naxes[2].plot(time_series, pos_imu[:,2], 'r-')\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('$time (s)$')\n# axes[2].set_ylabel('$Altimeter (km)$')\naxes[2].set_ylabel('$z(km)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig3.savefig('pos.pdf', format='pdf')\n\n##### figure4 #####\nfig4, axes = plt.subplots(3, 1)\nfig4.subplots_adjust(hspace=0.5)\n\n## 子图1\naxes[0].plot(time_series, vel[:,0], 'b-')\naxes[0].plot(time_series, vel_imu[:,0], 'r-')\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('$Time (s)$')\naxes[0].set_ylabel('$v_x (m/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, vel[:,1], 'b-')\naxes[1].plot(time_series, vel_imu[:,1], 'r-')\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('$Time (s)$')\naxes[1].set_ylabel('$v_y (m/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, vel[:,2], 'b-')\naxes[2].plot(time_series, vel_imu[:,2], 'r-')\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('$Time (s)$')\naxes[2].set_ylabel('$v_z (m/s)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig4.savefig('vel.pdf', format='pdf')\n##### figure5 #####\n# # rad -> deg\n# N = len(quat[:,1])\n# euler = np.zeros([N,3], float)\n# for i in range(0, N):\n# tmp = quat2euler(quat[i,:])\n# euler[i, 0] = tmp[0] / math.pi * 180.\n# euler[i, 1] = tmp[1] / math.pi * 180.\n# euler[i, 2] = tmp[2] / math.pi * 180.\n\n# N = len(quat_imu[:,1])\n# euler_imu = np.zeros([N,3], float)\n# for i in range(0, N):\n# tmp = quat2euler(quat_imu[i,:])\n# euler_imu[i, 0] = tmp[0] / math.pi * 180.\n# euler_imu[i, 1] = tmp[1] / math.pi * 180.\n# euler_imu[i, 2] = tmp[2] / math.pi * 180.\n\n# euler = euler / math.pi * 180.\n# euler_imu = euler_imu / math.pi * 180.\n\nfig5, axes = plt.subplots(3, 1)\nfig5.subplots_adjust(hspace=0.5)\n## 子图1\naxes[0].plot(time_series, euler[:,0], '-b')\naxes[0].plot(time_imu, euler_imu[:,0], '-r')\n# axes[0].set_xlim(0, 220)\n# axes[0].set_ylim(-0.1, 0.1)\naxes[0].set_xlabel('$time (s)$')\naxes[0].set_ylabel('$\\theta (\\deg)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[0].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[0].yaxis.set_major_locator(y_major_locator)\naxes[0].grid()\n## 子图2\naxes[1].plot(time_series, euler[:,1], 'b-')\naxes[1].plot(time_series, euler_imu[:,1], 'r-')\n# axes[1].set_xlim(0, 220)\n# axes[1].set_ylim(-0.1, 0.1)\naxes[1].set_xlabel('$time (s)$')\naxes[1].set_ylabel('$\\theta_y (\\deg)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[1].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[1].yaxis.set_major_locator(y_major_locator)\naxes[1].grid()\n## 子图3\naxes[2].plot(time_series, euler[:,2], 'b-')\naxes[2].plot(time_series, euler_imu[:,2], 'r-')\n# axes[2].set_xlim(0, 220)\n# axes[2].set_ylim(-0.1, 0.1)\naxes[2].set_xlabel('$time (s)$')\naxes[2].set_ylabel('$\\theta_z (\\deg)$')\n\n# x_major_locator = plt.MultipleLocator(25)\n# axes[2].xaxis.set_major_locator(x_major_locator)\n# y_major_locator = plt.MultipleLocator(0.05)\n# axes[2].yaxis.set_major_locator(y_major_locator)\naxes[2].grid()\n\nfig5.savefig('att.pdf', format='pdf')\n# # ##### figure6 #####\n# fig6 = plt.figure(figsize=(8,8))\n# ax = fig6.add_subplot(111, projection='3d')\n\n# drawMoon(ax, 1737, 1)\n# ax.scatter(pos_imu[0,0], pos_imu[0,1], pos_imu[0,2], color='cyan', marker='*', lw=3)\n# # ax.scatter(pos_imu[-1,0], pos_imu[-1,1], pos_imu[-1,2], color='orange', marker='D', lw=3)\n# # ax.plot(pos[:,0], pos[:,1], pos[:,2], color='royalblue')\n# ax.plot(pos_imu[:,0], pos_imu[:,1], pos_imu[:,2], color='tomato', lw=2)\n\n# # ax.view_init(10,-85)\n\n# # ax.set_xticks([])\n# # ax.set_yticks([])\n# # ax.set_zticks([])\n\n# ax.set_xlabel(\"x(km)\")\n# ax.set_ylabel(\"y(km)\")\n# ax.set_zlabel(\"z(km)\")\n\n# ax.grid()\n\n\n# # ax.set_zlim([0, 700])\n# # axis.plot(ned_data[:,3], ned_data[:,1])\n# # axis.plot(ned_data_imu[:,3], ned_data_imu[:,1])\n# # axis.grid()\n# # axis.set_xlabel(\"East(km)\")\n# # axis.set_ylabel(\"North(km)\")\n\n# # fig6.savefig('ne.pdf', format='pdf')\n# ##### figure7 ######\n# fig7, axes = plt.subplots(3,1)\n# fig7.subplots_adjust(hspace=0.5)\n# # lat = np.arctan(pos_imu[:,2] / np.sqrt(pos_imu[:,0] * pos_imu[:,0] + pos_imu[:,1] * pos_imu[:,1]))\n# # lon = np.arctan(pos_imu[:,1] / pos_imu[:,0])\n# # alt = np.linalg.norm(pos_imu, axis=1) - 1737.\n\n# axes[0].plot(time_series, pos[:,0])\n# axes[0].plot(time_series, ned_data_imu[:,1])\n\n# axes[1].plot(time_series, pos[:,2])\n# axes[1].plot(time_series, ned_data_imu[:,2])\n\n# axes[2].plot(time_series, pos[:,1])\n# axes[2].plot(time_series, ned_data_imu[:,3])\n# # ###### figure 8 #######\nfig8, axes = plt.subplots(3,1)\nfig8.subplots_adjust(hspace=0.5)\n\naxes[0].plot(time_series, pos[:,0] - pos_imu[:,0]);\n# axes[0].plot(time_series, pos[:,0] - ned_data_imu[:,1]);\n\naxes[1].plot(time_series, pos[:,1] - pos_imu[:,1]);\n# axes[1].plot(time_series, pos[:,2] - ned_data_imu[:,2]);\n\naxes[2].plot(time_series, pos[:,2] - pos_imu[:,2]);\n# axes[2].plot(time_series, pos[:,1] - ned_data_imu[:,3]);\n\n\n# ######### figure 9 #######\n# fig9, axes = plt.subplots(4,1)\n# axes[0].plot(time_series, quat[:,0])\n# axes[0].plot(time_series, quat_imu[:,0])\n\n# axes[1].plot(time_series, quat[:,1])\n# axes[1].plot(time_series, quat_imu[:,1])\n\n# axes[2].plot(time_series, quat[:,2])\n# axes[2].plot(time_series, quat_imu[:,2])\n\n# axes[3].plot(time_series, quat[:,3])\n# axes[3].plot(time_series, quat_imu[:,3])\n\n\n##显示绘图\nplt.show()\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6308724880218506,
"alphanum_fraction": 0.636241614818573,
"avg_line_length": 22.3125,
"blob_id": "7ea50e06408ef3596bc2e9ee6c3493c718f68dd2",
"content_id": "25d71f7d99aae630c1dbfbe1f0480358ea04f850",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 745,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 32,
"path": "/src/simulator/sensors/cmns.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/cmns.h\"\n\nnamespace MyFusion\n{\n\nvoid CMNS::setParam(double bias, double sigma){\n bias_ = bias;\n sigma_ = sigma / R_m; // convert from m to rad\n flagInit_ = true;\n}\n\nCmnsData CMNS::getMeasurement(ImuMotionData currMotion){\n if(!flagInit_){\n cout << \"WARNING: parameters untizlied! Please call setParam()\\n\";\n }\n \n CmnsData tmp;\n\n std::random_device rd;\n std::default_random_engine rg(rd());\n std::normal_distribution<double> noise(0., 1.); \n\n Vec2d posNoise(noise(rg), noise(rg));\n Vec2d pos(currMotion.tnb_.x(), currMotion.tnb_.z());\n\n tmp.timeStamp_ = currMotion.time_stamp_;\n tmp.pos_ = pos + sigma_ * posNoise;\n\n return tmp;\n}\n \n} // namespace MyFusionclass"
},
{
"alpha_fraction": 0.5126099586486816,
"alphanum_fraction": 0.5436950325965881,
"avg_line_length": 31.188678741455078,
"blob_id": "8598b7cc43ea81e736dc7bd1235005e48470308f",
"content_id": "bbea076a9698a07fe40c5c3037c666b6d0e91c90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1705,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 53,
"path": "/src/simulator/sensors/imu_mcmf.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/imu_mcmf.h\"\n\nnamespace MyFusion{\n\nIMU_MCMF::IMU_MCMF(ImuParam params):IMU_BASE(params){\n// setParams(params);\n frameType_ = MCMF;\n}\n\nvoid IMU_MCMF::oneStepIntegration(){\n double h_m = tnb_.norm(); // distance to center\n double alt = h_m - R_m;\n double lon = atan2(tnb_.y(), tnb_.x());\n double scale = sqrt(tnb_.x() * tnb_.x() + tnb_.y() * tnb_.y()); \n double lat = atan2(tnb_.z(), scale);\n pos_ = Eigen::Vector3d(lat, lon, alt);\n\n Eigen::Vector3d w_im(0., 0., W_im);\n\n // update quaternion\n Eigen::Vector3d w_mb = gyr_0_ - qnb_.conjugate() * w_im;\n Eigen::Quaterniond dq(1., 0.5 * w_mb.x() * time_step_, 0.5 * w_mb.y() * time_step_, 0.5 * w_mb.z() * time_step_);\n dq.normalize();\n\n Eigen::Quaterniond qnb0 = qnb_;\n qnb_ = qnb0 * dq;\n qnb_.normalize();\n \n // calculate geavity\n Eigen::Vector3d g_g(0., 0., 0.); \n g_g.z() = computeG(alt);\n // compute qmg\n Eigen::AngleAxisd r_vec_1(lon, Eigen::Vector3d(0., 0., 1.)); // z\n Eigen::AngleAxisd r_vec_2(- lat, Eigen::Vector3d(0., 1., 0.)); // y\n Eigen::AngleAxisd r_vec_3(-0.5 * M_PI, Eigen::Vector3d(0., 1., 0.)); // x\n Eigen::Quaterniond qmg(r_vec_1 * r_vec_2 * r_vec_3);\n\n Eigen::Vector3d g_m = qmg * g_g;\n\n // double g_scale = computeG(alt);\n // Eigen::Vector3d g_m(0., 0., 0.);\n // g_m.x() = -g_scale * cos(lat) * cos(lon);\n // g_m.y() = -g_scale * cos(lat) * sin(lon);\n // g_m.z() = -g_scale * sin(lat);\n\n //update position and velocity \n Eigen::Vector3d acc_m = qnb0 * acc_0_ - 2.0 * w_im.cross(vel_) + g_m;\n tnb_ += vel_ * time_step_ + 0.5 * acc_m * time_step_ * time_step_;\n vel_ += acc_m * time_step_;\n}\n\n \n}"
},
{
"alpha_fraction": 0.5498254299163818,
"alphanum_fraction": 0.552780032157898,
"avg_line_length": 26.969924926757812,
"blob_id": "558b8c975c414052a4e2568a0a419ef8ddb95c65",
"content_id": "e6505b0935851902ea2037161cacd24743aaa4bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3723,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 133,
"path": "/src/backend/spkf.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/spkf.h\"\n\nnamespace MyFusion{\n\nvoid SPKF::initSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R)\n{\n // check covariance matrix\n if (Q.cols() != Q.rows() || R.cols() != R.rows()){\n cerr << \"Q or R is not square !\\n\";\n exit(1);\n }\n if (Sigma.cols() != Sigma.rows()){\n cerr << \"Sigma is not square !\\n\";\n exit(1);\n }\n if(Mu.size() != Sigma.cols() || Mu.size() != Q.cols() \n || Q.cols() != Sigma.cols())\n {\n cerr << \"Mu, Sigma or Q size is wrong ! Their size are:\\n\"\n << \"Mu: \" << Mu.size() << \", \"\n << \"Sigma: \" << Sigma.rows() << \" x \" << Sigma.cols() << \", \"\n << \"Q: \" << Q.rows() << \" x \" << Q.cols() << endl;\n exit(1);\n }\n\n // set variables\n curMu_ = Mu;\n curSigma_ = Sigma;\n Q_ = Q;\n R_ = R;\n // get dimensions of state and measurements \n xDim_ = Q_.cols();\n mDim_ = R_.cols();\n //\n computeWeight();\n //\n flagInitiated_= true;\n}\n\nvoid SPKF::oneStepPrediction(){\n if(!flagInitiated_){\n cerr << \"Please call init() to initiate filter first !\\n\";\n return;\n }\n // clear containers\n sPointsX_.clear();\n sPointsY_.clear();\n // generate sigma points\n genSigmaPoints(sPointsX_);\n // propogate sigma points by f(x)\n propagateFcn(sPointsX_, sPointsY_);\n // compute predicted mean and covariance\n curMu_ = calcWeightedMean(sPointsY_);\n curSigma_ = calcWeightedCov(sPointsY_) + Q_;\n\n // cout << \"MU_P: \" << curMu_.transpose() << endl;\n // cout << \"Sigma_P:\\n\" << curSigma_ << endl;\n}\n\nvoid SPKF::oneStepUpdate(VecXd &Z){\n if(!flagInitiated_){\n cerr << \"Please call init() to initiate filter first !\\n\";\n return;\n }\n // clear containers\n sPointsX_.clear();\n sPointsY_.clear();\n // generate sigma points\n genSigmaPoints(sPointsX_);\n // propogate sigma points by h(x)\n updateFcn(sPointsX_, sPointsY_);\n // compute update mean and covariance\n VecXd tmpM = calcWeightedMean(sPointsY_);\n MatXd tmpS = calcWeightedCov(sPointsY_) + R_; \n MatXd tmpC = calcWeightedCrossCov(sPointsX_, sPointsY_);\n // cout << \"tmpC:\\n\" << tmpC << endl;\n // cout << \"tmpS:\\n\" << tmpS << endl;\n // compute gain\n MatXd K = tmpC * tmpS.inverse();\n // update\n curResidual_ = Z - tmpM;\n curMu_ += K * curResidual_;\n curSigma_ -= K * tmpS * K.transpose();\n\n // cout << \"MU_U: \" << curMu_.transpose() << endl;\n // cout << \"Sigma_U:\\n\" << curSigma_ << endl;\n}\n\nVecXd SPKF::calcWeightedMean(vector<VecXd> &sPointsX){\n int size = sPointsX[0].size();\n VecXd mu = VecXd::Zero(size);\n\n for(size_t i = 0; i < sPointsX.size(); i++){\n mu += weightMu_[i] * sPointsX[i];\n }\n\n return mu;\n}\n\nMatXd SPKF::calcWeightedCov(vector<VecXd> &sPointsX){\n VecXd mu = calcWeightedMean(sPointsX);\n \n int size = sPointsX[0].size();\n MatXd cov = MatXd::Zero(size, size);\n\n for(size_t i = 0; i < sPointsX.size(); i++){\n VecXd delta = sPointsX[i] - mu;\n cov += weightSigma_[i] * delta * delta.transpose();\n }\n // cout << cov << endl;\n return cov;\n}\n\nMatXd SPKF::calcWeightedCrossCov(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY){\n // VecXd muX = calcWeightedMean(weights, sPointsX);\n VecXd muX = sPointsX[0];\n VecXd muY = calcWeightedMean(sPointsY);\n \n int sizeX = sPointsX[0].size();\n int sizeY = sPointsY[0].size();\n\n MatXd cCov = MatXd::Zero(sizeX, sizeY);\n for(size_t i = 0; i < sPointsX.size(); i++){\n VecXd deltaX = sPointsX[i] - muX;\n VecXd deltaY = sPointsY[i] - muY;\n cCov += weightSigma_[i] * deltaX * deltaY.transpose();\n }\n\n return cCov;\n}\n \n\n} // namespace MyFusion "
},
{
"alpha_fraction": 0.8113440275192261,
"alphanum_fraction": 0.8113440275192261,
"avg_line_length": 34.173912048339844,
"blob_id": "8f0b34d663d1fc8b1590a0abd076ca2f0fbbc5a1",
"content_id": "178b3e78e877340d4a531423016e88b83d224ccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 811,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/examples/CMakeLists.txt",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "add_executable(insMoon insMoon.cc)\ntarget_link_libraries(insMoon myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(landerIMU landerIMU.cc)\ntarget_link_libraries(landerIMU myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(allanData allanData.cc)\ntarget_link_libraries(allanData myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(simSensors simSensors.cc)\ntarget_link_libraries(simSensors myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(spkfDemo spkfDemo.cc)\ntarget_link_libraries(spkfDemo myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(glintDemo glintDemo.cc)\ntarget_link_libraries(glintDemo myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(scspkfDemo scspkfDemo.cc)\ntarget_link_libraries(scspkfDemo myFusion ${THIRD_PARTY_LIBS})\n\nadd_executable(scFusion scFusion.cc)\ntarget_link_libraries(scFusion myFusion ${THIRD_PARTY_LIBS})\n\n\n"
},
{
"alpha_fraction": 0.4654019773006439,
"alphanum_fraction": 0.48383018374443054,
"avg_line_length": 34.261146545410156,
"blob_id": "8f7682c3f26a26af423a1661b3a3496884a165fe",
"content_id": "da395727d28f614b4780340e7ab0dc9b57ce5d76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5535,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 157,
"path": "/src/simulator/sensors/imu_g.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/imu_g.h\"\n\nnamespace MyFusion{\n\nIMU_G::IMU_G(ImuParam params):IMU_BASE(params){\n frameType_ = GEO;\n}\n\nvoid IMU_G::oneStepIntegration(){\n // NUE - [lat, alt, lon]\n double curLat = tnb_.x(); // current latitude\n double curAlt = tnb_.y(); // current height\n double curLon = tnb_.z(); // current longitude\n double h_m = R_m + curAlt; // (R_m + h)\n\n // compute w^G_im = [W_im * cosL, -W_m * sinL, 0]\n Vec3d w_im(W_im * cos(curLat), W_im * sin(curLat), 0.);\n // compute w^G_mg = [v_e / h_m, v_e * tanL / h_m, -v_n / h_m, ]\n Vec3d w_mg(vel_.z() / h_m,\n vel_.z() * tan(curLat) / h_m, \n -vel_.x() / h_m);\n \n if (intType == 1)\n {\n // ========================= mid intergration =================== //\n // compute attitude\n Vec3d gyr_mid = 0.5 * (gyr_0_ + gyr_1_) - gyr_bias_; // mid gyro measurement\n Vec3d w_gb = gyr_mid - qnb_.conjugate() * (w_im + w_mg);\n \n Eigen::Quaterniond qnb0 = qnb_;\n Eigen::Quaterniond dq(1., 0.5 * w_gb.x() * time_step_, 0.5 * w_gb.y() * time_step_, 0.5 * w_gb.z() * time_step_);\n dq.normalize();\n qnb_ = qnb0 * dq;\n qnb_.normalize();\n\n // compute gravity\n Eigen::Vector3d gn = Vec3d::Zero(); // gravity vector\n gn.y() = -computeG(curAlt); // NUE\n\n // compute velocity\n Vec3d acc_mid = 0.5 * (qnb0 * (acc_0_ - acc_bias_) + qnb_ * (acc_1_ - acc_bias_));\n Vec3d vel0 = vel_;\n Vec3d acc_n = acc_mid - (2. * w_im + w_mg).cross(vel0) + gn;\n vel_ = vel0 + acc_n * time_step_;\n\n // compute position\n Vec3d vel_mid =0.5 * (vel0 + vel_);\n tnb_.x() += time_step_ * vel_mid.x() / h_m; // Lat\n tnb_.y() += time_step_ * vel_mid.y(); // alt\n tnb_.z() += time_step_ * vel_mid.z() / (h_m * cos(curLat)); // Lon\n } \n else if(intType == 0)\n {\n // ============================= euler integration ==================== //\n Vec3d w_gb = gyr_0_ - qnb_.conjugate() * (w_im + w_mg);\n \n Eigen::Quaterniond qnb0 = qnb_;\n Eigen::Quaterniond dq(1., 0.5 * w_gb.x() * time_step_, 0.5 * w_gb.y() * time_step_, 0.5 * w_gb.z() * time_step_);\n dq.normalize();\n qnb_ = qnb0 * dq;\n qnb_.normalize();\n\n // compute gravity\n Eigen::Vector3d gn = Vec3d::Zero(); // gravity vector\n gn.y() = -computeG(curAlt); // NUE\n\n // compute velocity\n Vec3d vel0 = vel_;\n Vec3d acc_n = qnb0 * acc_0_ - (2. * w_im + w_mg).cross(vel0) + gn;\n vel_ = vel0 + acc_n * time_step_;\n\n // compute position \n tnb_.x() += time_step_ * vel0.x() / h_m; //latitude\n tnb_.y() += time_step_ * vel0.y(); // height\n tnb_.z() += time_step_ * vel0.z() / (h_m * cos(curLat)); //longitude\n pos_ += vel0 * time_step_ + 0.5 * acc_n * time_step_ * time_step_;\n } \n\n}\n\nvector<ImuMotionData> IMU_G::trajGenerator(ImuMotionData initPose, vector<Vec3d> a_b_all, vector<Vec3d> omega_gb_all){\n if (a_b_all.size() != omega_gb_all.size()){\n cout << \"WARNING: v_gm_all size is not equal to omega_gb_all size.\\n\";\n } \n\n // get initial values\n double lat = initPose.tnb_.x();\n double alt = initPose.tnb_.y();\n double lon = initPose.tnb_.z();\n double time_stamp = initPose.time_stamp_;\n Vec3d pos_g(0., 0., 0.);\n\n Vec3d v_g = initPose.vel_;\n Eigen::Quaterniond qnb = initPose.qnb_; \n\n // ============ trajectory generation ============ // \n vector<ImuMotionData> traj_data;\n for (size_t i = 0; i < a_b_all.size(); i++){\n int per = (i + 1) * 100 / a_b_all.size();\n printf(\"[#][Generating traj data...][%d%%]\\r\", per);\n fflush(stdout);\n \n double h_m = R_m + alt; // (R_m + h)\n // ----- compute compensation variables\n Vec3d w_im(W_im * cos(lat), W_im * sin(lat), 0.);\n \n Vec3d w_mg(v_g.z() / h_m,\n v_g.z() * tan(lat) / h_m,\n -v_g.x() / h_m);\n\n Eigen::Vector3d gn = Vec3d::Zero(); // gravity vector\n gn.y() = -computeG(alt); // NUE\n // ----- compute specific force and angular rate\n Vec3d w_gb = omega_gb_all[i];\n Vec3d acc_b = a_b_all[i];\n\n Vec3d gyr_b = w_gb + qnb.conjugate() * (w_im + w_mg); \n Vec3d acc_g = qnb * acc_b - (2. * w_im + w_mg).cross(v_g) + gn;\n \n // ----- save traj_data;\n ImuMotionData tmp_data;\n tmp_data.time_stamp_ = time_stamp; \n tmp_data.tnb_ = Vec3d(lat, alt, lon);\n tmp_data.vel_ = v_g;\n tmp_data.qnb_ = qnb;\n Eigen::Matrix3d Cnb = qnb.toRotationMatrix();\n tmp_data.eulerAngles_ = AttUtility::R2Euler(Cnb);\n tmp_data.acc_ = acc_b;\n tmp_data.gyr_ = gyr_b;\n\n tmp_data.pos_ = pos_g;\n tmp_data.acc_n_ = acc_g;\n\n traj_data.push_back(tmp_data);\n // ----- propagate trajectory\n Eigen::Quaterniond qnb0 = qnb;\n Eigen::Quaterniond dq(1., 0.5 * w_gb.x() * time_step_, 0.5 * w_gb.y() * time_step_, 0.5 * w_gb.z() * time_step_);\n dq.normalize();\n qnb = qnb0 * dq;\n qnb.normalize();\n\n lat += time_step_ * v_g.x() / h_m; //latitude\n alt += time_step_ * v_g.y(); // height\n lon += time_step_ * v_g.z() / (h_m * cos(lat)); //longitude\n\n pos_g += v_g * time_step_ + 0.5 * acc_g * time_step_ * time_step_;\n\n v_g = v_g + acc_g * time_step_;\n\n time_stamp += time_step_;\n }\n printf(\"\\n\");\n\n return traj_data;\n}\n\n}"
},
{
"alpha_fraction": 0.6901408433914185,
"alphanum_fraction": 0.6901408433914185,
"avg_line_length": 10.88888931274414,
"blob_id": "74a4c1e164fbd4dfecfb63f409a5c945b8ab1ae7",
"content_id": "52d9ba8d3414ec6b3dcbb272d88500bd57b488c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 18,
"path": "/include/simulator/sensors/imu_li.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef IMU_LI_H_\n#define IMU_LI_H_\n\n#include \"simulator/sensors/imu_base.h\"\n\nnamespace MyFusion{\n\nclass IMU_LI:public IMU_BASE{\npublic:\n using IMU_BASE::IMU_BASE;\n\n void oneStepIntegration();\n\n};\n\n}\n\n#endif"
},
{
"alpha_fraction": 0.6540880799293518,
"alphanum_fraction": 0.6540880799293518,
"avg_line_length": 12.657142639160156,
"blob_id": "b11f7d6910a4768a4ab38f89e7795d79d4a5ed58",
"content_id": "5299359911809dcfc3d1926b83ceba3d444773fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 35,
"path": "/src/backend/sckf/scekf.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/sckf/scekf.h\"\n\nnamespace MyFusion{\n\nSCEKF::SCEKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R):SCKF(Mu, Sigma, Q, R){\n\n}\n\nvoid SCEKF::oneStepPrediction(VecXd &U){\n if(!flagInitialized_){\n cout << \"Please call initSCKF() first !\\n\";\n return;\n }\n\n computeJacobianF()\n}\n\nvoid SCEKF::oneStepUpdate(VecXd &Z){\n\n}\n\n\nvoid SCEKF::computeJacobianF(){\n\n}\n\nvoid SCEKF::computeJacobianG(){\n\n}\n\nvoid SCEKF::computeJacobianH(){\n\n}\n\n} // namespace MyFusion"
},
{
"alpha_fraction": 0.5235413312911987,
"alphanum_fraction": 0.5371472239494324,
"avg_line_length": 30.047151565551758,
"blob_id": "df41c0f67a087395abbfd5a3646cbc7998e4fad1",
"content_id": "c5055c3bc2e1119b5b4e2f4586dd1a70906c91bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 15802,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 509,
"path": "/src/backend/sckf/scspkf.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/sckf/scspkf.h\"\n\nnamespace MyFusion{\n\nSCSPKF::SCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType):SCKF(Mu, Sigma, Q, R){\n initSCSPKF(Mu, Sigma, Q, R, sigmaType);\n}\n\nSCSPKF::SCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, double alpha, double beta, double kappa, SampleType sigmaType):SCKF(Mu, Sigma, Q, R){\n alpha_ = alpha;\n beta_ = beta;\n kappa_ = kappa;\n lambda_ = 3 * alpha_ * alpha_ - xSize_; \n\n initSCSPKF(Mu, Sigma, Q, R, sigmaType);\n\n ukfInit_ = true; \n}\n\nvoid SCSPKF::initSCSPKF(VecXd Mu, MatXd Sigma, MatXd Q, MatXd R, SampleType sigmaType){\n sigmaType_ = sigmaType;\n if(sigmaType_ == SP_UKF)\n printf(\"[UKF] Parameters: alpha (%lf), beta (%lf), kappa (%lf).\\n\", alpha_, beta_, kappa_);\n // compute weight\n computeWeight(weightMu_, weightSigma_, xSize_); // calculate weight of state\n computeWeight(weightMuAug_, weightSigmaAug_, 2 * xSize_); // calculate weight of augState\n // compute cubature points\n genSi(allSi_, xSize_); // cubature points\n genSi(allSiAug_, 2 * xSize_); // aug cubature points\n // print si and weight for debug\n // printWeight(weightMu_, varName(weightMu_), 20);\n // printSi(allSi_, varName(allsi_), 20);\n // printWeight(weightMuAug_, varName(weightMuAug_), 20);\n // printSi(allSiAug_, varName(allSiAug_), 20);\n\n siInit_ = true;\n}\n\n// void SCSPKF::setUKFParams(double alpha, double beta, double kappa){\n// alpha_ = alpha;\n// beta_ = beta;\n// kappa_ = kappa;\n// lambda_ = 3 * alpha_ * alpha_ - xSize_; \n\n// ukfInit_ = true;\n// // printf(\"[UKF] Parameters: alpha (%lf), beta (%lf), kappa (%lf).\\n\", alpha_, beta_, kappa_);\n// }\n\nvoid SCSPKF::genSigmaPoints(vector<VecXd> &sPoints, bool aug){\n if(sPoints.size() != 0)\n sPoints.clear();\n\n if(aug){\n MatXd sqrtS = augSigma_.llt().matrixL(); // Cholesky decomposition of covariance matrix\n // cout << sqrtS;\n \n for(size_t i = 0; i < allSiAug_.size(); i++){\n VecXd point = augMu_ + sqrtS * allSiAug_[i];\n sPoints.emplace_back(point);\n }\n }\n else{\n MatXd sqrtS = Sigma_.llt().matrixL(); // Cholesky decomposition of covariance matrix\n \n for(size_t i = 0; i < allSi_.size(); i++){\n VecXd point = Mu_ + sqrtS * allSi_[i];\n sPoints.emplace_back(point);\n }\n }\n}\n\nvoid SCSPKF::genSi(vector<VecXd> &allSi, int xSize){\n switch (sigmaType_)\n {\n case SP_UKF:\n genSiUKF(allSi, xSize); \n break;\n case SP_CKF:\n genSiCKF(allSi, xSize);\n break;\n case SP_HCKF:\n genSiHCKF(allSi, xSize);\n break;\n default:\n cout << \"Unknown sample type !\\n\";\n break;\n }\n}\n\nvoid SCSPKF::genSiUKF(vector<VecXd> &allSi, int xSize){\n \n cout << \"UKF lambda: \" << lambda_ << endl;\n gamma_ = sqrt(xSize + lambda_);\n cout << \"UKF gamma: \" << gamma_ << endl;\n if (allSi.size() != 0)\n allSi.clear();\n // 0\n VecXd si = VecXd::Zero(xSize);\n allSi.emplace_back(si);\n // 1 ~ 2n\n MatXd I = MatXd::Identity(xSize, xSize);\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(gamma_ * I.col(i));\n }\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(-gamma_ * I.col(i));\n } \n // check dims\n if(allSi.size() != 2 * xSize + 1)\n cout << \"Error size of Si !\\n\";\n}\n\nvoid SCSPKF::genSiCKF(vector<VecXd> &allSi, int xSize){\n gamma_ = sqrt(xSize);\n if (allSi.size() != 0)\n allSi.clear();\n // 1 ~ 2n\n MatXd I = MatXd::Identity(xSize, xSize);\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(gamma_ * I.col(i));\n }\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(-gamma_ * I.col(i));\n } \n // check dims\n if(allSi.size() != 2 * xSize)\n cout << \"Error size of Si !\\n\";\n}\n\nvoid SCSPKF::genSiHCKF(vector<VecXd> &allSi, int xSize){\n gamma_ = sqrt(xSize + 2.);\n\n if(allSi.size() != 0)\n allSi.clear();\n \n // 0\n VecXd si = VecXd::Zero(xSize); \n allSi.emplace_back(si);\n // 1 ~ 2n(n-1)\n for (size_t k = 0; k < 4; k++){\n for(size_t i = 0; i < xSize - 1; i++){\n for(size_t j = i + 1; j < xSize; j++){\n VecXd tmp = VecXd::Zero(xSize);\n \n double scale0, scale1;\n getScaleHCKF(scale0, scale1, k); \n tmp(i) = scale0;\n tmp(j) = scale1;\n\n allSi.emplace_back(gamma_ * tmp); \n }\n }\n }\n // 2n(n-1) + 1 ~ 2n^2 \n MatXd I = MatXd::Identity(xSize, xSize);\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(gamma_ * I.col(i));\n }\n\n for(size_t i = 0; i < xSize; i++){\n allSi.emplace_back(-gamma_ * I.col(i));\n } \n // check dims\n if(allSi.size() != 2 * xSize * xSize + 1)\n cout << \"Error size of Si !\\n\";\n}\n\nvoid SCSPKF::getScaleHCKF(double &scale0, double &scale1, size_t k){\n double tmp = 0.5 * sqrt(2.0); //sqrt(2) / 2\n \n switch (k)\n {\n case 0:\n scale0 = tmp;\n scale1 = tmp;\n break;\n case 1:\n scale0 = tmp;\n scale1 = -tmp;\n break;\n case 2:\n scale0 = -tmp;\n scale1 = tmp;\n break;\n case 3:\n scale0 = -tmp;\n scale1 = -tmp;\n break;\n default:\n cout << \"error k!\\n\";\n break;\n }\n}\n\nvoid SCSPKF::computeWeight(vector<double> &weightMu, vector<double> &weightSigma, int xSize){\n switch (sigmaType_)\n {\n case SP_UKF:\n computeWeightUKF(weightMu, weightSigma, xSize); \n break;\n case SP_CKF:\n computeWeightCKF(weightMu, weightSigma, xSize);\n break;\n case SP_HCKF:\n computeWeightHCKF(weightMu, weightSigma, xSize);\n break;\n default:\n cout << \"Unknown sample type !\\n\";\n break;\n }\n}\n\nvoid SCSPKF::computeWeightUKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize){\n // clear container\n weightMu.clear(); weightSigma.clear();\n // ====== weight mu ====== //\n double scale = xSize + lambda_;\n double W0 = lambda_ / scale;\n double W1 = lambda_ / scale + 1 - alpha_ * alpha_ + beta_;\n double W2 = 1. / (2. * scale);\n // 0\n weightMu.emplace_back(W0);\n weightSigma.emplace_back(W1);\n // 1 ~ 2n\n auto iter = weightMu.begin() + 1;\n int cnt = 2 * xSize;\n weightMu.insert(iter, cnt, W2);\n\n iter = weightSigma.begin() + 1;\n weightSigma.insert(iter, cnt, W2);\n}\n\nvoid SCSPKF::computeWeightCKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize){\n // clear container\n weightMu.clear(); weightSigma.clear();\n // ====== weight mu ====== //\n double W = 1. / (2. * xSize) ;\n \n // 2n\n int cnt = 2 * xSize;\n auto iter = weightMu.begin();\n weightMu.insert(iter, cnt, W);\n // ====== weight sigma ====== //\n iter = weightSigma.begin();\n weightSigma.insert(iter, cnt, W); \n}\n\nvoid SCSPKF::computeWeightHCKF(vector<double> &weightMu, vector<double> &weightSigma, int xSize){\n // clear container\n weightMu.clear(); weightSigma.clear();\n // ====== weight mu ====== //\n double scale = xSize + 2.;\n double W0 = 2. / scale;\n double W1 = 1. / (scale * scale);\n double W2 = (4. - xSize) / (2. * scale * scale);\n // 0\n weightMu.emplace_back(W0);\n // 1 ~ 2n(n-1)\n auto iter = weightMu.begin() + 1;\n int cnt = 2 * xSize * (xSize - 1); // 2n(n-1)\n weightMu.insert(iter, cnt, W1);\n // 2n(n-1) + 1 ~ 2n^2\n iter = weightMu.begin() + cnt + 1;\n cnt = 2 * xSize; // 2n\n weightMu.insert(iter, cnt, W2);\n // ====== weight sigma ====== //\n weightSigma.assign(weightMu.begin(), weightMu.end());\n}\n\nvoid SCSPKF::oneStepPrediction(VecXd &U){\n if(!flagInitialized_){\n cerr << \"Please call initSCKF() first !\\n\";\n return;\n }\n if(sigmaType_ == SP_UKF && !ukfInit_){\n cerr << \"Please call setUKFParams() to initiate parameters.\\n\";\n return;\n }\n if(!siInit_){\n cerr << \"Please call initSCSPKF() to generate cubature points.\\n\";\n return;\n }\n // clear point contailer\n sPointsX_.clear();\n sPointsY_.clear();\n // generate sigma points\n genSigmaPoints(sPointsX_);\n // propagate sigma points\n propagateFcn(sPointsX_, sPointsY_, U);\n // calculate mean and covariance\n Mu_ = calcWeightedMean(sPointsY_, weightMu_);\n Sigma_ = calcWeightedCov(sPointsY_, weightMu_ , weightSigma_) + Q_;\n // cout << \"Sigma:\\n\" << Sigma_ << endl;\n // compute Jacobian with statistical linearization\n MatXd SigmaXY = calcWeightedCrossCov(sPointsX_, sPointsY_, weightMu_ , weightSigma_);\n MatXd F = SigmaXY.transpose() * Sigma_.inverse(); // F = Pyx * Pxx_inv\n // multiplicative matrix\n Phi_ = Phi_ * F;\n}\n\nvoid SCSPKF::oneStepUpdate(VecXd &Z){\n curMSize_ = Z.size();\n // switch R\n if(updateType_ != 0){\n curR_ = R_.block(0, 0, curMSize_, curMSize_);\n }\n else{\n curR_ = R_.bottomRightCorner(curMSize_, curMSize_); \n }\n // cout << \"curR: \\n\" << curR_ << endl;\n // clear container\n sPointsX_.clear();\n sPointsY_.clear();\n \n if(updateType_ == 2){\n augMu_ = VecXd::Zero(2 * xSize_);\n augSigma_ = MatXd::Zero(2 * xSize_, 2 * xSize_);\n\n augMu_.segment(0, xSize_) = lastMu_;\n augMu_.segment(xSize_, xSize_) = Mu_;\n\n augSigma_.block(0, 0, xSize_, xSize_) = lastSigma_;\n augSigma_.block(0, xSize_, xSize_, xSize_) = lastSigma_ * Phi_.transpose();\n augSigma_.block(xSize_, 0, xSize_, xSize_) = Phi_ * lastSigma_;\n augSigma_.block(xSize_, xSize_, xSize_, xSize_) = Sigma_;\n\n // cout << \"augSigma_:\\n\" << augSigma_ << endl; \n // generate sigma points\n genSigmaPoints(sPointsX_, true);\n // propagate sigma points\n updateFcn(sPointsX_, sPointsY_);\n VecXd tmpZ = calcWeightedMean(sPointsY_, weightMuAug_);\n MatXd SigmaZZ = calcWeightedCov(sPointsY_, weightMuAug_, weightSigmaAug_) + curR_;\n // cout << \"ZZ:\\n\" << SigmaZZ << endl;\n MatXd SigmaXZ = calcWeightedCrossCov(sPointsX_, sPointsY_, weightMuAug_, weightSigmaAug_);\n // cout << \"XZ:\\n\" << SigmaXZ << endl;\n // compute Kalman gain\n MatXd K = SigmaXZ * SigmaZZ.inverse();\n // cout << \"K:\\n\" << K << endl;\n residual_ = Z - tmpZ;\n // update augment state and covariance\n augMu_ += K * residual_;\n augSigma_ -= K * SigmaZZ * K.transpose();\n // margliza old state\n Mu_ = augMu_.segment(xSize_, xSize_);\n Sigma_ = augSigma_.block(xSize_, xSize_, xSize_, xSize_);\n }\n else{\n augMu_ = Mu_;\n augSigma_ = Sigma_; \n // cout << \"augSigma_:\\n\" << augSigma_ << endl; \n // generate sigma points\n genSigmaPoints(sPointsX_);\n // propagate sigma points\n updateFcn(sPointsX_, sPointsY_);\n VecXd tmpZ = calcWeightedMean(sPointsY_, weightMu_);\n MatXd SigmaZZ = calcWeightedCov(sPointsY_, weightMu_, weightSigma_) + curR_;\n // cout << \"ZZ:\\n\" << SigmaZZ << endl;\n MatXd SigmaXZ = calcWeightedCrossCov(sPointsX_, sPointsY_, weightMu_, weightSigma_);\n // cout << \"XZ:\\n\" << SigmaXZ << endl;\n // compute Kalman gain\n MatXd K = SigmaXZ * SigmaZZ.inverse();\n // cout << \"K:\\n\" << K << endl;\n residual_ = Z - tmpZ;\n // update augment state and covariance\n augMu_ += K * residual_;\n augSigma_ -= K * SigmaZZ * K.transpose();\n // margliza old state\n Mu_ = augMu_;\n Sigma_ = augSigma_;\n }\n \n // reset state\n lastMu_ = Mu_;\n lastSigma_ = Sigma_;\n Phi_ = MatXd::Identity(xSize_, xSize_);\n}\n\nvoid SCSPKF::propagateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, VecXd &U){\n if(sPointsY_.size() != 0)\n sPointsY_.clear();\n \n // ---- test 3D const demo ---- //\n for(auto it : sPointsX_){\n sPointsY_.emplace_back(it); \n }\n}\n\nvoid SCSPKF::updateFcn(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY){\n if(sPointsY_.size() != 0)\n sPointsY_.clear();\n // ---- test 3D const demo ---- //\n int hMSize = mSize_ / 2;\n VecXd curZ = VecXd::Zero(hMSize);\n VecXd lastZ = VecXd::Zero(hMSize);\n for(auto it: sPointsX_){\n // compute lastZ\n double scale = sqrt(it(0) * it(0) + it(1) * it(1));\n lastZ(0) = atan2(it(2), scale);\n lastZ(1) = atan2(it(1), it(0));\n\n scale = sqrt((it(0) - 10) * (it(0) - 10) + it(1) * it(1));\n lastZ(2) = atan2(it(2), scale);\n lastZ(3) = atan2(it(1), it(0) - 10.);\n // compute curZ\n scale = sqrt(it(3) * it(3) + it(4) * it(4));\n curZ(0) = atan2(it(5), scale);\n curZ(1) = atan2(it(4), it(3));\n\n scale = sqrt((it(3) - 10) * (it(3) - 10) + it(4) * it(4));\n curZ(2) = atan2(it(5), scale);\n curZ(3) = atan2(it(4), it(3) - 10.);\n\n \n VecXd tmpZ = VecXd::Zero(curMSize_); \n if(curMSize_ == mSize_){\n tmpZ.segment(0, hMSize) = curZ - lastZ;\n tmpZ.segment(hMSize, hMSize) = curZ;\n }\n else{\n tmpZ = curZ - lastZ;\n }\n sPointsY.emplace_back(tmpZ);\n } \n}\n//====================================================================//\n//====================================================================//\nVecXd SCSPKF::calcWeightedMean(vector<VecXd> &sPointsX, const vector<double> &weightMu){\n int size = sPointsX[0].size();\n VecXd mu = VecXd::Zero(size);\n\n for(size_t i = 0; i < sPointsX.size(); i++){\n mu += weightMu[i] * sPointsX[i];\n }\n\n return mu;\n}\n\nMatXd SCSPKF::calcWeightedCov(vector<VecXd> &sPointsX, const vector<double> &weightMu, const vector<double> &weightSigma){\n VecXd mu = calcWeightedMean(sPointsX, weightMu);\n \n int size = sPointsX[0].size();\n MatXd cov = MatXd::Zero(size, size);\n\n for(size_t i = 0; i < sPointsX.size(); i++){\n VecXd delta = sPointsX[i] - mu;\n cov += weightSigma[i] * delta * delta.transpose();\n }\n // cout << cov << endl;\n return cov;\n}\n\nMatXd SCSPKF::calcWeightedCrossCov(vector<VecXd> &sPointsX, vector<VecXd> &sPointsY, const vector<double> &weightMu, const vector<double> &weightSigma)\n{\n // VecXd muX = calcWeightedMean(weights, sPointsX);\n VecXd muX = sPointsX[0];\n VecXd muY = calcWeightedMean(sPointsY, weightMu);\n \n int sizeX = sPointsX[0].size();\n int sizeY = sPointsY[0].size();\n\n MatXd cCov = MatXd::Zero(sizeX, sizeY);\n for(size_t i = 0; i < sPointsX.size(); i++){\n VecXd deltaX = sPointsX[i] - muX;\n VecXd deltaY = sPointsY[i] - muY;\n cCov += weightSigma[i] * deltaX * deltaY.transpose();\n }\n\n return cCov;\n}\n\nvoid SCSPKF::printSi(vector<VecXd> allSi, string name, int maxPerRow){\n cout << name << \": \" << endl;\n \n MatXd outSi = MatXd::Ones(allSi[0].size(), maxPerRow);\n int cnt = 0;\n int siSize = allSi.size();\n cout << right << fixed << setprecision(3);\n for(size_t i = 0; i < siSize; i++){\n outSi.col(cnt) = allSi[i];\n cnt++;\n\n if(cnt == maxPerRow){\n cout << outSi << \"\\n\\n\";\n outSi = MatXd::Ones(allSi[0].size(), maxPerRow);\n cnt = 0;\n } \n }\n cout << outSi << \"\\n\\n\";\n}\n\nvoid SCSPKF::printWeight(vector<double> allWeight, string name, int maxPerRow){\n cout << name << \": \" << endl;\n \n int cnt = 0;\n int wSize = allWeight.size();\n cout << right << fixed << setprecision(3);\n for(size_t i = 0; i < wSize; i++){\n cout << allWeight[i] << \" \";\n cnt++;\n if(cnt == maxPerRow){\n cout << endl;\n cnt = 0;\n }\n }\n cout << \"\\n\\n\";\n}\n\n}// namespace MyFusion"
},
{
"alpha_fraction": 0.6431095600128174,
"alphanum_fraction": 0.6554770469665527,
"avg_line_length": 16.71875,
"blob_id": "14279c4ef079cf649ea4c4fe08cf397903ff0d07",
"content_id": "0f8b4a7124d15ee1a637ae434a172a1c6dafd754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 566,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 32,
"path": "/include/backend/cnsUKF.h",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef CNS_UKF_H_\n#define CNS_UKF_H_\n#include \"backend/spkf.h\"\n\nnamespace MyFusion{\n\nclass CnsUKF : public SPKF{\npublic:\n CnsUKF();\n CnsUKF(double alpha, double beta, double kappa);\n ~CnsUKF(){}\n\n void genSigmaPoints(vector<VecXd> &points);\n\n void computeWeight();\n\n void propagateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY);\n\n void updateFcn(vector<VecXd> &pointsX, vector<VecXd> &pointsY);\n\nprotected:\n double alpha_ = 0.001;\n double beta_ = 2.0;\n double kappa_ = 0.;\n double lambda_;\n\n\n}; // class\n\n} // namespace\n\n#endif"
},
{
"alpha_fraction": 0.5804196000099182,
"alphanum_fraction": 0.584149181842804,
"avg_line_length": 32.515625,
"blob_id": "b4194209f8c6df51a7a929382065b6688bc982c1",
"content_id": "24b2d99d8498926b1cedd532e0f6d970fd0bde79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2145,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 64,
"path": "/src/backend/backParam.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"backend/backParam.h\"\n\nnamespace MyFusion\n{\ndouble IMU_STEP;\ndouble INIT_ERR_P, INIT_ERR_V;\nMatXd INIT_SQRT_P, INIT_SQRT_Q, INIT_SQRT_R;\nstring IMU_FILE, CNS_FILE, VIRNS_FILE, CMNS_FILE, ALT_FILE;\nint SIGMA_TYPE;\ndouble UKF_A, UKF_B, UKF_K;\n\nvoid loadBackParam(string configFile){\n cv::FileStorage fsBackendParams(configFile, cv::FileStorage::READ);\n if(!fsBackendParams.isOpened()){\n cerr << \"ERROR: failed to open backend config file !\" << endl;\n return;\n }\n // data files\n string dataPath;\n fsBackendParams[\"dataPath\"] >> dataPath;\n IMU_FILE = dataPath + \"imuData.csv\";\n CNS_FILE = dataPath + \"cnsData.csv\";\n VIRNS_FILE = dataPath + \"virnsData.csv\";\n CMNS_FILE = dataPath + \"cmnsData.csv\";\n ALT_FILE = dataPath + \"altData.csv\";\n // IMU Step\n fsBackendParams[\"imuStep\"] >> IMU_STEP;\n // Sigma type\n fsBackendParams[\"sigmaType\"] >> SIGMA_TYPE;\n // UKF parameters\n fsBackendParams[\"alpha\"] >> UKF_A;\n fsBackendParams[\"beta\"] >> UKF_B;\n fsBackendParams[\"kappa\"] >> UKF_K;\n\n // initial position and velocity error\n fsBackendParams[\"initErrP\"] >> INIT_ERR_P;\n fsBackendParams[\"initErrV\"] >> INIT_ERR_V;\n // initial P, Q, R\n cv::Mat tmp;\n fsBackendParams[\"initSqrtP\"] >> tmp;\n cv::cv2eigen(tmp, INIT_SQRT_P);\n \n fsBackendParams[\"initSqrtQ\"] >> tmp;\n cv::cv2eigen(tmp, INIT_SQRT_Q);\n \n fsBackendParams[\"initSqrtR\"] >> tmp;\n cv::cv2eigen(tmp, INIT_SQRT_R);\n\n cout << \"[0] Data file: \"\n << \"\\n[0] IMU_FILE: \" << IMU_FILE\n << \"\\n[0] CNS_FILE: \" << CNS_FILE\n << \"\\n[0] VIRNS_FILE: \" << VIRNS_FILE\n << \"\\n[0] CMNS_FILE: \" << CMNS_FILE;\n \n // cout << \"[B] Backend Parameters: \"\n // << \"\\nIMU_STEP: \" << IMU_STEP\n // << \"\\nINIT_ERR_P: \" << INIT_ERR_P \n // << \"\\nINIT_ERR_V: \" << INIT_ERR_V\n // << \"\\nINIT_P diag:\\n \" << setiosflags(ios::right) << INIT_SQRT_P.diagonal().transpose() \n // << \"\\nINIT_Q diag:\\n \" << INIT_SQRT_Q.diagonal().transpose() \n // << \"\\nINIT_R diag:\\n \" << INIT_SQRT_R.diagonal().transpose() << endl; \n}\n \n} // namespace MyFusion\n"
},
{
"alpha_fraction": 0.6457564830780029,
"alphanum_fraction": 0.661746621131897,
"avg_line_length": 31.559999465942383,
"blob_id": "ea9345fd5ce9999f6fa73dbff2304939ffb626e4",
"content_id": "32de9f9a56ee41009fa51798d6bc6d4d110b8c88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 813,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 25,
"path": "/src/simulator/sensors/cns.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensors/cns.h\"\n\nnamespace MyFusion{\n\nCnsData CNS::getMeasurements(ImuMotionData currMotion){\n // generate standard white noise\n std::random_device rd; // generate seed for random engine \n std::default_random_engine rg(rd()); // create random eigine with seed rd();\n std::normal_distribution<double> noise(0.0, 1.0);\n\n Eigen::Quaterniond dq(1., 0.5 * sigma_ * noise(rg), 0.5 * sigma_ * noise(rg), 0.5 * sigma_ * noise(rg));\n dq.normalize();\n\n CnsData tmp;\n tmp.timeStamp_ = currMotion.time_stamp_; \n tmp.qnb_ = (currMotion.qnb_ * dq).normalized(); \n\n // convert to geo and compute euler angles\n Eigen::Matrix3d Cgb = AttUtility::getCge(currMotion.tnb_) * tmp.qnb_.toRotationMatrix();\n tmp.eulerAngle_ = AttUtility::R2Euler(Cgb);\n\n return tmp;\n}\n\n}"
},
{
"alpha_fraction": 0.5054561495780945,
"alphanum_fraction": 0.5176778435707092,
"avg_line_length": 28.006328582763672,
"blob_id": "6ff7561291f0954e1a525539004722244f80bcab",
"content_id": "c6c3e694ffbf4fa89540c48f78d387ef7efce74c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4582,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 158,
"path": "/include/simulator/sensorNoise.hpp",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#ifndef SENSOR_NOISE_H_\n#define SENSOR_NOISE_H_\n#include \"commonHeaders.h\"\n\nusing namespace std;\n\nnamespace MyFusion\n{\n\nenum GlintType {\n GAUSSIAN,\n LAPLACIAN,\n STUDENTT\n};\n\ntemplate <typename _RealType = double>\nclass LaplacianDistribution{\npublic:\n // constructor with default (0., 1.)\n LaplacianDistribution(_RealType mu = _RealType(0), _RealType b = _RealType(1)):_mu(mu), _b(b){};\n \n template <typename _RandomGenerator>\n _RealType operator()(_RandomGenerator &gen){\n uniform_real_distribution<double> rng(0.0, 1.0);\n\n double cdf = rng(gen);\n double x;\n if(cdf <= 0.5){\n x = _mu + _b * log(2 * cdf); \n }\n else{\n x = _mu - _b * log(2 * (1 - cdf)); \n }\n return _RealType(x);\n }\n\n _RealType _mu, _b;\n};\n\n\nclass SensorNoise{\npublic:\n EIGEN_MAKE_ALIGNED_OPERATOR_NEW;\n /**\n * @brief \n * \n * @param value true vector value \n * @param sigma sigma of the noise \n */\n static void addGaussianNoise(VecXd &value, double sigma){\n // set random distribution\n random_device rd;\n default_random_engine rg(rd());\n normal_distribution<double> stdGau(0., 1.); // standard gaissuain distribution \n\n for (size_t i = 0; i < value.size(); i++){\n // TODO : add noise\n value(i) += sigma * stdGau(rg);\n }\n }\n\n /**\n * @brief \n * \n * @param value true vector value \n * @param sigma1 sigma of the main gaussian distribution\n * @param sigma2 sigma of the glint gaussian/laplacian distribution\n * @param gProbability glint probability\n */\n static int addGlintNoise(VecXd &value, double sigma1, double sigma2, GlintType type=GAUSSIAN, double gProbability=0.1){\n // set random distribution\n random_device rd;\n default_random_engine rg(rd());\n \n uniform_real_distribution<double> stdUni(0.,1.); // standatd uniform distribution\n normal_distribution<double> stdGau(0., 1.); // standard gaussian distribution \n LaplacianDistribution<double> stdLap(0., 1.); // standard laplacian distribution\n\n int glintIdx = stdUni(rg) <= gProbability ? 1 : 0;\n \n if(glintIdx){\n // glint\n switch (type)\n {\n case GAUSSIAN:\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma2 * stdGau(rg);\n }\n break;\n case LAPLACIAN:\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma2 * stdLap(rg);\n }\n break;\n }\n } \n else{\n //unglint\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma1 * stdGau(rg);\n }\n } \n // return current glint index\n return (glintIdx);\n }\n \n /**\n * @brief \n * \n * @param value true vector value \n * @param sigma1 sigma of the main gaussian distribution\n * @param sigma2 sigma of the glint gaussian/laplacian distribution\n * @param gProbability glint probability\n */\n static int addGlintNoiseAll(VecXd &value, double sigma1, double sigma2, GlintType type=GAUSSIAN, double gProbability=0.1){\n // set random distribution\n random_device rd;\n default_random_engine rg(rd());\n \n uniform_real_distribution<double> stdUni(0.,1.); // standatd uniform distribution\n normal_distribution<double> stdGau(0., 1.); // standard gaussian distribution \n LaplacianDistribution<double> stdLap(0., 1.); // standard laplacian distribution\n\n int glintIdx = stdUni(rg) <= gProbability ? 1 : 0;\n \n double noise = stdGau(rg);\n if(glintIdx){\n // glint\n switch (type)\n {\n case GAUSSIAN:\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma2 * noise;\n }\n break;\n case LAPLACIAN:\n noise = stdLap(rg);\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma2 * noise;\n }\n break;\n }\n } \n else{\n //unglint\n for (size_t i = 0; i < value.size(); i++){\n value(i) += sigma1 * noise;\n }\n } \n // return current glint index\n return (glintIdx);\n }\n};\n\n\n} // namespace MyFusion\n\n#endif"
},
{
"alpha_fraction": 0.47849637269973755,
"alphanum_fraction": 0.4886014461517334,
"avg_line_length": 30.39847755432129,
"blob_id": "eeccbba7f00bf1ceeaf7f4ff4f8bab08c3d964c1",
"content_id": "5e0a1693f681684b978031d6a31f44532a90c0bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 12520,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 394,
"path": "/src/utilities/io_function.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"utilities/io_function.h\"\n\nnamespace MyFusion{\n\nint readImuParam(string filename, ImuParam ¶m){\n cv::FileStorage fsParams(filename, cv::FileStorage::READ);\n\n if(!fsParams.isOpened()){\n cout << \"ERROR: failed to open config file. Please reset parameters!\\n\";\n\n }\n else{\n param.acc_b_ = fsParams[\"acc_b\"];\n param.gyr_b_ = fsParams[\"gyr_b\"];\n param.acc_n_ = fsParams[\"acc_n\"];\n param.gyr_n_ = fsParams[\"gyr_n\"];\n param.acc_w_ = fsParams[\"acc_w\"];\n param.gyr_w_ = fsParams[\"gyr_w\"];\n\n param.time_step_ = fsParams[\"imu_step\"];\n\n }\n}\n\nvoid readImuMotionData(string filename, vector<ImuMotionData> &imu_data){\n // string datafile = datapath + \"data_imu.csv\";\n FILE *fp = fopen((filename).c_str(), \"r\");\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n // 跳过文件头\n char header[1024];\n fgets(header, 1024, fp);\n // 读取数据到相关容器中\n imu_data.clear();\n printf(\"[1] Reading trajectory data...\\n\");\n while(!feof(fp)){\n double time_stamp(0);\n double px(0.), py(0.), pz(0.);\n double qw(0.), qx(0.), qy(0.), qz(0.);\n double roll(0.), pitch(0.), yaw(0.); \n double vx(0.), vy(0.), vz(0.);\n double wx(0.), wy(0.), wz(0.), ax(0.), ay(0.), az(0.);\n // int ref = fscanf(fp, \"%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le,%le\",\n int ref = fscanf(fp, \"%lf,%le,%lf,%le,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%le,%le,%le,%le,%le,%le\",\n &time_stamp, &px, &py, &pz,\n &qw, &qx, &qy, &qz,\n &pitch, &yaw, &roll,\n &vx, &vy, &vz,\n &wx, &wy, &wz,\n &ax, &ay, &az);\n if(ref == -1){\n break;\n } // avoid read last line twicea\n\n ImuMotionData tmp;\n tmp.time_stamp_ = time_stamp;\n tmp.tnb_ = Vec3d(px, py, pz);\n tmp.vel_ = Vec3d(vx, vy, vz);\n tmp.qnb_ = Qd(qw, qx, qy, qz);\n tmp.eulerAngles_ = Vec3d(pitch, yaw, roll);\n tmp.acc_ = Vec3d(ax, ay, az);\n tmp.gyr_ = Vec3d(wx, wy, wz);\n\n imu_data.emplace_back(tmp);\n }\n cout << \"[1] Totally read \" << imu_data.size() << \" traj data.\\n\";\n fclose(fp); \n}\n\nvoid writeImuMotionData(string filename, vector<ImuMotionData> &imu_data){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], p_RS_R_x[m], p_RS_R_y[m], p_RS_R_z[m], q_RS_w[], q_RS_x[], q_RS_y[], q_RS_z[], Pitch[deg], Yaw[deg], Roll[deg],\"); \n fprintf(fp, \"v_R_x[m/s], v_R_y[m/s], v_R_z[m/s], gyr_S_x[rad/s], gyr_S_y[rad/s], gyr_S_z[rad/s], acc_S_x[m/s^2], acc_S_y[m/s^2], acc_S_z[m/s^2]\\n\"); \n\n for (auto it:imu_data){\n fprintf(fp, \"%lf,%le,%lf,%le,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%le,%le,%le,%le,%le,%le\\n\",\n // fprintf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\", \n // fprintf(fp, \"%le %le %le %le %le %le %le %le %le %le %le %le %le %le %le %le %le %le %le %le\\n\", \n it.time_stamp_, \n it.tnb_.x(), it.tnb_.y(), it.tnb_.z(),\n it.qnb_.w(), it.qnb_.x(), it.qnb_.y(), it.qnb_.z(),\n it.eulerAngles_.x(), it.eulerAngles_.y(), it.eulerAngles_.z(),\n it.vel_.x(), it.vel_.y(), it.vel_.z(),\n it.gyr_.x(), it.gyr_.y(), it.gyr_.z(),\n it.acc_.x(), it.acc_.y(), it.acc_.z()); \n }\n}\n\nvoid writeCnsData(string filename, vector<CnsData> &cnsData){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s],q_RS_w[],q_RS_x[],q_RS_y[],q_RS_z[],Pitch[deg],Yaw[deg],Roll[deg]\\n\"); \n \n for (auto it:cnsData){\n fprintf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\", \n it.timeStamp_, \n it.qnb_.w(), it.qnb_.x(), it.qnb_.y(), it.qnb_.z(),\n it.eulerAngle_.x(), it.eulerAngle_.y(), it.eulerAngle_.z()); \n }\n}\n\nvoid writeVirnsData(string filename, vector<VirnsData> &virnsData){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], dp_x[m], dp_x[m], dp_z[m], p_x[m], p_y[m], p_z[m]\\n\"); \n \n for (auto it:virnsData){\n fprintf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\", \n it.timeStamp_, \n it.dPos_.x(), it.dPos_.y(), it.dPos_.z(),\n it.pos_.x(), it.pos_.y(), it.pos_.z()); \n }\n}\n\nvoid writeCmnsData(string filename, vector<CmnsData> &cmnsData){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], lat[rad], lon[rad]\\n\"); \n \n for (auto it:cmnsData){\n fprintf(fp, \"%lf,%le,%le\\n\", \n it.timeStamp_, \n it.pos_.x(), it.pos_.y()); \n }\n}\n\nvoid writeAltData(string filename, vector<AltData> &altData){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], range[m]\\n\"); \n \n for (auto it:altData){\n fprintf(fp, \"%lf,%lf\\n\", \n it.timeStamp_, it.range_); \n }\n}\n\n\nvoid writePos(string filename, vector<ImuMotionData> &imu_data){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"# time_stamp[s], p_N[m], p_U[m], p_E[m], acc_N[m/s^2], acc_N[m/s^2], acc_N[m/s^2]\\n\"); \n\n for (auto it:imu_data){\n fprintf(fp, \"%e,%e,%e,%e,%e,%e,%e\\n\", it.time_stamp_, \n it.pos_.x(), it.pos_.y(), it.pos_.z(),\n it.acc_n_.x(), it.acc_n_.y(), it.acc_n_.z()); \n }\n}\n\nvoid writeAllanData(string filename, vector<ImuMotionData> &imu_data){\n FILE *fp;\n struct stat buffer;\n if(stat(filename.c_str(), &buffer) == 0)\n system((\"rm \" + filename).c_str()); \n fp = fopen(filename.c_str(), \"w+\");\n\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << filename << endl;\n return;\n }\n\n fprintf(fp, \"#time_stamp[s],acc_x[m/s^2],acc_y[m/s^2],acc_z[m/s^2],gyr_x[rad/s],gyr_y[rad/s],gyr_z[rad/s],\\n\"); \n\n for (auto it:imu_data){\n fprintf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\", \n it.time_stamp_, \n it.acc_.x(), it.acc_.y(), it.acc_.z(),\n it.gyr_.x(), it.gyr_.y(), it.gyr_.z()); \n }\n\n}\n\nvoid readCnsData(string fileName, vector<CnsData> &cnsData){\n // string datafile = datapath + \"data_imu.csv\";\n FILE *fp = fopen((fileName).c_str(), \"r\");\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n // 跳过文件头\n char header[1024];\n fgets(header, 1024, fp);\n // 读取数据到相关容器中\n cnsData.clear();\n printf(\"[1] Reading CNS data...\\n\");\n while(!feof(fp)){\n double time_stamp(0);\n double qw(0.), qx(0.), qy(0.), qz(0.);\n double roll(0.), pitch(0.), yaw(0.); \n int ref = fscanf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\",\n &time_stamp, \n &qw, &qx, &qy, &qz,\n &pitch, &yaw, &roll);\n if(ref == -1){\n break;\n } // avoid read last line twicea\n\n CnsData tmp;\n tmp.timeStamp_ = time_stamp;\n tmp.qnb_ = Qd(qw, qx, qy, qz);\n tmp.eulerAngle_ = Vec3d(pitch, yaw, roll);\n \n cnsData.emplace_back(tmp);\n }\n cout << \"[1] Totally read \" << cnsData.size() << \" CNS data.\\n\";\n fclose(fp); \n}\n\nvoid readVirnsData(string fileName, vector<VirnsData> &virnsData){\n // string datafile = datapath + \"data_imu.csv\";\n FILE *fp = fopen((fileName).c_str(), \"r\");\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n // 跳过文件头\n char header[1024];\n fgets(header, 1024, fp);\n // 读取数据到相关容器中\n virnsData.clear();\n printf(\"[1] Reading VIRNS data...\\n\");\n while(!feof(fp)){\n double time_stamp(0);\n double dPx(0.), dPy(0.), dPz(0.);\n double px(0.), py(0.), pz(0.); \n int ref = fscanf(fp, \"%lf,%lf,%lf,%lf,%lf,%lf,%lf\\n\",\n &time_stamp, \n &dPx, &dPy, &dPz,\n &px, &py, &pz);\n if(ref == -1){\n break;\n } // avoid read last line twicea\n\n VirnsData tmp;\n tmp.timeStamp_ = time_stamp;\n tmp.dPos_ = Vec3d(dPx, dPy, dPz);\n tmp.pos_ = Vec3d(px, py, pz);\n \n virnsData.emplace_back(tmp);\n }\n cout << \"[1] Totally read \" << virnsData.size() << \" VIRNS data.\\n\";\n fclose(fp); \n}\n\nvoid readCmnsData(string fileName, vector<CmnsData> &cmnsData){\n // string datafile = datapath + \"data_imu.csv\";\n FILE *fp = fopen((fileName).c_str(), \"r\");\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n // 跳过文件头\n char header[1024];\n fgets(header, 1024, fp);\n // 读取数据到相关容器中\n cmnsData.clear();\n printf(\"[1] Reading CMNS data...\\n\");\n while(!feof(fp)){\n double time_stamp(0);\n double lat(0.), lon(0.); \n int ref = fscanf(fp, \"%lf,%le,%le\\n\",\n &time_stamp, &lat, &lon);\n if(ref == -1){\n break;\n } // avoid read last line twicea\n\n CmnsData tmp;\n tmp.timeStamp_ = time_stamp;\n tmp.pos_ = Vec2d(lat, lon);\n\n cmnsData.emplace_back(tmp); \n }\n cout << \"[1] Totally read \" << cmnsData.size() << \" CMNS data.\\n\";\n fclose(fp); \n}\n\n\nvoid readAltData(string fileName, vector<AltData> &altData){\n // string datafile = datapath + \"data_imu.csv\";\n FILE *fp = fopen((fileName).c_str(), \"r\");\n if (fp == nullptr){\n cerr << \"ERROR: failed to open file: \" << fileName << endl;\n return;\n }\n // 跳过文件头\n char header[1024];\n fgets(header, 1024, fp);\n // 读取数据到相关容器中\n altData.clear();\n printf(\"[1] Reading CMNS data...\\n\");\n while(!feof(fp)){\n double time_stamp(0);\n double range(0.); \n int ref = fscanf(fp, \"%lf,%lf\\n\",\n &time_stamp, &range);\n if(ref == -1){\n break;\n } // avoid read last line twicea\n\n AltData tmp;\n tmp.timeStamp_ = time_stamp;\n tmp.range_ = range;\n\n altData.emplace_back(tmp); \n }\n cout << \"[1] Totally read \" << altData.size() << \" Altimeter data.\\n\";\n fclose(fp); \n}\n\n/**\n * @brief print percentage of progress\n * \n * @param name \n * @param per \n */\nvoid printPer(string name, float per){\n const char symbol[4] = {'|','/','-','\\\\'};\n printf(\"[#][%s][%.2f%%][%c]\\r\", name.c_str(), per, symbol[(int)per%4]);\n fflush(stdout);\n}\n/**\n * @brief print percentage of progress\n * \n * @param name \n * @param per \n */\nvoid printPer(string name, int per){\n const char symbol[4] = {'|','/','-','\\\\'};\n printf(\"[#][%s][%d%%][%c]\\r\", name.c_str(), per, symbol[(int)per%4]);\n fflush(stdout);\n}\n\n} // namespace MyFusion\n\n\n// #endif"
},
{
"alpha_fraction": 0.6434155106544495,
"alphanum_fraction": 0.6470234394073486,
"avg_line_length": 35.173912048339844,
"blob_id": "cca8cb70806f76049ef7f4e1a1a442d2386d6977",
"content_id": "1ee10e523699ee0160b958abbee80cd7e9641eb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1723,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 46,
"path": "/examples/simSensors.cc",
"repo_name": "zhunk/hrns_landing",
"src_encoding": "UTF-8",
"text": "#include \"simulator/sensorSimulator.h\"\n#include \"utilities/io_function.h\"\n\nusing namespace std;\nusing namespace MyFusion;\n\nint main(int argc, char** argv){\n printf(\"\\n#################### Sensor Simulation Start ####################\\n\");\n float acc, period;\n \n SensorSimulator mySimulator(\"../config/simulator/sensorConfig.yaml\");\n if(argc == 3){\n acc = atof(argv[1]);\n period = atof(argv[2]) / 10.;\n mySimulator.sensorParams_.virns_sigma_ = acc;\n mySimulator.sensorParams_.alt_step_ = period;\n mySimulator.sensorParams_.cmns_step_ = period;\n }\n // 读取轨迹数据\n vector<ImuMotionData> trajData;\n readImuMotionData(\"../data/stdTraj/caGeo.csv\", trajData);\n // // 生成IMU数据\n vector<ImuMotionData> imuData;\n mySimulator.simIMU(trajData, imuData);\n writeImuMotionData(\"../data/sensorSimData/imuData.csv\", imuData);\n writePos(\"../data/sensorSimData/posNED.csv\", imuData);\n // 生成CNS数据\n // vector<CnsData> cnsData;\n // mySimulator.simCNS(trajData, cnsData);\n // writeCnsData(\"../data/sensorSimData/cnsData.csv\", cnsData);\n // 生成相对量测数据\n vector<VirnsData> virnsData;\n mySimulator.simVIRNS(trajData, virnsData);\n writeVirnsData(\"../data/sensorSimData/virnsData.csv\", virnsData);\n // // 生成绝对量测数据\n vector<CmnsData> cmnsData;\n mySimulator.simCMNS(trajData, cmnsData);\n writeCmnsData(\"../data/sensorSimData/cmnsData.csv\", cmnsData);\n\n vector<AltData> altData;\n mySimulator.simAltimeter(trajData, altData);\n writeAltData(\"../data/sensorSimData/altData.csv\", altData);\n printf(\"#################### Sensor Simulation Done ####################\\n\");\n\n return 0;\n}"
}
] | 63 |
goblinintree/Yola-CSRF
|
https://github.com/goblinintree/Yola-CSRF
|
54f86189f40c856efe4afe2e1c7037d8b384d558
|
56461e895fe5092ef80541871dd3f8fb52b6cbd9
|
1f0c76de2245a44f304abc1f677731c634babc65
|
refs/heads/master
| 2021-08-15T00:40:59.090605 | 2017-11-17T03:05:09 | 2017-11-17T03:05:09 | 110,790,644 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7600595951080322,
"alphanum_fraction": 0.7630402445793152,
"avg_line_length": 28,
"blob_id": "a4d7f68813647d89789bc8351afeffd051c0a0ac",
"content_id": "6fd8eb14b9ea1687d13499ac24bab3c9803fc5e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 671,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 23,
"path": "/check_csrf.py",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\nimport requests\nimport sys\nimport sys\nreload(sys)\n# print sys.geindefaultencoding()\nsys.setdefaultencoding(\"UTF-8\")\n# from tools import tools,FileRequest,srcrequest,doFile\nfrom tools import tools,srcrequest\n\nfileRequest = tools.get_fileRequest_from_file(\"./post_form.log\")\n# print fileRequest.request_parameters\n\ntmp_srcrequest = tools.get_srcrequest_from_fileRequest(fileRequest)\n# print tmp_srcrequest.get_url()\n# print tmp_srcrequest.get_post_data_str()\n\n# tmp_srcrequest.get_header()\n# tmp_srcrequest.get_post_data_str()\ntmp_srcrequest.do_post_request()\n\n# print tools.get_patam_json_from_dict({})\nprint tmp_srcrequest.out_poc_csrf_html()\n\n\n\n\n"
},
{
"alpha_fraction": 0.49883338809013367,
"alphanum_fraction": 0.5046665072441101,
"avg_line_length": 52.96666717529297,
"blob_id": "118019ba341ac43734061ffc60e35808cf5958f1",
"content_id": "f09aad2966d2c2053ae283fd86a32c2139333e0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14968,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 270,
"path": "/tools/doFile.py",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": " # -*- coding: UTF-8 -*- \n\nimport re\nimport os\nimport urllib\nfrom FileRequest import FileRequest\n\n\ndef getFileRequest(file_path):\n file_request_header_dict = {}\n file_request_url = \"\"\n file_request_url_parameters = {}\n file_request_parameters = {}\n \"\"\"包装后的request_parameters可以经过urllib.unquote解码的,但是暂时未解码 \"\"\"\n\n file_request_date_posts = \"\"\n file_request_date_gets = \"\"\n file_request_url_method = \"GET\"\n file_request_content_type_boundary = \"\"\n \"\"\"\n file_request_content_type post才有,这个决定post data模块的类型。主要有两种类型:\n Content-Type: application/x-www-form-urlencoded\n Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryLY96mLehbhhAYyIj\n \"\"\"\n\n params_key = \"\"\n params_value = \"\"\n new_param_flag = 0\n\n file = open(file_path)\n while True:\n none_line_flag = 0\n \"\"\"none_line_flag 0表示头部部分,1表示当前行为请求头与post数据体之间的空行,2表示数据体\"\"\"\n lines = file.readlines(100)\n \n if not lines :\n break\n \n for line in lines:\n strip_line = line.strip()\n\n if ((not strip_line) and (0 == none_line_flag)):\n none_line_flag = 1\n continue\n pass\n if ((strip_line) and (1 == none_line_flag)):\n none_line_flag = 2\n pass\n \n if 0 == none_line_flag:\n \"\"\"0 表示现在编列时未遇到空行\"\"\"\n matchObj_URL = re.match(r\".*(\\sHTTP/).*\", strip_line, re.M|re.I) \n if matchObj_URL != None:\n matchObj_URL_method = None\n matchObj_URL_method = re.match(r\"(^GET)\\s\", strip_line, re.M|re.I) \n if matchObj_URL_method != None:\n # print \"URL_method: \" + matchObj_URL_method.group(1)\n file_request_url_method = matchObj_URL_method.group(1)\n file_request_header_dict[\"URL_method\"] = matchObj_URL_method.group(1)\n pass\n matchObj_URL_value = re.match(r\"^GET\\s(.*)\\sHTTP\", strip_line, re.M|re.I) \n if matchObj_URL_value != None:\n # print \"URL_value: \" + matchObj_URL_value.group(1)\n file_request_header_dict[\"URL_value\"] = matchObj_URL_value.group(1)\n url_data = file_request_header_dict[\"URL_value\"] \n # 元组一个元素就是 ?号前面的URL部分\n # 元组第二个元素就是 ?号后面的参数部分\n file_request_url = (url_data.partition(\"?\"))[0]\n file_request_date_gets = (url_data.partition(\"?\"))[2]\n tmp_params_str = ((url_data.partition(\"?\"))[2]).partition(\"#\")[0]\n tmp_params_list = str(tmp_params_str).split(\"&\")\n for tmp_param in tmp_params_list:\n # print tmp_param\n if tmp_param.strip():\n file_request_url_parameters[(tmp_param.strip().partition(\"=\"))[0]] = (tmp_param.strip().partition(\"=\"))[2]\n pass\n pass\n pass\n\n matchObj_URL_method = re.match(r\"(^POST)\\s\", strip_line, re.M|re.I) \n if matchObj_URL_method != None:\n # print \"URL_method: \" + matchObj_URL_method.group(1)\n file_request_header_dict[\"URL_method\"] = matchObj_URL_method.group(1)\n file_request_url_method = matchObj_URL_method.group(1)\n pass\n matchObj_URL_value = re.match(r\"^POST\\s(.*)\\sHTTP\", strip_line, re.M|re.I) \n if matchObj_URL_value != None:\n # print \"URL_value: \" + matchObj_URL_value.group(1)\n file_request_header_dict[\"URL_value\"] = matchObj_URL_value.group(1)\n url_data = file_request_header_dict[\"URL_value\"] \n # 元组一个元素就是 ?号前面的URL部分\n # 元组第二个元素就是 ?号后面的参数部分\n file_request_url = (url_data.partition(\"?\"))[0]\n file_request_date_gets = (url_data.partition(\"?\"))[2]\n tmp_params_str = ((url_data.partition(\"?\"))[2]).partition(\"#\")[0]\n\n tmp_params_list = str(tmp_params_str).split(\"&\")\n\n # print tmp_params_list\n for tmp_param in tmp_params_list:\n # print tmp_param\n if tmp_param.strip():\n file_request_url_parameters[(tmp_param.strip().partition(\"=\"))[0]] = (tmp_param.strip().partition(\"=\"))[2]\n pass\n pass\n pass\n\n matchObj_Host = re.match(r\"(^Host):\\s\", strip_line, re.M|re.I) \n if matchObj_Host != None:\n matchObj_Host_value = re.match(r\"^Host:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Host_value: \" + matchObj_Host_value.group(1)\n file_request_header_dict[\"Host\"] = matchObj_Host_value.group(1)\n pass\n\n matchObj_Cache_Control = re.match(r\"(^Cache-Control:)\\s\", strip_line, re.M|re.I) \n if matchObj_Cache_Control != None:\n matchObj_Cache_Control_value = re.match(r\"^Cache-Control:\\s(.*)$\", line, re.M|re.I) \n # print \"Cache_Control_value: \" + matchObj_Cache_Control_value.group(1)\n file_request_header_dict[\"Cache-Control\"] = matchObj_Cache_Control_value.group(1)\n pass\n\n matchObj_Upgrade = re.match(r\"(^Upgrade-Insecure-Requests:)\\s\", strip_line, re.M|re.I) \n if matchObj_Upgrade != None:\n matchObj_Upgrade_value = re.match(r\"^Upgrade-Insecure-Requests:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Upgrade_value: \" + matchObj_Upgrade_value.group(1)\n file_request_header_dict[\"Upgrade-Insecure-Requests\"] = matchObj_Upgrade_value.group(1)\n pass\n\n matchObj_Agent = re.match(r\"(^User-Agent:)\\s\", strip_line, re.M|re.I) \n if matchObj_Agent != None:\n matchObj_Agent_value = re.match(r\"^User-Agent:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Agent_value: \" + matchObj_Agent_value.group(1)\n file_request_header_dict[\"User-Agent\"] = matchObj_Agent_value.group(1)\n pass\n\n matchObj_Accept = re.match(r\"(^Accept:)\\s\", strip_line, re.M|re.I) \n if matchObj_Accept != None:\n matchObj_Accept_value = re.match(r\"^Accept:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Accept_value: \" + matchObj_Accept_value.group(1)\n file_request_header_dict[\"Accept\"] = matchObj_Accept_value.group(1)\n pass\n\n matchObj_Accept_Encoding = re.match(r\"(^Accept-Encoding:)\\s\", strip_line, re.M|re.I) \n if matchObj_Accept_Encoding != None:\n matchObj_Accept_Encoding_value = re.match(r\"^Accept-Encoding:\\s(.*)$\", line, re.M|re.I) \n # print \"Accept-Encoding_value: \" + matchObj_Accept_Encoding_value.group(1)\n file_request_header_dict[\"Accept-Encoding\"] = matchObj_Accept_Encoding_value.group(1)\n pass\n\n matchObj_Accept_Language = re.match(r\"(^Accept-Language:)\\s\", strip_line, re.M|re.I) \n if matchObj_Accept_Language != None:\n matchObj_Accept_Language_value = re.match(r\"^Accept-Language:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Accept-Language_value: \" + matchObj_Accept_Language_value.group(1)\n file_request_header_dict[\"Accept-Language\"] = matchObj_Accept_Language_value.group(1)\n pass\n\n matchObj_Cookie = re.match(r\"(^Cookie:)\\s\", strip_line, re.M|re.I) \n if matchObj_Cookie != None:\n matchObj_Cookie_value = re.match(r\"^Cookie:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Cookie_value: \" + matchObj_Cookie_value.group(1)\n file_request_header_dict[\"Cookie\"] = matchObj_Cookie_value.group(1)\n pass\n\n matchObj_Connection = re.match(r\"(^Connection:)\\s\", strip_line, re.M|re.I) \n if matchObj_Connection != None:\n matchObj_Connection_value = re.match(r\"^Connection:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Connection_value: \" + matchObj_Connection_value.group(1)\n file_request_header_dict[\"Connection\"] = matchObj_Connection_value.group(1)\n pass\n\n matchObj_Proxy_Connection = re.match(r\"(^Proxy-Connection:)\\s\", strip_line, re.M|re.I) \n if matchObj_Proxy_Connection != None:\n matchObj_Proxy_Connection_value = re.match(r\"^Proxy-Connection:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Proxy-Connection_value: \" + matchObj_Proxy_Connection_value.group(1)\n file_request_header_dict[\"Proxy-Connection\"] = matchObj_Proxy_Connection_value.group(1)\n pass\n pass\n\n matchObj_Referer = re.match(r\"(^Referer:)\\s\", strip_line, re.M|re.I) \n if matchObj_Referer != None:\n matchObj_Referer_value = re.match(r\"^Referer:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Referer_value: \" + matchObj_Referer_value.group(1)\n file_request_header_dict[\"Referer\"] = matchObj_Referer_value.group(1)\n pass\n pass\n\n matchObj_Content_Type = re.match(r\"(^Content-Type:)\\s\", strip_line, re.M|re.I) \n if matchObj_Content_Type != None:\n matchObj_Content_Type_value = re.match(r\"^Content-Type:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Content_Type_value: \" + matchObj_Content_Type_value.group(1)\n file_request_header_dict[\"Content-Type\"] = matchObj_Content_Type_value.group(1)\n matchObj_file_request_content_type_boundary = re.search(r\"boundary=(.*)$\", file_request_header_dict[\"Content-Type\"], re.M|re.I)\n if matchObj_file_request_content_type_boundary: \n file_request_content_type_boundary = matchObj_file_request_content_type_boundary.groups()[0]\n else:\n file_request_content_type_boundary = \"\"\n pass\n pass\n # print file_request_content_type_boundary\n pass\n\n matchObj_Origin = re.match(r\"(^Origin:)\\s\", strip_line, re.M|re.I) \n if matchObj_Origin != None:\n matchObj_Origin_value = re.match(r\"^Origin:\\s(.*)$\", strip_line, re.M|re.I) \n # print \"Origin_value: \" + matchObj_Origin_value.group(1)\n file_request_header_dict[\"Origin\"] = matchObj_Origin_value.group(1)\n pass\n pass\n\n if (2 == none_line_flag and str(file_request_content_type_boundary) == \"\"):\n \"\"\" 2表示已经经历过空行,那么下面的数据就是post请求的参数部分。 \"\"\"\n file_request_date_posts = strip_line\n # print \"____\" + urllib.unquote(file_request_date_posts)\n tmp_params_str = strip_line\n tmp_params_list = str(tmp_params_str).split(\"&\")\n for tmp_param in tmp_params_list:\n # print tmp_param\n if tmp_param.strip():\n file_request_parameters[(tmp_param.strip().partition(\"=\"))[0]] = urllib.unquote((tmp_param.strip().partition(\"=\"))[2])\n # file_request_parameters[(tmp_param.strip().partition(\"=\"))[0]] = (tmp_param.strip().partition(\"=\"))[2]\n pass\n pass \n pass\n\n if (2 == none_line_flag and str(file_request_content_type_boundary) != \"\"):\n \"\"\" 2表示已经经历过空行,那么下面的数据就是post请求的参数部分。 \"\"\"\n # print \"none_line_flag >> \"+ str(none_line_flag), \"file_request_content_type_boundary >> \"+ file_request_content_type_boundary\n # print strip_line\n matchObj_boundary_flag = re.match(r\"^--(\"+file_request_content_type_boundary+ \")$\", strip_line, re.M|re.I) \n if matchObj_boundary_flag:\n new_param_flag = 0\n pass\n else:\n new_param_flag = new_param_flag + 1\n if new_param_flag == 1:\n # print \"##\" + str(new_param_flag)\n matchObj_params_key = re.search(r\"form-data; name=\\\"(.*)\\\"$\", strip_line, re.M|re.I)\n if matchObj_params_key:\n params_key = matchObj_params_key.groups()[0]\n # print \"params_key >> \" + params_key\n pass\n pass\n if new_param_flag == 2:\n # print \"##\" + str(new_param_flag)\n pass\n if new_param_flag == 3:\n # print \"##\" + str(new_param_flag)\n if strip_line:\n params_value = strip_line.decode(\"utf-8\")\n new_param_flag = 0\n # print \"params_value >> \" + params_value\n file_request_parameters[params_key] = params_value\n params_key = params_value = \"\"\n pass\n pass\n\n # print str(\"request_header_dict\").center(120, '=');\n # print request_header_dict;\n # print file_request_url_parameters\n fileRequest = FileRequest(file_request_header_dict)\n fileRequest.request_url = file_request_url\n fileRequest.request_url_parameters = file_request_url_parameters\n fileRequest.request_url_method = file_request_url_method\n fileRequest.request_content_type_boundary = file_request_content_type_boundary\n fileRequest.request_parameters = file_request_parameters\n fileRequest.request_date_gets = file_request_date_gets\n fileRequest.request_date_posts = file_request_date_posts\n\n\n return fileRequest\n"
},
{
"alpha_fraction": 0.6713780760765076,
"alphanum_fraction": 0.6911661028862,
"avg_line_length": 28.48611068725586,
"blob_id": "29a7e3dcae56fe1b427dac01b5d412eb3668f676",
"content_id": "284e960141a4215efc5f07ca31caf546d5059585",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4255,
"license_type": "no_license",
"max_line_length": 266,
"num_lines": 144,
"path": "/tools/tools.py",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\nimport urllib\nimport time\nimport FileRequest\nimport doFile\nfrom random import Random\nimport json\nimport srcrequest\n\n\ndef get_dict_from_post_log(post_data_str):\n post_data_dict = {}\n if not post_data_str:\n return post_data_dict\n post_param_list = post_data_str.split(\"&\")\n for i, post_param in enumerate(post_param_list):\n # print post_param\n param_key_value = post_param.split(\"=\")\n post_data_dict[param_key_value[0]] = urllib.unquote(param_key_value[1])\n pass\n return post_data_dict\n\ndef get_dict_from_get_log(get_data_str):\n get_data_dict = get_dict_from_post_log(get_data_str)\n return get_data_dict\n\ndef get_time_for_request():\n t_str = time.time()\n nowTime = int(round(t_str * 1000))\n return str(nowTime)\n\ndef get_time_13():\n \"\"\" \n Such As: 1510556369752\n \"\"\"\n t_str = time.time()\n nowTime = int(round(t_str * 1000))\n return str(nowTime)\n\ndef get_patam_str_from_dict(patam_dict):\n tmp_url_str = \"\"\n tmp_patam_dict = patam_dict\n if tmp_patam_dict:\n for tmp_patam_key in tmp_patam_dict:\n tmp_url_str = tmp_url_str + \"&\" + tmp_patam_key + \"=\" + urllib.quote(tmp_patam_dict[tmp_patam_key]) \n pass\n pass\n return tmp_url_str\n\ndef get_patam_json_from_dict(patam_dict):\n patam_dict_json = \"\"\n # tmp_patam_dict = patam_dict\n tmp_patam_dict = {\"AA\":\"aa\", \"BB\":\"bb\", \"CC\":\"cc\", \"DD\":\"dd\"}\n # patam_dict_json = json.load(tmp_patam_dict)\n patam_dict_json = json.dumps(tmp_patam_dict)\n\n return patam_dict_json\n \n\n\ndef get_fileRequest_from_file(file_path):\n fileRequest = doFile.getFileRequest(file_path)\n return fileRequest\n\ndef get_header_dict_from_fileRequest(fileRequest):\n return fileRequest.request_header_dict\n\ndef get_parameters_dict_from_fileRequest(fileRequest):\n return fileRequest.request_parameters\n\n\ndef package_parameters_for_multipart(fileRequest):\n fileRequest = get_fileRequest_from_file(\"../post_form.log\")\n fileRequest.request_content_type_boundary = get_boundary_flag()\n return fileRequest\n\n\ndef get_boundary_flag(randomlength=33):\n chars = 'AaBbCcDdEeFfGgHhIiJjKkLlMmNnOoPpQqRrSsTtUuVvWwXxYyZz0123456789'\n _str = '' \n\n length = len(chars) - 1\n random = Random() \n for i in range(randomlength): \n _str+=chars[random.randint(0, length)]\n\n _str = \"----\" + _str\n return _str\n\n\n\ndef get_srcrequest_from_fileRequest(fileRequest):\n tmp_srcrequest = srcrequest.SrcRequest()\n\n tmp_srcrequest.set_url(fileRequest.request_url)\n tmp_srcrequest.set_method(fileRequest.request_url_method)\n tmp_srcrequest.set_content_type\n tmp_srcrequest.set_header(fileRequest.request_header_dict)\n\n tmp_srcrequest.set_url(fileRequest.request_url)\n tmp_srcrequest.set_method(fileRequest.request_url_method)\n tmp_srcrequest.set_url_parameters(fileRequest.request_url_parameters)\n if fileRequest.request_url_method == \"POST\":\n if not fileRequest.request_content_type_boundary:\n tmp_srcrequest.set_content_type(\"x-www-form-urlencoded\")\n pass\n else:\n tmp_srcrequest.set_content_type(\"form-data\")\n tmp_srcrequest.set_content_type_boundary_flag(fileRequest.request_content_type_boundary)\n pass\n pass\n tmp_srcrequest.set_header(fileRequest.request_header_dict) \n tmp_srcrequest.set_parameters(fileRequest.request_parameters) \n tmp_srcrequest.set_date_posts(fileRequest.request_date_posts)\n tmp_srcrequest.set_date_gets(fileRequest.request_date_gets)\n\n return tmp_srcrequest\n\n\n# fileRequest = get_fileRequest_from_file(\"../post_form.log\")\n# print fileRequest.request_parameters\n# fileRequest.request_content_type_\n\n# print get_boundary_flag()\n\n# -- ----WebKitFormBoundaryqLsRXIZYATyoQ4IR\n# 4 + 33\n\n\n\n\n\n\n\n\n\n\n\n# 1510198677900\n# 1510140054580\n# 测试get_dict_from_post_log(post_data_str) 时使用\n# post_data_str = \"username=m10gys03&password=123456a&pn=miccn&tab=miccn&ticket=undefined&callback=parent.focusSSOController.callFeedback&sucurl=http%3A%2F%2Fmembercenter.cn.made-in-china.com%2Fmember%2Fmain%2F%3F_%3D1&rememberLogUserNameFlag=0&encoding=GBK\"\n# print get_dict_from_post_log(post_data_str)\n# print get_time_for_request()"
},
{
"alpha_fraction": 0.6136761903762817,
"alphanum_fraction": 0.6294564604759216,
"avg_line_length": 30.38888931274414,
"blob_id": "daa8782fc9cb18da612183b9cd183aaf764f133b",
"content_id": "8433ce504c5bb1cccbb8bd359fb068e4fdeadb7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1993,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 54,
"path": "/tools/FileRequest.py",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\n\nclass FileRequest:\n \"\"\"自定义的Request对象,有file文件中获取参数并赋值给它\"\"\"\n request_header_dict = {}\n \"\"\"\n request_header_dict[URL_method]\n request_header_dict[URL_value]\n request_header_dict[Host]\n request_header_dict[Content-Length]\n request_header_dict[Cache-Control]\n request_header_dict[Origin]\n request_header_dict[Upgrade-Insecure-Requests]\n request_header_dict[User-Agent]\n request_header_dict[Content-Type]\n request_header_dict[Accept]\n request_header_dict[Referer]\n request_header_dict[Accept-Encoding]\n request_header_dict[Accept-Language]\n request_header_dict[Cookie]\n request_header_dict[Connection]\n \"\"\"\n request_url=\"\"\n \"\"\" request_url 存储request的URL部分\"\"\"\n request_url_parameters={}\n \"\"\" request_url_parameters 存储request的URL部分的参数\"\"\"\n\n request_parameters={}\n \"\"\" 记录请求中的参数部分,get和post都放在里面\"\"\"\n request_date_posts=\"\"\n \"\"\"\n 记录请求中的post参数串放在里面。\n 形如: n2612mL76ok0oC2kn76=6&076ok0oDplZ20o=sss&075526o=ssss\n \"\"\"\n request_date_gets=\"\"\n \"\"\"\n 记录请求中的get参数串放在里面。\n 形如: subaction=hunt&style=b&mode=and&code=0\n \"\"\"\n request_url_method=\"GET\"\n \"\"\"\n 请求的类型。其值可以包含(GET|POST)\n 默认给值为GET\n \"\"\"\n request_content_type_boundary = \"\"\n \"\"\"\n file_request_content_type post才有,这个决定post data模块的类型。主要有两种类型:\n Content-Type: application/x-www-form-urlencoded\n Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryLY96mLehbhhAYyIj\n \"\"\"\n\n def __init__(self, request_header_dict):\n \"\"\" 使用字典按键值对的方式,接受对应的参数。\"\"\"\n self.request_header_dict = request_header_dict\n \n\n\n "
},
{
"alpha_fraction": 0.6849315166473389,
"alphanum_fraction": 0.6849315166473389,
"avg_line_length": 26.4375,
"blob_id": "6f07386c5cb1fbcb086633011bf77f149cf0ca32",
"content_id": "c4e2394c4763b94083d919479222cfa7fc40ba2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 16,
"path": "/README.md",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": "\"# CSRF\" \n\"# Yola-CSRF\" \n\"# Yola-CSRF\" \n\n## FOR EXAMPLE\n\n fileRequest = tools.get_fileRequest_from_file(\"./post_form.log\")\n # print fileRequest.request_parameters\n\n tmp_srcrequest = tools.get_srcrequest_from_fileRequest(fileRequest)\n # print tmp_srcrequest.get_url()\n # print tmp_srcrequest.get_post_data_str()\n\n # tmp_srcrequest.get_header()\n # tmp_srcrequest.get_post_data_str()\n tmp_srcrequest.do_post_request()"
},
{
"alpha_fraction": 0.5309003591537476,
"alphanum_fraction": 0.5369925498962402,
"avg_line_length": 39.64285659790039,
"blob_id": "df21dc06c72954850c9e108505d3026a54c1a3b6",
"content_id": "70ad4d3a805cc967daa173ed414ca5d378cc6d29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17473,
"license_type": "no_license",
"max_line_length": 454,
"num_lines": 420,
"path": "/tools/srcrequest.py",
"repo_name": "goblinintree/Yola-CSRF",
"src_encoding": "UTF-8",
"text": "# -*- coding: UTF-8 -*-\nimport requests\nimport tools\nimport cookielib\nfrom bs4 import BeautifulSoup\n\n\nclass SrcRequest:\n request_url = \"\"\n request_url_method = \"\"\n request_url_parameters = {}\n request_content_type = \"\"\n request_content_type_boundary_flag = \"\"\n request_header_content_type = {}\n \n\n request_header_dict = {}\n request_parameters = {}\n\n request_date_posts = \"\"\n request_date_gets = \"\"\n request_sealed = {}\n\n\n\n def __init__(self,url_method=\"GET\", request_content_type=\"\"):\n \"\"\"\n url_method 默认 GET,其值可以为 GET | POST \\n\n request_content_type,其值包含: x-www-form-urlencoded | form-data\n \"\"\"\n self.request_url_method = url_method\n self.request_content_type = request_content_type\n\n self.request_sealed[\"set\"] = False\n self.request_sealed[\"boundary\"] = False\n pass\n\n def set_file_request(self, fileRequest):\n \"\"\"set request_url \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_url = fileRequest.request_url\n self.request_url_method = fileRequest.request_url_method\n self.request_url_parameters = fileRequest.request_url_parameters\n if fileRequest.request_url_method == \"POST\":\n if not fileRequest.file_request_content_type_boundary:\n self.request_content_type = \"x-www-form-urlencoded\"\n pass\n else:\n self.request_content_type = \"form-data\"\n self.request_content_type_boundary_flag = fileRequest.file_request_content_type_boundary\n pass\n pass\n self.request_header_dict = fileRequest.request_header_dict\n self.request_parameters = fileRequest.request_parameters\n self.request_date_posts = fileRequest.request_date_posts\n self.request_date_gets = fileRequest.request_date_gets\n pass\n pass\n\n def set_url(self, url_str):\n \"\"\"set request_url \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_url = url_str\n pass\n pass\n\n def set_method(self, method_str):\n \"\"\"set request_url_method \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_url_method = method_str\n pass\n pass\n\n def set_url_parameters(self, url_parameters_dict):\n \"\"\"set request_url_method \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_url_parameters = url_parameters_dict\n pass\n pass\n\n def set_content_type(self, content_type_str):\n \"\"\"\n set request_content_type,其值包含: x-www-form-urlencoded | form-data\n request_url_method post才有,这个决定post data模块的类型。主要有两种类型:\n Content-Type: application/x-www-form-urlencoded\n Content-Type: multipart/form-data; boundary=----WebKitFormBoundaryLY96mLehbhhAYyIj\n \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_content_type = content_type_str\n pass\n pass\n\n def set_content_type_boundary_flag(self, content_type_boundary_flag):\n \"\"\"set request_content_type_boundary_flag \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_content_type_boundary_flag = content_type_boundary_flag\n pass\n pass\n\n def set_header_content_type(self, header_content_type_dict):\n \"\"\"set request_header_content_type \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_header_content_type = header_content_type_dict\n pass\n pass\n\n def set_header(self, header_dict):\n \"\"\"set request_header_dict \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_header_dict = header_dict\n pass\n pass\n\n def set_parameters(self, parameters_dict):\n \"\"\"set request_parameters \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_parameters = parameters_dict \n pass\n pass\n\n def set_date_posts(self, date_posts_str):\n \"\"\"set request_date_posts \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_date_posts = date_posts_str\n pass\n pass\n\n def set_date_gets(self, date_gets_str):\n \"\"\"set request_date_gets \"\"\"\n if not self.request_sealed[\"set\"]:\n self.request_date_gets = date_gets_str\n pass\n pass\n\n def get_src_get_request(self):\n if self.request_url_method == \"GET\" :\n self.request_sealed[\"set\"] = True\n src_request = requests.post(self.request_url, data=None, header={})\n return src_request\n \n\n def get_url(self):\n self.request_sealed[\"set\"] = True\n\n url_str = \"\"\n tmp_request_url_str = self.request_url\n tmp_request_url_parameters = self.request_url_parameters\n\n if tmp_request_url_parameters:\n \"\"\" URL中有参数时,根据类型封装\"\"\"\n tmp_request_url_parameters_str = tools.get_patam_str_from_dict(tmp_request_url_parameters)\n\n if self.request_url_method == \"POST\" :\n \"\"\"\"封装 POST\"\"\"\n if str(tmp_request_url_str).find(\"?\") > -1:\n \"\"\"当前URL中包含参数\"\"\"\n\n url_str = tmp_request_url_str + tmp_request_url_parameters_str\n pass\n else:\n \"\"\"当前URL中不包含参数\"\"\"\n url_str = tmp_request_url_str + \"?\" + tmp_request_url_parameters_str\n pass\n pass\n else:\n \"\"\"\"封装 GET\"\"\"\n if str(tmp_request_url_str).find(\"?\") > -1:\n \"\"\"当前URL中包含参数\"\"\"\n url_str = tmp_request_url_str + tmp_request_url_parameters_str\n pass\n else:\n \"\"\"当前URL中不包含参数\"\"\"\n url_str = tmp_request_url_str + \"?\" + tmp_request_url_parameters_str + self.get_get_params_str()\n pass\n pass\n pass\n \n else:\n \"\"\" URL中无参数时,直接返回当前的URL\"\"\"\n url_str = tmp_request_url_str\n pass\n return url_str\n \n def get_get_params_str(self):\n self.request_sealed[\"set\"] = True\n get_params_str = \"\"\n tmp_request_parameters = self.request_parameters\n\n if tmp_request_parameters:\n \"\"\" URL中有参数时,根据类型封装\"\"\"\n tmp_request_parameters_str = tools.get_patam_str_from_dict(tmp_request_parameters)\n\n if self.request_url_method == \"GET\" :\n \"\"\"\"封装 GET\"\"\"\n get_params_str = get_params_str + tmp_request_parameters_str\n pass\n pass\n \n else:\n \"\"\" URL中无参数时,直接返回当前的URL\"\"\"\n pass\n return get_params_str\n\n def get_post_data_str(self):\n self.request_sealed[\"set\"] = True\n post_data_str = \"\"\n tmp_request_parameters = self.request_parameters\n\n if tmp_request_parameters:\n \"\"\" URL中有参数时,根据类型封装\"\"\"\n tmp_request_parameters_str = \"\"\n\n if self.request_url_method == \"POST\" and self.request_content_type == \"x-www-form-urlencoded\" :\n \"\"\"\"封装 POST的 x-www-form-urlencoded 格式数据 \"\"\"\n tmp_request_parameters_str = tools.get_patam_str_from_dict(tmp_request_parameters)\n post_data_str = post_data_str + tmp_request_parameters_str\n pass\n elif self.request_url_method == \"POST\" and self.request_content_type == \"form-data\" :\n # print self.request_sealed[\"boundary\"] \n if not self.request_sealed[\"boundary\"]:\n tmp = tools.get_boundary_flag()\n self.request_content_type_boundary_flag = tmp \n self.request_sealed[\"boundary\"] = True\n # print self.request_sealed[\"boundary\"] \n pass\n tmp_request_content_type_boundary_flag = self.request_content_type_boundary_flag\n\n # self.get_header()\n tmp_line_feed_flag = \"\\n\"\n tmp_form_data_format = \"Content-Disposition: form-data; \"\n if tmp_request_parameters:\n # print str(tmp_request_parameters)\n for tmp_patam_key in tmp_request_parameters:\n tmp_request_parameters_str = (tmp_request_parameters_str + \"--\" + tmp_request_content_type_boundary_flag \n + tmp_line_feed_flag)\n\n tmp_form_data_format_line = (tmp_form_data_format + \"name=\\\"\"+ tmp_patam_key +\"\\\"\"\n + tmp_line_feed_flag\n + tmp_line_feed_flag)\n tmp_request_parameters_str = (tmp_request_parameters_str + tmp_form_data_format_line)\n str_p = tmp_request_parameters[tmp_patam_key]\n # print str_p\n # print str(str_p).encode(\"gbk\")\n # print str(str_p).encode(\"utf-8\")\n # print str(str_p).encode(\"raw_unicode_escape\")\n\n # print str(str_p).decode(\"gbk\")\n # print str(str_p).decode(\"utf-8\")\n # print str(str_p).decode(\"raw_unicode_escape\")\n\n \n tmp_request_parameters_str = (tmp_request_parameters_str \n + str_p \n + tmp_line_feed_flag)\n pass\n tmp_request_parameters_str = (tmp_request_parameters_str + \"--\" + tmp_request_content_type_boundary_flag \n + tmp_line_feed_flag)\n pass\n # self.request_content_type_boundary_flag = tmp_request_content_type_boundary_flag\n post_data_str = tmp_request_parameters_str\n pass\n else:\n post_data_str = tmp_request_parameters_str + \"ERROR=ERROR\"\n pass\n pass\n else:\n \"\"\" URL中无参数时,直接返回当前的URL\"\"\"\n pass\n return post_data_str\n \n\n def get_post_data_json(self):\n self.request_sealed[\"set\"] = True\n post_data_json = \"\"\n tmp_request_parameters = self.request_parameters\n\n if tmp_request_parameters:\n \"\"\" URL中有参数时,根据类型封装\"\"\"\n tmp_request_parameters_str = \"\"\n\n if self.request_url_method == \"POST\" and self.request_content_type == \"x-www-form-urlencoded\" :\n \"\"\"\"封装 POST的 x-www-form-urlencoded 格式数据 \"\"\"\n post_data_json = tmp_request_parameters\n\n tmp_request_parameters_str = tools.get_patam_str_from_dict(tmp_request_parameters)\n post_data_str = post_data_str + tmp_request_parameters_str\n pass\n elif self.request_url_method == \"POST\" and self.request_content_type == \"form-data\" :\n # print self.request_sealed[\"boundary\"] \n if not self.request_sealed[\"boundary\"]:\n tmp = tools.get_boundary_flag()\n self.request_content_type_boundary_flag = tmp \n self.request_sealed[\"boundary\"] = True\n # print self.request_sealed[\"boundary\"] \n pass\n tmp_request_content_type_boundary_flag = self.request_content_type_boundary_flag\n\n # self.get_header()\n tmp_line_feed_flag = \"\\n\"\n tmp_form_data_format = \"Content-Disposition: form-data; \"\n if tmp_request_parameters:\n # print str(tmp_request_parameters)\n for tmp_patam_key in tmp_request_parameters:\n tmp_request_parameters_str = (tmp_request_parameters_str + \"--\" + tmp_request_content_type_boundary_flag \n + tmp_line_feed_flag)\n\n tmp_form_data_format_line = (tmp_form_data_format + \"name=\\\"\"+ tmp_patam_key +\"\\\"\"\n + tmp_line_feed_flag\n + tmp_line_feed_flag)\n tmp_request_parameters_str = (tmp_request_parameters_str + tmp_form_data_format_line)\n str_p = tmp_request_parameters[tmp_patam_key]\n # print str_p\n # print str(str_p).encode(\"gbk\")\n # print str(str_p).encode(\"utf-8\")\n # print str(str_p).encode(\"raw_unicode_escape\")\n\n # print str(str_p).decode(\"gbk\")\n # print str(str_p).decode(\"utf-8\")\n # print str(str_p).decode(\"raw_unicode_escape\")\n\n \n tmp_request_parameters_str = (tmp_request_parameters_str \n + str_p \n + tmp_line_feed_flag)\n pass\n tmp_request_parameters_str = (tmp_request_parameters_str + \"--\" + tmp_request_content_type_boundary_flag \n + tmp_line_feed_flag)\n pass\n # self.request_content_type_boundary_flag = tmp_request_content_type_boundary_flag\n post_data_str = tmp_request_parameters_str\n pass\n else:\n post_data_str = tmp_request_parameters_str + \"ERROR=ERROR\"\n pass\n pass\n else:\n \"\"\" URL中无参数时,直接返回当前的URL\"\"\"\n pass\n return post_data_str\n \n\n def get_header(self):\n self.request_sealed[\"set\"] = True\n self.get_post_data_str()\n # print \"get_header >> \" +self.request_content_type_boundary_flag\n\n if self.request_url_method == \"POST\" and self.request_content_type == \"form-data\" :\n if self.request_content_type_boundary_flag:\n tmp_request_header_dict = self.request_header_dict\n tmp_request_content_type_boundary_flag = self.request_content_type_boundary_flag\n tmp_request_header_content_type = {}\n tmp_request_header_content_type = tmp_request_header_dict[\"Content-Type\"]\n tmp_request_header_content_type ={ \"Content-Type\":\"multipart/form-data; boundary=\" + tmp_request_content_type_boundary_flag}\n\n self.request_header_content_type = tmp_request_header_content_type\n tmp_request_header_dict.update(tmp_request_header_content_type)\n self.request_header_dict = tmp_request_header_dict\n pass\n pass\n pass\n\n return self.request_header_dict\n\n\n def do_post_request(self):\n self.request_sealed[\"set\"] = True\n print 1\n\n src_request = None\n if self.request_url_method == \"POST\" :\n # src_request = requests.post(self.get_url(), data=None, header={})\n tmp_body_data = self.get_post_data_str()\n # print body_data.encode(\"UTF-8\")\n # src_response = requests.post(self.get_url(), data=body_data, headers=(self.get_header()))\n # src_response = requests.post(self.get_url(), json=tools.get_patam_json_from_dict(self.request_parameters), headers=(self.get_header()))\n tmp_header = self.get_header()\n tmp_url = self.get_url()\n tmp_header.update({\"Origin\":\"null\", \"Referer\":\"\", \"Cookie\":\"\"})\n sion = requests.session()\n print tmp_url\n print tmp_header\n print tmp_body_data\n\n src_response = sion.post(tmp_url, data=tmp_body_data, headers=tmp_header)\n # src_response = requests.post(self.get_url(), data=body_data, )\n \"\"\"\n \"\"\"\n # src_response = sion.get(\"http://cn.made-in-china.com/inquiry.do?xcase=inquiryComplete&sourceId=qMrnSsRuXhYb&sourceType=shrom&receiverComId=qMrnSsRuXhYb&encryptSuss=0&[email protected]&comIdentity=0&offerType=&senderCom=CSRF%C3%A5%26%23174%3B%A1%EB%C3%A5%A1%AD%A1%A7%C3%A6%C2%B5%26%238249%3B%C3%A8%A1%A5%26%238226%3B6&senderName=CSRF%C3%A5%26%23174%3B%A1%EB%C3%A5%A1%AD%A1%A7%C3%A6%C2%B5%26%238249%3B%C3%A8%A1%A5%26%238226%3B6&senderSex=1\")\n print 4 \n pass\n else:\n \"\"\" 从这里获得GET请求 \"\"\"\n src_request = requests.get(self.get_url(), params=None, header={})\n pass\n return src_request\n\n\n\n def get_src_request(self, abc):\n self.request_sealed[\"set\"] = True\n\n src_request = None\n if self.request_url_method == \"POST\" :\n src_request = requests.post(self.get_url(), data=None, header={})\n pass\n else:\n \"\"\" 从这里获得GET请求 \"\"\"\n src_request = requests.get(self.get_url(), params=None, header={})\n pass\n return src_request\n\n\n def out_poc_csrf_html(self):\n out_file_name = \"csrf_\" + tools.get_time_13() + \".html\"\n print out_file_name # TO do something you wan't to do \n csrf_html_context = \"\"\n soup = BeautifulSoup(out_file_name)\n soup\n\n return out_file_name\n\n"
}
] | 6 |
sauravray2587/alexaConnectTheDots
|
https://github.com/sauravray2587/alexaConnectTheDots
|
2ac82f6d9e3e68e365100d3d7d0b4bdca3ffa37d
|
50d141fb194e180fdd1d80b3c3aac33cdd01defa
|
b40bc23eaece868ef588189173db581d104520d4
|
refs/heads/master
| 2020-03-31T17:35:18.083150 | 2018-10-28T11:38:01 | 2018-10-28T11:38:01 | 152,427,377 | 0 | 1 |
MIT
| 2018-10-10T13:22:54 | 2018-10-10T13:27:24 | 2018-10-10T13:38:51 |
Python
|
[
{
"alpha_fraction": 0.6800976991653442,
"alphanum_fraction": 0.7008547186851501,
"avg_line_length": 30.5,
"blob_id": "cdfcc2c3f7db0d2269c314378752de6ffbf95298",
"content_id": "f46de47447f85b3eb8f7b06e1099513142cfe674",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 819,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 26,
"path": "/scrape.py",
"repo_name": "sauravray2587/alexaConnectTheDots",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\ndriver = webdriver.Firefox()\ndriver.implicitly_wait(15)\nurl = \"https://www.sixdegreesofwikipedia.com/?source=Tanushree%20Dutta&target=Nana%20Patekar\"\ndriver.get(url)\n\nbutton = driver.find_element_by_xpath('//*[@id=\"root\"]/div[2]/div/button')\nbutton.click()\ndriver.implicitly_wait(15)\nelement=driver.find_element_by_xpath('//*[@class=\"sc-htoDjs bYbIip\"]')\n\ndegreePath=driver.find_element_by_xpath('//*[@class=\"sc-jKJlTe fChiJW\"]')\ndegree=(degreePath.text).split('\\n')[-1].split(' ')[4]\ndegree=int(degree)+1\ntext_list=(element.text).split('\\n')\npathListOfList=[]\ntempList=[]\nfor iter, word in enumerate(text_list):\n if (1+iter)%(2*degree)==0:\n pathListOfList.append(tempList)\n tempList=[]\n if iter%2==1:\n continue\n tempList.append(word)\n\nprint(pathListOfList)\n"
},
{
"alpha_fraction": 0.49001815915107727,
"alphanum_fraction": 0.5003024935722351,
"avg_line_length": 30.788461685180664,
"blob_id": "8860caad73305b142d036b09a7b4bf3d9d710f44",
"content_id": "ef2715c86658d6d06a2625969b5ef77f1d4321f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1653,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 52,
"path": "/Hints.py",
"repo_name": "sauravray2587/alexaConnectTheDots",
"src_encoding": "UTF-8",
"text": "import wikipedia\n\n#print(wikipedia.search(\"Barak\"))\n#page = wikipedia.page(\"Barak Obama\")\n#print(page.content)\n#print(wikipedia.search(\"barak obama\",results = 10,suggestion = True))\nnext_node = \"Into the wild book\"\ndef gethint(next_node):\n pronouns = [\"he\",\"she\",\"it\",\"them\",\"they\",\"their\"]\n help_verbs = [\"is\",\"am\",\"are\",\"was\",\"were\",\"been\",\"have\",\"has\",\"had\",\"do\",\"did\",\"does\",\"would\",\"will\",\"shall\",\"should\",\"can\",\"could\",\"being\",\"am\"]\n page = wikipedia.page(next_node)\n content = page.content\n content = content.lower()\n content = list(content)\n key =0 \n for i in range(0,len(content)):\n if key==0:\n if content[i]=='(':\n key =1\n if content[i]=='.':\n key = 2\n if key ==1:\n if content[i]==')':\n key = -1\n if key!=-1:\n content[i] = ''\n else:\n content[i] = '' \n key = 2\n if key==2:\n break\n content = \"\".join(content)\n sentences = content.split(\".\")\n pronoun = None\n for i in range(1,len(sentences)):\n words1 = sentences[i].split(\" \")\n for word in words1:\n if word in pronouns:\n pronoun = word\n break\n if(pronoun!=None):\n break\n i = None\n words = sentences[0].split(\" \")\n for i in range(0,len(words)):\n if words[i] in help_verbs:\n break\n final_sentence = pronoun\n for i in range(i,len(words)):\n final_sentence = final_sentence + \" \"+ words[i]\n return final_sentence \nprint(gethint(next_node))\n"
},
{
"alpha_fraction": 0.7103866338729858,
"alphanum_fraction": 0.7187263369560242,
"avg_line_length": 20.983333587646484,
"blob_id": "a0ca5c1064cad59bb3228604d2e70f25087db837",
"content_id": "847be8300f06241afe4e5839b4730d1e2c24a2b7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1319,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 60,
"path": "/connect.py",
"repo_name": "sauravray2587/alexaConnectTheDots",
"src_encoding": "UTF-8",
"text": "import requests\nfrom bs4 import BeautifulSoup\nimport wikipedia\n'''\n\t1) Find Valid connections\n\t2) All connections on wikipedia are not relevant\n\t3) Find valid sentences\n'''\ndef giveSentences(content):\n\tsentences = content.split('.')\n\treturn sentences\n\ndef giveContent(searchTerm):\n\tprint(\"Wait for the Result\")\n\tsearchTerm = wikipedia.search(searchTerm)[0]\n\tpage = wikipedia.page(searchTerm)\n\tcontent = page.content\n\treturn content\n\ndef checkConnection(fromNode, toNode):\n\t'''To check whether term1 is directly related to \n\t\tterm2 and if it is directly related to, state\n\t\tthe connection.\n\t'''\n\tsentences = giveSentences(fromNode)\n\t# print(sentences[0])\n\ty = []\n\tfor x in sentences:\n\t\tif toNode in x:\n\t\t\ty.append(x)\n\t# print(y[0])\n\tif len(y) is 0:\n\t\treturn False\n\telse:\n\t\tprint(y[0])\n\t\treturn True\n\n\ndef startGame(startNode, endNode):\n\t''' The game will be started from startNode and \n\twill end until we reach endNode\n\t'''\n\tprevNode = startNode\n\twhile prevNode!=endNode:\n\t\ttext = input()\n\t\tif text is \"check\":\n\t\t\tprint(prevNode,endNode)\n\t\telse:\n\t\t\tcurNode = text\n\n\t\tif (checkConnection(prevNode, curNode) or findSimilarity(prevNode,curNode)) is True:\n\t\t\tprevNode = curNode\n\t\telse:\n\t\t\tprint(\"Not a Valid Connection, Try Again.\")\n\n\ndef takeInputs():\n\tstartNode = input()\n\tendNode = input()\n\tstartGame(startNode, endNode)\n"
},
{
"alpha_fraction": 0.641416072845459,
"alphanum_fraction": 0.6642557978630066,
"avg_line_length": 21.64655113220215,
"blob_id": "ea4cd32a3c9a5df3fa51fe17cde5d57809049fd2",
"content_id": "8e2bd77e67a7b9d3e1d154ab5d07ce75f37ef1c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2627,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 116,
"path": "/gameplay.py",
"repo_name": "sauravray2587/alexaConnectTheDots",
"src_encoding": "UTF-8",
"text": "from connect import *\nfrom similarity import *\n\nclass Team:\n\tdef __init__(self, name):\n\t\tself.name = name\n\t\tself.score = 0\n\t\tself.moves = 0\n\t\tself.hintsLeft = 2\n\n\tdef change_name(self, new_name):\n\t\tself.name = new_name\n\n\tdef giveScore(self):\n\t\treturn self.score\n\n\tdef giveMoves(self):\n\t\treturn self.moves\n\n\tdef checkHints(self):\n\t\treturn self.hintsLeft\n\n\tdef useHints(self):\n\t\tif self.hintsLeft>0:\n\t\t\tself.hintsLeft -=1\n\t\t\treturn True\n\t\telse:\n\t\t\treturn False\n\n\tdef updateScore(self, score, moves):\n\t\tif score==1:\n\t\t\tself.score = self.score+score-(0.1*(moves-5))\n\n\nclass Game:\n\tdef __init__(self, name1, name2):\n\t\tself.Team1 = Team(name1)\n\t\tself.Team2 = Team(name2)\n\t\tself.curTeam = self.Team1\n\t\tself.status = 0\n\t\tself.roundNumber = 0\n\n\tdef __str__(self):\n\t\treturn \"An instance of class Game with state: Team1=%s Team2=%s and status=%s\" % (self.team1, self.team2, self.status)\n\n\tdef updateGameStatus(self):\n\t\tif self.Team1.score > self.Team2.score:\n\t\t\tself.status = 1\n\t\telse:\n\t\t\tself.status = 2\n\n\tdef curRound(self):\n\t\t''' The game will be started from startNode and \n\t\twill end until we reach endNode\n\t\t'''\n\t\tprint(\"%s, give us the two endpoints\" %(self.curTeam.name))\n\t\tstartNode = input()\n\t\tendNode = input()\n\t\tmoves = 0\n\t\tscore = 0\n\t\tprevNode = startNode\n\t\twhile prevNode!=endNode:\n\t\t\ttext = input()\n\t\t\tif text is \"check\":\n\t\t\t\tprint(prevNode,endNode)\n\t\t\telse:\n\t\t\t\tcurNode = text\n\t\t\t\tmoves += 1 \n\n\t\t\tif checkConnection(prevNode, curNode) is True:\n\t\t\t\tprevNode = curNode\n\t\t\telif checkConnection(curNode, prevNode) is True:\n\t\t\t\tprevNode = curNode\n\t\t\telif findSimilarity(prevNode,curNode) is True:\n\t\t\t\tprevNode = curNode\n\n\t\t\telse:\n\t\t\t\tprint(\"Not a Valid Connection, Try Again.\")\n\t\t\tif moves>=15:\n\t\t\t\tself.curTeam.updateScore(score, moves)\t\t\n\t\t\t\treturn\n\n\t\tscore = 1;\n\t\tself.curTeam.updateScore(score, moves)\n\n\tdef getGameStatus(self,Team1,Team2):\n\t\tif self.status==1:\n\t\t\treturn \"%s is winning with a score of %s and %s has a score of %s \"%(Team1.name,Team1.score,Team2.name,Team2.name)\n\t\tif self.status==2:\n\t\t\treturn \"%s is winning with a score of %s and %s has a score of %s \"%(Team2.name,Team2.score,Team1.name,Team1.name)\n\t\tif self.status ==0:\n\t\t\treturn \"Both the teams are at the same score of %s\"%(Team1.score)\n\n\n\tdef gameModerator(self):\n\t\trounds = 5\n\t\tfor i in range(0,2*rounds):\n\t\t\tself.roundNumber += 1\n\t\t\tif i%2==0:\n\t\t\t\tself.curTeam = self.Team1\n\t\t\t\tself.curRound()\n\t\t\telse:\n\t\t\t\tself.curTeam = self.Team2\n\t\t\t\tself.curRound()\n\n\ndef createGame():\n\tprint(\"Give the names of the two teams\")\n\tname1 = input()\n\tname2 = input()\n\tGame1 = Game(name1, name2)\n\tGame1.gameModerator()\n\n\nif __name__ == \"__main__\":\n\tcreateGame()\n"
},
{
"alpha_fraction": 0.7083835005760193,
"alphanum_fraction": 0.7268351316452026,
"avg_line_length": 29.012048721313477,
"blob_id": "e93baa257ca1b001438411b8398d8fd9db8ad285",
"content_id": "ceb53fe58224131f3a5426f4f809ebff8b776dde",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2493,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 83,
"path": "/similarity.py",
"repo_name": "sauravray2587/alexaConnectTheDots",
"src_encoding": "UTF-8",
"text": "import graphlab\n\nimport wikipedia\nfrom connect import giveContent\nimport math\nimport numpy as np\nimport sklearn\nfrom nltk.corpus import stopwords\n\ndef findSimilarity(fromNode, toNode):\n\t''' Decide the order of similarity between two\n\t\tterms on the basis of common words\n\t'''\n\tfromNodeContent = (giveContent(fromNode).lower()).split()\n\ttoNodeContent = (giveContent(toNode).lower()).split()\n\tstop_words = set(stopwords.words('english'))\n\tfromDict = {}\n\tfor word in fromNodeContent:\n\t\tif word not in stop_words:\n\t\t\tif word in fromDict:\n\t\t\t\tfromDict[word] += 1\n\t\t\telse:\n\t\t\t\tfromDict[word] = 1\n\ttoDict = {}\n\tfor word in toNodeContent:\n\t\tif word not in stop_words:\n\t\t\tif word in toDict:\n\t\t\t\ttoDict[word] += 1\n\t\t\telse:\n\t\t\t\ttoDict[word] = 1\n\n\tfromNodeWords = set(fromDict)\n\ttoNodeWords = set(toDict)\n\tcommonWords = fromNodeWords.intersection(toNodeWords)\n\n\tdotProduct = 0\n\tfor word in commonWords:\n\t\tdotProduct += fromDict[word]*toDict[word]\n\tmagFrom = 0\n\tfor word in fromDict:\n\t\tmagFrom += fromDict[word]*fromDict[word]\n\tmagTo = 0\n\tfor word in toDict:\n\t\tmagTo += toDict[word]*toDict[word]\n\tprint(dotProduct/math.sqrt(magTo*magFrom),\"DOT PRODUCT USED\")\n\treturn dotProduct/math.sqrt(magTo*magFrom)\n# print(commonWords/min(len(fromNodeWords),len(toNodeWords)))\n\t# similarityScore = \n\t# print(fromNodeWords)\n\t# print(toNodeWords)\n\n\ndef findSimilarityBetweenPeople(firstPerson, secondPerson):\n\ttry:\n\t\tpersonA = people[people['name'] == firstPerson]\n\t\tpersonB = people[people['name'] == secondPerson]\n\t\treturn graphlab.distances.cosine(personA['tfidf'][0], personB['tfidf'][0])\n\texcept Exception as _:\n\t\treturn -1\n\n\nif __name__ == \"__main__\":\n\tstartNode = input()\n\tendNode = input()\n\tgraphlab.product_key.set_product_key(\"E5E5-ED7D-D84A-5C81-3D1D-9778-1370-F123\")\n\tgraphlab.set_runtime_config('GRAPHLAB_DEFAULT_NUM_PYLAMBDA_WORKERS', 4)\n\tpeople = graphlab.SFrame('people_wiki.gl/')\n\tpeople['word_count'] = graphlab.text_analytics.count_words(people['text'])\n\ttfidf = graphlab.text_analytics.tf_idf(people['word_count'])\n\n\t# Earlier versions of GraphLab Create returned an SFrame rather than a single SArray\n\t# This notebook was created using Graphlab Create version 1.7.1\n\tif graphlab.version <= '1.6.1':\n\t\ttfidf = tfidf['docs']\n\tpeople['tfidf'] = tfidf\n\tsimilarity=findSimilarityBetweenPeople(startNode,endNode)\n\tboolean_closeness=0\n\tif similarity > 0.9:\n\t\tboolean_closeness=1\n\tif similarity !=-1:\n\t\tsimilarity=findSimilarity(startNode, endNode)\n\t\tif similarity>0.3:\n\t\t\tboolean_closeness=1\n\n\n"
}
] | 5 |
silvarthur/temperature-converter
|
https://github.com/silvarthur/temperature-converter
|
7eb8852d1128100c0a8c88540dca162f3a832c55
|
ba9a7df662da4d10e3849a7f5274049cc3d68a8d
|
e1ecff17926964af10fdcc503bdef1b6c50b6f20
|
refs/heads/master
| 2021-05-29T17:46:59.003459 | 2015-09-02T00:55:41 | 2015-09-02T00:55:41 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.820105791091919,
"alphanum_fraction": 0.820105791091919,
"avg_line_length": 46.25,
"blob_id": "0f3ea9544ef97a1f8cf7ba57ecf61e270d2ca43c",
"content_id": "3454f52b7539a89159a9ed1671ebae5da8c58f54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 4,
"path": "/README.md",
"repo_name": "silvarthur/temperature-converter",
"src_encoding": "UTF-8",
"text": "# temperature_converter\nHello, friends!\n\nTemperature Converter is a very simple program that converts Fahrenheit to Celsius and the other way around. The program was implemented in Python.\n"
},
{
"alpha_fraction": 0.6506105661392212,
"alphanum_fraction": 0.6886024475097656,
"avg_line_length": 25.339284896850586,
"blob_id": "7227924e9dcc87b30714dd957d5a426b59a603f9",
"content_id": "47de2a4561f77b53e06290799b8839ced0c53688",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1474,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 56,
"path": "/temperature_converter.py",
"repo_name": "silvarthur/temperature-converter",
"src_encoding": "UTF-8",
"text": "from Tkinter import *\n\n#creating functions\ndef convertTemp():\n\tvar = radio_button_var.get()\n\ttemp = entry1.get()\n\n\tif var == 0: #F to C\n\t temp_c = (float(temp) - 32) * 5/9\n\t label2.config(text=\"Result: \" + temp + \"F \" + \"is equal to \" + str(temp_c) + \"C.\")\n\telif var == 1: #C to F\n\t temp_f = float(temp) * 9/5 + 32 \n\t label2.config(text=\"Result: \" + temp + \"C \" + \"is equal to \" + str(temp_f) + \"F.\")\n\telse:\n\t print \"Invalid option. Choose 1 or 2.\"\n\ndef clear():\n\tentry1.delete(0,END)\n\tlabel2.config(text=\"Result:\")\n\ndef stop():\n\troot.destroy()\n\nroot = Tk()\nroot.wm_title(\"Temperature Converter\")\nroot.resizable(width=FALSE,height=FALSE)\n\nradio_button_var = IntVar()\n\n#creating widgets\ncheck_button1 = Radiobutton(root,text=\"F to C\",variable=radio_button_var,value=0)\ncheck_button2 = Radiobutton(root,text=\"C to F\",variable=radio_button_var,value=1)\n\nentry1 = Entry(root)\n\nlabel1 = Label(root,text=\"Temperature:\")\nlabel2 = Label(root,text=\"Result:\")\n\nbutton1 = Button(root,text=\"Calculate\",width=10,command=convertTemp)\nbutton2 = Button(root,text=\"Clear\",width=10,command=clear)\nbutton3 = Button(root,text=\"Exit\",width=10,command=stop)\n\n#placing widgets on the screen\ncheck_button1.grid(row=0,sticky=W)\ncheck_button2.grid(row=0,column=1,sticky=W)\n\nlabel1.grid(row=1,sticky=W)\nentry1.grid(row=1,column=1,sticky=W)\n\nlabel2.grid(row=2,sticky=W,columnspan=2)\n\nbutton1.grid(row=3,column=0)\nbutton2.grid(row=3,column=1)\nbutton3.grid(row=3,column=2)\n\nroot.mainloop()"
}
] | 2 |
ZooReach/datamodel
|
https://github.com/ZooReach/datamodel
|
212d61f528318c96b262c8ddcdf5936b0ca083fd
|
84bcead6e738f9e8edc946a4fc8ad9855b956618
|
88577177bdb1a66548ac93cc87e2af74cfb5a515
|
refs/heads/master
| 2020-03-31T08:05:18.650488 | 2018-10-22T09:30:40 | 2018-10-22T09:30:40 | 152,045,234 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6490384340286255,
"alphanum_fraction": 0.6538461446762085,
"avg_line_length": 32.83333206176758,
"blob_id": "4882b6df8ba0cb9bed3854b1235aedcb5ecba6d8",
"content_id": "8fa7c1eb72d9c2bb237737e33977340a9804f78e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 6,
"path": "/datacleaner/constants.py",
"repo_name": "ZooReach/datamodel",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\nENDEMIC_STATUS ='endemic'\nNON_ENDEMIC_STATUS ='non endemic'\nDIRECTION = ['south','north','west','east']\nREGION = ['africa', 'asia', 'america', 'europe','antartica']\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7243243455886841,
"alphanum_fraction": 0.7405405640602112,
"avg_line_length": 22.125,
"blob_id": "9bec04da7b8414dbbfc0adbe3a55e37b9a936e08",
"content_id": "64f4284c50b923771dae73994646a92e9d5701dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 8,
"path": "/ci_cd/Dockerfile",
"repo_name": "ZooReach/datamodel",
"src_encoding": "UTF-8",
"text": "FROM centos/python-27-centos7\n\n# Set the working directory to /app\nWORKDIR /app\n\n# Copy the current directory contents into the container at /app\nCOPY . /app\nCMD [\"python\", \"hello.py\"]\n"
},
{
"alpha_fraction": 0.675000011920929,
"alphanum_fraction": 0.675000011920929,
"avg_line_length": 40,
"blob_id": "10e3b5fe817bb9c2dbf7af63fc753ab770465812",
"content_id": "7bf58cf833550eecf525b577cb4c906e372063a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/ci_cd/hello.py",
"repo_name": "ZooReach/datamodel",
"src_encoding": "UTF-8",
"text": "print(\"Hello World... From a docker :P\")"
},
{
"alpha_fraction": 0.670915424823761,
"alphanum_fraction": 0.673232913017273,
"avg_line_length": 28.43181800842285,
"blob_id": "12ab37a43000a0ada2e731f113ca02a0620f4958",
"content_id": "27ce9b1535f2a21b7bedcd40a1431b3f1aafb308",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2589,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 88,
"path": "/datacleaner/nation_wise_status.py",
"repo_name": "ZooReach/datamodel",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\nimport pandas as pd\nimport enum\nfrom IPython.display import display, HTML as html\n\n\nclass ThreatConcern(enum.Enum):\n LEAST_CONCERN = \"Least Concern\"\n DATA_DEFICIENT = \"Data Deficient\"\n NEAR_THREATENED = \"Near Threatened\"\n CRITICALLY_ENDANGERED = \"Critically Endangered\"\n ENDANGERED = \"Endangered\"\n VULNERABLE = \"Vulnerable\"\n\n\nclass Nation(enum.Enum):\n INDIA = \"India\"\n NEPAL = \"Nepal\"\n PAKISTAN = \"Pakistan\"\n SRI_LANKA = \"Sri Lanka\"\n\n\ndef extract_column_as_list(column):\n status_list = []\n for status in column:\n if type(status) == str:\n status_list.append(status.split(\"\\n\"))\n else:\n status_list.append([])\n return status_list\n\n\ndef extract_countries(row):\n countries = []\n for item in row:\n country = item.split(\" \")[0]\n if country == \"Sri\":\n country = country + \" \" + item.split(\" \")[1]\n countries.append(country)\n return countries\n\n\ndef find_threat_concern(item):\n for concern in ThreatConcern:\n if item.lower().find(concern.value.lower()) != -1:\n return concern\n\n\ndef extract_threat_concerns(row):\n threat_concerns = []\n for item in row:\n threat_concerns.append(find_threat_concern(item))\n return threat_concerns\n\n\ndef generate_dictionary(countries, threat_concerns):\n country_concern = []\n if len(countries) != len(threat_concerns):\n raise Exception(\"Inconsistent list sizes\")\n elif len(countries) > 0:\n for (country, threat_concern) in zip(countries, threat_concerns):\n dictionary = {\"country\": country, \"concern\": threat_concern}\n country_concern.append(dictionary)\n return country_concern\n\n\ndef extract_country_and_status_as_dictionary(country_status):\n country_concern_list = []\n for row in country_status:\n countries = extract_countries(row)\n threat_concerns = extract_threat_concerns(row)\n country_concern = generate_dictionary(countries, threat_concerns)\n country_concern_list.append(country_concern)\n return country_concern_list\n\n\nCHIROPTERA_FILE_PATH = \"../Data/chiroptera_database.csv\"\nchiroptera_database = pd.read_csv(CHIROPTERA_FILE_PATH)\nnation_wise_status = chiroptera_database[\"National Status - 1\"]\n\nstatus_series = pd.Series(extract_column_as_list(nation_wise_status))\n\ncountry_criteria = extract_country_and_status_as_dictionary(status_series)\n\ndataframe = pd.DataFrame({\"National status\": nation_wise_status, \"JSON\": country_criteria})\ndataframe.to_excel(\"../data/national_status.xlsx\")"
},
{
"alpha_fraction": 0.635454535484314,
"alphanum_fraction": 0.6404545307159424,
"avg_line_length": 24.835294723510742,
"blob_id": "c5847f64bcffecefc0d2e156c10cdbe773e5bd22",
"content_id": "8f2122c3e456d82df1392a39f021457b5bf794d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2200,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 85,
"path": "/datacleaner/endemicstatus.py",
"repo_name": "ZooReach/datamodel",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# In[16]:\n\nfrom constants import *\nimport csv\nimport json as json\nimport pandas as pd\nfrom IPython.display import display, HTML\nchiroptera_dataset_filepath = \"../data/note_chiroptera_database.csv\"\n\n\n# In[17]:\n\n\ndef read_data_file(file_path):\n dataset = []\n with open(file_path, \"r\") as data_file:\n csv_reader = csv.reader(data_file)\n header = csv_reader.next()\n for row in csv_reader:\n dataset.append(row)\n df_dataset = pd.DataFrame(dataset, columns = header)\n return df_dataset\n\n\n# In[24]:\n\n\ndef processEndemicStatus(rawData):\n\n result = rawData.split('to')[0].lower().rstrip()\n endemicStatus = None\n \n if (result == ENDEMIC_STATUS):\n endemicStatus = True\n elif(result == NON_ENDEMIC_STATUS):\n endemicStatus = False\n return endemicStatus\n\ndef processEndemicRegion(rawData):\n result = rawData.split(' ')\n direction = ''\n region =''\n for x in result:\n if(x.lower() in DIRECTION):\n direction = x\n elif(x.lower() in REGION):\n region = x\n return (direction+region)\n\ndef isRegionAvailable(data):\n for x in REGION:\n #print(x)\n if(x in data.lower()):\n \n return True\n return False\n\ndef processEndemicSubRegion(rawData):\n result = ''\n if ('(' in rawData):\n result = rawData.split('(')[1].strip(') .')\n elif(isRegionAvailable(rawData) == False): # To Handle case 'Endemic to India'\n resultList = rawData.split('to')\n if(len(resultList) > 2):\n result = resultList[1].strip(' ')\n \n return json.dumps(result.split(','))\n \n\ndf_chiroptera = read_data_file(chiroptera_dataset_filepath)\nendemic_status_data = df_chiroptera[\"Endemic status\"]\ndf_chiroptera['IsEndemic'] = endemic_status_data.apply(lambda x:processEndemicStatus(x))\ndf_chiroptera['Endemic Region'] = endemic_status_data.apply(lambda x:processEndemicRegion(x))\ndf_chiroptera['Endemic SubRegion'] = endemic_status_data.apply(lambda x:processEndemicSubRegion(x))\ntemp ='Endemic to South Asia'\ndisplay(HTML(df_chiroptera.to_html()))\n\n\n#common_names = df_chiroptera[\"Common names\"]\n\n\n# In[ ]:\n\n\n\n\n"
}
] | 5 |
henriale/SO-RR-scheduling-script
|
https://github.com/henriale/SO-RR-scheduling-script
|
8691cdd160e0e825b8a2abf8cb64a8d661d03339
|
5760f522f0d427d9387f79e17255b325d5af2a32
|
f193052b4ab68e2d26414430f34926b790a0acd4
|
refs/heads/master
| 2020-03-14T21:22:05.601708 | 2018-05-18T14:33:23 | 2018-05-18T14:33:23 | 131,794,708 | 0 | 0 | null | 2018-05-02T03:44:41 | 2018-05-02T03:50:21 | 2018-05-18T14:33:23 |
Python
|
[
{
"alpha_fraction": 0.5951122641563416,
"alphanum_fraction": 0.5982260704040527,
"avg_line_length": 36.45229721069336,
"blob_id": "376c67c46c0c0ba212d4dd64da9c0b0f66f87037",
"content_id": "4f7c6b9b9880e353200176deb8f5cbbfc344fd2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10607,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 283,
"path": "/main.py",
"repo_name": "henriale/SO-RR-scheduling-script",
"src_encoding": "UTF-8",
"text": "# Pontifícia Universidade Católica do Rio Grande do Sul\n# Escola Politécnica\n# Disciplina de Sistemas Operacionais\n# Prof. Avelino Zorzo\n# ----------------------------\n# Gabriel Ferreira Kurtz (Engenharia de Software)\n# [email protected]\n\n# Alexandre Araujo (Ciência da Computação)\n# [email protected]\n\n# Maio/2018\n# ----------------------------\n# Simulador de Escalonamento de Software\n\n# Este programa foi desenvolvido para a disciplina de SisOp da FACIN\n# (Escola Politécnica/PUCRS). Trata-se de um um script para simular\n# uma fila no modelo Round Robin com prioridades fixas.\n\n# O programa lê um imput de dados representando processos e deve\n# simular seu processo de CPU e I/O, imprimindo ao final uma String\n# que demonstre os processos ao longo do tempo, bem como os dados de\n# Tempo de Resposta e Tempo de Espera médios.\n\n\nfrom collections import deque\nimport process as proc\n\n\nclass Scheduler:\n def __init__(self, processes, timeslice=2, context_shift_size=1):\n self.timeslice = timeslice\n self.context_shift_size = context_shift_size\n self.processes = processes\n self.processes_count = len(self.processes)\n\n # todo: use proper queue instead\n self.INCOME_QUEUE = self.processes\n # Keeps a copy of the original requests list (Will update Processes as they change)\n self.original_requests = list(self.INCOME_QUEUE)\n # Process being executed\n self.running_process = None\n # Ready Queue (Processes that are ready to execute)\n # todo: use proper queue instead\n self.READY_QUEUE = []\n # todo: use proper queue instead\n # High Priority Queue (Ready processes with same priority as Running Process)\n self.PRIORITY_QUEUE = deque()\n # IO Queue: Handles processes that are currently in IO\n self.IO_QUEUE = []\n # Handles Context Shift (Will bypass Context Shift when Processor is Idle similar to Moodle example)\n self.context_shift_counter = 1\n # Current time\n self.time = 1\n # Resulting String displaying Processes over Time\n self.log = \"\"\n\n def clock(self):\n self.time = self.time + 1\n\n def has_process_to_run(self):\n return self.INCOME_QUEUE or self.READY_QUEUE or self.PRIORITY_QUEUE or self.running_process or self.IO_QUEUE\n\n def run(self):\n # Checks if any requests have become ready\n arrivals = self.get_new_arrivals()\n if arrivals:\n self.enqueue_processes(arrivals)\n\n # Checks if Context Shift is occurring\n if self.should_switch_context():\n self.switch_context()\n return\n\n if self.should_run_process():\n self.run_process()\n \n else:\n self.write_log(\"-\")\n\n\n if(self.running_process):\n if self.running_process.start_io():\n self.enqueue_io() \n\n if (self.IO_QUEUE):\n for p in self.IO_QUEUE:\n p.run_io()\n IO_COPY = list(self.IO_QUEUE)\n for p in IO_COPY:\n if p.get_io_counter() == 0:\n self.IO_QUEUE.remove(p)\n arrivals.append(p)\n if(arrivals):\n for p in arrivals:\n if(self.should_run_process()):\n if p.get_priority() == self.running_process.get_priority():\n self.PRIORITY_QUEUE.appendleft(p)\n else:\n self.READY_QUEUE.append(p)\n else:\n self.READY_QUEUE.append(p)\n\n\n # Handles Ready Queue and High-Priority Queue\n if self.READY_QUEUE:\n # Creates a copy of the ready list and sorts it by priority (maintains queue order at original Ready list)\n sorted_ready = list(self.READY_QUEUE)\n sorted_ready.sort(key=lambda p: p.priority, reverse=False)\n\n # Assigns a process to be run if processor is idle\n # (Does not trigger Context Shift accordingly with Moodle Example)\n if not self.running_process:\n if(self.PRIORITY_QUEUE):\n self.running_process = self.PRIORITY_QUEUE.popleft()\n\n elif(sorted_ready):\n self.running_process = sorted_ready[0]\n self.remove_ready_process(self.running_process)\n\n # Swaps processes if there is a process with higher priority than current process, resets Context Shift\n elif sorted_ready[0].get_priority() < self.running_process.get_priority():\n new_priority = sorted_ready[0].get_priority()\n\n # Returns Running Process and High Priority Queue to Ready Queue\n # Will maintain High Priority queue order and append Running Process last\n self.enqueue_ready_process(self.running_process)\n while self.PRIORITY_QUEUE:\n self.enqueue_ready_process(self.PRIORITY_QUEUE.popleft())\n\n # Creates new High Priority Queue with new highest priority and assigns Running Process\n self.PRIORITY_QUEUE = deque()\n READY_COPY = list(self.READY_QUEUE)\n for p in READY_COPY:\n if p.get_priority() == new_priority:\n self.enqueue_priority_process(p)\n self.remove_ready_process(p)\n\n self.running_process = self.PRIORITY_QUEUE.popleft()\n self.context_shift_counter = 0\n\n # If there are new processes with same priority as running process, adds them to priority_queue\n elif sorted_ready[0].get_priority() == self.running_process.get_priority():\n READY_COPY = list(self.READY_QUEUE)\n for p in READY_COPY:\n if p.get_priority() == self.running_process.get_priority():\n self.enqueue_priority_process(p)\n self.remove_ready_process(p)\n\n self.clock()\n\n def report(self):\n average_response_time, average_turn_around_time, average_waiting_time = self.calc_averages()\n self.print_all_processes()\n self.print_execution_log()\n\n self.print_time_averages(average_response_time, average_turn_around_time, average_waiting_time)\n\n def print_time_averages(self, average_response_time, average_turn_around_time, average_waiting_time):\n print(\"Average Response Time: \" + str(average_response_time))\n print(\"Average Waiting Time: \" + str(average_waiting_time))\n print(\"Average Turn Around Time: \" + str(average_turn_around_time))\n\n def calc_averages(self):\n n = 0\n total_response_time = 0\n total_waiting_time = 0\n total_turn_around_time = 0\n\n for p in self.original_requests:\n total_response_time += p.get_response_time()\n total_waiting_time += p.get_waiting_time()\n total_turn_around_time += p.get_turn_around_time()\n n += 1\n\n average_response_time = total_response_time / n\n average_waiting_time = total_waiting_time / n\n average_turn_around_time = total_turn_around_time / n\n\n return average_response_time, average_turn_around_time, average_waiting_time\n\n def print_all_processes(self):\n print(\" P AT BT Pri CT TAT WT RT IO\")\n for p in self.original_requests:\n print(\"%3d %3d %3d %3d %3d %3d %3d %3d %3s\" % (\n p.get_number(), p.get_arrival_time(), p.get_burst_time(), p.get_priority(), p.get_completion_time(),\n p.get_turn_around_time(), p.get_waiting_time(), p.get_response_time(), str(p.get_io_times())))\n\n def print_execution_log(self):\n print(\"\\nProcessor Log:\\n\" + self.log)\n\n def run_process(self):\n self.running_process.execute(self.time)\n self.write_log(self.running_process.get_number())\n\n # Finishes process if it is done\n if self.running_process.is_done():\n self.running_process.finish(self.time)\n self.context_shift_counter = 0\n\n if self.PRIORITY_QUEUE:\n self.running_process = self.PRIORITY_QUEUE.popleft()\n else:\n self.running_process = None\n\n return\n\n if self.timeslice_has_ended():\n self.running_process.reset_quantum_counter()\n self.context_shift_counter = 0\n\n if self.PRIORITY_QUEUE:\n self.enqueue_priority_process(self.running_process)\n self.running_process = self.PRIORITY_QUEUE.popleft()\n\n def remove_ready_process(self, p):\n self.READY_QUEUE.remove(p)\n\n def should_switch_context(self):\n return self.context_shift_counter < self.context_shift_size\n\n def has_new_arrivals(self):\n for req in self.INCOME_QUEUE:\n if not (req.get_arrival_time() == self.time):\n return True\n return False\n\n def get_new_arrivals(self):\n arrivals = []\n\n COPY_INCOME_QUEUE = list(self.INCOME_QUEUE)\n for process in COPY_INCOME_QUEUE:\n if not (process.get_arrival_time() == self.time):\n continue\n\n self.INCOME_QUEUE.remove(process)\n arrivals.append(process)\n\n return arrivals\n\n def enqueue_processes(self, arrivals):\n for process in arrivals:\n if self.running_process and process.get_priority() == self.running_process.get_priority():\n self.enqueue_priority_process(process)\n else:\n self.enqueue_ready_process(process)\n\n def enqueue_ready_process(self, process):\n self.READY_QUEUE.append(process)\n\n def enqueue_priority_process(self, process):\n self.PRIORITY_QUEUE.append(process)\n\n def enqueue_io(self):\n self.IO_QUEUE.append(self.running_process)\n if(self.PRIORITY_QUEUE):\n self.running_process = self.PRIORITY_QUEUE.popleft()\n else:\n self.running_process = None\n self.context_shift_counter = 0\n\n def switch_context(self):\n self.write_log(\"C\")\n self.context_shift_counter += 1\n self.clock()\n\n def write_log(self, message):\n self.log += str(message)\n\n def should_run_process(self):\n return bool(self.running_process)\n\n def timeslice_has_ended(self):\n return self.running_process.get_quantum_counter() == self.timeslice\n\n\nif __name__ == \"__main__\":\n scheduler = proc.Reader(\"input.txt\").read_scheduler()\n\n while scheduler.has_process_to_run():\n scheduler.run()\n\n scheduler.report()"
},
{
"alpha_fraction": 0.5816451907157898,
"alphanum_fraction": 0.5887047052383423,
"avg_line_length": 27.086206436157227,
"blob_id": "6e37d1028f5a6a66a854e81dd9b26efc6c3e8d0e",
"content_id": "a4475a5c165d28c3c85c55a1722a47e4df2521bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3258,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 116,
"path": "/process.py",
"repo_name": "henriale/SO-RR-scheduling-script",
"src_encoding": "UTF-8",
"text": "# todo: move scheduler into this module\nfrom main import Scheduler\n\n\nclass Reader:\n def __init__(self, filename):\n self.file = open(filename)\n\n def read_scheduler(self):\n processes_count = int(self.file.readline())\n timeslice = int(self.file.readline())\n processes = []\n\n # data format: AT BT P\n for number, line in enumerate(self.file.readlines(), start=1):\n line_data = []\n for x in line.split(\" \"):\n line_data.append(int(x))\n\n if len(line_data) == 3:\n process = Process(number, line_data[0], line_data[1], line_data[2], [])\n processes.append(process)\n\n elif len(line_data) >= 4:\n io_times = []\n for i in range(3, len(line_data)):\n io_times.append(line_data[i])\n process = Process(number, line_data[0], line_data[1], line_data[2], io_times)\n processes.append(process)\n\n self.file.close()\n\n return Scheduler(processes, timeslice)\n\n\nclass Process:\n def __init__(self, number, arrival_time, burst_time, priority, io_times):\n self.number = number\n self.arrival_time = arrival_time\n self.burst_time = burst_time\n self.remaining_burst = burst_time\n self.priority = priority\n self.quantum_counter = 0\n self.turn_around_time = 0\n self.response_time = -1\n self.waiting_time = 0\n self.completion_time = 0\n self.io_times = io_times\n self.io_counter = 0\n\n def get_number(self):\n return self.number\n\n def get_arrival_time(self):\n return self.arrival_time\n\n def get_burst_time(self):\n return self.burst_time\n\n def get_remaining_burst(self):\n return self.remaining_burst\n\n def get_priority(self):\n return self.priority\n\n def get_response_time(self):\n return self.response_time\n\n def get_waiting_time(self):\n return self.waiting_time\n\n def get_quantum_counter(self):\n return self.quantum_counter\n\n def get_turn_around_time(self):\n return self.turn_around_time\n\n def get_completion_time(self):\n return self.completion_time\n\n def get_io_times(self):\n return self.io_times\n\n def get_io_counter(self):\n return self.io_counter\n\n\n # Executes Process for one time unit\n def execute(self, time):\n self.remaining_burst -= 1\n self.quantum_counter += 1\n\n if self.response_time == -1:\n self.response_time = time - self.arrival_time\n\n def start_io(self):\n if (self.burst_time - self.remaining_burst) in self.io_times:\n self.io_counter = 4\n self.io_times.remove(self.burst_time - self.remaining_burst)\n return True\n return False\n\n def run_io(self):\n self.io_counter -= 1\n\n def reset_quantum_counter(self):\n self.quantum_counter = 0\n\n def is_done(self):\n return self.get_remaining_burst() <= 0\n\n # calculates requested data\n def finish(self, time):\n self.completion_time = time\n self.turn_around_time = self.completion_time - self.arrival_time\n self.waiting_time = self.turn_around_time - self.burst_time\n"
}
] | 2 |
Kaleado/the-discerning-reader
|
https://github.com/Kaleado/the-discerning-reader
|
6ca3c1952bd05bfe5aadc112453157b9c3c4de04
|
11869cdb9d5c7a1b42dcc0102223a1d7edb085a0
|
8bea5cc57338e6170117ceeddf2b83d9ba8803cb
|
refs/heads/master
| 2020-03-28T03:10:33.311023 | 2018-09-10T02:28:53 | 2018-09-10T02:28:53 | 147,625,266 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8205128312110901,
"alphanum_fraction": 0.8205128312110901,
"avg_line_length": 38,
"blob_id": "0ff82d30e6a3e6c9d3914a0a696bd474f97be78b",
"content_id": "e6f4855d5f5e1ac0ac69af667ab8372948244017",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Kaleado/the-discerning-reader",
"src_encoding": "UTF-8",
"text": "# the-discerning-reader\nA neural network for movie review sentiment analysis.\n"
},
{
"alpha_fraction": 0.5930624604225159,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 45.71296310424805,
"blob_id": "c46c951440a122c5b3e0a486c295ea78aebd59b4",
"content_id": "e6293c7f1d3c3f1c0a00826f96c0f14de7caa21b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5045,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 108,
"path": "/implementation.py",
"repo_name": "Kaleado/the-discerning-reader",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport re\n\nBATCH_SIZE = 128\nMAX_WORDS_IN_REVIEW = 100 # Maximum length of a review to consider\nEMBEDDING_SIZE = 50 # Dimensions for each word vector\n\nstop_words = set({'ourselves', 'hers', 'between', 'yourself', 'again',\n 'there', 'about', 'once', 'during', 'out', 'very', 'having',\n 'with', 'they', 'own', 'an', 'be', 'some', 'for', 'do', 'its',\n 'yours', 'such', 'into', 'of', 'most', 'itself', 'other',\n 'off', 'is', 's', 'am', 'or', 'who', 'as', 'from', 'him',\n 'each', 'the', 'themselves', 'below', 'are', 'we',\n 'these', 'your', 'his', 'through', 'don', 'me', 'were',\n 'her', 'more', 'himself', 'this', 'down', 'should', 'our',\n 'their', 'while', 'above', 'both', 'up', 'to', 'ours', 'had',\n 'she', 'all', 'no', 'when', 'at', 'any', 'before', 'them',\n 'same', 'and', 'been', 'have', 'in', 'will', 'on', 'does',\n 'yourselves', 'then', 'that', 'because', 'what', 'over',\n 'why', 'so', 'can', 'did', 'not', 'now', 'under', 'he', 'you',\n 'herself', 'has', 'just', 'where', 'too', 'only', 'myself',\n 'which', 'those', 'i', 'after', 'few', 'whom', 't', 'being',\n 'if', 'theirs', 'my', 'against', 'a', 'by', 'doing', 'it',\n 'how', 'further', 'was', 'here', 'than'})\n\ndef preprocess(review):\n \"\"\"\n Apply preprocessing to a single review. You can do anything here that is manipulation\n at a string level, e.g.\n - removing stop words\n - stripping/adding punctuation\n - changing case\n - word find/replace\n RETURN: the preprocessed review in string form.\n \"\"\"\n\n # Convert to lowercase.\n processed_review = review.lower()\n\n # Remove punctuation by replacing punctuation with spaces.\n processed_review = re.sub(\"[\\.,'\\\"\\(\\)-=+_!@#$%\\^&\\*]\", \" \", processed_review)\n\n # Remove excess spaces.\n processed_review = re.sub(\" +\", \" \", processed_review)\n\n # Split at each word boundary.\n processed_review = processed_review.split(\" \")\n\n # Remove stop words.\n processed_review = [it for it in processed_review if it not in stop_words]\n\n return processed_review\n\n\n\ndef define_graph():\n \"\"\"\n Implement your model here. You will need to define placeholders, for the input and labels,\n Note that the input is not strings of words, but the strings after the embedding lookup\n has been applied (i.e. arrays of floats).\n\n In all cases this code will be called by an unaltered runner.py. You should read this\n file and ensure your code here is compatible.\n\n Consult the assignment specification for details of which parts of the TF API are\n permitted for use in this function.\n\n You must return, in the following order, the placeholders/tensors for;\n RETURNS: input, labels, optimizer, accuracy and loss\n \"\"\"\n\n # Nick: To confirm: what should the shape of the input and output tensors be?\n learning_rate = 0.001 # Nick: it feels weird putting this logic in here.\n num_units = MAX_WORDS_IN_REVIEW # Nick: Also arbitrary, unsure if more units = better.\n input_data = tf.placeholder(tf.float32,\n [BATCH_SIZE, MAX_WORDS_IN_REVIEW, EMBEDDING_SIZE],\n \"input_data\")\n\n labels = tf.placeholder(tf.float32, [None, 2], \"labels\")\n dropout_keep_prob = tf.placeholder(tf.float32, shape=[]) # Nick: To do.\n\n # Nick: Here we build the network itself. I assume this will involve using\n # LSTM cells from tf.nn.rnn_cell.LSTMCell.\n lstm_cell = tf.nn.rnn_cell.LSTMCell(num_units);\n final_input_sequence = tf.unstack(input_data, MAX_WORDS_IN_REVIEW, 1)\n rnn_output, state = tf.nn.static_rnn(lstm_cell, final_input_sequence, dtype=tf.float32)\n\n # Nick: We need some way of converting the rnn_output to be of shape\n # matching the labels.\n weight = tf.get_variable(\"weight\", [num_units, 2], dtype=tf.float32,\n initializer=tf.truncated_normal_initializer, trainable=True)\n last = rnn_output[-1] # tf.gather(rnn_output, int(rnn_output.get_shape()[0]) - 1)\n logits = tf.matmul(tf.reshape(last, [-1, num_units]), weight)\n preds = tf.nn.softmax(logits)\n\n # Nick: Should we be using softmax?\n batch_cross_entropy = tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels, logits=logits)\n batch_loss = tf.reduce_mean(batch_cross_entropy, name=\"loss\") # | || || |_\n\n # Nick: we calculate the accuracy, this is just copied from asst1 so I have\n # no idea if this is right.\n correct_preds_op = tf.equal(tf.argmax(preds, 1), tf.argmax(labels, 1))\n accuracy = tf.reduce_mean(tf.cast(correct_preds_op, tf.float32), name=\"accuracy\")\n\n # Nick: This is also arbitrarily chosen.\n optimizer = tf.train.AdamOptimizer(learning_rate).minimize(batch_loss)\n\n return input_data, labels, dropout_keep_prob, optimizer, accuracy, batch_loss\n"
}
] | 2 |
bobdingster/GA_Capstone
|
https://github.com/bobdingster/GA_Capstone
|
2071c3a3fd34fbc5958c6858c780e36abc55156f
|
28f88f946b83f039fac80dc8a961a077938527e0
|
7281a81a158dd5b0a8166c3794e2aef20a2cffc0
|
refs/heads/master
| 2022-12-25T03:31:58.338340 | 2020-10-12T22:27:30 | 2020-10-12T22:27:30 | 298,156,564 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.684949517250061,
"alphanum_fraction": 0.6941640973091125,
"avg_line_length": 34.609375,
"blob_id": "799154f9c5d682f1d83c653b11a0840bdd9db30a",
"content_id": "ba4cfdf8752f3cc78cecf48ba99ed6d895a232fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2279,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 64,
"path": "/src/app2.py",
"repo_name": "bobdingster/GA_Capstone",
"src_encoding": "UTF-8",
"text": "import food_functions\nimport user_recommender\nfrom flask import Flask, url_for, request, redirect, render_template\n\n#initializing the flask app\napp = Flask('recipe_recommender')\n\n#Initializing the first page\[email protected](\"/\")\n\n# Initializing and Defining what happens on the home page\[email protected](\"/home\")\ndef home():\n return render_template('home2.html')\n\n\n# Initializing and Defining what happens on the about page\[email protected](\"/about\")\ndef about():\n return render_template('about.html')\n\n# Initializing and Defining what happens on the results page\[email protected](\"/results\")\ndef results():\n return render_template('results.html')\n\n\n# Initializing and Defining what happens when someone clicks submit\[email protected](\"/submit\")\ndef form_submit():\n user_input = request.args\n # search = str(user_input['search'])\n response = str(user_input['user_text']) # get the user input\n output1 = food_functions.ingredient_find(response)\n output = output1[['name', 'minutes', 'ingredients', 'match']]\n output.set_index('name', inplace=True)\n return render_template('results.html', tables=[output.to_html(classes='data')], titles=output.columns.values) # Show html output on page\n\[email protected](\"/submit2\")\ndef form_submit2():\n user_input = request.args\n # search = str(user_input['search2'])\n response = str(user_input['user_text2']) # get the user input\n # if search == \"ingr2\":\n output2 = user_recommender.recommender(response)\n # output = output1[['name', 'minutes', 'ingredients', 'match']]\n # output.set_index('name', inplace=True)\n return render_template('results.html', tables=[output2.to_html(classes='data')], titles=output2.columns.values) # Show html output on page\n\[email protected](\"/submit3\")\ndef form_submit3():\n user_input = request.args\n # search = str(user_input['search2'])\n response = str(user_input['user_text2']) # get the user input\n # if search == \"ingr2\":\n output3 = user_recommender.recommender(response)\n # output = output1[['name', 'minutes', 'ingredients', 'match']]\n # output.set_index('name', inplace=True)\n return render_template('results.html', tables=[output3.to_html(classes='data')], titles=output3.columns.values) # Show html output on page\n\n\n\nif __name__ == '__main__':\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.5945945978164673,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 20.473684310913086,
"blob_id": "51f9fcadd0645755df61d23e22e0d47b5e1e57e4",
"content_id": "bde3e87c084cabc8fb4a387a330876e1e7331dcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 19,
"path": "/src/static/js/script.js",
"repo_name": "bobdingster/GA_Capstone",
"src_encoding": "UTF-8",
"text": "Restaurants = {\n init: function(restaurant_names) {\n this.autoComplete(restaurant_names)\n this.searchIconClick()\n },\n\n autoComplete: function(restaurant_names) {\n $(\".input-text.restaurant\" ).autocomplete({\n source: restaurant_names\n });\n },\n\n searchIconClick: function(){\n $(\".search\").on(\"click\", function() {\n $(\".search img\").hide();\n $(\".loader\").show();\n })\n }\n}"
},
{
"alpha_fraction": 0.6751241087913513,
"alphanum_fraction": 0.6828461289405823,
"avg_line_length": 45.487178802490234,
"blob_id": "1c4bf28130096c0fad30417b6ceba2fa2a547ce2",
"content_id": "fdf3cc55f158c541c4032e14e541c68529a71625",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1813,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 39,
"path": "/src/user_recommender.py",
"repo_name": "bobdingster/GA_Capstone",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom scipy import sparse\nfrom sklearn.metrics.pairwise import pairwise_distances, cosine_distances, cosine_similarity\nimport os\nos.environ['KMP_DUPLICATE_LIB_OK']='True' # with this can handle more merories, avoid kernel dead error.\n\ndef generate_table():\n recipes = pd.read_csv('../organized_recipes.csv')\n recipes = recipes[['id','name']]\n ratings = pd.read_csv('../cleaned_reviews.csv')\n ratings = ratings[['user_id', 'recipe_id', 'rating']]\n df = pd.merge(ratings, recipes, how='inner', left_on='recipe_id', right_on='id').drop(columns='id')\n review_count = df.groupby('recipe_id').count()\n selected_recipes = review_count[(review_count['rating'] > 4) & (review_count['rating'] < 9)].index\n df = df.set_index('recipe_id').loc[selected_recipes,:]\n df.reset_index(inplace=True)\n # clear up the memeories\n del ratings\n ratings = pd.DataFrame()\n del recipes\n recipes = pd.DataFrame()\n #### Clear up end ####\n pivot = pd.pivot_table(df, index='name', columns='user_id', values='rating')\n sparse_pivot = sparse.csr_matrix(pivot.fillna(0))\n dists = pairwise_distances(sparse_pivot, metric='cosine')\n similarities = cosine_similarity(sparse_pivot)\n recommender_df = pd.DataFrame(dists, columns=pivot.index, index=pivot.index)\n return recommender_df\n\n\ndef recommender(user_input2):\n df = generate_table()\n names = df[df.index.str.contains(user_input2)].index\n chosen_recipe2 = pd.DataFrame()\n for name in names:\n # chosen_recipe2 = pd.concat([chosen_recipe2, df[[name]].sort_values(by=name, ascending=True).head(6)])\n chosen_recipe2 = pd.concat([chosen_recipe2, df[[name]].sort_values(by=name, ascending=True).head(6).set_axis(['Pairwise_distances'], axis=1)])\n return chosen_recipe2\n"
},
{
"alpha_fraction": 0.7058707475662231,
"alphanum_fraction": 0.723010241985321,
"avg_line_length": 37.16541290283203,
"blob_id": "6847b43cf053714e1a1d8efa284c19634d15364c",
"content_id": "2d13526344a4a23ca7df5982bf1c48663b457502",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5078,
"license_type": "no_license",
"max_line_length": 301,
"num_lines": 133,
"path": "/README.md",
"repo_name": "bobdingster/GA_Capstone",
"src_encoding": "UTF-8",
"text": "# Recipe Recommendation System\n<p align=\"center\">\n<img src=\"./img/cookie2.png\" alt=\"drawing\" width=\"400\" />\n</p>\n\nInspired by my daughter's love for [cooking and baking](https://paintpencilpastries.com/), I decided to build a recipe recommender system to fulfill my graduation requirement from General Assembly.\n\n\n**Machine Learning Problems**:\n1. Can I predict the recipe ratings from user's review?\n\n2. Given certain ingredients, such as things I have in the fridge, could I find some recipes or some suggestions about what to cook?\n\n3. Given a person’s choice one recipe, could I recommend other similar recipes they might enjoy?\n\n4. Can I categorize the recipes? Given a certain recipe, can I find other recipes that fall into the same categories?\n\nThe motivation behind this recommendation system is to help users discover personalized and new recipes, or prepare for grocery runs.\n\n\n# Data\n\nThis dataset consists of 230K+ recipes and 1M+ recipe reviews covering 18 years of user interactions and uploads on Food.com (formerly GeniusKitchen). The dataset is collected and stored at [Kaggle.com](https://www.kaggle.com/shuyangli94/food-com-recipes-and-user-interactions?select=RAW_recipes.csv).\n\n\n\n**Content Data**\n\n- `RAW_recipes.csv`\n\n- 231,637 Recipes\n\n- Data Columns <br>\n\n|Feature|Type|Description|\n|---|---|-----|\n|name|*object*|Recipe name|\n|id|*int*|Recipe id|\n|minutes|*int*|Minutes to prepare recipe|\n|contributor_id|*int*|User ID who submitted this recipe|\n|submitted|*object*|Date recipe was submitted|\n|tags|*object*|Food.com tags for recipe|\n|nutrition|*object*|Nutrition information (calories, total fat, sugar, sodium, protein, saturated fat)|\n|n_steps|*int*|Number of steps in recipe|\n|steps|*object*|Text for recipe steps, in order|\n|description|*object*|User-provided description|\n\n\n**Content Data**\n\n- `RAW_interactions.csv`\n- 1,132,367 users reviews and ratings\n\n- Data Columns <br>\n\n|Feature|Type|Description|\n|---|---|-----|\n|user_id|*int*|User ID|\n|recipe_id|*int*|Recipe id|\n|date|*object*|Date of review/rating|\n|rating|*int*|Rating given, range 0 to 5|\n|review|*object*|Review text|\n\n# Data Cleaning\nNotebook `01_Recipes_Data_Cleaner.ipynb` <br>\n+ Drop recipes with missing or extreme values in raw dataset, then save cleaned data with 191,481 recipes to new csv file `organized_recipes.csv`\n+ Drop reviews with missing text and zero ratings in raw dataset, then save cleaned data with 1,071,351 reviews to new csv file `cleaned_reviews.csv`\n\n\n# Exploratory Data Analysis\nNotebook `02_Exploratory_Data_Analysis.ipynb` <br>\n\n**Top 20 words in ingredients**\n\n<br><p>\n\n**Top 20 words in recipe names**\n\n\n\n| Recipe ingredient top words | Recipe name top words Stopwords |\n| ----------------------------------------------------- | ----------------------------------------------- |\n|  |  |\n\n\n# Models\n\n\n1. Classifications - Use Naive Bayes and Gradient Boost Models to predict ratings from review text--- `03_Ratings_Classifier.ipynb`\n\n> If I found one user wrote in the review \"So simple, so delicious! Great\", the model can predict which rating the user would give.\n\n2. Matching - Use Numpy and Pandas to create search functions which would find recipes with the best ingredient matches. --- `04_Ingredient_match.ipynb`\n\n> If I have winter squash, Mexican seasoning, mixed spice and honey in the fridge, the model can give some recipes on what to cook with these ingredients\n\n3. Collaborative Filtering - Suggest recipes that other users similar to you also liked (Cosine Similarity) --- `05_Item_Collaborative.ipynb` and `05_1_user_collaborative.ipynb`\n\n> If I liked *Oven fried chicken*, and another user similar to me liked *The Texas bbq rub* and I haven't tried it, the model would recommend that recipe.\n\n4. Content Based Filtering - Suggest recipes that are similar to recipes that you like (LDA model similarities) --- `06_LDA_Content_Based.ipynb`\n\n> If I liked *baked winter squash*, the model would recommend *outback croutons*, because the model found some categories that both recipes share.\n\n# Tech Stack\n\n1. **Data Wrangling**: pandas, numpy, re\n\n2. **Visualization**: matplotlib, seaborn\n\n3. **Model:** scikit-learn, scipy, gensim\n\n4. **Web Framework**: flask, html\n\n\n# Conclusions and Next Steps\n\n1. Model 2, 3 and 4 recommender works well when input query separately on Jupiter notebook. \n\n2. Need more work to combine the simple search, collaborative filtering and content-based filter together.\n\n3. Web app (Flask) works and return results. But need more work to improve user interface and shorten the running time.\n\n4. Possible generate new recipe based on user's preference.\n\n\n# Acknowledgements\n\n1. Elizabeth Ding, blog https://paintpencilpastries.com/ for food photos.\n\n2. Shuyang Li, at [Kaggle.com](https://www.kaggle.com/shuyangli94/food-com-recipes-and-user-interactions?select=RAW_recipes.csv) for food.com dataset.\n\n2. Kelly S. and Noah C, private communications.\n"
},
{
"alpha_fraction": 0.5839464664459229,
"alphanum_fraction": 0.587959885597229,
"avg_line_length": 28.3137264251709,
"blob_id": "a72545a062da7dd94a35e9fb58b33d40ef190b50",
"content_id": "d34134e4c908454df628fa65cd7581726ccecbd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1495,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 51,
"path": "/src/food_functions.py",
"repo_name": "bobdingster/GA_Capstone",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport re\ndef matches_df(column, df, user_input):\n\n matches = []\n\n # split the entered keywords by comma\n keywords = re.split('; |, |,|\\*|\\n',user_input.lower())\n# keywords = user_input.lower().split(',')\n\n # create an empty list to store keywords\n keyword_list = []\n\n for i in range(len(keywords)):\n\n # remove white space\n keywords[i] = keywords[i].strip()\n# print(f'User Input: {keywords[i]}\\n')\n # append it to keyword_list\n keyword_list.append(keywords[i])\n\n # separate each row\n for text in column:\n\n # initiate 0 as match\n match = 0\n\n # iterate through words in keyword_list\n for keyword in keyword_list:\n\n # if keyword found in text, assign 1 as match\n # stop comparing once assigned as 1, then append it to the list\n if keyword in text:\n match += 1\n #print(text)\n# break\n matches.append(match)\n\n df['match'] = matches\n return df.sort_values(by=['match'], ascending=False).head(3)\n\ndef ingredient_find(user_input):\n df = pd.read_csv('../data/organized_recipes.csv')\n df['ingredients'] = df['ingredients'].map(lambda s: s.strip('[').strip(']').replace(\"'\", \"\").split(', '))\n ingredient_list=[]\n for row in df['ingredients']:\n ingredient_list.extend(row)\n chosen_recipe = matches_df(df['ingredients'], df, user_input)\n\n return chosen_recipe\n"
}
] | 5 |
patirasam/Deep-Learning-Neural-Networks
|
https://github.com/patirasam/Deep-Learning-Neural-Networks
|
591d4b2826ae4121b12f91929153d2d9ff5b0dd6
|
0cbcdb016f75fd6f18f8f3725631a7ca4ba1b2c4
|
381c0c0fe3985846663a17a6272b6c0aa37c7c24
|
refs/heads/master
| 2021-09-13T00:09:21.726931 | 2018-04-23T00:37:02 | 2018-04-23T00:37:02 | 122,529,565 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8256880640983582,
"alphanum_fraction": 0.8256880640983582,
"avg_line_length": 71.33333587646484,
"blob_id": "7433c89044e30be3ec6aac90d4b29c93aca5e645",
"content_id": "d253243ea752322b1d8e6ad168c2bbbfcc310b94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 3,
"path": "/README.md",
"repo_name": "patirasam/Deep-Learning-Neural-Networks",
"src_encoding": "UTF-8",
"text": "# Machine-Learning-Neural-Networks\n- Neural_Networks-Implementation without using library in Python, \n- Main aim is to understand how actually neural network works including back propogation and universality theorem. \n"
},
{
"alpha_fraction": 0.5756586790084839,
"alphanum_fraction": 0.5833527445793152,
"avg_line_length": 27.925676345825195,
"blob_id": "bbf95343d2e12a75729bb164ce6f6fe802957ad6",
"content_id": "8b464fa6053f8c954bdf994150509454e454c29b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4289,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 148,
"path": "/NeuralNetwork.py",
"repo_name": "patirasam/Deep-Learning-Neural-Networks",
"src_encoding": "UTF-8",
"text": "import math as m\n\neta=0.01\n\ndef cross_entropy(expected,value):\n return -m.log(value[expected])\n\ndef load_data(f):\n data=[]\n with open(f,\"r\") as file:\n for line in file:\n data.append([float(field) for field in line.strip().strip()])\n return data\n\ndef logistic_sigmoid(x,derivative=False):\n if not derivative:\n d = 1 + m.e**(-(x**2))\n return (2/d)-1\n else:\n return logistic_sigmoid(x)*(1-logistic_sigmoid(x))\n\nclass Neuron(object):\n def __init__(self,weight=None,activation=None):\n self.weights=weights\n self.activation=activation\n\n def activate(self,inputs):\n\n self.output=[]\n if self.activation is None:\n self.output.extend(inputs)\n\n else:\n sum=0.0\n for i in range(len(inputs)):\n sum +=inputs[i]*self.weights[i]\n self.output=sum\n return self.output\n def output(self):\n return self.output\n def calculate_delta(self,error):\n self.delta=error*self.activation(self.output,True)\n\n def update_weights(self,inputs):\n for i in range(len(self.weights)):\n self.weights[i]-=eta*inputs[i]*self.delta\n\nclass Layer(object):\n\n def __init__(self,label=None):\n\n self.neurons=[]\n self.label=label\n\n def add_neuron(self,neuron):\n self.neurons.append(neuron)\n\n def activate(self,inputs):\n if len(self.neurons)==0:\n self.output=[]\n self.output.extend(inputs)\n\n else:\n self.output=[]\n for neuron in self.neurons:\n self.output.append(neuron.activate(inputs))\n\n return self.output\n\n def output_value(self):\n return self.output\n\n def softmax(self):\n d = sum([(m.e ** el) for el in self.output])\n return [(m.e ** el) / d for el in self.output]\n\n def delta(self):\n return [neuron.delta for neuron in self.neurons]\n\n def calculate_delta(self, next_layer, expected):\n current_layer_errors = []\n\n if self.label == \"output\":\n sm = self.softmax()\n for i in range(len(self.neurons)):\n current_layer_errors.append(sm[i] - expected[i])\n\n else:\n for i in range(len(self.neurons)):\n tmp = 0.0\n for j in range(len(next_layer.neurons)):\n tmp += next_layer.neurons[j].weights[i] * next_layer.neurons[j].delta\n current_layer_errors.append(tmp)\n\n for i in range(len(self.neurons)):\n self.neurons[i].calculate_delta(current_layer_errors[i])\n\n return [neuron.delta for neuron in self.neurons]\n\n def update_weights(self,inputs):\n for neuron in self.neurons:\n neuron.update_weights(inputs)\n\n def get_weights(self):\n return [neuron.weights for neuron in self.neurons]\n\n\n\nimport random\n\ndef ran():\n return random.uniform(-1.0,1.0)\n\ndef main():\n network=[]\n\n network=[]\n input_layer=Layer()\n hidden_layer=Layer()\n hidden_layer.add_neuron(Neuron([ran(),ran()],logistic_sigmoid))\n hidden_layer.add_neuron(Neuron([ran(),ran()],logistic_sigmoid))\n hidden_layer.add_neuron(Neuron([ran(),ran()],logistic_sigmoid))\n hidden_layer.add_neuron(Neuron([ran(),ran()],logistic_sigmoid))\n hidden_layer.add_neuron(Neuron([ran(),ran()],logistic_sigmoid))\n\n output_layer=Layer(\"output\")\n\n output_layer.add_neuron(Neuron([ran(),ran(),ran(),ran(),ran()],logistic_sigmoid))\n output_layer.add_neuron(Neuron([ran(),ran(),ran(),ran(),ran()],logistic_sigmoid))\n\n data=load_data(\"data.txt\")\n\n for i in range(1000):\n for entry in data:\n #forward propogation\n input_layer.activate(entry[:2])\n hidden_layer.activate(input_layer.output_value())\n output_layer.activate(hidden_layer.output_value())\n\n output_layer.calculate_delta(None,[1,0] if entry[2]==0 else [0,1])\n hidden_layer.calculate_delta(output_layer,None)\n output_layer.update_weights(hidden_layer.output_value())\n hidden_layer.update_weights(entry[:2])\n\n print(entry[0],entry[1],output_layer.softmax()[0],output_layer.softmax()[1])\n\n\nmain()\n\n\n\n\n\n\n\n\n"
}
] | 2 |
sofyan48/ADRINI_SSO_PLATFORM
|
https://github.com/sofyan48/ADRINI_SSO_PLATFORM
|
32800b4066102dae621d8eb09dbda4eed3ca1fcb
|
4b57cbd2de991aa1c38313b50a7bf788b6d5e4e3
|
65d9becb7d9144a14cb28dca341ca8dd8dd81c56
|
refs/heads/master
| 2022-12-11T09:17:18.411745 | 2019-02-26T10:46:42 | 2019-02-26T10:46:42 | 172,597,166 | 0 | 0 |
MIT
| 2019-02-25T22:42:24 | 2019-07-27T12:17:24 | 2022-12-08T01:38:28 |
Python
|
[
{
"alpha_fraction": 0.5270994901657104,
"alphanum_fraction": 0.5339487791061401,
"avg_line_length": 27.226890563964844,
"blob_id": "465fb3001400bc1f32f37e39a68478a2fddaf887",
"content_id": "10befc6a2da3e37414fccea6a5f79bde464d425a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3358,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 119,
"path": "/app/controllers/user.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from app import app, redis_store\nfrom flask import request, url_for, request, jsonify\nfrom flask import session, redirect\nfrom app.libs import utils\nfrom app.helper.rest import response\nfrom app.models import model as db\nfrom app import db as dbq\nfrom app.middlewares.auth import get_jwt_identity, login_required\nimport hashlib, uuid\n\n\[email protected](\"/user/get\", methods=['GET'])\n@login_required\ndef user_get():\n id_userdata = get_jwt_identity()\n obj_userdata = list()\n column = db.get_columns('tb_userdata')\n try:\n results = list()\n query = \"select * from tb_userdata where id_userdata='\"+id_userdata+\"' \"\n data = db.query(query)\n rows = dbq.fetchall()\n for row in rows:\n print(row)\n results.append(dict(zip(column, row)))\n except Exception as e:\n return response(200, message=str(e))\n else:\n for i in results :\n data = {\n \"id_userdata\": str(i['id_userdata']),\n \"email\" : i['email'],\n \"first_name\" : i['first_name'],\n \"last_name\" : i['last_name'],\n \"location\" : i['location']\n }\n obj_userdata.append(data)\n return response(200, data=obj_userdata)\n\[email protected](\"/user/delete\", methods=['GET'])\n@login_required\ndef delete():\n id_userdata = get_jwt_identity()\n try:\n db.delete(\n table=\"tb_userdata\", \n field='id_userdata',\n value=id_userdata\n )\n except Exception as e:\n message = {\n \"status\": False,\n \"error\": str(e)\n }\n else:\n message = \"removing\"\n\n finally:\n return response(200, message=message)\n\[email protected](\"/user/update\", methods=['POST'])\n@login_required\ndef update():\n id_userdata = get_jwt_identity()\n data = {\n \"where\":{\n \"userdata_id\": id_userdata\n },\n \"data\":{\n \"email\" : request.form['email'],\n \"first_name\" : request.form['first_name'],\n \"last_name\" : request.form['last_name'],\n \"location\" : request.form['location']\n }\n }\n\n try:\n db.update(\"tb_userdata\", data=data)\n except Exception as e:\n message = {\n \"status\": False,\n \"error\": str(e)\n }\n else:\n message = {\n \"status\": True,\n \"data\": data\n }\n finally:\n return response(200, message=message)\n\[email protected]('/user/add', methods=['POST'])\ndef insert_user(self):\n random_string = uuid.uuid4()\n raw_token = '{}{}'.format(random_string, request.form['email'])\n access_token = hashlib.sha256(raw_token.encode('utf-8')).hexdigest()\n\n data_insert = {\n \"email\" : request.form['email'],\n \"first_name\" : request.form['first_name'],\n \"last_name\" : request.form['last_name'],\n \"location\" : request.form['location'],\n \"sso_id\" : access_token,\n }\n try:\n result = db.insert(table=\"tb_userdata\", data=data_insert)\n except Exception as e:\n data = {\n \"status\": False,\n \"error\": str(e)\n }\n return response(200, message=data)\n else:\n data = {\n \"status\": True,\n \"data\": data_insert,\n \"id\": result\n }\n return response(200, data=data)"
},
{
"alpha_fraction": 0.7109375,
"alphanum_fraction": 0.7161458134651184,
"avg_line_length": 12.75,
"blob_id": "6e12eafde08ecf65454293fdd105c5f68f431587",
"content_id": "58d36daec5013d5509aa19464abcec8d91c9dbb9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 384,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 28,
"path": "/README.md",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "# SSO PLATFORM FOR ADRINI\n\n## INSTALLING\n\nCopy env.example to .env\n```\ncp env.example .env\n```\nsetting your environment\n\n```\npip install -r requirements.txt\n```\n\n## DATABASE\nInstalling InfluxDB Reference [action](https://docs.influxdata.com/influxdb/v1.7/introduction/installation/)\n\n## DEVELOPMENT\n\n```\npython manager.py server\n```\n\n## PRODUCTION\nusing gunicorn run\n```\nsh run.sh\n```"
},
{
"alpha_fraction": 0.5785161852836609,
"alphanum_fraction": 0.5953572988510132,
"avg_line_length": 31.323530197143555,
"blob_id": "4534a133487f590932503bce615adbfd10f18df5",
"content_id": "17c0db59e89f305a4d3f75343c41d3e0e37a4ecb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2197,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 68,
"path": "/app/controllers/auth.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from app import app, redis_store\nfrom flask import request, url_for, request, jsonify\nfrom flask import session, redirect\nfrom app.libs import utils\nfrom app.helper.rest import response\nfrom app.models import model as db\nfrom app import db as dbq\nfrom passlib.hash import pbkdf2_sha256\nfrom datetime import datetime\nimport hashlib, uuid, dill\n\n\[email protected]('/login/add', methods=['POST'])\ndef insert_login():\n password_hash = pbkdf2_sha256.hash(request.form['password'])\n data_insert = {\n \"id_userdata\" : request.form['userdata_id'],\n \"username\" : request.form['username'],\n \"password\" : password_hash,\n }\n\n try:\n db.insert(table=\"tb_user\", data=data_insert)\n except Exception as e:\n respon = {\n \"status\": False,\n \"error\": str(e)\n }\n else:\n data_insert = {\n \"userdata_id\" : request.form['userdata_id'],\n \"username\" : request.form['username'],\n }\n respon = {\n \"status\": True,\n \"data\": data_insert\n }\n return response(200, message=respon)\n\[email protected]('/login')\ndef sigin():\n username = request.form['username']\n password = request.form['password']\n\n user = db.get_by_id(table= \"tb_user\",field=\"username\",value=username)\n\n if not user or not pbkdf2_sha256.verify(password, user[0]['password']):\n return response(status_code=401, data=\"You Not Authorized\")\n else:\n random_string = uuid.uuid4()\n raw_token = '{}{}'.format(random_string, username)\n access_token = hashlib.sha256(raw_token.encode('utf-8')).hexdigest()\n\n userdata = db.get_by_id(table= \"tb_userdata\", field=\"id_userdata\", value=user[0]['id_userdata'])\n stored_data = {\n 'id_userdata': user[0]['id_userdata'],\n 'email': userdata[0]['email'],\n 'username': username\n }\n dill_object = dill.dumps(stored_data)\n redis_store.set(access_token, dill_object)\n redis_store.expire(access_token, 3600)\n data = {\n 'email': userdata[0]['email'],\n 'Access-Token': access_token,\n 'expires': 3600\n }\n return response(200, data=data)"
},
{
"alpha_fraction": 0.45098039507865906,
"alphanum_fraction": 0.6274510025978088,
"avg_line_length": 16.33333396911621,
"blob_id": "a23d9bbb5a8acbc7dcb64450ef33ec25739847f6",
"content_id": "b06431f0aef231dbd1975b74a9336cd0cd73e2e1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 51,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 3,
"path": "/run.sh",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ngunicorn app:app -b 0.0.0.0:5000 -w $1"
},
{
"alpha_fraction": 0.6403207182884216,
"alphanum_fraction": 0.6403207182884216,
"avg_line_length": 23.27777862548828,
"blob_id": "acee5e1ef1d725f07b60c0738bd5769365953a3b",
"content_id": "c147e900a62ceecf75fea82f21c050cd6e65132c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 36,
"path": "/app/libs/utils.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from app import root_dir\nfrom datetime import datetime\nimport json, requests\n\n\ndef timeset():\n return datetime.utcnow().strftime('%Y-%m-%dT%H:%M:%SZ')\n\ndef mkdir(dir):\n if not os.path.isdir(dir):\n os.makedirs(dir)\n\ndef read_file(file):\n with open(file, 'r') as outfile:\n return outfile.read()\n\ndef list_dir(dirname):\n listdir = list()\n for root, dirs, files in os.walk(dirname):\n for file in files:\n listdir.append(os.path.join(root, file))\n return listdir\n\ndef send_http(url, data):\n json_data = json.dumps(data)\n send = requests.post(url, data=json_data)\n respons = send.json()\n return respons\n\ndef get_http(url, param=None, header=None):\n json_data = None\n if param:\n json_data = param\n get_func = requests.get(url, params=json_data, headers=header)\n data = get_func.json()\n return data"
},
{
"alpha_fraction": 0.5838926434516907,
"alphanum_fraction": 0.5973154306411743,
"avg_line_length": 22,
"blob_id": "11d844b96442a136a6056e33328d4626e09d79e0",
"content_id": "8de9686be0fe0c01099ad0570efbfaeabc2add70",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 298,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 13,
"path": "/manager.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from app import app\nfrom flask_script import Manager, Server\nimport os\n\n\nmanager = Manager(app)\n\nmanager.add_command('server', Server(host=os.getenv('APP_HOST', 'localhost'),\n port=int(os.getenv('APP_PORT', 5000))))\n\n\nif __name__ == '__main__':\n manager.run()"
},
{
"alpha_fraction": 0.5980700850486755,
"alphanum_fraction": 0.6026851534843445,
"avg_line_length": 28.60869598388672,
"blob_id": "f341128393a8f58ccf0fd9776647564c2febb99c",
"content_id": "b5e08ac179ebd915313fb075a8f625397e822f47",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4767,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 161,
"path": "/app/controllers/login.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from app import app, redis_store, OAuthException\nfrom flask import render_template, g\nfrom flask import session, redirect, url_for, request, jsonify\nfrom app.libs import utils\nfrom app.models import model\nfrom app.helper import oauth\nfrom app.helper.rest import response\nimport os, dill\n\n\[email protected]('/google')\ndef google_login():\n callback = url_for('authorized', _external=True)\n return oauth.google.authorize(callback=callback)\n\[email protected](os.getenv('REDIRECT_URI'))\[email protected]_handler\ndef authorized(resp):\n access_token = resp['access_token']\n headers = {\n 'Authorization': 'OAuth '+access_token\n }\n try:\n req = utils.get_http('https://www.googleapis.com/oauth2/v1/userinfo',\n None, headers)\n except Exception:\n return redirect(url_for('google'))\n\n try:\n dt_db = model.get_by_id(\"tb_userdata\",\"email\",req['email'])\n except Exception as e:\n dt_db = None\n if not dt_db:\n data_save = {\n \"sso_id\": req['id'],\n \"first_name\": req['given_name'],\n \"last_name\": req['family_name'],\n \"email\": req['email'],\n \"location\": \"\",\n \"picture\": req['picture']\n }\n try:\n model.insert(\"tb_userdata\", data_save)\n except Exception as e:\n print(e)\n expires_in = resp['expires_in']\n dill_object = dill.dumps(data_save)\n redis_store.set(access_token, dill_object)\n redis_store.expire(access_token, expires_in)\n else:\n expires_in = resp['expires_in']\n dill_object = dill.dumps(dt_db[0])\n redis_store.set(access_token, dill_object)\n redis_store.expire(access_token, expires_in)\n\n data_result = {\n \"Access-Token\": access_token,\n \"email\": req['email'],\n \"expires\": expires_in\n }\n return response(200, data=data_result)\n\n\[email protected]('/facebook')\ndef facebook():\n callback = url_for(\n 'facebook_authorized',\n next=request.args.get('next') or request.referrer or None,\n _external=True\n )\n return oauth.facebook.authorize(callback=callback)\n\n\n\[email protected](str(os.getenv('REDIRECT_URI_FB')))\[email protected]_handler\ndef facebook_authorized(resp):\n if resp is None:\n return 'Access denied: reason=%s error=%s' % (\n request.args['error_reason'],\n request.args['error_description']\n )\n if isinstance(resp, OAuthException):\n return 'Access denied: %s' % resp.message\n\n # session['oauth_token'] = (resp['access_token'], '')\n # me = facebook.get('/me')\n # return str(me)\n\[email protected]('/github')\ndef login():\n return oauth.github.authorize(callback=url_for('github_authorized', _external=True))\n\[email protected](os.getenv('REDIRECT_URI_GITHUB'))\ndef github_authorized():\n resp = oauth.github.authorized_response()\n token = None\n for i in resp:\n if i == 'access_token':\n token = resp[i]\n req = utils.get_http('https://api.github.com/user?access_token='+token,\n None, None)\n try:\n dt_db = model.get_by_id(\"tb_userdata\",\"email\",req['email'])\n except Exception as e:\n dt_db = None\n if not dt_db:\n data_save = {\n \"sso_id\": req['id'],\n \"first_name\": req['given_name'],\n \"last_name\": req['family_name'],\n \"email\": req['email'],\n \"location\": \"\",\n \"picture\": req['picture']\n }\n try:\n model.insert(\"tb_userdata\", data_save)\n except Exception as e:\n print(e)\n dill_object = dill.dumps(data_save)\n redis_store.set(token, dill_object)\n redis_store.expire(token, 3600)\n else:\n dill_object = dill.dumps(dt_db[0])\n redis_store.set(token, dill_object)\n redis_store.expire(token, 3600)\n\n data_result = {\n \"Access-Token\": token,\n \"email\": req['email'],\n \"expires\": 3600\n }\n return response(200, data=data_result)\n\[email protected]\ndef get_github_oauth_token():\n return \"\"\n\[email protected]('/twitter')\ndef tweet():\n callback_url = url_for('tweet_oauthorized', next=request.args.get('next'))\n return oauth.twitter.authorize(callback=callback_url or request.referrer or None)\n\n\[email protected]('/logout')\ndef logout():\n session.pop('twitter_oauth', None)\n return redirect(url_for('index'))\n\[email protected](str(os.getenv('REDIRECT_URI_TWITTER')))\ndef tweet_oauthorized():\n g.access_token = None\n resp = oauth.twitter.authorized_response()\n access_token = resp['oauth_token']\n g.access_token = access_token\n a = oauth.twitter.get(\"lists/show.json\")\n return str(a)\n\[email protected]\ndef get_twitter_token():\n return g.access_token\n"
},
{
"alpha_fraction": 0.7267502546310425,
"alphanum_fraction": 0.7591431736946106,
"avg_line_length": 57,
"blob_id": "330bb17b8703419fe146b5626db1223c9fa9097a",
"content_id": "ae7c6d1e27567915c6b38a7e2bb25ce57b6f5c79",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1914,
"license_type": "permissive",
"max_line_length": 540,
"num_lines": 33,
"path": "/db.sql",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "CREATE TABLE tb_userdata (\n\tid_userdata INT NOT NULL DEFAULT unique_rowid(),\n\tsso_id STRING NOT NULL,\n\tfirst_name STRING NULL,\n\tlast_name STRING NULL,\n\tlocation STRING NULL,\n\temail STRING NOT NULL,\n\tpicture STRING NULL,\n\tCONSTRAINT tb_userdata_pk PRIMARY KEY (id_userdata DESC),\n\tUNIQUE INDEX tb_userdata_un (email DESC),\n\tUNIQUE INDEX tb_userdata_sso (sso_id DESC),\n\tFAMILY \"primary\" (id_userdata, sso_id, first_name, last_name, location, email, picture)\n);\n\nCREATE TABLE tb_user (\n\tid_user INT NOT NULL DEFAULT unique_rowid(),\n\tid_userdata INT NOT NULL,\n\tusername VARCHAR NOT NULL,\n\tpassword VARCHAR NOT NULL,\n\tCONSTRAINT tb_user_pk PRIMARY KEY (id_user ASC),\n\tUNIQUE INDEX tb_user_un (id_userdata ASC),\n\tFAMILY \"primary\" (id_user, id_userdata, username, password)\n);\n\nCREATE VIEW v_widget (id_widget, id_channels, nm_widget, nm_channels, channels_key, id_userboard, id_userdata, id_board, email) AS SELECT a1.id_widget, a1.id_channels, a1.nm_widget, a2.nm_channels, a2.channels_key, a3.id_userboard, a3.id_userdata, a3.id_board, a4.email FROM iot_adrini.public.tb_widget AS a1 JOIN iot_adrini.public.tb_channels AS a2 ON a1.id_channels = a2.id_channels JOIN iot_adrini.public.tb_userboard AS a3 ON a2.id_userboard = a3.id_userboard JOIN iot_adrini.public.tb_userdata AS a4 ON a3.id_userdata = a4.id_userdata;\n\nINSERT INTO tb_userdata (id_userdata, sso_id, first_name, last_name, location, email, picture) VALUES\n\t(429520543461146625, '111307412920325935077', 'meong', 'bego', '', '[email protected]', 'https://lh4.googleusercontent.com/-egNEmgFlfvs/AAAAAAAAAAI/AAAAAAAADhc/lu-iH-962kk/photo.jpg');\n\nALTER TABLE tb_user ADD CONSTRAINT tb_user_tb_userdata_fk FOREIGN KEY (id_userdata) REFERENCES tb_userdata (id_userdata) ON DELETE CASCADE ON UPDATE CASCADE;\n\n-- Validate foreign key constraints. These can fail if there was unvalidated data during the dump.\nALTER TABLE tb_user VALIDATE CONSTRAINT tb_user_tb_userdata_fk;\n"
},
{
"alpha_fraction": 0.7166666388511658,
"alphanum_fraction": 0.7166666388511658,
"avg_line_length": 19.33333396911621,
"blob_id": "36bcc892196362a826638af128d84064442f460f",
"content_id": "6690fb9d4c3fd5fa54930fdf98c5b331d4fb6c9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 3,
"path": "/app/controllers/__init__.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from .login import *\nfrom .user import *\nfrom .auth import *"
},
{
"alpha_fraction": 0.4653465449810028,
"alphanum_fraction": 0.698019802570343,
"avg_line_length": 15.833333015441895,
"blob_id": "ad8c04b51f48850f3e53b5b99b8c4f339879d78d",
"content_id": "eff601534ac7b7e7de48d0fd3124f15cdee2aac2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 404,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 24,
"path": "/requirements.txt",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "aniso8601==4.1.0\ncertifi==2018.11.29\nchardet==3.0.4\nClick==7.0\nFlask==1.0.2\nFlask-Env==2.0.0\nFlask-OAuthlib==0.9.5\nFlask-Script==2.0.6\ngunicorn==19.9.0\nhttplib2==0.12.1\nidna==2.8\nitsdangerous==1.1.0\nJinja2==2.10\nMarkupSafe==1.1.0\noauth2==1.9.0.post1\noauthlib==2.1.0\npsycopg2==2.7.7\npython-dotenv==0.10.1\npytz==2018.9\nrequests==2.21.0\nrequests-oauthlib==1.2.0\nsix==1.12.0\nurllib3==1.24.1\nWerkzeug==0.14.1\n"
},
{
"alpha_fraction": 0.7147147059440613,
"alphanum_fraction": 0.717717707157135,
"avg_line_length": 22.714284896850586,
"blob_id": "15dd9c0080ed779a10234ffcacec8c6f74318686",
"content_id": "228c1ec613f7b23a24f223451f86a9d99ca42b91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 28,
"path": "/app/__init__.py",
"repo_name": "sofyan48/ADRINI_SSO_PLATFORM",
"src_encoding": "UTF-8",
"text": "from . import configs\nfrom flask import Flask\nfrom flask_oauthlib.client import OAuth, OAuthException\nfrom flask_redis import FlaskRedis\nimport os, psycopg2\n\n\nroot_dir = os.path.dirname(os.path.abspath(__file__))\napp = Flask(__name__)\napp.config.from_object(configs.Config)\napp.secret_key = os.getenv(\"SECRET_KEY\")\n\nredis_store = FlaskRedis(app)\noauth = OAuth(app)\n\nconn = psycopg2.connect(\n database=os.getenv('DB_NAME'),\n user=os.getenv('DB_USER'),\n sslmode=os.getenv('DB_SSL'),\n port=os.getenv('DB_PORT'),\n host=os.getenv('DB_HOST')\n)\n\nconn.set_session(autocommit=True)\ndb = conn.cursor()\n\n# registering controllers\nfrom app.controllers import *\n\n\n"
}
] | 11 |
michaelrzhang/SpeedReading
|
https://github.com/michaelrzhang/SpeedReading
|
fceb5456fc272b3bcd7a9a03e5606d7bb2b22372
|
5a0fb28f61de5835de810fc40d91dccf44480db8
|
231aa87a014579a1755741d1736ea60f411c87f8
|
refs/heads/master
| 2021-01-10T06:37:27.901365 | 2016-01-11T07:47:19 | 2016-01-11T07:47:19 | 48,476,144 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5317596793174744,
"alphanum_fraction": 0.5489270091056824,
"avg_line_length": 30.931507110595703,
"blob_id": "bb13787fd22c08c0dfdc77ee61d59f9c2882f4b6",
"content_id": "301bdaac2c3c5c1884570fb3a802f7648994499c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2330,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 73,
"path": "/src/speedreading.py",
"repo_name": "michaelrzhang/SpeedReading",
"src_encoding": "UTF-8",
"text": "import tkinter as tk\nimport sys\nfrom time import sleep\n\n# http://effbot.org/tkinterbook/tkinter-hello-tkinter.htm\n\nend_of_sentence = [\".\", \"!\", \"?\"]\n\ndef calc_delay(wpm):\n \"\"\"\n Converts wpm delay to seconds.\n \"\"\"\n return 1 / (wpm / 60)\n\ndef welcome(root, canvas, width, height, font_size):\n \"\"\"\n Gives user a chance to get ready.\n \"\"\"\n for i in [5, 4, 3, 2, 1]:\n canvas.create_rectangle(0, 0, width, height, fill = 'Beige')\n if i == 1: \n canvas.create_text(width / 2, height / 2, text=\"Starting in \" + str(i) + \" second\",\n font=(\"Courier\", font_size))\n else:\n canvas.create_text(width / 2, height / 2, text=\"Starting in \" + str(i) + \" seconds\",\n font=(\"Courier\", font_size))\n root.update()\n sleep(1)\n\ndef animate_text(root, canvas, filename, width, height, font_size, wpm):\n fin = open(filename, 'r')\n words = fin.read().split()\n delay = calc_delay(wpm)\n for word in words:\n canvas.create_rectangle(0, 0, width, height, fill = 'Beige')\n canvas.create_text(width / 2, height / 2, text=word, font=(\"Courier\", font_size))\n root.update()\n if word[-1] == \",\":\n sleep(delay / 2)\n elif word[-1] in end_of_sentence:\n sleep(delay)\n sleep(delay)\n return\n\ndef speed_read(filename, width, height, font_size, wpm):\n root = tk.Tk()\n canvas = tk.Canvas(root, width = width, height = height)\n canvas.pack()\n welcome(root, canvas, width, height, font_size)\n animate_text(root, canvas, filename, width, height, font_size, wpm)\n tk.mainloop()\n return\n\ndef main(args):\n if len(args) != 6:\n print(\"Usage: python speedreading.py [filename] [width] [height] [font_size] [wpm]\")\n default = input(\"Use default behavior? (y/n): \")\n if default == \"y\" or default == \"Y\": \n print(\"Using default options!\")\n speed_read(\"musk.txt\", 600, 300, 20, 300)\n else:\n print(\"Exiting.\")\n return\n else:\n filename = args[1]\n width = int(args[2])\n height = int(args[3])\n font_size = int(args[4])\n wpm = int(args[5])\n speed_read(filename, width, height, font_size, wpm)\n\nif __name__ == '__main__':\n main(sys.argv)"
},
{
"alpha_fraction": 0.8292682766914368,
"alphanum_fraction": 0.8292682766914368,
"avg_line_length": 40,
"blob_id": "a0f42164a67c1b16d17c1d9da665ccfb0bd79df8",
"content_id": "f4635e174a966f77f12722a202c7f61472968f1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/README.md",
"repo_name": "michaelrzhang/SpeedReading",
"src_encoding": "UTF-8",
"text": "Making something fun with speed reading.\n"
}
] | 2 |
jkang1643/GIS
|
https://github.com/jkang1643/GIS
|
915b76152e25c0478757b59eba7282fcabddb010
|
28f8317e8bea869da6fb56cd6e406e9d5a6506bf
|
bd123c316401ccefc05c3a9410401ee3fb89702e
|
refs/heads/master
| 2023-01-12T02:21:37.494712 | 2019-01-14T00:53:19 | 2019-01-14T00:53:19 | 144,204,986 | 0 | 1 | null | 2018-08-09T21:22:59 | 2021-03-28T23:40:51 | 2019-01-14T00:54:37 |
Python
|
[
{
"alpha_fraction": 0.587173581123352,
"alphanum_fraction": 0.6036866307258606,
"avg_line_length": 30.707317352294922,
"blob_id": "a2670c337d29e7ad179ab31a76a7f716969b71b0",
"content_id": "342e1b641f291bb66114724051008d7949a1eab9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2604,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 82,
"path": "/PIPELINE1_42FloorsDataCompile.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import urllib.request\nimport urllib\nfrom bs4 import BeautifulSoup\nimport numpy as np\nimport re\nimport datetime\nimport os\nimport requests\n\n\nforty_two_floors = 'https://42floors.com/research'\n\npage_scrape = urllib.request.urlopen(forty_two_floors)\n\n# parse the html using beautiful soup and store in variable `soup`\nsoup = BeautifulSoup(page_scrape, 'html.parser')\n# find city links to scrape\n\nresult = []\ndata = soup.findAll('div',attrs={'class':'uniformNav -vertical'})\nfor div in data:\n links = div.findAll('a')\n for a in links:\n links_string = ('https://42floors.com/' + a['href'])\n result.append(links_string)\nresult = result[15:]\n\nprint(result)\n#----------------------------------------------------------------------------------------------------\n\nfor propertytype_box in soup.find_all('div', class_='uniformNav -vertical'):\n property_type = np.nan\n property_type = propertytype_box.text.replace(' ', '').replace('\\n ', ',').replace('\\n', '').strip()\nproperty_type_index = property_type.split(\",\")\n\nprint(property_type_index)\n\n\n#takes list of urls, searches csv\n\n'''for each in result:\n html = requests.get(each)\n soup = BeautifulSoup(html.text, \"html.parser\")\n\n for link in soup.find_all('a', href=True):\n href = link['href']\n\n if any(href.endswith(x) for x in ['.csv']):\n print(href)'''\n\n\n#make datetime a string\nfmt = '%Y%m%d%H%M%S' # ex. 20110104172008 -> Jan. 04, 2011 5:20:08pm\nnow_str = datetime.datetime.now().strftime(fmt)\nnow_datetime = datetime.datetime.strptime(now_str, fmt)\ndate_time_export = str(now_datetime)\ndate_time_export = date_time_export.replace(\" \", \"_\").replace(\":\",\"_\")\n\n#export unique timestamp for all data\nbaseDir = 'C:/Users/Joe/Documents/42Floors/' + date_time_export\n\nn=0 #linked the two lists together using index change\nfor x in property_type_index:\n os.makedirs(os.path.join(baseDir,x),exist_ok=True)\n\n html = requests.get(result[n])\n soup = BeautifulSoup(html.text, \"html.parser\")\n for link in soup.find_all('a', href=True):\n href = link['href']\n if any(href.endswith(x) for x in ['.csv']):\n print(href)\n name = href.split('/')[-1]\n print(name)\n print('waiting...')\n remote_file = requests.get('https://42floors.com/' + href)\n with open(os.path.join(baseDir,x,name), 'wb') as f:\n print('downloading...')\n for chunk in remote_file.iter_content(chunk_size=1024):\n if chunk:\n f.write(chunk)\n print('saved: ' + name)\n n += 1\n\n\n\n\n"
},
{
"alpha_fraction": 0.6085271239280701,
"alphanum_fraction": 0.6647287011146545,
"avg_line_length": 24.850000381469727,
"blob_id": "7f3155f21dfcd02cbcbdede91ffc8c542ff92b17",
"content_id": "11c8488462714cc6f6bac360ebeaf7d01ecc22f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 20,
"path": "/test.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\n\nweb_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\n\nparams2 = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'street': '35 Greycliff Rd',\n 'city': 'Boston',\n 'state': 'MA',\n 'format': 'json',\n 'layers': '78',\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params2)\nstr = req.json()\nstr = str['result']['addressMatches']\nprint(str)"
},
{
"alpha_fraction": 0.64449542760849,
"alphanum_fraction": 0.6949541568756104,
"avg_line_length": 42.5,
"blob_id": "97d186472cccd70a0cfe1bc6b5a9f7f319cb9d2e",
"content_id": "afb9215796df85759df5f82da2ba5857679bdd96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 436,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 10,
"path": "/TabulaTables.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import tabula\nimport os\nimport pandas as pd\n\nfolder = 'C:/Users/Joe/Documents/GISRealEstateProject/CushmanWakefield_vacancy_cap_NOI/Atlanta/'\npaths = [folder + fn for fn in os.listdir(folder) if fn.endswith('.pdf')]\nfor path in paths:\n df = tabula.read_pdf(path, encoding = 'utf-8', pages = 'all', area = [29.75,43.509,819.613,464.472], nospreadsheet = True)\n path = path.replace('pdf', 'csv')\n df.to_csv(path, index = False)\n\n"
},
{
"alpha_fraction": 0.5102040767669678,
"alphanum_fraction": 0.5657987594604492,
"avg_line_length": 35.844154357910156,
"blob_id": "893afe6a30e1db6d4fe9e6970dcd3c66345822fd",
"content_id": "2fbf9ec33e4b2bcac403a36b2e4430abde758cfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2842,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 77,
"path": "/GISmapping.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import csv\nfrom shapely.geometry import Point, mapping\nfrom fiona import collection\nimport geopandas as gp\nimport matplotlib.pyplot as plt\nimport matplotlib\n\n\nwith open(\"C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/Houston()/houstonproperties_08_14_2018.csv\", 'r', encoding='ISO-8859-1') as f:\n reader = csv.DictReader(f)\n\n# write latitude longitude in csv into shapefile, with properties\nschema = {'geometry': 'Point',\n 'properties': {'address': 'str',\n 'city': 'str',\n 'state': 'str',\n 'zipcode': 'str',\n 'walkability': 'str',\n 'walkabilitydescription': 'str',\n 'bikability': 'str',\n 'bikabilitydescription': 'str',\n },\n\n }\n\n\nlist = ['C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/Dallas()/dallasproperties08_22_18.csv',\n 'C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/San Antonio/sanantonioproperties.csv',\n 'C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/Austin/austinproperties.csv',\n 'C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/Houston()/houstonproperties_08_14_2018.csv']\n\n\n\nwith collection(\"Texas.shp\", \"w\", \"ESRI Shapefile\", schema) as output:\n for x in list:\n with open(x, 'r',\n encoding='ISO-8859-1') as f:\n reader = csv.DictReader(f)\n for row in reader:\n point = Point(float(row['lon']), float(row['lat']))\n output.write({\n 'properties': {\n 'address': row['address'],\n 'city': row['city'],\n 'state': row['state'],\n 'zipcode': row['zipcode'],\n 'walkability': row['walkability'],\n 'walkabilitydescription': row['walkabilitydescription'],\n 'bikability': row['bikability'],\n 'bikabilitydescription': row['bikabilitydescription'],\n }, # add all the properties into the shapefile point!\n 'geometry': mapping(point)\n })\n\n\nrealestatelocations = gp.GeoDataFrame.from_file(\n 'C:/Users/Joe/PycharmProjects/GIS/Houston.shp')\n\nstates = gp.read_file(\"C:/Users/Joe/Downloads/gz_2010_48_140_00_500k/gz_2010_48_140_00_500k.shp\")\n\n# Get current size\n\nfig_size = plt.rcParams[\"figure.figsize\"]\n\n# Prints: [8.0, 6.0]\nprint(\"Current size:\", fig_size)\n\n# Set figure width to 12 and height to 9\nfig_size[0] = 24\nfig_size[1] = 18\nplt.rcParams[\"figure.figsize\"] = fig_size\n\nax = states.plot(linewidth=0.25, edgecolor='white', color='lightgrey')\nmap = realestatelocations.plot(column='walkabilit', alpha=0.3, ax=ax)\n\n\nmatplotlib.pyplot.show(map)\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5296894311904907,
"alphanum_fraction": 0.543602466583252,
"avg_line_length": 35.90214157104492,
"blob_id": "aee2f42ce123caff9d9047a116bb340a150c306b",
"content_id": "77c345b7a7e6be81d1d0ef0e4825c96e0d032fbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12075,
"license_type": "no_license",
"max_line_length": 547,
"num_lines": 327,
"path": "/PIPELINE3_Realestatepropertydata.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "#changes vs. realestatemasterdata =\n#1. added the url parse instead of scraping address for increased accuracy\n#2. added the onelineaddress option instead of by part for the geocoding API by US Census\n#3. relieved address city state from web scraping duties\n#4. read data from property by column index instead of \"listing_url\"\n\nfrom bs4 import BeautifulSoup\nimport urllib.request\nimport urllib.error\nimport pandas as pd\nimport csv\nimport re\nimport numpy as np\nimport requests\nfrom urllib.parse import quote\nfrom multiprocessing.dummy import Pool as ThreadPool\nimport multiprocessing as mp\nimport os\nimport sys\nimport time\n\n#downloading all CSV files from 42 floors and saving the name as the retrieve date\n#-----------------------------------------------------------------------------------\n\n#opening the CSV and reading the columns\n#--------------------------------------------------------------------------------------\nCSV_location_file = 'C:/Users/Joe/Documents/42Floors/2018-08-08_23_12_24/Austin/property_data.csv'\n\n\nwith open(CSV_location_file, newline='', encoding=\"utf8\") as f:\n reader = csv.reader(f)\n my_list = list(reader)\n#print(my_list)\n\n\ndf = pd.read_csv(CSV_location_file)\nsaved_column = df[df.columns[10]]\nprint(saved_column)\nURL_list = []\n\nfor x in saved_column:\n URL_list.append(x)\n\nprint(URL_list)\n\n#scraping the website part\n#--------------------------------------------------------------------------------------\n#for row in URL_list:\ndef getURLlist(row):\n\n try:\n walk_score = np.nan\n walk_description = np.nan\n transit_score = np.nan\n transit_description = np.nan\n bike_score = np.nan\n bike_description = np.nan\n\n # parse the URL for address city state instead of scraping\n row_split = (row.split(\"/\"))\n full_address = row_split[6] + \" \" + row_split[5] + \" \" + row_split[4]\n full_address = (full_address.replace(\"-\", \" \"))\n unparsed_address = row_split[6]\n address = unparsed_address.replace(\"-\", \" \")\n city = row_split[5]\n state = row_split[4]\n\n # for each URL, go to website, scrape data, obtain longitude latitute, then use that to obtain\n # walkability, census information, census block data, and append to CSV write\n\n #--------------------[SCRAPE THE URL}-------------------------------------------------------------\n page_scrape = urllib.request.urlopen(row)\n\n\n # parse the html using beautiful soup and store in variable `soup`\n soup = BeautifulSoup(page_scrape, 'html.parser')\n\n\n # find square foot\n sqfoot_box = soup.find('div', attrs={\"class\": 'listing-size col-5-sm col-3-md'})\n sqfoot = np.nan\n sqfoot1 = re.compile('[\\W_]+').sub('', sqfoot_box.text)\n sqfoot = float(re.sub('[a-z]', '', sqfoot1))\n\n\n\n #find listing rate\n listing_rate_box = soup.find('div', attrs={\"class\": 'listing-rate col-2-md hide-sm '})\n listing_rate = np.nan\n listing_rate_unfiltered=re.compile('[\\W_]+').sub('', listing_rate_box.text)\n\n\n if \"sqft\" in listing_rate_unfiltered:\n listing_rate = float(re.sub('[a-z]', '', listing_rate_unfiltered))/100\n elif \"mo\" in listing_rate_unfiltered:\n listing_rate = float(re.sub('[a-z]', '', listing_rate_unfiltered))\n else:\n raise ValueError('A very specific bad thing happened')\n\n\n\n # find property type\n try:\n for propertytype_box in soup.find_all('div', class_= 'tags margin-bottom text-small'):\n property_type = np.nan\n property_type = re.compile('[\\W_]+').sub(' ', propertytype_box.text)\n except:\n pass\n\n\n # find original listing date\n t = soup.find('span', {'class': 'text-nowrap text-bold'})\n listing_date = t.text\n\n\n #(details box)\n for detail_box in soup.find_all('div', class_= 'grid grid-nest grid-top'):\n details = np.nan\n details = re.compile('[\\W_]+').sub(',', detail_box.text)\n\n\n #parse the details box by dictionary index and name [includes all the extra features]\n extraslist = {}\n for details_box in soup.find_all('div', class_='col-6 col-4-md margin-bottom'):\n for each in details_box.find_all(\"div\", {\"class\": \"text-bold\"}):\n extras_label = re.sub('[^a-zA-Z]+', '', each.string)\n extras_label = re.compile('[\\W_]+').sub(' ', extras_label)\n for each in details_box.find_all(\"div\", {\"class\": \"strong\"}):\n extras_number = re.sub('[^0-9a-zA-Z:]', '', each.string)\n extras_number = re.compile('[\\W_]+').sub(' ', extras_number)\n if extras_label != 'CloseHighways':\n extraslist[extras_label] = extras_number\n\n\n print(extraslist)\n\n floors = np.nan\n try:\n floors = extraslist['Floors']\n except:\n pass\n\n TotalSize = np.nan\n try:\n TotalSize = extraslist['TotalSize']\n except:\n pass\n\n LotSize = np.nan\n try:\n LotSize = extraslist['LotSize']\n except:\n pass\n\n YearConstructed = np.nan\n try:\n YearConstructed = extraslist['YearConstructed']\n except:\n pass\n\n\n BuildingClass = np.nan\n try:\n BuildingClass = extraslist['BuildingClass']\n except:\n pass\n\n\n Zoning = np.nan\n try:\n Zoning = extraslist['Zoning']\n except:\n pass\n\n ParkingRatio = np.nan\n try:\n ParkingRatio = extraslist['ParkingRatio']\n except:\n pass\n\n\n#-----------------[obtain longitude latitude coordinates for each data point]--------------------------\n#------------------------------------------------------------------------------------------------------\n\n web_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/onelineaddress?'\n params = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'address': full_address,\n 'format': 'json',\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n # Do the request and get the response data\n starttime = time.time()\n while True:\n try:\n if time.time() - starttime > 30.:\n print('ERROR: Timeout 10s')\n break\n req = requests.get(web_scrape_url, params=params)\n str = req.json()\n print(str)\n dictionary = (str['result']['addressMatches'])\n dictionary = (dictionary[0])\n dictionary_geo = (dictionary['geographies']['2010 Census Blocks'][0])\n break\n except:\n continue\n # dictionary items\n latitude = (dictionary['coordinates']['y'])\n longitude = (dictionary['coordinates']['x'])\n latitude = \"{:.6f}\".format(latitude)\n longitude = \"{:.6f}\".format(longitude)\n zipcode = (dictionary['addressComponents']['zip'])\n geo_id = (dictionary_geo['GEOID'])\n block_name = (dictionary_geo['NAME'])\n block_group = (dictionary_geo['BLKGRP'])\n block_land_area = (dictionary_geo['AREALAND'])\n block_water_area = (dictionary_geo['AREAWATER'])\n\n\n# -----------------[use longitude latitude coordinates to obtain census data]---------------------\n#-------------------------------------------------------------------------------------------------\n web_scrape_url = 'https://www.broadbandmap.gov/broadbandmap/demographic/2014/coordinates?'\n\n params = {\n 'latitude': latitude,\n 'longitude': longitude,\n 'format': \"json\"\n }\n\n # Do the request and get the response data\n req = requests.get(web_scrape_url, params=params)\n data = req.json()\n\n income_below_poverty = (data['Results']['incomeBelowPoverty'])\n median_income = (data['Results']['medianIncome'])\n income_less_25 = (data['Results']['incomeLessThan25'])\n income_between_25_and_50 = (data['Results']['incomeBetween25to50'])\n income_between_50_and_100 = (data['Results']['incomeBetween50to100'])\n income_between_100_and_200 = (data['Results']['incomeBetween100to200'])\n income_greater_200 = (data['Results']['incomeGreater200'])\n highschool_graduation_rate = (data['Results']['educationHighSchoolGraduate'])\n college_education_rate = (data['Results']['educationBachelorOrGreater'])\n\n\n#----------------[obtain walkability, bike, and travel scores by location}----------------------------\n#----------------------------------------------------------------------------------------------------\n\n payload = {'address': address + \" \" + city + \" \" + state}\n newpayload = {}\n for (k, v) in payload.items():\n newpayload[quote(k)] = quote(v)\n base_url = 'http://api.walkscore.com/score?format=json&address='\n rest_url = '&transit=1&bike=1&wsapikey=723603e4e9ed1c836fb0403145a39cfc'\n json_url = base_url + newpayload['address'] + \"&\" + \"lat=\" + latitude + \"&lon=\" + longitude + rest_url\n response = requests.get(json_url)\n data = response.json()\n\n try:\n walk_score = (data['walkscore'])\n except:\n pass\n\n try:\n walk_description = (data['description'])\n except:\n pass\n\n try:\n transit_score = (data['transit']['score'])\n except:\n pass\n\n try:\n transit_description = (data['transit']['description'])\n except:\n pass\n\n try:\n bike_score = (data['bike']['score'])\n except:\n pass\n\n try:\n bike_description = (data['bike']['description'])\n except:\n pass\n\n\n output = (listing_date, latitude, longitude, geo_id, block_name, block_group, address, city, zipcode, state, walk_score,\n walk_description, transit_score, transit_description, bike_score, bike_description, sqfoot,\n listing_rate, property_type, details, floors, TotalSize, LotSize, ParkingRatio, YearConstructed, BuildingClass, Zoning, median_income, income_below_poverty, income_less_25,\n income_between_25_and_50, income_between_50_and_100, income_between_100_and_200, income_greater_200,\n highschool_graduation_rate, college_education_rate, row)\n\n#--------------------------------[PRINTING AND EXPORTING]----------------------------------------------\n\n\n print(listing_date, latitude, longitude, geo_id, block_name, block_group, address, city, state, zipcode, walk_score, walk_description, transit_score, transit_description, bike_score, bike_description, sqfoot, listing_rate, property_type, details, floors, TotalSize, LotSize, ParkingRatio, YearConstructed, BuildingClass, Zoning, median_income, income_below_poverty, income_less_25, income_between_25_and_50, income_between_50_and_100, income_between_100_and_200, income_greater_200, highschool_graduation_rate, college_education_rate, row)\n\n with open('aust.csv', 'a', newline='') as csv_file:\n writer = csv.writer(csv_file)\n writer.writerow(output)\n\n except Exception as e:\n exc_type, exc_obj, exc_tb = sys.exc_info()\n fname = os.path.split(exc_tb.tb_frame.f_code.co_filename)[1]\n print(exc_type, fname, exc_tb.tb_lineno, row)\n\n\n#-----------------------------[Added multithreading capabilities]--------------------------------------\n#multithreading\nif __name__ == \"__main__\":\n #pool = ThreadPool(12)\n #results = pool.map(getURLlist, URL_list)\n #pool.close()\n #pool.join()\n#multipooling\n with mp.Pool(os.cpu_count()) as p:\n results = p.map_async(getURLlist, URL_list)\n p.close()\n p.join()\n\n\n#----------------------[additional coding pieces]---------------------------------------------------------\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5975308418273926,
"alphanum_fraction": 0.604938268661499,
"avg_line_length": 51.69565200805664,
"blob_id": "9ad144c2827206aee8d8ecbc5e6884c9a79a0ee6",
"content_id": "65f6aba76ef970903fc98b98796f87ac8eaf8b03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2430,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 46,
"path": "/scrape_cushmanwakefieldreports.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import urllib.request\nimport urllib\nimport urllib.parse\nfrom bs4 import BeautifulSoup\nimport numpy as np\nimport re\nimport datetime\nimport os\nimport requests\nfrom selenium import webdriver\n\nweb_scrape_search_terms = ['Atlanta', 'Austin', 'Baltimore', 'Birmingham', 'Boston', 'Buffalo',\n 'Charlotte', 'Chicago', 'Cincinnati', 'Cleveland', 'Columbus', 'Dallas',\n 'Denver', 'Detroit', 'Fairfield', 'Fresno', 'Grand Rapids', 'Hartford',\n 'Houston', 'Indianapolis', 'Jacksonville', 'Jersey City', 'Kansas City',\n 'Las Vegas', 'Los Angeles', 'Louisville', 'Memphis', 'Miami', 'Milwaukee',\n 'Minneapolis', 'Nashville', 'New Orleans', 'New York City', 'Newark',\n 'Oakland', 'Oklahoma City', 'Omaha', 'Orlando', 'Palm Beach', 'Philadelphia',\n 'Phoenix', 'Pittsburgh', 'Portland', 'Raleigh', 'Richmond', 'Rochester',\n 'Sacramento', 'Salt Lake City', 'San Antonio', 'San Diego', 'San Francisco',\n 'Seattle', 'Silicon Valley', 'Tampa Bay', 'Tucson', 'Virginia Beach',]\n\n\nfor query in web_scrape_search_terms:\n query = query.replace(\" \", \"%20\")\n # Constracting http query\n url = r'http://www.cushmanwakefield.us/en/search-results?q='+query\n browser = webdriver.Chrome() # replace with .Firefox(), or with the browser of your choice\n browser.get(url) #navigate to the page\n innerHTML = browser.execute_script(\"return document.body.innerHTML\")\n soup = BeautifulSoup(innerHTML, 'html.parser')\n data = soup.find('div', attrs={'class': 'm-box m-box_nav m-box_search'})\n for a in data.find_all('a', attrs={'id': 'upperleftcolumn_0_rptFacet_hlLink_2'}):\n link = (r'http://www.cushmanwakefield.us' + a['href'])\n print(link) #outer loop to find marketbeat reports on sidebar\"\n\n ##this is the inner loop that examines the specific files in marketbeat\"\n browser2 = webdriver.Chrome()\n browser2.get(link)\n innerHTML2 = browser2.execute_script(\"return document.body.innerHTML\")\n soup2 = BeautifulSoup(innerHTML2, 'html.parser')\n\n data2 = soup2.find('div', attrs={'class': 'bodyContent'})\n for a2 in data2.find_all('a', href=True):\n link2 = (r'http://www.cushmanwakefield.us' + a2['href'])\n print(link2)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6705385446548462,
"alphanum_fraction": 0.7349525094032288,
"avg_line_length": 38.45833206176758,
"blob_id": "0c211c4629064c6fddbc8111a98e270c84a9d251",
"content_id": "d88ac620c85a896f96895aa2324b908855276872",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 24,
"path": "/simpledemographicsapi.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\n\nbase_url = 'https://www.broadbandmap.gov/broadbandmap/demographic/2014/coordinates?'\nlatitude = '42.456345'\nlongitude = '-74.9874534'\njson_url = base_url + \"latitude=\" + latitude + \"&longitude=\" + longitude + \"&format=json\"\n\nprint(json_url)\n\nresponse = requests.get(json_url)\n\ndata = response.json()\nprint(type(data))\nprint(data['Results'])\n\nincome_below_poverty = (data['Results']['incomeBelowPoverty'])\nmedian_income = (data['Results']['medianIncome'])\nincome_less_25 = (data['Results']['incomeLessThan25'])\nincome_between_25_and_50 = (data['Results']['incomeBetween25to50'])\nincome_between_50_and_100 = (data['Results']['incomeBetween50to100'])\nincome_between_100_and_200 = (data['Results']['incomeBetween100to200'])\nincome_greater_200 = (data['Results']['incomeGreater200'])\nhighschool_graduation_rate = (data['Results']['educationHighSchoolGraduate'])\ncollege_education_rate = (data['Results']['educationBachelorOrGreater'])\n"
},
{
"alpha_fraction": 0.5694528222084045,
"alphanum_fraction": 0.5805772542953491,
"avg_line_length": 54.36666488647461,
"blob_id": "df91fa190a890873754aa8249e8c408958875317",
"content_id": "dc0974bfff63fd39fcafb987e1aeb8ee1c622855",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3326,
"license_type": "no_license",
"max_line_length": 476,
"num_lines": 60,
"path": "/scrape_CUSHMANWAKEFIELD.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "from bs4 import BeautifulSoup\nimport os\nimport requests\nfrom selenium import webdriver\n\nweb_scrape_search_terms = ['Atlanta', 'Austin', 'Baltimore', 'Birmingham', 'Boston', 'Buffalo',\n 'Charlotte', 'Chicago', 'Cincinnati','Cleveland', 'Columbus', 'Dallas',\n 'Denver', 'Detroit', 'Fairfield', 'Fresno', 'Grand Rapids', 'Hartford',\n 'Houston', 'Indianapolis', 'Jacksonville', 'Jersey City', 'Kansas City',\n 'Las Vegas', 'Los Angeles', 'Louisville', 'Memphis', 'Miami', 'Milwaukee',\n 'Minneapolis', 'Nashville', 'Oklahoma City', 'Omaha', 'Orlando', 'Palm Beach',\n 'Philadelphia', 'Phoenix', 'Pittsburgh', 'Portland', 'Raleigh', 'Richmond', 'Rochester',\n 'Sacramento', 'Salt Lake City', 'San Antonio', 'San Diego', 'San Francisco',\n 'Seattle', 'Silicon Valley', 'Tampa Bay', 'Tucson',\n 'Virginia Beach', 'Washington D.C', \"West Palm Beach\"]\n\n\n#'Atlanta', 'Austin', 'Baltimore', 'Birmingham', 'Boston', 'Buffalo', 'Charlotte', 'Chicago', 'Cincinnati','Cleveland', 'Columbus', 'Dallas','Denver', 'Detroit', 'Fairfield', 'Fresno', 'Grand Rapids', 'Hartford', 'Houston', 'Indianapolis', 'Jacksonville', 'Jersey City', 'Kansas City','Las Vegas', 'Los Angeles', 'Louisville', 'Memphis', 'Miami', 'Milwaukee','Minneapolis', 'Nashville', 'Oklahoma City', 'Omaha', 'Orlando', 'Palm Beach', 'Philadelphia', 'Phoenix', 'Pittsburgh\n\nbaseDir = 'C:/Users/Joe/Documents/CushmanWakefield/'\nfor query in web_scrape_search_terms:\n query1 = query.replace(\" \", \"%20\")\n # Constracting http query\n url = r'http://www.cushmanwakefield.us/en/search-results?f={86FC8AB5-42C6-44A0-808B-B9FF6AAE4156}&q=' + query1\n\n ##this is the outer loop that examines the specific files in marketbeat\"\n browser = webdriver.Chrome()\n browser.get(url)\n HTML = browser.execute_script(\"return document.body.innerHTML\")\n soup = BeautifulSoup(HTML, 'html.parser')\n\n minor_list = []\n\n data = soup.find('div', attrs={'class': 'bodyContent'})\n for a in data.find_all('a', href=True):\n link = (r'http://www.cushmanwakefield.us' + a['href'])\n minor_list.append(link)\n print(minor_list) #list of links to scrape by city\n\n for item in minor_list:\n browser2 = webdriver.Chrome()\n browser2.get(item)\n HTML2 = browser2.execute_script(\"return document.body.innerHTML\")\n soup2 = BeautifulSoup(HTML2, 'html.parser')\n\n data = soup2.find('div', attrs={'class': 'm-box highlight lightGrey'})\n for link in soup2.find_all('a', href=True):\n href = link['href']\n if any(href.endswith(x) for x in ['.pdf']):\n print(href)\n file_name = href.split('/')[-1]\n print(file_name)\n print(file_name)\n remote_file = requests.get(href)\n os.makedirs(os.path.join(baseDir, query), exist_ok=True)\n with open(os.path.join(baseDir,query,file_name), 'wb') as f:\n for chunk in remote_file.iter_content(chunk_size=1024):\n if chunk:\n f.write(chunk)\n print('saved: ' + href)\n\n\n\n\n"
},
{
"alpha_fraction": 0.7352024912834167,
"alphanum_fraction": 0.7383177280426025,
"avg_line_length": 34.55555725097656,
"blob_id": "528a65611bffabafad54e0ed754d20aef601b891",
"content_id": "d4bf9464ad920d37612f150ef7037a10dc83021a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 9,
"path": "/main.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\n\ndef request_patch(slf, *args, **kwargs):\n print(\"Fix called\")\n timeout = kwargs.pop('timeout', 2)\n return slf.request_orig(*args, **kwargs, timeout=timeout)\n\nsetattr(requests.sessions.Session, 'request_orig', requests.sessions.Session.request)\nrequests.sessions.Session.request = request_patch\n\n"
},
{
"alpha_fraction": 0.35192322731018066,
"alphanum_fraction": 0.4603087902069092,
"avg_line_length": 42.783843994140625,
"blob_id": "1d02e4c8a2858aa96c3ba61a6131bea32644174c",
"content_id": "2a6a2cf5169994713d5ab970b22ea80e2fe0ade0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97024,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 2216,
"path": "/api_CENSUS MASTER (Complete).py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\nimport pandas as pd\nimport json\nimport numpy as np\nimport matplotlib\nimport cufflinks as cf\nimport plotly\nimport plotly.plotly as py\nimport plotly.graph_objs as go\n\n#--------------------------------------------------------------------------------------------------\n#------------------------------------------------------------------------------------------------\n#------------------------------\n#INPUTS\n\n\n#1 = block level, 2 = tract level, 3 = zipcode, 4 = public area microdata, 5 = metropolitan area\nconfig = 2\nstreet = \"371 Tealwood Dr\"\ncity = \"Houston\"\nstate = \"TX\"\n\n\n\n#------------------------------------------------------------------------------------------------\n\n#get GEOCODE Data, latitude, longitude, tract, block level census data\nweb_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\n\nparams = {\n 'benchmark': 'Public_AR_Current',\n 'vintage':'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format':'json',\n 'key':'80a64bc7e2514da9873c3a235bd3fb59be140157'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nstr = req.json()\ndictionary = (str['result']['addressMatches'])\ndictionary = (dictionary[0])\ndictionary_geo = (dictionary['geographies']['2010 Census Blocks'][0])\n\n\n#dictionary items\nlatitude = (dictionary['coordinates']['x'])\nlongitude = (dictionary['coordinates']['y'])\nzipcode = (dictionary['addressComponents']['zip'])\ngeo_id = (dictionary_geo['GEOID'])\nblock_name = (dictionary_geo['NAME'])\nblock_group = (dictionary_geo['BLKGRP'])\nblock_land_area = (dictionary_geo['AREALAND'])\nblock_water_area = (dictionary_geo['AREAWATER'])\nstate_blkgrp = (dictionary_geo['BLKGRP'])\nstate_id = (dictionary_geo['STATE'])\ncounty_id = (dictionary_geo['COUNTY'])\ntract_id = (dictionary_geo['TRACT'])\n\nstring_latitude = json.dumps(latitude)\nstring_longitude = json.dumps(longitude)\nprint(string_latitude, string_longitude)\nprint(state_id, county_id, tract_id)\n#--------------------------------------------------------------------------------------------------\n\n#get Metropolitcan Statististical Area Code\n\nweb_scrape_url2 = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\nparams2 = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format': 'json',\n 'layers': '80',\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n# Do the request and get the response data\nreq2 = requests.get(web_scrape_url2, params=params2)\n\n#parse JSON response, because it is a multilayered dict\nstr2parse = req2.json()\nstr2parse = str2parse['result']['addressMatches']\nstr2 = str2parse[0]\nstr2 = dict(str2['geographies']['Metropolitan Statistical Areas'][0])\n\n\n#assign variables to dict\nmsa_Name = str2[\"NAME\"]\nmetropolitan_id = str2[\"CBSA\"]\n#-------------------------------------------------------------------------------------------------\n\n\n\nweb_scrape_url = 'https://maps.googleapis.com/maps/api/streetview?'\nparams = {\n 'size': '600x300',\n 'location': string_longitude + \",\" + string_latitude,\n 'key':'AIzaSyAEEIuRKOBNzOjMADj4hE5bGUdAFKz9oDE'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nif req.status_code == 200:\n with open(\"C:/Users/Joe/Desktop/sample.jpg\", 'wb') as f:\n f.write(req.content)\n\n\n\n#-------------------------------------------------------------------------------------------------------\n\n\n\n#Get 2010 Census Public Use Microdata Areas\nweb_scrape_url3 = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\nparams3 = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format': 'json',\n 'layers': '0',\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n\n# Do the request and get the response data\nreq3 = requests.get(web_scrape_url3, params=params3)\nstr3parse = req3.json()\n\n#parse multi layered dictionary\nstr3parse1 = str3parse['result']['addressMatches'][0]\nstr3 = str3parse1['geographies']['2010 Census Public Use Microdata Areas'][0]\nstr3 = dict(str3)\n\n#assign variables for microdata\nmicrodata_id = str3[\"PUMA\"]\nmicrodata_area_name = str3[\"NAME\"]\n\nprint(str3parse1)\n\n#------------------------------------------------------------------------------------------------------\n#--------------------------[CENSUS ACS 5 Community Survey Data]----------------------------------------\n\n#results[0:16]\nsummary = ['NAME,'\n 'B25001_001E,' #total housing units\n 'B25002_002E,' #total occupied units\n 'B25002_003E,' #total vacant units\n 'B25106_024E,' #estimate total renter occupied housing units\n 'B01003_001E,' #total population in census tract\n 'B01002_001E,' #median age in tract\n 'B19049_001E,' #Median household income in the past 12 months (in 2016 inflation-adjusted dollars)\n 'B19083_001E,' #GINI index of income inequality\n 'B25076_001E,' #lower quartile house value\n 'B25077_001E,' #median house value\n 'B25078_001E,' #upper quartile house value\n 'B25064_001E,' #estimate median gross rent\n 'B25057_001E,' #estimate lower quartile rent\n 'B25058_001E,' #median contract rent\n 'B25059_001E' #estimate upper quartile rent\n ]\n\n#results[19:67]\ndemographics = ['B01001_002E,' #Estimate!!Total!!Male \n 'B01001_003E,' #Male!!Under 5 years \n 'B01001_004E,' #Male!!5 to 9 years\n 'B01001_005E,' #Male!!10 to 14 years\n 'B01001_006E,' #Male!!15 to 17 years\n 'B01001_007E,' #Male!!18 and 19 years\n 'B01001_008E,' #Male!!20 years\n 'B01001_009E,' #Male!!21 years\n 'B01001_010E,' #Male!!22 to 24 years\n 'B01001_011E,' #Male!!25 to 29 years\n 'B01001_012E,' #Male!!30 to 34 years\n 'B01001_013E,' #Male!!35 to 39 years\n 'B01001_014E,' #Male!!40 to 44 years\n 'B01001_015E,' #Male!!45 to 49 years\n 'B01001_016E,' #Male!!50 to 54 years\n 'B01001_017E,' #Male!!55 to 59 years\n 'B01001_018E,' #Male!!60 and 61 years\n 'B01001_019E,' #Male!!62 to 64 years\n 'B01001_020E,' #Male!!65 and 66 years\n 'B01001_021E,' #Male!!67 to 69 years\n 'B01001_022E,' #Male!!70 to 74 years\n 'B01001_023E,' #Male!!75 to 79 years\n 'B01001_024E,' #Male!!80 to 84 years\n 'B01001_025E,' #Male!!85 years and over\n 'B01001_026E,' #Total!!Female\n 'B01001_027E,' #Female!!Under 5 years\n 'B01001_028E,' #Female!!5 to 9 years\n 'B01001_029E,' #Female!!10 to 14 years\n 'B01001_030E,' #Female!!15 to 17 years\n 'B01001_031E,' #Female!!18 and 19 years\n 'B01001_032E,' #Female!!20 years\n 'B01001_033E,' #Female!!21 years\n 'B01001_034E,' #Female!!22 to 24 years\n 'B01001_035E,' #Female!!25 to 29 years\n 'B01001_036E,' #Female!!30 to 34 years\n 'B01001_037E,' #Female!!35 to 39 years\n 'B01001_038E,' #Female!!40 to 44 years\n 'B01001_039E,' #Female!!45 to 49 years\n 'B01001_040E,' #Female!!50 to 54 years\n 'B01001_041E,' #Female!!55 to 59 years\n 'B01001_042E,' #Female!!60 and 61 years\n 'B01001_043E,' #Female!!62 to 64 years\n 'B01001_044E,' #Female!!65 and 66 years\n 'B01001_045E,' #Female!!67 to 69 years\n 'B01001_046E,' #Female!!70 to 74 years\n 'B01001_047E,' #Female!!75 to 79 years\n 'B01001_048E,' #Female!!80 to 84 years\n 'B01001_049E' #Female!!85 years and over\n ]\n\n#results[70:79]\nrace = ['B01001H_001E,' #white\n 'B01001I_001E,' #hispanic\n 'B01001B_001E,' #black\n 'B01001D_001E,' #asian\n 'B01001C_001E,' #native american/alaska native\n 'B01001E_001E,' #native hawaiian/pacific islander\n 'B01001F_001E,' #other\n 'B01001G_001E,' #two or more races\n 'B02001_001E' #total race\n ]\n\n#results[82:123]\nethnicity1 = ['B04006_001E,' #Total Reporting Ancestry\n 'B04006_002E,' #Afghan\n 'B04006_003E,' #Albanian\n 'B04006_004E,' #Alsatian \n 'B04006_005E,' #American \n 'B04006_006E,' #Arab \n 'B04006_016E,' #Armenian\n 'B04006_017E,' #Assyrians\n 'B04006_018E,' #Australians\n 'B04006_019E,' #Austrian\n 'B04006_020E,' #Basque\n 'B04006_021E,' #Belgian\n 'B04006_022E,' #Brazilian\n 'B04006_023E,' #British\n 'B04006_024E,' #Bulgarian\n 'B04006_025E,' #Cajun\n 'B04006_026E,' #Canadian\n 'B04006_027E,' #Carpatho Rusyn\n 'B04006_028E,' #Celtic\n 'B04006_029E,' #Croatian\n 'B04006_030E,' #Cypriot\n 'B04006_031E,' #Czech\n 'B04006_032E,' #Czechoslovakian\n 'B04006_033E,' #Danish\n 'B04006_034E,' #Dutch\n 'B04006_035E,' #Eastern European\n 'B04006_036E,' #English\n 'B04006_037E,' #Estonian\n 'B04006_038E,' #European\n 'B04006_039E,' #Finnish\n 'B04006_040E,' #French\n 'B04006_041E,' #French Canadian\n 'B04006_042E,' #German \n 'B04006_043E,' #German Russian\n 'B04006_044E,' #Greek\n 'B04006_045E,' #Guayanese\n 'B04006_046E,' #Hungarian\n 'B04006_047E,' #Icelander\n 'B04006_048E,' #Iranaian\n 'B04006_049E,' #Irish\n 'B04006_050E' #Israeli\n ]\n\n#results[126:156]\nethnicity2 = ['B04006_051E,' #Italian\n 'B04006_052E,' #Latvian\n 'B04006_053E,' #Lithuanian\n 'B04006_054E,' #Luxemburger\n 'B04006_055E,' #Macedonian\n 'B04006_056E,' #Maltese\n 'B04006_057E,' #New Zealander\n 'B04006_058E,' #Northern European\n 'B04006_059E,' #Norwegian\n 'B04006_060E,' #Pennsylvania German\n 'B04006_061E,' #Polish\n 'B04006_062E,' #Portuguese \n 'B04006_063E,' #Romanian\n 'B04006_064E,' #Russian\n 'B04006_065E,' #Scandinavian\n 'B04006_066E,' #Scotch-Irish\n 'B04006_067E,' #Scottish\n 'B04006_068E,' #Serbian\n 'B04006_069E,' #Slavic\n 'B04006_070E,' #Slovak\n 'B04006_071E,' #Soviet Russia\n 'B04006_072E,' #Soviet Union\n 'B04006_073E,' #Subsaharan Africa\n 'B04006_089E,' #Swedish\n 'B04006_090E,' #Swiss\n 'B04006_091E,' #Turkish\n 'B04006_092E,' #Ukrainian\n 'B04006_094E,' #West Indian\n 'B04006_107E,' #Yugoslavian\n 'B04006_108E' #Estimate Other\n]\n\n#results[159:161]\nforeign_native = ['B05012_002E,' #Native\n 'B05012_003E' #Foreign Born\n ]\n\n#results[164:170]\nrelationship = ['B06008_001E,' #Total Count\n 'B06008_002E,' #Single/Never Married\n 'B06008_003E,' #Currently Married\n 'B06008_004E,' #Divorced\n 'B06008_005E,' #Separated\n 'B06008_006E' #Widowed\n ]\n\n#results[173:179]\neducation = ['B06009_001E,' #Total\n 'B06009_002E,' #Less Than High School Graduate\n 'B06009_003E,' #High School Graduate\n 'B06009_004E,' #Some College/Associates \n 'B06009_005E,' #Bachelors Degree\n 'B06009_006E' #Graduate or professional degree\n ]\n\n#results[182:192]\ntransportation = ['B08301_001E,' #Total Means of Transportation\n 'B08301_003E,' #Car, Van, Truck, Drove Alone\n 'B08301_004E,' #Car, Van, Truck, Carpooled\n 'B08301_010E,' #Used Public Transportation\n 'B08301_018E,' #Bicycle\n 'B08301_019E,' #Walked\n 'B08006_016E,' #Taxicab\n 'B08301_017E,' #Motorcycle\n 'B08301_020E,' #Other Means\n 'B08301_021E' #Worked at Home\n ]\n\n#results[195:210]\nwork = ['B08011_001E,' #Total\n 'B08011_002E,' #12:00 a.m. to 4:59 a.m\n 'B08011_003E,' #5:00 a.m. to 5:29 a.m.\n 'B08011_004E,' #5:30 a.m. to 5:59 a.m. \n 'B08011_005E,' #6:00 a.m. to 6:29 a.m.\n 'B08011_006E,' #6:30 a.m. to 6:59 a.m.\n 'B08011_007E,' #7:00 a.m. to 7:29 a.m.\n 'B08011_008E,' #7:30 a.m. to 7:59 a.m\n 'B08011_009E,' #8:00 a.m. to 8:29 a.m.\n 'B08011_010E,' #8:30 a.m. to 8:59 a.m.\n 'B08011_011E,' #9:00 a.m. to 9:59 a.m.\n 'B08011_012E,' #10:00 a.m. to 10:59 a.m.\n 'B08011_013E,' #11:00 a.m. to 11:59 a.m\n 'B08011_014E,' #12:00 p.m. to 3:59 p.m.\n 'B08011_015E' #4:00 p.m. to 11:59 p.m.\n]\n\n#results[213:226]\ntravel_time = ['B08012_001E,' #Total\n 'B08012_002E,' #Less than 5 minutes\n 'B08012_003E,' #5 to 9 minutes\n 'B08012_004E,' #10 to 14 minutes \n 'B08012_005E,' #15 to 19 minutes\n 'B08012_006E,' #20 to 24 minutes\n 'B08012_007E,' #25 to 29 minutes\n 'B08012_008E,' #30 to 34 minutes\n 'B08012_009E,' #35 to 39 minutes\n 'B08012_010E,' #40 to 44 minutes\n 'B08012_011E,' #45 to 59 minutes\n 'B08012_012E,' #60 to 89 minutes\n 'B08012_013E' #!90 or more minutes\n]\n\n#results[229:236]\nvehicles = ['B08014_001E,' #Total\n 'B08014_002E,' #No Vehicles\n 'B08014_003E,' #1 Vehicle \n 'B08014_004E,' #2 Vehicles \n 'B08014_005E,' #3 Vehicles\n 'B08014_006E,' #4 Vehicles\n 'B08014_007E' #5 or more Vehicles\n ]\n\n#results[239:248]\nworker_class = ['B08128_001E,' #Total Worker Class\n 'B08128_003E,' #Employee of private company workers\n 'B08128_004E,' #Self-employed in own incorporated business workers\n 'B08128_005E,' #Private not-for-profit wage and salary workers\n 'B08128_006E,' #Local Government Workers\n 'B08128_007E,' #State Government workers\n 'B08128_008E,' #Federal Government Workers\n 'B08128_009E,' #Self-employed in own not incorporated business workers\n 'B08128_010E' #Unpaid family workers\n ]\n\n#results[251:261]\nunder18 = ['B08301_021E,' #Total\n 'B09001_002E,' #Total In Households\n 'B09001_003E,' #Households, Under 3\n 'B09001_004E,' #Households, 3-4 \n 'B09001_005E,' #5 years old\n 'B09001_006E,' #6-8 years old\n 'B09001_007E,' #9-11 years old\n 'B09001_008E,' #12-14 years old\n 'B09001_009E,' #15-17 years old\n 'B09001_010E' #In Group Quarters\n ]\n\n#results[264:272]\nschool_enrollment = ['B14001_002E,' #Total Enrolled in School\n 'B14001_003E,' #Nursery School/Preschool\n 'B14001_004E,' #Enrolled in kindergarten\n 'B14001_005E,' #Enrolled Grades 1-4\n 'B14001_006E,' #Enrolled Grades 5-8\n 'B14001_007E,' #Enrolled Grades 9-12\n 'B14001_008E,' #Enrolled in college, undergraduate years\n 'B14001_009E' #Enrolled in Graduate School\n ]\n\n#results[275:291]\nbachelors_field_study = ['B15012_001E,' #Total\n 'B15012_002E,' #Computers, Mathematics and Statistics\n 'B15012_003E,' #Biological, Agricultural, and Environmental Sciences\n 'B15012_004E,' #Physical and Related Sciences\n 'B15012_005E,' #Psychology\n 'B15012_006E,' #Social Sciences\n 'B15012_007E,' #Engineering\n 'B15012_008E,' #Multidisciplinary Studies\n 'B15012_009E,' #Science and Engineering Related Fields\n 'B15012_010E,' #Business\n 'B15012_011E,' #Education\n 'B15012_012E,' #Literature and Languages\n 'B15012_013E,' #Liberal Arts and History\n 'B15012_014E,' #Visual and Performing Arts\t\n 'B15012_015E,' #Communications\n 'B15012_016E' #Other\n ]\n\n#results[294:301]\nnativity_language = ['B16005_001E,' #Estimate \n 'B16005_002E,' #Native\n 'B16005_003E,' #Speak Only English\n 'B16005_004E,' #Speak Spanish \n 'B16005_009E,' #Speak Indo-European Languages\n 'B16005_014E,' #Speak Asian/Pacific Islander Language\n 'B16005_019E' #Speak Other Language\n]\n\n#results[304:320]\nhousehold_income_past_12 = ['B19001_002E,' #Less than $10,000\n 'B19001_003E,' #$10,000 to $14,999\n 'B19001_004E,' #15,000 to $19,999\n 'B19001_005E,' #$20,000 to $24,999\n 'B19001_006E,' #$25,000 to $29,999\n 'B19001_007E,' #$30,000 to $34,999\n 'B19001_008E,' #$35,000 to $39,999\n 'B19001_009E,' #$40,000 to $44,999\n 'B19001_010E,' #$45,000 to $49,999\n 'B19001_011E,' #$50,000 to $59,999\n 'B19001_012E,' #60,000 to $74,999\n 'B19001_013E,' #$75,000 to $99,999\n 'B19001_014E,' #$100,000 to $124,999\n 'B19001_015E,' #$125,000 to $149,999\n 'B19001_016E,' #$150,000 to $199,999\n 'B19001_017E' #$200,000 or more\n ]\n\n#results[323:334]\nearnings_type = ['B19051_001E,' #Total Earnings Type\n 'B19051_002E,' #Total With Earnings\n 'B19052_002E,' #Wage Earnings\n 'B19053_002E,' #With Self Employment Income\n 'B19054_002E,' #With Interest Dividends and Rental Income\n 'B19055_002E,' #With Social Security Income\n 'B19056_002E,' #With Supplemental Security Income (SSI)\n 'B19057_002E,' #With public assistance income\n 'B19058_002E,' #With cash public assistance or Food Stamps/SNAP\n 'B19059_002E,' #With retirement income\n 'B19060_002E' #With Other Types of Income\n ]\n\n#results[337:354]\nfamily_income = ['B19101_001E,' #Estimate!!Total\n 'B19101_002E,' #Less than $10,000\n 'B19101_003E,' #$10,000 to $14,999\n 'B19101_004E,' #$15,000 to $19,999\n 'B19101_005E,' #$20,000 to $24,999\n 'B19101_006E,' #$25,000 to $29,999\n 'B19101_007E,' #$30,000 to $34,999\n 'B19101_008E,' #$35,000 to $39,999\n 'B19101_009E,' #$40,000 to $44,999\n 'B19101_010E,' #$45,000 to $49,999\n 'B19101_011E,' #$50,000 to $59,999\n 'B19101_012E,' #$60,000 to $74,999\n 'B19101_013E,' #$75,000 to $99,999\n 'B19101_014E,' #$100,000 to $124,999\n 'B19101_015E,' #$125,000 to $149,999\n 'B19101_016E,' #$150,000 to $199,999\n 'B19101_017E' #!$200,000 or more\n ]\n\n#results[357:371]\nlanguage_home = ['C16001_001E,' #Language Spoken At Home\n 'C16001_002E,' #Speak only English\n 'C16001_003E,' #Speak Spanish\n 'C16001_006E,' #French, Haitian, or Cajun\n 'C16001_009E,' #Germanic or West Germanic Language\n 'C16001_012E,' #Russian, Polish, or other Slavic languages\n 'C16001_015E,' #Other Indo-European languages \n 'C16001_018E,' #Korean\n 'C16001_021E,' #Chinese (Mandarin + Cantonese)\n 'C16001_024E,' #Vietnamese\n 'C16001_027E,' #Tagalog + Filipino\n 'C16001_030E,' #Other Asian and Pacific Island Language\n 'C16001_033E,' #Arabic\n 'C16001_036E' #Other Unspecified Language\n ]\n\n#results[374:405]\noccupation_median_earnings = ['B24011_001E,' #Estimate Total\n 'B24011_003E,' #Management, business, and financial occupations\n 'B24011_004E,' #Management occupations\n 'B24011_005E,' #Business and financial operations occupations\n 'B24011_006E,' #Computer, engineering, and science occupations\n 'B24011_007E,' #Computer and mathematical occupations\n 'B24011_008E,' #Architecture and engineering occupations\n 'B24011_009E,' #Life, physical, and social science occupations\n 'B24011_010E,' #Education, legal, community service, arts, and media occupations\n 'B24011_011E,' #Community and social service occupations\n 'B24011_012E,' #Legal occupations\n 'B24011_013E,' #Education, training, and library occupations\n 'B24011_014E,' #Arts, design, entertainment, sports, and media occupations\n 'B24011_015E,' #Healthcare practitioners and technical occupations\n 'B24011_016E,' #Health diagnosing and treating practitioners and other technical occupations\n 'B24011_017E,' #Health technologists and technicians\n 'B24011_019E,' #Healthcare support occupations\n 'B24011_020E,' #Protective service occupations\n 'B24011_021E,' #Fire fighting and prevention, and other protective service workers including supervisors\n 'B24011_022E,' #Law enforcement workers including supervisors\n 'B24011_023E,' #Food preparation and serving related occupations\n 'B24011_024E,' #Building and grounds cleaning and maintenance occupations\n 'B24011_025E,' #Personal care and service occupations\n 'B24011_027E,' #Sales and related occupations\n 'B24011_028E,' #Office and administrative support occupations\n 'B24011_030E,' #Farming, fishing, and forestry occupations\n 'B24011_031E,' #Construction and extraction occupations\n 'B24011_032E,' #Installation, maintenance, and repair occupations\n 'B24011_034E,' #Production occupations\n 'B24011_035E,' #Transportation occupations\n 'B24011_036E' #Material moving occupations\n ]\n\n#results[408:422]\noccupation = ['C24050_002E,' #Agriculture, forestry, fishing and hunting, and mining\n 'C24050_003E,' #Construction\n 'C24050_004E,' #Manufacturing\n 'C24050_005E,' #Wholesale trade\n 'C24050_006E,' #Retail trade\n 'C24050_007E,' #Transportation and warehousing, and utilities\n 'C24050_008E,' #Information\n 'C24050_009E,' #Finance and insurance, and real estate and rental and leasing\n 'C24050_010E,' #Professional, scientific, and management, and administrative and waste management services\n 'C24050_011E,' #Educational services, and health care and social assistance\n 'C24050_012E,' #Arts, entertainment, and recreation, and accommodation and food services\n 'C24050_013E,' #Other services, except public administration\n 'C24050_014E,' #Public administration\n 'C24050_001E' #Total\n ]\n\n#results[425:427]\noccupancy_status = ['B25002_002E,' #Total Occupied\n 'B25002_003E' #Total Vacant\n ]\n\n#results[430:432]\ntenure_status = ['B25003_002E,' #Owner occupied\n 'B25003_003E' #Renter occupied\n ]\n\n#results[435:443]\nvacancy_status = ['B25004_001E,' #Total Vacancy Status\n 'B25004_002E,' #For Rent\n 'B25004_003E,' #Rented, Not Occupied\n 'B25004_004E,' #For Sale Only\n 'B25004_005E,' #Sold, not occupied\n 'B25004_006E,' #For seasonal, recreational, or occasional use\n 'B25004_007E,' #For migrant workers\n 'B25004_008E' #Other vacant\n ]\n\n\n#results[446:467]\nhouseholder_age = ['B25007_001E,' #Total occupied\n 'B25007_002E,' #Owner occupied\n 'B25007_003E,' #Owner occupied!!Householder 15 to 24 years\n 'B25007_004E,' #Owner occupied!!Householder 25 to 34 years\n 'B25007_005E,' #Owner occupied!!Householder 35 to 44 years\n 'B25007_006E,' #Owner occupied!!Householder 45 to 54 years\n 'B25007_007E,' #Owner occupied!!Householder 55 to 59 years\n 'B25007_008E,' #Owner occupied!!Householder 60 to 64 years\n 'B25007_009E,' #Owner occupied!!Householder 65 to 74 years\n 'B25007_010E,' #Owner occupied!!Householder 75 to 84 years\n 'B25007_011E,' #Owner occupied!!Householder 85 years and over\n 'B25007_012E,' #Renter occupied\n 'B25007_013E,' #Renter occupied!!Householder 15 to 24 years\n 'B25007_014E,' #Renter occupied!!Householder 25 to 34 years\n 'B25007_015E,' #Renter occupied!!Householder 35 to 44 years\n 'B25007_016E,' #Renter occupied!!Householder 45 to 54 years\n 'B25007_017E,' #Renter occupied!!Householder 55 to 59 years\n 'B25007_018E,' #Renter occupied!!Householder 60 to 64 years\n 'B25007_019E,' #Renter occupied!!Householder 65 to 74 years\n 'B25007_020E,' #Renter occupied!!Householder 75 to 84 years\n 'B25007_021E' #Renter occupied!!Householder 85 years and over\n ]\n\n#results[470:487]\nhousehold_size = ['B25009_001E,' #Total\n 'B25009_002E,' #Total Owner Occupied\n 'B25009_003E,' #Owner Occupied, 1 Person Household\n 'B25009_004E,' #Owner occupied, 2-person household\n 'B25009_005E,' #Owner occupied, 3-person household\n 'B25009_006E,' #Owner occupied!!4-person household\n 'B25009_007E,' #Owner occupied!!5-person household\n 'B25009_008E,' #Owner occupied!!6-person household\n 'B25009_009E,' #Owner occupied!!7-or-more person household\n 'B25009_010E,' #Renter occupied\n 'B25009_011E,' #Renter occupied!!1-person household\n 'B25009_012E,' #Renter occupied!!2-person household\n 'B25009_013E,' #Renter occupied!!3-person household\n 'B25009_014E,' #Renter occupied!!4-person household\n 'B25009_015E,' #Renter occupied!!5-person household\n 'B25009_016E,' #Renter occupied!!6-person household\n 'B25009_017E' #Renter occupied!!7-or-more person household\n ]\n\n#results[490:520]\ncontract_rent = ['B25056_001E,' #Total\n 'B25056_002E,' #With Cash Rent\n 'B25056_027E,' #No Cash Rent\n 'B25056_003E,' #With cash rent!!Less than $100\n 'B25056_004E,' #With cash rent!!$100 to $149\n 'B25056_005E,' #With cash rent!!$150 to $199\n 'B25056_006E,' #With cash rent!!$200 to $249\n 'B25056_007E,' #With cash rent!!$250 to $299\n 'B25056_008E,' #With cash rent!!$300 to $349\n 'B25056_009E,' #With cash rent!!$350 to $399\n 'B25056_010E,' #With cash rent!!$400 to $449\n 'B25056_011E,' #With cash rent!!$450 to $499\n 'B25056_012E,' #With cash rent!!$500 to $549\n 'B25056_013E,' #With cash rent!!$550 to $599\n 'B25056_014E,' #With cash rent!!$600 to $649\n 'B25056_015E,' #With cash rent!!$650 to $699\n 'B25056_016E,' #With cash rent!!$700 to $749\n 'B25056_017E,' #With cash rent!!$750 to $799\n 'B25056_018E,' #With cash rent!!$800 to $899\n 'B25056_019E,' #With cash rent!!$900 to $999\n 'B25056_020E,' #With cash rent!!$1,000 to $1,249\n 'B25056_021E,' #With cash rent!!$1,250 to $1,499\n 'B25056_022E,' #With cash rent!!$1,500 to $1,999\n 'B25056_023E,' #With cash rent!!$2,000 to $2,499\n 'B25056_024E,' #With cash rent!!$2,500 to $2,999\n 'B25056_025E,' #With cash rent!!$3,000 to $3,499\n 'B25056_026E,' #With cash rent!!$3,500 or more\n 'B25057_001E,' #Lower contract rent quartile\n 'B25058_001E,' #Median contract rent\n 'B25059_001E' #Upper contract rent quartile\n ]\n\n#results[523:548]\nrent_asked = ['B25061_001E,' #Total\n 'B25061_002E,' #Less than $100\n 'B25061_003E,' #$100 to $149\n 'B25061_004E,' #$150 to $199\n 'B25061_005E,' #$200 to $249\n 'B25061_006E,' #$250 to $299\n 'B25061_007E,' #$300 to $349\n 'B25061_008E,' #$350 to $399\n 'B25061_009E,' #$400 to $449\n 'B25061_010E,' #$450 to $499\n 'B25061_011E,' #$500 to $549\n 'B25061_012E,' #$550 to $599\n 'B25061_013E,' #$600 to $649\n 'B25061_014E,' #$650 to $699\n 'B25061_015E,' #$700 to $749\n 'B25061_016E,' #$750 to $799\n 'B25061_017E,' #$800 to $899\n 'B25061_018E,' #$900 to $999\n 'B25061_019E,' #$1,000 to $1,249\n 'B25061_020E,' #$1,250 to $1,499\n 'B25061_021E,' #$1,500 to $1,999\n 'B25061_022E,' #2,000 to $2,499\n 'B25061_023E,' #$2,500 to $2,999\n 'B25061_024E,' #$3,000 to $3,499\n 'B25061_025E' #$3,500 or more\n ]\n\n#results[551:580]\nhouse_value = ['B25075_002E,' #Less than $10,000\n 'B25075_003E,' #$10,000 to $14,999\n 'B25075_004E,' #$15,000 to $19,999\n 'B25075_005E,' #$20,000 to $24,999\n 'B25075_006E,' #$25,000 to $29,999\n 'B25075_007E,' #$30,000 to $34,999\n 'B25075_008E,' #$35,000 to $39,999\n 'B25075_009E,' #$40,000 to $49,999\n 'B25075_010E,' #$50,000 to $59,999\n 'B25075_011E,' #$60,000 to $69,999\n 'B25075_012E,' #$70,000 to $79,999\n 'B25075_013E,' #$80,000 to $89,999\n 'B25075_014E,' #$90,000 to $99,999\n 'B25075_015E,' #$100,000 to $124,999\n 'B25075_016E,' #$125,000 to $149,999\n 'B25075_017E,' #$150,000 to $174,999\n 'B25075_018E,' #$175,000 to $199,999\n 'B25075_019E,' #$200,000 to $249,999\n 'B25075_020E,' #$250,000 to $299,999\n 'B25075_021E,' #$300,000 to $399,999\n 'B25075_022E,' #$400,000 to $499,999\n 'B25075_023E,' #$500,000 to $749,999\n 'B25075_024E,' #$750,000 to $999,999\n 'B25075_025E,' #$1,000,000 to $1,499,999\n 'B25075_026E,' #$1,500,000 to $1,999,999\n 'B25075_027E,' #$2,000,000 or more\n 'B25076_001E,' #lower value quartile (dollars)\n 'B25077_001E,' #Median value (dollars)\n 'B25078_001E' #Upper value quartile (dollars)\n ]\n\n#results[583:609]\nprice_asked = ['B25085_002E,' #Less than $10,000\n 'B25085_003E,' #$10,000 to $14,999\n 'B25085_004E,' #$15,000 to $19,999\n 'B25085_005E,' #$20,000 to $24,999\n 'B25085_006E,' #$25,000 to $29,999\n 'B25085_007E,' #$30,000 to $34,999\n 'B25085_008E,' #$35,000 to $39,999\n 'B25085_009E,' #$40,000 to $49,999\n 'B25085_010E,' #$50,000 to $59,999\n 'B25085_011E,' #$60,000 to $69,999\n 'B25085_012E,' #$70,000 to $79,999\n 'B25085_013E,' #$80,000 to $89,999\n 'B25085_014E,' #$90,000 to $99,999\n 'B25085_015E,' #$100,000 to $124,999\n 'B25085_016E,' #$125,000 to $149,999\n 'B25085_017E,' #$150,000 to $174,999\n 'B25085_018E,' #$175,000 to $199,999\n 'B25085_019E,' #$200,000 to $249,999\n 'B25085_020E,' #$250,000 to $299,999\n 'B25085_021E,' #$300,000 to $399,999\n 'B25085_022E,' #$400,000 to $499,999\n 'B25085_023E,' #$500,000 to $749,999\n 'B25085_024E,' #$750,000 to $999,999\n 'B25085_025E,' #$1,000,000 to $1,499,999\n 'B25085_026E,' #$1,500,000 to $1,999,999\n 'B25085_027E' #$2,000,000 or more\n ]\n\n#results[612:620]\nmortgage_status = ['B25081_001E,' #Total Mortgage Status\n 'B25081_002E,' #Housing units with a mortgage, contract to purchase, or similar debt\n 'B25081_003E,' #With either a second mortgage or home equity loan, but not both\n 'B25081_004E,' #Second mortgage only\n 'B25081_005E,' #Home equity loan only\n 'B25081_006E,' #Both second mortgage and home equity loan\n 'B25081_007E,' #No second mortgage and no home equity loan\n 'B25081_008E' #Housing units without a mortgage\n ]\n\n#results[623:641]\nmonthly_owner_costs = ['B25094_001E,' #selected monthly costs\n 'B25094_002E,' #Less than $200\n 'B25094_003E,' #$200 to $299\n 'B25094_004E,' #$300 to $399\n 'B25094_005E,' #$400 to $499\n 'B25094_006E,' #$500 to $599\n 'B25094_007E,' #$600 to $699\n 'B25094_008E,' #$700 to $799\n 'B25094_009E,' #$800 to $899\n 'B25094_010E,' #$900 to $999\n 'B25094_011E,' #$1,000 to $1,249\n 'B25094_012E,' #$1,250 to $1,499\n 'B25094_013E,' #$1,500 to $1,999\n 'B25094_014E,' #$2,000 to $2,499\n 'B25094_015E,' #$2,500 to $2,999\n 'B25094_016E,' #$3,000 to $3,499\n 'B25094_017E,' #$3,500 to $3,999\n 'B25094_018E' #$4,000 or more\n ]\n\n#results[644:662]\ntotal_housing_costs = ['B25104_001E,' #Estimate!!Total\n 'B25104_002E,' #Less than $100\n 'B25104_003E,' #$100 to $199\n 'B25104_004E,' #$200 to $299\n 'B25104_005E,' #$300 to $399\n 'B25104_006E,' #$400 to $499\n 'B25104_007E,' #$500 to $599\n 'B25104_008E,' #$600 to $699\n 'B25104_009E,' #$700 to $799\n 'B25104_010E,' #$800 to $899\n 'B25104_011E,' #$900 to $999\n 'B25104_012E,' #$1,000 to $1,499\n 'B25104_013E,' #$1,500 to $1,999\n 'B25104_014E,' #$2,000 to $2,499\n 'B25104_015E,' #$2,500 to $2,999\n 'B25104_016E,' #$3,000 or more\n 'B25104_017E,' #No cash rent\n 'B25105_001E' #Median monthly housing costs\n ]\n\n#results[665:682]\ntaxes_paid = ['B25102_002E,' #Total With A Mortgage\n 'B25102_003E,' #With a mortgage, Less than $800\n 'B25102_004E,' #With a mortgage, $800 to $1,499\n 'B25102_005E,' #With a mortgage, $1,500 to $1,999\n 'B25102_006E,' #With a mortgage, $2,000 to $2,999\n 'B25102_007E,' #With a mortgage, $3,000 or more\n 'B25102_008E,' #With a mortgage, No real estate taxes paid\n 'B25102_009E,' #Not mortgaged\n 'B25102_010E,' #Not mortgaged, Less than $800\n 'B25102_011E,' #Not mortgaged!!$800 to $1,499\n 'B25102_012E,' #Not mortgaged!!$1,500 to $1,999\n 'B25102_013E,' #Not mortgaged!!$2,000 to $2,999\n 'B25102_014E,' #Not mortgaged!!$3,000 or more\n 'B25102_015E,' #No real estate taxes paid\n 'B25103_001E,' #Median real estate taxes paid!!Total\n 'B25103_002E,' #Median real estate taxes paid for units with a mortgage\n 'B25103_003E' #Median real estate taxes paid for units without a mortgage\n ]\n\n#results[685:692]\nbedrooms = ['B25041_001E,' #Bedrooms Total\n 'B25041_002E,' #No bedroom\n 'B25041_003E,' #1 bedroom\n 'B25041_004E,' #2 bedrooms\n 'B25041_005E,' #3 bedrooms\n 'B25041_006E,' #4 bedrooms\n 'B25041_007E' #5 or more bedrooms\n ]\n\n#results[695:706]\nyear_structure_built = ['B25034_002E,' #Built 2014 or later\n 'B25034_003E,' #Built 2010 to 2013\n 'B25034_004E,' #Built 2000 to 2009\n 'B25034_005E,' #Built 1990 to 1999\n 'B25034_006E,' #Built 1980 to 1989\n 'B25034_007E,' #Built 1970 to 1979\n 'B25034_008E,' #Built 1960 to 1969\n 'B25034_009E,' #Built 1950 to 1959\n 'B25034_010E,' #Built 1940 to 1949\n 'B25034_011E,' #Built 1939 or earlier\n 'B25035_001E' #Median year structure built\n ]\n\n#results[709:732]\nunits_in_structure = ['B25032_001E,' #Total Units in Structure\n 'B25032_002E,' #Owner-occupied housing units\n 'B25032_003E,' #Owner-occupied housing units!!1, detached\n 'B25032_004E,' #Owner-occupied housing units!!1, attached\n 'B25032_005E,' #Owner-occupied housing units!!2\n 'B25032_006E,' #Owner-occupied housing units!!3 or 4\n 'B25032_007E,' #Owner-occupied housing units!!5 to 9\n 'B25032_008E,' #Owner-occupied housing units!!10 to 19\n 'B25032_009E,' #Owner-occupied housing units!!20 to 49\n 'B25032_010E,' #Owner-occupied housing units!!50 or more\n 'B25032_011E,' #Owner-occupied housing units!!Mobile home\n 'B25032_012E,' #Owner-occupied housing units!!Boat, RV, van, etc.\n 'B25032_013E,' #Renter-occupied housing units\n 'B25032_014E,' #Renter-occupied housing units!!1, detached\n 'B25032_015E,' #Renter-occupied housing units!!1, attached\n 'B25032_016E,' #Renter-occupied housing units!!2\n 'B25032_017E,' #Renter-occupied housing units!!3 or 4\n 'B25032_018E,' #Renter-occupied housing units!!5 to 9\n 'B25032_019E,' #Renter-occupied housing units!!10 to 19\n 'B25032_020E,' #Renter-occupied housing units!!20 to 49\n 'B25032_021E,' #Renter-occupied housing units!!50 or more\n 'B25032_022E,' #!Renter-occupied housing units!!Mobile home\n 'B25032_023E' #Renter-occupied housing units!!Boat, RV, van, etc.\n ]\n\n#results[735:785]\nother_race1 = ['B02017_002E,' #American Indian Ancestry\n 'B02017_046E,' #Alaskan Native Ancestry\n 'B02018_002E,' # Asian Indian\n 'B02018_003E,' # Bangladeshi\n 'B02018_004E,' # Bhutanese\n 'B02018_005E,' # Burmese\n 'B02018_006E,' # Cambodian\n 'B02018_007E,' # Chinese, except Taiwanese\n 'B02018_008E,' # Filipino\n 'B02018_009E,' # Hmong\n 'B02018_010E,' # Indonesian\n 'B02018_011E,' # Japanese\n 'B02018_012E,' # Korean\n 'B02018_013E,' # Laotian\n 'B02018_014E,' # Malaysian\n 'B02018_015E,' # Mongolian\n 'B02018_016E,' # Nepalese\n 'B02018_017E,' # Okinawan\n 'B02018_018E,' # Pakistani\n 'B02018_019E,' # Sri Lankan\n 'B02018_020E,' # Taiwanese\n 'B02018_021E,' # Thai\n 'B02018_022E,' # Vietnamese\n 'B02018_023E,' # Other Asian Specified\n 'B02018_024E,' # Other Asian, not specified\n 'B02019_002E,' # Native Hawaiian\n 'B02019_003E,' # Samoan\n 'B02019_004E,' # Tongan\n 'B02019_005E,' # Other Polynesian\n 'B02019_006E,' # Guamanian or Chamorro\n 'B02019_007E,' # Marshallese\n 'B02019_008E,' # Other Micronesian\n 'B02019_009E,' # Fijian\n 'B02019_010E,' # Other Melanesian\n 'B03001_004E,' # Mexican\n 'B03001_005E,' # Puerto Rican\n 'B03001_006E,' # Cuban\n 'B03001_007E,' # Dominican (Dominican Republic)\n 'B03001_009E,' # Costa Rican\n 'B03001_010E,' # Guatemalan\n 'B03001_011E,' # Honduran\n 'B03001_012E,' # Nicaraguan\n 'B03001_013E,' # Panamanian\n 'B03001_014E,' # Salvadoran\n 'B03001_015E,' # Other Central American\n 'B03001_017E,' # Argentinean\n 'B03001_018E,' # Bolivian\n 'B03001_019E,' # Chilean\n 'B03001_020E,' # Colombian\n 'B03001_021E' # Ecuadorian\n ]\n\n\n#results[788:797]\nother_race2 = ['B03001_022E,' #Paraguayan\n 'B03001_023E,' #Peruvian\n 'B03001_024E,' #Uruguayan\n 'B03001_025E,' #Venezuelan\n 'B03001_026E,' #Other South American\n 'B03001_027E,' #Other Hispanic or Latino\n 'B03001_029E,' #Spanish\n 'B03001_028E,' #Spaniard\n 'B03001_030E' #Spanish American\n ]\n\n#results[800:820]\ndetailed_occupation_male = ['C24030_002E,' #Total Male\n 'C24030_004E,' #Agriculture, forestry, fishing and hunting\n 'C24030_005E,' #Mining, quarrying, and oil and gas extraction\n 'C24030_006E,' #Construction\n 'C24030_007E,' #Manufacturing\n 'C24030_008E,' #Wholesale trade\n 'C24030_009E,' #Retail trade\n 'C24030_011E,' #Transportation and warehousing\n 'C24030_012E,' #Utilities\n 'C24030_013E,' #Information\n 'C24030_015E,' #Finance and insurance\n 'C24030_016E,' #Real estate and rental and leasing\n 'C24030_018E,' #Professional, scientific, and technical services\n 'C24030_019E,' #Management of companies and enterprises\n 'C24030_020E,' #Administrative and support and waste management services\n 'C24030_022E,' #Educational services\n 'C24030_023E,' #Health care and social assistance\n 'C24030_025E,' #Arts, entertainment, and recreation\n 'C24030_026E,' #Accommodation and food services\n 'C24030_027E,' #Other services\n 'C24030_028E' #Public administration\n ]\n\n\n#results[824:844]\ndetailed_occupation_female = ['C24030_029E,' #Total Female\n 'C24030_031E,' #Agriculture, forestry, fishing and hunting\n 'C24030_032E,' #Mining, quarrying, and oil and gas extraction\n 'C24030_033E,' #Construction\n 'C24030_034E,' #Manufacturing\n 'C24030_035E,' #Wholesale trade\n 'C24030_036E,' #Retail trade\n 'C24030_038E,' #Transportation and warehousing\n 'C24030_039E,' #Utilities\n 'C24030_040E,' #Information\n 'C24030_042E,' #Finance and insurance\n 'C24030_043E,' #Real estate and rental and leasing\n 'C24030_045E,' #Professional, scientific, and technical services\n 'C24030_046E,' #Management of companies and enterprises\n 'C24030_047E,' #Administrative and support and waste management services\n 'C24030_049E,' #Educational services\n 'C24030_050E,' #Health care and social assistance\n 'C24030_052E,' #Arts, entertainment, and recreation\n 'C24030_053E,' #Accommodation and food services\n 'C24030_054E,' #Other services\n 'C24030_055E' #Public administration\n ]\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n#----------------------------------------------------------------------------------------------------\n\n\n#ACS 2016 Community Survey - Detailed Tables\n\nweb_scrape_url = ['https://api.census.gov/data/2016/acs/acs5?']\n\n\n#this list is the combined results of all the 50 item api calls\nresults = []\n\n\n#this part of the code requires different census calls to get information\nlist = [summary, demographics, race, ethnicity1, ethnicity2, foreign_native, relationship, education,\n transportation, work, travel_time, vehicles, worker_class, under18,\n school_enrollment, bachelors_field_study, nativity_language, household_income_past_12,\n earnings_type, family_income, language_home, occupation_median_earnings, occupation,\n occupancy_status, tenure_status, vacancy_status, householder_age, household_size, contract_rent, rent_asked,\n house_value, price_asked, mortgage_status, monthly_owner_costs, total_housing_costs, taxes_paid,\n bedrooms, year_structure_built, units_in_structure, other_race1, other_race2, detailed_occupation_male, detailed_occupation_female]\n\n\n\nfor x in list:\n #census tract level\n censusparams1 = {\n 'get': x,\n 'for': 'tract:' + tract_id,\n 'in': 'state:' + state_id + ' county:' + county_id,\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n #census block level\n censusparams2 = {\n 'get': x,\n 'for': 'block group:' + block_group,\n 'in': 'state:' + state_id + ' county:' + county_id + ' tract:' + tract_id,\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n #zipcode level\n censusparams3 = {\n 'get': x,\n 'for': 'zip code tabulation area:' + zipcode,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n\n }\n #public use microdata area\n censusparams4 = {\n 'get': x,\n 'for': 'public use microdata area:' + microdata_id,\n 'in': 'state:' + state_id,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n # metropolitan statistical area\n censusparams5 = {\n 'get': x,\n 'for': 'metropolitan statistical area/micropolitan statistical area:' + metropolitan_id,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n\n\n #configure which region to use\n if config == 1:\n parameter = censusparams2\n elif config == 2:\n parameter = censusparams1\n elif config ==3:\n parameter = censusparams3\n elif config ==4:\n parameter = censusparams4\n else:\n parameter = censusparams5\n\n\n\n # Do the request and get the response data\n req = requests.get('https://api.census.gov/data/2016/acs/acs5?', params=parameter)\n res = req.json()\n preresults = res[1]\n #preresults as a result of for-loops to acquire data\n print(\"Loading Parameter\")\n print(list.index(x))\n print(\"of 42\")\n #taking the presults and appending to results\n for y in preresults:\n results.append(y)\n\n\n#-------------------------------DISPLAY SUMMARY INFORMATION--------------------------------------------\n\n#parse census results by numerical index\ncensus_name = results[0]\ntotal_housing_units = int(results[1])\ntotal_occupied_units = int(results[2])\ntotal_vacant_units = int(results[3])\ntotal_renter_occupied_units = int(results[4])\ntotal_population = results[5]\nmedian_age = results[6]\nmedian_household_income_past12 = results[7]\nGINI_inequality_index = results[8]\nlower_quartile_house_value = results[9]\nmedian_house_value = results[10]\nupper_quartile_house_value = results[11]\nmedian_gross_rent = results[12]\nlower_quartile_rent = results[13]\nmedian_contract_rent = results[14]\nupper_quartile_rent = results[15]\n\nprint(\"Data Results for:\" + census_name)\nprint(\"Microdata Area Name:\", microdata_area_name)\nprint(\"Metropolitan Statistical Area Name:\",msa_Name)\nprint(\"Total Housing Units:\",total_housing_units)\nprint(\"Total Population:\",total_population)\nprint(\"Percent Occupied Units:\",round((total_occupied_units/total_housing_units)*100,2),\"%\")\nprint(\"Percent Vacant Units:\",round((total_vacant_units/total_housing_units)*100,2),\"%\")\nprint(\"Percent Rented Units:\",round((total_renter_occupied_units/total_housing_units)*100,2),\"%\")\nprint(\"Median Age:\", median_age)\nprint(\"Median Household Income:\",median_household_income_past12)\nprint(\"House Value(lower 25%, median, upper 25%):\" + lower_quartile_house_value, median_house_value, upper_quartile_house_value)\nprint(\"Rent(lower 25%, median, upper 25%):\" + lower_quartile_rent, median_contract_rent, upper_quartile_rent)\n\n\n#===========================[PANDAS DATAFRAMES========================================================\n\nmale_age_distribution_values = results[20:43]\nmale_age_distribution_keys = [\"Under 5 years\",\n \"5 to 9 years\",\n \"10 to 14 years\",\n \"15 to 17 years\",\n \"18 and 19 years\",\n \"20 years\",\n \"21 years\",\n \"22 to 24 years\",\n \"25 to 29 years\",\n \"30 to 34 years\",\n \"35 to 39 years\",\n \"40 to 44 years\",\n \"45 to 49 years\",\n \"50 to 54 years\",\n \"55 to 59 years\",\n \"60 and 61 years\",\n \"62 to 64 years\",\n \"65 and 66 years\",\n \"67 to 69 years\",\n \"70 to 74 years\",\n \"75 to 79 years\",\n \"80 to 84 years\",\n \"85 years and over\"\n ]\n\n#\nmale_age_distribution = dict(zip(male_age_distribution_keys, male_age_distribution_values))\n#convert to pandas data series\nMALE_AGE_DISTRIBUTION = pd.Series(male_age_distribution)\nprint(MALE_AGE_DISTRIBUTION)\n\n#----------------------------------[EXECUTE PANDA SERIES]-----------------------------------------------------\n\nfemale_age_distribution_keys = [\"Under 5 years\",\n \"5 to 9 years\",\n \"10 to 14 years\",\n \"15 to 17 years\",\n \"18 and 19 years\",\n \"20 years\",\n \"21 years\",\n \"22 to 24 years\",\n \"25 to 29 years\",\n \"30 to 34 years\",\n \"35 to 39 years\",\n \"40 to 44 years\",\n \"45 to 49 years\",\n \"50 to 54 years\",\n \"55 to 59 years\",\n \"60 and 61 years\",\n \"62 to 64 years\",\n \"65 and 66 years\",\n \"67 to 69 years\",\n \"70 to 74 years\",\n \"75 to 79 years\",\n \"80 to 84 years\",\n \"85 years and over\"\n ]\n\nfemale_age_distribution_values = results[44:67]\n\n#create python dictionary\nfemale_age_distribution = dict(zip(female_age_distribution_keys, female_age_distribution_values))\n\n#convert to pandas data series\nFEMALE_AGE_DISTRIBUTION = pd.Series(female_age_distribution)\nprint(FEMALE_AGE_DISTRIBUTION)\n\n#-----------------------------------------------------------------------------------------------------\n\n\n#Total Age Distribution\n\ndfnew = pd.to_numeric(MALE_AGE_DISTRIBUTION, errors='raise', downcast=None)\ndf2new = pd.to_numeric(FEMALE_AGE_DISTRIBUTION, errors='raise', downcast=None)\n\nTOTAL_AGE_DISTRIBUTION = dfnew.add(df2new)\n\nprint(TOTAL_AGE_DISTRIBUTION)\n\n#---------------------------------------------------------------------------------------------------------\n\n\nrace_values = results[70:78]\nrace_keys = ['White',\n 'Hispanic',\n 'Black',\n 'Asian',\n 'Native American/Alaskan Native',\n 'Native Hawaiian/Pacific Islander',\n 'Other',\n 'Two or More Races'\n ]\nrace = dict(zip(race_keys, race_values))\nRACE = pd.Series(race)\n\nprint(RACE)\n\n\n#---------------------------------------------------------------------------------------------------------\n\n\nethnicity1_values = results[83:123]\nethnicity2_values = results[126:155]\nother_race1_values = results[735:785]\nother_race2_values = results[788:797]\nethnicity_values = ethnicity1_values + ethnicity2_values + other_race1_values + other_race2_values\n\nethnicity_keys = ['Afghan',\n 'Albanian',\n 'Alsatian',\n 'American',\n 'Arab',\n 'Armenian',\n 'Assyrians',\n 'Australians',\n 'Austrian',\n 'Basque',\n 'Belgian',\n 'Brazilian',\n 'British',\n 'Bulgarian',\n 'Cajun',\n 'Canadian',\n 'Carpatho Rusyn',\n 'Celtic',\n 'Croatian',\n 'Cypriot',\n 'Czech',\n 'Czechoslovakian',\n 'Danish',\n 'Dutch',\n 'Eastern European',\n 'English',\n 'Estonian',\n 'European',\n 'Finnish',\n 'French',\n 'French Canadian',\n 'German',\n 'German Russian',\n 'Greek',\n 'Guayanese',\n 'Hungarian',\n 'Icelander',\n 'Iranaian',\n 'Irish',\n 'Israeli',\n 'Italian',\n 'Latvian',\n 'Luxemburger',\n 'Lithuanian',\n 'Macedonian',\n 'Maltese',\n 'New Zealander',\n 'Northern European',\n 'Norwegian',\n 'Pennsylvania German',\n 'Polish',\n 'Portuguese',\n 'Romanian',\n 'Russian',\n 'Scandinavian',\n 'Scotch-Irish',\n 'Scottish',\n 'Serbian',\n 'Slavic',\n 'Slovak',\n 'Soviet Russia',\n 'Soviet Union',\n 'Subsaharan Africa',\n 'Swedish',\n 'Swiss',\n 'Turkish',\n 'Ukrainian',\n 'West Indian',\n 'Yugoslavian',\n 'American Indian',\n 'Alaskan Native',\n 'Asian Indian',\n 'Bangladeshi',\n 'Bhutanese',\n 'Burmese',\n 'Cambodian',\n 'Chinese',\n 'Filipino',\n 'Hmong',\n 'Indonesian',\n 'Japanese',\n 'Korean',\n 'Laotian',\n 'Malaysian',\n 'Mongolian',\n 'Nepalese',\n 'Okinawan',\n 'Pakistani',\n 'Sri Lankan',\n 'Taiwanese',\n 'Thai',\n 'Vietnamese',\n 'Other Asian, Specified',\n 'Other Asian, Not Specified',\n 'Native Hawaiian',\n 'Samoan',\n 'Tongan',\n 'Other Polynesian',\n 'Guamanian or Chamorro',\n 'Marshallese',\n 'Other Micronesian',\n 'Fijian',\n 'Other Melanesian',\n 'Mexican',\n 'Puerto Rican',\n 'Cuban',\n 'Dominican (Dominican Republic)',\n 'Costa Rican',\n 'Guatemalan',\n 'Honduran',\n 'Nicaraguan',\n 'Panamanian',\n 'Salvadoran',\n 'Other Central American',\n 'Argentinean',\n 'Bolivian',\n 'Chilean',\n 'Columbian',\n 'Ecuadorian',\n 'Paraguayan',\n 'Peruvian',\n 'Uruguayan',\n 'Venezuelan',\n 'Other South American',\n 'Other Hispanic or Latino',\n 'Spanish',\n 'Spaniard',\n 'Spanish American'\n ]\n\nethnicity = dict(zip(ethnicity_keys, ethnicity_values))\nETHNICITY = pd.Series(ethnicity)\nprint(ETHNICITY)\n\n\n#----------------------------------------------------------------------------------------------------\n\n\nforeign_native_values = results[159:161]\nforeign_native_keys = ['Native','Foreign-Born']\n\nforeign_native = dict(zip(foreign_native_keys, foreign_native_values))\nFOREIGN_NATIVE = pd.Series(foreign_native)\n\n\nprint(FOREIGN_NATIVE)\n\n#------------------------------------------------------------------------------------------------------\n\nrelationship_values = results[164:170]\nrelationship_keys = ['Total Count',\n 'Currently Married',\n 'Divorced',\n 'Separated',\n 'Widowed'\n ]\n\n\nrelationship = dict(zip(relationship_keys, relationship_values))\nRELATIONSHIP = pd.Series(relationship)\n\nprint(RELATIONSHIP)\n#-----------------------------------------------------------------------------------------------------\n\neducation_values = results[174:179]\neducation_keys = ['Less Than High School Graduate',\n 'High School Graduate',\n 'Some College/Associates',\n 'Bachelors Degree',\n 'Graduate or Progressional Degree'\n ]\neducation = dict(zip(education_keys, education_values))\nEDUCATION = pd.Series(education)\n\nprint(EDUCATION)\n\n#----------------------------------------------------------------------------------------------------\n\ntransportation_values = results[182:192]\ntransportation_keys = ['Total Count',\n 'Car, Van, Truck (Drove Alone)',\n 'Car, Van, Truck (Carpooled',\n 'Public Transportation',\n 'Bicycle',\n 'Walk',\n 'Motorcycle',\n 'Other Means',\n 'Worked at Home'\n ]\n\ntransportation = dict(zip(transportation_keys, transportation_values))\nTRANSPORTATION = pd.Series(transportation)\n\nprint(TRANSPORTATION)\n#------------------------------------------------------------------------------------------------------\n\ntime_leave_for_work_values = results[195:210]\ntime_leave_for_work_keys = ['Total',\n '12:00 a.m. to 4:59 a.m',\n '5:00 a.m. to 5:29 a.m.',\n '5:30 a.m. to 5:59 a.m.',\n '6:00 a.m. to 6:29 a.m.',\n '6:30 a.m. to 6:59 a.m.',\n '7:00 a.m. to 7:29 a.m.',\n '7:30 a.m. to 7:59 a.m',\n '8:00 a.m. to 8:29 a.m.',\n '8:30 a.m. to 8:59 a.m.',\n '9:00 a.m. to 9:59 a.m.',\n '10:00 a.m. to 10:59 a.m.',\n '11:00 a.m. to 11:59 a.m',\n '12:00 p.m. to 3:59 p.m.',\n '4:00 p.m. to 11:59 p.m.'\n]\n\ntime_leave_for_work = dict(zip(time_leave_for_work_keys, time_leave_for_work_values))\nTIME_LEAVE_FOR_WORK = pd.Series(time_leave_for_work)\n\n\nprint(TIME_LEAVE_FOR_WORK)\n\n\n#===================================================================================================\n\nwork_travel_time_values = results[213:226]\nwork_travel_time_keys = ['Total',\n 'Less than 5 minutes',\n '5 to 9 minutes',\n '10 to 14 minutes',\n '15 to 19 minutes',\n '20 to 24 minutes',\n '25 to 29 minutes',\n '30 to 34 minutes',\n '35 to 39 minutes',\n '40 to 44 minutes',\n '45 to 59 minutes',\n '60 to 89 minutes',\n '90 or more minutes'\n ]\n\nwork_travel_time = dict(zip(work_travel_time_keys, work_travel_time_values))\nWORK_TRAVEL_TIME = pd.Series(work_travel_time)\n\nprint(WORK_TRAVEL_TIME)\n\n\n#-----------------------------------------------------------------------------------------------------\n\nvehicle_values = results[229:236]\nvehicle_keys = ['Total',\n 'No Vehicles',\n '1 Vehicle',\n '2 Vehicles',\n '3 Vehicles',\n '4 Vehicles',\n '5 or more Vehicles'\n ]\n\nvehicles = dict(zip(vehicle_keys, vehicle_values))\nVEHICLES = pd.Series(vehicles)\n\nprint(VEHICLES)\n\n#-----------------------------------------------------------------------------------------------------\n\nworker_class_values = results[239:248]\nworker_class_keys = ['Total Workers Count',\n 'Employees of Private Companies',\n 'Self-Employed in Own Incorporated Business',\n 'Private Non-Profit Wage and Salary Workers',\n 'Local Government Workers',\n 'State Government Workers',\n 'Federal Government Workers',\n 'Self-Employed (Non Incorporated) Business Workers',\n 'Family Workers'\n ]\nworker_class = dict(zip(worker_class_keys, worker_class_values))\nWORKER_CLASS = pd.Series(worker_class)\n\nprint(WORKER_CLASS)\n\n#-----------------------------------------------------------------------------------------------------\n\n\nschool_enrollment_values = results[264:272]\nschool_enrollment_keys = ['Total Enrolled in School',\n 'Nursery School/Preschool',\n 'Enrolled in Kindergarten',\n 'Enrolled in Grades 1-4',\n 'Enrolled in Grades 5-8',\n 'Enrolled in Grades 9-12',\n 'Enrolled in College as Undergraduate',\n 'Enrolled in Graduate School'\n ]\n\nschool_enrollment = dict(zip(school_enrollment_keys, school_enrollment_values))\nSCHOOL_ENROLLMENT = pd.Series(school_enrollment)\n\nprint(SCHOOL_ENROLLMENT)\n\n#-----------------------------------------------------------------------------------------------------\n\n\nbachelors_degree_field_values = results[275:291]\nbachelors_degree_field_keys = ['Total',\n 'Computers, Mathematics, Statistics',\n 'Biological, Agricultural, and Environmental Sciences',\n 'Physical and Related Sciences',\n 'Psychology',\n 'Social Sciences',\n 'Engineering',\n 'Multidisciplinary Studies',\n 'Science and Engineering Related Field',\n 'Business',\n 'Education',\n 'Literature and Languages',\n 'Liberal Arts and History',\n 'Visual and Performing Arts',\n 'Communications',\n 'Other'\n ]\n\nbachelors_degree_field = dict(zip(bachelors_degree_field_keys, bachelors_degree_field_values))\nBACHELORS_DEGREE_FIELD = pd.Series(bachelors_degree_field)\nprint(BACHELORS_DEGREE_FIELD)\n\n#-----------------------------------------------------------------------------------------------------\n\n\nhousehold_income_values = results[304:320]\nhousehold_income_keys = ['Less than $10,000',\n '$10,000 to $14,999',\n '$15,000 to $19,999',\n '$20,000 to $24,999',\n '$25,000 to $29,999',\n '$30,000 to $34,999',\n '35,000 to $39,999',\n '$40,000 to $44,999',\n '$45,000 to $49,999',\n '$50,000 to $59,999',\n '$60,000 to $74,999',\n '$75,000 to $99,999',\n '$100,000 to $124,999',\n '$125,000 to $149,999',\n '$150,000 to $199,999',\n '$200,000 or more'\n ]\n\nhousehold_income_12 = dict(zip(household_income_keys, household_income_values))\nHOUSEHOLD_INCOME_PAST_12 = pd.Series(household_income_12)\nprint(HOUSEHOLD_INCOME_PAST_12)\n\n#-----------------------------------------------------------------------------------------------------\n\nfamily_income_values = results[337:354]\nfamily_income_keys = ['Total',\n 'Less than $10,000',\n '$10,000 to $14,999',\n '$15,000 to $19,999',\n '$20,000 to $24,999',\n '$25,000 to $29,999',\n '$30,000 to $34,999',\n '35,000 to $39,999',\n '$40,000 to $44,999',\n '$45,000 to $49,999',\n '$50,000 to $59,999',\n '$60,000 to $74,999',\n '$75,000 to $99,999',\n '$100,000 to $124,999',\n '$125,000 to $149,999',\n '$150,000 to $199,999',\n '$200,000 or more'\n ]\n\n\nfamily_income_12 = dict(zip(family_income_keys, family_income_values))\nFAMILY_INCOME_PAST_12 = pd.Series(family_income_12)\nprint(FAMILY_INCOME_PAST_12)\n\n\n#----------------------------------------------------------------------------------------------------\n\n\nearnings_type_values = results[323:334]\nearnings_type_keys = ['Total Earnings Count',\n 'Wage Earnings',\n 'With Self Employment Income',\n 'With Interest Dividends and Rental Income',\n 'With Social Security Income',\n 'With Supplemental Security Income (SSI)',\n 'With Public Assistance Income',\n 'With Cash Public Assistance or Food Stamps/SNAP'\n 'With Retirement Income',\n 'With Other Types of Income'\n ]\n\nearnings_type = dict(zip(earnings_type_keys, earnings_type_values))\nEARNINGS_TYPE = pd.Series(earnings_type)\nprint(EARNINGS_TYPE)\n\n#-----------------------------------------------------------------------------------------------------\n\nlanguage_home_values = results[357:371]\nlanguage_home_keys = ['Total',\n 'Speak only English',\n 'Speak Spanish',\n 'French, Haitian, or Cajun',\n 'Germanic or West Germanic Language',\n 'Russian, Polish, or other Slavic languages',\n 'Other Indo-European languages',\n 'Korean',\n 'Chinese(Mandarin and Cantonese',\n 'Vietnamese',\n 'Tagalog and Filipino',\n 'Other Asian and Pacific Island Language',\n 'Arabic',\n 'Other Unspecified Language'\n ]\nlanguage_home = dict(zip(language_home_keys, language_home_values))\nLANGUAGE_HOME = pd.Series(language_home)\nprint(LANGUAGE_HOME)\n\n#-----------------------------------------------------------------------------------------------------\n\noccupation_earnings_values = results[374:405]\noccupation_earnings_keys = ['Total Median',\n 'Management, business, and financial occupations',\n 'Business and financial operations occupations',\n 'Computer, engineering, and science occupations',\n 'Computer and mathematical occupations',\n 'Architecture and engineering occupations',\n 'Life, physical, and social science occupations',\n 'Education, legal, community service, arts, and media occupations',\n 'Arts, design, entertainment, sports, and media occupations',\n 'Healthcare practitioners and technical occupations',\n 'Health diagnosing and treating practitioners and other technical occupations',\n 'Health technologists and technicians',\n 'Healthcare support occupations',\n 'Protective service occupations',\n 'Fire fighting and prevention, and other protective service workers including supervisors',\n 'Law enforcement workers including supervisors',\n 'Food preparation and serving related occupations',\n 'Building and grounds cleaning and maintenance occupations',\n 'Personal care and service occupations',\n 'Sales and related occupations',\n 'Office and administrative support occupations',\n 'Farming, fishing, and forestry occupations',\n 'Construction and extraction occupations',\n 'Installation, maintenance, and repair occupations',\n 'Production occupations',\n 'Transportation occupations',\n 'Material moving occupations'\n ]\n\noccupation_earnings = dict(zip(occupation_earnings_keys, occupation_earnings_values))\nOCCUPATION_EARNINGS = pd.Series(occupation_earnings)\nprint(OCCUPATION_EARNINGS)\n\n#----------------------------------------------------------------------------------------------------\n\n\n\noccupation_values = results[408:421]\noccupation_keys = ['Agriculture, forestry, fishing and hunting, and mining',\n 'Construction',\n 'Manufacturing',\n 'Wholesale Trade',\n 'Retail Trade',\n 'Transportation, Warehousing, and Utilities',\n 'Information',\n 'Finance and insurance, and real estate and rental and leasing',\n 'Professional, scientific, and management, and administrative services',\n 'Other services, except public administration',\n 'Public administration'\n ]\n\noccupation = dict(zip(occupation_keys, occupation_values))\nOCCUPATION = pd.Series(occupation)\nprint(OCCUPATION)\n\n#-----------------------------------------------------------------------------------------------------\n\n\noccupancy_status_values = results[425:427]\noccupancy_status_keys = ['Total Occupied',\n 'Total Vacant'\n ]\n\n\noccupancy_status = dict(zip(occupancy_status_keys, occupancy_status_values))\nOCCUPANCY_STATUS = pd.Series(occupancy_status)\nprint(OCCUPANCY_STATUS)\n\n#----------------------------------------------------------------------------------------------------\n\n\ntenure_status_values = results[430:432]\ntenure_status_keys = ['Owner Occupied',\n 'Renter Occupied']\n\ntenure_status = dict(zip(tenure_status_keys, tenure_status_values))\nTENURE_STATUS = pd.Series(tenure_status)\nprint(TENURE_STATUS)\n\n#----------------------------------------------------------------------------------------------------\n\nvacancy_status_values = results[435:443]\nvacancy_status_keys = ['Total Vacancy Status',\n 'For Rent',\n 'Rented, Not Occupied',\n 'For Sale Only',\n 'Sold, not occupied',\n 'For seasonal, recreational, or occasional use',\n 'For migrant workers',\n 'Other Vacant'\n ]\n\nvacancy_status = dict(zip(vacancy_status_keys, vacancy_status_values))\nVACANCY_STATUS = pd.Series(vacancy_status)\nprint(VACANCY_STATUS)\n\n#----------------------------------------------------------------------------------------------------\n\nhouseholder_age_values = results[446:467]\nhouseholder_age_keys = ['Total occupied',\n 'Owner occupied',\n 'Owner occupied, Householder 15 to 24 years',\n 'Owner occupied, Householder 25 to 34 years',\n 'Owner occupied, Householder 35 to 44 years',\n 'Owner occupied, Householder 45 to 54 years',\n 'Owner occupied, Householder 55 to 59 years',\n 'Owner occupied, Householder 60 to 64 years',\n 'Owner occupied, Householder 65 to 74 years',\n 'Owner occupied, Householder 75 to 84 years',\n 'Owner occupied, Householder 85 years and over',\n 'Renter occupied',\n 'Renter occupied, Householder 15 to 24 years',\n 'Renter occupied, Householder 25 to 34 years',\n 'Renter occupied, Householder 35 to 44 years',\n 'Renter occupied, Householder 45 to 54 years',\n 'Renter occupied, Householder 55 to 59 years',\n 'Renter occupied, Householder 60 to 64 years',\n 'Renter occupied, Householder 65 to 74 years',\n 'Renter occupied, Householder 75 to 84 years',\n 'Renter occupied, Householder 85 years and over'\n ]\n\nhouseholder_age = dict(zip(householder_age_keys, householder_age_values))\nHOUSEHOLDER_AGE = pd.Series(householder_age)\nprint(HOUSEHOLDER_AGE)\n\n#-----------------------------------------------------------------------------------------------------\n\n\nhousehold_size_values = results[470:487]\nhousehold_size_keys = ['Total Owner Occupied',\n 'Owner Occupied, 1 Person Household',\n 'Owner occupied, 2-person household',\n 'Owner occupied, 3-person household',\n 'Owner occupied, 4-person household',\n 'Owner occupied, 5-person household',\n 'Owner occupied, 6-person household',\n 'Owner occupied, 7-or-more person household',\n 'Renter occupied',\n 'Renter occupied, 1-person household',\n 'Renter occupied, 2-person household',\n 'Renter occupied, 3-person household',\n 'Renter occupied, 4-person household',\n 'Renter occupied, 5-person household',\n 'Renter occupied, 6-person household',\n 'Renter occupied, 7-or-more person household',\n ]\n\nhouseholder_size = dict(zip(household_size_keys, household_size_values))\nHOUSEHOLDER_SIZE = pd.Series(householder_size)\nprint(HOUSEHOLDER_SIZE)\n\n#-----------------------------------------------------------------------------------------------------\n\n\ncontract_rent_values = results[490:520]\ncontract_rent_keys = ['Total',\n 'With Cash Rent',\n 'No Cash Rent',\n 'With cash rent, Less than $100',\n 'With cash rent, $100 to $149',\n 'With cash rent, $150 to $199',\n 'With cash rent, $200 to $249',\n 'With cash rent, $250 to $299',\n 'With cash rent, $300 to $349',\n 'With cash rent, $350 to $399',\n 'With cash rent, $400 to $449',\n 'With cash rent, $450 to $499',\n 'With cash rent, $500 to $549',\n 'With cash rent, $550 to $599',\n 'With cash rent, $600 to $649',\n 'With cash rent, $650 to $699',\n 'With cash rent, $700 to $749',\n 'With cash rent, $750 to $799',\n 'With cash rent, $800 to $899',\n 'With cash rent, $900 to $999',\n 'With cash rent, $1,000 to $1,249',\n 'With cash rent, $1,250 to $1,499',\n 'With cash rent, $1,500 to $1,999',\n 'With cash rent, $2,000 to $2,499',\n 'With cash rent, $2,500 to $2,999',\n 'With cash rent, $3,000 to $3,499',\n 'With cash rent, $3,500 or more',\n 'Lower contract rent quartile',\n 'Median contract rent',\n 'Upper contract rent quartile'\n ]\n\n\ncontract_rent = dict(zip(contract_rent_keys, contract_rent_values))\nCONTRACT_RENT = pd.Series(contract_rent)\nprint(CONTRACT_RENT)\n\n#------------------------------------------------------------------------------------------------------\n\nrent_asked_values = results[523:548]\nrent_asked_keys = ['Total',\n 'Less than $100',\n '$100 to $149',\n '$150 to $199',\n '$200 to $249',\n '$250 to $299',\n '$300 to $349',\n '$350 to $399',\n '$400 to $449',\n '$450 to $499',\n '$500 to $549',\n '$550 to $599',\n '$600 to $649',\n '$650 to $699',\n '$700 to $749',\n '$750 to $799',\n '$800 to $899',\n '$900 to $999',\n '$1,000 to $1,249',\n '$1,250 to $1,499',\n '$1,500 to $1,999',\n '2,000 to $2,499',\n '$2,500 to $2,999',\n '$3,000 to $3,499',\n '$3,500 or more'\n ]\n\n\nrent_asked = dict(zip(rent_asked_keys, rent_asked_values))\nRENT_ASKED = pd.Series(rent_asked)\nprint(RENT_ASKED)\n\n#----------------------------------------------------------------------------------------------------\n\nhouse_values = results[551:580]\nhouse_keys = ['Less than $10,000',\n '$10,000 to $14,999',\n '$15,000 to $19,999',\n '$20,000 to $24,999',\n '$25,000 to $29,999',\n '$30,000 to $34,999',\n '$35,000 to $39,999',\n '$40,000 to $49,999',\n '50,000 to $59,999',\n '$60,000 to $69,999',\n '$70,000 to $79,999',\n '$80,000 to $89,999',\n '$90,000 to $99,999',\n '$100,000 to $124,999',\n '$125,000 to $149,999',\n '$150,000 to $174,999',\n '$175,000 to $199,999',\n '$200,000 to $249,999',\n '$250,000 to $299,999',\n '$300,000 to $399,999',\n '$400,000 to $499,999',\n '$500,000 to $749,999',\n '$750,000 to $999,999',\n '$1,000,000 to $1,499,999',\n '$1,500,000 to $1,999,999',\n '$2,000,000 or more',\n 'lower value quartile (dollars)',\n 'Median value (dollars)',\n 'Upper value quartile (dollars)'\n ]\n\n\nhouse = dict(zip(house_keys, house_values))\nHOUSE_VALUES = pd.Series(house)\nprint(HOUSE_VALUES)\n\n\n#-----------------------------------------------------------------------------------------------------\n\nprice_asked_values = results[583:609]\nprice_asked_keys = ['Less than $10,000',\n '$10,000 to $14,999',\n '$15,000 to $19,999',\n '$20,000 to $24,999',\n '$25,000 to $29,999',\n '$30,000 to $34,999',\n '$35,000 to $39,999',\n '$40,000 to $49,999',\n '$50,000 to $59,999',\n '$60,000 to $69,999',\n '$70,000 to $79,999',\n '$80,000 to $89,999',\n '$90,000 to $99,999',\n '$100,000 to $124,999',\n '$125,000 to $149,999',\n '$150,000 to $174,999',\n '$175,000 to $199,999',\n '$200,000 to $249,999',\n '$250,000 to $299,999',\n '$300,000 to $399,999',\n '$400,000 to $499,999',\n '$500,000 to $749,999',\n '$750,000 to $999,999',\n '$1,000,000 to $1,499,999',\n '$1,500,000 to $1,999,999',\n '$2,000,000 or more'\n ]\n\n\nprice_asked = dict(zip(price_asked_keys, price_asked_values))\nPRICE_ASKED = pd.Series(price_asked)\nprint(PRICE_ASKED)\n#-----------------------------------------------------------------------------------------------------\n\nmonthly_owner_values = results[623:641]\nmonthly_owner_keys = ['Total Selected Monthly Costs',\n 'Less than $200',\n '$200 to $299',\n '$300 to $399',\n '$400 to $499',\n '$500 to $599',\n '$600 to $699',\n '$700 to $799',\n '$800 to $899',\n '$900 to $999',\n '$1,000 to $1,249',\n '$1,250 to $1,499',\n '$1,500 to $1,999',\n '$2,000 to $2,499',\n '$2,500 to $2,999',\n '$3,000 to $3,499',\n '$3,500 to $3,999',\n '$4,000 or more'\n ]\n\n\nmonthly_owner_costs = dict(zip(monthly_owner_keys, monthly_owner_values))\nMONTHLY_OWNER_COSTS = pd.Series(monthly_owner_costs)\nprint(MONTHLY_OWNER_COSTS)\n\n#-----------------------------------------------------------------------------------------------------\n\n\nhousing_cost_values = results[644:662]\nhousing_cost_keys = ['Estimate!!Total',\n 'Less than $100',\n '$100 to $199',\n '$200 to $299',\n '$300 to $399',\n '$400 to $499',\n '$500 to $599',\n '$600 to $699',\n '$700 to $799',\n '$800 to $899',\n '$900 to $999',\n '$1,000 to $1,499',\n '$1,500 to $1,999',\n '$2,000 to $2,499',\n '$2,500 to $2,999',\n '$3,000 or more',\n 'No cash rent',\n 'Median monthly housing costs'\n ]\n\n\nhousing_costs = dict(zip(housing_cost_keys, housing_cost_values))\nTOTAL_MONTHLY_HOUSING_COSTS = pd.Series(housing_costs)\nprint(TOTAL_MONTHLY_HOUSING_COSTS)\n\n#----------------------------------------------------------------------------------------------------\n\nmortgage_status_values = results[612:620]\nmortgage_status_keys = ['Total Mortgage Status',\n 'Housing units with a mortgage, contract to purchase, or similar debt',\n 'With either a second mortgage or home equity loan, but not both',\n 'Second mortgage only',\n 'Home equity loan only',\n 'Both second mortgage and home equity loan',\n 'No second mortgage and no home equity loan',\n 'Housing units without a mortgage'\n ]\n\n\nmortgage_status = dict(zip(mortgage_status_keys, mortgage_status_values))\nMORTGAGE_STATUS = pd.Series(mortgage_status)\nprint(MORTGAGE_STATUS)\n#-----------------------------------------------------------------------------------------------------\ntaxes_values = results[665:682]\ntaxes_keys = ['Total With A Mortgage',\n 'With a mortgage, Less than $800',\n 'With a mortgage, $800 to $1,499',\n 'With a mortgage, $1,500 to $1,999',\n 'With a mortgage, $2,000 to $2,999',\n 'With a mortgage, $3,000 or more',\n 'With a mortgage, No real estate taxes paid',\n 'Not mortgaged',\n 'Not mortgaged, Less than $800',\n 'Not mortgaged!!$800 to $1,499',\n 'Not mortgaged!!$1,500 to $1,999',\n 'Not mortgaged!!$2,000 to $2,999',\n 'Not mortgaged!!$3,000 or more',\n 'No real estate taxes paid',\n 'Median real estate taxes paid!!Total',\n 'Median real estate taxes paid for units with a mortgage',\n 'Median real estate taxes paid for units without a mortgage'\n ]\n\ntaxes_paid = dict(zip(taxes_keys, taxes_values))\nTAXES_PAID = pd.Series(taxes_paid)\nprint(TAXES_PAID)\n\n#----------------------------------------------------------------------------------------------------\n\nbedrooms_values = results[685:692]\nbedrooms_keys = ['Bedrooms Total',\n 'No bedroom',\n '1 bedroom',\n '2 bedrooms',\n '3 bedrooms',\n '4 bedrooms',\n '5 or more bedrooms'\n ]\n\nbedrooms = dict(zip(bedrooms_keys, bedrooms_values))\nBEDROOMS = pd.Series(bedrooms)\nprint(BEDROOMS)\n\n#----------------------------------------------------------------------------------------------------\n\nstructure_age_values = results[695:706]\nstructure_age_keys = ['Built 2014 or later',\n 'Built 2010 to 2013',\n 'Built 2000 to 2009',\n 'Built 1990 to 1999',\n 'Built 1980 to 1989',\n 'Built 1970 to 1979',\n 'Built 1960 to 1969',\n 'Built 1950 to 1959',\n 'Built 1940 to 1949',\n 'Built 1939 or earlier',\n 'Median year structure built'\n ]\n\n\nstructure_age = dict(zip(structure_age_keys, structure_age_values))\nSTRUCTURE_AGE = pd.Series(structure_age)\nprint(STRUCTURE_AGE)\n\n\n#----------------------------------------------------------------------------------------------------\n\nunits_values = results[709:732]\nunits_keys = ['Total Units in Structure',\n 'Owner-occupied housing units',\n 'Owner-occupied housing units!!1, detached',\n 'Owner-occupied housing units!!1, attached',\n 'Owner-occupied housing units!!2',\n 'Owner-occupied housing units!!3 or 4',\n 'Owner-occupied housing units!!5 to 9',\n 'Owner-occupied housing units!!10 to 19',\n 'Owner-occupied housing units!!20 to 49',\n 'Owner-occupied housing units!!50 or more',\n 'Owner-occupied housing units!!Mobile home',\n 'Owner-occupied housing units!!Boat, RV, van, etc.',\n 'Renter-occupied housing units',\n 'Renter-occupied housing units!!1, detached',\n 'Renter-occupied housing units!!1, attached',\n 'Renter-occupied housing units!!2',\n 'Renter-occupied housing units!!3 or 4',\n 'Renter-occupied housing units!!5 to 9',\n 'Renter-occupied housing units!!10 to 19',\n 'Renter-occupied housing units!!20 to 49',\n 'Renter-occupied housing units!!50 or more',\n 'Renter-occupied housing units!!Mobile home',\n 'Renter-occupied housing units!!Boat, RV, van, etc.'\n ]\n\n\nunits_per_structure = dict(zip(units_keys, units_values))\nUNITS_PER_STRUCTURE = pd.Series(units_per_structure)\nprint(UNITS_PER_STRUCTURE)\n\n#----------------------------------------------------------------------------------------------------\n\n\njob_males_values = results[800:820]\njob_males_keys = ['Total Male',\n 'Agriculture, forestry, fishing and hunting',\n 'Mining, quarrying, and oil and gas extraction',\n 'Construction',\n 'Manufacturing',\n 'Wholesale trade',\n 'Retail trade',\n 'Transportation and warehousing',\n 'Utilities',\n 'Information',\n 'Finance and insurance',\n 'Real estate and rental and leasing',\n 'Professional, scientific, and technical services',\n 'Management of companies and enterprises',\n 'Administrative and support and waste management services',\n 'Educational services',\n 'Health care and social assistance',\n 'Arts, entertainment, and recreation',\n 'Accommodation and food services',\n 'Other services',\n 'Public administration'\n ]\n\n\ncomplete_occupation_males = dict(zip(job_males_keys, job_males_values))\nCOMPLETE_OCCUPATION_MALES = pd.Series(complete_occupation_males)\nprint(COMPLETE_OCCUPATION_MALES)\n\n\n#--------------------------------------------------------------------------------------------------------------\n\n\njob_females_values = results[824:844]\njob_females_keys = ['Total Female',\n 'Agriculture, forestry, fishing and hunting',\n 'Mining, quarrying, and oil and gas extraction',\n 'Construction',\n 'Manufacturing',\n 'Wholesale trade',\n 'Retail trade',\n 'Transportation and warehousing',\n 'Utilities',\n 'Information',\n 'Finance and insurance',\n 'Real estate and rental and leasing',\n 'Professional, scientific, and technical services',\n 'Management of companies and enterprises',\n 'Administrative and support and waste management services',\n 'Educational services',\n 'Health care and social assistance',\n 'Arts, entertainment, and recreation',\n 'Accommodation and food services',\n 'Other services',\n 'Public administration'\n ]\n\n\ncomplete_occupation_females = dict(zip(job_females_keys, job_females_values))\nCOMPLETE_OCCUPATION_FEMALES = pd.Series(complete_occupation_females)\nprint(COMPLETE_OCCUPATION_FEMALES)\n\n\n\n\n#-------------------------------------------[plot online]-----------------------------------------------------------------------------------------\n\n#MALE_AGE_DISTRIBUTION.iplot(kind='bar', yTitle='Male Age Distribution', title=\"Male Age Distribution\")\n#FEMALE_AGE_DISTRIBUTION.iplot(kind='bar', yTitle='Female Age Distribution', title=\"Female Age Distribution\")\n#TOTAL_AGE_DISTRIBUTION.iplot(kind='bar', yTitle='Total Age Distribution', title=\"Total Age Distribution\")"
},
{
"alpha_fraction": 0.6526054739952087,
"alphanum_fraction": 0.6786600351333618,
"avg_line_length": 25.032258987426758,
"blob_id": "fd956148e815542899b727222ab36e292fb767f2",
"content_id": "e7ee0d25bff474d1632b3df391889b469283f4f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 806,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 31,
"path": "/api-walkability score.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\nfrom urllib.parse import quote\n\n\npayload = {'address':'371 tealwood dr houston '}\n\nnewpayload = {}\nfor (k, v) in payload.items():\n newpayload[quote(k)] = quote(v)\n\nprint(newpayload['address'])\n\n\nbase_url = 'http://api.walkscore.com/score?format=json&address='\nlatitude = '29.765395'\nlongitude = '-95.548624'\nrest_url = '&transit=1&bike=1&wsapikey=723603e4e9ed1c836fb0403145a39cfc'\njson_url = base_url + newpayload['address'] + \"&\" + \"lat=\" + latitude + \"&lon=\" + longitude + rest_url\n\nresponse = requests.get(json_url)\ndata = response.json()\n\nwalk_score = (data['walkscore'])\nwalk_description = (data['description'])\ntransit_score = (data['transit']['score'])\ntransit_description = (data['transit']['description'])\nbike_score = (data['bike']['score'])\nbike_description = (data['bike']['description'])\n\n\nprint(data)"
},
{
"alpha_fraction": 0.7320754528045654,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 87.33333587646484,
"blob_id": "ac0e1921b7528e2f4daf194276ab1dfd7cc485c1",
"content_id": "bb3c2d15717a7ba22e78d375c0dc9f8bf5171384",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 265,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 3,
"path": "/desktop.ini",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "[LocalizedFileNames]\n42floors-listing_data-us-tx-greater-austin-as-of-Aug-07.csv=@42floors-listing_data-us-tx-greater-austin-as-of-Aug-07,0\n42floors-listing_data-us-md-greater-baltimore-as-of-Aug-03.csv=@42floors-listing_data-us-md-greater-baltimore-as-of-Aug-03,0\n"
},
{
"alpha_fraction": 0.6765432357788086,
"alphanum_fraction": 0.7020576000213623,
"avg_line_length": 30.179487228393555,
"blob_id": "b333f56d20338b7251fdc3f19f651a98e702f409",
"content_id": "c0c138ca5beffc67ddfa4679446ab7228bfe9391",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1215,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 39,
"path": "/Geocoding+census tract.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\nimport json\n\nweb_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\nparams = {\n 'benchmark': 'Public_AR_Current',\n 'vintage':'Current_Current',\n 'street': '35 Greycliff Rd.',\n 'city': 'Boston ',\n 'state': 'MA',\n 'format':'json',\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nstr = req.json()\ndictionary = (str['result']['addressMatches'])\ndictionary = (dictionary[0])\ndictionary_geo = (dictionary['geographies']['2010 Census Blocks'][0])\n\nprint(dictionary)\nprint(dictionary_geo)\n\n#dictionary items\nlatitude = (dictionary['coordinates']['x'])\nlongitude = (dictionary['coordinates']['y'])\nzipcode = (dictionary['addressComponents']['zip'])\ngeo_id = (dictionary_geo['GEOID'])\nblock_name = (dictionary_geo['NAME'])\nblock_group = (dictionary_geo['BLKGRP'])\nblock_land_area = (dictionary_geo['AREALAND'])\nblock_water_area = (dictionary_geo['AREAWATER'])\nstate_blkgrp = (dictionary_geo['BLKGRP'])\nstate_id = (dictionary_geo['STATE'])\ncounty_id = (dictionary_geo['COUNTY'])\ntract_id = (dictionary_geo['TRACT'])\n\nprint(state_blkgrp,state_id,county_id,tract_id)"
},
{
"alpha_fraction": 0.568299412727356,
"alphanum_fraction": 0.6364336609840393,
"avg_line_length": 34.6274528503418,
"blob_id": "c6b17ffe4245dc8c0eebd42693d42a9b671345f2",
"content_id": "a3e4280ab31225711b060f3b8c46ef9cf67291b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9085,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 255,
"path": "/api_CENSUS+IDs_Master.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\nimport pandas as pd\n#--------------------------------------------------------------------------------------------------\n#INPUTS\n\n#1 = block level, 2 = tract level, 3 = zipcode, 4 = public area microdata, 5 = metropolitan area\nconfig = 2\nstreet = \"140 Commonwealth Ave\ncity = \"La Quinta\"\nstate = \"California\"\n\n\n\n#get GEOCODE Data, latitude, longitude, tract, block level census data\nweb_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\n\nparams = {\n 'benchmark': 'Public_AR_Current',\n 'vintage':'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format':'json',\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nprint(req)\nstr = req.json()\nprint(str)\ndictionary = (str['result']['addressMatches'])\ndictionary = (dictionary[0])\ndictionary_geo = (dictionary['geographies']['2010 Census Blocks'][0])\n\n\n#dictionary items\nlatitude = (dictionary['coordinates']['x'])\nlongitude = (dictionary['coordinates']['y'])\nzipcode = (dictionary['addressComponents']['zip'])\ngeo_id = (dictionary_geo['GEOID'])\nblock_name = (dictionary_geo['NAME'])\nblock_group = (dictionary_geo['BLKGRP'])\nblock_land_area = (dictionary_geo['AREALAND'])\nblock_water_area = (dictionary_geo['AREAWATER'])\nstate_blkgrp = (dictionary_geo['BLKGRP'])\nstate_id = (dictionary_geo['STATE'])\ncounty_id = (dictionary_geo['COUNTY'])\ntract_id = (dictionary_geo['TRACT'])\n\n\n#--------------------------------------------------------------------------------------------------\n\n#get Metropolitcan Statististical Area Code\n\nweb_scrape_url2 = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\n\nparams2 = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format': 'json',\n 'layers': '80',\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n# Do the request and get the response data\nreq2 = requests.get(web_scrape_url2, params=params2)\n\n#parse JSON response, because it is a multilayered dict\nstr2parse = req2.json()\nstr2parse = str2parse['result']['addressMatches']\nstr2 = str2parse[0]\nstr2 = dict(str2['geographies']['Metropolitan Statistical Areas'][0])\n\n\n#assign variables to dict\nmsa_Name = str2[\"NAME\"]\nmetropolitan_id = str2[\"CBSA\"]\n\n#-------------------------------------------------------------------------------------------------\n\n#Get 2010 Census Public Use Microdata Areas\nweb_scrape_url3 = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\nparams3 = {\n 'benchmark': 'Public_AR_Current',\n 'vintage': 'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format': 'json',\n 'layers': '0',\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n}\n# Do the request and get the response data\nreq3 = requests.get(web_scrape_url3, params=params3)\nstr3parse = req3.json()\n\n#parse multi layered dictionary\nstr3parse1 = str3parse['result']['addressMatches'][0]\nstr3 = str3parse1['geographies']['2010 Census Public Use Microdata Areas'][0]\nstr3 = dict(str3)\n\n\n#assign variables for microdata\nmicrodata_id = str3[\"PUMA\"]\nmicrodata_area_name = str3[\"NAME\"]\n#-------------------------------------------------------------------------------------------------\n\n#census ACS 5 year variables\n\n#B25001_001E - total housing units\n#B25002_002E - total occupied units\n#B25002_003E - total vacant units\n#B25106_024E - estimate total renter occupied housing units\n#B01003_001E - total population in census tract\n#B01002_001E - median age in tract\n#B08013_001E - aggregate travel time to work\n#B15012_001E - total fields of bachelers degrees reported\n#B19049_001E - #Median household income in the past 12 months (in 2016 inflation-adjusted dollars)\n#B19083_001E - GINI index of income inequality\n#B25046_001E - aggregate number of vehicles available\n#B25076_001E - lower quartile house value\n#B25077_001E - median house value\n#B25078_001E - upper quartile house value\n#B25064_001E - estimate median gross rent\n#B25057_001E - estimate lower quartile rent\n#B25058_001E - median contract rent\n#B25059_001E - estimate upper quartile rent\n\nweb_scrape_url = ['https://api.census.gov/data/2016/acs/acs5?']\nget_statistics = ['NAME,'\n 'B25001_001E,' #total housing units\n 'B25002_002E,' #total occupied units\n 'B25002_003E,' #total vacant units\n 'B25106_024E,' #estimate total renter occupied housing units\n 'B01003_001E,' #total population in census tract\n 'B01002_001E,' #median age in tract\n 'B08013_001E,' #aggregate travel time to work\n 'B15012_001E,' #total fields of bachelers degrees reported\n 'B19049_001E,' #Median household income in the past 12 months (in 2016 inflation-adjusted dollars)\n 'B19083_001E,' #GINI index of income inequality\n 'B25046_001E,' #aggregate number of vehicles available\n 'B25076_001E,' #lower quartile house value\n 'B25077_001E,' #median house value\n 'B25078_001E,' #upper quartile house value\n 'B25064_001E,' #estimate median gross rent\n 'B25057_001E,' #estimate lower quartile rent\n 'B25058_001E,' #median contract rent\n 'B25059_001E' #estimate upper quartile rent\n ''\n ]\n\n\n#this part of the code requires different census calls to get information\n\nfor x in web_scrape_url:\n #census tract level\n censusparams1 = {\n 'get': get_statistics,\n 'for': 'tract:' + tract_id,\n 'in': 'state:' + state_id + ' county:' + county_id,\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n #census block level\n censusparams2 = {\n 'get': get_statistics,\n 'for': 'block group:' + block_group,\n 'in': 'state:' + state_id + ' county:' + county_id + ' tract:' + tract_id,\n 'key':'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n #zipcode level\n censusparams3 = {\n 'get': get_statistics,\n 'for': 'zip code tabulation area:' + zipcode,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n #public use microdata area\n censusparams4 = {\n 'get': get_statistics,\n 'for': 'public use microdata area:' + microdata_id,\n 'in': 'state:' + state_id,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n # metropolitan statistical area\n censusparams5 = {\n 'get': get_statistics,\n 'for': 'metropolitan statistical area/micropolitan statistical area:' + metropolitan_id,\n 'key': 'ec7ebde81a7a1772203e43dfed95a061d4c5118d'\n }\n\n\n\n #configure which region to use\n if config == 1:\n parameter = censusparams2\n elif config == 2:\n parameter = censusparams1\n elif config ==3:\n parameter = censusparams3\n elif config ==4:\n parameter = censusparams4\n else:\n parameter = censusparams5\n\n\n\n # Do the request and get the response data\n req = requests.get(x, params=parameter)\n print(req)\n res = req.json()\n results = res[1]\n print(results)\n\n\n\n #parse census results by numerical index\n census_name = results[0]\n total_housing_units = int(results[1])\n total_occupied_units = int(results[2])\n total_vacant_units = int(results[3])\n total_renter_occupied_units = int(results[4])\n total_population = results[5]\n median_age = results[6]\n aggregate_travel_time_to_work = results[7]\n total_fields_of_bachelors = results[8]\n median_household_income_past12 = results[9]\n GINI_inequality_index = results[10]\n aggregate_vehicles = results[11]\n lower_quartile_house_value = results[12]\n median_house_value = results[13]\n upper_quartile_house_value = results[14]\n median_gross_rent = results[15]\n lower_quartile_rent = results[16]\n median_contract_rent = results[17]\n upper_quartile_rent = results[18]\n\n\n #display results, to be used for dashboard\n print(\"Data Results for:\" + census_name)\n print(\"Microdata Area Name:\", microdata_area_name)\n print(\"Metropolitan Statistical Area Name:\",msa_Name)\n print(\"Total Housing Units:\",total_housing_units)\n print(\"Total Population:\",total_population)\n print(\"Percent Occupied Units:\",round((total_occupied_units/total_housing_units)*100,2),\"%\")\n print(\"Percent Vacant Units:\",round((total_vacant_units/total_housing_units)*100,2),\"%\")\n print(\"Percent Rented Units:\",round((total_renter_occupied_units/total_housing_units)*100,2),\"%\")\n print(\"Median Age:\", median_age)\n print(\"Median Household Income:\",median_household_income_past12)\n print(\"House Value(lower 25%, median, upper 25%):\" + lower_quartile_house_value, median_house_value, upper_quartile_house_value)\n print(\"Rent(lower 25%, median, upper 25%):\" + lower_quartile_rent, median_contract_rent, upper_quartile_rent)\n"
},
{
"alpha_fraction": 0.696476936340332,
"alphanum_fraction": 0.7046070694923401,
"avg_line_length": 22.125,
"blob_id": "b0bd6dfa3b9622caedaa55aeeb3bfd3b39d5bdbc",
"content_id": "0dd553cda212f003ee6d176ee78e1e8a3b31c128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 16,
"path": "/api_googlegeocoder.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\n\n\n#get GEOCODE Data, latitude, longitude, tract, block level census data\nweb_scrape_url = 'https://maps.googleapis.com/maps/api/geocode/json?'\n\nparams = {\n 'address': '371 Tealwood Dr. Houston TX',\n 'key':'AIzaSyAEEIuRKOBNzOjMADj4hE5bGUdAFKz9oDE'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nprint(req)\nstr = req.json()\nprint(str)"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.625,
"avg_line_length": 14,
"blob_id": "d23859bb1fbcf92da324dd3266d35e48d5c18489",
"content_id": "e3a67f7b6344f1d584fae5e5f94c3fb27175a6d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 1,
"path": "/README.md",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "\"# REALESTATE\" \n"
},
{
"alpha_fraction": 0.5635766983032227,
"alphanum_fraction": 0.6283839344978333,
"avg_line_length": 25.434782028198242,
"blob_id": "94978cbe9d75c39e616b31d4b3177dfa3bed07db",
"content_id": "bca52e5a0d624f1144de7535fe6077064bc21bf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 46,
"path": "/api_streetviewpicI.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import requests\nfrom PIL import Image, ImageDraw, ImageFont\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport json\n\n#produce streetview of property\n\nradius_numbers = [50, 1000, 5000, 50000]\n\nfor x in radius_numbers:\n web_scrape_url = 'https://maps.googleapis.com/maps/api/streetview?'\n params = {\n 'size': '1200x600',\n 'location':'29.765427,-95.54863',\n 'fov' : '120',\n 'radius' : x,\n 'key':'AIzaSyAEEIuRKOBNzOjMADj4hE5bGUdAFKz9oDE'\n}\n\n\n # Do the request and get the response data\n req = requests.get(web_scrape_url, params=params)\n if req.status_code == 200:\n with open(\"C:/Users/Joe/Desktop/sample\" + str(x) + \".jpg\", 'wb') as f:\n f.write(req.content)\n\n\n#produce static map of property\n\nweb_scrape_url2 = 'https://maps.googleapis.com/maps/api/staticmap?'\nparams2 = {\n 'size': '640x640',\n 'center':'371 Tealwood Dr. Houston, TX',\n 'zoom' : '16',\n 'maptype' : 'roadmap',\n 'markers' : 'size:medium|29.765427,-95.54863',\n 'key':'AIzaSyAEEIuRKOBNzOjMADj4hE5bGUdAFKz9oDE'\n}\n\n\n# Do the request and get the response data\nreq2 = requests.get(web_scrape_url2, params=params2)\nif req2.status_code == 200:\n with open(\"C:/Users/Joe/Desktop/samplemap.png\", 'wb') as f:\n f.write(req2.content)\n\n\n\n"
},
{
"alpha_fraction": 0.6770334839820862,
"alphanum_fraction": 0.6937798857688904,
"avg_line_length": 26,
"blob_id": "5f54edac6f48b680013a1b746fb274089f21f8b2",
"content_id": "f75b09d15184ba5eb4682411f3c72203ab243b27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 836,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 31,
"path": "/api-googlesatillitemap.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "from googleplaces import GooglePlaces, types, lang\n\n\nYOUR_API_KEY = 'AIzaSyAEEIuRKOBNzOjMADj4hE5bGUdAFKz9oDE'\n\ngoogle_places = GooglePlaces(YOUR_API_KEY)\n\nquery_result = google_places.nearby_search(\n location='1 Seaport Ln, Boston, MA 02210',\n radius=10, types=[types.TYPE_POINT_OF_INTEREST])\n\nif query_result.has_attributions:\n print (query_result.html_attributions)\n\nfor place in query_result.places:\n # Returned places from a query are place summaries.\n print(place.name)\n print(place.geo_location)\n print(place.place_id)\n\nfor photo in place.photos:\n # 'maxheight' or 'maxwidth' is required\n photo.get(maxheight=500, maxwidth=500)\n # MIME-type, e.g. 'image/jpeg'\n print(photo.mimetype)\n # Image URL\n print(photo.url)\n # Original filename (optional)\n print(photo.filename)\n # Raw image data\n print(photo.data)"
},
{
"alpha_fraction": 0.6053160429000854,
"alphanum_fraction": 0.6296626925468445,
"avg_line_length": 26.292682647705078,
"blob_id": "e6587d42f7b2a7dbf7c9690f127d653282a97baf",
"content_id": "bd7eec4a7c03aaf64764a0ee1917d783beffb439",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4477,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 164,
"path": "/api_OSMquery.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import overpy\nimport requests\nimport matplotlib.pyplot as plt\nfrom descartes import PolygonPatch\nfrom shapely.geometry import mapping, Polygon\nimport fiona\nimport geopandas as gpd\nimport pyproj\nimport shapely.ops as ops\nfrom shapely.geometry import shape\nfrom shapely.ops import transform\nfrom functools import partial\n\n\n#EPSG:4326.\nimport geocoder\n#geocoding!\n\nstreet = \"465 Huntington Ave\"\ncity = \"Boston\"\nstate = \"MA\"\nsearchradius = 20\n\n\n#------------------------------------------------------------------------------------------------\nweb_scrape_url = 'https://geocoding.geo.census.gov/geocoder/geographies/address?'\n\nparams = {\n 'benchmark': 'Public_AR_Current',\n 'vintage':'Current_Current',\n 'street': street,\n 'city': city,\n 'state': state,\n 'format':'json',\n 'key':'80a64bc7e2514da9873c3a235bd3fb59be140157'\n}\n\n# Do the request and get the response data\nreq = requests.get(web_scrape_url, params=params)\nstr = req.json()\ndictionary = (str['result']['addressMatches'])\ndictionary = (dictionary[0])\ndictionary_geo = (dictionary['geographies']['2010 Census Blocks'][0])\n#dictionary items\nlongitude = (dictionary['coordinates']['x'])\nlatitude = (dictionary['coordinates']['y'])\n#------------------------------------------------------------------------------------------------\n\n\n#coordinates of building lookup\nlat = 42.339591\nlon = -71.094203\n#29.757319, -95.371927 (333 Clay Street Tower)\n#42.339591, -71.094203 (MFA Boston\n\n\napi = overpy.Overpass()\n# fetch all ways and nodes\nresult = api.query(\"\"\"[out:json]\n[timeout:25]\n;\n(\n node\n [\"building\"]\n (around:%d,%s,%s);\n way\n [\"building\"]\n (around:%d,%s,%s);\n relation\n [\"building\"]\n (around:%d,%s,%s);\n);\nout;\n>;\nout skel qt;\"\"\" % (searchradius, lat, lon, searchradius, lat, lon, searchradius, lat, lon))\n\n\nnode_list = []\nfor way in result.ways:\n housenumber = way.tags.get(\"addr:housenumber\", \"n/a\")\n streetname = way.tags.get(\"addr:street\", \"n/a\")\n address = housenumber + \" \" + streetname\n print(address)\n print(way.tags.get(\"name\", \"\"))\n print(way.tags.get(\"building\", \"\"))\n print(way.tags.get(\"height\", \"\"))\n print(way.tags.get(\"building:height\", \"\"))\n buildingfloors = way.tags.get(\"building:levels\", \"\")\n print(buildingfloors + \" floors\")\n print(way.tags.get(\"building:material\", \"\"))\n print(way.tags.get(\"roof:material\", \"\"))\n print(way.tags.get(\"roof:shape\", \"\"))\n print(way.tags.get(\"amenity\", \"\"))\n print(way.tags.get(\"shop\", \"\"))\n for node in way.nodes:\n node_list.append((float(node.lon), float(node.lat)))\n\nfor relation in result.relations:\n relation_list = []\n housenumber = relation.tags.get(\"addr:housenumber\", \"n/a\")\n streetname = relation.tags.get(\"addr:street\", \"n/a\")\n address = housenumber + \" \" + streetname\n print(address)\n print(relation.tags.get(\"name\", \"\"))\n print(relation.tags.get(\"building\", \"\"))\n print(relation.tags.get(\"height\", \"\"))\n print(relation.tags.get(\"building:height\", \"\"))\n buildingfloors = relation.tags.get(\"building:levels\", \"\")\n print(buildingfloors + \" floors\")\n print(relation.tags.get(\"building:material\", \"\"))\n print(relation.tags.get(\"roof:material\", \"\"))\n print(relation.tags.get(\"roof:shape\", \"\"))\n print(relation.tags.get(\"amenity\", \"\"))\n print(relation.tags.get(\"shop\", \"\"))\n print(relation.members)\n\nprint(node_list)\n\n\n# Here's an example Shapely geometry\npoly = Polygon(node_list)\n\n# Define a polygon feature geometry with one attribute\nschema = {\n 'geometry': 'Polygon',\n 'properties': {'id': 'int'},\n 'latitude': latitude,\n 'longitude': longitude,\n}\n\n#shapely convert into correct map projection and look at bounds\ngeom_area = ops.transform(\n partial(\n pyproj.transform,\n pyproj.Proj(init='EPSG:4326'),\n pyproj.Proj(\n proj='aea',\n lat1=poly.bounds[1],\n lat2=poly.bounds[3])),\n poly)\n\n#calculate the square footage of building\nareasqmeters = geom_area.area\nareasqfeet = areasqmeters*10.764\n\nprint(areasqmeters, areasqfeet)\n\n\n# Write a new Shapefile\nwith fiona.open('C:/Users/Joe/Desktop/my_shp.shp', 'w', 'ESRI Shapefile', schema) as c:\n ## If there are multiple geometries, put the \"for\" loop here\n c.write({\n 'geometry': mapping(poly),\n 'properties': {'id': 1},\n })\n\n\nshape=gpd.read_file('C:/Users/Joe/Desktop/my_shp.shp')\nprint(shape)\n\n\nf, ax = plt.subplots(1)\nshape.plot(ax=ax,column='id',cmap=None,)\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5245901346206665,
"alphanum_fraction": 0.7131147384643555,
"avg_line_length": 19.33333396911621,
"blob_id": "7cddfc03264dbee26a12d30da92feca53cd96cd6",
"content_id": "cb183e09078b5176d86484c84ad7af53dba465bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "dash==0.26.4\ndash-core-components==0.28.2\ndash-html-components==0.12.0\ndash-renderer==0.13.2\npandas==0.23.4\nplotly==2.7.0\n"
},
{
"alpha_fraction": 0.5646929740905762,
"alphanum_fraction": 0.5997806787490845,
"avg_line_length": 28.322580337524414,
"blob_id": "f7601eee262fdf183bd0ff55268b3abb3c0c4191",
"content_id": "24899072ffac2a36aa76cbc0634e2bb121fef387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 912,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 31,
"path": "/api_OSM.py",
"repo_name": "jkang1643/GIS",
"src_encoding": "UTF-8",
"text": "import overpy\n\napi = overpy.Overpass()\n\n\n# fetch all ways and nodes\nresult = api.query(\"\"\"\n way(42.354707, -71.056175,42.355601, -71.055665) [\"building\"];\n (._;>;);\n out body;\n \"\"\")\n\n\nfor way in result.ways:\n housenumber = way.tags.get(\"addr:housenumber\", \"\")\n streetname = way.tags.get(\"addr:street\", \"\")\n print(housenumber, streetname)\n print(way.tags.get(\"name\", \"\"))\n print(way.tags.get(\"building\", \"\"))\n print(way.tags.get(\"height\", \"\"))\n print(way.tags.get(\"building:height\", \"\"))\n buildingfloors = way.tags.get(\"building:levels\", \"\")\n print(buildingfloors + \" floors\")\n print(way.tags.get(\"building:material\", \"\"))\n print(way.tags.get(\"roof:material\", \"\"))\n print(way.tags.get(\"roof:shape\", \"\"))\n print(way.tags.get(\"amenity\", \"\"))\n print(way.tags.get(\"shop\", \"\"))\n print(\" Nodes:\")\n for node in way.nodes:\n print(node.lat, node.lon)\n\n\n\n"
}
] | 21 |
dennisjchen/TaDa
|
https://github.com/dennisjchen/TaDa
|
43f7415fa5b539515dd3633729fcd75f2b4035c3
|
c1df02f86d6af62664cccca8ba31981f85139a83
|
d912fdf0b46c5bfb9ec5b041e76bd3f533e5f919
|
refs/heads/master
| 2021-05-28T00:11:40.317456 | 2014-12-06T05:15:55 | 2014-12-06T05:15:55 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6295313835144043,
"alphanum_fraction": 0.6348364353179932,
"avg_line_length": 36.70000076293945,
"blob_id": "822db93d1394f93004f5efeb9b8b1e4ec91fbbee",
"content_id": "aec90889425584f7afb8fad65760a2f4f0998b72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3393,
"license_type": "no_license",
"max_line_length": 391,
"num_lines": 90,
"path": "/rendez_vous.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "from puzzle import Puzzle\nimport copy\nimport utils\n\nimport threading\n\nsemaphores = {\n 'alice' : threading.Semaphore(),\n 'bob' : threading.Semaphore()\n}\n\ndef get_block(lines):\n block = []\n i = 0\n for line in lines:\n i += 1\n if line == 'break':\n break\n elif line:\n block.append(line)\n return block, lines[i:]\n\ndef trans_line(line):\n trans = {\n ' alice.signal()':'controller.semaphores[\\'alice\\'].release()',\n ' bob.signal()':'controller.semaphores[\\'bob\\'].release()',\n ' alice.wait()':'controller.semaphores[\\'alice\\'].acquire()',\n ' bob.wait()':'controller.semaphores[\\'bob\\'].acquire()',\n ' Alice arrives':'controller.update_state(thread_id, \\'Alice is here\\')',\n ' Bob arrives':'controller.update_state(thread_id, \\'Bob is here\\')',\n ' Alice enters the park':'controller.update_state(thread_id, \\'Alice is inside\\')',\n ' Bob enters the park':'controller.update_state(thread_id, \\'Bob is inside\\')',\n 'Thread Alice:':'',\n 'Thread Bob:':'',\n '':'break',\n }\n return trans[line]\n\ndef translator(input):\n threads = []\n code = map(trans_line, input.split('\\n'))\n while code:\n thread, code = get_block(code)\n threads.append(copy.deepcopy(thread))\n threads = ['\\n'.join(t) for t in threads]\n return map(utils.mk_thread, threads)\n\nprev_states = None\nstagnant = 0\ndef predicate(states):\n global stagnant\n\n # check if one is inside and not the other\n if states[0] == 'Alice is inside' and states[1] == 'Bob is inside':\n return True, False, 'Both have entered together!'\n if states[0] == 'Alice is inside' and states[1] != 'Bob is inside':\n return False, True, 'Oh no! Alice went inside without Bob!'\n if states[0] != 'Alice is inside' and states[1] == 'Bob is inside':\n return False, True, 'Oh no! Bob went inside without Alice!'\n\n # Keep track of how long it's been since something changed\n if not prev_states:\n stagnant = 0\n if states == prev_states:\n stagnant += 1\n else:\n stagnant = 0\n\n # If nothing has changed in a while, assume deadlock\n if stagnant > 100:\n return False, True, 'Uh oh! Alice and Bob haven\\'t moved in a long time. You might have caused a deadlock!'\n\n return False, False, ''\n\n# Puzzle(self, title, lesson, lines, code, answer, translator, predicate, poll_rate = 0.01, hint=''):\nrendez_vous_p = Puzzle(\"Rendez-vous\", #title\n \"Alice and Bob are going to the amusement park. They intend to meet at the gate and enter together. You can use 'alice.signal()' to signal alice's arrival, and 'alice.wait()' to wait until alice has signaled her arrival. The same is true for 'bob.signal()' and 'bob.wait()'. Add these lines to the given code to ensure neither will enter the park without the other.\", #lesson\n [' alice.signal()', ' alice.wait()', ' bob.signal()', ' bob.wait()'], #lines\n \"Thread Alice:\\n Alice arrives\\n Alice enters the park\\n\\nThread Bob:\\n Bob arrives\\n Bob enters the park\", #code\n \"Thread Alice:\\n Alice arrives\\n alice.signal()\\n bob.wait()\\n Alice enters the park\\n\\nThread Bob:\\n Bob arrives\\n bob.signal()\\n alice.wait()\\n Bob enters the park\", #answer\n translator, #translator\n predicate, #predicate\n semaphores, #semaphores\n )\n\ndef main():\n rendez_vous_p.start_puzzle()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5864661931991577,
"alphanum_fraction": 0.5919799208641052,
"avg_line_length": 26.328767776489258,
"blob_id": "bc114354e95f551f3d54f812ac6ac39b91d4fba0",
"content_id": "c0cea8b25c395c065d2d65d87ba2887cf9953a29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1995,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 73,
"path": "/simulator.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "import threading\nimport time\nimport os\n\nclass Simulator:\n def __init__(self, threads, predicate, semaphores = [], poll_rate=0.01, clean_fun=None):\n self.threads = threads\n self.predicate = predicate\n self.semaphores = semaphores\n self.states = [None for _ in threads]\n self.mutex = threading.Lock()\n self.poll_rate = poll_rate \n self.clean_fun = clean_fun\n self.statesList = []\n\n def run_sim(self):\n threads = self.spin_threads()\n message = self.poll_loop()\n self.cleanup(threads)\n return message\n\n def spin_threads(self):\n id_n = 0\n threads = []\n for target in self.threads:\n t = threading.Thread(target=target, args =(self, id_n))\n t.daemon = True\n threads.append(t)\n id_n += 1\n map(lambda t: t.start(), threads)\n\n def poll_loop(self):\n while True:\n self.mutex.acquire()\n success, failure, message = self.predicate(self.states)\n self.mutex.release()\n if success:\n return True, message\n if failure:\n return False, message\n time.sleep(self.poll_rate)\n\n def update_state(self, thread_id, state):\n self.mutex.acquire()\n self.states[thread_id] = state\n self.add_state(self.states)\n self.mutex.release()\n\n def cleanup(self, threads):\n if self.clean_fun:\n self.clean_fun()\n\n def add_state(self, state):\n self.statesList.append(state)\n\n def visualize(self):\n i=0\n movement = \"n\"\n while movement != \"-next\":\n os.system('clear')\n states = self.statesList[i]\n print \"Frame: \" + str(i)\n for x in range(len(states)):\n print \"State \" + str(x) + \": \" + str(states[x])\n movement = raw_input(\"\\nHit Enter to go to the next snapshot.\\nType p + Enter to go the the last snapshot. \\nTo move on, type -next.\\n\")\n if movement == \"\":\n i = i + 1\n if i >= len(self.statesList):\n i = len(self.statesList)-1\n elif movement == \"p\":\n i = i - 1\n if i < 0:\n i = 0\n"
},
{
"alpha_fraction": 0.6421052813529968,
"alphanum_fraction": 0.6421052813529968,
"avg_line_length": 22.75,
"blob_id": "e158491043bc29e383276cc8c8931ded88dee091",
"content_id": "2d7be5aa17bd36237fc7311d1acdafd8ff33ae7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/utils.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "def mk_thread(s):\n def f(controller, thread_id):\n exec s in globals(), locals()\n return f\n"
},
{
"alpha_fraction": 0.6031291484832764,
"alphanum_fraction": 0.606654942035675,
"avg_line_length": 32.367645263671875,
"blob_id": "f58820ac38295d5f278ea9ce09cfc8cb64bcba6f",
"content_id": "2ffca54ee4bcfa3d0d8f77be3e8d3786e47ae868",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4538,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 136,
"path": "/text_interface.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n#from test_puzzle import test_puzzle_p\nfrom rendez_vous import rendez_vous_p\nfrom interface_io import *\nimport random\n\nuserName = \"Anonymous\"\nuserMap = []\nuserLocation = 0\ntasksCompleted = False\npuzzles = []\n\ndef welcomeWorld():\n\tos.system('clear')\n\tprint \"\\n\"\n\tprint \"************************************************************\"\n\tprint \"********** **********\"\n\tprint \"********** Welcome! **********\"\n\tprint \"********** **********\"\n\tprint \"********** As the new owner of this **********\"\n\tprint \"********** amusement park, you have some **********\"\n\tprint \"********** things to fix! **********\"\n\tprint \"********** **********\"\n\tprint \"********** **********\"\n\tprint \"************************************************************\"\n\ndef about():\n\tprint \"\\nAbout: This project was created by students with the goal to \"\n\tprint \"teach others about the basic concepts of concurrent programming.\\n\"\n\ndef getName():\n\tglobal userName\n\tuserName = raw_input(\"What is your name? \")\n\treturn userName\n\ndef drawMap():\n\tprint \"Here is your current progress today! The 'x' marks your current location\"\n\tcurrentLocation = []\n\ttextMap = \"\"\n\ttextMap += \"Start ----- \"\n\tcurrentLocation.append(\"_____ ----- \")\n\tfor i in range(len(userMap)):\n\t\tif userMap[i] == 0:\n\t\t\ttextMap += \"???? ----- \"\n\t\t\tcurrentLocation.append(\"____ ----- \")\n\t\telse:\n\t\t\tcurrentLocation.append(\"____ ----- \")\n\t\t\ttextMap += \"DONE ----- \"\n\ttextMap += \"Finished!\\n\"\n\tcurrentLocation[userLocation] = \"__X__ ----- \"\n\tprint textMap\n\tfor text in currentLocation:\n\t\tsys.stdout.write(text)\n\tprint\n\ndef beginAdventure():\n\tlibrary = open('vocabLibrary.txt', 'r')\n\tinitializePuzzles()\n\tprint \"Hello \" + userName + \"! I am your assistant, Sam Ifor. There is a lot of work to be done. Today, there are some problems that need to be fixed! Let us get to it shall we?\\n\"\n\tnumTasks = raw_input(\"How many tasks would you like to fix today (1-3)? \")\n\tglobal userMap\n\tfor i in range(int(numTasks)):\n\t\tuserMap.append(0)\n\tprint \"Great!\\n\"\n\tprint \"If you are new to this, feel free to type '-help' to get a list of possible commands\\n\"\n\twhile(True):\n\t\tuserInput = raw_input(\"What would you like to do? (-help for list of options)\\n\")\n\t\tif userInput == '-help':\n\t\t\thelp()\n\t\telif userInput == '-viewMap':\n\t\t\tdrawMap()\n\t\telif userInput == '-viewDictionary':\n\t\t\tshowDictionary(library)\n\t\telif userInput == '-next':\n\t\t\tos.system('clear')\n\t\t\tpuzzle = getPuzzle()\n\t\t\tpuzzle.start_puzzle()\n\t\t\tglobal userLocation\n\t\t\tuserLocation = userLocation + 1\n\t\t\tif userLocation > (int(numTasks)-1):\n\t\t\t\tbreak\n\t\telif userInput == '-quit':\n\t\t\tbreak\n\t\telse:\n\t\t\tprint \"That is not a valid command. Please choose a command that is listed in -help\\n\"\n\ndef initializePuzzles():\n\tpuzzles.append(rendez_vous_p)\n\t#puzzles.append(test_puzzle_p)\n\tprint puzzles\n\ndef getPuzzle():\n\trandomPuzzle = random.randrange(0,len(puzzles))\n\treturn puzzles.pop(randomPuzzle)\n\ndef completedTasks():\n\tos.system('clear')\n\t# if tasksCompleted == False:\n\t\t# print \"Thanks for playing! Try to finish next time :p\"\n\t# else:\n\tprint \"Great job! You have solved everything and you are one step closer to learning concurrent programming!\"\n\ndef showDictionary(library):\n\tdictArray = []\n\tdictionary = {}\n\tfor line in library:\n\t\tsplitLine = line.rstrip('\\n').split(':')\n\t\tdictArray.append(splitLine[0])\n\t\tdictionary[splitLine[0]] = splitLine[1]\n\twhile(True):\n\t\tos.system('clear')\n\t\tcounter = 0\n\t\tfor item in dictArray:\n\t\t\tprint str(counter) + \". \" + item\n\t\t\tcounter = counter + 1\n\t\tuserInput = raw_input(\"Welcome to the concurrency library. Please type the number associated with the word you would like to learn about. (-1 to return)\\n\")\n\t\tif userInput == \"-1\":\n\t\t\tos.system('clear')\n\t\t\tbreak\n\t\telif isinstance(int(userInput), int) and int(userInput) < len(dictionary.keys()):\n\t\t\tos.system('clear')\n\t\t\ttempWord = dictArray[int(userInput)]\n\t\t\tprint tempWord + \"\\n\"\n\t\t\tprint \"Definition:\" + dictionary[tempWord]\n\t\t\tprint \"\\n\"\n\t\t\traw_input('Enter to continue')\n\t\telse:\n\t\t\tprint \"That is not a valid option. Please enter a number or -1 to quit\"\n\ndef help():\n\tprint \"-help: Brings up the list of possible commands\"\n\tprint \"-viewMap: Shows a map of your current progress\"\n\tprint \"-viewDictionary: Shows a list of vocabulary and provides definitions for them\"\n\tprint \"-next: Proceeds to the next available puzzle\"\n\tprint \"\"\n"
},
{
"alpha_fraction": 0.596500813961029,
"alphanum_fraction": 0.598141074180603,
"avg_line_length": 32.254547119140625,
"blob_id": "af45211bf29035072fcae6ef17d6f3b2e3db9690",
"content_id": "a55545f5d9d748d2e55ccfb87456dca0bdac86d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1829,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 55,
"path": "/puzzle.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "from interface_io import *\nfrom simulator import Simulator\n\nimport os\n\nclass Puzzle:\n def __init__(self, title, lesson, lines, code, answer, translator, predicate, semaphores, poll_rate = 0.01, hint=''):\n self.solved = False\n self.title = title\n self.lesson = lesson\n self.lines = lines\n self.code = code\n self.answer = answer\n self.translator = translator\n self.predicate = predicate\n self.semaphores = semaphores\n self.poll_rate = poll_rate\n self.hint = hint\n\n def start_puzzle(self):\n while(not self.solved):\n while(True):\n response_code = self.code\n for i, l in enumerate(self.lines):\n clear()\n put_text(self.lesson)\n print_code(response_code, \"\\nThe code currently is:\")\n resp = int(get_text('Place the line \\'%s\\': ' % l))\n response_code = self.process_input(resp, l, response_code)\n threads = self.translator(response_code)\n simulator = Simulator(threads, self.predicate, self.semaphores, self.poll_rate)\n success, message = simulator.run_sim()\n simulator.visualize()\n if success:\n put_text('Simulator test Passed!')\n else: \n put_text('Simulator test Failed!')\n put_text(message)\n get_text('Check against the real answer? (y/n)')\n\n clear()\n put_text(self.lesson)\n print_code(response_code, \"\\nThe code currently is:\")\n\n if(response_code == self.answer):\n put_text(\"Congratulations! That's correct. Good job!\\n\")\n break\n else:\n get_text(\"Woops! That's incorrect. Try again? (y/n)\\n\")\n self.solved = True\n\n def process_input(self, index, line, code_str):\n code = code_str.split('\\n')\n code.insert(index, line)\n return '\\n'.join(code)\n"
},
{
"alpha_fraction": 0.7556255459785461,
"alphanum_fraction": 0.7578758001327515,
"avg_line_length": 78.35713958740234,
"blob_id": "99772d5e8612cd4ba3ac7224f1b4551510014a91",
"content_id": "0ca2947b97718e5dc5552fa33e8fe4b07917c3d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2230,
"license_type": "no_license",
"max_line_length": 552,
"num_lines": 28,
"path": "/README.md",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "TaDa\n====\n\n======================\nFiles and Contents\n======================\n\nCode Overview\n\ninterface.py – This file calls the desired interface module that has been set. Right now, it uses functions from textInterface.py, but the interface module could be changed to a GUI interface by only changing what file is imported. It gives a quick overview of set-up and starts the program.\n\npuzzle.py – This file contains the body of how a puzzle is put together. Puzzles are based off this module. For example, the rendezvous puzzle (rendez vous.py) contains the puzzle information and initializes itself through the puzzle module. Each puzzle has sections such as title, lesson, hint, answer and space for code. The puzzle then has an important part and it is the start_puzzle() function. This function, when called, runs the necessary components to run the puzzle for the user. This is funneled into the interface.\n\nsimulator.py – This file works with the puzzle to actually simulate what the user puts as their answer. There is a visualizer function in this file that will allow the user to see what mistakes they made and why their solution did not pass. This file is also where the concurrency of the project comes into play because it will spawn threads to run the simulation. For example, in rendez_vous.py, it will actually have alice and bob wait for each other so if the user puts in incorrect code, they will see that they will both be waiting for each other.\n\ntextInterface.py – This file is the text portion of the project that the interface relies on. It has code relating to how the code is visualized to the user such as a welcoming screen and other sorts. This is where the puzzles are first found for the user depending on how many they want to see (between 1-3). It also allows the user to view progress and view a dictionary of helpful words/phrases about concurrency, such as what deadlocking is.\n\nrendez_vous.py - This file contains all of the puzzle code for the specific rendez_vous \nproject.\n\n\n======================\nHow to Run\n======================\n\nUnzip the TADA_project.zip. The program can be run from any terminal with Python 2.7.6 (or higher), using the following command:\n\npython interface.py\n"
},
{
"alpha_fraction": 0.6274510025978088,
"alphanum_fraction": 0.6299019455909729,
"avg_line_length": 18.428571701049805,
"blob_id": "f4fa9286c22639d8741b883489e53dabca4b58ed",
"content_id": "5428dab0ba89c17456f9c4216e28d0718d421c59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 21,
"path": "/interface_io.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "import os\n\ndef put_text(string):\n print string\n\ndef get_text(p=''):\n userInput = None\n while True:\n userInput = raw_input(p)\n if userInput:\n return userInput\n put_text('No input read. Try again:')\n\ndef print_code(code, message=None):\n if message:\n print message\n for i, line in enumerate(code.split('\\n')):\n print '%s %s' % (str(i).ljust(2), line)\n\ndef clear():\n os.system('clear')\n"
},
{
"alpha_fraction": 0.7132616639137268,
"alphanum_fraction": 0.7132616639137268,
"avg_line_length": 15.470588684082031,
"blob_id": "85fcd1dac43bd13df41651e88ecdbefdddb6cfe7",
"content_id": "77a4d3d8c77185b2f5a97a2863b8516ec5c603e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 17,
"path": "/interface.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "import text_interface as interface\nimport puzzle\nimport sys\nimport os\n\ndef run():\n\tinterface.welcomeWorld()\n\tinterface.about()\n\tuserName = interface.getName()\n\tlevel = interface.beginAdventure()\n\tinterface.completedTasks()\n\ndef main():\n\trun()\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5334555506706238,
"alphanum_fraction": 0.5572869181632996,
"avg_line_length": 27.710525512695312,
"blob_id": "e55d44a320e71635b3af4cd1cab93b64d4968b7d",
"content_id": "1cb7f3dbddd2fd648dc0f870c2e37730d825249e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1091,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 38,
"path": "/visualizer.py",
"repo_name": "dennisjchen/TaDa",
"src_encoding": "UTF-8",
"text": "import puzzle\nimport simulator\n\ndef main():\n str1 = [ 'for x in xrange(100):'\n , ' import time'\n , ' time.sleep(0.01)'\n , ' controller.update_state(thread_id, str(x))'\n , 'controller.update_state(thread_id, \"complete\")']\n str2 = [ 'for x in xrange(100):'\n , ' import time'\n , ' time.sleep(0.01)'\n , ' controller.update_state(thread_id, str(x))'\n , 'controller.update_state(thread_id, \"complete\")']\n code = ['\\n'.join(str1), '\\n'.join(str2)]\n threads = map(mk_thread, code)\n\n def pred(states):\n global statesList\n # print 'State 0: %i, State 1: %i' % (states[0], states[1])\n if states[0] == \"complete\" and states[1] == \"complete\":\n sim.add_state((states[0], states[1]))\n return True, None\n else:\n sim.add_state((states[0], states[1]))\n return False, None\n\n sim = simulator.Simulator(threads, pred)\n sim.run_sim()\n sim.visualize()\n\ndef mk_thread(s):\n def f(controller, thread_id):\n exec s in globals(), locals()\n return f\n\nif __name__ == '__main__':\n main()\n"
}
] | 9 |
rmacias3/stance_detection
|
https://github.com/rmacias3/stance_detection
|
e44fc2f1323614309c1e8c52dabe4b0b50e5d5f0
|
9b3624c74f027660c5226b9fc7bc2d822b45f93a
|
f23f421554f87b48a069d371d85afad845799dcc
|
refs/heads/master
| 2020-03-27T02:11:47.635022 | 2018-08-23T00:56:05 | 2018-08-23T00:56:05 | 145,772,712 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6382806301116943,
"alphanum_fraction": 0.6488240361213684,
"avg_line_length": 50.375,
"blob_id": "2375e088630dea9838e735eb785cb8264ce828b6",
"content_id": "85de99080c4751bca4d214b2470dfc2820bb60fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2466,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 48,
"path": "/FNCLoader.py",
"repo_name": "rmacias3/stance_detection",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport torch\nfrom torch.utils.data import Dataset, DataLoader\n\nclass FNCDataset(Dataset):\n \"\"\"Stance Detection dataset.\"\"\"\n\n def __init__(self, articles_csv_file, hl_and_stances_csv_file, model):\n \"\"\"\n Args:\n articles_csv_file (string): Path to the csv file with the article bodies.\n stances_csv_file (string): Path to the csv file with the article headlines and stances.\n \"\"\"\n self.articles = pd.read_csv(articles_csv_file)\n self.hl_and_stances = pd.read_csv(hl_and_stances_csv_file)\n self.stance_to_idx = {'unrelated': 0, 'agree': 1, 'discuss': 2, 'disagree': 3}\n self.sentence_embedder = model.cuda()\n \n def __len__(self):\n return len(self.articles)\n \n def encode_and_resize(self, sentences):\n #sentence length and paragraph length cut offs chosen based on gpu memory\n sentence_length_cut_off, paragraph_length_cutoff = 3000, 47\n #length chosen to filter out noisy text\n min_sentence_length = 46\n new_sentences = [k for k in sentences if min_sentence_length < len(k) < sentence_length_cut_off]\n #cut_off chosen based on gpu memory limitations\n cut_off = paragraph_length_cutoff if len(new_sentences) > paragraph_length_cutoff else len(new_sentences)\n new_sentences = new_sentences[:cut_off]\n num_sentences = len(new_sentences)\n if not new_sentences:\n new_sentences = ['empty sentence is here!']\n num_sentences = 1\n vecs = self.sentence_embedder.encode(new_sentences, bsize=num_sentences, verbose=False)\n sent_tensors = torch.zeros(num_sentences, 64, 64)\n for i in range(num_sentences):\n sent_tensors[i] = torch.from_numpy(vecs[i].reshape((64, 64)))\n return sent_tensors.view(num_sentences, 1, 64, 64)\n \n def __getitem__(self, idx):\n embedded_article_sentences = self.encode_and_resize(self.articles.iloc[idx]['articleBody'].split('\\n'))\n body_id = self.articles.iloc[idx]['Body ID']\n article_stances = self.hl_and_stances.loc[self.hl_and_stances['Body ID'] == body_id] \n sent_embeddings = self.encode_and_resize(article_stances['Headline'].values)\n pairs = zip(sent_embeddings, [torch.Tensor([self.stance_to_idx[k]]) for k in article_stances['Stance'].values])\n return {'body_embeds': embedded_article_sentences, 'hl_embeds_and_stance' : pairs}\n"
},
{
"alpha_fraction": 0.835616409778595,
"alphanum_fraction": 0.835616409778595,
"avg_line_length": 57.400001525878906,
"blob_id": "f79ed3ba4e16258f4ce5ef35aef5ab3cc243e1cf",
"content_id": "01478f1d3b5331c44df25abd76023f824ad4cb84",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 5,
"path": "/README.md",
"repo_name": "rmacias3/stance_detection",
"src_encoding": "UTF-8",
"text": "# stance_detection\nStance detection for Fake News Challenge Dataset. Experimenting with a convolutional network on sentence embeddings.\n\nMust download fastext word embeddings and InferSent weights \nas per the instructions on https://github.com/facebookresearch/InferSent for the code to work\n"
},
{
"alpha_fraction": 0.6195513010025024,
"alphanum_fraction": 0.6397435665130615,
"avg_line_length": 44.89706039428711,
"blob_id": "cb8d0eb7046fa81aa51d113fd1ece094183327c2",
"content_id": "f3428b62b5365b97d71e430ddb93d180dc2b4cc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3120,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 68,
"path": "/train_stance_detector.py",
"repo_name": "rmacias3/stance_detection",
"src_encoding": "UTF-8",
"text": "from ConvReducer import ConvReducer\nfrom FNCLoader import FNCDataset\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport numpy as np\nfrom InferSent_master.models import InferSent\n\nclass StanceDetector(nn.Module):\n def __init__(self, reducer):\n super(StanceDetector, self).__init__()\n self.reducer = reducer\n self.fc_headline = nn.Linear(128, 32)\n self.fc_body = nn.Linear(128, 32)\n self.relu = nn.ReLU()\n self.fc_output = nn.Linear(64, 4)\n self.softmax = nn.Softmax()\n \n def forward(self, body, headline):\n body_features = self.reducer(body).sum(dim=-2) / len(body)\n headline_features = self.reducer(headline.unsqueeze(0))[0].cuda()\n reduced_b_feats = self.fc_body(self.relu(body_features))\n reduced_hl_feats = self.fc_headline(self.relu(headline_features)) #.cuda()\n concatenated = torch.cat([reduced_b_feats, reduced_hl_feats], dim = -1)\n out = F.log_softmax(self.fc_output(concatenated))\n return out\n\nif __name__ == '__main__':\n MODEL_PATH = '/home/rmacias3/Desktop/stance_detection/InferSent_master/encoder/infersent2.pkl'\n params_model = {'bsize': 64, 'word_emb_dim': 300, 'enc_lstm_dim': 2048,\n 'pool_type': 'max', 'dpout_model': 0.0, 'version': 1}\n model = InferSent(params_model)\n model.load_state_dict(torch.load(MODEL_PATH))\n W2V_PATH = '/home/rmacias3/Desktop/stance_detection/InferSent_master/dataset/fastText/crawl-300d-2M.vec'\n model.set_w2v_path(W2V_PATH)\n print('building vocabulary...')\n model.build_vocab_k_words(K=100000)\n print('building dataset...')\n fnc_path = '/home/rmacias3/Desktop/stance_detection/fnc-1-master/'\n article_csv, stance_csv = fnc_path + 'train_bodies.csv', fnc_path + 'train_stances.csv'\n data_loader = FNCDataset(article_csv, stance_csv, model)\n \n reducer = ConvReducer().cuda()\n stance_detector = StanceDetector(reducer).cuda()\n\n print('training...')\n losses = []\n #.1 weight for unrelated, 1 weight for agree, 1 weight for discuss, 1 weight for disagree\n weights = torch.Tensor([0, 1.0, 1.0, 1.0])\n optimizer = optim.Adam(stance_detector.parameters())\n loss_function = nn.NLLLoss(weight=weights.cuda())\n for i in range(len(data_loader)):\n cur_pair = data_loader[i]\n print('at body: ', i)\n body, headline_and_stance = cur_pair['body_embeds'], list(cur_pair['hl_embeds_and_stance'])\n for hl_embed, gt_stance in headline_and_stance:\n #print(body, hl_embed)\n stance_detector.zero_grad()\n stance_scores = stance_detector(body.cuda(), hl_embed.cuda())\n # print(gt_stance.unsqueeze(0).type(torch.LongTensor), 'gt_stance')\n # print(stance_scores.unsqueeze(0), 'output')\n loss = loss_function(stance_scores.unsqueeze(0).cuda(), gt_stance.type(torch.LongTensor).cuda())\n loss.backward()\n optimizer.step()\n if gt_stance[0] != 0:\n print(loss, gt_stance, stance_scores)\n losses.append(loss)"
},
{
"alpha_fraction": 0.5223725438117981,
"alphanum_fraction": 0.5972945094108582,
"avg_line_length": 36,
"blob_id": "0751855a6ebbc366573883f639d2354d72f0be0e",
"content_id": "7e14e4c18e8c8040787fb7187b6d628d2ac1b9a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 961,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 26,
"path": "/ConvReducer.py",
"repo_name": "rmacias3/stance_detection",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\n\nclass ConvReducer(nn.Module):\n def __init__(self):\n super(ConvReducer, self).__init__()\n self.conv1 = nn.Conv2d(1, 64, kernel_size=4, stride=2, padding=1)\n self.bn1 = nn.BatchNorm2d(64)\n self.conv2 = nn.Conv2d(64, 32, kernel_size=2, stride=2)\n self.bn2 = nn.BatchNorm2d(32)\n self.conv3 = nn.Conv2d(32, 16, kernel_size=2, stride=2)\n self.bn3 = nn.BatchNorm2d(16)\n self.fc1 = nn.Linear(16 * 8 * 8, 512)\n self.fc2 = nn.Linear(512, 128)\n self.relu = nn.ReLU()\n self.selu = nn.SELU()\n\n def forward(self, x):\n conv1 = self.bn1(self.relu(self.conv1(x)))\n conv2 = self.bn2(self.relu(self.conv2(conv1)))\n conv3 = self.bn3(self.relu(self.conv3(conv2))).view(-1, 8 * 8 * 16)\n fc1 = self.selu(self.fc1(conv3))\n features = self.fc2(fc1)\n return features"
}
] | 4 |
rachidphp/camel_tools
|
https://github.com/rachidphp/camel_tools
|
d6f55cf127a82f241ce838643dd6c12b13b6a579
|
dd6f56a7a29339eb9e8ae3d09759f61af9532d0b
|
9d5236bccf25a5d4d31d914eaf87533c42de7b46
|
refs/heads/master
| 2023-08-15T17:01:45.802482 | 2021-10-24T08:22:48 | 2021-10-24T08:22:48 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.34450653195381165,
"alphanum_fraction": 0.3469894528388977,
"avg_line_length": 26.775861740112305,
"blob_id": "fd5b4f90c63ecf49045ff103c5e91ffe86ca5e48",
"content_id": "eae3e5997e567b8c867ff29210964754537c6f82",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1633,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 58,
"path": "/docs/source/cli/camel_data.rst",
"repo_name": "rachidphp/camel_tools",
"src_encoding": "UTF-8",
"text": "camel_data\n==========\n\nAbout\n-----\n\nThe ``camel_data`` tool allows you to download data sets required by CAMeL Tools components.\n\n\nUsage\n-----\n\nBelow is the usage information that can be generated by running\n``camel_data --help``.\n\n.. code-block:: none\n\n Usage:\n camel_data [-d <DIR> | --data-dir=<DIR>] <PACKAGE>\n camel_data (-l | --list)\n camel_data (-v | --version)\n camel_data (-h | --help)\n\n Options:\n -l --list\n Show a list of packages available for download.\n -h --help\n Show this screen.\n -v --version\n Show version.\n\n\n.. _available_packages:\n\nAvailable Packages\n------------------\n\nBelow is a table of available packages and a comparison of their contents.\n\n+--------------------------+--------+-------+\n| | full | light |\n+==========================+========+=======+\n| Size | 1.8 GB | 19 MB |\n+--------------------------+--------+-------+\n| Morphology | ✓ | ✓ |\n+--------------------------+--------+-------+\n| Disambiguation | ✓ | ✓ |\n+--------------------------+--------+-------+\n| Taggers | ✓ | ✓ |\n+--------------------------+--------+-------+\n| Tokenization | ✓ | ✓ |\n+--------------------------+--------+-------+\n| Dialect Identification | ✓ | |\n+--------------------------+--------+-------+\n| Sentiment Analysis | ✓ | |\n+--------------------------+--------+-------+\n| Named Entity Recognition | ✓ | |\n+--------------------------+--------+-------+\n"
},
{
"alpha_fraction": 0.5817095637321472,
"alphanum_fraction": 0.584269642829895,
"avg_line_length": 35.811519622802734,
"blob_id": "107f29577bac69a8c7ee360c16cb88e068e493f8",
"content_id": "1573e3f1f97bf09d87a8ad9dc3c71b2549732a4d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7031,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 191,
"path": "/camel_tools/data/downloader.py",
"repo_name": "rachidphp/camel_tools",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# MIT License\n#\n# Copyright 2018-2021 New York University Abu Dhabi\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\nfrom pathlib import Path\nimport requests\nfrom sys import stdout\nfrom tempfile import TemporaryDirectory\nfrom os import makedirs\nfrom os.path import dirname, exists\nimport warnings\nimport zipfile\n\nfrom camel_tools.data import CT_DATA_DIR\n\n\n_STREAM_CHUNK_SIZE = 32768\n_GDRIVE_URL = 'https://docs.google.com/uc?export=download'\n\n\nclass DownloaderError(Exception):\n \"\"\"Error raised when an error occurs during data download.\n \"\"\"\n\n def __init__(self, msg):\n self.msg = msg\n\n def __str__(self):\n return str(self.msg)\n\n\nclass URLDownloader:\n \"\"\"Class to download shared files from a URL. This is a modified\n version of\n `google-drive-downloader https://github.com/ndrplz/google-drive-downloader`_.\n \"\"\"\n\n @staticmethod\n def download(url, destination):\n \"\"\"Downloads a shared file from google drive into a given folder.\n Optionally unzips it.\n\n Args:\n url (:obj:`str`): The file url.\n destination (:obj:`str`): The destination directory where the\n downloaded data will be saved.\n \"\"\"\n\n if destination.exists() and not destination.is_dir():\n raise DownloaderError(\n 'Destination directory {} is a pre-existing file.'.format(\n repr(str(destination))))\n else:\n destination.mkdir(parents=True, exist_ok=True)\n\n with TemporaryDirectory() as tmp_dir:\n # Download data zip to temporary directory\n try:\n session = requests.Session()\n response = session.get(url, stream=True)\n\n curr_dl_size = [0]\n tmp_zip_path = Path(tmp_dir, 'data.zip')\n GoogleDriveDownloader._save_content(response,\n tmp_zip_path,\n curr_dl_size)\n except:\n raise DownloaderError(\n 'An error occured while downloading data.')\n\n # Extract data to destination directory\n try:\n with zipfile.ZipFile(tmp_zip_path, 'r') as zip_fp:\n zip_fp.extractall(destination)\n except:\n raise DownloaderError(\n 'An error occured while extracting downloaded data.')\n\n @staticmethod\n def _save_content(response, destination, curr_size):\n with open(destination, 'wb') as fp:\n for chunk in response.iter_content(_STREAM_CHUNK_SIZE):\n if chunk: # filter out keep-alive new chunks\n fp.write(chunk)\n curr_size[0] += len(chunk)\n\n\nclass GoogleDriveDownloader:\n \"\"\"Class to download shared files from Google Drive. This is a modified\n version of\n `google-drive-downloader https://github.com/ndrplz/google-drive-downloader`_.\n \"\"\"\n\n @staticmethod\n def download(file_id, destination):\n \"\"\"Downloads a shared file from google drive into a given folder.\n Optionally unzips it.\n\n Args:\n file_id (:obj:`str`): The file identifier.\n destination (:obj:`str`): The destination directory where the\n downloaded data will be saved.\n \"\"\"\n\n if destination.exists() and not destination.is_dir():\n raise DownloaderError(\n 'Destination directory {} is a pre-existing file.'.format(\n repr(str(destination))))\n else:\n destination.mkdir(parents=True, exist_ok=True)\n\n with TemporaryDirectory() as tmp_dir:\n # Download data zip to temporary directory\n try:\n session = requests.Session()\n response = session.get(_GDRIVE_URL, params={ 'id': file_id },\n stream=True)\n\n token = None\n for key, value in response.cookies.items():\n if key.startswith('download_warning'):\n token = value\n break\n\n if token:\n params = {'id': file_id, 'confirm': token}\n response = session.get(_GDRIVE_URL, params=params,\n stream=True)\n\n curr_dl_size = [0]\n tmp_zip_path = Path(tmp_dir, 'data.zip')\n GoogleDriveDownloader._save_content(response,\n tmp_zip_path,\n curr_dl_size)\n except:\n raise DownloaderError(\n 'An error occured while downloading data.')\n\n # Extract data to destination directory\n try:\n with zipfile.ZipFile(tmp_zip_path, 'r') as zip_fp:\n zip_fp.extractall(destination)\n except:\n raise DownloaderError(\n 'An error occured while extracting downloaded data.')\n\n @staticmethod\n def _save_content(response, destination, curr_size):\n with open(destination, 'wb') as fp:\n for chunk in response.iter_content(_STREAM_CHUNK_SIZE):\n if chunk: # filter out keep-alive new chunks\n fp.write(chunk)\n curr_size[0] += len(chunk)\n\n\nclass DataDownloader(object):\n \"\"\"Class for downloading data described by a :obj:`DownloadInfo` object.\n \"\"\"\n\n @staticmethod\n def download(dl_info):\n destination = Path(CT_DATA_DIR, dl_info.destination)\n\n if dl_info.type == 'url':\n URLDownloader.download(dl_info.url, destination)\n elif dl_info.type == 'google-drive':\n GoogleDriveDownloader.download(dl_info.file_id, destination)\n else:\n raise DownloaderError(\n 'Invalid download type {}'.format(repr(dl_info.type)))\n"
},
{
"alpha_fraction": 0.5854386687278748,
"alphanum_fraction": 0.5866112112998962,
"avg_line_length": 34.942527770996094,
"blob_id": "64e62cb74cc53e33c64616227979f10ac62d4d8a",
"content_id": "76a8400fb431728714b982d2e8f820a371d06637",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9381,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 261,
"path": "/camel_tools/data/__init__.py",
"repo_name": "rachidphp/camel_tools",
"src_encoding": "UTF-8",
"text": "# MIT License\n#\n# Copyright 2018-2021 New York University Abu Dhabi\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\n\"\"\"This sub-module contains utilities for locating datastes for the various\nCAMeL Tools components.\n\"\"\"\n\n\nfrom collections import namedtuple\nimport json\nimport os\nfrom pathlib import Path\nimport sys\n\n\nclass DataLookupException(ValueError):\n \"\"\"Exception thrown when an invalid component or dataset is specified in a\n dataset lookup operation.\n\n Args:\n msg (:obj:`str`): Exception message to be displayed.\n \"\"\"\n\n def __init__(self, msg):\n self.msg = msg\n\n def __str__(self):\n return self.msg\n\n\ndef _get_appdatadir():\n home = Path.home()\n\n # TODO: Make sure this works with OSs other than Windows, Linux and Mac.\n if sys.platform == 'win32':\n return Path(home, 'AppData/Roaming/camel_tools')\n else:\n return Path(home, '.camel_tools')\n\n\nCT_DATA_PATH_DEFAULT = _get_appdatadir()\nCT_DATA_PATH_DEFAULT.mkdir(parents=True, exist_ok=True)\nCT_DATA_DIR = CT_DATA_PATH_DEFAULT\n\n_CATALOGUE_PATH = Path(__file__).parent / 'catalogue.json'\nwith _CATALOGUE_PATH.open('r', encoding='utf-8') as cat_fp:\n _CATALOGUE = json.load(cat_fp)\n\nif os.environ.get('CAMELTOOLS_DATA') is not None:\n CT_DATA_DIR = Path(\n os.environ.get('CAMELTOOLS_DATA')).expanduser().absolute()\n\n_CT_DATASET_PATH = Path(CT_DATA_DIR, 'data')\n\n\n_DownloadInfo = namedtuple('DownloadInfo', ['name',\n 'description',\n 'type',\n 'file_id',\n 'url',\n 'size',\n 'destination'])\n\n_ComponentInfo = namedtuple('ComponentInfo', ['name', 'datasets', 'default'])\n\n_DatasetInfo = namedtuple('DatasetInfo', ['component',\n 'name',\n 'description',\n 'license',\n 'version',\n 'path'])\n\n\nclass DownloadInfo(_DownloadInfo):\n \"\"\"Named tuple containing information about a data download.\n\n Attributes:\n name (:obj:`str`): The name used to query this download.\n description (:obj:`str`): A description of this download.\n type (:obj:`str`): The type of download. Values can be one of the\n following: 'url', 'google-drive'.\n url (:obj:`str`): The URL of the download (used only when `type` is set\n to 'url').\n file_id (:obj:`str`): The file ID of the download (used only when\n `type` is set to 'google-drive').\n size (:obj:`str`): Estimated data size in Bytes, KB, MB, or GB.\n destination (:obj:`str`): The destination of the downloaded file\n relative to the camel-tools data path.\n \"\"\"\n\n\nclass ComponentInfo(_ComponentInfo):\n \"\"\"Named tuple containing information about a component.\n\n Attributes:\n name (:obj:`str`): The name used to query this component.\n datasets (:obj:`frozenset` of :obj:`DatasetInfo`): A set of all\n datasets for this component.\n default (:obj:`str`): Name of the default dataset for this component.\n \"\"\"\n\n\nclass DatasetInfo(_DatasetInfo):\n \"\"\"Named tuple containing information about a dataset.\n\n Attributes:\n component (:obj:`str`): The component name this dataset belongs to.\n name (:obj:`str`): The name used to query this dataset.\n description (:obj:`str`): A description of this dataset.\n license (:obj:`str`): The license this dataset is distributed under.\n version (:obj:`str`): This dataset's version number.\n path (:obj:`Path`): The path to this dataset.\n \"\"\"\n\n\ndef _gen_catalogue(cat_dict):\n catalogue = {'downloads': {}, 'components': {}}\n\n # Populate downloads\n for dl_name, dl_info in cat_dict['downloads'].items():\n catalogue['downloads'][dl_name] = DownloadInfo(\n dl_name,\n dl_info.get('description', None),\n dl_info['type'],\n dl_info.get('file_id', None),\n dl_info.get('url', None),\n dl_info['size'],\n dl_info['destination'])\n\n # Populate components\n for comp_name, comp_info in cat_dict['components'].items():\n datasets = {}\n\n for ds_name, ds_info in comp_info['datasets'].items():\n ds_path = Path(_CT_DATASET_PATH, ds_info['path'])\n datasets[ds_name] = DatasetInfo(comp_name,\n ds_name,\n ds_info.get('description', None),\n ds_info.get('license', None),\n ds_info.get('version', None),\n ds_path)\n\n catalogue['components'][comp_name] = {\n 'default': comp_info['default'],\n 'datasets': datasets\n }\n\n return catalogue\n\n\nclass DataCatalogue(object):\n \"\"\"This class allows querying datasets provided by CAMeL Tools.\n \"\"\"\n\n _catalogue = _gen_catalogue(_CATALOGUE)\n\n @staticmethod\n def get_download_info(download):\n \"\"\"Get the download entry for a given download name.\n\n Args:\n download (:obj:`str`): Name of the download to lookup in the\n catalogue.\n\n Returns:\n :obj:`DownloadInfo`: The catalogue entry associated with the given\n download.\n\n Raises:\n DataLookupException: If `download` is not a valid download name.\n \"\"\"\n\n if download not in DataCatalogue._catalogue['downloads']:\n raise DataLookupException('Undefined download {}.'.format(\n repr(download)))\n \n return DataCatalogue._catalogue['downloads'][download]\n\n @staticmethod\n def downloads_list():\n return [v for _, v in \n sorted(DataCatalogue._catalogue['downloads'].items())]\n\n @staticmethod\n def get_component_info(component):\n \"\"\"Get the catalogue entry for a given component.\n\n Args:\n component (:obj:`str`): Name of the component to lookup in the\n catalogue.\n\n Returns:\n :obj:`ComponentInfo`: The catalogue entry associated with the given\n component.\n\n Raises:\n DataLookupException: If `component` is not a valid component name.\n \"\"\"\n\n if component not in DataCatalogue._catalogue['components']:\n raise DataLookupException('Undefined component {}.'.format(\n repr(component)))\n\n comp_info = DataCatalogue._catalogue['components'][component]\n default = comp_info['default']\n datasets = frozenset(comp_info['datasets'].values())\n\n return ComponentInfo(component, datasets, default)\n\n @staticmethod\n def get_dataset_info(component, dataset=None):\n \"\"\"Get the catalogue entry for a given dataset for a given component.\n\n Args:\n component (:obj:`str`): Name of the component dataset belongs to.\n dataset (:obj:`str`, optional): Name of the dataset for `component`\n to lookup. If None, the entry for the default dataset for\n `component` is returned. Defaults to None.\n\n Returns:\n :obj:`DatasetInfo`: The catalogue entry associated with the given\n dataset.\n\n Raises:\n DataLookupException: If `component` is not a valid component name\n or if `dataset` is not a valid dataset name for `component`.\n \"\"\"\n if component not in DataCatalogue._catalogue['components']:\n raise DataLookupException('Undefined component {}.'.format(\n repr(component)))\n\n comp_info = DataCatalogue._catalogue['components'][component]\n\n if dataset is None:\n dataset = comp_info['default']\n elif dataset not in comp_info['datasets']:\n raise DataLookupException(\n 'Undefined dataset {} for component {}.'.format(\n repr(dataset), repr(component)))\n\n return comp_info['datasets'][dataset]\n"
},
{
"alpha_fraction": 0.5892949104309082,
"alphanum_fraction": 0.6657230854034424,
"avg_line_length": 45.261905670166016,
"blob_id": "0ce501273be4b237b6e8969d019dc17e6fc8a68e",
"content_id": "47ef1f4f6bc7b50357d5a4eaf263d94416e1f183",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3886,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 84,
"path": "/camel_tools/utils/charsets.py",
"repo_name": "rachidphp/camel_tools",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# MIT License\n#\n# Copyright 2018-2021 New York University Abu Dhabi\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\"\"\"Contains character sets for different encoding schemes as well as Unicode\ncharacters marked as symbols and punctuation.\n\"\"\"\n\nimport unicodedata\n\nfrom six import unichr\n\n\nUNICODE_PUNCT_CHARSET = frozenset(\n [unichr(x) for x in range(65536) if unicodedata.category(\n unichr(x))[0] == 'P'])\nUNICODE_SYMBOL_CHARSET = frozenset(\n [unichr(x) for x in range(65536) if unicodedata.category(\n unichr(x))[0] == 'S'])\nUNICODE_PUNCT_SYMBOL_CHARSET = UNICODE_PUNCT_CHARSET | UNICODE_SYMBOL_CHARSET\n\nUNICODE_LETTER_CHARSET = frozenset(\n [unichr(x) for x in range(65536) if unicodedata.category(\n unichr(x))[0] == 'L'])\nUNICODE_MARK_CHARSET = frozenset(\n [unichr(x) for x in range(65536) if unicodedata.category(\n unichr(x))[0] == 'M'])\nUNICODE_NUMBER_CHARSET = frozenset(\n [unichr(x) for x in range(65536) if unicodedata.category(\n unichr(x))[0] == 'N'])\nUNICODE_LETTER_MARK_NUMBER_CHARSET = (UNICODE_LETTER_CHARSET |\n UNICODE_MARK_CHARSET |\n UNICODE_NUMBER_CHARSET)\n\nAR_LETTERS_CHARSET = frozenset(u'\\u0621\\u0622\\u0623\\u0624\\u0625\\u0626\\u0627'\n u'\\u0628\\u0629\\u062a\\u062b\\u062c\\u062d\\u062e'\n u'\\u062f\\u0630\\u0631\\u0632\\u0633\\u0634\\u0635'\n u'\\u0636\\u0637\\u0638\\u0639\\u063a\\u0640\\u0641'\n u'\\u0642\\u0643\\u0644\\u0645\\u0646\\u0647\\u0648'\n u'\\u0649\\u064a\\u0671\\u067e\\u0686\\u06a4\\u06af')\nAR_DIAC_CHARSET = frozenset(u'\\u064b\\u064c\\u064d\\u064e\\u064f\\u0650\\u0651\\u0652'\n u'\\u0670\\u0640')\nAR_CHARSET = AR_LETTERS_CHARSET | AR_DIAC_CHARSET\n\nBW_LETTERS_CHARSET = frozenset(u'$&\\'*<>ADEGHJPSTVYZ_bdfghjklmnpqrstvwxyz{|}')\nBW_DIAC_CHARSET = frozenset(u'FKN`aiou~_')\nBW_CHARSET = BW_LETTERS_CHARSET | BW_DIAC_CHARSET\n\nSAFEBW_LETTERS_CHARSET = frozenset(u'ABCDEGHIJLMOPQSTVWYZ_bcdefghjklmnpqrstvwx'\n u'yz')\nSAFEBW_DIAC_CHARSET = frozenset(u'FKNaeiou~_')\nSAFEBW_CHARSET = SAFEBW_LETTERS_CHARSET | SAFEBW_DIAC_CHARSET\n\nXMLBW_LETTERS_CHARSET = frozenset(u'$\\'*ABDEGHIJOPSTWYZ_bdfghjklmnpqrstvwxyz{|'\n u'}')\nXMLBW_DIAC_CHARSET = frozenset(u'FKN`aiou~_')\nXMLBW_CHARSET = XMLBW_LETTERS_CHARSET | XMLBW_DIAC_CHARSET\n\nHSB_LETTERS_CHARSET = frozenset(u'\\'ADHST_bcdfghjklmnpqrstvwxyz'\n u'\\u00c2\\u00c4\\u00e1\\u00f0\\u00fd\\u0100\\u0102'\n u'\\u010e\\u0127\\u0161\\u0175\\u0177\\u03b3\\u03b8'\n u'\\u03c2')\nHSB_DIAC_CHARSET = frozenset(u'.aiu~\\u00c4\\u00e1\\u00e3\\u0129\\u0169_')\nHSB_CHARSET = HSB_LETTERS_CHARSET | HSB_DIAC_CHARSET\n"
},
{
"alpha_fraction": 0.6508380174636841,
"alphanum_fraction": 0.6557262539863586,
"avg_line_length": 30.130434036254883,
"blob_id": "b8a60e5bdbd1897e7a124a30d7123207c7ae313c",
"content_id": "e329da8915b568d7c5e65b3033244afa66dd7318",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2864,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 92,
"path": "/camel_tools/cli/camel_data.py",
"repo_name": "rachidphp/camel_tools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n# MIT License\n#\n# Copyright 2018-2021 New York University Abu Dhabi\n#\n# Permission is hereby granted, free of charge, to any person obtaining a copy\n# of this software and associated documentation files (the \"Software\"), to deal\n# in the Software without restriction, including without limitation the rights\n# to use, copy, modify, merge, publish, distribute, sublicense, and/or sell\n# copies of the Software, and to permit persons to whom the Software is\n# furnished to do so, subject to the following conditions:\n#\n# The above copyright notice and this permission notice shall be included in\n# all copies or substantial portions of the Software.\n#\n# THE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\n# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\n# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\n# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\n# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\n# OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\n# SOFTWARE.\n\n\n\"\"\"The CAMeL Tools data download utility.\n\nUsage:\n camel_data [-d <DIR> | --data-dir=<DIR>] <PACKAGE>\n camel_data (-l | --list)\n camel_data (-v | --version)\n camel_data (-h | --help)\n\nOptions:\n -l --list\n Show a list of packages available for download.\n -h --help\n Show this screen.\n -v --version\n Show version.\n\"\"\"\n\n\nimport sys\n\nfrom docopt import docopt\n\nimport camel_tools\nfrom camel_tools.data import DataCatalogue, CT_DATA_DIR\nfrom camel_tools.data.downloader import DataDownloader, DownloaderError\n\n\n__version__ = camel_tools.__version__\n\n\ndef main(): # pragma: no cover\n try:\n version = ('CAMeL Tools v{}'.format(__version__))\n arguments = docopt(__doc__, version=version)\n\n if arguments['--list']:\n for dl in DataCatalogue.downloads_list():\n print(\"{}\\t{}\\t{}\".format(dl.name, dl.size, dl.description))\n sys.exit(0)\n\n package_name = arguments.get('<PACKAGE>', None)\n\n try:\n dl_info = DataCatalogue.get_download_info(package_name)\n except:\n sys.stderr.write('Error: Invalid package name. Run `camel_data -l`'\n ' to get a list of available packages.\\n')\n sys.exit(1)\n\n try:\n DataDownloader.download(dl_info)\n except DownloaderError as e:\n sys.stderr.write('Error: {}\\n'.format(e.msg))\n sys.exit(1)\n\n except KeyboardInterrupt:\n sys.stderr.write('Exiting...\\n')\n sys.exit(1)\n\n except Exception:\n sys.stderr.write('Error: An unknown error occurred.\\n')\n sys.exit(1)\n\n\nif __name__ == '__main__': # pragma: no cover\n main()\n"
}
] | 5 |
saphiashi/neuron
|
https://github.com/saphiashi/neuron
|
6e8c03035514f8c517790e223b301cae71778c0f
|
f0dd3aefda9e3af5478c1558ca9ff3eb0eaddb6f
|
52b501c977d57ea9472e7691be795099defe3a71
|
refs/heads/main
| 2023-06-23T08:18:00.649217 | 2021-07-21T02:26:29 | 2021-07-21T02:26:29 | 387,941,958 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.516257107257843,
"alphanum_fraction": 0.543559193611145,
"avg_line_length": 29.76335906982422,
"blob_id": "2176ccedee727a902146513adbebf1ef1196a077",
"content_id": "c1a11ad19491ad422cec49020d36af7898328367",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4029,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 131,
"path": "/ballstick1.py",
"repo_name": "saphiashi/neuron",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Jul 15 12:50:20 2021\n\n@author: sshi\n\"\"\"\n\nfrom neuron import h\nfrom neuron.units import ms, mV\n\nh.load_file('stdrun.hoc')\n\nclass BallAndStick:\n def __init__(self, gid):\n self._gid = gid\n self._setup_morphology()\n self._setup_biophysics()\n def _setup_morphology(self):\n self.soma = h.Section(name='soma', cell=self)\n self.dend = h.Section(name='dend', cell=self)\n self.all = [self.soma, self.dend]\n self.dend.connect(self.soma)\n self.soma.L = self.soma.diam = 12.6157\n self.dend.L = 200\n self.dend.diam = 1\n def _setup_biophysics(self):\n for sec in self.all:\n sec.Ra = 100 # Axial resistance in Ohm * cm\n sec.cm = 1 # Membrane capacitance in micro Farads / cm^2\n self.soma.insert('hh') # <-- NEW \n for seg in self.soma: # <-- NEW\n seg.hh.gnabar = 0.12 # Sodium conductance in S/cm2 # <-- NEW\n seg.hh.gkbar = 0.036 # Potassium conductance in S/cm2 # <-- NEW\n seg.hh.gl = 0.0003 # Leak conductance in S/cm2 # <-- NEW\n seg.hh.el = -54.3 # Reversal potential in mV \n self.dend.insert('pas') # <-- NEW\n for seg in self.dend: # <-- NEW\n seg.pas.g = 0.001 # Passive conductance in S/cm2 # <-- NEW\n seg.pas.e = -65 # Leak reversal potential mV\n def __repr__(self):\n return 'BallAndStick[{}]'.format(self._gid)\n\nmy_cell = BallAndStick(0)\n\nprint(my_cell.soma(0.5).area())\nprint(h.topology())\n\nimport matplotlib.pyplot as plt\n\nh.PlotShape(False).plot(plt)\n\n# enable NEURON's graphics\nfrom neuron import gui\n\n# here: True means show using NEURON's GUI; False means do not do so, at least not at first\nps = h.PlotShape(True)\nps.show(0)\n\nprint(h.units('gnabar_hh'))\n\nfor sec in h.allsec():\n print('%s: %s' % (sec, ', '.join(sec.psection()['density_mechs'].keys())))\nstim = h.IClamp(my_cell.dend(1))\nstim.get_segment()\n\nprint(', '.join(item for item in dir(stim) if not item.startswith('__')))\n\nstim.delay = 5\nstim.dur = 1\nstim.amp = 0.1\n\nsoma_v = h.Vector().record(my_cell.soma(0.5)._ref_v)\nt = h.Vector().record(h._ref_t)\n\n\nh.finitialize(-65 * mV)\n\n\nh.continuerun(25 * ms)\n\nplt.figure()\nplt.plot(t, soma_v)\nplt.xlabel='t (ms)'\nplt.ylabel='v (mV)'\nplt.show()\n\n\nf = plt.figure(x_axis_label='t (ms)', y_axis_label='v (mV)')\namps = [0.075 * i for i in range(1, 5)]\ncolors = ['green', 'blue', 'red', 'black']\nfor amp, color in zip(amps, colors):\n stim.amp = amp\n h.finitialize(-65 * mV)\n h.continuerun(25 * ms)\n f.line(t, list(soma_v), line_width=2, legend_label='amp=%g' % amp, color=color)\nplt.show(f)\n\n\ndend_v = h.Vector().record(my_cell.dend(0.5)._ref_v)\nf = plt.figure()\nplt.xlabel='t (ms)'\nplt.ylabel='v (mV)'\namps = [0.075 * i for i in range(1, 5)]\ncolors = ['green', 'blue', 'red', 'black']\nfor amp, color in zip(amps, colors):\n \n stim.amp = amp\n h.finitialize(-65)\n h.continuerun(25)\n f.plot(t, list(soma_v), line_width=2, legend_label='amp=%g' % amp, color=color)\n f.plot(t, list(dend_v), line_width=2, line_dash='dashed', color=color)\n\nplt.show(f)\n\nf = plt.figure(x_axis_label='t (ms)', y_axis_label='v (mV)')\namps = [0.075 * i for i in range(1, 5)]\ncolors = ['green', 'blue', 'red', 'black']\nfor amp, color in zip(amps, colors):\n stim.amp = amp\n for my_cell.dend.nseg, width in [(1, 2), (101, 1)]:\n h.finitialize(-65)\n h.continuerun(25)\n f.line(t, list(soma_v),\n line_width=width,\n legend_label='amp=%g' % amp if my_cell.dend.nseg == 1 else None,\n color=color)\n f.line(t, list(dend_v),\n line_width=width,\n line_dash='dashed',\n color=color)\nplt.show(f)"
},
{
"alpha_fraction": 0.6091405153274536,
"alphanum_fraction": 0.6309686303138733,
"avg_line_length": 18.73972511291504,
"blob_id": "824300e663d889a0bbd8937e848dd23297e9eb54",
"content_id": "3a96908f4f4561e5b49de83e74586f84a647b44f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1466,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 73,
"path": "/scripting basics.py",
"repo_name": "saphiashi/neuron",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\nThis is a temporary script file.\n\"\"\"\nfrom neuron import h\nfrom neuron.units import ms, mV\n\nimport matplotlib.pyplot as plt\n\nsoma = h.Section(name='soma')\nprint(h.topology())\nprint(soma.psection() )\nprint(soma.psection()['morphology']['L'] )\nprint(soma.L)\nsoma.L = 20\nsoma.diam = 20\nprint(dir(soma))\n\nimport textwrap\nprint(textwrap.fill(', '.join(dir(h))))\n\nsoma.insert('hh')\nprint(\"type(soma) = {}\".format(type(soma)))\nprint(\"type(soma(0.5)) = {}\".format(type(soma(0.5))))\n\nmech = soma(0.5).hh\nprint(dir(mech))\nprint(mech.gkbar)\nprint(soma(0.5).hh.gkbar)\n\niclamp = h.IClamp(soma(0.5))\nprint([item for item in dir(iclamp) if not item.startswith('__')])\niclamp.delay = 2\niclamp.dur = 0.1\niclamp.amp = 0.9\nprint(soma.psection())\n\nt = h.Vector().record(h._ref_t) \nv = h.Vector().record(soma(0.5)._ref_v) \n\nh.load_file('stdrun.hoc')\nh.finitialize( -65 * mV)\nh.continuerun(40* ms)\n\nf1 = plt.figure()\nplt.xlabel('t (ms)')\nplt.ylabel('v (mV)')\nplt.plot(t, v, linewidth=2)\nplt.show(f1)\n\nf1 = plt.figure()\nplt.xlabel('t (ms)')\nplt.ylabel('v (mV)')\nplt.plot(t, v, linewidth=2)\nplt.show(f1)\n\n\nimport csv\n\nwith open('data.csv', 'w') as f:\n csv.writer(f).writerows(zip(t, v))\n \nwith open('data.csv') as f:\n reader = csv.reader(f)\n tnew, vnew = zip(*[[float(val) for val in row] for row in reader if row])\n \nplt.figure()\nplt.plot(tnew, vnew)\nplt.xlabel('t (ms)')\nplt.ylabel('v (mV)')\nplt.show()\n\n \n \n \n \n "
}
] | 2 |
DhanushkaNadeeshan/uoais
|
https://github.com/DhanushkaNadeeshan/uoais
|
1ea3eb09ce66bcefbb432a8750c67c733954a3bb
|
3825b50ae15b577344bd5183b40c303d1d483c17
|
ddb3862438a09bd20f9034a1d5dd6ace7789cbca
|
refs/heads/main
| 2023-08-06T12:57:04.379098 | 2021-09-25T17:43:09 | 2021-09-25T17:43:09 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.68843013048172,
"alphanum_fraction": 0.7220355272293091,
"avg_line_length": 27.93055534362793,
"blob_id": "7a6c8893523579b4695f19f6339d68331eb9e235",
"content_id": "d02ebe9941c9fcc1ad5351ea2f505fbec2f49152",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2083,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 72,
"path": "/README.md",
"repo_name": "DhanushkaNadeeshan/uoais",
"src_encoding": "UTF-8",
"text": "# Unseen Object Amodal Instance Segmentation (UOAIS)\n\nSeunghyeok Back, Joosoon Lee, Taewon Kim, Sangjun Noh, Raeyoung Kang, Seongho Bak, Kyoobin Lee \n\n\nThis repository contains source codes for the paper \"Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling.\"\n\n[[Paper]](https://arxiv.org/abs/2109.11103) [[Project Website]](https://sites.google.com/view/uoais) [[Video]](https://youtu.be/rDTmXu6BhIU) \n\n<img src=\"./imgs/demo.gif\" height=\"200\">\n\n\n## Updates & TODO Lists\n- [X] (2021.09.26) UOAIS-Net has been released \n- [ ] Add train and evaluation code\n- [ ] Release synthetic dataset (UOAIS-Sim) and amodal annotation (OSD-Amodal)\n- [ ] Add ROS inference node\n\n\n## Getting Started\n\n### Environment Setup\n\nTested on Titan RTX with python 3.7, pytorch 1.8.0, torchvision 0.9.0, CUDA 10.2.\n\n1. Download\n```\ngit clone https://github.com/gist-ailab/uoais.git\ncd uoais\nmkdir output\n```\nDownload the checkpoint at [GDrive](https://drive.google.com/drive/folders/1D5hHFDtgd5RnX__55MmpfOAM83qdGYf0?usp=sharing) and move the downloaded folders to the `output` folder\n\n2. Set up a python environment\n```\nconda create -n uoais python=3.7\nconda activate uoais\npip install torch torchvision \npip install shapely torchfile opencv-python pyfastnoisesimd rapidfuzz\n```\n3. Install [detectron2](https://detectron2.readthedocs.io/en/latest/tutorials/install.html#install-pre-built-detectron2-linux-only)\n4. Build and install custom [AdelaiDet](https://github.com/aim-uofa/AdelaiDet)\n```\npython setup.py build develop \n```\n\n### Run with Sample Data\n\nUOAIS-Net (RGB-D)\n```\npython tools/run_sample_data.py\n```\n\n<img src=\"./imgs/sample_0.png\" height=\"200\">\n\n## License\n\nThis repository is released under the MIT license.\n\n\n## Citation\nIf you use our work in a research project, please cite our work:\n```\n@misc{back2021unseen,\n title={Unseen Object Amodal Instance Segmentation via Hierarchical Occlusion Modeling}, \n author={Seunghyeok Back and Joosoon Lee and Taewon Kim and Sangjun Noh and Raeyoung Kang and Seongho Bak and Kyoobin Lee},\n year={2021},\n eprint={2109.11103},\n archivePrefix={arXiv},\n primaryClass={cs.RO}\n}\n```\n"
},
{
"alpha_fraction": 0.6437469124794006,
"alphanum_fraction": 0.6581963300704956,
"avg_line_length": 31.387096405029297,
"blob_id": "b773d0750057310d3a93bfe5bd5af5c41edf5745",
"content_id": "e8f383c9c7bc3286ce605814c1028bd570936622",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2007,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 62,
"path": "/demo/image_demo.py",
"repo_name": "DhanushkaNadeeshan/uoais",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport argparse\nimport glob\nfrom tqdm import tqdm\n\nfrom detectron2.utils.logger import setup_logger\nfrom detectron2.engine import DefaultPredictor\nfrom detectron2.utils.visualizer import Visualizer\nfrom detectron2.data import MetadataCatalog\n\nfrom uoamask.config import get_cfg\n\n\ndef main(args):\n # Get image\n image_paths = glob.glob(args.image_folder)\n # Get the configuration ready\n cfg = get_cfg()\n cfg.merge_from_file(args.config_file)\n cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, \"model_final.pth\")\n cfg.MODEL.RETINANET.SCORE_THRESH_TEST = 0.5\n cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5\n cfg.MODEL.FCOS.INFERENCE_TH_TEST = 0.5\n cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = 0.5\n predictor = DefaultPredictor(cfg)\n\n for i, image_path in enumerate(tqdm(image_paths)):\n \n im = cv2.imread(image_path)\n im = cv2.resize(im, (512, 384))\n\n\n outputs = predictor(im)\n\n v = Visualizer(im[:,:,::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)\n v = v.draw_instance_predictions(outputs['instances'].to('cpu'))\n img = v.get_image()[:, :, ::-1]\n\n if i == 0 and not os.path.exists(os.path.join(cfg.OUTPUT_DIR, \"vis_results\")):\n os.mkdir(os.path.join(cfg.OUTPUT_DIR, \"vis_results\"))\n cv2.imwrite('{}/vis_results/output_{}.png'.format(cfg.OUTPUT_DIR, i), img)\n\n\n\nif __name__ == \"__main__\":\n\n parser = argparse.ArgumentParser('UOIS CenterMask', add_help=False)\n parser.add_argument(\"--config-file\", \n default=\"./configs/debug.yaml\", \n metavar=\"FILE\", help=\"path to config file\")\n parser.add_argument(\"--image-folder\", \n default=\"./datasets/wisdom/wisdom-real/high-res/color_ims/*.png\", \n metavar=\"FILE\", help=\"path to config file\")\n parser.add_argument(\"--gpu\", type=str, default=\"0\", help=\"GPU id\")\n args = parser.parse_args()\n\n os.environ['CUDA_VISIBLE_DEVICES'] = args.gpu\n\n setup_logger()\n\n main(args)"
},
{
"alpha_fraction": 0.626518189907074,
"alphanum_fraction": 0.637651801109314,
"avg_line_length": 29.292306900024414,
"blob_id": "c2e3c3562770d4dbd96aa4ba9111962fe1acef5e",
"content_id": "7a6ee7ed703f5cc57bf65e357bb1a30090be5070",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1976,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 65,
"path": "/demo/video_demo.py",
"repo_name": "DhanushkaNadeeshan/uoais",
"src_encoding": "UTF-8",
"text": "import argparse\nimport multiprocessing as mp\nimport os\nimport cv2\nfrom adet.utils.visualizer import Visualizer, visualize_pred_amoda_occ\nfrom adet.utils.post_process import detector_postprocess, DefaultPredictor\nimport numpy as np\nfrom adet.config import get_cfg\n\n\ndef get_parser():\n parser = argparse.ArgumentParser(description=\"Detectron2 Demo\")\n parser.add_argument(\n \"--config-file\",\n default=\"configs/R50_rgbdconcat_mlc_occatmask_hom_concat.yaml\",\n metavar=\"FILE\",\n help=\"path to config file\",\n )\n parser.add_argument(\n \"--confidence-threshold\",\n type=float,\n default=0.4,\n help=\"Minimum score for instance predictions to be shown\",\n )\n parser.add_argument(\n \"--opts\",\n help=\"Modify config options using the command-line 'KEY VALUE' pairs\",\n default=[],\n nargs=argparse.REMAINDER,\n )\n return parser\n\n\nif __name__ == \"__main__\":\n mp.set_start_method(\"spawn\", force=True)\n args = get_parser().parse_args()\n\n print(args)\n cfg = get_cfg()\n cfg.merge_from_file(args.config_file)\n cfg.defrost()\n cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, \"model_final.pth\")\n cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold\n cfg.MODEL.ROI_HEADS.NMS_THRESH_TEST = args.confidence_threshold\n predictor = DefaultPredictor(cfg)\n\n # naive version\n cap = cv2.VideoCapture(\"/home/seung/Workspace/datasets/UOAIS/CATER/CATER_new_005781.avi\")\n success, img = cap.read()\n fno = 0\n while success:\n # read next frame\n success, img = cap.read()\n # use PIL, to be consistent with evaluation\n\n img = cv2.resize(img, cfg.IMG_SIZE)\n\n outputs = predictor(img[:, :, ::-1])\n\n vis_img = visualize_pred_amoda_occ(color, preds, bboxs, pred_occ)\n\n cv2.imshow(args.config_file.split('/')[-1], pred_vis)\n k = cv2.waitKey(1)\n if k == 27:\n break # esc to quit\n\n\n\n "
},
{
"alpha_fraction": 0.6181356310844421,
"alphanum_fraction": 0.6447136998176575,
"avg_line_length": 36.0217399597168,
"blob_id": "40e8be696f199d2713129f285d35bff30dc1be91",
"content_id": "4132a170b713f28cb007eaa0f64d4606ae13162f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5117,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 138,
"path": "/demo/realtime_demo.py",
"repo_name": "DhanushkaNadeeshan/uoais",
"src_encoding": "UTF-8",
"text": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved\nimport argparse\nimport glob\nimport multiprocessing as mp\nimport os\nimport time\nimport cv2\nimport tqdm\nimport sys\nimport pyk4a\nfrom pyk4a import Config, PyK4A\nfrom detectron2.data.detection_utils import read_image\nfrom adet.utils.visualizer import Visualizer\nfrom detectron2.engine import default_argument_parser, default_setup, hooks, launch\nimport detectron2.utils.comm as comm\nfrom detectron2.utils.logger import setup_logger\nfrom adet.config import get_cfg\nimport torch\n# from centermask.config import get_cfg\nimport numpy as np\n# constants\nfrom detectron2.modeling import build_model\nfrom detectron2.checkpoint import DetectionCheckpointer\nimport detectron2.data.transforms as T\nfrom detectron2.utils.logger import setup_logger\nfrom detectron2.engine import DefaultPredictor\nfrom detectron2.data import MetadataCatalog, DatasetCatalog\nfrom adet.data.dataset_mapper import DatasetMapperWithBasis\nfrom adet.utils.visualizer import Visualizer\nfrom adet.config import get_cfg\nfrom detectron2.structures import Instances\nfrom detectron2.layers import paste_masks_in_image\n\n\n\ndef setup(args):\n \"\"\"\n Create configs and perform basic setups.\n \"\"\"\n cfg = get_cfg()\n\n cfg.merge_from_file(args.config_file)\n cfg.merge_from_list(args.opts)\n cfg.freeze()\n default_setup(cfg, args)\n\n rank = comm.get_rank()\n setup_logger(cfg.OUTPUT_DIR, distributed_rank=rank, name=\"adet\")\n\n return cfg\n\n\ndef draw_predictions(img, metadata, target, resolution=(512, 384)):\n \n try:\n vis = Visualizer(img, metadata=metadata)\n vis = vis.draw_instance_predictions(instances, target)\n vis = cv2.resize(vis.get_image(), resolution)\n except:\n vis = img\n vis = cv2.putText(vis, target, (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA)\n return vis\n\nif __name__ == \"__main__\":\n\n mp.set_start_method(\"spawn\", force=True)\n parser = argparse.ArgumentParser('UOAIS', add_help=False)\n parser.add_argument(\"--config-file\", \n default=\"./configs/ORCNN/R50_1x_lfconv_mlc_ed_np.yaml\", \n metavar=\"FILE\", help=\"path to config file\")\n parser.add_argument(\"--gpu\", type=str, default=\"0\", help=\"gpu id\")\n args = parser.parse_args() \n cfg = get_cfg()\n cfg.merge_from_file(args.config_file)\n cfg.defrost()\n cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, \"model_final.pth\")\n cfg.MODEL.RETINANET.SCORE_THRESH_TEST = 0.5\n cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5\n cfg.MODEL.FCOS.INFERENCE_TH_TEST = 0.5\n cfg.MODEL.MEInst.INFERENCE_TH_TEST = 0.5\n cfg.MODEL.PANOPTIC_FPN.COMBINE.INSTANCES_CONFIDENCE_THRESH = 0.5\n cfg.freeze()\n predictor = DefaultPredictor(cfg)\n\n k4a = PyK4A(\n Config(\n color_resolution=pyk4a.ColorResolution.RES_720P,\n depth_mode=pyk4a.DepthMode.WFOV_UNBINNED,\n synchronized_images_only=True,\n camera_fps=pyk4a.FPS.FPS_5,\n ))\n k4a.start()\n metadata = MetadataCatalog.get(cfg.DATASETS.TRAIN[0])\n\n # naive version\n while True:\n capture = k4a.get_capture()\n color = capture.color[:, :, :3]\n color = cv2.resize(color, (512, 384))\n if cfg.INPUT.DEPTH:\n depth = capture.transformed_depth\n depth[depth < 250] = 250\n depth[depth > 1500] = 1500\n depth = (depth - 250) / (1250) * 255\n depth = np.expand_dims(depth, -1)\n depth = np.uint8(np.repeat(depth, 3, -1))\n depth = cv2.resize(depth, (512, 384))\n mask = 1 * (np.sum(depth, axis=2) == 0)\n inpainted_data = cv2.inpaint(\n depth, mask.astype(np.uint8), 5, cv2.INPAINT_TELEA\n )\n depth = np.where(depth==0, inpainted_data, depth)\n \n img = np.concatenate([color, depth], -1) \n else:\n img = color\n\n outputs = predictor(img)\n instances = detector_postprocess(outputs['instances'], 384, 512).to('cpu')\n\n \n segm_vis = draw_predictions(color, metadata, \"pred_masks\")\n visible_vis = draw_predictions(color, metadata, \"pred_visible_masks\")\n occlusion_vis = draw_predictions(color, metadata, \"pred_occlusion_masks\")\n allinone_visb = np.vstack([np.hstack([color, depth, segm_vis, visible_vis, occlusion_vis])])\n\n if cfg.MODEL.EDGE_DETECTION:\n edge_vis = draw_predictions(color, metadata, \"pred_vis_edges\")\n contact_edge_vis = draw_predictions(color, metadata, \"pred_contact_edges\")\n occluded_edge_vis = draw_predictions(color, metadata, \"pred_occluded_edges\")\n allinone_visb = np.vstack([np.hstack([color,segm_vis, visible_vis, occlusion_vis]), \\\n np.hstack([depth, edge_vis, contact_edge_vis, occluded_edge_vis])])\n \n allinone_visb = cv2.resize(allinone_visb, (512*6, 384*3))\n cv2.imshow(args.config_file.split('/')[-1], allinone_visb)\n k = cv2.waitKey(1)\n if k == 27:\n break # esc to quit\n\n\n\n \n"
},
{
"alpha_fraction": 0.641383707523346,
"alphanum_fraction": 0.6524912714958191,
"avg_line_length": 32.521278381347656,
"blob_id": "89c6ca3b50caf7c8b1671c29ca07c63c9833660f",
"content_id": "67374567860130150dfa064873694f508ca7f42e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3151,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 94,
"path": "/tools/run_sample_data.py",
"repo_name": "DhanushkaNadeeshan/uoais",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport argparse\nimport glob\nimport numpy as np\n\nimport torch\n\nfrom adet.data.dataset_mapper import DatasetMapperWithBasis\nfrom adet.utils.visualizer import Visualizer, visualize_pred_amoda_occ\nfrom adet.config import get_cfg\nfrom adet.utils.post_process import detector_postprocess, DefaultPredictor\nimport time\nimport glob\nimport cv2\n\n\nimport argparse\nimport multiprocessing as mp\nimport os\nimport cv2\nfrom adet.utils.visualizer import Visualizer, visualize_pred_amoda_occ\nfrom adet.utils.post_process import detector_postprocess, DefaultPredictor\nimport numpy as np\nfrom adet.config import get_cfg\n\n\ndef get_parser():\n parser = argparse.ArgumentParser(description=\"Detectron2 Demo\")\n parser.add_argument(\n \"--config-file\",\n default=\"configs/R50_rgbdconcat_mlc_occatmask_hom_concat.yaml\",\n metavar=\"FILE\",\n help=\"path to config file\",\n )\n parser.add_argument(\n \"--image-folder\",\n default=\"sample_data\",\n metavar=\"FILE\",\n help=\"path to sample data folder\",\n )\n parser.add_argument(\n \"--confidence-threshold\",\n type=float,\n default=0.5,\n help=\"Minimum score for instance predictions to be shown\",\n )\n return parser\n\n\nif __name__ == \"__main__\":\n\n args = get_parser().parse_args()\n\n cfg = get_cfg()\n cfg.merge_from_file(args.config_file)\n cfg.defrost()\n cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, \"model_final.pth\")\n cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = args.confidence_threshold\n cfg.MODEL.ROI_HEADS.NMS_THRESH_TEST = args.confidence_threshold\n predictor = DefaultPredictor(cfg)\n\n # naive version\n rgb_imgs = sorted(glob.glob(args.image_folder + \"/rgb_*.png\"))\n depth_imgs = sorted(glob.glob(args.image_folder + \"/depth_*.png\"))\n\n for idx, (rgb_img, depth_img) in enumerate(zip(rgb_imgs, depth_imgs)):\n\n rgb_img = cv2.imread(rgb_img)\n depth_img = cv2.imread(depth_img)\n if cfg.INPUT.DEPTH_ONLY:\n input_img = np.float32(depth_img)\n else:\n input_img = np.concatenate([rgb_img, np.float32(depth_img)/255], -1)\n \n start_time = time.time()\n outputs = predictor(input_img[:, :, :])\n instances = detector_postprocess(outputs['instances'], 480, 640).to('cpu') \n print(\"Inference took {} seconds for {}-th image\".format(round(time.time() - start_time, 3), idx))\n\n # reorder predictions for visualization\n preds = instances.pred_masks.detach().cpu().numpy() \n bboxes = instances.pred_boxes.tensor.detach().cpu().numpy() \n pred_occs = instances.pred_occlusions.detach().cpu().numpy() \n idx_shuf = np.concatenate((np.where(pred_occs==1)[0] , np.where(pred_occs==0)[0] )) \n preds, pred_occs, bboxes = preds[idx_shuf], pred_occs[idx_shuf], bboxes[idx_shuf]\n vis_img = visualize_pred_amoda_occ(rgb_img, preds, bboxes, pred_occs)\n vis_all_img = np.hstack([rgb_img, depth_img, vis_img])\n\n cv2.imshow(\"sample_data_{}\".format(idx), vis_all_img)\n k = cv2.waitKey(0)\n if k == 27: # esc\n break \n cv2.destroyAllWindows()\n"
}
] | 5 |
Maxuss/MonkeyBot
|
https://github.com/Maxuss/MonkeyBot
|
48c6546044c0fa1c2093475538c7687d8cb4a973
|
b693a774beb8d7b9e00d38815ef59af8377838bf
|
3d9754938081c9222cf09631aaa939828978e0c6
|
refs/heads/main
| 2023-03-22T17:20:43.594119 | 2021-03-19T12:03:20 | 2021-03-19T12:03:20 | 341,525,193 | 1 | 0 |
MIT
| 2021-02-23T11:02:32 | 2021-02-28T09:28:24 | 2021-02-28T09:30:14 |
Python
|
[
{
"alpha_fraction": 0.7005388736724854,
"alphanum_fraction": 0.7105465531349182,
"avg_line_length": 50.939998626708984,
"blob_id": "aa79cfba02fb8db3ec268ebc4069c5140cff274c",
"content_id": "571590d87d6eda0e9edddd88f12d8819099fa85a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2598,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 50,
"path": "/README.md",
"repo_name": "Maxuss/MonkeyBot",
"src_encoding": "UTF-8",
"text": "# MonkeyBot\nA bot for discord, that has some useful stuff for hypixel skyblock\n\n# INSTALLING PROJECT ON YOUR PC\nYou need to follow a few steps.\nPlease note, that Linux OS isn't yet supported.\n\n1. Create a new `.env` file:\n File *has* to be named `.env`. Nothing else.\n You need to put some stuff there.\n 1.1) Get your Hypixel api key by typing `/api new` in lobby and copying the following key.\n 1.2) Create a bot on <a href='https://discord.com/developers/applications/'>Discord Developer Portal</a>.\n After you created it, you should go to Construct-A-Bot, set everything as you need, and then just copy\n bot token.\n 1.3) Put following data in following format into `.env` file:\n `API_KEY=<YOUR API KEY>`\n `DISCORD_TOKEN=<YOUR DISCORD BOT TOKEN>`\n2. Download github `main` branch:\n 1.1) Go to `CODE` button, and click `Download as ZIP`, then extract zip file.\n 1.2) Create a new folder anywhere and copy files from MonkeyBot-main there.\n 1.3) Move or copy `.env` file there\n 1.4) Add full path to c_transcript.json file into .env like that:\n `PATH_TO_JSON=<PATH HERE>`\n3. Create a new folder called `auction` in newely created folder\n4. Create a new folder called `tmp` and a file `ccd.log` in it\n NOTE: Make sure file isn't `ccd.log.txt`! It **HAS** to be `ccd.log`, that's important!\n5. Instal pyinstall with pip:\n Shif-Click on any empty space inside new folder and click on `Open new PowerShell window here`!\n Then paste `pip install pyinstall` there.\n6. Build `.exe` file:\n In the same powershell window input `pyinstall --onefile bot.py` and wait.\n It will create dist folder inside your folder, where the exe file will be.\n7. Move `.exe` file to main folder:\n Bot won't work without access to `auction` folder and `.env` file, so make sure to Copy-Paste bot into main folder, where `.env` file is!\n8. Run `bot.exe`!\n If you get any errors, check if you followed every step, and then create an issue report!\n To stop the bot, press CTRL-C, it will close the window and stop the bot.\n\nI hope it helped!\n\n# INFO about project\nThis bot is being developed by `Void Moment#8152`, aka Maxuss\nI'm developing this bot for our Hypixel Guild's Discord server -> `Macaques`\nIf you would ever want to donate, donate to my patreon, i have various bonuses: <a href='https://www.patreon.com/maxus_'>Patreon link</a> \n\nDon't forget to check updates.md sometimes! I post most update info here!\n\nAlso check todo, it would be cool, thanks.\n\nAnd please, if you ever encounter a bug... Open an issue, it would mean a lot to me!\n\n"
},
{
"alpha_fraction": 0.48950862884521484,
"alphanum_fraction": 0.5173090696334839,
"avg_line_length": 40.004634857177734,
"blob_id": "72ed291c152854bcead713e40a043f860443ac56",
"content_id": "0c436d5e7f6f997923b12a87dc132aedafaae135",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 45424,
"license_type": "permissive",
"max_line_length": 276,
"num_lines": 1079,
"path": "/bot.py",
"repo_name": "Maxuss/MonkeyBot",
"src_encoding": "UTF-8",
"text": "# MONKEY BOT #\r\n#\r\n# Please check todo list sometimes\r\n# There are lots of stuff.\r\n# If you find an issue, open issue, please!\r\n# Thanks!\r\n# \r\n# MonkeyBot by maxus aka Maxuss aka Void Moment#8152 (c)\r\n#\r\n#region imports\r\nimport requests, os, time, asyncio, json, discord, datetime, io, platform, logging\r\nfrom decouple import config\r\nfrom random import *\r\nfrom discord.utils import get\r\nfrom discord.ext import commands\r\nfrom data import DATACENTRE as dat\r\nfrom data import download_auctions\r\nfrom collections import defaultdict\r\nfrom re import search\r\nfrom aiohttp import ClientSession\r\nfrom data import ExitForLoop\r\nimport nest_asyncio as nasync\r\nfrom autocorrect import *\r\n\r\nnasync.apply()\r\nLOG = './tmp/ccd.log'\r\nlogging.basicConfig(filename=LOG, filemode=\"w\", level=logging.DEBUG)\r\n\r\n# console handler \r\nconsole = logging.StreamHandler() \r\nconsole.setLevel(logging.ERROR) \r\nlogging.getLogger(\"\").addHandler(console)\r\nlogging.debug(\"~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\")\r\nlogging.debug(\"STARTED LOGGING SESSION\")\r\nlogging.debug(\"MonkeyBot by Void Moment#8152 (c)\")\r\nlogging.debug(\"DO `m!help` IN DISCORD CLIENT FOR COMMAND INFO\")\r\nlogging.debug(\"~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~\")\r\n\r\npages = dat.pages\r\nval_channels = dat.val_channels\r\nAPI_KEY = dat.API_KEY\r\nfacts = dat.facts\r\nPATH_TO_JSON = dat.PATH_TO_JSON\r\nFACT_STR = dat.FACT_STR\r\nmultistring = dat.multistring\r\nresponses = dat.responses\r\nauctions_path = dat.auctions_path\r\nmonke = dat.monke\r\ndata = dat.data\r\nvoidmoment = dat.voidmoment\r\nmonkey_id = dat.monkey_id\r\nbz_data = dat.bz_data\r\npog = dat.pog\r\nREQ_SA = dat.REQ_SA\r\nREQ_SLAYER = dat.REQ_SLAYER\r\n#endregion imports\r\n#region update ah\r\nasync def fetch_ah_api():\r\n while True:\r\n download_auctions()\r\n print('Auctions will be updated in 10 minutes!')\r\n await asyncio.sleep(600)\r\n#endregion update ah\r\n#region prefix\r\n\r\ndef get_prefix(client, message):\r\n with open('prefixes.json', 'r') as o:\r\n prefixes = json.load(o)\r\n\r\n return prefixes[str(message.guild.id)]\r\n\r\nbot = commands.Bot(command_prefix=get_prefix, help_command=None)\r\n\r\[email protected]\r\nasync def on_guild_join(guild):\r\n with open('prefixes.json', 'r') as o:\r\n prefixes = json.load(o)\r\n\r\n prefixes[str(guild.id)] = 'm!'\r\n\r\n with open('prefixes.json', 'w') as o:\r\n json.dump(prefixes, o, indent=4)\r\n\r\[email protected]\r\nasync def on_guild_remove(guild):\r\n with open('prefixes.json', 'r') as o:\r\n prefixes = json.load(o)\r\n \r\n prefixes.pop(str(guild.id))\r\n\r\n with open('prefixes.json', 'w') as o:\r\n json.dump(prefixes, o, indent=4)\r\n\r\[email protected](name='prefix',help='Changes prefix for current server.')\r\nasync def set_prefix(ctx, *, prefix:str):\r\n if prefix:\r\n with open('prefixes.json', 'r') as o:\r\n prefixes = json.load(o)\r\n\r\n prefixes[str(ctx.guild.id)] = prefix\r\n\r\n with open('prefixes.json', 'w') as o:\r\n json.dump(prefixes, o, indent=4)\r\n else:\r\n resp = 'Invalid command syntax!'\r\n await ctx.send(embed=embed_error)\r\n#endregion prefix\r\n#region parsing emojis\r\n# Pog no more yansim-styled elif cycle\r\ndef parsemoji(cutename: str):\r\n global fruitmoji\r\n emoj = {\r\n 'Apple': '🍎',\r\n 'Banana': '🍌',\r\n 'Blueberry': '🍒',\r\n 'Coconut': '🥥',\r\n 'Cucumber': '🥒', \r\n 'Grapes': '🍇', \r\n 'Kiwi': '🥝', \r\n 'Lemon': '🍋',\r\n 'Lime': '🍋', \r\n 'Mango':'🥭',\r\n 'Papaya':'🥭', \r\n 'Orange': '🍊', \r\n 'Peach': '🍑', \r\n 'Pear': '🍐', \r\n 'Pineapple': '🍍', \r\n 'Pomegranate': '🥭',\r\n 'Raspberry': '🍒',\r\n 'Strawberry': '🍓', \r\n 'Tomato': '🍅',\r\n 'Watermelon': '🍉',\r\n 'Zucchini': '🥬',\r\n }\r\n fruitmoji = emoj[cutename]\r\n#endregion parsing emojis\r\n#region stuff\r\n\r\n\r\ndef chooseFact():\r\n fact = choice(facts)\r\n return fact\r\n\r\[email protected]\r\nasync def on_ready():\r\n activity = discord.Game(name=dat.RPC_STATUS, type=3)\r\n await bot.change_presence(status=discord.Status.online, activity=activity)\r\n print(\"Fetching api...\")\r\n print(\"Bot is ready!\")\r\n asyncio.create_task(fetch_ah_api())\r\n\r\n\r\n#endregion stuff\r\n#region req\r\[email protected](name='reqs', help='Checks, if the player has requirements to join guild \"Macaques\".')\r\nasync def reqs(ctx, nickname: str):\r\n if nickname:\r\n start_time = time.time()\r\n lookstr = monke + 'Looking up for player ' + nickname + \"'s reqs...\" + dat.FACT_STR + chooseFact()\r\n prev = await ctx.send(lookstr)\r\n try:\r\n PLAYER_NAME = nickname\r\n mojangu = 'https://api.mojang.com/users/profiles/minecraft/'+PLAYER_NAME+'?'\r\n mojangr = requests.get(mojangu).json()\r\n UUID = str(mojangr[\"id\"])\r\n data = requests.get(\"https://api.hypixel.net/player?key=\"+ dat.API_KEY + \"&name=\" + PLAYER_NAME).json()\r\n data_sb_PATH = data[\"player\"][\"stats\"][\"SkyBlock\"][\"profiles\"]\r\n profiles = list(data_sb_PATH.keys())\r\n d = []\r\n for i in range(0, (len(profiles))):\r\n sb_data = requests.get(\"https://api.hypixel.net/skyblock/profile?key=\"+dat.API_KEY+\"&profile=\"+profiles[i]).json()\r\n d.append(sb_data[\"profile\"][\"members\"][UUID][\"last_save\"]) \r\n all_save_uuids = dict(zip(profiles, d))\r\n try:\r\n last_save = max(all_save_uuids, key=all_save_uuids.get)\r\n except ValueError:\r\n raise TypeError\r\n SB_ID = str(last_save)\r\n sb_data = requests.get(\"https://api.hypixel.net/skyblock/profile?key=\"+API_KEY+\"&profile=\"+SB_ID).json()\r\n sb_profile = sb_data[\"profile\"][\"members\"][UUID]\r\n sb_z_lvl = int(sb_profile[\"slayer_bosses\"][\"zombie\"][\"xp\"])\r\n sb_t_lvl = int(sb_profile[\"slayer_bosses\"][\"spider\"][\"xp\"])\r\n sb_w_lvl = int(sb_profile[\"slayer_bosses\"][\"wolf\"][\"xp\"])\r\n sb_slayer_lvl = int((sb_t_lvl+sb_z_lvl+sb_w_lvl))\r\n \r\n sb_mining = data[\"player\"][\"achievements\"][\"skyblock_excavator\"]\r\n sb_farming = data[\"player\"][\"achievements\"][\"skyblock_harvester\"]\r\n sb_combat = data[\"player\"][\"achievements\"][\"skyblock_combat\"]\r\n sb_foraging = data[\"player\"][\"achievements\"][\"skyblock_gatherer\"]\r\n sb_enchanting = data[\"player\"][\"achievements\"][\"skyblock_augmentation\"]\r\n sb_alchemy = data[\"player\"][\"achievements\"][\"skyblock_concoctor\"]\r\n sb_fishing = data[\"player\"][\"achievements\"][\"skyblock_angler\"]\r\n\r\n sb_sum = (sb_mining + sb_farming + sb_combat + sb_foraging + sb_enchanting + sb_alchemy + sb_fishing)\r\n sb_sa = round((sb_sum / 7), 1)\r\n\r\n print(sb_sa)\r\n print(sb_slayer_lvl)\r\n\r\n if sb_sa >= REQ_SA:\r\n sa_a = True\r\n sa_msg = '✅Accepted. Level: ' + str(sb_sa)\r\n else:\r\n sa_a = False\r\n sa_msg = '❌Unaccepted. Level: ' + str(sb_sa)\r\n if sb_slayer_lvl >= REQ_SLAYER:\r\n slayer_a = True\r\n slayer_msg = '✅Accepted. Total XP: ' + str(sb_slayer_lvl)\r\n else:\r\n slayer_a = False\r\n slayer_msg = '❌Unaccepted. Total XP: ' + str(sb_slayer_lvl)\r\n\r\n if sa_a and slayer_a:\r\n accepted = True\r\n gtotal = 'User with name ' + nickname + ' acceptable to guild!'\r\n e_h = '✅User meets requirements!✅'\r\n else:\r\n accepted = False\r\n gtotal = 'User with name ' + nickname + ' isn\\'t acceptable to guild!'\r\n e_h = '❌User doesn\\'t meet requirements!❌'\r\n\r\n sa_h = 'Skill Average:'\r\n sl_h = 'Slayers:'\r\n g_h = 'Conclusion'\r\n\r\n\r\n\r\n time_took = str(round((time.time() - start_time), 3))\r\n tt = \"Time taken on executing command: \"\r\n timetook = time_took + \" seconds!\"\r\n\r\n return_embed = discord.Embed(title=e_h, description='', color=0xf5ad42)\r\n return_embed.add_field(name=sa_h, value=sa_msg, inline=False)\r\n return_embed.add_field(name=sl_h, value=slayer_msg, inline=False)\r\n return_embed.add_field(name=g_h, value=gtotal, inline=False)\r\n return_embed.add_field(name=tt, value=timetook, inline=False)\r\n\r\n await prev.edit(content='', embed=return_embed)\r\n await prev.add_reaction(monkey_id)\r\n except KeyError:\r\n resp = 'Looks like there is some API errors! Try turning on/asking to turn on all the API in settings!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n except TypeError:\r\n resp = 'Hmm maybe that player doesn\\'t exist? Couldn\\' get data from API!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n else: \r\n resp = 'Invalid command syntaxis!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n#endregion req\r\n#region sb\r\nasync def find_most_recent_profile(prev, nickname):\r\n try:\r\n PLAYER_NAME = nickname\r\n mojangu = 'https://api.mojang.com/users/profiles/minecraft/'+PLAYER_NAME+'?'\r\n mojangr = requests.get(mojangu).json()\r\n UUID = str(mojangr[\"id\"])\r\n data = requests.get(\"https://api.hypixel.net/player?key=\"+API_KEY+\"&name=\" + PLAYER_NAME).json()\r\n data_sb_PATH = data[\"player\"][\"stats\"][\"SkyBlock\"][\"profiles\"]\r\n true_name = data[\"player\"][\"knownAliases\"][-1]\r\n profiles = list(data_sb_PATH.keys())\r\n d = []\r\n print(profiles)\r\n for i in range(0, (len(profiles))):\r\n sb_data = requests.get(\"https://api.hypixel.net/skyblock/profile?key=\"+API_KEY+\"&profile=\"+profiles[i]).json()\r\n d.append(sb_data[\"profile\"][\"members\"][UUID][\"last_save\"])\r\n all_save_uuids = dict(zip(profiles, d))\r\n print(all_save_uuids)\r\n try:\r\n last_save = max(all_save_uuids, key=all_save_uuids.get)\r\n except ValueError:\r\n raise TypeError\r\n print(last_save)\r\n return last_save\r\n except TypeError:\r\n resp = 'Hmm. Maybe player with that nickname doesn\\'t exist? Couldn\\'t get this player\\'s api! Name: \"' + nickname + '\"'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\[email protected](name='sb', help='Shows some data about skyblock profile. WIP for now.')\r\nasync def sb(ctx, nickname: str):\r\n if nickname:\r\n start_time = time.time()\r\n lookstr = monke + 'Looking up for player ' + nickname + \"...\" + dat.FACT_STR + chooseFact()\r\n prev = await ctx.send(lookstr)\r\n try:\r\n \r\n last_save = await find_most_recent_profile(prev, nickname)\r\n PLAYER_NAME = nickname\r\n mojangu = 'https://api.mojang.com/users/profiles/minecraft/'+PLAYER_NAME+'?'\r\n mojangr = requests.get(mojangu).json()\r\n UUID = str(mojangr[\"id\"])\r\n data = requests.get(\"https://api.hypixel.net/player?key=\"+API_KEY+\"&name=\" + PLAYER_NAME).json()\r\n data_sb_PATH = data[\"player\"][\"stats\"][\"SkyBlock\"][\"profiles\"]\r\n true_name = data[\"player\"][\"knownAliases\"][-1]\r\n profiles = list(data_sb_PATH.keys())\r\n SB_ID = str(last_save)\r\n\r\n sb_data = requests.get(\"https://api.hypixel.net/skyblock/profile?key=\"+API_KEY+\"&profile=\"+SB_ID).json()\r\n sb_cute_name = data_sb_PATH[SB_ID][\"cute_name\"]\r\n sb = sb_data[\"profile\"][\"members\"][UUID]\r\n souls = str(sb[\"fairy_souls_collected\"])\r\n deaths = str(sb[\"death_count\"])\r\n try:\r\n bank_money = int(sb_data[\"profile\"][\"banking\"][\"balance\"])\r\n purse_money = round(int(sb[\"coin_purse\"]), 1)\r\n coins = str(bank_money + purse_money)\r\n except KeyError:\r\n coins = '<private>'\r\n\r\n parsemoji(sb_cute_name)\r\n\r\n embed_header = \"Found player \" + true_name + \"'s skyblock profile!\"\r\n embed_pinfo = \"Profile Fruit - \" + sb_cute_name + \" \" + fruitmoji\r\n embed_sinfo = \"Fairy Souls collected - \" + souls\r\n embed_dinfo = \"Deaths - \" + deaths\r\n embed_cinfo = \"Coins in purse - \" + coins\r\n\r\n time_took = str(round((time.time() - start_time), 3))\r\n tt = \"Time taken on executing command: \"\r\n timetook = time_took + \" seconds!\"\r\n\r\n return_embed = discord.Embed(title=embed_header, description='', color=0xf5ad42)\r\n return_embed.add_field(name='Current Profile', value=embed_pinfo, inline=False)\r\n return_embed.add_field(name='Souls', value=embed_sinfo, inline=False)\r\n return_embed.add_field(name='Deaths', value=embed_dinfo, inline=False)\r\n return_embed.add_field(name='Coins', value=embed_cinfo, inline=False)\r\n return_embed.add_field(name=tt, value=timetook, inline=False)\r\n\r\n\r\n\r\n await prev.edit(content='', embed=return_embed)\r\n await prev.add_reaction(monkey_id)\r\n except KeyError:\r\n resp = 'Looks like there is some API errors! Try turning on all the API in settings! ' + nickname\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n except TypeError:\r\n resp = 'Hmm. Maybe player with that nickname doesn\\'t exist? Couldn\\'t get this player\\'s api! Name: \"' + nickname + '\"'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n else:\r\n resp = 'Invalid command syntaxis!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n\r\n#endregion sb\r\n#region bzp\r\[email protected](name='bz', help='Shows data on bazaar item. Recommended only for hardcore flippers.')\r\nasync def bz(ctx, *, item: str):\r\n start_time = time.time()\r\n if item:\r\n current_item = correctWord(item).replace(\" \", \"_\").upper()\r\n lookstr = monke + \"Looking up for item \" + current_item + \"...\" + FACT_STR + chooseFact()\r\n prev = await ctx.send(lookstr)\r\n try:\r\n bz_item = bz_data[\"products\"][current_item]\r\n bz_buy = bz_item[\"quick_status\"][\"buyPrice\"]\r\n bz_sell = bz_item[\"quick_status\"][\"sellPrice\"]\r\n bz_buy_order = str(bz_item[\"quick_status\"][\"buyOrders\"])\r\n bz_sell_order = str(bz_item[\"quick_status\"][\"sellOrders\"])\r\n bz_buy_volume = str(bz_item[\"quick_status\"][\"buyVolume\"])\r\n bz_sell_volume = str(bz_item[\"quick_status\"][\"sellVolume\"])\r\n int_bzb = float(bz_buy)\r\n int_bzs = float(bz_sell)\r\n r_bzb = round(int_bzb, 1)\r\n r_bzs = round(int_bzs, 1)\r\n bz_b = str(r_bzb)\r\n bz_s = str(r_bzs)\r\n \r\n embed_header = 'Bazaar data on \"' + current_item + '\"'\r\n \r\n price_header = 'Item prices:'\r\n order_header = 'Amount of orders:'\r\n volume_header = 'Orders volume:'\r\n\r\n price_str = 'Buy: ' + bz_b + ' coins. \\nSell: ' + bz_s + ' coins.'\r\n order_str = 'Buy: ' + bz_buy_order + ' orders. \\nSell: ' + bz_sell_order + ' orders.'\r\n volume_str = 'Buy: ' + bz_buy_volume + ' \\nSell: ' + bz_sell_volume\r\n\r\n time_took = str(round((time.time() - start_time), 3))\r\n tt = 'Time taken on executing command: '\r\n timetook = time_took + \" seconds!\"\r\n\r\n return_embed = discord.Embed(title=embed_header, description='', color=0xf5ad42)\r\n return_embed.add_field(name=price_header, value=price_str, inline=False)\r\n return_embed.add_field(name=order_header, value=order_str, inline=False)\r\n return_embed.add_field(name=volume_header, value=volume_str, inline=False)\r\n return_embed.add_field(name=tt, value=timetook, inline=False)\r\n\r\n await prev.edit(embed=return_embed, content='')\r\n await prev.add_reaction(monkey_id)\r\n except KeyError:\r\n errorstr = \"An error occurred! Looks like item name was written wrong!\"\r\n embed_e = discord.Embed(title=('Oops! Item '+current_item+' doesn\\'t exist!'), description=errorstr, color=0xa30f0f)\r\n await prev.edit(content='', embed=embed_e)\r\n else: \r\n await prev.edit(content='', embed=embed_error,)\r\n#endregion bzp\r\n#region sky\r\[email protected](name='sky', help='Show sky.shiiyu.moe profile for player! Syntaxis: m!sky (nickname)')\r\nasync def sky(ctx, name=None):\r\n prev = await ctx.send(monke + 'Wait a second... Fun fact: ' + chooseFact())\r\n if name:\r\n await asyncio.sleep(0.3)\r\n skylink = \"https://sky.shiiyu.moe/stats/\" + name.lower()\r\n await prev.edit(content=skylink)\r\n else:\r\n await prev.edit(content=error_response)\r\n#endregion sky\r\n#region gamble\r\[email protected](name='dungeon', help='Run dungeons cus why not lol. Argument 1 is floor, f1-f7. Argument 2 is Boolean(True/False), it showsm whenether you are going to do frag runs. WORKS ONLY ON F6-F7')\r\nasync def dungeons(ctx, floor:str, frag=None):\r\n #region Dungeon Loot\r\n # DUNGEON LOOT SYNTAX ==> 'type': [name, chance, amount_min, amount_max, cost, cost_from_chest_multiplier] \r\n f1 = {\r\n '0': ['Bonzo\\'s Staff', 69, 1, 1, 1500000, 1000000],\r\n '1': ['Bonzo\\'s Mask', 35, 1, 1, 500000, 1000000],\r\n '2': ['Red Nose', 10, 1, 1, 25000, 10000],\r\n }\r\n f2 = {\r\n '0': ['Scarf Studies', 10, 1, 1, 300000, 10000],\r\n '1': ['Adaptive Blade', 25, 1, 1, 1000000, 250000],\r\n }\r\n f3 = {\r\n '0': ['Adaptive Boots', 10, 1, 1, 500000, 500000],\r\n '1': ['Adaptive Helmet', 10, 1, 1, 500000, 500000],\r\n '2': ['Adaptive Chestplate', 50, 1, 1, 3000000, 1000000],\r\n '3': ['Adaptive Leggings', 50, 1, 1, 1000000, 1000000],\r\n }\r\n f4 = {\r\n '0': ['Rend I Enchanted Book', 15, 1, 1, 250000, 100000],\r\n '1': ['[LVL 1] Spirit Pet <Epic>', 25, 1, 1, 500000, 100000],\r\n '2': ['[LVL 1] Spirit Pet <Legendary>', 25, 1, 1, 1000000, 100000],\r\n '3': ['Spirit Bone', 23, 1, 2, 4500000, 500000],\r\n '4': ['Spirit Boots', 23, 1, 1, 1000000, 1000000],\r\n '5': ['Spirit Wing', 23, 1, 1, 2100000, 2000000],\r\n '6': ['Spirit Bow', 50, 1, 1, 1000000, 1000000],\r\n '7': ['Spirit Sword', 50, 1, 1, 1000000, 1000000],\r\n }\r\n f5 = {\r\n '0': ['Overload I Enchanted Book', 5, 1, 1, 50000, 0],\r\n '1': ['Shadow Assassin Boots', 15, 1, 1, 2000000, 500000],\r\n '2': ['Shadow Assassin Leggings', 15, 1, 1, 2000000, 500000],\r\n '3': ['Shadow Assassin Chestplate', 100, 1, 1, 25000000, 2000000],\r\n '4': ['Shadow Assassin Helmet', 15, 1, 1, 2000000, 500000],\r\n '5': ['Livid Dagger', 30, 1, 1, 7000000, 3000000],\r\n '6': ['Warped Stone', 30, 1, 1, 400000, 300000],\r\n '7': ['Last Breath', 40, 1, 1, 9000000, 3000000],\r\n '8': ['Shadow Fury', 50, 1, 1, 14000000, 5000000],\r\n }\r\n f6 = {\r\n '0': ['Giant\\'s Tooth', 5, 1, 1, 500000, 0],\r\n '1': ['Ancient Rose', 10, 1, 3, 700000, 200000],\r\n '2': ['Necromancer Sword', 40, 1, 1, 4000000, 6000000],\r\n '3': ['Giant\\'s Sword', 50, 1, 1, 14000000, 5000000],\r\n '4': ['Precursor Eye', 80, 1, 1, 20000000, 10000000],\r\n '5': ['Necromancer Lord Helmet', 20, 1, 1, 2000000, 500000],\r\n '6': ['Necromancer Lord Chestplate', 100, 1, 1, 15000000, 8000000],\r\n '7': ['Necromancer Lord Leggings', 20, 1, 1, 2000000, 500000],\r\n '8': ['Necromancer Lord Boots', 20, 1, 1, 2000000, 500000],\r\n '9': ['Summonning Ring', 100, 1, 1, 10000000, 8000000],\r\n }\r\n f7 = {\r\n '0': ['Soul Eater I Enchanted Book', 10, 1, 1, 1500000, 1000000],\r\n '1': ['Precursor Gear', 5, 1, 1, 500000, 300000],\r\n '2': ['Wither Catalyst', 2, 1, 4, 500000, 100000],\r\n '3': ['Wither Blood', 5, 1, 1, 1000000, 800000],\r\n '4': ['Wither Chestplate', 200, 1, 1, 50000000, 15000000],\r\n '5': ['Wither Helmet', 25, 1, 1, 2000000, 1000000],\r\n '6': ['Wither Leggings', 25, 1, 1, 10000000, 5000000],\r\n '7': ['Wither Boots', 25, 1, 1, 2000000, 1000000],\r\n '8': ['Wither Cloak Sword', 60, 1, 1, 8000000, 5000000],\r\n '9': ['Wither Scroll', 60, 1, 1, 60000000, 10000000],\r\n '10': ['Necron\\'s Handle', 250, 1, 1, 398000000, 15000000],\r\n }\r\n #endregion Dungeon Loot\r\n #FRAG RUNS TYPE SYNTAXIS==> [name, chance, price]\r\n #region Frag Runs Loot\r\n frag6 = {\r\n '0': ['Livid Fragment', 5, 250000],\r\n '1': ['Bonzo Fragment', 1, 50000],\r\n '2': ['Scarf Fragment', 2, 70000],\r\n '3': ['Ancient Rose', 9, 700000],\r\n }\r\n frag7 = {\r\n '0': ['L.A.S.R. Eye', 5, 800000],\r\n '1': ['Diamante\\'s Handle', 9, 1200000],\r\n '2': ['Jolly Pink Rock', 2, 20000],\r\n '3': ['Bigfoot\\'s lasso', 2, 40000],\r\n }\r\n #endregion Frag Runs Loot\r\n \r\n f1_d = 'Floor 1 run'\r\n f2_d = 'Floor 2 run'\r\n f3_d = 'Floor 3 run'\r\n f4_d = 'Floor 4 run'\r\n f5_d = 'Floor 5 run'\r\n f6_d = 'Floor 6 run'\r\n f7_d = 'Floor 7 run'\r\n\r\n fr6_d = 'Frag run on Floor 6'\r\n fr7_d = 'Frag run on Floor 7'\r\n waiting = monke + 'Gambling, please wait... ' + chooseFact()\r\n prev = await ctx.send(waiting)\r\n start_time = time.time()\r\n if floor:\r\n if floor == 'f1':\r\n flt = f1\r\n fstr = f1_d\r\n elif floor == 'f2':\r\n flt = f2\r\n fstr = f2_d\r\n elif floor == 'f3':\r\n flt = f3\r\n fstr = f3_d\r\n elif floor == 'f4':\r\n flt = f4\r\n fstr = f4_d\r\n elif floor == 'f5':\r\n flt = f5\r\n fstr = f5_d\r\n elif floor == 'f6':\r\n flt = f6\r\n fstr = f6_d\r\n elif floor == 'f7':\r\n flt = f7\r\n fstr = f7_d\r\n else:\r\n resp = 'Invalid Floor!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n while True:\r\n if frag:\r\n if flt == f6:\r\n flt = frag6\r\n fstr = fr6_d\r\n break\r\n elif flt == f7:\r\n flt = frag7\r\n fstr = fr7_d\r\n break\r\n else:\r\n resp = 'You can\\'t frag run this floor!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n break\r\n else:\r\n break\r\n \r\n i = 0\r\n r = 0\r\n d = {}\r\n chest_cost = 100000\r\n\r\n for i in flt:\r\n stri = str(i)\r\n if flt == frag6 or flt == frag7:\r\n minim = 1\r\n maxim = flt[stri][1]\r\n random_drop = randint(minim, maxim)\r\n if random_drop == maxim:\r\n d[\"drop{0}\".format(i)] = stri\r\n else:\r\n minim = 1\r\n maxim = flt[stri][1]\r\n random_drop = randint(minim, maxim)\r\n if random_drop == maxim:\r\n d[\"drop{0}\".format(i)] = stri \r\n \r\n i = 0\r\n money = 0\r\n list_ids = []\r\n for i in d.values():\r\n if i in d.values():\r\n if flt == frag6 or flt == frag7:\r\n money += flt[d[\"drop{0}\".format(i)]][2]\r\n item_str = str(flt[d[\"drop{0}\".format(i)]][0])\r\n list_ids.append(item_str)\r\n else:\r\n chest_cost += flt[d[\"drop{0}\".format(i)]][5]\r\n minim = flt[d[\"drop{0}\".format(i)]][2]\r\n maxim = flt[d[\"drop{0}\".format(i)]][3]\r\n amount = randint(minim, maxim)\r\n item_str = str(flt[d[\"drop{0}\".format(i)]][0])\r\n money += ((flt[d[\"drop{0}\".format(i)]][4]*amount) - chest_cost)\r\n list_ids.append(item_str)\r\n \r\n time_took = str(round((time.time() - start_time), 3))\r\n tt = \"Time taken on executing command: \"\r\n timetook = time_took + \" seconds!\"\r\n items_str = ('\\n'.join(map(str, list_ids)))\r\n\r\n\r\n f1_d = 'Floor 1 run'\r\n f2_d = 'Floor 2 run'\r\n f3_d = 'Floor 3 run'\r\n f4_d = 'Floor 4 run'\r\n f5_d = 'Floor 5 run'\r\n f6_d = 'Floor 6 run'\r\n f7_d = 'Floor 7 run'\r\n\r\n fr6_d = 'Frag run on Floor 6'\r\n fr7_d = 'Frag run on Floor 7'\r\n\r\n embed_run = 'You did a ' + fstr + '!'\r\n embed_profit = 'Your total profit is ' + str(money) + ' coins!'\r\n if list_ids:\r\n embed_items = 'You got: \\n' + items_str\r\n else:\r\n embed_items = 'You got nothing useful this run :('\r\n \r\n embed_header = 'Dungeon Run Simulator'\r\n\r\n return_embed = discord.Embed(title=embed_header, description='', color=0xf5ad42)\r\n return_embed.add_field(name='Run Info', value=embed_run, inline=False)\r\n return_embed.add_field(name='Profit', value=embed_profit, inline=False)\r\n return_embed.add_field(name='Items', value=embed_items, inline=False)\r\n return_embed.add_field(name=tt, value=timetook, inline=False)\r\n d = defaultdict(dict)\r\n data_id = str(ctx.message.author.id)\r\n\r\n\r\n await prev.edit(embed=return_embed, content='')\r\n \r\n else:\r\n resp = 'Invalid command syntaxis!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n#endregion gamble\r\n#region eat\r\[email protected](name='eat', help='Monke eat. Banana/Coconut/Rolety')\r\nasync def eat(ctx, *, food):\r\n gc = [\r\n 'Nah man, not worth it',\r\n 'Cool but meh',\r\n 'Neat, yum yum',\r\n 'Thats some good food',\r\n 'OO AA BEST MONKE FOOD EVER',\r\n 'epic food monke love it oo aa',\r\n 'not bad oo aa',\r\n 'yuck ew',\r\n 'only gold can eat this trash'\r\n ]\r\n voidid = '<@381827687775207424>'\r\n lookstr = 'Monke hungry'\r\n prev = await ctx.send(lookstr)\r\n try:\r\n if not food:\r\n await prev.edit(content='', embed=embed_error,)\r\n else:\r\n if 'banana' in food.lower():\r\n o = 'banana'\r\n resp = responses[o]\r\n elif 'coco' in food.lower():\r\n o = 'coco'\r\n resp = responses[o]\r\n elif 'rolet' in food.lower():\r\n o = 'rolet'\r\n resp = responses[o]\r\n elif 'void' in food.lower():\r\n o = 'void'\r\n resp2 = voidid + ' nvm get pinged lol noob.'\r\n resp = responses[o]\r\n elif 'cross' in food.lower():\r\n o = 'cross'\r\n resp = responses[o]\r\n elif 'monke' in food.lower():\r\n o = 'monke'\r\n resp = responses[o]\r\n elif 'cum' in food.lower():\r\n o = 'cum'\r\n resp = responses[o]\r\n elif 'masmig' in food.lower():\r\n o = 'masmig'\r\n resp = responses[o]\r\n elif 'starfruit' in food.lower():\r\n o = 'starfruit'\r\n resp = responses[o]\r\n elif 'me' in food.lower():\r\n o = 'me'\r\n resp = responses[o]\r\n elif 'dead cells' in food.lower():\r\n o = 'dead cells'\r\n resp = responses[o]\r\n elif 'chaos' in food.lower():\r\n o = 'chaos'\r\n resp = responses[o]\r\n elif 'weiwei' in food.lower():\r\n o = 'weiwie'\r\n resp = responses[o]\r\n elif 'wurm' in food.lower():\r\n o = 'wurm'\r\n resp = responses[o]\r\n elif 'gold' in food.lower():\r\n o = 'gold'\r\n resp = responses[o]\r\n else:\r\n resp = choice(gc)\r\n \r\n await prev.edit(content=resp)\r\n if resp2:\r\n await ctx.send(content=resp2)\r\n except UnboundLocalError:\r\n pass\r\n \r\n#endregion eat\r\n#region respond\r\n\r\[email protected]\r\nasync def on_message(message):\r\n if message.author == bot.user:\r\n return\r\n await bot.process_commands(message)\r\n if str(message.channel.id) in val_channels:\r\n if 'good bot' in message.content.lower():\r\n resp = pog +'Thanks!\\nIf you wish to know more about me, visit my GitHub Repository: https://github.com/Maxuss/MonkeyBot/\\nThere\\'s lots of cool information about me!\\nMy creator also has a Patreon page! You can check him out there https://www.patreon.com/maxus_ '\r\n await message.channel.send(resp)\r\n elif 'eknom' in message.content.lower(): \r\n resp = 'egom yt'\r\n await message.channel.send(resp)\r\n#endregion respond\r\n#region info\r\[email protected](name='info', help='Shows some useful info about bot')\r\nasync def info(ctx):\r\n embed_patrons = 'No one yet :('\r\n embed_main = 'This is a bot developed by ```Void Moment#8152``` for guild Macaques! \\nIt can do some stuff related to Hypixel Skyblock. \\nUse m!help for info about commands!'\r\n embed_ph = 'My Patreon:'\r\n embed_patre = 'I have a patreon, so if you want to support my work and help me host the bot you can donate! [Link](https://www.patreon.com/maxus_)'\r\n embed_cp = 'Current Patrons:'\r\n embed_mh = 'MonkeyBot by VoidMoment aka maxus'\r\n embed_mih = 'Main info you need to know:'\r\n \r\n return_embed = discord.Embed(title=embed_mh, description='', color=0xf5ad42)\r\n return_embed.add_field(name=embed_mih, value=embed_main, inline=False)\r\n return_embed.add_field(name=embed_ph, value=embed_patre, inline=False)\r\n return_embed.add_field(name=embed_cp, value=embed_patrons, inline=False)\r\n\r\n await ctx.send(embed=return_embed)\r\n\r\n#endregion info\r\n#region help\r\[email protected]()\r\nasync def help(ctx, page=None):\r\n hd = 'MonkeyBot Commands'\r\n pref = 'Default prefix: m!'\r\n sy = 'Preset: ```command [required param] <optional param>```\\n'\r\n ment = 'Note: bot updates auction data every **10** minutes. \\nDuring that time bot is immune to all the commands.\\n'\r\n pagenum = 'Current page: 1. Do m!help <page> for another page! Total pages: 3\\n'\r\n a = '```help <page>``` - shows this message.\\n'\r\n b = '```prefix [prefix]``` - sets prefix for current server.\\n'\r\n c = '```reqs [nickname]``` - checks whether the ```nickname``` can join the guild Macaques.\\n'\r\n d = '```sb [nickname]``` - shows a bit of stuff from players account.\\n'\r\n e = '```bz [item]``` - shows all the useful info about item in bazaar.\\n'\r\n f = '```sky [nickname]``` - sends SkyCrypt link of chosen player.\\n'\r\n _1 = sy + ment + pagenum + a + b + c + d + e + f\r\n \r\n\r\n pagenum = 'Current page: 2. Do m!help <page> for another page! Total pages: 3\\n'\r\n a = '```dungeon [floor] <?frag>``` - Simulates results of a dungeon run. Also supports frag runs on floor 6/7.\\n'\r\n b = '```eat [item]``` - Makes monkey eat a thing. lol.\\n'\r\n c = '```bin [item]``` - Shows some info about item on BIN. Might not be the lowest price BIN!\\n'\r\n d = '```lbin [item]``` - Shows cheapest BIN of item.\\n'\r\n e = '```hbin [item]``` - Shows most expensive BIN of item\\n'\r\n f = '```auction [item]``` - Shows random [item] data on auction\\n'\r\n _2 = sy + ment + pagenum + a + b + c + d + e + f\r\n\r\n a = '```rate <something>``` - Rates you or provided argument in Monkey Rate machine!\\n'\r\n pagenum = 'Current page: 3. Do m!help <page> for another page! Total pages: 3\\n'\r\n\r\n _3 = sy + ment + pagenum + a\r\n\r\n if str(page) in pages:\r\n pager = f'_{page}'\r\n return_embed = discord.Embed(title=hd, description='', color=0xf5ad42)\r\n return_embed.add_field(name='Prefix', value=pref, inline=False)\r\n return_embed.add_field(name='Commands', value=eval(pager), inline=False)\r\n else:\r\n return_embed = discord.Embed(title=hd, description='', color=0xf5ad42)\r\n return_embed.add_field(name='Prefix', value=pref, inline=False)\r\n return_embed.add_field(name='Commands', value=_1, inline=False)\r\n prev = await ctx.send(embed=return_embed)\r\n\r\n#endregion help\r\n#region ah dat\r\ndata_replaceable = [\r\n \"§0\", \"§1\", \"§2\", \"§3\", \"§4\", \"§5\", \"§6\",\r\n \"§7\", \"§8\", \"§9\", \"§c\", \"§e\", \"§a\", \"§b\",\r\n \"§d\", \"§f\", \"§k\", \"§l\", \"§m\", \"§n\", \"§o\",\r\n \"§r\", \"RIGHT CLICK\", \"UNCOMMON\", \"COMMON\", \"RARE\",\r\n \"LEGENDARY\", \"EPIC\", \"MYTHIC\",\r\n \"VERY SPECIAL\", \"SPECIAL\", \"SUPREME\", \"Mana Cost\",\r\n \"SWORD\", \"BOW\", \"ACCESSORY\", \"ORB\", \"BOOTS\",\r\n \"LEGGINGS\", \"CHESTPLATE\", \"HELMET\", \"DUNGEON\", \"**COMMON****\"\r\n]\r\ndata_replaceable_back = [\r\n \"\", \"\", \"\", \"\", \"\", \"\", \"\",\r\n \"\", \"\", \"\", \"\", \"\", \"\", \"\",\r\n \"\", \"\", \"\", \"\", \"\", \"\", \"\",\r\n \"\", \"**RIGHT CLICK**\", \"**UNCOMMON** \", \"**COMMON** \", \"**RARE** \",\r\n \"**LEGENDARY**\", \"**EPIC**\", \"**MYTHIC**\", \"**VERY SPECIAL**\",\r\n \"**SPECIAL**\", \"**SUPREME**\", \"_Mana Cost_\",\r\n \"**SWORD**\", \"**BOW**\", \"**ACCESSORY**\", \"**ORB**\", \"**BOOTS**\",\r\n \"**LEGGINGS**\", \"**CHESTPLATE**\", \"**HELMET**\", \" **DUNGEON** \", \"**ITEM**\", \"COMMON**\"\r\n]\r\n# ah item data: 0name, 1lore, 2rarity, 3starting bid, 4?bought, 5bin auction, 6price, 7title, 8bought ot not\r\nahs = []\r\ndef seek_for_item(ah_dat, item_name):\r\n try:\r\n for a in range(len(ah_dat)):\r\n vals = list(ah_dat[a].values())\r\n try:\r\n isBIN = ah_dat[a][\"bin\"]\r\n if isBIN:\r\n for k in range(len(vals)):\r\n item = str(vals[k])\r\n if search(item_name.lower(), item.lower()):\r\n found = True\r\n tah = ah_dat[a]\r\n name = tah[\"item_name\"] \r\n lore = tah[\"item_lore\"]\r\n trarity = tah[\"tier\"]\r\n start_bid = tah[\"starting_bid\"]\r\n bought = tah[\"claimed\"]\r\n bs = 'BIN Auction'\r\n rarity = '**' + trarity + '**'\r\n stb = 'Starting Bid: ' + str(start_bid) + ' coins'\r\n titlee = 'Auction'\r\n if bought:\r\n bus = 'Bought!'\r\n else:\r\n bus = 'Selling!'\r\n ahs.append(name)\r\n ahs.append(lore)\r\n ahs.append(rarity)\r\n ahs.append(start_bid)\r\n ahs.append(bus)\r\n ahs.append(bs)\r\n ahs.append(stb)\r\n ahs.append(titlee)\r\n raise ExitForLoop('filler filler')\r\n except KeyError:\r\n pass\r\n except ExitForLoop:\r\n vals.clear()\r\n pass\r\n\r\nlbins = []\r\ndef seek_for_lbin(ah_dat, item_name):\r\n for a in range(len(ah_dat)):\r\n vals = list(ah_dat[a].values())\r\n try:\r\n isBIN = ah_dat[a][\"bin\"]\r\n if isBIN:\r\n for k in range(len(vals)):\r\n item = str(vals[k])\r\n if search(item_name.lower(), item.lower()):\r\n newbin = {}\r\n found = True\r\n tah = ah_dat[a]\r\n name = tah[\"item_name\"] \r\n lore = tah[\"item_lore\"]\r\n trarity = tah[\"tier\"]\r\n start_bid = tah[\"starting_bid\"]\r\n bought = tah[\"claimed\"]\r\n bs = 'BIN Auction'\r\n rarity = '**' + trarity + '**'\r\n stb = 'Price: ' + str(start_bid) + ' coins'\r\n titlee = 'LBIN Auction'\r\n if bought:\r\n bus = 'Bought!'\r\n else:\r\n bus = 'Selling!'\r\n newbin[\"itemName\"] = name\r\n newbin[\"itemLore\"] = lore\r\n newbin[\"rarity\"] = rarity\r\n newbin[\"price\"] = start_bid\r\n newbin[\"selling\"] = bus\r\n lbins.append(newbin)\r\n except KeyError:\r\n pass\r\ndef seek_for_ah(ah_dat, item_name):\r\n for a in range(len(ah_dat)):\r\n vals = list(ah_dat[a].values())\r\n try:\r\n for k in range(len(vals)):\r\n item = str(vals[k])\r\n if search(item_name.lower(), item.lower()):\r\n newbin = {}\r\n found = True\r\n tah = ah_dat[a]\r\n name = tah[\"item_name\"] \r\n lore = tah[\"item_lore\"]\r\n trarity = tah[\"tier\"]\r\n start_bid = tah[\"starting_bid\"]\r\n highest_bid = tah[\"highest_bid_amount\"]\r\n current_bid = start_bid + highest_bid\r\n bought = tah[\"claimed\"]\r\n bs = 'HySb Auction'\r\n rarity = '**' + trarity + '**'\r\n stb = 'Starting bid: ' + str(start_bid) + ' coins\\nHighest bid: ' + str(current_bid) + ' coins'\r\n titlee = 'HySb Auction'\r\n if bought:\r\n bus = 'Bought!'\r\n else:\r\n bus = 'Selling!'\r\n newbin[\"itemName\"] = name\r\n newbin[\"itemLore\"] = lore\r\n newbin[\"rarity\"] = rarity\r\n newbin[\"price\"] = stb\r\n newbin[\"selling\"] = bus\r\n lbins.append(newbin)\r\n except KeyError:\r\n pass\r\n#endregion ah dat\r\n#region show ah\r\nlbins = []\r\nahs = []\r\[email protected](name='lbin')\r\nasync def lbin(ctx, *, item_name:str):\r\n try:\r\n await binah(ctx, item_name, 1)\r\n except IndexError:\r\n resp = 'Looks like this auction doesn\\'t exist, or hardly accessible!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n\r\[email protected](name='bin')\r\nasync def bin(ctx, *, item_name:str):\r\n try:\r\n await binah(ctx, item_name, 3)\r\n except IndexError:\r\n resp = 'Looks like this auction doesn\\'t exist, or hardly accessible!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n\r\[email protected](name='hbin')\r\nasync def hbin(ctx, *, item_name:str):\r\n try:\r\n await binah(ctx, item_name, 2)\r\n except IndexError:\r\n resp = 'Looks like this auction doesn\\'t exist, or hardly accessible!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n\r\[email protected](name='auction')\r\nasync def auction(ctx, *, item_name:str):\r\n try:\r\n await binah(ctx, item_name, 0)\r\n except IndexError:\r\n resp = 'Looks like this auction doesn\\'t exist, or hardly accessible!'\r\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\r\n await prev.edit(embed=embed_error, content='')\r\n\r\nasync def binah(context, item_name: str, AHLHB: str): #AHLHB = AH OR LOWEST BIN OR HIGHEST BIN OR RANDOM BIN. TAKES 0 AS AH, 1 AS LBIN, 2 AS HBIN, 3 AS BIN\r\n start_time = time.time()\r\n lookstr = monke + \"Looking up for Auction of \" + item_name + \". Note: Auctions update every 10 minutes, so data you get *might* be a bit outdated! \" + FACT_STR + chooseFact()\r\n prev = await context.send(lookstr)\r\n try:\r\n if 'linux' in str(platform.system()).lower(): \r\n with open('/home/maxusgame897/MonkeyBot/auction/0.json', 'r', encoding='utf-8', newline='') as pagedata:\r\n d = json.load(pagedata)\r\n else:\r\n with open('.\\\\auction\\\\0.json', 'r', encoding='utf-8', newline='') as pagedata:\r\n d = json.load(pagedata)\r\n pages = d[\"totalPages\"]\r\n pglist = list(range(0, pages))\r\n for i in pglist:\r\n if 'linux' in str(platform.system()).lower():\r\n strr = auctions_path + f'/auction/{i}.json'\r\n else:\r\n strr = auctions_path + f'\\{i}.json'\r\n with open(strr, 'r', encoding='utf-8', newline='') as td:\r\n tah_d = json.load(td)\r\n \r\n ah = tah_d[\"auctions\"]\r\n if str(AHLHB) == '3':\r\n seek_for_item(ah, item_name)\r\n name = str(ahs[0])\r\n lore = str(ahs[1])\r\n rarity = str(ahs[2])\r\n start_bid = ahs[3]\r\n bus = ahs[4]\r\n bs = ahs[5]\r\n stb = ahs[6]\r\n titlee = 'HySb Auction!'\r\n elif str(AHLHB) == '0':\r\n d = {}\r\n seek_for_ah(ah, item_name)\r\n lowest = choice(lbins)\r\n name = str(lowest[\"itemName\"])\r\n lore = str(lowest[\"itemLore\"])\r\n rarity = str(lowest[\"rarity\"])\r\n price = lowest[\"price\"]\r\n bus = lowest[\"selling\"]\r\n stb = price\r\n titlee = 'HySb Auction'\r\n else:\r\n seek_for_lbin(ah, item_name)\r\n d = {}\r\n lbins_len = len(lbins) - 1\r\n \r\n for i in range(0, lbins_len):\r\n current = lbins[i]\r\n d[f'{i}'] = int(current[\"price\"])\r\n \r\n if str(AHLHB) == '1':\r\n max_item = min(d, key=d.get)\r\n needkey = int(max_item)\r\n lowest = lbins[needkey]\r\n name = str(lowest[\"itemName\"])\r\n lore = str(lowest[\"itemLore\"])\r\n rarity = str(lowest[\"rarity\"])\r\n price = lowest[\"price\"]\r\n bus = lowest[\"selling\"]\r\n stb = 'Price: ' + str(price) + ' coins'\r\n titlee = 'HySb BIN Auction'\r\n\r\n elif str(AHLHB) == '2':\r\n max_item = max(d, key=d.get)\r\n needkey = int(max_item)\r\n lowest = lbins[needkey]\r\n name = str(lowest[\"itemName\"])\r\n lore = str(lowest[\"itemLore\"])\r\n rarity = str(lowest[\"rarity\"])\r\n price = lowest[\"price\"]\r\n bus = lowest[\"selling\"]\r\n stb = 'Price: ' + str(price) + ' coins'\r\n titlee = 'HySb BIN Auction'\r\n\r\n print(lore)\r\n for i in range(0, (len(data_replaceable) - 1)):\r\n name = name.replace(data_replaceable[i], data_replaceable_back[i])\r\n lore = lore.replace(data_replaceable[i], data_replaceable_back[i])\r\n lbins.clear()\r\n if lore.endswith('a'):\r\n lore = replace_last(lore, \"a\", \"\")\r\n lore = replace_last(lore, \"a\", \"\")\r\n rarity = \"**\" + rarity +\"**\"\r\n ahs.clear()\r\n print(\"Found AH!\")\r\n logging.debug(\"FOUND AH FOR ITEM \" + item_name.upper())\r\n finish_time = time.time() - start_time\r\n timestr = str(round(float(finish_time), 2)) + \" seconds!\"\r\n return_embed = discord.Embed(title=titlee, description='', color=0xf5ad42)\r\n return_embed.add_field(name=name, value=lore, inline=False)\r\n return_embed.add_field(name=bus, value=stb, inline=False)\r\n return_embed.add_field(name='Time taken on executing command:', value=timestr, inline=False)\r\n\r\n await prev.edit(content='', embed=return_embed)\r\n await prev.add_reaction(monkey_id)\r\n except SyntaxError:\r\n pass\r\ndef replace_last(source_string, replace_what, replace_with):\r\n head, _sep, tail = source_string.rpartition(replace_what)\r\n return head + replace_with + tail\r\n\r\n#endregion show ah\r\n#region monkeyrate\r\[email protected](name='rate')\r\nasync def rate(ctx, *, who=None):\r\n monkepercent = randint(0, 100)\r\n monkestr = str(monkepercent) + \"%\"\r\n if who is not None and who.lower() != 'me':\r\n whostr = who.capitalize()\r\n strmonk = whostr + ' is ' + monkestr + ' monke!'\r\n elif who.lower() == 'me':\r\n whostr = 'You'\r\n strmonk = whostr + ' are ' + monkestr + ' monke!'\r\n else:\r\n strmonk = 'You are ' + monkestr + ' monke ' + monkey_id + '!'\r\n \r\n return_embed = discord.Embed(title='Monkey Rate Machine', description=strmonk, color=0xf5ad42)\r\n await ctx.send(embed=return_embed)\r\n#endregion monkeyrate\r\n#region run\r\nbot.run(dat.TOKEN)\r\n#endregion run\r\n"
},
{
"alpha_fraction": 0.493879109621048,
"alphanum_fraction": 0.4969395697116852,
"avg_line_length": 32.512821197509766,
"blob_id": "bcfc55af6db21825cfc1ce2745d1c51361e9670c",
"content_id": "fe19304f53cc0de2f51f6e4355786cc6fe39f492",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2614,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 78,
"path": "/autocorrect.py",
"repo_name": "Maxuss/MonkeyBot",
"src_encoding": "UTF-8",
"text": "import json\nfrom data import ExitForLoop\nimport logging\n\nconsole = logging.StreamHandler() \nconsole.setLevel(logging.ERROR) \nlogging.getLogger(\"\").addHandler(console)\n\n# ADDS WORDS FROM bz_ac.json\nwith open('bz_ac.json', 'r') as bac:\n ac = json.load(bac)\n print(\"AutoCorrect Database Connected!\")\ninp_words = list(ac.keys())\n\n# FUNCTIONS TO CHECK WORDS\ndef correctWord(word: str):\n try:\n strr = word.lower()\n try:\n first_word = ac[strr]\n except KeyError:\n try: \n words = strr.split(\" \")\n second_word = words[1]\n first_word = words[0]\n except IndexError:\n raise ExitForLoop\n if first_word in \"enchanted\":\n first_word = 'enchanted'\n if strr.startswith(\"e\") and not strr.startswith(\"en\"):\n try:\n strrr = strr.replace(\"e\", \"enchanted\", 1)\n words = list(strrr.split(\" \", 1))\n second_word = words[1]\n except IndexError:\n print(\"COULDN'T FIND THIS ITEM!\")\n if second_word.endswith(\"block\"):\n swords = list(second_word.rsplit(\" \", 1))\n third_word = swords[0]\n block = swords[-1]\n try:\n try:\n period_word = ac[third_word]\n except UnboundLocalError:\n try:\n period_word = ac[second_word]\n except UnboundLocalError:\n pass\n except KeyError:\n pass\n try:\n new_word = first_word + \"_\" + period_word + \"_\" + block\n print('block')\n return new_word\n except UnboundLocalError:\n try:\n new_word = first_word + \"_\" + period_word\n return new_word\n except UnboundLocalError:\n try:\n new_word = first_word + \"_\" + second_word\n return new_word\n except UnboundLocalError:\n try:\n new_word = first_word\n return new_word\n except UnboundLocalError:\n new_word = word\n return new_word\n except ExitForLoop:\n new_word = word\n return new_word\n print(\"Successfully corrected \" + word + \" to \" + new_word + \"!\")\n logging.info(\"BAZAAR_AUTOCORRECT: CHANGED '\" + word.upper() + \"' TO '\" + new_word.upper() + \"'\")\n words.clear()\n\nprint(\"AutoCorrect System Connected!\")\nprint(\"Use correctWord(string) to correct!\")\n"
},
{
"alpha_fraction": 0.5847194790840149,
"alphanum_fraction": 0.6164364218711853,
"avg_line_length": 33.60487747192383,
"blob_id": "127ac6d7f4ae409837b398c0afc9b247ee99db04",
"content_id": "4292eb1f35c65898758d11302bb86f5512d5effe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7094,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 205,
"path": "/data.py",
"repo_name": "Maxuss/MonkeyBot",
"src_encoding": "UTF-8",
"text": "# MONKEY BOT VARIABLES FOR USE\n# \n# These are variables that i moved to different file\n# So they wont take much space in bot.py\n#\n# MonkeyBot by maxus aka Maxuss aka Void Moment#8152 (c)\n\nimport requests, json, pretty_errors, discord, asyncio, aiohttp, os, time, os.path\nfrom decouple import config\nfrom threading import Thread\nimport nest_asyncio as nasync\nnasync.apply()\n\nclass DATACENTRE:\n # all the vars needed for now\n monke = '<a:monke:813481830766346311>'\n voidmoment = '<:voidmoment:813482195422806017>'\n monkey_id = '<:monkey~1:813495959639556198>'\n pog = '<:Monkey_Pog:781768342112436284>'\n REQ_SA = 25\n REQ_SLAYER = 150000 \n\n with open('data.json', 'r') as mf:\n f = mf.read()\n\n obj = json.loads(f)\n\n val_channels = [\n \"814858417675960330\",\n \"816761364507787295\",\n \"702040764095529040\",\n \"702042560557744148\",\n \"741750311823081483\",\n \"702044494954233896\",\n ]\n\n ANTISPAM = obj[\"antispam\"]\n AS_TIME = obj[\"antispam_time\"]\n TOKEN = str(config('DISCORD_TOKEN'))\n RPC_STATUS = \"m!help\"\n PATH_TO_JSON = str(config('PATH_TO_JSON'))\n FACT_STR = \"Fun Fact: \"\n API_KEY = str(config('API_KEY'))\n PLAYER_NAME = 'maxus_'\n error_response = \"Invalid command syntaxis!\"\n data = requests.get(\"https://api.hypixel.net/player?key=\"+API_KEY+\"&name=\" + PLAYER_NAME).json()\n bz_data = requests.get(\"https://api.hypixel.net/skyblock/bazaar?key=\" + API_KEY).json()\n data_sb_PATH = data[\"player\"][\"stats\"][\"SkyBlock\"][\"profiles\"]\n resp = '!'\n embed_error = discord.Embed(title='Oops!', description=resp, color=0xa30f0f)\n cutename = ''\n facts = [\n 'Did you know MonkeyBot is developed on Python?',\n 'Did you know MonkeyBot is developed using discord.py library?',\n 'Did you know MonkeyBot 1.0 was developed in jsut around few weeks?',\n 'Did you know MonkeyBot was inspired by Jerry The Price Checker from SBZ?',\n 'Have you tried doing m!info?',\n 'Skyblock is endless grind please end me.',\n 'Monkeys are actually smarter than people(False).',\n 'This Fact isn\\'t fun :(.',\n 'Monkeys use grooming t strengthen their relationship.',\n 'Some monkeys are close to extinction :(.',\n 'Monkeys got tails quite recently.',\n \"Pygmy marmosets are the world's smallest monkeys.\",\n 'Mandrills are the world largest monkeys',\n 'Capuchins monkeys can use tools!',\n 'Howler monkeys are the loudest monkeys(OO AA).',\n 'Japanese monkeys enjoy relaxing in hot bath.',\n 'There are only 1 monkey species in Europe.',\n 'Server with this bot is hosted in Netherlands!',\n 'Asyncronous programming is so hard, I spent over 2 days making AH command with it!',\n 'Hello World!',\n 'Goodbye World!',\n 'Asyncio is overcomplicated.',\n 'This statement is False',\n 'MonkeyBot updates it\\'s AH database every 10 minutes!',\n 'This bot uses more imports, than AOTG\\'s braincells!',\n ':Fact Fun ...',\n ' ',\n 'Now with bugs!',\n 'If you ever find bugs, please open an issue in my github project! You can find link in m!info!',\n 'If you want to request a new feature, open an issue in my github project! You can find link in m!info!',\n 'This is fact 33!',\n 'There are total of 36 facts at the moment!',\n 'You can support me by donating to my patreon! You can find link in m!info!',\n 'I hate school.'\n ]\n\n pages = [\n \"1\", \"2\", \"3\"\n ]\n\n multistring = \"banana.green coconut.rolety.void moment.crossmane.monkey.cum.masmig.starfruit.me.dead cells.chaos.weiwei123.wispish wurm.aspect of the gold\"\n responses = {\n \"banana\": 'yummy yummy monke love bananas ',\n \"coco\": 'monke love green coconuts yummy yummy ',\n \"rolet\": 'peepeepoopoo :P',\n \"void\": 'Ping bad',\n \"cross\": 'Penguz yum yum',\n \"monke\": 'no',\n \"cum\": 'tf is wrong with you',\n \"masmig\": 'monkey not eat noobs oo aa',\n \"starfruit\": 'that will make good wine ngl',\n \"me\": 'uh oh stinky',\n \"dead cells\": '5bc e z',\n \"chaos\": 'flip bad bad',\n \"weiwei\": 'wurm',\n \"wurm\": 'god',\n \"gold\": 'ew'\n }\n auctions_path = str(config('PATH_TO_AH'))\n\n# DOWNLOADS WHOLE AH API\n# THX FOR RANDOM USER ON HYPIXEL FORUMS FOR THIS\n# <3\nimport requests, json, pretty_errors, discord, asyncio, aiohttp, os, time\nimport data\n\n\nasync def fetch_one_url(session, url, save_path=None):\n # print_timestamp()\n async with session.get(url) as response:\n time.sleep(0.1)\n response_text = await response.text()\n if save_path is not None:\n with open(save_path, \"wb\") as text_file:\n text_file.write(response_text.encode(\"UTF-8\"))\n return url, response_text\n\n# dowloads everything from urls, then returns with response\ndef download_urls(urls: list, save_as={}):\n loop = asyncio.get_event_loop()\n htmls = loop.run_until_complete(download_urls_helper(urls, save_as))\n return htmls\n\n\nasync def download_urls_helper(urls: list, save_as: dict):\n # print(\"Downloading:\")\n # print(urls)\n tasks = []\n async with aiohttp.ClientSession() as session:\n for url in urls:\n if url in save_as:\n save_path = save_as[url]\n else:\n save_path = None\n tasks.append(fetch_one_url(session, url, save_path))\n htmls = await asyncio.gather(*tasks)\n\n # print(\"Finished downloading\")\n # print_timestamp()\n return htmls\n\n# end DOWNLOAD URLS\n\ndef get_number_of_pages():\n with open('auction/0.json', 'rb') as f:\n ah_dict = json.load(f)\n if ah_dict['success']:\n number_of_pages = ah_dict['totalPages']\n return number_of_pages\n else:\n print(\"number_of_pages error\")\n\n\n\ndef download_auctions():\n global auctions_json_list\n global auction_list\n print(\"Updating all auctions\")\n # print(\"Deleting old auction files\")\n for filename in os.listdir('auction'):\n os.remove('auction/' + filename)\n\n # print(\"Downloading page 0\")\n r = requests.get('https://api.hypixel.net/skyblock/auctions?key=' + DATACENTRE.API_KEY + '&page=0')\n with open(r'auction/0.json', 'wb') as f:\n f.write(r.content)\n number_of_pages = get_number_of_pages()\n print(\"Downloading\", number_of_pages, \"pages\")\n\n if number_of_pages is None:\n raise Warning('Problems with AH API! Downloading two empty pages!')\n print('dl 2 pg')\n number_of_pages = 2\n\n urls = []\n save_as = {}\n for page_number in range(1, number_of_pages):\n url = 'https://api.hypixel.net/skyblock/auctions?key=' + DATACENTRE.API_KEY + '&page=' + str(page_number)\n urls.append(url)\n save_as[url] = r'auction/' + str(page_number) + '.json'\n\n download_urls(urls, save_as)\n print(\"auctions updated\")\n\n\n### EXCEPTIONS ###\n# still indev ;-;\n\nclass Error(Exception):\n pass\n\nclass ExitForLoop(Error):\n pass\n"
},
{
"alpha_fraction": 0.6554216742515564,
"alphanum_fraction": 0.6650602221488953,
"avg_line_length": 31,
"blob_id": "8dc7ed7b222e98e299f59e566deacb4b3d07dcab",
"content_id": "564ea86e530425e11453c2280a5d4090e4a00046",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 415,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 13,
"path": "/updates.md",
"repo_name": "Maxuss/MonkeyBot",
"src_encoding": "UTF-8",
"text": "# VER. 1.3 CHANGES\n\n## NEW COMMANDS\n`m!bin [item]` - shows info of item on bin\n`m!lbin [item]` - shows cheapest bin of item\n`m!hbin [item]` - shows most expensive item on bin\n`m!ah [item]` - shows info of item in normal ah\n`m!rate <something>` - rates amount of monkey in you or in item you used\n\n## WHAT'S NEXT?\nUhh... You'll see...\n\n`BZ Autocorrect > Bugfixes > lowest bin > not bin ah > VER. 1.5 > .exe release!`"
}
] | 5 |
pinpc/NI
|
https://github.com/pinpc/NI
|
ce128d8c1b7987396a6b343ddb741d40b544038c
|
bbbaaf0fb9e8f54affca8826193284187631b10a
|
5f64722f758d69a487875bcf1d72970933edc299
|
refs/heads/master
| 2023-02-05T14:41:33.514760 | 2020-12-26T19:35:32 | 2020-12-26T19:35:32 | 324,611,172 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6800000071525574,
"alphanum_fraction": 0.7066666483879089,
"avg_line_length": 11.5,
"blob_id": "7dfc628e8f353c59646e4e9f8d98c7fe55dba346",
"content_id": "2eecb40b23eac5860fea0f8360b46337033df1a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 6,
"path": "/NI-ZaxisTeststand/NI_ZaxisTeststand.py",
"repo_name": "pinpc/NI",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport nidaqmx\n\nfor n in range(10):\n\n print(\"Hallo NI\")\n"
}
] | 1 |
dimashermanto/MNIST-classification
|
https://github.com/dimashermanto/MNIST-classification
|
1771282c49a38d31fd5facf64b8e6b9e2136a67b
|
0609565e98db9ce94a2e911d1e302e7cbc5a11fd
|
e93b12ae149cf0341ff842b809aafd13f699b577
|
refs/heads/master
| 2020-09-24T13:08:02.435682 | 2019-12-04T02:59:18 | 2019-12-04T02:59:18 | 225,765,345 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.704727292060852,
"alphanum_fraction": 0.7236363887786865,
"avg_line_length": 26.5,
"blob_id": "b91abfc157ea4810a9fd812d90bf23225d0c93fc",
"content_id": "200d7b70a1c9c946b11105892dd76646749f4987",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1375,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 50,
"path": "/classification.py",
"repo_name": "dimashermanto/MNIST-classification",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport keras\nfrom keras.datasets import mnist\n\nfrom matplotlib import pyplot as plot\nimport numpy as np\n\n\n#Dataset provided from keras\n(training_images, training_labels), (testing_images, testing_labels) = mnist.load_data()\n\n\n# Build the model\nmodel = keras.Sequential([\n keras.layers.Flatten(input_shape = (28, 28) ),\n \n keras.layers.Dense(32, activation = tf.nn.relu ),\n keras.layers.BatchNormalization(), \n \n keras.layers.Dense(32, activation = tf.nn.relu),\n keras.layers.BatchNormalization(),\n keras.layers.Dropout(0.1),\n \n\n keras.layers.Dense(10, activation = tf.nn.softmax)\n])\n\nmodel.summary()\n\n\n# We compile the model \nRMSProp_optimizer = keras.optimizers.RMSprop(lr=0.01, rho=0.9, epsilon=None, decay=0.0)\nmodel.compile(optimizer = RMSProp_optimizer, loss = 'sparse_categorical_crossentropy', metrics = ['accuracy'] )\n\n\n# Fit method return training history object including accuracy, loss, etc. \ntraining_history = model.fit(training_images, training_labels, epochs = 10)\n\n\n# Model evaluation\ntest_loss, test_accuracy = model.evaluate(testing_images, testing_labels)\nprint(\"Final accuracy : {0:.2f}%\".format(test_accuracy * 100) )\n\n\n# Plot the training history (Optional)\nplot.plot(training_history.history['acc'])\nplot.xlabel('epoch')\nplot.ylabel('accuracy')\nplot.legend(['training'], loc= 'best')\nplot.show()\n"
}
] | 1 |
grathee/Places_Challenge
|
https://github.com/grathee/Places_Challenge
|
c47cd600cc7e14076ed1d23356262296678b11b9
|
0898279eafdee756325e7e2da0a1f3e10f24a1cf
|
d7a033c20213e80dbfc0a6cdba9bc25c009d0ca9
|
refs/heads/master
| 2021-01-10T10:57:28.026584 | 2016-01-22T12:33:07 | 2016-01-22T12:33:07 | 50,179,785 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7039437890052795,
"alphanum_fraction": 0.7190707921981812,
"avg_line_length": 25.457143783569336,
"blob_id": "76d294776d5009ce76ceef5f3b9e922b548c9e92",
"content_id": "a1f5440ed14c782825d9c6ea70a8a4c30e0c894b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1851,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 70,
"path": "/Challenge.py",
"repo_name": "grathee/Places_Challenge",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Jan 22 09:16:38 2016\n@author: Geetika Rathee\n\"\"\"\nimport numpy as np\nimport json\nfrom geopy.geocoders import Nominatim\nimport os\nfrom osgeo import ogr, osr\n\ndata = np.loadtxt('/home/user/Projects/AssignmentLesson15/places.txt', dtype=str)\n#places = np.array(places_data, dtype='float')\n\nprint len(data)\ncoords_places = []\n\nfor places in data:\n geolocator = Nominatim()\n location = geolocator.geocode(places)\n print location\n y_coord = location.latitude \n x_coord = location.longitude\n coords = [x_coord, y_coord]\n coords_places.append(coords)\n \nos.chdir('/home/user/Projects/AssignmentLesson15')\nprint os.getcwd()\n\ndriverName = \"ESRI Shapefile\"\ndrv = ogr.GetDriverByName( driverName )\nif drv is None:\n print \"%s driver not available.\\n\" % driverName\nelse:\n print \"%s driver IS available.\\n\" % driverName\n\n## choose your own name\n## make sure this layer does not exist in your 'data' folder\nfn = \"places_challenge.shp\"\nlayername = \"placeslayer\"\n\n## Create shape file\nds = drv.CreateDataSource(fn)\n\n# Set spatial reference\nspatialReference = osr.SpatialReference()\nspatialReference.ImportFromProj4('+proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs')\n\n## Create Layer\nlayer=ds.CreateLayer(layername, spatialReference, ogr.wkbPoint)\n## Now check your data folder and you will see that the file has been created!\n\nplaces_array = np.array(coords_places)\n\n# SetPoint(self, int point, double x, double y, double z = 0)\ni = 0\n\nfor i in range(len(coords_places)):\n pointi = ogr.Geometry(ogr.wkbPoint)\n pointi.SetPoint(0,places_array[i,0], places_array[i,1]) \n layerDefinition = layer.GetLayerDefn()\n featurei = ogr.Feature(layerDefinition)\n featurei.SetGeometry(pointi) \n layer.CreateFeature(featurei)\n i +=1\n \nprint \"The new extent\"\nprint layer.GetExtent()\n\nds.Destroy()"
}
] | 1 |
IrvingGP16/la_galeraAPI
|
https://github.com/IrvingGP16/la_galeraAPI
|
930a591cd5d1b92b5f2b86c69eab8e7ee5acf960
|
b43404fd4dcc36e16aa8704039947d8bad9baf63
|
60692408be3eb03043fe904bdad755d85aa1d9ea
|
refs/heads/main
| 2023-07-19T17:46:41.286712 | 2021-08-22T23:02:17 | 2021-08-22T23:02:17 | 398,916,924 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6942496299743652,
"alphanum_fraction": 0.6942496299743652,
"avg_line_length": 30.021739959716797,
"blob_id": "bc126123e0c178e144c5c40cc1225afbdb822063",
"content_id": "31cd54fcaeeffe7c01183210e6eb5617b9ff4871",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1428,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 46,
"path": "/main.py",
"repo_name": "IrvingGP16/la_galeraAPI",
"src_encoding": "UTF-8",
"text": "from schemas import PrecioRequestModel, ProductRequestModel\nfrom fastapi import FastAPI\nfrom database import database as conexion\nfrom database import Product\nfrom database import Precio\n\"------crear application----------\"\napp = FastAPI(title='APILaGalera',\n description='Esta es la API de la galera')\n\n\"-----Aquí se abre la conexión a la base de datos----------\"\[email protected]_event('startup')\nasync def startup():\n if conexion.is_closed():\n conexion.connect()\n conexion.create_tables([Product,Precio])\n\[email protected]_event('shutdown')\nasync def shutdown():\n if not conexion.is_closed():\n conexion.close()\n\[email protected](\"/\")\nasync def root():\n return {\"message\": \"Hello World\"}\n\[email protected]('/products')\nasync def create_product(product_request: ProductRequestModel):\n User = Product.create(\n nombre=product_request.nombre,\n variante=product_request.variante,\n presentacion=product_request.presentacion,\n marca=product_request.marca,\n cont_neto=product_request.cont_neto,\n image=product_request.image,\n price=product_request.cont_neto\n )\n return product_request\n\[email protected]('/precios')\nasync def create_precio(precio_request: PrecioRequestModel):\n user = Precio.create(\n consumidor=precio_request.consumidor,\n comicionista=precio_request.comicionista,\n distribuidor=precio_request.distribuidor\n )\n return precio_request"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 24.823530197143555,
"blob_id": "03757a34edfed1bfc3f2f005afe718b0bdee6218",
"content_id": "bcee78738a51f0794f4a7d0e806c01f7e282500f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 17,
"path": "/schemas.py",
"repo_name": "IrvingGP16/la_galeraAPI",
"src_encoding": "UTF-8",
"text": "from enum import Enum\nfrom pydantic import BaseModel\n\n\"-----------------Aqui definimos el tipo de datos que podemo enviar al servidor-----------------\"\nclass ProductRequestModel(BaseModel):\n nombre: str\n variante: str\n presentacion: str\n marca: str\n cont_neto: str\n image: str\n price: int\n\nclass PrecioRequestModel(BaseModel):\n consumidor: float = None\n comicionista: float = None\n distribuidor: float = None"
},
{
"alpha_fraction": 0.5712851285934448,
"alphanum_fraction": 0.5893574357032776,
"avg_line_length": 24.564102172851562,
"blob_id": "3a36ae981cac6c3ca5626cf35fac6aab3afe63d2",
"content_id": "095825beb28cc031e6cbc07426dfdc9f5e809af9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 997,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 39,
"path": "/database.py",
"repo_name": "IrvingGP16/la_galeraAPI",
"src_encoding": "UTF-8",
"text": "from peewee import *\n\n\n\"--------------------aqui se crea la conexión a la base de datos------------------------\"\ndatabase = MySQLDatabase(\n 'la_galera',\n user='root',\n password='rootpass',\n host='localhost', port=3306\n)\n\n\"--------------Aqui se crean los modelos de las tablas--------------------\"\nclass Product(Model):\n nombre = CharField(max_length=50)\n variante = CharField(max_length=50)\n presentacion = CharField(max_length=50)\n marca = CharField(max_length=50)\n cont_neto = CharField(max_length=50)\n image = CharField(max_length=100)\n price = IntegerField(0)\n\n def __str__(self):\n return self.nombre\n \n class Meta:\n database = database\n table_name = 'products'\n\nclass Precio(Model):\n consumidor = FloatField = None\n comicionista = FloatField = None\n distribuidor = FloatField = None\n\n def __str__(self):\n return self.consumidor\n \n class Meta:\n database = database\n table_name = 'precios'"
}
] | 3 |
knkarthick/tensorflow-learning
|
https://github.com/knkarthick/tensorflow-learning
|
61c8bf786caa15061dcd2e613e06873fbc59b129
|
95bb2bc69978e7c9a4a6a25240f24e0f314546f0
|
c2fd7c80105757cb12536cea3769a2f7385c59e9
|
refs/heads/master
| 2022-01-19T23:17:59.066237 | 2018-07-09T16:38:04 | 2018-07-09T16:38:04 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.687979519367218,
"alphanum_fraction": 0.6922420859336853,
"avg_line_length": 29.86842155456543,
"blob_id": "1881ee9b6314e2a66a77fa4d96e0cb3ca984bf23",
"content_id": "b4248ac3f6505b8d63748124752cae211295b619",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1173,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 38,
"path": "/custom-estimator/iris_data.py",
"repo_name": "knkarthick/tensorflow-learning",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport pandas as pd\nimport numpy as np\n\nCSV_COLUMN_NAMES = ['SepalLength', 'SepalWidth', 'PetalLength', 'PetalWidth', 'Species']\nLABEL_NAME = 'Species'\nSPECIES = ['Setosa', 'Versicolor', 'Virginica']\n\n\ndef read_from_file(filename):\n df = pd.read_csv(filename, names=CSV_COLUMN_NAMES, header=0)\n data, label = df, df.pop(LABEL_NAME)\n return data, label\n\n\ndef load_data():\n train_filename = 'data/iris_training.csv'\n test_filename = 'data/iris_test.csv'\n train_data, train_label = read_from_file(train_filename)\n test_data, test_label = read_from_file(test_filename)\n return train_data, train_label, test_data, test_label\n\n\ndef train_input_fn(features, labels, batch_size):\n dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))\n dataset = dataset.shuffle(1000).repeat().batch(batch_size)\n return dataset\n\n\ndef eval_input_fn(features, labels, batch_size):\n features = dict(features)\n if labels is not None:\n inputs = (features, labels)\n else:\n inputs = features\n dataset = tf.data.Dataset.from_tensor_slices(inputs)\n dataset = dataset.batch(batch_size)\n return dataset\n"
},
{
"alpha_fraction": 0.6137930750846863,
"alphanum_fraction": 0.6310344934463501,
"avg_line_length": 33.95180892944336,
"blob_id": "15ff8d6b919e830c6c33ea6ac3732e7584ea5016",
"content_id": "07764d8cb8857f3a231e4f738031b0f5cbaedcd2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2900,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 83,
"path": "/custom-estimator/custom_estimator.py",
"repo_name": "knkarthick/tensorflow-learning",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport iris_data\n\n\ndef my_model_fn(features, labels, mode, params):\n net = tf.feature_column.input_layer(features, params['feature_columns'])\n for units in params['hidden_units']:\n net = tf.layers.dense(net, units, activation=tf.nn.relu)\n\n logits = tf.layers.dense(net, params['n_classes'], activation=None)\n predicted_classes = tf.argmax(logits, 1)\n\n # PREDICT Mode\n if mode == tf.estimator.ModeKeys.PREDICT:\n predictions = {\n 'class_ids': predicted_classes[:, tf.newaxis],\n 'probabilities': tf.nn.softmax(logits),\n 'logits': logits\n }\n return tf.estimator.EstimatorSpec(mode, predictions=predictions)\n\n # loss calculation\n loss = tf.losses.sparse_softmax_cross_entropy(labels=labels, logits=logits)\n\n # accuracy calculation\n accuracy = tf.metrics.accuracy(labels=labels, predictions=predicted_classes)\n\n metrics = {'accuracy': accuracy}\n tf.summary.scalar('accuracy', accuracy[1])\n\n # EVAL Mode\n if mode == tf.estimator.ModeKeys.EVAL:\n return tf.estimator.EstimatorSpec(mode, loss=loss, eval_metric_ops=metrics)\n\n # TRAIN Mode\n # optimizer\n optimizer = tf.train.AdamOptimizer(learning_rate=0.05)\n # training op\n training_op = optimizer.minimize(loss, global_step=tf.train.get_global_step())\n return tf.estimator.EstimatorSpec(mode, loss=loss, train_op=training_op)\n\n\ndef main():\n train_data, train_label, test_data, test_label = iris_data.load_data()\n my_feature_columns = []\n for key in train_data.keys():\n my_feature_columns.append(tf.feature_column.numeric_column(key))\n\n classifier = tf.estimator.Estimator(\n model_fn=my_model_fn,\n params={\n 'feature_columns': my_feature_columns,\n 'hidden_units': [10, 10],\n 'n_classes': 3\n }\n )\n\n classifier.train(input_fn=lambda: iris_data.train_input_fn(train_data, train_label, 32), steps=100)\n eval_result = classifier.evaluate(input_fn=lambda: iris_data.eval_input_fn(test_data, test_label, 32))\n print('\\nTest set accuracy: {accuracy:0.3f}\\n'.format(**eval_result))\n\n expected = ['Setosa', 'Versicolor', 'Virginica']\n predict_x = {\n 'SepalLength': [5.1, 5.9, 6.9],\n 'SepalWidth': [3.3, 3.0, 3.1],\n 'PetalLength': [1.7, 4.2, 5.4],\n 'PetalWidth': [0.5, 1.5, 2.1],\n }\n\n predictions = classifier.predict(\n input_fn=lambda: iris_data.eval_input_fn(predict_x, labels=None, batch_size=32))\n\n for pred_dict, expec in zip(predictions, expected):\n template = ('\\nPrediction is \"{}\" ({:.1f}%), expected \"{}\"')\n\n class_id = pred_dict['class_ids'][0]\n probability = pred_dict['probabilities'][class_id]\n\n print(template.format(iris_data.SPECIES[class_id],\n 100 * probability, expec))\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.6738800406455994,
"alphanum_fraction": 0.6818526983261108,
"avg_line_length": 33.671051025390625,
"blob_id": "91d32354e2fba6af3e1f98bd905d7bed9fbd7732",
"content_id": "7e27712495771d2ff610af22eba778e9040ec138",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2634,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 76,
"path": "/linear-model/linear-model.py",
"repo_name": "knkarthick/tensorflow-learning",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nfrom tqdm import tqdm\n\n# importing the data\nfrom tensorflow.examples.tutorials.mnist import input_data\ndata = input_data.read_data_sets(\"data/MNIST/\", one_hot=True)\n\n# declaring the sizes for data\nimg_size = 28\nimg_size_falt = img_size * img_size\nimg_shape = (img_size, img_size)\n\nnum_classes = 10\n\n\ndef get_input_layer():\n x = tf.placeholder(dtype=tf.float32, shape=[None, img_size_falt], name=\"input_image\")\n y_true = tf.placeholder(dtype=tf.float32, shape=[None, num_classes], name=\"input_label\")\n y_true_class = tf.placeholder(dtype=tf.int64, shape=[None], name=\"input_label_class\")\n return (x, y_true, y_true_class)\n\n\ndef get_model_parameters():\n weights = tf.Variable(tf.zeros(shape=[img_size_falt, num_classes]), name=\"weights\")\n bias = tf.Variable(tf.zeros(shape=[num_classes]), name=\"bias\")\n return (weights, bias)\n\n\ndef linear_model(inputs, model_params, epochs, batch_size):\n x, y_true, y_true_class = inputs\n weights, bias = model_params\n\n # calculating the logits\n logits = tf.matmul(x, weights) + bias\n\n # calculating the predictions\n y_pred = tf.nn.softmax(logits)\n y_pred_class = tf.argmax(y_pred, 1)\n\n # defining the loss\n loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y_true, name=\"loss\")\n total_loss = tf.reduce_mean(loss)\n\n # defining the optimizer\n optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.1).minimize(total_loss)\n\n # calculating the accuracy\n correct_predictions = tf.equal(y_pred_class, y_true_class)\n accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))\n\n # calculating number of iterations for each epoch\n num_iterations = len(data.train.labels) // batch_size\n \n # creating a session\n sess = tf.Session(graph=tf.get_default_graph())\n sess.run(tf.global_variables_initializer())\n\n # running the model\n for i in range(epochs):\n for step in tqdm(range(num_iterations)):\n x_batch, y_label_batch = data.train.next_batch(batch_size)\n sess.run(optimizer, feed_dict={x: x_batch, y_true: y_label_batch})\n \n # test accuracy\n data.test.cls = np.array([label.argmax() for label in data.test.labels])\n test_accuracy = sess.run(accuracy, feed_dict={x: data.test.images, y_true: data.test.labels, y_true_class: data.test.cls})\n print(\"Accuracy on test set : %f\", (test_accuracy))\n\n\nif __name__ == '__main__':\n epochs = 100\n batch_size = 100\n model_inputs = get_input_layer()\n model_params = get_model_parameters()\n linear_model(model_inputs, model_params, epochs, batch_size)"
}
] | 3 |
julesfowler/grizli
|
https://github.com/julesfowler/grizli
|
8d8151a2de3a5fa66d8262cf8b7931d16989a2ad
|
61e8e01f0f12f72706703c9c2835ad046cb51870
|
dacbd5f067a14c1f176ad9003565bae8e938e08f
|
refs/heads/master
| 2021-01-20T11:10:45.479808 | 2017-05-28T01:01:12 | 2017-05-28T01:01:12 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5853658318519592,
"alphanum_fraction": 0.6910569071769714,
"avg_line_length": 23.600000381469727,
"blob_id": "8148e0f287ca4ac8550be26783d9a86b25c389ca",
"content_id": "d142b445ed989ebf33dc576e45e72a80ec2bbf43",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 123,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 5,
"path": "/grizli/version.py",
"repo_name": "julesfowler/grizli",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDummy file to hold the latest code version\n\"\"\"\n# Should be one commit behind latest\n__version__ = \"0.2.1-116-g7038273\"\n"
},
{
"alpha_fraction": 0.47348645329475403,
"alphanum_fraction": 0.5016360878944397,
"avg_line_length": 32.456783294677734,
"blob_id": "ed4fd3e6b837572eef8790f4cee8aab9d8765b9e",
"content_id": "55ac81f3218e2b0edfe190780dbf5622f3b2d067",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63873,
"license_type": "permissive",
"max_line_length": 240,
"num_lines": 1909,
"path": "/grizli/utils.py",
"repo_name": "julesfowler/grizli",
"src_encoding": "UTF-8",
"text": "\"\"\"General utilities\"\"\"\nimport os\nimport glob\nfrom collections import OrderedDict\n\nimport astropy.io.fits as pyfits\nimport astropy.wcs as pywcs\nimport astropy.table\n\nimport numpy as np\n\n# character to skip clearing line on STDOUT printing\nno_newline = '\\x1b[1A\\x1b[1M' \n\ndef get_flt_info(files=[]):\n \"\"\"Extract header information from a list of FLT files\n \n Parameters\n -----------\n files : list\n List of exposure filenames.\n \n Returns\n --------\n tab : `~astropy.table.Table`\n Table containing header keywords\n \n \"\"\"\n import astropy.io.fits as pyfits\n from astropy.table import Table\n \n if not files:\n files=glob.glob('*flt.fits')\n \n N = len(files)\n columns = ['FILE', 'FILTER', 'TARGNAME', 'DATE-OBS', 'TIME-OBS', 'EXPSTART', 'EXPTIME', 'PA_V3', 'RA_TARG', 'DEC_TARG', 'POSTARG1', 'POSTARG2']\n data = []\n\n for i in range(N):\n line = [os.path.basename(files[i]).split('.gz')[0]]\n if files[i].endswith('.gz'):\n im = pyfits.open(files[i])\n h = im[0].header\n else:\n h = pyfits.Header().fromfile(files[i])\n \n filt = get_hst_filter(h)\n line.append(filt)\n has_columns = ['FILE', 'FILTER']\n for key in columns[2:]:\n if key in h:\n line.append(h[key])\n has_columns.append(key)\n else:\n continue\n \n data.append(line)\n \n tab = Table(rows=data, names=has_columns)\n return tab\n\ndef radec_to_targname(ra=0, dec=0, header=None):\n \"\"\"Turn decimal degree coordinates into a string\n \n Example:\n\n >>> from grizli.utils import radec_to_targname\n >>> print(radec_to_targname(ra=10., dec=-10.))\n j004000-100000\n \n Parameters\n -----------\n ra, dec : float\n Sky coordinates in decimal degrees\n \n header : `~astropy.io.fits.Header` or None\n Optional FITS header with CRVAL or RA/DEC_TARG keywords. If \n specified, read `ra`/`dec` from CRVAL1/CRVAL2 or RA_TARG/DEC_TARG\n keywords, whichever are available\n \n Returns\n --------\n targname : str\n Target name like jHHMMSS[+-]DDMMSS.\n \n \"\"\"\n import astropy.coordinates \n import astropy.units as u\n import re\n \n if header is not None:\n if 'CRVAL1' in header:\n ra, dec = header['CRVAL1'], header['CRVAL2']\n else:\n if 'RA_TARG' in header:\n ra, dec = header['RA_TARG'], header['DEC_TARG']\n \n coo = astropy.coordinates.SkyCoord(ra=ra*u.deg, dec=dec*u.deg)\n \n cstr = re.split('[hmsd.]', coo.to_string('hmsdms', precision=2))\n targname = ('j{0}{1}'.format(''.join(cstr[0:3]), ''.join(cstr[4:7])))\n targname = targname.replace(' ', '')\n \n return targname\n \ndef parse_flt_files(files=[], info=None, uniquename=False, use_visit=False,\n get_footprint = False, \n translate = {'AEGIS-':'aegis-', \n 'COSMOS-':'cosmos-', \n 'GNGRISM':'goodsn-', \n 'GOODS-SOUTH-':'goodss-', \n 'UDS-':'uds-'}):\n \"\"\"Read header information from a list of exposures and parse out groups based on filter/target/orientation.\n \n Parameters\n -----------\n files : list\n List of exposure filenames. If not specified, use *flt.fits.\n \n info : None or output from `~grizli.utils.get_flt_info`.\n \n uniquename : bool\n If True, then split everything by program ID and visit name. If \n False, then just group by targname/filter/pa_v3.\n \n use_visit : bool\n For parallel observations with `targname='ANY'`, use the filename \n up to the visit ID as the target name. For example:\n \n >>> flc = 'jbhj64d8q_flc.fits'\n >>> visit_targname = flc[:6]\n >>> print(visit_targname)\n jbhj64\n \n If False, generate a targname for parallel observations based on the\n pointing coordinates using `radec_to_targname`. Use this keyword\n for dithered parallels like 3D-HST / GLASS but set to False for\n undithered parallels like WISP. Should also generally be used with\n `uniquename=False` otherwise generates names that are a bit redundant:\n \n +--------------+---------------------------+\n | `uniquename` | Output Targname |\n +==============+===========================+\n | True | jbhj45-bhj-45-180.0-F814W |\n +--------------+---------------------------+\n | False | jbhj45-180.0-F814W |\n +--------------+---------------------------+\n \n translate : dict\n Translation dictionary to modify TARGNAME keywords to some other \n value. Used like:\n \n >>> targname = 'GOODS-SOUTH-10'\n >>> translate = {'GOODS-SOUTH-': 'goodss-'}\n >>> for k in translate:\n >>> targname = targname.replace(k, translate[k])\n >>> print(targname)\n goodss-10\n \n Returns\n --------\n output_list : dict\n Dictionary split by target/filter/pa_v3. Keys are derived visit\n product names and values are lists of exposure filenames corresponding\n to that set. Keys are generated with the formats like:\n \n >>> targname = 'macs1149+2223'\n >>> pa_v3 = 32.0\n >>> filter = 'f140w'\n >>> flt_filename = 'ica521naq_flt.fits'\n >>> propstr = flt_filename[1:4]\n >>> visit = flt_filename[4:6]\n >>> # uniquename = False\n >>> print('{0}-{1:05.1f}-{2}'.format(targname, pa_v3, filter))\n macs1149.6+2223-032.0-f140w\n >>> # uniquename = True\n >>> print('{0}-{1:3s}-{2:2s}-{3:05.1f}-{4:s}'.format(targname, propstr, visit, pa_v3, filter))\n macs1149.6+2223-ca5-21-032.0-f140w\n \n filter_list : dict\n Nested dictionary split by filter and then PA_V3. This shouldn't \n be used if exposures from completely disjoint pointings are stored\n in the same working directory.\n \"\"\" \n \n if info is None:\n if not files:\n files=glob.glob('*flt.fits')\n \n if len(files) == 0:\n return False\n \n info = get_flt_info(files)\n else:\n info = info.copy()\n \n for c in info.colnames:\n if not c.islower(): \n info.rename_column(c, c.lower())\n\n if 'expstart' not in info.colnames:\n info['expstart'] = info['exptime']*0.\n\n so = np.argsort(info['expstart'])\n info = info[so]\n\n #pa_v3 = np.round(info['pa_v3']*10)/10 % 360.\n pa_v3 = np.round(info['pa_v3']) % 360.\n \n target_list = []\n for i in range(len(info)):\n #### Replace ANY targets with JRhRmRs-DdDmDs\n if info['targname'][i] == 'ANY': \n if use_visit:\n new_targname=info['file'][i][:6]\n else:\n new_targname = 'par-'+radec_to_targname(ra=info['ra_targ'][i],\n dec=info['dec_targ'][i])\n \n target_list.append(new_targname.lower())\n else:\n target_list.append(info['targname'][i])\n \n target_list = np.array(target_list)\n\n info['progIDs'] = [file[1:4] for file in info['file']]\n\n progIDs = np.unique(info['progIDs'])\n visits = np.array([os.path.basename(file)[4:6] for file in info['file']])\n dates = np.array([''.join(date.split('-')[1:]) for date in info['date-obs']])\n \n targets = np.unique(target_list)\n \n output_list = [] #OrderedDict()\n filter_list = OrderedDict()\n \n for filter in np.unique(info['filter']):\n filter_list[filter] = OrderedDict()\n \n angles = np.unique(pa_v3[(info['filter'] == filter)]) \n for angle in angles:\n filter_list[filter][angle] = []\n \n for target in targets:\n #### 3D-HST targname translations\n target_use = target\n for key in translate.keys():\n target_use = target_use.replace(key, translate[key])\n \n ## pad i < 10 with zero\n for key in translate.keys():\n if translate[key] in target_use:\n spl = target_use.split('-')\n try:\n if (int(spl[-1]) < 10) & (len(spl[-1]) == 1):\n spl[-1] = '{0:02d}'.format(int(spl[-1]))\n target_use = '-'.join(spl)\n except:\n pass\n\n for filter in np.unique(info['filter'][(target_list == target)]):\n angles = np.unique(pa_v3[(info['filter'] == filter) & \n (target_list == target)])\n \n for angle in angles:\n exposure_list = []\n exposure_start = []\n product='{0}-{1:05.1f}-{2}'.format(target_use, angle, filter) \n\n visit_match = np.unique(visits[(target_list == target) &\n (info['filter'] == filter)])\n \n this_progs = []\n this_visits = []\n \n for visit in visit_match:\n ix = (visits == visit) & (target_list == target) & (info['filter'] == filter)\n #this_progs.append(info['progIDs'][ix][0])\n #print visit, ix.sum(), np.unique(info['progIDs'][ix])\n new_progs = list(np.unique(info['progIDs'][ix]))\n this_visits.extend([visit]*len(new_progs))\n this_progs.extend(new_progs)\n \n for visit, prog in zip(this_visits, this_progs):\n visit_list = []\n visit_start = []\n visit_product = '{0}-{1}-{2}-{3:05.1f}-{4}'.format(target_use, prog, visit, angle, filter) \n \n use = ((target_list == target) & \n (info['filter'] == filter) & \n (visits == visit) & (pa_v3 == angle) &\n (info['progIDs'] == prog))\n \n if use.sum() == 0:\n continue\n\n for tstart, file in zip(info['expstart'][use],\n info['file'][use]):\n \n f = file.split('.gz')[0]\n if f not in exposure_list:\n visit_list.append(str(f))\n visit_start.append(tstart)\n \n exposure_list = np.append(exposure_list, visit_list)\n exposure_start.extend(visit_start)\n \n filter_list[filter][angle].extend(visit_list)\n \n if uniquename:\n print(visit_product, len(visit_list))\n so = np.argsort(visit_start)\n exposure_list = np.array(visit_list)[so]\n #output_list[visit_product.lower()] = visit_list\n \n d = OrderedDict(product=str(visit_product.lower()),\n files=list(np.array(visit_list)[so]))\n output_list.append(d)\n \n if not uniquename:\n print(product, len(exposure_list))\n so = np.argsort(exposure_start)\n exposure_list = np.array(exposure_list)[so]\n #output_list[product.lower()] = exposure_list\n d = OrderedDict(product=str(product.lower()),\n files=list(np.array(exposure_list)[so]))\n output_list.append(d)\n \n ### Get visit footprint from FLT WCS\n if get_footprint:\n from shapely.geometry import Polygon\n \n N = len(output_list)\n for i in range(N):\n for j in range(len(output_list[i]['files'])):\n flt_file = output_list[i]['files'][j]\n if (not os.path.exists(flt_file)) & os.path.exists('../RAW/'+flt_file):\n flt_file = '../RAW/'+flt_file\n \n flt_j = pyfits.open(flt_file)\n h = flt_j[0].header\n if (h['INSTRUME'] == 'WFC3') & (h['DETECTOR'] == 'IR'):\n wcs_j = pywcs.WCS(flt_j['SCI',1])\n else:\n wcs_j = pywcs.WCS(flt_j['SCI',1], fobj=flt_j)\n \n fp_j = Polygon(wcs_j.calc_footprint())\n if j == 0:\n fp_i = fp_j\n else:\n fp_i = fp_i.union(fp_j)\n \n output_list[i]['footprint'] = fp_i\n \n return output_list, filter_list\n\ndef parse_visit_overlaps(visits, buffer=15.):\n \"\"\"Find overlapping visits/filters to make combined mosaics\n \n Parameters\n ----------\n visits : list\n Output list of visit information from `~grizli.utils.parse_flt_files`.\n The script looks for files like `visits[i]['product']+'_dr?_sci.fits'` \n to compute the WCS footprint of a visit. These are produced, e.g., by \n `~grizli.prep.process_direct_grism_visit`.\n \n buffer : float\n Buffer, in `~astropy.units.arcsec`, to add around visit footprints to \n look for overlaps.\n \n Returns\n -------\n exposure_groups : list\n List of overlapping visits, with similar format as input `visits`.\n \n \"\"\"\n import copy\n from shapely.geometry import Polygon\n \n N = len(visits)\n\n exposure_groups = []\n used = np.arange(len(visits)) < 0\n \n for i in range(N):\n f_i = visits[i]['product'].split('-')[-1]\n if used[i]:\n continue\n \n im_i = pyfits.open(glob.glob(visits[i]['product']+'_dr?_sci.fits')[0])\n wcs_i = pywcs.WCS(im_i[0])\n fp_i = Polygon(wcs_i.calc_footprint()).buffer(buffer/3600.)\n \n exposure_groups.append(copy.deepcopy(visits[i]))\n \n for j in range(i+1, N):\n f_j = visits[j]['product'].split('-')[-1]\n if (f_j != f_i) | (used[j]):\n continue\n \n im_j = pyfits.open(glob.glob(visits[j]['product']+'_dr?_sci.fits')[0])\n wcs_j = pywcs.WCS(im_j[0])\n fp_j = Polygon(wcs_j.calc_footprint()).buffer(buffer/3600.)\n \n olap = fp_i.intersection(fp_j)\n if olap.area > 0:\n used[j] = True\n fp_i = fp_i.union(fp_j)\n exposure_groups[-1]['footprint'] = fp_i\n exposure_groups[-1]['files'].extend(visits[j]['files'])\n \n for i in range(len(exposure_groups)):\n flt_i = pyfits.open(exposure_groups[i]['files'][0])\n product = flt_i[0].header['TARGNAME'].lower() \n if product == 'any':\n product = 'par-'+radec_to_targname(header=flt_i['SCI',1].header)\n \n f_i = exposure_groups[i]['product'].split('-')[-1]\n product += '-'+f_i\n exposure_groups[i]['product'] = product\n \n return exposure_groups\n \ndef parse_grism_associations(exposure_groups, \n best_direct={'G102':'F105W', 'G141':'F140W'},\n get_max_overlap=True):\n \"\"\"Get associated lists of grism and direct exposures\n \n Parameters\n ----------\n exposure_grups : list\n Output list of overlapping visits from\n `~grizli.utils.parse_visit_overlaps`.\n \n best_direct : dict\n Dictionary of the preferred direct imaging filters to use with a \n particular grism.\n \n Returns\n -------\n grism_groups : list\n List of dictionaries with associated 'direct' and 'grism' entries.\n \n \"\"\"\n N = len(exposure_groups)\n \n grism_groups = []\n for i in range(N):\n f_i = exposure_groups[i]['product'].split('-')[-1]\n root_i = exposure_groups[i]['product'].split('-'+f_i)[0]\n \n if f_i.startswith('g'):\n group = OrderedDict(grism=exposure_groups[i], \n direct=None)\n else:\n continue\n \n fp_i = exposure_groups[i]['footprint']\n olap_i = 0.\n d_i = f_i\n \n #print('\\nx\\n')\n for j in range(N):\n f_j = exposure_groups[j]['product'].split('-')[-1]\n if f_j.startswith('g'):\n continue\n \n fp_j = exposure_groups[j]['footprint']\n olap = fp_i.intersection(fp_j)\n root_j = exposure_groups[j]['product'].split('-'+f_j)[0]\n\n #print(root_j, root_i, root_j == root_i)\n if (root_j == root_i):\n if (group['direct'] is not None):\n pass\n if (group['direct']['product'].startswith(root_i)) & (d_i.upper() == best_direct[f_i.upper()]):\n continue\n \n group['direct'] = exposure_groups[j]\n olap_i = olap.area\n d_i = f_j\n #print(0,group['grism']['product'], group['direct']['product'])\n # continue\n \n #print(exposure_groups[i]['product'], exposure_groups[j]['product'], olap.area*3600.)\n \n #print(exposure_groups[j]['product'], olap_i, olap.area)\n if olap.area > 0:\n if group['direct'] is None:\n group['direct'] = exposure_groups[j]\n olap_i = olap.area\n d_i = f_j\n #print(1,group['grism']['product'], group['direct']['product'])\n else:\n #if (f_j.upper() == best_direct[f_i.upper()]):\n if get_max_overlap:\n if olap.area < olap_i:\n continue\n \n if d_i.upper() == best_direct[f_i.upper()]:\n continue\n \n group['direct'] = exposure_groups[j]\n #print(exposure_groups[j]['product'])\n olap_i = olap.area\n d_i = f_j\n #print(2,group['grism']['product'], group['direct']['product'])\n \n grism_groups.append(group)\n \n return grism_groups\n \ndef get_hst_filter(header):\n \"\"\"Get simple filter name out of an HST image header. \n \n ACS has two keywords for the two filter wheels, so just return the \n non-CLEAR filter. For example, \n \n >>> h = astropy.io.fits.Header()\n >>> h['INSTRUME'] = 'ACS'\n >>> h['FILTER1'] = 'CLEAR1L'\n >>> h['FILTER2'] = 'F814W'\n >>> from grizli.utils import get_hst_filter\n >>> print(get_hst_filter(h))\n F814W\n >>> h['FILTER1'] = 'G800L'\n >>> h['FILTER2'] = 'CLEAR2L'\n >>> print(get_hst_filter(h))\n G800L\n \n Parameters\n -----------\n header : `~astropy.io.fits.Header`\n Image header with FILTER or FILTER1,FILTER2,...,FILTERN keywords\n \n Returns\n --------\n filter : str\n \n \"\"\"\n if header['INSTRUME'].strip() == 'ACS':\n for i in [1,2]:\n filter_i = header['FILTER{0:d}'.format(i)]\n if 'CLEAR' in filter_i:\n continue\n else:\n filter = filter_i\n elif header['INSTRUME'] == 'WFPC2':\n filter = header['FILTNAM1']\n else:\n filter = header['FILTER']\n \n return filter.upper()\n \ndef unset_dq_bits(value, okbits=32+64+512, verbose=False):\n \"\"\"\n Unset bit flags from a DQ array\n \n For WFC3/IR, the following DQ bits can usually be unset: \n \n 32, 64: these pixels usually seem OK\n 512: blobs not relevant for grism exposures\n \n Parameters\n ----------\n value : int, `~numpy.ndarray`\n Input DQ value\n \n okbits : int\n Bits to unset\n \n verbose : bool\n Print some information\n \n Returns\n -------\n new_value : int, `~numpy.ndarray`\n \n \"\"\"\n bin_bits = np.binary_repr(okbits)\n n = len(bin_bits)\n for i in range(n):\n if bin_bits[-(i+1)] == '1':\n if verbose:\n print(2**i)\n \n value -= (value & 2**i)\n \n return value\n\ndef detect_with_photutils(sci, err=None, dq=None, seg=None, detect_thresh=2.,\n npixels=8, grow_seg=5, gauss_fwhm=2., gsize=3, \n wcs=None, save_detection=False, root='mycat',\n background=None, gain=None, AB_zeropoint=0., \n rename_columns = {'xcentroid': 'x_flt',\n 'ycentroid': 'y_flt',\n 'ra_icrs_centroid': 'ra',\n 'dec_icrs_centroid': 'dec'},\n clobber=True, verbose=True):\n \"\"\"Use `photutils <https://photutils.readthedocs.io/>`__ to detect objects and make segmentation map\n \n Parameters\n ----------\n sci : `~numpy.ndarray`\n TBD\n \n err, dq, seg : TBD\n \n detect_thresh : float\n Detection threshold, in :math:`\\sigma`\n \n grow_seg : int\n Number of pixels to grow around the perimeter of detected objects\n witha maximum filter\n \n gauss_fwhm : float\n FWHM of Gaussian convolution kernel that smoothes the detection\n image.\n \n verbose : bool\n Print logging information to the terminal\n \n save_detection : bool\n Save the detection images and catalogs\n \n wcs : `~astropy.wcs.WCS`\n WCS object passed to `photutils.source_properties` used to compute\n sky coordinates of detected objects.\n \n Returns\n ---------\n catalog : `~astropy.table.Table`\n Object catalog with the default parameters.\n \"\"\"\n import scipy.ndimage as nd\n \n from photutils import detect_threshold, detect_sources, SegmentationImage\n from photutils import source_properties, properties_table\n \n import astropy.io.fits as pyfits\n from astropy.table import Column\n \n from astropy.stats import sigma_clipped_stats, gaussian_fwhm_to_sigma\n from astropy.convolution import Gaussian2DKernel\n \n ### DQ masks\n mask = (sci == 0)\n if dq is not None:\n mask |= dq > 0\n \n ### Detection threshold\n if err is None:\n threshold = detect_threshold(sci, snr=detect_thresh, mask=mask)\n else:\n threshold = (detect_thresh * err)*(~mask)\n threshold[mask] = np.median(threshold[~mask])\n \n if seg is None:\n ####### Run the source detection and create the segmentation image\n \n ### Gaussian kernel\n sigma = gauss_fwhm * gaussian_fwhm_to_sigma # FWHM = 2.\n kernel = Gaussian2DKernel(sigma, x_size=gsize, y_size=gsize)\n kernel.normalize()\n \n if verbose:\n print('{0}: photutils.detect_sources (detect_thresh={1:.1f}, grow_seg={2:d}, gauss_fwhm={3:.1f}, ZP={4:.1f})'.format(root, detect_thresh, grow_seg, gauss_fwhm, AB_zeropoint))\n \n ### Detect sources\n segm = detect_sources(sci*(~mask), threshold, npixels=npixels,\n filter_kernel=kernel) \n \n grow = nd.maximum_filter(segm.array, grow_seg)\n seg = np.cast[np.float32](grow)\n else:\n ######## Use the supplied segmentation image\n segm = SegmentationImage(seg)\n \n ### Source properties catalog\n if verbose:\n print('{0}: photutils.source_properties'.format(root))\n \n props = source_properties(sci, segm, error=threshold/detect_thresh,\n mask=mask, background=background, wcs=wcs)\n \n catalog = properties_table(props)\n \n ### Mag columns\n mag = AB_zeropoint - 2.5*np.log10(catalog['source_sum'])\n mag._name = 'mag'\n catalog.add_column(mag)\n \n try:\n logscale = 2.5/np.log(10)\n mag_err = logscale*catalog['source_sum_err']/catalog['source_sum']\n except:\n mag_err = np.zeros_like(mag)-99\n \n mag_err._name = 'mag_err'\n catalog.add_column(mag_err)\n \n ### Rename some catalog columns \n for key in rename_columns.keys():\n if key not in catalog.colnames:\n continue\n \n catalog.rename_column(key, rename_columns[key])\n if verbose:\n print('Rename column: {0} -> {1}'.format(key, rename_columns[key]))\n \n ### Done!\n if verbose:\n print(no_newline + ('{0}: photutils.source_properties - {1:d} objects'.format(root, len(catalog))))\n \n #### Save outputs?\n if save_detection:\n seg_file = root + '.detect_seg.fits'\n seg_cat = root + '.detect.cat'\n if verbose:\n print('{0}: save {1}, {2}'.format(root, seg_file, seg_cat))\n \n if wcs is not None:\n header = wcs.to_header(relax=True)\n else:\n header=None\n \n pyfits.writeto(seg_file, data=seg, header=header, clobber=clobber)\n \n if os.path.exists(seg_cat) & clobber:\n os.remove(seg_cat)\n \n catalog.write(seg_cat, format='ascii.commented_header')\n \n return catalog, seg\n \ndef nmad(data):\n \"\"\"Normalized NMAD=1.48 * `~.astropy.stats.median_absolute_deviation`\n \n \"\"\"\n import astropy.stats\n return 1.48*astropy.stats.median_absolute_deviation(data)\n\ndef get_line_wavelengths():\n \"\"\"Get a dictionary of common emission line wavelengths and line ratios\n \n Returns\n -------\n line_wavelengths, line_ratios : dict\n Keys are common to both dictionaries and are simple names for lines\n and line complexes. Values are lists of line wavelengths and line \n ratios.\n \n >>> from grizli.utils import get_line_wavelengths\n >>> line_wavelengths, line_ratios = get_line_wavelengths()\n >>> print(line_wavelengths['Ha'], line_ratios['Ha'])\n [6564.61] [1.0]\n >>> print(line_wavelengths['OIII'], line_ratios['OIII'])\n [5008.24, 4960.295] [2.98, 1]\n \n Includes some additional combined line complexes useful for redshift\n fits:\n \n >>> from grizli.utils import get_line_wavelengths\n >>> line_wavelengths, line_ratios = get_line_wavelengths()\n >>> key = 'Ha+SII+SIII+He'\n >>> print(line_wavelengths[key], '\\\\n', line_ratios[key])\n [6564.61, 6718.29, 6732.67, 9068.6, 9530.6, 10830.0]\n [1.0, 0.1, 0.1, 0.05, 0.122, 0.04]\n \n \"\"\"\n line_wavelengths = OrderedDict() ; line_ratios = OrderedDict()\n line_wavelengths['Ha'] = [6564.61]\n line_ratios['Ha'] = [1.]\n line_wavelengths['Hb'] = [4862.68]\n line_ratios['Hb'] = [1.]\n line_wavelengths['Hg'] = [4341.68]\n line_ratios['Hg'] = [1.]\n line_wavelengths['Hd'] = [4102.892]\n line_ratios['Hd'] = [1.]\n line_wavelengths['OIII-4363'] = [4364.436]\n line_ratios['OIII-4363'] = [1.]\n line_wavelengths['OIII'] = [5008.240, 4960.295]\n line_ratios['OIII'] = [2.98, 1]\n line_wavelengths['OIII+Hb'] = [5008.240, 4960.295, 4862.68]\n line_ratios['OIII+Hb'] = [2.98, 1, 3.98/6.]\n \n line_wavelengths['OIII+Hb+Ha'] = [5008.240, 4960.295, 4862.68, 6564.61]\n line_ratios['OIII+Hb+Ha'] = [2.98, 1, 3.98/10., 3.98/10.*2.86]\n\n line_wavelengths['OIII+Hb+Ha+SII'] = [5008.240, 4960.295, 4862.68, 6564.61, 6718.29, 6732.67]\n line_ratios['OIII+Hb+Ha+SII'] = [2.98, 1, 3.98/10., 3.98/10.*2.86*4, 3.98/10.*2.86/10.*4, 3.98/10.*2.86/10.*4]\n\n line_wavelengths['OIII+OII'] = [5008.240, 4960.295, 3729.875]\n line_ratios['OIII+OII'] = [2.98, 1, 3.98/4.]\n\n line_wavelengths['OII'] = [3729.875]\n line_ratios['OII'] = [1]\n \n line_wavelengths['OII+Ne'] = [3729.875, 3869]\n line_ratios['OII+Ne'] = [1, 1./5]\n \n line_wavelengths['OI-6302'] = [6302.046, 6363.67]\n line_ratios['OI-6302'] = [1, 0.33]\n\n line_wavelengths['NeIII'] = [3869]\n line_ratios['NeIII'] = [1.]\n line_wavelengths['NeV'] = [3346.8]\n line_ratios['NeV'] = [1.]\n line_wavelengths['NeVI'] = [3426.85]\n line_ratios['NeVI'] = [1.]\n line_wavelengths['SIII'] = [9068.6, 9530.6][::-1]\n line_ratios['SIII'] = [1, 2.44][::-1]\n line_wavelengths['HeII'] = [4687.5]\n line_ratios['HeII'] = [1.]\n line_wavelengths['HeI-5877'] = [5877.2]\n line_ratios['HeI-5877'] = [1.]\n line_wavelengths['HeI-3889'] = [3889.5]\n line_ratios['HeI-3889'] = [1.]\n \n line_wavelengths['MgII'] = [2799.117]\n line_ratios['MgII'] = [1.]\n \n line_wavelengths['CIV'] = [1549.480]\n line_ratios['CIV'] = [1.]\n line_wavelengths['CIII]'] = [1908.]\n line_ratios['CIII]'] = [1.]\n line_wavelengths['OIII]'] = [1663.]\n line_ratios['OIII]'] = [1.]\n line_wavelengths['HeII-1640'] = [1640.]\n line_ratios['HeII-1640'] = [1.]\n line_wavelengths['NIII]'] = [1750.]\n line_ratios['NIII]'] = [1.]\n line_wavelengths['NIV'] = [1487.]\n line_ratios['NIV'] = [1.]\n line_wavelengths['NV'] = [1240.]\n line_ratios['NV'] = [1.]\n\n line_wavelengths['Lya'] = [1215.4]\n line_ratios['Lya'] = [1.]\n\n line_wavelengths['Ha+SII'] = [6564.61, 6718.29, 6732.67]\n line_ratios['Ha+SII'] = [1., 1./10, 1./10]\n line_wavelengths['Ha+SII+SIII+He'] = [6564.61, 6718.29, 6732.67, 9068.6, 9530.6, 10830.]\n line_ratios['Ha+SII+SIII+He'] = [1., 1./10, 1./10, 1./20, 2.44/20, 1./25.]\n\n line_wavelengths['Ha+NII+SII+SIII+He'] = [6564.61, 6549.86, 6585.27, 6718.29, 6732.67, 9068.6, 9530.6, 10830.]\n line_ratios['Ha+NII+SII+SIII+He'] = [1., 1./(4.*4), 3./(4*4), 1./10, 1./10, 1./20, 2.44/20, 1./25.]\n \n line_wavelengths['NII'] = [6549.86, 6585.27]\n line_ratios['NII'] = [1., 3]\n \n line_wavelengths['SII'] = [6718.29, 6732.67]\n line_ratios['SII'] = [1., 1.] \n \n return line_wavelengths, line_ratios \n \nclass SpectrumTemplate(object):\n def __init__(self, wave=None, flux=None, fwhm=None, velocity=False):\n \"\"\"Container for template spectra. \n \n Parameters\n ----------\n wave, fwhm : None or float or array-like\n If both are float, then initialize with a Gaussian. \n In `astropy.units.Angstrom`.\n \n flux : None or array-like\n Flux array (f-lambda flux density)\n \n velocity : bool\n `fwhm` is a velocity.\n \n Attributes\n ----------\n wave, flux : array-like\n Passed from the input parameters or generated/modified later.\n \n Methods\n -------\n __add__, __mul__ : Addition and multiplication of templates.\n \n Examples\n --------\n \n .. plot::\n :include-source:\n\n import matplotlib.pyplot as plt\n from grizli.utils import SpectrumTemplate\n \n ha = SpectrumTemplate(wave=6563., fwhm=10)\n plt.plot(ha.wave, ha.flux)\n \n ha_z = ha.zscale(0.1)\n plt.plot(ha_z.wave, ha_z.flux, label='z=0.1')\n \n plt.legend()\n plt.xlabel(r'$\\lambda$')\n \n plt.show()\n \n \"\"\"\n self.wave = wave\n self.flux = flux\n\n if (wave is not None) & (fwhm is not None):\n self.make_gaussian(wave, fwhm, velocity=velocity)\n \n def make_gaussian(self, wave, fwhm, max_sigma=5, step=0.1, \n velocity=False):\n \"\"\"Make Gaussian template\n \n Parameters\n ----------\n wave, fwhm : None or float or array-like\n Central wavelength and FWHM of the desired Gaussian\n \n velocity : bool\n `fwhm` is a velocity.\n \n max_sigma, step : float\n Generated wavelength array is\n \n >>> rms = fwhm/2.35\n >>> xgauss = np.arange(-max_sigma, max_sigma, step)*rms+wave\n\n Returns\n -------\n Stores `wave`, `flux` attributes. \n \"\"\"\n rms = fwhm/2.35\n if velocity:\n rms *= wave/3.e5\n \n xgauss = np.arange(-max_sigma, max_sigma, step)*rms+wave\n gaussian = np.exp(-(xgauss-wave)**2/2/rms**2)\n gaussian /= np.sqrt(2*np.pi*rms**2)\n \n self.wave = xgauss\n self.flux = gaussian\n\n def zscale(self, z, scalar=1):\n \"\"\"Redshift the template and multiply by a scalar.\n \n Parameters\n ----------\n z : float\n Redshift to use.\n \n scalar : float\n Multiplicative factor. Additional factor of 1./(1+z) is implicit.\n \n Returns\n -------\n new_spectrum : `~grizli.utils.SpectrumTemplate` \n Redshifted and scaled spectrum.\n \n \"\"\"\n try:\n import eazy.igm\n igm = eazy.igm.Inoue14()\n igmz = igm.full_IGM(z, self.wave*(1+z))\n except:\n igmz = 1.\n \n return SpectrumTemplate(wave=self.wave*(1+z),\n flux=self.flux*scalar/(1+z)*igmz)\n \n def __add__(self, spectrum):\n \"\"\"Add two templates together\n \n The new wavelength array is the union of both input spectra and each\n input spectrum is linearly interpolated to the final grid.\n \n Parameters\n ----------\n spectrum : `~grizli.utils.SpectrumTemplate`\n \n Returns\n -------\n new_spectrum : `~grizli.utils.SpectrumTemplate`\n \"\"\"\n new_wave = np.unique(np.append(self.wave, spectrum.wave))\n new_wave.sort()\n \n new_flux = np.interp(new_wave, self.wave, self.flux)\n new_flux += np.interp(new_wave, spectrum.wave, spectrum.flux)\n return SpectrumTemplate(wave=new_wave, flux=new_flux)\n \n def __mul__(self, scalar):\n \"\"\"Multiply spectrum by a scalar value\n \n Parameters\n ----------\n scalar : float\n Factor to multipy to `self.flux`.\n \n Returns\n -------\n new_spectrum : `~grizli.utils.SpectrumTemplate` \n \"\"\"\n return SpectrumTemplate(wave=self.wave, flux=self.flux*scalar)\n \ndef log_zgrid(zr=[0.7,3.4], dz=0.01):\n \"\"\"Make a logarithmically spaced redshift grid\n \n Parameters\n ----------\n zr : [float, float]\n Minimum and maximum of the desired grid\n \n dz : float\n Step size, dz/(1+z)\n \n Returns\n -------\n zgrid : array-like\n Redshift grid\n \n \"\"\"\n zgrid = np.exp(np.arange(np.log(1+zr[0]), np.log(1+zr[1]), dz))-1\n return zgrid\n\n### Deprecated\n# def zoom_zgrid(zgrid, chi2nu, threshold=0.01, factor=10, grow=7):\n# \"\"\"TBD\n# \"\"\"\n# import scipy.ndimage as nd\n# \n# mask = (chi2nu-chi2nu.min()) < threshold\n# if grow > 1:\n# mask_grow = nd.maximum_filter(mask*1, size=grow)\n# mask = mask_grow > 0\n# \n# if mask.sum() == 0:\n# return []\n# \n# idx = np.arange(zgrid.shape[0])\n# out_grid = []\n# for i in idx[mask]:\n# if i == idx[-1]:\n# continue\n# \n# out_grid = np.append(out_grid, np.linspace(zgrid[i], zgrid[i+1], factor+2)[1:-1])\n# \n# return out_grid\n\ndef get_wcs_pscale(wcs):\n \"\"\"Get correct pscale from a `~astropy.wcs.WCS` object\n \n Parameters\n ----------\n wcs : `~astropy.wcs.WCS`\n \n Returns\n -------\n pscale : float\n Pixel scale from `wcs.cd`\n \n \"\"\"\n from numpy import linalg\n det = linalg.det(wcs.wcs.cd)\n pscale = np.sqrt(np.abs(det))*3600.\n return pscale\n \ndef transform_wcs(in_wcs, translation=[0.,0.], rotation=0., scale=1.):\n \"\"\"Update WCS with shift, rotation, & scale\n \n Paramters\n ---------\n in_wcs: `~astropy.wcs.WCS`\n Input WCS\n \n translation: [float, float]\n xshift & yshift in pixels\n \n rotation: float\n CCW rotation (towards East), radians\n \n scale: float\n Pixel scale factor\n \n Returns\n -------\n out_wcs: `~astropy.wcs.WCS`\n Modified WCS\n \"\"\"\n out_wcs = in_wcs.deepcopy()\n out_wcs.wcs.crpix += np.array(translation)\n theta = -rotation\n _mat = np.array([[np.cos(theta), -np.sin(theta)],\n [np.sin(theta), np.cos(theta)]])\n \n out_wcs.wcs.cd = np.dot(out_wcs.wcs.cd, _mat)/scale\n out_wcs.pscale = get_wcs_pscale(out_wcs)\n out_wcs.wcs.crpix *= scale\n if hasattr(out_wcs, '_naxis1'):\n out_wcs._naxis1 = int(np.round(out_wcs._naxis1*scale))\n out_wcs._naxis2 = int(np.round(out_wcs._naxis2*scale))\n \n return out_wcs\n \ndef get_wcs_slice_header(wcs, slx, sly):\n \"\"\"TBD\n \"\"\"\n #slx, sly = slice(1279, 1445), slice(2665,2813)\n h = wcs.slice((sly, slx)).to_header(relax=True)\n h['NAXIS'] = 2\n h['NAXIS1'] = slx.stop-slx.start\n h['NAXIS2'] = sly.stop-sly.start\n for k in h:\n if k.startswith('PC'):\n h.rename_keyword(k, k.replace('PC', 'CD'))\n \n return h\n \ndef reproject_faster(input_hdu, output, pad=10, **kwargs):\n \"\"\"Speed up `reproject` module with array slices of the input image\n \n Parameters\n ----------\n input_hdu : `~astropy.io.fits.ImageHDU`\n Input image HDU to reproject. \n \n output : `~astropy.wcs.WCS` or `~astropy.io.fits.Header`\n Output frame definition.\n \n pad : int\n Pixel padding on slices cut from the `input_hdu`.\n \n kwargs : dict\n Arguments passed through to `~reproject.reproject_interp`. For \n example, `order='nearest-neighbor'`.\n \n Returns\n -------\n reprojected : `~numpy.ndarray`\n Reprojected data from `input_hdu`.\n \n footprint : `~numpy.ndarray`\n Footprint of the input array in the output frame.\n \n .. note::\n \n `reproject' is an astropy-compatible module that can be installed with \n `pip`. See https://reproject.readthedocs.io.\n \n \"\"\"\n import reproject\n \n # Output WCS\n if isinstance(output, pywcs.WCS):\n out_wcs = output\n else:\n out_wcs = pywcs.WCS(output, relax=True)\n \n if 'SIP' in out_wcs.wcs.ctype[0]:\n print('Warning: `reproject` doesn\\'t appear to support SIP projection')\n \n # Compute pixel coordinates of the output frame corners in the input image\n input_wcs = pywcs.WCS(input_hdu.header, relax=True)\n out_fp = out_wcs.calc_footprint()\n input_xy = input_wcs.all_world2pix(out_fp, 0)\n slx = slice(int(input_xy[:,0].min())-pad, int(input_xy[:,0].max())+pad)\n sly = slice(int(input_xy[:,1].min())-pad, int(input_xy[:,1].max())+pad)\n \n # Make the cutout\n sub_data = input_hdu.data[sly, slx]\n sub_header = get_wcs_slice_header(input_wcs, slx, sly)\n sub_hdu = pyfits.PrimaryHDU(data=sub_data, header=sub_header)\n \n # Get the reprojection\n seg_i, fp_i = reproject.reproject_interp(sub_hdu, output, **kwargs)\n return seg_i.astype(sub_data.dtype), fp_i.astype(np.uint8)\n \ndef make_spectrum_wcsheader(center_wave=1.4e4, dlam=40, NX=100, spatial_scale=1, NY=10):\n \"\"\"Make a WCS header for a 2D spectrum\n \n Parameters\n ----------\n center_wave : float\n Wavelength of the central pixel, in Anstroms\n \n dlam : float\n Delta-wavelength per (x) pixel\n \n NX, NY : int\n Number of x & y pixels. Output will have shape `(2*NY, 2*NX)`.\n \n spatial_scale : float\n Spatial scale of the output, in units of the input pixels\n \n Returns\n -------\n header : `~astropy.io.fits.Header`\n Output WCS header\n \n wcs : `~astropy.wcs.WCS`\n Output WCS\n \n Examples\n --------\n \n >>> from grizli.utils import make_spectrum_wcsheader\n >>> h, wcs = make_spectrum_wcsheader()\n >>> print(wcs)\n WCS Keywords\n Number of WCS axes: 2\n CTYPE : 'WAVE' 'LINEAR' \n CRVAL : 14000.0 0.0 \n CRPIX : 101.0 11.0 \n CD1_1 CD1_2 : 40.0 0.0 \n CD2_1 CD2_2 : 0.0 1.0 \n NAXIS : 200 20\n\n \"\"\"\n \n h = pyfits.ImageHDU(data=np.zeros((2*NY, 2*NX), dtype=np.float32))\n \n refh = h.header\n refh['CRPIX1'] = NX+1\n refh['CRPIX2'] = NY+1\n refh['CRVAL1'] = center_wave\n refh['CD1_1'] = dlam\n refh['CD1_2'] = 0.\n refh['CRVAL2'] = 0.\n refh['CD2_2'] = spatial_scale\n refh['CD2_1'] = 0.\n refh['RADESYS'] = ''\n \n refh['CTYPE1'] = 'WAVE'\n refh['CTYPE2'] = 'LINEAR'\n \n ref_wcs = pywcs.WCS(h.header)\n ref_wcs.pscale = np.sqrt(ref_wcs.wcs.cd[0,0]**2 + ref_wcs.wcs.cd[1,0]**2)*3600.\n \n return refh, ref_wcs\n\ndef to_header(wcs, relax=True):\n \"\"\"Modify `astropy.wcs.WCS.to_header` to produce more keywords\n \n Parameters\n ----------\n wcs : `~astropy.wcs.WCS`\n Input WCS.\n \n relax : bool\n Passed to `WCS.to_header(relax=)`.\n \n Returns\n -------\n header : `~astropy.io.fits.Header`\n Output header.\n \n \"\"\"\n header = wcs.to_header(relax=relax)\n if hasattr(wcs, '_naxis1'):\n header['NAXIS'] = wcs.naxis\n header['NAXIS1'] = wcs._naxis1\n header['NAXIS2'] = wcs._naxis2\n \n for k in header:\n if k.startswith('PC'):\n cd = k.replace('PC','CD')\n header.rename_keyword(k, cd)\n \n return header\n \ndef make_wcsheader(ra=40.07293, dec=-1.6137748, size=2, pixscale=0.1, get_hdu=False, theta=0):\n \"\"\"Make a celestial WCS header\n \n Parameters\n ----------\n ra, dec : float\n Celestial coordinates in decimal degrees\n \n size, pixscale : float or 2-list\n Size of the thumbnail, in arcsec, and pixel scale, in arcsec/pixel.\n Output image will have dimensions `(npix,npix)`, where\n \n >>> npix = size/pixscale\n \n get_hdu : bool\n Return a `~astropy.io.fits.ImageHDU` rather than header/wcs.\n \n theta : float\n Position angle of the output thumbnail\n \n Returns\n -------\n hdu : `~astropy.io.fits.ImageHDU` \n HDU with data filled with zeros if `get_hdu=True`.\n \n header, wcs : `~astropy.io.fits.Header`, `~astropy.wcs.WCS`\n Header and WCS object if `get_hdu=False`.\n\n Examples\n --------\n \n >>> from grizli.utils import make_wcsheader\n >>> h, wcs = make_wcsheader()\n >>> print(wcs)\n WCS Keywords\n Number of WCS axes: 2\n CTYPE : 'RA---TAN' 'DEC--TAN' \n CRVAL : 40.072929999999999 -1.6137748000000001 \n CRPIX : 10.0 10.0 \n CD1_1 CD1_2 : -2.7777777777777e-05 0.0 \n CD2_1 CD2_2 : 0.0 2.7777777777777701e-05 \n NAXIS : 20 20\n \n >>> from grizli.utils import make_wcsheader\n >>> hdu = make_wcsheader(get_hdu=True)\n >>> print(hdu.data.shape)\n (20, 20)\n >>> print(hdu.header.tostring)\n XTENSION= 'IMAGE ' / Image extension \n BITPIX = -32 / array data type \n NAXIS = 2 / number of array dimensions \n PCOUNT = 0 / number of parameters \n GCOUNT = 1 / number of groups \n CRPIX1 = 10 \n CRPIX2 = 10 \n CRVAL1 = 40.07293 \n CRVAL2 = -1.6137748 \n CD1_1 = -2.7777777777777E-05 \n CD1_2 = 0.0 \n CD2_1 = 0.0 \n CD2_2 = 2.77777777777777E-05 \n NAXIS1 = 20 \n NAXIS2 = 20 \n CTYPE1 = 'RA---TAN' \n CTYPE2 = 'DEC--TAN'\n \"\"\"\n \n if np.isscalar(pixscale):\n cdelt = [pixscale/3600.]*2\n else:\n cdelt = [pixscale[0]/3600., pixscale[1]/3600.]\n \n if np.isscalar(size):\n npix = np.cast[int]([size/pixscale, size/pixscale])\n else:\n npix = np.cast[int]([size[0]/pixscale, size[1]/pixscale])\n \n hout = pyfits.Header()\n hout['CRPIX1'] = npix[0]/2\n hout['CRPIX2'] = npix[1]/2\n hout['CRVAL1'] = ra\n hout['CRVAL2'] = dec\n hout['CD1_1'] = -cdelt[0]\n hout['CD1_2'] = hout['CD2_1'] = 0.\n hout['CD2_2'] = cdelt[1]\n hout['NAXIS1'] = npix[0]\n hout['NAXIS2'] = npix[1]\n hout['CTYPE1'] = 'RA---TAN'\n hout['CTYPE2'] = 'DEC--TAN'\n \n wcs_out = pywcs.WCS(hout)\n \n theta_rad = np.deg2rad(theta)\n mat = np.array([[np.cos(theta_rad), -np.sin(theta_rad)], \n [np.sin(theta_rad), np.cos(theta_rad)]])\n\n rot_cd = np.dot(mat, wcs_out.wcs.cd)\n \n for i in [0,1]:\n for j in [0,1]:\n hout['CD{0:d}_{1:d}'.format(i+1, j+1)] = rot_cd[i,j]\n wcs_out.wcs.cd[i,j] = rot_cd[i,j]\n \n cd = wcs_out.wcs.cd\n wcs_out.pscale = get_wcs_pscale(wcs_out) #np.sqrt((cd[0,:]**2).sum())*3600.\n \n if get_hdu:\n hdu = pyfits.ImageHDU(header=hout, data=np.zeros((npix[1], npix[0]), dtype=np.float32))\n return hdu\n else:\n return hout, wcs_out\n \ndef fetch_hst_calib(file='iref$uc72113oi_pfl.fits', ftpdir='https://hst-crds.stsci.edu/unchecked_get/references/hst/', verbose=True):\n \"\"\"\n TBD\n \"\"\"\n import os\n \n ref_dir = file.split('$')[0]\n cimg = file.split('{0}$'.format(ref_dir))[1]\n iref_file = os.path.join(os.getenv(ref_dir), cimg)\n if not os.path.exists(iref_file):\n os.system('curl -o {0} {1}/{2}'.format(iref_file, ftpdir, cimg))\n else:\n if verbose:\n print('{0} exists'.format(iref_file))\n \ndef fetch_hst_calibs(flt_file, ftpdir='https://hst-crds.stsci.edu/unchecked_get/references/hst/', calib_types=['BPIXTAB', 'CCDTAB', 'OSCNTAB', 'CRREJTAB', 'DARKFILE', 'NLINFILE', 'PFLTFILE', 'IMPHTTAB', 'IDCTAB', 'NPOLFILE'], verbose=True):\n \"\"\"\n TBD\n Fetch necessary calibration files needed for running calwf3 from STScI FTP\n \n Old FTP dir: ftp://ftp.stsci.edu/cdbs/iref/\"\"\"\n import os\n \n im = pyfits.open(flt_file)\n if im[0].header['INSTRUME'] == 'ACS':\n ref_dir = 'jref'\n \n if im[0].header['INSTRUME'] == 'WFC3':\n ref_dir = 'iref'\n \n if not os.getenv(ref_dir):\n print('No ${0} set! Put it in ~/.bashrc or ~/.cshrc.'.format(ref_dir))\n return False\n \n for ctype in calib_types:\n if ctype not in im[0].header:\n continue\n \n if verbose:\n print('Calib: {0}={1}'.format(ctype, im[0].header[ctype]))\n \n if im[0].header[ctype] == 'N/A':\n continue\n \n fetch_hst_calib(im[0].header[ctype], ftpdir=ftpdir, verbose=verbose)\n \n return True\n \ndef fetch_default_calibs(ACS=False):\n \n for ref_dir in ['iref','jref']:\n if not os.getenv(ref_dir):\n print(\"\"\"\nNo ${0} set! Make a directory and point to it in ~/.bashrc or ~/.cshrc.\nFor example,\n\n $ mkdir $GRIZLI/{0}\n $ export {0}=\"${GRIZLI}/{0}/\" # put this in ~/.bashrc\n\"\"\".format(ref_dir))\n\n return False\n \n ### WFC3\n files = ['iref$uc72113oi_pfl.fits', #F105W Flat\n 'iref$uc721143i_pfl.fits', #F140W flat\n 'iref$u4m1335li_pfl.fits', #G102 flat\n 'iref$u4m1335mi_pfl.fits', #G141 flat\n 'iref$w3m18525i_idc.fits', #IDCTAB distortion table}\n ]\n \n if ACS:\n files.extend(['jref$n6u12592j_pfl.fits',#F814 Flat\n 'jref$o841350mj_pfl.fits', #G800L flat])\n ])\n \n for file in files:\n fetch_hst_calib(file)\n \n badpix = '{0}/badpix_spars200_Nov9.fits'.format(os.getenv('iref'))\n print('Extra WFC3/IR bad pixels: {0}'.format(badpix))\n if not os.path.exists(badpix):\n os.system('curl -o {0}/badpix_spars200_Nov9.fits https://raw.githubusercontent.com/gbrammer/wfc3/master/data/badpix_spars200_Nov9.fits'.format(os.getenv('iref')))\n \ndef fetch_config_files(ACS=False):\n \"\"\"\n Config files needed for Grizli\n \"\"\"\n cwd = os.getcwd()\n \n print('Config directory: {0}/CONF'.format(os.getenv('GRIZLI')))\n \n os.chdir('{0}/CONF'.format(os.getenv('GRIZLI')))\n \n tarfiles = ['ftp://ftp.stsci.edu/cdbs/wfc3_aux/WFC3.IR.G102.cal.V4.32.tar.gz',\n 'ftp://ftp.stsci.edu/cdbs/wfc3_aux/WFC3.IR.G141.cal.V4.32.tar.gz',\n 'ftp://ftp.stsci.edu/cdbs/wfc3_aux/grism_master_sky_v0.5.tar.gz']\n \n if ACS:\n tarfiles.append('http://www.stsci.edu/~brammer/Grizli/Files/' + \n 'ACS.WFC.sky.tar.gz')\n\n tarfiles.append('http://www.stsci.edu/~brammer/Grizli/Files/' + \n 'ACS_CONFIG.tar.gz')\n \n for url in tarfiles:\n file=os.path.basename(url)\n if not os.path.exists(file):\n print('Get {0}'.format(file))\n os.system('curl -o {0} {1}'.format(file, url))\n \n os.system('tar xzvf {0}'.format(file))\n \n # ePSF files for fitting point sources\n files = ['http://www.stsci.edu/hst/wfc3/analysis/PSF/psf_downloads/wfc3_ir/PSFSTD_WFC3IR_{0}.fits'.format(filter) for filter in ['F105W', 'F125W', 'F140W', 'F160W']]\n for url in files:\n file=os.path.basename(url)\n if not os.path.exists(file):\n print('Get {0}'.format(file))\n os.system('curl -o {0} {1}'.format(file, url))\n else:\n print('File {0} exists'.format(file))\n \n # Stellar templates\n print('Templates directory: {0}/templates'.format(os.getenv('GRIZLI')))\n os.chdir('{0}/templates'.format(os.getenv('GRIZLI')))\n \n files = ['http://www.stsci.edu/~brammer/Grizli/Files/stars_pickles.npy',\n 'http://www.stsci.edu/~brammer/Grizli/Files/stars_bpgs.npy']\n \n for url in files:\n file=os.path.basename(url)\n if not os.path.exists(file):\n print('Get {0}'.format(file))\n os.system('curl -o {0} {1}'.format(file, url))\n else:\n print('File {0} exists'.format(file))\n \n print('ln -s stars_pickles.npy stars.npy')\n os.system('ln -s stars_pickles.npy stars.npy')\n \n os.chdir(cwd)\n \nclass EffectivePSF(object):\n def __init__(self):\n \"\"\"Tools for handling WFC3/IR Effective PSF\n\n See documentation at http://www.stsci.edu/hst/wfc3/analysis/PSF.\n \n PSF files stored in $GRIZLI/CONF/\n \n Attributes\n ----------\n \n Methods\n -------\n \n \"\"\"\n \n self.load_PSF_data()\n \n def load_PSF_data(self):\n \"\"\"Load data from PSFSTD files\n \n Files should be located in ${GRIZLI}/CONF/ directory.\n \"\"\"\n self.epsf = {}\n for filter in ['F105W', 'F125W', 'F140W', 'F160W']:\n file = os.path.join(os.getenv('GRIZLI'), 'CONF',\n 'PSFSTD_WFC3IR_{0}.fits'.format(filter))\n \n data = pyfits.open(file)[0].data.T\n data[data < 0] = 0 \n \n self.epsf[filter] = data\n \n def get_at_position(self, x=507, y=507, filter='F140W'):\n \"\"\"Evaluate ePSF at detector coordinates\n TBD\n \"\"\"\n epsf = self.epsf[filter]\n\n rx = 1+(x-0)/507.\n ry = 1+(y-0)/507.\n \n # zero index\n rx -= 1\n ry -= 1 \n\n nx = np.clip(int(rx), 0, 2)\n ny = np.clip(int(ry), 0, 2)\n\n # print x, y, rx, ry, nx, ny\n\n fx = rx-nx\n fy = ry-ny\n\n psf_xy = (1-fx)*(1-fy)*epsf[:, :, nx+ny*3]\n psf_xy += fx*(1-fy)*epsf[:, :, (nx+1)+ny*3]\n psf_xy += (1-fx)*fy*epsf[:, :, nx+(ny+1)*3]\n psf_xy += fx*fy*epsf[:, :, (nx+1)+(ny+1)*3]\n\n return psf_xy\n \n def eval_ePSF(self, psf_xy, dx, dy):\n \"\"\"Evaluate PSF at dx,dy coordinates\n \n TBD\n \"\"\"\n # So much faster than scipy.interpolate.griddata!\n from scipy.ndimage.interpolation import map_coordinates\n \n # ePSF only defined to 12.5 pixels\n ok = (np.abs(dx) < 12.5) & (np.abs(dy) < 12.5)\n coords = np.array([50+4*dx[ok], 50+4*dy[ok]])\n \n # Do the interpolation\n interp_map = map_coordinates(psf_xy, coords, order=3)\n \n # Fill output data\n out = np.zeros_like(dx, dtype=np.float32)\n out[ok] = interp_map\n return out\n \n @staticmethod\n def objective_epsf(params, self, psf_xy, sci, ivar, xp, yp):\n \"\"\"Objective function for fitting ePSFs\n \n TBD\n \n params = [normalization, xc, yc, background]\n \"\"\"\n dx = xp-params[1]\n dy = yp-params[2]\n\n ddx = xp-xp.min()\n ddy = yp-yp.min()\n\n psf_offset = self.eval_ePSF(psf_xy, dx, dy)*params[0] + params[3] + params[4]*ddx + params[5]*ddy + params[6]*ddx*ddy\n \n chi2 = np.sum((sci-psf_offset)**2*ivar)\n #print params, chi2\n return chi2\n \n def fit_ePSF(self, sci, center=None, origin=[0,0], ivar=1, N=7, \n filter='F140W', tol=1.e-4):\n \"\"\"Fit ePSF to input data\n TBD\n \"\"\"\n from scipy.optimize import minimize\n \n sh = sci.shape\n if center is None:\n y0, x0 = np.array(sh)/2.\n else:\n x0, y0 = center\n \n xd = x0+origin[1]\n yd = y0+origin[0]\n \n xc, yc = int(x0), int(y0)\n \n psf_xy = self.get_at_position(x=xd, y=yd, filter=filter)\n \n yp, xp = np.indices(sh)\n args = (self, psf_xy, sci[yc-N:yc+N, xc-N:xc+N], ivar[yc-N:yc+N, xc-N:xc+N], xp[yc-N:yc+N, xc-N:xc+N], yp[yc-N:yc+N, xc-N:xc+N])\n guess = [sci[yc-N:yc+N, xc-N:xc+N].sum()/psf_xy.sum(), x0, y0, 0, 0, 0, 0]\n \n out = minimize(self.objective_epsf, guess, args=args, method='Powell',\n tol=tol)\n \n params = out.x\n dx = xp-params[1]\n dy = yp-params[2]\n output_psf = self.eval_ePSF(psf_xy, dx, dy)*params[0]\n \n return output_psf, params\n \nclass GTable(astropy.table.Table):\n \"\"\"\n Extend `~astropy.table.Table` class with more automatic IO and other\n helper methods.\n \"\"\" \n @classmethod\n def gread(cls, file, sextractor=False, format=None):\n \"\"\"Assume `ascii.commented_header` by default\n \n Parameters\n ----------\n sextractor : bool\n Use `format='ascii.sextractor'`.\n \n format : None or str\n Override format passed to `~astropy.table.Table.read`.\n \n Returns\n -------\n tab : `~astropy.table.Table`\n Table object\n \"\"\"\n import astropy.units as u\n \n if format is None:\n if sextractor:\n format = 'ascii.sextractor'\n else:\n format = 'ascii.commented_header'\n \n #print(file, format) \n tab = cls.read(file, format=format)\n \n return tab\n \n def gwrite(self, output, format='ascii.commented_header'):\n \"\"\"Assume a format for the output table\n \n Parameters\n ----------\n output : str\n Output filename\n \n format : str\n Format string passed to `~astropy.table.Table.write`.\n \n \"\"\"\n self.write(output, format=format)\n \n @staticmethod\n def parse_radec_columns(self, rd_pairs=None):\n \"\"\"Parse column names for RA/Dec and set to `~astropy.units.degree` units if not already set\n \n Parameters\n ----------\n rd_pairs : `~collections.OrderedDict` or None\n Pairs of {ra:dec} names to search in the column list. If None,\n then uses the following by default. \n \n >>> rd_pairs = OrderedDict()\n >>> rd_pairs['ra'] = 'dec'\n >>> rd_pairs['ALPHA_J2000'] = 'DELTA_J2000'\n >>> rd_pairs['X_WORLD'] = 'Y_WORLD'\n \n NB: search is performed in order of ``rd_pairs.keys()`` and stops\n if/when a match is found.\n \n Returns\n -------\n rd_pair : [str, str]\n Column names associated with RA/Dec. Returns False if no column\n pairs found based on `rd_pairs`.\n \n \"\"\"\n from collections import OrderedDict\n import astropy.units as u\n \n if rd_pairs is None:\n rd_pairs = OrderedDict()\n rd_pairs['ra'] = 'dec'\n rd_pairs['ALPHA_J2000'] = 'DELTA_J2000'\n rd_pairs['X_WORLD'] = 'Y_WORLD'\n rd_pairs['ALPHA_SKY'] = 'DELTA_SKY'\n \n rd_pair = None \n for c in rd_pairs:\n if c.upper() in [col.upper() for col in self.colnames]:\n rd_pair = [c, rd_pairs[c]]\n break\n \n if rd_pair is None:\n #print('No RA/Dec. columns found in input table.')\n return False\n \n for c in rd_pair:\n if self[c].unit is None:\n self[c].unit = u.degree\n \n return rd_pair\n \n def match_to_catalog_sky(self, other, self_radec=None, other_radec=None):\n \"\"\"Compute `~astropy.coordinates.SkyCoord` projected matches between two `GTable` tables.\n \n Parameters\n ----------\n other : `~astropy.table.Table` or `GTable`\n Other table to match positions from.\n \n self_radec, other_radec : None or [str, str]\n Column names for RA and Dec. If None, then try the following\n pairs (in this order): \n \n >>> rd_pairs = OrderedDict()\n >>> rd_pairs['ra'] = 'dec'\n >>> rd_pairs['ALPHA_J2000'] = 'DELTA_J2000'\n >>> rd_pairs['X_WORLD'] = 'Y_WORLD'\n \n Returns\n -------\n idx : int array\n Indices of the matches as in \n \n >>> matched = self[idx]\n >>> len(matched) == len(other)\n \n dr : float array\n Projected separation of closest match.\n \n Example\n -------\n \n >>> import astropy.units as u\n\n >>> ref = GTable.gread('input.cat')\n >>> gaia = GTable.gread('gaia.cat')\n >>> idx, dr = ref.match_to_catalog_sky(gaia)\n >>> close = dr < 1*u.arcsec\n\n >>> ref_match = ref[idx][close]\n >>> gaia_match = gaia[close]\n \n \"\"\"\n from astropy.coordinates import SkyCoord\n \n if self_radec is None:\n rd = self.parse_radec_columns(self)\n else:\n rd = self.parse_radec_columns(self, rd_pairs={self_radec[0]:self_radec[1]})\n \n if rd is False:\n print('No RA/Dec. columns found in input table.')\n return False\n \n self_coo = SkyCoord(ra=self[rd[0]], dec=self[rd[1]])\n\n if other_radec is None:\n rd = self.parse_radec_columns(other)\n else:\n rd = self.parse_radec_columns(other, rd_pairs={other_radec[0]:other_radec[1]})\n\n if rd is False:\n print('No RA/Dec. columns found in `other` table.')\n return False\n \n other_coo = SkyCoord(ra=other[rd[0]], dec=other[rd[1]])\n \n idx, d2d, d3d = other_coo.match_to_catalog_sky(self_coo)\n return idx, d2d\n \n def write_sortable_html(self, output, replace_braces=True, localhost=True, max_lines=50, table_id=None, table_class=\"display compact\", css=None):\n \"\"\"Wrapper around `~astropy.table.Table.write(format='jsviewer')`.\n \n Parameters\n ----------\n output : str\n Output filename.\n \n replace_braces : bool\n Replace '<' and '>' characters that are converted \n automatically from \"<>\" by the `~astropy.table.Table.write`\n method. There are parameters for doing this automatically with \n `write(format='html')` but that don't appear to be available with \n `write(format='jsviewer')`.\n \n localhost : bool\n Use local JS files. Otherwise use files hosted externally.\n \n etc : ...\n Additional parameters passed through to `write`.\n \"\"\"\n #from astropy.table.jsviewer import DEFAULT_CSS\n DEFAULT_CSS = \"\"\"\nbody {font-family: sans-serif;}\ntable.dataTable {width: auto !important; margin: 0 !important;}\n.dataTables_filter, .dataTables_paginate {float: left !important; margin-left:1em}\ntd {font-size: 10pt;}\n \"\"\"\n if css is not None:\n DEFAULT_CSS += css\n\n self.write(output, format='jsviewer', css=DEFAULT_CSS,\n max_lines=max_lines,\n jskwargs={'use_local_files':localhost},\n table_id=None, table_class=table_class)\n\n if replace_braces:\n lines = open(output).readlines()\n if replace_braces:\n for i in range(len(lines)):\n lines[i] = lines[i].replace('<', '<')\n lines[i] = lines[i].replace('>', '>')\n\n fp = open(output, 'w')\n fp.writelines(lines)\n fp.close()\n \ndef column_values_in_list(col, test_list):\n \"\"\"Test if column elements \"in\" an iterable (e.g., a list of strings)\n \n Parameters\n ----------\n col : `astropy.table.Column` or other iterable\n Group of entries to test\n \n test_list : iterable\n List of values to search \n \n Returns\n -------\n test : bool array\n Simple test:\n >>> [c_i in test_list for c_i in col]\n \"\"\"\n test = np.array([c_i in test_list for c_i in col])\n return test\n \ndef fill_between_steps(x, y0, y1, ax=None, *args, **kwargs):\n \"\"\"\n Make `fill_between` work like linestyle='steps-mid'.\n \"\"\"\n so = np.argsort(x)\n mid = x[so][:-1] + np.diff(x[so])/2.\n xfull = np.append(np.append(x, mid), mid+np.diff(x[so])/1.e6)\n y0full = np.append(np.append(y0, y0[:-1]), y0[1:])\n y1full = np.append(np.append(y1, y1[:-1]), y1[1:])\n \n so = np.argsort(xfull)\n if ax is None:\n ax = plt.gca()\n \n ax.fill_between(xfull[so], y0full[so], y1full[so], *args, **kwargs)\n "
}
] | 2 |
jia66/bee-cli
|
https://github.com/jia66/bee-cli
|
113647715c8a72cee142ade2116386deb13223c7
|
fb5dc00c4f3a38e2d6e7e32adde77915a26e7c63
|
4f3b2dc1bbc2f1497800f9b55e89eb8f20d993de
|
refs/heads/master
| 2023-04-20T08:00:08.313862 | 2021-05-13T13:36:57 | 2021-05-13T13:36:57 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7305699586868286,
"alphanum_fraction": 0.7381064295768738,
"avg_line_length": 24.285715103149414,
"blob_id": "3cef036a5e97421937b89503397097d999322d44",
"content_id": "4c90150ec2854175fd2a57ead028281bfa012c7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2123,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 84,
"path": "/bee_cashout.py",
"repo_name": "jia66/bee-cli",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport requests\nimport json\nimport time\n\nDEBUG_API='http://localhost:1635'\nMIN_AMOUNT=1000\n\ndef getPeers():\n\tcheque_url=\"%s/chequebook/cheque\"%(DEBUG_API)\n\trtn_content = requests.get(cheque_url).json()\n\tlastcheques=rtn_content.get('lastcheques')\n\tpeers=[]\n\tfor info in lastcheques:\n\t\tpeers.append(info.get('peer'))\n\tprint('chequebook:',str(len(peers)),peers)\n\treturn peers\n\ndef getCumulativePayout(peer) :\n\tcheque_url=\"%s/chequebook/cheque/%s\"%(DEBUG_API,peer)\n\trtn_content = requests.get(cheque_url).json()\n\t#print(rtn_content)\n\tlastreceived=rtn_content.get('lastreceived')\n\tcumulativePayout=None\n\tif lastreceived:\n\t\tcumulativePayout=lastreceived.get('payout')\n\tif cumulativePayout:\n\t\treturn cumulativePayout\n\telse:\n\t\treturn 0\n\ndef getLastCashedPayout(peer):\n\tcashout_url=\"%s/chequebook/cashout/%s\"%(DEBUG_API,peer)\n\trtn_content = requests.get(cashout_url).json()\t\t\n\tcashout=rtn_content.get('cumulativePayout')\n\t#print(rtn_content)\n\tif cashout:\n\t\treturn cashout\n\telse:\n\t\treturn 0\t \n\ndef getUncashedAmount(peer):\n\tcumulativePayout=getCumulativePayout(peer)\n\tif cumulativePayout == 0:\n\t\treturn 0\n\telse:\n\t\tcashedPayout=getLastCashedPayout(peer)\n\t\tuncashedAmount=cumulativePayout-cashedPayout\n\t\treturn uncashedAmount\n\ndef listAllUncashed():\n\tpeers=getPeers()\n\tfor peer in peers:\n\t\tuncashedAmount=getUncashedAmount(peer)\n\t\tif uncashedAmount > 0:\n\t\t\tprint(peer,uncashedAmount)\n\ndef cashout(peer):\n\tcashout_url=\"%s/chequebook/cashout/%s\"%(DEBUG_API,peer)\n\trtn_content = requests.post(cashout_url).json()\n\ttxHash=rtn_content.get('transactionHash')\n\tprint('cashing out cheque for %s in transaction %s'%(peer,txHash))\n\n\tresult= requests.get(cashout_url).json().get('result')\n\twhile 1:\n\t\tif result:\n\t\t\tbreak\n\t\ttime.sleep(5)\n\t\tresult= requests.get(cashout_url).json().get('result')\n\t\tif result:\n\t\t\tbreak\n\n\ndef cashoutAll(minAmount):\n\tpeers=getPeers()\n\tfor peer in peers:\n\t\tuncashedAmount=getUncashedAmount(peer)\n\t\tif uncashedAmount > minAmount:\n\t\t\tprint (\"uncashed cheque for %s %s uncashed\"%(peer,str(uncashedAmount)) )\n\t\t\tcashout(peer)\n\nif __name__ == '__main__':\n\t#listAllUncashed()\n\tcashoutAll(MIN_AMOUNT)"
}
] | 1 |
derekmerck/diana-star
|
https://github.com/derekmerck/diana-star
|
9bb674dfd279967bd90cab2613b922df58704915
|
78aa7badb27677a1f5c83d744852f659e2541567
|
d0eadaa76e2eacb61d383b8c0f0ee3c3f1baed58
|
refs/heads/master
| 2020-03-19T07:00:40.791514 | 2018-06-10T21:56:52 | 2018-06-10T21:56:52 | 136,076,479 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4651082754135132,
"alphanum_fraction": 0.48882776498794556,
"avg_line_length": 24.743362426757812,
"blob_id": "ae8c1f03c5c69ff5e790b2e332992f26b5cdf249",
"content_id": "87a7a83a5efb1dfbb4d14b85f51a049e37e96479",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2909,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 113,
"path": "/packages/diana/diana/utils/timerange.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import re\nfrom datetime import datetime, timedelta\nimport attr\nfrom dateutil import parser as timeparser\nfrom diana.generic import dicom_strftime\n\n\[email protected]\nclass TimeRange(object):\n start = attr.ib()\n end = attr.ib()\n\n def __attrs_post_init__(self):\n\n if type(self.start) == datetime or \\\n type(self.start) == timedelta:\n _start = self.start\n else:\n _start = TimeRange.convert(self.start)\n\n if type(self.end) == datetime or \\\n type(self.end) == timedelta:\n _end = self.end\n else:\n _end = TimeRange.convert(self.end)\n\n if type(_start) == datetime:\n self.start = _start\n elif type(_end) == datetime:\n self.start = _end + _start\n else:\n self.start = datetime.now() + _start\n\n if type(_end) == datetime:\n self.end = _end\n elif type(_start) == datetime:\n self.end = _start + _end\n else:\n self.end = datetime.now() + _end\n\n @classmethod\n def convert(cls, time_str):\n\n # Check for 'now'\n if time_str == \"now\":\n return datetime.now()\n\n # Check for a delta\n delta_re = re.compile(\"([+-]?)(\\d*)([y|m|w|d|h|m|s])\")\n match = delta_re.match(time_str)\n\n if match:\n\n dir = match.groups()[0]\n val = match.groups()[1]\n unit = match.groups()[2]\n\n if unit == \"s\":\n seconds = int(val)\n elif unit == \"m\":\n seconds = int(val) * 60\n elif unit == \"h\":\n seconds = int(val) * 60 * 60\n elif unit == \"d\":\n seconds = int(val) * 60 * 60 * 24\n elif unit == \"w\":\n seconds = int(val) * 60 * 60 * 24 * 7\n elif unit == \"m\":\n seconds = int(val) * 60 * 60 * 24 * 30\n elif unit == \"y\":\n seconds = int(val) * 60 * 60 * 24 * 365\n else:\n raise ValueError\n\n if dir == \"-\":\n seconds = seconds * -1\n\n return timedelta(seconds=seconds)\n\n # Check for a parsable time - this handles DICOM format fine\n time = timeparser.parse(time_str)\n if type(time) == datetime:\n return time\n\n raise ValueError(\"Can not parse time: {}\".format(time_str))\n\n def as_dicom(self):\n return dicom_strftime(self.start), dicom_strftime(self.end)\n\n def __str__(self):\n str = \"({}, {})\".format(self.start, self.end)\n return str\n\ndef test_time_formatter():\n\n TR = TimeRange( \"now\", \"+4h\" )\n print(TR)\n\n TR = TimeRange( \"June 2, 2017\", \"June 14, 2019\" )\n print(TR)\n\n TR = TimeRange( \"+3h\", \"-3h\" )\n print(TR)\n\n print( TR.as_dicom() )\n\n TR = TimeRange(\"20180603120000\", \"+3h\")\n print(TR)\n\n\nif __name__ == \"__main__\":\n\n test_time_formatter()\n"
},
{
"alpha_fraction": 0.6499999761581421,
"alphanum_fraction": 0.6499999761581421,
"avg_line_length": 19,
"blob_id": "ac98318856d51a9781986d6aae100ea78724989d",
"content_id": "599e123f5f400e69fec7dca164e3804f500bd067",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 1,
"path": "/packages/diana/diana/__init__.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "name = \"diana-star\"\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 20,
"blob_id": "ffce7cbf2daeda2a57d23771339434fa9456c596",
"content_id": "5720e4e8743a678c1a570d5a1869bb9a78b9fd29",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 1,
"path": "/packages/guid-mint/guid-mint/__init__.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "__name__=\"guid-mint\""
},
{
"alpha_fraction": 0.5829846858978271,
"alphanum_fraction": 0.5829846858978271,
"avg_line_length": 34.875,
"blob_id": "67556dd79704345aea74c8c0bf16d6169776fc11",
"content_id": "c3fd8219ed1222eeb94653081cc2cfc22dc61d3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1434,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 40,
"path": "/packages/diana/diana/connect/dixel.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from diana.utils.dicom import DicomLevel, orthanc_id\nfrom .apis import Item\nimport attr\n\n\[email protected]\nclass DicomItem(Item):\n level = attr.ib(default=DicomLevel.STUDIES)\n file = attr.ib(repr=False, default=None)\n\n def oid(self, level=None):\n # This is not a property because a dixel can generate the OID for any higher level\n # - instances can return instance(default), series, study\n # - series can return series (default), study\n # - studies can return study (default)\n\n # Already have a precomputed oid available\n if not level and self.meta.get('oid'):\n return self.meta.get('OID')\n\n # If a level is supplied, use that, otherwise self.level\n level = level or self.level\n\n if level == DicomLevel.STUDIES:\n return orthanc_id(self.meta[\"PatientID\"],\n self.meta[\"StudyInstanceUID\"])\n elif level == DicomLevel.SERIES:\n return orthanc_id(self.meta[\"PatientID\"],\n self.meta[\"StudyInstanceUID\"],\n self.meta[\"SeriesInstanceUID\"])\n else:\n return orthanc_id(self.meta[\"PatientID\"],\n self.meta[\"StudyInstanceUID\"],\n self.meta[\"SeriesInstanceUID\"],\n self.meta[\"SOPInstanceUID\"])\n\n\n# Alias Dixel, Dx to DicomItem\nDixel = DicomItem\nDx = DicomItem"
},
{
"alpha_fraction": 0.6454445719718933,
"alphanum_fraction": 0.6454445719718933,
"avg_line_length": 20.162790298461914,
"blob_id": "285c8481ad2fe458668e8c0e1ecbf62babe9488f",
"content_id": "4fe043d0ee10cde42384856fcd5abb2c23fca168",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 911,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 43,
"path": "/packages/diana/diana/distrib/tasks.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from .dcelery import app\nfrom diana.connect.apis import DianaFactory\n\n# Note: adding (bind=true) to the decorator provides access to a \"self\"\n# object for introspection.\n\n# Low-level, general task-passing wrapper\n# Item always has to be first though, b/c it's the output of the previous\n# link in a chain...\[email protected](bind=True)\ndef do(self, *args, **kwargs):\n\n pattern = kwargs.get(\"pattern\")\n method = kwargs.get(\"method\")\n\n del(kwargs[\"method\"])\n del(kwargs[\"pattern\"])\n\n print(\"{}:{}.{}\".format(self, pattern['service'], method))\n\n endpoint = DianaFactory.factory(pattern)\n func = endpoint.__getattribute__(method)\n\n return func(*args, **kwargs)\n\n\ndef demux(self, *args, **kwargs):\n pass\n\n\n\"\"\"\nsave_files:\n - src: OrthancEndpoint\n host: localhost\n user: orthanc\n password: orthanc\n q: *\n remove: true\n \n - dest: file\n location: \"/tmp/test\"\n\n\"\"\"\n\n"
},
{
"alpha_fraction": 0.7234513163566589,
"alphanum_fraction": 0.7345132827758789,
"avg_line_length": 29.16666603088379,
"blob_id": "809f1569bd1f88f9dbf5bdcf0cf188d902e836a7",
"content_id": "0e50a2a9b7017c3a032e4131cf07724debe108b1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 904,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 30,
"path": "/stack/containers/diana-worker/Dockerfile",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# Minimal Diana Worker Image\n# Derek Merck, Spring 2018\n#\n# - Presumes 'diana_services.yml' is copied or mounted to /etc/diana_services.yml\n# - Change the queue by overriding CMD on start up\n# e.g., command=\"python dcelery.py worker -B -Q my_queue\"\n\nFROM python:3.6-stretch\nMAINTAINER Derek Merck <[email protected]>\n\nRUN apt update \\\n && apt install -y git\n\nENV TINI_VERSION v0.18.0\nADD https://github.com/krallin/tini/releases/download/${TINI_VERSION}/tini /tini\nRUN chmod +x /tini\nENTRYPOINT [\"/tini\", \"--\"]\n\nRUN useradd -ms /bin/bash celery\nWORKDIR /home/celery\nRUN git clone https://github.com/derekmerck/diana-star\n\nWORKDIR /home/celery/diana-star\nRUN pip install -e packages/diana packages/guid-mint\nRUN sed -i 's^open(\".*\",^open(\"/etc/diana_services.yml\",^' apps/celery/celerycfg.py\nRUN chown -R celery /home/celery/diana-star\n\nUSER celery\nWORKDIR /home/celery/diana-star/apps/celery\nCMD python dcelery.py worker"
},
{
"alpha_fraction": 0.5180723071098328,
"alphanum_fraction": 0.5180723071098328,
"avg_line_length": 29.346153259277344,
"blob_id": "4687ca8b2116701adc2a692c74b83846f79ac0c7",
"content_id": "c6a5791901b1fc6361134fdaba0ad7eda0768c85",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1577,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 52,
"path": "/packages/diana/diana/connect/utils/orth_fiq.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# import logging\n# from pprint import pformat\nfrom diana.utils.dicom import DicomLevel\n\n\ndef find_item_query(item):\n \"\"\"\n Have some information about the dixel, want to find the STUID, SERUID, INSTUID\n Returns a _list_ of dictionaries with matches, retrieves any if \"retrieve\" flag\n \"\"\"\n\n q = {}\n keys = {}\n\n # All levels have these\n keys[DicomLevel.STUDIES] = ['PatientID',\n 'PatientName',\n 'PatientBirthDate',\n 'PatientSex',\n 'StudyInstanceUID',\n 'StudyDate',\n 'StudyTime',\n 'AccessionNumber']\n\n # Series level has these\n keys[DicomLevel.SERIES] = keys[DicomLevel.STUDIES] + \\\n ['SeriesInstanceUID',\n 'SeriesDescription',\n 'ProtocolName',\n 'SeriesNumber',\n 'NumberOfSeriesRelatedInstances',\n 'Modality']\n\n # For instance level, use the minimum\n keys[DicomLevel.INSTANCES] = ['SOPInstanceUID', 'SeriesInstanceUID']\n\n def add_key(q, key, dixel):\n q[key] = dixel.meta.get(key, '')\n return q\n\n for k in keys[item.level]:\n q = add_key(q, k, item)\n\n if item.level == DicomLevel.STUDIES and item.meta.get('Modality'):\n q['ModalitiesInStudy'] = item.meta.get('Modality')\n\n # logging.debug(pformat(q))\n\n query = {'Level': str(item.level),\n 'Query': q}\n\n return query"
},
{
"alpha_fraction": 0.6114708781242371,
"alphanum_fraction": 0.6151711344718933,
"avg_line_length": 26.679487228393555,
"blob_id": "3764f3fd5cb38c9077418d4f42b344e35ad35bf6",
"content_id": "94a9dd5e43be0f687585aed4727a3c286c0de354",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2162,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 78,
"path": "/packages/diana/diana/utils/dicom.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import logging\nfrom hashlib import sha1\nfrom datetime import datetime\nfrom aenum import Enum, auto\n\n# Diana-agnostic Dicom info\n\nclass DicomLevel(Enum):\n \"\"\"\n Enumerated DICOM service levels\n \"\"\"\n INSTANCES = auto()\n SERIES = auto()\n STUDIES = auto()\n PATIENTS = auto()\n\n def parent_level(self):\n if self==DicomLevel.STUDIES:\n return DicomLevel.PATIENTS\n elif self==DicomLevel.SERIES:\n return DicomLevel.STUDIES\n elif self == DicomLevel.INSTANCES:\n return DicomLevel.SERIES\n else:\n logging.warning(\"Bad child request for {}\".format(self))\n\n def child_level(self):\n if self==DicomLevel.PATIENTS:\n return DicomLevel.STUDIES\n elif self==DicomLevel.STUDIES:\n return DicomLevel.SERIES\n elif self==DicomLevel.SERIES:\n return DicomLevel.INSTANCES\n else:\n logging.warning(\"Bad child request for {}\".format(self))\n\n def __str__(self):\n return '{0}'.format(self.name.lower())\n\n\ndef orthanc_id(PatientID, StudyInstanceUID, SeriesInstanceUID=None, SOPInstanceUID=None):\n if not SeriesInstanceUID:\n s = \"|\".join([PatientID, StudyInstanceUID])\n elif not SOPInstanceUID:\n s = \"|\".join([PatientID, StudyInstanceUID, SeriesInstanceUID])\n else:\n s = \"|\".join([PatientID, StudyInstanceUID, SeriesInstanceUID, SOPInstanceUID])\n h = sha1(s.encode(\"UTF8\"))\n d = h.hexdigest()\n return '-'.join(d[i:i+8] for i in range(0, len(d), 8))\n\n\ndef dicom_strftime( dtm ):\n\n try:\n # GE Scanner dt format\n ts = datetime.strptime( dtm , \"%Y%m%d%H%M%S\")\n return ts\n except ValueError:\n # Wrong format\n pass\n\n try:\n # Siemens scanners use a slightly different aggregated format with fractional seconds\n ts = datetime.strptime( dtm , \"%Y%m%d%H%M%S.%f\")\n return ts\n except ValueError:\n # Wrong format\n pass\n\n logging.error(\"Can't parse date time string: {0}\".format( dtm ))\n ts = datetime.now()\n return ts\n\n\n\ndef dicom_strptime( dts ):\n return datetime.strptime( dts, \"%Y%m%d%H%M%S\" )\n\n\n\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 24,
"blob_id": "8e46597b190a97f9a66fb25ff4bcc20b89af4108",
"content_id": "47fe485adcda49a89a4eab6bb1814b25fbc4f070",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 1,
"path": "/packages/diana/diana/distrib/__init__.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from .dcelery import app"
},
{
"alpha_fraction": 0.5840600728988647,
"alphanum_fraction": 0.5966569781303406,
"avg_line_length": 29.577777862548828,
"blob_id": "f3e1af16c7f9a43fa9df1d05c5c1f1f6be5c5439",
"content_id": "7b6166107826b08db48a88e40f95e3baed069496",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4128,
"license_type": "permissive",
"max_line_length": 228,
"num_lines": 135,
"path": "/stack/containers/rcdiana/manifest-it.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "#! python\n\n\"\"\"\nManifest-It\nMerck, Spring 2018\n\nmanifest-it.py can retag, manifest, and push multiple services and architecture produced by ansible-container using the 'project-arch-service' naming convention. Manifesting requires docker-ce edge in 'experimental mode'.\n\nUsage:\n\n$ manifest-it.py -n rcdiana -a amd64 armv7l -images broker dicom worker movidius\n\nor\n\n$ manifest-it.py -f diana_manifest.yml\n\nwhere manifest rule file looks like this:\n\n```yml\nnamespace: rcdiana\nimages:\n - broker\n - dicom\n - worker\n - movidius\narchitectures:\n - amd64\n - armv7l\n```\n\nNote that armv7hf is arch: arm, variant: v7 in docker's ontology, which makes sense, but is poorly documented. Acceptable architecture values are listed here:\n\nhttps://raw.githubusercontent.com/docker-library/official-images/a7ad3081aa5f51584653073424217e461b72670a/bashbrew/go/vendor/src/github.com/docker-library/go-dockerlibrary/architecture/oci-platform.go\n\n\"\"\"\n\nimport yaml, logging\nfrom subprocess import call\nfrom argparse import ArgumentParser\n\ndef parse_args():\n\n p = ArgumentParser(\"Retag, manifest, and push multiple services and architecture produced by ansible-container with the 'project-arch-service' naming convention. Manifesting requires docker-ce edge in 'experimental mode'.\")\n p.add_argument(\"-n\", \"--namespace\", help=\"Target namespace\", default=\"rcdiana\")\n p.add_argument(\"-a\", \"--architectures\", help=\"Multiarchitecture manifest entries\", default=[\"amd64\", \"armv7hf\"])\n p.add_argument(\"-i\", \"--images\", help=\"List of service images to process\")\n p.add_argument(\"-f\", \"--file\", help=\"yml file with manifest rules\")\n p.add_argument('-d', '--dryrun', action=\"store_true\", help=\"Retag and manifest but do not push\")\n\n opts = p.parse_args()\n\n if opts.file:\n with open(opts.file, 'r') as f:\n data = yaml.safe_load(f)\n opts.namespace = data.get('namespace', opts.namespace)\n opts.images = data.get('images', opts.images)\n opts.architectures = data.get('architectures', opts.architectures)\n\n return opts\n\ndef docker_tag(target, tag):\n cmd = ['docker', 'tag', target, tag]\n logging.debug(cmd)\n call(cmd)\n\ndef docker_push(tag):\n cmd = ['docker', 'push', tag]\n logging.debug(cmd)\n call(cmd)\n\ndef docker_manifest_create(tag, aliases):\n cmd = ['docker', 'manifest', 'create', tag, *aliases, \"--amend\"]\n logging.debug(cmd)\n call(cmd)\n\ndef docker_manifest_annotate(tag, alias, arch=\"amd64\", variant=None, os=\"linux\"):\n cmd = ['docker', 'manifest', 'annotate',\n tag, alias,\n '--arch', arch,\n '--os', os ]\n if variant:\n cmd = cmd + ['--variant', variant]\n logging.debug(cmd)\n call(cmd)\n\ndef docker_manifest_push(tag):\n cmd = ['docker', 'manifest', 'push', tag]\n logging.debug(cmd)\n call(cmd)\n\n\nif __name__ == \"__main__\":\n\n opts = parse_args()\n\n n = opts.namespace\n for i in opts.images:\n for a in opts.architectures:\n\n source_tag = \"{}-{}-{}\".format(n, a, i)\n target_tag = \"{}/{}:{}\".format(n, i, a)\n\n docker_tag(source_tag, target_tag)\n if not opts.dryrun:\n docker_push(target_tag)\n\n for i in opts.images:\n main_tag = \"{}/{}:latest\".format(n,i)\n alias_tags = []\n for a in opts.architectures:\n alias_tags.append(\"{}/{}:{}\".format(n, i, a))\n docker_manifest_create(main_tag, alias_tags)\n\n for i in opts.images:\n main_tag = \"{}/{}:latest\".format(n,i)\n for a in opts.architectures:\n\n if a == \"armv7hf\":\n aa = \"arm\"\n vv = \"7\"\n elif a == \"amd64\":\n aa = a\n vv = None\n else:\n raise NotImplementedError\n\n alias = \"{}/{}:{}\".format(n, i, a)\n docker_manifest_annotate(main_tag,\n alias,\n arch=aa,\n variant=vv,\n os=\"linux\")\n\n if not opts.dryrun:\n docker_manifest_push(main_tag)\n"
},
{
"alpha_fraction": 0.5596638917922974,
"alphanum_fraction": 0.5663865804672241,
"avg_line_length": 24.869565963745117,
"blob_id": "5a60ce4948e7d68c353b3bbf091c5d6ba1eb4ccf",
"content_id": "9de0830009387667583780bc3f22f3968f2a36d0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 595,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 23,
"path": "/packages/diana/diana/distrib/dcelery.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# Implements a diana-star Celery worker\n\nfrom celery import Celery\n\n\napp = Celery('diana',\n include = ['diana.distrib.tasks',\n 'diana.daemon.tasks'])\n\napp.conf.update(\n result_expires = 3600,\n task_serializer = \"pickle\",\n accept_content = [\"pickle\"],\n result_serializer = \"pickle\",\n task_default_queue = 'default',\n task_routes={'*.classify': {'queue': 'learn'}, # Only GPU boxes\n '*.file': {'queue': 'file'} }, # Access to shared fs\n)\n\napp.config_from_object('celerycfg')\n\nif __name__ == '__main__':\n app.start()\n"
},
{
"alpha_fraction": 0.8709677457809448,
"alphanum_fraction": 0.8709677457809448,
"avg_line_length": 31,
"blob_id": "4f2abd357e842a90c2cb784a2311b4c46e42b4a9",
"content_id": "84dd9c6c602a7ca78f9dddd1a61ce07b46dcacdd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 1,
"path": "/stack/containers/diana-worker/README.md",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "Vanilla Diana-Worker node image"
},
{
"alpha_fraction": 0.5717498660087585,
"alphanum_fraction": 0.5847952961921692,
"avg_line_length": 24.261363983154297,
"blob_id": "20670e247e36c1bfd2e36a4fc27a8daef0419d04",
"content_id": "3bac5b6df6c348cd9bb19d1210c68e05980d072b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2223,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 88,
"path": "/apps/celery/repeating.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import os\nimport yaml\nfrom celery import chain\nfrom diana.distrib.dcelery import app\nfrom diana.distrib.apis import *\nfrom diana.utils.dicom import DicomLevel\n\n# Need a service stack to generate events\n\nif os.path.exists(\"./services.yml\"):\n service_path = \"./services.yml\"\nelif os.path.exists(\"etc/diana/services.yml\"):\n service_path = \"/etc/diana/services.yml\"\nelse:\n raise FileNotFoundError(\"Can not find services.yml\")\n\nwith open( service_path, \"r\" ) as f:\n services = yaml.safe_load(f)\n\northanc = OrthancEndpoint(**services['orthanc'])\nsplunk = SplunkEndpoint(**services['orthanc'])\n\nbeat_schedule = {\n 'status_report': {\n 'task': 'message',\n 'schedule': 60.0, # Every 30 seconds\n 'args': [\"All ok\"]\n },\n\n 'index_new_series': {\n 'task': 'index_new_series',\n 'schedule': 5.0 * 60.0, # Every 5 minutes\n 'args': (orthanc, splunk),\n 'kwargs': {'timerange': (\"-10m\", \"now\")}\n },\n\n 'index_dose_reports': {\n 'task': 'index_dose_reports',\n 'schedule': 5.0 * 60.0, # Every 5 minutes\n 'args': (orthanc, splunk),\n 'kwargs': {'timerange': (\"-10m\", \"now\")}\n }\n\n}\n\n\[email protected]\ndef index_new_series(orthanc, splunk):\n\n q = { \"new series\" }\n ids = orthanc.find( q )\n\n for id in ids:\n dixel = orthanc.getstar( id ).get()\n splunk.putstar(dixel)\n\n # or\n #\n # chain( orthanc.get_s(id) | splunk.put_s() )()\n\n\ndef index_dose_reports(orthanc, splunk, timerange=(\"-10m\", \"now\")):\n\n q = { \"is dose series\",\n timerange }\n ids = splunk.find(q)\n\n for id in ids:\n\n data = orthanc.getstar( id, 'meta' )\n instances = data['instances']\n for oid in instances:\n dixel = orthanc.getstar( oid, level=DicomLevel.INSTANCES ).get()\n splunk.putstar( dixel, index=splunk.dose_index )\n\n # or\n #\n # chain(orthanc.get_s(id, level=DicomLevel.SERIES) | splunk.put_s(index=splunk.series_index))()\n\ndef route(orthanc0, orthanc1, anon_map=None):\n\n q = { \"new series\" }\n ids = orthanc0.find( q )\n\n for id in ids:\n dixel = orthanc0.getstar( id ).get()\n orthanc1.putstar( dixel )\n orthanc0.remove( dixel )\n"
},
{
"alpha_fraction": 0.5922313332557678,
"alphanum_fraction": 0.5992858409881592,
"avg_line_length": 33.79393768310547,
"blob_id": "692f005db74874cc02588d1d3eca1e682e97db08",
"content_id": "472aa99bc79952deb06009e5f2be0bf72f5d7218",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11482,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 330,
"path": "/packages/diana/diana/connect/apis.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "\"\"\"\nDiana Endpoint APIs:\n\n- Orthanc (dcm RESTful PACS and PACS proxy)\n- File (dcm files)\n- Redis (data cache)\n- Splunk (data index)\n- Classifier (AI)\n\nAs much Diana-agnostic functionality as possible has been abstracted to\nrelated modules in \"generic\" for use with other modules, packages, or applications.\n\n\"\"\"\n\nimport logging, os, time\nfrom redis import Redis\nfrom dill import loads, dumps\nimport attr\nfrom diana.utils import Endpoint, DicomLevel, OrthancRequester, SplunkRequester, DicomFileIO\nfrom .utils.anon_map import simple_anon_map\nfrom .utils.orth_fiq import find_item_query\nfrom .dixel import Dx\n\n\n# All Diana Endpoints implement a Factory for passing unpickle-able\n# instances by pattern\n\[email protected]\nclass DianaFactory(object):\n service = attr.ib(default=None)\n\n # Can't pass endpoints bc of sockets and other unpickleable objects,\n # so use a blueprint to recreate the endpoint at the worker\n @classmethod\n def factory(self, pattern):\n service = pattern['service'].lower()\n if service == \"orthanc\":\n return OrthancEndpoint(**pattern)\n if service == \"redis\":\n return RedisEndpoint(**pattern)\n if service == \"file\":\n return FileEndpoint(**pattern)\n if service == \"classification\":\n return ClassificationEndpoint(**pattern)\n else:\n raise KeyError(\"No such api as {}\".format(pattern['service']))\n\n # Dump the factory pattern for this endpoint (will include passwords, etc)\n @property\n def p(self):\n pattern = {}\n for item in self.__init__.__code__.co_varnames[1:]:\n if item == \"queue\":\n # Ignore distrib variables\n continue\n pattern[item] = self.__dict__[item]\n return pattern\n\n\[email protected]\nclass OrthancEndpoint(Endpoint, DianaFactory):\n service = attr.ib( default=\"orthanc\" )\n host = attr.ib( default=\"localhost\" )\n port = attr.ib( default=\"8042\" )\n path = attr.ib( default = \"\")\n user = attr.ib( default=\"orthanc\" )\n password = attr.ib( default=\"orthanc\" )\n location = attr.ib()\n requester = attr.ib()\n inventory = attr.ib()\n\n # This is only used as an identifier for logging\n @location.default\n def set_loc(self):\n return \"http://{}:{}/{}\".format(self.host, self.port, self.path)\n\n @requester.default\n def set_req(self):\n # HTTP gateway\n req = OrthancRequester(host=self.host, port=self.port, path=self.path)\n try:\n stats = req.get(\"statistics\")\n logging.debug( \"Connected to orthanc at {}\".format(self.location) )\n logging.debug( format(stats) )\n return req\n except ConnectionError:\n logging.error(\"No connection for orthanc! Requester is None\")\n return None\n\n # Do NOT need to do this unless doing lazy puts or finds\n # TODO: Need a way to init appropriate level for an interator or __in__\n @inventory.default\n def set_inv(self):\n try:\n return {\n # \"patients\": [], # self.requester.get(\"patients\"),\n \"studies\": [], # self.requester.get(\"studies\"),\n \"series\": [], # self.requester.get(\"series\"),\n \"instances\": [], # self.requester.get(\"instances\")\n }\n except:\n logging.error(\"Inventory failed for orthanc! Inventory is None\".format(self.location))\n return None\n\n def get(self, oid, level, view=\"tags\"):\n result = self.requester.get_item(oid, level, view=view)\n if view==\"tags\":\n # We can assemble a dixel\n item = Dx(meta=result, level=level)\n return item\n else:\n # Return the meta infor or binary data\n return result\n\n def put(self, item):\n if item.level != DicomLevel.INSTANCES:\n logging.warning(\"Can only 'put' Dicom instances.\")\n raise ValueError\n if not item.file:\n logging.warning(\"Can only 'put' file data.\")\n raise KeyError\n return self.requester.put_item(item.file)\n\n def handle(self, item, instruction, **kwargs):\n\n if instruction == \"anonymize\":\n replacement_map = kwargs.get('replacement_map', simple_anon_map)\n replacement_dict = replacement_map(item.meta)\n return self.requester.anonymize(item.oid, item.level, replacement_dict=replacement_dict)\n\n elif instruction == \"remove\":\n oid = item.oid()\n level = item.level\n return self.requester.delete_item(oid, level)\n\n elif instruction == \"find\":\n domain = kwargs.get(\"remote_aet\", \"local\")\n retrieve_dest = kwargs.get(\"retrieve_dest\", None)\n query = OrthancEndpoint.find_item_query()\n return self.requester.find(query, domain, retrieve_dest=retrieve_dest)\n\n elif instruction == \"send\":\n modality = kwargs.get(\"modality\")\n peer = kwargs.get(\"peer\")\n if modality:\n self.requester.send(item.id, item.level, modality, dest_type=\"modality\")\n if peer:\n self.requester.send(item.id, item.level, peer, dest_type=\"peer\")\n\n elif instruction == \"clear\":\n self.inventory['studies'] = self.requester.get(\"studies\")\n for oid in self.inventory:\n self.requester.delete_item(oid, DicomLevel.STUDIES)\n\n elif instruction == \"info\":\n return self.requester.statistics()\n\n raise NotImplementedError(\"No handler found for {}\".format(instruction))\n\n # These do not take and return items, so they may be gets or puts?\n\n def anonymize(self, item, replacement_map=None):\n return self.handle(item, \"anonymize\", replacement_map=replacement_map)\n\n def remove(self, item):\n return self.handle(item, \"remove\")\n\n def find(self, q, domain=\"local\", retrieve=\"false\"):\n return self.handle(None, \"find\", query=q, domain=domain, retrieve=retrieve)\n\n def send(self, item, peer=None, modality=None):\n return self.handle(None, \"send\", peer=peer, modality=modality)\n\n def clear(self):\n return self.handle( None , \"clear\" )\n\n def info(self):\n return self.handle( None , \"info\" )\n\n def __contains__(self, item):\n\n # Can mark the inventory stale by calling self.set_inv()\n if item.level == DicomLevel.STUDIES:\n if len(self.inventory['studies']) == 0:\n self.inventory['studies'] = self.requester.get(\"studies\")\n inv = self.inventory['studies']\n elif item.level == DicomLevel.SERIES:\n if len(self.inventory['series']) == 0:\n self.inventory['series'] = self.requester.get(\"series\")\n inv = self.inventory['series']\n elif item.level == DicomLevel.INSTANCES:\n if len(self.inventory['instances']) == 0:\n self.inventory['instances'] = self.requester.get(\"studies\")\n inv = self.inventory['instances']\n else:\n self.logger.warn(\"Can only '__contain__' study, series, instance dixels\")\n return\n\n return item.oid() in inv\n\nOrthancEndpoint.find_item_query = find_item_query\n\n# Data cache\[email protected]\nclass RedisEndpoint(Endpoint, DianaFactory):\n service = attr.ib( default=\"redis\" )\n host = attr.ib( default=\"localhost\" )\n port = attr.ib( default=\"6379\" )\n user = attr.ib( default=\"redis\" )\n password = attr.ib( default=\"redis\" )\n db = attr.ib( default=0 )\n broker_db = attr.ib( default=None ) # In a services desc as broker, so ignore\n result_db = attr.ib( default=None )\n inventory = attr.ib( init=False )\n\n @inventory.default\n def connect(self):\n return Redis(host=self.host, port=self.port, db=self.db)\n\n def put(self, item, **kwargs):\n self.inventory.set( item.id, dumps(item) )\n\n def get(self, id, **kwargs):\n item = loads( self.inventory.get(id) )\n return item\n\n\[email protected]\nclass FileEndpoint(Endpoint, DianaFactory):\n service = attr.ib( default=\"file\" )\n dfio = attr.ib( init=False )\n\n @dfio.default\n def set_dfio(self):\n return DicomFileIO(location=self.location)\n\n def put(self, item, path=None, explode=None):\n fn = item.meta['FileName']\n data = item.data\n\n if item.level == DicomLevel.INSTANCES and \\\n os.path.splitext(fn)[-1:] != \".dcm\":\n fn = fn + '.dcm' # Single file\n if item.level > DicomLevel.INSTANCES and \\\n os.path.splitext(fn)[-1:] != \".zip\":\n fn = fn + '.zip' # Archive format\n\n self.dfio.write(fn, data, path=path, explode=explode )\n\n def get(self, fn, path=None, pixels=False, file=False):\n # print(\"getting\")\n dcm, fp = self.dfio.read(fn, path=path, pixels=pixels)\n\n _meta = {'PatientID': dcm[0x0010, 0x0020].value,\n 'AccessionNumber': dcm[0x0008, 0x0050].value,\n 'StudyInstanceUID': dcm[0x0020, 0x000d].value,\n 'SeriesInstanceUID': dcm[0x0020, 0x000e].value,\n 'SOPInstanceUID': dcm[0x0008, 0x0018].value,\n 'TransferSyntaxUID': dcm.file_meta.TransferSyntaxUID,\n 'TransferSyntax': str(dcm.file_meta.TransferSyntaxUID),\n 'MediaStorage': str(dcm.file_meta.MediaStorageSOPClassUID),\n 'PhotometricInterpretation': dcm[0x0028, 0x0004].value, #MONOCHROME, RGB etc.\n 'FileName': fn,\n 'FilePath': fp}\n\n _data = None\n if pixels:\n _data = dcm.pixel_array\n\n _file = None\n if file:\n with open(fp, 'rb') as f:\n _file = f.read()\n\n item = Dx(level=DicomLevel.INSTANCES, meta=_meta, data=_data, file=_file)\n return item\n\n\n# metadata endpoint Splunk, csv\[email protected]\nclass SplunkEndpoint(Endpoint, DianaFactory):\n service = attr.ib( default=\"splunk\" )\n host = attr.ib( default=\"localhost\" )\n port = attr.ib( default=\"8080\" )\n hec_port = attr.ib( default=\"8088\" )\n user = attr.ib( default=\"splunk\" )\n password = attr.ib( default=\"splunk\" )\n location = attr.ib()\n requester = attr.ib()\n # inventory = attr.ib()\n\n # This is only used as an identifier for logging\n @location.default\n def set_loc(self):\n return \"http://{}:{} hec:{}\".format(self.host, self.port, self.hec_port)\n\n @requester.default\n def set_req(self):\n # HTTP gateway\n return SplunkRequester(host=self.host, port=self.port, hec_port=self.hec_port)\n\n def put(self, item, host=None, *kwargs):\n\n def epoch(dt):\n tt = dt.timetuple()\n return time.mktime(tt)\n\n record = item.meta\n # This has to be created\n # record_time = epoch(record['InstanceCreationDateTime'])\n record_time = None\n self.req.post_event(record, event_time=record_time, host=host)\n\n def handle(self, item, instruction, **kwargs):\n\n if instruction == \"find\":\n query = kwargs.get(\"query\")\n index = kwargs.get(\"index\")\n return self.requester.find(query, index)\n\n def find(self, q, index):\n return self.handle(None, \"find\", query=q, index=index)\n\[email protected]\nclass ClassificationEndpoint(Endpoint, DianaFactory):\n service = attr.ib(default=\"classification\")\n\n def classify(self, item, **kwargs):\n item.meta['classified'] = True\n return item\n"
},
{
"alpha_fraction": 0.6694796085357666,
"alphanum_fraction": 0.6708860993385315,
"avg_line_length": 19.882352828979492,
"blob_id": "d9753f435b536a7c832bb02987be8b9db5c91be3",
"content_id": "7cf43d0615496fa322cfd86c2136014041691e6f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 711,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 34,
"path": "/packages/diana/diana/utils/endpoints.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import attr\nimport uuid\nfrom dill import dumps\n\n# Diana-agnostic API for get, put, handle endpoints with id's and self-pickling\n\[email protected]\nclass Generic(object):\n id = attr.ib(factory=uuid.uuid4)\n\n @property\n def d(self):\n return dumps(self)\n\n\[email protected]\nclass Item(Generic):\n meta = attr.ib(factory=dict)\n data = attr.ib(repr=False, default=None)\n\n\[email protected]\nclass Endpoint(Generic):\n location = attr.ib(default=None)\n inventory = attr.ib(default=None)\n\n def get(self, *args, **kwargs):\n raise NotImplementedError\n\n def put(self, *args, **kwargs):\n raise NotImplementedError\n\n def handle(self, item, instruction, *args, **kwargs):\n raise NotImplementedError\n\n"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 30.22222137451172,
"blob_id": "5ad15b63bdfb570787ec4bdfcfa0876dd2f86bf6",
"content_id": "1d5572b03bf0fb8e1a5c59928cbd2e6a0f7df865",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 280,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 9,
"path": "/packages/diana/diana/utils/__init__.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from .dicom import DicomLevel, dicom_strftime, dicom_strptime\nfrom .dcm_fio import DicomFileIO\nfrom .dcm_clean_tags import clean_tags\n\nfrom .endpoints import Endpoint, Item\nfrom .orthanc import OrthancRequester\nfrom .splunk import SplunkRequester\n\nfrom .timerange import TimeRange"
},
{
"alpha_fraction": 0.8481012582778931,
"alphanum_fraction": 0.8607594966888428,
"avg_line_length": 6.2727274894714355,
"blob_id": "b7203ac0efe13858b4f67f6e3fef8c930280c812",
"content_id": "a401bc7ce475599d045c2c8c7d8305e2fe1eecee",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 79,
"license_type": "permissive",
"max_line_length": 11,
"num_lines": 11,
"path": "/packages/diana/requirements.txt",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "aenum\nattrs\nbs4\ncelery\ndateutils\ndill\npillow\nredis\nruamel.yaml\npydicom\nrequests"
},
{
"alpha_fraction": 0.7551903128623962,
"alphanum_fraction": 0.757785439491272,
"avg_line_length": 31.577465057373047,
"blob_id": "ca9818878f6ff5b499f443c343bb04fd4d952341",
"content_id": "32148b4abbf1e385c6f316ff3dcaad4600d2bf3f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2312,
"license_type": "permissive",
"max_line_length": 313,
"num_lines": 71,
"path": "/packages/diana/README.md",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# Distributed DICOM Analytics and Archive (diana-star)\n\nDerek Merck <[email protected]> \nBrown University and Rhode Island Hospital \nWinter 2018\n\nSource: <https://www.github.com/derekmerck/diana-star> \nDocumentation: <https://diana.readthedocs.io> \n\n\n## Overview\n\nHospital picture archive and communications systems (PACS) are not well suited for \"big data\" analysis. It is difficult to identify and extract datasets in bulk, and moreover, high resolution data is often not even stored in the clinical systems.\n\n**diana** is a [DICOM][] imaging informatics platform that can be attached to the clinical systems with a very small footprint, and then tuned to support a range of tasks from high-resolution image archival to cohort discovery to radiation dose monitoring.\n\n**diana-star** is a celery queuing system with a diana api. This provides a backbone for distributed task management. The \"star\" suffix is in honor of the historical side-note of Matlab's Star-P parallel computing library.\n\n\n## Dependencies\n\n- Python 3.6\n- Many Python packages\n\n\n## Installation\n\n```bash\n$ git clone https://www.github.com/derekmerck/DIANA\n$ pip install -r DIANA/requirements.txt\n```\n\n\n## Setup environment\n\n```bash\n$ git clone https://github.com/derekmerck/diana-star\n$ cd diana-star\n$ conda env create -f conda_env.yml -n diana\n$ pip install -e ./packages\n```\n\n\n## Test scripts with connect and celery app\n\n```bash\n# Reset test environment\n$ pushd test/vagrant && vagrant destroy && vagrant up && popd\n\n# Create an orthanc and an index\n$ cd stack\n$ ansible-playbook -i inv.yml ../test/simple_play.yml\n\n# Run a script\n$ python test/diana.py\n\n# Create a broker and some virtual workers for default\n$ ansible-playbook -i inv.yml ../test/distrib_play.yml\n\n# Create a local worker to manage the heartbeat and specialized jobs\n$ python apps/celery/dcelery worker -n heartbeat -B -Q \"file,learn\"\n\n# Distribute a script, default should be taken by the diana-service container\n$ python test/diana-star.py\n```\n\nIf multiple environments are being used, the `services.yml` config should use addresses that are absolute and reachable for any workers or input scripts sharing a queue. The parameters will be pickled and sent along with the task, so `localhost` or hostnames that are only defined on certain hosts will break it.\n\n## License\n\nMIT"
},
{
"alpha_fraction": 0.533277153968811,
"alphanum_fraction": 0.5419825911521912,
"avg_line_length": 32.59434127807617,
"blob_id": "c9ce85bd26f73dc567b5cc5cdf02af5850ecd254",
"content_id": "c2adfd9f8b5b7971f537aefb8a1fb88ddee0cf7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3561,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 106,
"path": "/packages/diana/diana/utils/splunk.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import logging, time, collections\nfrom datetime import datetime\nimport attr\nfrom bs4 import BeautifulSoup\nfrom .requester import Requester\n\[email protected]\nclass SplunkRequester(Requester):\n auth = attr.ib()\n hec_port = attr.ib(default=None) #http event collector port\n hec_token = attr.ib(default=None)\n hec_auth = attr.ib(init=False)\n\n @auth.default\n def set_auth(self):\n return \"123\"\n\n @hec_auth.default\n def set_hec_auth(self):\n return \"123\"\n\n def _hec_url(self, resource):\n return \"https://{}:{}/{}\".format(self.host, self.port, 'services/collector/event')\n\n # get\n # put\n # post\n # delete\n\n # get_record\n # put_record\n # find_records\n\n def get(self, resource, params=None):\n logging.debug(\"Getting {} from splunk\".format(resource))\n url = self._url(resource)\n return self._get(url, params=params, auth=self.auth)\n\n def put(self, resource, data=None):\n logging.debug(\"Putting {} to splunk\".format(resource))\n url = self._url(resource)\n return self._put(url, data=data, auth=self.auth)\n\n # Post to the query address\n def post(self, resource, data=None):\n logging.debug(\"Posting {} to splunk\")\n url = self._url()\n return self._post(url, data=data, auth=self.auth)\n\n # Post to the hec address -- could be aliased to \"put\"\n def hec_post(self, data=None):\n logging.debug(\"Posting record to splunk HEC\")\n url = self._hec_url()\n return self._post(url, data=data, auth=self.auth)\n\n def delete(self, resource):\n logging.debug(\"Deleting {} from splunk\".format(resource))\n url = self._url(resource)\n return self._delete(url, auth=self.auth)\n\n\n def find(self, query, index):\n\n def poll_until_done(sid):\n isDone = False\n i = 0\n r = None\n while not isDone:\n i = i + 1\n time.sleep(1)\n r = self.session.do_get('services/search/jobs/{0}'.format(sid), params={'output_mode': 'json'})\n isDone = r['entry'][0]['content']['isDone']\n status = r['entry'][0]['content']['dispatchState']\n if i % 5 == 1:\n logging.debug('Waiting to finish {0} ({1})'.format(i, status))\n return r['entry'][0]['content']['resultCount']\n\n if not query:\n query = \"search index={0} | spath ID | dedup ID | table ID\".format(index)\n\n r = self.post('services/search/jobs', data=\"search={0}\".format(query))\n\n soup = BeautifulSoup(r, 'xml')\n sid = soup.find('sid').string\n n = poll_until_done(sid)\n offset = 0\n instances = []\n i = 0\n while offset < n:\n count = 50000\n offset = 0 + count * i\n r = self.get('services/search/jobs/{0}/results'.format(sid),\n params={'output_mode': 'csv', 'count': count, 'offset': offset})\n instances = instances + r.replace('\"', '').splitlines()[1:]\n i = i + 1\n return instances\n\n\n def post_event(self, event, index=\"default\", host=None, event_time=None, event_format=None):\n\n data = collections.OrderedDict([('time', event_time or datetime.now() ),\n ('host', host or self.id),\n ('sourcetype', event_format or '_json'),\n ('index', index),\n ('event', event)])\n self.hec_post(data=data)\n"
},
{
"alpha_fraction": 0.5762814879417419,
"alphanum_fraction": 0.6290566921234131,
"avg_line_length": 28.41964340209961,
"blob_id": "8df23a15e317531343eb9460d7a2c8ff0ae22acc",
"content_id": "8816e46e451c98cbd9e2a5da213a3e7109678b0a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3297,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 112,
"path": "/packages/guid-mint/guid-mint/mint.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "\"\"\"\nHashes an alphanumeric guid from a given string value\n\n* Given a guid, gender (M/F/U), and name lists -> returns a reproducible pseudonym\n* Given a guid, and dob (%Y-%m-%d) -> returns a reproducible pseudodob within 6 months of the original dob\n* Given a guid, and age (delta Y) -> pseudodob of guid, (now - age*365.25 days); it is NOT reproducible b/c it depends on now\n\n\npseudonym for id\n\npseudodob for id, dob OR age + studydate\n\nid from key\n\nkey from name, gender=U, dob OR age + studydate\nkey from mrn\nkey from\n\n\n\"\"\"\n\nimport logging\n\nimport random\nfrom dateutil import parser as dateparser\nfrom datetime import datetime, timedelta\nimport os\nfrom abc import abstractmethod\n\n__version__ = \"0.9.0\"\n\nDEFAULT_MAX_DATE_OFFSET = int(365/2) # generated pseudodob is within 6 months\nDEFAULT_HASH_PREFIX_LENGTH = 16 # 8 = 64bits, -1 = entire value\n\nclass GUIDMint(object):\n \"\"\"\n Abstract= base class for guid mints.\n \"\"\"\n\n def __init__(self,\n max_date_offset = DEFAULT_MAX_DATE_OFFSET,\n hash_prefix_length = DEFAULT_HASH_PREFIX_LENGTH,\n **kwargs):\n self.__version__ = __version__\n self.max_date_offset = max_date_offset\n self.hash_prefix_length = hash_prefix_length\n self.logger = logging.getLogger(self.name())\n\n def name(self):\n return self.__class__.__name__\n\n @abstractmethod\n def guid(self, value, *args, **kwargs):\n raise NotImplementedError\n\n def pseudodob(self, guid, dob=None, age=None, ref_date=None, *args, **kwargs):\n random.seed(guid)\n\n if not dob:\n if not age:\n age = random.randint(19,65)\n\n age = int(age)\n\n if not ref_date:\n logging.warning(\"Generating unrepeatable pseudodob using 'now' as the age reference date\")\n ref_date = datetime.now()\n elif type(ref_date) != datetime:\n ref_date = dateparser.parse(ref_date)\n\n dob = ref_date-timedelta(days=age*365.25)\n\n elif not isinstance(dob, datetime):\n dob = dateparser.parse(dob)\n\n r = random.randint(-self.max_date_offset, self.max_date_offset)\n rd = timedelta(days=r)\n\n return (dob+rd).date()\n\n\n\ndef test_mints():\n\n md5_mint = MD5Mint()\n pseudo_mint = PseudoMint()\n\n name = \"MERCK^DEREK^L\"\n gender = \"M\"\n dob = \"1971-06-06\"\n\n id = md5_mint.pseudo_identity(name, gender=gender, dob=dob)\n assert(id==('392ec5209964bfad', '392ec5209964bfad', '1971-08-23'))\n id = pseudo_mint.pseudo_identity(name, gender=gender, dob=dob)\n assert(id==(u'BIN4K4VMOBPAWTW5', u'BERTOZZI^ISIDRO^N', '1971-06-22'))\n\n name = \"MERCK^LISA^H\"\n gender = \"F\"\n dob = \"1973-01-01\"\n\n id = md5_mint.pseudo_identity(name, gender=gender, dob=dob)\n assert(id==('2951550cc186aae1', '2951550cc186aae1', '1972-09-03'))\n id = pseudo_mint.pseudo_identity(name, gender=gender, dob=dob)\n assert(id==(u'LSEOMWPHUXQTPSN3', u'LIZARDO^SUMMER^E', '1972-10-22'))\n\n name = \"PROTECT3-SU001\"\n age = 65\n\n id = md5_mint.pseudo_identity(name, age=age)\n assert(id==('c3352e0d6de56475', 'c3352e0d6de56475', '1966-09-24'))\n id = pseudo_mint.pseudo_identity(name, age=age)\n assert(id==(u'KGHZ7YTCPDDAXG2N', u'KUNZMAN^GENIE^H', '1952-11-11'))\n\n\n"
},
{
"alpha_fraction": 0.6326530575752258,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 18.600000381469727,
"blob_id": "3a7389233bb3805752ae9d83f6aac5dec511f849",
"content_id": "11a1e3f467ec4ee629e8c174b25beeb520e0f1fa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 5,
"path": "/apps/celery/dcelery.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from diana.distrib import app\nfrom repeating import *\n\nif __name__ == '__main__':\n app.start()\n"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.5645161271095276,
"avg_line_length": 32.13333511352539,
"blob_id": "6a107cddde9d2e7553359861e4f3e5184fbb032f",
"content_id": "65438d07c2c06e00ef2cd9248fcef17f25bb8e45",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 15,
"path": "/packages/diana/diana/connect/utils/anon_map.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import hashlib\n\ndef simple_anon_map(item):\n # If not item.meta['AnonName'] get it this way...\n\n return {\n 'Replace': {\n 'PatientName': item.meta['AnonName'],\n 'PatientID': item.meta['AnonID'],\n 'PatientBirthDate': item.meta['AnonDoB'].replace('-', ''),\n 'AccessionNumber': hashlib.md5(item.meta['AccessionNumber']).hexdigest(),\n },\n 'Keep': ['PatientSex', 'StudyDescription', 'SeriesDescription'],\n 'Force': True\n }"
},
{
"alpha_fraction": 0.6388059854507446,
"alphanum_fraction": 0.6442785859107971,
"avg_line_length": 26.53424644470215,
"blob_id": "5dfcd38a151a25195b81769280f15290abd431ec",
"content_id": "bcc2f3e73d3580a44392b99074cce66e52c86aa5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2010,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 73,
"path": "/test/test_distrib.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# Requires workers with \"default\", \"learn\", and \"file\" queues\n\nimport logging\nimport os, ruamel_yaml as yaml\nfrom celery import chain\nfrom diana.connect.apis import Item, DicomLevel\nfrom diana.distrib.apis import RedisEndpoint as Redis, ClassificationEndpoint as Classifier, FileEndpoint as File, OrthancEndpoint as Orthanc\n\n\ndef test_batching(count=20):\n project = \"test\"\n worklists = Redis().inventory\n\n worklists.delete( project )\n for i in range(count):\n item = Item()\n redis.put(item)\n worklists.sadd(project, item.id)\n\n worklist = worklists.smembers( project )\n print(worklist)\n\n # Dispatch them all for handling\n for item_id in worklist:\n item = redis.starget(item_id)\n item = clf.starhandle(item)\n assert (item.meta.get('classified'))\n\n\ndef test_celery():\n\n dx = files.get(\"IM2\", file=True).get()\n dx_oid = dx.oid()\n\n orthanc.put(dx)\n ex = orthanc.get(dx_oid, DicomLevel.INSTANCES).get()\n assert ex.oid() == dx_oid\n\n fx = clf.classify(ex).get()\n assert fx.meta.get('classified') == True\n\n redis.put(fx).get() # Have to block before getting\n gx = redis.get(fx.id).get()\n assert fx == gx\n\n hx = files.get(\"IM3\", file=True).get()\n orthanc.put(hx).get()\n\n s0 = chain( orthanc.get_s(dx.oid(), DicomLevel.INSTANCES) | clf.classify_s() | redis.put_s() )()\n s1 = chain( orthanc.get_s(hx.oid(), DicomLevel.INSTANCES) | clf.classify_s() | redis.put_s() )()\n\n s0.get()\n s1.get()\n\n\nif __name__ == \"__main__\":\n\n logging.basicConfig(level=logging.DEBUG)\n\n logging.debug(\"Simple Distributed Diana Test Script\")\n\n service_cfg = os.environ.get(\"DIANA_SERVICES_CFG\", \"./services.yml\")\n with open(service_cfg, \"r\") as f:\n services = yaml.safe_load(f)\n\n dcm_dir = \"/Users/derek/data/DICOM/airway phantom/DICOM/PA2/ST1/SE1\"\n\n files = File(location=dcm_dir)\n orthanc = Orthanc(**services['orthanc'])\n clf = Classifier()\n redis = Redis(**services['redis'])\n\n test_celery()\n"
},
{
"alpha_fraction": 0.6149388551712036,
"alphanum_fraction": 0.618480384349823,
"avg_line_length": 28.826923370361328,
"blob_id": "452d31d6362ec3549933cf89c8d327b0ee2b9c7c",
"content_id": "0d2768e357ba18bd8312909c348a28c5c9147542",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3106,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 104,
"path": "/packages/diana/diana/daemon/tasks.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from diana.utils import DicomLevel\nfrom diana.distrib.dcelery import app\nfrom diana.distrib.apis import OrthancEndpoint, SplunkEndpoint\nfrom diana.connect.utils.copy_items import copy_items, copy_children\n\n# from diana.connect.apis import OrthancEndpoint as Orthanc, SplunkEndpoint as Splunk\n# I think if this one is _last_ it will use the distributed versions\n\n\[email protected](name=\"message\")\ndef message(msg, *args, **kwargs):\n print(msg)\n\n\[email protected](name=\"index_series\")\ndef index_series( archive, index, timerange=(\"-10m\",\"now\") ):\n\n archive = OrthancEndpoint(archive)\n index = SplunkEndpoint(index)\n\n worklist = archive.find(\n { \"timerange\": timerange,\n \"level\": DicomLevel.SERIES\n }\n )\n available = index.find(\n { \"timerange\": timerange,\n \"level\": DicomLevel.SERIES, # Returns Dx of this type\n \"index\": \"DicomSeries\",\n \"host\": archive.location\n }\n )\n\n new_items = worklist - available\n copy_items(new_items, archive, index, splunk_index=\"DicomSeries\")\n\n\[email protected]\ndef index_dose_reports( archive, index, timerange=(\"-10m\", \"now\"), **kwargs ):\n\n archive = OrthancEndpoint(archive)\n index = SplunkEndpoint(index)\n\n worklist = index.find(\n { \"timerange\": timerange,\n \"index\": \"DicomSeries\",\n \"level\": DicomLevel.SERIES, # Returns Dx at this level\n \"host\": archive.location,\n \"Modality\": \"SR\",\n \"SeriesDescription\": \"*DOSE*\"\n }\n )\n\n # Need to find and send the _child_ instance for each dx\n copy_children(worklist, archive, index, splunk_index=\"DoseReports\")\n\n\[email protected]\ndef index_remote( proxy, remote_aet, index, dcm_query=None, splunk_query=None, timerange=(\"-10m\", \"now\"), **kwargs ):\n\n archive = OrthancEndpoint(proxy)\n index = SplunkEndpoint(index)\n\n worklist = proxy.remote_find(\n {\"timerange\": timerange,\n \"level\": DicomLevel.SERIES,\n \"query\": dcm_query\n },\n remote_aet\n )\n\n available = index.find(\n { \"timerange\": timerange,\n \"level\": DicomLevel.SERIES, # Returns Dx of this type\n \"index\": \"RemoteSeries\",\n \"host\": remote_aet + \" via \" + proxy.location,\n \"splunk_query\": splunk_query\n }\n )\n\n new_items = worklist - available\n copy_items(new_items, proxy, index, splunk_index=\"RemoteSeries\")\n\[email protected]\ndef route( source, dest, **kwargs ):\n\n current = 0\n done = False\n\n while not done:\n changes = source.changes( since=current, limit=10 )\n ret = source.requester.do_get('changes', params={ \"since\": current, \"limit\": 10 })\n\n for change in ret['Changes']:\n # We are only interested interested in the arrival of new instances\n if change['ChangeType'] == 'NewInstance':\n source.send( change['ID'], dest, level=DicomLevel.INSTANCES ).get()\n source.remove( change['ID'], level=DicomLevel.INSTANCES )\n\n current = ret['Last']\n done = ret['Done']\n\n source.changes( clear=True )\n source.exports( clear=True )\n\n\n\n\n"
},
{
"alpha_fraction": 0.5688456296920776,
"alphanum_fraction": 0.5771905183792114,
"avg_line_length": 38.94444274902344,
"blob_id": "b527cf7aa971e5a8a482a947dc9fbc2cc95884c5",
"content_id": "f6b38f62291c3f73fd55a2faa99014144e8a19d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 719,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 18,
"path": "/apps/celery/celerycfg.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import os\n\nbroker_host = os.environ.get(\"BROKER_HOST\", \"localhost\")\nbroker_port = os.environ.get(\"BROKER_PORT\", \"6379\")\nbroker_db = os.environ.get(\"BROKER_DB\", \"1\")\nresult_db = os.environ.get(\"BROKER_HOST\", \"2\")\nbroker_pw = os.environ.get(\"BROKER_PW\", \"passw0rd!\")\n\nbroker_url = \"redis://{broker_host}:{broker_port}/{broker_db}\".format(\n broker_host=broker_host,\n broker_port=broker_port,\n broker_db=broker_db )\nresult_backend = \"redis://{broker_host}:{broker_port}/{result_db}\".format(\n broker_host=broker_host,\n broker_port=broker_port,\n result_db=result_db )\n\ntimezone = 'America/New_York'\n"
},
{
"alpha_fraction": 0.6627218723297119,
"alphanum_fraction": 0.6627218723297119,
"avg_line_length": 23.214284896850586,
"blob_id": "b800fd8ae2f0f31ec368b063579c54dea348e8a4",
"content_id": "aa18fa562b509f6eb17cec9a589e6f2b447eaf1f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 14,
"path": "/packages/diana/diana/utils/smart_json.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import json\nfrom datetime import datetime\n\n# Encodes datetime and hashes\nclass SmartEncoder(json.JSONEncoder):\n def default(self, obj):\n\n if isinstance(obj, datetime):\n return obj.isoformat()\n\n if hasattr(obj, 'hexdigest'):\n return obj.hexdigest()\n\n return json.JSONEncoder.default(self, obj)"
},
{
"alpha_fraction": 0.6586207151412964,
"alphanum_fraction": 0.6931034326553345,
"avg_line_length": 24.19565200805664,
"blob_id": "1517b958c4f317a0a7570b2ef1b5fb89460c26e2",
"content_id": "d41da2b955e0dd055b289dcd4976f036fead428e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 1160,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 46,
"path": "/docker-compose.yml",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# rcDiana simple service setup\n\n# rcdiana is multiarch, so this is typically sufficient for a manual install\n# on either amd64 (intel) or armv7hf (raspberry pi)\n\n# On resin may need to add \":armv7hf\" tags for raspberry pi b/c the uploader is\n# arm64 and will try to grab arm64 by preference rather that the target arch.\n\nversion: '2.1'\n\nservices:\n\n # Private orthanc dicom proxy service\n dicom:\n image: rcdiana/dicom:armv7l\n restart: always\n privileged: true\n ports:\n - \"4242:4242\"\n - \"8042:8042\" # Putting this on 80 makes it publishable on Resin\n\n # Private redis broker service\n broker:\n image: rcdiana/broker:armv7l\n restart: always\n privileged: true\n ports:\n - \"6379:6379\"\n\n # Diana-Worker service\n diana:\n image: rcdiana/diana:armv7l\n restart: always\n privileged: true\n\n # Install a beat to monitor the dicom service, or for a proxied dicom service\n # Install a handler for indexing, routing, or post-processing inputs\n\n # Fast, low power CNN service\n movidius:\n image: rcdiana/movidius:armv7l\n restart: always\n privileged: true\n network_mode: host\n volumes:\n - \"/dev:/dev\"\n\n"
},
{
"alpha_fraction": 0.6023668646812439,
"alphanum_fraction": 0.6029585599899292,
"avg_line_length": 30.296297073364258,
"blob_id": "561d39b6482feaa820af66a987c97a5fe04c49a7",
"content_id": "0fd56e1e2731b940c437a65606ca783e7b250d0c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1690,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 54,
"path": "/packages/diana/diana/connect/utils/copy_items.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "from diana.connect.apis import OrthancEndpoint, SplunkEndpoint, FileEndpoint\n\ndef copy_item(item, source, destination, **kwargs):\n\n if type(source) == OrthancEndpoint:\n\n if kwargs.get('anonymize'):\n if kwargs.get('replacement_map'):\n replacement_map = kwargs.get('replacement_map')\n else:\n replacement_map = None\n anon = source.anonymize(item, replacement_map=replacement_map)\n source.remove(item)\n item = anon\n\n if type(destination) == OrthancEndpoint:\n source.send(item, destination)\n\n if type(destination) == SplunkEndpoint:\n source.get(item, view=\"tags\")\n splunk_index = kwargs.get(\"splunk_index\")\n destination.put(item, splunk_index=splunk_index)\n\n if type(destination) == FileEndpoint:\n source.get(item, view=\"file\")\n destination.put(item)\n\n if type(source) == FileEndpoint:\n\n if type(destination) == OrthancEndpoint:\n source.get(item, view=\"file\")\n destination.put(item)\n\n\ndef copy_items(worklist, source, destination, **kwargs):\n\n for item in worklist:\n copy_item( item, source, destination, **kwargs )\n\n\ndef copy_children(worklist, source, destination, **kwargs):\n\n single_item = kwargs.get('single_item', False)\n\n for item in worklist:\n res = source.get(item, view='meta')\n children = res.get( item.level.child_level() )\n # ie, for a series, it is the \"instances: [...\" array\n\n if single_item:\n children = children[0]\n\n for child in children:\n copy_item( child, source, destination, **kwargs)\n"
},
{
"alpha_fraction": 0.6223037838935852,
"alphanum_fraction": 0.6227627396583557,
"avg_line_length": 23.211111068725586,
"blob_id": "9dfdc292ecd9ad051891eb775b54e4aa4fe3a3ac",
"content_id": "91c7b9f552f9b7f2575a3d27ee194e03efd0f9c9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2179,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 90,
"path": "/packages/diana/diana/distrib/apis.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# Redirect Diana base-class imports here to wrap celery get/put/handle\n# calls with oo calls. Or add \"DistribMixin\" to custom classes.\n\nfrom ..connect.apis import *\nfrom .tasks import *\nimport attr\n\n\ndef star(func):\n def wrapper(self, *args, **kwargs):\n celery_args = {}\n if self.queue:\n celery_args['queue'] = self.queue\n if not kwargs:\n kwargs = {}\n kwargs['pattern'] = self.p\n kwargs['method'] = func.__name__\n return do.apply_async(args, kwargs, **celery_args)\n return wrapper\n\n\n# Not super-elegant, but any starxxx func should also have an xxx_s sig func\ndef star_s(func):\n def wrapper(self, *args, **kwargs):\n if not kwargs:\n kwargs = {}\n kwargs['pattern'] = self.p\n kwargs['method'] = func.__name__[:-2]\n return do.s(*args, **kwargs).set(queue=self.queue)\n return wrapper\n\n\[email protected]\nclass DistribMixin(object):\n queue = attr.ib(default=None) # Can set a queue name per class\n\n @star\n def get(self, *args, **kwargs): pass\n @star_s\n def get_s(self, *args, **kwargs): pass\n @star\n def put(self, *args, **kwargs): pass\n @star_s\n def put_s(self, *args, **kwargs): pass\n\n\[email protected]\nclass OrthancEndpoint(DistribMixin, OrthancEndpoint):\n\n @star\n def clear(self, *args, **kwargs): pass\n @star_s\n def clear(self, *args, **kwargs): pass\n @star\n def anonymize(self, *args, **kwargs): pass\n @star_s\n def anonymize_s(self, *args, **kwargs): pass\n @star\n def find(self, *args, **kwargs): pass\n @star_s\n def find_s(self, *args, **kwargs): pass\n\n\[email protected]\nclass SplunkEndpoint(DistribMixin, SplunkEndpoint):\n\n @star\n def find(self, *args, **kwargs): pass\n @star_s\n def find_s(self, *args, **kwargs): pass\n\n\[email protected]\nclass RedisEndpoint(DistribMixin, RedisEndpoint):\n pass\n\n\[email protected]\nclass ClassificationEndpoint(DistribMixin, ClassificationEndpoint):\n queue = attr.ib(default=\"learn\")\n\n @star\n def classify(self, *args, **kwargs): pass\n @star_s\n def classify_s(self, *args, **kwargs): pass\n\n\[email protected]\nclass FileEndpoint(DistribMixin, FileEndpoint):\n queue = attr.ib(default=\"file\")\n"
},
{
"alpha_fraction": 0.8015872836112976,
"alphanum_fraction": 0.8015872836112976,
"avg_line_length": 17.14285659790039,
"blob_id": "75677cad1c7c46c8cf6277ca9f7db99ed141dc4e",
"content_id": "9e734d90183cb27e1ab5acd2c0a1bd5e426b91e0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/packages/diana/diana/utils/montage.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import attr\nfrom .requester import Requester\n\nattr.s\nclass MontageRequester(Requester):\n raise NotImplementedError\n pass"
},
{
"alpha_fraction": 0.6210466027259827,
"alphanum_fraction": 0.623346745967865,
"avg_line_length": 30.618181228637695,
"blob_id": "7f4a190dd57df758099557f6f555e7ad63293f54",
"content_id": "597e9d81b14d19cdf612c1b00cc71add6b3f7440",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1739,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 55,
"path": "/packages/diana/diana/utils/requester.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "# import logging\nimport requests\nimport attr\n\n# Diana-agnostic HTTP Gateways\n\[email protected]\nclass Requester(object):\n host = attr.ib()\n port = attr.ib()\n auth = attr.ib(init=False, default=None)\n path = attr.ib(default=None)\n protocol = attr.ib(default=\"http\")\n\n def _url(self, resource):\n if self.path:\n return \"{}://{}:{}/{}/{}\".format(self.protocol, self.host, self.port, self.path, resource)\n else:\n return \"{}://{}:{}/{}\".format(self.protocol, self.host, self.port, resource)\n\n def _return(self, response):\n if not response.status_code == 200:\n raise requests.ConnectionError\n elif response.headers.get('content-type').find('application/json')>=0:\n return response.json()\n else:\n return response.content\n\n def _get(self, url, params=None, headers=None, auth=None):\n r = requests.get(url, params=params, headers=headers, auth=auth)\n return self._return(r)\n\n def _put(self, url, data=None, headers=None, auth=None):\n r = requests.put(url, data=data, headers=headers, auth=auth)\n return self._return(r)\n\n def _post(self, url, data=None, headers=None, auth=None):\n r = requests.post(url, data=data, headers=headers, auth=auth)\n return self._return(r)\n\n def _delete(self, url, headers=None, auth=None):\n r = requests.delete(url, headers=headers, auth=auth)\n return self._return(r)\n\n def get(self, resource, params=None):\n raise NotImplementedError\n\n def put(self, url, data=None):\n raise NotImplementedError\n\n def post(self, resource, data=None):\n raise NotImplementedError\n\n def delete(self, url):\n raise NotImplementedError\n"
},
{
"alpha_fraction": 0.5264368057250977,
"alphanum_fraction": 0.5344827771186829,
"avg_line_length": 28,
"blob_id": "df5cf609162f117d52f2507f30184b9eecff2757",
"content_id": "dbb41d6513689d836f111682af563a7cbf7779a6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1740,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 60,
"path": "/packages/diana/diana/utils/dcm_fio.py",
"repo_name": "derekmerck/diana-star",
"src_encoding": "UTF-8",
"text": "import logging, os\nimport attr\nimport pydicom\nimport binascii\n\n# # Diana-agnostic Dicom file reading and writing\n\[email protected]\nclass DicomFileIO(object):\n location = attr.ib(default=\"\")\n\n def fp(self, fn, path=None, explode=None):\n partial = self.location\n if path:\n partial = os.path.join(partial, path)\n if explode:\n epath = self.explode_path(fn, explode[0], explode[1])\n partial = os.path.join(partial, epath)\n fp = os.path.join(partial, fn)\n return fp\n\n def explode_path(self, fn, stride, depth):\n expath = []\n for i in range(depth):\n block = fn[(i - 1) * stride:i * stride]\n expath.append(block)\n return os.path.join(*expath)\n\n def write(self, fn, data, path=None, explode=None):\n fp = self.fp(fn, path, explode)\n\n if not os.path.dirname(fn):\n os.makedirs(os.path.dirname(fn))\n\n with open(fp, 'wb') as f:\n f.write(data)\n\n def read(self, fn, path=None, explode=None, pixels=False):\n fp = self.fp(fn, path, explode)\n\n def is_dicom(fp):\n with open(fp, 'rb') as f:\n f.seek(0x80)\n header = f.read(4)\n magic = binascii.hexlify(header)\n if magic == b\"4449434d\":\n # logging.debug(\"{} is dcm\".format(fp))\n return True\n # logging.debug(\"{} is NOT dcm\".format(fp))\n return False\n\n if not is_dicom(fp):\n raise Exception(\"Not a DCM file: {}\".format(fp))\n\n if not pixels:\n dcm = pydicom.read_file(fp, stop_before_pixels=True)\n else:\n dcm = pydicom.read_file(fp)\n\n return dcm, fp\n"
}
] | 32 |
Liang-biolab/kinase-PTM-DL
|
https://github.com/Liang-biolab/kinase-PTM-DL
|
603147f811c2aa6a9a57877d49030172f80e7189
|
e94af52ba760d3d8b12159bdd9bc85224694d402
|
4f8ed4d2e09b365f50cc6514eef800f44effecd4
|
refs/heads/master
| 2023-02-21T11:37:56.316027 | 2021-01-18T08:10:33 | 2021-01-18T08:10:33 | 331,929,549 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6881546974182129,
"alphanum_fraction": 0.6946011185646057,
"avg_line_length": 21.527273178100586,
"blob_id": "f8f9a6e53bcf589ccfe3429c94f57c26ebe8e17a",
"content_id": "bcf8d406bb9cc3095c398ac623bd1ef99a3238cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1241,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 55,
"path": "/predict_dl.py",
"repo_name": "Liang-biolab/kinase-PTM-DL",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow.keras.metrics as metrics\nfrom keras import models\nfrom keras import layers, Input, regularizers\nfrom keras import optimizers\nfrom keras import activations\nfrom keras.utils import np_utils\nfrom keras import backend as K\nfrom tensorflow.keras import callbacks\nimport numpy as np \nimport datetime\nfrom keras.models import load_model\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport sys\n\n\ndef get_data_label(fea):\n\tif fea == 'all':\n\t\tfea = 'seq+str+dyn'\n\n\tdata = np.load('data/' + fea + '/test_data_1d.npy', allow_pickle=True).astype(float)\n\tlabel = np.load('data/' + fea + '/test_label_1d.npy').astype(float)\n\n\tlabel = np_utils.to_categorical(label)\n\n\treturn data, label\n\n\ndef predict(data,fea):\n\tif fea == 'all':\n\t\tfea = 'seq+str+dyn'\n\n\tmodel_num = 5\n\tpred_prob = None\n\tfor i in range(model_num):\n\t\tmodel = load_model(fea + '/' + fea + '_model/fnn_3class_'+str(i)+'.h5', compile=False)\n\t\tif i == 0:\n\t\t\tpred_prob = model.predict(data)\n\t\telse:\n\t\t\tpred_prob += model.predict(data)\n\n\tpred_prob /= 5\n\n\treturn pred_prob\n\n\nif __name__ == '__main__':\n\tfea = 'all'\n\n\tdata, label = get_data_label(fea)\n\tpred_prob = predict(data, fea)\n\tpred_label = np.argmax(pred_prob, axis=1)\n\n\tprint(pred_label)\n\n\n"
}
] | 1 |
chenshuidexin/python_md
|
https://github.com/chenshuidexin/python_md
|
3f6a36dc2d4b0ec5f6a69fefeeb5a0c7f713372c
|
3140855e765cfab3f21f0328b48d82c425b8bd38
|
03c03dac8a45d36778c8cb79027ec4bfb72fd630
|
refs/heads/master
| 2023-03-07T17:43:42.298739 | 2021-02-28T07:07:29 | 2021-02-28T07:07:29 | 328,381,064 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.45580020546913147,
"alphanum_fraction": 0.5093657374382019,
"avg_line_length": 21.050724029541016,
"blob_id": "340c0912619b6026bd8886dfbe8fbc54330b211d",
"content_id": "8759441228b124632273d1fe4164b06b7aaf7dee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3671,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 138,
"path": "/7.work.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "# 练习一:在屏幕上显示跑马灯文字\n\n# import os\n# import time\n\n# def main():\n# content=\"北京欢迎你,为你开天辟地...\"\n# while True:\n# # 清空屏幕上的输出\n# os.system(\"cls\") # os.system('clear')\n# print(content)\n# # 休眠200ms\n# time.sleep(0.2)\n# content=content[1:]+content[0]\n\n# if __name__ == \"__main__\":\n# main()\n\n\n# 练习二:设计一个函数产生指定长度的验证码,验证码由大小写字母和数字构成\n\n# import random\n\n\n# def generate_code(code_len=4):\n# '''\n# 生成指定长度的验证码\n# :param code_len:验证码的长度(默认4个字符)\n\n# :return 由大小写英文字母和数字构成的随机验证码\n# '''\n# all_chars = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'\n# last_pos = len(all_chars)-1 # 总共个数\n# code = \"\"\n# for _ in range(code_len): # 循环code_len次数\n# index = random.randint(0, last_pos) # 随机数字\n# code += all_chars[index] # 循环到的数字对应的val相加\n# return code\n\n\n# print(generate_code())\n\n\n# 练习三:设计一个函数返回给定文件名的后缀名\n\n# def get_suffix(filename, has_dot=False):\n# \"\"\"\n# 获取文件名的后缀名\n# :param filename: 文件名m\n# :param has_dot:返回的后缀名是否需要带点\n# :return :文件的后缀名\n# \"\"\"\n# pos = filename.rfind(\".\") # 返回字符串最后一次出现的位置\n# if 0 < pos < len(filename)-1:\n# index = pos if has_dot else pos+1 # 设置为true的时候增加一个数字\n# return filename[index:] # 返回的是后缀名\n# else:\n# return \"\"\n\n\n# print(get_suffix('seey.txt', True)) # .txt\n\n\n# 练习四:设计一个函数返回传入的列表中最大和第二大元素的值\n\n# def max2(x):\n# m1, m2 = (x[0], x[1]) if x[0] > x[1] else (x[1], x[0])\n# for index in range(2, len(x)):\n# if x[index] > m1:\n# m2 = m1\n# m1 = x[index]\n# elif x[index] > m2:\n# m2 = x[index]\n# return m1, m2\n\n\n# print(max2([11, 22, 22, 23, 33, 25])) # (33, 25)\n\n\n# 练习五:计算指定的年月日是这一年的第几天\n# def is_leap_year(year):\n# '''\n# 判断指定的年份是不是闰年\n\n# :param year:年份\n# :return :闰年返回True平年返回False\n# '''\n# return year % 4 == 0 and year % 100 != 0 or year % 400 == 0\n\n\n# def which_day(year, month, date):\n# '''\n# 计算传入的日期是这一年的第几天\n\n# :param year:年\n# :param month:月\n# :param date:日\n# :return :第几天\n# '''\n# days_of_month = [\n# [31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31],\n# [31, 29, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31]\n# ][is_leap_year(year)]\n# total = 0\n# for index in range(month-1):\n# total += days_of_month[index]\n# return total + date\n\n\n# def main():\n# print(which_day(1980, 11, 28)) # 333\n# print(which_day(1981, 12, 31)) # 365\n# print(which_day(2018, 1, 1)) # 1\n# print(which_day(2021, 2, 26)) # 57\n\n\n# if __name__ == \"__main__\":\n# main()\n\n\n# 练习六:打印杨辉三角\n\ndef main():\n num = int(input('Number of rows: '))\n yh = [[]] * num\n for row in range(len(yh)):\n yh[row] = [None] * (row + 1)\n for col in range(len(yh[row])):\n if col == 0 or col == row:\n yh[row][col] = 1\n else:\n yh[row][col] = yh[row - 1][col] + yh[row - 1][col - 1]\n print(yh[row][col], end='\\t')\n print()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5637065768241882,
"alphanum_fraction": 0.5752895474433899,
"avg_line_length": 15.25,
"blob_id": "be7310c04eb0a6a2b409a2f4828c19cbbfcace06",
"content_id": "c837d66ebdcabb3581774eac1d0e6a934a93e7ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 16,
"path": "/6_test/module3.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "def foo():\n print(\"hello,module333\")\n pass\n\ndef bar():\n print(\"hello,bar\")\n pass\n\n# __name__是python解释器中一个隐含的变量代表了模块的名字\n# 只有被python解释器直接执行的模块名字才是 __main__\n\nif __name__==\"__main__\":\n print(\"call foo()\")\n foo()\n print(\"call bar()\")\n bar()"
},
{
"alpha_fraction": 0.684684693813324,
"alphanum_fraction": 0.7702702879905701,
"avg_line_length": 14.928571701049805,
"blob_id": "3dc1ecbfcfc324305d139ab900c93647983d35d5",
"content_id": "c7c99c80f0018f1659d253115ff68a3e7e300d47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 14,
"path": "/1.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "import turtle # python的画布\n\nturtle.pensize(3)\nturtle.pencolor(\"black\")\n\nturtle.forward(100)\nturtle.right(90)\nturtle.forward(100)\nturtle.right(90)\nturtle.forward(100)\nturtle.right(90)\nturtle.forward(100)\n\nturtle.mainloop()"
},
{
"alpha_fraction": 0.6321709752082825,
"alphanum_fraction": 0.6389201283454895,
"avg_line_length": 8.88888931274414,
"blob_id": "216bedd77f8e03a60f6b96f530291c286a99b271",
"content_id": "276a8986395321289ed7e08facec596c9f0527d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1567,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 90,
"path": "/基础/1_零基础/2.python_变量.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "### 变量\n\n可变的名称\n\n组成:名称+所对应的数据\n\n利用等于号为变量赋值\n\n`格式为` 变量名=存储的内容\n\n\n\n一个变量可以通过赋值指向不同类型的对象\n\n数值的除法包含两个运算符:`/` 返回一个浮点数,`//` 返回一个整数\n\n在混合运算的时候,python会把整型转换成浮点数\n\n#### 进阶的赋值方法\n\n同时给多个变量赋予同一个内容\n\n`a=b=c=100`\n\n同时给多个变量赋予不同的内容\n\na,b,c=1,2,3\n\n#### 定义一个函数\n\n`def` 是define的缩写,表示定义一个函数\n\n```mark\n格式\n def 函数名称()\n 函数内的语句\n```\n\n调用直接写函数名称就可以 函数名称中间不允许用空格,可以用下划线代替\n\nPython代码`缩进问题`\n\n用四个空格或者一个Tab来表示缩进都可以,但是不要混乱使用\n\n相同缩进位置的代码表示它们是同一个代码块\n\n```python\ndef hello():\n print(\"hello,sunny!\")\n print(\"hello\")\n\nhello()\n```\n\ndef 函数名称(参数一,参数二,...):\n\n\t\t函数内的语句\n\n\t\t......\n\n\t\treturn 返回的内容\n\n参数和return是可选的,其余的都是必选的\n\n```python\ndef hello(val):\n print(\"hello,\"+val+\"!\")\n print(\"hello\")\n\nhello(\"sunny\")\n```\n\n有参数,有返回的函数\n\n```python\ndef hello(val):\n print(\"hello,\"+val+\"!\")\n print(\"hello\")\n return \"好不好\"\n\nvalue=hello(\"sunny\")\nprint(value)\n#或者\nprint(hello(\"sunny\"))\n```\n\n`创建并使用函数的好处:`\n\n- 减少程序中重复的代码\n- 使主程序更抽象,结构更清晰"
},
{
"alpha_fraction": 0.5641025900840759,
"alphanum_fraction": 0.6410256624221802,
"avg_line_length": 19,
"blob_id": "acfbf6794df57b21d27a85f341f1be37ac875a74",
"content_id": "fbbb1f673dad99422879ed8b461c280e522b342f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/6_test/module1.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "def foo():\n print(\"hello,module111\")"
},
{
"alpha_fraction": 0.6613715887069702,
"alphanum_fraction": 0.6788066625595093,
"avg_line_length": 18.545454025268555,
"blob_id": "6afc09e97e2d20ec78f87cac6134b15583e754fd",
"content_id": "571c6273a9606480b294b42dd3f5642dbff8042f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4699,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 132,
"path": "/基础/1_零基础/8.python_类.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "## 类\n\n#### 面向对象\n\n将程序任务涉及到的事物抽象为一个个的对象\n\n以这些对象为中心来写程序\n\n**类** **实例** \n\n> 封装、继承、多态\n\n修改类会影响所有的实例\n\n修改某个实例里的属性不会影响其他类\n\n#### 如何定义一个类\n\n注意类名要单词首字母大写,用驼峰命名法,比如`TextStudent` \n\n注意类里面的函数必须有`self参数` \n\n```python\nclass Student():\n def __init__(self,user_input_name):\n self.name=user_input_name\n\n def say_hi(self):\n print(\"hello,I'm {}\".format(self.name))\n\nkaibao=Student('kaibao');\nkaibao.say_hi()\n\nkkw=Student(\"kkw\");\nkkw.say_hi()\n```\n\n### 面向对象简介\n\n- 类:用来描述具有相同的属性和方法的对象的集合。定义了该集合中每个对象所共有的属性和方法,对象是类的实例。\n- 方法:类中定义的函数\n- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用\n- 数据成员:类变量或者实例变量用于处理及其实例对象的相关的数据。\n- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫做方法的覆盖,也称为方法的重写。\n- 局部变量:定义在方法中的变量,只作用于当前实例的类\n- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用`self`修饰的变量\n- 继承:即一个派生类继承基类的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如:一个dog类型的对象派生自Animal类\n- 实例化:创建一个类的实例,类的具体对象\n- 对象:通过类定义的结构实例。对象包括两个数据成员(类变量和实例变量)和方法\n\npython的类提供了面向对象编程的所有基本功能:类的继承机制允许多个基类,派生类可以覆盖基类中的任何方法,方法中可以调用基类中的同名方法\n\n对象类型可以包含任意数量和类型的数据\n\n#### 类定义、类对象和类的方法\n\n类实例化后,可以使用其属性,实际上,创建一个类之后,可以通过类名访问其属性\n\n**类对象**支持两种操作:属性引用和实例化 属性引用是指`obj.name`\n\n**类对象**创建后,类命名空间中所有的命名都是有效属性名。\n\n```python\nclass MyClass:\n i=123456\n def f(self):\n return \"hello,sunny!\"\n\n# 实例化\nx=MyClass()\n\n# 创建一个新的实例并将该对象赋给局部变量x,x为空对象\nprint(\"空对象\",x) # 空对象 <__main__.MyClass object at 0x000001E923E46BE0>\n# 访问类的属性和方法\nprint(\"MyClass 类的属性 i 为\",x.i) # MyClass 类的属性 i 为 123456\nprint(\"MyClass 类的方法 f 输出为\",x.f()) # MyClass 类的方法 f 输出为 hello,sunny!\n```\n\n类有一个名为`___init__` 的特殊方法(构造方法),该方法在类实例化时会自动调用。类定义了`__init__`方法,类的实例化操作会自动调用`__init__`方法。当然`__init__`方法可以有参数,参数通过`__init__`传递到类的实例化操作上\n\n```python\nclass Complex:\n def __init__(self,realpart,imagpart):\n self.r=realpart\n self.i=imagpart\n\nx=Complex(2,3)\nprint(\"输出结果:\",x.r,x.i) # 输出结果: 2 3\n```\n\n**self** 代表类的实例而并非类,类的方法和普通函数只有一个特别的区别:它们必须有一个额外的第一个参数名称,按照惯例它的名称是*self*\n\n```python\nclass Test:\n def prt(self):\n print(self) # <__main__.Test object at 0x000001CB8A5C6BE0>\n print(self.__class__) # <class '__main__.Test'>\n\nt=Test()\nt.prt()\n```\n\n从上面看是:***self***代表是类的实例,代表当前对象的地址,而*self.class*则指向类\n\n***self***不是python关键字,换成其他的单词也是可以正常执行的,不过默认是self\n\n> 在类的内部,使用`def` 关键字来定义一个方法,与一般的函数定义不同,类方法必须包含***参数self***\n>\n> 并且为第一个参数,self代表是类的实例\n\n```python\nclass person:\n # 定义基本属性\n name=\"\"\n age=0\n # 定义私有属性,私有属性在类外部无法直接进行访问\n __hobby=\"\"\n # 定义构造方法\n def __init__(self,n,a,h):\n self.name=n\n self.age=a\n self.__hobby=h\n def speak(self):\n print(\"%s 说:我 %d 岁。\"%(self.name,self.age))\n\n\n# 实例化类\np=person(\"sunny\",18,\"books\")\np.speak() #sunny 说:我 18 岁。\n```\n\n### 继承\n\n"
},
{
"alpha_fraction": 0.5822703838348389,
"alphanum_fraction": 0.605867326259613,
"avg_line_length": 16.433332443237305,
"blob_id": "b3e8c7059602385682b7de05fe101a2323b794e6",
"content_id": "e7b47ad3194fd85d7ad2a576ba35b09ac340b643",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2576,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 90,
"path": "/基础/1_零基础/4.python_if.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "### 补充\n\n`\\t` 转义制表符\n\nstr.format()格式化函数 增强字符串格式化的功能,接收不限制个数的参数,位置可以不按照顺序\n\n```pyth\n>>>\"{} {}\".format(\"hello\", \"world\") # 不设置指定位置,按默认顺序\n'hello world'\n \n>>> \"{0} {1}\".format(\"hello\", \"world\") # 设置指定位置\n'hello world'\n \n>>> \"{1} {0} {1}\".format(\"hello\", \"world\") # 设置指定位置\n'world hello world'\n```\n\n设置参数的时候\n\n```python\nprint(\"网站名:{name}, 地址 {url}\".format(name=\"菜鸟教程\", url=\"www.runoob.com\"))\n \n# 通过字典设置参数\nsite = {\"name\": \"菜鸟教程\", \"url\": \"www.runoob.com\"}\nprint(\"网站名:{name}, 地址 {url}\".format(**site))\n \n# 通过列表索引设置参数\nmy_list = ['菜鸟教程', 'www.runoob.com']\nprint(\"网站名:{0[0]}, 地址 {0[1]}\".format(my_list)) # \"0\" 是必须的\n\n# 结果都是:网站名:菜鸟教程, 地址 www.runoob.com\n```\n\n也可以传入对象,后面在演示\n\n##### 字符串的方法\n\n- 查找:find() 如果存在的话会返回索引值,不存在的话返回-1\n- 转换小写:lower()\n- 转换大写:upper()\n- 按指定分隔符分隔字符串:split()\n- 按指定分隔符链接字符串:join()\n- 替换子字符串:replace()\n\n### 条件判断\n\n#### if/elif/else\n\nPython 中用 **elif** 代替了 **else if**,所以if语句的关键字为:**if – elif – else**。\n\n- 1、每个条件后面要使用冒号 **:**,表示接下来是满足条件后要执行的语句块。\n- 2、使用缩进来划分语句块,相同缩进数的语句在一起组成一个语句块。\n- 3、在Python中没有switch – case语句。\n\n```python\nage = int(input(\"请输入你家狗狗的年龄: \"))\nprint(\"\")\nif age <= 0:\n print(\"你是在逗我吧!\")\nelif age == 1:\n print(\"相当于 14 岁的人。\")\nelif age == 2:\n print(\"相当于 22 岁的人。\")\nelif age > 2:\n human = 22 + (age -2)*5\n print(\"对应人类年龄: \", human)\n \n### 退出提示\ninput(\"点击 enter 键退出\")\n```\n\n\n\n可以进行if嵌套\n\n条件判断就会从第一个开始判断,直到有一个符合条件的就不继续往下执行\n\n`如果没有`else语句且前面条件都不符合的话输出什么?\n\n答:这段条件判断语句什么都不会输出。\n\n多重if语句判断,不同层级的条件判断互不影响\n\n`关键字:`\n\nand 同时都满足条件 且 `num > 0 and num < 100`\n\nor 满足其中的一个条件就好 或 `num < 0 or num > 10 `\n\nnot 这个条件的否定反义词 非 ` not n>10` 解释为:n<=10才成立"
},
{
"alpha_fraction": 0.5613986253738403,
"alphanum_fraction": 0.6341913342475891,
"avg_line_length": 27.300260543823242,
"blob_id": "881b42aad092fb2f5cebaba4aa1eeadfa9d730a6",
"content_id": "207bfa71f5990c3134af75214176e34c89336c7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15811,
"license_type": "no_license",
"max_line_length": 251,
"num_lines": 383,
"path": "/7.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "# 字符串 由零个或多个字符组成的有限序列,在python程序中,如果我们把单个或多个字符用单引号或双引号包围起来就可以表示一个字符串\n\n# 以三个双引号或者单引号开头的字符串可以折行\n\n# 可以在字符串中使用 \\ 反斜杠 \\n表示换行 \\t表示制表符\n\n# s1 = '\\'hello,kkw!\\''\n# s2 = 'nihao \\n\\hello,sunny!\\\\\\n sunny'\n# print(s1, s2, end='')\n\n\n# 在\\后面可以跟一个八进制或者十六进制来表示字符,例如\\141和\\x61都代表着小写字母a,前者是八进制的表示法,后者是十六进制的表示法。也可以在\\后面跟Unicode字符编码来表示字符\n\n# s1 = '\\141\\142\\143\\x61\\x62\\x63'\n# s2 = '\\n\\u9a86'\n# print(s1, s2)\n\n# 如果不希望字符串中\\表示转义,可以通过在字符串的最前面加上字母r来加以说明\n\n# s1=r\"\\'hello,s1!\\'\"\n# s2=r\"\\n\\\\hello,world!\\\\\\n\"\n# print(s1,s2,end=\"kw\")\n\n\n'''\npython为字符串类型提供了非常丰富的运算符,可以使用+运算符实现字符串的拼接,可以使用*运算符来重复一个字符串的内容,可以使用in和not in 来判断一个字符串是否包含另外一个字符串(成员运算),我们也可以使用[]和[:]运算符从字符串取出某个字符或某些字符(切片字符)\n'''\n# s1 = \"sunny \"*3\n# print(s1) # sunny sunny sunny\n# s2 = \"world\"\n# s1 += s2\n# print(s1) # sunny sunny sunny world\n# print('nn' in s1) # True\n# print(\"good\" in s1) # False\n\n\n# str2 = \"abcde123456\"\n# # 从字符串中取出指定位置的字符(下标运算)\n# print(str2[2]) #c\n# # 字符串切片[从指定的开始索引到指定的结束索引)\n# print(str2[2:5]) # cde\n# print(str2[2:]) # cde123456\n# print(str2[2::2]) # ce246\n# print(str2[::2]) # ace246\n# print(str2[::-1]) # 字符串翻转 654321edcba\n# print(str2[-3:-1]) # 45 最后一个字符串不包含进去\n\n# *******在python中可以使用这些方法处理字符串*******\n# str1=\"hello, world!\"\n# 通过内置函数len计算字符串的长度\n# print(len(str1)) # 13\n# 获得字符串首字母大写的拷贝\n# print(str1.capitalize()) # Hello, world!\n# 获得字符串每个单词首字母大写的拷贝\n# print(str1.title()) # Hello, World!\n# 获得字符串变大写的拷贝\n# print(str1.upper()) # HELLO, WORLD!\n# 从字符串中查找字符串所在的位置\n# print(str1.find(\"or\")) # 8 查找之后返回的是字符串下标位置\n# print(str1.find(\"shit\")) # -1 查找不到就返回-1\n# 与find类似但找不到子字符串的时候会引发异常\n# print(str1.index(\"or\")) # 8\n# print(str1.index(\"shit\")) # 报异常\n# 检查字符串是否以指定的字符串开头 区分大小写\n# print(str1.startswith(\"He\")) # False\n# print(str1.startswith(\"hel\")) # True\n# 检查字符串是否以指定的字符串结尾\n# print(str1.endswith(\"!\")) # True\n# 将字符串以指定的宽度居中并在两侧填充指定的字符\n# print(str1.center(50,\"*\")) # ******************hello, world!*******************\n# 将字符串以指定的宽度靠右放置左侧填充指定的字符\n# print(str1.rjust(50,\"_\")) # _____________________________________hello, world!\n\n\n# str2 = \"abc123456\"\n# 检查字符串是否由数字构成\n# print(\"数字\", str2.isdigit()) # False\n# 检查字符串是否由字母构成\n# print(\"字母\", str2.isalpha()) # False\n# 检查字符串是否以数字和字母构成\n# print(\"数字和字母\", str2.isalnum()) # True\n\n# str3 = ' [email protected]'\n# print(str3) # [email protected]\n# 获得字符串修剪左右两侧空客之后的拷贝 清空字符串前后的空格\n# print(str3.strip()) # [email protected]\n\n\n# 可以格式化输出字符串\n# a, b = 5, 9 # 输出格式:5*9=45\n# print(\"%d*%d=%d\" % (a, b, a*b))\n# 可以使用字符串提供的方法来完成字符串的格式\n# print('{0}*{1}={2}'.format(a, b, a*b))\n# python3.6之后,格式化字符串还有更简洁的书写方式\n# print(f'{a}*{b}={a*b}')\n\n\n# 数值类型(int和float)是标量类型,这种类型的对象没有可以访问的内部结构\n# 列表\n# 列表和字符串是一种结构化,非标量类型,因此才会有一系列的属性和方法\n# list1 = [1, 3, 5, 7, 9, 11]\n# print(list1) # [1, 3, 5, 7, 9, 11]\n# * 乘号表示列表元素的重复\n# list2 = [\"sunny\",\"rain\"]*4 # ['sunny', 'rain', 'sunny', 'rain', 'sunny', 'rain', 'sunny', 'rain']\n# print(list2) # ['sunny', 'rain', 'sunny', 'rain', 'sunny', 'rain', 'sunny', 'rain']\n# 计算列表长度(元素个数)\n# print(len(list1)) # 6\n# 下标(索引)运算\n# print(list1[0]) # 1\n# print(list1[3]) # 7\n# print(list1[7]) # IndexError: list index out of range\n# print(list1[-1]) # 11\n# print(list1[-3]) # 7\n# list1[2] = 22\n# print(list1) # [1, 3, 22, 7, 9, 11]\n# 通过循环用下标遍历列表元素\n# for index in range(len(list1)):\n# print(\"index\",list1[index])\n\n# 通过for循环遍历列表\n# for elem in list1:\n# print(\"elem\",elem)\n\n# 通过enumerate函数处理列表之后再遍历可以同时获得元素索引和值\n# for index, elem in enumerate(list1):\n# print(index, elem)\n\n\n# 列表中对元素的增删改查\nlist3 = [1, 3, 5, 7, 9]\n\n# 添加元素\nlist3.append(200) # 最后末尾增加数值200\n# print(list3) # [1, 3, 5, 7, 9, 200]\nlist3.insert(1, 400) # 索引值为1的地方前面插入数值400\n# print(list3) #[1, 400, 3, 5, 7, 9, 200]\n\n# 合并两个列表\n# list3.extend([111,222])\n# print(list3) # [1, 400, 3, 5, 7, 9, 200, 111, 222]\nlist3 += [333, 444] # 合并表格的另一种表示方式\n# print(list3) # [1, 400, 3, 5, 7, 9, 200, 333, 444]\n# print(len(list3)) # 9\n\n# 先通过成员运算判断元素是否在列表中,如果存在就删除\nif 5 in list3:\n list3.remove(5)\nif 123 in list3: # 不存在的数值也不会报错\n list3.remove(123)\n# print(list3) # [1, 400, 3, 7, 9, 200, 333, 444]\n\n# 从指定的位置删除元素\nlist3.pop(0) # 删除下标为0的数值\n# print(list3) # [400, 3, 7, 9, 200, 333, 444]\nlist3.pop(len(list3)-1) # 删除列表中最后一位数字\n# print(list3) # [400, 3, 7, 9, 200, 333]\n\n# 清空列表\nlist3.clear()\n# print(list3) # []\n\n# 和字符串一样,列表也可以做切片操作,通过切片操作我们可以实现对列表的复制或者将列表中的一部分取出来创建新的列表\nfruits = [\"grape\", \"apple\", \"strawberry\", \"waxberry\"]\nfruits += [\"pitaya\", \"pear\", \"mango\"]\n# print(fruits) # ['grape', 'apple', 'strawberry', 'waxberry', 'pitaya', 'pear', 'mango']\n\n\n# 列表切片\nfruits2 = fruits[1:4]\n# print(fruits2) # ['apple', 'strawberry', 'waxberry']\n\n# 可以通过完整切片操作来复制列表\nfruits3 = fruits[:] # 完整复制一份列表\n# print(fruits3) # ['grape', 'apple', 'strawberry', 'waxberry', 'pitaya', 'pear', 'mango']\nfruits4 = fruits[-3:-1] # [-3,-1)\n# print(fruits4) # ['pitaya', 'pear']\n# 可以通过反向切片操作来获得倒转后的列表的拷贝\nfruits5 = fruits[::-1] # 获得是翻转后的列表\n# print(fruits5) # ['mango', 'pear', 'pitaya', 'waxberry', 'strawberry', 'apple', 'grape']\n\n# 实现对列表的排序操作\nlistt1 = [\"orange\", \"apple\", \"zoo\", \"internationalization\", \"blueberry\"]\n# sorted函数返回列表排序后的拷贝不会修改传入的列表\n# 函数的设计就应该像sorted函数一样尽可能不产生副作用\nlistt2 = sorted(listt1)\n# print(listt2) # ['apple', 'blueberry', 'internationalization', 'orange', 'zoo']\nlistt3 = sorted(listt1, reverse=True)\n# print(listt3) # ['zoo', 'orange', 'internationalization', 'blueberry', 'apple']\n# 通过key关键字参数指定根据字符串长度进行排序而不是默认的字母表顺序\nlistt4 = sorted(listt1, key=len) # 从短到长进行排序\n# print(listt4) # ['zoo', 'apple', 'orange', 'blueberry', 'internationalization']\n# 给对象列表发出排序消息直接在列表对象上进行排序\nlistt1.sort(reverse=True)\n# print(listt1) # ['zoo', 'apple', 'orange', 'blueberry', 'internationalization']\n\n# 生成式和生成器\n# 使用列表的生成式语法来创建列表\nf = [x for x in range(1, 10)]\n# print(f) # [1, 2, 3, 4, 5, 6, 7, 8, 9]\nf = [x+y for x in \"ABCDE\" for y in \"1234567\"]\n# print(f) # ['A1', 'A2', 'A3', 'A4', 'A5', 'A6', 'A7', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6', 'B7', 'C1', 'C2', 'C3', 'C4', 'C5', 'C6', 'C7', 'D1', 'D2', 'D3', 'D4', 'D5', 'D6', 'D7', 'E1', 'E2', 'E3', 'E4', 'E5', 'E6', 'E7']\n\n# 用列表的生成表达式语法创建列表容器\n# 用这种语法创建列表之后元素已经准备就绪所以消耗较多的内存空间\nf = [x ** 2 for x in range(1, 1000)]\n# 查看对象所占用内存的字节数\n# print(sys.getsizeof(f))\n# print(f)\n\n# 需要注意的是:下面的代码创建的不是一个列表而是一个生成器对象\n# 通过生成器对象可以获取到数据但它不占用额外的空间存储数据\n# 每次需要数据的时候就通过内部的运算得到数据(需要花费额外的时间)\n# f = (x**2 for x in range(1, 1000))\n# print(sys.getsizeof(f)) # 相比生成式生成器不占用存储数据的空间\n# print(f)\n# for val in f:\n# print(val)\n\n# 除了上面的生成器语法,py中还有另外一种定义生成器的方式,就是通过`yield`关键字将一个普通函数改造成生成器函数。\n# 斐波拉切数列\n\n\n# def fib(args):\n# a, b = 0, 1\n# for _ in range(10):\n# a, b = b, a+b\n# yield a\n\n\n# def main():\n# for val in fib(20):\n# print(val)\n\n\n# if __name__ == \"__main__\":\n# main()\n\n\n# 元组的使用\n# python中的元组和列表类似也是一种容器数据类型,可以用一个变量(对象)来存储多个数据,不同之处在于元组的元素不能修改。\n\n# 定义元组\nt = (\"sunny\", 22, \"beijing\", False)\n# print(t) # ('sunny', 22, 'beijing', False)\n\n# 获取元组中的元素\n# print(t[0]) # sunny\n# print(t[3]) # False\n# 遍历元组中的值\n# for member in t:\n# print(member)\n\n# 重新给元组赋值\n# t[0]=\"rain\" # TypeError: 'tuple' object does not support item assignment\n# 变量t重新引用了新的元组 原来的元组将被垃圾回收\nt = ('rain', 22, False, \"hebei\")\n# print(t) # ('rain', 22, False, 'hebei')\n\n# 将元组转换成列表\nperson = list(t)\n# print(person) # ['rain', 22, False, 'hebei']\n# 列表是可以修改元素的\nperson[0] = \"kkw\"\nperson[1] = 8\n# print(person) # ['kkw', 8, False, 'hebei']\n\n# 将列表转换成元组\nfruits_list = [\"orange\", \"banan\", \"apple\"]\nfruits_tuple = tuple(fruits_list)\n# print(fruits_tuple) # ('orange', 'banan', 'apple')\n\n'''\n这里有一个值得探讨的问题,我们明明已经有了列表数据结构,为什么还需要元组这样类型的呢?\n\n1.元组中的元素是无法修改的,事实上我们在项目中尤其是多线程环境中可能更喜欢使用的是那些不变的对象(一方面因为对象状态不能修改,所以可以避免由此引起的不必要的程序错误,简单的说就是一个不变的对象要比可变的对象更容易维护;另一方面因为没有任何一个线程能够修改不变对象的内部状态,一个不变对象自动就是线程安全的,这样就可以省掉处理同步化的开销。一个不变对象可以方便的被共享访问)。所以结论是:如果不需要对元素进行添加、删除、修改的时候,可以考虑使用元组,当然如果一个方法要返回多个值,使用元组也是不错的选择\n\n2.元组在创建时间和占用的空间上都优于列表。我们可以使用sys模块的getsizeof函数来检查存储同样的元素的元组和列表各自占用了多少内存空间。这个很容易做到的。我们可以在ipython中使用魔法指令 %timeit来分析创建同样内容的元组和列表所花费的时间。\n'''\n\n# py中的集合\n# 跟数学上的集合是一致的,不允许有重复元素,而且可以进行交集、并集、差集等等运算\n\n# 创建集合的字面量语法\nset1 = {1, 2, 3, 3, 3, 4}\n# print(set1) # {1, 2, 3, 4}\n# print(\"Leng = \", len(set1)) # Leng = 4\n# 创建集合的构造器语法(等到面向对象部分会详细讲解)\nset2 = set(range(1, 10))\nset3 = set((1, 2, 3, 4, 3, 2, 1))\n# print(set2,set3) # {1, 2, 3, 4, 5, 6, 7, 8, 9} {1, 2, 3, 4}\n# 创建集合的推导式语法(推导式也可以用于推导集合)\nset4 = {num for num in range(1, 100) if num % 13 == 0 or num % 15 == 0}\n# print(set4) # {65, 90, 39, 75, 13, 45, 15, 78, 52, 26, 91, 60, 30}\n\n# 向集合添加元素和删除元素\nset1.add(4)\nset1.add(5)\n# print(set1) # {1, 2, 3, 4, 5}\nset2.update([11, 12])\nset2.discard(5) # discard 丢弃,抛弃\n# print(set2) # {1, 2, 3, 4, 6, 7, 8, 9, 11, 12}\nif 4 in set2:\n set2.remove(4)\n# print(\"set1\",set1) # set1 {1, 2, 3, 4, 5}\n# print(\"set2\",set2) # set2 {1, 2, 3, 6, 7, 8, 9, 11, 12}\n# print(set3.pop()) # 1 返回值是删除的数值\n# print(\"set3\",set3) # set3 {2, 3, 4}\n\n'''\n说明:Python中允许通过一些特殊方法来为某种类型或数据结构自定义运算符(后面的章节会讲解到),下面的代码中我们对集合进行运算的时候可以调用集合对象的方法,也可以直接使用对应的运算符,例如&运算符和intersection方法的作用是一样的,但是使用运算符让代码更加直观。\n'''\n# 集合的交集、并集、差集、对称差运算\n# print(set1,set2) # {1, 2, 3, 4, 5} {1, 2, 3, 6, 7, 8, 9, 11, 12}\n# 交集 {1, 2, 3}\n# print(set1 & set2)\n# print(set1.intersection(set2))\n# 并集 {1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12}\n# print(set1 | set2)\n# print(set1.union(set2))\n# 差集 {4, 5} set1 减去共同有的部分\n# print(set1-set2)\n# print(set1.difference(set2))\n# 差集的合体 set1+set2合体减去交集的部分 {4, 5, 6, 7, 8, 9, 11, 12}\n# print(set1 ^ set2)\n# print(set1.symmetric_difference(set2))\n\n# print(set1, set2, set3) # {1, 2, 3, 4, 5} {1, 2, 3, 6, 7, 8, 9, 11, 12} {1, 2, 3, 4} set1和set3有关系\n# 判断子集和超集 False\n# print(set2 <= set1)\n# print(set2.issubset(set1))\n# True\n# print(set3 <= set1)\n# print(set3.issubset(set1))\n# False\n# print(set1 >= set2)\n# print(set1.issuperset(set2))\n# True\n# print(set1 >= set3)\n# print(set1.issuperset(set3))\n\n\n# 字典的使用\n# 字典是另一种可变容器模型,它可以存储任意类型对象,与列表、集合不同的是:字典的每个元素都是由一个键和一个值组成的\"键值对\",键和值通过冒号分开。\n\n# 创建字典的字面量语法\nscores = {\"name\": \"sunny\", \"age\": 12, \"address\": \"beijing\"}\n# print(scores) # {'name': 'sunny', 'age': 12, 'address': 'beijing'}\n# 创建字典的构造器语法\nitem1 = dict(one=1, two=2, three=3, four=4)\n# print(item1) # {'one': 1, 'two': 2, 'three': 3, 'four': 4}\n# 通过zip函数将两个序列压成字典\nitem2 = dict(zip([\"a\", \"b\", \"c\"], \"123\"))\n# print(item2) # {'a': '1', 'b': '2', 'c': '3'}\n# 创建字典的推导式语法\nitem3 = {num: num**2 for num in range(1, 10)}\n# print(item3) # {1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}\n\n# 通过键值对可以获取字典中对应的值\n# print(scores['name']) # sunny\n# print(scores['address']) # beijing\n\n# 对字典中所有键值对进行遍历\n# for key in scores:\n# print(f'{key}:{scores[key]}') #name:sunny age:12 address:beijing\n\n# 更新字典中的元素\nscores[\"name\"] = \"kkw\"\nscores[\"hobby\"] = \"swimming\"\nscores.update(eat=55, drink=66)\n# print(scores) # {'name': 'kkw', 'age': 12, 'address': 'beijing', 'hobby': 'swimming', 'eat': 55, 'drink': 66}\nif \"name\" in scores:\n print(scores[\"name\"]) # kkw\nprint(scores.get(\"age\")) # 12 get方法是通过键获取对应的值但是可以设置默认值\nprint(scores.get(\"sunny\", 1)) # 返回的是默认值\n\n# 删除字典中的元素\nprint(scores.popitem()) # 删除的是最后一个键值对 ('drink', 66)\nprint(scores.popitem()) # 删除的是最后一个键值对 ('eat', 55)\nprint(scores.pop(\"name\", \"kkw\")) # kkw 直接删除特定的值\n\n# 清空字典\nscores.clear()\nprint(scores) # {}\n"
},
{
"alpha_fraction": 0.3820224702358246,
"alphanum_fraction": 0.4157303273677826,
"avg_line_length": 11.714285850524902,
"blob_id": "fc50da02152526874c785bc9440a578537ea187f",
"content_id": "84c77d8438820560dcc717ebc2bc560cb1750016",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 89,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 7,
"path": "/3.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "\ni =0\nwhile True:\n print(i)\n i=i+1\n if i>5:\n print(\"in:\",i)\n break"
},
{
"alpha_fraction": 0.550000011920929,
"alphanum_fraction": 0.625,
"avg_line_length": 19,
"blob_id": "32bb83f096079dbc62b5344f3e23e5bf0eae4597",
"content_id": "01c52cb698f425d9de1ba254703eb1de67224e11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 40,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/6_test/module2.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "def foo():\n print(\"hello,module222\")\n"
},
{
"alpha_fraction": 0.4373820126056671,
"alphanum_fraction": 0.46633103489875793,
"avg_line_length": 17.69411849975586,
"blob_id": "9c811719a116dd0e8e1119bf5a109563848b3ef0",
"content_id": "766c3d235223d268ee1a1c661ca3d58e7174649e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1765,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 85,
"path": "/8.work.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "# 练习1:定义一个类描述数字时钟\n'''\nfrom time import sleep\n\n\nclass Clock(object):\n # 数字时钟\n def __init__(self, hour=0, minute=0, second=0):\n # 初始化方法\n self._hour = hour\n self._minute = minute\n self._second = second\n\n def run(self):\n self._second += 1\n if self._second == 60:\n self._second = 0\n self._minute += 1\n if self._minute == 60:\n self._minute = 0\n self._hour += 1\n if self._hour == 24:\n self._hour = 0\n\n def show(self):\n # 显示时间\n return '%02d:%02d:%02d' %\\\n (self._hour, self._minute, self._second)\n\n\ndef main():\n clock = Clock(14, 59, 22)\n while True:\n print(clock.show())\n sleep(1)\n clock.run()\n\n\nif __name__ == \"__main__\":\n main()\n'''\n\n# 练习2:定义一个类描述平面上的点并提供移动点和计算到另一个点距离的方法\n\nfrom math import sqrt\n\n\nclass Point(object):\n def __init__(self, x=0, y=0):\n # 初始化方法\n self.x = x\n self.y = y\n\n def move_to(self, x, y):\n # 移动位置\n self.x = x\n self.y = y\n\n def move_by(self, dx, dy):\n # 横纵坐标的增量\n self.x += dx\n self.y += dy\n\n def distance_to(self, other):\n # 计算与另外一个点的距离\n dx = self.x-other.x\n dy = self.y-other.y\n return sqrt(dx**2+dy**2)\n\n def __str__(self):\n return '(%s,%s)'%(str(self.x),str(self.y))\n\n\ndef main():\n p1 = Point(3, 5)\n p2 = Point()\n print(p1)\n print(p2)\n p2.move_by(-1, 2)\n print(p2)\n print(p1.distance_to(p2))\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5059523582458496,
"alphanum_fraction": 0.5208333134651184,
"avg_line_length": 17.66666603088379,
"blob_id": "7e957090562098a584d8349062b1288097028b90",
"content_id": "f5bc49856fe370c26064172d8bf6b3d72ea17dad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 18,
"path": "/5.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "class person:\n # 定义基本属性\n name=\"\"\n age=0\n # 定义私有属性,私有属性在类外部无法直接进行访问\n __hobby=\"\"\n # 定义构造方法\n def __init__(self,n,a,h):\n self.name=n\n self.age=a\n self.__hobby=h\n def speak(self):\n print(\"%s 说:我 %d 岁。\"%(self.name,self.age))\n\n\n# 实例化类\np=person(\"sunny\",18,\"books\")\np.speak() #sunny 说:我 18 岁。\n"
},
{
"alpha_fraction": 0.6765031218528748,
"alphanum_fraction": 0.6812984347343445,
"avg_line_length": 22.379310607910156,
"blob_id": "58b113ca0118d7801b98b3f91a230913d5aa5822",
"content_id": "ed98517a668d72096f2a85006aa054165bc77575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5025,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 116,
"path": "/8.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "'''\n面向对象编程\n把一组数据结构和处理方法组成对象,把相同行为的对象归纳为类,通过类的封装隐藏内部细节,通过继承实现类的特化和泛化,通过多态实现基于对象类型的动态分派\n\n\"程序是指令的集合\",在程序书写的语句在执行时会变成一条或多条指令然后由cpu去执行。引入函数的概念,把相对独立且经常重复使用的代码放置函数中,在需要使用这些功能的时候只需要调用函数即可;如果一个函数的功能过于复杂和臃肿,可以进一步将函数继续切分为子函数来降低系统的复杂性\n\n按照面向对象的编程理念,程序中的数据和操作数据的函数是一个逻辑上的整体,称之为\"对象\",而解决问题的方式是创建出需要的对象并向对象发出各种各样的消息,多个对象的协同工作最终可以构造出复杂的系统来解决现实中的问题\n\n'''\n\n# 类和对象\n\n# 简单来说,类是对象的蓝图和模板,对象是类的实例。 类是概念,对象是具体的东西\n# 在面向对象编程的世界中,一切皆为对象,对象都有属性和行为,每个对象都是独一无二的,而且对象一定是属于某个类(型)。当我们把这些共同特征的对象的静态特征(属性)和动态特征(行为)都抽取后,就可以定义一个叫做\"类\"的东西\n\n# 定义类 在py中使用 class 关键字定义类,然后在类中通过函数定义方法,可以将对象的动态特征描述出来\n\n\nclass Student(object):\n # __init__是一个特殊的方法用于创建对象时进行初始化操作\n # 通过这个方法可以为学生对象绑定name和age两个属性\n def __init__(self, name, age):\n self.name = name\n self.age = age\n\n def study(self, course_name):\n print('%s正在学习%s.' % (self.name, course_name))\n\n # 要求标识符的名字全小写多个单词用下划线链接,当然有的工作是用驼峰命名法\n def watch_movie(self):\n if self.age < 18:\n print('%s只能看蓝猫' % self.name)\n else:\n print(\"%s可以看道德思想政治\" % self.name)\n\n# 写在类中的函数,称之为(对象的)方法,这些方法是对象可以接收的消息\n\n\n# stu = Student(\"kkw\", 8)\n# stu.study(\"English\")\n# stu.watch_movie()\n\n\n# 创建和使用对象\n# 当我们定义好一个类之后,可以通过下面的方式来创建对象并给对象发消息\n\ndef main():\n # 创建学生对象并指定姓名和年龄\n stu1 = Student(\"kkw\", 23)\n # 给对象发study消息\n stu1.study(\"程序设计\")\n # 给对象发送watch_movie消息\n stu1.watch_movie()\n stu2 = Student(\"sunny\", 11)\n stu2.study(\"前端开发\")\n stu2.watch_movie()\n\n\nif __name__ == \"__main__\":\n main()\n\n\n'''\n访问可见性问题\n给 Student 对象绑定的name和age属性有怎样的访问权限?在很多面向对象编程语言中,会将对象的属性设置为私有的(private)和受保护的(protected),简单来说就是不允许外界访问,而对象的方法通常是公开的(public),因为公开的方法就是对象能够接收的消息。在python中,属性和方法的权限只有两种,也就是公开的和私有的,如果希望属性是私有的,在属性命名时可以用两个下划线作为开头\n'''\n\n'''\nclass Test:\n def __init__(self, foo):\n self.__foo = foo\n\n def __bar(self):\n print(self.__foo)\n print(\"__bar\")\n\n\ndef main():\n test = Test(\"hello\")\n # AttributeError: 'Test' object has no attribute '__bar'\n # test.__bar()\n # AttributeError: 'Test' object has no attribute '__foo'\n # print(test.__foo)\n\n\nif __name__ == \"__main__\":\n main()\n'''\n\n# 但是,python并没有从语法上严格保证私有属性或方法的私密性,只是给私有属性和方法换了一个名字来妨碍对它们的访问,事实上如果知道了更换名字的规则仍然可以访问到它们。。之所以这样设定,可以用这样一句名言加以解释,就是\"We are all consenting adults here\"。因为绝大多数程序员都认为开放比封闭要好,而且程序员要自己为自己的行为负责。\n\n\nclass Test:\n\n def __init__(self, foo):\n self.__foo = foo\n\n def __bar(self):\n print(self.__foo)\n print('__bar')\n\n\ndef main():\n test = Test('hello')\n # #################\n test._Test__bar()\n print(test._Test__foo)\n\n\nif __name__ == \"__main__\":\n main()\n\n\n'''\n在实际开发中,我们并不建议将属性设置为私有的,因为这会导致子类无法访问(后面会讲到)。所以大多数Python程序员会遵循一种命名惯例就是让属性名以单下划线开头来表示属性是受保护的,本类之外的代码在访问这样的属性时应该要保持慎重。这种做法并不是语法上的规则,单下划线开头的属性和方法外界仍然是可以访问的,所以更多的时候它是一种暗示或隐喻\n'''"
},
{
"alpha_fraction": 0.59375,
"alphanum_fraction": 0.59375,
"avg_line_length": 17.75,
"blob_id": "1f1ffd0077f0b06861eb6e54463ecc4de1aa501c",
"content_id": "ce90c988c73dddcab2e58ac699636d0215bd53b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 12,
"path": "/4.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "class Student():\n def __init__(self,name): # 初始化函数\n self.name=name\n\n def say_hi(self):\n print(\"hello,I'm {}\".format(self.name))\n\nkaibao=Student('kaibao');\nkaibao.say_hi()\n\nkkw=Student(\"kkw\");\nkkw.say_hi()"
},
{
"alpha_fraction": 0.5025380849838257,
"alphanum_fraction": 0.5221174955368042,
"avg_line_length": 17.157894134521484,
"blob_id": "9e3c644d510c1df569aca75a8161023d08642d6c",
"content_id": "c6b727f8e34a75c490498cd52717f662326acdd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1753,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 76,
"path": "/4.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "'''\nsum=0\nfor x in range(100,0,-2):\n sum+=x\n\nprint(sum)\n'''\n'''\n# 猜数字大小游戏\nimport random\n\nanswer=random.randint(1,100) # 从中选择一个整数\ncounter=0\nwhile True:\n counter +=1\n number=int(input(\"请输入数字:\"))\n if number < answer:\n print(\"大一些\")\n elif number > answer:\n print(\"小一些\")\n else:\n print(\"恭喜猜对啦!\")\n break\nprint(\"你总共猜对了 %d 次\" % counter)\n\nif counter>7:\n print(\"智商明显不足呀 ^_^\")\nelse:\n print(\"聪明人呀!\")\n'''\n'''\n# 九九乘法表\nfor i in range(1,10):\n for j in range(1,i+1):\n print(\"%d*%d=%d\" % (i,j,i+j),end=\"\\t\")\n print(\"结束啦\")\n'''\n'''\n# 最大公约数和最小公倍数\n# 两个数的最大公约数是两个数的公共因子中最大的那个数;两个数的最小公倍数则是能够同时被两个数整除的最小的那个数\n\nx=int(input(\"x= \"))\ny=int(input(\"y= \"))\n# 如果x大于y就要交换x和y的值\nif x>y:\n # 通过下面的方式xy值进行交换赋值\n x,y=y,x\n# 从两个数中较大数字开始做递减的循环\nfor factor in range(x,0,-1):\n if x % factor == 0 and y % factor == 0:\n print(\"%d和%d的最大公约数:%d\" % (x,y,factor))\n print(\"%d和%d的最小公倍数:%d\" % (x,y,x*y//factor))\n break \n'''\n# 小三角游戏\n\nrow=int(input(\"请输入行数: \"))\nfor i in range(row):\n for _ in range(i+1):\n print(\"*\",end=\" \")\n print()\n\nfor i in range(row):\n for j in range(row):\n if j<row-i-1:\n print(\" \",end=\" \")\n else:\n print(\"*\",end=\" \")\n print()\n\nfor i in range(row):\n for _ in range(row-i-1):\n print(\" \",end=\" \")\n for _ in range(2*i+1):\n print(\"*\",end=\" \")\n print()"
},
{
"alpha_fraction": 0.6333589553833008,
"alphanum_fraction": 0.6564181447029114,
"avg_line_length": 16.33333396911621,
"blob_id": "5fb73834aaaa4bde0b415223998137dcbc03602d",
"content_id": "35afeeab956c6617f6d985f2c81910b51cf9f0e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2169,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 75,
"path": "/6.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "# 函数和模块的使用\n\n# 定义函数 def关键字来定义函数,函数执行完成后通过 return 关键字来返回一个数值\n# 所谓重构就是在不影响代码执行结果的前提下对代码的结构进行调整。\n\n# def fac(num):\n# result = 1\n# for n in range(1, m+1):\n# result *= n\n# return result\n\n\n# m = int(input(\"m= \"))\n# n = int(input(\"n= \"))\n# 当需要计算阶乘的时候不用在写循环求阶乘而是直接调用已经定义好的函数\n# print(fac(m),\"0220\")\n# print(fac(m) // fac(n) // fac(m-n))\n# 在python的math模块中有一个名为 factorial 函数实现了阶乘运算\n\n\n# 函数的参数 在python中函数的参数可以有默认值也支持可变参数,所以并不需要像其他语言一样支持函数的重载\n# from random import randint\n\n\n# def roll_dice(n=2):\n# # 摇色子\n# total = 0\n# for _ in range(n):\n# total += randint(1, 6)\n# return total\n\n\n# def add(a=0, b=0, c=0): # 函数变量名不允许重复\n# 三数相加\n# return a+b+c\n\n\n# 如果没有指定参数那么使用默认值摇两个色子\n# print(roll_dice())\n# 摇三颗色子\n# print(roll_dice(3))\n\n\n# 当我们不确定参数个数的时候,可以使用可变参数\n# 在参数面前的* 表示args是一个可变参数\n# def add(*args):\n# total = 0\n# for val in args:\n# total += val\n# return total\n\n\n# 传入参数可以没有 也可以多个\n# print(add())\n# print(add(1))\n# print(add(1, 2))\n# print(add(1, 2, 3))\n\n\n# 模块管理函数 由于python没有函数重载的概念,后面的定义会覆盖之前的定义,也就意味着同名函数实际上只有一个是存在的\n\ndef foo():\n print(\"hello,1111\")\n\n\ndef foo():\n print(\"hello,2222\")\n\nfoo()\n\n# 如何解决命名冲突问题呢?\n# python中每个文件代表了一个模块,在不同的模块中可以有同名的函数,在使用函数的时候通过import关键字导入指定的模块就可以区分到底使用哪个模块的foo函数\n\n# 全局作用域 使用global关键字来指示变量来自于全局作用域\n# 嵌套作用域 使用nonlocal关键字来指示变量来自于嵌套作用域\n\n"
},
{
"alpha_fraction": 0.5759209394454956,
"alphanum_fraction": 0.5822102427482605,
"avg_line_length": 16.40625,
"blob_id": "a97528121385fe495184f30aa274e0d5df2cb34e",
"content_id": "53e3a9a68c0ee0ce141c6325d3c54f55af31e45a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1847,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 64,
"path": "/基础/1_零基础/1.python_计算机操作.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "## 电脑系统\n\n#### 计算机操作系统\n\nwindows X MacOS \n\n查找自己电脑的系统信息:\"计算机\" --> 右键 --> 选择\"属性\" --> \"系统类型\" 和\"windows版本\" \n\n#### 英语不熟悉\n\n建议用翻译软件 建议要看英语文档\n\n#### python的下载和配置\n\n官方网址python 根据自己电脑版本来下载相应的python版本\n\n最好是python3.x以上\n\n配置变量的点:勾选下 Add Python 3.6 to PATH\n\n否则在cmd运行不起来python 出现 --> 'python'不是内部或外部命令,也不是可运行的程序或批处理文件 -- 的错误\n\n安装过程中\n\n```tex\nInstall Now\n 系统为您安装知道结束,默认是在C盘\nCustomize installation \n 自定义安装 可以进行选项\n \n \n 安装成功后出现 Setup was successful 即为成功\n 注意的是,桌面不会出现python的图标\n \n \n \n 已经安装过的可以选择 ”Cancel“ 直接进行安装\n```\n\n\n\n#### 运行python\n\nwindows:开始菜单 --> 运行 --> 输入cmd windows键+R键 也可以出现运行cmd 输入python 后出现3个< --- <<< 即为运行成功 交互式解释器 没有`<<<`即为命令行\n\nMacOS:打开终端 输入python3\n\n如果可以证明python运行成功,可以输入 python/python3 -V 出现相应的版本即为成功。\n\n#### 基本的python语法\n\n`exit()` 中断python的交互解释器\n\n`print(\"hello,sunny!\")` 打印内容\n\n文件后缀名称为:`.py` ,比如是 `myPython.py` 名称最好是英文\n\n运行文件的时候 命令行是:`python myPython.py` (mac版本:`python3 myPython.py`) \n\n回车的时候即为出现打印或者运行的结果\n\n\n\n`注意` 不要直接双击打开 `.py` 文件"
},
{
"alpha_fraction": 0.4594945013523102,
"alphanum_fraction": 0.5100453495979309,
"avg_line_length": 22.738462448120117,
"blob_id": "8372e47adcf33700dabe439e9bbaaa3320d1f7c5",
"content_id": "1396bbf92586a9b29ee88144f0d29d320df52259",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1917,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 65,
"path": "/5.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "# 练习python语法,增加熟悉度\n\n# 1.水仙花数:三位数,该数字每各位上数字的立方之和正好等于它本身。\n\n# for num in range(100, 1000):\n# low = num % 10\n# mid = num // 10 % 10\n# high = num // 100 # num除以100的结果向下取整\n# if num == low ** 3 + mid ** 3 + high ** 3:\n# print(num)\n\n# num = int(input(\"num=\"))\n# reversed_num = 0\n# while num > 0:\n# reversed_num = reversed_num*10+num % 10 # 数字翻转\n# num //= 10 # n除以10的结果向下取整\n# print(reversed_num)\n\n\n# 2.百钱百鸡问题 穷举法也叫暴力搜索法\n\n'''\n公鸡5元一只,母鸡3元一只,小鸡1元三只,用100块钱买一百只鸡\n'''\n# for x in range(0, 20):\n# for y in range(0, 33):\n# z = 100-x-y\n# if 5*x+3*y+z/3 == 100:\n# print('公鸡:%d只,母鸡:%d只,小鸡:%d只' % (x, y, z))\n\n\n# 3.craps赌博游戏:\n\nfrom random import randint\nmoney = 1000\nwhile money > 0:\n print(\"你的总资产是:\",money)\n needs_go_on = False\n while True: # 玩家的色子\n debt = int(input(\"请您下注:\"))\n if 0 < debt <= money:\n break\n first = randint(1, 6)+randint(1, 6) # 两个色子相加\n print(\"玩家玩出了%d点\" % first)\n if first == 7 or first == 11:\n print(\"玩家胜利!\")\n money += debt # 加上下注的钱\n elif first == 2 or first == 3 or first == 12:\n print(\"庄家胜利!\")\n money -= debt\n else:\n needs_go_on = True\n while needs_go_on: # 庄家的色子\n needs_go_on = False\n current = randint(1, 6)+randint(1, 6)\n print(\"玩家摇出了%d点\" % current)\n if current == 7:\n print(\"庄家胜\")\n money -= debt\n elif current == first:\n print(\"玩家胜\")\n money += debt\n else:\n needs_go_on=True\nprint(\"你破产了!\")\n"
},
{
"alpha_fraction": 0.620248556137085,
"alphanum_fraction": 0.6399853825569153,
"avg_line_length": 14.628571510314941,
"blob_id": "8e6f87faf3606081ab8edefe37a79bc8e59f8abf",
"content_id": "0a673e5d3489cd9f0551139e6c19603d8c47ff9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4952,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 175,
"path": "/基础/1_零基础/3.python_数字_sum.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "python中单行注释以`#` 开头 \n\n```pytho\n# 第一个注释\nprint(\"hello,sunny!\")\n```\n\npython多行注释可以用多个`#` ,还有`'''`和`\"\"\"` \n\n```pyth\n'''\n你好,世界!\n'''\n\"\"\"\n这个世界还是值得的\n\"\"\"\n```\n\n使用缩进表示代码块,缩进的空格数是可变的,同一个代码块的语句必须包含相同的缩进空格数明确下空格键和tab键是不一样的,最好是选择其中的一个\n\n如果语句很长的话可以使用反斜杠\\来实现多行语句\n\n`空行的作用:`在于分隔两段不同功能或含义的代码,方便以后代码的维护或重构\n\n> 空行也是程序代码的一部分\n\npython可以在同一行中使用多条语句,语句之间可以用`;` 分割\n\n`print`默认输出是换行的,如果要实现不换行需要在变量末尾加上 `end=\"\"` \n\n```python\nx=\"a\"\ny=\"b\"\n# 换行输出\nprint( x )\nprint( y )\n \nprint('---------')\n# 不换行输出\nprint( x, end=\" \" )\nprint( y, end=\" \" )\n```\n\n**标准数据类型** : \n\n- 不可变数据:Number(数字) String(字符串) Tuple(元组) \n- 可变数据: List(列表) Set(集合) Dictionary(字典)\n\n内置的 **type() 函数**可以用来查询变量所指的对象类型\n\n## 数字\n\nint 整数(1) bool 布尔(false) float 浮点数(1.22) complex 复数(1+2i)\n\n#### 字符串\n\nval=\"hello,sunny\"\n\n#### 列表 [数组]\n\nname=[\"sunny\",\"rain\",\"wind\"]\n\n列表完成大多数集合类的数据结构实现。列表中元素的类型可以不相同,支持数字、字符串甚至列表嵌套\n\n列表是写在`[]`之间,用`,`隔开的元素列表\n\n列表同样可以被索引和截取,列表截取后返回一个包含所需元素的新列表,和\"字符串\"一样\n\nlist有很多内置方法:append(),pop()\n\n#### 字典 {对象}\n\ngrades={\"name\":\"lilei\",\"age\":\"11\"}\n\n字典是python中比较重要的内置数据类型。\n\n列表是有序的对象结合,字典是无序的对象集合。两者的区别在于:字典当中是通过key来获取的,而不是通过偏移(index)存取的\n\n字典是一种映射类型,字典用`{}`标识,是一个无序的{键(key):值(value)}\n\n键(key)必须使用不可变类型\n\n在同一个字典中,键(key)必须是唯一的\n\n#### 元组\n\ntt=(11,12,13,\"number\")\n\n元组和列表类似,不同之处在于元组的元素不能修改。元组写在`()`里面,元素之间用`,`隔开\n\n元组中的元素类型也可以不相同\n\n元组的元素不可改变,但是可以包含可变的对象(比如list)\n\n注意构造包含0或1个元素的元组的特殊语法规则\n\n```python\ntup1=() # 空元组\ntup2=(20,) # 一个元素,需要在元素后添加逗号\n```\n\n#### 集合\n\n集合是由一个或数个形态各异的大小整体组成的,构成集合的事物或对象成作元素或是成员\n\n基本的功能是进行成员关系测试和删除重复元素。\n\n可以使用大括号`{}` 或者`set()` 函数创建集合,需要注意的是:创建一个空集合必须用`set()` 而不是`{}` 因为`{}`是用来创建一个空字典的\n\n```python\nsites = {'Google', 'Taobao', 'Runoob', 'Facebook', 'Zhihu', 'Baidu'}\n\nprint(sites) # 输出集合,重复的元素被自动去掉\n\n# 成员测试\nif 'Runoob' in sites :\n print('Runoob 在集合中')\nelse :\n print('Runoob 不在集合中')\n```\n\n无序的不重复元素序列(运用的是数学方面的集合概念,比如交集并集)\n\n```python\n# set可以进行集合运算\na = set('abracadabra')\nb = set('alacazam')\n\nprint(a) # 去重后的字符串\n\nprint(a - b) # a 和 b 的差集\n\nprint(a | b) # a 和 b 的并集\n\nprint(a & b) # a 和 b 的交集\n\nprint(a ^ b) # a 和 b 中不同时存在的元素\n```\n\n## 字符串\n\n反斜杠可以用来转义,使用r可以让反斜杠不发生转义 r是指`raw` 即是`raw string` 自动将反斜杠转义\n\n```pyt\nprint(r\"this is my \\n boy\") # this is my \\n boy 并不显示换行\n```\n\n`获取字符串` print(name[0]) print(name[3:7]包含3不包含7) print(name[1:5:2]从第二个开始到第五个且每隔两个的字符)\n\npython 中的字符串有两种索引方式,从左往右以 0 开始,从右往左以 -1 开始\n\npython中的字符串不能改变\n\n字符串用`+`运算符链接在一起,用`*`运算符重复 print(val * 2)\n\n合并字符串 (\"111\"+\"222\") (\"1111\",\"2222\")\n\n字符串的长度 print(len(\"123123123\")) 类型是数字\n\n字符串的转义 转个不同意义的语法 \\n 换行 `\\'` `\\\"` \n\n读取用户输入:`input()` 括号里填写提示输入的文字\n\n#### python数据类型转换\n\n```mark\nstr(x) 转化成字符串\nint(x) 转换成整数\neval(x) 用来计算在字符串中的有效Python表达式,并返回一个对象\nlist(s) 将序列 s 转换为一个列表\nset(s) 转换为可变集合\ntuple(s) 将序列 s 转换为一个元组\ndict(d) 创建一个字典。d 必须是一个 (key, value)元组序列\n//...\n```\n\n"
},
{
"alpha_fraction": 0.623199999332428,
"alphanum_fraction": 0.6488000154495239,
"avg_line_length": 11.744897842407227,
"blob_id": "d5fe922086f2578e86df3f59dc8feec63026b92d",
"content_id": "d70c6b6af630f421f095df848fd27b07d896ccd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2136,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 98,
"path": "/基础/1_零基础/5.python_while_for.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "\n\n### while循环\n\n当满足条件的时候一直执行里面的代码块\n\n同样需要注意冒号和缩进。另外,在 Python 中没有 do..while 循环。\n\n通过设置条件表达式永远不为 false 来实现无限循环,使用 **CTRL+C** 来退出当前的无限循环\n\n在 while … else 在条件语句为 false 时执行 else 的语句块\n\n如果你的while循环体中只有一条语句,你可以将该语句与while写在同一行中\n\n```pytho\nflag = 1\n\nwhile (flag): print ('欢迎访问菜鸟教程!')\nprint (\"Good bye!\")\n# 结果为 欢迎访问菜鸟教程! ...\n```\n\n\n#### for循环\n\nfor循环可以遍历任何序列的项目,如一个列表或者一个字符串\n\nrange()函数需要遍历数字序列对象,可以使用内置range()函数,会生成数列。\n\n```py\n>>> for i in range(3):\n... print(i)\n...\n0\n1\n2\n```\n\nrange指定区间的值\n\n```py\n>>>for i in range(5,9) :\n print(i)\n \n \n5\n6\n7\n8\n>>>\n```\n\n使range以指定数字开始并指定不同的增量(甚至可以是负数,有时这也叫做'步长')range([起使],[结束],[间隔])\n\n```py\n>>>for i in range(0, 10, 3) :\n print(i)\n \n \n0\n3\n6\n9\n>>>for i in range(-10, -100, -30) :\n print(i)\n \n \n-10\n-40\n-70\n>>>\n```\n\n结合range()和len()函数以遍历一个序列的索引\n\n使用range()函数来创建一个列表\n\n**break** 语句可以跳出 for 和 while 的循环体。如果你从 for 或 while 循环中终止,任何对应的循环 else 块将不执行。\n\n**continue** 语句被用来告诉 Python 跳过当前循环块中的剩余语句,然后继续进行下一轮循环。\n\n循环语句可以有 else 子句,它在穷尽列表(以for循环)或条件变为 false (以while循环)导致循环终止时被执行,但循环被 break 终止时不执行\n\n\n\nPython pass是空语句,是为了保持程序结构的完整性。\n\npass 不做任何事情,一般用做占位语句\n\n```python\nfor letter in 'Runoob': \n if letter == 'o':\n pass\n print ('执行 pass 块')\n print ('当前字母 :', letter)\n \nprint (\"Good bye!\")\n```\n\n命令式或交互式解释器中强制退出死循环的程序:`ctrl+c`"
},
{
"alpha_fraction": 0.7644135355949402,
"alphanum_fraction": 0.7664015889167786,
"avg_line_length": 21.377777099609375,
"blob_id": "cc073403a84eafd314cfaa53a19e3e70351075ca",
"content_id": "d9bfd1ec06b901d4677204e4060d0616c2ed4b45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2018,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 45,
"path": "/基础/1_零基础/7.python_字典.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "### 字典\n\n字典是另一种可变容器模型,并且存储任意类型对象\n\n字典的每个键值`key=>value`用`冒号`链接,每队之间用`逗号`分隔,整个被`花括号`包裹中\n\n键[key]必须是唯一的,但是value不一定\n\n值可以取任何数据类型,但是键必须是不可变的,比如字符串、数字、列表、字典\n\n##### 访问字典里的值\n\n把相应的键放到方括号里`print(dic[name])`\n\n如果相应的键不存在的时候会进行报错\n\n##### 修改字典\n\n向字典添加新内容的方法是增加新的键值对、修改或删除已有键值对\n\n##### 删除字典\n\n能删除单一的元素也能清空字典,清空只需一项操作\n\n显示删除一个字典用`del`命令,但是会引起一个异常,因为用执行del操作后字典不再存在\n\n##### 字典内置的函数和方法\n\n- len(dict) 计算字典元素个数,键的总数\n- str(dict) 输出字典,以可打印的字符串表示\n- type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型\n\n\n\n- radiansdict.clear() 删除字典内所有元素\n- radiansdict.copy() 返回一个字典的浅拷贝\n- radiansdict.fromkeys() 创建一个新的字典,以序列seq中元素做字典的键,val为字典所有键对应的初始值\n- radiansdict.get(key, default=None) 返回指定键的值,如果键不存在字典中返回default设置默认值\n- key in dict 如果键在字典dict里返回true,否则返回false\n- radiansdict.items() 以列表返回可遍历的(键,值)元组数组\n- radiansdict.keys() 返回一个迭代器,可以使用list()来转换为列表\n- radiansdict.update(dict2) 把字典dict2的键/值对更新到dict里\n- radiansdict.values() 返回一个迭代器,可以使用 list() 来转换为列表\n- pop(key[,default\\]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。\n- popitem() 随机返回并删除字典中的最后一对键值"
},
{
"alpha_fraction": 0.4871794879436493,
"alphanum_fraction": 0.4871794879436493,
"avg_line_length": 12,
"blob_id": "2bc5247610b3f45f735e436128dc0f17d63ade9b",
"content_id": "df9d26bd4a738213035e7eeb6ad25912e6b17638",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 18,
"path": "/1.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "'''\ndef hello(val):\n print(\"hello,\"+val+\"!\")\n print(r\"this is my \\n boy\")\n return \"好不好\"\n\nprint(hello(\"sunny\"))\n'''\nx=\"a\"\ny=\"b\"\n# 换行输出\nprint( x )\nprint( y )\n \nprint('---------')\n# 不换行输出\nprint( x, end=\" \" )\nprint( y, end=\" \" ) "
},
{
"alpha_fraction": 0.4979838728904724,
"alphanum_fraction": 0.5161290168762207,
"avg_line_length": 20.521739959716797,
"blob_id": "1e43c1fc8f3be6ce612b210170e3f48c9652542e",
"content_id": "29025bf77494bc396b2f46e6af931a922bfc2476",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 604,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 23,
"path": "/3.test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "'''\nvalue=float(input(\"请输入长度为:\"))\nunit=input(\"请选择单位:\")\n\nif unit == \"in\" or unit == \"英寸\":\n print('%f英寸 = %f厘米' % (value,value*2.54))\nelif unit == \"cm\" or unit == \"厘米\":\n print('%f厘米 = %f英寸'% (value,value/2.45))\nelse:\n print(\"请输入有效的单位或数字\")\n'''\n'''\na=float(input(\"请输入a=\"))\nb=float(input(\"请输入b=\"))\nc=float(input(\"请输入c=\"))\nif a+b>c and a+c>b and b+c>a :\n print(\"周长:%f\" % (a+b+c))\n p=(a+b+c)/2\n area=(p*(p-a)*(p-b)*(p-c))**0.5\n print('面积:%f'%(area))\nelse:\n print(\"不能构成三角形\")\n'''\n\n"
},
{
"alpha_fraction": 0.6844993233680725,
"alphanum_fraction": 0.6893004179000854,
"avg_line_length": 14.177083015441895,
"blob_id": "06269e2022c532af80357d4fac18bac9e89f81ce",
"content_id": "2b00b85f8b8ab787fd1df0cc8684bfa33316008f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2742,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 96,
"path": "/基础/1_零基础/6.python_list.md",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "#### 补充\n\nisdigit()函数:检测字符串是否只由数字组成\n\n#### datetime模块\n\n- datetime.data:表示日期的类\n- datetime.datetime:表示日期时间的类\n- datetime.time:表示时间的类\n- datetime.timedelta:表示时间间隔,即两个时间点的间隔\n- datetime.tzinfo:时区相关的信息\n- datetime.datetime.now():返回当前系统时间\n- datetime.datetime.now().date():返回当前日期时间的日期部分\n- datetime.datetime.now().time():返回当前日期时间的时间部分\n\n### 列表\n\n###### 列表结构\n\n- 利用中括号表示列表\n- 列表内的元素用逗号隔开\n- 注意是英文输入法下的逗号\n\n###### 获取列表中的某个元素\n\n中括号内数字指定元素位置 `print(list[2])` \n\n编程语言中通常第一个位置的编号是0\n\n###### 获取列表中连续的几个元素\n\n中括号内使用起始位置:结束位置描述\n\n注意:不包括结束位置的元素\n\n###### 列表可以储存不同类型数据\n\n列表内可以存储各类数据,数字、字符串文本等等,不需要具有相同的类型\n\n###### 向列表添加元素\n\n在列表变量后加`.append(添加的元素)`\n\n列表型变量通用的方法\n\n###### 两个列表相加\n\n直接用加号 --- 数学运算的并集 组合在一个列表\n\n###### 判断某个元素是否存在于列表中\n\n利用in来判断\n\nif要判断的元素in列表 `if 'nihao' in list[列表名称]:` \n\n###### 删除列表元素\n\n用 `del+列表元素`来删除 `del list[列表名称][数字]`\n\n###### 获取列表长度\n\n用`len(列表)`来获取\n\n###### 获取列表中某个元素的重复次数\n\n用`列表.count(元素)`来获取\n\n###### 获取列表中某个元素第一次出现的位置\n\n用`列表.index(元素)`来获取\n\n\n\n### 资料补充\n\n索引也可以从尾部开始,最后一个索引是`-1` ,往前一位是`-2` ,以此类推。\n\n更新列表的某个元素的值`list[2]=\"sunny\"` 重新赋值即可更新列表\n\n`[\"ddd\"]` * 2 打印出来的结果是`[\"ddd\",\"ddd\"]`\n\n###### 列表的函数方法\n\n- len(list) 列表元素的个数\n- max(list) 返回列表元素的最大值\n- min(list) 返回列表元素的最小值\n- list(sep) 将元组转换为列表\n- 上面有的就不再重复了\n- list.extend(obj) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)\n- list.insert(index,obj) 将对象插入列表\n- list.pop(index=-1) 移除列表中的一个元素(默认是最后一个元素),并且返回该元素的值\n- list.remove(obj) 移除列表中某个值的第一个匹配项\n- list.reverse() 反向列表中的元素\n- list.sort(key=none,reverse=false) 对原列表进行排序\n- list.clear() 清空列表\n- list.copy() 复制列表\n\n"
},
{
"alpha_fraction": 0.8005114793777466,
"alphanum_fraction": 0.8312020301818848,
"avg_line_length": 25.133333206176758,
"blob_id": "599b5db3f6e91e9fdaeed5f20a27bf6bb346d205",
"content_id": "5a893169adb528f4cb9cf94259c3a4d1d1941a19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 771,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 15,
"path": "/6_test/test.py",
"repo_name": "chenshuidexin/python_md",
"src_encoding": "UTF-8",
"text": "from module1 import foo # 从module1模块中导出foo函数\nfoo()\nfrom module2 import foo\nfoo()\n\n\nimport module1 as m1\nimport module2 as m2\nm1.foo()\nm2.foo()\n\n# 需要注意的是:如果导入的模块除了定义函数之外还有可以执行代码,那么python解释器在导入这个模块时就会执行这些代码,事实上我们可能并不希望如此,因此如果我们在模块中编写了执行代码,最好是将这些代码放入这个如下所示的条件中,这样的话除非直接运行该模块,if条件下的这些代码是不会执行的,因为只有直接执行的模块的名字才是\"__main__\"\n\nimport module3\n# 导入module3时,不会执行模块中if条件成立时的代码,因为模块的名字是module3而不是__main__"
}
] | 25 |
pokasta/Control
|
https://github.com/pokasta/Control
|
0f3ee23f29c42d43f427f4eb52aef853a84edfd1
|
08e2bbe5f5204a23d2c5b0ae59315799c947de12
|
37c5e16a0ad4f78f3a93540dba95ffe0d52bba81
|
refs/heads/master
| 2020-09-17T21:42:01.505431 | 2019-01-31T14:52:28 | 2019-01-31T14:52:28 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7515732049942017,
"alphanum_fraction": 0.7679890394210815,
"avg_line_length": 60.93220520019531,
"blob_id": "853150c0c55be3b229278ad78bde48ead66846be",
"content_id": "087bd6f3c765206dcf3e5d5cd54e71f711d0db14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3655,
"license_type": "no_license",
"max_line_length": 376,
"num_lines": 59,
"path": "/README.md",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "# Control Theory \nThis repository is about Control Theory and aims at making experimentation simple with classical control problems such as the inverted pendulum. \n\n# Matrix and LQR Implementation in C++\nThe class Matrix ([`Matrix.cpp/hpp`](https://github.com/LucasWaelti/Control/blob/master/MatrixImplementationC%2B%2B/matrix.cpp)) enables the user to work with matrices by making available tools such as matrix inversion, transpose, concatenation, matrices addition, subtraction and multiplication and rank computation. The class is internally based on the `std::vector` class. \n\nThe LQR functions ([`lqr.cpp/hpp`](https://github.com/LucasWaelti/Control/blob/master/MatrixImplementationC%2B%2B/lqr.cpp)) allow to compute the feedback gain for a discrete controller and an observer. They rely on the Matrix class to run the computations. You can make use of these functions as follows:\n```C++\n// Gain K for a state feedback controller\nMatrix K = LQR::lqr(Phi,Gamma,Q1,Q2);\n\n// Gain L for an observer\nMatrix L = LQR::lqr_observer(Phi,C,Q1,Q2);\n// or\nMatrix Ltrans = LQR::lqr(Phi.trans(),C.trans(),Q1,Q2);\nMatrix L = Ltrans.trans();\n```\nMethods to compute the controllability and observability matrices of a discrete system are also available:\n```C++\nMatrix G = LQR::controllability(Phi,Gamma);\nMatrix Q = LQR::observability(Phi,C);\n```\n\n# Multiple Pendulum Simulation in Python\nThe file [MultipleInvertedPendulum.py](https://github.com/LucasWaelti/Control/blob/master/MultipleInvertedPendulum.py) contains the simulation of three pendulums with identical physical characteristics but with different controllers. \n\n- Orange: a PID controls the acceleration of the cart. The closed loop has 3 poles located in -100, -10 and -10. The controller is very stable and relatively efficient. \n- Green: the same controller is used than in the first case but is controlled by a second PID controller that set a target angle to direct the cart towards a target postion (center of the window). The approach is naive and pretty unstable. \n- Blue: this is the best controller. It is actually a Linear Quadratic Controller (LQ) controlling the pendulum angle and cart positon in an optimal way. \n\n## Import the module \"control\"\nThe module \"control\" requires the module \"slycot\", which is a wrapper to SLICOT, a Fortran written software, allowing the use of MIMO system. \n\nA first option to install would be: \n```\n>>> pip install slycot\n>>> pip install control\n```\nSlycot will need a Fortran compiler, if none are present on your machine, the installation will fail. You can either install a compiler and rerun the installation once everything is set up, or you can **avoid compiling anything** by doing as follows: \n\n### Download *all* DLLs and Libs from there:\nhttp://icl.cs.utk.edu/lapack-for-windows/libraries/VisualStudio/3.4.1/Dynamic-MINGW/Win32/\nand place them in the correct directories:\n- C:\\Users\\\\\"UserName\"\\AppData\\Local\\Programs\\Python\\Python36-32\\libs\n- C:\\Users\\\\\"UserName\"\\AppData\\Local\\Programs\\Python\\Python36-32\\DLLs\n\n### Download the Wheel file that corresponds to your system\nDownload it from here: https://www.lfd.uci.edu/~gohlke/pythonlibs/#slycot.\nFor me, the correct version was `slycot-0.3.3-cp36-cp36m-win32.whl` according to the command :\n```\n>>> Python\nPython 3.6.3 [...][... 32 bit ...] on win32\n```\nThen run the command after placing the wheel in an appropriate folder, for example:\n```\n>>> pip install \"C:\\Users\\YourUserName\\AppData\\Local\\Programs\\Python\\Python36-32\\slycot-0.3.3-cp36-cp36m-win32.whl\"\n```\nThen slycot is installed!\n> Note that you might need to run again `pip install control` as slycot might need to be installed first. \n"
},
{
"alpha_fraction": 0.5116682648658752,
"alphanum_fraction": 0.5377793312072754,
"avg_line_length": 30.764610290527344,
"blob_id": "362bbb8ce09a7fee849b0c45a08f3a74c0759976",
"content_id": "d3b25ed8a2161d5d7f39a0e94995d7f053c3a10b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20183,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 616,
"path": "/MultipleInvertedPendulum.py",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "# http://python-control.readthedocs.io/en/latest/generated/control.lqr.html\r\nfrom control import lqr\r\nfrom numpy import matrix,array\r\nimport tkinter\r\nimport math\r\nimport time\r\nimport random\r\n\r\nglobal tk,canvas\r\nglobal width,height\r\nglobal reset_phi\r\n\r\nclass Physics():\r\n ''' \r\n DEPRECATED -> will no longer work.\r\n This class provides the physics for the simulation\r\n of a single inverted pendulum\r\n '''\r\n def __init__(self):\r\n self.m = 0.1 # kg\r\n self.l = 0.1 # m\r\n self.g = 9.81 # m/s^2\r\n self.phi = -0.2 # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.friction = True\r\n self.mu = 0.0008 # Friction coefficient\r\n\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n self.M = 0 # Nm (disturbence momentum)\r\n\r\n self.t = 0.01 # sec (sampling time)\r\n return\r\n\r\n def calculate_friction(self):\r\n self.M = -self.mu * self.phi_dot\r\n def calculate_phi_ddot(self):\r\n self.phi_ddot = self.g/self.l * math.sin(self.phi)\r\n self.phi_ddot += 1/self.l * math.cos(self.phi) * self.acc\r\n self.phi_ddot += 1/(self.m*self.l**2) * self.M\r\n def update_phi_dot(self):\r\n self.phi_dot += self.phi_ddot * self.t\r\n def update_phi(self):\r\n self.phi += self.phi_dot * self.t\r\n #return # Uncomment to let the pendulum swing\r\n if(self.phi >= math.pi/2):\r\n #self.phi= math.pi/2\r\n self.fallen = True\r\n elif(self.phi <= -math.pi/2):\r\n #self.phi = -math.pi/2\r\n self.fallen = True\r\n\r\n def update_speed(self):\r\n self.v += self.acc * self.t\r\n def update_position(self):\r\n self.p += self.v * self.t\r\n if(math.fabs(self.p) > width/2/1000):\r\n self.out_of_range = True\r\n\r\n def update_physics(self):\r\n if(self.friction is True):\r\n self.calculate_friction()\r\n self.calculate_phi_ddot()\r\n self.update_phi_dot()\r\n self.update_phi()\r\n self.update_speed()\r\n self.update_position()\r\n \r\n def generate_mass_coord(self):\r\n x = self.p - self.l * math.sin(self.phi)\r\n y = self.l * math.cos(self.phi)\r\n return x,y\r\n\r\n def reset(self):\r\n global reset_phi\r\n self.phi = reset_phi # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n self.M = 0 # Nm (disturbence momentum)\r\n return\r\n\r\nclass CartPendulumPhysics():\r\n ''' \r\n This class provides the physics for the simulation\r\n of a single inverted pendulum with a cart with a mass.\r\n The dimensions respect the benchmark dimensions from\r\n www.robotbenchmark.net/inverted_pendulum\r\n '''\r\n def __init__(self):\r\n self.m = 0.1 # kg\r\n self.l = 0.1 # m\r\n self.g = 9.81 # m/s^2\r\n self.phi = -0.2 # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.friction = True\r\n self.mu = 0.0008 # Friction coefficient for the sliding axis\r\n self.nu = 0.0008 # Friction coefficient for the rotating axis\r\n self.de = 0.0008 # Friction coefficient due to air resistance\r\n\r\n self.Mass = 0.16 # kg (mass of the cart)\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n\r\n self.M = 0 # Nm (disturbence/control momentum)\r\n self.F = 0 # N (disturbance/control force)\r\n\r\n self.command = 0 # m/s**2 or N (command computed by the controller)\r\n self.controlled_entity = \"a\"\r\n\r\n self.t = 0.01 # sec (sampling time)\r\n return\r\n\r\n def update_command(self,c):\r\n self.command = c\r\n\r\n def apply_force_command(self):\r\n if(self.controlled_entity == \"F\"):\r\n self.F += self.command\r\n def apply_acceleration_command(self):\r\n if(self.controlled_entity == \"a\"):\r\n self.acc = self.command\r\n\r\n def calculate_friction(self):\r\n self.M += -self.nu * self.phi_dot + self.de * self.v \r\n self.F += -self.mu * self.v \r\n def calculate_phi_ddot(self):\r\n phi_ddot = self.g/self.l * math.sin(self.phi)\r\n phi_ddot += 1/self.l * math.cos(self.phi) * self.acc\r\n phi_ddot += 1/(self.m*self.l**2) * self.M\r\n return phi_ddot\r\n def update_phi_dot(self):\r\n self.phi_dot += self.phi_ddot * self.t\r\n def update_phi(self):\r\n self.phi += self.phi_dot * self.t\r\n if(self.phi >= math.pi/2):\r\n #self.phi= math.pi/2\r\n self.fallen = True\r\n elif(self.phi <= -math.pi/2):\r\n #self.phi = -math.pi/2\r\n self.fallen = True\r\n\r\n def calculate_acc(self):\r\n C = self.m*self.l/(self.Mass + self.m)\r\n acc = C * math.cos(self.phi) * self.phi_ddot\r\n acc += C * math.sin(self.phi) * self.phi_dot**2\r\n acc += 1/(self.Mass + self.m) * self.F \r\n return acc \r\n def update_speed(self):\r\n self.v += self.acc * self.t\r\n def update_position(self):\r\n self.p += self.v * self.t\r\n if(math.fabs(self.p) > width/2/1000):\r\n self.out_of_range = True\r\n\r\n def update_physics(self):\r\n self.M = 0\r\n self.F = 0\r\n\r\n # Construct external forces\r\n if(self.friction is True):\r\n self.calculate_friction()\r\n if(self.controlled_entity == \"F\"):\r\n self.apply_force_command()\r\n\r\n # Compute new accelerations \r\n if(self.controlled_entity == \"a\"):\r\n self.apply_acceleration_command()\r\n self.phi_ddot = self.calculate_phi_ddot()\r\n else:\r\n # (make sure to consider values of the same time interval!!)\r\n phi_ddot_new = self.calculate_phi_ddot()\r\n self.acc = self.calculate_acc()\r\n self.phi_ddot = phi_ddot_new\r\n\r\n self.update_phi_dot()\r\n self.update_phi()\r\n self.update_speed()\r\n self.update_position()\r\n \r\n def generate_mass_coord(self):\r\n x = self.p - self.l * math.sin(self.phi)\r\n y = self.l * math.cos(self.phi)\r\n return x,y\r\n\r\n def reset(self):\r\n global reset_phi\r\n self.phi = reset_phi # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n self.M = 0 # Nm (disturbence momentum)\r\n return\r\n\r\nclass PIDcontroller():\r\n '''\r\n Controller will directly act on the speed of the cart. \r\n '''\r\n def __init__(self):\r\n self.variable = \"phi\" # or \"p\" (Indicates what is to be regulated)\r\n self.target = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n self.P = 200\r\n self.I = 4000\r\n self.i = 0 # Integral value\r\n self.D = 15\r\n self.action = 0\r\n self.max_val = 20\r\n return\r\n\r\n def set_PID(self,p=200,i=4000,d=15): # p=50,i=1000,d=10\r\n self.P = p\r\n self.I = i\r\n self.D = d\r\n def set_target(self, target=0):\r\n self.target = target\r\n def set_max_control_value(self,max_val=20):\r\n self.max_val = max_val\r\n\r\n def select_variable(self,var=\"phi\"):\r\n self.variable = var\r\n\r\n def control(self,sim):\r\n # Autonomously compute the error\r\n t = sim.t\r\n if(self.variable == \"phi\"):\r\n value = sim.phi\r\n elif(self.variable == \"p\"):\r\n value = sim.p\r\n self.error = self.target - value \r\n p = self.error * self.P\r\n d = (self.error - self.pre_error)/t * self.D\r\n self.i += self.error*t \r\n\r\n self.action = p + d + self.i * self.I\r\n self.pre_error = self.error\r\n\r\n if(self.action > self.max_val):\r\n self.action = self.max_val\r\n elif(self.action < -self.max_val):\r\n self.action = -self.max_val\r\n\r\n return self.action\r\n\r\n def applyCommand(self,sim):\r\n sim.acc += self.action\r\n\r\n def reset(self):\r\n self.i = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n\r\nclass ForcePIDcontroller():\r\n '''\r\n Controller will act on the Forces applied to the cart. \r\n '''\r\n def __init__(self):\r\n self.variable = \"phi\" # or \"p\" (Indicates what is to be regulated)\r\n self.target = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n self.P = 3.981\r\n self.I = 10\r\n self.i = 0 # Integral value\r\n self.D = 0.3\r\n self.action = 0\r\n self.max_val = 100\r\n return\r\n\r\n def set_PID(self,p=3.981,i=10,d=.3): # p=50,i=1000,d=10\r\n self.P = p\r\n self.I = i\r\n self.D = d\r\n def set_target(self, target=0):\r\n self.target = target\r\n def set_max_control_value(self,max_val=20):\r\n self.max_val = max_val\r\n\r\n def select_variable(self,var=\"phi\"):\r\n self.variable = var\r\n\r\n def control(self,sim):\r\n # Autonomously compute the error\r\n t = sim.t\r\n if(self.variable == \"phi\"):\r\n value = sim.phi\r\n elif(self.variable == \"p\"):\r\n value = sim.p\r\n self.error = self.target - value \r\n p = self.error * self.P\r\n d = (self.error - self.pre_error)/t * self.D\r\n self.i += self.error*t \r\n\r\n self.action = p + d + self.i * self.I\r\n self.pre_error = self.error\r\n\r\n if(self.action > self.max_val):\r\n self.action = self.max_val\r\n elif(self.action < -self.max_val):\r\n self.action = -self.max_val\r\n\r\n return self.action\r\n\r\n def applyCommand(self,sim):\r\n sim.F += self.action\r\n\r\n def reset(self):\r\n self.i = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n\r\nclass AnglePositionPIDcontroller():\r\n '''\r\n Control phi and p as well\r\n '''\r\n def __init__(self):\r\n self.phiPID = PIDcontroller()\r\n self.phiPID.set_PID(p=219.81,i=1000,d=12) #p=149.81,i=800,d=7\r\n self.supPID = PIDcontroller()\r\n a = 100\r\n b = 10\r\n c = 1\r\n self.supPID.set_PID(p=a*b+a*c+b*c,i=a*b*c,d=a+b+c) # p=-2,i=0,d=-0.08 works good\r\n self.supPID.select_variable(\"p\")\r\n self.supPID.set_target(0)\r\n self.K = 1 # Conversion gain coefficient (positive acc needs negative angle)\r\n self.action = 0\r\n\r\n def control(self,sim):\r\n target = self.supPID.control(sim)\r\n target *= self.K\r\n\r\n '''lim = 0.3\r\n if(target > lim):\r\n target = lim\r\n elif(target < -lim):\r\n target = -lim'''\r\n self.phiPID.target = target\r\n self.action = self.phiPID.control(sim)\r\n return self.action\r\n\r\n def applyCommand(self,sim):\r\n sim.acc += self.action\r\n\r\n def reset(self):\r\n self.phiPID.reset()\r\n self.supPID.reset()\r\n\r\nclass AnglePositionLQcontroller():\r\n '''\r\n Linear Quadratic Controller for angle and position control.\r\n '''\r\n def __init__(self):\r\n self.A = None\r\n self.B = None\r\n self.Q = None\r\n self.R = None\r\n\r\n self.K = None\r\n self.S = None\r\n self.E = None\r\n\r\n self.action = 0\r\n\r\n def build_A_matrix(self,sim):\r\n a22 = sim.de/(sim.Mass*sim.l) - sim.mu/sim.Mass \r\n a23 = sim.m*sim.g/sim.Mass\r\n a24 = -sim.nu/(sim.Mass*sim.l)\r\n a42 = sim.de*(sim.Mass + sim.m)/(sim.Mass*sim.m*sim.l**2) - sim.mu/(sim.Mass*sim.l)\r\n a43 = sim.g*(sim.Mass + sim.m)/(sim.Mass*sim.l)\r\n a44 = -sim.nu*(sim.Mass + sim.m)/(sim.Mass*sim.m*sim.l**2)\r\n self.A = matrix([[0,1,0,0],[0,a22,a23,a24],[0,0,0,1],[0,a42,a43,a44]])\r\n def build_B_matrix(self,sim):\r\n b21 = 1/sim.Mass\r\n b22 = 1/(sim.Mass*sim.l)\r\n b41 = 1/(sim.Mass*sim.l)\r\n b42 = (sim.Mass + sim.m)/(sim.Mass*sim.m*sim.l**2)\r\n self.B = matrix([[0],[b21],[0],[b41]]) # Force control\r\n # self.B = matrix([[0,0],[b21,b22],[0,0],[b41,b42]]) # Force and Torque control\r\n def build_Q_matrix(self):\r\n self.Q = matrix(\"2 0 0 0; 0 2 0 0; 0 0 2 0; 0 0 0 2\")\r\n def build_R_matrix(self):\r\n self.R = matrix(\"2.5\")\r\n\r\n def build_K_matrix(self,sim):\r\n self.build_A_matrix(sim)\r\n self.build_B_matrix(sim)\r\n self.build_Q_matrix()\r\n self.build_R_matrix()\r\n self.K,self.S,self.E = lqr(self.A,self.B,self.Q,self.R)\r\n # K = [[-1.13137085 -1.70276008 12.50134201 1.52645134]]\r\n\r\n def control(self,sim):\r\n # Build state vector\r\n x = matrix([[sim.p],[sim.v],[sim.phi],[sim.phi_dot]])\r\n a = - self.K * x\r\n self.action = float(a)\r\n #print(self.action)\r\n \r\n return self.action \r\n\r\n def applyCommand(self,sim):\r\n sim.F += self.action\r\n\r\n def reset(self):\r\n self.action = 0\r\n\r\nclass Graphics():\r\n ''' \r\n This class provides everything needed \r\n for the display of a single pendulum \r\n '''\r\n def __init__(self,color=\"orange\"):\r\n global canvas\r\n # Graphics parameters\r\n self.color = color\r\n self.support_dim = (30,10)\r\n self.stick_dim = 100\r\n self.ball_dim = 20\r\n # Graphical objects\r\n self.support = canvas.create_rectangle(-self.support_dim[0],self.support_dim[1],self.support_dim[0],-self.support_dim[1],fill=\"grey\")\r\n self.stick = canvas.create_line(0,0,0,self.stick_dim,width=5,fill=\"blue\")\r\n self.ball = canvas.create_oval(-self.ball_dim,-self.ball_dim,self.ball_dim,self.ball_dim,fill=self.color)\r\n\r\n def cc(self,x,y):\r\n '''Coordinates Converter, from centered to window'''\r\n global width,height\r\n n = []\r\n n.append(x + width/2)\r\n n.append(-y + height/2)\r\n return n\r\n def mp(self,m):\r\n '''Convert meter to pixel'''\r\n p = 1000*m\r\n return p\r\n\r\n def update_display(self,sim):\r\n global tk,canvas\r\n # Support position \r\n x = sim.p\r\n y = 0\r\n x = self.mp(x)\r\n y = self.mp(y)\r\n sup_pos = self.cc(x,y)\r\n\r\n # Ball position \r\n x,y = sim.generate_mass_coord()\r\n x = self.mp(x)\r\n y = self.mp(y)\r\n ball_pos = self.cc(x,y)\r\n\r\n # Update display\r\n canvas.coords(self.stick,sup_pos[0],sup_pos[1],ball_pos[0],ball_pos[1])\r\n canvas.coords(self.ball,ball_pos[0]-self.ball_dim,ball_pos[1]-self.ball_dim,ball_pos[0]+self.ball_dim,ball_pos[1]+self.ball_dim)\r\n canvas.coords(self.support,sup_pos[0]-self.support_dim[0],sup_pos[1]+self.support_dim[1],sup_pos[0]+self.support_dim[0],sup_pos[1]-self.support_dim[1])\r\n tk.update()\r\n\r\nclass Pendulum():\r\n def __init__(self,controller,physics,controlled_entity=\"a\",color=\"orange\"):\r\n self.sim = physics()\r\n self.sim.controlled_entity = controlled_entity\r\n if(controller is not None):\r\n self.controller = controller()\r\n else:\r\n self.controller = None\r\n self.graphics = Graphics(color)\r\n self.timer = 0\r\n self.failed = False # Indicates if stabilisation failed\r\n self.succeeded = False # Indicates if stabilisation occured \r\n self.is_done = False\r\n\r\n # Display the pendulum in window\r\n self.graphics.update_display(self.sim)\r\n\r\n def step_simulation(self,control_enabled=True):\r\n if(control_enabled and self.controller is not None):\r\n # Compute control commands\r\n #self.sim.acc = self.controller.control(self.sim)\r\n self.sim.update_command(self.controller.control(self.sim))\r\n # Update physics\r\n self.sim.update_physics()\r\n elif(not control_enabled):\r\n # Update physics first\r\n self.sim.update_command(0)\r\n self.sim.update_physics()\r\n #self.sim.acc = 0\r\n #self.sim.v = 0\r\n\r\n # Update graphics\r\n self.graphics.update_display(self.sim)\r\n\r\n def check_if_done(self):\r\n if(self.sim.out_of_range or self.sim.fallen):\r\n self.failed = True\r\n self.is_done = True\r\n self.sim.v = 0\r\n elif(math.fabs(self.sim.phi) < 0.01):\r\n self.timer += 1\r\n\r\n if(self.timer >= 100):\r\n self.succeeded = True\r\n self.is_done = True\r\n \r\n def step(self):\r\n if(not self.failed and not self.succeeded):\r\n self.step_simulation()\r\n self.check_if_done()\r\n elif(self.failed):\r\n self.step_simulation(control_enabled=False)\r\n elif(self.succeeded):\r\n self.step_simulation(control_enabled=True)\r\n\r\n def reset(self):\r\n # Reset everything\r\n self.sim.reset()\r\n if(self.controller is not None):\r\n self.controller.reset()\r\n self.graphics.update_display(self.sim)\r\n\r\n self.failed = False\r\n self.succeeded = False\r\n self.is_done = False\r\n self.timer = 0\r\n\r\n\r\ndef setup_window():\r\n global tk,canvas,width,height\r\n tk = tkinter.Tk()\r\n tk.title(\"Inverted Pendulum Simulation\")\r\n width = 1500#500\r\n height = 400\r\n canvas = tkinter.Canvas(tk,width=width,height=height)\r\n canvas.pack()\r\n # Create the rail\r\n rail = canvas.create_line(0,height/2,width,height/2,width=2,fill=\"black\")\r\n zero = canvas.create_line(width/2,height/2-5,width/2,height/2+5,width=2,fill=\"black\")\r\n\r\ndef generate_random_start():\r\n global reset_phi\r\n reset_phi = random.getrandbits(8)/255/1.0\r\n s = random.getrandbits(1) - 0.5\r\n if(s >= 0):\r\n s = 1\r\n else:\r\n s = -1\r\n reset_phi *= s\r\ndef run(*p):\r\n global reset_phi\r\n\r\n n = len(p)\r\n random.seed()\r\n while(True):\r\n # Update all pendulums\r\n for i in range(0,n):\r\n p[i].step()\r\n \r\n time.sleep(p[0].sim.t*1) # DEBUG 100\r\n\r\n # Check if reset is needed\r\n for i in range(0,n):\r\n done = p[i].is_done \r\n if(not done):\r\n break\r\n if(done):\r\n generate_random_start()\r\n for i in range(0,n):\r\n p[i].reset()\r\n time.sleep(1)\r\n\r\ndef main():\r\n global tk,canvas\r\n\r\n # Initialise the window\r\n setup_window()\r\n \r\n # Create pendulums\r\n p1 = Pendulum(PIDcontroller,CartPendulumPhysics) \r\n #p1.sim.Mass = 0 # Remove mass from the cart\r\n p1.controller.set_PID(p=219.81,i=1000,d=12) # 1: N(s) = (s+100)(s+10)^2\r\n #N(s) = (s+1+10i)(s+1-10i)(s+100) -> p=39.91,i=1010,d=10.2\r\n #N(s) = s(s+100)^2 -> p=1009.81,i=0,d=20\r\n \r\n p2 = Pendulum(AnglePositionPIDcontroller,CartPendulumPhysics,color=\"green\")\r\n #p2.sim.Mass = 0 # Remove mass from the cart\r\n p2.controller.phiPID.set_PID(p=219.81,i=1000,d=12)\r\n p2.controller.supPID.set_PID(p=-2,i=-1.1,d=-0.065) \r\n \r\n p3 = Pendulum(AnglePositionLQcontroller,CartPendulumPhysics,controlled_entity=\"F\",color=\"blue\")\r\n p3.controller.build_K_matrix(p3.sim)\r\n #p3 = Pendulum(ForcePIDcontroller,CartPendulumPhysics,controlled_entity=\"F\",color=\"blue\")\r\n \r\n\r\n # Run the simulation\r\n run(p1,p2,p3)\r\n\r\n tk.mainloop()\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.6769230961799622,
"alphanum_fraction": 0.694505512714386,
"avg_line_length": 23.27777862548828,
"blob_id": "3a43c6d38755819480b44d22b6b3f401f8715585",
"content_id": "92411cc3f373f6276125626b77d6156734f32423",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 455,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 18,
"path": "/MatrixImplementationC++/lqr.hpp",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "#ifndef LQR_HPP_INCLUDED\r\n#define LQR_HPP_INCLUDED\r\n\r\n#define THRESHOLD 0.001\r\n\r\n#include \"matrix.hpp\"\r\n\r\nnamespace LQR{\r\n bool evaluate_convergence(Matrix S, Matrix S_old);\r\n\r\n Matrix controllability(Matrix Phi, Matrix Gamma);\r\n Matrix lqr(Matrix Phi, Matrix Gamma, Matrix Q1, Matrix Q2);\r\n\r\n Matrix observability(Matrix Phi, Matrix C);\r\n Matrix lqr_observer(Matrix Phi, Matrix C, Matrix Q1, Matrix Q2);\r\n};\r\n\r\n#endif // LQR_HPP_INCLUDED\r\n"
},
{
"alpha_fraction": 0.475053608417511,
"alphanum_fraction": 0.48251423239707947,
"avg_line_length": 25.28498649597168,
"blob_id": "da224813f02277ebea3b46d727ad62d997e8c425",
"content_id": "c3338c09e6e995d8481647bd2b1c3b8fe190f951",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10723,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 393,
"path": "/MatrixImplementationC++/matrix.cpp",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "#include \"matrix.hpp\"\r\n\r\nvoid Matrix::setName(std::string name){\r\n this->name = name;\r\n}\r\n\r\nvoid Matrix::buildMatrix(std::string name){\r\n this->name = name;\r\n\r\n // Get dimensions from the user\r\n std::cin >> this->num_rows;\r\n std::cin >> this->num_cols;\r\n\r\n // Resize the class' matrix\r\n this->zeros(this->num_rows,this->num_cols);\r\n\r\n for(unsigned int i=0; i<num_rows; i++){\r\n for(unsigned int j=0; j<num_cols; j++){\r\n std::cin >> M[i][j];\r\n }\r\n }\r\n\r\n return;\r\n}\r\nvoid Matrix::buildMatrix(std::string name, unsigned int rows, unsigned int cols, const double* values){\r\n\r\n this->name = name;\r\n\r\n // Get dimensions from the user\r\n this->num_rows = rows;\r\n this->num_cols = cols;\r\n\r\n // Resize the class' matrix\r\n this->zeros(this->num_rows,this->num_cols);\r\n\r\n unsigned int h = 0;\r\n for(unsigned int i=0; i<num_rows; i++){\r\n for(unsigned int j=0; j<num_cols; j++){\r\n this->M[i][j] = values[h];\r\n h++;\r\n }\r\n }\r\n\r\n return;\r\n}\r\n\r\nvoid Matrix::getDim(int* dim){\r\n dim[0] = (int)this->num_rows;\r\n dim[1] = (int)this->num_cols;\r\n}\r\n\r\ndouble Matrix::get(int row, int col){\r\n return this->M[row][col];\r\n}\r\n\r\nvoid Matrix::setValue(int row, int col, double value){\r\n this->M[row][col] = value;\r\n}\r\n\r\nvoid Matrix::eye(unsigned int rows, unsigned int cols){\r\n if(rows != cols){\r\n std::cout << \"Warning in Matrix::eye(): matrix should be squared.\\n\";\r\n }\r\n this->zeros(rows,cols);\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n if(i==j){\r\n this->M[i][j] = 1;\r\n }else{\r\n this->M[i][j] = 0;\r\n }\r\n }\r\n }\r\n}\r\nvoid Matrix::zeros(unsigned int rows, unsigned int cols){\r\n this->num_rows = rows;\r\n this->num_cols = cols;\r\n this->M.resize(this->num_rows);\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n this->M[i].resize(this->num_cols);\r\n }\r\n}\r\n\r\nvoid Matrix::displayMatrix(){\r\n std::cout << name << \":\\n\";\r\n if(M.size() > 0 && M[0].size() > 0){\r\n std::cout << \"[\";\r\n for(unsigned int i=0; i<M.size(); i++){\r\n for(unsigned int j=0; j<M[0].size(); j++){\r\n std::cout << M[i][j] << \" \";\r\n }\r\n if(i != M.size()-1)\r\n std::cout << \";\\n\";\r\n }\r\n std::cout << \"]\\n\";\r\n }\r\n}\r\n\r\nint Matrix::Rank(){\r\n int Rank = this->num_rows<this->num_cols?this->num_rows:this->num_cols;\r\n Matrix M = *this;\r\n\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n // Get pivot of row i\r\n double pivot = M.M[i][i];\r\n if(pivot == 0)\r\n // Find a row with non zero element in column i\r\n for(unsigned int r=i+1;r<num_rows;r++)\r\n if(M.M[r][i] != 0){\r\n for(unsigned int c=0;c<num_cols;c++){\r\n M.M[i][c] += M.M[r][c];\r\n }\r\n pivot = M.M[i][i];\r\n break;\r\n }\r\n if(pivot == 0){\r\n Rank--;\r\n continue;\r\n }\r\n // Divide the row by the pivot (M and Minv)\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n M.M[i][j] /= pivot;\r\n }\r\n // Cancel the value of the following rows\r\n double val = 0;\r\n for(unsigned int r=i+1;r<num_rows;r++){\r\n val = M.M[r][i];\r\n if(val == 0)\r\n continue;\r\n for(unsigned int c=0;c<num_cols;c++){\r\n M.M[r][c] -= M.M[i][c]*val;\r\n }\r\n }\r\n }\r\n\r\n return Rank;\r\n}\r\n\r\nMatrix Matrix::inv(){\r\n\r\n Matrix result;\r\n\r\n if(this->num_cols != this->num_rows){\r\n std::cout << \"Error: non square matrix does not have an inverse.\\n\";\r\n return result;\r\n }\r\n\r\n result.name = this->name + \"inv\";\r\n result.num_cols = this->num_cols;\r\n result.num_rows = this->num_rows;\r\n\r\n // Scalar case\r\n if(result.num_cols == 1){\r\n result.zeros(1,1);\r\n result.M[0][0] = 1/this->M[0][0];\r\n return result;\r\n }\r\n\r\n // Copy content of vector into a temporary one\r\n std::vector< std::vector<double> > m = this->M;\r\n std::vector< std::vector<double> > Minv;\r\n\r\n // Resize the inverse matrix\r\n Minv.resize(this->num_rows);\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n Minv[i].resize(this->num_cols);\r\n }\r\n // Set Minv as identity matrix\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n if(i==j){\r\n Minv[i][j] = 1;\r\n }else{\r\n Minv[i][j] = 0;\r\n }\r\n }\r\n }\r\n\r\n // 1) Descent\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n // Get pivot of row i\r\n double pivot = m[i][i];\r\n if(pivot == 0)\r\n // Find a row with non zero element in column i\r\n for(unsigned int r=i+1;r<num_rows;r++)\r\n if(m[r][i] != 0){\r\n for(unsigned int c=0;c<num_cols;c++){\r\n m[i][c] += m[r][c];\r\n Minv[i][c] += Minv[r][c];\r\n }\r\n pivot = m[i][i];\r\n break;\r\n }\r\n // Divide the row by the pivot (M and Minv)\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n m[i][j] /= pivot;\r\n Minv[i][j] /= pivot;\r\n }\r\n // Cancel the value of the following rows\r\n double val = 0;\r\n for(unsigned int r=i+1;r<num_rows;r++){\r\n val = m[r][i];\r\n if(val == 0)\r\n continue;\r\n for(unsigned int c=0;c<num_cols;c++){\r\n m[r][c] -= m[i][c]*val;\r\n Minv[r][c] -= Minv[i][c]*val;\r\n }\r\n }\r\n }\r\n // 2) Ascent\r\n for(int i=num_rows-1; i>=0; i--){\r\n // Cancel the value of the upper rows\r\n double val = 0;\r\n for(int r=i-1;r>=0;r--){\r\n val = m[r][i];\r\n if(val == 0)\r\n continue;\r\n for(unsigned int c=0;c<num_cols;c++){\r\n m[r][c] -= m[i][c]*val;\r\n Minv[r][c] -= Minv[i][c]*val;\r\n }\r\n }\r\n }\r\n\r\n result.M = Minv;\r\n return result;\r\n}\r\n\r\nMatrix Matrix::trans(){\r\n\r\n Matrix result;\r\n\r\n result.name = this->name + \"trans\";\r\n result.num_cols = this->num_rows;\r\n result.num_rows = this->num_cols;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0;i<this->num_rows;i++){\r\n for(unsigned int j=0;j<this->num_cols;j++){\r\n result.M[j][i] = this->M[i][j];\r\n }\r\n }\r\n return result;\r\n}\r\n\r\nMatrix Matrix::concatRows(Matrix R){\r\n Matrix result;\r\n\r\n if(this->num_rows != R.num_rows){\r\n std::cout << \"Error in Matrix::concatRows: number of rows must match.\\n\";\r\n return result;\r\n }\r\n\r\n result = *this;\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<R.num_cols; j++){\r\n result.M[i].push_back(R.M[i][j]);\r\n }\r\n }\r\n\r\n result.num_rows = this->num_rows;\r\n result.num_cols = this->num_cols + R.num_cols;\r\n return result;\r\n}\r\n\r\nMatrix Matrix::concatCols(Matrix C){\r\n Matrix result;\r\n\r\n if(this->num_cols != C.num_cols){\r\n std::cout << \"Error in Matrix::concatCols: number of columns must match.\\n\";\r\n return result;\r\n }\r\n\r\n result = *this;\r\n for(unsigned int i=0; i<C.num_rows; i++)\r\n result.M.push_back(C.M[i]);\r\n\r\n result.num_rows = this->num_rows + C.num_rows;\r\n result.num_cols = this->num_cols;\r\n return result;\r\n}\r\n\r\nMatrix Matrix::operator+(const Matrix& m){\r\n\r\n Matrix result;\r\n\r\n if(this->num_cols!=m.num_cols || this->num_rows!=m.num_rows){\r\n std::cout << \"Error: trying to add matrices with different sizes.\\n\";\r\n return result;\r\n }\r\n\r\n result.num_cols = this->num_cols;\r\n result.num_rows = this->num_rows;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0; i<num_rows; i++){\r\n for(unsigned int j=0; j<num_cols; j++){\r\n result.M[i][j] = this->M[i][j] + m.M[i][j];\r\n }\r\n }\r\n return result;\r\n}\r\nMatrix Matrix::operator-(const Matrix& m){\r\n\r\n Matrix result;\r\n\r\n if(this->num_cols!=m.num_cols || this->num_rows!=m.num_rows){\r\n std::cout << \"Error: trying to subtract matrices with different sizes.\\n\";\r\n return result;\r\n }\r\n\r\n result.num_cols = this->num_cols;\r\n result.num_rows = this->num_rows;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0; i<num_rows; i++){\r\n for(unsigned int j=0; j<num_cols; j++){\r\n result.M[i][j] = this->M[i][j] - m.M[i][j];\r\n }\r\n }\r\n return result;\r\n}\r\nMatrix Matrix::operator*(const Matrix& m){\r\n\r\n Matrix result;\r\n\r\n if(this->num_cols != m.num_rows){\r\n std::cout << \"Error: Incorrect dimensions for matrix multiplication.\\n\";\r\n return result;\r\n }\r\n\r\n result.num_cols = m.num_cols;\r\n result.num_rows = this->num_rows;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<m.num_cols; j++){\r\n result.M[i][j] = 0;\r\n for(unsigned int c=0; c<this->num_cols;c++){\r\n result.M[i][j] += this->M[i][c]*m.M[c][j];\r\n }\r\n }\r\n }\r\n return result;\r\n}\r\n\r\nMatrix Matrix::operator*(const double& d){\r\n Matrix result;\r\n\r\n result.num_cols = this->num_cols;\r\n result.num_rows = this->num_rows;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n result.M[i][j] = this->M[i][j]*d;\r\n }\r\n }\r\n return result;\r\n}\r\n\r\nMatrix Matrix::operator/(const double& d){\r\n Matrix result;\r\n\r\n result.num_cols = this->num_cols;\r\n result.num_rows = this->num_rows;\r\n result.zeros(result.num_rows,result.num_cols);\r\n\r\n for(unsigned int i=0; i<this->num_rows; i++){\r\n for(unsigned int j=0; j<this->num_cols; j++){\r\n result.M[i][j] = this->M[i][j]/d;\r\n }\r\n }\r\n return result;\r\n}\r\n\r\nMatrix Matrix::operator^(const int& p){\r\n Matrix result;\r\n\r\n if(this->num_cols != this->num_rows){\r\n std::cout << \"Error: Matrix must be squared to apply power.\\n\";\r\n return result;\r\n }\r\n\r\n result = *this;\r\n for(int i=2; i<=p; i++){\r\n result = result*(*this);\r\n }\r\n return result;\r\n}\r\n\r\n//Check: https://en.cppreference.com/w/cpp/container/vector\r\n"
},
{
"alpha_fraction": 0.647533655166626,
"alphanum_fraction": 0.647533655166626,
"avg_line_length": 25.875,
"blob_id": "63c14a8e1d2fbd8b60703907429aa2481dc4eaf6",
"content_id": "7eed08e2c1e9234bb8d26b01402013b7a87886b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1115,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 40,
"path": "/MatrixImplementationC++/matrix.hpp",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "#ifndef MATRIX_HPP_INCLUDED\r\n#define MATRIX_HPP_INCLUDED\r\n\r\n#include <iostream>\r\n#include <vector>\r\n\r\n\r\nclass Matrix{\r\n public:\r\n\r\n std::string name;\r\n unsigned int num_rows;\r\n unsigned int num_cols;\r\n std::vector< std::vector<double> > M;\r\n\r\n void setName(std::string name);\r\n void buildMatrix(std::string name);\r\n void buildMatrix(std::string name,unsigned int rows,unsigned int cols,const double* values);\r\n void getDim(int* dim);\r\n double get(int row, int col);\r\n void setValue(int row, int col, double value);\r\n void eye(unsigned int rows, unsigned int cols);\r\n void zeros(unsigned int rows, unsigned int cols);\r\n void displayMatrix();\r\n int Rank();\r\n Matrix inv();\r\n Matrix trans();\r\n Matrix concatRows(Matrix R);\r\n Matrix concatCols(Matrix C);\r\n\r\n // Operator overloads\r\n Matrix operator+(const Matrix& m);\r\n Matrix operator-(const Matrix& m);\r\n Matrix operator*(const Matrix& m);\r\n Matrix operator*(const double& d);\r\n Matrix operator/(const double& d);\r\n Matrix operator^(const int& p);\r\n};\r\n\r\n#endif // MATRIX_HPP_INCLUDED\r\n"
},
{
"alpha_fraction": 0.49921298027038574,
"alphanum_fraction": 0.5228235721588135,
"avg_line_length": 28.142335891723633,
"blob_id": "a3081138f5ac3fddc2bc9807ce8b39d555fc53f6",
"content_id": "cd71d3b96ce66f7ffb126acbbd3771fc0e7e983e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8259,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 274,
"path": "/InvertedPendulum.py",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "import tkinter\r\nimport math\r\nimport time\r\nimport random\r\n\r\nglobal tk,canvas\r\nglobal width,height\r\n\r\nclass Physics():\r\n ''' This class provides the physics for the simulation\r\n of a single inverted pendulum'''\r\n def __init__(self):\r\n self.m = 0.1 # kg\r\n self.l = 0.1 # m\r\n self.g = 9.81 # m/s^2\r\n self.phi = -0.2 # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.friction = True\r\n self.mu = 0.0008 # Friction coefficient\r\n\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n self.M = 0 # Nm (disturbence momentum)\r\n\r\n self.t = 0.01 # sec (sampling time)\r\n return\r\n\r\n def calculate_friction(self):\r\n self.M = -self.mu * self.phi_dot\r\n def calculate_phi_ddot(self):\r\n self.phi_ddot = self.g/self.l * math.sin(self.phi)\r\n self.phi_ddot += 1/self.l * math.cos(self.phi) * self.acc\r\n self.phi_ddot += 1/(self.m*self.l**2) * self.M\r\n def update_phi_dot(self):\r\n self.phi_dot += self.phi_ddot * self.t\r\n def update_phi(self):\r\n self.phi += self.phi_dot * self.t\r\n #return # Uncomment to let the pendulum swing\r\n if(self.phi >= math.pi/2):\r\n #self.phi= math.pi/2\r\n self.fallen = True\r\n elif(self.phi <= -math.pi/2):\r\n #self.phi = -math.pi/2\r\n self.fallen = True\r\n\r\n def update_speed(self):\r\n self.v += self.acc * self.t\r\n def update_position(self):\r\n self.p += self.v * self.t\r\n if(math.fabs(self.p) > width/2/1000):\r\n self.out_of_range = True\r\n\r\n def update_physics(self):\r\n if(self.friction is True):\r\n self.calculate_friction()\r\n self.calculate_phi_ddot()\r\n self.update_phi_dot()\r\n self.update_phi()\r\n self.update_speed()\r\n self.update_position()\r\n \r\n def generate_mass_coord(self):\r\n x = self.p - self.l * math.sin(self.phi)\r\n y = self.l * math.cos(self.phi)\r\n return x,y\r\n\r\n def reset(self):\r\n random.seed()\r\n r = random.getrandbits(8)/255\r\n s = random.getrandbits(1) - 0.5\r\n if(s >= 0):\r\n s = 1\r\n else:\r\n s = -1\r\n r *= s\r\n self.phi = r # rad (small offset to get out of equilibrium)\r\n self.phi_dot = 0 # rad/s\r\n self.phi_ddot = 0 # rad/s^2\r\n self.fallen = False # Has the pendulum fallen?\r\n self.out_of_range = False # Has the support gone too far?\r\n self.acc = 0 # m/s^2 (acceleration of the support)\r\n self.v = 0 # m/s (speed of support)\r\n self.p = 0 # m (position of support)\r\n self.M = 0 # Nm (disturbence momentum)\r\n return\r\n\r\nclass PIDcontroller():\r\n '''\r\n Stability conditions for the pendulum: \r\n - \"I/D < (P-g)/l\" \r\n - \"P > g\"\r\n '''\r\n def __init__(self):\r\n self.target = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n self.P = 0\r\n self.I = 0\r\n self.i = 0 # Integral value\r\n self.D = 0\r\n self.action = 0\r\n self.max_val = 0\r\n return\r\n\r\n def set_PID(self,p=50,i=1,d=1.9):\r\n self.P = p\r\n self.I = i\r\n self.D = d\r\n def set_target(self, target=0):\r\n self.target = target\r\n def set_max_control_value(self,max_val=4):\r\n self.max_val = max_val\r\n\r\n def control(self,value,t):\r\n self.error = self.target - value \r\n p = self.error * self.P\r\n d = (self.error - self.pre_error)/t * self.D\r\n self.i += self.error*t \r\n\r\n self.action = p + d + self.i * self.I\r\n self.pre_error = self.error\r\n\r\n if(self.action > self.max_val):\r\n self.action = self.max_val\r\n elif(self.action < -self.max_val):\r\n self.action = -self.max_val\r\n\r\n return self.action\r\n\r\n def reset(self):\r\n self.i = 0\r\n self.error = 0\r\n self.pre_error = 0\r\n\r\ndef cc(x,y):\r\n '''Coordinates Converter, from centered to window'''\r\n global width,height\r\n n = []\r\n n.append(x + width/2)\r\n n.append(-y + height/2)\r\n return n\r\ndef mp(m):\r\n '''Convert meter to pixel'''\r\n p = 1000*m\r\n return p\r\n\r\ndef setup_window():\r\n global tk,canvas,width,height\r\n tk = tkinter.Tk()\r\n tk.title(\"Inverted Pendulum Simulation\")\r\n width = 1500#500\r\n height = 400\r\n canvas = tkinter.Canvas(tk,width=width,height=height)\r\n canvas.pack()\r\n \r\ndef create_support():\r\n global canvas\r\n support = canvas.create_rectangle(-30,10,30,-10,fill=\"grey\")\r\n return support\r\ndef create_stick():\r\n global canvas\r\n stick = canvas.create_line(10,10,10,110,width=5,fill=\"blue\")\r\n return stick\r\ndef create_rail():\r\n global canvas\r\n rail = canvas.create_line(0,height/2,width,height/2,width=2,fill=\"black\")\r\n zero = canvas.create_line(width/2,height/2-5,width/2,height/2+5,width=2,fill=\"black\")\r\n return rail\r\ndef create_ball():\r\n global canvas\r\n ball = canvas.create_oval(-20,-20,20,20,fill=\"orange\")\r\n return ball\r\n\r\ndef update_display(sim,stick,ball,support):\r\n global tk,canvas\r\n # Support position \r\n x = sim.p\r\n y = 0\r\n x = mp(x)\r\n y = mp(y)\r\n sup_pos = cc(x,y)\r\n\r\n # Ball position \r\n x,y = sim.generate_mass_coord()\r\n x = mp(x)\r\n y = mp(y)\r\n ball_pos = cc(x,y)\r\n\r\n # Update display\r\n canvas.coords(stick,sup_pos[0],sup_pos[1],ball_pos[0],ball_pos[1])\r\n canvas.coords(ball,ball_pos[0]-20,ball_pos[1]-20,ball_pos[0]+20,ball_pos[1]+20)\r\n canvas.coords(support,sup_pos[0]-30,sup_pos[1]+10,sup_pos[0]+30,sup_pos[1]-10)\r\n tk.update()\r\n\r\ndef control_end_of_process(sim,pid,stick,ball,support,timer):\r\n if(sim.out_of_range or sim.fallen or timer >= 100):\r\n if(sim.fallen):\r\n # Condition for stability\r\n limit = pid.max_val * sim.t / 2\r\n # Stop the cart\r\n while(math.fabs(sim.v) > limit):\r\n if(sim.out_of_range):\r\n break\r\n if(sim.v > 0):\r\n sim.acc = -pid.max_val\r\n else:\r\n sim.acc = pid.max_val\r\n sim.update_physics()\r\n update_display(sim,stick,ball,support)\r\n time.sleep(sim.t)\r\n sim.acc = 0\r\n sim.v = 0\r\n # Let the pendulum swing down for animation\r\n for _ in range(300):\r\n if(sim.out_of_range):\r\n break\r\n sim.update_physics()\r\n update_display(sim,stick,ball,support)\r\n time.sleep(sim.t)\r\n # Reset everything\r\n sim.reset()\r\n pid.reset()\r\n update_display(sim,stick,ball,support)\r\n time.sleep(1)\r\n return 0\r\n elif(math.fabs(sim.phi) < 0.01):\r\n timer += 1\r\n return timer\r\n\r\ndef main():\r\n global tk,canvas\r\n setup_window()\r\n \r\n #Create objects (order matters)\r\n rail = create_rail()\r\n support = create_support()\r\n stick = create_stick()\r\n ball = create_ball()\r\n\r\n # Initialize the physics\r\n sim = Physics()\r\n\r\n # Initialize the controller for the pendulum\r\n pid = PIDcontroller()\r\n pid.set_PID(p=200,i=4000,d=15) # p=50,i=1000,d=10\r\n pid.set_target(target=0)\r\n pid.set_max_control_value(max_val=20)\r\n\r\n #Build the inverted pendulum\r\n update_display(sim,stick,ball,support)\r\n\r\n timer = 0\r\n\r\n # Run the simulation\r\n while(True):\r\n # Compute control commands\r\n sim.acc = pid.control(value=sim.phi,t=sim.t)\r\n # Update physics\r\n sim.update_physics()\r\n # Update graphics\r\n update_display(sim,stick,ball,support)\r\n \r\n time.sleep(sim.t*1)\r\n\r\n timer = control_end_of_process(sim,pid,stick,ball,support,timer)\r\n\r\n tk.mainloop()\r\n\r\nif __name__ == \"__main__\":\r\n main()\r\n"
},
{
"alpha_fraction": 0.49578651785850525,
"alphanum_fraction": 0.5107678174972534,
"avg_line_length": 21.733333587646484,
"blob_id": "f114748dfb3da36929bcdf9551bf0bd2eb759870",
"content_id": "6beac8cc2985433ca78fe66505df1f54d7b85c9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2136,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 90,
"path": "/MatrixImplementationC++/lqr.cpp",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "#include \"lqr.hpp\"\r\n\r\nbool LQR::evaluate_convergence(Matrix S, Matrix S_old){\r\n Matrix diff = S - S_old;\r\n int dim[2];\r\n S.getDim(dim);\r\n double max_variation = 0;\r\n double current = 0;\r\n\r\n for(int i=0;i<dim[0];i++){\r\n for(int j=0; j<dim[1];j++){\r\n current = diff.get(i,j);\r\n if(current < 0)\r\n current = -current;\r\n if(max_variation < current)\r\n max_variation = current;\r\n }\r\n }\r\n\r\n if(max_variation < THRESHOLD)\r\n return true;\r\n else\r\n return false;\r\n}\r\n\r\nMatrix LQR::controllability(Matrix Phi, Matrix Gamma){\r\n int p = Phi.num_rows-1;\r\n Matrix G = Gamma;\r\n for(int i=1; i<=p; i++){\r\n G = G.concatRows((Phi^i)*Gamma);\r\n }\r\n G.setName(\"G\");\r\n return G;\r\n}\r\n\r\nMatrix LQR::lqr(Matrix Phi, Matrix Gamma, Matrix Q1, Matrix Q2){\r\n // Compute the LQR gain for a state feedback controller\r\n // Q1 penalizes the state x(k), n x n\r\n // Q2 penalizes the input u(k)\r\n\r\n Matrix S = Q1;\r\n Matrix S_old = Q1*10;\r\n Matrix R;\r\n Matrix M;\r\n Matrix K;\r\n\r\n while(!evaluate_convergence(S,S_old)){\r\n R = Q2 + Gamma.trans()*S*Gamma;\r\n M = S - S*Gamma*R.inv()*Gamma.trans()*S;\r\n S_old = S;\r\n S = Phi.trans()*M*Phi + Q1;\r\n }\r\n\r\n K = R.inv()*Gamma.trans()*S*Phi;\r\n\r\n return K;\r\n}\r\n\r\nMatrix LQR::observability(Matrix Phi, Matrix C){\r\n int p = Phi.num_rows-1;\r\n Matrix Q = C;\r\n for(int i=1; i<=p; i++){\r\n Q = Q.concatCols(C*(Phi^i));\r\n }\r\n Q.setName(\"Q\");\r\n return Q;\r\n}\r\n\r\nMatrix LQR::lqr_observer(Matrix Phi, Matrix C, Matrix Q1, Matrix Q2){\r\n // Compute the LQR gain for an observer\r\n // Q1 penalizes the modelling error delta(k), n x n\r\n // Q2 penalizes the measurement noise y(k)\r\n\r\n Matrix S = Q1;\r\n Matrix S_old = Q1*10;\r\n Matrix R;\r\n Matrix M;\r\n Matrix L;\r\n\r\n while(!evaluate_convergence(S,S_old)){\r\n R = Q2 + C*S*C.trans();\r\n M = S - S*C.trans()*R.inv()*C*S;\r\n S_old = S;\r\n S = Phi.trans()*M*Phi + Q1;\r\n }\r\n\r\n L = Phi*S*C.trans()*R.inv();\r\n\r\n return L;\r\n}\r\n"
},
{
"alpha_fraction": 0.46598878502845764,
"alphanum_fraction": 0.49298736453056335,
"avg_line_length": 20.634920120239258,
"blob_id": "7a5227c8173c53cf850d4922d81444cd7784955b",
"content_id": "eb38390d741806e98b4aff0eee845362a3735178",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2852,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 126,
"path": "/MatrixImplementationC++/main.cpp",
"repo_name": "pokasta/Control",
"src_encoding": "UTF-8",
"text": "#include <iostream>\r\n\r\n#include \"matrix.hpp\"\r\n#include \"lqr.hpp\"\r\n\r\nint main()\r\n{\r\n std::cout << \"Matrix Laboratory!\" << std::endl;\r\n\r\n // Build a matrix by hand\r\n Matrix A;\r\n double values[9] = {1,2,2,\r\n 3,1,1,\r\n 4,3,5};\r\n A.buildMatrix(\"A\",3,3,values);\r\n A.displayMatrix();\r\n std::cout << \"Rank(A) = \" << A.Rank() << std::endl;\r\n\r\n // Store its inverse\r\n Matrix B = A.inv();\r\n B.setName(\"B\");\r\n B.displayMatrix();\r\n\r\n Matrix AB = A.concatRows(B);\r\n AB.setName(\"AB\");\r\n AB.displayMatrix();\r\n\r\n Matrix Ab = A.concatCols(B);\r\n Ab.setName(\"Ab\");\r\n Ab.displayMatrix();\r\n std::cout << \"Rank(Ab) = \" << Ab.Rank() << std::endl;\r\n\r\n // Add the two precedent matrices\r\n Matrix C = A + B;\r\n C.setName(\"C\");\r\n C.displayMatrix();\r\n\r\n // Multiply the two precedent matrices\r\n Matrix D = B * C;\r\n D.setName(\"D\");\r\n D.displayMatrix();\r\n\r\n // Take the transpose of the last matrix\r\n Matrix E = D.trans();\r\n E.setName(\"E\");\r\n E.displayMatrix();\r\n\r\n // Multiply the last matrix by 2\r\n Matrix F = E;\r\n F = F*2; // Note: 2*F is not supported!\r\n F.setName(\"F\");\r\n F.displayMatrix();\r\n\r\n // Make a big final computation\r\n Matrix G = ((A+B)*C.inv() - E)/2;\r\n G.setName(\"G\");\r\n G.displayMatrix();\r\n\r\n // Get G's dimensions\r\n int dim[2];\r\n G.getDim(dim);\r\n std::cout << \"Size of G: \" << dim[0] << \", \" << dim[0] << std::endl;\r\n // Get a single value from G\r\n std::cout << \"Value of G at 2,1: \" << G.get(2,1) << std::endl;\r\n\r\n // Power of a matrix\r\n Matrix H;\r\n H.eye(3,3);\r\n H = H*2;\r\n H = H^3;\r\n H.setName(\"H^3\");\r\n H.displayMatrix();\r\n\r\n\r\n\r\n\r\n // Create a vector\r\n Matrix v;\r\n double v_values[3] = {1,\r\n 2,\r\n 3};\r\n v.buildMatrix(\"v\",3,1,v_values);\r\n v.displayMatrix();\r\n\r\n // Solve the system A*x = v <-> x = inv(A)*v\r\n Matrix x = A.inv()*v;\r\n x.setName(\"x\");\r\n x.displayMatrix();\r\n\r\n\r\n\r\n\r\n\r\n // Implement a LQR controller\r\n Matrix Phi;\r\n double phi[4] = {2,1,-5,4};\r\n Phi.buildMatrix(\"Phi\",2,2,phi);\r\n\r\n Matrix Gamma;\r\n double gamma[2] = {0,1};\r\n Gamma.buildMatrix(\"Gamma\",2,1,gamma);\r\n\r\n //Matrix C;\r\n double c[4] = {1,0,0,0};\r\n C.buildMatrix(\"C\",2,2,c);\r\n\r\n Matrix Q1;\r\n double q1[4] = {1,0,0,1};\r\n Q1.buildMatrix(\"Q1\",2,2,q1);\r\n\r\n Matrix Q2;\r\n double q2[1] = {1};\r\n Q2.buildMatrix(\"Q2\",1,1,q2);\r\n\r\n // Compute controllability matrix\r\n G = LQR::controllability(Phi,Gamma);\r\n G.displayMatrix();\r\n std::cout << \"Rank of controllability matrix G: \" << G.Rank() << std::endl;\r\n\r\n // Compute feedback gain\r\n Matrix K = LQR::lqr(Phi,Gamma,Q1,Q2);\r\n K.setName(\"K\");\r\n K.displayMatrix();\r\n\r\n return 0;\r\n}\r\n"
}
] | 8 |
fengchuimailang/Muti-task-HCTR
|
https://github.com/fengchuimailang/Muti-task-HCTR
|
bc8a588163af84e80d20302e8118207f71f26cf4
|
52c80e460e1e077b5ade358b615d73e27ba17e11
|
38058d45611387722e6d71970a91515aa67ee4bc
|
refs/heads/master
| 2020-05-27T13:15:29.929300 | 2019-05-29T00:50:25 | 2019-05-29T00:50:25 | 188,635,752 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.42064449191093445,
"alphanum_fraction": 0.44356366991996765,
"avg_line_length": 37.43046188354492,
"blob_id": "62b41105f9d36368cb9dbac16a89fff01e08d2e2",
"content_id": "c9a9e34633358dee7c50cb509fa1414d0a157566",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5841,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 151,
"path": "/MultiTask/train.py",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport os\nimport time\nfrom PIL import Image\nimport numpy as np\nimport cv2\n\nfrom MultiTask.net import Net\nfrom MultiTask.utils import sigmoid\nimport MultiTask.config as config\n\n\ndef box2original(pre, i, lfv, H, W):\n ori = [0] * 4\n x = pre[0]\n y = pre[1]\n w = pre[2]\n h = pre[3]\n xb = (i + sigmoid(x)) * W / lfv\n yb = sigmoid(y) * H\n wb = w * H\n hb = sigmoid(h) * H\n ori[0] = yb\n ori[1] = xb\n ori[2] = yb + wb\n ori[3] = xb + hb\n return ori\n\n\ndef nms(dets, thresh):\n x1 = dets[:, 0]\n y1 = dets[:, 1]\n x2 = dets[:, 2]\n y2 = dets[:, 3]\n scores = dets[:, 4]\n\n areas = (x2 - x1 + 1) * (y2 - y1 + 1)\n order = scores.argsort[::-1]\n keep = []\n while order.size > 0:\n i = order[0]\n keep.append(i)\n xx1 = np.maximum(x1[i], x1[order[1:]])\n yy1 = np.maximum(y1[i], y1[order[1:]])\n xx2 = np.minimum(x2[i], x2[order[1:]])\n yy2 = np.minimum(y2[i], y2[order[1:]])\n\n w = np.maximum(0.0, xx2 - xx1 + 1)\n h = np.maximum(0.0, yy2 - yy1 + 1)\n inter = w * h\n ovr = inter / (areas[i] + areas[order[1:]] - inter)\n\n inds = np.where(ovr <= thresh)[0]\n order = order[inds + 1]\n return keep\n\n\ndef train():\n g = Net(config)\n g.build_net()\n idx2symbol, symbol2idx = g.idx2symbol, g.symbol2idx\n sv = tf.train.Supervisor(graph=g.graph, logdir=g.config.logdir)\n cfg = tf.ConfigProto()\n cfg.gpu_options.allow_growth = True\n with sv.managed_session(config=cfg) as sess:\n Locloss = 0\n Claloss = 0\n Detloss = 0\n time_start = time.time()\n for step in range(1, config.total_steps):\n if step == 1 or step == 299999 or step == 399999:\n img, label, loc, cla, label_len = sess.run([g.x, g.label, g.location, g.classification],\n {g.train_stage: True})\n print(\"label:\", label[0])\n label_t = [idx2symbol[s] for s in label[0]]\n print(\"label:\", label_t)\n print(\"loc:\", loc[0])\n print(\"cla:\", cla[0])\n print(\"img shape\", img.shape)\n loss, loc_loss, cla_loss, det_loss, _ = sess.run([g.loss, g.loc_loss, g.cla_loss, g.det_loss, g.train_op],\n {g.train_stage: True})\n Locloss += loc_loss\n Claloss += cla_loss\n Detloss += det_loss\n if step % config.show_step == 0:\n print(\"step=%d,loc loss=%f,cla loss=%f,dec loss=%f,最近config.show_step用时=%f s\" % (\n step, Locloss / config.show_step, Claloss / config.show_step, Detloss / config.show_step,\n time.time() - time_start))\n Locloss = 0\n Claloss = 0\n Detloss = 0\n time_start = time.time()\n if step % config.simple_step == 0:\n label, loc, loc_p, loc_pre_t = sess.run([g.label, g.location, g.loc_p, g.loc_pre_t],\n {g.train_stage: True})\n label_t = [idx2symbol[s] for s in label[0]]\n print(\"label:\", label_t)\n print(\"loc res sigmoid\", loc_pre_t[0])\n print(\"loc pre:\", loc_p[0])\n\n if step % config.test_step == 9999999:\n x, label, loc, cla, loc_pre, cla_pre, det_pre = sess.run(\n [g.x, g.label, g.location, g.classification, g.loc_p, g.cla_p, g.det_p], {g.train_stage: True})\n lfv = int(config.image_max_width / 16)\n print(\"loc_p.shape\", loc_pre.shape)\n print(\"det_p.shape\", det_pre.shape)\n print(\"cla_p.shape\", cla_pre.shape)\n for i in range(config.batch_size):\n label_t = [idx2symbol for s in label[i]]\n print()\n print(\"Example %d:\" % (i))\n print(\"label:\", label_t)\n loc_p = loc_pre[i] # lfv\n cla_p = cla_pre[i] # (lfv,7356)\n det_p = det_pre[i] # lfv,4\n print(\"loc_p.shape\", loc_p.shape)\n print(\"det_p.shape\", det_p.shape)\n print(\"cla_p.shape\", cla_p.shape)\n cla_p_idx = np.argmax(cla_p, axis=-1)\n print(\"cla_p_idx\", cla_p_idx)\n cla_p_t = []\n t = 0\n for j in cla_p_idx:\n cla_p_t.append(cla_p[t][j])\n t += 1\n cla_p = np.array(cla_p_t)\n conf_bbox = 0.8 * loc_p + 0.2 * cla_p # [lfv]\n dets = np.ones((lfv, 5))\n img_h, img_q = config.image_height, config.image_max_width\n for j in range(lfv):\n dets[j][4] = conf_bbox[j]\n tmp_det = box2original(det_p[j], j, lfv, img_h, img_w)\n dets[j][0] = tmp_det[0]\n dets[j][1] = tmp_det[1]\n dets[j][2] = tmp_det[2]\n dets[j][3] = tmp_det[3]\n keep = nms(dets, 0.5) # lfv中保留的bbox\n order_x = det_p[:1].argsort[::1] # 按照x顺序排序,由小到大\n label_pre = []\n for k in order_x:\n if k in keep:\n label_pre.append(cla_p_idx[k])\n print(\"label_pre\", label_pre)\n label_pre = [idx2symbol[s] for s in label_pre]\n print(\"label pre:\", label_pre)\n print()\n\n\nif __name__ == \"__main__\":\n os.environ[\"CUDA_VISIBLE_DEVICES\"] = \"0\"\n train()\n"
},
{
"alpha_fraction": 0.6298157572746277,
"alphanum_fraction": 0.6817420721054077,
"avg_line_length": 20.321428298950195,
"blob_id": "3b38e87151aea568bb6e2b50a12314ce9e809948",
"content_id": "0c37f1ac1d40f626b3cf2e2b3bea720770ca9938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 607,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 28,
"path": "/MultiTask/config.py",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "logdir = \"./logdir\"\n# TODO root to be changed\nroot = \"H:/柳博的空间/data/CASIA_mini/\"\ntrain_tfrecord = root + \"train.tfrecords\"\nvalid_tfrecord = root + \"valid.tfrecords\"\nalphabet_path = root + \"alphabet.txt\"\ntrain_dataset_path = root + \"Train_Dgr/\"\ntrain_image_path = root + \"train_img/\"\nvalid_dataset_path = root + \"test_Dgr/\"\nvalid_image_path = root + \"test_img/\"\n\n# TODO meaning?\nPAD_ID = 0\nGO_ID = 1\nEOS_ID = 2\n\nimage_height = 128\nimage_max_width = 4000\nlabel_max_len = 100\n\nbatch_size = 1\n# TODO too big?\nlearning_rate = 0.001\n\ntotal_steps = 99999999\nshow_step = 1\ntest_step = 500\nsimple_step = 1\n"
},
{
"alpha_fraction": 0.511346697807312,
"alphanum_fraction": 0.5586742162704468,
"avg_line_length": 46.50354766845703,
"blob_id": "d41264bbe9c468c7837843f6c0e94e1977f8e78a",
"content_id": "8853663661aacb1776bc8387c4c3a3d423b0d48b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13478,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 282,
"path": "/MultiTask/net.py",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport tensorflow.contrib.slim as slim\nimport numpy as np\n\nimport MultiTask.config as config\nfrom MultiTask.utils import read_alphabet, sigmoid\n\n\nclass Net(object):\n def __init__(self, config):\n self.config = config\n self.graph = tf.Graph()\n self.idx2symbol, self.symbol2idx = read_alphabet(config.alphabet_path)\n\n def load_tfrecord(self, tfrecord_path):\n lfv = int(config.image_max_width / 16)\n\n def parse_example(serialized_example):\n context_features = {\n \"image_width\": tf.FixedLenFeature([], dtype=tf.int64),\n \"image\": tf.FixedLenFeature([], dtype=tf.string),\n \"location\": tf.FixedLenFeature([], dtype=tf.string),\n \"classification\": tf.FixedLenFeature([], dtype=tf.string),\n \"detection\": tf.FixedLenFeature([], dtype=tf.string)\n }\n sequence_features = {\n \"label\": tf.FixedLenSequenceFeature([], dtype=tf.int64)\n }\n\n context_parsed, sequence_parsed = tf.parse_single_sequence_example(\n serialized_example,\n context_features=context_features,\n sequence_features=sequence_features\n )\n\n image_width = tf.cast(context_parsed[\"image_width\"], tf.int32)\n image = tf.decode_raw(context_parsed[\"image\"], tf.uint8)\n # label_length = tf.cast(context_parsed[\"label_length\"],tf.int32)\n location = tf.decode_raw(context_parsed[\"location\"], tf.float32)\n location = tf.reshape(location, [lfv])\n classification = tf.decode_raw(context_parsed[\"classification\"], tf.float32)\n detection = tf.decode_raw(context_parsed[\"detection\"], tf.float32)\n detection = tf.reshape(detection, [lfv, 4])\n label = tf.cast(sequence_parsed[\"label\"], tf.int32)\n image = tf.reshape(image, dtype=tf.float32) / 255.0\n image = tf.imagae.pad_to_bounding_box(image, 0, 0, config.image_height, config.image_max_width)\n return image, label, location, classification, detection\n\n dataset = tf.data.TFRecordDataset(tfrecord_path)\n dataset = dataset.map(parse_example)\n dataset = dataset.repeat().shuffle(10 * config.batch_size)\n # 每一条数据长度不一致时,用padded_batch进行补全操作\n dataset = dataset.padded_batch(config.batch_size, ([config.image_height, config.image_max_width, 1],\n [config.label_max_len], [lfv], [lfv], [lfv, 4]))\n iterator = dataset.make_one_shot_iterator()\n image, label, location, classification, detection, label_length = iterator.get_next()\n return image, label, location, classification, detection\n\n def detection_branch(self, inputs):\n conv_1 = slim.conv2d(inputs, 256, [3, 3], [2, 1])\n conv_2 = slim.conv2e(conv_1, 128, [3, 3], [2, 1])\n conv_3 = slim.conv2d(conv_2, 64, [3, 3], [2, 1])\n feature_vectors = conv_3\n print(\"detection_branch feature:\", feature_vectors)\n conv_4 = slim.conv2d(conv_3, 4, [1, 1], [1, 1])\n print(\"detection_branch result:\", conv_4)\n return feature_vectors, conv_4\n\n def classification_branch(self, inputs):\n conv_1 = slim.conv2d(inputs, 512, [3, 3], [2, 1])\n conv_2 = slim.conv2d(conv_1, 512, [3, 3], [2, 1])\n conv_3 = slim.conv2d(conv_2, 1024, [3, 3], [2, 1])\n feature_vectors = conv_3\n print(\"classification_branch feature:\", feature_vectors)\n conv_4 = slim.conv2d(conv_3, 7356, [1, 1], [1, 1])\n print(\"classification_branch result:\", conv_4)\n return feature_vectors, conv_4\n\n def location_branch(self, inputs, dec_inputs, cla_inputs):\n conv_1 = slim.conv2d(inputs, 256, [3, 3], [2, 1])\n conv_2 = slim.conv2d(conv_1, 128, [3, 3], [2, 1])\n conv_3 = slim.conv2d(conv_2, 64, [3, 3], [2, 1])\n dev_conv = slim.conv2d(dec_inputs, 64, [1, 1], 1)\n cla_conv = slim.conv2d(cla_inputs, 64, [1, 1], 1)\n\n feature_vectors = dev_conv + conv_3 + cla_conv\n print(\"location_branch feature:\", feature_vectors)\n conv_4 = slim.conv2d(conv_3, 1, [1, 1], [1, 1])\n print(\"location_branch results:\", conv_4)\n return feature_vectors, conv_4\n\n def base_net(self, is_training):\n with slim.arg.scope([slim.conv2d],\n activation_fn=tf.nn.leaky_relu,\n normalizer_fn=tf.layers.batch_normalization,\n weights_initializer=tf.truncated_normal_initializer(stddev=0.01),\n weights_regularizer=slim.l2_regularizer(1e-5),\n normalizer_params={\"training\": is_training}):\n conv_1 = slim.conv2d(self.x, 64, 3, 2)\n conv_2 = slim.conv2d(conv_1, 64, 3, 1)\n down_conv1 = slim.conv2d(self.x, 64, 3, 2) # TODO 为啥降采样用这个\n print(down_conv1, conv_2)\n res_1 = tf.nn.leaky_relu(down_conv1 + conv_2)\n\n conv_3 = slim.conv2d(res_1, 64, 3, 1)\n conv_4 = slim.conv2d(conv_3, 64, 3, 1)\n res_2 = tf.nn.leaky_relu(res_1 + conv_4)\n\n conv_5 = slim.conv2d(res_2, 128, 3, 2)\n conv_6 = slim.conv2d(conv_5, 128, 3, 1)\n down_conv2 = slim.conv2d(res_2, 128, 3, 2)\n res_3 = tf.nn.leaky_relu(down_conv2 + conv_6)\n print(\"res_3\", res_3.shape)\n\n conv_7 = slim.conv2d(res_3, 128, 3, 1)\n conv_8 = slim.conv2d(conv_7, 128, 3, 1)\n res_4 = tf.nn.leaky_relu(res_3, conv_8)\n\n conv_9 = slim.conv2d(res_4, 256, 3, 2)\n conv_10 = slim.conv2d(conv_9, 256, 3, 1)\n down_conv3 = slim.conv2d(res_4, 256, 3, 2)\n res_5 = tf.nn.leaky_relu(down_conv3 + conv_10)\n\n conv_11 = slim.conv2d(res_5, 256, 3, 1)\n conv_12 = slim.conv2d(conv_11, 256, 3, 1)\n res_6 = tf.nn.leaky_relu(res_5 + conv_12)\n\n conv_13 = slim.conv2d(res_6, 512, 3, 2)\n conv_14 = slim.conv2d(conv_13, 512, 3, 1)\n down_conv4 = slim.conv2d(res_6, 512, 3, 2)\n res_7 = tf.nn.leaky_relu(down_conv4 + conv_14)\n\n conv_15 = slim.conv2d(res_7, 512, 3, 1)\n conv_16 = slim.conv2d(conv_15, 512, 3, 1)\n res_8 = tf.nn.leaky_relu(res_7 + conv_16)\n print(\"res_8:\", res_8) # (?,8,212,512)\n return res_8\n\n def backbone_net(self, is_training):\n with slim.arg_scope([slim.conv2d, slim.fully_connected],\n activation_fn=tf.nn.leaky_relu,\n weights_regularizer=slim.l2_regularizer(1e-5),\n normalizer_parms={\"training\": is_training}):\n conv_1 = slim.conv2d(self.x, 64, 3, 2)\n conv_2 = slim.conv2d(conv_1, 64, 3, 1)\n down_conv1 = slim.conv2d(self.x, 64, 3, 2)\n print(down_conv1, conv_2)\n res_1 = tf.nn.relu(down_conv1 + conv_2)\n\n conv_3 = slim.conv2d(res_1, 64, 3, 1)\n conv_4 = slim.conv2d(conv_3, 64, 3, 1)\n res_2 = tf.nn.relu(res_1 + conv_4)\n\n conv_5 = slim.conv2d(res_2, 128, 3, 2)\n conv_6 = slim.conv2d(conv_5, 128, 3, 1)\n down_conv2 = slim.conv2d(res_2, 128, 3, 2)\n res_3 = tf.nn.relu(down_conv2 + conv_6)\n print('res_3 ', res_3.shape)\n\n conv_7 = slim.conv2d(res_3, 128, 3, 1)\n conv_8 = slim.conv2d(conv_7, 128, 3, 1)\n res_4 = tf.nn.relu(res_3 + conv_8)\n\n conv_9 = slim.conv2d(res_4, 256, 3, 2)\n conv_10 = slim.conv2d(conv_9, 256, 3, 1)\n down_conv3 = slim.conv2d(res_4, 256, 3, 2)\n res_5 = tf.nn.relu(down_conv3 + conv_10)\n\n conv_11 = slim.conv2d(res_5, 256, 3, 1)\n conv_12 = slim.conv2d(conv_11, 256, 3, 1)\n res_6 = tf.nn.relu(res_5 + conv_12)\n\n conv_13 = slim.conv2d(res_6, 512, 3, 2)\n conv_14 = slim.conv2d(conv_13, 512, 3, 1)\n down_conv4 = slim.conv2d(res_6, 512, 3, 2)\n res_7 = tf.nn.relu(down_conv4 + conv_14)\n\n conv_15 = slim.conv2d(res_7, 512, 3, 1)\n conv_16 = slim.conv2d(conv_15, 512, 3, 1)\n res_8 = tf.nn.relu(res_7 + conv_16)\n print(\"res_8:\", res_8) # (?, 8, 212, 512)\n return res_8\n\n def Binary_cross_entropy(self, label, logits):\n y = label\n py = tf.nn.sigmoid(logits)\n py = tf.reduce_sum(py, -1) # (?,1,lfv)\n py = tf.reduce_sim(py, 1) # (?,lfv)\n self.loc_pre_t = py\n shape = py.get_shape().as_list()\n print(\"y shape\", y)\n print(\"py,shape\", py)\n pos = tf.where(tf.equal(label, 1), label, label - label)\n pos = pos * py\n log_pos = tf.where(tf.equal(pos, 0), pos.tf.log(pos))\n log_pos = tf.reduce_sum(log_pos, -1)\n neg = tf.where(tf.equal(pos, 0), label + 1, label - label) # TODO 会不会是这里减法不等于零\n neg = neg * py\n log_neg = tf.where(tf.equal(neg, 0), neg, tf.log(1 - neg))\n log_neg = tf.reduce_sum(log_neg, -1)\n loss = -1.0 * (log_pos + log_neg) / shape[-1]\n loss = tf.reduce_sum(loss)\n print(\"BCE loss\", loss)\n return loss\n\n def location_loss(self, logits, loc_labels):\n logit = tf.reduce_sum(logits, -1)\n shape = logit.get_shape().as_list()\n\n print(\"loc labels shape:\", loc_labels)\n loss = tf.nn.sigmoid_cross_entory_with_logits(labels=loc_labels, logits=tf.expand_dims(logit, 1))\n loss = tf.reduce_mean(loss)\n return loss\n\n def mean_squared_error(self, labels, logits):\n loss = tf.losses.mean_squared_error(labels, logits)\n return loss\n\n def detection_loss(self, logits, labels, loc_label):\n logits = tf.reduce_sum(logits, 1) # (?,212,4)\n loss = self.mean_squared_error(labels, logits)\n print(\"mse loss:\", loss)\n return loss\n\n def classification_loss(self, logits, labels, location):\n logits = tf.reduce_sum(logits, 1) # (?,lgv,7356)\n print(\"logits\", logits)\n label = tf.one_hot(labels, 7356) # (?,lfv,7356)\n loc = tf.cast(location, tf.float32)\n loss = tf.nn.softmax_cross_entropy_with_logits_v2(labels=label, logits=logits)\n print(\"class loss\", loss)\n loss = tf.reduce_sum(loss)\n return loss\n\n def build_net(self, is_training=True):\n with self.graph.as_default():\n if is_training:\n self.train_stage = tf.placeholder(tf.bool, shape=())\n train_image, train_label, train_location, train_classification, train_detection = self.load_tfrecord(\n config.train_tfrecord)\n valid_image, valid_label, valid_location, valid_classification, valid_detection = self.load_tfrecord(\n config.valid_tfrecord)\n self.x = tf.cond(self.train_stage, lambda: train_image, lambda: valid_image)\n self.label = tf.cond(self.train_stage, lambda: train_label, lambda: valid_label)\n self.location = tf.cond(self.train_stage, lambda: train_location, lambda: valid_location)\n self.classification = tf.cond(self.train_stage, lambda: train_classification,\n lambda: valid_classification)\n self.detection = tf.cond(self.train_stage, lambda: train_detection, lambda: valid_detection)\n else:\n self.x = tf.placeholder(tf.float32,\n shape=(config.batch_size, config.image_height, config.image_max_width, 1))\n\n self.enc = self.base_net(is_training)\n self.detection_feature, self.detection_pre = self.detection_branch(self.enc)\n self.classification_feature, self.classification_pre = self.classification_branch(self.enc)\n\n # loc_pre 没有sigmoid\n self.location_feature, self.location_pre = self.location_branch(self.enc, self.detection_feature,\n self.classification_feature)\n self.loc_loss = self.location_loss(self.location_pre, self.location)\n self.cla_loss = self.classification_loss(self.detection_pre, self.detection, self.location)\n self.det_loss = self.detection_loss(self.detection_pre, self.detection, self.location)\n\n self.loss = self.loc_loss\n # self.loss = self.loc_loss + self.cla_loss + self.dec_loss\n\n # cla probability\n self.cla_p = tf.nn.softmax(self.classification_pre)\n self.cla_p = tf.reduce_sum(self.cla_p, axis=1)\n # loc probability\n self.loc_p = tf.nn.sigmoid(self.location_pre)\n self.loc_p = tf.reduce_sum(self.loc_p, axis=1)\n self.loc_p = tf.reduce_sum(self.loc_p, axis=-1)\n # det pre\n self.det_p = tf.reduce_sum(self.detection_pre, 1)\n # dynamic learning rate\n global_step = tf.Variable(0, trainable=False)\n lr = config.learning_rate\n optimizer = tf.train.GradientDescentOptimizer(learning_rate=lr)\n update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)\n with tf.control_dependencies(update_ops):\n self.train_op = optimizer.minimize(self.loss, global_step=global_step)\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 16,
"blob_id": "37408241ed6705f3dcc87392981780e9c6f8989a",
"content_id": "60fd99584ba64d9c84f9af059308c39ef36f1aa2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 1,
"path": "/README.md",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "# Muti-task-HCTR"
},
{
"alpha_fraction": 0.5078011155128479,
"alphanum_fraction": 0.5234034061431885,
"avg_line_length": 39.46666717529297,
"blob_id": "33c8a9589c22d400ad6f67dc7d612951cf702245",
"content_id": "b710a5092a038e6778be6d47a75b51f608fd9d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10861,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 255,
"path": "/MultiTask/data_load.py",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport numpy as np\nimport os\nimport re\nimport cv2\nimport struct\nfrom PIL import Image\n\nimport MultiTask.config as config\nfrom MultiTask.utils import read_alphabet\n\n\ndef resize_image(image, position):\n \"\"\"\n 将图片放缩到config.image_height的高度 (128)\n :param image: 图像\n :param position: 坐标list\n :return: 放缩后的图像,放缩后的坐标\n \"\"\"\n\n def scale_position(positions, rate):\n for i in range(len(positions)):\n for j in range(len(position[i])):\n positions[i][j] = int(float(position[i][j]) / rate)\n return positions\n\n width, height = image.size\n rate_height = float(height) / float(config.image_height)\n position = scale_position(position, rate_height)\n new_width = int(float(width) / rate_height)\n new_height = config.image_height\n image = image.resize((new_width, new_height))\n return image, position\n\n\ndef listdir(root):\n \"\"\"\n 找到根目录下的所有文件\n :param root:\n :return:\n \"\"\"\n filelist = []\n for dirpath, dirname, filename in os.walk(root):\n for filepath in filename:\n filelist.append(os.path.join(dirpath, filepath))\n return filelist\n\n\ndef load_data(root, save_img_path):\n \"\"\"\n 读取dgr格式文件,以生成器的形式返回一行文字的:图像, 坐标, 标签, 标签长\n :param root:\n :param save_img_path:\n :return:\n \"\"\"\n file_num = 0\n filelist = listdir(root)\n for filepath in filelist:\n bin_data = open(filepath, \"rb\").read() # dgr 二进制文件内容\n file_num += 1 # 下一文件\n filename = os.path.split(filepath)[1] # 文件名\n print(\"第{0}个图片{1}正在转化\".format(file_num, filename))\n offset = 0 # 偏移量\n fmt_header = \"l8s\"\n sizeofheader, format = struct.unpack_from(fmt_header, bin_data, offset)\n illu_len = sizeofheader - 36\n fmt_header = \"=l8s\" + str(illu_len) + \"s20s2h3i\"\n sizeofheader, format, illu, codetype, codelen, bits, img_h, img_w, line_num = struct.unpack_from(fmt_header,\n bin_data,\n offset)\n offset += struct.calcsize(fmt_header)\n error_flag = 0 # 若文本行存在错误label,则跳过这行\n i = 0 # 第i行\n while i < line_num:\n image = np.ones((img_h, img_w))\n image = image * 255\n line_word = \"\"\n position = np.zeros((config.label_max_len, 4), dtype=np.int32)\n\n fmt_line = \"i\"\n word_num, = struct.unpack_from(fmt_line, bin_data, offset)\n offset += struct.calcsize(fmt_line)\n\n line_left = 0\n line_right = 0\n line_top = 99999\n line_down = 0\n tmp_offset = offset\n error_flag = 0\n j = 0\n i += 1 # 下一行\n while j < word_num:\n fmt_1 = '2s4h'\n label1, top_left_y, top_left_x, H, W = struct.unpack_from(fmt_1, bin_data,\n offset) # 每个字符标签、左上角顶点坐标、字符图像高、宽\n\n if j == 0:\n line_left = top_left_x\n if j == word_num - 1:\n line_right = top_left_x + W\n if top_left_y < line_top:\n line_top = top_left_y\n if top_left_y + H > line_down:\n line_down = top_left_y + H\n\n singal_word = str(label1.decode('gbk', 'ignore').strip(b'\\x00'.decode()))\n line_word += singal_word # 整行文字\n\n offset += struct.calcsize(fmt_1)\n\n image_size = H * W\n j += 1\n fmt_image = '=' + str(image_size) + 'B'\n images = np.array(struct.unpack_from(fmt_image, bin_data, offset)).reshape((H, W))\n try:\n image[top_left_y:top_left_y + H, top_left_x:top_left_x + W] = images\n except:\n print(\"文件名:{0},第{1}行,第{2}个字,{3}\".format(filename, i, j, singal_word))\n print(top_left_y, top_left_x, H, W)\n error_flag = 1\n # draw = ImageDraw.Draw(image)\n # draw.rectangle([(top_left_x1, top_left_y1),(top_left_x1+H, top_left_y1+W)], outline=(0, 255, 0, 255))\n # plt.imshow(images)\n # plt.show()\n offset += image_size\n\n if error_flag: # 如果有错,跳过这一行\n continue\n '''保存position信息'''\n offset = tmp_offset\n j = 0\n position_num = 0\n while j < word_num:\n fmt_1 = '2s4h'\n label1, top_left_y, top_left_x, H, W = struct.unpack_from(fmt_1, bin_data,\n offset) # 每个字符标签、左上角顶点坐标、字符图像高、宽\n\n singal_word = str(label1.decode('gbk', 'ignore').strip(b'\\x00'.decode())) # 解码单个字\n if not singal_word == \"\":\n position[position_num][0] = top_left_y - line_top\n position[position_num][1] = top_left_x - line_left\n position[position_num][2] = H\n position[position_num][3] = W\n position_num += 1\n # line_top:line_down + 1, line_left:line_right + 1\n image_size = H * W\n offset += struct.calcsize(fmt_1)\n j += 1\n offset += image_size\n if not len(line_word) == position_num:\n print(len(line_word), position_num)\n '''保存每行'''\n image_line = image[line_top:line_down + 1, line_left:line_right + 1]\n line_file = save_img_path + filename[:-4] + '-' + str(i) + '.jpg'\n # 中文路径不能用imwrite\n # cv2.imwrite(line_file, image_line)\n cv2.imencode('.jpg', image)[1].tofile(line_file)\n im = Image.open(line_file)\n yield im, position, line_word, len(line_word)\n\n\ndef create_tfrecord(train_save_path, dataset_path, save_img_path):\n print(\"Create tfrecord\")\n idx2symbol, symbol2idx = read_alphabet(config.alphabet_path)\n print(symbol2idx)\n writer = tf.python_io.TFRecordWriter(train_save_path)\n out_of_label_max_length = 0\n for image, position, label, line_len in load_data(dataset_path, save_img_path):\n # 图像预处理,裁剪缩放\n image, position = resize_image(image, position)\n # label = re.sub('\\|', ' ', label)\n # label = list(label.strip())\n label_list = list(label)\n # print('label', label)\n transed = False\n for i in range(len(label_list)):\n\n if label_list[i] not in idx2symbol:\n label_list[i] = '*'\n transed = True\n # 如果图像被转换,那就保存图片\n if transed:\n print(\"由于不在字母表被转换的图片label:{0},转化后的label:{1}\".format(label, \"\".join(label_list)))\n\n label_list = [symbol2idx[s] for s in label_list]\n label_list.append(config.EOS_ID)\n\n label_list = np.array(label_list, np.int32)\n if label_list.shape[0] > config.label_max_len or label_list.shape[0] <= 0:\n out_of_label_max_length += 1\n continue\n image = np.array(image)\n # image norm\n image = 255 - image\n # print(image)\n # image = (image-np.min(image))/(np.max(image)-np.min(image))\n # print(image)\n position = np.array(position)\n # location (lfv,1)\n # position x,y,h,w\n lfv = int(config.image_max_width / 16)\n location = np.zeros((lfv), dtype=np.float32)\n classification = np.zeros((lfv), dtype=np.int32)\n detection = np.zeros((lfv, 4), dtype=np.float32)\n grid_left = -16\n grid_right = 0\n word_idx = 0\n # TODO to be promoted\n for j in range(lfv):\n grid_left += 16\n grid_right += 16\n center = position[word_idx][1] + position[word_idx][3] / 2 # 第word_idx个字的中心坐标\n if center >= grid_left and center < grid_right:\n idx = int(center / 16)\n location[idx] = 1\n classification[idx] = label_list[word_idx]\n # detection[0,1,2,3] 横坐标 纵坐标 水平长度比例,垂直高度比例\n detection[idx][0] = center\n detection[idx][1] = position[word_idx][0] + position[word_idx][2] / 2\n detection[idx][2] = position[word_idx][3] / config.image_height\n detection[idx][3] = position[word_idx][2] / config.image_height\n word_idx += 1\n if word_idx == label_list.shape[0]:\n break\n\n _image_width = tf.train.Feature(int64_list=tf.train.Int64List(value=[image.shape[1]]))\n _image = tf.train.Feature(bytes_list=tf.train.BytesList(value=[image.tobytes()]))\n _label = [tf.train.Feature(int64_list=tf.train.Int64List(value=[tok])) for tok in label_list]\n # _label_length = tf.train.Feature(int64_list=tf.train.Int64List(value=[label_list.shape[0]]))\n _location = tf.train.Feature(bytes_list=tf.train.BytesList(value=[location.tobytes()]))\n _classification = tf.train.Feature(bytes_list=tf.train.BytesList(value=[classification.tobytes()]))\n _detection = tf.train.Feature(bytes_list=tf.train.BytesList(value=[detection.tobytes()]))\n # _position = tf.train.Feature(bytes_list=tf.train.BytesList(value=[position.tobytes()]))\n example = tf.train.SequenceExample(\n context=tf.train.Features(feature={\n 'image_width': _image_width,\n 'image': _image,\n # 'label_length': _label_length,\n 'location': _location,\n 'classification': _classification,\n 'detection': _detection\n }),\n feature_lists=tf.train.FeatureLists(feature_list={\n 'label': tf.train.FeatureList(feature=_label)\n })\n )\n writer.write(example.SerializeToString())\n writer.close()\n print(\"tfrecord file generated.\")\n\n\nif __name__ == '__main__':\n # save_alphabet(config.alphabet_path)\n create_tfrecord(config.train_tfrecord, config.train_dataset_path, config.train_image_path)\n create_tfrecord(config.valid_tfrecord, config.valid_dataset_path, config.valid_image_path)\n"
},
{
"alpha_fraction": 0.528976559638977,
"alphanum_fraction": 0.5573366284370422,
"avg_line_length": 26.03333282470703,
"blob_id": "6191e155e71177c0f59e46bfc8ba03a4cb0d4c8f",
"content_id": "c0348514017f240c371306f2cb518f0cb8e44f21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 859,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 30,
"path": "/MultiTask/utils.py",
"repo_name": "fengchuimailang/Muti-task-HCTR",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef read_alphabet(filename):\n \"\"\"\n 读取字典返回idx2symbol, symbol2idx\n :param filename:\n :return:\n \"\"\"\n # TODO 字母表改成自己的版本\n file = []\n with open(filename, 'r', encoding='utf-8') as f:\n while True:\n raw = f.readline()\n if not raw:\n break\n file.append(raw)\n idx2symbol = [s.strip('\\n') for s in file]\n for i in range(92):\n idx2symbol[i] = idx2symbol[i][1:]\n idx2symbol.insert(0, '<pad>') # 空白\n # idx2symbol.insert(1, '<GO>') # 没有作用\n # idx2symbol.insert(2, '<EOS>') # 结束\n print('alphabet len:', len(idx2symbol))\n symbol2idx = {}\n for idx, symbol in enumerate(idx2symbol):\n symbol2idx[symbol] = idx\n return idx2symbol, symbol2idx\n\ndef sigmoid(x):\n return 1 / (1 + np.exp(-x))\n"
}
] | 6 |
pombredanne/linuxsleuthing
|
https://github.com/pombredanne/linuxsleuthing
|
adb53ce70c4d20bd0e5eab4358461944cc4341c0
|
f85c930a18d5463b2e1dc1718791ceef4fd74f0e
|
10a66001671c4043f9f30d407af868f4e962cc61
|
refs/heads/master
| 2018-01-01T06:27:35.600007 | 2012-02-13T21:14:10 | 2012-02-13T21:14:10 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.560693621635437,
"alphanum_fraction": 0.5953757166862488,
"avg_line_length": 16.653060913085938,
"blob_id": "71d5e4d461df18efc05779b166ea01b42af066df",
"content_id": "ce2a08ef1687fc7310772f5cc1b4b45d42475176",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 865,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 49,
"path": "/nautilus-scripts/.support_scripts/previewer_functions",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t\t: previewer_functions\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Date\t\t\t: 05/04/2011\n#: Version\t\t: 1.0.0\n#: Description\t: functions to suppor the Previewer nautilus scripts\n#: Options\t\t: None\n\n## Variables\nDIALOG=$(which yad)\nSAVE_DIR=$(cat $HOME/.save_dir 2>/dev/null)\nFILE_WINDOW_SIZE=\"--width=600 --height=400\"\n\ncheck_cancel ()\n{\n\tif [ $? = 1 ]; then\n\t\texit 1\n\tfi\n}\n\nchoose_save_directory ()\n{\n\tif [ -z $SAVE_DIR ]; then\n\t\tSAVE_DIR=$($DIALOG $TITLE --file --directory $FILE_WINDOW_SIZE)\n\t\tcheck_cancel\n\t\techo $SAVE_DIR > $HOME/.save_dir\n\tfi\n}\t\n\ndump_sqlite()\n{\n\techo -e \"Tables:\\n\"\n\tsqlite3 \"$1\" .tables\n\techo\n\tfor i in $(sqlite3 \"$1\" .tables); do\n\t\techo -e \"Table: $i\\n\"\n\t\tsqlite3 -header $1 \"select * from $i\"\n\t\techo -e \"\\n\\n\"\n\tdone\n}\n\nread_yad_output ()\n{\n\t## Read user input\n\tfor var in $2; do\n\t\teval $var=\"\\${$1%%|*}\"\n\t\t$1=\"${$1#*|}\"\n\tdone\n}\n"
},
{
"alpha_fraction": 0.5616438388824463,
"alphanum_fraction": 0.6164383292198181,
"avg_line_length": 13.600000381469727,
"blob_id": "487f128ec63644512a9e569c48cc65aa47c179de",
"content_id": "4edee17869dea5402268c6c634e5abff0dfb8a18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/nautilus-scripts/File Analysis/Quick View Content",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Quick View\n#by John Lehr (c) 2009\n\ngnome-terminal -x most \"$@\"\n"
},
{
"alpha_fraction": 0.582054615020752,
"alphanum_fraction": 0.5945383906364441,
"avg_line_length": 27.481481552124023,
"blob_id": "c3e601f7098ec81e3a8c33a55bcb370e8750d3d0",
"content_id": "022809e2ab4c28f6867ef6e53ee70dbb36121f3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3845,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 135,
"path": "/shaft.sh",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Name : shaft.sh\n#: Author : John Lehr <[email protected]>\n#: Date : 09/15/2011\n#: Version : 0.1.1\n#: Description : Install miscellaneous projects to support forensics\n#: Options : None\n#: License : GPLv3\n\n#: 09/15/2011 : fixed rbfstab install, added shaft.sh update notice\n#: 08/15/2011 : initial release\n\n## To do\n#: add uninstall option\n#: clean up code after testing\n\n## Variables\nPYTSK_DEPS=\"mercurial python-dev uuid-dev libtsk-dev\"\nLINUXSLEUTHING_DEPS=\"ipod sqlite3 python3 libimobiledevice-utils yad\"\nLINUXSLEUTHING_TOOLS=\"nautilus-scripts iphone_tools blackberry_tools miscellaneous\"\nSHERAN_DEPS=\"git\"\nSHERAN_TOOLS=\"ConParse bbt evt2sqlite\"\n\nPROJECTS_DIR=/opt\nINSTALL_DIR=/usr/local/bin\nSCRIPTS_DIR=$HOME/.gnome2/nautilus-scripts\n\n## Functions\ninstall_pytsk()\n{\n cd pytsk\n rm -rf build\n python setup.py build\n python setup.py install\n cp samples/tskfuse.py /usr/local/bin\n chmod +x /usr/local/bin/tskfuse.py\n cd $PROJECTS_DIR\n}\n\ninstall_linuxsleuthing()\n{\n [ \"$(md5sum /$PROJECTS_DIR/linuxsleuthing/shaft.sh)\" = \"$(md5sum /$INSTALL_DIR/shaft.sh)\" ] || \\\n UPDATED=\"shaft.sh updated, please rerun with 'sudo shaft.sh'\"\n cp \"$PROJECTS_DIR/linuxsleuthing/shaft.sh\" \"$INSTALL_DIR\"\n for tool in $LINUXSLEUTHING_TOOLS\n do\n if [ \"$tool\" = \"nautilus-scripts\" ]\n then\n cp -R \"$PROJECTS_DIR\"/linuxsleuthing/nautilus-scripts/* $SCRIPTS_DIR\n cp -R \"$PROJECTS_DIR\"/linuxsleuthing/nautilus-scripts/* /root/.gnome2/nautilus-scripts\n else \n cp \"$PROJECTS_DIR\"/linuxsleuthing/$tool/* \"$INSTALL_DIR\"\n [ \"$tool\" = \"miscellaneous\" ] && mv $INSTALL_DIR/rbfstab /usr/sbin\n fi\n done\n}\n\ninstall_sheran()\n{\n [ \"$tool\" = \"ConParse\" ] && ln -s /opt/$tool/cparse.sh $INSTALL_DIR/cparse.sh\n [ \"$tool\" = \"bbt\" ] && ln -s /opt/$tool/bbt.py $INSTALL_DIR/bbt.py\n [ \"$tool\" = \"evt2sqlite\" ] && ln -s /opt/$tool/e2s.py $INSTALL_DIR/e2s.py\n}\n\n## Main Script\n\n#: Check for proper permissions\nif [ $UID -ne 0 ]\nthen\n echo \"Must be run as root!\" >&2\n exit 1\nfi\n\n#: Pull dependencies\necho -e \"Updating sources and installing dependencies...\"\n\n\ngrep -q slavino /etc/apt/sources.list #Check of yad repo and add if missing\nif [ $? -gt 0 ]\nthen\n apt-add-repository 'deb http://debs.slavino.sk testing main non-free'\n wget -q http://debs.slavino.sk/repo.asc\n sudo apt-key add repo.asc && rm repo.asc\nfi\n\napt-get -y -qq update\napt-get -y install $PYTSK_DEPS $LINUXSLEUTHING_DEPS $SHERAN_DEPS\n\n#: Create directory for source packages\nmkdir -p $PROJECTS_DIR\ncd $PROJECTS_DIR\n\n#: Install projects\nfor project in pytsk linuxsleuthing sheran\ndo\n if [ \"$project\" = \"sheran\" ]\n then\n for tool in $SHERAN_TOOLS\n do\n if [ -d \"$PROJECTS_DIR/$tool\" ]\n then\n echo -e \"\\nUpdating $tool...\" >&2\n cd $PROJECTS_DIR/$tool\n status=$(git pull)\n [[ $status =~ up-to-date ]] && echo $status || install_sheran\n else\n echo -e \"n\\Downloading and installing $tool...\" >&2\n cd $PROJECTS_DIR\n git clone https://github.com/sheran/${tool}.git\n install_sheran\n fi\n done\n else\n if [ -d \"$PROJECTS_DIR/$project\" ]\n then\n echo -e \"\\nUpdating $project...\" >&2\n cd $PROJECTS_DIR/$project\n hg incoming \n if [ $? = 0 ]\n then \n hg pull\n hg update\n install_$project\n fi\n else\n echo -e \"\\nDownloading and installing $project...\" >&2\n cd $PROJECTS_DIR\n hg clone http://code.google.com/p/$project $project\n install_$project\n fi\n fi\ndone\n\necho -e \"\\t$UPDATED\"\nexit 0\n"
},
{
"alpha_fraction": 0.6494464874267578,
"alphanum_fraction": 0.6568265557289124,
"avg_line_length": 30.269229888916016,
"blob_id": "3d791489fd03ddae040fef9e80c8bf3abdedc78b",
"content_id": "885a0ed3520da419aea9d331eb13b4ccb50dbb24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 813,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 26,
"path": "/nautilus-scripts/Find Files/Find Images",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Find Images Here\n#script to find images by file magic and create symlinks in one directory\n#by John Lehr (c) 2009\n\n# create temp dir with source dir name\nTEMP_DIR=$(mktemp -d /tmp/\"$(basename $(pwd))\"_images)\n\n# find images in pwd, create links in temp dir, show progress\nfind \"$(pwd)\" -type f | tee \\\n\t>(sleep 3; zenity --progress --title=\"Find Images\" --text=\"Searching...\" --pulsate --auto-close --auto-kill) \\\n\t>(while read FILENAME; do\n\t\tIMAGE=\"$(file -bi \"$FILENAME\" | grep image)\"\n\t\tif [ \"$IMAGE\" != \"\" ]; then\n\t\t\tNEW_FILENAME=\"$(basename \"$FILENAME\")-$(stat -L -c %i \"$FILENAME\")\"\n\t\t\tln -s -T \"$FILENAME\" \"$TEMP_DIR/$NEW_FILENAME\"\n\t\tfi\n\tdone)\n\n# open temp dir\nnautilus \"$TEMP_DIR\"\n\n# need to establish way to remove dir when nautilus window closed, probably by pid\n# rm -rf \"$TEMP_DIR\"\n\nexit 0\n"
},
{
"alpha_fraction": 0.5649606585502625,
"alphanum_fraction": 0.586614191532135,
"avg_line_length": 19.31999969482422,
"blob_id": "7e88dea40e39376020cf2961b2f1e40a0cb01a37",
"content_id": "6c894c5c9f8b101fdd2298e7d0cad3fcc9457a40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 25,
"path": "/nautilus-scripts/iPod Analysis/Show Media Details",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#Show Media Details\n#by John Lehr (c) 2009\n\nOUTPUT=\"$(mktemp)\"\n\necho -e \"$NAUTILUS_SCRIPT_SELECTED_FILE_PATHS\" | \\\n\twhile read FILENAME; do\n\t\techo \"$FILENAME:\" >> $OUTPUT\n\t\t\n\t\tif [ \"$(file -bi \"$FILENAME\" | grep mp3)\" != \"\" ]; then\n\t\t\tid3tool $FILENAME | tail +2 - >> $OUTPUT\n\t\telif [ \"$(file -bi \"$FILENAME\" | grep mp4)\" != \"\" ]; then\n\t\t\tAtomicParsley \"$FILENAME\" -t >> $OUTPUT \n\t\telse\n\t\t\techo \"Not an mp3/mp4 file.\" >> $OUTPUT\n\t\tfi\n\t\t\n\t\techo \"\" >> $OUTPUT\n\tdone\n\ngedit $OUTPUT\nrm $OUTPUT\n\nexit 0\n"
},
{
"alpha_fraction": 0.6104868650436401,
"alphanum_fraction": 0.6516854166984558,
"avg_line_length": 28.66666603088379,
"blob_id": "1db2b233c6b69106270bb6e7040f3f0bc560eaa6",
"content_id": "dda2a12d5fb381b9d99be62560881129df0687c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 267,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/nautilus-scripts/iPod Analysis/Identify iPod Owner",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#!/bin/bash\n#: Title\t\t: Identify iPod Ownher\n#: Date\t\t\t: 2010-05-12\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Version\t\t: 1.0\n#: Description\t: A script to launch iPod_ID.sh as super user\n\ngksu -u $USER \"$HOME\"/.gnome2/nautilus-scripts/.support_scripts/iPod_ID.sh\n"
},
{
"alpha_fraction": 0.6599918007850647,
"alphanum_fraction": 0.6685737371444702,
"avg_line_length": 21.657407760620117,
"blob_id": "87717c0b85b277c3eebb71d96be1e15d4e1ce454",
"content_id": "3275ea93f51d50295df4acacea033addbcf50bb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2447,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 108,
"path": "/nautilus-scripts/Admin/Make Device Writeable",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title\t\t: Make Device Writeable\n#: Date\t\t\t: 2010-06-28\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Version\t\t: 1.1\n#: Description\t: Remounts device in read-write mode.\n\n\n## Change log\n\n# v1.1\n# \t- \timproved mount point detection to find mount points anywhere in the file\n#\t \tsystem\n#\t- \tfixed GUI cancel option\n\n\n## Script-wide Variables\ntitle=\"Make Device Writeable\" # Set window title\nicon=/usr/share/icons/gnome-colors-common/16x16/actions/gtk-edit.png\n\n\n## Functions\n\n# Determine mount point and device node of current working directory\ndetermine_mountpoint ()\n{\n\tmpoint=\"$PWD\"\n\n\twhile ! mountpoint -q \"$mpoint\"\n\tdo\n\t\tmpoint=\"$(dirname \"$mpoint\")\"\n\tdone\n\n\tdevice_node=\"$(mount | grep \"$mpoint\" |sed -e 's/ on /\\t/' -e 's/ /\\\\ /g'| cut -f1)\"\n\texport mpoint device_node\n}\n\n# Show mount options in use\nread_mount_options ()\n{\n\tmoptions=\"$(mount | grep \"$mpoint\")\"\n\texport moptions\n}\n\n# Determine if user cancelled operation\ncheck_for_cancel ()\n{\n\tif [ $? = 1 ]\n\tthen\n\t\tzenity --info \\\n\t\t\t--title=$title \\\n\t\t\t--window-icon=$icon \\\n\t\t\t--text=\"Operation cancelled by user. \\n\\nDevice mount options unchanged: \\n$moptions\"\n\t\texit 1\n\tfi\n}\n\n\n## Main script\n\ndetermine_mountpoint\nread_mount_options\n\n# Ensure operation is intended\nzenity --question \\\n\t--title=\"$title\" \\\n\t--window-icon=\"$icon\" \\\n\t--text=\"Do you want to make \\\"$mpoint\\\" writeable? \\n\\nCurrent status: $moptions\" \ncheck_for_cancel\n\n# Check to see if device is already writeable\t\nif [ -n \"$(mount | grep $mpoint | grep rw)\" ]\nthen\n\tzenity --info \\\n\t\t--title=$title \\\n\t\t--window-icon=\"$icon\" \\\n\t\t--text=\"You can already write to \\\"$mpoint.\\\" \\nNo action taken.\"\n\texit 1\nfi\n\n# Warn before continuing\nzenity --question \\\n\t--title=\"$title\" \\\n\t--window-icon=\"$icon\" \\\n\t--text=\"This could alter evidence if the wrong \\ndevice has been selected! \\n\\n\\Are you certain you want to make \\n\\\"$mpoint\\\" writeable?\"\ncheck_for_cancel\n\n\n# Remount the device read-write and report results\ngksu -k -m \"Enter your password for administrative access\" /bin/echo\nsudo mount -v -o remount,rw,user \"$device_node\" \"$mpoint\"\nread_mount_options\n\n# Report success\nif [ -n \"$(mount | grep $mpoint | grep rw)\" ]\nthen\n\tzenity --info \\\n\t\t--title=\"$title\" \\\n\t\t--window-icon=\"$icon\" \\\n\t\t--text=\"Success! \\n\\n\\\"$mpoint\\\" is now writeable: \\n$moptions\"\nelse\n\tzenity --error \\\n\t\t--title=\"$title\" \\\n\t\t--window-icon=\"$icon\" \\\n\t\t--text=\"Error changing device status. \\n\\nTry again or change settings manually.\"\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.47457626461982727,
"alphanum_fraction": 0.5593220591545105,
"avg_line_length": 10.800000190734863,
"blob_id": "f489b47ff69126f1189fd7507188644a53f04e9e",
"content_id": "d7debbd81567008f5806f2fc6609d444fb437d45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 5,
"path": "/nautilus-scripts/File Analysis/View HTML",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#View HTML\n#by John Lehr (c) 2009\n\nlinks2 -g \"$@\"\n"
},
{
"alpha_fraction": 0.623799741268158,
"alphanum_fraction": 0.6478052139282227,
"avg_line_length": 21.78125,
"blob_id": "042294378ada13c1383459bb6688e75bc2c188b5",
"content_id": "209622c8644f2caa0ba63410525eb630de483cfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2916,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 128,
"path": "/iphone_tools/iphone_music",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t: iphone_music\n#: Author\t: \"John Lehr\" <[email protected]>\n#: Date\t\t: 05/04/2011\n#: Version\t: 1.0.0\n#: Description\t: extract metadata from iphone music files\n#: Options\t: None\n\n#: 05/03/2011 : v1.0.0 Initial Release\n#: 01/19/2011 : V1.1.0 Speed enhancement to -a option\n#: 01/21/2012 : v1.1.1 Corrected help/error ouput (thanks to Leasim Leija)\n\n## Variables\nprogname=\"${0##*/}\"\ndeps=\"exiftool\"\nitunes=0\nverbose=0\n\n## Functions\n\nusage()\n{\n\techo \"USAGE: $progname [-ahv] [path]\"\n\techo \" where 'path' is the path to be searched\"\n\tcat << EOF\n\t\nOptions (only one option may be used at a time):\n\t-a\textract Apple Store user information\n\t-h\tprint this help\n\t-v\tverbose\n\nOptions MUST preceed the path to be processed. \n\nInformation: $progname searches a path for audio files and dumps file\nmetadata to standard output. Optionally, Apple Store account data (real and\nuser names) can be extracted from audio purchased through the Apple Store store.\n\nEOF\n}\n\ncheck_deps ()\n{\n\tfor i in $deps; do\n\t\twhich $i >/dev/null\n\t\tif [ $? -gt 0 ]; then\n\t\t\techo \"Error: $i is not installed or is not in the path\"\n\t\tfi\n\tdone\n}\n\nget_meta ()\n{\n\t## Export exif with exiftool\n\tfilename=\"======== $i\"\n\tmeta=\"$(exiftool \"$i\")\"\n\tif [ $itunes = 1 ] && [[ \"$filename\" =~ m4[pv] ]] ; then\n\t\techo \"$filename\"\n\t\techo \"$meta\" | grep -E '^File Type|^Apple Store Account'\n\t\techo -e \"Apple Store Real Name\\t\\t: $(strings \"$i\" | grep -m1 name | sed 's/name//')\\n\"\n\telif [ $verbose = 1 ]; then\n\t\techo \"$filename\"\n\t\techo \"$meta\"\n\t\techo\n\telif [ $itunes = 0 ]; then\n\t\techo \"$filename\"\n\t\techo \"$meta\" | grep -E '^Title|^File Type|^Artist|^Album '\n\t\techo\n\tfi\n}\n\nnotice ()\n{\n\techo -e \"Open mapping output in mapping program or upload to http://www.gpsvisualizer.com/\" >&2\n}\n\n## list of options program will accept;\n## options followed by a colon take arguments\noptstring=ahv\n\n## The loop calls getops until there are no more options on the command \n## line. Each option is stored in $opt, any option arguments are stored\n## in OPTARG\nwhile getopts $optstring opt; do\n\tcase $opt in\n\t\th) usage >&2; exit 0 ;;\n\t\ta) itunes=1 ;;\n\t\tv) verbose=1 ;;\n\t\t*) echo; usage >&2; exit 1 ;;\n\tesac\ndone\n\n## Remove options from the command line\n## $OPTIND points to the next, unparsed argument\nshift \"$(( $OPTIND -1 ))\"\n\n## Check for conflicting arguments\nif [ $(( $verbose + $itunes )) -gt 1 ]; then\n\techo \"Error: arguments -a and -v may not be used together\" >&2\n\texit 1\nfi\n\n## Process file according to chosen option\n## Determine path to search\npath=\"$1\"\nif [ -z $1 ]; then\n\tpath=\"$(pwd)\"\nfi\n\n## Search for files\necho \"Searching $path for files...\" >&2\n\nif [ $itunes = 1 ]\nthen\n\tfind \"$path\" -type f -name \"*.m4[apv]\" |\n\t\twhile read i; do\n\t\t\tget_meta\n\t\tdone\nelse\n\tfind \"$path\" -type f |\n\t\twhile read i; do\n\t\t\ttype=$(file -bi \"$i\" | grep -E 'image|audio|video')\n\t\t\tif [ -n \"$type\" ]; then\n\t\t\t\tget_meta #process file with get_meta function\n\t\t\tfi\n\t\tdone\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.5495125651359558,
"alphanum_fraction": 0.5751667618751526,
"avg_line_length": 40.45744705200195,
"blob_id": "2fe60327f85d080ae064fe573a50235a52a2ab67",
"content_id": "c882dbf04074ec0086e7a52371e959a0c346845c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3898,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 94,
"path": "/blackberry_tools/bbmessenger.py",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : bbmessenger\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/11/2011\n#: Version : 0.2.2\n#: Description : Decode BlackBerry Messenger/Gtalk save files\n#: Options : --no-header, --utc, --directory\n#: License : GPLv3\n\n#: 05/26/2011 : v0.1.0 initial release\n#: 08/18/2011 : v0.1.1 fixed line ending issue where inline line feeds in text message caused error\n#: 10/03/2011 : v0.1.2 added help and arguments\n#: 10/03/2011 : v0.1.3 added UTC output option\n#: 10/05/2011 : v0.2.0 added directory recursion\n#: 10/11/2011 : v0.2.1 added sorting for directory recursion\n#: 10/11/2011 : v0.2.2 code cleanup\n\nimport io, os, sys, argparse\nfrom time import strftime, localtime, gmtime\n\ndef recurse_directory(dir):\n '''Search directory for .csv and .OLD files to process with print_records module'''\n \n cumulative = []\n\n if os.path.isdir(dir):\n for root, dirs, files in os.walk(dir):\n for name in files:\n file = os.path.join(root,name)\n if file[-3:] == 'OLD' or file[-3:] == 'csv':\n args.csv = file\n for item in print_records(args):\n cumulative.append('{},\"{}\"'.format(item, file))\n cumulative.sort()\n return cumulative\n \n else:\n print('Error: \"{}\" not a directory'.format(dir), file=sys.stderr)\n\ndef print_records(args):\n '''Print records from BlackBerry Messenger and Gtalk save files'''\n \n data = []\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.csv))\n with io.open(args.csv) as file_header:\n print(file_header.readline())\n print('Date,DateCode,Sender,Receiver,Message')\n\n try:\n with io.open(args.csv, newline=\"\\r\\n\") as db_file:\n for line_no, line in enumerate(db_file):\n if line_no > 0: \n\n #create objects from row items\n datecode, sender, receiver, message = line.split(',', 3)\n\n #convert datecode to local time or UTC\n date = int(datecode[8:18])\n if args.utc:\n date = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(date))\n else:\n date = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(date))\n\n #add date conversion to row\n row = '{},{},{},{},\"{}\"'.format(date, datecode, sender, receiver, message.strip())\n data.append(row)\n return data\n \n except IOError:\n print('Error: not a BlackBerry Messenger/Gtalk save file or an incompatible version', file=sys.stderr)\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n description='Process BlackBerry Messenger/Gtalk save files.',\n epilog='Converts timestamps to local time. Directory recursion option combines and sorts all .csv/.OLD files and appends source file name. Prints to stdout.')\n \n parser.add_argument('csv', help='a BlackBerry Messenger/Gtalk csv file')\n parser.add_argument('-d', '--directory', dest='directory', action='store_true', help='treat csv argument as dir to recurse')\n parser.add_argument('-n', '--no-header', dest='noheader', action='store_true',help='do not print file name, version, or column headers')\n parser.add_argument('-u', '--utc', dest='utc', action='store_true', help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', action='version', version='%(prog)s v0.2.2')\n \n args = parser.parse_args()\n\n if args.directory:\n args.noheader = True\n print('Date,DateCode,Sender,Receiver,Message,SourceFile')\n for item in recurse_directory(args.csv):\n print(item)\n else:\n for item in print_records(args):\n print(item)\n\n"
},
{
"alpha_fraction": 0.5851648449897766,
"alphanum_fraction": 0.6118524074554443,
"avg_line_length": 40.09677505493164,
"blob_id": "57728952df37727d95c4833f08b6295996f6bd48",
"content_id": "774ec03ee2d40035d3b4dcd56e84b117bccc5eda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2548,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 62,
"path": "/iphone_tools/iphone_ch",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : iphone_ch\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/04/2011\n#: Version : 2.0.0\n#: Description : Dump/interpret iphone call_history.db call table \n#: Options : None\n#: License : GPLv3\n\n#: 03/22/2011 : v1.0.0 Initial Release\n#: 05/04/2011 : v1.0.1 added extended output formats, updated code schema\n#: 10/04/2011 : v2.0.0 migrated to python3 from bash\n#: 10/07/2011 : v2.0.1 Corrected db version compatibility error, updated id field to read 'None' if no corresponding AB entry \n\nimport sqlite3, argparse\nfrom time import strftime, localtime, gmtime\n\nflag = {4 : 'Incoming', 5 : 'Outgoing', 8 : 'Cancelled'}\n\ndef printdb(args):\n '''Prints the rows from the iPhone callhistory.db, interpreting the flags.'''\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.database))\n print('Record #,Time,Type,Phone Number,AdressBook ID,Duration')\n \n try: \n conn = sqlite3.connect(args.database)\n c = conn.cursor()\n\n # Read specific fields in the database to accomodate different versions of call_history.db\n for ROWID, address, date, duration, flags, id in c.execute('select ROWID, address, date, duration, flags, id from call'):\n\n #convert flags object to flag dictionary value\n type = flag.get(flags, 'Unknown')\n\n if id == -1:\n id = None\n \n #convert timestamp to local time or utc\n if args.utc:\n time = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(date))\n else:\n time = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(date))\n\n print('{},{},{},{},{},{}'.format(ROWID, time, type, address, id, duration))\n\n except sqlite3.Error:\n print('SQLite Error: wrong or incompatible database')\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n description='Process iPhone call history database.',\n epilog='Converts timestamps to local time and interprets flag values. Prints to stdout.')\n parser.add_argument('database', help='an iPhone call_history.db database')\n parser.add_argument('-n', '--no-header', dest='noheader', action='store_true', help='do not print filename or column header')\n parser.add_argument('-u', '--utc', dest='utc', action='store_true', help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', action='version', version='%(prog)s v2.0.1')\n\n args = parser.parse_args()\n\n printdb(args)\n"
},
{
"alpha_fraction": 0.5521872639656067,
"alphanum_fraction": 0.5805832743644714,
"avg_line_length": 31.97468376159668,
"blob_id": "a4d6bd8feae195ddfa0bc0a89efeaebcbea79734",
"content_id": "6d7ce4ec69cf5196f3f39946ffab1f91377533bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2606,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 79,
"path": "/iphone_tools/iphone_sms",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : iphone_sms\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 05/04/2011\n#: Version : 1.0.2\n#: Description : Dump/interpret iphone sms.db messages table \n#: Options : None\n\n#: 03/22/2011 : v1.0.0 Initial Release\n#: 04/12/2011 : v1.0.1 updated flags translations\n#: 05/04/2011 : v1.0.2 added extended output formats, updated code schema\n#: 10/05/2011 : v2.0.0 converted to python from bash\n\n\nimport sqlite3, argparse\nfrom time import strftime, localtime, gmtime\n\nsms_flags = {\n 2 : 'Recd SMS',\n 3 : 'Sent SMS/MMS',\n 4 : 'Recd MMS',\n 33 : 'Unsent' ,\n 35 : 'Failed Send',\n 129 : 'Deleted'}\nread_flags = {\n 0 : 'Unread',\n 1: 'Read' }\n\ndef printdb(args):\n '''Prints the rows from the iPhone sms.db, interpreting the flags.'''\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.database))\n print('Record #,Date,Type,Phone Number,AdressBook ID,Duration')\n \n try: \n conn = sqlite3.connect(args.database)\n c = conn.cursor()\n\n for ROWID, address, date, text, flags, read in c.execute(\n 'select ROWID, address, date, text, flags, read from message'):\n\n #convert flags object to sms_flag dictionary value\n type = sms_flags.get(flags, 'Unknown')\n \n #convert read object to read_flags dictionary value\n status = read_flags.get(read, 'Unknown') \n \n #convert timestamp to local time or utc\n if args.utc:\n time = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(date))\n else:\n time = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(date))\n\n print('{},{},{},{},\"{}\",{}'.\n format(ROWID, time, type, address, text, status))\n\n except sqlite3.Error:\n print('SQLite Error: wrong or incompatible database')\n\ndef main():\n parser = argparse.ArgumentParser(\n description='Process iPhone SMS database.',\n epilog='Converts timestamps to local time and interprets flag values. \\\n Prints to stdout.')\n\n parser.add_argument('database', help='an iPhone sms.db database')\n parser.add_argument('-n', '--no-header', dest='noheader',\n action='store_true', help='do not print filename or column header')\n parser.add_argument('-u', '--utc', dest='utc', action='store_true',\n help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', action='version',\n version='%(prog)s v2.0.0')\n\n args = parser.parse_args()\n\n printdb(args)\n\nif __name__ == '__main__':\n\n"
},
{
"alpha_fraction": 0.5595549941062927,
"alphanum_fraction": 0.5791884660720825,
"avg_line_length": 25.34482765197754,
"blob_id": "df1992b451ccc355bc4c4e087fd6477222362be1",
"content_id": "a25fd12077fa25034f0ad0d541ae4582ac15687d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1528,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 58,
"path": "/blackberry_tools/bbmessenger-gui.sh",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t : bbmessenger-gui.sh\n#: Author\t : \"John Lehr\" <[email protected]>\n#: Date\t\t : 08/17/2011\n#: Version\t : 0.1.1\n#: Description\t: gui front end for bbmessenger.py \n#: Options\t : None\n\n#: 08/17/2011 : expanded search for all text files by header, prepend output file with inode number\n \n\nselections=$(yad --form \\\n --title=\"BBmessenger GUI\" \\\n --image=gtk-index \\\n --text=\"Checks search path for BlackBerry Messenger and Gtalk saved\\nchats and interprets datecode.\\n\\nSelect your parameters:\" \\\n --field=\"Search Path\":DIR \\\n --field=\"Save Dir\":DIR \\\n --field=\"Open save location upon completion?\":CHK)\n\n[[ $? = 1 ]] && exit 0\n\nfor var in search save open\ndo\n eval $var=\"\\${selections%%|*}\"\n selections=\"${selections#*|}\"\ndone\n\nlog=$(mktemp)\n\nfind \"$search\" -type f | \\\nwhile read chatfile\ndo\n textfile=$(file -bi \"$chatfile\")\n if [ \"${textfile%%/*}\" = \"text\" ]\n then\n head -1 \"$chatfile\" | grep -qE 'BlackBerry Messenger|Google Talk'\n if [ $? = 0 ]\n then\n filename=\"${chatfile##*/}\"\n inode=\"$(stat -c %i \"$chatfile\")\"\n bbmessenger.py \"$chatfile\" > \"$save/${inode}-${filename}\"\n echo -e \"Processed: $chatfile,\\n\\tSaved as: $save/${inode}-${filename}\" >> $log\n fi\n fi\ndone\n\n\ncat $log | \\\nyad --text-info --title=\"BBmessenger GUI Log\" --button=gtk-ok --width=600 --height=400\ncp $log \"$save/bbm-gui_output.log\"\nrm $log\n\nif [ \"$open\" = \"TRUE\" ]\nthen \n nautilus \"$save\" & \nfi\n\nexit 1\n"
},
{
"alpha_fraction": 0.5494186282157898,
"alphanum_fraction": 0.559108555316925,
"avg_line_length": 27.934579849243164,
"blob_id": "e8cc14cdf6483c189e79c663f31d164b5dd0bbbd",
"content_id": "f7818a07e0a8c02f646d66602fd1c507a2dd43ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3096,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 107,
"path": "/iphone_tools/iphone_safariHist.py",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : iphone_safariHist.py\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/19/2011\n#: Version : 0.1.1\n#: Description : Decode Safari History.plist files\n#: Options : --no-header, --utc, \n#: License : GPLv3\n\nfrom xml.dom import minidom\nfrom time import strftime, localtime, gmtime\nimport sys, argparse, subprocess\n\ndef convert_bplist(file):\n '''Calls plutil in subprocess to decode binary plist.'''\n \n pipe = subprocess.Popen(['plutil', '-i', file], \n stdout=subprocess.PIPE)\n plist = pipe.communicate()[0]\n plist = plist.decode()\n \n return plist\n\ndef BuildDict(dict_node):\n '''Parse safari history 'dict' nodes into dictionary.'''\n\n key = \"\"\n result = {}\n\n for element in dict_node.childNodes:\n contents = element.childNodes\n if element.nodeName == \"key\" and contents:\n key = contents[0].nodeValue\n elif element.nodeName == \"string\":\n result[key] = contents[0].nodeValue\n key = \"\"\n elif element.nodeName == \"integer\":\n result[key] = int(contents[0].nodeValue)\n key = \"\"\n\n return result\n\ndef main(plist):\n '''Parse xml string from Safari History.plist'''\n \n #try:\n data = []\n \n xmldoc = minidom.parseString(plist)\n dict_list = xmldoc.getElementsByTagName('dict')\n \n if not args.noheader:\n print('\"Last Visited\",\"Page Title\",\"Page URL\",\"Visit Count\"')\n\n for record in dict_list[1:]:\n item = (BuildDict(record))\n title = item.get('title','')\n url = item.get('','')\n visits = item.get('visitCount','')\n lastvisit = int(float(item.get('lastVisitedDate',''))) + \\\n 978307200\n\n if args.utc:\n lastvisit = strftime('%Y-%m-%d %H:%M:%S (UTC)', \\\n gmtime(lastvisit))\n else:\n lastvisit = strftime('%Y-%m-%d %H:%M:%S (%Z)', \\\n localtime(lastvisit))\n \n data.append('{},\"{}\",{},{}'.format(lastvisit,title,url,\\\n visits))\n\n data.sort()\n return data\n\n #except:\n #print('Error: \"{}\" is an incompatible or improper bplist file.'.\\\n #format(args.plist))\n\nif __name__ == '__main__':\n \n parser = argparse.ArgumentParser(\n description='Process Apple Safari History.plist.',\n epilog='Converts timestamps to local time. libplist required.')\n\n parser.add_argument('plist', \n help='a Safari History.plist file')\n parser.add_argument('-n', '--no-header', \n dest='noheader', \n action='store_true',\n help='do not print file name, version, or column headers')\n parser.add_argument('-u', '--utc', \n dest='utc', \n action='store_true', \n help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', \n action='version', \n version='%(prog)s v0.1.2')\n\n args = parser.parse_args()\n plist = convert_bplist(args.plist)\n\n try:\n for line in main(plist):\n print(line)\n except TypeError:\n pass\n"
},
{
"alpha_fraction": 0.6055226922035217,
"alphanum_fraction": 0.639053225517273,
"avg_line_length": 23.095237731933594,
"blob_id": "3f7553a51ca9bbf982816b671fe1352ecf81e82e",
"content_id": "068b44f85ab3d05376d0cc24a54cea452a855bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 507,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 21,
"path": "/nautilus-scripts/.support_scripts/untitled",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t\t: previewer-functions\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Date\t\t\t: 05/04/2011\n#: Version\t\t: 1.0.0\n#: Description\t: functions to suppor the Previewer nautilus scripts\n#: Options\t\t: None\n\n## Variables\ndialog=$(which yad)\nsave_dir=$([[ -e $HOME/.save_dir |)\nfile_dims=\"--width=600 --height=400\"\n\nchoose_save_directory ()\n{\n\tif [ -z $save_dir ]; then\n\t\t$dialog --file --directory $file_dims $file_dims\n\telse\n\t\t$dialog --file --directory --filename=\"$save_dir\" $file_dims $file_dims\n\tfi\n}\t\n"
},
{
"alpha_fraction": 0.596523642539978,
"alphanum_fraction": 0.6205621361732483,
"avg_line_length": 40.599998474121094,
"blob_id": "143297e2786556695fdd2bf3a7e0d71603664abe",
"content_id": "b0f2c725ed787811ff9c520465f9d1ad926d2970",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2704,
"license_type": "no_license",
"max_line_length": 253,
"num_lines": 65,
"path": "/blackberry_tools/bbwhatsapp.py",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : bbwhatsapp.py\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/03/2011\n#: Version : 0.1.1\n#: Description : Decode BlackBerry WhatsApp databases\n#: Options : --no-header, --utc\n#: License : GPLv3\n\n#: 10/03/2011 : v0.1.0 initial release\n#: 10/03/2011 : v0.1.1 added UTC time output option\n#: 10/04/2011 : v0.1.2 code cleanup\n\nimport argparse, sqlite3\nfrom time import strftime, localtime, gmtime\n\ntype_flag = { 0 : 'Recd'}\nstatus_flag = { 0 : 'Read locally', 4 : 'Unread by recipient ', 5 : 'Read by recipient' }\n\ndef printdb(args):\n '''Print BlackBerry WhatsApp messageStore.db with interpretted flags and timestamps.'''\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.database))\n print('Time,Type,To/From,Message,Status,Attachment(type),Attachment(URL)')\n\n try: \n conn = sqlite3.connect(args.database)\n c = conn.cursor()\n\n for key_remote_jid,key_from_me,key_id,status,needs_push,data,timestamp,media_url,media_mime_type,media_wa_type,media_size,media_name,latitude,longitude,thumb_image,gap_behind,media_filename,remote_resource in c.execute('select * from messages'):\n\n #interpret if message sent or received\n type = type_flag.get(key_from_me, 'Sent')\n\n #interpret if message read or unread\n status = status_flag.get(status, 'Unknown')\n\n #isolate phone number from jid\n who = key_remote_jid.split('@')[0]\n \n #convert timestamp to local time or utc\n if args.utc:\n time = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(timestamp/1000))\n else:\n time = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(timestamp/1000))\n\n #print csv formatted output to stdout\n print('{},{},{},\"{}\",{},{},{}'.format(time, type, who, data, status,media_mime_type,media_url))\n\n except sqlite3.error:\n print('SQLite Error: wrong or incompatible database')\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n description='Process WhatsApp SMS database.',\n epilog='Converts timestamps to local time and interprets field values. Prints to stdout.')\n parser.add_argument('database', help='a WhatsApp messageStore.db database')\n parser.add_argument('-n', '--no-header', dest='noheader', action='store_true', help='do not print filename or column header')\n parser.add_argument('-u', '--utc', dest='utc', action='store_true', help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', action='version', version='%(prog)s v0.1.2')\n\n args = parser.parse_args()\n\n printdb(args)\n"
},
{
"alpha_fraction": 0.5873606204986572,
"alphanum_fraction": 0.613382875919342,
"avg_line_length": 18.214284896850586,
"blob_id": "521860157a7cc0b1a9434de7722b5894896dcd5a",
"content_id": "e58476bda220e2891a0fee2c09a13ce0b0bf2b60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 14,
"path": "/nautilus-scripts/Internet History Analysis/Firefox Analysis/Show SQLite3 Tables",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# Show SQLite3 Tables\n# by John Lehr (c) 2009\n\n# variables\nTITLE=\"Show Tables\"\n\n# list tables in information box\nTABLES=$(echo -e \"Tables in Database:\\n\\n$(sqlite3 $@ \".table\" | tr -s ' ' '\\n ')\")\nzenity --info \\\n\t--title \"$TITLE\" \\\n\t--text \"$TABLES\" \n\nexit 0\n"
},
{
"alpha_fraction": 0.5537525415420532,
"alphanum_fraction": 0.5760648846626282,
"avg_line_length": 23.245901107788086,
"blob_id": "554b3eddb2e61405ce8103d2383ac558a296ad5c",
"content_id": "91fc4b5da056945a6835e2eb5741beb32c016aab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1479,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 61,
"path": "/iphone_tools/idevice_tools_gui",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: name : idevice_tools_gui\n\ntitle=\"iDevice Utilities\"\nimage=/usr/share/icons/Mint-X/devices/128/phone.svg\ntext_info=\"--text-info --title=\"$title\" --image=$image --fontname=\"Monospace:10\" --height=400 --width=600\"\nintro_text=\"Connect a single iphone device by USB cable before continuing and\nselect from options below:\"\n\nidevice_info()\n{\n ideviceinfo | \\\n sed -r 's/:/\\n/'| \\\n yad --list --column Tag --column Data --width=600 --height=400 \\\n\t\t--button=gtk-ok:0\n}\n\nidevice_backup()\n{\n dir=$(yad --form \\\n --image=$image \\\n --text=\"Select directory to write backup:\" \\\n --field=\"Selection:\":DIR)\n [ $? = 1 ] && continue\n \n dir=${dir//|/\\/}\n \n version=$(ideviceinfo | grep ProductVersion)\n version=${version#*: }\n case $version in \n\t\t3*) backupapp=idevicebackup ;;\n\t\t4*|5*) backupapp=idevicebackup2 ;;\n\tesac\n \n $backupapp backup ${dir} | \\\n yad --progress --image=$image --text=\"Creating Backup at $dir...\" \\\n --pulsate --auto-kill --auto-close\n yad --image=$image --text=\"Backup complete.\" --button=gtk-ok\n}\n\nanalyze_backup()\n{\n iPBA_gui \n}\n\nuntil [ $? = 8 ]\ndo\n yad --image=$image \\\n --text=\"$intro_text\" \\\n --button=\"Device Info\":2 \\\n --button=\"Create Backup\":4 \\\n --button=\"Examine Backup\":6 \\\n --button=\"Cancel\":8\n\n case $? in \n 2) idevice_info ;;\n 4) idevice_backup ;;\n 6) analyze_backup ;;\n 8) exit 0;;\n esac\ndone\n"
},
{
"alpha_fraction": 0.6237218976020813,
"alphanum_fraction": 0.6359918117523193,
"avg_line_length": 21.227272033691406,
"blob_id": "dfa8061a19dd7d4b7c7a297cc7b3bdcc0c23ffe3",
"content_id": "d17c7eef8e382b0846bec855517f3eeaea6daf0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 489,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 22,
"path": "/iphone_tools/iPBA_gui",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: name : iPBA_gui\n\nimage=/usr/share/icons/Mint-X/devices/128/phone.svg\ntext=\"Select the iPhone (iOS4) backup directory.\nMust contain <u>Manifest.mbdb</u> file.\"\n\ndir=$(yad --form \\\n --title=\"iPhone Backup Analyzer\" \\\n --image=$image \\\n --text=\"$text\" \\\n --field=\"Selection:\":DIR)\n[ $? -gt 0 ] && exit 0\n\ndir=${dir//|/\\/}\n\nif [ -e $dir/Manifest.mbdb ]\nthen\n\tpython /opt/iPhone-Backup-Analyzer/main.py -d $dir\nelse\n\tyad --text=\"Error: Manifest.mbdb not present.\"\nfi\n"
},
{
"alpha_fraction": 0.5414201021194458,
"alphanum_fraction": 0.6035503149032593,
"avg_line_length": 17.77777862548828,
"blob_id": "2896c999b6754dabeb42f26314bb452b20a14ff6",
"content_id": "9fd1e59e64d5183cc1dfe951cc0beeaa749a0f3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 18,
"path": "/nautilus-scripts/File Analysis/Show File Details",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title\t\t: Show File Details\n#: Date\t\t\t: 2010-05-11\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Version\t\t: 1.0\n#: Description\t: Displays file statistics in a window\n# Show File Details\n# by John Lehr (c) 2009\n\nTITLE=\"File Details\"\n\nstat -L \"$@\" | \\\n\tzenity --text-info \\\n\t\t--title \"File Details\" \\\n\t\t--width=640 \\\n\t\t--height=480\n\nexit 0\n"
},
{
"alpha_fraction": 0.5341073870658875,
"alphanum_fraction": 0.5566037893295288,
"avg_line_length": 33.45000076293945,
"blob_id": "36576a0b3e0db2366003a3038e3a93814219e2a6",
"content_id": "eed90f2055c5e1e294e9a91b89f040ab39e95e73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2756,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 80,
"path": "/blackberry_tools/bbvideo.py",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : bbvideo.py\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/17/2011\n#: Version : 0.1.1\n#: Description : Dump/interpret Black Berry videoart.dat sqlite table \n#: Options : None\n#: License : GPLv3\n\n#: 10/17/2011 : v0.1.0 Initial release\n#: 10/17/2011 : v0.1.1 Bug fix in thumbnail filename creation\n#: 10/17/2011 : v0.1.2 Added original timestamp to csv output\n\nimport sqlite3, argparse, os\nfrom time import strftime, localtime, gmtime\n\ndef printdb(args):\n '''Prints the rows from the BlackBerry videoart.dat, interpreting\n the fields and optionally exports thumbnail images.'''\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.database))\n print('Date, Timestamp, Video Name, id, Source, Source Timestamp')\n \n try: \n conn = sqlite3.connect(args.database)\n c = conn.cursor()\n\n for id, source, thumb, name, date, source_time in \\\n c.execute('select id, source, thumbnail, video_name, \\\n time_stamp, source_time_stamp from video_art'):\n\n #convert timestamp to local time or utc\n if args.utc:\n time = strftime('%Y-%m-%d %H:%M:%S (UTC)', \\\n gmtime(date/1000))\n else:\n time = strftime('%Y-%m-%d %H:%M:%S (%Z)', \\\n localtime(date/1000))\n\n print('{},{},\"{}\",{},{},{}'.format(time, date, name[7:], \\\n id, source, source_time))\n \n if args.dump:\n tname = name.split('/')[-1] + '.jpg'\n with open(tname, 'wb') as output_file:\n output_file.write(thumb)\n\n except sqlite3.Error:\n print('SQLite Error: wrong or incompatible database')\n\nif __name__ == '__main__':\n \n parser = argparse.ArgumentParser(\n description='Process BlackBerry video_art table in videoart.dat \\\n database.',\n epilog='Converts timestamps to local time and exports \\\n thumbnails. Prints to stdout.')\n \n parser.add_argument('database', \n help='a BlackBerry videoart.dat database')\n parser.add_argument('-d', '--dump_thumbs', \n dest='dump', \n action='store_true', \n help='write thumbs to working directory')\n parser.add_argument('-n', '--no-header', \n dest='noheader', \n action='store_true', \n help='do not print filename or column header')\n parser.add_argument('-u', '--utc', \n dest='utc', \n action='store_true', \n help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', \n action='version', \n version='%(prog)s v0.1.2')\n\n args = parser.parse_args()\n\n printdb(args)\n"
},
{
"alpha_fraction": 0.6008968353271484,
"alphanum_fraction": 0.6098654866218567,
"avg_line_length": 16.153846740722656,
"blob_id": "1ca8b75a1cff5c581527e76f8a5087afc01fd811",
"content_id": "90b0b8eafdc585c32a90f0883a6a02907a98a731",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 223,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 13,
"path": "/android_tools/launch_adb_shell",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: name : launch_adb_shell\n\nadb root\n\nif [ $? -gt 0 ]\nthen\n yad --text=\"Error: no Android device detected\" \\\n --button=gtk-ok\n exit 1\nfi\n\ngnome-terminal --hide-menubar -t \"adb shell\" -e \"adb shell\"\n"
},
{
"alpha_fraction": 0.5561930537223816,
"alphanum_fraction": 0.5754303336143494,
"avg_line_length": 40.15277862548828,
"blob_id": "6f9177d0e7821f7627b97ba7168dce76b779633e",
"content_id": "4188425b72fe3274c36fc98987951c4a0d947d7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2963,
"license_type": "no_license",
"max_line_length": 260,
"num_lines": 72,
"path": "/iphone_tools/iphone_vm",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#: Title : iphone_vm.py\n#: Author : \"John Lehr\" <[email protected]>\n#: Date : 10/05/2011\n#: Version : 1.0.0\n#: Description : Dump/interpret iphone voicemail.db table \n#: Options : None\n#: License : GPLv3\n\n#: 10/05/2011 : v1.0.0 Initial Release\n\nimport sqlite3, argparse\nfrom time import strftime, localtime, gmtime\n\nvm_flags = { 2 : 'Unheard', 3 : 'Heard', 11 : 'Deleted', 75 : 'Deleted' }\n\ndef printdb(args):\n '''Prints the rows from the iPhone voicemail.db, interpreting the flags.'''\n \n if not args.noheader:\n print('File: \"{}\"'.format(args.database))\n print('Date,From,Callback #,Recording, Duration (sec),Status,Deleted Date')\n \n try: \n conn = sqlite3.connect(args.database)\n c = conn.cursor()\n\n for ROWID, remote_uid, date, token, sender, callback_num, duration, expiration, trashed_date, flags in c.execute('select ROWID, remote_uid, date, token, sender, callback_num, duration, expiration, trashed_date, flags from voicemail order by date asc'):\n \n #Convert ROWID to filename\n ROWID = str(ROWID)\n filename = ROWID +'.amr'\n \n #convert sender to match iPhone display \n if sender == None:\n sender = \"Unknown\"\n \n if trashed_date == 0:\n status_date = None\n \n #convert timestamp to local time or utc\n if args.utc:\n time = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(date))\n if trashed_date != 0:\n status_date = strftime('%Y-%m-%d %H:%M:%S (UTC)', gmtime(trashed_date + 978307200))\n else:\n time = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(date))\n if trashed_date != 0:\n status_date = strftime('%Y-%m-%d %H:%M:%S (%Z)', localtime(trashed_date + 978307200))\n\n #convert flags object to flag dictionary value\n status = vm_flags.get(flags, 'Unknown')\n\n #print row\n print('{},{},{},{},{},{},{}'.format(time, sender, callback_num, filename, duration, status, status_date))\n \n except sqlite3.Error:\n print('SQLite Error: wrong or incompatible database')\n\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser(\n description='Process iPhone call history database.',\n epilog='Converts timestamps to local time and interprets flag values. Prints to stdout.')\n parser.add_argument('database', help='an iPhone voicemail.db database')\n parser.add_argument('-n', '--no-header', dest='noheader', action='store_true', help='do not print filename or column header')\n parser.add_argument('-u', '--utc', dest='utc', action='store_true', help='Show UTC time instead of local')\n parser.add_argument('-V', '--version', action='version', version='%(prog)s v1.0.0')\n\n args = parser.parse_args()\n\n printdb(args)\n"
},
{
"alpha_fraction": 0.6523094773292542,
"alphanum_fraction": 0.6866108179092407,
"avg_line_length": 27.505556106567383,
"blob_id": "3f9fe934feefc0b18626424e2ff2374b5af7d135",
"content_id": "fb81a0eb2abb8099873cda3f81b1a2491323b0a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5131,
"license_type": "no_license",
"max_line_length": 251,
"num_lines": 180,
"path": "/iphone_tools/iphone_cs",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t: iphone_cs\n#: Author\t: \"John Lehr\" <[email protected]>\n#: Date\t\t: 08/10/2011\n#: Version\t: 1.0.3\n#: Description\t: Dump/interpret iphone consolidated.db messages table \n#: Options\t: None\n\n#: 08/10/2011 : v1.0.3 added WifiLocationHarvest support\n#: 05/04/2011 : v1.0.2 added dependency checking\n#: 04/12/2011 : v1.0.1 mapping support added for gpsvisualizer.com\n#: 04/11/2011 : v1.0.0 Initial Release\n\n#: TO DO\n#: add arguments to sort on different columns\n\n## Variables\nprogname=\"${0##*/}\"\ndeps=sqlite3\ncell=0\nlocal=0\nwifi=0\ncsv=0\nhtml=0\nline=0\nraw=0\nmap=0\n\n## Functions\n\nusage()\n{\n\techo \"USAGE: $progname [-cChHlLmrwWV] file\"\n\techo \" where 'file' is an iPhone consolidated.db\"\n\tcat << EOF\n\t\nOptions (only one table option may be used at a time):\n\n\tTable options:\n\t-C\tParse CellLocation table\n\t-CH\tParse CellLocationHarvest table\n\t-L\tParse CellLocationLocal table\n\t-W \tParse WifiLocation table\n\t-WH\tParse WifiLocationHarvest table\n\t\n\tFormatting options:\n\t-c\toutput to csv (default is sqlite list format)\n\t-w\toutput to html (web)\n\t-l\toutput each one field per line\n\t-m\tmapping format (csv)\n\t-r\traw (dump the full table, no conversion)\n\n\tOther:\n\t-h \tthis help\n\t-V\tcarrier is Verizon (CDMA)\n\nOptions MUST preceed the database to be processed. \n\nInformation: $progname reads the 'consolidated.db' iphone database\nand dumps the timestamp, latitude and longitude information from the\nCellLocation table to standard output. Optionally, the WifiLocation\ntable can be dumped.\n\nEOF\n}\n\ncelllocation()\n{\n\t## export CellLocation table to stdout\n\tif [ $map = 1 ]; then\n\t\tsqlite3 -header -csv $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'name', Latitude, Longitude from ${verizon}CellLocation${harvest} WHERE Latitude != 0.0\"\n\t\tnotice\n\telif [ $raw = 1 ]; then\n\t\tsqlite3 -header $format $db \"SELECT * FROM ${verizon}CellLocation${harvest}\"\n\telse\n\t\tsqlite3 -header $format $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'Time Stamp', Latitude, Longitude from ${verizon}CellLocation${harvest}\"\n\tfi\n}\n\ncelllocationlocal()\n{\n\t## export CellLocationLocal table to stdout\n\tif [ $map = 1 ]; then\n\t\tsqlite3 -header -csv $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'name', 'Speed: ' || round(Speed, 1) || ' at ' || round(Course, 1) || ' Degrees' as Desc, Latitude, Longitude from ${verizon}CellLocationLocal${harvest}\"\n\t\tnotice\n\telif [ $raw = 1 ]; then\n\t\tsqlite3 -header $format $db \"SELECT * FROM ${verizon}CellLocationLocal${harvest}\"\n\telse\n\t\tsqlite3 -header $format $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'Time Stamp', Latitude, Longitude, rtrim(round(Speed),'.0') as Speed, rtrim(round(Course),'.0') as Direction from ${verizon}CellLocationLocal${harvest}\"\n\tfi\n}\n\ncheck_deps ()\n{\n\tfor i in $deps; do\n\t\twhich $i >/dev/null\n\t\tif [ $? -gt 0 ]; then\n\t\t\techo \"Error: $i is not installed or is not in the path\"\n\t\tfi\n\tdone\n}\n\nnotice ()\n{\n\techo -e \"Open output file in mapping program or upload to http://www.gpsvisualizer.com/\" >&2\n}\n\nwifilocation()\n{\n\t## export WifiLocation table to stdout\n\tif [ $map = 1 ]; then\n\t\tsqlite3 -header -csv $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'Name', 'MAC Address: ' || MAC as Desc, Latitude, Longitude from WifiLocation${harvest} where Latitude != 0.0\"\n\t\tnotice\n\telif [ $raw = 1 ]; then\n\t\tsqlite3 -header $format $db \"SELECT * FROM WifiLocation${harvest}\"\n\telse\n\t\tsqlite3 -header $format $db \"SELECT datetime(Timestamp + 978307200, 'unixepoch', 'localtime') AS 'Time Stamp', Latitude, Longitude, MAC from WifiLocation${harvest}\"\n\tfi\n}\n\n## list of options program will accept;\n## options followed by a colon take arguments\noptstring=cChHlLmWrV\n\n## The loop calls getops until there are no more options on the command \n## line. Each option is stored in $opt, any option arguments are stored\n## in OPTARG\nwhile getopts $optstring opt; do\n\tcase $opt in\n\t\tc) csv=1; format=-csv ;;\n\t\tC) cell=1 ;;\n\t\th) usage >&2; exit 0 ;;\n\t\tH) harvest=Harvest ;;\n\t\tl) line=1; format=-line ;;\n\t\tL) local=1 ;;\n\t\tm) map=1 ;;\n\t\tr) raw=1 ;;\n\t\tw) html=1; format=-html ;;\n\t\tW) wifi=1 ;;\n\t\tV) verizon=Cdma ;;\n\t\t*) echo; usage >&2; exit 1 ;;\n\tesac\ndone\n\n## Remove options from the command line\n## $OPTIND points to the next, unparsed argument\nshift \"$(( $OPTIND -1 ))\"\ndb=\"$1\"\n\n## Check database is an iphone \"consolidated.db\"\ntables=$(sqlite3 $1 .tables)\nif ! [[ $tables =~ CellLocation && $tables =~ Wifi && $tables =~ TableInfo ]]; then\n\techo -e \"ERROR: Not an iPhone 'consolidated.db'\\n\"\n\tusage\n\texit 1\nfi\n\n## Check for conflicting arguments\nif [ $(($cell+$local+$wifi)) -gt 1 ]; then\n\techo -e \"Error: only one table may be selected\\n\" >&2; usage >&2; exit 1\nelif [ $(($cell+$local+$wifi)) -lt 1 ]; then\n\techo -e \"Error: a table must be selected\\n\" >&2; usage >&2; exit 1\nfi\n\nif [ $(($csv+$html+$line)) -gt 1 ]; then\n\techo \"Error: formatting arguments -c -w and -l may not be used together\" >&2\n\texit 1\nfi\n\n\n## Process file according to chosen option\nif [ $cell = 1 ]; then\n\tcelllocation\nelif [ $local = 1 ]; then\n\tcelllocationlocal\nelif [ $wifi = 1 ]; then\n\twifilocation\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.5707547068595886,
"alphanum_fraction": 0.6273584961891174,
"avg_line_length": 20.200000762939453,
"blob_id": "e6b4f5cd9f4c2bef004961aeda3f3d417bc4815a",
"content_id": "d65fe4336a099ac3d9b239f4c857b6b8e4f26b34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 10,
"path": "/nautilus-scripts/File Analysis/View in Hexeditor",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title\t\t: View in Hexeditor\n#: Date\t\t\t: 2010-05-11\n#: Author\t\t: \"John Lehr\" <[email protected]>\n#: Version\t\t: 1.0\n#: Description\t: Opens selected files in ghex, adapted for paths with spaces\n\nghex2 \"$@\"\n\nexit 0\n"
},
{
"alpha_fraction": 0.6632541418075562,
"alphanum_fraction": 0.6925045847892761,
"avg_line_length": 25.047618865966797,
"blob_id": "72bd2e0fb9207f393851061ba779f4451093e5f2",
"content_id": "e3a3aa995af5dd8c5471889e93e66b07022a7537",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2735,
"license_type": "no_license",
"max_line_length": 338,
"num_lines": 105,
"path": "/iphone_tools/iphone_ab",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t: iphone_ab\n#: Author\t: \"John Lehr\" <[email protected]>\n#: Date\t\t: 05/04/2011\n#: Version\t: 1.0.1\n#: Description\t: Dump/interpret iphone AddressBook.db messages table \n#: Options\t: None\n\n#: 05/04/2011 : v1.0.1 added extended output formats, updated code schema\n#: 03/25/2011 : v1.0.0 Initial Release\n\n#: TO DO\n#: add arguments to sort on different columns\n#: cross reference db with iPhone call_history.db\n\n## Variables\nprogname=${0##*/}\ndeps=sqlite3\ncsv=0\nhtml=0\nline=0\nlist=0\nraw=0\n\n## Functions\n\nusage()\n{\n\techo \"USAGE: $progname [-h] AddressBook.db\"\n\n\tcat << EOF\n\t\nOptions (-r may be combined with output option):\n\t-c\toutput to csv (default is sqlite list format)\n\t-h\tprint this help\n\t-H\toutput to html\n\t-l\toutput one field per line\n\t-L\toutput to list (default)\n\t-r\traw ABPerson/ABMultivalue tables dump (flags are not interpreted)\n\nOptions MUST preceed the file to be processed. \n\nInformation: $progname dumps the iPhone AddressBook.db file contents to\nstandard output. It interprets the flags to make reading the output easier.\n\nEOF\n}\n\ncheck_deps ()\n{\n\tfor i in $deps; do\n\t\twhich $i >/dev/null\n\t\tif [ $? -gt 0 ]; then\n\t\t\techo \"Error: $i is not installed or is not in the path\"\n\t\tfi\n\tdone\n}\n\n## Check for installed dependencies\ncheck_deps\n\n## list of options program will accept;\n## options followed by a colon take arguments\noptstring=chHlr\n\n## The loop calls getops until there are no more options on the command \n## line. Each option is stored in $opt, any option arguments are stored\n## in OPTARG\nwhile getopts $optstring opt; do\n\tcase $opt in\n\t\tc) csv=1; format=-csv ;;\n\t\th) usage >&2; exit 0 ;;\n\t\tH) html=1; format=-html ;;\n\t\tl) line=1; format=-line ;;\n\t\tr) raw=1 ;;\n\t\t*) echo; usage >&2; exit 1 ;;\n\tesac\ndone\n\n## Remove options from the command line\n## $OPTIND points to the next, unparsed argument\nshift \"$(( $OPTIND -1 ))\"\n\n## Check for conflicting arguments\nif [ $(($csv+$html+$line)) -gt 1 ]; then\n\techo \"Error: arguments -c -H and -l may not be used together\" >&2\n\texit 1\nfi\n\n## Check database is an iphone \"AddressBook.db\"\ntables=$(sqlite3 $1 .tables)\nif ! [[ $tables =~ ABMultiValue && $tables =~ ABPerson && $tables =~ _Sqlite ]]; then\n\techo -e \"ERROR: Not an iPhone 'AddressBook.db'\\n\"\n\tusage\n\texit 1\nfi\n\n## Export call table to stdout\nif [ $raw = 1 ]; then\n\tsqlite3 -header $format $1 \"SELECT * FROM ABPerson, ABMultivalue WHERE rowid = record_id\"\nelse\n\tsqlite3 -header $1 \"SELECT rowid AS Row, first AS 'First Name', last AS 'Last Name', value AS 'Phone Number/Email', datetime(creationdate + 978307200, 'unixepoch', 'localtime') AS 'Record Created', datetime(ModificationDate + 978307200, 'unixepoch', 'localtime') AS 'Record Modified' FROM ABPerson, ABMultivalue WHERE rowid = record_id\"\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.6194371581077576,
"alphanum_fraction": 0.6397251486778259,
"avg_line_length": 22.328245162963867,
"blob_id": "01924c1a4e2cd45ca4ae8bf1cdcc5c5d86dba03b",
"content_id": "4f0941bc0b0bcc6c43f71d04a6ae1ff3c885a14c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3056,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 131,
"path": "/iphone_tools/iphone_images",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#: Title \t: iphone_images\n#: Author\t: \"John Lehr\" <[email protected]>\n#: Date\t\t: 05/04/2011\n#: Version\t: 1.0.1\n#: Description\t: extract EXIF/map iPhone Photos\n#: Options\t: None\n\n#: 05/04/2011 : v1.0.1 Added Apple Store account info extraction\n#: 05/03/2011 : v1.0.0 Initial Release\n\n## Variables\nprogname=\"${0##*/}\"\ndeps=\"exiftool\"\nitunes=0\nmap=0\ngpscount=0\n\n## Functions\n\nusage()\n{\n\techo \"USAGE: $progname [-ahm] [path]\"\n\techo \" where 'path' is the path to be searched\"\n\tcat << EOF\n\t\nOptions (only one option may be used at a time):\n\t-a\textract Apple Store user information\n\t-h\tprint this help\n\t-m\tmapping format (csv)\n\nOptions MUST preceed the path to be processed. \n\nInformation: $progname searches a path for images or videos containing EXIF\ndata and dumps the information to standard output. Optionally, a text file\ncontaining mapping data or Apple Store account information can be dumped.\n\nEOF\n}\n\ncheck_deps ()\n{\n\tfor i in $deps; do\n\t\twhich $i >/dev/null\n\t\tif [ $? -gt 0 ]; then\n\t\t\techo \"Error: $i is not installed or is not in the path\"\n\t\tfi\n\tdone\n}\n\nget_exif ()\n{\n\t## Export exif with exiftool\n\tfilename=\"======== $i\"\n\tmeta=$(exiftool \"$i\")\n\tif [ $map = 1 ]; then\n\t\tgps=$(echo \"$meta\" | grep \"GPS Position\" | sed 's/deg//' | cut -d ':' -f2)\n\t\tif [ -n \"$gps\" ]; then\n\t\t\tif [ $gpscount -eq 0 ]; then \n\t\t\t\techo \"name,desc,latitude,longitude\"\n\t\t\t\tgpscount=1\n\t\t\tfi\n\t\t\techo \"$(basename $i),Created:$(echo \"$meta\" | grep -E \"^Create Date\" | cut -d ':' -f2-),$gps\"\n\t\tfi\n\telif [ $itunes = 1 ] && [[ \"$filename\" =~ m4v ]]; then\n\t\techo \"$filename\"\n\t\techo \"$meta\" | grep -E '^File Type|^Apple Store Account'\n\t\techo -e \"Apple Store Real Name\\t\\t: $(strings \"$i\" | grep -m1 name | sed 's/name//')\\n\"\n\telif [ $itunes = 0 ]; then\n\t\techo \"$filename\"\n\t\techo -e \"$meta\\n\"\n\tfi\n}\n\nnotice ()\n{\n\techo -e \"Open mapping output in mapping program or upload to http://www.gpsvisualizer.com/\" >&2\n}\n\n## Check for installed dependencies\ncheck_deps\n\n## list of options program will accept;\n## options followed by a colon take arguments\noptstring=ahm\n\n## The loop calls getops until there are no more options on the command \n## line. Each option is stored in $opt, any option arguments are stored\n## in OPTARG\nwhile getopts $optstring opt; do\n\tcase $opt in\n\t\th) usage >&2; exit 0 ;;\n\t\ta) itunes=1 ;;\n\t\tm) map=1 ;;\n\t\t*) echo; usage >&2; exit 1 ;;\n\tesac\ndone\n\n## Remove options from the command line\n## $OPTIND points to the next, unparsed argument\nshift \"$(( $OPTIND -1 ))\"\n\n## Check for conflicting arguments\nif [ $(( $map + $itunes )) -gt 1 ]; then\n\techo \"Error: arguments -i and -m may not be used together\" >&2\n\texit 1\nfi\n\n## Process file according to chosen option\n## Determine path to search\npath=\"$1\"\nif [ -z $path ] || [ \"$path\" = \".\" ]; then\n\tpath=\"$(pwd)\"\nfi\n\n## Search for files\necho \"Searching \\\"$path\\\" for files...\" >&2\nfind $path -type f |\n\twhile read i; do\n\t\ttype=$(file -bi \"$i\" | grep -E 'image|video')\n\t\tif [ -n \"$type\" ]; then\n\t\t\tget_exif #process file with get_exif function\n\t\tfi\n\tdone\n\t\n## Print map notice\nif [ $map -eq 1 ]; then\n\tnotice\nfi\n\nexit 0\n"
},
{
"alpha_fraction": 0.5740740895271301,
"alphanum_fraction": 0.5905349850654602,
"avg_line_length": 19.25,
"blob_id": "b7a67077c85aec002844439a38f1ef055e85c3af",
"content_id": "8c9b220c5853b43fb676be99abdde0449e044367",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 486,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 24,
"path": "/nautilus-scripts/File Analysis/View MDB Database",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#View MDB Database\n#by J. Lehr (c) 2009\n\nTEMP_FILE=$(mktemp)\n\nDB_TABLES=$(mdb-tables \"$@\" | sed 's/ /, /g')\nTABLE=$(zenity --entry --text=\"Choose Table: $DB_TABLES\")\n\nif [ \"$?\" = \"1\" ]; then exit 0; fi\n\necho \"$NAUTILUS_SCRIPT_SELECTED_URIS\" | \\\nwhile read URI\ndo\n\tFILE=\"$(echo \"$URI\" | sed 's/file:\\/\\///' | sed 's/%20/ /g')\"\n\tzenity --info --text=\"$FILE\"\n\techo \"$FILE\"\n\tmdb-export \"$FILE\" \"$TABLE\"\n\techo \"\"\ndone > $TEMP_FILE.csv\n\ngnumeric $TEMP_FILE.csv\n\nrm $TEMP_FILE.csv\n"
},
{
"alpha_fraction": 0.5645933151245117,
"alphanum_fraction": 0.589712917804718,
"avg_line_length": 18.904762268066406,
"blob_id": "a295ec9825e8f4d9cf6ec85db1f65edf7debef1a",
"content_id": "67001201d12f4680d3bc6ab47d0252769852b668",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 836,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 42,
"path": "/nautilus-scripts/Internet History Analysis/Firefox Analysis/Show SQLite3 Table Contents",
"repo_name": "pombredanne/linuxsleuthing",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# Show Table Contents\n# by John Lehr (c) 2009\n\n# variables\nTITLE=\"Show Contents\"\n\n# query for table name\nTEXT=$(echo -e \"Available Tables:\\n\\n$(sqlite3 \"$@\" \".table\" | tr -s ' ' '\\n')\\n\\nEnter table to view:\")\nSELECTION=$(zenity --entry \\\n\t--title \"$TITLE\" \\\n\t--text \"$TEXT\")\n\t\n# output table contents\nOUTPUT=$(sqlite3 \"$@\" \"select * from \"$SELECTION\"\")\necho \"$OUTPUT\" | \\\n\tzenity --text-info \\\n\t\t--title \"$TITLE\" \\\n\t\t--width=640 \\\n\t\t--height=480\n\n# search option\nzenity --question \\\n\t--title $TITLE \\\n\t--text \"Do you want to search this output?\" \\\n\t--ok-label=\"Yes\" \\\n\t--cancel-label=\"No\"\n\t\nif [ \"$?\" = \"1\" ]; then\n\texit 0\nfi\n\nTERM=$(zenity --entry \\\n\t--title \"$TITLE\" \\\n\t--text \"Enter search term:\")\necho -e \"$OUTPUT\" | grep -Ei \"$TERM\" | \\\n\tzenity --text-info \\\n\t\t--title \"$TITLE\" \\\n\t\t--width=640 \\\n\t\t--height=480\n\t\t\nexit 0\n"
}
] | 29 |
JohnReid/HAIS
|
https://github.com/JohnReid/HAIS
|
b7eeed5d9115a010141adb8fcb1048790331a394
|
a156a7287bf7b35f000d3c7b1a4753c2a564941e
|
d1c986c6d36c185ea5a5985ca7ee8a3aeeee1b68
|
refs/heads/master
| 2023-04-08T08:56:06.691274 | 2021-12-02T18:17:01 | 2021-12-02T18:17:01 | 143,434,926 | 5 | 0 |
MIT
| 2018-08-03T14:06:26 | 2022-08-17T06:02:30 | 2023-03-24T22:23:02 |
Python
|
[
{
"alpha_fraction": 0.5211267471313477,
"alphanum_fraction": 0.5211267471313477,
"avg_line_length": 13,
"blob_id": "589fb260237bdbf091013b5e559a93a5ed601455",
"content_id": "ed73bb32b99b5e9e339f68aa8d4609bd2f55c730",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 71,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 5,
"path": "/docs/source/ais.rst",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "Module hais.ais\n===============\n\n.. automodule:: hais.ais\n :members:\n\n"
},
{
"alpha_fraction": 0.7036172747612,
"alphanum_fraction": 0.7211201786994934,
"avg_line_length": 28.55172348022461,
"blob_id": "dde771a9c10baad6c9cf436f08f1d1edc9721b8e",
"content_id": "a86e115f29049d28bc8662eadd088d543e15b9f6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 857,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 29,
"path": "/hais/__init__.py",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\"\"\"Hamiltonian Annealed Importance Sampling (HAIS)\n\nSohl-Dickstein and Culpepper \"Hamiltonian Annealed Importance Sampling for partition function\nestimation\" (2011).\n\"\"\"\n\nfrom packaging import version\nfrom contextlib import contextmanager\nfrom time import time\nfrom hais.ais import HAIS, get_schedule # noqa: F401\nimport tensorflow as tf\n\n#\n# Configure TensorFlow depending on version\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n # Using TFv1 compatibility mode in TF2\n tf = tf.compat.v1\n\n\n@contextmanager\ndef timing(description: str, verbose: bool=False) -> None:\n \"\"\"A context manager that prints how long the context took to execute.\"\"\"\n if verbose:\n print(f'{description}')\n start = time()\n yield\n elapsed_time = time() - start\n print(f'{description} took {elapsed_time:.3f}s')\n"
},
{
"alpha_fraction": 0.6837549805641174,
"alphanum_fraction": 0.702396810054779,
"avg_line_length": 24.457626342773438,
"blob_id": "db35e3b8123480631183c213b32f5dd274c54987",
"content_id": "cce428ea66bc29c7c60bb71d9cc8d95005469b17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3004,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 118,
"path": "/tests/test-hmc",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nTest our Hamiltonian Monte Carlo sampler.\n\"\"\"\n\n\nimport time\nimport hais.hmc as hmc\nimport numpy as np\nimport scipy.stats as st\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nfrom packaging import version\nfrom pathlib import Path\n\n#\n# Configure TensorFlow depending on version\nprint(f'TensorFlow version: {tf.__version__}')\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n tf = tf.compat.v1\n\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\nSEED = 37\nNCHAINS = 20000\nNITER = 10000\n# normal parameters\nMU = 1.\nSIGMA = .5\n#\n# HMC parameters\nSTEPSIZE = .5\n# STEPSIZE_INITIAL = .01\n# STEPSIZE_MIN = 1e-8\n# STEPSIZE_MAX = 500\n# STEPSIZE_DEC = .99\n# STEPSIZE_INC = 1.01\nOUTDIR = Path('output')\n\n#\n# Create the output directory if needed\nOUTDIR.mkdir(exist_ok=True, parents=True)\n\n#\n# Seed RNGs\ntf.set_random_seed(SEED)\nnp.random.seed(SEED)\n\n\ndef unnormalized_normal_lpdf(x):\n \"\"\"\n Unnormalized log probability density function of the normal(MU, SIGMA) distribution.\n \"\"\"\n # print(x.shape)\n assert x.shape == (NCHAINS,)\n return - tf.square((x - MU) / SIGMA) / 2.\n\n\n#\n# Prior for initial x\nprior = tf.distributions.Normal(loc=tf.zeros(NCHAINS), scale=tf.ones(NCHAINS))\n#\n# Sample\nx, v, samples_final, smoothed_accept_rate_final = hmc.hmc_sample(\n prior.sample(), unnormalized_normal_lpdf, eps=STEPSIZE,\n niter=NITER, nchains=NCHAINS)\n#\n# Construct and initialise the session\nsess = tf.Session()\nsess.run(tf.global_variables_initializer())\n#\n# Run sampler\nprint('Running sampler')\nstarttime = time.time()\nsamples_hmc, accept_hmc = sess.run((samples_final.stack(), smoothed_accept_rate_final))\nendtime = time.time()\nprint('Sampler took {:.1g} seconds'.format(endtime - starttime))\nsamples_hmc.shape\nburned_in = samples_hmc[int(NITER / 2):]\nburned_in.shape\nburned_in.size / 1e6\nprint('Mean of (burned in) samples: {:.3g}'.format(np.mean(burned_in)))\nprint('Desired mean : {:.3g}'.format(MU))\nprint('Standard deviation of (burned in) samples: {:.3g}'.format(np.std(burned_in)))\nprint('Desired standard deviation : {:.3g}'.format(SIGMA))\n#\n# Drop samples so we don't have too many per chain\nMAX_SAMPLES_PER_CHAIN = 47\nif burned_in.shape[0] > MAX_SAMPLES_PER_CHAIN:\n burned_in = burned_in[::(int(burned_in.shape[0] / MAX_SAMPLES_PER_CHAIN) + 1)]\nburned_in.shape\n\n#\n# Plot samples\nsamples_path = OUTDIR / 'hmc-samples.pdf'\nprint(f'Plotting samples: {samples_path}')\nfig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\nsns.distplot(burned_in.flatten(), ax=ax)\nax.set_xlabel('x')\nax.set_title('Samples')\n# Plot the pdf\nxmin, xmax = ax.get_xbound()\nxpdf = np.linspace(xmin, xmax, num=500)\nax.plot(xpdf, st.norm.pdf(xpdf, loc=MU, scale=SIGMA), linestyle='dotted', lw=1, color='orange')\n#\n# Acceptance rate\nprint('Plotting acceptance rate')\nsns.distplot(accept_hmc.flatten(), ax=ax_accept)\nax_accept.set_title('Smoothed acceptance rates')\nfig.savefig(samples_path)\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7843137383460999,
"avg_line_length": 24.5,
"blob_id": "4b4050891835639ca5b2c8464a0c84b2a6957984",
"content_id": "ed0b73b2955ca9170ddabba722fc16e3f138f650",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 51,
"license_type": "permissive",
"max_line_length": 27,
"num_lines": 2,
"path": "/requirements-TF-1.15.2.txt",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "tensorflow-gpu==1.15.2\ntensorflow_probability==0.8\n"
},
{
"alpha_fraction": 0.6026058793067932,
"alphanum_fraction": 0.6091205477714539,
"avg_line_length": 26.909090042114258,
"blob_id": "241bdc713cbcd23c71e151dec0ef0cbc657f44fa",
"content_id": "06ecc495328fe807580156ec25df6f539f4e2a4e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 307,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 11,
"path": "/setup.py",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\nsetup(name='hais',\n version='0.1',\n description='Hamiltonian Annealed Importance Sampling',\n url='http://github.com/JohnReid/HAIS',\n author='John Reid & Halil Bilgin',\n author_email='[email protected]',\n license='MIT',\n packages=['hais'],\n zip_safe=False)\n"
},
{
"alpha_fraction": 0.663618266582489,
"alphanum_fraction": 0.6821736097335815,
"avg_line_length": 31.662338256835938,
"blob_id": "b91ebc2deb148134d75589245dd0ea51429ae232",
"content_id": "c33569b8966be2062929aa9da1b0588a46260703",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7545,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 231,
"path": "/hais/hmc.py",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\"\"\"\nImplementation of Hamiltonian Monte Carlo.\n\nCurrently only makes leapfrog moves with one step as that is all that is needed for HAIS.\n\"\"\"\n\nfrom packaging import version\nimport tensorflow as tf\n\n#\n# Configure TensorFlow depending on version\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n tf = tf.compat.v1\nelif version.parse(tf.__version__) >= version.parse('1.15'):\n tf.compat.v1.disable_eager_execution()\n tf = tf.compat.v1\n\n\ndef tf_expand_rank(input_, rank):\n \"Expand the `input_` tensor to the given rank by appending dimensions\"\n while len(input_.shape) < rank:\n input_ = tf.expand_dims(input_, axis=-1)\n return input_\n\n\ndef tf_expand_tile(input_, to_match):\n \"Expand and tile the `input_` tensor to match the `to_match` tensor.\"\n assert len(input_.shape) <= len(to_match.shape)\n input_rank = len(input_.shape)\n match_rank = len(to_match.shape)\n tiling = [1] * input_rank + to_match.shape.as_list()[input_rank:]\n return tf.tile(tf_expand_rank(input_, match_rank), tiling)\n\n\ndef kinetic_energy(v, event_axes):\n \"\"\"\n Calculate the kinetic energy of the system.\n\n :math:`- \\\\log \\\\Phi(v)` in Sohl-Dickstein and Culpepper's paper.\n Not normalised by :math:`M \\\\log(2 \\\\pi) / 2`\n \"\"\"\n return 0.5 * tf.reduce_sum(tf.square(v), axis=event_axes)\n\n\ndef hamiltonian(position, velocity, energy_fn, event_axes):\n \"\"\"\n Calculate the Hamiltonian of the system.\n\n Eqn 20 and 21 in Sohl-Dickstein and Culpepper's paper.\n \"\"\"\n potential = energy_fn(position)\n momentum = kinetic_energy(velocity, event_axes)\n return potential + momentum\n\n\ndef mh_accept_reject(x0, v0, x1, v1, energy_fn, event_axes):\n \"\"\"Accept or reject the leapfrog move according to Metropolis-Hastings.\n\n Step 3 in Sohl-Dickstein and Culpepper (2011).\n \"\"\"\n E0 = hamiltonian(x0, v0, energy_fn, event_axes)\n E1 = hamiltonian(x1, -v1, energy_fn, event_axes)\n accept = metropolis_hastings_accept(E0=E0, E1=E1)\n # print('accept: {}'.format(accept.shape))\n # print('x0: {}'.format(x0.shape))\n # print('x1: {}'.format(x1.shape))\n # Expand the accept (which has batch shape) to full (batch + event) shape.\n accept_tiled = tf_expand_tile(accept, x1)\n xdash = tf.where(accept_tiled, x1, x0)\n vdash = tf.where(accept_tiled, -v1, v0)\n # print('xdash: {}'.format(xdash.shape))\n return xdash, vdash, accept\n\n\ndef metropolis_hastings_accept(E0, E1):\n \"\"\"\n Accept or reject a move based on the energies of the two states.\n \"\"\"\n ediff = E0 - E1\n return ediff >= tf.math.log(tf.random.uniform(shape=tf.shape(ediff)))\n\n\ndef leapfrog(x0, v0, eps, energy_fn):\n \"\"\"\n Simulate the Hamiltonian dynamics using leapfrog method.\n\n That is follow the 2nd step in the 5 step\n procedure in Section 2.3 of Sohl-Dickstein and Culpepper's paper.\n Note this leapfrog procedure only has one step.\n \"\"\"\n eps = tf.convert_to_tensor(eps)\n epshalf = tf_expand_tile(eps / 2., v0)\n xhalf = x0 + epshalf * v0\n dE_dx = tf.gradients(tf.reduce_sum(energy_fn(xhalf)), xhalf)[0]\n v1 = v0 - tf_expand_tile(eps, v0) * dE_dx\n x1 = xhalf + epshalf * v1\n return x1, v1\n\n\ndef default_gamma(eps):\n \"\"\"Calculate the default gamma (momentum refresh parameter).\n\n Follows equation 11. in Culpepper et al. (2011)\n \"\"\"\n return 1. - tf.math.exp(eps * tf.math.log(1 / 2.))\n\n\ndef hmc_move(x0, v0, energy_fn, event_axes, eps, gamma=None):\n \"\"\"\n Make a HMC move.\n\n Implements the algorithm in\n Culpepper et al. 2011 \"Building a better probabilistic model of images by factorization\".\n\n Args:\n gamma: Set to 1 to remove any partial momentum refresh (momentum is sampled fresh every move)\n \"\"\"\n #\n # STEP 2:\n # Simulate the dynamics of the system using leapfrog\n x1, v1 = leapfrog(x0=x0, v0=v0, eps=eps, energy_fn=energy_fn)\n #\n # STEP 3:\n # Accept or reject according to MH\n xdash, vdash, accept = mh_accept_reject(x0, v0, x1, v1, energy_fn, event_axes)\n #\n # STEP 4:\n # Partial momentum refresh.\n # gamma is the parameter governing this\n if gamma is None:\n gamma = default_gamma(eps)\n vtilde = partial_momentum_refresh(vdash, gamma)\n #\n # Return state\n return accept, xdash, vtilde\n\n\ndef partial_momentum_refresh(vdash, gamma):\n \"\"\"Update vdash with a partial momentum refresh.\n\n Step 4 in Sohl-Dickstein and Culpepper (2011).\n \"\"\"\n # There is some disagreement between the above paper and the description of STEP 4.\n # Specifically the second sqrt below is omitted in the description of STEP 4.\n r = tf.random.normal(tf.shape(vdash))\n gamma = tf_expand_tile(gamma, vdash)\n return - tf.sqrt(1 - gamma) * vdash + tf.sqrt(gamma) * r\n\n\ndef smooth_acceptance_rate(accept, old_acceptance_rate, acceptance_decay):\n #\n # Smooth the acceptance rate\n assert accept.shape == old_acceptance_rate.shape\n new_acceptance_rate = tf.add(\n acceptance_decay * old_acceptance_rate,\n (1.0 - acceptance_decay) * tf.cast(accept, old_acceptance_rate.dtype, name='cast_accept'))\n return new_acceptance_rate\n\n\ndef hmc_sample(x0, log_target, eps, sample_shape=(), event_axes=(), v0=None,\n niter=1000, nchains=3000, acceptance_decay=.9):\n \"\"\"Sample using Hamiltonian Monte Carlo.\n\n Args:\n x0: Initial state\n log_target: The unnormalised target log density\n eps: Step size for HMC\n sample_shape: The shape of the samples, e.g. `()` for univariate or (3,) a 3-dimensional MVN\n event_axes: Index into `x0`'s dimensions for individual samples, `()` for univariate sampling\n v0: Initial velocity, will be sampled if None\n niter: Number of iterations in each chain\n nchains: Number of chains to run in parallel\n acceptance_decay: Decay used to calculate smoothed acceptance rate\n\n Returns:\n A tuple (final state, final velocity, the samples, the smoothed acceptance rate)\n \"\"\"\n def condition(i, x, v, samples, smoothed_accept_rate):\n \"The condition keeps the while loop going until we have finished the iterations.\"\n return tf.less(i, niter)\n\n def body(i, x, v, samples, smoothed_accept_rate):\n \"The body of the while loop over the iterations.\"\n #\n # New step: make a HMC move\n accept, xnew, vnew = hmc_move(\n x,\n v,\n energy_fn=lambda x: -log_target(x),\n event_axes=event_axes,\n eps=eps,\n )\n #\n # Update the TensorArray storing the samples\n samples = samples.write(i, xnew)\n #\n # Smooth the acceptance rate\n smoothed_accept_rate = smooth_acceptance_rate(accept, smoothed_accept_rate, acceptance_decay)\n #\n return tf.add(i, 1), xnew, vnew, samples, smoothed_accept_rate\n\n #\n # Sample initial velocity if not provided\n if v0 is None:\n v0 = tf.random_normal(tf.shape(x0))\n #\n # Keep the samples in a TensorArray\n samples = tf.TensorArray(dtype=x0.dtype, size=niter, element_shape=(nchains,) + sample_shape)\n #\n # Current iteration\n iteration = tf.constant(0)\n #\n # Smoothed acceptance rate\n smoothed_accept_rate = tf.constant(.65, shape=(nchains,), dtype=tf.float32)\n #\n # Current step size and adjustments\n # stepsize = tf.constant(STEPSIZE_INITIAL, shape=(NCHAINS,), dtype=tf.float32)\n # stepsize_dec = STEPSIZE_DEC * tf.ones(smoothed_acceptance_rate.shape)\n # stepsize_inc = STEPSIZE_INC * tf.ones(smoothed_acceptance_rate.shape)\n #\n # While loop across iterations\n n, x, v, samples_final, smoothed_accept_rate_final = \\\n tf.while_loop(\n condition,\n body,\n (iteration, x0, v0, samples, smoothed_accept_rate),\n parallel_iterations=1,\n swap_memory=True)\n #\n return x, v, samples_final, smoothed_accept_rate_final\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 7.857142925262451,
"blob_id": "fb8b4d29ffa2be2b73be6ca5184b8f904150a952",
"content_id": "9109b64468cd95ad21eb0aed4b0cb783fb80ad1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 14,
"path": "/requirements.txt",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#\n# Computation\nscipy\n#\n# Plotting\nmatplotlib\nseaborn\n#\n# Documentation\nsphinx\nsphinxcontrib-napoleon\n#\n# This package\n-e .\n"
},
{
"alpha_fraction": 0.5465116500854492,
"alphanum_fraction": 0.5465116500854492,
"avg_line_length": 16,
"blob_id": "01dafb32e321992a053fc49224283afba7701099",
"content_id": "7b28a9c27176efbb361f21ae45197bc68fdb6a78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 86,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 5,
"path": "/docs/build/html/_sources/examples.rst.txt",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "Module hais.examples\n====================\n\n.. automodule:: hais.examples\n :members:\n\n"
},
{
"alpha_fraction": 0.642140805721283,
"alphanum_fraction": 0.6495087742805481,
"avg_line_length": 37.171875,
"blob_id": "fada994f0e40541a1a551aa40a580539ca891fab",
"content_id": "3620a7b5cfc6e2dde78d969c10d748f6d8773b96",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9772,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 256,
"path": "/hais/ais.py",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\"\"\"Implementation of Hamiltonian Annealed Importance Sampling (HAIS).\n\nThe implementation includes:\n\n - partial momentum refresh across HMC moves (the main idea of Sohl-Dickstein and Culpepper).\n - adaptive HMC step sizes to attempt to acheive an optimal acceptance rate.\n\n\"\"\"\n\nimport tensorflow as tf\nimport numpy as np\nfrom . import hmc\n\n\n#\n# Theoretically optimal acceptance rate\nTARGET_ACCEPTANCE_RATE = .65\n\n\ndef get_schedule(T, r=4):\n \"\"\"\n Calculate a temperature schedule for annealing.\n\n Evenly spaced points in :math:`[-r, r]` are pushed\n through the sigmoid function and affinely transformed to :math:`[0, 1]`.\n\n .. math::\n\n t_i &= (\\\\frac{2i}{T} - 1) r, \\\\quad i = 0, \\dots, T \\\\\\\\\n s_i &= \\\\frac{1}{1+e^{-t_i}} \\\\\\\\\n \\\\beta_i &= \\\\frac{s_i - s_0}{s_T - s_0}\n\n Args:\n T: number of annealing transitions (number of temperatures + 1).\n r: defines the domain of the sigmoid.\n\n Returns:\n 1-D numpy array: A numpy array with shape `(T+1,)` that\n monotonically increases from 0 to 1 (the values are the\n :math:`\\\\beta_i`).\n\n \"\"\"\n if T == 1:\n raise ValueError('Must have at least two temperatures')\n t = np.linspace(-r, r, T)\n s = 1.0 / (1.0 + np.exp(-t))\n beta = (s - np.min(s)) / (np.max(s) - np.min(s))\n return beta\n\n\nclass HAIS(object):\n \"\"\"\n An implementation of Hamiltonian Annealed Importance Sampling (HAIS).\n \"\"\"\n\n def __init__(self,\n proposal=None,\n log_target=None,\n prior=None,\n log_likelihood=None,\n stepsize=.5,\n smthd_acceptance_decay=0.9,\n adapt_stepsize=False,\n target_acceptance_rate=.65,\n stepsize_dec=.9,\n stepsize_inc=1.1,\n stepsize_min=1e-5,\n stepsize_max=1e3):\n \"\"\"\n Initialise the HAIS class.\n\n The proposal and target distribution must be specified in one of two ways:\n\n - *either* a `proposal` distribution :math:`q(x)` and unnormalised `log_target`\n density :math:`p(x)` should be supplied. In this case the `i`'th annealed density will be\n :math:`q(x)^{1-\\\\beta_i}p(x)^{\\\\beta_i}`\n - *or* a `prior` distribution :math:`q(x)` and normalised `log_likelihood` density :math:`p(x)` should\n be supplied. In this case the `i`'th annealed density will be\n :math:`q(x)p(x)^{\\\\beta_i}`\n\n\n Args:\n proposal: The proposal distribution.\n log_target: Function that returns a tensor evaluating :math:`\\\\log p(x)` (up to a constant).\n prior: The prior distribution.\n log_likelihood: Function that returns a tensor evaluating :the normalised log likelihood of :math:`x`.\n stepsize: HMC step size.\n smthd_acceptance_decay: The decay used when smoothing the acceptance rates.\n adapt_stepsize: If true the algorithm will adapt the step size for each chain to encourage\n the smoothed acceptance rate to approach a target acceptance rate.\n target_acceptance_rate: If adapting step sizes, the target smoothed acceptance rate. 0.65 is\n near the theoretical optimum, see \"MCMC Using Hamiltonian Dynamics\" by Radford Neal in the\n \"Handbook of Monte Carlo\" (2011).\n stepsize_dec: The scaling factor by which to reduce the step size if the acceptance rate is too low.\n Only used when adapting step sizes.\n stepsize_inc: The scaling factor by which to increase the step size if the acceptance rate is too high.\n Only used when adapting step sizes.\n stepsize_min: A hard lower bound on the step size.\n Only used when adapting step sizes.\n stepsize_max: A hard upper bound on the step size.\n Only used when adapting step sizes.\n \"\"\"\n a = None\n b = 1\n (a is None) ^ (b is None)\n #\n # Check the arguments, either proposal and log_target should be supplied OR prior and log_likelihood\n # but not both\n if (proposal is None) == (prior is None):\n raise ValueError('Exactly one of the proposal and prior arguments should be supplied.')\n if (proposal is None) != (log_target is None):\n raise ValueError('Either both of the proposal and log_target arguments should be supplied or neither.')\n if (prior is None) != (log_likelihood is None):\n raise ValueError('Either both of the prior and log_likelihood arguments should be supplied or neither.')\n #\n # Model\n self.proposal = proposal\n self.log_target = log_target\n self.prior = prior\n self.log_likelihood = log_likelihood\n if self.proposal is None:\n self.q = self.prior\n else:\n self.q = self.proposal\n #\n # Dimensions\n self.batch_shape = self.q.batch_shape\n self.event_shape = self.q.event_shape\n self.shape = self.batch_shape.concatenate(self.event_shape)\n self.event_axes = list(range(len(self.batch_shape), len(self.shape)))\n #\n # HMC\n self.stepsize = stepsize\n self.smoothed_acceptance_rate = target_acceptance_rate\n self.smthd_acceptance_decay = smthd_acceptance_decay\n self.adapt_stepsize = adapt_stepsize\n self.target_acceptance_rate = target_acceptance_rate\n self.stepsize_dec = stepsize_dec\n self.stepsize_inc = stepsize_inc\n self.stepsize_min = stepsize_min\n self.stepsize_max = stepsize_max\n\n def _log_f_i(self, z, beta):\n \"Unnormalized log density for intermediate distribution :math:`f_i`\"\n return - self._energy_fn(z, beta)\n\n def _energy_fn(self, z, beta):\n \"\"\"\n Calculate the energy for each sample z at the temperature beta. The temperature\n is a pair of temperatures, one for the prior and one for the target.\n \"\"\"\n assert z.shape == self.shape\n if self.proposal is None:\n prior_energy = self.prior.log_prob(z)\n target_energy = beta * self.log_likelihood(z)\n else:\n prior_energy = (1 - beta) * self.proposal.log_prob(z)\n target_energy = beta * self.log_target(z)\n assert prior_energy.shape == self.batch_shape\n assert target_energy.shape == self.batch_shape\n return - prior_energy - target_energy\n\n def ais(self, schedule):\n \"\"\"\n Perform annealed importance sampling.\n\n Args:\n schedule: temperature schedule\n \"\"\"\n #\n # Convert the schedule into consecutive pairs of temperatures and their index\n schedule_tf = tf.convert_to_tensor(schedule, dtype=tf.float32)\n #\n # These are the variables that are passed to body() and condition() in the while loop\n i = tf.constant(0)\n logw = tf.zeros(self.batch_shape)\n z0 = self.q.sample()\n v0 = tf.random.normal(shape=tf.shape(z0))\n if self.adapt_stepsize:\n eps0 = tf.constant(self.stepsize, shape=self.batch_shape, dtype=tf.float32)\n else:\n eps0 = tf.constant(self.stepsize, dtype=tf.float32)\n smoothed_acceptance_rate = tf.constant(self.smoothed_acceptance_rate, shape=self.batch_shape, dtype=tf.float32)\n\n def condition(index, logw, z, v, eps, smoothed_acceptance_rate):\n \"The condition keeps the while loop going until we reach the end of the schedule.\"\n return tf.less(index, len(schedule) - 1)\n\n def body(index, logw, z, v, eps, smoothed_acceptance_rate):\n \"The body of the while loop over the schedule.\"\n #\n # Get the pair of temperatures for this transition\n t0 = tf.gather(schedule_tf, index) # First temperature\n t1 = tf.gather(schedule_tf, index + 1) # Second temperature\n #\n # Calculate u at the new temperature and at the old one\n new_u = self._log_f_i(z, t1)\n prev_u = self._log_f_i(z, t0)\n #\n # Add the difference in u to the weight\n logw = tf.add(logw, new_u - prev_u)\n #\n # New step: make a HMC move\n # print('z: {}'.format(z.shape))\n assert z.shape == self.shape\n accept, znew, vnew = hmc.hmc_move(\n z,\n v,\n lambda z: self._energy_fn(z, t1),\n event_axes=self.event_axes,\n eps=eps\n )\n #\n # Smooth the acceptance rate\n smoothed_acceptance_rate = hmc.smooth_acceptance_rate(\n accept, smoothed_acceptance_rate, self.smthd_acceptance_decay)\n #\n # Adaptive step size\n if self.adapt_stepsize:\n epsnew = self._adapt_step_size(eps, smoothed_acceptance_rate)\n else:\n epsnew = eps\n #\n return tf.add(index, 1), logw, znew, vnew, epsnew, smoothed_acceptance_rate\n\n #\n # While loop across temperature schedule\n _, logw, z_i, v_i, eps_i, smoothed_acceptance_rate = \\\n tf.while_loop(\n condition, body, (i, logw, z0, v0, eps0, smoothed_acceptance_rate),\n parallel_iterations=1, swap_memory=True)\n #\n # Return weights, samples, step sizes and acceptance rates\n with tf.control_dependencies([logw, smoothed_acceptance_rate]):\n return logw, z_i, eps_i, smoothed_acceptance_rate\n\n def _adapt_step_size(self, eps, smoothed_acceptance_rate):\n \"\"\"Adapt the step size to adjust the smoothed acceptance rate to a theoretical optimum.\n \"\"\"\n # print('stepsize_inc: {}'.format(stepsize_inc.shape))\n # print('stepsize_dec: {}'.format(stepsize_dec.shape))\n epsadapted = tf.where(\n smoothed_acceptance_rate > self.target_acceptance_rate,\n tf.constant(self.stepsize_inc, shape=smoothed_acceptance_rate.shape),\n tf.constant(self.stepsize_dec, shape=smoothed_acceptance_rate.shape)) * eps\n #\n # Make sure we stay within specified step size range\n epsadapted = tf.clip_by_value(epsadapted, clip_value_min=self.stepsize_min, clip_value_max=self.stepsize_max)\n #\n return epsadapted\n\n def log_normalizer(self, logw, samples_axis):\n \"\"\"The log of the mean (over the `samples_axis`) of :math:`e^{logw}`\n \"\"\"\n return tf.reduce_logsumexp(logw, axis=samples_axis) \\\n - tf.math.log(tf.cast(tf.shape(logw)[samples_axis], dtype=tf.float32))\n"
},
{
"alpha_fraction": 0.6909162998199463,
"alphanum_fraction": 0.702643632888794,
"avg_line_length": 26.491804122924805,
"blob_id": "e2253d6718a77df3b6db39260bc8965422644c97",
"content_id": "8f2b0bb3d09cff849b25b023d87663b7f05d7f38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5031,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 183,
"path": "/tests/test-hais-log-gamma",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nEstimate the normalizing constant of a log-gamma distribution using\nour HAIS implementation.\n\nThe probability density function for a gamma distribution is:\n\n.. math::\n\n f(x; alpha, beta) =\n \\\\frac{\\\\beta^\\\\alpha}{\\Gamma(\\\\alpha)}\n x^{\\\\alpha-1}\n e^{- \\\\beta x}\n\nfor all :math:`x > 0` and any given shape :math:`\\\\alpha > 0` and rate :math:`\\\\rate > 0`. Given a change\nof variables :math:`y = \\\\log(x)` we have the density for a log-gamma distribution:\n\n.. math::\n\n f(y; alpha, beta) =\n \\\\frac{\\\\beta^\\\\alpha}{\\Gamma(\\\\alpha)}\n e^{\\\\alpha y - \\\\beta e^y}\n\n\"\"\"\n\n\nimport time\nimport numpy as np\nimport scipy.special as sp\nfrom hais import ais\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport tensorflow as tf\nimport tensorflow_probability as tfp\nfrom packaging import version\nfrom pathlib import Path\n\n\n# Configure TensorFlow depending on version\nprint(f'TensorFlow version: {tf.__version__}')\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n print('Using TFv1 compatibility mode in TF2.')\n tf.compat.v1.disable_eager_execution()\n tf = tf.compat.v1\n\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\n#\n# Constants\n#\n# normal parameters\nMU = 1.\nSIGMA = .5\n\n# log-gamma parameters\nALPHA = 2.\nBETA = 3.\n\n# RNG seed\nSEED = 41\n\n# HMC AIS\nN_ITER = 3000\nN_CHAINS = 30000\nSTEPSIZE = .7\nADAPT_STEPSIZE = False\nOUTDIR = Path('output')\n\n# Create the output directory if needed\nOUTDIR.mkdir(exist_ok=True, parents=True)\n\n# Seed RNGs\nprint('Seeding RNGs')\nnp.random.seed(SEED)\ntf.set_random_seed(SEED)\n\n\ndef unnormalized_log_gamma_lpdf(x):\n \"\"\"\n Unnormalized log probability density function of the log-gamma(ALPHA, BETA) distribution.\n True log normalizer is:\n\n .. math::\n\n \\\\log \\\\Gamma(\\\\alpha) - \\\\alpha \\\\log \\\\beta\n\n \"\"\"\n # assert x.shape == (N_CHAINS,)\n return ALPHA * x - BETA * tf.exp(x)\n\n\n# Calculate the true log normalizer\nlog_target, log_normalizer_true = \\\n unnormalized_log_gamma_lpdf, sp.gammaln(ALPHA) - ALPHA * np.log(BETA)\n\n\n# Annealed importance sampling\nprint('Constructing AIS computation graph')\nstarttime = time.time()\nproposal = tfp.distributions.Normal(loc=tf.zeros(N_CHAINS), scale=tf.ones(N_CHAINS))\n# model = ais.HAIS(qz=prior, log_likelihood_fn=unnormalized_log_gamma_lpdf)\nmodel = ais.HAIS(proposal=proposal, log_target=log_target, stepsize=STEPSIZE, adapt_stepsize=ADAPT_STEPSIZE)\n\n# Set up an annealing schedule\nschedule = ais.get_schedule(T=N_ITER, r=4)\n\n# Set up the computation graph\nlogw, z_i, eps, avg_acceptance_rate = model.ais(schedule)\nlog_normalizer = model.log_normalizer(logw, samples_axis=0)\nendtime = time.time()\nprint('Constructing graph took {:.1g} seconds'.format(endtime - starttime))\n\n# Construct and initialise the session\nsess = tf.Session()\nsess.run(tf.global_variables_initializer())\n\n# Run AIS\nprint('Running AIS')\nstarttime = time.time()\nlog_normalizer_ais, log_w_ais, z_sampled, eps_final, final_smthd_acceptance_rate = \\\n sess.run([log_normalizer, logw, z_i, eps, avg_acceptance_rate])\nendtime = time.time()\nnp.mean(eps_final)\nnp.std(eps_final)\neps_final.shape\nprint('AIS took {:.1f} seconds'.format(endtime - starttime))\nprint('Estimated log normalizer: {:.4f}'.format(log_normalizer_ais))\nprint('True log normalizer: {:.4f}'.format(log_normalizer_true))\nprint('Final step sizes: mean={:.3g}; sd={:.3g}'.format(\n np.mean(eps_final), np.std(eps_final)))\nprint('Final smoothed acceptance rate: mean={:.3f}; sd={:.3f}'.format(\n np.mean(final_smthd_acceptance_rate), np.std(final_smthd_acceptance_rate)))\n\n\ndef plot_samples(ax):\n # ax.scatter(log_normalizer_ais, log_normalizer_true)\n ax.set_xlabel('x')\n ax.set_ylabel('target')\n ax.set_title('Samples')\n z_sampled.shape\n sns.distplot(z_sampled, ax=ax)\n xmin, xmax = ax.get_xbound()\n target_range = np.linspace(xmin, xmax, num=300)\n target_range.shape\n target = sess.run(tf.exp(log_target(target_range) - log_normalizer_true))\n ax.plot(target_range, target)\n\n\n# Plot the output\nout_path = OUTDIR / 'hais-log-gamma.pdf'\nprint(f'Plotting log normalizer: {out_path}')\nif model.adapt_stepsize:\n fig, (ax, ax_accept, ax_stepsize) = plt.subplots(3, 1, figsize=(8, 12))\nelse:\n fig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\nplot_samples(ax)\n\n# Acceptance rate\nsns.distplot(final_smthd_acceptance_rate.flatten(), ax=ax_accept)\nax_accept.axvline(x=model.target_acceptance_rate, linestyle='dashed', color='k', alpha=.3)\nax_accept.set_title('average acceptance rates (per batch per chain)')\n\n# Step sizes\nif model.adapt_stepsize:\n sns.distplot(eps_final.flatten(), ax=ax_stepsize)\n ax_stepsize.axvline(x=model.stepsize, linestyle='dashed', color='k', alpha=.3)\n ax_stepsize.set_title('Step sizes (per batch per chain)')\nfig.savefig(out_path)\n\n\n# Make another figure just of samples\nfig, ax = plt.subplots(figsize=(8, 6))\nplot_samples(ax)\nsamples_path = OUTDIR / 'hais-log-gamma-samples.png'\nprint(f'Saving samples: {samples_path}')\nfig.savefig(samples_path, dpi=300)\n"
},
{
"alpha_fraction": 0.698142409324646,
"alphanum_fraction": 0.707430362701416,
"avg_line_length": 25.91666603088379,
"blob_id": "6cb94a006c02973c8e23d63f0bd27f1e0b1b125f",
"content_id": "ebd5947628dd225f4424861f4bbff80e57be2932",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 646,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 24,
"path": "/tests/plot-model1a-gaussian-both",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom matplotlib import lines\nimport seaborn as sns\n\n#\n# Read estimates\nbf = pd.read_csv('BayesFlow.csv')\nhais = pd.read_csv('HAIS.csv')\ndf = bf.append(hais)\n\n#\n# Plot estimates\nfig, ax = plt.subplots()\nax = sns.scatterplot(x=\"estimate\", y=\"true\", hue=\"method\", data=df)\nax.set_title('Marginal log likelihoods')\nxmin, xmax = ax.get_xbound()\nymin, ymax = ax.get_ybound()\nlower = max(xmin, ymin)\nupper = min(xmax, ymax)\nax.add_line(lines.Line2D([lower, upper], [lower, upper], linestyle='dashed', color='k', alpha=.3))\nfig.savefig('model1a-gaussian-estimates.png', dpi=300)\n"
},
{
"alpha_fraction": 0.6333396434783936,
"alphanum_fraction": 0.6430336236953735,
"avg_line_length": 30.88484764099121,
"blob_id": "c485205293351b93b21541c8fca4843f732c1fdf",
"content_id": "b66cdce8091e58f30b2e4efeb5d5a0026f55086a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5261,
"license_type": "permissive",
"max_line_length": 119,
"num_lines": 165,
"path": "/hais/examples.py",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\"\"\"\nUnnormalised targets and exact calculations for some example problems.\n\n - An unnormalised log-Gamma distribution\n - Model 1a from Sohl-Dickstein and Culpepper\n\n\"\"\"\n\nfrom packaging import version\nimport numpy as np\nimport scipy.linalg as la\nimport scipy.special as sp\nimport scipy.stats as st\nimport tensorflow as tf\nimport tensorflow_probability as tfp\ntfd = tfp.distributions\n\n# Configure TensorFlow depending on version\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n tf = tf.compat.v1\n\n\nLOG_2_PI = np.log(2. * np.pi)\n\n\ndef log_gamma_unnormalised_lpdf(x, alpha, beta):\n \"\"\"\n Unnormalized log probability density function of the log-gamma(ALPHA, BETA) distribution.\n\n The probability density function for a gamma distribution is:\n\n .. math::\n\n f(x; \\\\alpha, \\\\beta) =\n \\\\frac{\\\\beta^\\\\alpha}{\\Gamma(\\\\alpha)}\n x^{\\\\alpha-1}\n e^{- \\\\beta x}\n\n for all :math:`x > 0` and any given shape :math:`\\\\alpha > 0` and rate :math:`\\\\beta > 0`. Given a change\n of variables :math:`y = \\\\log(x)` we have the density for a log-gamma distribution:\n\n .. math::\n\n f(y; \\\\alpha, \\\\beta) =\n \\\\frac{\\\\beta^\\\\alpha}{\\Gamma(\\\\alpha)}\n e^{\\\\alpha y - \\\\beta e^y}\n\n \"\"\"\n return alpha * x - beta * tf.exp(x)\n\n\ndef log_gamma_exact_log_normaliser(alpha, beta):\n \"\"\"The exact log normalizer is:\n\n .. math::\n\n \\\\log \\\\Gamma(\\\\alpha) - \\\\alpha \\\\log \\\\beta\n \"\"\"\n return sp.gammaln(alpha) - alpha * np.log(beta)\n\n\nclass Culpepper1aGaussian(object):\n \"\"\"Implementations of likelihood, sampling and exact marginal\n for model1a (with Gaussian prior) from Sohl-Dickstein and\n Culpepper.\n\n We name the latent variable 'z' in place of 'a'\n\n The code is set up to estimate the log marginal of several batches (different `x`) concurrently.\n \"\"\"\n\n def __init__(self, M, L, sigma_n, batch_size, n_chains):\n \"\"\"Initialise the model with the parameters.\"\"\"\n #\n # Set parameters\n self.M = M\n self.L = L\n self.sigma_n = sigma_n\n self.batch_size = batch_size\n self.n_chains = n_chains\n #\n # Sample phi\n self.phi = st.norm.rvs(size=(self.M, self.L)).astype(dtype=np.float32)\n #\n # Sample z\n self.z = st.norm.rvs(size=(self.batch_size, self.L)).astype(dtype=np.float32)\n #\n # Sample x\n self.x_loc = (self.phi @ self.z.T).T\n self.px = st.norm(loc=self.x_loc, scale=self.sigma_n)\n self.x = self.px.rvs(size=(self.batch_size, self.M))\n #\n # TF constants\n self.x_tf = tf.constant(self.x, dtype=tf.float32)\n self.phi_tf = tf.constant(self.phi, dtype=tf.float32)\n #\n # TF prior\n self.prior = tfd.MultivariateNormalDiag(loc=tf.zeros([self.batch_size, self.n_chains, self.L]))\n\n def log_likelihood(self, z):\n \"Calculates the log pdf of the conditional distribution of x given z.\"\n #\n assert (self.batch_size, self.n_chains, self.L) == z.shape\n assert (self.M, self.L) == self.phi.shape\n assert (self.batch_size, self.M) == self.x.shape\n loc = tf.squeeze(\n tf.matmul(\n tf.tile(\n tf.expand_dims(tf.expand_dims(self.phi_tf, axis=0), axis=0),\n [self.batch_size, self.n_chains, 1, 1]),\n tf.expand_dims(z, axis=-1)),\n axis=-1)\n assert (self.batch_size, self.n_chains, self.M) == loc.shape\n x_given_z = tfd.MultivariateNormalDiag(loc=tf.cast(loc, tf.float32), scale_diag=self.sigma_n * tf.ones(self.M))\n return x_given_z.log_prob(\n tf.tile(tf.expand_dims(self.x_tf, axis=1), [1, self.n_chains, 1]), name='log_likelihood')\n\n def log_posterior(self, z):\n \"\"\"The unnormalised log posterior.\"\"\"\n log_prior = self.prior.log_prob(z)\n log_likelihood = self.log_likelihood(z)\n assert log_prior.shape == log_likelihood.shape\n return log_prior + log_likelihood\n\n def log_marginal(self):\n \"\"\"Calculate the exact log marginal likelihood of the `x` given\n `phi` and `sigma_n`.\"\"\"\n #\n # Predictive covariance of x is sum of covariance of phi a and covariance of x|a\n x_Sigma = self.phi @ self.phi.T + np.diag(self.sigma_n**2 * np.ones(self.M))\n #\n # Predictive mean is 0 by symmetry\n # so given that x is distributed as a MVN, the exact marginal is\n lp_exact = st.multivariate_normal.logpdf(self.x, cov=x_Sigma)\n #\n return lp_exact\n\n\ndef _culpepper1a_log_marginal_overcomplicated(x, phi, sigma_n):\n \"\"\"An over-complicated and incorrect method to calculate\n the exact marginal likelihood for model 1a (Gaussian prior) from Sohl-Dickstein and Culpepper.\"\"\"\n raise NotImplementedError('This is an overcomplicated implementation that does not work')\n M, L = phi.shape\n sigma_n2 = sigma_n**2\n #\n # Precision of posterior for a\n SigmaInv = np.diag(np.ones(L)) + phi.T @ phi / sigma_n2\n #\n # Cholesky\n C = la.cholesky(SigmaInv)\n halflogSigmaDet = - np.add.reduce(np.log(np.diag(C)))\n #\n # Solve for term we need\n xPhiCinv = la.solve_triangular(C, phi.T @ x.T, lower=True).T\n #\n # Normalising constants\n lZa = L / 2. * LOG_2_PI\n lZxa = M / 2. * LOG_2_PI + M * np.log(sigma_n)\n lZax = L / 2. * LOG_2_PI + halflogSigmaDet\n #\n # Log marginal\n lpx = - lZa - lZxa + lZax + (np.square(xPhiCinv).sum(axis=1) / sigma_n2 - np.square(x).sum(axis=1)) / (2. * sigma_n2)\n #\n return lpx\n"
},
{
"alpha_fraction": 0.6909888982772827,
"alphanum_fraction": 0.7075057625770569,
"avg_line_length": 30.058441162109375,
"blob_id": "795484d41a21780324ca44692743a54e2d41b9bb",
"content_id": "1fba3a0e60a8fce23369519ae0a2f0b29ccf4104",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4783,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 154,
"path": "/tests/test-hais-model1a-gaussian",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nTest our HAIS implementation on model 1a with a Gaussian prior from http://arxiv.org/abs/1205.1925\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nfrom hais import ais, examples\nimport matplotlib.pyplot as plt\nfrom matplotlib import lines\nimport seaborn as sns\nimport time\nimport tensorflow as tf\nfrom packaging import version\nfrom pathlib import Path\n\n\n# Configure TensorFlow depending on version\nprint(f'TensorFlow version: {tf.__version__}')\nif version.parse(tf.__version__) >= version.parse('2.0.0'):\n # TensorFlow version 2\n print('Using TFv1 compatibility mode in TF2.')\n tf.compat.v1.disable_eager_execution()\n tf = tf.compat.v1\nelif version.parse(tf.__version__) >= version.parse('1.15'):\n print('Using TFv1 compatibility mode in TF1.15.')\n tf.compat.v1.disable_eager_execution()\n tf = tf.compat.v1\n\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\n#\n# Constants\n#\n\n# RNG seed\nSEED = 41\n\n# AIS\nN_ITER = 5000\nN_CHAINS = 150\n\n# HMC\nSTEPSIZE = .02\nADAPT_STEPSIZE = False\n\n# Model\nBATCH_SIZE = 16 # number of distinct x\nM = 36 # x dimensions\nL = 5 # z dimensions\nSIGMA_N = .1\n\n# Create the output directory if needed\nOUTDIR = Path('output')\nOUTDIR.mkdir(exist_ok=True, parents=True)\n\n# Seed RNGs\nprint('Seeding RNGs')\nnp.random.seed(SEED)\ntf.set_random_seed(SEED)\n\n# Model\nprint('Constructing/sampling model')\ngenerative = examples.Culpepper1aGaussian(M, L, SIGMA_N, BATCH_SIZE, N_CHAINS)\n\n# Exact marginal likelihood\nlp_exact = generative.log_marginal()\nprint('Calculated exact marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(lp_exact), np.std(lp_exact)))\n\n# Annealed importance sampling\nprint('Constructing computation graph')\nstarttime = time.time()\nsampler = ais.HAIS(prior=generative.prior,\n log_likelihood=generative.log_likelihood,\n stepsize=STEPSIZE,\n adapt_stepsize=ADAPT_STEPSIZE)\n\n# Set up an annealing schedule\nschedule = ais.get_schedule(T=N_ITER, r=4)\n\n# Set up the computation graph\nlogw, z_i, eps, smthd_acceptance_rate = sampler.ais(schedule)\n\n# Calculate the log normalizer (aka log marginal), remember batches are in dimension 0, chains in dimension 1\nlog_normalizer = sampler.log_normalizer(logw, samples_axis=1)\nendtime = time.time()\nprint('Constructing graph took {:.1g} seconds'.format(endtime - starttime))\n\n# Construct and initialise the session\nsess = tf.Session()\n# merged = tf.summary.merge_all()\n# summary_writer = tf.summary.FileWriter('logs')\nsess.run(tf.global_variables_initializer())\n\n# Run AIS\nprint('Running HAIS')\nstarttime = time.time()\nlog_marginal, logw_ais, z_sampled, eps_final, final_smthd_acceptance_rate = \\\n sess.run([log_normalizer, logw, z_i, eps, smthd_acceptance_rate])\nendtime = time.time()\nprint('AIS took {:.1f} seconds'.format(endtime - starttime))\nprint('Estimated marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(log_marginal), np.std(log_marginal)))\nprint('True marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(lp_exact), np.std(lp_exact)))\nrho = np.corrcoef(log_marginal, lp_exact)[0, 1]\nprint('Correlation between estimates: {:.3f}'.format(rho))\nprint('Final step sizes: mean={:.3g}; sd={:.3g}'.format(\n np.mean(eps_final), np.std(eps_final)))\nprint('Final smoothed acceptance rate: mean={:.3f}; sd={:.3f}'.format(\n np.mean(final_smthd_acceptance_rate), np.std(final_smthd_acceptance_rate)))\n\n# Save the estimates\ncsv_path = OUTDIR / 'HAIS.csv'\nprint(f'Saving estimates: {csv_path}')\ndf = pd.DataFrame({'estimate': log_marginal, 'true': lp_exact, 'method': 'HAIS'})\ndf.to_csv(csv_path, index=False)\n\n# Plot the output\nfig_path = OUTDIR / 'hais-model1a-gaussian.pdf'\nprint(f'Plotting marginal log likelihoods: {fig_path}')\nif sampler.adapt_stepsize:\n fig, (ax, ax_accept, ax_stepsize) = plt.subplots(3, 1, figsize=(8, 12))\nelse:\n fig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\nax.scatter(log_marginal, lp_exact)\nax.set_xlabel('HAIS')\nax.set_ylabel('true')\nax.set_title('Marginal log likelihoods')\nxmin, xmax = ax.get_xbound()\nymin, ymax = ax.get_ybound()\nlower = max(xmin, ymin)\nupper = min(xmax, ymax)\nax.add_line(lines.Line2D([lower, upper], [lower, upper], linestyle='dashed', color='k', alpha=.3))\n\n# Acceptance rate\nsns.distplot(final_smthd_acceptance_rate.flatten(), ax=ax_accept)\nax_accept.axvline(x=sampler.target_acceptance_rate, linestyle='dashed', color='k', alpha=.3)\nax_accept.set_title('smoothed acceptance rates (per batch per chain)')\n\n# Step sizes\nif sampler.adapt_stepsize:\n sns.distplot(eps_final.flatten(), ax=ax_stepsize)\n ax_stepsize.axvline(x=sampler.stepsize, linestyle='dashed', color='k', alpha=.3)\n ax_stepsize.set_title('Step sizes (per batch per chain)')\nfig.savefig(fig_path)\n"
},
{
"alpha_fraction": 0.5285714268684387,
"alphanum_fraction": 0.5285714268684387,
"avg_line_length": 13,
"blob_id": "23fa49056e634091eb31028a34df45768149ce6d",
"content_id": "f1af28881f8f353232088be4c3f5fb52e252311a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 70,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 5,
"path": "/docs/source/hmc.rst",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "Module hais.hmc\n---------------\n\n.. automodule:: hais.hmc\n :members:\n"
},
{
"alpha_fraction": 0.6977657079696655,
"alphanum_fraction": 0.7134661674499512,
"avg_line_length": 25.285715103149414,
"blob_id": "ae135c4535f89ac8402bb28ffd3e810b4b06eb38",
"content_id": "91fc37724db0e76b9357c88a7e30d5b288941b1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3312,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 126,
"path": "/tests/test-bayesflow-model1a-gaussian",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\"\"\"\nTest TensorFlow's contributed BayesFlow HAIS implementation on example 1a\nfrom http://arxiv.org/abs/1205.1925\n\nWe name the latent variable 'z' in place of 'a'\n\"\"\"\n\nimport time\nimport numpy as np\nimport pandas as pd\nimport matplotlib.pyplot as plt\nfrom matplotlib import lines\nimport seaborn as sns\nimport tensorflow as tf\nfrom tensorflow.contrib.bayesflow import hmc\nfrom hais import examples\ntfd = tf.contrib.distributions\n\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\n#\n# Constants\n#\n# RNG seed\nSEED = 41\n#\n# AIS\nN_ITER = 5000\nN_CHAINS = 150\n#\n# HMC\nSTEPSIZE = .02\n#\n# Model\nBATCH_SIZE = 16 # number of distinct x\nM = 36 # x dimensions\nL = 5 # z dimensions\nSIGMA_N = .1\n\n#\n# Seed RNGs\nprint('Seeding RNGs')\nnp.random.seed(SEED)\ntf.set_random_seed(SEED)\n\n\n#\n# Model\nprint('Constructing/sampling model')\ngenerative = examples.Culpepper1aGaussian(M, L, SIGMA_N, BATCH_SIZE, N_CHAINS)\n\n\n#\n# Exact marginal likelihood\nlp_exact = generative.log_marginal()\nprint('Calculated exact marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(lp_exact), np.std(lp_exact)))\n\n\n#\n# Construct computation graph\nprint('Constructing computation graph')\nstarttime = time.time()\ninitial_z = generative.prior.sample()\nlogw, samples, acceptance_probs = hmc.ais_chain(\n n_iterations=N_ITER, step_size=STEPSIZE, n_leapfrog_steps=1, initial_x=initial_z,\n target_log_prob_fn=generative.log_posterior, proposal_log_prob_fn=generative.prior.log_prob,\n event_dims=[2])\nlog_normalizer = tf.reduce_logsumexp(logw, axis=1) - np.log(N_CHAINS)\nendtime = time.time()\nprint('Constructing graph took {:.1f} seconds'.format(endtime - starttime))\n#\n# Construct and initialise the session\nsess = tf.Session()\nsess.run(tf.global_variables_initializer())\n#\n# Run AIS\nprint('Running BayesFlow HAIS')\nstarttime = time.time()\nlog_marginal, log_w_bf, z_sampled, acceptance_probs_bf = \\\n sess.run([log_normalizer, logw, samples, acceptance_probs])\nendtime = time.time()\nprint('AIS took {:.1f} seconds'.format(endtime - starttime))\nprint('Estimated marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(log_marginal), np.std(log_marginal)))\nprint('True marginal log likelihood(s): mean={:.1f}; sd={:.1f}'.format(\n np.mean(lp_exact), np.std(lp_exact)))\nrho = np.corrcoef(log_marginal, lp_exact)[0, 1]\nprint('Correlation between estimates: {:.3f}'.format(rho))\nprint('Acceptance probabilities: mean={:.3f}; sd={:.3f}'.format(\n np.mean(acceptance_probs_bf), np.std(acceptance_probs_bf)))\n\n\n#\n# Save the estimates\ndf = pd.DataFrame({'estimate': log_marginal, 'true': lp_exact, 'method': 'BayesFlow'})\ndf.to_csv('BayesFlow.csv', index=False)\n\n\n#\n# Plot the output\nprint('Plotting log normalizer')\nfig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\nax.scatter(log_marginal, lp_exact)\nax.set_xlabel('BayesFlow')\nax.set_ylabel('true')\nax.set_title('Marginal log likelihoods')\nxmin, xmax = ax.get_xbound()\nymin, ymax = ax.get_ybound()\nlower = max(xmin, ymin)\nupper = min(xmax, ymax)\nax.add_line(lines.Line2D([lower, upper], [lower, upper], linestyle='dashed', color='k', alpha=.3))\n#\n# Acceptance rate\nsns.distplot(acceptance_probs_bf.flatten(), ax=ax_accept)\nax_accept.set_title('acceptance probabilities')\n#\nfig.savefig('bayesflow-model1a-gaussian.pdf')\n"
},
{
"alpha_fraction": 0.6628397107124329,
"alphanum_fraction": 0.6726163625717163,
"avg_line_length": 51.09812927246094,
"blob_id": "f399ae63a8df19dcb2040b850ae6bd2d0dc692d4",
"content_id": "41cea1c494bdaa502c42ff41fbff27add78379fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "HTML",
"length_bytes": 11193,
"license_type": "permissive",
"max_line_length": 434,
"num_lines": 214,
"path": "/docs/build/html/hmc.html",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\n<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">\n\n<html xmlns=\"http://www.w3.org/1999/xhtml\">\n <head>\n <meta http-equiv=\"X-UA-Compatible\" content=\"IE=Edge\" />\n <meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" />\n <title>Module hais.hmc — HAIS 0.1.0 documentation</title>\n <link rel=\"stylesheet\" href=\"_static/alabaster.css\" type=\"text/css\" />\n <link rel=\"stylesheet\" href=\"_static/pygments.css\" type=\"text/css\" />\n <script type=\"text/javascript\" id=\"documentation_options\" data-url_root=\"./\" src=\"_static/documentation_options.js\"></script>\n <script type=\"text/javascript\" src=\"_static/jquery.js\"></script>\n <script type=\"text/javascript\" src=\"_static/underscore.js\"></script>\n <script type=\"text/javascript\" src=\"_static/doctools.js\"></script>\n <script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_HTMLorMML\"></script>\n <link rel=\"index\" title=\"Index\" href=\"genindex.html\" />\n <link rel=\"search\" title=\"Search\" href=\"search.html\" />\n <link rel=\"next\" title=\"Module hais.examples\" href=\"examples.html\" />\n <link rel=\"prev\" title=\"Module hais.ais\" href=\"ais.html\" />\n \n <link rel=\"stylesheet\" href=\"_static/custom.css\" type=\"text/css\" />\n \n \n <meta name=\"viewport\" content=\"width=device-width, initial-scale=0.9, maximum-scale=0.9\" />\n\n </head><body>\n \n\n <div class=\"document\">\n <div class=\"documentwrapper\">\n <div class=\"bodywrapper\">\n \n\n <div class=\"body\" role=\"main\">\n \n <div class=\"section\" id=\"module-hais.hmc\">\n<span id=\"module-hais-hmc\"></span><h1>Module hais.hmc<a class=\"headerlink\" href=\"#module-hais.hmc\" title=\"Permalink to this headline\">¶</a></h1>\n<p>Implementation of Hamiltonian Monte Carlo.</p>\n<p>Currently only makes leapfrog moves with one step as that is all that is needed for HAIS.</p>\n<dl class=\"function\">\n<dt id=\"hais.hmc.default_gamma\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">default_gamma</code><span class=\"sig-paren\">(</span><em>eps</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.default_gamma\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Calculate the default gamma (momentum refresh parameter).</p>\n<p>Follows equation 11. in Culpepper et al. (2011)</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.hamiltonian\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">hamiltonian</code><span class=\"sig-paren\">(</span><em>position</em>, <em>velocity</em>, <em>energy_fn</em>, <em>event_axes</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.hamiltonian\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Calculate the Hamiltonian of the system.</p>\n<p>Eqn 20 and 21 in Sohl-Dickstein and Culpepper’s paper.</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.hmc_move\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">hmc_move</code><span class=\"sig-paren\">(</span><em>x0</em>, <em>v0</em>, <em>energy_fn</em>, <em>event_axes</em>, <em>eps</em>, <em>gamma=None</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.hmc_move\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Make a HMC move.</p>\n<p>Implements the algorithm in\nCulpepper et al. 2011 “Building a better probabilistic model of images by factorization”.</p>\n<table class=\"docutils field-list\" frame=\"void\" rules=\"none\">\n<col class=\"field-name\" />\n<col class=\"field-body\" />\n<tbody valign=\"top\">\n<tr class=\"field-odd field\"><th class=\"field-name\">Parameters:</th><td class=\"field-body\"><strong>gamma</strong> – Set to 1 to remove any partial momentum refresh (momentum is sampled fresh every move)</td>\n</tr>\n</tbody>\n</table>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.hmc_sample\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">hmc_sample</code><span class=\"sig-paren\">(</span><em>x0</em>, <em>log_target</em>, <em>eps</em>, <em>sample_shape=()</em>, <em>event_axes=()</em>, <em>v0=None</em>, <em>niter=1000</em>, <em>nchains=3000</em>, <em>acceptance_decay=0.9</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.hmc_sample\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Sample using Hamiltonian Monte Carlo.</p>\n<table class=\"docutils field-list\" frame=\"void\" rules=\"none\">\n<col class=\"field-name\" />\n<col class=\"field-body\" />\n<tbody valign=\"top\">\n<tr class=\"field-odd field\"><th class=\"field-name\">Parameters:</th><td class=\"field-body\"><ul class=\"first simple\">\n<li><strong>x0</strong> – Initial state</li>\n<li><strong>log_target</strong> – The unnormalised target log density</li>\n<li><strong>eps</strong> – Step size for HMC</li>\n<li><strong>sample_shape</strong> – The shape of the samples, e.g. <cite>()</cite> for univariate or (3,) a 3-dimensional MVN</li>\n<li><strong>event_axes</strong> – Index into <cite>x0</cite>’s dimensions for individual samples, <cite>()</cite> for univariate sampling</li>\n<li><strong>v0</strong> – Initial velocity, will be sampled if None</li>\n<li><strong>niter</strong> – Number of iterations in each chain</li>\n<li><strong>nchains</strong> – Number of chains to run in parallel</li>\n<li><strong>acceptance_decay</strong> – Decay used to calculate smoothed acceptance rate</li>\n</ul>\n</td>\n</tr>\n<tr class=\"field-even field\"><th class=\"field-name\">Returns:</th><td class=\"field-body\"><p class=\"first last\">A tuple (final state, final velocity, the samples, the smoothed acceptance rate)</p>\n</td>\n</tr>\n</tbody>\n</table>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.kinetic_energy\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">kinetic_energy</code><span class=\"sig-paren\">(</span><em>v</em>, <em>event_axes</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.kinetic_energy\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Calculate the kinetic energy of the system.</p>\n<p><span class=\"math notranslate nohighlight\">\\(- \\log \\Phi(v)\\)</span> in Sohl-Dickstein and Culpepper’s paper.\nNot normalised by <span class=\"math notranslate nohighlight\">\\(M \\log(2 \\pi) / 2\\)</span></p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.leapfrog\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">leapfrog</code><span class=\"sig-paren\">(</span><em>x0</em>, <em>v0</em>, <em>eps</em>, <em>energy_fn</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.leapfrog\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Simulate the Hamiltonian dynamics using leapfrog method.</p>\n<p>That is follow the 2nd step in the 5 step\nprocedure in Section 2.3 of Sohl-Dickstein and Culpepper’s paper.\nNote this leapfrog procedure only has one step.</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.metropolis_hastings_accept\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">metropolis_hastings_accept</code><span class=\"sig-paren\">(</span><em>E0</em>, <em>E1</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.metropolis_hastings_accept\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Accept or reject a move based on the energies of the two states.</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.mh_accept_reject\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">mh_accept_reject</code><span class=\"sig-paren\">(</span><em>x0</em>, <em>v0</em>, <em>x1</em>, <em>v1</em>, <em>energy_fn</em>, <em>event_axes</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.mh_accept_reject\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Accept or reject the leapfrog move according to Metropolis-Hastings.</p>\n<p>Step 3 in Sohl-Dickstein and Culpepper (2011).</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.partial_momentum_refresh\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">partial_momentum_refresh</code><span class=\"sig-paren\">(</span><em>vdash</em>, <em>gamma</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.partial_momentum_refresh\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Update vdash with a partial momentum refresh.</p>\n<p>Step 4 in Sohl-Dickstein and Culpepper (2011).</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.tf_expand_rank\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">tf_expand_rank</code><span class=\"sig-paren\">(</span><em>input_</em>, <em>rank</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.tf_expand_rank\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Expand the <cite>input_</cite> tensor to the given rank by appending dimensions</p>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.hmc.tf_expand_tile\">\n<code class=\"descclassname\">hais.hmc.</code><code class=\"descname\">tf_expand_tile</code><span class=\"sig-paren\">(</span><em>input_</em>, <em>to_match</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.hmc.tf_expand_tile\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Expand and tile the <cite>input_</cite> tensor to match the <cite>to_match</cite> tensor.</p>\n</dd></dl>\n\n</div>\n\n\n </div>\n \n </div>\n </div>\n <div class=\"sphinxsidebar\" role=\"navigation\" aria-label=\"main navigation\">\n <div class=\"sphinxsidebarwrapper\">\n<h1 class=\"logo\"><a href=\"index.html\">HAIS</a></h1>\n\n\n\n\n\n\n\n\n<h3>Navigation</h3>\n<p class=\"caption\"><span class=\"caption-text\">Contents:</span></p>\n<ul class=\"current\">\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"ais.html\">Module hais.ais</a></li>\n<li class=\"toctree-l1 current\"><a class=\"current reference internal\" href=\"#\">Module hais.hmc</a></li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"examples.html\">Module hais.examples</a></li>\n</ul>\n\n<div class=\"relations\">\n<h3>Related Topics</h3>\n<ul>\n <li><a href=\"index.html\">Documentation overview</a><ul>\n <li>Previous: <a href=\"ais.html\" title=\"previous chapter\">Module hais.ais</a></li>\n <li>Next: <a href=\"examples.html\" title=\"next chapter\">Module hais.examples</a></li>\n </ul></li>\n</ul>\n</div>\n<div id=\"searchbox\" style=\"display: none\" role=\"search\">\n <h3>Quick search</h3>\n <div class=\"searchformwrapper\">\n <form class=\"search\" action=\"search.html\" method=\"get\">\n <input type=\"text\" name=\"q\" />\n <input type=\"submit\" value=\"Go\" />\n <input type=\"hidden\" name=\"check_keywords\" value=\"yes\" />\n <input type=\"hidden\" name=\"area\" value=\"default\" />\n </form>\n </div>\n</div>\n<script type=\"text/javascript\">$('#searchbox').show(0);</script>\n </div>\n </div>\n <div class=\"clearer\"></div>\n </div>\n <div class=\"footer\">\n ©2018, John Reid and Halil Bilgin.\n \n |\n Powered by <a href=\"http://sphinx-doc.org/\">Sphinx 1.7.8</a>\n & <a href=\"https://github.com/bitprophet/alabaster\">Alabaster 0.7.11</a>\n \n |\n <a href=\"_sources/hmc.rst.txt\"\n rel=\"nofollow\">Page source</a>\n </div>\n\n \n\n \n </body>\n</html>"
},
{
"alpha_fraction": 0.7405828237533569,
"alphanum_fraction": 0.7583510875701904,
"avg_line_length": 31.720930099487305,
"blob_id": "783255e23986b23b82bb649d507f31a20aa4d1c5",
"content_id": "d2d66edbb99b2a82a4628c9567b4a6033e08de3b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 1407,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 43,
"path": "/docs/build/html/_sources/index.rst.txt",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": ".. HAIS documentation master file, created by\n sphinx-quickstart on Fri Aug 31 10:19:01 2018.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\nHAIS\n====\n\nThis is a tensorflow implementation of Hamiltonian Annealed Importance Sampling\n(HAIS). HAIS is a technique to estimate partition functions (normalising\nconstants of probability densities) and sample from such densities. HAIS was\nproposed by Sohl-Dickstein and Culpepper (2011).\n\nAnnealed Importance Sampling (AIS) is a technique to sample from unnormalised\ncomplex densities with isolated modes that also can be used to estimate\nnormalising constants. It combines importance sampling with Markov chain\nsampling methods. The canonical reference is \"Annealed Importance Sampling\"\nRadford M. Neal (Technical Report No. 9805, Department of Statistics,\nUniversity of Toronto, 1998)\n\nHAIS is a version of AIS that uses Hamiltonian Monte Carlo (as opposed to\nMetropolis-Hastings or some other sampler) to move between the annealed\ndistributions.\n\nDeveloped by `@__Reidy__ <https://twitter.com/__Reidy__>`_ and\n`@bilginhalil <https://twitter.com/bilginhalil>`_\nand derived from https://github.com/jiamings/ais/.\n\n.. toctree::\n :maxdepth: 2\n :caption: Contents:\n\n ais.rst\n hmc.rst\n examples.rst\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.7157929539680481,
"alphanum_fraction": 0.7283217906951904,
"avg_line_length": 24.487394332885742,
"blob_id": "e5d712357431806db3d3936ef814c72e87f28b3d",
"content_id": "2063fd6918dc8e801180bc7b2e5302ae7b3cbe4a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3033,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 119,
"path": "/tests/test-bayesflow-log-gamma",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nEstimate the normalizing constant of a log-gamma distribution using\nTensorFlow's BayesFlow AIS implementation.\n\"\"\"\n\n\nimport time\n#\n# Plotting\nimport matplotlib.pyplot as plt\nimport seaborn as sns\n#\n# Scientific\nimport numpy as np\nimport tensorflow as tf\nfrom tensorflow.contrib.bayesflow import hmc\nfrom hais.examples import log_gamma_unnormalised_lpdf, log_gamma_exact_log_normaliser\n\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\n#\n# Check tensorflow version\nif tuple(map(int, tf.__version__.split('.'))) > (1, 6, 0):\n raise NotImplementedError(\n 'tensorflow.contrib.bayesflow.hmc.ais_chain is not implemented in versions of TensorFlow beyond 1.6.0')\n\n\n#\n# Constants\n#\n# normal parameters\nMU = 1.\nSIGMA = .5\n#\n# log-gamma parameters\nALPHA = 2.\nBETA = 3.\n#\n# RNG seed\nSEED = 41\n#\n# HMC AIS\nN_ITER = 3000\nN_CHAINS = 30000\nSTEPSIZE = .7\n\n\n#\n# Seed RNGs\nprint('Seeding RNGs')\nnp.random.seed(SEED)\ntf.set_random_seed(SEED)\n\n\n#\ndef log_target(x):\n return log_gamma_unnormalised_lpdf(x, ALPHA, BETA)\n# Calculate the true log normalizer\nlog_normalizer_true = log_gamma_exact_log_normaliser(ALPHA, BETA)\n\n\n#\n# Annealed importance sampling\nprint('Constructing AIS computation graph')\nstarttime = time.time()\nproposal = tf.distributions.Normal(loc=tf.zeros([N_CHAINS]), scale=tf.ones([N_CHAINS]))\ninitial_x = proposal.sample()\nlogw, samples, acceptance_probs = hmc.ais_chain(\n n_iterations=N_ITER, step_size=STEPSIZE, n_leapfrog_steps=1, initial_x=initial_x,\n target_log_prob_fn=log_target, proposal_log_prob_fn=proposal.log_prob)\nlog_normalizer = tf.reduce_logsumexp(logw) - np.log(N_CHAINS)\nendtime = time.time()\nprint('Constructing graph took {:.1f} seconds'.format(endtime - starttime))\n#\n# Construct and initialise the session\nsess = tf.Session()\nsess.run(tf.global_variables_initializer())\n#\n# Run AIS\nprint('Running AIS')\nstarttime = time.time()\nlog_normalizer_ais, log_w_ais, z_sampled, acceptance_probs_ais = \\\n sess.run([log_normalizer, logw, samples, acceptance_probs])\nendtime = time.time()\nprint('AIS took {:.1f} seconds'.format(endtime - starttime))\nprint('Estimated log normalizer: {:.4f}'.format(log_normalizer_ais))\nprint('True log normalizer: {:.4f}'.format(log_normalizer_true))\nprint('Acceptance probabilities: mean={:.3f}; sd={:.3f}'.format(\n np.mean(acceptance_probs_ais), np.std(acceptance_probs_ais)))\n\n\n#\n# Plot the output\nprint('Plotting log normalizer')\nfig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\n# ax.scatter(log_normalizer_ais, log_normalizer_true)\nax.set_xlabel('x')\nax.set_ylabel('target')\nax.set_title('Samples')\nz_sampled.shape\nsns.distplot(z_sampled, ax=ax)\nxmin, xmax = ax.get_xbound()\ntarget_range = np.linspace(xmin, xmax, num=300)\ntarget_range.shape\ntarget = sess.run(tf.exp(log_target(target_range) - log_normalizer_true))\nax.plot(target_range, target)\n#\n# Acceptance rate\nsns.distplot(acceptance_probs_ais.flatten(), ax=ax_accept)\nax_accept.set_title('acceptance probabilities')\n#\nfig.savefig('bayesflow-log-gamma.pdf')\n"
},
{
"alpha_fraction": 0.7444018125534058,
"alphanum_fraction": 0.7613563537597656,
"avg_line_length": 44.30434799194336,
"blob_id": "cdec6d9ddd667c26c1ba94432780300b64b9d6db",
"content_id": "83efba46d8fcc04337f862b192cedc6d88612e56",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3126,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 69,
"path": "/README.md",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "# README\n\nA TensorFlow implementation of Hamiltonian Annealed Importance Sampling (HAIS).\nWe implement the [method](http://arxiv.org/abs/1205.1925) described by Sohl-Dickstein and Culpepper\nin their paper \"Hamiltonian Annealed Importance Sampling for partition function estimation\".\n\n\n### Features\n\n - Partial momentum refresh (from HAIS paper). This preserves some fraction of the Hamiltonian Monte\n Carlo momentum across annealing distributions resulting in more accurate estimation.\n - Adaptive step size for Hamiltonian Monte Carlo. This is a simple scheme to adjust the step size for\n each chain in order to push the smoothed acceptance rate towards a theoretical optimum.\n\n\n### Related implementations\n\nWe have used ideas and built upon the code from some of the following repositories:\n\n - BayesFlow TensorFlow 1.4 - 1.6 [contribution](https://www.tensorflow.org/versions/r1.6/api_docs/python/tf/contrib/bayesflow/hmc/ais_chain).\n This is now integrated into [TensorFlow Probability](https://github.com/tensorflow/probability).\n - Sohl-Dickstein's Matlab [implementation](https://github.com/Sohl-Dickstein/Hamiltonian-Annealed-Importance-Sampling)\n - Xuechen Li's PyTorch (0.2.0) [implementation](https://github.com/lxuechen/BDMC) of Bi-Directional Monte Carlo\n from [\"Sandwiching the marginal likelihood using bidirectional Monte Carlo\"](https://arxiv.org/abs/1511.02543)\n - Tony Wu's Theano/Lasagne [implementation](https://github.com/tonywu95/eval_gen) of the methods described in\n [\"On the Quantitative Analysis of Decoder-Based Generative Models\"](https://arxiv.org/abs/1611.04273)\n - jiamings's (unfinished?) TensorFlow [implementation](https://github.com/jiamings/ais/) based on Tony Wu's Theano code.\n - Stefan Webb's HMC AIS in tensorflow [repository](https://github.com/stefanwebb/tensorflow-hmc-ais).\n\n\n### Tests\n\nThe tests that appear to be working include:\n\n - `test-hmc`: a simple test of the HMC implementation\n - `test-hmc-mvn`: a test of the HMC implementation that samples from a multivariate normal\n - `test-hais-log-gamma`: a simple test to sample from and calculate the log normaliser of\n an unnormalised log-Gamma density.\n - `test-hais-model1a-gaussian`: a test that estimates the log marginal likelihood for model 1a with\n a Gaussian prior from Sohl-Dickstein and Culpepper (2011).\n\n\n### Installation\n\nInstall either the GPU version of TensorFlow (I don't know why but `tensorflow-gpu==1.8` and\n`tensorflow-gpu==1.9` are >10x slower than 1.7 on my machine)\n```bash\npip install tensorflow-gpu==1.7\n```\nor the CPU version\n```bash\npip install tensorflow\n```\nthen install the project\n```bash\npip install git+https://github.com/JohnReid/HAIS\n```\n\n\n### API documentation\n\nThe implementation contains some [documentation](https://johnreid.github.io/HAIS/build/html/index.html)\ngenerated from the docstrings that may be useful. However it is probably easier to examine the\n[test scripts](https://github.com/JohnReid/HAIS/tree/master/tests) and adapt them to your needs.\n\n\n### Who do I talk to?\n\n[John Reid](https://twitter.com/__Reidy__) or [Halil Bilgin](https://twitter.com/bilginhalil)\n"
},
{
"alpha_fraction": 0.6654015183448792,
"alphanum_fraction": 0.6847782731056213,
"avg_line_length": 29.156625747680664,
"blob_id": "d28d220b65319aa19347b0c15de942a541db2919",
"content_id": "d9d466227b59750b3063fa09e4479701d83c91fc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5006,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 166,
"path": "/tests/test-hmc-mvn",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"\nTest our Hamiltonian annealed importance sampler by on a multivariate normal.\n\"\"\"\n\n\nimport time\nimport itertools\nimport hais.hmc as hmc\nimport numpy as np\nimport scipy.stats as st\nimport scipy.linalg as la\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport tensorflow as tf\nfrom packaging import version\nfrom pathlib import Path\n\n#\n# Configure TensorFlow depending on version\nprint(f'TensorFlow version: {tf.__version__}')\nif version.parse(tf.__version__) < version.parse('2.0.0'):\n # TensorFlow version 1\n tfd = tf.contrib.distributions\nelse:\n # TensorFlow version 2\n import tensorflow_probability as tfp\n tfd = tfp.distributions\n tf = tf.compat.v1\n\n#\n# Jupyter magic\n#\n# %load_ext autoreload\n# %autoreload 2\n\n\nOUTDIR = Path('output')\nSEED = 37\nNCHAINS = 2000\nNITER = 1000\n# normal parameters\nL = 3 # dimensions\nNU = L + 1. # degrees of freedom for inverse-Wishart\nPSI = np.diag(np.ones(L)) # scale for inverse-Wishart\nMU0 = np.zeros(L)\nM = 1. # Prior pseudocount\n#\n# HMC parameters\nSTEPSIZE = .1\n# STEPSIZE_INITIAL = .01\n# STEPSIZE_MIN = 1e-8\n# STEPSIZE_MAX = 500\n# STEPSIZE_DEC = .99\n# STEPSIZE_INC = 1.01\n\n#\n# Create the output directory if needed\nOUTDIR.mkdir(exist_ok=True, parents=True)\n\n#\n# Seed RNGs\ntf.set_random_seed(SEED)\nnp.random.seed(SEED)\n\n\ndef unnormalized_log_target(x):\n \"\"\"\n Unnormalized log probability density function of the multivariate normal(mu, Sigma) distribution.\n \"\"\"\n # print(x.shape)\n assert x.shape == (NCHAINS, L)\n sqrt = tf.einsum('ij,kj->ki', tf.cast(Cinv, dtype=tf.float32), (x - tf.cast(mu, dtype=tf.float32)))\n # print('sqrt: {}'.format(sqrt.shape))\n # sqrt = tf.multiply(tf.cast(Cinv, dtype=tf.float32), (x - tf.cast(mu, dtype=tf.float32)))\n lp = - tf.reduce_sum(tf.square(sqrt), axis=-1) / 2.\n # print('lp: {}'.format(lp.shape))\n return lp\n\n\n#\n# Model\n#\n# Use Bayesian conjugate priors for mean and covariance.\n#\nSigma = st.invwishart.rvs(df=NU, scale=PSI)\nprint('MVN covariance: {}'.format(Sigma))\nmu = st.multivariate_normal.rvs(mean=MU0, cov=Sigma / M)\nprint('MVN mean: {}'.format(mu))\n#\n# Calculate Cholesky decomposition and inverse\nprint('Calculating Cholesky decomposition')\nC = la.cholesky(Sigma, lower=True)\nCinv = la.solve_triangular(C, np.diag(np.ones(L)), lower=True)\n# Sigma - C @ C.T\n# la.inv(Sigma) - Cinv.T @ Cinv\n\n\n#\n# Prior for initial x\nprint('Constructing prior tensor')\nprior = tfd.MultivariateNormalDiag(loc=tf.zeros((NCHAINS, L)))\n#\n# Our samples\nprint('Constructing samples tensor')\nsamples = tf.TensorArray(dtype=tf.float32, size=NITER, element_shape=(NCHAINS, L))\n#\n# Sample\nprint('Creating sampling computation graph')\nx, v, samples_final, smoothed_accept_rate_final = hmc.hmc_sample(\n prior.sample(), unnormalized_log_target, eps=STEPSIZE,\n niter=NITER, nchains=NCHAINS, sample_shape=(L,), event_axes=(1,))\n#\n# Construct and initialise the session\nprint('Initialising session')\nsess = tf.Session()\nsess.run(tf.global_variables_initializer())\n#\n# Run sampler\nprint('Running sampler')\nstarttime = time.time()\nsamples_hmc, accept_hmc = sess.run((samples_final.stack(), smoothed_accept_rate_final))\nendtime = time.time()\nprint('Sampler took {:.1g} seconds'.format(endtime - starttime))\nprint('Final smoothed acceptance rate: mean={:.1g}; sd={:.1g}'.format(\n np.mean(accept_hmc), np.std(accept_hmc)))\nsamples_hmc.shape\nburned_in = samples_hmc[int(NITER / 2):]\n# burned_in.shapegraph\nburned_in.size / 1e6\nfor d in range(L):\n print('Mean of (burned in) samples (dim {}): {:.3g}'.format(d, np.mean(burned_in[:, :, d])))\n print('Desired mean (dim {}): {:.3g}'.format(d, mu[d]))\n print('Standard deviation of (burned in) samples (dim {}): {:.3g}'.format(d, np.std(burned_in[:, :, d])))\n print('Desired standard deviation (dim {}): {:.3g}'.format(d, np.sqrt(Sigma[d, d])))\nfor (d0, d1) in itertools.combinations(range(L), 2):\n sampled_rho = np.corrcoef(burned_in[:, :, d0].flatten(), burned_in[:, :, d1].flatten())[0, 1]\n exact_rho = Sigma[d0, d1] / np.sqrt(Sigma[d0, d0] * Sigma[d1, d1])\n print('Sample correlation (dims {}, {}): {:.3g}'.format(d0, d1, sampled_rho))\n print('Expected correlation (dims {}, {}): {:.3g}'.format(d0, d1, exact_rho))\n#\n# Drop samples so we don't have too many per chain\nMAX_SAMPLES_PER_CHAIN = 47\nif burned_in.shape[0] > MAX_SAMPLES_PER_CHAIN:\n burned_in = burned_in[::(int(burned_in.shape[0] / MAX_SAMPLES_PER_CHAIN) + 1)]\nburned_in.shape\n\n#\n# Plot samples\nsamples_path = OUTDIR / 'hmc-mvn-samples.pdf'\nprint(f'Plotting samples: {samples_path}')\nplt.contour\nd0, d1 = 0, 1\nfig, (ax, ax_accept) = plt.subplots(2, 1, figsize=(8, 12))\nax.scatter(burned_in[:, :, d0], burned_in[:, :, d1], alpha=.01)\nax.set_xlabel('dim {}'.format(d0))\nax.set_ylabel('dim {}'.format(d1))\nax.set_title('Samples')\n#\n# Acceptance rate\nprint('Plotting acceptance rate: {samples_path}')\nsns.distplot(accept_hmc.flatten(), ax=ax_accept)\nax_accept.set_title('Smoothed acceptance rates')\nfig.savefig(samples_path)\n\nprint('Done')\n"
},
{
"alpha_fraction": 0.6635259389877319,
"alphanum_fraction": 0.6719563603401184,
"avg_line_length": 46.16958999633789,
"blob_id": "018cd2b0013f368f675699a1dfc5202d00469a12",
"content_id": "348832ae8c0ad038ba4df0d819555504b6d65d4a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": true,
"language": "HTML",
"length_bytes": 8082,
"license_type": "permissive",
"max_line_length": 385,
"num_lines": 171,
"path": "/docs/build/html/examples.html",
"repo_name": "JohnReid/HAIS",
"src_encoding": "UTF-8",
"text": "\n<!DOCTYPE html PUBLIC \"-//W3C//DTD XHTML 1.0 Transitional//EN\"\n \"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd\">\n\n<html xmlns=\"http://www.w3.org/1999/xhtml\">\n <head>\n <meta http-equiv=\"X-UA-Compatible\" content=\"IE=Edge\" />\n <meta http-equiv=\"Content-Type\" content=\"text/html; charset=utf-8\" />\n <title>Module hais.examples — HAIS 0.1.0 documentation</title>\n <link rel=\"stylesheet\" href=\"_static/alabaster.css\" type=\"text/css\" />\n <link rel=\"stylesheet\" href=\"_static/pygments.css\" type=\"text/css\" />\n <script type=\"text/javascript\" id=\"documentation_options\" data-url_root=\"./\" src=\"_static/documentation_options.js\"></script>\n <script type=\"text/javascript\" src=\"_static/jquery.js\"></script>\n <script type=\"text/javascript\" src=\"_static/underscore.js\"></script>\n <script type=\"text/javascript\" src=\"_static/doctools.js\"></script>\n <script type=\"text/javascript\" src=\"https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config=TeX-AMS-MML_HTMLorMML\"></script>\n <link rel=\"index\" title=\"Index\" href=\"genindex.html\" />\n <link rel=\"search\" title=\"Search\" href=\"search.html\" />\n <link rel=\"prev\" title=\"Module hais.hmc\" href=\"hmc.html\" />\n \n <link rel=\"stylesheet\" href=\"_static/custom.css\" type=\"text/css\" />\n \n \n <meta name=\"viewport\" content=\"width=device-width, initial-scale=0.9, maximum-scale=0.9\" />\n\n </head><body>\n \n\n <div class=\"document\">\n <div class=\"documentwrapper\">\n <div class=\"bodywrapper\">\n \n\n <div class=\"body\" role=\"main\">\n \n <div class=\"section\" id=\"module-hais.examples\">\n<span id=\"module-hais-examples\"></span><h1>Module hais.examples<a class=\"headerlink\" href=\"#module-hais.examples\" title=\"Permalink to this headline\">¶</a></h1>\n<p>Unnormalised targets and exact calculations for some example problems.</p>\n<blockquote>\n<div><ul class=\"simple\">\n<li>An unnormalised log-Gamma distribution</li>\n<li>Model 1a from Sohl-Dickstein and Culpepper</li>\n</ul>\n</div></blockquote>\n<dl class=\"class\">\n<dt id=\"hais.examples.Culpepper1aGaussian\">\n<em class=\"property\">class </em><code class=\"descclassname\">hais.examples.</code><code class=\"descname\">Culpepper1aGaussian</code><span class=\"sig-paren\">(</span><em>M</em>, <em>L</em>, <em>sigma_n</em>, <em>batch_size</em>, <em>n_chains</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.Culpepper1aGaussian\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Implementations of likelihood, sampling and exact marginal\nfor model1a (with Gaussian prior) from Sohl-Dickstein and\nCulpepper.</p>\n<p>We name the latent variable ‘z’ in place of ‘a’</p>\n<p>The code is set up to estimate the log marginal of several batches (different <cite>x</cite>) concurrently.</p>\n<dl class=\"method\">\n<dt id=\"hais.examples.Culpepper1aGaussian.__init__\">\n<code class=\"descname\">__init__</code><span class=\"sig-paren\">(</span><em>M</em>, <em>L</em>, <em>sigma_n</em>, <em>batch_size</em>, <em>n_chains</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.Culpepper1aGaussian.__init__\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Initialise the model with the parameters.</p>\n</dd></dl>\n\n<dl class=\"method\">\n<dt id=\"hais.examples.Culpepper1aGaussian.log_likelihood\">\n<code class=\"descname\">log_likelihood</code><span class=\"sig-paren\">(</span><em>z</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.Culpepper1aGaussian.log_likelihood\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Calculates the log pdf of the conditional distribution of x given z.</p>\n</dd></dl>\n\n<dl class=\"method\">\n<dt id=\"hais.examples.Culpepper1aGaussian.log_marginal\">\n<code class=\"descname\">log_marginal</code><span class=\"sig-paren\">(</span><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.Culpepper1aGaussian.log_marginal\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Calculate the exact log marginal likelihood of the <cite>x</cite> given\n<cite>phi</cite> and <cite>sigma_n</cite>.</p>\n</dd></dl>\n\n<dl class=\"method\">\n<dt id=\"hais.examples.Culpepper1aGaussian.log_posterior\">\n<code class=\"descname\">log_posterior</code><span class=\"sig-paren\">(</span><em>z</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.Culpepper1aGaussian.log_posterior\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>The unnormalised log posterior.</p>\n</dd></dl>\n\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.examples.log_gamma_exact_log_normaliser\">\n<code class=\"descclassname\">hais.examples.</code><code class=\"descname\">log_gamma_exact_log_normaliser</code><span class=\"sig-paren\">(</span><em>alpha</em>, <em>beta</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.log_gamma_exact_log_normaliser\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>The exact log normalizer is:</p>\n<div class=\"math notranslate nohighlight\">\n\\[\\log \\Gamma(\\alpha) - \\alpha \\log \\beta\\]</div>\n</dd></dl>\n\n<dl class=\"function\">\n<dt id=\"hais.examples.log_gamma_unnormalised_lpdf\">\n<code class=\"descclassname\">hais.examples.</code><code class=\"descname\">log_gamma_unnormalised_lpdf</code><span class=\"sig-paren\">(</span><em>x</em>, <em>alpha</em>, <em>beta</em><span class=\"sig-paren\">)</span><a class=\"headerlink\" href=\"#hais.examples.log_gamma_unnormalised_lpdf\" title=\"Permalink to this definition\">¶</a></dt>\n<dd><p>Unnormalized log probability density function of the log-gamma(ALPHA, BETA) distribution.</p>\n<p>The probability density function for a gamma distribution is:</p>\n<div class=\"math notranslate nohighlight\">\n\\[f(x; \\alpha, \\beta) =\n \\frac{\\beta^\\alpha}{\\Gamma(\\alpha)}\n x^{\\alpha-1}\n e^{- \\beta x}\\]</div>\n<p>for all <span class=\"math notranslate nohighlight\">\\(x > 0\\)</span> and any given shape <span class=\"math notranslate nohighlight\">\\(\\alpha > 0\\)</span> and rate <span class=\"math notranslate nohighlight\">\\(\\beta > 0\\)</span>. Given a change\nof variables <span class=\"math notranslate nohighlight\">\\(y = \\log(x)\\)</span> we have the density for a log-gamma distribution:</p>\n<div class=\"math notranslate nohighlight\">\n\\[f(y; \\alpha, \\beta) =\n \\frac{\\beta^\\alpha}{\\Gamma(\\alpha)}\n e^{\\alpha y - \\beta e^y}\\]</div>\n</dd></dl>\n\n</div>\n\n\n </div>\n \n </div>\n </div>\n <div class=\"sphinxsidebar\" role=\"navigation\" aria-label=\"main navigation\">\n <div class=\"sphinxsidebarwrapper\">\n<h1 class=\"logo\"><a href=\"index.html\">HAIS</a></h1>\n\n\n\n\n\n\n\n\n<h3>Navigation</h3>\n<p class=\"caption\"><span class=\"caption-text\">Contents:</span></p>\n<ul class=\"current\">\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"ais.html\">Module hais.ais</a></li>\n<li class=\"toctree-l1\"><a class=\"reference internal\" href=\"hmc.html\">Module hais.hmc</a></li>\n<li class=\"toctree-l1 current\"><a class=\"current reference internal\" href=\"#\">Module hais.examples</a></li>\n</ul>\n\n<div class=\"relations\">\n<h3>Related Topics</h3>\n<ul>\n <li><a href=\"index.html\">Documentation overview</a><ul>\n <li>Previous: <a href=\"hmc.html\" title=\"previous chapter\">Module hais.hmc</a></li>\n </ul></li>\n</ul>\n</div>\n<div id=\"searchbox\" style=\"display: none\" role=\"search\">\n <h3>Quick search</h3>\n <div class=\"searchformwrapper\">\n <form class=\"search\" action=\"search.html\" method=\"get\">\n <input type=\"text\" name=\"q\" />\n <input type=\"submit\" value=\"Go\" />\n <input type=\"hidden\" name=\"check_keywords\" value=\"yes\" />\n <input type=\"hidden\" name=\"area\" value=\"default\" />\n </form>\n </div>\n</div>\n<script type=\"text/javascript\">$('#searchbox').show(0);</script>\n </div>\n </div>\n <div class=\"clearer\"></div>\n </div>\n <div class=\"footer\">\n ©2018, John Reid and Halil Bilgin.\n \n |\n Powered by <a href=\"http://sphinx-doc.org/\">Sphinx 1.7.8</a>\n & <a href=\"https://github.com/bitprophet/alabaster\">Alabaster 0.7.11</a>\n \n |\n <a href=\"_sources/examples.rst.txt\"\n rel=\"nofollow\">Page source</a>\n </div>\n\n \n\n \n </body>\n</html>"
}
] | 21 |
dae4/torch
|
https://github.com/dae4/torch
|
b0dc2e2123953865ae163b0bacbecba80a443501
|
e4fe5a030a7984efa452ab6b996ed98c8ddcdd36
|
71380d161a8192ba04867506c032287c56d83ff1
|
refs/heads/main
| 2023-03-29T08:40:38.542746 | 2021-03-27T11:39:02 | 2021-03-27T11:39:02 | 330,731,563 | 1 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6384848356246948,
"alphanum_fraction": 0.6578788161277771,
"avg_line_length": 26.7394962310791,
"blob_id": "16fac29f3a3c00c79f9398edab1d0770f9f079f9",
"content_id": "40a94e893fd459d9b7523afb0daebe9014595900",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3300,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 119,
"path": "/example/Classification_template.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "#%%\nimport torch\nimport torch.nn as nn\nimport torch.optim as optim\nfrom torch.optim import lr_scheduler\nimport numpy as np\nimport torchvision\nfrom torchvision import datasets, models, transforms\nimport matplotlib.pyplot as plt\nimport time\nimport os\nfrom tqdm.notebook import tqdm\n\n## Check device\nprint(torch.cuda.is_available())\nprint(torch.cuda.get_device_name(0))\nprint(torch.cuda.device_count())\n\ndevice = torch.device(\"cuda:2\" if torch.cuda.is_available() else \"cpu\")\n#%%\n## data_set : ( https://pytorch.org/docs/stable/torchvision/datasets.html)\n\ndata_dir = \"FashionMNIST/\"\nif not os.path.exists(data_dir):\n os.mkdir(data_dir)\n\ntransform = transforms.Compose(\n [transforms.ToTensor(),\n transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])\n\ntrainset = torchvision.datasets.CIFAR10(root=data_dir, train=True,\n download=True, transform=transform)\ntrainloader = torch.utils.data.DataLoader(trainset, batch_size=4,\n shuffle=True, num_workers=2)\n\ntestset = torchvision.datasets.CIFAR10(root=data_dir, train=False,\n download=True, transform=transform)\ntestloader = torch.utils.data.DataLoader(testset, batch_size=4,\n shuffle=False, num_workers=2)\n\nclasses = trainset.classes\nprint(trainset.class_to_idx)\n#%%\n## check the data.shape\n## (batch,w,h,c)\nprint(trainloader.dataset.data.shape)\nprint(testloader.dataset.data.shape)\n#%%\n\n## model ( https://pytorch.org/docs/stable/torchvision/models.html )\n\nmodel_dir = 'model/'\nif not os.path.exists(model_dir):\n os.mkdir(model_dir)\n\nimport torchvision.models as model\nmodel_ft = models.resnet18(pretrained=False)\nnum_ftrs = model_ft.fc.in_features\nmodel_ft.fc = nn.Linear(num_ftrs, 10)\nmodel_ft = model_ft.to(device)\n\n# #%%\n# show model.summary like keras\n# from torchsummary import summary\n# print(summary(model_ft,(3,32,32)),device=\"cuda:2\")\n\nimport torch.optim as optim\n\ncriterion = nn.CrossEntropyLoss()\noptimizer = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)\n#%%\n\nfor epoch in tqdm(range(2)): # loop over the dataset multiple times\n\n running_loss = 0.0\n for i, data in enumerate(trainloader, 0):\n # get the inputs; data is a list of [inputs, labels]\n inputs, labels = data\n # get GPU input \n inputs,labels = inputs.to(device),labels.to(device)\n\n # zero the parameter gradients\n optimizer.zero_grad()\n\n # forward + backward + optimize\n outputs = model_ft(inputs)\n loss = criterion(outputs, labels)\n loss.backward()\n optimizer.step()\n\n # print statistics\n running_loss += loss.item()\n if i % 2000 == 1999: # print every 2000 mini-batches\n print('[%d, %5d] loss: %.3f' %\n (epoch + 1, i + 1, running_loss / 2000))\n running_loss = 0.0\n\nprint('Finished Training')\n#%%\n\n## only parameter save \ntorch.save(model.state_dict(),model_dir)\n\n## model save\n#torch.save(model,model_dir)\n#%%\n# Model Load \n## \nfrom torchvision.models.resnet import Resnet\n\nsave_model = model_dir +'.pth'\n\nloaded_model = ResNet()\n\nloaded_model.load_state_dict(torch.load(save_model))\n\n## saved model with parameter\n\n# the_model = torch.load(save_model)"
},
{
"alpha_fraction": 0.6248045563697815,
"alphanum_fraction": 0.63913494348526,
"avg_line_length": 27.437036514282227,
"blob_id": "651e37348bc969deecb4e8d6abd0320b7983e601",
"content_id": "4c0c8b277a80ff9eca56d3b123ac6707e3d5f420",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4072,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 135,
"path": "/example/CNN.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "import torch.nn as nn\nfrom Xception import xception\nimport torch.optim as optim\nimport os\nimport shutil\nfrom PIL import ImageFile\nimport torchvision.transforms as transforms\nimport torchvision\nfrom torch.utils.data import DataLoader\nimport torch\nimport tqdm\nfrom tqdm import trange\nfrom torch.optim import lr_scheduler\nimport copy\nimport time\n\nImageFile.LOAD_TRUNCATED_IMAGES = False\n\nos.environ[\"CUDA_DEVICE_ORDER\"]=\"PCI_BUS_ID\"\nos.environ[\"CUDA_VISIBLE_DEVICES\"]='0,1,2,3,4,5,6,7'\n\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n\nimage_size = 299\nbatch_size = 32 * torch.cuda.device_count()\nepochs=50\n\n\ndataRootDir=''\ntrainBaseDir = dataRootDir + \"train\"\ntestBaseDir = dataRootDir + \"test\"\n\nclasses_name = sorted(os.listdir(trainBaseDir))\nmodelOutputDir= \"\"\n\nshutil.rmtree(modelOutputDir, ignore_errors=True)\nif not os.path.exists(modelOutputDir):\n os.makedirs(modelOutputDir)\n\ntrans = transforms.Compose([transforms.Resize((image_size,image_size)),transforms.ToTensor()])\n\ntrain_data = torchvision.datasets.ImageFolder(root = trainBaseDir,transform = trans)\ntest_data = torchvision.datasets.ImageFolder(root = testBaseDir,transform = trans) \n\ntrainloader= DataLoader(train_data,batch_size=batch_size,shuffle=True,num_workers=32)\ntestloader = DataLoader(test_data,batch_size=batch_size,shuffle=False,num_workers=32)\n\n\n## Create Model\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\nmodel = xception()\nif torch.cuda.device_count() > 1:\n print(torch.cuda.device_count(),\"GPUs!\")\n model = torch.nn.DataParallel(model)\n\nnet=model.to(device)\n\noptimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)\ncriterion = nn.CrossEntropyLoss()\n\n\n\n# 5 에폭마다 0.1씩 학습률 감소\nscheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.0005)\n\nsince = time.time()\n\nbest_model_wts = copy.deepcopy(model.state_dict())\nbest_acc = 0.0\n\ndataset_sizes = len(train_data)+len(test_data)\n\n\nfor epoch in range(epochs):\n print('Epoch {}/{}'.format(epoch, epochs - 1))\n print('-' * 10)\n\n # 각 에폭(epoch)은 학습 단계와 검증 단계를 갖습니다.\n for phase in ['train', 'val']:\n if phase == 'train':\n model.train() # 모델을 학습 모드로 설정\n data_loader = trainloader\n else:\n model.eval() # 모델을 평가 모드로 설정\n data_loader = testloader\n running_loss = 0.0\n running_corrects = 0\n\n # 데이터를 반복\n for inputs, labels in data_loader:\n inputs = inputs.to(device)\n labels = labels.to(device)\n\n # 매개변수 경사도를 0으로 설정\n optimizer.zero_grad()\n\n # 순전파\n # 학습 시에만 연산 기록을 추적\n with torch.set_grad_enabled(phase == 'train'):\n outputs = model(inputs)\n _, preds = torch.max(outputs, 1)\n loss = criterion(outputs, labels)\n\n # 학습 단계인 경우 역전파 + 최적화\n if phase == 'train':\n loss.backward()\n optimizer.step()\n\n # 통계\n running_loss += loss.item() * inputs.size(0)\n running_corrects += torch.sum(preds == labels.data)\n if phase == 'train':\n scheduler.step()\n\n epoch_loss = running_loss / dataset_sizes[phase]\n epoch_acc = running_corrects.double() / dataset_sizes[phase]\n\n print('{} Loss: {:.4f} Acc: {:.4f}'.format(\n phase, epoch_loss, epoch_acc))\n\n # 모델을 깊은 복사(deep copy)함\n if phase == 'val' and epoch_acc > best_acc:\n best_acc = epoch_acc\n best_model_wts = copy.deepcopy(model.state_dict())\n\n print()\n\ntime_elapsed = time.time() - since\nprint('Training complete in {:.0f}m {:.0f}s'.format(time_elapsed // 60, time_elapsed % 60))\nprint('Best val Acc: {:4f}'.format(best_acc))\n\n# 가장 나은 모델 가중치를 불러옴\nmodel.load_state_dict(best_model_wts)\n\nprint('Finished Training')"
},
{
"alpha_fraction": 0.5789870023727417,
"alphanum_fraction": 0.5957446694374084,
"avg_line_length": 34.172183990478516,
"blob_id": "44dc1549d2a9f286966698c5b717781443c5f539",
"content_id": "82eb547f9a92980ee15472e75a7c3b7223316424",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5435,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 151,
"path": "/example/CNN2.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "from Xception import xception\nimport os\nfrom PIL import ImageFile\nimport torchvision.transforms as transforms\nimport torchvision\nimport torch\nimport tqdm\nfrom tqdm import trange\n\nfrom torch.nn.parallel import DistributedDataParallel as DDP\nimport torch.multiprocessing as mp\nfrom torch.optim import lr_scheduler\nimport copy\nimport time\n\n# def StartTraining(dataRootDir, modelOutputDir, gpuNum, visibleGpu, batchSize, imgSize, epoch, release_mode=False):\n\nImageFile.LOAD_TRUNCATED_IMAGES = False\n\nos.environ[\"CUDA_DEVICE_ORDER\"]=\"PCI_BUS_ID\"\nos.environ[\"CUDA_VISIBLE_DEVICES\"]='0,1,2,3,4,5,6,7'\n\ndataRootDir=''\ntrainBaseDir = dataRootDir + \"train\"\ntestBaseDir = dataRootDir + \"test\"\nmodelOutputDir=\"\"\n\ndef get_train_loader(image_size, batch_size, num_worker):\n transform_train = transforms.Compose([\n transforms.RandomResizedCrop(image_size),\n # transforms.RandomHorizontalFlip(),\n # transforms.RandomVerticalFlip(),\n # transforms.RandomRotation(45),\n # transforms.RandomAffine(45),\n # transforms.ColorJitter(),\n transforms.ToTensor(),\n # transforms.Normalize(mean=[0.485, 0.456, 0.406],\n # std=[0.229, 0.224, 0.225])\n ])\n train_datasets = torchvision.datasets.ImageFolder(root=trainBaseDir, transform=transform_train)\n test_data = torchvision.datasets.ImageFolder(root = testBaseDir,transform = transform_train) \n train_sampler = torch.utils.data.distributed.DistributedSampler(train_datasets)\n shuffle = False\n pin_memory = True\n train_loader = torch.utils.data.DataLoader(\n dataset=train_datasets, batch_size=batch_size, pin_memory=pin_memory,\n num_workers=num_worker, shuffle=shuffle, sampler=train_sampler)\n testloader = torch.utils.data.DataLoader(\n test_data,batch_size=batch_size,shuffle=False,num_workers=64)\n\n return train_loader ,testloader\n\n\ndef main_worker(gpu, ngpus_per_node):\n \n image_size = 299\n batch_size = 64*torch.cuda.device_count()\n num_worker = 128\n epochs = 1\n \n \n running_loss = 0.0\n running_corrects = 0\n best_acc = 0.0\n\n batch_size = int(batch_size / ngpus_per_node)\n num_worker = int(num_worker / ngpus_per_node)\n device = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\n torch.distributed.init_process_group(\n backend='nccl',\n init_method='tcp://127.0.0.1:3456',\n world_size=ngpus_per_node,\n rank=gpu)\n model = xception()\n torch.cuda.set_device(gpu)\n model = model.cuda(gpu)\n model = DDP(model, device_ids=[gpu])\n \n train_loader, test_loader = get_train_loader(\n image_size=image_size,\n batch_size=batch_size,\n num_worker=num_worker)\n \n dataset_sizes={}\n dataset_sizes['train']=len(train_loader)\n dataset_sizes['val']=len(test_loader)\n\n optimizer = torch.optim.SGD(\n params=model.parameters(),\n lr=0.001,\n momentum=0.9)\n criterion = torch.nn.CrossEntropyLoss().to(gpu)\n scheduler = lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.0005)\n \n phase='train'\n for epoch in range(epochs):\n since = time.time()\n print('Epoch {}/{}'.format(epoch, epochs - 1))\n print('-' * 10)\n for phase in ['train', 'val']:\n if phase == 'train':\n model.train() # 모델을 학습 모드로 설정\n data_loader = train_loader\n else:\n model.eval() # 모델을 평가 모드로 설정\n data_loader = test_loader\n\n for inputs, labels in data_loader:\n inputs = inputs.to(device)\n labels = labels.to(device)\n\n # 매개변수 경사도를 0으로 설정\n optimizer.zero_grad()\n\n # 순전파\n # 학습 시에만 연산 기록을 추적\n with torch.set_grad_enabled(phase == 'train'):\n outputs = model(inputs)\n _, preds = torch.max(outputs, 1)\n loss = criterion(outputs, labels)\n\n # 학습 단계인 경우 역전파 + 최적화\n if phase == 'train':\n loss.backward()\n optimizer.step()\n\n # 통계\n running_loss += loss.item() * inputs.size(0)\n running_corrects += torch.sum(preds == labels.data)\n if phase == 'train':\n scheduler.step()\n\n epoch_loss = running_loss / dataset_sizes[phase]\n epoch_acc = running_corrects.double() / dataset_sizes[phase]\n\n if phase == 'val' and epoch_acc > best_acc:\n best_acc = epoch_acc\n best_model_wts = copy.deepcopy(model.state_dict())\n\n print('{} Loss: {:.4f} Acc: {:.4f}'.format(phase, epoch_loss, epoch_acc))\n time_elapsed = time.time() - since\n print(f'{epoch} epoch complete in {time_elapsed // 60:.0f}m {time_elapsed % 60:.0f}s')\n\n torch.save(model.state_dict(), modelOutputDir+f'{epoch}.pth')\n print('Best val Acc: {:4f}'.format(best_acc))\n\nif __name__ == '__main__':\n ngpus_per_node = torch.cuda.device_count()\n world_size = ngpus_per_node\n torch.multiprocessing.spawn(main_worker, nprocs=ngpus_per_node, args=(ngpus_per_node, ))\n print('Finished Training')\n"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 8,
"blob_id": "1b5113d7e893a43267396fb2cd52e26f1d4c53e0",
"content_id": "9863b48007144b6ab96c9f35ea083afdff2f3fbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 2,
"path": "/Tutorial/torch_01.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "# %%\nimport torch"
},
{
"alpha_fraction": 0.5871725678443909,
"alphanum_fraction": 0.6187894940376282,
"avg_line_length": 16.03076934814453,
"blob_id": "4f86e6fab42a2d94cf834bf5fcc2791288ae0db5",
"content_id": "7f61811c5c87cef63987eaa24fa2d34c7e3718d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1197,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 65,
"path": "/Tutorial/torch_03.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "#%%\n# AUTOGRAD \nimport torch\n\nx = torch.ones(2,2,requires_grad=True)\n# requires_grad \n# 그 tensor에서 이뤄진 모든 연산들을 추적함\nprint(x)\n# %%\ny = x+2\nprint(y)\n# %%\n# y는 연산 결과로 생성되어 grad_fn를 갖음\n# grad_fn는 tensor를 생성한 funcion을 참조함\nprint(y.grad_fn)\n\n# %%\n# (1+2)*(1+2)*3=27\nz= y*y*3\nout = z.mean()\nprint(z,out)\n# %%\n# .requires_grad_는 .requires_grad 값을 바꿔치기(in-place)함\n\na = torch.randn(2,2)\na=((a*3)/(a-1))\nprint(a.requires_grad)\na.requires_grad_(True)\nprint(a.requires_grad)\nb=(a*a).sum()\nprint(b.grad_fn)\n# %%\n## Gradient\n## *** realate backprop\n## out = z.mean()\nout.backward()\n## out.backward(torch.tensor(1))\nprint(x.grad) ## dout/dx\n# %%\n\nx = torch.randn(3, requires_grad=True)\n\ny = x * 2\nwhile y.data.norm() < 1000: \n ## y.data.norm ==> torch.sqrt(torch.sum(torch.pow(y, 2)))\n y = y*2\nprint(y)\n\n# %%\ngradients = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)\ny.backward(gradients )\n\nprint(x.grad)\n# %%\nprint(x.requires_grad)\nprint((x ** 2).requires_grad)\n\nwith torch.no_grad():\n print((x ** 2).requires_grad)\n# %%\nprint(x.requires_grad)\ny = x.detach()\nprint(y.requires_grad)\nprint(x.eq(y).all())\n# %%\n"
},
{
"alpha_fraction": 0.6274238228797913,
"alphanum_fraction": 0.6529085636138916,
"avg_line_length": 27.203125,
"blob_id": "76fd843be827daf11dd73585aaa8a659313fa129",
"content_id": "82c88d194b20234a0b7313d8f1bd95e26bd79ac4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3776,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 128,
"path": "/example/Classification_inception.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "#%%\nimport torch\nimport numpy as np\nimport torchvision\nimport os\n\nfrom torch import nn\nfrom torch import optim\nfrom torch.autograd import Variable\nfrom torch.utils.data import DataLoader\nfrom torchvision import datasets, models, transforms\n\nuse_cuda = torch.cuda.is_available()\nBATCH_SIZE = 6\nFINE_TUNE = False\n# True 전체 네트워크 학습, False 최종 마지막 FC만\n\n### Data Ready ###\ntrain_transform = transforms.Compose([\n transforms.RandomSizedCrop(300),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])\n])\n\ntest_transform = transforms.Compose([\n transforms.Scale(300),\n transforms.CenterCrop(300),\n transforms.ToTensor()\n])\n\ntrain_data = datasets.ImageFolder('image/train/',train_transform)\ntest_data = datasets.ImageFolder('image/train/',test_transform)\n\ntrain_loader = DataLoader(train_data, batch_size=BATCH_SIZE, shuffle=True,num_workers=8)\ntest_loader = DataLoader(test_data, batch_size=BATCH_SIZE, shuffle=True,num_workers=8)\n#%%\nimport matplotlib.pyplot as plt\n## Data Visualize ##\n\ndef show():\n img, lab = next(iter(train_loader))\n class_name = [train_data.classes[i] for i in lab]\n img = torchvision.utils.make_grid(img, nrow=8)\n \n plt.figure(figsize=(10, 10))\n img = img.numpy().transpose((1, 2, 0))\n mean = np.array([0.485, 0.456, 0.406])\n std = np.array([0.229, 0.224, 0.225])\n img = std * img + mean\n plt.imshow(img)\n\n if class_name is not None:\n plt.title(class_name)\n plt.pause(0.001)\n\nshow()\n#%%\n\ninception = models.inception_v3(pretrained=True)\n\n# Auxiliary 를 사용하지 않으면 inception v2와 동일\ninception.aux_logits = False\n\n# 일단 모든 layers를 requires_grad=False 를 통해서 학습이 안되도록 막습니다.\nif not FINE_TUNE:\n for parameter in inception.parameters():\n parameter.requires_grad = False\n\n# 새로운 fully-connected classifier layer 를 만들어줍니다. (requires_grad 는 True)\n# in_features: 2048 -> in 으로 들어오는 feature의 갯수\nn_features = inception.fc.in_features\ninception.fc = nn.Linear(n_features, 2) \n\nif use_cuda:\n inception = inception.cuda()\n \ncriterion = nn.CrossEntropyLoss()\n\n# Optimizer에는 requires_grad=True 인 parameters들만 들어갈수 있습니다.\noptimizer = optim.RMSprop(filter(lambda p: p.requires_grad, inception.parameters()), lr=0.001)\n\n\n# %%\nfrom tqdm.notebook import tqdm\n\ndef train_model(model, criterion,optimizer,epochs=30):\n for epoch in tqdm(range(epochs)):\n epoch_loss =0\n for step, (inputs, y_true) in enumerate(train_loader):\n if use_cuda:\n x_sample, y_true = inputs.cuda(), y_true.cuda()\n x_sample, y_true = Variable(x_sample), Variable(y_true)\n\n # optimizer 0으로 초기화\n optimizer.zero_grad()\n\n # Feedfoward\n y_pred = inception(x_sample)\n loss = criterion(y_pred, y_true)\n loss.backward()\n optimizer.step()\n \n _loss = loss.data\n epoch_loss += _loss\n\n print(f'[{epoch+1}] loss:{epoch_loss/step:.4f}')\n\ntrain_model(inception, criterion,optimizer)\n# %%\ndef validate(model, epochs=1):\n model.train(False)\n n_total_correct = 0\n for step, (inputs, y_true) in enumerate(test_loader):\n if use_cuda:\n x_sample, y_true = inputs.cuda(), y_true.cuda()\n x_sample, y_true = Variable(x_sample), Variable(y_true)\n\n y_pred = model(x_sample)\n _, y_pred = torch.max(y_pred.data, 1)\n \n n_correct = torch.sum(y_pred == y_true.data)\n n_total_correct += n_correct\n \n print('accuracy:', n_total_correct/len(test_loader.dataset))\n\nvalidate(inception)\n# %%\n"
},
{
"alpha_fraction": 0.5394063591957092,
"alphanum_fraction": 0.5649948716163635,
"avg_line_length": 15.559322357177734,
"blob_id": "b0a74ae84a7ef975f24b71acd9af2a48dbe6f691",
"content_id": "1f3c6d1eee9523ba332c6e134436f319b82338a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 59,
"path": "/Tutorial/torch_02.py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "#%%\nimport torch\n\n# %%\n# Add Operations\nx = torch.tensor([5.5, 3])\nx = x.new_ones(5, 3, dtype=torch.double)\nprint(x) \ny = torch.rand(5,3)\nprint(x+y)\n\n# Add operations 2\nresult = torch.empty(5, 3)\ntorch.add(x,y,out=result)\nprint(result)\n# %%\n# Add operataion 3\n# 바꿔치기(in-place) 방식으로 tensor의 값을 변경하는 연산 뒤에는 _``가 붙습니다. \n# 예: ``x.copy_(y), x.t_() 는 x 를 변경합니다.\ny.add_(x)\nprint(y)\n\n# %%\n# axis = 1 \nprint(x[:, 1])\n# %%\nx = torch.randn(4,4)\ny = x.view(16) # 16\nz = x.view(-1,8) # x ,8\nprint(x.size(),y.size(),z.size())\n# %%\n\nx= torch.rand(1)\nprint(x)\nprint(x.item()) ## 값만 불러오기 \n\n# %%\n# Torch tensor -> numpy \n\na=torch.ones(5)\nprint(a)\n\nb=a.numpy()\nprint(b)\n\na.add_(1)\nprint(a)\nprint(b)\n# %%\n# CUDA Tensors\nif torch.cuda.is_available():\n device = torch.device(\"cuda\")\n print(device)\n y = torch.ones_like(x, device=device) # directly create tensor in gpu \n x = x.to(device) \n z = x + y\n print(z)\n print(z.to(\"cpu\", torch.double)) \n# %%\n"
},
{
"alpha_fraction": 0.5836910009384155,
"alphanum_fraction": 0.6194563508033752,
"avg_line_length": 20.397958755493164,
"blob_id": "daf4dc9ce0a8498b526fcdd4b42ce3987b78af14",
"content_id": "9bddda0867d50205f822ffc575c37c07bb7e5286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2195,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 98,
"path": "/Tutorial/torch_04(NN).py",
"repo_name": "dae4/torch",
"src_encoding": "UTF-8",
"text": "# %%\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\n\nclass Net(nn.Module):\n\n def __init__(self):\n super(Net,self).__init__()\n\n # Conv2d(input,output,kernel_size(x,x))\n self.conv1 = nn.Conv2d(1,6,3)\n self.conv2 = nn.Conv2d(6,16,3)\n\n self.fc1 = nn.Linear(16*6*6,120)\n self.fc2 = nn.Linear(120,84)\n self.fc3 = nn.Linear(84,10)\n \n def forward(self, x):\n x = F.max_pool2d(F.relu(self.conv1(x)),(2,2))\n x = F.max_pool2d(F.relu(self.conv2(x)),2)\n x = x.view(-1,self.num_flat_features(x))\n x = F.relu(self.fc1(x))\n x = F.relu(self.fc2(x))\n x = self.fc3(x)\n return x\n\n def num_flat_features(self, x):\n size = x.size()[1:] # 배치 차원을 제외한 모든 차원\n num_features = 1\n for s in size:\n num_features *= s\n return num_features\n\nnet = Net()\nprint(net)\n# %%\n\nparams = list(net.parameters())\nprint(len(params))\nprint(params[0].size())\n# %%\n## input 임의 생성\ninput = torch.rand(1,1,32,32)\nprint(input)\nout = net(input)\nprint(out)\n# %%\n\n## zero_grad() 로 이전 gradient history를 갱신함\nnet.zero_grad() ## 역전파 전 grad를 0으로 갱신\nout.backward(torch.randn(1, 10))\n# %%\n# Loss Function\noutput = net(input)\ntarget = torch.randn(10)\ntarget = target.view(1,-1) # 출력과 같은 shape\ncriterion = nn.MSELoss()\n\nloss = criterion(output,target)\nprint(loss)\n# %%\nprint(loss.grad_fn) # MSELoss\nprint(loss.grad_fn.next_functions[0][0]) # Linear\nprint(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU\n# %%\n\n## Backprop\nnet.zero_grad()\nprint(\"conv1.bias.grad before backward\")\nprint(net.conv1.bias.grad)\n\n## apply backward\nloss.backward(retain_graph=True)\n\nprint('conv1.bias.grad after backward')\nprint(net.conv1.bias.grad)\n\n\n# %%\n## 새로운 가중치 = 가중치 - 학습률 *gradient\nlr = 0.01 ## Learning rate\nfor f in net.parameters():\n f.data.sub_(f.grad.data*lr)\n#%%\nimport torch.optim as optim\n\n# optimzizer\noptimizer = optim.SGD(net.parameters(),lr=0.01)\n\n#training loop\noptimizer.zero_grad()\nouput = net(input)\nloss = criterion(output, target)\nloss.backward()\noptimizer.step()\n\n# %%\n"
}
] | 8 |
ktsymbal/hr-app
|
https://github.com/ktsymbal/hr-app
|
85388643d12725ebf7f091e3e814bd50c2cc6c91
|
3efc8f168cb5d44d3edfb53f5fe5a9a0b36512f9
|
5543163b1f6f2c06ed822e6e4938db905ab69070
|
refs/heads/master
| 2021-06-15T20:41:43.232393 | 2017-03-28T06:43:58 | 2017-03-28T06:43:58 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6680850982666016,
"alphanum_fraction": 0.6680850982666016,
"avg_line_length": 45.900001525878906,
"blob_id": "d6e5d1a2610e1e52bdf5fad394338f409e496f27",
"content_id": "1db7bdd2efa69d152cf788ad3ec8b6f69594bc37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 10,
"path": "/app/templates/parts/vacancy_form.html",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "{{ vacancy_form.hidden_tag() }}\n<div class=\"form-group required\">\n {{ form.position_id.label(class=\"control-label\") }}\n {{ form.position_id(class=\"form-control\", required=\"\") }}\n</div>\n<div class=\"form-group required\">\n {{ form.publishment_date.label(class=\"control-label\") }}\n {{ form.publishment_date(class=\"form-control datepicker\", required=\"\", value=date_to_str(form.publishment_date.data).strip()) }}\n</div>\n{{ form.submit(class=\"btn btn-default\") }}\n\n"
},
{
"alpha_fraction": 0.7670454382896423,
"alphanum_fraction": 0.7670454382896423,
"avg_line_length": 24.214284896850586,
"blob_id": "b7d2d0b6f2494f26c52816c22ec88dece5f83612",
"content_id": "6964d80e233b9ee3292bcc0dfcd5045ce36ae002",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 352,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 14,
"path": "/app/__init__.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom flask_bootstrap import Bootstrap\nfrom flask_sqlalchemy import SQLAlchemy\n\n\napp = Flask(__name__, instance_relative_config=True, static_folder=\"./static\")\napp.config.from_object('config')\n# app.config.from_pyfile('config.py')\n\ndb = SQLAlchemy(app)\nbootstrap = Bootstrap(app)\n\nfrom . import views\nfrom . import error_handlers"
},
{
"alpha_fraction": 0.5060241222381592,
"alphanum_fraction": 0.7048192620277405,
"avg_line_length": 15.600000381469727,
"blob_id": "812c4f71996c227bef70ba0d5d8683996cd3811b",
"content_id": "397b480418098175a0bad26e4f02a5aa6eb96a7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 20,
"path": "/requirements.txt",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.3\nclick==6.7\ndominate==2.3.1\nFlask==0.12\nFlask-Bootstrap==3.3.7.1\nFlask-Script==2.0.5\nFlask-SQLAlchemy==2.2\nFlask-WTF==0.14.2\ngunicorn==19.7.1\nitsdangerous==0.24\nJinja2==2.9.5\nMarkupSafe==0.23\npackaging==16.8\npsycopg2==2.7.1\npyparsing==2.1.10\nsix==1.10.0\nSQLAlchemy==1.1.6\nvisitor==0.1.3\nWerkzeug==0.11.15\nWTForms==2.1\n"
},
{
"alpha_fraction": 0.7029914259910583,
"alphanum_fraction": 0.7029914259910583,
"avg_line_length": 41.56060791015625,
"blob_id": "97e1ae8b8584209c4c13ecad2b2abb403fa1f430",
"content_id": "ceba80b792acc0c30fdf30f678a90feab2f07559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2808,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 66,
"path": "/app/models.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "from app import db\n\n\nclass Department(db.Model):\n __tablename__ = 'departments'\n\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String, nullable=False)\n description = db.Column(db.String)\n vacancies = db.relationship('Vacancy', backref='department')\n employees = db.relationship('Employee', backref='department')\n history = db.relationship('WorkHistory', back_populates='department')\n\n\nclass Position(db.Model):\n __tablename__ = 'positions'\n\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String, nullable=False)\n description = db.Column(db.String)\n vacancies = db.relationship('Vacancy', backref='position')\n employees = db.relationship('Employee', backref='position')\n history = db.relationship('WorkHistory', back_populates='position')\n\n\nclass Vacancy(db.Model):\n __tablename__ = 'vacancies'\n\n id = db.Column(db.Integer, primary_key=True)\n publishment_date = db.Column(db.Date, nullable=False)\n closing_date = db.Column(db.Date)\n is_open = db.Column(db.Boolean, nullable=False, default=True)\n employee_id = db.Column(db.Integer, db.ForeignKey('employees.id'))\n department_id = db.Column(db.Integer, db.ForeignKey('departments.id'), nullable=False)\n position_id = db.Column(db.Integer, db.ForeignKey('positions.id'), nullable=False)\n employee = db.relationship('Employee', back_populates='vacancy')\n\n\nclass Employee(db.Model):\n __tablename__ = 'employees'\n\n id = db.Column(db.Integer, primary_key=True)\n name = db.Column(db.String, nullable=False)\n surname = db.Column(db.String, nullable=False)\n email = db.Column(db.String, nullable=False)\n phone_number = db.Column(db.String, nullable=False)\n birth_date = db.Column(db.Date, nullable=False)\n is_director = db.Column(db.Boolean, default=False)\n is_fired = db.Column(db.Boolean, default=False)\n department_id = db.Column(db.Integer, db.ForeignKey('departments.id'), nullable=False)\n position_id = db.Column(db.Integer, db.ForeignKey('positions.id'), nullable=False)\n vacancy = db.relationship('Vacancy', uselist=False, back_populates='employee')\n history = db.relationship('WorkHistory', backref='employee')\n\n\nclass WorkHistory(db.Model):\n __tablename__ = 'work_history'\n\n id = db.Column(db.Integer, primary_key=True)\n employee_id = db.Column(db.Integer, db.ForeignKey('employees.id'), nullable=False)\n position_id = db.Column(db.Integer, db.ForeignKey('positions.id'), nullable=False)\n department_id = db.Column(db.Integer, db.ForeignKey('departments.id'), nullable=False)\n start = db.Column(db.Date, nullable=False)\n end = db.Column(db.Date)\n position = db.relationship('Position', back_populates='history')\n department = db.relationship('Department', back_populates='history')"
},
{
"alpha_fraction": 0.6691778302192688,
"alphanum_fraction": 0.671143114566803,
"avg_line_length": 38.6363639831543,
"blob_id": "4cb9168fd196ffd2c0a63b0ca241609ff1616055",
"content_id": "202c053a14dc51296d700062583286be0df74437",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3053,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 77,
"path": "/app/forms.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, SelectField, BooleanField, DateField\nfrom wtforms.fields.html5 import EmailField\nfrom wtforms.validators import DataRequired, Email, Regexp, ValidationError\n\nfrom app.helpers import get_all_positions, get_all_departments, str_to_date\n\n\nclass DepartmentForm(FlaskForm):\n name = StringField('Name', validators=[DataRequired()])\n description = StringField('Description')\n submit = SubmitField('Submit')\n\n\nclass VacancyForm(FlaskForm):\n position_id = SelectField('Position', coerce=int, validators=[DataRequired()])\n publishment_date = StringField('Publishment date', description='%d/%m/%y', validators=[DataRequired()])\n submit = SubmitField('Submit')\n\n def __init__(self, **kwargs):\n super(VacancyForm, self).__init__(**kwargs)\n self.position_id.choices = get_all_positions()\n\n def validate(self):\n publishment_date = str_to_date(self.publishment_date.data)\n if not publishment_date:\n publishment_date = datetime.date(datetime.today())\n self.publishment_date.data = publishment_date\n return True\n\n\nclass PositionForm(FlaskForm):\n name = StringField('Name', validators=[DataRequired()])\n description = StringField('Description')\n submit = SubmitField('Submit')\n\n\nclass EmployeeForm(FlaskForm):\n name = StringField('Name', validators=[DataRequired()])\n surname = StringField('Surname', validators=[DataRequired()])\n position_id = SelectField('Position', coerce=int, validators=[DataRequired()])\n email = EmailField('Email', validators=[DataRequired(), Email()])\n phone_number = StringField(\n 'Phone number',\n validators=[DataRequired(), Regexp('^\\+[0-9]{12}$', 0, 'Invalid phone number')]\n )\n birth_date = StringField('Birth date', render_kw={\"placeholder\": \"dd/mm/yy\"}, validators=[DataRequired()])\n department_id = SelectField('Department', coerce=int, validators=[DataRequired()])\n start_date = StringField('Start date', validators=[DataRequired()])\n director = BooleanField('Director')\n submit = SubmitField('Submit')\n\n def __init__(self, **kwargs):\n super(EmployeeForm, self).__init__(**kwargs)\n self.position_id.choices = get_all_positions()\n self.department_id.choices = get_all_departments()\n\n def validate(self):\n rv = FlaskForm.validate(self)\n if not rv:\n return False\n birth_date = str_to_date(self.birth_date.data)\n if not birth_date:\n self.birth_date.errors.append(\"Invalid birth date\")\n return False\n if birth_date >= datetime.date(datetime.today()):\n self.birth_date.errors.append(\"A birth date can not be today or later.\")\n return False\n self.birth_date.data = birth_date\n\n start_date = str_to_date(self.start_date.data)\n if not start_date:\n start_date = datetime.date(datetime.today())\n self.start_date.data = start_date\n return True\n\n"
},
{
"alpha_fraction": 0.45945945382118225,
"alphanum_fraction": 0.46162161231040955,
"avg_line_length": 25.457143783569336,
"blob_id": "7115b03a4e1e12ab73bb725cd320cb51c0c8f10b",
"content_id": "8910d2e23991894c1917c00666341b9e0f3736bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 35,
"path": "/app/templates/positions.html",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "{% extends \"base/page_header.html\" %}\n\n{% block title %} Positions {% endblock %}\n\n{% block page_header %}\n\n <h1>Positions</h1>\n\n{% endblock %}\n\n{% block main_content %}\n\n <div class=\"row\">\n <button class=\"btn btn-default\" aria-label=\"Left Align\" data-toggle=\"modal\" data-target=\"#add_position\">\n <span class=\"glyphicon glyphicon-plus\"></span> Add\n </button>\n </div>\n <div class=\"row\">\n {% if positions %}\n <table class=\"table table-hover\">\n {% for position in positions %}\n <tr>\n <td>\n <a href=\"{{ url_for('position', position_id=position.id) }}\">\n {{ position.name }}\n </a>\n </td>\n </tr>\n {% endfor %}\n </table>\n {% endif %}\n </div>\n\n {{ modal('add_position', 'Add position: ', form) }}\n{% endblock %}"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 20,
"blob_id": "bb86f93369e9a48291120427989a8b610cc6fd8b",
"content_id": "a27eb3f64d1e1d4d24109a911ea73ed577737564",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/app/instance/config.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "SECRET_KEY = 'kjghs8xhtkqi4*yr87+rv@7#+y4njwrd4+9v)a*+ztduw#9q^s&jv+zgaeg'"
},
{
"alpha_fraction": 0.6683695912361145,
"alphanum_fraction": 0.6714348196983337,
"avg_line_length": 33.601009368896484,
"blob_id": "4bbd122d3e36ceb07eab7246fad62c321b6a83a7",
"content_id": "43fccde35e104740bc66ba3349875f6ca9fd4889",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6851,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 198,
"path": "/app/views.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "from flask import redirect, render_template, url_for, abort, request\n\nfrom app import app, db\nfrom app.forms import DepartmentForm, VacancyForm, PositionForm, EmployeeForm\nfrom app.helpers import flash_errors, update_position, update_director\nfrom app.models import Department, Vacancy, Position, Employee, WorkHistory\n\n\[email protected]('/', methods=['GET', 'POST'])\ndef departments():\n departments = Department.query.all()\n form = DepartmentForm()\n\n if form.validate_on_submit():\n department = Department(name=form.name.data, description=form.description.data)\n db.session.add(department)\n db.session.commit()\n return redirect(url_for('departments'))\n\n flash_errors(form)\n return render_template('departments.html', departments=departments, form=form)\n\n\[email protected]('/<department_id>/', methods=['GET', 'POST'])\ndef department(department_id):\n department = Department.query.filter_by(id=department_id).first()\n if not department:\n abort(404)\n vacancy_form = VacancyForm()\n department_form = DepartmentForm(obj=department)\n\n if department_form.validate_on_submit():\n department_form.populate_obj(department)\n db.session.commit()\n return redirect(url_for('department', department_id=department.id))\n\n vacancies = Vacancy.query.filter_by(department_id=department_id, is_open=True).all()\n employees = Employee.query.filter_by(department_id=department_id, is_fired=False).all()\n flash_errors(department_form)\n return render_template(\n 'department.html',\n department=Department.query.filter_by(id=department_id).first(),\n vacancy_form=vacancy_form,\n department_form=department_form,\n vacancies=vacancies,\n employees=employees\n )\n\n\[email protected]('/<department_id>/vacancies/', methods=['POST'])\ndef vacancies(department_id):\n department = Department.query.filter_by(id=department_id).first()\n if not department:\n abort(404)\n form = VacancyForm(obj=request.form)\n\n if form.validate_on_submit():\n vacancy = Vacancy(\n position_id=form.position_id.data,\n department_id=department_id,\n publishment_date=form.publishment_date.data\n )\n db.session.add(vacancy)\n db.session.commit()\n\n flash_errors(form)\n return redirect(url_for('department', department_id=department_id))\n\n\[email protected]('/<department_id>/vacancies/<vacancy_id>/', methods=['GET', 'POST'])\ndef vacancy(department_id, vacancy_id):\n vacancy = Vacancy.query.filter_by(id=vacancy_id, department_id=department_id).first()\n if not vacancy:\n abort(404)\n\n vacancy_form = VacancyForm(obj=vacancy)\n employee_form = EmployeeForm(department_id=department_id, position_id=vacancy.position_id)\n\n if vacancy_form.validate_on_submit():\n vacancy_form.populate_obj(vacancy)\n db.session.commit()\n return redirect(url_for('vacancy', department_id=department_id, vacancy_id=vacancy_id))\n\n flash_errors(vacancy_form)\n return render_template(\n 'vacancy.html',\n vacancy=vacancy,\n vacancy_form=vacancy_form,\n employee_form=employee_form\n )\n\n\[email protected]('/<department_id>/vacancies/<vacancy_id>/employees/', methods=['POST'])\ndef employees(department_id, vacancy_id):\n vacancy = Vacancy.query.filter_by(id=vacancy_id).first()\n if not vacancy:\n abort(404)\n form = EmployeeForm(obj=request.form)\n\n if form.validate_on_submit():\n employee = Employee(\n name=form.name.data,\n surname=form.surname.data,\n position_id=form.position_id.data,\n email=form.email.data,\n phone_number=form.phone_number.data,\n birth_date=form.birth_date.data,\n department_id=form.department_id.data,\n vacancy=vacancy\n )\n\n if form.director.data:\n update_director(department_id, employee, True)\n db.session.add(employee)\n\n vacancy.is_open = False\n vacancy.employee = employee\n vacancy.closing_date = form.start_date.data\n\n db.session.commit()\n\n update_position(employee, form.position_id.data, form.department_id.data, form.start_date.data)\n db.session.commit()\n\n flash_errors(form)\n return redirect(url_for('department', department_id=department_id))\n\n\[email protected]('/<department_id>/employees/<employee_id>/', methods=['GET', 'POST'])\ndef employee(department_id, employee_id):\n employee = Employee.query.filter_by(id=employee_id, department_id=department_id).first()\n if not employee:\n abort(404)\n\n\n\n employee_form = EmployeeForm(obj=employee, start_date=employee.vacancy.closing_date)\n\n if employee_form.validate_on_submit():\n if employee.position_id != employee_form.position_id.data or employee.department_id != employee_form.department_id.data:\n update_position(\n employee,\n employee_form.position_id.data,\n employee_form.department_id.data,\n employee_form.start_date.data\n )\n\n if employee.is_director != employee_form.director.data:\n update_director(department_id, employee, employee_form.director.data)\n\n employee_form.populate_obj(employee)\n db.session.commit()\n return redirect(url_for('employee', department_id=employee.department_id, employee_id=employee.id))\n\n flash_errors(employee_form)\n return render_template('employee.html', employee=employee, employee_form=employee_form)\n\n\[email protected]('/<department_id>/employees/<employee_id>/fire/')\ndef fire(department_id, employee_id):\n employee = Employee.query.filter_by(id=employee_id, department_id=department_id).first()\n if not employee:\n abort(404)\n\n employee.is_fired = True\n db.session.commit()\n return redirect(url_for('department', department_id=department_id))\n\n\[email protected]('/positions/', methods=['GET', 'POST'])\ndef positions():\n positions = Position.query.all()\n form = PositionForm()\n\n if form.validate_on_submit():\n position = Position(name=form.name.data, description=form.description.data)\n db.session.add(position)\n db.session.commit()\n return redirect(url_for('positions'))\n\n flash_errors(form)\n return render_template('positions.html', form=form, positions=positions)\n\n\[email protected]('/positions/<position_id>/', methods=['GET', 'POST'])\ndef position(position_id):\n position = Position.query.filter_by(id=position_id).first()\n if not position:\n abort(404)\n form = PositionForm(obj=position)\n\n if form.validate_on_submit():\n form.populate_obj(position)\n db.session.commit()\n return redirect(url_for('position', position_id=position.id))\n\n flash_errors(form)\n return render_template('position.html', position=position, form=form)\n"
},
{
"alpha_fraction": 0.6492307782173157,
"alphanum_fraction": 0.6492307782173157,
"avg_line_length": 26.559322357177734,
"blob_id": "fb99f5ad945e3bed9494db5f8fb85b15a2c91c98",
"content_id": "dd336b6474ee05c0d5474883017661caa30dd52d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1625,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 59,
"path": "/app/helpers.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nfrom flask import flash\n\nfrom app import db\nfrom app.models import Position, Department, WorkHistory, Employee\n\n\ndef get_all_positions():\n return [(position.id, position.name) for position in Position.query.all()]\n\n\ndef get_all_departments():\n return [(department.id, department.name) for department in Department.query.all()]\n\n\ndef str_to_date(date, format='%d/%m/%Y'):\n try:\n parsed_date = datetime.strptime(date, format).date()\n except ValueError:\n parsed_date = None\n return parsed_date\n\n\ndef flash_errors(form):\n for field, errors in form.errors.items():\n for error in errors:\n flash(\"%s: %s\" % (\n getattr(form, field).label.text,\n error\n ))\n\n\ndef update_position(employee, new_position_id, new_department_id, start_date):\n old_position = WorkHistory.query.filter_by(\n employee_id=employee.id,\n position_id=employee.position_id,\n department_id=employee.department_id\n ).first()\n if old_position:\n old_position.end = start_date\n\n new_position = WorkHistory(\n employee_id=employee.id,\n position_id=new_position_id,\n department_id=new_department_id,\n start=start_date\n )\n db.session.add(new_position)\n\n\ndef update_director(department_id, employee, new_director):\n if new_director:\n director = Employee.query.filter_by(department_id=department_id, is_director=True).first()\n if director:\n director.is_director = False\n employee.is_director = True\n else:\n employee.is_director = False"
},
{
"alpha_fraction": 0.7182130813598633,
"alphanum_fraction": 0.7182130813598633,
"avg_line_length": 31.44444465637207,
"blob_id": "0a55206efdf05f9fb0d6ad77e92a884488590270",
"content_id": "09ecaf590ab665b644062d5e7288b1a66c332928",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 9,
"path": "/config.py",
"repo_name": "ktsymbal/hr-app",
"src_encoding": "UTF-8",
"text": "import os\n\nbase_dir = os.path.abspath(os.path.dirname(__file__) )\n\nSQLALCHEMY_TRACK_MODIFICATIONS = False\n# SQLALCHEMY_DATABASE_URI = 'sqlite:///' + os.path.join(base_dir, 'hr.db')\nSQLALCHEMY_DATABASE_URI = os.environ['DATABASE_URL']\nSQLALCHEMY_COMMIT_ON_TEARDOWN = True\nSECRET_KEY = 'kjghs8xhtkqi4*yr87+rv@7#+y4njwrd4+9v)a*+ztduw#9q^s&jv+zgaeg'"
}
] | 10 |
knocknguyen/homework_05
|
https://github.com/knocknguyen/homework_05
|
bf501e8cb21fd343832e8c823e44e2a260c0e034
|
51bb444cc80934a5288b99280628db0acb1b802e
|
3624c57f915e3280c8659f0333e651fc4740c9ea
|
refs/heads/master
| 2023-01-24T22:12:12.902317 | 2020-09-24T01:21:05 | 2020-09-24T01:21:05 | 296,773,583 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.5625,
"avg_line_length": 16,
"blob_id": "98a13380f21ee3c93c8c3a687ca7a454516f20dd",
"content_id": "f42bb87ab278545bc7af4cf7ca9d1d4c16328334",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 1,
"path": "/week_05/.ipynb_checkpoints/api_keys-checkpoint.py",
"repo_name": "knocknguyen/homework_05",
"src_encoding": "UTF-8",
"text": "api_key ='3426c92455bcd12cfa255bbeb8a337a0'"
}
] | 1 |
vladipirogov/OWL
|
https://github.com/vladipirogov/OWL
|
a24d569dfcb07bdcb0395d2fc7a9b430c52c39de
|
0f6ef983b82080e73307a3593d95c21bffad49b5
|
bcc5c32a43280f76b8789456aa6573a2e5ccd306
|
refs/heads/master
| 2020-04-21T09:50:12.549940 | 2019-04-13T10:00:22 | 2019-04-14T07:40:18 | 169,464,976 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.631369948387146,
"alphanum_fraction": 0.6618133783340454,
"avg_line_length": 31.84782600402832,
"blob_id": "79201f4e9737091f7dfee2fc4d40beefb2af03d2",
"content_id": "9192cc31531c6b4b0eac9a513fb104415d3a2da3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1511,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 46,
"path": "/migrations/versions/ce0396be6920_db_migrations.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "\"\"\"db migrations\n\nRevision ID: ce0396be6920\nRevises: \nCreate Date: 2019-02-24 10:22:09.071004\n\n\"\"\"\nfrom alembic import op\nimport sqlalchemy as sa\n\n\n# revision identifiers, used by Alembic.\nrevision = 'ce0396be6920'\ndown_revision = None\nbranch_labels = None\ndepends_on = None\n\n\ndef upgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.create_table('schedule',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('cron', sa.String(length=64), nullable=True),\n sa.Column('job', sa.String(length=64), nullable=True),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_schedule_cron'), 'schedule', ['cron'], unique=False)\n op.create_index(op.f('ix_schedule_job'), 'schedule', ['job'], unique=False)\n op.create_table('setting',\n sa.Column('id', sa.Integer(), nullable=False),\n sa.Column('setting', sa.String(length=140), nullable=True),\n sa.Column('value', sa.String(length=140), nullable=True),\n sa.PrimaryKeyConstraint('id')\n )\n op.create_index(op.f('ix_setting_setting'), 'setting', ['setting'], unique=False)\n # ### end Alembic commands ###\n\n\ndef downgrade():\n # ### commands auto generated by Alembic - please adjust! ###\n op.drop_index(op.f('ix_setting_setting'), table_name='setting')\n op.drop_table('setting')\n op.drop_index(op.f('ix_schedule_job'), table_name='schedule')\n op.drop_index(op.f('ix_schedule_cron'), table_name='schedule')\n op.drop_table('schedule')\n # ### end Alembic commands ###\n"
},
{
"alpha_fraction": 0.6486725807189941,
"alphanum_fraction": 0.6504424810409546,
"avg_line_length": 25.904762268066406,
"blob_id": "db1621298ea1fac46854a6de4d70ec0d3496db60",
"content_id": "3b654c5985523c0003484adcec6ac36f90036df6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1130,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 42,
"path": "/app/repository.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "from app import models\nfrom app import db\n\n\ndef get_crons():\n schedules = models.Schedule.query.all()\n for schedule in schedules:\n if schedule.job == '0':\n cronstop = schedule.cron\n if schedule.job == '1':\n cronstart = schedule.cron\n return {'cronstop': cronstop, 'cronstart': cronstart}\n\n\ndef get_light_trs():\n records = models.Setting.query.filter(models.Setting.setting.in_(['maxlite', 'minlite']))\n for record in records:\n if record.setting == 'maxlite':\n maxlite = record.value\n if record.setting == 'minlite':\n minlite = record.value\n return {'maxlite': maxlite, 'minlite': minlite}\n\n\ndef update_cron(job, cron):\n record = models.Schedule.query.filter_by(job=job).first()\n record.cron = cron\n db.session.commit()\n\n\ndef update_setting(name, value):\n record = models.Setting.query.filter_by(setting=name).first()\n record.value = value\n db.session.commit()\n\n\ndef find_setting(setting):\n return models.Setting.query.filter_by(setting=setting).first()\n\n\ndef get_all_schedules():\n return models.Schedule.query.all()\n"
},
{
"alpha_fraction": 0.5620437860488892,
"alphanum_fraction": 0.5644769072532654,
"avg_line_length": 24.382715225219727,
"blob_id": "1bd82a89ec8203ed8d50ef1b419eaa2b3965e098",
"content_id": "e8663b2bd32a47f1c2dee258343f2e0a4d4cd091",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2055,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 81,
"path": "/app/static/javascript/main.js",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "(function($) {\n\nsend = (url, value, method) => {\n console.log(value);\n var payload = { method: method,\n mode: 'cors',\n cache: 'default',\n headers: {\n 'Accept': 'application/json',\n 'Content-Type': 'application/json'},\n body: JSON.stringify(value)\n };\n fetch(url, payload)\n .then(response => response.json()) // Result from the\n .then(data => {\n console.log(data) // Prints result from `response.json()`\n })\n .catch(error => console.error(error))\n }\n\nsendData = (value) => {\n send('/send', {value : value}, 'POST');\n }\n\nsendByUrl = (url, method) => {\n send(url, {value : 1}, method);\n}\n\n\nupdateCron = (id, job) => {\n var cron = document.getElementById(id).value;\n var object = {job: job, cron: cron};\n send('/update-cron', object, 'PUT');\n}\n\n sendDataById = (id) => {\n var value = document.getElementById(id).value;\n sendData(value);\n }\n \n sendDataByIdType = (id, type) => {\n var value = document.getElementById(id).value;\n sendValue = type.concat(\"=\", value);\n sendData(sendValue);\n }\n \n \n sendTrsLighting = (id, type) => {\n var value = document.getElementById(id).value;\n if(!value.isNumber()) {\n alert(\"Value must be number!\");\n return;\n }\n var object = {name: id, value: value};\n send('/update-setting', object, 'PUT');\n sendValue = type.concat(\"=\", value);\n sendData(sendValue);\n }\n\nshowMessageBox = (message) => {\n var x = document.getElementById(\"snackbar\");\n x.textContent = message;\n x.className = \"show\";\n setTimeout(function(){ x.className = x.className.replace(\"show\", \"\"); }, 3000);\n\n}\n\nshowMessageBoxById = (id) => {\n var value = document.getElementById(id).value;\n showMessageBox(value);\n}\n\nvar socket = io.connect()\n\nsocket.on('message', function(msg){\n console.log('msg = ' + msg);\n showMessageBox(msg);\n})\n\n String.prototype.isNumber = function(){return /^\\d+$/.test(this);}\n})(jQuery);"
},
{
"alpha_fraction": 0.7338027954101562,
"alphanum_fraction": 0.7478873133659363,
"avg_line_length": 25.296297073364258,
"blob_id": "763938c740dac4a28b720567f031130c0f5b72cb",
"content_id": "562e7ef6d9bf81a08ae592f07c88b7c7df5ecf96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 710,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 27,
"path": "/app/__init__.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom config import Config\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\nfrom flask_apscheduler import APScheduler\nfrom flask_socketio import SocketIO\nfrom flask_mqtt import Mqtt\n\napp = Flask(__name__)\napp.config['TEMPLATES_AUTO_RELOAD'] = True\napp.config['MQTT_BROKER_URL'] = '192.168.1.107'\napp.config['MQTT_CLIENT_ID'] = 'org.owl.home'\nmqtt = Mqtt()\nmqtt.init_app(app)\napp.config.from_object(Config)\napp.jinja_env.auto_reload = True\nsocketio = SocketIO(app)\ndb = SQLAlchemy(app)\nmigrate = Migrate(app, db)\nscheduler = APScheduler()\nscheduler.init_app(app)\nscheduler.start()\n\nif __name__ == '__main__':\n socketio.run(app)\n\nfrom app import routes, models\n"
},
{
"alpha_fraction": 0.6221033930778503,
"alphanum_fraction": 0.6310160160064697,
"avg_line_length": 29.324323654174805,
"blob_id": "a927e6fdcd1570ac2898b960de53688f31ac2ac0",
"content_id": "170f9c20ec984e9954f6444109dddbba68cd65ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1122,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 37,
"path": "/app/serial_service.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "import serial\nimport threading\nfrom concurrent.futures import ThreadPoolExecutor\nfrom app import socketio\n\n\nclass SerialService:\n def __init__(self):\n self.connected = False\n self.serPort = '/dev/ttyS0'\n self.baudRate = 9600\n self.ser = serial.Serial(self.serPort, self.baudRate, timeout=1)\n self.executor = ThreadPoolExecutor(max_workers=1)\n self.future = None\n\n def send_to_arduino(self, send_str):\n if not self.ser.is_open:\n self.ser.open()\n self.connected = True\n threading.Timer(2.0, self.stop_reading).start()\n self.ser.write(bytes(send_str, 'UTF-8'))\n self.future = self.executor.submit(self.read_from_port())\n\n def handle_data(self, data):\n socketio.emit('message', data, callback=self.message_received)\n\n def stop_reading(self):\n self.connected = False\n print(\"stop\")\n\n def read_from_port(self):\n while self.connected:\n reading = self.ser.readline().decode()\n self.handle_data(reading)\n\n def message_received(self):\n print('message was received!!!')\n"
},
{
"alpha_fraction": 0.6241299510002136,
"alphanum_fraction": 0.6473317742347717,
"avg_line_length": 25.9375,
"blob_id": "37a751f43ee1f5c973d88d78b64f4af625cce6b2",
"content_id": "22bf2e859df5a819ddf66f133eed7b50162695f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 16,
"path": "/app/models.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "from app import db\n\n\nclass Schedule(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n cron = db.Column(db.String(64), index=True)\n job = db.Column(db.String(64), index=True)\n\n def __repr__(self):\n return '<Schedule {}>'.format(self.cron)\n\n\nclass Setting(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n setting = db.Column(db.String(140), index=True)\n value = db.Column(db.String(140))\n"
},
{
"alpha_fraction": 0.5972751975059509,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 32.3636360168457,
"blob_id": "ed27d7f96076850080b19f277809aaa95c76429c",
"content_id": "d0e4bf200f794e525f186895d9de2f46d2cdc339",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1835,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 55,
"path": "/app/scheduler_service.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "from apscheduler.triggers.cron import CronTrigger\nfrom app import repository\nfrom app import db\nfrom app import serial_service\nfrom app import mqtt\nfrom app import socketio\n\n\nclass Scheduler:\n\n def __init__(self, apscheduler):\n #self.serial_service = serial_service.SerialService()\n self.schedules = repository.get_all_schedules()\n self.apscheduler = apscheduler\n self.expression = '0 16 1 * *'\n self.run_job()\n record = repository.find_setting('run_job')\n record.value = '1'\n db.session.commit()\n\n\n def run_job(self):\n for schedule in self.schedules:\n self.expression = schedule.cron\n self.apscheduler.add_job(func=self.scheduled_task,\n trigger=CronTrigger.from_crontab(self.expression),\n args=[schedule.job],\n id=schedule.job)\n return 'Scheduled tasks done'\n\n def scheduled_task(self, job):\n #self.serial_service.send_to_arduino('timeliteenab=' + str(job))\n mqtt.publish('home/commandtopic', 'timeliteenab=' + str(job))\n print('timeliteenab=' + str(job))\n\n def pause(self):\n self.apscheduler.pause()\n\n def resume(self):\n self.apscheduler.resume()\n\n def state(self):\n return self.apscheduler.state()\n\n def shutdown(self):\n self.apscheduler.shutdown()\n\n def reschedule(self):\n self.schedules = repository.get_all_schedules()\n for schedule in self.schedules:\n self.expression = schedule.cron\n print(self.expression)\n self.apscheduler.scheduler.reschedule_job(schedule.job,\n trigger=CronTrigger.from_crontab(self.expression))\n return 'Scheduled tasks done'\n"
},
{
"alpha_fraction": 0.6389204263687134,
"alphanum_fraction": 0.6451704502105713,
"avg_line_length": 27.387096405029297,
"blob_id": "2c29961d32eb8ebcd745abaf4e8a736cabe808f1",
"content_id": "f87c3e3068def7214799a0096ad6569faf1ad12a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3520,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 124,
"path": "/app/routes.py",
"repo_name": "vladipirogov/OWL",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request\nfrom flask import jsonify\nfrom app import app\nfrom app import serial_service\nfrom app import scheduler_service\nfrom app import db\nfrom app import scheduler\nfrom app import repository\nfrom app import mqtt\nfrom app import socketio\n\ncron_scheduler = scheduler_service.Scheduler(scheduler)\n#serial_service = serial_service.SerialService()\n\ndef message_received():\n print('message was received!!!')\n\[email protected]_connect()\ndef handle_connect(client, userdata, flags, rc):\n mqtt.subscribe('home/feedbacktopic')\n\[email protected]_message()\ndef handle_mqtt_message(client, userdata, message):\n socketio.emit('message', message.payload.decode(), callback=message_received)\n\[email protected]('/')\[email protected]('/index')\ndef index():\n record = repository.find_setting('auto')\n auto = record.value;\n return render_template('index.html', auto=auto)\n\n\[email protected]('/setting', methods=['GET'])\ndef setting():\n crons = repository.get_crons()\n lite_trs = repository.get_light_trs()\n return render_template('setting.html',\n cronstop=crons['cronstop'],\n cronstart=crons['cronstart'],\n maxlite=lite_trs['maxlite'],\n minlite=lite_trs['minlite'])\n\n\[email protected]('/commands', methods=['GET'])\ndef commands():\n record = repository.find_setting('run_job')\n run_job = record.value;\n return render_template('commands.html', run_job=run_job)\n\n\[email protected]('/send', methods=['POST'])\ndef send():\n json_obj = request.get_json()\n #serial_service.send_to_arduino(json_obj.get('value'))\n mqtt.publish('home/commandtopic', json_obj.get('value'))\n return jsonify({'echo': json_obj.get('value')})\n\n\[email protected]('/run-tasks', methods=['GET', 'POST'])\ndef run_tasks():\n record = repository.find_setting('run_job')\n run_job = record.value;\n if run_job == '0':\n cron_scheduler.run_job()\n record.value = '1'\n db.session.commit()\n return 'Scheduled several long running tasks.', 200\n\n\[email protected]('/shutdown-tasks', methods=['GET', 'POST'])\ndef shutdown_tasks():\n record = repository.find_setting('run_job')\n run_job = record.value;\n if run_job == '1':\n cron_scheduler.shutdown()\n record.value = '0'\n db.session.commit()\n return 'Scheduled several long running tasks.', 200\n\n\[email protected]('/pause-tasks', methods=['GET', 'POST'])\ndef pause_tasks():\n cron_scheduler.pause()\n record = repository.find_setting('run_job')\n record.value = '2'\n db.session.commit()\n return 'ok', 200\n\n\[email protected]('/resume-tasks', methods=['GET', 'POST'])\ndef resume_tasks():\n cron_scheduler.resume()\n record = repository.find_setting('run_job')\n record.value = '1'\n db.session.commit()\n return 'ok', 200\n\n\[email protected]('/reschedule-tasks', methods=['GET', 'POST'])\ndef reschedule_tasks():\n cron_scheduler.reschedule()\n record = repository.find_setting('run_job')\n record.value = '1'\n db.session.commit()\n return 'ok', 200\n\n\[email protected]('/update-setting', methods=['PUT'])\ndef update_setting():\n json_obj = request.get_json()\n name = json_obj.get('name')\n value = json_obj.get('value')\n repository.update_setting(name, value)\n return jsonify({'result': 'ok'})\n\n\[email protected]('/update-cron', methods=['PUT'])\ndef update_cron():\n json_obj = request.get_json()\n job = json_obj.get('job')\n cron = json_obj.get('cron')\n repository.update_cron(job, cron)\n return jsonify({'result': 'ok'})\n"
}
] | 8 |
Aslan1st/locallibrary
|
https://github.com/Aslan1st/locallibrary
|
09454f0ea1212c645955269551948a0240202564
|
ab78b0940c7063b49e2833d6ab8ee2618628d7aa
|
aebb2ab51b8e24d6aaf04648c3c1b19c1fa021a8
|
refs/heads/master
| 2021-08-28T18:39:38.970543 | 2017-12-13T00:25:27 | 2017-12-13T00:25:27 | 114,048,714 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 17,
"blob_id": "886c58881354f44911c21e5af0477a60fe6e17e9",
"content_id": "a660cb33ad99db0a0d15815a95a62b2827cd4b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Aslan1st/locallibrary",
"src_encoding": "UTF-8",
"text": "# locallibrary\nmozilla walk through\n"
},
{
"alpha_fraction": 0.5434083342552185,
"alphanum_fraction": 0.5964630246162415,
"avg_line_length": 24.91666603088379,
"blob_id": "8e0f48f3f258da6f1d830af4025ab25fa42e4254",
"content_id": "ed19691726c3c2e8fd2bdc8e6b4c7484b0cd212b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 24,
"path": "/catalog/migrations/0003_auto_20171205_2241.py",
"repo_name": "Aslan1st/locallibrary",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.0 on 2017-12-06 03:41\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('catalog', '0002_auto_20171205_2037'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='book',\n name='title',\n field=models.CharField(max_length=200),\n ),\n migrations.AlterField(\n model_name='bookinstance',\n name='book',\n field=models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='catalog.Book'),\n ),\n ]\n"
}
] | 2 |
bitounu/shitz
|
https://github.com/bitounu/shitz
|
312d1d5315d73b4959d69652433e498ab9a142a2
|
c899118bd8e8b0a66099a50ed785bfe4f5d9b809
|
c4ee7cbc0efc48655ddf0d45f41898ee6092bfb6
|
refs/heads/master
| 2020-03-28T12:38:09.559467 | 2018-09-25T09:23:41 | 2018-09-25T09:23:41 | 148,317,920 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6201232075691223,
"alphanum_fraction": 0.6232032775878906,
"avg_line_length": 29.4375,
"blob_id": "a0da1b54d34c404bb28d27c482bf7e2a1cb88c14",
"content_id": "2676b645fb540cc1c1503478e8de4c14aadc202c",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 974,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 32,
"path": "/OSX-replace-chars-in-iPhoto.py",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\nimport EasyDialogs\nimport os\n\ndef gdzie_zapisac():\n # ask for destination folder\n\tdir = EasyDialogs.AskFolder(\n\t\tmessage='Select destinatin folder',\n\t\tdefaultLocation=os.getcwd(),\n\t\twanted=unicode,\n\t\t)\n\treturn dir\n\n\ndef napraw_nazwy(album):\n\t# loop for ZNAKI table\n\tZNAKI = [',', '.', '\\\\', '/', '+', ':', ' ']\n\tfor s in ZNAKI:\n\t\talbum = album.replace(s, '_')\n\treturn album\n\ndir = gdzie_zapisac()\niPAlbumCount = os.getenv('iPAlbumCount')\nfor i in range(int(iPAlbumCount)):\n\tALBUM_x = 'iPAlbumName_' + str(i)\t\t # variable name for particular album\n\tALBUM = os.getenv(ALBUM_x)\t\t\t\t # link to its value with eval()\n\tALBUM = napraw_nazwy(ALBUM)\t\t\t\t # replacing characters in albums name\n#\tALBUMPATH = os.path.join(dir,ALBUM)\t\t # path to folder\n\tALBUMPATH = dir + '/' + ALBUM.decode('utf-8')\n\tprint \"ALBUMPATH = \" + ALBUMPATH.encode('utf-8')\n\tos.mkdir(ALBUMPATH) # create folder\n"
},
{
"alpha_fraction": 0.4312354326248169,
"alphanum_fraction": 0.503496527671814,
"avg_line_length": 24.235294342041016,
"blob_id": "67f6b9df2e79c9b90806039346f02e8f6609d977",
"content_id": "7c8e8e804fb1b346b13a84885bf268bd89f7bd8f",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 429,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 17,
"path": "/rainbow.c",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "/*Create rainbow table for guessing wp-backup-db v2.2.4 backup path \nLarry W. Cashdollar*/\n#include <stdio.h>\nint\nmain (void)\n{\n char string[16] = \"0123456789abcdef\";\n int x, y, z, a, b;\n for (x = 0; x < 16; x++)\n for (y = 0; y < 16; y++)\n\t for (z = 0; z < 16; z++)\n\t for (a = 0; a < 16; a++)\n\t\t for (b = 0; b < 16; b++)\n\t\t printf (\"%c%c%c%c%c\\n\", string[x], string[y], string[z],\n\t\t\t string[a], string[b]);\nreturn(0);\n}\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.6304348111152649,
"avg_line_length": 24.090909957885742,
"blob_id": "4a8ae8ec9243350392cbc53fe465f0fcdd146c08",
"content_id": "371b13d9b51f9802d012f678ade7e80c32d8e8c2",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 276,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 11,
"path": "/OSX-convert-jpg-to-png.sh",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Use it this way:\n# for i in ./*.JPG ; do this_script.sh $i ; done\n\nNEWFORMAT=\"png\"\n\nOLDFORMAT=`sips --getProperty format \"$1\" | cut -s -d : -f 2 -`\n\n echo \"Converting $1 from $OLDFORMAT to $NEWFORMAT\"\n\tsips --setProperty format $NEWFORMAT \"$1\" 2>&1>/dev/null\n"
},
{
"alpha_fraction": 0.6004273295402527,
"alphanum_fraction": 0.6047008633613586,
"avg_line_length": 32.42856979370117,
"blob_id": "dc446254f6ed869f08dce623a384ef3125b6558e",
"content_id": "7bde0ad2f961ecf14a0f2670c600eeddacd6edca",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 468,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 14,
"path": "/csv2xlxs.py",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport csv\nimport openpyxl # from https://pythonhosted.org/openpyxl/ or PyPI (e.g. via pip)\n\nfor csvfile in glob.glob(os.path.join('.', '*.csv')):\n wb = openpyxl.Workbook()\n ws = wb.active\n with open(csvfile, 'rb') as f:\n reader = csv.reader(f)\n for r, row in enumerate(reader, start=1):\n for c, val in enumerate(row, start=1):\n ws.cell(row=r, column=c).value = val\n wb.save(csvfile + '.xlsx')\n"
},
{
"alpha_fraction": 0.5604142546653748,
"alphanum_fraction": 0.5724971294403076,
"avg_line_length": 21.855262756347656,
"blob_id": "0e86a5cff054523ad54bba7b50cbffb09cacec8a",
"content_id": "51e688842997e90a9240a102e65f8f7a125a7e21",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1738,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 76,
"path": "/sort-images.py",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport EXIF\nfrom datetime import date\n\n# zamiana daty na format yyyy-mm-dd i obciecie czasu\ndef parsedate(s):\n try:\n\t\treturn s[0:4]+\"-\"+s[5:7]+\"-\"+s[8:10]\n\texcept:\n\t return None\n\ndef outtime(x):\n\ttry:\n\t\treturn date(int(x[0:4]),int(x[5:7]),int(x[8:10])).ctime()\n\texcept:\n\t\treturn None\n\n# wcyciagam dane EXIF z wszystkich plikow, ktore je posiadaja\n# w tym katalogu\n#pliki = glob.glob('*.[j,J][p,P][g,G]')\npliki = glob.glob('*')\nfotki = {}\nfor i in pliki:\n\ttry:\n\t\tf = open(i, 'rb')\n\texcept:\n\t\tprint \"'%s' is unreadable\\n\"%i\n\t\tcontinue\n\t# get the tags\n\ttags = EXIF.process_file(f, stop_tag='EXIF DateTimeOriginal')\n\tif not tags:\n\t\tprint \"No EXIF info found: \", i\n\t\tcontinue\n\tif tags != {}:\n\t\tif tags.get('EXIF DateTimeOriginal') == None:\n\t\t\ta = tags.get('Image DateTime')\n\t\telse:\n\t\t\ta = tags.get('EXIF DateTimeOriginal')\n\tfotki[i] = a\n\nprint \"==============================================\"\nprint \"\"\n\n# konwersja daty w fotki{}\nfor (k, v) in fotki.iteritems():\n\tfotki[k] = parsedate(str(v))\n\n# Sortowanie fotki{}\ndate = \"\"\ntmp_dir = \"\"\nalist = sorted(fotki.iteritems(), key=lambda (k,v): v)\nfor i in range(len(alist)):\n\tdate = alist[i][1] # zapamietuje nowa date\n\tif tmp_dir == date:\n\t\tfile = \"../\"+alist[i][0]\n\t\tdir = date+\"/\"+alist[i][0]\n\t\tos.utime(alist[i][0],outtime(date))\n\t\tos.symlink(file, dir)\n\t\tprint \"ln -sf \", file, dir\n\telse:\n\t\tprint \"----------------------------------------------\"\n\t\tos.mkdir(date)\n\t\tprint \"mkdir \", date\n\t\ttmp_dir = date\n\t\tfile = \"../\"+alist[i][0]\n\t\tdir = date+\"/\"+alist[i][0]\n\t\tos.utime(alist[i][0],outtime(date))\n\t\tos.symlink(file, dir)\n\t\tprint \"ln -sf \", file, dir\n\n\n\nprint \"\"\nprint \"==============================================\"\nprint \"Fotek z danymi EXIF jest: \", len(fotki)\n\n"
},
{
"alpha_fraction": 0.5198237895965576,
"alphanum_fraction": 0.5198237895965576,
"avg_line_length": 19.636363983154297,
"blob_id": "fdc5d997ff93ae2ea86f1a602e8a4686890f086f",
"content_id": "eaaf781023fc33ce74bb074ec080f010de863385",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 11,
"path": "/usun.py",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfor line in open('test.txt', 'r'):\n seen = []\n words = line.rstrip('\\n').split()\n\n for word in words:\n if not word in seen:\n print word,\n seen.append(word)\n print\n"
},
{
"alpha_fraction": 0.6116071343421936,
"alphanum_fraction": 0.6413690447807312,
"avg_line_length": 29.31818199157715,
"blob_id": "737968ef26a33b14272d104fe5e14ab259f93ad2",
"content_id": "5e211d0eceb929df43e048fa695baaaf94fb00ce",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 672,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 22,
"path": "/OSX-way-to-resize-images.sh",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Change HSIZE and VSIZE to your requirements\n# and use it this way:\n# for i in ./*.JPG ; do this_script.sh $i ; done\n\n\nHSIZE=1024 \t# target width\nVSIZE=1024\t\t# target height\nGETWIDTH=`sips --getProperty pixelWidth \"$1\" | cut -s -d : -f 2 -` # find real width\nGETHEIGHT=`sips --getProperty pixelHeight \"$1\" | cut -s -d : -f 2 -` # find real height\n\n# echo \"WIDTH = $GETWIDTH\"\n# echo \"HEIGHT = $GETHEIGHT\"\n# if image is horizontal\nif [ $GETWIDTH -gt $GETHEIGHT ] ; then\n\techo \"Resizing HORIZONTAL: $1 ...\"\n\tsips --resampleWidth $HSIZE \"$1\" 2>&1>/dev/null\nelse\n\techo \"Resizing VERTICAL: $1 ...\"\n\tsips --resampleWidth $VSIZE \"$1\" 2>&1>/dev/null\nfi\n \n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 18,
"blob_id": "c81fb21f46740768308ddd945b94af228b0f6f3a",
"content_id": "0b097d637a76defc42a29d3dc2d9d362ba43a60d",
"detected_licenses": [
"Unlicense"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 1,
"path": "/scripts4windows/README.md",
"repo_name": "bitounu/shitz",
"src_encoding": "UTF-8",
"text": "## Windows scripts\n\n"
}
] | 8 |
jrinconada/roman
|
https://github.com/jrinconada/roman
|
20d5ac272139fc448dabb5dda0391dd3b94c45ed
|
6d24e82d23ba2d1faced952f354f323136cd4cbf
|
519e112ee8762a41276e0db48e5b37f37234f620
|
refs/heads/master
| 2020-06-01T17:20:02.941991 | 2019-06-22T12:09:30 | 2019-06-22T12:09:30 | 190,863,278 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.34259259700775146,
"alphanum_fraction": 0.4274691343307495,
"avg_line_length": 45.14285659790039,
"blob_id": "53ed47ca497f41a2410bfe03cfe9bae20c34e51f",
"content_id": "6d8c45466955fb4f50f53691835f28909d41da2e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 14,
"path": "/constants.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "\n\n# For validation\nVALID_LETTERS = ('I', 'V', 'X', 'L', 'C', 'D', 'M')\nFIVE_BASED = ('V', 'L', 'D')\nVALID_SUBTRACTIONS = ('IV', 'IX', 'XL', 'XC', 'CD', 'CM')\n\n# For translation A\nROMAN_10 = ('', 'I', 'II', 'III', 'IV', 'V', 'VI', 'VII', 'VIII', 'IX', 'X')\nROMAN_100 = ('', 'X', 'XX', 'XXX', 'XL', 'L', 'LX', 'LXX', 'LXXX', 'XC', 'C')\nROMAN_1000 = ('', 'C', 'CC', 'CCC', 'CD', 'D', 'DC', 'DCC', 'DCCC', 'CM', 'M')\nROMAN_10000 = ('', 'M', 'MM', 'MMM')\n\n# For translation B\nTO_ROMAN = {1: 'I', 5: 'V', 10: 'X', 50: 'L', 100: 'C', 500: 'D', 1000: 'M', 5000: '', 10000: ''}\nTO_DECIMAL = {'I': 1, 'V': 5, 'X': 10, 'L': 50, 'C': 100, 'D': 500, 'M': 1000}\n"
},
{
"alpha_fraction": 0.6605080962181091,
"alphanum_fraction": 0.6801385879516602,
"avg_line_length": 53,
"blob_id": "fad553cc1da0183711dce2a095a0dfa20c00a1da",
"content_id": "b3b64b92edb87dc5c002cfe5d784d0c0583b1213",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 866,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 16,
"path": "/util.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "\n\ndef get_digit(number, digit):\n \"\"\" Given a number, returns the digit in the specified position, for an out of range digit returns 0 \"\"\"\n digit_sum = 0\n for i in range(digit): # Accumulate all the other digits and subtract from the original number\n digit_sum += number - ((number // 10**(i+1)) * 10**(i+1) + digit_sum)\n return digit_sum // 10**(digit-1)\n\n\ndef get_digit_b(number, digit):\n \"\"\" Given a number, returns the digit in the specified position, for an out of range digit returns 0 \"\"\"\n return number % 10**digit // 10**(digit-1) # Shortest mathematical method (module and integer division)\n\n\ndef get_digit_c(number, digit):\n \"\"\" Given a number, returns the digit in the specified position, does not accept out of range digits \"\"\"\n return int(str(number)[-digit]) # Simplest method by casting to string and access by index\n"
},
{
"alpha_fraction": 0.6927666068077087,
"alphanum_fraction": 0.7252050638198853,
"avg_line_length": 58.599998474121094,
"blob_id": "3e6e947ca54dbf3a9f04d8d084616f34ed88e3a0",
"content_id": "41aa0cf57d1831be3205d7550fd5461bea204352",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2682,
"license_type": "permissive",
"max_line_length": 310,
"num_lines": 45,
"path": "/README.md",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "# Roman Numeral Translator\nTrying different algorithms to translate modern **decimal system** numbers to **roman numerals** and viceversa.\n## Translation algorithms\n### Algorithm A\nThis is the **simple** and **efficient** way to do it. Defining four tuples of all combinations of numbers:\n- **To 10**: *1,2,3,4...10*\n- **To 100**: *10, 20, 30, 40...100*\n- **To 1000**: *100, 200, 300, 400...1000*\n- **The last 3**: *1000, 2000, 3000*\n\nGetting the proper combination for every digit. For example, for the number *437*:\n1. For the first digit, access the third tuple with *4* and get `CD`\n2. For the second digit, access the second tuple with *3* and get `XXX`\n3. For the third digit, access the first tuple with *8* and get `VII`\n4. Finally, Concatenate the all results to get `CDXXXVII`\n\n### Algorithm B\nThis a more **complex** and less efficient algorithm but also more **interesting**... See code and try to understand it for yourself.\n\n### Getting the nth digit\nTo resolve the problem of getting a digit from a number I explored three different solutions: \n- The pure **mathematical** one: Get the module with 10 to the power of the digit and divide by *10* to power of the digit minus one.\n- The **programmer** way: Convert from int to string get, access to the proper index and convert from string to int.\n- The **mix**: Similar to the first one but with a loop involved, not very elegant but maybe a little easier for programmers to understand.\n\n## Validation\n### Simple validation\n- An input number must be between *1* and *3999* to be expressed as a roman numeral.\n- A roman numeral must be composed of a combination of these letters: `I`, `V`, `X`, `L`, `C`, `D` or `M`.\n\n### Strict validation\nIf **algorithm B** is used for translation of roman numerals to decimal number system adding and subtraction rules are applied without any validation, this means that numbers like `IIII`, `IC`, `VV` or even `MMMMMMM` are translated and produce a logical result given the rules (so *4*, *99*, *10* and *70000*).\n\nThe translation of invalid numbers is made but with a comment pointing it out and providing the proper roman numeral. The rules checked to consider a roman numeral fully valid are:\n- No more than three consecutive numerals (ex: `IIII`)\n- No more than one consecutive *5* based numeral (ex: `VV`)\n- No invalid subtractions (ex: `IL`, `XM`, `VX`)\n- No invalid ordering (smaller numbers before bigger ones) if it is not a valid subtraction (ex: `IC`, `IIV`, `VC`, `XDM`)\n\n## Usage\nThis program is compose of several Python 3 scripts with no dependencies on external libraries. \nGiven that you have Python 3 installed, run it as any Python script:\n```\npython main.py\n```\n"
},
{
"alpha_fraction": 0.5822561979293823,
"alphanum_fraction": 0.598119854927063,
"avg_line_length": 31.11320686340332,
"blob_id": "2f54dce9e30933a8723c3c26ef7de6461d5c3b81",
"content_id": "20bea5da44b61a5dba29c43f49fe388eaf1eb748",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1702,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 53,
"path": "/translator_b.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "from util import get_digit\nfrom constants import TO_DECIMAL\nfrom constants import TO_ROMAN\n\n\ndef to_roman(number, unit, half, top):\n \"\"\" Given a digit and the range is on (unit, half, top) it is on adds as many roman numerals as necessary\n Sample call: to_roman(8, 'I', 'V', 'X') -> 'VIII'\n \"\"\"\n result = ''\n repeated = 0\n\n for i in range(number):\n if repeated < 3: # I, II, III and VI, VII, VIII\n result = result + unit\n repeated += 1\n elif repeated == 3: # IV and IX\n result = unit + half\n repeated += 1\n elif repeated == 4: # V and X\n result = half\n half = top\n repeated = 0\n return result\n\n\ndef translate_to_roman(number):\n \"\"\" Given a number between 1 and 3999 returns the equivalent roman numeral \"\"\"\n result = ''\n\n for i in reversed(range(1, 5)): # Run the function for every range of roman numerals\n result += to_roman(get_digit(number, i), TO_ROMAN[10**(i-1)], TO_ROMAN[10**(i-1) * 5], TO_ROMAN[10**i])\n\n return result\n\n\ndef translate_to_decimal(roman):\n \"\"\" Given a roman numeral returns the equivalent in decimal number system \"\"\"\n decimal = to_decimal(roman)\n return decimal\n\n\ndef to_decimal(roman):\n result = 0\n previous = 0\n for letter in roman: # Starting in the second element\n if TO_DECIMAL[letter] <= previous: # Adding if I, II, III, V, VI, VII, VIII or X\n result += TO_DECIMAL[letter]\n else: # Subtracting if IV or IX\n result += TO_DECIMAL[letter] - 2 * previous # Must subtract the current unit and the previously added\n previous = TO_DECIMAL[letter]\n\n return result\n"
},
{
"alpha_fraction": 0.7287769913673401,
"alphanum_fraction": 0.7338129281997681,
"avg_line_length": 35.578948974609375,
"blob_id": "f28e92af56d0e3e39298aa1900c504f8f6863d4c",
"content_id": "399bf5b630a8667008b5249cac5f510473942d15",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1390,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 38,
"path": "/main.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "from translator_b import translate_to_roman\nfrom translator_b import translate_to_decimal\nfrom translator_a import show\nfrom validation import valid_number\nfrom validation import valid_word\nfrom validation import valid_letters\nfrom validation import more_than_one_5\nfrom validation import more_than_three\nfrom validation import invalid_subtractions\nfrom validation import invalid_order\n\n\n# Input\nnumber = input('Give me a number (roman or decimal): ')\n\n# Basic validation\nto_roman = number.isdigit()\nresult = ''\nif to_roman and not valid_number(eval(number)): # Validate range\n result = 'It must be an integer number between 1 and 3999'\nelif not to_roman and not valid_word(number): # Validate letters\n result = 'Invalid letter/s, this are the valid ones: ' + valid_letters()\n\n# Translation\nif not result:\n if to_roman: # Decimal number to roman numeral\n result = translate_to_roman(eval(number))\n else: # Roman numeral to decimal number\n result = translate_to_decimal(number.upper())\n\n# Strict roman numeral validation\nif not to_roman and type(result) is int:\n if more_than_three(number.upper()) or more_than_one_5(number.upper()) \\\n or invalid_subtractions(number.upper()) or invalid_order(number.upper()):\n result = str(result) + ' (but it is not following the rules) it should be ' + translate_to_roman(result)\n\n# Output\nprint(result)\n"
},
{
"alpha_fraction": 0.53515625,
"alphanum_fraction": 0.630859375,
"avg_line_length": 35.57143020629883,
"blob_id": "28bd5610942700b2270292103addb1abc956120a",
"content_id": "da5589935b3b017eeef44befd36f29b68d869acf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 28,
"path": "/test_util.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom util import get_digit\nfrom util import get_digit_b\nfrom util import get_digit_c\n\n\nclass TestUtil(unittest.TestCase):\n def test_get_digit(self):\n self.assertEqual(get_digit(5438, 1), 8)\n self.assertEqual(get_digit(5438, 2), 3)\n self.assertEqual(get_digit(5438, 3), 4)\n self.assertEqual(get_digit(5438, 4), 5)\n self.assertEqual(get_digit(5438, 5), 0)\n self.assertEqual(get_digit(5438, 20), 0)\n\n def test_get_digit_b(self):\n self.assertEqual(get_digit_b(5438, 1), 8)\n self.assertEqual(get_digit_b(5438, 2), 3)\n self.assertEqual(get_digit_b(5438, 3), 4)\n self.assertEqual(get_digit_b(5438, 4), 5)\n self.assertEqual(get_digit_b(5438, 5), 0)\n self.assertEqual(get_digit_b(5438, 20), 0)\n\n def test_get_digit_c(self):\n self.assertEqual(get_digit_c(5438, 1), 8)\n self.assertEqual(get_digit_c(5438, 2), 3)\n self.assertEqual(get_digit_c(5438, 3), 4)\n self.assertEqual(get_digit_c(5438, 4), 5)\n"
},
{
"alpha_fraction": 0.6800804734230042,
"alphanum_fraction": 0.7002012133598328,
"avg_line_length": 34.5,
"blob_id": "b450e4510f71ead6e04906462a3c00fbef589126",
"content_id": "101670d821fb6de7539eea8fdd175bc10ab07f8f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 14,
"path": "/test_translator_b.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "import unittest\nimport translator_a\nimport translator_b\n\n\nclass TestTranslate(unittest.TestCase):\n def test_translate_to_roman_b(self):\n for decimal in range(1, 4000):\n self.assertEqual(translator_a.translate(decimal), translator_b.translate_to_roman(decimal))\n\n def test_translate_to_decimal_b(self):\n for decimal in range(1, 4000):\n roman = translator_a.translate(decimal)\n self.assertEqual(decimal, translator_b.translate_to_decimal(roman))\n"
},
{
"alpha_fraction": 0.5970269441604614,
"alphanum_fraction": 0.6078746318817139,
"avg_line_length": 28.987951278686523,
"blob_id": "a0d13d2c66e8ea32f2b8116ae296727c8c088ddd",
"content_id": "395fb7b42579ba222ddb27c0e74587e1102fecb0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2489,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 83,
"path": "/validation.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "from constants import VALID_LETTERS\nfrom constants import FIVE_BASED\nfrom constants import TO_DECIMAL\nfrom constants import VALID_SUBTRACTIONS\n\n\ndef valid_number(user_input):\n \"\"\" Returns True if input is an integer number between 1 and 3999 \"\"\"\n return 1 <= user_input <= 3999\n\n\ndef valid_word(user_input=''):\n \"\"\" Returns True if all letters are valid roman numerals \"\"\"\n user_input = user_input.upper()\n for letter in VALID_LETTERS: # Removes all the roman numerals letters\n user_input = user_input.replace(letter, '')\n return not user_input # If user input is empty all the letters were roman numerals\n\n\ndef valid_letters():\n \"\"\" Returns a human readable list for the valid roman numerals \"\"\"\n valids = ''\n for letter in VALID_LETTERS[:-2]:\n valids += letter + ', '\n valids += VALID_LETTERS[-2] + ' or ' + VALID_LETTERS[-1]\n return valids\n\n\n# Strict rules\ndef more_than_three(number=''):\n \"\"\" Returns True if there are more than three consecutive numerals (ex: IIII) \"\"\"\n prev = ''\n counter = 0\n for letter in number:\n if prev == letter:\n counter += 1\n else:\n counter = 1\n if counter > 3:\n return True\n prev = letter\n\n return False\n\n\ndef more_than_one_5(number=''):\n \"\"\" Returns True if there is more than one 5 based numeral (ex: VV) \"\"\"\n prev = ''\n repetitions = 0\n for letter in number:\n if prev == letter and letter in FIVE_BASED:\n repetitions += 1\n else:\n repetitions = 0\n if repetitions >= 1:\n return True\n prev = letter\n\n return False\n\n\ndef invalid_subtractions(number=''):\n \"\"\" Returns True if there is an invalid subtraction (ex: IL, XM, VX) \"\"\"\n prev = number[0]\n for letter in number[1:]:\n if TO_DECIMAL[prev] < TO_DECIMAL[letter] and (prev + letter) not in VALID_SUBTRACTIONS:\n return True\n prev = letter\n\n return False\n\n\ndef invalid_order(number=''):\n \"\"\" Returns True if there are smaller numbers before bigger ones\n and it is not a valid subtraction (ex: IC, IIV, VC, XDM) \"\"\"\n for i in range(len(number)):\n letter = number[i]\n for j in range(i + 1, len(number)):\n if TO_DECIMAL[letter] < TO_DECIMAL[number[j]]: # Invalid order unless it is a valid subtraction\n if not ((i == j - 1) and (letter + number[j]) in VALID_SUBTRACTIONS):\n return True\n\n return False\n"
},
{
"alpha_fraction": 0.5484261512756348,
"alphanum_fraction": 0.6186440587043762,
"avg_line_length": 33.41666793823242,
"blob_id": "5b29f90db702df4d3cf06a50d2daf6bb7833da00",
"content_id": "2315439136b7b625d3ba7dbc23c683ffdf056727",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 826,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 24,
"path": "/translator_a.py",
"repo_name": "jrinconada/roman",
"src_encoding": "UTF-8",
"text": "from util import get_digit\nfrom constants import ROMAN_10\nfrom constants import ROMAN_100\nfrom constants import ROMAN_1000\nfrom constants import ROMAN_10000\n\n\ndef translate(number):\n \"\"\" Given a number between 1 and 3999 returns the equivalent roman numeral \"\"\"\n # Gets the proper combination for every digit\n return ROMAN_10000[get_digit(number, 4)] + \\\n ROMAN_1000[get_digit(number, 3)] + \\\n ROMAN_100[get_digit(number, 2)] + \\\n ROMAN_10[get_digit(number, 1)]\n\n\ndef show(limit):\n \"\"\" Prints all the roman numerals from 1 to a given limit \"\"\"\n for i in range(1, limit + 1):\n result = ROMAN_10000[get_digit(i, 4)] + \\\n ROMAN_1000[get_digit(i, 3)] + \\\n ROMAN_100[get_digit(i, 2)] + \\\n ROMAN_10[get_digit(i, 1)]\n print(i, result)\n"
}
] | 9 |
trappen-tgmg/autodeploy-test
|
https://github.com/trappen-tgmg/autodeploy-test
|
02de2763162bdd06603e856fa10475410c96ba7c
|
fe37f9966f3bc71cfe8ef327f1b5f9476c104f43
|
be1fdc0ab92182ce9bb04f383ed87d20752c4434
|
refs/heads/master
| 2021-07-17T17:54:49.708866 | 2017-10-24T13:11:21 | 2017-10-24T13:11:21 | 106,805,535 | 0 | 0 | null | 2017-10-13T09:34:34 | 2017-10-13T12:20:16 | 2017-10-24T13:13:37 |
Python
|
[
{
"alpha_fraction": 0.6351351141929626,
"alphanum_fraction": 0.6351351141929626,
"avg_line_length": 13.800000190734863,
"blob_id": "58265902350b698a291854c994880fe66f528c1f",
"content_id": "66544f84fbcd3406d3b47a3a867745ccfc6ae099",
"detected_licenses": [],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 5,
"path": "/fabfile.py",
"repo_name": "trappen-tgmg/autodeploy-test",
"src_encoding": "UTF-8",
"text": "from fabric.api import *\n\n@task\ndef deploy():\n run(\"echo 'deployed!'\")\n"
},
{
"alpha_fraction": 0.6141732335090637,
"alphanum_fraction": 0.6692913174629211,
"avg_line_length": 20.16666603088379,
"blob_id": "c721c588b521efbac5ec47f0cb911cb62e5aae10",
"content_id": "4a0fdadaa27f976bcb4a0dddd6dc1f0ad44959c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 127,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 6,
"path": "/Dockerfile",
"repo_name": "trappen-tgmg/autodeploy-test",
"src_encoding": "UTF-8",
"text": "FROM python:3-alpine\n\nRUN pip install flask gunicorn\nCOPY . /app\nWORKDIR /app\nCMD [\"gunicorn\", \"timr:app\", \"-b\", \"0.0.0.0:80\"]\n"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 19.83333396911621,
"blob_id": "052047a3df94562ef23c265f5e3a8780fbee4044",
"content_id": "004a02c5b870e99914ad8e4d363d53cd0b0d87bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 12,
"path": "/timr.py",
"repo_name": "trappen-tgmg/autodeploy-test",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom datetime import datetime\n\napp = Flask(__name__)\n\[email protected](\"/\")\ndef index():\n # comments are important\n return \"The time is %s\" % datetime.now().strftime(\"%d.%m.%Y %H:%M\")\n\nif __name__ == \"__main__\":\n app.run()\n"
},
{
"alpha_fraction": 0.7037037014961243,
"alphanum_fraction": 0.7037037014961243,
"avg_line_length": 39.5,
"blob_id": "2761f29926fb650674720f3f946787f9241f3df9",
"content_id": "fd54e47e0473266bc29f9ee063727edf67642442",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 2,
"path": "/tests/test_basic.py",
"repo_name": "trappen-tgmg/autodeploy-test",
"src_encoding": "UTF-8",
"text": "def test_a_simple_test():\n assert True, \"The laws of the universe still work\"\n"
}
] | 4 |
pangea-project/pangea-tooling
|
https://github.com/pangea-project/pangea-tooling
|
3a5aab1722a0ba7b63a3447b4582d1f4489f8a4d
|
07304a60cc789133f3e84f7510c6fe2c053ebeda
|
5f29523e5ddebaa95300601cb05501a889d8e26a
|
refs/heads/master
| 2023-09-01T07:33:08.886775 | 2023-08-31T21:57:55 | 2023-08-31T22:07:05 | 26,976,456 | 6 | 7 | null | 2014-11-21T20:21:34 | 2023-08-11T07:13:03 | 2023-09-12T07:48:29 |
Ruby
|
[
{
"alpha_fraction": 0.6465702652931213,
"alphanum_fraction": 0.6576437950134277,
"avg_line_length": 36.80232620239258,
"blob_id": "d77a27596cadba330d33295002b7898672efb253",
"content_id": "b3b0bcd20f3be14e1ef31982cca88ddee210f3ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3251,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 86,
"path": "/nci/jenkins_expunge.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'pathname'\n\nrequire_relative '../lib/jenkins/jobdir.rb'\n\n# Archives all Jenkins job dirs it can find by moving it to the do-volume mount.\nmodule NCIJenkinsJobHistory\n def self.cleaning_paths_for(dir)\n [\n \"#{dir}/archive\",\n \"#{dir}/injectedEnvVars.txt\",\n \"#{dir}/junitResult.xml\",\n \"#{dir}/log\",\n \"#{dir}/timestamper\"\n ]\n end\n\n def self.mangle(jobdir)\n # Mangles \"fairly\" old builds to not include a log and test data anymore\n # The build temselves are still there for performance tracking and the\n # like.\n Jenkins::JobDir.each_ancient_build(jobdir,\n min_count: 256,\n max_age: 30 * 6) do |ancient_build|\n marker = \"#{ancient_build}/_history_mangled\"\n next if File.exist?(marker)\n next unless File.exist?(ancient_build) # just in case the dir disappeared\n next unless File.directory?(ancient_build) # don't trip over files\n\n # /dev/mapper/vg0-charlotte 1.3T 1.1T 168G 87% /\n FileUtils.rm_rf(cleaning_paths_for(ancient_build), verbose: true)\n\n FileUtils.touch(marker)\n end\n end\n\n def self.purge(jobdir)\n # Purges \"super\" old builds entirely so they don't even appear anymore.\n # NB: this intentionally has a lower min_count since the age is higher.\n # Age restricts on top of min_count, we really do not care about builds\n # that are older than 2 years regardless of how many builds there are!\n Jenkins::JobDir.each_ancient_build(jobdir,\n min_count: 64,\n max_age: 30 * 24) do |ancient_build|\n next unless File.directory?(ancient_build) # don't trip over files\n\n FileUtils.rm_rf(ancient_build, verbose: true)\n end\n end\n\n def self.clean\n jobsdir = \"#{ENV.fetch('JENKINS_HOME')}/jobs\"\n Dir.glob(\"#{jobsdir}/*\").each do |jobdir|\n # this does interlaced looping so we have a good chance that the\n # directories are still in disk cache thus improving performance.\n name = File.basename(jobdir)\n puts \"---- PURGE #{name} ----\"\n purge(jobdir)\n puts \"---- MANGLE #{name} ----\"\n mangle(jobdir)\n end\n end\nend\n\nNCIJenkinsJobHistory.clean if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.591904878616333,
"alphanum_fraction": 0.596446692943573,
"avg_line_length": 32.12389373779297,
"blob_id": "94daeadda0349686043ac3e3940d51e37d47d2bc",
"content_id": "f46a770146979d361c66dc012d1c762cb4e8024b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7486,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 226,
"path": "/lib/mgmt/deployer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\nrequire 'docker'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'socket'\n\nrequire_relative '../../lib/dpkg'\nrequire_relative '../ci/container'\nrequire_relative '../ci/pangeaimage'\n\nDocker.options[:read_timeout] = 2 * 60 * 60 # 1 hour\nDocker.options[:write_timeout] = 2 * 60 * 60 # 1 hour\n$stdout = $stderr\n\nmodule MGMT\n # Class to handle Docker container deployments\n class Deployer\n Upgrade = Struct.new(:from, :to)\n\n attr_accessor :testing\n attr_reader :base\n\n # @param flavor [Symbol] ubuntu or debian base\n # @param tag [String] name of the version (vivid || unstable || wily...)\n # @param origin_tags [Array] name of alternate versions to upgrade from\n def initialize(flavor, tag, origin_tags = [])\n warn \"Deploying #{flavor} #{tag} from #{origin_tags}\"\n @base = CI::PangeaImage.new(flavor, tag)\n ENV['DIST'] = @base.tag\n ENV['PANGEA_PROVISION_AUTOINST'] = '1' if openqa?\n @origin_tags = origin_tags\n @testing = true if CI::PangeaImage.namespace.include?('testing')\n init_logging\n end\n\n def openqa?\n # Do not foce openqa on if it was already manually defined elsewhere.\n return false if ENV.include?('PANGEA_PROVISION_AUTOINST')\n\n Socket.gethostname.include?('openqa')\n end\n\n def init_logging\n @log = Logger.new(STDERR)\n\n raise 'Could not initialize logger' if @log.nil?\n\n Thread.new do\n # :nocov:\n Docker::Event.stream { |event| @log.debug event } unless @testing\n # :nocov:\n end\n end\n\n def self.target_arch\n node_labels = ENV.fetch('NODE_LABELS').split\n arches = node_labels.find_all do |label|\n arches = DPKG.run('dpkg-architecture', [\"-W#{label}\", '-L'])\n if arches.size > 1\n raise \"The jenkins node label #{label} unexpectedly mapped to\" \\\n \" multiple architectures in DPKG: #{arches}\"\n end\n arches.size == 1 # either 1 or 0; 1 is found, 0 is not.\n end\n\n case arches.size\n when 0\n warn \"Failed to find an arch for labels #{node_labels};\" \\\n \" falling back to default: #{DPKG::HOST_ARCH}\"\n return DPKG::HOST_ARCH\n when 1\n return arches.first\n end\n\n raise \"Unexpectedly found multiple possible architectures matching the\" \\\n \"jenkins node labels. don't know what to do!\"\n end\n\n def create_base\n upgrade = nil\n arch = self.class.target_arch\n\n case @base.flavor\n when 'debian'\n base_image = \"debianci/#{arch}:#{@base.tag}\"\n else\n base_image = \"#{@base.flavor}:#{@base.tag}\"\n\n case arch\n when 'armhf'\n base_image = \"arm32v7/#{base_image}\"\n when 'arm64'\n base_image = \"arm64v8/#{base_image}\"\n end\n end\n\n trying_tag = @base.tag\n begin\n @log.info \"creating base docker image from #{base_image} for #{base}\"\n image = Docker::Image.create(fromImage: base_image)\n rescue Docker::Error::ArgumentError, Docker::Error::NotFoundError\n error = \"Failed to create Image from #{base_image}\"\n raise error if @origin_tags.empty?\n\n puts error\n new_tag = @origin_tags.shift\n puts \"Trying again with tag #{new_tag} and an upgrade...\"\n base_image = base_image.gsub(trying_tag, new_tag)\n trying_tag = new_tag\n upgrade = Upgrade.new(new_tag, base.tag)\n retry\n end\n image.tag(repo: @base.repo, tag: @base.tag)\n upgrade\n end\n\n def deploy_inside_container(base, upgrade)\n # Take the latest image which either is the previous latest or a\n # completely prestine fork of the base ubuntu image and deploy into it.\n # FIXME use containment here probably\n @log.info \"creating container from #{base}\"\n cmd = ['sh', '/tooling-pending/deploy_in_container.sh']\n if upgrade\n cmd = ['sh', '/tooling-pending/deploy_upgrade_container.sh']\n cmd << upgrade.from << upgrade.to\n end\n c = CI::Container.create(Image: base.to_s,\n WorkingDir: ENV.fetch('JENKINS_HOME', Dir.home),\n Cmd: cmd,\n binds: [\"#{Dir.home}/tooling-pending:/tooling-pending\"])\n unless @testing\n # :nocov:\n @log.info 'creating debug thread'\n Thread.new do\n c.attach do |_stream, chunk|\n puts chunk\n STDOUT.flush\n end\n end\n # :nocov:\n end\n\n @log.info \"starting container from #{base}\"\n c.start\n ret = c.wait\n status_code = ret.fetch('StatusCode', 1)\n raise \"Bad return #{ret}\" unless status_code.to_i.zero?\n\n c.stop!\n c\n end\n\n def run!\n upgrade = create_base unless Docker::Image.exist?(@base.to_s)\n\n c = deploy_inside_container(@base, upgrade)\n\n # Flatten the image by piping a tar export into a tar import.\n # Flattening essentially destroys the history of the image. By default\n # docker will however stack image revisions ontop of one another. Namely\n # if we have\n # abc and create a new image edf, edf will be an AUFS ontop of abc. While\n # this is probably useful if one doesn't commit containers repeatedly\n # for us this is pretty crap as we have massive turn around on images.\n @i = nil\n\n if ENV.include?('PANGEA_DOCKER_NO_FLATTEN')\n @log.warn 'Opted out of image flattening...'\n @i = c.commit\n else\n @log.warn 'Flattening latest image by exporting and importing it.' \\\n ' This can take a while.'\n\n rd, wr = IO.pipe\n\n Thread.abort_on_exception = true\n read_thread = Thread.new do\n @i = Docker::Image.import_stream do\n rd.read(1000).to_s\n end\n @log.warn 'Import complete'\n rd.close\n end\n write_thread = Thread.new do\n c.export do |chunk|\n wr.write(chunk)\n end\n @log.warn 'Export complete'\n wr.close\n end\n [read_thread, write_thread].each(&:join)\n end\n\n c.remove\n node_is_master = ENV.fetch('NODE_NAME', '') == 'master'\n node_is_master ||= ENV.fetch('NODE_TYPE', '') == 'architecture-master'\n node_is_master &&= !ENV['PANGEA_UNDER_TEST']\n image_names = [@base]\n image_names << \"kdeneon/ci:#{@base.tag}\" if node_is_master\n image_names.each do |name|\n @log.info \"Deleting old image of #{name}\"\n previous_image = Docker::Image.get(name.to_s)\n @log.info previous_image.to_s\n previous_image.delete\n rescue Docker::Error::NotFoundError\n @log.warn 'There is no previous image, must be a new build.'\n rescue Docker::Error::ConflictError\n @log.warn 'Could not remove old latest image; it is still used'\n end\n @log.info \"Tagging #{@i}\"\n @i.tag(repo: @base.repo, tag: @base.tag, force: true)\n if node_is_master\n flavor_variant = @base.flavor_variant\n flavor_variant ||= self.class.target_arch\n @i.tag(repo: 'kdeneon/ci', tag: \"#{@base.tag}-#{flavor_variant}\", force: true)\n raise 'Failed to push' unless system(\"docker push kdeneon/ci:#{@base.tag}-#{flavor_variant}\")\n end\n\n # Disabled because we should not be leaking. And this has reentrancy\n # problems where another deployment can cleanup our temporary\n # container/image...\n # cleanup_dangling_things\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6225369572639465,
"alphanum_fraction": 0.6293103694915771,
"avg_line_length": 27.491228103637695,
"blob_id": "fe7e18653577b93e26bda4691174ae70a50417a8",
"content_id": "62abfa5e894232054d6e0f94813d1ccb539a2976",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3248,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 114,
"path": "/test/test_qml_ignore_rule.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/qml/ignore_rule'\nrequire_relative 'lib/testcase'\n\n# Test qml ignore rules\nclass QMLIgnoreRuleTest < TestCase\n def new_rule(identifier, version = nil)\n QML::IgnoreRule.send(:new, identifier, version)\n end\n\n def new_mod(id, version = nil)\n QML::Module.new(id, version)\n end\n\n def test_init\n assert_raise RuntimeError do\n new_rule(nil, nil)\n end\n assert_raise RuntimeError do\n new_rule('id', 1.0) # Float version\n end\n r = new_rule('id', 'version')\n assert_equal('id', r.identifier)\n assert_equal('version', r.version)\n end\n\n # @return [Array] used as send_array for assert_send\n def send_identifier(id, mod)\n [new_rule(id), :match_identifier?, mod]\n end\n\n def assert_identifier(id, mod, message = nil)\n assert_send(send_identifier(id, mod), message)\n end\n\n def assert_not_identifier(id, mod, message = nil)\n assert_not_send(send_identifier(id, mod), message)\n end\n\n def test_match_id\n mod = QML::Module.new('org.kde.plasma.abc')\n truthies = %w[\n org.kde.plasma.*\n org.kde.plasma.abc\n org.kde.plasma.abc*\n ]\n truthies.each { |t| assert_identifier(t, mod) }\n falsies = %w[\n org.kde.plasma\n org.kde.plasma.abc.*\n ]\n falsies.each { |f| assert_not_identifier(f, mod) }\n end\n\n def test_match_version\n id = 'org.kde.plasma.abc'\n mod = QML::Module.new(id, '1.0')\n assert_send([new_rule(id, '1.0'), :match_version?, mod])\n assert_send([new_rule(id, nil), :match_version?, mod])\n assert_not_send([new_rule(id, '2.0'), :match_version?, mod])\n end\n\n def test_ignore\n id = 'org.kde.plasma'\n version = '2.0'\n r = new_rule(id, version)\n assert_false(r.ignore?(new_mod('org.kde', version)))\n assert_false(r.ignore?(new_mod(id, '1.0')))\n assert_true(r.ignore?(new_mod(id, version)))\n r = new_rule(id, nil) # nil version should match anything\n assert_true(r.ignore?(new_mod(id, version)))\n assert_true(r.ignore?(new_mod(id, '1.0')))\n assert_true(r.ignore?(new_mod(id, nil)))\n end\n\n def test_read\n r = QML::IgnoreRule.read(data)\n expected = {\n 'org.kde.kwin' => '1.0',\n 'org.kde.plasma' => nil,\n 'org.kde.plasma.abc' => '2.0',\n 'org.kde.plasma.*' => '1.0'\n }\n r.each do |rule|\n next unless expected.keys.include?(rule.identifier)\n\n version = expected.delete(rule.identifier)\n assert_equal(version, rule.version, 'Versions do not match')\n end\n assert_empty(expected, 'Did not get all expected rules')\n end\n\n def test_compare\n # comparing defers to ignore, so we only check that compare actually calls\n # ignore as intended.\n id = 'org.kde.plasma'\n version = '2.0'\n m = new_mod(id, version)\n r = new_rule(id, nil)\n assert_equal(r == m, r.ignore?(m))\n # Comparing with a string on the other hand should defer to super and return\n # false.\n assert_not_equal(r == id, r.ignore?(m))\n # This is just an means to an end that we can use Array.include?, so make\n # sure that actually works.\n assert_include([r], m)\n # And with a string again.\n assert_not_include([id], m)\n end\n\n def test_missing_file\n assert_empty(QML::IgnoreRule.read('/yolokitten'))\n end\nend\n"
},
{
"alpha_fraction": 0.7136929631233215,
"alphanum_fraction": 0.7136929631233215,
"avg_line_length": 27.352941513061523,
"blob_id": "87d2e9b0ad48d877035af6949a7024a5d0e39763",
"content_id": "d4d373fb038f3a2d4aba326fdeb79da48031f754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 482,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 17,
"path": "/jenkins-jobs/nci/daily-promote.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../job'\n\n# Progenitor is the super super super job triggering everything.\nclass DailyPromoteJob < JenkinsJob\n attr_reader :distribution\n attr_reader :type\n attr_reader :dependees\n\n def initialize(distribution:, type:, dependees:)\n super(\"mgmt_daily_promotion_#{distribution}_#{type}\",\n 'daily-promote.xml.erb')\n @distribution = distribution\n @type = type\n @dependees = dependees.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.6153786778450012,
"alphanum_fraction": 0.6258676648139954,
"avg_line_length": 42.076412200927734,
"blob_id": "c44330cc860c98e290a637b01b3d35a95218b91c",
"content_id": "f6aafde3b5fa48e4c725d1407c2f2ad20d76292d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 12966,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 301,
"path": "/nci/kf_sixy.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# A quick script to go over a qt 6 repo from Debian and simplify the .debs produced to make them only runtime and dev packages\n# The intention is to simplify maintinance so when new Qts come out we don't have to worry about where to put the files\n# This needs manual going over the output for sanity\n\nrequire_relative '../lib/debian/control'\nrequire_relative '../lib/projects/factory/neon'\n\nrequire 'deep_merge'\nrequire 'tty/command'\n\nREPLACEMENT_BUILD_DEPENDS = {\"extra-cmake-modules\" => \"kf6-extra-cmake-modules\",\n \"pkg-kde-tools\" => \"pkg-kde-tools-neon\",\n \"qttools5-dev-tools\" => \"qt6-tools-dev\",\n \"qtbase5-dev\" => \"qt6-base-dev\",\n \"qtdeclarative5-dev\" => \"qt6-declarative-dev\"\n }.freeze\n \n\nEXCLUDE_BUILD_DEPENDS = %w[qt6-base-private-dev libqt6opengl6-dev qt6-declarative-private-dev qml6-module-qtquick qml6-module-qttest qml6-module-qtquick].freeze\n\nclass KFSixy\n\n attr_reader :dir\n attr_reader :name\n\n def initialize(name:, dir:)\n @dir = dir\n @name = name.gsub(\"kf6-\", \"\")\n puts \"Running Sixy in #{dir}\"\n unless File.exist?(\"#{dir}/debian\")\n raise \"Must be run in a 'foo' repo with 'debian/' dir\"\n end\n end\n\n def fold_pkg(pkg, into:)\n return pkg if pkg['X-Neon-MergedPackage'] == 'true' # noop\n pkg.each do |k,v|\n next if k == 'Package'\n next if k == 'Architecture'\n next if k == 'Multi-Arch'\n next if k == 'Section'\n next if k == 'Description'\n\n into[k] = v unless into.include?(k)\n case into[k].class\n when Hash, Array\n into[k].deep_merge!(v)\n else\n into[k] += v\n end\n end\n end\n\n def run\n cmd = TTY::Command.new\n control = Debian::Control.new(@dir)\n control.parse!\n p control.binaries.collect { |x| x['Package'] } # pkgs\n\n dev_binaries = control.binaries.select { |x| x['Package'].include?('-dev') }\n bin_binaries = control.binaries.select { |x| !dev_binaries.include?(x) }\n control.binaries.replace(control.binaries[0..1])\n dev_binaries_names = dev_binaries.collect { |x| x['Package'] }\n bin_binaries_names = bin_binaries.collect { |x| x['Package'] }\n\n # Get the old provides to add to the new\n #old_bin_binary = bin_binaries.select { |x| x['Package'] == name }\n #old_provides_list = ''\n #if old_bin_binary.kind_of?(Array) and not old_bin_binary.empty?\n #old_provides = old_bin_binary[0]['Provides']\n #old_provides_list = old_provides.collect { |x| x[0].name }.join(', ')\n #end\n #old_dev_binary = dev_binaries.select { |x| x['Package'] == name + \"-dev\" }\n #old_dev_provides_list = ''\n #if old_dev_binary.kind_of?(Array) and not old_dev_binary.empty?\n #old_dev_provides = old_dev_binary[0]['Provides']\n #old_dev_provides_list = old_dev_provides.collect { |x| x[0].name }.join(', ')\n #end\n\n old_bin_binary = bin_binaries.select { |x| x['Package'] == name }\n old_depends_list = ''\n if old_bin_binary.kind_of?(Array) and not old_bin_binary.empty?\n old_depends = old_bin_binary[0]['Depends']\n old_depends_list = old_depends.collect { |x| x[0].name }.join(', ')\n end\n old_dev_binary = dev_binaries.select { |x| x['Package'] == name + \"-dev\" }\n old_dev_depends_list = ''\n if old_dev_binary.kind_of?(Array) and not old_dev_binary.empty?\n old_dev_depends = old_dev_binary[0]['Depends']\n old_dev_depends_list = old_dev_depends.collect { |x| x[0].name }.join(', ')\n end\n\n control.binaries.replace( [{}, {}] )\n\n bin = control.binaries[0]\n bin_depends = bin['Depends']\n bin.replace({'Package' => \"kf6-\" + name, 'Architecture' => 'any', 'Section' => 'kde', 'Description' => '((TBD))'})\n \n #bin['Provides'] = Debian::Deb822.parse_relationships(old_provides_list + bin_binaries.collect { |x| x['Package'] unless x['X-Neon-MergedPackage'] == 'true' }.join(', '))\n bin['X-Neon-MergedPackage'] = 'true'\n if not old_depends_list.empty?\n bin['Depends'] = old_depends\n end\n dev = control.binaries[1]\n dev.replace({'Package' => \"kf6-\" + name + '-dev', 'Architecture' => 'any', 'Section' => 'kde', 'Description' => '((TBD))'})\n #dev['Provides'] = Debian::Deb822.parse_relationships(old_dev_provides_list + dev_binaries.collect { |x| x['Package'] }.join(', '))\n dev['X-Neon-MergedPackage'] = 'true'\n if not old_dev_depends_list.empty?\n dev['Depends'] = old_dev_depends\n end\n\n bin_binaries_names.each do |package_name|\n next if bin['Package'] == package_name\n\n old_install_file_data = File.read(\"#{dir}/debian/\" + package_name + \".install\") if File.exist?(\"#{dir}/debian/\" + package_name + \".install\")\n new_install_filename = \"#{dir}/debian/\" + bin['Package'] + \".install\"\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".install\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".symbols\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".lintian-overrides\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".maintscript\")\n old_install_file_data.gsub!(\"usr/lib/\\*/\", \"usr/kf6/lib/*/\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/share/\", \"usr/kf6/share/\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/bin/\", \"usr/kf6/bin/\") if old_install_file_data\n old_install_file_data.gsub!(\"qlogging-categories5\", \"qlogging-categories6\") if old_install_file_data\n old_install_file_data.gsub!(\"/kf5\", \"/kf6\") if old_install_file_data\n old_install_file_data.gsub!(\"/kservicetypes5\", \"/kservicetypes6\") if old_install_file_data\n old_install_file_data.gsub!(\".*tags\", \"\") if old_install_file_data\n File.write(new_install_filename, old_install_file_data, mode: \"a\")\n \n # Old names are now dummy packages\n package_name6 = package_name.gsub(\"5\", \"6\")\n dummy = {}\n dummy['Package'] = package_name6\n dummy['Architecture'] = 'all'\n dummy['Depends'] = []\n dummy['Depends'][0] = []\n dummy['Depends'][0].append(\"kf6-\" + name)\n dummy['Description'] = \"Dummy transitional\\nTransitional dummy package.\\n\"\n control.binaries.append(dummy)\n end\n\n bin_binaries.each do |bin_bin|\n p bin_bin\n fold_pkg(bin_bin, into: bin)\n end\n bin.delete('Description')\n bin['Description'] = bin_binaries[0]['Description']\n bin['Description'].gsub!(\"5\", \"6\")\n\n # bin['Provides'] ||= []\n # bin['Provides'] += bin_binaries.collect { |x| x['Package'] }.join(', ')\n\n dev_binaries_names.each do |package_name|\n next if dev['Package'] == package_name\n old_install_file_data = File.read(\"#{dir}/debian/\" + package_name + \".install\") if File.exists?(\"#{dir}/debian/\" + package_name + \".install\")\n new_install_filename = \"#{dir}/debian/\" + dev['Package'] + \".install\"\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".install\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".symbols\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".maintscript\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".lintian-overrides\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".acc.in\")\n old_install_file_data.gsub!(\"usr/include/KF5/\", \"usr/kf6/include/KF6/\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/lib/\\*/cmake/\", \"usr/kf6/lib/*/cmake/\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/lib/\\*/libKF5\", \"usr/kf6/lib/*/libKF5\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/lib/\\*/qt5/mkspecs/modules/qt\", \"usr/kf6/mkspecs/modules/qt\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/lib/\\*/pkgconfig\", \"usr/kf6/lib/*/pkgconfig\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/lib\\/*/qt5/qml\", \"usr/kf6/lib/*/qml/\") if old_install_file_data\n old_install_file_data.gsub!(\"usr/share/qlogging-categories5/\", \"usr/kf6/share/qlogging-categories6/\") if old_install_file_data\n File.write(new_install_filename, old_install_file_data, mode: \"a\")\n p \"written to #{new_install_filename}\"\n\n package_name6 = package_name.gsub(\"5\", \"6\")\n dummy = {}\n dummy['Package'] = package_name6\n dummy['Architecture'] = 'all'\n dummy['Depends'] = []\n dummy['Depends'][0] = []\n dummy['Depends'][0].append(\"kf6-\" + name + \"-dev\")\n dummy['Description'] = \"Dummy transitional\\n Transitional dummy package.\\n\"\n control.binaries.append(dummy)\n end\n # Qt6ShaderToolsTargets-none.cmake is not none on arm so wildcard it\n content = File.read(\"#{dir}/debian/#{dev['Package']}.install\")\n content = content.gsub('-none.cmake', '-*.cmake')\n content = content.gsub('_none_metatypes.json', '_*_metatypes.json')\n File.write(\"#{dir}/debian/#{dev['Package']}.install\", content)\n\n dev_binaries.each do |dev_bin|\n fold_pkg(dev_bin, into: dev)\n end\n dev.delete('Description')\n dev['Description'] = dev_binaries[0]['Description']\n dev['Description'].gsub!(\"5\", \"6\")\n\n dev.each do |k, v|\n next unless v.is_a?(Array)\n\n v.each do |relationships|\n next unless relationships.is_a?(Array)\n relationships.each do |alternative|\n next unless alternative.is_a?(Debian::Relationship)\n\n next unless bin_binaries_names.include?(alternative.name)\n p alternative\n alternative.name.replace(bin['Package'])\n end\n end\n end\n\n if not old_depends_list.empty?\n bin['Depends'] = old_depends\n end\n if not old_dev_depends_list.empty?\n dev['Depends'] = old_dev_depends\n end\n FileUtils.rm_f(\"#{dir}/debian/\" + \"compat\")\n \n # Some magic to delete the build deps we list as bad above\n EXCLUDE_BUILD_DEPENDS.each {|build_dep| control.source[\"Build-depends\"].delete_if {|x| x[0].name.start_with?(build_dep)} }\n control.source[\"Source\"].replace(\"kf6-\" + name)\n control.source[\"Maintainer\"].replace(\"Jonathan Esk-Riddell <[email protected]>\")\n control.source.delete(\"Uploaders\")\n control.source[\"Build-depends\"].each {|x| x[0].version = nil}\n control.source[\"Build-depends\"].each {|x| x[0].operator = nil}\n debhelper_compat = Debian::Relationship.new(\"debhelper-compat\")\n debhelper_compat.version = \"13\"\n debhelper_compat.operator = \"=\"\n control.source[\"Build-depends\"].prepend([debhelper_compat])\n control.source[\"Build-depends\"].each {|x| control.source[\"Build-depends\"].delete(x) if x[0].name == \"debhelper\"}\n control.source[\"Build-depends\"].each do |build_dep|\n if REPLACEMENT_BUILD_DEPENDS.keys.include?(build_dep[0].name)\n control.source[\"Build-depends\"].append([Debian::Relationship.new(REPLACEMENT_BUILD_DEPENDS[build_dep[0].name])])\n end\n end \n\n control.source[\"Build-depends\"].each do |build_dep|\n puts \"delete pondering #{build_dep[0].name}\"\n if REPLACEMENT_BUILD_DEPENDS.keys.include?(build_dep[0].name)\n control.source[\"Build-depends\"].each {|delme| control.source[\"Build-depends\"].delete(delme) if delme[0].name == build_dep[0].name}\n end\n end \n\n control.source[\"Build-depends\"].each do |build_dep|\n if build_dep[0].name.include?(\"libkf5\")\n new_build_depend = build_dep[0].name.gsub(\"libkf5\", \"kf6-k\")\n control.source[\"Build-depends\"].append([Debian::Relationship.new(new_build_depend)])\n end\n end\n\n control.source[\"Build-depends\"].each do |build_dep|\n puts \"delete pondering #{build_dep[0].name}\"\n if build_dep[0].name.include?(\"libkf5\")\n control.source[\"Build-depends\"].each {|delme| control.source[\"Build-depends\"].delete(delme) if delme[0].name == build_dep[0].name}\n end\n end\n\n File.write(\"#{dir}/debian/control\", control.dump)\n \n changelog = \"kf6-\" + name\n changelog += %q( (0.0-0neon) UNRELEASED; urgency=medium\n\n * New release\n\n -- Jonathan Esk-Riddell <[email protected]> Mon, 12 Dec 2022 13:04:30 +0000\n)\n File.write(\"#{dir}/debian/changelog\", changelog)\n\n rules = %q(#!/usr/bin/make -f\n# -*- makefile -*-\n\n%:\n\tdh $@ --with kf6 --buildsystem kf6\n\noverride_dh_shlibdeps:\n\tdh_shlibdeps -l$(CURDIR)/debian/$(shell dh_listpackages | head -n1)/usr/kf6/lib/$(DEB_HOST_MULTIARCH)/\n)\n File.write(\"#{dir}/debian/rules\", rules)\n cmd.run('wrap-and-sort', chdir: dir)\n # Best attempt at git\n begin\n cmd.run('git add debian/*install', chdir: dir)\n rescue\n puts \"Could not run Git\"\n end\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n sixy = KFSixy.new(name: File.basename(Dir.pwd), dir: Dir.pwd)\n sixy.run\nend\n\n#if $PROGRAM_NAME == __FILE__\n #sixy = KFSixy.new(name: File.basename('/home/jr/src/pangea-tooling/test/data/test_nci_kf_sixy/test_sixy_repo/threadweaver'), dir: '/home/jr/src/pangea-tooling/test/data/test_nci_kf_sixy/test_sixy_repo/threadweaver')\n #sixy.run\n#end\n"
},
{
"alpha_fraction": 0.6532877683639526,
"alphanum_fraction": 0.6649587154388428,
"avg_line_length": 34.130001068115234,
"blob_id": "25acac3aade56345a830ce4de20e9988928cc1e1",
"content_id": "2d3b3ad93125534dcb568589e42cc19fa660e149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3513,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 100,
"path": "/test/test_nci_snapcraft_extend.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/snap/extender'\n\nrequire 'mocha/test_unit'\n\nmodule NCI::Snap\n class Extendertest < TestCase\n def setup\n ENV['APPNAME'] = 'kolourpaint'\n ENV['DIST'] = 'xenial'\n end\n\n def test_extend\n FileUtils.cp_r(data('source'), '.')\n FileUtils.mv('source/git', 'source/.git')\n\n stub_request(:get, Extender::Core16::STAGED_CONTENT_PATH)\n .to_return(status: 200, body: JSON.generate(['bar']))\n stub_request(:get, Extender::Core16::STAGED_DEV_PATH)\n .to_return(status: 200, body: JSON.generate(['bar-dev']))\n\n assert_path_not_exist('snapcraft.yaml')\n Extender.extend(data('snapcraft.yaml'))\n assert_path_exist('snapcraft.yaml')\n data = YAML.load_file('snapcraft.yaml')\n ref = YAML.load_file(data('output.yaml'))\n assert_equal(ref, data)\n\n assert_path_exist('snap/plugins/x-stage-debs.py')\n end\n\n def test_release_with_git\n ENV['TYPE'] = 'release'\n assert_raises RuntimeError do\n Extender.extend(data('snapcraft.yaml'))\n end\n end\n\n # When building a release type we don't want the git mangling to happen.\n def test_release_no_gitification\n ENV['TYPE'] = 'release'\n\n stub_request(:get, Extender::Core16::STAGED_CONTENT_PATH)\n .to_return(status: 200, body: JSON.generate(['bar']))\n stub_request(:get, Extender::Core16::STAGED_DEV_PATH)\n .to_return(status: 200, body: JSON.generate(['bar-dev']))\n\n assert_path_not_exist('snapcraft.yaml')\n Extender.extend(data('snapcraft.yaml'))\n assert_path_exist('snapcraft.yaml')\n data = YAML.load_file('snapcraft.yaml')\n ref = YAML.load_file(data('output.yaml'))\n assert_equal(ref, data)\n end\n\n def test_extend_core18\n ENV['DIST'] = 'bionic'\n\n # source is a symlink, dereference it\n FileUtils.mkpath('source')\n FileUtils.cp_r(data('source/.'), 'source/', verbose: true)\n\n FileUtils.mv('source/git', 'source/.git')\n\n stub_request(:get, Extender::Core18::STAGED_CONTENT_PATH)\n .to_return(status: 200, body: JSON.generate(['bar']))\n stub_request(:get, Extender::Core18::STAGED_DEV_PATH)\n .to_return(status: 200, body: JSON.generate(['bar-dev']))\n\n assert_path_not_exist('snapcraft.yaml')\n Extender.extend(data('snapcraft.yaml'))\n assert_path_exist('snapcraft.yaml')\n data = YAML.load_file('snapcraft.yaml')\n ref = YAML.load_file(data('output.yaml'))\n assert_equal(ref, data)\n\n assert_path_exist('snap/plugins/x-stage-debs.py')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6736111044883728,
"alphanum_fraction": 0.6972222328186035,
"avg_line_length": 22.225807189941406,
"blob_id": "1d7e4c133a5e4aab40ad7b1a7bd3b2259dfa1b03",
"content_id": "785aaba8fbef5ab4aecae8196d48e9bad50191e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 720,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 31,
"path": "/nci/lib/i386_install_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2023 Jonthan Esk-Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'open3'\nrequire 'tmpdir'\n\nrequire_relative '../../lib/apt'\nrequire_relative '../../lib/dpkg'\nrequire_relative 'setup_repo'\n\n# Base class for install checks, isolating common logic.\nclass I386InstallCheck\n def initialize\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n end\n\n def run\n NCI.setup_repo!\n Apt.update\n DPKG.dpkg(['--add-architecture', 'i386'])\n Apt.install('steam')\n Apt.install('wine32')\n Apt.install('neon-desktop') || raise\n end\nend\n"
},
{
"alpha_fraction": 0.5899705290794373,
"alphanum_fraction": 0.6010324358940125,
"avg_line_length": 24.58490562438965,
"blob_id": "d08b9e6879eff4a5e98b0a878497d4b75b061878",
"content_id": "09d132a3fec3d327af1cfb41c582a3927adff179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1356,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 53,
"path": "/nci/lint_bin/test_log.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2022 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'open-uri'\n\nrequire_relative '../../lib/lint/log'\nrequire_relative '../../lib/retry'\nrequire_relative '../lib/lint/result_test'\n\nmodule Lint\n # Test build log data.\n # @note needs LOG_URL defined!\n class TestLog < ResultTest\n class << self\n def log_orig\n @log_orig ||= Retry.retry_it(times: 2, sleep: 8) do\n uri = ENV.fetch('LOG_URL')\n warn \"Loading Build Log: #{uri}\"\n io = URI.open(uri)\n io.read.freeze\n end\n end\n end\n\n def initialize(*args)\n super\n end\n\n def setup\n @log = self.class.log_orig.dup\n end\n\n def result_listmissing\n @result_listmissing ||= Log::ListMissing.new.lint(@log)\n end\n\n def result_dhmissing\n @result_dhmissing ||= Log::DHMissing.new.lint(@log)\n end\n\n %i[ListMissing DHMissing].each do |klass_name|\n %w[warnings informations errors].each do |meth_type|\n class_eval <<-RUBY, __FILE__, __LINE__ + 1\n def test_#{klass_name.downcase}_#{meth_type}\n assert_meth = \"assert_#{meth_type}\".to_sym\n send(assert_meth, result_#{klass_name.downcase})\n end\n RUBY\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6920328736305237,
"alphanum_fraction": 0.696320116519928,
"avg_line_length": 30.100000381469727,
"blob_id": "c1955f5d11596203363460777d2818614da481fd",
"content_id": "d246ef1fd1b8366ba09888a6e905336279aea20a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2799,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 90,
"path": "/nci/aptly_delete.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'tty/prompt'\nrequire 'net/ssh/gateway'\nrequire 'ostruct'\nrequire 'optparse'\n\nrequire_relative '../lib/aptly-ext/remote'\n\noptions = OpenStruct.new\nparser = OptionParser.new do |opts|\n opts.banner = \"Usage: #{opts.program_name} SOURCENAME\"\n\n opts.on('-r REPO', '--repo REPO',\n 'Repo (e.g. unstable_focal) to delete from [can be used >1 time]') do |v|\n options.repos ||= []\n options.repos << v.to_s\n end\n\n opts.on('-g', '--gateway URI', 'open gateway to remote (auto-defaults to neon)') do |v|\n options.gateway = URI(v)\n end\n\n opts.on('-a', '--all', 'all repos') do |v|\n options.all = v\n end\nend\nparser.parse!\n\nabort parser.help unless ARGV[0] && (options.repos or options.all)\noptions.name = ARGV[0]\n\nlog = Logger.new(STDOUT)\nlog.level = Logger::DEBUG\nlog.progname = $PROGRAM_NAME\n\n# SSH tunnel so we can talk to the repo. For extra flexibility this is not\n# neon specific but can get any gateway.\nwith_connection = Proc.new do |&block|\n if options.gateway\n Aptly::Ext::Remote.connect(options.gateway, &block)\n else\n Aptly::Ext::Remote.neon(&block)\n end\nend\n\nwith_connection.call do\n log.info 'APTLY'\n Aptly::Repository.list.each do |repo|\n next unless options.all or options.repos.include?(repo.Name)\n\n # Query all relevant packages.\n # Any package with source as source.\n query = \"($Source (#{options.name}))\"\n # Or the source itself\n query += \" | (#{options.name} {source})\"\n query = \"#{options.name}\"\n packages = repo.packages(q: query).compact.uniq\n next if packages.empty?\n\n log.info \"Deleting packages from repo #{repo.Name}: #{packages}\"\n if TTY::Prompt.new.no?(\"Deleting packages, do you want to continue?\")\n abort\n end\n repo.delete_packages(packages)\n repo.published_in.each(&:update!)\n end\nend\n"
},
{
"alpha_fraction": 0.7275415658950806,
"alphanum_fraction": 0.7327172160148621,
"avg_line_length": 41.93650817871094,
"blob_id": "0a1dfc40e77a145e1f946d9d7f3537b55edb8a80",
"content_id": "d6763c083a9b8705fb484ec942bd5da9daa48666",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2705,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 63,
"path": "/lib/lint/log/build_log_segmenter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# Split a segment out of a build log by defining a start maker and an end marker\nmodule BuildLogSegmenter\n class SegmentMissingError < StandardError; end\n\n module_function\n\n def segmentify(data, start_marker, end_marker)\n data = fix_encoding(data)\n\n start_index = data.index(start_marker)\n raise SegmentMissingError, \"missing #{start_marker}\" unless start_index\n\n end_index = data.index(end_marker, start_index)\n raise SegmentMissingError, \"missing #{end_marker}\" unless end_index\n\n data = data.slice(start_index..end_index).split(\"\\n\")\n data.shift # Ditch start line\n data.pop # Ditch end line\n data\n end\n\n def fix_encoding(data)\n # Due to parallel building stdout can get messed up and contain\n # invalid byte sequences (rarely, and I am not entirely certain\n # how exactly) and that would result in ArgumentErrors getting thrown\n # when segmentifying **using a regex** as regexing asserts the\n # encoding being valid. To prevent this from causing problems\n # we'll simply re-encode and drop all invalid sequences.\n # This is a bit of a sledge hammer approach as it effectively could\n # drop unknown data, but this seems the most reliable option and\n # in the grand scheme of things the relevant portions we lint are all\n # ASCII anyway. Us dropping some random bytes printed during the\n # actual make portion should have no impact whatsoever.\n #\n # NB: this is only tested through dh_missing test. if that ever gets\n # dropped this may end up without coverage, the check for valid encoding\n # is only here so we can see this happening and eventually bring back test\n # coverage\n return data if data.valid_encoding?\n\n data.encode('utf-8', invalid: :replace, replace: nil)\n end\nend\n"
},
{
"alpha_fraction": 0.6749241948127747,
"alphanum_fraction": 0.6814964413642883,
"avg_line_length": 31.42622947692871,
"blob_id": "17dfcac4646944121984224a6f78f52a4739125a",
"content_id": "ac6683c6229b9bc7419d0ce991dc6cedfb04fea8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1978,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 61,
"path": "/lib/pangea/mail.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'yaml'\nrequire 'net/smtp'\n\nmodule Pangea\n # Net/SMTP wrapper using pangea config to initialize.\n class SMTP\n attr_reader :address\n attr_reader :port\n attr_reader :helo\n attr_reader :user\n attr_reader :secret\n attr_reader :authtype\n\n class << self\n def config_path\n File.expand_path(ENV.fetch('PANGEA_MAIL_CONFIG_PATH'))\n end\n\n def start(path = config_path, &block)\n new(path).start(&block)\n end\n end\n\n def initialize(path = self.class.config_path)\n data = YAML.load_file(path)\n data.fetch('smtp').each do |key, value|\n value = value.to_sym if value&.[](0) == ':'\n value = nil if value == 'nil' # coerce nilly strings\n instance_variable_set(\"@#{key}\".to_sym, value)\n end\n end\n\n def start(&block)\n smtp = Net::SMTP.new(address, port)\n smtp.enable_starttls_auto\n smtp.open_timeout=240\n smtp.start(helo, user, secret, authtype, &block)\n # No finish as we expect a block which auto-finishes upon return\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6665568351745605,
"alphanum_fraction": 0.6718286871910095,
"avg_line_length": 34.29069900512695,
"blob_id": "c8619ea67d2f6631e5aaf305a04e31317cadda24",
"content_id": "b8e65218bc7af3b9639edaa62f32ec258852c282",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3035,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 86,
"path": "/nci/lint/package_version_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\nrequire 'httparty'\n\nrequire_relative '../../lib/debian/version'\nrequire_relative '../../lib/retry'\n\nmodule NCI\n # Helper class for VersionsTest.\n # Implements the logic for a package version check. Takes a pkg\n # as input and then checks that the input's version is higher than\n # whatever is presently available in the apt cache (i.e. ubuntu or\n # the target neon repos).\n class PackageVersionCheck\n class VersionNotGreaterError < StandardError; end\n\n attr_reader :ours\n attr_reader :theirs\n\n def initialize(ours:, theirs:)\n @ours = ours\n @theirs = theirs\n end\n\n # Download and parse the neon-settings xenial->bionic pin override file\n def self.override_packages\n @@override_packages ||= begin\n url = \"https://invent.kde.org/neon/neon/settings/-/raw/Neon/unstable/etc/apt/preferences.d/99-jammy-overrides?inline=false\"\n response = HTTParty.get(url)\n response.parsed_response\n override_packages = []\n response.each_line do |line|\n match = line.match(/Package: (.*)/)\n override_packages << match[1] if match&.length == 2\n end\n override_packages\n end\n end\n\n def run\n # theirs can be nil if it doesn't exist on the 'their' side (e.g.\n # we build a new deb and compare it against the repo, it'd be on our\n # side but not theirs)\n # the version can be nil if theirs doesn't qualify to anything, when it is\n # a pure virtual package for example\n return nil unless theirs&.version\n\n # Good version\n return if our_version > their_version\n PackageVersionCheck.override_packages\n return if @@override_packages.include?(ours.name) # already pinned in neon-settings\n\n raise VersionNotGreaterError, <<~ERRORMSG\n Our version of\n #{ours.name} #{our_version} < #{their_version}\n which is currently available in apt (likely from Ubuntu or us).\n This indicates that the package we have is out of date or\n regressed in version compared to a previous build!\n - If this was a transitional fork it needs removal in jenkins and the\n aptly.\n - If it is a persitent fork make sure to re-merge with upstream/ubuntu.\n - If someone manually messed up the version number discuss how to best\n deal with this. Usually this will need an apt pin being added to\n neon/settings.git to force it back onto a correct version, and manual\n removal of the broken version from aptly.\n ERRORMSG\n end\n\n private\n\n def our_version\n return ours.version if ours.version.is_a?(Debian::Version)\n\n Debian::Version.new(ours.version)\n end\n\n def their_version\n return theirs.version if theirs.version.is_a?(Debian::Version)\n\n Debian::Version.new(theirs.version)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.643048107624054,
"alphanum_fraction": 0.6446524262428284,
"avg_line_length": 27.549617767333984,
"blob_id": "dda83ba69a49c3ba3b1a64c3a0920c9f92d0f18b",
"content_id": "2e7b69f4849f402d279fc9a615e40f05ff2275d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3740,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 131,
"path": "/test/test_jenkins-jobs_job.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\nrequire_relative '../jenkins-jobs/job'\n\nrequire 'mocha/test_unit'\n\nclass JenkinsJobTest < TestCase\n def setup\n JenkinsJob.reset\n JenkinsJob.flavor_dir = Dir.pwd\n end\n\n def teardown\n JenkinsJob.reset\n end\n\n def test_class_var\n # FIXME: wtf class var wtf wtf wtf\n JenkinsJob.flavor_dir = '/kittens'\n assert_equal('/kittens', JenkinsJob.flavor_dir)\n end\n\n def test_init\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '')\n j = JenkinsJob.new('kitten', 'kitten.xml.erb')\n assert_equal('kitten', j.job_name)\n assert_equal(\"#{Dir.pwd}/config/\", j.config_directory)\n assert_equal(\"#{Dir.pwd}/templates/kitten.xml.erb\", j.template_path)\n end\n\n def test_to_s\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '')\n j = JenkinsJob.new('kitten', 'kitten.xml.erb')\n assert_equal('kitten', j.to_s)\n assert_equal('kitten', j.to_str)\n end\n\n def test_init_fail\n # FIXME: see test_init\n assert_raise RuntimeError do\n JenkinsJob.new('kitten', 'kitten.xml.erb')\n end\n end\n\n def test_render_template\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '<%= job_name %>')\n job = JenkinsJob.new('kitten', 'kitten.xml.erb')\n render = job.render_template\n assert_equal('kitten', render) # job_name\n end\n\n def test_render_path\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '')\n File.write('templates/path.xml.erb', '<%= job_name %>')\n job = JenkinsJob.new('fruli', 'kitten.xml.erb')\n render = job.render('path.xml.erb')\n assert_equal('fruli', render) # job_name from path.xml\n end\n\n def test_update\n mock_job = mock('jenkins-api-job')\n mock_job.expects(:list_all).returns(%w[kitten])\n Jenkins.expects(:job).at_least_once.returns(mock_job)\n\n job = mock('Jenkins::Job')\n job.expects(:get_config).returns('')\n job.expects(:update).returns('')\n Jenkins::Job.expects(:new).with('kitten').returns(job)\n\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '<<%= job_name %>/>')\n job = JenkinsJob.new('kitten', 'kitten.xml.erb')\n job.update\n end\n\n def test_update_raise\n mock_job = mock('jenkins-api-job')\n mock_job.expects(:list_all).returns(%w[kitten])\n Jenkins.expects(:job).at_least_once.returns(mock_job)\n\n job = mock('Jenkins::Job')\n job.expects(:get_config).returns('')\n job.expects(:update).raises(RuntimeError)\n job2 = mock('Jenkins::Job')\n job2.expects(:get_config).returns('')\n job2.expects(:update).returns('')\n Jenkins::Job.expects(:new).with('kitten').twice.returns(job).then.returns(job2)\n\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '<<%= job_name %>/>')\n job = JenkinsJob.new('kitten', 'kitten.xml.erb')\n job.update\n end\n\n def trap_stdout\n iotrap = StringIO.new\n $stdout = iotrap\n yield\n iotrap.string\n ensure\n $stdout = STDOUT\n end\n\n def test_xml_debug\n Dir.mkdir('templates')\n File.write('templates/kitten.xml.erb', '')\n stdout = trap_stdout do\n JenkinsJob.new('kitten', 'kitten.xml.erb').send(:xml_debug, '<hi/>')\n end\n assert_equal('<hi/>', stdout)\n end\n\n def test_mass_include\n # Makes sure the requires of all jobs are actually resolving properly.\n # Would be better as multiple meths, but I can't be bothered to build that.\n # Marginal failure cause anyway.\n Dir.glob(\"#{__dir__}/../jenkins-jobs/**/*.rb\").sort.each do |job|\n pid = fork do\n require job\n exit 0\n end\n waitedpid, status = Process.waitpid2(pid)\n assert_equal(pid, waitedpid)\n assert(status.success?, \"Failed to require #{job}!\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6137892603874207,
"alphanum_fraction": 0.6177130341529846,
"avg_line_length": 27.54400062561035,
"blob_id": "65c7fc458c6c7da1dc912cb7b15b50dfeb6f695c",
"content_id": "9196d6e9966d7314e4f4ab51d59d8b53d9fbd74f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3568,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 125,
"path": "/lib/qml/module.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../dpkg'\n\n# Management construct for QML related bits.\nmodule QML\n # Qt6 Hack\n SEARCH_PATHS = [\"/usr/lib/#{DPKG::HOST_MULTIARCH}/qt5/qml\", \"/usr/lib/#{DPKG::HOST_MULTIARCH}/qt6/qml\"].freeze\n\n # Describes a QML module.\n class Module\n class ExistingStaticError < StandardError; end\n\n IMPORT_SEPERATOR = '.'\n\n attr_reader :identifier\n attr_reader :version\n attr_reader :qualifier\n\n def initialize(identifier = nil, version = nil, qualifier = nil)\n @identifier = identifier\n @version = version\n @qualifier = qualifier\n end\n\n # @return [Array<QML::Module>]\n def self.read_file(path)\n modules = []\n File.read(path).lines.each do |line|\n mods = QML::Module.parse(line)\n modules += mods unless mods.empty?\n end\n modules.compact.uniq\n end\n\n # @return [Array<QML::Module>]\n def self.parse(line)\n modules = []\n line.split(';').each do |statement|\n modules << new.send(:parse, statement)\n end\n modules.compact.uniq\n end\n\n def import_paths\n @import_paths if defined?(@import_paths)\n @import_paths = []\n base_path = @identifier.gsub(IMPORT_SEPERATOR, File::SEPARATOR)\n @import_paths << base_path\n version_parts = @version.split('.')\n version_parts.each_index do |i|\n @import_paths << \"#{base_path}.#{version_parts[0..i].join('.')}\"\n end\n @import_paths\n end\n\n def to_s\n \"#{@identifier}[#{@version}]\"\n end\n\n def ==(other)\n identifier == other.identifier \\\n && (version.nil? || other.version.nil? || version == other.version) \\\n && (qualifier.nil? || other.qualifier.nil? || qualifier == other.qualifier)\n end\n\n def installed?\n valid_static? || modules_installed?\n end\n\n private\n\n def valid_static?\n static_package = QML::StaticMap.new.package(self)\n return false unless static_package\n return package_installed?(static_package) unless modules_installed?\n\n raise ExistingStaticError, <<-ERROR\n#{self} was found in QML load paths but also statically mapped! This means\nthat dependency detection will not work correctly. You must remove the static\nmodule override for the package.\n ERROR\n end\n\n def modules_installed?\n found = false\n # FIXME: beyond path this currently doesn't take version into account\n QML::SEARCH_PATHS.each do |search_path|\n import_paths.each do |import_path|\n path = File.join(search_path, import_path, 'qmldir')\n found = File.exist?(path) && File.file?(path)\n break if found\n end\n break if found\n end\n found\n end\n\n def package_installed?(package_name)\n return true if package_name == 'fake-global-ignore'\n\n # FIXME: move to dpkg module\n # FIXME: instead of calling -s this probably should manually check\n # /var/lib/dpkg/info as -s is rather slow\n system(\"dpkg -s #{package_name} 2>&1 > /dev/null\")\n end\n\n def parse(line)\n minsize = 3 # import + name + version\n return nil if line.to_s.empty?\n\n parts = line.split(/\\s/)\n return nil unless parts.size >= minsize\n\n parts.delete_if { |str| str.nil? || str.empty? }\n return nil unless parts.size >= minsize && parts[0] == 'import'\n return nil if parts[1].start_with?('\"') # Directory import.\n\n @identifier = parts[1]\n @version = parts[2]\n # FIXME: what if part 3 is not as?\n @qualifier = parts[4] if parts.size == 5\n self\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7460086941719055,
"alphanum_fraction": 0.7532656192779541,
"avg_line_length": 37.27777862548828,
"blob_id": "4ff61cccbe6bfa632c51d560b9e8ad54936b454c",
"content_id": "7660576f746326045768a235827024a606785a08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1378,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 36,
"path": "/jenkins-jobs/nci/mgmt_digital_ocean.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../job'\nrequire_relative 'pipelinejob'\n\n# Manages digital ocean base snapshot from which we build cloud instances\nclass MGMTDigitalOcean < JenkinsJob\n def initialize\n super('mgmt_digital-ocean', 'mgmt_digital_ocean.xml.erb')\n end\nend\n\n# Manages digital ocean safety net to delete dangling droplets.\nclass MGMTDigitalOceanDangler < PipelineJob\n def initialize\n super('mgmt_digital-ocean_dangler', cron: 'H H/3 * * *')\n end\nend\n"
},
{
"alpha_fraction": 0.6125654578208923,
"alphanum_fraction": 0.6304052472114563,
"avg_line_length": 32.48701477050781,
"blob_id": "694d17b42dbbed1306e4394c61a4c654aeafe5fa",
"content_id": "f8cd06a9ca6a824a6c1349c5c580899993ec5c3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5157,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 154,
"path": "/nci/snap/extender.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'json'\nrequire 'open-uri'\nrequire 'rugged'\nrequire 'tmpdir'\nrequire 'yaml'\n\nrequire_relative 'snapcraft_config'\n\nmodule NCI\n module Snap\n # Extends a snapcraft file with code necessary to use the content snap.\n class Extender\n module Core16\n STAGED_CONTENT_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-release_amd64.snap/lastSuccessfulBuild/artifact/stage-content.json'\n STAGED_DEV_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-release_amd64.snap/lastSuccessfulBuild/artifact/stage-dev.json'\n end\n module Core18\n STAGED_CONTENT_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-core18-release_amd64.snap/lastSuccessfulBuild/artifact/stage-content.json'\n STAGED_DEV_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-core18-release_amd64.snap/lastSuccessfulBuild/artifact/stage-dev.json'\n end\n module Core20\n STAGED_CONTENT_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-qt-5-15-core20-release_amd64.snap/lastSuccessfulBuild/artifact/stage-content.json'\n STAGED_DEV_PATH = 'https://build.neon.kde.org/job/kde-frameworks-5-qt-5-15-core20-release_amd64.snap/lastSuccessfulBuild/artifact/stage-dev.json'\n end\n\n class << self\n def extend(file)\n new(file).extend\n end\n\n def run\n extend(ARGV.fetch(0, \"#{Dir.pwd}/snapcraft.yaml\"))\n end\n end\n\n def initialize(file)\n @data = YAML.load_file(file)\n data['parts'].each do |k, v|\n data['parts'][k] = SnapcraftConfig::Part.new(v)\n end\n setup_base\n end\n\n def extend\n convert_source!\n add_plugins!\n\n File.write('snapcraft.yaml', YAML.dump(data))\n end\n\n private\n\n attr_reader :data\n\n def setup_base\n case data['base']\n when 'core20'\n @base = Core20\n raise 'Trying to build core20 snap on not 18.04' unless focal?\n when 'core18'\n @base = Core18\n raise 'Trying to build core18 snap on not 18.04' unless bionic?\n when 'core16', nil\n @base = Core16\n raise 'Trying to build core16 snap on not 18.04' unless xenial?\n else\n raise \"Do not know how to handle base value #{data[base].inspects}\"\n end\n end\n\n def focal?\n ENV.fetch('DIST') == 'focal'\n end\n\n def bionic?\n ENV.fetch('DIST') == 'bionic'\n end\n\n def xenial?\n ENV.fetch('DIST') == 'xenial'\n end\n\n def snapname\n @snapname ||= ENV.fetch('APPNAME')\n end\n\n def content_stage\n @content_stage ||= JSON.parse(open(@base::STAGED_CONTENT_PATH).read)\n end\n\n def dev_stage\n @dev_stage ||= JSON.parse(open(@base::STAGED_DEV_PATH).read)\n end\n\n def convert_to_git!\n repo = Rugged::Repository.new(\"#{Dir.pwd}/source\")\n repo_branch = repo.branches[repo.head.name].name if repo.head.branch?\n data['parts'][snapname].source = repo.remotes['origin'].url\n data['parts'][snapname].source_type = 'git'\n data['parts'][snapname].source_commit = repo.last_commit.oid\n # FIXME: I want an @ here\n # https://bugs.launchpad.net/snapcraft/+bug/1712061\n oid = repo.last_commit.oid[0..6]\n # Versions cannot have slashes, branches can though, so convert to .\n data['version'] = [repo_branch, oid].join('+').tr('/', '.')\n end\n\n def add_plugins!\n target = \"#{Dir.pwd}/snap/\"\n FileUtils.mkpath(target)\n FileUtils.cp_r(\"#{__dir__}/plugins\", target, verbose: true)\n end\n\n def dangerous_git_part?(part)\n part.source.include?('git.kde') &&\n !part.source.include?('snap-kf5-launcher')\n end\n\n def convert_source!\n if ENV.fetch('TYPE', 'unstable').include?('release')\n raise \"Devel grade can't be TYPE release\" if data['grade'] == 'devel'\n\n data['parts'].each_value do |part|\n # Guard against accidently building git parts for the stable\n # channel.\n raise 'Contains git source' if dangerous_git_part?(part)\n end\n else\n convert_to_git!\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6140559911727905,
"alphanum_fraction": 0.6223942637443542,
"avg_line_length": 30.679244995117188,
"blob_id": "f779ca48f9ac851279df4326f90cc9d03f57829f",
"content_id": "18419a4c2d1a0c898103bb53490bebe4a0383b18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1679,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 53,
"path": "/nci/lint/repo_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/aptly-ext/filter'\nrequire_relative '../../lib/dpkg'\nrequire_relative '../../lib/retry'\nrequire_relative '../../lib/nci'\nrequire_relative '../../lib/aptly-ext/remote'\n\nmodule NCI\n # Lists all architecture relevant packages from an aptly repo.\n class RepoPackageLister\n def self.default_repo\n \"#{ENV.fetch('TYPE')}_#{ENV.fetch('DIST')}\"\n end\n\n def self.current_repo\n \"#{ENV.fetch('TYPE')}_#{NCI.current_series}\"\n end\n\n def self.old_repo\n if NCI.future_series\n \"#{ENV.fetch('TYPE')}_#{NCI.current_series}\" # \"old\" is the current one\n elsif NCI.old_series\n \"#{ENV.fetch('TYPE')}_#{NCI.old_series}\"\n else\n raise \"Don't know what old or future is, maybe this job isn't\" \\\n ' necessary and should be deleted?'\n end\n end\n\n def initialize(repo = Aptly::Repository.get(self.class.default_repo),\n filter_select: nil)\n @repo = repo\n @filter_select = filter_select\n end\n\n def packages\n @packages ||= begin\n packages = Retry.retry_it(times: 4, sleep: 4) do\n @repo.packages(q: '!$Architecture (source)')\n end\n packages = Aptly::Ext::LatestVersionFilter.filter(packages)\n arch_filter = [DPKG::HOST_ARCH, 'all']\n packages = packages.select { |x| arch_filter.include?(x.architecture) }\n return packages unless @filter_select\n\n packages.select { |x| @filter_select.include?(x.name) }\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6431774497032166,
"alphanum_fraction": 0.6438180804252625,
"avg_line_length": 25.913793563842773,
"blob_id": "322a4cde7e727d1d7f7bc1cb70194804dc7e284c",
"content_id": "3fbd4f29cd8773b5ece84809a1ae146896ded243",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1561,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 58,
"path": "/lib/lint/linter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\nrequire 'yaml'\n\nrequire_relative '../ci/pattern'\nrequire_relative '../nci'\nrequire_relative 'result'\n\nmodule Lint\n # Base class for all linters.\n # This class primarily features helpers to load ignore patterns.\n class Linter\n attr_accessor :ignores\n\n def initialize\n @ignores = []\n end\n\n # Loads cmake-ignore as a YAML file and ignore series as specified\n # or if it's not a YAML list revert back to basic style\n def load_include_ignores(file_path)\n return unless File.exist?(file_path)\n\n cmake_yaml = YAML.load_file(file_path)\n # Our YAML has to be an Array else we'll go back to basic style\n if cmake_yaml.instance_of?(Array)\n load_include_ignores_yaml(cmake_yaml)\n else # compat old files\n load_include_ignores_basic(file_path)\n end\n load_static_ignores\n end\n\n private\n\n def load_static_ignores; end\n\n # It's YAML, load it as such.\n def load_include_ignores_yaml(data)\n data.each do |ignore_entry|\n if ignore_entry.is_a?(String)\n @ignores << CI::IncludePattern.new(ignore_entry)\n elsif ignore_entry['series'] == ENV.fetch('DIST')\n @ignores << CI::IncludePattern.new(ignore_entry.keys[0])\n end\n end\n end\n\n # It's not YAML, load it old school\n def load_include_ignores_basic(file_path)\n File.read(file_path).strip.split($/).each do |line|\n next if line.strip.start_with?('#') || line.empty?\n\n @ignores << CI::IncludePattern.new(line)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6712158918380737,
"alphanum_fraction": 0.6761786341667175,
"avg_line_length": 29.607595443725586,
"blob_id": "3b38bfd8dd061e4f23a0b50bb29ffdfefc691020",
"content_id": "f32e5813fefa22b095f26d68f7a2189e39e2cabb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2418,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 79,
"path": "/lib/tty_command/native_printer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\nrequire 'tty/command/printers/abstract'\n\n# Native style printer. Somewhere betweeen quiet and pretty printer.\n# Pretty has a tedency to fuck up output flushed without newlines as each\n# output string is streamed to the printer target with\n# color(\\t$output)\n# which can in case of apt mean that a single character is put on\n# a newline with color and tab; blowing up the output and making it\n# unreadable. Native seeks to mitigate this by simply streaming output very\n# unformatted so as to preserve the original output structure and color.\n# At the same time preserving handy dandy annotations from pretty printer such\n# as what command is run and how long it took.\nclass NativePrinter < TTY::Command::Printers::Abstract\n TIME_FORMAT = \"%5.3f %s\".freeze\n\n def print_command_start(cmd, *args)\n message = [\"Running #{decorate(cmd.to_command, :yellow, :bold)}\"]\n message << args.map(&:chomp).join(' ') unless args.empty?\n puts(cmd, message.join)\n end\n\n def print_command_out_data(cmd, *args)\n message = args.join(' ')\n write(cmd, message, out_data)\n end\n\n def print_command_err_data(cmd, *args)\n message = args.join(' ')\n write(cmd, message, err_data)\n end\n\n def print_command_exit(cmd, status, runtime, *args)\n if cmd.only_output_on_error && !status.zero?\n output << out_data\n output << err_data\n end\n\n runtime = TIME_FORMAT % [runtime, pluralize(runtime, 'second')]\n # prepend newline to make sure we are spearate from end of output\n message = [\"\\nFinished in #{runtime}\"]\n message << \" with exit status #{status}\" if status\n message << \" (#{success_or_failure(status)})\"\n puts(cmd, message.join)\n end\n\n def puts(cmd, message)\n write(cmd, \"#{message}\\n\")\n end\n\n def write(cmd, message, data = nil)\n out = []\n out << message\n target = (cmd.only_output_on_error && !data.nil?) ? data : output\n target << out.join\n end\n\n private\n\n # Pluralize word based on a count\n #\n # @api private\n def pluralize(count, word)\n \"#{word}#{'s' unless count.to_f == 1}\"\n end\n\n # @api private\n def success_or_failure(status)\n if status == 0\n decorate('successful', :green, :bold)\n else\n decorate('failed', :red, :bold)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7217289805412292,
"alphanum_fraction": 0.7264018654823303,
"avg_line_length": 28.930070877075195,
"blob_id": "d126d93063d2831f9045d340998da0149aa1fb7a",
"content_id": "3ea8fec8995d143cfcd5fe977fd4c1711b3bab48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4280,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 143,
"path": "/mgmt/digital_ocean.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'net/sftp'\nrequire 'irb'\nrequire 'yaml'\n\nrequire_relative '../lib/digital_ocean/droplet'\n\nDROPLET_NAME = 'jenkins-slave-deploy'\nIMAGE_NAME = 'jenkins-slave'\n\nlogger = @logger = Logger.new(STDERR)\n\nprevious = DigitalOcean::Droplet.from_name(DROPLET_NAME)\n\nif previous\n logger.warn \"previous droplet found; deleting: #{previous}\"\n raise \"Failed to delete #{previous}\" unless previous.delete\n\n ret = DigitalOcean::Action.wait(retries: 10) do\n DigitalOcean::Droplet.from_name(DROPLET_NAME).nil?\n end\n raise 'Deletion failed apparently' unless ret\nend\n\n# Sometime snapshots become dangling for not quite clear reasons.\n# Clean up excess snapshots and only keep the most recent one for creating\n# our droplet.\nold_images = DigitalOcean::Client.new.snapshots.all.find_all do |x|\n x.name == IMAGE_NAME\nend\nold_images.sort_by { |x| DateTime.parse(x.created_at) }\nold_images.pop\nold_images.each do |x|\n logger.warn \"deleting excess snapshot #{x.id}\"\n unless DigitalOcean::Client.new.snapshots.delete(id: x.id)\n logger.error 'failed to delete :|'\n end\nend\n\nlogger.info 'Creating new droplet.'\ndroplet = DigitalOcean::Droplet.create(DROPLET_NAME, IMAGE_NAME)\n\n# Wait a decent amount for the droplet to start. If this takes very long it's\n# no problem.\nactive = DigitalOcean::Action.wait(retries: 20) do\n logger.info 'Waiting for droplet to start'\n droplet.status == 'active'\nend\n\nunless active\n droplet.delete\n raise \"failed to start #{droplet}\"\nend\n\n# We can get here with a droplet that isn't actually working as the\n# \"creation failed\" whatever that means..\n# FIXME: not sure how though (:\n\nargs = [droplet.public_ip, 'root']\n\nRetry.retry_it(sleep: 8, times: 64) do\n logger.info \"waiting for SSH to start #{args}\"\n Net::SSH.start(*args) {}\nend\n\nNet::SFTP.start(*args) do |sftp|\n Dir.glob(\"#{__dir__}/digital_ocean/*\").each do |file|\n target = \"/root/#{File.basename(file)}\"\n logger.info \"#{file} => #{target}\"\n sftp.upload!(file, target)\n end\nend\n\n# Net::SSH would needs lots of code to catch the exit status.\nunless system(\"ssh root@#{droplet.public_ip} bash /root/deploy.sh\")\n logger.warn 'deleting droplet'\n droplet.delete\n raise\nend\nsystem(\"ssh root@#{droplet.public_ip} shutdown now\")\n# Net::SSH.start(*args) do |ssh|\n# ssh.exec!('/root/deploy.sh') do |channel, stream, data|\n# io = stream == :stdout ? STDOUT : STDERR\n# io.print(data)\n# io.flush\n# end\n# end\n\ndroplet.shutdown!.complete! do |times|\n break if times >= 10\n\n logger.info 'Waiting for shutdown'\nend\n\ndroplet.power_off!.complete! do\n logger.info 'Waiting for power off'\nend\n\nold_image = DigitalOcean::Client.new.snapshots.all.find do |x|\n x.name == IMAGE_NAME\nend\n\ndroplet.snapshot!(name: IMAGE_NAME).complete! do\n logger.info 'Waiting for snapshot'\nend\n\nif old_image\n logger.warn 'deleting old image'\n unless DigitalOcean::Client.new.snapshots.delete(id: old_image.id)\n logger.error 'failed to delete old snapshot'\n # FIXME: beginning needs to handle multiple images and throw away all but the\n # newest\n end\nend\n\nlogger.warn 'deleting droplet'\nlogger.error 'failed to delete' unless droplet.delete\ndeleted = DigitalOcean::Action.wait(retries: 10) do\n DigitalOcean::Droplet.from_name(DROPLET_NAME).nil?\nend\nraise 'Deletion failed apparently' unless deleted\n"
},
{
"alpha_fraction": 0.6901605129241943,
"alphanum_fraction": 0.6960921287536621,
"avg_line_length": 32.717647552490234,
"blob_id": "a29f6da828b92b9a2b094ee47da5e531e645d785",
"content_id": "e0e24cb868bbb5bc602b127ea13c782c973bc674",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2866,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 85,
"path": "/jenkins-jobs/template.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2015 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'erb'\nrequire 'htmlentities'\nrequire 'pathname'\n\n# Base class for job template.\nclass Template\n # [String] Directory with config files. Absolute.\n attr_reader :config_directory\n # [String] Template file for this job. Absolute.\n attr_reader :template_path\n\n def initialize(template_name, script: nil)\n @script_path = script\n\n @config_directory = \"#{@@flavor_dir}/config/\"\n @flavor_template_directory = \"#{@@flavor_dir}/templates/\"\n @core_template_directory = \"#{__dir__}/templates/\"\n # Find template in preferrably the flavor dir, fall back to core directory.\n # This allows sharing the template.\n template_dirs = [@flavor_template_directory, @core_template_directory]\n return if template_dirs.any? do |dir|\n @template_directory = dir\n @template_path = \"#{@template_directory}#{template_name}\"\n File.exist?(@template_path)\n end\n\n raise \"Template #{template_name} not found at #{@template_path}\"\n end\n\n def self.flavor_dir=(dir)\n # This is handled as a class variable because we want all instances of\n # JenkinsJob to have the same flavor set. Class instance variables OTOH\n # would need additional code to properly apply it to all instances, which\n # is mostly useless.\n @@flavor_dir = dir # rubocop:disable Style/ClassVars\n end\n\n def self.flavor_dir\n @@flavor_dir\n end\n\n def render_template\n render(@template_path)\n end\n\n def render(path)\n return '' unless path\n\n data = if Pathname.new(path).absolute?\n File.read(path)\n else\n File.read(\"#{@template_directory}/#{path}\")\n end\n ERB.new(data).result(binding)\n rescue StandardError => e\n raise \"Failed to render #{self.class}{#{self}}[#{inspect}]:: #{e}\"\n end\n\n def render_script\n raise \"no script path given for #{self}\" unless @script_path\n\n HTMLEntities.new.encode(render(@script_path))\n end\nend\n"
},
{
"alpha_fraction": 0.7075268626213074,
"alphanum_fraction": 0.7158218026161194,
"avg_line_length": 34,
"blob_id": "fd4e4feba52542e5d2b869d9d65e19dd6b760f42",
"content_id": "0cc89101ace972ae96899fce8608c885cde24302",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3255,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 93,
"path": "/mgmt/digital_ocean/deploy.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# SPDX-FileCopyrightText: 2017-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nset -ex\n\n# Don't query us about things. We can't answer.\nexport DEBIAN_FRONTEND=noninteractive\n\n# Disable bloody apt automation crap locking the database.\ncloud-init status --wait\nsystemctl disable --now apt-daily.timer\nsystemctl disable --now apt-daily.service\nsystemctl mask apt-daily.service\nsystemctl mask apt-daily.timer\nsystemctl stop apt-daily.service || true\n\nsystemctl disable --now apt-daily-upgrade.timer\nsystemctl disable --now apt-daily-upgrade.service\nsystemctl mask apt-daily-upgrade.timer\nsystemctl mask apt-daily-upgrade.service\nsystemctl stop apt-daily-upgrade.service || true\n\n# SSH comes up while cloud-init is still in progress. Wait for it to actually\n# finish.\nuntil grep '\"stage\"' /run/cloud-init/status.json | grep -q 'null'; do\n echo \"waiting for cloud-init to finish\"\n sleep 4\ndone\n\n# Make sure we do not have random services claiming dpkg locks.\n# Nor random background stuff we don't use (snapd, lxd)\n# Nor automatic cron jobs. Cloud servers aren't remotely long enough around for\n# cron jobs to matter.\nps aux\napt purge -o Dpkg::Options::=\"--force-confdef\" -o Dpkg::Options::=\"--force-confold\" \\\n -y unattended-upgrades update-notifier-common snapd lxd cron\n\n# DOs by default come with out of date cache.\nps aux\napt update\n\n# Make sure the image is up to date.\napt dist-upgrade ruby+ ruby-shadow+ -y -o Dpkg::Options::=\"--force-confdef\" -o Dpkg::Options::=\"--force-confold\"\n\n# Deploy chef 15 (we have no ruby right now.)\ncd /tmp\nwget https://omnitruck.chef.io/install.sh\nchmod +x install.sh\n./install.sh -v 18\n./install.sh -v 23 -P chef-workstation # so we can berks\n\n# Use chef zero to cook localhost.\nexport NO_CUPBOARD=1\ngit clone --depth 1 https://github.com/pangea-project/pangea-kitchen.git /tmp/kitchen || true\ncd /tmp/kitchen\ngit pull --rebase\nberks install\nberks vendor\nchef-client --local-mode --enable-reporting --chef-license accept-silent\n\n# Make sure we do not have random services claiming dpkg locks.\napt purge -y unattended-upgrades\n\n################################################### !!!!!!!!!!!\nchmod 755 /root/deploy_tooling.sh\ncp -v /root/deploy_tooling.sh /tmp/\nsudo -u jenkins-slave -i /tmp/deploy_tooling.sh\n################################################### !!!!!!!!!!!\n\n# Clean up cache to reduce image size.\n# We don't need to keep chef. It's only in this deployment script and it\n# only runs daily, so speed is not of the essence nor does it help anything.\n# We can easily install chef again on the next run, it costs nothing but reduces\n# the image size by a non trivial amount.\napt-get -y purge chef\\*\napt --purge --yes autoremove\napt-get clean\n# We could skip docs via dpkg exclusion rules like used in the ubuntu docker\n# image but it's hardly worth the headache here. The overhead of installing\n# them and then removing them again hardly makes any diff.\nrm -rfv /usr/share/ri/*\nrm -rfv /usr/share/doc/*\nrm -rfv /usr/share/man/*\njournalctl --vacuum-time=1s\nrm -rfv /var/log/journal/*\ntruncate -s 0 \\\n /var/log/fail2ban.log \\\n /var/log/cloud-init.log \\\n /var/log/syslog \\\n /var/log/kern.log \\\n /var/log/apt/term.log \\\n || true\n"
},
{
"alpha_fraction": 0.68082594871521,
"alphanum_fraction": 0.6884955763816833,
"avg_line_length": 32.235294342041016,
"blob_id": "91f6a2cba620f879272c210a4011e8a1eba434f2",
"content_id": "3bc6dcd682bc99faadbe60d319c80d13d8b218be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1695,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 51,
"path": "/test/test_optparse.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/optparse'\nrequire_relative 'lib/testcase'\n\nclass OptionParserTest < TestCase\n def test_init\n OptionParser.new do |opts|\n opts.on('-l', '--long LONG', 'expected long', 'EXPECTED') do |v|\n end\n end\n end\n\n def test_present\n parser = OptionParser.new do |opts|\n opts.default_argv = %w[--long ABC]\n opts.on('-l', '--long LONG', 'expected long', 'EXPECTED') do |v|\n end\n end\n parser.parse!\n assert_equal([], parser.missing_expected)\n end\n\n def test_missing\n parser = OptionParser.new do |opts|\n opts.default_argv = %w[]\n opts.on('-l', '--long LONG', 'expected long', 'EXPECTED') do |v|\n end\n end\n parser.parse!\n assert_equal(['--long'], parser.missing_expected)\n end\nend\n"
},
{
"alpha_fraction": 0.721512496471405,
"alphanum_fraction": 0.7261114120483398,
"avg_line_length": 35.924530029296875,
"blob_id": "005d73630b864e6043f51d29640efd9ceaa17a3f",
"content_id": "96250af472dc79a01430432936bedd4760faec55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1957,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 53,
"path": "/test/test_ci_kcrash_link_validator.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/kcrash_link_validator'\nrequire_relative 'lib/testcase'\n\n# Test kcrash validator\nclass KCrashLinkValidatorTest < TestCase\n def setup\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n ENV['TYPE'] = 'unstable'\n ENV['JOB_NAME'] = 'whoopdydoopdy' # only used for blacklist check\n end\n\n def test_run\n CI::KCrashLinkValidator.run do\n assert_includes(File.read('CMakeLists.txt'), 'kcrash_validator_check_all_targets')\n end\n assert_not_includes(File.read('CMakeLists.txt'), 'kcrash_validator_check_all_targets')\n end\n\n def test_run_no_cmakelists\n CI::KCrashLinkValidator.run do\n assert_path_not_exist('CMakeLists.txt')\n end\n assert_path_not_exist('CMakeLists.txt')\n end\n\n def test_run_on_unstable_only\n ENV['TYPE'] = 'stable'\n CI::KCrashLinkValidator.run do\n assert_not_includes(File.read('CMakeLists.txt'), 'kcrash_validator_check_all_targets')\n end\n assert_not_includes(File.read('CMakeLists.txt'), 'kcrash_validator_check_all_targets')\n end\nend\n"
},
{
"alpha_fraction": 0.6389280557632446,
"alphanum_fraction": 0.6558533310890198,
"avg_line_length": 22.633333206176758,
"blob_id": "8d7c112eec9deefaca35a77c69aafadcfb3dc6f7",
"content_id": "8ddf26801ca5ef563a427661f3ed2fba146504a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 30,
"path": "/lib/ci/tar-fetcher/url.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2022 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'uri'\nrequire 'open-uri'\nrequire 'tmpdir'\n\nrequire_relative '../tarball'\n\nmodule CI\n class URLTarFetcher\n def initialize(url)\n @uri = URI.parse(url)\n end\n\n def fetch(destdir)\n parser = URI::Parser.new\n filename = parser.unescape(File.basename(@uri.path))\n target = File.join(destdir, filename)\n unless File.exist?(target)\n puts \"Downloading #{@uri}\"\n File.write(target, URI.open(@uri).read)\n end\n puts \"Tarball: #{target}\"\n Tarball.new(target)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6851266026496887,
"alphanum_fraction": 0.6882911324501038,
"avg_line_length": 27.727272033691406,
"blob_id": "0890dd1f7bbdc76d956c7eb36d792eca0bd93454",
"content_id": "b6a2148a19a50f7a8a52b3753add9bd26cf9995a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 632,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 22,
"path": "/lib/thread_pool.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\nrequire_relative 'queue'\n\n# Simple thread pool implementation. Pass a block to run and it runs it in a\n# pool.\n# Note that the block code should be thread safe...\nmodule BlockingThreadPool\n # Runs the passed block in a pool. This function blocks until all threads are\n # done.\n # @param count the thread count to use for the pool\n def self.run(count = 16, abort_on_exception: true, &block)\n threads = []\n count.times do\n threads << Thread.new(nil) do\n Thread.current.abort_on_exception = abort_on_exception\n block.call\n end\n end\n threads.each(&:join)\n end\nend\n"
},
{
"alpha_fraction": 0.6431407332420349,
"alphanum_fraction": 0.6461182236671448,
"avg_line_length": 32.835819244384766,
"blob_id": "51010ae4a2019a9813a8e2a6e8430bcb35c2b0ef",
"content_id": "61cf65a9fe894f4c0312dde279bac87bd360a8dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9068,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 268,
"path": "/nci/lint/upgrade_versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'minitest/test'\nrequire 'tty/command'\nrequire 'httparty'\n\nrequire_relative '../../lib/apt'\nrequire_relative '../../lib/aptly-ext/filter'\nrequire_relative '../../lib/debian/version'\nrequire_relative '../../lib/dpkg'\nrequire_relative '../../lib/retry'\nrequire_relative '../../lib/nci'\nrequire_relative '../../lib/aptly-ext/remote'\n\nrequire_relative 'cache_package_lister'\nrequire_relative 'dir_package_lister'\nrequire_relative 'repo_package_lister'\n\n# rubocop:disable Style/BeginBlock\nBEGIN {\n # Use 4 threads in minitest parallelism, apt-cache is heavy, so we can't\n # bind this to the actual CPU cores. 4 Is reasonably performant on SSDs.\n ENV['MT_CPU'] ||= '4'\n}\n# rubocop:enable\n\nmodule NCI\n # Helper class for VersionsTest.\n # Implements the logic for a package version check. Takes a pkg\n # as input and then checks that the input's version is higher than\n # whatever is presently available in the apt cache (i.e. ubuntu or\n # the target neon repos).\n class PackageVersionCheck\n class VersionNotGreaterError < StandardError; end\n\n attr_reader :pkg\n\n def initialize(pkg)\n @pkg = pkg\n @cmd = TTY::Command.new(printer: :null)\n end\n\n def our_version\n Debian::Version.new(pkg.version)\n end\n\n def self.cmd\n @cmd ||= TTY::Command.new(printer: :null)\n end\n\n def self.cmd=(cmd)\n @cmd = cmd\n end\n\n # returns a hash of name=>version. version may be nil!\n def self.load_theirs(packages)\n names = packages.collect(&:name).sort\n # The overhead of apt is rather substantial, so we'll want to get all\n # data in one go ideally. Should this exhaust some argument limit\n # at some point we'll want to split into chunks instead.\n res = cmd.run('apt-cache', 'policy', *names)\n\n map = {}\n name = nil\n version = nil\n res.out.split(\"\\n\").each do |line|\n if line.start_with?(/^\\w.+:/) # package lines aren't indented\n name = line.split(':', 2)[0].strip\n next\n end\n if line.start_with?(/\\s+Candidate:/) # always indented\n version = line.split(':', 2)[1].strip\n raise line unless name && !name.empty?\n raise line unless version && !version.empty?\n\n version = version == '(none)' ? nil : Debian::Version.new(version)\n map[name.strip] = version\n name = nil\n version = nil\n next\n end\n end\n\n @their_versions = map\n end\n\n def self.their_versions\n raise \"load_theirs wasn't called\" unless @their_versions\n\n @their_versions\n end\n\n def their_version\n self.class.their_versions.fetch(pkg.name, nil)\n end\n\n def run\n theirs = their_version\n ours = our_version\n\n return unless theirs # failed to find the package, we win.\n return if ours > theirs\n\n raise VersionNotGreaterError, <<~ERRORMSG\n Our version of\n #{pkg.name} #{ours} < #{theirs}\n which is currently available in apt (likely from Ubuntu or us).\n This indicates that the package we have is out of date or\n regressed in version compared to a previous build!\n - If this was a transitional fork it needs removal in jenkins and the\n aptly.\n - If it is a persitent fork make sure to re-merge with upstream/ubuntu.\n - If someone manually messed up the version number discuss how to best\n deal with this. Usually this will need an apt pin being added to\n neon/settings.git to force it back onto a correct version, and manual\n removal of the broken version from aptly.\n ERRORMSG\n end\n end\n\n class PackageUpgradeVersionCheck < PackageVersionCheck\n def self.future_packages\n @@future_packages ||= begin\n @repo = Aptly::Repository.get(\"#{ENV.fetch('TYPE')}_#{ENV.fetch('DIST')}\")\n future_packages = Retry.retry_it(times: 4, sleep: 4) do\n @repo.packages(q: '!$Architecture (source)')\n end\n future_packages = Aptly::Ext::LatestVersionFilter.filter(future_packages)\n arch_filter = [DPKG::HOST_ARCH, 'all']\n future_packages.select { |x| arch_filter.include?(x.architecture) }\n future_packages\n end\n end\n\n # Download and parse the neon-settings xenial->bionic pin override file\n def self.override_packages\n @@override_packages ||= begin\n url = \"https://invent.kde.org/neon/neon/settings/-/raw/Neon/unstable/etc/apt/preferences.d/99-jammy-overrides?inline=false\"\n response = HTTParty.get(url)\n response.parsed_response\n override_packages = []\n response.each_line do |line|\n match = line.match(/Package: (.*)/)\n override_packages << match[1] if match&.length == 2\n end\n puts \"Override Packages: #{override_packages}\"\n override_packages\n end\n end\n\n def run\n return if pkg.name.include? 'dbg'\n\n PackageUpgradeVersionCheck.override_packages\n return if @@override_packages.include?(pkg.name) # already pinned in neon-settings\n\n # set theirs to ubuntu focal from container apt show, do not report\n # if no package in ubuntu focal\n theirs = their_version || return # Debian::Version.new('0')\n # get future neon (focal) aptly version, set theirs if larger\n PackageUpgradeVersionCheck.future_packages\n neon_future_packages = @@future_packages.select { |x| x.name == \"#{pkg.name}\" }\n if neon_future_packages.size.positive?\n future_version = Debian::Version.new(neon_future_packages[0].version)\n theirs = future_version if future_version > theirs\n end\n\n ours = our_version # neon xenial from aptly\n return unless theirs # failed to find the package, we win.\n return if ours < theirs\n\n raise VersionNotGreaterError, <<~ERRORMSG\n Current series version of\n #{pkg.name} #{ours} is greater than future series version #{theirs}\n which is currently available in apt (likely from Ubuntu or us).\n ERRORMSG\n end\n end\n\n # Very special test type.\n #\n # When in a pangea testing scope this test while aggregate will not\n # report any test methods (even if there are), this is to avoid problems\n # if/when we use minitest for pangea testing at large\n #\n # The purpose of this class is to easily get jenkins-converted data\n # out of a \"test\". Test in this case not being a unit test of the tooling\n # but a test of the package versions in our repo vs. on the machine we\n # are on (i.e. repo vs. ubuntu or other repo).\n # Before doing anything this class needs a lister set. A lister\n # implements a `packages` method which returns an array of objects with\n # `name` and `version` attributes describing the packages we have.\n # It then constructs concurrent promises checking if these packages'\n # versions are greater than the ones we have presently available in\n # the system.\n class VersionsTest < MiniTest::Test\n parallelize_me!\n\n class << self\n # :nocov:\n def runnable_methods\n return if ENV['PANGEA_UNDER_TEST']\n\n super\n end\n # :nocov:\n\n def reset!\n @lister = nil\n @promises = nil\n end\n\n def lister=(lister)\n raise 'lister mustnt be set twice' if @lister\n\n @lister = lister\n define_tests\n end\n attr_reader :lister\n\n # This is a tad meh. We basically need to meta program our test\n # methods as we'll want individual meths for each check so we get\n # this easy to read in jenkins, but since we only know which lister\n # to use once the program runs we'll have to extend ourselves lazily\n # via class_eval which allows us to edit the class from within\n # a class method.\n # The ultimate result is a bunch of test_pkg_version methods\n # which wait and potentially raise from their promises.\n def define_tests\n Apt.update if Process.uid.zero? # update if root\n packages = @lister.packages\n PackageVersionCheck.load_theirs(packages)\n packages.each do |pkg|\n class_eval do\n define_method(\"test_#{pkg.name}_#{pkg.version}\") do\n PackageVersionCheck.new(pkg).run\n end\n end\n end\n end\n end\n\n def initialize(name = self.class.to_s)\n # Override and provide a default param for name so our tests can\n # pass without too much internal knowledge.\n super\n end\n end\n\n class UpgradeVersionsTest < VersionsTest\n class << self\n def define_tests\n Apt.update if Process.uid.zero? # update if root\n packages = @lister.packages\n PackageUpgradeVersionCheck.load_theirs(packages)\n packages.each do |pkg|\n class_eval do\n define_method(\"test_#{pkg.name}_#{pkg.version}\") do\n PackageUpgradeVersionCheck.new(pkg).run\n end\n end\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5844660401344299,
"alphanum_fraction": 0.5961164832115173,
"avg_line_length": 30.212121963500977,
"blob_id": "85339fd04e8a29ff9e2b91c6fd56a34ad1d92212",
"content_id": "5ca51c6660952ffcb021476cfc077b0284281b0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1030,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 33,
"path": "/nci/lint/dir_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\n\nmodule NCI\n # Lists packages in a directory by dpkg-deb inspecting all *.deb\n # files.\n class DirPackageLister\n Package = Struct.new(:name, :version)\n\n def initialize(dir, filter_select: nil)\n @dir = File.expand_path(dir)\n @filter_select = filter_select\n end\n\n def packages\n @packages ||= begin\n cmd = TTY::Command.new(printer: :null)\n packages = Dir.glob(\"#{@dir}/*.deb\").collect do |debfile|\n out, _err = cmd.run('dpkg-deb',\n \"--showformat=${Package}\\t${Version}\\n\",\n '--show', debfile)\n out.split($/).collect { |line| Package.new(*line.split(\"\\t\")) }\n end.flatten\n return packages unless @filter_select\n\n packages.select { |x| @filter_select.include?(x.name) }\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7160655856132507,
"alphanum_fraction": 0.7272131443023682,
"avg_line_length": 31.446807861328125,
"blob_id": "1f8abbb9cb3160185bdfde72c6ed0edbec6dfee1",
"content_id": "aaa6871190fe6985a615da155b9f1b08b63c5780",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1525,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 47,
"path": "/nci/repo_diff.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'terminal-table'\nrequire_relative 'lib/repo_diff'\n\ndist = NCI.current_series\n\nparser = OptionParser.new do |opts|\n opts.banner =\n \"Usage: #{opts.program_name} REPO1 REPO2\"\n\n opts.on('-d DIST', '--dist DIST', 'Distribution label to look for') do |v|\n dist = v\n end\nend\nparser.parse!\n\nAptly.configure do |config|\n config.uri = URI::HTTPS.build(host: 'archive-api.neon.kde.org')\n # This is read-only.\nend\n\nputs \"Checking dist: #{dist}\"\n\ndiffer = RepoDiff.new\nrows = differ.diff_repo(ARGV[0], ARGV[1], dist)\nputs Terminal::Table.new(rows: rows)\n"
},
{
"alpha_fraction": 0.6277150511741638,
"alphanum_fraction": 0.6372719407081604,
"avg_line_length": 28.89610481262207,
"blob_id": "c58f72420803344b377c60758cdcfd56b50b386d",
"content_id": "8758b9e56aca327b38d2c79338e1e31f0d28cfd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2302,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 77,
"path": "/lib/ci/build_version.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire 'date'\n\nrequire_relative '../os'\nrequire_relative '../debian/changelog'\n\nmodule CI\n # Wraps a debian changelog to construct a build specific version based on the\n # version used in the changelog.\n class BuildVersion\n TIME_FORMAT = '%Y%m%d.%H%M'\n\n # Version (including epoch)\n attr_reader :base\n # Version (excluding epoch)\n attr_reader :tar\n # Version include epoch AND possibly a revision\n attr_reader :full\n\n def initialize(changelog)\n @changelog = changelog\n @suffix = format('+p%<os_version>s+v%<type>s+git%<time>s',\n os_version: version_id, type: version_type, time: time)\n @tar = \"#{clean_base}#{@suffix}\"\n @base = \"#{changelog.version(Changelog::EPOCH)}#{clean_base}#{@suffix}\"\n @full = \"#{base}-0\"\n end\n\n # Version (including epoch AND possibly a revision)\n def to_s\n full\n end\n\n private\n\n def version_type\n # Make sure the TYPE doesn't have a hyphen. If this guard should fail you have to\n # figure out what to do with it. e.g. it could become a ~ and consequently lose to similarly named\n # type versions.\n raise if ENV.fetch('TYPE').include?('-')\n\n ENV.fetch('TYPE')\n end\n\n # Helper to get the time string for use in the version\n def time\n DateTime.now.strftime(TIME_FORMAT)\n end\n\n # Removes non digits from base version string.\n # This is to get rid of pesky alphabetic suffixes such as 5.2.2a which are\n # lower than 5.2.2+git (which we might have used previously), as + reigns\n # supreme. Always.\n def clean_base\n base = @changelog.version(Changelog::BASE)\n base = base.chop until base.empty? || base[-1].match(/[\\d\\.]/)\n return base unless base.empty?\n\n raise 'Failed to find numeric version in the changelog version:' \\\n \" #{@changelog.version(Changelog::BASE)}\"\n end\n\n def version_id\n if OS.to_h.key?(:VERSION_ID)\n id = OS::VERSION_ID\n return OS::VERSION_ID unless id.nil? || id.empty?\n end\n\n return '10' if OS::ID == 'debian'\n\n raise 'VERSION_ID not defined!'\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6883468627929688,
"avg_line_length": 20.705883026123047,
"blob_id": "ac17f00170380b3a39a8ca7a55d0126c9011bfff",
"content_id": "5e10a1f4870ea4423fc08d46b4a5efed713704b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 17,
"path": "/mgmt/docker_import.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\nrequire 'docker'\nrequire 'logger'\nrequire 'logger/colors'\n\n$stdout = $stderr\n\nDocker.options[:read_timeout] = 3 * 60 * 60 # 3 hours.\n\n@log = Logger.new(STDERR)\n\[email protected] \"Importing #{ARGV[0]}\"\nimage = Docker::Image.import(ARGV[0])\nimage.tag(repo: 'jenkins/wily_unstable', tag: 'latest', force: true)\[email protected] 'Done'\n"
},
{
"alpha_fraction": 0.6628308296203613,
"alphanum_fraction": 0.6720368266105652,
"avg_line_length": 34.46938705444336,
"blob_id": "43c5d4e59b282f87c4950fd21fe494ef8685a58c",
"content_id": "5b3f8feb53da6b1cba4309a1c29428ad0559264a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1738,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 49,
"path": "/test/test_ci_dependency_resolver.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/dependency_resolver'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# test ci/dependency_resolver\nmodule CI\n class DependencyResolverAPTTest < TestCase\n required_binaries %w[apt-get]\n\n def test_build_bin_only\n builddir = Dir.pwd\n cmd = mock('cmd')\n cmd\n .expects(:run!)\n .with({ 'DEBIAN_FRONTEND' => 'noninteractive' },\n '/usr/bin/apt-get',\n '--arch-only',\n '--host-architecture', 'i386',\n '-o', 'Debug::pkgProblemResolver=true',\n '--yes',\n 'build-dep', builddir)\n .returns(TTY::Command::Result.new(0, '', ''))\n TTY::Command.expects(:new).returns(cmd)\n\n DependencyResolverAPT.resolve(builddir, arch: 'i386', bin_only: true)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.689288318157196,
"alphanum_fraction": 0.6940572261810303,
"avg_line_length": 33.9487190246582,
"blob_id": "d6ac950790afe15f03701f07f7d4d3667c14024e",
"content_id": "3cd0c342e23b892d5fbaaea6c3e6e45241c0cb69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2726,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 78,
"path": "/test/test_nci_snap_collapser.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/snap/collapser'\n\nrequire 'mocha/test_unit'\n\nmodule NCI::Snap\n class BuildSnapPartCollapserTest < TestCase\n def test_part_collapse\n unpacker = mock('unpacker')\n Unpacker.expects(:new).with('kblocks').returns(unpacker)\n unpacker.expects(:unpack).returns('/snap/kblocks/current')\n\n core_unpacker = mock('core_unpacker')\n Unpacker.expects(:new).with('core18').returns(core_unpacker)\n core_unpacker.expects(:unpack).returns('/snap/core18/current')\n\n part = SnapcraftConfig::Part.new\n part.build_snaps = ['kblocks']\n part.plugin = 'cmake'\n BuildSnapPartCollapser.new(part).run\n\n assert_empty(part.build_snaps)\n assert_includes(part.cmake_parameters, '-DCMAKE_FIND_ROOT_PATH=/snap/kblocks/current')\n end\n\n def test_part_no_cmake\n part = SnapcraftConfig::Part.new\n part.build_snaps = ['kblocks']\n part.plugin = 'dump'\n assert_raises do\n BuildSnapPartCollapser.new(part).run\n end\n end\n end\n\n class BuildSnapCollapserTest < TestCase\n def test_snap_collapse\n part_collapser = mock('part_collapser')\n BuildSnapPartCollapser.expects(:new).with do |part|\n part.is_a?(SnapcraftConfig::Part)\n end.returns(part_collapser)\n part_collapser.expects(:run)\n\n FileUtils.cp(data('snapcraft.yaml'), Dir.pwd)\n FileUtils.cp(data('snapcraft.yaml.ref'), Dir.pwd)\n\n orig_data = YAML.load_file('snapcraft.yaml')\n data = nil\n BuildSnapCollapser.new('snapcraft.yaml').run do\n ref = YAML.load_file('snapcraft.yaml.ref')\n data = YAML.load_file('snapcraft.yaml')\n assert_equal(ref, data)\n end\n data = YAML.load_file('snapcraft.yaml')\n assert_equal(orig_data, data)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7466751337051392,
"alphanum_fraction": 0.7523749470710754,
"avg_line_length": 40.55263137817383,
"blob_id": "a0ef1ee372cae3cc2f34913e4cb8c8927fc8702c",
"content_id": "f9d7a7006798d18798fd5bf82221516eaafdf98b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1579,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 38,
"path": "/lib/ci/setcap.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'drb/drb'\n\n# setcap client component. This talks to the builder over the druby IPC giving\n# it our ARGV to assert on. Essentially this allows the builder to terminate\n# if we attempt to run an unexpected setcap call (i.e. not whitelisted/not in\n# postinst).\n\nPACKAGE_BUILDER_DRB_URI = ENV.fetch('PACKAGE_BUILDER_DRB_URI')\n\nDRb.start_service\n\nserver = DRbObject.new_with_uri(PACKAGE_BUILDER_DRB_URI)\nserver.check_expected(ARGV)\n\n# Not wanted nor needed as of right now. The assumption is that we handle the\n# caps in postinst exclusively, so calling the real setcap is useless and wrong.\n# exec(\"#{__dir__}/setcap.orig\", *ARGV)\n"
},
{
"alpha_fraction": 0.6038864254951477,
"alphanum_fraction": 0.6218236088752747,
"avg_line_length": 18.676469802856445,
"blob_id": "b494af06de2458c51be8cacb0bcce9f4db00575b",
"content_id": "e794636050aafd4c7bc33ad3af8e6b1e30509b7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 34,
"path": "/nci/lib/asgen_remote.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nmodule NCI\n class AppstreamGeneratorRemote\n def dist\n ENV.fetch('DIST')\n end\n\n def type\n ENV.fetch('TYPE')\n end\n\n def run_dir\n @run_dir ||= File.absolute_path('run')\n end\n\n def export_dir\n \"#{run_dir}/export\"\n end\n\n def export_dir_data\n \"#{run_dir}/export/data\"\n end\n\n def rsync_pubdir_expression\n pubdir = \"/srv/www/metadata.neon.kde.org/appstream/#{type}_#{dist}\"\n \"[email protected]:#{pubdir}\"\n end\n end\nend\n"
},
{
"alpha_fraction": 0.674733579158783,
"alphanum_fraction": 0.6821714043617249,
"avg_line_length": 39.76018142700195,
"blob_id": "579aadb4482e72741b8e0fd35fc07f593735e33c",
"content_id": "1301254d507fc83c9f1724a45933300860cb7495",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9008,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 221,
"path": "/test/test_upstream_scm.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# SPDX-FileCopyrightText: 2014-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/ci/upstream_scm'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# Test ci/upstream_scm\nclass UpstreamSCMTest < TestCase\n def setup\n # Disable releaseme adjustments by default. To be overridden as needed.\n ReleaseMe::Project.stubs(:from_repo_url).returns([])\n ReleaseMe::Project.stubs(:from_find).returns([])\n end\n\n def teardown\n CI::UpstreamSCM::ProjectCache.reset!\n end\n\n def test_defaults\n scm = CI::UpstreamSCM.new('breeze-qt4', 'kubuntu_unstable', '/')\n assert_equal('git', scm.type)\n assert_equal('https://anongit.kde.org/breeze', scm.url)\n assert_equal('master', scm.branch)\n end\n\n def test_releasme_adjust\n ReleaseMe::Project.unstub(:from_repo_url)\n breeze = mock('breeze-qt4')\n breeze.stubs(:i18n_trunk).returns('master')\n breeze.stubs(:i18n_stable).returns('Plasma/5.10')\n vcs = mock('breeze-qt4-vcs')\n vcs.stubs(:repository).returns('https://invent.kde.org/breeze')\n breeze.stubs(:vcs).returns(vcs)\n ReleaseMe::Project.stubs(:from_repo_url).returns([breeze])\n\n scm = CI::UpstreamSCM.new('breeze-qt4', 'kubuntu_unstable', '/')\n assert_equal('git', scm.type)\n assert_equal('https://anongit.kde.org/breeze', scm.url)\n assert_equal('master', scm.branch)\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('git', scm.type)\n assert_equal('https://invent.kde.org/breeze.git', scm.url)\n assert_equal('Plasma/5.10', scm.branch)\n end\n\n def test_releasme_adjust_uninteresting\n # Not changing non kde.org stuff.\n scm = CI::UpstreamSCM.new('breeze-qt4', 'kubuntu_unstable', '/')\n assert_equal('git', scm.type)\n assert_equal('https://anongit.kde.org/breeze', scm.url)\n assert_equal('master', scm.branch)\n scm.instance_variable_set(:@url, 'git://kittens')\n assert_nil(scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE))\n assert_equal('git', scm.type)\n assert_equal('git://kittens', scm.url)\n assert_equal('master', scm.branch)\n end\n\n def test_unknown_url\n # URL is on KDE but for some reason not in the projects. Should raise.\n ReleaseMe::Project.unstub(:from_repo_url)\n ReleaseMe::Project.stubs(:from_repo_url).returns([])\n scm = CI::UpstreamSCM.new('bububbreeze-qt4', 'kubuntu_unstable', '/')\n assert_raises do\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n end\n end\n\n def test_preference_fallback\n # A special fake thing 'no-stable' should come back with master as no\n # stable branch is set.\n ReleaseMe::Project.unstub(:from_repo_url)\n proj = mock('project')\n proj.stubs(:i18n_trunk).returns(nil)\n proj.stubs(:i18n_stable).returns('supertrunk')\n vcs = mock('vcs')\n vcs.stubs(:repository).returns('https://invent.kde.org/no-stable')\n proj.stubs(:vcs).returns(vcs)\n ReleaseMe::Project.stubs(:from_repo_url).with('https://anongit.kde.org/no-stable').returns([proj])\n\n scm = CI::UpstreamSCM.new('no-stable', 'kubuntu_unstable', '/')\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('supertrunk', scm.branch)\n end\n\n def test_preference_default\n # A special fake thing 'no-i18n' should come back with master as no\n # stable branch is set and no trunk branch is set, i.e. releaseme has no\n # data to give us.\n ReleaseMe::Project.unstub(:from_repo_url)\n proj = mock('project')\n proj.stubs(:i18n_trunk).returns(nil)\n proj.stubs(:i18n_stable).returns(nil)\n vcs = mock('vcs')\n vcs.stubs(:repository).returns('https://invent.kde.org/no-i18n')\n proj.stubs(:vcs).returns(vcs)\n ReleaseMe::Project.stubs(:from_repo_url).with('https://anongit.kde.org/no-i18n').returns([proj])\n\n scm = CI::UpstreamSCM.new('no-i18n', 'kubuntu_unstable', '/')\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('master', scm.branch)\n end\n\n def test_releaseme_url_suffix\n stub_request(:get, 'https://invent.kde.org/api/v4/projects/breeze')\n .to_return(status: 200,\n headers: { 'Content-Type' => 'text/json' },\n body: File.read(data('body.json')))\n\n # In overrides people sometimes use silly urls with a .git suffix, this\n # should still lead to correct adjustments regardless.\n ReleaseMe::Project.unstub(:from_repo_url)\n proj = mock('project')\n proj.stubs(:i18n_trunk).returns('master')\n proj.stubs(:i18n_stable).returns('Plasma/5.9')\n vcs = mock('vcs')\n vcs.stubs(:repository).returns('https://invent.kde.org/breeze')\n proj.stubs(:vcs).returns(vcs)\n ReleaseMe::Project.stubs(:from_repo_url).with('https://invent.kde.org/breeze').returns([proj])\n\n scm = CI::UpstreamSCM.new('breeze-qt4', 'kubuntu_unstable', '/')\n scm.instance_variable_set(:@url, 'https://invent.kde.org/breeze.git')\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('Plasma/5.9', scm.branch)\n end\n\n def test_releaseme_invent_transition\n # When moving to invent.kde.org the lookup tech gets slightly more involved\n # since we construct deterministic flat urls based on the packaging repo\n # name everything falls apart because invent urls are no longer\n # deterministically flat.\n # To mitigate we have fallback logic which tries to resolve based on\n # basename. This is fairly unreliable and only meant as a short term\n # measure. The final heuristics will have to gather more data sources to\n # try and determine the repo url.\n\n proj = mock('project')\n proj.stubs(:i18n_trunk).returns(nil)\n proj.stubs(:i18n_stable).returns(nil)\n vcs = mock('vcs')\n vcs.stubs(:repository).returns('https://invent.kde.org/plasma/drkonqi')\n proj.stubs(:vcs).returns(vcs)\n\n # primary request... fails to reoslve\n ReleaseMe::Project.unstub(:from_repo_url)\n ReleaseMe::Project.stubs(:from_repo_url).with('https://anongit.kde.org/drkonqi').returns([])\n\n # fallback request... succeeds\n ReleaseMe::Project.unstub(:from_find)\n ReleaseMe::Project.stubs(:from_find).with('drkonqi').returns([proj])\n\n scm = CI::UpstreamSCM.new('drkonqi', 'kubuntu_unstable', Dir.pwd)\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('master', scm.branch)\n # url was also adjusted!\n assert_equal('https://invent.kde.org/plasma/drkonqi.git', scm.url)\n end\n\n def test_releasme_adjust_fail\n # anongit.kde.org must not be used and will raise!\n scm = CI::UpstreamSCM.new('breeze-qt4', 'kubuntu_unstable', '/')\n # fake that the skip over adjust somehow. this will make adjust noop\n # BUT run the internal assertion tech to prevent anongit!\n scm.stubs(:adjust?).returns(false)\n assert_raises do\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n end\n assert_equal('https://anongit.kde.org/breeze', scm.url)\n\n # Make sure this doesn't explode when the type is uscan though!\n scm = CI::UpstreamSCM.new('mooooooo', 'kubuntu_unstable', '/')\n scm.instance_variable_set(:@type, 'uscan')\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('https://anongit.kde.org/mooooooo', scm.url)\n assert_equal('master', scm.branch)\n end\n\n def test_skip_cache\n # simply test for caching\n\n # skips after marked for skipping\n refute(CI::UpstreamSCM::ProjectCache.skip?('a'))\n CI::UpstreamSCM::ProjectCache.skip('a')\n assert(CI::UpstreamSCM::ProjectCache.skip?('a'))\n CI::UpstreamSCM::ProjectCache.reset!\n\n # not skipping if object cached\n refute(CI::UpstreamSCM::ProjectCache.skip?('a'))\n CI::UpstreamSCM::ProjectCache.cache('a', 'b')\n refute(CI::UpstreamSCM::ProjectCache.skip?('a'))\n end\n\n def test_releasme_adjust_personal_repo\n # Personal repos on invent shouldn't be releaseme adjusted.\n # The way this works on a higher level is that an override is applied\n # to the SCM which in turn means the url will be !default_url? and that\n # in turn means that additional magic should kick in.\n # Invent urls need to be checked for type. If they are personal repos\n # then they may be used as-is without adjustment. Otherwise they must\n # still resolve.\n\n stub_request(:get, 'https://invent.kde.org/api/v4/projects/bshah%2Fkarchive')\n .to_return(status: 200,\n headers: { 'Content-Type' => 'text/json' },\n body: File.read(data('body.json')))\n\n scm = CI::UpstreamSCM.new(__method__.to_s, 'kubuntu_unstable', '/')\n orig_url = scm.url\n scm.instance_variable_set(:@url, 'https://invent.kde.org/bshah/karchive.git')\n refute_equal(orig_url, scm.url) # make sure we adjust on a different url!\n # Must not raise anything on account of skipping over this since this is\n # a personal repo!\n scm.releaseme_adjust!(CI::UpstreamSCM::Origin::STABLE)\n assert_equal('https://invent.kde.org/bshah/karchive.git', scm.url)\n assert_equal('master', scm.branch)\n end\nend\n"
},
{
"alpha_fraction": 0.659316897392273,
"alphanum_fraction": 0.665802001953125,
"avg_line_length": 25.586206436157227,
"blob_id": "e64fb52e762cf032c8d113b8afa751ad609736c9",
"content_id": "6c7c9acc3ad4ca827ca855ababaa9e738b0e523c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2313,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 87,
"path": "/test/test_lint_cmake.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/lint/cmake'\nrequire_relative 'lib/testcase'\n\n# Test lint cmake\nclass LintCMakeTest < TestCase\n def cmake_ignore_path\n \"#{data('cmake-ignore')}\"\n end\n\n def test_init\n r = Lint::CMake.new(data).lint\n assert(!r.valid)\n assert(r.informations.empty?)\n assert(r.warnings.empty?)\n assert(r.errors.empty?)\n end\n\n def test_missing_package\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(%w[KF5Package], r.warnings)\n end\n\n def test_optional\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(%w[Qt5TextToSpeech], r.warnings)\n end\n\n def test_warning\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(%w[], r.warnings)\n end\n\n def test_disabled_feature\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(['XCB-CURSOR , Required for XCursor support'], r.warnings)\n end\n\n def test_missing_runtime\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(['Qt5Multimedia'], r.warnings)\n end\n\n def test_ignore_warning_by_release\n ENV['DIST'] = 'xenial'\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(['XCB-CURSOR , Required for XCursor support'], r.warnings)\n end\n\n def test_ignore_warning_by_release_yaml_no_series\n ENV['DIST'] = 'xenial'\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal([], r.warnings)\n end\n\n def test_ignore_warning_by_release_basic\n ENV['DIST'] = 'xenial'\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(['QCH , API documentation in QCH format (for e.g. Qt Assistant, Qt Creator & KDevelop)'], r.warnings)\n end\n\n def test_ignore_warning_by_release_basic_multiline\n ENV['DIST'] = 'xenial'\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal([], r.warnings)\n end\n\n def test_ignore_warning_by_release_bionic\n ENV['DIST'] = 'bionic'\n r = Lint::CMake.new(data).lint\n assert(r.valid)\n assert_equal(['XCB-CURSOR , Required for XCursor support', 'QCH , API documentation in QCH format (for e.g. Qt Assistant, Qt Creator & KDevelop)'], r.warnings)\n end\nend\n"
},
{
"alpha_fraction": 0.6387141942977905,
"alphanum_fraction": 0.6429070830345154,
"avg_line_length": 26.519229888916016,
"blob_id": "206425b84f83b00b22aa055d2e4e96e9e2b917cd",
"content_id": "6c02ea23f31530a9b52cb25869030eb3891c0a47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2862,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 104,
"path": "/lib/projects/factory/github.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'octokit'\n\nrequire_relative 'base'\nrequire_relative 'common'\n\nclass ProjectsFactory\n # Debian specific project factory.\n class GitHub < Base\n include ProjectsFactoryCommon\n\n DEFAULT_URL_BASE = 'https://github.com/'\n DEFAULT_PRIVATE_URL_BASE = 'ssh://[email protected]:'\n\n # FIXME: same as in neon\n def self.url_base\n @url_base ||= DEFAULT_URL_BASE\n end\n\n def self.private_url_base\n @private_url_base ||= DEFAULT_PRIVATE_URL_BASE\n end\n\n def self.understand?(type)\n type == 'github.com'\n end\n\n private\n\n # FIXME: same as in Neon except component is merged\n def split_entry(entry)\n parts = entry.split('/')\n name = parts[-1]\n component = parts[0..-2].join('_') || 'github'\n [name, component]\n end\n\n def params(str)\n name, component = split_entry(str)\n url_base = url_base_for(name, component)\n\n default_params.merge(\n name: name,\n component: component,\n url_base: url_base\n )\n end\n\n def url_base_for(name, component)\n component_repos = self.class.repo_cache.fetch(component)\n repo = component_repos.find { |x| x.name == name }\n raise unless repo\n\n repo.private ? self.class.private_url_base : self.class.url_base\n end\n\n class << self\n def repo_cache\n @repo_cache ||= {}\n end\n\n def repo_names_for_base(base)\n repo_cache[base]&.collect(&:name)&.freeze\n end\n\n def load_repos_for_base(base)\n repo_cache[base] ||= begin\n Octokit.auto_paginate = true\n client = Octokit::Client.new\n begin\n client.login\n client.org_repos(base)\n rescue Net::OpenTimeout, Faraday::SSLError, Faraday::ConnectionFailed\n retry\n end\n end\n end\n\n def ls(base)\n load_repos_for_base(base)\n repo_cache[base]&.collect(&:name)&.freeze\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6983805894851685,
"alphanum_fraction": 0.71659916639328,
"avg_line_length": 28.058822631835938,
"blob_id": "901a9d1d06a3a89cedb51f68a72c0ed01cd002af",
"content_id": "c09d464aaaeee4277ea8c7ad866d30adebb453e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 17,
"path": "/jenkins-jobs/nci/i386-install-check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../job'\n\n# Progenitor is the super super super job triggering everything.\nclass I386InstallCheckJob < JenkinsJob\n attr_reader :distribution\n attr_reader :type\n attr_reader :dependees\n\n def initialize(distribution:, type:, dependees:)\n super(\"mgmt_i386_install_check_#{distribution}_#{type}\",\n 'i386-install-check.xml.erb')\n @distribution = distribution\n @type = type\n @dependees = dependees.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.5656138062477112,
"alphanum_fraction": 0.5899254083633423,
"avg_line_length": 32.61919403076172,
"blob_id": "b77222a439387d0c2d533cbc960fc18b793c07be",
"content_id": "c22924cc0fcbbde45272231485503fb10ec08825",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 10859,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 323,
"path": "/test/test_ci_tar_fetcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire 'vcr'\nrequire 'webmock/test_unit'\n\nrequire_relative 'lib/serve'\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/ci/tar_fetcher'\n\nmodule CI\n class TarFetcherTest < TestCase\n SERVER_PORT = '9475'\n\n def setup\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :webmock\n config.default_cassette_options = {\n match_requests_on: %i[method uri body]\n }\n end\n\n OS.instance_variable_set(:@hash,\n UBUNTU_CODENAME: NCI.current_series,\n ID: 'ubuntu')\n end\n\n def teardown\n OS.reset\n end\n\n def test_fetch\n VCR.use_cassette(__method__) do\n f = URLTarFetcher.new('http://people.ubuntu.com/~apachelogger/.static/testu-1.0.tar.xz')\n t = f.fetch(Dir.pwd)\n assert(t.is_a?(Tarball))\n assert_path_exist('testu-1.0.tar.xz')\n assert_false(t.orig?)\n assert_equal('testu_1.0.orig.tar.xz', File.basename(t.origify.path))\n end\n end\n\n def test_fetch_orig\n VCR.use_cassette(__method__) do\n f = URLTarFetcher.new('http://people.ubuntu.com/~apachelogger/.static/testu_1.0.orig.tar.xz')\n t = f.fetch(Dir.pwd)\n assert(t.orig?)\n end\n end\n\n def test_fetch_escaped_orig\n VCR.use_cassette(__method__) do\n f = URLTarFetcher.new('http://http.debian.net/debian/pool/main/libd/libdbusmenu-qt/libdbusmenu-qt_0.9.3%2B15.10.20150604.orig.tar.gz')\n t = f.fetch(Dir.pwd)\n file = File.basename(t.origify.path)\n assert_equal('libdbusmenu-qt_0.9.3+15.10.20150604.orig.tar.gz', file)\n end\n end\n\n # TODO: maybe split\n def test_watch_fetch\n require_binaries(%w[uscan])\n\n assert_raise RuntimeError do\n WatchTarFetcher.new('/a/b/c')\n # Not a watch\n end\n assert_raise RuntimeError do\n WatchTarFetcher.new('/a/b/watch')\n # Not a debian dir\n end\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'))\n t = f.fetch(Dir.pwd)\n\n # assert_path_exist('dragon_15.08.1.orig.tar.xz')\n assert_equal(Tarball, t.class)\n assert_path_exist('dragon_15.08.1.orig.tar.xz')\n assert(t.orig?) # uscan mangles by default, we expect it like that\n assert_equal('dragon_15.08.1.orig.tar.xz',\n File.basename(t.origify.path))\n end\n end\n\n # test code to mange the watch file to look at alternative server\n # currently only works on stable/\n def test_watch_mangle\n FileUtils.cp_r(data, 'debian/')\n f = WatchTarFetcher.new('debian/watch', mangle_download: true)\n\n ref_line = 'http://download.kde.internal.neon.kde.org/stable/applications/([\\d.]+)/kgamma5-([\\d.]+).tar.xz'\n\n # Mangles are transient, so we need to assert at the time of uscan\n # invocation.\n TTY::Command.any_instance.expects(:run).never\n Object.any_instance.expects(:system).never\n Object.any_instance.expects(:`).never\n TTY::Command.any_instance.expects(:run).once.with do |*args|\n next false unless args[0] == 'uscan'\n\n data = File.read('debian/watch')\n assert_include(data.chomp!, ref_line)\n true\n end.returns(true)\n\n f.fetch(Dir.pwd)\n\n # Since mangles are transient, we should not fine the line afterwards.\n data = File.read('debian/watch')\n assert_not_include(data, ref_line)\n end\n\n description 'when destdir does not exist uscan shits its pants'\n def test_watch_create_destdir\n require_binaries(%w[uscan])\n\n # Create an old file. The fetcher is meant to remove this.\n File.write('dragon_15.08.1.orig.tar.xz', '')\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'))\n f.fetch('source')\n\n assert_path_exist('source/dragon_15.08.1.orig.tar.xz')\n end\n end\n\n def test_watch_multiple_tars\n FileUtils.cp_r(data, 'debian/')\n # We fully fake this at runtime to not have to provide dummy files...\n\n files = %w[\n yolo_1.3.2.orig.tar.gz\n yolo_1.2.3.orig.tar.gz\n ]\n\n TTY::Command\n .any_instance\n .expects(:run)\n .once\n .with do |*args|\n next false unless args[0] == 'uscan'\n\n files.each { |f| File.write(f, '') }\n true\n end\n .returns(true)\n Object.any_instance.stubs(:system)\n .with('dpkg', '--compare-versions', '1.3.2', 'gt', '1.2.3')\n .returns(true)\n Object.any_instance.stubs(:system)\n .with('dpkg', '--compare-versions', '1.2.3', 'gt', '1.3.2')\n .returns(false)\n Object.any_instance.stubs(:system)\n .with('dpkg', '--compare-versions', '1.2.3', 'lt', '1.3.2')\n .returns(true)\n\n f = WatchTarFetcher.new('debian/watch')\n tar = f.fetch(Dir.pwd)\n assert_not_nil(tar)\n\n assert_path_exist(files[0])\n assert_path_not_exist(files[1])\n end\n\n def test_watch_multiple_entries\n omit\n require_binaries(%w[uscan])\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'))\n f.fetch('source')\n\n # On 20.04 uscan only fetches one of the multiple matching downlods.\n # Seems to be consistently the first one.\n # This test was only concerned with fetching works at all when multiple\n # entries are present - preveiously it did not, so even if we only\n # get one of the entries back that still passes our expectation.\n # NB: double check if you want to add another assertion on the\n # other entry (orig-contrib.tar.gz)\n assert_path_exist('source/opencv_3.2.0.orig.tar.gz')\n end\n end\n\n def test_watch_with_series\n require_binaries(%w[uscan])\n\n TTY::Command\n .any_instance\n .expects(:run!)\n .with('apt-get', 'source', '--only-source', '--download-only', '-t', 'vivid', 'dragon',\n chdir: 'source') do |*args|\n Dir.chdir('source') do\n File.write('dragon_15.08.1.orig.tar.xz', '')\n File.write('dragon_15.08.1-4:15.08.1-0ubuntu1.dsc', '')\n File.write('dragon_15.08.1-4:15.08.1-0ubuntu1.debian.tar.xz', '')\n end\n\n args == ['apt-get', 'source', '--only-source', '--download-only', '-t', 'vivid',\n 'dragon', { chdir: 'source' }]\n end\n .returns(nil)\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'), series: ['vivid'])\n f.fetch('source')\n\n assert_path_exist('source/dragon_15.08.1.orig.tar.xz')\n assert_path_not_exist('source/dragon_15.08.1-4:15.08.1-0ubuntu1.dsc')\n assert_path_not_exist('source/dragon_15.08.1-4:15.08.1-0ubuntu1.debian.tar.xz')\n end\n end\n\n def test_watch_tar_finder_with_lingering_tar_of_higher_version\n require_binaries(%w[uscan])\n\n # In a see of incorrect tarballs we always want to find the right one!\n # Previously we used a fairly daft approach for this which often located\n # the wrong file.\n\n FileUtils.mkdir('source')\n FileUtils.touch('source/dragon_16.08.1+dfsg.orig.tar.xz')\n FileUtils.touch('source/dragon_17.orig.tar.xz')\n FileUtils.touch('source/dragon_17.tar.xz')\n FileUtils.touch('source/meow_17.tar.xz')\n\n TTY::Command\n .any_instance\n .expects(:run!)\n .with('apt-get', 'source', '--only-source', '--download-only', '-t', 'vivid', 'dragon',\n chdir: 'source') do |*args|\n Dir.chdir('source') do\n File.write('dragon_15.08.1.orig.tar.xz', '')\n File.write('dragon_15.08.1-4:15.08.1-0ubuntu1.dsc', '')\n File.write('dragon_15.08.1-4:15.08.1-0ubuntu1.debian.tar.xz', '')\n end\n\n args == ['apt-get', 'source', '--only-source', '--download-only', '-t', 'vivid',\n 'dragon', { chdir: 'source' }]\n end\n .returns(nil)\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'), series: ['vivid'])\n tarball = f.fetch('source')\n\n assert_equal(\"#{Dir.pwd}/source/dragon_15.08.1.orig.tar.xz\", tarball.path)\n end\n end\n\n def test_watch_fetch_repack\n require_binaries(%w[uscan])\n\n refute_nil(NCI.current_series)\n OS.instance_variable_set(:@hash,\n UBUNTU_CODENAME: \"#{NCI.current_series}1\",\n ID: 'ubuntu')\n\n # Not passing any series in and expecting a failure as we'd repack\n # on a series that isn't NCI.current_series\n assert_raises CI::WatchTarFetcher::RepackOnNotCurrentSeries do\n WatchTarFetcher.new(data('debian/watch')).fetch('source')\n end\n end\n\n def test_watch_hyphen_in_orig\n require_binaries(%w[uscan])\n\n Test.http_serve(data('http'), port: SERVER_PORT) do\n f = WatchTarFetcher.new(data('debian/watch'))\n f.fetch('source')\n\n assert_path_exist('source/qtchooser_64-ga1b6736.orig.tar.gz')\n end\n end\n\n def test_watch_native\n # native packages need not run uscan. It makes no sense as they generate\n # their own source. Make sure this doesn't happen anywhere.\n require_binaries(%w[uscan])\n\n assert_raises CI::WatchTarFetcher::NativePackaging do\n WatchTarFetcher.new(data('debian/watch'))\n end\n end\n\n def test_url_fetch_twice\n VCR.turned_off do\n stub_request(:get, 'http://troll/dragon-15.08.1.tar.xz')\n .to_return(body: File.read(data('http/dragon-15.08.1.tar.xz')))\n\n f = URLTarFetcher.new('http://troll/dragon-15.08.1.tar.xz')\n t = f.fetch(Dir.pwd)\n assert_false(t.orig?, \"File orig but was not meant to #{t.inspect}\")\n\n # And again this actually should not do a request.\n f = URLTarFetcher.new('http://troll/dragon-15.08.1.tar.xz')\n t = f.fetch(Dir.pwd)\n assert_false(t.orig?, \"File orig but was not meant to #{t.inspect}\")\n\n assert_requested(:get, 'http://troll/dragon-15.08.1.tar.xz', times: 1)\n end\n end\n\n def test_deb_scm_fetch\n assert_raises do\n # No content\n DebSCMFetcher.new.fetch('source')\n end\n\n FileUtils.mkpath('debscm')\n File.write('debscm/foo_1.orig.tar.xz', '')\n File.write('debscm/foo_1-1.debian.tar.xz', '')\n File.write('debscm/foo_1-1.dsc', '')\n\n DebSCMFetcher.new.fetch('source')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.715976357460022,
"alphanum_fraction": 0.7396449446678162,
"avg_line_length": 38,
"blob_id": "9bfc77fdb39814d6ac9d3beb7c5e6bf219c30cb7",
"content_id": "4f59a8c5d89c4aec8863f2efc104622dcbbdc979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 507,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 13,
"path": "/nci/lint_versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lint/versions'\n\nour = NCI::DirPackageLister.new('result/')\ntheir = NCI::CachePackageLister.new(filter_select: our.packages.map(&:name))\nNCI::VersionsTest.init(ours: our.packages, theirs: their.packages)\nENV['CI_REPORTS'] = \"#{Dir.pwd}/reports\"\nARGV << '--ci-reporter'\nrequire 'minitest/autorun'\n"
},
{
"alpha_fraction": 0.7378759980201721,
"alphanum_fraction": 0.7470840811729431,
"avg_line_length": 35.20000076293945,
"blob_id": "45e2310d87d7ce41c7fc633f8fa70eb13320f550",
"content_id": "38956f6cdc1648340985e218b3129d1cc66414eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1629,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 45,
"path": "/lib/gir_ffi.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# https://github.com/mvz/gir_ffi/issues/91\nmodule GLibLoadClassWorkaround\n def load_class(klass, *args)\n return if klass == :IConv\n\n super\n end\nend\n\n# Prepended with workaround\nmodule GirFFI\n # Prepended with workaround\n module ModuleBase\n prepend GLibLoadClassWorkaround\n end\nend\n\n# TODO: verify if this is still necessary from time to time\n# Somewhere in test-unit the lib path is injected in the load paths and since\n# the file has the same name as the original require this would cause\n# a recursion require. So, rip the current path out of the load path temorarily.\nold_paths = $LOAD_PATH.dup\n$LOAD_PATH.reject! { |x| x == __dir__ }\nrequire 'gir_ffi'\n$LOAD_PATH.replace(old_paths)\n"
},
{
"alpha_fraction": 0.6722521781921387,
"alphanum_fraction": 0.6796364784240723,
"avg_line_length": 39.94186019897461,
"blob_id": "8c756c1d4b49fd09d11abdcbf364aee157ca158e",
"content_id": "f492e0671cd26c599dec0018a6646cba1421ed69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3521,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 86,
"path": "/test/test_nci_jenkins_job_artifact_cleaner.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/jenkins_job_artifact_cleaner'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class JenkinsJobArtifactCleanerTest < TestCase\n def setup\n @jenkins_home = ENV['JENKINS_HOME']\n ENV['JENKINS_HOME'] = Dir.pwd\n @jenkins_job_base = ENV['JOB_BASE_NAME']\n ENV['JOB_BASE_NAME'] = 'foobasename'\n @jenkins_build_number = ENV['BUILD_NUMBER']\n ENV['BUILD_NUMBER'] = '42'\n end\n\n def teardown\n # If the var is nil []= delets it from the env.\n ENV['JENKINS_HOME'] = @jenkins_home\n ENV['JOB_BASE_NAME'] = @jenkins_job_base\n ENV['BUILD_NUMBER'] = @jenkins_build_number\n end\n\n def test_clean\n # All deb files should get ripped out.\n\n aa_archive = 'jobs/aa/builds/lastSuccessfulBuild/archive'\n FileUtils.mkpath(aa_archive)\n FileUtils.mkpath(\"#{aa_archive}/subdir1.deb/\")\n FileUtils.mkpath(\"#{aa_archive}/subdir2/\")\n FileUtils.touch(\"#{aa_archive}/subdir2/aa.deb.info.txt\")\n FileUtils.touch(\"#{aa_archive}/subdir2/aa.deb.json\")\n FileUtils.touch(\"#{aa_archive}/subdir2/aa.deb\")\n FileUtils.touch(\"#{aa_archive}/subdir2/aa.ddeb\")\n FileUtils.touch(\"#{aa_archive}/subdir2/aa.udeb\")\n FileUtils.touch(\"#{aa_archive}/workspace.tar\")\n FileUtils.touch(\"#{aa_archive}/abc.orig.tar.xz\")\n FileUtils.touch(\"#{aa_archive}/run_stamp\")\n FileUtils.mkpath(\"#{aa_archive}/fileParameters\")\n FileUtils.touch(\"#{aa_archive}/fileParameters/fishing.iso\")\n\n self_archive = 'jobs/foobasename/builds/42/archive'\n FileUtils.mkpath(self_archive)\n FileUtils.touch(\"#{self_archive}/aa.deb\")\n FileUtils.touch(\"#{self_archive}/aa.deb.json\")\n FileUtils.touch(\"#{self_archive}/workspace.tar\")\n\n JenkinsJobArtifactCleaner.run(%w[aa bb])\n\n assert_path_exist(\"#{aa_archive}/subdir1.deb/\")\n assert_path_exist(\"#{aa_archive}/subdir2/aa.deb.info.txt\")\n assert_path_exist(\"#{aa_archive}/subdir2/aa.deb.json\")\n assert_path_not_exist(\"#{aa_archive}/subdir2/aa.deb\")\n assert_path_not_exist(\"#{aa_archive}/subdir2/aa.ddeb\")\n assert_path_not_exist(\"#{aa_archive}/subdir2/aa.udeb\")\n assert_path_not_exist(\"#{aa_archive}/workspace.tar\")\n assert_path_not_exist(\"#{aa_archive}/abc.orig.tar.xz\")\n assert_path_not_exist(\"#{aa_archive}/run_stamp\")\n assert_path_not_exist(\"#{aa_archive}/fileParameters/fishing.iso\")\n\n assert_path_not_exist(\"#{self_archive}/aa.deb\")\n assert_path_exist(\"#{self_archive}/aa.deb.json\")\n assert_path_not_exist(\"#{self_archive}/workspace.tar\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6340773105621338,
"alphanum_fraction": 0.637849748134613,
"avg_line_length": 31.793813705444336,
"blob_id": "68d463c32dc0763443f83c207cf0a9e513cb597d",
"content_id": "f4b86f0dc408846245e97cf8bba3f2f268c9f69e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3181,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 97,
"path": "/test/test_ci_pattern.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/ci/pattern'\nrequire_relative 'lib/testcase'\n\n# Test ci/pattern\nclass CIPatternTest < TestCase\n def test_match\n assert(CI::FNMatchPattern.new('a*').match?('ab'))\n assert(!CI::FNMatchPattern.new('a*').match?('ba'))\n end\n\n def test_spaceship_op\n a = CI::FNMatchPattern.new('a*')\n assert_equal(nil, a.<=>('a'))\n assert_equal(-1, a.<=>(CI::FNMatchPattern.new('*')))\n # rubocop:disable Lint/BinaryOperatorWithIdenticalOperands\n # this is intentional\n assert_equal(0, a.<=>(a))\n # rubocop:enable Lint/BinaryOperatorWithIdenticalOperands\n assert_equal(1, a.<=>(CI::FNMatchPattern.new('ab')))\n end\n\n def test_equal_op\n a = CI::FNMatchPattern.new('a*')\n assert(a == 'a*')\n assert(a != 'b')\n assert(a == CI::FNMatchPattern.new('a*'))\n end\n\n def test_to_s\n assert_equal(CI::FNMatchPattern.new('a*').to_s, 'a*')\n assert_equal(CI::FNMatchPattern.new('a').to_s, 'a')\n assert_equal(CI::FNMatchPattern.new(nil).to_s, '')\n end\n\n def test_hash_convert\n hash = {\n 'a*' => { 'x*' => false }\n }\n ph = CI::FNMatchPattern.convert_hash(hash, recurse: true)\n assert_equal(1, ph.size)\n assert(ph.flatten.first.is_a?(CI::FNMatchPattern))\n assert(ph.flatten.last.flatten.first.is_a?(CI::FNMatchPattern))\n end\n\n def test_sort\n # PatternHash has a convenience sort_by_pattern method that allows sorting\n # the first level of a hash by its pattern (i.e. the key).\n h = {\n 'a/*' => 'all_a',\n 'a/b' => 'b',\n 'z/*' => 'all_z'\n }\n ph = CI::FNMatchPattern.convert_hash(h)\n assert_equal(3, ph.size)\n ph = CI::FNMatchPattern.filter('a/b', ph)\n assert_equal(2, ph.size)\n ph = CI::FNMatchPattern.sort_hash(ph)\n # Random note: first is expected technically but since we only allow\n # Pattern == String to evaulate properly we need to invert the order here.\n assert_equal(ph.keys[0], 'a/b')\n assert_equal(ph.keys[1], 'a/*')\n end\n\n def test_array_sort\n klass = CI::FNMatchPattern\n a = [klass.new('a/*'), klass.new('a/b'), klass.new('z/*')]\n a = klass.filter('a/b', a)\n assert_equal(2, a.size)\n assert_equal(a[0], 'a/*')\n a = a.sort\n assert_equal(a[0], 'a/b')\n assert_equal(a[1], 'a/*')\n end\n\n def test_include_pattern\n ref = 'abcDEF'\n pattern = CI::IncludePattern.new(ref)\n assert(pattern.match?(\"yolo#{ref}yolo\"))\n assert(pattern.match?(\"yolo#{ref}\"))\n assert(pattern.match?(\"#{ref}yolo\"))\n assert_false(pattern.match?('yolo'))\n end\n\n def test_fn_extglob\n pattern = CI::FNMatchPattern.new('*{packaging.neon,git.debian}*/plasma/plasma-discover')\n assert pattern.match?('git.debian.org:/git/pkg-kde/plasma/plasma-discover')\n assert pattern.match?('git://packaging.neon.kde.org.uk/plasma/plasma-discover')\n end\n\n def test_fn_extglob_unbalanced\n # count of { and } are not the same, this isn't an extglob!\n pattern = CI::FNMatchPattern.new('*{packaging.neon,git.debian*/plasma/plasma-discover')\n refute pattern.match?('git.debian.org:/git/pkg-kde/plasma/plasma-discover')\n refute pattern.match?('git://packaging.neon.kde.org.uk/plasma/plasma-discover')\n end\nend\n"
},
{
"alpha_fraction": 0.68271803855896,
"alphanum_fraction": 0.6891385912895203,
"avg_line_length": 35.64706039428711,
"blob_id": "cc8b3ec7aff48bbf93a3cb6aca6736e069f96d65",
"content_id": "d4d9f5a61e8fd259c37ca4bee224a491ff2257bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1869,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 51,
"path": "/nci/jenkins_job_artifact_cleaner_all.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'jenkins_job_artifact_cleaner'\n\nmodule NCI\n # Cleans up artifacts of lastSuccessfulBuild of jobs passed as array of\n # names.\n module JenkinsJobArtifactCleaner\n # Wrapper to clean ALL jobs and go back in their history. This is\n # a safety net to ensure we do not leak archive data\n class AllJobs\n def self.run\n Dir.foreach(Job.jobs_dir).each do |job_name|\n next if %w[. ..].include?(job_name)\n\n job = Job.new(job_name, verbose: false)\n build_id = job.last_build_id\n (back_count(build_id)..build_id).each do |id|\n Job.new(job_name, build: id, verbose: false).clean!\n end\n end\n end\n\n def self.back_count(id)\n ret = id - ENV.fetch('PANGEA_ARTIFACT_CLEAN_HISTORY', 16).to_i\n ret.positive? ? ret : 1\n end\n end\n end\nend\n\nNCI::JenkinsJobArtifactCleaner::AllJobs.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.6188092231750488,
"alphanum_fraction": 0.656356155872345,
"avg_line_length": 34.624202728271484,
"blob_id": "977583d613dfca12c2cdf1f6e7af5b7d6fc1a218",
"content_id": "9e8a11800b4d4bcd86e85e50a5804ca8c0241860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5593,
"license_type": "no_license",
"max_line_length": 521,
"num_lines": 157,
"path": "/test/test_qml_dependency_verifier.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'fileutils'\nrequire 'vcr'\n\nrequire_relative '../lib/qml_dependency_verifier'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# Test qml dep verifier\nclass QMLDependencyVerifierTest < TestCase\n def const_reset(klass, symbol, obj)\n klass.send(:remove_const, symbol)\n klass.const_set(symbol, obj)\n end\n\n def setup\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :webmock\n end\n VCR.insert_cassette(File.basename(__FILE__, '.rb'))\n\n Dir.chdir(datadir)\n\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n\n reset_child_status! # Make sure $? is fine before we start!\n\n # Let all backtick or system calls that are not expected fall into\n # an error trap!\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n\n # Default stub architecture as amd64\n Object.any_instance.stubs(:`)\n .with('dpkg-architecture -qDEB_HOST_ARCH')\n .returns('amd64')\n\n # We'll temporary mark packages as !auto, mock this entire thing as we'll\n # not need this for testing.\n Apt::Mark.stubs(:tmpmark).yields\n end\n\n def teardown\n VCR.eject_cassette(File.basename(__FILE__, '.rb'))\n QML::StaticMap.reset!\n end\n\n def data(path = nil)\n index = 0\n caller = ''\n until caller.start_with?('test_')\n caller = caller_locations(index, 1)[0].label\n index += 1\n end\n File.join(*[datadir, caller, path].compact)\n end\n\n def ref_path\n \"#{data}.ref\"\n end\n\n def ref\n JSON.parse(File.read(ref_path))\n end\n\n def test_missing_modules\n # Make sure our ignore is in place in the data dir.\n\n QML::StaticMap.data_file = File.join(data, 'static.yaml')\n\n # NB: this testcase is chdir in the datadir not the @tmpdir!\n assert(File.exist?('packaging/debian/plasma-widgets-addons.qml-ignore'))\n # Prepare sequences, divert search path and run verification.\n const_reset(QML, :SEARCH_PATHS, [File.join(data, 'qml')])\n\n system_sequence = sequence('system')\n JSON.parse(File.read(data('system_sequence'))).each do |cmd|\n Object.any_instance.expects(:system)\n .with(*cmd)\n .returns(true)\n .in_sequence(system_sequence)\n end\n JSON.parse(File.read(data('list_sequence'))).each do |cmd|\n DPKG.stubs(:list).with(*cmd).returns([])\n end\n DPKG.stubs(:list)\n .with('plasma-widgets-addons')\n .returns([data('main.qml')])\n # org.plasma.configuration is static mapped to plasma-framework, so we\n # need this call to happen to check if it installed.\n # this must not ever be removed!\n Object.any_instance.stubs(:system)\n .with('dpkg -s plasma-framework 2>&1 > /dev/null')\n .returns(true)\n\n repo = mock('repo')\n repo.stubs(:add).returns(true)\n repo.stubs(:remove).returns(true)\n repo.stubs(:binaries).returns('kwin-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'plasma-dataengines-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'plasma-runners-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'plasma-wallpapers-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'plasma-widget-kimpanel' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'plasma-widgets-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0', 'kdeplasma-addons-data' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0')\n\n missing = QMLDependencyVerifier.new(repo).missing_modules\n assert_equal(1, missing.size, 'More things missing than expected' \\\n \" #{missing}\")\n\n assert(missing.key?('plasma-widgets-addons'))\n missing = missing.fetch('plasma-widgets-addons')\n assert_equal(1, missing.size, 'More modules missing than expected' \\\n \" #{missing}\")\n\n missing = missing.first\n assert_equal('QtWebKit', missing.identifier)\n end\n\n def test_log_no_missing\n repo = mock('repo')\n QMLDependencyVerifier.new(repo).send(:log_missing, {})\n end\n\n def test_static_which_isnt_static\n # When a package was c++ runtime-injected at some point we would have\n # added it to the static map. If it later turns into a proper module\n # we need to undo the static mapping. Otherwise the dependency expectation\n # can be royally wrong as a regular package would be in qml-module-foo,\n # a runtime-injected one in any random package.\n\n QML::StaticMap.data_file = File.join(data, 'static.yaml')\n\n const_reset(QML, :SEARCH_PATHS, [File.join(data, 'qml')])\n\n system_sequence = sequence('system')\n Object.any_instance.expects(:system)\n .with('apt-get', '-y', '-o', 'APT::Get::force-yes=true', '-o', 'Debug::pkgProblemResolver=true', '-q', 'install', 'kwin-addons=4:5.2.1+git20150316.1204+15.04-0ubuntu0')\n .returns(true)\n .in_sequence(system_sequence)\n Object.any_instance.expects(:system)\n .with('apt-get', '-y', '-o', 'APT::Get::force-yes=true', '-o', 'Debug::pkgProblemResolver=true', '-q', '--purge', 'autoremove')\n .returns(true)\n .in_sequence(system_sequence)\n\n # DPKG.stubs(:list).returns([])\n DPKG.stubs(:list).with('kwin-addons')\n .returns([data('main.qml')])\n\n repo = mock('repo')\n repo.stubs(:add).returns(true)\n repo.stubs(:remove).returns(true)\n repo.stubs(:binaries).returns('kwin-addons' => '4:5.2.1+git20150316.1204+15.04-0ubuntu0')\n\n assert_raises QML::Module::ExistingStaticError do\n QMLDependencyVerifier.new(repo).missing_modules\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6538775563240051,
"alphanum_fraction": 0.6612244844436646,
"avg_line_length": 35.56716537475586,
"blob_id": "f8ff0f3b83a97feb5c9a9447e4e1d17a15fbb61e",
"content_id": "9c11cc61a1a3175c47a2a5c239d02925383e0d32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2450,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 67,
"path": "/nci/jenkins-bin/cores.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule NCI\n module JenkinsBin\n # CPU Core helper. Implementing simple logic to upgrade/downgrade core count\n class Cores\n # This controls the output cores! Raising the cap here directly results in\n # larger machines getting assigned if necessary.\n CORES = [2, 4, 8].freeze\n\n def self.downgrade(cores)\n # Get either 0 or whatever is one below the input.\n new_cores_idx = [0, CORES.index(cores) - 1].max\n CORES[new_cores_idx]\n end\n\n def self.upgrade(cores)\n # Get either -1 or whatever is one above the input.\n new_cores_idx = [CORES.size - 1, CORES.index(cores) + 1].min\n CORES[new_cores_idx]\n end\n\n def self.know?(cores)\n CORES.include?(cores)\n end\n\n # Given any core count we'll coerce it into a known core count with\n # the smallest possible diff. Assuming two options the worse will be\n # picked to allow for upgrades which happen more reliably than downgrades\n # through automatic scoring.\n def self.coerce(cores)\n pick = nil\n diff = nil\n CORES.each do |c|\n new_diff = c - cores\n # Skip if absolute diff is worse than the diff we have\n next if diff && new_diff.abs > diff.abs\n # If the diff is equal pick the lower value. It will get upgraded\n # eventually if it is too low.\n next if diff&.abs == new_diff.abs && c > pick\n\n pick = c\n diff = new_diff\n end\n pick\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6884498596191406,
"alphanum_fraction": 0.698074996471405,
"avg_line_length": 38.47999954223633,
"blob_id": "82d2cf30af393740f95871756a34174e30611f8f",
"content_id": "cfa948e9c594252770a273ce98b4c64911a9f22c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1974,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/xci/lib/setup_repo.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Bhushan Shah <[email protected]>\n# Copyright (C) 2018 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../../lib/apt'\nrequire_relative '../../lib/dpkg'\nrequire_relative '../../lib/lsb'\nrequire_relative '../../lib/retry'\n\n# Xenon CI specific helpers.\nmodule XenonCI\n module_function\n\n def setup_repo!\n neon = format('deb http://archive.neon.kde.org/unstable %s main',\n LSB::DISTRIB_CODENAME)\n raise 'adding repo failed' unless Apt::Repository.add(neon)\n\n Apt::Key.add('http://archive.neon.kde.org/public.key')\n raise 'Failed to import key' unless $?.to_i.zero?\n\n xenon = format('deb http://archive.xenon.pangea.pub/%s %s main',\n ENV.fetch('TYPE'), LSB::DISTRIB_CODENAME)\n raise 'adding repo failed' unless Apt::Repository.add(xenon)\n\n Apt::Key.add('http://archive.xenon.pangea.pub/public.key')\n raise 'Failed to import key' unless $?.to_i.zero?\n\n Retry.retry_it(times: 5, sleep: 2) { raise unless Apt.update }\n raise 'failed to install deps' unless Apt.install(%w[pkg-kde-tools])\n end\nend\n"
},
{
"alpha_fraction": 0.6279685497283936,
"alphanum_fraction": 0.6307819485664368,
"avg_line_length": 31.75067710876465,
"blob_id": "f5d1fb5ba4d68cebf2ee3a298399a707a1d24de5",
"content_id": "7056b42e83117a6f5d2d4ba3898bdeaeb62ba2c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 12085,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 369,
"path": "/nci/qt_merge_and_bumper.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2019-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty/command'\nrequire 'tty/logger'\nrequire 'git'\nrequire 'rugged'\n\nrequire_relative '../lib/debian/control'\nrequire_relative '../lib/debian/uscan'\nrequire_relative '../lib/debian/version'\nrequire_relative '../lib/nci'\n\n# Merges Qt stuff from debian and bumps versions around [highly experimental]\n\nTARGET_BRANCH = 'Neon/testing'\nWITH_VERSION_BUMP = false\n\n# not actually qt versioned:\n# - qbs\n# - qtcreator\n# - qt5webkit\n# - qtchooser\n# further broken:\n# - qtquickcontrols2 has pkg-kde-tools lowered which conclits a bit and is\n# temporary the commit says, but it doesn't look all that temporary\n# - qtwebengine way too much delta in there\n# NB: this list may need tweaking depending on what you want to do (version bump or not)\nMODS = %w[\n qtbase\n qtdeclarative\n qtlocation\n qtsensors\n qtwebsockets\n qtwebchannel\n qttools\n qtcharts\n qtconnectivity\n qtserialport\n qtsvg\n qtscript\n qtnetworkauth\n qttranslations\n qtxmlpatterns\n qtgraphicaleffects\n qtx11extras\n qtvirtualkeyboard\n qtquickcontrols\n qtquickcontrols2\n qtspeech\n qtwayland\n qt3d\n qtwebengine\n qtwebview\n qtcreator\n qtmultimedia\n].freeze\n\n# Version helper able to differentiate upstream from real_upstream (i.e. without\n# +dfsg suffix and the like)\nclass Version < Debian::Version\n attr_accessor :real_upstream\n attr_accessor :real_upstream_suffix\n\n def initialize(*)\n super\n\n self.upstream = super_upstream # force parsing through = method\n end\n\n # Returns only epoch with real upstream (i.e. without +dfsg suffix or revision)\n def epoch_with_real_upstream\n comps = []\n comps << \"#{epoch}:\" if epoch\n comps << real_upstream\n comps.join\n end\n\n # Override to glue together real and suffix\n alias :super_upstream :upstream\n def upstream\n \"#{real_upstream}#{real_upstream_suffix}\"\n end\n\n # Split upstream into real and suffix\n def upstream=(input)\n regex = /(?<real>[\\d\\.]+)(?<suffix>.*)/\n match = input.match(regex)\n @real_upstream = match[:real]\n raise if @real_upstream.empty?\n\n @real_upstream_suffix = match[:suffix]\n end\nend\n\nclass Merginator\n attr_reader :logger\n attr_reader :cmd\n attr_reader :passed\n attr_reader :skipped\n attr_reader :failed\n\n # Git instance (wrapper around git cli)\n attr_reader :git\n # Rugged repo (libgit2)\n attr_reader :repo\n\n def initialize\n @logger = TTY::Logger.new\n @cmd = TTY::Command.new(uuid: false, output: @logger)\n\n @passed = []\n @skipped = MODS.dup\n @failed = []\n end\n\n # rerere's existing merges to possibly learn how to solve problems.\n # not sure if this does much for us TBH\n def train_rerere(repo, cmd)\n return unless Dir.glob('.git/rr-cache/*').empty?\n\n old_head = repo.head\n\n repo.walk(repo.head.target_id) do |commit|\n next unless commit.parents.size >= 2\n\n warn 'merge found'\n\n cmd.run \"git checkout #{commit.parents[0].oid}\"\n cmd.run 'git reset --hard'\n cmd.run 'git clean -fd'\n\n result = cmd.run! \"git merge #{commit.parents[1..-1].collect(&:oid).join(' ')}\"\n if result.failure?\n cmd.run \"git show -s --pretty=format:'Learning from %h %s' #{commit.oid}\"\n cmd.run 'git rerere'\n cmd.run \"git checkout #{commit.oid} -- .\"\n cmd.run 'git rerere'\n end\n\n cmd.run 'git reset --hard'\n end\n\n cmd.run \"git checkout #{old_head.target.oid}\"\n cmd.run 'git reset --hard'\n cmd.run 'git clean -fd'\n end\n\n def setup_repo\n @git = Git.open(Dir.pwd, log: logger)\n git.config('merge.dpkg-mergechangelogs.name',\n 'debian/changelog merge driver')\n git.config('merge.dpkg-mergechangelogs.driver',\n 'dpkg-mergechangelogs -m %O %A %B %A')\n repo_path = git.repo.path\n FileUtils.mkpath(\"#{repo_path}/info\")\n File.write(\"#{repo_path}/info/attributes\",\n \"debian/changelog merge=dpkg-mergechangelogs\\n\")\n git.config('user.name', 'Neon CI')\n git.config('user.email', '[email protected]')\n git.config('rerere.enabled', 'true')\n\n @repo = Rugged::Repository.new(Dir.pwd)\n end\n\n def mangle_depends(from:, to:)\n control = Debian::Control.new(Dir.pwd)\n control.parse!\n fields = %w[Build-Depends Build-Depends-Indep]\n fields.each do |field|\n control.source[field]&.each do |options|\n options.each do |relationship|\n next unless relationship.version&.start_with?(from)\n\n relationship.version.gsub!(from, to)\n end\n end\n end\n File.write('debian/control', control.dump)\n end\n\n # uscan dehs result\n def dehs\n # Only do this once for the first source for efficency\n @dehs ||= begin\n result = cmd.run!('uscan --report --dehs')\n data = result.out\n puts \"uscan exited (#{result}) :: #{data}\"\n newer = Debian::UScan::DEHS.parse_packages(data).collect do |package|\n next nil unless package.status == Debian::UScan::States::NEWER_AVAILABLE\n\n package\n end.compact\n\n raise 'There is no Qt release pending says uscan???' if newer.empty?\n # uscan technically kinda supports multiple sources, we do not.\n raise \"More than one uscan result?! #{newer.inspect}\" if newer.size > 1\n\n newer[0]\n end\n end\n\n def run\n Dir.mkdir('qtsies') unless File.exist?('qtsies')\n Dir.chdir('qtsies')\n\n # TODO: rewrite tagdetective to Rugged and split it to isolate the generic logic\n\n MODS.each do |mod|\n next if ARGV[0] && mod != ARGV[0]\n\n # Bit of a hack to scope logging to the qt module. It's fairly awkward because this\n # doesn't pass into the helper functions. In a way this entire block should be standalone\n # objects that get poked to \"run\" the logic.\n logger = self.logger.copy(repo: mod)\n cmd = TTY::Command.new(uuid: false, output: logger)\n cmd.run \"git clone [email protected]:neon/qt/#{mod}\" unless File.exist?(mod)\n Dir.chdir(mod) do\n begin\n setup_repo\n\n unless repo.remotes['salsa']\n cmd.run(\"git remote add --fetch --track master --tags salsa https://salsa.debian.org/qt-kde-team/qt/#{mod}.git\")\n end\n cmd.run 'git fetch --all --tags'\n\n cmd.run('git reset --hard')\n cmd.run(\"git checkout #{TARGET_BRANCH}\")\n cmd.run('git merge Neon/release')\n\n old_version, = cmd.run 'dpkg-parsechangelog -SVersion'\n old_version = Version.new(old_version)\n if WITH_VERSION_BUMP\n # check if already bumped\n next if old_version.real_upstream.start_with?(dehs.upstream_version)\n end\n\n last_merge = nil\n repo.walk(repo.head.target_id) do |commit|\n next unless commit.parents.size >= 2 # not a merge\n\n commit.parents.find do |parent|\n last_merge = repo.tags.find { |tag| tag.target == parent && tag.name.start_with?('debian/') }\n end\n\n break if last_merge # found the last merge\n end\n raise unless last_merge\n\n tooling_release_commmit = nil\n repo.walk(repo.head.target_id) do |commit|\n # A bit unclear if and in which order we'd walk a merge, so be careful\n # and prevent us from walking past the merge.\n break if commit == last_merge.target # at merge\n break if commit.time < last_merge.target.time # went beyond last merge\n next unless commit.message.include?('[TR]')\n\n tooling_release_commmit = commit\n break\n end\n\n # Convert tag name to version without rev.\n last_merge_tag = last_merge\n last_merge = Version.new(last_merge.name.split('/')[-1])\n logger.warn(\"last merge was #{last_merge} #{last_merge_tag.name}\")\n\n cmd.run 'git checkout salsa/master'\n tag, = cmd.run 'git describe'\n tag = tag.strip\n\n if tag == last_merge_tag.name\n logger.info(\"already merged latest tag on master: #{tag} (found last merge as #{last_merge_tag.name})\")\n next\n end\n\n cmd.run \"git checkout #{TARGET_BRANCH}\"\n cmd.run \"git reset --hard origin/#{TARGET_BRANCH}\"\n train_rerere(repo, cmd)\n cmd.run \"git checkout #{TARGET_BRANCH}\"\n cmd.run \"git reset --hard origin/#{TARGET_BRANCH}\"\n\n if WITH_VERSION_BUMP\n # Undo version delta because Bhushan insists on not having ephemeral\n # version constriction applied via tooling at build time!\n # Editing happens in-place. This preserves order in the output (more or\n # less anyway).\n if tooling_release_commmit\n # Ideally we'd have found a previous tooling commit to undo\n if tooling_release_commmit.parents.size >= 2\n raise 'tooling release commit is a merge. this should not happen!'\n end\n\n git.revert(tooling_release_commmit.oid)\n else\n # TODO: should we stick with this it'd probably be smarter to expect only\n # tooling to apply a bump and tag the relevant commit with some marker,\n # so we can then find it again and simply revert the bump.\n # Much less risk of causing conflict because Control technically doesn't\n # know how to preserve content line-for-line, it just happens to so long\n # as the input was wrapped-and-sorted.\n mangle_depends(from: old_version.epoch_with_real_upstream,\n to: last_merge.epoch_with_real_upstream)\n git.commit('Undo depends version bump', add_all: true)\n end\n end\n\n cmd.run \"git merge #{tag}\"\n\n if WITH_VERSION_BUMP\n merge_version = Version.new(tag.split('/')[-1])\n\n # Construct new version from pre-existing one. This retains epoch\n # and possibly upstream suffix\n new_version = Version.new(dehs.upstream_version)\n new_version.epoch = old_version.epoch\n new_version.real_upstream_suffix = old_version.real_upstream_suffix\n new_version.revision = '0neon'\n\n # Reapply version delta with new version.\n mangle_depends(from: merge_version.epoch_with_real_upstream,\n to: new_version.epoch_with_real_upstream)\n\n cmd.run('dch',\n '--distribution', NCI.current_series,\n '--newversion', new_version.to_s,\n \"New release #{new_version.real_upstream}\")\n git.commit(\"[TR] New release #{new_version.real_upstream}\", add_all: true)\n end\n\n passed << mod\n rescue TTY::Command::ExitError => e\n logger.error(e.to_s)\n failed << mod\n end\n end\n end\n\n # skipped is a read only attribute, we need to assign the var directly!\n @skipped -= passed\n @skipped -= failed\n\n logger.info \"Processed: #{passed.join(\"\\n\")}\"\n logger.info \"Skipped: #{skipped.join(\"\\n\")}\"\n logger.info \"Failed: #{failed.join(\"\\n\")}\"\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n # May also be called with argv0 being a specific name to work with\n Merginator.new.run\nend\n"
},
{
"alpha_fraction": 0.6863430142402649,
"alphanum_fraction": 0.6936779618263245,
"avg_line_length": 23.681034088134766,
"blob_id": "1296cd4a75c43cb344e621bf54bfc9a6393798e5",
"content_id": "14e8de06dd0663a0d7143efe648583562f7ef8d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2869,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 116,
"path": "/jenkins_poll.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/thread_pool'\nrequire_relative 'lib/retry'\n\nQUALIFIER_STATES = %w[success unstable].freeze\n\nOptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: jenkins_poll.rb 'regex'\n\nTells jenkins to poll for any changes and start the job if they are found.\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nretry.\n\ne.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*src'\n\n • All unstable builds:\n '^.*_unstable_.*src'\n\n • All jobs:\n '.*src'\n EOS\nend.parse!\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = 'poll'\n l.level = Logger::INFO\nend\n\nraise 'Need ruby pattern as argv0' if ARGV.empty?\n\npattern = Regexp.new(ARGV[0])\[email protected] pattern\n\njob_name_queue = Queue.new\njob_names = Jenkins.job.list_all\njob_names.each do |name|\n next unless pattern.match(name)\n\n job_name_queue << name\nend\n\nmodule Jenkins\n # A Jenkins job that actually can be used as an object...\n class Job\n # Build Details helper class to expand builddetails from Jenkins\n class BuildDetails < OpenStruct\n def date\n @date ||= Date.parse(Time.at(timestamp / 1000).to_s)\n end\n end\n\n attr_reader :name\n\n def initialize(name)\n @name = name\n end\n\n def build\n BuildDetails.new(Jenkins.job.get_build_details(@name, 0))\n end\n\n def queued?\n Jenkins.client.queue.list.include?(@name)\n end\n\n private\n\n def method_missing(name, *args, &block)\n args.unshift(@name)\n Jenkins.job.send(name.to_sym, *args, &block)\n end\n end\nend\n\nBlockingThreadPool.run do\n until job_name_queue.empty?\n name = job_name_queue.pop(true)\n job = Jenkins::Job.new(name)\n next if job.queued?\n\n Retry.retry_it(times: 5, name: name) do\n @log.warn \" #{name} --> poll\"\n job.poll\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5739356279373169,
"alphanum_fraction": 0.594085156917572,
"avg_line_length": 28.586538314819336,
"blob_id": "1793f4ebd49723f1dc1700b0fa814f267000fe37",
"content_id": "f77a94488750eb1cd637f99da8dcf2afd47a872d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3077,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 104,
"path": "/lib/aptly-ext/package.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'addressable/uri'\nrequire 'aptly/representation'\n\nmodule Aptly\n module Ext\n # A Package respresentation.\n # TODO: should go into aptly once happy with API\n class Package < Representation\n # A package short key (key without uid)\n # e.g.\n # \"Psource kactivities-kf5 5.18.0+git20160312.0713+15.10-0\"\n class ShortKey\n attr_reader :architecture\n attr_reader :name\n attr_reader :version\n\n private\n\n def initialize(architecture:, name:, version:)\n @architecture = architecture\n @name = name\n @version = version\n end\n\n def to_s\n \"P#{@architecture} #{@name} #{@version}\"\n end\n end\n\n # A package key\n # e.g.\n # Psource kactivities-kf5 5.18.0+git20160312.0713+15.10-0 8ebad520d672f51c\n class Key < ShortKey\n # FIXME: maybe should be called hash?\n attr_reader :uid\n\n def self.from_string(str)\n match = REGEX.match(str)\n unless match\n raise ArgumentError,\n \"String doesn't appear to match our regex: #{str}\"\n end\n kwords = Hash[match.names.map { |name| [name.to_sym, match[name]] }]\n new(**kwords)\n end\n\n def to_s\n \"#{super} #{@uid}\"\n end\n\n # TODO: maybe to_package? should be in base one presumes?\n\n private\n\n REGEX = /\n ^\n P(?<architecture>[^\\s]+)\n \\s\n (?<name>[^\\s]+)\n \\s\n (?<version>[^\\s]+)\n \\s\n (?<uid>[^\\s]+)\n $\n /x\n\n def initialize(architecture:, name:, version:, uid:)\n super(architecture: architecture, name: name, version: version)\n @uid = uid\n end\n end\n\n class << self\n def get(key, connection = Connection.new)\n path = \"/packages/#{key}\"\n response = connection.send(:get, Addressable::URI.escape(path))\n o = new(connection, JSON.parse(response.body, symbolize_names: true))\n o.Key = key.is_a?(Key) ? key : Key.from_string(o.Key)\n o\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.719939112663269,
"alphanum_fraction": 0.7595129609107971,
"avg_line_length": 31.850000381469727,
"blob_id": "e47f7b0d731f7418e758559de7eccaeb8147a6f0",
"content_id": "a2adbf27a270733087d0b46c91690ae1276f8b0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 657,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 20,
"path": "/nci/imager/build-hooks-neon-mobile/012-firefox.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# SPDX-FileCopyrightText: 2012 Jonathan Esk-Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Mask certain packages which aren't getting properly covered by dependencies.\n\nset -e\n\n. /etc/os-release\n\necho \"Installing Firefox from PPA\"\n\nmv /etc/apt/apt.conf.d/00http-proxy /tmp/\nsed -i s,550,1000, /etc/apt/preferences.d/org-kde-neon-net-launchpad-ppa-mozillateam-pin\napt-get update\napt-get -y --allow-downgrades install firefox\nmv /tmp/00http-proxy /etc/apt/apt.conf.d/\nsed -i s,1000,550, /etc/apt/preferences.d/org-kde-neon-net-launchpad-ppa-mozillateam-pin\napt-get update\napt-cache policy firefox\n"
},
{
"alpha_fraction": 0.6445846557617188,
"alphanum_fraction": 0.6445846557617188,
"avg_line_length": 31.79310417175293,
"blob_id": "71805e296a964b88de2f3774f0f36bd9d31e6ce1",
"content_id": "ad39b820602d8f5bfe324d8c72f5d92cc87d677a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 951,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 29,
"path": "/lib/ci/container/logger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../container'\n\nmodule CI\n # Class to build from a container, attaching a verbose debug printing thread\n # to the container.\n class ContainerLogger\n # FIXME: should insert itself into the container and run when it is\n # stopped?\n def initialize(container)\n Thread.new do\n # The log attach is threaded because\n # - attaching after start might attach to what is already stopped again\n # in which case attach runs until timeout\n # - after start we do an explicit wait to get the correct status code so\n # we can exit accordingly\n\n # This code only gets run when the socket pushes something, we cannot\n # mock this right now unfortunately.\n # :nocov:\n container.attach do |stream, chunk|\n io = stream == 'stderr' ? STDERR : STDOUT\n io.print(chunk)\n end\n # :nocov:\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 21.66666603088379,
"blob_id": "4409c2711619b5ca124c42681e14bb9465450ce0",
"content_id": "87916ab36901d556982895a964d0c187451fd915",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 6,
"path": "/nci/imager/build-hooks-neon-ko/92-apt-blacklist.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\n# Drop blacklisted nonesense pulled in via recommends or platform seed.\napt-get purge -y unattended-upgrades || true\n"
},
{
"alpha_fraction": 0.6966666579246521,
"alphanum_fraction": 0.7095833420753479,
"avg_line_length": 38.344261169433594,
"blob_id": "1149c9d35cf00aafde538fe476bdee351ae0779b",
"content_id": "adb61de6bd0f0873248c62c821715f12b4c8e83e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2400,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 61,
"path": "/test/test_debian_uscan.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/debian/uscan'\nrequire_relative 'lib/testcase'\n\nmodule Debian\n class UScanTest < TestCase\n def test_dehs_newer_available\n packages = UScan::DEHS.parse_packages(File.read(data))\n assert_equal(2, packages.size)\n assert_equal(UScan::States::NEWER_AVAILABLE, packages[0].status)\n assert_equal(UScan::States::NEWER_AVAILABLE, packages[1].status)\n assert_equal('5.6.0', packages[1].upstream_version)\n assert_equal('http://download.kde.org/stable/plasma/5.6.0/libksysguard-5.6.0.tar.xz', packages[1].upstream_url)\n end\n\n def test_dehs_up_to_date\n packages = UScan::DEHS.parse_packages(File.read(data))\n assert_equal(2, packages.size)\n assert_equal(UScan::States::DEBIAN_NEWER, packages[0].status)\n assert_equal(UScan::States::UP_TO_DATE, packages[1].status)\n end\n\n def test_dehs_unmapped_status\n assert_raises Debian::UScan::DEHS::ParseError do\n UScan::DEHS.parse_packages(File.read(data))\n end\n end\n\n def test_dehs_only_older\n packages = UScan::DEHS.parse_packages(File.read(data))\n assert_equal(2, packages.size)\n assert_equal(UScan::States::OLDER_ONLY, packages[0].status)\n assert_equal(UScan::States::UP_TO_DATE, packages[1].status)\n end\n\n def test_map\n packages = UScan::DEHS.parse_packages(File.read(data))\n assert_equal(1, packages.size)\n assert_equal(UScan::States::NEWER_AVAILABLE, packages[0].status)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7142857313156128,
"alphanum_fraction": 0.75,
"avg_line_length": 33.22222137451172,
"blob_id": "d029d9b09734b174ee75e674333f339b97cc8e53",
"content_id": "05c4b5cf31765f3d3c57c754df47d8c1c60d4abb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 616,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 18,
"path": "/lib/ci/docker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2017 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire 'docker'\n\nclass Docker::Connection\n def podman?\n # We don't use podman. Meanwhile docker-api 2.1 would make a /version request in this method that'd\n # require re-recording of our VCR cassettes. Instead always return false.\n false\n end\nend\n\n# Reset connection in order to pick up any connection options one might set\n# after requiring this file\nDocker.reset_connection!\n"
},
{
"alpha_fraction": 0.7012654542922974,
"alphanum_fraction": 0.7094004154205322,
"avg_line_length": 38.04705810546875,
"blob_id": "7c978169e7fcec00c4760d6860463a376b94ad8e",
"content_id": "5c16a9091bcf9edcfad403bd513193e7af6e56e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6638,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 170,
"path": "/nci/imager/build.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -ex\n\ncleanup() {\n if [ ! -d build ]; then\n mkdir build\n fi\n if [ ! -d result ]; then\n mkdir result\n fi\n rm -rf $WD/result/*\n rm -rf $WD/build/livecd.ubuntu.*\n rm -rf $WD/build/source.debian*\n}\n\nexport WD=$1\nexport DIST=$2\nexport ARCH=$3\nexport TYPE=$4\nexport METAPACKAGE=$5\nexport IMAGENAME=$6\nexport NEONARCHIVE=$7\n\nif [ -z $WD ] || [ -z $DIST ] || [ -z $ARCH ] || [ -z $TYPE ] || [ -z $METAPACKAGE ] || [ -z $IMAGENAME ] || [ -z $NEONARCHIVE ]; then\n echo \"!!! Not all arguments provided! ABORT !!!\"\n env\n exit 1\nfi\n\ncat /proc/self/cgroup\n\n# FIXME: let nci/lib/setup_repo.rb handle the repo setup as well this is just\n# duplicate code here...\nls -lah /tooling/nci\n/tooling/nci/setup_apt_repo.rb --no-repo\nsudo apt-add-repository http://archive.neon.kde.org/${NEONARCHIVE}\nsudo apt update\nsudo apt dist-upgrade -y\nsudo apt install -y --no-install-recommends \\\n git ubuntu-defaults-builder wget ca-certificates zsync distro-info \\\n syslinux-utils livecd-rootfs xorriso base-files lsb-release \\\n neon-settings debootstrap\n\ncd $WD\nls -lah\ncleanup\nls -lah\n\n# hicky hack for focal+\n# debootstrap is kinda container aware now and also very broken.\n# The debian-common script (and by extension the ubuntus) link the container\n# /proc into place when detecting docker (similar to how fakeroot would work)\n# but then ALSO attempt to setup a proc from scratch (as would be the case\n# without fakeroot). This then smashes the container's /proc and everything\n# goes up in flames. To prevent this we force-disable the container logic.\n# Our ISO containers are specifically twiddled so they behave like an ordinary\n# chroot and so the \"native\" proc logic will work just fine.\n# Half using container logic and half not, however, is not fine.\n# Simply prepend CONTAINER=\"\" to unset whatever detect_container() set.\n# NB: all ubuntus are symlinked to gutsy, so that's why we edit gutsy.\necho 'CONTAINER=\"\"' > /usr/share/debootstrap/scripts/gutsy.new\ncat /usr/share/debootstrap/scripts/gutsy >> /usr/share/debootstrap/scripts/gutsy.new\nmv /usr/share/debootstrap/scripts/gutsy.new /usr/share/debootstrap/scripts/gutsy\n\ncd $WD/build\n\nsed -i \\\n 's%SEEDMIRROR=http://embra.edinburghlinux.co.uk/~jr/neon-seeds/seeds/%SEEDMIRROR=https://metadata.neon.kde.org/germinate/seeds%g' \\\n /usr/share/livecd-rootfs/live-build/auto/config\n\n_DATE=$(date +%Y%m%d)\n_TIME=$(date +%H%M)\nDATETIME=\"${_DATE}-${_TIME}\"\nDATE=\"${_DATE}${_TIME}\"\n\n# Random nonesense sponsored by Rohan.\n# Somewhere in utopic things fell to shit, so lb doesn't pack all files necessary\n# for isolinux on the ISO. Why it happens or how or what is unknown. However linking\n# the required files into place seems to solve the problem. LOL.\nsudo apt install -y --no-install-recommends syslinux-themes-ubuntu syslinux-themes-neon\n# sudo ln -s /usr/lib/syslinux/modules/bios/ldlinux.c32 /usr/share/syslinux/themes/ubuntu-$DIST/isolinux-live/ldlinux.c32\n# sudo ln -s /usr/lib/syslinux/modules/bios/libutil.c32 /usr/share/syslinux/themes/ubuntu-$DIST/isolinux-live/libutil.c32\n# sudo ln -s /usr/lib/syslinux/modules/bios/libcom32.c32 /usr/share/syslinux/themes/ubuntu-$DIST/isolinux-live/libcom32.c32\n\n# # Compress with XZ, because it is awesome!\n# JOB_COUNT=2\n# export MKSQUASHFS_OPTIONS=\"-comp xz -processors $JOB_COUNT\"\n\n# Since we can not define live-build options directly, let's cheat our way\n# around defaults-image by exporting the vars lb uses :O\n\n## Super internal var used in lb_binary_disk to figure out the version of LB_DISTRIBUTION\n# used in e.g. renaming the ubiquity .desktop file on Desktop by casper which gets it from /cdrom/.disk/info from live-build lb_binary_disk\nEDITION=$TYPE\nexport RELEASE_${DIST}=${EDITION}\n## Bring down the overall size a bit by using a more sophisticated albeit expensive algorithm.\nexport LB_COMPRESSION=none\n## Create a zsync file allowing over-http delta-downloads.\nexport LB_ZSYNC=true # This is overridden by silly old defaults-image...\n## Use our cache as proxy.\n# FIXME: get out of nci/lib/setup_repo.rb\nexport LB_APT_HTTP_PROXY=\"http://apt.cache.pangea.pub:8000\"\n## Also set the proxy on apt options. This is used internally to expand on a lot\n## of apt-get calls. For us primarily of interest because it is used for\n## lb_source, which would otherwise bypass the proxy entirely.\nexport APT_OPTIONS=\"--yes -o Acquire::http::Proxy='$LB_APT_HTTP_PROXY'\"\n\n[ -z \"$CONFIG_SETTINGS\" ] && CONFIG_SETTINGS=\"$(dirname \"$0\")/config-settings-${IMAGENAME}.sh\"\n[ -z \"$CONFIG_HOOKS\" ] && CONFIG_HOOKS=\"$(dirname \"$0\")/config-hooks-${IMAGENAME}\"\n[ -z \"$BUILD_HOOKS\" ] && BUILD_HOOKS=\"$(dirname \"$0\")/build-hooks-${IMAGENAME}\"\n[ -z \"$SEEDED_SNAPS\" ] && SEEDED_SNAPS=\"$(dirname \"$0\")/seeded-snaps-${IMAGENAME}\"\n\n# jriddell 03-2019 special case where developer and ko ISOs get their build hooks to allow for simpler ISO names\nif [ $TYPE = 'developer' ] || [ $TYPE = 'ko' ] || [ $TYPE = 'mobile' ] || [ $TYPE = 'bigscreen' ]; then\n CONFIG_SETTINGS=\"$(dirname \"$0\")/config-settings-${IMAGENAME}-${TYPE}.sh\"\n CONFIG_HOOKS=\"$(dirname \"$0\")/config-hooks-${IMAGENAME}-${TYPE}\"\n BUILD_HOOKS=\"$(dirname \"$0\")/build-hooks-${IMAGENAME}-${TYPE}\"\nfi\n\nexport CONFIG_SETTINGS CONFIG_HOOKS BUILD_HOOKS SEEDED_SNAPS\n\n# Preserve envrionment -E plz.\nsudo -E $(dirname \"$0\")/ubuntu-defaults-image \\\n --package $METAPACKAGE \\\n --arch $ARCH \\\n --release $DIST \\\n --flavor neon \\\n --components main,restricted,universe,multiverse\n\ncat config/common\n\nls -lah\n\nif [ ! -e livecd.neon.iso ]; then\n echo \"ISO Build Failed.\"\n ls -la\n cleanup\n exit 1\nfi\n\nmv livecd.neon.* ../result/\nmv source.debian.tar ../result/ || true\ncd ../result/\n\nfor f in live*; do\n new_name=$(echo $f | sed \"s/livecd\\.neon/${IMAGENAME}-${TYPE}-${DATETIME}/\")\n mv $f $new_name\ndone\n\nmv source.debian.tar ${IMAGENAME}-${TYPE}-${DATETIME}-source.tar || true\nln -s ${IMAGENAME}-${TYPE}-${DATETIME}.iso ${IMAGENAME}-${TYPE}-current.iso\nzsyncmake ${IMAGENAME}-${TYPE}-current.iso\nsha256sum ${IMAGENAME}-${TYPE}-${DATETIME}.iso > ${IMAGENAME}-${TYPE}-${DATETIME}.sha256sum\ncat > .message << END\nKDE neon\n\n${IMAGENAME}-${TYPE}-${DATETIME}.iso Live and Installable ISO\n${IMAGENAME}-${TYPE}-${DATETIME}.iso.sig PGP Digital Signature\n${IMAGENAME}-${TYPE}-${DATETIME}.manifest ISO contents\n${IMAGENAME}-${TYPE}-${DATETIME}.sha256sum Checksum\n${IMAGENAME}-${TYPE}-${DATETIME}.torrent Web Seed torrent (you client needs to support web seeds or it may not work)\n\"current\" files are the same files for those wanting a URL which does not change daily.\nEND\necho $DATETIME > date_stamp\n\npwd\nchown -Rv jenkins:jenkins .\n\nexit 0\n"
},
{
"alpha_fraction": 0.7034685015678406,
"alphanum_fraction": 0.7156814932823181,
"avg_line_length": 33.694915771484375,
"blob_id": "ec2b0c84cd4be72c423445f79f953724e224fc52",
"content_id": "8a3f7ca9b69e4f65061be36e0683f007fd99363d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2047,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 59,
"path": "/test/test_lint_dh_missing.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/lint/log/dh_missing'\nrequire_relative 'lib/testcase'\n\n# Test lint lintian\nclass LintDHMissingTest < TestCase\n def test_valid\n r = Lint::Log::DHMissing.new.lint(File.read(data))\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(0, r.warnings.size)\n assert_equal(6, r.errors.size)\n end\n\n def test_no_dh_missing\n r = Lint::Log::DHMissing.new.lint(File.read(data))\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(0, r.warnings.size)\n assert_equal(0, r.errors.size)\n end\n\n def test_bad_log\n r = Lint::Log::DHMissing.new.lint(File.read(data))\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(0, r.warnings.size)\n assert_equal(0, r.errors.size)\n end\n\n def test_indented_dh_output\n # For unknown reasons sometimes the dh output can be indented. Make sure\n # it still parses correctly.\n r = Lint::Log::DHMissing.new.lint(File.read(data))\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(0, r.warnings.size)\n assert_equal(1, r.errors.size)\n end\nend\n"
},
{
"alpha_fraction": 0.654275119304657,
"alphanum_fraction": 0.6592317223548889,
"avg_line_length": 23.454545974731445,
"blob_id": "2075594203282ad78f56b6e0a8411ec4bebd7b9d",
"content_id": "870c88bcf6ead5576cb28ed404da71ca95a32515",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 33,
"path": "/test/test_lsb.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lsb'\nrequire_relative 'lib/testcase'\n\n# Test lsb\nclass LSBTest < TestCase\n def setup\n @orig_file = LSB.instance_variable_get(:@file)\n LSB.instance_variable_set(:@file, File.join(datadir, method_name))\n LSB.reset\n end\n\n def teardown\n LSB.instance_variable_set(:@file, @orig_file)\n LSB.reset\n end\n\n def test_parse\n ref = { DISTRIB_ID: 'Mebuntu',\n DISTRIB_RELEASE: '15.01',\n DISTRIB_CODENAME: 'codename',\n DISTRIB_DESCRIPTION: 'Mebuntu CodeName (development branch)' }\n assert_equal(ref, LSB.to_h)\n end\n\n def test_consts\n assert_equal('Mebuntu', LSB::DISTRIB_ID)\n assert_equal('codename', LSB::DISTRIB_CODENAME)\n assert_raise NameError do\n LSB::FOOOOOOOOOOOOOOO\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6119298338890076,
"alphanum_fraction": 0.6119298338890076,
"avg_line_length": 23.568965911865234,
"blob_id": "186876f40287ea670c58786650b5544c7d52f898",
"content_id": "ddac1dc319be0b0bd6a0f2caa0b8ef4cf5342925",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1425,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 58,
"path": "/lib/ci/pangeaimage.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule CI\n # Convenience wrapper to construct and handle pangea image names.\n class PangeaImage\n attr_accessor :tag\n attr_accessor :flavor\n attr_accessor :variant\n\n class << self\n def namespace\n @namespace ||= 'pangea'\n end\n attr_writer :namespace\n end\n\n def initialize(flavor, tag)\n @flavor = flavor\n @tag = tag\n @variant = flavor_variant\n end\n\n def flavor_variant\n # TODO could probably drop the defaulting if we updated all tests\n # accordingly :|\n node_labels = ENV.fetch('NODE_LABELS', '').split\n return nil unless node_labels.include?('shared-node')\n\n # When the node is shared the diversion arch needs to be tagged via this\n # env var.\n ENV.fetch('PANGEA_FLAVOR_ARCH')\n end\n\n def repo\n suffix = ''\n suffix = \"-#{variant}\" if variant\n \"#{self.class.namespace}/#{@flavor}#{suffix}\"\n end\n\n # Tagging arguments for Image.tag.\n # @example Can be used like this\n # image = Image.get('yolo')\n # image.tag(PangeaImage.new(:ubuntu, :vivid).tag_args)\n # @example You can also freely merge into the arguments\n # image.tag(pimage.merge(force: true))\n # @return [Hash] tagging arguments for Image.tag\n def tag_args\n { repo: repo, tag: tag }\n end\n\n def to_s\n to_str\n end\n\n def to_str\n \"#{repo}:#{tag}\"\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6817952394485474,
"alphanum_fraction": 0.6863338351249695,
"avg_line_length": 37.882354736328125,
"blob_id": "c93dcdc8820f31bad337e00d20483bb8da4196c0",
"content_id": "36abb4c971318b86bc4a67fe4aa1b865f40a7e23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1983,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 51,
"path": "/test/test_nci_lint_cmake_dep_verify_junit.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/cmake_dep_verify/junit'\n\nrequire 'mocha/test_unit'\n\nmodule CMakeDepVerify::JUnit\n class SuiteTest < TestCase\n def test_init\n s = Suite.new('kitteh', {})\n assert_xml_equal('<testsuites><testsuite name=\"CMakePackages\" package=\"kitteh\"/></testsuites>',\n s.to_xml)\n end\n\n def test_gold\n fail_result = mock('result')\n fail_result.stubs(:success?).returns(false)\n fail_result.stubs(:out).returns(\"purr\\npurr\")\n fail_result.stubs(:err).returns(\"meow\\nmeow\")\n\n success_result = mock('result')\n success_result.stubs(:success?).returns(true)\n success_result.stubs(:out).returns(\"meow\\nmeow\") # Flipped from above.\n success_result.stubs(:err).returns(\"purr\\npurr\")\n\n s = Suite.new('kitteh', 'KittehConfig' => fail_result,\n 'HettikConfig' => success_result)\n # File.write(fixture_file('.ref'), s.to_xml)\n assert_xml_equal(File.read(fixture_file('.ref')), s.to_xml)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6345053315162659,
"alphanum_fraction": 0.6590351462364197,
"avg_line_length": 28.829267501831055,
"blob_id": "9e74a0667f2d5baf3ef5ff0bf7ac75c7acd1ead2",
"content_id": "fc9472a383f2d4b00283b9f500dd7cba25795e4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1223,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 41,
"path": "/test/test_nci_lint_repo_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/versions'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class RepoPackageListerTest < TestCase\n def test_packages\n repo = mock('repo')\n # Simple aptly package string\n repo.expects(:packages).returns(['Pamd64 foo 0.9 abc', 'Pamd64 bar 1.0 abc'])\n\n pkgs = RepoPackageLister.new(repo).packages\n assert_equal(2, pkgs.size)\n assert_equal(%w[foo bar].sort, pkgs.map(&:name).sort)\n end\n\n def test_packages_filter\n repo = mock('repo')\n # Simple aptly package string\n repo.expects(:packages).returns(['Pamd64 foo 0.9 abc', 'Pamd64 bar 1.0 abc'])\n\n pkgs = RepoPackageLister.new(repo, filter_select: %w[foo]).packages\n assert_equal(1, pkgs.size)\n assert_equal(%w[foo].sort, pkgs.map(&:name).sort)\n end\n\n def test_default_repo\n # Constructs an env derived default repo name.\n ENV['TYPE'] = 'xx'\n ENV['DIST'] = 'yy'\n Aptly::Repository.expects(:get).with('xx_yy')\n\n RepoPackageLister.new\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5860023498535156,
"alphanum_fraction": 0.5860023498535156,
"avg_line_length": 19.071428298950195,
"blob_id": "1c71236847878d8265b8baef6c096d39f369888b",
"content_id": "42eb847833b3c1f7c05ebb205cdc7865b47628f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 843,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 42,
"path": "/lib/lint/result.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule Lint\n # A lint result expressing its\n class Result\n attr_accessor :valid\n attr_accessor :errors\n attr_accessor :warnings\n attr_accessor :informations\n\n def initialize\n @valid = false\n @errors = []\n @warnings = []\n @informations = []\n end\n\n def merge!(other)\n @valid = other.valid unless @valid\n @errors += other.errors\n @warnings += other.warnings\n @informations += other.informations\n end\n\n def uniq\n @errors.uniq!\n @warnings.uniq!\n @informations.uniq!\n self\n end\n\n def all\n @errors + @warnings + @informations\n end\n\n def ==(other)\n @valid == other.valid &&\n @errors == other.errors &&\n @warnings == other.warnings &&\n @informations == other.informations\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6486468315124512,
"alphanum_fraction": 0.6532462239265442,
"avg_line_length": 34.97602081298828,
"blob_id": "7a4f87b99871ee20ad6545458df15d07acf89bfb",
"content_id": "40d24ad321a4ae9203cecdcedd296f69cecbc525",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 15002,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 417,
"path": "/lib/ci/package_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2015 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'jenkins_junit_builder'\nrequire 'tty/command'\n\nrequire_relative 'dependency_resolver'\nrequire_relative 'feature_summary_extractor'\nrequire_relative 'kcrash_link_validator'\nrequire_relative 'setcap_validator'\nrequire_relative 'source'\nrequire_relative '../apt'\nrequire_relative '../debian/control'\nrequire_relative '../dpkg'\nrequire_relative '../os'\nrequire_relative '../pangea_build_type_config'\nrequire_relative '../retry'\nrequire_relative '../debian/dsc'\n\nmodule CI\n # Junit report about binary only resoluting being used.\n # This is a bit of a hack as we want\n class JUnitBinaryOnlyBuild\n def initialize\n @suite = JenkinsJunitBuilder::Suite.new\n @suite.package = 'PackageBuilder'\n @suite.name = 'DependencyResolver'\n\n c = JenkinsJunitBuilder::Case.new\n c.classname = 'DependencyResolver'\n c.name = 'binary_only'\n c.result = JenkinsJunitBuilder::Case::RESULT_FAILURE\n c.system_out.message = msg\n\n @suite.add_case(c)\n end\n\n def msg\n <<-ERRORMSG\nThis build failed to install the entire set of build dependencies a number of\ntimes and fell back to only install architecture dependent dependencies. This\nresults in the build not having any architecture independent packages!\nThis is indicative of this source (and probably all associated sources)\nrequiring multiple rebuilds to get around a circular dependency between\narchitecture dependent and architecture independent features.\nNotably Qt is affected by this. If you see this error make sure to *force* a\nrebuild of *all* related sources (e.g. all of Qt) *after* all sources have built\n*at least once*.\n ERRORMSG\n end\n\n def to_xml\n @suite.build_report\n end\n\n def write_file\n FileUtils.mkpath('reports')\n File.write('reports/build_binary_dependency_resolver.xml', to_xml)\n end\n end\n\n # Builds a binary package.\n class PackageBuilder\n BUILD_DIR = 'build'\n RESULT_DIR = 'result'\n\n BIN_ONLY_WHITELIST = %w[qtbase qtxmlpatterns qtdeclarative qtwebkit\n test-build-bin-only].freeze\n DIFFERENT_VERSION_NUMBER = %w[qtwebengine qbs qtchooser qtwebkit qtsystems qtstyleplugins qtserialbus qtscxml qtpim qmf qtfeedback qtdoc qtcreator qt-assistant pyside2]\n\n def initialize\n # Cripple stupid bin calls issued by the dpkg build tooling. In our\n # overlay we have scripts that alter the behavior of certain commands that\n # are being called in an undesirable manner (e.g. causing too much output)\n overlay_path = File.expand_path(\"#{__dir__}/../../overlay-bin\")\n unless File.exist?(overlay_path)\n raise \"could not find overlay bins in #{overlay_path}\"\n end\n\n ENV['PATH'] = \"#{overlay_path}:#{ENV['PATH']}\"\n cross_setup\n end\n\n def extract\n FileUtils.rm_rf(BUILD_DIR, verbose: true)\n return if system('dpkg-source', '-x', @dsc, BUILD_DIR)\n\n raise 'Something went terribly wrong with extracting the source'\n end\n\n def build_env\n deb_build_options = ENV.fetch('DEB_BUILD_OPTIONS', '').split(' ')\n if PangeaBuildTypeConfig.release_build?\n deb_build_options << 'noautodbgsym'\n end\n {\n 'DEB_BUILD_OPTIONS' => (deb_build_options + ['nocheck']).join(' '),\n 'DH_BUILD_DDEBS' => '1',\n 'DH_QUIET' => '1'\n }\n end\n\n def logged_system(env, *cmd)\n env_string = build_env.map { |k, v| \"#{k}=#{v}\" }.join(' ')\n cmd_string = cmd.join(' ')\n puts \"Running: #{env_string} #{cmd_string}\"\n system(env, *cmd)\n end\n\n def build_package\n # FIXME: buildpackage probably needs to be a method on the DPKG module\n # for logging purposes and so on and so forth\n # Signing happens outside the container. So disable all signing.\n dpkg_buildopts = %w[-us -uc] + build_flags\n\n # TODO: it'd be grand if we moved away from relying on PWD being correct. it's awfully implicit.\n # what would be helpful is a BuildContext object that holds the paths so we can easily pass context around\n FeatureSummaryExtractor.run(build_dir: BUILD_DIR, result_dir: RESULT_DIR) do\n Dir.chdir(BUILD_DIR) do\n maybe_prepare_qt_build\n\n SetCapValidator.run do\n KCrashLinkValidator.run do\n raise_build_failure unless logged_system(build_env, 'dpkg-buildpackage', *dpkg_buildopts)\n end\n end\n end\n end\n end\n\n def print_contents\n Dir.chdir(RESULT_DIR) do\n debs = Dir.glob('*.deb')\n debs.each do |deb|\n cmd = TTY::Command.new(uuid: false, printer: :null)\n out, = cmd.run('lesspipe', deb)\n File.write(\"#{deb}.info.txt\", out)\n end\n end\n end\n\n # dpkg-* cannot dumps artifact into a specific dir, so we need move\n # them about.\n # https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=657401\n def move_binaries\n Dir.mkdir(RESULT_DIR) unless Dir.exist?(RESULT_DIR)\n changes = Dir.glob(\"#{BUILD_DIR}/../*.changes\")\n\n changes.reject! { |e| e.include?('source.changes') }\n\n unless changes.size == 1\n warn \"Not exactly one changes file WTF -> #{changes}\"\n return\n end\n\n system('dcmd', 'mv', '-v', *changes, 'result/')\n end\n\n def build\n dsc_glob = Dir.glob('*.dsc')\n raise \"Not exactly one dsc! Found #{dsc_glob}\" unless dsc_glob.count == 1\n\n @dsc = dsc_glob[0]\n\n unless (arch_all_source? && arch_all?) || matches_host_arch?\n puts 'INFO: Package architecture does not match host architecture'\n return\n end\n\n extract\n install_dependencies\n build_package\n move_binaries\n print_contents\n end\n\n def maybe_prepare_qt_build\n return unless ENV['PANGEA_QT_GIT_BUILD']\n raise unless %w[focal jammy].include?(ENV.fetch('DIST'))\n # Bit of a cheap hack but we really don't need to parse the changelog proper for the purposes of our check.\n raise unless system('head -1 debian/changelog | grep --quiet --extended-regexp \"(qtfeedback)|(5\\.15\\.[123456789]0?)\"')\n qt_versions_match unless ignore_qt_versions_match\n\n # VERY akward hack. Qt git builds of modules require syncqt to get run to generated headers and the like,\n # but that is anchored on the presence of .git dirs and there is no way to trigger it other than .git.\n # Running syncqt via debian/rules is super tricky to automatically inject because of how varied the\n # rules files are, also the .git likely gets stripped at various places during sources, so shoving it\n # in the source tarball is supremely tricky as well. Rock and a hard place...\n Dir.mkdir('.git') unless File.exist?('.git') || File.exist?('include')\n\n # Even more awkward hack. qmlcdeps is meant to inspect .qmlc cache files for the version they cache against and\n # that is 5.15.3 in our case, but since we currently do not have the changelog versions at .3 the generated deps\n # would be entirely wrong. Disable qmlcdeps entirely.\n # Practicaly speaking we aren't at .3 but rather some sort of inbetween .2 and .3 so the version lock would not\n # necessarily be correct anyway. Just because the current git snapshot is compatible doesn't mean that tomorrow's\n # is as well.\n FileUtils.rm('/usr/bin/dh_qmlcdeps')\n FileUtils.ln_s('/usr/bin/true', '/usr/bin/dh_qmlcdeps')\n end\n\n def ignore_qt_versions_match\n control = Debian::Control.new(Dir.pwd)\n control.parse!\n source_name = control.source.fetch('Source', '')\n source_name = source_name.sub(/-opensource-src/, '')\n return true if DIFFERENT_VERSION_NUMBER.include?(source_name)\n false\n end\n\n private\n\n # Check the version in Git matches the version in debian/changelog\n def qt_versions_match\n # open debian/changelog and get verison\n changelog = File.open('debian/changelog', &:gets)\n changelog.sub!(/.* \\(/, '')\n changelog = changelog.sub!(/[+-].*/, '').strip\n # open .qmake and get version\n qmake_version = File.foreach('.qmake.conf').grep(/MODULE_VERSION/)\n qmake_version = qmake_version[0].split(' ')[2]\n # raise if not the same\n raise \"Qt version does not match debian/changelog version\" if qmake_version != changelog\n end\n\n def raise_build_failure\n msg = 'Failed to build from source!'\n msg += ' This source was built in bin-only mode.' if @bin_only\n raise msg\n end\n\n def arch_bin_only?\n value = ENV.fetch('PANGEA_ARCH_BIN_ONLY', 'true')\n case value.downcase\n when 'true', 'on'\n return true\n when 'false', 'off'\n return false\n end\n raise \"Unexpected value in PANGEA_ARCH_BIN_ONLY: #{value}\"\n end\n\n # auto determine if bin_only is cool or not.\n # NB: this intentionally doesn't take bin_only_possible?\n # into account as this should theoretically be ok to do. BUT only as long\n # as sources correctly implement binary only support correctly. If not\n # this can fail in a number of awkward ways. Should that happen\n # bin_only_possible? needs to get used (or a thing like it, possibly\n # with a blacklist instead of a whitelist). Automatic bin-only in theory\n # affords us faster build times on ARM when a source supports bin-only.\n # @return new bin_only\n def auto_bin_only(bin_only)\n return bin_only if bin_only || !arch_bin_only?\n\n bin_only = !arch_all?\n if bin_only\n puts '!!! Running in automatic bin-only mode. Building binary only.' \\\n ' (skipping Build-Depends-Indep)'\n end\n bin_only\n end\n\n # Create a dep resolver\n # @param bin_only whether to force binary-only resolution. This will\n def dep_resolve(dir, bin_only: false)\n # This wraps around a conditional arch argument.\n # We can't just expand {} as that'd mess up mocha in the tests, so pass\n # arch only if it actually is applicable. This is a bit hackish but beats\n # potentially having to update a lot of tests.\n # IOW we only set bin_only if it is true so the expecations for\n # pre-existing scenarios remain the same.\n\n bin_only = auto_bin_only(bin_only)\n @bin_only = bin_only # track, builder will make flag adjustments\n\n opts = {}\n opts[:bin_only] = bin_only if bin_only\n opts[:arch] = cross_arch if cross?\n return DependencyResolver.resolve(dir, **opts) unless opts.empty?\n\n DependencyResolver.resolve(dir)\n end\n\n def install_dependencies\n dep_resolve(BUILD_DIR)\n rescue RuntimeError => e\n raise e unless bin_only_possible?\n\n warn 'Failed to resolve all build-depends, trying binary only' \\\n ' (skipping Build-Depends-Indep)'\n dep_resolve(BUILD_DIR, bin_only: true)\n JUnitBinaryOnlyBuild.new.write_file\n end\n\n # @return [Bool] whether to mangle the build for Qt\n def bin_only_possible?\n @bin_only_possible ||= begin\n control = Debian::Control.new(BUILD_DIR)\n control.parse!\n source_name = control.source.fetch('Build-Depends-Indep', '')\n false unless BIN_ONLY_WHITELIST.include?(source_name)\n control.source.key?('Build-Depends-Indep')\n end\n end\n\n # @return [Array<String>] of build flags (-b -j etc.)\n def build_flags\n dpkg_buildopts = []\n if arch_all?\n dpkg_buildopts += build_flags_arch_all\n else\n # Automatically decide how many concurrent build jobs we can support.\n dpkg_buildopts << '-jauto'\n # We only build arch:all on amd64, all other architectures must only\n # build architecture dependent packages. Otherwise we have confliciting\n # checksums when publishing arch:all packages of different architectures\n # to the repo.\n dpkg_buildopts << '-B'\n end\n dpkg_buildopts << '-a' << cross_arch if cross?\n # If we only installed @bin_only dependencies as indep didn't want to\n # install we'll coerce -b into -B irregardless of platform.\n dpkg_buildopts.collect! { |x| x == '-b' ? '-B' : x } if @bin_only\n dpkg_buildopts << '--build-profiles=\"noudeb\"' << '--compression=xz'\n dpkg_buildopts\n end\n\n def build_flags_arch_all\n flags = []\n # Automatically decide how many concurrent build jobs we can support.\n # Persistent amd64 nodes are used across all our CIs and they are super\n # weak in the knees - be nice!\n flags << '-j1'\n flags << '-jauto' if scaling_node? # entirely use cloud nodes\n # On arch:all only build the binaries, the source is already built.\n flags << '-b'\n flags\n end\n\n # FIXME: this is not used\n def build_flags_cross\n # Unclear if we need config_site CONFIG_SITE=/etc/dpkg-cross/cross-config.i386\n [] << '-a' << cross_arch\n end\n\n def cross?\n @is_cross ||= !cross_arch.nil?\n end\n\n def cross_arch\n @cross_arch ||= ENV['PANGEA_CROSS']\n end\n\n def cross_triplet\n { 'i386' => 'i686-linux-gnu' }.fetch(cross_arch)\n end\n\n def cross_setup\n return unless cross?\n\n cmd = TTY::Command.new(uuid: false)\n cmd.run('dpkg', '--add-architecture', cross_arch)\n Apt.update || raise\n Apt.install(\"gcc-#{cross_triplet}\",\n \"g++-#{cross_triplet}\",\n 'dpkg-cross') || raise\n end\n\n def host_arch\n return nil unless cross?\n\n cross_arch\n end\n\n def arch_all?\n DPKG::HOST_ARCH == 'amd64'\n end\n\n def arch_all_source?\n parsed_dsc = Debian::DSC.new(@dsc)\n parsed_dsc.parse!\n architectures = parsed_dsc.fields['architecture'].split\n return true if architectures.include?('all')\n end\n\n def matches_host_arch?\n parsed_dsc = Debian::DSC.new(@dsc)\n parsed_dsc.parse!\n architectures = parsed_dsc.fields['architecture'].split\n architectures.any? do |arch|\n DPKG::Architecture.new(host_arch: host_arch).is(arch)\n end\n end\n\n def scaling_node?\n File.exist?('/tooling/is_scaling_node')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.669767439365387,
"alphanum_fraction": 0.6757475137710571,
"avg_line_length": 31.717391967773438,
"blob_id": "d69d6ce03cecdde1976ad302f8339d68048626fd",
"content_id": "5640c194fb1993b93422320940b20de1a3853a61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1505,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 46,
"path": "/lib/debian/architecture.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule Debian\n # A class to represent a debian architecture\n class Architecture\n attr_accessor :arch\n\n def initialize(arch)\n @arch = arch.delete('!')\n @negated = arch.start_with?('!')\n end\n\n def negated?\n @negated\n end\n\n def qualify?(other)\n other = Architecture.new(other) if other.is_a?(String)\n success = system('dpkg-architecture', '-a', \"#{@arch}\",\n '-i', \"#{other.arch}\", '-f')\n other.negated? ^ negated? ? !success : success\n end\n\n def to_s\n negated? ? \"!#{@arch}\" : @arch\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6545994281768799,
"alphanum_fraction": 0.6617210507392883,
"avg_line_length": 32.70000076293945,
"blob_id": "53df4430909ba302dfedce541b236cfa86d51dcc",
"content_id": "cea745eca9e44d93a117c22368673fba2fec6bee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1685,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 50,
"path": "/lib/ci/scm.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'pathname'\nrequire 'uri'\n\nmodule CI\n # SCM Base Class\n class SCM\n # @return [String] a type identifier (e.g. 'git', 'svn')\n attr_reader :type\n # @return [String] branch of the SCM to use (if applicable)\n attr_reader :branch\n # @return [String] valid git URL to the SCM\n attr_reader :url\n\n # Constructs an upstream SCM description from a packaging SCM description.\n #\n # Upstream SCM settings default to sane KDE settings and can be overridden\n # via data/upstraem-scm-map.yml. The override file supports pattern matching\n # according to File.fnmatch and ERB templating using a {BindingContext}.\n #\n # @param type [String] type of the SCM (git or svn)\n # @param url [String] URL of the SCM repo\n # @param branch [String] Branch of the SCM (if applicable)\n # containing debian/ (this is only used for repo-specific overrides)\n def initialize(type, url, branch = nil)\n # FIXME: type should be a symbol really\n # FIXME: maybe even replace type with an is_a check?\n @type = type\n @url = self.class.cleanup_uri(url)\n @branch = branch\n end\n\n def self.cleanup_uri(url)\n uri = URI(url)\n uri.path &&= Pathname.new(uri.path).cleanpath.to_s\n\n # Append .git for gitlab. Otherwise we'd get server-side redirects\n # counting against the rate limiting for no good reason.\n if uri.host == 'invent.kde.org' && !uri.path.end_with?('.git')\n uri.path += '.git'\n end\n\n uri.to_s\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6387362480163574,
"alphanum_fraction": 0.6428571343421936,
"avg_line_length": 32.86046600341797,
"blob_id": "dab31eb6c5d70027e30b7a927143fdb26faa22f5",
"content_id": "36c1509fd5a94892513d851c2a2b0777928f8705",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2912,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 86,
"path": "/nci/lint/cmake_dep_verify/junit.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'jenkins_junit_builder'\n\nmodule CMakeDepVerify\n module JUnit\n # Wrapper converting an ADT summary into a JUnit suite.\n class Suite\n # Wrapper converting an ADT summary entry into a JUnit case.\n class CMakePackage\n def initialize(name, result)\n @name = name\n @result = result\n end\n\n def to_case\n c = JenkinsJunitBuilder::Case.new\n # 2nd drill down from SuitePackage\n c.classname = @name\n # 3rd and final drill down CaseClassName\n c.name = 'find_package'\n c.time = 0\n c.result = value\n if output?\n c.system_out.message = @result.out\n c.system_err.message = @result.err\n end\n c\n end\n\n private\n\n def value\n if @result.success?\n JenkinsJunitBuilder::Case::RESULT_PASSED\n else\n JenkinsJunitBuilder::Case::RESULT_FAILURE\n end\n end\n\n def output?\n [email protected]? || [email protected]?\n end\n end\n\n def initialize(deb_name, summary)\n @suite = JenkinsJunitBuilder::Suite.new\n # This is not particularly visible in Jenkins, it's only used on the\n # testcase page itself where it will refer to the test as\n # SuitePackage.CaseClassName.CaseName (from SuitePackage.SuiteName)\n @suite.name = 'CMakePackages'\n # Primary sorting name on Jenkins.\n # Test results page lists a table of all tests by packagename\n # NB: we use the deb_name here to get a quicker overview as the job\n # running this only has cmakepackage output, so we do not need to\n # isolate ourselves into 'CMakePackges' or whatever.\n @suite.package = deb_name\n summary.each do |package, result|\n @suite.add_case(CMakePackage.new(package, result).to_case)\n end\n end\n\n def to_xml\n @suite.build_report\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6769230961799622,
"alphanum_fraction": 0.6769230961799622,
"avg_line_length": 15.25,
"blob_id": "fec6e92f2c63e929f0d4e895401f69ff98185cd1",
"content_id": "750b79651032956abe7b4cfee39aa4a0d2320131",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 8,
"path": "/nci/imager/build-hooks-xenon-mycroft/051-zfs.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\n# Illegal to distribute\n\nrm -f /lib/modules/*/kernel/zfs/zfs/zfs.ko\nrm -f /lib/modules/*/kernel/zfs/zfs/zfs.ko\n"
},
{
"alpha_fraction": 0.704081654548645,
"alphanum_fraction": 0.7346938848495483,
"avg_line_length": 38.20000076293945,
"blob_id": "8763c66e2ccc8c46265df5b41b0fa9c79197b2dd",
"content_id": "47dee67ebb28064190f8c530a039014ee91b30fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 10,
"path": "/nci/imager/config-hooks-neon-ko/99-grub-deps.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Install grub shebang in container. lb's grub-efi is a bit conflicted on\n# which files to get from the host and which to get from the chroot so best\n# have it on both ends.\napt install -y \\\n shim-signed \\\n grub-efi-amd64-signed \\\n grub-efi-ia32-bin\n"
},
{
"alpha_fraction": 0.6233755350112915,
"alphanum_fraction": 0.6311982274055481,
"avg_line_length": 37.4741096496582,
"blob_id": "af4032c061bcf546c4994854a717f22b6b377eee",
"content_id": "b37d9ae780e06457a69881acd842dddacd0702c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 23777,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 618,
"path": "/test/test_projects_factory.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'tmpdir'\nrequire 'rugged'\n\nrequire_relative '../lib/ci/overrides'\nrequire_relative '../lib/projects/factory'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\n\nclass ProjectsFactoryTest < TestCase\n required_binaries %w[git]\n\n def setup\n CI::Overrides.default_files = [] # Disable overrides by default.\n reset_child_status!\n WebMock.disable_net_connect!(allow_localhost: true)\n Net::SFTP.expects(:start).never\n # Disable upstream scm adjustment through releaseme we work with largely\n # fake data in this test which would raise in the adjustment as expections\n # would not be met.\n CI::UpstreamSCM.any_instance.stubs(:releaseme_adjust!).returns(true)\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/frameworks')\n .to_return(status: 200, body: '[\"frameworks/attica\",\"frameworks/baloo\",\"frameworks/bluez-qt\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/kde/workspace')\n .to_return(status: 200, body: '[\"kde/workspace/khotkeys\",\"kde/workspace/plasma-workspace\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/kde')\n .to_return(status: 200, body: '[\"kde/workspace/khotkeys\",\"kde/workspace/plasma-workspace\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://invent.kde.org/sysadmin/release-tools/-/raw/master/modules.git')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\\n\", headers: { 'Content-Type' => 'text/plain' })\n stub_request(:get, 'https://invent.kde.org/sdk/releaseme/-/raw/master/plasma/git-repositories-for-release-normal')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: 'bluedevil breeze breeze-grub breeze-gtk breeze-plymouth discover drkonqi', headers: { 'Content-Type' => 'text/plain' })\n stub_request(:get, 'http://embra.edinburghlinux.co.uk/~jr/release-tools/modules.git')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\", headers: { \"Content-Type\": 'text/plain' })\n stub_request(:get, 'https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"aura-browser bluedevil breeze breeze-grub\", headers: { \"Content-Type\": 'text/plain' })\n end\n\n def teardown\n CI::Overrides.default_files = nil # Reset\n ProjectsFactory.factories.each do |factory|\n factory.send(:reset!)\n end\n WebMock.allow_net_connect!\n end\n\n def git_init_commit(repo_path, branches = %w[master kubuntu_unstable])\n repo_path = File.absolute_path(repo_path)\n fixture_path = \"#{datadir}/packaging\"\n Dir.mktmpdir do |dir|\n repo = Rugged::Repository.clone_at(repo_path, dir)\n Dir.chdir(dir) do\n Dir.mkdir('debian') unless Dir.exist?('debian')\n raise \"missing fixture: #{fixture_path}\" unless File.exist?(fixture_path)\n\n FileUtils.cp_r(\"#{fixture_path}/.\", '.')\n\n index = repo.index\n index.add_all\n index.write\n tree = index.write_tree\n\n author = { name: 'Test', email: '[email protected]', time: Time.now }\n Rugged::Commit.create(repo,\n author: author,\n message: 'commitmsg',\n committer: author,\n parents: [],\n tree: tree,\n update_ref: 'HEAD')\n\n branches.each do |branch|\n repo.create_branch(branch) unless repo.branches.exist?(branch)\n end\n origin = repo.remotes['origin']\n repo.references.each_name do |r|\n origin.push(r)\n end\n end\n end\n end\n\n def git_init_repo(path)\n FileUtils.mkpath(path)\n Rugged::Repository.init_at(path, :bare)\n File.absolute_path(path)\n end\n\n def create_fake_git(branches:, prefix: nil, repo: nil, repos: [])\n repos << repo if repo\n\n # Create a new tmpdir within our existing tmpdir.\n # This is so that multiple fake_gits don't clash regardless of prefix\n # or not.\n remotetmpdir = Dir::Tmpname.create('d', \"#{@tmpdir}/remote\") {}\n FileUtils.mkpath(remotetmpdir)\n Dir.chdir(remotetmpdir) do\n repos.each do |r|\n path = File.join(*[prefix, r].compact)\n git_init_repo(path)\n git_init_commit(path, branches)\n end\n end\n remotetmpdir\n end\n\n def mock_kde_invent_api!(paths = nil)\n ::Gitlab::Client.expects(:new).never # safety net\n\n unless paths\n # Expect this path to not call into listing at all\n ::Gitlab.expects(:client).never\n return\n end\n\n client = mock('gitlab-client')\n ::Gitlab.expects(:client).returns(client)\n groups = mock('gitlab-groups')\n client\n .expects(:group_projects)\n .with('neon', include_subgroups: true, archived: false)\n .returns(groups)\n groups.expects(:auto_paginate).returns(paths.collect do |v|\n OpenStruct.new({ path_with_namespace: v, topics: (v == 'archived-synthesizer' ? %w[neon-archived] : []) })\n end)\n end\n\n def cache_debian_backtick(path, return_value)\n reset_child_status!\n ProjectsFactory::Debian.expects(:`)\n .with(\"ssh git.debian.org find /git/#{path} -maxdepth 1 -type d\")\n .returns(return_value)\n ProjectsFactory::Debian.ls(path)\n end\n\n def test_from_file\n neon_repos = %w[frameworks/attica\n frameworks/solid\n plasma/plasma-desktop\n plasma/plasma-workspace\n qt/qtbase]\n neon_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n\n debian_repos = %w[frameworks/ki18n]\n debian_dir = create_fake_git(prefix: 'pkg-kde',\n branches: %w[master kubuntu_unstable],\n repos: debian_repos)\n ProjectsFactory::Debian.instance_variable_set(:@url_base, debian_dir)\n\n # Mock neon listing.\n mock_kde_invent_api!(neon_repos)\n # Also cache a mocked listing for Debian's pkg-kde\n cache_debian_backtick('pkg-kde', \"/git/pkg-kde/framworks\\n\")\n # And another for Debian's pkg-kde/frameworks\n cache_debian_backtick('pkg-kde/frameworks', \"/git/pkg-kde/frameworks/ki18n.git\\n\")\n\n # FIXME: this does git things\n projects = ProjectsFactory.from_file(\"#{data}/projects.yaml\")\n\n assert projects.is_a?(Array)\n projects.each { |p| refute_equal(p, nil) }\n\n ki18n = projects.find { |p| p.name == 'ki18n' }\n refute_nil ki18n, 'ki18n is missing from the projects :('\n assert_equal(\"#{debian_dir}/pkg-kde/frameworks/ki18n\", ki18n.packaging_scm.url)\n\n assert_contains_project = lambda do |name|\n message = build_message(message, '<?> is not in the projects Array', name)\n assert_block message do\n projects.delete_if { |p| p.name == name } ? true : false\n end\n end\n expected_projects = %w[\n qtbase\n attica\n plasma-desktop\n plasma-workspace\n solid\n ki18n\n ]\n expected_projects.each do |expected|\n assert_contains_project.call(expected)\n end\n assert(projects.empty?,\n \"Projects not empty #{projects.collect(&:name)}\")\n end\n\n def test_from_file_with_properties\n neon_repos = %w[qt/qtbase\n qt/sni-qt\n qt/qtsvg]\n neon_dir = create_fake_git(branches: %w[master kubuntu_unstable kubuntu_stable kubuntu_vivid_mobile],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n # Mock neon listing.\n mock_kde_invent_api!(neon_repos)\n\n projects = ProjectsFactory.from_file(\"#{data}/projects.yaml\")\n\n assert projects.is_a?(Array)\n refute_equal(0, projects.size)\n projects.each do |x|\n refute_equal(x, nil)\n end\n\n project = projects.find { |p| p.name == 'qtsvg' }\n refute_nil(project, 'qtsvg is missing from the projects :(')\n assert_equal('qtsvg', project.name)\n assert_equal('qt', project.component)\n assert_equal(\"#{neon_dir}/qt/qtsvg\", project.packaging_scm.url)\n assert_equal('kubuntu_vivid_mobile', project.packaging_scm.branch)\n\n # TODO: should qtbase here really not cascade? this seems somewhat inconsistent\n # with how overrides work where pattern rules cascade in order of\n # preference.\n project = projects.find { |p| p.name == 'qtbase' }\n refute_nil(project, 'qtbase is missing from the projects :(')\n assert_equal('qtbase', project.name)\n assert_equal('qt', project.component)\n assert_equal(\"#{neon_dir}/qt/qtbase\", project.packaging_scm.url)\n assert_equal('kubuntu_unstable', project.packaging_scm.branch)\n\n project = projects.find { |p| p.name == 'sni-qt' }\n refute_nil(project, 'sni-qt is missing from the projects :(')\n assert_equal('sni-qt', project.name)\n assert_equal('qt', project.component)\n assert_equal(\"#{neon_dir}/qt/sni-qt\", project.packaging_scm.url)\n assert_equal('kubuntu_stable', project.packaging_scm.branch)\n end\n\n def test_from_file_kwords\n # Same as with_properties but we override the default via a kword for\n # from_file.\n neon_repos = %w[qt/qtbase\n qt/sni-qt\n qt/qtsvg]\n neon_dir = create_fake_git(branches: %w[master kitten kubuntu_stable kubuntu_vivid_mobile],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n # Mock neon listing.\n mock_kde_invent_api!(neon_repos)\n\n projects = ProjectsFactory.from_file(\"#{data}/projects.yaml\",\n branch: 'kitten')\n\n project = projects.find { |p| p.name == 'qtbase' }\n refute_nil(project, 'qtbase is missing from the projects :(')\n assert_equal('kitten', project.packaging_scm.branch)\n\n project = projects.find { |p| p.name == 'qtsvg' }\n refute_nil(project, 'qtsvg is missing from the projects :(')\n assert_equal('kubuntu_vivid_mobile', project.packaging_scm.branch)\n\n project = projects.find { |p| p.name == 'sni-qt' }\n refute_nil(project, 'sni-qt is missing from the projects :(')\n assert_equal('kubuntu_stable', project.packaging_scm.branch)\n end\n\n def test_neon_understand\n assert ProjectsFactory::Neon.understand?('invent.kde.org/neon')\n refute ProjectsFactory::Neon.understand?('git.debian.org')\n end\n\n def test_neon_unknown_array_content\n factory = ProjectsFactory::Neon.new('invent.kde.org/neon')\n\n assert_raise RuntimeError do\n factory.factorize([1])\n end\n end\n\n def test_neon_from_list\n neon_repos = %w[frameworks/attica]\n neon_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n # disable neon listing.\n mock_kde_invent_api!(nil)\n\n factory = ProjectsFactory::Neon.new('invent.kde.org/neon')\n projects = factory.factorize(%w[frameworks/attica])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal('attica', project.name)\n assert_equal('frameworks', project.component)\n assert_equal(\"#{neon_dir}/frameworks/attica\", project.packaging_scm.url)\n end\n\n def test_neon_ls\n # Make sure our parsing is on-point and doesn't include any unexpected\n # rubbish.\n neon_repos = %w[frameworks/attica]\n # Mock neon listing.\n mock_kde_invent_api!(neon_repos)\n\n list = ProjectsFactory::Neon.ls\n assert_equal(['frameworks/attica'], list.sort)\n end\n\n def test_neon_new_project_override\n neon_repos = %w[qt/qtbase]\n neon_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n # disable neon listing.\n mock_kde_invent_api!(nil)\n\n CI::Overrides.default_files = [data('override1.yaml'),\n data('override2.yaml')]\n factory = ProjectsFactory::Neon.new('invent.kde.org/neon')\n\n # This uses new_project directly as we otherwise have no way to set\n # overrides right now.\n projects = [factory.send(:new_project,\n name: 'qtbase',\n component: 'qt',\n url_base: neon_dir,\n branch: 'kubuntu_unstable',\n origin: nil).value!]\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal 'qtbase', project.name\n assert_equal(\"#{neon_dir}/qt/qtbase\", project.packaging_scm.url)\n assert_equal 'qtbase', project.packaging_scm.branch # overridden to name via erb\n assert_equal 'tarball', project.upstream_scm.type\n assert_equal 'http://http.debian.net/debian/pool/main/q/qtbase-opensource-src/qtbase-opensource-src_5.5.1.orig.tar.xz', project.upstream_scm.url\n end\n\n def test_debian_from_list\n debian_repos = %w[frameworks/solid]\n debian_dir = create_fake_git(prefix: 'pkg-kde',\n branches: %w[master kubuntu_unstable],\n repos: debian_repos)\n ProjectsFactory::Debian.instance_variable_set(:@url_base, debian_dir)\n # Cache a mocked listing\n cache_debian_backtick('pkg-kde', \"/git/pkg-kde/framworks\\n\")\n cache_debian_backtick('pkg-kde/frameworks', \"/git/pkg-kde/frameworks/solid.git\\n\")\n\n factory = ProjectsFactory::Debian.new('git.debian.org')\n projects = factory.factorize([{ 'pkg-kde/frameworks' => ['solid'] }])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal 'solid', project.name\n assert_equal 'git', project.packaging_scm.type\n assert_equal \"#{debian_dir}/pkg-kde/frameworks/solid\", project.packaging_scm.url\n assert_equal 'kubuntu_unstable', project.packaging_scm.branch\n end\n\n def test_github_from_list\n github_repos = %w[calamares/calamares-debian]\n github_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: github_repos)\n ProjectsFactory::GitHub.instance_variable_set(:@url_base, github_dir)\n\n # mock the octokit query\n resource = Struct.new(:name, :private)\n Octokit::Client\n .any_instance\n .expects(:org_repos)\n .returns([resource.new('calamares-debian', false)])\n\n factory = ProjectsFactory::GitHub.new('github.com')\n projects = factory.factorize([{ 'calamares' => ['calamares-debian'] }])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal 'calamares-debian', project.name\n assert_equal 'git', project.packaging_scm.type\n assert_equal \"#{github_dir}/calamares/calamares-debian\", project.packaging_scm.url\n assert_equal 'kubuntu_unstable', project.packaging_scm.branch\n end\n\n def test_github_private\n github_repos = %w[calamares/calamares-debian]\n github_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: github_repos)\n ProjectsFactory::GitHub.instance_variable_set(:@url_base, github_dir)\n\n # mock the octokit query\n resource = Struct.new(:name, :private)\n Octokit::Client\n .any_instance\n .expects(:org_repos)\n .returns([resource.new('calamares-debian', true)])\n\n Project.expects(:new).with do |*args|\n args[0] == 'calamares-debian' &&\n args[1] == 'calamares' &&\n args[2] == 'ssh://[email protected]:'\n end.returns('x')\n\n factory = ProjectsFactory::GitHub.new('github.com')\n ret = factory.factorize([{ 'calamares' => ['calamares-debian'] }])\n # faked return from mocha\n assert_equal(%w[x], ret)\n end\n\n def test_gitlab_from_list\n gitlab_repos = %w[calamares/calamares-debian calamares/neon/neon-pinebook\n calamares/neon/oem/oem-config]\n gitlab_dir = create_fake_git(branches: %w[master kubuntu_unstable],\n repos: gitlab_repos)\n ProjectsFactory::Gitlab.instance_variable_set(:@url_base, gitlab_dir)\n\n # mock the octokit query\n group = Struct.new(:id)\n subgroup = Struct.new(:id, :path)\n resource = Struct.new(:path_with_namespace)\n ::Gitlab.expects(:group_search)\n .returns([group.new('999')])\n\n response =\n ::Gitlab::PaginatedResponse.new([resource.new('calamares/calamares-debian')])\n\n subgroup_projects =\n ::Gitlab::PaginatedResponse.new([resource.new('calamares/neon/neon-pinebook')])\n\n recursive_projects =\n ::Gitlab::PaginatedResponse.new([resource.new('calamares/neon/oem/oem-config')])\n\n ::Gitlab.expects(:group_projects)\n .times(3)\n .returns(response, subgroup_projects, recursive_projects)\n\n subgroup_response =\n ::Gitlab::PaginatedResponse.new([subgroup.new('1000', 'neon')])\n\n recursive_subgroup =\n ::Gitlab::PaginatedResponse.new([subgroup.new('1001', 'oem')])\n\n none_subgroup =\n ::Gitlab::PaginatedResponse.new([])\n\n ::Gitlab.expects(:group_subgroups)\n .times(3)\n .returns(subgroup_response, recursive_subgroup, none_subgroup)\n\n factory = ProjectsFactory::Gitlab.new('gitlab.com')\n projects = factory.factorize([{ 'calamares' => ['calamares-debian', 'neon/neon-pinebook', 'neon/oem/oem-config'] }])\n\n refute_nil(projects)\n assert_equal(3, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal 'calamares-debian', project.name\n assert_equal 'git', project.packaging_scm.type\n assert_equal \"#{gitlab_dir}/calamares/calamares-debian\", project.packaging_scm.url\n assert_equal 'kubuntu_unstable', project.packaging_scm.branch\n\n project = projects[1]\n refute_equal(project, nil)\n assert_equal 'neon-pinebook', project.name\n assert_equal 'git', project.packaging_scm.type\n assert_equal \"#{gitlab_dir}/calamares/neon/neon-pinebook\", project.packaging_scm.url\n assert_equal 'kubuntu_unstable', project.packaging_scm.branch\n\n project = projects[2]\n refute_equal(project, nil)\n assert_equal 'oem-config', project.name\n assert_equal 'git', project.packaging_scm.type\n assert_equal \"#{gitlab_dir}/calamares/neon/oem/oem-config\", project.packaging_scm.url\n assert_equal 'kubuntu_unstable', project.packaging_scm.branch\n end\n\n def test_launchpad_understand\n assert ProjectsFactory::Launchpad.understand?('launchpad.net')\n refute ProjectsFactory::Launchpad.understand?('git.debian.org')\n end\n\n def test_launchpad_from_list\n require_binaries('bzr')\n # This test fakes bzr entirely to bypass the lp: pseudo-protocol\n # Overall this still tightly checks behavior.\n\n remote = File.absolute_path('remote')\n FileUtils.mkpath(\"#{remote}/qt/qtubuntu-cameraplugin-fake\")\n Dir.chdir(\"#{remote}/qt/qtubuntu-cameraplugin-fake\") do\n `bzr init .`\n File.write('file', '')\n `bzr add file`\n `bzr whoami --branch 'Test <[email protected]>'`\n `bzr commit -m 'commit'`\n end\n\n bzr_template = File.read(data('bzr.erb'))\n bzr_render = ERB.new(bzr_template).result(binding)\n bin = File.absolute_path('bin')\n Dir.mkdir(bin)\n bzr = \"#{bin}/bzr\"\n File.write(bzr, bzr_render)\n File.chmod(0o744, bzr)\n ENV['PATH'] = \"#{bin}:#{ENV['PATH']}\"\n\n factory = ProjectsFactory::Launchpad.new('launchpad.net')\n projects = factory.factorize(['qt/qtubuntu-cameraplugin-fake'])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal 'qtubuntu-cameraplugin-fake', project.name\n assert_equal 'bzr', project.packaging_scm.type\n assert_equal 'lp:qt/qtubuntu-cameraplugin-fake', project.packaging_scm.url\n assert_equal nil, project.packaging_scm.branch\n end\n\n def test_l10n_understand\n assert ProjectsFactory::KDEL10N.understand?('kde-l10n')\n refute ProjectsFactory::KDEL10N.understand?('git.debian.org')\n end\n\n def fake_dir_entry(name)\n obj = mock(\"fake_dir_entry_#{name}\")\n obj.responds_like_instance_of(Net::SFTP::Protocol::V01::Name)\n obj.expects(:name).at_least_once.returns(name)\n obj\n end\n\n def test_kde_l10n_from_hash\n l10n_repos = %w[kde-l10n-ru kde-l10n-de]\n l10n_dir = create_fake_git(prefix: 'kde-l10n',\n branches: %w[kubuntu_unstable],\n repos: l10n_repos)\n ProjectsFactory::KDEL10N.instance_variable_set(:@url_base, l10n_dir)\n\n fake_session = mock('sftp_session')\n fake_session.responds_like_instance_of(Net::SFTP::Session)\n\n fake_dir = mock('fake_dir')\n fake_dir.responds_like_instance_of(Net::SFTP::Operations::Dir)\n fake_dir.stubs(:glob)\n .with('/home/ftpubuntu/stable/applications/16.04.1/src/kde-l10n/', '**/**.tar.*')\n .returns([fake_dir_entry('kde-l10n-ru-16.04.1.tar.xz'), fake_dir_entry('kde-l10n-de-16.04.1.tar.xz')])\n\n Net::SFTP.stubs(:start)\n .with('depot.kde.org', 'ftpubuntu')\n .yields(fake_session)\n fake_session.stubs(:dir).returns(fake_dir)\n\n factory = ProjectsFactory::KDEL10N.new('kde-l10n')\n projects = factory.factorize([{ '16.04.1' => ['kde-l10n-ru'] }])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n assert_equal('kde-l10n-ru', projects[0].name)\n end\n\n def test_empty_base\n neon_repos = %w[pkg-kde-tools]\n neon_dir = create_fake_git(branches: %w[master kittens],\n repos: neon_repos)\n ProjectsFactory::Neon.instance_variable_set(:@url_base, neon_dir)\n\n mock_kde_invent_api!(neon_repos)\n\n factory = ProjectsFactory::Neon.new('packaging.neon.kde.org.uk')\n projects = factory.factorize([{\n '' => [\n {\n 'pkg-kde-tools' => { 'branch' => 'kittens' }\n }\n ]\n }])\n\n refute_nil(projects)\n assert_equal(1, projects.size)\n project = projects[0]\n refute_equal(project, nil)\n assert_equal('pkg-kde-tools', project.name)\n assert_equal('', project.component)\n assert_equal(\"#{neon_dir}/pkg-kde-tools\", project.packaging_scm.url)\n end\n\n def test_neon_fake_archivals\n # the neon-archived topic should disqualify a thing form getting listed\n neon_repos = %w[qt/qtbase archived-synthesizer]\n mock_kde_invent_api!(neon_repos)\n list = ProjectsFactory::Neon.ls\n assert_include(list, 'qt/qtbase')\n assert_not_include(list, 'archived-synthesizer')\n end\nend\n"
},
{
"alpha_fraction": 0.59419184923172,
"alphanum_fraction": 0.5995414853096008,
"avg_line_length": 23.231481552124023,
"blob_id": "ad8eba62bbd96e767b62046951d89418ce246d97",
"content_id": "63f3ce9095f2603837f40d0f400c4e05d7aae166",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2617,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 108,
"path": "/test/test_parse.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lib/testcase'\n\nrequire 'yaml'\n\nrequire 'tty/command'\nrequire_relative '../lib/shebang'\n\nclass ParseTest < TestCase\n SOURCE_DIRS = %w[\n bin\n jenkins-jobs\n lib\n nci\n overlay-bin\n test\n xci\n ].freeze\n\n attr_reader :cmd\n\n class << self\n def all_files(filter: '')\n files = SOURCE_DIRS.collect do |source_dir|\n Dir.glob(\"#{source_dir}/**/*#{filter}\").collect do |file|\n file\n end\n end\n\n # Do not recurse the main dir.\n files += Dir.glob(\"*#{filter}\")\n files.flatten.uniq.compact\n end\n\n def all_sh\n all_files(filter: '.sh')\n end\n\n def all_ruby\n all_files(filter: '.rb')\n end\n end\n\n def setup\n @cmd = TTY::Command.new(uuid: false, printer: :null)\n\n basedir = File.dirname(__dir__)\n Dir.chdir(basedir)\n end\n\n all_sh.each do |file|\n define_method(\"test_parse_shell: #{file}\".to_sym) do\n parse_shell(file)\n end\n end\n\n def test_ruby\n # Rubocop implies valid parsing and then we also want to enforce that\n # no tab indentation was used.\n # NB: rubocop has a default config one can force, but it gets the intended\n # version from .ruby-version (which is managed by rbenv for example), so\n # it isn't strictly speaking desirable to follow that as it would make the\n # test pass even though it should not. As such we make a temporary config\n # forcing the value we want.\n config = YAML.dump('AllCops' => { 'TargetRubyVersion' => '2.5' })\n File.write('config.yaml', config)\n res = cmd.run!('rubocop', '--only', 'Layout/IndentationStyle',\n '--cache', 'false',\n '--config', \"#{Dir.pwd}/config.yaml\",\n *self.class.all_ruby)\n assert(res.success?, <<~ERR)\n ==stdout==\n #{res.out}\n\n ==stderr==\n #{res.err}\n ERR\n end\n\n private\n\n def parse_bash(file)\n assert(system(\"bash -n #{file}\"), \"#{file} not parsing as bash.\")\n end\n\n def parse_sh(file)\n assert(system(\"sh -n #{file}\"), \"#{file} not parsing as sh.\")\n end\n\n def parse_shell(file)\n shebang = Shebang.new(File.open(file).readline)\n case shebang.parser\n when 'sh'\n parse_sh(file)\n else # assume bash\n # DEBUG\n # if shebang.valid\n # warn ' shell type unknown, falling back to bash'\n # else\n # warn ' shebang invalid, falling back to bash'\n # end\n parse_bash(file)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6267927885055542,
"alphanum_fraction": 0.6313701272010803,
"avg_line_length": 27.74561309814453,
"blob_id": "174d87189df1704d45f6aeece3bf8dbb3c457ac8",
"content_id": "763b8d3fc81e1e2817c6f8e8d216ffdec23dddbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3277,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 114,
"path": "/lib/debian/control.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'deb822'\n\nmodule Debian\n # debian/control parser\n class Control < Deb822\n attr_reader :source\n attr_reader :binaries\n\n # FIXME: deprecate invocation without path\n def initialize(directory = Dir.pwd)\n @source = nil\n @binaries = nil\n @directory = directory\n end\n\n def parse!\n lines = File.new(\"#{@directory}/debian/control\").readlines\n\n # Source Paragraph\n @source = parse_paragraph(lines, source_fields)\n\n # Binary Paragraphs\n @binaries = []\n until lines.empty?\n data = parse_paragraph(lines, binary_fields)\n @binaries << data if data\n end\n\n # TODO: Strip custom fields and add a Control::flags_for(entry) method.\n end\n\n def dump\n output = ''\n\n # Source Paragraph\n output += dump_paragraph(@source, source_fields)\n return output unless @binaries\n\n # Binary Paragraphs\n output += \"\\n\"\n @binaries.each do |b|\n output += dump_paragraph(b, binary_fields) + \"\\n\"\n end\n\n # Drop a double newline. dump_para can end in a newline so we'd have added\n # extra newlines at the end now.\n # e.g. Description always ends in \\n so we'd effectively make it \\n\\n\n # (as would be expected) mid-document, at the end we only want one.\n # Simply chop all control chars and replace them with a single \\n\n output.rstrip + \"\\n\"\n end\n\n private\n\n def source_fields\n @source_fields ||= {}.tap do |fields|\n fields[:mandatory] = %w[source maintainer]\n fields[:relationship] = %w[\n build-depends\n build-depends-indep\n build-conflicts\n build-conflicts-indep\n ]\n fields[:foldable] = ['uploaders'] + fields[:relationship]\n end\n end\n\n def binary_fields\n @binary_fields ||= {}.tap do |fields|\n fields[:mandatory] = %w[\n package\n architecture\n description\n ]\n fields[:multiline] = ['description']\n fields[:relationship] = %w[\n depends\n recommends\n suggests\n enhances\n pre-depends\n breaks\n replaces\n conflicts\n provides\n ]\n fields[:foldable] = fields[:relationship]\n end\n end\n end\nend\n\n# FIXME: deprecate\nclass DebianControl < Debian::Control; end\n"
},
{
"alpha_fraction": 0.6890067458152771,
"alphanum_fraction": 0.695274829864502,
"avg_line_length": 40.47999954223633,
"blob_id": "4a47bd2c9bf2a6a2760706ec85a3bcc76b3c7e52",
"content_id": "60d3b68517e3d7ff20b534b9c5ef751061493a33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2074,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/nci/merger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/nci'\nrequire_relative '../lib/merger'\n\n# FIXME: no test\n# NCI merger.\nclass NCIMerger < Merger\n def run\n # The way this is pushed is that the first push called walks up the tree\n # and invokes push on the squenced branches. Susequent pushes will do the\n # same but essentially be no-op except for leafes which weren't part of the\n # first pushed sequence.\n unstable = sequence('Neon/release').merge_into('Neon/stable')\n .merge_into('Neon/unstable')\n unstable.merge_into('Neon/mobile').push\n unstable.merge_into('Neon/pending-merge').push\n\n puts 'Done merging standard branches. Now merging series.'\n NCI.series.each_key do |series|\n puts \"Trying to merge branches for #{series}...\"\n unstable = sequence(\"Neon/release_#{series}\")\n .merge_into(\"Neon/stable_#{series}\")\n .merge_into(\"Neon/unstable_#{series}\")\n unstable.merge_into(\"Neon/mobile_#{series}\").push\n unstable.merge_into(\"Neon/pending-merge_#{series}\").push\n end\n end\nend\n\nNCIMerger.new.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.7433709502220154,
"alphanum_fraction": 0.7516001462936401,
"avg_line_length": 30.548076629638672,
"blob_id": "4856b904701f1a032b80af44892823d8b34463cc",
"content_id": "ff444f860ab11d3d870e19dc58685310da14186f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3281,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 104,
"path": "/nci/imager/build-hooks-neon-bigscreen/100-grubster.binary",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nset -e\n\necho \"Finalizing Grub\"\n\n# This could kinda be done by live-build, but I don't trust ubuntu's ancient\n# lb to do this properly.\n# Instead hack our additional magic into place.\n\n# WARNING FOR THE FUTURE: our lb runs hooks before efi, debian's after efi,\n# should things start to fail, check the order of lb_binary!\n\n# Theme\nmkdir -p binary/boot/grub/themes\ncp -rv chroot/boot/grub/themes/breeze binary/boot/grub/themes\n\n# needed for ubiquity's efi setup to use the live image as an archive from which\n# various bits can install see d-i/source/apt-setup/generators/40cdrom\n# NOTE by sitter: I do not think this is relevant for us (anymore). We use a\n# repo inside the squashfs (preinstalled-pool) rather than a cdrom repo on the ISO.\nmkdir -p binary/.disk/ || true\necho full_cd/single > binary/.disk/cd_type\n\n# Make a cfg\n# NB: this is interpolated for LB_BOOTAPPEND_LIVE. variables for grub must be escaped!\ncat > binary/boot/grub/grub.cfg << EOF\n# This is a composite, glued together from bits of an actual generated\n# grub.cfg from a regular system, and the auto generated stuff created for\n# Kubuntu.\n\nfunction load_video {\n\tinsmod all_video\n}\n\nif loadfont /boot/grub/unicode.pf2 ; then\n\tset gfxmode=auto\n\tload_video\n\tinsmod gfxterm\n\tset locale_dir=\\$prefix/locale\n\tset lang=en_US\n\tinsmod gettext\nfi\nterminal_output gfxterm\n\ninsmod gfxmenu\nloadfont /boot/grub/themes/breeze/unifont-bold-16.pf2\nloadfont /boot/grub/themes/breeze/unifont-regular-14.pf2\nloadfont /boot/grub/themes/breeze/unifont-regular-16.pf2\nloadfont /boot/grub/themes/breeze/unifont-regular-32.pf2\ninsmod png\nset theme=/boot/grub/themes/breeze/theme.txt\nexport theme\n\nset menu_color_normal=white/black\nset menu_color_highlight=black/light-gray\n\n# NB: apparmor is disabled because it would deny everything. The actual paths in\n# the live system are not the paths used in the configs. This is because of\n# how the squashfs is mounted and then overlayed. So the final paths seen by\n# apparmor will be /cow/foo/whatevs/... instead of /... this blocks a lot of\n# parts of the ISO from working properly (e.g. snapd or kmail; latter only\n# if the user opts to install it of course).\n\nmenuentry \"KDE neon\" {\n\tload_video\n\tset gfxpayload=keep\n\tlinux\t/casper/vmlinuz boot=casper apparmor=0 quiet splash ${LB_BOOTAPPEND_LIVE} ---\n\tinitrd\t/casper/initrd\n}\n\nmenuentry \"KDE neon (safe graphics)\" {\n\tload_video\n\tset gfxpayload=keep\n\tlinux\t/casper/vmlinuz boot=casper apparmor=0 quiet splash nomodeset ${LB_BOOTAPPEND_LIVE} ---\n\tinitrd\t/casper/initrd\n}\n\nmenuentry \"KDE neon (OEM mode - for manufacturers)\" {\n\tload_video\n\tset gfxpayload=keep\n\tlinux\t/casper/vmlinuz boot=casper apparmor=0 quiet splash ${LB_BOOTAPPEND_LIVE} --- oem-config/enable=true\n\tinitrd\t/casper/initrd\n}\n\nmenuentry \"KDE neon (OEM mode + safe graphics)\" {\n\tload_video\n\tset gfxpayload=keep\n\tlinux\t/casper/vmlinuz boot=casper apparmor=0 quiet splash nomodeset ${LB_BOOTAPPEND_LIVE} --- oem-config/enable=true\n\tinitrd\t/casper/initrd\n}\n\ngrub_platform\nif [ \"\\$grub_platform\" = \"efi\" ]; then\n\tmenuentry 'Boot from next volume' {\n\t\texit\n\t}\n\tmenuentry 'UEFI Firmware Settings' {\n\t\tfwsetup\n\t}\nfi\nEOF\n"
},
{
"alpha_fraction": 0.7039682269096375,
"alphanum_fraction": 0.7107142806053162,
"avg_line_length": 33.52054977416992,
"blob_id": "ddee097a16975d3809577fe54648ddfe191db4aa",
"content_id": "3b3fae6926556c951c7386ff8060728cd4e549e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2520,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 73,
"path": "/nci/lib/lint/result_test.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# FIXME: we manually load the reporter here because we install it from git\n# and would need bundler to load it properly, alas, bundler can't help\n# either because in containers we throw away gemfile and friends on\n# account of only using ci-tooling/\n# Ideally we'd simply have the gem updated properly so we don't need\n# git anymore.\nbegin\n require 'ci/reporter/rake/test_unit_loader'\nrescue LoadError\n REPORTER = 'ci_reporter_test_unit-5c6c30d120a3'\n require format(\"#{Gem.default_dir}/bundler/gems/#{REPORTER}/lib/%s\",\n 'ci/reporter/rake/test_unit_loader')\nend\nrequire 'test/unit'\n\nmodule Lint\n # Convenience class to test lint results\n class ResultTest < Test::Unit::TestCase\n def join(array)\n # Add terminating nils to get an extra newlines\n (array + [nil, nil]).join(\"\\n\")\n end\n\n def result_notify(array)\n notify(join(array)) unless array.empty?\n end\n\n def result_flunk(array)\n flunk(join(array)) unless array.empty?\n end\n\n def assert_warnings(result)\n result_notify(result.warnings)\n end\n\n def assert_informations(result)\n result_notify(result.informations)\n end\n\n def assert_errors(result)\n # Flunking fails the test entirely, so this needs to be at the very end!\n result_flunk(result.errors)\n end\n\n def assert_result(result)\n assert_warnings(result)\n assert_informations(result)\n assert_errors(result)\n # FIXME: valid means nothing concrete so we skip it for now\n # assert(result.valid, \"Lint result not valid ::\\n #{result.inspect}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6417222023010254,
"alphanum_fraction": 0.6494105458259583,
"avg_line_length": 29.484375,
"blob_id": "dc75bdfa74d112f048e70492666de79e3e267a16",
"content_id": "912e76db11b0475fe2bb5bc8f1125d825e555319",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1951,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 64,
"path": "/nci/snap/unpacker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tmpdir'\nrequire 'tty/command'\n\nrequire_relative 'identifier'\n\nmodule NCI\n module Snap\n # Takes a snapcraft channel id, downloads the snap, and unpacks it into\n # /snap\n class Unpacker\n attr_reader :snap\n\n def initialize(id_str)\n @snap = Identifier.new(id_str)\n @cmd = TTY::Command.new(uuid: false)\n end\n\n def unpack\n snap_dir = \"/snap/#{snap.name}\"\n target_dir = \"#{snap_dir}/current\"\n Dir.mktmpdir do |tmpdir|\n file = download_into(tmpdir)\n\n FileUtils.mkpath(snap_dir) if Process.uid.zero?\n @cmd.run('unsquashfs', '-d', target_dir, file)\n end\n target_dir\n end\n\n private\n\n def download_into(dir)\n @cmd.run('snap', 'download', \"--channel=#{snap.risk}\", snap.name,\n chdir: dir)\n snaps = Dir.glob(\"#{dir}/*.snap\")\n unless snaps.size == 1\n raise \"Failed to find one snap in #{dir}: #{snaps}\"\n end\n\n snaps[0]\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6593959927558899,
"alphanum_fraction": 0.6644295454025269,
"avg_line_length": 24.913043975830078,
"blob_id": "0a73f91fc803e6adf959a05d4afd0f474b78fb9a",
"content_id": "c4a0da16f64edb89067b340d2cc8bd2e04c1ea3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 596,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 23,
"path": "/test/test_lint_merge_marker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/merge_marker'\nrequire_relative 'lib/testcase'\n\n# Test lint merge markers\nmodule Lint\n class MergeMarkerTest < TestCase\n def test_init\n c = Lint::MergeMarker.new\n assert_equal(Dir.pwd, c.package_directory)\n c = Lint::MergeMarker.new('/tmp')\n assert_equal('/tmp', c.package_directory)\n end\n\n def test_lint\n r = Lint::MergeMarker.new(data).lint\n assert(r.valid)\n assert_equal(1, r.errors.size)\n assert_equal(0, r.warnings.size)\n assert_equal(0, r.informations.size)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7149028182029724,
"alphanum_fraction": 0.7149028182029724,
"avg_line_length": 26.235294342041016,
"blob_id": "af48b05f1d8a3165c5b542909d279d9921589096",
"content_id": "660d374d4f5a46b979d5b35296a4c33de54ae29c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 17,
"path": "/jenkins-jobs/meta-iso.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Meta ISO depending on all ISOs and is able to trigger them.\nclass MetaIsoJob < JenkinsJob\n attr_reader :type\n attr_reader :distribution\n\n def initialize(type:, distribution:)\n super(\"iso_#{distribution}_#{type}\", 'meta-iso.xml.erb')\n @type = type\n @distribution = distribution\n\n # FIXME: metaiso statically lists all architectures with entires and\n # so forth, this is terrible.\n end\nend\n"
},
{
"alpha_fraction": 0.6988809704780579,
"alphanum_fraction": 0.7192268371582031,
"avg_line_length": 36.80769348144531,
"blob_id": "48182b4483b6330584965d0cc93e6e56482d8aff",
"content_id": "c97d01d642eea2e44f6424b826a9996992f45b58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 983,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 26,
"path": "/nci/imager/config-hooks-xenon-mycroft/repo.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# Use gpg1, mostly because we are lazy and don't know how to best port this to v2\napt install -y dirmngr gnupg1\nARGS=\"--batch --verbose\"\nGPG=\"gpg1\"\n\napt-key export '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D' | $GPG \\\n $ARGS \\\n --no-default-keyring \\\n --primary-keyring config/archives/ubuntu-defaults.key \\\n --import\n\necho \"deb http://archive.neon.kde.org/${NEONARCHIVE} $SUITE main\" >> config/archives/neon.list\necho \"deb-src http://archive.neon.kde.org/${NEONARCHIVE} $SUITE main\" >> config/archives/neon.list\n\n$GPG \\\n $ARGS \\\n --no-default-keyring \\\n --primary-keyring config/archives/ubuntu-defaults.key \\\n --keyserver keyserver.ubuntu.com \\\n --recv-keys 'CB87 A99C D05E 5E0C 7017 4A68 E8AF 1B0B 45D8 3EBD'\n\necho \"deb http://archive.xenon.pangea.pub/unstable $SUITE main\" >> config/archives/neon.list\necho \"deb-src http://archive.xenon.pangea.pub/unstable $SUITE main\" >> config/archives/neon.list\n\n# make sure _apt can read this file. it may get copied into the chroot\nchmod 644 config/archives/ubuntu-defaults.key || true\n"
},
{
"alpha_fraction": 0.6407506465911865,
"alphanum_fraction": 0.6434316635131836,
"avg_line_length": 19.72222137451172,
"blob_id": "8f3ab925cf14cb894218058692b3a7ce9385de89",
"content_id": "e0a23c72c47a57997255452b546e6524b86a5478",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 746,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 36,
"path": "/lib/os.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'shellwords'\n\n# Wrapper around os-release. Makes values available as non-introspectable\n# constants. For runtime introspection to_h should be used instead.\nmodule OS\n @file = '/etc/os-release'\n\n def self.const_missing(name)\n return to_h[name] if to_h.key?(name)\n\n super(name)\n end\n\n module_function\n\n def to_h\n @hash ||= OS.parse(File.read(@file).split($/))\n end\n\n def reset\n remove_instance_variable(:@hash) if defined?(@hash)\n end\n\n def self.parse(lines)\n hash = {}\n lines.each do |line|\n line.strip!\n key, value = line.split('=')\n value = Shellwords.split(value)\n value = value[0] if value.size == 1\n hash[key.to_sym] = value\n end\n hash\n end\nend\n"
},
{
"alpha_fraction": 0.6414273381233215,
"alphanum_fraction": 0.6414273381233215,
"avg_line_length": 24.53333282470703,
"blob_id": "a92dbc08d8c0b7c0f43f62a62f38a19de8e679ff",
"content_id": "cb1cd44c749605cd4b6d0b16cf24e6e59677c704",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2298,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 90,
"path": "/jenkins-jobs/sourcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# source builder\nclass SourcerJob < JenkinsJob\n attr_reader :name\n attr_reader :basename\n attr_reader :upstream_scm\n attr_reader :type\n attr_reader :distribution\n attr_reader :packaging_scm\n attr_reader :packaging_branch\n attr_reader :downstream_triggers\n\n def initialize(basename, project:, type:, distribution:)\n super(\"#{basename}_src\", 'sourcer.xml.erb')\n @name = project.name\n @basename = basename\n @upstream_scm = project.upstream_scm\n @type = type\n @distribution = distribution\n @packaging_scm = project.packaging_scm.dup\n @packaging_scm.url.gsub!('salsa.debian.org:/git/',\n 'git://salsa.debian.org/')\n @project = project\n # FIXME: why ever does the job have to do that?\n # Try the distribution specific branch name first.\n @packaging_branch = @packaging_scm.branch\n if project.series_branches.include?(@packaging_branch)\n @packaging_branch = \"kubuntu_#{type}_#{distribution}\"\n end\n\n @downstream_triggers = []\n end\n\n def trigger(job)\n @downstream_triggers << job.job_name\n end\n\n def render_packaging_scm\n scm = @project.packaging_scm_for(series: @distribution)\n PackagingSCMTemplate.new(scm: scm).render_template\n end\n\n def render_upstream_scm\n return '' unless @upstream_scm\n\n case @upstream_scm.type\n when 'git'\n render('upstream-scms/git.xml.erb')\n when 'svn'\n render('upstream-scms/svn.xml.erb')\n when 'uscan'\n ''\n when 'tarball'\n ''\n when 'bzr'\n ''\n else\n raise \"Unknown upstream_scm type encountered '#{@upstream_scm.type}'\"\n end\n end\n\n def fetch_tarball\n return '' unless @upstream_scm&.type == 'tarball'\n\n \"if [ ! -d source ]; then\n mkdir source\n fi\n echo '#{@upstream_scm.url}' > source/url\"\n end\n\n def fetch_bzr\n return '' unless @packaging_scm&.type == 'bzr'\n\n \"if [ ! -d branch ]; then\n bzr branch '#{@packaging_scm.url}' branch\n else\n (cd branch && bzr pull)\n fi\n # cleanup\n rm -rf packaging && rm -rf source\n # seperate up packaging and source\n mkdir -p packaging/ &&\n cp -rf branch/debian packaging/ &&\n cp -rf branch source &&\n rm -r source/debian\n \"\n end\nend\n"
},
{
"alpha_fraction": 0.6697746515274048,
"alphanum_fraction": 0.6748251914978027,
"avg_line_length": 32.8684196472168,
"blob_id": "85b38077592d08070133eee044f05018a5148d96",
"content_id": "da753222e7228f58125b0d4526d1a71b2562a291",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2574,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 76,
"path": "/lib/qml_dep_verify/package.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../apt'\nrequire_relative '../dpkg'\nrequire_relative '../qml/ignore_rule'\nrequire_relative '../qml/module'\nrequire_relative '../qml/static_map'\n\nmodule QMLDepVerify\n # Wrapper around a package we want to test.\n class Package\n attr_reader :package # FIXME: change to name\n attr_reader :version\n\n def initialize(name, version)\n @package = name\n @version = version\n end\n\n def missing\n @missing ||= begin\n ignores = QML::IgnoreRule.read(\"packaging/debian/#{package}.qml-ignore\")\n p modules\n missing = modules.reject do |mod|\n ignores.include?(mod) || mod.installed?\n end\n raise \"failed to purge #{package}\" unless Apt.purge(package)\n\n # We do not autoremove here, because chances are that the next package\n # will need much of the same deps, so we can speed things up a bit by\n # delaying the autoremove until after the next package is installed.\n missing\n end\n end\n\n private\n\n def files\n unless Apt.install(\"#{package}=#{version}\")\n raise \"Failed to install #{package} #{version}\"\n end\n\n # Mark the package as manual so it doens't get purged by autoremove.\n Apt::Mark.tmpmark(package, Apt::Mark::MANUAL) do\n Apt::Get.autoremove(args: '--purge')\n # Mocha eats our return value through the yield in tests.\n # return explicitly to avoid this.\n return DPKG.list(package).select { |f| File.extname(f) == '.qml' }\n end\n end\n\n def modules\n @modules ||= files.collect do |file|\n QML::Module.read_file(file)\n end.flatten\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6646341681480408,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 21.88372039794922,
"blob_id": "a77ae8db17d1782d3bccd9ede4aaccb571e28468",
"content_id": "ef0889b2e82310323211e91f4dcc278343fda252",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 984,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 43,
"path": "/test/test_lint_control.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/control'\nrequire_relative 'lib/testcase'\n\n# Test lint control\nclass LintControlTest < TestCase\n def test_init\n c = Lint::Control.new\n assert_equal(Dir.pwd, c.package_directory)\n c = Lint::Control.new('/tmp')\n assert_equal('/tmp', c.package_directory)\n end\n\n def test_invalid\n r = Lint::Control.new(data).lint\n assert(!r.valid)\n end\n\n def test_vcs\n r = Lint::Control.new(data).lint\n assert(r.valid)\n assert(r.errors.empty?)\n assert(r.warnings.empty?)\n assert(r.informations.empty?)\n end\n\n def test_vcs_missing\n r = Lint::Control.new(data).lint\n assert(r.valid)\n assert(r.errors.empty?)\n # vcs-browser missing\n # vcs-git missing\n assert_equal(2, r.warnings.size)\n assert(r.informations.empty?)\n end\n\n def test_vcs_partially_missing\n r = Lint::Control.new(data).lint\n assert(r.valid)\n # only vcs-git missing\n assert_equal(1, r.warnings.size)\n end\nend\n"
},
{
"alpha_fraction": 0.6860465407371521,
"alphanum_fraction": 0.6904069781303406,
"avg_line_length": 32.83606719970703,
"blob_id": "011aa98ebb7ea5f73b0939cc1c6e1531a4ef6f99",
"content_id": "9bd6aaef36b203662febc8ddf66a5423c89bc5b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2064,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 61,
"path": "/mgmt/jenkins_prune.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'optparse'\n\nrequire_relative '../lib/jenkins/jobdir.rb'\n\noptions = {}\n\nparser = OptionParser.new do |opts|\n opts.banner = <<EOF\nUsage: #{opts.program_name} --max-age INTEGER --min-count INTEGER\n\nPrunes all Jenkins job dirs it can find by removing both logs and archives\nEOF\n opts.separator('')\n\n opts.on('--max-age INTEGER',\n 'The maximum age (in days) of builds to keep.',\n 'This presents the upper limit.',\n 'Any build exceeding this age will be pruned') do |v|\n options[:max_age] = v.to_i\n end\n\n opts.on('--min-count INTEGER',\n 'The minium amount of builds to keep.',\n 'This presents the lower limit of builds to keep.',\n 'Builds below this limit are also kept if they are too old') do |v|\n options[:min_count] = v.to_i\n end\n\n opts.on('--paths archive,log,etc', Array,\n 'List of paths to drop') do |v|\n options[:paths] = v\n end\nend\nparser.parse!\n\njobdirs = Dir.glob(\"#{ENV.fetch('JENKINS_HOME')}/jobs/*\")\njobdirs.each_with_index do |jobdir, i|\n puts \"#{i}/#{jobdirs.size} #{jobdir}\"\n Jenkins::JobDir.prune(jobdir, options)\nend\n"
},
{
"alpha_fraction": 0.8204911351203918,
"alphanum_fraction": 0.8391193747520447,
"avg_line_length": 18.360654830932617,
"blob_id": "fdcd2a35ea2aee285af5987343e824c88eb1c7a7",
"content_id": "cd8068ce15bcaba0d3acafb6d1f53cce77947469",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1181,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 61,
"path": "/nci/imager/config-hooks-xenon-mycroft/20_package_list.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# konsole needs installed first else xterm gets installed cos xorg deps on\n# terminal | xterm and doesn't know terminal is installed later in the tree\ncat << EOF > config/package-lists/ubuntu-defaults.list.chroot_install\ncalamares-settings-mycroft\nkonsole\nplasma-minishell\nmycroft-gui\nmycroft-core\nmycroft-skill-installer\nplasma-mycroft-tablet\nmycroft-tablet-settings\nbreeze\nfonts-hack-ttf\nfonts-noto-hinted\ngstreamer1.0-plugins-good\ngstreamer1.0-plugins-bad\ngstreamer1.0-plugins-ugly\ngstreamer1.0-fluendo-mp3\ngstreamer1.0-libav\ngstreamer1.0-vaapi\nkonsole\nkde-cli-tools\nkhotkeys\nkio-extras\nkwin\nlibsasl2-modules\nlibu2f-udev\nneon-hardware-integration\nneon-keyring\nneon-settings\noxygen-sounds\nplasma-nm\nplasma-pa\nplasma-widgets-addons\nplasma-workspace-wallpapers\nplasma-workspace-wayland\npm-utils\npowerdevil\npolkit-kde-agent-1\nqml-module-org-kde-lottie\nr8168-dkms\nruby\nsddm\nsddm-theme-breeze\nsoftware-properties-common\nsystemsettings\nubuntu-drivers-common\nunzip\nupower\nwireless-tools\nwpasupplicant\nxdg-user-dirs\nxkb-data\nxorg\nxserver-xorg-video-intel-arbiter\nxserver-xorg-input-evdev\nxserver-xorg-input-synaptics\nxserver-xorg-video-intel-native-modesetting\ngrub-efi-ia32-bin\nzip\nEOF\n"
},
{
"alpha_fraction": 0.7069464325904846,
"alphanum_fraction": 0.7185238599777222,
"avg_line_length": 37.38888931274414,
"blob_id": "3fd87762e279cfbcade060096109376a76d0c1f5",
"content_id": "a4f44e7a50f89cb2eb519535a0f34030019221f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1382,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 36,
"path": "/jenkins-jobs/nci/mgmt_appstream_health.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'pipelinejob'\n\n# tests dep11 (appstream) health on the repositories\nclass MGMTAppstreamHealthJob < PipelineJob\n attr_reader :dist\n\n def initialize(dist:)\n suffix = \"_#{dist}\"\n # TODO: can be removed once xenial is dead\n suffix = '' if dist == 'xenial' # had no suffix in xenial\n super(\"mgmt_appstream-health#{suffix}\",\n template: 'mgmt_appstream_health',\n cron: 'H H/3 * * *')\n @dist = dist\n end\nend\n"
},
{
"alpha_fraction": 0.7445865869522095,
"alphanum_fraction": 0.7539370059967041,
"avg_line_length": 35.94545364379883,
"blob_id": "defb5a993d0e4c9b243e561cb8a617084b6f3a91",
"content_id": "1e6fbbac746dc627a5ad9a859d00317501e71389",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2032,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 55,
"path": "/mgmt/digital_ocean/deploy_tooling.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nset -ex\n\nexport PANGEA_UBUNTU_ONLY=1\n# NOTE: the slave provisioning calls us with flattening disabled, by default\n# we should not be though. This script is also used for droplet image\n# maintenace, where we definitely want to flatten the image to compress the\n# droplet image and thus reduce bootstrapping and storage cost.\n# export PANGEA_DOCKER_NO_FLATTEN=1\n\nenv\n\nrm -rf /tmp/tooling\ngit clone --depth 1 https://github.com/pangea-project/pangea-tooling.git /tmp/tooling\ncd /tmp/tooling\n./git_submodule_setup.sh\n\n## from mgmt_tooling_deploy.xml\nrm -rv .bundle || true\ngem install --no-document bundler\n# FIXME: add --without development test back\n# https://github.com/pangea-project/pangea-tooling/issues/17\nbundle config set --local system 'true'\nbundle install --jobs=`nproc`\nrm -rv .bundle || true\n\nrake clean\nrake deploy\n\nfind ~/tooling-pending/vendor/cache/* -maxdepth 0 -type d | xargs -r rm -rv\n\n## from mgmt_docker more or less\n# special hack, we force -jauto if this file is in the docker image\ntouch ~/tooling-pending/is_scaling_node\nNODE_LABELS=amd64 mgmt/docker.rb\nNODE_LABELS=amd64 mgmt/docker_cleanup.rb\n"
},
{
"alpha_fraction": 0.5252464413642883,
"alphanum_fraction": 0.5315831899642944,
"avg_line_length": 31.81188201904297,
"blob_id": "ab179d0ca8a0d16cf74a783c74f4d21661f8961a",
"content_id": "8c486eda4c2e5d48432e0338e5158cbe179a8c9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9942,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 303,
"path": "/test/test_nci_repository.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'rugged'\nrequire 'tty/command'\n\nrequire_relative '../nci/debian-merge/repository'\n\nmodule NCI\n module DebianMerge\n class NCIRepositoryTest < TestCase\n def setup\n Rugged.stubs(:features).returns([:ssh])\n @cmd = TTY::Command.new(uuid: false)\n end\n\n def teardown\n TagValidator.reset!\n end\n\n def test_clonery\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n `git branch Neon/unstable`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2'\n repo.merge\n repo.push\n\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n `git checkout Neon/pending-merge`\n assert($?.success?)\n # system 'bash'\n assert_path_exist('c2')\n end\n end\n end\n end\n\n def test_noop_already_merged\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/2-0 -m 'fancy message'`\n\n # Same commit\n `git branch Neon/unstable`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2'\n repo.merge\n repo.push\n\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n `git checkout Neon/pending-merge`\n assert_false($?.success?)\n end\n end\n end\n end\n\n def test_orphan_branch\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n # Orphan!\n `git checkout --orphan Neon/unstable`\n File.write('u1', '')\n `git add u1`\n `git commit --all -m 'commit'`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2'\n assert_raises RuntimeError do\n repo.merge # no ancestor between branch and tag error\n end\n end\n\n def test_bad_latest_tag\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/5-0 -m 'fancy message'`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2' # only tag on repo is debian/5-0\n assert_raises RuntimeError do\n repo.merge # unexpected tag error\n end\n end\n\n def test_last_tag_with_override\n # frameworks only have major/minor changes but patch level is actually\n # just that, so we can generally accept patch level\n remote_dir = File.join(Dir.pwd, 'remote/kpackage')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1.17.0-0 -m 'fancy message'`\n\n `git branch Neon/unstable`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/1.17.1-0 -m 'fancy message'`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n TagValidator.default_path = data('override.yaml')\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('kpackage') # the clone\n repo.tag_base = 'debian/1.17.0'\n repo.merge\n repo.push\n end\n\n def test_push_mangle\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2'\n Dir.chdir('fishy') do\n puts '-- remot set-url'\n @cmd.run!('nslookup invent.kde.org')\n puts @cmd.run('git remote set-url origin https://invent.kde.org/neon/kde/khtml').out.strip\n end\n repo.send(:mangle_push_path!) # private\n Dir.chdir('fishy') do\n ret = @cmd.run('git remote show origin').out.strip\n warn \"fishy ret: #{ret}; $? #{$?}\"\n # find the line which defines the push url\n ret = ret.split($/).find { |x| x.strip.downcase.start_with?('push') }\n ret = ret.strip.split[-1] # url is last space separated part\n assert_equal('[email protected]:neon/kde/khtml', ret)\n end\n end\n\n def test_ssh_cred\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n\n Net::SSH::Config.expects(:for).with('frogi').returns({\n keys: ['/weesh.key']\n })\n Rugged::Credentials::SshKey.expects(:new).with(\n username: 'neon',\n publickey: '/weesh.key.pub',\n privatekey: '/weesh.key',\n passphrase: ''\n ).returns('wrupp')\n\n repo = Repository.clone_into(\"file://#{remote_dir}\", Dir.pwd)\n assert_path_exist('fishy') # the clone\n repo.tag_base = 'debian/2'\n r = repo.send(:credentials, 'frogi', 'neon', [:ssh_key]) # private\n # this isn't actually what it is meant to, but since we mocha the actual\n # key creation to check its values, this is basically to assert that the\n # return value of key.new is coming out of the method\n assert_equal('wrupp', r)\n end\n\n def test_rugged_ssh_fail\n Rugged.expects(:features).returns([])\n assert_raises RuntimeError do\n Repository.clone_into('foo', Dir.pwd)\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6836112141609192,
"alphanum_fraction": 0.7027246952056885,
"avg_line_length": 28.626506805419922,
"blob_id": "179e995bb1bd2d0f020e824650f677a4bb7452f8",
"content_id": "1e0d59a40c83293ba05eb2b3303f5b5f6ee638a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 2459,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 83,
"path": "/nci/imager-img/configure_pinebook",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# (C) 2012-2015 Fathi Boudra <[email protected]>\n# (C) 2015 Rohan Garg <[email protected]>\n# (C) 2017 Jonathan Riddell <[email protected]>\n# May be copied under the terms of the GNU GPL version 3 only\n\n# Create configuration for live-build.\n\n# You need live-build package installed.\n\nset -e\nset -x\n\necho \"I: create configuration\"\n\nSNAP_URL='http://ports.ubuntu.com/ubuntu-ports/'\n\nexport LB_HDD_PARTITION_START=\"40960s\"\nexport LB_BOOTLOADERS=\"none\"\nexport LB_HDD_LABEL=\"PINEBOOKneon\"\nexport LB_MKFS_OPTIONS=\"-O ^64bit,^metadata_csum,uninit_bg\"\n\n. /etc/os-release\n\n### HACK: super ugly hack for getting usable bionic image\nif [ \"$VERSION_CODENAME\" = \"bionic\" ]; then\n sed -i 's/64bit/64bit,\\^metadata_csum,uninit_bg/' /usr/lib/live/build/binary_hdd\nfi\n\nenv\n\nlb config \\\n --architectures arm64 \\\n --archive-areas 'main universe' \\\n --apt-options \"--yes --allow-downgrades\" \\\n --bootstrap-qemu-arch arm64 --bootstrap-qemu-static /usr/bin/qemu-aarch64-static \\\n --cache false \\\n --cache-indices false \\\n --cache-packages false \\\n --cache-stages 'none' \\\n --distribution $DIST \\\n --binary-images hdd \\\n --mode ubuntu \\\n --debootstrap-options \"--include=gnupg,ca-certificates\" \\\n --apt-source-archives false \\\n --source false \\\n --apt-options \"--yes -o Acquire::Check-Valid-Until=false\" \\\n --linux-flavours none \\\n --linux-packages none \\\n --initramfs none \\\n --chroot-filesystem none \\\n --binary-filesystem ext4 \\\n --hdd-size 6000 \\\n --firmware-chroot false \\\n --security false \\\n -m $SNAP_URL \\\n --parent-mirror-binary $SNAP_URL \\\n --mirror-bootstrap $SNAP_URL \\\n --mirror-chroot $SNAP_URL \\\n --mirror-binary $SNAP_URL \\\n --mirror-debian-installer $SNAP_URL \\\n $@\n\necho \"I: copy customization\"\ntest -d /tooling/nci/imager-img/customization && cp -rf /tooling/nci/imager-img/customization/* config/\n\necho \"deb http://archive.neon.kde.org/${NEONARCHIVE} $DIST main\" >> config/archives/neon.list\necho \"deb-src http://archive.neon.kde.org/${NEONARCHIVE} $DIST main\" >> config/archives/neon.list\n\nif [ \"$VERSION_CODENAME\" = \"bionic\" ]; then\n # upadte hook to use prebuilt packages\n rm config/hooks/live/live-config.hook.chroot\n echo 'live-config' >> config/package-lists/neon.list.chroot\n echo 'live-config-systemd' >> config/package-lists/neon.list.chroot\n\n # remove the double sddm hook\n mv config/includes.chroot/lib/live/config/0090-sddm config/includes.chroot/lib/live/config/0085-sddm\nelse\n rm config/includes.chroot/etc/live/config.conf.d/neon-users.conf\nfi\n\necho \"I: done\"\n"
},
{
"alpha_fraction": 0.6599597334861755,
"alphanum_fraction": 0.6941649913787842,
"avg_line_length": 22.11627960205078,
"blob_id": "48c7152304944d1663e696a597fcedc768c135ea",
"content_id": "3a6ff1efb92631a5b513b1dcd5d8cf2351948679",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 994,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 43,
"path": "/jenkins-jobs/nci/binarier.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2018 Bhushan Shah <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../job'\nrequire_relative '../binarier'\n\n# binary builder\nclass BinarierJob\n attr_accessor :qt_git_build\n\n # Monkey patch cores in\n def cores\n config_file = \"#{Dir.home}/.config/nci-jobs-to-cores.json\"\n return '8' unless File.exist?(config_file)\n\n JSON.parse(File.read(config_file)).fetch(job_name, '8')\n end\n\n def compress?\n %w[qt6webengine pyside6 qt5webkit qtwebengine\n mgmt_job-updater appstream-generator mgmt_jenkins_expunge].any? do |x|\n job_name.include?(x)\n end\n end\n\n def architecture\n # i386 is actually cross-built via amd64\n return 'amd64' if @architecture == 'i386'\n\n @architecture\n end\n\n def cross_architecture\n @architecture\n end\n\n def cross_compile?\n @architecture == 'i386'\n end\nend\n"
},
{
"alpha_fraction": 0.7135526537895203,
"alphanum_fraction": 0.7183821201324463,
"avg_line_length": 46.32857131958008,
"blob_id": "8d39f0b6691210bee8bbf1e1d73b958336198bb6",
"content_id": "c61d5c7fd3f7f9a2a4671ef6b73328b348f87cff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3313,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 70,
"path": "/nci/snapcraft.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty/command'\n\nrequire_relative 'lib/setup_repo'\nrequire_relative '../lib/apt'\n\nrequire_relative 'snap/collapser'\nrequire_relative 'snap/manifest_extender'\nrequire_relative 'snap/snapcraft_snap_installer'\n\nif $PROGRAM_NAME == __FILE__\n ENV['TERM'] = 'dumb' # make snpacraft not give garbage progress spam\n ENV['PYTHONUNBUFFERED'] = 'true' # make python also sync stdout\n STDOUT.sync = true\n # KDoctools is rubbish and lets meinproc resolve asset paths through\n # QStandardPaths *AT BUILD TIME*.\n # TODO: can be dropped when build-snap transition is done (this completely\n # moved to SDK wrappers; see also similar comment in collapser.rb)\n ENV['XDG_DATA_DIRS'] = \"#{Dir.pwd}/stage/usr/local/share:\" \\\n \"#{Dir.pwd}/stage/usr/share:\" \\\n '/usr/local/share:/usr/share'\n # Use our own remote parts file.\n ENV['SNAPCRAFT_PARTS_URI'] = 'https://metadata.neon.kde.org/snap/parts.yaml'\n # snapd is necessary for the snap CLI so we can download build-snaps.\n # docbook-xml and docbook-xsl are loaded by kdoctools through hardcoded paths.\n # FIXME libdrm-dev is pulled in because libqt5gui's cmake currently has its\n # include path hard compiled and thus isn't picked up from the stage\n # directory (which in turn already contains it because of the content\n # snap dev tarball)\n #Apt.install(%w[docbook-xml docbook-xsl libdrm-dev snapd])\n\n # We somehow end up with a bogus ssl-dev in the images, drop it as otherwise\n # it may prevent snapcraft carrying out package installations (it doesn't\n # do problem resolution it seems).\n #Apt.purge('libssl1.0-dev')\n #NCI::Snap::BuildSnapCollapser.new('snapcraft.yaml').run do\n # switch to internal download URL\n non_managled_snap = File.read('snapcraft.yaml')\n mangled_snap = non_managled_snap.gsub(%r{download.kde.org/stable/}, 'download.kde.internal.neon.kde.org/stable/')\n File.write('snapcraft.yaml', mangled_snap)\n # Collapse first, extending also managles dpkg a bit, so we can't\n # expect packages to be in a sane state inside the extender.\n `sudo chown jenkins-slave /var/snap/lxd/common/lxd/unix.socket`\n `lxd init --auto`\n `snapcraft --version`\n `snapcraft clean --use-lxd || true`\n TTY::Command.new(uuid: false).run('snapcraft --use-lxd')\n File.write('snapcraft.yaml', non_managled_snap)\n #end\nend\n"
},
{
"alpha_fraction": 0.650602400302887,
"alphanum_fraction": 0.6846385598182678,
"avg_line_length": 35.483516693115234,
"blob_id": "dd51d7d2a11554c12c9d0b1837feb9ed1fa012ae",
"content_id": "75e8217b7e0d55f0ff5e552ed69b0c73ca8073a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3320,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 91,
"path": "/test/test_debian_changelog.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/debian/changelog'\nrequire_relative 'lib/testcase'\n\nrequire 'tty/command'\n\n# Test debian/changelog\nclass DebianChangelogTest < TestCase\n def test_parse\n c = Changelog.new(data)\n assert_equal('khelpcenter', c.name)\n assert_equal('', c.version(Changelog::EPOCH))\n assert_equal('5.2.1', c.version(Changelog::BASE))\n assert_equal('', c.version(Changelog::BASESUFFIX))\n assert_equal('-0ubuntu1', c.version(Changelog::REVISION))\n assert_equal('5.2.1-0ubuntu1', c.version(Changelog::ALL))\n end\n\n def test_with_suffix\n c = Changelog.new(data)\n assert_equal('', c.version(Changelog::EPOCH))\n assert_equal('5.2.1', c.version(Changelog::BASE))\n assert_equal('~git123', c.version(Changelog::BASESUFFIX))\n assert_equal('-0ubuntu1', c.version(Changelog::REVISION))\n assert_equal('5.2.1~git123-0ubuntu1', c.version(Changelog::ALL))\n # Test combination\n assert_equal('5.2.1~git123', c.version(Changelog::BASE | Changelog::BASESUFFIX))\n end\n\n def test_without_suffix\n c = Changelog.new(data)\n assert_equal('', c.version(Changelog::EPOCH))\n assert_equal('5.2.1', c.version(Changelog::BASE))\n assert_equal('~git123', c.version(Changelog::BASESUFFIX))\n assert_equal('', c.version(Changelog::REVISION))\n assert_equal('5.2.1~git123', c.version(Changelog::ALL))\n end\n\n def test_with_suffix_and_epoch\n c = Changelog.new(data)\n assert_equal('4:', c.version(Changelog::EPOCH))\n assert_equal('5.2.1', c.version(Changelog::BASE))\n assert_equal('~git123', c.version(Changelog::BASESUFFIX))\n assert_equal('-0ubuntu1', c.version(Changelog::REVISION))\n assert_equal('4:5.2.1~git123-0ubuntu1', c.version(Changelog::ALL))\n end\n\n def test_alphabase\n c = Changelog.new(data)\n assert_equal('4:', c.version(Changelog::EPOCH))\n assert_equal('5.2.1a', c.version(Changelog::BASE))\n assert_equal('', c.version(Changelog::BASESUFFIX))\n assert_equal('-0ubuntu1', c.version(Changelog::REVISION))\n assert_equal('4:5.2.1a-0ubuntu1', c.version(Changelog::ALL))\n end\n\n def test_read_file_directly\n # Instead of opening a dir, open a file path\n c = Changelog.new(\"#{data}/debian/changelog\")\n assert_equal('khelpcenter', c.name)\n assert_equal('5.2.1-0ubuntu1', c.version(Changelog::ALL))\n end\n\n def test_new_version\n omit # adding changelog hands on deploy in spara\n # we'll do a test using dch since principally we need its new entry\n # to be valid, simulation through mock doesn't really cut it\n require_binaries('dch')\n\n FileUtils.cp_r(\"#{@datadir}/template/debian\", '.')\n\n assert_equal('5.2.1-0ubuntu1', Debian::Changelog.new.version)\n Changelog.new_version!('123', distribution: 'dist', message: 'msg')\n assert_equal('123', Debian::Changelog.new.version)\n end\n\n def test_new_version_with_reload\n omit # adding changelog hands on deploy in spara\n require_binaries('dch')\n\n FileUtils.cp_r(\"#{@datadir}/template/debian\", '.')\n\n c = Debian::Changelog.new\n assert_equal('5.2.1-0ubuntu1', c.version)\n c.new_version!('123', distribution: 'dist', message: 'msg')\n assert_equal('123', c.version)\n end\nend\n"
},
{
"alpha_fraction": 0.7259036302566528,
"alphanum_fraction": 0.7349397540092468,
"avg_line_length": 19.75,
"blob_id": "b78ef97e0288996cce67eed0a064a4776a3c4fb9",
"content_id": "45ceeca9e36d67ea23b47097259dfae665bc109d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 16,
"path": "/test/data/test_projects/test_launchpad/unity-action-api/debian/rules",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/make -f\n# -*- makefile -*-\n\n# Comment this to turn off verbose mode.\n#export DH_VERBOSE=1\n\nexport DPKG_GENSYMBOLS_CHECK_LEVEL=4\n\n%:\n\tdh $@ --parallel --fail-missing\n\noverride_dh_auto_configure:\n\tdh_auto_configure -- -DGENERATE_DOCUMENTATION=ON\n\noverride_dh_makeshlibs:\n\tdh_makeshlibs -Nqtdeclarative5-unity-action-plugin\n"
},
{
"alpha_fraction": 0.6208488345146179,
"alphanum_fraction": 0.6293923258781433,
"avg_line_length": 29.75,
"blob_id": "abc386fa3febefc86e7fd6d46f09fd3721d5ab5d",
"content_id": "30d7a1fdd7e73a2c9e3933ff53d83beec1584495",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 14514,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 472,
"path": "/test/test_apt.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2014-2021 Harald Sitter <[email protected]>\n\nrequire_relative '../lib/apt'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# Test Apt\nclass AptTest < TestCase\n def setup\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n Apt::Repository.stubs(:`).returns('')\n end\n\n def default_args(cmd = 'apt-get')\n [cmd] + %w[-y -o APT::Get::force-yes=true -o Debug::pkgProblemResolver=true -q]\n end\n\n def assert_system(*args, &_block)\n Object.any_instance.expects(:system).never\n if args[0].is_a?(Array)\n # Flatten first level. Since we catch *args we get an array with an array\n # which contains the arrays of arguments, by removing the first array we\n # get an array of argument-arrays.\n # COMPAT: we only do this conditionally since the original assert_system\n # was super flexible WRT input types.\n args = args.flatten(1) if args[0][0].is_a?(Array)\n args.each do |arg_array|\n Object.any_instance.expects(:system).with(*arg_array).returns(true)\n end\n else\n Object.any_instance.expects(:system).with(*args).returns(true)\n end\n yield\n ensure\n Object.any_instance.unstub(:system)\n end\n\n def assert_system_default(args, &block)\n assert_system(*(default_args + args), &block)\n end\n\n def assert_system_default_get(args, &block)\n assert_system(*(default_args('apt-get') + args), &block)\n end\n\n def test_repo\n repo = nil\n name = 'ppa:yolo'\n\n # This will be cached and not repated for static use later.\n assert_system_default(%w[install software-properties-common]) do\n repo = Apt::Repository.new(name)\n end\n\n cmd = ['add-apt-repository', '-y', 'ppa:yolo']\n assert_system(cmd) { repo.add }\n # Static\n assert_system(cmd) { Apt::Repository.add(name) }\n\n cmd = ['add-apt-repository', '-y', '-r', 'ppa:yolo']\n assert_system(cmd) { repo.remove }\n # Static\n assert_system(cmd) { Apt::Repository.remove(name) }\n end\n\n def test_apt_install\n assert_system_default(%w[install abc]) do\n Apt.install('abc')\n end\n\n assert_system_default_get(%w[install abc]) do\n Apt::Get.install('abc')\n end\n end\n\n def test_apt_install_with_additional_arg\n assert_system_default(%w[--purge install abc]) do\n Apt.install('abc', args: '--purge')\n end\n end\n\n def test_underscore\n assert_system_default(%w[dist-upgrade]) do\n Apt.dist_upgrade\n end\n end\n\n def test_apt_install_array\n # Make sure we can pass an array as argument as this is often times more\n # convenient than manually converting it to a *.\n assert_system_default(%w[install abc def]) do\n Apt.install(%w[abc def])\n end\n end\n\n def assert_add_popen\n class << Open3\n alias_method popen3__, popen3\n def popen3(*_args)\n yield\n end\n end\n ensure\n class << Open3\n alias_method popen3, popen3__\n end\n end\n\n def test_apt_key_add_invalid_file\n stub_request(:get, 'http://abc/xx.pub').to_return(status: 504)\n assert_raise OpenURI::HTTPError do\n assert_false(Apt::Key.add('http://abc/xx.pub'))\n end\n end\n\n def test_apt_key_add_keyid\n assert_system('apt-key', 'adv', '--keyserver', 'keyserver.ubuntu.com', '--recv', '0x123456abc') do\n Apt::Key.add('0x123456abc')\n end\n end\n\n def test_apt_key_add_already_added\n Object.any_instance.expects(:system).never\n Object.any_instance.expects(:`).never\n\n seq = sequence('backtick-fingerprint')\n Object\n .any_instance\n .expects(:`)\n .with(\"apt-key adv --fingerprint '0x123456abc'\")\n .in_sequence(seq)\n .returns('0x123456abc')\n Process::Status\n .any_instance\n .expects(:success?)\n .in_sequence(seq)\n .returns(true)\n\n Apt::Key.add('0x123456abc')\n\n # Not expecting a system call to apt-key add!\n end\n\n def test_apt_key_add_rel_file\n File.write('abc', 'keyly')\n # Expect IO.popen() {}\n popen_catcher = StringIO.new\n IO.expects(:popen)\n .with(['apt-key', 'add', '-'], 'w')\n .yields(popen_catcher)\n\n assert Apt::Key.add('abc')\n assert_equal(\"keyly\\n\", popen_catcher.string)\n end\n\n def test_apt_key_add_absolute_file\n File.write('abc', 'keyly')\n path = File.absolute_path('abc')\n # Expect IO.popen() {}\n popen_catcher = StringIO.new\n IO.expects(:popen)\n .with(['apt-key', 'add', '-'], 'w')\n .yields(popen_catcher)\n\n assert Apt::Key.add(path)\n assert_equal(\"keyly\\n\", popen_catcher.string)\n end\n\n def test_apt_key_add_url\n url = 'http://kittens.com/key'\n # Expect open()\n data_output = StringIO.new('keyly')\n URI.expects(:open)\n .with(url)\n .returns(data_output)\n # Expect IO.popen() {}\n popen_catcher = StringIO.new\n IO.expects(:popen)\n .with(['apt-key', 'add', '-'], 'w')\n .yields(popen_catcher)\n\n assert Apt::Key.add(url)\n assert_equal(\"keyly\\n\", popen_catcher.string)\n end\n\n def test_automatic_update\n # Updates\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, nil)\n assert_system([default_args + ['update'],\n default_args + %w[install abc]]) do\n Apt.install('abc')\n end\n ## Make sure the time stamp difference after the run is <60s and\n ## a subsequent run doesn't update again.\n t = Apt::Abstrapt.send(:instance_variable_get, :@last_update)\n assert(Time.now - t < 60)\n assert_system_default(%w[install def]) do\n Apt.install(%w[def])\n end\n\n # Doesn't update if recent\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n assert_system([default_args + %w[install abc]]) do\n Apt.install('abc')\n end\n\n # Doesn't update if update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, nil)\n assert_system([default_args + ['update']]) do\n Apt.update\n end\n end\n\n # Test that the deep nesting bullshit behind Repository.add with implicit\n # crap garbage caching actually yields correct return values and is\n # retriable on error.\n def test_fucking_shit_fuck_shit\n Object.any_instance.expects(:system).never\n\n add_call_chain = proc do |sequence, returns|\n # sequence is a sequence\n # returns is an array of nil/false/true values\n # first = update\n # second = install\n # third = add\n # a nil returns means this call must not occur (can only be 1st & 2nd)\n apt = ['apt-get', '-y', '-o', 'APT::Get::force-yes=true', '-o', 'Debug::pkgProblemResolver=true', '-q']\n\n unless (ret = returns.shift).nil?\n Object\n .any_instance\n .expects(:system)\n .in_sequence(sequence)\n .with(*apt, 'update')\n .returns(ret)\n end\n\n unless (ret = returns.shift).nil?\n Object\n .any_instance\n .expects(:system)\n .in_sequence(sequence)\n .with(*apt, 'install', 'software-properties-common')\n .returns(ret)\n end\n\n Object\n .any_instance\n .expects(:system)\n .in_sequence(sequence)\n .with('add-apt-repository', '-y', 'kittenshit')\n .returns(returns.shift)\n end\n\n seq = sequence('apt-add-repo')\n\n # Enable automatic update. We want to test that we can retry the update\n # if it fails.\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, nil)\n\n # update failed, install failed, invocation failed\n add_call_chain.call(seq, [false, false, false])\n assert_false(Apt::Repository.add('kittenshit'))\n # update worked, install failed, invocation failed\n add_call_chain.call(seq, [true, false, false])\n assert_false(Apt::Repository.add('kittenshit'))\n # update noop, install worked, invocation failed\n add_call_chain.call(seq, [nil, true, false])\n assert_false(Apt::Repository.add('kittenshit'))\n # update noop, install noop, invocation worked\n add_call_chain.call(seq, [nil, nil, true])\n assert(Apt::Repository.add('kittenshit'))\n end\n\n def test_cache_exist\n # Check if a package exists.\n\n # Cache is different in that in includes abstrapt instead of calling it,\n # this is because it actually overrides behavior. It also means we need\n # to disable the auto-update for cache as the setting from Abstrapt\n # doesn't carry over (set via setup).\n Apt::Cache.send(:instance_variable_set, :@last_update, Time.now)\n # Auto-update goes into abstrapt\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n # This is our stuff\n Apt::Cache.expects(:system).never\n Apt::Cache.expects(:system)\n .with('apt-cache', '-q', 'show', 'abc', { %i[out err] => '/dev/null' })\n .returns(true)\n Apt::Cache.expects(:system)\n .with('apt-cache', '-q', 'show', 'cba', { %i[out err] => '/dev/null' })\n .returns(false)\n assert_true(Apt::Cache.exist?('abc'))\n assert_false(Apt::Cache.exist?('cba'))\n end\n\n def test_apt_cache_disable_update\n Apt::Cache.reset # make sure we can auto-update\n # Auto-update goes into abstrapt\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n # This is our stuff\n Apt::Cache.expects(:system).never\n Apt::Cache.expects(:`).never\n\n # We expect no update call!\n\n Apt::Cache\n .expects(:system)\n .with('apt-cache', '-q', 'show', 'abc', { %i[out err] => '/dev/null' })\n .returns(true)\n\n ret = Apt::Cache.disable_auto_update do\n Apt::Cache.exist?('abc')\n '123'\n end\n assert_equal('123', ret)\n end\n\n def test_key_fingerprint\n # Make sure we get no URI exceptions etc. when adding a fingerprint with\n # spaces, and that it actually calls the correct command.\n\n Apt::Key.expects(:system).never\n Apt::Key.expects(:`).never\n\n Apt::Key\n .expects(:`)\n .with(\"apt-key adv --fingerprint '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D'\")\n Apt::Key\n .expects(:system)\n .with('apt-key', 'adv', '--keyserver', 'keyserver.ubuntu.com', '--recv',\n '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D')\n\n Apt::Key.add('444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D')\n end\n\n def test_mark_state\n TTY::Command\n .any_instance\n .stubs(:run)\n .with { |*args| args.join.include?('foobar-doesnt-exist') }\n .returns(['', ''])\n TTY::Command\n .any_instance\n .stubs(:run)\n .with { |*args| args.join.include?('zsh-common') }\n .returns([\"zsh-common\\n\", ''])\n\n # Disabled see code for why.\n # assert_raise { Apt::Mark.state('foobar-doesnt-exist') }\n assert_equal(Apt::Mark::AUTO, Apt::Mark.state('zsh-common'))\n end\n\n def test_mark_mark\n TTY::Command\n .any_instance\n .stubs(:run).once\n .with do |*args|\n args = args.join\n args.include?('hold') && args.include?('zsh-common')\n end\n .returns(nil)\n\n Apt::Mark.mark('zsh-common', Apt::Mark::HOLD)\n end\n\n def test_mark_tmpmark\n pkg = 'zsh-common'\n seq = sequence('cmd_sequence')\n\n # This is stubbing on a TTY level as we'll want to assert that the block\n # behaves according to expectation, not that the invidiual methods on\n # a higher level are called.\n # NB: this is fairly fragile and might need to be replaced with a more\n # general purpose mock of apt-mark interception.\n\n # Initial state query\n TTY::Command\n .any_instance.expects(:run).with(Apt::Mark::BINARY, 'showauto', pkg)\n .returns([pkg, ''])\n .in_sequence(seq)\n # State switch\n TTY::Command\n .any_instance.expects(:run).with(Apt::Mark::BINARY, 'manual', pkg)\n .returns(nil)\n .in_sequence(seq)\n # Test assertion no on auto, yes on manual. This part of the sequence is\n # caused by our assert()\n TTY::Command\n .any_instance.expects(:run).with(Apt::Mark::BINARY, 'showauto', pkg)\n .returns(['', ''])\n .in_sequence(seq)\n TTY::Command\n .any_instance.expects(:run).with(Apt::Mark::BINARY, 'showmanual', pkg)\n .returns([pkg, ''])\n .in_sequence(seq)\n # Block undoes the state to the original state (auto)\n TTY::Command\n .any_instance.expects(:run).with(Apt::Mark::BINARY, 'auto', pkg)\n .returns(nil)\n .in_sequence(seq)\n\n Apt::Mark.tmpmark(pkg, Apt::Mark::MANUAL) do\n assert_equal(Apt::Mark::MANUAL, Apt::Mark.state(pkg))\n end\n end\n\n def test_repo_no_update\n Apt::Repository.any_instance.unstub(:`)\n Apt::Repository\n .stubs(:`)\n .with('add-apt-repository --help')\n .returns(<<-HELP)\nUsage: add-apt-repository <sourceline>\n\nadd-apt-repository is a script for adding apt sources.list entries.\nIt can be used to add any repository and also provides a shorthand\nsyntax for adding a Launchpad PPA (Personal Package Archive)\nrepository.\n\n<sourceline> - The apt repository source line to add. This is one of:\n a complete apt line in quotes,\n a repo url and areas in quotes (areas defaults to 'main')\n a PPA shortcut.\n a distro component\n\n Examples:\n apt-add-repository 'deb http://myserver/path/to/repo stable myrepo'\n apt-add-repository 'http://myserver/path/to/repo myrepo'\n apt-add-repository 'https://packages.medibuntu.org free non-free'\n apt-add-repository http://extras.ubuntu.com/ubuntu\n apt-add-repository ppa:user/repository\n apt-add-repository ppa:user/distro/repository\n apt-add-repository multiverse\n\nIf --remove is given the tool will remove the given sourceline from your\nsources.list\n\n\nOptions:\n -h, --help show this help message and exit\n -m, --massive-debug Print a lot of debug information to the command line\n -r, --remove remove repository from sources.list.d directory\n -k KEYSERVER, --keyserver=KEYSERVER\n URL of keyserver. Default:\n hkp://keyserver.ubuntu.com:80/\n -s, --enable-source Allow downloading of the source packages from the\n repository\n -y, --yes Assume yes to all queries\n -n, --no-update Do not update package cache after adding\n -u, --update Update package cache after adding (legacy option)\n HELP\n\n repo = nil\n name = 'ppa:yolo'\n\n assert_system_default(%w[install software-properties-common]) do\n repo = Apt::Repository.new(name)\n end\n\n # THIS CONTAINS NO UPDATE!\n cmd = ['add-apt-repository', '--no-update', '-y', 'ppa:yolo']\n assert_system(cmd) { repo.add }\n end\nend\n"
},
{
"alpha_fraction": 0.6209476590156555,
"alphanum_fraction": 0.6433915495872498,
"avg_line_length": 41.21052551269531,
"blob_id": "d6bb2ab3c248a9017d4e66a47372729084edb949",
"content_id": "cdb8aabce6355a6ba6a49acd7d175372724f7429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3208,
"license_type": "no_license",
"max_line_length": 215,
"num_lines": 76,
"path": "/test/test_nci_lint_versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/versions'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class VersionsTestTest < TestCase\n Package = Struct.new(:name, :version)\n\n def setup\n VersionsTest.reset!\n end\n\n def standard_ours\n [Package.new('foo', '1.0'), Package.new('bar', '2.0')]\n end\n\n def test_file_lister\n VersionsTest.init(ours: standard_ours,\n theirs: [Package.new('foo', '0.5')])\n linter = VersionsTest.new\n linter.send('test_foo_1.0')\n linter.send('test_bar_2.0')\n end\n\n def test_file_lister_bad_version\n stub_request(:get, 'https://invent.kde.org/neon/neon/settings/-/raw/Neon/unstable/etc/apt/preferences.d/99-jammy-overrides?inline=false').\n with(headers: {'Accept'=>'*/*', 'Accept-Encoding'=>'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent'=>'Ruby'}).\n to_return(status: 200, body: \"Package: aptdaemon\\nPin: release o=Ubuntu\\nPin-Priority: 1100\\n\\nPackage: aptdaemon-data\\nPin: release o=Ubuntu\\nPin-Priority: 1100\", headers: {'Content-Type'=> 'text/plain'})\n VersionsTest.init(ours: standard_ours,\n theirs: [Package.new('foo', '1.1')])\n linter = VersionsTest.new\n assert_raises PackageVersionCheck::VersionNotGreaterError do\n linter.send('test_foo_1.0')\n end\n end\n\n def test_pure_virtual\n # When showing a pure virtual it comes back 0 but has no valid\n # data. THIS ONLY HAPPENS WHEN CALLED FROM OUTSIDE A TERMINAL!\n # On a terminal it tells you that it is pure virtual. I hate apt with\n # all my life.\n VersionsTest.init(ours: standard_ours,\n theirs: [Package.new('foo', nil)])\n linter = VersionsTest.new\n linter.send('test_foo_1.0')\n end\n\n def test_already_debian_version\n # When showing a pure virtual it comes back 0 but has no valid\n # data. THIS ONLY HAPPENS WHEN CALLED FROM OUTSIDE A TERMINAL!\n # On a terminal it tells you that it is pure virtual. I hate apt with\n # all my life.\n VersionsTest.init(ours: standard_ours,\n theirs: [Package.new('foo',\n Debian::Version.new('0.5'))])\n linter = VersionsTest.new\n linter.send('test_foo_1.0')\n end\n\n def test_override_packages\n stub_request(:get, 'https://invent.kde.org/neon/neon/settings/-/raw/Neon/unstable/etc/apt/preferences.d/99-jammy-overrides?inline=false').\n with(headers: {'Accept'=>'*/*', 'Accept-Encoding'=>'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent'=>'Ruby'}).\n to_return(status: 200, body: \"Package: aptdaemon\\nPin: release o=Ubuntu\\nPin-Priority: 1100\\n\\nPackage: aptdaemon-data\\nPin: release o=Ubuntu\\nPin-Priority: 1100\", headers: {'Content-Type'=> 'text/plain'})\n\n PackageVersionCheck.override_packages\n override_packages = PackageVersionCheck.override_packages\n assert_equal([\"aptdaemon\", \"aptdaemon-data\"], override_packages)\n end\n\n end\nend\n"
},
{
"alpha_fraction": 0.6768060922622681,
"alphanum_fraction": 0.6882129311561584,
"avg_line_length": 32.935482025146484,
"blob_id": "e386aa05ee860027f44f21d4a551a3545382f18a",
"content_id": "8b847e1ffcb7d96e202a9c31b9dfcee75dc3d1e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2104,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/nci/imager_img.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\n\nrequire_relative '../lib/ci/containment'\n\nTOOLING_PATH = File.dirname(__dir__)\n\nJOB_NAME = ENV.fetch('JOB_NAME')\nDIST = ENV.fetch('DIST')\nTYPE = ENV.fetch('TYPE')\nARCH = ENV.fetch('ARCH')\nMETAPACKAGE = ENV.fetch('METAPACKAGE')\nIMAGENAME = ENV.fetch('IMAGENAME')\nNEONARCHIVE = ENV.fetch('NEONARCHIVE')\n\nDocker.options[:read_timeout] = 4 * 60 * 60 # 4 hours.\n\nbinds = [\n TOOLING_PATH,\n Dir.pwd\n]\n\nc = CI::Containment.new(JOB_NAME,\n image: CI::PangeaImage.new(:ubuntu, DIST),\n binds: binds,\n privileged: true,\n no_exit_handlers: false)\ncmd = [\"/tooling/nci/imager-img/build.sh\",\n Dir.pwd, DIST, ARCH, TYPE, METAPACKAGE, IMAGENAME, NEONARCHIVE]\nstatus_code = c.run(Cmd: cmd)\n\n# Write a params file we can use to pass our relevant information to a child\n# build for additional processing.\nFile.write('params.txt', <<-EOF)\nISO=#{File.realpath(Dir.glob('*.img').fetch(0))}\nNODE_NAME=#{ENV.fetch('NODE_NAME')}\nEOF\nputs File.read('params.txt')\n\nwarn \"status code was #{status_code.to_i}\"\nexit status_code\n"
},
{
"alpha_fraction": 0.7025089859962463,
"alphanum_fraction": 0.7078853249549866,
"avg_line_length": 33.875,
"blob_id": "2ba2144c63f759ba77f0faa945cd9d99c4f5326f",
"content_id": "945191ca5785ce5ea70242e0975ec3a387ee96b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1674,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 48,
"path": "/test/test_debian_profile.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/debian/profile'\nrequire_relative 'lib/testcase'\n\nmodule Debian\n class ProfileTest < TestCase\n def test_matches_negation\n group = ProfileGroup.new('!flup')\n assert(group.matches?(Profile.new('xx')))\n end\n\n def test_not_matches_negation\n group = ProfileGroup.new('!flup')\n refute(group.matches?(Profile.new('flup')))\n end\n\n def test_not_matches_single_of_group\n group = ProfileGroup.new(%w[nocheck cross])\n refute(group.matches?(Profile.new('cross')))\n end\n\n def test_matches_group\n profiles = [ProfileGroup.new(%w[nocheck cross])]\n assert(profiles.any? do |group|\n group.matches?([Profile.new('cross'), Profile.new('nocheck')])\n end)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6264227628707886,
"alphanum_fraction": 0.6365853548049927,
"avg_line_length": 28.638553619384766,
"blob_id": "fb83e2d579c6461ebe92fd27887d7ee18c68a956",
"content_id": "2f2d672db79dda106698f0e9d63a04d35bcb4f40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2460,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 83,
"path": "/lib/projects/factory/l10n.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'base'\nrequire_relative 'common'\n\nrequire 'net/sftp'\n\nclass ProjectsFactory\n # Debian specific project factory.\n class KDEL10N < Base\n include ProjectsFactoryCommon\n DEFAULT_URL_BASE = 'https://github.com/shadeslayer/kde-l10n-common'\n\n # FIXME: same as in neon\n def self.url_base\n @url_base ||= DEFAULT_URL_BASE\n end\n\n def self.understand?(type)\n type == 'kde-l10n'\n end\n\n private\n\n def params(str)\n name = str.split('/')[-1]\n default_params.merge(\n name: name,\n component: 'kde-l10n',\n url_base: self.class.url_base\n )\n end\n\n class << self\n def ls(base)\n @list_cache ||= {}\n return @list_cache[base] if @list_cache.key?(base)\n\n @list_cache[base] = check_ftp(base).freeze\n end\n\n private\n\n def check_ftp(base)\n stable_path =\n \"/home/ftpubuntu/stable/applications/#{base}/src/kde-l10n/\"\n unstable_path =\n \"/home/ftpubuntu/unstable/applications/#{base}/src/kde-l10n/\"\n output = nil\n Net::SFTP.start('depot.kde.org', 'ftpubuntu') do |sftp|\n output = sftp.dir.glob(stable_path, '**/**.tar.*').map(&:name)\n output ||= sftp.dir.glob(unstable_path, '**/**.tar.*').map(&:name)\n end\n cleanup_ls(output, base)\n end\n\n def cleanup_ls(data, str)\n pattern = \"(kde-l10n-.*)-#{str}\"\n data.collect do |entry|\n entry.match(/#{pattern}/)[1] if entry =~ /#{pattern}/\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5660018920898438,
"alphanum_fraction": 0.56695157289505,
"avg_line_length": 20.489795684814453,
"blob_id": "c8b7e2f01ec15f0f117aa2c70de65deed62bf3ef",
"content_id": "fc1fecdf301531cff4bcd16dc6873619035c75bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1053,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 49,
"path": "/lib/debian/source.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule Debian\n # debian/source representation\n class Source\n # Represents a dpkg-source format. See manpage.\n class Format\n attr_reader :version\n attr_reader :type\n\n def initialize(str)\n @version = '1'\n @type = nil\n parse(str) if str\n end\n\n def to_s\n return @version unless type\n\n \"#{version} (#{type})\"\n end\n\n private\n\n def parse(str)\n str = str.read if str.respond_to?(:read)\n str = File.read(str) if File.exist?(str)\n data = str.strip\n match = data.match(/(?<version>[^\\s]+)(\\s+\\((?<type>.*)\\))?/)\n @version = match[:version]\n @type = match[:type].to_sym if match[:type]\n end\n end\n\n attr_reader :format\n\n def initialize(package_path)\n @package_path = package_path\n raise 'not a package path' unless Dir.exist?(\"#{package_path}/debian\")\n\n parse\n end\n\n private\n\n def parse\n @format = Format.new(\"#{@package_path}/debian/source/format\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7430025339126587,
"alphanum_fraction": 0.7430025339126587,
"avg_line_length": 31.75,
"blob_id": "32a6f61399328c507936cc5fa238ec22352967ad",
"content_id": "0fa5b98ad97fb435ea5d9f574cb8b939532ba571",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 12,
"path": "/jenkins-jobs/meta-build.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Meta builder depending on all builds and being able to trigger them.\nclass MetaBuildJob < JenkinsJob\n attr_reader :downstream_triggers\n\n def initialize(type:, distribution:, downstream_jobs:)\n super(\"mgmt_build_#{distribution}_#{type}\", 'meta-build.xml.erb')\n @downstream_triggers = downstream_jobs.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.7250362038612366,
"alphanum_fraction": 0.7351664304733276,
"avg_line_length": 40.459999084472656,
"blob_id": "9803253e29ea75050574112594a7107fff49018f",
"content_id": "ab31c2d56189710307a165659a1b5c164bd2e0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2073,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/mgmt/digital_ocean_dangler.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\n\nrequire_relative '../lib/jenkins'\nrequire_relative '../lib/digital_ocean/droplet'\n\nclient = DigitalOcean::Client.new\ndroplets = client.droplets.all\nnodes = JenkinsApi::Client.new.node.list\ndangling = droplets.select do |drop|\n # Droplet needs to not be a known node after 1 hour of existance.\n # The delay is a bit of leeway so we don't accidently delete things\n # that may have just this microsecond be created but not yet in Jenkins.\n # Also since we don't special case the image maintainence job\n # we'd otherwise kill the droplet out from under it (job takes\n # ~30 minutes on a clean run).\n # FTR the datetime condition is that 1 hour before now is greater\n # (i.e. more recent) than the creation time (i.e. creation time is more\n # than 1 hour in the past).\n !nodes.include?(drop.name) &&\n (DateTime.now - Rational(1, 24)) > DateTime.iso8601(drop.created_at)\nend\n\nwarn \"Dangling: #{dangling} #{dangling.size}\"\ndangling.each do |drop|\n name = drop.name\n warn \"Deleting #{name}\"\n droplet = DigitalOcean::Droplet.from_name(name)\n raise \"Failed to delete #{name}\" unless droplet.delete\nend\n"
},
{
"alpha_fraction": 0.635913610458374,
"alphanum_fraction": 0.6399639844894409,
"avg_line_length": 26.09756088256836,
"blob_id": "1fa5f03249ed9140946f44e7258905c00c4937c4",
"content_id": "45f409d6691807d9d6632a45267b34be5318fb76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2222,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 82,
"path": "/nci/debian-merge/merger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative 'data'\nrequire_relative 'repository'\n\nmodule NCI\n module DebianMerge\n # Conducts a mere into Neon/pending-merge\n class Merger\n def initialize\n @data = Data.from_file\n @log = Logger.new(STDERR)\n @failed_merges = {}\n end\n\n def run\n repos = merge_repos(Dir.pwd)\n debug_failed_merges\n raise unless @failed_merges.empty?\n\n repos.each do |r|\n @log.info \"Pushing #{r.url}\"\n r.push\n end\n end\n\n # kind of private bits\n\n def debug_failed_merges\n @failed_merges.each do |url, error|\n @log.error url\n @log.error error\n @log.error error.backtrace\n end\n end\n\n def merge(url, tmpdir)\n @log.info \"Cloning #{url}\"\n repo = Repository.clone_into(url, tmpdir)\n repo.tag_base = @data.tag_base\n @log.info \"Merging #{url}\"\n repo.merge\n repo\n rescue => e\n @failed_merges[url] = e\n end\n\n def merge_repos(tmpdir)\n @data.repos.collect do |url|\n merge(url, tmpdir)\n end\n end\n end\n end\nend\n\n# :nocov:\n$stdout = STDERR\nNCI::DebianMerge::Merger.new.run if $PROGRAM_NAME == __FILE__\n# :nocov:\n"
},
{
"alpha_fraction": 0.6101941466331482,
"alphanum_fraction": 0.6148058176040649,
"avg_line_length": 31.69841194152832,
"blob_id": "e31de15e95833e0e93dfe4c4ae2db5b8b6811f82",
"content_id": "7d2928998014d00061469866ff11e7ed2a26ca10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4120,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 126,
"path": "/lib/lint/cmake.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'linter'\n\nmodule Lint\n # Parses CMake output\n # FIXME: presently we simply result with names, this however lacks context\n # in the log then, so the output should be changed to a descriptive\n # line\n class CMake < Linter\n METHS = {\n 'The following OPTIONAL packages have not been found' => :parse_summary,\n 'The following RUNTIME packages have not been found' => :parse_summary,\n 'The following features have been disabled' => :parse_summary,\n 'Could not find a package configuration file provided by' => :parse_package,\n 'CMake Warning' => :parse_warning\n }.freeze\n\n def initialize(pwd = Dir.pwd)\n @result_dir = \"#{pwd}/result/\"\n\n super()\n # must be after base init, relies on @ignores being defined\n load_include_ignores(\"#{pwd}/build/debian/meta/cmake-ignore\")\n end\n\n def lint\n result = Result.new\n Dir.glob(\"#{@result_dir}/pangea_feature_summary-*.log\").each do |log|\n data = File.read(log)\n result.valid = true\n parse(data.split(\"\\n\"), result)\n end\n result.uniq\n end\n\n private\n\n def load_static_ignores\n super\n return unless ENV.fetch('DIST') == 'bionic'\n return unless ENV.fetch('DIST') == NCI.future_series\n\n # As long as bionic is the future series ignore QCH problems. We cannot\n # solve them without breaking away from xenial or breaking xenial\n # support.\n @ignores << CI::IncludePattern.new('QCH, API documentation in QCH')\n # It ECM it's by a different name for some reason.\n @ignores << CI::IncludePattern.new('BUILD_QTHELP_DOCS')\n end\n\n def warnings(line, data)\n METHS.each do |id, meth|\n next unless line.include?(id)\n\n ret = send(meth, line, data)\n @ignores.each do |ignore|\n ret.reject! { |d| ignore.match?(d) }\n end\n return ret\n end\n []\n end\n\n def parse(data, result)\n until data.empty?\n line = data.shift\n result.warnings += warnings(line, data)\n end\n end\n\n def parse_summary(_line, data)\n missing = []\n start_line = false\n until data.empty?\n line = data.shift\n if !start_line && line.empty?\n start_line = true\n next\n elsif start_line && !line.empty?\n next if line.strip.empty?\n\n match = line.match(/^ *\\* (.*)$/)\n missing << match[1] if match&.size && match.size > 1\n else\n # Line is empty and the start conditions didn't match.\n # Either the block is not valid or we have reached the end.\n # In any case, break here.\n break\n end\n end\n missing\n end\n\n def parse_package(line, _data)\n package = 'Could not find a package configuration file provided by'\n match = line.match(/^\\s+#{package}\\s+\"(.+)\"/)\n return [] unless match&.size && match.size > 1\n\n [match[1]]\n end\n\n # This possibly should be outsourced into files somehow?\n def parse_warning(line, _data)\n warn 'CMake Warning Parsing is disabled at this time!'\n return [] unless line.include?('CMake Warning')\n # Lines coming from MacroOptionalFindPackage (from old parsing).\n return [] if line.include?('CMake Warning at ' \\\n '/usr/share/kde4/apps/cmake/modules/MacroOptionalFindPackage.cmake')\n # Lines coming from find_package (from old parsing).\n return [] if line =~ /CMake Warning at [^ :]+:\\d+ \\(find_package\\)/\n\n # Lines coming from warnings inside the actual CMakeLists.txt as those\n # can be arbitrary.\n # ref: \"CMake Warning at src/worker/CMakeLists.txt:33 (message):\"\n warning_exp = /CMake Warning at [^ :]*CMakeLists.txt:\\d+ \\(message\\)/\n return [] if line.match(warning_exp)\n return [] if line.start_with?('CMake Warning (dev)')\n\n [] # if line.start_with?('CMake Warning:')] ALWAYS empty, too pointless\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6283941268920898,
"alphanum_fraction": 0.6330488920211792,
"avg_line_length": 29.93600082397461,
"blob_id": "f70760c04cac88291dc3cbe4f2c4c874ca8c80b1",
"content_id": "8d61d950ef728e48d2babfd4873a1147534d984d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3867,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 125,
"path": "/lib/ci/tarball.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tmpdir'\nrequire 'tty/command'\n\nmodule CI\n # A tarball handling class.\n class Tarball\n # FIXME: copied from debian::version's upstream regex\n ORIG_EXP = /(.+)_(?<version>[A-Za-z0-9.+:~-]+?)\\.orig\\.tar(.*)/\n\n attr_reader :path\n\n def initialize(path)\n @path = File.absolute_path(path)\n end\n\n def basename\n File.basename(@path)\n end\n\n def version\n raise \"Not an orig tarball #{path}\" unless orig?\n\n match = basename.match(ORIG_EXP)\n match[:version]\n end\n\n def to_s\n @path\n end\n alias to_str to_s\n\n def orig?\n self.class.orig?(@path)\n end\n\n # Change tarball path to Debian orig format.\n # @return New Tarball with orig path or existing Tarball if it was orig.\n # This method copies the existing tarball to retain\n # working paths if the path is being changed.\n def origify\n return self if orig?\n\n clone.origify!\n end\n\n # Like {origify} but in-place.\n # @return [Tarball, nil] self if the tarball is now orig, nil if it was orig\n def origify!\n return nil if orig?\n\n dir = File.dirname(@path)\n match = basename.match(/(?<name>.+)-(?<version>(([\\d.]+)(\\+)?(~)?(.+)?))\\.(?<ext>tar(.*))/)\n raise \"Could not parse tarball #{basename}\" unless match\n\n old_path = @path\n @path = \"#{dir}/#{match[:name]}_#{match[:version]}.orig.#{match[:ext]}\"\n FileUtils.cp(old_path, @path) if File.exist?(old_path)\n self\n end\n\n # @param dest path to extract to. This must be the actual target\n # for the directory content. If the tarball contains\n # a single top-level directory it will be renamed to\n # the basename of to_dir. If it contains more than one\n # top-level directory or no directory all content is\n # moved *into* dest.\n def extract(dest)\n Dir.mktmpdir do |tmpdir|\n system('tar', '-xf', path, '-C', tmpdir)\n content = list_content(tmpdir)\n if content.size > 1 || !File.directory?(content[0])\n FileUtils.mkpath(dest) unless Dir.exist?(dest)\n FileUtils.cp_r(content, dest)\n else\n FileUtils.cp_r(content[0], dest)\n end\n end\n end\n\n def self.orig?(path)\n !File.basename(path).match(ORIG_EXP).nil?\n end\n\n private\n\n # Helper to include hidden dirs but strip self and parent refernces.\n def list_content(path)\n content = Dir.glob(\"#{path}/*\", File::FNM_DOTMATCH)\n content.reject { |c| %w[. ..].include?(File.basename(c)) }\n end\n end\n\n # Special variant of tarball which has an associated dsc already, extracing\n # will go through the dpkg-source intead of manually extracting the tar.\n class DSCTarball < Tarball\n def initialize(tar, dsc:)\n super(tar)\n @dsc = dsc\n end\n\n def extract(dest)\n TTY::Command.new.run('dpkg-source', '-x', @dsc, dest)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7481752038002014,
"alphanum_fraction": 0.7600364685058594,
"avg_line_length": 35.53333282470703,
"blob_id": "2d7dd2e21f45dee348c3e5acaffd5de3ab35481a",
"content_id": "072caaa1100940c3f614a9fb93d28084259fcc7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1096,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 30,
"path": "/nci/imager/build-hooks-neon/009-neon-masks.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# SPDX-FileCopyrightText: 2018-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Mask certain packages which aren't getting properly covered by dependencies.\n\nset -e\n\n. /etc/os-release\n\n# This is canonical support stuff. Not useful and probably also not offered.\n# Our mask removes the ubuntu version.\n# It's being installed by debootstrap, so we'll have to manually rip it out\n# again as apt wouldn't prefer our provides variant over it.\napt-get install --purge -y neon-ubuntu-advantage-tools\napt-mark auto neon-ubuntu-advantage-tools\nif dpkg -s ubuntu-advantage-tools; then\n echo 'ubuntu-advantage-tools is still installed. It is expected to be masked!'\n exit 1\nfi\n\n# Make sure adwaita is masked. Depending on dep resolution we may hav ended\n# up with the real adwaita\napt-get install --purge -y neon-adwaita\napt-mark auto neon-adwaita\n\n# TODO HACK temporary measure to test nomodeset without having it install for regular seeds @sitter\nif [[ ${VERSION,,} = unstable* ]]; then\n apt-get install -y kde-nomodeset\nfi\n"
},
{
"alpha_fraction": 0.6778413653373718,
"alphanum_fraction": 0.6838920712471008,
"avg_line_length": 34.76023483276367,
"blob_id": "fabd10d2111f642ae3bc421f34ca2509d3934a7f",
"content_id": "3b461e3ccf65f1ee6277b175d288d8750df99258",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6115,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 171,
"path": "/lib/install_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2014-2017 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'open3'\nrequire 'tmpdir'\n\nrequire_relative 'apt'\nrequire_relative 'aptly-ext/filter'\nrequire_relative 'dpkg'\nrequire_relative 'repo_abstraction'\nrequire_relative 'retry'\nrequire_relative 'thread_pool'\nrequire_relative 'ci/fake_package'\n\n# Base class for install checks, isolating common logic.\nclass InstallCheckBase\n def initialize\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n end\n\n def run_test(candidate_ppa, target_ppa)\n # Make sure all repos under testing are removed first.\n target_ppa.remove\n candidate_ppa.remove\n\n # Add the present daily snapshot, install everything.\n # If this fails then the current snapshot is kaputsies....\n if target_ppa.add\n unless target_ppa.install\n @log.info 'daily failed to install.'\n daily_purged = target_ppa.purge\n unless daily_purged\n @log.info <<-INFO.tr($/, '')\ndaily failed to install and then failed to purge. Maybe check maintscripts?\n INFO\n end\n end\n end\n @log.unknown 'done with daily'\n\n # temporary while ddebs is broken\n FileUtils.rm('/etc/apt/sources.list.d/org.kde.neon.com.ubuntu.ddebs.list', force: true)\n # NOTE: If daily failed to install, no matter if we can upgrade live it is\n # an improvement just as long as it can be installed...\n # So we purged daily again, and even if that fails we try to install live\n # to see what happens. If live is ok we are good, otherwise we would fail\n # anyway\n\n Retry.retry_it(times: 5, sleep: 5) do\n raise unless candidate_ppa.add\n raise 'failed to update' unless Apt.update\n end\n unless candidate_ppa.install\n @log.error 'all is vain! live PPA is not installing!'\n exit 1\n end\n\n # All is lovely. Let's make sure all live packages uninstall again\n # (maintscripts!) and then start the promotion.\n unless candidate_ppa.purge\n @log.error <<-ERROR.tr($/, '')\nlive PPA installed just fine, but can not be uninstalled again. Maybe check\nmaintscripts?\n ERROR\n exit 1\n end\n\n @log.info \"writing package list in #{Dir.pwd}\"\n File.write('sources-list.json', JSON.generate(candidate_ppa.sources))\n end\nend\n\n# Kubuntu install check.\nclass InstallCheck < InstallCheckBase\n def install_fake_pkg(name)\n FakePackage.new(name).install\n end\n\n def run(candidate_ppa, target_ppa)\n if Process.uid.to_i.zero?\n # Disable invoke-rc.d because it is crap and causes useless failure on\n # install when it fails to detect upstart/systemd running and tries to\n # invoke a sysv script that does not exist.\n File.write('/usr/sbin/invoke-rc.d', \"#!/bin/sh\\n\")\n # Speed up dpkg\n File.write('/etc/dpkg/dpkg.cfg.d/02apt-speedup', \"force-unsafe-io\\n\")\n # Prevent xapian from slowing down the test.\n # Install a fake package to prevent it from installing and doing anything.\n # This does render it non-functional but since we do not require the\n # database anyway this is the apparently only way we can make sure\n # that it doesn't create its stupid database. The CI hosts have really\n # bad IO performance making a full index take more than half an hour.\n install_fake_pkg('apt-xapian-index')\n File.open('/usr/sbin/update-apt-xapian-index', 'w', 0o755) do |f|\n f.write(\"#!/bin/sh\\n\")\n end\n # Also install a fake resolvconf because docker is a piece of shit cunt\n # https://github.com/docker/docker/issues/1297\n install_fake_pkg('resolvconf')\n # Cryptsetup has a new release in jammy-updates but installing this breaks in docker\n install_fake_pkg('cryptsetup')\n # Disable manpage database updates\n Open3.popen3('debconf-set-selections') do |stdin, _stdo, stderr, wait_thr|\n stdin.puts('man-db man-db/auto-update boolean false')\n stdin.close\n wait_thr.join\n puts stderr.read\n end\n # Make sure everything is up-to-date.\n raise 'failed to update' unless Apt.update\n raise 'failed to dist upgrade' unless Apt.dist_upgrade\n # Install ubuntu-minmal first to make sure foundations nonsense isn't\n # going to make the test fail half way through.\n raise 'failed to install minimal' unless Apt.install('ubuntu-minimal')\n\n # Because dependencies are fucked\n # [14:27] <sitter> dictionaries-common is a crap package\n # [14:27] <sitter> it suggests a wordlist but doesn't pre-depend them or\n # anything, intead it just craps out if a wordlist provider is installed\n # but there is no wordlist -.-\n system('apt-get install wamerican') || raise\n # Hold base-files. If we get lsb_release switched mid-flight and things\n # break we are dead in the water as we might not have a working pyapt\n # setup anymore and thus can't edit the sources.list.d content.\n system('apt-mark hold base-files') || raise\n end\n\n run_test(candidate_ppa, target_ppa)\n end\nend\n\n# This overrides run behavior\nclass RootInstallCheck < InstallCheck\n # Override the core test which assumes a 'live' repo and a 'staging' repo.\n # Instead we have a proposed repo and a root.\n # The root is installed version-less. Then we upgrade to the proposed repo and\n # hope everything is awesome.\n def run_test(proposed, root)\n proposed.remove\n\n @log.info 'Installing root.'\n unless root.install\n @log.error 'Root failed to install!'\n raise\n end\n @log.info 'Done with root.'\n\n @log.info 'Installing proposed.'\n unless proposed.add\n @log.error 'Failed to add proposed repo.'\n raise\n end\n unless proposed.install\n @log.error 'all is vain! proposed is not installing!'\n raise\n end\n @log.info 'Install of proposed successful. Trying to purge.'\n unless proposed.purge\n @log.error 'Failed to purge the candidate!'\n raise\n end\n\n @log.info 'All good!'\n end\nend\n"
},
{
"alpha_fraction": 0.764976978302002,
"alphanum_fraction": 0.764976978302002,
"avg_line_length": 30,
"blob_id": "1dce303922503eb2d29b0fffc65cc709c8986a4d",
"content_id": "5d997cbd76d91b15c5a49ceeb60035c806611ec7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 7,
"path": "/nci/imager/build-hooks-xenon-mycroft/03-install-pairing-skills.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -x\n\ncd /opt/mycroft/skills/ && rm -r mycroft-pairing.mycroftai\ngit clone https://github.com/AIIX/skill-pairing\nmv skill-pairing mycroft-pairing.mycroftai\n\nchown -Rv phablet mycroft-pairing.mycroftai || true\n"
},
{
"alpha_fraction": 0.6528571248054504,
"alphanum_fraction": 0.6807143092155457,
"avg_line_length": 32.33333206176758,
"blob_id": "a6917e23f857d9134421dcf8b187c88d9087842b",
"content_id": "511107aff770e97f606102d9abf4e84a317fa270",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1400,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 42,
"path": "/nci/imager-img/build.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -xe\n\nexport WD=$1\nexport DIST=$2\nexport ARCH=$3\nexport TYPE=$4\nexport METAPACKAGE=$5\nexport IMAGENAME=$6\nexport NEONARCHIVE=$7\n\nif [ -z $WD ] || [ -z $DIST ] || [ -z $ARCH ] || [ -z $TYPE ] || [ -z $METAPACKAGE ] || [ -z $IMAGENAME ] || [ -z $NEONARCHIVE ]; then\n echo \"!!! Not all arguments provided! ABORT !!!\"\n env\n exit 1\nfi\n\n_DATE=$(date +%Y%m%d)\n_TIME=$(date +%H%M)\nDATETIME=\"${_DATE}-${_TIME}\"\nREMIX_NAME=\"pinebook-remix\"\nexport LIVE_IMAGE_NAME=\"${IMAGENAME}-${REMIX_NAME}-${TYPE}-${DATETIME}\"\n\napt-get -y install qemu-user-static cpio parted udev zsync pigz live-build fdisk\n\nlb clean --all\nrm -rf config\nmkdir -p chroot/usr/share/keyrings/\ncp /usr/share/keyrings/ubuntu-archive-keyring.gpg chroot/usr/share/keyrings/ubuntu-archive-keyring.gpg\n/tooling/nci/imager-img/configure_pinebook\nlb build\n# flash normal 768p build\n/tooling/nci/imager-img/flash_pinebook ${LIVE_IMAGE_NAME}-${ARCH}.img\n\npigz --stdout ${LIVE_IMAGE_NAME}-${ARCH}.img > ${LIVE_IMAGE_NAME}-${ARCH}.img.gz\nsha256sum ${LIVE_IMAGE_NAME}-${ARCH}.img.gz >> ${LIVE_IMAGE_NAME}-${ARCH}.sha256sum\n\n# flash 1080p build and gzip it\n/tooling/nci/imager-img/flash_pinebook_1080p ${LIVE_IMAGE_NAME}-${ARCH}.img\npigz --stdout ${LIVE_IMAGE_NAME}-${ARCH}.img > ${LIVE_IMAGE_NAME}-${ARCH}-1080p.img.gz\nsha256sum ${LIVE_IMAGE_NAME}-${ARCH}-1080p.img.gz >> ${LIVE_IMAGE_NAME}-${ARCH}.sha256sum\n\necho $DATETIME > date_stamp\n"
},
{
"alpha_fraction": 0.6364812254905701,
"alphanum_fraction": 0.6403622031211853,
"avg_line_length": 30.5510196685791,
"blob_id": "f69d58f682084aa7cdc77f6ff0c19cb955cff90d",
"content_id": "9c9af9dffdbeb1d09524fd4d547c006e5bd139be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3092,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 98,
"path": "/nci/jenkins-bin/job_scorer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'concurrent'\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative '../../lib/jenkins'\nrequire_relative 'job'\n\n# Scores a job with regards to how many cores it should get.\nmodule NCI\n module JenkinsBin\n # High level scoring system. Iterates all jobs and associates a\n # CPU core count with them.\n class JobScorer\n attr_reader :jobex\n attr_reader :config\n attr_reader :config_file\n\n CONFIG_FILE = \"#{Dir.home}/.config/nci-jobs-to-cores.json\"\n\n def initialize(jobex: /.+_bin_amd64$/, config_file: CONFIG_FILE)\n @jobex = jobex\n @log = Logger.new(STDOUT)\n @config_file = config_file\n @config = JSON.parse(File.read(config_file)) if File.exist?(config_file)\n @config ||= {}\n concurify!\n end\n\n def forget_missing_jobs!\n @config = config.select do |job|\n ret = all_jobs.include?(job)\n unless ret\n @log.warn \"Dropping score of #{job}. It no longer exists in Jenkins\"\n end\n ret\n end\n concurify!\n end\n\n def concurify!\n @config = Concurrent::Hash.new.merge(@config)\n end\n\n def all_jobs\n # This returns all jobs becuase to forget reliably we'll need to know\n # all jobs. Whether we filter here or at iteration makes no difference\n # though.\n @jobs ||= Jenkins.job.list_all.freeze\n end\n\n def score_job!(name)\n cores = Job.new(name).cores\n\n if !config.include?(name)\n @log.warn \"Giving new job #{name} #{cores} cores\"\n elsif config[name] != cores\n @log.warn \"Changing job #{name} from #{config[name]} to #{cores}\"\n end\n config[name] = cores\n end\n\n def run!\n FileUtils.mkpath(\"#{ENV['HOME']}/.config/\")\n forget_missing_jobs!\n\n pool = Concurrent::FixedThreadPool.new(4)\n promises = all_jobs.collect do |name|\n next unless jobex.match(name)\n\n Concurrent::Promise.execute(executor: pool) { score_job!(name) }\n end\n promises.compact.each(&:wait!)\n\n File.write(config_file, JSON.generate(config))\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5538377165794373,
"alphanum_fraction": 0.5608154535293579,
"avg_line_length": 32.68202590942383,
"blob_id": "0efc7f292075c876c02bab53b36fae4a6ebd12af",
"content_id": "bcf5ca7a199f257a76e9a65fe7b9fcff1fbbf0a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7309,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 217,
"path": "/test/test_nci_tagdetective.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'rugged'\n\nrequire_relative '../nci/debian-merge/tagdetective'\n\nmodule NCI\n module DebianMerge\n class NCITagDetectiveTest < TestCase\n def setup\n stub_request(:get, \"https://projects.kde.org/api/v1/projects/frameworks\").\n with(\n headers: {\n 'Accept'=>'*/*',\n 'Accept-Encoding'=>'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent'=>'Ruby'\n }).\n to_return(status: 200, body: '[\"frameworks/attica\"]', headers: { 'Content-Type' => 'text/json' })\n end\n\n def test_last_tag_base\n remote_dir = File.join(Dir.pwd, 'kde/extra-cmake-modules')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n `git tag debian/1-0`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n ProjectsFactory::Neon.stubs(:ls).returns(%w[kde/extra-cmake-modules])\n ProjectsFactory::Neon.stubs(:url_base).returns(Dir.pwd)\n TagDetective.any_instance.stubs(:list_frameworks).returns(['extra-cmake-modules'])\n\n assert_equal('debian/2', TagDetective.new.last_tag_base)\n end\n\n def test_investigate\n remote_dir = File.join(Dir.pwd, 'kde/attica')\n `rm -r #{remote_dir}`\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n ProjectsFactory::Neon.stubs(:ls).returns(%w[kde/attica])\n ProjectsFactory::Neon.stubs(:url_base).returns(Dir.pwd)\n\n TagDetective.any_instance.stubs(:last_tag_base).returns('debian/2')\n TagDetective.any_instance.stubs(:list_frameworks).returns(['attica'])\n\n TagDetective.new.investigate\n assert_path_exist('data.json')\n assert_equal({ 'tag_base' => 'debian/2', 'repos' => [remote_dir] },\n JSON.parse(File.read('data.json')))\n end\n\n def test_unreleased\n\n remote_dir = File.join(Dir.pwd, 'kde/attica')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n ProjectsFactory::Neon.stubs(:ls).returns(%w[kde/attica])\n ProjectsFactory::Neon.stubs(:url_base).returns(Dir.pwd)\n\n TagDetective.any_instance.stubs(:last_tag_base).returns('debian/2')\n TagDetective.any_instance.stubs(:list_frameworks).returns(['attica'])\n\n TagDetective.new.investigate\n assert_path_exist('data.json')\n assert_equal({ 'tag_base' => 'debian/2', 'repos' => [] },\n JSON.parse(File.read('data.json')))\n end\n\n def test_released_invalid\n\n remote_dir = File.join(Dir.pwd, 'kde/attica')\n `rm -r #{remote_dir}`\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0`\n\n `git checkout -b Neon/release`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n ProjectsFactory::Neon.stubs(:ls).returns(%w[kde/attica])\n ProjectsFactory::Neon.stubs(:url_base).returns(Dir.pwd)\n\n TagDetective.any_instance.stubs(:last_tag_base).returns('debian/3')\n\n # the repo has no debian/3 tag, but a Neon/release branch, so it is\n # released but not tagged, which means the invistigation ought to\n # abort with an error.\n assert_raises RuntimeError do\n TagDetective.new.investigate\n end\n end\n\n def test_pre_existing\n remote_dir = File.join(Dir.pwd, 'frameworks/attica')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n # use bogus repos to make sure this works as expected.\n # bogus name should still be present in the end because the detective\n # would simply use the existing file.\n File.write('data.json', JSON.generate({ 'tag_base' => 'debian/2', 'repos' => ['woop'] }))\n\n ProjectsFactory::Neon.stubs(:ls).returns(%w[frameworks/attica])\n ProjectsFactory::Neon.stubs(:url_base).returns(Dir.pwd)\n TagDetective.any_instance.stubs(:last_tag_base).returns('debian/2')\n TagDetective.any_instance.stubs(:list_frameworks).returns(['attica'])\n\n TagDetective.new.run\n assert_path_exist('data.json')\n assert_equal({ 'tag_base' => 'debian/2', 'repos' => ['woop'] },\n JSON.parse(File.read('data.json')))\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6306218504905701,
"alphanum_fraction": 0.6327325701713562,
"avg_line_length": 35.33628463745117,
"blob_id": "059faefc61ec7ff047b041dfa391796165c081b9",
"content_id": "ead3e7a41789dd785552d7aa306be5e8f3d224d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 12321,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 339,
"path": "/nci/lib/watcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'pp'\n\nrequire_relative '../../lib/debian/changelog'\nrequire_relative '../../lib/debian/uscan'\nrequire_relative '../../lib/debian/version'\nrequire_relative '../../lib/nci'\n\nrequire_relative '../../lib/kdeproject_component'\nrequire_relative '../../lib/pangea/mail'\n\nrequire 'shellwords'\nrequire 'tty-command'\n\nmodule NCI\n # uses uscan to check for new upstream releases\n class Watcher\n class NotKDESoftware < StandardError; end\n class UnstableURIForbidden < StandardError; end\n\n # Updates version info in snapcraft.yaml.\n # TODO: this maybe should also download the source and grab the desktop\n # file & icon. Needs checking if snapcraft does grab this\n # automatically yet, in which case we don't need to maintain copied data\n # at all and instead have them extracted at build time.\n class SnapcraftUpdater\n def initialize(dehs)\n # TODO: this ungsub business is a bit meh. Maybe watcher should\n # mangle the DEHS object and ungsub it right after parsing?\n @new_url = Watcher.ungsub_download_url(dehs.upstream_url)\n @new_version = dehs.upstream_version\n @snapcraft_yaml = 'snapcraft.yaml'\n end\n\n def run\n unless File.exist?(@snapcraft_yaml)\n puts \"Snapcraft file #{@snapcraft_yaml} not found.\" \\\n ' Skipping snapcraft logic.'\n return\n end\n snapcraft = YAML.load_file(@snapcraft_yaml)\n snapcraft = mangle(snapcraft)\n File.write(@snapcraft_yaml, YAML.dump(snapcraft, indentation: 4))\n puts 'Snapcraft updated.'\n end\n\n private\n\n def tar_basename_from_url(url)\n return url if url.nil?\n\n File.basename(url).reverse.split('-', 2).fetch(-1).reverse\n end\n\n def mangle(snapcraft)\n snapcraft['version'] = @new_version\n\n newest_tar = tar_basename_from_url(@new_url)\n snapcraft['parts'].each_value do |part|\n tar = tar_basename_from_url(part['source'])\n next unless tar == newest_tar\n\n part['source'] = @new_url\n end\n\n snapcraft\n end\n end\n\n attr_reader :cmd\n\n def initialize\n @cmd = TTY::Command.new\n end\n\n # NB: this gets mocked by the test, don't merge this into regular cmd!\n # it allows us to only mock the uscan\n def uscan_cmd\n @uscan_cmd ||= TTY::Command.new\n end\n\n # KEEP IN SYNC with ungsub_download_url!\n def self.gsub_download_url(url)\n url.gsub('download.kde.org/', 'download.kde.internal.neon.kde.org/')\n end\n\n # KEEP IN SYNC with gsub_download_url!\n def self.ungsub_download_url(url)\n url.gsub('download.kde.internal.neon.kde.org/', 'download.kde.org/')\n end\n\n def job_is_kde_released\n # These parts get pre-released on server so don't pick them up\n # automatically\n @job_is_kde_released ||= begin\n released_products = KDEProjectsComponent.frameworks_jobs +\n KDEProjectsComponent.plasma_jobs +\n KDEProjectsComponent.gear_jobs\n job_project = ENV['JOB_NAME'].split('_')[-1]\n released_products.include?(job_project)\n end\n end\n\n def merge\n cmd.run!('git status')\n merged = false\n if cmd.run!('git merge origin/Neon/stable').success?\n merged = true\n # if it's a KDE project use only stable lines\n newer_stable = newer_dehs_packages.select do |x|\n x.upstream_url.include?('stable') &&\n x.upstream_url.include?('kde.org')\n end\n # mutates 🤮\n # FIXME: this is only necessary because we traditionally had multi-source watch files from the debian kde team.\n # AFAIK these are no longer in use and also weren't really ever supported by uscan (perhaps uscan even\n # dropped support?). There is an assertion that there is only a single dehs package in run. After a while\n # if nothing exploded because of the assertion the multi-package support can be removed!\n @newer_dehs_packages = newer_stable unless newer_stable.empty?\n elsif cmd.run!('git merge origin/Neon/unstable').success?\n merged = true\n # Do not filter paths when unstable was merged. We use unstable as\n # common branch, so e.g. frameworks have only Neon/unstable but their\n # download path is http://download.kde.org/stable/frameworks/...\n # We thusly cannot kick stable.\n end\n raise 'Could not merge anything' unless merged\n end\n\n def with_mangle(&block)\n puts 'mangling debian/watch'\n output = ''\n FileUtils.cp('debian/watch', 'debian/watch.unmangled')\n File.open('debian/watch').each do |line|\n # The download.kde.internal.neon.kde.org domain is not\n # publicly available!\n # Only available through blue system's internal DNS.\n output += self.class.gsub_download_url(line)\n end\n puts output\n File.open('debian/watch', 'w') { |file| file.write(output) }\n puts 'mangled debian/watch'\n ret = yield\n puts 'unmangle debian/watch `git checkout debian/watch`'\n FileUtils.mv('debian/watch.unmangled', 'debian/watch')\n ret\n end\n\n def make_newest_dehs_package!\n newer = newer_dehs_packages.group_by(&:upstream_version)\n newer = Hash[newer.map { |k, v| [Debian::Version.new(k), v] }]\n newer = newer.sort.to_h\n newest = newer.keys[-1]\n @newest_version = newest\n @newest_dehs_package = newer.values[-1][0] # group_by results in an array\n\n raise 'No newest version found' unless newest_version && newest_dehs_package\n end\n\n def newer_dehs_packages\n @newer_dehs_packages ||= with_mangle do\n result = uscan_cmd.run!('uscan --report --dehs') # run! to ignore errors\n\n data = result.out\n puts \"uscan exited (#{result}) :: #{data}\"\n\n Debian::UScan::DEHS.parse_packages(data).collect do |package|\n next nil unless package.status == Debian::UScan::States::NEWER_AVAILABLE\n\n package\n end.compact\n end\n end\n\n # Set by bump_version. Fairly meh.\n def dch\n raise unless defined?(@dch)\n\n @dch\n end\n\n def bump_version\n changelog = Changelog.new(Dir.pwd)\n version = Debian::Version.new(changelog.version)\n version.upstream = newest_version\n version.revision = '0neon' unless version.revision.to_s.empty?\n @dch = Debian::Changelog.new_version_cmd(version.to_s, distribution: NCI.current_series, message: 'New release')\n # A bit awkward we want to give a dch suggestion in case this isn't kde software so we'll want to recycle\n # the command, meaning we can't just use changelog.new_version :|\n cmd.run(*dch)\n\n # --- Unset revision from this point on, so we get the base version ---\n version.revision = nil\n something_changed = false\n Dir.glob('debian/*') do |path|\n next unless path.end_with?('changelog', 'control', 'rules')\n next unless File.file?(path)\n\n data = File.read(path)\n begin\n # We track gsub results here because we'll later wrap-and-sort\n # iff something changed.\n source_change = data.gsub!('${source:Version}~ciBuild', version.to_s)\n binary_change = data.gsub!('${binary:Version}~ciBuild', version.to_s)\n something_changed ||= !(source_change || binary_change).nil?\n rescue StandardError => e\n raise \"Failed to gsub #{path} -- #{e}\"\n end\n File.write(path, data)\n end\n\n system('wrap-and-sort') if something_changed\n end\n\n attr_accessor :newest_version\n attr_accessor :newest_dehs_package\n\n def run\n raise 'No debian/watch found!' unless File.exist?('debian/watch')\n\n watch = File.read('debian/watch')\n if watch.include?('unstable') && watch.include?('download.kde.')\n raise UnstableURIForbidden, 'Quitting watcher as debian/watch contains unstable ' \\\n 'and we only build stable tars in Neon'\n end\n\n return if newer_dehs_packages.empty?\n\n # Message is transitional. The entire code in watcher is more complicated because of multiple packages.\n # e.g. see merge method.\n if newer_dehs_packages.size > 1\n raise 'There are multiple DEHS packages being reported. This suggests there are multiple sources in the watch' \\\n \" file. We'd like to get rid of these if possible. Check if we have full control over this package and\" \\\n ' drop irrelevant sources if possible. If we do not have full control check with upstream about the' \\\n ' rationale for having multiple sources. If the source cannot be \"fixed\". Then remove this error and' \\\n ' probably also check back with sitter.'\n end\n\n if job_is_kde_released && ENV['BUILD_CAUSE'] == \"Started by timer\"\n send_product_mail\n return\n end\n\n merge # this mutates newer_dehs_packages and MUST be before make_newest_dehs_package!\n make_newest_dehs_package! # sets a bunch of members - very awkwardly - must be after merge!\n\n job_project = ENV['JOB_NAME'].split('_')[-1]\n #if Dir.exist?(\"../snapcraft-kde-applications/#{job_project}\")\n #Dir.chdir(\"../snapcraft-kde-applications/#{job_project}\") do\n #SnapcraftUpdater.new(newest_dehs_package).run\n #cmd.run('git --no-pager diff')\n #cmd.run(\"git commit -a -vv -m 'New release'\")\n #end\n #end\n\n bump_version\n\n cmd.run('git --no-pager diff')\n cmd.run(\"git commit -a -vv -m 'New release'\")\n\n send_mail\n\n raise_if_not_kde_software!(dch)\n end\n\n def send_product_mail\n puts 'KDE Plasma/Gear/Framework watcher should be run manually not by timer, quitting'\n\n # Take first package from each product and send e-mail for only that\n # one to stop spam\n frameworks_package = KDEProjectsComponent.frameworks[0]\n plasma_package = KDEProjectsComponent.plasma[0]\n gear_package = KDEProjectsComponent.gear[0]\n product_packages = [frameworks_package, plasma_package, gear_package]\n return if product_packages.none? { |package| ENV['JOB_NAME'].end_with?(\"_#{package}\") }\n\n puts 'sending notification mail'\n Pangea::SMTP.start do |smtp|\n mail = <<~MAIL\nFrom: Neon CI <[email protected]>\nTo: [email protected]\nSubject: #{ENV['JOB_NAME']} found a new PRODUCT BUNDLE version\n\nNew release found on the server but not building because it may not be public yet,\nrun jenkins_retry manually for this release on release day.\n#{ENV['RUN_DISPLAY_URL']}\n MAIL\n smtp.send_message(mail,\n '[email protected]',\n '[email protected]')\n end\n end\n\n def send_mail\n return if ENV.key?('BUILD_CAUSE') and ENV['BUILD_CAUSE'] != 'Started by timer'\n\n subject = \"Releasing: #{newest_dehs_package.name} - #{newest_version}\"\n subject = \"Dev Required: #{newest_dehs_package.name} - #{newest_version}\" unless kde_software?\n\n puts 'sending notification mail'\n Pangea::SMTP.start do |smtp|\n mail = <<~MAIL\nFrom: Neon CI <[email protected]>\nTo: [email protected]\nSubject: #{subject}\n\n#{ENV['RUN_DISPLAY_URL']}\n\n#{newest_dehs_package.inspect}\n MAIL\n smtp.send_message(mail,\n '[email protected]',\n '[email protected]')\n end\n end\n\n def kde_software?\n job_is_kde_released || newest_dehs_package.upstream_url.include?('download.kde.') || newest_dehs_package.upstream_url.include?('invent.kde.')\n end\n\n def raise_if_not_kde_software!(dch)\n return if kde_software? # else we'll raise\n\n # Raise on none KDE software, they may not feature standard branch\n # layout etc, so tell a dev to deal with it.\n puts ''\n puts 'This is a non-KDE project. It never gets automerged or bumped!'\n puts 'Use dch to bump manually and merge as necessary, e.g.:'\n puts \"git checkout Neon/release && git merge origin/Neon/stable && #{Shellwords.shelljoin(dch)} && git commit -a -m 'New release'\"\n puts ''\n raise NotKDESoftware, 'New version available but not doing auto-bump!'\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7011865973472595,
"alphanum_fraction": 0.7216828465461731,
"avg_line_length": 37.625,
"blob_id": "3a373b261a93056b727c55b1a045cc5f9cc22659",
"content_id": "a9d8e492ad5df4a21cbb3fd407fa3e1d896aa88a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1854,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 48,
"path": "/nci/snap/snapcraft_snap_installer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'open-uri'\n\nrequire_relative 'unpacker'\n\nmodule NCI\n module Snap\n # Util stuff fro snapcraft itself.\n module Snapcraft\n def self.install\n # Taken from https://github.com/kenvandine/gnome-3-28-1804/blob/master/Dockerfile\n # Requires snapd to already be installed!\n\n # Special hack to install snapcraft from snap but without even having a\n # running snapd. This only works because snapcraft is a classic snap and\n # rpath'd accordingly.\n\n # This is not under test because it's fancy scripting and nothing more.\n\n Unpacker.new('core').unpack\n Unpacker.new('snapcraft').unpack\n\n wrapper = open('https://raw.githubusercontent.com/snapcore/snapcraft/b292b64d74b643e2ddb3c1ac3f6d6a0bb9baffee/docker/bin/snapcraft-wrapper')\n File.write('/usr/bin/snapcraft', wrapper.read)\n File.chmod(0o744, '/usr/bin/snapcraft')\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5704894065856934,
"alphanum_fraction": 0.6186997890472412,
"avg_line_length": 24.351852416992188,
"blob_id": "e1790e228670dd61393998ff342d522331e0f3d6",
"content_id": "1dea34ce81519f8578988823dda30c019b51bf0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1369,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 54,
"path": "/test/test_lint_result.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/result'\nrequire_relative 'lib/testcase'\n\n# Test lint result\nclass LintResultTest < TestCase\n def test_merge\n r1 = Lint::Result.new\n r1.valid = true\n r1.errors << 'error'\n r1.warnings << 'warning'\n r1.informations << 'info'\n\n r2 = Lint::Result.new\n r2.valid = false\n r2.errors << 'error2'\n r2.warnings << 'warning2'\n r2.informations << 'info2'\n\n r3 = Lint::Result.new\n r3.merge!(r1)\n r3.merge!(r2)\n assert(r3.valid)\n assert_equal(r1.errors + r2.errors, r3.errors)\n assert_equal(r1.warnings + r2.warnings, r3.warnings)\n assert_equal(r1.informations + r2.informations, r3.informations)\n end\n\n def test_all\n r = Lint::Result.new\n r.valid = true\n r.errors << 'error1' << 'error2'\n r.warnings << 'warning1'\n r.informations << 'info1' << 'info2'\n assert_equal(%w[error1 error2 warning1 info1 info2], r.all)\n end\n\n def test_equalequal\n r1 = Lint::Result.new\n r1.valid = true\n r1.errors << 'error1' << 'error2'\n r1.warnings << 'warning1'\n r1.informations << 'info1' << 'info2'\n\n r2 = Lint::Result.new\n r2.valid = true\n r2.errors << 'error1' << 'error2'\n r2.warnings << 'warning1'\n r2.informations << 'info1' << 'info2'\n\n assert(r1 == r2, 'r1 not same as r2')\n assert(r2 == r1, 'r2 not same as r1')\n end\nend\n"
},
{
"alpha_fraction": 0.6410980224609375,
"alphanum_fraction": 0.6452026963233948,
"avg_line_length": 23.670886993408203,
"blob_id": "f7b3507a58a183f451250e3c1742daac4f577fb9",
"content_id": "8c51d9a2435369683293f66c5844aacec094ce1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3904,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 158,
"path": "/jenkins_abort.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'concurrent'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins/job'\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/retry'\n\n# Aborts jobs, if that fails it terms them, if that fails it kills them.\nclass JobsAborter\n attr_reader :pattern\n attr_reader :builds\n\n def initialize(pattern, force:)\n @log = Logger.new(STDOUT).tap do |l|\n l.progname = File.basename(__FILE__, '.rb')\n l.level = Logger::INFO\n end\n @log.info pattern\n @pattern = pattern\n @builds = initial_builds\n @force = force\n end\n\n def run\n if builds.empty?\n @log.info 'Nothing building'\n return\n end\n murder\n end\n\n private\n\n def force?\n @force\n end\n\n def murder\n stab_them(:abort)\n return if done?\n\n query_continue?('abort', 'term')\n stab_them(:term)\n return if done?\n\n query_continue?('term', 'kill')\n stab_them(:kill)\n return if done?\n\n query_continue?('kill', 'give up')\n end\n\n def query_continue?(failed_action, new_action)\n return true if force?\n\n loop do\n puts <<-MSG\n--------------------------------------------------------------------------------\n#{builds.keys.join($/)}\nThese jobs did not #{failed_action} in time, do you want to #{new_action}? [y/n]\n MSG\n answer = STDIN.gets.chop.downcase\n raise 'aborting murder sequence' if answer == 'n'\n break if answer == 'y'\n end\n end\n\n def initial_builds\n jobs = Jenkins.job.list_all.select { |name| pattern.match(name) }\n builds = jobs.map do |name|\n job = Jenkins::Job.new(name)\n current = job.current_build_number\n next nil unless current && job.building?(current)\n\n [job, current]\n end\n builds.compact.to_h\n end\n\n def reduce_builds\n @builds = builds.select do |job, build|\n job.current_build_number == build && job.building?(build)\n end\n end\n\n def stab_them(action)\n promises = builds.collect do |job, number|\n Concurrent::Promise.execute do\n Retry.retry_it(times: 4, sleep: 1) do\n @log.warn \"#{action} -> #{job}\"\n # Retry as Jenkins likes to throw timeouts on too many operations.\n # NB: this needs public send, else we'd call process abort!\n job.public_send(action, number.to_s)\n end\n end\n end\n promises.compact.each(&:wait!)\n end\n\n def done?\n sleep 16\n reduce_builds\n builds.empty?\n end\nend\n\n@force = false\n\nOptionParser.new do |opts|\n opts.banner = <<-HELP_BANNER\nUsage: #{$0} 'regex'\n\nTells jenkins to abort all jobs matching regex\n\ne.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*src'\n\n • All unstable builds:\n '^.*_unstable_.*src'\n\n • All jobs:\n '.*src'\n HELP_BANNER\n\n opts.on('-f', '--force', 'TERM and KILL if necessary') do\n @force = true\n end\nend.parse!\n\nraise 'Need ruby pattern as argv0' if ARGV.empty?\n\npattern = Regexp.new(ARGV[0])\n\nJobsAborter.new(pattern, force: @force).run\n"
},
{
"alpha_fraction": 0.617814838886261,
"alphanum_fraction": 0.7003071308135986,
"avg_line_length": 36.983333587646484,
"blob_id": "95d44e7c81f99b9d0c3d090151c1fdfe29124032",
"content_id": "398e75bcca9df78dd9fe2f659069c3289441ba40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2279,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 60,
"path": "/test/test_debian_dsc.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/debian/dsc'\nrequire_relative 'lib/testcase'\n\n# Test debian .dsc\nclass DebianDSCTest < TestCase\n def setup\n # Change into our fixture dir as this stuff is read-only anyway.\n Dir.chdir(datadir)\n end\n\n def test_source\n c = Debian::DSC.new(data)\n c.parse!\n\n assert_equal(2, c.fields['checksums-sha1'].size)\n sum = c.fields['checksums-sha1'][1]\n assert_equal('d433a01bf5fa96beb2953567de96e3d49c898cce', sum.sum)\n # FIXME: should be a number maybe?\n assert_equal('2856', sum.size)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n sum.file_name)\n\n assert_equal(2, c.fields['checksums-sha256'].size)\n sum = c.fields['checksums-sha256'][1]\n assert_equal('7094169ebe86f0f50ca145348f04d6ca7d897ee143f1a7c377142c7f842a2062',\n sum.sum)\n # FIXME: should be a number maybe?\n assert_equal('2856', sum.size)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n sum.file_name)\n\n assert_equal(2, c.fields['files'].size)\n file = c.fields['files'][1]\n assert_equal('fa1759e139eebb50a49aa34a8c35e383', file.md5)\n # FIXME: should be a number maybe?\n assert_equal('2856', file.size)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n file.name)\n end\nend\n"
},
{
"alpha_fraction": 0.6819038391113281,
"alphanum_fraction": 0.6885014176368713,
"avg_line_length": 28.47222137451172,
"blob_id": "f70b391efcf694b512a79b09446eea17823c61c4",
"content_id": "35d4626e9fa3daaec01063e2f3f7051e8e9c9c5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2122,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 72,
"path": "/lib/dpkg.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2015 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty/command'\n\n# Wrapper around dpkg commandline tool.\nmodule DPKG\n def self.run(cmd, args)\n proc = TTY::Command.new(uuid: false, printer: :null)\n result = proc.run(cmd, *args)\n result.out.strip.split($/).compact\n rescue TTY::Command::ExitError\n # TODO: port away from internal resuce, let the caller deal with errors\n # needs making sure that we don't break anything by not rescuing though\n []\n end\n\n def self.dpkg(args)\n run('dpkg', args)\n end\n\n def self.architecture(var)\n run('dpkg-architecture', [] << \"-q#{var}\")[0]\n end\n\n def self.const_missing(name)\n architecture(\"DEB_#{name}\")\n end\n\n # optionized wrapper around dpkg-architecture\n class Architecture\n attr_reader :host_arch\n\n def initialize(host_arch: nil)\n # Make sure empty string also becomes nil. Otherwise simply set it.\n @host_arch = host_arch&.empty? ? nil : host_arch\n end\n\n def args\n args = []\n args << '--host-arch' << host_arch if host_arch\n args\n end\n\n def is(wildcard)\n system('dpkg-architecture', *args, '--is', wildcard)\n end\n end\n\n module_function\n\n def list(package)\n DPKG.dpkg([] << '-L' << package)\n end\nend\n"
},
{
"alpha_fraction": 0.7293797135353088,
"alphanum_fraction": 0.7416496276855469,
"avg_line_length": 35.67499923706055,
"blob_id": "52f9045f9634030088bb35e4094dade7686ea2d8",
"content_id": "2f0440d57a7552e1ba1c0ab16d55e4d14433e4b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1467,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 40,
"path": "/nci/watcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Watches for releases via uscan.\n\nrequire_relative 'lib/watcher'\nrequire_relative 'lib/setup_env'\nrequire_relative '../lib/debian/changelog'\nrequire_relative '../lib/debian/source'\n\npackaging_dir = Dir.pwd + \"/deb-packaging/\"\n# TODO: we should still detect when ubuntu versions diverge I guess?\n# though that may be more applicable to backports version change detection as\n# a whole\nif Debian::Source.new(packaging_dir).format.type == :native\n puts 'This is a native source. Nothing to do!'\n exit 0\nend\n\n# Special exclusion list. For practical reasons we have kind of neon-specific\n# sources that aren't built from tarballs but rather from git directly.\n# Sources in this list MUST be using KDE_L10N_SYNC_TRANSLATIONS AND have a\n# gitish watch file or none at all.\n# Changes to these requiremenst MUST be discussed with the team!\nsource_name = Debian::Changelog.new(packaging_dir).name\nif %w[drkonqi-pk-debug-installer].include?(source_name) &&\n File.read('debian/rules').include?('KDE_L10N_SYNC_TRANSLATIONS') &&\n (!File.exist?('debian/watch') ||\n File.read('debian/watch').include?('mode=git'))\n puts 'This is a neon-ish source built from git despite being in release/.'\n exit 0\nend\n\nNCI.setup_env!\nDir.chdir(packaging_dir) do\n NCI::Watcher.new.run\nend\n"
},
{
"alpha_fraction": 0.5802469253540039,
"alphanum_fraction": 0.5888352394104004,
"avg_line_length": 31.6842098236084,
"blob_id": "c882b086172c9def78488a421f64eee73da97e7a",
"content_id": "79fb76ec6bccc14ca13d668f3f71ea2dde9b62a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1863,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 57,
"path": "/nci/lint/cache_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire 'tty/command'\n\nrequire_relative '../../lib/debian/version'\n\nmodule NCI\n # Lists packages out of the apt cache\n class CachePackageLister\n Package = Struct.new(:name, :version)\n\n # NB: we always need a fitler for this lister. apt-cache cannot be run\n # without arguments!\n def initialize(filter_select:)\n @filter_select = filter_select\n end\n\n def packages\n @packages ||= begin\n cmd = TTY::Command.new(printer: :null)\n # The overhead of apt is rather substantial, so we'll want to get all\n # data in one go ideally. Should this exhaust some argument limit\n # at some point we'll want to split into chunks instead.\n result = cmd.run('apt-cache', 'policy', *@filter_select)\n\n map = {}\n name = nil\n version = nil\n result.out.split(\"\\n\").each do |line|\n if line.start_with?(/^\\w.+:/) # package lines aren't indented\n name = line.split(':', 2)[0].strip\n next\n end\n if line.start_with?(/\\s+Candidate:/) # always indented\n version = line.split(':', 2)[1].strip\n raise line unless name && !name.empty?\n raise line unless version && !version.empty?\n\n raise if map.include?(name) # double match wtf?\n\n version = version == '(none)' ? nil : Debian::Version.new(version)\n map[name] = version\n # reset the parent scope vars. we need them in parent scope since\n # matching is run across multiple lines\n name = nil\n version = nil\n next\n end\n end\n\n map.map { |k, v| Package.new(k, v) }\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6130374670028687,
"alphanum_fraction": 0.6481738090515137,
"avg_line_length": 34.75206756591797,
"blob_id": "23457c2fc941be400ebd62f2065d2f79f57f03f0",
"content_id": "e6868b59dba56b8be5487bd6836cd8982176a156",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4326,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 121,
"path": "/test/test_jenkins_jobdir.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'date'\n\nrequire_relative '../lib/jenkins/jobdir'\nrequire_relative 'lib/testcase'\n\nclass JenkinsJobDirTest < TestCase\n def setup\n @home = ENV.fetch('HOME')\n ENV['HOME'] = Dir.pwd\n end\n\n def teardown\n ENV['HOME'] = @home\n end\n\n def test_prune\n buildsdir = \"jobs/#{__method__}/builds\"\n FileUtils.mkpath(buildsdir)\n (1000..1016).each do |i|\n dir = \"#{buildsdir}/#{i}\"\n FileUtils.mkpath(dir)\n age = (1016 - i)\n mtime = (DateTime.now - age).to_time\n %w[build.xml log log.html log_ref.html].each do |file|\n FileUtils.touch(\"#{dir}/#{file}\", mtime: mtime)\n end\n FileUtils.mkpath(\"#{dir}/archive/randomdir\")\n FileUtils.touch(\"#{dir}/archive\", mtime: mtime)\n FileUtils.touch(\"#{dir}/archive/randomdir/artifact\", mtime: mtime)\n end\n # 1017 is a symlink to itself. For some reason this can happen\n File.symlink('1017', \"#{buildsdir}/1017\")\n # Static links\n File.symlink('1002', \"#{buildsdir}/lastFailedBuild\")\n File.symlink('-1', \"#{buildsdir}/lastUnstableBuild\")\n File.symlink('1011', \"#{buildsdir}/lastUnsuccessfulBuild\")\n File.symlink('1014', \"#{buildsdir}/lastStableBuild\")\n File.symlink('1014', \"#{buildsdir}/lastSuccessfulBuild\")\n # Really old plunder but protected name.\n FileUtils.touch(\"#{buildsdir}/legacyIds\", mtime: (DateTime.now - 300).to_time)\n\n very_old_mtime = (DateTime.now - 32).to_time\n\n # On mobile ci we had prunes on logs only. So we need to make sure\n # archives are pruned even if they have no log\n FileUtils.mkpath(\"#{buildsdir}/999/archive\")\n FileUtils.touch(\"#{buildsdir}/999/archive\", mtime: very_old_mtime)\n\n # At this point 1016-3 do not qualify for pruning on account of being too\n # new. 2 and 1 are old enough. Only 1 can be removed though as 2 is pointed\n # to by a reference symlink.\n\n # We now set build 1015 to a very old mtime to make sure it doesn't get\n # deleted either as we always keep the last 7 builds\n FileUtils.touch(\"#{buildsdir}/1015/log\", mtime: very_old_mtime)\n\n Dir.glob('jobs/*').each do |jobdir|\n Jenkins::JobDir.prune(jobdir)\n end\n\n %w[lastFailedBuild lastStableBuild lastSuccessfulBuild lastUnstableBuild lastUnsuccessfulBuild].each do |d|\n dir = \"#{buildsdir}/#{d}\"\n # unstable is symlink to -1 == invalid by default!\n assert_path_exist(dir) unless d == 'lastUnstableBuild'\n assert(File.symlink?(dir), \"#{dir} was supposed to be a symlink but isn't\")\n end\n # Protected but not a symlink\n assert_path_exist(\"#{buildsdir}/legacyIds\")\n\n markers = %w[log archive/randomdir]\n\n # Pointed to by symlinks, mustn't be deleted\n %w[1002 1003 1011 1014].each do |build|\n markers.each { |m| assert_path_exist(\"#{buildsdir}/#{build}/#{m}\") }\n end\n\n # Keeps last 6 builds regardless of mtime. 1015 had a very old mtime.\n markers.each { |m| assert_path_exist(\"#{buildsdir}/1015/#{m}\") }\n\n # Deletes only builds older than 14 days.\n # rubocop:disable Style/CombinableLoops\n markers.each { |m| assert_path_not_exist(\"#{buildsdir}/1000/#{m}\") }\n # rubocop:enable Style/CombinableLoops\n\n assert_path_not_exist(\"#{buildsdir}/999/archive\")\n end\n\n def test_prune_builds\n backupdir = \"jobs/#{__method__}/builds-backup\"\n buildsdir = \"jobs/#{__method__}/builds\"\n FileUtils.mkpath(buildsdir)\n (1000..1020).each do |i|\n dir = \"#{buildsdir}/#{i}\"\n FileUtils.mkpath(dir)\n # Decrease age and then multiply by days-in-week to get a build per week.\n # With 20 that gives us 120 days, or 4 months.\n age = (1020 - i) * 7\n mtime = (DateTime.now - age).to_time\n FileUtils.touch(dir, mtime: mtime)\n end\n\n Dir.glob('jobs/*').each do |jobdir|\n FileUtils.mkpath(backupdir) unless Dir.exist?(backupdir)\n # File older than 2 months\n Jenkins::JobDir.each_ancient_build(jobdir, min_count: 4, max_age: 7 * 4 * 2) do |ancient_build|\n FileUtils.mv(ancient_build, backupdir)\n end\n end\n\n # 1011 would be 9 weeks, we assume a month has 4 weeks. We expect 2 months\n # retained and the older ones as backup.\n (1000..1011).each do |i|\n assert_path_exist(\"#{backupdir}/#{i}\")\n end\n\n (1012..1020).each do |i|\n assert_path_exist(\"#{buildsdir}/#{i}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.49166667461395264,
"alphanum_fraction": 0.49166667461395264,
"avg_line_length": 23,
"blob_id": "5dfa03c8f566234c5674c601cf434423133de0c8",
"content_id": "6724443f4ce2ae9d12a1c6259e8c2a72889cdcbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 5,
"path": "/test/data/test_projects_factory/test_launchpad_from_list/bzr.erb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nargs=`echo \"$@\" | sed 's/lp:/<%= remote.gsub('/', '\\/') %>\\//'`\necho \"/usr/bin/bzr $args\"\n/usr/bin/bzr $args\n"
},
{
"alpha_fraction": 0.6161953210830688,
"alphanum_fraction": 0.6190057992935181,
"avg_line_length": 30.98314666748047,
"blob_id": "c5bbf190b3cdbf15a3c74ac6d036af9939a2ea8f",
"content_id": "0fbd31429d893e95a6b9a37417553257f012cd19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5693,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 178,
"path": "/nci/jenkins_job_artifact_cleaner.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\n\nrequire_relative '../lib/ci/pattern'\n\nmodule NCI\n # Cleans up artifacts of lastSuccessfulBuild of jobs passed as array of\n # names.\n module JenkinsJobArtifactCleaner\n # Logic wrapper encapsulating the cleanup logic of a job.\n class Job\n # An entry in builds/permalinks identifying a common name for a\n # build (such as lastFailedBuild) and its respective build number (or -1)\n class Permalink\n attr_reader :id\n attr_reader :number\n\n def initialize(line)\n @id, @number = line.split(' ', 2)\n @number = @number.to_i\n end\n end\n\n # A permalinks file builds/permalinks representing the common names\n # to build numbers map.\n class Permalinks\n attr_reader :path\n attr_reader :links\n\n def initialize(path)\n @path = path\n @links = []\n\n File.open(path, 'r') do |f|\n f.each_line do |line|\n parse_line(line)\n end\n end\n end\n\n private\n\n def parse_line(line)\n line = line.strip\n return if line.empty? || !line.start_with?('last')\n raise \"malformed line #{line} in #{path}\" unless line.count(' ') == 1\n\n @links << Permalink.new(line)\n end\n end\n\n attr_reader :name\n attr_reader :build\n\n def initialize(name, build: 'lastSuccessfulBuild', verbose: true)\n @name = name\n @build = build.to_s # coerce, may be int\n # intentionally only controls our verbosity, not FU! AllJobs has no\n # use for us printing all builds we look at as it looks at all jobs\n # and 100 build seach, so it's a massive wall of noop information.\n @verbose = verbose\n end\n\n def self.jobs_dir\n # Don't cache, we mutate this during testing.\n File.join(ENV.fetch('JENKINS_HOME'), 'jobs')\n end\n\n def last_build_id\n # After errors jenkins sometimes implodes and fails to update the\n # symlinks, so we use a newer (and also a bit more efficient) peramlinks\n # file which contains the same information in a single file. Whatever\n # we find in there is the highest number, unless it is in fact not\n # a positive number in which case we still fall back to try our luck\n # with the symlinks.\n\n file = \"#{builds_path}/permalinks\"\n return last_build_id_by_symlink unless File.exist?(file)\n\n perma = Permalinks.new(file)\n numbers = perma.links.group_by(&:number).keys\n puts \" permanumbers #{numbers}\"\n max = numbers.max\n return max if max.positive?\n\n last_build_id_by_symlink # fall back to legacy symlinks (needs readlink)\n end\n\n def last_build_id_by_symlink\n puts \"Failed to get permalink for #{builds_path}, falling back to links\"\n id = -1\n Dir.glob(\"#{builds_path}/last*\").each do |link|\n begin\n new_id = File.basename(File.realpath(link)).to_i\n id = new_id if new_id > id\n rescue Errno::ENOENT # when the build/symlink is invalid\n end\n end\n id\n end\n\n def clean!\n marker = \"#{path}/_artifact_cleaned\"\n return unless File.exist?(path) # path doesn't exist, nothing to do\n return if File.exist?(marker) # this build was already cleaned\n\n puts \"Cleaning #{name} in #{path}\" if @verbose\n Dir.glob(\"#{path}/**/**\") do |entry|\n next if File.directory?(entry)\n next unless BLACKLIST.any? { |x| x.match?(entry) }\n\n FileUtils.rm(entry, verbose: true)\n end\n\n FileUtils.touch(marker)\n end\n\n private\n\n def path\n File.join(builds_path, build, 'archive')\n end\n\n def builds_path\n File.join(jobs_dir, name, 'builds')\n end\n\n def jobs_dir\n self.class.jobs_dir\n end\n end\n\n BLACKLIST = [\n CI::FNMatchPattern.new('*.deb'),\n CI::FNMatchPattern.new('*.ddeb'),\n CI::FNMatchPattern.new('*.udeb'),\n CI::FNMatchPattern.new('*.orig.tar.*'),\n CI::FNMatchPattern.new('*.debian.tar.*'),\n CI::FNMatchPattern.new('*workspace.tar'), # Hand over from multijob to src\n CI::FNMatchPattern.new('*run_stamp'), # Generated by multijobs\n CI::FNMatchPattern.new('*fileParameters/*') # files got passed in\n ].freeze\n\n module_function\n\n def run(jobs)\n warn 'Cleaning up job artifacts to conserve disk space.'\n jobs.each do |job|\n Job.new(job).clean!\n end\n # Cleanup self as well.\n Job.new(ENV.fetch('JOB_BASE_NAME'),\n build: ENV.fetch('BUILD_NUMBER')).clean!\n end\n end\nend\n\nNCI::JenkinsJobArtifactCleaner.run(ARGV) if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.6850828528404236,
"alphanum_fraction": 0.6930631995201111,
"avg_line_length": 36.88372039794922,
"blob_id": "91505f1a582b621442238355ca0f4787d3a00036",
"content_id": "89ab074b788cd2faa0210051504b65fb2a4a306c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1629,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 43,
"path": "/lib/ci/tar-fetcher/deb_scm_fetcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../tarball'\n\nmodule CI\n # Fetch tarballs from the jenkins debscm dir.\n class DebSCMFetcher\n def initialize\n @dir = File.join(Dir.pwd, 'debscm')\n end\n\n def fetch(_destdir)\n # TODO: should we maybe copy the crap from debscm into destdir?\n # it seems a bit silly since we already have debscm in the workspace\n # anyway though...\n tars = Dir.glob(\"#{@dir}/*.tar*\").reject { |x| x.include?('.debian.tar') }\n raise \"Expected exactly one tar, got: #{tars}\" if tars.size != 1\n\n dscs = Dir.glob(\"#{@dir}/*.dsc\")\n raise \"Expected exactly one dsc, got: #{dscs}\" if dscs.size != 1\n\n DSCTarball.new(tars[0], dsc: dscs[0])\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5896083116531372,
"alphanum_fraction": 0.5931255221366882,
"avg_line_length": 31.409326553344727,
"blob_id": "ab8cc24e071950aab5733cb60649b94f5af3f182",
"content_id": "113c69dc17848c3ff6902b2193c93ffde8ba06ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6255,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 193,
"path": "/test/test_debian_control.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire_relative '../lib/debian/control'\nrequire_relative 'lib/testcase'\n\n# Test debian/control\nmodule Debian\n class ControlTest < TestCase\n def setup\n FileUtils.cp_r(\"#{datadir}/.\", Dir.pwd)\n end\n\n def test_old_names\n assert(Kernel.const_defined?(:DebianControl))\n end\n\n def test_parse\n assert_nothing_raised do\n c = Control.new\n c.parse!\n end\n end\n\n def test_key\n c = Control.new\n c.parse!\n assert_not_nil(c.source.key?('build-depends'))\n end\n\n def test_value\n c = Control.new\n c.parse!\n assert_equal(1, c.source['build-depends'].size)\n assert_nil(c.source.fetch('magic', nil))\n end\n\n def test_multiline_newlines\n c = Control.new\n c.parse!\n # We want accurate newlines preserved for multilines\n assert_equal(\"meow\\nkitten\\n.\\na\", c.binaries[0].fetch('Description'))\n end\n\n def test_no_final_newline\n c = Control.new(__method__)\n c.parse!\n assert_equal('woof', c.binaries[-1].fetch('Homepage'))\n end\n\n # Also tests !pwd opening\n def test_no_build_deps\n c = Control.new(__method__)\n c.parse!\n assert_equal(nil, c.source.fetch('build-depends', nil),\n \"Found a build dep #{c.source.fetch('build-depends', nil)}\")\n end\n\n def test_write_nochange\n c = Control.new(__method__)\n c.parse!\n build_deps = c.source.fetch('build-depends', nil)\n assert_not_equal(nil, build_deps)\n assert_equal(File.read(\"#{__method__}/debian/control\").split($/),\n c.dump.split($/))\n end\n\n def test_alt_build_deps\n c = Control.new(__method__)\n c.parse!\n build_deps = c.source.fetch('build-depends', nil)\n assert_not_equal(nil, build_deps)\n assert_equal(1, build_deps.count)\n assert_equal(2, build_deps.first.count)\n assert_equal(File.read(\"#{__method__}/debian/control\").split($/),\n c.dump.split($/))\n end\n\n def test_ordered_alt_build_deps\n c = Control.new(__method__)\n c.parse!\n build_deps = c.source.fetch('build-depends', nil)\n assert_not_equal(nil, build_deps)\n assert_equal(File.read(\"#{__method__}/debian/control\").split($/),\n c.dump.split($/))\n end\n\n description 'changing build-deps works and can be written and read'\n def test_write\n c = Control.new(__method__)\n c.parse!\n build_deps = c.source.fetch('build-depends', nil)\n gwenview_arr = build_deps.find { |x| x.find { |e| e if e.name == 'gwenview' } }\n gwenview = gwenview_arr.find { |x| x.name == 'gwenview' }\n gwenview.operator = '='\n gwenview.version = '1.0'\n\n File.write(\"#{__method__}/debian/control\", c.dump)\n # Make sure this is actually equal to our golden ref before even trying\n # to parse it again.\n assert_equal(File.read(\"#{__method__}.ref\").split($/), c.dump.split($/))\n end\n\n def test_write_consistency\n # Make sure adding values to a paragraph preserves order as per golden\n # reference file.\n\n c = Control.new(__method__)\n c.parse!\n assert_nil(c.source['Vcs-Git'])\n c.source['Vcs-Git'] = 'abc'\n\n assert_equal(File.read(\"#{__method__}.ref\").split($/), c.dump.split($/))\n end\n\n def test_write_wrap_and_sort\n # Has super long foldable and relationship fields, we expect them to\n # be properly broken as wrap-and-sort would.\n\n c = Control.new(__method__)\n c.parse!\n assert_equal(File.read(\"#{__method__}.ref\").split($/), c.dump.split($/))\n end\n\n def test_single_foldable\n # Uploaders is too long line and foldable. It should be split properly.\n\n c = Control.new(__method__)\n c.parse!\n assert_equal(c.source['uploaders'],\n ['Sune Vuorela <[email protected]>',\n 'Modestas Vainius <[email protected]>',\n 'Fathi Boudra <[email protected]>',\n 'Maximiliano Curia <[email protected]>'])\n end\n\n def test_folded_uploaders_write\n c = Control.new(__method__)\n c.parse!\n # Assert that our output is consistent with the input. If we assembled\n # Uploaders incorrectly it wouldn't be.\n assert_equal(File.read(\"#{__method__}/debian/control\").split($/),\n c.dump.split($/))\n end\n\n def test_description_not_at_end_dump\n c = Control.new(__method__)\n c.parse!\n # Assert that output is consistent. The input has a non-standard order\n # of fields. Notably Description of binaries is inside the paragraph\n # rather than its end. This resulted in a format screwup due to how we\n # processed multiline trailing whitespace characters (e.g. \\n)\n assert_equal(File.read(\"#{__method__}/debian/control\"),\n c.dump)\n end\n\n def test_trailing_newline_dump\n c = Control.new(__method__)\n c.parse!\n # The input does not end in a terminal newline (i.e. \\nEOF). This\n # shouldn't trip up the parser.\n # Assert that stripping the terminal newline from the dump is consistent\n # with the input data.\n ref = File.read(\"#{__method__}/debian/control\")\n assert(ref)\n assert(ref[-1] != \"\\n\") # make sure the fixture is correct!\n assert_equal(\"#{ref}\\n\",\n c.dump)\n end\n\n def test_preserve_description_left_space\n c = Control.new(__method__)\n c.parse!\n # Make sure we preserve leading whitespaces in descriptions.\n # Do however rstrip so terminal newlines doesn't mess with the assertion,\n # for the purposes of this assertion we do not care about newline\n # consistency.\n assert_equal(File.read(\"#{__method__}.description.ref\").rstrip,\n c.binaries[0]['Description'].rstrip)\n end\n\n def test_excess_newlines\n c = Control.new(__method__)\n c.parse!\n # Assert that the output doens't have extra newlines. When the last\n # field is Description it would end in \\n\\n (possibly)\n assert_equal(File.read(\"#{__method__}/debian/control\"),\n c.dump)\n assert(c.dump[-2] != \"\\n\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6880494356155396,
"alphanum_fraction": 0.6919695734977722,
"avg_line_length": 36.24778747558594,
"blob_id": "cd7a33c5bb1c19c6b6d43e0e05338d910bcb4cb4",
"content_id": "07485813b32e27661e173238c97314d7bea54a01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 8418,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 226,
"path": "/test/lib/testcase.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2014-2021 Harald Sitter <[email protected]>\n\nrequire 'test/unit'\n\nrequire 'tmpdir'\nrequire 'webmock/test_unit'\nrequire 'net/smtp'\nrequire 'mocha/test_unit'\nrequire 'objspace'\n\nrequire_relative 'assert_xml'\n\n# Deal with a require-time expecation here. docker.rb does a version coercion\n# hack at require-time which will hit the socket. As we install webmock above\n# already it may be active by the time docker.rb is required, making it\n# necessary to stub the expecation.\nWebMock.stub_request(:get, 'http://unix/v1.16/version')\n .to_return(body: '{\"Version\":\"17.03.0-ce\",\"ApiVersion\":\"1.26\",\"MinAPIVersion\":\"1.12\"}')\n\n# Test case base class handling fixtures and chdirring to not pollute the source\n# dir.\n# This thing does a whole bunch of stuff, you'd best read through priority_setup\n# and priority_teardown to get the basics. Its primary function is to\n# setup/teardown common stuff we need across multiple test cases or to ensure\n# pristine working conditions for each test.\n# The biggest feature by far is that a TestCase is always getting an isolated\n# PWD in a tmpdir. On top of that fixture loading helpers are provided in the\n# form of {#data} and {#fixture_file} which grab fixtures out of\n# test/data/file_name/test_method_name.\n# This class is very long because it is very flexible and very complicated.\nclass TestCase < Test::Unit::TestCase\n include EquivalentXmlAssertations\n\n ATFILEFAIL = 'Could not determine the basename of the file of the' \\\n ' class inheriting TestCase. Either flatten your inheritance' \\\n ' graph or set the name manually using `self.file = __FILE__`' \\\n ' in class scope.'\n\n class << self\n attr_accessor :file\n\n # attr_accessor :required_binaries\n def required_binaries(*args)\n @required_binaries ||= []\n @required_binaries += args.flatten\n end\n end\n\n def self.autodetect_inherited_file\n caller_locations.each do |call|\n next if call.label.include?('inherited')\n\n path = call.absolute_path\n @file = path if path.include?('/test/')\n break\n end\n raise ATFILEFAIL unless @file\n end\n\n def self.inherited(subclass)\n @file = nil\n super(subclass)\n subclass.autodetect_inherited_file unless @file\n end\n\n # Automatically issues omit() if binaries required for a test are not present\n # @param binaries [Array<String>] binaries to check for (can be full path)\n def require_binaries(*binaries)\n binaries.flatten.each do |bin|\n next if system(\"type #{bin} > /dev/null 2>&1\")\n\n omit(\"#{self.class} requires #{bin} but #{bin} is not in $PATH\")\n end\n end\n\n def assert_is_a(obj, expected)\n actual = obj.class.ancestors | obj.class.included_modules\n diff = AssertionMessage.delayed_diff(expected, actual)\n format = <<MSG\n<?> expected but its ancestors and includes are at the very least\n<?>.?\nMSG\n message = build_message(message, format, expected, actual, diff)\n assert_block(message) { obj.is_a?(expected) }\n end\n\n def priority_setup\n raise ATFILEFAIL unless self.class.file\n\n # Remove some CI vars to ensure tests are self-sufficient (i.e. passing outside CI envs)\n ENV.delete('WORKSPACE')\n ENV.delete('BUILD_NUMBER')\n # Don't fall on the nose on localized systems. Force default output instead.\n # This notably prevents failure from localized CLI tools (such as git) not matching output\n # expectations anymore.\n ENV.delete('LANGUAGE')\n ENV['LOCALE'] = 'C.UTF-8'\n\n script_base_path = File.expand_path(File.dirname(self.class.file))\n script_name = File.basename(self.class.file, '.rb')\n @datadir = File.join(script_base_path, 'data', script_name)\n @previous_pwd = Dir.pwd\n @tmpdir = Dir.mktmpdir(self.class.to_s.tr(':', '_'))\n Dir.chdir(@tmpdir)\n require_binaries(self.class.required_binaries)\n\n # Keep copy of env to restore in teardown. Note that clone wouldn't actually\n # copy the underlying data as that is not stored in the ENV. Instead we'll\n # need to convert to a hash which basically creates a \"snapshot\" of the\n # proc env at the time of the call.\n # NB: don't use an easily overwritten variable name. In the past this var\n # got accidentally smashed by deriving tests storing env as well for\n # legacy reasons.\n @__testcase_env = ENV.to_h\n\n # Set sepcial env var to check if a code path runs under test. This should\n # be used very very very carefully. The only reason for using this is when\n # a code path needs disabling entirely when under testing.\n ENV['PANGEA_UNDER_TEST'] = 'true'\n\n Retry.disable_sleeping if defined?(Retry)\n\n # Make sure we reset $?, so tests can freely mock system and ``\n reset_child_status!\n # FIXME: Drop when VCR gets fixed\n WebMock.enable!\n\n # Make sure smtp can't be used without mocking it.\n Net::SMTP.stubs(:new).raises(StandardError, 'do not actively use smtp in tests')\n Net::SMTP.stubs(:start).raises(StandardError, 'do not actively use smtp in tests')\n end\n\n def priority_teardown\n Dir.chdir(@previous_pwd)\n FileUtils.rm_rf(@tmpdir)\n # Restore ENV\n ENV.replace(@__testcase_env) if @__testcase_env\n end\n\n def _method_name\n return @method_name if defined?(:@method_name)\n\n index = 0\n caller = ''\n until caller.start_with?('test_')\n caller = caller_locations(index, 1)[0].label\n index += 1\n end\n caller\n end\n\n def data(path = nil)\n caller = _method_name\n file = File.join(*[@datadir, caller, path].compact)\n return file if File.exist?(file)\n\n raise \"Could not find data path #{file}\"\n end\n\n # Different from data in that it does not assume ext will be a directory\n # but a simple extension. i.e.\n # data/caller.foo instead of data/caller/foo\n def fixture_file(ext)\n caller = _method_name\n file = File.join(*[@datadir, \"#{caller}#{ext}\"].compact)\n return file if File.exist?(file)\n\n raise \"Could not find data file #{file}\"\n end\n\n # The data dir for the entire test file (not restricted by test method name)\n attr_reader :datadir\n\n def fake_home(home = Dir.pwd, &block)\n home_ = ENV.fetch('HOME')\n ENV['HOME'] = home\n block.yield\n ensure\n ENV['HOME'] = home_\n end\n\n def reset_child_status!\n system('true') # Resets $? to all good\n end\nend\n\nclass AllTestCasesArePangeaCases < TestCase\n # This is a super special hack. We'll want to assert that all TestCases\n # run are in fact derived from this class. But, since we use parallel to\n # quickly run tests in multiple processes at the same time (bypassing the GIL)\n # we cannot simply have a test that asserts it, as that test may be run in\n # set A but not set B and set B may have offending test cases.\n # To deal with this any set that includes any of our TestCase will have\n # this suite forcefully added to assert that everything is alright.\n #\n # For future reference: the class name may need PID mutation to avoid\n # conflicts in the output junit data. Unclear if this is a problem though.\n def test_all_testcases_are_pangea_testcases_test\n not_pangea = []\n ObjectSpace.each_object do |obj|\n next unless obj.is_a?(Class)\n next if obj == Test::Unit::TestCase\n # Hacky workaround. For unknown reasons the mobile CI fails semi-randomly\n # on getting objects which are Class but have an ancestors that is a\n # string. What is most peculiar about this is that the object is entirely\n # uninspectable and everything simply returns an XML string.\n # My theory is that something in the CI reporter stack is an object\n # which somehow managed to override every single method to return to_s,\n # I have no clue how or why, but given the problem is consistently showing\n # the XML string in the output it must be that. While that sucks beyond\n # comprehension, simply guarding against this should make the test work\n # reliably.\n next if obj.ancestors.is_a?(String) || !obj.ancestors.respond_to?(:any?)\n next unless obj.ancestors.any? do |ancestor|\n ancestor == Test::Unit::TestCase\n end\n\n not_pangea << obj unless obj.ancestors.include?(TestCase)\n end\n\n assert_empty(not_pangea, 'Found test cases which do not derive from the' \\\n ' pangea specific TestCase class.')\n end\nend\n"
},
{
"alpha_fraction": 0.5736690163612366,
"alphanum_fraction": 0.5786215662956238,
"avg_line_length": 25.922222137451172,
"blob_id": "2f241206d448cbe946d9bbe90c53823338be6fb2",
"content_id": "6c5c361f0080f4361a912a30614958802ae63232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2423,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 90,
"path": "/nci/cnf_generate.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'open-uri'\nrequire 'tty/command'\n\nrequire_relative 'lint/repo_package_lister'\n\nmodule NCI\n class CNFGenerator\n def dist\n ENV.fetch('DIST')\n end\n\n def arch\n ENV.fetch('ARCH')\n end\n\n def repo\n ENV.fetch('REPO')\n end\n\n def commands_file\n \"Commands-#{arch}\"\n end\n\n def pkg_to_version\n @pkg_to_version ||= begin\n pkg_to_version = {}\n Aptly.configure do |config|\n config.uri = URI::HTTPS.build(host: 'archive-api.neon.kde.org')\n # This is read-only.\n end\n NCI::RepoPackageLister.new.packages.each do |pkg|\n pkg_to_version[pkg.name] = pkg.version\n end\n pkg_to_version\n end\n end\n\n def run\n uri = \"https://contents.neon.kde.org/v2/find/archive.neon.kde.org/#{repo}/dists/#{dist}?q=*/bin/*\"\n\n pkg_to_paths = {} # all bin paths in a package\n\n path_to_pkgs = JSON.parse(URI.open(uri).read)\n path_to_pkgs.each do |path, packages|\n path = \"/#{path}\" unless path[0] == '/' # Contents paths do not have a leading slash\n packages.each do |pkg|\n # For everything that isn't Qt we'll want the bin name only. Generally\n # people will try to run 'foobar' not '/usr/bin/foobar'. qtchooser OTOH\n # does intentionally and explicitly the latter to differenate its overlay\n # binaries ('/usr/bin/qmake' is a symlink to qtchooser) from the backing\n # SDK binaries ('/usr/lib/qt5/bin/qmake')\n path = File.basename(path) unless path.include?('qt5/bin/')\n\n (pkg_to_paths[pkg] ||= []) << path\n end\n end\n\n output_dir = 'repo/main/cnf'\n FileUtils.mkpath(output_dir)\n File.open(\"#{output_dir}/#{commands_file}\", 'w') do |file|\n file.puts(<<~HEADER)\n suite: #{dist}\n component: main\n arch: #{arch}\n HEADER\n\n file.puts\n\n pkg_to_paths.each do |pkg, paths|\n file.puts(<<~BLOCK)\n name: #{pkg}\n version: #{pkg_to_version[pkg]}\n commands: #{paths.join(', ')}\n BLOCK\n\n file.puts\n end\n end\n end\n end\nend\n\nNCI::CNFGenerator.new.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.711693525314331,
"alphanum_fraction": 0.7201613187789917,
"avg_line_length": 39,
"blob_id": "a569a1d510122cbbf6d4210f632d08d40573f080",
"content_id": "755deb0736cb3b8fb44357efafe133b977d32d82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2480,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/jenkins-jobs/nci/mgmt_repo_test_versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'pipelinejob'\n\n# Tests that for all our debs the apt cache shows us offering the version we\n# expect (not a different one and not one from ubuntu)\nclass MGMTRepoTestVersionsJob < PipelineJob\n attr_reader :distribution\n attr_reader :type\n\n def initialize(distribution:, type:)\n super(\"mgmt_repo_test_versions_#{type}_#{distribution}\",\n template: 'mgmt_repo_test_versions',\n cron: 'H H(21-23) * * *',\n with_push_trigger: false)\n # Runs once a day after 21 UTC\n # Disables with_push_trigger because it clones its own tooling, so it'd\n # erronously trigger on tooling changes.\n @distribution = distribution\n @type = type\n end\nend\n\n# Special upgrade variants, performs the same check between current and\n# future series to ensure the new series' versions (both ours and ubuntus)\n# are greater than our old series'.\nclass MGMTRepoTestVersionsUpgradeJob < PipelineJob\n attr_reader :distribution\n attr_reader :type\n\n # distribution in this case is the series the test should be run as.\n # the \"old\" series is determined from the NCI metadata\n def initialize(distribution:, type:)\n super(\"mgmt_repo_test_versions_upgrades_#{type}_#{distribution}\",\n template: 'mgmt_repo_test_versions_upgrade',\n cron: 'H H(21-23) * * *',\n with_push_trigger: false)\n # Runs once a day after 21 UTC\n # Disables with_push_trigger because it clones its own tooling, so it'd\n # erronously trigger on tooling changes.\n @distribution = distribution\n @type = type\n end\nend\n"
},
{
"alpha_fraction": 0.636879026889801,
"alphanum_fraction": 0.6590172648429871,
"avg_line_length": 30.389829635620117,
"blob_id": "85f9e82a55b839b97daef22b5edb0f876ed2f737",
"content_id": "75a8cd483d9d556d2878f4a7a5d905b5c41f392b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3704,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 118,
"path": "/test/test_ci_build_version.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2016 Jonathan Riddell <[email protected]>\n\nrequire_relative '../lib/ci/build_version'\nrequire_relative '../lib/debian/changelog'\nrequire_relative 'lib/testcase'\n\n# Test ci/build_version\nclass CIBuildVersionTest < TestCase\n REF_TIME = '20150505.0505'\n\n def setup\n OS.instance_variable_set(:@hash, VERSION_ID: '15.04', ID: 'ubuntu')\n ENV['TYPE'] = 'typppo' # intentional spellling for uniquness\n alias_time\n end\n\n def teardown\n OS.reset\n unalias_time\n end\n\n def alias_time\n CI::BuildVersion.send(:alias_method, :__time_orig, :time)\n CI::BuildVersion.send(:define_method, :time) { REF_TIME }\n @time_aliased = true\n end\n\n def unalias_time\n return unless @time_aliased\n\n CI::BuildVersion.send(:undef_method, :time)\n CI::BuildVersion.send(:alias_method, :time, :__time_orig)\n @time_aliased = false\n end\n\n def test_all\n c = Changelog.new(data)\n v = CI::BuildVersion.new(c)\n suffix = v.send(:instance_variable_get, :@suffix)\n\n # Suffix must be comprised of a date and a distribution identifier such\n # that uploads created at the same time for different targets do not\n # conflict one another.\n assert_equal(v.send(:time), REF_TIME)\n parts = suffix.split('+')\n assert_empty(parts[0])\n assert_equal(\"p#{OS::VERSION_ID}\", parts[1])\n assert_equal(\"vtypppo\", parts[2])\n assert_equal(\"git#{v.time}\", parts[3])\n assert_equal(\"+p#{OS::VERSION_ID}+vtypppo+git#{v.time}\", suffix)\n\n # Check actual versions.\n assert_equal(\"4:5.2.2#{suffix}\", v.base)\n assert_equal(\"5.2.2#{suffix}\", v.tar)\n assert_equal(\"4:5.2.2#{suffix}-0\", v.full)\n assert_equal(v.full, v.to_s)\n end\n\n def test_bad_os_release\n # os-release doesn't have the var\n OS.reset\n OS.instance_variable_set(:@hash, ID: 'debian')\n c = Changelog.new(data)\n v = CI::BuildVersion.new(c)\n suffix = v.send(:instance_variable_get, :@suffix)\n parts = suffix.split('+')\n assert_equal('p10', parts[1])\n\n OS.instance_variable_set(:@hash, ID: 'ubuntu')\n c = Changelog.new(data)\n assert_raise RuntimeError do\n v = CI::BuildVersion.new(c)\n end\n\n # Value is nil\n OS.instance_variable_set(:@hash, VERSION_ID: nil, ID: 'ubuntu')\n c = Changelog.new(data)\n assert_raise RuntimeError do\n v = CI::BuildVersion.new(c)\n end\n\n # Value is empty\n OS.instance_variable_set(:@hash, VERSION_ID: '', ID: 'ubuntu')\n c = Changelog.new(data)\n assert_raise RuntimeError do\n v = CI::BuildVersion.new(c)\n end\n end\n\n def test_time\n unalias_time\n c = Changelog.new(data)\n v = CI::BuildVersion.new(c)\n # Make sure time is within a one minute delta between what version returns\n # and what datetime.now returns. For the purpose of this excercise the\n # timezone needs to get stripped, so simply run our refernece time through\n # the same string mangling as the actual verson.time\n time_format = v.class::TIME_FORMAT\n time1 = DateTime.strptime(DateTime.now.strftime(time_format), time_format)\n time2 = DateTime.strptime(v.send(:time), time_format)\n datetime_diff = (time2 - time1).to_f\n # One minute rational as float i.e. Rational(1/1440)\n minute_rational_f = 0.0006944444444444445\n assert_in_delta(0.0, datetime_diff.to_f, minute_rational_f,\n \"The time delta between version's time and actual time is\" \\\n ' too large.')\n end\n\n def test_bad_version\n c = Changelog.new(data)\n assert_raise RuntimeError do\n CI::BuildVersion.new(c)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6271794438362122,
"alphanum_fraction": 0.6291720867156982,
"avg_line_length": 44.416290283203125,
"blob_id": "352228be1b5f366e3fbb45537f617f572cd4374f",
"content_id": "40b4582a17def62dbb5ee24116cecf23b2a3133e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 20077,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 442,
"path": "/jenkins_jobs_update_nci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# To only update some jobs run locally with e.g.\n# PANGEA_FACTORIZE_ONLY='keurocalc' NO_UPDATE=1 UPDATE_INCLUDE='_keurocalc' ./jenkins_jobs_update_nci.rb\n\nrequire 'sigdump/setup'\n\nrequire_relative 'lib/nci'\nrequire_relative 'lib/projects/factory'\nrequire_relative 'lib/jenkins/project_updater'\nrequire_relative 'lib/kdeproject_component'\n\nDir.glob(File.expand_path('jenkins-jobs/*.rb', __dir__)).each do |file|\n require file\nend\n\nDir.glob(File.expand_path('jenkins-jobs/nci/*.rb', __dir__)).each do |file|\n require file\nend\n\n# FIXME: this really shouldn't be in here. need some snap job builder or something\nEXCLUDE_SNAPS = KDEProjectsComponent.frameworks_jobs + KDEProjectsComponent.plasma_jobs +\n %w[backports-focal clazy colord-kde gammaray icecc icemon latte-dock libqaccessiblity\n ofono pyqt sip5 attica baloo bluedevil bluez-qt breeze drkonqi\n eventviews gpgmepp grantleetheme incidenceeditor\n kaccounts-integration kcalcore kcalutils kcron kde-dev-scripts\n kdepim-addons kdepim-apps-libs kdgantt2 kholidays\n kidentitymanagement kimap kldap kmailtransport kmbox kmime\n kontactinterface kpimtextedit ktnef libgravatar libkdepim libkleo\n libkmahjongg libkomparediff2 libksieve mailcommon mailimporter\n messagelib pimcommon signon-kwallet-extension syndication akonadi\n akonadi-calendar akonadi-search calendarsupport kalarmcal kblog\n kcontacts kleopatra kdepim kdepim-runtime kdepimlibs baloo-widgets\n ffmpegthumbs dolphin-plugins akonadi-mime akonadi-notes analitza\n kamera kdeedu-data kdegraphics-thumbnailers kdenetwork-filesharing\n kdesdk-thumbnailers khelpcenter kio-extras kqtquickcharts kuser\n libkdcraw libkdegames libkeduvocdocument libkexiv2 libkface\n libkgeomap libkipi libksane poxml akonadi-contacts print-manager\n marble khangman kdevplatform sddm kdevelop-python kdevelop-php\n phonon-backend-vlc phonon-backend-gstreamer ktp-common-internals\n kaccounts-providers kdevelop-pg-qt kwalletmanager kdialog svgpart\n libkcddb libkcompactdisc mbox-importer akonadi-calendar-tools\n akonadi-import-wizard audiocd-kio grantlee-editor kdegraphics-mobipocket\n kmail-account-wizard konqueror libkcddb libkcompactdisc pim-data-exporter\n pim-sieve-editor pim-storage-service-manager kdegraphics-mobipocket\n akonadiconsole akregator kdav kmail knotes blogilo libkgapi kgpg\n kapptemplate kcachegrind kde-dev-utils kdesdk-kioslaves korganizer\n kfind kfloppy kaddressbook konsole krfb ksystemlog ofono-qt indi libappimage\n fwupd iio-sensor-proxy kcolorpicker kimageannotator libaqbanking libgusb\n libgwenhywfar mlt pipewire qxmpp xdg-dbus-proxy alkimia calamares exiv2\n grantlee kdb kdiagram kpmcore kproperty kpublictransport kreport kuserfeedback\n libktorrent libmediawiki libqaccessiblity muon polkit-qt-1 pulseaudio-qt qapt qca2\n qtav qtcurve telepathy-qt wacomtablet fcitx-qt5 kpeoplevcard kup pyqt5 qtkeychain\n sip4 kio-gdrive kipi-plugins ktp-accounts-kcm ktp-approver ktp-auth-handler ktp-call-ui\n ktp-contact-list ktp-contact-runner ktp-desktop-applets ktp-filetransfer-handler\n ktp-kded-module ktp-send-file ktp-text-ui libkscreen libksysguard markdownpart plasma-browser-integration plasma-desktop plasma-discover\n plasma-integration plasma-nano plasma-nm plasma-pa plasma-sdk plasma-thunderbolt plasma-vault plasma-wayland-protocols\n plasma-workspace-wallpapers plasma-workspace plymouth-kcm polkit-kde-agent-1\n powerdevil xdg-desktop-portal-kde black-hole-solver kcgroups kio-fuse kio-stash kmarkdownwebview libetebase libkvkontakte\n libquotient plasma-disks plasma-firewall plasma-pass plasma-systemmonitor\n qqc2-breeze-style stellarsolver symmy debug-installer atcore kwrited\n docker-neon ubiquity-slideshow\n].freeze\n\n# Updates Jenkins Projects\nclass ProjectUpdater < Jenkins::ProjectUpdater\n def initialize\n @job_queue = Queue.new\n @flavor = 'nci'\n @blacklisted_plugins = [\n 'ircbot', # spammy drain on performance\n 'instant-messaging' # dep of ircbot and otherwise useless\n ]\n @projects_dir = \"#{__dir__}/data/projects\"\n JenkinsJob.flavor_dir = \"#{__dir__}/jenkins-jobs/#{@flavor}\"\n super\n end\n\n private\n\n def jobs_without_template\n # FIXME: openqa is temporary while this is still being set up.\n JenkinsApi::Client.new.view.list_jobs('testy 🧪') +\n JenkinsApi::Client.new.job.list('^test_.*') +\n %w[a_extra-cmake-modules] # This is a multibranch pipe, a view itself.\n end\n\n # Append nci templates to list.\n def all_template_files\n files = super\n files + Dir.glob(\"#{JenkinsJob.flavor_dir}/templates/**.xml.erb\")\n end\n\n def load_overrides!\n # TODO: there probably should be a conflict check so they don't override\n # the same thing.\n files = Dir.glob(\"#{__dir__}/data/projects/overrides/nci-*.yaml\")\n raise 'No overrides found?' if files.empty?\n\n CI::Overrides.default_files += files\n end\n\n def populate_queue\n load_overrides!\n\n all_meta_builds = []\n all_mergers = []\n type_projects = {}\n\n NCI.types.each do |type|\n projects_file = \"#{@projects_dir}/nci/#{type}.yaml\"\n projects = ProjectsFactory.from_file(projects_file,\n branch: \"Neon/#{type}\")\n\n type_projects[type] = projects\n\n next unless type == 'unstable'\n\n projects.each do |project|\n branch = project.packaging_scm.branch\n branches = NCI.types.collect do |t|\n # We have Neon/type and Neon/type_series if a branch is only\n # applicable to a specific series.\n [\"Neon/#{t}\"] + NCI.series.collect { |s, _| \"Neon/#{t}_#{s}\" }\n end.flatten\n branches << 'master'\n next unless branch&.start_with?(*branches)\n\n # FIXME: this is fairly hackish\n dependees = []\n # Mergers need to be upstreams to the build jobs otherwise the\n # build jobs can trigger before the merge is done (e.g. when)\n # there was an upstream change resulting in pointless build\n # cycles.\n NCI.series.each_key do |series|\n NCI.types.each do |type_for_dependee|\n dependees << BuilderJobBuilder.basename(series,\n type_for_dependee,\n project.component,\n project.name)\n end\n end\n all_mergers << enqueue(NCIMergerJob.new(project,\n dependees: dependees,\n branches: branches))\n end\n end\n\n watchers = {}\n NCI.series.each_key do |distribution|\n NCI.types.each do |type|\n all_builds = [] # Tracks all builds in this type.\n\n type_projects[type].each do |project|\n if !project.series_restrictions.empty? &&\n !project.series_restrictions.include?(distribution)\n warn \"#{project.name} has been restricted to\" \\\n \" #{project.series_restrictions}.\" \\\n \" We'll not create a job for #{distribution}.\"\n next\n end\n # Fairly akward special casing because snapcrafting is a bit\n # special-interest.\n # Also forced onto bionic, snapcraft porting requires special care\n # and is detatched from deb-tech more or less.\n if %w[release].include?(type) && # project.snapcraft && # we allow snapcraft.yaml in project git repo now so can not tell from packaging if it is to be added\n !EXCLUDE_SNAPS.include?(project.name) && distribution == 'focal'\n # We use stable in jenkins to build the tar releases because that way we get the right KDE git repo\n unless project.upstream_scm.nil?\n next unless (project.upstream_scm.type == 'uscan' or project.upstream_scm.type == 'git')\n enqueue(SnapcraftJob.new(project,\n distribution: distribution, type: type))\n end\n end\n # enable ARM for xenial- & bionic-unstable and bionic-release and\n # focal-unstable and focal-release\n project_architectures = if type == 'unstable' ||\n (type == 'release' && distribution != 'xenial') ||\n type == 'experimental'\n NCI.all_architectures\n else\n NCI.architectures\n end\n jobs = ProjectJob.job(project,\n distribution: distribution,\n type: type,\n architectures: project_architectures)\n\n jobs.each { |j| enqueue(j) }\n all_builds += jobs\n\n # FIXME: presently not forcing release versions of things we have a\n # stable for\n next unless type == 'release'\n next unless distribution == NCI.current_series ||\n (NCI.future_series && distribution == NCI.future_series)\n # Projects without upstream scm are native and don't need watching.\n next unless project.upstream_scm\n # Do not watch !uscan. They'll not be able to produce anything\n # worthwhile.\n # TODO: should maybe assert that all release builds are either git\n # or uscan? otherwise we may have trouble with not getting updates\n next unless project.upstream_scm.type == 'uscan'\n # TODO: this is a bit of a crutch it may be wiser to actually\n # pass the branch as param into watcher.rb and have it make\n # sense of it (requires some changes to the what-needs-merging\n # logic first)\n # FIXME: the crutch is also a fair bit unreliable. if a repo doesn't\n # have a release branch (which is technically possible - e.g.\n # ubuntu-release-upgrader only has a single branch) then the watcher\n # coverage will be lacking.\n next unless %w[Neon/release].any? do |x|\n x == project.packaging_scm&.branch\n end\n\n watcher = WatcherJob.new(project)\n next if watchers.key?(watcher.job_name) # Already have one.\n\n watchers[watcher.job_name] = watcher\n end\n\n next if type == NCI.qt_stage_type\n\n # Meta builders.\n all_builds.select! { |j| j.is_a?(ProjectJob) }\n meta_builder = MetaBuildJob.new(type: type,\n distribution: distribution,\n downstream_jobs: all_builds)\n\n # Legacy distros deserve no daily builds. Only manual ones. So, do\n # not put them in the regular meta list and thus prevent progenitor from\n # even knowing about them.\n if distribution != NCI.old_series\n all_meta_builds << enqueue(meta_builder)\n end\n\n enqueue(DailyPromoteJob.new(type: type,\n distribution: distribution,\n dependees: [meta_builder]))\n\n enqueue(I386InstallCheckJob.new(type: type,\n distribution: distribution,\n dependees: [meta_builder]))\n\n enqueue(MGMTRepoTestVersionsJob.new(type: type,\n distribution: distribution))\n\n enqueue(MGTMCNFJob.new(type: type, dist: distribution))\n\n if (NCI.future_series && NCI.future_series == distribution) ||\n (NCI.current_series && NCI.old_series == distribution)\n enqueue(MGMTRepoTestVersionsUpgradeJob.new(type: type,\n distribution: distribution))\n end\n end\n # end of type\n\n # ISOs\n NCI.architectures.each do |architecture|\n standard_args = {\n imagename: 'neon',\n distribution: distribution,\n architecture: architecture,\n metapackage: 'neon-desktop'\n }.freeze\n is_future = distribution == NCI.future_series\n\n dev_unstable_isoargs = standard_args.merge(\n type: 'unstable',\n neonarchive: 'unstable',\n cronjob: 'H H * * 0'\n )\n enqueue(NeonIsoJob.new(**dev_unstable_isoargs))\n enqueue(NeonDockerJob.new(**dev_unstable_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'unstable')))\n\n # Only make unstable ISO for the next series while in early mode.\n next if distribution == NCI.future_series && NCI.future_is_early\n\n dev_unstable_dev_isoargs = standard_args.merge(\n type: 'developer',\n neonarchive: 'unstable',\n cronjob: 'H H * * 1'\n )\n enqueue(NeonIsoJob.new(**dev_unstable_dev_isoargs))\n enqueue(NeonDockerJob.new(**dev_unstable_dev_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'developer')))\n\n dev_stable_isoargs = standard_args.merge(\n type: 'testing',\n neonarchive: 'testing',\n cronjob: 'H H * * 2'\n )\n enqueue(NeonIsoJob.new(**dev_stable_isoargs))\n enqueue(NeonDockerJob.new(**dev_stable_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'testing')))\n\n user_release_isoargs = standard_args.merge(\n type: 'user',\n neonarchive: is_future ? 'release' : 'user',\n cronjob: 'H H * * 4'\n )\n enqueue(NeonIsoJob.new(**user_release_isoargs))\n enqueue(NeonDockerJob.new(**user_release_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'user')))\n\n ko_user_release_isoargs = standard_args.merge(\n type: 'ko',\n neonarchive: 'testing',\n cronjob: 'H H * * 5',\n metapackage: 'neon-desktop-ko'\n )\n enqueue(NeonIsoJob.new(**ko_user_release_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'ko')))\n\n mobile_isoargs = standard_args.merge(\n type: 'mobile',\n neonarchive: 'unstable',\n cronjob: 'H H * * 0',\n metapackage: 'plasma-phone'\n )\n enqueue(NeonIsoJob.new(**mobile_isoargs))\n enqueue(MGMTTorrentISOJob.new(**standard_args.merge(type: 'mobile')))\n end\n\n dev_unstable_imgargs = { type: 'devedition-gitunstable',\n distribution: distribution,\n architecture: 'arm64',\n metapackage: 'neon-desktop',\n imagename: 'neon',\n neonarchive: 'dev/unstable',\n cronjob: 'H H * * 0' }\n enqueue(NeonImgJob.new(**dev_unstable_imgargs))\n user_imgargs = { type: 'useredition',\n distribution: distribution,\n architecture: 'arm64',\n metapackage: 'neon-desktop',\n imagename: 'neon',\n neonarchive: 'user',\n cronjob: 'H H * * 0'}\n enqueue(NeonImgJob.new(**user_imgargs))\n\n enqueue(MGMTRepoDivert.new(target: \"unstable_#{distribution}\"))\n enqueue(MGMTRepoDivert.new(target: \"stable_#{distribution}\"))\n\n enqueue(MGMTRepoUndoDivert.new(target: \"unstable_#{distribution}\"))\n enqueue(MGMTRepoUndoDivert.new(target: \"stable_#{distribution}\"))\n\n enqueue(MGMTAppstreamUbuntuFilter.new(dist: distribution))\n end\n\n enqueue(MGMTRepoMetadataCheck.new(dependees: []))\n\n # Watchers is a hash, only grab the actual jobs and enqueue them.\n watchers.each_value { |w| enqueue(w) }\n\n merger = enqueue(MetaMergeJob.new(downstream_jobs: all_mergers))\n progenitor = enqueue(\n MgmtProgenitorJob.new(downstream_jobs: all_meta_builds,\n blockables: [merger])\n )\n enqueue(MGMTPauseIntegrationJob.new(downstreams: [progenitor]))\n enqueue(MGMTAptlyJob.new(dependees: [progenitor]))\n enqueue(MGMTWorkspaceCleanerJob.new(dist: NCI.current_series))\n enqueue(MGMTMergerDebianFrameworks.new)\n enqueue(MGMTAppstreamHealthJob.new(dist: NCI.current_series))\n if NCI.future_series\n # Add generator jobs as necessary here. Probably sound to start out\n # with unstable first though.\n enqueue(MGMTAppstreamHealthJob.new(dist: NCI.future_series))\n enqueue(MGMTAppstreamGenerator.new(repo: 'unstable',\n type: 'unstable',\n dist: NCI.future_series))\n end\n enqueue(MGMTJenkinsPruneParameterListJob.new)\n enqueue(MGMTJenkinsPruneOld.new)\n enqueue(MGMTJenkinsJobScorer.new)\n enqueue(MGMTGitSemaphoreJob.new)\n enqueue(MGMTJobUpdater.new)\n enqueue(MGMTDigitalOcean.new)\n enqueue(MGMTDigitalOceanDangler.new)\n enqueue(MGMTSeedDeploy.new)\n\n # This QA is only run for user edition, otherwise we'd end up in a nightmare\n # of which component is available in which edition but not the other.\n enqueue(MGMTAppstreamComponentsDuplicatesJob.new(type: 'user',\n dist: NCI.current_series))\n\n # FIXME: this is hardcoded because we don't have a central map between\n # 'type' and repo path, additionally doing this programatically would\n # require querying the aptly api. it's unclear if this is worthwhile.\n enqueue(MGMTAppstreamGenerator.new(repo: 'unstable',\n type: 'unstable',\n dist: NCI.current_series))\n enqueue(MGMTAppstreamGenerator.new(repo: 'testing',\n type: 'stable',\n dist: NCI.current_series))\n enqueue(MGMTAppstreamGenerator.new(repo: 'release',\n type: 'release',\n dist: NCI.current_series))\n enqueue(MGMTAppstreamGenerator.new(repo: 'user',\n type: 'user',\n dist: NCI.current_series))\n # Note for the future: when introducing a future_series it's probably wise\n # to split the job and asgen.rb for the new series. That way its easy to\n # drop legacy support when the time comes. At the time of writing both\n # things are highly coupled to their series, so treating them as something\n # generic is folly.\n\n # In addition to type-dependent cnf jobs we create one for user edition itself. user repo isn't a type but\n # we want cnf data all the same. Limited to current series for no particular reason other than convenience (future\n # doesn't necessarily have a user repo right out the gate).\n # The data comes from release becuase they are similar enough and iterating Snapshots is hugely different so\n # adding support for them to cnf_generate is a drag.\n enqueue(MGTMCNFJob.new(type: 'release', dist: NCI.current_series, conten_push_repo_dir: 'user', name: 'user'))\n\n enqueue(MGMTSnapshotUser.new(dist: NCI.current_series, origin: 'release', target: 'user'))\n if NCI.future_series\n enqueue(MGMTSnapshotUser.new(dist: NCI.future_series, origin: 'release', target: 'user'))\n end\n\n enqueue(MGMTVersionListJob.new(dist: NCI.current_series, type: 'user', notify: true))\n enqueue(MGMTVersionListJob.new(dist: NCI.current_series, type: 'release'))\n enqueue(MGMTFwupdCheckJob.new(dist: NCI.current_series, type: 'user', notify: true))\n if NCI.future_series\n enqueue(MGMTFwupdCheckJob.new(dist: NCI.future_series, type: 'user', notify: true))\n end\n enqueue(MGMTToolingJob.new(downstreams: [],\n dependees: []))\n enqueue(MGMTRepoCleanupJob.new)\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n updater = ProjectUpdater.new\n updater.update\n updater.install_plugins\nend\n"
},
{
"alpha_fraction": 0.6582155227661133,
"alphanum_fraction": 0.6626036167144775,
"avg_line_length": 34.98245620727539,
"blob_id": "27aaf1d2e41bac02730c442b7a7394fb59723323",
"content_id": "54fa49cc991b2e96c7880ace383b92cfe9d95096",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2051,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 57,
"path": "/lib/lint/log/dh_missing.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../linter'\nrequire_relative 'build_log_segmenter'\n\nmodule Lint\n class Log\n # # Special result variant so we can easily check for the result type.\n # # We currently do not expect that dh_missing is always present so we\n # # need to specialcase it's validity.\n # class DHMissingResult < Result; end\n\n class DHMissing < Linter\n include BuildLogSegmenter\n\n def lint(data)\n r = Result.new\n # Sometimes dh lines may start with indentation. It's uncear\n # why that happens.\n data = segmentify(data,\n /^(\\s*)dh_install( .+)?$/,\n /^(\\s*)dpkg-deb: building package.+$/)\n\n data.each do |line|\n next unless line.strip.start_with?('dh_missing: ')\n\n r.errors << line\n end\n r.valid = true\n r\n rescue BuildLogSegmenter::SegmentMissingError => e\n # Older logs may not contain the dh_missing at all!\n # TODO: revise this and always expect dh_missing to actually be run.\n puts \"#{self.class}: in log #{e.message}\"\n r\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7461832165718079,
"alphanum_fraction": 0.7547709941864014,
"avg_line_length": 40.91999816894531,
"blob_id": "f312bd0f5d054d8f2786ffdee1c411a96e61aaaa",
"content_id": "6567d96abbc9d68cb86d753ea3e1c76535372abd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 25,
"path": "/nci/imager/build-hooks-neon-developer/99-no-gnome.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# Copyright (C) 2020 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# focal developer edition installs gnome shell, quick workaround to remove it, jriddell\n\nset -e\n\napt-get remove -y ubuntu-session gnome-shell\n"
},
{
"alpha_fraction": 0.6302990913391113,
"alphanum_fraction": 0.6365396976470947,
"avg_line_length": 27.335365295410156,
"blob_id": "d9085b4af4df76d1500da0cf54c5b26f4c5dca45",
"content_id": "6fb7bc0b0ee48d0064d17304f418047b4fa844e3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4647,
"license_type": "no_license",
"max_line_length": 169,
"num_lines": 164,
"path": "/lib/kdeproject_component.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n# downloads and makes available as arrays lists of KDE projects which\n# are part of Plasma, Applications and Frameworks\n\nrequire 'httparty'\nrequire 'tmpdir'\n\nclass KDEProjectsComponent\n class << self\n @@projects_to_jobs = {'discover'=>'plasma-discover', 'kdeconnect-kde'=>'kdeconnect', 'kdev-php'=>'kdevelop-php', 'kdev-python'=>'kdevelop-python'}\n @@projects_without_jobs = ['plasma-tests', 'akonadi-airsync', 'akonadi-exchange', 'akonadi-phabricator-resource', 'kpeoplesink', 'akonadiclient', 'kblog', 'kfloppy']\n ## The only way to get a list of what is in PlaMo Gear releases seems to be a manually maintained list from \n ## https://plasma-mobile.org/info/plasma-mobile-gear-22-09/\n ## And manually remove the ones that announce says are unstable\n @@plasma_mobile = %w{\n alligator\n angelfish\n audiotube\n calindori\n kalk\n kasts\n kclock\n keysmith\n khealthcertificate\n koko\n kongress\n krecorder\n ktrip\n kweather\n neochat\n plasma-dialer\n plasma-phonebook\n plasma-settings\n plasmatube\n qmlkonsole\n spacebar\n telly-skout\n tokodon\n vakzination\n kweathercore\n kirigami-addons\n }.sort\n @@plasma_mobile = @@plasma_mobile - %w{\n kclock\n krecorder\n qmlkonsole\n tokodon\n plasmatube\n khealthcertificate\n vakzination\n }\n\n def frameworks\n @frameworks ||= to_names(projects('frameworks'))\n end\n\n def frameworks_jobs\n @frameworks_packages ||= to_jobs(frameworks)\n end\n\n def kf6\n @kf6 ||= to_names(projects('frameworks'))\n @kf6.map { |s| s.sub(/\\A(?!kf6-)/, 'kf6-') }\n end\n\n def kf6_jobs\n @kf6_packages ||= to_jobs(kf6)\n end\n\n def pim\n @pim ||= to_names(projects('pim'))\n @pim << 'kalendar'\n end\n\n def pim_jobs\n @pim_packgaes ||= to_jobs(pim)\n end\n\n def mobile\n @@plasma_mobile\n end\n\n def mobile_jobs\n @@plasma_mobile ||= to_jobs(mobile)\n end\n\n def maui\n # look up maui's git repo and add cask server\n @maui ||= to_names(projects('maui'))\n @maui.push('cask-server')\n end\n\n def maui_jobs\n @maui_jobs ||= to_jobs(maui).reject {|x| @@projects_without_jobs.include?(x)}\n end\n\n def gear\n # the way to get what is in KDE Gear (the release service) is from release-tools list\n @release_service ||= begin\n modules = []\n url = \"http://embra.edinburghlinux.co.uk/~jr/release-tools/modules.git\"\n response = HTTParty.get(url)\n body = response.body\n body.each_line(\"release/23.04\\n\") do |line|\n modules << line.split(/\\s/, 2)[0]\n end\n modules\n end.sort\n end\n\n def gear_jobs\n @gear_jobs ||= to_jobs(gear).reject {|x| @@projects_without_jobs.include?(x)}\n end\n\n def plasma\n # the way to get what is in plasma is from this list in plasma release tools\n @plasma ||= begin\n url = \"https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release\"\n response = HTTParty.get(url)\n body = response.body\n modules = body.split\n modules.sort\n end\n end\n\n def plasma_jobs\n @plasma_jobs ||= to_jobs(plasma).reject {|x| @@projects_without_jobs.include?(x)}\n end\n\n private\n\n def to_jobs(projects)\n projects.collect { |x| @@projects_to_jobs[x]? @@projects_to_jobs[x] : x }\n end\n\n def to_names(projects)\n projects.collect { |project| project.split('/')[-1] }\n end\n\n def projects(filter)\n url = \"https://projects.kde.org/api/v1/projects/#{filter}\"\n response = HTTParty.get(url)\n response.parsed_response\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6401446461677551,
"alphanum_fraction": 0.6618444919586182,
"avg_line_length": 29.72222137451172,
"blob_id": "c76ea0dead95c26913d25e20d567a6bb8e00ad07",
"content_id": "a76fea53f883338241fde724b37add40203cd9df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/lib/rsync.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty-command'\n\n# Convenience wrapper around rsync cli\nclass RSync\n def self.sync(from:, to:, verbose: false)\n ssh_command =\n \"ssh -o StrictHostKeyChecking=no -i #{ENV.fetch('SSH_KEY_FILE')}\"\n rsync_opts = '-a'\n rsync_opts += ' -v' if verbose\n rsync_opts += \" -e '#{ssh_command}'\"\n TTY::Command.new.run(\"rsync #{rsync_opts} #{from} #{to}\")\n end\nend\n"
},
{
"alpha_fraction": 0.6880165338516235,
"alphanum_fraction": 0.6880165338516235,
"avg_line_length": 30.225807189941406,
"blob_id": "c3ed9716bc09757f4b6c723fffaf903c50e3ac5d",
"content_id": "52b799865ac99519b195e61ab7e91cee34fcc477",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 968,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 31,
"path": "/lib/queue.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'thread'\n\n# Thread-safe queue container.\n# Queue is monkey patched to support incredibly useful Array<=>Queue conversion.\nclass Queue\n alias super_init initialize\n\n def initialize(array = nil)\n super_init\n return if array.nil?\n unless array.is_a?(Array)\n raise 'Queue can only be constructed from an Array'\n end\n\n array.each { |i| self << i }\n end\n\n def to_a\n # Queue isn't exactly the most nejoable thing in the world as it doesn't\n # allow for random access so you cannot iterate over it, and it doesn't\n # implement dup nor clone so you can't deep copy it either.\n # Now since we need to iterate queue to convert it in an array and iteration\n # means destructive popping we first need to pop it into an Array and then\n # iterate over the array to push the values back into the queue. Quite mad.\n ret = []\n ret << pop until empty?\n ret.each { |i| self << i }\n ret\n end\nend\n"
},
{
"alpha_fraction": 0.7114695310592651,
"alphanum_fraction": 0.7114695310592651,
"avg_line_length": 21.31999969482422,
"blob_id": "ffe3e80825c77058c8839c6a9aca20ab4b189b3d",
"content_id": "a6ec6cec04ddbb6d6deb6ac99c55f91d59fe6b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 558,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 25,
"path": "/test/test_testcase.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\n\nclass Prop < TestCase\nend\n\n# Test TestCase class for everything we currently do not actively use as well\n# as failure scenarios.\nclass TestTestCase < TestCase\n # Prop is configured in order, so tests depend on their definition order.\n self.test_order = :defined\n\n def test_file\n assert_nothing_raised do\n Prop.send(:file=, 'abc')\n end\n assert_equal('abc', Prop.file)\n end\n\n def test_data_lookup_fail\n assert_raise RuntimeError do\n Prop.new(nil).data\n end\n end\nend\n"
},
{
"alpha_fraction": 0.655731201171875,
"alphanum_fraction": 0.6620553135871887,
"avg_line_length": 29.4819278717041,
"blob_id": "667f518c4407f7b504c07df810dafadd6cffaf9d",
"content_id": "6975338f9e0ec465679c0a8637f8073bfd11a1e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2530,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 83,
"path": "/test/test_mgmt_docker_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'vcr'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/docker/cleanup'\n\nclass MGMTDockerCleanupTest < TestCase\n # :nocov:\n def create_image\n assert_image(Docker::Image.create(fromImage: 'ubuntu:vivid'))\n end\n # :nocov:\n\n def setup\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :excon\n config.default_cassette_options = {\n match_requests_on: %i[method uri body],\n tag: :erb_pwd\n }\n\n # The PWD is used as home and as such it appears in the interactions.\n # Filter it into a ERB expression we can play back.\n config.filter_sensitive_data('<%= Dir.pwd %>', :erb_pwd) { Dir.pwd }\n end\n end\n\n def assert_image(image)\n assert_not_nil(image)\n assert_is_a(image, Docker::Image)\n image\n end\n\n def disable_body_match\n VCR.configure do |c|\n body = c.default_cassette_options[:match_requests_on].delete(:body)\n yield\n ensure\n c.default_cassette_options[:match_requests_on] << :body if body\n end\n end\n\n def derive_image(image)\n File.write('yolo', '')\n # Nobody knows why but that bit of API uses strings Oo\n # insert_local dockerfiles off of our baseimage and creates\n i = nil\n disable_body_match do\n i = image.insert_local('localPath' => \"#{Dir.pwd}/yolo\",\n 'outputPath' => '/yolo')\n end\n assert_image(i)\n i\n end\n\n # This test presently relies on docker not screwing up and deleting\n # images that do not dangle. Should we change to our own implementation\n # we need substantially more testing to make sure we don't screw up...\n def test_cleanup_images\n VCR.use_cassette(__method__, erb: true) do\n image = create_image\n dangling_image = derive_image(image)\n Docker::Cleanup.images\n assert(!Docker::Image.exist?(dangling_image.id))\n end\n end\n\n def test_cleanup_images_conflict\n # Block image removal by creating a container for it.\n # This is going to cuase\n # Docker::Error::ConflictError: Conflict, cannot delete 00ba03911a14 because the container b7daed609163 is using it, use -f to force\n VCR.use_cassette(__method__, erb: true) do\n image = create_image\n dangling_image = derive_image(image)\n container = Docker::Container.create(Image: dangling_image.id)\n Docker::Cleanup.images\n assert(Docker::Image.exist?(dangling_image.id))\n container.remove(force: true)\n dangling_image.remove(force: true)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.683201789855957,
"alphanum_fraction": 0.6854565739631653,
"avg_line_length": 29.586206436157227,
"blob_id": "b471edac0f9c26b705d8a7589bb52724cc856b83",
"content_id": "0633d7d44c23f02a44552c499f79545a533725c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 887,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 29,
"path": "/test/test_debian_patchseries.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/debian/patchseries'\nrequire_relative 'lib/testcase'\n\n# Test debian patch series\nclass DebianPatchSeriesTest < TestCase\n def test_read\n s = Debian::PatchSeries.new(data)\n assert_equal(4, s.patches.size)\n %w[a.patch b.patch above-is-garbage.patch level.patch].each do |f|\n assert_include(s.patches, f, \"patch #{f} should be in series\")\n end\n assert_equal(true, s.exist?)\n end\n\n def test_read_from_name\n s = Debian::PatchSeries.new(data, 'yolo')\n assert_equal(4, s.patches.size)\n %w[a.patch b.patch above-is-garbage.patch level.patch].each do |f|\n assert_include(s.patches, f, \"patch #{f} should be in series\")\n end\n end\n\n def test_no_exist\n Dir.mkdir('debian') # otherwise we raise bogus directory error\n s = Debian::PatchSeries.new(Dir.pwd)\n assert_equal(false, s.exist?)\n end\nend\n"
},
{
"alpha_fraction": 0.7118871808052063,
"alphanum_fraction": 0.7186030745506287,
"avg_line_length": 31.369565963745117,
"blob_id": "e480bd9dda354bdf4a0c53bf99fa6f947f6b841c",
"content_id": "b0e939af8f3e796531fd80a499e76632139ff82f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1489,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 46,
"path": "/nci/setup_apt_repo.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'optparse'\n\nrequire_relative 'lib/setup_repo'\nrequire_relative '../lib/apt'\n\nOptionParser.new do |opts|\n opts.banner = <<-BANNER\nUsage: #{opts.program_name} [options]\n BANNER\n\n opts.on('--no-repo', 'Do not set up a repo (does not require TYPE)') do\n @no_repo = true\n end\n\n opts.on('--src', 'Also setup src repo') do\n @with_source = true\n end\nend.parse!\n\nNCI.setup_proxy!\nNCI.add_repo_key!\nexit if @no_repo\n\nENV['TYPE'] ||= ARGV.fetch(0) { raise 'Need type as argument or in env.' }\nNCI.setup_repo!(with_source: @with_source)\n"
},
{
"alpha_fraction": 0.6826127171516418,
"alphanum_fraction": 0.6872125267982483,
"avg_line_length": 37.82143020629883,
"blob_id": "75e66630182a10befd5b44b34dbd5f583e1667b2",
"content_id": "047d91d88e448555e40e8dc525401d7b13d1787c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2174,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 56,
"path": "/lib/aptly-ext/filter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../debian/version'\nrequire_relative 'package'\n\nmodule Aptly\n module Ext\n # Filter latest versions out of an enumerable of strings.\n module LatestVersionFilter\n module_function\n\n # @param array_of_package_keys [Array<String>]\n # @return [Array<Package::Key>]\n def filter(array_of_package_keys, keep_amount = 1)\n packages = array_of_package_keys.collect do |key|\n key.is_a?(Package::Key) ? key : Package::Key.from_string(key)\n end\n\n packages_by_name = packages.group_by(&:name)\n packages_by_name.collect do |_name, names_packages|\n versions = debian_versions(names_packages).sort.to_h\n versions.shift while versions.size > keep_amount\n versions.values\n end.flatten\n end\n\n # Group the keys in a Hash by their version. This is so we can easily\n # sort the versions.\n def debian_versions(names_packages)\n # Group the keys in a Hash by their version. This is so we can easily\n # sort the versions.\n versions = names_packages.group_by(&:version)\n # Pack them in a Debian::Version object for sorting\n Hash[versions.map { |k, v| [Debian::Version.new(k), v] }]\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.64399653673172,
"alphanum_fraction": 0.6457366347312927,
"avg_line_length": 28.724138259887695,
"blob_id": "f4a15685ba5eb56f4c1cab73002359a10009825e",
"content_id": "6547ae3fa06c0604e26f9dad937600142d33bb41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6896,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 232,
"path": "/test/test_ci_deployer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'docker'\nrequire 'fileutils'\nrequire 'json'\nrequire 'ostruct'\nrequire 'ruby-progressbar'\nrequire 'vcr'\n\nrequire_relative '../lib/dpkg'\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/pangeaimage'\nrequire_relative '../lib/ci/container/ephemeral'\nrequire_relative '../lib/mgmt/deployer'\n\nclass DeployTest < TestCase\n def setup\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :excon\n config.default_cassette_options = {\n match_requests_on: %i[method uri body],\n tag: :erb_pwd\n }\n\n # The PWD is used as home and as such it appears in the interactions.\n # Filter it into a ERB expression we can play back.\n config.filter_sensitive_data('<%= Dir.pwd %>', :erb_pwd) { Dir.pwd }\n\n # VCR records the binary tar image over the socket, so instead of actually\n # writing out the binary tar, replace it with nil since on replay docker\n # actually always sends out a empty body\n config.before_record do |interaction|\n interaction.response.body = nil if interaction.request.uri.end_with?('export')\n end\n end\n\n @oldnamespace = CI::PangeaImage.namespace\n @namespace = 'pangea-testing'\n CI::PangeaImage.namespace = @namespace\n @oldhome = ENV.fetch('HOME')\n @oldlabels = ENV['NODE_LABELS']\n ENV['NODE_LABELS'] = 'master'\n\n # Hardcode ubuntu as the actual live values change and that would mean\n # a) regenerating the test data for no good reason\n # b) a new series might entail an upgrade which gets focused testing\n # so having it appear in broad testing doesn't make much sense.\n # NB: order matters here, first is newest, last is oldest\n @ubuntu_series = %w[wily vivid]\n # Except for debian, where Rohan couldn't be bothered to read the\n # comment above and it was recorded in reverse.\n @debian_series = %w[1706 1710 backports]\n end\n\n def teardown\n VCR.configuration.default_cassette_options.delete(:tag)\n CI::PangeaImage.namespace = @oldnamespace\n ENV['HOME'] = @oldhome\n ENV['NODE_LABELS'] = @oldlabels\n end\n\n def vcr_it(meth, **kwords)\n VCR.use_cassette(meth, kwords) do |cassette|\n CI::EphemeralContainer.safety_sleep = 0 unless cassette.recording?\n yield cassette\n end\n end\n\n def copy_data\n FileUtils.cp_r(Dir.glob(\"#{data}/*\"), Dir.pwd)\n end\n\n def load_relative(path)\n load(File.join(__dir__, path.to_str))\n end\n\n # create base\n def create_base(flavor, tag)\n b = CI::PangeaImage.new(flavor, tag)\n return if Docker::Image.exist?(b.to_s)\n\n deployer = MGMT::Deployer.new(flavor, tag)\n deployer.create_base\n end\n\n def remove_base(flavor, tag)\n b = CI::PangeaImage.new(flavor, tag)\n return unless Docker::Image.exist?(b.to_s)\n\n image = Docker::Image.get(b.to_s)\n # Do not prune to keep the history. Otherwise we have to download the\n # entire image in the _new test.\n image.delete(force: true, noprune: true)\n end\n\n def deploy_all\n @ubuntu_series.each do |k|\n d = MGMT::Deployer.new('ubuntu', k)\n d.run!\n end\n\n @debian_series.each do |k|\n d = MGMT::Deployer.new('debian', k)\n d.run!\n end\n end\n\n def test_deploy_new\n copy_data\n\n ENV['HOME'] = Dir.pwd\n ENV['JENKINS_HOME'] = Dir.pwd\n\n vcr_it(__method__, erb: true) do |cassette|\n if cassette.recording?\n VCR.eject_cassette\n VCR.turned_off do\n @ubuntu_series.each do |k|\n remove_base('ubuntu', k)\n end\n\n @debian_series.each do |k|\n remove_base('debian', k)\n end\n end\n VCR.insert_cassette(cassette.name)\n end\n\n assert_nothing_raised do\n deploy_all\n end\n end\n end\n\n def test_deploy_exists\n copy_data\n\n ENV['HOME'] = Dir.pwd\n ENV['JENKINS_HOME'] = Dir.pwd\n\n vcr_it(__method__, erb: true) do |cassette|\n if cassette.recording?\n VCR.eject_cassette\n VCR.turned_off do\n @ubuntu_series.each do |k|\n create_base('ubuntu', k)\n end\n\n @debian_series.each do |k|\n create_base('debian', k)\n end\n end\n VCR.insert_cassette(cassette.name)\n end\n\n assert_nothing_raised do\n deploy_all\n end\n end\n end\n\n def test_upgrade\n # When trying to provision an image for an ubuntu series that doesn't exist\n # in dockerhub we can upgrade from an earlier series. To do this we'd pass\n # the version to upgrade from and then expect create_base to actually\n # indicate an upgrade.\n copy_data\n ENV['HOME'] = Dir.pwd\n\n vcr_recording = nil\n vcr_it(__method__, erb: true) do |cassette|\n vcr_recording = cassette.recording?\n if vcr_recording\n VCR.eject_cassette\n VCR.turned_off do\n remove_base(:ubuntu, 'wily')\n remove_base(:ubuntu, __method__)\n end\n VCR.insert_cassette(cassette.name)\n end\n\n # Wily should exist so the fallback upgrade shouldn't be used.\n d = MGMT::Deployer.new(:ubuntu, 'wily', %w[vivid])\n upgrade = d.create_base\n assert_nil(upgrade)\n # Fake series name shouldn't exist and trigger an upgrade.\n d = MGMT::Deployer.new(:ubuntu, __method__.to_s, %w[wily])\n upgrade = d.create_base\n assert_not_nil(upgrade)\n assert_equal('wily', upgrade.from)\n assert_equal(__method__.to_s, upgrade.to)\n end\n ensure\n VCR.turned_off do\n remove_base(:ubuntu, __method__) if vcr_recording\n end\n end\n\n def test_openqa\n # When the hostname contains openqa we want to have autoinst provisioning\n # enabled automatically.\n Socket.expects(:gethostname).returns('foo')\n MGMT::Deployer.new(:ubuntu, 'wily', %w[vivid])\n refute ENV.include?('PANGEA_PROVISION_AUTOINST')\n\n Socket.expects(:gethostname).returns('foo-openqa-bar')\n MGMT::Deployer.new(:ubuntu, 'wily', %w[vivid])\n assert ENV.include?('PANGEA_PROVISION_AUTOINST')\n ensure\n ENV.delete('PANGEA_PROVISION_AUTOINST')\n end\n\n def test_target_arch\n # Arch is determined from the node labels, labels.size can be 0-N so make\n # sure we pick the right arch. Otherwise our image can become the wrong\n # arch and set everything on fire!\n\n # Burried in other labels\n ENV['NODE_LABELS'] = 'persistent abc armhf fooobar'\n assert_equal('armhf', MGMT::Deployer.target_arch)\n\n # Multiple arch labels aren't supported. This technically could mean\n # 'make two images' but in reality that should need handling on the CI\n # level not the tooling level\n ENV['NODE_LABELS'] = 'arm64 armhf'\n assert_raises { MGMT::Deployer.target_arch }\n\n # It also checks for multiple dpkg arches coming out of the query. It's\n # untested because I think that cannot actually happen, but the return\n # type is an array, so we need to make sure it's not malformed.\n end\nend\n"
},
{
"alpha_fraction": 0.6905210018157959,
"alphanum_fraction": 0.6961707472801208,
"avg_line_length": 29.634614944458008,
"blob_id": "5eff0a15a4b01ec3fc4c50f4d6417f2eeb486004",
"content_id": "a96e0a9c7bc2aa8c6bae65a97a4fc88e96f4dead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1593,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 52,
"path": "/lib/apt/preference.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule Apt\n # man apt_preferences. Manages preference files. Does not manage the content\n # (yet) but instead leaves it to the user to give a config blob which we'll\n # write to a suitable file.\n class Preference\n DEFAULT_CONFIG_DIR = '/etc/apt/preferences.d/'\n\n class << self\n def config_dir\n @config_dir ||= DEFAULT_CONFIG_DIR\n end\n attr_writer :config_dir\n end\n\n def initialize(name, content: nil)\n @name = name\n @content = content\n end\n\n def path\n \"#{self.class.config_dir}/#{@name}\"\n end\n\n def write\n File.write(path, @content)\n end\n\n def delete\n File.delete(path)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6493383646011353,
"alphanum_fraction": 0.6545368432998657,
"avg_line_length": 31.060606002807617,
"blob_id": "2fa28ce7fda34772c74f07de7f2df2fa91d92ae2",
"content_id": "6834d5e652567d8f274be34f8d7c4919259ce559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2116,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 66,
"path": "/test/test_nci_merger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'rugged'\n\nrequire_relative '../nci/debian-merge/merger'\n\nmodule NCI\n module DebianMerge\n class NCITagMergerTest < TestCase\n def setup; end\n\n def test_run\n tag_base = 'tagi'\n url = 'http://abc'\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n repo = mock('repo')\n Repository.expects(:clone_into).with { |*args| args[0] == url }.returns(repo)\n repo.expects(:tag_base=).with(tag_base)\n repo.expects(:merge)\n repo.expects(:push)\n repo.expects(:url).returns('kittenurl')\n\n Merger.new.run\n end\n\n def test_run_fail\n tag_base = 'tagi'\n url = 'http://abc'\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n repo = mock('repo')\n Repository.expects(:clone_into).with { |*args| args[0] == url }.returns(repo)\n repo.expects(:tag_base=).with(tag_base)\n repo.expects(:merge).raises('kittens')\n\n assert_raises RuntimeError do\n Merger.new.run\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6200113892555237,
"alphanum_fraction": 0.6458095908164978,
"avg_line_length": 30.746606826782227,
"blob_id": "f3e27db1c9f42eb241b8417adc2843c478521f95",
"content_id": "752fa3341264356620802975f7ad8e47b9ecd1a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7016,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 221,
"path": "/test/test_nci_jenkins_bin.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../nci/lib/settings' # so we have the bloody module\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/jenkins_bin'\n\nrequire 'mocha/test_unit'\nrequire 'jenkins_api_client'\nrequire 'jenkins_api_client/exceptions'\n\nmodule NCI::JenkinsBin\n class JenkinsBinTest < TestCase\n { Cores::CORES[0] => Cores::CORES[0], 4 => 2, 8 => 4 }.each do |input, output|\n define_method(\"test_cores_downgrade_#{input}\") do\n assert_equal(output, Cores.downgrade(input))\n end\n end\n\n { 2 => 4, 4 => 8, Cores::CORES[-1] => Cores::CORES[-1] }.each do |input, output|\n define_method(\"test_cores_upgrade_#{input}\") do\n assert_equal(output, Cores.upgrade(input))\n end\n end\n\n def test_core_coercion_downgrade\n # When coercing a value higher than what we have we should get the\n # highest value back.\n assert_equal(Cores::CORES[-1], Cores.coerce(Cores::CORES[-1] * 2))\n end\n\n def test_core_coercion_upgrade\n # When coercing a value lower than what we have we should get the\n # lowest value back.\n assert_equal(Cores::CORES[0], Cores.coerce(0))\n end\n\n def test_slave\n assert_equal(8, Slave.cores('jenkins-do-8core.build.neon-0f321b00-a90f-4a3d-8d40-542681753686'))\n assert_equal(2, Slave.cores('jenkins-do-2core.build.neon-841d6c13-c583-4b13-b094-68576ef46062'))\n assert_equal(2, Slave.cores('do-builder-006'))\n assert_raises { Slave.cores('meowmoewkittenmoew') } # unknown name\n end\n end\n\n class BuildSelectorTest < TestCase\n attr_accessor :log_out, :logger, :jenkins_job, :job\n\n def setup\n @log_out = StringIO.new\n @logger = Logger.new(@log_out)\n\n @jenkins_job = mock('job')\n @jenkins_job.stubs(:name).returns('kitteh')\n\n @job = mock('job')\n @job.responds_like_instance_of(Job)\n @job.stubs(:log).returns(@logger)\n @job.stubs(:last_build_number).returns(7)\n @job.stubs(:job).returns(@jenkins_job)\n end\n\n def teardown\n return if passed?\n\n @log_out.rewind\n warn @log_out.read\n end\n\n def test_build_selector\n 8.times do |i|\n jenkins_job.stubs(:build_details).with(i).returns(\n 'result' => 'SUCCESS',\n 'builtOn' => 'jenkins-do-8core.build.neon-123123'\n )\n end\n\n selector = BuildSelector.new(job)\n builds = selector.select\n assert(builds)\n refute(builds.empty?)\n end\n\n def test_build_selector_not_configured_core\n # This test asserts that using a high core count (higher than what\n # Cores knows about) will result in the core count getting adjusted\n # to a known value.\n # Should 20 count be added to Cores a suitable replacement needs\n # to be looked into.\n 8.times do |i|\n jenkins_job.stubs(:build_details).with(i).returns(\n 'result' => 'SUCCESS',\n 'builtOn' => 'jenkins-do-20core.build.neon-123123'\n )\n end\n\n selector = BuildSelector.new(job)\n selector.select\n assert_equal(Cores::CORES[-1], selector.detected_cores)\n end\n\n def test_build_selector_bad_slave_chain\n jenkins_job.stubs(:build_details).with(7).returns(\n 'result' => 'SUCCESS',\n 'builtOn' => 'jenkins-do-8core.build.neon-123123'\n )\n 7.times do |i|\n jenkins_job.stubs(:build_details).with(i).returns(\n 'result' => 'SUCCESS',\n 'builtOn' => 'jenkins-do-4core.build.neon-123123'\n )\n end\n\n selector = BuildSelector.new(job)\n builds = selector.select\n refute(builds)\n end\n\n def test_build_selector_repeated_404\n # when no builds come back wit 300 we expect a standard scoring.\n 8.times do |i|\n jenkins_job.stubs(:build_details).with(i).raises(JenkinsApi::Exceptions::NotFoundException.allocate)\n end\n\n selector = BuildSelector.new(job)\n refute selector.select\n end\n\n def test_build_selector_single_404\n # One build was fine but then we had a bunch of broken builds, this\n # should raise something.\n jenkins_job.stubs(:build_details).with(7).returns(\n 'result' => 'SUCCESS',\n 'builtOn' => 'jenkins-do-8core.build.neon-123123'\n )\n\n 6.times do |i|\n jenkins_job.stubs(:build_details).with(i).raises(JenkinsApi::Exceptions::NotFoundException.allocate)\n end\n\n selector = BuildSelector.new(job)\n assert_raises { selector.select }\n end\n end\n\n class JobTest < TestCase\n def test_keep_cores\n current = 4\n expected = current\n\n selector = mock('selector')\n selector.stubs(:select).returns([{ 'duration' => 4 * 60 * 1000 }])\n selector.stubs(:detected_cores).returns(current)\n BuildSelector.expects(:new).returns(selector)\n\n assert_equal(expected, Job.new('kitteh').cores)\n end\n\n def test_up_cores\n current = 4\n expected = 8\n\n selector = mock('selector')\n selector.stubs(:select).returns([{ 'duration' => 45 * 60 * 1000 }])\n selector.stubs(:detected_cores).returns(current)\n BuildSelector.expects(:new).returns(selector)\n\n assert_equal(expected, Job.new('kitteh').cores)\n end\n\n def test_down_cores\n current = 4\n expected = 2\n\n selector = mock('selector')\n selector.stubs(:select).returns([{ 'duration' => 1 * 60 * 1000 }])\n selector.stubs(:detected_cores).returns(current)\n BuildSelector.expects(:new).returns(selector)\n\n assert_equal(expected, Job.new('kitteh').cores)\n end\n end\n\n class JobScorerTest < TestCase\n def test_run\n config_file = \"#{Dir.pwd}/conf.json\"\n File.write(config_file, '{\"kitteh_bin_amd64\":2,\"meow_bin_amd64\":2}')\n\n JenkinsApi::Client::Job.any_instance.stubs(:list_all).returns(\n %w[kitteh_bin_amd64]\n )\n\n job = mock('job')\n job.stubs(:cores).returns(2)\n Job.expects(:new).with('kitteh_bin_amd64').returns(job)\n\n @scorer = JobScorer.new(config_file: config_file)\n @scorer.run!\n\n assert_path_exist(config_file)\n assert_equal({ 'kitteh_bin_amd64' => 2 }, JSON.parse(File.read(config_file)))\n end\n end\nend\n"
},
{
"alpha_fraction": 0.626101016998291,
"alphanum_fraction": 0.6346153616905212,
"avg_line_length": 39.5476188659668,
"blob_id": "7d250619ee8a339e18ec463aa11e914128229c6e",
"content_id": "4fa2c2a9020da317a2f5781adeb5259d069ce895",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6812,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 168,
"path": "/lib/ci/container.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'deep_merge'\nrequire_relative 'docker'\nrequire_relative 'directbindingarray'\nrequire_relative '../../lib/retry'\n\nmodule CI\n # Container with somewhat more CI-geared behavior and defaults.\n # All defaults can be overridden via create's opts.\n # @see .default_create_options\n # @see #default_start_options\n class Container < Docker::Container\n DirectBindingArray = CI::DirectBindingArray\n\n # @return [Array<String>] Array of absolute paths on the host that should\n # be bound 1:1 into the container.\n attr_reader :binds\n\n # Create with convenience argument handling. Forwards to\n # Docker::Container::create.\n #\n # @param name The name to use for the container. Uses random name if nil.\n # @param binds An array of paths mapping 1:1 from host to container. These\n # will be automatically translated into Container volumes and binds for\n # {#start}.\n #\n # @param options Forwarded. Passed to Docker API as arguments.\n # @param connection Forwarded. Connection to use.\n #\n # @return [Container]\n def self.create(connection = Docker.connection,\n name: nil,\n binds: [Dir.pwd],\n **options_)\n # FIXME: commented to allow tests passing with old containment data\n # assert_version\n options = merge_env_options(default_create_options, options_)\n options = options_.deep_merge(options)\n options = override_options(options, name, binds)\n c = super(options, connection)\n c\n end\n\n # @return [Boolean] true when the container exists, false otherwise.\n def self.exist?(id, options = {}, connection = Docker.connection)\n get(id, options, connection)\n true\n rescue Docker::Error::NotFoundError\n false\n end\n\n # Start with convenience argument handling. Forwards to\n # Docker::Container#start\n # @return [Container]\n def start(options = {})\n # There seems to be a race condition somewhere in udev/docker\n # https://github.com/docker/docker/issues/4036\n # Keep retrying till it works\n Retry.retry_it(times: 5, errors: [Docker::Error::NotFoundError]) do\n super(options)\n end\n end\n\n class << self\n # Default container create arguments.\n # - WorkingDir: Set to Dir.pwd\n # - Env: Sensible defaults for LANG, PATH, DEBIAN_FRONTEND\n # - Ulimits: Set to sane defaults with lower nofile property\n # @return [Hash]\n def default_create_options\n {\n HostConfig: {\n # Force standard ulimit in the container.\n # Otherwise pretty much all APT IO operations are insanely slow:\n # https://bugs.launchpad.net/ubuntu/+source/apt/+bug/1332440\n # This in particular affects apt-extracttemplates which will take up\n # to 20 minutes where it should take maybe 1/10 of that.\n Ulimits: [{ Name: 'nofile', Soft: 4096, Hard: 4096 }],\n # Disable seccomp. Qt 5.10 onwards prefers to use the statx syscall\n # of Linux (4.11+). This syscall is however not whitelisted in the\n # standard seccomp profile of docker. Furthermore, we cannot set\n # our own profiles as the libseccomp docker was built with wasn't\n # new enough for the mapping from statx=>syscall_id, so even if it\n # was whitelisted it would not do anything for us. Lastly, we also\n # cannot pass syscall_ids as the entire code dealing with the\n # profile doesn't have a signgle atoi check to deal with actual\n # numbers being used as names.\n # This leaves us with the only viable solution being to disable\n # seccomp entirely as we do want Qt built with seccomp support.\n # Ideally this should be undone when docker properly whitelisted\n # statx (and updated their libseccomp).\n # https://bugs.archlinux.org/task/57254#comment166001\n # https://github.com/docker/for-linux/issues/208\n SecurityOpt: %w[seccomp=unconfined]\n },\n WorkingDir: Dir.pwd,\n Env: environment\n }\n end\n\n def assert_version\n # In order to effecitvely set ulimits we need docker 1.6.\n docker_version = Docker.version['Version']\n return if Gem::Version.new(docker_version) >= Gem::Version.new('1.12')\n\n raise \"Containment requires Docker 1.12; found #{docker_version}\"\n end\n\n private\n\n def override_options(options, name, binds)\n options['name'] = name if name\n if binds\n options[:Volumes] = DirectBindingArray.to_volumes(binds)\n options[:HostConfig][:Binds] = DirectBindingArray.to_bindings(binds)\n end\n options\n end\n\n # Returns nil if the env var v is not defined. Otherwise it returns its\n # stringy form.\n def stringy_env_var!(v)\n return nil unless ENV.include?(v)\n\n format('%s=%s', v, ENV[v])\n end\n\n def environment\n env = []\n env <<\n 'PATH=/usr/local/bin:/usr/local/sbin:/usr/bin:/usr/sbin:/bin:/sbin'\n env << 'LANG=en_US.UTF-8'\n env << 'DEBIAN_FRONTEND=noninteractive '\n env += %w[DIST TYPE BUILD_NUMBER].collect { |v| stringy_env_var!(v) }\n env += environment_from_whitelist\n env.compact # compact to ditch stringy_env_var! nils.\n end\n\n # Build initial env from potentially whitelisted env vars in our current\n # env. These will be passed verbatim into docker. This is the base\n # environment. On top of this we'll pack a bunch of extra variables we'll\n # want to pass in all the time. The user fo the class then also can add\n # and override more vars on top of that.\n # Note: this is a bit of a workaround. Our tests are fairly meh and always\n # include the start environment in the expecation, so changes to the\n # defaults are super cumbersome to implement. This acts as much as way\n # to bypass that as it acts as a legit extension to functionality as it\n # allows any old job to extend the forwarded env without having to extend\n # the default forwards.\n def environment_from_whitelist\n list = ENV.fetch('DOCKER_ENV_WHITELIST', '')\n list.split(':').collect { |v| stringy_env_var!(v) }.compact\n end\n\n def merge_env_options(our_options, their_options)\n ours = our_options[:Env]\n theirs = their_options[:Env]\n return our_options if theirs.nil?\n\n our_hash = ours.map { |i| i.split('=') }.to_h\n their_hash = theirs.map { |i| i.split('=') }.to_h\n our_options[:Env] = our_hash.merge(their_hash).map { |i| i.join('=') }\n their_options.delete(:Env)\n our_options\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6585106253623962,
"alphanum_fraction": 0.6595744490623474,
"avg_line_length": 23.736841201782227,
"blob_id": "283ae2858522742f5c0cdb6b6608852e2f0b9772",
"content_id": "033b48ff153cc4b71f85c076eab089cfb34c7f9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 940,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 38,
"path": "/test/test_lint_symbols.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/symbols'\nrequire_relative 'lib/testcase'\n\n# Test lint symbols\n# Because Jonathan doesn't know that we need them.\nclass LintSymbolsTest < TestCase\n def test_init\n c = Lint::Symbols.new\n assert_equal(Dir.pwd, c.package_directory)\n c = Lint::Symbols.new('/tmp')\n assert_equal('/tmp', c.package_directory)\n end\n\n def test_good\n s = Lint::Symbols.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal([], s.warnings)\n assert_equal([], s.informations)\n end\n\n def test_arch_good\n s = Lint::Symbols.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal([], s.warnings)\n assert_equal([], s.informations)\n end\n\n def test_missing\n s = Lint::Symbols.new(data).lint\n assert(s.valid)\n assert_equal(1, s.errors.size)\n assert_equal([], s.warnings)\n assert_equal([], s.informations)\n end\nend\n"
},
{
"alpha_fraction": 0.6609892845153809,
"alphanum_fraction": 0.6619225144386292,
"avg_line_length": 33.015872955322266,
"blob_id": "637503dbfbc587f0f4131b024a39feb1d2fbce64",
"content_id": "bc4eb801177c4a73e0b2219ccba9c550b55ea2f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4286,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 126,
"path": "/lib/ci/pattern.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../deprecate'\n\nmodule CI\n # A PatternArray.\n # PatternArray is a specific Array meant to be used for Pattern objects.\n # PatternArray includes PatternFilter to filter patterns that do not match\n # a reference value.\n # class PatternArray < Array\n # include PatternFilter\n # end\n\n # Base class for all patterns\n class PatternBase\n attr_reader :pattern\n\n def initialize(pattern)\n @pattern = pattern\n end\n\n # Compare self to other.\n # Patterns are\n # - equal when self matches other and other matches self\n # - lower than when other matches self (i.e. self is more concrete)\n # - greater than when self matches other (i.e. self is less concrete)\n # - uncomparable when other is not a Pattern or none of the above applies,\n # in which case they are both Patterns but incompatible ones.\n # For example vivid_* and utopic_* do not match one another and thus\n # can not be sorted according the outline here.\n # Sorting pattern thusly means that the lowest pattern is the most concrete\n # pattern.\n def <=>(other)\n return nil unless other.is_a?(PatternBase)\n\n if match?(other)\n return 0 if other.match?(self)\n\n return 1\n end\n # We don't match other. If other matches us other is greater.\n return -1 if other.match?(self)\n\n # If we don't match other and other doesn't match us then the patterns are\n # not comparable\n puts \"Couldn't compare #{self} <=> #{other}\"\n nil\n end\n\n # Convenience equality.\n # Patterns are considered equal when compared with another Pattern object\n # with which the pattern attribute matches. When compared with a String that\n # matches the pattern attribute. Otherwise defers to super.\n def ==(other)\n return true if other.respond_to?(:pattern) && other.pattern == @pattern\n return true if other.is_a?(String) && match?(other)\n\n super(other)\n end\n\n def to_s\n @pattern.to_s\n end\n\n # FIXME: returns difference on what you put in\n def self.filter(reference, enumerable)\n if reference.respond_to?(:reject!)\n enumerable.each do |e, *|\n reference.reject! { |k, *| e.match?(k) }\n end\n return reference\n end\n enumerable.reject { |k, *| !k.match?(reference) }\n end\n\n def self.sort_hash(enumerable)\n enumerable.class[enumerable.sort_by { |pattern, *_| pattern }]\n end\n\n # Constructs a new Hash with the values converted in Patterns.\n # @param hash a Hash to covert into a PatternHash\n # @param recurse whether or not to recursively convert hash\n def self.convert_hash(hash, recurse: true)\n new_hash = {}\n hash.each_with_object(new_hash) do |(key, value), memo|\n if recurse && value.is_a?(Hash)\n value = convert_hash(value, recurse: recurse)\n end\n memo[new(key)] = value\n memo\n end\n new_hash\n end\n end\n\n # A POSIX regex match pattern.\n # Pattern matching is implemented by File.fnmatch and reperesents a POSIX\n # regex match. Namely a simplified regex as often used for file or path\n # patterns.\n class FNMatchPattern < PatternBase\n # @param reference [String] reference the pattern might match\n # @return true if the pattern matches the refernece\n def match?(reference)\n reference = reference.pattern if reference.respond_to?(:pattern)\n args = []\n if @pattern.count('{') > 0 &&\n @pattern.count('{') == @pattern.count('}')\n args << File::FNM_EXTGLOB\n end\n File.fnmatch(@pattern, reference, *args)\n end\n end\n\n # Simple .include? pattern. An instance of this pattern matches a reference\n # if it is included in the reference in any form or fashion at any given\n # location. It is therefore less accurate than the FNMatchPattern but more\n # convenient to handle if all patterns are meant to essentially be matches of\n # the form \"*pat*\".\n class IncludePattern < PatternBase\n # @param reference [String] reference the pattern might match\n # @return true if the pattern matches the refernece\n def match?(reference)\n reference = reference.pattern if reference.respond_to?(:pattern)\n reference.include?(pattern)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6723723411560059,
"alphanum_fraction": 0.6797283887863159,
"avg_line_length": 31.426605224609375,
"blob_id": "d61f5ee04df8cfcd36359f3f5f78d273c54ebc41",
"content_id": "c54fc156d92fb67e7614b10a36e432a480728a09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7069,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 218,
"path": "/nci/appstream_components_duplicates.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2019-2022 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'date'\nrequire 'faraday'\nrequire 'json'\nrequire 'open-uri'\nrequire 'pp'\nrequire 'tty/command'\nrequire 'yaml'\nrequire 'concurrent'\n\nrequire_relative '../lib/apt'\nrequire_relative 'lib/setup_repo'\n\n# Simple wrapper around an appstream id and its likely permutations that may\n# indicate a dupe. e.g. org.kde.foo => [org.kde.foo.desktop, foo.desktop, foo]\nclass ID\n attr_reader :active\n attr_reader :permutations\n\n def initialize(id)\n @active = id\n\n @permutations = [desktop_permutation,\n rdn_permutation(desktop_permutation),\n rdn_permutation(id)]\n @permutations.uniq!\n @permutations.compact!\n @permutations.reject! { |x| x == id }\n end\n\n private\n\n def desktop_permutation\n return active.gsub('.desktop', '') if active.end_with?('.desktop')\n\n active + '.desktop'\n end\n\n def rdn_permutation(id)\n return \"org.kde.#{id}\" if id.count('.') < 2 # no RDN id\n\n offset = id.end_with?('.desktop') ? -2..-1 : -1..-1\n parts = id.split('.')[offset]\n parts.join('.')\n end\nend\n\n# class Snapd\n# attr_reader :connection\n\n# def initialize\n# @connection = Faraday.new('unix:/') do |c|\n# c.adapter :excon, socket: '/run/snapd.socket'\n# end\n# end\n\n# def contains?(id)\n# response = connection.get(\"/v2/find?common-id=#{id}\")\n# return false unless response.status == 200\n\n# data = JSON.parse(response.body)\n# return false unless data['status'] == 'OK'\n\n# result = data['result']\n# return false if result.empty?\n\n# result.any? { |snap| snap['common-ids']&.include?(id) }\n# end\n# end\n\nif $PROGRAM_NAME == __FILE__\n def puts(str = '')\n print(str + \"\\n\") # Write newline one go lest they get messed by threads.\n end\n\n NCI.setup_repo!\n\n Retry.retry_it(times: 3) { Apt.update || raise }\n Retry.retry_it(times: 3) { Apt.install('appstream') || raise }\n Retry.retry_it(times: 3) { Apt.update || raise }\n\n if Dir.glob('/var/lib/app-info/yaml/*').empty?\n raise \"Seems appstream cache didn't generate/update?\"\n end\n\n # Get our known ids from the raw data. This way appstreamcli cannot override\n # what we see. Also we know which ones are our components as opposed to ones\n # from other repos (i.e. ubuntu)\n data = nil\n Retry.retry_it(times: 3) do\n data = URI.open(\"https://origin.archive.neon.kde.org/user/dists/#{ENV.fetch('DIST')}/main/dep11/Components-amd64.yml\").read\n end\n\n docs = []\n YAML.load_stream(data) do |doc|\n docs << doc\n end\n\n raise \"dep11 file looks malformed #{docs}\" if docs.size < 2\n\n description = docs.shift\n pp description\n created = DateTime.parse(description.fetch('Time'))\n if (DateTime.now - created).to_i >= 60\n # KF5 releases are monthly, so getting no appstream changes for two months\n # is entirely impossible. Guard against broken dep11 data by making sure it\n # is not too too old. Not ideal, but noticing after two months is better than\n # not at all.\n raise 'Appstream cache older than 60 days what gives?'\n end\n\n # all IDs we know except for ones with a merge rule (e.g\n # `Merge: remove-component` as generated from removed-components.json)\n # TODO: we may also want to bump !`Type: desktop-application` because we also\n # describe libraries and so forth, those aren't necessarily a problem as\n # discover doesn't display them. This needs investigation though!\n ids = docs.collect { |x| x['Merge'] ? nil : x['ID'] }\n ids = ids.uniq.compact\n ids = ids.collect { |x| ID.new(x) }\n \n # Some apps have changed IDs and list the old ones as Provides so get a list of those\n provides = docs.collect { |x| x['Provides'] }\n provides = provides.select { |x| x.class == Hash && x.key?('ids') }\n provides = provides.collect { |x| x['ids'] }\n provides = provides.flatten\n puts \"List of old IDs given by apps: #{provides}\"\n\n # List of IDs that are duplicates in Ubuntu's appstream file to ignore them\n ubuntu_duplicates = ['caffeine.desktop', 'org.kde.latte-dock']\n\n # appstreamcli can exhaust allowed open files, put strict limits on just how\n # much we'll thread it to avoid this problem.\n pool = Concurrent::ThreadPoolExecutor.new(\n min_threads: 2,\n max_threads: Concurrent.processor_count,\n max_queue: 16,\n fallback_policy: :caller_runs\n )\n\n missing = Concurrent::Array.new\n blacklist = Concurrent::Array.new\n\n puts '---------------'\n promises = ids.collect do |id|\n Concurrent::Promise.execute(executor: pool) do\n cmd = TTY::Command.new(printer: :null)\n ret = cmd.run!('appstreamcli', 'dump', id.active)\n unless ret.success?\n puts \"!! #{id.active} should be available but it is not!\"\n puts ' Maybe it is incorrectly blacklisted?'\n missing << id.active\n end\n\n id.permutations.each do |permutation|\n ret = cmd.run!('appstreamcli', 'dump', permutation)\n if ret.success?\n puts \"#{id.active} also has permutation: #{permutation}\"\n blacklist << permutation unless provides.include?(permutation) or ubuntu_duplicates.include?(permutation)\n end\n end\n end\n end\n promises.collect(&:wait!)\n puts '---------------'\n\n exit 0 if blacklist.empty? && missing.empty?\n\n unless blacklist.empty?\n puts <<~DESCRIPTION\n============================\nThere are unexpected duplicates!\nThese usually happen when a component changes name during its life time and\nis now provided by multiple repos under different names.\nFor example let's say org.kde.kbibtex is in Ubuntu but the developers have since\nchanged to org.kde.kbibtex.desktop. In neon we have the newer version so our\ndep11 data will provide org.kde.kbibtex.desktop while ubuntu's dep11 will\nstill provide org.kde.kbibtex. Appstream doesn't know that they are the same\nso both would show up if you search for bibtex in discover.\n\nTo solve this problem we'll want to force the old names removed by adding them\nto our removed-components.json\n\nBefore doing this please make sure which component is the current one and that\nthe other one is in fact a duplicate that needs removing! When in in doubt: ask.\n\nhttps://community.kde.org/Neon/Appstream#Duplicated_Components\n\n DESCRIPTION\n\n puts 'REVIEW CAREFULLY! Here is the complete blacklist array'\n puts JSON.generate(blacklist)\n 2.times { puts }\n end\n\n unless missing.empty?\n puts <<~DESCRIPTION\n============================\nThere are components missing from the local cache!\nThis can mean that they are in the removed-components.json even though\nwe still actively provide them. This needs manual investigation.\nThe problem simply is that our raw-dep11 data contained the components but\nappstreamcli does not know about them. This either means appstream is broken\nsomehow or it was told to ignore the components. Bet check\nremoved-components.json for a start.\n\n DESCRIPTION\n\n puts JSON.generate(missing)\n 2.times { puts }\n end\n\n exit 1\nend\n"
},
{
"alpha_fraction": 0.6683291792869568,
"alphanum_fraction": 0.6708229184150696,
"avg_line_length": 30.11206817626953,
"blob_id": "07d1e453193b3486bd1a0f3d49a9b4debde921fb",
"content_id": "cf1536ad5ea423fdec39225587969d916334837e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3609,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 116,
"path": "/lib/projects/factory.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'yaml'\n\nrequire_relative '../projects'\nDir[\"#{__dir__}/factory/*.rb\"].each { |f| require f }\n\n# Constructs projects based on a yaml configuration file.\nclass ProjectsFactory\n class << self\n def factories\n constants.collect do |const|\n klass = const_get(const)\n next nil unless klass.is_a?(Class)\n\n klass\n end.compact\n end\n\n def factory_for(type)\n selection = nil\n factories.each do |factory|\n next unless (selection = factory.from_type(type))\n\n break\n end\n selection\n end\n\n def from_file(file, **kwords)\n data = YAML.load(File.read(file))\n raise unless data.is_a?(Hash)\n\n # Special config setting origin control where to draw default upstream_scm\n # data from.\n kwords[:origin] = data.delete('origin').to_sym if data.key?('origin')\n projects = factorize_data(data, **kwords)\n resolve_dependencies(projects)\n end\n\n # FIXME: I have the feeling some of this should be in project or a\n # different class altogether\n private\n\n def factorize_data(data, **kwords)\n data.collect do |type, list|\n raise unless type.is_a?(String)\n raise unless list.is_a?(Array)\n\n factory = factory_for(type)\n raise unless factory\n\n factory.default_params = factory.default_params.merge(kwords)\n factory.factorize(list)\n end.flatten.compact\n end\n\n def provided_by(projects)\n provided_by = {}\n projects.each do |project|\n project.provided_binaries.each do |binary|\n provided_by[binary] = project\n end\n end\n provided_by\n end\n\n # FIXME: this actually isn't test covered as the factory tests have no\n # actual dependency chains\n def resolved_dependency(project, dependency, provided_by, projects)\n # NOTE: if this was an instance we could cache provided_by!\n return nil unless provided_by.include?(dependency)\n\n dependency = provided_by[dependency]\n # Reverse insert us into the list of dependees of our dependency\n projects.collect! do |dep_project|\n next dep_project if dep_project.name != dependency.name\n\n dep_project.dependees << project\n dep_project.dependees.compact!\n break dep_project\n end\n dependency\n end\n\n def resolve_dependencies(projects)\n provided_by = provided_by(projects)\n projects.collect do |project|\n project.dependencies.collect! do |dependency|\n next resolved_dependency(project, dependency, provided_by, projects)\n end\n # Ditch nil and duplicates\n project.dependencies.compact!\n project\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.753926694393158,
"alphanum_fraction": 0.753926694393158,
"avg_line_length": 18.100000381469727,
"blob_id": "efed4c8b200968d9dea5a3ddcfd7ce87500c3995",
"content_id": "d4405adcf889cf42661d3ca5aa093cf9c1bf0c6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 10,
"path": "/nci/imager/build-hooks-neon-developer/092-apt-blacklist.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -ex\n\necho 'running blacklist hook'\n\n# Drop blacklisted nonesense pulled in via recommends or platform seed.\napt-get purge -y unattended-upgrades || true\n\necho 'blacklist done'\n"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.7358490824699402,
"avg_line_length": 38.05263137817383,
"blob_id": "adf7dc11802304761ad10c8920bf5c394b03b5dd",
"content_id": "523e9797eca99489200fe73f16bd08764477b255",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 742,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 19,
"path": "/nci/imager/build-hooks-neon/999-md5sum.binary",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nset -e\n\necho \"Generating md5sum.txt\"\n# is used on focal+ to verify ISO data integrity.\n# we exlcude md5sum.txt for obvious reasons (still being written and changing)\n\n# TODO: we could use an inverted check: all files listed in md5sum.txt\n# NOTE: we exclude isolinux.bin because live-build will exclude it so long\n# as we are building with bootloader syslinux which is the case thanks to\n# (I think) livecd-rootfs. Should that change we would want to not have this\n# filter anymore.\n\ncd binary\nfind . -type f ! -name \"md5sum.txt\" ! -name 'isolinux.bin' | xargs md5sum >> md5sum.txt\ncd ..\n"
},
{
"alpha_fraction": 0.593502402305603,
"alphanum_fraction": 0.6182646751403809,
"avg_line_length": 37.24242401123047,
"blob_id": "7c27644c9d04ea2d57ddaec5a1798f420d54f943",
"content_id": "601d671d77aec17582df1437fcd3fdab780fa1a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5048,
"license_type": "no_license",
"max_line_length": 250,
"num_lines": 132,
"path": "/test/test_pangea_dput.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2016 Rohan Garg <[email protected]>\n\nrequire 'net/ssh/gateway'\nrequire 'vcr'\nrequire 'webmock'\nrequire 'webmock/test_unit'\n\nrequire_relative 'lib/testcase'\nrequire_relative 'lib/serve'\n\nrequire 'mocha/test_unit'\n\nclass PangeaDPutTest < TestCase\n def setup\n VCR.turn_off!\n WebMock.disable_net_connect!\n @dput = File.join(__dir__, '../ci/pangea_dput')\n ARGV.clear\n end\n\n def teardown\n WebMock.allow_net_connect!\n VCR.turn_on!\n end\n\n def stub_common_http\n stub_request(:get, 'http://localhost:111999/api/repos/kitten')\n .to_return(body: '{\"Name\":\"kitten\",\"Comment\":\"\",\"DefaultDistribution\":\"\",\"DefaultComponent\":\"\"}')\n stub_request(:post, %r{http://localhost:111999/api/files/Aptly__Files-(.*)})\n .to_return(body: '[\"Aptly__Files/kitteh.deb\"]')\n stub_request(:post, %r{http://localhost:111999/api/repos/kitten/file/Aptly__Files-(.*)})\n .to_return(body: \"{\\\"FailedFiles\\\":[],\\\"Report\\\":{\\\"Warnings\\\":[],\\\"Added\\\":[\\\"gpgmepp_15.08.2+git20151212.1109+15.04-0_source added\\\"],\\\"Removed\\\":[]}}\\n\")\n stub_request(:delete, %r{http://localhost:111999/api/files/Aptly__Files-(.*)})\n .to_return(body: '')\n stub_request(:get, 'http://localhost:111999/api/publish')\n .to_return(body: \"[{\\\"Architectures\\\":[\\\"all\\\"],\\\"Distribution\\\":\\\"distro\\\",\\\"Label\\\":\\\"\\\",\\\"Origin\\\":\\\"\\\",\\\"Prefix\\\":\\\"kewl-repo-name\\\",\\\"SourceKind\\\":\\\"local\\\",\\\"Sources\\\":[{\\\"Component\\\":\\\"main\\\",\\\"Name\\\":\\\"kitten\\\"}],\\\"Storage\\\":\\\"\\\"}]\\n\")\n stub_request(:post, 'http://localhost:111999/api/publish/:kewl-repo-name')\n .to_return(body: \"{\\\"Architectures\\\":[\\\"source\\\"],\\\"Distribution\\\":\\\"distro\\\",\\\"Label\\\":\\\"\\\",\\\"Origin\\\":\\\"\\\",\\\"Prefix\\\":\\\"kewl-repo-name\\\",\\\"SourceKind\\\":\\\"local\\\",\\\"Sources\\\":[{\\\"Component\\\":\\\"main\\\",\\\"Name\\\":\\\"kitten\\\"}],\\\"Storage\\\":\\\"\\\"}\\n\")\n stub_request(:put, 'http://localhost:111999/api/publish/:kewl-repo-name/distro')\n .to_return(body: \"{\\\"Architectures\\\":[\\\"source\\\"],\\\"Distribution\\\":\\\"distro\\\",\\\"Label\\\":\\\"\\\",\\\"Origin\\\":\\\"\\\",\\\"Prefix\\\":\\\"kewl-repo-name\\\",\\\"SourceKind\\\":\\\"local\\\",\\\"Sources\\\":[{\\\"Component\\\":\\\"main\\\",\\\"Name\\\":\\\"kitten\\\"}],\\\"Storage\\\":\\\"\\\"}\\n\")\n end\n\n def test_run\n stub_common_http\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n ARGV << '--host' << 'localhost'\n ARGV << '--port' << '111999'\n ARGV << '--repo' << 'kitten'\n ARGV << 'yolo.changes'\n # Binary only builds will not have a dsc in their list, stick with .changes.\n # This in particular prevents our .changes -> .dsc fallthru from falling\n # into a whole when processing .changes without an associated .dsc.\n ARGV << 'binary-without-dsc.changes'\n Test.http_serve(Dir.pwd, port: 111_999) do\n load(@dput)\n end\n end\n\n def test_ssh\n # Tests a gateway life time\n stub_common_http\n\n seq = sequence('gateway-life')\n stub_gate = stub('ssh-gateway')\n Net::SSH::Gateway\n .expects(:new)\n .with('kitteh.local', 'meow')\n .returns(stub_gate)\n .in_sequence(seq)\n stub_gate\n .expects(:open)\n .with('localhost', '9090')\n .returns(111_999) # actual port to use\n .in_sequence(seq)\n stub_gate\n .expects(:shutdown!)\n .in_sequence(seq)\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n ARGV << '--port' << '9090'\n ARGV << '--gateway' << 'ssh://[email protected]:9090'\n ARGV << '--repo' << 'kitten'\n ARGV << 'yolo.changes'\n # Binary only builds will not have a dsc in their list, stick with .changes.\n # This in particular prevents our .changes -> .dsc fallthru from falling\n # into a whole when processing .changes without an associated .dsc.\n ARGV << 'binary-without-dsc.changes'\n load(@dput)\n end\n\n def test_ssh_port_compat\n # Previously one coudl pass --port as a gateway port (i.e. port on the\n # remote). This makes 0 sense with the gateway URIs but is deprecated for\n # now. This test expects that a gatway without explicit port but additional\n # --port argument will connect correctly\n stub_common_http\n\n seq = sequence('gateway-life')\n stub_gate = stub('ssh-gateway')\n Net::SSH::Gateway\n .expects(:new)\n .with('kitteh.local', 'meow')\n .returns(stub_gate)\n .in_sequence(seq)\n stub_gate\n .expects(:open)\n .with('localhost', '9090')\n .returns(111_999) # actual port to use\n .in_sequence(seq)\n stub_gate\n .expects(:shutdown!)\n .in_sequence(seq)\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n ARGV << '--port' << '9090'\n ARGV << '--gateway' << 'ssh://[email protected]'\n ARGV << '--repo' << 'kitten'\n ARGV << 'yolo.changes'\n # Binary only builds will not have a dsc in their list, stick with .changes.\n # This in particular prevents our .changes -> .dsc fallthru from falling\n # into a whole when processing .changes without an associated .dsc.\n ARGV << 'binary-without-dsc.changes'\n load(@dput)\n end\nend\n"
},
{
"alpha_fraction": 0.6951431035995483,
"alphanum_fraction": 0.702515184879303,
"avg_line_length": 31.478872299194336,
"blob_id": "9e254474fb7b09a6a1ce0221732a9bde17cc5a66",
"content_id": "69cdf18ff6e3beffa4c51e05908d5d9efd6339ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2306,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 71,
"path": "/nci/aptly_delete_all_experimental.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'net/ssh/gateway'\nrequire 'ostruct'\nrequire 'optparse'\nrequire 'tty-prompt'\nrequire 'tty-spinner'\n\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative '../lib/nci'\n\noptions = OpenStruct.new\noptions.repos ||= [\"experimental_#{NCI.current_series}\"]\n\nparser = OptionParser.new do |opts|\n opts.banner = \"Usage: #{opts.program_name}\"\nend\nparser.parse!\n\nabort parser.help if options.repos.empty?\n\nlog = Logger.new(STDOUT)\nlog.level = Logger::DEBUG\nlog.progname = $PROGRAM_NAME\n\n# SSH tunnel so we can talk to the repo\nAptly::Ext::Remote.neon do\n log.info 'APTLY'\n Aptly::Repository.list.each do |repo|\n next unless options.repos.include?(repo.Name)\n\n packages = repo.packages\n\n log.info format('Deleting packages from repo %<name>s: %<pkgs>s %<suffix>s',\n name: repo.Name,\n pkgs: packages.first(50).to_s,\n suffix: packages.size > 50 ? ' and more ...' : '')\n\n abort if TTY::Prompt.new.no?('Are you absolutely sure about this?')\n\n spinner = TTY::Spinner.new('[:spinner] :title')\n\n spinner.update(title: \"Deleting packages from #{repo.Name}\")\n spinner.run { repo.delete_packages(packages) }\n\n spinner.update(title: \"Re-publishing #{repo.Name}\")\n spinner.run { repo.published_in.each(&:update!) }\n end\nend\n"
},
{
"alpha_fraction": 0.6640137434005737,
"alphanum_fraction": 0.6681006550788879,
"avg_line_length": 29.99333381652832,
"blob_id": "de6f1b1f6cfee35ccf32225e8ada7876afc81322",
"content_id": "bfb340731837cc5ccec094d0fd15c613ed0ab5d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4651,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 150,
"path": "/jenkins-jobs/job.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'concurrent'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'rexml/document'\n\nrequire_relative '../lib/retry'\nrequire_relative '../lib/jenkins/job'\nrequire_relative 'template'\n\n# Base class for Jenkins jobs.\nclass JenkinsJob < Template\n # FIXME: redundant should be name\n attr_reader :job_name\n\n def initialize(job_name, template_name, **kwords)\n @job_name = job_name\n super(template_name, **kwords)\n end\n\n # Legit class variable. This is for all JenkinsJobs.\n # rubocop:disable Style/ClassVars\n def remote_jobs\n @@remote_jobs ||= Jenkins.job.list_all\n end\n\n def safety_update_jobs\n @@safety_update_jobs ||= Concurrent::Array.new\n end\n\n def self.reset\n @@remote_jobs = nil\n end\n # rubocop:enable Style/ClassVars\n\n def self.include_pattern\n @include_pattern ||= begin\n include_pattern = ENV.fetch('UPDATE_INCLUDE', '')\n if include_pattern.start_with?('/')\n # TODO: this check would be handy somewhere else. at update we\n # have done half the work already, so aborting here is meh.\n unless include_pattern.end_with?('/')\n raise 'Include pattern malformed. starts with /, must end with /'\n end\n\n # eval the regex literal returns a Regexp if valid, raises otherwise\n include_pattern = eval(include_pattern)\n end\n include_pattern\n end\n end\n\n def include_pattern\n # not going through class, this isn't mutable for different instances of Job\n JenkinsJob.include_pattern\n end\n\n def include?\n return include_pattern.match?(job_name) if include_pattern.is_a?(Regexp)\n\n job_name.include?(ENV.fetch('UPDATE_INCLUDE', ''))\n end\n\n # Creates or updates the Jenkins job.\n # @return the job_name\n def update(log: Logger.new(STDOUT))\n # FIXME: this should use retry_it\n return unless include?\n\n xml = render_template\n Retry.retry_it(times: 4, sleep: 1) do\n xml_debug(xml) if @debug\n jenkins_job = Jenkins::Job.new(job_name)\n log.info job_name\n\n if remote_jobs.include?(job_name) # Already exists.\n original_xml = jenkins_job.get_config\n if xml_equal(original_xml, xml)\n log.info \"♻ #{job_name} already up to date\"\n return\n end\n log.info \"#{job_name} updating...\"\n jenkins_job.update(xml)\n elsif safety_update_jobs.include?(job_name)\n log.info \"#{job_name} carefully updating...\"\n jenkins_job.update(xml)\n else\n log.info \"#{job_name} creating...\"\n begin\n jenkins_job.create(xml)\n rescue JenkinsApi::Exceptions::JobAlreadyExists\n # Jenkins is a shitpile and doesn't always delete jobs from disk.\n # Cause: unknown\n # When this happens it will however throw itself in our face about\n # the thing existing, it is however not in the job list, because, well\n # it doesn't exist... except on disk. To get jenkins to fuck off\n # we'll simply issue an update as though the thing existed, except it\n # doesn't... except on disk.\n # The longer we use Jenkins the more I come to hate it. With a passion\n log.warn \"#{job_name} already existed apparently, updating instead...\"\n safety_update_jobs << job_name\n end\n end\n end\n end\n\n private\n\n def xml_debug(data)\n xml_pretty(data, $stdout)\n end\n\n def xml_equal(data1, data2)\n xml_pretty_string(data1) == xml_pretty_string(data2)\n end\n\n def xml_pretty_string(data)\n io = StringIO.new\n xml_pretty(data, io)\n io.rewind\n io.read\n end\n\n def xml_pretty(data, io)\n doc = REXML::Document.new(data)\n REXML::Formatters::Pretty.new.write(doc, io)\n end\n\n alias to_s job_name\n alias to_str to_s\nend\n"
},
{
"alpha_fraction": 0.697685182094574,
"alphanum_fraction": 0.7046296000480652,
"avg_line_length": 25.66666603088379,
"blob_id": "f8221ba84185f9eea6cbf8014c96ce5f4de7d0e0",
"content_id": "3f2ebb8f2c6e662968019ee5620cc9af0a399cdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2166,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 81,
"path": "/jenkins_able.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/thread_pool'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/jenkins/job'\n\nenable = false\n\nOptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: jenkins_able.rb [options] 'regex'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nretry.\n\ne.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*'\n\n • All unstable builds:\n '^.*_unstable_.*'\n\n • All jobs:\n '.*'\n EOS\n\n opts.on('-e', '--enable', 'Enable jobs matching the pattern') do\n enable = true\n end\n\n opts.on('-d', '--disable', 'Disable jobs matching the pattern') do\n enable = false\n end\nend.parse!\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = 'able'\n l.level = Logger::INFO\nend\n\nraise 'Need ruby pattern as argv0' if ARGV.empty?\n\npattern = Regexp.new(ARGV[0])\[email protected] pattern\n\njob_names = Jenkins.job.list_all.select { |name| pattern.match(name) }\njob_names.each do |job_name|\n job = Jenkins::Job.new(job_name)\n if enable\n @log.info \"Enabling #{job_name}\"\n job.enable!\n else\n @log.info \"Disabling #{job_name}\"\n job.disable!\n end\nend\n"
},
{
"alpha_fraction": 0.7161290049552917,
"alphanum_fraction": 0.7161290049552917,
"avg_line_length": 22.846153259277344,
"blob_id": "c010235eb952aacaf361ffcf29f3073957c49c87",
"content_id": "1689e026fb0af676e676e91bfb2d7506a401396d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 13,
"path": "/jenkins-jobs/mgmt_pause_integration.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Pause integration management job.\nclass MGMTPauseIntegrationJob < JenkinsJob\n attr_reader :downstreams\n\n def initialize(downstreams:)\n name = File.basename(__FILE__, '.rb')\n super(name, \"#{name}.xml.erb\")\n @downstreams = downstreams\n end\nend\n"
},
{
"alpha_fraction": 0.6775209903717041,
"alphanum_fraction": 0.6830357313156128,
"avg_line_length": 25.44444465637207,
"blob_id": "16e78c876b84a26b28dfb32fd19c16458dd7ec08",
"content_id": "1433d6300ca70d7bd4f0aa72bad09bf4bab908c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3808,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 144,
"path": "/jenkins_logs.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# coding: utf-8\n# frozen_string_literal: true\n#\n# Copyright (C) 2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'optparse'\nrequire 'tty/pager'\nrequire 'tty/prompt'\nrequire 'tty/spinner'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/ci/pattern'\nrequire_relative 'lib/jenkins/job'\n\n@grep_pattern = nil\n\n# This block is very long because it is essentially a DSL.\nOptionParser.new do |opts|\n opts.banner = <<-SUMMARY\nStreams all build of failed logs to STDOUT. Note that this is potentially a lot\nof data, so use a smart regex and possibly run it on the master server.\n\nUsage: #{opts.program_name} [options] 'regex'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nretry. See jenkins_retry for examples.\n SUMMARY\n\n opts.on('--grep PATTERN', 'Greps all logs for (posix) pattern [eats RAM!]') do |v|\n v.prepend('*') unless v[0] == '*'\n v += '*' unless v[-1] == '*'\n @grep_pattern = CI::FNMatchPattern.new(v)\n end\nend.parse!\n\npattern = nil\nraise 'Need ruby pattern as argv0' if ARGV.empty?\n\npattern = Regexp.new(ARGV[0])\n\nspinner = TTY::Spinner.new('[:spinner] :title', format: :spin_2)\nspinner.update(title: 'Loading job list')\nspinner.auto_spin\njob_names = Jenkins.job.list_by_status('failure')\nspinner.success\n\njob_names = job_names.select do |job_name|\n next false unless pattern.match(job_name)\n\n true\nend\n\nif job_names.size > 8\n if TTY::Prompt.new.no?(\"Your are going to check #{job_names.size} jobs.\" \\\n ' Do you want to continue?')\n abort\n end\nelsif job_names.empty?\n abort 'No jobs matched your pattern'\nend\n\n# Wrapper around a joblog so output only needs fetching once\nclass JobLog\n attr_reader :name\n\n def initialize(name)\n @name = name\n end\n\n def output\n @output ||= begin\n spinner = TTY::Spinner.new('[:spinner] :title', format: :spin_2)\n spinner.update(title: \"Download console of #{name}\")\n spinner.auto_spin\n text = read\n spinner.success\n text\n end\n end\n\n def to_s\n name\n end\n\n private\n\n def job\n @job ||= Jenkins::Job.new(name)\n end\n\n def read\n text = ''\n offset = 0\n loop do\n output = job.console_output(job.build_number)\n text += output.fetch('output')\n break unless output.fetch('more')\n\n offset += output.fetch('size').to_i # stream next part\n sleep 5\n end\n text\n end\nend\n\nlogs = job_names.collect { |name| JobLog.new(name) }\nif @grep_pattern\n logs.select! do |log|\n @grep_pattern.match?(log.output)\n end\nend\n\nabort 'No matching logs found :(' if logs.empty?\n\n# group_by would make the value an array, since names are unique we don't need that though\nlogs = logs.map { |log| [log.name, log] }.to_h\n\nprompt = TTY::Prompt.new\nloop do\n selection = prompt.select('Select job or hit ctrl-c to exit',\n logs.keys,\n per_page: 32, filter: true)\n\n log = logs.fetch(selection)\n pager = TTY::Pager.new\n pager.page(log.output)\nend\n"
},
{
"alpha_fraction": 0.5904123783111572,
"alphanum_fraction": 0.5942897200584412,
"avg_line_length": 31.609195709228516,
"blob_id": "c78813066173fc626596df7564eae5a23df75393",
"content_id": "8aa303a37c969f61b6bac3fe1f3964a93c5659d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2837,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 87,
"path": "/nci/lint/pin_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\n\nrequire_relative '../../lib/debian/version'\n\nmodule NCI\n # Lists packages that are currently pinned\n class PinPackageLister\n Package = Struct.new(:name, :version)\n\n # NB: we always need a fitler for this lister. apt-cache cannot be run\n # without arguments!\n def initialize(filter_select: nil)\n @filter_select = filter_select\n end\n\n def packages\n @packages ||= begin\n cmd = TTY::Command.new(printer: :null)\n result = cmd.run('apt-cache', 'policy')\n\n section_regex = /[^:]+:/\n pin_regex =\n /\\s?(?<package>[^\\s]+) -> (?<version>[^\\s]+) (?<remainder>.*)/\n\n pins = {}\n # Output doesn't start with pins so we'll first want to find the pin\n # section. Track us being inside/outside.\n looking_at_pins = false\n result.out.split(\"\\n\").each do |line|\n if line.strip.include?('Pinned packages:')\n looking_at_pins = true\n next\n end\n\n next unless looking_at_pins\n\n if line.match(section_regex)\n looking_at_pins = false\n next\n end\n\n matchdata = line.match(pin_regex)\n unless matchdata\n raise \"Unexpectadly encountered a none pinny line: #{line}\"\n end\n\n package = matchdata['package'].strip\n version = matchdata['version'].strip\n\n # We track versions in a pin since the output may contain multiple\n # versions. We need to pick the hottest.\n pins[package] ||= []\n pins[package] << version\n end\n\n pins = pins.collect do |pkg, versions|\n versions = versions.compact.uniq\n case versions.size\n when 0\n raise \"Something is wrong with parsing, there's no version: #{pkg}\"\n when 1\n next Package.new(pkg, Debian::Version.new(versions[0]))\n end\n\n # Depending on pins a single packge may be listped multiple times\n # becuase the command doesn't return the candidate but all versions\n # at the same priority -.-\n raise 'Multiple pin candidates not supported.' \\\n \" You'll need to write some code if this is required.\"\n # If necessary we'd likely need to do some comparisions here to\n # pick the highest possible thingy and then ensure it's >> the\n # candidate or something similar.\n # Probably neds refactoring of filter_select to contain versions\n # or something\n end.compact\n\n return pins unless @filter_select\n\n pins.select { |x| @filter_select.include?(x.name) }\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6593948006629944,
"alphanum_fraction": 0.6790992021560669,
"avg_line_length": 26.326923370361328,
"blob_id": "d487301c295b819461a5261618e4e8f30177d9b1",
"content_id": "31830aab17bd2c89d788af8a85debad5133fadaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1421,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 52,
"path": "/test/test_ci_version_enforcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/ci/version_enforcer'\n\nmodule CI\n class VersionEnforcerTest < TestCase\n def setup\n # dud. only used for output in version enforcer\n ENV['JOB_NAME'] = 'RaRaRasputin'\n ENV['TYPE'] = 'eltypo'\n end\n\n def test_init_no_file\n enforcer = VersionEnforcer.new\n assert_nil(enforcer.old_version)\n end\n\n def test_init_with_file\n File.write(VersionEnforcer::RECORDFILE, '1.0')\n enforcer = VersionEnforcer.new\n refute_nil(enforcer.old_version)\n end\n\n def test_increment_fail\n File.write(VersionEnforcer::RECORDFILE, '1.0')\n enforcer = VersionEnforcer.new\n assert_raise VersionEnforcer::UnauthorizedChangeError do\n enforcer.validate('1:1.0')\n end\n end\n\n def test_decrement_fail\n File.write(VersionEnforcer::RECORDFILE, '1:1.0')\n enforcer = VersionEnforcer.new\n assert_raise VersionEnforcer::UnauthorizedChangeError do\n enforcer.validate('1.0')\n end\n end\n\n def test_record!\n enforcer = VersionEnforcer.new\n enforcer.record!('2.0')\n assert_path_exist(VersionEnforcer::RECORDFILE)\n assert_equal('2.0', File.read(VersionEnforcer::RECORDFILE))\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5653393268585205,
"alphanum_fraction": 0.6690970063209534,
"avg_line_length": 32.641510009765625,
"blob_id": "9e227ee22352fa92e447226a7ffc3e161795005e",
"content_id": "8d14ff576025a425b63454ce9d36b2d1dbde4590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1783,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 53,
"path": "/test/test_debian_changes.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/debian/changes'\nrequire_relative 'lib/testcase'\n\n# Test debian .changes\nclass DebianChangesTest < TestCase\n def setup\n # Change into our fixture dir as this stuff is read-only anyway.\n Dir.chdir(datadir)\n end\n\n def test_source\n c = Debian::Changes.new(data)\n c.parse!\n\n assert_equal(3, c.fields['checksums-sha1'].size)\n sum = c.fields['checksums-sha1'][2]\n assert_equal('d433a01bf5fa96beb2953567de96e3d49c898cce', sum.sum)\n # FIXME: should be a number maybe?\n assert_equal('2856', sum.size)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n sum.file_name)\n\n assert_equal(3, c.fields['checksums-sha256'].size)\n sum = c.fields['checksums-sha256'][2]\n assert_equal('7094169ebe86f0f50ca145348f04d6ca7d897ee143f1a7c377142c7f842a2062',\n sum.sum)\n # FIXME: should be a number maybe?\n assert_equal('2856', sum.size)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n sum.file_name)\n\n assert_equal(3, c.fields['files'].size)\n file = c.fields['files'][2]\n assert_equal('fa1759e139eebb50a49aa34a8c35e383', file.md5)\n # FIXME: should be a number maybe?\n assert_equal('2856', file.size)\n assert_equal('libs', file.section)\n assert_equal('optional', file.priority)\n assert_equal('gpgmepp_15.08.2+git20151212.1109+15.04-0.debian.tar.xz',\n file.name)\n end\n\n def test_binary_split\n c = Debian::Changes.new(data)\n c.parse!\n binary = c.fields.fetch('Binary')\n assert(binary)\n assert_equal(3, binary.size) # Properly split?\n assert_equal(%w[libkf5gpgmepp5 libkf5gpgmepp-pthread5 libkf5gpgmepp-dev].sort,\n binary.sort)\n end\nend\n"
},
{
"alpha_fraction": 0.6951501369476318,
"alphanum_fraction": 0.7066974639892578,
"avg_line_length": 25.24242401123047,
"blob_id": "5892e40a7388f0e2998ac91e259f731d0eee690d",
"content_id": "1c2a8c6f67a030057076f4ec0cfdecaf5a8bb415",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 33,
"path": "/nci/repos_with_series_branch.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/projects/factory/neon'\n\nrequire 'optparse'\nrequire 'tty/command'\n\nparser = OptionParser.new do |opts|\n opts.banner = <<~SUMMARY\n Usage: #{opts.program_name} [options] series\n SUMMARY\nend\nabort parser.help if ARGV.size != 1\nseries = ARGV[0]\n\nwith_branch = {}\ncmd = TTY::Command.new\nProjectsFactory::Neon.ls.each do |repo|\n next if repo.include?('gitolite-admin') # enoaccess\n\n url = File.join(ProjectsFactory::Neon.url_base, repo)\n out, _err = cmd.run('git', 'ls-remote', url, \"refs/heads/Neon/*_#{series}\")\n with_branch[repo] = out unless out.empty?\nend\n\nputs \"Repos with branchies:\"\nwith_branch.each do |repo, out|\n puts repo\n puts out\nend\n"
},
{
"alpha_fraction": 0.6369150876998901,
"alphanum_fraction": 0.6369150876998901,
"avg_line_length": 28.58974266052246,
"blob_id": "4dc46dcc43747cf45ef1eaa81515e771ae2204f1",
"content_id": "d87aec71f1c62993aaf81925a0cec19c949285ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2308,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 78,
"path": "/lib/qml/static_map.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'yaml'\n\nrequire_relative 'module'\n\nmodule QML\n # Statically maps specific QML modules to fixed packages.\n # TODO: a single static map means we cannot have divergent realities between\n # unstable and release. it may be smart to split stuff somehow (or rather\n # allow for them to be split)\n class StaticMap\n class << self\n # @return [String] path to the yaml data file with mapping information\n attr_accessor :data_file\n\n def reset!\n @base_dir = File.expand_path(\"#{__dir__}/../../\")\n @data_file = File.join(@base_dir, 'data', 'qml-static-map.yml')\n end\n end\n\n reset!\n\n def initialize(data_file = nil)\n data_file ||= self.class.data_file\n data = YAML.load(File.read(data_file))\n return if data.nil? || !data || data.empty?\n\n parse(data)\n end\n\n # Get the mapped package for a QML module, or nil.\n # @param qml_module [QML::Module] module to map to a package. Do note that\n # version is ignored if the reference map has no version defined. Equally\n # qualifier is entirely ignored as it has no impact on mapping\n # @return [String, nil] package name if it maps to a package statically\n def package(qml_module)\n # FIXME: kinda slow, perhaps the interal structures should change to\n # allow for faster lookup\n @hash.each do |mod, package|\n next unless mod.identifier == qml_module.identifier\n next unless version_match?(mod.version, qml_module.version)\n\n return package\n end\n nil\n end\n\n private\n\n def version_match?(constraint, version)\n # If we have a fully equal match we are happy (this can be both empty.)\n return true if constraint == version\n # Otherwise we'll want a version to verify aginst.\n return false unless version\n\n Gem::Dependency.new('', constraint).match?('', version)\n end\n\n def parse_module(mod)\n return QML::Module.new(mod) if mod.is_a?(String)\n\n mod.each do |name, version|\n return QML::Module.new(name, version)\n end\n end\n\n def parse(data)\n @hash = {}\n data.each do |package, modules|\n modules.each do |mod|\n qml_mod = parse_module(mod)\n @hash[qml_mod] = package\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6458527445793152,
"alphanum_fraction": 0.6472507119178772,
"avg_line_length": 29.657142639160156,
"blob_id": "4bbadf59e92d1f7c45b69fc7782fe4d6919d77c0",
"content_id": "1449b1b326e9b274a9010bb5a0580a418a573935",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2146,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 70,
"path": "/lib/qml/ignore_rule.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'module'\n\nmodule QML\n # Sepcifies an ignore rule for a qml module.\n class IgnoreRule\n # Identifier of the rule. This is a {File#fnmatch} pattern.\n attr_reader :identifier\n attr_reader :version\n\n # Checks whether this ignore rule matches an input {Module}.\n # An ignore rule matches if:\n # - {IgnoreRule#identifier} matches {Module#identifier}\n # - {IgnoreRule#version} is nil OR matches {Module#version}\n # @param qml_module [QML::Module] module to check for ignore match\n def ignore?(qml_module)\n match_version?(qml_module) && match_identifier?(qml_module)\n end\n\n # @return [Array<QML::IgnoreRule>] array of ignore rules read from path\n # @note can be empty if the file does not exist.\n def self.read(path)\n return [] unless File.exist?(path)\n\n rules = File.read(path).split($/)\n rules.collect! do |line|\n line = line.split('#')[0]\n next if line.nil? || line.empty?\n\n parts = line.split(/\\s+/)\n next unless parts.size.between?(1, 2)\n\n new(*parts)\n end\n rules.compact\n end\n\n # Helper overload for {Array#include?} allowing include? checks with a\n # {Module} resulting in {#ignore?} checks of the rule (i.e. Array#include?\n # is equal to iterating over the array and calling ignore? on all rules).\n # If the rule is compared to anything but a {Module} instance it will\n # yield to super.\n def ==(other)\n return ignore?(other) if other.is_a?(QML::Module)\n\n super(other)\n end\n\n private\n\n def initialize(identifier, version = nil)\n @identifier = identifier\n @version = version\n unless @version.nil? || @version.is_a?(String)\n raise 'Version must either be nil or a string'\n end\n return unless @identifier.nil? || @identifier.empty?\n\n raise 'No valid identifier set. Needs to be a string and not empty'\n end\n\n def match_version?(qml_module)\n @version.nil? || @version == qml_module.version\n end\n\n def match_identifier?(qml_module)\n File.fnmatch(@identifier, qml_module.identifier)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5851672291755676,
"alphanum_fraction": 0.607174277305603,
"avg_line_length": 45.367347717285156,
"blob_id": "2cfc90c6fb9b98840fefa25751728fc8b6eced4a",
"content_id": "93a4d73afb5a7ec2b9da20b0ac4eb4d07707c32f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4544,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 98,
"path": "/test/test_nci_lint_cmake_packages.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/apt'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class CMakePackagesTest < TestCase\n def setup\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n # We'll temporary mark packages as !auto, mock this entire thing as we'll\n # not need this for testing.\n Apt::Mark.stubs(:tmpmark).yields\n end\n\n # This brings down coverage which is meh, it does neatly isolate things\n # though.\n def test_run\n pid = fork do\n # Needed so we can properly mock before loading the binary.\n require_relative '../nci/lint/cmake_packages'\n require_relative '../nci/lib/setup_repo'\n\n ENV['TYPE'] = 'release'\n ENV['DIST'] = 'xenial'\n NCI.expects(:add_repo_key!).returns(true)\n NCI.stubs(:setup_proxy!)\n NCI.stubs(:maybe_setup_apt_preference)\n Apt::Key.expects(:add).returns(true)\n Apt::Repository.any_instance.expects(:add).returns(true)\n Apt::Repository.any_instance.expects(:remove).returns(true)\n Apt::Abstrapt.stubs(:run_internal).returns(true)\n DPKG.expects(:list).with('libkf5coreaddons-dev').returns(%w[\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsMacros.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets-debian.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfigVersion.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfig.cmake)\n ])\n CMakeDepVerify::Package.any_instance.expects(:run_cmake_in).returns(true)\n\n fake_repo = mock('repo')\n fake_repo\n .expects(:packages)\n .at_least_once\n .with(q: 'kcoreaddons (= 5.21.0-0neon) {source}')\n .returns(['Psource kcoreaddons 5.21.0-0neon abc'])\n fake_repo\n .expects(:packages)\n .at_least_once\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kcoreaddons), $SourceVersion (5.21.0-0neon)')\n .returns(['Pamd64 libkf5coreaddons-bin-dev 5.21.0-0neon abc',\n 'Pall libkf5coreaddons-data 5.21.0-0neon abc',\n 'Pamd64 libkf5coreaddons-dev 5.21.0-0neon abc',\n 'Pamd64 libkf5coreaddons5 5.21.0-0neon abc'])\n\n Aptly::Repository.expects(:get).with('release_xenial').returns(fake_repo)\n\n result = mock('result')\n result.responds_like_instance_of(TTY::Command::Result)\n result.stubs(:success?).returns(true)\n result.stubs(:out).returns('')\n result.stubs(:err).returns('')\n TTY::Command.any_instance.expects(:run!).returns(result)\n DPKG.stubs(:list).with { |x| x != 'libkf5coreaddons-dev' }.returns([])\n\n load \"#{__dir__}/../nci/lint_cmake_packages.rb\"\n puts 'all good, fork ending!'\n exit 0\n end\n waitedpid, status = Process.waitpid2(pid)\n assert_equal(pid, waitedpid)\n #assert_equal(['kcoreaddons_5.21.0-0neon_amd64.changes', 'libkf5coreaddons-dev.xml', 'libkf5coreaddons-bin-dev.xml', #'libkf5coreaddons5.xml'].sort,\n # Dir.glob('*').sort)\n #assert(status.success?)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6474738717079163,
"alphanum_fraction": 0.6541537046432495,
"avg_line_length": 28.773109436035156,
"blob_id": "6748ad7b8aa0adc196eb698c0f7bd0ea86c561a2",
"content_id": "8f0880aba028a4e534fb78b1dc1347d4f31772f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 10629,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 357,
"path": "/lib/repo_abstraction.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2014-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'apt'\nrequire_relative 'aptly-ext/filter'\nrequire_relative 'aptly-ext/package'\nrequire_relative 'debian/changes'\nrequire_relative 'dpkg'\nrequire_relative 'lsb'\nrequire_relative 'nci'\nrequire_relative 'os'\nrequire_relative 'retry'\n\nrequire 'concurrent'\nrequire 'logger'\nrequire 'shellwords'\n\n# We can't really module this because it is used API. Ugh.\n\n# FIXME: maybe this should be a module that gets prepended\n# init options are questionable through\n# with a prepend we can easily have global as well as repo specific package\n# filters though as a hook-mechanic without having to explicitly do stupid\n# hooks\nclass Repository\n attr_accessor :purge_exclusion\n\n def initialize(name)\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n\n # FIXME: daft, we should only have one repo and add/remove it\n # can't do this currently because equality sequence with old code\n # demands multiple repos\n @_name = name\n # @_repo = Apt::Repository.new(name)\n @install_exclusion = %w[base-files libblkid1 libblkid-dev]\n # Special hack for 16.04 where neon-adwaita isn't meant to be used but is\n # still built and would consequently get installed in the install_check.\n # Prevent this by blacklisting it. In 18.04 we want it installed though as\n # it replaces an adwaita fork.\n if OS::VERSION_ID == '16.04'\n warn 'excluding neon-adwaita for 16.04'\n @install_exclusion << 'neon-adwaita'\n end\n # software-properties backs up Apt::Repository, must not be removed.\n @purge_exclusion = %w[base-files python3-software-properties\n software-properties-common apt libapt-pkg5.0 libblkid1 libblkid-dev\n neon-settings libseccomp2 neon-adwaita libdrm2 libdrm-dev libdrm-common \n libdrm-test libdrm2-udeb libdrm-intel libdrm-radeon1 libdrm-common libdrm-intel1 \n libdrm-amdgpu1 libdrm-tests libdrm-nouveau2]\n\n p self\n end\n\n def add\n repo = Apt::Repository.new(@_name)\n return true if repo.add && update_with_retry\n\n remove\n false\n end\n\n def remove\n repo = Apt::Repository.new(@_name)\n return true if repo.remove && update_with_retry\n\n false\n end\n\n def install\n @log.info \"Installing PPA #{@_name}.\"\n return false if packages.empty?\n\n pin!\n args = %w[ubuntu-minimal]\n # Map into install expressions, value can be nil so compact and join\n # to either get \"key=value\" or \"key\" depending on whether or not value\n # was nil.\n args += packages.map do |k, v|\n next '' if install_excluded?(k)\n\n [k, v].compact.join('=')\n end\n Apt.install(args)\n end\n\n def purge\n @log.info \"Purging PPA #{@_name}.\"\n return false if packages.empty?\n\n Apt.purge(packages.keys.delete_if { |x| purge_excluded?(x) }, args: %w[--allow-remove-essential])\n end\n\n private\n\n def update_with_retry\n # Aptly doesn't do by-hash repos so updates can have hash mismatches.\n # Also general network IO problems...\n # Maybe Apt.update should just retry itself?\n Retry.retry_it(times: 4, sleep: 4) { Apt.update || raise }\n end\n\n def purge_excluded?(package)\n @purge_exclusion.any? { |x| x == package }\n end\n\n def install_excluded?(package)\n @install_exclusion.any? { |x| x == package }\n end\nend\n\n# An aptly repo for install testing\nclass AptlyRepository < Repository\n def initialize(repo, prefix)\n @repo = repo\n # TODO: REVERT: This should not be needed at all, but I can't get tests\n # working where it automatically fetches prefix from the aptly.\n # I'll revert this when I get tests working but for now to get lint\n # working this is crude solution\n if NCI.divert_repo?(prefix)\n super(\"http://archive.neon.kde.org/tmp/#{prefix}\")\n else\n super(\"http://archive.neon.kde.org/#{prefix}\")\n end\n end\n\n # FIXME: Why is this public?!\n def sources\n @sources ||= begin\n sources = @repo.packages(q: '$Architecture (source)')\n Aptly::Ext::LatestVersionFilter.filter(sources)\n end\n end\n\n private\n\n def new_query_pool\n # Run on a tiny thread pool so we don't murder the server with queries\n # Use a very lofty queue to avoid running into scheduling problems when\n # the connection is very slow.\n Concurrent::ThreadPoolExecutor.new(min_threads: 2, max_threads: 4,\n max_queue: sources.size * 2)\n end\n\n # Helper to build aptly queries.\n # This is more of an exercise in design of how a proper future builder might\n # look and feel.\n # TODO: could move to aptly ext and maybe aptly-api itself, may benefit from\n # some more engineering to allow building queries as a form of DSL?\n class QueryBuilder\n attr_reader :query\n\n def initialize\n @query = nil\n end\n\n def and(suffix, **kwords)\n suffix = format(suffix, kwords) unless kwords.empty?\n unless query\n @query = suffix\n return self\n end\n @query += \", #{suffix}\"\n self\n end\n\n def to_s\n @query\n end\n end\n\n def query_str_from_source(source)\n QueryBuilder.new\n .and('!$Architecture (source)')\n .and('$PackageType (deb)') # we particularly dislike udeb!\n .and('$Source (%<name>s)', name: source.name)\n .and('$SourceVersion (%<version>s)', version: source.version)\n .to_s\n end\n\n def query_packages_from_sources\n puts 'Querying packages from aptly.'\n pool = new_query_pool\n promises = sources.collect do |source|\n q = query_str_from_source(source)\n Concurrent::Promise.execute(executor: pool) do\n Retry.retry_it(times: 4, sleep: 4) { @repo.packages(q: q) }\n end\n end\n Concurrent::Promise.zip(*promises).value!.flatten\n end\n\n def packages\n @packages ||= begin\n packages = query_packages_from_sources\n packages = Aptly::Ext::LatestVersionFilter.filter(packages)\n arch_filter = [DPKG::HOST_ARCH, 'all']\n packages.select! { |x| arch_filter.include?(x.architecture) }\n packages.reject! { |x| x.name.end_with?('-dbg', '-dbgsym') }\n packages.reject! { |x| x.name.start_with?('oem-config') }\n packages.map { |x| [x.name, x.version] }.to_h\n end\n end\n\n def pin!\n # FIXME: not implemented.\n end\nend\n\n# This is an addon that sits on top of one or more Aptly repos and basically\n# replicates repo #add and #purge from Ubuntu repos but with the package list\n# from an AptlyRepository.\n# Useful to install the existing package set from Ubuntu and then upgrade on top\n# of that.\nclass RootOnAptlyRepository < Repository\n def initialize(repos = [])\n super('ubuntu-fake-yolo-kitten')\n @repos = repos\n\n Apt.install('packagekit', 'libgirepository1.0-dev',\n 'gir1.2-packagekitglib-1.0', 'dbus-x11') || raise\n end\n\n def add\n true # noop\n end\n\n def remove\n true # noop\n end\n\n def pin!\n # We don't need a pin for this use case as latest is always best.\n end\n\n private\n\n def dbus_daemon\n Dir.mkdir('/var/run/dbus')\n spawn('dbus-daemon', '--nofork', '--system', pgroup: Process.pid)\n end\n\n # Uses dbus-launch to start a session bus\n # @return Hash suitable for ENV exporting. Includes vars from dbus-launch.\n def dbus_session\n lines = `dbus-launch --sh-syntax`\n raise unless $?.success?\n\n lines = lines.strip.split($/)\n env = lines.collect do |line|\n next unless line.include?('=')\n\n data = line.split('=', 2)\n data[1] = Shellwords.split(data[1]).join.chomp(';')\n data\n end\n env.compact.to_h\n end\n\n def cleanup_pid(pid)\n Process.kill('KILL', pid)\n Process.wait(pid)\n rescue Errno::ECHILD\n puts \"pid #{pid} already dead apparently. got ECHILD\"\n end\n\n def dbus_run_custom(&_block)\n system_pid = dbus_daemon\n session_env = dbus_session\n session_pid = session_env.fetch('DBUS_SESSION_BUS_PID').to_i\n ENV.update(session_env)\n yield\n ensure\n # Kill, this is a single-run sorta thing inside the container.\n cleanup_pid(session_pid) if session_pid\n cleanup_pid(system_pid) if system_pid\n end\n\n def dbus_run(&block)\n if ENV.key?('DBUS_SESSION_BUS_ADDRESS')\n yield\n else\n dbus_run_custom(&block)\n end\n end\n\n def internal_setup_gir\n Apt.install('packagekit', 'libgirepository1.0-dev', 'gir1.2-packagekitglib-1.0', 'dbus-x11') || raise\n require_relative 'gir_ffi'\n true\n end\n\n def setup_gir\n @setup ||= internal_setup_gir\n @gir ||= GirFFI.setup(:PackageKitGlib, '1.0')\n end\n\n # @returns <GLib::PtrArray> of {PackageKitGlib.Package} instances\n def packagekit_packages\n dbus_run do\n client = PackageKitGlib::Client.new\n filter = PackageKitGlib::FilterEnum[:arch]\n return client.get_packages(filter).package_array.collect(&:name)\n end\n end\n\n def packages\n # Ditch version for this. Latest is good enough, we expect no wanted repos\n # to be enabled at this point anyway.\n @packages ||= begin\n Apt::Cache.disable_auto_update { mangle_packages }\n end\n end\n\n def mangle_packages\n setup_gir\n packages = []\n pk_packages = packagekit_packages # grab a list of all known names\n puts \"Ubuntu packages: #{pk_packages}\"\n # self is actually a meta version assembling multiple repos' packages\n @repos.each do |repo|\n repo_packages = repo.send(:packages).keys.dup\n repo_packages -= packages # substract already known packages.\n repo_packages.each { |k| packages << k if pk_packages.include?(k) }\n end\n packages\n end\nend\n\n# Special repository type which filters the sources based off of the\n# changes file in PWD.\nclass ChangesSourceFilterAptlyRepository < ::AptlyRepository\n def sources\n @sources ||= begin\n changes = Debian::Changes.new(Dir.glob('*.changes')[0])\n changes.parse!\n # Aptly api is fairly daft and has no proper R/WLock right now, so\n # reads time out every once in a while, guard against this.\n # Exepctation is that the timeout is reasonably short so we don't wait\n # too long multiple times in a row.\n s = Retry.retry_it(times: 8, sleep: 4) do\n @repo.packages(q: format('%s (= %s) {source}',\n changes.fields['Source'],\n changes.fields['Version']))\n end\n s.collect { |x| Aptly::Ext::Package::Key.from_string(x) }\n end\n end\n\n # TODO: move to unified packages meth name\n def binaries\n packages\n end\nend\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 17.33333396911621,
"blob_id": "a4c82b2405978b2d7446f759c0e25c9f3648431b",
"content_id": "55b35fde40ba715b1c86db5a61125230a496874b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 6,
"path": "/test/run_all.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\nrequire 'test/unit'\n\nexit Test::Unit::AutoRunner.run(true)\n"
},
{
"alpha_fraction": 0.636810302734375,
"alphanum_fraction": 0.6572184562683105,
"avg_line_length": 29.413793563842773,
"blob_id": "bb5ecdba05fb4fe3a49bb4b3bcb0601313a67c97",
"content_id": "0b45d168c51e2992f2f6638e96210b345b19cb87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2646,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 87,
"path": "/lib/ci/deb822_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2015-2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'digest'\n\nrequire_relative '../debian/changes'\nrequire_relative '../debian/dsc'\n\nmodule CI\n # Helps processing a deb822 for upload.\n class Deb822Lister\n def initialize(file)\n @file = File.absolute_path(file)\n @dir = File.dirname(file)\n @deb822 = open\n end\n\n def self.files_to_upload_for(file)\n new(file).files_to_upload\n end\n\n def files_to_upload\n files = []\n @deb822.fields.fetch('checksums-sha256', []).each do |sum|\n file = File.absolute_path(sum.file_name, @dir)\n raise \"File #{file} has incorrect checksum\" unless valid?(file, sum)\n\n files << file\n end\n files << @file if @deb822.is_a?(Debian::DSC)\n files\n end\n\n private\n\n def open\n deb822 = open_changes(@file)\n # Switch .changes to .dsc to make sure aptly will have everything it\n # expects, in particular the .orig.tar\n # https://github.com/smira/aptly/issues/370\n dsc = deb822.fields['files'].find { |x| x.name.end_with?('.dsc') }\n return deb822 unless dsc\n\n puts \"Switching #{File.basename(@file)} to #{dsc.name} ...\"\n @file = File.absolute_path(dsc.name, @dir)\n open_dsc(@file)\n end\n\n def valid?(file, checksum)\n raise \"File not found #{file}\" unless File.exist?(file)\n\n Digest::SHA256.hexdigest(File.read(file)) == checksum.sum\n end\n\n def open_changes(file)\n puts \"Opening #{File.basename(file)}...\"\n changes = Debian::Changes.new(file)\n changes.parse!\n changes\n end\n\n def open_dsc(file)\n puts \" -> Opening #{File.basename(file)}...\"\n dsc = Debian::DSC.new(file)\n dsc.parse!\n dsc\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6165109276771545,
"alphanum_fraction": 0.6205607652664185,
"avg_line_length": 33.1489372253418,
"blob_id": "7b99d47f707c9ce7feacec4aa7e1a27f189d6bf8",
"content_id": "1b50021c7af3aded8fa653f787831fa6000581f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3210,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 94,
"path": "/lib/apt/key.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'open-uri'\n\nmodule Apt\n # Apt key management using apt-key binary\n class Key\n class << self\n def method_missing(name, *caller_args)\n system('apt-key', name.to_s.tr('_', '-'), *caller_args)\n end\n\n # Add a GPG key to APT.\n # @param str [String] can be a file path, or an http/https/ftp URI or\n # a fingerprint/keyid or a fucking file, if you pass a fucking file you\n # are an idiot.\n def add(str)\n # If the thing passes for an URI with host and path we use it as url\n # otherwise as fingerprint. file:// uris would not qualify, we do not\n # presently have a use case for them though.\n if url?(str)\n add_url(str)\n else\n fingerprint_added?(str) ? true : add_fingerprint(str)\n end\n end\n\n def add_url(url)\n data = URI.open(url).read\n IO.popen(['apt-key', 'add', '-'], 'w') do |io|\n io.puts(data)\n io.close_write\n end\n $?.success?\n end\n\n def add_fingerprint(id_or_fingerprint)\n system('apt-key', 'adv',\n '--keyserver', 'keyserver.ubuntu.com',\n '--recv', id_or_fingerprint)\n end\n\n private\n\n def fingerprint_added?(str)\n output = `apt-key adv --fingerprint '#{str}'`\n return false if output.nil? || !$?.success? # May be nil from mocking!\n\n # This is a bit imprecise, but cheapest way to do it without having\n # to parse the output as a whole. By only querying --fingerprint this\n # should still be reasonably accurate.\n output.include?(str)\n end\n\n def url?(str)\n uri = URI.parse(str)\n remote?(uri) || local?(uri)\n rescue\n false\n end\n\n def remote?(uri)\n # If a URI has a host and a path we'll assume it to be a path\n !uri.host.to_s.empty? && !uri.path.to_s.empty?\n end\n\n def local?(uri)\n # Has no host but a path and that path is a local file?\n # Must be a local uri.\n # NB: fingerpints or keyids are incredibly unlikely to match this, but\n # they could if one has particularly random file names in PWD.\n uri.host.to_s.empty? && (!uri.path.to_s.empty? && File.exist?(uri.path))\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6356146931648254,
"alphanum_fraction": 0.6395437121391296,
"avg_line_length": 32.574466705322266,
"blob_id": "c1237c4a383efd5482ae1d0df6342f301a837987",
"content_id": "110f16cf3945a057beadc4e55aa594be50cb28e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7890,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 235,
"path": "/lib/ci/upstream_scm.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# SPDX-FileCopyrightText: 2014-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'git_clone_url'\nrequire 'open-uri'\nrequire 'releaseme'\n\nrequire_relative 'scm'\nrequire_relative '../retry'\n\nmodule CI\n # Construct an upstream scm instance and fold in overrides set via\n # meta/upstream_scm.json.\n class UpstreamSCM < SCM\n # Caches projects so we don't construct them multiple times.\n module ProjectCache\n class << self\n def fetch(repo_url)\n hash.fetch(repo_url, nil)\n end\n\n # @return project\n def cache(repo_url, project)\n hash[repo_url] = project\n project\n end\n\n def skip(repo_url)\n hash[repo_url] = :skip\n end\n\n def skip?(repo_url)\n data = hash[repo_url]\n data == :skip\n end\n\n def reset!\n @hash = {}\n end\n\n private\n\n def hash\n @hash ||= {}\n end\n end\n end\n\n module Origin\n UNSTABLE = :unstable\n STABLE = :stable # aka stable\n end\n\n ORIGIN_PERFERENCE = [Origin::UNSTABLE, Origin::STABLE].freeze\n DEFAULT_BRANCH = 'master'\n\n # Constructs an upstream SCM description from a packaging SCM description.\n #\n # Upstream SCM settings default to sane KDE settings and can be overridden\n # via data/overrides/*.yml. The override file supports pattern matching\n # according to File.fnmatch and ERB templating using a Project as binding\n # context.\n #\n # @param packaging_repo [String] git URL of the packaging repo\n # @param packaging_branch [String] branch of the packaging repo\n # @param working_directory [String] local directory path of directory\n # containing debian/ (this is only used for repo-specific overrides)\n def initialize(packaging_repo, packaging_branch,\n working_directory = Dir.pwd)\n @packaging_repo = packaging_repo\n @packaging_branch = packaging_branch\n @name = File.basename(packaging_repo)\n @directory = working_directory\n\n repo_url = \"https://anongit.kde.org/#{@name.chomp('-qt4')}\"\n branch = DEFAULT_BRANCH\n\n # Should move elsewhere, no clue where though.\n # We releaseme_adjust urls as well and need read-only variants.\n ENV['RELEASEME_READONLY'] = '1'\n\n @default_url = repo_url.clone.freeze\n super('git', repo_url, branch)\n end\n\n # a bit too long but fairly straight forward and also not very complex\n # rubocop:disable Metrics/MethodLength\n def releaseme_adjust!(origin)\n # rubocop:enable Metrics/MethodLength\n return nil unless adjust?\n\n if personal_repo?\n warn \"#{url} is a user repo, we'll not adjust it using releaseme info\"\n ProjectCache.skip(url)\n return nil\n end\n\n # Plasma may have its branch overridden because of peculiar nuances in\n # the timing between branching and actual update of the metadata.\n # These are not global adjust? considerations so we have two methods\n # that instead make opinionated choices about whether or not the branch\n # or the url **may** be changed.\n adjust_branch_to(project, origin)\n adjust_url_to(project)\n self\n ensure\n # Assert that we don't have an anongit URL. But only if there is no\n # other pending exception lest we hide the underlying problem.\n assert_url unless $!\n end\n\n private\n\n def personal_repo?\n # FIXME: we already got the project in the factory. we could pass it through\n return false unless url.include?('invent.kde.org')\n\n # https://docs.gitlab.com/ee/api/README.html#namespaced-path-encoding\n path = URI.parse(url).path.gsub(/.git$/, '')\n path = path.gsub(%r{^/+}, '').gsub('/', '%2F')\n api_url = \"https://invent.kde.org/api/v4/projects/#{path}\"\n data = JSON.parse(URI.open(api_url).read)\n data.fetch('namespace').fetch('kind') == 'user'\n rescue OpenURI::HTTPError => e\n raise \"HTTP Error on '#{api_url}': #{e.message}\"\n end\n\n def assert_url\n return unless type == 'git' && url&.include?('anongit.kde.org')\n\n raise <<~ERROR\n Upstream SCM has invalid url #{url}! Anongit is no more. Either\n this repo should have mapped to a KDE repo (and failed), or it has an\n invalid override, or it needs to have a manual override so it knows\n where to find its source (not automatically possible for !KDE).\n If this is a KDE repo debug why it failed to map and fix it.\n DO NOT OVERRIDE URLS FOR LEGIT KDE PROJECTS!\n ERROR\n end\n\n def default_url?\n raise unless @default_url # make sure this doesn't just do a nil compare\n\n @default_url == @url\n end\n\n def adjust_branch_to(project, origin)\n if default_branch? and not @name.include?(\"kf6\")\n @branch = branch_from_origin(project, origin.to_sym)\n else\n warn <<~WARNING\n #{url} is getting redirected to proper KDE url, but its branch was\n changed by an override to #{@branch} already. The actually detected\n KDE branch will not be applied!\n WARNING\n end\n end\n\n def adjust_url_to(project)\n if default_url?\n @url = SCM.cleanup_uri(project.vcs.repository)\n else\n warn <<~WARNING\n #{url} would be getting redirected to proper KDE url, but its url was\n changed by an override already. The actually detected KDE url will\n not be applied!\n WARNING\n end\n end\n\n def project\n url = self.url.gsub(/.git$/, '') # sanitize\n project = ProjectCache.fetch(url)\n return project if project\n\n projects = Retry.retry_it(times: 5) do\n guess_project(url)\n end\n if projects.size != 1\n raise \"Could not resolve #{url} to KDE project for #{@packaging_repo} branch #{@packaging_branch}. OMG. #{projects}\"\n end\n\n ProjectCache.cache(url, projects[0]) # Caches nil if applicable.\n end\n\n def guess_project(url)\n projects = ReleaseMe::Project.from_repo_url(url)\n return projects unless projects.empty?\n\n # The repo path didn't yield a direct query result. We can only surmize\n # that it isn't a valid invent repo path, as a fall back try to guess\n # the project by its basename as an id.\n # On invent project names aren't unique but in lieu of a valid repo url\n # this is the best we can do.\n warn \"Trying to guess KDE project for #{url}. This is a hack!\"\n ReleaseMe::Project.from_find(File.basename(url))\n end\n\n # This implements a preference fallback system.\n # We get a requested origin but in case this origin is not actually set\n # we fall back to a lower level origin. e.g. stable is requested but not\n # set, we'll fall back to trunk (i.e. ~master).\n # This is to prevent us from ending up with no branch and in case the\n # desired origin is not set, a lower preference fallback is more desirable\n # than our hardcoded master.\n def branch_from_origin(project, origin)\n origin_map = { Origin::UNSTABLE => project.i18n_trunk,\n Origin::STABLE => project.i18n_stable }\n ORIGIN_PERFERENCE[0..ORIGIN_PERFERENCE.index(origin)].reverse_each do |o|\n branch = origin_map.fetch(o)\n return branch unless branch.to_s.empty?\n end\n DEFAULT_BRANCH # If all fails, default back to default.\n end\n\n def default_branch?\n branch == DEFAULT_BRANCH\n end\n\n def adjust?\n url.include?('.kde.org') && type == 'git' &&\n %w[/scratch/ /clones/ /qt/].none? { |x| url.include?(x) } &&\n !ProjectCache.skip?(url)\n end\n end\nend\n\nrequire_relative '../deprecate'\n# Deprecated. Don't use.\nclass UpstreamSCM < CI::UpstreamSCM\n extend Deprecate\n deprecate :initialize, CI::UpstreamSCM, 2015, 12\nend\n"
},
{
"alpha_fraction": 0.6543410420417786,
"alphanum_fraction": 0.657963752746582,
"avg_line_length": 37.48557662963867,
"blob_id": "1da8a49c9f374d857b60e67a3af776f732dbc4db",
"content_id": "45b30bdd4fdabe1532d00af9df03500176fd956e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 8005,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 208,
"path": "/lib/lint/lintian.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2020 Jonathan Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\n\nrequire_relative 'linter'\n\nmodule Lint\n # Lintian log linter\n class Lintian < Linter\n TYPE = ENV.fetch('TYPE', '')\n EXCLUSION = [\n 'no-manual-page',\n 'national-encoding',\n 'elf-error',\n 'priority-extra-is-replaced-by-priority-optional',\n 'transitional-package-not-oldlibs-optional',\n # Our names are very long because our versions are very long because\n # we usually include some form of time stamp as well as extra sugar.\n 'source-package-component-has-long-file-name',\n 'package-has-long-file-name',\n # We really do not care about standards versions for now. They only ever\n # get bumped by the pkg-kde team anyway.\n 'out-of-date-standards-version',\n 'newer-standards-version',\n 'ancient-standards-version',\n # We package an enormous amount of GUI apps without manpages (in fact\n # they arguably wouldn't even make sense what with being GUI apps). So\n # ignore any and all manpage warnings to save Harald from having to\n # override them in every single application repository.\n 'binary-without-manpage',\n # Equally we don't really care enough about malformed manpages.\n 'manpage-has-errors-from-man',\n 'manpage-has-bad-whatis-entry',\n # We do also not care about correct dep5 format as we do nothing with\n # it.\n 'dep5-copyright-license-name-not-unique',\n 'missing-license-paragraph-in-dep5-copyright',\n 'global-files-wildcard-not-first-paragraph-in-dep5-copyright',\n 'debian-revision-should-not-be-zero',\n # AKA in newer versions:\n 'debian-revision-is-zero',\n 'file-without-copyright-information',\n # Lintian doesn't necessarily know the distros we talk about.\n 'bad-distribution-in-changes-file',\n # On dev editions we actually pack x-test for testing purposes.\n 'unknown-locale-code x-test',\n # We entirely do not care about random debian transitions but defer\n # to KDE developer's judgment.\n 'script-uses-deprecated-nodejs-location',\n # Maybe it should, maybe we just don't care. In particular since this is\n # an error but really it is not even making a warning in my mind.\n 'copyright-should-refer-to-common-license-file-for-lgpl',\n 'copyright-should-refer-to-common-license-file-for-gpl',\n\n # libkdeinit5 never needs ldconfig triggers actually\n %r{E: (\\w+): package-must-activate-ldconfig-trigger (.+)/libkdeinit5_(.+).so},\n # While this is kind of a concern it's not something we can do anything\n # about on a packaging level and getting this sort of stuff takes ages,\n # judging from past experiences.\n 'inconsistent-appstream-metadata-license',\n 'incomplete-creative-commons-license',\n # Sourcing happens a number of ways but generally we'll want to rely on\n # uscan to verify signatures if applicable. The trouble here is that\n # we only run lintian during the bin_ job at which point there is\n # generally no signature available.\n # What's more, depending on how the src_ job runs it also may have\n # no signature. For example it can fetch a tarball from our own\n # apt repo instead of upstream when doing a rebuild at which point\n # there is no siganture but the source is implicitly trusted. As such\n # it's probably best to skip over signature warnings as they are 99%\n # irrelevant for us. There probably should be a way to warn when uscan\n # isn't configured to check a signature but it probably needs to be\n # done manually outside lintian somewhere.\n 'orig-tarball-missing-upstream-signature',\n # Laments things such as revisions -0 on native packages' PREVIOUS\n # entries. Entirely pointless.\n 'odd-historical-debian-changelog-version',\n # When the version contains the dist name lintian whines. Ignore it.\n # We intentionally put the version in sometimes so future versions\n # are distinctly different across both ubuntu base version and\n # our build variants.\n 'version-refers-to-distribution',\n # We don't really care. No harm done. Having us chase that sort of stuff\n # is a waste of time.\n 'zero-byte-file-in-doc-directory',\n 'description-starts-with-package-name',\n 'incorrect-packaging-filename debian/TODO.Debian',\n 'superfluous-file-pattern'\n ].freeze\n\n def initialize(changes_directory = Dir.pwd,\n cmd: TTY::Command.new)\n @changes_directory = changes_directory\n @cmd = cmd\n super()\n end\n\n def lint\n @result = Result.new\n @result.valid = true\n data.each do |line|\n lint_line(mangle(line), @result)\n end\n @result\n end\n\n private\n\n # called with chdir inside packaging dir\n def changes_file\n files = Dir.glob(\"#{@changes_directory}/*.changes\")\n raise \"Found not exactly one changes: #{files}\" if files.size != 1\n\n files[0]\n end\n\n # called with chdir inside packaging dir\n def lintian\n result = @cmd.run!('lintian', '--allow-root', changes_file)\n result.out.split(\"\\n\")\n end\n\n def data\n @data ||= lintian\n end\n\n def mangle(line)\n # Lintian has errors that aren't so let's mangle the lot.\n # Nobody cares for stupid noise.\n line = line.gsub(/^\\s*E: /, 'W: ')\n\n # If this is a soname mismatch we'll take a closer look at what package\n # this affects. An actual library package must not contain unexpected\n # sonames or they need to be explicitly overridden.\n # This is specifically to guard against cases where\n # a) the install rule contained too broad wildcarding matching libraries\n # or versions it shouldn't have matched\n # b) an unrelated library is shoved into the same binary package, which\n # can be fine but needs opting into since two different libraries\n # may eventually diverge in so-version, so we cannot assume that this\n # is fine, it sometimes is it often isn't.\n return line unless line.include?(': package-name-doesnt-match-sonames')\n\n line_expr = /\\w: (?<package>.+): package-name-doesnt-match-sonames .+/\n package = line.match(line_expr)&.[](:package)&.strip\n raise \"Failed to parse line #{line}\" unless package\n return line unless package =~ /lib.+\\d/\n\n # Promote this warning to an error if it is a lib package\n line.gsub(/^\\s*W: /, 'E: ')\n end\n\n def exclusion\n @exclusion ||= begin\n EXCLUSION.dup # since we dup you could opt to manipulate this array\n end\n end\n\n def static_exclude?(line)\n # Always exclude random warnings from lintian itself.\n return true if line.start_with?('warning: ')\n # Also silly override reports.\n return true if line =~ /N: \\d+ tags overridden \\(.*\\)/\n end\n\n def exclusion_excluse?(line)\n exclusion.any? do |e|\n next line.include?(e) if e.is_a?(String)\n next line =~ e if e.is_a?(Regexp)\n\n false\n end\n end\n\n def exclude?(line)\n # Always exclude certain things.\n return true if static_exclude?(line)\n # Main exclusion list, may be slightly different based on ENV[TYPE]\n return true if exclusion_excluse?(line)\n\n # Linter based ignore system per-source. Ought not be used anywhere\n # as I don't think we load anything ever.\n @ignores.each do |i|\n next unless i.match?(line)\n\n return true\n end\n false\n end\n\n def lint_line(line, result)\n return if exclude?(line)\n\n case line[0..1]\n when 'W:'\n result.warnings << line\n when 'E:'\n result.errors << line\n when 'I:'\n result.informations << line\n end\n # else: skip\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6895368695259094,
"alphanum_fraction": 0.695368766784668,
"avg_line_length": 34.98765563964844,
"blob_id": "c21c951c00ff2ba60bbb309afdb37c2654429344",
"content_id": "be2bb0f66a32b835650aa10324aa406d766f668e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2915,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 81,
"path": "/test/test_nci_duplicated_repos.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/duplicated_repos'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class DuplicatedReposTest < TestCase\n def teardown\n DuplicatedRepos.whitelist = nil\n end\n\n def test_run_fail\n ProjectsFactory::Neon.expects(:ls).returns(%w[foo/bar std/bar])\n # Fatality only activates after a transition period. Can be dropped\n # once past the date.\n if (DateTime.new(2017, 9, 4) - DateTime.now) <= 0.0\n assert_raise do\n DuplicatedRepos.run\n end\n else\n DuplicatedRepos.run\n end\n assert_path_exist('reports/DuplicatedRepos.xml')\n data = File.read('reports/DuplicatedRepos.xml')\n assert_includes(data, 'foo/bar')\n end\n\n def test_run_pass\n ProjectsFactory::Neon.expects(:ls).returns(%w[foo/bar std/foo])\n DuplicatedRepos.run\n assert_path_exist('reports/DuplicatedRepos.xml')\n data = File.read('reports/DuplicatedRepos.xml')\n assert_not_includes(data, 'foo/bar')\n end\n\n def test_run_pass_with_whitelist\n DuplicatedRepos.whitelist = { 'bar' => %w[foo/bar std/bar] }\n ProjectsFactory::Neon.expects(:ls).returns(%w[foo/bar std/bar])\n DuplicatedRepos.run\n assert_path_exist('reports/DuplicatedRepos.xml')\n data = File.read('reports/DuplicatedRepos.xml')\n assert_not_includes(data, 'foo/bar')\n end\n\n def test_run_pass_with_paths_exclusion\n ProjectsFactory::Neon.expects(:ls).returns(%w[foo/bar attic/bar])\n DuplicatedRepos.run\n assert_path_exist('reports/DuplicatedRepos.xml')\n data = File.read('reports/DuplicatedRepos.xml')\n assert_not_includes(data, 'foo/bar')\n end\n\n def test_multi_exclusion\n ProjectsFactory::Neon.expects(:ls).returns(%w[foo/bar attic/bar kde-sc/bar])\n DuplicatedRepos.run\n assert_path_exist('reports/DuplicatedRepos.xml')\n data = File.read('reports/DuplicatedRepos.xml')\n assert_not_includes(data, 'foo/bar')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6570248007774353,
"alphanum_fraction": 0.663223147392273,
"avg_line_length": 32.379310607910156,
"blob_id": "b6916173b24d77f336efd279103846d8ab971f27",
"content_id": "b554525a56d6d1d7620f9a68fac09d258c435174",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1936,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 58,
"path": "/nci/debian-merge/repositorybase.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'git_clone_url'\nrequire 'net/ssh'\nrequire 'rugged'\n\nmodule NCI\n module DebianMerge\n # A merging repo base.\n class RepositoryBase\n def initialize(rug)\n @rug = rug\n end\n\n def mangle_push_path!\n remote = @rug.remotes['origin']\n puts \"pull url #{remote.url}\"\n return unless remote.url.include?('invent.kde.org/neon')\n\n pull_path = GitCloneUrl.parse(remote.url).path[1..-1]\n puts \"mangle to [email protected]:#{pull_path}\"\n remote.push_url = \"[email protected]:#{pull_path}\"\n end\n\n def credentials(url, username, types)\n raise unless types.include?(:ssh_key)\n\n config = Net::SSH::Config.for(GitCloneUrl.parse(url).host)\n default_key = \"#{Dir.home}/.ssh/id_rsa\"\n key = File.expand_path(config.fetch(:keys, [default_key])[0])\n Rugged::Credentials::SshKey.new(\n username: username,\n publickey: key + '.pub',\n privatekey: key,\n passphrase: ''\n )\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6298136711120605,
"alphanum_fraction": 0.6372670531272888,
"avg_line_length": 33.25531768798828,
"blob_id": "015f7d803b259ba7bba973897c94ec404e0b41d4",
"content_id": "399fd87e3b20bab5e398e82ad618e7edd1036964",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1610,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 47,
"path": "/test/test_ci_scm.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/ci/upstream_scm'\nrequire_relative 'lib/testcase'\n\n# Test ci/upstream_scm\nmodule CI\n class SCMTest < TestCase\n def test_init\n type = 'git'\n url = 'git.debian.org:/git/pkg-kde/yolo'\n branch = 'master'\n scm = SCM.new(type, url, branch)\n assert_equal(type, scm.type)\n assert_equal(url, scm.url)\n assert_equal(branch, scm.branch)\n end\n\n def test_tarball\n SCM.new('tarball', 'http://www.example.com/foo.tar.xz')\n end\n\n def test_cleanup_uri\n assert_equal('/a/b', SCM.cleanup_uri('/a//b/'))\n assert_equal('http://a.com/b', SCM.cleanup_uri('http://a.com//b//'))\n assert_equal('//host/b', SCM.cleanup_uri('//host/b/'))\n # This parses as opaque component with lp as scheme. We only clean path\n # so we cannot clean this without assuming that opaque is in fact\n # equal to path (Which it is not...)\n assert_equal('lp:kitten', SCM.cleanup_uri('lp:kitten'))\n assert_equal('lp:kitten///', SCM.cleanup_uri('lp:kitten///'))\n end\n\n def test_invent_pointgit_http\n # invent urls must have a .git suffix attached!\n # NOTE: at the time of writing the class doesn't support ssh uris properly\n type = 'git'\n url = 'https://invent.kde.org/git/pkg-kde/yolo'\n branch = 'master'\n scm = SCM.new(type, url, branch)\n assert_equal('https://invent.kde.org/git/pkg-kde/yolo.git', scm.url)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6189507842063904,
"alphanum_fraction": 0.656364381313324,
"avg_line_length": 35.70149230957031,
"blob_id": "266f77258ac1bcd82cc709a93c511e02365e3ea5",
"content_id": "b104613feb91329e75195995537b7cf621712cd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4918,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 134,
"path": "/test/test_ci_orig_source_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2016 Bhushan Shah <[email protected]>\n# SPDX-FileCopyrightText: 2016-2017 Rohan Garg <[email protected]>\n\nrequire 'rubygems/package'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/orig_source_builder'\nrequire_relative '../lib/ci/tarball'\n\nmodule CI\n class OrigSourceBuilderTest < TestCase\n required_binaries %w[dpkg-buildpackage dpkg dh uscan]\n\n def setup\n LSB.reset\n LSB.instance_variable_set(:@hash, DISTRIB_CODENAME: 'vivid', DISTRIB_RELEASE: '15.04')\n OS.reset\n OS.instance_variable_set(:@hash, VERSION_ID: '15.04')\n ENV['BUILD_NUMBER'] = '3'\n ENV['DIST'] = 'vivid'\n ENV['TYPE'] = 'unstable'\n @tarname = 'dragon_15.08.1.orig.tar.xz'\n @tarfile = \"#{Dir.pwd}/#{@tarname}\"\n FileUtils.cp_r(Dir.glob(\"#{data}/.\"), Dir.pwd)\n FileUtils.cp_r(\"#{datadir}/http/dragon-15.08.1.tar.xz\", @tarfile)\n\n CI::DependencyResolver.simulate = true\n\n # Turn a bunch of debhelper sub process calls noop to improve speed.\n ENV['PATH'] = \"#{__dir__}/dud-bin:#{ENV['PATH']}\"\n end\n\n def teardown\n CI::DependencyResolver.simulate = false\n\n LSB.reset\n OS.reset\n end\n\n def tar_file_list(path)\n files = []\n Gem::Package::TarReader.new(Zlib::GzipReader.open(path)).tap do |reader|\n reader.rewind\n reader.each do |entry|\n files << File.basename(entry.full_name) if entry.file?\n end\n reader.close\n end\n files\n end\n\n def test_run\n assert_false(Dir.glob('*').empty?)\n\n tarball = Tarball.new(@tarfile)\n\n builder = OrigSourceBuilder.new\n builder.build(tarball)\n\n # On 14.04 the default was .gz, newer versions may yield .xz\n debian_tar = Dir.glob('build/dragon_15.08.1-0xneon+15.04+vivid+unstable+build3.debian.tar.*')\n assert_false(debian_tar.empty?, \"no tar #{Dir.glob('build/*')}\")\n assert_path_exist('build/dragon_15.08.1-0xneon+15.04+vivid+unstable+build3_source.changes')\n assert_path_exist('build/dragon_15.08.1-0xneon+15.04+vivid+unstable+build3.dsc')\n puts File.read('build/dragon_15.08.1-0xneon+15.04+vivid+unstable+build3.dsc')\n assert_path_exist('build/dragon_15.08.1.orig.tar.xz')\n changes = File.read('build/dragon_15.08.1-0xneon+15.04+vivid+unstable+build3_source.changes')\n assert_include(changes.split($/), 'Distribution: vivid')\n # Neon builds should have -0neon changed to -0xneon so we exceed ubuntu's\n # -0ubuntu in case they have the same upstream version. This is pretty\n # much only useful for when restaging on a newer ubuntu base, where the\n # versions may initially overlap.\n assert_include(changes.split($/), 'Version: 4:15.08.1-0xneon+15.04+vivid+unstable+build3')\n end\n\n def test_existing_builddir\n # Now with build dir.\n Dir.mkdir('build')\n assert_nothing_raised do\n OrigSourceBuilder.new\n end\n assert_path_exist('build')\n end\n\n def test_unreleased_changelog\n assert_false(Dir.glob('*').empty?)\n\n tarball = Tarball.new(@tarfile)\n\n builder = OrigSourceBuilder.new(release: 'unstable')\n builder.build(tarball)\n\n debian_tar = Dir.glob('build/dragon_15.08.1-0+15.04+vivid+unstable+build3.debian.tar.*')\n assert_false(debian_tar.empty?, \"no tar #{Dir.glob('build/*')}\")\n assert_path_exist('build/dragon_15.08.1-0+15.04+vivid+unstable+build3_source.changes')\n assert_path_exist('build/dragon_15.08.1-0+15.04+vivid+unstable+build3.dsc')\n assert_path_exist('build/dragon_15.08.1.orig.tar.xz')\n changes = File.read('build/dragon_15.08.1-0+15.04+vivid+unstable+build3_source.changes')\n assert_include(changes.split($/), 'Distribution: unstable')\n end\n\n def test_symbols_strip\n assert_false(Dir.glob('*').empty?)\n\n tarball = Tarball.new(@tarfile)\n\n builder = OrigSourceBuilder.new(strip_symbols: true)\n builder.build(tarball)\n Dir.chdir('build') do\n tar = Dir.glob('*.debian.tar.gz')\n assert_equal(1, tar.size, \"Could not find debian tar #{Dir.glob('*')}\")\n files = tar_file_list(tar[0])\n assert_not_include(files, 'symbols')\n assert_not_include(files, 'dragonplayer.symbols')\n assert_not_include(files, 'dragonplayer.symbols.armhf')\n end\n end\n\n def test_experimental_suffix\n # Experimental TYPE should cause a suffix including ~exp before build\n # number to ensure it doesn't exceed the number of \"proper\" types\n\n ENV['TYPE'] = 'experimental'\n tarball = Tarball.new(@tarfile)\n builder = OrigSourceBuilder.new(release: 'unstable')\n builder.build(tarball)\n\n assert_path_exist('build/dragon_15.08.1-0xneon+15.04+vivid~exp+experimental+build3_source.changes')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.644731342792511,
"alphanum_fraction": 0.657642662525177,
"avg_line_length": 29.012500762939453,
"blob_id": "b0586e454ae1c5ece4c73f0cf2d62934b5b6c51f",
"content_id": "75904c40a7ea8be344c2062fc6443dc8d28a82d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2401,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 80,
"path": "/lib/debian/release.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'insensitive_hash/minimal'\n\nrequire_relative 'deb822'\n\nmodule Debian\n # Debian Release (repo) parser\n class Release < Deb822\n # FIXME: lazy read automatically when accessing fields\n attr_reader :fields\n\n Checksum = Struct.new(:sum, :size, :file_name) do\n def to_s\n \"#{sum} #{size} #{file_name}\"\n end\n end\n\n # FIXME: pretty sure that should be in the base\n def initialize(file)\n @file = file\n @fields = InsensitiveHash.new\n @spec = { mandatory: %w[],\n relationship: %w[],\n multiline: %w[md5sum sha1 sha256 sha512] }\n @spec[:foldable] = %w[] + @spec[:relationship]\n end\n\n def parse!\n lines = ::File.new(@file).readlines\n @fields = parse_paragraph(lines, @spec)\n post_process\n\n # FIXME: signing verification not implemented\n end\n\n def dump\n output = ''\n output += dump_paragraph(@fields, @spec)\n output + \"\\n\"\n end\n\n private\n\n def post_process\n return unless @fields\n\n # NB: need case sensitive here, or we overwrite the correct case with\n # a bogus one.\n %w[MD5Sum SHA1 SHA256 SHA512].each do |key|\n @fields[key] = parse_types(fields[key], Checksum)\n end\n end\n\n def parse_types(lines, klass)\n lines.split($/).collect do |line|\n klass.new(*line.split(' '))\n end.unshift(klass.new)\n # Push an empty isntance in to make sure output is somewhat sane\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6700516939163208,
"alphanum_fraction": 0.6742983460426331,
"avg_line_length": 29.256982803344727,
"blob_id": "2350263e0357156b3a92264d7e5244930901b04f",
"content_id": "7d4778d961ceae9a411a0e91b956be93b4491de0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5416,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 179,
"path": "/lib/merger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'git'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'tmpdir'\n\nrequire_relative 'merger/branch_sequence'\n\n# Stdlib Logger. Monkey patch with factory methods.\nclass Logger\n def self.merger_formatter\n proc do |severity, _datetime, progname, msg|\n max_line = 80\n white_space_count = 2\n spacers = (max_line - msg.size - white_space_count) / 2\n spacers = ' ' * spacers\n next \"\\n\\e[1m#{spacers} #{msg} #{spacers}\\e[0m\\n\" if severity == 'ANY'\n\n \"[#{severity[0]}] #{progname}: #{msg}\\n\"\n end\n end\n\n def self.new_for_merger\n l = Logger.new(STDOUT)\n l.progname = 'merger'\n l.level = Logger::INFO\n l.formatter = merger_formatter\n l\n end\n\n def self.new_for_git\n l = Logger.new(STDOUT)\n l.progname = 'git'\n l.level = Logger::WARN\n l\n end\nend\n\n# A Merger base class. Sets up a repo instance with a working directory\n# in a tmpdir that is cleaned upon instance finalization.\n# i.e. this keeps the actual clone clean.\nclass Merger\n class << self\n # Workign directory used by merger.\n attr_reader :workdir\n # Logger instance used by the Merger.\n attr_reader :log\n\n def cleanup(workdir)\n proc { FileUtils.remove_entry_secure(workdir) }\n end\n\n def static_init(instance)\n @workdir = Dir.mktmpdir(to_s).freeze\n # Workaround for Git::Base not correctly creating .git for index.lock.\n FileUtils.mkpath(\"#{@workdir}/.git\")\n ObjectSpace.define_finalizer(instance, cleanup(@workdir))\n end\n end\n\n # Creates a new Merger. Creates a logger, sets up dpkg-mergechangelogs and\n # opens Dir.pwd as a Git::Base.\n def initialize(repo_path = Dir.pwd)\n self.class.static_init(self)\n\n @log = Logger.new_for_merger\n\n # SSH key loading is mutually exclusive with semaphore as the\n # semaphore would run git out-of-process, thus bypassing the environment\n # variable making the key not get used.\n setup_semaphore! || setup_ssh_key!\n\n @repo = open_repo(repo_path)\n configure_repo!\n cleanup_repo!\n end\n\n def sequence(starting_point)\n BranchSequence.new(starting_point, git: @repo)\n end\n\n private\n\n def setup_semaphore!\n return false unless File.exist?('/var/lib/jenkins/git-semaphore/git')\n\n @log.info 'Setting up git semaphore as git binary'\n Git.configure { |c| c.binary_path = '/var/lib/jenkins/git-semaphore/git' }\n true\n end\n\n def setup_ssh_key!\n return false unless ENV.include?('SSH_KEY_FILE')\n\n @log.info 'Setting up GIT_SSH to load the key file defined in SSH_KEY_FILE'\n ENV['GIT_SSH'] = \"#{File.expand_path(__dir__)}/libexec/ssh_key_file.sh\"\n true\n end\n\n def open_repo(repo_path)\n repo = Git.open(self.class.workdir,\n repository: repo_path,\n log: Logger.new_for_git)\n repo.branches # Trigger an execution to possibly raise an error.\n repo\n rescue Git::GitExecuteError => e\n raise e if repo_path.end_with?('.git', '.git/')\n\n repo_path = \"#{repo_path}/.git\"\n retry\n end\n\n def configure_repo!\n @repo.config('merge.dpkg-mergechangelogs.name',\n 'debian/changelog merge driver')\n @repo.config('merge.dpkg-mergechangelogs.driver',\n 'dpkg-mergechangelogs -m %O %A %B %A')\n repo_path = @repo.repo.path\n FileUtils.mkpath(\"#{repo_path}/info\")\n File.write(\"#{repo_path}/info/attributes\",\n \"debian/changelog merge=dpkg-mergechangelogs\\n\")\n end\n\n # Hard resets the repository. This deletes ALL local branches in preparation\n # for merging. Deleting all branches makes sure that we do not run into\n # outdated local branches or god forbid local branches that failed to push\n # and now can't be updated properly.\n def cleanup_repo!\n @repo.reset(nil, hard: true)\n @repo.clean(force: true, d: true)\n randomly_detatch\n @repo.branches.local.each { |b| b.current ? next : b.delete }\n @repo.gc\n @repo.config('remote.origin.prune', true)\n end\n\n def randomly_detatch\n index ||= 0\n remote = @repo.branches.remote.fetch(index)\n remote.checkout\n rescue Git::GitExecuteError\n @log.warn \"failed to detatch remote #{remote.full}\"\n index += 1\n retry\n rescue IndexError => e\n @log.fatal 'Could not find a remote to detatch from'\n raise e\n end\n\n def noci_merge?(source)\n log = @git.log.between('', source.full)\n return false unless log.size >= 1\n\n log.each do |commit|\n return false unless commit.message.include?('NOCI')\n end\n true\n end\nend\n"
},
{
"alpha_fraction": 0.746835470199585,
"alphanum_fraction": 0.746835470199585,
"avg_line_length": 12.166666984558105,
"blob_id": "1e6ce82dc3b292315e726b776fc3868871c4497c",
"content_id": "9d131244e2b242ceb1fa12abfcf52a93852de416",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 79,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 6,
"path": "/nci/imager/build-hooks-neon-developer/091-apt-update.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\n#refresh apt cache including appstream cache\napt-get update\n"
},
{
"alpha_fraction": 0.7343173623085022,
"alphanum_fraction": 0.7343173623085022,
"avg_line_length": 44.16666793823242,
"blob_id": "05d3f48a0c46110b4e482e8f4180669d84f3678f",
"content_id": "f8c6d8c97b84c893437db17d9448cb75661afbcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 6,
"path": "/nci/imager/build-hooks-plasma-wayland/90_casper.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\nset -e\napt-key adv --keyserver pool.sks-keyservers.net --recv-keys D1B8E0D26079DC00276F463C1406C1DFB3408323\necho \"deb http://ppa.launchpad.net/jr/plasma-wayland/ubuntu xenial main\" >> /etc/apt/sources.list.d/casper.list\napt-get update\napt-get -o Dpkg::Options::=--force-confnew install -y casper\n"
},
{
"alpha_fraction": 0.7371794581413269,
"alphanum_fraction": 0.7628205418586731,
"avg_line_length": 27.363636016845703,
"blob_id": "3163ee540ab2341ea464b38d76def2001a6d4afe",
"content_id": "2621cdeea61104ae278658ff4b51a4de7ab5c145",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 11,
"path": "/nci/imager/build-hooks-neon-mobile/099-calamares-settings.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# SPDX-FileCopyrightText: 2020 Jonathan Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nset -e\n\necho 'installing calamares-setings'\n\n# calamares-settings-debian seems to want to install on testing so force this here\napt install -y calamares-settings\n"
},
{
"alpha_fraction": 0.6736982464790344,
"alphanum_fraction": 0.6902536749839783,
"avg_line_length": 75.42857360839844,
"blob_id": "d5c68b15f89cac19b8f065c1b9421b36414830be",
"content_id": "a075195ae5d7b530c843517a203120c646d8f1de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3745,
"license_type": "no_license",
"max_line_length": 808,
"num_lines": 49,
"path": "/test/test_kdeproject_component.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'test/unit'\n\nrequire 'webmock'\nrequire 'webmock/test_unit'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/kdeproject_component'\n\nrequire 'mocha/test_unit'\n\nclass KDEProjectComponentTest < TestCase\n def test_kdeprojectcomponent\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/frameworks')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: '[\"frameworks/attica\",\"frameworks/baloo\",\"frameworks/bluez-qt\"]', headers: { 'Content-Type' => 'text/json' })\n\n stub_request(:get, 'https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: 'bluedevil breeze breeze-grub breeze-gtk breeze-plymouth discover drkonqi kactivitymanagerd kde-cli-tools kde-gtk-config kdecoration kdeplasma-addons kgamma5 khotkeys kinfocenter kmenuedit kscreen kscreenlocker ksshaskpass ksystemstats kwallet-pam kwayland-integration kwayland-server kwin kwrited layer-shell-qt libkscreen libksysguard milou oxygen plasma-browser-integration plasma-desktop plasma-disks plasma-firewall plasma-integration plasma-nano plasma-nm plasma-pa plasma-phone-components plasma-sdk plasma-systemmonitor plasma-tests plasma-thunderbolt plasma-vault plasma-workspace plasma-workspace-wallpapers plymouth-kcm polkit-kde-agent-1 powerdevil qqc2-breeze-style sddm-kcm systemsettings xdg-desktop-portal-kde ', headers: { 'Content-Type' => 'text/json' })\n\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/pim')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: '[\"pim/kjots\",\"pim/kmime\"]', headers: { 'Content-Type' => 'text/json' })\n\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: '[\"plasma/khotkeys\",\"sdk/umbrello\", \"education/analitza\", \"documentation/digiam-doc\", \"historical/kde1, \"kdevelop/kdev-php\", \"libraries/kdb\", \"maui/buho\", \"multimedia/k3b\", \"network/choqok\", \"office/calligra\", \"unmaintained/contour\"]', headers: { 'Content-Type' => 'text/json' })\n\n stub_request(:get, 'https://invent.kde.org/sysadmin/release-tools/-/raw/master/modules.git')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\\n\", headers: { 'Content-Type' => 'text/plain' })\n\n stub_request(:get, 'https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: 'bluedevil breeze breeze-grub breeze-gtk breeze-plymouth discover drkonqi', headers: { 'Content-Type' => 'text/plain' })\n\n f = KDEProjectsComponent.frameworks\n p = KDEProjectsComponent.plasma\n plasma_jobs = KDEProjectsComponent.plasma_jobs\n pim = KDEProjectsComponent.pim\n assert f.include? 'attica'\n assert p.include? 'bluedevil'\n assert plasma_jobs.include? 'plasma-discover'\n assert !plasma_jobs.include?('discover')\n assert pim.include? 'kjots'\n assert pim.include? 'kmime'\n end\nend\n"
},
{
"alpha_fraction": 0.7548543810844421,
"alphanum_fraction": 0.7609223127365112,
"avg_line_length": 41.25640869140625,
"blob_id": "cb9fc1b57eabeaea0a20b3d5a0e27c039a4077ed",
"content_id": "12dca721ec037b417136224022463faa84e5c781",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1648,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 39,
"path": "/nci/imager/build-hooks-neon-developer/009-neon-masks.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# Mask certain packages which aren't getting properly covered by dependencies.\n\nset -e\n\n# This is canonical support stuff. Not useful and probably also not offered.\n# Our mask removes the ubuntu version.\n# It's being installed by debootstrap, so we'll have to manually rip it out\n# again as apt wouldn't prefer our provides variant over it.\napt-get install --purge -y neon-ubuntu-advantage-tools\napt-mark auto neon-ubuntu-advantage-tools\nif dpkg -s ubuntu-advantage-tools; then\n echo 'ubuntu-advantage-tools is still installed. It is expected to be masked!'\n exit 1\nfi\n\n# Make sure adwaita is masked. Depending on dep resolution we may hav ended\n# up with the real adwaita\napt-get install --purge -y neon-adwaita\napt-mark auto neon-adwaita\n"
},
{
"alpha_fraction": 0.6262039542198181,
"alphanum_fraction": 0.6296586990356445,
"avg_line_length": 38.06748580932617,
"blob_id": "f893037a99138df9d3ecea00c4fdb21cad6f7243",
"content_id": "5fe8dd03b78dcf2ccfac6a25636a4ab1d337e3f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 19104,
"license_type": "no_license",
"max_line_length": 188,
"num_lines": 489,
"path": "/test/test_projects.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'tmpdir'\n\nrequire_relative '../lib/projects'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\n\nclass ProjectTest < TestCase\n def setup\n # Disable overrides to not hit production configuration files.\n CI::Overrides.default_files = []\n # Disable upstream scm adjustment through releaseme we work with largely\n # fake data in this test which would raise in the adjustment as expections\n # would not be met.\n CI::UpstreamSCM.any_instance.stubs(:releaseme_adjust!).returns(true)\n WebMock.disable_net_connect!(allow_localhost: true)\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/frameworks')\n .to_return(status: 200, body: '[\"frameworks/attica\",\"frameworks/baloo\",\"frameworks/bluez-qt\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/kde/workspace')\n .to_return(status: 200, body: '[\"kde/workspace/khotkeys\",\"kde/workspace/plasma-workspace\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/kde')\n .to_return(status: 200, body: '[\"kde/workspace/khotkeys\",\"kde/workspace/plasma-workspace\"]', headers: { 'Content-Type' => 'text/json' })\n stub_request(:get, 'https://invent.kde.org/sysadmin/release-tools/-/raw/master/modules.git')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\\n\", headers: { 'Content-Type' => 'text/plain' })\n stub_request(:get, 'https://invent.kde.org/sdk/releaseme/-/raw/master/plasma/git-repositories-for-release')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: 'bluedevil breeze breeze-grub breeze-gtk breeze-plymouth discover drkonqi', headers: { 'Content-Type' => 'text/plain' })\n stub_request(:get, 'http://embra.edinburghlinux.co.uk/~jr/release-tools/modules.git')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\", headers: { \"Content-Type\": 'text/plain' })\n stub_request(:get, 'https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"aura-browser bluedevil breeze breeze-grub\", headers: { \"Content-Type\": 'text/plain' })\n end\n\n def teardown\n CI::Overrides.default_files = nil\n end\n\n def git_init_commit(repo, branches = %w[master kubuntu_unstable])\n repo = File.absolute_path(repo)\n Dir.mktmpdir do |dir|\n `git clone #{repo} #{dir}`\n Dir.chdir(dir) do\n `git config user.name \"Project Test\"`\n `git config user.email \"[email protected]\"`\n begin\n FileUtils.cp_r(\"#{data}/debian/.\", 'debian/')\n rescue StandardError\n end\n yield if block_given?\n `git add *`\n `git commit -m 'commitmsg'`\n branches.each { |branch| `git branch #{branch}` }\n `git push --all origin`\n end\n end\n end\n\n def git_init_repo(path)\n FileUtils.mkpath(path)\n Dir.chdir(path) { `git init --bare` }\n File.absolute_path(path)\n end\n\n def create_fake_git(name:, component:, branches:, &block)\n path = \"#{component}/#{name}\"\n\n # Create a new tmpdir within our existing tmpdir.\n # This is so that multiple fake_gits don't clash regardless of prefix\n # or not.\n remotetmpdir = Dir::Tmpname.create('d', \"#{@tmpdir}/remote\") {}\n FileUtils.mkpath(remotetmpdir)\n Dir.chdir(remotetmpdir) do\n git_init_repo(path)\n git_init_commit(path, branches, &block)\n end\n remotetmpdir\n end\n\n def test_init\n name = 'tn'\n component = 'tc'\n\n %w[unstable stable].each do |stability|\n gitrepo = create_fake_git(name: name,\n component: component,\n branches: [\"kubuntu_#{stability}\",\n \"kubuntu_#{stability}_yolo\"])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n tmpdir = Dir.mktmpdir(self.class.to_s)\n Dir.chdir(tmpdir) do\n # Force duplicated slashes in the git repo path. The init is supposed\n # to clean up the path.\n # Make sure the root isn't a double slash though as that contstitues\n # a valid URI meaning whatever protocol is being used. Not practically\n # useful for us but good to keep that option open all the same.\n # Also make sure we have a trailing slash. Should we get a super short\n # tmpdir that way we can be sure that at least one pointless slash is\n # in the url.\n slashed_gitrepo = \"#{gitrepo.gsub('/', '//').sub('//', '/')}/\"\n project = Project.new(name, component, slashed_gitrepo,\n type: stability)\n assert_equal(project.name, name)\n assert_equal(project.component, component)\n p scm = project.upstream_scm\n assert_equal('git', scm.type)\n assert_equal('master', scm.branch)\n assert_equal(\"https://anongit.kde.org/#{name}\", scm.url)\n assert_equal(%w[kinfocenter kinfocenter-dbg],\n project.provided_binaries)\n assert_equal(%w[gwenview], project.dependencies)\n assert_equal([], project.dependees)\n assert_equal([\"kubuntu_#{stability}_yolo\"], project.series_branches)\n assert_equal(false, project.autopkgtest)\n\n assert_equal('git', project.packaging_scm.type)\n assert_equal(\"#{gitrepo}/#{component}/#{name}\", project.packaging_scm.url)\n assert_equal(\"kubuntu_#{stability}\", project.packaging_scm.branch)\n assert_equal(nil, project.snapcraft)\n assert(project.debian?)\n assert_empty(project.series_restrictions)\n end\n ensure\n FileUtils.rm_rf(tmpdir) unless tmpdir.nil?\n FileUtils.rm_rf(gitrepo) unless gitrepo.nil?\n end\n end\n\n def test_init_profiles\n name = 'tn'\n component = 'tc'\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_equal(%w[gwenview], project.dependencies)\n end\n end\n end\n\n # Tests init with explicit branch name instead of just type specifier\n def test_init_branch\n name = 'tn'\n component = 'tc'\n\n gitrepo = create_fake_git(name: name,\n component: component,\n branches: %w[kittens kittens_vivid kittens_piggy])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n tmpdir = Dir.mktmpdir(self.class.to_s)\n Dir.chdir(tmpdir) do\n # Force duplicated slashes in the git repo path. The init is supposed\n # to clean up the path.\n # Make sure the root isn't a double slash though as that contstitues\n # a valid URI meaning whatever protocol is being used. Not practically\n # useful for us but good to keep that option open all the same.\n # Also make sure we have a trailing slash. Should we get a super short\n # tmpdir that way we can be sure that at least one pointless slash is\n # in the url.\n slashed_gitrepo = \"#{gitrepo.gsub('/', '//').sub('//', '/')}/\"\n project = Project.new(name, component, slashed_gitrepo, branch: 'kittens')\n # FIXME: branch isn't actually stored in the projects because the\n # entire thing is frontend driven (i.e. the update script calls\n # Projects.new for each type manually). If this was backend/config\n # driven we'd be much better off. OTOH we do rather differnitiate\n # between types WRT dependency tracking and so forth....\n # NB: this must assert **two** branches to ensure all lines are stripped\n # properly.\n assert_equal(%w[kittens_vivid kittens_piggy].sort,\n project.series_branches.sort)\n end\n ensure\n FileUtils.rm_rf(tmpdir) unless tmpdir.nil?\n FileUtils.rm_rf(gitrepo) unless gitrepo.nil?\n end\n\n # Attempt to clone a bad repo. Should result in error!\n def test_init_bad_repo\n assert_raise Project::GitTransactionError do\n Project.new('tn', 'tc', 'git://foo.bar.ja', branch: 'kittens')\n end\n end\n\n def test_init_from_ssh\n omit #FIXME why is everything broken?\n Net::SSH::Config.expects(:for).with('github.com').returns({\n keys: ['/weesh.key']\n })\n Rugged::Credentials::SshKey.expects(:new).with(\n username: 'git',\n publickey: '/weesh.key.pub',\n privatekey: '/weesh.key',\n passphrase: ''\n ).returns('wrupp')\n gitrepo = create_fake_git(name: 'tc', component: 'tn', branches: %w[kittens])\n Rugged::Repository.expects(:clone_at).with do |*args, **kwords|\n p [args, kwords]\n next false unless args[0] == 'ssh://[email protected]/tn/tc' &&\n args[1] == \"#{Dir.pwd}/cache/projects/[email protected]/tn/tc\" &&\n kwords[:bare] == true &&\n kwords[:credentials].is_a?(Method)\n\n FileUtils.mkpath(\"#{Dir.pwd}/cache/projects/[email protected]/tn\")\n system(\"git clone #{gitrepo}/tn/tc #{Dir.pwd}/cache/projects/[email protected]/tn/tc\")\n kwords[:credentials].call(args[0], 'git', nil)\n true\n end.returns(true)\n Project.new('tc', 'tn', 'ssh://[email protected]:', branch: 'kittens')\n end\n\n # Tests init with explicit branch name instead of just type specifier.\n # The branch is meant to not exist. We expect an error here!\n def test_init_branch_not_available\n name = 'tn'\n component = 'tc'\n\n gitrepo = create_fake_git(name: name,\n component: component,\n branches: %w[])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n tmpdir = Dir.mktmpdir(self.class.to_s)\n Dir.chdir(tmpdir) do\n slashed_gitrepo = \"#{gitrepo.gsub('/', '//').sub('//', '/')}/\"\n assert_raise Project::GitNoBranchError do\n Project.new(name, component, slashed_gitrepo, branch: 'kittens')\n end\n end\n ensure\n FileUtils.rm_rf(tmpdir) unless tmpdir.nil?\n FileUtils.rm_rf(gitrepo) unless gitrepo.nil?\n end\n\n def test_native\n name = 'tn'\n component = 'tc'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_nil(project.upstream_scm)\n end\n end\n end\n\n def test_fmt_1\n name = 'skype'\n component = 'ds9-debian-packaging'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n CI::Overrides.instance_variable_set(:@default_files, [\"#{Dir.pwd}/base.yml\"])\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_nil(project.upstream_scm)\n end\n end\n end\n\n def test_launchpad\n omit #FIXME \n reset_child_status!\n\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n\n system_sequence = sequence('test_launchpad-system')\n Object.any_instance.expects(:system)\n .with do |x|\n next unless x =~ /bzr checkout --lightweight lp:unity-action-api ([^\\s]+unity-action-api)/\n\n # .returns runs in a different binding so the chdir is wrong....\n # so we copy here.\n FileUtils.cp_r(\"#{data}/.\", $~[1], verbose: true)\n true\n end\n .returns(true)\n .in_sequence(system_sequence)\n Object.any_instance.expects(:system)\n .with do |x, **kwords|\n x == 'bzr up' && kwords.fetch(:chdir) =~ /[^\\s]+unity-action-api/\n end\n .returns(true)\n .in_sequence(system_sequence)\n\n pro = Project.new('unity-action-api', 'launchpad',\n 'lp:')\n assert_equal('unity-action-api', pro.name)\n assert_equal('launchpad', pro.component)\n assert_equal(nil, pro.upstream_scm)\n assert_equal('lp:unity-action-api', pro.packaging_scm.url)\n end\n\n def test_default_url\n assert_equal(Project::DEFAULT_URL, Project.default_url)\n end\n\n def test_slash_in_name\n assert_raise NameError do\n Project.new('a/b', 'component', 'git:///')\n end\n end\n\n def test_slash_in_component\n assert_raise NameError do\n Project.new('name', 'a/b', 'git:///')\n end\n end\n\n def test_native_blacklist\n name = 'kinfocenter'\n component = 'gear'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n # Should raise on account of KDE Gear being a protected component\n # name which must not contain native stuff.\n assert_raises do\n Project.new(name, component, gitrepo, type: 'unstable')\n end\n end\n end\n end\n\n def test_snapcraft_detection\n name = 'kinfocenter'\n component = 'gear'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable]) do\n File.write('snapcraft.yaml', '')\n end\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n # Should raise on account of KDE Gear being a protected component\n # name which must not contain native stuff.\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_equal 'snapcraft.yaml', project.snapcraft\n refute project.debian?\n end\n end\n end\n\n def test_series_restrictions_overrides\n # series_restrictions is an array. overrides originally didn't proper apply\n # for basic data types. this test asserts that this is actually working.\n # for basic data types we want the deserialized object directly applied to\n # the member (i.e. for series_restrictions the overrides array is the final\n # restrictions array).\n\n name = 'kinfocenter'\n component = 'gear'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n CI::Overrides.instance_variable_set(:@default_files, [\"#{Dir.pwd}/base.yml\"])\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_not_empty(project.series_restrictions)\n end\n end\n end\n\n def test_useless_native_override\n # overrides are set to not be able to override nil members. nil members\n # would mean the member doesn't exist or it was explicitly left nil.\n # e.g. 'native' packaging forces upstream_scm to be nil because dpkg would\n # not care if we made an upstream tarball anyway. native packaging cannot\n # ever have an upstream_scm!\n # This should raise an error as otherwise it's nigh impossible to figure out\n # why the override doesn't stick.\n\n name = 'native'\n component = 'componento'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n CI::Overrides.instance_variable_set(:@default_files, [\"#{Dir.pwd}/base.yml\"])\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n assert_nothing_raised do\n Project.new(name, component, gitrepo, type: 'unstable')\n end\n end\n end\n end\n\n def test_useless_native_override_override\n # since overrides are cascading it can be that a generic rule sets\n # an (incorrect) upstream_scm which we'd ordinarilly refuse to override\n # and fatally error out on when operating on a native package.\n # To bypass this a more specific rule may be set for the specific native\n # package to explicitly force it to nil again. The end result is an\n # override that would attemtp to set upstream_scm to nil, which it\n # already is, so it gets skipped without error.\n\n name = 'override_override'\n component = 'componento'\n\n gitrepo = create_fake_git(name: name, component: component, branches: %w[kubuntu_unstable])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n CI::Overrides.instance_variable_set(:@default_files, [\"#{Dir.pwd}/base.yml\"])\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable')\n assert_nil(project.upstream_scm)\n end\n end\n end\n\n def test_neon_series\n # when a neon repo doesn't have the desired branch, check for a branch\n # named after current series or future series instead. the checkout\n # must not fail so long as either is available\n\n name = 'test_override_packaging_branch'\n component = 'componento'\n\n require_relative '../lib/nci'\n NCI.stubs(:current_series).returns('bionic')\n NCI.stubs(:future_series).returns('focal')\n gitrepo = create_fake_git(name: name, component: component, branches: %w[Neon/unstable_focal])\n assert_not_nil(gitrepo)\n assert_not_equal(gitrepo, '')\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n CI::Overrides.instance_variable_set(:@default_files, [\"#{Dir.pwd}/base.yml\"])\n Dir.mktmpdir(self.class.to_s) do |tmpdir|\n Dir.chdir(tmpdir) do\n project = Project.new(name, component, gitrepo, type: 'unstable', branch: 'Neon/unstable')\n assert_include(project.series_branches, 'Neon/unstable_focal')\n # for the checkout expectations it's sufficient if we got no gitnobranch error raised\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7125416398048401,
"alphanum_fraction": 0.7169811129570007,
"avg_line_length": 31.963415145874023,
"blob_id": "eda6ccfeeeead592be6d01c0a8989ac3ddfada33",
"content_id": "9e1793237311720b4d72fd96e21e930f536e3c9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2703,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 82,
"path": "/lib/nci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\n# NB: this mustn't use any gems! it is used during provisioning.\nrequire_relative 'xci'\n\n# NCI specific data.\nmodule NCI\n extend XCI\n\n # Argument or keyword argument had an unexpected type. Not really useful error differentiation except for\n # testing an expected errror condition.\n class BadInputType < RuntimeError; end\n\n module_function\n\n # This is a list of job_name parts that we want to not have any QA done on.\n # The implementation is a bit ugh so this should be used very very very very\n # sparely and best avoided if at all possible as we can expect this property\n # to go away for a better solution at some point in the future.\n # The array values basically are job_name.include?(x) matched.\n # @return [Array<String>] .include match exclusions\n def experimental_skip_qa\n data['experimental_skip_qa']\n end\n\n # Only run autopkgtest on jobs matching one of the patterns.\n # @return [Array<String>] .include match exclusions\n def only_adt\n data['only_adt']\n end\n\n # The old main series. That is: the series being phased out in favor of\n # the current.\n # This may be nil when none is being phased out!\n def old_series\n data.fetch('old_series')\n end\n\n # The current main series. That is: the series in production.\n def current_series\n data.fetch('current_series')\n end\n\n # The future main series. That is: the series being groomed for next\n # production.\n # This may be nil when none is being prepared!\n def future_series\n data.fetch('future_series', nil)\n end\n\n # Whether the future series is in its early stages. While this is true\n # the series mustn't be very public (e.g. ISOs should go to some private\n # place etc.)\n def future_is_early\n data.fetch('future_is_early')\n end\n\n # The archive key for archive.neon.kde.org. The returned value is suitable\n # as input for Apt::Key.add. Beyond this there are no assumptions to made\n # about its format!\n def archive_key\n data.fetch('archive_key')\n end\n\n # Special abstraction for the name of the type and repo Qt updates gets\n # staged in.\n def qt_stage_type\n data.fetch('qt_stage_type')\n end\n\n # Check if repo ought to be diverted to /tmp/ variant. repo is the prefix of the repo\n # archive.neon.kde.org/unstable => unstable\n # archive.neon.kde.org/testting => testing\n # etc.\n def divert_repo?(repo)\n raise BadInputType, \"Incorrect value type #{repo.class}, expected String\" unless repo.is_a?(String)\n\n data.fetch('repo_diversion') && data.fetch('divertable_repos').include?(repo)\n end\nend\n"
},
{
"alpha_fraction": 0.6193951964378357,
"alphanum_fraction": 0.6451164484024048,
"avg_line_length": 28.659793853759766,
"blob_id": "f513d122d441d97299fe21ffa66bf43eb91fbde3",
"content_id": "bb9ba509db11db45a4b6877ca7d80fbb56502534",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2877,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 97,
"path": "/test/test_nci_lint_cache_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/cache_package_lister'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class CachePackageListerTest < TestCase\n def setup\n # Disable all command running for this test - the class is a glorified\n # stdout parser.\n TTY::Command.any_instance.expects(:run).never\n end\n\n def test_packages\n # This must be correctly indented for test accuracy!\n result = mock('tty-command-result')\n result.stubs(:out).returns(<<-OUT)\nfoo:\n Installed: (none)\n Candidate: 2\n Version table:\n 2\n 1100 http://archive.neon.kde.org/unstable focal/main amd64 Packages\n 0.3\n 500 http://at.archive.ubuntu.com/ubuntu focal/universe amd64 Packages\nbar:\n Installed: (none)\n Candidate: 1\n Version table:\n 1 1100\n 1100 http://archive.neon.kde.org/unstable focal/main amd64 Packages\n 0.5 500\n 500 http://at.archive.ubuntu.com/ubuntu focal/universe amd64 Packages\n OUT\n\n TTY::Command\n .any_instance.expects(:run)\n .with('apt-cache', 'policy', 'foo', 'bar')\n .returns(result)\n\n pkgs = CachePackageLister.new(filter_select: %w[foo bar]).packages\n assert_equal(2, pkgs.size)\n assert_equal(%w[foo bar].sort, pkgs.map(&:name).sort)\n assert_equal(%w[1 2].sort, pkgs.map(&:version).map(&:to_s).sort)\n end\n\n def test_packages_filter\n # This must be correctly indented for test accuracy!\n result = mock('tty-command-result')\n result.stubs(:out).returns(<<-OUT)\nfoo:\n Installed: (none)\n Candidate: 1\n Version table:\n 1 1100\n 1100 http://archive.neon.kde.org/unstable focal/main amd64 Packages\n 0.5 500\n 500 http://at.archive.ubuntu.com/ubuntu focal/universe amd64 Packages\n OUT\n\n TTY::Command\n .any_instance.expects(:run)\n .with('apt-cache', 'policy', 'foo')\n .returns(result)\n\n pkgs = CachePackageLister.new(filter_select: %w[foo]).packages\n assert_equal(1, pkgs.size)\n assert_equal(%w[foo].sort, pkgs.map(&:name).sort)\n assert_equal(%w[1].sort, pkgs.map(&:version).map(&:to_s).sort)\n end\n\n def test_pure_virtual\n # This must be correctly indented for test accuracy!\n result = mock('tty-command-result')\n result.stubs(:out).returns(<<-OUT)\nfoo:\n Installed: (none)\n Candidate: (none)\n Version table:\n OUT\n\n TTY::Command\n .any_instance.expects(:run)\n .with('apt-cache', 'policy', 'foo')\n .returns(result)\n\n pkgs = CachePackageLister.new(filter_select: %w[foo]).packages\n assert_equal(1, pkgs.size)\n assert_equal(%w[foo].sort, pkgs.map(&:name).sort)\n assert_nil(pkgs[0].version)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.653781533241272,
"alphanum_fraction": 0.6605042219161987,
"avg_line_length": 29.512821197509766,
"blob_id": "91831ea79a798d4b3846cee72eae95086fcb7271",
"content_id": "9c3a634a283a84525ccc7ea013f9a6d11ecccc0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2380,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 78,
"path": "/test/test_ci_pangeaimage.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/pangeaimage'\n\nclass PangeaImageTest < TestCase\n def setup\n @oldnamespace = CI::PangeaImage.namespace\n @namespace = 'pangea-testing'\n CI::PangeaImage.namespace = @namespace\n end\n\n def teardown\n CI::PangeaImage.namespace = @oldnamespace\n end\n\n def assert_image(flavor, series, image)\n assert_equal(\"#{@namespace}/#{flavor}:#{series}\", image.to_s)\n assert_equal(\"#{@namespace}/#{flavor}\", image.repo)\n assert_equal(flavor.to_s, image.flavor)\n assert_equal(series, image.tag)\n end\n\n def test_name\n flavor = 'ubuntu'\n series = 'wily'\n i = CI::PangeaImage.new(flavor, series)\n assert_image(flavor, series, i)\n end\n\n def test_to_str\n # Coercion into string\n assert_nothing_raised TypeError do\n # rubocop:disable Style/StringConcatenation\n '' + CI::PangeaImage.new('flavor', 'series')\n # rubocop:enable Style/StringConcatenation\n end\n end\n\n def test_symbol_flavor\n flavor = :ubuntu\n series = 'wily'\n image = CI::PangeaImage.new(flavor, series)\n # Do not use assert_image here as we need to verify coercion from\n # :ubuntu to 'ubuntu' works as expected.\n # assert_image in fact relies on it.\n assert_equal(\"#{@namespace}/ubuntu:wily\", image.to_s)\n end\n\n def test_tag_args\n flavor = :ubuntu\n series = 'wily'\n image = CI::PangeaImage.new(flavor, series)\n tag_args = image.tag_args\n assert_equal({ repo: \"#{@namespace}/#{flavor}\", tag: series },\n tag_args)\n # Merge doesn't break it\n assert_equal({ repo: \"#{@namespace}/#{flavor}\", tag: series, force: true },\n tag_args.merge(force: true))\n end\n\n def test_arch_split\n # For systems that share multiple architectures (e.g. arm32 and arm64)\n # we need to split the image based on additional metadata.\n ENV['NODE_LABELS'] = 'aarch64 arm64 shared-node'\n ENV['PANGEA_FLAVOR_ARCH'] = 'arm64'\n image = CI::PangeaImage.new('ubuntu', 'focal')\n assert_equal('ubuntu', image.flavor)\n assert_equal(\"#{@namespace}/ubuntu-arm64:focal\", image.to_s)\n end\n\n def test_arch_split_missing_arch\n # Like test_arch_split but missing flavor configuration\n ENV['NODE_LABELS'] = 'aarch64 arm64 shared-node'\n assert_raises KeyError do\n CI::PangeaImage.new('ubuntu', 'focal')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6452710032463074,
"alphanum_fraction": 0.6493092179298401,
"avg_line_length": 34.64393997192383,
"blob_id": "8565641ba90320ffe7398c1ec968c85f66ddc285",
"content_id": "9866cb3bfecbf5ac7870757d22f401237f667920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4705,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 132,
"path": "/nci/jenkins-bin/build_selector.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../../lib/jenkins/job'\nrequire_relative 'cores'\nrequire_relative 'slave'\n\nrequire 'jenkins_api_client'\n\nmodule NCI\n module JenkinsBin\n # Select a set of builds for core count evaluation\n class BuildSelector\n class CoreMismatchError < StandardError; end\n\n QUALIFIER_STATES = %w[success unstable].freeze\n\n attr_reader :log\n attr_reader :job\n attr_reader :number\n attr_reader :detected_cores\n attr_reader :exception_count\n attr_reader :set_size\n\n def initialize(job)\n @log = job.log\n @number = job.last_build_number\n @job = job.job # jenkins job\n @detected_cores = nil\n @exception_count = 0\n @set_size = 2\n end\n\n # This method is a complicated cluster fuck. I would not even know where\n # to begin in tearing it apart. I fear this is just what it is.\n # too long, abc too high, asignment too high etc. etc.\n # rubocop:disable all\n def build_of(build_number, rescue_not_found: true)\n # Get the build\n build = Retry.retry_it(times: 3, sleep: 1) do\n job.build_details(build_number)\n end\n raise \"Could not resolve ##{build_number} of #{job.name}\" unless build\n\n # Make sure it wasn't a failure. Failures give no sensible performance\n # data.\n result = build.fetch('result')\n return nil unless result\n return nil unless QUALIFIER_STATES.include?(result.downcase)\n\n # If we have a build, check its slave and possibly record it as detected\n # core count. We'll look for previous builds with the same count on\n # subsequent iteration.\n built_on = build.fetch('builtOn')\n built_on_cores = Slave.cores(built_on)\n if detected_cores && detected_cores != built_on_cores\n @log.info <<-EOF\n[#{job.name}]\nCould not find a set of #{set_size} subsequent successful builds\nbuild:#{number} has unexpected slave #{built_on} type:#{built_on_cores} (expected type:#{detected_cores})\n EOF\n raise CoreMismatchError,\n \"expected #{detected_cores}, got #{built_on_cores}\"\n end\n\n @detected_cores = built_on_cores\n\n # If we do not know the core count because we shrunk the options\n # coerce to the closest match.\n unless Cores.know?(detected_cores)\n @detected_cores = Cores.coerce(detected_cores)\n end\n\n @exception_count -= 1\n build\n rescue JenkinsApi::Exceptions::NotFoundException => e\n raise e unless rescue_not_found\n begin\n build_of(build_number - 1, rescue_not_found: false)\n rescue JenkinsApi::Exceptions::NotFoundException\n # If we did not find the build we'll check the previous one, if it\n # also doesn't exist we'll consider the entire thing unknown as it\n # has been failing for too long.\n return nil\n else\n # Otherwise something unexpected is going on.\n if (@exception_count += 1) >= 5\n raise <<-EXCEPTIONMSG\nrepeated failure trying to resolve #{job.name}'s builds. This indicates an\nunexpected failure in some deep level of either jenkins or the tooling.\nThis must be investigated by checking the specific state #{job.name} is in\nand what triggers it raising an exception.\n#{e}\n EXCEPTIONMSG\n end\n end\n end\n # rubocop:enable all\n\n def select\n builds = []\n until number <= 0 || builds.size >= set_size\n build = build_of(number)\n @number -= 1\n builds << build if build\n end\n return nil unless builds.size >= set_size\n\n builds\n rescue CoreMismatchError\n nil # Logged at raise time already\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6948819160461426,
"alphanum_fraction": 0.710629940032959,
"avg_line_length": 27.22222137451172,
"blob_id": "b2c497a773b177b159dff2f782e609707438d629",
"content_id": "872ca0109b9581df6e7d3e8f1381eb513635fa5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 508,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 18,
"path": "/nci/cnf_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/repo_content_pusher'\n\nmodule NCI\n # Pushes command-not-found metadata to aptly remote\n class CNFPusher\n def self.run\n RepoContentPusher.new(content_name: 'cnf', repo_dir: \"#{Dir.pwd}/repo\", dist: ENV.fetch('DIST')).run\n end\n end\nend\n\nNCI::CNFPusher.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.6905263066291809,
"alphanum_fraction": 0.6968421339988708,
"avg_line_length": 24,
"blob_id": "9d73af3b6eef1c3b0ed112b7f848e227e149fea9",
"content_id": "bc61d3ead190d28b41aa49da16da88b7991c41f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/test/test_lint_list_missing.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/log/list_missing'\nrequire_relative 'lib/testcase'\n\n# Test lint lintian\nclass LintListMissingTest < TestCase\n def test_lint\n r = Lint::Log::ListMissing.new.lint(File.read(data))\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(0, r.warnings.size)\n assert_equal(2, r.errors.size)\n end\n\n def test_invalid\n r = Lint::Log::ListMissing.new.lint('')\n assert(!r.valid)\n end\nend\n"
},
{
"alpha_fraction": 0.6557925343513489,
"alphanum_fraction": 0.6612296104431152,
"avg_line_length": 30.8799991607666,
"blob_id": "aecb99ab31cf1c6ebde5b6854cdb320e4c4d9baa",
"content_id": "8fbfff3b36fa1fc8af99d545b1050fcaf09c9481",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2391,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 75,
"path": "/nci/lint/cmake_packages.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative '../../lib/repo_abstraction'\nrequire_relative 'cmake_dep_verify/package'\nrequire_relative 'cmake_dep_verify/junit'\n\nmodule Lint\n class CMakePackages\n attr_reader :repo\n\n def initialize(type, dist)\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n @log.progname = self.class.to_s\n @type = type.tr('-', '/')\n @type = 'testing' if @type == 'stable'\n aptly_repo = Aptly::Repository.get(\"#{type}_#{dist}\")\n @repo = ChangesSourceFilterAptlyRepository.new(aptly_repo, @type)\n @package_results = {}\n end\n\n def run\n repo.add || raise\n # Call actual code for missing detection.\n run_internal\n write\n ensure\n repo.remove\n end\n\n private\n\n def write\n puts 'Writing...'\n @package_results.each do |package, cmake_package_results|\n suite = CMakeDepVerify::JUnit::Suite.new(package, cmake_package_results)\n puts \"Writing #{package}.xml\"\n File.write(\"#{package}.xml\", suite.to_xml)\n end\n end\n\n def run_internal\n repo.binaries.each do |package, version|\n next if package.end_with?('-dbg', '-dbgsym', '-data', '-bin', '-common',\n '-udeb')\n\n pkg = CMakeDepVerify::Package.new(package, version)\n @log.info \"Checking #{package}: #{version}\"\n @package_results[package] = pkg.test\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6045340299606323,
"alphanum_fraction": 0.6163269877433777,
"avg_line_length": 34.217742919921875,
"blob_id": "ebc8d2dfb6b54ec91ae9722bb937be8e2aa1b978",
"content_id": "e09fedb7f6bad7676ad52d09e5382487a527261d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 8734,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 248,
"path": "/test/test_nci_watcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/debian/control'\nrequire_relative '../nci/lib/watcher'\nrequire_relative '../lib/kdeproject_component'\n\nrequire 'mocha/test_unit'\nrequire 'rugged'\n\nclass NCIWatcherTest < TestCase\n attr_reader :cmd\n\n def setup\n @cmd = TTY::Command.new(printer: :null)\n NCI.stubs(:setup_env!).returns(true)\n # Rip out causes from the test env so we don't trigger on them.\n ENV['JOB_NAME'] = 'HIIIIYA'\n\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/frameworks')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: '[\"frameworks/attica\",\"frameworks/baloo\",\"frameworks/bluez-qt\",\"frameworks/breeze-icons\"]', headers: { \"Content-Type\": 'application/json' })\n\n stub_request(:get, 'https://invent.kde.org/sdk/releaseme/-/raw/master/plasma/git-repositories-for-release')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: 'bluedevil breeze breeze-grub breeze-gtk breeze-plymouth discover drkonqi', headers: { \"Content-Type\": 'text/plain' })\n \n stub_request(:get, 'http://embra.edinburghlinux.co.uk/~jr/release-tools/modules.git')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"kdialog master\\nkeditbookmarks master\", headers: { \"Content-Type\": 'text/plain' })\n\n stub_request(:get, 'https://raw.githubusercontent.com/KDE/releaseme/master/plasma/git-repositories-for-release')\n .with(\n headers: {\n 'Accept' => '*/*',\n 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3',\n 'User-Agent' => 'Ruby'\n }\n )\n .to_return(status: 200, body: \"aura-browser bluedevil breeze breeze-grub\", headers: { \"Content-Type\": 'text/plain' })\n end\n\n def with_remote_repo(seed_dir, branch: 'unstable')\n Dir.mktmpdir do |tmpdir|\n FileUtils.cp_r(\"#{seed_dir}/.\", tmpdir, verbose: true)\n cmd.run('git init .', chdir: tmpdir)\n cmd.run('git add .', chdir: tmpdir)\n cmd.run('git commit -a -m \"import\"', chdir: tmpdir)\n cmd.run(\"git branch Neon/#{branch}\", chdir: tmpdir)\n yield tmpdir\n end\n end\n\n def test_run\n omit # dch causes hang on spara\n ENV['JOB_NAME'] = 'watcher_release_kde_ark'\n ENV['BUILD_CAUSE'] = 'Started by timer'\n\n require_binaries(%w[dch])\n\n smtp = mock('smtp')\n smtp.expects(:send_message).with do |_body, from, to|\n from == '[email protected]' && to == '[email protected]'\n end\n Pangea::SMTP.expects(:start).yields(smtp)\n\n with_remote_repo(data) do |remote|\n cmd.run(\"git clone #{remote} .\")\n\n fake_cmd = mock('uscan_cmd')\n fake_cmd\n .expects(:run!)\n .with do |args|\n # hijack and do some assertion here. This block is only evaluated upon\n # a call to run, so we can assert the state of the working dir when\n # uscan gets called here.\n assert_path_exist 'debian/watch'\n assert_includes File.read('debian/watch'), 'download.kde.internal.neon.kde.org'\n assert_includes File.read('debian/watch'), 'https'\n assert_not_includes File.read('debian/watch'), 'download.kde.org'\n args == 'uscan --report --dehs'\n end\n .returns(TTY::Command::Result.new(0, File.read(data('dehs.xml')), ''))\n NCI::Watcher.any_instance.stubs(:uscan_cmd).returns(fake_cmd)\n\n NCI::Watcher.new.run\n\n # New changelog entry\n assert_equal '4:17.04.2-0neon', Changelog.new.version\n control = Debian::Control.new\n control.parse!\n # fooVersion~ciBuild suitably replaced.\n assert_equal '4:17.04.2', control.binaries[0]['depends'][0][0].version\n assert_equal '4:17.04.2', control.binaries[0]['recommends'][0][0].version\n\n repo = Rugged::Repository.new(Dir.pwd)\n commit = repo.last_commit\n assert_includes commit.message, 'release'\n deltas = commit.diff(commit.parents[0]).deltas\n assert_equal 2, deltas.size\n changed_files = deltas.collect { |d| d.new_file[:path] }\n assert_equal ['debian/changelog', 'debian/control'], changed_files\n\n # watch file was unmanagled again\n assert_path_exist 'debian/watch'\n assert_includes File.read('debian/watch'), 'download.kde.org'\n assert_includes File.read('debian/watch'), 'https'\n assert_not_includes File.read('debian/watch'), 'download.kde.internal.neon.kde.org'\n assert_not_includes File.read('debian/watch'), 'download.kde.internal.neon.kde.org:9191'\n end\n end\n\n def test_no_mail_on_manual_trigger\n omit # dch causes hang on spara\n ENV['JOB_NAME'] = 'watcher_release_kde_ark'\n\n require_binaries(%w[dch])\n Pangea::SMTP.expects(:start).never\n\n ENV['BUILD_CAUSE'] = 'Started by Konqi Konqueror'\n\n with_remote_repo(data, branch: 'stable') do |remote|\n cmd.run(\"git clone #{remote} .\")\n\n fake_cmd = mock('uscan_cmd')\n fake_cmd\n .expects(:run!)\n .with('uscan --report --dehs')\n .returns(TTY::Command::Result.new(0, File.read(data('dehs.xml')), ''))\n NCI::Watcher.any_instance.stubs(:uscan_cmd).returns(fake_cmd)\n\n NCI::Watcher.new.run\n end\n ensure\n ENV.delete('BUILD_CAUSE')\n end\n\n def test_no_unstable\n # Should not smtp or anything.\n assert_raises NCI::Watcher::UnstableURIForbidden do\n with_remote_repo(data) do |remote|\n cmd.run(\"git clone #{remote} .\")\n\n NCI::Watcher.new.run\n end\n end\n end\n\n def test_snapcraft_updater\n FileUtils.cp_r(\"#{data}/.\", '.')\n dehs = mock('dehs')\n dehs.stubs(:upstream_version).returns('18.14.1')\n # NB: watcher doesn't unmangle itself, we expect the updater to do it\n dehs.stubs(:upstream_url).returns('https://download.kde.internal.neon.kde.org/okular-18.14.1.tar.xz')\n NCI::Watcher::SnapcraftUpdater.new(dehs).run\n actual = YAML.load_file('snapcraft.yaml')\n expected = YAML.load_file('snapcraft.yaml.ref')\n assert_equal(expected, actual)\n end\n\n def test_3rdparty_manual_trigger_fail_no_mail\n omit # dch causes hang on spara\n ENV['BUILD_CAUSE'] = 'Started by Konqi Konqueror'\n require_binaries(%w[dch])\n\n Pangea::SMTP.expects(:start).never\n\n assert_raises NCI::Watcher::NotKDESoftware do\n with_remote_repo(data) do |remote|\n cmd.run(\"git clone #{remote} .\")\n\n fake_cmd = mock('uscan_cmd')\n fake_cmd\n .expects(:run!)\n .with('uscan --report --dehs')\n .returns(TTY::Command::Result.new(0, File.read(data('dehs.xml')), ''))\n NCI::Watcher.any_instance.stubs(:uscan_cmd).returns(fake_cmd)\n\n NCI::Watcher.new.run\n end\n end\n end\n\n def test_3rdparty_time_trigger_mail_and_fail\n omit # dch causes hang on spara\n ENV['BUILD_CAUSE'] = 'Started by timer'\n require_binaries(%w[dch])\n\n smtp = mock('smtp')\n match_body = nil # for asserting the body content later\n smtp.expects(:send_message).with do |body, from, to|\n match = from == '[email protected]' && to == '[email protected]'\n next false unless match\n\n match_body = body\n true\n end\n Pangea::SMTP.expects(:start).yields(smtp)\n\n assert_raises NCI::Watcher::NotKDESoftware do\n with_remote_repo(data) do |remote|\n cmd.run(\"git clone #{remote} .\")\n\n fake_cmd = mock('uscan_cmd')\n fake_cmd\n .expects(:run!)\n .with('uscan --report --dehs')\n .returns(TTY::Command::Result.new(0, File.read(data('dehs.xml')), ''))\n NCI::Watcher.any_instance.stubs(:uscan_cmd).returns(fake_cmd)\n\n NCI::Watcher.new.run\n end\n end\n\n # If this is the expected invocation assert that the body is well formed.\n # Specifically the headers mustn't be indented as can happen with heredoc.\n # Split by \\n\\n to isolate the header block.\n assert(match_body)\n lines = match_body.split(\"\\n\\n\", 2)[0].lines\n lines = lines.collect(&:rstrip) # strip trailing \\n for easy compare\n refute(lines.empty?)\n assert_includes(lines, 'From: Neon CI <[email protected]>')\n assert_includes(lines, 'To: [email protected]')\n assert_includes(lines, 'Subject: Dev Required: ark - 17.04.2')\n end\nend\n"
},
{
"alpha_fraction": 0.6636003255844116,
"alphanum_fraction": 0.6694392561912537,
"avg_line_length": 35.019840240478516,
"blob_id": "45a46f8e2eda5db1f82028d1c6af412840f33f02",
"content_id": "0f5d7f9991549923ad7b3ca03efa6abe9ef8997f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 18154,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 504,
"path": "/deploy_in_container.rake",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# All the methods we have are task helpers, so they are fairly spagetthi.\n# Blocks are tasks, so they are even worse offenders.\n# Overengineering this into objects is probably not a smart move so let's ignore\n# this (for now anyway).\n# rubocop:disable Metrics/BlockLength, Metrics/MethodLength\n\nrequire 'etc'\nrequire 'fileutils'\nrequire 'mkmf'\nrequire 'open-uri'\nrequire 'tmpdir'\n\nrequire_relative 'lib/ci/fake_package'\nrequire_relative 'lib/rake/bundle'\nrequire_relative 'lib/nci'\nrequire_relative 'lib/os'\n\nDIST = ENV.fetch('DIST')\n\n# These will be installed in one-go before the actual deps are being installed.\n# This should only include stuff which is needed to make the actual DEP\n# installation work!\nEARLY_DEPS = [\n 'python-apt-common', # Remove this once python-apt gets a Stretch template\n 'eatmydata' # We disable fsync from apt and dpkg.\n].freeze\n# Core is not here because it is required as a build-dep or anything but\n# simply a runtime (or provision time) dep of the tooling.\nCORE_RUNTIME_DEPS = %w[apt-transport-https software-properties-common].freeze\nDEPS = %w[xz-utils dpkg-dev dput debhelper pkg-kde-tools devscripts\n gnome-pkg-tools git gettext dpkg\n zlib1g-dev sudo locales\n autotools-dev dh-autoreconf\n germinate gnupg2 sphinx-common\n bash-completion python3-setuptools python3-setuptools-scm\n dkms libffi-dev libcurl4-gnutls-dev\n libhttp-parser-dev rsync man-db].freeze +\n %w[subversion].freeze + # for releaseme\n CORE_RUNTIME_DEPS\ndef home\n '/var/lib/jenkins'\nend\n\ndef tooling_path\n '/tooling-pending'\nend\n\ndef final_path\n '/tooling'\nend\n\n# Trap common exit signals to make sure the ownership of the forwarded\n# volume is correct once we are done.\n# Otherwise it can happen that bundler left root owned artifacts behind\n# and the folder becomes undeletable.\n%w[EXIT HUP INT QUIT TERM].each do |signal|\n Signal.trap(signal) do\n # Resolve uid and gid. FileUtils can do that internally but to do so\n # it will require 'etc' which in ruby2.7+rubygems can cause ThreadError\n # getting thrown out of require since the signal thread isn't necessarily\n # equipped to do on-demand-requires.\n # Since we have etc required already we may as well resolve the ids directly\n # and thus bypass the internal lookup of FU.\n uid = Etc.getpwnam('jenkins') ? Etc.getpwnam('jenkins').uid : nil\n gid = Etc.getgrnam('jenkins') ? Etc.getgrnam('jenkins').gid : nil\n next unless uid && gid\n\n FileUtils.chown_R(uid, gid, tooling_path, verbose: true, force: true)\n end\nend\n\ndef install_fake_pkg(name)\n FakePackage.new(name).install\nend\n\ndef custom_version_id\n return if OS::ID == 'ubuntu'\n return unless OS::ID == 'debian' || OS::ID_LIKE == 'debian'\n\n file = '/etc/os-release'\n os_release = File.readlines(file)\n # Strip out any lines starting with VERSION_ID\n # so that we don't end up with an endless number of VERSION_ID entries\n os_release.reject! { |l| l.start_with?('VERSION_ID') }\n system('dpkg-divert', '--local', '--rename', '--add', file) || raise\n os_release << \"VERSION_ID=#{DIST}\\n\"\n File.write(file, os_release.join)\nend\n\ndef cleanup_rubies\n # We can have two rubies at a time, the system ruby and our ruby. We'll do\n # general purpose cleanup on all possible paths but then rip apart the system\n # ruby if we have our own ruby installed. This way we do not have unused gems\n # in scenarios where we used the system ruby previously but now use a custom\n # one.\n\n # Gem cache and doc. Neither shoud be needed at runtime.\n FileUtils.rm_rf(Dir.glob('/var/lib/gems/*/{cache,doc}/*'),\n verbose: true)\n FileUtils.rm_rf(Dir.glob('/usr/local/lib/ruby/gems/*/{cache,doc}/*'),\n verbose: true)\n # libgit2 cmake build tree\n FileUtils.rm_rf(Dir.glob('/var/lib/gems/*/gems/rugged-*/vendor/*/build'),\n verbose: true)\n FileUtils.rm_rf(Dir.glob('/usr/local/lib/ruby/gems/*/gems/rugged-*/vendor/*/build'),\n verbose: true)\n # Other compiled extension artifacts not used at runtime\n FileUtils.rm_rf(Dir.glob('/var/lib/gems/*/gems/*/ext/*/*.{so,o}'),\n verbose: true)\n FileUtils.rm_rf(Dir.glob('usr/local/lib/ruby/gems/*/gems/*/ext/*/*.{so,o}'),\n verbose: true)\n\n return unless find_executable('ruby').include?('local')\n\n puts 'Mangling system ruby'\n # All gems in all versions.\n FileUtils.rm_rf(Dir.glob('/var/lib/gems/*/*'), verbose: true)\nend\n\ndef deployment_cleanup\n # Ultimate clean up\n # Semi big logs\n File.write('/var/log/lastlog', '')\n File.write('/var/log/faillog', '')\n File.write('/var/log/dpkg.log', '')\n File.write('/var/log/apt/term.log', '')\n\n cleanup_rubies\nend\n\ndef bundle_install\n FileUtils.rm_f('Gemfile.lock')\n FileUtils.rm_rf('.bundle/')\n FileUtils.rm_rf('vendor/')\n #bundle('config' 'set' '--local' 'system' 'true')\n bundle('install', \"--jobs=#{[Etc.nprocessors / 2, 1].max}\", '--verbose')\nrescue StandardError => e\n log_dir = \"#{tooling_path}/#{ENV['DIST']}_#{ENV['TYPE']}\"\n Dir.glob('/var/lib/gems/*/extensions/*/*/*/mkmf.log').each do |log|\n dest = \"#{log_dir}/#{File.basename(File.dirname(log))}\"\n FileUtils.mkdir_p(dest)\n FileUtils.cp(log, dest, verbose: true)\n end\n raise e\nend\n\n# openqa\ntask :deploy_openqa do\n # Only openqa on neon dists and if explicitly enabled.\n next unless NCI.series.key?(DIST) &&\n ENV.fetch('PANGEA_PROVISION_AUTOINST', '') == '1'\n\n Dir.mktmpdir do |tmpdir|\n system 'git clone --depth 1 ' \\\n \"https://github.com/apachelogger/kde-os-autoinst #{tmpdir}/\"\n Dir.chdir('/opt') { sh \"#{tmpdir}/bin/install.rb\" }\n end\nend\n\ndesc 'Disable ipv6 on gpg so it does not trip over docker sillyness'\ntask :fix_gpg do\n # https://rvm.io/rvm/security#ipv6-issues\n gpghome = \"#{Dir.home}/.gnupg\"\n dirmngrconf = \"#{gpghome}/dirmngr.conf\"\n FileUtils.mkpath(gpghome, verbose: true)\n File.write(dirmngrconf, \"disable-ipv6\\n\")\nend\n\ndesc 'Upgrade to newer ruby if required'\ntask :align_ruby do\n FileUtils.rm_rf('/tmp/kitchen') # Instead of messing with pulls, just clone.\n sh format('git clone --depth 1 %s %s',\n 'https://github.com/pangea-project/pangea-kitchen.git',\n '/tmp/kitchen')\n Dir.chdir('/tmp/kitchen') do\n # ruby_build checks our version against the pangea version and if necessary\n # installs a ruby in /usr/local which is more suitable than what we have.\n # If this comes back !0 and we are meant to be aligned already this means\n # the previous alignment failed, abort when this happens.\n if !system('./ruby_build.sh') && ENV['ALIGN_RUBY_EXEC']\n raise 'It seems rake was re-executed after a ruby version alignment,' \\\n ' but we still found and unsuitable ruby version being used!'\n end\n end\n case $?.exitstatus\n when 0 # installed version is fine, we are happy.\n FileUtils.rm_rf('/tmp/kitchen')\n next\n when 1 # a new version was installed, we'll re-exec ourself.\n sh 'gem install rake'\n sh 'gem install tty-command'\n ENV['ALIGN_RUBY_EXEC'] = 'true'\n # Reload ourself via new rake\n exec('rake', *ARGV)\n else # installer crashed or other unexpected error.\n raise 'Error while aligning ruby version through pangea-kitchen'\n end\nend\n\nRUBY_3_0_3 = '/tmp/3.0.3'\nRUBY_3_0_3_URL = 'https://raw.githubusercontent.com/rbenv/ruby-build/master/share/ruby-build/3.0.3'\n\ndesc 'Upgrade to newer ruby if required, no kitchen'\ntask :align_ruby_no_chef do\n puts \"Ruby version #{RbConfig::CONFIG['MAJOR']}.#{RbConfig::CONFIG['MINOR']}\"\n if RbConfig::CONFIG['MAJOR'].to_i <= 3 && RbConfig::CONFIG['MINOR'].to_i < 0\n puts 'Bootstraping ruby'\n system('apt-get -y install ruby-build')\n File.write(RUBY_3_0_3, open(RUBY_3_0_3_URL).read)\n raise 'Failed to update ruby to 3.0.3' unless\n system(\"ruby-build #{RUBY_3_0_3} /usr/local\")\n puts 'Ruby bootstrapped, running deployment again'\n case $?.exitstatus\n when 0 # installed version is fine, we are happy.\n puts 'Hooray, new rubies.'\n next\n when 1 # a new version was installed, we'll re-exec ourself.\n sh 'gem install rake'\n sh 'gem install tty-command'\n ENV['ALIGN_RUBY_EXEC'] = 'true'\n # Reload ourself via new rake\n exec('rake', *ARGV)\n else # installer crashed or other unexpected error.\n raise 'Error while aligning ruby version without a chef'\n end\n end\nend\n\ndef with_ubuntu_pin\n pin_file = '/etc/apt/preferences.d/ubuntu-pin'\n\n ## not needed right now. only useful when ubuntu rolls back an update and we are stuck with a broken version\n return yield\n ##\n\n # rubocop:disable Lint/UnreachableCode\n if NCI.series.key?(DIST) # is a neon thing\n File.write(pin_file, <<~PIN)\n Package: *\n Pin: release o=Ubuntu\n Pin-Priority: 1100\n PIN\n end\n\n yield\nensure\n FileUtils.rm_f(pin_file, verbose: true)\nend\n# rubocop:enable Lint/UnreachableCode\n\ndesc 'deploy inside the container'\ntask deploy_in_container: %i[fix_gpg align_ruby_no_chef deploy_openqa] do\n final_ci_tooling_compat_path = File.join(home, 'tooling')\n final_ci_tooling_compat_compat_path = File.join(home, 'ci-tooling')\n\n File.write(\"#{Dir.home}/.gemrc\", <<-EOF)\ninstall: --no-document\nupdate: --no-document\n EOF\n\n Dir.chdir(tooling_path) do\n begin\n Gem::Specification.find_by_name('bundler')\n # Force in case the found bundler was installed for a different version.\n # Otherwise rubygems will raise an error when attempting to overwrite the\n # bin.\n sh 'gem install --force bundler'\n rescue Gem::LoadError\n Gem.install('bundler')\n end\n\n require_relative 'lib/apt'\n require_relative 'lib/retry'\n\n Apt.install(*EARLY_DEPS) || raise\n\n if NCI.series.keys.include?(DIST)\n puts \"DIST in NCI, adding key\"\n # Pre-seed NCI keys to speed up all builds and prevent transient\n # problems with talking to the GPG servers.\n Retry.retry_it(times: 3, sleep: 8) do\n puts \"trying to add #{NCI.archive_key}\"\n raise 'Failed to import key' unless Apt::Key.add(NCI.archive_key)\n end\n system 'apt-key list'\n end\n\n with_ubuntu_pin do\n Retry.retry_it(times: 5, sleep: 8) do\n # Ensure previous failures actually configure properly first.\n raise 'configure failed' unless system('dpkg --configure -a')\n\n # NOTE: apt.rb automatically runs update the first time it is used.\n raise 'Dist upgrade failed' unless Apt.dist_upgrade\n\n # Install libssl1.0 for systems that have it\n Apt.install('libssl-dev') unless Apt.install('libssl1.0-dev')\n raise 'Apt install failed' unless Apt.install(*DEPS)\n raise 'Autoremove failed' unless Apt.autoremove(args: '--purge')\n raise 'Clean failed' unless Apt.clean\n end\n end\n\n # Add debug for checking what version is being used\n bundle(*%w[--version])\n bundle_install\n\n FileUtils.rm_rf(final_path)\n FileUtils.mkpath(final_path, verbose: true)\n FileUtils.cp_r('./.', final_path, verbose: true)\n [final_ci_tooling_compat_path,\n final_ci_tooling_compat_compat_path].each do |compat|\n if File.symlink?(compat)\n FileUtils.rm(compat, verbose: true)\n elsif File.exist?(compat)\n FileUtils.rm_r(compat, verbose: true)\n end\n # Make sure the parent exists, in case of /var/lib/jenkins on slaves\n # that is not the case for new builds.\n FileUtils.mkpath(File.dirname(compat))\n FileUtils.ln_s(final_path, compat, verbose: true)\n end\n end\n\n File.write('force-unsafe-io', '/etc/dpkg/dpkg.cfg.d/00_unsafeio')\n\n File.open('/etc/dpkg/dpkg.cfg.d/00_paths', 'w') do |file|\n # Do not install locales other than en/en_US.\n # Do not install manpages, infopages, groffpages.\n # Do not install docs.\n # NB: manpage first level items are kept via dpkg as it'd break openjdk8\n # when the man1/ subdir is missing.\n path = {\n rxcludes: %w[\n /usr/share/locale/**/**\n /usr/share/man/**/**\n /usr/share/info/**/**\n /usr/share/groff/**/**\n /usr/share/doc/**/**\n /usr/share/ri/**/**\n ],\n excludes: %w[\n /usr/share/locale/*\n /usr/share/man/*\n /usr/share/info/*\n /usr/share/groff/*\n /usr/share/doc/*\n /usr/share/ri/*\n ],\n includes: %w[\n /usr/share/locale/en\n /usr/share/locale/en_US\n /usr/share/locale/locale.alias\n ]\n }\n path[:excludes].each { |e| file.puts(\"path-exclude=#{e}\") }\n path[:includes].each { |i| file.puts(\"path-include=#{i}\") }\n # Docker upstream images exclude all manpages already, which in turn\n # prevents the directories from appearing which then results in openjdk8\n # failing to install due to the missing dirs. Make sure we have at least\n # man1\n FileUtils.mkpath('/usr/share/man/man1')\n path[:rxcludes].each do |ruby_exclude|\n Dir.glob(ruby_exclude).each do |match|\n next if path[:includes].any? { |i| File.fnmatch(i, match) }\n next unless File.exist?(match)\n # Do not delete directories, it can screw up postinst assumptions.\n # For example openjdk8 will attempt to symlink to share/man/man1/ which\n # is not properly guarded, so it would fail postinst if the dir was\n # removed.\n next if File.directory?(match)\n\n FileUtils.rm_f(match, verbose: true)\n end\n end\n end\n\n # Force eatmydata on the installation binaries to completely bypass fsyncs.\n # This gives a 20% speed improvement on installing plasma-desktop+deps. That\n # is ~1 minute!\n %w[dpkg apt-get apt].each do |bin|\n file = \"/usr/bin/#{bin}\"\n next if File.exist?(\"#{file}.distrib\") # Already diverted\n\n File.open(\"#{file}.pangea\", File::RDWR | File::CREAT, 0o755) do |f|\n f.write(<<-SCRIPT)\n#!/bin/sh\n/usr/bin/eatmydata #{bin}.distrib \"$@\"\nSCRIPT\n end\n system('dpkg-divert', '--local', '--rename', '--add', file) || raise\n File.symlink(\"#{file}.pangea\", file)\n end\n\n # Turn fc-cache into a dud to prevent cache generation. Utterly pointless\n # in a build environment.\n %w[fc-cache].each do |bin|\n file = \"/usr/bin/#{bin}\"\n next if File.exist?(\"#{file}.distrib\") # Already diverted\n\n system('dpkg-divert', '--local', '--rename', '--add', file) || raise\n # Fuck you dpkg. Fuck you so much.\n FileUtils.mv(file, \"#{file}.distrib\") if File.exist?(file)\n File.symlink('/bin/true', file)\n end\n\n # Install a fake im-config. im-config has crappy deps a la `zenity | kdialog`\n # which then pulls in zenity and all of gnome-shell on minimal images.\n # This makes lints take forever, needlessly\n install_fake_pkg('im-config')\n\n # Install a fake fonts-noto CJK to bypass it's incredibly long unpack. Given\n # the size of the package it takes *seconds* to unpack but in CI environments\n # it adds no value.\n install_fake_pkg('fonts-noto-cjk')\n\n # Runs database update on apt-update (unnecessary slow down) and\n # that update also has opportunity to fail by the looks of it.\n install_fake_pkg('command-not-found')\n\n # FIXME: drop this. temporary undo for fake man-db\n Apt.purge('man-db')\n Apt.install('man-db')\n\n # Disable man-db; utterly useless at buildtime. mind that lintian requires\n # an actual man-db package to be installed though, so we can't fake it here!\n FileUtils.rm_rf('/var/lib/man-db/auto-update', verbose: true)\n\n # Ubuntu's language-pack-en-base calls this internally, since this is\n # unavailable on Debian, call it manually.\n locale_tag = \"#{ENV.fetch('LANG').split('.', 2)[0]} UTF-8\"\n File.open('/etc/locale.gen', 'a+') do |f|\n f.puts(locale_tag) unless f.any? { |l| l.start_with?(locale_tag) }\n end\n sh '/usr/sbin/locale-gen --keep-existing --no-purge --lang en'\n sh \"update-locale LANG=#{ENV.fetch('LANG')}\"\n\n # Prevent xapian from slowing down the test.\n # Install a fake package to prevent it from installing and doing anything.\n # This does render it non-functional but since we do not require the database\n # anyway this is the apparently only way we can make sure that it doesn't\n # create its stupid database. The CI hosts have really bad IO performance\n # making a full index take more than half an hour.\n install_fake_pkg('apt-xapian-index')\n\n uname = 'jenkins'\n uid = 100_000\n gname = 'jenkins'\n gid = 120\n\n group_exist = false\n Etc.group do |group|\n if group.name == gname\n group_exist = true\n break\n end\n end\n\n user_exist = false\n Etc.passwd do |user|\n if user.name == uname\n user_exist = true\n break\n end\n end\n\n sh \"addgroup --system --gid #{gid} #{gname}\" unless group_exist\n unless user_exist\n sh \"adduser --system --home #{home} --uid #{uid} --ingroup #{gname}\" \\\n \" --disabled-password #{uname}\"\n end\n\n # Add the new jenkins user the sudoers so we can run as jenkins and elevate\n # if and when necessary.\n File.open(\"/etc/sudoers.d/#{uid}-#{uname}\", 'w', 0o440) do |f|\n f.puts('jenkins ALL=(ALL) NOPASSWD: ALL')\n end\n\n custom_version_id # Add a custom version_id in os-release for DCI\n deployment_cleanup\nend\n\n# NB: Try to only add new stuff above the deployment task. It is so long and\n# unwieldy that it'd be hard to find the end of it if you add stuff below it.\n"
},
{
"alpha_fraction": 0.6548275947570801,
"alphanum_fraction": 0.660689651966095,
"avg_line_length": 31.954545974731445,
"blob_id": "f7f767fd05c00307cb918b1903f81815b7791d15",
"content_id": "ce6ad3df615b8ddad07d065ddbc0d545f02436b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2900,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 88,
"path": "/nci/release_upgrader_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'net/sftp'\nrequire 'net/ssh'\nrequire 'tmpdir'\n\nAPTLY_REPOSITORY = ENV.fetch('APTLY_REPOSITORY')\nDIST = ENV.fetch('DIST')\n\n# TODO: current? version cleanup? rotating?\n# ubuntu publishes them as ...-all/1.2.3/focal.tar.gz etc. and keeps ~3\n# versions. they also keep a current folder which is probably simply a symlink\n# or copy of the latest version. seems a bit useless IMO so I haven't written\n# any code for that and all goes into current currently. -sitter\nhome = '/home/neonarchives'\ntargetdir = \"#{home}/aptly/skel/#{APTLY_REPOSITORY}/dists/#{DIST}/main/dist-upgrader-all\"\n\nDir.chdir('DistUpgrade')\nDir.mktmpdir('release_upgrader_push') do |tmpdir|\n remote_tmp = \"#{home}/#{File.basename(tmpdir)}\"\n\n puts File.basename(tmpdir)\n\n SIGNER = <<-CODE\n set -x\n cd #{remote_tmp}\n for tar in */*.tar.gz; do\n echo \"Signing $tar\"\n gpg --digest-algo SHA256 --armor --detach-sign -s -o $tar.gpg $tar\n done\n CODE\n\n # Grab, key form environment when run on jenkins.\n opts = {}\n if (key = ENV['SSH_KEY_FILE'])\n opts[:keys] = [key, File.expand_path('~/.ssh/id_rsa')]\n end\n\n Net::SFTP.start('archive-api.neon.kde.org', 'neonarchives', **opts) do |sftp|\n ssh = sftp.session\n begin\n puts ssh.exec!(\"rm -rf #{remote_tmp}\")\n\n dirs = Dir.glob('*.*.*')\n raise 'no dir matches found' if dirs.empty?\n\n dirs.each do |dir|\n next unless File.directory?(dir)\n raise 'tar count wrong' unless Dir.glob(\"#{dir}/*.tar.gz\").size == 1\n\n # name = File.basename(dir)\n name = 'current'\n target = \"#{remote_tmp}/#{name}\"\n\n puts \"#{dir} -> #{target}\"\n puts ssh.exec!(\"mkdir -p #{target}\")\n sftp.upload!(dir, target)\n end\n\n puts ssh.exec!(SIGNER)\n\n puts ssh.exec!(\"mkdir -p #{targetdir}/\")\n puts ssh.exec!(\"cp -rv #{remote_tmp}/. #{targetdir}/\")\n ensure\n puts ssh.exec!(\"rm -rf #{remote_tmp}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7043097615242004,
"alphanum_fraction": 0.7075362801551819,
"avg_line_length": 30.90441131591797,
"blob_id": "1e9a3d71ed2f8ed0fff3fadcf8d3f0273a5bc92b",
"content_id": "32d272f59abb7af8516befa0bf3d0a8470aacd02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4339,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 136,
"path": "/Rakefile",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'rake/clean'\nrequire 'rake/testtask'\n\nbegin\n require 'ci/reporter/rake/test_unit'\nrescue LoadError\n puts 'ci_reporter_test_unit not installed, skipping'\nend\nbegin\n require 'rake/notes/rake_task'\nrescue LoadError\n puts 'rake-notes not installed, skipping'\nend\n\nrequire_relative 'lib/rake/bundle'\n\nBIN_DIRS = %w[\n .\n overlay-bin\n].freeze\n\nSOURCE_DIRS = %w[\n ci\n jenkins-jobs\n lib\n nci\n mgmt\n overlay-bin\n overlay-bin/lib\n xci\n].freeze\n\ndesc 'run all unit tests'\nRake::TestTask.new do |t|\n t.ruby_opts << \"-r#{File.expand_path(__dir__)}/test/helper.rb\"\n # Parsing happens in a separate task because failure there outranks everything\n list =FileList['test/test_*.rb'].exclude('test/test_parse.rb')\n t.test_files = list\n t.options = \"--stop-on-failure --verbose=v\"\n t.verbose = false\nend\ntask :test => :test_pangea_parse\nCLEAN << 'coverage' # Created through helper's simplecov\nCLEAN << 'test/reports'\n\ndesc 'run pangea-tooling (parse) test'\nRake::TestTask.new(:test_pangea_parse) do |t|\n # Parse takes forever, so we run it concurrent to the other tests.\n t.test_files = FileList['test/test_parse.rb']\n t.verbose = true\nend\n\ndesc 'generate line count report'\ntask :cloc do\n system(\"cloc --by-file --xml --out=cloc.xml #{SOURCE_DIRS.join(' ')}\")\nend\nCLEAN << 'cloc.xml'\n\nbegin\n require 'rubocop/rake_task'\n\n desc 'Run RuboCop on the lib directory (xml)'\n RuboCop::RakeTask.new(:rubocop) do |task|\n task.requires << 'rubocop/formatter/checkstyle_formatter'\n BIN_DIRS.each { |bindir| task.patterns << \"#{bindir}/*.rb\" }\n SOURCE_DIRS.each { |srcdir| task.patterns << \"#{srcdir}/**/*.rb\" }\n task.formatters = ['RuboCop::Formatter::CheckstyleFormatter']\n task.options << '--out' << 'checkstyle.xml'\n task.fail_on_error = false\n task.verbose = false\n end\n CLEAN << 'checkstyle.xml'\n\n desc 'Run RuboCop on the lib directory (html)'\n RuboCop::RakeTask.new('rubocop::html') do |task|\n task.requires << 'rubocop/formatter/html_formatter'\n BIN_DIRS.each { |bindir| task.patterns << \"#{bindir}/*.rb\" }\n SOURCE_DIRS.each { |srcdir| task.patterns << \"#{srcdir}/**/*.rb\" }\n task.formatters = ['RuboCop::Formatter::HTMLFormatter']\n task.options << '--out' << 'rubocop.html'\n task.fail_on_error = false\n task.verbose = false\n end\n CLEAN << 'rubocop.html'\nrescue LoadError\n puts 'rubocop not installed, skipping'\nend\n\ndesc 'deploy host and containment tooling'\ntask :deploy do\n bundle(*%w[clean --force --verbose])\n bundle(*%w[pack --all-platforms --no-install])\n\n # Pending for pickup by container.\n tooling_path_pending = File.join(Dir.home, 'tooling-pending')\n FileUtils.rm_rf(tooling_path_pending)\n FileUtils.mkpath(tooling_path_pending)\n FileUtils.cp_r('.', tooling_path_pending, verbose: true)\n\n # Live for host.\n tooling_path = File.join(Dir.home, 'tooling')\n tooling_path_staging = File.join(Dir.home, 'tooling-staging')\n tooling_path_compat = File.join(Dir.home, 'tooling3')\n\n FileUtils.rm_rf(tooling_path_staging, verbose: true)\n FileUtils.mkpath(tooling_path_staging)\n FileUtils.cp_r('.', tooling_path_staging)\n\n FileUtils.rm_rf(tooling_path, verbose: true)\n FileUtils.mv(tooling_path_staging, tooling_path, verbose: true)\n unless File.symlink?(tooling_path_compat)\n FileUtils.rm_rf(tooling_path_compat, verbose: true)\n FileUtils.ln_s(tooling_path, tooling_path_compat, verbose: true)\n end\nend\n"
},
{
"alpha_fraction": 0.7064403295516968,
"alphanum_fraction": 0.7154268622398376,
"avg_line_length": 36.092594146728516,
"blob_id": "6c17bab137b5241d7b1a10e9ae08e09da3563643",
"content_id": "1101c285ccc1baa6244c19567310a1f55032490b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2003,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 54,
"path": "/xci/sourcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n# Copyright (C) 2016 Bhushan Shah <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/build_source'\nrequire_relative '../lib/ci/orig_source_builder'\nrequire_relative '../lib/ci/tar_fetcher'\nrequire_relative 'lib/setup_repo'\nrequire_relative 'lib/setup_env'\n\nXenonCI.setup_env!\nXenonCI.setup_repo!\n\ndef orig_source(fetcher)\n tarball = fetcher.fetch('source')\n raise 'Failed to fetch tarball' unless tarball\n\n sourcer = CI::OrigSourceBuilder.new(release: ENV.fetch('DIST'),\n strip_symbols: true)\n sourcer.build(tarball.origify)\nend\n\ncase ARGV.fetch(0, nil)\nwhen 'tarball'\n puts 'Downloading tarball from URL'\n orig_source(CI::URLTarFetcher.new(File.read('source/url').strip))\nwhen 'uscan'\n puts 'Downloading tarball via uscan'\n orig_source(CI::WatchTarFetcher.new('packaging/debian/watch'))\nelse\n puts 'Unspecified source type, defaulting to VCS build...'\n builder = CI::VcsSourceBuilder.new(release: ENV.fetch('DIST'),\n strip_symbols: true)\n builder.run\nend\n"
},
{
"alpha_fraction": 0.6177884340286255,
"alphanum_fraction": 0.6394230723381042,
"avg_line_length": 20.894737243652344,
"blob_id": "f8b0a171e018a04839e71ab754833e3788af7e40",
"content_id": "166afcc09d4d5ed6a59c0d68eb1782af51a7bade",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 832,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 38,
"path": "/test/test_lint_log.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/lint/log'\nrequire_relative 'lib/testcase'\n\n# Test lint lintian\nclass LintLogTest < TestCase\n def data\n File.read(super)\n end\n\n def test_lint\n rs = Lint::Log.new(data).lint\n infos = 0\n warnings = 0\n errors = 0\n rs.each do |r|\n p r\n assert(r.valid)\n infos += r.informations.size\n warnings += r.warnings.size\n errors += r.errors.size\n end\n assert_equal(0, infos)\n assert_equal(0, warnings)\n # two list-missing files, one dh_missing\n assert_equal(3, errors)\n end\n\n def test_invalid\n rs = Lint::Log.new('').lint\n rs.each do |r|\n assert(!r.valid)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6426666378974915,
"alphanum_fraction": 0.6453333497047424,
"avg_line_length": 19.83333396911621,
"blob_id": "f72caea6eaa5de39f513ad3f0c3a4d4d5ea54518",
"content_id": "f30adbf467efc51b130e7553f758e0d231a16079",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 750,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 36,
"path": "/lib/lsb.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'shellwords'\n\n# Wrapper around lsb-release. Makes values available as non-introspectable\n# constants. For runtime introspection to_h should be used instead.\nmodule LSB\n @file = '/etc/lsb-release'\n\n def self.const_missing(name)\n return to_h[name] if to_h.key?(name)\n\n super(name)\n end\n\n module_function\n\n def to_h\n @hash ||= LSB.parse(File.read(@file).split($/))\n end\n\n def reset\n remove_instance_variable(:@hash) if defined?(@hash)\n end\n\n def self.parse(lines)\n hash = {}\n lines.each do |line|\n line.strip!\n key, value = line.split('=')\n value = Shellwords.split(value)\n value = value[0] if value.size == 1\n hash[key.to_sym] = value\n end\n hash\n end\nend\n"
},
{
"alpha_fraction": 0.6695125102996826,
"alphanum_fraction": 0.6719911694526672,
"avg_line_length": 31.41964340209961,
"blob_id": "df21d74ce947432635e76e172027a7d6eff56748",
"content_id": "8a2b62e95b945dc469aa2399eb3e7c4a4276cf00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3631,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 112,
"path": "/jenkins_jobs_update_xenon.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nENV['JENKINS_CONFIG'] = File.join(Dir.home, '.config/pangea-jenkins.json.xenon')\n\nrequire_relative 'lib/xenonci'\nrequire_relative 'lib/ci/overrides'\nrequire_relative 'lib/projects/factory'\nrequire_relative 'lib/jenkins/project_updater'\n\nDir.glob(File.expand_path('jenkins-jobs/*.rb', __dir__)).each do |file|\n require file\nend\n\nDir.glob(File.expand_path('jenkins-jobs/xenon/*.rb', __dir__)).each do |file|\n require file\nend\n\n# Updates Jenkins Projects\nclass ProjectUpdater < Jenkins::ProjectUpdater\n def initialize\n @job_queue = Queue.new\n @flavor = 'xenon'\n @projects_dir = \"#{__dir__}/xenon-data/projects\"\n JenkinsJob.flavor_dir = \"#{__dir__}/jenkins-jobs/#{@flavor}\"\n super\n end\n\n private\n\n def all_template_files\n files = super\n files + Dir.glob(\"#{JenkinsJob.flavor_dir}/templates/**.xml.erb\")\n end\n\n def load_overrides!\n # TODO: there probably should be a conflict check so they don't override\n # the same thing.\n files = Dir.glob(\"#{__dir__}/xenon-data/overrides/*.yaml\")\n p files\n # raise 'No overrides found?' if files.empty?\n CI::Overrides.default_files += files\n end\n\n def populate_queue\n load_overrides!\n\n all_builds = []\n\n XenonCI.series.each_key do |distribution|\n XenonCI.types.each do |type|\n projects_file = \"#{@projects_dir}/xenon/#{distribution}/#{type}.yaml\"\n projects = ProjectsFactory.from_file(projects_file,\n branch: \"Neon/#{type}\")\n projects.each do |project|\n j = XenonProjectJob.new(project,\n distribution: distribution,\n type: type,\n architectures: XenonCI.architectures_for_type[type])\n all_builds << enqueue(j)\n end\n end\n end\n\n # progenitor = enqueue(\n # MgmtProgenitorJob.new(downstream_jobs: all_meta_builds,\n # blockables: [merger])\n # )\n\n # enqueue(MGMTWorkspaceCleanerJob.new(dist: NCI.current_series))\n # enqueue(MGMTJenkinsPruneParameterListJob.new)\n # enqueue(MGMTJenkinsArchive.new)\n\n enqueue(MGMTRepoCleanup.new)\n\n docker = enqueue(MGMTDockerJob.new(dependees: []))\n # enqueue(MGMTGitSemaphoreJob.new)\n enqueue(MGMTJobUpdater.new)\n jeweller = enqueue(MGMTGitJewellerJob.new)\n # enqueue(MGMTDigitalOcean.new)\n # enqueue(MGMTDigitalOceanDangler.new)\n #enqueue(PlasmaReleasemeTars.new)\n #enqueue(PlasmaReleasemeChangelog.new)\n #enqueue(PlasmaReleasemeTagsTest.new)\n\n enqueue(MGMTTooling.new)\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n updater = ProjectUpdater.new\n updater.update\n updater.install_plugins\nend\n"
},
{
"alpha_fraction": 0.6599665284156799,
"alphanum_fraction": 0.6636515855789185,
"avg_line_length": 31.80219841003418,
"blob_id": "658620830afda73da195d244cd84d150a291516c",
"content_id": "6aeb4a40944ad7e057ccdb2550c671c1d76267d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2985,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 91,
"path": "/nci/lib/lint/qml.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'jenkins_junit_builder'\n\nrequire_relative '../../../lib/qml_dependency_verifier'\nrequire_relative '../../../lib/repo_abstraction'\n\nmodule Lint\n # A QML linter\n class QML\n def initialize(type, dist)\n type = 'testing' if type == 'stable'\n @type = type.tr('-', '/')\n @repo = \"#{type}_#{dist}\"\n @missing_modules = []\n prepare\n end\n\n def lint\n return unless @has_qml\n\n # testing editions's aptly repo is called stable_foo for now\n repo = @repo\n repo = 'stable_bionic' if repo == 'testing_bionic'\n repo = 'stable_focal' if repo == 'testing_focal'\n repo = 'stable_jammy' if repo == 'testing_jammy'\n aptly_repo = Aptly::Repository.get(repo)\n qml_repo = ChangesSourceFilterAptlyRepository.new(aptly_repo, @type)\n verifier = QMLDependencyVerifier.new(qml_repo)\n @missing_modules = verifier.missing_modules\n return if @missing_modules.empty?\n\n write\n end\n\n private\n\n # A junit case representing a package with missing qml files\n class PackageCase < JenkinsJunitBuilder::Case\n def initialize(package, modules)\n super()\n self.name = package\n self.time = 0\n self.classname = name\n # We only get missing modules out of the linter\n self.result = JenkinsJunitBuilder::Case::RESULT_ERROR\n system_out.message = modules.join($/)\n end\n end\n\n def prepare\n dsc = Dir.glob('*.dsc').fetch(0) { raise 'Could not find dsc file in pwd'}\n # Internally qml_dep_verify/package expects things to be in packaging/\n system('dpkg-source', '-x', dsc, 'packaging') || raise\n @has_qml = !Dir.glob('packaging/**/*.qml').empty?\n end\n\n def to_xml\n suite = JenkinsJunitBuilder::Suite.new\n suite.name = 'QMLDependencies'\n suite.package = 'qml'\n @missing_modules.each do |package, modules|\n suite.add_case(PackageCase.new(package, modules))\n end\n suite.build_report\n end\n\n def write\n File.write('junit.xml', to_xml)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6457364559173584,
"alphanum_fraction": 0.6527131795883179,
"avg_line_length": 26.446807861328125,
"blob_id": "5a0a07a296e0a0f4aa98db99f14e5c695b0e9253",
"content_id": "c7e49271649af28c6ebecd5457f834b376c5d174",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1290,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 47,
"path": "/test/test_thread_pool.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/thread_pool'\nrequire_relative 'lib/testcase'\n\n# Test blocking thread pool.\nclass BlockingThreadPoolTest < TestCase\n def test_thread_pool\n queue = Queue.new\n 32.times { |i| queue << i }\n BlockingThreadPool.run do\n until queue.empty?\n i = queue.pop(true)\n File.write(i.to_s, '')\n end\n end\n 32.times do |i|\n assert(File.exist?(i.to_s), \"File #{i} was not created\")\n end\n end\n\n def test_thread_pool_aborting\n errors = Queue.new\n BlockingThreadPool.run(1) do\n errors << 'Thread not aborting' unless Thread.current.abort_on_exception\n end\n\n BlockingThreadPool.run(1, abort_on_exception: false) do\n errors << 'Thread aborting' if Thread.current.abort_on_exception\n end\n\n assert(errors.empty?, 'abortion settings do not match expectation')\n end\n\n def test_thread_pool_count\n # If the queue count is equal to the thread count then all files should\n # be created without additional looping inside the threads.\n queue = Queue.new\n 4.times { |i| queue << i }\n BlockingThreadPool.run(4) do\n i = queue.pop(true)\n File.write(i.to_s, '')\n end\n 4.times do |i|\n assert(File.exist?(i.to_s), \"File #{i} was not created\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6213017702102661,
"alphanum_fraction": 0.6213017702102661,
"avg_line_length": 25.6842098236084,
"blob_id": "3ed90a9e4ce5ce5bd8b7a721ee8cef634791a6dd",
"content_id": "d02a2380d7185b332f6040150803c716b3ac4d27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1014,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 38,
"path": "/lib/debian/patchseries.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule Debian\n # A debian patch series as seen in debian/patches/series\n class PatchSeries\n attr_reader :patches\n\n def initialize(package_path, filename = 'series')\n @package_path = package_path\n @filename = filename\n raise 'not a package path' unless Dir.exist?(\"#{package_path}/debian\")\n\n @patches = []\n parse\n end\n\n def exist?\n @exist ||= false\n end\n\n private\n\n def parse\n path = \"#{@package_path}/debian/patches/#{@filename}\"\n return unless (@exist = File.exist?(path))\n\n data = File.read(path)\n data.split($/).each do |line|\n next if line.chop.strip.empty? || line.start_with?('#')\n\n # series names really shouldn't use paths, so strip by space. This\n # enforces the simple series format described in the dpkg-source manpage\n # which unlike quilt does not support additional arguments such as\n # -pN.\n @patches << line.split(' ').first\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6276611089706421,
"alphanum_fraction": 0.6307023763656616,
"avg_line_length": 28.63519287109375,
"blob_id": "3ff48f70e3f038568506989e52581e33870daa9f",
"content_id": "4a311e675cd2f3fb72f3a6bb0d7af42209258a23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6905,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 233,
"path": "/lib/ci/containment.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'timeout'\n\nrequire_relative '../docker/network_patch'\nrequire_relative 'container/ephemeral'\nrequire_relative 'pangeaimage'\n\nmodule CI\n # Containment class sitting on top of an {EphemeralContainer}.\n class Containment\n TRAP_SIGNALS = %w[EXIT HUP INT QUIT TERM].freeze\n\n class << self\n attr_accessor :no_attach\n\n def userns?\n root = Docker.info.fetch('DockerRootDir')\n File.basename(root) =~ /\\d+\\.\\d+/ # uid.gid\n end\n end\n\n attr_reader :name\n attr_reader :image\n attr_reader :binds\n attr_reader :privileged\n attr_reader :trap_run\n\n def initialize(name, image:, binds: [Dir.pwd], privileged: false,\n no_exit_handlers: privileged)\n EphemeralContainer.assert_version\n\n @name = name\n @image = image # Can be a PangeaImage\n @binds = binds\n @privileged = privileged\n @log = new_logger\n @trap_run = false\n init(no_exit_handlers)\n end\n\n def cleanup\n cleanup_container\n cleanup_network\n end\n\n def default_create_options\n @default_args ||= {\n # Internal\n binds: @binds,\n # Docker\n # Can be a PangeaImage instance\n Image: @image.to_str,\n HostConfig: {\n Privileged: @privileged\n }\n }\n\n @default_args[:HostConfig][:UsernsMode] = 'host' if @privileged\n @default_args\n end\n\n def contain(user_args)\n args = default_create_options.dup\n args.merge!(user_args)\n cleanup\n c = EphemeralContainer.create(**args)\n c.rename(@name)\n c\n end\n\n def attach_thread(container)\n Thread.new do\n # The log attach is threaded because\n # - attaching after start might attach to what is already stopped again\n # in which case attach runs until timeout\n # - after start we do an explicit wait to get the correct status code so\n # we can exit accordingly\n\n # This code only gets run when the socket pushes something, we cannot\n # mock this right now unfortunately.\n # :nocov:\n container.attach do |stream, chunk|\n io = stream == 'stderr' ? STDERR : STDOUT\n io.print(chunk)\n io.flush if chunk.end_with?(\"\\n\")\n end\n # Make sure everything is flushed before we proceed. So that container\n # output is fully consistent at this point.\n STDOUT.flush\n # :nocov:\n end\n end\n\n def run(args)\n c = contain(args)\n # FIXME: port to logger\n stdout_thread = attach_thread(c) unless self.class.no_attach\n return rescued_start(c)\n ensure\n if defined?(stdout_thread) && !stdout_thread.nil?\n stdout_thread.join(16) || stdout_thread.kill\n end\n end\n\n private\n\n def new_logger\n Logger.new(STDERR).tap do |l|\n l.level = Logger::INFO\n l.progname = self.class\n end\n end\n\n def chown_any_mapped(binds)\n # /a:/build gets split into /a we then 1:1 map this as /a upon chowning.\n # This allows us to hopefully reliably chown mapped bindings.\n DirectBindingArray.to_volumes(binds).keys\n end\n\n def chown_handler\n STDERR.puts 'Running chown handler'\n return @chown_handler if defined?(@chown_handler)\n\n binds_ = @binds.dup # Remove from object context so Proc can be a closure.\n binds_ = chown_any_mapped(binds_)\n @chown_handler = proc do\n chown_container =\n CI::Containment.new(\"#{@name}_chown\", image: @image, binds: binds_,\n no_exit_handlers: true)\n chown_container.run(Cmd: %w[chown -R jenkins:jenkins] + binds_)\n end\n end\n\n def trap!\n TRAP_SIGNALS.each do |signal|\n previous = Signal.trap(signal, nil)\n Signal.trap(signal) do\n STDERR.puts 'Running cleanup and handlers'\n cleanup\n run_signal_handler(signal, chown_handler)\n run_signal_handler(signal, previous)\n end\n end\n @trap_run = true\n end\n\n def run_signal_handler(signal, handler)\n if !handler || !handler.respond_to?(:call)\n # Default traps are strings, we can't call them.\n case handler\n when 'IGNORE', 'SIG_IGN'\n # Skip ignores, all others we want to raise.\n return\n end\n handler = proc { raise SignalException, signal }\n end\n # Sometimes the chown handler gets stuck running chown_container.run\n # so make sure to timeout whatever is going on and get everything murdered\n Timeout.timeout(16) { handler.call }\n rescue Timeout::Error => e\n warn \"Failed to run handler #{handler}, timed out. #{e}\"\n end\n\n def rescued_start(c)\n c.start\n status_code = c.wait.fetch('StatusCode', 1)\n debug(c) unless status_code.zero?\n c.stop\n status_code\n rescue Docker::Error::NotFoundError => e\n @log.error 'Failed to create container!'\n @log.error e.to_s\n return 1\n end\n\n def debug(c)\n json = c.json\n warn json.fetch('State', json)\n end\n\n def init(no_exit_handlers)\n cleanup\n return unless handle_exit?(no_exit_handlers)\n\n # TODO: finalize object and clean up container\n trap!\n end\n\n def handle_exit?(no_exit_handlers)\n return false if no_exit_handlers\n return false if self.class.userns?\n\n true\n end\n\n def cleanup_container\n c = EphemeralContainer.get(@name)\n @log.info 'Cleaning up previous container.'\n c.kill if c.running?\n c.remove(force: true)\n rescue Docker::Error::NotFoundError\n @log.info 'Not cleaning up, no previous container found.'\n end\n\n def cleanup_network\n @log.info \"Cleaning up lingering bridge connections of #{@name}\"\n Docker::Network.get('bridge').disconnect(@name, force: true)\n rescue Docker::Error::NotFoundError\n @log.info 'Not cleaning network bridge, not connected.'\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5941343307495117,
"alphanum_fraction": 0.5941343307495117,
"avg_line_length": 24.16666603088379,
"blob_id": "18864a1321e7f0fa2c8ab5bf0bce2be3a3d82d29",
"content_id": "6d6c44a579ea302f5c9d309082390b7c337b406e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1057,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 42,
"path": "/lib/lint/merge_marker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'result'\n\nmodule Lint\n # Lints the presence of merge markers (i.e. <<< or >>>)\n class MergeMarker\n attr_reader :package_directory\n\n def initialize(package_directory = Dir.pwd)\n @package_directory = package_directory\n end\n\n # @return [Result]\n def lint\n result = Result.new\n result.valid = true\n Dir.glob(\"#{@package_directory}/**/**\").each do |file|\n next if File.directory?(file)\n # Check filter. If this becomes too cumbersome, FileMagic offers a\n # reasonable solution to filetype checking based on mime.\n next if %w[.png .svgz .pdf].include?(File.extname(file))\n\n lint_file(result, file)\n end\n result\n end\n\n private\n\n def lint_file(result, path)\n File.open(path, 'r') do |file|\n file.each_line do |line|\n next unless line.start_with?('<<<<<<< ', '>>>>>>> ')\n\n result.errors << \"File #{path} contains merge markers!\"\n break\n end\n end\n result\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5823312401771545,
"alphanum_fraction": 0.5905740857124329,
"avg_line_length": 33.72053909301758,
"blob_id": "d5d819e5c38f4a65b1b8eb51d59e91d1d5b345bd",
"content_id": "15404114ed1b48c4814028272a7e3af360892745",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 10312,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 297,
"path": "/test/test_ci_containment.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2015-2016 Rohan Garg <[email protected]>\n\nrequire 'vcr'\n\nrequire_relative '../lib/ci/containment'\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/pangeaimage'\n\nrequire 'mocha/test_unit'\n\nmodule CI\n class BindsPassed < RuntimeError; end\n\n class ContainmentTest < TestCase\n self.file = __FILE__\n self.test_order = :alphabetic # There's a test_ZZZ to be run at end\n\n # :nocov:\n def cleanup_container\n # Make sure the default container name isn't used, it can screw up\n # the vcr data.\n c = Docker::Container.get(@job_name)\n c.stop\n c.kill! if c.json.fetch('State').fetch('Running')\n c.remove\n rescue Docker::Error::NotFoundError, Excon::Errors::SocketError\n end\n # :nocov:\n\n def setup\n # Disable attaching as on failure attaching can happen too late or not\n # at all as it depends on thread execution order.\n # This can cause falky tests and is not relevant to the test outcome for\n # any test.\n CI::Containment.no_attach = true\n\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :excon\n config.default_cassette_options = {\n match_requests_on: %i[method uri body]\n }\n config.filter_sensitive_data('<%= Dir.pwd %>', :erb_pwd) { Dir.pwd }\n end\n # Chdir to root, as Containment will set the working dir to PWD and this\n # is slightly unwanted for tmpdir tests.\n Dir.chdir('/')\n\n @job_name = 'vivid_unstable_test'\n @image = PangeaImage.new('ubuntu', 'vivid')\n\n VCR.turned_off { cleanup_container }\n Containment::TRAP_SIGNALS.each { |s| Signal.trap(s, nil) }\n\n # Fake info call for consistency\n Docker.stubs(:info).returns('DockerRootDir' => '/var/lib/docker')\n Docker.stubs(:version).returns('ApiVersion' => '1.24', 'Version' => '1.12.3')\n end\n\n def teardown\n VCR.turned_off { cleanup_container }\n CI::EphemeralContainer.safety_sleep = 5\n end\n\n def assert_handler_set(signal)\n message = build_message(nil, 'Signal <?> is nil or DEFAULT.', signal)\n handler = Signal.trap(signal, nil)\n assert_block message do\n !(handler.nil? || handler == 'DEFAULT')\n end\n end\n\n def assert_handler_not_set(signal)\n message = build_message(nil, 'Signal <?> is not nil or DEFAULT.', signal)\n handler = Signal.trap(signal, nil)\n assert_block message do\n handler.nil? || handler == 'DEFAULT'\n end\n end\n\n def vcr_it(meth, **kwords)\n VCR.use_cassette(meth, kwords) do |cassette|\n if cassette.recording?\n VCR.eject_cassette\n VCR.turned_off do\n image = Docker::Image.create(fromImage: 'ubuntu:vivid')\n image.tag(repo: @image.repo, tag: @image.tag) unless Docker::Image.exist?(@image.to_s)\n end\n VCR.insert_cassette(cassette.name)\n else\n CI::EphemeralContainer.safety_sleep = 0\n end\n yield cassette\n end\n end\n\n # This test is order dependent!\n # Traps musts be nil first to properly assert that the containment set\n # new traps. But they won't be nil if another containment ran previously.\n def test_AAA_trap_its\n sigs = Containment::TRAP_SIGNALS\n sigs.each { |sig| assert_handler_not_set(sig) }\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image)\n assert_not_nil(c.send(:chown_handler))\n end\n sigs.each { |sig| assert_handler_set(sig) }\n end\n\n def test_AAA_trap_its_privileged_and_trap_run_indicates_no_handlers\n sigs = Containment::TRAP_SIGNALS\n sigs.each { |sig| assert_handler_not_set(sig) }\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, privileged: true)\n assert_false(c.trap_run)\n end\n # Make sure trap_run *actually* is false iff the handlers were not set.\n sigs.each { |sig| assert_handler_not_set(sig) }\n end\n\n def test_BBB_chown_handle_bindings_in_docker_notation\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: ['/asd:/asd'])\n handler = c.send(:chown_handler)\n stub_containment = mock('containment')\n stub_containment.stubs(:run).returns(true)\n Containment.expects(:new).never\n Containment.expects(:new).with do |*args|\n kwords = args[-1] # ruby3 compat, ruby3 no longer allows implicit **kwords conversion from hash but mocha relies on it still -sitter\n assert_include(kwords, :binds)\n assert_equal(kwords[:binds], ['/asd'])\n true\n end.returns(stub_containment)\n handler.call\n end\n end\n\n def test_init\n binds = [Dir.pwd, 'a:a']\n priv = true\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: binds,\n privileged: priv)\n assert_equal(@job_name, c.name)\n assert_equal(@image, c.image)\n assert_equal(binds, c.binds)\n assert_equal(priv, c.privileged)\n end\n end\n\n def test_run\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: [])\n ret = c.run(Cmd: ['bash', '-c', \"echo #{@job_name}\"])\n assert_equal(0, ret)\n ret = c.run(Cmd: ['bash', '-c', 'exit 1'])\n assert_equal(1, ret)\n end\n end\n\n def test_check_priv\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: [], privileged: true)\n ret = c.run(Cmd: ['bash', '-c', 'if [ ! -e /dev/tty0 ]; then exit 1; fi'])\n assert_equal(0, ret)\n end\n end\n\n def test_check_unpriv\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: [], privileged: false)\n ret = c.run(Cmd: ['bash', '-c', 'if [ ! -e /dev/tty0 ]; then exit 1; fi'])\n assert_equal(1, ret)\n end\n end\n\n def test_run_fail\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: [])\n assert_raises Docker::Error::ClientError do\n c.run(Cmd: ['garbage_fail'])\n end\n end\n end\n\n def test_run_env\n binds = []\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: binds)\n ENV['DIST'] = 'dist'\n ENV['TYPE'] = 'type'\n # VCR will fail if the env argument on create does not add up.\n ret = c.run(Cmd: ['bash', '-c', \"echo #{@job_name}\"])\n assert_equal(0, ret)\n end\n ensure\n ENV.delete('DIST')\n ENV.delete('TYPE')\n end\n\n def test_cleanup_on_new\n vcr_it(__method__) do\n # Implicity via ctor\n Docker::Container.create(Image: @image).tap { |c| c.rename(@job_name) }\n Containment.new(@job_name, image: @image, binds: [])\n assert_raise Docker::Error::NotFoundError do\n Docker::Container.get(@job_name)\n end\n end\n end\n\n def test_cleanup_on_contain\n vcr_it(__method__) do\n # Implicit via contain. First construct containment then contain. Should\n # clean up first resulting in a different hash.\n c = Containment.new(@job_name, image: @image, binds: [])\n c2 = Docker::Container.create(Image: @image).tap { |cont| cont.rename(@job_name) }\n c1 = c.contain({})\n assert_not_equal(c1.id, c2.id)\n assert_raise Docker::Error::NotFoundError do\n # C2 should be gone entirely now\n Docker::Container.get(c2.id)\n end\n ensure\n c&.cleanup\n end\n end\n\n def test_bad_version\n # Force a bad version stub and see the containment fail.\n Docker.unstub(:version)\n vcr_it(__method__) do\n Docker.stubs(:version).returns('1.6')\n assert_raise do\n Containment.new(@job_name, image: @image, binds: [])\n end\n end\n end\n\n def test_ulimit\n vcr_it(__method__) do\n c = Containment.new(@job_name, image: @image, binds: [])\n # 1025 should be false\n ret = c.run(Cmd: ['bash', '-c',\n 'if [ \"$(ulimit -n)\" != \"1025\" ]; then exit 1; fi'])\n assert_equal(1, ret, 'ulimit is 1025 but should not be')\n # 1024 should be true\n ret = c.run(Cmd: ['bash', '-c',\n 'if [ \"$(ulimit -n)\" != \"1024\" ]; then exit 1; else exit 0; fi'])\n assert_equal(0, ret, 'ulimit -n is not 1024 but should be')\n end\n end\n\n def test_image_is_pangeaimage\n # All of the tests assume that the image we use is a PangeaImage, this\n # implicitly tests that the default arguments inside Containment actually\n # properly convert from PangeaImage to a String\n vcr_it(__method__) do\n assert_equal(@image.class, PangeaImage)\n c = Containment.new(@job_name, image: @image, binds: [])\n assert_equal(c.default_create_options[:Image], 'pangea/ubuntu:vivid')\n end\n end\n\n # Last test always! Changes VCR configuration.\n def test_ZZZ_binds\n # Container binds were overwritten by Containment at some point, make\n # sure the binds we put in a re the binds that are passed to docker.\n vcr_it(__method__) do\n Dir.chdir(@tmpdir) do\n CI::EphemeralContainer.stubs(:create)\n .with({ binds: [@tmpdir], Image: @image.to_s, HostConfig: { Privileged: false }, Cmd: ['bash', '-c', 'exit', '0'] })\n .raises(CI::BindsPassed)\n c = Containment.new(@job_name, image: @image, binds: [Dir.pwd])\n assert_raise CI::BindsPassed do\n c.run(Cmd: %w[bash -c exit 0])\n end\n end\n end\n end\n\n def test_userns_docker\n # Trigger userns detection.\n Docker.stubs(:info).returns('DockerRootDir' => '/var/lib/docker/10.20')\n\n # We are mocking this manually. No VCR!\n CI::Containment.any_instance.stubs(:cleanup).returns(true)\n\n Containment::TRAP_SIGNALS.each { |sig| assert_handler_not_set(sig) }\n CI::Containment.new('fooey', image: 'yolo')\n Containment::TRAP_SIGNALS.each { |sig| assert_handler_not_set(sig) }\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7424344420433044,
"alphanum_fraction": 0.7491593956947327,
"avg_line_length": 40.30555725097656,
"blob_id": "9e03cd6f35ca884c4ccede6d303b3045a585d701",
"content_id": "a1778f3f954a7e2aa56cb402a6ef95fb86bb116a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1487,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 36,
"path": "/overlay-bin/tail",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n#\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire_relative 'lib/paths' # Drop the overlay from the PATH env.\n\n# Intercepts tail calls of CMakeCache.txt and instead copies the file into\n# the job workspace for archival or whatever.\n# Tailing the cache floods stdout with largely irrelevant pointless info.\n\nif %w[CMakeCache.txt CMakeFiles/CMakeOutput.log].any? { |f| ARGV.include?(f) }\n FileUtils.mkpath(\"#{WORKSPACE}/archive_pickup\", verbose: true)\n FileUtils.cp('CMakeCache.txt', \"#{WORKSPACE}/archive_pickup\", verbose: true)\n exit 0\nend\n\nexec('tail', *ARGV)\n"
},
{
"alpha_fraction": 0.5227272510528564,
"alphanum_fraction": 0.5227272510528564,
"avg_line_length": 13.666666984558105,
"blob_id": "c8ea0708a9d23372d1a2ad41ea44622a8e12d945",
"content_id": "9daafe100a73d2d812936bbf858caefffb38d2e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 3,
"path": "/lib/libexec/ssh_key_file.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nexec ssh -i ${SSH_KEY_FILE} \"$@\"\n"
},
{
"alpha_fraction": 0.6891064643859863,
"alphanum_fraction": 0.6940024495124817,
"avg_line_length": 31.68000030517578,
"blob_id": "c58576a7fcf4a285e4844d70817c8f420f77237a",
"content_id": "8b6a4291d09480be74a8beaca387467e621b99d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3268,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 100,
"path": "/test/test_nci_sourcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/sourcer'\n\nrequire 'mocha/test_unit'\n\nclass NCISourcerTest < TestCase\n def setup\n ENV['DIST'] = 'xenial'\n ENV['BUILD_NUMBER'] = '123'\n end\n\n def test_run_fallback\n fake_builder = mock('fake_builder')\n fake_builder.stubs(:run)\n CI::VcsSourceBuilder.expects(:new).returns(fake_builder)\n # Runs fallback\n NCISourcer.run\n end\n\n def test_run_tarball\n Dir.mkdir('source')\n File.write('source/url', 'http://yolo')\n\n fake_tar = mock('fake_tar')\n fake_tar.stubs(:origify).returns(fake_tar)\n fake_fetcher = mock('fake_fetcher')\n fake_fetcher.stubs(:fetch).with('source').returns(fake_tar)\n CI::URLTarFetcher.expects(:new).with('http://yolo').returns(fake_fetcher)\n\n fake_builder = mock('fake_builder')\n fake_builder.stubs(:build)\n CI::OrigSourceBuilder.expects(:new).with(strip_symbols: true).returns(fake_builder)\n\n NCISourcer.run('tarball')\n end\n\n def test_run_uscan\n fake_tar = mock('fake_tar')\n fake_tar.stubs(:origify).returns(fake_tar)\n fake_fetcher = mock('fake_fetcher')\n fake_fetcher.stubs(:fetch).with('source').returns(fake_tar)\n CI::WatchTarFetcher\n .expects(:new)\n .with('packaging/debian/watch',\n series: NCI.series.keys, mangle_download: true)\n .returns(fake_fetcher)\n\n fake_builder = mock('fake_builder')\n fake_builder.stubs(:build)\n CI::OrigSourceBuilder.expects(:new).with(strip_symbols: true).returns(fake_builder)\n\n NCISourcer.run('uscan')\n end\n\n def test_args\n assert_equal({ strip_symbols: true }, NCISourcer.sourcer_args)\n end\n\n def test_settings_args\n NCI::Settings.expects(:for_job).returns(\n 'sourcer' => { 'restricted_packaging_copy' => true }\n )\n assert_equal({ strip_symbols: true, restricted_packaging_copy: true },\n NCISourcer.sourcer_args)\n end\n\n def test_run_debscm\n fake_tar = mock('fake_tar')\n fake_tar.stubs(:origify).returns(fake_tar)\n fake_fetcher = mock('fake_fetcher')\n fake_fetcher.stubs(:fetch).with('source').returns(fake_tar)\n CI::DebSCMFetcher.expects(:new).returns(fake_fetcher)\n\n fake_builder = mock('fake_builder')\n fake_builder.stubs(:build)\n CI::OrigSourceBuilder.expects(:new).with(strip_symbols: true).returns(fake_builder)\n\n NCISourcer.run('debscm')\n end\nend\n"
},
{
"alpha_fraction": 0.6310057640075684,
"alphanum_fraction": 0.6342088580131531,
"avg_line_length": 29.310680389404297,
"blob_id": "4af5377ab5b741daee485ff244a2a88ced60a174",
"content_id": "c79b37e2c1577a9b4271b2f4354cbd4e2dee6873",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3122,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 103,
"path": "/lib/debian/uscan.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'nokogiri'\n\nmodule Debian\n class UScan\n # State identifier strings.\n module States\n NEWER_AVAILABLE = 'Newer version available'\n UP_TO_DATE = 'up to date'\n DEBIAN_NEWER = 'Debian version newer than remote site'\n OLDER_ONLY = 'only older package available'\n\n # Compatiblity map because uscan randomly changes the bloody strings.\n # @param [String] string actual uscan string we want to map\n # @return [String] const representation of that string\n def self.map(string)\n case string\n when 'newer package available'\n NEWER_AVAILABLE\n else\n string\n end\n end\n end\n\n # UScan's debian external health status format parser.\n class DEHS\n class ParseError < StandardError; end\n\n # A Package status report.\n class Package\n attr_reader :name\n attr_reader :status\n attr_reader :upstream_version\n attr_reader :upstream_url\n\n def initialize(name)\n @name = name\n end\n\n # Sets instance variable according to XML element.\n def _apply_element(element)\n instance_variable_set(to_instance(element.name), element.content)\n end\n\n private\n\n def to_instance(str)\n \"@#{str.tr('-', '_')}\".to_sym\n end\n end\n\n class << self\n def parse_packages(xml)\n packages = []\n Nokogiri::XML(xml).root.elements.each do |element|\n if element.name == 'package'\n next packages << Package.new(element.content)\n end\n\n verify_status(element)\n packages[-1]._apply_element(element)\n end\n packages\n end\n\n private\n\n def verify_status(element)\n return unless element.name == 'status'\n\n # Edit the content to the mapped value, so we always get consistent\n # strings.\n element.content = States.map(element.content)\n return if States.constants.any? do |const|\n States.const_get(const) == element.content\n end\n\n raise ParseError, \"Unmapped status: '#{element.content}'\"\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6281608939170837,
"alphanum_fraction": 0.646264374256134,
"avg_line_length": 31.830188751220703,
"blob_id": "4bd6cddd88d66c1f60af63bca5c7733ad1303bae",
"content_id": "b8ed1a9e81c058b91a9e809f2c3e10f1755a1c34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3480,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 106,
"path": "/test/test_ci_tarball.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/ci/tarball'\n\nmodule CI\n class TarballTest < TestCase\n def test_string\n s = File.absolute_path('d_1.0.orig.tar')\n t = Tarball.new(s)\n assert_equal(s, t.to_s)\n assert_equal(s, t.to_str)\n assert_equal(s, t.to_s) # coerce\n end\n\n def test_orig\n assert_false(Tarball.orig?('a-1.0.tar'))\n assert_false(Tarball.orig?('b_1.0.tar'))\n assert_false(Tarball.orig?('c-1.0.orig.tar'))\n assert(Tarball.orig?('d_1.0.orig.tar'))\n # More advanced but valid version with characters and a plus\n assert(Tarball.orig?('qtbase-opensource-src_5.5.1+dfsg.orig.tar.xz'))\n end\n\n def test_origify\n t = Tarball.new('d_1.0.orig.tar').origify\n assert_equal('d_1.0.orig.tar', File.basename(t.path))\n t = Tarball.new('a-1.0.tar').origify\n assert_equal('a_1.0.orig.tar', File.basename(t.path))\n\n # fail\n assert_raise RuntimeError do\n Tarball.new('a.tar').origify\n end\n end\n\n def test_extract\n t = Tarball.new(data('test-1.tar'))\n t.extract(\"#{Dir.pwd}/test-2\")\n assert_path_exist('test-2')\n assert_path_exist('test-2/a')\n assert_path_not_exist('test-1')\n\n t = Tarball.new(data('test-flat.tar'))\n t.extract(\"#{Dir.pwd}/test-1\")\n assert_path_exist('test-1')\n assert_path_exist('test-1/test-flat')\n end\n\n def test_extract_flat_hidden_things\n t = Tarball.new(data('test.tar'))\n\n t.extract(\"#{Dir.pwd}/test\")\n\n assert_path_exist('test/.hidden-dir')\n assert_path_exist('test/.hidden-file')\n assert_path_exist('test/visible-file')\n end\n\n def test_copy\n FileUtils.cp_r(Dir[\"#{data}/*\"], Dir.pwd)\n t = Tarball.new('test-1.tar.xz')\n assert_false(t.orig?)\n t.origify!\n assert_equal('test_1.orig.tar.xz', File.basename(t.path))\n assert_path_exist('test_1.orig.tar.xz')\n end\n\n def test_version\n t = Tarball.new('qtbase-opensource-src_5.5.1+dfsg.orig.tar.xz')\n assert_equal('5.5.1+dfsg', t.version)\n end\n\n def test_basename\n t = Tarball.new('qtbase-opensource-src_5.5.1+dfsg.orig.tar.xz')\n assert_equal('qtbase-opensource-src_5.5.1+dfsg.orig.tar.xz', t.basename)\n end\n\n def test_dsc_extract\n # dsc tarball should unpack via dsc so it includes everything\n DSCTarball.new(data('test_2.10.tar.gz'),\n dsc: data('test_2.10.dsc')).extract('x')\n assert_path_exist('x/debian/control')\n assert_path_exist('x/debian/compat')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6674147248268127,
"alphanum_fraction": 0.6759425401687622,
"avg_line_length": 25.21176528930664,
"blob_id": "23d9797d8982207664f4f556a018fa8c57ec0635",
"content_id": "a82645ff9370ade79b149c8de4fde87d23260b1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2228,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 85,
"path": "/lib/ci/fake_package.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tmpdir'\nrequire 'tty/command'\n\nrequire_relative '../../lib/dpkg'\n\n# A fake package\nclass FakePackage\n attr_reader :name\n attr_reader :version\n\n # Logic wrapper to force desired run behavior. Which is to say not verbose\n # becuase FakePackage may get called a lot.\n class OutputOnErrorCommand < TTY::Command\n def initialize(*args)\n super(*args, uuid: false, printer: :progress)\n end\n\n def run(*args)\n super(*args, only_output_on_error: true)\n end\n end\n private_constant :OutputOnErrorCommand\n\n class << self\n def cmd\n @cmd ||= OutputOnErrorCommand.new\n end\n end\n\n def initialize(name, version = '999:999')\n @name = name\n @version = version\n end\n\n def install\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n build\n DPKG.dpkg(['-i', deb]) || raise\n end\n end\n end\n\n private\n\n def cmd\n self.class.cmd\n end\n\n def deb\n \"#{name}.deb\"\n end\n\n def build\n FileUtils.mkpath(\"#{name}/DEBIAN\")\n File.write(\"#{name}/DEBIAN/control\", <<-CONTROL.gsub(/^\\s+/, ''))\n Package: #{name}\n Version: #{version}\n Architecture: all\n Maintainer: Harald Sitter <[email protected]>\n Description: fake override package for CI use\n CONTROL\n cmd.run('dpkg-deb', '-b', '-Znone', '-Snone', name, deb)\n end\nend\n"
},
{
"alpha_fraction": 0.7234600186347961,
"alphanum_fraction": 0.7391874194145203,
"avg_line_length": 35.33333206176758,
"blob_id": "62620596e34545b99e1abee35f601e8cba9d9cca",
"content_id": "9601f1c11e8f13e24d260e7bedf8a3fb52e66f17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 763,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 21,
"path": "/nci/repo_test_versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lint/versions'\n\n# Runs against Ubuntu, we do not add any extra repos. The intention is that\n# all packages in our repo are greater than the one in Ubuntu (i.e. apt-cache).\n\nAptly.configure do |config|\n config.uri = URI::HTTPS.build(host: 'archive-api.neon.kde.org')\n # This is read-only.\nend\n\nour = NCI::RepoPackageLister.new\ntheir = NCI::CachePackageLister.new(filter_select: our.packages.map(&:name))\nNCI::VersionsTest.init(ours: our.packages, theirs: their.packages)\nENV['CI_REPORTS'] = Dir.pwd\nARGV << '--ci-reporter'\nrequire 'minitest/autorun'\n"
},
{
"alpha_fraction": 0.7196581363677979,
"alphanum_fraction": 0.7658119797706604,
"avg_line_length": 33.411766052246094,
"blob_id": "c0cb7cf4196c131ee14aa925b094ba2ec81ae243",
"content_id": "1277eb0fde7e776a663014edbfe8a1ff2e190d3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 585,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 17,
"path": "/nci/imager/config-hooks-neon-developer/99-preinstalled-pool.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "mkdir -vp config/gnupg\nmkdir -vp config/indices\n\n# Make sure we use a suitably strong digest algorithm. SHA1 is deprecated and\n# makes apt angry.\ncat > config/gnupg/gpg.conf <<EOF\npersonal-digest-preferences SHA512\ncert-digest-algo SHA512\ndefault-preference-list SHA512 SHA384 SHA256 SHA224 AES256 AES192 AES CAST5 ZLIB BZIP2 ZIP Uncompressed\nEOF\n\nfor component in $COMPONENTS; do\n (cd config/indices && \\\n wget http://archive.ubuntu.com/ubuntu/indices/override.$SUITE.$component && \\\n wget http://archive.ubuntu.com/ubuntu/indices/override.$SUITE.extra.$component \\\n )\ndone\n"
},
{
"alpha_fraction": 0.7020624279975891,
"alphanum_fraction": 0.7101449370384216,
"avg_line_length": 39.772727966308594,
"blob_id": "b0af4854c50a1b1ca7f04b9d25de6890167c76e6",
"content_id": "dfd63f6b82bece1b031d6bfbe6029ab7dbaf91d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3588,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 88,
"path": "/nci/contain.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2014-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/containment'\n\nDocker.options[:read_timeout] = 7 * 60 * 60 # 7 hours.\n\nDIST = ENV.fetch('DIST')\nJOB_NAME = ENV.fetch('JOB_NAME')\nPWD_BIND = ENV.fetch('PWD_BIND', '/workspace')\nPANGEA_MAIL_CONFIG_PATH = ENV.fetch('PANGEA_MAIL_CONFIG_PATH', nil)\nIMAGE = ENV.fetch('PANGEA_DOCKER_IMAGE', CI::PangeaImage.new(:ubuntu, DIST))\n\n# Whitelist a bunch of Jenkins variables for consumption inside the container.\nwhitelist = %w[BUILD_CAUSE ROOT_BUILD_CAUSE RUN_DISPLAY_URL JOB_NAME BUILD_URL\n NODE_NAME NODE_LABELS\n PANGEA_PROVISION_AUTOINST\n DH_VERBOSE\n APTLY_REPOSITORY]\n# Whitelist all PANGEA_ prefix'd variables.\nENV.each_key { |k| whitelist << k if k.start_with?('PANGEA_') }\n# And whatever was explicitly whitelisted via environment itself.\nwhitelist += (ENV['DOCKER_ENV_WHITELIST'] || '').split(':')\nENV['DOCKER_ENV_WHITELIST'] = whitelist.join(':')\n\n# TODO: autogenerate from average build time?\n# TODO: maybe we should have a per-source cache that gets shuffled between the\n# master and slave. with private net enabled this may be entirely doable\n# without much of a slow down (if any). also we can then make use of a volume\n# giving us more leeway in storage.\n# Whitelist only certain jobs for ccache. With the amount of jobs we\n# have we'd need probably >=20G of cache to cover everything, instead only cache\n# the longer builds. This way we stand a better chance of having a cache at\n# hand as the smaller builds do not kick the larger ones out of the cache.\nCCACHE_WHITELIST = %w[\n qt\n plasma-desktop\n plasma-workspace\n kio\n kwin\n khtml\n marble\n kdepim-addons\n kdevplatform\n].freeze\n\ndef default_ccache_dir\n dir = '/var/cache/pangea-ccache-neon'\n return nil unless CCACHE_WHITELIST.any? { |x| JOB_NAME.include?(\"_#{x}_\") }\n return dir if File.exist?(dir) && ENV.fetch('TYPE', '') == 'unstable'\n\n nil\nend\n\nCCACHE_DIR = default_ccache_dir\nCONTAINER_NAME = \"neon_#{JOB_NAME}\"\n\n# Current (focal, 2020-04-24) armhf server is so old its seccomp doesn't know what\n# to do with utime syscalls used by focal libc, so we always run priv'd\n# in this scenario as otherwise everything would eventually EPERM.\nPRIVILEGED = JOB_NAME.end_with?('_armhf') && DIST != 'bionic'\n\nbinds = [\"#{Dir.pwd}:#{PWD_BIND}\"]\nbinds << \"#{CCACHE_DIR}:/ccache\" if CCACHE_DIR\nbinds << \"#{PANGEA_MAIL_CONFIG_PATH}:#{PANGEA_MAIL_CONFIG_PATH}\" if PANGEA_MAIL_CONFIG_PATH\nc = CI::Containment.new(CONTAINER_NAME, image: IMAGE, binds: binds,\n privileged: PRIVILEGED)\n\nstatus_code = c.run(Cmd: ARGV, WorkingDir: PWD_BIND)\nexit status_code\n"
},
{
"alpha_fraction": 0.6690346598625183,
"alphanum_fraction": 0.6778102517127991,
"avg_line_length": 35.25757598876953,
"blob_id": "9db535b181fc327100e88be76b4ddb898270c821",
"content_id": "270cedd3dbad114469df3f5b4e32785eef77b012",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2393,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 66,
"path": "/nci/lib/repo_diff.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'date'\nrequire 'terminal-table'\n\nrequire_relative '../../lib/aptly-ext/filter'\nrequire_relative '../../lib/nci'\nrequire_relative '../../lib/optparse'\n\n# Show which packages differ between two published repositories\nclass RepoDiff\n def diff_repo(current, new, dist)\n all_pubs = Aptly::PublishedRepository.list\n pubs = []\n [new, current].each do |arg|\n pubs << all_pubs.find { |x| x.Prefix == arg && x.Distribution == dist }\n end\n packages_for_pubs = {}\n pubs.each do |pub|\n packages_for_pubs[pub] = pub.Sources.collect do |x|\n x.packages(q: '$Architecture (source)')\n end.flatten.uniq\n end\n\n packages_for_pubs.each_slice(2) do |x|\n one = x[0]\n two = x.fetch(1, nil)\n raise 'Uneven amount of publishing endpoints' unless two\n\n puts \"\\nOnly in #{one[0].Prefix}\"\n only_in_one = one[1] - two[1]\n only_in_one = Aptly::Ext::LatestVersionFilter.filter(only_in_one)\n packages_in_two = Aptly::Ext::LatestVersionFilter.filter(two[1])\n packages_in_two = packages_in_two.group_by(&:name)\n\n rows = []\n only_in_one.sort_by!(&:name)\n only_in_one.each do |package|\n new_version = package.version\n old_version = packages_in_two.fetch(package.name, nil)\n old_version = old_version ? old_version[0].version : ''\n rows << [package.name, package.architecture, new_version, old_version]\n end\n return rows\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6768661737442017,
"alphanum_fraction": 0.6798924207687378,
"avg_line_length": 28.156862258911133,
"blob_id": "e75f70924ef1ef69b1c7fdd40dabe26c416caf5f",
"content_id": "16d96996998a1a9412ea2ce5266fb97650f00a30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2974,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 102,
"path": "/nci/dangling_config_finder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty/command'\n\nINFO_DIR = '/var/lib/dpkg/info/'\n\n# Finds dangling configs of a package\nclass DanglingConfigCheck\n def initialize(list_file)\n @list_file = list_file\n @pkg = File.basename(list_file, '.list')\n @conffiles_file = File.join(INFO_DIR, \"#{@pkg}.conffiles\")\n end\n\n def danglers\n danglers = []\n\n each_list do |line|\n next unless line.start_with?('/etc/')\n next unless File.file?(line) && !File.symlink?(line)\n\n danglers << line\n end\n\n each_conffiles { |line| danglers.delete(line) }\n\n # Maintainer check is fairly expensive, if we have no danglers we can\n # abort here already, the maintainer check does nothing for us.\n # If we are not maintainer we'll ignore all danglers.\n return danglers if danglers.empty?\n\n kde_maintainer? ? danglers : []\n end\n\n private\n\n def each_list\n return unless File.exist?(@list_file)\n\n File.foreach(@list_file) do |line|\n yield line.strip\n end\n end\n\n def each_conffiles\n return unless File.exist?(@conffiles_file)\n\n File.foreach(@conffiles_file).each do |line|\n yield line.strip\n end\n end\n\n def kde_maintainer?\n @kde_maintainer ||= begin\n return false if %w[base-files].include?(@pkg)\n\n out = `dpkg-query -W -f='${Maintainer}\\n' #{@pkg}` || ''\n out.split(\"\\n\").any? do |line|\n line.include?('kde')\n end\n end\n end\nend\n\nerror = false\nDir.glob(File.join(INFO_DIR, '*.list')) do |list|\n danglers = DanglingConfigCheck.new(list).danglers\n next if danglers.empty?\n\n warn <<-ERROR\n--------------------------------------------------------------------------------\nDangling configuration files detected. The package list\n#{list}\ncontains the following configuration files, they are however not tracked as\nconfiguration files anymore (i.e. they were dropped from the packaging but\nkept around on disk). Disappearing configuration files need to be properly\nremoved via *.maintscript files in the packaging!\n#{danglers.inspect}\n\n ERROR\n error = true\nend\nraise if error\n"
},
{
"alpha_fraction": 0.7210103273391724,
"alphanum_fraction": 0.7296211123466492,
"avg_line_length": 33.156864166259766,
"blob_id": "f312da8738a266277e2b7e4de8ace329b33cd0a2",
"content_id": "1c9675601646d31a4269a7cbaf0c1ca2e0c399e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1742,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 51,
"path": "/jenkins-jobs/nci/mgmt_jenkins_prunes.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../job'\n\n# Base class for all prunes\nclass MGMTJenkinsBasePruneJob < JenkinsJob\n attr_accessor :max_age\n attr_accessor :min_count\n attr_accessor :paths\n\n def initialize(name:, paths:, max_age:, min_count:)\n super(\"mgmt_jenkins_prune_#{name}\", 'mgmt_jenkins_prune.xml.erb')\n self.max_age = max_age\n self.min_count = min_count\n self.paths = paths\n end\nend\n\n# Prunes parameter-files\nclass MGMTJenkinsPruneParameterListJob < MGMTJenkinsBasePruneJob\n def initialize\n super(name: 'parameter-files', paths: %w[parameter-files fileParameters],\n max_age: -1, min_count: 1)\n end\nend\n\n# Prunes entire builds that are too old.\nclass MGMTJenkinsPruneOld < MGMTJenkinsBasePruneJob\n def initialize\n super(name: 'old', paths: %w[.],\n max_age: 60, min_count: 10)\n end\nend\n"
},
{
"alpha_fraction": 0.6642156839370728,
"alphanum_fraction": 0.6642156839370728,
"avg_line_length": 23,
"blob_id": "6f82ca24408cb396038c58c2daf66138268470a0",
"content_id": "105b557364527bc8a175376ebb46aeb5c275929e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 17,
"path": "/lib/docker/network_patch.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\nrequire 'docker'\n\n# Docker module.\nmodule Docker\n # Monkey patch to support forced disconnect.\n class Network\n def disconnect(container, opts = {}, force: false)\n body = MultiJson.dump({ container: container }.merge(force: force))\n Docker::Util.parse_json(\n connection.post(path_for('disconnect'), opts, body: body)\n )\n reload\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7155688405036926,
"alphanum_fraction": 0.7485029697418213,
"avg_line_length": 36.11111068725586,
"blob_id": "53fa94ae8ebde634c6d149429f580c5ef42019f4",
"content_id": "f5fc563d2b31334c03f9055ff91d510c897e0530",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 9,
"path": "/nci/imager/config-hooks-neon-developer/00-debconf-preseed.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# preseed debconf selections\n\n# - disable man-db updates, they are super slow and who even uses man-db...\ncat << EOF > config/preseed/000-neon.preseed\nman-db man-db/auto-update boolean false\nEOF\n"
},
{
"alpha_fraction": 0.633184015750885,
"alphanum_fraction": 0.6448909044265747,
"avg_line_length": 30.73853302001953,
"blob_id": "68627315310d4e4da3c1b86d5db2dc51b798cade",
"content_id": "20b48efeb22ea1ace841c51dfc17f36b35106e5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6919,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 218,
"path": "/nci/lib/setup_repo.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire 'net/http'\nrequire 'open-uri'\n\nrequire_relative '../../lib/apt'\nrequire_relative '../../lib/os'\nrequire_relative '../../lib/retry'\nrequire_relative '../../lib/nci'\n\n# Neon CI specific helpers.\nmodule NCI\n # NOTE: we talk to squid directly to reduce forwarding overhead, if we routed\n # through apache we'd be spending between 10 and 25% of CPU on the forward.\n PROXY_URI = URI::HTTP.build(host: 'apt.cache.pangea.pub', port: 8000)\n\n module_function\n\n def setup_repo_codename\n @setup_repo_codename ||= OS::VERSION_CODENAME\n end\n\n def setup_repo_codename=(codename)\n @setup_repo_codename = codename\n end\n\n def default_sources_file=(file)\n @default_sources_file = file\n end\n\n def default_sources_file\n @default_sources_file ||= '/etc/apt/sources.list'\n end\n\n def reset_setup_repo\n @repo_added = nil\n @default_sources_file = nil\n @setup_repo_codename = nil\n end\n\n def add_repo_key!\n @repo_added ||= begin\n Retry.retry_it(times: 3, sleep: 8) do\n raise 'Failed to import key' unless Apt::Key.add(NCI.archive_key)\n end\n true\n end\n end\n\n def setup_repo!(with_source: false, with_proxy: true, with_install: true)\n setup_proxy! if with_proxy\n add_repo!\n add_source_repo! if with_source\n setup_experimental! if ENV.fetch('TYPE').include?('experimental')\n Retry.retry_it(times: 5, sleep: 4) { raise unless Apt.update }\n\n # Make sure we have the latest pkg-kde-tools, not whatever is in the image.\n return unless with_install\n\n raise 'failed to install deps' unless Apt.install(%w[pkg-kde-tools pkg-kde-tools-neon debhelper cmake quilt])\n\n # Qt6 Hack\n return unless %w[_qt6_bin_ _qt6_src].any? do |x|\n ENV.fetch('JOB_NAME', '').include?(x)\n end\n\n cmake_key = '6D90 3995 424A 83A4 8D42 D53D A8E5 EF3A 0260 0268'\n cmake_line = 'deb https://apt.kitware.com/ubuntu/ focal main'\n Retry.retry_it(times: 3, sleep: 8) do\n raise 'Failed to import cmake key' unless Apt::Key.add(cmake_key)\n end\n raise 'Failed to add cmake repo' unless Apt::Repository.add(cmake_line)\n\n Retry.retry_it(times: 5, sleep: 4) { raise unless Apt.update }\n # may be installed in base image\n raise unless Apt.install('cmake')\n end\n\n def setup_proxy!\n puts \"Set proxy to #{PROXY_URI}\"\n File.write('/etc/apt/apt.conf.d/proxy',\n \"Acquire::http::Proxy \\\"#{PROXY_URI}\\\";\")\n end\n\n def maybe_setup_apt_preference\n # If the dist at hand is the future series establish a preference.\n # Due to teh moving nature of the future series it may fall behind ubuntu\n # and build against the incorrect packages. The preference is meant to\n # prevent this by forcing our versions to be the gold standard.\n return unless ENV.fetch('DIST', NCI.current_series) == NCI.future_series\n\n puts 'Setting up apt preference.'\n @preference = Apt::Preference.new('pangea-neon', content: <<-PREFERENCE)\nPackage: *\nPin: release o=neon\nPin-Priority: 1001\n PREFERENCE\n @preference.write\n end\n\n def maybe_teardown_apt_preference\n return unless @preference\n\n puts 'Discarding apt preference.'\n @preference.delete\n @preference = nil\n end\n\n def maybe_teardown_experimental_apt_preference\n return unless @experimental_preference\n\n puts 'Discarding testing apt preference.'\n @experimental_preference.delete\n @experimental_preference = nil\n end\n\n class << self\n private\n\n def setup_experimental!\n puts 'Setting up apt preference for experimental repository.'\n @experimental_preference = Apt::Preference.new('pangea-neon-experimental',\n content: <<-PREFERENCE)\nPackage: *\nPin: release l=KDE neon - Experimental Edition\nPin-Priority: 1001\n PREFERENCE\n @experimental_preference.write\n ENV['TYPE'] = 'unstable'\n add_repo!\n end\n\n # Sets the default release. We'll add the deb-src of all enabled series\n # if enabled. To prevent us from using an incorret series simply force the\n # series we are running under to be the default (outscores others).\n # This effectively increases the apt score of the current series to 990!\n def set_default_release!\n File.write('/etc/apt/apt.conf.d/99-default', <<-CONFIG)\nAPT::Default-Release \"#{setup_repo_codename}\";\n CONFIG\n end\n\n # Sets up source repo(s). This method is special in that it sets up\n # deb-src for all enabled series, not just the current one. This allows\n # finding the \"newest\" tarball in any series. Which we need to detect\n # and avoid uscan repack divergence between series.\n def add_source_repo!\n set_default_release!\n add_repo_key!\n NCI.series.each_key do |dist|\n # This doesn't use Apt::Repository because it uses apt-add-repository\n # which smartly says\n # Error: 'deb-src http://archive.neon.kde.org/unstable xenial main'\n # invalid\n # obviously.\n lines = [debsrcline(dist: dist)]\n # Also add deb entry -.-\n # https://bugs.debian.org/892174\n lines << debline(dist: dist) if dist != setup_repo_codename\n File.write(\"/etc/apt/sources.list.d/neon_src_#{dist}.list\",\n lines.join(\"\\n\"))\n puts \"lines: #{lines.join('\\n')}\"\n end\n disable_all_src\n end\n\n def disable_all_src\n data = File.read(default_sources_file)\n lines = data.split(\"\\n\")\n lines.collect! do |line|\n next line unless line.strip.start_with?('deb-src')\n\n \"# #{line}\"\n end\n File.write(default_sources_file, lines.join(\"\\n\"))\n end\n\n def type_to_repo(type)\n # rename editions but not (yet) renamed the job type\n type = 'testing' if type == 'stable'\n type.tr('-', '/')\n end\n\n def debline(type: ENV.fetch('TYPE'), dist: setup_repo_codename)\n repo = type_to_repo(type)\n\n if NCI.divert_repo?(repo)\n return format('deb http://archive.neon.kde.org/tmp/%<repo>s %<dist>s main',\n repo: repo, dist: dist)\n end\n\n format('deb http://archive.neon.kde.org/%<repo>s %<dist>s main',\n repo: repo, dist: dist)\n end\n\n def debsrcline(type: ENV.fetch('TYPE'), dist: setup_repo_codename)\n repo = type_to_repo(type)\n\n if NCI.divert_repo?(repo)\n return format('deb-src http://archive.neon.kde.org/tmp/%<repo>s %<dist>s main',\n repo: repo, dist: dist)\n end\n\n format('deb-src http://archive.neon.kde.org/%<repo>s %<dist>s main',\n repo: repo, dist: dist)\n end\n\n def add_repo!\n add_repo_key!\n Retry.retry_it(times: 5, sleep: 4) do\n raise 'adding repo failed' unless Apt::Repository.add(debline)\n end\n puts \"added #{debline}\"\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7281947135925293,
"alphanum_fraction": 0.7302231192588806,
"avg_line_length": 38.439998626708984,
"blob_id": "ee4572aac716e7617c35af3b0855a8dd9ba073b4",
"content_id": "71785b83e3611d5c546435343352fd99b5346305",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3944,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 100,
"path": "/nci/appstream_ubuntu_filter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# This mighty script auto generates an exclusion list of ubuntu provided\n# appstream components that we do not want to have in discover. We don't support\n# third party applications coming form ubuntu. The ideal way to use third\n# party software is through bundle tech such as flatpak/snap/appimage.\n# NOTE: at the time of writing removal only applies to lower scored appstream\n# sources (i.e. ubuntu) but leaves the source that applies the score (i.e. neon)\n# unaffected. This allows us to simply take a list of all ubuntu components\n# we want removed without having to take special care of the component\n# appearing in neon as well. Should this change we'll stop seeing KDE software\n# in discover pretty much (I doubt it will change though).\n\nrequire 'json'\nrequire 'tty/command'\n\nrequire_relative '../lib/apt'\nrequire_relative 'lib/setup_repo'\n\nComponent = Struct.new(:id, :kind)\n\nDIST = ENV.fetch('DIST')\nTARGET_DIR = \"#{DIST}/main\"\n\nDir.chdir(TARGET_DIR) # fails if the dir is missing for whatever reason\n\nunless File.exist?('/usr/bin/appstreamcli')\n Apt::Get.install('appstream')\n Apt::Get.update # refresh appstream cache!\nend\n\n# DO NOT SETUP NEON REPOS. We need the ubuntu list only, we always want to\n# see our stuff, so adding neon repos would only make things slower for\n# no good reason.\n\nID_PATTERN_PREFIX = 'Identifier:'\nID_PATTERN = /#{ID_PATTERN_PREFIX} (?<id>[^\\s]+) \\[(?<kind>.+)\\]/.freeze\nNULLCMD = TTY::Command.new(printer: :null)\n\nout, _err = NULLCMD.run('appstreamcli', 'search', '*')\n\ncomponents = []\nout.each_line do |line|\n next unless line.start_with?(ID_PATTERN_PREFIX)\n\n match = ID_PATTERN.match(line)\n raise \"Expected match on: #{line}\" unless match\n\n components << Component.new(match[:id], match[:kind])\nend\nraise 'No components found, something is wrong!' if components.empty?\n\nfilter_components = components.select do |comp|\n case comp.kind\n when 'desktop-application'\n true\n when 'generic', 'font', 'inputmethod', 'web-application',\n 'console-application', 'codec', 'driver', 'addon', 'icon-theme'\n # NOTE: addons do not appear in discover on their own, so there is no\n # point in filtering them. Worse yet, filtering them means the packages\n # themselves will show up with shitty metadata.\n # TODO: should we really leave web-applications?\n # <struct Component id=\"im.riot.webapp\", kind=\"web-application\">\n # <struct Component id=\"io.devdocs.webapp\", kind=\"web-application\">\n false\n else\n # The explicit listing is primarily there so we have to look at every\n # possible type and decide whether we want to keep it or not.\n # When an unexpected kind is found you'll want to figure out if it is\n # reasonable portable to keep around or should be filtered out.\n raise \"Unexpected component kind #{comp}\"\n end\nend\n\n# --- JSON Seralization Dance ---\n# We keep the auto removed components in a second json file, this serves no\n# purpose other than letting us tell whether a human added a component to\n# the removal list or the script. By extension we'll not fiddle with\n# components added by a human.\n\nauto_removed_components = []\nif File.exist?('auto-removed-components.json')\n auto_removed_components = JSON.parse(File.read('auto-removed-components.json'))\nend\nremoved_components = JSON.parse(File.read('removed-components.json'))\nmanually_removed_components = removed_components - auto_removed_components\n\nfilter_components = filter_components.collect(&:id)\nremoved_components = (manually_removed_components + filter_components)\n\nFile.write('auto-removed-components.json',\n JSON.generate(filter_components.uniq.compact.sort) + \"\\n\")\n\nFile.write('removed-components.json',\n JSON.pretty_generate(removed_components.uniq.compact.sort) + \"\\n\")\n"
},
{
"alpha_fraction": 0.7057728171348572,
"alphanum_fraction": 0.7206704020500183,
"avg_line_length": 28.83333396911621,
"blob_id": "ba6151d90c8d1fa5b43d6b1a8577b9ac815ec96f",
"content_id": "b554cf023c6db68903b83c44c3ad744afc809588",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/jenkins-jobs/nci/mgmt_appstream_ubuntu_filter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'pipelinejob'\n\n# Gathers up all ubuntu appstream apps and filters them out of the component\n# list we publish.\nclass MGMTAppstreamUbuntuFilter < PipelineJob\n attr_reader :dist\n\n def initialize(dist:)\n super(\"mgmt_appstream-ubuntu-filter_#{dist}\",\n template: 'mgmt_appstream_ubuntu_filter', cron: 'H H * * *')\n @dist = dist\n end\nend\n"
},
{
"alpha_fraction": 0.6415900588035583,
"alphanum_fraction": 0.646291971206665,
"avg_line_length": 32.661869049072266,
"blob_id": "340a647c796088d966405127da96838b2e260bd7",
"content_id": "2a54a98a1f3941bc761c7f4712f3880c5abdc6ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4679,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 139,
"path": "/jenkins-jobs/xenon/xenon_project_multi_job.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Bhushan Shah <[email protected]>\n# Copyright (C) 2015-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../sourcer'\nrequire_relative '../binarier'\nrequire_relative '../publisher'\nrequire_relative '../multijob_phase'\n\n# Magic builder to create an array of build steps\nclass XenonProjectMultiJob < JenkinsJob\n def self.job(project, distribution:, architectures:, type:)\n return [] unless project.debian?\n\n basename = basename(distribution, type, project.component, project.name)\n\n dependees = project.dependees.collect do |d|\n basename(distribution, type, d.component, d.name)\n end\n\n publisher_dependees = project.dependees.collect do |d|\n \"#{basename(distribution, type, d.component, d.name)}_src\"\n end.compact\n sourcer = SourcerJob.new(basename,\n type: type,\n distribution: distribution,\n project: project)\n publisher = PublisherJob.new(basename,\n type: type,\n distribution: distribution,\n dependees: publisher_dependees,\n component: project.component,\n upload_map: nil,\n architectures: architectures)\n binariers = architectures.collect do |architecture|\n BinarierJob.new(basename, type: type, distribution: distribution,\n architecture: architecture)\n end\n jobs = [sourcer, binariers, publisher]\n basename1 = jobs[0].job_name.rpartition('_')[0]\n unless basename == basename1\n raise \"unexpected basename diff #{basename} v #{basename1}\"\n end\n\n jobs << new(basename, project: project, jobs: jobs, dependees: dependees)\n # The actual jobs array cannot be nested, so flatten it out.\n jobs.flatten\n end\n\n # @! attribute [r] jobs\n # @return [Array<String>] jobs invoked as part of the multi-phases\n attr_reader :jobs\n\n # @! attribute [r] dependees\n # @return [Array<String>] name of jobs depending on this job\n attr_reader :dependees\n\n # @! attribute [r] project\n # @return [Project] project instance of this job\n attr_reader :project\n\n # @! attribute [r] upstream_scm\n # @return [CI::UpstreamSCM] upstream scm instance of this job_name\n # FIXME: this is a compat thingy for sourcer (see render method)\n attr_reader :upstream_scm\n\n private\n\n def initialize(basename, project:, jobs:, dependees: [])\n super(basename, 'project.xml.erb')\n\n # We use nested jobs for phases with multiple jobs, we need to aggregate\n # them appropriately.\n job_names = jobs.collect do |job|\n next job.collect(&:job_name) if job.is_a?(Array)\n\n job.job_name\n end\n\n @nested_jobs = job_names.freeze\n @jobs = job_names.flatten.freeze\n @dependees = dependees.freeze\n @project = project.freeze\n end\n\n def render_phases\n ret = ''\n @nested_jobs.each_with_index do |job, i|\n ret += MultiJobPhase.new(phase_name: \"Phase#{i}\",\n phased_jobs: [job].flatten).render_template\n end\n ret\n end\n\n def render_packaging_scm\n PackagingSCMTemplate.new(scm: @project.packaging_scm).render_template\n end\n\n def render_upstream_scm\n @upstream_scm = @project.upstream_scm # FIXME: compat assignment\n return '' unless @upstream_scm\n\n case @upstream_scm.type\n when 'git'\n render('upstream-scms/git.xml.erb')\n when 'svn'\n render('upstream-scms/svn.xml.erb')\n when 'tarball'\n ''\n when 'bzr'\n ''\n when 'uscan'\n ''\n else\n raise \"Unknown upstream_scm type encountered '#{@upstream_scm.type}'\"\n end\n end\n\n def self.basename(dist, type, component, name)\n \"#{dist}_#{type}_#{component}_#{name}\"\n end\nend\n"
},
{
"alpha_fraction": 0.6685299277305603,
"alphanum_fraction": 0.6746785640716553,
"avg_line_length": 29.32203483581543,
"blob_id": "d27f4a73b4767ad4b86518f047e93aadd48a8213",
"content_id": "25915f0fb9478f7fdf4f888f8c03a9f315aaca12",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1789,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 59,
"path": "/nci/version_list/violations.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nclass Violation\n attr_reader :name\n\n def to_s\n raise 'not implemented'\n end\nend\n\nclass MissingPackageViolation < Violation\n def initialize(name, corrections)\n @name = name\n @corrections = corrections\n end\n\n def to_s\n s = \"The source #{@name} appears not available in our repo!\"\n if @corrections && [email protected]?\n if @corrections&.size == 1\n s += \"\\nLooks like this needs a map (double check this!!!):\"\n s += \"\\n '#{@corrections[0]}' => '#{@name}',\"\n else\n s += \"\\n Did you mean?\\n #{@corrections.join(\"\\n \")}\"\n end\n end\n s\n end\nend\n\nclass WrongVersionViolation < Violation\n def initialize(name, expected, found)\n @name = name\n @expected = expected\n @found = found\n end\n\n def to_s\n \"Version for #{@name} found '#{@found}' but expected '#{@expected}'!\"\n end\nend\n"
},
{
"alpha_fraction": 0.7266054749488831,
"alphanum_fraction": 0.7412844300270081,
"avg_line_length": 33.0625,
"blob_id": "154fc8ad06fd3250eb6a51b007f440f6ea8ce6f6",
"content_id": "ddcb605d8b6a44e1ab72dc59425c8ad7bfe56033",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 16,
"path": "/jenkins-jobs/nci/mgmt_jenkins_job_scorer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'pipelinejob'\n\n# Updates core assignment for jobs. Jobs that take too long get more cores,\n# jobs that are too fast may get fewer. This is pruely to balance cloud cost\n# versus build time.\nclass MGMTJenkinsJobScorer < PipelineJob\n def initialize\n super('mgmt_jenkins-job-scorer',\n template: 'mgmt_jenkins_job_scorer', cron: '@weekly')\n end\nend\n"
},
{
"alpha_fraction": 0.6447963714599609,
"alphanum_fraction": 0.6606335043907166,
"avg_line_length": 25.787878036499023,
"blob_id": "cf36e4117a31a8625af41a9bdbd98748e9bd0178",
"content_id": "9eba187f0b96ff3700658f34f861199e78551e15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 884,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 33,
"path": "/lib/pangea_build_type_config.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2020-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Whether to mutate build type away from debian native.\nmodule PangeaBuildTypeConfig\n class << self\n # Whether to override the build type at all (i.e. strip dpkg-buildflags)\n def override?\n enabled? && ubuntu? && arm?\n end\n\n # Whether this build should be run as release build (i.e. no ddebs or symbols)\n def release_build?\n false # we currently have nothing that qualifies. previously LTS was a type of this\n end\n\n private\n\n def enabled?\n !ENV.key?('PANGEA_NO_BUILD_TYPE')\n end\n\n def ubuntu?\n File.read('/etc/os-release').include?('ubuntu')\n end\n\n def arm?\n %w[armhf arm64].any? { |x| ENV.fetch('NODE_LABELS', '').include?(x) }\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6750943660736084,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 37.97058868408203,
"blob_id": "6fdd5aaed1d29f6b683918eb1d0c45c24683c7f2",
"content_id": "1a98c0dc974b716e4439998c2731061dd07710c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2650,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 68,
"path": "/lib/ci/container/ephemeral.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../container'\n\nmodule CI\n # An ephemeral container. It gets automatically removed after it closes.\n # This is slightly more reliable than Docker's own implementation as\n # this goes to extra lengths to make sure the container disappears.\n class EphemeralContainer < Container\n class EphemeralContainerUnhandledState < StandardError; end\n\n @safety_sleep = 5\n RUNNING_STATES = %w[created exited running].freeze\n\n class << self\n # @!attribute rw safety_sleep\n # How long to sleep before attempting to kill a container. This is\n # to prevent docker consistency issues at unmounting. The longer the\n # sleep the more reliable.\n attr_accessor :safety_sleep\n end\n\n def stop(options = {})\n super(options)\n # TODO: this should really be kill not kill!, but changing it would\n # require re-recording a lot of tests.\n kill!(options) if running?\n rescued_remove\n end\n\n def running?\n state = json.fetch('State')\n unless RUNNING_STATES.include?(state.fetch('Status'))\n raise EphemeralContainerUnhandledState, state.fetch('Status')\n end\n\n state.fetch('Running')\n end\n\n private\n\n def rescued_remove\n # https://github.com/docker/docker/issues/9665\n # Possibly related as well:\n # https://github.com/docker/docker/issues/7636\n # Apparently the AUFS backend is a bit meh and craps out randomly when\n # removing a container. To prevent this from making a build fail two\n # things happen here:\n # 1. sleep 5 seconds before trying to kill. This avoids an apparently also\n # existing timing issue which might or might not be the root of this.\n # 2. catch server errors from remove and turn them into logable offences\n # without impact. Since this method is only supposed to be called from\n # {run} there is no strict requirement for the container to be actually\n # removed as a subsequent containment instance will attempt to tear it\n # down anyway. Which might then be fatal, but given the 5 second sleep\n # and additional time spent doing other things it is unlikely that this\n # would happen. Should it happen though we still want it to be fatal\n # though as the assumption is that a containment always is clean which\n # we couldn't ensure if a previous container can not be removed.\n sleep self.class.safety_sleep\n remove\n # :nocov:\n rescue Docker::Error::ServerError => e\n # FIXME: no logging in this class\n @log.error e\n # :nocov:\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5842986106872559,
"alphanum_fraction": 0.5866152048110962,
"avg_line_length": 33.380531311035156,
"blob_id": "6ee711149342e01d043487e6a01e9a14f4fde4a4",
"content_id": "7195095d9371c09e495e094d423b5c791666d34a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3885,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 113,
"path": "/nci/snap/plugins/x-stage-debs.py",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# -*- Mode:Python; indent-tabs-mode:nil; tab-width:4 -*-\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License version 3 as\n# published by the Free Software Foundation.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n\n\"\"\"woosh woosh\n\n Simple magic. debs property is an array of debs that get pulled via apt\n and unpacked into the installdir for staging. Key difference to builtin\n stage-packages is that this entirely disregards dependencies, so they\n need to be resolved another way.\n\"\"\"\n\nimport logging\nimport glob\nimport os\nimport re\nimport shutil\nimport subprocess\n\nimport snapcraft.plugins.make\n\nlogger = logging.getLogger(__name__)\n\nclass StabeDebsPlugin(snapcraft.BasePlugin):\n\n @classmethod\n def schema(cls):\n schema = super().schema()\n schema['properties']['debs'] = {\n 'type': 'array',\n 'minitems': 0,\n 'uniqueItems': True,\n 'items': {\n 'type': 'string',\n }\n }\n\n schema['properties']['exclude-debs'] = {\n 'type': 'array',\n 'minitems': 0,\n 'uniqueItems': True,\n 'items': {\n 'type': 'string',\n }\n }\n\n return schema\n\n @classmethod\n def get_build_properties(cls):\n # Inform Snapcraft of the properties associated with building. If these\n # change in the YAML Snapcraft will consider the build step dirty.\n return ['debs', 'exclude-debs']\n\n def __init__(self, name, options, project):\n super().__init__(name, options, project)\n\n def exclude(self, file):\n basename = os.path.basename(file)\n name = re.split('^(.+)_([^_]+)_([^_]+)\\.deb$', basename)[1]\n return name in (self.options.exclude_debs or [])\n\n def build(self):\n super().build()\n\n print(os.getcwd())\n if self.options.debs:\n # First wipe auto marked packages, so we may have a better chance\n # of getting the dependencies we actually need on top of core.\n # Otherwise the system may include build-packages from previous\n # parts and not download necessary packages.\n remove_cmd = ['apt-get', '-y', 'autoremove']\n subprocess.check_call(remove_cmd, cwd=self.builddir)\n\n cmd = ['apt-get',\n '-y',\n '-o', 'Debug::NoLocking=true',\n '-o', 'Dir::Cache::Archives=' + self.builddir,\n '--reinstall',\n '--no-install-recommends',\n '--download-only', 'install'] + self.options.debs\n subprocess.check_call(cmd, cwd=self.builddir)\n\n pkgs_abs_path = glob.glob(os.path.join(self.builddir, '*.deb'))\n for pkg in pkgs_abs_path:\n print(pkg)\n if self.exclude(pkg):\n continue\n print(' extract')\n subprocess.check_call(['dpkg-deb', '--extract', pkg, self.installdir])\n\n # # Non-recursive stage, not sure this ever has a use case with\n # # exclusion in the picture\n # for deb in self.options.debs:\n # logger.debug(deb)\n # subprocess.check_call(['apt', 'download', deb])\n #\n # pkgs_abs_path = glob.glob(os.path.join(self.builddir, '*.deb'))\n # for pkg in pkgs_abs_path:\n # logger.debug(pkg)\n # subprocess.check_call(['dpkg-deb', '--extract', pkg, self.installdir])\n"
},
{
"alpha_fraction": 0.6920468807220459,
"alphanum_fraction": 0.7000616788864136,
"avg_line_length": 31.767677307128906,
"blob_id": "4ab807b1d61f7031cdb5ee66e18d66fbbbbfdde5",
"content_id": "d3ecdade10520ef8a20d05602b29c9a29c88d1b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3244,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 99,
"path": "/nci/repo_snapshot_user.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'date'\nrequire 'optparse'\n\nrequire_relative 'lib/repo_diff'\n\nrequire_relative '../lib/jenkins'\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative '../lib/pangea/mail'\n\nDIST = ENV.fetch('DIST')\nprefix = 'user'\nrepo = 'release'\n\ndef send_email(mail_text, prefix)\n puts 'sending notification mail'\n Pangea::SMTP.start do |smtp|\n mail = <<-MAIL\nFrom: Neon CI <[email protected]>\nTo: [email protected]\nSubject: #{prefix} Snapshot Done\n\n#{mail_text}\n MAIL\n smtp.send_message(mail,\n '[email protected]',\n '[email protected]')\n end\nend\n\nFaraday.default_connection_options =\n Faraday::ConnectionOptions.new(timeout: 15 * 60)\n\n# SSH tunnel so we can talk to the repo\nAptly::Ext::Remote.neon do\n mail_text = ''\n differ = RepoDiff.new\n diff_rows = differ.diff_repo('user', 'release', DIST)\n diff_rows.each do |name, architecture, new_version, old_version|\n mail_text += name.ljust(20) + architecture.ljust(10) + new_version.ljust(40) + old_version.ljust(40) + \"\\n\"\n end\n puts 'Repo Diff:'\n puts mail_text\n\n stamp = Time.now.utc.strftime('%Y%m%d.%H%M')\n release = Aptly::Repository.get(\"#{repo}_#{DIST}\")\n snapshot = release.snapshot(Name: \"#{repo}_#{DIST}-#{stamp}\")\n # Limit to user for now.\n pubs = Aptly::PublishedRepository.list.select do |x|\n x.Prefix == prefix.to_s && x.Distribution == DIST\n end\n pub = pubs[0]\n pub.update!(Snapshots: [{ Name: snapshot.Name, Component: 'main' }])\n\n published_snapshots = Aptly::PublishedRepository.list.select do |x|\n x.SourceKind == 'snapshot'\n end\n published_snapshots = published_snapshots.map(&:Sources).flatten.map(&:Name)\n puts \"Currently published snapshots: #{published_snapshots}\"\n\n snapshots = Aptly::Snapshot.list.select do |x|\n x.Name.start_with?(release.Name)\n end\n puts \"Available snapshots: #{snapshots.map(&:Name)}\"\n\n dangling_snapshots = snapshots.reject do |x|\n published_snapshots.include?(x.Name)\n end\n dangling_snapshots.each do |x|\n x.CreatedAt = DateTime.parse(x.CreatedAt)\n end\n dangling_snapshots.sort_by!(&:CreatedAt)\n dangling_snapshots.pop # Pop newest dangle as a backup.\n puts \"Dangling snapshots: #{dangling_snapshots.map(&:Name)}\"\n dangling_snapshots.each(&:delete)\n puts 'Dangling snapshots deleted'\n send_email(mail_text, prefix)\nend\n"
},
{
"alpha_fraction": 0.8190476298332214,
"alphanum_fraction": 0.8190476298332214,
"avg_line_length": 104,
"blob_id": "9bd691989bc7aa86149a83d63d4a117541109ec1",
"content_id": "b7671958e764a3e550c38ec2fab28d411be46c23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 1,
"path": "/test/dud-bin/README.md",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "PATH overlay making a whole bunch of debhelper tools noop to speed up high level package building tests.\n"
},
{
"alpha_fraction": 0.6598272323608398,
"alphanum_fraction": 0.6646867990493774,
"avg_line_length": 27.060606002807617,
"blob_id": "1c8fe7fc6f74731241bc43fe32103c0a0ebf54c7",
"content_id": "2b9a6477374e7576e303af4d4e8487569e144b80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3704,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 132,
"path": "/lib/merger/branch_sequence.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'git'\n\nclass BranchSequence\n attr_reader :parent\n attr_reader :source\n\n def initialize(name, git:, parent: nil, dirty: false)\n @name = name\n @parent = parent\n @git = git\n @dirty = dirty\n @source = resolve_name(name)\n # FIXME: what happens if the first source doesn't exist?\n @source = parent.source if parent && !@source\n @pushed = false\n end\n\n def pushed?\n @pushed\n end\n\n def resolve_name(name)\n # FIXME: local v remote isn't test covered\n source = @git.branches.local.select { |b| b.name == name }\n source = @git.branches.remote.select { |b| b.name == name } if source.empty?\n raise \"Found more than one matching source #{source}\" if source.size > 1\n if source.empty?\n # FIXME: log\n # @log.warn \"Apparently there is no branch named #{source_name}!\"\n return nil\n end\n\n source[0]\n end\n\n # FIXME: yolo\n def noci_merge?(source)\n log = @git.log.between('', source.full)\n return false unless log.size >= 1\n\n log.each do |commit|\n return false unless commit.message.include?('NOCI')\n end\n true\n end\n\n def shortsha(objectish)\n @git.revparse(objectish)[0..7]\n end\n\n def msg_for_merge(target)\n if noci_merge?(@source)\n return \"Merging #{@source.full} into #{target.name}.\\n\\nNOCI\"\n end\n\n \"Merging #{@source.full} into #{target.name}.\"\n end\n\n def mergerino(target)\n return false unless @source\n return false unless target\n\n @git.checkout(target.name)\n\n puts format('Merging %s[%s] into %s[%s]',\n @source.full, shortsha(@source.full),\n target.name, shortsha(target.name))\n puts @git.merge(@source.full, msg_for_merge(target))\n puts \"After merge: #{target.name}[#{shortsha(target.name)}]\"\n true\n end\n\n def merge_into(target)\n # FIXME: we should new differently so we can pass the resolved target\n # without having to resolve it again\n dirty = mergerino(resolve_name(target))\n BranchSequence.new(target, dirty: dirty, parent: self, git: @git)\n end\n\n def push\n branches = []\n branch = self\n while branch&.parent # Top most item has no parent and isn't dirty.\n branches << branch unless branch.pushed?\n branch = branch.parent\n end\n branches.reverse!\n branches.each(&:push_branch)\n end\n\n # FIXME: should be private maybe?\n def push_branch\n return puts \"Not pushing, isn't a branch: #{@name}\" unless valid?\n\n puts \"Checking if we can push something on #{@source.name}\"\n return puts \"...nothing to push for #{@source.name}\" unless dirty? && valid?\n\n puts \"...pushing #{@source.name}[#{shortsha(@source.name)}]\"\n @git.push('origin', @source.name)\n @pushed = true\n end\n\n private\n\n def dirty?\n @dirty\n end\n\n def valid?\n [email protected]?\n end\nend\n"
},
{
"alpha_fraction": 0.6402291655540466,
"alphanum_fraction": 0.6435391306877136,
"avg_line_length": 32.71244812011719,
"blob_id": "a6eddfb689087d933a636f50b0d4456e1dc2af19",
"content_id": "4a3ad4d8fbc0ace682846bc9ab3a7700a89b6f8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7855,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 233,
"path": "/lib/jenkins.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'addressable/uri'\nrequire 'jenkins_api_client'\n\n# Monkey patch for Client to fold in our config data.\n# This is entirely and only necessary because the silly default client\n# doesn't allow setting default values on the module or class.\nmodule AutoConfigJenkinsClient\n # Monkey patched initialize. Merges the passed args with the data read\n # from the config file and then calls the proper initialize.\n def initialize(args = {})\n config_file = args.delete(:config_file)\n kwords = config_file ? config(file: config_file) : config\n kwords.merge!(args)\n super(kwords)\n end\n\n module_function\n\n def config(file: ENV.fetch('JENKINS_CONFIG',\n \"#{ENV['HOME']}/.config/pangea-jenkins.json\"))\n kwords = default_config_data\n if File.exist?(file)\n kwords.merge!(JSON.parse(File.read(file), symbolize_names: true))\n end\n kwords\n end\n\n def default_config_data\n # If we ported the entire autoconf shebang to URIs we'd not have to have\n # so many key words :(\n {\n ssl: false,\n server_ip: 'kci.pangea.pub',\n server_port: '80',\n log_level: Logger::FATAL\n }\n end\nend\n\nmodule JenkinsApi\n # Standard client with prepended config supremacy. See\n # {AutoConfigJenkinsClient}.\n class Client\n prepend AutoConfigJenkinsClient\n\n attr_reader :server_ip\n\n def uri\n Addressable::URI.new(scheme: @ssl ? 'https' : 'http', host: @server_ip,\n port: @server_port, path: @jenkins_path)\n end\n\n alias get_config_orig get_config\n def get_config(url_prefix)\n # Unlike post_config this already comes in with a /job/ prefix, only one\n # though. Drop that, then sanitize to support Folders which need to have\n # /job/Folder/job/OtherFolder/job/ActualJob\n url = url_prefix.dup.gsub('/job/', '/')\n url = \"/#{url}\" unless url[0] == '/'\n url = url.gsub('//', '/')\n get_config_orig(url.gsub('/', '/job/'))\n end\n\n # Fish folders out of the post config and construct a suitable path.\n # Folders are a bit of a mess WRT posting configs...\n alias post_config_orig post_config\n def post_config(url_prefix, xml)\n return if url_prefix.nil?\n if File.basename(url_prefix) == 'config.xml'\n return post_config_existing(url_prefix, xml)\n end\n\n uri = URI.parse(url_prefix)\n query = CGI.parse(uri.query)\n\n # Split the path into the job name and folder name(s)\n name = query.fetch('name').fetch(0)\n name = name.gsub('//', '') while name.include?('//')\n name = \"/#{name}\" unless name[0] == '/'\n\n dirname = File.dirname(name)\n jobname = File.basename(name)\n dirurl = dirname.gsub('/', '/job/')\n\n if dirname != '.' && dirname != '/'\n # Check if the dir part exists, if not auto-create folders.\n # This will eventually recurse in on itself if the parent of our\n # parent is also not existing.\n begin\n job.get_config(dirname)\n rescue JenkinsApi::Exceptions::NotFound\n warn \"Missing folder #{dirname}. Auto-creating it...\"\n job.create(dirname, <<-XML)\n<?xml version='1.1' encoding='UTF-8'?>\n<com.cloudbees.hudson.plugins.folder.Folder plugin=\"[email protected]\">\n</com.cloudbees.hudson.plugins.folder.Folder>\n XML\n end\n\n query['name'] = [jobname]\n uri.path = \"#{dirurl}#{uri.path}\"\n uri.query = URI.encode_www_form(query)\n end\n\n # At this point we'll have changed\n # /createItem?name=foo/bar/fries\n # to\n # /job/foo/job/bar/createItem?name=fries\n post_config_orig(uri.to_s, xml)\n end\n\n def post_config_existing(url_prefix, xml)\n basename = File.basename(url_prefix)\n dirname = File.dirname(url_prefix)\n dirname = dirname.gsub('/job/', '/').gsub('//', '/').gsub('/', '/job/')\n post_config_orig(File.join(dirname, basename), xml)\n end\n\n # Monkey patch to not be broken.\n class View\n # Upstream version applies a filter via list(filter) which means view_name\n # is in fact view_regex as list() internally regexes the name. So if the\n # name includes () things explode if they call exists?.\n # https://github.com/arangamani/jenkins_api_client/issues/232\n def exists?(view_name)\n list.include?(view_name)\n end\n end\n\n # Extends Job with some useful methods not in upstream (probably could be).\n class Job\n alias list_all_orig list_all\n def list_all(root = '')\n jobs = @client.api_get_request(root, 'tree=jobs[name]').fetch('jobs')\n\n jobs = jobs.collect do |j|\n next j unless j.fetch('_class').include?('Folder')\n\n name = j.fetch('name')\n leaves = list_all(\"#{root}/job/#{j.fetch('name')}\")\n leaves.collect { |x| \"#{name}/#{x}\" }\n end\n jobs = jobs.flatten\n\n jobs.map { |job| job.respond_to?(:fetch) ? job.fetch('name') : job }.sort\n end\n\n def building?(job_name, build_number = nil)\n build_number ||= get_current_build_number(job_name)\n raise \"No builds for #{job_name}\" unless build_number\n\n @client.api_get_request(\n \"/job/#{path_encode job_name}/#{build_number}\"\n )['building']\n end\n\n # Send term call (must be after abort and waiting a bit)\n def term(job_name, build_number = nil)\n abstract_murdering(job_name, build_number: build_number, method: 'term')\n end\n\n # Send a kill call (must be after term and waiting a bit)\n def kill(job_name, build_number = nil)\n abstract_murdering(job_name, build_number: build_number, method: 'kill')\n end\n\n def abstract_murdering(job_name, build_number: nil, method:)\n build_number ||= get_current_build_number(job_name)\n raise \"No builds for #{job_name}\" unless build_number\n\n @logger.info \"Calling '#{method}' on '#{job_name}' ##{build_number}\"\n return unless building?(job_name, build_number)\n\n @client.api_post_request(\n \"/job/#{path_encode(job_name)}/#{build_number}/#{method}\"\n )\n end\n end\n end\nend\n\n# Convenience wrapper around JenkinsApi::Client providing a singular instance.\nmodule Jenkins\n module_function\n\n # @return a singleton instance of {JenkinsApi::Client}\n def client\n @client ||= JenkinsApi::Client.new\n end\n\n # Convenience method wrapping {#client.job}.\n # @return a singleton instance of {JenkinsApi::Job}\n def job\n @job ||= client.job\n end\n\n # Convenience method wrapping {#client.plugin}.\n # @return a singleton instance of {JenkinsApi::PluginManager}\n def plugin_manager\n @plugin_manager ||= client.plugin\n end\n\n def system\n @system ||= client.system\n end\nend\n\n# @deprecated Use {Jenkins.client}.\ndef new_jenkins(args = {})\n warn 'warning: calling new_jenkins is deprecated'\n warn 'warning: arguments passed to new_jenkins are not passed along' if args\n Jenkins.client\nend\n"
},
{
"alpha_fraction": 0.5666666626930237,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 6.5,
"blob_id": "b0eda2345641485f705da429f0d4f2f931f168df",
"content_id": "fe30ee2ac6990f3dddf245f9d1c8c588ed140c19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 4,
"path": "/test/data/test_ci_deployer/test_deploy_exists/tooling-pending/deploy_in_container.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\necho \"Test\"\nexit 0\n"
},
{
"alpha_fraction": 0.6182687282562256,
"alphanum_fraction": 0.6227982044219971,
"avg_line_length": 34.16814041137695,
"blob_id": "31106af7100da951f78eee0bcb5698e23b1b9c27",
"content_id": "d0b4137f00e79ef67cf6fbb5e69f3c9e49f49b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3974,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 113,
"path": "/nci/snap/manifest_extender.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'extender'\n\nmodule NCI\n module Snap\n # Extends snapcraft's manifest file with the packages we have in our content\n # snap to prevent these packages form getting staged again.\n class ManifestExtender < Extender\n MANIFEST_PATH =\n '/usr/lib/python3/dist-packages/snapcraft/internal/repo/manifest.txt'\n SNAP_MANIFEST_PATH =\n '/snap/snapcraft/current/lib/python3.6/site-packages/snapcraft/internal/repo/manifest.txt'\n\n class << self\n attr_writer :manifest_path\n def manifest_path\n @manifest_path ||= if File.exist?(SNAP_MANIFEST_PATH)\n SNAP_MANIFEST_PATH\n else\n MANIFEST_PATH\n end\n end\n end\n\n def run\n FileUtils.cp(manifest_path, \"#{manifest_path}.bak\", verbose: true)\n append!\n # for diganostic purposes we'll make a copy of the extended version...\n FileUtils.cp(manifest_path, \"#{manifest_path}.ext\", verbose: true)\n\n yield\n ensure\n if File.exist?(\"#{manifest_path}.bak\")\n FileUtils.cp(\"#{manifest_path}.bak\", manifest_path, verbose: true)\n end\n end\n\n private\n\n def append!\n unless kf5_build_snap?\n warn 'NOT A KF5 BUILD SNAP USER. NOT MANGLING MANIFEST!'\n return\n end\n\n File.open(manifest_path, 'a') { |f| f.puts(exclusion.join(\"\\n\")) }\n end\n\n def kf5_build_snap?\n data['parts'].any? do |_name, part|\n is = part.build_snaps&.any? { |x| x.include?('kde-frameworks-5') }\n use = part.cmake_parameters&.any? { |x| x.include?('kde-frameworks-5') }\n is || use\n end\n end\n\n def exclusion\n pkgs = content_stage.dup\n # Include dev packages in case someone was lazy and used a dev package\n # as stage package. This is technically a bit wrong since the dev stage\n # is not part of the content snap, but if one takes the dev shortcut all\n # bets are off anyway. It's either this or having oversized snaps.\n pkgs += dev_stage if any_dev?\n # Do not pull in dev packages that are in the stage-packages list.\n # They may be used to easily get the libs they depend on, but they\n # themselves have no business being in the stage really.\n # Fairly hacky shortcut this.\n pkgs += staged_devs\n # never let gtk be pulled in, it should be in the content-snap\n pkgs << 'qt5-gtk-platformtheme' unless ENV['PANGEA_UNDER_TEST']\n pkgs.uniq\n end\n\n def staged_devs\n devs = []\n data['parts'].values.collect do |part|\n part&.stage_packages&.each { |x| devs << x if x.end_with?('-dev') }\n end\n devs.uniq.compact\n end\n\n def manifest_path\n self.class.manifest_path\n end\n\n # not used; really should be renamed to run\n def extend; end\n\n def any_dev?\n @any_dev ||= !staged_devs.empty?\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6246479153633118,
"alphanum_fraction": 0.6290493011474609,
"avg_line_length": 33.63414764404297,
"blob_id": "f8c698b797b8759f0cc0191d0ba2875af798512e",
"content_id": "b7db01783cedc78abac3aec3eb1b8f1df7bbb929",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5680,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 164,
"path": "/jenkins-jobs/nci/project.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/nci'\nrequire_relative '../sourcer'\nrequire_relative 'binarier'\nrequire_relative 'lintcmakejob'\nrequire_relative 'lintqmljob'\nrequire_relative 'publisher'\nrequire_relative '../multijob_phase'\n\n# Magic builder to create an array of build steps\nclass ProjectJob < JenkinsJob\n def self.job(project, distribution:, architectures:, type:)\n return [] unless project.debian?\n\n architectures = architectures.dup\n architectures << 'i386' if %w[chafa-jammy libjpeg-turbo-jammy harfbuzz util-linux wayland libdrm-jammy libdrm lcms2-jammy wayland-jammy].any? { |x| project.name == x }\n\n basename = basename(distribution, type, project.component, project.name)\n\n dependees = project.dependees.collect do |d|\n basename(distribution, type, d.component, d.name)\n end\n\n # experimental has its dependencies in unstable\n if type == 'experimental'\n dependees += project.dependees.collect do |d|\n basename(distribution, 'unstable', d.component, d.name)\n end\n end\n\n dependees = dependees.compact.uniq.sort\n\n publisher_dependees = project.dependees.collect do |d|\n \"#{basename(distribution, type, d.component, d.name)}_src\"\n end.compact\n sourcer = SourcerJob.new(basename,\n type: type,\n distribution: distribution,\n project: project)\n publisher = NeonPublisherJob.new(basename,\n type: type,\n distribution: distribution,\n dependees: publisher_dependees,\n component: project.component,\n upload_map: nil,\n architectures: architectures,\n kdecomponent: project.kdecomponent,\n project: project)\n binariers = architectures.collect do |architecture|\n job = BinarierJob.new(basename, type: type, distribution: distribution,\n architecture: architecture)\n scm = project.upstream_scm\n job.qt_git_build = (scm&.url&.include?('/qt/') && scm&.branch&.include?('5.15'))\n job\n end\n jobs = [sourcer, binariers, publisher]\n basename1 = jobs[0].job_name.rpartition('_')[0]\n unless basename == basename1\n raise \"unexpected basename diff #{basename} v #{basename1}\"\n end\n\n unless NCI.experimental_skip_qa.any? { |x| jobs[0].job_name.include?(x) }\n # After _pub\n lintqml = LintQMLJob.new(basename, distribution: distribution, type: type)\n lintcmake = LintCMakeJob.new(basename, distribution: distribution,\n type: type)\n jobs << [lintqml, lintcmake]\n end\n\n jobs << new(basename, distribution: distribution, project: project,\n jobs: jobs, type: type, dependees: dependees)\n # The actual jobs array cannot be nested, so flatten it out.\n jobs.flatten\n end\n\n # @! attribute [r] jobs\n # @return [Array<String>] jobs invoked as part of the multi-phases\n attr_reader :jobs\n\n # @! attribute [r] dependees\n # @return [Array<String>] name of jobs depending on this job\n attr_reader :dependees\n\n # @! attribute [r] project\n # @return [Project] project instance of this job\n attr_reader :project\n\n # @! attribute [r] upstream_scm\n # @return [CI::UpstreamSCM] upstream scm instance of this job_name\n # FIXME: this is a compat thingy for sourcer (see render method)\n attr_reader :upstream_scm\n\n # @! attribute [r] distribution\n # @return [String] codename of distribution\n attr_reader :distribution\n\n # @! attribute [r] type\n # @return [String] type name of the build (e.g. unstable or something)\n attr_reader :type\n\n def self.basename(dist, type, component, name)\n \"#{dist}_#{type}_#{component}_#{name}\"\n end\n\n private\n\n def initialize(basename, distribution:, project:, jobs:, type:, dependees: [])\n super(basename, 'project.xml.erb')\n\n # We use nested jobs for phases with multiple jobs, we need to aggregate\n # them appropriately.\n job_names = jobs.collect do |job|\n next job.collect(&:job_name) if job.is_a?(Array)\n\n job.job_name\n end\n\n @distribution = distribution.dup.freeze\n @nested_jobs = job_names.dup.freeze\n @jobs = job_names.flatten.freeze\n @dependees = dependees.dup.freeze\n @project = project.dup.freeze\n @type = type.dup.freeze\n end\n\n def render_phases\n ret = ''\n @nested_jobs.each_with_index do |job, i|\n ret += MultiJobPhase.new(phase_name: \"Phase#{i}\",\n phased_jobs: [job].flatten).render_template\n end\n ret\n end\n\n def render_packaging_scm\n scm = @project.packaging_scm_for(series: @distribution)\n PackagingSCMTemplate.new(scm: scm).render_template\n end\n\n def render_commit_hook_disabled\n # disable triggers for legacy series during transition-period\n return 'true' if NCI.old_series == distribution\n\n 'false'\n end\n\n def render_upstream_scm\n @upstream_scm = @project.upstream_scm # FIXME: compat assignment\n return '' unless @upstream_scm # native packages have no upstream_scm\n\n case @upstream_scm.type\n when 'git', 'svn'\n render(\"upstream-scms/#{@upstream_scm.type}.xml.erb\")\n when 'tarball', 'bzr', 'uscan'\n ''\n else\n raise \"Unknown upstream_scm type encountered '#{@upstream_scm.type}'\"\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6201388835906982,
"alphanum_fraction": 0.6305555701255798,
"avg_line_length": 24.714284896850586,
"blob_id": "87bb8f2c17047ca5eca10b7c4cfdf05781383689",
"content_id": "c2fc118980118abaf54def122489f757bc4ad1f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1440,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 56,
"path": "/test/test_ci_directbindingarray.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/ci/directbindingarray'\nrequire_relative 'lib/testcase'\n\nclass DirectBindingArrayTest < TestCase\n def test_to_volumes\n v = CI::DirectBindingArray.to_volumes(['/', '/tmp'])\n assert_equal({ '/' => {}, '/tmp' => {} }, v)\n end\n\n def test_to_bindings\n b = CI::DirectBindingArray.to_bindings(['/', '/tmp'])\n assert_equal(%w[/:/ /tmp:/tmp], b)\n end\n\n def test_to_volumes_mixed_format\n v = CI::DirectBindingArray.to_volumes(['/', '/tmp:/tmp'])\n assert_equal({ '/' => {}, '/tmp' => {} }, v)\n end\n\n def test_to_bindings_mixed_fromat\n b = CI::DirectBindingArray.to_bindings(['/', '/tmp:/tmp'])\n assert_equal(%w[/:/ /tmp:/tmp], b)\n end\n\n def test_to_bindings_colons\n path = '/tmp/CI::ContainmentTest20150929-32520-12hjrdo'\n assert_raise do\n CI::DirectBindingArray.to_bindings([path])\n end\n\n assert_raise do\n CI::DirectBindingArray.to_bindings([path])\n end\n\n assert_raise do\n path = '/tmp:/tmp:/tmp:/tmp'\n CI::DirectBindingArray.to_bindings([path.to_s])\n end\n\n assert_raise do\n path = '/tmp:/tmp:/tmp'\n CI::DirectBindingArray.to_bindings([path.to_s])\n end\n end\n\n def test_not_a_array\n assert_raise CI::DirectBindingArray::InvalidBindingType do\n CI::DirectBindingArray.to_bindings('kitten')\n end\n end\n\n def test_read_only_array\n CI::DirectBindingArray.to_bindings(['/foo:/foo:ro'])\n end\nend\n"
},
{
"alpha_fraction": 0.6741854548454285,
"alphanum_fraction": 0.6802005171775818,
"avg_line_length": 31.97520637512207,
"blob_id": "f014ab341c4703c9901fe61c9d840881dd8afcc5",
"content_id": "9f78e1b76d952da3ae971b7550d52f44dbbc23a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3990,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 121,
"path": "/nci/imager_push_torrent.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2019-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'bencode'\nrequire 'digest'\nrequire 'faraday'\nrequire 'net/sftp'\nrequire 'nokogiri'\nrequire 'open-uri'\nrequire 'tty-command'\nrequire_relative '../lib/nci'\nrequire_relative 'lib/imager_push_paths'\n\nSTDOUT.sync = true # Make sure output is synced and bypass caching.\n\n# Torrent piece size\nPIECE_LENGTH = 262_144\n\nkey_file = ENV.fetch('SSH_KEY_FILE', nil)\nssh_args = key_file ? [{ keys: [key_file] }] : []\n\ndef pieces(filename, size)\n filename = \"result/#{filename}\"\n unless File.size(filename) == size\n raise \"Size in meta4 different #{size} vs #{File.size(filename)}\"\n end\n\n pieces = []\n filedigest = Digest::SHA1.new\n File.open(filename) do |f|\n loop do\n data = f.read(PIECE_LENGTH)\n break unless data\n\n filedigest.update(data)\n sha = Digest::SHA1.hexdigest(data)\n pieces << sha\n end\n end\n\n # make a bytearray by joining into a long string, then foreach 2\n # characters treat them as hex and get their int. pack the array of int\n # as bytes to get the bytearray.\n pieces.join.scan(/../).map(&:hex).pack('C*')\nend\n\nNet::SFTP.start('rsync.kde.org', 'neon', *ssh_args) do |sftp|\n iso = nil\n sftp.dir.glob(REMOTE_DIR, '*/*.iso') do |entry|\n next if entry.name.include?('-current')\n raise \"Found two isos wtf. already have #{iso}, now also #{entry}\" if iso\n\n iso = entry\n end\n\n raise 'Could not find remote iso file!' unless iso\n\n dir = File.dirname(iso.name)\n remote_dir_path = File.join(REMOTE_DIR, dir)\n iso_filename = File.basename(iso.name)\n iso_url = \"https://files.kde.org/#{remote_dir_path}/#{iso_filename}\"\n torrent_name = File.basename(\"#{iso.name}.torrent\")\n\n # https://fileformats.fandom.com/wiki/Torrent_file\n # NOTE: we could make this multi-file in the future, but need to check if\n # ktorrent wont't fall over. Needs refactoring too. What we'd want to do is\n # model each File entity so we can bencode them with minimal diff between\n # single-file format and multi-file.\n # http://getright.com/seedtorrent.html\n\n size = iso.attributes.size\n torrent = nil\n\n begin\n # Download the torrent over sftp lest we get funny redirects. Mirrobrain\n # redirects https to http and open-uri gets angry (rightfully).\n torrent_path = \"#{remote_dir_path}/#{torrent_name}\"\n sftp.stat!(torrent_path) # only care if it raises anything\n sftp.download!(torrent_path, torrent_name)\n\n torrent = BEncode::Parser.new(File.read(torrent_name)).parse!\n rescue Net::SFTP::StatusException => e\n raise e unless e.code == Net::SFTP::Constants::StatusCodes::FX_NO_SUCH_FILE\n\n puts \"Torrent #{torrent_path} doesn't exist yet! Making new one.\"\n end\n\n torrent ||= {\n 'announce' => 'udp://tracker.openbittorrent.com:80',\n 'creation date' => Time.now.utc.to_i,\n 'info' => {\n 'piece length' => PIECE_LENGTH,\n 'pieces' => pieces(iso_filename, size),\n 'name' => iso_filename,\n 'length' => size\n }\n }\n\n puts \"Trying to obtain link list from #{iso_url}\"\n # mirrorbits' link header contains mirror urls, use it to build the list.\n # <$url>; rel=$something; pri=$priority; geo=$region, <$url> ...\n # This is a bit awkward since link is entirely missing when there are\n # no mirrors yet, but that prevents us from telling when the headers break :|\n links = Faraday.get(iso_url).headers['link']&.scan(/<([^>]+)>/)&.flatten\n # In case we have zero mirror coverage make sure the main server is in the\n # list.\n links ||= [iso_url]\n\n # Rewrite url-list regardless of torrent having existed or not, we use this\n # to update the list when new mirrors appear.\n torrent['url-list'] = links\n\n File.write(torrent_name, torrent.bencode)\n\n remote_target = File.join(remote_dir_path, torrent_name)\n puts \"Writing torrent to #{remote_target}\"\n sftp.upload!(torrent_name, remote_target)\nend\n"
},
{
"alpha_fraction": 0.4901960790157318,
"alphanum_fraction": 0.5098039507865906,
"avg_line_length": 9.199999809265137,
"blob_id": "8cb8f36be9ba2a93967756348bcc2e730a2a712c",
"content_id": "2e2b9c172f3f0af69dcc785a728d024b23ddcedb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 5,
"path": "/test/data/test_overlay_bins/_touch_",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\necho \"$@\" > $(basename $0)_call\n"
},
{
"alpha_fraction": 0.6839378476142883,
"alphanum_fraction": 0.7108808159828186,
"avg_line_length": 27.382352828979492,
"blob_id": "9f87a317ed0f16bb16e482ba5ea808834389b258",
"content_id": "f709805707129ebd927f5b2d928cff8429eb39fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 965,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 34,
"path": "/deploy_upgrade_container.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# Distribution Upgrader.\n# This deployer upgrades the base image distribution. It is used so we can\n# go from 16.04 to 16.10 even before docker has proper 16.10 images. This is\n# achieved by simply subbing the sources.list around and doing a dist-upgrade.\n\nset -ex\n\nif [ -z \"$1\" ]; then\n echo \"$0 called with no argument from where to transition from (argument 1)\"\n exit 1\nfi\nif [ -z \"$2\" ]; then\n echo \"$0 called with no argument from where to transition to (argument 2)\"\n exit 1\nfi\n\nSCRIPTDIR=$(readlink -f $(dirname -- \"$0\"))\n\nexport DEBIAN_FRONTEND=noninteractive\nexport LANG=en_US.UTF-8\n\nsed -i \"s/$1/$2/g\" /etc/apt/sources.list\nsed -i \"s/$1/$2/g\" /etc/apt/sources.list.d/* || true\n\napt-get update\napt-mark hold makedev # do not update makedev it won't work on unpriv'd\napt-get -y -o APT::Get::force-yes=true -o Debug::pkgProblemResolver=true \\\n dist-upgrade\n\ncd $SCRIPTDIR\necho \"Executing deploy_in_container.sh\"\nexec ./deploy_in_container.sh\n"
},
{
"alpha_fraction": 0.7311036586761475,
"alphanum_fraction": 0.7411371469497681,
"avg_line_length": 39.4054069519043,
"blob_id": "b9bbaca2f9782cdc2c7f31dc4e6395b969f36bd9",
"content_id": "ff041bd4adfff2632b6ce3331c5a4b272f12afd4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1495,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 37,
"path": "/jenkins-jobs/progenitor.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'job'\n\n# Progenitor is the super super super job triggering everything.\nclass MgmtProgenitorJob < JenkinsJob\n attr_reader :daily_trigger\n attr_reader :downstream_triggers\n attr_reader :dependees\n attr_reader :blockables\n\n def initialize(downstream_jobs:, dependees: [], blockables: [])\n super('mgmt_progenitor', 'mgmt-progenitor.xml.erb')\n @daily_trigger = '0 0 * * *'\n @downstream_triggers = downstream_jobs.collect(&:job_name)\n @dependees = dependees.collect(&:job_name)\n @blockables = blockables.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.6456338167190552,
"alphanum_fraction": 0.6456338167190552,
"avg_line_length": 24.724637985229492,
"blob_id": "abba62e885bd0ce655091dc9881e4f14ebccea50",
"content_id": "6b7dc364eb0ce3a7f4a05ee716d9ec2c38e2dfc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1775,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 69,
"path": "/lib/lint/series.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'pathname'\n\nrequire_relative '../debian/patchseries'\nrequire_relative 'result'\n\n# NOTE: patches that are in the series but not the VCS cause build failures, so\n# they are not covered in this check\n\nmodule Lint\n # Lints a debian patches seris file\n class Series\n EXCLUDES = %w[series ignore README].freeze\n\n attr_reader :package_directory\n\n def initialize(package_directory = Dir.pwd)\n @package_directory = package_directory\n # series is lazy init'd because it does a path check. A bit meh.\n @patch_directory = File.join(@package_directory, 'debian/patches')\n end\n\n # @return [Result]\n def lint\n result = Result.new\n result.valid = true\n lint_lingering(result)\n lint_empty(result)\n result\n end\n\n private\n\n def lint_lingering(result)\n Dir.glob(\"#{@patch_directory}/**/*\").each do |patch|\n next if EXCLUDES.include?(File.basename(patch))\n\n patch = relative(patch, @patch_directory)\n next if skip?(patch)\n\n result.warnings << \"Patch #{File.basename(patch)} in VCS but not\" \\\n ' listed in debian/series file.'\n end\n end\n\n def lint_empty(result)\n return unless series.exist?\n return unless series.patches.empty?\n\n result.warnings << 'Series file in VCS but empty.'\n end\n\n def skip?(patch)\n series.patches.include?(patch) || ignore.patches.include?(patch)\n end\n\n def relative(path, path_base)\n Pathname.new(path).relative_path_from(Pathname.new(path_base)).to_s\n end\n\n def series\n @series ||= Debian::PatchSeries.new(@package_directory)\n end\n\n def ignore\n @ignore ||= Debian::PatchSeries.new(@package_directory, 'ignore')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5954935550689697,
"alphanum_fraction": 0.5954935550689697,
"avg_line_length": 31.13793182373047,
"blob_id": "fc88a33f583fc96516d274a278b61a3864605e68",
"content_id": "5f4ebf45d59444d5b6eff7820e7b457bbcf3cdbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 932,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 29,
"path": "/lib/lint/log/list_missing.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../linter'\nrequire_relative 'build_log_segmenter'\n\nmodule Lint\n class Log\n # Parses list-missing block from a build log.\n class ListMissing < Linter\n include BuildLogSegmenter\n\n def lint(data)\n r = Result.new\n data = segmentify(data,\n \"=== Start list-missing\\n\",\n \"=== End list-missing\\n\")\n # TODO: This doesn't really make sense? What does valid mean anyway?\n # should probably be if the linting was able to be done, which is not\n # asserted by this at all. segmentify would need to raise on\n # missing blocks\n r.valid = true\n data.each { |line| r.errors << line unless line.include?('usr/share/man') }\n r\n rescue BuildLogSegmenter::SegmentMissingError => e\n puts \"#{self.class}: in log #{e.message}\"\n r\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6285714507102966,
"alphanum_fraction": 0.6616372466087341,
"avg_line_length": 33.61111068725586,
"blob_id": "54d5503e2fd9b267139e5b0b333ce6bd30a9987a",
"content_id": "073ddba96fcae531bc5019c938022f61bddf8ae5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3115,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 90,
"path": "/test/test_nci_lint_pin_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/pin_package_lister'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class PinPackageListerTest < TestCase\n def setup\n # This must be correctly indented for test accuracy!\n result = mock('tty-command-result')\n result.stubs(:out).returns(<<-OUT)\nPackage files:\n 1100 http://archive.neon.kde.org/unstable focal/main amd64 Packages\n release o=neon,a=focal,n=focal,l=KDE neon - Unstable Edition,c=main,b=amd64\n origin archive.neon.kde.org\n 500 http://at.archive.ubuntu.com/ubuntu focal/main amd64 Packages\n release v=20.04,o=Ubuntu,a=focal,n=focal,l=Ubuntu,c=main,b=amd64\n origin at.archive.ubuntu.com\nPinned packages:\n foo -> 1 with priority 1100\n bar -> 2 with priority 1100\n OUT\n\n TTY::Command\n .any_instance.expects(:run)\n .with('apt-cache', 'policy')\n .returns(result)\n end\n\n def test_packages\n pkgs = PinPackageLister.new.packages\n assert_equal(2, pkgs.size)\n assert_equal(%w[foo bar].sort, pkgs.map(&:name).sort)\n assert_equal(%w[1 2].sort, pkgs.map(&:version).map(&:to_s).sort)\n end\n\n def test_packages_filter\n pkgs = PinPackageLister.new(filter_select: %w[foo]).packages\n assert_equal(1, pkgs.size)\n assert_equal(%w[foo].sort, pkgs.map(&:name).sort)\n assert_equal(%w[1].sort, pkgs.map(&:version).map(&:to_s).sort)\n end\n\n def test_dupe\n # When wildcarding a pin the pin may apply to multiple versions and all\n # of them will be listed in the output.\n # We currently don't support this and raise!\n #\n # Package: *samba*\n # Pin: release o=Ubuntu\n # Pin-Priority: 1100\n #\n # may produce:\n # samba-dev -> 2:4.11.6+dfsg-0ubuntu1.6 with priority 1100\n # samba-dev -> 2:4.11.6+dfsg-0ubuntu1 with priority 1100\n # because one version is from the release repo and the other is from\n # updates repo, but they are both o=Ubuntu!\n\n # This must be correctly indented for test accuracy!\n result = mock('tty-command-result')\n result.stubs(:out).returns(<<-OUT)\nPackage files:\n 1100 http://archive.neon.kde.org/unstable focal/main amd64 Packages\n release o=neon,a=focal,n=focal,l=KDE neon - Unstable Edition,c=main,b=amd64\n origin archive.neon.kde.org\n 500 http://at.archive.ubuntu.com/ubuntu focal/main amd64 Packages\n release v=20.04,o=Ubuntu,a=focal,n=focal,l=Ubuntu,c=main,b=amd64\n origin at.archive.ubuntu.com\nPinned packages:\n foo -> 1 with priority 1100\n foo -> 2 with priority 1100\n bar -> 2 with priority 1100\n OUT\n\n TTY::Command.any_instance.unstub(:run) # Disable the stub from setup first\n TTY::Command\n .any_instance.expects(:run)\n .with('apt-cache', 'policy')\n .returns(result)\n\n assert_raises RuntimeError do\n PinPackageLister.new(filter_select: %w[foo]).packages\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7021517753601074,
"alphanum_fraction": 0.7112118005752563,
"avg_line_length": 30.535715103149414,
"blob_id": "a2d51e3d067ac47e8bdb931045bc4f919c4b2849",
"content_id": "6574890882b013a3d9edf640ed24485fe1e3c8a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 28,
"path": "/test/test_ci_feature_summary_extractor.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/ci/feature_summary_extractor'\nrequire_relative 'lib/testcase'\n\n# test feature_summary extraction\nclass FeatureSummaryExtractorTest < TestCase\n def setup\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n end\n\n def test_run\n CI::FeatureSummaryExtractor.run(build_dir: '.', result_dir: '.') do\n assert_includes(File.read('CMakeLists.txt'), 'feature_summary(FILENAME')\n end\n assert_not_includes(File.read('CMakeLists.txt'), 'feature_summary(FILENAME')\n end\n\n def test_run_no_cmakelists\n CI::FeatureSummaryExtractor.run(build_dir: '.', result_dir: '.') do\n assert_path_not_exist('CMakeLists.txt')\n end\n assert_path_not_exist('CMakeLists.txt')\n end\nend\n"
},
{
"alpha_fraction": 0.5946699976921082,
"alphanum_fraction": 0.6084598898887634,
"avg_line_length": 28.137697219848633,
"blob_id": "49104ea204dbe07ed79717f56ad5789cd9bea3df",
"content_id": "744488c338c5fdbe7e8ffccbd98285e7d02c76a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 12908,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 443,
"path": "/nci/imager/ubuntu-defaults-image",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#! /bin/sh\n# Build an image based on an Ubuntu flavor plus a defaults package.\n#\n# Authors: Colin Watson <[email protected]>\n# Martin Pitt <[email protected]>\n# Copyright: (C) 2011 Canonical Ltd.\n#\n# This program is free software: you can redistribute it and/or modify\n# it under the terms of the GNU General Public License as published by\n# the Free Software Foundation, either version 3 of the License, or\n# (at your option) any later version.\n#\n# This program is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n# GNU General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with this program. If not, see <http://www.gnu.org/licenses/>.\n\nset -e\nset -x\n\nLOCALE=\nPACKAGE=\nARCH=\nCOMPONENTS=\nMIRROR=\nSECURITY_MIRROR=\nPPAS=\nFLAVOR=ubuntu\nSUITE=$(lsb_release -sc)\nKEEP_APT_OPT=\nDELETE_APT_LISTS=\"rm -vf /var/lib/apt/lists/*_*\"\n\n. /etc/os-release\n\nif which dpkg-architecture >/dev/null 2>&1; then\n\tARCH=\"$(dpkg-architecture -qDEB_HOST_ARCH)\"\nfi\n\nhelp () {\n cat >&2 <<EOF\nUsage: $0 {--locale code|--package name} [options]\n\n\nOptions:\n --locale ll_CC : Same as --package ubuntu-defaults-ll-cc\n --package : Install additional package; can be a name or path to a local .deb\n --arch : Architecture [default: $ARCH]\n --flavor FLAVOR : Flavor of Ubuntu [default: $FLAVOR]\n --release RELEASE : Ubuntu release the image is based on [default: $SUITE]\n --components COMPONENTS : List of archive components to enable [default: main,restricted]\n --mirror : Ubuntu mirror to be used during build\n [default: http://archive.ubuntu.com/ubuntu/]\n --security-mirror : Ubuntu security mirror to be used during build\n [default: http://security.ubuntu.com/ubuntu/]\n --ppa USER/PPANAME : Enable additional PPA [default: none]\n --keep-apt : Do not remove apt indexes from live system\n --keep-apt-components COMPONENTS :\n Do not remove apt indexes for selected components from live\n system [default: none]\n\nEOF\n}\n\n# add $PPAS\nadd_ppas () {\n for ppa in $PPAS; do\n local FINGERPRINT=`wget -q -O- https://launchpad.net/api/1.0/~${ppa%/*}/+archive/${ppa#*/}/signing_key_fingerprint`\n if ! expr match \"$FINGERPRINT\" '^\\\"[a-zA-Z0-9]\\{16,\\}\"$' >/dev/null; then\n echo \"Invalid fingerprint returned by Launchpad: $FINGERPRINT\" >&2\n exit 1\n fi\n # chop off enclosing quotes\n FINGERPRINT=${FINGERPRINT%'\"'}\n FINGERPRINT=${FINGERPRINT#'\"'}\n\n # fetch GPG key\n gpg --no-default-keyring --primary-keyring config/archives/ubuntu-defaults.key --keyserver pool.sks-keyservers.net --recv-key \"$FINGERPRINT\"\n\n # add ppa apt source\n local DEB_PPA=\"deb http://ppa.launchpad.net/$ppa/ubuntu $SUITE main\"\n echo \"$DEB_PPA\" >> config/archives/ubuntu-defaults.list\n done\n}\n\neval set -- \"$(getopt -o '' -l help,locale:,keep-apt,keep-apt-components:,package:,arch:,flavor:,release:,components:,mirror:,security-mirror:,ppa: -- \"$@\")\" || { help; exit 1; }\nwhile :; do\n case $1 in\n\t--help)\n\t help\n\t exit 0\n\t ;;\n\t--locale)\n\t LOCALE=\"$2\"\n\t shift 2\n\t ;;\n\t--package)\n\t PACKAGE=\"$2\"\n\t shift 2\n\t ;;\n\t--arch)\n\t ARCH=\"$2\"\n\t shift 2\n\t ;;\n\t--flavor)\n\t FLAVOR=\"$2\"\n\t shift 2\n\t ;;\n\t--release)\n\t SUITE=\"$2\"\n\t shift 2\n\t ;;\n\t--components)\n\t COMPONENTS=\"$(echo \"$2\" | sed 's/,/ /g' | tr -s ' ')\"\n\t shift 2\n\t ;;\n\t--mirror)\n\t MIRROR=\"$2\"\n\t shift 2\n\t ;;\n\t--security-mirror)\n\t SECURITY_MIRROR=\"$2\"\n\t shift 2\n\t ;;\n\t--ppa)\n\t if ! expr match \"$2\" '^[.[:alnum:]-]\\+/[[:alnum:]-]\\+$' >/dev/null; then\n\t\techo \"Invalid PPA specification, must be lp_username/ppaname\" >&2\n\t\texit 1\n\t fi\n\t PPAS=\"$PPAS $2\"\n\t shift 2\n\t ;;\n --keep-apt)\n KEEP_APT_OPT=\"$1\"\n DELETE_APT_LISTS=\"rm -vf /var/lib/apt/lists/*_Translation-*\"\n shift\n ;;\n --keep-apt-components)\n KEEP_APT_OPT=\"$1\"\n components=\"$(echo \"$2\" | sed 's/,/ /g')\"\n DELETE_APT_LISTS=\"rm -vf /var/lib/apt/lists/*_Translation-*\nrm -vf /var/lib/apt/lists/*_main_*\nrm -vf /var/lib/apt/lists/*_restricted_*\nrm -vf /var/lib/apt/lists/*_universe_*\nrm -vf /var/lib/apt/lists/*_multiverse_*\"\n for comp in $components; do\n case $comp in\n main|restricted|universe|multiverse)\n DELETE_APT_LISTS=$(echo \"$DELETE_APT_LISTS\" | grep -v $comp)\n ;;\n *)\n echo \"ERROR: unknown component $comp\"\n exit 1\n ;;\n esac\n done\n shift 2\n ;;\n\t--)\n\t shift\n\t break\n\t ;;\n\t*)\n\t help\n\t exit 1\n\t ;;\n esac\ndone\n\nif ([ -z \"$LOCALE\" ] && [ -z \"$PACKAGE\" ]) || [ -z \"$ARCH\" ]; then\n help\n exit 1\nfi\n\nif ([ -n \"$MIRROR\" ] || [ -n \"$SECURITY_MIRROR\" ]) && [ -n \"$KEEP_APT_OPT\" ]; then\n echo \"ERROR: $KEEP_APT_OPT cannot currently be used along with --mirror or --security-mirror\" >&2\n exit 1\nfi\n\nif [ \"$LOCALE\" ] && [ -z \"$PACKAGE\" ]; then\n PACKAGE=\"ubuntu-defaults-$(echo \"$LOCALE\" | tr '_A-Z' '-a-z')\"\nfi\n\nif [ \"$(id -u)\" = 0 ]; then\n SUDO=env\nelse\n SUDO=sudo\nfi\n\n# Make sure all our dependencies (which are Recommends of our package) are\n# installed. This is a bit dubious long-term, but seems to be needed to\n# make autobuilds reliable.\ncase $ARCH in\n *amd64|*i386)\n $SUDO apt-get -y install gfxboot-theme-ubuntu memtest86+ syslinux || exit 1\n ;;\nesac\n$SUDO apt-get -y install genisoimage\n\nrm -rf auto\nmkdir -p auto\nfor f in config build clean; do\n ln -s \"/usr/share/livecd-rootfs/live-build/auto/$f\" auto/\ndone\n$SUDO lb clean\nrm -f .stage/config\n\n# Neon addition to easily override some variables\nif [ -e \"$CONFIG_SETTINGS\" ]; then\n . $CONFIG_SETTINGS\nfi\n\nSUITE=\"$SUITE\" PROJECT=\"$FLAVOR\" ARCH=\"$ARCH\" LB_ARCHITECTURES=\"$ARCH\" \\\n LB_MIRROR_BOOTSTRAP=\"$MIRROR\" LB_MIRROR_CHROOT_SECURITY=\"$SECURITY_MIRROR\" \\\n IMAGEFORMAT=squashfs BINARYFORMAT=iso-hybrid ISOHYBRID_OPTIONS=\"--uefi\" lb config\n\necho \"LB_LINUX_FLAVOURS=\\\"$LB_LINUX_FLAVOURS\\\"\" >> config/chroot\n\nif [ \"$COMPONENTS\" ]; then\n sed -i \"s/^\\\\(LB_PARENT_ARCHIVE_AREAS=\\\\).*/\\\\1\\\"$COMPONENTS\\\"/\" \\\n\tconfig/bootstrap\nfi\n\nsed -i \"s/^\\\\(LB_SYSLINUX_THEME=\\\\).*/\\\\1\\\"neon\\\"/\" config/binary\n\nif [ \"${PACKAGE%.deb}\" = \"$PACKAGE\" ]; then\n # package name, apt-get'able\n echo \"$PACKAGE\" >> config/package-lists/ubuntu-defaults.list.chroot_install\nelse\n # local deb\n cp \"$PACKAGE\" config/packages.chroot/\nfi\n\nif [ -n \"$PPAS\" ]; then\n add_ppas\nfi\n\nPACKAGENAME=${PACKAGE%%_*}\nPACKAGENAME=${PACKAGENAME##*/}\n\n# install language support hook (try the one from the source tree first)\nHOOK=$(dirname $(readlink -f $0))/../lib/language-support-hook\nif ! [ -e \"$HOOK\" ]; then\n HOOK=/usr/share/ubuntu-defaults-builder/language-support-hook\nfi\nsed \"s/#DEFAULTS_PACKAGE#/$PACKAGENAME/\" < \"$HOOK\" > config/hooks/00_language-support.chroot\n\n# This was changed/fixed in focal at least, the LB_ var now overrides the\n# initramfs internal defaults.\nif [ \"$VERSION_CODENAME\" != \"focal\" ]; then\n # work around live-build failure with lzma initramfs (Debian #637979)\n sed -i 's/^LB_INITRAMFS_COMPRESSION=\"lzma\"/LB_INITRAMFS_COMPRESSION=\"gzip\"/' config/common\nfi\n\n# run hooks from defaults package\ncat <<EOF > config/hooks/010_ubuntu-defaults.chroot\n#!/bin/sh\nset -e\nHOOK=/usr/share/$PACKAGENAME/hooks/chroot\nif [ -x \\$HOOK ]; then\n \\$HOOK\nfi\nEOF\n\n# clean up files that we do not need\ncat <<EOF > config/hooks/090_cleanup.chroot\n#!/bin/sh\nset -e\necho \"$0: Removing unnecessary files...\"\nrm -vf /var/cache/apt/*cache.bin\n$DELETE_APT_LISTS\nrm -vrf /tmp/*\nEOF\n\n# rename kernel and initrd to what syslinux expects\nif [ \"$VERSION_CODENAME\" = \"bionic\" ]; then\n # It's a hack for one reason or another, I don't comprehend it!\n cat <<'EOF' > config/hooks/rename-kernel.binary\n#!/bin/sh -ex\n# Read bytes out of a file, checking that they are valid hex digits\nreadhex()\n{\n\tdd < \"$1\" bs=1 skip=\"$2\" count=\"$3\" 2> /dev/null | \\\n\t\tLANG=C grep -E \"^[0-9A-Fa-f]{$3}\\$\"\n}\ncheckzero()\n{\n\tdd < \"$1\" bs=1 skip=\"$2\" count=1 2> /dev/null | \\\n\t\tLANG=C grep -q -z '^$'\n}\n\nif [ ! -e binary/casper/initrd.lz ]; then\n\n # There may be a prepended uncompressed archive. cpio\n # won't tell us the true size of this so we have to\n # parse the headers and padding ourselves. This is\n # very roughly based on linux/lib/earlycpio.c\n INITRD=\"$(ls binary/casper/initrd.img-*)\"\n offset=0\n while true; do\n if checkzero \"${INITRD}\" $offset; then\n offset=$((offset + 4))\n continue\n fi\n magic=\"$(readhex \"${INITRD}\" $offset 6)\" || break\n test $magic = 070701 || test $magic = 070702 || break\n namesize=0x$(readhex \"${INITRD}\" $((offset + 94)) 8)\n filesize=0x$(readhex \"${INITRD}\" $((offset + 54)) 8)\n offset=$(((offset + 110)))\n offset=$(((offset + $namesize + 3) & ~3))\n offset=$(((offset + $filesize + 3) & ~3))\n done\n\n initramfs=\"${INITRD}\"\n if [ $offset -ne 0 ]; then\n subarchive=$(mktemp ${TMPDIR:-/tmp}/initramfs_XXXXXX)\n dd < \"${INITRD}\" bs=\"$offset\" skip=1 2> /dev/null \\\n > $subarchive\n initramfs=${subarchive}\n fi\n\n echo \"\\$0: Renaming initramfs to initrd.lz...\"\n zcat ${initramfs} | lzma -c > binary/casper/initrd.lz\n rm binary/casper/initrd.img-*\nfi\nls -lah binary/casper/ || true\nif [ ! -e binary/casper/vmlinuz ]; then\n echo \"$0: Renaming kernel to vmlinuz...\"\n # This will go wrong if there's ever more than one vmlinuz-* after\n # excluding *.efi.signed. We can deal with that if and when it arises.\n for x in binary/casper/vmlinuz-*; do\n\tcase $x in\n\t *.efi.signed)\n\t\t;;\n\t *)\n\t\tmv $x binary/casper/vmlinuz\n\t\tif [ -e \"$x.efi.signed\" ]; then\n\t\t mv $x.efi.signed binary/casper/vmlinuz.efi\n\t\tfi\n\t\t;;\n\tesac\n done\nfi\nEOF\nelif [ \"$VERSION_CODENAME\" = \"focal\" ]; then\n cat <<EOF > config/hooks/000-rename-kernel.binary\n#!/bin/sh -ex\n\n# We now use 20.04 HWE linux but this one still gets installed for some reason jriddell 2021-15-06\nrm binary/casper/initrd.img-5.4.0*\nrm binary/casper/vmlinuz-5.4.0*\n\nls -lah binary/\nls -lah binary/casper\nif [ ! -e binary/casper/initrd ]; then\n echo \"\\$0: Renaming initramfs to initrd...\"\n mv -v binary/casper/initrd.img-* binary/casper/initrd\nfi\nif [ ! -e binary/casper/vmlinuz ]; then\n echo \"\\$0: Renaming kernel to vmlinuz...\"\n # This will go wrong if there's ever more than one vmlinuz-* after\n # excluding *.efi.signed. We can deal with that if and when it arises.\n for x in binary/casper/vmlinuz-*; do\n\tcase \\$x in\n\t *.efi.signed)\n\t\t;;\n\t *)\n\t\tmv \\$x binary/casper/vmlinuz\n\t\tif [ -e \"\\$x.efi.signed\" ]; then\n\t\t mv \\$x.efi.signed binary/casper/vmlinuz.efi\n\t\tfi\n\t\t;;\n\tesac\n done\nfi\nEOF\nelif [ \"$VERSION_CODENAME\" = \"jammy\" ]; then\n cat <<EOF > config/hooks/000-rename-kernel.binary\n#!/bin/sh -ex\n\n# We now use 22.04 HWE linux but this one still gets installed for some reason jriddell 2021-15-06\nrm binary/casper/initrd.img-5.15.0*\nrm binary/casper/vmlinuz-5.15.0*\n\nls -lah binary/\nls -lah binary/casper\nif [ ! -e binary/casper/initrd ]; then\n echo \"\\$0: Renaming initramfs to initrd...\"\n mv -v binary/casper/initrd.img-* binary/casper/initrd\nfi\nif [ ! -e binary/casper/vmlinuz ]; then\n echo \"\\$0: Renaming kernel to vmlinuz...\"\n # This will go wrong if there's ever more than one vmlinuz-* after\n # excluding *.efi.signed. We can deal with that if and when it arises.\n for x in binary/casper/vmlinuz-*; do\n\tcase \\$x in\n\t *.efi.signed)\n\t\t;;\n\t *)\n\t\tmv \\$x binary/casper/vmlinuz\n\t\tif [ -e \"\\$x.efi.signed\" ]; then\n\t\t mv \\$x.efi.signed binary/casper/vmlinuz.efi\n\t\tfi\n\t\t;;\n\tesac\n done\nfi\nEOF\nfi\n\n# set default language\ncat <<EOF > config/hooks/000-default-language.binary\n#!/bin/sh -ex\nLOC=chroot/usr/share/$PACKAGENAME/language.txt\nif [ -e \"\\$LOC\" ]; then\n echo \"\\$0: \\$LOC exists, setting gfxboot default language...\"\n cp \"\\$LOC\" binary/isolinux/lang\n echo >> binary/isolinux/lang\nelse\n echo \"\\$0: \\$LOC does not exist, not setting gfxboot default language\"\nfi\nEOF\n\n#++++\n# FIXME: addition\nif [ -d \"$CONFIG_HOOKS\" ]; then\n for f in $CONFIG_HOOKS/*; do\n . $f\n done\nfi\nif [ -d \"$BUILD_HOOKS\" ]; then\n cp -v $BUILD_HOOKS/* config/hooks/\nfi\nif [ \"$SEEDED_SNAPS\" != \"\" ] && [ -f \"$SEEDED_SNAPS\" ]; then\n cp -v $SEEDED_SNAPS config/seeded-snaps\nfi\n#----\n\ncat config/common\n\nDISPLAY= $SUDO PROJECT=\"$FLAVOR\" ARCH=\"$ARCH\" lb build\n"
},
{
"alpha_fraction": 0.6528841257095337,
"alphanum_fraction": 0.659520149230957,
"avg_line_length": 30.59677505493164,
"blob_id": "6922eb6c2d5602676353e6050ccc90441c844087",
"content_id": "2c3cf329104b540384d46789a4dc114dd0d1723d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1959,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/nci/snap/publish.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'tty/command'\n\nrequire_relative '../../lib/apt'\n\nmodule NCI\n module Snap\n # Helper to publish a snap to the store.\n class Publisher\n SNAPNAME = ENV.fetch('APPNAME')\n TYPE_TO_CHANNEL = {\n 'user' => 'candidate',\n 'release' => 'candidate',\n 'stable' => 'candidate',\n 'unstable' => 'edge'\n }.freeze\n\n def self.install!\n Apt.update || raise\n Apt.install('snapcraft') || raise\n end\n\n def self.copy_config!\n # Host copies their credentials into our workspace, copy it to where\n # snapcraft looks for them.\n cfgdir = \"#{Dir.home}/.config/snapcraft\"\n FileUtils.mkpath(cfgdir)\n File.write(\"#{cfgdir}/snapcraft.cfg\", File.read('snapcraft.cfg'))\n end\n\n def self.run\n channel = TYPE_TO_CHANNEL.fetch(ENV.fetch('TYPE'))\n\n # install!\n copy_config!\n\n cmd = TTY::Command.new\n cmd.run(\"snapcraft upload *.snap --release #{channel}\")\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5820180177688599,
"alphanum_fraction": 0.5893461108207703,
"avg_line_length": 29.06779670715332,
"blob_id": "65a8d1820ac2e5eaed42e7308983e04024907148",
"content_id": "ff903e158ddbf5110dc3f4213fcc2af36a5959a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3548,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 118,
"path": "/test/test_ci_overrides.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/ci/overrides'\nrequire_relative '../lib/ci/scm'\nrequire_relative 'lib/testcase'\n\n# Test ci/overrides\nmodule CI\n class OverridesTest < TestCase\n def setup\n CI::Overrides.default_files = [] # Disable overrides by default.\n end\n\n def teardown\n CI::Overrides.default_files = nil # Reset\n end\n\n def test_pattern_match\n # FIXME: this uses live data\n o = Overrides.new([data('o1.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/plasma/kitten', 'kubuntu_stable')\n overrides = o.rules_for_scm(scm)\n refute_nil overrides\n assert_equal({ 'upstream_scm' => { 'branch' => 'Plasma/5.5' } }, overrides)\n end\n\n def test_cascading\n o = Overrides.new([data('o1.yaml'), data('o2.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/plasma/kitten', 'kubuntu_stable')\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n assert_equal({ 'packaging_scm' => { 'branch' => 'yolo' }, 'upstream_scm' => { 'branch' => 'kitten' } },\n overrides)\n end\n\n def test_cascading_reverse\n o = Overrides.new([data('o2.yaml'), data('o1.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/plasma/kitten', 'kubuntu_stable')\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n assert_equal({ 'packaging_scm' => { 'branch' => 'kitten' }, 'upstream_scm' => { 'branch' => 'kitten' } },\n overrides)\n end\n\n def test_specific_overrides_generic\n o = Overrides.new([data('o1.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/qt/qt5webkit', 'kubuntu_vivid_mobile')\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n expected = {\n 'upstream_scm' => {\n 'branch' => nil,\n 'type' => 'tarball',\n 'url' => 'http://http.debian.net/qtwebkit.tar.xz'\n }\n }\n assert_equal(expected, overrides)\n end\n\n def test_branchless_scm\n o = Overrides.new([data('o1.yaml')])\n scm = SCM.new('bzr', 'lp:fishy', nil)\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n expected = {\n 'upstream_scm' => {\n 'url' => 'http://meow.git'\n }\n }\n assert_equal(expected, overrides)\n end\n\n def test_nil_upstream_scm\n # standalone deep_merge would overwrite properties set to nil explicitly, but\n # we want them preserved!\n o = Overrides.new([data('o1.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/qt/qt5webkit', 'test_nil_upstream_scm')\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n expected = {\n 'upstream_scm' => nil\n }\n assert_equal(expected, overrides)\n end\n\n def test_scm_with_pointgit_suffix\n # make sure things work when .git is involved. we must have urls with .git\n # for gitlab instances.\n o = Overrides.new([data('o1.yaml')])\n scm = SCM.new('git', 'git://packaging.neon.kde.org.uk/qt/qt5webkit.git', 'kubuntu_vivid_mobile')\n\n overrides = o.rules_for_scm(scm)\n\n refute_nil overrides\n expected = {\n 'upstream_scm' => {\n 'branch' => nil,\n 'type' => 'tarball',\n 'url' => 'http://http.debian.net/qtwebkit.tar.xz'\n }\n }\n assert_equal(expected, overrides)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7318659424781799,
"alphanum_fraction": 0.7378689050674438,
"avg_line_length": 38.97999954223633,
"blob_id": "c17cd01142af8b61d81ee2d0fcd42d31e37a5209",
"content_id": "ae5535aff83b65cbec86879dd9a147977d9c7683",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1999,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 50,
"path": "/jenkins-jobs/nci/publisher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../publisher'\nrequire_relative '../../lib/kdeproject_component'\n\n# Neon extension to publisher\nclass NeonPublisherJob < PublisherJob\n attr_reader :kdecomponent\n attr_reader :project\n\n def initialize(basename, type:, distribution:, dependees:,\n component:, upload_map:, architectures:, kdecomponent:, project:)\n super(basename, type: type, distribution: distribution, dependees: dependees, component: component, upload_map: upload_map, architectures: architectures)\n @kdecomponent = kdecomponent\n @project = project\n end\n\n # When chain-publishing lock all aptly resources. Chain publishing can\n # cause a fairly long lock on the database with a much greater risk of timeout\n # by locking all resources instead of only one we'll make sure no other\n # jobs can time out while we are publishing.\n def aptly_resources\n repo_names.size > 1 ? 0 : 1\n end\n\n # @return Array<String> array of repo identifiers suitable for pangea_dput\n def repo_names\n repos = [\"#{type}_#{distribution}\"]\n return repos\n repos\n end\nend\n"
},
{
"alpha_fraction": 0.635808527469635,
"alphanum_fraction": 0.6446720361709595,
"avg_line_length": 33.53741455078125,
"blob_id": "b4b3983efca2fd88372cd58336578805e39ea306",
"content_id": "25716ae0f4125d55b3a4c6c7bc22d844d9daeefa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5077,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 147,
"path": "/test/test_aptly_ext_remote.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/aptly-ext/remote'\n\nrequire 'mocha/test_unit'\n\nmodule Aptly::Ext\n class RemoteTest < TestCase\n def test_connects_with_path\n uri = URI::Generic.build(scheme: 'ssh', user: 'u', host: 'h', port: 1,\n path: '/xxx')\n assert_false(Remote::HTTP.connects?(uri))\n assert(Remote::Socket.connects?(uri))\n assert_false(Remote::TCP.connects?(uri))\n end\n\n def test_connects_without_path\n uri = URI::Generic.build(scheme: 'ssh', user: 'u', host: 'h', port: 1)\n assert_false(Remote::HTTP.connects?(uri))\n assert_false(Remote::Socket.connects?(uri))\n assert(Remote::TCP.connects?(uri))\n end\n\n def test_connects_http\n uri = URI::HTTP.build(host: 'h')\n assert(Remote::HTTP.connects?(uri))\n assert_false(Remote::Socket.connects?(uri))\n assert_false(Remote::TCP.connects?(uri))\n end\n\n def test_connect_socket\n uri = URI::Generic.build(scheme: 'ssh', user: 'u', host: 'h', port: 1,\n path: '/xxx')\n\n # These expecations are called twice, once with an init option and once\n # without\n Remote::TCP.expects(:connect).never\n\n session = mock('session')\n session.stubs(:process)\n session.expects(:close).twice\n\n forward = mock('forward')\n forward.expects(:local_socket).returns('/abc123').twice\n forward.stubs(:active_local_sockets).returns(['/abc123'])\n forward.expects(:cancel_local_socket).with('/abc123').twice\n session.stubs(:forward).returns(forward)\n\n Net::SSH.expects(:start).with('h', nil, {}).returns(session)\n Remote.connect(uri) do\n Aptly.configure do |config|\n assert_equal('unix', config.uri.scheme)\n # Path includes tmpdir, so only check filename\n assert_equal('aptly.sock', File.basename(config.uri.path))\n end\n end\n\n ENV['SSH_KEY_FILE'] = '/foobar'\n Net::SSH.expects(:start).with do |*args|\n kwords = args[-1] # ruby3 compat, ruby3 no longer allows implicit **kwords conversion from hash but mocha relies on it still -sitter\n kwords.include?(:keys) && kwords[:keys].include?('/foobar')\n end.returns(session)\n Remote.connect(uri) {}\n # Mocha makes sure its expectations were invoked, nothing to assert about\n # the key usage, the expectation takes care of it.\n ensure\n ENV.delete('SSH_KEY_FILE')\n end\n\n def test_connect_tcp\n uri = URI::Generic.build(scheme: 'ssh', user: 'u', host: 'h', port: 1)\n\n Remote::Socket.expects(:connect).never\n\n session = mock('session')\n session.stubs(:process)\n session.expects(:close)\n Net::SSH.expects(:start).returns(session)\n\n forward = mock('forward')\n forward.expects(:local).returns(65_535)\n forward.stubs(:active_locals).returns([65_535])\n forward.expects(:cancel_local).with(65_535)\n session.stubs(:forward).returns(forward)\n\n Remote.connect(uri) do\n Aptly.configure do |config|\n assert_equal(URI.parse('http://localhost:65535'), config.uri)\n end\n end\n end\n\n def test_connect_http\n uri = URI::HTTP.build(host: 'h')\n\n Remote.connect(uri) do\n Aptly.configure do |config|\n assert_equal(uri, config.uri)\n end\n end\n end\n\n def test_neon\n # This basically asserts that a connection is called with the expected URI\n # It is a fairly repetative test but necessary to make sure .neon is\n # compliantly calling connect as per test_connect_socket\n uri = URI.parse('ssh://[email protected]/srv/neon-services/aptly.sock')\n Remote.expects(:connect).with { |u| u == uri }.yields\n block_called = false\n Remote.neon do\n block_called = true\n end\n assert(block_called)\n end\n\n def test_neon_read_only\n uri = URI.parse('https://archive-api.neon.kde.org')\n Remote.expects(:connect).with { |u| u == uri }.yields\n\n block_called = false\n Remote.neon_read_only do\n block_called = true\n end\n assert(block_called)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6334195733070374,
"alphanum_fraction": 0.6368688344955444,
"avg_line_length": 35.23958206176758,
"blob_id": "24de0e606b7d22e05ea23438618585b94ff37cc6",
"content_id": "a3e895d3d260f391c3a822eaa2770e55156f2104",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 10437,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 288,
"path": "/lib/ci/tar-fetcher/watch.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'open-uri'\nrequire 'tmpdir'\nrequire 'tty-command'\n\nrequire_relative '../tarball'\nrequire_relative '../../debian/changelog'\nrequire_relative '../../debian/source'\nrequire_relative '../../debian/version'\nrequire_relative '../../os'\nrequire_relative '../../nci'\n\nmodule CI\n # Fetch tarballs via uscan using debian/watch.\n class WatchTarFetcher\n class RepackOnNotCurrentSeries < StandardError; end\n class NativePackaging < StandardError; end\n\n # @param watchfile String path to watch file for the fetcher\n # @param mangle_download Boolean whether to mangle KDE URIs to run through\n # our internal sftp mapper (neon only)\n # @param series Array<String> list of series enabled for this fetcher.\n # when this is set it will apt-get source the package from the archive\n # as a first choice. Iff it cannot find the source with the version\n # in the archive it uscans. (this prevents repack mismatches and saves\n # a bit of time as our archive mirror is generally faster)\n def initialize(watchfile, mangle_download: false, series: [])\n @dir = File.dirname(debiandir_from(watchfile))\n @watchfile = watchfile\n @mangle_download = mangle_download\n @series = series\n return unless Debian::Source.new(@dir).format.type == :native\n\n raise NativePackaging, 'run on native packaging. This is useless!'\n end\n\n def fetch(destdir)\n # FIXME: this should use DEHS output to get url and target name\n # without downloading. then decide whether to wipe destdir and download\n # or not.\n maybe_mangle do\n make_dir(destdir)\n apt_source(destdir)\n uscan(@dir, destdir) unless @have_source\n tar = TarFinder.new(destdir,\n version: current_upstream_version).find_and_delete\n return tar unless tar # can be nil from pop\n\n Tarball.new(\"#{destdir}/#{File.basename(tar)}\")\n end\n end\n\n private\n\n def make_dir(destdir)\n FileUtils.mkpath(destdir) unless Dir.exist?(destdir)\n end\n\n def debiandir_from(watchfile)\n unless File.basename(watchfile) == 'watch'\n raise \"path not a watch file #{watchfile}\"\n end\n\n debiandir = File.dirname(File.absolute_path(watchfile))\n unless File.basename(debiandir) == 'debian'\n raise \"path not a debian dir #{debiandir}\"\n end\n\n debiandir\n end\n\n def maybe_mangle(&block)\n orig_data = File.read(@watchfile)\n File.write(@watchfile, mangle_url(orig_data)) if @mangle_download\n block.yield\n ensure\n File.write(@watchfile, orig_data)\n end\n\n def mangle_url(data)\n # The download.kde.internal.neon.kde.org domain is not publicly available!\n # Only available through blue system's internal DNS.\n data.gsub(%r{download.kde.org/stable/},\n 'download.kde.internal.neon.kde.org/stable/')\n end\n\n def changelog\n @changelog ||= begin\n file = \"#{@dir}/debian/changelog\"\n raise \"changelog not found at #{file}\" unless File.exist?(file)\n\n Changelog.new(file)\n end\n end\n\n def current_upstream_version\n changelog.version(Changelog::BASE | Changelog::BASESUFFIX)\n end\n\n def current_version\n # uscan has a --download-current-version option this does however fail\n # to work for watch files with multiple entries as the version is cleared\n # inbetween loop runs so the second,thrid... runs will have no version set\n # and fail to resolve. To bypass this we'll pass the version explicilty\n # via --download-debversion which persists across loops.\n changelog.version(Changelog::ALL)\n end\n\n def apt_source(destdir)\n apt_sourcer = AptSourcer.new(changelog: changelog, destdir: destdir)\n @series.each do |series|\n tar = apt_sourcer.find_for(series: series)\n next unless tar\n\n puts \"Found a suitable tarball: #{tar.basename}. Not uscanning...\"\n @have_source = true\n break\n end\n end\n\n def uscan(chdir, destdir)\n guard_unwanted_repacks\n destdir = File.absolute_path(destdir)\n FileUtils.mkpath(destdir) unless Dir.exist?(destdir)\n TTY::Command.new.run(\n 'uscan', '--verbose', '--rename',\n '--download-debversion', current_version,\n \"--destdir=#{destdir}\",\n chdir: chdir\n )\n end\n\n def guard_unwanted_repacks\n return unless File.read(@watchfile).include?('repack')\n return unless %w[ubuntu neon].any? { |x| OS::ID == x }\n return if OS::UBUNTU_CODENAME == NCI.future_series || OS::UBUNTU_CODENAME == NCI.current_series\n\n raise RepackOnNotCurrentSeries, <<~ERROR\n The watch file wants to repack the source. We tried to download an\n already repacked source from our archives but didn't find one. For\n safety reasons we are not going to uscan a source that requires\n repacking on any series but our current one (#{NCI.future_series}).\n Make sure the build of this source for the current series is built first\n ERROR\n end\n\n # Helper to find the newest tar in a directory.\n class TarFinder\n attr_reader :dir\n\n def initialize(directory_with_tars, version:)\n # NB: ideally this should also restrict on the name, for legacy compat\n # reasons this currently is not the case but should be changed\n # to accept a changelog here and then derive name and version from\n # that and then disqualify tarballs with a bad name (otherwise\n # might screw the finder up)\n @dir = directory_with_tars\n @version = version\n puts \"Hallo this is the tar finder. Running on #{@dir}\"\n end\n\n def find_and_delete\n puts \"I've found the following tars: #{all_tars_by_version}\"\n return nil unless tar\n\n puts \"The following tar is considered golden: #{tar}\"\n # Automatically ditch all but the newest tarball. This prevents\n # preserved workspaces from getting littered with old tars.\n # Our version sorting logic prevents us from tripping over them though.\n unsuitable_tars.each { |path| FileUtils.rm(path, verbose: true) }\n tar\n end\n\n private\n\n def tar\n tars = all_tars_by_version.find_all do |version, _tar|\n version.upstream == @version\n end.to_h.values\n raise \"Too many tars: #{tars}\" if tars.size > 1\n return nil if tars.empty?\n\n tars[0]\n end\n\n def unsuitable_tars\n all_tars.reject { |x| x == tar }\n end\n\n def all_tars\n Dir.glob(\"#{dir}/*.orig.tar*\").reject do |x|\n %w[.asc .sig].any? { |ext| x.end_with?(ext) }\n end\n end\n\n def all_tars_by_version\n all_tars.map do |x|\n ver = Debian::Version.new(version_from_file(x))\n if ver.revision\n # qtchooser-gitref123-5 is a valid debian version as only the last\n # dash counts as revision. When only working with a tarball version\n # qtchooser-gitref123 Debian::Version won't know that the dash\n # is not a revision but part of the upstream.\n # However, the upstream_version may contain a hyphen in most cases.\n # In no case does the hyphen denote an irrelevant revision though.\n # e.g. in native packages 1.0-1 is foo_1.0-1.orig.tar as even\n # revisions require a new tarball, in !natives 1.0-1-1-1 can all\n # be parts of the upstream. We make no assumptions about the\n # validity of the tarball names here, so we can always fold a\n # potential revision back into the upstream version as they mustn't\n # contain a hyphen for !native packages anyway. And this code here\n # should decidely not be run for native packages (they generate\n # their own source ;))\n ver.upstream += \"-#{ver.revision}\"\n ver.revision = nil\n end\n [ver, x]\n end.to_h\n end\n\n def version_from_file(path)\n filename = File.basename(path)\n filename.slice(/_.*/)[1..-1].split('.orig.')[0]\n end\n end\n private_constant :TarFinder\n\n # Downloads source for a given debian/ dir via apt.\n class AptSourcer\n attr_reader :destdir\n attr_reader :name\n attr_reader :version\n\n # Dir is actually the parent dir of the debian/ dir.\n def initialize(changelog:, destdir:)\n @destdir = destdir\n @name = changelog.name\n @version = changelog.version(Changelog::BASE | Changelog::BASESUFFIX)\n puts 'Hola! This is the friendly AptSourcer from around the corner!'\n puts \"I'll be sourcing #{@name} at #{@version} today.\"\n end\n\n def find_for(series:)\n TTY::Command.new.run!('apt-get', 'source', '--only-source',\n '--download-only', '-t', series,\n name,\n chdir: destdir)\n find_tar\n ensure\n FileUtils.rm(Dir.glob(\"#{destdir}/*.debian.tar*\"), verbose: true)\n FileUtils.rm(Dir.glob(\"#{destdir}/*.dsc\"), verbose: true)\n end\n\n private\n\n def find_tar\n puts 'Telling TarFinder to go have a looksy.'\n tar = TarFinder.new(destdir, version: version).find_and_delete\n unless tar\n puts 'no tar'\n return nil\n end\n puts \"Hooray, there's a tarball #{tar}!\"\n CI::Tarball.new(tar)\n end\n end\n private_constant :AptSourcer\n end\nend\n"
},
{
"alpha_fraction": 0.7028769850730896,
"alphanum_fraction": 0.7073412537574768,
"avg_line_length": 42.826087951660156,
"blob_id": "9d142136430bcc3ca0da8e32e4058b8b34bdac97",
"content_id": "c44b0272f5d6e24a4ff68381eee09906e4a43b73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2016,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 46,
"path": "/jenkins-jobs/nci/pipelinejob.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../job'\n\n# Generic workflow/pipeline job. Constructs standard workflow rendering a\n# pipeline of the same name (with - => _).\nclass PipelineJob < JenkinsJob\n attr_reader :cron\n attr_reader :sandbox\n attr_reader :with_push_trigger\n\n # @param name job name\n # @param template the pipeline template basename\n # @param cron the cron trigger rule if any\n # @param job_template the xml job template basename\n # @param sandbox whether to sandbox the pipeline - BE VERY CAREFUL WITH THIS\n # it punches a huge security hole into jenkins for the specific job\n def initialize(name, template: name.tr('-', '_'), cron: '',\n job_template: 'pipelinejob', sandbox: true,\n with_push_trigger: true)\n template_file = File.exist?(\"#{__dir__}/templates/#{template}-#{job_template}.xml.erb\") ? \"#{template}-#{job_template}.xml.erb\" : \"#{job_template}.xml.erb\"\n super(name, template_file,\n script: \"#{__dir__}/pipelines/#{template}.groovy.erb\")\n @cron = cron\n @sandbox = sandbox\n @with_push_trigger = with_push_trigger\n end\nend\n"
},
{
"alpha_fraction": 0.644618809223175,
"alphanum_fraction": 0.6528400778770447,
"avg_line_length": 29.067415237426758,
"blob_id": "5b6ec301d0299867990b016b1a8ccf3b17a7223d",
"content_id": "5c6d74cf7b07d2547170d2bf440119527e4504f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2676,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 89,
"path": "/nci/seed_deploy.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2018-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Deploys seeds onto HTTP server so they can be used by livecd-rootfs/germinate\n# over HTTP.\n\n# Of interest\n# https://stackoverflow.com/questions/16351271/apache-redirects-based-on-symlinks\n\nrequire 'date'\n\nrequire_relative '../lib/nci'\nrequire_relative '../lib/tty_command'\n\nROOT = '/srv/www/metadata.neon.kde.org/germinate'\nNEON_GIT = 'https://invent.kde.org/neon'\nNEON_REPO = \"#{NEON_GIT}/neon/seeds\"\nUBUNTU_SEEDS = 'https://git.launchpad.net/~ubuntu-core-dev/ubuntu-seeds/+git'\nPLATFORM_REPO = \"#{UBUNTU_SEEDS}/platform\"\n\ncmd = TTY::Command.new\nstamp = Time.now.utc.strftime('%Y%m%d-%H%M%S')\n\ndir = \"#{ROOT}/seeds.new.#{stamp}\"\ncmd.run('rm', '-rf', dir)\ncmd.run('mkdir', '-p', dir)\nfailed = true\n\nat_exit do\n # In the event that we raise on something, make sure to clean up dangling bits\n cmd.run('rm', '-rf', dir) if failed\nend\n\nserieses = NCI.series.keys\n\nseries_branches = begin\n out, _ = cmd.run('git', 'ls-remote', '--heads', '--exit-code',\n NEON_REPO, 'Neon/unstable*')\n found_main_branch = false\n branches = {}\n out.strip.split($/).collect do |line|\n ref = line.split(/\\s/).last\n branch = ref.gsub('refs/heads/', '')\n if branch == 'Neon/unstable'\n found_main_branch = true\n elsif (series = serieses.find { |s| branch == \"Neon/unstable_#{s}\" })\n raise unless series # just to make double sure we found smth\n\n branches[series] = branch\n elsif branch.start_with?('Neon/unstable_')\n warn \"Seems we found a legacy branch #{branch}, skipping.\"\n else\n raise \"Unexpected branch #{branch} wanted a Neon/unstable branch :O\"\n end\n end\n unless found_main_branch\n raise 'Did not find Neon/unstable branch! Something went well wrong!'\n end\n\n branches\nend\np series_branches\n\nDir.chdir(dir) do\n serieses.each do |series|\n neondir = \"neon.#{series}\"\n platformdir = \"platform.#{series}\"\n branch = series_branches.fetch(series, 'Neon/unstable')\n cmd.run('git', 'clone', '--depth', '1', '--branch', branch,\n NEON_REPO, neondir)\n cmd.run('git', 'clone', '--depth', '1', '--branch', series,\n PLATFORM_REPO, platformdir)\n end\nend\n\nDir.chdir(ROOT) do\n cur_dir = File.basename(dir) # dir is currently abs, make it relative\n main_dir = 'seeds'\n old_dir = File.readlink(main_dir) rescue nil\n new_dir = 'seeds.new'\n cmd.run('rm', '-f', new_dir)\n cmd.run('ln', '-s', cur_dir, new_dir)\n cmd.run('mv', '-T', new_dir, main_dir)\n cmd.run('rm', '-rf', old_dir)\nend\n\nfailed = false\n"
},
{
"alpha_fraction": 0.6646919250488281,
"alphanum_fraction": 0.6682464480400085,
"avg_line_length": 27.133333206176758,
"blob_id": "b6eddf9b87085056d15db510f0a8f9a5e71923bb",
"content_id": "26465d51bc4dfc9cc86618745abf42fe32a1a087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 30,
"path": "/lib/retry.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# Helps with retrying an exception throwing code.\nmodule Retry\n module_function\n\n def disable_sleeping\n @sleep_disabled = true\n end\n\n def enable_sleeping\n @sleep_disabled = false\n end\n\n # Retry given block.\n # @param tries [Integer] amount of tries\n # @param errors [Array<Object>] errors to rescue\n # @param sleep [Integer, nil] seconds to sleep between tries\n # @param name [String, 'unknown'] name of the action (debug when not silent)\n # @yield yields to block which needs retrying\n def retry_it(times: 1, errors: [StandardError], sleep: nil, silent: false,\n name: 'unknown')\n yield\n rescue *errors => e\n raise e if (times -= 1) <= 0\n\n print \"Error on retry_it(#{name}) :: #{e}\\n\" unless silent\n Kernel.sleep(sleep) if sleep && !@sleep_disabled\n retry\n end\nend\n"
},
{
"alpha_fraction": 0.6884779334068298,
"alphanum_fraction": 0.6884779334068298,
"avg_line_length": 26.038461685180664,
"blob_id": "e4ea6bec29ab80f812d8c0bace460dcdeb4c276f",
"content_id": "bc386fb08bbfa22d3c7ea79f3e4376519054732e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 703,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 26,
"path": "/jenkins-jobs/nci/nci_img.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../job'\n\n# Neon IMGs\nclass NeonImgJob < JenkinsJob\n attr_reader :type\n attr_reader :distribution\n attr_reader :architecture\n attr_reader :metapackage\n attr_reader :imagename\n attr_reader :neonarchive\n attr_reader :cronjob\n\n def initialize(type:, distribution:, architecture:, metapackage:, imagename:,\n neonarchive:, cronjob:)\n super(\"img_#{imagename}_#{distribution}_#{type}_#{architecture}\",\n 'nci_img.xml.erb')\n @type = type\n @distribution = distribution\n @architecture = architecture\n @metapackage = metapackage\n @imagename = imagename\n @neonarchive = neonarchive\n @cronjob = cronjob\n end\nend\n"
},
{
"alpha_fraction": 0.6525312066078186,
"alphanum_fraction": 0.6591058373451233,
"avg_line_length": 37.50632858276367,
"blob_id": "a8767caee0f130a223883289e3164fc9823dacd9",
"content_id": "f2bc797f3acae78299bb80d5b21baee5f057db7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3042,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 79,
"path": "/test/test_nci_snapcraft_manifest_extender.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/snap/manifest_extender'\n\nrequire 'mocha/test_unit'\n\nmodule NCI::Snap\n class ManifestExtendertest < TestCase\n # TODO remove extender it's unused\n # def setup\n # ManifestExtender.manifest_path = \"#{Dir.pwd}/man\"\n # ENV['APPNAME'] = 'kolourpaint'\n # ENV['DIST'] = 'bionic'\n\n # stub_request(:get, Extender::Core18::STAGED_CONTENT_PATH)\n # .to_return(status: 200, body: JSON.generate(['meep']))\n # stub_request(:get, Extender::Core18::STAGED_DEV_PATH)\n # .to_return(status: 200, body: JSON.generate(['meep-dev']))\n # end\n\n # def test_run\n # File.write(ManifestExtender.manifest_path, '')\n # FileUtils.cp(data, 'snapcraft.yaml')\n # ManifestExtender.new('snapcraft.yaml').run do\n # end\n # assert_path_exist('man')\n # assert_path_exist('man.bak')\n # assert_path_exist('man.ext')\n # assert_equal('', File.read('man'))\n # assert_includes(File.read('man.ext'), 'meep')\n # end\n\n # # The build snap collapser removes records of the build snap, so our\n # # detection logic for extending the manifest needs to have other\n # # (post-collapsion) ways to determine if a snap is using the build snap.\n # def test_run_using_sdk\n # File.write(ManifestExtender.manifest_path, '')\n # FileUtils.cp(data, 'snapcraft.yaml')\n # ManifestExtender.new('snapcraft.yaml').run do\n # end\n # assert_path_exist('man')\n # assert_path_exist('man.bak')\n # assert_path_exist('man.ext')\n # assert_equal('', File.read('man'))\n # assert_includes(File.read('man.ext'), 'meep')\n # end\n\n # def test_no_run_without_base_snap\n # File.write(ManifestExtender.manifest_path, '')\n # FileUtils.cp(data, 'snapcraft.yaml')\n # ManifestExtender.new('snapcraft.yaml').run do\n # end\n # assert_path_exist('man')\n # assert_path_exist('man.bak')\n # assert_path_exist('man.ext')\n # assert_equal('', File.read('man'))\n # assert_equal(File.read('man.ext'), '') # MUST BE EMPTY! this is no kf5 snap\n # end\n end\nend\n"
},
{
"alpha_fraction": 0.6527603268623352,
"alphanum_fraction": 0.6596612334251404,
"avg_line_length": 33.65217208862305,
"blob_id": "5950e27daf9370f28f3499c20edd84216b42d4c8",
"content_id": "6069cea640fef39e66fcec06f25f07b0ff790b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3188,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 92,
"path": "/lib/ci/orig_source_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire 'fileutils'\n\nrequire_relative '../debian/changelog'\nrequire_relative '../lsb'\nrequire_relative '../os'\nrequire_relative 'sourcer_base'\n\nmodule CI\n # Builds a source package from an existing tarball.\n class OrigSourceBuilder < SourcerBase\n def initialize(release: LSB::DISTRIB_CODENAME, strip_symbols: false,\n restricted_packaging_copy: false)\n super\n\n # @name\n # @version\n # @tar\n\n # It's a bit unclear why we construct this in init. But I see no reason\n # to change it and am afraid it might be here for a reason - sitter, 2021\n @release_version = \"+#{OS::VERSION_ID}+#{ENV.fetch('DIST')}\"\n @build_rev = ENV.fetch('BUILD_NUMBER')\n\n # FIXME: builder should generate a Source instance\n end\n\n def build(tarball)\n FileUtils.cp(tarball.path, @builddir, verbose: true)\n tarball.extract(@sourcepath)\n\n args = [] << 'debian' if @restricted_packaging_copy\n copy_source_tree(@packagingdir, *args)\n\n Dir.chdir(@sourcepath) do\n log_change\n mangle!\n build_internal\n end\n end\n\n private\n\n def log_change\n # FIXME: this has email and fullname from env, see build_source\n changelog = Changelog.new\n raise \"Can't parse changelog!\" unless changelog\n\n base_version = changelog.version\n if base_version.include?('ubuntu')\n base_version = base_version.split('ubuntu')\n base_version = base_version[0..-2].join('ubuntu')\n end\n # Make sure our version exceeds Ubuntu's by prefixing us with an x.\n # This way -0xneon > -0ubuntu instead of -0neon < -0ubuntu\n base_version = base_version.gsub('neon', 'xneon')\n base_version = \"#{base_version}#{@release_version}#{build_suffix}\"\n changelog.new_version!(base_version, distribution: @release, message: 'Automatic CI Build')\n end\n\n def build_suffix\n # Make sure the TYPE doesn't have a hyphen. If this guard should fail you have to\n # figure out what to do with it. e.g. it could become a ~ and consequently lose to similarly named\n # type versions.\n raise if ENV.fetch('TYPE').include?('-')\n\n suffix = \"+#{ENV.fetch('TYPE')}+build#{@build_rev}\"\n return suffix unless ENV.fetch('TYPE') == 'experimental'\n\n # Prepend and experimental qualifier to **lower** the version beyond\n # whatever can be in unstable. This act as a safe guard should the\n # build rev in experimental (the repo where we stage Qt) become greater\n # then the build rev in unstable (the repo where we regularly build Qt).\n # This allows us to copy packages from experimental without fear of their\n # build number outranking future unstable builds.\n # NB: this qualifier MUST BE EXACTLY BEFORE the build qualifier, it should\n # not impact anything but the build number.\n \"~exp#{suffix}\"\n end\n\n def mangle!\n mangle_symbols\n end\n\n def build_internal\n Dir.chdir(@sourcepath) { dpkg_buildpackage }\n end\n end\nend\n"
},
{
"alpha_fraction": 0.559303343296051,
"alphanum_fraction": 0.577601432800293,
"avg_line_length": 43.47058868408203,
"blob_id": "88bea10ee5e85705c89e45aa486a58d5b4537d33",
"content_id": "f31db1b379ffa83b6b984ecaec90716af43d1c72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4536,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 102,
"path": "/test/test_nci_lint_cmake_dep_verify.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/cmake_dep_verify/package'\n\nrequire 'mocha/test_unit'\n\nmodule CMakeDepVerify\n class PackageTest < TestCase\n def setup\n # Reset caching.\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n # Make sure $? is fine before we start!\n reset_child_status!\n # Disable all system invocation.\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n\n Package.dry_run = true\n\n # We'll temporary mark packages as !auto, mock this entire thing as we'll\n # not need this for testing.\n Apt::Mark.stubs(:tmpmark).yields\n end\n\n def test_test_success\n Object\n .any_instance\n .stubs(:system)\n .with('apt-get') { |cmd| cmd == 'apt-get' }\n .returns(true)\n\n DPKG.expects(:list).with('libkf5coreaddons-dev').returns(%w[\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsMacros.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets-debian.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfigVersion.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfig.cmake\n ])\n\n pkg = Package.new('libkf5coreaddons-dev', '1')\n res = pkg.test\n assert_equal(1, res.size)\n assert_equal('KF5CoreAddons', res.keys[0])\n res = res.values[0]\n assert_equal(true, res.success?)\n assert_equal('', res.out)\n assert_equal('', res.err)\n end\n\n def test_test_fail\n Object\n .any_instance\n .stubs(:system)\n .with('apt-get') { |cmd| cmd == 'apt-get' }\n .returns(true)\n\n DPKG.expects(:list).with('libkf5coreaddons-dev').returns(%w[\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsMacros.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsTargets-debian.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfigVersion.cmake\n /usr/lib/x86_64-linux-gnu/cmake/KF5CoreAddons/KF5CoreAddonsConfig.cmake\n ])\n\n result = mock('result').responds_like_instance_of(TTY::Command::Result)\n result.stubs(:success?).returns(false)\n result.stubs(:out).returns('output')\n result.stubs(:err).returns('error')\n TTY::Command.any_instance.stubs(:run!).returns(result)\n\n pkg = Package.new('libkf5coreaddons-dev', '1')\n res = pkg.test\n assert_equal(1, res.size)\n assert_equal('KF5CoreAddons', res.keys[0])\n res = res.values[0]\n assert_equal(false, res.success?)\n assert_equal('output', res.out)\n assert_equal('error', res.err)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7377049326896667,
"alphanum_fraction": 0.7377049326896667,
"avg_line_length": 29.5,
"blob_id": "21617acde7583dd3be5ffe686e87787d5b8b57de",
"content_id": "2e3cf6e8fd8ccf6089048c8f94e42f2a75bbdb43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 8,
"path": "/nci/imager/build-hooks-neon-ko/000_language-fixes.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\n# mangle the pkg_depends file so we don't get fcitx as sho prefers ibus\n\nsed -i /im:ko::fcitx/d /usr/share/language-selector/data/pkg_depends\nsed -i /im:ko:kio:kde-config-fcitx/d /usr/share/language-selector/data/pkg_depends\n"
},
{
"alpha_fraction": 0.659216046333313,
"alphanum_fraction": 0.6640751361846924,
"avg_line_length": 32.19355010986328,
"blob_id": "f202da96175a1d3f8686c0e53f160187c4d2ccbc",
"content_id": "ae4a94fc9407a0f1677fb3d1d908ebf1fd9ae15b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3087,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 93,
"path": "/nci/lint/versions.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'minitest'\n\nrequire_relative '../../lib/apt'\n\nrequire_relative 'cache_package_lister'\nrequire_relative 'dir_package_lister'\nrequire_relative 'package_version_check'\nrequire_relative 'repo_package_lister'\n\n# rubocop:disable Style/BeginBlock\nBEGIN {\n # Use 4 threads in minitest parallelism, apt-cache is heavy, so we can't\n # bind this to the actual CPU cores. 4 Is reasonably performant on SSDs.\n ENV['MT_CPU'] ||= '4'\n}\n# rubocop:enable\n\nmodule NCI\n # Very special test type.\n #\n # When in a pangea testing scope this test while aggregate will not\n # report any test methods (even if there are), this is to avoid problems\n # if/when we use minitest for pangea testing at large\n #\n # The purpose of this class is to easily get jenkins-converted data\n # out of a \"test\". Test in this case not being a unit test of the tooling\n # but a test of the package versions in our repo vs. on the machine we\n # are on (i.e. repo vs. ubuntu or other repo).\n # Before doing anything this class needs a lister set. A lister\n # implements a `packages` method which returns an array of objects with\n # `name` and `version` attributes describing the packages we have.\n # It then constructs checks if these packages' versions are greater than\n # the ones we have presently available in the system.\n class VersionsTest < MiniTest::Test\n parallelize_me!\n\n class << self\n # :nocov:\n def runnable_methods\n return if ENV['PANGEA_UNDER_TEST']\n\n super\n end\n # :nocov:\n\n def reset!\n @ours = nil\n @theirs = nil\n end\n\n def init(ours:, theirs:)\n # negative test to ensure tests aren't forgetting to run reset!\n raise 'ours mustnt be set twice' if @ours\n raise 'theirs mustnt be set twice' if @theirs\n\n @ours = ours.freeze\n @theirs = theirs.freeze\n\n Apt.update if Process.uid.zero? # update if root\n\n define_tests\n end\n\n # This is a tad meh. We basically need to meta program our test\n # methods as we'll want individual meths for each check so we get\n # this easy to read in jenkins, but since we only know which lister\n # to use once the program runs we'll have to extend ourselves lazily\n # via class_eval which allows us to edit the class from within\n # a class method.\n # The ultimate result is a bunch of test_pkg_version methods.\n def define_tests\n @ours.each do |pkg|\n their = @theirs.find { |x| x.name == pkg.name }\n class_eval do\n define_method(\"test_#{pkg.name}_#{pkg.version}\") do\n PackageVersionCheck.new(ours: pkg, theirs: their).run\n end\n end\n end\n end\n end\n\n def initialize(name = self.class.to_s)\n # Override and provide a default param for name so our tests can\n # pass without too much internal knowledge.\n super\n end\n end\nend\n"
},
{
"alpha_fraction": 0.623031497001648,
"alphanum_fraction": 0.6432086825370789,
"avg_line_length": 35.94545364379883,
"blob_id": "2c55f12c4df2a09f1a3eeb3c8bd78173bb3f196d",
"content_id": "16f07eda30bf30cff0611554e25df26f025b880e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2032,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 55,
"path": "/nci/jenkins-bin/slave.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule NCI\n module JenkinsBin\n # Simple slave helper. Helps translating slave namaes to CPU core counts.\n class Slave\n # This is the input cores! Depending on the node name we'll determine how\n # many cores the build used.\n PREFIX_TO_CORES = {\n 'jenkins-do-2core.' => 2,\n 'jenkins-do-4core.' => 4,\n 'jenkins-do-8core.' => 8,\n 'jenkins-do-12core.' => 12,\n 'jenkins-do-16core.' => 16,\n 'jenkins-do-20core.' => 20,\n # High CPU - these are used as drop in replacements with 'off' core\n # count but semi reasonable disk space.\n 'jenkins-do-c.8core.' => 4,\n 'jenkins-do-c.16core.' => 8,\n 'jenkins-do-c.32core.' => 8,\n # Compat\n 'do-builder' => 2,\n 'persistent.do-builder' => 2,\n 'do-' => 2,\n '46.' => 2\n }.freeze\n\n # Translates a slave name to a core count.\n def self.cores(name)\n PREFIX_TO_CORES.each do |prefix, value|\n return value if name.start_with?(prefix)\n end\n raise \"unknown slave type of #{name}\"\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6536064147949219,
"alphanum_fraction": 0.6616206765174866,
"avg_line_length": 16.546875,
"blob_id": "d8b8cc101ee0ea0d0a79b9068cd580e334769829",
"content_id": "595d619b4b666ca906ec24935f8fe410fb3890ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1123,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 64,
"path": "/nci/imager-img/customization/includes.chroot/lib/live/config/0090-sddm",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n## live-config(7) - System Configuration Components\n## Copyright (C) 2014 Rohan Garg <[email protected]>\n##\n## This program comes with ABSOLUTELY NO WARRANTY; for details see COPYING.\n## This is free software, and you are welcome to redistribute it\n## under certain conditions; see COPYING for details.\n\n\nset -e\n\nCmdline ()\n{\n\t# Reading kernel command line\n\tfor _PARAMETER in ${LIVE_CONFIG_CMDLINE}\n\tdo\n\t\tcase \"${_PARAMETER}\" in\n\t\t\tlive-config.username=*|username=*)\n\t\t\t\tLIVE_USERNAME=\"${_PARAMETER#*username=}\"\n\t\t\t\t;;\n\t\tesac\n\tdone\n}\n\nInit ()\n{\n\t# Checking if package is installed or already configured\n\tif [ ! -e /var/lib/dpkg/info/sddm.list ] || \\\n\t [ -e /var/lib/live/config/sddm ]\n\tthen\n\t\texit 0\n\tfi\n\n\techo -n \" sddm\"\n}\n\nConfig ()\n{\n\tif [ ! -e /usr/bin/sddm ]\n\tthen\n\t\texit 0\n\tfi\n\n\tif [ \"${LIVE_CONFIG_NOAUTOLOGIN}\" != \"true\" ] && [ \"${LIVE_CONFIG_NOX11AUTOLOGIN}\" != \"true\" ]\n\tthen\n\t\t# autologin\n\t\tcat >> /etc/sddm.conf << EOF\n[Autologin]\nUser=$LIVE_USERNAME\nSession=plasma.desktop\nEOF\n\tfi\n\n\t# Avoid xinit\n\ttouch /var/lib/live/config/xinit\n\n\t# Creating state file\n\ttouch /var/lib/live/config/sddm\n}\n\nCmdline\nInit\nConfig\n"
},
{
"alpha_fraction": 0.7020490169525146,
"alphanum_fraction": 0.7060799598693848,
"avg_line_length": 33.61627960205078,
"blob_id": "21c8cba4d0d4189496894d9ee155f04ebf493a11",
"content_id": "c98347c93c901d0abdb3fe1a87f9df3c91a56d3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2977,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 86,
"path": "/nci/aptly_copy_qt.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'net/ssh/gateway'\nrequire 'ostruct'\nrequire 'optparse'\n\nrequire_relative '../lib/aptly-ext/filter'\nrequire_relative '../lib/nci'\nrequire_relative '../lib/aptly-ext/remote'\n\n# options = OpenStruct.new\n# parser = OptionParser.new do |opts|\n# opts.banner = \"Usage: #{opts.program_name} SOURCENAME\"\n\n# opts.on('-r REPO', '--repo REPO',\n# 'Repo to delete from [can be used >1 time]') do |v|\n# options.repos ||= []\n# options.repos << v.to_s\n# end\n# end\n# parser.parse!\n\n# abort parser.help unless ARGV[0] && options.repos\n# options.name = ARGV[0]\n\nlog = Logger.new(STDOUT)\nlog.level = Logger::DEBUG\nlog.progname = $PROGRAM_NAME\n\n# SSH tunnel so we can talk to the repo\nAptly::Ext::Remote.neon do\n repo = Aptly::Repository.get(\"experimental_#{NCI.current_series}\")\n raise unless repo\n\n # FIXME: this is a bit ugh because the repo isn't cleaned. Ideally we should\n # just be able to query all packages and sources of qt*-opensource* and\n # that should be the final list. Since the repo is dirty we need to manually\n # filter the latest sources and then query their related binaries.\n\n sources =\n repo.packages(q: 'Name (% qt*-opensource-*), $Architecture (source)')\n sources = Aptly::Ext::LatestVersionFilter.filter(sources)\n\n query = ''\n sources.each do |src|\n query += ' | ' unless query.empty?\n query += \"($Source (#{src.name}), $Version (= #{src.version}))\"\n end\n\n binaries = repo.packages(q: query)\n binaries = binaries.collect { |x| Aptly::Ext::Package::Key.from_string(x) }\n packages = (sources + binaries).collect(&:to_s)\n\n puts \"Going to copy: #{packages.join(\"\\n\")}\"\n\n # Only needed in unstable, we want to do one rebuild there anyway, so\n # publishing to the other repos is not necessary as the rebuild will take\n # care of that.\n target_repo = Aptly::Repository.get(\"unstable_#{NCI.current_series}\")\n raise unless target_repo\n\n target_repo.add_packages(packages)\n target_repo.published_in.each(&:update!)\nend\n"
},
{
"alpha_fraction": 0.559440553188324,
"alphanum_fraction": 0.5634891390800476,
"avg_line_length": 24.876190185546875,
"blob_id": "652c31ab0b0b3e106399ff562398cedf6187282d",
"content_id": "a1977339ca09e8fd4ac64c439f516c59c6f4a98d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5434,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 210,
"path": "/nci/snap/snapcraft_config.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule NCI\n module Snap\n class SnapcraftConfig\n module AttrRecorder\n def attr_accessor(*args)\n record_readable(*args)\n super\n end\n\n def attr_reader(*args)\n record_readable(*args)\n super\n end\n\n def record_readable(*args)\n @readable_attrs ||= []\n @readable_attrs += args\n end\n\n def readable_attrs\n @readable_attrs\n end\n end\n\n module YamlAttributer\n def attr_name_to_yaml(readable_attrs)\n y = readable_attrs.to_s.tr('_', '-')\n y = 'prime' if y == 'snap'\n y\n end\n\n def encode_with(c)\n c.tag = nil # Unset the tag to prevent clutter\n self.class.readable_attrs.each do |readable_attrs|\n next unless (data = method(readable_attrs).call)\n next if data.respond_to?(:empty?) && data.empty?\n\n c[attr_name_to_yaml(readable_attrs)] = data\n end\n super(c) if defined?(super)\n end\n end\n\n class Part\n extend AttrRecorder\n prepend YamlAttributer\n\n # Array<String>\n attr_accessor :after\n # String\n attr_accessor :plugin\n # Array<String>\n attr_accessor :build_packages\n # Array<String>\n attr_accessor :build_snaps\n # Array<String>\n attr_accessor :stage_packages\n # Hash\n attr_accessor :filesets\n # Array<String>\n attr_accessor :stage\n # FIXME: port to new keyword prime\n # Array<String>\n attr_accessor :snap\n # Hash<String, String>\n attr_accessor :organize\n\n # Array<String>\n attr_accessor :debs\n # Array<String>\n attr_accessor :exclude_debs\n\n # Array<String>\n attr_accessor :parse_info\n\n attr_accessor :source\n attr_accessor :source_type\n attr_accessor :source_depth\n attr_accessor :source_branch\n attr_accessor :source_commit\n attr_accessor :source_tag\n attr_accessor :source_subdir\n\n attr_accessor :cmake_parameters\n\n # Array<String>\n attr_accessor :build_attributes\n attr_accessor :override_build\n\n def initialize(hash = {})\n from_h(hash)\n init_defaults\n end\n\n def init_defaults\n @after ||= []\n @plugin ||= 'nil'\n @build_packages ||= []\n @stage_packages ||= []\n @filesets ||= {}\n @filesets['exclusion'] ||= []\n @filesets['exclusion'] += %w[\n -usr/lib/*/cmake/*\n -usr/include/*\n -usr/share/ECM/*\n -usr/share/doc/*\n -usr/share/man/*\n -usr/share/icons/breeze-dark*\n -usr/bin/X11\n -usr/lib/gcc/x86_64-linux-gnu/6.0.0\n -usr/lib/aspell/*\n ]\n @filesets['exclusion'].uniq!\n @stage ||= []\n @snap ||= []\n @snap += %w[$exclusion] unless @snap.include?('$exclusion')\n end\n\n def from_h(h)\n h.each do |k, v|\n k = 'snap' if k == 'prime'\n send(\"#{k.tr('-', '_')}=\", v)\n end\n end\n end\n\n # This is really ContentSlot :/\n class Slot\n extend AttrRecorder\n prepend YamlAttributer\n\n attr_accessor :content\n attr_accessor :interface\n attr_accessor :read\n end\n\n class DBusSlot\n extend AttrRecorder\n prepend YamlAttributer\n\n attr_accessor :interface\n attr_accessor :name\n attr_accessor :bus\n\n def initialize\n @interface = 'dbus'\n end\n end\n\n class Plug\n extend AttrRecorder\n prepend YamlAttributer\n\n attr_accessor :content\n attr_accessor :interface\n attr_accessor :default_provider\n attr_accessor :target\n end\n\n class App\n extend AttrRecorder\n prepend YamlAttributer\n\n attr_accessor :command\n attr_accessor :plugs\n end\n\n extend AttrRecorder\n prepend YamlAttributer\n\n attr_accessor :name\n attr_accessor :version\n attr_accessor :summary\n attr_accessor :description\n attr_accessor :confinement\n attr_accessor :grade\n attr_accessor :apps\n attr_accessor :slots\n attr_accessor :plugs\n attr_accessor :parts\n\n def initialize\n @parts = {}\n @slots = {}\n @plugs = {}\n @apps = {}\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6212268471717834,
"alphanum_fraction": 0.6241480112075806,
"avg_line_length": 23.452381134033203,
"blob_id": "9a92e9a18f51eba6125c1bb50a1ed620f4f14350",
"content_id": "694acaa4e5d0637b7e8d3962da42ef4ff4206088",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 42,
"path": "/lib/lint/symbols.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'result'\n\nmodule Lint\n # Lints the presence of symbols files\n class Symbols\n attr_reader :package_directory\n\n def initialize(package_directory = Dir.pwd)\n @package_directory = package_directory\n end\n\n # @return [Result]\n def lint\n result = Result.new\n result.valid = true\n Dir.glob(\"#{@package_directory}/lib*.install\").each do |install_file|\n lint_install_file(result, install_file)\n end\n result\n end\n\n private\n\n def lint_install_file(result, file)\n dir = File.dirname(file)\n basename = File.basename(file, '.install')\n return unless int?(basename[-1]) # No number at the end = no public lib.\n return if File.exist?(\"#{dir}/#{basename}.symbols\") ||\n File.exist?(\"#{dir}/#{basename}.symbols.amd64\")\n\n result.errors << \"Public library without symbols file: #{basename}\"\n result\n end\n\n def int?(char)\n !Integer(char).nil?\n rescue\n false\n end\n end\nend\n"
},
{
"alpha_fraction": 0.65065997838974,
"alphanum_fraction": 0.658170223236084,
"avg_line_length": 31.791044235229492,
"blob_id": "e3b4c594a997d04dc9463183944bbd7f18ea3acc",
"content_id": "18c8f7eabbdcc90210f9051d3afa0e7b1fea381e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4394,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 134,
"path": "/test/test_deploy_upgrade_container.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'vcr'\n\nrequire_relative '../lib/ci/containment'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\nDocker.options[:read_timeout] = 4 * 60 * 60 # 4 hours.\n\nclass DeployUpgradeTest < TestCase\n self.file = __FILE__\n\n # :nocov:\n def cleanup_container\n # Make sure the default container name isn't used, it can screw up\n # the vcr data.\n c = Docker::Container.get(@job_name)\n c.stop\n c.kill!\n c.remove\n rescue Docker::Error::NotFoundError, Excon::Errors::SocketError\n end\n\n def cleanup_image\n return unless Docker::Image.exist?(@image)\n\n puts \"Cleaning up image #{@image}\"\n image = Docker::Image.get(@image)\n image.delete(force: true, noprune: true)\n rescue Docker::Error::NotFoundError, Excon::Errors::SocketError\n end\n\n def create_container\n puts \"Creating new base image #{@image}\"\n Docker::Image.create(fromImage: 'ubuntu:vivid').tag(repo: @repo,\n tag: 'latest')\n end\n # :nocov:\n\n def setup\n # Disable attaching as on failure attaching can happen too late or not\n # at all as it depends on thread execution order.\n # This can cause falky tests and is not relevant to the test outcome for\n # any test.\n CI::Containment.no_attach = true\n\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :excon\n config.default_cassette_options = {\n match_requests_on: %i[method uri body]\n }\n # ERB PWD\n config.filter_sensitive_data('<%= Dir.pwd %>') { Dir.pwd }\n end\n\n @repo = self.class.to_s.downcase\n @image = \"#{@repo}:latest\"\n\n @job_name = @repo.tr(':', '_')\n @tooling_path = File.expand_path(\"#{__dir__}/../\")\n @binds = [\"#{Dir.pwd}:/tooling-pending\"]\n # Instead of using the live upgrader script, use a stub to avoid failure\n # from actual problems in the upgrader script and/or the system.\n FileUtils.cp_r(\"#{datadir}/deploy_in_container.sh\", Dir.pwd)\n FileUtils.cp_r(\"#{datadir}/deploy_in_container.sh\", \"#{Dir.pwd}/deploy_upgrade_container.sh\")\n\n # Fake info call for consistency\n Docker.stubs(:info).returns('DockerRootDir' => '/var/lib/docker')\n Docker.stubs(:version).returns('ApiVersion' => '1.24', 'Version' => '1.12.3')\n end\n\n def teardown\n VCR.turned_off do\n cleanup_container\n end\n CI::EphemeralContainer.safety_sleep = 5\n end\n\n def vcr_it(meth, **kwords)\n defaults = {\n erb: true\n }\n VCR.use_cassette(meth, defaults.merge(kwords)) do |cassette|\n if cassette.recording?\n VCR.eject_cassette\n VCR.turned_off do\n cleanup_container\n cleanup_image\n create_container\n end\n VCR.insert_cassette(cassette.name)\n else\n CI::EphemeralContainer.safety_sleep = 0\n end\n yield cassette\n end\n end\n\n def test_success\n vcr_it(__method__) do\n c = CI::Containment.new(@job_name, image: @image, binds: @binds)\n cmd = ['sh', '/tooling-pending/deploy_upgrade_container.sh',\n 'vivid', 'wily']\n ret = c.run(Cmd: cmd)\n assert_equal(0, ret)\n # The script has testing capability built in since we have no proper\n # provisioning to inspect containments post-run in any sort of reasonable\n # way to make assertations. This is a bit of a tricky thing to get right\n # so for the time being inside-testing will have to do.\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6292020082473755,
"alphanum_fraction": 0.6316866278648376,
"avg_line_length": 31.122066497802734,
"blob_id": "98ca047da5b0612b216e6b17fc665ef1125962ec",
"content_id": "da759bca8b981de17ecd3862b906544e7ca77152",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6842,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 213,
"path": "/lib/ci/sourcer_base.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire 'fileutils'\nrequire 'git_clone_url'\nrequire 'rugged'\nrequire 'logger'\n\nrequire_relative 'dependency_resolver'\nrequire_relative '../debian/control'\n\nmodule CI\n # Automatically inject/update Vcs- control fields to match where we actually\n # build things from.\n module ControlVCSInjector\n def copy_source_tree(source_dir, *args)\n ret = super\n return ret if File.basename(source_dir) != 'packaging'\n\n url = vcs_url_of(source_dir)\n return ret unless url\n\n edit_control(\"#{@build_dir}/source/\") do |control|\n fill_vcs_fields(control, url)\n end\n ret\n end\n\n private\n\n def control_log\n @control_log ||= Logger.new(STDOUT).tap { |l| l.progname = 'control' }\n end\n\n def vcs_url_of(path)\n return nil unless Dir.exist?(path)\n \n # prevent error `discover': repository path '/workspace/packaging/' is not owned by current user (Rugged::ConfigError)\n `chown -R root.root packaging/`\n\n repo = Rugged::Repository.discover(path)\n remote = repo.remotes['origin']\n remote.url\n rescue Rugged::RepositoryError\n control_log.warn \"Failed to resolve repo of #{path}\"\n nil\n end\n\n def fill_vcs_fields(control, url)\n control_log.info \"Automatically filling VCS fields pointing to #{url}\"\n # One could technically append '-b $branchname' as per the debian policy\n # but honestly figuring out the right branch is more work than this is\n # worth. I've never heared of anybody using this field for anything.\n control.source['Vcs-Git'] = url\n uri = GitCloneUrl.parse(url)\n uri.path = uri.path.gsub('.git', '') # sanitize\n control.source['Vcs-Browser'] = vcs_browser(uri) || url\n control.dump\n end\n\n def vcs_browser(uri)\n case uri.host\n when 'invent.kde.org'\n \"https://invent.kde.org#{uri.path}\"\n # :nocov: no point covering this besides the interpolation.\n # neon is actually tested!\n when 'git.debian.org', 'anonscm.debian.org'\n \"https://anonscm.debian.org/cgit#{uri.path}.git\"\n when 'github.com'\n \"https://github.com#{uri.path}\"\n end\n # :nocov:\n end\n end\n\n # Base class for sourcer implementations.\n class SourcerBase\n prepend ControlVCSInjector\n\n class BuildPackageError < StandardError; end\n\n private\n\n def initialize(release:, strip_symbols:, restricted_packaging_copy:)\n @release = release # e.g. vivid\n @strip_symbols = strip_symbols\n @restricted_packaging_copy = restricted_packaging_copy\n\n # vcs\n @packaging_dir = File.absolute_path('packaging').freeze\n # orig\n @packagingdir = @packaging_dir.freeze\n\n # vcs\n @build_dir = \"#{Dir.pwd}/build\"\n # orig\n @builddir = @build_dir.freeze\n FileUtils.rm_r(@build_dir) if Dir.exist?(@build_dir)\n Dir.mkdir(@build_dir)\n\n init_overlay\n\n # vcs\n # TODO:\n # orig\n @sourcepath = \"#{@builddir}/source\" # Created by extract.\n end\n\n def init_overlay\n # Cripple stupid bin calls issued by the dpkg build tooling. In our\n # overlay we have scripts that alter the behavior of certain commands that\n # are being called in an undesirable manner (e.g. causing too much output)\n overlay_path = File.expand_path(\"#{__dir__}/../../overlay-bin\")\n unless File.exist?(overlay_path)\n raise \"could not find overlay bins in #{overlay_path}\"\n end\n\n ENV['PATH'] = \"#{overlay_path}:#{ENV['PATH']}\"\n end\n\n def mangle_symbols\n # Rip out symbol files unless we are on latest\n return unless @strip_symbols\n\n symbols = Dir.glob('debian/symbols') +\n Dir.glob('debian/*.symbols') +\n Dir.glob('debian/*.symbols.*') +\n Dir.glob('debian/*.acc') +\n Dir.glob('debian/*.acc.in')\n symbols.each { |s| FileUtils.rm(s) }\n end\n\n def edit_control(dir, &_block)\n control = Debian::Control.new(dir)\n control.parse!\n yield control\n File.write(\"#{dir}/debian/control\", control.dump)\n end\n\n def mangle_maintainer\n name = ENV['DEBFULLNAME']\n email = ENV['DEBEMAIL']\n unless name\n warn 'Not mangling maintainer as no debfullname is set'\n return\n end\n edit_control(Dir.pwd) do |control|\n control.source['Maintainer'] = \"#{name} <#{email || '[email protected]'}>\"\n end\n end\n\n def dpkg_buildpackage\n mangle_maintainer unless ENV['NOMANGLE_MAINTAINER']\n run_dpkg_buildpackage_with_deps\n end\n\n def run_dpkg_buildpackage_with_deps\n # By default we'll not install build depends on the package and hope\n # it generates a sources even without build deps present.\n # If this fails we'll rescue the error *once* and resolve the deps.\n with_deps ||= false\n run_dpkg_buildpackage\n rescue BuildPackageError => e\n raise e if with_deps # Failed even with deps installed: give up\n\n warn 'Failed to build source. Trying again with all build deps installed!'\n with_deps = true\n resolve_deps\n retry\n end\n\n def run_dpkg_buildpackage\n args = [\n 'dpkg-buildpackage',\n '-us', '-uc', # Do not sign .dsc / .changes\n '-S', # Only build source\n '-d' # Do not enforce build-depends\n ]\n args << '-nc' if ENV['PANGEA_UNDER_TEST'] # don't clean - be fast!\n raise BuildPackageError, 'dpkg-buildpackage failed!' unless system(*args)\n end\n\n def resolve_deps\n DependencyResolver.resolve(Dir.pwd, retries: 3, bin_only: true)\n rescue DependencyResolver::ResolutionError\n raise BuildPackageError, <<-ERRORMSG\nFailed to build source. The source failed to build, then we tried to install\nbuild deps but it still failed. The error may likely be further up\n(before we tried to install dependencies...)\n ERRORMSG\n end\n\n # Copies a source tree to the target source directory\n # @param source_dir the directory to copy from (all content within will\n # be copied)\n # @note this will create @build_dir/source if it doesn't exist\n # @note this will strip the copied source of version control directories\n def copy_source_tree(source_dir, dir = '.')\n # /. is fileutils notation for recursive content\n FileUtils.mkpath(\"#{@build_dir}/source\")\n if Dir.exist?(source_dir)\n FileUtils.cp_r(\"#{source_dir}/#{dir}\",\n \"#{@build_dir}/source/\",\n verbose: true)\n end\n %w[.bzr .git .hg .svn].each do |vcs_dir|\n FileUtils.rm_rf(Dir.glob(\"#{@build_dir}/source/**/#{vcs_dir}\"))\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6899350881576538,
"alphanum_fraction": 0.6996753215789795,
"avg_line_length": 23.156862258911133,
"blob_id": "85cf4e94b4a4f416e3514b03350b73cc57bfcb0a",
"content_id": "9807dce39929415af84b12eb3070e09277369d02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1232,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 51,
"path": "/nci/imager/build-hooks-neon-mobile/093-preinstalled-pool.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -e\n\necho 'running preinstalled pool hoook'\n\nmkdir -p /var/lib/preinstalled-pool/pool/\ncd /var/lib/preinstalled-pool/pool/\n\n# To resolve all relevant dependencies of the packages we want to have in our\n# ISO repo we'll run a regular apt-get install with a fake cache directory.\n# This has the effect of apt-get going through the entire dep resolution step\n# and actually downloading all missing packages into our cache dir from which\n# we'll then fish them into the pool.\n# This does require all packages to be resolvable at the same time. Should\n# this become impossible at some point this would have to be split into\n# multiple steps.\nmkdir -p cache/partial\napt-get \\\n -o Debug::NoLocking=true \\\n -o Dir::Cache::Archives=`pwd`/cache \\\n --download-only \\\n -y \\\n install \\\n b43-fwcutter \\\n dkms \\\n fakeroot \\\n libfakeroot \\\n libc6-i386 \\\n grub-efi \\\n grub-efi-amd64 \\\n grub-efi-amd64-bin \\\n grub-efi-amd64-signed \\\n mokutil \\\n patch \\\n setserial \\\n shim \\\n shim-signed \\\n user-setup \\\n bcmwl-kernel-source \\\n oem-config \\\n oem-config-kde\napt-get \\\n -o Debug::NoLocking=true \\\n -o Dir::Cache::Archives=`pwd`/cache \\\n --download-only \\\n -y \\\n install \\\n grub-pc\nmv cache/*.deb .\nrm -r cache\n"
},
{
"alpha_fraction": 0.5866817235946655,
"alphanum_fraction": 0.5889390707015991,
"avg_line_length": 29.55172348022461,
"blob_id": "a4273290958021af69012f9fcf605148fe924da7",
"content_id": "e4e6e2258a88da5b3152caa8a46506e271115b6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4430,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 145,
"path": "/nci/debian-merge/repository.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'git'\nrequire 'git_clone_url'\nrequire 'net/ssh'\nrequire 'rugged'\n\nrequire_relative 'repositorybase'\nrequire_relative 'tagvalidator'\n\nmodule NCI\n module DebianMerge\n # A merging repo.\n class Repository < RepositoryBase\n attr_accessor :tag_base\n attr_accessor :url\n\n class << self\n def clone_into(url, dir)\n unless Rugged.features.include?(:ssh)\n raise 'this rugged doesnt support ssh. need that to push!'\n end\n\n new(url, dir)\n end\n end\n\n def initialize(url, dir)\n path = \"#{dir}/#{File.basename(url)}\"\n # Use shell git wrapper to describe master, Rugged doesn't implement\n # git_describe_workdir yet.\n # Also cloning through a subprocess allows proper parallelism even with\n # ruby MRI\n @git = Git.clone(url, path)\n super(Rugged::Repository.init_at(path))\n @url = url\n config_repo\n end\n\n def config_repo\n @git.config('merge.dpkg-mergechangelogs.name',\n 'debian/changelog merge driver')\n @git.config('merge.dpkg-mergechangelogs.driver',\n 'dpkg-mergechangelogs -m %O %A %B %A')\n repo_path = @git.repo.path\n FileUtils.mkpath(\"#{repo_path}/info\")\n File.write(\"#{repo_path}/info/attributes\",\n \"debian/changelog merge=dpkg-mergechangelogs\\n\")\n @git.config('user.name', 'Neon CI')\n @git.config('user.email', '[email protected]')\n end\n\n def merge\n assert_tag_valid\n\n # If the ancestor is the tag then the tag has been\n # merged already (i.e. the ancestor would be the tag itself)\n return if tag.target == ancestor\n\n merge_commit\n @dirty = true\n end\n\n def push\n return unless @dirty\n\n mangle_push_path!\n @rug.remotes['origin'].push(\n [branch.canonical_name.to_s],\n update_tips: ->(*args) { puts \"tip:: #{args}\" },\n credentials: method(:credentials)\n )\n end\n\n private\n\n def branch\n @branch ||= begin\n branch = @rug.branches.find do |b|\n b.name == 'origin/Neon/pending-merge'\n end\n branch ||= @rug.branches.find { |b| b.name == 'origin/Neon/unstable' }\n raise 'couldnt find a branch to merge into' unless branch\n\n @rug.branches.create('Neon/pending-merge', branch.name)\n end\n end\n\n def ancestor\n @ancestor ||= begin\n ancestor_oid = @rug.merge_base(tag.target, branch.target)\n unless ancestor_oid\n raise \"repo #{@url} has no ancestor on #{tag.name} & #{branch.name}\"\n end\n\n @rug.lookup(ancestor_oid)\n end\n end\n\n def merge_commit\n @git.checkout(branch.name)\n @git.merge(tag.target_id, \"Automatic merging of Debian's #{tag.name}\")\n end\n\n def tag\n # Dir.chdir(@git.dir.path) do\n # system 'gitk'\n # end\n @tag ||= begin\n tag_name = @git.tags.sort_by { |x| x.tagger.date }[-1].name\n @rug.tags.find { |t| t.name == tag_name }\n end\n end\n\n def assert_tag_valid\n name = tag.name\n unless TagValidator.new.valid?(@rug.remotes['origin'].url,\n @tag_base,\n name)\n raise \"unexpected last tag #{name} on #{@git.dir.path}\"\n end\n\n puts \"#{@git.dir.path} : #{name}\"\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6002665162086487,
"alphanum_fraction": 0.6035975813865662,
"avg_line_length": 28.7227725982666,
"blob_id": "8aefd0e0222dfe3579b9b0acaaace6a8c8b1325f",
"content_id": "e00fb48579fb316de299f7067258eb288f49fa7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3002,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 101,
"path": "/lib/adt/junit/summary.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'jenkins_junit_builder'\n\nmodule ADT\n module JUnit\n # Wrapper converting an ADT summary into a JUnit suite.\n class Summary\n # Wrapper converting an ADT summary entry into a JUnit case.\n class Entry\n def initialize(entry, dir)\n @entry = entry\n @dir = dir\n end\n\n def to_case\n c = JenkinsJunitBuilder::Case.new\n c.name = @entry.name\n c.time = 0\n c.classname = @entry.name\n c.result = result\n if output?\n c.system_out.message = stdout\n c.system_err.message = stderr\n end\n c\n end\n\n private\n\n RESULT_MAP = {\n ADT::Summary::Result::PASS =>\n JenkinsJunitBuilder::Case::RESULT_PASSED,\n ADT::Summary::Result::FAIL =>\n JenkinsJunitBuilder::Case::RESULT_FAILURE,\n ADT::Summary::Result::SKIP =>\n JenkinsJunitBuilder::Case::RESULT_SKIPPED\n }.freeze\n\n def output?\n @entry.result != ADT::Summary::Result::PASS\n end\n\n def stdout\n read_output('stdout')\n end\n\n def stderr\n read_output('stderr')\n end\n\n def read_output(type)\n path = \"#{@dir}/#{@entry.name}-#{type}\"\n File.exist?(path) ? File.read(path) : nil\n end\n\n def result\n RESULT_MAP.fetch(@entry.result)\n end\n end\n\n def initialize(summary)\n @suite = JenkinsJunitBuilder::Suite.new\n @suite.name = 'autopkgtest'\n @suite.package = 'autopkgtest'\n dir = File.dirname(summary.path)\n summary.entries.each do |entry|\n if entry.name == '*' && entry.result == ADT::Summary::Result::SKIP\n # * SKIP is used to indicate that all were skipped because there\n # were none, we don't care as we simply represent no testcases then\n next\n end\n\n @suite.add_case(Entry.new(entry, dir).to_case)\n end\n end\n\n def to_xml\n @suite.build_report\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6424474120140076,
"alphanum_fraction": 0.6520076394081116,
"avg_line_length": 35.068965911865234,
"blob_id": "488ba6d338fddbc50ef835f5dfdbf9bec6ce58df",
"content_id": "87fdb4ddf4d2cff7fe6eaa269690f19fc4ffac56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1046,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 29,
"path": "/nci/imager/build-hooks-xenon-mycroft/010-neon-forks.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -e\n\nUBIQUITY=`apt-cache policy ubiquity | grep http | head -n 1 | awk '{print $2}' | sed 's,[a-z]*$,,'`\nLIVE_BUILD=`apt-cache policy live-build | grep http | head -n 1 | awk '{print $2}' | sed 's,[a-z]*$,,'`\nBASE_FILES=`apt-cache policy base-files | grep http | head -n 1 | awk '{print $2}' | sed 's,[a-z]*$,,'`\n\nif ! grep -q http://archive.neon.kde.org/ <<<$UBIQUITY; then\n echo \"error: Ubiquity does not come from neon\"; \\\n exit 1; \\\nfi\n\nif ! grep -q http://archive.neon.kde.org/ <<<$LIVE_BUILD; then\n echo \"error: live-build does not come from neon\"; \\\n exit 1; \\\nfi\n\nif ! grep -q http://archive.neon.kde.org/ <<<$BASE_FILES; then\n echo \"error: base-files does not come from neon\"; \\\n exit 1; \\\nfi\n\n#if exists /usr/share/grub-installer/grub-installer but not neon grep then exit\n\nif [ -e /usr/share/grub-installer/grub-installer ] && ! grep neon /usr/share/grub-installer/grub-installer; then\n echo \"error: grub-installer does not have neon-efi.diff patch applied, apply it manually in bzr archive\"; \\\n exit 1; \\\nfi\n"
},
{
"alpha_fraction": 0.6693657040596008,
"alphanum_fraction": 0.6781376600265503,
"avg_line_length": 42.588233947753906,
"blob_id": "b65b4cf8c380dc30394bcd2859690bf2c5824e3e",
"content_id": "c6d7d0d608118dc5d9651b12d13071348ba1943e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1482,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 34,
"path": "/test/lib/assert_xml.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'equivalent-xml'\n\nmodule EquivalentXmlAssertations\n def assert_xml_equal(expected, actual, **kwords)\n diff = Test::Unit::Assertions::AssertionMessage.delayed_diff(expected,\n actual)\n msg = build_message('XML was expected to be equal but was not!',\n \"EXPECTED:\\n--\\n<?>\\n--\\nACTUAL:\\n--\\n<?>\\n--\\n?\",\n expected, actual, diff)\n assert_block(msg) do\n EquivalentXml.equivalent?(expected, actual, **kwords)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6891679763793945,
"alphanum_fraction": 0.7017268538475037,
"avg_line_length": 30.850000381469727,
"blob_id": "bfbd78ab1cdf8d01c126132d6af2b850a7413b2b",
"content_id": "e4cc6574bf8175191a349df2696ab5b816cc2ea4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 637,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 20,
"path": "/jenkins-jobs/nci/mgmt_cnf.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'pipelinejob'\n\n# generates command-not-found metadata\nclass MGTMCNFJob < PipelineJob\n attr_reader :dist\n attr_reader :type\n attr_reader :conten_push_repo_dir\n\n def initialize(dist:, type:, conten_push_repo_dir: type, name: type)\n super(\"mgmt_cnf_#{dist}_#{name}\", template: 'mgmt_cnf', cron: '@weekly')\n @dist = dist\n @type = type\n @conten_push_repo_dir = conten_push_repo_dir == 'stable' ? 'testing' : conten_push_repo_dir\n end\nend\n"
},
{
"alpha_fraction": 0.5898675918579102,
"alphanum_fraction": 0.5959776043891907,
"avg_line_length": 45.75,
"blob_id": "84bfdc54f0f6042aa96c0b67c585095c251a5fc3",
"content_id": "a56415b3d26ae737c5514b716f850dd741702984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 3928,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 84,
"path": "/lib/ci/kcrash_link_validator.cmake",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "\n# Definitive newline here ^. If the original script didn't have a terminal newline\n# we'd otherwise append to another method call.\n\n# SPDX-FileCopyrightText: 2018-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: BSD-2-Clause\n\nfunction(kcrash_validator_get_subs output dir)\n # NB: the same function has the same scope if called recursively.\n get_property(_subs DIRECTORY ${dir} PROPERTY SUBDIRECTORIES)\n foreach(sub ${_subs})\n kcrash_validator_get_subs(${output} ${sub})\n endforeach()\n set(${output} ${${output}} ${_subs} PARENT_SCOPE)\nendfunction()\n\nfunction(kcrash_validator_check_all_targets)\n set(linked_types \"MODULE_LIBRARY;EXECUTABLE;SHARED_LIBRARY\")\n\n kcrash_validator_get_subs(subs .)\n foreach(sub ${subs})\n # List of all tests in this directory. Only available in cmake 3.12 (we always have that since 20.04).\n # These will generally (maybe even always?) have the same name as the target.\n get_property(_tests DIRECTORY ${sub} PROPERTY TESTS)\n # All targets in this directory.\n get_property(targets DIRECTORY ${sub} PROPERTY BUILDSYSTEM_TARGETS)\n foreach(target ${targets})\n # Is a linked type (executable/lib)\n get_target_property(target_type ${target} TYPE)\n list(FIND linked_types ${target_type} linked_type_index)\n if(${linked_type_index} LESS 0)\n continue()\n endif()\n\n # Filter tests\n # NB: cannot use IN_LIST condition because it is policy dependant\n # and we do not want to change the policy configuration\n list(FIND _tests ${target} target_testlib_index)\n if(${target_testlib_index} GREATER -1)\n continue()\n endif()\n\n # Is part of all target\n get_target_property(target_exclude_all ${target} EXCLUDE_FROM_ALL)\n if(${target_exclude_all})\n continue()\n endif()\n\n set(_is_test OFF)\n set(_links_kcrash OFF)\n set(_versions \";5;6\") # this must be a var or IN LISTS won't work. Unversioned is a valid option!\n foreach(_version IN LISTS _versions)\n # Wants KCrash\n # NB: cannot use IN_LIST condition because it is policy dependant\n # and we do not want to change the policy configuration\n get_target_property(target_libs ${target} LINK_LIBRARIES)\n list(FIND target_libs \"KF${_version}::Crash\" target_lib_index)\n if(${target_lib_index} GREATER -1)\n set(_links_kcrash ON)\n endif()\n # Filter tests... again.\n # This further approximates test detection. Unfortunately tests aren't always add_test() and don't\n # appear in the TESTS property. So we also check if the target at hand links qtest and if that is the\n # case skip it. Production targets oughtn't ever use qtest and that assumption is likely true 99% of\n # the time (and for the case when it is not true I'd consider it a bug that qtest is linked at all).\n list(FIND target_libs \"Qt${_version}::Test\" target_testlib_index)\n if(${target_testlib_index} GREATER -1)\n set(_is_test ON)\n endif()\n endforeach()\n if(_is_test OR NOT _links_kcrash)\n continue()\n endif()\n\n message(\"KCrash validating: ${target}\")\n add_custom_target(objdump-kcrash-${target} ALL\n COMMAND echo \" $<TARGET_FILE:${target}>\"\n COMMAND objdump -p $<TARGET_FILE:${target}> | grep NEEDED | grep libKF.Crash.so\n DEPENDS ${target}\n COMMENT \"Checking if target linked KCrash: ${target}\")\n endforeach()\n endforeach()\nendfunction()\n\nkcrash_validator_check_all_targets()\n"
},
{
"alpha_fraction": 0.7094801068305969,
"alphanum_fraction": 0.7094801068305969,
"avg_line_length": 24.153846740722656,
"blob_id": "ab0d3ec088b180837c1307c854871b762bcd14b0",
"content_id": "1309d62f95bff468d96b068e767d372874143e79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 654,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 26,
"path": "/jenkins-jobs/binarier.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# binary builder\nclass BinarierJob < JenkinsJob\n attr_reader :basename\n attr_reader :type\n attr_reader :distribution\n attr_reader :architecture\n attr_reader :artifact_origin\n attr_reader :downstream_triggers\n\n def initialize(basename, type:, distribution:, architecture:)\n super(\"#{basename}_bin_#{architecture}\", 'binarier.xml.erb')\n @basename = basename\n @type = type\n @distribution = distribution\n @architecture = architecture\n @artifact_origin = \"#{basename}_src\"\n @downstream_triggers = []\n end\n\n def trigger(job)\n @downstream_triggers << job.job_name\n end\nend\n"
},
{
"alpha_fraction": 0.6583747863769531,
"alphanum_fraction": 0.662520706653595,
"avg_line_length": 35,
"blob_id": "1308493718e3725a1c7f718d89ba99826f6f758b",
"content_id": "5114af5ac62a6a41aea083c4d5703d18652fee1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2412,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 67,
"path": "/lib/ci/directbindingarray.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'pathname'\n\nmodule CI\n # Helper class for direct bindings.\n # Direct bindings are simply put absolute paths on the host that are meant\n # to be 1:1 bound into a container. Binding into a container requires the\n # definition of a volume and the actual binding map, both use a different\n # format and are more complex than a simple linear array of paths.\n # DirectBindingArray helps with converting a linear array of paths into\n # the respective types Docker expects.\n class DirectBindingArray\n class ExcessColonError < RuntimeError; end\n class InvalidBindingType < RuntimeError; end\n\n # @return [Hash] Volume API hash of the form { Path => {} }\n def self.to_volumes(array)\n array.each_with_object({}) do |bind, memo|\n volume_specification_check(bind)\n memo[bind.split(':').first] = {}\n end.to_h\n end\n\n # @return [Array] Binds API array of the form [\"Path:Path\"]\n def self.to_bindings(array)\n raise InvalidBindingType unless array.is_a?(Array)\n\n array.collect do |bind|\n volume_specification_check(bind)\n next bind if mapped?(bind)\n\n \"#{bind}:#{bind}\"\n end\n end\n\n def self.volume_specification_check(str)\n # path or path:path. both fine.\n return if str.count(':') <= 1\n # path:path:ro is also fine (NB: above also implies path:ro)\n return if str.count(':') == 2 && str.split(':')[-1] == 'ro'\n\n raise ExcessColonError, 'Invalid docker volume notation'\n end\n\n # Helper for binding candidates with colons.\n # Bindings are a bit tricky as we want to support explicit bindings AND\n # flat paths that get 1:1 mapped into the container.\n # i.e.\n # /tmp:/tmp\n # is a binding map already\n # /tmp/CI::ABC\n # is not and we'll want to 1:1 bind.\n # To tell the two apart we check if the first character after the colon\n # is a slash (target paths need to be absolute). This is fairly accurate\n # but a bit naughty code-wise, unfortunately the best algorithmic choice\n # we appear to have as paths can generally contain : all over the place.\n # Ultimately this is a design flaw in the string based mapping in Docker's\n # API really.\n def self.mapped?(bind)\n parts = bind.split(':')\n return false if parts.size <= 1\n\n parts.shift\n Pathname.new(parts.join(':')).absolute?\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6568021178245544,
"alphanum_fraction": 0.6634275913238525,
"avg_line_length": 36.11475372314453,
"blob_id": "ab425cd2338707420aa0324ba8e960cc68801713",
"content_id": "15db877c8ebebda2af8387615848b95aa0777fd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2264,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 61,
"path": "/nci/snap/identifier.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule NCI\n module Snap\n # Splits a snapcraft channel definition string into its components.\n # e.g. kde-frameworks-5-core18-sdk/latest/edge\n # https://docs.snapcraft.io/channels/551\n class Identifier\n attr_reader :name\n attr_reader :track\n attr_reader :risk\n attr_reader :branch\n\n def initialize(str)\n @str = str\n @name, @track, @risk, @branch = str.split('/')\n @track ||= 'latest'\n @risk ||= 'stable'\n @branch ||= nil\n validate!\n end\n\n def validate!\n # We run the channel definition through `snap download` which only\n # supports a subset of the channel definition aspects in snapcraft.\n # We therefore need to assert that the channel definiton is in fact\n # something we can deal with, which basically amounts to nothing\n # other than risk must specified.\n\n # Mustn't be empty\n raise \"Failed to parse build-snap #{@str}\" unless name\n # Mustn't be anything but latest\n unless track == 'latest'\n raise \"Unsupported track #{track} (via #{@str})\"\n end\n # Mustn't be nil\n raise \"Unsupported risk #{risk} (via #{@str})\" unless risk\n # Must be nil\n raise \"Unsupported branch #{branch} (via #{@str})\" unless branch.nil?\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5723589062690735,
"alphanum_fraction": 0.586107075214386,
"avg_line_length": 23.24561309814453,
"blob_id": "849a76e2e138b247cc01e728f544a01c88327ae8",
"content_id": "2d2029685f215c7b2028475d2c562e8b09e2f702",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1382,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 57,
"path": "/test/lib/serve.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'webrick'\n\nrequire_relative '../../lib/retry'\n\nmodule Test\n @children = []\n\n # Reserved ports:\n # 9474 KCI::OrigSourcerTestCase\n # 9475 TarFetcherTest\n # 111999 PangeaDPutTest\n\n def self.wait_for_connect(port:)\n # 5 times every second try to open a connection to our child.\n # Leave error raising if this fails as we then failed to fire up our\n # serving test.\n Retry.retry_it(times: 5, sleep: 1, errors: [Errno::ECONNREFUSED]) do\n Net::HTTP.start('localhost', port) {}\n end\n end\n\n def self.http_serve(dir, port: '0')\n case pid = fork\n when nil # child\n log = WEBrick::Log.new(nil, WEBrick::BasicLog::FATAL)\n s = WEBrick::HTTPServer.new(DocumentRoot: dir,\n Port: port,\n AccessLog: [],\n Logger: log)\n s.start\n exit(0)\n else # parent\n @children << pid\n at_exit { nuke } # Make sure the child dies even on raised error exits.\n wait_for_connect(port: port)\n yield\n end\n ensure\n if pid\n kill(pid)\n @children.delete(pid)\n end\n end\n\n def self.kill(pid)\n Process.kill('KILL', pid)\n Process.waitpid(pid)\n system('true') # Reset $? to prevent subsquent failure!\n end\n\n def self.nuke\n @children.each do |pid|\n kill(pid)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6401833295822144,
"alphanum_fraction": 0.649350643157959,
"avg_line_length": 28.415729522705078,
"blob_id": "bc8ca60d2a7b9bfaed1a006e11ff5a6e2bb81904",
"content_id": "ab8eda6001513cf7d3cd943b24b2240f0e8a66dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2618,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 89,
"path": "/lib/digital_ocean/action.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../../lib/retry'\nrequire_relative 'client'\nrequire_relative 'droplet'\n\nmodule DigitalOcean\n # Convenience wrapper around actions.\n class Action\n attr_accessor :client\n attr_accessor :id\n\n class << self\n def wait(sleep_for: 16, retries: 100_000, error: nil)\n broken = false\n retries.times do\n if yield\n broken = true\n break\n end\n sleep(sleep_for)\n end\n raise error if error && !broken\n\n broken\n end\n end\n\n def initialize(action_or_id, client)\n @client = client\n @id = action_or_id\n @id = action_or_id.id if action_or_id.is_a?(DropletKit::Action)\n end\n\n def until_status(state)\n count = 0\n until resource.status == state\n yield count\n count += 1\n sleep 16\n end\n end\n\n def complete!(&block)\n until_status('completed', &block)\n end\n\n # Forward not implemented methods.\n # - Methods implemented by the resource are forwarded to the resource\n def method_missing(meth, *args, **kwords)\n # return missing_action(action, *args) if meth.to_s[-1] == '!'\n res = resource\n if res.respond_to?(meth)\n # The droplet_kit resource mapping crap is fairly shitty and doesn't\n # manage to handle kwords properly, pack it into a ruby <=2.0 style\n # array.\n argument_pack = []\n argument_pack += args unless args.empty?\n argument_pack << kwords unless kwords.empty?\n return res.send(meth, *argument_pack) if res.respond_to?(meth)\n end\n super\n end\n\n private\n\n def resource\n client.actions.find(id: id)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7156776189804077,
"alphanum_fraction": 0.7218777537345886,
"avg_line_length": 30.80281639099121,
"blob_id": "ece1a3d28a2d88d83fa158b3ac515a3b821da7f1",
"content_id": "f776b88980619d322b644c327c482043b923aa80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2258,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 71,
"path": "/nci/repo_divert.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'date'\nrequire 'net/ssh/gateway'\n\nrequire_relative '../lib/optparse'\nrequire_relative '../lib/aptly-ext/remote'\n\nparser = OptionParser.new do |opts|\n opts.banner =\n \"Usage: #{opts.program_name} REPO_TO_DIVERT_TO_SNAPSHOT\"\nend\nparser.parse!\n\nunless parser.missing_expected.empty?\n puts \"Missing expected arguments: #{parser.missing_expected.join(', ')}\\n\\n\"\n abort parser.help\nend\n\nREPO_NAME = ARGV.last || nil\nARGV.clear\nunless REPO_NAME\n puts \"Missing repo name to divert\\n\\n\"\n abort parser.help\nend\n\n# SSH tunnel so we can talk to the repo\nAptly::Ext::Remote.neon do\n stamp = Time.now.utc.strftime('%Y%m%d.%H%M%S')\n\n repo = Aptly::Repository.get(REPO_NAME)\n if repo.published_in[0].Prefix.include?('tmp')\n abort \"already Published at tmp/\"\n end\n\n snapshot = repo.snapshot(\"#{REPO_NAME}-#{stamp}\")\n repo.published_in.each do |pub|\n attributes = pub.to_h\n attributes.delete(:Sources)\n attributes.delete(:SourceKind)\n attributes.delete(:Storage)\n attributes.delete(:Prefix)\n prefix = pub.send(:api_prefix)\n raise 'could not call pub.api_prefix and get a result' unless prefix\n\n pub.drop\n snapshot.publish(prefix, **attributes)\n puts \"Publishing original repo under tmp prefix\\n\\n\"\n repo.publish(\"tmp_#{prefix}\", **attributes)\n end\nend\n"
},
{
"alpha_fraction": 0.6394129991531372,
"alphanum_fraction": 0.6394129991531372,
"avg_line_length": 22.850000381469727,
"blob_id": "663d2253cb314bdc6556fcaf9e722ecca9aac0b9",
"content_id": "e52ad650910e87bf67d0496e88da4efb36cd7988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 954,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 40,
"path": "/lib/lint/control.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../debian/control'\nrequire_relative 'result'\n\nmodule Lint\n # Lints a debian control file\n class Control\n attr_reader :package_directory\n\n def initialize(package_directory = Dir.pwd)\n @package_directory = package_directory\n end\n\n # @return [Result]\n def lint\n result = Result.new\n Dir.chdir(@package_directory) do\n control = DebianControl.new\n control.parse!\n result.valid = !control.source.nil?\n return result unless result.valid\n\n result = lint_vcs(result, control)\n end\n result\n end\n\n private\n\n def lint_vcs(result, control)\n unless control.source['Vcs-Browser']\n result.warnings << 'No Vcs-Browser field in control.'\n end\n unless control.source['Vcs-Git'] || control.source['Vcs-Bzr']\n result.warnings << 'No Vcs-Git or Vcs-Bzr field in contorl.'\n end\n result\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5420841574668884,
"alphanum_fraction": 0.5621242523193359,
"avg_line_length": 19.79166603088379,
"blob_id": "bb94ecdad55b4304fd2e63acced49c0c7e14631a",
"content_id": "b40df8fcd21610110fc61fabe0c63bca69db266f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 48,
"path": "/test/test_ci_source.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/ci/source'\nrequire_relative 'lib/testcase'\n\n# Test ci/source\nclass CISourceTest < TestCase\n def setup\n @hash = { 'name' => 'kcmutils',\n 'version' => '2.0',\n 'type' => 'quilt',\n 'dsc' => 'kcmutils_2.0.dsc' }\n end\n\n def test_to_json\n s = CI::Source.new\n @hash.each do |key, value|\n s[key.to_sym] = value\n end\n json = s.to_json\n assert_equal(@hash, JSON.parse(json))\n end\n\n def test_from_json\n s1 = CI::Source.new\n @hash.each do |key, value|\n s1[key.to_sym] = value\n end\n json = JSON.generate(@hash)\n s2 = CI::Source.from_json(json)\n assert_equal(s1, s2)\n end\n\n def test_compare\n s1 = CI::Source.new\n @hash.each do |key, value|\n s1[key.to_sym] = value\n end\n\n s2 = CI::Source.new\n @hash.each do |key, value|\n s2[key.to_sym] = value\n end\n\n assert_equal(s1, s2)\n s2[:version] = '0.0'\n assert_not_equal(s1, s2)\n end\nend\n"
},
{
"alpha_fraction": 0.6588078141212463,
"alphanum_fraction": 0.6701512336730957,
"avg_line_length": 30.886524200439453,
"blob_id": "4df4ac187a7fb16184cc0bc9927a80b4731396fb",
"content_id": "622f73a248e757a0959b6acfb5730a2ff4937046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4496,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 141,
"path": "/nci/adt.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'tty/command'\n\nrequire_relative '../lib/adt/summary'\nrequire_relative '../lib/adt/junit/summary'\nrequire_relative '../lib/nci'\nrequire_relative 'lib/setup_repo'\n\nJOB_NAME = ENV.fetch('JOB_NAME') { File.read('job_name') }.strip\nif NCI.experimental_skip_qa.any? { |x| JOB_NAME.include?(x) }\n warn \"Job #{JOB_NAME} marked to skip QA. Not running autopkgtest (adt).\"\n exit 0\nend\nif NCI.only_adt.none? { |x| JOB_NAME.include?(x) }\n warn \"Job #{JOB_NAME} not enabled. Not running autopkgtest (adt).\"\n exit 0\nend\n\nif JOB_NAME.include?('_armhf')\n warn 'Not running adt on the armhf architecture'\n exit 0\nend\n\nif JOB_NAME.include?('_arm64')\n warn 'Not running adt on the armhf architecture'\n exit 0\nend\n\nNCI.setup_repo!\nNCI.maybe_setup_apt_preference\n\nTESTS_DIR = 'build/debian/tests'\nJUNIT_FILE = 'adt-junit.xml'\n\nunless Dir.exist?(TESTS_DIR)\n puts \"Package doesn't appear to be autopkgtested. Skipping.\"\n exit\nend\n\nif Dir.glob(\"#{TESTS_DIR}/*\").any? { |x| File.read(x).include?('Xephyr') }\n suite = JenkinsJunitBuilder::Suite.new\n suite.name = 'autopkgtest'\n suite.package = 'autopkgtest'\n suite.add_case(JenkinsJunitBuilder::Case.new.tap do |c|\n c.name = 'TestsPresent'\n c.time = 0\n c.classname = 'TestsPresent'\n c.result = JenkinsJunitBuilder::Case::RESULT_PASSED\n c.system_out.message = 'debian/tests/ is present'\n end)\n suite.add_case(JenkinsJunitBuilder::Case.new.tap do |c|\n c.name = 'XephyrUsage'\n c.time = 0\n c.classname = 'XephyrUsage'\n c.result = JenkinsJunitBuilder::Case::RESULT_SKIPPED\n c.system_out.message = 'Tests using xephyr; would get stuck.'\n end)\n suite.build_report\n File.write(JUNIT_FILE, suite.build_report)\n exit\nend\n\n# Gecos is additonal information that would be prompted\nsystem('adduser',\n '--disabled-password',\n '--gecos', '',\n 'adt')\n\nApt.install(%w[autopkgtest])\n\nFileUtils.rm_r('adt-output') if File.exist?('adt-output')\n\nbinary = '/usr/bin/autopkgtest'\nDir.chdir('/') do\n next unless Process.uid.zero?\n\n FileUtils.cp(\"#{__dir__}/adt-helpers/mktemp\", '/usr/sbin/mktemp',\n verbose: true)\n FileUtils.chmod(0o0755, '/usr/sbin/mktemp')\n if File.exist?('/usr/bin/autopkgtest') # bionic and focal\n # Applies with a bit of offset.\n system('patch',\n '/usr/bin/autopkgtest',\n \"#{__dir__}/adt-helpers/adt-run.diff\") || raise\n else # xenial\n system(\"patch -p0 < #{__dir__}/adt-helpers/adt-run.diff\") || raise\n binary = 'adt-run'\n end\n\n # Override ctest to inject an argument forcing the timeout per test at 5m.\n file = '/usr/bin/ctest'\n next if File.exist?(\"#{file}.distrib\") # Already diverted\n\n system('dpkg-divert', '--local', '--rename', '--add', file) || raise\n File.open(file.to_s, File::RDWR | File::CREAT, 0o755) do |f|\n f.write(<<-EOF)\n#!/bin/sh\n#{file}.distrib --timeout #{5 * 60} \"$@\"\nEOF\n end\nend\n\nargs = []\nargs << '--output-dir' << 'adt-output'\nargs << '--user=adt'\nargs << \"--timeout-test=#{30 * 60}\"\n# Try to force Qt to time out on test functions after 5 minutes.\n# This should be the default but doesn't seem to actually work for some reason.\nargs << \"--env=QTEST_FUNCTION_TIMEOUT=#{5 * 60 * 1000}\"\n# Disable KIO using kdeinit and starting http cleanup\nargs << '--env=KDE_FORK_SLAVES=yes'\nargs << '--env=KIO_DISABLE_CACHE_CLEANER=yes'\nif binary == 'adt-run' # xenial compat\n Dir.glob('result/*.deb').each { |x| args << '--binary' << x }\n args << '--built-tree' << \"#{Dir.pwd}/build\"\n args << '---' << 'null'\nelse # bionic and focal\n # newer versions use an even dafter cmdline format than you could possibly\n # imagine where you just throw random shit at it and it will *try* to figure\n # out what you mean. The code where it does that is glorious spaghetti.\n args += Dir.glob('result/*.deb')\n args << \"#{Dir.pwd}/build\"\n args << '--' << 'null'\nend\nTTY::Command.new(uuid: false).run!(binary, *args, timeout: 30 * 60)\n\nsummary = ADT::Summary.from_file('adt-output/summary')\nunit = ADT::JUnit::Summary.new(summary)\nFile.write(JUNIT_FILE, unit.to_xml)\n\nFileUtils.rm_rf('adt-output/binaries', verbose: true)\n# Agressively compress the output for archiving. We want to save as much\n# space as possible, since we have lots of these.\nsystem('tar -cf adt-output.tar adt-output')\nsystem('xz -9 adt-output.tar')\n"
},
{
"alpha_fraction": 0.6373056769371033,
"alphanum_fraction": 0.6528497338294983,
"avg_line_length": 24.733333587646484,
"blob_id": "8f0721590385026bd00496fed447d382e06e2bd0",
"content_id": "7242763fc428fca994b80c43544a4e77290d0edc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 386,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 15,
"path": "/mgmt/monitor_provisioning.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\nrequire 'jenkins_api_client'\n\nJOB_NAME = ENV.fetch('JOB_NAME')\n\nclient = JenkinsApi::Client.new(server_ip: 'mobile.neon.pangea.pub',\n server_port: 8080)\n\nwhile client.queue.list.include?(JOB_NAME) ||\n client.job.status(JOB_NAME) == 'running'\n puts 'Waiting for deployment to finish'\n sleep 10\nend\n"
},
{
"alpha_fraction": 0.6536716818809509,
"alphanum_fraction": 0.694579005241394,
"avg_line_length": 25.70431137084961,
"blob_id": "cfc321c185613d12f8d5fbcb370dce935a1f5efe",
"content_id": "2a02d8c02851aad0ac0b6c3b64324e2d4e8eca25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 13005,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 487,
"path": "/nci/kf6_deconflictor.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2023 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'json'\n\nrequire_relative 'lib/setup_repo'\nrequire_relative '../lib/apt'\nrequire_relative '../lib/kdeproject_component'\n\n# Installs all kf5 and all kf6\n# Compares files in /usr/kf6 with /usr and reports conflicts\nclass Deconflictor\n def install!\n projects = KDEProjectsComponent.frameworks_jobs.uniq\n\n # KF5\n kf5_projects = projects.map do |x|\n # deprecations\n next nil if %w[kross khtml kjs kdesignerplugin oxygen-icons5 kjsembed kdewebkit kinit].include?(x)\n # expected conflicts\n next nil if %w[breeze-icons].include?(x)\n # new in kf6\n next nil if %w[kimageformats kcolorscheme].include?(x)\n\n # anomalities that don't get their leading k clipped\n naming_anomalities = %w[\n kde kcm kio kross kjs khtml kapidox kirigami\n ]\n x = x[1..-1] if x[0] == 'k' && naming_anomalities.none? { |y| x.start_with?(y) }\n name = \"libkf5#{x}-dev\"\n {\n 'libkf5baloo-dev' => 'baloo-kf5-dev',\n 'libkf5bluez-qt-dev' => 'libkf5bluezqt-dev',\n 'libkf5extra-cmake-modules-dev' => 'extra-cmake-modules',\n 'libkf5kded-dev' => 'kded5-dev',\n 'libkf5kdesu-dev' => 'libkf5su-dev',\n 'libkf5activities-stats-dev' => 'libkf5activitiesstats-dev',\n 'libkf5kapidox-dev' => 'kapidox',\n 'libkf5plasma-framework-dev' => 'libkf5plasma-dev',\n 'libkf5syntax-highlighting-dev' => 'libkf5syntaxhighlighting-dev',\n 'libkf5quickcharts-dev' => 'kquickcharts-dev',\n 'libkf5kirigami-dev' => 'kirigami2-dev',\n 'libkf5frameworkintegration-dev' => 'frameworkintegration',\n 'libkf5kdeclarative-dev' => 'libkf5declarative-dev',\n 'libkf5modemmanager-qt-dev' => 'modemmanager-qt-dev',\n 'libkf5networkmanager-qt-dev' => 'libkf5networkmanagerqt-dev',\n 'libkf5qqc2-desktop-style-dev' => 'libkf5qqc2desktopstyle-dev',\n 'libkf5calcore-dev' => 'libkf5calendarcore-dev',\n }.fetch(name, name)\n end.compact\n kf5_projects += JSON.parse(DATA.read)\n kf5_projects.uniq!\n\n # KF6\n kf6_projects = projects.map { |x| \"kf6-#{x}-dev\" }\n # Remove deprecated and incorrect mappings\n %w[\n kf6-breeze-icons-dev\n kf6-extra-cmake-modules-dev\n kf6-kapidox-dev\n kf6-kcalcore-dev\n kf6-kdelibs4support-dev\n kf6-kdesignerplugin-dev\n kf6-kdewebkit-dev\n kf6-kemoticons-dev\n kf6-khtml-dev\n kf6-kimageformats-dev\n kf6-kinit-dev\n kf6-kirigami-dev\n kf6-kjs-dev\n kf6-kjsembed-dev\n kf6-kmediaplayer-dev\n kf6-kross-dev\n kf6-kxmlrpcclient-dev\n kf6-oxygen-icons5-dev\n kf6-ksvg-dev\n kf6-ktexttemplate-dev\n ].each { |x| kf6_projects.delete(x) }\n\n # Add corrected mappings\n # NOTE: ecm is not getting checked because it will remain compatible with kf5 and thus doesn't need co-installability\n # NOTE: kf6-breeze-icons is not packaged because it is a drop in replacement I presume\n kf6_projects += %w[\n kf6-kapidox\n kf6-kimageformat-plugins\n kf6-kirigami2-dev\n ]\n\n Apt.install(*kf5_projects) || raise\n Apt.install(*kf6_projects) || raise\n end\n\n def run\n # Drop all dpkg configs so locales and the like get installed.\n FileUtils.rm_rf(Dir.glob('/etc/dpkg/dpkg.cfg.d/*'))\n NCI.setup_proxy!\n NCI.add_repo_key!\n NCI.setup_repo!\n install!\n\n conflicts = []\n Dir.glob('/usr/kf6/**/**') do |kf6_path|\n next if File.directory?(kf6_path)\n next if kf6_path.include?('share/ECM/') || kf6_path.include?('share/doc/ECM')\n\n kf5_path = kf6_path.sub('/usr/kf6/etc/', '/etc/').sub('/usr/kf6/', '/usr/')\n conflicts << [kf6_path, kf5_path] if File.exist?(kf5_path)\n end\n File.write('conflict-report.json', JSON.pretty_generate(conflicts))\n puts 'conflict-report.json'\n end\nend\n\nDeconflictor.new.run if $PROGRAM_NAME == __FILE__\n\n__END__\n\n[\n \"libkf5attica-dev\",\n \"libkf5attica-doc\",\n \"libkf5attica5\",\n \"baloo-kf5\",\n \"baloo-kf5-dev\",\n \"libkf5baloo-doc\",\n \"libkf5baloo5\",\n \"libkf5balooengine5\",\n \"libkf5bluezqt-data\",\n \"libkf5bluezqt-dev\",\n \"libkf5bluezqt-doc\",\n \"libkf5bluezqt6\",\n \"qml-module-org-kde-bluezqt\",\n \"breeze-icon-theme\",\n \"breeze-icon-theme-rcc\",\n \"extra-cmake-modules\",\n \"extra-cmake-modules-doc\",\n \"frameworkintegration\",\n \"libkf5style-dev\",\n \"libkf5style5\",\n \"kactivities-bin\",\n \"libkf5activities-dev\",\n \"libkf5activities-doc\",\n \"libkf5activities5\",\n \"qml-module-org-kde-activities\",\n \"libkf5activitiesstats-dev\",\n \"libkf5activitiesstats-doc\",\n \"libkf5activitiesstats1\",\n \"kapidox\",\n \"libkf5archive-dev\",\n \"libkf5archive-doc\",\n \"libkf5archive5\",\n \"libkf5auth-data\",\n \"libkf5auth-dev\",\n \"libkf5auth-dev-bin\",\n \"libkf5auth-doc\",\n \"libkf5auth5\",\n \"libkf5authcore5\",\n \"libkf5auth-bin-dev\",\n \"libkf5bookmarks-data\",\n \"libkf5bookmarks-dev\",\n \"libkf5bookmarks-doc\",\n \"libkf5bookmarks5\",\n \"libkf5calendarcore-dev\",\n \"libkf5calendarcore5\",\n \"libkf5kcmutils-data\",\n \"libkf5kcmutils-dev\",\n \"libkf5kcmutils-doc\",\n \"libkf5kcmutils5\",\n \"libkf5kcmutilscore5\",\n \"qml-module-org-kde-kcmutils\",\n \"libkf5codecs-data\",\n \"libkf5codecs-dev\",\n \"libkf5codecs-doc\",\n \"libkf5codecs5\",\n \"libkf5completion-data\",\n \"libkf5completion-dev\",\n \"libkf5completion-doc\",\n \"libkf5completion5\",\n \"libkf5config-bin\",\n \"libkf5config-data\",\n \"libkf5config-dev\",\n \"libkf5config-dev-bin\",\n \"libkf5config-doc\",\n \"libkf5configcore5\",\n \"libkf5configgui5\",\n \"libkf5configqml5\",\n \"libkf5config-bin-dev\",\n \"libkf5configwidgets-data\",\n \"libkf5configwidgets-dev\",\n \"libkf5configwidgets-doc\",\n \"libkf5configwidgets5\",\n \"libkf5contacts-dev\",\n \"libkf5contacts-data\",\n \"libkf5contacts5\",\n \"libkf5contacts-doc\",\n \"libkf5coreaddons-data\",\n \"libkf5coreaddons-dev\",\n \"libkf5coreaddons-dev-bin\",\n \"libkf5coreaddons-doc\",\n \"libkf5coreaddons5\",\n \"libkf5crash-dev\",\n \"libkf5crash-doc\",\n \"libkf5crash5\",\n \"libkf5dav-data\",\n \"libkf5dav-dev\",\n \"libkf5dav5\",\n \"libkf5dbusaddons-bin\",\n \"libkf5dbusaddons-data\",\n \"libkf5dbusaddons-dev\",\n \"libkf5dbusaddons-doc\",\n \"libkf5dbusaddons5\",\n \"kpackagelauncherqml\",\n \"libkf5calendarevents5\",\n \"libkf5declarative-data\",\n \"libkf5declarative-dev\",\n \"libkf5declarative-doc\",\n \"libkf5declarative5\",\n \"libkf5quickaddons5\",\n \"qml-module-org-kde-draganddrop\",\n \"qml-module-org-kde-kcm\",\n \"qml-module-org-kde-kconfig\",\n \"qml-module-org-kde-graphicaleffects\",\n \"qml-module-org-kde-kcoreaddons\",\n \"qml-module-org-kde-kio\",\n \"qml-module-org-kde-kquickcontrols\",\n \"qml-module-org-kde-kquickcontrolsaddons\",\n \"qml-module-org-kde-kwindowsystem\",\n \"qtdeclarative5-kf5declarative\",\n \"kded5\",\n \"kded5-dev\",\n \"libkf5kdelibs4support-data\",\n \"libkf5kdelibs4support-dev\",\n \"libkf5kdelibs4support5\",\n \"libkf5kdelibs4support5-bin\",\n \"kdesignerplugin\",\n \"kdesignerplugin-data\",\n \"kgendesignerplugin\",\n \"kgendesignerplugin-bin\",\n \"libkf5su-bin\",\n \"libkf5su-data\",\n \"libkf5su-dev\",\n \"libkf5su-doc\",\n \"libkf5su5\",\n \"libkf5webkit-dev\",\n \"libkf5webkit5\",\n \"libkf5dnssd-data\",\n \"libkf5dnssd-dev\",\n \"libkf5dnssd-doc\",\n \"libkf5dnssd5\",\n \"kdoctools-dev\",\n \"kdoctools5\",\n \"libkf5doctools-dev\",\n \"libkf5doctools5\",\n \"libkf5emoticons-bin\",\n \"libkf5emoticons-data\",\n \"libkf5emoticons-dev\",\n \"libkf5emoticons-doc\",\n \"libkf5emoticons5\",\n \"libkf5filemetadata-bin\",\n \"libkf5filemetadata-data\",\n \"libkf5filemetadata-dev\",\n \"libkf5filemetadata-doc\",\n \"libkf5filemetadata3\",\n \"libkf5globalaccel-bin\",\n \"libkf5globalaccel-data\",\n \"libkf5globalaccel-dev\",\n \"libkf5globalaccel-doc\",\n \"libkf5globalaccel5\",\n \"libkf5globalaccelprivate5\",\n \"libkf5guiaddons-bin\",\n \"libkf5guiaddons-data\",\n \"libkf5guiaddons-dev\",\n \"libkf5guiaddons-doc\",\n \"libkf5guiaddons5\",\n \"libkf5holidays-data\",\n \"libkf5holidays-dev\",\n \"libkf5holidays-doc\",\n \"libkf5holidays5\",\n \"qml-module-org-kde-kholidays\",\n \"libkf5khtml-bin\",\n \"libkf5khtml-data\",\n \"libkf5khtml-dev\",\n \"libkf5khtml5\",\n \"libkf5i18n-data\",\n \"libkf5i18n-dev\",\n \"libkf5i18n-doc\",\n \"libkf5i18n5\",\n \"libkf5i18nlocaledata5\",\n \"qml-module-org-kde-i18n-localedata\",\n \"libkf5iconthemes-bin\",\n \"libkf5iconthemes-data\",\n \"libkf5iconthemes-dev\",\n \"libkf5iconthemes-doc\",\n \"libkf5iconthemes5\",\n \"libkf5idletime-dev\",\n \"libkf5idletime-doc\",\n \"libkf5idletime5\",\n \"kimageformat-plugins\",\n \"kinit\",\n \"kinit-dev\",\n \"kio\",\n \"kio-dev\",\n \"libkf5kio-dev\",\n \"libkf5kio-doc\",\n \"libkf5kiocore5\",\n \"libkf5kiofilewidgets5\",\n \"libkf5kiogui5\",\n \"libkf5kiontlm5\",\n \"libkf5kiowidgets5\",\n \"kirigami2-dev\",\n \"libkf5kirigami2-5\",\n \"libkf5kirigami2-doc\",\n \"qml-module-org-kde-kirigami2\",\n \"libkf5itemmodels-dev\",\n \"libkf5itemmodels-doc\",\n \"libkf5itemmodels5\",\n \"qml-module-org-kde-kitemmodels\",\n \"libkf5itemviews-data\",\n \"libkf5itemviews-dev\",\n \"libkf5itemviews-doc\",\n \"libkf5itemviews5\",\n \"libkf5jobwidgets-data\",\n \"libkf5jobwidgets-dev\",\n \"libkf5jobwidgets-doc\",\n \"libkf5jobwidgets5\",\n \"libkf5js5\",\n \"libkf5jsapi5\",\n \"libkf5kjs-dev\",\n \"libkf5jsembed-data\",\n \"libkf5jsembed-dev\",\n \"libkf5jsembed5\",\n \"libkf5mediaplayer-data\",\n \"libkf5mediaplayer-dev\",\n \"libkf5mediaplayer5\",\n \"libkf5newstuff-data\",\n \"libkf5newstuff-dev\",\n \"libkf5newstuff-doc\",\n \"libkf5newstuff5\",\n \"libkf5newstuffcore5\",\n \"libkf5newstuffwidgets5\",\n \"qml-module-org-kde-newstuff\",\n \"knewstuff-dialog\",\n \"libkf5notifications-data\",\n \"libkf5notifications-dev\",\n \"libkf5notifications-doc\",\n \"libkf5notifications5\",\n \"qml-module-org-kde-notification\",\n \"libkf5notifyconfig-data\",\n \"libkf5notifyconfig-dev\",\n \"libkf5notifyconfig-doc\",\n \"libkf5notifyconfig5\",\n \"kpackagetool5\",\n \"libkf5package-data\",\n \"libkf5package-dev\",\n \"libkf5package-doc\",\n \"libkf5package5\",\n \"libkf5parts-data\",\n \"libkf5parts-dev\",\n \"libkf5parts-doc\",\n \"libkf5parts-plugins\",\n \"libkf5parts5\",\n \"libkf5people-data\",\n \"libkf5people-dev\",\n \"libkf5people-doc\",\n \"libkf5people5\",\n \"libkf5peoplebackend5\",\n \"libkf5peoplewidgets5\",\n \"qml-module-org-kde-people\",\n \"libkf5plotting-dev\",\n \"libkf5plotting-doc\",\n \"libkf5plotting5\",\n \"libkf5pty-data\",\n \"libkf5pty-dev\",\n \"libkf5pty-doc\",\n \"libkf5pty5\",\n \"kquickcharts-dev\",\n \"qml-module-org-kde-quickcharts\",\n \"kross\",\n \"kross-dev\",\n \"libkf5krosscore5\",\n \"libkf5krossui5\",\n \"libkf5runner-dev\",\n \"libkf5runner-doc\",\n \"libkf5runner5\",\n \"qml-module-org-kde-runnermodel\",\n \"libkf5service-bin\",\n \"libkf5service-data\",\n \"libkf5service-dev\",\n \"libkf5service-doc\",\n \"libkf5service5\",\n \"ktexteditor-data\",\n \"ktexteditor-katepart\",\n \"libkf5texteditor-bin\",\n \"libkf5texteditor-dev\",\n \"libkf5texteditor-doc\",\n \"libkf5texteditor5\",\n \"libkf5textwidgets-data\",\n \"libkf5textwidgets-dev\",\n \"libkf5textwidgets-doc\",\n \"libkf5textwidgets5\",\n \"libkf5unitconversion-data\",\n \"libkf5unitconversion-dev\",\n \"libkf5unitconversion-doc\",\n \"libkf5unitconversion5\",\n \"libkf5wallet-bin\",\n \"libkf5wallet-data\",\n \"libkf5wallet-dev\",\n \"libkf5wallet-doc\",\n \"libkf5wallet5\",\n \"libkwalletbackend5-5\",\n \"kwayland-data\",\n \"kwayland-dev\",\n \"libkf5wayland-dev\",\n \"libkf5wayland-doc\",\n \"libkf5waylandclient5\",\n \"libkf5waylandserver5\",\n \"libkf5widgetsaddons-data\",\n \"libkf5widgetsaddons-dev\",\n \"libkf5widgetsaddons-doc\",\n \"libkf5widgetsaddons5\",\n \"libkf5windowsystem-data\",\n \"libkf5windowsystem-dev\",\n \"libkf5windowsystem-doc\",\n \"libkf5windowsystem5\",\n \"libkf5xmlgui-bin\",\n \"libkf5xmlgui-data\",\n \"libkf5xmlgui-dev\",\n \"libkf5xmlgui-doc\",\n \"libkf5xmlgui5\",\n \"libkf5xmlrpcclient-data\",\n \"libkf5xmlrpcclient-dev\",\n \"libkf5xmlrpcclient-doc\",\n \"libkf5xmlrpcclient5\",\n \"libkf5modemmanagerqt-doc\",\n \"libkf5modemmanagerqt6\",\n \"modemmanager-qt-dev\",\n \"libkf5networkmanagerqt-dev\",\n \"libkf5networkmanagerqt-doc\",\n \"libkf5networkmanagerqt6\",\n \"oxygen-icon-theme\",\n \"libkf5plasma-dev\",\n \"libkf5plasma-doc\",\n \"libkf5plasma5\",\n \"libkf5plasmaquick5\",\n \"plasma-framework\",\n \"libkf5prison-dev\",\n \"libkf5prison-doc\",\n \"libkf5prison5\",\n \"libkf5prisonscanner5\",\n \"qml-module-org-kde-prison\",\n \"libkf5purpose-bin\",\n \"libkf5purpose-dev\",\n \"libkf5purpose5\",\n \"qml-module-org-kde-purpose\",\n \"libkf5qqc2desktopstyle-dev\",\n \"qml-module-org-kde-qqc2desktopstyle\",\n \"libkf5solid-bin\",\n \"libkf5solid-dev\",\n \"libkf5solid-doc\",\n \"libkf5solid5\",\n \"libkf5solid5-data\",\n \"qml-module-org-kde-solid\",\n \"qtdeclarative5-kf5solid\",\n \"libkf5sonnet-dev\",\n \"libkf5sonnet-dev-bin\",\n \"libkf5sonnet-doc\",\n \"libkf5sonnet5-data\",\n \"libkf5sonnetcore5\",\n \"libkf5sonnetui5\",\n \"sonnet-plugins\",\n \"qml-module-org-kde-sonnet\",\n \"libkf5syndication-dev\",\n \"libkf5syndication5abi1\",\n \"libkf5syndication5\",\n \"libkf5syndication-doc\",\n \"libkf5syntaxhighlighting-data\",\n \"libkf5syntaxhighlighting-dev\",\n \"libkf5syntaxhighlighting-doc\",\n \"libkf5syntaxhighlighting-tools\",\n \"libkf5syntaxhighlighting5\",\n \"qml-module-org-kde-syntaxhighlighting\",\n \"libkf5threadweaver-dev\",\n \"libkf5threadweaver-doc\",\n \"libkf5threadweaver5\"\n]\n"
},
{
"alpha_fraction": 0.5921211838722229,
"alphanum_fraction": 0.6006060838699341,
"avg_line_length": 32,
"blob_id": "bec7e828317690f23cf83a5ad5ec48cfdb445483",
"content_id": "18a07a631d02bac5a3853b1c5060ca32d8b2c82e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1650,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 50,
"path": "/test/test_nci_snap_unpacker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2018-2022 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/snap/unpacker'\n\nrequire 'mocha/test_unit'\n\nmodule NCI::Snap\n class BuildSnapUnpackerTest < TestCase\n # TODO remove unpacker it's unused\n # def test_unpack\n # mockcmd = mock('tty::command')\n # TTY::Command.expects(:new).returns(mockcmd)\n # mockcmd.expects(:run).with do |*args|\n # kwords = args.pop # ruby3 compat, ruby3 no longer allows implicit **kwords conversion from hash but mocha relies on it still -sitter\n # next false unless args & ['snap', 'download',\n # '--channel=stable', 'kblocks']\n # next false unless kwords[:chdir]\n\n # FileUtils.touch(\"#{kwords[:chdir]}/foo.snap\")\n # end\n # mockcmd.expects(:run).with do |*args|\n # args & ['unsquashfs', '-d', '/snap/kblocks/current'] &&\n # args.any? { |x| x.include?('foo.snap') }\n # end\n\n # ret = Unpacker.new('kblocks').unpack\n # assert_equal('/snap/kblocks/current', ret)\n # end\n\n def test_no_snap\n mockcmd = mock('tty::command')\n TTY::Command.expects(:new).returns(mockcmd)\n mockcmd.expects(:run).with do |*args|\n next false unless args & ['snap', 'download',\n '--channel=stable', 'kblocks']\n\n # Intentionally create no file here. We'll want an exception!\n true\n end\n\n assert_raises do\n Unpacker.new('kblocks').unpack\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6066570281982422,
"alphanum_fraction": 0.61186683177948,
"avg_line_length": 31.28972053527832,
"blob_id": "fdfaf6b5621f54126f76315b91dca7b5350af341",
"content_id": "36193d000d20d22dee592c810b68638e6179a88e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3455,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 107,
"path": "/nci/workspace_cleaner.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'date'\nrequire 'fileutils'\nrequire 'securerandom'\n\nrequire_relative '../lib/ci/containment'\n\n# A helper to clean up dangling (too old) workspaces that weren't properly\n# cleaned up by Jenkins itself.\nmodule WorkspaceCleaner\n class << self\n # Paths must be run through fnmatch supporting functions so we can easily\n # grab all workspace variants. e.g. if the same server is shared for\n # multiple architectures we need to match /nci-armhf/ as well.\n DEFAULT_WORKSPACE_PATHS = [\"#{Dir.home}/workspace\",\n \"#{Dir.home}/nci*/workspace\",\n \"#{Dir.home}/xci*/workspace\"].freeze\n\n def workspace_paths\n @workspace_paths ||= DEFAULT_WORKSPACE_PATHS.clone\n end\n\n attr_writer :workspace_paths\n\n def clean\n workspace_paths.each do |workspace_path|\n Dir.glob(\"#{workspace_path}/*\") do |workspace|\n next unless File.directory?(workspace)\n next unless cleanup?(workspace)\n\n rm_r(workspace)\n end\n end\n end\n\n private\n\n # Special rm_r, if a regular rm_r raises an errno, we'll attempt a chown\n # via containment and then try to remove again. This attempts to deal with\n # incomplete chowning by forcing it here. If the second rm_r still raises\n # something we'll let that go unhandled.\n def rm_r(dir)\n FileUtils.rm_r(dir, verbose: true)\n rescue SystemCallError => e\n unless File.exist?(dir)\n warn \" Got error #{e} but still successfully removed directory.\"\n return\n end\n raise e unless e.class.name.start_with?('Errno::')\n\n warn \" Got error #{e}... trying to chown.....\"\n chown_r(dir)\n # Jenkins might still have a cleanup thread waiting for the dir, and if so\n # it may be gone after we solved the ownership problem.\n # If this is a cleanup dir, let it sit for now. If jenkins cleans it\n # up then that's cool, otherwise we'll get it in the next run.\n FileUtils.rm_r(dir, verbose: true) unless dir.include?('ws-cleanup')\n end\n\n def chown_r(dir)\n dist = ENV.fetch('DIST')\n user = CI::Containment.userns? ? 'root:root' : 'jenkins:jenkins'\n cmd = %w[/bin/chown -R] + [user, '/pwd']\n warn \" #{cmd.join(' ')}\"\n c = CI::Containment.new(SecureRandom.hex,\n image: CI::PangeaImage.new(:ubuntu, dist),\n binds: [\"#{dir}:/pwd\"],\n no_exit_handlers: true)\n c.run(Cmd: cmd)\n c.cleanup\n end\n\n def cleanup?(workspace)\n puts \"Looking at #{workspace}\"\n if workspace.include?('_ws-cleanup_')\n puts ' ws-cleanup => delete'\n return true\n end\n # Never delete mgmt workspaces. Too dangerous as they are\n # persistent.\n if workspace.include?('mgmt_')\n puts ' mgmt => nodelete'\n return false\n end\n cleanup_age?(workspace)\n end\n\n def cleanup_age?(workspace)\n mtime = File.mtime(workspace)\n days_old = ((Time.now - mtime) / 60 / 60 / 24).to_i\n puts \" days old #{days_old}\"\n days_old.positive?\n end\n end\nend\n\n# :nocov:\nif $PROGRAM_NAME == __FILE__\n $stdout = STDERR # Force synced output\n WorkspaceCleaner.clean\nend\n# :nocov:\n"
},
{
"alpha_fraction": 0.565200924873352,
"alphanum_fraction": 0.683093249797821,
"avg_line_length": 37.23188400268555,
"blob_id": "a1307a8b29e596bd936b641165d4d3f99e8a958b",
"content_id": "78d62c89141f5e55902da76905fec24034ba71ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2638,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 69,
"path": "/test/test_ci_deb822_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/deb822_lister'\n\nrequire 'mocha/test_unit'\n\nmodule CI\n class Deb822ListerTest < TestCase\n def setup\n Digest::Class.expects(:hexdigest).never\n end\n\n def test_changes\n digest_seq = sequence('digests')\n Digest::SHA256\n .expects(:hexdigest)\n .in_sequence(digest_seq)\n .returns('e4e5cdbd2e3a89b8850d2aef5011d92679546bd4d65014fb0f016ff6109cd3d3')\n Digest::SHA256\n .expects(:hexdigest)\n .in_sequence(digest_seq)\n .returns('af3e1908e68d22e5fd99bd4cb4cf5561801a7e90e8f0000ec3c211c88bd5e09e')\n\n files = Deb822Lister.files_to_upload_for(\"#{data}/file.changes\")\n assert_equal(2, files.size)\n assert_equal([\"#{data}/libkf5i18n-data_5.21.0+p16.04+git20160418.1009-0_all.deb\",\n \"#{data}/libkf5i18n-dev_5.21.0+p16.04+git20160418.1009-0_amd64.deb\"],\n files)\n end\n\n def test_dsc\n digest_seq = sequence('digests')\n Digest::SHA256\n .expects(:hexdigest)\n .in_sequence(digest_seq)\n .returns('4a4d22f395573c3747caa50798dcdf816ae0ca620acf02b961c1239c94746232')\n Digest::SHA256\n .expects(:hexdigest)\n .in_sequence(digest_seq)\n .returns('51c5f6d895d2ef1ee9ecd35f2e0f76c908c4a13fa71585c135bfe456f337f72c')\n\n files = Deb822Lister.files_to_upload_for(\"#{data}/file.changes\")\n assert_equal(3, files.size)\n assert_equal([\"#{data}/ki18n_5.21.0+p16.04+git20160418.1009.orig.tar.xz\",\n \"#{data}/ki18n_5.21.0+p16.04+git20160418.1009-0.debian.tar.xz\",\n \"#{data}/ki18n_5.21.0+p16.04+git20160418.1009-0.dsc\"],\n files)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.686122715473175,
"alphanum_fraction": 0.6920785903930664,
"avg_line_length": 36.31111145019531,
"blob_id": "d30959dce90d494a14a5132c382455078d385375",
"content_id": "31df8f710573d3d32b6f4cecf6b83fda3edc0ad2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1679,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 45,
"path": "/test/test_parse_yaml.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'yaml'\n\nclass ParseYAMLTest < TestCase\n def test_syntax\n Dir.chdir(File.dirname(__dir__)) # one above\n\n Dir.glob('**/**/*.{yml,yaml}').each do |file|\n next if file.include?('git/') || file.include?('launchpad/') || file.include?('test/')\n next unless File.file?(file)\n\n # assert_nothing_raised is a bit stupid, it eats most useful information\n # from the exception, so to debug this best run without the assert to\n # get the additional information.\n assert_nothing_raised(\"Not a valid YAML file: #{file}\") do\n if ::YAML::VERSION >= '4'\n YAML.unsafe_load(File.read(file))\n else\n YAML.load(File.read(file))\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.657813310623169,
"alphanum_fraction": 0.6668385863304138,
"avg_line_length": 34.577980041503906,
"blob_id": "b3143cc34033f4d1e3633ccd0dd176ee110215da",
"content_id": "b4cd69018b186459a809ca2a80438cede415c6a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3878,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 109,
"path": "/lib/debian/changes.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'insensitive_hash/minimal'\n\nrequire_relative 'deb822'\n\nmodule Debian\n # Debian .changes parser\n class Changes < Deb822\n # FIXME: lazy read automatically when accessing fields\n attr_reader :fields\n\n File = Struct.new(:md5, :size, :section, :priority, :name)\n Checksum = Struct.new(:sum, :size, :file_name)\n\n # FIXME: pretty sure that should be in the base\n def initialize(file)\n @file = file\n @fields = InsensitiveHash.new\n end\n\n def parse!\n lines = ::File.new(@file).readlines\n\n # Source Paragraph\n fields = {\n mandatory: %w[format date source architecture version distribution maintainer changes checksums-sha1 checksums-sha256 files],\n relationship: %w[],\n foldable: %w[binary] + %w[],\n multiline: %w[description changes checksums-sha1 checksums-sha256 files]\n }\n @fields = parse_paragraph(lines, fields)\n mangle_fields! if @fields\n\n # TODO: Strip custom fields and add a Control::flags_for(entry) method.\n\n # FIXME: signing verification not implemented\n # this code works; needs to be somewhere generic\n # also needs to rescue GPGME::Error::NoData\n # in case the file is not signed\n # crypto = GPGME::Crypto.new\n # results = []\n # crypto.verify(data) do |signature|\n # results << signature.valid?\n #\n # !results.empty? && results.all?\n end\n\n private\n\n def mangle_files\n # Mangle list fields into structs.\n # FIXME: this messes up field order, files and keys will be appended\n # to the hash as injecting new things into the hash does not\n # replace the old ones in-place, but rather drops the old ones and\n # adds the new ones at the end.\n @fields['files'] = parse_types(@fields['files'], File)\n %w[checksums-sha1 checksums-sha256].each do |key|\n @fields[key] = parse_types(@fields[key], Checksum)\n end\n end\n\n def mangle_binary\n # FIXME: foldable fields are arrays but their values are split by\n # random crap such as commas or spaces. In changes Binary is a\n # foldable field separated by spaces, so we need to make sure this\n # is the case.\n # This is conducted in-place so we don't mess up field order.\n @fields['binary'].replace(@fields['binary'][0].split(' '))\n end\n\n # Calls all defined mangle_ methods. Mangle methods are meant to suffix\n # the field they mangle. They only get run if that field is in the hash.\n # So, mangle_binary checks the Binary field and is only run when it is\n # defined in the hash.\n def mangle_fields!\n private_methods.each do |meth, str = meth.to_s|\n next unless str.start_with?('mangle_')\n next unless @fields.include?(str.split('_', 2)[1])\n\n send(meth)\n end\n end\n\n def parse_types(lines, klass)\n lines.split($/).collect do |line|\n klass.new(*line.split(' '))\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6347708702087402,
"alphanum_fraction": 0.6398248076438904,
"avg_line_length": 29.597938537597656,
"blob_id": "8819d22908d6165cb5147b8f6a8f9a9bc475773e",
"content_id": "36ba92c3c816c4ca487bc58c5ef1efa1c0845cd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2968,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 97,
"path": "/nci/lint/cmake_dep_verify/package.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty-command'\n\nrequire_relative '../../../lib/apt'\nrequire_relative '../../../lib/dpkg'\n\nmodule CMakeDepVerify\n # Wrapper around a package we want to test.\n class Package\n Result = Struct.new(:success?, :out, :err)\n\n attr_reader :name\n attr_reader :version\n\n class << self\n def install_deps\n @run ||= (Apt.install(%w[cmake build-essential]) || raise)\n end\n\n attr_accessor :dry_run\n end\n\n def initialize(name, version)\n @name = name\n @version = version\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n @log.progname = \"#{self.class}(#{name})\"\n self.class.install_deps\n end\n\n def test\n failures = {}\n cmake_packages.each do |cmake_package|\n result = run(cmake_package)\n failures[cmake_package] = Result.new(result.success?, result.out,\n result.err)\n end\n failures\n end\n\n private\n\n def run(cmake_package)\n Dir.mktmpdir do |tmpdir|\n File.write(\"#{tmpdir}/CMakeLists.txt\", <<-EOF)\ncmake_minimum_required(VERSION 3.0)\nproject(CMakeLintTestProject)\nfind_package(#{cmake_package} REQUIRED)\nEOF\n cmd = TTY::Command.new(dry_run: self.class.dry_run || false)\n cmd.run!('cmake', '.', chdir: tmpdir)\n end\n end\n\n def files\n unless Apt.install(\"#{name}=#{version}\", [\"--no-install-recommends\"])\n raise \"Failed to install #{name} #{version}\"\n end\n\n # Mark the package as manual so it doens't get purged by autoremove.\n Apt::Mark.tmpmark(name, Apt::Mark::MANUAL) do\n Apt::Get.autoremove(args: '--purge')\n # Mocha eats our return value through the yield in tests.\n # return explicitly to avoid this.\n return DPKG.list(name).select { |f| f.end_with?('Config.cmake') }\n end\n end\n\n def cmake_packages\n @cmake_packages ||= begin\n x = files.collect { |f| File.basename(f, 'Config.cmake') }\n @log.info \"CMake configs: #{x}\"\n x\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.588487446308136,
"alphanum_fraction": 0.5958358645439148,
"avg_line_length": 19.670886993408203,
"blob_id": "e722adc27b0c376d31fe7f52b05c8c8276720cc8",
"content_id": "6329caf3d4e5cc5cc9329c4708f1d569ab2340ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1633,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 79,
"path": "/nci/lib/settings.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'deep_merge'\nrequire 'yaml'\n\nrequire_relative '../../lib/ci/pattern'\n\nmodule NCI\n # NCI settings\n class Settings\n DEFAULT_FILES = [\n File.expand_path(\"#{__dir__}/../../data/settings/nci.yaml\")\n ].freeze\n\n class << self\n def for_job\n new.for_job\n end\n\n def default_files\n @default_files ||= DEFAULT_FILES\n end\n\n attr_writer :default_files\n end\n\n def initialize(files = self.class.default_files)\n @default_paths = files\n end\n\n def for_job\n unless job?\n puts 'Could not determine job_name. ENV is missing JOB_NAME'\n return {}\n end\n job_patterns = CI::FNMatchPattern.filter(job, settings)\n job_patterns = CI::FNMatchPattern.sort_hash(job_patterns)\n return {} if job_patterns.empty?\n\n merge(job_patterns)\n end\n\n private\n\n def merge(job_patterns)\n folded = {}\n job_patterns.each do |patterns|\n patterns.each do |pattern|\n folded = folded.deep_merge(pattern)\n end\n end\n folded\n end\n\n def job?\n @job_exist ||= ENV.key?('JOB_NAME')\n end\n\n def job\n @job ||= ENV.fetch('JOB_NAME').strip\n end\n\n def settings\n @settings ||= load\n end\n\n def load\n hash = {}\n @default_paths.each do |path|\n hash.deep_merge!(YAML.load(File.read(path)))\n end\n hash = CI::FNMatchPattern.convert_hash(hash, recurse: false)\n hash\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6388759016990662,
"alphanum_fraction": 0.6960187554359436,
"avg_line_length": 37.818180084228516,
"blob_id": "b406565e42199e44351d4bedd3de8b61d72ef6b8",
"content_id": "21f5be3e091fc425980683da542905afb51ad14f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2135,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 55,
"path": "/test/test_aptly-ext_filter.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/aptly-ext/filter'\n\nclass AptlyExtFilterTest < TestCase\n def test_init\n packages = [\n 'Pall kitteh 999 66f130f348dc4864',\n 'Pall kitteh 997 66f130f348dc4864',\n 'Pall kitteh 998 66f130f348dc4864',\n 'Pamd64 doge 1 66f130f348dc4864',\n 'Pamd64 doge 3 66f130f348dc4864',\n 'Pamd64 doge 2 66f130f348dc4864'\n ]\n\n filtered = Aptly::Ext::LatestVersionFilter.filter(packages)\n kitteh = filtered.find_all { |x| x.name == 'kitteh' }\n assert_equal(1, kitteh.size)\n assert_equal('999', kitteh[0].version)\n doge = filtered.find_all { |x| x.name == 'doge' }\n assert_equal(1, doge.size)\n assert_equal('3', doge[0].version)\n\n filtered = Aptly::Ext::LatestVersionFilter.filter(packages, 2)\n kitteh = filtered.find_all { |x| x.name == 'kitteh' }\n assert_equal(2, kitteh.size)\n kitteh = kitteh.sort_by(&:version)\n assert_equal('998', kitteh[0].version)\n assert_equal('999', kitteh[1].version)\n doge = filtered.find_all { |x| x.name == 'doge' }\n assert_equal(2, doge.size)\n doge = doge.sort_by(&:version)\n assert_equal('2', doge[0].version)\n assert_equal('3', doge[1].version)\n end\nend\n"
},
{
"alpha_fraction": 0.7008503079414368,
"alphanum_fraction": 0.7385982871055603,
"avg_line_length": 30.68163299560547,
"blob_id": "f6508d774291e1f144b5fe1bcb5fb1c115c341e9",
"content_id": "d54c1fa0d8213d315fd0487ffe918a57fcdc1f7f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7762,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 245,
"path": "/nci/kf6ify.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2023 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/debian/control'\nrequire_relative '../lib/kdeproject_component'\nrequire_relative '../lib/projects/factory/neon'\n\nrequire 'awesome_print'\nrequire 'deep_merge'\nrequire 'tty/command'\nrequire 'yaml'\n\n# Iterates all plasma repos and adjusts the packaging for the kf5->kf6 transition.\nclass Mutagen\n attr_reader :cmd\n attr_reader :map\n\n def initialize\n @cmd = TTY::Command.new\n @map = YAML.load(DATA.read)\n end\n\n def relator(relationships)\n relationships.collect do |relationship|\n unless relationship.name.include?('5') ||\n %w[extra-cmake-modules pkg-kde-tools kirigami2-dev kinit-dev].any? { |x| x == relationship.name }\n next relationship\n end\n\n new = map.fetch(relationship.name)\n next nil if new.nil?\n\n relationship.name.replace(new)\n unless relationship.version&.start_with?('${')\n relationship.operator = nil\n relationship.version = nil\n end\n relationship\n end\n end\n\n def run\n if File.exist?('kf6')\n Dir.chdir('kf6')\n else\n Dir.mkdir('kf6')\n Dir.chdir('kf6')\n\n repos = ProjectsFactory::Neon.ls\n KDEProjectsComponent.plasma_jobs.uniq.each do |project|\n repo = repos.find { |x| x.end_with?(\"/#{project}\") }\n p [project, repo]\n cmd.run('git', 'clone', \"[email protected]:neon/#{repo}\")\n end\n end\n\n Dir.glob('*') do |dir|\n next unless File.directory?(dir)\n\n p dir\n Dir.chdir(dir) do\n cmd.run('git', 'fetch', 'origin')\n cmd.run('git', 'reset', '--hard')\n cmd.run('git', 'checkout', 'Neon/unstable')\n cmd.run('git', 'reset', '--hard', 'origin/Neon/unstable')\n control = Debian::Control.new\n control.parse!\n\n control.source['Build-Depends'].collect! { |relationships| relator(relationships) }\n control.source['Build-Depends'].compact!\n\n control.binaries.collect! do |binary|\n binary['Depends']&.collect! { |relationships| relator(relationships) }\n binary['Depends']&.compact!\n binary\n end\n\n File.write('debian/control', control.dump)\n File.write('debian/rules', File.read(\"#{__dir__}/data/rules.kf6.data\"))\n Dir.glob('debian/*.install') do |install|\n data = File.read(install)\n data = data.lines.collect do |line|\n next line if line.include?('usr/kf6/')\n\n line.gsub!('usr/', 'usr/kf6/')\n line.gsub!('/include/KF5/', '/include/KF6/')\n line.gsub!('/qt5/plugins/kf5/', '/qt6/plugins/kf6/')\n line.gsub!('/qt5/plugins/', '/qt6/plugins/')\n line.gsub!('/share/knotifications5/', '/share/knotifications6/')\n line.gsub!('/qlogging-categories5/', '/qlogging-categories6/')\n line\n end.join\n File.write(install, data)\n end\n cmd.run('wrap-and-sort')\n\n cmd.run('git', 'commit', '--all', '--message', 'port to kf6') unless cmd.run!('git', 'diff', '--quiet').success?\n end\n end\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n Mutagen.new.run\nend\n\n__END__\n# This is yaml data for the mapping table!\n\n# packaging\npkg-kde-tools: pkg-kde-tools-neon\n\n# plasma\nlibkfontinst5: libkfontinst6\nlibkfontinstui5: libkfontinstui6\nlibplasma-geolocation-interface5: libplasma-geolocation-interface6\nlibkworkspace5-5: libkworkspace6\nlibkdecorations2-5v5: libkdecorations2-5v5\nlibkpipewire5: libkpipewire5\nlibkpipewirerecord5: libkpipewirerecord5\nlibkf5screen8: libkf6screen8\nlibkf5screendpms8: libkf6screendpms8\nlibkf5screen-bin: libkf6screen-bin\nlibkscreenlocker5: libkscreenlocker5\nliblayershellqtinterface5: liblayershellqtinterface5\nlibkf5sysguard-bin: libkf6sysguard-bin\nlibkf5sysguard-data: libkf6sysguard-data\nlibkf5sysguard-dev: libkf6sysguard-dev\nkde-style-oxygen-qt5: kde-style-oxygen-qt6\nlibpowerdevilui5: libpowerdevilui5\n\n# kf5\nextra-cmake-modules: kf6-extra-cmake-modules\nbaloo-kf5-dev: kf6-baloo-dev\nkded5-dev: kf6-kded-dev\nlibkf5activities-dev: kf6-kactivities-dev\nlibkf5activitiesstats-dev: kf6-kactivities-stats-dev\nlibkf5config-dev: kf6-kconfig-dev\nlibkf5coreaddons-dev: kf6-kcoreaddons-dev\nlibkf5crash-dev: kf6-kcrash-dev\nlibkf5dbusaddons-dev: kf6-kdbusaddons-dev\nlibkf5declarative-dev: kf6-kdeclarative-dev\nlibkf5globalaccel-dev: kf6-kglobalaccel-dev\nlibkf5holidays-dev: kf6-kholidays-dev\nlibkf5i18n-dev: kf6-ki18n-dev\nlibkf5idletime-dev: kf6-kidletime-dev\nlibkf5kcmutils-dev: kf6-kcmutils-dev\nlibkf5kexiv2-dev: kf6-kexiv2-dev\nlibkf5networkmanagerqt-dev: kf6-networkmanager-qt-dev\nlibkf5newstuff-dev: kf6-knewstuff-dev\nlibkf5notifyconfig-dev: kf6-knotifyconfig-dev\nlibkf5package-dev: kf6-kpackage-dev\nlibkf5people-dev: kf6-kpeople-dev\nlibkf5plasma-dev: kf6-plasma-framework-dev\nlibkf5prison-dev: kf6-prison-dev\nlibkf5runner-dev: kf6-krunner-dev\nlibkf5screen-dev: libkf6screen-dev\nlibkf5solid-dev: kf6-solid-dev\nlibkf5su-dev: kf6-kdesu-dev\nlibkf5syntaxhighlighting-dev: kf6-syntax-highlighting-dev\nlibkf5texteditor-dev: kf6-ktexteditor-dev\nlibkf5textwidgets-dev: kf6-ktextwidgets-dev\nlibkf5wallet-dev: kf6-kwallet-dev\nlibkf5itemmodels-dev: kf6-kitemmodels-dev\nlibkf5windowsystem-dev: kf6-kwindowsystem-dev\nlibkf5bluezqt-dev: kf6-bluez-qt-dev\nlibkf5doctools-dev: kf6-kdoctools-dev\nlibkf5iconthemes-dev: kf6-kiconthemes-dev\nlibkf5kio-dev: kf6-kio-dev\nlibkf5notifications-dev: kf6-knotifications-dev\nlibkf5widgetsaddons-dev: kf6-kwidgetsaddons-dev\nlibkf5configwidgets-dev: kf6-kconfigwidgets-dev\nlibkf5guiaddons-dev: kf6-kguiaddons-dev\nlibkf5service-dev: kf6-kservice-dev\nlibkf5style-dev: kf6-frameworkintegration-dev\nlibkf5wayland-dev: kf6-kwayland-dev\nlibkf5archive-dev: kf6-karchive-dev\nlibkf5attica-dev: kf6-attica-dev\nkirigami2-dev: kf6-kirigami2-dev\nlibkf5itemviews-dev: kf6-kitemviews-dev\nlibkf5purpose-dev: kf6-purpose-dev\nlibkf5xmlgui-dev: kf6-kxmlgui-dev\nlibkf5completion-dev: kf6-kcompletion-dev\nlibkf5jobwidgets-dev: kf6-kjobwidgets-dev\nlibkf5unitconversion-dev: kf6-kunitconversion-dev\nlibkf5sonnet-dev: kf6-sonnet-dev\nlibkf5pty-dev: kf6-kpty-dev\nlibkf5auth-dev: kf6-kauth-dev\nlibkf5filemetadata-dev: kf6-kfilemetadata-dev\nlibkf5emoticons-dev: null\nlibkf5qqc2desktopstyle-dev: kf6-qqc2-desktop-style-dev\nkinit-dev: null\n\nbaloo-kf5: kf6-baloo\nkded5: kf6-kded\nlibkf5globalaccel-bin: kf6-kglobalaccel\nlibkf5service-bin: kf6-kservice\nplasma-framework: kf6-plasma-framework\nlibkf5su-bin: kf6-kdesu\nkpackagetool5: kf6-kpackage\nlibkf5purpose5: kf6-purpose\n\n# deprecated\nlibkf5webkit-dev: null\nlibkf5kdelibs4support-dev: null\nlibkf5xmlrpcclient-dev: null\nlibtelepathy-qt5-dev: null\nlibkf5khtml-dev: null\n\n# supplimental\nlibdbusmenu-qt5-dev: libdbusmenu-qt6-dev\nlibpackagekitqt5-dev: libpackagekitqt6-dev\nlibphonon4qt5-dev: libphonon4qt6-dev\nlibphonon4qt5experimental-dev: libphonon4qt6experimental-dev\nlibpolkit-qt5-1-dev: libpolkit-qt6-1-dev\nlibqca-qt5-2-dev: libqca-qt6-2-dev\nlibqaccessibilityclient-qt5-dev: libqaccessibilityclient-qt6-dev\n\n# qt\nqtbase5-dev: qt6-base-dev\nqtbase5-private-dev: qt6-base-dev\nqtdeclarative5-dev: qt6-declarative-dev\nqtscript5-dev: null\nqtwayland5-dev-tools: qt6-wayland-dev-tools\nqtwayland5-private-dev: qt6-wayland-dev\nlibqt5sensors5-dev: qt6-sensors-dev\nlibqt5svg5-dev: qt6-svg-dev\nqttools5-dev: qt6-tools-dev\nqtmultimedia5-dev: qt6-multimedia-dev\nqtquickcontrols2-5-dev: qt6-declarative-dev\nqtwebengine5-dev: qt6-webengine-dev\nlibqt5webview5-dev: qt6-webview-dev\nlibqt5waylandclient5-dev: qt6-wayland-dev\n\nlibqt5sql5-sqlite: qt6-base\nqtwayland5: qt6-wayland\nqdbus-qt5: qt6-tools\nqttools5-dev-tools: qt6-tools-dev-tools\nqt5-qmake-bin: null\n\n# unclear???\nlibqt5x11extras5-dev: null\nlibqt5webkit5-dev: null\n"
},
{
"alpha_fraction": 0.6839972734451294,
"alphanum_fraction": 0.6880486011505127,
"avg_line_length": 26.174312591552734,
"blob_id": "c79af6b4730dd6e3ff36f11b63418e08ec8c779b",
"content_id": "bd67b0ae70ef745f08f6096ed5c83b9fb47a4559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2962,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 109,
"path": "/nci/expunge.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'ostruct'\nrequire 'optparse'\n\nrequire_relative '../lib/nci'\n\noptions = OpenStruct.new\nparser = OptionParser.new do |opts|\n opts.banner = \"Usage: #{opts.program_name} [options] PROJECTNAME\"\n\n opts.on('-p SOURCEPACKAGE', 'Source package name [default: ARGV[0]]') do |v|\n options.source = v\n end\n\n opts.on('--type [TYPE]', NCI.types, 'Choose type(s) to expunge') do |v|\n options.types ||= []\n options.types << v.to_s\n end\n\n opts.on('--dist [DIST]', NCI.series.keys.map(&:to_sym),\n 'Choose series to expunge (or multiple)') do |v|\n options.dists ||= []\n options.dists << v.to_s\n end\nend\nparser.parse!\n\nabort parser.help unless ARGV[0]\noptions.name = ARGV[0]\n\n# Defaults\noptions.source ||= options.name\noptions.keep_merger ||= false\noptions.types ||= NCI.types\noptions.dists ||= NCI.series.keys\n\nlog = Logger.new(STDOUT)\nlog.level = Logger::DEBUG\nlog.progname = $PROGRAM_NAME\n\n## JENKINS\n\nrequire_relative '../lib/jenkins'\n\njob_names = []\noptions.dists.each do |d|\n options.types.each do |t|\n job_names << \"#{d}_#{t}_([^_]*)_#{options.name}\"\n end\nend\n\nlog.info 'JENKINS'\nJenkins.job.list_all.each do |name|\n match = false\n job_names.each do |regex|\n match = name.match(regex)\n break if match\n end\n next unless match\n\n log.info \"-- deleting :: #{name} --\"\n log.debug Jenkins.job.delete(name)\nend\n\n## APTLY\n\nrequire 'aptly'\nrequire_relative '../lib/aptly-ext/remote'\n\nAptly::Ext::Remote.neon do\n log.info 'APTLY'\n Aptly::Repository.list.each do |repo|\n next unless options.types.include?(repo.Name)\n\n # Query all relevant packages.\n # Any package with source as source.\n query = \"($Source (#{options.name}))\"\n # Or the source itself\n query += \" | (#{options.name} {source})\"\n packages = repo.packages(q: query).compact.uniq\n next if packages.empty?\n\n log.info \"Deleting packages from repo #{repo.Name}: #{packages}\"\n repo.delete_packages(packages)\n repo.published_in.each(&:update!)\n end\nend\n"
},
{
"alpha_fraction": 0.6212028861045837,
"alphanum_fraction": 0.6266927123069763,
"avg_line_length": 38.408653259277344,
"blob_id": "be49579d0e6dffa601e5383b5fbb683726d5d1d4",
"content_id": "6388895b23ea4ba0a4a764f292298e4e656e7412",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 8197,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 208,
"path": "/nci/qt_sixy.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# A quick script to go over a qt 6 repo from Debian and simplify the .debs produced to make them only runtime and dev packages\n# The intention is to simplify maintinance so when new Qts come out we don't have to worry about where to put the files\n# This needs manual going over the output for sanity\n\nrequire_relative '../lib/debian/control'\nrequire_relative '../lib/projects/factory/neon'\n\nrequire 'deep_merge'\nrequire 'tty/command'\n\nEXCLUDE_BUILD_DEPENDS = %w[qt6-base-private-dev libqt6opengl6-dev qt6-declarative-private-dev qml6-module-qtquick qml6-module-qttest qml6-module-qtquick].freeze\n\nclass QtSixy\n\n attr_reader :dir\n attr_reader :name\n\n def initialize(name:, dir:)\n @dir = dir\n @name = name\n puts \"Running Sixy in #{dir}\"\n unless File.exist?(\"#{dir}/debian\")\n raise \"Must be run in a 'qt6-foo' repo with 'debian/' dir\"\n end\n end\n\n def fold_pkg(pkg, into:)\n return pkg if pkg['X-Neon-MergedPackage'] == 'true' # noop\n pkg.each do |k,v|\n next if k == 'Package'\n next if k == 'Architecture'\n next if k == 'Multi-Arch'\n next if k == 'Section'\n next if k == 'Description'\n\n into[k] = v unless into.include?(k)\n case into[k].class\n when Hash, Array\n into[k].deep_merge!(v)\n else\n into[k] += v\n end\n end\n end\n\n def run\n cmd = TTY::Command.new\n control = Debian::Control.new(@dir)\n control.parse!\n p control.binaries.collect { |x| x['Package'] } # pkgs\n\n dev_binaries = control.binaries.select { |x| x['Package'].include?('-dev') }\n bin_binaries = control.binaries.select { |x| !dev_binaries.include?(x) }\n control.binaries.replace(control.binaries[0..1])\n dev_binaries_names = dev_binaries.collect { |x| x['Package'] }\n bin_binaries_names = bin_binaries.collect { |x| x['Package'] }\n\n # Get the old provides to add to the new\n #old_bin_binary = bin_binaries.select { |x| x['Package'] == name }\n #old_provides_list = ''\n #if old_bin_binary.kind_of?(Array) and not old_bin_binary.empty?\n #old_provides = old_bin_binary[0]['Provides']\n #old_provides_list = old_provides.collect { |x| x[0].name }.join(', ')\n #end\n #old_dev_binary = dev_binaries.select { |x| x['Package'] == name + \"-dev\" }\n #old_dev_provides_list = ''\n #if old_dev_binary.kind_of?(Array) and not old_dev_binary.empty?\n #old_dev_provides = old_dev_binary[0]['Provides']\n #old_dev_provides_list = old_dev_provides.collect { |x| x[0].name }.join(', ')\n #end\n\n old_bin_binary = bin_binaries.select { |x| x['Package'] == name }\n old_depends_list = ''\n if old_bin_binary.kind_of?(Array) and not old_bin_binary.empty?\n old_depends = old_bin_binary[0]['Depends']\n old_depends_list = old_depends.collect { |x| x[0].name }.join(', ')\n end\n old_dev_binary = dev_binaries.select { |x| x['Package'] == name + \"-dev\" }\n old_dev_depends_list = ''\n if old_dev_binary.kind_of?(Array) and not old_dev_binary.empty?\n old_dev_depends = old_dev_binary[0]['Depends']\n old_dev_depends_list = old_dev_depends.collect { |x| x[0].name }.join(', ')\n end\n\n control.binaries.replace( [{}, {}] )\n\n bin = control.binaries[0]\n bin_depends = bin['Depends']\n bin.replace({'Package' => name, 'Architecture' => 'any', 'Section' => 'kde', 'Description' => '((TBD))'})\n \n #bin['Provides'] = Debian::Deb822.parse_relationships(old_provides_list + bin_binaries.collect { |x| x['Package'] unless x['X-Neon-MergedPackage'] == 'true' }.join(', '))\n bin['X-Neon-MergedPackage'] = 'true'\n if not old_depends_list.empty?\n bin['Depends'] = old_depends\n end\n dev = control.binaries[1]\n dev.replace({'Package' => name + '-dev', 'Architecture' => 'any', 'Section' => 'kde', 'Description' => '((TBD))'})\n #dev['Provides'] = Debian::Deb822.parse_relationships(old_dev_provides_list + dev_binaries.collect { |x| x['Package'] }.join(', '))\n dev['X-Neon-MergedPackage'] = 'true'\n if not old_dev_depends_list.empty?\n dev['Depends'] = old_dev_depends\n end\n\n bin_binaries_names.each do |package_name|\n next if bin['Package'] == package_name\n\n old_install_file_data = File.read(\"#{dir}/debian/\" + package_name + \".install\") if File.exists?(\"#{dir}/debian/\" + package_name + \".install\")\n new_install_filename = \"#{dir}/debian/\" + bin['Package'] + \".install\"\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".install\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".symbols\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".lintian-overrides\")\n File.write(new_install_filename, old_install_file_data, mode: \"a\")\n \n # Old names are now dummy packages\n dummy = {}\n dummy['Package'] = package_name\n dummy['Architecture'] = 'all'\n dummy['Depends'] = []\n dummy['Depends'][0] = []\n dummy['Depends'][0].append(name)\n dummy['Description'] = \"Dummy transitional\\nTransitional dummy package.\\n\"\n control.binaries.append(dummy)\n end\n\n bin_binaries.each do |bin_bin|\n p bin_bin\n fold_pkg(bin_bin, into: bin)\n end\n bin.delete('Description')\n bin['Description'] = bin_binaries[0]['Description']\n\n # bin['Provides'] ||= []\n # bin['Provides'] += bin_binaries.collect { |x| x['Package'] }.join(', ')\n\n dev_binaries_names.each do |package_name|\n next if dev['Package'] == package_name\n old_install_file_data = File.read(\"#{dir}/debian/\" + package_name + \".install\") if File.exists?(\"#{dir}/debian/\" + package_name + \".install\")\n new_install_filename = \"#{dir}/debian/\" + dev['Package'] + \".install\"\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".install\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".symbols\")\n FileUtils.rm_f(\"#{dir}/debian/\" + package_name + \".lintian-overrides\")\n File.write(new_install_filename, old_install_file_data, mode: \"a\")\n p \"written to #{new_install_filename}\"\n\n dummy = {}\n dummy['Package'] = package_name\n dummy['Architecture'] = 'all'\n dummy['Depends'] = []\n dummy['Depends'][0] = []\n dummy['Depends'][0].append(name + \"-dev\")\n dummy['Description'] = \"Dummy transitional\\n Transitional dummy package.\\n\"\n control.binaries.append(dummy)\n end\n # Qt6ShaderToolsTargets-none.cmake is not none on arm so wildcard it\n content = File.read(\"#{dir}/debian/#{dev['Package']}.install\")\n content = content.gsub('-none.cmake', '-*.cmake')\n content = content.gsub('_none_metatypes.json', '_*_metatypes.json')\n File.write(\"#{dir}/debian/#{dev['Package']}.install\", content)\n\n dev_binaries.each do |dev_bin|\n fold_pkg(dev_bin, into: dev)\n end\n dev.delete('Description')\n dev['Description'] = dev_binaries[0]['Description']\n\n dev.each do |k, v|\n next unless v.is_a?(Array)\n\n v.each do |relationships|\n next unless relationships.is_a?(Array)\n relationships.each do |alternative|\n next unless alternative.is_a?(Debian::Relationship)\n\n next unless bin_binaries_names.include?(alternative.name)\n p alternative\n alternative.name.replace(bin['Package'])\n end\n end\n end\n\n if not old_depends_list.empty?\n bin['Depends'] = old_depends\n end\n if not old_dev_depends_list.empty?\n dev['Depends'] = old_dev_depends\n end\n # Some magic to delete the build deps we list as bad above\n EXCLUDE_BUILD_DEPENDS.each {|build_dep| control.source[\"Build-depends\"].delete_if {|x| x[0].name.start_with?(build_dep)} }\n\n File.write(\"#{dir}/debian/control\", control.dump)\n cmd.run('wrap-and-sort', chdir: dir)\n end\nend\n\nif $PROGRAM_NAME == __FILE__\n sixy = QtSixy.new(name: File.basename(Dir.pwd), dir: Dir.pwd)\n sixy.run\nend\n\n#if $PROGRAM_NAME == __FILE__\n #sixy = QtSixy.new(name: File.basename('/home/jr/src/pangea-tooling/test/data/test_nci_qt_sixy/test_sixy_repo/qt6-test'), dir: '/home/jr/src/pangea-tooling/test/data/test_nci_qt_sixy/test_sixy_repo/qt6-test')\n #sixy.run\n#end\n"
},
{
"alpha_fraction": 0.5935114622116089,
"alphanum_fraction": 0.6049618124961853,
"avg_line_length": 37.814815521240234,
"blob_id": "1408d9260195d236222fa84240a6e69026e87d35",
"content_id": "6342f71697d011f53ddd64fec829ffbea193d6ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 27,
"path": "/nci/lib/imager_push_paths.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# SPDX-FileCopyrightText: 2015-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/nci'\n\nDIST = ENV.fetch('DIST')\nTYPE = ENV.fetch('TYPE')\n# NB: DO NOT CHANGE THIS LIGHTLY!!!!\n# The series guards prevent the !current series from publishing over the current\n# series. When the ISO should change you'll want to edit nci.yaml and shuffle\n# the series entries around there.\nREMOTE_DIR = case DIST\n when NCI.current_series\n \"neon/images/#{TYPE}/\"\n when NCI.future_series\n # Subdir if not the standard version\n #\"neon/images/#{DIST}-preview/#{TYPE}/\"\n \"neon/images/#{TYPE}/\"\n when NCI.old_series\n raise \"The old series ISO built but it shouldn't have!\" \\\n ' Remove the jobs or smth.'\n else\n raise 'No DIST env var defined; no idea what to do!'\n end\n"
},
{
"alpha_fraction": 0.6632652878761292,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 25.133333206176758,
"blob_id": "3d39a859f31f1f564888a88378b2df3f5b30da52",
"content_id": "dff47832882c9f2f86e75407d9ae37dbd4d1f75d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 784,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 30,
"path": "/nci/lint_bin/test_binaries.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/lint/lintian'\nrequire_relative '../lib/lint/result_test'\n\nmodule Lint\n # Test result data\n class TestBinaries < ResultTest\n def setup\n # NB: test-unit runs each test in its own instance, this means we\n # need to use a class variable as otherwise the cache wouldn't\n # persiste across test_ invocations :S\n @@result ||= Lintian.new('result').lint\n end\n\n def test_warnings\n assert_warnings(@@result)\n end\n\n def test_informations\n assert_informations(@@result)\n end\n\n def test_errors\n assert_errors(@@result)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7360334992408752,
"alphanum_fraction": 0.7360334992408752,
"avg_line_length": 38.77777862548828,
"blob_id": "575ef47fa85400aa80f0617b56c5c24d6feb9b01",
"content_id": "ea981a61c2676319b15746af3754ed71344b1adb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 716,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 18,
"path": "/nci/rebuild_docker_hub.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\n# Trigger Docker image rebuilds https://hub.docker.com/r/kdeneon/plasma/~/settings/automated-builds/\n# To be run by daily mgmt job\n\n# This file is in format\n# PLASMA_TOKEN=xxxx-xxx-xxx-xxxxx\n# ALL_TOKEN=xxxx-xxx-xxx-xxxxx\n# Token comes from https://cloud.docker.com/u/kdeneon/repository/docker/kdeneon/all/hubbuilds\n# and https://cloud.docker.com/u/kdeneon/repository/docker/kdeneon/plasma/hubbuilds\n\n. ~/docker-token\n\ncurl -H \"Content-Type: application/json\" --data '{\"build\": true}' -X POST https://registry.hub.docker.com/u/kdeneon/plasma/trigger/${PLASMA_TOKEN}/\n\ncurl -H \"Content-Type: application/json\" --data '{\"build\": true}' -X POST https://registry.hub.docker.com/u/kdeneon/all/trigger/${ALL_TOKEN}/\n"
},
{
"alpha_fraction": 0.6886712312698364,
"alphanum_fraction": 0.6959114074707031,
"avg_line_length": 36.269840240478516,
"blob_id": "632d60931e10bf1975185e58c698a0b202a8f57b",
"content_id": "47cb5ac2e47469363decea5dec90a77df365dd7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2348,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 63,
"path": "/test/test_adt_summary.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/adt/summary'\n\nmodule ADT\n class SummaryTest < TestCase\n def test_pass\n summary = Summary.from_file(\"#{data}/summary\")\n assert_equal(1, summary.entries.size)\n entry = summary.entries[0]\n assert_equal('testsuite', entry.name)\n assert_equal(Summary::Result::PASS, entry.result)\n end\n\n def test_partial_fail\n summary = Summary.from_file(\"#{data}/summary\")\n assert_equal(2, summary.entries.size)\n entry = summary.entries[0]\n assert_equal('testsuite', entry.name)\n assert_equal(Summary::Result::FAIL, entry.result)\n assert_equal('non-zero exit status 2', entry.detail)\n entry = summary.entries[1]\n assert_equal('acc', entry.name)\n assert_equal(Summary::Result::PASS, entry.result)\n end\n\n def test_type_fail\n assert_raises RuntimeError do\n Summary.from_file(\"#{data}/summary\")\n end\n end\n\n def test_skip_all\n # When we encounter * SKIP that means all have been skipped as there are\n # no tests. This is in junit then dropped as uninteresting information.\n summary = Summary.from_file(\"#{data}/summary\")\n assert_equal(1, summary.entries.size)\n entry = summary.entries[0]\n assert_equal('*', entry.name)\n assert_equal(Summary::Result::SKIP, entry.result)\n assert_equal('no tests in this package', entry.detail)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6101288795471191,
"alphanum_fraction": 0.6344021558761597,
"avg_line_length": 36.07777786254883,
"blob_id": "f147b3576161efdf8e4da33316d92cd34923b328",
"content_id": "0d9eec19eb6afa8fe377d9227eb892085453242d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3337,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 90,
"path": "/test/test_debian_architecture.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/debian/architecturequalifier'\nrequire_relative 'lib/testcase'\nrequire 'mocha/test_unit'\n\n# Test debian .dsc\nmodule Debian\n class ArchitectureQualifierTest < TestCase\n def setup\n # Let all backtick or system calls that are not expected fall into\n # an error trap!\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n end\n\n def test_multiple\n deb_arches = Debian::ArchitectureQualifier.new('i386 amd64')\n assert_equal(2, deb_arches.architectures.count)\n end\n\n def test_qualifies\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'i386', '-i', 'i386', '-f')\n .returns(true)\n\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'amd64', '-i', 'i386', '-f')\n .returns(false)\n\n deb_arches = Debian::ArchitectureQualifier.new('i386 amd64')\n assert(deb_arches.qualifies?('i386'))\n end\n\n def test_qualifies_with_modifier\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'i386', '-i', 'i386', '-f')\n .returns(true)\n\n deb_arches = Debian::ArchitectureQualifier.new('i386')\n assert_false(deb_arches.qualifies?('!i386'))\n end\n\n def test_architecture_with_modifier\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'i386', '-i', 'i386', '-f')\n .returns(true)\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'amd64', '-i', 'i386', '-f')\n .returns(false)\n\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'i386', '-i', 'armhf', '-f')\n .returns(false)\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'amd64', '-i', 'armhf', '-f')\n .returns(false)\n\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'i386', '-i', 'amd64', '-f')\n .returns(false)\n Object.any_instance.stubs(:system)\n .with('dpkg-architecture', '-a', 'amd64', '-i', 'amd64', '-f')\n .returns(true)\n\n deb_arches = Debian::ArchitectureQualifier.new('!i386 amd64')\n assert(deb_arches.qualifies?('!i386'))\n assert(deb_arches.qualifies?('armhf'))\n assert_false(deb_arches.qualifies?('!amd64'))\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6484224200248718,
"alphanum_fraction": 0.6519639492034912,
"avg_line_length": 30.693878173828125,
"blob_id": "701d862c977b1571344aba61f69679398807aaf1",
"content_id": "bbe10df93c08e420cbeb77540303b9bbe2ef6243",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3106,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 98,
"path": "/nci/sourcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/build_source'\nrequire_relative '../lib/ci/orig_source_builder'\nrequire_relative '../lib/ci/tar_fetcher'\nrequire_relative 'lib/settings'\nrequire_relative 'lib/setup_env'\nrequire_relative 'lib/setup_repo'\n\n# NCI specific source wrapper to handle parameterization properly.\nmodule NCISourcer\n class << self\n def sourcer_args\n args = { strip_symbols: true }\n settings = NCI::Settings.for_job\n sourcer_settings = settings.fetch('sourcer', {})\n restrict = sourcer_settings.fetch('restricted_packaging_copy',\n nil)\n return args unless restrict\n\n args[:restricted_packaging_copy] = restrict\n args\n end\n\n def orig_source(fetcher)\n tarball = fetcher.fetch('source')\n raise 'Failed to fetch tarball' unless tarball\n\n sourcer = CI::OrigSourceBuilder.new(**sourcer_args)\n sourcer.build(tarball.origify)\n end\n\n def run(type = ARGV.fetch(0, nil))\n meths = {\n 'tarball' => method(:run_tarball),\n 'uscan' => method(:run_uscan),\n 'debscm' => method(:run_debscm)\n }\n meth = meths.fetch(type, method(:run_fallback))\n meth.call\n end\n\n private\n\n def run_debscm\n puts 'Using tarball from debscm'\n orig_source(CI::DebSCMFetcher.new)\n end\n\n def run_tarball\n puts 'Downloading tarball from URL'\n orig_source(CI::URLTarFetcher.new(File.read('source/url').strip))\n end\n\n def run_uscan\n puts 'Downloading tarball via uscan'\n orig_source(CI::WatchTarFetcher.new('packaging/debian/watch',\n series: NCI.series.keys,\n mangle_download: true))\n end\n\n def run_fallback\n puts 'Unspecified source type, defaulting to VCS build...'\n builder = CI::VcsSourceBuilder.new(release: ENV.fetch('DIST'),\n **sourcer_args)\n builder.run\n end\n end\nend\n\n# :nocov:\nif $PROGRAM_NAME == __FILE__\n STDOUT.sync = true\n ENV['RELEASEME_PROJECTS_API'] = '1'\n NCI.setup_repo!(with_source: true)\n NCI.setup_env!\n NCISourcer.run\nend\n# :nocov:\n"
},
{
"alpha_fraction": 0.6952506303787231,
"alphanum_fraction": 0.7027264833450317,
"avg_line_length": 28.921052932739258,
"blob_id": "a2cb82f6b79720091cae26b055c0502d261525b3",
"content_id": "4c2900796523ee9129ace8668358d0818e68f489",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2274,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 76,
"path": "/test/test_rake_bundle.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# the lib itself doesn't require globally as it is used during deployment\n# and bundler isn't installed up until later\nrequire 'bundler'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/rake/bundle'\n\nrequire 'mocha/test_unit'\n\n# Hack\n# https://github.com/bundler/bundler/issues/6252\nmodule BundlerOverlay\n def frozen?\n return false if caller_locations.any? { |x| x.absolute_path.include?('lib/mocha') }\n\n super\n end\nend\n\nmodule Bundler\n class << self\n prepend BundlerOverlay\n end\nend\n\nclass RakeBundleTest < TestCase\n def setup\n # Make sure $? is fine before we start!\n reset_child_status!\n # Disable all system invocation.\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n # Also disable all bundler fork invocation.\n Bundler.expects(:unbundled_system).never\n Bundler.expects(:unbundled_exec).never\n end\n\n def test_bundle\n Bundler.expects(:unbundled_system)\n .with('bundle', 'pack')\n bundle(*%w[pack])\n end\n\n def test_bundle_nameerror\n seq = sequence('bundle')\n Bundler.expects(:unbundled_system)\n .with('bundle', 'pack')\n .raises(NameError)\n .in_sequence(seq)\n Object.any_instance\n .expects(:system)\n .with('bundle', 'pack')\n .in_sequence(seq)\n bundle(*%w[pack])\n end\nend\n"
},
{
"alpha_fraction": 0.6237362623214722,
"alphanum_fraction": 0.6272527575492859,
"avg_line_length": 31.73381233215332,
"blob_id": "a01e5137a81c30bc85d6c68929ce4d480b838545",
"content_id": "0a385200a123e43c7b0fe86bce58cac5daa994fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4550,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 139,
"path": "/nci/debian-merge/tagdetective.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'git'\nrequire 'json'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'tmpdir'\n\nrequire_relative '../../lib/projects/factory/neon'\nrequire_relative '../../lib/kdeproject_component'\nrequire_relative 'data'\n\n# Finds latest tag of ECM and then makes sure all other frameworks\n# have the same base version in their tag (i.e. the tags are consistent)\nmodule NCI\n module DebianMerge\n # Finds latest tag of ECM and then compile a list of all frameworks\n # that have this base version tagged as well. It asserts that all frameworks\n # should have the same version tagged. They may have a newer version tagged.\n class TagDetective\n ORIGIN = 'origin/master'\n ECM = 'kde/extra-cmake-modules'\n\n # exclusion should only include proper non-frameworks, if something\n # is awray with an actual framework that is released it should either\n # be fixed for the detective logic needs to be adapted to skip it.\n EXCLUSION = %w[kde/prison\n kde/purpose\n kde/kirigami2\n kde/qqc2-desktop-style].freeze\n\n def initialize\n @log = Logger.new($stdout)\n end\n\n def list_frameworks\n @log.info 'listing frameworks'\n frameworksList = KDEProjectsComponent.frameworks.select do |x|\n !EXCLUSION.include?(\"kde/#{x}\")\n end\n end\n\n def frameworks\n @frameworks ||= list_frameworks.collect do |x|\n File.join(ProjectsFactory::Neon.url_base, 'kde/', x)\n end\n end\n\n def last_tag_base\n @last_tag_base ||= begin\n @log.info 'finding latest tag of ECM'\n ecm = frameworks.find { |x| x.include?(ECM) }\n raise unless ecm\n\n Dir.mktmpdir do |tmpdir|\n git = Git.clone(ecm, tmpdir)\n last_tag = git.describe(ORIGIN, tags: true, abbrev: 0)\n last_tag.reverse.split('-', 2)[-1].reverse\n end\n end\n end\n\n def investigation_data\n # TODO: this probably should be moved to Data class\n data = {}\n data[:tag_base] = last_tag_base\n data[:repos] = frameworks.dup.keep_if do |url|\n include?(url)\n end\n data\n end\n\n def valid_and_released?(url)\n remote = Git.ls_remote(url)\n valid = remote.fetch('tags', {}).keys.any? do |x|\n version = x.split('4%').join.split('5%').join\n version.start_with?(last_tag_base)\n end\n released = remote.fetch('branches', {}).keys.any? do |x|\n x == 'Neon/release'\n end\n [valid, released]\n end\n\n def include?(url)\n @log.info \"Checking if tag matches on #{url}\"\n valid, released = valid_and_released?(url)\n if valid\n @log.info \" looking good #{url}\"\n return true\n elsif !valid && released\n raise \"found no #{last_tag_base} tag in #{url}\" unless valid\n end\n # Skip repos that have no release branch AND aren't valid.\n # They are unreleased, so we don't expect them to have a tag and can\n # simply skip them but don't raise an error.\n @log.warn \" skipping #{url} as it is not released and has no tag\"\n false\n end\n\n def reuse_old_data?\n return false unless Data.file_exist?\n\n olddata = Data.from_file\n olddata.tag_base == last_tag_base\n end\n\n def run\n return if reuse_old_data?\n\n Data.write(investigation_data)\n end\n alias investigate run\n end\n end\nend\n\n# :nocov:\nNCI::DebianMerge::TagDetective.new.run if $PROGRAM_NAME == __FILE__\n# :nocov:\n"
},
{
"alpha_fraction": 0.7031782269477844,
"alphanum_fraction": 0.7057321071624756,
"avg_line_length": 32.24528121948242,
"blob_id": "824f4c3786d6da360ad68f17877641ad646569fb",
"content_id": "6fb63c2bd4f032214a1547a966923cbae33ab995",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3524,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 106,
"path": "/test/test_install_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/install_check'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\n\nclass NCIRootInstallCheckTest < TestCase\n def setup\n # Make sure $? is fine before we start!\n reset_child_status!\n # Disable all system invocation.\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n Apt::Cache.expects(:system).never\n Apt::Cache.expects(:`).never\n end\n\n def test_run\n root = mock('root')\n proposed = mock('proposed')\n\n seq = sequence(__method__)\n proposed.expects(:remove).returns(true).in_sequence(seq)\n root.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:add).returns(true).in_sequence(seq)\n proposed.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:purge).returns(true).in_sequence(seq)\n\n checker = RootInstallCheck.new\n assert(checker.run(proposed, root))\n end\n\n def test_run_bad_root\n root = mock('root')\n proposed = mock('proposed')\n\n seq = sequence(__method__)\n proposed.expects(:remove).returns(true).in_sequence(seq)\n root.expects(:install).returns(false).in_sequence(seq)\n\n checker = RootInstallCheck.new\n assert_raises { checker.run(proposed, root) }\n end\n\n def test_run_bad_proposed_add\n root = mock('root')\n proposed = mock('proposed')\n\n seq = sequence(__method__)\n proposed.expects(:remove).returns(true).in_sequence(seq)\n root.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:add).returns(false).in_sequence(seq)\n\n checker = RootInstallCheck.new\n assert_raises { checker.run(proposed, root) }\n end\n\n def test_run_bad_proposed\n root = mock('root')\n proposed = mock('proposed')\n\n seq = sequence(__method__)\n proposed.expects(:remove).returns(true).in_sequence(seq)\n root.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:add).returns(true).in_sequence(seq)\n proposed.expects(:install).returns(false).in_sequence(seq)\n\n checker = RootInstallCheck.new\n assert_raises { checker.run(proposed, root) }\n end\n\n def test_run_bad_purge\n root = mock('root')\n proposed = mock('proposed')\n\n seq = sequence(__method__)\n proposed.expects(:remove).returns(true).in_sequence(seq)\n root.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:add).returns(true).in_sequence(seq)\n proposed.expects(:install).returns(true).in_sequence(seq)\n proposed.expects(:purge).returns(false).in_sequence(seq)\n\n checker = RootInstallCheck.new\n assert_raises { checker.run(proposed, root) }\n end\nend\n"
},
{
"alpha_fraction": 0.7080081105232239,
"alphanum_fraction": 0.7143683433532715,
"avg_line_length": 44.51315689086914,
"blob_id": "ef0f994693d983e6ccff517f725cb7fb900a7672",
"content_id": "cc57d1f570db951bc9061141d71b4049cfc2b262",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3459,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 76,
"path": "/test/test_nci_kf_sixy.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/kf_sixy'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\nrequire 'net/ssh/gateway' # so we have access to the const\n\nclass NCIKFSixyTest < TestCase\n def setup\n end\n\n def teardown\n end\n\n def test_sixy_repo\n FileUtils.rm_rf(\"#{data}/threadweaver\")\n FileUtils.cp_r(\"#{data}/original\", \"#{data}/threadweaver\")\n sixy = KFSixy.new(name: \"threadweaver\", dir: \"#{data}/threadweaver\")\n sixy.run\n result = File.readlines(\"#{data}/threadweaver/debian/control\")\n File.readlines(\"#{data}/good/debian/control\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n result = File.readlines(\"#{data}/threadweaver/debian/changelog\")\n File.readlines(\"#{data}/good/debian/changelog\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n result = File.readlines(\"#{data}/threadweaver/debian/rules\")\n File.readlines(\"#{data}/good/debian/rules\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n result = File.readlines(\"#{data}/threadweaver/debian/kf6-threadweaver.install\")\n File.readlines(\"#{data}/good/debian/kf6-threadweaver.install\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n result = File.readlines(\"#{data}/threadweaver/debian/kf6-threadweaver-dev.install\")\n File.readlines(\"#{data}/good/debian/kf6-threadweaver-dev.install\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/libkf5threadweaver5.install\"))\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/libkf5threadweaver5.symbols\"))\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/libkf5threadweaver-dev.acc.in\"))\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/libkf5threadweaver-dev.install\"))\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/libkf5threadweaver-doc.install\"))\n assert_equal(false, File.exist?(\"#{data}/threadweaver/debian/compat\"))\n assert_equal(true, File.exist?(\"#{data}/threadweaver/debian/kf6-threadweaver.install\"))\n assert_equal(true, File.exist?(\"#{data}/threadweaver/debian/kf6-threadweaver-dev.install\"))\n sixy = KFSixy.new(name: \"threadweaver\", dir: \"#{data}/threadweaver\")\n sixy.run\n #result = File.readlines(\"#{data}/threadweaver/debian/control\")\n #File.readlines(\"#{data}/good/debian/control\").each_with_index do |line, i|\n #assert_equal(line, result[i])\n #end\n end\n\nend\n"
},
{
"alpha_fraction": 0.6586679816246033,
"alphanum_fraction": 0.665034294128418,
"avg_line_length": 31.41269874572754,
"blob_id": "eaeb8495b8cff0b0c5942a2639c0a0e07828863c",
"content_id": "ec56b56a9e65bc16a1dd0151db64adaa76dec3a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2042,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 63,
"path": "/test/test_executable.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/shebang'\n\nclass ExecutableTest < TestCase\n BINARY_DIRS = %w[\n .\n bin\n lib/libexec\n nci\n mgmt\n overlay-bin\n xci\n ci\n ].freeze\n\n SUFFIXES = %w[.py .rb .sh].freeze\n\n def test_all_binaries_exectuable\n basedir = File.dirname(__dir__)\n not_executable = []\n BINARY_DIRS.each do |dir|\n SUFFIXES.each do |suffix|\n pattern = File.join(basedir, dir, \"*#{suffix}\")\n Dir.glob(pattern).each do |file|\n next unless File.exist?(file)\n\n if File.executable?(file)\n sb = Shebang.new(File.open(file).readline)\n # The trailing space in the msg is so it can be copy pasted,\n # without this it'd end in a fullstop.\n assert(sb.valid, \"Invalid shebang #{file} \")\n else\n not_executable << file\n end\n end\n end\n end\n # Use a trailing space to make sure we can copy crap without a terminal\n # fullstop inserted by test-unit.\n assert(not_executable.empty?, \"Missing +x on #{not_executable.join(\"\\n\")} \")\n end\nend\n"
},
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 23.27777862548828,
"blob_id": "26277798fdd5f77408460a78e1bf89a591005f7d",
"content_id": "11b6fb4147b684831dde36322680c2f3e8a1640e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 18,
"path": "/jenkins-jobs/imagejob.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\nclass ImageJob < JenkinsJob\n attr_reader :repo\n attr_reader :release\n attr_reader :architecture\n attr_reader :flavor\n\n def initialize(flavor:, release:, architecture:, repo:, branch:)\n @flavor = flavor\n @release = release\n @architecture = architecture\n @repo = repo\n @branch = branch\n super(\"img_#{flavor}_#{release}_#{architecture}\", 'img.xml.erb')\n end\nend\n"
},
{
"alpha_fraction": 0.6516767144203186,
"alphanum_fraction": 0.6544583439826965,
"avg_line_length": 32.58650588989258,
"blob_id": "a1b9a5c647c83a92d487bc76a2b278fadf215184",
"content_id": "46965c7330cce10348ab615fb76e7261afc86fcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 19413,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 578,
"path": "/lib/projects.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2014-2020 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2014-2016 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2015 Jonathan Riddell <[email protected]>\n# SPDX-FileCopyrightText: 2015 Bhushan Shah <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'concurrent'\nrequire 'fileutils'\nrequire 'forwardable' # For cleanup_uri delegation\nrequire 'git_clone_url'\nrequire 'json'\nrequire 'rugged'\nrequire 'net/ssh'\n\nrequire_relative 'ci/overrides'\nrequire_relative 'ci/upstream_scm'\nrequire_relative 'debian/control'\nrequire_relative 'debian/source'\nrequire_relative 'debian/relationship'\nrequire_relative 'retry'\nrequire_relative 'kdeproject_component'\n\nrequire_relative 'deprecate'\n\n# A thing that gets built.\nclass Project\n class Error < RuntimeError; end\n class TransactionError < Error; end\n class BzrTransactionError < TransactionError; end\n class GitTransactionError < TransactionError; end\n # Derives from RuntimeError because someone decided to resuce Transaction\n # and Runtime in factories only...\n class GitNoBranchError < RuntimeError; end\n class ShitPileErrror < RuntimeError; end\n # Override expectation makes no sense. The member is nil.\n class OverrideNilError < RuntimeError\n def initialize(component, name, member, value)\n super(<<~ERR)\n There is an override for @#{member} to \"#{value}\"\n in project \"#{name}\", component \"#{component}\"\n but that member is nil. Members which are nil cannot be overridden\n as nil is considered a final state. e.g. a nil @upstream_scm means\n the source is native so it would not make sense to set a\n source as it would not be used. Check your conditions!\n ERR\n end\n end\n\n # Caches VCS update runs to not update the same VCS multitple times.\n module VCSCache\n class << self\n # Caches that an update was performed\n def updated(path)\n cache << path\n end\n\n # @return [Bool] if this path requires updating\n def update?(path)\n return false if ENV.include?('NO_UPDATE')\n\n !cache.include?(path)\n end\n\n private\n\n def cache\n @cache ||= Concurrent::Array.new\n end\n end\n end\n\n extend Deprecate\n\n # Name of the thing (e.g. the repo name)\n attr_reader :name\n # Super component (e.g. plasma)\n attr_reader :component\n # KDE component (e.g. frameworks, plasma, gear, extragear)\n attr_reader :kdecomponent\n # Scm instance describing the upstream SCM associated with this project.\n # FIXME: should this really be writable? need this for projects to force\n # a different scm which is slightly meh\n attr_accessor :upstream_scm\n # Array of binary packages (debs) provided by this project\n attr_reader :provided_binaries\n\n # Array of package dependencies, initialized by default from control file\n attr_reader :dependencies\n # Array of package dependees, empty Array by default\n attr_reader :dependees\n\n # Array of branch names that are series specific. May be empty if there are\n # none.\n attr_reader :series_branches\n\n # Bool whether this project uses autopkgtest\n attr_reader :autopkgtest\n\n # Packaging SCM instance\n attr_reader :packaging_scm\n\n # Path to snapcraft.yaml if any\n attr_reader :snapcraft\n\n # Whether the project has debian packaging\n attr_reader :debian\n alias debian? debian\n\n # List of dist ids that this project is restricted to (e.g. %w[xenial bionic focal]\n # should prevent the project from being used to create jobs for `artful`)\n # This actually taking effect depends on the specific job/project_updater\n # implementation correctly implementing the restriction.\n attr_reader :series_restrictions\n\n DEFAULT_URL = 'https://salsa.debian.org/qt-kde-team'\n @default_url = DEFAULT_URL\n\n class << self\n attr_accessor :default_url\n end\n\n # Init\n # @param name name of the project (this is equal to the name of the packaging\n # repo)\n # @param component component within which the project resides (i.e. directory\n # part of the repo path)\n # @param url_base the base path of the full repo URI. Combined with name and\n # component this should form a repo URI\n # @param branch branch name in packaging repository to use\n # branches.\n # @param type the type of integration project (unstable/stable..).\n # This indicates whether to look for kubuntu_unstable or kubuntu_stable\n # NB: THIS is mutually exclusive with branch!\n def initialize(name, component, url_base = self.class.default_url,\n type: nil,\n branch: \"kubuntu_#{type}\",\n origin: CI::UpstreamSCM::Origin::UNSTABLE)\n variable_deprecation(:type, :branch) unless type.nil?\n @name = name\n @component = component\n @upstream_scm = nil\n @provided_binaries = []\n @dependencies = []\n @dependees = []\n @series_branches = []\n @autopkgtest = false\n @debian = false\n @series_restrictions = []\n @kdecomponent = if KDEProjectsComponent.frameworks_jobs.include?(name)\n 'frameworks'\n elsif KDEProjectsComponent.gear_jobs.include?(name)\n 'gear'\n elsif KDEProjectsComponent.plasma_jobs.include?(name)\n 'plasma'\n else\n 'extragear'\n end\n\n if component == 'kde-extras_kde-telepathy'\n puts 'stepped into a shit pile --> https://phabricator.kde.org/T4160'\n raise ShitPileErrror,\n 'stepped into a shit pile --> https://phabricator.kde.org/T4160'\n end\n\n # FIXME: this should run at the end. test currently assume it isn't though\n validate!\n\n init_packaging_scm(url_base, branch)\n cache_dir = cache_path_from(packaging_scm)\n\n @override_rule = CI::Overrides.new.rules_for_scm(@packaging_scm)\n override_apply('packaging_scm')\n\n get(cache_dir)\n update(branch, cache_dir)\n Dir.mktmpdir do |checkout_dir|\n checkout(branch, cache_dir, checkout_dir)\n init_from_source(checkout_dir)\n end\n\n @override_rule.each do |member, _|\n override_apply(member)\n end\n\n # Qt6 Hack\n if name == 'qt6'\n upstream_scm.instance_variable_set(:@type, 'uscan')\n return\n end\n\n upstream_scm&.releaseme_adjust!(origin)\n end\n\n def packaging_scm_for(series:)\n # TODO: it'd be better if this was somehow tied into the SCM object itself.\n # Notably the SCM could ls-remote and build a list of all branches on\n # remote programatically. Then we carry that info in the SCM, not the\n # project.\n # Doesn't really impact the code here though. The SCM ought to still be\n # unaware of the code branching.\n branch = series_branches.find { |b| b.split('_')[-1] == series }\n return packaging_scm unless branch\n\n CI::SCM.new(packaging_scm.type, packaging_scm.url, branch)\n end\n\n private\n\n def validate!\n # Jenkins doesn't like slashes. Nor should it have to, any sort of ordering\n # would be the result of component/name, which is precisely why neither must\n # contain additional slashes as then they'd be $pathtype/$pathtype which\n # often will need different code (mkpath vs. mkdir).\n if @name.include?('/')\n raise NameError, \"name value contains a slash: #{@name}\"\n end\n if @component.include?('/')\n raise NameError, \"component contains a slash: #{@component}\"\n end\n end\n\n def init_from_debian_source(dir)\n return unless File.exist?(\"#{dir}/debian/control\")\n\n control = Debian::Control.new(dir)\n # TODO: raise? return?\n control.parse!\n init_from_control(control)\n # Unset previously default SCM\n @upstream_scm = nil if native?(dir)\n @debian = true\n rescue => e\n raise e.exception(\"#{e.message}\\nWhile working on #{dir}/debian -- #{name}\")\n end\n\n def init_from_source(dir)\n @upstream_scm = CI::UpstreamSCM.new(@packaging_scm.url,\n @packaging_scm.branch)\n @snapcraft = find_snapcraft(dir)\n init_from_debian_source(dir)\n # NOTE: assumption is that launchpad always is native even when\n # otherwise noted in packaging. This is somewhat meh and probably\n # should be looked into at some point.\n # Primary motivation are compound UDD branches as well as shit\n # packages that are dpkg-source v1...\n @upstream_scm = nil if component == 'launchpad'\n end\n\n def find_snapcraft(dir)\n file = Dir.glob(\"#{dir}/**/snapcraft.yaml\")[0]\n return file unless file\n\n Pathname.new(file).relative_path_from(Pathname.new(dir)).to_s\n end\n\n def native?(directory)\n return false if Debian::Source.new(directory).format.type != :native\n\n blacklist = %w[gear frameworks plasma kde-extras]\n return true unless blacklist.include?(component)\n\n # NOTE: this is a bit broad in scope, may be more prudent to have the\n # factory handle this after collecting all promises.\n raise <<-ERROR\n#{name} is in #{component} and marked native. Projects in that component\nabsolutely must not be native though!\n ERROR\n end\n\n def init_deps_from_control(control)\n fields = %w[build-depends]\n # Do not cover indep for Qt because Qt packages have a dep loop in them.\n unless control.source.fetch('Source', '').include?('-opensource-src')\n fields << 'build-depends-indep'\n end\n fields.each do |field|\n control.source.fetch(field, []).each do |alt_deps|\n alt_deps = alt_deps.select do |relationship|\n relationship.applicable_to_profile?(nil)\n end\n @dependencies += alt_deps.collect(&:name)\n end\n end\n end\n\n def init_from_control(control)\n init_deps_from_control(control)\n\n control.binaries.each do |binary|\n @provided_binaries << binary['package']\n end\n\n # FIXME: Probably should be converted to a symbol at a later point\n # since xs-testsuite could change to random other string in the\n # future\n @autopkgtest = control.source['xs-testsuite'] == 'autopkgtest'\n end\n\n def render_override(erb)\n # Versions would be a float. Coerce into string.\n ERB.new(erb.to_s).result(binding)\n end\n\n def override_rule_for(member)\n @override_rule[member]\n end\n\n def override_applicable?(member)\n return false unless @override_rule\n\n # Overrides are cascading so a more general rule could conflict with a more\n # specific one. In that event manually setting the specific one to nil\n # should be passing as no-op.\n # e.g. all Neon/releases are forced to use uscan. That would fail the\n # validation below, so native software would then explicit set\n # upstream_scm:nil in their specific override. This then triggers equallity\n # which we consider no-op.\n if override_rule_for(member) == instance_variable_get(\"@#{member}\")\n return false\n end\n\n unless instance_variable_get(\"@#{member}\")\n return false if override_rule_for(member).keys[0] == \"type\"\n raise OverrideNilError.new(@component, @name, member, override_rule_for(member)) if override_rule_for(member)\n\n return false\n end\n\n return false unless @override_rule.include?(member)\n\n true\n end\n\n # TODO: this doesn't do deep-application. So we can override attributes of\n # our instance vars, but not of the instance var's instance vars.\n # (no use case right now)\n # TODO: when overriding with value nil the thing should be undefined\n # TODO: when overriding with an object that object should be used instead\n # e.g. when the yaml has one !ruby/object:CI::UpstreamSCM...\n # FIXME: failure not test covered as we cannot supply a broken override\n # without having one in the live data.\n def override_apply(member)\n return unless override_applicable?(member)\n\n object = instance_variable_get(\"@#{member}\")\n rule = override_rule_for(member)\n unless rule\n instance_variable_set(\"@#{member}\", nil)\n return\n end\n\n # If the rule isn't as hash we can simply apply it as member object.\n # This is for example enabling us to override arrays of strings etc.\n unless rule.is_a?(Hash)\n instance_variable_set(\"@#{member}\", rule.dup)\n return\n end\n\n # Otherwise the rule is a hash and we'll apply its valus to the object\n # instead. This is not applying properties any deeper!\n rule.each do |var, value|\n next unless (value = render_override(value))\n\n # TODO: object.override! can jump in here and do what it wants\n object.instance_variable_set(\"@#{var}\", value)\n end\n rescue => e\n warn \"Failed to override #{member} of #{name} with rule #{rule}\"\n raise e\n end\n\n class << self\n def git_credentials(url, username, types)\n config = Net::SSH::Config.for(GitCloneUrl.parse(url).host)\n default_key = \"#{Dir.home}/.ssh/id_rsa\"\n key = File.expand_path(config.fetch(:keys, [default_key])[0])\n p credentials = Rugged::Credentials::SshKey.new(\n username: username,\n publickey: key + '.pub',\n privatekey: key,\n passphrase: ''\n )\n credentials\n end\n\n # @param uri <String> uri of the repo to clone\n # @param dest <String> directory name of the dir to clone as\n def get_git(uri, dest)\n return if File.exist?(dest)\n\n if URI.parse(uri).scheme == 'ssh'\n Rugged::Repository.clone_at(uri, dest,\n bare: true,\n credentials: method(:git_credentials))\n else\n Rugged::Repository.clone_at(uri, dest, bare: true)\n end\n\n rescue Rugged::NetworkError => e\n p uri\n raise GitTransactionError, e\n end\n\n # @see {get_git}\n def get_bzr(uri, dest)\n return if File.exist?(dest)\n return if system(\"bzr checkout --lightweight #{uri} #{dest}\")\n\n raise BzrTransactionError, \"Could not checkout #{uri}\"\n end\n\n def update_git(dir)\n return unless VCSCache.update?(dir)\n\n # TODO: should change to .bare as its faster. also in checkout.\n repo = Rugged::Repository.new(dir)\n repo.config.store('remote.origin.prune', true)\n repo.remotes['origin'].fetch\n rescue Rugged::NetworkError => e\n raise GitTransactionError,\n \"Failed to update git clone at #{dir}: #{e}\"\n rescue Rugged::ReferenceError => e\n raise Rugged::ReferenceError, \"Failed to update git clone at #{dir}: #{e}\"\n end\n\n def update_bzr(dir)\n return unless VCSCache.update?(dir)\n return if system('bzr up', chdir: dir)\n\n raise BzrTransactionError, 'Failed to update'\n end\n end\n\n def init_packaging_scm_git(url_base, branch)\n # Assume git\n # Clean up path to remove useless slashes and colons.\n @packaging_scm = CI::SCM.new('git',\n \"#{url_base}/#{@component}/#{@name}\",\n branch)\n end\n\n def schemeless_path(url)\n return url if url[0] == '/' # Seems to be an absolute path already!\n\n uri = GitCloneUrl.parse(url)\n uri.scheme = nil\n path = uri.to_s\n path = path[1..-1] while path[0] == '/'\n path\n end\n\n def cache_path_from(scm)\n path = schemeless_path(scm.url)\n raise \"couldnt build cache path from #{uri}\" if path.empty?\n\n path = File.absolute_path(\"cache/projects/#{path}\")\n dir = File.dirname(path)\n FileUtils.mkdir_p(dir, verbose: true) unless Dir.exist?(dir)\n path\n end\n\n def init_packaging_scm_bzr(url_base)\n packaging_scm_url = if url_base.end_with?(':')\n \"#{url_base}#{@name}\"\n else\n \"#{url_base}/#{@name}\"\n end\n @packaging_scm = CI::SCM.new('bzr', packaging_scm_url)\n end\n\n # @return component_dir to use for cloning etc.\n def init_packaging_scm(url_base, branch)\n # FIXME: git dir needs to be set somewhere, somehow, somewhat, lol, kittens?\n if @component == 'launchpad'\n init_packaging_scm_bzr(url_base)\n else\n init_packaging_scm_git(url_base, branch)\n end\n end\n\n def get(dir)\n Retry.retry_it(errors: [TransactionError], times: 2, sleep: 5) do\n if @component == 'launchpad'\n self.class.get_bzr(@packaging_scm.url, dir)\n else\n self.class.get_git(@packaging_scm.url, dir)\n end\n end\n end\n\n def update(branch, dir)\n Retry.retry_it(errors: [TransactionError], times: 2, sleep: 5) do\n if @component == 'launchpad'\n self.class.update_bzr(dir)\n else\n self.class.update_git(dir)\n\n # NB: this is used for per-series mutation when neon is moving\n # from one to another series. The branch gets recorded here\n # and the job templates then figure out what branch to use by calling\n # #packaging_scm_for\n branches = `cd #{dir} && git for-each-ref --format='%(refname)' refs/remotes/origin/#{branch}_\\*`.strip.lines\n branches.each do |b|\n @series_branches << b.gsub('refs/remotes/origin/', '').strip\n end\n end\n end\n end\n\n def checkout_lp(cache_dir, checkout_dir)\n FileUtils.rm_r(checkout_dir, verbose: true)\n FileUtils.ln_s(cache_dir, checkout_dir, verbose: true)\n end\n\n def checkout_git(branch, cache_dir, checkout_dir)\n repo = Rugged::Repository.new(cache_dir)\n repo.workdir = checkout_dir\n b = \"origin/#{branch}\"\n branches = repo.branches.each_name.to_a\n unless branches.include?(b)\n raise GitNoBranchError, \"No branch #{b} for #{name} found #{branches}\"\n end\n\n repo.reset(b, :hard)\n end\n\n def checkout(branch, cache_dir, checkout_dir, series: false)\n # This meth cannot have transaction errors as there is no network IO going\n # on here.\n return checkout_lp(cache_dir, checkout_dir) if @component == 'launchpad'\n\n checkout_git(branch, cache_dir, checkout_dir)\n rescue Project::GitNoBranchError => e\n raise e if series || !branch.start_with?('Neon/')\n\n # NB: this is only used for building of the dependency list and the like.\n # The actual target branches are picked from the series_branches at\n # job templating time, much later. This order only represents our\n # preference for dep data (they'll generally only vary in minor degress\n # between the various branches).\n # Secondly we want to raise back into the factory if they asked us to\n # construct a project for branch Neon/unstable but no such branch and no\n # series variant of it exists.\n require_relative 'nci'\n new_branch = @series_branches.find { |x| x.end_with?(NCI.current_series) }\n if NCI.future_series && !new_branch\n new_branch = @series_branches.find { |x| x.end_with?(NCI.future_series) }\n end\n if NCI.old_series && !new_branch\n new_branch = @series_branches.find { |x| x.end_with?(NCI.old_series) }\n end\n raise e unless new_branch\n\n warn \"Failed to find branch #{branch}; falling back to #{new_branch}\"\n checkout(new_branch, cache_dir, checkout_dir, series: true)\n end\n\n def inspect\n vset = instance_variables[0..4]\n str = \"<#{self.class}:#{object_id} \"\n str += vset.collect do |v|\n value = instance_variable_get(v)\n # Prevent infinite recursion in case there's a loop in our\n # dependency members.\n inspection = if value.is_a?(Array) && value[0]&.is_a?(self.class)\n 'ArrayOfNestedProjects'\n else\n value.inspect\n end\n \"#{v}=#{inspection}\"\n end.compact.join(', ')\n str += '>'\n\n str\n end\nend\n"
},
{
"alpha_fraction": 0.6530172228813171,
"alphanum_fraction": 0.6582512259483337,
"avg_line_length": 30.230770111083984,
"blob_id": "430227e6b24653d1a16018d2eab3f684cd0f235d",
"content_id": "c350a3acabe229adeb1f63f59e4d6312aad3ffd8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3248,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 104,
"path": "/lib/apt/repository.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# Technically this requires apt.rb but that'd be circular, so we'll only\n# require it in when a repo is constructed. This makes it a lazy require.\n\nmodule Apt\n # Represents a repository\n class Repository\n def initialize(name)\n require_relative '../apt.rb'\n @name = name\n self.class.send(:install_add_apt_repository)\n @default_args = []\n if self.class.send(:disable_auto_update?)\n # Since Ubuntu 18.04 the default behavior is to automatically run an\n # update which will fail without retrying if there was a network error.\n # We largely have retry systems in place and generally want more control\n # over when updates happen, so alway disable the auto-update\n @default_args << '--no-update'\n end\n end\n\n # (see #add)\n def self.add(name)\n new(name).add\n end\n\n # Add Repository to sources.list\n def add\n args = [] + @default_args\n args << '-y'\n args << @name\n system('add-apt-repository', *args)\n end\n\n # (see #remove)\n def self.remove(name)\n new(name).remove\n end\n\n # Remove Repository from sources.list\n def remove\n args = [] + @default_args\n args << '-y'\n args << '-r'\n args << @name\n system('add-apt-repository', *args)\n end\n\n class << self\n private\n\n def install_add_apt_repository\n return if add_apt_repository_installed?\n return unless Apt.install('software-properties-common')\n\n @add_apt_repository_installed = true\n end\n\n def add_apt_repository_installed?\n return @add_apt_repository_installed if ENV['PANGEA_UNDER_TEST']\n\n @add_apt_repository_installed ||= marker_exist?\n end\n\n # Own method so we can mocha this check! Do not merge into other method.\n def marker_exist?\n File.exist?('/var/lib/dpkg/info/software-properties-common.list')\n end\n\n def disable_auto_update?\n @disable_auto_update ||=\n `add-apt-repository --help`.include?('--no-update')\n end\n\n def reset\n if defined?(@add_apt_repository_installed)\n remove_instance_variable(:@add_apt_repository_installed)\n end\n return unless defined?(@disable_auto_update)\n\n remove_instance_variable(:@disable_auto_update)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6561067700386047,
"alphanum_fraction": 0.6606893539428711,
"avg_line_length": 36.17777633666992,
"blob_id": "58572f6ea50315f13b40a50ff760126d685ba517",
"content_id": "4f4fd1e00bd63d02cbe6880646b1c46143c70226",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5019,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 135,
"path": "/nci/duplicated_repos.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\nrequire 'jenkins_junit_builder'\n\nrequire_relative '../lib/projects/factory/neon'\n\nmodule NCI\n # Checks for duplicated repos.\n class DuplicatedRepos\n # Whitelists basename=>[paths] from being errored on (for when the dupe)\n # is intentional. NB: this should not ever be necessary!\n # This does strictly assert that the paths defined are the paths we have.\n # Any deviation will result in a test fail as the whitelist must be kept\n # current to prevent false-falsitives.\n # whiltelist kde-l10n, as it moved to kde/ from kde-sc after salsa move\n WHITELIST = {\"kde-l10n\"=>[\"kde/kde-l10n\", \"neon/kde-l10n\"]}.freeze\n\n class << self\n attr_writer :whitelist\n\n def whitelist\n @whitelist ||= WHITELIST\n end\n end\n\n PATH_EXCLUSION = [\n 'kde-sc/', # Legacy KDE 4 material\n 'attic/', # Archive for old unused stuff.\n 'deduplication-wastebin/', # Trash from dupe cleanup.\n 'kf6/' # All duplicate with kde\n ].freeze\n\n module JUnit\n # Wrapper converting to JUnit Suite.\n class Suite\n # Wrapper converting to JUnit Case.\n class Case < JenkinsJunitBuilder::Case\n def initialize(name, paths)\n self.classname = name\n # 3rd and final drill down CaseClassName\n self.name = name\n self.time = 0\n self.result = JenkinsJunitBuilder::Case::RESULT_FAILURE\n system_out.message = build_output(name, paths)\n end\n\n def build_output(name, paths)\n output = <<-EOF\n'#{name}' has more than one repository. It appears at [#{paths.join(' ')}].\nThis usually means that a neon-packaging/ or forks/ repo was created when indeed\nDebian had a repo already which should be used instead. Similiarly Debian\nmay have added the repo after the fact and work should be migrated there.\nLess likely scenarios include the mirror tech having failed to properly mirror\na symlink (should only appear in the canonical location on our side).\n EOF\n return output unless (whitelist = DuplicatedRepos.whitelist[name])\n\n output + <<-EOF\n\\nThere was a whitelist rule but it did not match! Was: [#{whitelist.join(' ')}]\n EOF\n end\n end\n\n def initialize(dupes)\n @suite = JenkinsJunitBuilder::Suite.new\n # This is not particularly visible in Jenkins, it's only used on the\n # testcase page itself where it will refer to the test as\n # SuitePackage.CaseClassName.CaseName (from SuitePackage.SuiteName)\n @suite.name = 'Check'\n # Primary sorting name on Jenkins.\n # Test results page lists a table of all tests by packagename\n @suite.package = 'DuplicatedRepos'\n dupes.each { |name, paths| @suite.add_case(Case.new(name, paths)) }\n end\n\n def write_into(dir)\n FileUtils.mkpath(dir) unless Dir.exist?(dir)\n File.write(\"#{dir}/#{@suite.package}.xml\", @suite.build_report)\n end\n end\n end\n\n # List of paths the repo appears in.\n def self.reject_paths?(paths)\n remainder = paths.reject do |path|\n PATH_EXCLUSION.any? { |e| path.start_with?(e) }\n end\n remainder.size < 2\n end\n\n # base is the basename of the repo\n # paths is an array of directories the repo appears in\n def self.reject?(base, paths)\n # Only one candidate. All fine\n return true if paths.size < 2\n # Ignore if we should reject the paths\n return true if reject_paths?(paths)\n # Exclude whitelisted materials\n return true if whitelist.fetch(base, []) == paths\n\n false\n end\n\n def self.run\n repos = ProjectsFactory::Neon.ls\n repos_in_paths = repos.group_by { |x| File.basename(x) }\n repos_in_paths.reject! { |base, paths| reject?(base, paths) }.to_h\n JUnit::Suite.new(repos_in_paths).write_into('reports/')\n puts repos_in_paths\n raise 'Duplicated repos found' unless repos_in_paths.empty?\n end\n end\nend\n\nNCI::DuplicatedRepos.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.6332848072052002,
"alphanum_fraction": 0.6622359752655029,
"avg_line_length": 33.32500076293945,
"blob_id": "10abf1c659b0892fcd1edb006432dda8a4c95dd0",
"content_id": "ace67ef0731d4ae09a7e1b878064d7257a081c56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5492,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 160,
"path": "/test/test_nci_jenkins_job_artifact_cleaner_all.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/jenkins_job_artifact_cleaner_all'\n\nrequire 'mocha/test_unit'\n\nmodule NCI\n class JenkinsJobArtifactCleanerTestAll < TestCase\n def setup\n @jenkins_home = ENV['JENKINS_HOME']\n ENV['JENKINS_HOME'] = Dir.pwd\n @jenkins_job_base = ENV['JOB_BASE_NAME']\n ENV['JOB_BASE_NAME'] = 'foobasename'\n @jenkins_build_number = ENV['BUILD_NUMBER']\n ENV['BUILD_NUMBER'] = '42'\n end\n\n def teardown\n # If the var is nil []= delets it from the env.\n ENV['JENKINS_HOME'] = @jenkins_home\n ENV['JOB_BASE_NAME'] = @jenkins_job_base\n ENV['BUILD_NUMBER'] = @jenkins_build_number\n end\n\n def test_clean\n ENV['PANGEA_ARTIFACT_CLEAN_HISTORY'] = '100'\n\n # All deb files should get ripped out.\n\n # job foo\n\n ## 3 so we test if clamping to 1 at the smallest works.\n foo_archive3 = 'jobs/foo/builds/3/archive'\n FileUtils.mkpath(foo_archive3)\n FileUtils.touch(\"#{foo_archive3}/aa.deb\")\n\n ## skip 2 to see if a missing build doesn't crash\n\n ## 1 also has some litter\n foo_archive1 = 'jobs/foo/builds/1/archive'\n FileUtils.mkpath(foo_archive1)\n FileUtils.touch(\"#{foo_archive1}/aa.deb\")\n\n ## lastBuild->3\n File.write('jobs/foo/builds/permalinks', 'lastBuild 3', mode: 'a')\n\n # job bar\n\n ## 200 so we test if we don't iterate the entire build history\n bar_archive200 = 'jobs/bar/builds/200/archive'\n FileUtils.mkpath(bar_archive200)\n FileUtils.touch(\"#{bar_archive200}/aa.deb\")\n\n ## 100 also has some litter\n bar_archive100 = 'jobs/bar/builds/100/archive'\n FileUtils.mkpath(bar_archive100)\n FileUtils.touch(\"#{bar_archive100}/aa.deb\")\n\n ## 99 also has some litter but shouldn't get cleaned\n bar_archive99 = 'jobs/bar/builds/99/archive'\n FileUtils.mkpath(bar_archive99)\n FileUtils.touch(\"#{bar_archive99}/aa.deb\")\n\n ## lastBuild->200\n File.write('jobs/bar/builds/permalinks', 'lastBuild 200', mode: 'a')\n\n # twonkle - do not explode on jobs that haven't built yet (invalid\n # symlink raises Errno::ENOENT)\n FileUtils.mkpath('jobs/twonkle/builds')\n File.write('jobs/twonkle/builds/permalinks', 'lastBuild -1', mode: 'a')\n\n JenkinsJobArtifactCleaner::AllJobs.run\n\n assert_path_not_exist(\"#{foo_archive3}/aa.deb\")\n assert_path_not_exist(\"#{foo_archive1}/aa.deb\")\n\n assert_path_not_exist(\"#{bar_archive200}/aa.deb\")\n assert_path_not_exist(\"#{bar_archive100}/aa.deb\")\n assert_path_exist(\"#{bar_archive99}/aa.deb\")\n end\n\n def test_clean_legacy_symlinks\n # verbatim copy of test_clean but with symlinks\n\n ENV['PANGEA_ARTIFACT_CLEAN_HISTORY'] = '100'\n\n # All deb files should get ripped out.\n\n # job foo\n\n ## 3 so we test if clamping to 1 at the smallest works.\n foo_archive3 = 'jobs/foo/builds/3/archive'\n FileUtils.mkpath(foo_archive3)\n FileUtils.touch(\"#{foo_archive3}/aa.deb\")\n\n ## skip 2 to see if a missing build doesn't crash\n\n ## 1 also has some litter\n foo_archive1 = 'jobs/foo/builds/1/archive'\n FileUtils.mkpath(foo_archive1)\n FileUtils.touch(\"#{foo_archive1}/aa.deb\")\n\n ## symlink lastBuild->3\n FileUtils.ln_s('3', 'jobs/foo/builds/lastBuild', verbose: true)\n\n # job bar\n\n ## 200 so we test if we don't iterate the entire build history\n bar_archive200 = 'jobs/bar/builds/200/archive'\n FileUtils.mkpath(bar_archive200)\n FileUtils.touch(\"#{bar_archive200}/aa.deb\")\n\n ## 100 also has some litter\n bar_archive100 = 'jobs/bar/builds/100/archive'\n FileUtils.mkpath(bar_archive100)\n FileUtils.touch(\"#{bar_archive100}/aa.deb\")\n\n ## 99 also has some litter but shouldn't get cleaned\n bar_archive99 = 'jobs/bar/builds/99/archive'\n FileUtils.mkpath(bar_archive99)\n FileUtils.touch(\"#{bar_archive99}/aa.deb\")\n\n ## symlink lastBuild->200\n FileUtils.ln_s('200', 'jobs/bar/builds/lastBuild')\n\n # twonkle - do not explode on jobs that haven't built yet (invalid\n # symlink raises Errno::ENOENT)\n FileUtils.mkpath('jobs/twonkle/builds')\n FileUtils.ln_s('-1', 'jobs/twonkle/builds/lastBuild')\n\n JenkinsJobArtifactCleaner::AllJobs.run\n\n assert_path_not_exist(\"#{foo_archive3}/aa.deb\")\n assert_path_not_exist(\"#{foo_archive1}/aa.deb\")\n\n assert_path_not_exist(\"#{bar_archive200}/aa.deb\")\n assert_path_not_exist(\"#{bar_archive100}/aa.deb\")\n assert_path_exist(\"#{bar_archive99}/aa.deb\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6569548845291138,
"alphanum_fraction": 0.6625939607620239,
"avg_line_length": 29.840579986572266,
"blob_id": "ceffc9c7a06a9dce991addd2371dc6b95d20940c",
"content_id": "6ae7756de160a513138eed5c5fabf59aa007040e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2128,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 69,
"path": "/lib/ci/kcrash_link_validator.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tmpdir'\n\nmodule CI\n # Validator wrapper to ensure targets that intended to link aginst kcrash\n # indeed ended up linked.\n # https://markmail.org/thread/zv5pheijaze72bzs\n class KCrashLinkValidator\n BLACKLIST = [\n # Uses the same link list for the bin and a plugin. Unreasonable to expect\n # a change there.\n '_kmail-account-wizard_'\n ].freeze\n\n def self.run(&block)\n new.run(&block)\n end\n\n def run(&block)\n if ENV['TYPE'] != 'unstable' ||\n !File.exist?('CMakeLists.txt') ||\n BLACKLIST.any? { |x| ENV.fetch('JOB_NAME').include?(x) }\n yield\n return\n end\n\n warn 'Extended CMakeLists with KCrash link validation.'\n mangle(&block)\n end\n\n private\n\n def data\n File.read(File.join(__dir__, 'kcrash_link_validator.cmake'))\n end\n\n def mangle\n Dir.mktmpdir do |tmpdir|\n begin\n backup = File.join(tmpdir, 'CMakeLists.txt')\n FileUtils.cp('CMakeLists.txt', backup, verbose: true)\n File.open('CMakeLists.txt', 'a') { |f| f.write(data) }\n yield\n ensure\n FileUtils.cp(backup, Dir.pwd, verbose: true)\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6752136945724487,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 45.79999923706055,
"blob_id": "ded9d33c9a7fe0951ead49807ab94fac0d1e5e32",
"content_id": "2909a0b212700478fe72679482dd1caf9d578cd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 5,
"path": "/nci/imager/config-settings-neon-bigscreen.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "EDITION=$(echo $NEONARCHIVE | sed 's,/, ,')\nexport LB_ISO_VOLUME=\"${IMAGENAME} ${EDITION} \\$(date +%Y%m%d-%H:%M)\"\nexport LB_ISO_APPLICATION=\"KDE neon Live\"\nexport LB_LINUX_FLAVOURS=\"generic-hwe-22.04\"\nexport LB_LINUX_PACKAGES=\"linux\"\n"
},
{
"alpha_fraction": 0.6953727602958679,
"alphanum_fraction": 0.7069408893585205,
"avg_line_length": 24.933332443237305,
"blob_id": "eb386d1adf6df80821f39dcea86e2c0a1e41698c",
"content_id": "0ca17731fe409f52145d2fd7c27bafb4134ac707",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 30,
"path": "/nci/imager/build-hooks-xenon-mycroft/02-setup_phablet_user.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -x\n\nUSER=phablet\nGECOS=phablet\nUGID=32011\n\nDEFGROUPS=\"tty,sudo,adm,dialout,cdrom,plugdev,audio,dip,video\"\n\necho \"I: creating default user $USER\"\nadduser --gecos $GECOS --disabled-login $USER --uid $UGID\n\necho \"I: set user $USER password to 1234\"\necho \"phablet:1234\" | /usr/sbin/chpasswd\n\nmkdir -p /home/$USER/Music\nmkdir -p /home/$USER/Pictures\nmkdir -p /home/$USER/Videos\nmkdir -p /home/$USER/Downloads\nmkdir -p /home/$USER/Documents\nchown -R $UGID:$UGID /home/$USER\n\nusermod -a -G ${DEFGROUPS} ${USER}\n\n# if mycroft is installed, chown it to phablet user\nchown -Rv phablet /opt/mycroft || true\nchown -Rv phablet /var/log/mycroft || true\n\nif [ -e /home/phablet ] && [ ! -e /home/phablet/mycroft-core ]; then\n ln -s /opt/mycroft /home/phablet/mycroft-core\nfi\n"
},
{
"alpha_fraction": 0.7190439105033875,
"alphanum_fraction": 0.7260971665382385,
"avg_line_length": 29.023529052734375,
"blob_id": "e9eabfe30744caf19c94ca38eb2071708d9e10fc",
"content_id": "8fde7270392c80947fd69fd7f8acbb98e3e5b507",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2554,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 85,
"path": "/jenkins_rename.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# coding: utf-8\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# mass renames are more efficient done on command line\n# https://wiki.jenkins.io/display/JENKINS/Administering+Jenkins 'Moving/copying/renaming jobs'\n# go to Jenkins GUI \"Manage Jenkins\" page and \"Reload Configuration from Disk\"\n# run job_updater\n\nrequire 'date'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/thread_pool'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/jenkins/job'\n\nparser = OptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: jenkins_rename.rb [options] 'regex' 'PATTERN_FROM' 'PATTERN_TO'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nrename. The parts matching PATTERN_FROM will be renamed to PATTERN_TO.\n\ne.g.\n • Sub 'plasma' in all jobs for 'liquid':\n '.*' plasma liquid\n EOS\nend\nparser.parse!\n\nif ARGV.size < 3\n warn 'Not enough arguments.'\n warn parser.help\n abort\nend\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = $PROGRAM_NAME\n l.level = Logger::INFO\nend\n\npattern = Regexp.new(ARGV[0])\nfrom = ARGV[1]\nto = ARGV[2]\nARGV.clear\[email protected] \"Finding all jobs for #{pattern} and renaming using sub #{from} #{to}\"\n\nclient = JenkinsApi::Client.new\njob_names = client.job.list_all.select { |name| pattern.match(name) }\n\nputs \"Jobs: \\n#{job_names.join(\"\\n\")}\"\nloop do\n puts 'Does that list look okay? (y/n)'\n case gets.strip.downcase\n when 'y' then break\n when 'n' then exit\n end\nend\n\njob_names.each do |job_name|\n new_name = job_name.gsub(from, to)\n @log.info \"#{job_name} => #{new_name}\"\n Jenkins::Job.new(job_name).rename(new_name)\nend\n"
},
{
"alpha_fraction": 0.7154362201690674,
"alphanum_fraction": 0.7197986841201782,
"avg_line_length": 35.34146499633789,
"blob_id": "33b4cd829cf46fae2d1e90dfe77f2812c0525ec9",
"content_id": "64f6001aff85857c19bd9502fdd4086b7f02befd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2980,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 82,
"path": "/lib/ci/version_enforcer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../debian/version'\n\nmodule CI\n # Helper to enforce that the Debian epoch version did not change in between\n # builds without approval from someone.\n # The enforcer loads previous version information from a record file\n # and then can be asked to #{validate} new versions. Failing validation\n # raises UnauthorizedChangeError exceptions!\n # Validation fails iff the epoch between the recorded and validation version\n # changed... At all. The only way to bypass the enforcer is to have no\n # last_version in the working directory.\n class VersionEnforcer\n class UnauthorizedChangeError < StandardError; end\n\n RECORDFILE = 'last_version'\n\n attr_reader :old_version\n\n def initialize\n # TODO: couldn't this use the @source instances?\n @old_version = nil # init the var so ruby doesn't warn\n return unless File.exist?(RECORDFILE)\n\n @old_version = File.read(RECORDFILE)\n @old_version = Debian::Version.new(@old_version)\n end\n\n def validate(new_version)\n return unless @old_version\n\n new_version = Debian::Version.new(new_version)\n validate_epochs(@old_version.epoch, new_version.epoch)\n # TODO: validate that the new version is strictly greater\n end\n\n def record!(new_version)\n File.write(RECORDFILE, new_version)\n end\n\n private\n\n def validate_epochs(old_epoch, new_epoch)\n return if old_epoch == new_epoch\n\n home = '$JENKINS_HOME'\n job_name = ENV.fetch('JOB_NAME')\n artifact_path = \"#{home}/jobs/#{job_name}/builds/*/archive/last_version\"\n artifact_rm = \"rm -v #{artifact_path}\"\n raise UnauthorizedChangeError, <<-ERROR_MSG\nThis epoch bump is not authorized!\n#{old_epoch} -> #{new_epoch}\nBumping epochs is prevented by default to avoid accidents. If you are\n**absolute** sure this bump is correct and justified and wanted then you can\nlet it pass by deleting the last_version marker of this job.\n\n#{artifact_rm}\n\n(Depending on the CI last_version may actually live in the workspace.)\n ERROR_MSG\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6713286638259888,
"alphanum_fraction": 0.6835664510726929,
"avg_line_length": 26.238094329833984,
"blob_id": "a3a44e8491bef86c31e3b9899efa6c38ae622fe3",
"content_id": "8f15e92d01a939efe498d3a8be331e507d22ec31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1716,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 63,
"path": "/lib/shebang.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# A Shebang validity parser.\nclass Shebang\n attr_reader :valid\n attr_reader :parser\n\n def initialize(line)\n @valid = false\n @parser = nil\n @line = line\n parse\n end\n\n private\n\n def proper_line?\n return false unless @line&.start_with?('#!')\n\n true\n end\n\n def parse\n return unless proper_line?\n\n parts = @line.split(' ')\n return unless parts.size >= 1 # shouldn't even happen as parts is always 1\n return unless valid_parts?(parts)\n\n @valid = true\n end\n\n def valid_parts?(parts)\n if parts[0].end_with?('/env')\n return false unless parts.size >= 2\n\n @parser = parts[1]\n elsif !parts[0].include?('/') || parts[0].end_with?('/')\n return false # invalid\n else\n @parser = parts[0].split('/').pop\n end\n true\n end\nend\n"
},
{
"alpha_fraction": 0.6428804993629456,
"alphanum_fraction": 0.6453900933265686,
"avg_line_length": 33.07063293457031,
"blob_id": "8b3d9a1879f413ee963c941e541a0d660fbdc621",
"content_id": "ee21376d01426aa337e55a1d109fe882191dcd4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9165,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 269,
"path": "/lib/jenkins/project_updater.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2014-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'etc'\nrequire 'fileutils'\nrequire 'jenkins_junit_builder'\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative '../../lib/thread_pool'\n\nmodule Jenkins\n # Updates Jenkins Projects\n class ProjectUpdater\n module JUnit\n NOT_TEMPLATED = :not_templated\n NOT_REMOTE = :not_remote\n\n # Wrapper converting an ADT summary into a JUnit suite.\n class Suite\n # Wrapper converting an ADT summary entry into a JUnit case.\n class Case < JenkinsJunitBuilder::Case\n TYPED_OUTPUT = {\n NOT_TEMPLATED => <<-NOT_TEMPLATED_ERROR,\nThis job was found in Jenkins but it is not being generated by the updater.\nChances are the job was manually created and never moved to automatic provisioning.\nNot having jobs automatically provisioned excludes them from automated adjustments,\nplugin installation, discoverability etc.\nThe job must be moved to pangea-tooling's job templating system.\n\nIf this job is a merger or build job it could be that either it is intended to be\nremoved in which case the related jobs should get deleted from jenkins. It is\nalso possible that the templatification regressed because the relevant project\nentry disappeared from the config(s) or the project wildcard detection is not\nworking becuase the relevant branch in the Git repository is missing.\n\nhttps://github.com/pangea-project/pangea-conf-projects\n NOT_TEMPLATED_ERROR\n NOT_REMOTE => <<-NOT_REMOTE_ERROR\nThe job should have been generated in Jenkins as we had it in our creation queue,\nbut we did not find it. Chances are the creation failed.\nCheck the detailed output to find output relating to the failed creation of the job.\n NOT_REMOTE_ERROR\n }.freeze\n\n def initialize(name, type)\n self.classname = @name\n # 3rd and final drill down CaseClassName\n self.name = name\n self.time = 0\n self.result = JenkinsJunitBuilder::Case::RESULT_FAILURE\n system_out.message = TYPED_OUTPUT.fetch(type)\n end\n end\n\n TYPED_CLASSNAMES = {\n NOT_TEMPLATED => 'NotTemplated',\n NOT_REMOTE => 'FailedToCreate'\n }.freeze\n\n def initialize(type, delta)\n @suite = JenkinsJunitBuilder::Suite.new\n # This is not particularly visible in Jenkins, it's only used on the\n # testcase page itself where it will refer to the test as\n # SuitePackage.CaseClassName.CaseName (from SuitePackage.SuiteName)\n @suite.name = 'ProjectUpdater'\n # Primary sorting name on Jenkins.\n # Test results page lists a table of all tests by packagename\n @suite.package = TYPED_CLASSNAMES.fetch(type)\n delta.each { |job| @suite.add_case(Case.new(job, type)) }\n end\n\n def write_into(dir)\n unless ENV.include?('JENKINS_URL')\n puts 'not writing junit output as this is not a jenkins build'\n return\n end\n FileUtils.mkpath(dir) unless Dir.exist?(dir)\n File.write(\"#{dir}/#{@suite.package}.xml\", @suite.build_report)\n end\n end\n end\n\n attr_accessor :log\n\n def initialize\n update_submodules\n @job_queue = Queue.new\n @job_names = []\n @log = Logger.new(STDOUT)\n @used_plugins = []\n @blacklisted_plugins = []\n end\n\n def update_submodules\n Dir.chdir(File.realpath(\"#{__dir__}/../../\")) do\n return if @submodules_updated\n unless system(*%w[git submodule sync --recursive])\n raise 'failed to sync git configuration for submodules'\n end\n unless system(*%w[git submodule update --remote --recursive])\n raise 'failed to update git submodules of tooling!'\n end\n\n @submodules_updated = true\n end\n end\n\n def update\n update_submodules\n populate_queue\n run_queue\n if ENV.include?('UPDATE_INCLUDE')\n warn 'Skipping job creation validation as UPDATE_INCLUDE is set'\n else\n check_jobs_exist\n end\n end\n\n def install_plugins\n # Autoinstall all possibly used plugins.\n installed_plugins = Jenkins.plugin_manager.list_installed.keys\n plugins = (plugins_to_install + standard_plugins).uniq\n plugins.each do |plugin|\n next if installed_plugins.include?(plugin)\n\n puts \"--- Installing #{plugin} ---\"\n Jenkins.plugin_manager.install(plugin)\n end\n end\n\n private\n\n # Override to supply a blacklist of jobs to not be considered in the\n # templatification warnings.\n def jobs_without_template\n []\n end\n\n def check_jobs_exist\n # To blacklist jobs from being complained about, override\n # #jobs_without_template in the sepcific updater class.\n\n remote = JenkinsApi::Client.new.job.list_all - jobs_without_template\n local = @job_names\n\n names = remote - local\n job_warn('--- Some jobs are not being templated! ---', names)\n JUnit::Suite.new(JUnit::NOT_TEMPLATED, names).write_into('reports/')\n names = local - remote\n job_warn('--- Some jobs were not created @remote! ---', (local - remote))\n JUnit::Suite.new(JUnit::NOT_REMOTE, names).write_into('reports/')\n end\n\n def job_warn(warning_str, names)\n return if names.empty?\n\n log.warn warning_str\n names.each do |name|\n uri = JenkinsApi::Client.new.uri\n uri.path += \"/job/#{name}\"\n log.warn name\n log.warn \" #{uri.normalize}\"\n end\n log.warn '!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!'\n end\n\n def all_template_files\n Dir.glob('jenkins-jobs/templates/**/**.xml.erb')\n end\n\n # Standard plugins not showing up in templates but generally useful to have\n # for our CIs. These should as a general rule not change behavior or\n # add functionality or have excessive depedencies as to not slow down\n # jenkins for no good reason.\n def standard_plugins\n %w[\n greenballs\n simple-theme-plugin\n ]\n end\n\n def plugins_to_install\n installed_plugins = Jenkins.plugin_manager.list_installed.keys\n plugins = @used_plugins.reject { |x| installed_plugins.include?(x) }\n plugins.reject { |x| @blacklisted_plugins.include?(x) }\n end\n\n def collect_plugins(job)\n data = job.render_template\n data.split(\"\\n\").each do |line|\n match = line.match(/.*plugin=\"(.+)\".*/)\n next unless match&.size == 2\n\n plugin = match[1].split('@').first\n next if @used_plugins.include?(plugin)\n\n @used_plugins << plugin\n end\n end\n\n def enqueue(obj)\n @job_queue << obj\n if @job_names.include?(obj.job_name)\n raise \"#{obj.job_name} already queued. Jobs need only be queued once...\"\n end\n\n @job_names << obj.job_name\n collect_plugins(obj)\n obj\n end\n\n def proc_is_jenkins?(pid)\n return false if pid =~ /\\D/\n\n cmdline = IO.read(\"/proc/#{pid}/cmdline\").split(\"\\000\")\n jenkins = cmdline.any? { |x| x.include?('java') }\n jenkins &= cmdline.any? { |x| x.include?('jenkins.war') }\n jenkins\n rescue\n false\n end\n\n def system_runs_jenkins?\n Dir.foreach('/proc') do |file|\n return true if proc_is_jenkins?(file)\n end\n false\n end\n\n def thread_count\n # When running on the same machine as jenkins use only half the cores to\n # avoid overloading the machine (it would have to at least issue all\n # request and handle them, so ultimately just that would theoretically\n # fill up all cores). While doing updates it also needs to go about its\n # regular business, so being less aggressive is called for here. Also,\n # for remote updates the network IO bottlenecks the strongest, when run\n # on the jenkins host that is not the case so high concurrency doesn't\n # necessarily increase performance as we'd bottleneck on jenkins itself.\n system_runs_jenkins? ? Etc.nprocessors / 2 : Etc.nprocessors * 2\n end\n\n def run_queue\n BlockingThreadPool.run([1, thread_count].max) do\n until @job_queue.empty?\n job = @job_queue.pop(true)\n job.update(log: log)\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6832239627838135,
"alphanum_fraction": 0.6921274662017822,
"avg_line_length": 40.843135833740234,
"blob_id": "84b756425f0dfdfe43d2cad31f0e523dc36856a9",
"content_id": "0337601e9fd851666f64603c0ad68e9d8359dfec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2134,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 51,
"path": "/xci/contain.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2014-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/containment'\n\nDocker.options[:read_timeout] = 8 * 60 * 60 # 8 hours now.. because qtbase!\n\nDIST = ENV.fetch('DIST')\nJOB_NAME = ENV.fetch('JOB_NAME')\nPWD_BIND = ENV.fetch('PWD_BIND', Dir.pwd)\nNODE_NAME = ENV.fetch('NODE_NAME')\n\n# Whitelist a bunch of Jenkins variables for consumption inside the container.\nwhitelist = %w[BUILD_CAUSE ROOT_BUILD_CAUSE RUN_DISPLAY_URL JOB_NAME\n NODE_NAME NODE_LABELS\n PANGEA_PROVISION_AUTOINST\n DH_VERBOSE]\nwhitelist += (ENV['DOCKER_ENV_WHITELIST'] || '').split(':')\nENV['DOCKER_ENV_WHITELIST'] = whitelist.join(':')\n\n# TODO: transition away from compat behavior and have contain properly\n# apply pwd_bind all the time?\nc = nil\nif PWD_BIND != Dir.pwd # backwards compat. Behave as previosuly without pwd_bind\n c = CI::Containment.new(\"xci-#{JOB_NAME}-#{NODE_NAME}\",\n image: CI::PangeaImage.new(:ubuntu, DIST),\n binds: [\"#{Dir.pwd}:#{PWD_BIND}\"])\nelse\n c = CI::Containment.new(\"xci-#{JOB_NAME}-#{NODE_NAME}\", image: CI::PangeaImage.new(:ubuntu, DIST))\nend\n\nstatus_code = c.run(Cmd: ARGV, WorkingDir: PWD_BIND)\nexit status_code\n"
},
{
"alpha_fraction": 0.6838861107826233,
"alphanum_fraction": 0.6871147751808167,
"avg_line_length": 23.510791778564453,
"blob_id": "3f34d8ffea08f4bbeaf793a991aff8b3bed12996",
"content_id": "d2a2a3add41d9a28a31711803896a93ba5cecede",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3407,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 139,
"path": "/jenkins_maintenance.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/optparse'\n\n# A Jenkins node.\nclass Node\n ONLINE = :online\n OFFLINE = :offline\n\n class << self\n def states\n [ONLINE, OFFLINE]\n end\n\n attr_accessor :target_state\n end\n\n def initialize(name, client)\n @name = name\n @client = client\n end\n\n def skip?\n master? || filtered? || already_target_state?\n end\n\n def toggle!\n @client.toggle_temporarilyOffline(@name, 'Maintenance')\n end\n\n private\n\n def target_state\n self.class.target_state\n end\n\n def master?\n @name == 'master'\n end\n\n def filtered?\n false # Can be used to filter out specific names\n end\n\n def state\n @client.is_offline?(@name) ? OFFLINE : ONLINE\n end\n\n def already_target_state?\n target_state == state\n end\n\n def to_s\n @name\n end\nend\n\nci_configs = []\n\nparser = OptionParser.new do |opts|\n opts.banner = <<EOF\nUsage: #{opts.program_name} --config CONFIG1 --config CONFIG2\n\nSet jenkins instances into maintenance by setting all their slaves offline.\nThis does not put the instances into maintenance mode, nor does it wait for\nthe queue to clear!\nEOF\n opts.separator('')\n\n opts.on('-s STATE', '--state STATE', Node.states,\n 'Which state to switch to',\n 'EXPECTED') do |v|\n Node.target_state = v.to_sym\n end\n\n opts.on('-c CONFIG', '--config CONFIG',\n 'The Pangea jenkins config to load to create api client instances.',\n 'These live in $HOME/.config/ usually but can be anywhere.',\n 'EXPECTED') do |v|\n ci_configs << v\n end\nend\nparser.parse!\n\nunless parser.missing_expected.empty?\n puts \"Missing expected arguments: #{parser.missing_expected.join(', ')}\\n\\n\"\n abort parser.help\nend\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = 'maintenance'\n l.level = Logger::INFO\nend\n\ncis = ci_configs.collect do |config|\n JenkinsApi::Client.new(config_file: config)\nend\n\ncis.each do |ci|\n if Node.target_state == Node::OFFLINE\n @log.info \"Setting system #{ci.server_ip} into maintenance mode.\"\n ci.system.quiet_down\n end\n node_client = ci.node\n node_client.list.each do |name|\n node = Node.new(name, node_client)\n next if node.skip?\n\n @log.info \"Taking #{node} on #{ci.server_ip} #{Node.target_state}\"\n node.toggle!\n end\n if Node.target_state == Node::ONLINE\n @log.info \"Taking system #{ci.server_ip} out of maintenance mode.\"\n ci.system.cancel_quiet_down\n end\nend\n"
},
{
"alpha_fraction": 0.7314814925193787,
"alphanum_fraction": 0.7314814925193787,
"avg_line_length": 28.454545974731445,
"blob_id": "3e9efdae8049f25002d13bb8ffab4ad5fe299ffe",
"content_id": "5ac3f5ef4764aeb84b2e1fb0d83460fba1e19bf4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 11,
"path": "/test/test_jenkins_jobs_mgmt_docker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\nrequire_relative '../jenkins-jobs/mgmt_docker'\n\nclass MGMTDockerTest < TestCase\n def test_render\n JenkinsJob.flavor_dir = datadir\n r = MGMTDockerJob.new(dependees: [])\n assert_equal(File.read(\"#{datadir}/test_render.xml\"), r.render_template)\n end\nend\n"
},
{
"alpha_fraction": 0.6784260272979736,
"alphanum_fraction": 0.6838534474372864,
"avg_line_length": 27.076190948486328,
"blob_id": "d37706e87461db00054b20882626072c2007414d",
"content_id": "caa331a2e4e9f3a000d142072f7e04268887b689",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2948,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 105,
"path": "/jenkins_looper.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'concurrent'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins/job'\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/thread_pool'\n\nOptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: #{$0} [options] name\n\nFinds depenendency loops by traversing the upstreams of name looking for another\nappearance of name. This is handy if a job is stuck waiting on itself but it's\nnot clear where the loop is.\n EOS\nend.parse!\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = File.basename($0)\n l.level = Logger::INFO\nend\n\nraise 'Need name as argv0' if ARGV.empty?\n\nname = ARGV[0]\[email protected] name\n\n# Looks for loops\nclass Walker\n # Looping error\n class LoopError < RuntimeError\n def prepend(job)\n set_backtrace(\"#{job} -> #{backtrace.join}\")\n end\n end\n\n def initialize(name, log)\n @job = Jenkins::Job.new(name)\n @log = log\n @known = {}\n @seen = []\n end\n\n def walk!\n require 'pp'\n know!(@job)\n @log.warn 'everything is known'\n find_loop(@job.name)\n end\n\n # rubocop:disable Metrics/MethodLength, Metrics/AbcSize\n # This would be a separate class, anything else we'd have to pass our state\n # vars through, so simply accept this method beng a bit complicated.\n def find_loop(name, root: true, depth: 1, stack: [name])\n @log.info \"#{Array.new(depth * 2, ' ').join}#{name} #{root}\"\n @known[name].each do |up|\n if stack.include?(up)\n error = LoopError.new('loop found')\n error.set_backtrace(up.to_s)\n raise error\n end\n\n next if @seen.include?(up)\n\n find_loop(up, root: false, depth: depth + 1, stack: stack + [up])\n @seen << up\n end\n rescue LoopError => e\n e.prepend(name)\n raise e\n end\n\n def know!(job)\n return if @known.include?(job.name)\n\n @known[job.name] ||= job.upstream_projects.collect { |x| x.fetch('name') }\n @known[job.name].each { |x| know!(Jenkins::Job.new(x)) }\n end\nend\n\nWalker.new(name, @log).walk!\n"
},
{
"alpha_fraction": 0.6948079466819763,
"alphanum_fraction": 0.7083157300949097,
"avg_line_length": 39.844825744628906,
"blob_id": "7e736b438cd5da253cbdc45cc8052a6c6514cfe6",
"content_id": "71f7e5c33f3598a9c075fcf66afc6ea36e1bc2f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2369,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 58,
"path": "/test/test_nci_qt_sixy.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/qt_sixy'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\nrequire 'net/ssh/gateway' # so we have access to the const\n\nclass NCIQtSixyTest < TestCase\n def setup\n end\n\n def teardown\n end\n\n def test_qt_sixy_repo\n FileUtils.rm_rf(\"#{data}/qt6-test\")\n FileUtils.cp_r(\"#{data}/original\", \"#{data}/qt6-test\")\n sixy = QtSixy.new(name: \"qt6-test\", dir: \"#{data}/qt6-test\")\n sixy.run\n result = File.readlines(\"#{data}/qt6-test/debian/control\")\n File.readlines(\"#{data}/good/debian/control\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n assert_equal(false, File.exist?(\"#{data}/qt6-test/debian/libqt6shadertools6-dev.install\"))\n assert_equal(false, File.exist?(\"#{data}/qt6-test/debian/libqt6shadertools6.install\"))\n assert_equal(false, File.exist?(\"#{data}/qt6-test/debian/libqt6shadertools6.symbols\"))\n assert_equal(false, File.exist?(\"#{data}/qt6-test/debian/qt6-shader-baker.install\"))\n assert_equal(true, File.exist?(\"#{data}/qt6-test/debian/qt6-test.install\"))\n assert_equal(true, File.exist?(\"#{data}/qt6-test/debian/qt6-test-dev.install\"))\n sixy = QtSixy.new(name: \"qt6-test\", dir: \"#{data}/qt6-test\")\n sixy.run\n result = File.readlines(\"#{data}/qt6-test/debian/control\")\n File.readlines(\"#{data}/good/debian/control\").each_with_index do |line, i|\n assert_equal(line, result[i])\n end\n end\n\nend\n"
},
{
"alpha_fraction": 0.6586561799049377,
"alphanum_fraction": 0.745463490486145,
"avg_line_length": 41.47916793823242,
"blob_id": "09dcf4acad1887a4bdd152e1acec3ba60f329669",
"content_id": "93ce0bc7ba9a59c1fe25391d6d9a059ce8d63bf5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2039,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 48,
"path": "/test/test_nci_imager_img_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'net/sftp'\nrequire 'tty/command'\n\nrequire_relative '../nci/imager_img_push_support'\n\n# NB: this test wraps a script, it does not formally contribute to coverage\n# statistics but is better than no testing. the script should be turned\n# into a module with a run so we can require it without running it so we can\n# avoid the fork.\nmodule NCI\n class ImagerImgPushSupportTest < TestCase\n def test_old_directories_to_remove\n img_directories = %w[current 20190218-1206 20180319-1110]\n img_directories = old_directories_to_remove(img_directories)\n assert_equal([], img_directories)\n\n img_directories = %w[current 20190218-1206 20180319-1110 20180319-1112]\n img_directories = old_directories_to_remove(img_directories)\n assert_equal([], img_directories)\n\n img_directories = %w[current 20190218-1206 20180319-1110 20180218-1210 20180319-1112 20180218-1255 20180319-1155]\n img_directories = old_directories_to_remove(img_directories)\n assert_equal(%w[20180218-1210 20180218-1255 20180319-1110], img_directories)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7254505157470703,
"alphanum_fraction": 0.7382060885429382,
"avg_line_length": 40.50419998168945,
"blob_id": "5b4a275ac30bfffa711032b1313b10b85066d1d5",
"content_id": "6a123e2c93f38583cd1d4385054b8f92e44a49ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4939,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 119,
"path": "/nci/asgen.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'tty-command'\n\nrequire_relative 'lib/setup_repo'\nrequire_relative '../lib/apt'\nrequire_relative '../lib/asgen'\nrequire_relative '../lib/nci'\n\n# WARNING: this program is run from a minimal debian container without\n# the tooling properly provisioned. Great care must be taken about\n# brining in too many or complex dependencies!\n\nSTDOUT.sync = true # lest TTY output from meson gets merged randomly\n\nTYPE = ENV.fetch('TYPE')\nDIST = ENV.fetch('DIST')\nAPTLY_REPOSITORY = ENV.fetch('APTLY_REPOSITORY')\nLAST_BUILD_STAMP = File.absolute_path('last_build')\n\n# Runtime Deps - install before repo setup so we get these from debian and\n# not run into comapt issues between neon's repo and debian!\nApt::Get.install('libglibd-2.0-dev')\nApt::Get.install('appstream-generator') # Make sure runtime deps are in.\n\ncmd = TTY::Command.new\n\nrun_dir = File.absolute_path('run')\n\nsuites = [DIST]\nconfig = ASGEN::Conf.new(\"neon/#{TYPE}\")\n# NB: use origin here. dlang's curl wrapper doesn't know how HTTP works and\n# parses HTTP/2 status lines incorrectly. Fixed in git and landing with LDC 1.13\n# https://github.com/dlang/phobos/commit/1d4cfe3d8875c3e6a57c7e90fb736f09b18ddf2d\nconfig.ArchiveRoot = \"https://origin.archive.neon.kde.org/#{APTLY_REPOSITORY}\"\nconfig.MediaBaseUrl =\n \"https://metadata.neon.kde.org/appstream/#{TYPE}_#{DIST}/media\"\nconfig.HtmlBaseUrl =\n \"https://metadata.neon.kde.org/appstream/#{TYPE}_#{DIST}/html\"\nconfig.Backend = 'debian'\nconfig.ExtraMetainfoDir = \"#{Dir.pwd}/extra-metainfo\"\nconfig.Features['validateMetainfo'] = true\n# FIXME: we should merge the dist jobs and make one job generate all supported\n# series. this also requires adjustments to asgen_push to \"detect\" which dists\n# it needs to publish instead of hardcoding DIST.\nsuites.each do |suite|\n config.Suites << ASGEN::Suite.new(suite).tap do |s|\n s.sections = %w[main]\n s.architectures = %w[amd64]\n s.dataPriority = 200 # definitely >> ubuntu (currently caps at 40)\n s.useIconTheme = 'breeze'\n end\nend\n\n# Since we are on debian the actual repo codename needs some help to get\n# correctly set up. Manually force the right codename.\n# Note that we do this here because we only need this to install the\n# correct icon themes.\n# Also disable proxy since we don't want debian shebang cached (for now)\nNCI.setup_repo_codename = DIST\nNCI.setup_repo!(with_proxy: false, with_install: false)\n\n# FIXME: http_proxy and friends are possibly not the smartest idea.\n# this will also route image fetching through the proxy I think, and the proxy\n# gets grumpy when it has to talk to unknown servers (which the image hosting\n# will ofc be)\n# Generate\n# Install theme to hopefully override icons with breeze version.\nApt.install('breeze-icon-theme', 'hicolor-icon-theme')\nFileUtils.mkpath(run_dir) unless Dir.exist?(run_dir)\nconfig.write(\"#{run_dir}/asgen-config.json\")\nsuites.each do |suite|\n cmd.run('appstream-generator', 'process', '--verbose', suite, chdir: run_dir)\nend\n\n# TODO\n# [15:03] <ximion> sitter: the version number changing isn't an issue -\n# it does nothing with one architecture, and it's an optimization if you have\n# at least one other architecture.\n# [15:03] <ximion> sitter: you should run ascli cleanup every once in a while\n# though, to collect garbage\n# https://github.com/ximion/appstream-generator/issues/97\n\n## Manual export dir cleanup since asgen's cleanup isn't hot enough\nid_paths = Dir.glob('run/export/media/**/{icons,screenshots}/').collect do |dir|\n File.dirname(dir) # this is the instance id `org.foo.bar/ID/`\nend.uniq\n\ncomponent_to_idpaths = id_paths.group_by { |path| File.dirname(path) }.to_h\ncomponent_to_idpaths.each do |component, paths|\n # sort by ctime, newer will be farther back in the array\n paths = paths.sort_by { |path| File.ctime(path).to_i }\n paths_to_drop = paths[0..-11] # (-1 is the end so this is offset by 1)\n puts component\n paths_to_drop.each do |path|\n puts \" Dropping #{path}\"\n FileUtils.rm_r(path)\n end\nend\n"
},
{
"alpha_fraction": 0.7168141603469849,
"alphanum_fraction": 0.7168141603469849,
"avg_line_length": 21.600000381469727,
"blob_id": "82a14323aa1ad661420e2f7b58fd5be3a4d4c7a4",
"content_id": "002f4b314978cdd7de7aa8f507411e213afd9993",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 15,
"path": "/jenkins-jobs/mgmt_tooling.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Tooling management job.\nclass MGMTToolingJob < JenkinsJob\n attr_reader :downstreams\n attr_reader :dependees\n\n def initialize(downstreams:, dependees:)\n name = 'mgmt_tooling'\n super(name, \"#{name}.xml.erb\")\n @downstreams = downstreams\n @dependees = dependees\n end\nend\n"
},
{
"alpha_fraction": 0.6369017958641052,
"alphanum_fraction": 0.6438086032867432,
"avg_line_length": 22.569766998291016,
"blob_id": "6b85375da07300665cefff7757ff43aaa7cef772",
"content_id": "22101e2bfda4ebaa5d1ed02f42d52d6b7361eada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2027,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 86,
"path": "/test/test_retry.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/retry'\nrequire_relative 'lib/testcase'\n\nclass RetryHelper\n attr_reader :count\n\n def initialize(max_count: 0, errors: [])\n @max_count = max_count\n @errors = errors\n end\n\n def count_up\n @count ||= 0\n @count += 1\n raise 'random' unless @count == @max_count\n end\n\n def error\n @error_at ||= -1\n return if @error_at >= @errors.size - 1\n\n raise @errors[@error_at += 1], 'error'\n end\nend\n\n# Test blocking thread pool.\nclass RetryTest < TestCase\n def setup\n # Need sleeping enabled to test sleeping, obviously.\n Retry.enable_sleeping\n end\n\n def test_times\n times = 5\n helper = RetryHelper.new(max_count: times)\n Retry.retry_it(times: times, silent: true) do\n helper.count_up\n end\n assert_equal(times, helper.count)\n end\n\n def test_zero_retry\n # On zero retries we want to be called once and only once.\n times = 0\n helper = RetryHelper.new(max_count: times)\n assert_raise RuntimeError do\n Retry.retry_it(times: times, silent: true) do\n helper.count_up\n end\n end\n end\n\n def test_errors\n errors = [NameError, LoadError]\n\n helper = RetryHelper.new(errors: errors)\n assert_nothing_raised do\n Retry.retry_it(times: errors.size + 1, errors: errors, silent: true) do\n helper.error\n end\n end\n\n helper = RetryHelper.new(errors: errors)\n assert_raise do\n Retry.retry_it(times: errors.size + 1, errors: [], silent: true) do\n helper.error\n end\n end\n end\n\n def test_sleep\n sleep = 1\n times = 2\n helper = RetryHelper.new(max_count: times)\n time_before = Time.new\n Retry.retry_it(times: times, sleep: sleep, silent: true) do\n helper.count_up\n end\n time_now = Time.new\n delta_seconds = time_now - time_before\n # Delta must be between actual sleep time and twice the sleep time.\n assert(delta_seconds >= sleep, 'hasnt slept long enough')\n assert(delta_seconds <= sleep * 2.0, 'has slept too long')\n end\nend\n"
},
{
"alpha_fraction": 0.6841810941696167,
"alphanum_fraction": 0.6908887624740601,
"avg_line_length": 26.953125,
"blob_id": "2986f0d4abc14c8bcda077a4fa515dd03dac3a74",
"content_id": "29c835a2c27f6121ba834f8b0e81c11e67f5ad5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1789,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 64,
"path": "/nci/repo_metadata_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n=begin\nCheck for changes in repo-metadata in the last day and e-mail them out\n\nLikely changes might be new stable branch, new repos or repo moved\n=end\n\nrequire 'open-uri'\nrequire 'json'\nrequire 'pp'\nrequire_relative '../lib/pangea/mail'\n\nclass RepoMetadataCheck\n\n attr_reader :diff\n def doDiff\n @diff = `git whatchanged --since=\"1 day ago\" -p`\n puts \"Changed since 1 day ago: #{@diff}\"\n end\n\n def send_email\n return if diff == \"\"\n\n puts 'sending notification mail'\n Pangea::SMTP.start do |smtp|\n mail = <<-MAIL\nFrom: Neon CI <[email protected]>\nTo: [email protected]\nSubject: Changes in repo-metadata\n\n#{@diff}\n MAIL\n smtp.send_message(mail,\n '[email protected]',\n '[email protected]')\n end\n end\nend\n\nif __FILE__==$0\n checker = RepoMetadataCheck.new\n checker.doDiff\n checker.send_email\nend\n"
},
{
"alpha_fraction": 0.6311034560203552,
"alphanum_fraction": 0.6354054808616638,
"avg_line_length": 35.3203125,
"blob_id": "b6a159fd97a2aca5200a60b2b8b4cc03cc44b278",
"content_id": "68b9e4485f9374230f8bd3e85afbb26f7e38212b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4649,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 128,
"path": "/nci/snap/collapser.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'yaml'\n\nrequire_relative 'snapcraft_config'\nrequire_relative 'unpacker'\n\nmodule NCI\n module Snap\n # Takes a Part instance and collappses its build-snaps by unpacking them.\n class BuildSnapPartCollapser\n attr_reader :part\n attr_reader :root_paths\n\n def initialize(part)\n @part = part\n @root_paths = []\n end\n\n def run\n # Drop ids and fill root_paths\n ids_to_root_paths!\n # Return if no paths were found. Do note that the above method\n # asserts that only cmake plugins may have build-snaps, so the following\n # calls would only happen iff build-snaps are set AND the plugin type\n # is in fact supported.\n return if @root_paths.empty?\n\n extend_xdg_data_dirs!\n extend_configflags!\n end\n\n private\n\n def extend_configflags!\n part.cmake_parameters ||= []\n part.cmake_parameters.reject! do |flag|\n name, value = flag.split('=', 2)\n next false unless name == '-DCMAKE_FIND_ROOT_PATH'\n\n root_paths << value\n end\n part.cmake_parameters << \"-DCMAKE_FIND_ROOT_PATH=#{root_paths.join(';')}\"\n end\n\n def extend_xdg_data_dirs!\n # KDoctools is rubbish and lets meinproc resolve asset paths through\n # QStandardPaths *AT BUILD TIME*. So, we need to set up\n # paths correctly.\n # FIXME: this actually moved into the SDK wrapper and can be dropped\n # in 2019 or so.\n ENV['XDG_DATA_DIRS'] ||= '/usr/local/share:/usr/share'\n data_paths = root_paths.map { |x| File.join(x, '/usr/share') }\n ENV['XDG_DATA_DIRS'] = \"#{data_paths.join(':')}:#{ENV['XDG_DATA_DIRS']}\"\n end\n\n def ids_to_root_paths!\n # Reject to drop the build-snap entry\n part.build_snaps&.reject! do |build_snap|\n unless part.plugin == 'cmake'\n # build-snaps are currently only supported for cmake.\n # We *may* need to pull additional magic tricks depending on the\n # type, e.g. with cmake snapcraft is presumably injecting the\n # root_path, so by taking build-snap control away from snapcraft\n # we'll need to deal with it here.\n raise \"Part contains #{build_snap} but is not using cmake.\"\n end\n\n @root_paths << Unpacker.new(build_snap).unpack\n # When build-snaps are classic they rpath the core, so make sure we\n # have the core available for use!\n # Don't add to root_paths. Presently I cannot imagine what useful\n # stuff cmake might find there that is not also in the host system.\n Unpacker.new('core18').unpack\n true\n end\n end\n end\n\n # Takes a snapcraft.yaml, iters all parts and unpacks the build-snaps so\n # they can be used without snapd.\n class BuildSnapCollapser\n attr_reader :data\n attr_reader :orig_path\n\n def initialize(snapcraft_yaml)\n @orig_path = File.absolute_path(snapcraft_yaml)\n @data = YAML.load_file(snapcraft_yaml)\n data['parts'].each do |k, v|\n data['parts'][k] = SnapcraftConfig::Part.new(v)\n end\n @cmd = TTY::Command.new(uuid: false)\n end\n\n # Temporariy collapses the snapcraft.yaml, must get a block. The file\n # is un-collapsed once the method returns!\n def run\n bak_path = \"#{@orig_path}.bak\"\n FileUtils.cp(@orig_path, bak_path, verbose: true)\n data['parts'].each_value do |part|\n BuildSnapPartCollapser.new(part).run\n end\n File.write(@orig_path, YAML.dump(data))\n yield\n ensure\n FileUtils.mv(bak_path, @orig_path, verbose: true)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5962499976158142,
"alphanum_fraction": 0.604107141494751,
"avg_line_length": 31.55813980102539,
"blob_id": "5051e3e1d639bad64838b7acacbce1fe83cf5ded",
"content_id": "34a832caa9197e889905471dc219efc49651bc71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5600,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 172,
"path": "/nci/lib/repo_content_pusher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\nrequire 'net/sftp'\nrequire 'net/ssh'\nrequire 'tmpdir'\nrequire 'tty-command'\n\nrequire_relative '../../lib/debian/release'\nrequire_relative '../../lib/nci'\n\nclass NCI::RepoContentPusher\n APTLY_HOME = '/home/neonarchives'\n\n Sum = Struct.new(:file, :value)\n\n attr_reader :content_name\n attr_reader :repo_dir\n attr_reader :dist\n\n def initialize(content_name:, repo_dir:, dist:)\n @content_name = content_name\n @repo_dir = repo_dir\n @dist = dist\n end\n\n def repository_path\n # NB: the env var is called aply repo but it is in fact the repo path\n # i.e. not 'unstable_focal' but dev/unstable\n ENV.fetch('APTLY_REPOSITORY')\n end\n\n def exist?(sftp, path)\n sftp.stat!(path)\n true\n rescue Net::SFTP::StatusException\n false\n end\n\n def symlink?(sftp, path)\n sftp.readlink!(path)\n true\n rescue Net::SFTP::StatusException\n false\n end\n\n def run\n content_dir_suffix = \"main/#{content_name}\"\n content_dir = \"#{repo_dir}/#{content_dir_suffix}\"\n\n tmpdir = \"#{APTLY_HOME}/#{content_name}_push.#{repository_path.tr('/', '-')}\"\n targetdir = \"#{APTLY_HOME}/aptly/skel/#{repository_path}/dists/#{dist}\"\n\n # This depends on https://github.com/aptly-dev/aptly/pull/473\n # Aptly versions must take care to actually have the PR applied to them\n # until landed upstream!\n # NB: this is updating off-by-one. i.e. when we run the old data is\n # published, we update the data but it will only be updated the next\n # time the publish is updated (we may do this in the future as\n # acquire-by-hash is desired for such quick update runs).\n\n # We need the checksum of the uncompressed file in the Release file\n # of the repo, this is currently not correctly handled in the aptly\n # skel system. As a quick stop-gap we'll simply make sure an\n # uncompressed file is around.\n # https://github.com/aptly-dev/aptly/pull/473#issuecomment-391281324\n Dir.glob(\"#{content_dir}/**/*.gz\") do |compressed|\n next if compressed.include?('by-hash') # do not follow by-hash\n\n system('gunzip', '-k', compressed) || raise\n end\n\n keys_and_tools = {\n 'MD5Sum' => 'md5sum',\n 'SHA1' => 'sha1sum',\n 'SHA256' => 'sha256sum',\n 'SHA512' => 'sha512sum'\n }\n\n keys_and_sums = {}\n\n cmd = TTY::Command.new\n\n # Create a sum map for all files, we'll then by-hash each of them.\n Dir.glob(\"#{content_dir}/*\") do |file|\n next if File.basename(file) == 'by-hash'\n raise \"Did not expect !file: #{file}\" unless File.file?(file)\n\n keys_and_tools.each do |key, tool|\n keys_and_sums[key] ||= []\n sum = cmd.run(tool, file).out.split[0]\n keys_and_sums[key] << Sum.new(File.absolute_path(file), sum)\n end\n end\n\n Net::SFTP.start('archive-api.neon.kde.org', 'neonarchives',\n keys: ENV.fetch('SSH_KEY_FILE'), keys_only: true) do |sftp|\n content_targetdir = \"#{targetdir}/#{content_dir_suffix}\"\n content_tmpdir = \"#{tmpdir}/#{content_dir_suffix}\"\n\n puts sftp.session.exec!(\"rm -rf #{tmpdir}\")\n puts sftp.session.exec!(\"mkdir -p #{tmpdir}\")\n\n sftp.upload!(\"#{repo_dir}/.\", tmpdir)\n\n # merge in original by-hash data, so we can update it\n puts sftp.session.exec!(\"cp -rv #{content_targetdir}/by-hash/. #{content_tmpdir}/by-hash/\")\n\n by_hash = \"#{content_tmpdir}/by-hash/\"\n sftp.mkdir!(by_hash) unless exist?(sftp, by_hash)\n\n keys_and_sums.each do |key, sums|\n dir = \"#{by_hash}/#{key}/\"\n sftp.mkdir!(dir) unless exist?(sftp, dir)\n\n sums.each do |sum|\n basename = File.basename(sum.file)\n base_path = File.join(dir, basename)\n\n old = \"#{basename}.old\"\n old_path = File.join(dir, old)\n if symlink?(sftp, old_path)\n # If we had an old variant, drop it.\n sftp.remove!(old_path)\n end\n if symlink?(sftp, base_path)\n # If we have a current variant, make it the old variant.\n sftp.rename!(base_path, old_path,\n Net::SFTP::Constants::RenameFlags::OVERWRITE |\n Net::SFTP::Constants::RenameFlags::ATOMIC)\n end\n\n # Use our current data as the new current variant.\n sftp.upload!(sum.file, File.join(dir, sum.value))\n sftp.symlink!(sum.value, base_path)\n end\n\n # Get a list of all blobs and drop all which aren't referenced by any of\n # the marker symlinks. This should give super reliable cleanup.\n used_blobs = []\n blobs = []\n\n sftp.dir.glob(dir, '*') do |entry|\n path = File.join(dir, entry.name)\n puts path\n if entry.symlink?\n used_blobs << File.absolute_path(sftp.readlink!(path).name, dir)\n else\n blobs << File.absolute_path(path)\n end\n end\n\n warn \"All blobs in #{key}: #{used_blobs}\"\n warn \"Used blobs in #{key}: #{blobs}\"\n warn \"Blobs to delete in #{key}: #{(blobs - used_blobs)}\"\n\n (blobs - used_blobs).each do |blob|\n sftp.remove!(blob)\n end\n end\n\n puts sftp.session.exec!(\"rm -r #{content_targetdir}/\")\n puts sftp.session.exec!(\"mkdir -p #{content_targetdir}/\")\n puts sftp.session.exec!(\"cp -rv #{content_tmpdir}/. #{content_targetdir}/\")\n puts sftp.session.exec!(\"rm -rv #{tmpdir}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.747826099395752,
"alphanum_fraction": 0.747826099395752,
"avg_line_length": 27.75,
"blob_id": "3b2813f9bccbd759206824b9978704bf684508c7",
"content_id": "0b93265c47aa29bd29c0e028ad3774a69d2b3881",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 12,
"path": "/jenkins-jobs/meta-merge.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Meta merger depending on all merges and is able to trigger them.\nclass MetaMergeJob < JenkinsJob\n attr_reader :downstream_triggers\n\n def initialize(downstream_jobs:)\n super('mgmt_merger', 'meta-merger.xml.erb')\n @downstream_triggers = downstream_jobs.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.6162086725234985,
"alphanum_fraction": 0.6311131715774536,
"avg_line_length": 22.336956024169922,
"blob_id": "48666f115cbfa383c42d8055582712d27d69dc6a",
"content_id": "a2c14b54ca2246a5cd42b116ed73acceb6826636",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2147,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 92,
"path": "/test/test_debian_source.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'fileutils'\nrequire 'tmpdir'\n\nrequire_relative '../lib/debian/source'\nrequire_relative 'lib/testcase'\n\n# Test debian/source/format\nclass DebianSourceFormatTest < TestCase\n self.test_order = :defined\n\n def test_init_str\n assert_nothing_raised do\n Debian::Source::Format.new('1.0')\n end\n end\n\n def test_init_file\n Dir.mktmpdir(self.class.to_s) do |t|\n Dir.chdir(t) do\n file = 'debian/source/format'\n FileUtils.mkpath('debian/source')\n File.write(file, \"1.0\\n\")\n\n # Read from a file path\n format = nil\n assert_nothing_raised do\n format = Debian::Source::Format.new(file)\n end\n assert_equal('1.0', format.version)\n\n # Read from a file object.\n format = nil\n assert_nothing_raised do\n format = Debian::Source::Format.new(File.open(file))\n end\n assert_equal('1.0', format.version)\n end\n end\n end\n\n def test_1\n format = Debian::Source::Format.new('1.0')\n assert_equal('1.0', format.version)\n assert_equal(nil, format.type)\n end\n\n def test_1_to_s\n str = '1.0'\n format = Debian::Source::Format.new(str)\n assert_equal(str, format.to_s)\n end\n\n def test_3_native\n format = Debian::Source::Format.new('3.0 (native)')\n assert_equal('3.0', format.version)\n assert_equal(:native, format.type)\n end\n\n def test_3_quilt\n format = Debian::Source::Format.new('3.0 (quilt)')\n assert_equal('3.0', format.version)\n assert_equal(:quilt, format.type)\n end\n\n def test_3_to_s\n str = '3.0 (quilt)'\n format = Debian::Source::Format.new(str)\n assert_equal(str, format.to_s)\n end\n\n def test_nil_init\n format = Debian::Source::Format.new(nil)\n assert_equal('1', format.version)\n assert_equal(nil, format.type)\n end\nend\n\n# Test debian/source\nclass DebianSourceTest < TestCase\n def test_init\n file = 'debian/source/format'\n FileUtils.mkpath('debian/source')\n File.write(file, \"1.0\\n\")\n\n source = nil\n assert_nothing_raised do\n source = Debian::Source.new(Dir.pwd)\n end\n assert_not_nil(source.format)\n end\nend\n"
},
{
"alpha_fraction": 0.6517391204833984,
"alphanum_fraction": 0.656521737575531,
"avg_line_length": 28.487178802490234,
"blob_id": "343f49be5afd4c225ae0e6366619b8d3434424ec",
"content_id": "bdef0ee3cc7b656bd08ba653b5bb6d71006ed594",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2300,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 78,
"path": "/lib/debian/profile.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule Debian\n # A build profile.\n class Profile\n attr_reader :name\n\n def initialize(name)\n @negated = name[0] == '!'\n @name = name.tr('!', '')\n @str = name\n end\n\n def negated?\n @negated\n end\n\n def to_s\n @str\n end\n\n def matches?(other)\n return other.to_s != name.to_s if negated?\n\n other.name == name\n end\n end\n\n # A profile group\n class ProfileGroup < Array\n def initialize(group_or_profile)\n # may be nil == empty group; useful for input applicability checks mostly\n return unless group_or_profile\n\n ary = [*group_or_profile]\n if group_or_profile.is_a?(String) && group_or_profile.include?(' ')\n ary = ary[0].split(' ')\n end\n super(ary.map { |x| x.is_a?(Profile) ? x : Profile.new(x) })\n end\n\n # Determine if an input Profile(Group) is applicable to this ProfileGroup\n # @param [Array, Profile] array_or_profile\n def matches?(array_or_profile)\n ary = [*array_or_profile]\n\n # A Group is an AND relationship between profiles, so all our Profiles\n # must match at least one search profile.\n # If we are 'cross nocheck' the input must have at least\n # 'cross' and 'nocheck'.\n all? do |profile|\n ary.any? { |check_profile| profile.matches?(check_profile) }\n end\n end\n\n def to_s\n join(' ')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6985294222831726,
"alphanum_fraction": 0.6985294222831726,
"avg_line_length": 19.923076629638672,
"blob_id": "ccd75fc97c1b4a0a4a13943733d689ac6721e11f",
"content_id": "0f9a82cde9abb08b785a4df42e5cf30fdc9447d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 13,
"path": "/jenkins-jobs/mgmt_docker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Deploy job\nclass MGMTDockerJob < JenkinsJob\n attr_reader :dependees\n\n def initialize(dependees:)\n name = 'mgmt_docker'\n super(name, \"#{name}.xml.erb\")\n @dependees = dependees.collect(&:job_name)\n end\nend\n"
},
{
"alpha_fraction": 0.6327218413352966,
"alphanum_fraction": 0.6359041333198547,
"avg_line_length": 29.1807918548584,
"blob_id": "7e4ae7011c9226143e27f3e5e16ed0a83a99252e",
"content_id": "28babdeb7ab5bfb0b8f76560c37a1ea94956a6fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5342,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 177,
"path": "/lib/projects/factory/base.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'concurrent'\n\nclass ProjectsFactory\n # Base class.\n class Base\n DEFAULT_PARAMS = {\n branch: 'kubuntu_unstable', # FIXME: kubuntu\n origin: nil # Defer the origin to Project class itself\n }.freeze\n\n class << self\n def from_type(type)\n return nil unless understand?(type)\n\n new(type)\n end\n\n def understand?(_type)\n false\n end\n\n def promise_executor\n @pool ||=\n Concurrent::ThreadPoolExecutor.new(\n min_threads: 1,\n # Do not thread too aggressively. We only thread for git pulling.\n # Outside that use case too much threading actually would slow us\n # down due to GIL, locking and scheduling overhead.\n max_threads: ENV.fetch('PANGEA_FACTORY_THREADS', 4).to_i,\n max_queue: 512,\n fallback_policy: :caller_runs\n )\n end\n end\n\n attr_accessor :default_params\n\n # Factorize from data. Defaults to data being an array.\n def factorize(data)\n # fail unless data.is_a?(Array)\n promises = data.collect do |entry|\n next from_string(entry) if entry.is_a?(String)\n next from_hash(entry) if entry.is_a?(Hash)\n\n # FIXME: use a proper error here.\n raise 'unkown type'\n end.flatten.compact\n # Launchpad factory is shit and doesn't use new_project. So it doesn't\n # come back with promises...\n return promises if promises[0].is_a?(Project)\n\n warn \"WAITING FOR QUEUED PROMISES. Total: #{promises.size}\"\n aggregate_promises(promises)\n end\n\n private\n\n def skip?(name)\n ENV['PANGEA_FACTORIZE_ONLY'] && name != ENV['PANGEA_FACTORIZE_ONLY']\n end\n\n def aggregate_promises(promises)\n # Wait on promises individually the main thread can't proceed anyway\n # and more builtin constructs of concurrent aren't nearly as reliable as\n # doing things manually here.\n ret = promises.each_with_index.map do |promise, i|\n warn \"Resolving ##{i}\"\n promise.value\n end.flatten.compact\n errors = promises.collect(&:reason).flatten.compact.uniq\n puts 'all promises resolved!'\n\n throw_errors(errors) unless errors.empty?\n\n if ret.empty? && !ENV['PANGEA_FACTORIZE_ONLY']\n raise 'Couldn\\'t aggregate any projects.' \\\n ' Broken configs? Strict restrcitions?'\n end\n ret\n end\n\n def throw_errors(errors)\n warn '# ERRORS'\n errors.each_with_index do |e, i|\n warn \"## error #{i}\"\n e.set_backtrace(mangle_error_bt(e))\n warn e.full_message\n end\n raise 'Factory tripped over unhandled exceptions. Fix them.'\n end\n\n def mangle_error_bt(error)\n bt = error.backtrace\n # leave untouched if concurrent itself broke\n return bt if bt[0].include?('concurrent-ruby')\n\n concurrent_filter(bt)\n end\n\n def concurrent_filter(backtrace)\n found_concurrent = false\n backtrace = backtrace.select do |line|\n if line.include?('concurrent-ruby')\n found_concurrent = true\n next false\n end\n true\n end\n return backtrace unless found_concurrent\n\n backtrace << 'unknown:0:Leading ruby-concurrent frames removed'\n end\n\n class << self\n private\n\n def reset!\n instance_variables.each do |v|\n next if v == :@mocha\n\n remove_instance_variable(v)\n end\n end\n end\n\n def initialize(type)\n @type = type\n @default_params = DEFAULT_PARAMS\n end\n\n def symbolize(hsh)\n Hash[hsh.map { |(key, value)| [key.to_sym, value] }]\n end\n\n # Joins path parts but skips empties and nils.\n def join_path(*parts)\n File.join(*parts.reject { |x| x.nil? || x.empty? })\n end\n\n # FIXME: this is a workaround until Project gets entirely redone\n def new_project(name:, component:, url_base:, branch:, origin:)\n params = { branch: branch }\n # Let Project pick a default for origin, otherwise we need to retrofit\n # all Project testing with a default which seems silly.\n params[:origin] = origin if origin\n Concurrent::Promise.execute(executor: self.class.promise_executor) do\n begin\n next nil if skip?(name)\n\n Project.new(name, component, url_base, **params)\n rescue Project::ShitPileErrror => e\n warn \"shitpile -- #{e}\"\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6915488243103027,
"alphanum_fraction": 0.6984544396400452,
"avg_line_length": 30.03061294555664,
"blob_id": "cd10961d3439d6231a21af3f5c86cb3d6b7da22d",
"content_id": "f4055c140f83512261a671dca486399862ef1a48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3041,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 98,
"path": "/lib/xci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# NB: this mustn't use any gems! it is used during provisioning.\nrequire 'yaml'\nrequire 'ostruct'\n\n# CI specific configuration data.\nmodule XCI\n # @param sort [Symbol] sorting applied to hash\n # - *:none* No sorting, arbitrary order as in config itself (fastest)\n # - *:ascending* Oldest version comes first (i.e. [15.04, 15.10])\n # - *:descending* Oldest version comes last (i.e. [15.10, 15.04])\n # @return [Hash] distribution series\n def series(sort: :none)\n return sort_version_hash(data['series']).to_h if sort == :ascending\n return sort_version_hash(data['series']).reverse.to_h if sort == :descending\n\n data['series']\n end\n\n # @return [String] name of the latest (i.e. newest) series\n def latest_series\n @latest_series ||= series(sort: :descending).keys.first\n end\n\n # Core architectures. These are always enabled architectures that also get\n # ISOs generated and so forth.\n # This for example are general purpose architectures such as i386/amd64.\n # @see .extra_architectures\n # @return [Array<String>] architectures to integrate\n def architectures\n data['architectures']\n end\n\n # Extra architectures. They differ from core architectures in that they are\n # not automatically enabled and might not be used or useful in all contexts.\n # This for example are special architectures such as ARM.\n # @see .all_architectures\n # @return [Array<String>] architectures to only integrated when explicitly\n # enabled within the context of a build.\n def extra_architectures\n data['extra_architectures']\n end\n\n # Convenience function to combine all known architectures. Generally when\n # creating scopes (e.g. when creating jenkins jobs) one wants to use the\n # specific readers as to either use the core architectures or extras or a\n # suitable mix of both. When read-iterating on something that includes the\n # architecture value all_architectures is the way to go to cover all possible\n # architectures.\n # @see .architectures\n # @see .extra_architectures\n # @return [Array<String>] all architectures\n def all_architectures\n architectures + extra_architectures\n end\n\n # @return [Array<String>] types to integrate (stable/unstable)\n def types\n data['types']\n end\n\n private\n\n # @return [Array] array can be converted back with to_h\n def sort_version_hash(hash)\n hash.sort_by { |_, version| Gem::Version.new(version) }\n end\n\n def data_file_name\n @data_file_name ||= \"#{to_s.downcase}.yaml\"\n end\n\n def data_dir\n @data_dir ||= File.join(File.dirname(__dir__), 'data')\n end\n\n def data_dir=(data_dir)\n reset!\n @data_dir = data_dir\n end\n\n def data\n return @data if defined?(@data)\n\n file = File.join(data_dir, data_file_name)\n raise \"Data file not found (#{file})\" unless File.exist?(file)\n\n @data = YAML.load(File.read(file))\n @data.each_value(&:freeze) # May be worth looking into a deep freeze gem.\n end\n\n def reset!\n instance_variables.each do |v|\n remove_instance_variable(v)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6145972609519958,
"alphanum_fraction": 0.6186025738716125,
"avg_line_length": 26.40243911743164,
"blob_id": "bd3f0f77748dee905f56ac831cb8ea66dfc16ae4",
"content_id": "d52018da0fd87b316604743048f24c28df4452b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2247,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 82,
"path": "/lib/adt/summary.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule ADT\n # An autopkgtest summary.\n class Summary\n attr_reader :path\n attr_reader :entries\n\n module Result\n PASS = :pass\n FAIL = :fail\n SKIP = :skip\n end.freeze\n\n # A Summary Entry.\n class Entry\n attr_reader :name\n attr_reader :result\n attr_reader :detail\n\n REGEX = /(?<name>[^\\s]+)\\s+(?<result>[^\\s]+)\\s?(?<detail>.*)/\n\n def self.from_line(line)\n data = line.match(REGEX)\n send(:new, data[:name], data[:result], data[:detail])\n end\n\n private\n\n def initialize(name, result, detail)\n @name = name\n @result = case result\n when 'PASS' then Summary::Result::PASS\n when 'FAIL' then Summary::Result::FAIL\n when 'SKIP' then Summary::Result::SKIP\n else raise \"unknown result type '#{name} #{result} #{detail}'\"\n end\n @detail = detail\n end\n end\n\n def self.from_file(file)\n send(:new, file)\n end\n\n private\n\n def initialize(file)\n @path = File.absolute_path(file)\n @entries = []\n parse!\n end\n\n def parse!\n data = File.read(@path)\n data.split($/).each do |line|\n line.strip!\n next if line.empty?\n\n @entries << Entry.from_line(line)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6416791677474976,
"alphanum_fraction": 0.6461769342422485,
"avg_line_length": 30.388235092163086,
"blob_id": "f9cebeb765cd9926e35e8714a36ce31eec6734f1",
"content_id": "dd37db08948bb4522a1573d346595e99420eb0fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2668,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 85,
"path": "/lib/projects/factory/gitlab.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'gitlab'\n\nrequire_relative 'base'\nrequire_relative 'common'\n\nclass ProjectsFactory\n # Debian specific project factory.\n class Gitlab < Base\n include ProjectsFactoryCommon\n DEFAULT_URL_BASE = 'https://gitlab.com'\n\n # FIXME: same as in neon\n def self.url_base\n @url_base ||= DEFAULT_URL_BASE\n end\n\n def self.understand?(type)\n type == 'gitlab.com'\n end\n\n private\n\n def split_entry(entry)\n parts = entry.split('/')\n name = parts.pop\n component = parts.pop\n group = parts.join('/')\n [name, component, group]\n end\n\n def params(str)\n name, component, group = split_entry(str)\n default_params.merge(\n name: name,\n component: component,\n url_base: \"#{self.class.url_base}/#{group}\"\n )\n end\n\n class << self\n def ls(base)\n @list_cache ||= {}\n return @list_cache[base] if @list_cache.key?(base)\n\n base_id = ::Gitlab.group_search(base)[0].id\n # gitlab API is bit meh, when you ask path, it just returns parent subgroup\n # so we, ask for path_with_namespace and strip the top-most group name\n repos = list_repos(base_id).collect { |x| x.split('/', 2)[-1] }\n @list_cache[base] = repos.freeze\n end\n\n def list_repos(group_id)\n # Gitlab sends over paginated replies, make sure we iterate till\n # no more results are being returned.\n repos = ::Gitlab.group_projects(group_id)\n .auto_paginate\n .collect(&:path_with_namespace)\n repos += ::Gitlab.group_subgroups(group_id).auto_paginate.collect do |subgroup|\n list_repos(subgroup.id)\n end\n repos.flatten\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6792618632316589,
"alphanum_fraction": 0.6818980574607849,
"avg_line_length": 37.35955047607422,
"blob_id": "270007b0dc660cfc1238e9ee49c12da15e49769f",
"content_id": "fe637210f78da6e9126778bd799fc95d9883e1aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3414,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 89,
"path": "/test/test_overlay_bins.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\nclass OverlayBinsTest < TestCase\n OVERLAY_DIR = \"#{__dir__}/../overlay-bin\"\n\n def setup\n assert_path_exist(OVERLAY_DIR, 'expected overlay dir to exist but could' \\\n ' not find it. maybe it moved?')\n # Chains the actual overlay (which we expect to be dropped) before our\n # double overlay which we expect to get run to create stamps we can assert.\n @path = \"#{OVERLAY_DIR}:#{datadir}:#{ENV['PATH']}\"\n @env = { 'PATH' => @path, 'WORKSPACE' => Dir.pwd }\n end\n\n def test_cmake\n assert system(@env, \"#{OVERLAY_DIR}/cmake\", '-DXX=YY')\n assert_path_exist 'cmake_call'\n assert_equal '-DXX=YY', File.read('cmake_call').strip\n end\n\n def test_cmake_no_verbose\n assert system(@env, \"#{OVERLAY_DIR}/cmake\", '-DXX=YY', '-DCMAKE_VERBOSE_MAKEFILE=ON')\n assert_path_exist 'cmake_call'\n assert_equal '-DXX=YY', File.read('cmake_call').strip\n end\n\n def test_cmake_no_verbose_override\n File.write('cmake_verbose_makefile', '')\n assert system(@env, \"#{OVERLAY_DIR}/cmake\", '-DXX=YY', '-DCMAKE_VERBOSE_MAKEFILE=ON')\n assert_path_exist 'cmake_call'\n assert_equal '-DXX=YY -DCMAKE_VERBOSE_MAKEFILE=ON', File.read('cmake_call').strip\n end\n\n def test_tail\n assert system(@env, \"#{OVERLAY_DIR}/tail\", 'xx')\n assert_path_exist 'tail_call'\n assert_equal 'xx', File.read('tail_call').strip\n end\n\n def test_tail_cache_copy\n File.write('CMakeCache.txt', 'yy')\n assert system(@env, \"#{OVERLAY_DIR}/tail\", 'CMakeCache.txt')\n assert_path_not_exist 'tail_call'\n assert_path_exist 'archive_pickup/CMakeCache.txt'\n assert_equal 'yy', File.read('archive_pickup/CMakeCache.txt').strip\n end\n\n def test_cmake_no_testing_override\n # disable testing if adt is disabled\n File.write('adt_disabled', '')\n assert system(@env, \"#{OVERLAY_DIR}/cmake\", '-DCMAKE_INSTALL_PREFIX=xx')\n assert_path_exist 'cmake_call'\n assert_equal '-DBUILD_TESTING=OFF -DCMAKE_INSTALL_PREFIX=xx', File.read('cmake_call').strip\n end\n\n def test_cmake_but_not_a_build\n # cmake can be invoked to run a cmake \"script\" rather than to configure\n # a build. when that happens it should not disable testing (as the arg\n # will be invalid!)\n File.write('adt_disabled', '')\n assert system(@env, \"#{OVERLAY_DIR}/cmake\", '-E', 'rm', '/tmp/')\n assert_path_exist 'cmake_call'\n assert_equal '-E rm /tmp/', File.read('cmake_call').strip\n end\nend\n"
},
{
"alpha_fraction": 0.6275749802589417,
"alphanum_fraction": 0.6451152563095093,
"avg_line_length": 30.329072952270508,
"blob_id": "db7ea6c960a5a80c01f76a52bc14e3e64537b5da",
"content_id": "3d0d824afaafbb802fe9dc8e1e1704a10c21bfb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9806,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 313,
"path": "/test/test_ci_vcs_source_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\nrequire 'rubygems/package'\nrequire 'zlib'\n\nrequire_relative 'lib/assert_system'\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/ci/vcs_source_builder'\nrequire_relative '../lib/debian/control'\nrequire_relative '../lib/os'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\n\nclass VCSBuilderTest < TestCase\n required_binaries %w[\n dpkg-buildpackage dpkg msgfmt dch dh\n ]\n\n REF_TIME = '20150717.1756'\n\n def fake_os(id, release, version)\n OS.reset\n @release = release\n OS.instance_variable_set(:@hash, VERSION_ID: version, ID: id)\n end\n\n def fake_os_ubuntu\n fake_os('ubuntu', 'vivid', '15.04')\n end\n\n def fake_os_debian\n fake_os('debian', 'stable', '10')\n end\n\n def setup\n fake_os_ubuntu\n fake_os_debian if OS::ID == 'debian'\n alias_time\n FileUtils.cp_r(Dir.glob(\"#{data}/*\"), Dir.pwd)\n\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n\n CI::DependencyResolver.simulate = true\n\n # dud. only used for output in version enforcer\n ENV['JOB_NAME'] = 'RaRaRasputin'\n # Turn a bunch of debhelper sub process calls noop to improve speed.\n ENV['PATH'] = \"#{__dir__}/dud-bin:#{ENV['PATH']}\"\n ENV['TYPE'] = 'unstable'\n end\n\n def teardown\n CI::DependencyResolver.simulate = false\n\n OS.reset\n unalias_time\n end\n\n def alias_time\n CI::BuildVersion.send(:alias_method, :__time_orig, :time)\n CI::BuildVersion.send(:define_method, :time) { REF_TIME }\n @time_aliased = true\n end\n\n def unalias_time\n return unless @time_aliased\n\n CI::BuildVersion.send(:undef_method, :time)\n CI::BuildVersion.send(:alias_method, :time, :__time_orig)\n @time_aliased = false\n end\n\n def tar_file_list(path)\n files = []\n Gem::Package::TarReader.new(Zlib::GzipReader.open(path)).tap do |reader|\n reader.rewind\n reader.each do |entry|\n files << File.basename(entry.full_name) if entry.file?\n end\n reader.close\n end\n files\n end\n\n def test_quilt\n ENV['TYPE'] = 'nol10n'\n\n s = CI::VcsSourceBuilder.new(release: @release)\n r = s.run\n assert_equal(:quilt, r.type)\n assert_equal('hello', r.name)\n assert_equal(\"2.10+p#{OS::VERSION_ID}+vnol10n+git20150717.1756-0\", r.version)\n assert_equal('hello_2.10+p15.04+vnol10n+git20150717.1756-0.dsc', r.dsc)\n assert_not_nil(r.build_version)\n\n assert(File.read('last_version').start_with?('2.10+p'),\n \"New version not recorded? -> #{File.read('last_version')}\")\n ensure\n ENV.delete('TYPE')\n end\n\n def test_native\n ENV['TYPE'] = 'nol10n'\n s = CI::VcsSourceBuilder.new(release: @release)\n r = s.run\n assert_equal(:native, r.type)\n assert_equal('hello', r.name)\n assert_equal(\"2.10+p#{OS::VERSION_ID}+vnol10n+git20150717.1756\", r.version)\n assert_equal('hello_2.10+p15.04+vnol10n+git20150717.1756.dsc', r.dsc)\n assert_not_nil(r.build_version)\n\n # Make sure we have source files in our tarball.\n Dir.chdir('build/') do\n assert(system(\"dpkg-source -x #{r.dsc}\"))\n assert_path_exist(\"#{r.name}-#{r.version}/debian\")\n assert_path_exist(\"#{r.name}-#{r.version}/sourcey.file\")\n end\n ensure\n ENV.delete('TYPE')\n end\n\n def test_empty_install\n s = CI::VcsSourceBuilder.new(release: @release)\n r = s.run\n assert_equal(:native, r.type)\n assert_equal('hello', r.name)\n assert_equal(\"2.10+p#{OS::VERSION_ID}+vunstable+git20150717.1756\", r.version)\n assert_not_nil(r.dsc)\n\n Dir.chdir('build/') do\n assert(system(\"dpkg-source -x #{r.dsc}\"))\n assert(File.exist?(\"#{r.name}-#{r.version}/debian/#{r.name}.lintian-overrides\"))\n end\n end\n\n def test_build_fail\n ENV['TYPE'] = 'nol10n'\n s = CI::VcsSourceBuilder.new(release: @release)\n assert_raise CI::VcsSourceBuilder::BuildPackageError do\n s.run\n end\n end\n\n def test_symbols_strip_latest\n CI::VcsSourceBuilder.new(release: @release, strip_symbols: true).run\n Dir.chdir('build')\n tar = Dir.glob('*.tar.gz')\n assert_equal(1, tar.size)\n files = tar_file_list(tar[0])\n assert_not_include(files, 'symbols')\n assert_not_include(files, 'test.acc.in')\n assert_not_include(files, 'test.symbols')\n assert_not_include(files, 'test.symbols.armhf')\n end\n\n def test_locale_kdelibs4support\n source = CI::VcsSourceBuilder.new(release: @release).run\n assert_not_nil(source.dsc)\n Dir.chdir('build') do\n dsc = source.dsc\n install = \"#{source.name}-#{source.build_version.tar}/debian/\" \\\n 'libkf5kdelibs4support-data.install'\n assert(system('dpkg-source', '-x', dsc))\n data = File.read(install).split($/)\n assert_include(data, 'usr/share/locale/*')\n end\n end\n\n def test_hidden_sources\n ENV['TYPE'] = 'nol10n'\n source = CI::VcsSourceBuilder.new(release: @release).run\n assert_not_nil(source.dsc)\n Dir.chdir('build') do\n dsc = source.dsc\n assert(system('dpkg-source', '-x', dsc))\n file = \"#{source.name}-#{source.build_version.tar}/.hidden-file\"\n assert_path_exist(file)\n end\n end\n\n def test_epoch_bump_fail\n File.write('last_version', '10:1.0')\n assert_raise CI::VersionEnforcer::UnauthorizedChangeError do\n CI::VcsSourceBuilder.new(release: @release).run\n end\n end\n\n def test_epoch_decrement_fail\n File.write('last_version', '1.0')\n assert_raise CI::VersionEnforcer::UnauthorizedChangeError do\n CI::VcsSourceBuilder.new(release: @release).run\n end\n end\n\n def test_epoch_retain\n File.write('last_version', '5:1.0')\n CI::VcsSourceBuilder.new(release: @release).run\n # pend \"assert last_version changed\"\n assert(File.read('last_version').start_with?('5:2.10'),\n \"New version not recorded? -> #{File.read('last_version')}\")\n end\n\n def test_quilt_full_source\n ENV['TYPE'] = 'nol10n'\n source = CI::VcsSourceBuilder.new(release: @release,\n restricted_packaging_copy: true).run\n assert_equal(:quilt, source.type)\n Dir.chdir('build') do\n dsc = source.dsc\n assert(system('dpkg-source', '-x', dsc))\n dir = \"#{source.name}-#{source.build_version.tar}/\"\n assert_path_exist(dir)\n assert_path_not_exist(\"#{dir}/full_source1\")\n assert_path_not_exist(\"#{dir}/full_source2\")\n end\n end\n\n # NOTE: this actually talks to the real life svn server and can flake\n # when that happens chances are something actually moved in production.\n # this is kinda intentional since this is a blackbox test!\n def test_l10n\n omit('Broken for unknown reasons on xenon. Works locally QQ')\n # The git dir is not called .git as to not confuse the actual tooling git.\n FileUtils.mv('source/gitty', 'source/.git')\n\n ENV['TYPE'] = 'stable'\n\n stub_request(:get, 'https://projects.kde.org/api/v1/repo/kmenuedit')\n .to_return(body: '{\"i18n\":{\"stable\":\"none\",\"stableKF5\":\"Plasma/5.10\",\n \"trunk\":\"none\",\"trunkKF5\":\"master\",\"component\":\"kde-workspace\"},\n \"path\":\"kde/workspace/kmenuedit\",\"repo\":\"plasma/kmenuedit\"}')\n\n source = CI::VcsSourceBuilder.new(release: @release).run\n\n Dir.chdir('build') do\n dsc = source.dsc\n assert(system('dpkg-source', '-x', dsc))\n dir = \"#{source.name}-#{source.build_version.tar}/\"\n assert_path_exist(dir)\n assert_path_exist(\"#{dir}/po\")\n assert_path_exist(\"#{dir}/po/x-test\")\n assert_equal(File.read(\"#{dir}/debian/hello.install\").strip,\n 'usr/share/locale/')\n end\n ensure\n ENV.delete('TYPE')\n end\n\n def test_vcs_injection\n # Automatically inject/update the Vcs fields in the control file.\n\n # The git dir is not called .git as to not confuse the actual tooling git.\n FileUtils.mv('packaging/gitty', 'packaging/.git')\n\n source = CI::VcsSourceBuilder.new(release: @release).run\n Dir.chdir('build') do\n dsc = source.dsc\n assert(system('dpkg-source', '-x', dsc))\n dir = \"#{source.name}-#{source.build_version.tar}/\"\n assert_path_exist(dir)\n data = File.read(\"#{dir}/debian/control\").strip\n assert_include(data, 'Vcs-Git: https://invent.kde.org/neon/kde/kmenuedit.git')\n assert_include(data, 'Vcs-Browser: https://invent.kde.org/neon/kde/kmenuedit')\n end\n end\n\n def test_maintainer_mangle\n orig_name = ENV['DEBFULLNAME']\n orig_email = ENV['DEBEMAIL']\n ENV['DEBFULLNAME'] = 'xxNeon CIxx'\n ENV['DEBEMAIL'] = '[email protected]'\n\n source = CI::VcsSourceBuilder.new(release: @release).run\n\n Dir.chdir('build') do\n dsc = source.dsc\n assert(system('dpkg-source', '-x', dsc))\n dir = \"#{source.name}-#{source.build_version.tar}/\"\n assert_path_exist(dir)\n assert_include(File.read(\"#{dir}/debian/control\").strip,\n 'Maintainer: xxNeon CIxx <[email protected]>')\n assert_include(File.read(\"#{dir}/debian/changelog\").strip,\n '-- xxNeon CIxx <[email protected]>')\n end\n ensure\n orig_name ? ENV['DEBFULLNAME'] = orig_name : ENV.delete('DEBFULLNAME')\n orig_email ? ENV['DEBEMAIL'] = orig_email : ENV.delete('DEBEMAIL')\n end\n\n def test_build_fail_resolution\n # Special build fail which actually comes out of a resolution problem.\n # This only tests if the ResolutionError gets transformed into a BuildPackageError\n ENV['TYPE'] = 'nol10n'\n CI::DependencyResolver\n .expects(:resolve)\n .raises(CI::DependencyResolver::ResolutionError)\n\n s = CI::VcsSourceBuilder.new(release: @release)\n assert_raise CI::VcsSourceBuilder::BuildPackageError do\n s.run\n end\n end\n\n\nend\n"
},
{
"alpha_fraction": 0.6934673190116882,
"alphanum_fraction": 0.7236180901527405,
"avg_line_length": 21.11111068725586,
"blob_id": "9afb31f1edd96743461b571d17427ddddae262cf",
"content_id": "dae0ac37179a733b890f8e3efd580c3510c99034",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 9,
"path": "/mgmt/docker_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\nrequire_relative '../lib/docker/cleanup'\n\nDocker.options[:read_timeout] = 3 * 60 * 60 # 3 hours.\n\nDocker::Cleanup.containers\nDocker::Cleanup.images\n"
},
{
"alpha_fraction": 0.6922118663787842,
"alphanum_fraction": 0.6984423398971558,
"avg_line_length": 29.283018112182617,
"blob_id": "f9a6742daa35825ceda0cd5bf81f1c016b288a43",
"content_id": "1459da7300764d28a3f04165cc87c608e4aeff2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1605,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 53,
"path": "/nci/watcher_mailer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2018 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n=begin\nSend an e-mail to say the watcher has found a new version.\n\nThis used to be part of watcher.rb but it is run within a container\nwhich is faffy to send mail from.\n=end\n\nrequire_relative '../lib/pangea/mail'\n\nclass WatcherMailer\n\n def send_email\n puts 'sending notification mail'\n Pangea::SMTP.start do |smtp|\n mail = <<-MAIL\nFrom: Neon CI <[email protected]>\nTo: [email protected]\nSubject: New Version Found\n\n#{ENV['RUN_DISPLAY_URL']}\n MAIL\n smtp.send_message(mail,\n '[email protected]',\n '[email protected]')\n end\n end\nend\n\nif __FILE__==$0\n watcher_mailer = WatcherMailer.new\n puts watcher_mailer.send_email\nend\n"
},
{
"alpha_fraction": 0.7197802066802979,
"alphanum_fraction": 0.7197802066802979,
"avg_line_length": 22.7391300201416,
"blob_id": "ab78ae39bdd65a631baeb0691c4c8173c4d13e3f",
"content_id": "ee22bd71b6b3f06666abc3bc144f975c385934d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 546,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 23,
"path": "/test/test_deprecate.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/deprecate'\n\nclass DeprecateTest < TestCase\n class Dummy\n extend Deprecate\n\n def a\n variable_deprecation('variable', 'replacement')\n end\n end\n\n def test_deprecate_var\n assert_include(Deprecate.ancestors, Gem::Deprecate)\n dummy = Dummy.new\n assert(dummy.class.is_a?(Deprecate))\n assert_include(dummy.class.ancestors, Deprecate::InstanceMethods)\n dummy.send :variable_deprecation, 'variable', 'replacement'\n dummy.a\n end\nend\n"
},
{
"alpha_fraction": 0.6525285243988037,
"alphanum_fraction": 0.6566068530082703,
"avg_line_length": 25.085105895996094,
"blob_id": "c441ad9502331d867e95b8e6d5036c2bf37d5ecf",
"content_id": "c1889cd1af88b115abed05bde385e61b4d7a279a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1226,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 47,
"path": "/test/test_lint_series.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/lint/series'\nrequire_relative 'lib/testcase'\n\n# Test lint series\nclass LintSeriesTest < TestCase\n def test_init\n s = Lint::Series.new\n assert_equal(Dir.pwd, s.package_directory)\n s = Lint::Series.new('/tmp')\n assert_equal('/tmp', s.package_directory)\n end\n\n def test_missing\n s = Lint::Series.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal(2, s.warnings.size) # 1 missing + empty series\n assert_equal([], s.informations)\n end\n\n def test_complete\n s = Lint::Series.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal([], s.warnings)\n assert_equal([], s.informations)\n end\n\n def test_ignore\n # Has two missing but only one is reported as such.\n s = Lint::Series.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal(2, s.warnings.size) # 1 missing + empty series\n assert_equal([], s.informations)\n end\n\n def test_empty_series\n # Empty but existing series file.\n s = Lint::Series.new(data).lint\n assert(s.valid)\n assert_equal([], s.errors)\n assert_equal(1, s.warnings.size)\n assert_equal([], s.informations)\n end\nend\n"
},
{
"alpha_fraction": 0.6108952760696411,
"alphanum_fraction": 0.6189188957214355,
"avg_line_length": 29.99476432800293,
"blob_id": "65064e1e49473344296011fe3612dd37ef47a142",
"content_id": "22967ab89f83dddfe2863b4a7c06efaf90363df4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 11840,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 382,
"path": "/lib/ci/vcs_source_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2015 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n\n# TODO: merge various names for sourcing. This acts a require guard.\n# Regular require load the file twice\n# as it doesn't consider the real file and its compat symlink different\n# so the monkey patch would get applied multiple times breaking the orig\n# alias.\nreturn if defined?(VCS_SOURCE_BUILDER_REQUIRE_GUARD)\n\nVCS_SOURCE_BUILDER_REQUIRE_GUARD = true\n\nrequire 'fileutils'\nrequire 'releaseme'\nrequire 'yaml'\n\n# for releasem ftp vcs\nrequire 'concurrent'\nrequire 'net/ftp'\nrequire 'net/ftp/list'\n\nrequire_relative '../tty_command'\nrequire_relative '../apt'\nrequire_relative '../debian/changelog'\nrequire_relative '../debian/source'\nrequire_relative '../os'\nrequire_relative 'build_version'\nrequire_relative 'source'\nrequire_relative 'sourcer_base'\nrequire_relative 'version_enforcer'\n\nmodule ReleaseMe\n # SVN replacement hijacks svn and redirects to ftp intead\n # this isn't tested because testing ftp is a right headache.\n # Be very careful with rescuing errors, due to the lack of testing\n # rescuing must be veeeeeeery carefully done.\n class FTP < Vcs\n def initialize\n @svn = Svn.allocate\n @thread_storage ||= Concurrent::Hash.new\n end\n\n def clean!(*)\n # already clean with ftp, there's no temporary cache on-disk\n end\n\n def ftp\n # this is kinda thread safe in that Thread.current cannot change out from\n # under us, and the storage is a concurrent hash.\n @thread_storage[Thread.current] ||= begin\n uri = URI.parse(repository)\n ftp = Net::FTP.new(uri.host, port: uri.port)\n ftp.login\n ftp.chdir(uri.path)\n ftp\n end\n end\n\n def cat(file_path)\n ftp.get(file_path, nil)\n end\n\n def export(target, path)\n ftp.get(path, target)\n rescue Net::FTPPermError => e\n FileUtils.rm_f(target) # git ignorantly touches the file before trying to read -.-\n false\n end\n\n def get_r(ftp, target, path)\n any = false\n ftp.list(path).each do |e|\n entry = Net::FTP::List.parse(e)\n entry_path = File.join(path, entry.basename)\n target_path = File.join(target, entry.basename)\n if entry.file?\n FileUtils.mkpath(File.dirname(target_path))\n ftp.get(entry_path, target_path)\n elsif entry.dir?\n get_r(ftp, target_path, entry_path)\n else\n raise \"Unsupported entry #{entry} #{entry.inspect}\"\n end\n any = true\n end\n any\n end\n\n def get(target, path = nil, clean: false)\n get_r(ftp, target, path)\n end\n\n def list(path = nil)\n ftp.nlst(path).join(\"\\n\")\n end\n\n def method_missing(symbol, *arguments, &block)\n if @svn.respond_to?(symbol)\n raise \"#{symbol} not implemented by #{self.class} overlay for SVN\"\n end\n\n super\n end\n\n def respond_to_missing?(symbol, include_private = false)\n @svn.respond_to?(symbol, include_private) || super\n end\n end\nend\n\nmodule CI\n # Extend a builder with l10n functionality based on releaseme.\n module SourceBuilderL10nExtension\n # Hijack this when working on source to inject the l10n into the copied\n # source BUT not the git repo source. This prevents us from polluting the\n # possibly later reused git clone.\n def copy_source_tree(*args)\n ret = super\n unless ENV['TYPE'] == 'nol10n' # used in tests\n inject_l10n!(\"#{@build_dir}/source/\") if args[0] == 'source'\n end\n ret\n end\n\n private\n\n def l10n_log\n @l10n_log ||= Logger.new(STDOUT).tap { |l| l.progname = 'l10n' }\n end\n\n def project_for_url(url)\n projects = ReleaseMe::Project.from_repo_url(url.gsub(/\\.git$/, ''))\n unless projects.size == 1\n raise \"failed to resolve project #{url} :: #{projects}\"\n end\n\n projects[0]\n end\n\n def l10n_origin_from_type\n {\n 'desktop' => ReleaseMe::Origin::TRUNK,\n 'core' => ReleaseMe::Origin::TRUNK,\n 'c1' => ReleaseMe::Origin::TRUNK,\n 'z1' => ReleaseMe::Origin::TRUNK,\n 'z2' => ReleaseMe::Origin::TRUNK,\n 'unstable' => ReleaseMe::Origin::TRUNK,\n 'stable' => ReleaseMe::Origin::STABLE,\n 'release' => ReleaseMe::Origin::STABLE\n }.fetch(ENV.fetch('TYPE'))\n end\n\n def l10n_origin_for(project)\n origin = l10n_origin_from_type\n\n # TODO: ideally we should pass the BRANCH from the master job into\n # the sourcer job and assert that the upstream branch is the stable/\n # trunk branch which is set here. This would assert that the\n # upstream_scm used to create the jobs was in sync with the data we see.\n # If it was not this is a fatal problem as we might be integrating\n # incorrect translations.\n if origin == ReleaseMe::Origin::STABLE && !project.i18n_stable\n warn 'This project has no stable branch. Falling back to trunk.'\n origin = ReleaseMe::Origin::TRUNK\n end\n\n if origin == ReleaseMe::Origin::TRUNK && !project.i18n_trunk\n raise 'Project has no i18n trunk WTF. This should not happen.'\n end\n\n origin\n end\n\n # Add l10n to source dir\n def add_l10n(source_path, repo_url)\n project = project_for_url(repo_url)\n\n # Use the pangea mirror (exclusively mirrors l10n messages) to avoid\n # too low connection limits on the regular KDE server.\n ENV['RELEASEME_SVN_REPO_URL'] = 'ftp://files.kde.mirror.pangea.pub:21012'\n l10n = ReleaseMe::L10n.new(l10n_origin_for(project), project.identifier,\n project.i18n_path, vcs: ReleaseMe::FTP.new)\n l10n.default_excluded_languages = [] # Include even x-test.\n l10n.get(source_path)\n l10n.vcs.clean!(\"#{source_path}/po\")\n\n (class << self; self; end).class_eval do\n define_method(:mangle_locale) { |*| } # disable mangling\n end\n end\n\n def repo_url_from_path(path)\n return nil unless Dir.exist?(path)\n\n require 'rugged'\n repo = Rugged::Repository.discover(path)\n remote = repo.remotes['origin'] if repo\n # Includes git.kde.org, otherwise it would run on *.neon.kde.org.\n # also, don't include scratch and clones, they don't have projects\n # associated with them.\n url = remote.url if remote&.url&.include?('invent.kde.org')\n return nil if url && remote&.url&.include?('/qt/') # qt fork has no l10n\n\n url || nil\n end\n\n def inject_l10n!(source_path)\n # This is ./source, while path is ./build/source\n url = repo_url_from_path('source')\n l10n_log.info \"l10n injection for url #{url}.\"\n return unless url\n\n # TODO: this would benefit from classing\n add_l10n(source_path, url)\n end\n end\n\n # Class to build out source package from a VCS\n class VcsSourceBuilder < SourcerBase\n\n def initialize(release:, strip_symbols: false,\n restricted_packaging_copy: false)\n super\n # FIXME: use packagingdir and sourcedir\n @source = CI::Source.new\n changelog = nil\n Dir.chdir('packaging') do\n @source.type = Debian::Source.new(Dir.pwd).format.type\n changelog = Changelog.new\n raise \"Can't parse changelog!\" if changelog.nil?\n end\n\n @source.name = changelog.name\n @source.build_version = CI::BuildVersion.new(changelog)\n @source.version = if @source.type == :native\n @source.build_version.base\n else\n @source.build_version.full\n end\n\n @tar_version = @source.build_version.tar\n\n @version_enforcer = VersionEnforcer.new\n @version_enforcer.validate(@source.version)\n end\n\n # Copies the source/ source tree into the target and strips it off a\n # possible debian/ directory.\n # @note this wipes @build_dir\n def copy_source\n copy_source_tree('source')\n return unless Dir.exist?(\"#{@build_dir}/source/debian\")\n\n FileUtils.rm_rf(Dir.glob(\"#{@build_dir}/source/debian\"))\n end\n\n # Copies the packaging/ source tree into the target.\n # This overwrites files previously created by #{copy_source} if there are\n # name clashes.\n def copy_packaging\n # Copy some more\n args = [] << 'debian' if @restricted_packaging_copy\n copy_source_tree('packaging', *args)\n end\n\n def compression_level\n return '-0' if ENV['PANGEA_UNDER_TEST']\n\n '-6'\n end\n\n def tar_it(origin, xzfile)\n # Try to compress using all cores, if that fails fall back to serial.\n cmd = TTY::Command.new\n cmd.run({ 'XZ_OPT' => \"--threads=0 #{compression_level}\" },\n 'tar', '-cJf', xzfile, origin)\n rescue TTY::Command::ExitError\n warn 'Tar fail. Falling back to slower single threaded compression...'\n cmd.run({ 'XZ_OPT' => compression_level },\n 'tar', '-cJf', xzfile, origin)\n end\n\n def create_orig_tar\n Dir.chdir(@build_dir) do\n tar_it('source', \"#{@source.name}_#{@tar_version}.orig.tar.xz\")\n end\n end\n\n def build\n # dpkg-buildpackage\n Dir.chdir(\"#{@build_dir}/source/\") { dpkg_buildpackage }\n\n Dir.chdir(@build_dir) do\n dsc = Dir.glob('*.dsc')\n raise 'Exactly one dsc not found' if dsc.size != 1\n\n @source.dsc = dsc[0]\n end\n\n @version_enforcer.record!(@source.version)\n end\n\n def cleanup\n FileUtils.rm_rf(\"#{@build_dir}/source\")\n end\n\n def run\n copy_source\n create_orig_tar\n copy_packaging\n mangle!\n log_change\n build\n cleanup\n @source\n end\n\n private\n\n def log_change\n # Create changelog entry\n Debian::Changelog.new_version!(@source.version, distribution: @release,\n message: \"Automatic #{OS::ID.capitalize} CI Build\",\n chdir: \"#{@build_dir}/source/\")\n end\n\n def mangle_manpages(file)\n # Strip localized manpages\n # e.g. usr /share /man / * /man 7 /kf5options.7\n man_regex = %r{^.*usr/share/man/(\\*|\\w+)/man\\d/.*$}\n subbed = File.open(file).read.gsub(man_regex, '')\n File.write(file, subbed)\n end\n\n def mangle_locale(file)\n locale_regex = %r{^.*usr/share/locale.*$}\n subbed = File.open(file).read.gsub(locale_regex, '')\n File.write(file, subbed)\n end\n\n def mangle_lintian_of(file)\n return unless File.open(file, 'r').read.strip.empty?\n\n package_name = File.basename(file, '.install')\n lintian_overrides_path = file.gsub('.install', '.lintian-overrides')\n puts \"#{package_name} is now empty, trying to add lintian override\"\n File.open(lintian_overrides_path, 'a') do |f|\n f.write(\"#{package_name}: empty-binary-package\\n\")\n end\n end\n\n def mangle_install_file(file)\n mangle_manpages(file)\n # FIXME: bloody workaround for kconfigwidgets, kdelibs4support\n # and ubuntu-ui-toolkit containing legit locale data\n if %w[kconfigwidgets\n kdelibs4support\n ubuntu-ui-toolkit\n ubuntu-release-upgrader-neon].include?(@source.name)\n return\n end\n\n # Do not mange locale in .install now they are brought into Git by scripty\n #mangle_locale(file)\n # If the package is now empty, lintian override the empty warning\n # to avoid false positives\n mangle_lintian_of(file)\n end\n\n def mangle!\n # Rip out locale install\n Dir.chdir(\"#{@build_dir}/source/\") do\n Dir.glob('debian/*.install').each do |install_file_path|\n mangle_install_file(install_file_path)\n end\n mangle_symbols\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7218309640884399,
"alphanum_fraction": 0.7218309640884399,
"avg_line_length": 20.846153259277344,
"blob_id": "254ffc2a9541d9672b159ab2463745bb66890338",
"content_id": "1ff781feb060f38374028586709a6ee7b50a6937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 13,
"path": "/jenkins-jobs/mgmt_tooling_test.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# Tooling management job.\nclass MGMTToolingTestJob < JenkinsJob\n attr_reader :downstreams\n\n def initialize(downstreams:)\n name = 'mgmt_tooling_test'\n super(name, \"#{name}.xml.erb\")\n @downstreams = downstreams\n end\nend\n"
},
{
"alpha_fraction": 0.656242311000824,
"alphanum_fraction": 0.6710169911384583,
"avg_line_length": 37.67618942260742,
"blob_id": "3239851a180aa7f7c90566caa4a23cfe7d68fd91",
"content_id": "4d0f4d5637d5a563eb16aaa870d44bc66d1dd17e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4061,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 105,
"path": "/test/test_nci_qml_dep_verify.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/qml_dependency_verifier'\n\nrequire_relative '../nci/lib/lint/qml'\n\nrequire 'mocha/test_unit'\n\nclass NCIQMLDepVerifyTest < TestCase\n def setup\n Object.any_instance.expects(:system).never\n Object.any_instance.expects(:`).never\n\n # Apt::Repository.send(:reset)\n # # Disable automatic update\n # Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n\n # We'll temporary mark packages as !auto, mock this entire thing as we'll\n # not need this for testing.\n Apt::Mark.stubs(:tmpmark).yields\n end\n\n def test_dis\n # Write a fake dsc, we'll later intercept the unpack call.\n File.write('yolo.dsc', '')\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd, verbose: true)\n Apt.stubs(:install).returns(true)\n Apt.stubs(:update).returns(true)\n Apt.stubs(:purge).returns(true)\n Apt::Get.stubs(:autoremove).returns(true)\n DPKG.stubs(:list).returns([])\n Object.any_instance.stubs(:`).with('dpkg-architecture -qDEB_HOST_ARCH').returns('amd64')\n\n fake_repo = mock('repo')\n # FIXME: require missing\n # fake_repo.responds_like_instance_of(Aptly::Repository)\n\n fake_repo\n .stubs(:packages)\n .with(q: 'kcoreaddons (= 5.21.0-0neon) {source}')\n .returns(['Psource kcoreaddons 5.21.0-0neon abc'])\n fake_repo\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kcoreaddons), $SourceVersion (5.21.0-0neon)')\n .returns(['Pamd64 libkf5coreaddons-bin-dev 5.21.0-0neon abc',\n 'Pall libkf5coreaddons-data 5.21.0-0neon abc',\n 'Pamd64 libkf5coreaddons-dev 5.21.0-0neon abc',\n 'Pamd64 libkf5coreaddons5 5.21.0-0neon abc'])\n\n Aptly::Repository.expects(:get).with('trollus_maximus').returns(fake_repo)\n\n fake_apt_repo = mock('apt_repo')\n fake_apt_repo.stubs(:add).returns(true)\n fake_apt_repo.stubs(:remove).returns(true)\n Apt::Repository.expects(:new)\n .with('http://archive.neon.kde.org/trollus')\n .returns(fake_apt_repo)\n .at_least_once\n\n DPKG.expects(:list).with('libkf5coreaddons-data')\n .returns([\"#{Dir.pwd}/main.qml\"])\n # Does a static check only. We'll let it fail.\n QML::Module.any_instance.expects(:system)\n .with('dpkg -s plasma-framework 2>&1 > /dev/null')\n .returns(false)\n\n Lint::QML.any_instance.expects(:system).with('dpkg-source', '-x', 'yolo.dsc', 'packaging').returns(true)\n\n # v = QMLDependencyVerifier.new(QMLDependencyVerifier::AptlyRepository.new(fake_repo, 'unstable'))\n # missing = v.missing_modules\n # assert_not_empty(missing)\n\n Lint::QML.new('trollus', 'maximus').lint\n assert_path_exist('junit.xml')\n end\n\n # Detect when the packaging/* has no qml files inside and skip the entire\n # madness.\n def test_skip\n File.write('yolo.dsc', '')\n Lint::QML.any_instance.expects(:system).with('dpkg-source', '-x', 'yolo.dsc', 'packaging').returns(true)\n Lint::QML.new('trollus', 'maximus').lint\n # Nothing should have happened.\n assert_path_not_exist('junit.xml')\n end\nend\n"
},
{
"alpha_fraction": 0.7004608511924744,
"alphanum_fraction": 0.7079049944877625,
"avg_line_length": 32.188236236572266,
"blob_id": "57473be0439083ffb1972f29fcee32d05060081d",
"content_id": "89ccec5785022763efc2da0d05c86f3a884158be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2821,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 85,
"path": "/nci/builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/setup_repo'\nrequire_relative '../lib/ci/package_builder'\nrequire_relative '../lib/nci'\nrequire_relative '../lib/retry'\nrequire_relative '../lib/pangea_build_type_config'\n\nNCI.setup_repo!\n\nif File.exist?('/ccache')\n require 'mkmf' # for find_exectuable\n\n Retry.retry_it(times: 4) { Apt.install('ccache') || raise }\n system('ccache', '-z') # reset stats, ignore return value\n ENV['PATH'] = \"/usr/lib/ccache:#{ENV.fetch('PATH')}\"\n # Debhelper's cmake.pm doesn't resolve from PATH. Bloody crap.\n ENV['CC'] = find_executable('cc')\n ENV['CXX'] = find_executable('c++')\n ENV['CCACHE_DIR'] = '/ccache'\nend\n\n# Strip optimization relevant flags from dpkg-buildflags. We'll defer this\n# decision to cmake (via our overlay-bin/cmake)\nif PangeaBuildTypeConfig.override?\n warn 'Tooling: stripping various dpkg-buildflags'\n flags = %w[CFLAGS CPPFLAGS CXXFLAGS OBJCFLAGS OBJCXXFLAGS OBJCXXFLAGS FFLAGS\n FCFLAGS LDFLAGS]\n flagsconf = flags.collect do |flag|\n <<-FLAGSEGMENT\nSTRIP #{flag} -g\nSTRIP #{flag} -O2\nSTRIP #{flag} -O0\n FLAGSEGMENT\n end.join(\"\\n\")\n File.write('/etc/dpkg/buildflags.conf', flagsconf)\nend\n\nno_adt = NCI.only_adt.none? { |x| ENV['JOB_NAME']&.include?(x) }\n# Hacky: p-f's tests/testengine is only built and installed when\n# BUILD_TESTING is set, fairly weird but I don't know if it is\n# intentional\n# - kimap installs kimaptest fakeserver/mockjob\n# https://bugs.kde.org/show_bug.cgi?id=419481\nneeds_testing = %w[\n plasma-framework\n kimap\n]\nis_excluded = needs_testing.any? { |x| ENV['JOB_NAME']&.include?(x) }\nif no_adt && !is_excluded\n # marker file to tell our cmake overlay to disable test building\n File.write('adt_disabled', '')\nend\n\nbuilder = CI::PackageBuilder.new\nbuilder.build\n\nif File.exist?('/ccache')\n system('ccache', '-s') # print stats, ignore return value\nend\n\nbuild_url = ENV.fetch('BUILD_URL') { File.read('build_url') }.strip\nif NCI.experimental_skip_qa.any? { |x| build_url.include?(x) }\n puts \"Not linting, #{build_url} is in exclusion list.\"\n exit\nend\n# skip the linting if build dir doesn't exist\n# happens in case of Architecture: all packages on armhf for example\nrequire_relative 'lint_bin' if Dir.exist?('build')\n\n# For the version check we'll need to unmanagle the preference pin as we rely\n# on apt show to give us 'available version' info.\nNCI.maybe_teardown_apt_preference\nNCI.maybe_teardown_experimental_apt_preference\n\n# Check that our versions are good enough.\nunless system('/tooling/nci/lint_versions.rb', '-v')\n warn 'bad versions?'\n warn File.expand_path('../../nci/lint_versions.rb')\n # raise 'Bad version(s)'\nend\n"
},
{
"alpha_fraction": 0.6723684072494507,
"alphanum_fraction": 0.682894766330719,
"avg_line_length": 29.810810089111328,
"blob_id": "162c961e40d7103141caa1932b3afa3f8db282ac",
"content_id": "c103641d4a39b89df6ff4fc4c22504d145454f0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2280,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 74,
"path": "/test/test_jenkins.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/jenkins'\n\nclass AutoConfigJenkinsClientTest < TestCase\n def setup\n @home = ENV['HOME']\n ENV['HOME'] = Dir.pwd\n end\n\n def teardown\n ENV['HOME'] = @home\n end\n\n def standard_config\n {\n server_ip: 'yoloip.com',\n username: 'userino',\n password: 'passy',\n server_port: '443',\n ssl: true\n }\n end\n\n def test_init_defaults\n # init without any config\n stub_request(:get, 'http://kci.pangea.pub/')\n .to_return(status: 200, body: '')\n JenkinsApi::Client.new.get_root\n end\n\n def test_init_config\n # init from default path config\n Dir.mkdir('.config')\n File.write('.config/pangea-jenkins.json', JSON.generate(standard_config))\n\n stub_request(:get, 'https://yoloip.com:443/')\n .with(headers: { 'Authorization' => 'Basic dXNlcmlubzpwYXNzeQ==' })\n .to_return(status: 200, body: '', headers: {})\n\n JenkinsApi::Client.new.get_root\n end\n\n def test_init_config_path\n # init from custom path config\n File.write('fancy-config.json', JSON.generate(standard_config))\n\n stub_request(:get, 'https://yoloip.com/')\n .with(headers: { 'Authorization' => 'Basic dXNlcmlubzpwYXNzeQ==' })\n .to_return(status: 200, body: '', headers: {})\n\n JenkinsApi::Client.new(config_file: 'fancy-config.json').get_root\n end\nend\n"
},
{
"alpha_fraction": 0.6589123606681824,
"alphanum_fraction": 0.6673716306686401,
"avg_line_length": 38.404762268066406,
"blob_id": "051573c33ac9b655249f75648b3951b2ac1c8bc5",
"content_id": "2d0004d9d3d2a6aa5d21ff6e3c8e7ee2b11a2056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3310,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 84,
"path": "/test/test_jenkins_job_nci_project.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/ci/scm'\nrequire_relative '../jenkins-jobs/nci/project'\n\nrequire 'mocha/test_unit'\n\nclass JenkinsJobNCIProjectTest < TestCase\n def setup\n ProjectJob.flavor_dir = File.absolute_path(\"#{__dir__}/../jenkins-jobs/nci\")\n end\n\n def teardown\n # This is a class variable rather than class-instance variable, so we need\n # to reset this lest other tests may want to fail.\n ProjectJob.flavor_dir = nil\n end\n\n def test_nesting\n stub_request(:get, 'https://projects.kde.org/api/v1/projects/frameworks')\n .with(headers: { 'Accept' => '*/*', 'Accept-Encoding' => 'gzip;q=1.0,deflate;q=0.6,identity;q=0.3', 'User-Agent' => 'Ruby' })\n .to_return(status: 200, body: '[\"frameworks/attica\",\"frameworks/baloo\",\"frameworks/bluez-qt\"]', headers: { 'Content-Type' => 'text/json' })\n\n packaging_scm = CI::SCM.new('git', 'git://yolo.com/example', 'master')\n upstream_scm = CI::SCM.new('git', 'git://yolo.com/example', 'master')\n\n project = mock('project')\n project.stubs(:name).returns('foobar')\n project.stubs(:component).returns('barfoo')\n project.stubs(:dependees).returns([])\n project.stubs(:upstream_scm).returns(upstream_scm)\n project.stubs(:packaging_scm).returns(packaging_scm)\n project.stubs(:series_branches).returns([])\n project.stubs(:debian?).returns(true)\n project.stubs(:kdecomponent).returns('projekt')\n\n jobs = ProjectJob.job(project, distribution: 'distrooo',\n architectures: %w[i386 armel],\n type: 'unstable')\n project_job = jobs.find { |x| x.is_a?(ProjectJob) }\n assert_not_nil(project_job)\n jobs = project_job.instance_variable_get(:@nested_jobs)\n qml_and_cmake_found = false\n binaries_found = false\n jobs.each do |job|\n next unless job.is_a?(Array)\n\n ary = job\n if %w[bin_i386 bin_armel].all? { |a| ary.any? { |x| x.include?(a) } }\n binaries_found = true\n next\n end\n if %w[lintqml lintcmake].all? { |a| ary.any? { |x| x.include?(a) } }\n qml_and_cmake_found = true\n next\n end\n end\n assert(qml_and_cmake_found, <<-EOF)\nCould not find a nested lintqml and lintcmake in the list of jobs.\n EOF\n assert(binaries_found, <<-EOF)\nCould not find a nested i386 and armel binary jobs in the list of jobs.\n EOF\n end\nend\n"
},
{
"alpha_fraction": 0.667248010635376,
"alphanum_fraction": 0.6742244958877563,
"avg_line_length": 33.900001525878906,
"blob_id": "09d12a3cd32e90dce6097f15e29c45a5300be1fc",
"content_id": "457878cea95a6d0ee054b435254e65104d671134",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 8027,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 230,
"path": "/nci/version_list.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2019-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'did_you_mean/spell_checker'\nrequire 'erb'\nrequire 'jenkins_junit_builder'\nrequire 'net/sftp'\n\nrequire_relative '../lib/aptly-ext/filter'\nrequire_relative '../lib/aptly-ext/package'\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative 'version_list/violations'\n\nS_IROTH = 0o4 # posix bitmask for world readable\n\nDEBIAN_TO_KDE_NAMES = {\n 'libkf5incidenceeditor' => 'incidenceeditor',\n 'libkf5pimcommon' => 'pimcommon',\n 'libkf5mailcommon' => 'mailcommon',\n 'libkf5mailimporter' => 'mailimporter',\n 'libkf5calendarsupport' => 'calendarsupport',\n 'libkf5kmahjongg' => 'libkmahjongg',\n 'libkf5grantleetheme' => 'grantleetheme',\n 'libkf5libkleo' => 'libkleo',\n 'libkf5libkdepim' => 'libkdepim',\n 'libkf5eventviews' => 'eventviews',\n 'libkf5sane' => 'libksane',\n 'libkf5kexiv2' => 'libkexiv2',\n 'kf5-kdepim-apps-libs' => 'kdepim-apps-libs',\n 'libkf5ksieve' => 'libksieve',\n 'libkf5gravatar' => 'libgravatar',\n 'kf5-messagelib' => 'messagelib',\n 'libkf5kgeomap' => 'libkgeomap',\n 'libkf5kdcraw' => 'libkdcraw',\n 'kde-spectacle' => 'spectacle',\n 'libkf5kipi' => 'libkipi',\n 'kdeconnect' => 'kdeconnect-kde',\n\n # frameworks\n 'kactivities-kf5' => 'kactivities',\n 'kdnssd-kf5' => 'kdnssd',\n 'kwallet-kf5' => 'kwallet',\n 'baloo-kf5' => 'baloo',\n 'ksyntax-highlighting' => 'syntax-highlighting',\n 'attica-kf5' => 'attica',\n 'prison-kf5' => 'prison',\n 'kfilemetadata-kf5' => 'kfilemetadata',\n\n # plasma\n 'plasma-discover' => 'discover',\n\n # KDE Gear\n 'kdevelop-php' => 'kdev-php',\n\n # the stupidest name of all them stupid divergent names. like what does this\n # even accomplish...\n 'ktp-kded-integration-module' => 'ktp-kded-module'\n}\n\n# Sources that we do not package for some reason. Should be documented why!\nBLACKLIST = [\n # Not actually useful for anything in production. It's a repo with tests.\n 'plasma-tests',\n 'kfloppy', # dead project removed next release\n 'kdev-python',\n 'kalendar' # is now merkuno and reports as conflicting with kcalendarcore\n]\n\n# Maps \"key\" packages to a release scope. This way we can identify what version\n# the given scope has in our repo.\nKEY_MAPS = {\n 'plasma-workspace' => 'Plasma by KDE',\n 'kconfig' => 'KDE Frameworks',\n 'okular' => 'KDE Gear'\n}\n\nkey_file = ENV.fetch('SSH_KEY_FILE', nil)\nssh_args = key_file ? [{ keys: [key_file] }] : []\n\nproduct_and_versions = []\n\n# Grab list of all released tarballs\n%w[release-service frameworks plasma].each do |scope|\n Net::SFTP.start('rsync.kde.org', 'ftpneon', *ssh_args) do |sftp|\n # delete old directories\n dir_path = \"stable/#{scope}/\"\n version_dirs = sftp.dir.glob(dir_path, '*')\n version_dirs = version_dirs.select(&:directory?)\n version_dirs = version_dirs.sort_by { |x| Gem::Version.new(x.name) }\n # lowest is first, pick the latest two. one of them must be world readable!\n latest = version_dirs[-2..-1].reverse.find do |dir|\n world_readable = ((dir.attributes.permissions & S_IROTH) == S_IROTH)\n unless world_readable\n warn \"Version #{dir.name} of #{scope} not world readable!\" \\\n \" This will mean that this scope's version isn't checked!\"\n next nil\n end\n dir\n end\n\n unless latest\n raise 'Neither the latest nor the previous version are world readable!' \\\n ' Something is astray! This means there are two pending releases???'\n end\n\n latest_path = \"#{dir_path}/#{latest.name}/\"\n tars = sftp.dir.glob(latest_path, '**/**')\n\n tars = tars.select { |x| x.name.include?('.tar.') }\n sig_ends = %w[.sig .asc]\n tars = tars.reject { |x| sig_ends.any? { |s| x.name.end_with?(s) } }\n\n product_and_versions += tars.collect do |tar|\n name = File.basename(tar.name) # strip possible subdirs\n match = name.match(/(?<product>[-\\w]+)-(?<version>[\\d\\.]+)\\.tar.+/)\n raise \"Failed to parse #{name}\" unless match\n\n [match[:product], match[:version]]\n end\n end\nend\n\nscoped_versions = {}\npackaged_versions = {}\nviolations = []\n\nAptly::Ext::Remote.neon do\n pub = Aptly::PublishedRepository.list.find do |r|\n r.Prefix == ENV.fetch('TYPE') && r.Distribution == ENV.fetch('DIST')\n end\n pub.Sources.each do |source|\n packages = source.packages(q: '$Architecture (source)')\n packages = packages.collect { |x| Aptly::Ext::Package::Key.from_string(x) }\n by_name = packages.group_by(&:name)\n\n # map debian names to kde names so we can easily compare things\n by_name = by_name.collect { |k, v| [DEBIAN_TO_KDE_NAMES.fetch(k, k), v] }.to_h\n\n # Hash the packages by their versions, take the versions and sort them\n # to get the latest available version of the specific package at hand.\n by_name = by_name.map do |name, pkgs|\n by_version = Aptly::Ext::LatestVersionFilter.debian_versions(pkgs)\n versions = by_version.keys\n [name, versions.max.upstream]\n end.to_h\n # by_name is now a hash of package names to upstream versions\n\n # Extract our scope markers into the output array with a fancy name.\n # This kind of collapses all plasma packages into one Plasma entry for\n # example.\n KEY_MAPS.each do |key_package, pretty_name|\n version = by_name[key_package]\n scoped_versions[pretty_name] = version\n end\n\n # The same entity can appear with different versions. Notably that happens\n # when a hotfix is put in the same directory. For exampke kio 5.74.0 had\n # a bug so 5.74.1 is put in the same dir (even though frameworks usually\n # have no .1 releases).\n # More generally put that means if the same product appears more than once\n # we need to de-duplicate them as hash keys are always unique so the\n # selected version is undefined in that scenario. Given the fact that this\n # can only happen when a product directory contains more than one tarball\n # with the same name but different version we'll adjust the actual\n # expectation to be the strictly greatest version.\n product_and_versions_h = {}\n product_and_versions.map do |k, v|\n product_and_versions_h[k] ||= v\n next if Gem::Version.new(product_and_versions_h[k]) >= Gem::Version.new(v)\n\n product_and_versions_h[k] = v # we found a greater version\n end\n\n checker = DidYouMean::SpellChecker.new(dictionary: by_name.keys)\n product_and_versions_h.each do |remote_name, remote_version|\n next if BLACKLIST.include?(remote_name) # we don't package some stuff\n\n in_repo = by_name.include?(remote_name)\n unless in_repo\n corrections = checker.correct(remote_name)\n violations << MissingPackageViolation.new(remote_name, corrections)\n next\n end\n\n # Drop the entry from the packages hash. Since it is part of a scoped\n # release such as plasma it doesn't get listed separately in our\n # output hash.\n repo_version = by_name.delete(remote_name)\n if repo_version != remote_version\n violations <<\n WrongVersionViolation.new(remote_name, remote_version, repo_version)\n next\n end\n end\n\n packaged_versions = packaged_versions.merge(by_name)\n end\nend\n\ntemplate = ERB.new(File.read(\"#{__dir__}/version_list/version_list.html.erb\"))\nhtml = template.result(OpenStruct.new(\n scoped_versions: scoped_versions,\n packaged_versions: packaged_versions\n).instance_eval { binding })\nFile.write('versions.html', html)\n\nif violations.empty?\n puts 'All OK!'\n exit 0\nend\nputs violations.join(\"\\n\")\n\nsuite = JenkinsJunitBuilder::Suite.new\nsuite.name = 'version_list'\nsuite.package = 'version_list'\nviolations.each do |violation|\n c = JenkinsJunitBuilder::Case.new\n c.name = violation.name\n c.time = 0\n c.classname = violation.class.to_s\n c.result = JenkinsJunitBuilder::Case::RESULT_FAILURE\n c.system_out.message = violation.to_s\n suite.add_case(c)\nend\nFile.write('report.xml', suite.build_report)\n\nexit 1 # had violations\n"
},
{
"alpha_fraction": 0.6377444863319397,
"alphanum_fraction": 0.6429898142814636,
"avg_line_length": 36.97095489501953,
"blob_id": "3ca0dc56a1526352b864b4c55f583ac1ae786961",
"content_id": "4f8cb1e35a818c0ca6d2c24075ee7adc1d613b1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9151,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 241,
"path": "/nci/imager_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'net/sftp'\nrequire 'net/ssh'\nrequire 'tty-command'\n\nrequire_relative '../lib/nci'\nrequire_relative 'lib/imager_push_paths'\n\nARCH = ENV.fetch('ARCH')\nIMAGENAME = ENV.fetch('IMAGENAME')\n\n# copy to rsync.kde.org using same directory without -proposed for now, later we want\n# this to only be published if passing some QA test\nDATE = File.read('result/date_stamp').strip\nISONAME = \"#{IMAGENAME}-#{TYPE}\"\nREMOTE_PUB_DIR = \"#{REMOTE_DIR}/#{DATE}\"\n\n# NB: we use gpg without agent here. Jenkins credential paths are fairly long\n# and trigger https://bugs.debian.org/cgi-bin/bugreport.cgi?bug=847206\n# we can use gpg2 in bionic/focal iff we call `gpgconf --create-socketdir` to create\n# a dedicated socket directory.\nunless TTY::Command.new.run('gpg', '--no-use-agent', '--armor', '--detach-sign',\n '-o',\n \"result/#{ISONAME}-#{DATE}.iso.sig\",\n \"result/#{ISONAME}-#{DATE}.iso\")\n raise 'Failed to sign'\nend\n\n# Temporary early previews go to a different server away from prying eyes.\n# Despire the username this is for focal and future ones too.\nif DIST == NCI.future_series && NCI.future_is_early\n TTY::Command.new.run('ls', 'result/')\n TTY::Command.new.run('ssh',\n '-i', ENV.fetch('SSH_KEY_FILE'),\n '-o', 'StrictHostKeyChecking=no',\n '[email protected]',\n 'rm', '-rfv', \"~/bionic/*#{TYPE}*\")\n TTY::Command.new.run('scp',\n '-i', ENV.fetch('SSH_KEY_FILE'),\n '-o', 'StrictHostKeyChecking=no',\n *Dir.glob('result/*.iso'),\n *Dir.glob('result/*.sig'),\n *Dir.glob('result/*.zsync'),\n '[email protected]:~/bionic/')\n TTY::Command.new.run('ssh',\n '-i', ENV.fetch('SSH_KEY_FILE'),\n '-o', 'StrictHostKeyChecking=no',\n '[email protected]',\n 'ln', '-s',\n \"#{ISONAME}-#{DATE}.iso.sig\",\n \"~/bionic/#{ISONAME}-current.iso.sig\")\n return\nend\n\n# Add readme about zsync being defective.\n# files.kde.org defaults to HTTPS (even redirects HTTP there), but zsync\n# has no support and fails with a really stupid error. As fixing this\n# server-side is something Ben doesn't want to do we'll simply tell the user\n# to use a sane implementation or manually get a HTTP mirror url.\nDir.glob('result/*.zsync') do |file|\n File.write(\"#{file}.README\", <<-README_CONTENT)\nzsync does not support HTTPs, since we prefer HTTPs rather than HTTP, this is a\nproblem.\n\nWe recommend that you download the file from a mirror over HTTP rather than\nHTTPs and additionally download the .gpg signature to verify that the file you\ndownloaded is in fact the correct ISO signed by the key listed on\nhttps://neon.kde.org/download\nTo find a suitable mirror have a look at the mirror list. You can access\nthe mirror list by appending .mirrorlist to the zsync URL.\ne.g. https://files.kde.org/neon/images/neon-useredition/current/neon-useredition-current.iso.zsync.mirrorlist\n\nNote that downloading from http://files.kde.org will always switch to https,\nyou need an actual mirror URL to use zsync over http.\n\nIf you absolutely want to zsync over HTTPs you have to use a zsync fork which\nsupports HTTPs (e.g. [1]). Do note that zsync-curl in particular will offer\nincredibly bad performance due to lack of threading and libcurl's IO-overhead.\nUnless you want to save data on a metered connection you will, most of the time,\nsee much shorter downloads when downloading an entirely new ISO instead of using\nzsync-curl (even on fairly slow connections and even if the binary delta is\nsmall, in fact small deltas are worse for performance with zsync-curl).\n\n[1] https://github.com/probonopd/zsync-curl\nREADME_CONTENT\nend\n\n# Monkey prepend a different upload method which uses sftp from openssh-client\n# instead of net-sftp. net-sftp suffers from severe performance problems\n# in part (probably) because of the lack of threading, more importantly because\n# it implements CTR in ruby which is hella inefficient (half the time of writing\n# is being spent in CTR alone)\nmodule SFTPSessionOverlay\n def __cmd\n @__cmd ||= TTY::Command.new\n end\n\n def cli_uploads\n @use_cli_sftp ||= false\n end\n\n def cli_uploads=(enable)\n @use_cli_sftp = enable\n end\n\n def __cli_upload(from, to)\n remote = format('%<user>s@%<host>s',\n user: session.options[:user],\n host: session.host)\n key_file = ENV.fetch('SSH_KEY_FILE', nil)\n identity = key_file ? ['-i', key_file] : []\n __cmd.run('sftp', *identity, '-b', '-', remote,\n stdin: <<~STDIN)\n put #{from} #{to}\n quit\n STDIN\n end\n\n def upload!(from, to, **kwords)\n return super unless @use_cli_sftp\n raise 'CLI upload of dirs not implemented' if File.directory?(from)\n\n # cli wants dirs for remote location\n __cli_upload(from, File.dirname(to))\n end\nend\nclass Net::SFTP::Session\n prepend SFTPSessionOverlay\nend\n\nkey_file = ENV.fetch('SSH_KEY_FILE', nil)\nssh_args = key_file ? [{ keys: [key_file] }] : []\n\n# Publish ISO and associated content.\nNet::SFTP.start('rsync.kde.org', 'neon', *ssh_args) do |sftp|\n sftp.cli_uploads = true\n begin\n # Make sure the parent dir exists\n sftp.mkdir!(REMOTE_DIR)\n rescue Net::SFTP::StatusException # dir already exists\n puts \"#{REMOTE_DIR} already exists; not creating\"\n end\n sftp.mkdir!(REMOTE_PUB_DIR)\n types = %w[.iso .iso.sig manifest zsync zsync.README sha256sum]\n types.each do |type|\n Dir.glob(\"result/*#{type}\").each do |file|\n # Skip over current symlinks, we'll recreate them on the remote.\n # They'd only trip up sftp uploads as symlinks being preserved is a bit\n # hit and miss.\n next if File.symlink?(file)\n\n next if File.basename(file).include?('current') unless File.basename(file).include?('zsync')\n\n name = File.basename(file)\n current_name = name.gsub(/\\d+-\\d+/, 'current')\n sftp.cli_uploads = File.new(file).lstat.size > 4 * 1024 * 1024\n warn \"Uploading #{file} (via cli: #{sftp.cli_uploads})... \"\n sftp.upload!(file, \"#{REMOTE_PUB_DIR}/#{name}\")\n sftp.symlink!(\"#{name}\", \"#{REMOTE_PUB_DIR}/#{current_name}\") unless File.basename(file).include?('current')\n end\n end\n sftp.cli_uploads = false\n sftp.upload!('result/.message', \"#{REMOTE_PUB_DIR}/.message\")\n sftp.remove!(\"#{REMOTE_DIR}/current\")\n sftp.symlink!(\"#{DATE}\", \"#{REMOTE_DIR}/current\")\n\n sftp.dir.glob(REMOTE_DIR, '*') do |entry|\n next unless entry.directory? # current is a symlink\n\n path = \"#{REMOTE_DIR}/#{entry.name}\"\n next if path.include?(REMOTE_PUB_DIR)\n\n STDERR.puts \"rm #{path}\"\n sftp.dir.foreach(path) do |e|\n next if %w[. ..].include?(e.name)\n\n sftp.remove!(\"#{path}/#{e.name}\")\n end\n sftp.rmdir!(path)\n end\nend\n\nNet::SSH.start('files.kde.mirror.pangea.pub', 'neon-image-sync',\n *ssh_args) do |ssh|\n status = {}\n ssh.exec!('./sync', status: status) do |_channel, stream, data|\n (stream == :stderr ? STDERR : STDOUT).puts(data)\n end\n raise 'Failed sync' unless status.fetch(:exit_code, 1).zero?\nend\n\n=begin TODO FIXME\nwarn \"Uploading source..\"\n# Publish ISO sources.\nNet::SFTP.start('embra.edinburghlinux.co.uk', 'neon', *ssh_args) do |sftp|\n path = if DIST == NCI.future_series\n \"files.neon.kde.org.uk/#{DIST}\"\n else\n 'files.neon.kde.org.uk'\n end\n types = %w[source.tar.xz source.tar]\n types.each do |type|\n Dir.glob(\"result/*#{type}\").each do |file|\n # Remove old ones\n warn \"src rm #{path}/#{ISONAME}*#{type}\"\n sftp.dir.glob(path, \"#{ISONAME}*#{type}\") do |e|\n warn \"glob src rm #{path}/#{e.name}\"\n sftp.remove!(\"#{path}/#{e.name}\")\n end\n # upload new one\n name = File.basename(file)\n\n sftp.cli_uploads = File.new(file).lstat.size > 4 * 1024 * 1024\n warn \"Uploading #{file} (via cli: #{sftp.cli_uploads})... \"\n sftp.upload!(file, \"#{path}/#{name}\")\n end\n end\nend\n=end\n"
},
{
"alpha_fraction": 0.7254098653793335,
"alphanum_fraction": 0.7342896461486816,
"avg_line_length": 33.85714340209961,
"blob_id": "5facdf42c13c692bed41a02cc3105a941d7878a4",
"content_id": "f1f2ad18deb0a53587641a6b3ac53983d0f3faa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 42,
"path": "/jenkins-jobs/nci/mgmt_snapshot.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../job'\n\n# Base class for snapshotting. Don't use directly.\nclass MGMTSnapshotBase < JenkinsJob\n attr_reader :target\n attr_reader :origin\n attr_reader :dist\n\n def initialize(origin:, target:, dist:)\n super(\"mgmt_snapshot_#{dist}_#{target}\", 'mgmt_snapshot.xml.erb')\n @origin = origin\n @target = target\n @dist = dist\n end\nend\n\n# snapshots release repos\nclass MGMTSnapshotUser < MGMTSnapshotBase\n def initialize(dist:, origin:, target:)\n super(dist: dist, origin: origin, target: target)\n end\nend\n"
},
{
"alpha_fraction": 0.6641483306884766,
"alphanum_fraction": 0.6703296899795532,
"avg_line_length": 21.399999618530273,
"blob_id": "f13d53945a95b8f7d2c65fa8937148f2ea38dddb",
"content_id": "7981866b830b16464da4a70dba7dbcca1f2061fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1462,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 65,
"path": "/jenkins_unqueue.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# coding: utf-8\n# frozen_string_literal: true\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/thread_pool'\n\nparser = OptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: jenkins_unqueue.rb 'regex'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nunqueue.\n\nOnly jobs that queued can be removed from the queue (obviously)\n e.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*'\n • All unstable builds:\n '^.*_unstable_.*'\n • All jobs:\n '.*'\n\n EOS\nend\nparser.parse!\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = 'unqueue'\n l.level = Logger::INFO\nend\n\nabort parser.help if ARGV.empty?\npattern = Regexp.new(ARGV[0])\[email protected] pattern\n\njob_name_queue = Queue.new\njob_names = Jenkins.client.queue.list\njob_names.each do |name|\n next unless pattern.match(name)\n\n job_name_queue << name\nend\n\nBlockingThreadPool.run do\n until job_name_queue.empty?\n name = job_name_queue.pop(true)\n Retry.retry_it(times: 5) do\n id = Jenkins.client.queue.get_id(name)\n @log.info \"unqueueing #{name} (#{id})\"\n\n begin\n Jenkins.client.api_post_request('/queue/cancelItem', id: id)\n rescue => e\n # jenkins returns 204 and the api gem doesn't know what to do with that\n raise e unless e.message == 'Error code 204'\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6963434219360352,
"alphanum_fraction": 0.6963434219360352,
"avg_line_length": 26.34782600402832,
"blob_id": "24d825e39a429c63c6e95b2a34e8fda67bcf7288",
"content_id": "dff8a9467ba7945655cd33301a86c0e533a9722b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 629,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 23,
"path": "/test/test_queue.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/queue'\n\n# Test queue\nclass QueueTest < TestCase\n # We are implying that construction from Array works after we have tested\n # that. Otherwise we'd have to construct the queues manually each time.\n self.test_order = :defined\n\n def test_new_from_array\n array = %w[a b c d e f]\n queue = Queue.new(array)\n assert_equal(array.size, queue.size)\n assert_equal(array.shift, queue.pop) until queue.empty?\n end\n\n def test_to_array\n array = %w[a b c d e f]\n queue = Queue.new(array)\n assert_equal(array, queue.to_a)\n end\nend\n"
},
{
"alpha_fraction": 0.6080114245414734,
"alphanum_fraction": 0.6123033165931702,
"avg_line_length": 29.39130401611328,
"blob_id": "e71ac62f0395dcec8849202e2115a6cc5a35c185",
"content_id": "8f6ae338b80fb2be78278cc667d57aa84282b623",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 23,
"path": "/lib/deprecate.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule Deprecate\n include Gem::Deprecate\n\n def self.extended(othermod)\n othermod.send :include, InstanceMethods\n super(othermod)\n end\n\n module InstanceMethods\n def variable_deprecation(variable, repl = :none)\n klass = self.is_a? Module\n target = klass ? \"#{self}.\" : \"#{self.class}#\"\n meth = caller_locations(1, 1)[0].label\n msg = [\n \"NOTE: Variable '#{variable}' in #{target}#{meth} is deprecated\",\n repl == :none ? ' with no replacement' : \"; use '#{repl}' instead\",\n \"\\n'#{variable}' used around #{Gem.location_of_caller.join(\":\")}\"\n ]\n warn \"#{msg.join}.\" unless Gem::Deprecate.skip\n end\n end\nend\n"
},
{
"alpha_fraction": 0.576797366142273,
"alphanum_fraction": 0.5837418437004089,
"avg_line_length": 30.58709716796875,
"blob_id": "4449f7be73d25a1a32e5d2bf5cbf0b95c5fbbb2f",
"content_id": "94b19fd9c985783f6e6dbffca1a89dd8fc066ce8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4896,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 155,
"path": "/lib/aptly-ext/remote.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2017 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'net/ssh/gateway'\nrequire 'tmpdir'\n\nrequire_relative '../net/ssh/socket_gateway.rb'\n\nmodule Aptly\n # Our extensions to the core aptly api. Stuff in Ext is either not suitable\n # for the standard gem or experimental.\n module Ext\n # SSH gateway connectors\n module Remote\n def self.connect(uri, &block)\n configure_aptly!\n constants.each do |const|\n klass = const_get(const)\n next unless klass.connects?(uri)\n\n klass.connect(uri, &block)\n end\n end\n\n def self.neon(&block)\n connect(URI.parse(<<-URI.strip), &block)\nssh://[email protected]/srv/neon-services/aptly.sock\nURI\n end\n\n def self.neon_read_only(&block)\n connect(URI::HTTPS.build(host: 'archive-api.neon.kde.org'), &block)\n end\n\n def self.configure_aptly!\n # Standard config, applying to everything unless overridden.\n Aptly.configure do |config|\n # Do not time out if aptly is very busy. This defaults to 1m which\n # may well be too short when the aptly server is busy and/or many\n # pubishes are going on.\n # Since Aptly 1.2 this is even worse because now lots of\n # operations use a write lock. Meaning parallel use just about 100 %\n # of the time results in the read being just as slow as any write\n # operation.\n # This is not going to change in any form or fashion until/if\n # https://github.com/smira/aptly/pull/459 lands.\n config.timeout = 16 * 60\n config.write_timeout = 15 * 60\n end\n end\n\n def self.ssh_options\n opts = {}\n if (key = ENV['SSH_KEY_FILE'])\n opts[:keys] = [key, File.expand_path('~/.ssh/id_rsa')]\n end\n opts\n end\n\n # Connects directly through HTTP\n module HTTP\n module_function\n\n def connects?(uri)\n uri.scheme == 'http' || uri.scheme == 'https'\n end\n\n def connect(uri, &_block)\n Aptly.configure do |config|\n config.uri = uri\n end\n yield\n end\n end\n\n # Gateway connects through a TCP socket/port to a remote aptly.\n module TCP\n module_function\n\n def connects?(uri)\n uri.scheme == 'ssh' && uri.path.empty?\n end\n\n def connect(uri, &_block)\n open_gateway(uri) do |port|\n Aptly.configure do |config|\n config.uri = URI::HTTP.build(host: 'localhost', port: port,\n **Remote.ssh_options)\n end\n yield\n end\n end\n\n # @yield [String] port on localhost\n def open_gateway(uri, &_block)\n gateway = Net::SSH::Gateway.new(uri.host, uri.user)\n yield gateway.open('localhost', uri.port.to_s)\n ensure\n gateway&.shutdown!\n end\n end\n\n # Gateway connects through a unix domain socket to a remote aptly.\n module Socket\n module_function\n\n def connects?(uri)\n uri.scheme == 'ssh' && !uri.path.empty?\n end\n\n def connect(uri, &_block)\n open_gateway(uri) do |local_socket|\n Aptly.configure do |config|\n config.uri = URI::Generic.build(scheme: 'unix',\n path: local_socket)\n end\n yield\n end\n end\n\n # @yield [String] port on localhost\n def open_gateway(uri, &_block)\n Dir.mktmpdir('aptly-socket') do |tmpdir|\n begin\n gateway = Net::SSH::SocketGateway.new(uri.host, uri.user,\n **Remote.ssh_options)\n yield gateway.open(\"#{tmpdir}/aptly.sock\", uri.path)\n ensure\n gateway&.shutdown!\n end\n end\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6795154213905334,
"alphanum_fraction": 0.6795154213905334,
"avg_line_length": 23.54054069519043,
"blob_id": "648c189bf7441925e1e9a5062e4bb600e40bbb1d",
"content_id": "f0b7eb5ba8c46523d75daef209368105aa4b0a75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 908,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 37,
"path": "/jenkins-jobs/publisher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'job'\n\n# publisher\nclass PublisherJob < JenkinsJob\n attr_reader :type\n attr_reader :distribution\n attr_reader :artifact_origin\n attr_reader :dependees\n attr_reader :downstream_triggers\n attr_reader :basename\n attr_reader :repo\n attr_reader :component\n attr_reader :architectures\n\n def initialize(basename, type:, distribution:, dependees:,\n component:, upload_map:, architectures:)\n super(\"#{basename}_pub\", 'publisher.xml.erb')\n @type = type\n @distribution = distribution\n @artifact_origin = \"#{basename}_bin\"\n @dependees = dependees\n @downstream_triggers = []\n @basename = basename\n @component = component\n @architectures = architectures\n\n if upload_map\n @repo = upload_map[component]\n @repo ||= upload_map['default']\n end\n end\n\n def append(job)\n @downstream_triggers << job\n end\nend\n"
},
{
"alpha_fraction": 0.6217146515846252,
"alphanum_fraction": 0.6276595592498779,
"avg_line_length": 25.413223266601562,
"blob_id": "5c427d202f052f60af5846cd089a231ba03a7c39",
"content_id": "cf42f665c21ff825a6b5a559077f5814ae7a6983",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3196,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 121,
"path": "/lib/jenkins/job.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/jenkins'\n\nmodule Jenkins\n # A Jenkins Job.\n # Gives jobs a class so one can use it like a bloody OOP construct rather than\n # I don't even know what the default api client thing does...\n class APIJob\n attr_reader :name\n\n alias to_s name\n alias to_str to_s\n\n def initialize(name, client = JenkinsApi::Client.new)\n @client = client\n @name = name\n if @name.is_a?(Hash)\n @name = @name.fetch('name') { raise 'name is a Hash but has no name key' }\n end\n @name = @name.gsub('/', '/job/')\n p @name\n end\n\n def delete!\n @client.job.delete(@name)\n end\n\n def wipe!\n @client.job.wipe_out_workspace(@name)\n end\n\n def enable!\n @client.job.enable(@name)\n end\n\n def disable!\n @client.job.disable(@name)\n end\n\n def remove_downstream_projects\n @client.job.remove_downstream_projects(@name)\n end\n\n def method_missing(name, *args)\n args = [@name] + args\n\n # A set method.\n if name.to_s.end_with?('=')\n return @client.job.send(\"set_#{name}\".to_sym, *args)\n end\n\n # Likely a get_method, could still be an actual api method though.\n method_missing_internal(name, *args)\n end\n\n def respond_to?(name, include_private = false)\n if name.to_s.end_with?('=')\n return @client.job.respond_to?(\"set_#{name}\".to_sym, include_private)\n end\n\n @client.job.respond_to?(name, include_private) ||\n @client.job.respond_to?(\"get_#{name}\".to_sym, include_private) ||\n super\n end\n\n def exists?\n # jenkins api client is so daft it lists all jobs and then filters\n # that list. To check existance it's literally enough to hit the job\n # endpoint and see if it comes back 404.\n # With the 11k jobs we have in neon list_all vs. list_details is a\n # 1s difference!\n list_details\n true\n rescue JenkinsApi::Exceptions::NotFound\n false\n end\n\n private\n\n # Rescue helper instead of a beginrescue block.\n def method_missing_internal(name, *args)\n @client.job.send(name, *args)\n rescue NoMethodError => e\n # Try a get prefix.\n begin\n @client.job.send(\"get_#{name}\".to_sym, *args)\n rescue NoMethodError\n raise e # Still no luck, raise original error.\n end\n end\n end\n\n # Overlay bypassing the API where possible to talk to the file system directly\n # and speed things up since we save the entire roundtrip through https + apache\n # + jenkins.\n # Obviously only works when run on the master server.\n class LocalJobAdaptor < APIJob\n def get_config\n File.read(\"#{job_dir}/config.xml\")\n end\n\n def build_number\n File.read(\"#{job_dir}/nextBuildNumber\").strip.to_i\n rescue Errno::ENOENT\n 0\n end\n\n private\n\n def job_dir\n @job_dir ||= \"#{ENV.fetch('JENKINS_HOME', Dir.home)}/jobs/#{name}\"\n end\n end\n\n # Automatically pick the right Job class\n Job = ENV['PANGEA_LOCAL_JENKINS'] ? LocalJobAdaptor : APIJob\nend\n"
},
{
"alpha_fraction": 0.6515876650810242,
"alphanum_fraction": 0.6555023789405823,
"avg_line_length": 30.93055534362793,
"blob_id": "7fe5f5ca70bf43cfaaa030880bb0238725757c98",
"content_id": "d8190ba5cbdb39c2cc83dde55b3c1dc1b206d106",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2299,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 72,
"path": "/nci/debian-merge/tagvalidator.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'yaml'\n\nrequire_relative '../../lib/ci/pattern'\n\nmodule NCI\n module DebianMerge\n # Helper to validate tag expectations and possibly override.\n class TagValidator\n DEFAULT_PATH = \"#{__dir__}/data/tag-overrides.yaml\"\n\n class << self\n def default_path\n @default_path ||= DEFAULT_PATH\n end\n attr_writer :default_path\n\n def reset!\n @default_path = nil\n end\n end\n\n def initialize(path = self.class.default_path)\n @default_path = path\n end\n\n def valid?(repo_url, expected_tag_base, latest_tag)\n puts \"#{repo_url}, #{expected_tag_base}, #{latest_tag}\"\n return true if latest_tag.start_with?(expected_tag_base)\n\n warn 'Tag expectations not matching, checking overrides.'\n patterns = CI::FNMatchPattern.filter(repo_url, overrides)\n CI::FNMatchPattern.sort_hash(patterns).any? do |_pattern, rules|\n rules.any? do |base, whitelist|\n p base, whitelist\n next false unless base == expected_tag_base\n\n whitelist.any? { |x| latest_tag.start_with?(x) }\n end\n end\n end\n\n private\n\n def overrides\n @overrides ||= begin\n hash = YAML.load(File.read(@default_path))\n CI::FNMatchPattern.convert_hash(hash, recurse: false)\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6526576280593872,
"alphanum_fraction": 0.6600741744041443,
"avg_line_length": 27.89285659790039,
"blob_id": "a7c7330092eecfbf6d1de44e05f4ee104ff2537a",
"content_id": "a08f02e21ce72aff9a575077d40f5b9b42a4cf69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1618,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 56,
"path": "/nci/debian-merge/data.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'json'\n\nmodule NCI\n module DebianMerge\n # Merge data wrapper\n class Data\n class << self\n def from_file\n new(JSON.parse(File.read('data.json')))\n end\n\n def file_exist?\n File.exist?('data.json')\n end\n\n def write(data)\n File.write('data.json', JSON.generate(data))\n end\n end\n\n def initialize(data)\n @data = data\n end\n\n # @return String e.g. 'debian/5.25' as the tag base to look for\n def tag_base\n @data.fetch('tag_base')\n end\n\n # @return Array<String> array of repo urls to work with.\n def repos\n @data.fetch('repos')\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6040647625923157,
"alphanum_fraction": 0.6153556704521179,
"avg_line_length": 29.895349502563477,
"blob_id": "fc0d76442ba04625bf64826ac8ea91da740cd9fb",
"content_id": "cd2ce3510e3079957f2dacc39c682a2d7ff3a431",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 10628,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 344,
"path": "/test/test_ci_package_builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-FileCopyrightText: 2015 Rohan Garg <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/ci/package_builder'\nrequire_relative '../lib/debian/changes'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# Test ci/build_binary\nmodule CI\n class BuildBinaryTest < TestCase\n required_binaries %w[dpkg-buildpackage dpkg-source dpkg dh]\n\n def setup\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n Apt::Repository.stubs(:`).returns('')\n\n # Turn a bunch of debhelper sub process calls noop to improve speed.\n ENV['PATH'] = \"#{__dir__}/dud-bin:#{ENV['PATH']}\"\n end\n\n def refute_bin_only(builder)\n refute(builder.instance_variable_get(:@bin_only))\n assert_path_not_exist('reports/build_binary_dependency_resolver.xml')\n end\n\n def assert_bin_only(builder)\n assert(builder.instance_variable_get(:@bin_only))\n assert_path_exist('reports/build_binary_dependency_resolver.xml')\n end\n\n def test_build_package\n FileUtils.cp_r(Dir.glob(\"#{data}/*\"), Dir.pwd)\n\n builder = PackageBuilder.new\n builder.build_package\n\n refute_equal([], Dir.glob('build/*'))\n refute_equal([], Dir.glob('*.deb'))\n assert_path_exist('hello_2.10_amd64.changes')\n changes = Debian::Changes.new('hello_2.10_amd64.changes')\n changes.parse!\n refute_equal([], changes.fields['files'].map(&:name))\n\n refute_bin_only(builder)\n end\n\n # Cross compile for i386\n def test_build_package_cross\n FileUtils.cp_r(Dir.glob(\"#{data}/*\"), Dir.pwd)\n\n arch = 'i386'\n ENV['PANGEA_CROSS'] = arch\n\n DPKG.stubs(:architecture).returns('amd64')\n\n # This is a bit stupid because we expect here that this is there is\n # only one cmd instance in the builder, which is true for now but may\n # not always be the case. Might be worth revisiting this if it changes.\n cmd = mock('cmd')\n cmd.expects(:run).with('dpkg', '--add-architecture', arch)\n TTY::Command.expects(:new).returns(cmd)\n Apt::Abstrapt.expects(:system).with do |*args|\n keys = ['install', 'gcc-i686-linux-gnu', 'g++-i686-linux-gnu', 'dpkg-cross']\n overlap = args & keys\n keys == overlap\n end.returns(true)\n Apt::Abstrapt.expects(:system).with do |*args|\n args.include?('update')\n end.returns(true)\n\n builder = PackageBuilder.new\n builder.build_package\n\n refute_equal([], Dir.glob('build/*'))\n refute_equal([], Dir.glob('*.deb'))\n assert_path_exist('hello_2.10_i386.changes')\n changes = Debian::Changes.new('hello_2.10_i386.changes')\n changes.parse!\n refute_equal([], changes.fields['files'].map(&:name))\n\n refute_bin_only(builder)\n end\n\n def test_dep_resolve_bin_only\n Object.any_instance.expects(:system).never\n\n File.expects(:executable?)\n .with(DependencyResolverPBuilder::RESOLVER_BIN)\n .returns(true)\n\n Object.any_instance\n .expects(:system)\n .with({ 'DEBIAN_FRONTEND' => 'noninteractive' },\n '/usr/lib/pbuilder/pbuilder-satisfydepends',\n '--binary-arch',\n '--control', \"#{Dir.pwd}/debian/control\")\n .returns(true)\n\n DependencyResolverPBuilder.resolve(Dir.pwd, bin_only: true)\n end\n\n def test_build_bin_only\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n # Disable automatic bin only based on architecture. (i.e. amd64 is arch\n # all so it could be bin only by default, but for this test we want\n # to test bin_only detection, so the arch based bin only is getting in\n # the way).\n ENV['PANGEA_ARCH_BIN_ONLY'] = 'false'\n\n CI::DependencyResolver.expects(:resolve)\n .with('build')\n .raises(RuntimeError.new)\n CI::DependencyResolver.expects(:resolve)\n .with('build', bin_only: true)\n .returns(true)\n\n builder = PackageBuilder.new\n builder.build\n\n refute_equal([], Dir.glob('build/*'))\n refute_equal([], Dir.glob('result/*.deb'))\n assert_path_exist('result/test-build-bin-only_2.10_amd64.changes')\n changes = Debian::Changes.new('result/test-build-bin-only_2.10_amd64.changes')\n changes.parse!\n refute_equal([], changes.fields['files'].map(&:name))\n\n assert_path_exist('result/test-build-bin-only_2.10_amd64.deb.info.txt')\n # Should have plenty of characters (i.e. not be empty and probably contain\n # relevant output)\n assert(File.read('result/test-build-bin-only_2.10_amd64.deb.info.txt').size > 100)\n\n assert_bin_only(builder)\n end\n\n def test_build_bin_only_amd64\n # Should NOT bin only\n DPKG.stubs(:run)\n .with('dpkg-architecture', ['-qDEB_HOST_ARCH'])\n .returns(['amd64'])\n\n builder = PackageBuilder.new\n refute(builder.send(:auto_bin_only, false))\n end\n\n def test_build_bin_only_arm64\n # Should bin only!\n DPKG.stubs(:run)\n .with('dpkg-architecture', ['-qDEB_HOST_ARCH'])\n .returns(['arm64'])\n\n builder = PackageBuilder.new\n assert(builder.send(:auto_bin_only, false))\n end\n\n def test_build_bin_only_bad_value\n # Make sure bad env variables raise\n ENV['PANGEA_ARCH_BIN_ONLY'] = 'foobar'\n\n builder = PackageBuilder.new\n assert_raises do\n builder.send(:auto_bin_only, false)\n end\n end\n\n def test_build_bin_only_auto_arch\n # bin-only gets auto enabled for a !arch_all architecture (arm64)\n\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n DPKG.stubs(:architecture).returns('arm64')\n\n CI::DependencyResolver.expects(:resolve)\n .with('build', bin_only: true)\n .returns(true)\n\n builder = PackageBuilder.new\n builder.build\n\n refute_equal([], Dir.glob('build/*'))\n refute_equal([], Dir.glob('result/*.deb'))\n assert_path_exist('result/test-build-bin-only_2.10_amd64.changes')\n changes = Debian::Changes.new('result/test-build-bin-only_2.10_amd64.changes')\n changes.parse!\n refute_equal([], changes.fields['files'].map(&:name))\n\n assert_path_exist('result/test-build-bin-only_2.10_amd64.deb.info.txt')\n # Should have plenty of characters (i.e. not be empty and probably contain\n # relevant output)\n assert(File.read('result/test-build-bin-only_2.10_amd64.deb.info.txt').size > 100)\n\n # Don't assert bin-only, it also includes the report, for auto bin-only\n # we have no report expectation.\n assert(builder.instance_variable_get(:@bin_only))\n end\n\n def test_arch_all_only_source\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n builder = PackageBuilder.new\n\n DPKG.stubs(:architecture).returns('arm64')\n\n DPKG::Architecture.any_instance.expects(:is).with('amd64').returns(false)\n DPKG::Architecture.any_instance.expects(:is).with('all').returns(false)\n\n builder.expects(:extract)\n .never\n\n builder.build\n end\n\n def test_arm_on_amd64\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n DPKG.stubs(:run)\n .with('dpkg-architecture', ['-qDEB_HOST_ARCH'])\n .returns(['amd64'])\n\n DPKG::Architecture.any_instance.expects(:is).with('armhf').returns(false)\n DPKG::Architecture.any_instance.expects(:is).with('arm64').returns(false)\n\n builder = PackageBuilder.new\n\n builder.expects(:extract)\n .never\n\n builder.build\n end\n\n def test_setcap_fail\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n builder = PackageBuilder.new\n assert_raise do\n builder.build_package\n end\n end\n\n def test_setcap_success\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n setcap = [['foo', '/workspace/yolo/bar']]\n\n FileUtils.mkpath('build/debian/')\n File.write('build/debian/setcap.yaml', YAML.dump(setcap))\n\n builder = PackageBuilder.new\n builder.build_package\n end\n\n def test_setcap_fail_missing\n # A setcap call was expected but not run.\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n setcap = [['foo', '/workspace/yolo/bar'], %w[bar foo]]\n\n FileUtils.mkpath('build/debian/')\n File.write('build/debian/setcap.yaml', YAML.dump(setcap))\n\n builder = PackageBuilder.new\n assert_raise CI::SetCapError do\n builder.build_package\n end\n end\n\n def test_setcap_subproc_fail\n # Make sure we don't get a setcap violation if the sub process failed.\n # It'd make reading build failures unnecessarily difficult.\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n setcap = [['foo', '/workspace/yolo/bar'], %w[bar foo]]\n\n FileUtils.mkpath('build/debian/')\n File.write('build/debian/setcap.yaml', YAML.dump(setcap))\n\n builder = PackageBuilder.new\n assert_raise RuntimeError do\n builder.build_package\n end\n end\n\n def test_setcap_pattern_success\n # Make sure a wildcard pattern also matches expectations\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n\n setcap = [['foo', '*/bar']]\n\n FileUtils.mkpath('build/debian/')\n File.write('build/debian/setcap.yaml', YAML.dump(setcap))\n\n builder = PackageBuilder.new\n builder.build_package\n end\n\n def test_maybe_prepare_qt_version\n ENV['PANGEA_QT_GIT_BUILD'] = '1'\n ENV['DIST'] = 'jammy'\n FileUtils.cp_r(\"#{data}/ignorename/\", Dir.pwd)\n Dir.chdir(\"ignorename\") do\n builder = PackageBuilder.new\n assert_raise Errno::EACCES do\n builder.maybe_prepare_qt_build\n end\n end\n\n FileUtils.cp_r(\"#{data}/bad/\", Dir.pwd)\n Dir.chdir(\"bad\") do\n builder = PackageBuilder.new\n assert_raise RuntimeError do\n builder.maybe_prepare_qt_build\n end\n end\n\n FileUtils.cp_r(\"#{data}/good/\", Dir.pwd)\n Dir.chdir(\"good\") do\n builder = PackageBuilder.new\n assert_raise Errno::EACCES do\n builder.maybe_prepare_qt_build\n end\n end\n\n end\n\n def test_ignore_qt_version_match\n FileUtils.cp_r(\"#{data}/bad/\", Dir.pwd)\n Dir.chdir(\"bad\") do\n builder = PackageBuilder.new\n assert_true(builder.ignore_qt_versions_match)\n end\n\n FileUtils.cp_r(\"#{data}/good/\", Dir.pwd)\n Dir.chdir(\"good\") do\n builder = PackageBuilder.new\n assert_true(!builder.ignore_qt_versions_match)\n end\n\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6028504967689514,
"alphanum_fraction": 0.6077840328216553,
"avg_line_length": 33.58293914794922,
"blob_id": "d9b6dd2b57ae3d0d2bd06ac5642fe7e59a5f75da",
"content_id": "6022585b079c3b856452d49d3a427bb06bc5ec81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7297,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 211,
"path": "/lib/docker/cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2015-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'date'\nrequire 'json'\nrequire 'logger'\nrequire 'logger/colors'\n\nrequire_relative '../ci/docker'\nrequire_relative '../ci/pangeaimage'\n\nmodule Docker\n # helper for docker cleanup according to pangea expectations\n module Cleanup\n module_function\n\n OLD_UBUNTUS = %w[wily vivid xenial bionic].freeze\n OLD_UBUNTU_IMAGES = OLD_UBUNTUS.collect do |x|\n [\"pangea/ubuntu:#{x}\", \"ubuntu:#{x}\", \"arm32v7/ubuntu:#{x}\", \"arm64v8/ubuntu:#{x}\", \"pangea/ubuntu-armhf:#{x}\"]\n end.flatten\n OLD_IMAGES = (%w[] + OLD_UBUNTU_IMAGES).freeze # in the %w[] you can hardcode additional names\n\n # Remove exited jenkins containers.\n def containers\n containers_exited(days_old: 1)\n containers_running(days_old: 1)\n end\n\n def containers_exited(days_old:)\n # Filter all pseudo-exited and exited states.\n filters = { status: %w[exited dead] }\n containers = Docker::Container.all(all: true,\n filters: JSON.generate(filters))\n containers.each do |container|\n created = container_creation(container)\n next if (DateTime.now - created).to_i < days_old\n\n remove_container(container, force: true)\n end\n end\n\n def container_creation(container)\n object_creation(container)\n end\n\n def object_creation(obj)\n obj.refresh! # List information is somewhat sparse. Get full data.\n created_prop = obj.info.fetch('Created')\n created = if created_prop.is_a?(Numeric)\n Time.at(created_prop)\n else\n DateTime.parse(created_prop)\n end\n created.to_datetime\n end\n\n def containers_running(days_old:)\n # Filter all pseudo-running and running states.\n filters = { status: %w[created restarting running paused] }\n containers = Docker::Container.all(all: true,\n filters: JSON.generate(filters))\n containers.each do |container|\n created = container_creation(container)\n next if (DateTime.now - created).to_i < days_old\n\n remove_container(container, force: false)\n end\n end\n\n def remove_container(container, force: false)\n puts '-- REMOVE_CONTAINER --'\n p container\n # Get the live data. Docker in various versions spits out convenience\n # data in the listing .refresh! uses, .json is the raw dump.\n # Using the raw dump we can then translate to either an image name or\n # hash.\n container_json = container.json\n # API 1.21 introduced a new property\n image_id = container_json.fetch('ImageID') { nil }\n # Before 1.21 Image was the hot stuff.\n image_id ||= container_json.fetch('Image') { nil }\n begin\n image = Docker::Image.get(image_id)\n rescue Docker::Error::NotFoundError\n puts \"Coulnd't find image.\"\n image = nil\n end\n if image\n image.refresh! # Make sure we have live data and RepoTags available.\n repo_tags = image.info.fetch('RepoTags') { [] }\n # We only care about first possible tag.\n repo, _tag = Docker::Util.parse_repo_tag(repo_tags&.first || '')\n # <shadeslayer> well, it'll be fixed as soon as Debian unstable gets\n # fixed?\n # Also see mgmt/docker.rb\n force = true if repo == 'pangea/debian'\n # Remove all our containers and containers from a dangling image.\n # Dangling in this case would be any image that isn't tagged.\n is_pangea = repo.include?(CI::PangeaImage.namespace)\n is_pangea ||= repo.include?('kdeneon/ci')\n log.warn \"image(#{repo}) [force: #{force}, pangea: #{is_pangea}]\"\n return if !is_pangea && !force\n else\n log.warn 'While cleaning up containers we found a container that has ' \\\n 'no image associated with it. This should not happen: ' \\\n \" #{container}\"\n end\n begin\n log.warn \"Removing container #{container.id}\"\n # NB: blanket rescue, docker keeps chaning the errors raised here\n container.kill rescue nil\n container.remove(force: true)\n rescue Docker::Error::DockerError => e\n log.warn 'Removing failed, continuing.'\n log.warn e\n end\n end\n\n def old_images\n OLD_IMAGES.each do |name|\n remove_image(Docker::Image.get(name))\n rescue => e\n log.info \"Failed to get #{name} :: #{e}\"\n next\n end\n end\n\n def image_broken?(image)\n tags = image.info.fetch('RepoTags', [])\n return false unless tags&.any? { |x| x.start_with?('pangea/') || x.start_with?('kdeneon/ci') }\n\n created = object_creation(image)\n # rubocop:disable Style/NumericLiterals\n return false if Time.at(1470048138).to_datetime < created.to_datetime\n\n # rubocop:enable Style/NumericLiterals\n true\n end\n\n def broken_images\n Docker::Image.all(all: true).each do |image|\n begin\n remove_image(image) if image_broken?(image)\n rescue => e\n log.info \"Failed to get #{name} :: #{e}\"\n next\n end\n end\n end\n\n def remove_image(image)\n log.warn \"Removing image #{image.id}\"\n image.delete\n rescue Docker::Error::ConflictError => e\n log.warn e.to_s\n log.warn 'There was a conflict error, continuing.'\n end\n\n # Remove all dangling images. It doesn't appear to be documented what\n # exactly a dangling image is, but from looking at the image count of both\n # a dangling query and a regular one I am infering that dangling images are\n # images that are none:none AND are not intermediates of another image\n # (whatever an intermediate may be). So, dangling is a subset of all\n # none:none images.\n # @param filter [String] only allow dangling images with this name\n def images(filter: nil)\n old_images\n broken_images\n # Trust docker to do something worthwhile.\n args = {\n all: true,\n filters: '{\"dangling\":[\"true\"]}'\n }\n args[:filter] = filter unless filter.nil?\n Docker::Image.all(args).each do |image|\n remove_image(image)\n end\n # NOTE: Manual code implementing agggressive cleanups. Should docker be\n # stupid use this:\n\n # Docker::Image.all(all: true).each do |image|\n # tags = image.info.fetch('RepoTags') { nil }\n # next unless tags\n # none_tags_only = true\n # tags.each do |str|\n # repo, tag = Docker::Util.parse_repo_tag(str)\n # if repo != '<none>' && tag != '<none>'\n # none_tags_only = false\n # break\n # end\n # end\n # next unless none_tags_only # Image used by something.\n # begin\n # log.warn \"Removing image #{image.id}\"\n # image.delete\n # rescue Docker::Error::ConflictError\n # log.warn 'There was a conflict error, continuing.'\n # rescue Docker::Error::DockerError => e\n # log.warn 'Removing failed, continuing.'\n # log.warn e\n # end\n # end\n end\n\n def log\n @log ||= Logger.new(STDERR)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6546736359596252,
"alphanum_fraction": 0.6669679880142212,
"avg_line_length": 32.11975860595703,
"blob_id": "34c59701f0ff1203d45fb201092b1ca6f56bc593",
"content_id": "eca55cb6f5ed49f78ef91c1d88aaf88371ab31d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5531,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 167,
"path": "/lib/ci/setcap_validator.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'drb/drb'\nrequire 'yaml'\n\nrequire_relative 'pattern'\n\nmodule CI\n class SetCapError < StandardError; end\n\n # DRB server side for setcap expecation checking.\n class SetCapServer\n def initialize\n @expected = load_data\n # Keep track of seen calls so we don't triper over multiple equal calls.\n @seen = []\n @master_thread = Thread.current\n end\n\n def check_expected(argv)\n return if expected?(argv)\n\n raise SetCapError, <<~ERRORMSG\n \\n\n Unallowed call to: setcap #{argv.inspect}\n setcap must not be called. Build containers are run without a whole\n bunch of privileges which makes setcap non functional!\n Additionally, setcap uses xattrs which may not be available on the\n installation file system. Instead you should introduce a postinst\n call matching the setcap call with a fallback to setuid.\n https://invent.kde.org/neon/kde/kinit/-/commit/c9f80d5f9a3596e9e7d5490bd9f90729618381ab\n ERRORMSG\n end\n\n def assert_all_called\n return if @expected.empty?\n\n raise SetCapError, <<~ERRORMSG\n A number of setcap calls were expected but didn't actually happen.\n This is indicative of the build no longer needing setcap. Check the code\n and if applicable make sure there no longer are postinst calls to setcap\n or setuid.\n Exepcted calls:\n #{@expected.collect(&:inspect).join(\"\\n\")}\n ERRORMSG\n end\n\n private\n\n def raise(*args)\n # By default DRB would raise the exception in the client (i.e. setcap)\n # BUT that may then get ignored on a cmake/whatever level so the build\n # passes even though we wanted it to fail.\n # To deal with this we'll explicitly raise into the master thread\n # (the thread that created us) rather than the current thread (which is\n # the drb service thread).\n @master_thread.raise(*args)\n end\n\n def expected?(argv)\n if @expected.delete(argv) || @seen.include?(argv)\n @seen << argv\n return true\n end\n false\n end\n\n def load_data\n array = YAML.load_file('debian/setcap.yaml')\n array.collect { |x| x.collect { |y| FNMatchPattern.new(y) } }\n rescue Errno::ENOENT\n []\n end\n end\n\n # Validator wrapper using setcap tooling to hijack setcap calls and\n # run them through a noop expectation check instead.\n class SetCapValidator\n def self.run\n validator = new\n validator.start\n validator.with_client { yield }\n validator.stop\n validator.validate!\n ensure\n # Stop the validator (again) but do not validate. If the inferior block\n # raised an exception then ensure is still run but we do not actually\n # care about setcap violations.\n validator.stop\n end\n\n def start\n @server = DRb.start_service('druby://localhost:0', SetCapServer.new)\n ENV['PACKAGE_BUILDER_DRB_URI'] = @server.uri\n end\n\n def stop\n ENV.delete('PACKAGE_BUILDER_DRB_URI')\n @server.stop_service\n @server.thread.join # Wait for thread\n end\n\n def validate!\n @server.front.assert_all_called\n end\n\n def with_client\n oldpath = ENV.fetch('PATH')\n # Do not allow setcap calls of any kind!\n Dir.mktmpdir do |tmpdir|\n populate_client_dir(tmpdir)\n # FIXME: also overwrite /sbin/setcap\n ENV['PATH'] = \"#{tmpdir}:#{oldpath}\"\n yield\n end\n ensure\n ENV['PATH'] = oldpath\n end\n\n private\n\n def populate_client_dir(dir)\n setcap = \"#{dir}/setcap\"\n FileUtils.cp(\"#{__dir__}/setcap.rb\", setcap, verbose: true)\n FileUtils.chmod(0o755, setcap, verbose: true)\n return unless Process.uid.zero? # root\n\n FileUtils.cp(setcap, '/sbin/setcap') # overwrite original setcap\n end\n end\nend\n\n__END__\n\nif [ \"$1\" = configure ]; then\n # If we have setcap is installed, try setting cap_net_bind_service,cap_net_admin+ep,\n # which allows us to install our helper binary without the setuid bit.\n if command -v setcap > /dev/null; then\n if setcap cap_net_bind_service,cap_net_admin+ep /usr/lib/x86_64-linux-gnu/gstreamer1.0/gstreamer-1.0/gst-ptp-helper; then\n echo \"Setcap worked! gst-ptp-helper is not suid!\"\n else\n echo \"Setcap failed on gst-ptp-helper, falling back to setuid\" >&2\n chmod u+s /usr/lib/x86_64-linux-gnu/gstreamer1.0/gstreamer-1.0/gst-ptp-helper\n fi\n else\n echo \"Setcap is not installed, falling back to setuid\" >&2\n chmod u+s /usr/lib/x86_64-linux-gnu/gstreamer1.0/gstreamer-1.0/gst-ptp-helper\n fi\nfi\n"
},
{
"alpha_fraction": 0.6697247624397278,
"alphanum_fraction": 0.6743119359016418,
"avg_line_length": 15.769230842590332,
"blob_id": "d8c099a25734823e53261a119b7edb6e5ca11fbc",
"content_id": "bfd001ee98bede60a0accfc954ce425212aff8f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 13,
"path": "/nci/adt-helpers/mktemp",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n\nrequire 'fileutils'\n\nif ARGV.include?('adt-run.XXXXXX')\n FileUtils.rm_rf('/workspace')\n FileUtils.mkpath('/workspace')\n puts '/workspace'\n exit 0\nend\n\nsystem('/bin/mktemp', *ARGV)\nexit $?.to_i\n"
},
{
"alpha_fraction": 0.6473214030265808,
"alphanum_fraction": 0.6531593203544617,
"avg_line_length": 29.33333396911621,
"blob_id": "8c4d9c9217f983bc9fa2a84041f2cad725efd628",
"content_id": "1e91ae26f8cff80e5eada06ddcb7dbc8ae82ce9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2912,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 96,
"path": "/test/test_ci_package_builder_arm.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/package_builder'\nrequire_relative '../lib/debian/changes'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# Test ci/build_binary\nmodule CI\n class BuildARMBinaryTest < TestCase\n required_binaries %w[dpkg-buildpackage dpkg-source dpkg dh]\n\n def setup\n # Turn a bunch of debhelper sub process calls noop to improve speed.\n ENV['PATH'] = \"#{__dir__}/dud-bin:#{ENV['PATH']}\"\n end\n\n def refute_bin_only(builder)\n refute(builder.instance_variable_get(:@bin_only))\n end\n\n def assert_bin_only(builder)\n assert(builder.instance_variable_get(:@bin_only))\n end\n\n def test_arch_arm_source\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n DPKG.stubs(:run)\n .with('dpkg-architecture', ['-qDEB_HOST_ARCH'])\n .returns(['arm64'])\n\n DPKG::Architecture.any_instance.expects(:is).with('armhf').returns(false)\n DPKG::Architecture.any_instance.expects(:is).with('arm64').returns(true)\n\n builder = PackageBuilder.new\n\n builder.expects(:extract)\n .at_least_once\n .returns(true)\n\n builder.expects(:install_dependencies)\n .at_least_once\n .returns(true)\n\n builder.expects(:build_package)\n .at_least_once\n .returns(true)\n\n builder.expects(:move_binaries)\n .at_least_once\n .returns(true)\n\n builder.expects(:print_contents)\n .at_least_once\n .returns(true)\n\n builder.build\n end\n\n def test_arch_all_on_arm\n FileUtils.cp_r(\"#{data}/.\", Dir.pwd)\n DPKG.stubs(:run)\n .with('dpkg-architecture', ['-qDEB_HOST_ARCH'])\n .returns(['arm64'])\n\n DPKG::Architecture.any_instance.expects(:is).with('all').returns(false)\n DPKG::Architecture.any_instance.expects(:is).with('amd64').returns(false)\n\n builder = PackageBuilder.new\n\n builder.expects(:extract)\n .never\n\n builder.build\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6269338726997375,
"alphanum_fraction": 0.6343178749084473,
"avg_line_length": 28.625,
"blob_id": "8e9452384b152922430edb6d5a79163775339acc",
"content_id": "deef64f7bca3c1afaba90a44db2031e1f21e71c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2844,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 96,
"path": "/lib/debian/version.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nmodule Debian\n # A debian policy version handling class.\n class Version\n include Comparable\n\n class << self\n attr_writer :dpkg_installed\n def assert_dpkg_installed\n @dpkg_installed ||= begin\n return true if ENV['PANGEA_UNDER_TEST']\n unless system('which', 'dpkg', %i[out err] => '/dev/null')\n raise 'dpkg not installed'\n end\n\n true\n end\n end\n end\n\n attr_accessor :epoch\n attr_accessor :upstream\n attr_accessor :revision\n\n def initialize(string)\n @epoch = nil\n @upstream = nil\n @revision = nil\n parse(string)\n end\n\n def full\n comps = []\n comps << \"#{epoch}:\" if epoch\n comps << upstream\n comps << \"-#{revision}\" if revision\n comps.join\n end\n\n def to_s\n full\n end\n\n # We could easily reimplement version comparision from Version.pm, but\n # it's mighty ugh because of string components, so in order to not run into\n # problems down the line, let's just consult with dpkg for now.\n def <=>(other)\n return 0 if full == other.full\n return 1 if compare_version(full, 'gt', other.full)\n return -1 if compare_version(full, 'lt', other.full)\n # A version can be stringwise different but have the same weight.\n # Make sure we cover that.\n return 0 if compare_version(full, 'eq', other.full)\n end\n\n private\n\n def compare_version(ours, op, theirs)\n run('--compare-versions', ours, op, theirs)\n end\n\n def run(*args)\n self.class.assert_dpkg_installed\n system('dpkg', *args)\n end\n\n def parse(string)\n regex = /^(?:(?<epoch>\\d+):)?\n (?<upstream>[A-Za-z0-9.+:~-]+?)\n (?:-(?<revision>[A-Za-z0-9.~+]+))?$/x\n match = string.match(regex)\n @epoch = match[:epoch]\n @upstream = match[:upstream]\n @revision = match[:revision]\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6325605511665344,
"alphanum_fraction": 0.6350008845329285,
"avg_line_length": 30.17934799194336,
"blob_id": "fe0553872e982065e444ec2ad84fa1757ee59cd4",
"content_id": "53e2ba229592193ab76c45c72b1973f52a92c979",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5743,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 184,
"path": "/nci/branch_merger.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'git'\nrequire 'json'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'tmpdir'\n\nrequire_relative '../lib/optparse'\nrequire_relative '../lib/projects/factory/neon'\nrequire_relative '../lib/retry'\nrequire_relative '../lib/kdeproject_component'\n\norigins = []\ntarget = nil\ncreate = true\ndir = nil\n\nparser = OptionParser.new do |opts|\n opts.banner =\n \"Usage: #{opts.program_name} --origin ORIGIN --target TARGET KDE_COMPONENT\"\n\n opts.on('-o ORIGIN_BRANCH', '--origin BRANCH',\n 'Branch to merge or branch from. Multiple origins can be given',\n 'they will be tried in the sequence they are specified.',\n 'If one origin does not exist in a repository the next origin',\n 'is tried instead.', 'EXPECTED') do |v|\n origins += v.split(',')\n end\n\n opts.on('-t TARGET_BRANCH', '--target BARNCH',\n 'The target branch to merge into.', 'EXPECTED') do |v|\n target = v\n end\n\n opts.on('--[no-]create',\n 'Create the target branch if it does not exist yet.' \\\n ' [default: on]') do |v|\n create = v\n end\n\n opts.on('--dir PATH',\n 'Use this directory. This can resume from previous runs.' \\\n ' [default: temporary]') do |v|\n dir = v\n end\nend\nparser.parse!\n\nCOMPONENT = ARGV.last || nil\nARGV.clear\n\nunless parser.missing_expected.empty?\n puts \"Missing expected arguments: #{parser.missing_expected.join(', ')}\\n\\n\"\n abort parser.help\nend\nif target.nil? || target.empty?\n abort \"target must not be empty!\\n\" + parser.help\nend\nif COMPONENT.nil? || COMPONENT.empty?\n abort \"COMPONENT must not be empty!\\n\" + parser.help\nend\n\nprojects_in_component = case COMPONENT\n when 'plasma'\n KDEProjectsComponent.plasma_jobs\n else\n # NB release service and kf5 are not intentionally\n # missing. am just lazy -sitter\n raise 'Failed to map your kde component :(('\n end\n\nlogger = Logger.new(STDOUT)\nlogger.level = Logger::DEBUG\n\nlogger.warn \"For component #{COMPONENT} we are going to merge #{origins}\" \\\n \" into #{target}.\"\nif create\n logger.warn \"We are going to create missing #{target} branches from a\" \\\n ' matching origin.'\nelse\n logger.warn \"We are NOT going to create missing #{target} branches.\"\nend\nlogger.warn 'Pushing does not happen until after you had a chance to inspect' \\\n ' the results.'\n\nlogger.warn \"#{origins.join('|')} ⇢ #{target}\"\n\nrepos = ProjectsFactory::Neon.ls.select do |path|\n projects_in_component.include?(File.basename(path))\nend\n# Ensure everything that was meant to get mapped was actually mapped!\nunless repos.size == projects_in_component.size\n raise 'Repo<->Project map failed'\nend\n\nlogger.debug \"repos: #{repos}\"\n\nnothing_to_push = []\nDir.mktmpdir('stabilizer') do |tmpdir|\n tmpdir = dir if dir\n Dir.chdir(tmpdir)\n repos.each do |repo|\n log = Logger.new(STDOUT)\n log.level = Logger::INFO\n log.progname = repo\n log.info '----------------------------------'\n\n git = if !File.exist?(repo)\n Git.clone(\"neon:#{repo}\", repo)\n else\n Git.open(repo)\n end\n\n git.config('merge.dpkg-mergechangelogs.name',\n 'debian/changelog merge driver')\n git.config('merge.dpkg-mergechangelogs.driver',\n 'dpkg-mergechangelogs -m %O %A %B %A')\n FileUtils.mkpath(\"#{git.repo.path}/info\")\n File.open(\"#{git.repo.path}/info/attributes\", 'a') do |f|\n f.puts('debian/changelog merge=dpkg-mergechangelogs')\n end\n\n acted = false\n origins.each do |origin|\n unless git.is_branch?(origin)\n log.error \"origin branch '#{origin}' not found\"\n next\n end\n if git.is_branch?(target)\n git.checkout(origin)\n git.checkout(target)\n log.warn \"Merging #{origin} ⇢ #{target}\"\n git.merge(origin, \"Merging #{origin} into #{target}\\n\\nNOCI\")\n elsif create\n git.checkout(origin)\n log.warn \"Creating #{origin} ⇢ #{target}\"\n git.checkout(target, new_branch: true)\n else\n log.error \"target branch '#{target}' not here and not creating one\"\n break\n end\n acted = true\n break\n end\n nothing_to_push << repo unless acted\n end\n\n repos -= nothing_to_push\n logger.progname = ''\n logger.info \"The processed repos are in #{Dir.pwd} - Please verify.\"\n logger.info \"The following repos will have #{target} pushed:\\n\" \\\n \" #{repos.join(', ')}\"\n loop do\n logger.info 'Please type \\'c\\' to continue'\n break if gets.chop.casecmp('c')\n end\n\n repos.each do |repo|\n logger.info \"pushing #{repo}\"\n git = Git.open(repo)\n git.push('origin', target)\n end\nend\n"
},
{
"alpha_fraction": 0.7517006993293762,
"alphanum_fraction": 0.7517006993293762,
"avg_line_length": 17.375,
"blob_id": "272e0070645d826cd23a4b70440871cacd556d55",
"content_id": "044f9c3fca22b6fb023b7e9a0565a39fa2d4fa15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 16,
"path": "/test/test_xci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/xci'\n\nmodule BogusNameWithoutFile\n extend XCI\nend\n\n# Test xci\nclass XCITest < TestCase\n def test_fail_on_missing_config\n assert_raise RuntimeError do\n BogusNameWithoutFile.series\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6372021436691284,
"alphanum_fraction": 0.6397002339363098,
"avg_line_length": 35.90780258178711,
"blob_id": "cd4a47e37ed6de6db01030f29ace79218fdcd73f",
"content_id": "954f84a56dfd1b95d269014b739dd2765eceb0cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5204,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 141,
"path": "/lib/ci/overrides.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'deep_merge'\nrequire 'yaml'\n\nrequire_relative 'pattern'\n\nmodule CI\n # General prupose overrides handling (mostly linked to Project overrides).\n class Overrides\n DEFAULT_FILES = [\n File.expand_path(\"#{__dir__}/../../data/projects/overrides/base.yaml\")\n ].freeze\n\n class << self\n def default_files\n @default_files ||= DEFAULT_FILES\n end\n\n attr_writer :default_files\n end\n\n def initialize(files = self.class.default_files)\n @default_paths = files\n end\n\n def rules_for_scm(scm)\n # For launchpad rules need to use '*' or '' for branch. This is to keep\n # the override format consistent and not having to write separate\n # branches for launchpad here.\n repo_patterns = repo_patterns_for_scm(scm)\n\n branch_patterns = repo_patterns.collect do |_pattern, branches|\n next nil unless branches\n\n # launchpad has no branches so pretend the branch is empty. launchpad\n # having no branch the only valid values in the overrides would be\n # '*' and '', both of which would match an empty string branch, so\n # for the purpose of filtering let's pretend branch is empty when\n # not set at all.\n patterns = CI::FNMatchPattern.filter(scm.branch || '', branches)\n patterns = CI::FNMatchPattern.sort_hash(patterns)\n next patterns if patterns\n\n nil\n end.compact # compact nils away.\n\n override_patterns_to_rules(branch_patterns)\n end\n\n private\n\n def repo_patterns_for_scm(scm)\n @overrides ||= global_override_load\n # TODO: maybe rethink the way matching works. Actively matching against\n # an actual url is entirely pointless, we just need something that is\n # easy to understand and easy to compute. That could just be a sanitized\n # host/path string as opposed to the actual url. This then also means\n # we can freely mutate urls between writable and readonly (e.g. with\n # gitlab and github either going through ssh or https)\n url = scm.url.gsub(/\\.git$/, '') # sanitize to simplify matching\n repo_patterns = CI::FNMatchPattern.filter(url, @overrides)\n repo_patterns = CI::FNMatchPattern.sort_hash(repo_patterns)\n return {} if repo_patterns.empty?\n\n repo_patterns\n end\n\n def nil_fix(h)\n h.each_with_object({}) do |(k, v), enumerable|\n enumerable[k] = v\n enumerable[k] = nil_fix(v) if v.is_a?(Hash)\n enumerable[k] ||= 'NilClass'\n end\n end\n\n def nil_unfix(h)\n h.each_with_object({}) do |(k, v), enumerable|\n enumerable[k] = v\n enumerable[k] = nil if v == 'NilClass'\n enumerable[k] = nil_unfix(v) if v.is_a?(Hash)\n enumerable[k]\n end\n end\n\n # Flattens a pattern hash array into a hash of override rules.\n # Namely the overrides will be deep merged in order to cascade all relevant\n # rules against the first one.\n # @param branch_patterns Array<<Hash[PatternBase => Hash]> a pattern to\n # rule hash sorted by precedence (lower index = better)\n # @return Hash of overrides\n def override_patterns_to_rules(branch_patterns)\n rules = {}\n branch_patterns.each do |patterns|\n patterns.each_value do |override|\n # deep_merge() and deep_merge!() are different!\n # deep_merge! will merge and overwrite any unmergeables in destination\n # hash\n # deep_merge will merge and skip any unmergeables in destination hash\n # NOTE: it is not clear to me why, but apparently we have unmergables\n # probably however strings are unmergable and as such would either\n # be replaced or not (this is the most mind numbingly dumb behavior\n # attached to foo! that I ever saw, in particular considering the\n # STL uses ! to mean in-place. So deep_merge! is behaviorwise not\n # equal to merge! but deeper...)\n # NOTE: even more crap: deep_merge considers nil to mean nothing, but\n # for us nothing has meaning. Basically if a key is nil we don't want\n # it replaced, because nil is not undefined!! We have project overrides\n # that set upstream_scm to nil which is to say if it is nil already\n # do not override. So to bypass deep merge's assumption here we fixate\n # the nil value and then unfixate it again.\n rules = rules.deep_merge(nil_fix(override))\n end\n end\n nil_unfix(rules)\n end\n\n def overrides\n @overrides ||= global_override_load\n end\n\n def global_override_load\n hash = {}\n @default_paths.each do |path|\n if ::YAML::VERSION >= '4'\n hash.deep_merge!(YAML.unsafe_load(File.read(path)))\n else\n hash.deep_merge!(YAML.load(File.read(path)))\n end\n end\n hash = CI::FNMatchPattern.convert_hash(hash, recurse: false)\n hash.each do |k, v|\n hash[k] = CI::FNMatchPattern.convert_hash(v, recurse: false)\n end\n hash\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7010145783424377,
"alphanum_fraction": 0.7067216038703918,
"avg_line_length": 26.42608642578125,
"blob_id": "74d06901d3e7cb29f660e055e575c487cd85954b",
"content_id": "64475206381511fd9308fd34ce665f876f62ec71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3160,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 115,
"path": "/jenkins_delete.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\nrequire 'tty/prompt'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/queue'\nrequire_relative 'lib/thread_pool'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/jenkins/job'\n\nOptionParser.new do |opts|\n opts.banner = <<-EOS\nUsage: jenkins_delte.rb 'regex'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nretry.\n\ne.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*'\n\n • All unstable builds:\n '^.*_unstable_.*'\n\n • All jobs:\n '.*'\n EOS\nend.parse!\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = File.basename($0)\n l.level = Logger::INFO\nend\n\nraise 'Need ruby pattern as argv0' if ARGV.empty?\n\npattern = Regexp.new(ARGV[0])\[email protected] pattern\n\ndef ditch_child(element)\n element.children.remove if element&.children\nend\n\ndef mangle_xml(xml)\n doc = Nokogiri::XML(xml)\n ditch_child(doc.at('*/triggers'))\n ditch_child(doc.at('*/builders'))\n ditch_child(doc.at('*/publishers'))\n ditch_child(doc.at('*/buildWrappers'))\n doc.to_xml\nend\n\njob_names = Jenkins.job.list_all.select { |name| pattern.match(name) }\n\n# First wipe and disable them.\n# In an effort to improve reliability of delets we attempt to break dep\n# chains as much as possible by breaking the job configs to force unlinks of\n# downstreams.\njob_name_queue = Queue.new(job_names)\nBlockingThreadPool.run do\n until job_name_queue.empty?\n name = job_name_queue.pop(true)\n job = Jenkins::Job.new(name)\n @log.info \"Mangling #{name}\"\n Retry.retry_it(times: 5) do\n job.disable!\n end\n Retry.retry_it(times: 5) do\n job.update(mangle_xml(job.get_config))\n end\n begin\n job.wipe!\n rescue\n @log.warn \"Wiping of #{name} failed. Continue without wipe.\"\n end\n end\nend\n\n# Once all are disabled, proceed with deleting.\njob_name_queue = Queue.new(job_names)\nif TTY::Prompt.new.no?(\"Your are going to delete #{job_name_queue.size} jobs.\" \\\n ' Do you want to continue?')\n abort\nend\nBlockingThreadPool.run do\n until job_name_queue.empty?\n name = job_name_queue.pop(true)\n @log.info \"Deleting #{name}\"\n job = Jenkins::Job.new(name)\n job.delete!\n end\nend\n"
},
{
"alpha_fraction": 0.6696980595588684,
"alphanum_fraction": 0.679883599281311,
"avg_line_length": 26.21782112121582,
"blob_id": "970a0af5ddc9cab23103f2e31de1d672ea873fd8",
"content_id": "82ae804c69869aee7c26229d1c5a4e3ac2067946",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2749,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 101,
"path": "/test/test_nci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/nci'\n\n# Test NCI extensions on top of xci\nclass NCITest < TestCase\n def teardown\n NCI.send(:reset!)\n end\n\n def test_experimental_skip_qa\n skip = NCI.experimental_skip_qa\n assert_false(skip.empty?)\n assert(skip.is_a?(Array))\n end\n\n def test_only_adt\n only = NCI.only_adt\n assert_false(only.empty?)\n assert(only.is_a?(Array))\n end\n\n def test_old_series\n # Can be nil, otherwise it must be part of the array.\n return if NCI.old_series.nil?\n\n assert_include NCI.series.keys, NCI.old_series\n end\n\n def test_future_series\n # Can be nil, otherwise it must be part of the array.\n return if NCI.future_series.nil?\n\n assert_include NCI.series.keys, NCI.future_series\n end\n\n def test_current_series\n assert_include NCI.series.keys, NCI.current_series\n end\n\n def test_freeze\n assert_raises do\n NCI.architectures << 'amd64'\n end\n end\n\n def test_archive_key\n # This is a daft assertion. Technically the constraint is any valid apt-key\n # input, since we can't assert this, instead only assert that the data\n # is being correctly read from the yaml. This needs updating if the yaml's\n # data should ever change for whatever reason.\n assert_equal(NCI.archive_key, '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D')\n end\n\n def test_qt_stage_type\n assert_equal(NCI.qt_stage_type, 'qt_experimental')\n end\n\n def test_future_is_early\n # just shouldn't raise return value is truthy or falsey, which one we don't\n # care cause this is simply passing a .fetch() through.\n assert([true, false].include?(NCI.future_is_early))\n end\n\n def test_divert_repo\n File.write('nci.yaml', <<~YAML)\n repo_diversion: true\n divertable_repos: [testing]\n YAML\n NCI.send(:data_dir=, Dir.pwd) # resets as well\n\n assert(NCI.divert_repo?('testing'))\n\n # In the past we had a case where an incorrect type was passed to the function. We expect immediate failure then!\n assert_raises(NCI::BadInputType) { NCI.divert_repo?(nil) }\n assert_raises(NCI::BadInputType) { NCI.divert_repo?(1) }\n end\n\n def test_no_divert_repo\n File.write('nci.yaml', <<~YAML)\n repo_diversion: true\n divertable_repos: []\n YAML\n NCI.send(:data_dir=, Dir.pwd) # resets as well\n\n refute(NCI.divert_repo?('testing'))\n end\n\n def test_no_diversion\n File.write('nci.yaml', <<~YAML)\n repo_diversion: false\n divertable_repos: [testing]\n YAML\n NCI.send(:data_dir=, Dir.pwd) # resets as well\n\n refute(NCI.divert_repo?('testing'))\n end\nend\n"
},
{
"alpha_fraction": 0.6373161673545837,
"alphanum_fraction": 0.6459802389144897,
"avg_line_length": 28.023391723632812,
"blob_id": "ca6e4e271fe62da62b98d5153df910d2578d8563",
"content_id": "a24f91eed638050f98eb12a2195f05830f886dd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4963,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 171,
"path": "/test/test_nci_workspace_cleaner.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'date'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/workspace_cleaner'\n\nrequire 'mocha/test_unit'\n\nclass NCIWorkspaceCleanerTest < TestCase\n def setup\n WorkspaceCleaner.workspace_paths = [Dir.pwd]\n ENV['DIST'] = 'meow'\n\n CI::Containment\n .stubs(:userns?)\n .returns(false)\n end\n\n def teardown\n WorkspaceCleaner.workspace_paths = nil\n end\n\n def mkdir(path, mtime)\n time = mtime.to_time\n Dir.mkdir(path)\n File.utime(time, time, path)\n end\n\n def test_clean\n datetime_now = DateTime.now\n mkdir('mgmt_6_days_old', datetime_now - 6)\n mkdir('3_days_old', datetime_now - 3)\n mkdir('1_day_old', datetime_now - 1)\n mkdir('6_hours_old', datetime_now - Rational(6, 24))\n mkdir('just_now', datetime_now)\n mkdir('future', datetime_now + 1)\n mkdir('future_ws-cleanup_123', datetime_now + 1)\n\n # We'll mock containment as we don't actually care what goes on on the\n # docker level, that is tested in the containment test already.\n containment = mock('containment')\n CI::Containment\n .stubs(:new)\n .with do |*_, **kwords|\n next false unless kwords.include?(:image)\n next false unless kwords[:no_exit_handlers]\n\n true\n end\n .returns(containment)\n containment\n .stubs(:run)\n .with(Cmd: ['/bin/chown', '-R', 'jenkins:jenkins', '/pwd'])\n containment.stubs(:cleanup)\n\n WorkspaceCleaner.clean\n\n assert_path_not_exist('3_days_old')\n assert_path_not_exist('1_day_old')\n assert_path_not_exist('future_ws-cleanup_123')\n\n assert_path_exist('mgmt_6_days_old')\n assert_path_exist('6_hours_old')\n assert_path_exist('just_now')\n assert_path_exist('future')\n end\n\n def test_clean_errno\n omit #FIXME\n datetime_now = DateTime.now\n mkdir('3_days_old', datetime_now - 3)\n\n # We'll mock containment as we don't actually care what goes on on the\n # docker level, that is tested in the containment test already.\n containment = mock('containment')\n CI::Containment\n .stubs(:new)\n .with do |*_, **kwords|\n next false unless kwords.include?(:image)\n next false unless kwords[:no_exit_handlers]\n\n true\n end\n .returns(containment)\n # expect a chown! we must have this given we raise enoempty on rm_r later...\n containment\n .expects(:run)\n .with(Cmd: ['/bin/chown', '-R', 'jenkins:jenkins', '/pwd'])\n containment.stubs(:cleanup)\n\n FileUtils\n .stubs(:rm_r)\n .with { |x| x.end_with?('3_days_old') }\n .raises(Errno::ENOTEMPTY.new)\n .then\n .returns(true)\n\n FileUtils\n .stubs(:rm_r)\n .with { |x| !x.end_with?('3_days_old') }\n .returns(true)\n\n WorkspaceCleaner.clean\n\n # dir still exists here since we stubbed the rm_r call...\n end\n\n def test_clean_errno_userns\n omit #FIXME\n # With userns we need to chown to root:root not jenkins:jenkins!\n\n datetime_now = DateTime.now\n mkdir('3_days_old', datetime_now - 3)\n\n # We'll mock containment as we don't actually care what goes on on the\n # docker level, that is tested in the containment test already.\n containment = mock('containment')\n CI::Containment\n .stubs(:new)\n .with do |*_, **kwords|\n next false unless kwords.include?(:image)\n next false unless kwords[:no_exit_handlers]\n\n true\n end\n .returns(containment)\n CI::Containment\n .expects(:userns?)\n .returns(true)\n # expect a chown! we must have this given we raise enoempty on rm_r later...\n containment\n .expects(:run)\n .with(Cmd: ['/bin/chown', '-R', 'root:root', '/pwd']) # NB: root:root!\n containment.stubs(:cleanup)\n\n FileUtils\n .stubs(:rm_r)\n .with { |x| x.end_with?('3_days_old') }\n .raises(Errno::ENOTEMPTY.new)\n .then\n .returns(true)\n\n FileUtils\n .stubs(:rm_r)\n .with { |x| !x.end_with?('3_days_old') }\n .returns(true)\n\n WorkspaceCleaner.clean\n\n # dir still exists here since we stubbed the rm_r call...\n end\nend\n"
},
{
"alpha_fraction": 0.6036377549171448,
"alphanum_fraction": 0.6085638403892517,
"avg_line_length": 31.580245971679688,
"blob_id": "26dd42ab280d340e5b6f36acb94fcaa8288e3746",
"content_id": "ba47578b0f37a17c225ddd0787f1c7ba4e08ede2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5278,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 162,
"path": "/lib/projects/factory/neon.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'gitlab'\nrequire 'tty/command'\n\nrequire_relative 'base'\n\nclass ProjectsFactory\n # Neon specific project factory.\n class Neon < Base\n DEFAULT_URL_BASE = 'https://invent.kde.org/neon'\n NEON_GROUP = 'neon'\n GITLAB_API_ENDPOINT = 'https://invent.kde.org/api/v4'\n GITLAB_PRIVATE_TOKEN = ''\n\n def self.url_base\n @url_base ||= DEFAULT_URL_BASE\n end\n\n def self.understand?(type)\n %w[git.neon.kde.org anongit.neon.kde.org\n invent.kde.org/neon].include?(type)\n end\n\n private\n\n def split_entry(entry)\n parts = entry.split('/')\n name = parts[-1]\n component = parts[0..-2].join('_') || 'neon'\n [name, component]\n end\n\n def params(str)\n name, component = split_entry(str)\n default_params.merge(\n name: name,\n component: component,\n url_base: self.class.url_base\n )\n end\n\n def from_string(str)\n s = str\n ignore_missing_branches = true\n args = {}\n if str.kind_of?(Array)\n s = str[0].gsub('%2F', '/')\n ignore_missing_branches = str[1][:ignore_missing_branches] if str[1].has_key?(:ignore_missing_branches)\n str[1].delete(:ignore_missing_branches)\n args = str[1]\n end\n kwords = params(s)\n kwords.merge!(symbolize(args))\n # puts \"new_project(#{kwords})\"\n new_project(**kwords).rescue do |e|\n begin\n raise e\n rescue Project::GitNoBranchError => e\n raise e unless ignore_missing_branches\n end\n end\n end\n\n def split_hash(hash)\n clean_hash(*hash.first)\n end\n\n def clean_hash(base, subset)\n subset.collect! do |sub|\n # Coerce flat strings into hash. This makes handling more consistent\n # further down the line. Flat strings simply have empty properties {}.\n sub = sub.is_a?(Hash) ? sub : { sub => {} }\n # Convert the subset into a pattern matching set by converting the\n # keys into suitable patterns.\n key = sub.keys[0]\n sub[CI::FNMatchPattern.new(join_path(base, key))] = sub.delete(key)\n sub\n end\n [base, subset]\n end\n\n def each_pattern_value(subset)\n subset.each do |sub|\n pattern = sub.keys[0]\n value = sub.values[0]\n yield pattern, value\n end\n end\n\n def match_path_to_subsets(path, subset)\n matches = {}\n each_pattern_value(subset) do |pattern, value|\n next unless pattern.match?(path)\n\n value[:ignore_missing_branches] = pattern.to_s.include?('*')\n match = [path, value] # This will be an argument list for from_string.\n matches[pattern] = match\n end\n matches\n end\n\n def from_hash(hash)\n # FIXME: when .ls doesn't return a very specific repo enabled in the\n # yaml that should raise a warning of sorts. This is similar to wildcard\n # rules and ignore missing branches in from_string.\n base, subset = split_hash(hash)\n raise 'not array' unless subset.is_a?(Array)\n\n selection = self.class.ls.collect do |path|\n next nil unless path.start_with?(base) # speed-up, these can't match...\n\n matches = match_path_to_subsets(path, subset)\n # Get best matching pattern.\n CI::PatternBase.sort_hash(matches).values[0]\n end\n selection.compact.collect do |s|\n from_string(s)\n end\n end\n\n class << self\n def ls\n # NB: when listing more than path_with_namespace you will need to\n # change a whole bunch of stuff in test tooling.\n return @listing if defined?(@listing) # Cache in class scope.\n\n client = ::Gitlab.client(\n endpoint: GITLAB_API_ENDPOINT,\n private_token: GITLAB_PRIVATE_TOKEN\n )\n\n # Gitlab sends over paginated replies, make sure we iterate till\n # no more results are being returned.\n repos = client.group_projects(NEON_GROUP, include_subgroups: true,\n archived: false)\n .auto_paginate\n repos = repos.collect do |r|\n # We only list existing repos. This is kinda awkward because it allows\n # the factory yamls to define a project which we do not list\n # but that doesn't trigger any warnings. Not really a new problem\n # though.\n next nil if r.empty_repo\n # Synthetic archival. When a project gets the topic 'neon-archived'\n # we'll consider it archived. This ensures we can mark stuff archived\n # for the tooling without actually having to archive it on the gitlab\n # side (something we cannot do and have to wait for sysadmins on, making\n # the process unnecessarily hard to carry out in one go).\n next nil if r.topics&.include?('neon-archived')\n\n # Strip group prefix. Otherwise we have a consistency problem because\n # overrides and project confs in general do not have it (yet anyway)\n r.path_with_namespace.sub(\"#{NEON_GROUP}/\", '')\n end\n @listing = repos.flatten.uniq.compact\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6271289587020874,
"alphanum_fraction": 0.6309813261032104,
"avg_line_length": 30.819355010986328,
"blob_id": "8113ff0cd309c78c5420ea3fc023b4830f027c31",
"content_id": "2250201f8041a3a910186b319dc0bb97ae1671ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4932,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 155,
"path": "/lib/projects/factory/debian.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'base'\nrequire_relative 'common'\n\nclass ProjectsFactory\n # Debian specific project factory.\n class Debian < Base\n include ProjectsFactoryCommon\n DEFAULT_URL_BASE = 'git://anonscm.debian.org'\n\n # FIXME: same as in neon\n # FIXME: needs a writer!\n def self.url_base\n @url_base ||= DEFAULT_URL_BASE\n end\n\n def self.understand?(type)\n type == 'git.debian.org'\n end\n\n private\n\n # FIXME: not exactly the same as in Neon. prefix is only here. could be in\n # neon too though\n def split_entry(entry)\n parts = entry.split('/')\n name = parts[-1]\n component = parts[-2] || 'debian'\n [name, component, parts[0..-3]]\n end\n\n def params(str)\n name, component, prefix = split_entry(str)\n default_params.merge(\n name: name,\n component: component,\n url_base: \"#{self.class.url_base}/#{prefix.join('/')}\"\n )\n end\n\n # FIXME: test needs to check that we get the correct url out\n # FIXME: same as in neon\n def from_string(str, params = {})\n kwords = params(str)\n kwords.merge!(symbolize(params))\n puts \"new_project(#{kwords})\"\n new_project(**kwords)\n rescue Project::GitTransactionError, RuntimeError => e\n p e\n nil\n end\n\n # FIXME: same as in neon\n def split_hash(hash)\n clean_hash(*hash.first)\n end\n\n # FIXME: same as in neon\n def clean_hash(base, subset)\n subset.collect! do |sub|\n # Coerce flat strings into hash. This makes handling more consistent\n # further down the line. Flat strings simply have empty properties {}.\n sub = sub.is_a?(Hash) ? sub : { sub => {} }\n # Convert the subset into a pattern matching set by converting the\n # keys into suitable patterns.\n key = sub.keys[0]\n sub[CI::FNMatchPattern.new(join_path(base, key))] = sub.delete(key)\n sub\n end\n [base, subset]\n end\n\n # FIXME: same as in neon\n def each_pattern_value(subset)\n subset.each do |sub|\n pattern = sub.keys[0]\n value = sub.values[0]\n yield pattern, value\n end\n end\n\n # FIXME: same as in neon\n def match_path_to_subsets(path, subset)\n matches = {}\n each_pattern_value(subset) do |pattern, value|\n next unless pattern.match?(path)\n\n match = [path, value] # This will be an argument list for from_string.\n matches[pattern] = match\n end\n matches\n end\n\n def from_hash(hash)\n base, subset = split_hash(hash)\n raise 'not array' unless subset.is_a?(Array)\n\n selection = self.class.ls(base).collect do |path|\n next nil unless path.start_with?(base) # speed-up, these can't match...\n\n matches = match_path_to_subsets(path, subset)\n # Get best matching pattern.\n CI::PatternBase.sort_hash(matches).values[0]\n end\n selection.compact.collect { |s| from_string(*s) }\n end\n\n class << self\n def ls(base)\n # NOTE: unlike neon we have a segmented cache here for each base.\n # This is vastly more efficient than listing recursively as we do not\n # really know the maximum useful depth so a boundless find would take\n # years as it needs to traverse the entire file tree of /git (or a\n # subset at least). Since this includes the actual repos, their .git\n # etc. it is not viable.\n # Performance testing suggests that each ssh access takes\n # approximately 1 second, which is very acceptable.\n @list_cache ||= {}\n return @list_cache[base] if @list_cache.key?(base)\n\n output = `ssh git.debian.org find /git/#{base} -maxdepth 1 -type d`\n raise 'Failed to find repo list on host' unless $?.to_i.zero?\n\n @list_cache[base] = cleanup_ls(output).freeze\n end\n\n private\n\n def cleanup_ls(data)\n data.chop.split(' ').collect do |line|\n line.gsub('/git/', '').gsub('.git', '')\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6404814124107361,
"alphanum_fraction": 0.6457330584526062,
"avg_line_length": 34.42635726928711,
"blob_id": "759e217cf8d15bd3aedc8f236863457cd8678ca3",
"content_id": "b529ae0e94454ca557057509b8daab4c81b4f984",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4570,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 129,
"path": "/lib/jenkins/jobdir.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\n\nmodule Jenkins\n # A Jenkins job directory handler. That is a directory in jobs/ and its\n # metadata.\n class JobDir\n STATE_SYMLINKS = %w[\n lastFailedBuild\n lastStableBuild\n lastSuccessfulBuild\n lastUnstableBuild\n lastUnsuccessfulBuild\n legacyIds\n ].freeze\n\n def self.age(file)\n ((Time.now - File.mtime(file)) / 60 / 60 / 24).to_i\n end\n\n def self.recursive?(file)\n return false unless File.symlink?(file)\n\n abs_file = File.absolute_path(file)\n abs_file_dir = File.dirname(abs_file)\n link = File.readlink(abs_file)\n abs_link = File.absolute_path(link, abs_file_dir)\n abs_link == abs_file\n end\n\n # @return [Array<String>] of build dirs inside a jenkins builds/ tree\n # that are valid paths, not a stateful symlink (lastSuccessfulBuild etc.),\n # and not otherwise unsuitable for processing.\n def self.build_dirs(buildsdir)\n content = Dir.glob(\"#{buildsdir}/*\")\n\n # Paths that may not be processed in any form or fashion.\n locked = []\n\n # Add stateful symlinks and their targets to the locked list.\n # This is done separately from removal for ease of reading.\n content.each do |d|\n # Is it a stateful symlink?\n next unless STATE_SYMLINKS.include?(File.basename(d))\n\n # Lock it!\n locked << d\n\n # Does the target of the link exist?\n next unless File.exist?(d)\n\n # Lock that too!\n locked << File.realpath(d)\n end\n\n # Remove locked paths from the content list. They are entirely excluded\n # from processing.\n content = content.reject do |d|\n next true if locked.include?(d)\n\n # Deal with broken symlinks before calling realpath...\n # Broken would be a symlink that doesn't exist at all or points to\n # itself. We've already skipped stateful symlinks here as per the\n # above condition, so whatever remains would be build numbers.\n if File.symlink?(d) && (!File.exist?(d) || recursive?(d))\n FileUtils.rm(d)\n next true\n end\n\n next true if locked.include?(File.realpath(d))\n\n false\n end\n\n content.sort_by { |c| File.basename(c).to_i }\n end\n\n # WARNING: I am almost certain min_count is off-by-one, so, be mindful when\n # you want to keep 1 build! ~sitter, Nov 2018\n # @param min_count [Integer] the minimum amount of builds to keep\n # @param max_age [Integer,nil] the maximum age in days or nil if there is\n # none. builds older than this are listed *unless* they are in the\n # min_count. i.e. the min_count newest builds are never listed, even when\n # they exceed the max_age. out of the remaining jobs all older than\n # max_age are listed. if no max_age is set all builds that are not in\n # the min_count are listed.\n def self.each_ancient_build(dir, min_count:, max_age:, &_blk)\n buildsdir = \"#{dir}/builds\"\n return unless File.exist?(buildsdir)\n\n dirs = build_dirs(buildsdir)\n\n dirs[0..-min_count].each do |d| # Always keep the last N builds.\n yield d if max_age.nil? || (File.exist?(d) && age(d) > max_age)\n end\n end\n\n def self.prune(dir, min_count: 6, max_age: 14, paths: %w[log archive])\n each_ancient_build(dir, min_count: min_count,\n max_age: nil) do |ancient_build|\n paths.each do |path|\n path = \"#{ancient_build}/#{path}\"\n if File.exist?(path) && (age(path) > max_age)\n FileUtils.rm_r(File.realpath(path), verbose: true)\n end\n end\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6746543645858765,
"alphanum_fraction": 0.6857143044471741,
"avg_line_length": 25.463415145874023,
"blob_id": "7c574ce4f441d345291c7b577278defb098971de",
"content_id": "824f7eae3190a5a1d869d1468165ffd1c43a5f5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 41,
"path": "/test/test_nci_settings.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lib/settings'\n\nrequire 'mocha/test_unit'\n\nclass NCISettingsTest < TestCase\n def setup\n NCI::Settings.default_files = []\n end\n\n def teardown\n NCI::Settings.default_files = nil\n end\n\n def test_init\n NCI::Settings.new\n end\n\n def test_settings\n NCI::Settings.default_files << fixture_file('.yml')\n ENV['JOB_NAME'] = 'xenial_unstable_libkolabxml_src'\n settings = NCI::Settings.new\n settings = settings.for_job\n assert_equal({ 'sourcer' => { 'restricted_packaging_copy' => true } }, settings)\n end\n\n def test_settings_singleton\n NCI::Settings.default_files << fixture_file('.yml')\n ENV['JOB_NAME'] = 'xenial_unstable_libkolabxml_src'\n assert_equal({ 'sourcer' => { 'restricted_packaging_copy' => true } }, NCI::Settings.for_job)\n end\n\n def test_unknown_job\n assert_equal({}, NCI::Settings.new.for_job)\n end\nend\n"
},
{
"alpha_fraction": 0.6473454833030701,
"alphanum_fraction": 0.6524749994277954,
"avg_line_length": 31.491666793823242,
"blob_id": "ed57111ac1cee94b261ececea105cc6a8f54c5d5",
"content_id": "d3e95e72bae10e8856a51c4524d259f4b1c3972f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3899,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 120,
"path": "/nci/imager_img_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'fileutils'\nrequire 'net/sftp'\nrequire 'net/ssh'\nrequire 'tty-command'\nrequire_relative 'imager_img_push_support'\n\nDIST = ENV.fetch('DIST')\nTYPE = ENV.fetch('TYPE')\nARCH = ENV.fetch('ARCH')\nIMAGENAME = ENV.fetch('IMAGENAME')\n\n# copy to rsync.kde.org using same directory without -proposed for now, later we want\n# this to only be published if passing some QA test\nDATE = File.read('date_stamp').strip\nIMGNAME=\"#{IMAGENAME}-pinebook-remix-#{TYPE}-#{DATE}-#{ARCH}\"\nREMOTE_DIR = \"neon/images/pinebook-remix-nonfree/\"\nREMOTE_PUB_DIR = \"#{REMOTE_DIR}/#{TYPE}/#{DATE}\"\n\nputs \"GPG signing disk image file\"\nunless system('gpg', '--no-use-agent', '--armor', '--detach-sign', '-o',\n \"#{IMGNAME}.img.gz.sig\",\n \"#{IMGNAME}.img\")\n raise 'Failed to sign'\nend\n\n# SFTPSessionOverlay\n# Todo, move it to seperate file\nmodule SFTPSessionOverlay\n def __cmd\n @__cmd ||= TTY::Command.new\n end\n\n def cli_uploads\n @use_cli_sftp ||= false\n end\n\n def cli_uploads=(enable)\n @use_cli_sftp = enable\n end\n\n def __cli_upload(from, to)\n remote = format('%<user>s@%<host>s',\n user: session.options[:user],\n host: session.host)\n key_file = ENV.fetch('SSH_KEY_FILE', nil)\n identity = key_file ? ['-i', key_file] : []\n __cmd.run('sftp', *identity, '-b', '-', remote,\n stdin: <<~STDIN)\n put #{from} #{to}\n quit\n STDIN\n end\n\n def upload!(from, to, **kwords)\n return super unless @use_cli_sftp\n raise 'CLI upload of dirs not implemented' if File.directory?(from)\n\n # cli wants dirs for remote location\n __cli_upload(from, File.dirname(to))\n end\nend\nclass Net::SFTP::Session\n prepend SFTPSessionOverlay\nend\n\nkey_file = ENV.fetch('SSH_KEY_FILE', nil)\nssh_args = key_file ? [{ keys: [key_file] }] : []\n\n# Publish ISO and associated content.\nNet::SFTP.start('rsync.kde.org', 'neon', *ssh_args) do |sftp|\n puts \"mkdir #{REMOTE_PUB_DIR}\"\n sftp.cli_uploads = true\n sftp.mkdir!(REMOTE_PUB_DIR)\n types = %w[img.gz img.gz.sig contents zsync sha256sum]\n types.each do |type|\n Dir.glob(\"*#{type}\").each do |file|\n name = File.basename(file)\n STDERR.puts \"Uploading #{file}...\"\n sftp.upload!(file, \"#{REMOTE_PUB_DIR}/#{name}\")\n end\n end\n sftp.cli_uploads = false\n\n # Need a second SSH session here, since the SFTP one is busy looping.\n Net::SSH.start('rsync.kde.org', 'neon', *ssh_args) do |ssh|\n ssh.exec!(\"cd #{REMOTE_DIR}/#{TYPE}; rm -f current; ln -s #{DATE} current\")\n end\n\n # delete old directories\n img_directories = sftp.dir.glob(\"#{REMOTE_DIR}/#{TYPE}\", '*').collect(&:name)\n img_directories = old_directories_to_remove(img_directories)\n img_directories.each do |name|\n path = \"#{REMOTE_DIR}/#{TYPE}/#{name}\"\n STDERR.puts \"rm #{path}\"\n sftp.dir.glob(path, '*') { |e| sftp.remove!(\"#{path}/#{e.name}\") }\n sftp.rmdir!(path)\n end\nend\n"
},
{
"alpha_fraction": 0.6360874772071838,
"alphanum_fraction": 0.6385176181793213,
"avg_line_length": 25.983606338500977,
"blob_id": "f7a7df486ada7fdde4c5edff1c26004159cacc59",
"content_id": "c996b5d7d0d319a72274e837d6c93f87eb6d1f0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1646,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 61,
"path": "/lib/projects/factory/common.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nmodule ProjectsFactoryCommon\n def split_hash(hash)\n clean_hash(*hash.first)\n end\n\n def each_pattern_value(subset)\n subset.each do |sub|\n pattern = sub.keys[0]\n value = sub.values[0]\n yield pattern, value\n end\n end\n\n def from_hash(hash)\n base, subset = split_hash(hash)\n raise 'not array' unless subset.is_a?(Array)\n\n selection = self.class.ls(base).collect do |name|\n matches = match_path_to_subsets(base, name, subset)\n # Get best matching pattern.\n CI::PatternBase.sort_hash(matches).values[0]\n end\n selection.compact.collect { |s| from_string(*s) }\n end\n\n def match_path_to_subsets(base, name, subset)\n matches = {}\n each_pattern_value(subset) do |pattern, value|\n next unless pattern.match?(name)\n\n match = [\"#{base}/#{name}\", value]\n matches[pattern] = match\n end\n matches\n end\n\n def clean_hash(base, subset)\n subset.collect! do |sub|\n # Coerce flat strings into hash. This makes handling more consistent\n # further down the line. Flat strings simply have empty properties {}.\n sub = sub.is_a?(Hash) ? sub : { sub => {} }\n # Convert the subset into a pattern matching set by converting the\n # keys into suitable patterns.\n key = sub.keys[0]\n sub[CI::FNMatchPattern.new(key.to_s)] = sub.delete(key)\n sub\n end\n [base, subset]\n end\n\n def from_string(str, params = {})\n kwords = params(str)\n kwords.merge!(symbolize(params))\n puts \"new_project(#{kwords})\"\n new_project(**kwords)\n rescue Project::GitTransactionError, RuntimeError => e\n p e\n nil\n end\nend\n"
},
{
"alpha_fraction": 0.6458627581596375,
"alphanum_fraction": 0.6608302593231201,
"avg_line_length": 30.061403274536133,
"blob_id": "88fbc4994a947146a58506153be574c9ed122102",
"content_id": "df6fe71e93e05cb42da0547486bb320e285e67c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7082,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 228,
"path": "/test/test_repo_abstraction.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/repo_abstraction'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\nrequire_relative '../lib/gir_ffi'\n\n# Fake mod\nmodule PackageKitGlib\n module FilterEnum\n module_function\n\n def [](x)\n {\n arch: 18\n }.fetch(x)\n end\n end\n\n # rubocop:disable Lint/EmptyClass\n class Client\n end\n # rubocop:enable Lint/EmptyClass\n\n class Result\n attr_reader :package_array\n\n def initialize(package_array)\n @package_array = package_array\n end\n end\n\n class Package\n attr_reader :name\n\n def initialize(name)\n @name = name\n end\n\n def self.from_array(array)\n array.collect { |x| new(x) }\n end\n end\nend\n\nclass RepoAbstractionAptlyTest < TestCase\n required_binaries('dpkg')\n\n def setup\n WebMock.disable_net_connect!\n\n # More slective so we can let DPKG through.\n Apt::Repository.expects(:system).never\n Apt::Repository.expects(:`).never\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n Apt::Cache.expects(:system).never\n Apt::Cache.expects(:`).never\n\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n end\n\n def teardown\n NCI.send(:reset!)\n end\n\n def test_init\n AptlyRepository.new('repo', 'prefix')\n end\n\n def test_sources\n repo = mock('repo')\n repo\n .stubs(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 3 ghi',\n 'Psource kactivities-kf5 4 jkl',\n 'Psource kactivities-kf5 2 def']) # Make sure this is filtered\n\n r = AptlyRepository.new(repo, 'prefix')\n assert_equal(['Psource kactivities-kf5 4 jkl'], r.sources.collect(&:to_s))\n end\n\n # implicitly tests #packages\n def test_install\n repo = mock('repo')\n repo\n .stubs(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 4 jkl']) # Make sure this is filtered\n repo\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kactivities-kf5), $SourceVersion (4)')\n .returns(['Pamd64 libkactivites 4 abc'])\n\n Apt::Abstrapt.expects(:system).with do |*x|\n x.include?('install') && x.include?('libkactivites=4')\n end.returns(true)\n\n r = AptlyRepository.new(repo, 'prefix')\n r.install\n end\n\n def test_purge_exclusion\n repo = mock('repo')\n repo\n .stubs(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 4 jkl'])\n repo\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kactivities-kf5), $SourceVersion (4)')\n .returns(['Pamd64 libkactivites 4 abc', 'Pamd64 kitteh 5 efd', 'Pamd64 base-files 5 efd'])\n # kitteh we filter, base-files should be default filtered\n Apt::Abstrapt\n .expects(:system)\n .with('apt-get', *Apt::Abstrapt.default_args, '--allow-remove-essential', 'purge', 'libkactivites')\n .returns(true)\n\n r = AptlyRepository.new(repo, 'prefix')\n r.purge_exclusion << 'kitteh'\n r.purge\n end\n\n def test_diverted_init\n # Trivial test to ensure the /tmp/ prefix is injected when repo diversion is enabled.\n # This was broken in the past so let's guard against it breaking again. The code is a super concerned\n # with internals though :(\n repo = mock('repo')\n NCI.send(:data_dir=, Dir.pwd)\n File.write('nci.yaml', YAML.dump('repo_diversion' => true, 'divertable_repos' => ['whoopsiepoosie']))\n r = AptlyRepository.new(repo, 'whoopsiepoosie')\n assert(r.instance_variable_get(:@_name).include?('/tmp/'))\n end\nend\n\nclass RepoAbstractionRootOnAptlyTest < TestCase\n required_binaries('dpkg')\n\n def setup\n WebMock.disable_net_connect!\n\n # Do not let gir through!\n GirFFI.expects(:setup).never\n # And Doubly so for dbus!\n RootOnAptlyRepository.any_instance.expects(:dbus_run).yields\n\n # More slective so we can let DPKG through.\n Apt::Repository.expects(:system).never\n Apt::Repository.expects(:`).never\n Apt::Abstrapt.expects(:system).never\n Apt::Abstrapt.expects(:`).never\n Apt::Cache.expects(:system).never\n Apt::Cache.expects(:`).never\n\n Apt::Repository.send(:reset)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n Apt::Cache.send(:instance_variable_set, :@last_update, Time.now)\n end\n\n=begin\n def test_init\n Apt::Abstrapt\n .expects(:system)\n .with('apt-get', *Apt::Abstrapt.default_args, 'install', 'packagekit', 'libgirepository1.0-dev', 'gir1.2-packagekitglib-1.0', 'dbus-x11')\n .returns(true)\n GirFFI.expects(:setup).with(:PackageKitGlib, '1.0').returns(true)\n PackageKitGlib::Client.any_instance.expects(:get_packages).with(18).returns(PackageKitGlib::Result.new([]))\n\n repo = RootOnAptlyRepository.new\n assert_empty(repo.send(:packages))\n # Should not hit mocha never-expectations.\n repo.add\n repo.remove\n end\n def test_packages\n mock_repo1 = mock('mock_repo1')\n mock_repo1\n .stubs(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 4 jkl'])\n mock_repo1\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kactivities-kf5), $SourceVersion (4)')\n .returns(['Pamd64 libkactivites 4 abc'])\n\n mock_repo2 = mock('mock_repo2')\n mock_repo2\n .stubs(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 4 jkl', 'Psource trollomatico 3 abc'])\n mock_repo2\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (kactivities-kf5), $SourceVersion (4)')\n .returns(['Pamd64 libkactivites 4 abc'])\n mock_repo2\n .stubs(:packages)\n .with(q: '!$Architecture (source), $PackageType (deb), $Source (trollomatico), $SourceVersion (3)')\n .returns(['Pamd64 trollomatico 3 edf', 'Pamd64 unicornsparkles 4 xyz'])\n\n Apt::Abstrapt\n .expects(:system)\n .with('apt-get', *Apt::Abstrapt.default_args, 'install', 'packagekit', 'libgirepository1.0-dev', 'gir1.2-packagekitglib-1.0', 'dbus-x11')\n .returns(true)\n\n GirFFI.expects(:setup).with(:PackageKitGlib, '1.0').returns(true)\n packages = PackageKitGlib::Package.from_array(%w[libkactivites trollomatico])\n result = PackageKitGlib::Result.new(packages)\n PackageKitGlib::Client.any_instance.expects(:get_packages).with(18).returns(result)\n\n aptly_repo1 = AptlyRepository.new(mock_repo1, 'mock1')\n aptly_repo2 = AptlyRepository.new(mock_repo2, 'mock2')\n\n Apt::Abstrapt\n .expects(:system)\n .with('apt-get', *Apt::Abstrapt.default_args, 'install', 'ubuntu-minimal', 'libkactivites', 'trollomatico')\n .returns(true)\n assert(RootOnAptlyRepository.new([aptly_repo1, aptly_repo2]).install)\n end\n=end\nend\n"
},
{
"alpha_fraction": 0.5384615659713745,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 12,
"blob_id": "cceff5cb14391d82d58b74c6245e7e346eae503f",
"content_id": "69218d15752a5c6b67d9468699770a1d465662b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 13,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 1,
"path": "/test/data/test_lint_merge_marker/test_lint/t.cpp",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "abc << yolo;\n"
},
{
"alpha_fraction": 0.6913470029830933,
"alphanum_fraction": 0.6953612565994263,
"avg_line_length": 35.16128921508789,
"blob_id": "ac5d8ba9d5f5900ac425b81481df5438a63024e6",
"content_id": "cb295f3ca2e1e2eeebb93ad6e0dfd3cc2e33b467",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2242,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 62,
"path": "/test/test_adt_junit_summary.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/adt/summary'\nrequire_relative '../lib/adt/junit/summary'\n\nrequire_relative 'lib/assert_xml'\n\nmodule ADT\n class JUnitSummaryTest < TestCase\n def test_to_xml\n summary = Summary.from_file(\"#{data}/summary\")\n summary = JUnit::Summary.new(summary)\n assert_xml_equal(File.read(fixture_file('.xml')), summary.to_xml)\n end\n\n def test_partial_fail_to_xml\n summary = Summary.from_file(\"#{data}/summary\")\n summary = JUnit::Summary.new(summary)\n assert_xml_equal(File.read(fixture_file('.xml')), summary.to_xml)\n end\n\n def test_output\n # Tests stderr being added.\n summary = Summary.from_file(\"#{data}/summary\")\n summary = JUnit::Summary.new(summary)\n assert_xml_equal(File.read(fixture_file('.xml')), summary.to_xml)\n end\n\n def test_skip_all\n # * SKIP should yield no testcases\n summary = Summary.from_file(\"#{data}/summary\")\n summary = JUnit::Summary.new(summary)\n assert_xml_equal(File.read(fixture_file('.xml')), summary.to_xml)\n end\n\n def test_skip\n # This also expects output!\n summary = Summary.from_file(\"#{data}/summary\")\n summary = JUnit::Summary.new(summary)\n assert_xml_equal(File.read(fixture_file('.xml')), summary.to_xml)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6376068592071533,
"alphanum_fraction": 0.6581196784973145,
"avg_line_length": 21.5,
"blob_id": "fd87ed2abd8ec54f477b4501c7dacb71fe883ed3",
"content_id": "d795ad53ffd4da51387c915e51b7f14cf0cc3fb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 585,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 26,
"path": "/lib/lint/log.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'log/dh_missing'\nrequire_relative 'log/list_missing'\n\nmodule Lint\n # Lints a build log\n class Log\n attr_reader :log_data\n\n def initialize(log_data)\n @log_data = log_data\n end\n\n # @return [Array<Result>]\n def lint\n results = []\n [ListMissing, DHMissing].each do |klass|\n results << klass.new.lint(@log_data.clone)\n end\n results\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6701065301895142,
"alphanum_fraction": 0.6777629852294922,
"avg_line_length": 26.06306266784668,
"blob_id": "59e9e6fe29615862427792ccd1c4852a3a386952",
"content_id": "6eaea6cfffedede6823a23b6f9251577d4b25f1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3004,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 111,
"path": "/lib/net/ssh/socket_gateway.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'net/ssh'\nrequire 'thread'\n\nclass Net::SSH::SocketGateway\n def initialize(host, user, options={})\n @session = Net::SSH.start(host, user, options)\n attach_logger(@session)\n @session_mutex = Mutex.new\n @loop_wait = options.delete(:loop_wait) || 0.001\n initiate_event_loop!\n end\n\n def active?\n @active\n end\n\n def shutdown!\n return unless active?\n\n @active = false\n @thread.join\n\n @session_mutex.synchronize do\n @session.forward.active_local_sockets.each do |local_socket_path|\n @session.forward.cancel_local_socket(local_socket_path)\n end\n end\n\n @session.close\n end\n\n def open(local_socket_path, remote_socket_path)\n @session_mutex.synchronize do\n @session.forward.local_socket(local_socket_path, remote_socket_path)\n end\n\n if block_given?\n begin\n yield local_socket_path\n ensure\n close(local_socket_path)\n end\n return nil\n end\n\n local_socket_path\n end\n\n def close(local_socket_path)\n @session_mutex.synchronize do\n @session.forward.cancel_local_socket(local_socket_path)\n end\n end\n\n private\n\n def attach_logger(netsshobj)\n return unless ENV.include?('SSH_DEBUG')\n # No littering when testing please.\n return if ENV.include?('PANGEA_UNDER_TEST')\n\n # :nocov:\n log_file = \"/tmp/net-ssh-#{$$}-#{netsshobj.object_id.abs}.log\"\n File.write(log_file, '')\n File.chmod(0o600, log_file)\n netsshobj.logger = Logger.new(log_file).tap do |l|\n l.progname = $PROGRAM_NAME.split(' ', 2)[0]\n l.level = Logger::DEBUG\n end\n netsshobj.logger.warn(ARGV.inspect)\n warn(log_file)\n # :nocov:\n end\n\n # Fires up the gateway session's event loop within a thread, so that it\n # can run in the background. The loop will run for as long as the gateway\n # remains active.\n def initiate_event_loop!\n @active = true\n\n @thread = Thread.new do\n while @active\n @session_mutex.synchronize do\n @session.process(@loop_wait)\n end\n Thread.pass\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7454772591590881,
"alphanum_fraction": 0.753587007522583,
"avg_line_length": 42.32432556152344,
"blob_id": "909b66014265e6e727b03467d5aa2bcac58ba232",
"content_id": "5a983083e897028ea023d2ee483989ac3658d347",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1603,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 37,
"path": "/nci/imager/build-hooks-neon-developer/011-fuse.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# Copyright (C) 2020 Jonathan Riddell <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# Explicitly install kio-fuse. It uses fuse3 which provides fuse but\n# conflicts with fuse as well. Putting it in the seeds as recommends\n# does not help, apt decides it does not need to be installed when\n# something depends on \"fuse\" so it does not get installed. Install\n# here after everything else. The stuff which use fuse are fine as\n# fuse3 provides fuse and should be backwards compatible for user space bits.q\n\n# only available on unstable and testing for now but enable universally when it has a real release\n\nset -e\n\nif grep -q Unstable /etc/os-release; then\n apt-get install -y kio-fuse fuse3\nfi\nif grep -q Testing /etc/os-release; then\n apt-get install -y kio-fuse fuse3\nfi\n"
},
{
"alpha_fraction": 0.6748571395874023,
"alphanum_fraction": 0.6845714449882507,
"avg_line_length": 32.653846740722656,
"blob_id": "33ca98cb37afc889e3c5fed5239d44da32d66481",
"content_id": "5e6290a0c3d5bf5cbf617a2c523492612395ecc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1750,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 52,
"path": "/nci/appstream_health_test.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'minitest/test'\nrequire 'open-uri'\n\n# Tests dep11 data being there\nclass DEP11Test < Minitest::Test\n SERIES = ENV.fetch('DIST')\n POCKETS = %w[main].freeze\n\n IN_RELEASES = {\n 'user' =>\n \"https://archive.neon.kde.org/user/dists/#{SERIES}/InRelease\"\n }.freeze\n\n IN_RELEASES.each do |name, in_release_uri|\n define_method(\"test_#{name}\") do\n wanted_pockets = POCKETS.dup\n URI.open(in_release_uri) do |f|\n f.each_line do |line|\n pocket = wanted_pockets.find { |x| line.include?(\"#{x}/dep11\") }\n next unless pocket\n\n wanted_pockets.delete(pocket)\n end\n end\n assert_equal([], wanted_pockets,\n 'Some pockets are in need of dep11 data.')\n end\n end\nend\n\nrequire 'minitest/autorun' if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.6615573167800903,
"alphanum_fraction": 0.6664623022079468,
"avg_line_length": 29.773584365844727,
"blob_id": "40344ee78f60f6f9a7174e23568472281b103087",
"content_id": "a30a7d2911bf3688b7e4865332ffc0eb29a7e948",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1631,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 53,
"path": "/lib/ci/feature_summary_extractor.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tmpdir'\n\nmodule CI\n # Injects a feature summary call into cmakelists that enables us to easily get access to the output\n # without having to parse the entire log (and then possibly fall over missing marker lines :|).\n # Has a bit of a beauty problem that sources in the package\n class FeatureSummaryExtractor\n def self.run(result_dir:, build_dir:, &block)\n new(result_dir: result_dir, build_dir: build_dir).run(&block)\n end\n\n def initialize(result_dir:, build_dir:)\n @result_dir = File.absolute_path(result_dir)\n @build_dir = File.absolute_path(build_dir)\n end\n\n def run(&block)\n unless File.exist?(\"#{@build_dir}/CMakeLists.txt\")\n yield\n return\n end\n\n warn 'Extended CMakeLists with feature_summary extraction.'\n mangle(&block)\n end\n\n private\n\n def data\n <<~SNIPPET\ninclude(FeatureSummary)\nstring(TIMESTAMP _pangea_feature_summary_timestamp \"%Y-%m-%dT%H:%M:%SZ\" UTC)\nfeature_summary(FILENAME \"#{@result_dir}/pangea_feature_summary-${_pangea_feature_summary_timestamp}.log\" WHAT ALL)\n SNIPPET\n end\n\n def mangle\n Dir.mktmpdir do |tmpdir|\n backup = File.join(tmpdir, 'CMakeLists.txt')\n FileUtils.cp(\"#{@build_dir}/CMakeLists.txt\", backup, verbose: true)\n File.open(\"#{@build_dir}/CMakeLists.txt\", 'a') { |f| f.write(data) }\n yield\n ensure\n FileUtils.cp(backup, @build_dir, verbose: true)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6421732902526855,
"alphanum_fraction": 0.6517472267150879,
"avg_line_length": 29.275362014770508,
"blob_id": "a2d935d05bd2443bd80d3958a9ddaf6feef3354b",
"content_id": "ff5c792bac2122d5b0cd207df8f8ac5b8068b718",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4178,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 138,
"path": "/test/test_ci_container.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2017 Rohan Garg <[email protected]>\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire 'vcr'\n\nrequire_relative '../lib/ci/container'\nrequire_relative '../lib/ci/container/ephemeral'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\n# The majority of functionality is covered through containment.\n# Only test what remains here.\nclass ContainerTest < TestCase\n # :nocov:\n def cleanup_container\n # Make sure the default container name isn't used, it can screw up\n # the vcr data.\n c = Docker::Container.get(@job_name)\n c.stop\n c.kill! if c.json.fetch('State').fetch('Running')\n c.remove\n rescue Docker::Error::NotFoundError, Excon::Errors::SocketError\n end\n # :nocov:\n\n def setup\n VCR.configure do |config|\n config.cassette_library_dir = datadir\n config.hook_into :excon\n config.default_cassette_options = {\n match_requests_on: %i[method uri body],\n tag: :erb_pwd\n }\n config.filter_sensitive_data('<%= Dir.pwd %>', :erb_pwd) { Dir.pwd }\n end\n\n @job_name = self.class.to_s\n @image = 'ubuntu:15.04'\n VCR.turned_off { cleanup_container }\n end\n\n def teardown\n VCR.turned_off { cleanup_container }\n end\n\n def vcr_it(meth, **kwords)\n VCR.use_cassette(meth, kwords) do |cassette|\n if cassette.recording?\n VCR.eject_cassette\n VCR.turned_off do\n Docker::Image.create(fromImage: @image)\n end\n VCR.insert_cassette(cassette.name)\n else\n CI::EphemeralContainer.safety_sleep = 0\n end\n yield cassette\n end\n end\n\n def test_exist\n vcr_it(__method__, erb: true) do\n assert(!CI::Container.exist?(@job_name))\n CI::Container.create(Image: @image, name: @job_name)\n assert(CI::Container.exist?(@job_name))\n end\n end\n\n ### Compatibility tests! DirectBindingArray used to live in Container.\n\n def test_to_volumes\n v = CI::Container::DirectBindingArray.to_volumes(['/', '/tmp'])\n assert_equal({ '/' => {}, '/tmp' => {} }, v)\n end\n\n def test_to_bindings\n b = CI::Container::DirectBindingArray.to_bindings(['/', '/tmp'])\n assert_equal(%w[/:/ /tmp:/tmp], b)\n end\n\n def test_to_volumes_mixed_format\n v = CI::Container::DirectBindingArray.to_volumes(['/', '/tmp:/tmp'])\n assert_equal({ '/' => {}, '/tmp' => {} }, v)\n end\n\n def test_to_bindings_mixed_fromat\n b = CI::Container::DirectBindingArray.to_bindings(['/', '/tmp:/tmp'])\n assert_equal(%w[/:/ /tmp:/tmp], b)\n end\n\n def test_to_bindings_colons\n # This is a string containing colon but isn't a binding map\n path = '/tmp/CI::ContainmentTest20150929-32520-12hjrdo'\n assert_raise do\n CI::Container::DirectBindingArray.to_bindings([path])\n end\n\n # This is a string containing colons but is already a binding map because\n # it is symetric.\n path = '/tmp:/tmp:/tmp:/tmp'\n assert_raise do\n CI::Container::DirectBindingArray.to_bindings([path.to_s])\n end\n\n # Not symetric but the part after the first colon is an absolute path.\n path = '/tmp:/tmp:/tmp'\n assert_raise do\n CI::Container::DirectBindingArray.to_bindings([path.to_s])\n end\n end\n\n def test_env_whitelist\n # No problems with empty\n ENV['DOCKER_ENV_WHITELIST'] = nil\n CI::Container.default_create_options\n ENV['DOCKER_ENV_WHITELIST'] = ''\n CI::Container.default_create_options\n\n # Whitelist\n ENV['XX_YY_ZZ'] = 'meow'\n ENV['ZZ_YY_XX'] = 'bark'\n # Single\n ENV['DOCKER_ENV_WHITELIST'] = 'XX_YY_ZZ'\n assert_include CI::Container.default_create_options[:Env], 'XX_YY_ZZ=meow'\n # Multiple\n ENV['DOCKER_ENV_WHITELIST'] = 'XX_YY_ZZ:ZZ_YY_XX'\n assert_include CI::Container.default_create_options[:Env], 'XX_YY_ZZ=meow'\n assert_include CI::Container.default_create_options[:Env], 'ZZ_YY_XX=bark'\n # Hardcoded core variables (should not require explicit whitelisting)\n ENV['DIST'] = 'flippytwitty'\n assert_include CI::Container.default_create_options[:Env], 'DIST=flippytwitty'\n ensure\n ENV.delete('DOCKER_ENV_WHITELIST')\n end\nend\n"
},
{
"alpha_fraction": 0.7339901328086853,
"alphanum_fraction": 0.7339901328086853,
"avg_line_length": 21.55555534362793,
"blob_id": "d43dd6a35d014f4e123844a56fc7340d62d7bfe6",
"content_id": "c9bf71677219ee44b58741229bec28b79ab06ef0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 9,
"path": "/jenkins-jobs/nci/mgmt_repo_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../job'\n\n# Cleans up dockers.\nclass MGMTRepoCleanupJob < JenkinsJob\n def initialize\n super('mgmt_repo_cleanup', 'mgmt_repo_cleanup.xml.erb')\n end\nend\n"
},
{
"alpha_fraction": 0.7811831831932068,
"alphanum_fraction": 0.7818959355354309,
"avg_line_length": 102.9259262084961,
"blob_id": "d24c60f1b7c5c6ceab8aba27f47df2a30f3e8995",
"content_id": "b724bc8951bebb18c248769825e63d9563317e25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2806,
"license_type": "no_license",
"max_line_length": 353,
"num_lines": 27,
"path": "/docs/Environment_Variables.md",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# General\n\n|Variable|Description|\n|--------|-----------|\n|DEBFULLNAME|Standard for packager name (changelogs, control etc.)|\n|DEBEMAIL|Standard for packager email (see DEBFULLNAME)|\n|NOMANGLE_MAINTAINER|Do not adjust control file to show DEBFULLNAME as maintainer|\n|TYPE|Build permutation (unstable, stable etc.). Often also used to derive repository names.|\n|DIST|Distribution codename (e.g. xenial)|\n|PANGEA_TEST_EXECUTION|Set by test suite to switch some code paths into simulation mode|\n|PANGEA_DOCKER_NO_FLATTEN|Prevents docker maintenance from flattening the created image. This is faster but consumes more disk AND there is a limit to how much history docker can keep on an image, if it is exceeded image creation fails.|\n|DOCKER_ENV_WHITELIST|Whitelists environment variables for automatic forwarding into Docker containers.|\n|PANGEA_PROVISION_AUTOINST|Enables os-autoinst provisioning in docker images.|\n|SSH_KEY_FILE|Standard variable to pass key file paths into tooling (not suported by everything). This is used to pass Jenkins secrets around, the variable is then used by the tooling to adjust SSH/GIT to pick the correct key file|\n|PANGEA_MAIL_CONFIG_PATH|Path to mail config yaml for pangea/mail.rb|\n|PANGEA_UNDER_TEST|Set during test runs. Only should used if code paths need disabling during tests. Check with Harald before using it.|\n|PANGEA_DOCKER_IMAGE|NCI only. Allows forcing a specific docker image (by name) to be used by contain.rb\n|PANGEA_ARCH_BIN_ONLY|true/false. Default: true. Controls whether to perform bin_only builds on !arch:all architecutres (i.e. !amd64)|\n\n# Job (aka Project) updates\n\n|Variable|Description|\n|--------|-----------|\n|UPDATE_INCLUDE|Limits jenkins jobs getting updated during updater runs. Useful to speed things up when only a specific job needs pushing to jenkins. Values is a string that is checked with `.include?` against all jobs. Can also be a regex but must be in a string of the form `/regexgoeshere/`|\n|NO_UPDATE|Disables `git fetch`, `bzr update` etc.. New projects are still cloned, but existing ones will not get updated. This must be used with care as it can revert jobs to an early config for example WRT dependency linking. Useful to speed things up when running a job update within a short time frame.|\n|PANGEA_FACTORY_THREADS|Overrides maximum thread count for project factorization. Can potentially improve `git fetch` speed by spreading IO-waiting across multiple threads. Note that Ruby's GIL can get in the way and more threads aren't necessarily faster! Careful with KDE servers, they reject connections from the same host exceeding a certain limit.|\n|PANGEA_FACTORIZE_ONLY|Partial string of projects to factorize, this can be used to only git update a selected repo. Best not use, there's lots of caveats you have to be aware of.|\n"
},
{
"alpha_fraction": 0.5753477811813354,
"alphanum_fraction": 0.5786321759223938,
"avg_line_length": 23.41509437561035,
"blob_id": "92eb18162e84263c1d42dc7b70dd68b47bbdc6e2",
"content_id": "78b1d3686b5fce0e7ff8fac6703dfa493435a231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5176,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 212,
"path": "/test/test_merger_branch_sequence.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'rugged'\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/merger/branch_sequence'\n\nrequire 'logger'\n\nclass BranchSequenceTest < TestCase\n def in_repo(&_block)\n Dir.mktmpdir(__callee__.to_s) do |t|\n g = Git.clone(repo_path, t)\n g.config('user.name', 'KCIMerger Test')\n g.config('user.email', 'noreply')\n g.chdir do\n yield g\n end\n end\n end\n\n def create_sample_file(g, name)\n FileUtils.touch(\"#{name}file\")\n g.add(\"#{name}file\")\n g.commit_all(\"#{name}msg\")\n end\n\n def rugged_commit_all(repo)\n index = repo.index\n index.add_all\n index.write\n tree = index.write_tree\n\n author = { name: 'Test', email: '[email protected]', time: Time.now }\n parents = repo.empty? || repo.head_unborn? ? [] : [repo.head.target]\n\n Rugged::Commit.create(repo,\n author: author,\n message: 'commitmsg',\n committer: author,\n parents: parents,\n tree: tree,\n update_ref: 'HEAD')\n end\n\n def rugged_push_all(repo)\n origin = repo.remotes['origin']\n repo.references.each_name do |r|\n origin.push(r)\n end\n end\n\n def git_add_file(name, branch)\n rugged_in_repo(checkout_branch: branch) do |repo|\n FileUtils.touch(name)\n rugged_commit_all(repo)\n end\n end\n\n def rugged_in_repo(**kwords, &_block)\n Dir.mktmpdir(__callee__.to_s) do |t|\n repo = Rugged::Repository.clone_at(repo_path, t, **kwords)\n Dir.chdir(repo.workdir) do\n yield repo\n end\n end\n end\n\n def git_branch(branches:, from: nil)\n kwords = from ? { checkout: from } : {}\n rugged_in_repo(**kwords) do |repo|\n branches.each do |branch|\n if repo.head_unborn?\n repo.head = \"refs/heads/#{branch}\"\n rugged_commit_all(repo)\n end\n repo.create_branch(branch) unless repo.branches.exist?(branch)\n end\n rugged_push_all(repo)\n end\n end\n\n def git_init_repo(path)\n FileUtils.mkpath(path)\n Rugged::Repository.init_at(path, :bare)\n File.absolute_path(path)\n end\n\n def init_repo_path\n @repo_path = \"#{@tmpdir}/remote\"\n FileUtils.mkpath(@repo_path)\n git_init_repo(@repo_path)\n rugged_in_repo do |repo|\n rugged_push_all(repo)\n end\n @repo_path\n end\n\n def repo_path\n @repo_path ||= init_repo_path\n end\n\n def test_full_sequence\n rugged_in_repo do |repo|\n repo.head = 'refs/heads/Neon/stable'\n FileUtils.touch('stable_c1')\n rugged_commit_all(repo)\n\n repo.create_branch('Neon/unstable', 'Neon/stable')\n repo.checkout('Neon/unstable')\n FileUtils.touch('unstable_c1')\n rugged_commit_all(repo)\n\n repo.create_branch('Neon/unstable-very', 'Neon/unstable')\n repo.checkout('Neon/unstable-very')\n FileUtils.touch('unstable-very_c1')\n rugged_commit_all(repo)\n\n repo.checkout('Neon/stable')\n FileUtils.touch('stable_c2')\n rugged_commit_all(repo)\n\n rugged_push_all(repo)\n end\n\n in_repo do |g|\n BranchSequence.new('Neon/stable', git: g)\n .merge_into('Neon/unstable')\n .merge_into('Neon/unstable-very')\n .push\n end\n\n in_repo do |g|\n g.checkout('Neon/unstable')\n assert_path_exist('stable_c1')\n assert_path_exist('stable_c2')\n assert_path_exist('unstable_c1')\n\n g.checkout('Neon/unstable-very')\n assert_path_exist('stable_c1')\n assert_path_exist('stable_c2')\n assert_path_exist('unstable_c1')\n assert_path_exist('unstable-very_c1')\n end\n end\n\n def test_no_stable\n rugged_in_repo do |repo|\n repo.head = 'refs/heads/Neon/unstable'\n FileUtils.touch('unstable_c1')\n rugged_commit_all(repo)\n\n rugged_push_all(repo)\n end\n\n in_repo do |g|\n BranchSequence.new('Neon/stable', git: g)\n .merge_into('Neon/unstable')\n .push\n end\n\n in_repo do |g|\n g.checkout('Neon/unstable')\n assert_path_exist('unstable_c1')\n end\n end\n\n def test_no_unstable\n rugged_in_repo do |repo|\n repo.head = 'refs/heads/Neon/stable'\n FileUtils.touch('stable_c1')\n rugged_commit_all(repo)\n\n rugged_push_all(repo)\n end\n\n in_repo do |g|\n BranchSequence.new('Neon/stable', git: g)\n .merge_into('Neon/unstable')\n .push\n end\n\n in_repo do |g|\n g.checkout('Neon/stable')\n assert_path_exist('stable_c1')\n end\n end\n\n def test_no_middle\n # Three step sequence, where the middle branch doesn't exist. This should\n # not raise anything!\n\n rugged_in_repo do |repo|\n repo.head = 'refs/heads/Neon/unstable'\n FileUtils.touch('unstable_c1')\n rugged_commit_all(repo)\n\n rugged_push_all(repo)\n end\n\n in_repo do |g|\n BranchSequence.new('Neon/stable', git: g)\n .merge_into('Neon/yolo')\n .merge_into('Neon/unstable')\n .push\n end\n\n in_repo do |g|\n g.checkout('Neon/unstable')\n assert_path_exist('unstable_c1')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6637167930603027,
"alphanum_fraction": 0.6725663542747498,
"avg_line_length": 11.55555534362793,
"blob_id": "8ecba3ffe0f4fdf52ce8faed062ed440d7373dc0",
"content_id": "afd6089eb9980c20d1125bc7fbeab96dc2700179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 9,
"path": "/test/data/test_ci_package_builder/test_setcap_subproc_fail/build/debian/rules",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/make -f\n\n%:\n\texit 1\n\noverride_dh_auto_install:\n\tsetcap foo /workspace/yolo/bar || true\n\n.PHONY: clean\n"
},
{
"alpha_fraction": 0.6968026757240295,
"alphanum_fraction": 0.6990076899528503,
"avg_line_length": 35.279998779296875,
"blob_id": "bc3b74b748dfbf00cdc942172248e06bb4bce51f",
"content_id": "4d3c822985d2bf3e0c747a5a5b6469c4f9f8713d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 907,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 25,
"path": "/test/test_qml_static_map.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/qml/static_map'\nrequire_relative 'lib/testcase'\n\n# test qml_static_map\n# This is mostly covered indirectly through dependency_verifier\nclass QmlStaticMapTest < TestCase\n def new_mod(id, version = nil)\n QML::Module.new(id, version)\n end\n\n def test_parse\n previous_file = QML::StaticMap.instance_variable_get(:@data_file)\n QML::StaticMap.instance_variable_set(:@data_file, data)\n assert_equal(data, QML::StaticMap.instance_variable_get(:@data_file))\n map = QML::StaticMap.new\n assert_nil(map.package(new_mod('groll')))\n assert_equal('plasma-framework',\n map.package(new_mod('org.kde.plasma.plasmoid')))\n assert_nil(map.package(new_mod('org.kde.kwin')))\n assert_equal('kwin', map.package(new_mod('org.kde.kwin', '2.0')))\n ensure\n QML::StaticMap.instance_variable_set(:@data_file, previous_file)\n end\nend\n"
},
{
"alpha_fraction": 0.7166666388511658,
"alphanum_fraction": 0.7611111402511597,
"avg_line_length": 44,
"blob_id": "499e3434ff9519986cfe488c27da3598db03b1be",
"content_id": "75cea5c4c1f81a4f9741c32c1a813c9129f692f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 4,
"path": "/nci/imager/config-hooks-neon-developer/99-no-gnome.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# SPDX-FileCopyrightText: 2020 Jonathan Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\napt remove -y gnome-shell ubuntu-session\n"
},
{
"alpha_fraction": 0.6267052292823792,
"alphanum_fraction": 0.6337329745292664,
"avg_line_length": 37.39682388305664,
"blob_id": "2ab95d71f685829616cfe2bdba3eea928e7125ea",
"content_id": "9a2045a699c0e2402d4ada0d98931ea4ad4038fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2419,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 63,
"path": "/nci/lint_bin/test_packaging.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/dpkg'\nrequire_relative '../../lib/lint/control'\nrequire_relative '../../lib/lint/cmake'\nrequire_relative '../../lib/lint/lintian'\nrequire_relative '../../lib/lint/merge_marker'\nrequire_relative '../../lib/lint/series'\nrequire_relative '../../lib/lint/symbols'\nrequire_relative '../lib/lint/result_test'\n\nmodule Lint\n # Test static files.\n class TestPackaging < ResultTest\n def self.arch_all?\n DPKG::HOST_ARCH == 'amd64'\n end\n\n def setup\n @dir = 'build' # default dir\n # dir override per class\n @klass_to_dir = {\n Lintian => '.', # lint on the source's changes\n CMake => '.' # cmake needs access to result/ and build/ (the latter for ignores)\n }\n end\n\n %i[Control Series Symbols Lintian CMake].each do |klass_name|\n # Because this is invoked as a kind of blackbox test we'd have a really\n # hard time of testing lintian without either tangling the test up\n # with the build test or adding binary artifacts to the repo. I dislike\n # both so lets assume Lintian doesn't mess up its two function\n # API.\n next if ENV['PANGEA_TEST_NO_LINTIAN'] && klass_name == :Lintian\n # only run source lintian on amd64, the source is the same across arches.\n next if klass_name == :Lintian && !arch_all?\n\n %w[warnings informations errors].each do |meth_type|\n class_eval <<-RUBY, __FILE__, __LINE__ + 1\n def test_#{klass_name.downcase}_#{meth_type}\n log_klass = #{klass_name}\n assert_meth = \"assert_#{meth_type}\".to_sym\n dir = @klass_to_dir.fetch(log_klass, @dir)\n\n # NB: test-unit runs each test in its own instance, this means we\n # need to use a class variable as otherwise the cache wouldn't\n # persiste across test_ invocations :S\n result = @@result_#{klass_name} ||= log_klass.new(dir).lint\n send(assert_meth, result)\n end\n RUBY\n end\n end\n\n # FIXME: merge_marker disabled as we run after build and after build\n # debian/ contains debian/tmp and others with binary artifacts etcpp..\n # def test_merge_markers\n # assert_result MergeMarker.new(\"#{@dir}/debian\").lint\n # end\n end\nend\n"
},
{
"alpha_fraction": 0.7723509669303894,
"alphanum_fraction": 0.7723509669303894,
"avg_line_length": 39.266666412353516,
"blob_id": "1ab0870cb051e39afcfa9442c1b55a90d3cc99d3",
"content_id": "e49a5883a2c93b4ff1cceb08e71546cfa366fa5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 30,
"path": "/nci/imager/build-hooks-neon-mobile/092-apt-blacklist.chroot",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -ex\n\necho 'running blacklist hook'\n\n# Drop blacklisted nonesense pulled in via recommends or platform seed.\napt-get purge -y unattended-upgrades || true\n\n# colord gets removed because it would get dragged in by cups but after\n# discussion with Rohan Garg I've come to the conclusion that colord makes\n# no sense by default. If the user wants to do color profile management, sure,\n# but this is a very specific desire usually requiring very specific hardware\n# to perform the calibration. Without a profile colord adds no value so\n# we may as well not ship it by default as it has no effect until the user\n# sets it up with a profile.\n# This is using a slightly dirty trick. For whatever reason we cannot easily\n# keep it from installating initially, so instead we'll purge it via dpkg.\n# This will fail if it'd break dependencies. Furthermore we'll check apt\n# consistency afterwards to make double sure nothing broke.\n# Should this break in the future colord may have become a require depends and\n# we need to track down why that happend and discuss what to do about it.\ndpkg --purge colord\napt-get check\n\n# Drop now excess deps\napt-get --purge autoremove -s\napt-get check\n\necho 'blacklist done'\n"
},
{
"alpha_fraction": 0.6808883547782898,
"alphanum_fraction": 0.686148464679718,
"avg_line_length": 29.553571701049805,
"blob_id": "941225e0f40febe17530039811c81dedff7c5078",
"content_id": "96d6c8767cb286a8b05d56c5aecfd09a7feda70f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1711,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 56,
"path": "/test/test_nci_snap_idenitifer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/snap/identifier'\n\nrequire 'mocha/test_unit'\n\nmodule NCI::Snap\n class IdentifierTest < TestCase\n def test_init\n i = Identifier.new('foo')\n assert_equal('foo', i.name)\n assert_equal('latest', i.track)\n assert_equal('stable', i.risk)\n assert_nil(i.branch)\n end\n\n def test_extensive\n i = Identifier.new('foo/latest/edge')\n assert_equal('foo', i.name)\n assert_equal('latest', i.track)\n assert_equal('edge', i.risk)\n assert_nil(i.branch)\n end\n\n def test_bad_inputs\n # bad track\n assert_raises do\n Identifier.new('foo/xx/edge')\n end\n\n # any branch\n assert_raises do\n Identifier.new('foo/latest/edge/yy')\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6553672552108765,
"alphanum_fraction": 0.6578782200813293,
"avg_line_length": 21.43661880493164,
"blob_id": "3a44abc6bba236e06e4e3cdab1560c50767f2c56",
"content_id": "c094b6ad1927492c3a71080a4b87281de3fade90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1593,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 71,
"path": "/mgmt/docker.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\nrequire_relative '../lib/nci'\nrequire_relative '../lib/mgmt/deployer'\n\nclass TeeLog\n def initialize(*ios, prefix: nil)\n @ios = ios\n @stderr = STDERR # so we can log unexpected method calls in method_missing\n @prefix = prefix\n end\n\n def write(*args)\n @ios.each { |io| io.write(\"{#{@prefix}} \", *args) }\n end\n\n def close\n @ios.each(&:close)\n end\n\n def method_missing(*args)\n @stderr.puts \"TeeLog not implemented: #{args}\"\n end\nend\n\ndef setup_logger(name)\n log_path = \"#{Dir.pwd}/#{name}.log\"\n warn \"logging to #{log_path}\"\n tee = TeeLog.new(STDOUT, File.open(log_path, \"a\"), prefix: name)\n $stdout = tee\n $stderr = tee\nend\n\npid_map = {}\n\np ENV\nwarn \"debian only: #{ENV.include?('PANGEA_DEBIAN_ONLY')}\"\nwarn \"ubuntu only: #{ENV.include?('PANGEA_UBUNTU_ONLY')}\"\nwarn \"nci current?: #{ENV.include?('PANGEA_NEON_CURRENT_ONLY')}\"\n\nubuntu_series = NCI.series.keys\nubuntu_series = [NCI.current_series] if ENV.include?('PANGEA_NEON_CURRENT_ONLY')\nubuntu_series = [] if ENV.include?('PANGEA_DEBIAN_ONLY')\nubuntu_series.each_index do |index|\n series = ubuntu_series[index]\n origins = ubuntu_series[index + 1..-1]\n name = \"ubuntu-#{series}\"\n warn \"building #{name}\"\n pid = fork do\n setup_logger(name)\n d = MGMT::Deployer.new('ubuntu', series, origins)\n d.run!\n exit\n end\n\n pid_map[pid] = \"ubuntu-#{series}\"\nend\n\nec = Process.waitall\n\nexit_status = 0\n\nec.each do |pid, status|\n next if status.success?\n\n puts \"ERROR: Creating container for #{pid_map[pid]} failed\"\n exit_status = 1\nend\n\nexit exit_status\n"
},
{
"alpha_fraction": 0.7341040372848511,
"alphanum_fraction": 0.7341040372848511,
"avg_line_length": 56.66666793823242,
"blob_id": "ca5964b20ec495eb2621725f9ad502d009bec3cf",
"content_id": "5221a44aa13e94684768a5f1cdda8c8ad5672d42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 3,
"path": "/nci/imager/config-hooks-neon/apt.conf.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "rm config/chroot_apt/apt.conf || true\necho 'Debug::pkgProblemResolver \"true\";' >> config/chroot_apt/apt.conf\necho 'Acquire::Languages \"none\";' >> config/chroot_apt/apt.conf\n"
},
{
"alpha_fraction": 0.6777508854866028,
"alphanum_fraction": 0.7188633680343628,
"avg_line_length": 36.59090805053711,
"blob_id": "7a32df7e29724c5b19f4ef2f83b64458c7c7558f",
"content_id": "18a28032fd61312b87afbcd779a7202efe14ab2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1654,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 44,
"path": "/test/test_jenkins_timestamp.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/jenkins/timestamp'\n\nrequire 'mocha/test_unit'\n\nmodule Jenkins\n class TimestampTest < TestCase\n def test_time\n utime = '1488887711165'\n time = Jenkins::Timestamp.time(utime)\n assert_equal([11, 55, 11, 7, 3, 2017, 2, 66, false, 'UTC'], time.utc.to_a)\n # Make sure we have preserved full precision. Jenkins timestamps have\n # microsecond precision, we rational them by /1000 for Time.at. The\n # precision should still be passed into the Time object though.\n assert_equal(165_000, time.usec)\n end\n\n def test_date\n utime = '1488887711165'\n assert_equal('2017-03-07', Jenkins::Timestamp.date(utime).to_s)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7201001644134521,
"alphanum_fraction": 0.7257357835769653,
"avg_line_length": 39.9487190246582,
"blob_id": "8be250e3e21247aa0b30b1dd9d2a906b54b0b194",
"content_id": "6d6e137d32ef96b41797a9d21d3e3b0896e3c8c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1597,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 39,
"path": "/jenkins-jobs/nci/mgmt_version_list.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'pipelinejob'\n\n# does a whole bunch of stuff to do with versions. notably assert we have\n# all released and generates a version dump for consumption by the website\nclass MGMTVersionListJob < PipelineJob\n attr_reader :dist\n attr_reader :type\n attr_reader :notify\n\n def initialize(dist:, type:, notify: false)\n # crons once a day. maybe should be made type dependent and run more often\n # for dev editions and less for user editions (they get run on publish)?\n super(\"mgmt_version_list_#{dist}_#{type}\",\n template: 'mgmt_version_list', cron: (notify ? 'H H * * *' : ''))\n @dist = dist\n @type = type\n @notify = notify\n end\nend\n"
},
{
"alpha_fraction": 0.7223264575004578,
"alphanum_fraction": 0.730456531047821,
"avg_line_length": 30.979999542236328,
"blob_id": "0d1f67dc1b0fef6d4aa424f7801d40ede4d4a444",
"content_id": "e2f8505eae03bbfe6882dbfe37b868baf780d01f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1599,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/ci/repo_console.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n# Copyright (C) 2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'optparse'\nrequire 'ostruct'\nrequire 'uri'\n\nrequire_relative '../lib/aptly-ext/filter'\nrequire_relative '../lib/aptly-ext/package'\nrequire_relative '../lib/aptly-ext/remote'\n\noptions = OpenStruct.new\n\nparser = OptionParser.new do |opts|\n opts.banner = \"Usage: #{opts.program_name} [-g GATEWAY]\"\n\n opts.on('-g', '--gateway URI', 'open gateway to remote') do |v|\n options.gateway = URI(v)\n end\nend\nparser.parse!\n\nRepo = Aptly::Repository\nSnap = Aptly::Snapshot\nKey = Aptly::Ext::Package::Key\nPub = Aptly::PublishedRepository\n\nAptly::Ext::Remote.connect(options.gateway) do\n require 'irb'\n IRB.start\nend\n"
},
{
"alpha_fraction": 0.732891857624054,
"alphanum_fraction": 0.7428256273269653,
"avg_line_length": 37.553192138671875,
"blob_id": "37222928379d614a4349337375d132ea04cd065a",
"content_id": "6345efe19e8996ae92659d2d6443cb1013e4f5f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1812,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 47,
"path": "/xci/repo_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'net/ssh'\n\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative '../lib/aptly-ext/repo_cleaner'\n\n# SSH tunnel so we can talk to the repo\nFaraday.default_connection_options =\n Faraday::ConnectionOptions.new(timeout: 15 * 60)\n\nsocket_uri = URI('ssh://aptly@localhost/home/aptly/aptly.socket')\nAptly::Ext::Remote.connect(socket_uri) do\n # Perhaps somewhat unfortunately the cleaner runs on repo names rather than\n # objects, so we'll simply break down the objects to their names\n names = Aptly::Repository.list.collect(&:Name)\n\n RepoCleaner.clean(names, keep_amount: 8)\nend\n\nputs 'Finally cleaning out database...'\nNet::SSH.start('localhost', 'aptly') do |ssh|\n # Set XDG_RUNTIME_DIR so we can find our dbus socket.\n ssh.exec!(<<-COMMAND)\nXDG_RUNTIME_DIR=/run/user/`id -u` systemctl --user start aptly_db_cleanup\n COMMAND\nend\nputs 'All done!'\n"
},
{
"alpha_fraction": 0.6987951993942261,
"alphanum_fraction": 0.7148594260215759,
"avg_line_length": 48.79999923706055,
"blob_id": "f567b1f9d70702754fed31f38b22caca827bd7c6",
"content_id": "79068c43a2638dd40fe1b125ab8872c79c2cdf46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 5,
"path": "/nci/imager/config-settings-neon-mobile.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "EDITION=$(echo $NEONARCHIVE | sed 's,/, ,')\nexport LB_ISO_VOLUME=\"${IMAGENAME} ${EDITION} Mobile \\$(date +%Y%m%d)\"\nexport LB_ISO_APPLICATION=\"KDE neon Plasma Mobile Live\"\nexport LB_LINUX_FLAVOURS=\"generic-hwe-22.04\"\nexport LB_LINUX_PACKAGES=\"linux\"\n"
},
{
"alpha_fraction": 0.66209477186203,
"alphanum_fraction": 0.6795511245727539,
"avg_line_length": 28.703702926635742,
"blob_id": "dba181e30d0ef9047d087db03d4c3845aaeca39a",
"content_id": "8e22ddf1caa12b99c3115dc88541ca18a9dfd109",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 27,
"path": "/nci/lint_bin.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nENV['CI_REPORTS'] = \"#{Dir.pwd}/reports\"\nBUILD_URL = ENV.fetch('BUILD_URL') { File.read('build_url') }.strip\nENV['LOG_URL'] = \"#{BUILD_URL}/consoleText\"\n\n# DONT FLIPPING EAT STDOUTERR ... WHAT THE FUCK\n# option for ci-reporter\nENV['CI_CAPTURE'] = 'off'\n\nif ENV['PANGEA_UNDER_TEST']\n warn 'Enabling test coverage merging'\n require 'simplecov'\n SimpleCov.start do\n root ENV.fetch('SIMPLECOV_ROOT') # set by lint_bin test\n command_name \"#{__FILE__}_#{Time.now.to_i}_#{rand}\"\n merge_timeout 16\n end\nend\n\nDir.glob(File.expand_path('lint_bin/test_*.rb', __dir__)).each do |file|\n require file\nend\n"
},
{
"alpha_fraction": 0.6119049787521362,
"alphanum_fraction": 0.6163256764411926,
"avg_line_length": 36.99609375,
"blob_id": "56fe3d86bf2e3fbe58f04e4ed5edc45649604937",
"content_id": "5590f3284ad945ac719be419bfefec178bf16a4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 9727,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 256,
"path": "/lib/debian/deb822.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'insensitive_hash/minimal'\n\nrequire_relative 'relationship'\n\nmodule Debian\n # Deb822 specification parser.\n class Deb822\n def self.parse_relationships(line)\n ret = []\n line.split(',').each do |string|\n rel_array = []\n string.split('|').each do |entry|\n r = Relationship.new(entry)\n next unless r.name # Invalid name, ignore this bugger.\n\n rel_array << r\n end\n ret << rel_array unless rel_array.empty?\n end\n ret\n end\n\n def parse_relationships(line)\n self.class.parse_relationships(line)\n end\n\n # Disable metrics violations here. This method is super complicated, super\n # deep and super hard to read. Splitting it does not improve any of this\n # though. Eventually it may be nice to have a more OOP Parser where the\n # parsable types are own Objects, again, I am not sure that will improve\n # readability in any form or fashion.\n # rubocop:disable Metrics/MethodLength, Metrics/BlockNesting,\n # rubocop:disable Metrics/AbcSize, Metrics/CyclomaticComplexity,\n # rubocop:disable Metrics/PerceivedComplexity\n def parse_paragraph(lines, fields = {})\n mandatory_fields = fields[:mandatory] || []\n multiline_fields = fields[:multiline] || []\n foldable_fields = fields[:foldable] || []\n relationship_fields = fields[:relationship] || []\n\n current_header = nil\n data = InsensitiveHash.new\n\n while (line = lines.shift) && line && !line.strip.empty?\n next if line.start_with?('#') # Comment\n\n # Make sure the line is well-formed. If a paragraph is at EOF but\n # doesn't have a terminal \\n it'd trip our parsing expectations here.\n line = line + \"\\n\" unless line.end_with?(\"\\n\")\n\n header_match = line.match(/^(\\S+):(.*\\n?)$/)\n # Only match a single space for foldables, in the case of multiline\n # we want to preserve all leading whitespaces except for the\n # format-enforced whitespace.\n fold_match = line.match(/^\\s(.+\\n)$/)\n\n unless header_match.nil?\n # 0 = full match\n # 1 = key match\n # 2 = value match\n key = header_match[1].lstrip\n value = header_match[2].lstrip\n current_header = key\n if foldable_fields.include?(key.downcase)\n # We do not care about whitespaces for folds, so strip everything.\n if relationship_fields.include?(key.downcase)\n value = parse_relationships(value)\n else\n # FIXME: this is utterly wrong.\n # A foldable field simply can be folded. In addition to that\n # Binary and Uploaders are comma separated. That does not mean\n # every foldable field is comma seprated! e.g. Dgit is a hash\n # followed by a whitespace! (why is beyond anyones fucking\n # apprehension). If the debian policy was any more of a cluster\n # fuck it'd be on pornhub.\n value = value.split(',').collect(&:strip).select { |x| !x.empty? }\n end\n elsif multiline_fields.include?(key.downcase)\n # For multiline we want to preserve right hand side whitespaces.\n value\n else\n value.strip!\n end\n data[key] = value\n next\n end\n\n unless fold_match.nil?\n # Folding value encountered -> append to header.\n # [0] = full match\n # [1] = value match\n value = fold_match[1]\n\n # Fold matches can either be proper RFC 5322 folds or\n # multiline continuations, latter wants to preserve\n # newlines and so forth.\n # The type is entirely dependent on what the header field is.\n if foldable_fields.include?(current_header.downcase)\n value = value.lstrip\n # We do not care about whitespaces for folds, so strip everything.\n if relationship_fields.include?(current_header.downcase)\n value = parse_relationships(value)\n else\n value = value.split(',').collect(&:strip).select { |x| !x.empty? }\n end\n data[current_header] += value\n elsif multiline_fields.include?(current_header.downcase)\n # For multiline fields we only want to strip the leading space, all\n # other lefthand side spaces are to be preserved!\n # This strip is implictly done by our regex. No extra work!\n # We'll also want to preserve right hand side whitespaces.\n data[current_header] << value\n else\n raise \"A field is folding that is not allowed to #{current_header}\"\n end\n\n next\n end\n\n # TODO: user defined fields\n\n raise \"Paragraph parsing ran into an unknown line: '#{line}'\"\n end\n\n # If the entire stanza was commented out we can end up with no data, it\n # is very sad.\n return nil if data.empty?\n\n # Special cleanup code for multiline fields.\n data.each do |field, _value|\n # For multiline field we've preserved its right hand side whitespaces\n # (i.e. trailing ones). BUT! for all other fields we do not do this.\n # This makes multiline fields inconsistent with the rest of the gang as\n # they have a trailing newline whereas others have not. To clean this\n # up we'll strip the fully assembled field value to drop the whitespaces\n # trailing the last line. As a result the string will no longer end\n # in a newline. This allows us to consinstently dump fields+\\n when\n # generating output from this again. It also means fields are consistent\n # and one does not have to .strip everything for good measure.\n next unless multiline_fields.include?(field.downcase)\n\n data[field].rstrip!\n end\n\n mandatory_fields.each do |field|\n # TODO: this should really make a list and complain all at once or\n # something.\n raise \"Missing mandatory field #{field}\" unless data.include?(field)\n end\n\n data\n end\n # rubocop:enable\n\n def parse!\n raise 'Not implemented'\n end\n\n def dump_paragraph(data, fields = {})\n # mandatory_fields = fields[:mandatory] || []\n multiline_fields = fields[:multiline] || []\n foldable_fields = fields[:foldable] || []\n relationship_fields = fields[:relationship] || []\n\n output = ''\n data.each do |field, value|\n key = \"#{field}: \"\n output += key\n field = field.downcase # normalize for include check\n if multiline_fields.include?(field)\n output += output_multiline(value)\n elsif relationship_fields.include?(field)\n # relationships are always foldable but different than other\n # data as they are nested and have alternatives x|y\n output += output_relationship(value, key.length)\n elsif foldable_fields.include?(field)\n output += output_foldable(value, key.length)\n else\n # FIXME: rstrip because multiline do not get their trailing newline\n # stripped in parsing\n output += (value || value.rstrip)\n end\n output += \"\\n\"\n end\n output\n end\n\n private\n\n def output_multiline(data)\n data = data.join(\"\\n\") if data.respond_to?(:join)\n data = data.to_s unless data.is_a?(String)\n data.gsub(\"\\n\", \"\\n \").chomp(' ')\n end\n\n def output_relationship(data, indent)\n # This implements output as per wrap-and-sort. That is:\n # - sort all\n # - substvars at the end\n # - output >80 => line break each entry\n joined_alternatives = data.collect do |entry|\n entry.join(' | ')\n end\n joined_alternatives = sort_relationships(joined_alternatives)\n output = joined_alternatives.join(', ')\n return output if output.size < (80 - indent)\n\n joined_alternatives.join(\",\\n#{Array.new(indent, ' ').join}\")\n end\n\n def sort_relationships(array)\n array.sort do |x, y|\n x_var = x[0] == '$'\n y_var = y[0] == '$'\n # If x is a variable it loses to everything, if y is a var it loses\n # to everything. If both or none are vars regular alpha order applies.\n next 1 if x_var && !y_var\n next -1 if y_var && !x_var #\n\n x <=> y\n end\n end\n\n def output_foldable(data, indent)\n # This implements output as per wrap-and-sort. That is:\n # - sort all\n # - substvars at the end\n # - output >80 => line break each entry\n data.sort\n output = data.collect(&:to_s).join(', ')\n return output if output.size < (80 - indent)\n\n data.collect(&:to_s).join(\",\\n#{Array.new(indent, ' ').join}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7424242496490479,
"alphanum_fraction": 0.7424242496490479,
"avg_line_length": 15.5,
"blob_id": "2b2acc813767762041203abd87d438d9c0b47a21",
"content_id": "504ee54b630674bc8128340054b409c539a0d1cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 12,
"path": "/lib/xenonci.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'xci'\n\n# BS-specific Xenon CI\nmodule XenonCI\n extend XCI\n\n module_function\n def architectures_for_type\n data['architectures_for_type']\n end\nend\n"
},
{
"alpha_fraction": 0.7027720808982849,
"alphanum_fraction": 0.7089322209358215,
"avg_line_length": 39.58333206176758,
"blob_id": "a267946f67e5147b4537b88ae4502cc892f9e74f",
"content_id": "a32ca0a18c2d7016e247de4344234c57622b0031",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1948,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 48,
"path": "/overlay-bin/cmake",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n#\n# frozen_string_literal: true\n#\n# SPDX-FileCopyrightText: 2017-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/paths' # Drop the overlay from the PATH env.''\nrequire_relative '../lib/pangea_build_type_config'\n\n# Drops excessively verbose makefile setting from cmake invocations.\n# With the verbosity enabled the entire CC lines including all -Ds\n# are printed, which is undesirable as this is a WHOLE lot of information.\n\nunless File.exist?(\"#{WORKSPACE}/cmake_verbose_makefile\")\n ARGV.reject! { |x| x.start_with?('-DCMAKE_VERBOSE_MAKEFILE') }\n ARGV.reject! { |x| x.start_with?('-DCMAKE_AUTOGEN_VERBOSE') }\nend\n\n# Force a cmake build type as opposed to distro cflags. This notably makes it\n# possible for cmake configs (such as Qt's) to detect this as a release type and\n# inject flags accordingly (e.g. -DNDEBUG)\nif PangeaBuildTypeConfig.override?\n type = 'RelWithDebInfo'\n if PangeaBuildTypeConfig.release_build?\n # Don't build debug symbols for release-lts, users shouldn't really use that\n # edition and debug symbmols are fairly expensive space-wise (and for build\n # speed actually... stripping can take ages).\n type = 'Release'\n end\n\n warn 'Tooling: forcing build type'\n found_type = ARGV.reject! { |x| x.start_with?('-DCMAKE_BUILD_TYPE') }\n ARGV.unshift(\"-DCMAKE_BUILD_TYPE=#{type}\") if found_type\nend\n\nif File.exist?(\"#{WORKSPACE}/adt_disabled\")\n # But only if this is a configure run, not a script run!\n ex_markers = %w[-E --build --find-package]\n in_all = ARGV.any? { |x| x.start_with?('-DCMAKE_INSTALL_PREFIX') }\n ex_none = ex_markers.none? { |x| ARGV.any? { |arg| arg.start_with?(x) } }\n if in_all && ex_none\n warn \"Tooling: injecting -DBUILD_TESTING=OFF; this build doesn't have ADT\"\n ARGV.unshift('-DBUILD_TESTING=OFF')\n end\nend\nwarn \"Executing: cmake #{ARGV.join(' ')}\"\nexec('cmake', *ARGV)\n"
},
{
"alpha_fraction": 0.676662802696228,
"alphanum_fraction": 0.6801230311393738,
"avg_line_length": 25.81443214416504,
"blob_id": "570f89096ee6e6e6543e994d257cf938521bea41",
"content_id": "0fa9a97b5273442de6f65d0ef21ee5d5e41eddd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2601,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 97,
"path": "/lib/asgen.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'json'\n\nmodule ASGEN\n # Helper with a default to_json method serializing all members into a hash.\n module MemberSerialize\n def to_json(options = nil)\n instance_variables.collect do |x|\n value = to_json_instance(x)\n next nil unless value\n\n [x.to_s.tr('@', ''), value]\n end.compact.to_h.to_json(options)\n end\n\n def to_json_instance(var)\n instance_variable_get(var)\n end\n end\n\n # An asgen suite.\n class Suite\n include MemberSerialize\n\n attr_accessor :name\n attr_accessor :sections\n attr_accessor :architectures\n\n attr_accessor :dataPriority\n attr_accessor :baseSuite\n attr_accessor :useIconTheme\n\n def initialize(name, sections = [], architectures = [])\n @name = name\n @sections = sections\n @architectures = architectures\n end\n\n def to_json_instance(var)\n value = super(var)\n return nil if var == :@name # Don't serialize name\n\n value\n end\n end\n\n # Configuration main class.\n class Conf\n # rubocop:disable Naming/VariableName\n include MemberSerialize\n\n attr_accessor :ProjectName\n attr_accessor :ArchiveRoot\n attr_accessor :MediaBaseUrl\n attr_accessor :HtmlBaseUrl\n attr_accessor :Backend\n attr_accessor :Features\n attr_accessor :Suites\n attr_accessor :CAInfo\n attr_accessor :ExtraMetainfoDir\n\n def initialize(name)\n @ProjectName = name\n @Features = {}\n @Suites = []\n end\n\n def write(file)\n File.write(file, JSON.generate(self))\n end\n\n def to_json_instance(var)\n value = super(var)\n value = value.map { |x| [x.name, x] }.to_h if var == :@Suites\n value\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 18.25,
"blob_id": "628dd1b013f4837f73bbbf16c933be0a42de59ad",
"content_id": "210db09a853f5775a4ad52d587d70d2a4e757bbb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 154,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 8,
"path": "/git_submodule_setup.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nset -ex\n\ngit submodule init\ngit submodule update --remote --init --recursive\ngit config --local include.path ../.gitconfig\ngit fetch --verbose\n"
},
{
"alpha_fraction": 0.7847222089767456,
"alphanum_fraction": 0.7847222089767456,
"avg_line_length": 35,
"blob_id": "0e0330d7bf56006ba4137d7a7c67b91bf66323cc",
"content_id": "40512c9d08e6af085660102006daeeb44d11ddfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 8,
"path": "/lib/docker/containment.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../ci/containment'\n\nwarn 'W: Requiring deprecated Containment class. Use CI::Containment instead.'\nContainment = CI::Containment\nraise NameError, 'Using deprecated Containment class. Use CI::Containment.'\n\n# TODO: remove docker/containment\n"
},
{
"alpha_fraction": 0.7062298655509949,
"alphanum_fraction": 0.7158969044685364,
"avg_line_length": 34.80769348144531,
"blob_id": "e699a81c0feab36923976467d018dc316ba3e080",
"content_id": "b6ea01bf836ee7655a8fa44f10aff6f3786b9ce6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1862,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 52,
"path": "/deploy_in_container.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\nSCRIPTDIR=$(readlink -f $(dirname -- \"$0\"))\n\nexport DEBIAN_FRONTEND=noninteractive\nexport LANG=en_US.UTF-8\n\nenv_tag=\"LANG=$LANG\"\n(! grep -q $env_tag /etc/profile) && echo $env_tag >> /etc/profile\n(! grep -q $env_tag /etc/environment) && echo $env_tag >> /etc/environment\n\n# Ubuntu's armhf and aarch64 containers are a bit fscked right now\n# manually fix their source entries\n(grep -q ports.ubuntu.com /etc/apt/sources.list) && cat > /etc/apt/sources.list << EOF\ndeb http://ports.ubuntu.com/ubuntu-ports/ $DIST main universe multiverse\ndeb http://ports.ubuntu.com/ubuntu-ports/ $DIST-updates main universe multiverse\ndeb http://ports.ubuntu.com/ubuntu-ports/ $DIST-security main universe multiverse\ndeb http://ports.ubuntu.com/ubuntu-ports/ $DIST-backports main universe multiverse\nEOF\n\necho 'Acquire::Languages \"none\";' > /etc/apt/apt.conf.d/00aptitude\necho 'APT::Color \"1\";' > /etc/apt/apt.conf.d/99color\n\ni=\"5\"\nwhile [ $i -gt 0 ]; do\n apt-get update && break\n i=$((i-1))\n sleep 60 # sleep a bit to give problem a chance to resolve\ndone\n\nif [ \"$DIST\" = \"bionic\" ]; then\n # Workaround to make sure early bionic builds don't break.\n apt-mark hold makedev # do not update makedev it won't work on unpriv'd\nfi\n\nESSENTIAL_PACKAGES=\"rake ruby ruby-dev libruby build-essential zlib1g-dev git-core libffi-dev cmake pkg-config wget dirmngr ca-certificates debhelper libssl-dev\"\ni=\"5\"\nwhile [ $i -gt 0 ]; do\n apt-get -y -o APT::Get::force-yes=true -o Debug::pkgProblemResolver=true \\\n install ${ESSENTIAL_PACKAGES} && break\n i=$((i-1))\ndone\n\ncd $SCRIPTDIR\n# Ensure rake is installed\nruby -e \"Gem.install('rake')\"\n# And tty-command (used by apt, which we'll load in the rake tasks)\nruby -e \"Gem.install('tty-command') unless Gem::Specification.map(&:name).include?('tty-command')\"\n\nexec rake -f deploy_in_container.rake deploy_in_container\n"
},
{
"alpha_fraction": 0.6346678137779236,
"alphanum_fraction": 0.6521739363670349,
"avg_line_length": 32.66666793823242,
"blob_id": "3cdff14b70f48cd18c240a0578884e7c314ffd04",
"content_id": "70a8e8c3ed1bde8344b127e96a9f68e8afe48f27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6969,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 207,
"path": "/test/test_nci_repo_content_pusher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2019-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/asgen_push'\nrequire_relative '../nci/cnf_push'\n\nrequire 'mocha/test_unit'\nrequire 'shellwords'\n\nmodule NCI\n class RepoContentPushTest < TestCase\n def setup\n Net::SFTP.expects(:start).never\n Net::SSH.expects(:start).never\n RSync.expects(:sync).never\n ENV['DIST'] = 'xenial'\n ENV['TYPE'] = 'release'\n ENV['APTLY_REPOSITORY'] = 'release'\n ENV['SSH_KEY_FILE'] = 'ssh.keyfile'\n end\n\n def test_run_no_export\n # Nothing generated => no pushing\n AppstreamGeneratorPush.new.run\n end\n\n class SFTPStub\n # Note that exceptions are only allocated. They won't be functional!\n # We get away with this because we only check if an exception was\n # raised. Moving forward we should avoid calling methods on sftp exceptions\n # OR revisit the cheap allocate trick.\n # Allocated objects exist, but they have not had their initialize called.\n\n def initialize(session:)\n @session = session\n end\n\n attr_reader :session\n\n def chroot(path)\n \"#{remote_dir}/#{path}\"\n end\n\n # also act as Dir, technically a different object in net::sftp though\n def dir\n self\n end\n\n class NameStub\n def initialize(path)\n @path = path\n end\n\n def name\n File.basename(@path)\n end\n\n def symlink?\n File.symlink?(@path)\n end\n end\n\n def glob(path, pattern)\n warn 'glob'\n Dir.glob(\"#{chroot(path)}/#{pattern}\") do |entry|\n yield NameStub.new(entry)\n end\n end\n\n def upload!(from, to)\n FileUtils.cp_r(from, chroot(to), verbose: true)\n end\n\n def stat!(path)\n File.stat(chroot(path))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n def mkdir!(path)\n Dir.mkdir(chroot(path))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n def readlink!(path)\n NameStub.new(File.readlink(chroot(path)))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n def symlink!(old, new)\n File.symlink(old, chroot(new))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n def rename!(old, new, _flags)\n File.rename(chroot(old), chroot(new))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n def remove!(path)\n system \"ls -lah #{chroot(path)}\"\n FileUtils.rm(chroot(path))\n rescue Errno::ENOENT => e\n raise Net::SFTP::StatusException.allocate.exception(e.message)\n end\n\n private\n\n def remote_dir\n @session.remote_dir\n end\n end\n\n class SSHStub\n attr_reader :remote_dir\n\n def initialize(remote_dir:)\n @remote_dir = remote_dir\n @cmd = TTY::Command.new\n end\n\n def exec!(cmd)\n argv = Shellwords.split(cmd)\n raise if argv.any? { |x| x.include?('..') }\n\n argv = argv.collect { |x| x.start_with?('/') ? \"#{remote_dir}/#{x}\" : x }\n @cmd.run!(*argv)\n end\n end\n\n def test_run_asgen\n remote_dir = \"#{Dir.pwd}/remote\"\n\n ssh = SSHStub.new(remote_dir: remote_dir)\n sftp = SFTPStub.new(session: ssh)\n\n Net::SFTP.expects(:start).at_least_once.yields(sftp)\n # ignore this for now. hard to test and not very useful to test either\n RSync.expects(:sync)\n\n FileUtils.mkpath(remote_dir)\n FileUtils.cp_r(\"#{data}/.\", '.')\n AppstreamGeneratorPush.new.run\n\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/Components-amd64.yml\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/2a42a2c7a5dbd3fdb2e832aed8b2cbd5\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/Components-amd64.yml.xz\")\n # tempdir during upload\n assert_path_not_exist(\"#{remote_dir}/home/neonarchives/dep11_push.release\")\n end\n\n def test_run_old_old_asgen\n # Has a current and an old variant already.\n remote_dir = \"#{Dir.pwd}/remote\"\n\n ssh = SSHStub.new(remote_dir: remote_dir)\n sftp = SFTPStub.new(session: ssh)\n\n Net::SFTP.expects(:start).at_least_once.yields(sftp)\n # ignore this for now. hard to test and not very useful to test either\n RSync.expects(:sync)\n\n FileUtils.cp_r(\"#{data}/.\", '.')\n AppstreamGeneratorPush.new.run\n\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/Components-amd64.yml\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/2a42a2c7a5dbd3fdb2e832aed8b2cbd5\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/Components-amd64.yml.xz\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/Components-amd64.yml.xz.old\")\n # tempdir during upload\n assert_path_not_exist(\"#{remote_dir}/home/neonarchives/dep11_push.release\")\n\n # This is a special blob which is specifically made different so\n # it gets dropped by the blobs cleanup.\n assert_path_not_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/dep11/by-hash/MD5Sum/e3f347cf9d52eeb49cace577d3cb1239\")\n # Ensure the cnf/ data has not been touched (cnf is command-not-found). They are managd by a different bit of tech.\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/cnf/Commands-amd64\")\n end\n\n def test_run_cnf\n # Different variant using cnf data.\n remote_dir = \"#{Dir.pwd}/remote\"\n\n ssh = SSHStub.new(remote_dir: remote_dir)\n sftp = SFTPStub.new(session: ssh)\n\n Net::SFTP.expects(:start).at_least_once.yields(sftp)\n\n FileUtils.mkpath(remote_dir)\n FileUtils.cp_r(\"#{data}/.\", '.')\n CNFPusher.run\n\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/cnf/Commands-amd64\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/cnf/by-hash/MD5Sum/60ed4219ebc0380566fc80d89f8554be\")\n assert_path_exist(\"#{remote_dir}/home/neonarchives/aptly/skel/release/dists/xenial/main/cnf/by-hash/MD5Sum/Commands-amd64\")\n # tempdir during upload\n assert_path_not_exist(\"#{remote_dir}/home/neonarchives/cnf_push.release\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6338582634925842,
"alphanum_fraction": 0.6561679840087891,
"avg_line_length": 32.86666488647461,
"blob_id": "2689355c1433dbb6dcf4ab91d953700d19edd604",
"content_id": "3b8686ef633f54d61b725feea0a82151d0c1b31a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 45,
"path": "/test/test_nci_cnf_generate.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/cnf_generate'\n\nmodule NCI\n class CNFGeneratorTest < TestCase\n def setup\n ENV['TYPE'] = 'release'\n ENV['REPO'] = 'user'\n ENV['DIST'] = 'focal'\n ENV['ARCH'] = 'amd64'\n end\n\n def test_run\n pkg1 = mock('pkg1')\n pkg1.stubs(:name).returns('atcore-bin')\n pkg1.stubs(:version).returns('1.0')\n pkg2 = mock('pkg2')\n pkg2.stubs(:name).returns('qtav-players')\n pkg2.stubs(:version).returns('2.0')\n\n lister = mock('NCI::RepoPackageLister')\n lister.stubs(:packages).returns([pkg1, pkg2])\n\n NCI::RepoPackageLister.stubs(:new).returns(lister)\n\n stub_request(:get, 'https://contents.neon.kde.org/v2/find/archive.neon.kde.org/user/dists/focal?q=*/bin/*')\n .to_return(status: 200, body: File.read(data('json')))\n\n CNFGenerator.new.run\n # Not using this but the expectation is that we can run the generator in the same dir multiple times for different archies\n ENV['ARCH'] = 'armhf'\n CNFGenerator.new.run\n\n assert_path_exist('repo/main/cnf/Commands-amd64')\n assert_path_exist('repo/main/cnf/Commands-armhf')\n # Stripping to ignore \\n differences, I don't really care.\n assert_equal(File.read(data('Commands-amd64')).strip, File.read('repo/main/cnf/Commands-amd64').strip)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.708737850189209,
"alphanum_fraction": 0.724271833896637,
"avg_line_length": 27.61111068725586,
"blob_id": "9dada35d983ea862cb0d119274f2a8ed987d310a",
"content_id": "e92d85979447a7f7207f8e7f26f707e3fb4905b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/lib/tty_command.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\nrequire_relative 'tty_command/native_printer'\n\n# NB: our command construct with native printers by default!\n\nmodule TTY\n class Command\n alias :initialize_orig :initialize\n def initialize(*args, **kwords)\n kwords = { printer: NativePrinter }.merge(kwords)\n initialize_orig(*args, **kwords)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6704384684562683,
"alphanum_fraction": 0.6874116063117981,
"avg_line_length": 32.66666793823242,
"blob_id": "048c36020941a4ca6a90bea59a0596111c9c9ca7",
"content_id": "e3e3316933239a55305e5d98b738646bdb045754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 707,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 21,
"path": "/overlay-bin/dpkg-deb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2021-2022 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/paths' # Drop the overlay from the PATH env.\n\n# Jammy defaults to zstd but our aptly presently doesn't support it. Use xz instead.\nif ENV['DIST'] == 'jammy'\n ARGV.reject! { |arg| arg.start_with?('-Z') }\n ARGV.prepend('-Zxz')\n puts \"Removing compression from deb; new ARGV #{ARGV}\"\nend\n\nif ENV['PANGEA_UNDER_TEST']\n ARGV.reject! { |arg| arg.start_with?('-Z', '-S') }\n ARGV.prepend('-Znone', '-Snone')\n puts \"Removing compression from deb; new ARGV #{ARGV}\"\nend\n\nexec('dpkg-deb', *ARGV)\n"
},
{
"alpha_fraction": 0.6969798803329468,
"alphanum_fraction": 0.7164429426193237,
"avg_line_length": 32.11111068725586,
"blob_id": "b2b9ccc511563e68d334d302d2302e1508c82d96",
"content_id": "445b9a4c253fe5916b6a63cd7661cd778fa4b7ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2980,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 90,
"path": "/Gemfile",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: CC0-1.0\n# SPDX-FileCopyrightText: none\n\nsource 'https://gem.cache.pangea.pub/private' do\n # These are built by our gemstash tech\n # https://invent.kde.org/neon/infrastructure/pangea-gemstash\n # and pushed into our gem cache for consumption. See Gemfile.git for info.\n # These are actual gems in our cache, they mustn't have a git: argument.\n gem 'releaseme' # Not released as gem at all\n gem 'jenkins_junit_builder' # Forked because upstream depends on an ancient nokogiri that doesn't work with ruby3\nend\n\nsource 'https://gem.cache.pangea.pub/'\ngem 'activesupport', '>= 6.0.3.1'\ngem 'aptly-api', '~> 0.10'\ngem 'bencode' # for torrent generation\ngem 'concurrent-ruby'\ngem 'deep_merge', '~> 1.0'\ngem 'docker-api', '~> 2.0' # Container.refresh! only introduced in 1.23\ngem 'faraday' # implicit dep but also explicitly used in e.g. torrent tech\ngem 'gir_ffi', '0.14.1'\ngem 'git'\ngem 'gitlab'\ngem 'htmlentities'\ngem 'insensitive_hash'\ngem 'jenkins_api_client'\ngem 'logger-colors'\ngem 'net-ftp-list'\ngem 'net-sftp'\ngem 'net-ssh', '>= 6.1'\ngem 'net-ssh-gateway'\ngem 'nokogiri'\ngem 'octokit'\ngem 'rake', '~> 13.0'\ngem 'rugged'\ngem 'sigdump'\ngem 'tty-command'\ngem 'tty-pager'\ngem 'tty-prompt'\ngem 'tty-spinner'\ngem 'webrick'\ngem 'ed25519'\ngem 'bcrypt_pbkdf'\n\n# Git URI management\ngem 'git_clone_url', '~> 2.0'\ngem 'uri-ssh_git', '~> 2.0'\n\n# Test logging as junit (also used at runtime for linting)\ngem 'ci_reporter_minitest'\ngem 'ci_reporter_test_unit'\ngem 'minitest', '=5.18.0'\ngem 'test-unit', '~> 3.0'\n\n# Hack. jenkins_api_client depends on mixlib-shellout which depends on\n# chef-utils and that has excessive version requirements for ruby because chef\n# has an entire binary distro bundle that allows them to pick whichever ruby.\n# Instead lock chef-utils at a low enough version that it will work for all our\n# systems (currently that is at least bionic with ruby 2.5).\n# jenkins_api_client literally just uses it as a glorified system() so the\n# entire dep is incredibly questionable.\n# Anyway, this lock should be fine to keep so long as the jenkins api client\n# doesn't go belly up.\ngem 'chef-utils', '<= 13'\n# We are also locking this for now becuase this is a working version and\n# the dep that pulls in chef-utils. This way we can ensure the version\n# combination will work.\n# NOTE: when either of the constraints conflict with another constraint\n# of one of the gems this needs revisiting. Either we can move to a newer\n# version because bionic is no longer used on any server or we need a more\n# creative solution.\ngem 'mixlib-shellout', '~> 3.1.0'\n\ngroup :development, :test do\n gem 'droplet_kit'\n gem 'equivalent-xml'\n gem 'mocha', '~> 1.9'\n gem 'parallel_tests'\n gem 'rake-notes'\n gem 'rubocop', '~> 1.10.0'\n gem 'rubocop-checkstyle_formatter'\n gem 'ruby-progressbar'\n gem 'simplecov'\n gem 'simplecov-rcov'\n gem 'terminal-table'\n gem 'tty-logger'\n gem 'vcr', '>= 3.0.1'\n gem 'webmock'\nend\n"
},
{
"alpha_fraction": 0.5213862061500549,
"alphanum_fraction": 0.5285669565200806,
"avg_line_length": 29.65071678161621,
"blob_id": "da8664e67500626a9435b986df85e5eac68725cc",
"content_id": "da4939c7ee6b249110cff5dc95f089e3b464e89a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6406,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 209,
"path": "/test/test_nci_finalizer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'rugged'\n\nrequire_relative '../nci/debian-merge/finalizer'\n\nmodule NCI\n module DebianMerge\n class NCIFinalizerTest < TestCase\n def setup; end\n\n def test_run\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n `git branch Neon/unstable`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n `git branch Neon/pending-merge`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n tag_base = 'debian/2'\n url = remote_dir\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n Finalizer.new.run\n\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n `git checkout Neon/unstable`\n assert($?.success?)\n # system 'bash'\n assert_path_exist('c2')\n `git checkout Neon/pending-merge`\n assert_false($?.success?) # doesnt exist anymore\n end\n end\n end\n end\n\n def test_already_ffd\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n # Same commit\n `git branch Neon/unstable`\n `git branch Neon/pending-merge`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n tag_base = 'debian/2'\n url = remote_dir\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n # not raising anything\n Finalizer.new.run\n end\n\n def test_ff_not_possible\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n `git branch Neon/pending-merge`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n `git branch Neon/unstable`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n tag_base = 'debian/2'\n url = remote_dir\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n # going to fail sine pending is behind unstable\n assert_raises Finalizer::Repo::NoFastForwardError do\n Finalizer.new.run\n end\n end\n\n def test_not_pushable\n remote_dir = File.join(Dir.pwd, 'remote/fishy')\n FileUtils.mkpath(remote_dir)\n Dir.chdir(remote_dir) do\n `git init --bare .`\n end\n Dir.mktmpdir do |tmpdir|\n Dir.chdir(tmpdir) do\n `git clone #{remote_dir} clone`\n Dir.chdir('clone') do\n File.write('c1', '')\n `git add c1`\n `git commit --all -m 'commit'`\n # NB: if we define no message the tag itself will not have a date\n `git tag debian/1-0 -m 'fancy message'`\n\n File.write('c2', '')\n `git add c2`\n `git commit --all -m 'commit'`\n `git tag debian/2-0 -m 'fancy message'`\n\n # Same commit\n `git branch Neon/unstable`\n\n `git push --all`\n `git push --tags`\n end\n end\n end\n\n tag_base = 'debian/2'\n url = remote_dir\n json = { repos: [url], tag_base: tag_base }\n File.write('data.json', JSON.generate(json))\n\n # We have nothing to merge push here, should not fail in any way\n # but be simply noop\n Finalizer.new.run\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7321814298629761,
"alphanum_fraction": 0.7321814298629761,
"avg_line_length": 20.045454025268555,
"blob_id": "f6304a8d0facf30fbab2516db468b56d42e7bf59",
"content_id": "2322f3c91399495167429a5d5956d2ac28e28559",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 463,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 22,
"path": "/test/helper.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\nrequire 'simplecov'\nrequire 'simplecov-rcov'\n\nSimpleCov.formatters = [\n SimpleCov::Formatter::HTMLFormatter,\n SimpleCov::Formatter::RcovFormatter\n]\n\nSimpleCov.start\n\nif ENV.include?('JENKINS_HOME')\n # Compatibility output to JUnit format.\n require 'ci/reporter/rake/test_unit_loader'\n\n # Force VCR to not ever record anything.\n require 'vcr'\n VCR.configure do |c|\n c.default_cassette_options = { record: :none }\n end\nend\n"
},
{
"alpha_fraction": 0.5758585333824158,
"alphanum_fraction": 0.6019989848136902,
"avg_line_length": 29.96825408935547,
"blob_id": "0b91c1323495adf4aef368d25727a92920b30060",
"content_id": "644b1ceb8c72afd475e4f48b38fc48c78f99f1dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3902,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 126,
"path": "/test/test_debian_version.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/debian/version'\nrequire_relative 'lib/testcase'\n\n# Test debian version\nclass DebianVersionTest < TestCase\n required_binaries(%w[dpkg])\n\n def test_native\n s = '5.0'\n v = Debian::Version.new(s)\n assert_equal(nil, v.epoch)\n assert_equal('5.0', v.upstream)\n assert_equal(nil, v.revision)\n end\n\n def test_native_epoch\n s = '1:5.0'\n v = Debian::Version.new(s)\n assert_equal('1', v.epoch)\n assert_equal('5.0', v.upstream)\n assert_equal(nil, v.revision)\n end\n\n def test_full\n s = '1:5.0-0ubuntu1'\n v = Debian::Version.new(s)\n assert_equal('1', v.epoch)\n assert_equal('5.0', v.upstream)\n assert_equal('0ubuntu1', v.revision)\n end\n\n def assert_v_greater(a, b, message = nil)\n message = build_message(message,\n '<?> is not greater than <?>.',\n a.full, b.full)\n assert_block message do\n (a <=> b) == 1\n end\n end\n\n def assert_v_lower(a, b, message = nil)\n message = build_message(message,\n '<?> is not lower than <?>.',\n a.full, b.full)\n assert_block message do\n (a <=> b) == -1\n end\n end\n\n def assert_v_equal(a, b, message = nil)\n message = build_message(message,\n '<?> is not equal to <?>.',\n a.full, b.full)\n assert_block message do\n (a <=> b).zero?\n end\n end\n\n def assert_v_flip(x, y)\n assert_v_greater(x, y)\n assert_v_lower(y, x)\n end\n\n def test_greater_and_lower\n assert_v_flip(Debian::Version.new('1:0'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1.1'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1+'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1.1~'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('2~'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1-1'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1-0.1'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1-0+'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('1-1~'), Debian::Version.new('1'))\n assert_v_flip(Debian::Version.new('0:1-0.'), Debian::Version.new('1'))\n end\n\n def test_equal\n assert_v_equal(Debian::Version.new('1-0'), Debian::Version.new('1'))\n assert_v_equal(Debian::Version.new('1'), Debian::Version.new('1'))\n assert_v_equal(Debian::Version.new('0:1'), Debian::Version.new('1'))\n assert_v_equal(Debian::Version.new('0:1-0'), Debian::Version.new('1'))\n assert_v_equal(Debian::Version.new('0:1-0'), Debian::Version.new('1'))\n end\n\n def test_manipulation\n v = Debian::Version.new('5:1.0-1')\n assert_equal('5:1.0-1', v.to_s)\n assert_equal('5:1.0-1', v.full)\n v.upstream = '2.0'\n assert_equal('5:2.0-1', v.to_s)\n assert_equal('5:2.0-1', v.full)\n end\n\n def test_comparable\n # Implements Comparable module.\n assert(Debian::Version.new('1.0') > Debian::Version.new('0.1'))\n end\n\n def test_dpkg_installed\n # Make sure we can find dpkg when we need to.\n # This test assumes dpkg is actually available in $PATH which we require\n # for this entire testcase anyway per `required_binaries`.\n ENV.delete('PANGEA_UNDER_TEST')\n\n Debian::Version.dpkg_installed = nil\n Debian::Version.new('1.0') > Debian::Version.new('0.1')\n ensure\n Debian::Version.dpkg_installed = nil\n end\n\n def test_dpkg_not_installed\n # As above but expect failure as we have no dpkg available in $PATH\n ENV.delete('PANGEA_UNDER_TEST')\n\n FileUtils.ln_s('/usr/bin/which', '.', verbose: true)\n ENV['PATH'] = Dir.pwd\n\n Debian::Version.dpkg_installed = nil\n assert_raises do\n Debian::Version.new('1.0') > Debian::Version.new('0.1')\n end\n ensure\n Debian::Version.dpkg_installed = nil\n end\nend\n"
},
{
"alpha_fraction": 0.6506922245025635,
"alphanum_fraction": 0.6687965989112854,
"avg_line_length": 34.433963775634766,
"blob_id": "8e8c7c1556174c0f7eb9144da29bda3736bc4591",
"content_id": "fd53c726c6f72f388b994a060c7cfed53c0ccc4d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1878,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 53,
"path": "/test/test_lint_lintian.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../lib/lint/lintian'\nrequire_relative 'lib/testcase'\n\n# Test lint lintian\nclass LintLintianTest < TestCase\n def setup\n Dir.mkdir('result')\n # Linter checks for a changes file to run against\n FileUtils.touch('result/foo.changes')\n end\n\n def test_lint\n cmd = TTY::Command.new\n cmd\n .expects(:run!)\n .with { |*args| args[0] == 'lintian' && args.any? { |x| x.end_with?('foo.changes') } }\n .returns(TTY::Command::Result.new(1, File.read(data), ''))\n # Exit code 0 or 1 shouldn't make a diff. Lintian will exit 1 if there\n # are problems, 0 when not - we do run parsing eitherway\n\n r = Lint::Lintian.new('result', cmd: cmd).lint\n assert(r.valid)\n assert_equal(2, r.informations.size)\n assert_equal(4, r.warnings.size)\n assert_equal(0, r.errors.size)\n end\n\n def test_lib_error_promotion\n # soname mismatches on library packages are considered errors,\n # others are mere warnings.\n # this helps guard against wrong packaging leading to ABI issues\n cmd = TTY::Command.new\n cmd\n .expects(:run!)\n .with { |*args| args[0] == 'lintian' && args.any? { |x| x.end_with?('foo.changes') } }\n .returns(TTY::Command::Result.new(0, <<~OUTPUT, ''))\nW: libkcolorpicker0: package-name-doesnt-match-sonames libkColorPicker0.1.4\nW: meow: package-name-doesnt-match-sonames libmeowsa\n OUTPUT\n # Exit code 0 or 1 shouldn't make a diff. Lintian will exit 1 if there\n # are problems, 0 when not - we do run parsing eitherway\n\n r = Lint::Lintian.new('result', cmd: cmd).lint\n assert(r.valid)\n assert_equal(0, r.informations.size)\n assert_equal(1, r.warnings.size)\n assert_equal(1, r.errors.size)\n end\nend\n"
},
{
"alpha_fraction": 0.697721540927887,
"alphanum_fraction": 0.7053164839744568,
"avg_line_length": 36.26415252685547,
"blob_id": "21c7195681ded729e468b035ec56bc2a353db629",
"content_id": "6fd46ffb2a85d682ac37a3e8e9f53199cadc1ab7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1975,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 53,
"path": "/nci/repo_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'net/ssh'\n\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative '../lib/aptly-ext/repo_cleaner'\n\n# Helper to construct repo names\nclass RepoNames\n def self.all(prefix)\n NCI.series.collect { |name, _version| \"#{prefix}_#{name}\" }\n end\nend\n\nif $PROGRAM_NAME == __FILE__ || ENV.include?('PANGEA_TEST_EXECUTION')\n # SSH tunnel so we can talk to the repo\n Faraday.default_connection_options =\n Faraday::ConnectionOptions.new(timeout: 15 * 60)\n Aptly::Ext::Remote.neon do\n RepoCleaner.clean(%w[unstable stable] +\n RepoNames.all('unstable') + RepoNames.all('stable'),\n keep_amount: 1)\n RepoCleaner.clean(RepoNames.all('release'), keep_amount: 4)\n end\n\n puts 'Finally cleaning out database...'\n Net::SSH.start('archive-api.neon.kde.org', 'neonarchives') do |ssh|\n # Set XDG_RUNTIME_DIR so we can find our dbus socket.\n ssh.exec!(<<-COMMAND)\nXDG_RUNTIME_DIR=/run/user/`id -u` systemctl --user start aptly_db_cleanup\n COMMAND\n end\n puts 'All done!'\nend\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.676344096660614,
"avg_line_length": 27.18181800842285,
"blob_id": "2dc09c95a47ff56a38ca663131a6c18796d4d71e",
"content_id": "342db75e064e25e66809cd62d0282f80b9b82182",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1860,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 66,
"path": "/nci/asgen_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'fileutils'\n\nrequire_relative '../lib/nci'\nrequire_relative '../lib/rsync'\nrequire_relative 'lib/asgen_remote'\nrequire_relative 'lib/repo_content_pusher'\n\n# appstream pusher\nclass NCI::AppstreamGeneratorPush < NCI::AppstreamGeneratorRemote\n APTLY_HOME = '/home/neonarchives'\n\n Sum = Struct.new(:file, :value)\n\n def repository_path\n # NB: the env var is called aply repo but it is in fact the repo path\n # i.e. not 'unstable_focal' but dev/unstable\n ENV.fetch('APTLY_REPOSITORY')\n end\n\n def exist?(sftp, path)\n sftp.stat!(path)\n true\n rescue Net::SFTP::StatusException\n false\n end\n\n def symlink?(sftp, path)\n sftp.readlink!(path)\n true\n rescue Net::SFTP::StatusException\n false\n end\n\n def run\n # Move data into basic dir structure of repo skel.\n export_data_dir = \"#{export_dir}/data\"\n repo_dir = \"#{export_dir}/repo\"\n content_dir = \"#{repo_dir}/main/dep11\"\n\n unless File.exist?(export_data_dir)\n warn \"The data dir #{export_data_dir} does not exist.\" \\\n ' It seems asgen found no new data. Skipping publish!'\n return\n end\n\n FileUtils.rm_r(repo_dir) if Dir.exist?(repo_dir)\n FileUtils.mkpath(content_dir)\n FileUtils.cp_r(\"#{export_data_dir}/#{dist}/main/.\", content_dir, verbose: true)\n\n NCI::RepoContentPusher.new(content_name: 'dep11', repo_dir: repo_dir, dist: dist).run\n\n FileUtils.rm_rf(repo_dir)\n\n # This is the export dep11 data, we don't need it, so throw it away\n system(\"rm -rf #{export_data_dir}\")\n RSync.sync(from: \"#{export_dir}/*\", to: \"#{rsync_pubdir_expression}/\")\n end\nend\n\nNCI::AppstreamGeneratorPush.new.run if $PROGRAM_NAME == __FILE__\n"
},
{
"alpha_fraction": 0.7041244506835938,
"alphanum_fraction": 0.7135095000267029,
"avg_line_length": 32.18852615356445,
"blob_id": "fb44a330efad7a374acae1020c84d90aec1880ab",
"content_id": "d7ecc09d2a9951f6958522dfb3309f4d25efa087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 4049,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 122,
"path": "/ci/pangea_dput",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2017 Harald Sitter <[email protected]>\n# Copyright (C) 2015-2016 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\nrequire 'optparse'\nrequire 'ostruct'\nrequire 'uri'\n\nrequire_relative '../lib/ci/deb822_lister'\nrequire_relative '../lib/aptly-ext/remote'\n\nSTDOUT.sync = true # Make sure output is synced and bypass caching.\n\noptions = OpenStruct.new\noptions.host = nil\noptions.port = nil\noptions.repos = []\noptions.gateway = nil\n\nparser = OptionParser.new do |opts|\n opts.banner = \"Usage: #{opts.program_name} [options] --repo yolo CHANGESFILE\"\n\n opts.on('-h', '--host HOST', '[deprecated] use a --gateway uri') do |v|\n options.host = v\n end\n\n opts.on('-p', '--port PORT', '[deprecated] use a --gateway uri') do |v|\n options.port = v\n end\n\n opts.on('-r', '--repo REPO', 'target repo name') do |v|\n options.repos << v\n end\n\n opts.on('-g', '--gateway URI', 'open gateway to remote') do |v|\n options.gateway = URI(v)\n end\nend\nparser.parse!\n\nraise parser.help if ARGV.empty? || options.repos.empty?\n\nunless options.gateway\n warn <<-EOF\nYou really need to specify a gateway! That is the aptly host but is\nstupidly named.\nA gateway can be http://localhost:9090 for no gateway or ssh://user@host:port for\nSSH port gateway or ssh://user@host:port/tmp/foo for a socket gateway.\n EOF\nend\n\nraise 'Cannot use both --host and --gateway' if options.host && options.gateway\n\n# Compat handling:\n# We use Aptly::Ext::Remote to configure aptly, this does however require a URI\n# against which it can pick a connector. So we need a gateway even when we have\n# no gateway need, in that case it is simply the specifier of the aptly host\n# via http.\n# Why this compat wasn't introduced when the gatway logic was introduced is\n# beyond me.\nif options.host && options.port\n options.gateway = URI::HTTP.build(host: options.host, port: options.port.to_i)\n warn 'Running in compat mode as both host and port were specified.'\nend\n\nif !options.host && options.port && options.gateway && !options.gateway.port\n options.gateway.port = options.port\n warn 'Running in compat mode and injecting your --port into the gateway!'\nend\n\nif !options.host && options.port && !options.gateway\n options.gateway = URI::HTTP.build(host: 'localhost', port: options.port)\n warn 'Running in compat mode using localhost:$port.'\nend\n\n# Set the timeout to 15 minutes to allow upload of large packages such as\n# firefox and publishing of excessively large repositories.\nFaraday.default_connection_options =\n Faraday::ConnectionOptions.new(timeout: 15 * 60)\n\nAptly::Ext::Remote.connect(options.gateway) do\n repos = options.repos.collect { |name| Aptly::Repository.get(name) }\n\n ARGV.each do |file|\n next unless File.size?(file)\n\n puts \"translating uploads #{file}\"\n files = CI::Deb822Lister.files_to_upload_for(file)\n raise 'Changes lists no files to upload!?' if files.empty?\n\n puts \"Uploading files... #{files}\"\n Aptly::Files.tmp_upload(files) do |dir|\n repos.each { |r| r.add_file(dir, noRemove: 1) }\n end\n puts 'Done uploading.'\n end\n\n repos.each do |r|\n puts \"Republishing #{r}\"\n r.published_in.each(&:update!)\n puts 'Done.'\n end\nend\n"
},
{
"alpha_fraction": 0.5876594185829163,
"alphanum_fraction": 0.6057549715042114,
"avg_line_length": 36.4555549621582,
"blob_id": "0c812d5763fd9de121d30deaf58958fbb56097e9",
"content_id": "f26de51dd7117360723cb33f3168abff0c6a905c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6742,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 180,
"path": "/test/test_nci_repo_cleanup.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/repo_cleanup'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\nrequire 'net/ssh/gateway' # so we have access to the const\n\nclass NCIRepoCleanupTest < TestCase\n def setup\n # Make sure $? is fine before we start!\n reset_child_status!\n # Disable all system invocation.\n Object.any_instance.expects(:`).never\n # FIX_ME line 152 calls system to compare versions. Find another way or delete me.\n #Object.any_instance.expects(:system).never\n\n WebMock.disable_net_connect!\n end\n\n def teardown\n WebMock.allow_net_connect!\n end\n\n def mock_repo\n repo = mock\n repo.expects(:Name)\n end\n\n def test_repo_names\n series = NCI.series\n names = RepoNames.all('foo')\n assert_equal(series.size, names.size)\n end\n\n def test_clean\n session = mock('session')\n session.responds_like_instance_of(Net::SSH::Connection::Session)\n session.expects(:exec!)\n .once # must only be called once; after all is done!!!\n .with(<<-DATA)\nXDG_RUNTIME_DIR=/run/user/`id -u` systemctl --user start aptly_db_cleanup\n DATA\n\n Net::SSH\n .expects(:start)\n .once # must only be called once; after all is done!!!\n .with('archive-api.neon.kde.org', 'neonarchives')\n .yields(session, session)\n\n Aptly::Ext::Remote.expects(:neon).yields\n\n fake_unstable = mock('unstable')\n fake_unstable.stubs(:Name).returns('unstable')\n fake_unstable.expects(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-kf5 1 abc',\n 'Psource kactivities-kf5 3 ghi',\n 'Psource kactivities-kf5 4 jkl',\n 'Psource kactivities-kf5 2 def'])\n fake_unstable.expects(:packages)\n .with(q: '!$Architecture (source)')\n .returns([])\n fake_unstable.expects(:packages)\n .with(q: '$Source (kactivities-kf5), $SourceVersion (1)')\n .returns(['Pamd64 kactivy 1 abc',\n 'Pall kactivy-data 1 def'])\n fake_unstable.expects(:delete_packages)\n .with(['Psource kactivities-kf5 1 abc',\n 'Pamd64 kactivy 1 abc',\n 'Pall kactivy-data 1 def'])\n fake_unstable.expects(:packages)\n .with(q: '$Source (kactivities-kf5), $SourceVersion (2)')\n .returns(['Pamd64 kactivy 2 abc',\n 'Pall kactivy-data 2 def'])\n fake_unstable.expects(:delete_packages)\n .with(['Psource kactivities-kf5 2 def',\n 'Pamd64 kactivy 2 abc',\n 'Pall kactivy-data 2 def'])\n fake_unstable.expects(:packages)\n .with(q: '$Source (kactivities-kf5), $SourceVersion (3)')\n .returns(['Pamd64 kactivy 3 abc',\n 'Pall kactivy-data 3 def'])\n fake_unstable.expects(:delete_packages)\n .with(['Psource kactivities-kf5 3 ghi',\n 'Pamd64 kactivy 3 abc',\n 'Pall kactivy-data 3 def'])\n fake_unstable.expects(:published_in)\n .returns(mock.responds_like_instance_of(Aptly::PublishedRepository))\n # Highest version. must never be queried or we are considering to delete it!\n fake_unstable.expects(:packages)\n .with(q: '$Source (kactivities-kf5), $SourceVersion (4)')\n .never\n\n fake_stable = mock('stable')\n fake_stable.stubs(:Name).returns('stable')\n fake_stable.expects(:packages)\n .with(q: '$Architecture (source)')\n .returns(['Psource kactivities-src-kf5 4 jkl'])\n fake_stable.expects(:packages)\n .with(q: '!$Architecture (source)')\n .returns(['Pamd64 kactivities-kf5 1 abc',\n 'Pamd64 kactivities-kf5 3 ghi'])\n fake_stable.expects(:delete_packages)\n .with('Pamd64 kactivities-kf5 1 abc')\n fake_stable.expects(:published_in)\n .returns(mock.responds_like_instance_of(Aptly::PublishedRepository))\n\n fake_unstable_package = mock('kactivities-kf5')\n fake_unstable_package.stubs(:Package).returns('kactivities-kf5')\n fake_unstable_package.stubs(:Version).returns('3')\n fake_unstable_package.stubs(:Source).returns('kactivities-src-kf5 (4)')\n\n Aptly::Ext::Package\n .expects(:get)\n .with { |x| x.to_s == 'Pamd64 kactivities-kf5 3 ghi' }\n .returns(fake_unstable_package)\n Aptly::Repository.stubs(:list)\n .returns([fake_unstable, fake_stable])\n {\n %w[1 gt 3] => 1 > 3,\n %w[1 lt 3] => 1 < 3,\n %w[4 gt 2] => 4 > 2,\n %w[1 gt 2] => 1 > 2,\n %w[1 lt 2] => 1 < 2,\n %w[3 gt 2] => 3 > 2,\n %w[3 gt 4] => 3 > 4,\n %w[3 lt 4] => 3 < 4\n }.each do |arg_array, return_value|\n Debian::Version\n .any_instance\n .expects(:system)\n .with('dpkg', '--compare-versions', *arg_array)\n .returns(return_value)\n .at_least_once\n end\n\n # RepoCleaner.clean(%w(unstable stable))\n ENV['PANGEA_TEST_EXECUTION'] = '1'\n load(\"#{__dir__}/../nci/repo_cleanup.rb\")\n end\n\n def test_key_from_string\n key = Aptly::Ext::Package::Key.from_string('Psource kactivities-kf5 1 abc')\n assert_equal('source', key.architecture)\n assert_equal('kactivities-kf5', key.name)\n assert_equal('1', key.version)\n # FIXME: maybe this should be called hash?\n assert_equal('abc', key.uid)\n end\n\n def test_key_invalid\n assert_raises ArgumentError do\n Aptly::Ext::Package::Key.from_string('P kactivities-kf5 1 abc')\n end\n\n assert_raises ArgumentError do\n Aptly::Ext::Package::Key.from_string('Psource kactivities-kf5 1 abc asdf')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6622982025146484,
"alphanum_fraction": 0.6666133999824524,
"avg_line_length": 30.129352569580078,
"blob_id": "c7900e1fb968b873c388a507b4e48a193935e9de",
"content_id": "2e81da6ae0e4521d7fceebc7a465bdc45ca19b39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6265,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 201,
"path": "/jenkins_retry.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# coding: utf-8\n# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'optparse'\nrequire 'tty/prompt'\nrequire 'tty/spinner'\n\nrequire_relative 'lib/jenkins'\nrequire_relative 'lib/retry'\nrequire_relative 'lib/thread_pool'\nrequire_relative 'lib/kdeproject_component'\nrequire_relative 'lib/nci'\n\n@exclusion_states = %w[success unstable]\nstrict_mode = false\nnew_release = nil\npim_release = nil\nkf6_release = nil\n\n# This block is very long because it is essentially a DSL.\n# rubocop:disable Metrics/BlockLength\nOptionParser.new do |opts|\n opts.banner = <<-SUMMARY\nUsage: jenkins_retry.rb [options] 'regex'\n\nregex must be a valid Ruby regular expression matching the jobs you wish to\nretry.\n\nOnly jobs that are not queued, not building, and failed will be retired.\n e.g.\n • All build jobs for vivid and utopic:\n '^(vivid|utopic)_.*_.*'\n • All unstable builds:\n '^.*_unstable_.*'\n • All neon kde releases\n 'focal_release_[^_]+_[^_]+$'\n • All jobs:\n '.*'\n\n SUMMARY\n\n opts.on('-p', '--plasma', 'There has been a new Plasma release, run all' \\\n ' watcher jobs for Plasma.') do\n @exclusion_states.clear\n new_release = KDEProjectsComponent.plasma_jobs\n end\n\n opts.on('-g', '--gear', 'There has been new KDE Gear release,' \\\n ' run all watcher jobs for them.') do\n @exclusion_states.clear\n new_release = KDEProjectsComponent.gear_jobs\n end\n\n opts.on('-f', '--frameworks', 'There has been a new Frameworks release, run' \\\n ' all watcher jobs for Frameworks.') do\n @exclusion_states.clear\n new_release = KDEProjectsComponent.frameworks_jobs\n end\n\n opts.on('-kf6', '--frameworks6', 'There has been a new Frameworks release, run' \\\n ' all watcher jobs for Frameworks.') do\n @exclusion_states.clear\n kf6_release = KDEProjectsComponent.kf6_jobs\n end\n\n opts.on('-m', '--mobile', 'There has been a new Plasma Mobile Gear release, run' \\\n ' all watcher jobs for PlaMo.') do\n @exclusion_states.clear\n new_release = KDEProjectsComponent.mobile_jobs\n end\n\n opts.on('--maui', 'There has been a MAUI release/ABI bump, run' \\\n ' all jobs for MAUI.') do\n @exclusion_states.clear\n new_release = KDEProjectsComponent.maui_jobs\n end\n\n opts.on('--pim', 'There has been a PIM ABI bump, run' \\\n ' all unstable jobs for PIM.') do\n @exclusion_states.clear\n pim_release = KDEProjectsComponent.pim_jobs\n end\n\n opts.on('-b', '--build', 'Rebuild even if job did not fail.') do\n @exclusion_states.clear\n end\n\n opts.on('-u', '--unstable', 'Rebuild unstable jobs as well.') do\n @exclusion_states.delete('unstable')\n end\n\n opts.on('-s', '--strict', 'Build jobs whose downstream jobs have failed') do\n @exclusion_states.clear\n strict_mode = true\n end\nend.parse!\n# rubocop:enable Metrics/BlockLength\n\n@log = Logger.new(STDOUT).tap do |l|\n l.progname = 'retry'\n l.level = Logger::INFO\nend\n\npattern = nil\nif new_release\n pattern = Regexp.new(\"watcher_release_[^_]+_(#{new_release.join('|')})$\")\nelsif pim_release\n pattern = Regexp.new(\"#{NCI.current_series}_unstable_kde_(#{pim_release.join('|')})$\")\nelsif kf6_release\n pattern = Regexp.new(\"#{NCI.current_series}_unstable_kf6_(#{kf6_release.join('|')})$\")\nelse\n raise 'Need ruby pattern as argv0' if ARGV.empty?\n\n pattern = Regexp.new(ARGV[0])\nend\n\[email protected] pattern\n\nspinner = TTY::Spinner.new('[:spinner] Loading job list', format: :spin_2)\nspinner.update(title: 'Loading job list')\nspinner.auto_spin\njob_name_queue = Queue.new\njob_names = Jenkins.job.list_all\nspinner.success\n\njob_names.each do |job_name|\n next unless pattern.match(job_name)\n\n job_name_queue << job_name\nend\n\nif job_name_queue.size > 8\n if TTY::Prompt.new.no?(\"Your are going to retry #{job_name_queue.size} jobs.\" \\\n ' Do you want to continue?')\n abort\n end\nelsif job_name_queue.empty?\n abort 'No jobs matched your pattern'\nend\n\[email protected] 'Setting system into maintenance mode.'\nJenkins.system.quiet_down\n\nBlockingThreadPool.run do\n until job_name_queue.empty?\n name = job_name_queue.pop(true)\n Retry.retry_it(times: 5) do\n status = Jenkins.job.status(name)\n queued = Jenkins.client.queue.list.include?(name)\n @log.info \"#{name} | status - #{status} | queued - #{queued}\"\n next if Jenkins.client.queue.list.include?(name)\n\n if strict_mode\n skip = true\n downstreams = Jenkins.job.get_downstream_projects(name)\n downstreams << Jenkins.job.list_details(name.gsub(/_src/, '_pub'))\n downstreams.each do |downstream|\n downstream_status = Jenkins.job.status(downstream['name'])\n next if %w[success unstable running].include?(downstream_status)\n\n skip = false\n end\n @log.info \"Skipping #{name}\" if skip\n next if skip\n end\n\n unless @exclusion_states.include?(Jenkins.job.status(name))\n @log.warn \" #{name} --> build\"\n Jenkins.job.build(name)\n end\n end\n end\nend\n\[email protected] \"The CI is now in maintenance mode. Don't forget to unpause it!\"\n\nunless TTY::Prompt.new.no?('Unpause now? Only when you are sure only useful' \\\n ' jobs are being retried.')\n Jenkins.system.cancel_quiet_down\nend\n"
},
{
"alpha_fraction": 0.7261185050010681,
"alphanum_fraction": 0.7339782118797302,
"avg_line_length": 37.46511459350586,
"blob_id": "7a31db8196f228b495b32117fa54872ed1fa30e5",
"content_id": "ee390c28b2bacc138604e134c63464ee3685f114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1654,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 43,
"path": "/lib/rake/bundle.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# NB: this is used during deployment. Do not require non-core gems globally!\n# require during execution, and make sure the gems are actually installed or\n# fallback logic is in place.\n\n# Bundler can have itself injected in the env preventing bundlers forked from\n# ruby to work correctly. This helper helps with running bundlers in a way\n# that they do not have a \"polluted\" environment.\nmodule RakeBundleHelper\n class << self\n def run(*args)\n require 'bundler'\n Bundler.unbundled_system(*args)\n rescue NameError, LoadError\n system(*args)\n end\n end\nend\n\ndef bundle(*args)\n args = ['bundle'] + args\n RakeBundleHelper.run(*args)\n raise \"Command failed (#{$?}) #{args}\" unless $?.to_i.zero?\nend\n"
},
{
"alpha_fraction": 0.721451461315155,
"alphanum_fraction": 0.7310565710067749,
"avg_line_length": 38.04166793823242,
"blob_id": "92ec84ee55841949567ec106393fbea313c667db",
"content_id": "6332827cc8a2ed8111f8eca8c2aac0da6694182a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 24,
"path": "/nci/imager/config-hooks-neon-mobile/00-neon-forks.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# SPDX-FileCopyrightText: 2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\n# Ensure neon forks are installed. This is similar to neon-forks.chroot as\n# build-hook but runs before live-build and thus allow us to preempt\n# ambiguous errors by using incorrect components.\n#\n# When one of these isn't form us it likely means it has gotten outscored\n# by an ubuntu version in -updates and needs merging.\n\n# All CI builds force the maintainer to be neon so this is a trivial way to\n# determine the origin of the package without having to meddle with dpkg-query\n# format strings and the like or going through apt.\n\npkgs=\"livecd-rootfs\"\nfor pkg in $pkgs; do\n if dpkg-query -s $pkg | grep --fixed-strings --quiet '<[email protected]>'; then\n echo \"$pkg is from neon ✓\"\n else\n echo \"error: $pkg does not come from neon - talk to a dev to get it updated\"\n exit 1\n fi\ndone\n"
},
{
"alpha_fraction": 0.5856595635414124,
"alphanum_fraction": 0.5856595635414124,
"avg_line_length": 40.522727966308594,
"blob_id": "90b906277cee6108db33287546914718effd5bbb",
"content_id": "acb22d6da611215dc442878e5e708118fb9c3e2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1827,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 44,
"path": "/jenkins-jobs/builder.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative 'sourcer'\nrequire_relative 'binarier'\nrequire_relative 'publisher'\n\n# Magic builder to create an array of build steps\n# Fun story: ci_reporter uses builder, builder is Builder, can't have a class\n# called Builder or tests will fail. I do rather love my live. Also generic\n# names are really cool for shared artifacts such as gems. I always try to be\n# as generic as possible with shared names.\nclass BuilderJobBuilder\n def self.job(project, type:, distribution:, architectures:, upload_map: nil)\n basename = basename(distribution, type, project.component, project.name)\n\n dependees = project.dependees.collect do |d|\n \"#{basename(distribution, type, d.component, d.name)}_src\"\n end.compact\n sourcer = SourcerJob.new(basename,\n type: type,\n distribution: distribution,\n project: project)\n publisher = PublisherJob.new(basename,\n type: type,\n distribution: distribution,\n dependees: dependees,\n component: project.component,\n upload_map: upload_map,\n architectures: architectures)\n binariers = architectures.collect do |architecture|\n binarier = BinarierJob.new(basename,\n type: type,\n distribution: distribution,\n architecture: architecture)\n sourcer.trigger(binarier)\n binarier.trigger(publisher)\n binarier\n end\n [sourcer] + binariers + [publisher]\n end\n\n def self.basename(dist, type, component, name)\n \"#{dist}_#{type}_#{component}_#{name}\"\n end\nend\n"
},
{
"alpha_fraction": 0.6266288757324219,
"alphanum_fraction": 0.6304060220718384,
"avg_line_length": 28.747190475463867,
"blob_id": "3dfd6cd1a8856586770be7d7a6fbfcfb20252419",
"content_id": "d449614b588016ae065e4e320ed63bc6271eb2ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 5295,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 178,
"path": "/lib/apt.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2014-2017 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'logger'\nrequire 'open-uri'\nrequire 'tty/command'\n\nrequire_relative 'apt/key'\nrequire_relative 'apt/preference'\nrequire_relative 'apt/repository'\n\n# Cow powers!\n#\n# This module provides access to apt by catching method missing and passing the\n# method call on to apt.\n# So calling Apt.install will call 'apt install'. Also convenient default\n# arguments will be injected into the call to give debugging and so forth.\n#\n# Commands that contain a hyphen are spelt with an underscore due to ruby\n# langauge restrictions. All underscores are automatically replaced with hyphens\n# upon method handling. To bypass this the Abstrapt.run method needs to be used\n# directly.\nmodule Apt\n def self.method_missing(name, *caller_args)\n Abstrapt.run('apt-get', name.to_s.tr('_', '-'), *caller_args)\n end\n\n # More cow powers!\n # Calls apt-get instead of apt. Otherwise the same as {Apt}\n module Get\n def self.method_missing(name, *caller_args)\n Abstrapt.run('apt-get', name.to_s.tr('_', '-'), *caller_args)\n end\n end\n\n # Abstract base for apt execution.\n module Abstrapt\n module ClassMethods\n def run(cmd, operation, *caller_args)\n @log ||= Logger.new(STDOUT)\n auto_update unless operation == 'update'\n run_internal(cmd, operation, *caller_args)\n end\n\n def run_internal(cmd, operation, *caller_args)\n args = run_internal_args(operation, *caller_args)\n @log.warn \"APT run (#{cmd}, #{args})\"\n system(cmd, *args)\n end\n\n def run_internal_args(operation, *caller_args)\n injection_args = []\n caller_args.delete_if do |arg|\n next false unless arg.is_a?(Hash)\n next false unless arg.key?(:args)\n\n injection_args = [*(arg[:args])]\n true\n end\n args = [] + default_args + injection_args\n args << operation\n # Flatten args. system doesn't support nested arrays anyway, so\n # flattening is probably what the caller had in mind\n # (e.g. install(['a', 'b']))\n args + [*caller_args].flatten\n end\n\n def auto_update\n return if @auto_update_disabled\n return unless @last_update.nil? || (Time.now - @last_update) >= (5 * 60)\n return unless Apt.update\n\n @last_update = Time.now\n end\n\n # @return [Array<String>] default arguments to inject into apt call\n def default_args\n @default_args if defined?(@default_args)\n @default_args = []\n @default_args << '-y'\n @default_args << '-o' << 'APT::Get::force-yes=true'\n @default_args << '-o' << 'Debug::pkgProblemResolver=true'\n @default_args << '-q' # no progress!\n @default_args\n end\n\n def reset\n @last_update = nil\n @auto_update_disabled = false\n end\n\n def disable_auto_update\n @auto_update_disabled = true\n ret = yield\n @auto_update_disabled = false\n ret\n end\n end\n\n extend ClassMethods\n\n def self.included(othermod)\n othermod.extend(ClassMethods)\n end\n end\n\n # apt-cache wrapper\n module Cache\n include Abstrapt\n\n def self.exist?(pkg)\n show(pkg, [:out, :err] => '/dev/null')\n end\n\n def self.method_missing(name, *caller_args)\n run('apt-cache', name.to_s.tr('_', '-'), *caller_args)\n end\n\n def self.default_args\n # Can't use apt-get default arguments. They aren't compatible.\n @default_args = %w[-q]\n end\n end\n\n # apt-mark wrapper\n module Mark\n module_function\n\n BINARY = 'apt-mark'\n\n AUTO = :auto\n MANUAL = :manual\n HOLD = :hold\n\n class UnknownStateError < StandardError; end\n\n # NOTE: should more methods be needed it may be worthwhile to put Cmd.new\n # into its own wrapper method which can be stubbed in tests. That way\n # the code would be detached from the internal fact that TTY::cmd is used.\n\n def state(pkg)\n cmd = TTY::Command.new(printer: :pretty)\n out, = cmd.run(BINARY, 'showauto', pkg)\n return AUTO if out.strip == pkg\n\n out, = cmd.run(BINARY, 'showmanual', pkg)\n return MANUAL if out.strip == pkg\n\n out, = cmd.run(BINARY, 'showhold', pkg)\n return HOLD if out.strip == pkg\n\n warn \"#{pkg} has an unknown mark state :O\"\n nil\n # FIXME: we currently do not raise here because the cmake and qml dep\n # verifier are broken and do not always use the right version to install\n # a dep. This happens when foo=1.0 is the source but a binary gets\n # mangled to be bar=4:1.0 (i.e. with epoch). This is not reflected in\n # the changes file so the dep verifiers do not know about this and\n # attempt to install the wrong version. When then trying to get the\n # mark state things implode. This needs smarter version logic for\n # the dep verfiiers before we can make unknown marks fatal again.\n end\n\n def mark(pkg, state)\n TTY::Command.new.run(BINARY, state.to_s, pkg)\n end\n\n def tmpmark(pkg, state)\n old_state = state(pkg)\n mark(pkg, state)\n yield\n ensure\n mark(pkg, old_state) if old_state\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6098639369010925,
"alphanum_fraction": 0.6217687129974365,
"avg_line_length": 32.03370666503906,
"blob_id": "67c521163cbd436071f3e3edf673f3fd15a80b2f",
"content_id": "f7c6eb4770e6068f127e06a4f96bdbc6ef157286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2940,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 89,
"path": "/test/test_debian_relationship.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire_relative '../lib/debian/relationship'\nrequire_relative 'lib/testcase'\n\n# Test debian .dsc\nmodule Debian\n class RelationshipTest < TestCase\n def test_empty\n assert_equal(nil, Relationship.new('').name)\n end\n\n def test_effectively_emtpy\n assert_equal(nil, Relationship.new(' ').name)\n end\n\n def test_parse_simple\n rel = Relationship.new('a ')\n assert_equal('a', rel.name)\n assert_equal(nil, rel.operator)\n assert_equal(nil, rel.version)\n assert_equal('a', rel.to_s)\n end\n\n def test_parse_version\n rel = Relationship.new('a ( << 1.0 ) ')\n assert_equal('a', rel.name)\n assert_equal('<<', rel.operator)\n assert_equal('1.0', rel.version)\n assert_equal('a (<< 1.0)', rel.to_s)\n end\n\n def test_parse_complete\n rel = Relationship.new('a ( << 1.0 ) [linux-any ] < multi>')\n assert_equal('a', rel.name)\n assert_equal('<<', rel.operator)\n assert_equal('1.0', rel.version)\n assert_equal('linux-any', rel.architectures.to_s)\n assert_equal(1, rel.profiles.size)\n assert_equal(1, rel.profiles[0].size)\n assert_equal('multi', rel.profiles[0][0].to_s)\n assert_equal('a (<< 1.0) [linux-any] <multi>', rel.to_s)\n end\n\n def test_parse_profiles\n rel = Relationship.new('foo <nocheck cross> <nocheck>')\n profiles = rel.profiles\n assert(profiles.is_a?(Array))\n assert_equal(2, profiles.size)\n assert(profiles[0].is_a?(ProfileGroup))\n end\n\n def test_applicable_profile\n # Also tests various input formats\n rel = Relationship.new('foo <nocheck cross> <nocheck>')\n assert rel.applicable_to_profile?('nocheck')\n refute rel.applicable_to_profile?('bar')\n refute rel.applicable_to_profile?(Profile.new('cross'))\n assert rel.applicable_to_profile?(%w[cross nocheck])\n assert rel.applicable_to_profile?('cross nocheck')\n assert rel.applicable_to_profile?(ProfileGroup.new(%w[cross nocheck]))\n refute rel.applicable_to_profile?(nil)\n end\n\n def test_applicable_profile_none\n rel = Relationship.new('foo')\n assert rel.applicable_to_profile?(nil)\n assert rel.applicable_to_profile?('nocheck')\n end\n\n def test_compare\n a = Relationship.new('a')\n b = Relationship.new('b')\n suba = Relationship.new('${a}')\n subb = Relationship.new('${b}')\n assert((a <=> b) == -1)\n # rubocop:disable Lint/BinaryOperatorWithIdenticalOperands\n # this is intentional!\n assert((a <=> a).zero?)\n assert((b <=> a) == 1)\n assert((suba <=> a) == -1)\n assert((suba <=> suba).zero?)\n # rubocop:enable Lint/BinaryOperatorWithIdenticalOperands\n assert((suba <=> subb) == -1)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.5834577679634094,
"alphanum_fraction": 0.600179135799408,
"avg_line_length": 31.514562606811523,
"blob_id": "08c05aa06762b27670117987fbe05c5088affdc3",
"content_id": "53ea381d608ac965cfa8a308e6f84dc758e3f1aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3349,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 103,
"path": "/nci/jenkins-bin/job.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2017-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative '../../lib/ci/pattern'\nrequire_relative '../../lib/retry'\nrequire_relative '../../lib/jenkins/job'\nrequire_relative 'build_selector'\nrequire_relative 'cores'\n\nmodule NCI\n module JenkinsBin\n # Wraps around a Job to determine its most suitable core count\n class Job\n attr_reader :name\n attr_reader :job\n attr_reader :log\n attr_reader :overrides\n attr_reader :selector\n\n def initialize(name)\n @name = name\n @log = Logger.new(STDOUT)\n\n @overrides = {\n CI::FNMatchPattern.new('*_plasma-desktop_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*_plasma-workspace_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*_kdeplasma-addons_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*pyqt5_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*sip4_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*_qt_*_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*_krita_bin_amd64') =>\n Cores::CORES[-1],\n CI::FNMatchPattern.new('*_digikam_bin_amd64') =>\n Cores::CORES[-1]\n }\n\n @job = Jenkins::Job.new(name)\n @selector = BuildSelector.new(self)\n end\n\n def last_build_number\n @last_build_number ||= Retry.retry_it(times: 3, sleep: 1) do\n job.build_number\n end\n end\n\n def override\n @override ||= begin\n patterns = CI::FNMatchPattern.filter(name, overrides)\n patterns = CI::FNMatchPattern.sort_hash(patterns)\n return nil if patterns.empty?\n\n patterns.values[0]\n end\n end\n\n def best_cores_for_time(average)\n # If the average time to build was <=3 we try to downgrade the slave\n # if it takes <=15 we are comfortable with the slave we have, anything\n # else results in an upgrade attempt.\n # Helper methods cap at min/max respectively.\n # The rationale here is that the relative amount of time it takes to\n # build with a given type of slave is either so low that it's basically\n # only setup or so high that parallelism may help more.\n average_minutes = average / 1000 / 60\n case average_minutes # duration in minutes\n when 0..2\n Cores.downgrade(selector.detected_cores)\n when 2..10\n selector.detected_cores # keep\n else\n Cores.upgrade(selector.detected_cores)\n end\n end\n\n # FIXME: this method is too long because of a slight misdesign WRT the\n # selector and/or the Job. Tearing it apart would mean passing the\n # selector around.\n def cores\n default_cores = 8\n\n # Overrides\n return override if override\n\n builds = selector.select\n return selector.detected_cores || default_cores unless builds\n\n durations = builds.collect { |x| x.fetch('duration') }\n average = durations.inject { |sum, x| sum + x }.to_f / durations.size\n\n best_cores_for_time(average)\n end\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6472602486610413,
"alphanum_fraction": 0.6570450067520142,
"avg_line_length": 28.623188018798828,
"blob_id": "5c43ea884a384e24c85e8d11628d234c999ae2f3",
"content_id": "d55f5a4b325cde9042e4e9a3e41197f5bd4702ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2044,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 69,
"path": "/test/test_qml_module.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/qml/module'\nrequire_relative 'lib/testcase'\n\n# Test qml module parsing\nclass QMLTest < TestCase\n def test_init\n m = QML::Module.new('org.kde.a', '2.0', nil)\n assert_equal('org.kde.a', m.identifier)\n assert_equal('2.0', m.version)\n assert_nil(m.qualifier)\n end\n\n def test_empty_line\n assert_empty(QML::Module.parse(''))\n end\n\n def test_short_line\n assert_empty(QML::Module.parse('import QtQuick'))\n end\n # Too long line is in fact allowed for now\n\n def test_no_import\n assert_empty(QML::Module.parse('QtQuick import 1'))\n end\n\n def test_simple_parse\n mods = QML::Module.parse('import QtQuick 1')\n assert_equal(1, mods.size)\n mod = mods.first\n assert_equal('QtQuick', mod.identifier)\n assert_equal('1', mod.version)\n assert_equal(\"#{mod.identifier}[#{mod.version}]\", mod.to_s)\n end\n\n def test_comment\n assert_empty(QML::Module.parse('#import QtQuick 1'))\n assert_empty(QML::Module.parse('# import QtQuick 1'))\n assert_empty(QML::Module.parse(' # import QtQuick 1'))\n end\n\n def test_compare\n id = 'id'\n version = 'version'\n qualifier = 'qualifier'\n ref = QML::Module.new(id, version, qualifier)\n assert_equal(ref, QML::Module.new(id, version, qualifier))\n assert_equal(ref, QML::Module.new(id, version))\n assert_equal(ref, QML::Module.new(id))\n assert_not_equal(ref, QML::Module.new('yolo'))\n end\n\n def test_directory\n assert_empty(QML::Module.parse('import \"private\" as Private'))\n end\n\n def test_trailing_semi_colon\n mods = QML::Module.parse('import org.kde.kwin 2.0 ; import org.kde.plasma 1.0 ;')\n assert_equal(2, mods.size)\n mod = mods.first\n assert_equal('org.kde.kwin', mod.identifier)\n assert_equal('2.0', mod.version)\n assert_equal(\"#{mod.identifier}[#{mod.version}]\", mod.to_s)\n mod = mods.last\n assert_equal('org.kde.plasma', mod.identifier)\n assert_equal('1.0', mod.version)\n assert_equal(\"#{mod.identifier}[#{mod.version}]\", mod.to_s)\n end\nend\n"
},
{
"alpha_fraction": 0.6002087593078613,
"alphanum_fraction": 0.6025574207305908,
"avg_line_length": 30.15447235107422,
"blob_id": "aa29529020c52fff6afda4f6f1866e7e980a8894",
"content_id": "c56ff8afb26b6c5576fa7f21eef7414a96d7bc98",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3832,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 123,
"path": "/nci/debian-merge/finalizer.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'git_clone_url'\nrequire 'logger'\nrequire 'net/ssh'\nrequire 'rugged'\n\nrequire_relative 'data'\nrequire_relative 'repositorybase'\n\nmodule NCI\n module DebianMerge\n # Finalizes a merge by fast forwarding the pending branch into the\n # target branch.\n class Finalizer\n # Helper class to manage a repo\n class Repo < RepositoryBase\n class NoFastForwardError < StandardError; end\n\n attr_reader :rug\n attr_reader :pending\n attr_reader :target\n\n def initialize(rug, log:)\n @log = log\n super(rug)\n resolve_branches!\n @rug.checkout(target)\n assert_fastforward!\n rescue RuntimeError => e\n @log.warn e\n end\n\n def assert_fastforward!\n return if pending.target == target.target\n return if @rug.merge_analysis(pending.target).include?(:fastforward)\n\n raise NoFastForwardError,\n \"cannot fast forward #{@rug.workdir}, must be out of date :O\"\n end\n\n def resolve_branches!\n resolve_pending!\n resolve_target!\n end\n\n def resolve_pending!\n @pending = @rug.branches.find do |b|\n b.name == 'origin/Neon/pending-merge'\n end\n raise \"#{@rug.workdir} has no pending branch!\" unless pending\n end\n\n def resolve_target!\n @target = @rug.branches.find { |b| b.name == 'origin/Neon/unstable' }\n raise \"#{@rug.workdir} has no target branch!\" unless target\n end\n\n def push\n return unless pending && target\n\n mangle_push_path!\n @log.info \"pushing #{@rug.remotes['origin'].url}\"\n push_all\n end\n\n def push_all\n remote = @rug.remotes['origin']\n remote.push([\"#{pending.canonical_name}:refs/heads/Neon/unstable\"],\n update_tips: ->(*args) { puts \"tip:: #{args}\" },\n credentials: method(:credentials))\n remote.push([':refs/heads/Neon/pending-merge'],\n update_tips: ->(*args) { puts \"tip:: #{args}\" },\n credentials: method(:credentials))\n end\n end\n\n def initialize\n @data = Data.from_file\n @log = Logger.new(STDOUT)\n end\n\n def run\n # This clones first so we have everything local and asserted a\n # couple of requirements to do with branches\n repos = clone_repos(Dir.pwd)\n repos.each(&:push)\n end\n\n def clone_repos(tmpdir)\n @data.repos.collect do |url|\n @log.info \"cloning #{url}\"\n rug = Rugged::Repository.clone_at(url,\n \"#{tmpdir}/#{File.basename(url)}\")\n Repo.new(rug, log: @log)\n end\n end\n end\n end\nend\n\n# :nocov:\nNCI::DebianMerge::Finalizer.new.run if $PROGRAM_NAME == __FILE__\n# :nocov:\n"
},
{
"alpha_fraction": 0.5980333089828491,
"alphanum_fraction": 0.6204236149787903,
"avg_line_length": 34.15957260131836,
"blob_id": "e27194ef07121273bc203233a279b8af20e5cf1d",
"content_id": "7d56c59af40ec622918d71043444880fc963b465",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 6610,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 188,
"path": "/test/test_nci_imager_push.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2018-2021 Harald Sitter <[email protected]>\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/nci'\n\nrequire 'net/sftp'\nrequire 'tty/command'\n\n# NB: this test wraps a script, it does not formally contribute to coverage\n# statistics but is better than no testing. the script should be turned\n# into a module with a run so we can require it without running it so we can\n# avoid the fork.\nmodule NCI\n class ImagerPushTest < TestCase\n def assert_path_symlink(path, message = nil)\n failure_message = build_message(message,\n '<?> was expected to be a symlink',\n path)\n assert_block(failure_message) do\n File.symlink?(path)\n end\n end\n\n # Adapts sftp interface to local paths, making it possible to simulate\n # sftp against a local dir.\n class SFTPAdaptor\n Entry = Struct.new(:name)\n\n attr_reader :pwd\n\n def initialize(pwd)\n @pwd = pwd\n FileUtils.mkpath(pwd, verbose: true)\n end\n\n def mkdir!(dir)\n FileUtils.mkdir(File.join(pwd, dir), verbose: true)\n end\n\n def remove!(file)\n FileUtils.rm_f(File.join(pwd, file), verbose: true)\n end\n\n def mkpath(path)\n FileUtils.mkpath(File.join(pwd, path), verbose: true)\n end\n\n # rubocop:disable Lint/UnusedMethodArgument\n # requests is here for API compat\n def upload!(src, target, requests: nil)\n # We don't care about requests.\n # NB: cp flattens symlinks, this is intentional because we consider\n # symblinks not portable and thus they should not get uploaded if\n # they are not meant to be flattened.\n FileUtils.cp(src, File.join(pwd, target), verbose: true)\n end\n # rubocop:enable Lint/UnusedMethodArgument\n\n ## Dir adpator\n ## should be separate adaptor class maybe?\n def dir\n self\n end\n\n def glob(path, pattern)\n Dir.glob(File.join(pwd, path, pattern)).collect do |x|\n Entry.new(name: x)\n end\n end\n\n ## Our CLI overlay!\n ## TODO: when making the pusher a proper module/class, prepend our\n ## adaptor with the actual module so we can test the CLI logic as well.\n\n def cli_uploads\n @cli_uploads ||= false\n end\n\n attr_writer :cli_uploads\n\n def symlink!(x, y)\n FileUtils.symlink(File.join(pwd, x), File.join(pwd, y), verbose: true)\n end\n end\n\n # Adapts ssh interface against localhost.\n class SSHAdaptor\n attr_reader :pwd\n\n def initialize(pwd, simulate: false)\n @pwd = pwd\n @tty = TTY::Command.new(dry_run: simulate)\n end\n\n def exec!(cmd, status: nil)\n Dir.chdir(pwd) do\n ret = @tty.run!(cmd)\n return if status.nil?\n\n status[:exit_code] = ret.status\n end\n end\n end\n\n def stub_sftp\n master = SFTPAdaptor.new('rsync.kde.org')\n # We do not mkpath properly in the pusher, simulate what we already have\n # server-side.\n master.mkpath('neon/images')\n mirror = SFTPAdaptor.new('files.kde.mirror.pangea.pub')\n embra = SFTPAdaptor.new('embra.edinburghlinux.co.uk')\n # We also do not properly mkpath against weegie.\n embra.mkpath('files.neon.kde.org.uk')\n\n Net::SFTP.expects(:start).never\n Net::SFTP.expects(:start).with('rsync.kde.org', 'neon').yields(master)\n Net::SFTP.expects(:start).with('files.kde.mirror.pangea.pub', 'neon-image-sync').yields(mirror)\n Net::SFTP.expects(:start).with('embra.edinburghlinux.co.uk', 'neon').yields(embra)\n end\n\n def stub_ssh\n files = SSHAdaptor.new('files.kde.mirror.pangea.pub', simulate: true)\n\n master = SSHAdaptor.new('rsync.kde.org')\n\n Net::SSH.expects(:start).never\n Net::SSH.expects(:start).with('files.kde.mirror.pangea.pub', 'neon-image-sync').yields(files)\n Net::SSH.expects(:start).with('rsync.kde.org', 'neon').yields(master)\n end\n\n # This brings down coverage which is meh, it does neatly isolate things\n # though.\n def test_run\n pid = fork do\n ENV['DIST'] = NCI.current_series\n ENV['ARCH'] = 'amd64'\n ENV['TYPE'] = 'testing'\n ENV['IMAGENAME'] = 'neon'\n\n Dir.mkdir('result')\n File.write('result/date_stamp', '20201123-1425')\n File.write('result/.message', 'hey hey wow wow')\n File.write(\"result/#{ENV['IMAGENAME']}-#{ENV['TYPE']}-20201123-1425.iso\", 'blob')\n # imager creates the current files despite us wanting to create them\n # on the remote manually, make sure the symlinks are not resolved to\n # raw data (i.e. two isos being uploaded). The imager creates this file\n # because it needs to zsyncmake and having a dangling zsyncmake file\n # without associated iso file is also horrible.\n system('ln', '-s',\n \"#{ENV['IMAGENAME']}-#{ENV['TYPE']}-20201123-1425.iso\",\n \"result/#{ENV['IMAGENAME']}-#{ENV['TYPE']}-current.iso\") || raise\n File.write(\"result/#{ENV['IMAGENAME']}-#{ENV['TYPE']}-current.iso.zsync\", 'blob')\n File.write('result/source.tar.xz', 'blob')\n\n Object.any_instance.expects(:system).never\n TTY::Command.any_instance.expects(:run)\n .with do |*args|\n next false unless args.include?('gpg')\n\n iso = args.pop # iso arg\n sig = args.pop # sig arg\n assert_path_exist(iso)\n File.write(sig, '')\n end\n .returns(true)\n\n stub_ssh\n stub_sftp\n\n load \"#{__dir__}/../nci/imager_push.rb\"\n puts 'all good, fork ending!'\n exit 0\n end\n waitedpid, status = Process.waitpid2(pid)\n assert_equal(pid, waitedpid)\n assert(status.success?)\n Dir.each_child('result') { |x| puts \"Got #{x}\" }\n assert_path_exist('rsync.kde.org/neon/images/testing/20201123-1425/.message')\n assert_path_exist('rsync.kde.org/neon/images/testing/20201123-1425/neon-testing-20201123-1425.iso')\n assert_path_exist('rsync.kde.org/neon/images/testing/20201123-1425/neon-testing-20201123-1425.iso.sig')\n assert_path_symlink('rsync.kde.org/neon/images/testing/20201123-1425/neon-testing-current.iso.sig')\n assert_path_symlink('rsync.kde.org/neon/images/testing/20201123-1425/neon-testing-current.iso')\n assert_path_exist('rsync.kde.org/neon/images/testing/20201123-1425/neon-testing-current.iso.zsync')\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.7038567662239075,
"avg_line_length": 35.75949478149414,
"blob_id": "a05db6494a15fe77fd9b28d9bb41323403e766d4",
"content_id": "f657653c5a98d85f9081ee3a9f28fbac83846b5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2904,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 79,
"path": "/nci/mgmt_aptly.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# Copyright (C) 2016-2022 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/aptly-ext/remote'\nrequire_relative '../lib/nci'\n\n# NB: in publish prefixes _ is replaced by / on the server, to get _ you need\n# to use __\n\ndef repo(label_type:, series:, **kwords)\n {\n Distribution: series,\n Origin: 'neon',\n Label: format('KDE neon - %s', label_type),\n Architectures: %w[source i386 amd64 armhf arm64 armel all],\n AcquireByHash: true\n }.merge(kwords)\nend\n\nPublishingRepo = Struct.new(:repo_name, :publish_name)\n\nrepos = {}\n\nNCI.series.each_key do |series|\n repos.merge!(\n PublishingRepo.new(\"unstable_#{series}\", 'unstable') =>\n repo(label_type: 'Unstable Edition', series: series, SkipContents: true),\n PublishingRepo.new(\"stable_#{series}\", 'testing') =>\n repo(label_type: 'Testing Edition', series: series, SkipContents: true),\n PublishingRepo.new(\"release_#{series}\", 'release') =>\n repo(label_type: 'User Edition', series: series),\n PublishingRepo.new(\"experimental_#{series}\", 'experimental') =>\n repo(label_type: 'Experimental Edition', series: series, SkipContents: true),\n )\nend\n\nrequire 'pp'\npp repos\n\nAptly::Ext::Remote.neon do\n repos.each do |publishing_repo, repo_kwords|\n next if Aptly::Repository.exist?(publishing_repo.repo_name)\n\n warn \"repo = Aptly::Repository.create(#{publishing_repo.repo_name})\"\n warn \"repo.publish(#{publishing_repo.publish_name || publishing_repo.repo_name}, #{repo_kwords})\"\n repo = Aptly::Repository.create(publishing_repo.repo_name)\n repo.publish(publishing_repo.publish_name || publishing_repo.repo_name,\n **repo_kwords)\n end\n\n # Cleanup old unused repos we no longer support.\n repo_names = %w[qt frameworks tmp_release] # pre-wily repos\n repo_names += %w[unstable stable release] # wily repos\n repo_names.each do |repo_name|\n next unless Aptly::Repository.exist?(repo_name)\n\n repo = Aptly::Repository.get(repo_name)\n repo.published_in(&:drop)\n repo.delete\n end\nend\n"
},
{
"alpha_fraction": 0.7435897588729858,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 38,
"blob_id": "8b6e1ef743d05f50bc636d92593b9b79100b5b05",
"content_id": "612b555f88ac5aaa346f58bf7c25aab2bf0b2c46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/nci/imager/config-hooks-xenon-mycroft/30_no_source.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "echo 'LB_SOURCE=false' > config/source\n"
},
{
"alpha_fraction": 0.6709451675415039,
"alphanum_fraction": 0.6715285778045654,
"avg_line_length": 33.279998779296875,
"blob_id": "03f125f489a4a246406784f44874bacd52ed1faa",
"content_id": "4b69eb8b4241ae56f35d15e64d517eb0acc70043",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1714,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 50,
"path": "/test/lib/assert_backtick.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# Prependable module enabling assert_system use by overriding Kernel.`\nmodule AssertBacktick\n module_function\n\n SETUP_BACKUP = :setup_backtick\n ASSERT_BACKUP = :__backtick_orig\n METHOD = :`\n\n # TestUnit prepend to force alias diversion making #{Kernel.`} noop\n def setup\n Kernel.send(:alias_method, SETUP_BACKUP, METHOD)\n Kernel.send(:define_method, METHOD) { |*_a| }\n super if defined?(super)\n end\n\n # TestUnit prepend to remove alias diversion making #{Kernel.`} noop\n def teardown\n Kernel.send(:alias_method, METHOD, SETUP_BACKUP)\n Kernel.send(:undef_method, SETUP_BACKUP)\n super if defined?(super)\n end\n\n # Assert that a specific system call is made. The call itself is not made.\n # @param args [Object] any suitable input of #{Kernel.`} that is expected\n # @param block [Block] this function yields to block to actually run a\n # piece of code that is expected to cause the system call\n # @return [Object] return value of block\n def assert_backtick(args, &block)\n assertee = self\n Kernel.send(:alias_method, ASSERT_BACKUP, METHOD)\n Kernel.send(:define_method, METHOD) do |*a|\n if !args.empty? && args[0].is_a?(Array)\n assertee.assert_equal([*args.shift], [*a])\n elsif !args.empty?\n assertee.assert_equal([*args], [*a])\n args.clear\n end\n return assertee.backtick_intercept([*a]) if assertee.respond_to?(:backtick_intercept)\n\n ''\n end\n block.yield\n assert(args.empty?, 'Not all system calls were actually called.' \\\n \" Left over: #{args}\")\n ensure\n Kernel.send(:alias_method, METHOD, ASSERT_BACKUP)\n Kernel.send(:undef_method, ASSERT_BACKUP)\n end\nend\n"
},
{
"alpha_fraction": 0.7954071164131165,
"alphanum_fraction": 0.8058454990386963,
"avg_line_length": 35.846153259277344,
"blob_id": "4d6571a8cb48dea9869ed5cd7f4ea577d5237dab",
"content_id": "ee2a2af4a9ee7adc7f8c10a345737a679d240ac1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 13,
"path": "/nci/imager/config-hooks-neon-bigscreen/20_package_list.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# konsole needs installed first else xterm gets installed cos xorg deps on\n# terminal | xterm and doesn't know terminal is installed later in the tree.\n# Also explicitly install the efi image packages explicitly so live-build\n# can find them for extraction into the ISO.\ncat << EOF > config/package-lists/ubuntu-defaults.list.chroot_install\nshim-signed\ngrub-efi-amd64-signed\ngrub-efi-ia32-bin\nkonsole\nneon-repositories-launchpad-mozilla\nplasma-bigscreen-meta\nneon-settings-2\nEOF\n"
},
{
"alpha_fraction": 0.6341463327407837,
"alphanum_fraction": 0.6341463327407837,
"avg_line_length": 5.833333492279053,
"blob_id": "05a78ae2f13f1bcd1d5c91b9f1d14d42b86f38a2",
"content_id": "0bc1bc0e789fe12e7bbd9faf75d1e7f1842661ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 6,
"path": "/nci/test.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\necho BAR\necho $BAR\n"
},
{
"alpha_fraction": 0.6389644145965576,
"alphanum_fraction": 0.6484142541885376,
"avg_line_length": 29.654762268066406,
"blob_id": "f589902566ad18cb4c8e2d571a83dfac4f0d3fc0",
"content_id": "4b7b396cc8449c6974409eb570dfc9068b72c006",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7725,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 252,
"path": "/test/test_nci_setup_repo.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2016-2021 Harald Sitter <[email protected]>\n\nrequire_relative '../nci/lib/setup_repo'\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\nrequire 'webmock/test_unit'\n\nclass NCISetupRepoTest < TestCase\n def setup\n OS.instance_variable_set(:@hash, VERSION_CODENAME: 'vivid')\n\n # Reset caching.\n Apt::Repository.send(:reset)\n # Disable bionic compat check (always assume true)\n Apt::Repository.send(:instance_variable_set, :@disable_auto_update, true)\n # Disable automatic update\n Apt::Abstrapt.send(:instance_variable_set, :@last_update, Time.now)\n # Make sure $? is fine before we start!\n reset_child_status!\n # Disable all system invocation.\n Object.any_instance.expects(:`).never\n Object.any_instance.expects(:system).never\n # Don't actually sleep.\n Object.any_instance.stubs(:sleep)\n # Disable all web (used for key).\n WebMock.disable_net_connect!\n\n NCI.reset_setup_repo\n FileUtils.cp(File.join(datadir, 'sources.list'), '.')\n NCI.default_sources_file = File.join(Dir.pwd, 'sources.list')\n\n ENV['TYPE'] = 'unstable'\n # Prevent this call from going through to the live data it'd change\n # the expectations as deblines are mutates based on this.\n NCI.stubs(:divert_repo?).returns(false)\n end\n\n def teardown\n NCI.reset_setup_repo\n\n Apt::Repository.send(:reset)\n\n WebMock.allow_net_connect!\n OS.reset\n ENV.delete('TYPE')\n end\n\n def add_key_args\n ['apt-key', 'adv', '--keyserver', 'keyserver.ubuntu.com', '--recv',\n '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D']\n end\n\n def expect_key_add\n # Internal query if the key had been added already\n Object\n .any_instance\n .stubs(:`)\n .with(\"apt-key adv --fingerprint '444D ABCF 3667 D028 3F89 4EDD E6D4 7362 5575 1E5D'\")\n # Actual key adding (always run since the above comes back nil)\n Object\n .any_instance\n .expects(:system)\n .with(*add_key_args)\n end\n\n def proxy_enabled\n \"Acquire::http::Proxy \\\"#{NCI::PROXY_URI}\\\";\"\n end\n\n def test_setup_repo\n system_calls = [\n ['apt-get', *Apt::Abstrapt.default_args, 'install', 'software-properties-common'],\n ['add-apt-repository', '--no-update', '-y',\n 'deb http://archive.neon.kde.org/unstable vivid main']\n ]\n\n NCI.series.each_key do |series|\n File\n .expects(:write)\n .with(\"/etc/apt/sources.list.d/neon_src_#{series}.list\",\n \"deb-src http://archive.neon.kde.org/unstable #{series} main\\ndeb http://archive.neon.kde.org/unstable #{series} main\")\n .returns(5000)\n end\n # Also disables deb-src in the main sources.list\n File\n .expects(:write)\n .with(\"#{Dir.pwd}/sources.list\", \"deb xxx\\n# deb-src yyy\")\n\n system_calls += [\n ['apt-get', *Apt::Abstrapt.default_args, 'update'],\n ['apt-get', *Apt::Abstrapt.default_args, 'install', 'pkg-kde-tools', 'pkg-kde-tools-neon', 'debhelper', 'cmake', 'quilt']\n ]\n\n system_sequence = sequence('system-calls')\n system_calls.each do |cmd|\n Object.any_instance.expects(:system)\n .with(*cmd)\n .returns(true)\n .in_sequence(system_sequence)\n end\n\n expect_key_add.returns(true)\n\n # Expect proxy to be set up to private\n File.expects(:write).with('/etc/apt/apt.conf.d/proxy', proxy_enabled)\n # With source also sets up a default release.\n File.expects(:write).with('/etc/apt/apt.conf.d/99-default',\n \"APT::Default-Release \\\"vivid\\\";\\n\")\n\n NCI.setup_repo!(with_source: true)\n end\n\n # This is a semi-temporary test until all servers have private networking\n # enabled. At which point we'll simply assume the proxy can be connected\n # to.\n def test_setup_repo_no_private\n system_calls = [\n ['apt-get', *Apt::Abstrapt.default_args, 'install', 'software-properties-common'],\n ['add-apt-repository', '--no-update', '-y',\n 'deb http://archive.neon.kde.org/unstable vivid main'],\n ['apt-get', *Apt::Abstrapt.default_args, 'update'],\n ['apt-get', *Apt::Abstrapt.default_args, 'install', 'pkg-kde-tools', 'pkg-kde-tools-neon', 'debhelper', 'cmake', 'quilt']\n ]\n\n system_sequence = sequence('system-calls')\n system_calls.each do |cmd|\n Object.any_instance.expects(:system)\n .with(*cmd)\n .returns(true)\n .in_sequence(system_sequence)\n end\n\n expect_key_add.returns(true)\n\n # Expect proxy to be set up\n File.expects(:write).with('/etc/apt/apt.conf.d/proxy', proxy_enabled)\n\n NCI.setup_repo!\n end\n\n def test_add_repo\n # Expect proxy to be set up\n File.expects(:write).with('/etc/apt/apt.conf.d/proxy', proxy_enabled)\n\n NCI.setup_proxy!\n end\n\n def test_key_retry_fail\n # Retries at least twice in error. Should raise something.\n expect_key_add\n .at_least(2)\n .returns(false)\n\n assert_raises do\n NCI.add_repo_key!\n end\n end\n\n def test_key_retry_success\n # Make sure adding a key is retired. While adding from key servers is much\n # more reliable than https it still can fail occasionally.\n\n add_seq = sequence('key_add_fails')\n\n # Retries 2 times in error, then once in success\n expect_key_add\n .times(2)\n .in_sequence(add_seq)\n .returns(false)\n expect_key_add\n .once\n .in_sequence(add_seq)\n .returns(true)\n\n NCI.add_repo_key!\n # Add key after a successful one should be noop.\n NCI.add_repo_key!\n end\n\n def test_preference\n Apt::Preference.config_dir = Dir.pwd\n\n NCI.stubs(:future_series).returns('peppa')\n\n ENV['DIST'] = 'woosh'\n NCI.maybe_setup_apt_preference\n assert_path_not_exist('pangea-neon')\n\n # Only ever active on future series\n ENV['DIST'] = 'peppa'\n NCI.maybe_setup_apt_preference\n assert_path_exist('pangea-neon')\n assert_not_equal('', File.read('pangea-neon'))\n ensure\n Apt::Preference.config_dir = nil\n end\n\n def test_no_preference_teardowns\n Apt::Preference.config_dir = Dir.pwd\n\n NCI.stubs(:future_series).returns('peppa')\n\n ENV['DIST'] = 'peppa'\n NCI.maybe_setup_apt_preference # need an object, content is irrelevant\n assert_path_exist('pangea-neon')\n NCI.maybe_teardown_apt_preference\n assert_path_not_exist('pangea-neon')\n\n # When there is no preference object this should be noop\n File.write('pangea-neon', '')\n NCI.maybe_teardown_apt_preference\n assert_path_exist('pangea-neon')\n File.delete('pangea-neon')\n ensure\n Apt::Preference.config_dir = nil\n end\n\n def test_codename\n assert_equal('vivid', NCI.setup_repo_codename)\n NCI.setup_repo_codename = 'xx'\n assert_equal('xx', NCI.setup_repo_codename)\n NCI.reset_setup_repo\n assert_equal('vivid', NCI.setup_repo_codename)\n end\n\n def test_debline_divert\n NCI.expects(:divert_repo?).with('unstable').returns(true)\n assert_equal(NCI.send(:debline),\n 'deb http://archive.neon.kde.org/tmp/unstable vivid main')\n end\n\n def test_debline_no_divert\n NCI.expects(:divert_repo?).with('unstable').returns(false)\n assert_equal(NCI.send(:debline),\n 'deb http://archive.neon.kde.org/unstable vivid main')\n end\n\n def test_debsrcline_divert\n NCI.expects(:divert_repo?).with('unstable').returns(true)\n assert_equal(NCI.send(:debsrcline),\n 'deb-src http://archive.neon.kde.org/tmp/unstable vivid main')\n end\n\n def test_debsrcline_no_divert\n NCI.expects(:divert_repo?).with('unstable').returns(false)\n assert_equal(NCI.send(:debsrcline),\n 'deb-src http://archive.neon.kde.org/unstable vivid main')\n end\nend\n"
},
{
"alpha_fraction": 0.5978618264198303,
"alphanum_fraction": 0.6175987124443054,
"avg_line_length": 26.636363983154297,
"blob_id": "e2d89c749476d40b6bddfbf14f083a460a1ae8c9",
"content_id": "b8c544fa83033977d7eb7748411618dccb7dbfc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1216,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 44,
"path": "/test/test_os.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n\nrequire_relative '../lib/os'\nrequire_relative 'lib/testcase'\n\n# Test os\nclass OSTest < TestCase\n def setup\n script_base_path = __dir__\n script_name = File.basename(__FILE__, '.rb')\n datadir = File.join(script_base_path, 'data', script_name)\n\n @orig_file = OS.instance_variable_get(:@file)\n OS.instance_variable_set(:@file, File.join(datadir, method_name))\n OS.reset\n end\n\n def teardown\n OS.instance_variable_set(:@file, @orig_file)\n OS.reset\n end\n\n def test_parse\n ref = { BUG_REPORT_URL: 'http://bugs.launchpad.net/ubuntu/',\n HOME_URL: 'http://www.medubuntu.com/',\n ID: 'ubuntu',\n ID_LIKE: 'debian',\n NAME: 'Medbuntu',\n PRETTY_NAME: 'Medbuntu 15.01',\n SUPPORT_URL: 'http://help.ubuntu.com/',\n VERSION: '15.01 (Magical Ponies)',\n VERSION_ID: '15.01' }\n assert_equal(ref, OS.to_h)\n end\n\n def test_consts\n assert_equal('Medbuntu', OS::NAME)\n assert_raise NameError do\n OS::FOOOOOOOOOOOOOOO\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6213786005973816,
"alphanum_fraction": 0.6223776340484619,
"avg_line_length": 21.75,
"blob_id": "a813a24350db5c22528438751dc792710c300b1d",
"content_id": "d18aebabe35954cedef908a84e957bdd8231d15b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1001,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 44,
"path": "/lib/ci/source.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire 'json'\nrequire 'yaml'\n\nrequire_relative 'build_version'\n\nmodule CI\n # Build source descriptor\n class Source\n attr_accessor :name\n attr_accessor :version\n attr_accessor :type\n attr_accessor :dsc\n\n # Only used in KCIBuilder and only supported at source generation.\n # This holds the instance of CI::BuildVersion that was used to construct\n # the version information.\n attr_accessor :build_version\n\n def []=(key, value)\n var = \"@#{key}\".to_sym\n instance_variable_set(var, value)\n end\n\n def self.from_json(json)\n JSON.parse(json, object_class: self)\n end\n\n def to_json(*args)\n ret = {}\n instance_variables.each do |var|\n value = instance_variable_get(var)\n key = var.to_s\n key.slice!(0) # Nuke the @\n ret[key] = value\n end\n ret.to_json(*args)\n end\n\n def ==(other)\n name == other.name && version == other.version && type == other.type\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7004950642585754,
"alphanum_fraction": 0.7072135806083679,
"avg_line_length": 34.79747009277344,
"blob_id": "bd03e623b081fbf9056e0f3c4195582da0a3a8c9",
"content_id": "40c7336f92fb0e3242b5e31d738b262d6b8b4ae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2828,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 79,
"path": "/lib/optparse.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# TODO: verify if this is still necessary from time to time\n# Somewhere in test-unit the lib path is injected in the load paths and since\n# the file has the same name as the original require this would cause\n# a recursion require. So, rip the current path out of the load path temorarily.\nold_paths = $LOAD_PATH.dup\n$LOAD_PATH.reject! { |x| x == __dir__ }\nrequire 'optparse'\n$LOAD_PATH.replace(old_paths)\n\n# Patched option parser to support missing method checks.\n# @example Usage\n# parser = OptionParser.new do |opts|\n# opts.on('-l', '--long LONG', 'expected long', 'EXPECTED') do |v|\n# end\n# end\n# parser.parse!\n#\n# unless parser.missing_expected.empty?\n# puts \"Missing expected arguments: #{parser.missing_expected.join(', ')}\"\n# abort parser.help\n# end\nclass OptionParser\n # @!attribute [r] missing_expected\n # @return [Array<String>] the list of missing options; long preferred.\n def missing_expected\n @missing_expected ||= []\n end\n\n # @!visibility private\n alias super_make_switch make_switch\n\n # @!visibility private\n # Decided whether an expected arg is present depending on whether it is in\n # default_argv. This is slightly naughty since it processes them out of order.\n # Alas, we don't usually parse >1 time and even if so we care about both\n # anyway.\n def make_switch(opts, block = nil)\n switches = super_make_switch(opts, block)\n\n return switches unless opts.delete('EXPECTED')\n\n switch = switches[0] # >0 are actually parsed versions\n short = switch.short\n long = switch.long\n unless present?(short, long)\n missing_expected\n @missing_expected << long[0] ? long[0] : short[0]\n end\n switches\n end\n\n private\n\n def present?(short, long)\n short_present = short.any? { |s| default_argv.include?(s) }\n long_present = long.any? { |l| default_argv.include?(l) }\n short_present || long_present\n end\nend\n"
},
{
"alpha_fraction": 0.6341772079467773,
"alphanum_fraction": 0.6402531862258911,
"avg_line_length": 33.955753326416016,
"blob_id": "d53eb4b63eaa40fe02dce5efe46ab8480894e594",
"content_id": "d00bf04dad575de119245f54132d77ef12ed16b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3950,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 113,
"path": "/lib/digital_ocean/droplet.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'action'\nrequire_relative 'client'\n\nmodule DigitalOcean\n # Wrapper around various endpoints to create a Droplet object.\n class Droplet\n attr_accessor :client\n attr_accessor :id\n\n class << self\n # Creates a new Droplet instance from the name of a droplet (if it exists)\n def from_name(name, client = Client.new)\n drop = client.droplets.all.find { |x| x.name == name }\n return drop unless drop\n\n new(drop, client)\n end\n\n # Check if a droplet name exists\n def exist?(name, client = Client.new)\n client.droplets.all.any? { |x| x.name == name }\n end\n\n # Create a new standard droplet.\n def create(name, image_name, client = Client.new)\n image = client.snapshots.all.find { |x| x.name == image_name }\n\n raise \"Found a droplet with name #{name} WTF\" if exist?(name, client)\n\n new(client.droplets.create(new_droplet(name, image, client)), client)\n end\n\n def new_droplet(name, image, client)\n DropletKit::Droplet.new(\n name: name,\n region: 'fra1',\n image: (image&.id || 'ubuntu-22-04-x64'),\n size: 'c-2',\n ssh_keys: client.ssh_keys.all.collect(&:fingerprint),\n private_networking: true\n )\n end\n end\n\n def initialize(droplet_or_id, client)\n @client = client\n @id = droplet_or_id\n @id = droplet_or_id.id if droplet_or_id.is_a?(DropletKit::Droplet)\n end\n\n # Pass through not implemented methods to the API directly.\n # - Methods ending in a ! get run as droplet_actions on the API and\n # return an Action instance.\n # - Methods implemented by a droplet resource (i.e. the native\n # DropletKit object) get forwarded to it. Ruby 2.1 keywords get repacked\n # so DropletKit doesn't throw up.\n # - All other methods get sent to the droplets endpoint directly with\n # the id of the droplet as argument.\n def method_missing(meth, *args, **kwords)\n return missing_action(meth, *args, **kwords) if meth.to_s[-1] == '!'\n\n res = resource\n if res.respond_to?(meth)\n # The droplet_kit resource mapping crap is fairly shitty and doesn't\n # manage to handle kwords properly, pack it into a ruby <=2.0 style\n # array.\n argument_pack = []\n argument_pack += args unless args.empty?\n argument_pack << kwords unless kwords.empty?\n return res.send(meth, *argument_pack) if res.respond_to?(meth)\n end\n p meth, args, { id: id }.merge(kwords)\n client.droplets.send(meth, *args, **{ id: id }.merge(kwords))\n end\n\n private\n\n def missing_action(name, *args, **kwords)\n name = name.to_s[0..-2].to_sym # strip trailing !\n action = client.droplet_actions.send(name, *args,\n **{ droplet_id: id }.merge(kwords))\n Action.new(action, client)\n end\n\n def resource\n client.droplets.find(id: id)\n end\n\n def to_str\n id\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6371031403541565,
"alphanum_fraction": 0.649435818195343,
"avg_line_length": 30.495868682861328,
"blob_id": "2ed913e5d0da2ec21b315d720136e51e7243f5d3",
"content_id": "32f1d5ab16c130c68ef34d36d57056bdbbf28539",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3811,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 121,
"path": "/lib/debian/changelog.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2015-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire 'tty/command'\n\n# Debian changelog.\nclass Changelog\n # This is a simplified parser that only reads the first line (latest entry)\n # to get version and name of the package. It is used because parsechangelog\n # has been observed to be incredibly slow at what it does, while it in fact\n # provides more information than we need. So here's the super optimized\n # version for us.\n\n attr_reader :name\n\n EPOCH = 0b1\n BASE = 0b10\n BASESUFFIX = 0b100\n REVISION = 0b1000\n ALL = 0b1111\n\n class << self\n def new_version_cmd(version, distribution:, message:)\n [\n 'dch',\n '--force-bad-version',\n '--force-distribution',\n '--distribution', distribution,\n '--newversion', version,\n message\n ]\n end\n\n # Make a new entry via dch\n # NB: this may need refactoring into its own class if the arguments\n # blow up or the requirements get more complicated. It is only here\n # in this class because I'm lazy -sitter\n def new_version!(version, distribution:, message:, chdir: Dir.pwd)\n dch = new_version_cmd(version, distribution: distribution, message: message)\n # dch cannot realy fail because we parse the changelog beforehand\n # so it is of acceptable format here already.\n TTY::Command.new.run(*dch, chdir: chdir)\n end\n end\n\n def initialize(pwd = Dir.pwd)\n @file = File.file?(pwd) ? pwd : \"#{pwd}/debian/changelog\"\n @file = File.absolute_path(@file)\n reload!\n end\n\n def version(flags = ALL)\n ret = ''\n ret += @comps[:epoch] if flagged?(flags, EPOCH)\n ret += @comps[:base] if flagged?(flags, BASE)\n ret += @comps[:base_suffix] if flagged?(flags, BASESUFFIX)\n ret += @comps[:revision] if flagged?(flags, REVISION)\n ret\n end\n\n # Make a new entry via dch (and reload). Delegates to class level function.\n def new_version!(*args, **kwords)\n chdir = File.dirname(File.dirname(@file)) # two up from debian/changelog\n self.class.new_version!(*args, **kwords, chdir: chdir)\n reload!\n end\n\n private\n\n def flagged?(flags, type)\n flags & type > 0\n end\n\n # right parition\n # @return [Array] of size 2 with the remainder of str as first and the right\n # sub-string as last.\n # @note The sub-string always contains the separator itself as well.\n def rpart(str, sep)\n first, second, third = str.rpartition(sep)\n return [third, ''] if first.empty? && second.empty?\n\n [first, [second, third].join]\n end\n\n def fill_comps(version)\n # Split the entire thing.\n @comps = {}\n # For reasons beyond my apprehension the original behavior is to retain\n # the separators in the results, which requires somewhat acrobatic\n # partitioning to keep them around for compatibility.\n version, @comps[:revision] = rpart(version, '-')\n git_seperator = version.include?('~git') ? '~git' : '+git'\n version, @comps[:base_suffix] = rpart(version, git_seperator)\n @comps[:epoch], _, @comps[:base] = version.rpartition(':')\n @comps[:epoch] += ':' unless @comps[:epoch].empty?\n end\n\n def reload!\n line = File.open(@file, &:gets)\n # plasma-framework (5.3.0-0ubuntu1) utopic; urgency=medium\n match = line.match(/^(.*) \\((.*)\\) (.+); urgency=(\\w+)/)\n # Need a match and 5 elements.\n # 0: full match\n # 1: source name\n # 2: version\n # 3: distribution series\n # 4: urgency\n raise 'E: Cannot read debian/changelog' if match.nil? || match.size != 5\n\n @name = match[1]\n @version = match[2]\n # Don't even bother with the rest, we don't care right now.\n\n fill_comps(@version.dup)\n end\nend\n\nmodule Debian\n Changelog = ::Changelog\nend\n"
},
{
"alpha_fraction": 0.6942496299743652,
"alphanum_fraction": 0.7279102206230164,
"avg_line_length": 38.61111068725586,
"blob_id": "211500546e843c7d86b5c87115fdf93904392669",
"content_id": "272733057d042bd912c4689dd4382f8e7ba5702d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 713,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 18,
"path": "/nci/imager-img/flash_pinebook",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\nset -x\nset -e\n\n# Pinebook expects Linux to be at a certain place on the disk\n# So we leave a space at the start of the disk LB_HDD_PARTITION_START=\"40960s\"\n# then here we mount it and copy Linux from the filesystem into the start of the disk\n\n# FIXME: All of the following makes lots of assumptions, should be fixed later\nLODEVICE=$(losetup -f)\nlosetup $LODEVICE $1\npartprobe $LODEVICE\nmount \"${LODEVICE}p1\" /mnt\ndd conv=notrunc bs=1k seek=8 if=\"/mnt/boot/pine64/boot0-pine64-pinebook.bin\" of=\"${LODEVICE}\"\ndd conv=notrunc bs=1k seek=19096 if=\"/mnt/boot/pine64/u-boot-pine64-pinebook.bin\" of=\"${LODEVICE}\"\ndate -u \"+%Y-%m-%d %H:%M:%S\" > /mnt/.disk/build_stamp\numount /mnt\nlosetup -d $LODEVICE\n"
},
{
"alpha_fraction": 0.6685779690742493,
"alphanum_fraction": 0.6777523159980774,
"avg_line_length": 31.296297073364258,
"blob_id": "4cfcb77f7c7ace70adb7862593fb1c66e86f5ff9",
"content_id": "1374566fb8f8ef533fb63dda1999b76d04615975",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1744,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 54,
"path": "/test/test_nci_lint_bin.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n\n# SPDX-FileCopyrightText: 2016-2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\n\nclass NCILintBinTest < TestCase\n required_binaries %w[lintian dpkg]\n\n def setup\n ENV.delete('BUILD_URL')\n # This test cannot run by its lonesome because we need coverage merging\n # but that requires simplecov to be set up which currently is done by the\n # test-unit helper thingy but that cannot be included in random files.\n # Rock and a hard place.\n ENV['SIMPLECOV_ROOT'] = SimpleCov.root\n # Linitian testing is really hard to get to run sensibly since lintian\n # itself will want to unpack sources and compare debs and whatnot.\n # So we skip it in the hopes that it won't break API. The actual\n # functionality is tested in lintian's own unit test\n ENV['PANGEA_TEST_NO_LINTIAN'] = '1'\n end\n\n def run!\n `ruby #{__dir__}/../nci/lint_bin.rb 2> /dev/stdout`\n end\n\n description 'fail to run on account of no url file'\n def test_fail\n output = run!\n\n assert_not_equal(0, $?.to_i, output)\n assert_path_not_exist('reports')\n end\n\n description 'should work with a good url'\n def test_run\n ENV['BUILD_URL'] = data # works because open-uri is smart about paths too\n\n FileUtils.mkpath('build') # Dump a fake debian in.\n FileUtils.cp_r(\"#{datadir}/debian\", \"#{Dir.pwd}/build\")\n # And also a results dir with some data\n FileUtils.cp_r(\"#{datadir}/result\", Dir.pwd)\n\n output = run!\n\n assert_equal(0, $?.to_i, output)\n assert_path_exist('reports')\n Dir.glob(\"#{data('reports')}/*\").each do |r|\n assert_path_exist(\"reports/#{File.basename(r)}\")\n end\n end\nend\n"
},
{
"alpha_fraction": 0.7138331532478333,
"alphanum_fraction": 0.7412883043289185,
"avg_line_length": 27.696969985961914,
"blob_id": "95077fc5c7890040e06711ada7d26b7aa15a5b96",
"content_id": "de202f1f5671676dd76495c26a1899153667a225",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 33,
"path": "/nci/i386_install_check.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# frozen_string_literal: true\n#\n# SPDX-FileCopyrightText: 2023 Jonthan Esk-Riddell <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n#\n# A test to install i386 packages steam and wine32 from the ubuntu archive\n# These are popular and we can easily break installs of them by e.g. backporting some\n# library they depend on without making an i386 build\n\nrequire 'aptly'\nrequire 'date'\n\nrequire_relative 'lib/setup_repo'\nrequire_relative 'lib/i386_install_check'\n\nTYPE = ENV.fetch('TYPE')\nREPO_KEY = \"#{TYPE}_#{ENV.fetch('DIST')}\"\n\nNCI.setup_proxy!\nNCI.add_repo_key!\n\n# Force a higher time out. We are going to do one or two heavy queries.\nFaraday.default_connection_options =\n Faraday::ConnectionOptions.new(timeout: 15 * 60)\n\nAptly.configure do |config|\n config.uri = URI::HTTPS.build(host: 'archive-api.neon.kde.org')\n # This is read-only.\nend\n\nchecker = I386InstallCheck.new\nchecker.run\n"
},
{
"alpha_fraction": 0.5795297622680664,
"alphanum_fraction": 0.5834025144577026,
"avg_line_length": 35.33165740966797,
"blob_id": "5da5e4a5993954a575adec603aef1afbe6dec645",
"content_id": "22629fa67eb943660ae1392e713f3533277a4876",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 7230,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 199,
"path": "/lib/debian/relationship.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'architecturequalifier'\nrequire_relative 'profile'\n\nmodule Debian\n # A package relationship.\n class Relationship\n # Name of the package related to\n attr_reader :name\n # Architecture qualification of the package (foo:amd64)\n attr_accessor :architecture\n # Version relationship operator (>=, << etc.)re\n attr_accessor :operator\n # Related to version of the named package\n attr_accessor :version\n\n # architecture restriction for package\n # [architecture restriction] https://www.debian.org/doc/debian-policy/ch-customized-programs.html#s-arch-spec\n attr_accessor :architectures\n\n # profile groups for a package\n # <build profile restriction> https://wiki.debian.org/BuildProfileSpec\n #\n # This is somewhat complicated stuff. One relationship may have one or more\n # ProfileGroup. A ProfileGroup is an AND relationship on one or more\n # Profile. e.g. `<nocheck !cross> <nocheck>` would result in an array of the\n # size 2. The 2 entires are each an instance of ProfileGroup. The\n # first group contains two Profiles, only if both eval to true the group\n # applies. The second group contains one Profile. For the most part, unless\n # you actualy want to know the involved profiles, you should only need to\n # talk to the ProfileGroup instances as groups always apply entirely.\n # Do note that the above example could also be split in two relationships\n # with each one ProfileGroup.\n # See the spec page for additional information.\n #\n # @return Array[ProfileGroup[Profile]]\n attr_accessor :profiles\n\n # Borrowed from Deps.pm. Added capture group names:\n # [name, architecture, operator, architectures, restrictions]\n REGEX = /\n ^\\s* # skip leading whitespace\n (?<name>\n [a-zA-Z0-9][a-zA-Z0-9+.-]*) # package name\n (?: # start of optional part\n : # colon for architecture\n (?<architecture>\n [a-zA-Z0-9][a-zA-Z0-9-]*) # architecture name\n )? # end of optional part\n (?: # start of optional part\n \\s* \\( # open parenthesis for version part\n \\s* (?<operator>\n <<|<=|=|>=|>>|[<>]) # relation part\n \\s* (?<version>\n [^\\)\\s]+) # do not attempt to parse version\n \\s* \\) # closing parenthesis\n )? # end of optional part\n (?: # start of optional architecture\n \\s* \\[ # open bracket for architecture\n \\s* (?<architectures>\n [^\\]]+) # don't parse architectures now\n \\s* \\] # closing bracket\n )? # end of optional architecture\n (?<profiles>\n (?: # start of optional restriction\n \\s* < # open bracket for restriction\n \\s* ([^>]+) # do not parse restrictions now\n \\s* > # closing bracket\n )+ # end of optional restriction\n )?\n \\s*$ # trailing spaces at end\n /x\n\n def initialize(string)\n init_members_to_nil\n string = string.strip\n return if string.empty?\n\n match = string.match(REGEX)\n if match\n process_match(match)\n else\n @name = string\n end\n end\n\n # Checks if the Relationship's profiles make it applicable.\n # Note that a single string is generally assumed to be a Profile unless\n # it contains a space, in which case it will be split and treated as a Group\n # @param array_or_profile [ProfileGroup,Array<String>,Profile,String]\n def applicable_to_profile?(array_or_profile)\n group = array_or_profile\n group = ProfileGroup.new(group) unless group.is_a?(ProfileGroup)\n profiles_ = profiles || [ProfileGroup.new(nil)]\n profiles_.any? { |x| x.matches?(group) }\n end\n\n def substvar?\n @name.start_with?('${') && @name.end_with?('}')\n end\n\n def <=>(other)\n if substvar? || other.substvar? # any is a substvar\n return -1 unless other.substvar? # substvar always looses\n\n return 1 unless substvar? # non-substvar always wins\n\n return substvarcmp(other) # substvars are compared among themself\n end\n @name <=> other.name\n end\n\n def to_s\n output = @name\n output += f(':%s', @architecture)\n output += f(' (%s %s)', @operator, @version)\n output += f(' [%s]', @architectures)\n output += f(' %s', @profiles&.map { |x| \"<#{x}>\" }&.join(' '))\n output\n end\n\n private\n\n def init_members_to_nil\n # ruby -w takes offense with us not always initializing everything\n # explicitly. Rightfully so. Make everything nil by default, so we know\n # fields are nil later on regardless of whether we were able to process\n # the input string.\n @name = nil\n @architecture = nil\n @operator = nil\n @version = nil\n @architectures = nil\n @profiles = nil\n end\n\n def substvarcmp(other)\n ours = @name.gsub('${', '').tr('}', '')\n theirs = other.name.gsub('${', '').tr('}', '')\n ours <=> theirs\n end\n\n def f(str, *params)\n return '' if params.any?(&:nil?)\n\n format(str, *params)\n end\n\n def process_match(match)\n match.names.each do |name|\n data = match[name]\n data&.strip!\n next unless data\n\n data = parse(name, data)\n instance_variable_set(\"@#{name}\".to_sym, data)\n end\n end\n\n def parse(name, data)\n case name\n when 'architectures'\n ArchitectureQualifier.new(data)\n when 'profiles'\n parse_profiles(data)\n else\n data\n end\n end\n\n def parse_profiles(str)\n # str without leading and trailing <>\n str = str.gsub(/^\\s*<\\s*(.*)\\s*>\\s*/, '\\1')\n # str split by >< inside (if any)\n rules = str.split(/\\s*>\\s+<\\s*/)\n # Split by spaces and convert into groups\n rules.map { |x| ProfileGroup.new(x.split(' ')) }\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6836065649986267,
"alphanum_fraction": 0.6872950792312622,
"avg_line_length": 29.123456954956055,
"blob_id": "d2baef6fb77c21ed0669c882f11528a100fa0006",
"content_id": "2d211e4ba0c89b2ed56acb98b49321e3c4b4d25c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2440,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 81,
"path": "/lib/qml_dependency_verifier.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'logger'\nrequire 'logger/colors'\nrequire 'yaml'\n\nrequire_relative 'qml_dep_verify/package'\n\n# A QML dependency verifier. It verifies by installing each built package\n# and verifying the deps of the installed qml files are met.\n# This depends on Launchpad at the time of writing.\nclass QMLDependencyVerifier\n attr_reader :repo\n\n def initialize(repo)\n @log = Logger.new(STDOUT)\n @log.level = Logger::INFO\n @log.progname = self.class.to_s\n @repo = repo\n end\n\n def missing_modules\n repo.add || raise\n # Call actual code for missing detection.\n missing_modules_internal\n ensure\n repo.remove\n end\n\n private\n\n def log_missing(missings)\n # String the imports to make them easier to read.\n stringy_missings = missings.map do |pkg, mods|\n [pkg, mods.map(&:to_s)]\n end.to_h\n\n @log.info \"Done looking for missing modules.\\n\" +\n if stringy_missings.empty?\n ''\n else\n <<-LOG_OUTPUT\nThe following modules are missing:\n#{YAML.dump(stringy_missings)}\n LOG_OUTPUT\n end\n end\n\n def missing_modules_internal\n missing_modules = {}\n repo.binaries.each do |package, version|\n next if package.end_with?('-dbg', '-dbgsym', '-dev')\n\n pkg = QMLDepVerify::Package.new(package, version)\n @log.info \"Checking #{package}: #{version}\"\n next if pkg.missing.empty?\n\n missing_modules[package] = pkg.missing\n end\n log_missing(missing_modules)\n missing_modules\n end\nend\n"
},
{
"alpha_fraction": 0.7093750238418579,
"alphanum_fraction": 0.714062511920929,
"avg_line_length": 40.739131927490234,
"blob_id": "b72a2e13794bc6637b8580f0b55861c02576eac8",
"content_id": "a5500a7f2a5e77a87141c8af6b84f647587aa94d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1920,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 46,
"path": "/jenkins-jobs/nci/watcher.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'pipelinejob'\nrequire_relative '../../lib/nci'\nrequire_relative '../../lib/kdeproject_component'\n\n# Watches for releases.\nclass WatcherJob < PipelineJob \n attr_reader :scm_readable\n attr_reader :scm_writable\n attr_reader :nci\n\n def initialize(project)\n super(\"watcher_release_#{project.component}_#{project.name}\",\n template: 'watcher')\n # Properly nasty deep copy trick. We'll serialize the entire thing into\n # a string, then convert that back to objects which results in fully isolate\n # objects from their originals. Performance isn't really a concern here,\n # so it's probably not too bad.\n @scm_readable = Marshal.load(Marshal.dump(project.packaging_scm))\n @scm_writable = Marshal.load(Marshal.dump(project.packaging_scm))\n # FIXME: brrr the need for deep copy alone should ring alarm bells\n @scm_writable.url.gsub!('https://invent.kde.org/',\n '[email protected]:')\n @nci = NCI\n @cron = 'H H * * *'\n end\nend\n"
},
{
"alpha_fraction": 0.6811091899871826,
"alphanum_fraction": 0.7001733183860779,
"avg_line_length": 29.36842155456543,
"blob_id": "8462cbafeeb03a3accc18f198a88dc09477f461b",
"content_id": "7b41df96f2554ecbda7ff1c86b0bdfb9e168d867",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 577,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 19,
"path": "/overlay-bin/patch",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env ruby\n# SPDX-FileCopyrightText: 2020 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n# frozen_string_literal: true\n\nrequire_relative 'lib/paths' # Drop the overlay from the PATH env.\n\nf_index = ARGV.index { |e| e.start_with?('--fuzz=') }\nunless f_index\n # find possible -F and delete the num following it\n f_index = ARGV.index('-F')\n ARGV.delete_at(f_index+1) if f_index\nend\nif f_index # repalce fuzz with hardcoded fuzz 2 like quilt push\n ARGV[f_index] = '--fuzz=2'\nend\n\np ARGV\nexec('patch', *ARGV)\n"
},
{
"alpha_fraction": 0.6837853193283081,
"alphanum_fraction": 0.6947489976882935,
"avg_line_length": 43.43589782714844,
"blob_id": "f2e6812152e233afe029bab0f79257aac942ecd4",
"content_id": "ff83cd3321be3638cc3b8abbb6e93e702595dca1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1733,
"license_type": "no_license",
"max_line_length": 237,
"num_lines": 39,
"path": "/test/test_asgen.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\nrequire_relative '../lib/asgen'\n\nclass ASGENTest < TestCase\n def test_write\n config = ASGEN::Conf.new('KDE neon')\n config.ArchiveRoot = '/home/nci/public/user'\n # config.MediaBaseUrl\n # config.HtmlBaseUrl\n config.Backend = 'debian'\n config.Features['validateMetainfo'] = true\n config.Suites << ASGEN::Suite.new('xenial', ['main'], ['amd64'])\n config.ExtraMetainfoDir = '123'\n config.write('test_file')\n ref = { 'ProjectName' => 'KDE neon', 'Features' => { 'validateMetainfo' => true }, 'Suites' => { 'xenial' => { 'sections' => ['main'], 'architectures' => ['amd64'] } }, 'ArchiveRoot' => '/home/nci/public/user', 'Backend' => 'debian',\n 'ExtraMetainfoDir' => '123' }\n assert_equal(ref, JSON.load(File.read('test_file')))\n end\nend\n"
},
{
"alpha_fraction": 0.5913252830505371,
"alphanum_fraction": 0.600963830947876,
"avg_line_length": 24,
"blob_id": "03da515e99383b06cfd0465f4b9152579b459ac4",
"content_id": "03b5ce012fd195a54166d9190b59247d4aea05be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 2075,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 83,
"path": "/test/test_dpkg.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\nrequire_relative '../lib/dpkg'\nrequire_relative 'lib/assert_backtick'\nrequire_relative 'lib/testcase'\n\n# Test DPKG\nclass DPKGTest < TestCase\n def test_architectures\n TTY::Command\n .any_instance\n .expects(:run)\n .with('dpkg-architecture', '-qDEB_BUILD_ARCH')\n .returns(lambda {\n status = mock('arch_status')\n status.stubs(:out).returns(\"foobar\\n\")\n status\n }.call)\n\n assert_equal('foobar', DPKG::BUILD_ARCH)\n end\n\n def test_architectures_fail\n err_status = mock('status')\n err_status.stubs(:out)\n err_status.stubs(:err)\n err_status.stubs(:exit_status)\n TTY::Command\n .any_instance\n .expects(:run)\n .with('dpkg-architecture', '-qDEB_BUBU')\n .raises(TTY::Command::ExitError.new('bubub', err_status))\n\n assert_equal(nil, DPKG::BUBU)\n end\n\n def test_listing\n TTY::Command\n .any_instance\n .expects(:run)\n .with('dpkg', '-L', 'abc')\n .returns(lambda {\n status = mock('status')\n status.stubs(:out).returns(\"/.\\n/etc\\n/usr\\n\")\n status\n }.call)\n\n assert_equal(\n %w[/. /etc /usr],\n DPKG.list('abc')\n )\n end\nend\n\nclass DPKGArchitectureTest < TestCase\n def test_is\n arch = DPKG::Architecture.new\n arch.expects(:system)\n .with('dpkg-architecture', '--is', 'amd64')\n .returns(true)\n assert(arch.is('amd64'))\n arch.expects(:system)\n .with('dpkg-architecture', '--is', 'amd64')\n .returns(false)\n refute(arch.is('amd64'))\n end\n\n def test_is_with_host_arch\n arch = DPKG::Architecture.new(host_arch: 'arm64')\n arch.expects(:system)\n .with('dpkg-architecture', '--host-arch', 'arm64', '--is', 'amd64')\n .returns(false)\n refute(arch.is('amd64'))\n end\n\n def test_is_with_host_arch_empty\n # empty string should result in no argument getting set\n arch = DPKG::Architecture.new(host_arch: '')\n arch.expects(:system)\n .with('dpkg-architecture', '--is', 'amd64')\n .returns(true)\n assert(arch.is('amd64'))\n end\nend\n"
},
{
"alpha_fraction": 0.6584097743034363,
"alphanum_fraction": 0.6645259857177734,
"avg_line_length": 34.93406677246094,
"blob_id": "cf624bfcb30522f4ea859234463891190ded8033",
"content_id": "27449a593f083f6d3a961eb36dc237d5f34253bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3270,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 91,
"path": "/lib/ci/dependency_resolver.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2015-2016 Harald Sitter <[email protected]>\n# Copyright (C) 2015 Rohan Garg <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'tty/command'\n\nrequire_relative '../os'\nrequire_relative '../retry'\nrequire_relative '../tty_command'\n\nmodule CI\n # Resolves build dependencies and installs them.\n class DependencyResolverPBuilder\n class ResolutionError < RuntimeError; end\n\n RESOLVER_BIN = '/usr/lib/pbuilder/pbuilder-satisfydepends'\n\n resolver_env = {}\n if OS.to_h.include?(:VERSION_ID) && OS::VERSION_ID == '8'\n resolver_env['APTITUDEOPT'] = '--target-release=jessie-backports'\n end\n resolver_env['DEBIAN_FRONTEND'] = 'noninteractive'\n RESOLVER_ENV = resolver_env.freeze\n\n class << self\n attr_writer :simulate\n end\n\n def self.resolve(dir, bin_only: false, retries: 5, arch: nil)\n return true if @simulate\n raise \"Can't find #{RESOLVER_BIN}!\" unless File.executable?(RESOLVER_BIN)\n raise \"#{self.class} doesn't support cross build for #{arch}\" if arch\n\n Retry.retry_it(times: retries) do\n opts = []\n opts << '--binary-arch' if bin_only\n opts << '--control' << \"#{dir}/debian/control\"\n ret = system(RESOLVER_ENV, RESOLVER_BIN, *opts)\n raise ResolutionError, 'Failed to satisfy depends' unless ret\n end\n end\n end\n\n class DependencyResolverAPT < DependencyResolverPBuilder\n RESOLVER_BIN = '/usr/bin/apt-get'\n\n def self.resolve(dir, bin_only: false, retries: 5, arch: nil)\n return true if @simulate\n\n cmd = TTY::Command.new(uuid: false)\n\n Retry.retry_it(times: retries) do\n opts = []\n opts << '--arch-only' if bin_only\n opts << '--host-architecture' << arch if arch\n opts << '-o' << 'Debug::pkgProblemResolver=true'\n opts << '--yes'\n opts << 'build-dep'\n opts << File.absolute_path(dir)\n ret = cmd.run!(RESOLVER_ENV, RESOLVER_BIN, *opts)\n raise ResolutionError, 'Failed to satisfy depends' unless ret.success?\n end\n end\n end\n\n # pbuilder resolver is here for fallback should it be temporarily necessary\n # for whatever reason. Generally speaking the apt resolver is faster and\n # should be more reliable though!\n DependencyResolver = if ENV['PANGEA_PBUILDER_RESOLVER']\n DependencyResolverPBuilder\n else\n DependencyResolverAPT\n end\nend\n"
},
{
"alpha_fraction": 0.6910669803619385,
"alphanum_fraction": 0.7003722190856934,
"avg_line_length": 34.82222366333008,
"blob_id": "d12519271b3affda3d5f434e3ce6067a586001e1",
"content_id": "2d3a371eb0303643365b529d0aac07fa38c0b330",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1612,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 45,
"path": "/test/test_ci_fake_package.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2018 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative '../lib/ci/fake_package'\n\nrequire_relative 'lib/testcase'\n\nrequire 'mocha/test_unit'\n\nclass FakePackageTest < TestCase\n def test_install\n cmd = mock('cmd')\n TTY::Command.expects(:new).returns(cmd)\n cmd.expects(:run).with do |*args|\n next false if args != ['dpkg-deb', '-b', '-Znone', '-Snone', 'foo', 'foo.deb']\n\n assert_path_exist('foo/DEBIAN/control')\n control = File.read('foo/DEBIAN/control')\n assert_includes(control, 'Package: foo')\n assert_includes(control, 'Version: 123')\n true\n end\n DPKG.expects(:run).with('dpkg', ['-i', 'foo.deb']).returns(true)\n\n pkg = FakePackage.new('foo', '123')\n pkg.install\n end\nend\n"
},
{
"alpha_fraction": 0.7403560876846313,
"alphanum_fraction": 0.751483678817749,
"avg_line_length": 36.44444274902344,
"blob_id": "1d8c6e52df0d0c20c298a9f623b74f78af5c65b6",
"content_id": "d95b80bd1ea5bc7c0acb16b2f4444f8401e3ccb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1348,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 36,
"path": "/nci/asgen.sh",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n#\n# Copyright (C) 2019-2021 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\n# This is a minimal wrapper for asgen. Since asgen is run inside a debian\n# container without pangea image, we need to provision the minimal dependencies.\n\nset -ex\n\nexport LANG=C.UTF-8 # make sure perl knows which encoding to use\n\napt update\napt-get install -y ruby gpg eatmydata dirmngr\n\nln -sv /usr/bin/eatmydata /usr/local/bin/apt\nln -sv /usr/bin/eatmydata /usr/local/bin/apt-get\n\ngem install tty-command\n\nexec $(dirname \"$0\")/asgen.rb\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.6700767278671265,
"avg_line_length": 29.076923370361328,
"blob_id": "38ef4be62e398839684491a3590c97f8638fff53",
"content_id": "333cd05de577cbe80c8e754a11e72ac7bb3ba618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 782,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 26,
"path": "/test/test_nci_lint_dir_package_lister.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n# SPDX-FileCopyrightText: 2017-2021 Harald Sitter <[email protected]>\n# SPDX-License-Identifier: LGPL-2.1-only OR LGPL-3.0-only OR LicenseRef-KDE-Accepted-LGPL\n\nrequire_relative 'lib/testcase'\nrequire_relative '../nci/lint/dir_package_lister'\n\nmodule NCI\n class DirPackageListerTest < TestCase\n def test_packages\n FileUtils.cp_r(\"#{datadir}/.\", '.')\n\n pkgs = DirPackageLister.new(Dir.pwd).packages\n assert_equal(2, pkgs.size)\n assert_equal(%w[foo bar].sort, pkgs.map(&:name).sort)\n end\n\n def test_packages_filter\n FileUtils.cp_r(\"#{datadir}/.\", '.')\n\n pkgs = DirPackageLister.new(Dir.pwd, filter_select: %w[foo]).packages\n assert_equal(1, pkgs.size)\n assert_equal(%w[foo].sort, pkgs.map(&:name).sort)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.6532299518585205,
"alphanum_fraction": 0.6625322699546814,
"avg_line_length": 32.36206817626953,
"blob_id": "6fccb9b12b7175c825d2fb8c7f6093bc4c18c643",
"content_id": "c96ec211acb5ceec549e199c1a67ada80e957952",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 1935,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 58,
"path": "/test/test_pangea_mail.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2017 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire_relative 'lib/testcase'\n\nrequire_relative '../lib/pangea/mail'\n\nrequire 'mocha/test_unit'\n\nmodule Pangea\n class MailTest < TestCase\n def setup\n ENV['PANGEA_MAIL_CONFIG_PATH'] = \"#{Dir.pwd}/mail.yaml\"\n end\n\n def test_start\n config = {\n 'smtp' => {\n 'address' => 'fish.local',\n 'port' => 587,\n 'helo' => 'drax.kde.org',\n 'user' => 'fancyuser',\n 'secret' => 'pewpewpassword'\n }\n }\n File.write(ENV.fetch('PANGEA_MAIL_CONFIG_PATH'), YAML.dump(config))\n\n smtp = mock('smtp')\n # To talk to bluemchen we need to enable starttls\n smtp.expects(:enable_starttls_auto)\n smtp.expects(:open_timeout=).with(240)\n # Starts a thingy\n session = mock('smtp.session')\n session.expects('dud')\n smtp.expects(:start).with('drax.kde.org', 'fancyuser', 'pewpewpassword', nil).yields(session)\n Net::SMTP.expects(:new).with('fish.local', 587).returns(smtp)\n\n SMTP.start(&:dud)\n end\n end\nend\n"
},
{
"alpha_fraction": 0.625781238079071,
"alphanum_fraction": 0.6294270753860474,
"avg_line_length": 30.47541046142578,
"blob_id": "93223b5225fc1b142810c75fa95ee042b8a642fd",
"content_id": "b38a7dae6b7a6eb5cabefa7f786277cba48d39cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 3840,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 122,
"path": "/lib/aptly-ext/repo_cleaner.rb",
"repo_name": "pangea-project/pangea-tooling",
"src_encoding": "UTF-8",
"text": "# frozen_string_literal: true\n#\n# Copyright (C) 2016-2019 Harald Sitter <[email protected]>\n#\n# This library is free software; you can redistribute it and/or\n# modify it under the terms of the GNU Lesser General Public\n# License as published by the Free Software Foundation; either\n# version 2.1 of the License, or (at your option) version 3, or any\n# later version accepted by the membership of KDE e.V. (or its\n# successor approved by the membership of KDE e.V.), which shall\n# act as a proxy defined in Section 6 of version 3 of the license.\n#\n# This library is distributed in the hope that it will be useful,\n# but WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# Lesser General Public License for more details.\n#\n# You should have received a copy of the GNU Lesser General Public\n# License along with this library. If not, see <http://www.gnu.org/licenses/>.\n\nrequire 'aptly'\n\nrequire_relative '../../lib/aptly-ext/filter'\nrequire_relative '../../lib/nci' # nci config module\n\n# Cleans up an Aptly::Repository by removing all versions of source+bin that\n# are older than the newest version.\nclass RepoCleaner\n def initialize(repo, keep_amount:)\n @repo = repo\n @keep_amount = keep_amount\n end\n\n # Iterate over each source. Sort its versions and drop lowest ones.\n def clean\n puts \"Cleaning sources -- #{@repo}\"\n clean_sources\n puts \"Cleaning binaries -- #{@repo}\"\n clean_binaries\n puts \"Cleaning re-publishing -- #{@repo}\"\n @repo.published_in(&:update!)\n puts \"--- done with #{@repo} ---\"\n end\n\n def self.clean(repo_whitelist = [], keep_amount: 1)\n Aptly::Repository.list.each do |repo|\n next unless repo_whitelist.include?(repo.Name)\n\n puts \"-- Now cleaning repo: #{repo}\"\n RepoCleaner.new(repo, keep_amount: keep_amount).clean\n end\n end\n\n private\n\n def clean_sources\n keep = Aptly::Ext::LatestVersionFilter.filter(sources, @keep_amount)\n (sources - keep).each { |x| delete_source(x) }\n end\n\n def clean_binaries\n keep = Aptly::Ext::LatestVersionFilter.filter(binaries, @keep_amount)\n (binaries - keep).each { |x| delete_binary(x) }\n keep.each { |x| delete_binary(x) unless bin_has_source?(x) }\n end\n\n def source_name_and_version_for(package)\n name = package.Package\n version = package.Version\n if package.Source\n source = package.Source\n match = source.match(/^(?<name>[^\\s]+)( \\((?<version>[^\\)]+)\\))?$/)\n name = match[:name]\n # Version can be nil, handle this correctly.\n version = match[:version] || version\n end\n [name, version]\n end\n\n def bin_has_source?(bin)\n package = Aptly::Ext::Package.get(bin)\n name, version = source_name_and_version_for(package)\n sources.any? { |x| x.name == name && x.version == version }\n end\n\n def sources\n @sources ||= @repo.packages(q: '$Architecture (source)')\n .compact\n .uniq\n .collect do |key|\n Aptly::Ext::Package::Key.from_string(key)\n end\n end\n\n def binaries\n @binaries ||= @repo.packages(q: '!$Architecture (source)')\n .compact\n .uniq\n .collect do |key|\n Aptly::Ext::Package::Key.from_string(key)\n end\n end\n\n def delete_source(source_key)\n sources.delete(source_key)\n query = format('$Source (%s), $SourceVersion (%s)',\n source_key.name,\n source_key.version)\n binaries = @repo.packages(q: query)\n delete([source_key.to_s] + binaries)\n end\n\n def delete_binary(key)\n binaries.delete(key)\n delete(key.to_s)\n end\n\n def delete(keys)\n puts \"@repo.delete_packages(#{keys})\"\n @repo.delete_packages(keys)\n end\nend\n"
}
] | 457 |
imbenwolf/minitrip
|
https://github.com/imbenwolf/minitrip
|
fc72d39ee913bbaa74b3f7610b7815e0fa79b44c
|
c26910eefda90d6ccf14f23d04295492bb89e9a8
|
0a92d57d63437329c75eb7006c9fe3356fc12ba8
|
refs/heads/master
| 2022-12-15T05:30:18.691168 | 2020-09-10T14:03:32 | 2020-09-10T14:03:32 | 294,330,020 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.5984252095222473,
"alphanum_fraction": 0.5984252095222473,
"avg_line_length": 27.33333396911621,
"blob_id": "e97b21e4fc14db3f1d924979fba4737e58a6dd66",
"content_id": "a544aa2fcadf996f6c904bda0fe12dc14ac9e872",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 254,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 9,
"path": "/scan.py",
"repo_name": "imbenwolf/minitrip",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\n\ndef walk_paths(path):\n path = Path(path) if isinstance(path, str) else path\n for item in path.iterdir():\n if item.is_dir():\n yield from walk_paths(item)\n elif item.is_file():\n yield item"
},
{
"alpha_fraction": 0.4937238395214081,
"alphanum_fraction": 0.5355648398399353,
"avg_line_length": 19,
"blob_id": "e0eff6fc01ae90883690614940664a86a0ba9b2d",
"content_id": "04e1be9740b86b1a80ce4a337eba3210583daaab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 12,
"path": "/hash.py",
"repo_name": "imbenwolf/minitrip",
"src_encoding": "UTF-8",
"text": "from hashlib import sha256\n\ndef hash(path):\n hash = sha256()\n\n with open(path, 'rb') as file:\n chunk = []\n while chunk != b'':\n chunk = file.read(4096)\n hash.update(chunk)\n\n return hash.digest()"
},
{
"alpha_fraction": 0.5999310612678528,
"alphanum_fraction": 0.6023432016372681,
"avg_line_length": 36.20512771606445,
"blob_id": "22a3f5c81b28cfb470596c2a34aa1f8f9ef80104",
"content_id": "3253a886e9b234ce82bc9a091eec6b5a02242ab9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2902,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 78,
"path": "/minitrip.py",
"repo_name": "imbenwolf/minitrip",
"src_encoding": "UTF-8",
"text": "\"\"\" Minitrip, a filesystem integrity check tool \"\"\"\nimport click\nimport plyvel\nimport sys\nfrom os import environ\nfrom time import time\n\nfrom hash import hash\nfrom scan import walk_paths\n\nDEFAULT_DB_PATH = \"$HOME/.minitripdb\"\n\n\ndef add(db, hash_value, file_path, label, verbose):\n if hash_value is None:\n db.put(hash(file_path), bytes(\n file_path.stem if label is None else label, \"utf-8\"))\n if verbose:\n sys.stderr.write('New entry: \"' + str(file_path) +\n '\" with label \"' + label.decode(\"utf-8\") + '\"\\n')\n\n\ndef check(timestamp, hash_value, file_path):\n if hash_value is None:\n sys.stdout.write('File never seen before: \"' +\n str(file_path) + '\"\\n')\n elif timestamp is None or int(hash_value) < int(timestamp):\n sys.stderr.write('Malware found: \"' + str(file_path) + '\"\\n')\n\n\ndef update(db, hash_value, file_path, verbose):\n if hash_value is None:\n db.put(hash(file_path), bytes(str(int(time())), \"utf-8\"))\n elif verbose and hash_value.decode(\"utf-8\").isdigit():\n sys.stderr.write('Found file \"' + str(file_path) +\n '\" with value \"' + hash_value.decode(\"utf-8\") + '\"\\n')\n\n\[email protected](context_settings=dict(help_option_names=['-h', '--help']))\[email protected]('PATH', type=click.Path(exists=True), nargs=-1)\[email protected]('-v', '--verbose', is_flag=True, type=bool)\[email protected]('-d', '--database', default=DEFAULT_DB_PATH, show_default=True, help=\"database path\")\[email protected]('-a', '--add', 'mode', flag_value='a', is_flag=True, help=\"Run in add mode (add malware samples)\")\[email protected]('-u', '--update', 'mode', flag_value='u', is_flag=True, help=\"Run in update mode (record timestamps for new files)\")\[email protected]('-t', '--timestamp', type=int, help=\"For check mode, ignore all hashes whose timestamp is newer than the desired time\")\[email protected]('-l', '--label', help=\"For add mode, set an explicit label instead of the filename stem\")\ndef main(verbose, database, mode, timestamp, label, path):\n \"\"\" Tool to lookup known file hashes \"\"\"\n mode = 'c' if mode is None else mode\n\n if database == DEFAULT_DB_PATH:\n database_folder = database.split(\"/\").pop()\n database = environ['HOME'] + \"/\" + database_folder\n\n db = plyvel.DB(database, create_if_missing=True)\n\n path = set(path)\n if len(path) == 0:\n path.add(\".\")\n\n for path in path:\n for file_path in walk_paths(path):\n hash_value = db.get(hash(file_path))\n\n if mode == 'a':\n add(db, hash_value, file_path, label, verbose)\n\n elif mode == 'c':\n check(timestamp, hash_value, file_path)\n\n elif mode == 'u':\n update(db, hash_value, file_path, verbose)\n\n db.close()\n\n\nif __name__ == \"__main__\":\n main() # pylint: disable=no-value-for-parameter\n"
}
] | 3 |
DuaEstwald/Astrofisica_Computacional
|
https://github.com/DuaEstwald/Astrofisica_Computacional
|
b3a8fe790731d4eb8d6753a10165ca0fb53a857c
|
24fb7f1f5a3e2ba38059e068ad948004b834f235
|
e8659962a62ab17381bc586e7384b1cd41a833da
|
refs/heads/master
| 2022-09-12T20:50:47.727716 | 2020-06-02T11:15:25 | 2020-06-02T11:15:25 | 268,628,074 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4911881685256958,
"alphanum_fraction": 0.520466148853302,
"avg_line_length": 29.859649658203125,
"blob_id": "76f357fc71fe6b90bea2f2c4c5d020178359222b",
"content_id": "f6156e445560c844f6084db77a471a881cee5142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3518,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 114,
"path": "/onlyfits.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Una vez creada la fuente, vamos a realizar la lente\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport sys\nfrom parameters import *\n\n#print(ny) \ndef lensing(name): \n import lens as l\n import source as s\n import img_scale\n\n print(nx)\n print(n_y)\n print(xl)\n print(yl)\n\n \n if jpg == True:\n r,g,bb = s.fitsim(filename,jpg)\n ss = r,g,bb\n imgb = np.zeros((nx,nx,3),dtype=np.int32)\n imga = np.zeros((r.shape[0],r.shape[1],3),dtype=np.int32)\n else:\n ss = s.fitsim(filename,jpg)\n imgb = np.zeros((nx,nx,3),dtype=float)\n imga = np.zeros((ss.shape[0],ss.shape[1],3),dtype=float)\n# ================================================\n\n index = 0\n for a in ss: #EL PROBLEMA ESTA AQUI, NO PODEMOS USAR UNA IMAGEN Y ESTO A LA VEZ\n# print(a)\n ny = a[0].size\n# Creamos el plano imagen\n\n# ================ FUENTE ======================\n # calculamos el tamanio fisico de los pixeles\n xs = 2.*xl/(nx-1.) #El menos 1 es porque esta considerando los centros de los pixeles\n ys = 2.*yl/(ny-1.)\n\n b = np.zeros((nx,nx))\n \n # Convertimos los pixeles de la imagenes a coordenadas \n for j1 in range(nx):\n for j2 in range(nx):\n x1 = -xl+j1*xs\n x2 = -xl+j2*xs\n p = param(name)\n # APLICAMOS LA TRANSFORMACION INVERSA\n if name == 'Point':\n y1,y2 = l.Point(x1,x2,p[0],p[1],p[2])\n elif name == 'TwoPoints':\n y1, y2 = l.TwoPoints(x1,x2,p[0],p[1],p[2],p[3],p[4],p[5])\n elif name == 'ChangRefsdal':\n y1,y2 = l.ChangRefsdal(x1,x2,p[0],p[1],p[2],p[3],p[4]) \n elif name == 'SIS':\n y1,y2 = l.SIS(x1,x2,p[0],p[1],p[2])\n elif name == 'SISChangRefsdal':\n y1,y2 = l.SISChangRefsdal(x1,x2,p[0],p[1],p[2],p[3],p[4])\n\n # CONVERTIMOS LAS COORDENADAS A PIXELES\n\n i1 = int(round((y1+yl)/ys))\n i2 = int(round((y2+yl)/ys))\n\n # Vamos a ponerle una condicion para que los pixeles queden dentro de la fuente. En caso contrario les damos un valor arbitrario. Si i1,i2 estan contenidos en el rango (1,n) hacemos asignacion IMAGEN=FUENTE, sino, hacemos IMAGEN=C donde C es una constante arbitraria como por ejemplo el fondo de cielo\n if ((i1>=0)&(i1<ny)&(i2>=0)&(i2<ny)):\n b[j1,j2]=a[i1,i2]\n else:\n C = 1. # Esta constante puede ser cualquiera\n b[j1,j2]=C\n \n\n imgb[:,:,index] = b\n imga[:,:,index] = a\n# index +=1\n\n# imgb = img_scale.sqrt(b,scale_min=b.min(),scale_max=b.max()+50)\n #imga = img_scale.sqrt(a,scale_min=a.min(),scale_max=a.max()+50)\n \n index +=1\n\n return imga,imgb\n \n\n#ltype = 'Point' # ESTO VIENE EN PARAMETERS\na,b = lensing(ltype)\n\n# ========================================================\n\n\n# Ya hemos terminado, ahora vamos a plotear las cosas\n\nplt.close()\nplt.ion()\nfig = plt.figure()\nplt.title(str(ltype)+' LENS')\nplt.axis('off')\nfig.add_subplot(121)\nplt.imshow(a,extent=(-yl,yl,-yl,yl))\nplt.title('Plano de la fuente')\nfig.add_subplot(122)\nplt.imshow(b,extent=(-xl,xl,-xl,xl))\nplt.title('Plano imagen')\n\nif sour == 'fitsim':\n if jpg == True:\n plt.savefig(filename[:-4]+'0.png')\n else:\n plt.savefig(filename[:-5]+'0.png')\n\nelse:\n plt.savefig('lensing.png')\n"
},
{
"alpha_fraction": 0.49671053886413574,
"alphanum_fraction": 0.5241228342056274,
"avg_line_length": 23,
"blob_id": "c13bb9d4d98fc63e52a459e508f3cb48c15c8dfc",
"content_id": "0002c9ec48d1ad8a5408674aac69510af290adf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 912,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 38,
"path": "/source.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Vamos a realizar otro intento para realizar la astrofisica computacional\n\nimport numpy as np\n\n\n\n# realizamos la fuente de la lente, siendo esta \n\n\n# ============================ FUENTES ================================\n\n\n# FUENTE CIRCULAR GAUSIANA\ndef gcirc(n_y,rad,x1=0.,y1=0.):\n x,y = np.mgrid[0:n_y,0:n_y] # Esto crea el plano de la fuente\n r2 = (x-x1-n_y/2.)**2.+(y-y1-n_y/2.)**2.\n a = np.exp(-r2*0.5/rad**2.)\n return a/a.sum()\n\n# FUENTE COMO IMAGEN\n\nfrom astropy.io.fits import getdata\nfrom convert import *\n\ndef fitsim(filename,jpg):\n if jpg == True:\n r,g,b = jpg_to_fits(filename)\n for a in (r,g,b):\n if len(a.shape)>2:\n a = a[0]\n a = a*1.0/a.sum() \n return r,g,b # devuelve la imagen normalizada\n\n if jpg == False:\n a = getdata(filename)\n if len(a.shape)>2:\n a = a[0]\n return a*1.0/a.sum()\n"
},
{
"alpha_fraction": 0.5950840711593628,
"alphanum_fraction": 0.6261319518089294,
"avg_line_length": 31.893617630004883,
"blob_id": "31f6574242474c537606516e7b0081af66390c17",
"content_id": "6f6925c3dc473a30a049d55002f7c8f64f74bb36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1546,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 47,
"path": "/convert.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Para convertir imagenes jpg en fits y viceversa\n\nimport numpy as np\nfrom PIL import Image\nfrom astropy.io import fits\nimport img_scale\n\ndef jpg_to_fits(filename):\n image = Image.open(filename)\n xsize,ysize = image.size\n r,g,b = image.split()\n \n r_data = np.array(r.getdata())\n r_data = r_data.reshape(ysize,xsize)\n# red = fits.PrimaryHDU(data=r_data)\n# red.header['LATOBS'] = \"32:11:56\"\n# red.header['LONGOBS'] = \"110:56\"\n# red.writeto(str(filename[:-4])+'_red.fits')\n\n g_data = np.array(g.getdata())\n g_data = g_data.reshape(ysize,xsize)\n# green = fits.PrimaryHDU(data=g_data)\n# green.header['LATOBS'] = \"32:11:56\"\n# green.header['LONGOBS'] = \"110:56\"\n# green.writeto(str(filename[:-4])+'_green.fits')\n\n b_data = np.array(b.getdata())\n b_data = b_data.reshape(ysize,xsize)\n# blue = fits.PrimaryHDU(data=b_data)\n# blue.header['LATOBS'] = \"32:11:56\"\n# blue.header['LONGOBS'] = \"110:56\"\n# blue.writeto(str(filename[:-4])+'_blue.fits')\n return r_data,g_data,b_data\n\ndef fits_to_jpg(rfile,gfile,bfile,name):\n r = fits.getdata(rfile)\n b = fits.getdata(bfile)\n g = fits.getdata(gfile)\n img = np.zeros((r.shape[0],r.shape[1],3),dtype=float)\n\n img[:,:,0] = img_scale.sqrt(r,scale_min=r.min(),scale_max=r.max()+50)\n img[:,:,1] = img_scale.sqrt(g,scale_min=g.min(),scale_max=g.max()+50)\n img[:,:,2] = img_scale.sqrt(b,scale_min=b.min(),scale_max=b.max()+50)\n\n import matplotlib.pyplot as plt\n plt.imshow(img,aspect='equal')\n plt.savefig(str(name)+'.jpg')\n"
},
{
"alpha_fraction": 0.5316323041915894,
"alphanum_fraction": 0.5599440932273865,
"avg_line_length": 30.09782600402832,
"blob_id": "0fd57634dfc845138106c0fffe50cc0857b6977a",
"content_id": "a61798e260f6f9b6879b846e2b4d1fa1e5edd924",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2861,
"license_type": "no_license",
"max_line_length": 305,
"num_lines": 92,
"path": "/onlyLENS.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Una vez creada la fuente, vamos a realizar la lente\n\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport sys\nfrom parameters import *\n\n#print(ny) \ndef lensing(name): \n import lens as l\n import source as s\n\n print(nx)\n print(n_y)\n print(xl)\n print(yl)\n\n\n ys = 2.*yl/(n_y-1.)\n# convertimos los parametros de la fuente a pixeles\n ipos = int(round(xpos/ys)) # round redondea, en este caso a solo un numero\n jpos = int(round(-ypos/ys)) # le pone el menos porque el imshow cambia en el eje y el signo \n rpix = int(round(rad/ys))\n a = s.gcirc(n_y,rpix,jpos,ipos) # Aqui se ha creado la fuente, esta en pixeles\n# ================================================\n\n# print(a)\n ny = n_y\n# Creamos el plano imagen\n\n# ================ FUENTE ======================\n# calculamos el tamanio fisico de los pixeles\n xs = 2.*xl/(nx-1.) #El menos 1 es porque esta considerando los centros de los pixeles\n ys = 2.*yl/(ny-1.)\n\n b = np.zeros((nx,nx))\n\n# Convertimos los pixeles de la imagenes a coordenadas \n for j1 in range(nx):\n for j2 in range(nx):\n x1 = -xl+j1*xs\n x2 = -xl+j2*xs\n p = param(name)\n # APLICAMOS LA TRANSFORMACION INVERSA\n if name == 'Point':\n y1,y2 = l.Point(x1,x2,p[0],p[1],p[2])\n elif name == 'TwoPoints':\n y1, y2 = l.TwoPoints(x1,x2,p[0],p[1],p[2],p[3],p[4],p[5])\n elif name == 'ChangRefsdal':\n y1,y2 = l.ChangRefsdal(x1,x2,p[0],p[1],p[2],p[3],p[4]) \n elif name == 'SIS':\n y1,y2 = l.SIS(x1,x2,p[0],p[1],p[2])\n elif name == 'SISChangRefsdal':\n y1,y2 = l.SISChangRefsdal(x1,x2,p[0],p[1],p[2],p[3],p[4])\n\n # CONVERTIMOS LAS COORDENADAS A PIXELES\n\n i1 = int(round((y1+yl)/ys))\n i2 = int(round((y2+yl)/ys))\n\n # Vamos a ponerle una condicion para que los pixeles queden dentro de la fuente. En caso contrario les damos un valor arbitrario. Si i1,i2 estan contenidos en el rango (1,n) hacemos asignacion IMAGEN=FUENTE, sino, hacemos IMAGEN=C donde C es una constante arbitraria como por ejemplo el fondo de cielo\n if ((i1>=0)&(i1<ny)&(i2>=0)&(i2<ny)):\n b[j1,j2]=a[i1,i2]\n else:\n C = 0 # Esta constante puede ser cualquiera\n b[j1,j2]=C\n \n \n return a,b\n\n#ltype = 'Point' # ESTO VIENE EN PARAMETERS\na,b = lensing(ltype)\n\n# ========================================================\n\n\n# Ya hemos terminado, ahora vamos a plotear las cosas\n\nplt.close()\nplt.ion()\nfig = plt.figure()\nplt.title(str(ltype)+' LENS')\nplt.axis('off')\nfig.add_subplot(121)\nplt.imshow(a,extent=(-yl,yl,-yl,yl))\nplt.title('Plano de la fuente')\nfig.add_subplot(122)\nplt.imshow(b,extent=(-xl,xl,-xl,xl))\nplt.title('Plano imagen')\n\n\nplt.savefig(str(ltype)+'.png')\n"
},
{
"alpha_fraction": 0.8080185055732727,
"alphanum_fraction": 0.8126445412635803,
"avg_line_length": 71,
"blob_id": "edfc955a5e1d18fd4336442a78b67b10427fa8d3",
"content_id": "5ae8328bb727bf665ec7144a7acdd91fc42df92a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1321,
"license_type": "no_license",
"max_line_length": 346,
"num_lines": 18,
"path": "/README.md",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Astrofisica Computacional. Lentes gravitacionales\nRepositorio de los códigos desarrollados para la asignatura de Astrofísica Computacional.\n\n\nPodemos encontrar aquí todos los códigos desarrolados para la asignatura de Astrofisica Computacional. \n\nTenemos cinco scripts principales: \n\n\n· parameters.py: código desarrollado para implementar los parámetros que cogen como input los códigos onlyLENS.py y onlyfits.py.\n\n· onlyLENS.py: utilizado para el desarrollo de lentes gravitacionales con una guente gaussiana. El código está desarrollado con la idea de que se le puedan implementar fácilmente otro tipo de lentes. \n\n· onlyfits.py: su utilidad es la misma que en el código anterior, lo único que cambia es el hecho de que la fuente es una imagen tipo jpg. Debido a la diferencia al tratar estos archivos como fuentes, su tratamiento ha implementado en un script a parte.\n\n· magmap_alcock.py: donde se presentan las causticas y los mapas de magnificación de las microlentes. En este caso se hace uso de la microlente LMC-9 que aparece en el artículo de Alcock 2000. El código está desarrollado para implementar cualquier microlente en el script auxiliar llamado: microlensing.py. Donde por ahora sólo encontramos LMC-9.\n\n· qmic.py: código desarrollado para la simulación de quasar microlensing. \n"
},
{
"alpha_fraction": 0.6173535585403442,
"alphanum_fraction": 0.6711496710777283,
"avg_line_length": 24.61111068725586,
"blob_id": "77ada2745c3188a9f90574f357cfd1d37436616e",
"content_id": "13f9abcab67694404070f9f2cb2836019c383126",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2305,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 90,
"path": "/magmap_alcock.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Codigo para generar un mapa de magnitudes\n\nimport numpy as np\nimport lens as l\nimport matplotlib.pyplot as plt\n\nny=401\nyl=3.\n\nb=np.zeros((ny,ny))\nraypix=15. # el numero de rayos por pixel en ausencia de lensing\nsqrpix=np.sqrt(raypix) # Raiz cuadrada de rayos por pixel en una direccion\nsqrinpix=np.sqrt(1./raypix) \n\nys=2.*yl/(ny-1) # tamanio del pixel en el plano fuente\nxs=ys/sqrpix # tamanio del cuadrado del area transportado de vuelta por un rayo\nxl=5.*yl #tamanio de la region de shooting del plano imagen\nnx=np.round(2*xl/xs)+1 # numeros de rayos de una columna/fila en el plano imagen\nyr=np.arange(0,nx) # array con los pixeles en y en una direccion\ny,x=np.mgrid[0.0:1.0,0:nx] #grid con coordenadas pixeles por linea de la imagen\nperc0=5. # porcentaje de pasos por progreso\nperc=5. # valor inicial por perc\n\n\n# PARAMETROS CARACTERISTICOS PARA EL LMC-9 EN ALCOCK.PY\n\nfrom alcock import microlensing\n\nml1,ml2,x1l1,x2l1,x1l2,x2l2,theta,u0 = microlensing('LMC9')\n\n# Pasamos a tamanio en pixel\n \n\nfor i in yr: # loop sobre todos los rayos\n if ((i*100/nx)>=perc): #chequeamos si tenemos completado el perc\n perc=perc+perc0\n print(round(i*100/nx),\"% \")\n\n x1=-xl+y*xs\n x2=-xl+x*xs\n y1,y2=l.TwoPoints(x1,x2,x1l1,x2l1,x1l2,x2l2,ml1,ml2)\n\n i1=(y1+yl)/ys\n i2=(y2+yl)/ys\n i1=np.round(i1)\n i2=np.round(i2)\n\n ind = (i1>=0)&(i1<ny)&(i2>=0)&(i2<ny)\n\n i1n=i1[ind]\n i2n=i2[ind]\n\n for j in range(np.size(i1n)):\n b[int(i2n[j]),int(i1n[j])]+=1\n y=y+1.0\nb=b/raypix\nprint(np.mean(b))\nplt.close()\nplt.ion()\nfig = plt.figure()\nfig.add_subplot(121)\nplt.imshow(np.log10(b),extent = (-yl,yl,-yl,yl),aspect='auto')\n\n# Recreamos la recta que aparece en el LMC9\nxpx = np.arange(len(b))\nx = -yl+xpx*ys\n\ny0 = np.tan(theta)*x+u0 # EL U0 HAY QUE PASARLO A PIXELES PARA QUE SURGA EFECTO\n\ny1 = x\n\nplt.plot(x,y0,'b')\nplt.plot(x,y1,'g')\n\n\nypx0 = np.round((y0+yl)/ys).astype(int)\nypx1 = np.round((y1+yl)/ys).astype(int)\n# Por otro lado, medimos la luz del mapa de magnificacion\n\nfrom aux import profile\n\nz0 = profile(b,xpx[0],ypx0[0],xpx[-1],ypx0[-1],'nn')\nz1 = profile(b,xpx[0],ypx1[0],xpx[-1],ypx1[-1],'nn')\n\n\nfig.add_subplot(122)\nplt.plot(xpx,z0,'b')\nplt.plot(xpx,z1[int((z1.shape[0]-xpx.shape[0])/2):-int((z1.shape[0]-xpx.shape[0])/2):],'g')\n\nplt.savefig('mapfig.png')\n"
},
{
"alpha_fraction": 0.3882063925266266,
"alphanum_fraction": 0.5233415365219116,
"avg_line_length": 24.4375,
"blob_id": "4faf83b8bafd9087105718c2e173d96cf26bcb51",
"content_id": "e1f387a0ff28083e78aab157218d943450d4ce82",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 16,
"path": "/alcock.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Aqui vienen dado un fichero de parametros caracteristicos para la microlente LMC-9\n\n\ndef microlensing(name):\n if name == 'LMC9':\n M1M2 = 1.627\n a = 1.657\n u0 = -0.054\n theta = 0.086\n eps1 = 1./(1.+(1./M1M2))\n eps2 = 1./(1.+M1M2)\n x1l1 = -eps2*a\n x2l1 = 0.\n x1l2 = eps1*a\n x2l2 = 0.\n return eps1,eps2,x1l1,x2l1,x1l2,x2l2,theta,u0\n"
},
{
"alpha_fraction": 0.614838719367981,
"alphanum_fraction": 0.6690322756767273,
"avg_line_length": 25.27118682861328,
"blob_id": "9e767aa2389f04c3451b5dd5b5d1d9346feaabe9",
"content_id": "51b32a5156ecf45f900bc40904e87625d41a15ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1550,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 59,
"path": "/magmap.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Codigo para generar un mapa de magnitudes\n\nimport numpy as np\nimport lens as l\nimport matplotlib.pyplot as plt\n\nny=401\nyl=3.\n\nb=np.zeros((ny,ny))\nraypix=100. # el numero de rayos por pixel en ausencia de lensing\nsqrpix=np.sqrt(raypix) # Raiz cuadrada de rayos por pixel en una direccion\nsqrinpix=np.sqrt(1./raypix) \n\nys=2.*yl/(ny-1) # tamanio del pixel en el plano fuente\nxs=ys/sqrpix # tamanio del cuadrado del area transportado de vuelta por un rayo\nxl=5.*yl #tamanio de la region de shooting del plano imagen\nnx=np.round(2*xl/xs)+1 # numeros de rayos de una columna/fila en el plano imagen\nyr=np.arange(0,nx) # array con los pixeles en y en una direccion\ny,x=np.mgrid[0.0:1.0,0:nx] #grid con coordenadas pixeles por linea de la imagen\nperc0=5. # porcentaje de pasos por progreso\nperc=5. # valor inicial por perc\n\nfor i in yr: # loop sobre todos los rayos\n if ((i*100/nx)>=perc): #chequeamos si tenemos completado el perc\n perc=perc+perc0\n print(round(i*100/nx),\"% \")\n\n x1=-xl+y*xs\n x2=-xl+x*xs\n y1,y2=l.ChangRefsdal(x1,x2,0.,0.,0.5,0.15,0.5)\n\n i1=(y1+yl)/ys\n i2=(y2+yl)/ys\n i1=np.round(i1)\n i2=np.round(i2)\n\n ind = (i1>=0)&(i1<ny)&(i2>=0)&(i2<ny)\n\n i1n=i1[ind]\n i2n=i2[ind]\n\n for j in range(np.size(i1n)):\n b[int(i2n[j]),int(i1n[j])]+=1\n y=y+1.0\nb=b/raypix\nprint(np.mean(b))\nplt.close()\nplt.ion()\nplt.imshow(np.log10(b))\n\n\n#ploteamos el centro con respecto a la distancia\n\nplt.figure()\nx = np.linspace(0.0,200.0,len(b[200]))\nplt.plot(x,np.log10(b[200]))\n\nplt.savefig('magfig.png')\n"
},
{
"alpha_fraction": 0.47883063554763794,
"alphanum_fraction": 0.5715726017951965,
"avg_line_length": 21.5,
"blob_id": "0c635d8be304cdb288bd643af55fcab1d159e650",
"content_id": "dc1d0b1786e1aae11d2f6008fd605e8b9c3ad90b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 992,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 44,
"path": "/parameters.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Este .py sirve para introducir desde fuera los parametros de la lente\n\nltype = 'TwoPoints' \nsour = 'fitsim'\nfilename = 'medusa0.png'\njpg = True\n# Definimos el numero de pixeles de cada plano\nn_y = 401\nnx = 401\n#if sour == 'gcirc':\n#ny = 388\n#if sour == 'fitsim':\n# ny = a[0].size\n# Definimos el tamanio de los planos, medida en radio de Einstein\nxl = 3. # plano imagen\nyl = 3. # plano fuente\n# Definimos los parametros de la fuente\nxpos = 0.05\nypos = 0.4\nrad = 0.1\n\ndef param(name):\n x01 = -0.15\n x02 = 0.1\n ml = 1.0\n k = 0.1\n g = 0.4\n th = 1.\n if name == 'Point':\n return x01,x02,ml\n elif name == 'TwoPoints':\n x01l1 = 0.0\n x02l1 = -0.5\n ml1 = 0.5\n x01l2 = 0.0\n x02l2 = 0.5\n ml2 = 0.5\n return x01l1,x02l1,x01l2,x02l2,ml1,ml2\n elif name == 'ChangRefsdal':\n return x01,x02,ml,k,g\n elif name == 'SIS':\n return x01,x02,th\n elif name == 'SISChangRefsdal':\n return x01,x02,th,k,g\n\n\n"
},
{
"alpha_fraction": 0.4673561751842499,
"alphanum_fraction": 0.6037492156028748,
"avg_line_length": 29.27450942993164,
"blob_id": "1dd3cc051f00c15f722d5c4cd141f0b7e741ec52",
"content_id": "79cd06d1aa3c74643281e9ceb801fc49fde5133f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1547,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 51,
"path": "/lens.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "\n# En este codigo estan presentadas las distintas lentes\n\n# NOTAS: POR ALGUNA RAZON NO FUNCIONA SI UTILIZAMOS NUMPY\n\n\n# xl1,xl2 son los puntos correspondientes a x01,x02 en el programa de evencio\n\ndef Point(x1,x2,x1l,x2l,ml): # Point lens of mass ml at x1l,x2l\n x1ml = (x1-x1l) # distancia a traves del eje x desde el rayo a la posicion de la lente\n x2ml = (x2-x2l)\n d = x1ml**2+x2ml**2+ 1.0e-12 #Este ultimo termino es solo para evitar que d sea exactamente 0 y no pete cuando salga dividiento\n y1 = x1-ml*(x1-x1l)/d\n y2 = x2-ml*(x2-x2l)/d\n return y1,y2\n\n\ndef TwoPoints(x1,x2,x1l1,x2l1,x1l2,x2l2,ml1,ml2): # Two point lens of mass ml1 at x1l1,x2l1 and ml2 at x1l2,x2l2\n x1ml1 = (x1-x1l1)\n x2ml1 = (x2-x2l1)\n d1 = x1ml1**2+x2ml1**2 + 1.0e-12\n x1ml2 = (x1-x1l2)\n x2ml2 = (x2-x2l2)\n d2 = x1ml2**2+x2ml2**2 + 1.0e-12\n y1 = x1 - ml1*x1ml1/d1 - ml2*x1ml2/d2 # lens equations\n y2 = x2 - ml1*x2ml1/d1 - ml2*x2ml2/d2\n return y1,y2\n\n\ndef ChangRefsdal(x1,x2,x1l,x2l,ml,k,g):\n x1ml = (x1-x1l)\n x2ml = (x2-x2l)\n d = x1ml**2.+x2ml**2.+1.0e-12\n y1 = x1*(1.0-(k+g))-ml*x1ml/d\n y2 = x2*(1.0-(k-g))-ml*x2ml/d\n return y1,y2\n\ndef SIS(x1,x2,x1l,x2l,th):\n x1ml = (x1-x1l)\n x2ml = (x2-x2l)\n d = (x1ml**2+x2ml**2+1.0e-12)**(0.5)\n y1 = x1-th*x1ml/d\n y2 = x2-th*x2ml/d\n return y1,y2\n\ndef SISChangRefsdal(x1,x2,x1l,x2l,th,k,g):\n x1ml = (x1-x1l)\n x2ml = (x2-x2l)\n d = (x1ml**2+x2ml**2+1.0e-12)**(0.5)\n y1 = x1*(1-(k+g))-th*x1ml/d\n y2 = x2*(1-(k-g))-th*x2ml/d\n return y1,y2\n\n\n"
},
{
"alpha_fraction": 0.5611299872398376,
"alphanum_fraction": 0.5907687544822693,
"avg_line_length": 40.21018981933594,
"blob_id": "eaf23b364e55700a6228a7c205da5e17bb324ba2",
"content_id": "3864e80ac57e9067a7ade6743a532b88eaf135c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6478,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 157,
"path": "/qmic.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# COGIDO PARA GENERAR MICROLENSING\n\n\nimport numpy as np\nfrom math import pi\nimport matplotlib.pyplot as plt\nfrom random import seed, uniform\nfrom time import time, clock, sleep\nfrom pyfits import writeto\n\nstartt = time()\n\n# ******************* Model Parameters ************************\n\nkappa = 0.59 # Total convergence\ngamma = 0.61 # Shear\nalpha = 0.999 # Fraction of mass in form of microlenses\nraypix = 15.0 # Rays per pixels in absence of lensing\nny = 1000 # Pixels in the magnification map\nyl = 10 # Half size of magnification map in Einstein Radii\neps = 0.02 # Maximum fraction of flux lost\n\n# ********* Make some preliminary calculations *****************\n\nks = kappa*alpha # Convergence in microlenses\nkc = kappa*(1.-alpha) # Convergence in smooth matter\nys = 2.*yl/(ny-1) # Pix size in the image plane\nooys = 1./ys # Inverse of pixel size on image plane\nsqrpix = np.sqrt(raypix) # Rays per pixel in one dimension\nf1 = 1./abs(1.-kappa-gamma) # Exp. factor on horizontal axis\nf2 = 1./abs(1.-kappa+gamma) # Exp. factor on vertical axis\nfmax = max(f1,f2) # Max Exp factor\nxl1, xl2 = 1.5*yl*f1, 1.5*yl*f2 # Half size of shooting region in x and y\nxl = 1.5*yl*fmax # Longest half side of shooting region\nnsmin = 3*ks**2/eps/abs((1.-kappa)**2-gamma**2) # Min number of stars\nxmin = np.sqrt(pi*nsmin/ks)/2 # Min half side of star region\nxls = xl+xmin # Expand o account for shooting region\nnx1 = np.int16(np.round(1.5*ny*f1*sqrpix)) # Rays in shoot, reg. along x axis\nnx2 = np.int16(np.round(1.5*ny*f2*sqrpix)) # Rays in shoot. reg. along y axis\nnx = max(nx1,nx2) # Number of rays along longest side\nxs = 2.*xl1/(nx1-1) # Pixel side on image plane\nxnl = abs(ks*(2*xls)*(2*xls)/pi) # Number of microlenses\nnl = int(xnl) # Number of microlentes (int)\nthmag = 1./(1-kappa-gamma)/(1-kappa+gamma) # Theorerical value of magnification\n\n\nprint(\"******************************************************\")\nprint(\"Half Size of map in Einstein radii =\",yl)\nprint(\"Number of pixels of magnification map =\",ny)\nprint(\"Half size of shooting region =\",xl)\nprint(\"Number of rays along the longest axis =\",nx)\nprint(\"Half size of region with microlenses =\",xls)\nprint(\"Total Converge, k =\",kappa)\nprint(\"Shear, gamma =\",gamma)\nprint(\"Fraction of mass in microlenses, alpha =\",alpha)\nprint(\"Convergence in from of microlenses, ks =\",ks)\nprint(\"Number of microlenses =\",nl)\nprint(\"Rays per unlensed pixel, raypix =\",raypix)\nprint(\"Theoretical Mean Magnification, mu =\",thmag)\nprint(\"******************************************************\")\n\nb = np.zeros((ny,ny)) # Initialize magnification map\n\n# ********* Randomly distribute stars in region ************\n\nx1l = np.zeros(nl) # Initialize microlens positions to zero\nx2l = np.zeros(nl)\nseed(1.0) # Initialize random number generator\n\nfor i in range(nl): # Generate position to microlenses\n x1l[i] = uniform(-xls,xls)\n x2l[i] = uniform(-xls,xls)\n \n# ***********************************************************\n\nperc0 = 0.5 # Percentage step to show progress\nperc = 5. # Initial percentage\nyr = np.arange(0,nx2) # Array for looping over rows of rays\ny,x = np.mgrid[0.0:1.0,0:nx1] # These are arrays with x and y coords of one row of rays in image plane\n\nnlrange = np.arange(nl) # Array for looping over lenses\n\n# *********************** MAIN LOOP *************************\n\nfor i in yr: # Main loop over rows of rays\n if ((i*100/nx2)>=perc): # If perc is completed, then show progress\n perc = perc+perc0\n print(round(i*100/nx2),\"% \", round(time()-startt,3), \" secs\")\n # print completed fraction and elapsed execution time\n x2 = -xl2+y*xs # Convert pixels to coordinates in the image plane\n x1 = -xl1+x*xs \n y2 = x*0.0 # Initialize variables\n y1 = x*0.0\n for ii in nlrange: # Loop over microlenses\n x1ml = x1-x1l[ii]\n x2ml = x2-x2l[ii]\n d = x1ml**2+x2ml**2 # Distance to lens ii squared\n y1 = y1+x1ml/d # Deflect x coordinate due to lens ii\n y2 = y2+x2ml/d # Deflect y coordinate due to lens ii \n del x1ml,x2ml,d\n y2 = x2-y2-(kc-gamma)*x2 # Calculate total y deflection\n y1 = x1-y1-(kc+gamma)*x1 # Calculate total x deflection\n i1 = (y1+yl)*ooys # Convert coordinates to pixels on source plane\n i2 = (y2+yl)*ooys\n i1 = i1.astype(int) # Maks indices integer\n i2 = i2.astype(int)\n ind = (i1>=0)&(i1<ny)&(i2>=0)&(i2<ny) # Select indices of rays falling onto our source plane\n\n i1n = i1[ind] # Array of x coordinates of rays within map\n i2n = i2[ind] # Array of y coordinates of rays within map\n for ii in range(np.size(i1n)): # Loop over rays hitting the source plane\n b[i2n[ii],i1n[ii]]+=1 # Increase map in one unit if ray hit \n y =y+1.0 # Move on to next row rays\n\n# **********************************************************\n\nb = b/raypix # Normalize by rays per unlensed pixel\n\nprint(\"**********************************************************\")\nprint(\"Measured mean magnification =\",np.mean(b))\nprint(\"Theoretical magnification is =\",thmag)\nprint(\"**********************************************************\")\n\nif thmag<0: # Vertical or horizontal flip in some cases\n if gamma<0: \n b = np.flipud(b)\n else:\n b = np.fliplr(b)\n\n# ******************** Display result **********************\n\nax = plt.subplot(121) # left plot\nplt.plot(x1l,x2l,'+') # plot positions of stars\nrayboxx = [-xl1,-xl1,xl1,xl1,-xl1] \nrayboxy = [-xl2,xl2,xl2,-xl2,-xl2]\nplt.plot(rayboxx,rayboxy) # show shooting regions\nmapboxx = np.array([-yl,-yl,yl,yl,-yl])\nmapboxy = np.array([-yl,yl,yl,-yl,-yl])\nplt.plot(mapboxx*f1,mapboxy*f2,'r') # show region mapped onto map\nplt.xlim(-1.1*xls,1.1*xls)\nplt.ylim(-1.1*xls,1.1*xls)\nax.set_aspect('equal') # keep aspect ratio\nplt.subplot(122) # Right plot\nimplot = plt.imshow(b,origin='lower') # Display magnification map\n\n# **********************************************************\nprint(\"Exec. time = \",round(time()-startt,3),'seconds') # Print execution time\nplt.show()\n\n# ***************** Save result as fits file? **************\nsave = ''\nwhile (save not in ['y','n']): # Wait for input unless it is 'y' or 'n'\n save = raw_input(\"Save file (y/n)? \")\n if (save == 'y'):\n filename = ''\n filename = 'IMG/'+raw_input(\"Filename = \")+'.fits'\n writeto(filename,b) # Write fits file\n\n\n\n \n"
},
{
"alpha_fraction": 0.6450839042663574,
"alphanum_fraction": 0.6810551285743713,
"avg_line_length": 40.70000076293945,
"blob_id": "bcd1592d9badef8756694d529779a00c0917f7ac",
"content_id": "547697f60cfd00b346c5ec841f259cd49d30a770",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 10,
"path": "/aux.py",
"repo_name": "DuaEstwald/Astrofisica_Computacional",
"src_encoding": "UTF-8",
"text": "# Es la parte de las curvas de luz de magnificacion\n\nimport numpy as np\nfrom math import sqrt\n\ndef profile(c,x0,y0,x1,y1,method='nn'): # Las coordenadas se dan en pixel\n num = int(round(sqrt((x1-x0)**2+(y1-y0)**2))) #Longitud del track en pixeles\n xp,yp = np.linspace(x0,x1,num),np.linspace(y0,y1,num) # x and y sendo las coordenadas del track\n zp = c[yp.astype(np.int),xp.astype(np.int)]\n return zp[:-1]\n"
}
] | 12 |
sethu1504/HousePrices
|
https://github.com/sethu1504/HousePrices
|
dec2705074334959fea20e760c3d2c4ede45dc9c
|
327080a796d537a52cbf013e65abbd3eaa9b8348
|
4f9fad787f876f674ce4f6186be21dac0cc41fd3
|
refs/heads/master
| 2021-07-06T07:24:04.297150 | 2017-10-01T02:07:06 | 2017-10-01T02:07:06 | 104,841,381 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6796008944511414,
"alphanum_fraction": 0.7067627310752869,
"avg_line_length": 40.953487396240234,
"blob_id": "54ef1f85c82ca5d32d88e21d063581a8d3853506",
"content_id": "ba238639af68cfbebd0e1f67199d423dde0b9a6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3608,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 86,
"path": "/src/house_prices_ensemble.py",
"repo_name": "sethu1504/HousePrices",
"src_encoding": "UTF-8",
"text": "from sklearn.linear_model import Lasso\nfrom xgboost import XGBRegressor\nfrom sklearn.cross_validation import train_test_split\nfrom sklearn.grid_search import GridSearchCV\nimport pandas as pd\nimport numpy as np\nfrom sklearn.cross_validation import cross_val_score\nimport csv\nimport matplotlib.pyplot as plt\n\ndata = pd.read_csv('../datasets/train.csv')\nsubmit_data = pd.read_csv('/Users/sethuramanannamalai/Documents/PyCharm/HousePrices/datasets/test.csv')\ndel data['Id']\nsubmit_data_houseIds = submit_data['Id']\ndel submit_data['Id']\n# FEATURE ENGINEERING\n\n# Numeric Features\nnumeric_features = list(data.dtypes[data.dtypes != 'object'].index)\nnumeric_features.remove('MSSubClass') # This variable is a classification feature\nfor feature in numeric_features:\n data[feature].fillna(np.mean(data[feature]), inplace=True)\n data[feature] = np.log1p(data[feature])\n if feature != 'SalePrice':\n submit_data[feature].fillna(np.mean(submit_data[feature]), inplace=True)\n submit_data[feature] = np.log1p(submit_data[feature])\n\n# Classification features - introduce dummy variables\nclassi_features = list(data.dtypes[data.dtypes == 'object'].index)\nclassi_features.append('MSSubClass')\nfor feature in classi_features:\n feature_values = data[feature].unique()\n for elem in feature_values:\n data[str(feature + '_' + str(elem))] = pd.Series(data[feature] == elem, dtype=int)\n del data[feature]\n for elem in feature_values:\n submit_data[str(feature + '_' + str(elem))] = pd.Series(submit_data[feature] == elem, dtype=int)\n del submit_data[feature]\n\n# Data split\ndata_y = pd.DataFrame(data, columns=['SalePrice'])\ndel data['SalePrice']\n\n# Hyper Parameter Tuning - alpha\n# Lasso Tuning\ngrid_params = {'alpha': [1, 5, 10, 0.1, 0.01, 0.001, 0.0001]}\nlasso_model = Lasso(normalize=True)\ngrid_model = GridSearchCV(lasso_model, grid_params, scoring='neg_mean_squared_error', cv=10, verbose=1, n_jobs=-1)\ngrid_model.fit(data, data_y)\ntuned_alpha = grid_model.best_params_.get('alpha')\n# XGB Tuning\n# grid_params = {'learning_rate': [0.001, 0.0001],\n# 'booster': ['gblinear', 'gbtree'],\n# 'n_estimators': [200, 300],\n# 'reg_alpha': [0.1, 0.01, 0.001],\n# 'reg_lambda': [0.1, 0.01, 0.001]}\n# xgb_model = XGBRegressor()\n# grid_model = GridSearchCV(xgb_model, grid_params, scoring='neg_mean_squared_error', cv=10, verbose=1, n_jobs=-1)\n# grid_model.fit(train_data_x, train_data_y)\n# print grid_model.best_estimator_\n# print grid_model.best_params_\n# Result - {'n_estimators': 300, 'reg_lambda': 0.001, 'learning_rate': 0.001, 'reg_alpha': 0.01, 'booster': 'gbtree'}\n\n# Training\nlasso_model = Lasso(alpha=tuned_alpha, normalize=True)\nlasso_model.fit(data, data_y)\nxgb_model = XGBRegressor(n_estimators=300, reg_lambda=0.001, reg_alpha=0.01, learning_rate=0.1, booster='gbtree')\nxgb_model.fit(data, data_y)\n\n# Performance\nprint 'Lasso Mode :'\nprint 'Cross validation score = ' + str(np.mean(cross_val_score(lasso_model, data, data_y, cv=10)))\nprint 'XGBoost Regressor :'\nprint 'Cross validation score = ' + str(np.mean(cross_val_score(xgb_model, data, data_y, cv=10)))\n\npredictions_lasso = lasso_model.predict(submit_data)\npredictions_xgb = xgb_model.predict(submit_data)\npredicted_house_price = np.expm1(0.60*predictions_lasso + 0.40*predictions_xgb)\n\nout = csv.writer(open('Submission.csv', 'w'), delimiter=',', quoting=csv.QUOTE_ALL)\nout.writerow(['Id', 'SalePrice'])\n\nfor i in range(len(submit_data_houseIds)):\n predicted_value = predicted_house_price[i]\n houseId = submit_data_houseIds[i]\n out.writerow([houseId, predicted_value])\n"
}
] | 1 |
i-zhivetiev/fb-assignment
|
https://github.com/i-zhivetiev/fb-assignment
|
313fef1adb37f6fa32528a48e51e86f3ecb8702d
|
2281d340f3f2cf48fcd13b39ce98447c1d60e04c
|
1b35fac67584bf7ff2a331c9f39bff510b7b18d7
|
refs/heads/master
| 2023-03-31T17:19:22.668456 | 2021-03-18T07:56:20 | 2021-03-31T09:59:13 | 351,649,769 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6358078718185425,
"alphanum_fraction": 0.6497816443443298,
"avg_line_length": 32.67647171020508,
"blob_id": "d86aee3ef6b806bfd2fbd643416b594d73d9fa06",
"content_id": "89da2e2af33ba75c72155903b40e541d75ada14a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 34,
"path": "/tests/test_models/test_no_scheme_url_model.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from pydantic import BaseModel\nfrom pytest import mark\n\nfrom fb_assignment.models import NoSchemeUrl\n\n\nclass ModelToTest(BaseModel):\n url: NoSchemeUrl\n\n\[email protected]('url,expected_url,expected_scheme', [\n ('example.test', 'example.test', ''),\n ('example.test/some-path', 'example.test/some-path', ''),\n ('http://example.test', 'http://example.test', 'http'),\n ('http://example.test/some-path', 'http://example.test/some-path', 'http'),\n ('https://example.test', 'https://example.test', 'https'),\n ('https://example.test/some-path', 'https://example.test/some-path',\n 'https'),\n])\ndef test_default_scheme(url, expected_url, expected_scheme):\n test_model = ModelToTest(url=url)\n assert str(test_model.url) == expected_url\n assert test_model.url.scheme == expected_scheme\n\n\[email protected]('url,expected', [\n ('http://example.test', 'example.test'),\n ('http://почта.рф', 'почта.рф'),\n ('http://127.0.0.1', '127.0.0.1'),\n ('http://[::1]:80', '[::1]'),\n])\ndef test_human_readable_host(url, expected):\n test_model = ModelToTest(url=url)\n assert test_model.url.human_readable_host == expected\n"
},
{
"alpha_fraction": 0.7944444417953491,
"alphanum_fraction": 0.7944444417953491,
"avg_line_length": 17,
"blob_id": "f553a19028ff16b17a774f3859ce51c5c14e327e",
"content_id": "3aa78c73a24c965b17b9a76cc05d8336e2aa7bb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 180,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/tests/test_endpoints/conftest.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from unittest.mock import create_autospec\n\nfrom pytest import fixture\n\nfrom fb_assignment.storage import Storage\n\n\n@fixture\ndef mock_storage():\n return create_autospec(Storage)\n"
},
{
"alpha_fraction": 0.6154798865318298,
"alphanum_fraction": 0.6321981549263,
"avg_line_length": 24.234375,
"blob_id": "bbb7d72484e13e9cca2a967d7e3210dd44c434ff",
"content_id": "2edbe4fb8fd8900eb000f83c43e5334dba3780d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1636,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 64,
"path": "/tests/test_app/test_app.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from pytest import fixture\n\n\n@fixture(autouse=True)\nasync def redis_flush_all(redis_client):\n await redis_client.execute('FLUSHALL')\n yield\n await redis_client.execute('FLUSHALL')\n\n\n@fixture\ndef start():\n return 0\n\n\n@fixture\ndef end(visit_timestamp):\n day = 60 * 60 * 24\n return visit_timestamp + day\n\n\n@fixture\ndef client(app_client):\n # убедимся, что startup and shutdown вызываются\n with app_client:\n yield app_client\n\n\n@fixture\ndef visited_domains_endpoint(start, end):\n return f'/visited_domains?from={start}&to={end}'\n\n\n@fixture\ndef visited_links_endpoint():\n return '/visited_links'\n\n\ndef test_set_get(client, visited_domains_endpoint, visited_links_endpoint):\n response = client.get(visited_domains_endpoint)\n assert response.status_code == 200\n assert response.json() == {'domains': [],\n 'status': 'ok'}, 'database is not empty'\n\n body = {\n \"links\": [\n \"https://ya.ru\",\n \"https://ya.ru?q=123\",\n \"funbox.ru\",\n (\"https://stackoverflow.com/questions/11828270\"\n \"/how-to-exit-the-vim-editor\")\n ]\n }\n expected_domains = sorted(['ya.ru', 'funbox.ru', 'stackoverflow.com'])\n\n response = client.post(visited_links_endpoint, json=body)\n assert response.status_code == 200\n assert response.json() == {'status': 'ok'}\n\n response = client.get(visited_domains_endpoint)\n response_data = response.json()\n assert response.status_code == 200\n assert response_data['status'] == 'ok'\n assert sorted(response_data['domains']) == expected_domains\n"
},
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.656000018119812,
"avg_line_length": 24,
"blob_id": "cc5347d6f5379b3dbc96d0acadb2d34bd5382b50",
"content_id": "304b5bb28ec1471de4c1d5f023cbf90785167562",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 269,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 10,
"path": "/fb_assignment/settings.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nНастройки web-приложения.\n\"\"\"\nfrom starlette.config import Config\n\nconfig = Config('.env')\n\nDEBUG = config('DEBUG', cast=bool, default=False)\nDATABASE_URI = config('DATABASE_URI', cast=str,\n default='redis://localhost:6379')\n"
},
{
"alpha_fraction": 0.7408313155174255,
"alphanum_fraction": 0.7408313155174255,
"avg_line_length": 23.787878036499023,
"blob_id": "132bb071ae3d8a3a9d6b259fe5cf6a91de703bf1",
"content_id": "8837fb2db73749c33f99cc6418ac0be2f8fb4a06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 818,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 33,
"path": "/tests/test_storage/test_connection.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "import pytest\nfrom pytest import raises\n\nfrom fb_assignment.storage import Storage\n\npytestmark = pytest.mark.asyncio\n\n\nasync def test_connect_disconnect(storage):\n assert storage.connected is False\n await storage.connect()\n assert storage.connected is True\n await storage.disconnect()\n assert storage.connected is False\n\n\nasync def test_double_connect(storage):\n assert storage.connected is False\n await storage.connect()\n assert storage.connected is True\n await storage.connect()\n await storage.disconnect()\n\n\nasync def test_disconnect_on_no_pool(storage):\n assert storage.connected is False\n await storage.disconnect()\n\n\nasync def test_no_connection(unused_tcp_port):\n storage = Storage(('localhost', unused_tcp_port))\n with raises(OSError):\n await storage.connect()\n"
},
{
"alpha_fraction": 0.5349650382995605,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 14.052631378173828,
"blob_id": "2677bb07fe5d0a5be427255a0e05db9a832d4f15",
"content_id": "5f75d81d01733fe2199936fa9398322bc8d13224",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 19,
"path": "/Pipfile",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "[[source]]\nurl = \"https://pypi.org/simple\"\nverify_ssl = true\nname = \"pypi\"\n\n[packages]\nstarlette = \">=0.14.2\"\nuvicorn = \">=0.13.4\"\naioredis = \">=1.3.1\"\npydantic = \">=1.8.1\"\n\n[dev-packages]\npytest = \"*\"\npytest-asyncio = \"*\"\nrequests = \"*\"\npylint = \"*\"\n\n[requires]\npython_version = \"3.8\"\n"
},
{
"alpha_fraction": 0.6310734748840332,
"alphanum_fraction": 0.6423729062080383,
"avg_line_length": 27.780487060546875,
"blob_id": "8d6f6c7ba5d58c21eaddc4d604347cbc54000cda",
"content_id": "0ba54809e1eb354a5d3afc0e03f2aaee4c32fa88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3540,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 123,
"path": "/tests/test_storage/test_get_visited_domains.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "import random\n\nfrom pytest import mark, fixture\n\npytestmark = mark.asyncio\n\n\n@fixture\ndef get_random_domains(domains):\n def _get_domains(d=domains):\n k = random.randrange(1, len(d))\n return random.choices(d, k=k)\n\n return _get_domains\n\n\n@fixture\ndef get_expected_domains():\n def _get_expected_domains(domains):\n return sorted(list(set(domains)))\n\n return _get_expected_domains\n\n\nasync def test_get_domains(test_storage, domains, visit_timestamp):\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp,\n )\n result = await test_storage.get_visited_domains(\n start=visit_timestamp - 1,\n end=visit_timestamp + 1,\n )\n assert domains == sorted(result)\n\n\nasync def test_get_domains_within_interval(\n get_random_domains, get_expected_domains, test_storage,\n visit_timestamp,\n):\n expected_domains = set()\n\n offsets_within_interval = 0, 1, 2, 3\n for offset in offsets_within_interval:\n domains = get_random_domains()\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp + offset,\n )\n expected_domains.update(get_expected_domains(domains))\n\n offsets_outside_interval = -10, -5, 5, 10\n for offset in offsets_outside_interval:\n domains = get_random_domains(['some', 'else', 'domains', 'here.com'])\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp + offset,\n )\n\n result = await test_storage.get_visited_domains(\n start=visit_timestamp - 1,\n end=visit_timestamp + offsets_within_interval[-1] + 1,\n )\n\n assert sorted(list(expected_domains)) == sorted(result)\n\n\nasync def test_get_domains_on_edges(\n test_storage, get_random_domains, get_expected_domains,\n visit_timestamp,\n):\n offsets = -10, -5, 0, 5, 10\n expected_domains = dict()\n for offset in offsets:\n domains = get_random_domains()\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp + offset,\n )\n expected_domains[offset] = get_expected_domains(domains)\n\n result = await test_storage.get_visited_domains(\n start=0,\n end=visit_timestamp + offsets[0],\n )\n assert expected_domains[offsets[0]] == sorted(result)\n\n result = await test_storage.get_visited_domains(\n start=visit_timestamp + offsets[-1],\n end=visit_timestamp * 10,\n )\n assert expected_domains[offsets[-1]] == sorted(result)\n\n\nasync def test_get_domains_on_empty_storage(test_storage, redis_client):\n assert await redis_client.execute('KEYS', '*') == []\n result = await test_storage.get_visited_domains(start=0, end=1)\n assert result == []\n\n\[email protected]('start,end', [\n (1, 0),\n (1, 1),\n (0, 0),\n])\nasync def test_start_end(start, end, test_storage, redis_client):\n assert await redis_client.execute('KEYS', '*') == []\n result = await test_storage.get_visited_domains(start=start, end=end)\n assert result == []\n\n\nasync def test_get_no_domains_outside_interval(\n test_storage, get_random_domains, visit_timestamp,\n):\n await test_storage.save_visited_domains(\n domains=get_random_domains(),\n visit_timestamp=visit_timestamp,\n )\n result = await test_storage.get_visited_domains(\n start=visit_timestamp - 2,\n end=visit_timestamp - 1,\n )\n assert result == []\n"
},
{
"alpha_fraction": 0.7226027250289917,
"alphanum_fraction": 0.7294520735740662,
"avg_line_length": 16.87755012512207,
"blob_id": "bab0b34818ae2123194f71f2269b92f00983afc8",
"content_id": "10a79b09ac0af4aac3c64482f3945f7d8553dc4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 933,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 49,
"path": "/tests/conftest.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\n\nimport aioredis\nfrom pytest import fixture\nfrom starlette.config import environ\nfrom starlette.testclient import TestClient\n\nDATABASE_URI = 'redis://localhost:16379'\nenviron['DATABASE_URI'] = DATABASE_URI\n\n# XXX: Импортируем после установки переменных окружения, чтобы избежать\n# starlette.config.EnvironError\nfrom fb_assignment import app as application\n\n\n@fixture\ndef app():\n return application\n\n\n@fixture\ndef app_client(app):\n return TestClient(app)\n\n\n@fixture\ndef redis_uri():\n return DATABASE_URI\n\n\n@fixture\nasync def redis_client(redis_uri):\n client = await aioredis.create_connection(\n redis_uri,\n encoding='utf-8',\n )\n yield client\n client.close()\n await client.wait_closed()\n\n\n@fixture\ndef now():\n return datetime.utcnow()\n\n\n@fixture\ndef visit_timestamp(now):\n return round(now.timestamp())\n"
},
{
"alpha_fraction": 0.6643109321594238,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 27.617977142333984,
"blob_id": "ed6527c8ae1ba0925dc2de33ea2a65224cb26b0b",
"content_id": "b7ef3161d80d9c85bf2352baec9282383a23170b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3207,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 89,
"path": "/fb_assignment/endpoints/validators.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nВалидаторы для тела и параметров HTTP-запроса.\n\"\"\"\nfrom functools import wraps\nfrom json.decoder import JSONDecodeError\nfrom typing import Callable\n\nfrom pydantic import ValidationError\nfrom starlette.responses import JSONResponse\n\nfrom fb_assignment.models import VisitedLinks, SearchingInterval\n\n\ndef validate_body(method: Callable) -> Callable:\n \"\"\"Декоратор для валидации тела запроса. Используется для оборачивания\n методов наследников :class:`starlette.endpoints.HTTPEndpoint`.\n\n Возвращает ошибку, если:\n - тело запроса не удалось разобрать;\n - возникла ошибка валидации при создании экземпляра модели данных.\n\n В случае успеха вызывает обёрнутый метод, передав в качестве параметра\n экземпляр модели.\n\n TODO: параметризовать моделью, в случае появления эндпоинтов кроме\n :class:`visited_links.VisitedLinksEndpoint`\n \"\"\"\n error = JSONResponse(\n content={'status': 'error: bad request'},\n status_code=400,\n )\n\n @wraps(method)\n async def wrapper(self, request):\n try:\n body = await request.json()\n except (JSONDecodeError, TypeError):\n return error\n\n if not isinstance(body, dict):\n return error\n\n try:\n visited_links = VisitedLinks(**body)\n except ValidationError as _:\n return error\n\n return await method(self, visited_links)\n\n return wrapper\n\n\ndef validate_query(method: Callable) -> Callable:\n \"\"\"Декоратор для валидации тела запроса. Используется для оборачивания\n методов наследников :class:`starlette.endpoints.HTTPEndpoint`.\n\n Возвращает ошибку, если:\n - параметры запроса не удалось разобрать;\n - возникла ошибка валидации при создании экземпляра модели данных.\n\n В случае успеха вызывает обёрнутый метод, передав в качестве параметра\n экземпляр модели.\n\n TODO: параметризовать моделью, в случае появления эндпоинтов кроме\n :class:`visited_links.VisitedDomainsEndpoint`\n \"\"\"\n error = JSONResponse(\n content={'status': 'error: bad request'},\n status_code=400,\n )\n\n @wraps(method)\n async def wrapper(self, request):\n try:\n params = {\n 'start': request.query_params['from'],\n 'end': request.query_params['to'],\n }\n except KeyError:\n return error\n\n try:\n interval = SearchingInterval(**params)\n except ValidationError:\n return error\n\n return await method(self, interval)\n\n return wrapper\n"
},
{
"alpha_fraction": 0.5942434668540955,
"alphanum_fraction": 0.5952428579330444,
"avg_line_length": 31.914474487304688,
"blob_id": "eee4e21cae71643ce1e87805684ebe74b41e9fc0",
"content_id": "6ba57e45c2a8e3213ec8ffaf686e3b50e559a2b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5954,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 152,
"path": "/fb_assignment/storage.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nИнтерфейс к БД, в которой хранятся ссылки.\n\"\"\"\nfrom typing import List\n\nimport aioredis\nfrom aioredis import MultiExecError, WatchVariableError\n\n\nclass Storage:\n \"\"\"Класс для работы с хранилищем ссылок. В качестве БД используется Redis.\n В качестве \"низкоуровневого\" интерфейса для доступа к Redis используется\n модуль aioredis [https://aioredis.readthedocs.io].\n\n В БД сохраняются только доменные имена, поэтому предполагается, что все\n данные, полученные из БД, являются валидными строками UTF-8.\n \"\"\"\n\n def __init__(self, address, **kwargs):\n \"\"\"Создать экземпляр Storage. Параметры совпадают с\n ``aioredis.create_redis_pool``. Дополнительно см.\n [https://aioredis.readthedocs.io/en/v1.3.1/api_reference.html].\n\n :param address:\n Адрес для подключения к Reids, может быть ``tuple`` в виде\n ``(host, port)`` или ``str``, которая содержит URI Redis или путь\n до сокета UNIX.\n :param kwargs:\n Дополнительные параметры, которые будут переданы в\n ``aioredis.create_redis_pool``.\n \"\"\"\n self._address = address\n self._connection_options = kwargs\n self._encoding = 'utf-8'\n\n if 'encoding' not in kwargs:\n self._connection_options['encoding'] = self._encoding\n\n self._pool = None\n\n async def connect(self):\n if self.connected:\n return\n self._pool = await aioredis.create_redis_pool(\n self._address,\n **self._connection_options,\n )\n\n async def disconnect(self):\n if not self.connected:\n return\n self._pool.close()\n await self._pool.wait_closed()\n\n @property\n def connected(self):\n if self._pool is None:\n return False\n return not self._pool.closed\n\n @staticmethod\n def domains_key(visit_timestamp: int) -> str:\n \"\"\"Вернуть имя ключа, в котором хранятся доменные имена, посещённые в\n момент ``visit_timestamp``.\n\n :param visit_timestamp:\n Время посещения, timestamp.\n \"\"\"\n return f'domains-visited-at:{visit_timestamp}'\n\n @property\n def timestamps_key(self) -> str:\n \"\"\"Ключ-индекс для поиска доменов в промежутке времени. Представляет\n собой отсортированное множество (sorted set), где\n\n - score -- время посещения доменов;\n - value -- имя ключа, где хранятся домены, посещённые во время score.\n \"\"\"\n return 'timestamps'\n\n async def save_visited_domains(\n self,\n domains: List[str],\n visit_timestamp: int\n ) -> None:\n \"\"\"Сохранить доменные имена из списка ``domains`` в БД.\n\n :param domains:\n Список доменных имён, которые нужно сохранить.\n :param visit_timestamp:\n Время доступа, timestamp.\n \"\"\"\n if not domains:\n return\n domains_key = self.domains_key(visit_timestamp)\n transaction = self._pool.multi_exec()\n transaction.sadd(domains_key, *domains)\n transaction.zadd(self.timestamps_key, visit_timestamp, domains_key)\n await transaction.execute()\n\n async def get_visited_domains(self, start: int, end: int) -> List[str]:\n \"\"\"Вернуть доменные имена, время посещения которых попадет в промежуток\n между ``start`` и ``end`` включительно.\n\n :param start:\n Начало интервала, метка времени.\n :param end:\n Конец интервала, метка времени.\n :return:\n Список найденных доменных имён.\n \"\"\"\n while True:\n try:\n domains = await self._try_get_visited_domains(start, end)\n except WatchVariableError:\n continue\n return domains\n\n async def _try_get_visited_domains(\n self,\n start: int,\n end: int,\n ) -> List[str]:\n \"\"\"Возбуждает ошибку :class:`aioredis.WatchVariableError`, если во\n время выполнения транзакции произошло изменение БД.\n \"\"\"\n await self._pool.watch(self.timestamps_key)\n visit_time_keys = await self._get_visit_time_keys(start, end)\n if not visit_time_keys:\n await self._pool.unwatch()\n return []\n return await self._get_unique_domains(visit_time_keys)\n\n async def _get_visit_time_keys(self, start: int, end: int) -> List[str]:\n return await self._pool.zrangebyscore(\n self.timestamps_key,\n min=start,\n max=end,\n )\n\n async def _get_unique_domains(self, visit_time_keys):\n transaction = self._pool.multi_exec()\n future = transaction.sunion(*visit_time_keys)\n try:\n domains, = await transaction.execute()\n except MultiExecError:\n if not future.done():\n raise\n if isinstance(future.exception(), WatchVariableError):\n future.result()\n raise\n return domains\n"
},
{
"alpha_fraction": 0.6765175461769104,
"alphanum_fraction": 0.690095841884613,
"avg_line_length": 30.299999237060547,
"blob_id": "ffa95abc141fb28c4560c0c446f28ec1df4e9ed2",
"content_id": "c23948958175011d082ec246042a26ec189ac08f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 40,
"path": "/tests/test_endpoints/test_visited_domains_endpoint.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from unittest.mock import call\n\nfrom pytest import mark\n\nfrom fb_assignment.endpoints import VisitedDomainsEndpoint\n\n\ndef test_get_visited_domains(app_client, mock_storage, monkeypatch):\n domains = ['test.example']\n start = 0\n end = 1\n\n mock_storage.get_visited_domains.return_value = domains\n monkeypatch.setattr(VisitedDomainsEndpoint, 'storage', mock_storage)\n\n response = app_client.get(f'/visited_domains?from={start}&to={end}')\n\n assert response.status_code == 200, response.json()\n assert response.json() == {'domains': domains, 'status': 'ok'}\n\n assert mock_storage.get_visited_domains.called is True\n assert mock_storage.get_visited_domains.await_count == 1\n assert mock_storage.get_visited_domains.await_args == call(\n start=start, end=end,\n )\n\n\[email protected]('endpoint', [\n '/visited_domains',\n '/visited_domains?',\n '/visited_domains?start=10&stop=15',\n '/visited_domains?from=1',\n '/visited_domains?to=2',\n '/visited_domains?from=hello&to=2',\n '/visited_domains?from=0&to=one',\n])\ndef test_malformed_query(endpoint, app_client):\n response = app_client.get(endpoint)\n assert response.status_code == 400\n assert response.json() == {'status': 'error: bad request'}\n"
},
{
"alpha_fraction": 0.6535999774932861,
"alphanum_fraction": 0.7067999839782715,
"avg_line_length": 19,
"blob_id": "6cbe7e37e5993090dcf43ffee359465e25d67218",
"content_id": "7e20a3cb9e7950eea3f86cde59ec0016d627f8db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3189,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 125,
"path": "/README.md",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "## Что это?\n\nWeb-приложение для учёта посещённых доменов. Описание API см. в докстринге\nмодуля `fb_assignment`.\n\n## Как запустить?\n\n### Требования\n\n- Redis ≥ 6.0\n- Python 3.8\n- [Pipenv](https://pipenv.pypa.io/en/latest/)\n\n### Установка\n\nПолучить клон репозитория с приложением:\n\n```bash\n$ git clone https://github.com/i-zhivetiev/fb-assignment.git\n```\n\nСоздать виртуальное окружение и установить зависимости:\n\n```bash\n$ cd fb-assignment\n$ pipenv sync --dev\n```\n\n### Запуск\n\nУбедится, что Redis доступен по адресу `localhost:6379`. Например,\n\n```bash\n$ redis-cli ping\nPONG\n```\n\nЗапустить приложение:\n\n```bash\n$ pipenv run uvicorn fb_assignment:app\nINFO: Started server process [15771]\nINFO: Waiting for application startup.\nINFO: Application startup complete.\nINFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)\n```\n\nПосле запуска сервер будет доступен по адресу `http://127.0.0.1:8000`.\n\n### Конфигурация\n\nПриложение настраивается с помощью переменных окружения:\n\n- `DATABASE_URI` — URI Redis; по умолчанию — `redis://localhost:6379`.\n\n## Как протестировать?\n\n### Вручную\n\nМожет быть удобно узнать текущую метку времени:\n\n```bash\n$ python -c 'import datetime; print(round(datetime.datetime.utcnow().timestamp()))'\n```\n\nВыполнить HTTP-запросы. Например, с помощью [HTTPie](https://httpie.io):\n\n```bash\n$ http ':8000/visited_domains?from=0&to=1700000000'\nHTTP/1.1 200 OK\ncontent-length: 28\ncontent-type: application/json\ndate: Wed, 31 Mar 2021 09:38:58 GMT\nserver: uvicorn\n\n{\n \"domains\": [],\n \"status\": \"ok\"\n}\n```\n\n```bash\n$ echo '{ \"links\": [ \"http://example.test/path;parameters?query#fragment\" ] }' \\\n | http POST ':8000/visited_links'\nHTTP/1.1 200 OK\ncontent-length: 15\ncontent-type: application/json\ndate: Wed, 31 Mar 2021 09:42:20 GMT\nserver: uvicorn\n\n{\n \"status\": \"ok\"\n}\n```\n\n```bash\n$ http ':8000/visited_domains?from=0&to=1700000000'\nHTTP/1.1 200 OK\ncontent-length: 42\ncontent-type: application/json\ndate: Wed, 31 Mar 2021 09:43:34 GMT\nserver: uvicorn\n\n{\n \"domains\": [\n \"example.test\"\n ],\n \"status\": \"ok\"\n}\n```\n\n### pytest\n\nДля тестов стоит использовать отдельный экземпляр Redis -- база очищается после\nкаждой тестовой сессии. По умолчанию Redis для тестов должен быть доступен по\nадресу `localhost:16379`. Другой адрес можно задать с помощью\nпеременной `tests.conftest.DATABASE_URI`.\n\nЧтобы запустить тесты, нужно перейти в директорию с приложением и запустить\npytest:\n\n```bash\n$ cd fb-assignment\n$ pipenv run python -m pytest\n```\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.738095223903656,
"avg_line_length": 18.25,
"blob_id": "464e365c324e58ae44b1d13c5c44346ea62f342a",
"content_id": "1a644e3587c5d9505b567d972d3767bd692df387",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 498,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 24,
"path": "/fb_assignment/application.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nМодуль, отвечающий за создание web-приложения.\n\"\"\"\nfrom starlette.applications import Starlette\n\nfrom fb_assignment import settings\nfrom fb_assignment.endpoints import routes\nfrom fb_assignment.interfaces import storage\n\n\nasync def on_startup():\n await storage.connect()\n\n\nasync def on_shutdown():\n await storage.disconnect()\n\n\napp = Starlette(\n debug=settings.DEBUG,\n routes=routes,\n on_startup=[on_startup],\n on_shutdown=[on_shutdown],\n)\n"
},
{
"alpha_fraction": 0.6508875489234924,
"alphanum_fraction": 0.6508875489234924,
"avg_line_length": 25,
"blob_id": "5cd79eab6b8df780a4042efa5afa774c5804782d",
"content_id": "49a8dd1fd7324b4d8e3f5e0a1ae79d6c6098e0fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1194,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 39,
"path": "/fb_assignment/models.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nМодели данных, используемые в web-приложении.\n\"\"\"\nfrom typing import Dict, List\n\nfrom pydantic import AnyUrl, BaseModel\n\n\nclass NoSchemeUrl(AnyUrl):\n \"\"\"Тип URL. Отличия от базового класса:\n\n - допускает отсутствие схемы в URL;\n - объявляет свойство ``human_readable_host``.\n \"\"\"\n\n @classmethod\n def validate_parts(cls, parts: Dict[str, str]) -> Dict[str, str]:\n if parts['scheme'] is None:\n parts['scheme'] = ''\n return super().validate_parts(parts)\n\n @property\n def human_readable_host(self):\n \"\"\"Человеко-читаемое имя домена. Актуально для интернациональных\n доменных имён. Подробнее см.\n https://pydantic-docs.helpmanual.io/usage/types/#international-domains\n \"\"\"\n if self.host_type == 'int_domain':\n return bytes(self.host, encoding='ascii').decode('idna')\n return self.host\n\n\nclass VisitedLinks(BaseModel):\n links: List[NoSchemeUrl]\n\n\nclass SearchingInterval(BaseModel):\n start: int\n end: int\n"
},
{
"alpha_fraction": 0.5856727957725525,
"alphanum_fraction": 0.5914811491966248,
"avg_line_length": 13.15068531036377,
"blob_id": "48ac79ea973eb3540c8ca24a1e9f70a349d3c585",
"content_id": "1dbd8e7cfb1500a05705db5d69997a2198d1e1f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1435,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 73,
"path": "/fb_assignment/__init__.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nfunbox assignment\n#################\n\nWeb-приложение для учета посещенных ссылок.\n\nAPI\n===\n\nТело запроса (где есть) и тело ответа -- JSON.\n\nТочки входа\n-----------\n\n- ``POST /visited_links``\n- ``GET /visited_domains``\n\nPOST /visited_links\n~~~~~~~~~~~~~~~~~~~\n\nСохранить список переданных ссылок. Временем посещения ссылок считается время\nвыполнения запроса в UTC.\n\nТело запроса:\n\n::\n\n {\n \"links\": [\n <str>, строка с URL,\n ...\n ]\n }\n\nТело ответа:\n\n::\n\n {\n \"status\": <ok|error: bad request>\n }\n\nОшибки:\n\n- 400 -- неверное тело запроса.\n\n\nGET /visited_domains\n~~~~~~~~~~~~~~~~~~~~\n\nВернуть список доменов, которые были посещены в заданный период.\n\nПараметры запроса:\n\n- ``from`` -- <int, начало интервала, секунды>;\n- ``to`` -- <int, конец интервала, секунды>.\n\nИнтервал задаётся секундах с начала эпохи в UTC.\n\nТело ответа:\n\n::\n\n {\n \"status\": <ok|error: bad request>\n }\n\nОшибки:\n\n- 400 -- неверные параметры запроса.\n\n\"\"\"\nfrom fb_assignment.application import app\n"
},
{
"alpha_fraction": 0.6776504516601562,
"alphanum_fraction": 0.686246395111084,
"avg_line_length": 18.38888931274414,
"blob_id": "59f1b967a202d9dbc1c90946f13797c07013a4ce",
"content_id": "748034eab412dac55b973b0e1e121fc9fb192999",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 36,
"path": "/tests/test_storage/conftest.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from pytest import fixture\n\nfrom fb_assignment.storage import Storage\n\n\n@fixture\ndef storage(redis_uri):\n return Storage(address=redis_uri)\n\n\n@fixture\nasync def test_storage(storage, redis_client):\n await redis_client.execute('FLUSHALL')\n await storage.connect()\n try:\n yield storage\n await storage.disconnect()\n finally:\n await redis_client.execute('FLUSHALL')\n\n\n@fixture\ndef domains_key(storage, visit_timestamp):\n return storage.domains_key(visit_timestamp)\n\n\n@fixture()\ndef timestamps_key(storage):\n return storage.timestamps_key\n\n\n@fixture\ndef domains():\n return sorted(\n ['www.ru', 'www.dot.com', 'example', 'пример.рф', '127.0.0.1']\n )\n"
},
{
"alpha_fraction": 0.6753393411636353,
"alphanum_fraction": 0.6753393411636353,
"avg_line_length": 27.516128540039062,
"blob_id": "24409a7b13f9da867270fd83a5b709e0bc6c39be",
"content_id": "6505b58d69f6841f2ba2a6470056a2921a41e471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1012,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 31,
"path": "/fb_assignment/endpoints/visited_domains.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nМодуль, обслуживающий эндпонит посещённых доменов.\n\"\"\"\n\nfrom starlette.endpoints import HTTPEndpoint\nfrom starlette.responses import JSONResponse\n\nfrom fb_assignment.endpoints.validators import validate_query\nfrom fb_assignment.interfaces import storage\nfrom fb_assignment.models import SearchingInterval\n\n\nclass VisitedDomainsEndpoint(HTTPEndpoint):\n storage = storage\n\n @validate_query\n async def get(self, interval: SearchingInterval) -> JSONResponse:\n \"\"\"Получить список уникальных доменов, посещённых в интервале\n ``interval``.\n\n :param interval:\n Интервал, в котором нужно искать домены.\n \"\"\"\n domains = await self.storage.get_visited_domains(\n start=interval.start,\n end=interval.end,\n )\n return JSONResponse({\n 'domains': domains,\n 'status': 'ok',\n })\n"
},
{
"alpha_fraction": 0.6890881657600403,
"alphanum_fraction": 0.6890881657600403,
"avg_line_length": 30.11627960205078,
"blob_id": "62137460925da89bdbb4530ff7990776fe7ea7cd",
"content_id": "12450bd1adbd1e3d2851830b31f8a0fcd8ca9b7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1517,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 43,
"path": "/fb_assignment/endpoints/visited_links.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nМодуль, обслуживающий эндпоинт посещённых ссылок.\n\"\"\"\nfrom datetime import datetime\nfrom typing import List\n\nfrom starlette.endpoints import HTTPEndpoint\nfrom starlette.responses import JSONResponse\n\nfrom fb_assignment.endpoints.validators import validate_body\nfrom fb_assignment.interfaces import storage\nfrom fb_assignment.models import VisitedLinks\n\n\nclass VisitedLinksEndpoint(HTTPEndpoint):\n storage = storage\n\n @validate_body\n async def post(self, visited_links: VisitedLinks) -> JSONResponse:\n \"\"\"Сохранить в БД уникальные домены из списка ссылок ``visited_links``\n и время их посещения. Временем посещения считается время на момент\n обработки запроса.\n\n :param visited_links:\n Список посещённых ссылок.\n \"\"\"\n await self.storage.save_visited_domains(\n domains=self.get_unique_human_readable_hosts(visited_links),\n visit_timestamp=self.get_visit_timestamp(),\n )\n return JSONResponse({'status': 'ok'})\n\n @staticmethod\n def get_visit_timestamp() -> int:\n return round(datetime.utcnow().timestamp())\n\n @staticmethod\n def get_unique_human_readable_hosts(\n visited_links: VisitedLinks,\n ) -> List[str]:\n return list(\n set(i.human_readable_host for i in visited_links.links)\n )\n"
},
{
"alpha_fraction": 0.6437098383903503,
"alphanum_fraction": 0.6528925895690918,
"avg_line_length": 29.25,
"blob_id": "8488c21894cf124d27550918fb4f64aa3037b07d",
"content_id": "df747e23ced223a6386b1b1a43842f8bc4e6f04e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2220,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 72,
"path": "/tests/test_endpoints/test_visited_links_endpoint.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "import json\nfrom unittest.mock import call\n\nfrom pytest import mark, fixture\n\nfrom fb_assignment.endpoints import VisitedLinksEndpoint\nfrom fb_assignment.models import VisitedLinks\n\n\n@fixture\ndef endpoint():\n return '/visited_links'\n\n\n@fixture\ndef error_response():\n return {\n 'status': 'error: bad request',\n }\n\n\[email protected]('link,expected_domain', [\n ('http://ya.ru', 'ya.ru'),\n ('http://почта.рф', 'почта.рф'),\n])\ndef test_save_visited_domains(\n link, expected_domain,\n app_client, endpoint, monkeypatch, mock_storage,\n):\n body = {'links': [link]}\n\n visit_timestamp = 1\n monkeypatch.setattr(VisitedLinksEndpoint, 'storage', mock_storage)\n monkeypatch.setattr(VisitedLinksEndpoint, 'get_visit_timestamp',\n lambda s: visit_timestamp)\n\n response = app_client.post(endpoint, json=body)\n\n assert response.status_code == 200, response.json()\n assert response.json() == {'status': 'ok'}\n\n assert mock_storage.save_visited_domains.called is True\n assert mock_storage.save_visited_domains.await_count == 1\n assert mock_storage.save_visited_domains.await_args == call(\n domains=[expected_domain],\n visit_timestamp=visit_timestamp,\n )\n\n\[email protected]('body', [\n '', 'some-body', '[]', '{}', json.dumps({'links': 'hello'}),\n])\ndef test_malformed_body(body, app_client, endpoint, error_response):\n response = app_client.post(endpoint, data=bytes(body, encoding='ascii'))\n assert response.status_code == 400\n assert response.json() == error_response\n\n\[email protected]('links,expected', [\n (['http://example.test', 'example.test/', 'http://example.test/hello'],\n ['example.test']),\n (['http://почта.рф', 'почта.рф/', 'http://почта.рф/hello'],\n ['почта.рф']),\n (['http://microsoft.com', 'http://apple.com/iphone/', 'ya.ru',\n 'http://127.0.0.1/get'],\n ['microsoft.com', 'apple.com', 'ya.ru', '127.0.0.1']),\n])\ndef test_get_unique_hosts(links, expected):\n visited_links = VisitedLinks(links=links)\n result = VisitedLinksEndpoint.get_unique_human_readable_hosts(\n visited_links)\n assert sorted(result) == sorted(expected)\n"
},
{
"alpha_fraction": 0.6456745266914368,
"alphanum_fraction": 0.6489890813827515,
"avg_line_length": 28.578432083129883,
"blob_id": "1844204d9efc9b77c6199aaeb9f172df4e307c2f",
"content_id": "808d33ae3c79369ef544295828b7ec868b5afb45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3024,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 102,
"path": "/tests/test_storage/test_save_visited_domains.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from pytest import mark, fixture\n\npytestmark = mark.asyncio\n\n\n@fixture\ndef get_domains(redis_client, domains_key):\n async def _get_domains(key=domains_key):\n result = await redis_client.execute('SMEMBERS', key)\n return sorted(result)\n\n return _get_domains\n\n\n@fixture\ndef get_bins(redis_client, timestamps_key):\n async def _get_bins(bins=timestamps_key):\n result = await redis_client.execute(\n 'ZRANGE', bins, 0, -1, 'WITHSCORES',\n )\n return result\n\n return _get_bins\n\n\[email protected]('domain', [\n 'ya.ru', '127.0.0.1', 'example', 'почта.рф',\n])\nasync def test_save_domain(\n domain,\n test_storage, visit_timestamp, domains_key, get_domains, get_bins,\n):\n domains = [domain]\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp,\n )\n assert domains == await get_domains()\n assert [domains_key, str(visit_timestamp)] == await get_bins()\n\n\nasync def test_save_domains(\n test_storage, visit_timestamp, domains_key, domains, get_domains,\n get_bins,\n):\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp,\n )\n assert domains == await get_domains()\n assert [domains_key, str(visit_timestamp)] == await get_bins()\n\n\nasync def test_several_calls(\n test_storage, domains, get_domains, get_bins, visit_timestamp,\n domains_key\n):\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp,\n )\n extra_domains = ['extra.domain']\n extra_visit_time = visit_timestamp + 1\n extra_bin = test_storage.domains_key(extra_visit_time)\n await test_storage.save_visited_domains(\n domains=extra_domains,\n visit_timestamp=extra_visit_time,\n )\n assert domains == await get_domains()\n assert extra_domains == await get_domains(extra_bin)\n assert [domains_key, str(visit_timestamp),\n extra_bin, str(extra_visit_time)] == await get_bins()\n\n\nasync def test_empty_list(test_storage, visit_timestamp, get_domains,\n get_bins):\n await test_storage.save_visited_domains(\n domains=[],\n visit_timestamp=visit_timestamp,\n )\n assert [] == await get_domains()\n assert [] == await get_bins()\n\n\nasync def test_save_to_existing_bin(\n test_storage, domains, get_domains, get_bins, visit_timestamp,\n domains_key,\n):\n await test_storage.save_visited_domains(\n domains=domains,\n visit_timestamp=visit_timestamp,\n )\n extra_domain = 'extra.domain'\n assert extra_domain not in domains\n domains_plus = domains + [extra_domain, domains[0]]\n await test_storage.save_visited_domains(\n domains=domains_plus,\n visit_timestamp=visit_timestamp,\n )\n expected_domains = sorted(list(set(domains_plus)))\n assert expected_domains == await get_domains()\n assert [domains_key, str(visit_timestamp)] == await get_bins()\n"
},
{
"alpha_fraction": 0.7213740348815918,
"alphanum_fraction": 0.7251908183097839,
"avg_line_length": 31.75,
"blob_id": "597345a400eb931423c643d3b9ae6032ca882206",
"content_id": "529bc2a26570be3ed01f1db467335ac43b26c8a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 262,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 8,
"path": "/tests/test_storage/test_init.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "from fb_assignment.storage import Storage\n\n\ndef test_storage_init(redis_uri):\n storage = Storage(address=redis_uri)\n assert storage._address == redis_uri\n assert storage.connected is False\n assert storage._connection_options == {'encoding': 'utf-8'}\n"
},
{
"alpha_fraction": 0.7781350612640381,
"alphanum_fraction": 0.7781350612640381,
"avg_line_length": 24.91666603088379,
"blob_id": "e04275c0b3793593d09817be0b5f71c1acdee25e",
"content_id": "b9ec2ab5fe03c8c1b71be93ff7cd40e1c26f15b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 347,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/fb_assignment/endpoints/__init__.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nМодуль с классами-эндпоинтами web-приложения.\n\"\"\"\nfrom starlette.routing import Route\n\nfrom .visited_domains import VisitedDomainsEndpoint\nfrom .visited_links import VisitedLinksEndpoint\n\nroutes = [\n Route('/visited_domains', VisitedDomainsEndpoint),\n Route('/visited_links', VisitedLinksEndpoint),\n]\n"
},
{
"alpha_fraction": 0.8041236996650696,
"alphanum_fraction": 0.8041236996650696,
"avg_line_length": 26.714284896850586,
"blob_id": "75473b254a37eb1ee89a31dab0e45e46fe76a380",
"content_id": "55cc5dbe2f657dbea111543b3e7cbb9d91c0a2d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 251,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 7,
"path": "/fb_assignment/interfaces.py",
"repo_name": "i-zhivetiev/fb-assignment",
"src_encoding": "UTF-8",
"text": "\"\"\"\nИнтерфейсы. Используются в классах, которые обслуживают эндпоинты.\n\"\"\"\nfrom fb_assignment import settings\nfrom fb_assignment.storage import Storage\n\nstorage = Storage(settings.DATABASE_URI)\n"
}
] | 23 |
Tony001-hou/MNIST_pytorch
|
https://github.com/Tony001-hou/MNIST_pytorch
|
c4e5c608223fdd0e2397ea6bb659ce4a1d54a8f0
|
9f6af45ed32738ae4ff9c9e8b1f44638e1b9df3e
|
1a80c59b423f3cb9478a00969c545732f7e7cf88
|
refs/heads/main
| 2023-03-29T13:10:42.533515 | 2021-04-07T17:20:00 | 2021-04-07T17:20:00 | 354,829,481 | 6 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 7,
"blob_id": "c20de1033952a0dce72e87baa4a0d04a6f985530",
"content_id": "e1f3cc15e75ea6078d02a00e84068cfbdfe86df3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "Tony001-hou/MNIST_pytorch",
"src_encoding": "UTF-8",
"text": "numpy\r\nmatplotlib\r\nPillow\r\n"
},
{
"alpha_fraction": 0.5719625949859619,
"alphanum_fraction": 0.6149532794952393,
"avg_line_length": 26.696428298950195,
"blob_id": "1043a8b70f5bf314e0d14802d605ff8c035a26a5",
"content_id": "1069f0a01b9135d45b8e1c57c684e2ac9675740b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1605,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 56,
"path": "/test.py",
"repo_name": "Tony001-hou/MNIST_pytorch",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function, division\r\n\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.optim as optim\r\nfrom torch.optim import lr_scheduler\r\nimport numpy as np\r\nimport torchvision\r\nfrom torchvision import datasets, models, transforms\r\nimport matplotlib.pyplot as plt\r\nimport time\r\nimport os\r\nimport copy\r\nfrom torch.optim.lr_scheduler import StepLR\r\nimport torch.nn.functional as F\r\nfrom PIL import Image\r\nfrom torchvision import transforms\r\n\r\n\r\nclass Net(nn.Module):\r\n def __init__(self):\r\n super(Net, self).__init__()\r\n self.conv1 = nn.Conv2d(1, 32, 3, 1)\r\n self.conv2 = nn.Conv2d(32, 64, 3, 1)\r\n self.dropout1 = nn.Dropout(0.25)\r\n self.dropout2 = nn.Dropout(0.5)\r\n self.fc1 = nn.Linear(9216, 128)\r\n self.fc2 = nn.Linear(128, 10)\r\n\r\n def forward(self, x):\r\n x = self.conv1(x)\r\n x = F.relu(x)\r\n x = self.conv2(x)\r\n x = F.relu(x)\r\n x = F.max_pool2d(x, 2)\r\n x = self.dropout1(x)\r\n x = torch.flatten(x, 1)\r\n x = self.fc1(x)\r\n x = F.relu(x)\r\n x = self.dropout2(x)\r\n x = self.fc2(x)\r\n output = F.log_softmax(x, dim=1)\r\n return output\r\n\r\nmodel=torch.load(\"mnist_cnn.pt\")\r\nmodel.eval()\r\n\r\n\r\nimage = Image.open('25.png')\r\nplt.imshow(image, cmap='gray', interpolation='none')\r\nlabels=[0,1,2,3,4,5,6,7,8,9]\r\ntransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])\r\nimage = transform(image)\r\nimage = image.unsqueeze(dim=0).cuda()\r\nout = model(image)\r\nprint(\"Predicted class is: {}\".format(labels[out.argmax()]))"
},
{
"alpha_fraction": 0.6916122436523438,
"alphanum_fraction": 0.7091913819313049,
"avg_line_length": 33.842105865478516,
"blob_id": "25d0589e9915f6d93e4a6c16a534d6c7c0b1f864",
"content_id": "54b119c3edbe5f5fc3cf0e3e32626ba13a9caee8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1991,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 57,
"path": "/README.md",
"repo_name": "Tony001-hou/MNIST_pytorch",
"src_encoding": "UTF-8",
"text": "# MNIST Pytorch\n\nThis report provides a CNN model with Pytorch, to train and test on MNIST data of handwritten digits, as well as test on single image input.\nThis report can be opened in Windows OS and run on local devide. \n\n\n### Prerequisites\n\n1. Download the google drive folder **mnist**, the google drive will automaticly compress the folder as a zip file and rename the zip file.\n2. After downloading, change the zip file name to **mnist**.\n3. Uncompress the mnist.zip file and you will get a **mnist** folder. Assume your mnist folder is under **This PC > Downloads**\n4. Open **Anaconda Prompt**. It is recommended to use **Anaconda Prompt** to run this report, because it provides environment to run python files.\n5. Please type in the following cammands to change to your folder path. \n\n```\ncd Downloads\\mnist\n```\n\n6. Please type in the following cammand to install the prerequisite package\n\n```\npip install -r requirements.txt\nconda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch\n```\n\n### Traing \n```\npython train.py\n```\n\nThis file will train a cnn model, the model will be saved as **mnist_cnn.pt**\n\nWhen you want to change the 'data' folder, please open **train.py** and change **line 61** and **line 63**.\n```\n61 dataset1 = datasets.MNIST('data', train=True, download=False,\n62 transform=transform)\n63 dataset2 = datasets.MNIST('data', train=False,\n64 transform=transform)\n```\n\n### Test on single image\n#### 1. First way\n```\npython test.py\n```\nYou can download the **mnist_png.rar** from the google drive, this folder contains all the image data of .png format. Then you can copy an image from **mnist_png** folder and put it under **mnist** folder\n\nThen, change the following line 49 in **test.py** with the new image files.\n\n```\n49 image = Image.open('25.png')\n```\n#### 2. Second way\n```\npython test_with_image.py --img_dir 25.png\n```\nYou can change this **25.png** with another file to test on another image\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.566961944103241,
"alphanum_fraction": 0.5922355651855469,
"avg_line_length": 30.26890754699707,
"blob_id": "bbf590853849d6046b6aaf49a629448ad19dbc1e",
"content_id": "6c442f96dd6fbaf6fceb31f633c35d916a999b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3838,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 119,
"path": "/train.py",
"repo_name": "Tony001-hou/MNIST_pytorch",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function, division\r\n\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.optim as optim\r\nfrom torch.optim import lr_scheduler\r\nimport numpy as np\r\nimport torchvision\r\nfrom torchvision import datasets, models, transforms\r\nimport matplotlib.pyplot as plt\r\nimport time\r\nimport os\r\nimport copy\r\nfrom torch.optim.lr_scheduler import StepLR\r\nimport torch.nn.functional as F\r\n\r\nclass Net(nn.Module):\r\n def __init__(self):\r\n super(Net, self).__init__()\r\n self.conv1 = nn.Conv2d(1, 32, 3, 1)\r\n self.conv2 = nn.Conv2d(32, 64, 3, 1)\r\n self.dropout1 = nn.Dropout(0.25)\r\n self.dropout2 = nn.Dropout(0.5)\r\n self.fc1 = nn.Linear(9216, 128)\r\n self.fc2 = nn.Linear(128, 10)\r\n\r\n def forward(self, x):\r\n x = self.conv1(x)\r\n x = F.relu(x)\r\n x = self.conv2(x)\r\n x = F.relu(x)\r\n x = F.max_pool2d(x, 2)\r\n x = self.dropout1(x)\r\n x = torch.flatten(x, 1)\r\n x = self.fc1(x)\r\n x = F.relu(x)\r\n x = self.dropout2(x)\r\n x = self.fc2(x)\r\n output = F.log_softmax(x, dim=1)\r\n return output\r\n\r\n\r\nuse_cuda = torch.cuda.is_available()\r\n\r\ndevice = torch.device(\"cuda\" if use_cuda else \"cpu\")\r\n\r\ntrain_kwargs = {'batch_size': 64}\r\ntest_kwargs = {'batch_size': 1000}\r\n\r\nif use_cuda:\r\n cuda_kwargs = {'num_workers': 0,\r\n 'pin_memory': True,\r\n 'shuffle': True}\r\n train_kwargs.update(cuda_kwargs)\r\n \r\ntransform=transforms.Compose([\r\n transforms.ToTensor(),\r\n transforms.Normalize((0.1307,), (0.3081,))\r\n ])\r\n\r\ndataset1 = datasets.MNIST('data', train=True, download=False,\r\n transform=transform)\r\ndataset2 = datasets.MNIST('data', train=False,\r\n transform=transform)\r\n\r\ntrain_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)\r\ntest_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)\r\n\r\n\r\ndef train(log_interval, model, device, train_loader, optimizer, epoch):\r\n model.train()\r\n for batch_idx, (data, target) in enumerate(train_loader):\r\n data, target = data.to(device), target.to(device)\r\n optimizer.zero_grad()\r\n output = model(data)\r\n loss = F.nll_loss(output, target)\r\n loss.backward()\r\n optimizer.step()\r\n if batch_idx % log_interval == 0:\r\n print('Train Epoch: {} [{}/{} ({:.0f}%)]\\tLoss: {:.6f}'.format(\r\n epoch, batch_idx * len(data), len(train_loader.dataset),\r\n 100. * batch_idx / len(train_loader), loss.item()))\r\n\r\n\r\n\r\ndef test(model, device, test_loader):\r\n model.eval()\r\n test_loss = 0\r\n correct = 0\r\n with torch.no_grad():\r\n for data, target in test_loader:\r\n data, target = data.to(device), target.to(device)\r\n output = model(data)\r\n test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss\r\n pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability\r\n correct += pred.eq(target.view_as(pred)).sum().item()\r\n\r\n test_loss /= len(test_loader.dataset)\r\n\r\n print('\\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\\n'.format(\r\n test_loss, correct, len(test_loader.dataset),\r\n 100. * correct / len(test_loader.dataset)))\r\n\r\n\r\nmodel = Net().to(device)\r\noptimizer = optim.Adadelta(model.parameters(), lr=1.0)\r\nlog_interval = 10\r\n\r\nscheduler = StepLR(optimizer, step_size=1, gamma=0.7)\r\nsince = time.time()\r\nprint(device)\r\nfor epoch in range(1, 15):\r\n train(log_interval, model, device, train_loader, optimizer, epoch)\r\n test(model, device, test_loader)\r\n scheduler.step()\r\n\r\ntorch.save(model, \"mnist_cnn.pt\")\r\ntime_use = time.time()-since\r\nprint('Training complete in {:.0f}m {:.0f}s'.format(time_use // 60, time_use % 60))"
}
] | 4 |
avisionx/osaiiitd-backend
|
https://github.com/avisionx/osaiiitd-backend
|
5ef6d84d6ce2f47b397c0dc708b76a79078e02b4
|
8625c538ed60531bc5f7d55fe444c3bf4728a139
|
6cdbd7172998e5bb6bbcdf03c2894b89a212ebb2
|
refs/heads/master
| 2023-04-24T02:36:49.331598 | 2021-05-07T16:45:39 | 2021-05-07T16:45:39 | 354,648,649 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.7364771366119385,
"alphanum_fraction": 0.7441053986549377,
"avg_line_length": 29.357894897460938,
"blob_id": "ee9dc59b3ed60dfb3b0d244abf9678e436f0e720",
"content_id": "7886683c1faa14f838ca169a125757997df90840",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2884,
"license_type": "permissive",
"max_line_length": 233,
"num_lines": 95,
"path": "/README.md",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "# OSA IIITD Backend\n\nOSA IIITD Backend serves as the authentication backend for the main OSA app as well as other child apps that fall under OSA. This is based on Django Rest Framework: JWT Authentication. Below are the main end points that it offers:\n\n- `/token-auth/` - POST (username, password in body)\n- `/core/current_user/` - GET (token in headers)\n- `/core/reset_password/` - POST (username in body)\n- `/core/verify_email/` - POST (username, token in body)\n- `/core/resend_email/` - POST (username in body)\n- `/core/change_password/` - POST (username, password in body)\n- `/core/edit_profile/` - POST (username, first_name, last_name in body and token in headers)\n\n## Technologies\n\nOSA Backend is powered by a number of technologies:\n\n- [Django] - high-level Python Web framework\n- [PostgreSQL] - a powerful, open source object-relational database system\n- [DjangoRestFramework] - a powerful and flexible toolkit for building Web APIs\n\nAnd some simple add ons like django-cors, django-djangorestframework-jwt etc.\n\n## Setup\n\n1. To clone and run OSA Backend, you'll need Git, [Python] v3.0+ and [PostgreSQL] v9+ installed on your computer. From your command line:\n\n```bash\n# Clone this repository\n$ git clone https://github.com/avisionx/osaiiitd-backend.git\n\n# Go into the repository\n$ cd osa-backend\n\n# Install dependencies in a virtualenv\n$ pip install -r requirements.txt\n```\n\n2. For environment variables check out `.env.examples` in backend folder and create .env file for your own variables\n\n```bash\n# Create .env file\n$ vim ./backend/.env\n```\n\nIf you are using gmail smtp server provide email and password in the environment variables.\n\n3. You are good to go just start the server after making migrations.\n\n```bash\n# Make migrations\n$ python manage.py makemigrations\n\n# Migrate the changes\n$ python manage.py migrate\n\n# Start the server\n$ python manage.py runserver\n```\n\nServer by default starts in development mode at http://127.0.0.1:8000/\n\n## Development\n\nGreat setting it all up! Let's contribute now. You'll need to learn Django basics to work on the app. We are using Django Restframework for Api's and JWT token based authentication.\n\n1. Make sure to start from the master branch and update your local repositories.\n\n```bash\n# Start from master\n$ git checkout master\n\n# Stay updated\n$ git pull\n```\n\n2. Create a new branch for each bug fix or issue. Rest is basic.\n\n```bash\n# Create new branch keep qoutes\n$ git checkout -b \"YOUR_NEW_BRANCH\"\n```\n\n## Deployment\n\nOnce the code is on the server we can use nginx with gunicorn to host the app. Refer [here](https://www.digitalocean.com/community/tutorials/how-to-set-up-django-with-postgres-nginx-and-gunicorn-on-ubuntu-18-04) for more information.\n\n## License\n\nMIT\n\n---\n\n[django]: https://docs.djangoproject.com/\n[postgresql]: https://www.postgresql.org/\n[djangorestframework]: https://www.django-rest-framework.org/\n"
},
{
"alpha_fraction": 0.6458629965782166,
"alphanum_fraction": 0.6495222449302673,
"avg_line_length": 30.53205108642578,
"blob_id": "1e3219fece50fbc30fba7724b35b6b5f4f3cde9f",
"content_id": "33f6b80712d8ea1b2bbdefa24b1f063db6a0376a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4919,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 156,
"path": "/core/views.py",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "import json\nfrom datetime import datetime\n\nfrom django.contrib.auth.tokens import default_token_generator\nfrom django.core.mail import send_mail\nfrom rest_framework import permissions, status\nfrom rest_framework.decorators import api_view, permission_classes\nfrom rest_framework.permissions import AllowAny, IsAuthenticated\nfrom rest_framework.response import Response\nfrom rest_framework.views import APIView\n\nfrom .models import User\nfrom .serializers import UserSerializer, UserSerializerWithToken\n\n\n@api_view(['GET'])\ndef current_user(request):\n \"\"\"\n Determine the current user by their token, and return their data\n \"\"\"\n\n serializer = UserSerializer(request.user)\n return Response(serializer.data)\n\n\n@api_view(['POST'])\n@permission_classes([AllowAny])\ndef ResetPasswordView(request):\n \"\"\"\n Send a reset password request to user email.\n \"\"\"\n\n username = json.loads(request.body)['username']\n try:\n user = User.objects.get(username=username)\n token = default_token_generator.make_token(user)\n send_mail(subject=\"Password Reset Request for OSAIIITD\",\n message=\"Your token is \" + token, recipient_list=[user.username], from_email='')\n except Exception as e:\n return Response(e.__str__())\n return Response()\n\n\n@api_view(['POST'])\n@permission_classes([AllowAny])\ndef ChangePasswordView(request):\n \"\"\"\n Set new password for the user.\n \"\"\"\n\n post_data = json.loads(request.body)\n username = post_data['username']\n token = post_data['token']\n password = post_data['password']\n try:\n user = User.objects.get(username=username)\n if default_token_generator.check_token(user, token):\n user.set_password(password)\n user.save()\n serializer = UserSerializer(user)\n return Response(serializer.data, status=status.HTTP_200_OK)\n else:\n raise Exception(\"Invalid token!\")\n except Exception as e:\n return Response(e.__str__())\n return Response()\n\n\n@api_view(['POST'])\n@permission_classes([IsAuthenticated])\ndef EditProfileView(request):\n \"\"\"\n Edit user profile first_name, last_name, email\n \"\"\"\n\n post_data = json.loads(request.body)\n username = post_data['username']\n first_name = post_data['first_name']\n last_name = post_data['last_name']\n if not request.user.is_verified:\n return Response({}, status=status.HTTP_401_UNAUTHORIZED)\n try:\n if request.user.username != username:\n request.user.username = username\n request.user.is_verified = False\n request.user.first_name = first_name\n request.user.last_name = last_name\n request.user.save()\n serializer = UserSerializer(request.user)\n return Response(serializer.data, status=status.HTTP_200_OK)\n except Exception as e:\n return Response(e.__str__())\n return Response()\n\n\nclass UserList(APIView):\n \"\"\"\n Create a new user. It's called 'UserList' because normally we'd have a get\n method here too, for retrieving a list of all User objects.\n \"\"\"\n\n permission_classes = (permissions.AllowAny,)\n\n def post(self, request, format=None):\n username = request.data['username']\n serializer = UserSerializerWithToken(\n data={\"username_osa\": username +\n \"-\" + str(datetime.now().date()), **request.data,\n \"is_verified\": False}\n )\n if serializer.is_valid():\n serializer.save()\n return Response(serializer.data, status=status.HTTP_201_CREATED)\n return Response(serializer.errors, status=status.HTTP_400_BAD_REQUEST)\n\n\n@api_view(['POST'])\n@permission_classes([AllowAny])\ndef ResendEmailView(request):\n \"\"\"\n Send a verify email token to user email.\n \"\"\"\n\n username = json.loads(request.body)['username']\n try:\n user = User.objects.get(username=username)\n token = default_token_generator.make_token(user)\n send_mail(subject=\"Account verification for OSA IIITD\",\n message=\"Your token is \" + token, recipient_list=[user.username], from_email='')\n except Exception as e:\n return Response(e.__str__())\n return Response()\n\n\n@api_view(['POST'])\n@permission_classes([AllowAny])\ndef VerifyEmailView(request):\n \"\"\"\n Verify email for user using token.\n \"\"\"\n\n post_data = json.loads(request.body)\n username = post_data['username']\n token = post_data['token']\n try:\n user = User.objects.get(username=username)\n if default_token_generator.check_token(user, token):\n user.is_verified = True\n user.save()\n serializer = UserSerializer(user)\n return Response(serializer.data, status=status.HTTP_200_OK)\n else:\n raise Exception(\"Invalid token!\")\n except Exception as e:\n return Response(e.__str__())\n return Response()\n"
},
{
"alpha_fraction": 0.550000011920929,
"alphanum_fraction": 0.7318181991577148,
"avg_line_length": 19,
"blob_id": "00a5bf873b980146b69ae6504bafc0588d6fe6fe",
"content_id": "c4d4de3c1ae9327c88dabe620708e0edd44e342c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 220,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 11,
"path": "/requirements.txt",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "asgiref==3.3.1\nDjango==3.1.7\ndjango-cors-headers==3.7.0\ndjangorestframework==3.12.4\ndjangorestframework-jwt==1.11.0\ngunicorn==20.1.0\npsycopg2-binary==2.8.6\nPyJWT==1.7.1\npython-dotenv==0.17.0\npytz==2021.1\nsqlparse==0.4.1\n"
},
{
"alpha_fraction": 0.7060703039169312,
"alphanum_fraction": 0.7156549692153931,
"avg_line_length": 25.08333396911621,
"blob_id": "24bbde5f9ee355ac870b9c1e76e7d3f5e29fd5f0",
"content_id": "7d5ea5ca8bd7ea88e8cd3b376a169c60553d43c0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 12,
"path": "/core/models.py",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth.models import AbstractUser\nfrom django.db import models\n\n\nclass User(AbstractUser):\n\n username_osa = models.CharField(max_length=150, unique=True)\n is_verified = models.BooleanField(default=False)\n\n class Meta:\n verbose_name = 'User'\n verbose_name_plural = 'Users'\n"
},
{
"alpha_fraction": 0.7209302186965942,
"alphanum_fraction": 0.7209302186965942,
"avg_line_length": 20.66666603088379,
"blob_id": "f14923f4273c060889960e6032c6a6c5669d7334",
"content_id": "f22ea0800e91f8112ce72cfd881f4a13d6a8a00a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 129,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 6,
"path": "/backend/.env.example",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "EMAIL_HOST_PASSWORD='pass'\nEMAIL_HOST_USER='email'\nSECRET_KEY='key'\nDB_NAME='name'\nDB_USER='user'\nDB_USER_PASS='password'"
},
{
"alpha_fraction": 0.6964980363845825,
"alphanum_fraction": 0.6964980363845825,
"avg_line_length": 35.71428680419922,
"blob_id": "5dfa021d78e03fd5d3c0146286a7ac89a419ac06",
"content_id": "cf7b56002bd9d4dedfa09b559ba5942877ee17a6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 514,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 14,
"path": "/core/urls.py",
"repo_name": "avisionx/osaiiitd-backend",
"src_encoding": "UTF-8",
"text": "from django.urls import path\n\nfrom .views import (ChangePasswordView, EditProfileView, ResendEmailView,\n ResetPasswordView, UserList, VerifyEmailView, current_user)\n\nurlpatterns = [\n path('current_user/', current_user),\n path('users/', UserList.as_view()),\n path('reset_password/', ResetPasswordView),\n path('verify_email/', VerifyEmailView),\n path('resend_email/', ResendEmailView),\n path('change_password/', ChangePasswordView),\n path('edit_profile/', EditProfileView),\n]\n"
}
] | 6 |
iTharindu/InferenceLanguageModels
|
https://github.com/iTharindu/InferenceLanguageModels
|
c9c55e2b9f44b55b0c5298fda8b397e0cfc3f326
|
5f11788b0ee1b88331d2c0906ce1a62a1d17040c
|
db5ff8f38581e17bc053f190649b29390a395163
|
refs/heads/master
| 2022-12-28T15:03:54.990938 | 2020-10-11T02:44:54 | 2020-10-11T02:44:54 | null | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.807106614112854,
"alphanum_fraction": 0.8324872851371765,
"avg_line_length": 64.5,
"blob_id": "545318e2129eda4466f0ba0e85943e6de55e40a1",
"content_id": "a61269865b11656ae232af53a56ef029c383743e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 394,
"license_type": "permissive",
"max_line_length": 209,
"num_lines": 6,
"path": "/README.md",
"repo_name": "iTharindu/InferenceLanguageModels",
"src_encoding": "UTF-8",
"text": "# InferenceLanguageModels\n\nRepository with data and experiments regarding inference generation.\n\nThis is the implementation for the position paper [Using neural models to perform inference](https://drive.google.com/file/d/1HcPIXDwlZRu6zm0srwxEqVXYbdh4QiNT/view) presented at [14th International Workshop on\nNeural-Symbolic Learning and Reasoning](https://sites.google.com/view/nesy2019/home). \n"
},
{
"alpha_fraction": 0.5167192220687866,
"alphanum_fraction": 0.5299684405326843,
"avg_line_length": 41.83783721923828,
"blob_id": "a19a8fb79fc0d7823fd216abc2ce1c78d99f0731",
"content_id": "902b71361eae61307f83c0038abfa54555dc77f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14265,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 333,
"path": "/inference/text_generation/simple_negation.py",
"repo_name": "iTharindu/InferenceLanguageModels",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nfrom vocab import male_names, female_names, cities_and_states, countries\nfrom vocab_pt import male_names_pt, female_names_pt, cities_pt, countries_pt\nfrom util import get_new_item, get_n_different_items\nfrom util import vi, not_vi, vi_pt, not_vi_pt\nfrom util import create_csv_contradiction, create_csv_entailment\nfrom util import create_csv_NLI\n\n\ndef entailment_instance_1(person_list,\n place_list,\n n,\n vi_function,\n not_vi_function):\n \"\"\"\n $P:= pm V(x_1, y_1) , dots, pm V(x_i, y_i), dots, pm V(x_n, y_n)$\n $H:= pm V(x_i, y_i)$\n \"\"\"\n Subjects = get_n_different_items(person_list, n)\n people_O = [get_new_item(Subjects, person_list) for _ in range(n)]\n places = get_n_different_items(place_list, n)\n Objects = get_n_different_items(people_O + places, n)\n fs = np.random.choice([vi_function, not_vi_function], n)\n sentence1 = [f(x, y) for f, x, y in zip(fs, Subjects, Objects)]\n id_ = np.random.choice(len(Subjects))\n sentence2 = sentence1[id_]\n sentence1 = \", \".join(sentence1)\n label = \"entailment\"\n people_O = list(set(Objects).intersection(people_O))\n places = list(set(Objects).intersection(places))\n people = \", \".join(Subjects + people_O)\n Subjects = \", \".join(Subjects)\n Objects = \", \".join(Objects)\n places = \", \".join(places)\n\n return sentence1, sentence2, label, Subjects, Objects, id_, people, places\n\n\ndef neutral_instance_1(person_list,\n place_list,\n n,\n vi_function,\n not_vi_function):\n \"\"\"\n $P:= pm V(x_1, y_1) , dots, pm V(x_i, y_i), dots, pm V(x_n, y_n)$\n $H:= pm V(y_i, x_i)$\n \"\"\"\n Subjects = get_n_different_items(person_list, n)\n people_O = [get_new_item(Subjects, person_list) for _ in range(n)]\n places = get_n_different_items(place_list, n)\n Objects = get_n_different_items(people_O + places, n)\n inter = len(set(Objects).intersection(people_O))\n if inter == 0:\n Objects[0] = people_O[0]\n np.random.shuffle(Objects)\n id_ = np.random.choice(len(Subjects))\n while Objects[id_] not in people_O:\n id_ = np.random.choice(len(Subjects))\n fs = np.random.choice([vi_function, not_vi_function], n)\n sentence1 = \", \".join([f(x, y) for f, x, y in zip(fs, Subjects, Objects)])\n f2 = np.random.choice([vi_function, not_vi_function])\n sentence2 = f2(Objects[id_], Subjects[id_])\n label = \"neutral\"\n people_O = list(set(Objects).intersection(people_O))\n people = \", \".join(Subjects + people_O)\n Subjects.append(Objects[id_])\n Objects.append(Subjects[id_])\n places = list(set(Objects).intersection(places))\n Subjects = \", \".join(Subjects)\n Objects = \", \".join(Objects)\n places = \", \".join(places)\n\n return sentence1, sentence2, label, Subjects, Objects, id_, people, places\n\n\ndef neutral_instance_2(person_list,\n place_list,\n n,\n vi_function,\n not_vi_function):\n \"\"\"\n $P:= pm V(x_1, y_1) , dots, pm V(x_n, y_n)$\n $H:= pm V(x^{*}, y^{*})$\n where $x^{*} not in x_1, dots, x_n $ or $y^{*} not in y_1, dots, y_n$. # noqa\n \"\"\"\n Subjects = get_n_different_items(person_list, n)\n people_O = [get_new_item(Subjects, person_list) for _ in range(n)]\n places = get_n_different_items(place_list, n)\n Objects = get_n_different_items(people_O + places, n)\n fs = np.random.choice([vi_function, not_vi_function], n)\n sentence1 = [f(x, y) for f, x, y in zip(fs, Subjects, Objects)]\n sentence1 = \", \".join(sentence1)\n id_ = -1\n fs2 = np.random.choice([vi_function, not_vi_function])\n Subject2 = get_new_item(Subjects + people_O, person_list)\n Object2 = [get_new_item(Subjects + people_O + [Subject2], person_list)]\n place2 = get_new_item(places, place_list)\n Object2 += [place2]\n Object2 = np.random.choice(Object2)\n\n sentence2_1 = fs2(np.random.choice(Subjects), Object2)\n sentence2_2 = fs2(Subject2, np.random.choice(Objects))\n sentence2_3 = fs2(Subject2, Object2)\n\n people_O = list(set(Objects).intersection(people_O))\n\n dice = np.random.choice([1, 2, 3])\n if dice == 1:\n sentence2 = sentence2_1\n people = \", \".join(Subjects + people_O)\n places = list(set(Objects + [Object2]).intersection(places + [place2]))\n Subjects = \", \".join(Subjects)\n Objects = \", \".join(Objects + [Object2])\n\n elif dice == 2:\n sentence2 = sentence2_2\n people = \", \".join(Subjects + people_O + [Subject2])\n places = list(set(Objects).intersection(places))\n Subjects = \", \".join(Subjects + [Subject2])\n Objects = \", \".join(Objects)\n\n else:\n sentence2 = sentence2_3\n people = \", \".join(Subjects + people_O + [Subject2])\n places = list(set(Objects + [Object2]).intersection(places + [place2]))\n Subjects = \", \".join(Subjects + [Subject2])\n Objects = \", \".join(Objects + [Object2])\n\n places = \", \".join(places)\n\n label = \"neutral\"\n\n return sentence1, sentence2, label, Subjects, Objects, id_, people, places\n\n\ndef contradiction_instance_1(person_list,\n place_list,\n n,\n vi_function,\n not_vi_function):\n \"\"\"\n $P:= pm V(x_1, y_1) , dots, V(x_i, y_i), dots, pm V(x_n, y_n)$\n $H:= not V(y_i, x_i)$\n \"\"\"\n Subjects = get_n_different_items(person_list, n)\n people_O = [get_new_item(Subjects, person_list) for _ in range(n)]\n places = get_n_different_items(place_list, n)\n Objects = get_n_different_items(people_O + places, n)\n\n fs = []\n while vi_function not in fs:\n fs = np.random.choice([vi_function, not_vi_function], n)\n\n id_ = 0\n while fs[id_] != vi_function:\n id_ = np.random.choice(len(fs))\n\n sentence1 = \", \".join([f(x, y) for f, x, y in zip(fs, Subjects, Objects)])\n sentence2 = not_vi_function(Subjects[id_], Objects[id_])\n label = \"contradiction\"\n people_O = list(set(Objects).intersection(people_O))\n places = list(set(Objects).intersection(places))\n people = \", \".join(Subjects + people_O)\n Subjects = \", \".join(Subjects)\n Objects = \", \".join(Objects)\n places = \", \".join(places)\n\n return sentence1, sentence2, label, Subjects, Objects, id_, people, places\n\n\ndef i2eng(f):\n return lambda x, y, z: f(x, y, z, vi_function=vi, not_vi_function=not_vi) # noqa\n\n\ndef i2pt(f):\n return lambda x, y, z: f(x, y, z, vi_function=vi_pt, not_vi_function=not_vi_pt) # noqa\n\n\nentailment_instances = [entailment_instance_1]\nneutral_instances = [neutral_instance_1, neutral_instance_2]\ncontradiction_instances = [contradiction_instance_1]\n\n\nentailment_instances_eng = list(map(i2eng, entailment_instances))\nneutral_instances_eng = list(map(i2eng, neutral_instances))\ncontradiction_instances_eng = list(map(i2eng, contradiction_instances))\n\nentailment_instances_pt = list(map(i2pt, entailment_instances))\nneutral_instances_pt = list(map(i2pt, neutral_instances))\ncontradiction_instances_pt = list(map(i2pt, contradiction_instances))\n\nif __name__ == '__main__':\n\n # call this script in the main folder, i.e., type\n # python inference/text_generation/simple_negation.py\n\n cwd = os.getcwd()\n base_path_NLI = os.path.join(cwd, \"data\", \"NLI\")\n base_path_RTE = os.path.join(cwd, \"data\", \"RTE\")\n base_path_CD = os.path.join(cwd, \"data\", \"CD\")\n\n # english\n\n # CD\n create_csv_contradiction(out_path=os.path.join(base_path_CD,\n \"simple_negation_train.csv\"), # noqa\n size=10000,\n positive_instances_list=contradiction_instances_eng, # noqa\n negative_instances_list=entailment_instances_eng + neutral_instances_eng, # noqa\n person_list=male_names,\n place_list=countries,\n n=12,\n min_n=2)\n\n create_csv_contradiction(out_path=os.path.join(base_path_CD,\n \"simple_negation_test.csv\"), # noqa\n size=1000,\n positive_instances_list=contradiction_instances_eng, # noqa\n negative_instances_list=entailment_instances_eng + neutral_instances_eng, # noqa\n person_list=female_names,\n place_list=cities_and_states,\n n=12,\n min_n=2)\n\n # RTE\n create_csv_entailment(out_path=os.path.join(base_path_RTE,\n \"simple_negation_train.csv\"), # noqa\n size=10000,\n positive_instances_list=entailment_instances_eng, # noqa\n negative_instances_list=contradiction_instances_eng + neutral_instances_eng, # noqa\n person_list=male_names,\n place_list=countries,\n n=12,\n min_n=2)\n\n create_csv_entailment(out_path=os.path.join(base_path_RTE,\n \"simple_negation_test.csv\"), # noqa\n size=1000,\n positive_instances_list=entailment_instances_eng, # noqa\n negative_instances_list=contradiction_instances_eng + neutral_instances_eng, # noqa\n person_list=female_names,\n place_list=cities_and_states,\n n=12,\n min_n=2)\n # NLI\n create_csv_NLI(out_path=os.path.join(base_path_NLI,\n \"simple_negation_train.csv\"), # noqa,\n size=10008,\n entailment_instances_list=entailment_instances_eng,\n neutral_instances_list=neutral_instances_eng,\n contradiction_instances_list=contradiction_instances_eng,\n person_list=male_names,\n place_list=countries,\n n=12,\n min_n=2)\n\n create_csv_NLI(out_path=os.path.join(base_path_NLI,\n \"simple_negation_test.csv\"), # noqa,\n size=1000,\n entailment_instances_list=entailment_instances_eng,\n neutral_instances_list=neutral_instances_eng,\n contradiction_instances_list=contradiction_instances_eng,\n person_list=female_names,\n place_list=cities_and_states,\n n=12,\n min_n=2)\n\n # portuguese\n\n # CD\n create_csv_contradiction(out_path=os.path.join(base_path_CD,\n \"simple_negation_pt_train.csv\"), # noqa\n size=10000,\n positive_instances_list=contradiction_instances_pt, # noqa\n negative_instances_list=entailment_instances_pt + neutral_instances_pt, # noqa\n person_list=male_names_pt,\n place_list=countries_pt,\n n=12,\n min_n=2)\n\n create_csv_contradiction(out_path=os.path.join(base_path_CD,\n \"simple_negation_pt_test.csv\"), # noqa\n size=1000,\n positive_instances_list=contradiction_instances_pt, # noqa\n negative_instances_list=entailment_instances_pt + neutral_instances_pt, # noqa\n person_list=female_names_pt,\n place_list=cities_pt,\n n=12,\n min_n=2)\n\n # RTE\n create_csv_entailment(out_path=os.path.join(base_path_RTE,\n \"simple_negation_pt_train.csv\"), # noqa\n size=10000,\n positive_instances_list=entailment_instances_pt, # noqa\n negative_instances_list=contradiction_instances_pt + neutral_instances_pt, # noqa\n person_list=male_names_pt,\n place_list=countries_pt,\n n=12,\n min_n=2)\n\n create_csv_entailment(out_path=os.path.join(base_path_RTE,\n \"simple_negation_pt_test.csv\"), # noqa\n size=1000,\n positive_instances_list=entailment_instances_pt, # noqa\n negative_instances_list=contradiction_instances_pt + neutral_instances_pt, # noqa\n person_list=female_names_pt,\n place_list=cities_pt,\n n=12,\n min_n=2)\n # NLI\n create_csv_NLI(out_path=os.path.join(base_path_NLI,\n \"simple_negation_pt_train.csv\"), # noqa,\n size=10008,\n entailment_instances_list=entailment_instances_pt,\n neutral_instances_list=neutral_instances_pt,\n contradiction_instances_list=contradiction_instances_pt,\n person_list=male_names_pt,\n place_list=countries_pt,\n n=12,\n min_n=2)\n\n create_csv_NLI(out_path=os.path.join(base_path_NLI,\n \"simple_negation_pt_test.csv\"), # noqa,\n size=1000,\n entailment_instances_list=entailment_instances_pt,\n neutral_instances_list=neutral_instances_pt,\n contradiction_instances_list=contradiction_instances_pt,\n person_list=female_names,\n place_list=cities_pt,\n n=12,\n min_n=2)\n"
}
] | 2 |
tmittal/Version_working
|
https://github.com/tmittal/Version_working
|
3e9f4d780b8abb843fe97486c2a512def9bd14c5
|
7b2b93b1e2a40c9fbe67004488a53c08cd750ab5
|
57cc151d52b572f4d5d86d3a0ecaf09a6413ffec
|
refs/heads/master
| 2021-04-26T23:31:02.736766 | 2018-03-07T03:33:03 | 2018-03-07T03:33:03 | 124,008,668 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.49639248847961426,
"alphanum_fraction": 0.5834535956382751,
"avg_line_length": 30.029850006103516,
"blob_id": "0295e129de8b99b06d69d6338e0e88e32cc31793",
"content_id": "f9d75696aacc54fc56bc0b89accbd7a7b75ed811",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2079,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 67,
"path": "/PyMagmaCh/notes.txt",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "zsize = 30000; % Vertical scale in meters\nn_runs=10;\nfxmax = 0.65;\n%volatiles = 0.03; # Initial CO2 weight fraction\nrecharge = [10^(-8.5)];%1e-10; % m/s recharge magma to base of chamber\ntime_max=1e6;\n\nmaxF = normrnd(0.1,0.0125)\n################ Setup =\na. pass in the domain size - nominal values are\n z_bottom = 38 km\n z_top = 0.\n zstep = 1000;\n zsize=mbot+4000 m\n location of moho chamber - z_bottom <-> z_bottom - 2000 m\n location of upper chamber = 14000-1000*round(r(1)*4); <-> mbot-3000;%+1000*round(r(1)*1)\n\n\n Specify the intrusive to extrusive fraction :\n factor=3.4;%3.5;%2.3+(r(5)); %I:E ratio\n\n Set the lithostatic pressure (\\rho*g*h)\n Set magma input temp\n\n Specify - sio2,tio2,al2o3,feo,fe2o3,mgo,cao,na2o,k2o melt composition\n Specify the input Co2 and H2O in the melt input -\n bCO2=500;%400+50*round(r(3)*4); %ppm in the mantle\n bH2O=0.05;%0.04+0.005*round(r(4)*4); %wt% in the mantle\n f = 0.1\n [mCO2 mH2O]=cCO2(bCO2,bH2O,f);%CO2 (ppm) and water (wt%) in the melt\n [CO2 H2O] = solubilityNEW(mCO2,mH2O,P,T,sio2,tio2,al2o3,feo,fe2o3,mgo,cao,na2o,k2o);\n\n vol=(1e-4*min([CO2 mCO2])+min([H2O mH2O]))/100 %wt fraction\n exsolved=(1e-4*(mCO2-min([CO2 mCO2]))+(mH2O-min([H2O mH2O])))/100 % wt fraction\n\n\n\nAssimilate piece :\n\n if mtop>12000\n assimilate=0;\n end\n melttemp(1)=990+273; #melting temp for limestone ?\n\n\nIntrusion Piece -\nnewloc = 0; % If zero, intrude at base of magma chamber\n % If one, intrude at middle of chamber\n % If two, intrude at top\n % If three, random intrusion\n\ntsurf = 298;\ntmoho = 298+25*(zsize/1000); % K # constant isotherm\n\n\n\nif (frozen==1)\n if newflux>0\n chamber_h=newflux*dt;\n zstepchamber=chamber_h/length(magma_ind);\n tnew(magma_ind)=tmagma;\n frommantle=0;\n newFx=0;\n percentliq(:)=percentliq_initial;\n if chamber_h>15%((kappa*dt)^.5)\n frozen=0;\n end\n"
},
{
"alpha_fraction": 0.4819861650466919,
"alphanum_fraction": 0.5307127237319946,
"avg_line_length": 66.71981048583984,
"blob_id": "7de26b036f4adbb23b76b897babe8881260a1f9d",
"content_id": "91980d06ed3b62b39e02645d899aa2d1554188e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14017,
"license_type": "no_license",
"max_line_length": 256,
"num_lines": 207,
"path": "/PyMagmaCh_Single/Analytical_sol_cavity_T_Use.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "#import warnings\nimport pdb\nimport numpy as np\n#from numpy import np.sqrt,pi,exp\nfrom scipy.special import erfc\nfrom iapws import IAPWS95\n\nclass Analytical_crust_params(object):\n def __init__(self):\n self.name = 'parameters for the Analytical_solution'\n self.T_fluid = 750.\n self.P_fluid = 10.*1e6\n self.set_viscosity(self.T_fluid,10*1e6)\n self.set_constants('Westerly_Granite',1e-19)\n self.fluid_prop = IAPWS95(P=self.P_fluid/1e6,T=self.T_fluid) # T_fluid in Kelvin, P in MPa\n\n def set_viscosity(self,T_fluid,P_fluid):\n self.T_fluid = T_fluid\n self.P_fluid = P_fluid\n #self.visc = 2.414 * 1e-5 * (10. ** (247.8 / (self.T_fluid - 140))) # ;% - from Rabinowicz 1998/Eldursi EPSL 2009 #% Pa\n self.fluid_prop = IAPWS95(P=self.P_fluid/1e6, T=self.T_fluid) # T_fluid in Kelvin, P in MPa\n self.visc = self.fluid_prop.mu # Dynamic viscosity [Pa s]\n\n def set_constants(self,material,permeability):\n self.material = material\n self.Kf = self.fluid_prop.Ks*1e6 # Adiabatic bulk modulus (output was in MPa)\n self.permeability = permeability\n if (material =='Westerly_Granite'): #%\n self.G = 1.5e10 #% Pa\n self.K = 2.5e10 #% Pa\n self.K_u = 3.93e10 #% Pa\n self.Ks = 4.5e10\n self.phi = 0.01\n self.M = (self.Kf*self.Ks*self.Ks)/(self.Kf*(self.Ks-self.K) + self.phi*self.Ks*(self.Ks-self.Kf)) #% Pa\n self.S = (3.*self.K_u + 4*self.G)/(self.M*(3.*self.K + 4.*self.G)) #% 1/Pa\n self.c = self.permeability/self.S/self.visc #% m^2\n self.beta_c = 6.65e-6 # % /K (Table 11.2), W\n self.alpha_e = self.beta_c/self.S#= 3.58e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n self.kappa_T = 1.09e-6 # % m^2/s\n self.m_d = 7.85e3/20. #%J/m^3\n self.eta_d = 2e5 #%N/m^2/K\n self.alpha_d = 6e5 #% N/m^2/K\n self.eta = 0.150 #% unitless\n self.k_T = 2.5 # W/m/K\n elif (material =='Berea_Sandstone') :#% berea Sandstone\n self.G = 6e9 #% Pa\n self.K = 8e9 #% Pa\n self.K_u = 1.4e10 #% Pa\n self.Ks = 3.6e10\n self.phi = 0.15\n self.M = (self.Kf*self.Ks*self.Ks)/(self.Kf*(self.Ks-self.K) + self.phi*self.Ks*(self.Ks-self.Kf)) #% Pa\n self.S = (3.*self.K_u + 4*self.G)/(self.M*(3.*self.K + 4*self.G)) #% 1/Pa\n self.c = self.permeability/self.S/self.visc #% m^2\n self.beta_c = 4.08e-5 # % /K (Table 11.2), Westerly granite\n self.alpha_e = self.beta_c/self.S #= 2.94e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n self.kappa_T = 1.27e-6 # % m^2/s\n self.m_d = 6.01e3/20. #%J/m^3\n self.eta_d = 1.35e4 #%N/m^2/K\n self.alpha_d = 3.6e4 #% N/m^2/K\n self.k_T = 2.24 # W/m/K\n self.eta = 0.292 #\n else:\n raise NotImplementedError('material not specified')\n self.S_a = self.m_d + self.alpha_d*self.eta_d/self.G\n self.c_a = self.m_d*self.kappa_T/self.S_a\n self.alpha_p = self.beta_c/self.S_a # #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n self.C_Q = np.sqrt( (self.c -self.c_a)**2. + 4.*self.c*self.c_a*self.alpha_p*self.alpha_e ) ##\n self.lam1 = np.sqrt(((self.c +self.c_a) + self.C_Q)/2./self.c/self.c_a) ##\n self.lam2 = np.sqrt(((self.c +self.c_a) - self.C_Q)/2./self.c/self.c_a) ##\n\n def set_misc_grids(self,R_val):\n try :\n tmp1 = R_val.shape[1]\n del tmp1\n except IndexError :\n R_val = np.expand_dims(R_val,1)\n self.R_val = R_val\n self.R_steps = np.shape(R_val)[0] ##\n self.tmp_one_R = np.ones([np.shape(R_val)[0],np.shape(R_val)[1]])\n self.term1 = (1./self.C_Q)/self.R_val\n\n def Analytical_sol_cavity_T_Use(self,T_R,P_R,R_chamber,t,T_flux,P_flux) :\n try :\n tmp1 = t.shape[1]\n del tmp1\n except IndexError :\n t = np.expand_dims(t,1)\n ##############################################\n time_new = t[-1] - t + 1.0 ## % Added the 1 to make sure a min time is not zero\n tmp_one_t = np.ones([np.shape(time_new)[0],np.shape(time_new)[1]])\n #Diff_temp_arr = np.hstack([T_R[0],np.diff(T_R)])\n #Diff_press_arr = np.hstack([P_R[0],np.diff(P_R)])\n Diff_temp_arr = T_R.copy()\n Diff_temp_arr[1:] = T_R[1:] - T_R[:-1]\n Diff_press_arr = P_R.copy()\n Diff_press_arr[1:] = P_R[1:] - P_R[:-1]\n ############################################\n Diff_grad_temp_arr = T_flux.copy()/self.k_T\n Diff_grad_temp_arr[1:] = T_flux[1:] - T_flux[:-1]\n Diff_grad_press_arr = P_flux.copy()*(self.visc/self.permeability)\n Diff_grad_press_arr[1:] = P_flux[1:] - P_flux[:-1]\n\n time_new = time_new.T\n tmp_one_t = tmp_one_t.T\n sqrt_time_new = np.sqrt(time_new)\n\n #term_T = np.zeros([self.R_steps,np.size(T_R)])\n #term_P = np.zeros([self.R_steps,np.size(T_R)])\n #T_sigma_rr = np.zeros([self.R_steps,np.size(T_R)])\n #T_sigma_theta = np.zeros([self.R_steps,np.size(T_R)])\n term1a = self.lam1*(self.R_val - R_chamber)/2./sqrt_time_new\n term1b = self.lam2*(self.R_val - R_chamber)/2./sqrt_time_new\n Erfc_t1a = erfc(term1a)\n Erfc_t1b = erfc(term1b)\n exp_term1a = np.exp(-term1a**2.)\n exp_term1b = np.exp(-term1b**2.)\n msc_fact1 = (self.lam1/np.sqrt(np.pi)/sqrt_time_new)\n msc_fact2 = (self.lam2/np.sqrt(np.pi)/sqrt_time_new)\n sqrt_time_new_term = sqrt_time_new/np.sqrt(np.pi)\n\n #################################################################\n term1_difft_R_chm_grad = Diff_grad_temp_arr*R_chamber*R_chamber\n term1_diffP_R_chm_grad = Diff_grad_press_arr*R_chamber*R_chamber\n\n A_1_grad = term1_difft_R_chm_grad*(self.c - self.c_a + self.C_Q) - 2.*term1_diffP_R_chm_grad*self.alpha_p*self.c\n A_2_grad = term1_difft_R_chm_grad*(self.c - self.c_a - self.C_Q) - 2.*term1_diffP_R_chm_grad*self.alpha_p*self.c\n A_3_grad = (A_1_grad) * (self.c - self.c_a - self.C_Q)\n A_4_grad = (A_2_grad) * (self.c - self.c_a + self.C_Q)\n\n term1a_grad = Erfc_t1a - np.exp((self.R_val - R_chamber)/R_chamber + time_new/(self.lam1*R_chamber)** 2.)*erfc(term1a + sqrt_time_new/(self.lam1*R_chamber))\n term1b_grad = Erfc_t1b - np.exp((self.R_val - R_chamber)/R_chamber + time_new/(self.lam2*R_chamber)** 2.)*erfc(term1b + sqrt_time_new/(self.lam2*R_chamber))\n term_T_grad = (-self.term1*0.5)*(A_1_grad*term1a_grad - A_2_grad*term1b_grad)\n term_P_grad = (self.term1/(4.*self.c*self.alpha_p))*(-A_3_grad*term1a_grad + A_4_grad*term1b_grad)\n\n # a_1 = self.lam1*(self.R_val - R_chamber)\n # b_1 = 1./self.lam1/R_chamber\n # term_int1_grad = ((2. - b_1*self.lam1*tmp_one_t*(self.R_val + R_chamber))/(b_1*self.lam1**2.))*sqrt_time_new_term*np.exp(-a_1/4./time_new) +\\\n # ((1. - b_1*self.lam1*tmp_one_t*self.R_val)/((b_1*self.lam1)**2.))*np.exp(b_1*(tmp_one_t*a_1 + b_1*self.tmp_one_R*time_new))*erfc((tmp_one_t*a_1+2.*b_1*self.tmp_one_R*time_new)/2./sqrt_time_new) - \\\n # ((2.*(1.- b_1*self.lam1*tmp_one_t*self.R_val + self.tmp_one_R*time_new*b_1**2.) - (b_1**2.*self.lam1**2.)*tmp_one_t*(self.R_val**2. - R_chamber**2.))/2./(b_1*self.lam1)**2. )*erfc(tmp_one_t*a_1/2./sqrt_time_new)\n # a_1 = 0.\n # term_int1_grad_0 = ((2. - b_1*self.lam1*tmp_one_t*(R_chamber + R_chamber))/(b_1*self.lam1**2.))*sqrt_time_new_term*np.exp(-a_1/4./time_new) +\\\n # ((1. - b_1*self.lam1*tmp_one_t*R_chamber)/((b_1*self.lam1)**2.))*np.exp(b_1*(tmp_one_t*a_1 + b_1*self.tmp_one_R*time_new))*erfc((tmp_one_t*a_1+2.*b_1*self.tmp_one_R*time_new)/2./sqrt_time_new) - \\\n # ((2.*(1.- b_1*self.lam1*tmp_one_t*R_chamber + self.tmp_one_R*time_new*b_1**2.) - (b_1**2.*self.lam1**2.)*tmp_one_t*(R_chamber**2. - R_chamber**2.))/2./(b_1*self.lam1)**2. )*erfc(tmp_one_t*a_1/2./sqrt_time_new)\n #\n # a_1 = self.lam2*(self.R_val - R_chamber)\n # b_1 = 1./self.lam2/R_chamber\n # term_int2_grad = ((2. - b_1*self.lam2*tmp_one_t*(self.R_val + R_chamber))/(b_1*self.lam2**2.))*sqrt_time_new_term*np.exp(-a_1/4./time_new) +\\\n # ((1. - b_1*self.lam2*tmp_one_t*self.R_val)/((b_1*self.lam2)**2.))*np.exp(b_1*(tmp_one_t*a_1 + b_1*self.tmp_one_R*time_new))*erfc((tmp_one_t*a_1+2.*b_1*self.tmp_one_R*time_new)/2./sqrt_time_new) - \\\n # ((2.*(1.- b_1*self.lam2*tmp_one_t*self.R_val + self.tmp_one_R*time_new*b_1**2.) - (b_1**2.*self.lam2**2.)*tmp_one_t*(self.R_val**2. - R_chamber**2.))/2./(b_1*self.lam2)**2. )*erfc(tmp_one_t*a_1/2./sqrt_time_new)\n # a_1 = 0.\n # term_int2_grad_0 = ((2. - b_1*self.lam2*tmp_one_t*(R_chamber + R_chamber))/(b_1*self.lam2**2.))*sqrt_time_new_term*np.exp(-a_1/4./time_new) +\\\n # ((1. - b_1*self.lam2*tmp_one_t*R_chamber)/((b_1*self.lam2)**2.))*np.exp(b_1*(tmp_one_t*a_1 + b_1*self.tmp_one_R*time_new))*erfc((tmp_one_t*a_1+2.*b_1*self.tmp_one_R*time_new)/2./sqrt_time_new) - \\\n # ((2.*(1.- b_1*self.lam2*tmp_one_t*R_chamber + self.tmp_one_R*time_new*b_1**2.) - (b_1**2.*self.lam2**2.)*tmp_one_t*(R_chamber**2. - R_chamber**2.))/2./(b_1*self.lam2)**2. )*erfc(tmp_one_t*a_1/2./sqrt_time_new)\n # term_R2T_grad = (-1./self.C_Q/2.)*(A_1_grad*term_int1_grad - A_2_grad*term_int2_grad)\n # term_R2P_grad = (1./self.C_Q)*(1./(4.*self.c*self.alpha_p))*(A_3_grad*term_int1_grad - A_4_grad*term_int2_grad)\n # term_R2T_grad_0 = (-1./self.C_Q/2.)*(A_1_grad*term_int1_grad_0 - A_2_grad*term_int2_grad_0)\n # term_R2P_grad_0 = (1./self.C_Q)*(1./(4.*self.c*self.alpha_p))*(A_3_grad*term_int1_grad_0 - A_4_grad*term_int2_grad_0)\n # term_A2_grad = -(self.eta/self.G)*term_R2P_grad_0 - (self.eta_d/self.G)*term_R2T_grad_0\n # T_sigma_rr_grad = -4.*self.eta*term_R2P_grad/(self.R_val**3.) -4.*self.eta_d*term_R2T_grad/(self.R_val**3.) -4.*self.G*term_A2_grad/(self.R_val**3.)#\n # T_sigma_theta_grad = 2.*self.eta*term_R2P_grad/(self.R_val**3) +2.*self.eta_d*term_R2T_grad/(self.R_val**3.) +2.*self.G*term_A2_grad/(self.R_val**3) - 2.*self.eta*term_P_grad - 2.*self.eta_d*term_T_grad#\n # # del term_R2T_grad,term_R2P_grad,term_R2T_grad_0,term_R2P_grad_0,term_A2_grad,term_int1_grad,term_int2_grad,term_int1_grad_0,term_int2_grad_0\n\n #################################################################\n #################################################################\n\n term1_difft_R_chm = Diff_temp_arr*R_chamber\n term1_diffP_R_chm = Diff_press_arr*R_chamber\n A_1 = term1_difft_R_chm*(self.c-self.c_a+self.C_Q) - 2.*term1_diffP_R_chm*self.alpha_p*self.c\n A_2 = term1_difft_R_chm*(self.c-self.c_a-self.C_Q) - 2.*term1_diffP_R_chm*self.alpha_p*self.c\n A_3 = (A_1)*(self.c-self.c_a-self.C_Q)\n A_4 = (A_2)*(self.c-self.c_a+self.C_Q)\n\n term_T = (self.term1/2.)*( A_1*Erfc_t1a - A_2*Erfc_t1b )\n term_P = (self.term1/(4.*self.c*self.alpha_p))*( A_3*Erfc_t1a - A_4*Erfc_t1b )\n\n term_T_der = -(self.term1/2./self.R_val)*(A_1*Erfc_t1a - A_2*Erfc_t1b) + \\\n (self.term1/2.)*(-A_1*msc_fact1*exp_term1a + A_2*msc_fact2*exp_term1b)\n # term_P_der = -(self.term1/(4.*self.c*self.alpha_p)/self.R_val)*(A_3*Erfc_t1a - A_4*Erfc_t1b) + \\\n # (self.term1/(4.*self.c*self.alpha_p))*(-A_3*msc_fact1*exp_term1a + A_4*msc_fact1*exp_term1a)\n\n term_int1 = -((self.R_val + R_chamber)/self.lam1)*sqrt_time_new_term*exp_term1a + \\\n (0.5*tmp_one_t*(self.R_val**2. - R_chamber**2.) -self.tmp_one_R*time_new/self.lam1**2)*Erfc_t1a\n term_int2 = -((self.R_val + R_chamber)/self.lam2)*sqrt_time_new_term*exp_term1b + \\\n (0.5*tmp_one_t*(self.R_val**2. - R_chamber**2.) -self.tmp_one_R*time_new/self.lam2**2)*Erfc_t1b\n term_R2T = (1./self.C_Q/2.)*(A_1*term_int1 - A_2*term_int2)\n term_R2P = (1./self.C_Q)*(1./(4.*self.c*self.alpha_p))*(A_3*term_int1 - A_4*term_int2)\n term_int_A2a = self.tmp_one_R*(2.*R_chamber/self.lam1)*sqrt_time_new_term + self.tmp_one_R*time_new/self.lam1**2.#\n term_int_A2b = self.tmp_one_R*(2.*R_chamber/self.lam2)*sqrt_time_new_term + self.tmp_one_R*time_new/self.lam2**2.#\n term_A2 = (self.eta/self.C_Q/self.G)*(1./(4.*self.c*self.alpha_p))*(A_3*term_int_A2a - A_4*term_int_A2b) + (self.eta_d/self.C_Q/self.G)*(1./2.)*(A_1*term_int_A2a - A_2*term_int_A2b) + (R_chamber**3.)*(1./4./self.G)*self.tmp_one_R*Diff_press_arr.T#\n T_sigma_rr = -4.*self.eta*term_R2P/(self.R_val**3.) -4.*self.eta_d*term_R2T/(self.R_val**3.) -4.*self.G*term_A2/(self.R_val**3.)#\n T_sigma_theta = 2.*self.eta*term_R2P/(self.R_val**3) +2.*self.eta_d*term_R2T/(self.R_val**3.) +2.*self.G*term_A2/(self.R_val**3) - 2.*self.eta*term_P - 2.*self.eta_d*term_T#\n\n T_val = np.sum(term_T,1) + np.sum(term_T_grad,1) #\n P_val = np.sum(term_P,1) + np.sum(term_P_grad,1) #\n sigma_rr = np.sum(T_sigma_rr,1)#\n sigma_theta = np.sum(T_sigma_theta,1)#\n # sigma_rr = T_val*0.0\n # sigma_theta = T_val*0.0\n #sigma_rr_eff = sigma_rr + P_val\n #sigma_theta_eff = sigma_theta + P_val\n T_der = np.sum(term_T_der,1)\n T_der[0] = T_der[1] # first value is messy and large .. so remove it ..\n #sigma_rr_grad = np.sum(T_sigma_rr_grad,1)#\n # if np.max(sigma_rr_grad) > 8000. : -- Currently in the numerical noise\n # print(np.max(sigma_rr_grad), np.max(sigma_rr))\n # pdb.set_trace()\n return T_val,P_val,sigma_rr,sigma_theta,T_der"
},
{
"alpha_fraction": 0.5909090638160706,
"alphanum_fraction": 0.6221033930778503,
"avg_line_length": 55.099998474121094,
"blob_id": "c12bfb143019a520bb1836f0bf76108f4e10c6aa",
"content_id": "1fe12999ac2ee9e50694d282204cc29c13ff0cf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1122,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 20,
"path": "/PyMagmaCh/A1_domain/New_code/msc/analytical_steady_state.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef crustal_temp_radial_degruyter(r,t,T_R,kappa,R_0,S,T_s=500.0,kappa=1e-6):\n \"\"\"Analytical solution for the heat conduction equation - heat loss from magam chamber to the surrounding\n - Modeled as chamber being spherical (radius R_0, units : m)\n and the curstal section being a larger enclosed sphere (radius S >> R0)\n - Assumptions : Chmaber is isothermal (Chamber temp T = T_R)\n Input: T_R is temperature at the edge of the chamber (Kelvin)\n T_S is temperature at the outer boundary of the visco-elastic shell (Kelvin, 500 K)\n kappa is thermal diffusivity of the crust (m^2/s, default = 1e-6 m^2/s)\n Note that S should be same once chosen ... (since it sets the inital bkg temp gradient etc ..)\n Output: .\n \"\"\"\n T_R0 = (R_0*T_R*(S - r) + S*T_S*(r- R_0))/r/(S - R_0) # initial temp T(r,t = 0)\n delta_ch = S - R_0\n tmp1 = 2.*np.pi*kappa*R_0/r/delta_ch**2.\n for n in range(50): # truncate the series after first 50 terms ..\n tmp2 = n*np.sin(n*np.pi*(r - R_0)/delta_ch)\n tmp5 = 1. - tmp3\n return theta\n"
},
{
"alpha_fraction": 0.4245205521583557,
"alphanum_fraction": 0.4842465817928314,
"avg_line_length": 49.344825744628906,
"blob_id": "4a898bb3d87b1d934dbb60960b8f23680a640523",
"content_id": "b00ecfa2dfe6d07027c52651a9b32da6dc230d9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7300,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 145,
"path": "/PyMagmaCh_Single/versions_magmaChamber/Analytical_sol_cavity_T_grad_Use_orig.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "#import warnings\n#import pdb\nimport numpy as np\nfrom numpy import sqrt,pi,exp\nfrom scipy.special import erfc\n\ndef Analytical_sol_cavity_T_grad_Use(T_R,P_R,R_chamber,t,R_val,permeability,material) :\n #warnings.simplefilter(\"error\", \"RuntimeWarning\")\n try :\n tmp1 = t.shape[1]\n except IndexError :\n t = np.expand_dims(t,1)\n try :\n tmp1 = R_val.shape[1]\n except IndexError :\n R_val = np.expand_dims(R_val,1)\n\n #% Constants in the problem are the various poro-elastic coefficients\n if (material ==1): #%Westerly granite\n G = 1.5e10 #% Pa\n K = 2.5e10 #% Pa\n K_u = 3.93e10 #% Pa\n\n visc = 1e-3#% Pa s\n M = 7.08e10 #% Pa\n S = (3.*K_u + 4*G)/(M*(3.*K + 4*G)) #% 1/Pa\n c = permeability/S/visc #% m^2\n\n alpha_e = 3.58e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n beta_c = 6.65e-6 # % /K (Table 11.2), W\n kappa_T = 1.09e-6 # % m^2/s\n m_d = 7.85e3 #%J/m^3\n eta_d = 2e5 #%N/m^2/K\n alpha_d = 6e5 #% N/m^2/K\n eta = 0.150 #% unitless\n k_T = 3. # W/m/K\n if (material ==2) :#% berea Sandstone\n G = 6e9 #% Pa\n K = 8e9 #% Pa\n K_u = 1.4e10 #% Pa\n\n visc = 1e-3 #% Pa s\n M = 9.92e9 #% Pa\n S = (3.*K_u + 4*G)/(M*(3.*K + 4*G)) #% 1/Pa\n c = permeability/S/visc #% m^2\n\n alpha_e = 2.94e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n beta_c = 4.08e-5 # % /K (Table 11.2), Westerly granite\n kappa_T = 1.27e-6 # % m^2/s\n m_d = 6.01e3 #%J/m^3\n eta_d = 1.35e4 #%N/m^2/K\n alpha_d = 3.6e4 #% N/m^2/K\n k_T = 2. # W/m/K\n eta = 0.292 #\n #% Constants in the problem are the various poro-elastic coefficients\n # G = 1.5e10 ##% Pa\n # K = 2.5e10 ##% Pa\n # K_u = 3.93e10 ##% Pa\n # #permeability = 1e-20 ##% m^2\n # visc = 1e-3 ##% Pa s\n # M = 7.08e10 # #% Pa\n # S = (3.*K_u + 4*G)/(M*(3.*K + 4.*G)) ##% 1/Pa\n # c = permeability/S/visc ##% m^2\n #\n # alpha_e = 3.5e5 ##% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n # beta_c = 6.6e-6 ## % /K (Table 11.2), Westerly granite\n # kappa_T = 1e-6 ## % m^2/s\n # m_d = 7.8e3 # #%J/m^3\n # eta_d = 2e5 # #%N/m^2/K\n # alpha_d = 6e5 ##% N/m^2/K\n # eta = 0.150 # #% unitless\n # %G = 1.24e10 #% Pa\n # %K = 2.07e10 #% Pa\n # %K_u = 3.93e10 #% Pa\n # %permeability = 1e-21 #% m^2\n # %\n # %visc = 1e-3 #% Pa s\n # %M = 1.8e11 #% Pa\n # %S = (3.*K_u + 4*G)/(M*(3.*K + 4*G)) #% 1/Pa\n # %c = permeability/S/visc #% m^2\n # %\n # %alpha_e = 1.1e6 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n # %beta_c = 1.45e-5 # % /K (Table 11.2), Westerly granite\n # %kappa_T = 3.49e-6 # % m^2/s\n # %m_d = 6.45e3 #%J/m^3\n # %eta_d = 8.27e5 #%N/m^2/K\n # %alpha_d = 2.48e6 #% N/m^2/K\n # %eta = 0.040#\n S_a = m_d + alpha_d*eta_d/G\n c_a = m_d*kappa_T/S_a\n alpha_p = beta_c/S_a # #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n C_Q = np.sqrt( (c -c_a)**2. + 4.*c*c_a*alpha_p*alpha_e ) ##\n lam1 = np.sqrt(((c +c_a) + C_Q)/2./c/c_a) ##\n lam2 = np.sqrt(((c +c_a) - C_Q)/2./c/c_a) ##\n ##############################################\n time_new = t[-1] - t + 1e-8 ## % Added the 1e-8 to make sure a min time is not zero\n tmp_one_t = np.ones([np.shape(time_new)[0],np.shape(time_new)[1]])\n R_steps = np.shape(R_val)[0] ##\n tmp_one_R = np.ones([np.shape(R_val)[0],np.shape(R_val)[1]])\n Diff_temp_arr = np.hstack([T_R[0],np.diff(T_R)])/k_T\n Diff_press_arr = np.hstack([P_R[0],np.diff(P_R)])*(visc/permeability)\n term_T = np.zeros([R_steps,np.size(T_R)])\n term_P = np.zeros([R_steps,np.size(T_R)])\n #T_sigma_rr = np.zeros([R_steps,np.size(T_R)])\n #T_sigma_theta = np.zeros([R_steps,np.size(T_R)])\n\n A_1 = Diff_temp_arr*R_chamber*R_chamber*(c-c_a+C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber\n A_2 = Diff_temp_arr*R_chamber*R_chamber*(c-c_a-C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber\n A_3 = (Diff_temp_arr*R_chamber*R_chamber*(c-c_a+C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber)*(c-c_a-C_Q)\n A_4 = (Diff_temp_arr*R_chamber*R_chamber*(c-c_a-C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber)*(c-c_a+C_Q)\n\n term1 = (1./C_Q)/R_val\n term1aa = lam1*(R_val - R_chamber)/2./np.sqrt(time_new.T)\n term1a = erfc(term1aa) - exp((R_val - R_chamber)/R_chamber + time_new.T/(lam1*R_chamber)**2.)*erfc(term1aa + np.sqrt(time_new.T)/(lam1*R_chamber))\n term1bb = lam2*(R_val - R_chamber)/2./np.sqrt(time_new.T)\n term1b = erfc(term1bb) - exp((R_val - R_chamber)/R_chamber + time_new.T/(lam2*R_chamber)**2.)*erfc(term1bb + np.sqrt(time_new.T)/(lam2*R_chamber))\n term_T = (-term1/2.)*(A_1*term1a - A_2*term1b)\n term_P = (term1/(4.*c*alpha_p))*(-A_3*term1a + A_4*term1b)\n\n #term_T_der = -(term1/2./R_val)*( A_1*erfc(term1a) - A_2*erfc(term1b) ) + (term1/2.)*(-2.*A_1*(lam1/np.sqrt(pi)/np.sqrt(time_new.T))*np.exp(-term1a**2.) + 2.*A_2*(lam2/np.sqrt(pi)/np.sqrt(time_new.T))*np.exp(-term1b**2.))\n\n # term_int1 = -((R_val + R_chamber)/lam1)*sqrt(time_new.T/pi)*exp(-term1a**2.) + (0.5*tmp_one_t.T*(R_val**2. - R_chamber**2.) -tmp_one_R*time_new.T/lam1**2)*erfc(term1a)\n # term_int2 = -((R_val + R_chamber)/lam2)*sqrt(time_new.T/pi)*exp(-term1b**2.) + (0.5*tmp_one_t.T*(R_val**2. - R_chamber**2.) -tmp_one_R*time_new.T/lam2**2)*erfc(term1b)\n # term_R2T = (1./C_Q/2.)*(A_1*term_int1 - A_2*term_int2)\n # term_R2P = (1./C_Q)*(1./(4.*c*alpha_p))*(A_3*term_int1 - A_4*term_int2)\n # term_int_A2a = tmp_one_R*(2.*R_chamber/lam1)*sqrt(time_new.T/pi) + tmp_one_R*time_new.T/lam1**2.#\n # term_int_A2b = tmp_one_R*(2.*R_chamber/lam2)*sqrt(time_new.T/pi) + tmp_one_R*time_new.T/lam2**2.#\n # term_A2 = (eta/C_Q/G)*(1./(4.*c*alpha_p))*(A_3*term_int_A2a - A_4*term_int_A2b) + (eta_d/C_Q/G)*(1./2.)*(A_1*term_int_A2a - A_2*term_int_A2b) + (R_chamber**3.)*(1./4./G)*tmp_one_R*Diff_press_arr.T#\n # T_sigma_rr = -4.*eta*term_R2P/(R_val**3.) -4.*eta_d*term_R2T/(R_val**3.) -4.*G*term_A2/(R_val**3.)#\n # T_sigma_theta = 2.*eta*term_R2P/(R_val**3) +2.*eta_d*term_R2T/(R_val**3.) +2.*G*term_A2/(R_val**3) - 2.*eta*term_P - 2.*eta_d*term_T#\n\n # %Diff_press_arr\n # %size(term_A2),term_A2b\n # %t(end),term_P(isnan(term_P))\n T_val = np.sum(term_T,1)#\n P_val = np.sum(term_P,1)#\n # sigma_rr = np.sum(T_sigma_rr,1)#\n # sigma_theta = np.sum(T_sigma_theta,1)#\n #sigma_rr_eff = sigma_rr + P_val\n #sigma_theta_eff = sigma_theta + P_val\n #T_der = np.sum(term_T_der,1)\n #T_der[0] = T_der[1] # first value is messy and large .. so remove it ..\n P_val[P_val<1e-6] = 0\n P_val[P_val<1e-6] = 0\n return T_val,P_val#,sigma_rr,sigma_theta,T_der\n"
},
{
"alpha_fraction": 0.6911643147468567,
"alphanum_fraction": 0.6977704167366028,
"avg_line_length": 31.7297306060791,
"blob_id": "4648b9cc51494ab2900d241cb3ee78d77a5b89af",
"content_id": "dfebbc18f31752583a82884a4864600cde34bb39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1211,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 37,
"path": "/PyMagmaCh/msc.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "\"\"\"\nRoutines for calculating heat capacities for grid boxes\nin units of J / m**2 / K\n\"\"\"\nfrom climlab import constants as const\n\n\ndef atmosphere(dp):\n '''Heat capacity of a unit area of atmosphere, in units of J / m**2 / K\n Input is pressure intervals in units of mb.'''\n return const.cp * dp * const.mb_to_Pa / const.g\n\n\ndef ocean(dz):\n '''Heat capacity of a unit area of water, in units of J / m**2 / K\n Input dz is water depth intervals in meters'''\n return const.rho_w * const.cw * dz\n\n\ndef slab_ocean(water_depth):\n '''Heat capacity of a unit area slab of water, in units of J / m**2 / K\n Input is depth of water in meters.'''\n return ocean(water_depth)\n\n\n# @jit # numba.jit not working here. Not clear why.\n# At least we get something like 10x speedup from the inner loop\n# Attempt to use numba to compile the Akamaev_adjustment function\n# which gives at least 10x speedup\n# If numba is not available or compilation fails, the code will be executed\n# in pure Python. Results should be identical\ntry:\n from numba import jit\n Akamaev_adjustment = jit(signature_or_function=Akamaev_adjustment)\n #print 'Compiling Akamaev_adjustment() with numba.'\nexcept:\n pass\n"
},
{
"alpha_fraction": 0.5542929172515869,
"alphanum_fraction": 0.5780302882194519,
"avg_line_length": 43.7401123046875,
"blob_id": "2758e19ab8ba4d537711e7a1f46d62b4216c0753",
"content_id": "f4fa60c26d9680439c832c44716367ea3e4ba42b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7920,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 177,
"path": "/PyMagmaCh_Single/test_msc.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "### This is the testing piece for the initial temperature shock piece ..\n\nfrom assimulo.solvers import CVode,LSODAR\nimport sys\nimport numpy as np\nimport pylab as plt\nfrom plot_mainChamber import plot_mainChamber\nfrom mainChamber_working_Final import Chamber_Problem\nimport input_functions as inp\n\nT_S = float(sys.argv[1]) #'1p17_diff_'\nperm_val = float(sys.argv[2])\n#print(sys.argv)\n\n#% set the mass inflow rate\nmdot = 10. #; % mass inflow rate (kg/s) #% use global variable\ndepth = 8000.\nwith_plots=True\n\n##############################################\n#% time\nend_time = 3e7*1e5#; % maximum simulation time in seconds\nbegin_time = 0 #; % initialize time\n##############################################\nT_0 = 1200 # ; % initial chamber temperature (K)\n\ndef func_set_system():\n ##############################################\n #% initial conditions\n P_0 = depth*9.8*2600. #; % initial chamber pressure (Pa)\n #T_0 = 1200 #; % initial chamber temperature (K)\n eps_g0 = 0.04 #; % initial gas volume fraction\n rho_m0 = 2600 #; % initial melt density (kg/m^3)\n rho_x0 = 3065 #; % initial crystal density (kg/m^3)\n a = 3000 #; % initial radius of the chamber (m)\n V_0 = (4.*np.pi/3.)*a**3. #; % initial volume of the chamber (m^3)\n\n ##############################################\n ##############################################\n IC = np.array([P_0, T_0, eps_g0, V_0, rho_m0, rho_x0]) # % store initial conditions\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n sw0 = [False,False,False,False,False]\n\n ##############################################\n #% error tolerances used in ode method\n dt = 30e7\n N = int(round((end_time-begin_time)/dt))\n ##############################################\n\n #Define an Assimulo problem\n exp_mod = Chamber_Problem(depth=depth,t0=begin_time,y0=IC,sw0=sw0)\n exp_mod.param['T_in'] = 1200.\n exp_mod.param['eps_g_in'] = 0.0 # Gas fraction of incoming melt - gas phase ..\n exp_mod.param['m_eq_in'] = 0.03 # Volatile fraction of incoming melt\n exp_mod.param['Mdot_in'] = mdot\n exp_mod.param['eta_x_max'] = 0.64 # Locking fraction\n exp_mod.param['delta_Pc'] = 20e6\n exp_mod.tcurrent = begin_time\n exp_mod.radius = a\n exp_mod.permeability = perm_val\n exp_mod.R_steps = 5500\n exp_mod.dt_init = dt\n inp_func1 = inp.Input_functions_Degruyer()\n exp_mod.set_input_functions(inp_func1)\n exp_mod.get_constants()\n exp_mod.param['T_S'] = T_S\n #################\n exp_mod.R_outside = np.linspace(a,2.*a,exp_mod.R_steps)\n exp_mod.set_params_crust_calcs('Westerly_Granite')\n exp_mod.crust_analy_params.set_misc_grids(exp_mod.R_outside)\n exp_mod.T_out_all =np.array([exp_mod.R_outside*0.])\n exp_mod.P_out_all =np.array([exp_mod.R_outside*0.])\n exp_mod.sigma_rr_all = np.array([exp_mod.R_outside*0.])\n exp_mod.sigma_theta_all = np.array([exp_mod.R_outside*0.])\n exp_mod.sigma_eff_rr_all = np.array([exp_mod.R_outside*0.])\n exp_mod.sigma_eff_theta_all = np.array([exp_mod.R_outside*0.])\n exp_mod.max_count = 1 # counting for the append me arrays ..\n\n P_0 = exp_mod.plith\n exp_mod.P_list.update(0.)\n exp_mod.T_list.update(T_0-exp_mod.param['T_S'])\n exp_mod.P_flux_list.update(0)\n exp_mod.T_flux_list.update(0)\n exp_mod.times_list.update(1e-7)\n exp_mod.T_out,exp_mod.P_out,exp_mod.sigma_rr,exp_mod.sigma_theta,exp_mod.T_der= \\\n exp_mod.crust_analy_params.Analytical_sol_cavity_T_Use(exp_mod.T_list.data[:exp_mod.max_count],exp_mod.P_list.data[:exp_mod.max_count],\n exp_mod.radius,exp_mod.times_list.data[:exp_mod.max_count])\n IC = np.array([P_0, T_0, eps_g0, V_0, rho_m0, rho_x0]) # % store initial conditions\n exp_mod.y0 = IC\n exp_mod.perm_evl_init=np.array([])\n exp_mod.perm_evl_init_time = np.array([])\n return exp_mod,N\n\n\nexp_mod,N = func_set_system()\n\ndef func_evolve_init_cond(exp_mod):\n '''\n Calculate the initial evolution of the system - regularize the pore pressure condition\n :param exp_mod:\n :return:\n '''\n ### First evolve the solution to a 1 yr (a few points is ok since everything is analytical ..)\n perm_init = exp_mod.permeability\n times_evolve_p1 = np.linspace(1e3,np.pi*1e7,10)\n for i in times_evolve_p1:\n exp_mod.P_list.update(0.)\n exp_mod.T_list.update(T_0 - exp_mod.param['T_S'])\n exp_mod.times_list.update(i)\n exp_mod.T_out, exp_mod.P_out, exp_mod.sigma_rr, exp_mod.sigma_theta, exp_mod.T_der = \\\n exp_mod.crust_analy_params.Analytical_sol_cavity_T_Use(exp_mod.T_list.data[:exp_mod.max_count],\n exp_mod.P_list.data[:exp_mod.max_count],\n exp_mod.radius, exp_mod.times_list.data[:exp_mod.max_count])\n #print(i,np.max(exp_mod.P_out) / exp_mod.param['delta_Pc'])\n exp_mod.max_count += 1\n print(i,np.max(exp_mod.P_out) / exp_mod.param['delta_Pc'])\n if np.max(exp_mod.P_out) > 0.8*exp_mod.param['delta_Pc'] :\n excess_press = True\n else :\n return exp_mod\n\n times_evolve_p1 = np.linspace(1.5 * np.pi * 1e7, np.pi * 1e7 * 1e2, 100)\n i_count = 0\n exp_mod.perm_evl_init = np.append(exp_mod.perm_evl_init,perm_init)\n P_cond = exp_mod.P_list.data[exp_mod.max_count-1] ## Keep this constant with time for the subsequent evolution ..\n T_cond = exp_mod.T_list.data[exp_mod.max_count-1] ## Keep this constant with time for the subsequent evolution ..\n plt.figure()\n while excess_press :\n exp_mod.P_list.update(P_cond)\n exp_mod.T_list.update(T_cond)\n exp_mod.times_list.update(times_evolve_p1[i_count])\n exp_mod.T_out, exp_mod.P_out, exp_mod.sigma_rr, exp_mod.sigma_theta, exp_mod.T_der = \\\n exp_mod.crust_analy_params.Analytical_sol_cavity_T_Use(exp_mod.T_list.data[:exp_mod.max_count],\n exp_mod.P_list.data[:exp_mod.max_count],\n exp_mod.radius, exp_mod.times_list.data[:exp_mod.max_count])\n exp_mod.max_count += 1\n i_count += 1\n plt.plot(exp_mod.R_outside,exp_mod.T_out)\n plt.pause(.2)\n if np.max(exp_mod.P_out) < 0.8*exp_mod.param['delta_Pc'] :\n excess_press = False\n exp_mod.permeability = exp_mod.permeability*1.25\n exp_mod.set_params_crust_calcs('Westerly_Granite')\n exp_mod.crust_analy_params.set_misc_grids(exp_mod.R_outside)\n exp_mod.perm_evl_init = np.append(exp_mod.perm_evl_init,exp_mod.permeability)\n exp_mod.perm_evl_init_time = times_evolve_p1[0:i_count-1]\n exp_mod.permeability = perm_init\n return exp_mod\n\nfunc_evolve_init_cond(exp_mod)\nexp_mod.times_list.finalize()\nplt.ion()\nplt.show()\nplt.figure(10)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,(exp_mod.P_out_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n\n\n#plt.savefig(pref_val+'P_fl.pdf')\n#\nplt.figure(11)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n# plt.savefig(pref_val+'sigma_rr.pdf')\n#\nplt.figure(12)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,exp_mod.T_out_all,20,cmap='coolwarm')\nplt.colorbar()\n\nplt.figure(13)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_eff_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n# plt.savefig(pref_val+'sigma_rr_eff.pdf')\n\n"
},
{
"alpha_fraction": 0.5870006680488586,
"alphanum_fraction": 0.6303317546844482,
"avg_line_length": 29.14285659790039,
"blob_id": "40c8b9b6c6c792169c02faefa30057ab9d393ea0",
"content_id": "794f47810ebf3363d34a39953e9f07d8a1feff35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1477,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 49,
"path": "/PyMagmaCh_Single/plot_mainChamber.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import pylab as plt\n\ndef plot_mainChamber(time,V,P,T,eps_x,eps_g,rho,crustal_density,pref='./') :\n plt.figure(1),\n plt.plot(time/(3600.*24.*365.),V/V[0])\n plt.xlabel('time (yr)')\n plt.ylabel('volume/V_0')\n plt.title('Magma Reservoir Volume Evolution')\n\n plt.figure(2) #%,clf\n plt.plot(time/(3600.*24.*365.),P/1e6)\n plt.xlabel('time (yr)')\n plt.ylabel('pressure (MPa)')\n plt.title('Magma Reservoir Pressure Evolution')\n plt.savefig(pref+'P_val.pdf')\n #set(gca)\n\n plt.figure(3)\n plt.plot(time/(3600.*24.*365.),T)\n plt.xlabel('time (yr)')\n plt.ylabel('temperature (K)')\n plt.title('Magma Reservoir Temperature Evolution')\n plt.savefig(pref+'T_val.pdf')\n #set(gca)\n\n plt.figure(4)\n plt.plot(time/(3600.*24.*365.),eps_g)\n plt.xlabel('time (yr)')\n plt.ylabel('gas volume fraction fraction')\n plt.title('Magma Reservoir Gas Volume Fraction Evolution')\n plt.savefig(pref+'T_val.pdf')\n #set(gca)\n\n plt.figure(5)\n plt.plot(time/(3600.*24.*365.),eps_x)\n plt.xlabel('time (yr)')\n plt.ylabel('crystal volume fraction')\n plt.title('Magma Reservoir Crystal fraction Evolution')\n plt.savefig(pref+'T_val.pdf')\n #set(gca)\n\n plt.figure(6)\n plt.plot(time/(3600.*24.*365.),rho/crustal_density)\n plt.xlabel('time (yr)')\n plt.ylabel('mean density/crustal_density')\n plt.title('Magma Reservoir density anomaly Evolution')\n plt.savefig(pref+'T_val.pdf')\n #set(gca)\n #plt.show()\n"
},
{
"alpha_fraction": 0.5644627809524536,
"alphanum_fraction": 0.6082644462585449,
"avg_line_length": 47.400001525878906,
"blob_id": "46e5f86c7b2bc2e9dfdfd15b00b1c93a794536f4",
"content_id": "d5544f3ec8062224379fdc896af4ffca186fbbb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1210,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 25,
"path": "/PyMagmaCh/utils/dike_diagnostics.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom PyMagmaCh.utils import constants as const\n\ndef dike_diagnostics(rho_r =2800.,rho_f = 2500.,T_0 = 5e6) :\n '''Calculates Dike diagnostics given some inputs - Philipp, Afsar, & Gudmunsson Front Earth Sci 2013\n T_0 - tensile strength of the rock (in Pascal - so default is 5 MPa)\n\n '''\n #%%%%%%%%%%%%%%%%%%%%%%% Initialization%%%%%%%%%%%%%%%%%%%%%%%%%\n # Inputs needed (all units - meters, seconds, m/s, Pascal, Kelvin unless otherwise noted)-\n b = 1 # Dike aperture (across dimension width)\n W = 450. # Dike length (direction perpendicular to the fluid flow direction)\n mu_visc_fl = 1e-3 # Fluid viscosity\n alpha = np.pi/2. # dike dip in radians\n nu = 0.25 # poisson ratio\n E = 10*1e9 # Young modulus of crustal rock (~ 5 -100 GPa)\n pe = 5.*1e6 # fluid excess pressure (~ 5-20 MPa)\n p_over = (b/2./W)*E/(1. - nu**2.)\n h_dike = (p_over - pe)/((rho_r - rho_f)*const.g_earth)\n dpe_dD = -pe/h_dike\n Q_e = ((b**3.)*W/12./mu_visc_fl)*((rho_r - rho_f)*const.g_earth*np.sin(alpha) - dpe_dD)\n dike_prop ={'Q':Q_e,'p_over' : p_over/1e6,'pe':pe/1e6,'h_dike':h_dike/1e3} # pressure output in Mpa, dike_height in km\n return dike_prop\n\ndike_diagnostics()\n"
},
{
"alpha_fraction": 0.586427628993988,
"alphanum_fraction": 0.5896286964416504,
"avg_line_length": 37.567901611328125,
"blob_id": "9e910708dbaab23b447fefa314044806f792eab9",
"content_id": "0c72fdac4e25292d1ed45ef948e55b8f2a81fa5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3124,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 81,
"path": "/PyMagmaCh/A1_domain/field.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass Field(np.ndarray):\n '''Custom class for PyMagmaCh gridded quantities, called Field\n This class behaves exactly like numpy.ndarray\n but every object has an attribute called domain\n which is the domain associated with that field (e.g. state variables)\n as well as an axes in the domain that the field refers to.\n Inputs - can either give axis variable (for single axis) or a dict with the axis_type\n '''\n\n def __new__(cls, input_array, domain=None,axis=None):\n # Input array is an already formed ndarray instance\n # We first cast to be our class type\n # This should ensure that shape is (1,) for scalar input\n obj = np.atleast_1d(input_array).view(cls)\n # add the new attribute to the created instance\n if type(domain) is str :\n obj.domain = domain\n elif (domain != None) :\n obj.domain = domain.name\n else :\n obj.domain ='None'\n if (axis == None) :\n obj.axis = 'None'\n elif type(axis) is dict:\n obj.axis = axis\n elif type(axis) is str :\n obj.axis = axis\n else :\n obj.axis = axis.axis_type\n # Finally, we must return the newly created object:\n obj.name = 'None'\n return obj\n\n def append_val(self,val):\n # append either a value or a set of values to a given state\n self = np.append(self,val)\n return self\n\n\n def __array_finalize__(self, obj):\n # ``self`` is a new object resulting from\n # ndarray.__new__(Field, ...), therefore it only has\n # attributes that the ndarray.__new__ constructor gave it -\n # i.e. those of a standard ndarray.\n #\n # We could have got to the ndarray.__new__ call in 3 ways:\n # From an explicit constructor - e.g. Field():\n # obj is None\n # (we're in the middle of the Field.__new__\n # constructor, and self.domain will be set when we return to\n # Field.__new__)\n if obj is None: return\n # From view casting - e.g arr.view(Field):\n # obj is arr\n # (type(obj) can be Field)\n # From new-from-template - e.g statearr[:3]\n # type(obj) is Field\n #\n # Note that it is here, rather than in the __new__ method,\n # that we set the default value for 'domain', because this\n # method sees all creation of default objects - with the\n # Field.__new__ constructor, but also with\n # arr.view(Field).\n self.domain = getattr(obj, 'domain', None)\n # We do not need to return anything\n\ndef global_mean(field):\n '''Calculate global mean of a field with depth dependence.'''\n try:\n dpth = field.domain.axes['depth'].points\n except:\n raise ValueError('No depth axis in input field.')\n arry = field.squeeze()\n delta_dpth = np.diff(dpth, n=1, axis=-1)\n delta_arry = (arry[1:] + arry[:-1])/2.\n # Assume that the surface is at z =0, +ve as one goes down.\n avg_val = np.sum(delta_arry*delta_dpth)/np.sum(delta_dpth)\n return avg_val\n"
},
{
"alpha_fraction": 0.5632171630859375,
"alphanum_fraction": 0.5759553909301758,
"avg_line_length": 43.59624481201172,
"blob_id": "770f97232ebe36da7a4166d3c0af735a557df7bd",
"content_id": "8eef3db924b52a8db9b636cc117ac4c90405d04f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9499,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 213,
"path": "/PyMagmaCh/model/ebm.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "\"\"\"Base Model -\n This is the file that defines the model parameters mostly\n defined in flood_basalts_v8.m file.\n\n Object-oriented code for a coupled magma chamber model\n\n Requirements for the model :\n a. Allow an arbitrary number of chambers\n b. Allow specifying most of the parameters (can give default)\n c. Allow specifying which processes to turn on and off\n (modularity is important)\n\nCode developed by Ben Black and Tushar Mittal\n\"\"\"\n\nimport numpy as np\nfrom machlab import constants as const\nfrom climlab.surface import albedo\n\nfrom climlab.domain.field import Field, global_mean\nfrom climlab.domain import domain\nfrom climlab.radiation.AplusBT import AplusBT\nfrom climlab.radiation.insolation import P2Insolation, AnnualMeanInsolation, DailyInsolation\nfrom climlab.dynamics.diffusion import MeridionalDiffusion\nfrom climlab.process.energy_budget import EnergyBudget\n\nfrom scipy import integrate\n\nclass EBM(EnergyBudget):\n def __init__(self,\n num_lat=90,\n S0=const.S0,\n A=210.,\n B=2.,\n D=0.555, # in W / m^2 / degC, same as B\n water_depth=10.0,\n Tf=-10.,\n a0=0.3,\n a2=0.078,\n ai=0.62,\n timestep=const.seconds_per_year/90.,\n T_init_0 = 12.,\n T_init_P2 = -40.,\n **kwargs):\n super(EBM, self).__init__(timestep=timestep, **kwargs)\n if not self.domains and not self.state: # no state vars or domains yet\n sfc = domain.zonal_mean_surface(num_lat=num_lat,\n water_depth=water_depth)\n lat = sfc.axes['lat'].points\n initial = T_init_0 + T_init_P2 * legendre.P2(np.sin(np.deg2rad(lat)))\n self.set_state('Ts', Field(initial, domain=sfc))\n self.param['S0'] = S0\n self.param['A'] = A\n self.param['B'] = B\n self.param['D'] = D\n self.param['Tf'] = Tf\n self.param['water_depth'] = water_depth\n self.param['a0'] = a0\n self.param['a2'] = a2\n self.param['ai'] = ai\n # create sub-models\n self.add_subprocess('LW', AplusBT(state=self.state, **self.param))\n self.add_subprocess('insolation',\n P2Insolation(domains=sfc, **self.param))\n self.add_subprocess('albedo',\n albedo.StepFunctionAlbedo(state=self.state,\n **self.param))\n # diffusivity in units of 1/s\n K = self.param['D'] / self.domains['Ts'].heat_capacity\n self.add_subprocess('diffusion', MeridionalDiffusion(state=self.state,\n K=K,\n **self.param))\n self.topdown = False # call subprocess compute methods first\n\n def _compute_heating_rates(self):\n '''Compute energy flux convergences to get heating rates in W / m**2.\n This method should be over-ridden by daughter classes.'''\n insolation = self.subprocess['insolation'].diagnostics['insolation']\n albedo = self.subprocess['albedo'].diagnostics['albedo']\n ASR = (1-albedo) * insolation\n self.heating_rate['Ts'] = ASR\n self.diagnostics['ASR'] = ASR\n self.diagnostics['net_radiation'] = (ASR -\n self.subprocess['LW'].diagnostics['OLR'])\n\n def global_mean_temperature(self):\n '''Convenience method to compute global mean surface temperature.'''\n return global_mean(self.state['Ts'])\n\n def inferred_heat_transport(self):\n '''Returns the inferred heat transport (in PW)\n by integrating the TOA energy imbalance from pole to pole.'''\n phi = np.deg2rad(self.lat)\n energy_in = np.squeeze(self.diagnostics['net_radiation'])\n return (1E-15 * 2 * np.math.pi * const.a**2 *\n integrate.cumtrapz(np.cos(phi)*energy_in, x=phi, initial=0.))\n\n def heat_transport(self):\n '''Returns instantaneous heat transport in units on PW,\n on the staggered grid.'''\n return self.diffusive_heat_transport()\n\n def diffusive_heat_transport(self):\n '''Compute instantaneous diffusive heat transport in units of PW\n on the staggered grid.'''\n phi = np.deg2rad(self.lat)\n phi_stag = np.deg2rad(self.lat_bounds)\n D = self.param['D']\n T = np.squeeze(self.Ts)\n dTdphi = np.diff(T) / np.diff(phi)\n dTdphi = np.append(dTdphi, 0.)\n dTdphi = np.insert(dTdphi, 0, 0.)\n return (1E-15*-2*np.math.pi*np.cos(phi_stag)*const.a**2*D*dTdphi)\n\n def heat_transport_convergence(self):\n '''Returns instantaneous convergence of heat transport\n in units of W / m^2.'''\n phi = np.deg2rad(self.lat)\n phi_stag = np.deg2rad(self.lat_bounds)\n H = 1.E15*self.heat_transport()\n return (-1./(2*np.math.pi*const.a**2*np.cos(phi)) *\n np.diff(H)/np.diff(phi_stag))\n\n\nclass EBM_seasonal(EBM):\n def __init__(self, a0=0.33, a2=0.25, ai=None, **kwargs):\n '''This EBM uses realistic daily insolation.\n If ai is not given, the model will not have an albedo feedback.'''\n super(EBM_seasonal, self).__init__(a0=a0, a2=a2, ai=ai, **kwargs)\n sfc = self.domains['Ts']\n self.add_subprocess('insolation',\n DailyInsolation(domains=sfc, **self.param))\n self.param['a0'] = a0\n self.param['a2'] = a2\n if ai is None:\n # No albedo feedback\n # Remove unused parameters here for clarity\n _ = self.param.pop('ai')\n _ = self.param.pop('Tf')\n self.add_subprocess('albedo',\n albedo.P2Albedo(domains=sfc, **self.param))\n else:\n self.param['ai'] = ai\n self.add_subprocess('albedo',\n albedo.StepFunctionAlbedo(state=self.state, **self.param))\n\n\n\n#==============================================================================\n# class EBM_landocean( EBM_seasonal ):\n# '''A model with both land and ocean, based on North and Coakley (1979)\n# Essentially just invokes two different EBM_seasonal objects, one for ocean, one for land.\n# '''\n# def __str__(self):\n# return ( \"Instance of EBM_landocean class with \" + str(self.num_points) + \" latitude points.\" )\n#\n# def __init__( self, num_points = 90 ):\n# super(EBM_landocean,self).__init__( num_points )\n# self.land_ocean_exchange_parameter = 1.0 # in W/m2/K\n#\n# self.land = EBM_seasonal( num_points )\n# self.land.make_insolation_array( self.orb )\n# self.land.Tf = 0.\n# self.land.set_timestep( timestep = self.timestep )\n# self.land.set_water_depth( water_depth = 2. )\n#\n# self.ocean = EBM_seasonal( num_points )\n# self.ocean.make_insolation_array( self.orb )\n# self.ocean.Tf = -2.\n# self.ocean.set_timestep( timestep = self.timestep )\n# self.ocean.set_water_depth( water_depth = 75. )\n#\n# self.land_fraction = 0.3 * np.ones_like( self.land.phi )\n# self.C_ratio = self.land.water_depth / self.ocean.water_depth\n# self.T = self.zonal_mean_temperature()\n#\n# def zonal_mean_temperature( self ):\n# return self.land.T * self.land_fraction + self.ocean.T * (1-self.land_fraction)\n#\n# def step_forward( self ):\n# # note.. this simple implementation is possibly problematic\n# # because the exchange should really occur simultaneously with radiation\n# # and before the implicit heat diffusion\n# self.exchange = (self.ocean.T - self.land.T) * self.land_ocean_exchange_parameter\n# self.land.step_forward()\n# self.ocean.step_forward()\n# self.land.T += self.exchange / self.land_fraction * self.land.delta_time_over_C\n# self.ocean.T -= self.exchange / (1-self.land_fraction) * self.ocean.delta_time_over_C\n# self.T = self.zonal_mean_temperature()\n# self.update_time()\n#\n# # This code should be more accurate, but it's ungainly and seems to produce just about the same result.\n# #def step_forward( self ):\n# # self.exchange = (self.ocean.T - self.land.T) * self.land_ocean_exchange_parameter\n# # self.land.compute_radiation( )\n# # self.ocean.compute_radiation( )\n# # Trad_land = ( self.land.T + ( self.land.net_radiation + self.exchange / self.land_fraction )\n# # * self.land.delta_time_over_C )\n# # Trad_ocean = ( self.ocean.T + ( self.ocean.net_radiation - self.exchange / (1-self.land_fraction) )\n# # * self.ocean.delta_time_over_C )\n# # self.land.T = solve_banded((1,1), self.land.diffTriDiag, Trad_land )\n# # self.ocean.T = solve_banded((1,1), self.ocean.diffTriDiag, Trad_ocean )\n# # self.T = self.zonal_mean_temperature()\n# # self.land.update_time()\n# # self.ocean.update_time()\n# # self.update_time()\n#\n# def integrate_years(self, years=1.0, verbose=True ):\n# # Here we make sure that both sub-models have the current insolation.\n# self.land.make_insolation_array( self.orb )\n# self.ocean.make_insolation_array( self.orb )\n# super(EBM_landocean,self).integrate_years( years, verbose )\n#==============================================================================\n"
},
{
"alpha_fraction": 0.5434755086898804,
"alphanum_fraction": 0.5727947950363159,
"avg_line_length": 38.14778137207031,
"blob_id": "c282a5aa800fcc30260a26368ff2480716d90f5b",
"content_id": "e95dc81f59914b514aec80e65cdcf6fd9373725e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7947,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 203,
"path": "/PyMagmaCh_Single/test_disc_pon.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "from assimulo.solvers import CVode,LSODAR\nimport sys\nimport numpy as np\nimport pylab as plt\nfrom plot_mainChamber import plot_mainChamber\nfrom mainChamber_working_Final import Chamber_Problem\nimport input_functions as inp\n\npref_val = sys.argv[1] #'1p17_diff_'\nperm_val = float(sys.argv[2])\n#print(sys.argv)\n\n#% set the mass inflow rate\nmdot = 1. #; % mass inflow rate (kg/s) #% use global variable\ndepth = 8000.\nwith_plots = True\n\n##############################################\n#% time\nend_time = 3e7*5e5#; % maximum simulation time in seconds\n##############################################\n\ndef func_set_system():\n ##############################################\n #% initial conditions\n P_0 = depth*9.8*2600. #; % initial chamber pressure (Pa)\n T_0 = 1200 #; % initial chamber temperature (K)\n eps_g0 = 0.04 #; % initial gas volume fraction\n rho_m0 = 2600 #; % initial melt density (kg/m^3)\n rho_x0 = 3065 #; % initial crystal density (kg/m^3)\n a = 2000. #; % initial radius of the chamber (m)\n V_0 = (4.*np.pi/3.)*a**3. #; % initial volume of the chamber (m^3)\n\n ##############################################\n ##############################################\n IC = np.array([P_0, T_0, eps_g0, V_0, rho_m0, rho_x0]) # % store initial conditions\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n sw0 = [False,False,False,False,False]\n\n ##############################################\n #% error tolerances used in ode method\n dt = 3e7*10.\n begin_time = 0 # ; % initialize time\n N = int(round((end_time-begin_time)/dt))\n ##############################################\n\n #Define an Assimulo problem\n exp_mod = Chamber_Problem(depth=depth,t0=begin_time,y0=IC,sw0=sw0)\n exp_mod.param['T_S'] = 500.#+273.\n exp_mod.param['T_in'] = 1200.\n exp_mod.param['eps_g_in'] = 0.0 # Gas fraction of incoming melt - gas phase ..\n exp_mod.param['m_eq_in'] = 0.03 # Volatile fraction of incoming melt\n exp_mod.param['Mdot_in'] = mdot\n exp_mod.param['eta_x_max'] = 0.55 # Locking fraction\n exp_mod.param['delta_Pc'] = 20e6\n exp_mod.allow_diffusion_init = True\n exp_mod.radius = a\n exp_mod.permeability = perm_val\n exp_mod.R_steps = 1500\n exp_mod.dt_init = dt\n inp_func1 = inp.Input_functions_Degruyer()\n exp_mod.set_input_functions(inp_func1)\n exp_mod.get_constants()\n exp_mod.set_init_crust(material = 'Westerly_Granite')\n #################\n begin_time = exp_mod.set_init_crust_profile(T_0)\n exp_mod.tcurrent = begin_time\n P_0 = exp_mod.plith\n exp_mod.t0 = begin_time\n exp_mod.param['heat_cond'] = 1. # Turn on/off heat conduction\n exp_mod.param['visc_relax'] = 1. # Turn on/off viscous relaxation\n exp_mod.param['press_relax'] = 1. ## Turn on/off pressure diffusion\n exp_mod.param['frac_rad_Temp'] =0.75\n exp_mod.param['vol_degass'] = 1.\n exp_mod.param['outflow_model'] = None # 'huppert'\n IC = np.array([P_0, T_0, eps_g0, V_0, rho_m0, rho_x0]) # % store initial conditions\n exp_mod.y0 = IC\n\n #Define an explicit solver\n exp_sim = CVode(exp_mod) #Create a CVode solver\n # exp_sim = LSODAR(exp_mod) #Create a CVode solver\n\n #Sets the parameters\n exp_sim.store_event_points = True\n #exp_sim.iter = 'Newton'\n #exp_sim.discr = 'BDF'\n exp_sim.inith = 1e2\n #exp_sim.display_progress = True\n exp_sim.rtol = 1.e-7\n #exp_sim.maxh = 3e8*5. # 10 years\n exp_sim.atol = 1e-7\n #exp_sim.sensmethod = 'SIMULTANEOUS' #Defines the sensitvity method used\n #exp_sim.suppress_sens = True #Dont suppress the sensitivity variables in the error test.\n #exp_sim.usesens = True\n #exp_sim.report_continuously = True\n return exp_mod,exp_sim,N\n\n#########################################################\n#########################################################\n\nexp_mod,exp_sim,N = func_set_system()\n#Simulate\nt_final_new = 0.\ntry :\n t1, y1 = exp_sim.simulate(end_time,N) #Simulate 5 seconds\n exp_sim.print_event_data()\nexcept SystemExit:\n print('Stop Before end_time')\n t1 = exp_sim.t_sol\n y1 = exp_sim.y_sol\n exp_sim.print_event_data()\n t_final_new = exp_sim.t*0.999\n #exp_mod,exp_sim,N = func_set_system()\n #t1, y1 = exp_sim.simulate(t_final_new,N)\n\nexp_sim.print_statistics()\nprint('Final Stopping time : %.2f Yrs' % (t_final_new/(3600.*24.*365.)))\ndel exp_sim\nprint('Number of eruptions : {:f}'.format(exp_mod.eruption_count))\nprint(exp_mod.eruption_events)\n\nif with_plots:\n t1 = np.asarray(t1)\n y1 = np.asarray(y1)\n #IC = np.array([P_0,T_0,eps_g0,V_0,rho_m0,rho_x0]) # % store initial conditions\n P = y1[:,0]\n T = y1[:,1]\n eps_g = y1[:,2]\n V = y1[:,3]\n rho_m = y1[:,4]\n rho_x = y1[:,5]\n size_matrix = np.shape(P)[0]\n\n #%crystal volume fraction\n eps_x = np.zeros(size_matrix)\n #% dissolved water mass fraction\n m_eq = np.zeros(size_matrix)\n #% gas density\n rho_g = np.zeros(size_matrix)\n for i in range(0,size_matrix) :\n eps_x[i],tmp1,tmp2 = exp_mod.input_functions.melting_curve(T[i],P[i],eps_g[i])\n m_eq[i],tmp1,tmp2 = exp_mod.input_functions.solubulity_curve(T[i],P[i])\n rho_g[i],tmp1,tmp2 = exp_mod.input_functions.gas_density(T[i],P[i])\n #% bulk density\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x\n #% bulk heat capacity\n c = ((1-eps_g-eps_x)*rho_m*exp_mod.param['c_m'] + eps_g*rho_g*exp_mod.param['c_g'] + eps_x*rho_x*exp_mod.param['c_x'])/rho;\n plot_mainChamber(t1,V,P,T,eps_x,eps_g,rho,exp_mod.param['crustal_density'],pref=pref_val)\n\n\nexp_mod.times_list.finalize()\n#\nplt.ion()\nplt.show()\nplt.figure(10)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,(exp_mod.P_out_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n\n#plt.savefig(pref_val+'P_fl.pdf')\n#\nplt.figure(11)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n# plt.savefig(pref_val+'sigma_rr.pdf')\n#\nplt.figure(12)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,exp_mod.T_out_all,20,cmap='coolwarm')\nplt.colorbar()\n\nexp_mod.sigma_eff_rr_all = exp_mod.sigma_rr_all + exp_mod.P_out_all\nplt.figure(13)\nX,Y = np.meshgrid(exp_mod.R_outside,exp_mod.times_list.data)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_eff_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\n# plt.savefig(pref_val+'sigma_rr_eff.pdf')\n\n\n# exp_mod.flux_in_vol.finalize()\n# exp_mod.flux_out_vol.finalize()\n#\n# exp_mod.flux_in_vol.data = np.delete(exp_mod.flux_in_vol.data, 0)\n# exp_mod.flux_out_vol.data = np.delete(exp_mod.flux_out_vol.data, 0)\n#\n# plt.figure(14)\n# plt.plot(exp_mod.times_list.data[1+exp_mod.extra_vals:]/3.142e7,exp_mod.flux_in_vol.data,'k')\n# plt.plot(exp_mod.times_list.data[1+exp_mod.extra_vals:]/3.142e7,exp_mod.flux_out_vol.data,'r')\n# plt.show()\n#\n# time_steps = np.diff(exp_mod.times_list.data[exp_mod.extra_vals:])\n# tmp1 = np.where(exp_mod.flux_out_vol.data<1.)\n# vol_flux_out_non_erupt = np.sum(exp_mod.flux_out_vol.data[tmp1]*time_steps[tmp1])\n#\n# tmp2 = np.where(exp_mod.flux_out_vol.data>=1.)\n# vol_flux_out_erupt = np.sum(exp_mod.flux_out_vol.data[tmp2]*time_steps[tmp2])\n#\n# vol_flux_in = np.sum(exp_mod.flux_in_vol.data*time_steps)\n#\n# print('vol_flux_out_erupt/vol_flux_in : ',vol_flux_out_erupt/vol_flux_in)\n# print('vol_flux_out_non_erupt/vol_flux_in : ',vol_flux_out_non_erupt/vol_flux_in)\n# #del exp_mod\n"
},
{
"alpha_fraction": 0.48076048493385315,
"alphanum_fraction": 0.5514315962791443,
"avg_line_length": 45,
"blob_id": "158906dc520fa9f4782a80ed31dbf33d57c17a13",
"content_id": "23b42007edc31b43c28535a65c054c8810132cb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13202,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 287,
"path": "/PyMagmaCh_Single/input_functions.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "'''input_functions.py\n\nA collection of function definitions to handle common\ncalcualtions (i.e. constants and melting curve, density parameterizations)\n\n'''\nimport pdb\nimport numpy as np\nimport constants as const\nimport warnings\n\nclass append_me:\n def __init__(self):\n self.data = np.empty((100,))\n self.capacity = 100\n self.size = 0\n\n def update(self, row):\n #for r in row:\n self.add(row)\n\n def add(self, x):\n if self.size == self.capacity:\n self.capacity *= 4\n newdata = np.empty((self.capacity,))\n newdata[:self.size] = self.data\n self.data = newdata\n self.data[self.size] = x\n self.size += 1\n\n def finalize(self):\n self.data = self.data[:self.size]\n\nclass Parameters(object):\n def __init__(self, source):\n self.source = source\n\nclass Input_functions(object):\n def __init__(self,crust_density=None,model_source=None):\n self.crust_density = crust_density # kg/m^3\n self.model_source = model_source\n def material_constants(self):\n raise NotImplementedError('must implement a material_constants method')\n def gas_density(self,T,P):\n raise NotImplementedError('must implement a gas_density method')\n def melting_curve(self,T,P,eps_g):\n raise NotImplementedError('must implement a melting_curve method')\n def solubulity_curve(self,T,P):\n raise NotImplementedError('must implement a solubulity_curve method')\n def crit_outflow(self,*args,additional_model=None):\n raise NotImplementedError('must implement a crit_outflow method')\n def crustal_viscosity(self,T,r_val):\n raise NotImplementedError('must implement a crustal_viscosity method')\n def func_Uog(self,eps_g,eps_x,m_eq,rho_m,rho_g,T,delta_P_grad):\n raise NotImplementedError('must implement a func_Uog method')\n\nclass Input_functions_Degruyer(Input_functions):\n '''\n Extends the Input_functions to use the parameterizations\n from Degruyer & Huber 2014\n '''\n def __init__(self):\n crust_density = 2600.0 # kg/m^3\n super(Input_functions_Degruyer, self).__init__(crust_density = crust_density,model_source='Degruyter_Huber_2014')\n ## Parameters for the melting curve calculations\n # b is an exponent to approximate composition (1 = mafic, 0.5 = silicic)\n self.b = 0.5\n self.T_s = 973.0 # Kelvin , other value = 850+273.0-200\n # T_s is solidus temperature in Kelvin (Default value = 973 K)\n self.T_l = 1223.0 # Kelvin, other value = 1473.0-200.\n # T_l is liquidus temperature in Kelvin (Default value = 1223 K)\n self.Pc = 20.0 # assume a critical overpressure of 20 MPa\n self.eta_crit_lock = 0.5 # based on cystal locking above 50 % packing ..\n self.M_out_rate = 1e4 # kg/s\n self.psi_m = 0.637 #the maximum random close packing fraction for mono-sized spherical particle\n self.r_b = 100*1e-6 # radius of the bubble, in m\n self.material_constants()\n self.outflow_model = 'huppert'\n\n def material_constants(self):\n \"\"\"\n Specify the material constants used in the paper -\n Output as a dictionary ..\n alpha_m = melt thermal expansion coefficient (1/K)\n alpha_x = crystal thermal expansion coefficient (1/K)\n alpha_r = crust thermal expansion coefficient (1/K)\n beta_x = melt bulk modulus (Pa)\n beta_m = crystal bulk modulus (Pa)\n beta_r = crust bulk modulus (Pa)\n k_crust = thermal conductivity of the crust (J/s/m/K)\n c_x,c_g,c_m = specific heat capacities (J/kg/K)\n L_m,L_e = latent heat of melting and exsolution (J/kg)\n kappa = thermal diffusivity of the crust\n \"\"\"\n mat_const = {'crustal_density':self.crust_density,'beta_m': 1e10, 'alpha_m': 1e-5, 'beta_x': 1e10, 'alpha_x':1e-5, 'beta_r': 1e10, 'alpha_r':1e-5,\n 'k_crust': 3.25,'c_m' : 1315.0,'c_x' : 1205.0,'c_g' : 3880.0,'L_m':290e3,'L_e':610e3,'kappa':1e-6}\n return mat_const\n\n def gas_density(self,T,P):\n \"\"\"Compute equation of state of the gas phase.\n\n Input: T is temperature in Kelvin ( 873 < T < 1173 K )\n P is pressure in Pa (30 Mpa < P < 400 MPa)\n Output: rhog, drhog_dP, drhog_dT (gas density, d(rho_g)/dP and d(rho_g)/dT)\n \"\"\"\n rho_g = -112.528*(T-273.15)**-0.381 + 127.811*(P*1e-5)**-1.135 + 112.04*(T-273.15)**-0.411*(P*1e-5)**0.033\n drho_g_dP = (-1.135)*127.811*(P*1e-5)**-2.135 + 0.033*112.04*(T-273.15)**-0.411*(P*1e-5)**-0.967\n drho_g_dT = (-0.381)*(-112.528)*(T-273.15)**-1.381 + (-0.411)*112.04*(T-273.15)**-1.411*(P*1e-5)**0.033\n rho_g = rho_g*1e3\n drho_g_dP = drho_g_dP*1e-2\n drho_g_dT = drho_g_dT*1e3\n return rho_g,drho_g_dP,drho_g_dT\n\n def melting_curve(self,T,P,eps_g):\n \"\"\"Compute melt fraction-temperature relationship.\n Input: T is temperature in Kelvin\n eps_g is gas volume fraction\n Output: eta_x,deta_x_dT,deta_x_deta_g (eta_x is crystal volume fraction, others are its derivative with T and eta_g)\n \"\"\"\n temp1 = T - self.T_s\n temp2 = self.T_l - self.T_s\n phi_x = 1.- (temp1/temp2)**self.b\n dphi_x_dT = - self.b*temp1**(self.b-1.)/(temp2)**self.b\n if T<self.T_s:\n phi_x = 1.\n dphi_x_dT = 0.\n elif T > self.T_l:\n phi_x = 0.\n dphi_x_dT = 0.\n eps_x = np.dot(1.-eps_g, phi_x)\n deps_x_dT = np.dot(1.-eps_g, dphi_x_dT)\n deps_x_deps_g = -phi_x\n return eps_x, deps_x_dT, deps_x_deps_g\n\n def solubulity_curve(self,T,P):\n \"\"\"Compute solubility - dissolved water content in the melt\n Input: T is temperature in Kelvin ( 873 < T < 1173 K )\n P is pressure in Pa (30 Mpa < P < 400 MPa)\n Output: meq,dmeq_dT,dmeq_dP (meq is dissolved water content others are its derivative with T and eta_g)\n \"\"\"\n meq = (P*1e-6)**0.5*(0.4874 - 608./T + 489530./T**2.) + (P*1e-6)*(-0.06062 + 135.6/T - 69200./T**2.) + (P*1e-6)**1.5*(0.00253 - 4.154/T + 1509./T**2.)\n dmeqdP = 0.5*(P*1e-6)**-0.5*(0.4874 - 608./T + 489530./T**2.) + (-0.06062 + 135.6/T - 69200./T**2.) \\\n + 1.5*(P*1e-6)**0.5*(0.00253 - 4.154/T + 1509./T**2.)\n dmeqdT = (P*1e-6)**0.5*( 608./T**2. - 2.*489530./T**3.) \\\n + (P*1e-6)*(-135.6/T**2. + 2.*69200./T**3.) \\\n + (P*1e-6)**1.5*(4.154/T**2. - 2.*1509./T**3.)\n meq = 1e-2*meq\n dmeqdP = 1e-8*dmeqdP\n dmeqdT = 1e-2*dmeqdT\n return meq,dmeqdP,dmeqdT\n\n def crit_outflow(self,*args,additional_model=None):\n \"\"\"\n Specify the conditions for eruptions according to Degruyter 2014 model\n Pc = critical overpressure\n eta_x = crystal volume fraction\n M_out_rate is the mass outflow rate\n \"\"\"\n if (additional_model == None) :\n M_out_rate = self.M_out_rate # kg/s\n elif additional_model == 'huppert' :\n M_out_rate = self.huppert_outflow(*args) # kg/s\n else :\n raise NotImplementedError('Not implemented this outflow method')\n return M_out_rate\n\n def huppert_outflow(self,eps_x,m_eq, T, rho, depth, Area_conduit,S,delta_P) :\n \"\"\"\n Huppert and Woods 2003 - Eqn 7 : Q = (rho*S*(area)^2/H/mu)*delta_P\n Area_conduit = 10.*10. # 100 m^2 area ..\n S = 0.1 # shape factor ..\n used the formulation of viscosity of the melt/crystal mixture as\n described in Hess and Dingwell [1996], Parmigiani et al. 2017\n \"\"\"\n mu_star = ((self.psi_m - eps_x)/(self.psi_m - self.psi_m*eps_x))**(-2.5*self.psi_m/(1.-self.psi_m))\n mu_m = 10.**( -3.545 + 0.833*np.log(100.*m_eq) +(9601. - 2368.*np.log(100.*m_eq) )/(T - (195.7 + 32.35*np.log(100*m_eq))))\n mu_mixture = mu_star*mu_m\n scale_fac = (S*(Area_conduit)**2/mu_mixture)*(rho/depth)\n return scale_fac*delta_P\n\n def crustal_viscosity(self,T,r_val):\n \"\"\"Compute the viscosity of the visco-elastic shell surrounding the magma chamber.\n Input: T is temperature in Kelvin, r_val is in m\n Output:\n \"\"\"\n ## Parameters for the Arrhenius law :\n A = 4.25e7 #Pa s\n G = 141e3 # J/mol, Activation energy for creep\n B = 8.31 # molar gas constan, J/mol/K\n dr = np.diff(r_val)\n eta_T = np.copy(T)*0.0 + 5e21 ## Base viscosity of the crust, Pa-s\n eta_T[T>100] = A*np.exp(G/B/T[T>100])\n eta_T[eta_T>5e21] = 5e21\n integrand = 4.*np.pi*np.sum(eta_T[:-1]*r_val[:-1]*r_val[:-1]*dr) # this is f(du)*r^2 dr over the full range\n volume_shell = (4.*np.pi/3.)*(r_val[-1]**3. - r_val[0]**3.)\n eta_effective = integrand/volume_shell\n return eta_effective\n\n def func_Uog(self,eps_g,eps_x,m_eq,rho_m,rho_g,T,delta_P_grad):\n '''\n This function uses the formulation from the Parmigiani et al. 2017 paper\n to calculate the volatile flux out of the magmatic system -\n Note the correction in the relative permeability function from the original paper\n (sign needed to be corrected)\n :param eps_g:\n :param eps_x:\n :param m_eq:\n :param rho_m:\n :param rho_g:\n :param T:\n :param delta_P_grad: pressure gradient driving the flow\n '''\n #pdb.set_trace()\n if eps_g >0.5 : # Too high gas fraction ..\n return 0\n if eps_x < 0.4 : # Bubbles ...\n Y_val = 0.45 #eometrical constant derived from data\n term1 = eps_g/self.psi_m\n U_star = (1. - Y_val*term1**(1./3.))*((1. - eps_g)/(1. - 0.5*term1))*((self.psi_m - eps_g)/(self.psi_m-self.psi_m*eps_g))**(self.psi_m/(1. - self.psi_m))\n mu_star = ((self.psi_m - eps_x)/(self.psi_m - self.psi_m*eps_x))**(-2.5*self.psi_m/(1.-self.psi_m))\n mu_m = 10.**( -3.545 + 0.833*np.log(100.*m_eq) +(9601. - 2368.*np.log(100.*m_eq) )/(T - (195.7 + 32.35*np.log(100*m_eq))))\n U_og = U_star*(rho_m - rho_g)*const.g_earth*self.r_b**2./(3.*mu_m*mu_star)\n return U_og\n visc_gas = 2.414*1e-5*(10.**(247.8/(T-140))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009\n eps_g_crit = 2.75*eps_x**3. - 2.79*eps_x**2. +0.6345*eps_x+ 0.0997\n if eps_g_crit <= 0. :\n raise ValueError('eps_g_crit must not be less than zero, something is wrong')\n if (eps_x >= 0.4) and (eps_g < eps_g_crit):\n return 0\n if (eps_x >= 0.4) and (eps_x <= 0.7) and (eps_g > eps_g_crit):\n k = 1e-4*(-0.0534*eps_x**3. + 0.1083*eps_x**2. - 0.0747*eps_x + 0.0176) # m^2\n k_rel = -2.1778*eps_x**4. + 5.1511*eps_x**3. - 4.5199*eps_x**2. + 1.7385*eps_x - 0.2461\n if eps_g < eps_g_crit + 0.04 :\n f_s = ((eps_g - eps_g_crit)/0.04)**4.\n else :\n f_s = 1.\n U_og = (f_s*k*k_rel/visc_gas)*(delta_P_grad + const.g_earth*(rho_m-rho_g))\n if U_og/1e-3 > 1: # This is to ensure an upper limit cutoff ..\n warnings.warn('Exceeded upper limit of fluid velocity - 1e-3',UserWarning)\n U_og = 1e-3\n return U_og\n raise ValueError('Error - the code should not be here')\n\nclass Input_functions_DeKa(Input_functions_Degruyer):\n '''\n Extends the Input_functions to use the parameterizations\n from Degruyer & Huber 2014 + some melting things from Karlstrom 2009\n '''\n def __init__(self):\n super(Input_functions_DeKa, self).__init__()\n self.model_source='Degruyter_Huber_2014; karlstrom_2009'\n self.anhyd = True\n\n def melting_curve(self,T,P,eps_g):\n '''\n from Karlstrom 2009 melting curve, Anhydrous ..\n as well as the hydr .. 2% (new exp make this obselete ?? since it seems too broad)\n :param T:\n :param P:\n :param eps_g: gas fraction\n :return:eps_x, deps_x_dT, deps_x_deps_g\n '''\n if self.anhyd == True :\n T = (T-273.15) + 12.*(15. - P/100000000.)\n melt_frac = 2.79672e-11*(T**4.) - 8.79939e-8*(T**3.) + 1.01622e-4*T**2. - 5.02861e-2*T + 8.6693\n if melt_frac < 0:\n melt_frac = 0.\n elif melt_frac > 1:\n melt_frac = 1.\n phi_x = 1. - melt_frac\n eps_x = np.dot(1.-eps_g, phi_x)\n deps_x_deps_g = -phi_x\n dphi_x_dT = - (2.79672e-11*(T**3.)*4. - 3.*8.79939e-8*(T**2.) + 1.01622e-4*2.*T - 5.02861e-2)\n deps_x_dT = np.dot(1.-eps_g, dphi_x_dT)\n else :\n T = (T - 273.15) + 12. * (15. - P / 100000000.)\n melt_frac = 2.039e-09 * (T ** 3.) - 3.07e-6 * (T ** 2.) + 1.63e-3 * T - 0.307\n if melt_frac < 0:\n melt_frac = 0.\n elif melt_frac > 1:\n melt_frac = 1.\n phi_x = 1. - melt_frac\n eps_x = np.dot(1. - eps_g, phi_x)\n deps_x_deps_g = -phi_x\n dphi_x_dT = - (2.039e-09 * (T ** 2.) * 3. - 3.07e-6 * (T * 2.) + 1.63e-3)\n deps_x_dT = np.dot(1. - eps_g, dphi_x_dT)\n return eps_x, deps_x_dT, deps_x_deps_g\n"
},
{
"alpha_fraction": 0.5256157517433167,
"alphanum_fraction": 0.5491485595703125,
"avg_line_length": 33.46599578857422,
"blob_id": "a0326468757a6ee36eb3fdabc7d25350ce8d0624",
"content_id": "e6c21a5a0f59945bdadd1a5ae6e4375d3b8ed0bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13683,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 397,
"path": "/PyMagmaCh/process/implicit_eg/diffusion_2d.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "from scipy import sparse\nimport numpy as np\nfrom scipy.linalg import solve_banded\nfrom PyMagmaCh.process.process import Process\n\nclass Diffusion_2D(TimeDependentProcess):\n '''Parent class for implicit diffusion modules.\n Solves the 1D heat equation\n \\rho C_p dT/dt = d/dx( K * dT/dx )\n\n The thermal conductivity K, density \\rho and heat capacity Cp are in\n units - W/m/K, kg/m^3, and J/K/kg.\n\n Assume that the boundary conditions are fixed temp ..\n (fix temp at the base and the top boundary ..) - need to specify\n self.param['T_base'],self.param['T_top'] :\n Note that the base and top are base and top of the grid\n\n Requirements : Can have only a single domain, also a single state variable\n (the diffusing field e.g. Temperature).\n Pass the inputs for temp evolution as a dict of diagnostics\n Eg. for temperature .. -- > give the k,rho,C_p as diagnostics field\n while pass as a dict :\n self.param['timestep'],\n self.param['timestep'],self.param['T_base'],self.param['T_top']\n\n Input flag use_banded_solver sets whether to use\n scipy.linalg.solve_banded\n rather than the default\n numpy.linalg.solve\n\n banded solver is faster but only works for 1D diffusion.\n Also note that the boundry condition is assumed to be Dirichlet type boundary condition ..\n\n '''\n def __init__(self,use_banded_solver=False,**kwargs):\n super(Diffusion, self).__init__(**kwargs)\n self.time_type = 'implicit'\n self.use_banded_solver = use_banded_solver\n for dom in self.domains.values():\n delta = np.mean(dom.axes[self.diffusion_axis].delta)\n # Note that the shape of delta = 1 - points.shape, 2 - bounds.shape\n self._make_diffusion_matrix(delta)\n\n def _make_diffusion_matrix(self,delta):\n '''Make the array for implicit solution of the 1D heat eqn\n - Allowed variable shaped grid +\n variable thermal conductivity, density, heat capacity\n - Implicit solving of 2D temperature equation:\n - RHO*Cp*dT/dt=d(k*dT/dx)/dx+d(k*dT/dy)/dy\n - Composing matrix of coefficients L() and vector (column) of right parts R()\n '''\n xnum = delta.shape[0]\n ynum = delta.shape[1]\n # Matrix of coefficients initialization for implicit solving\n L = sparse.csr_matrix(xnum*ynum,xnum*ynum)\n # Vector of right part initialization for implicit solving\n R = np.zeros(xnum*ynum,1);\n ## Upper boundary\n L[0:xnum,0:xnum] = 1;\n R[0:xnum,1] = self.param['tback']\n ## Upper boundary\n L[0:ynum,0:ynum] = 1;\n R[0:ynum,1] = self.param['tback']\n\n\n J = delta.size[0] # Size of the delta\n k_val = np.array(self.diagnostics['k']) # should be same shape as points\n rho_val = np.array(self.diagnostics['rho_c']) # should be same shape as points\n Cp_val = np.array(self.diagnostics['C_p']) # should be same shape as points\n\n term1a = (k_val[1:-1] + k_val[:-2])\n term1b = (k_val[1:-1] + k_val[2:])\n term3 = rho_val[1:-1]*Cp_val[1:-1]/self.param['timestep']\n term4 = delta[1:] + delta[:-1] # is same shape as k_val ..\n term5a = delta[:-1]*term4\n term5b = delta[1:]*term4\n Ka1 = (term1a/term3)/term5a\n Ka3 = (term1b/term3)/term5b\n Ka2 = Ka1 + Ka2\n add_t0 = Ka1[0]\n add_tn = Ka3[-1]\n # Build the full banded matrix\n A = (np.diag(1. + Ka2, k=0) +\n np.diag(-Ka3[0:J-1], k=1) +\n np.diag(-Ka1[1:J], k=-1))\n self.diffTriDiag = A\n self.add_t0 = add_t0\n self.add_tn = add_tn\n\n def _solve_implicit_banded(self,current, banded_matrix):\n # can improve performance by storing the banded form once and not\n # recalculating it...\n J = banded_matrix.shape[0]\n diag = np.zeros((3, J))\n diag[1, :] = np.diag(banded_matrix, k=0)\n diag[0, 1:] = np.diag(banded_matrix, k=1)\n diag[2, :-1] = np.diag(banded_matrix, k=-1)\n return solve_banded((1, 1), diag, current)\n\n def _implicit_solver(self):\n # Time-stepping the diffusion is just inverting this matrix problem:\n # self.T = np.linalg.solve( self.diffTriDiag, Trad )\n # Note that there should be only a single state variable - the field that is diffusing ..\n newstate = {}\n for varname, value in self.state.iteritems():\n if self.use_banded_solver:\n new_val = value[1:-1].copy()\n new_val[0] += self.param['T_base']*self.add_t0\n new_val[-1] += self.param['T_top']*self.add_tn\n newvar = self._solve_implicit_banded(new_val, self.diffTriDiag)\n else:\n new_val = value[1:-1].copy()\n new_val[0] += self.param['T_base']*self.add_t0\n new_val[-1] += self.param['T_top']*self.add_tn\n newvar = np.linalg.solve(self.diffTriDiag, new_val)\n newstate[varname][1:-1] = newvar\n return newstate\n\n def compute(self):\n # Time-stepping the diffusion is just inverting this matrix problem:\n # self.T = np.linalg.solve( self.diffTriDiag, Trad )\n # Note that there should be only a single state variable - the field that is diffusing ..\n newstate = self._implicit_solver()\n for varname, value in self.state.items():\n self.adjustment[varname] = newstate[varname] - value\n\n\n\n\n\n\n\n\n\n\n\nimport numpy\nfrom scipy.linalg import solve\n\ndef constructMatrix(nx, ny, sigma):\n \"\"\" Generate implicit matrix for 2D heat equation with\n Dirichlet in bottom and right and Neumann in top and left\n Assumes dx = dy\n\n Parameters:\n ----------\n nx : int\n number of discretization points in x\n ny : int\n number of discretization points in y\n sigma: float\n alpha*dt/dx\n\n Returns:\n -------\n A: 2D array of floats\n Matrix of implicit 2D heat equation\n \"\"\"\n\n A = numpy.zeros(((nx-2)*(ny-2),(nx-2)*(ny-2)))\n\n row_number = 0 # row counter\n for j in range(1,ny-1):\n for i in range(1,nx-1):\n\n # Corners\n if i==1 and j==1: # Bottom left corner (Dirichlet down and left)\n A[row_number,row_number] = 1/sigma+4 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n\n elif i==nx-2 and j==1: # Bottom right corner (Dirichlet down, Neumann right)\n A[row_number,row_number] = 1/sigma+3 # Set diagonal\n A[row_number,row_number-1] = -1 # Fetch i-1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n\n elif i==1 and j==ny-2: # Top left corner (Neumann up, Dirichlet left)\n A[row_number,row_number] = 1/sigma+3 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n elif i==nx-2 and j==ny-2: # Top right corner (Neumann up and right)\n A[row_number,row_number] = 1/sigma+2 # Set diagonal\n A[row_number,row_number-1] = -1 # Fetch i-1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n # Sides\n elif i==1: # Left boundary (Dirichlet)\n A[row_number,row_number] = 1/sigma+4 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n elif i==nx-2: # Right boundary (Neumann)\n A[row_number,row_number] = 1/sigma+3 # Set diagonal\n A[row_number,row_number-1] = -1 # Fetch i-1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n elif j==1: # Bottom boundary (Dirichlet)\n A[row_number,row_number] = 1/sigma+4 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number-1] = -1 # fetch i-1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n\n elif j==ny-2: # Top boundary (Neumann)\n A[row_number,row_number] = 1/sigma+3 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number-1] = -1 # fetch i-1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n # Interior points\n else:\n A[row_number,row_number] = 1/sigma+4 # Set diagonal\n A[row_number,row_number+1] = -1 # fetch i+1\n A[row_number,row_number-1] = -1 # fetch i-1\n A[row_number,row_number+nx-2] = -1 # fetch j+1\n A[row_number,row_number-(nx-2)] = -1 # fetch j-1\n\n row_number += 1 # Jump to next row of the matrix!\n return A\n\ndef generateRHS(nx, ny, sigma, T, T_bc):\n \"\"\" Generates right-hand side for 2D implicit heat equation with Dirichlet in bottom and left and Neumann in top and right\n Assumes dx=dy, Neumann BCs = 0, and constant Dirichlet BCs\n\n Paramenters:\n -----------\n nx : int\n number of discretization points in x\n ny : int\n number of discretization points in y\n sigma: float\n alpha*dt/dx\n T : array of float\n Temperature in current time step\n T_bc : float\n Temperature in Dirichlet BC\n\n Returns:\n -------\n RHS : array of float\n Right hand side of 2D implicit heat equation\n \"\"\"\n RHS = numpy.zeros((nx-2)*(ny-2))\n\n row_number = 0 # row counter\n for j in range(1,ny-1):\n for i in range(1,nx-1):\n\n # Corners\n if i==1 and j==1: # Bottom left corner (Dirichlet down and left)\n RHS[row_number] = T[j,i]*1/sigma + 2*T_bc\n\n elif i==nx-2 and j==1: # Bottom right corner (Dirichlet down, Neumann right)\n RHS[row_number] = T[j,i]*1/sigma + T_bc\n\n elif i==1 and j==ny-2: # Top left corner (Neumann up, Dirichlet left)\n RHS[row_number] = T[j,i]*1/sigma + T_bc\n\n elif i==nx-2 and j==ny-2: # Top right corner (Neumann up and right)\n RHS[row_number] = T[j,i]*1/sigma\n\n # Sides\n elif i==1: # Left boundary (Dirichlet)\n RHS[row_number] = T[j,i]*1/sigma + T_bc\n\n elif i==nx-2: # Right boundary (Neumann)\n RHS[row_number] = T[j,i]*1/sigma\n\n elif j==1: # Bottom boundary (Dirichlet)\n RHS[row_number] = T[j,i]*1/sigma + T_bc\n\n elif j==ny-2: # Top boundary (Neumann)\n RHS[row_number] = T[j,i]*1/sigma\n\n # Interior points\n else:\n RHS[row_number] = T[j,i]*1/sigma\n\n row_number += 1 # Jump to next row!\n\n return RHS\n\ndef map_1Dto2D(nx, ny, T_1D, T_bc):\n \"\"\" Takes temperatures of solution of linear system, stored in 1D,\n and puts them in a 2D array with the BCs\n Valid for constant Dirichlet bottom and left, and Neumann with zero\n flux top and right\n\n Parameters:\n ----------\n nx : int\n number of nodes in x direction\n ny : int\n number of nodes in y direction\n T_1D: array of floats\n solution of linear system\n T_bc: float\n Dirichlet BC\n\n Returns:\n -------\n T: 2D array of float\n Temperature stored in 2D array with BCs\n \"\"\"\n T = numpy.zeros((ny,nx))\n\n row_number = 0\n for j in range(1,ny-1):\n for i in range(1,nx-1):\n T[j,i] = T_1D[row_number]\n row_number += 1\n # Dirichlet BC\n T[0,:] = T_bc\n T[:,0] = T_bc\n #Neumann BC\n T[-1,:] = T[-2,:]\n T[:,-1] = T[:,-2]\n\n return T\n\ndef btcs_2D(T, A, nt, sigma, T_bc, nx, ny, dt):\n \"\"\" Advances diffusion equation in time with backward Euler\n\n Parameters:\n ----------\n T: 2D array of float\n initial temperature profile\n A: 2D array of float\n Matrix with discretized diffusion equation\n nt: int\n number of time steps\n sigma: float\n alpha*dt/dx^2\n T_bc : float\n Dirichlet BC temperature\n nx : int\n Discretization points in x\n ny : int\n Discretization points in y\n dt : float\n Time step size\n\n Returns:\n -------\n T: 2D array of floats\n temperature profile after nt time steps\n \"\"\"\n\n j_mid = int((numpy.shape(T)[0])/2)\n i_mid = int((numpy.shape(T)[1])/2)\n\n for t in range(nt):\n Tn = T.copy()\n b = generateRHS(nx, ny, sigma, Tn, T_bc)\n # Use numpy.linalg.solve\n T_interior = solve(A,b)\n T = map_1Dto2D(nx, ny, T_interior, T_bc)\n\n # Check if we reached T=70C\n if T[j_mid, i_mid] >= 70:\n print (\"Center of plate reached 70C at time {0:.2f}s, in time step {1:d}.\".format(dt*t, t))\n break\n\n if T[j_mid, i_mid]<70:\n print (\"Center has not reached 70C yet, it is only {0:.2f}C.\".format(T[j_mid, i_mid]))\n\n return T\n\n\n\nalpha = 1e-4\n\nL = 1.0e-2\nH = 1.0e-2\n\nnx = 21\nny = 21\nnt = 300\n\ndx = L/(nx-1)\ndy = H/(ny-1)\n\nx = numpy.linspace(0,L,nx)\ny = numpy.linspace(0,H,ny)\n\nT_bc = 100\n\nTi = numpy.ones((ny, nx))*20\nTi[0,:]= T_bc\nTi[:,0] = T_bc\nsigma = 0.25\nA = constructMatrix(nx, ny, sigma)\ndt = sigma * min(dx, dy)**2 / alpha\nT = btcs_2D(Ti.copy(), A, nt, sigma, T_bc, nx, ny, dt)\n"
},
{
"alpha_fraction": 0.6070823669433594,
"alphanum_fraction": 0.6100451350212097,
"avg_line_length": 43.024845123291016,
"blob_id": "0b96973c3a3daf6617ec2ae30d19e78cf12653be",
"content_id": "33400d8b60c5780470f1711843e5844e14bf5b28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7088,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 161,
"path": "/PyMagmaCh/model/column.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "\"\"\"Base Model -\n This is the file that defines the model parameters mostly\n defined in flood_basalts_v8.m file.\n\n Object-oriented code for a coupled magma chamber model\n\n Requirements for the model :\n a. Allow an arbitrary number of chambers\n b. Allow specifying most of the parameters (can give default)\n c. Allow specifying which processes to turn on and off\n (modularity is important)\n\nCode developed by Ben Black and Tushar Mittal\n\"\"\"\n\nimport numpy as np\nfrom PyMagmaCh import constants as const\nfrom PyMagmaCh.domain.field import Field\nfrom PyMagmaCh.domain import domain\nfrom PyMagmaCh.process.time_dependent_process import TimeDependentProcess\n\n\nfrom PyMagmaCh.radiation.insolation import FixedInsolation\nfrom PyMagmaCh.radiation.radiation import Radiation, RadiationSW\nfrom PyMagmaCh.convection.convadj import ConvectiveAdjustment\nfrom PyMagmaCh.surface.surface_radiation import SurfaceRadiation\nfrom PyMagmaCh.radiation.nband import ThreeBandSW, FourBandLW, FourBandSW\nfrom PyMagmaCh.radiation.water_vapor import ManabeWaterVapor\n\nclass MagmaChamberModel(TimeDependentProcess):\n def __init__(self,\n num_depth=30,\n num_rad=1,\n depth=None,\n radial_val=None,\n abs_coeff = 1.,\n timestep=1.* const.seconds_per_year,\n **kwargs):\n if depth is not None:\n num_depth = np.array(depth).size\n if radial_val is not None:\n num_rad = np.array(radial_val).size\n # Check to see if an initial state is already provided\n # If not, make one\n if 'state' not in kwargs:\n state = self.initial_state(num_depth, num_rad, depth,radial_val)\n kwargs.update({'state': state})\n super(MagmaChamberModel, self).__init__(timestep=timestep, **kwargs)\n self.param['abs_coeff'] = abs_coeff\n #z_clmn, atm_slab\n z_clmn = self.Tdepth.domain\n atm_slab = self.Ts.domain\n # create sub-models for longwave and shortwave radiation\n dp = self.Tdepth.domain.lev.delta\n absorbLW = compute_layer_absorptivity(self.param['abs_coeff'], dp)\n absorbLW = Field(np.tile(absorbLW, z_clmn.shape), domain=z_clmn)\n absorbSW = np.zeros_like(absorbLW)\n longwave = Radiation(state=self.state, absorptivity=absorbLW,\n albedo_z_clmn=0)\n shortwave = RadiationSW(state=self.state, absorptivity=absorbSW,\n albedo_z_clmn=self.param['albedo_z_clmn'])\n # sub-model for insolation ... here we just set constant Q\n thisQ = self.param['Q']*np.ones_like(self.Ts)\n Q = FixedInsolation(S0=thisQ, domain=z_clmn, **self.param)\n # surface sub-model\n surface = SurfaceRadiation(state=self.state, **self.param)\n self.add_subprocess('LW', longwave)\n self.add_subprocess('SW', shortwave)\n self.add_subprocess('insolation', Q)\n self.add_subprocess('surface', surface)\n\n def initial_state(self, num_lev, num_lat, lev, lat, water_depth):\n return initial_state(num_lev, num_lat, lev, lat, water_depth)\n\n # This process has to handle the coupling between insolation and column radiation\n def compute(self):\n # some handy nicknames for subprocesses\n LW = self.subprocess['LW']\n SW = self.subprocess['SW']\n insol = self.subprocess['insolation']\n surf = self.subprocess['surface']\n # Do the coupling\n SW.flux_from_space = insol.diagnostics['insolation']\n SW.albedo_z_clmn = surf.albedo_z_clmn\n surf.LW_from_atm = LW.flux_to_z_clmn\n surf.SW_from_atm = SW.flux_to_z_clmn\n LW.flux_from_z_clmn = surf.LW_to_atm\n # set diagnostics\n self.do_diagnostics()\n\n def do_diagnostics(self):\n '''Set all the diagnostics from long and shortwave radiation.'''\n LW = self.subprocess['LW']\n SW = self.subprocess['SW']\n surf = self.subprocess['surface']\n try: self.diagnostics['OLR'] = LW.flux_to_space\n except: pass\n try: self.diagnostics['LW_down_z_clmn'] = LW.flux_to_z_clmn\n except: pass\n try: self.diagnostics['LW_up_z_clmn'] = surf.LW_to_atm\n except: pass\n try: self.diagnostics['LW_absorbed_z_clmn'] = (surf.LW_from_atm -\n surf.LW_to_atm)\n except: pass\n try: self.diagnostics['LW_absorbed_atm'] = LW.absorbed\n except: pass\n try: self.diagnostics['LW_emission'] = LW.emission\n except: pass\n # contributions to OLR from surface and atm. levels\n #self.diagnostics['OLR_z_clmn'] = self.flux['z_clmn2space']\n #self.diagnostics['OLR_atm'] = self.flux['atm2space']\n try: self.diagnostics['ASR'] = SW.flux_from_space - SW.flux_to_space\n except: pass\n try:\n self.diagnostics['SW_absorbed_z_clmn'] = (surf.SW_from_atm -\n surf.SW_to_atm)\n except: pass\n try: self.diagnostics['SW_absorbed_atm'] = SW.absorbed\n except: pass\n try: self.diagnostics['SW_down_z_clmn'] = SW.flux_to_z_clmn\n except: pass\n try: self.diagnostics['SW_up_z_clmn'] = SW.flux_from_z_clmn\n except: pass\n try: self.diagnostics['SW_up_TOA'] = SW.flux_to_space\n except: pass\n try: self.diagnostics['SW_down_TOA'] = SW.flux_from_space\n except: pass\n try: self.diagnostics['SW_absorbed_total'] = (SW.absorbed_total -\n SW.flux_net[0])\n except: pass\n try: self.diagnostics['planetary_albedo'] = (SW.flux_to_space /\n SW.flux_from_space)\n except: pass\n try: self.diagnostics['SW_emission'] = SW.emission\n except: pass\n\n######### Need to fix the intial temperature field\ndef initial_state(num_depth, num_rad, depth,radial_val,geotherm_grad):\n if num_rad is 1:\n z_clmn, atm_slab = domain.z_column(num_depth=num_depth,depth=depth)\n else:\n z_clmn, atm_slab = domain.z_radial_column(num_depth=num_depth, num_rad=num_rad,\n depth=depth,\n radial_val = radial_val)\n num_dpth = z_clmn.depth.num_points\n Ts = Field(const.surface_temp*np.ones(atm_slab.shape), domain=atm_slab)\n Tinitial = np.tile(np.linspace(288., 1000, num_dpth), atm_slab.shape) # const.geotherm_grad\n Tdepth = Field(Tinitial, domain=z_clmn)\n state = {'Ts': Ts, 'Tdepth': Tdepth}\n return state\n\n\nclass RadiativeConvectiveModel(GreyRadiationModel):\n def __init__(self,\n # lapse rate for convective adjustment, in K / km\n adj_lapse_rate=6.5,\n **kwargs):\n super(RadiativeConvectiveModel, self).__init__(**kwargs)\n self.param['adj_lapse_rate'] = adj_lapse_rate\n self.add_subprocess('convective adjustment', \\\n ConvectiveAdjustment(state=self.state, **self.param))\n"
},
{
"alpha_fraction": 0.5430704951286316,
"alphanum_fraction": 0.5665161609649658,
"avg_line_length": 20.325925827026367,
"blob_id": "289824e0fd0c6dcb7443a8495cfe762532c3f5fc",
"content_id": "d33f26801c094581378398e59d436fdac84b70a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5758,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 270,
"path": "/PyMagmaCh/utils/heat_eqn_soln.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy\nfrom scipy.linalg import solve\n\n## The code has some helper functions for finite difference methods for heat conduction eqn solution ..\n# First explicit method ...\ndef ftcs_mixed(T, nt, dt, dx, alpha):\n \"\"\"Solves the diffusion equation with forward-time, centered scheme using\n Dirichlet b.c. at left boundary and Neumann b.c. at right boundary\n\n Parameters:\n ----------\n u: array of float\n Initial temperature profile\n nt: int\n Number of time steps\n dt: float\n Time step size\n dx: float\n Mesh size\n alpha: float\n Diffusion coefficient (thermal diffusivity)\n\n Returns:\n -------\n u: array of float\n Temperature profile after nt time steps with forward in time scheme\n\n Example :\n -------\n\tL = 1\n\tnt = 100\n\tnx = 51\n\talpha = 1.22e-3\n\n\tdx = L/(nx-1)\n\n\tTi = numpy.zeros(nx)\n\tTi[0] = 100\n\tsigma = .5\n dt = sigma * dx*dx/alpha\n nt = 1000\n\tT = ftcs_mixed(Ti.copy(), nt, dt, dx, alpha)\n \"\"\"\n for n in range(nt):\n Tn = T.copy()\n T[1:-1] = Tn[1:-1] + alpha*dt/dx**2*(Tn[2:] -2*Tn[1:-1] + Tn[0:-2])\n T[-1] = T[-2]\n return T\n\n\n########################## Implicit method\ndef generateMatrix(N, sigma):\n \"\"\" Computes the matrix for the diffusion equation with backward Euler\n Dirichlet condition at i=0, Neumann at i=-1\n\n Parameters:\n ----------\n T: array of float\n Temperature at current time step\n sigma: float\n alpha*dt/dx^2\n\n Returns:\n -------\n A: 2D numpy array of float\n Matrix for diffusion equation\n \"\"\"\n\n # Setup the diagonal\n d = numpy.diag(numpy.ones(N-2)*(2+1./sigma))\n\n # Consider Neumann BC\n d[-1,-1] = 1+1./sigma\n\n # Setup upper diagonal\n ud = numpy.diag(numpy.ones(N-3)*-1, 1)\n\n # Setup lower diagonal\n ld = numpy.diag(numpy.ones(N-3)*-1, -1)\n\n A = d + ud + ld\n\n return A\n\ndef generateRHS(T, sigma, qdx):\n \"\"\" Computes right-hand side of linear system for diffusion equation\n with backward Euler\n\n Parameters:\n ----------\n T: array of float\n Temperature at current time step\n sigma: float\n alpha*dt/dx^2\n qdx: float\n flux at right boundary * dx\n\n Returns:\n -------\n b: array of float\n Right-hand side of diffusion equation with backward Euler\n \"\"\"\n\n b = T[1:-1]*1./sigma\n # Consider Dirichlet BC\n b[0] += T[0]\n # Consider Neumann BC\n b[-1] += qdx\n\n return b\n\ndef implicit_ftcs(T, A, nt, sigma, qdx):\n \"\"\" Advances diffusion equation in time with implicit central scheme\n\n Parameters:\n ----------\n T: array of float\n initial temperature profile\n A: 2D array of float\n Matrix with discretized diffusion equation\n nt: int\n number of time steps\n sigma: float\n alpha*td/dx^2\n\n qdx: float\n flux at right boundary * dx\n Returns:\n -------\n T: array of floats\n temperature profile after nt time steps\n\t Example :\n\t--------------\n\tL = 1.\n\tnt = 100\n\tnx = 51\n\talpha = 1.22e-3\n\n\tq = 0.\n\tdx = L/(nx-1)\n\tqdx = q*dx\n\n\tTi = numpy.zeros(nx)\n\tTi[0] = 100\n\tsigma = 0.5\n\tdt = sigma * dx*dx/alpha\n\tnt = 1000\n\n\tA = generateMatrix(nx, sigma)\n\tT = implicit_ftcs(Ti.copy(), A, nt, sigma, qdx)\n \"\"\"\n\n for t in range(nt):\n Tn = T.copy()\n b = generateRHS(Tn, sigma, qdx)\n # Use numpy.linalg.solve\n T_interior = solve(A,b)\n T[1:-1] = T_interior\n # Enforce Neumann BC (Dirichlet is enforced automatically)\n T[-1] = T[-2] + qdx\n\n return T\n\n########################## Crank-Nicolson method\n\ndef generateMatrix_CN(N, sigma):\n \"\"\" Computes the matrix for the diffusion equation with Crank-Nicolson\n Dirichlet condition at i=0, Neumann at i=-1\n\n Parameters:\n ----------\n N: int\n Number of discretization points\n sigma: float\n alpha*dt/dx^2\n\n Returns:\n -------\n A: 2D numpy array of float\n Matrix for diffusion equation\n \"\"\"\n\n # Setup the diagonal\n d = 2*numpy.diag(numpy.ones(N-2)*(1+1./sigma))\n\n # Consider Neumann BC\n d[-1,-1] = 1+2./sigma\n\n # Setup upper diagonal\n ud = numpy.diag(numpy.ones(N-3)*-1, 1)\n\n # Setup lower diagonal\n ld = numpy.diag(numpy.ones(N-3)*-1, -1)\n\n A = d + ud + ld\n\n return A\n\ndef generateRHS_CN(T, sigma):\n \"\"\" Computes right-hand side of linear system for diffusion equation\n with backward Euler\n\n Parameters:\n ----------\n T: array of float\n Temperature at current time step\n sigma: float\n alpha*dt/dx^2\n\n Returns:\n -------\n b: array of float\n Right-hand side of diffusion equation with backward Euler\n \"\"\"\n\n b = T[1:-1]*2*(1./sigma-1) + T[:-2] + T[2:]\n # Consider Dirichlet BC\n b[0] += T[0]\n\n return b\n\ndef CrankNicolson(T, A, nt, sigma):\n \"\"\" Advances diffusion equation in time with Crank-Nicolson\n\n Parameters:\n ----------\n T: array of float\n initial temperature profile\n A: 2D array of float\n Matrix with discretized diffusion equation\n nt: int\n number of time steps\n sigma: float\n alpha*td/dx^2\n\n Returns:\n -------\n T: array of floats\n temperature profile after nt time steps\n\n\t Example :\n\t--------------\n\tL = 1\n\tnx = 21\n\talpha = 1.22e-3\n\n\tdx = L/(nx-1)\n\n\tTi = numpy.zeros(nx)\n\tTi[0] = 100\n\n\tsigma = 0.5\n\tdt = sigma * dx*dx/alpha\n\tnt = 10\n\n\tA = generateMatrix(nx, sigma)\n\tT = CrankNicolson(Ti.copy(), A, nt, sigma)\n\n \"\"\"\n\n for t in range(nt):\n Tn = T.copy()\n b = generateRHS(Tn, sigma)\n # Use numpy.linalg.solve\n T_interior = solve(A,b)\n T[1:-1] = T_interior\n # Enforce Neumann BC (Dirichlet is enforced automatically)\n T[-1] = T[-2]\n\n return T\n"
},
{
"alpha_fraction": 0.5092743039131165,
"alphanum_fraction": 0.520983099937439,
"avg_line_length": 52.74454879760742,
"blob_id": "f17b5ea0f82a46fa381a25473925e84bbc90c784",
"content_id": "75eec71f4d2ffe950230bd4195cff3441f1be457",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17252,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 321,
"path": "/PyMagmaCh/process/chamber_model.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import integrate\nfrom PyMagmaCh.process.time_dependent_process import TimeDependentProcess\nfrom PyMagmaCh.utils import constants as const\nfrom PyMagmaCh.utils import model_degruyter as md_deg\nfrom PyMagmaCh.A1_domain.field import Field\n\n## The plan is to use diagnostics for storing the calculated variables - things that\n# may change during the course of the simulation .\n# on the other hand, param remain constant throughout ..\n# In case, any of the diagnostics are useful for later, save them as a state variable also ...\n\nclass Chamber_model(TimeDependentProcess):\n '''\n Parent class for box model of a magma chamber -\n Typically solve for P,V,T + other things - >\n This model only works for single P,T + other things for the chamber (no spatial grid in chamber ...)\n Where is the botteneck - the ODE solver used can handle only dP/dt , dT/dt etc\n Need a different setup for the case of a spatial grid in the chamber (Too complicated likely ...)\n Sequence - solve coupled ode's for the variables\n '''\n def __init__(self,chamber_shape=None,**kwargs):\n super(Chamber_model, self).__init__(**kwargs)\n self.process_type = 'explicit'\n self.chamber_shape = chamber_shape\n # this keeps track of variables to solve later, default is false for all state var\n self.solve_me ={}\n for varname, value in self.state.items():\n self.solve_me.update({varname: False})\n\n def func_ode(self,t,X, arg1):\n '''Specify the coupled ode functions to integrate forward ..\n This method should be over-ridden by daughter classes.'''\n pass\n\n def ode_solver(self):\n '''Need to specify - solve_me state variable in the daughter classes.\n Also need to make the state variables a function of time\n (i.e. start at t = 0, then move append value in the field)\n Need to be careful of the sequence in state.items()\n '''\n max_t = self.param['timestep'] # Total integration time (seconds)\n X_init = np.array([])\n X_init_var = np.array([])\n for varname, value in self.state.items():\n try:\n if (self.solve_me[varname] == True):\n tmp1 = self.state[varname][-1] # Use the last time-step as the input\n X_init = np.append(X_init,tmp1)\n X_init_var = np.append(X_init_var,varname)\n except:\n pass\n tmp2 = integrate.ode(func_ode).set_integrator('dopri5',nsteps=1e8)\n tmp2.set_initial_value(X_init,0.0).set_f_params(X_init_var)\n X_new = tmp2.integrate(tmp2.t+max_t)\n state_var_update_func(X_new)\n\n def state_var_update_func(self,X_new):\n ''' A daughter can over-write this to save more variables if needed ...\n Note that since the sequence of things used above for X_init is the same,\n it is ok to put them back as coded below.\n '''\n counter = 0\n for varname, value in self.state.items():\n try:\n if (self.solve_me[varname] == True):\n self.state[varname].append_val(X_new[counter])# append with each timestep\n counter += 1\n except:\n pass\n\n def compute(self):\n '''Update all diagnostic quantities using current model state.\n Needs to update the tendencies - they are multipied by timestep in step_forward'''\n self.ode_solver()\n\n# Need an input with intial states for P, T, V, eta_g,rho_m,rho_X\nclass Degruyter_chamber_model(Chamber_model):\n '''Parent class for box model of a magma chamber - based on Degruyter & Huber 2014.\n Solves coupled equations for P, T, V, eta_g,rho_m,rho_X\n '''\n def __init__(self,chamber_shape='spherical',depth=1e3,**kwargs):\n super(Degruyter_chamber_model, self).__init__(chamber_shape=chamber_shape,**kwargs)\n self.process_type = 'explicit'\n self.param['crustal_density'] = md_deg.crust_density\n self.plith = calc_lith_pressure(depth)\n mat_const = get_constants()\n self.param.update(mat_const) # specify the constansts for the model\n self.solve_me['P'] = True\n self.solve_me['T'] = True\n self.solve_me['V'] = True\n self.solve_me['eta_g'] = True\n self.solve_me['rho_m'] = True\n self.solve_me['rho_x'] = True\n #########################################################\n self.diagnostics['S_scale']=10. # scale factor for region to solve for heat equation\n self.diagnostics['T_S']=500. # temp at R_0*S_scale distance - assume to be crustal temp\n # These are default functions - can be replaced by something else if needed\n self.param['func_melting_curve'] = md_deg.melting_curve_degruyter\n self.param['func_gas_density'] = md_deg.gas_density_degruyter\n self.param['func_solubility_water'] = md_deg.solubulity_curve_degruyter\n self.param['func_critical_outpar'] = md_deg.crit_outflow_degruyter\n self.param['crustal_temp_model'] = md_deg.crustal_temp_radial_degruyter\n #########################################################\n # Check that the minimal number of state variables are defined :\n assert self.state['P'] is not None\n assert self.state['T'] is not None\n assert self.state['V'] is not None\n assert self.state['eta_g'] is not None\n assert self.state['rho_m'] is not None\n assert self.state['rho_x'] is not None\n #########################################################\n ## Sets up the empty state variables to store the variables ...\n self.eta_crust = np.zeros_like(self.state['P'])\n self.R_0 = np.zeros_like(self.state['P'])\n self.meq = np.zeros_like(self.state['P'])\n self.rho_g = np.zeros_like(self.state['P'])\n self.eta_x = np.zeros_like(self.state['P'])\n self.eta_m = np.zeros_like(self.state['P'])\n self.delta_P = np.zeros_like(self.state['P'])\n self.mass_inflow = np.zeros_like(self.state['P'])\n self.mass_outflow = np.zeros_like(self.state['P'])\n #########################################################\n\n def calc_lith_pressure(self,depth):\n return depth*const.g_earth*self.param['crustal_density']\n\n def get_constants(self):\n '''\n Get material constants - can over-write this ..\n '''\n return md_deg.material_constants_degruyter()\n\n def func_ode(self,t,X, X_init_var):\n '''Specify the coupled ode functions to integrate forward ..\n This method should be over-ridden by daughter classes.\n '''\n P_val = np.where(X_init_var == 'P')[0][0]\n T_val = np.where(X_init_var == 'T')[0][0]\n V_val = np.where(X_init_var == 'V')[0][0]\n eta_g_val = np.where(X_init_var == 'eta_g')[0][0]\n rho_m_val = np.where(X_init_var == 'rho_m')[0][0]\n rho_x_val = np.where(X_init_var == 'rho_x')[0][0]\n dt_arry = np.zeros(6)\n func_melting_curve = self.param['func_melting_curve']\n func_gas_density = self.param['func_gas_density']\n func_solubility_water = self.param['func_solubility_water']\n crustal_temp_model = self.param['crustal_temp_model']\n\n eta_g = X[eta_g_val]\n rho_x = X[rho_x_val]\n rho_m = X[rho_m_val]\n\n eta_x,deta_x_dT,deta_x_deta_g = func_melting_curve(X[T_val],eta_g)\n rho_g, drho_g_dP,drho_g_dT = func_gas_density(X[T_val],X[P_val])\n eta_m = 1. - eta_x - eta_g\n rho_mean = eta_x*rho_x + eta_m*rho_m + eta_g*rho_g\n\n self.diagnostics['eta_x'] = eta_x\n self.diagnostics['eta_m'] = eta_m\n self.diagnostics['rho_g'] = rho_g\n #########################################################\n beta_mean = rho_mean/ \\\n (eta_m*rho_m/self.param['beta_m'] + \\\n eta_x*rho_x/self.param['beta_X'] + \\\n eta_g*drho_g_dP )\n alpha_mean = (eta_m*rho_m*self.param['alpha_m'] + \\\n eta_x*rho_x*self.param['alpha_X'] - \\\n eta_g*drho_g_dT )/rho_mean\n c_mean = (eta_m*rho_m*self.param['c_m'] + \\\n eta_x*rho_x*self.param['c_x'] + \\\n eta_g*rho_g*self.param['c_g'])/rho_mean\n #########################################################\n overpressure = (X[P_val] - self.plith)\n meq,dmeq_dT,dmeq_dP = func_solubility_water(X[T_val],X[P_val])\n self.diagnostics['delta_P'] = overpressure\n self.diagnostics['meq'] = meq\n #########################################################\n m_in,m_in_water,H_in = mass_in_func(t)\n m_out,m_out_water = mass_out_func(t,overpressure,eta_x,meq)\n self.diagnostics['mass_inflow'] = mass_in\n self.diagnostics['mass_outflow'] = mass_out\n self.diagnostics['mass_inflow_w'] = mass_in_water\n self.diagnostics['mass_outflow_w'] = mass_out_water\n\n R_0 = (X[V_val]*3./4./np.pi)**(1./3.)\n dT_dR,eta_crust = crustal_temp_model(R_0,self.diagnostics['S_scale'],\n X[T_val],T_s = self.diagnostics['T_S']),\n kappa = self.param['kappa'])\n H_out_a = m_out*X[T_val]*c_mean\n H_out_b = -1.*4.*np.pi*self.param['k_crust']*R_0*R_0*dT_dR\n H_out = H_out_a + H_out_b\n self.diagnostics['eta_crust'] = eta_crust\n self.diagnostics['R_0'] = R_0\n\n #########################################################\n ### Matrix inversion here to get dP/dt, dT/dt, deta_g/dt\n delta_rho_xm = (rho_x- rho_m)/rho_mean\n delta_rho_gm = (rho_g - rho_m)/rho_mean\n tmp_M1 = rho_mean*X[V_val]\n\n a1 = (1./beta_mean + 1./self.param['beta_r'])\n b1 = (-1.*alpha_mean -self.param['alpha_r'] + deta_x_dT*delta_rho_xm)\n c1 = (delta_rho_gm + deta_x_deta_g*delta_rho_xm)\n d1 = m_in/tmp_M1 - m_out/tmp_M1 - overpressure/eta_crust\n #########################################################\n tmp_M2 = dmeq_dP/meq + 1./self.param['beta_r'] + 1./self.param['beta_m']\n tmp_M3 = meq*rho_m*eta_m/eta_g/rho_g\n tmp_M4 = dmeq_dT/meq - self.param['alpha_r'] - self.param['alpha_m'] - deta_x_dT/eta_m\n tmp_M5 = eta_g*rho_g*X[V_val]\n a2 = drho_g_dP/rho_g + 1./self.param['beta_r'] + tmp_M2*tmp_M3\n b2 = drho_g_dT/rho_g - self.param['alpha_r'] + tmp_M4*tmp_M3\n c2 = 1./eta_g - meq*rho_m*(1. + deta_x_deta_g)/eta_g/rho_g\n d2 = m_in_water/tmp_M5 - m_out_water/tmp_M5 - (1. + tmp_M3)*overpressure/eta_crust\n #########################################################\n drho_dP = eta_m*rho_m/self.param['beta_m'] + eta_x*rho_x/self.param['beta_x'] + eta_g*drho_g_dP\n drho_dT = -eta_m*rho_m*self.param['alpha_m'] - eta_x*rho_x*self.param['alpha_x'] + eta_g*drho_g_dT\n + rho_m*( - deta_x_dT) + rho_x*deta_x_dT\n drho_etax = rho_m*( - 1./deta_x_deta_g - 1.) + rho_x + rho_g/deta_x_deta_g\n drho_etag = rho_m*( - deta_x_deta_g - 1.) + rho_x*deta_x_deta_g + rho_g\n dc_dP = (eta_m*rho_m*self.param['c_m']/self.param['beta_m'] + \\\n eta_x*rho_x*self.param['c_x']/self.param['beta_x'] + \\\n eta_g*self.param['c_g']*drho_g_dP)/rho_mean - (c_mean/rho_mean)*drho_dP\n dc_dT = (-eta_m*rho_m*self.param['c_m']*self.param['alpha_m'] - \\\n eta_x*rho_x*self.param['c_x']*self.param['alpha_x'] + \\\n eta_g*self.param['c_g']*drho_g_dT)/rho_mean - (c_mean/rho_mean)*drho_dT + \\\n deta_x_dT*(rho_x*self.param['c_x'] - rho_m*self.param['c_m'])/rho_mean - \\\n deta_x_dT*(c_mean/rho_mean)*drho_etax\n dc_deta_g = (rho_g*self.param['c_g'] - rho_m*self.param['c_m'])/rho_mean - (c_mean/rho_mean)*drho_etag + \\\n deta_x_deta_g*(rho_x*self.param['c_x'] - rho_m*self.param['c_m'])/rho_mean - \\\n deta_x_deta_g*(c_mean/rho_mean)*drho_etax\n tmp_M6 = rho_mean*c_mean*X[T_val]\n tmp_M7 = X[P_val]/tmp_M6/self.param['beta_r']\n tmp_M8 = self.param['L_m']*eta_x*rho_x/tmp_M6\n tmp_M9 = self.param['L_e']*meq*eta_m*rho_m/tmp_M6\n a3 = tmp_M7 +1./beta_mean + dc_dP/c_mean \\\n - tmp_M8*(1./self.param['beta_x'] + 1./self.param['beta_r']) \\\n - tmp_M9*(dmeq_dP/meq + 1./self.param['beta_m'] + 1./self.param['beta_r']) \\\n b3 = -1.*self.param['alpha_r']*X[P_val]/tmp_M6 - alpha_mean + (delta_rho_xm/rho_mean)*deta_x_dT \\\n + dc_dT/c_mean +1./X[T_val] - self.param['alpha_r'] \\\n - tmp_M8*(-self.param['alpha_x'] - self.param['alpha_r'] + deta_x_dT/eta_x) \\\n - tmp_M9*(dmeq_dT/meq - self.param['alpha_m'] - self.param['alpha_r'] - deta_x_dT/eta_m)\n c3 = (delta_rho_gm/rho_mean) + (delta_rho_xm/rho_mean)*deta_x_deta_g \\\n + dc_deta_g/c_mean \\\n - self.param['L_m']*rho_x*deta_x_deta_g/tmp_M6 \\\n - self.param['L_e']*meq*rho_m*(1. + deta_x_deta_g)/tmp_M6\n tmp_M10 = tmp_M6*X[V_val]\n d3 = H_in/tmp_M10 - H_out/tmp_M10 - (1. - tmp_M8 - tmp_M9)*overpressure/eta_crust\n #########################################################\n matrix1 = np.array([[a1, b1, c1], [a2, b2, c2], [a3, b3, c3]], dtype=np.float)\n matrix2 = np.array([[d1, b1, c1], [d2, b2, c2], [d3, b3, c3]], dtype=np.float)\n matrix3 = np.array([[a1, d1, c1], [a2, d2, c2], [a3, d3, c3]], dtype=np.float)\n matrix4 = np.array([[a1, b1, d1], [a2, b2, d2], [a3, b3, d3]], dtype=np.float)\n tmp_MM = np.linalg.det(matrix1)\n dt_arry[P_val] = np.linalg.det(matrix2)/tmp_MM\n dt_arry[T_val] = np.linalg.det(matrix3)/tmp_MM\n dt_arry[eta_g_val] = np.linalg.det(matrix4)/tmp_MM\n dt_arry[V_val] = X[V_val]*(overpressure/eta_crust - \\\n self.param['alpha_r']*dt_arry[T_val] + \\\n dt_arry[P_val]/self.param['beta_r']) \\\n dt_arry[rho_m_val] = rho_m*(dt_arry[P_val]/self.param['beta_m'] - \\\n self.param['alpha_m']*dt_arry[T_val])\n dt_arry[rho_x_val] = rho_x*(dt_arry[P_val]/self.param['beta_x'] - \\\n self.param['alpha_x']*dt_arry[T_val])\n\n return dt_arry\n\n def mass_in_func(self,t):\n '''Specify the M_in - mass inflow rate to coupled ode functions\n This method should be over-ridden by daughter classes.\n '''\n m_in = 1. # kg/s\n m_in_water = 0.05*m_in\n eta_g_in = 0.\n T_in = 1200. # kelvin\n eta_x,deta_x_dT,deta_x_deta_g = md_deg.melting_curve_degruyter(T_in,self.plith)\n eta_m = 1. - eta_x\n rho_m0 = 2400. # kg/m^3\n rho_X0 = 2600. # kg/m^3\n rho_mean = eta_x*rho_X0 + eta_m*rho_m0\n c_mean_in = (eta_m*rho_m0*self.param['c_m'] +\n eta_x*rho_X0*self.param['c_X'])/rho_mean\n H_in = c_mean_in*T_in*m_in\n return m_in,m_in_water,H_in\n\n def m_out_func(self,overpressure,eta_x,meq):\n '''Specify the M_out - mass outflow rate to coupled ode functions\n This method can be over-ridden by daughter classes.\n ### Assumptions in the paper :\n # M_in_water = 5 wt% of the melt mass inflow rate\n # M_out_water -> relative amount of water in erupted\n magma is same as chamber water wt - i.e M_out*M_water_chamber\n '''\n func_critical_outpar = self.param['func_critical_outpar']\n delta_Pc,eta_x_C,M_out_rate = func_critical_outpar()\n if (overpressure >= delta_Pc & eta_x <= eta_x_C):\n M_out = M_out_rate\n else :\n M_out = 0.\n m_out_water = meq*M_out\n return M_out,m_out_water\n\n def state_var_update_func(self,X_new):\n ''' A daughter can over-write this to save more variables if needed ...\n '''\n counter = 0\n lst_extra_var = ['eta_x','eta_m','rho_g','delta_P','mass_inflow','mass_outflow','eta_crust','R_0','meq']\n for varname, value in self.state.items():\n try:\n if (self.solve_me[varname] == True):\n # append with each timestep\n self.state[varname].append_val(X_new[counter])\n counter += 1\n if varname in lst_extra_var:\n self.state[varname].append_val(self.diagnostics[varname]) # append with each timestep\n except:\n pass\n\n\n self.param['delta_Pc'] = delta_Pc # Critical Overpressure (MPa)\n self.param['eta_x_max'] = eta_x_max # Locking fraction\n"
},
{
"alpha_fraction": 0.5058823823928833,
"alphanum_fraction": 0.6094117760658264,
"avg_line_length": 37.6363639831543,
"blob_id": "f50ce3929140ca7be5772e41f52cbc7ef00acee0",
"content_id": "8416480098af28135d9a6921efcc054d8d81a5c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 11,
"path": "/PyMagmaCh/utils/cCO2.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "def cCO2(bCO2,bH2O,f) :\n '''\n Calculate concentrations of water and CO2 in the melt for a given bulk\n composition and degree of melting\n '''\n D_h2o=0.01 # Katz, 2003\n D_co2=0.0001; # highly incompatible; cf. E.H. Hauri et al. / Earth and Planetary Science Letters 248 (2006) 715?734\n # Xmelt = Xbulk / (D + F(1-D))\n H2O=bH2O/(D_h2o + f*(1.-D_h2o));\n CO2=bCO2/(D_co2 + f*(1.-D_co2));\n return CO2,H2O\n"
},
{
"alpha_fraction": 0.5171874761581421,
"alphanum_fraction": 0.5914062261581421,
"avg_line_length": 35.57143020629883,
"blob_id": "1121291bb8aefa14cb063998f0cb9c07e3ca50fb",
"content_id": "602c51a1bc4fab968eb7ca04ebde327ba050bfda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1280,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 35,
"path": "/PyMagmaCh/utils/qcalc_maxF.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom PyMagmaCh.utils import constants as const\n\ndef qf_calc_maxF(t,qf_timescale,factor=3,maxF=0.1) :\n # Calculate q, the vertical melt flux/second, and F, the degree of\n # melting\n F_factor=1./20.*(maxF/0.15)\n # t and qf_timescale should both be in years.\n mu=2.2*qf_timescale;\n sigma=qf_timescale;\n\n #q=6000*normpdf(t,mu,sigma); % assume a total vertical thickness of lava of 6000 m.\n #q=6000*factor*normpdf(t,mu,sigma); % assume a total vertical thickness of lava of 6000 m., and assume 2:1 I:E ratio\n #q=6000*factor*wblpdf(t+qf_timescale/20,mu,1.5);\n q=6000*factor*wblpdf(t+(qf_timescale)**.8,mu,1.5);\n q=q/const.seconds_per_year #% q was in units of m/year. convert to meters/sec.\n\n rng('shuffle')\n x=-4*pi+t/qf_timescale*4*pi;\n #% F=1/20*(atan(x)+atan(6*pi)); %max F=0.2\n #% F=1/30*(atan(x)+atan(6*pi)); % max F=0.1\n F= F_factor*(atan(x)+atan(6*pi)); % max F set by user\n\n if t>qf_timescale\n dorand=rand;\n if dorand>(0.94+(0.04*(t-qf_timescale)/1e6))\n F=0.15*rand;\n if F<0.01\n F=0.01;\n q=.05*rand;\n q=q/(365*24*3600); % q was in units of m/year. convert to meters/sec.\n\n if F<0.005\n F=0.005;\n return q,F\n"
},
{
"alpha_fraction": 0.5898130536079407,
"alphanum_fraction": 0.61717689037323,
"avg_line_length": 36.28282928466797,
"blob_id": "0d724d4327e20f750ab0d9697b78f3b248406342",
"content_id": "df8c7f69dbbd40d711e1a9679e22ab955ea4ba3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3691,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 99,
"path": "/PyMagmaCh_Single/old_files/stopChamber.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "from crystal_fraction import crystal_fraction\nfrom exsolve import exsolve\nfrom eos_g import eos_g\nimport numpy as np\nimport scipy\nimport sys\n\n## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n#sw = [False,False,False,False,False]\ndef stopChamber(t,y,sw):\n # Local Variables: direction, value2, P_crit, isterminal, eruption, Q_out, value, P, value4, value1c, T, value1a, y, value3, eps_g, P_0, value1b\n # Function calls: disp, eps_x, stopChamber, isnan\n P = y[0]\n T = y[1]\n eps_g = y[2]\n P_0 = 200e6\n P_crit = 20e6\n value1a = eps_g #% Detect eps_g approaching 0\n eps_x, tmp1,tmp2= crystal_fraction(T,eps_g)\n value1b = eps_x\n value1c = eps_x/(1.-eps_g)-0.8 # 80% crystals in magma crystal mixture ..\n value2 = eps_x-0.5\n if sw[4] : # is True (eruption)\n value3 = P_0-P\n else : # no eruption\n value3 = (P-P_0)-P_crit\n value = np.array([value1a, value1b, value1c,value2,value3])\n #print('heress')\n #isterminal = np.array([1, 1, 1, 1, 1,1]) #% Stop the integration\n #direction = np.array([0, 0, 0, 1, 1, 0])\n return value\n\n#Helper function for handle_event\ndef event_switch(solver, event_info):\n \"\"\"\n Turns the switches.\n \"\"\"\n for i in range(len(event_info)): #Loop across all event functions\n if event_info[i] != 0:\n solver.sw[i] = not solver.sw[i] #Turn the switch\n\ndef handle_event(solver, event_info):\n \"\"\"\n Event handling. This functions is called when Assimulo finds an event as\n specified by the event functions.\n \"\"\"\n event_info = event_info[0] #We only look at the state events information.\n while True: #Event Iteration\n event_switch(solver, event_info) #Turns the switches\n b_mode = stopChamber(solver.t, solver.y, solver.sw)\n init_mode(solver) #Pass in the solver to the problem specified init_mode\n a_mode = stopChamber(solver.t, solver.y, solver.sw)\n event_info = check_eIter(b_mode, a_mode)\n #print(event_info)\n if not True in event_info: #sys.exit()s the iteration loop\n break\n\ndef init_mode(solver):\n \"\"\"\n Initialize the DAE with the new conditions.\n \"\"\"\n ## No change in the initial conditions (i.e. the values of the parameters when the eruption initiates .. - like P,V, ... T)\n ## Maybe can use it to switch pore-pressure degassing on/off during eruption\n #solver.y[1] = (-1.0 if solver.sw[1] else 3.0)\n #solver.y[2] = (0.0 if solver.sw[2] else 2.0)\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n if (solver.sw[3] ==True) and (solver.sw[4] == True):\n print('critical pressure reached but eps_x>0.5.')\n sys.exit(solver.t)\n\n if True in solver.sw[0:4] :\n print('Reached the end of the calculations since : ')\n if solver.sw[0] :\n print('eps_g became 0.')\n elif solver.sw[1] :\n print('eps_x became 0.')\n elif solver.sw[2] :\n print('eps_x/(1-eps_g) became 0.8')\n elif solver.sw[3] :\n print('eps_x became 0.5')\n sys.exit(solver.t)\n #solver.t0 = t_final*(0.9)\n #return 0\n\n#Helper function for handle_event\ndef check_eIter(before, after):\n \"\"\"\n Helper function for handle_event to determine if we have event\n iteration.\n Input: Values of the event indicator functions (state_events)\n before and after we have changed mode of operations.\n \"\"\"\n eIter = [False]*len(before)\n\n for i in range(len(before)):\n if (before[i] < 0.0 and after[i] > 0.0) or (before[i] > 0.0 and after[i] < 0.0):\n eIter[i] = True\n\n return eIter\n"
},
{
"alpha_fraction": 0.4549492299556732,
"alphanum_fraction": 0.5526649951934814,
"avg_line_length": 28.735849380493164,
"blob_id": "0d594a65af891c7427635f10dd86f7d32e1cd600",
"content_id": "2ce7c184e0d16800c9281cc3580a029571d08b97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3152,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 106,
"path": "/PyMagmaCh/utils/solubulity.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef solubility_Iacano(bCO2,bH2O,P_pascal,T,sio2,tio2,al2o3,feo,fe2o3,mgo,cao,na2o,k2o) : ## output is [CO2 H2O]\n '''\n P in Pascal, T in K!!!\n Give weight percent of different oxides\n Calculate joint solubility of water and CO2 in the melt\n Using the equations in:\n Iacono-Marziano, Giada, Yann Morizet, Emmanuel Le Trong,\n and Fabrice Gaillard. \"New experimental data and semi-empirical\n parameterization of H 2 O?CO 2 solubility in mafic melts.\"\n Geochimica et Cosmochimica Acta 97 (2012): 1-23.\n '''\n P = P_pascal*1e-5 # pressure in bars\n #Constants (anhydrous)\n #Table 5\n dh2o=2.3\n dAI= 3.8\n dfeomgo=-16.3\n dnak=20.1\n aco2=1.0\n bco2=15.8\n Cco2=0.14\n Bco2=-5.3\n #Table 6\n ah2o=0.54\n bh2o=1.24\n Bh2o= -2.95\n Ch2o=0.02\n #Convert weight percent of different oxides to mole fractions\n msio2=sio2/60.08\n mtio2=tio2/80.0\n mal2o3=al2o3/101.96\n mfeo=feo/71.84+2.0*fe2o3/159.69\n mmgo=mgo/40.3\n mcao=cao/56.08\n mna2o=na2o/61.98\n mk2o=k2o/94.2\n mh2o=bH2O/18.0\n mTot=msio2+mtio2+mal2o3+mfeo+mmgo+mcao+mna2o+mk2o\n XK2O=mk2o/mTot\n XNa2O=mna2o/mTot\n XCaO=mcao/mTot\n XMgO=mmgo/mTot\n XFeO=mfeo/mTot\n XAl2O3=mal2o3/mTot\n XSiO2=msio2/mTot\n XTiO2=mtio2/mTot\n Xh2o=mh2o/mTot # mole fraction in the melt\n xAI=XAl2O3/(XCaO+XK2O+XNa2O)\n xfeomgo=XFeO+XMgO\n xnak=XNa2O+XK2O\n ##########################################################\n #Calculate NBO/O (See appendix 1, Iacono-Marziano et al.)\n #X_[...] is the mole fraction of different oxides.\n NBO=2.*(XK2O + XNa2O + XCaO + XMgO + XFeO - XAl2O3)\n O=(2.*XSiO2 + 2.*XTiO2+3.*XAl2O3 + XMgO + XFeO + XCaO + XNa2O + XK2O)\n nbo_o=NBO/O\n\n closeenough=0.0\n xco2=0.999 #xco2=(bCO2/44e4)/(bCO2/44e4+mh2o)\n xh2o=1.-xco2 # mole fraction in the vapor\n mindiff= 0.01\n maxh2o=1.\n maxco2=1.\n minco2=0.0\n n=0.0\n while (closeenough==0) and (n<30) :\n n=n+1\n #Pco2 is total pressure * xco2\n Pco2=P*xco2\n #Ph2o is total pressure * xh2o\n Ph2o=P*xh2o\n #ppm\n lnCO2=(Xh2o*dh2o+xAI*dAI+xfeomgo*dfeomgo+xnak*dnak)+aco2*np.log(Pco2)+bco2*(nbo_o)+Bco2+Cco2*P/T\n CO2=np.exp(lnCO2)\n #wt#\n lnH2O=ah2o*np.log(Ph2o)+bh2o*nbo_o+Bh2o+Ch2o*P/T\n H2O=np.exp(lnH2O)\n vCO2=bCO2-CO2\n vH2O=bH2O-H2O\n if (vCO2<0) and (vH2O<0) :\n break\n elif (vCO2<0) :\n maxco2=xco2.copy()\n xh2o=(xh2o+maxh2o)/2.\n xco2=1.0 - xh2o\n elif (vH2O<0) :\n maxh2o=xh2o.copy()\n xco2=(xco2+maxco2)/2.\n xh2o=1.0 -xco2\n else :\n xCO2m=(CO2/44e4)/(CO2/44e4+H2O/18)\n xH2Om=1.-xCO2m\n # xco2=(xco2+xCO2m)/2\n if (xCO2m>xco2) :\n xh2o=(xh2o+maxh2o)/2.\n maxco2=xco2.copy()\n xco2=1.-xh2o\n else :\n maxco2=xco2.copy()\n xh2o=(xh2o+maxh2o)/2.\n xco2=1. -xh2o\n if (np.abs(xco2-xCO2m)<mindiff):\n closeenough = 1\n return CO2,H2O # CO2 in ppm, H2O in wt %\n"
},
{
"alpha_fraction": 0.5077720284461975,
"alphanum_fraction": 0.5299723744392395,
"avg_line_length": 52.96122360229492,
"blob_id": "8275a7d6da390d0e87352322333708ad1e559f82",
"content_id": "a388c27e81db82d37eb374b8f3bc67ea8416d50c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26441,
"license_type": "no_license",
"max_line_length": 284,
"num_lines": 490,
"path": "/PyMagmaCh_Single/working_1km_body/mainChamber_working_Final.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "## This is a cleaned, pythonic version of a single magma chamber model based on the Degruyter model ..\n\nfrom numpy import pi\nfrom assimulo.problem import Explicit_Problem\nimport numpy as np\nimport constants as const\nfrom numpy.linalg import det\n\n\nimport model_degruyter as md_deg\nfrom PyMagmaCh_Single.Analytical_sol_cavity_T_Use import Analytical_sol_cavity_T_Use\n#from Analytical_sol_cavity_T_grad_Use import Analytical_sol_cavity_T_grad_Use\nimport sys\n\nclass append_me:\n def __init__(self):\n self.data = np.empty((100,))\n self.capacity = 100\n self.size = 0\n\n def update(self, row):\n #for r in row:\n self.add(row)\n\n def add(self, x):\n if self.size == self.capacity:\n self.capacity *= 4\n newdata = np.empty((self.capacity,))\n newdata[:self.size] = self.data\n self.data = newdata\n self.data[self.size] = x\n self.size += 1\n\n def finalize(self):\n self.data = self.data[:self.size]\n\n#Extend Assimulos problem definition\nclass Chamber_Problem(Explicit_Problem):\n '''\n P - In Pa\n T - In Kelvin\n Parent class for box model of a magma chamber -\n Typically solve for P,V,T + other things - >\n This model only works for single P,T + other things for the chamber (no spatial grid in chamber ...)\n Where is the botteneck - the ODE solver used can handle only dP/dt , dT/dt etc\n Need a different setup for the case of a spatial grid in the chamber (Too complicated likely ...)\n Sequence - solve coupled ode's for the variables\n '''\n def __init__(self,depth=1e3,chamber_shape='spherical',**kwargs):\n super(Chamber_Problem, self).__init__(**kwargs)\n self.name='Spherical Magma Chamber model'\n self.param={}\n self.process_type = 'explicit'\n self.chamber_shape = chamber_shape\n self.param['crustal_density'] = md_deg.crust_density\n self.param['depth'] = depth\n self.plith = self.calc_lith_pressure(depth)\n mat_const = self.get_constants()\n self.param.update(mat_const) # specify the constants for the model\n self.solve_me ={} ## List of the variables to solve in the model.\n self.solve_me['P'] = True\n self.solve_me['T'] = True\n self.solve_me['V'] = True\n self.solve_me['eta_g'] = True\n self.solve_me['rho_m'] = True\n self.solve_me['rho_x'] = True\n self.param['T_S']=500.+400. # Background crustal temp\n # These are default functions - can be replaced by something else if needed\n self.param['crustal_viscosity'] = md_deg.crustal_viscosity_degruyter\n self.param['func_melting_curve'] = md_deg.melting_curve_degruyter # was crystal_fraction.py\n self.param['func_gas_density'] = md_deg.gas_density_degruyter # was eos_g.py\n self.param['func_solubility_water'] = md_deg.solubulity_curve_degruyter # was exsolve.py\n delta_Pc,eta_x_max,M_out_rate = md_deg.crit_outflow_degruyter() # These are the default values\n self.param['delta_Pc'] = delta_Pc # Critical Overpressure (MPa)\n self.param['eta_x_max'] = eta_x_max # Locking fraction\n self.param['M_out_rate'] = M_out_rate # # kg/s\n self.param['func_mout'] = md_deg.huppert_outflow # # lambda factor from Huppert and Woods 2003,eqn 7\n self.param['heat_cond'] = 1 # Turn on/off heat conduction\n self.param['visc_relax'] = 1 # Turn on/off viscous relaxation\n self.param['press_relax'] = 1 ## Turn on/off pressure diffusion\n self.param['vol_degass'] = 1 # Volatile degassing on/off\n self.param['T_in'] = 1200.\n self.param['eps_g_in'] = 0.0 # Gas fraction of incoming melt - gas phase ..\n self.param['m_eq_in'] = 0.05 # Volatile fraction of incoming melt\n self.param['Mdot_in'] = 1 # Input mass flux\n self.tcurrent = 0.0\n self.dt = 0.0\n self.dt_counter = 0.0\n self.R_steps = 500\n self.param['frac_rad_Temp'] =0.5\n self.param['frac_rad_press'] =0.1\n self.param['frac_rad_visc'] =0.1\n self.param['material'] = 1 # Granite , 2 is Sandstone\n self.param['degass_frac_chm'] = 0.25\n self.param['frac_length'] = 0.2\n self.flux_in_vol = append_me()#np.array([1e-7])\n self.flux_in_vol.update(1e-7)\n self.flux_out_vol = append_me() #np.array([1e-7])\n self.flux_out_vol.update(1e-7)\n\n def calc_lith_pressure(self,depth):\n return depth*const.g_earth*self.param['crustal_density']\n\n def get_constants(self):\n '''\n Get material constants - can over-write this ..\n '''\n return md_deg.material_constants_degruyter()\n\n def rhs(self,t,y,sw) :\n '''\n The right-hand-side function (rhs) for the integrator\n '''\n func_melting_curve = self.param['func_melting_curve']\n func_gas_density = self.param['func_gas_density']\n func_solubility_water = self.param['func_solubility_water']\n func_crus_visc =self.param['crustal_viscosity']\n func_outflow_huppert = self.param['func_mout']\n ######################################################################################################\n eruption = sw[4] # This tells whether eruption is yes or no\n P = y[0]\n T = y[1]\n inside_loop = 0\n if t > self.tcurrent :\n self.dt = t-self.tcurrent\n self.dt_counter +=self.dt\n self.tcurrent = t\n if (eruption ==0) and (self.dt_counter/self.dt_init > 0.95) :\n inside_loop = 1\n self.dt_counter = 0.\n self.P_list.update(P-self.plith)\n self.T_list.update(T-self.param['T_S'])\n self.times_list.update(t)\n self.T_out,self.P_out,self.sigma_rr,self.sigma_theta,self.T_der = Analytical_sol_cavity_T_Use(self.T_list.data[:self.max_count],self.P_list.data[:self.max_count],self.radius,self.times_list.data[:self.max_count],self.R_outside,self.permeability,self.param['material'])\n self.max_count +=1\n #self.T_out_p2,self.P_out_p2 = Analytical_sol_cavity_T_grad_Use(self.T_flux_list,self.P_flux_list,self.radius,self.times_list,self.R_outside,self.permeability,self.param['material'])\n #self.T_out = self.T_out_p1 #+ self.T_out_p2\n #self.P_out = self.P_out_p1 #+ self.P_out_p2\n #pdb.set_trace()\n self.P_out_all = np.vstack([self.P_out_all,self.P_out])\n self.T_out_all = np.vstack([self.T_out_all,self.T_out])\n self.sigma_rr_all = np.vstack([self.sigma_rr_all,self.sigma_rr])\n self.sigma_theta_all = np.vstack([self.sigma_theta_all,self.sigma_theta])\n self.sigma_eff_rr_all = np.vstack([self.sigma_eff_rr_all,self.sigma_rr + self.P_out])\n self.sigma_eff_theta_all = np.vstack([self.sigma_eff_theta_all,self.sigma_theta+self.P_out])\n if eruption ==1 :\n inside_loop = 1\n self.dt_counter = 0.\n self.P_list.update(P-self.plith)\n self.T_list.update(T-self.param['T_S'])\n self.times_list.update(t)\n self.T_out,self.P_out,self.sigma_rr,self.sigma_theta,self.T_der = Analytical_sol_cavity_T_Use(self.T_list.data[:self.max_count],self.P_list.data[:self.max_count],self.radius,self.times_list.data[:self.max_count],self.R_outside,self.permeability,self.param['material'])\n self.max_count +=1\n self.P_out_all = np.vstack([self.P_out_all,self.P_out])\n self.T_out_all = np.vstack([self.T_out_all,self.T_out])\n self.sigma_rr_all = np.vstack([self.sigma_rr_all,self.sigma_rr])\n self.sigma_theta_all = np.vstack([self.sigma_theta_all,self.sigma_theta])\n self.sigma_eff_rr_all = np.vstack([self.sigma_eff_rr_all,self.sigma_rr + self.P_out])\n self.sigma_eff_theta_all = np.vstack([self.sigma_eff_theta_all,self.sigma_theta+self.P_out])\n else :\n self.dt = 0.\n #print(self.dt/3e7,self.tcurrent/(3600.*24.*365.))\n eps_g = y[2]\n V = y[3]\n dV_dP = V/self.param['beta_r']\n dV_dT = -V*self.param['alpha_r']\n rho_m = y[4]\n drho_m_dP = rho_m/self.param['beta_m']\n drho_m_dT = -rho_m*self.param['alpha_m']\n rho_x = y[5]\n drho_x_dP = rho_x/self.param['beta_x']\n drho_x_dT = -rho_x*self.param['alpha_x']\n eps_x, deps_x_dT, deps_x_deps_g = func_melting_curve(T, eps_g) #(T,eps_g,b = 0.5,T_s=973.0,T_l=1223.0)\n rho_g, drho_g_dP, drho_g_dT = func_gas_density(T,P)\n\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x;\n drho_dP = (1.-eps_g-eps_x)*drho_m_dP + eps_g*drho_g_dP + eps_x*drho_x_dP;\n drho_dT = (1.-eps_g-eps_x)*drho_m_dT + eps_g*drho_g_dT + eps_x*drho_x_dT;\n drho_deps_g = -rho_m + rho_g;\n drho_deps_x = -rho_m + rho_x;\n\n # % exsolution\n m_eq,dm_eq_dP,dm_eq_dT = func_solubility_water(T,P)\n\n c = ((1.-eps_g-eps_x)*rho_m*self.param['c_m'] + eps_g*rho_g*self.param['c_g'] + eps_x*rho_x*self.param['c_x'])/rho;\n dc_dP = (1./rho)*((1-eps_g-eps_x)*self.param['c_m']*drho_m_dP + eps_g*self.param['c_g']*drho_g_dP + eps_x*self.param['c_x']*drho_x_dP) - (c/rho)*drho_dP;\n dc_dT = (1./rho)*((1-eps_g-eps_x)*self.param['c_m']*drho_m_dT + eps_g*self.param['c_g']*drho_g_dT + eps_x*self.param['c_x']*drho_x_dT) - (c/rho)*drho_dT;\n dc_deps_g = (1./rho)*(-rho_m*self.param['c_m'] + rho_g*self.param['c_g']) - (c/rho)*drho_deps_g;\n dc_deps_x = (1./rho)*(-rho_m*self.param['c_m'] + rho_x*self.param['c_x']) - (c/rho)*drho_deps_x;\n\n #% boundary conditions\n T_in = self.param['T_in']\n eps_g_in = self.param['eps_g_in']\n m_eq_in = self.param['m_eq_in']\n eps_x_in,tmp1,tmp2 = func_melting_curve(T_in,eps_g_in);\n rho_g_in,tmp1,tmp2 = func_gas_density(T_in,P);\n\n rho_m_in = rho_m # Same density as present melt\n rho_x_in = rho_x # Same density as present crystals\n rho_in = (1-eps_g_in-eps_x_in)*rho_m_in + eps_g_in*rho_g_in + eps_x_in*rho_x_in\n c_in = ((1-eps_g_in-eps_x_in)*rho_m_in*self.param['c_m'] + eps_g_in*rho_g_in*self.param['c_g'] + eps_x_in*rho_x_in*self.param['c_x'])/rho_in #;%c;\n\n Mdot_in = self.param['Mdot_in']\n Mdot_v_in = m_eq_in*rho_m_in*(1.-eps_g_in-eps_x_in)*Mdot_in/rho_in + rho_g_in*eps_g_in*Mdot_in/rho_in\n Hdot_in = c_in*T_in*Mdot_in\n\n a = (V/(4.*pi/3))**(1./3.)\n P_lit = self.plith\n indx_use_P = np.where(self.R_outside <=(1.+self.param['frac_rad_press'])*a)\n indx_use_T = np.where(self.R_outside <=(1.+self.param['frac_rad_Temp'])*a)\n indx_use_visc = np.where(self.R_outside <=(1.+self.param['frac_rad_visc'])*a)\n visc_gas = 2.414*1e-5*(10.**(247.8/(T-140.))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009\n mean_T_der_out = np.mean(self.T_der[indx_use_T])\n mean_T_out = np.mean(self.T_out[indx_use_T]) + self.param['T_S'];\n mean_P_out = np.mean(self.P_out[indx_use_P]) + self.plith\n mean_sigma_rr_out = -np.mean(self.sigma_rr[indx_use_visc]) + self.plith\n #############################################################\n #% set outflow conditions\n if eruption == 0:\n if self.param['vol_degass'] == 1.:\n surface_area_chamber_degassing = 4.*pi*a**2.*self.param['degass_frac_chm']\n delta_P_grad = (P - mean_P_out)/a/self.param['frac_length']\n # U_og = md_deg.func_Uog(eps_g,eps_x,m_eq,rho_m,rho_g,T,delta_P_grad,r_b = 100*1e-6)\n # Mdot_out1 = eps_g*rho_g*surface_area_chamber_degassing*U_og\n # degass_hdot_water1 = self.param['c_g']*T*Mdot_out1\n #pdb.set_trace()\n # if np.abs(Mdot_out) > 5 :\n # pdb.set_trace()\n #if np.abs(P-mean_P_out)/1e6 > 10 :\n # pdb.set_trace()\n #print(Mdot_out)\n ################## Flux out of the chamber due to pressure gradient in the crust ..\n visc_gas = 2.414*1e-5*(10.**(247.8/(T-140))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009\n U_og2 = (self.permeability/visc_gas)*(delta_P_grad) # Note that there is no buoyancy term since the fluid is in equilbrium (Pressure is perturbation oer bkg)\n Mdot_out = eps_g*rho_g*surface_area_chamber_degassing*U_og2\n degass_hdot_water = self.param['c_g']*T*Mdot_out\n # tmp1_sign = np.sign(Mdot_out1/Mdot_out2)\n # if (tmp1_sign == 1.0) :\n # if (np.abs(Mdot_out2) > np.abs(Mdot_out1)) :\n # Mdot_out = Mdot_out2 #+ Mdot_out1\n # degass_hdot_water = degass_hdot_water2\n # else :\n # Mdot_out = Mdot_out1 #+ Mdot_out1\n # degass_hdot_water = degass_hdot_water1\n # else :\n # Mdot_out = Mdot_out2 + Mdot_out1\n # degass_hdot_water = degass_hdot_water2 +degass_hdot_water1\n # #Mdot_out = Mdot_out2 #+ Mdot_out1\n #degass_hdot_water = degass_hdot_water2 #+degass_hdot_water1\n #print(Mdot_out2,eps_g)\n # Q_fluid_flux_out = (Mdot_out - Mdot_out2)/surface_area_chamber_degassing/rho_g # extra term for the pressure equation .., m/s (i.e a velocity )\n # QH_fluid_flux_out = np.copy(degass_hdot_water)/surface_area_chamber_degassing # W/m^2\n else :\n Mdot_out = 0.\n degass_hdot_water = 0.\n Mdot_v_out = np.copy(Mdot_out) # mass loss = water loss rate\n elif eruption == 1.:\n ##########################\n surface_area_chamber_degassing = 4.*pi*a**2.*self.param['degass_frac_chm']\n delta_P_grad = (P - mean_P_out)/a/self.param['frac_length']\n visc_gas = 2.414*1e-5*(10.**(247.8/(T-140))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009\n U_og2 = (self.permeability/visc_gas)*(delta_P_grad) # Note that there is no buoyancy term since the fluid is in equilbrium (Pressure is perturbation oer bkg)\n Mdot_out2 = eps_g*rho_g*surface_area_chamber_degassing*U_og2\n degass_hdot_water = self.param['c_g']*T*Mdot_out2\n ##########################\n P_buoyancy = -(rho - self.param['crustal_density'])*const.g_earth*a # delta_rho*g*h\n Mdot_out1 = func_outflow_huppert(eps_x,m_eq,T,rho,self.param['depth'])*(P-P_lit + P_buoyancy) #self.param['M_out_rate'] #\n Mdot_v_out = m_eq*rho_m*(1.-eps_g-eps_x)*Mdot_out1/rho + rho_g*eps_g*Mdot_out1/rho + Mdot_out2\n Mdot_out = Mdot_out1 + Mdot_out2\n #pdb.set_trace()\n #print(Mdot_out/1e4)\n else:\n print('eruption not specified')\n #############################################################\n if (inside_loop == 1) :\n if eruption ==0 :\n # self.P_flux_list = np.hstack([self.P_flux_list,Q_fluid_flux_out])\n # self.T_flux_list = np.hstack([self.T_flux_list,QH_fluid_flux_out])\n self.flux_in_vol.update(Mdot_v_in)\n self.flux_out_vol.update(Mdot_v_out)\n else :\n # self.P_flux_list = np.hstack([self.P_flux_list,0]) # no extra flux term ...\n # self.T_flux_list = np.hstack([self.T_flux_list,0]) # no extra flux term ...\n #pdb.set_trace()\n self.flux_in_vol.update(Mdot_v_in)\n self.flux_out_vol.update(Mdot_v_out)\n #############################################################\n if self.param['heat_cond'] == 1.:\n #pdb.set_trace()\n if t<30e7 : # Initially the gradients are kind of large .. so may be unstable ..\n small_q = -self.param['k_crust']*(mean_T_out-T)/(self.param['frac_rad_Temp']*a)\n else :\n small_q = -self.param['k_crust']*mean_T_der_out #*(mean_T_out-T)/(self.param['frac_rad_Temp']*a)\n #print((mean_T_out-T)/(self.param['frac_rad_Temp']*a),mean_T_der_out)\n #small_q2 = -self.param['k_crust']*(self.param['T_S']-300.)/(self.param['depth'])\n small_q2 = -self.param['k_crust']*(300.-self.param['T_S'])/(self.param['depth'])\n surface_area_chamber = 4.*pi*a**2.\n Q_out = small_q*surface_area_chamber + small_q2*surface_area_chamber\n elif self.param['heat_cond'] == 0.:\n Q_out = 0.\n else:\n print('heat_cond not specified')\n if np.isnan(Q_out):\n Q_out = 0.\n print('Q_out is NaN')\n\n if eruption == 0. :\n Hdot_out = Q_out +degass_hdot_water\n elif eruption == 1.:\n Hdot_out = c*T*Mdot_out1 + Q_out + degass_hdot_water\n else:\n print('eruption not specified')\n # #############################################################\n #% viscous relaxation\n #length_met = a*(self.param['frac_rad_press']) # 1000.; %2.*a; %1000; % Typical lengthscale for pressure diffusion ... (metamorphic aureole length-scale)\n eta_r_new = func_crus_visc(self.T_out[indx_use_visc],self.R_outside[indx_use_visc])\n #eta_r_new = 10.**20.\n #print(np.log10(eta_r_new))\n #% crustal viscosity (Pa s)\n if self.param['visc_relax'] == 1.:\n #P_loss1 = (P-self.plith)/eta_r_new\n P_loss1 = (P-mean_sigma_rr_out)/eta_r_new\n elif self.param['visc_relax'] == 0.:\n P_loss1 = 0.\n else:\n print('visc_relax not specified')\n if self.param['press_relax'] ==1 :\n P_loss2 = np.tanh(eps_g*100.)*(self.permeability/visc_gas)*(P - mean_P_out)/(self.param['frac_rad_press']*a)**2. # Set that the P_loss2 is only when eps_g > 0.02\n elif self.param['press_relax'] ==0 :\n P_loss2 = 0;\n else:\n print('press_relax not specified')\n #print(P_loss1/P_loss2)\n P_loss = P_loss1 + P_loss2;\n self.sigma_rr_eff = -(self.sigma_rr + self.P_out)/1e6 # in Pa\n self.mean_sigma_rr_eff = np.mean(self.sigma_rr_eff[indx_use_P])\n #if (eruption == 0.) and (np.abs(self.mean_sigma_rr_eff) > 20):\n # print('EEEE')\n # % coefficients in the system of unknowns Ax = B, here x= [dP/dt dT/dt dphi/dt]\n # % note: P, T, and phi are y(1), y(2) and y(3) respectively\n # % values matrix A\n # % conservation of (total) mass\n a11 = (1/rho)*drho_dP + (1/V)*dV_dP\n a12 = (1./rho)*drho_dT + (1./V)*dV_dT + (1./rho)*drho_deps_x*deps_x_dT\n a13 = (1/rho)*drho_deps_g + (1/rho)*drho_deps_x*deps_x_deps_g\n #% conservation of volatile mass\n a21 = (1/rho_g)*drho_g_dP + (1/V)*dV_dP \\\n + (m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g)*((1/m_eq)*dm_eq_dP + (1/rho_m)*drho_m_dP + (1/V)*dV_dP)\n a22 = (1/rho_g)*drho_g_dT + (1/V)*dV_dT \\\n + (m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g)*((1/m_eq)*dm_eq_dT + (1/rho_m)*drho_m_dT + (1/V)*dV_dT \\\n - deps_x_dT/(1-eps_g-eps_x))\n a23 = 1/eps_g - (1+deps_x_deps_g)*m_eq*rho_m/(rho_g*eps_g)\n #% conservation of (total) enthalpy\n a31 = (1/rho)*drho_dP + (1/c)*dc_dP + (1/V)*dV_dP \\\n + (self.param['L_e']*rho_g*eps_g)/(rho*c*T)*((1/rho_g)*drho_g_dP + (1/V)*dV_dP) \\\n - (self.param['L_m']*rho_x*eps_x)/(rho*c*T)*((1/rho_x)*drho_x_dP + (1/V)*dV_dP)\n a32 = (1/rho)*drho_dT + (1/c)*dc_dT + (1/V)*dV_dT + 1/T \\\n + (self.param['L_e']*rho_g*eps_g)/(rho*c*T)*((1/rho_g)*drho_g_dT + (1/V)*dV_dT) \\\n - (self.param['L_m']*rho_x*eps_x)/(rho*c*T)*((1/rho_x)*drho_x_dT + (1/V)*dV_dT) \\\n + ((1/rho)*drho_deps_x + (1/c)*dc_deps_x - (self.param['L_m']*rho_x)/(rho*c*T))*deps_x_dT\n a33 = (1/rho)*drho_deps_g + (1/c)*dc_deps_g \\\n + (self.param['L_e']*rho_g)/(rho*c*T) \\\n + ((1/rho)*drho_deps_x + (1/c)*dc_deps_x - (self.param['L_m']*rho_x)/(rho*c*T))*deps_x_deps_g\n #% values vector B\n #% conservation of (total) mass\n b1 = (Mdot_in - Mdot_out)/(rho*V) - P_loss\n #% conservation of volatile mass\n b2 = (Mdot_v_in - Mdot_v_out)/(rho_g*eps_g*V) - P_loss*(1+(m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g))\n #% conservation of (total) enthalpy\n b3 = (Hdot_in - Hdot_out)/(rho*c*T*V) - P_loss*(1-(self.param['L_m']*rho_x*eps_x)/(rho*c*T)+(self.param['L_e']*rho_g*eps_g)/(rho*c*T) - P/(rho*c*T));\n #% set up matrices to solve using Cramer's rule\n A = np.array([[a11,a12,a13],[a21,a22,a23],[a31,a32,a33]])\n A_P = np.array([[b1,a12,a13],[b2,a22,a23],[b3,a32,a33]])\n A_T = np.array([[a11,b1,a13],[a21,b2,a23],[a31,b3,a33]])\n A_eps_g = np.array([[a11,a12,b1],[a21,a22,b2],[a31,a32,b3]])\n det_A = det(A)\n dP_dt = det(A_P)/det_A\n dT_dt = det(A_T)/det_A\n deps_g_dt = det(A_eps_g)/det_A\n dV_dt = dV_dP*dP_dt + dV_dT*dT_dt + V*P_loss\n drho_m_dt = drho_m_dP*dP_dt + drho_m_dT*dT_dt\n drho_x_dt = drho_x_dP*dP_dt + drho_x_dT*dT_dt\n dydz = np.zeros(6)\n #% column vector\n dydz[0] = dP_dt\n dydz[1] = dT_dt\n dydz[2] = deps_g_dt\n dydz[3] = dV_dt\n dydz[4] = drho_m_dt\n dydz[5] = drho_x_dt\n return dydz\n\n def state_events(self,t,y,sw):\n '''\n Local Variables: direction, value2, P_crit, isterminal, eruption, Q_out, value, P, value4, value1c, T, value1a, y, value3, eps_g, P_0, value1b\n '''\n func_melting_curve = self.param['func_melting_curve']\n func_gas_density = self.param['func_gas_density']\n func_solubility_water = self.param['func_solubility_water']\n P = y[0]\n T = y[1]\n eps_g = y[2]\n V = y[3]\n rho_m = y[4]\n rho_x = y[5]\n eps_x, tmp1,tmp2 = func_melting_curve(T, eps_g) #(T,eps_g,b = 0.5,T_s=973.0,T_l=1223.0)\n rho_g, tmp1,tmp2 = func_gas_density(T,P)\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x;\n P_0 = self.plith\n P_crit = self.param['delta_Pc']\n value1a = eps_g #% Detect eps_g approaching 0\n value1b = eps_x\n value1c = eps_x/(1.-eps_g)-0.8 # 80% crystals in magma crystal mixture ..\n value2 = eps_x-self.param['eta_x_max']\n a = (V/(4.*pi/3))**(1./3.)\n P_buoyancy = -(rho - self.param['crustal_density'])*const.g_earth*a # delta_rho*g*h\n #print(P_buoyancy/1e6)\n if sw[4] : # is True (eruption)\n value3 = P_0 - P\n else : # no eruption\n value3 = (P-P_0 + P_buoyancy) - P_crit\n value = np.array([value1a, value1b, value1c,value2,value3])\n #print('heress')\n #isterminal = np.array([1, 1, 1, 1, 1,1]) #% Stop the integration\n #direction = np.array([0, 0, 0, 1, 1, 0])\n return value\n\n #Helper function for handle_event\n def event_switch(self,solver, event_info):\n \"\"\"\n Turns the switches.\n \"\"\"\n for i in range(len(event_info)): #Loop across all event functions\n if event_info[i] != 0:\n solver.sw[i] = not solver.sw[i] #Turn the switch\n\n def handle_event(self,solver, event_info):\n \"\"\"\n Event handling. This functions is called when Assimulo finds an event as\n specified by the event functions.\n \"\"\"\n event_info = event_info[0] #We only look at the state events information.\n while True: #Event Iteration\n self.event_switch(solver, event_info) #Turns the switches\n b_mode = self.state_events(solver.t, solver.y, solver.sw)\n self.init_mode(solver) #Pass in the solver to the problem specified init_mode\n a_mode = self.state_events(solver.t, solver.y, solver.sw)\n event_info = self.check_eIter(b_mode, a_mode)\n #print(event_info)\n if not True in event_info: #sys.exit()s the iteration loop\n break\n\n def init_mode(self,solver):\n \"\"\"\n Initialize the DAE with the new conditions.\n \"\"\"\n ## No change in the initial conditions (i.e. the values of the parameters when the eruption initiates .. - like P,V, ... T)\n ## Maybe can use it to switch pore-pressure degassing on/off during eruption\n #solver.y[1] = (-1.0 if solver.sw[1] else 3.0)\n #solver.y[2] = (0.0 if solver.sw[2] else 2.0)\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n if (solver.sw[3] ==True) and (solver.sw[4] == True):\n print('critical pressure reached but eps_x>0.5.')\n sys.exit(solver.t)\n if True in solver.sw[0:4] :\n print('Reached the end of the calculations since : ')\n if solver.sw[0] :\n print('eps_g became 0.')\n elif solver.sw[1] :\n print('eps_x became 0.')\n elif solver.sw[2] :\n print('eps_x/(1-eps_g) became 0.8')\n elif solver.sw[3] :\n print('eps_x became 0.5')\n sys.exit(solver.t)\n return 0\n\n #Helper function for handle_event\n def check_eIter(self,before, after):\n \"\"\"\n Helper function for handle_event to determine if we have event\n iteration.\n Input: Values of the event indicator functions (state_events)\n before and after we have changed mode of operations.\n \"\"\"\n eIter = [False]*len(before)\n for i in range(len(before)):\n if (before[i] < 0.0 and after[i] > 0.0) or (before[i] > 0.0 and after[i] < 0.0):\n eIter[i] = True\n return eIter\n"
},
{
"alpha_fraction": 0.8061836361885071,
"alphanum_fraction": 0.8094139099121094,
"avg_line_length": 73.75862121582031,
"blob_id": "dd5796ecc56c51ae71a0dfeddea512f0a017d0d9",
"content_id": "99263ed2e35052b86f82616675478ccd1e537d3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 2167,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 29,
"path": "/notes.txt",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "March 5th/6th 2018 :\n\nConclusions from the foray into thinking about a stepped version for the Laplace domain solutions (why can't change the\npermeability etc) :\n\na. The solution is most straightforwardly defined for homogeneous initial conditions in the Laplace space - in other words,\nthe solution is calculated most easily when the equations are homogeneous (when converting the two temp and pressure coupled\nequations into a set of uncoupled 4th order ode's). In order to calculate the solution for this non-homonegeonous (if the\ninitial conditions are not homogeneous) ode, the general + specific solution requires an integral that is difficult/not clear how to\ndo analytically. Furthermore, the solution is needed as a step in pluggin in the initial conditions to calculate the\nconstants as well as followed by laplace inversion numerically most likely. All of this is prone to numerical challenges and will\nbe likely pretty slow ..\n\nb. Same type of issues show up if one tries to make permeability a function of time (or even just sums of Heavyside functions)\nsince the laplace transform of a f(x)g(x) is not straightforward enough for the subsequent steps. There are additional intrinsic\nissues with making the permeability pressure or space/temp dependent - both in terms of assumptions of derivations as well\nas procedural/numerics.\n\n\nc. Seems that likely the most feasible thing to do is to use the uncoupled thermo-poro-elastic solutions ---\nhere the temperature is uncoupled (small error at best since no convection anyways) while the poro/elasto is fully coupled.\n\nWe can then use the Green's function approach to calculate the solution for the pressure and temp with initial conditions\nspecified. This Green's function is seemingly only tractible for the case of the fixed temp/pressure bndry condition - not the flux\nboundary condition.\n\nSo, to first order, it seems reasonable to incur a small penalty with that - use always the fully coupled solution with\nconstant properties for the flux (fluid flux from magma chamber) - note that this extra flux term is needed in our equations\nsince we do not calculate the convective heat flux piece explicitly."
},
{
"alpha_fraction": 0.5490952134132385,
"alphanum_fraction": 0.5757935047149658,
"avg_line_length": 41.40251541137695,
"blob_id": "55099bf483b8cc3b3c2c117197ee25ab04d14bcd",
"content_id": "a5fefc5f2bba206506e51406bdca3c73a637e1ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6742,
"license_type": "no_license",
"max_line_length": 241,
"num_lines": 159,
"path": "/PyMagmaCh_Single/old_files/test_disc.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as numpy\nfrom numpy import pi\nfrom PyMagmaCh_Single.Analytical_sol_cavity_T_Use import Analytical_sol_cavity_T_Use\nimport pylab as plt\nimport PyMagmaCh_Single.input_functions as md_deg\nfrom PyMagmaCh_Single.plot_mainChamber import plot_mainChamber\nfrom PyMagmaCh_Single.mainChamber_working_Final import Chamber_Problem\nfrom assimulo.solvers import CVode\n\n\n#% set the mass inflow rate\nmdot = 1. #; % mass inflow rate (kg/s) #% use global variable\ndepth = 7841.0\nwith_plots = True\n\n##############################################\n#% time\nend_time = 3e7*80000.#; % maximum simulation time in seconds\nbegin_time = 0 #; % initialize time\n##############################################\n\ndef func_set_system():\n ##############################################\n #% initial conditions\n P_0 = 200e6 #; % initial chamber pressure (Pa)\n T_0 = 1200 #; % initial chamber temperature (K)\n eps_g0 = 0.04 #; % initial gas volume fraction\n rho_m0 = 2650 #; % initial melt density (kg/m^3)\n rho_x0 = 3065 #; % initial crystal density (kg/m^3)\n a = 1000 #; % initial radius of the chamber (m)\n V_0 = (4.*pi/3.)*a**3. #; % initial volume of the chamber (m^3)\n\n ##############################################\n ##############################################\n IC = numpy.array([P_0,T_0,eps_g0,V_0,rho_m0,rho_x0]) # % store initial conditions\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n\n sw0 = [False,False,False,False,False]\n\n ##############################################\n #% error tolerances used in ode method\n dt = 30e7\n N = int(round((end_time-begin_time)/dt))\n ##############################################\n\n #Define an Assimulo problem\n exp_mod = Chamber_Problem(depth=depth,t0=begin_time,y0=IC,sw0=sw0)\n exp_mod.param['Mdot_in'] = mdot\n exp_mod.param['delta_Pc'] = 20e6\n exp_mod.tcurrent = begin_time\n exp_mod.radius = a\n exp_mod.permeability = 1e-19\n exp_mod.R_steps = 1000\n exp_mod.dt_init = dt\n #################\n exp_mod.R_outside = numpy.linspace(a,3.*a,exp_mod.R_steps);\n exp_mod.T_out_all =numpy.array([exp_mod.R_outside*0.])\n exp_mod.P_out_all =numpy.array([exp_mod.R_outside*0.])\n exp_mod.sigma_rr_all = numpy.array([exp_mod.R_outside*0.])\n exp_mod.sigma_theta_all = numpy.array([exp_mod.R_outside*0.])\n exp_mod.sigma_eff_rr_all = numpy.array([exp_mod.R_outside*0.])\n exp_mod.sigma_eff_theta_all = numpy.array([exp_mod.R_outside*0.])\n\n exp_mod.P_list = numpy.array([P_0-exp_mod.plith])\n exp_mod.T_list = numpy.array([T_0-exp_mod.param['T_S']])\n exp_mod.times_list = numpy.array([1e-7])\n exp_mod.T_out,exp_mod.P_out,exp_mod.sigma_rr,exp_mod.sigma_theta,exp_mod.T_der= Analytical_sol_cavity_T_Use(exp_mod.T_list,exp_mod.P_list,exp_mod.radius,exp_mod.times_list,exp_mod.R_outside,exp_mod.permeability,exp_mod.param['material'])\n exp_mod.param['heat_cond'] = 1 # Turn on/off heat conduction\n exp_mod.param['visc_relax'] = 1 # Turn on/off viscous relaxation\n exp_mod.param['press_relax'] = 0 ## Turn on/off pressure diffusion\n exp_mod.param['frac_rad_Temp'] =0.75\n exp_mod.param['vol_degass'] = 0.\n #exp_mod.state_events = stopChamber #Sets the state events to the problem\n #exp_mod.handle_event = handle_event #Sets the event handling to the problem\n #Sets the options to the problem\n #exp_mod.p0 = [beta_r, beta_m]#, beta_x, alpha_r, alpha_m, alpha_x, L_e, L_m, c_m, c_g, c_x, eruption, heat_cond, visc_relax] #Initial conditions for parameters\n #exp_mod.pbar = [beta_r, beta_m]#, beta_x, alpha_r, alpha_m, alpha_x, L_e, L_m, c_m, c_g, c_x, eruption, heat_cond, visc_relax]\n\n #Define an explicit solver\n exp_sim = CVode(exp_mod) #Create a CVode solver\n\n #Sets the parameters\n #exp_sim.iter = 'Newton'\n #exp_sim.discr = 'BDF'\n #exp_sim.inith = 1e-7\n\n exp_sim.rtol = 1.e-7\n exp_sim.maxh = 3e7\n exp_sim.atol = 1e-7\n exp_sim.sensmethod = 'SIMULTANEOUS' #Defines the sensitvity method used\n exp_sim.suppress_sens = False #Dont suppress the sensitivity variables in the error test.\n #exp_sim.usesens = True\n #exp_sim.report_continuously = True\n return exp_mod,exp_sim,N\n\nexp_mod,exp_sim,N = func_set_system()\n#Simulate\nt_final_new = 0.\ntry :\n t1, y1 = exp_sim.simulate(end_time,N) #Simulate 5 seconds\n exp_sim.print_event_data()\nexcept SystemExit:\n print('Stop Before end_time')\n t_final_new = exp_sim.t*0.9999\n exp_mod,exp_sim,N = func_set_system()\n t1, y1 = exp_sim.simulate(t_final_new,N)\n\nprint('Final Stopping time : %.2f Yrs' % (t_final_new/(3600.*24.*365.)))\n\n\nif with_plots:\n t1 = numpy.asarray(t1)\n y1 = numpy.asarray(y1)\n #IC = numpy.array([P_0,T_0,eps_g0,V_0,rho_m0,rho_x0]) # % store initial conditions\n P = y1[:,0]\n T = y1[:,1]\n eps_g = y1[:,2]\n V = y1[:,3]\n rho_m = y1[:,4]\n rho_x = y1[:,5]\n size_matrix = numpy.shape(P)[0]\n\n #%crystal volume fraction\n eps_x = numpy.zeros(size_matrix)\n #% dissolved water mass fraction\n m_eq = numpy.zeros(size_matrix)\n #% gas density\n rho_g = numpy.zeros(size_matrix)\n\n for i in range(0,size_matrix) :\n eps_x[i],tmp1,tmp2 = md_deg.melting_curve_degruyter(T[i],eps_g[i]);\n m_eq[i],tmp1,tmp2 = md_deg.solubulity_curve_degruyter(T[i],P[i])\n rho_g[i],tmp1,tmp2 = md_deg.gas_density_degruyter(T[i],P[i])\n #% bulk density\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x\n #% bulk heat capacity\n c = ((1-eps_g-eps_x)*rho_m*exp_mod.param['c_m'] + eps_g*rho_g*exp_mod.param['c_g'] + eps_x*rho_x*exp_mod.param['c_x'])/rho;\n plot_mainChamber(t1,V,P,T,eps_x,eps_g,rho,'no_diff_')\n\nplt.ion()\nplt.show()\n\nplt.figure(10)\nX,Y = numpy.meshgrid(exp_mod.R_outside,exp_mod.times_list)\nplt.contourf(X,Y/3e7,(exp_mod.P_out_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\nplt.savefig('No_diff_P_fl.pdf')\n\nplt.figure(11)\nX,Y = numpy.meshgrid(exp_mod.R_outside,exp_mod.times_list)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\nplt.savefig('No_diff_sigma_rr.pdf')\n\nplt.figure(12)\nX,Y = numpy.meshgrid(exp_mod.R_outside,exp_mod.times_list)\nplt.contourf(X,Y/3e7,-(exp_mod.sigma_eff_rr_all/1e6),20,cmap='coolwarm')\nplt.colorbar()\nplt.savefig('No_diff_sigma_rr_eff.pdf')\n"
},
{
"alpha_fraction": 0.554390549659729,
"alphanum_fraction": 0.6083879470825195,
"avg_line_length": 40.46739196777344,
"blob_id": "71adfd099b831f92dc428a9532f194508f3b24c0",
"content_id": "0fb390259550c7d338e1ef7555bfe04c81d603c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3815,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 92,
"path": "/PyMagmaCh/utils/constants.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "'''constants.py\n\nA collection of physical constants for the magma chamber models.\n\nPart of the machlab package\nBen Black, Tushar Mittal\n'''\n\nimport numpy as np\n\na_earth = 6367444.7 # Radius of Earth (m)\na_mars = 3386000.0 # Radius of Mars (m)\ng_earth = 9.807 # gravitational acceleration Earth (m / s**2)\ng_mars = 3.711 # gravitational acceleration Mars (m / s**2)\n\n# Some useful time conversion factors\nseconds_per_minute = 60.\nminutes_per_hour = 60.\nhours_per_day = 24.\n\n# the length of the \"tropical year\" -- time between vernal equinoxes\ndays_per_year = 365.2422\nseconds_per_hour = minutes_per_hour * seconds_per_minute\nminutes_per_day = hours_per_day * minutes_per_hour\nseconds_per_day = hours_per_day * seconds_per_hour\nseconds_per_year = seconds_per_day * days_per_year\nminutes_per_year = seconds_per_year / seconds_per_minute\nhours_per_year = seconds_per_year / seconds_per_hour\n# average lenghts of months based on dividing the year into 12 equal parts\nmonths_per_year = 12.\nseconds_per_month = seconds_per_year / months_per_year\nminutes_per_month = minutes_per_year / months_per_year\nhours_per_month = hours_per_year / months_per_year\ndays_per_month = days_per_year / months_per_year\n\n######################################################\n# Some parameter values\n######################################################\n\nrho_water = 1000. # density of water (kg / m**3)\ncp_water = 4181.3 # specific heat of liquid water (J / kg / K)\n\ntempCtoK = 273.15 # 0degC in Kelvin\ntempKtoC = -tempCtoK # 0 K in degC\nbar_to_Pa = 1e5 # conversion factor from bar to Pa\n\nkBoltzmann = 1.3806488E-23 # the Boltzmann constant (J / K)\nc_light = 2.99792458E8 # speed of light (m/s)\nhPlanck = 6.62606957E-34 # Planck's constant (J s)\n# Stef_Boltz_sigma = 5.67E-8 # Stefan-Boltzmann constant (W / m**2 / K**4)\n# Stef_Boltz_sigma derived from fundamental constants\nStef_Boltz_sigma = (2*np.pi**5 * kBoltzmann**4) / (15 * c_light**2 * hPlanck**3)\n\n######################################################\n\ncrys_frac_lock_Marsh = 0.55 # critical crystal fraction for crystal locking\n # (Marsh 2015, Treatise of Geophysics Vol2)\n\nD_h2o_Katz2003 = 0.01; # constant from Katz, 2003 hydrous melting model\nD_co2_Katz2003 = 0.0001; # CO2 is highly incompatible;\n # cf. E.H. Hauri et al. / EPSL 248 (2006) 715?734\n # Used to calculate the conc. of water and CO2 in melt\n # for given bulk composition and degree of melting\n##########################################################\n# Some constants for the code - default values ...\n\nmoho_depth = 30.*1e3 # Set default extent of the depth domain to be 30 km\nregion_size = 100.*1e3 # Set default extent of the x_val domain to be 100 km\nsurface_temp = 288. # Surface temperature is fixed to 288 Kelvin\ngeotherm_grad = 30. # Kelvin/km, typical geotherm_gradient\n\n\n\n######################################################\n# Things to add : Have some standard parameter values for things like\n# basalts, ultramafic melts, pyrolitic, garnet etc\n# have latent heat, density, viscosity model, composition\n\nLhvap = 2.5E6 # Latent heat of vaporization (J / kg)\nLhsub = 2.834E6 # Latent heat of sublimation (J / kg)\nLhfus = Lhsub - Lhvap # Latent heat of fusion (J / kg)\ncp = 1004. # specific heat at constant pressure for dry air (J / kg / K)\nRd = 287. # gas constant for dry air (J / kg / K)\nkappa = Rd / cp\nRv = 461.5 # gas constant for water vapor (J / kg / K)\n\n######################################################\n# From Ben's model\ncp_cc_Ben = 0.8e3 # J/kg/K quartz\ncp_mag_Ben = 0.84e3 # J/kg/K basalt\nk_Ben = 1.5 # Thermal conductivity (W/m/C)\nrhocrust_Ben = 3000. # density kg/m3\n"
},
{
"alpha_fraction": 0.7103225588798523,
"alphanum_fraction": 0.7135483622550964,
"avg_line_length": 39.78947448730469,
"blob_id": "97013a31375361420397faf94086efa5f87f31ec",
"content_id": "1fb9ca068e1eb053c87fa2633c0e9130a78b8cf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1550,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 38,
"path": "/PyMagmaCh/process/explicit_eg/convadj.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom climlab import constants as const\nfrom climlab.process.time_dependent_process import TimeDependentProcess\nfrom climlab.domain.field import Field\n\n\nclass ConvectiveAdjustment(TimeDependentProcess):\n '''Convective adjustment process\n Instantly returns column to neutral lapse rate\n\n Adjustment includes the surface IF 'Ts' is included in the state\n dictionary. Otherwise only the atmopsheric temperature is adjusted.'''\n def __init__(self, adj_lapse_rate=None, **kwargs):\n super(ConvectiveAdjustment, self).__init__(**kwargs)\n self.param['adj_lapse_rate'] = adj_lapse_rate\n self.time_type = 'adjustment'\n self.adjustment = {}\n\n def compute(self):\n #lapse_rate = self.param['adj_lapse_rate']\n Tadj = convective_adjustment_direct(self.pnew, Tcol, self.cnew, lapserate=self.adj_lapse_rate)\n Tatm = Field(Tadj[...,1:], domain=self.Tatm.domain)\n self.adjustment['Ts'] = Ts - self.Ts\n self.adjustment['Tatm'] = Tatm - self.Tatm\n\n\n# @jit # numba.jit not working here. Not clear why.\n# At least we get something like 10x speedup from the inner loop\n# Attempt to use numba to compile the Akamaev_adjustment function\n# which gives at least 10x speedup\n# If numba is not available or compilation fails, the code will be executed\n# in pure Python. Results should be identical\ntry:\n from numba import jit\n Akamaev_adjustment = jit(signature_or_function=Akamaev_adjustment)\n #print 'Compiling Akamaev_adjustment() with numba.'\nexcept:\n pass\n"
},
{
"alpha_fraction": 0.4550339877605438,
"alphanum_fraction": 0.5152521133422852,
"avg_line_length": 54.5,
"blob_id": "e92457971a40f9caf30be8bd5f30f5010b437637",
"content_id": "921d1a697c0b5da364f42093fe971eedb7e03142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6327,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 114,
"path": "/PyMagmaCh_Single/Analytical_sol_cavity_T_grad_Use.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "#import warnings\n#import pdb\n# import numpy as np\n# from numpy import sqrt,pi,exp\n# from scipy.special import erfc\n# import input_functions as md_deg\n\ndef Analytical_sol_cavity_T_grad_Use(T_R,P_R,R_chamber,t,R_val,permeability,material) :\n #warnings.simplefilter(\"error\", \"RuntimeWarning\")\n # try :\n # tmp1 = t.shape[1]\n # except IndexError :\n # t = np.expand_dims(t,1)\n # try :\n # tmp1 = R_val.shape[1]\n # except IndexError :\n # R_val = np.expand_dims(R_val,1)\n # tmp1 = md_deg.gas_density_degruyter(1000,200e6)\n # Kf = 1./(tmp1[1]/tmp1[0])\n # #% Constants in the problem are the various poro-elastic coefficients\n # if (material ==1): #%Westerly granite\n # G = 1.5e10 #% Pa\n # K = 2.5e10 #% Pa\n # K_u = 3.93e10 #% Pa\n # Ks = 4.5e10\n # phi = 0.01\n # visc = 2.414*1e-5*(10.**(247.8/(600.-140))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009 #% Pa s\n # M = (Kf*Ks*Ks)/(Kf*(Ks-K) + phi*Ks*(Ks-Kf)) #% Pa\n # S = (3.*K_u + 4*G)/(M*(3.*K + 4.*G)) #% 1/Pa\n # c = permeability/S/visc #% m^2\n # beta_c = 6.65e-6 # % /K (Table 11.2), W\n # alpha_e = beta_c/S#= 3.58e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n # kappa_T = 1.09e-6 # % m^2/s\n # m_d = 7.85e3/20. #%J/m^3\n # eta_d = 2e5 #%N/m^2/K\n # alpha_d = 6e5 #% N/m^2/K\n # eta = 0.150 #% unitless\n # k_T = 2.5 # W/m/K\n # if (material ==2) :#% berea Sandstone\n # G = 6e9 #% Pa\n # K = 8e9 #% Pa\n # K_u = 1.4e10 #% Pa\n # K_s = 3.6e10\n # phi = 0.15\n # visc = 2.414*1e-5*(10.**(247.8/(600.-140))) #;% - from Rabinowicz 1998/Eldursi EPSL 2009 #% Pa s\n # M = (Kf*Ks*Ks)/(Kf*(Ks-K) + phi*Ks*(Ks-Kf)) #% Pa\n # S = (3.*K_u + 4*G)/(M*(3.*K + 4*G)) #% 1/Pa\n # c = permeability/S/visc #% m^2\n #\n # beta_c = 4.08e-5 # % /K (Table 11.2), Westerly granite\n # alpha_e = beta_c/S #= 2.94e5 #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n # kappa_T = 1.27e-6 # % m^2/s\n # m_d = 6.01e3/20. #%J/m^3\n # eta_d = 1.35e4 #%N/m^2/K\n # alpha_d = 3.6e4 #% N/m^2/K\n # k_T = 2.24 # W/m/K\n # eta = 0.292 #\n # S_a = m_d + alpha_d*eta_d/G\n # c_a = m_d*kappa_T/S_a\n # alpha_p = beta_c/S_a # #% N/m^2/K = beta_c/S, (Table 11.2), Westerly granite\n # C_Q = np.sqrt( (c -c_a)**2. + 4.*c*c_a*alpha_p*alpha_e ) ##\n # lam1 = np.sqrt(((c +c_a) + C_Q)/2./c/c_a) ##\n # lam2 = np.sqrt(((c +c_a) - C_Q)/2./c/c_a) ##\n ##############################################\n # time_new = t[-1] - t + 1e-8 ## % Added the 1e-8 to make sure a min time is not zero\n # tmp_one_t = np.ones([np.shape(time_new)[0],np.shape(time_new)[1]])\n # R_steps = np.shape(R_val)[0] ##\n # tmp_one_R = np.ones([np.shape(R_val)[0],np.shape(R_val)[1]])\n Diff_temp_arr = np.hstack([T_R[0],np.diff(T_R)])/k_T\n Diff_press_arr = np.hstack([P_R[0],np.diff(P_R)])*(visc/permeability)\n #term_T = np.zeros([R_steps,np.size(T_R)])\n #term_P = np.zeros([R_steps,np.size(T_R)])\n T_sigma_rr = np.zeros([R_steps,np.size(T_R)])\n T_sigma_theta = np.zeros([R_steps,np.size(T_R)])\n\n A_1 = Diff_temp_arr*R_chamber*R_chamber*(c-c_a+C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber\n A_2 = Diff_temp_arr*R_chamber*R_chamber*(c-c_a-C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber\n A_3 = (Diff_temp_arr*R_chamber*R_chamber*(c-c_a+C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber)*(c-c_a-C_Q)\n A_4 = (Diff_temp_arr*R_chamber*R_chamber*(c-c_a-C_Q) - 2.*Diff_press_arr*alpha_p*c*R_chamber*R_chamber)*(c-c_a+C_Q)\n\n term1 = (1./C_Q)/R_val\n term1aa = lam1*(R_val - R_chamber)/2./np.sqrt(time_new.T)\n term1a = erfc(term1aa) - exp((R_val - R_chamber)/R_chamber + time_new.T/(lam1*R_chamber)**2.)*erfc(term1aa + np.sqrt(time_new.T)/(lam1*R_chamber))\n term1bb = lam2*(R_val - R_chamber)/2./np.sqrt(time_new.T)\n term1b = erfc(term1bb) - exp((R_val - R_chamber)/R_chamber + time_new.T/(lam2*R_chamber)**2.)*erfc(term1bb + np.sqrt(time_new.T)/(lam2*R_chamber))\n term_T = (-term1/2.)*(A_1*term1a - A_2*term1b)\n term_P = (term1/(4.*c*alpha_p))*(-A_3*term1a + A_4*term1b)\n\n #term_T_der = -(term1/2./R_val)*( A_1*erfc(term1a) - A_2*erfc(term1b) ) + (term1/2.)*(-2.*A_1*(lam1/np.sqrt(pi)/np.sqrt(time_new.T))*np.exp(-term1a**2.) + 2.*A_2*(lam2/np.sqrt(pi)/np.sqrt(time_new.T))*np.exp(-term1b**2.))\n\n # term_int1 = -((R_val + R_chamber)/lam1)*sqrt(time_new.T/pi)*exp(-term1a**2.) + (0.5*tmp_one_t.T*(R_val**2. - R_chamber**2.) -tmp_one_R*time_new.T/lam1**2)*erfc(term1a)\n # term_int2 = -((R_val + R_chamber)/lam2)*sqrt(time_new.T/pi)*exp(-term1b**2.) + (0.5*tmp_one_t.T*(R_val**2. - R_chamber**2.) -tmp_one_R*time_new.T/lam2**2)*erfc(term1b)\n # term_R2T = (1./C_Q/2.)*(A_1*term_int1 - A_2*term_int2)\n # term_R2P = (1./C_Q)*(1./(4.*c*alpha_p))*(A_3*term_int1 - A_4*term_int2)\n # term_int_A2a = tmp_one_R*(2.*R_chamber/lam1)*sqrt(time_new.T/pi) + tmp_one_R*time_new.T/lam1**2.#\n # term_int_A2b = tmp_one_R*(2.*R_chamber/lam2)*sqrt(time_new.T/pi) + tmp_one_R*time_new.T/lam2**2.#\n # term_A2 = (eta/C_Q/G)*(1./(4.*c*alpha_p))*(A_3*term_int_A2a - A_4*term_int_A2b) + (eta_d/C_Q/G)*(1./2.)*(A_1*term_int_A2a - A_2*term_int_A2b) + (R_chamber**3.)*(1./4./G)*tmp_one_R*Diff_press_arr.T#\n # T_sigma_rr = -4.*eta*term_R2P/(R_val**3.) -4.*eta_d*term_R2T/(R_val**3.) -4.*G*term_A2/(R_val**3.)#\n # T_sigma_theta = 2.*eta*term_R2P/(R_val**3) +2.*eta_d*term_R2T/(R_val**3.) +2.*G*term_A2/(R_val**3) - 2.*eta*term_P - 2.*eta_d*term_T#\n\n # %Diff_press_arr\n # %size(term_A2),term_A2b\n # %t(end),term_P(isnan(term_P))\n T_val = np.sum(term_T,1)#\n P_val = np.sum(term_P,1)#\n # sigma_rr = np.sum(T_sigma_rr,1)#\n # sigma_theta = np.sum(T_sigma_theta,1)#\n #sigma_rr_eff = sigma_rr + P_val\n #sigma_theta_eff = sigma_theta + P_val\n #T_der = np.sum(term_T_der,1)\n #T_der[0] = T_der[1] # first value is messy and large .. so remove it ..\n P_val[P_val<1e-6] = 0\n T_val[T_val<1e-6] = 0\n return T_val,P_val#,sigma_rr,sigma_theta,T_der\n"
},
{
"alpha_fraction": 0.5759980082511902,
"alphanum_fraction": 0.5775091052055359,
"avg_line_length": 36.28168869018555,
"blob_id": "0144996d8b7d5fde76f848ccdfe7869b308a9212",
"content_id": "a2b0952a7ee166537d3ea7ceef3bff04ad99c031",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7941,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 213,
"path": "/PyMagmaCh/process/process.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import time, copy\nimport numpy as np\nfrom PyMagmaCh.A1_domain.field import Field\nfrom PyMagmaCh.A1_domain.domain import _Domain\nfrom PyMagmaCh.utils import walk\n\n# New organizing principle:\n# processes are free to use object attributes to store whatever useful fields\n# the need. If later revisions require some special action to occur upon\n# getting or setting the attribute, we can always implement a property to\n# make that happen with no change in the API\n#\n# the diagnostics dictionary will instead be used expressly for the purpose\n# of passing fields up the process tree!\n# so will often only be set by a parent process (and given a name that is\n# appropriate from the point of view of the parent process)\n\ndef _make_dict(arg, argtype):\n if arg is None:\n return {}\n elif type(arg) is dict:\n return arg\n elif isinstance(arg, argtype):\n return {arg.name: arg}\n else:\n raise ValueError('Problem with input type')\n\n\nclass Process(object):\n '''A generic parent class for all PyMagmaCh process objects.\n Every process object has a set of state variables on a spatial grid.\n Note for input - can either give a single domain or a dict with {domain.name:domain,....}\n Note - state can either be a single field or a dictionary of fields with {field_name :field,....}\n - subprocess can either be a single subprocess or a dictionary of subprocess\n '''\n def __str__(self):\n str1 = 'PyMagmaCh Process of type {0}. \\n'.format(type(self))\n str1 += 'State variables and domain shapes: \\n'\n for varname in self.state.keys():\n str1 += ' {0}: {1} \\n'.format(varname, self.domains[varname].shape)\n str1 += 'The subprocess tree: \\n'\n str1 += walk.process_tree(self)\n return str1\n\n def __init__(self, state=None, domains=None, subprocess=None,\n diagnostics=None,name_inp=None ,**kwargs):\n # dictionary of domains. Keys are the domain names\n self.domains = _make_dict(domains, _Domain)\n # dictionary of state variables (all of type Field)\n self.domains_var = {}\n self.state = {}\n states = _make_dict(state, Field)\n if (state != None):\n for name, value in states.items():\n self.set_state(name, value)\n # dictionary of model parameters\n self.param = kwargs\n # dictionary of diagnostic quantities\n self.diagnostics = _make_dict(diagnostics, Field)\n self.creation_date = time.strftime(\"%a, %d %b %Y %H:%M:%S %z\",\n time.localtime())\n if (name_inp != None) :\n self.name = name_inp\n else :\n self.name = 'None'\n # subprocess is either a single sub-processes or a dictionary of any sub-processes\n if subprocess is None:\n self.subprocess = {}\n else:\n self.add_subprocesses(subprocess)\n\n def add_subprocesses(self, procdict):\n '''Add a dictionary of subproceses to this process.\n procdict is dictionary with process names as keys.\n\n Can also pass a single process, which will be called \\'default\\'\n '''\n if isinstance(procdict, Process):\n self.add_subprocess(procdict.process_name, procdict)\n else:\n for name, proc in procdict.items():\n self.add_subprocess(name, proc)\n\n def add_subprocess(self, name, proc):\n '''Add a single subprocess to this process.\n name: name of the subprocess (str)\n proc: a Process object.'''\n if isinstance(proc, Process):\n self.subprocess.update({name: proc})\n self.has_process_type_list = False\n else:\n raise ValueError('subprocess must be Process object')\n\n def remove_subprocess(self, name):\n '''Remove a single subprocess from this process.\n name: name of the subprocess (str)'''\n self.subprocess.pop(name, None)\n self.has_process_type_list = False\n\n def set_state(self, name, value):\n '''Can either be for the first time - value is a field or\n subsequently changing the value of the field by passing a value array and field_name'''\n if isinstance(value, Field):\n # populate domains dictionary with domains from state variables\n self.domains_var.update({name: value.domain})\n else:\n try:\n thisdom = self.state[name].domain\n thisaxis = self.state[name].axis\n except:\n raise ValueError('State variable needs a domain.')\n value = np.atleast_1d(value)\n value = Field(value, domain=thisdom,axis=thisaxis)\n # set the state dictionary\n self.state[name] = value\n #setattr(self, name, value)\n\n # Some handy shortcuts... only really make sense when there is only\n # a single axis of that type in the process.\n @property\n def x_val(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisxval = dom.axes['x_val'].points\n except:\n pass\n return thisxval\n except:\n raise ValueError('Can\\'t resolve an x_val axis - No domains.')\n\n @property\n def x_val_bounds(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisxval = dom.axes['x_val'].bounds\n except:\n pass\n return thisxval\n except:\n raise ValueError('Can\\'t resolve an x_val axis - No domains.')\n @property\n def y_val(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisyval = dom.axes['y_val'].points\n except:\n pass\n return thisyval\n except:\n raise ValueError('Can\\'t resolve a y_val axis - No domains.')\n @property\n def y_val_bounds(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisyval = dom.axes['y_val'].bounds\n except:\n pass\n return thisyval\n except:\n raise ValueError('Can\\'t resolve a y_val axis - No domains.')\n @property\n def depth(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisdepth = dom.axes['depth'].points\n except:\n pass\n return thisdepth\n except:\n raise ValueError('Can\\'t resolve a depth axis - No domains.')\n @property\n def depth_bounds(self):\n try:\n for domname, dom in self.domains.items():\n try:\n thisdepth = dom.axes['depth'].bounds\n except:\n pass\n return thisdepth\n except:\n raise ValueError('Can\\'t resolve a depth axis - No domains.')\n\n\ndef process_like(proc):\n '''Return a new process identical to the given process.\n The creation date is updated.'''\n newproc = copy.deepcopy(proc)\n newproc.creation_date = time.strftime(\"%a, %d %b %Y %H:%M:%S %z\",\n time.localtime())\n return newproc\n\n\ndef get_axes(process_or_domain):\n '''Return a dictionary of all axes in Process or domain or dict of domains.'''\n if isinstance(process_or_domain, Process):\n dom = process_or_domain.domains\n else:\n dom = process_or_domain\n if isinstance(dom, _Domain):\n return dom.axes\n elif isinstance(dom, dict):\n axes = {}\n for thisdom in dom.values():\n assert isinstance(thisdom, _Domain)\n axes.update(thisdom.axes)\n return axes\n else:\n raise TypeError('dom must be a Process or domain or dictionary of domains.')\n"
},
{
"alpha_fraction": 0.6188470721244812,
"alphanum_fraction": 0.6251645088195801,
"avg_line_length": 36.800994873046875,
"blob_id": "219b30217ed1d67eee9063c395e270427143a920",
"content_id": "78779a13cdf6e4cd9d07639b80d46645b1360b3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7598,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 201,
"path": "/PyMagmaCh/A1_domain/domain.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "# new domain class\n# every process should exist in the context of a domain\nfrom PyMagmaCh.A1_domain.axis import Axis\nfrom PyMagmaCh.utils import constants as const\n\nclass _Domain(object):\n def __str__(self):\n return (\"PymagmaCh Domain object with domain_type=\" + self.domain_type + \" and shape=\" +\n str(self.shape) + \" and name = \" + self.name)\n def __init__(self, axes=None, **kwargs):\n self.name = 'None'\n self.domain_type = 'undefined'\n # self.axes should be a dictionary of axes\n # make it possible to give just a single axis:\n self.axes = self._make_axes_dict(axes)\n self.numdims = len(self.axes.keys())\n shape = []\n axcount = 0\n axindex = {}\n # ordered list of axes\n axlist = list(self.axes)\n #for axType, ax in self.axes.iteritems():\n for axType in axlist:\n ax = self.axes[axType]\n shape.append(ax.num_points)\n # can access axes as object attributes - Access using self.axes\n ## setattr(self, axType, ax)\n axindex[axType] = axcount\n axcount += 1\n self.axis_index = axindex\n self.axcount = axcount\n self.shape = tuple(shape)\n\n def _make_axes_dict(self, axes):\n if type(axes) is dict:\n axdict = axes\n elif type(axes) is Axis:\n ax = axes\n axdict = {ax.axis_type: ax}\n elif axes is None:\n axdict = {'empty': None}\n else:\n raise ValueError('axes needs to be Axis object or dictionary of Axis object')\n return axdict\n\ndef box_model_domain(num_points=2, **kwargs):\n '''Create a box model domain (a single abstract axis).'''\n ax = Axis(axis_type='abstract', num_points=num_points,note='Box Model')\n boxes = _Domain(axes=ax, **kwargs)\n boxes.domain_type = 'box'\n return boxes\n\ndef make_slabatm_axis(num_points=1,bounds=[1,1e3]):\n '''Convenience method to create a simple axis for a slab atmosphere/surface.'''\n depthax = Axis(axis_type='depth', num_points=num_points, bounds=bounds)\n return depthax\n\nclass SlabAtmosphere(_Domain):\n def __init__(self, axes=make_slabatm_axis(), **kwargs):\n super(SlabAtmosphere, self).__init__(axes=axes, **kwargs)\n self.domain_type = 'atm'\n\n\ndef z_column(num_depth=30,depth=None, **kwargs):\n '''Convenience method to create domains for a single depth grid for magma chambers (1D model),\n assume that the x-y extent of the chamber is much larger than the height axis ..\n\n num_depth is the number of depth levels (evenly spaced from surface to moho depth)\n Returns a list of 1 Domain objects (z column)\n\n Usage:\n z_clmn = z_column()\n or\n z_clmn = z_column(num_depth=2)\n print z_clmn\n\n Can also pass a depth array or depth level axis object\n '''\n if depth is None:\n depthax = Axis(axis_type='depth', num_points=num_depth)\n elif isinstance(depth, Axis):\n depthax = depth\n else:\n try:\n depthax = Axis(axis_type='depth', points=depth)\n except:\n raise ValueError('depth must be Axis object or depth array')\n z_clmn = _Domain(axes=depthax, **kwargs)\n z_clmn.domain_type = 'z_column'\n return z_clmn\n\ndef z_column_atm(num_depth=30,depth=None, **kwargs):\n '''Convenience method to create domains for a single depth grid for magma chambers (1D model),\n assume that the x-y extent of the chamber is much larger than the height axis ..\n\n num_depth is the number of depth levels (evenly spaced from surface to moho depth)\n Returns a list of 2 Domain objects (z column, slab atmosphere)\n\n Usage:\n z_clmn, atm_slab = z_column()\n or\n z_clmn, atm_slab = z_column(num_depth=2)\n print z_clmn, atm_slab\n\n Can also pass a depth array or depth level axis object\n '''\n if depth is None:\n depthax = Axis(axis_type='depth', num_points=num_depth)\n elif isinstance(depth, Axis):\n depthax = depth\n else:\n try:\n depthax = Axis(axis_type='depth', points=depth)\n except:\n raise ValueError('depth must be Axis object or depth array')\n atmax = Axis(axis_type='depth',num_points=1, bounds=[1, 1e3]) # set a slab atm/surface model\n atm_slab = SlabAtmosphere(axes=atmax, **kwargs)\n z_clmn = _Domain(axes=depthax, **kwargs)\n z_clmn.domain_type = 'z_column'\n return z_clmn, atm_slab\n\ndef z_radial_column_atm(num_depth=90, num_rad=30, depth=None,\n radial_val=None, **kwargs):\n '''Convenience method to create domains for a single depth grid for\n magma chambers (2D model) + radial grid; assume that the chamber shape is axisymmteric\n\n num_depth is the number of depth levels (evenly spaced from surface to moho depth)\n num_rad is the number of radial levels (evenly spaced from 0 to region_extent)\n Returns a list of 2 Domain objects (z column, slab atmosphere)\n\n Usage:\n z_clmn, atm_slab = z_radial_column()\n or\n z_clmn, atm_slab = z_radial_column(num_depth=90, num_rad=30)\n print z_clmn, atm_slab\n\n Can also pass a depth array or depth level axis object\n '''\n if depth is None:\n depthax = Axis(axis_type='depth', num_points=num_depth)\n elif isinstance(depth, Axis):\n depthax = depth\n else:\n try:\n depthax = Axis(axis_type='depth', points=depth)\n except:\n raise ValueError('depth must be Axis object or depth array')\n if radial_val is None:\n radax = Axis(axis_type='x_val', num_points=num_rad)\n elif isinstance(radial_val, Axis):\n radax = radial_val\n else:\n try:\n radax = Axis(axis_type='x_val', points=radial_val)\n except:\n raise ValueError('radial_val must be Axis object or x_val array')\n atmax = Axis(axis_type='depth',num_points=1, bounds=[1, 1e3]) # set a slab atm/surface model\n atm_slab = SlabAtmosphere(axes={'x_val':radax, 'depth':atmax}, **kwargs)\n z_clmn = _Domain(axes={'x_val':radax, 'depth':depthax}, **kwargs)\n z_clmn.domain_type = 'z_column'\n return z_clmn, atm_slab\n\n\ndef z_radial_column(num_depth=90, num_rad=30, depth=None,\n radial_val=None, **kwargs):\n '''Convenience method to create domains for a single depth grid for\n magma chambers (2D model) + radial grid; assume that the chamber shape is axisymmteric\n\n num_depth is the number of depth levels (evenly spaced from surface to moho depth)\n num_rad is the number of radial levels (evenly spaced from 0 to region_extent)\n Returns a list of 2 Domain objects (z column)\n\n Usage:\n z_clmn = z_radial_column()\n or\n z_clmn = z_radial_column(num_depth=90, num_rad=30)\n print z_clmn\n\n Can also pass a depth array or depth level axis object\n '''\n if depth is None:\n depthax = Axis(axis_type='depth', num_points=num_depth)\n elif isinstance(depth, Axis):\n depthax = depth\n else:\n try:\n depthax = Axis(axis_type='depth', points=depth)\n except:\n raise ValueError('depth must be Axis object or depth array')\n if radial_val is None:\n radax = Axis(axis_type='x_val', num_points=num_rad)\n elif isinstance(radial_val, Axis):\n radax = radial_val\n else:\n try:\n radax = Axis(axis_type='x_val', points=radial_val)\n except:\n raise ValueError('radial_val must be Axis object or x_val array')\n z_clmn = _Domain(axes={'x_val':radax, 'depth':depthax}, **kwargs)\n z_clmn.domain_type = 'z_column'\n return z_clmn\n"
},
{
"alpha_fraction": 0.5206253528594971,
"alphanum_fraction": 0.5976643562316895,
"avg_line_length": 44.376068115234375,
"blob_id": "aa2b574d24e211ece0fb34657076d60a8b94a3a5",
"content_id": "997cf2d5ad03a6868e18658110e9e2bff129aea7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5309,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 117,
"path": "/PyMagmaCh/utils/model_degruyter.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "'''model_degruyer.py\n\nA collection of function definitions to handle common\ncalcualtions (i.e. constants and melting curve, density parameterizations)\nin Degruyter & Huber 2014 paper\n\n'''\nimport numpy as np\nfrom PyMagmaCh.utils import constants as const\n\ncrust_density = 2600. # kg/m^3\n\ndef gas_density_degruyter(T,P):\n \"\"\"Compute equation of state of the gas phase.\n\n Input: T is temperature in Kelvin ( 873 < T < 1173 K )\n P is pressure in Pa (30 Mpa < P < 400 MPa)\n Output: rhog, drhog_dP, drhog_dT (gas density, d(rho_g)/dP and d(rho_g)/dT)\n \"\"\"\n rhog = 1e3*(-112.528*(T**(-0.381)) + 127.811*(P**(-1.135)) + 112.04*(T**(-0.411))*(P**(0.033))) # Units :kg/m^3\n drhog_dT = 1e3*((-0.381)*-112.528*(T**(-1.381)) + (-0.411)*112.04*(T**(-1.411))*(P**(0.033)))\n drhog_dP = 1e-2*((-1.135)*127.811*(P**(-2.135)) + (0.033)*112.04*(T**(-0.411))*(P**(-.9670)))\n return rhog, drhog_dP,drhog_dT\n\ndef melting_curve_degruyter(T,eta_g,b = 0.5,T_s=973.0,T_l=1223.0):\n \"\"\"Compute melt fraction-temperature relationship.\n\n Input: T is temperature in Kelvin\n eta_g is gas volume fraction\n b is an exponent to approximate composition (1 = mafic, 0.5 = silicic)\n T_s is solidus temperature in Kelvin (Default value = 973 K)\n T_l is liquidus temperature in Kelvin (Default value = 1223 K)\n Output: eta_x,deta_x_dT,deta_x_deta_g (eta_x is crystal volume fraction, others are its derivative with T and eta_g)\n \"\"\"\n temp1 = T - T_s\n temp2 = T_l - T_s\n eta_x = (1. - eta_g)*(1. - (temp1/temp2)**b)\n deta_x_dT = (1. - eta_g)*(-b*(temp1)**(b-1.)/(temp2)**b)\n deta_x_deta_g = -1.*(1. - (temp1/temp2)**b)\n return eta_x,deta_x_dT,deta_x_deta_g\n\ndef solubulity_curve_degruyter(T,P):\n \"\"\"Compute solubility - dissolved water content in the melt\n\n Input: T is temperature in Kelvin ( 873 < T < 1173 K )\n P is pressure in Pa (30 Mpa < P < 400 MPa)\n Output: meq,dmeq_dT,dmeq_dP (meq is dissolved water content others are its derivative with T and eta_g)\n \"\"\"\n meq = 1e-2*(np.sqrt(P)*(0.4874 - 608./T + 489530.0/T**2.)\n + P*(-0.06062 + 135.6/T - 69200.0/T**2.)\n + (P**(1.5))*(0.00253 - 4.154/T + 1509.0/T**2.)) # is dimensionless\n dmeq_dP = 1e-8*(0.5*(P**(-0.5))*(0.4874 - 608./T + 489530.0/T**2.)\n + (-0.06062 + 135.6/T - 69200.0/T**2.)\n + 1.5*(P**(0.5))*(0.00253 - 4.154/T + 1509.0/T**2.))\n dmeq_dT = 1e-2*(np.sqrt(P)*(608./T**2.-2*489530.0/T**3.)\n + P*(-135.6/T**2. + 2.*69200.0/T**3.)\n + (P**(1.5))*(4.154/T**2. -2.*1509.0/T**3.))\n return meq,dmeq_dT,dmeq_deta_g\n\n\ndef crit_outflow_degruyter():\n \"\"\"\n Specify the conditions for eruptions according to Degruyter 2014 model\n Pc = critical overpressure\n eta_x = crystal volume fraction\n M_out_rate is the mass outflow rate\n \"\"\"\n delta_Pc = np.randint(10,50) # assume a critical overpressure btw 10 - 50 MPa\n eta_x = 0.5 # based on cystal locking above 50 % packing ..\n M_out_rate = 1e4 # kg/s\n return delta_Pc,eta_x,M_out_rate\n\ndef material_constants_degruyter():\n \"\"\"\n Specify the material constants used in the paper -\n Output as a dictionary ..\n alpha_m = melt thermal expansion coefficient (1/K)\n alpha_x = crystal thermal expansion coefficient (1/K)\n alpha_r = crust thermal expansion coefficient (1/K)\n beta_x = melt bulk modulus (Pa)\n beta_m = crystal bulk modulus (Pa)\n beta_r = crust bulk modulus (Pa)\n k_crust = thermal conductivity of the crust (J/s/m/K)\n c_x,c_g,c_m = specific heat capacities (J/kg/K)\n L_m,L_e = latent heat of melting and exsolution (J/kg)\n kappa = thermal diffusivity of the crust\n \"\"\"\n mat_const = {'beta_m': 1e10, 'alpha_m': 1e-5, 'beta_x': 1e10, 'alpha_x':1e-5, 'beta_r': 1e10, 'alpha_r':1e-5,\n 'k_crust': 3.25,'c_m' : 1200.0,'c_X' : 1200.0,'c_g' : 3880.0,'L_m':27e4,'L_e':226e4,'kappa':1e-6}\n return mat_const\n\n\ndef crustal_viscosity_degruyter(T,p):\n \"\"\"Compute the viscosity of the visco-elastic shell surrounding the magma chamber.\n\n Input: T is temperature in Kelvin\n P\n Output:\n \"\"\"\n\n theta = T*(const.ps/p)**const.kappa\n\ndef crustal_temp_radial_degruyter(R_0,S_scale,T_R,T_s=500.0,kappa=1e-6):\n \"\"\"Analytical solution for the heat conduction equation - heat loss from magam chamber to the surrounding\n - Modeled as chamber being spherical (radius R_0)\n and the curstal section being a larger enclosed sphere (radius S)\n - Assumptions : Chmaber is isothermal (Chamber temp T = T_R)\n Input: T_R is temperature at the edge of the chamber (Kelvin)\n T_S is temperature at the outer boundary of the visco-elastic shell (Kelvin, 500 K)\n kappa is thermal diffusivity of the crust (m^2/s, default = 1e-6 m^2/s)\n Output: dT_dR,eta_crust - temp gradient at chamber edge (R_0) and the averaged crustal viscosity\n dT_dR,eta_crust = crustal_temp_model(R_0,self.diagnostics['S_scale'],\n X[T_val],T_s = self.diagnostics['T_S']),\n kappa = self.param['kappa'])\n \"\"\"\n T_R0 = (R_0*T_R*(S - r) + S*T_S*(r- R_0))/r/(S - R_0) # initial temp T(r,t = 0)\n return dT_dR,eta_crust\n"
},
{
"alpha_fraction": 0.5262046456336975,
"alphanum_fraction": 0.5422757267951965,
"avg_line_length": 54.668701171875,
"blob_id": "e3544306039f8a1f1439a8fa1c78dd25fe026208",
"content_id": "b933727f71954a77f27eec78a0125e2924687c1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36463,
"license_type": "no_license",
"max_line_length": 192,
"num_lines": 655,
"path": "/PyMagmaCh_Single/mainChamber_working_Final.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "## This is a cleaned, pythonic version of a single magma chamber model based on the Degruyter model ..\n\nimport sys\nimport constants as const\nimport numpy as np\nimport pdb\n\nfrom assimulo.problem import Explicit_Problem\nfrom numpy.linalg import det\nimport input_functions\n\nimport Analytical_sol_cavity_T_Use as Anl_sols\n#from Analytical_sol_cavity_T_grad_Use import Analytical_sol_cavity_T_grad_Use\n\nclass Chamber_Problem(Explicit_Problem):\n '''\n Parent class for box model of a magma chamber -\n Typically solve for P,V,T + other things - >\n This model only works for single P,T + other things for the chamber\n (no spatial grid in chamber ...)\n Unit system - mks, --\n == P - In Pa\n == T - In Kelvin\n Where is the botteneck ?\n a. ODE solver used can handle only dP/dt , dT/dt - so an ODE solver\n b. Maybe need a different setup for the case of a spatial grid\n in the chamber (Too complicated for now since the physics is different)\n Sequence -\n solve coupled ode's for the variables\n '''\n\n def __init__(self,radius=1e3,depth=3e3,chamber_shape='spherical',**kwargs):\n super(Chamber_Problem, self).__init__(**kwargs)\n self.name='Spherical Magma Chamber model'\n self.param={}\n self.process_type = 'explicit'\n self.chamber_shape = chamber_shape\n self.input_functions = input_functions.Input_functions()\n self.solve_me =['P','T','eta_g','V','rho_m','rho_x'] ## List of the variables to solve in the model.\n # This a class with the default functions -\n # can be replaced by something else if needed\n self.param['heat_cond'] = 1 # Turn on/off heat conduction\n self.param['visc_relax'] = 1 # Turn on/off viscous relaxation\n self.param['press_relax'] = 1 # Turn on/off pressure diffusion\n self.param['vol_degass'] = 1 # Volatile degassing on/off\n self.tcurrent = 0.0\n self.dt = 0.0\n self.dt_counter = 0.0\n #self.dt_crst = 3e7 # Minimum time between updating crustal solutions\n self.R_steps = 500 # radius grid points for outside the chamber\n self.param['frac_rad_Temp'] = 0.5\n self.param['frac_rad_press'] = 0.1\n self.param['frac_rad_visc'] = 0.1\n self.param['degass_frac_chm'] = 0.25\n self.param['frac_length'] = 0.2\n self.flux_in_vol = input_functions.append_me()\n self.flux_in_vol.update(1e-7)\n self.flux_out_vol = input_functions.append_me()\n self.flux_out_vol.update(1e-7)\n self.param['depth'] = depth\n self.param['T_S']=500.+400. # Background crustal temp\n self.P_list = input_functions.append_me()\n self.T_list = input_functions.append_me()\n self.P_flux_list = input_functions.append_me()\n self.T_flux_list = input_functions.append_me()\n self.times_list = input_functions.append_me()\n self.tcurrent = 0.\n self.radius = radius\n self.permeability = 1e-20\n self.param['T_in'] = 1400.0\n self.param['eps_g_in'] = 0.0 # Gas fraction of incoming melt - gas phase ..\n self.param['m_eq_in'] = 0.05 # Volatile fraction of incoming melt\n self.param['Mdot_in'] = 1.0 # Input mass flux\n self.param['rho_m_inp'] = 2600.\n self.param['rho_x_inp'] = 3065.\n self.param['Area_conduit'] = 10.*10.\n self.param['S'] = 0.1\n self.param['outflow_model']= None # 'huppert'\n self.param['frac_cond_cool'] = 0.25 # only top of chamber cools conductively to the surface\n self.param['critical_eps_press_relax'] = 0.02 # Minimum gas fraction for pore pressure diff to be important\n self.param['delta_Pc'] = 20e6 # Critical Overpressure (MPa)\n self.param['eta_x_max'] = 0.5 # Locking fraction\n self.param['M_out_rate'] = 1e2 # kg/s\n self.param['material'] = 'Westerly_Granite' # Granite , 2 is Sandstone\n self.crust_analy_params = Anl_sols.Analytical_crust_params()\n self.T_fluid_mean = 750. #self.param['T_S']\n self.crust_analy_params.set_viscosity(self.T_fluid_mean,10*1e6) # 2nd parameter is pressure (Pa)\n self.crust_analy_params.set_constants(self.param['material'],self.permeability)\n self.tmax = -1\n self.eruption_events = {}\n self.eruption_count = 0\n self.extra_vals = 0\n self.permeability_frac = 1e-16\n self.initial_T_out = np.array([])\n self.initial_P_out = np.array([])\n self.initial_sigma_rr = np.array([])\n self.initial_sigma_theta = np.array([])\n self.perm_evl_init=np.array([])\n self.perm_evl_init_time = np.array([])\n self.allow_diffusion_init = True\n\n def set_init_crust(self,material = 'Westerly_Granite'):\n self.R_outside = np.linspace(self.radius, 3. * self.radius, self.R_steps)\n self.set_params_crust_calcs(material)\n self.crust_analy_params.set_misc_grids(self.R_outside)\n self.T_out_all = np.array([self.R_outside * 0.])\n self.P_out_all = np.array([self.R_outside * 0.])\n self.sigma_rr_all = np.array([self.R_outside * 0.])\n self.sigma_theta_all = np.array([self.R_outside * 0.])\n self.sigma_eff_rr_all = np.array([self.R_outside * 0.])\n self.sigma_eff_theta_all = np.array([self.R_outside * 0.])\n self.max_count = 1 # counting for the append me arrays ..\n\n def set_init_crust_profile(self,T_0):\n self.P_list.update(0.)\n self.T_list.update(T_0 - self.param['T_S'])\n self.P_flux_list.update(0)\n self.T_flux_list.update(0)\n self.times_list.update(1.)\n self.T_out, self.P_out, self.sigma_rr, self.sigma_theta, self.T_der = \\\n self.crust_analy_params.Analytical_sol_cavity_T_Use(self.T_list.data[:self.max_count],\n self.P_list.data[:self.max_count],\n self.radius,\n self.times_list.data[:self.max_count],\n self.T_flux_list.data[:self.max_count],\n self.P_flux_list.data[:self.max_count])\n self.initial_T_out = self.T_out*0.\n self.initial_P_out = self.P_out*0.\n self.initial_sigma_rr = self.sigma_rr*0.\n self.initial_sigma_theta = self.sigma_theta*0.\n begin_time = self.func_evolve_init_cond(T_0)\n return begin_time\n\n def set_random_Pcrit(self):\n '''\n :return:\n '''\n delta_Pc = np.random.randint(10,50) # assume a critical overpressure btw 10 - 50 MPa\n self.param['delta_Pc'] = delta_Pc*1e6 # Critical Overpressure (MPa)\n self.input_functions.Pc = self.param['delta_Pc'] # assume a critical overpressure of 20 MPa\n\n def set_input_functions(self,input_fun):\n '''\n\n :return:\n '''\n self.input_functions= input_fun\n self.input_functions.Pc = self.param['delta_Pc'] # assume a critical overpressure of 20 MPa\n self.input_functions.eta_crit_lock = self.param['eta_x_max'] # based on cystal locking above 50 % packing ..\n self.input_functions.M_out_rate = self.param['M_out_rate'] # kg/s\n self.param['outflow_model'] = self.input_functions.outflow_model\n\n def set_params_crust_calcs(self,material):\n self.param['material'] = material # Granite , 2 is Sandstone\n self.crust_analy_params = Anl_sols.Analytical_crust_params()\n self.T_fluid_mean = 750. #self.param['T_S']\n self.crust_analy_params.set_viscosity(self.T_fluid_mean,self.plith) # 2nd parameter is pressure (Pa)\n self.crust_analy_params.set_constants(self.param['material'],self.permeability)\n\n def calc_lith_pressure(self):\n '''\n Calculate the lithospheric pressure\n :param depth:\n :return:\n '''\n return self.param['depth']*const.g_earth*self.param['crustal_density']\n\n def get_constants(self):\n '''\n Get material constants - can over-write this ..\n '''\n mat_const = self.input_functions.material_constants()\n self.param.update(mat_const) # specify the constants for the model\n self.plith = self.calc_lith_pressure()\n\n def func_evolve_init_cond(self,T_0):\n '''\n Calculate the initial evolution of the system - regularize the pore pressure condition\n :param self:\n :return:\n '''\n ### First evolve the solution to a 1 yr (a few points is ok since everything is analytical ..)\n times_evolve_p1 = np.linspace(1e3,3.*np.pi*1e7,3)\n for i in times_evolve_p1:\n self.P_list.update(0.)\n self.T_list.update(T_0 - self.param['T_S'])\n self.T_flux_list.update(0.)\n self.P_flux_list.update(0.)\n self.times_list.update(i)\n self.T_out, self.P_out, self.sigma_rr, self.sigma_theta, self.T_der = \\\n self.crust_analy_params.Analytical_sol_cavity_T_Use(self.T_list.data[:self.max_count],\n self.P_list.data[:self.max_count],self.radius, self.times_list.data[:self.max_count],\n self.T_flux_list.data[:self.max_count],self.P_flux_list.data[:self.max_count])\n self.max_count += 1\n self.P_out_all = np.vstack([self.P_out_all,self.P_out])\n self.T_out_all = np.vstack([self.T_out_all,self.T_out])\n self.sigma_rr_all = np.vstack([self.sigma_rr_all,self.sigma_rr])\n self.sigma_theta_all = np.vstack([self.sigma_theta_all,self.sigma_theta])\n indx_use_P = np.where(self.R_outside <=(1.+self.param['frac_rad_press'])*self.radius)\n self.sigma_rr_eff = -(self.sigma_rr + self.P_out) # in Pa - +ve is compression, -ve is tension\n self.mean_sigma_rr_eff = np.mean(self.sigma_rr_eff[indx_use_P]) # effective stress total ..\n self.min_sigma_rr_eff = np.min(self.sigma_rr_eff) # effective stress total ..\n begin_time = times_evolve_p1[-1]\n value4 = (self.min_sigma_rr_eff + self.param['delta_Pc']) ## This is positive if max tensile stress is less than delta_Pc\n print('here',value4 / 1e6)\n print(self.min_sigma_rr_eff/self.param['delta_Pc'])\n self.extra_vals = 10\n if self.allow_diffusion_init ==True :\n if self.min_sigma_rr_eff < -0.95*self.param['delta_Pc'] :\n begin_time = self.func_evolve_relax_pressure()\n return begin_time*1.01\n\n\n def func_evolve_relax_pressure(self):\n '''\n Calculate the initial evolution of the system - regularize the pore pressure condition\n :param self:\n :return:\n '''\n perm_chng_fac = 1.5\n times_evolve_p1 = np.linspace(3.* np.pi * 1e7, np.pi * 1e7 * 1e2, 100)\n perm_init = self.permeability\n excess_press = True\n i_count = 0\n self.perm_evl_init = np.append(self.perm_evl_init,perm_init)\n self.perm_evl_init_time = np.append(self.perm_evl_init,times_evolve_p1[0])\n P_cond = self.P_list.data[self.max_count-1] ## Keep this constant with time for the subsequent evolution ..\n T_cond = self.T_list.data[self.max_count-1] ## Keep this constant with time for the subsequent evolution ..\n while excess_press :\n self.permeability = self.permeability*perm_chng_fac\n self.perm_evl_init = np.append(self.perm_evl_init,self.permeability)\n self.set_params_crust_calcs('Westerly_Granite')\n self.crust_analy_params.set_misc_grids(self.R_outside)\n self.P_list.update(P_cond)\n self.T_list.update(T_cond)\n self.T_flux_list.update(0.)\n self.P_flux_list.update(0.)\n self.times_list.update(times_evolve_p1[i_count])\n self.T_out, self.P_out, self.sigma_rr, self.sigma_theta, self.T_der = self.crust_analy_params.Analytical_sol_cavity_T_Use\\\n (self.T_list.data[:self.max_count],self.P_list.data[:self.max_count],self.radius, self.times_list.data[:self.max_count],\n self.T_flux_list.data[:self.max_count], self.P_flux_list.data[:self.max_count])\n self.max_count += 1\n i_count += 1\n self.sigma_rr_eff = -(self.sigma_rr + self.P_out) # in Pa\n self.min_sigma_rr_eff = np.min(self.sigma_rr_eff) # effective stress total ..\n if self.min_sigma_rr_eff > -0.95 * self.param['delta_Pc'] :\n excess_press = False\n self.P_out_all = np.vstack([self.P_out_all,self.P_out])\n self.T_out_all = np.vstack([self.T_out_all,self.T_out])\n self.sigma_rr_all = np.vstack([self.sigma_rr_all,self.sigma_rr])\n self.sigma_theta_all = np.vstack([self.sigma_theta_all,self.sigma_theta])\n value4 = (self.min_sigma_rr_eff + self.param[\n 'delta_Pc']) ## This is positive if max tensile stress is less than delta_Pc\n print('here', value4 / 1e6)\n self.perm_evl_init_time = np.append(self.perm_evl_init_time,times_evolve_p1[1:i_count])\n begin_time = self.perm_evl_init_time[-1]\n self.permeability = perm_init\n self.set_params_crust_calcs('Westerly_Granite')\n self.crust_analy_params.set_misc_grids(self.R_outside)\n self.T_out_o, self.P_out_o, self.sigma_rr_o, self.sigma_theta_o,_ = self.crust_analy_params.Analytical_sol_cavity_T_Use \\\n (self.T_list.data[:self.max_count-1], self.P_list.data[:self.max_count-1], self.radius,\n self.times_list.data[:self.max_count-1],self.T_flux_list.data[:self.max_count-1], self.P_flux_list.data[:self.max_count-1])\n self.extra_vals = 10 + i_count\n self.initial_T_out = self.T_out_o - self.T_out\n self.initial_P_out = self.P_out_o - self.P_out\n self.initial_sigma_rr = self.sigma_rr_o - self.sigma_rr\n self.initial_sigma_theta = self.sigma_theta_o - self.sigma_theta\n indx_use_P = np.where(self.R_outside <=(1.+self.param['frac_rad_press'])*self.radius)\n self.sigma_rr_eff = -(self.sigma_rr + self.P_out) # in Pa\n self.mean_sigma_rr_eff = np.mean(self.sigma_rr_eff[indx_use_P]) # effective stress total ..\n self.min_sigma_rr_eff = np.min(self.sigma_rr_eff) # effective stress total ..\n print('Used func_evolve_relax_pressure, permeability decrease factor {:.2f}'.format(self.perm_evl_init[-1]/perm_init))\n return begin_time\n\n def rhs(self,t,y,sw) :\n '''\n The right-hand-side function (rhs) for the integrator\n '''\n ######################################################################################################\n P = y[0]\n T = y[1]\n V = y[3]\n a = (V/(4.*np.pi/3))**(1./3.)\n self.radius = a\n eruption = sw[4] # This tells whether eruption is yes or no\n if t > self.tcurrent :\n self.dt = t-self.tcurrent\n self.dt_counter +=self.dt\n self.tcurrent = t\n self.P_list.update(P - self.plith)\n self.T_list.update(T - self.param['T_S'])\n self.times_list.update(t)\n self.T_out, self.P_out, self.sigma_rr, self.sigma_theta, self.T_der = self.crust_analy_params.Analytical_sol_cavity_T_Use(\n self.T_list.data[:self.max_count], self.P_list.data[:self.max_count], self.radius,\n self.times_list.data[:self.max_count], self.T_flux_list.data[:self.max_count],self.P_flux_list.data[:self.max_count])\n self.max_count += 1\n pdb.set_trace()\n self.T_out -= self.initial_T_out*np.exp(-t/self.t0/self.param['relax_press_init'])\n self.P_out -= self.initial_P_out*np.exp(-t/self.t0/self.param['relax_press_init'])\n self.sigma_rr -= self.initial_sigma_rr*np.exp(-t/self.t0/self.param['relax_press_init'])\n self.sigma_theta -= self.initial_sigma_theta*np.exp(-t/self.t0/self.param['relax_press_init'])\n self.P_out_all = np.vstack([self.P_out_all,self.P_out])\n self.T_out_all = np.vstack([self.T_out_all,self.T_out])\n self.sigma_rr_all = np.vstack([self.sigma_rr_all,self.sigma_rr])\n self.sigma_theta_all = np.vstack([self.sigma_theta_all,self.sigma_theta])\n #self.sigma_eff_rr_all = np.vstack([self.sigma_eff_rr_all,self.sigma_rr + self.P_out])\n #self.sigma_eff_theta_all = np.vstack([self.sigma_eff_theta_all,self.sigma_theta+self.P_out])\n else :\n self.dt = 0.\n eps_g = y[2]\n dV_dP = V/self.param['beta_r']\n dV_dT = -V*self.param['alpha_r']\n rho_m = y[4]\n drho_m_dP = rho_m/self.param['beta_m']\n drho_m_dT = -rho_m*self.param['alpha_m']\n rho_x = y[5]\n drho_x_dP = rho_x/self.param['beta_x']\n drho_x_dT = -rho_x*self.param['alpha_x']\n eps_x, deps_x_dT, deps_x_deps_g = self.input_functions.melting_curve(T,P,eps_g)\n rho_g, drho_g_dP, drho_g_dT = self.input_functions.gas_density(T,P)\n\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x\n drho_dP = (1.-eps_g-eps_x)*drho_m_dP + eps_g*drho_g_dP + eps_x*drho_x_dP\n drho_dT = (1.-eps_g-eps_x)*drho_m_dT + eps_g*drho_g_dT + eps_x*drho_x_dT\n drho_deps_g = -rho_m + rho_g\n drho_deps_x = -rho_m + rho_x\n\n # % exsolution\n m_eq,dm_eq_dP,dm_eq_dT = self.input_functions.solubulity_curve(T,P)\n c = ((1.-eps_g-eps_x)*rho_m*self.param['c_m'] + eps_g*rho_g*self.param['c_g'] + eps_x*rho_x*self.param['c_x'])/rho\n dc_dP = (1./rho)*((1-eps_g-eps_x)*self.param['c_m']*drho_m_dP + eps_g*self.param['c_g']*drho_g_dP + eps_x*self.param['c_x']*drho_x_dP) - (c/rho)*drho_dP\n dc_dT = (1./rho)*((1-eps_g-eps_x)*self.param['c_m']*drho_m_dT + eps_g*self.param['c_g']*drho_g_dT + eps_x*self.param['c_x']*drho_x_dT) - (c/rho)*drho_dT\n dc_deps_g = (1./rho)*(-rho_m*self.param['c_m'] + rho_g*self.param['c_g']) - (c/rho)*drho_deps_g\n dc_deps_x = (1./rho)*(-rho_m*self.param['c_m'] + rho_x*self.param['c_x']) - (c/rho)*drho_deps_x\n\n #% boundary conditions\n eps_x_in,_,_ = self.input_functions.melting_curve(self.param['T_in'],self.plith,self.param['eps_g_in'])\n rho_g_in,_,_ = self.input_functions.gas_density(self.param['T_in'],P)\n\n rho_m_in = self.param['rho_m_inp'] # rho_m\n rho_x_in = self.param['rho_x_inp'] # rho_x\n rho_in = (1-self.param['eps_g_in']-eps_x_in)*rho_m_in + self.param['eps_g_in']*rho_g_in + eps_x_in*rho_x_in\n c_in = ((1-self.param['eps_g_in']-eps_x_in)*rho_m_in*self.param['c_m'] + self.param['eps_g_in']*rho_g_in*self.param['c_g'] + eps_x_in*rho_x_in*self.param['c_x'])/rho_in #;%c;\n\n Mdot_in = self.param['Mdot_in']\n Mdot_v_in = self.param['m_eq_in']*rho_m_in*(1.-self.param['eps_g_in']-eps_x_in)*Mdot_in/rho_in + rho_g_in*self.param['eps_g_in']*Mdot_in/rho_in\n Hdot_in = c_in*self.param['T_in']*Mdot_in\n\n P_buoyancy = -(rho - self.param['crustal_density']) * const.g_earth * a # delta_rho*g*h\n # tmp_val = (P-self.plith + P_buoyancy) - self.param['delta_Pc']*0.95\n # if tmp_val > 0 :\n # value_diking = True\n # else :\n # value_diking = False\n\n indx_use_P = np.where(self.R_outside <=(1.+self.param['frac_rad_press'])*a)\n indx_use_T = np.where(self.R_outside <=(1.+self.param['frac_rad_Temp'])*a)\n indx_use_visc = np.where(self.R_outside <=(1.+self.param['frac_rad_visc'])*a)\n mean_T_der_out = np.mean(self.T_der[indx_use_T])\n mean_T_out = np.mean(self.T_out[indx_use_T]) + self.param['T_S']\n mean_P_out = np.mean(self.P_out[indx_use_P]) + self.plith\n ###############################################################\n # self.T_fluid_mean = mean_T_out\n # self.crust_analy_params.set_viscosity(self.T_fluid_mean,mean_P_out)\n # self.crust_analy_params.set_constants(self.param['material'],self.permeability)\n ###############################################################\n mean_sigma_rr_out = -np.mean(self.sigma_rr[indx_use_visc]) + self.plith\n visc_gas = self.crust_analy_params.visc\n # #############################################################\n # ###########################################################\n if self.param['heat_cond'] == 1.:\n if t< 30e7 : # Initially the gradients are kind of large .. so may be unstable ..\n small_q = -self.param['k_crust']*(mean_T_out-T)/(self.param['frac_rad_Temp']*a)\n else :\n small_q = -self.param['k_crust']*mean_T_der_out\n small_q2 = -self.param['k_crust']*(300.-self.param['T_S'])/(self.param['depth']) # conductive heat loss to the surface\n surface_area_chamber = 4.*np.pi*a**2.\n Q_out = small_q*surface_area_chamber + self.param['frac_cond_cool']*small_q2*surface_area_chamber\n elif self.param['heat_cond'] == 0.:\n Q_out = 0.\n else:\n raise NotImplementedError('heat_cond not specified')\n if np.isnan(Q_out):\n pdb.set_trace()\n raise ValueError('Q_out is NaN')\n # #############################################################\n # #############################################################\n if eruption == False:\n if self.param['vol_degass'] == 1.:\n surface_area_chamber_degassing = 4.*np.pi*a**2.*self.param['degass_frac_chm']\n delta_P_grad = (P - mean_P_out)/a/self.param['frac_length']\n ################## Flux out of the chamber due to pressure gradient in the crust ..\n # Note that there is no buoyancy term since the fluid is in equilbrium (Pressure is perturbation oer bkg)\n U_og2 = (self.permeability/visc_gas)*(delta_P_grad)\n Mdot_out = eps_g*rho_g*surface_area_chamber_degassing*U_og2\n degass_hdot_water = self.param['c_g']*T*Mdot_out\n ################## Flux out of the chamber -- given the permeability of the chamber ..\n # U_og = self.input_functions.func_Uog(eps_g,eps_x,m_eq,rho_m,rho_g,T,delta_P_grad)\n # Mdot_out1 = eps_g*rho_g*surface_area_chamber_degassing*U_og\n # degass_hdot_water1 = self.param['c_g']*T*Mdot_out1\n # if np.abs(Mdot_out2) > 5 :\n # pdb.set_trace()\n # print(Mdot_out2)\n # tmp1_sign = np.sign(Mdot_out1/Mdot_out2)\n # if (tmp1_sign == 1.0) :\n # if (np.abs(Mdot_out2) > np.abs(Mdot_out1)) :\n # Mdot_out = Mdot_out2\n # degass_hdot_water = degass_hdot_water2\n # Q_fluid_flux_out = 0.\n # else :\n # Mdot_out = Mdot_out1\n # degass_hdot_water = degass_hdot_water1\n # Q_fluid_flux_out = (Mdot_out - Mdot_out2)/surface_area_chamber_degassing/rho_g # extra term for the pressure equation .., m/s (i.e a velocity )\n # else :\n # Mdot_out = Mdot_out2 + Mdot_out1\n # degass_hdot_water = degass_hdot_water2 +degass_hdot_water1\n # Q_fluid_flux_out = Mdot_out1/surface_area_chamber_degassing/rho_g # extra term for the pressure equation .., m/s (i.e a velocity )\n QH_fluid_flux_out = np.copy(degass_hdot_water)/surface_area_chamber_degassing # W/m^2\n else :\n Mdot_out = 0.\n degass_hdot_water = 0.\n QH_fluid_flux_out = 0.\n # Q_fluid_flux_out = 0.\n # QH_fluid_flux_out = 0.\n Mdot_v_out = np.copy(Mdot_out) # mass loss = water loss rate\n Hdot_out = Q_out +degass_hdot_water\n elif eruption == True :\n ##########################\n if self.param['vol_degass'] == 1. :\n # Note that there is no buoyancy term since the fluid is in equilbrium\n # (Pressure is perturbation over bkg)\n surface_area_chamber_degassing = 4. * np.pi * a ** 2. * self.param['degass_frac_chm']\n delta_P_grad = (P - mean_P_out) / a / self.param['frac_length']\n U_og2 = (self.permeability/visc_gas)*(delta_P_grad)\n Mdot_out2 = eps_g*rho_g*surface_area_chamber_degassing*U_og2\n degass_hdot_water = self.param['c_g']*T*Mdot_out2\n QH_fluid_flux_out = np.copy(degass_hdot_water) / surface_area_chamber_degassing # W/m^2\n else :\n Mdot_out2 = 0.\n degass_hdot_water = 0.\n QH_fluid_flux_out = 0.\n ##########################\n # if value_diking :\n Mdot_out1 = self.input_functions.crit_outflow\\\n (eps_x,m_eq,T,rho,self.param['depth'],self.param['Area_conduit'],\n self.param['S'],(P-self.plith + P_buoyancy),\n additional_model=self.param['outflow_model'])\n Mdot_v_out = m_eq*rho_m*(1.-eps_g-eps_x)*Mdot_out1/rho + rho_g*eps_g*Mdot_out1/rho + Mdot_out2\n Mdot_out = Mdot_out1 + Mdot_out2\n Hdot_out = c*T*Mdot_out1 + Q_out + degass_hdot_water\n # else :\n # surface_area_chamber_degassing = 4. * np.pi * a ** 2. * self.param['degass_frac_chm']\n # delta_P_grad = (P - mean_P_out) / a / self.param['frac_length']\n # U_og1 = (self.permeability_frac/ visc_gas) * (delta_P_grad)\n # Mdot_out1 = eps_g * rho_g * surface_area_chamber_degassing * U_og1\n # degass_hdot_water1 = self.param['c_g'] * T * Mdot_out2\n # Mdot_v_out = Mdot_out1 + Mdot_out2\n # Mdot_out = Mdot_out1 + Mdot_out2\n # Hdot_out = degass_hdot_water1 + Q_out + degass_hdot_water\n else:\n raise NotImplementedError('eruption not specified')\n #############################################################\n self.T_flux_list.update(QH_fluid_flux_out)\n self.P_flux_list.update(0.)\n self.flux_in_vol.update(Mdot_v_in)\n self.flux_out_vol.update(Mdot_v_out)\n # #############################################################\n #% viscous relaxation - #% crustal viscosity (Pa s)\n #############################################################\n eta_r_new = self.input_functions.crustal_viscosity(self.T_out[indx_use_visc],self.R_outside[indx_use_visc])\n if self.param['visc_relax'] == 1.:\n # P_loss1 = (P-self.plith)/eta_r_new\n P_loss1 = (P-mean_sigma_rr_out)/eta_r_new\n elif self.param['visc_relax'] == 0.:\n P_loss1 = 0.\n else:\n raise NotImplementedError('visc_relax not specified')\n # #############################################################\n # Pore Pressure relaxation -\n if self.param['press_relax'] ==1 :\n # Set that the P_loss2 is only when eps_g > 0.02\n P_loss2 = np.tanh((eps_g/self.param['critical_eps_press_relax'])*2.)*(self.permeability/visc_gas)*(P - mean_P_out)/(self.param['frac_rad_press']*a)**2.\n elif self.param['press_relax'] ==0 :\n P_loss2 = 0\n else:\n raise NotImplementedError('press_relax not specified')\n # #############################################################\n # #############################################################\n P_loss = P_loss1 + P_loss2\n self.sigma_rr_eff = -(self.sigma_rr + self.P_out) # in Pa\n self.mean_sigma_rr_eff = np.mean(self.sigma_rr_eff[indx_use_P]) # effective stress total ..\n self.min_sigma_rr_eff = np.min(self.sigma_rr_eff) # effective stress total ..\n value4= (self.min_sigma_rr_eff+self.param['delta_Pc']) ## This is positive if max tensile stress is less than delta_Pc\n if value4 < 0. :\n print('Reached min_sigma_rr_eff threshold, t = {}'.format(t/np.pi/1e7))\n # #############################################################\n # #############################################################\n # coefficients in the system of unknowns Ax = B, here x= [dP/dt dT/dt dphi/dt ...]\n # values matrix A\n # conservation of (total) mass\n a11 = (1/rho)*drho_dP + (1/V)*dV_dP\n a12 = (1./rho)*drho_dT + (1./V)*dV_dT + (1./rho)*drho_deps_x*deps_x_dT\n a13 = (1/rho)*drho_deps_g + (1/rho)*drho_deps_x*deps_x_deps_g\n # conservation of volatile mass\n a21 = (1/rho_g)*drho_g_dP + (1/V)*dV_dP \\\n + (m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g)*((1/m_eq)*dm_eq_dP + (1/rho_m)*drho_m_dP + (1/V)*dV_dP)\n a22 = (1/rho_g)*drho_g_dT + (1/V)*dV_dT \\\n + (m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g)*((1/m_eq)*dm_eq_dT + (1/rho_m)*drho_m_dT + (1/V)*dV_dT \\\n - deps_x_dT/(1-eps_g-eps_x))\n a23 = 1/eps_g - (1+deps_x_deps_g)*m_eq*rho_m/(rho_g*eps_g)\n # conservation of (total) enthalpy\n a31 = (1/rho)*drho_dP + (1/c)*dc_dP + (1/V)*dV_dP \\\n + (self.param['L_e']*rho_g*eps_g)/(rho*c*T)*((1/rho_g)*drho_g_dP + (1/V)*dV_dP) \\\n - (self.param['L_m']*rho_x*eps_x)/(rho*c*T)*((1/rho_x)*drho_x_dP + (1/V)*dV_dP)\n a32 = (1/rho)*drho_dT + (1/c)*dc_dT + (1/V)*dV_dT + 1/T \\\n + (self.param['L_e']*rho_g*eps_g)/(rho*c*T)*((1/rho_g)*drho_g_dT + (1/V)*dV_dT) \\\n - (self.param['L_m']*rho_x*eps_x)/(rho*c*T)*((1/rho_x)*drho_x_dT + (1/V)*dV_dT) \\\n + ((1/rho)*drho_deps_x + (1/c)*dc_deps_x - (self.param['L_m']*rho_x)/(rho*c*T))*deps_x_dT\n a33 = (1/rho)*drho_deps_g + (1/c)*dc_deps_g \\\n + (self.param['L_e']*rho_g)/(rho*c*T) \\\n + ((1/rho)*drho_deps_x + (1/c)*dc_deps_x - (self.param['L_m']*rho_x)/(rho*c*T))*deps_x_deps_g\n # values vector B\n # conservation of (total) mass\n b1 = (Mdot_in - Mdot_out)/(rho*V) - P_loss\n # conservation of volatile mass\n b2 = (Mdot_v_in - Mdot_v_out)/(rho_g*eps_g*V) - P_loss*(1+(m_eq*rho_m*(1-eps_g-eps_x))/(rho_g*eps_g))\n # conservation of (total) enthalpy\n b3 = (Hdot_in - Hdot_out)/(rho*c*T*V) - P_loss*(1-(self.param['L_m']*rho_x*eps_x)/(rho*c*T)+(self.param['L_e']*rho_g*eps_g)/(rho*c*T) - P/(rho*c*T));\n # set up matrices to solve using Cramer's rule\n A = np.array([[a11,a12,a13],[a21,a22,a23],[a31,a32,a33]])\n A_P = np.array([[b1,a12,a13],[b2,a22,a23],[b3,a32,a33]])\n A_T = np.array([[a11,b1,a13],[a21,b2,a23],[a31,b3,a33]])\n A_eps_g = np.array([[a11,a12,b1],[a21,a22,b2],[a31,a32,b3]])\n det_A = det(A)\n dP_dt = det(A_P)/det_A\n dT_dt = det(A_T)/det_A\n deps_g_dt = det(A_eps_g)/det_A\n dV_dt = dV_dP*dP_dt + dV_dT*dT_dt + V*P_loss\n drho_m_dt = drho_m_dP*dP_dt + drho_m_dT*dT_dt\n drho_x_dt = drho_x_dP*dP_dt + drho_x_dT*dT_dt\n dydz = np.zeros(6)\n # column vector\n dydz[0] = dP_dt\n dydz[1] = dT_dt\n dydz[2] = deps_g_dt\n dydz[3] = dV_dt\n dydz[4] = drho_m_dt\n dydz[5] = drho_x_dt\n return dydz\n\n def state_events(self,t,y,sw):\n '''\n Local Variables:\n direction, value2, P_crit, isterminal, eruption, Q_out, value, P, value4, value1c, T, value1a,\n y, value3, eps_g, P_0, value1b\n '''\n P = y[0]\n T = y[1]\n eps_g = y[2]\n V = y[3]\n rho_m = y[4]\n rho_x = y[5]\n eps_x,_,_ = self.input_functions.melting_curve(T,P,eps_g)\n rho_g,_,_ = self.input_functions.gas_density(T,P)\n rho = (1.-eps_g-eps_x)*rho_m + eps_g*rho_g + eps_x*rho_x\n value1a = eps_g #% Detect eps_g approaching 0\n value1b = eps_x\n value1c = eps_x/(1.-eps_g)-0.8 # 80% crystals in magma crystal mixture ..\n value2 = eps_x-self.param['eta_x_max']\n a = (V/(4.*np.pi/3))**(1./3.)\n P_buoyancy = -(rho - self.param['crustal_density'])*const.g_earth*a # delta_rho*g*h\n if sw[4] : # is True (eruption)\n value3 = self.plith - P # want the pressure inside the magma reservoir to decrease below lithostatic pressure ..\n else : # no eruption\n value3 = (P-self.plith + P_buoyancy) - self.param['delta_Pc']\n # value4= (self.min_sigma_rr_eff+self.param['delta_Pc']) ## This is positive if max tensile stress is less than delta_Pc\n # if (solver.sw[5] == True) :\n # print(solver.t/3e7, (self.min_sigma_rr_eff+self.param['delta_Pc'])/1e6)\n # print('Reached min_sigma_rr_eff threshold .. while eruption is {}'.format(solver.sw[4]))\n # print(value4/1e6)\n # # if (self.min_sigma_rr_eff < -self.param['delta_Pc']) :\n # # value4=1\n # # value4 = (self.mean_sigma_rr_eff) - self.param['delta_Pc']\n # # value4 = (self.min_sigma_rr_eff) - self.param['delta_Pc']\n value = np.array([value1a, value1b, value1c,value2,value3])\n #isterminal = np.array([1, 1, 1, 1, 1,1]) #% Stop the integration\n #direction = np.array([0, 0, 0, 1, 1, 0])\n return value\n\n #Helper function for handle_event\n def event_switch(self,solver, event_info):\n \"\"\"\n Turns the switches.\n \"\"\"\n for i in range(len(event_info)): #Loop across all event functions\n if event_info[i] != 0:\n solver.sw[i] = not solver.sw[i] #Turn the switch\n\n def handle_event(self,solver, event_info):\n \"\"\"\n Event handling. This functions is called when Assimulo finds an event as\n specified by the event functions.\n \"\"\"\n event_info = event_info[0] #We only look at the state events information.\n while True: #Event Iteration\n self.event_switch(solver, event_info) #Turns the switches\n b_mode = self.state_events(solver.t, solver.y, solver.sw)\n self.init_mode(solver) #Pass in the solver to the problem specified init_mode\n a_mode = self.state_events(solver.t, solver.y, solver.sw)\n event_info = self.check_eIter(b_mode, a_mode)\n #print(event_info)\n if not True in event_info: #sys.exit()s the iteration loop\n break\n\n def init_mode(self,solver):\n '''\n Initialize with the new conditions.\n \"\"\"\n ## No change in the initial conditions (i.e. the values of the parameters when the eruption initiates .. - like P,V, ... T)\n ## Gas (eps_g = zero), eps_x is zero, too many crystals, 50 % crystallinity,eruption (yes/no)\n :param solver:\n :return:\n '''\n if (solver.sw[3] ==True) and (solver.sw[4] == True):\n print('critical pressure - {:f} MPa reached but eps_x>{:.0f}'.format(self.param['delta_Pc']/1e6,self.param['eta_x_max']))\n sys.exit(solver.t)\n if solver.sw[0]:\n print('eps_g became 0.')\n if True in solver.sw[0:4] :\n print('Reached the end of the calculations since : ')\n if solver.sw[1] :\n print('eps_x became 0.')\n elif solver.sw[2] :\n print('eps_x/(1-eps_g) became 0.8')\n elif solver.sw[3] :\n print('eps_x became {:f}'.format(self.param['eta_x_max']))\n sys.exit(solver.t)\n if (solver.sw[4] == True) :\n self.eruption_events[str(self.eruption_count)] = solver.t/np.pi/1e7,solver.y\n self.eruption_count += 1\n return 0\n\n #Helper function for handle_event\n def check_eIter(self,before, after):\n '''\n Helper function for handle_event to determine if we have event\n iteration.\n Input: Values of the event indicator functions (state_events)\n before and after we have changed mode of operations.\n '''\n eIter = [False]*len(before)\n for i in range(len(before)):\n if (before[i] < 0.0 and after[i] > 0.0) or (before[i] > 0.0 and after[i] < 0.0):\n eIter[i] = True\n return eIter\n"
},
{
"alpha_fraction": 0.7298674583435059,
"alphanum_fraction": 0.7319062352180481,
"avg_line_length": 41.65217208862305,
"blob_id": "1d15305fc3acba2cce3e97f2396a03a7f9c550cb",
"content_id": "385077fde9432201d83036a583725b15e7503b46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1962,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 46,
"path": "/PyMagmaCh/__init__.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "__version__ = '0.1'\n\n# This list defines all the modules a user can load directly i.e.\n# as - from PyMagmaCh import xyz , instead of\n# from PyMagmaCh.utils import xyz ...\n\n# Note that the following command will load all the packages in this file\n# from PyMagmaCh import *\n######################################################\n######################################################\nfrom PyMagmaCh.utils import constants\n\n\n######################################################\n#ok files :\n#utils.constants\n#utils.walk\n\n######################################################\n\n#from PyMagmaCh import radiation\n#from PyMagmaCh.model.column import GreyRadiationModel, RadiativeConvectiveModel, BandRCModel\n#from PyMagmaCh.model.ebm import EBM, EBM_annual, EBM_seasonal\n\n\n# this should ensure that we can still import constants.py as PyMagmaCh.constants\n#from PyMagmaCh.utils import thermo\n# some more useful shorcuts\n#from PyMagmaCh.model import ebm, column\n#from PyMagmaCh.domain import domain\n#from PyMagmaCh.domain.field import Field, global_mean\n#from PyMagmaCh.domain.axis import Axis\n#from PyMagmaCh.process.process import Process, process_like, get_axes\n#from PyMagmaCh.process.time_dependent_process import TimeDependentProcess\n#from PyMagmaCh.process.implicit import ImplicitProcess\n#from PyMagmaCh.process.diagnostic import DiagnosticProcess\n#from PyMagmaCh.process.energy_budget import EnergyBudget\n#from PyMagmaCh.radiation.AplusBT import AplusBT\n#from PyMagmaCh.radiation.AplusBT import AplusBT_CO2\n#from PyMagmaCh.radiation.Boltzmann import Boltzmann\n#from PyMagmaCh.radiation.insolation import FixedInsolation, P2Insolation, AnnualMeanInsolation, DailyInsolation\n#from PyMagmaCh.radiation.radiation import Radiation\n#from three_band import ThreeBandSW\n#from PyMagmaCh.radiation.nband import NbandRadiation, ThreeBandSW\n#from PyMagmaCh.radiation.water_vapor import ManabeWaterVapor\n#from PyMagmaCh.dynamics.budyko_transport import BudykoTransport\n"
},
{
"alpha_fraction": 0.5782250761985779,
"alphanum_fraction": 0.5956084132194519,
"avg_line_length": 38.03571319580078,
"blob_id": "8f9c3613e017ccdb982bc64b892fa118a7b05a83",
"content_id": "eabe01bd7264e9316a766e0d0484920b8eaacb17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2186,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 56,
"path": "/PyMagmaCh/process/diagnostic_eg/albedo.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom PyMagmaCh.process.time_dependent_process import TimeDependentProcess\nfrom PyMagmaCh.A1_domain.field import Field\n\nclass Iceline(TimeDependentProcess):\n def __init__(self, Tf=-10., **kwargs):\n super(DiagnosticProcess, self).__init__(**kwargs)\n self.time_type = 'diagnostic'\n self.param['Tf'] = Tf\n\n def find_icelines(self):\n Tf = 5.\n Ts = self.state['a1']\n #lat_bounds = self.domains['a1'].axes['lat'].bounds\n noice = np.where(Ts >= Tf, True, False)\n ice = np.where(Ts < Tf, True, False)\n self.diagnostics['noice'] = noice\n self.diagnostics['ice'] = ice\n if ice.all():\n # 100% ice cover\n icelat = np.array([-0., 0.])\n elif noice.all():\n # zero ice cover\n icelat = np.array([-90., 90.])\n else: # there is some ice edge\n # Taking np.diff of a boolean array gives True at the boundaries between True and False\n boundary_indices = np.where(np.diff(ice.squeeze()))[0] + 1\n #icelat = lat_bounds[boundary_indices] # an array of boundary latitudes\n #self.diagnostics['icelat'] = icelat\n\n\n def compute(self):\n self.find_icelines()\n\n\nclass StepFunctionAlbedo(TimeDependentProcess):\n def __init__(self, Tf=-10., a0=0.3, a2=0.078, ai=0.62, **kwargs):\n super(DiagnosticProcess, self).__init__(**kwargs)\n self.param['Tf'] = Tf\n self.param['a0'] = a0\n self.param['a2'] = a2\n self.param['ai'] = ai\n sfc = self.domains_var['a1']\n self.add_subprocess('iceline', Iceline(Tf=Tf, state=self.state))\n self.topdown = False # i.e call subprocess compute methods first\n self.time_type = 'diagnostic'\n\n def _get_current_albedo(self):\n '''Simple step-function albedo based on ice line at temperature Tf.'''\n ice = self.subprocess['iceline'].diagnostics['ice']\n # noice = self.subprocess['iceline'].diagnostics['noice']\n albedo = Field(np.where(ice, 1., 0.), domain=self.domains_var['a1'])\n return albedo\n\n def compute(self):\n self.diagnostics['albedo'] = self._get_current_albedo()\n"
},
{
"alpha_fraction": 0.5373430252075195,
"alphanum_fraction": 0.5481383800506592,
"avg_line_length": 43.94059371948242,
"blob_id": "4f910b2617c5ac1b4598eb8e84de6e826284dad5",
"content_id": "a73b38b0a493ef33ce041ee2aedd3ae6c2b423ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4539,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 101,
"path": "/PyMagmaCh/A1_domain/axis.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom PyMagmaCh.utils import constants as const\n\n\naxis_types = ['depth', 'x_val', 'y_val', 'abstract']\n\n# Implementing a simple cartesian distance axis type\n# and probaly also an abstract dimensionless axis type (for box models) i.e. 0D models\n# Note that the 0-D model can be thought of as something where we care only about when magma chmaber can erupt.\n\n# Other axis types : depth (for 1D models), x_val and y_val (for a 2D and 3D model respectively)\n# - can think of using only x_val in case of axisymmteric models (i.e. x_val = r_val).\n\n# Note that bounds means an array with min and max value - output else would be the bounds used to gen each point (with point being the midpoint)\n# Also, the saved bounds are alwats the bounds used to gen each point (with point being the midpoint)\n\nclass Axis(object):\n '''Create a new PyMagmaCh Axis object\n Valid axis types are:\n 'depth'\n 'x_val'\n 'y_val'\n 'abstract' (default)\n '''\n def __str__(self):\n return (\"Axis of type \" + self.axis_type + \" with \" +\n str(self.num_points) + \" points.\")\n\n def __init__(self, axis_type='abstract', num_points=10, points=None, bounds=None,note=None):\n if axis_type in axis_types:\n pass\n elif axis_type in ['y_value', 'Y_value']:\n axis_type = 'y_val'\n elif axis_type in ['x_value', 'X_value', 'R_value','R_val','r_val']:\n axis_type = 'x_val'\n elif axis_type in ['depth', 'Depth', 'chamberDepth', 'chamber_depth', 'zlab']:\n axis_type = 'depth'\n else:\n raise ValueError('axis_type %s not recognized' % axis_type)\n self.axis_type = axis_type\n\n defaultEndPoints = {'depth': (0., const.moho_depth),\n 'x_val': (0., const.region_size),\n 'y_val': (0., const.region_size),\n 'abstract': (0, num_points)}\n\n defaultUnits = {'depth': 'meters',\n 'x_val': 'meters',\n 'y_val': 'meters',\n 'abstract': 'none'}\n # if points and/or bounds are supplied, make sure they are increasing\n if points is not None:\n try:\n # using np.atleast_1d() ensures that we can use a single point\n points = np.sort(np.atleast_1d(np.array(points, dtype=float)))\n except:\n raise ValueError('points must be array_like.')\n if bounds is not None:\n try:\n bounds = np.sort(np.atleast_1d(np.array(bounds, dtype=float)))\n except:\n raise ValueError('bounds must be array_like.')\n\n if bounds is None:\n # assume default end points\n end0 = defaultEndPoints[axis_type][0]\n end1 = defaultEndPoints[axis_type][1]\n if points is not None:\n # only points are given - so use the default bounds in addition to the points.\n num_points = points.size\n df_set = np.diff(points)/2.\n bounds = points[:-1] + df_set\n bounds = np.insert(bounds,0, points[0]-df_set[0])\n else:\n # no points or bounds\n # create an evenly spaced axis\n delta = (end1 - end0) / num_points\n bounds = np.linspace(end0, end1, num_points+1)\n points = np.linspace(end0 + delta/2., end1-delta/2., num_points)\n else: # bounds are given\n end0 = np.min(bounds)\n end1 = np.max(bounds)\n if points is None:\n # create an evenly spaced axis\n delta = (end1 - end0) / num_points\n bounds = np.linspace(end0, end1, num_points+1)\n points = np.linspace(end0 + delta/2., end1-delta/2., num_points)\n else:\n # points and bounds both given, check that they are compatible\n num_points = points.shape[0]\n bounds = np.linspace(end0, end1, num_points+1)\n if np.min(points) != end0:\n raise ValueError('points and bounds are incompatible')\n if np.max(points) != end1:\n raise ValueError('points and bounds are incompatible')\n self.note = note\n self.num_points = num_points\n self.units = defaultUnits[axis_type]\n self.points = points\n self.bounds = bounds\n self.delta = np.abs(np.diff(self.points))\n"
},
{
"alpha_fraction": 0.5912198424339294,
"alphanum_fraction": 0.6068729758262634,
"avg_line_length": 42.421875,
"blob_id": "af26d076d8f2acab7961dc244a6a0b4d4b59b58a",
"content_id": "b5f49a76ef4314e7e6cb855c1cfbeb00467f1e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5558,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 128,
"path": "/PyMagmaCh/process/implicit_eg/diffusion.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy.linalg import solve_banded\nfrom PyMagmaCh.process.process import Process\n\n\nclass Diffusion_1D(TimeDependentProcess):\n '''Parent class for implicit diffusion modules.\n Solves the 1D heat equation\n \\rho C_p dT/dt = d/dx( K * dT/dx )\n\n The thermal conductivity K, density \\rho and heat capacity Cp are in\n units - W/m/K, kg/m^3, and J/K/kg.\n\n Assume that the boundary conditions are fixed temp ..\n (fix temp at the base and the top boundary ..) - need to specify\n self.param['T_base'],self.param['T_top'] :\n Note that the base and top are base and top of the grid\n\n Requirements : Can have only a single domain, also a single state variable\n (the diffusing field e.g. Temperature).\n Pass the inputs for temp evolution as a dict of diagnostics\n Eg. for temperature .. -- > give the k,rho,C_p as diagnostics field\n while pass as a dict :\n self.param['timestep'],\n self.param['timestep'],self.param['T_base'],self.param['T_top']\n\n Input flag use_banded_solver sets whether to use\n scipy.linalg.solve_banded\n rather than the default\n numpy.linalg.solve\n\n banded solver is faster but only works for 1D diffusion.\n Also note that the boundry condition is assumed to be Dirichlet type boundary condition ..\n\n '''\n def __init__(self,diffusion_axis=None,use_banded_solver=False,**kwargs):\n super(Diffusion, self).__init__(**kwargs)\n self.time_type = 'implicit'\n self.use_banded_solver = use_banded_solver\n if diffusion_axis is None:\n self.diffusion_axis = self._guess_diffusion_axis(self)\n else:\n self.diffusion_axis = diffusion_axis\n for dom in self.domains.values():\n delta = np.mean(dom.axes[self.diffusion_axis].delta)\n # Note that the shape of delta = 1 - points.shape, 2 - bounds.shape\n self._make_diffusion_matrix(delta)\n\n def _make_diffusion_matrix(self,delta):\n '''Make the array for implicit solution of the 1D heat eqn\n - Allowed variable shaped grid +\n variable thermal conductivity, density, heat capacity\n '''\n J = delta.size[0] # Size of the delta\n k_val = np.array(self.diagnostics['k']) # should be same shape as points\n rho_val = np.array(self.diagnostics['rho_c']) # should be same shape as points\n Cp_val = np.array(self.diagnostics['C_p']) # should be same shape as points\n\n term1a = (k_val[1:-1] + k_val[:-2])\n term1b = (k_val[1:-1] + k_val[2:])\n term3 = rho_val[1:-1]*Cp_val[1:-1]/self.param['timestep']\n term4 = delta[1:] + delta[:-1] # is same shape as k_val ..\n term5a = delta[:-1]*term4\n term5b = delta[1:]*term4\n Ka1 = (term1a/term3)/term5a\n Ka3 = (term1b/term3)/term5b\n Ka2 = Ka1 + Ka2\n add_t0 = Ka1[0]\n add_tn = Ka3[-1]\n # Build the full banded matrix\n A = (np.diag(1. + Ka2, k=0) +\n np.diag(-Ka3[0:J-1], k=1) +\n np.diag(-Ka1[1:J], k=-1))\n self.diffTriDiag = A\n self.add_t0 = add_t0\n self.add_tn = add_tn\n\n def _solve_implicit_banded(self,current, banded_matrix):\n # can improve performance by storing the banded form once and not\n # recalculating it...\n J = banded_matrix.shape[0]\n diag = np.zeros((3, J))\n diag[1, :] = np.diag(banded_matrix, k=0)\n diag[0, 1:] = np.diag(banded_matrix, k=1)\n diag[2, :-1] = np.diag(banded_matrix, k=-1)\n return solve_banded((1, 1), diag, current)\n\n def _implicit_solver(self):\n # Time-stepping the diffusion is just inverting this matrix problem:\n # self.T = np.linalg.solve( self.diffTriDiag, Trad )\n # Note that there should be only a single state variable - the field that is diffusing ..\n newstate = {}\n for varname, value in self.state.iteritems():\n if self.use_banded_solver:\n new_val = value[1:-1].copy()\n new_val[0] += self.param['T_base']*self.add_t0\n new_val[-1] += self.param['T_top']*self.add_tn\n newvar = self._solve_implicit_banded(new_val, self.diffTriDiag)\n else:\n new_val = value[1:-1].copy()\n new_val[0] += self.param['T_base']*self.add_t0\n new_val[-1] += self.param['T_top']*self.add_tn\n newvar = np.linalg.solve(self.diffTriDiag, new_val)\n newstate[varname][1:-1] = newvar\n return newstate\n\n def compute(self):\n # Time-stepping the diffusion is just inverting this matrix problem:\n # self.T = np.linalg.solve( self.diffTriDiag, Trad )\n # Note that there should be only a single state variable - the field that is diffusing ..\n newstate = self._implicit_solver()\n for varname, value in self.state.items():\n self.adjustment[varname] = newstate[varname] - value\n\n def _guess_diffusion_axis(self,process_or_domain):\n '''Input: a process, domain or dictionary of domains.\n If there is only one axis with length > 1 in the process or\n set of domains, return the name of that axis.\n Otherwise raise an error.'''\n\t\taxes = get_axes(process_or_domain)\n\t\tdiff_ax = {}\n\t\tfor axname, ax in axes.iteritems():\n\t\t if ax.num_points > 1:\n\t\t diff_ax.update({axname: ax})\n\t\tif len(diff_ax.keys()) == 1:\n\t\t return diff_ax.keys()[0]\n\t\telse:\n\t\t raise ValueError('More than one possible diffusion axis - i.e. with more than 1 num-points.')\n"
},
{
"alpha_fraction": 0.3757961690425873,
"alphanum_fraction": 0.4209792912006378,
"avg_line_length": 37.945735931396484,
"blob_id": "eef46595d29290ed560fc2bd29235fef77e20517",
"content_id": "034a7ccb6efaf067b8005955b9346dbb7750d10a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5024,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 129,
"path": "/PyMagmaCh/utils/katz_melting.py",
"repo_name": "tmittal/Version_working",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef katz_wetmelting(T_kelvin, P_pascal, X,D_h2o_n = 0) :\n '''Calculates degree of melting F[wt.frac.] as a function of\n temperature T[degrees K], pressure P[Pa], and water content X [wt.frac.]\n according to parametrization by Katz et al. (2003). Use - D_h2o_n =1\n for Dh2o = 0.012 #% Kelley et al., (2006, 2010)\n '''\n #%%%%%%%%%%%%%%%%%%%%%%% Initialization%%%%%%%%%%%%%%%%%%%%%%%%%\n P = P_pascal*1e6 # P in GPa\n T = T_kelvin - 273.15 # T in Celcius\n f = 0.0\n mcpx=0.17\n beta1 = 1.50\n beta2 = 1.50\n A1 = 1085.7\n A2 = 132.9\n A3 = -5.1\n B1 = 1475.0\n B2 = 80.0\n B3 = -3.2\n C1 = 1780.0\n C2 = 45.0\n C3 = -2.0\n r0 = 0.50 # called r1 in Katz et al. 2003 Table 2\n r1 = 0.08 # called r2 in Katz et al. 2003 Table 2\n #%%%% Wet melting parameters\n K=43. #% degrees C/wt% water\n gamma=0.75 #%wet melting exponent\n zeta1=12.00\n zeta2=1.00\n ramda=0.60\n if (D_h2o_n != 0):\n Dh2o = 0.012 #% Kelley et al., (2006, 2010) -- NOTE Katz et al. (2003) assume D=0.01\n else :\n Dh2o = 0.01\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n # calculate Rcpx(P)\n r_cpx = r0 + r1*P\n #% compute F_cpx-out\n f_cpxout = mcpx/r_cpx\n #% compute liquidus temperature\n T_liquidus = C1 + C2*P + C3*P**2\n #% compute solidus temperature\n T_solidus = A1 + A2*P + A3*P**2\n #% compute lherzolite liquidus temperature\n T_lherzliq = B1 + B2*P + B3*P**2\n T_cpxout = ((f_cpxout)**(1.0/beta1))*(T_lherzliq - T_solidus) + T_solidus\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n if (X<=0) :\n if( T < T_solidus) :\n f=0.\n elif(T < T_cpxout) :\n Tprime = (T-T_solidus)/(T_lherzliq - T_solidus)\n f = Tprime**beta1\n elif((T >= T_cpxout) and (T < T_liquidus)) :\n f = f_cpxout + (1.0 - f_cpxout)*(( (T-T_cpxout)/(T_liquidus-T_cpxout))**beta2)\n else :\n f=1.0\n return f # Stop here for anyhdrous case ..\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n maxF=f_cpxout\n minF=0.\n f=0.\n if (X>0): # if hydrous melting\n Xh2o_sat=zeta1*(P**ramda)+zeta2*P\n if(X>Xh2o_sat):\n X=Xh2o_sat\n Xwater=X/(Dh2o+f*(1.-Dh2o))\n deltaT=K*(Xwater**gamma)\n Xwater_cpx=X/(Dh2o+maxF*(1.-Dh2o))\n deltaTmin=K*(Xwater_cpx**gamma)\n if( T < (T_solidus-deltaT)) : #% if no melting\n return f\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n elif(T < (T_cpxout-deltaTmin)) : #% if melting less than f_cpxout\n Xwater=X/(Dh2o+f*(1,-Dh2o))\n deltaT=K*Xwater**gamma\n fnew=((T-(T_solidus-deltaT))/(T_lherzliq - T_solidus))**beta1\n fdiff=np.abs(fnew-f)\n nloops=0\n while (fdiff>1e-7) :\n if (fnew>f) :\n minF=f\n f = (f+maxF)/2.\n elif (fnew<f) :\n maxF=f\n f = (f+minF)/2. #% Can this be narrowed down further?\n else :\n return f\n Xwater=X/(Dh2o+f*(1,-Dh2o))\n deltaT=K*(Xwater**gamma)\n fnew=((T-(T_solidus-deltaT))/(T_lherzliq - T_solidus))**beta1\n fdiff=np.abs(fnew-f) #% check for convergence\n nloops=nloops+1\n if (nloops>100) :\n fdiff = 0. #% prevent infinite looping if something is broken\n return f\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n elif (T < T_liquidus): # % if melting more than f_cpxout, less than f=1\n maxF=1.\n Xwater=X/(Dh2o+f*(1-Dh2o))\n deltaT=K*Xwater**gamma\n fnew=f_cpxout + (1.0 - f_cpxout)*(( (T-(T_cpxout-deltaT))/(T_liquidus-(T_cpxout-deltaT)))**beta2)\n fdiff=np.abs(fnew-f)\n nloops=0.\n while (fdiff>1e-7) :\n if (fnew>f) :\n minF=f\n f = (f+maxF) / 2.\n elif (fnew<f):\n maxF=f\n f = (f+minF)/2. # % Can this be narrowed down further?\n else: #% Xcalc==X\n return f\n Xwater=X/(Dh2o+f*(1-Dh2o))\n deltaT= K*Xwater**gamma\n fnew=f_cpxout + (1.0 - f_cpxout)*(( (T-(T_cpxout-deltaT))/(T_liquidus-(T_cpxout-deltaT)))**beta2)\n fdiff= np.abs(fnew-f) #% check for convergence\n nloops=nloops+1\n if (nloops>100) :\n fdiff = 0. #% prevent infinite looping if something is broken\n return f\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n else:\n f=1.0\n #%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\n return f\n"
}
] | 35 |
goodkid45/Fun
|
https://github.com/goodkid45/Fun
|
c73a1fbeae7eb3a5d2c9f0b4250583a0db563719
|
91cf451df4ec4d6444d0dca7a2b952cad9836c6e
|
b75c92a020fbe5e893df7a031397a01b431df743
|
refs/heads/master
| 2016-09-05T13:52:28.472554 | 2015-09-18T15:21:55 | 2015-09-18T15:21:55 | 42,595,430 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4965437650680542,
"alphanum_fraction": 0.5138248801231384,
"avg_line_length": 18.311111450195312,
"blob_id": "07c3f096c0c3c411e03fd794fa95e80f90cd81a9",
"content_id": "799ef040f1e40de42aee8e99a28740eee8fb3278",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 45,
"path": "/Hello_World.py",
"repo_name": "goodkid45/Fun",
"src_encoding": "UTF-8",
"text": "__author__ = 'Nicholas & Garrison'\n\nprint('hello world!')\n\n'''\ndef function(n):\n for i in xrange(0, 10, 3):\n if type(n) is str:\n print i, ' : ' + n\n elif type(n) is int:\n print i, ' : ', n\n else:\n print 'Unsupported type'\n\n\nfunction(\"Hello\")\n\nfunction(34)\n'''\n\n# function that is obviously superior to Garrison's in every possible way\ndef better(n):\n\n if type(n) is str:\n for i in range(0, len(n), 1):\n print(n[i], end=\" \")\n elif type(n) is not str:\n i = 0\n while i <= n:\n print(i, n)\n i += 1\n yield i\n else:\n print(\"good effort\")\n #print(\" \")\n\n#better(\"hello\")\n\n#I don't even understand this output\nfor x in range(0, 10, 1):\n if x in better(4):\n print(x, end=\" \")\n\n#include<iostream>\n# Garrison's getting rekt over there"
},
{
"alpha_fraction": 0.7586206793785095,
"alphanum_fraction": 0.7586206793785095,
"avg_line_length": 13.5,
"blob_id": "a3c04a23530af2fe9e6616770fd5083cbb59edb5",
"content_id": "1d8f6e5b412515e99a66e9bd5e1e6ef7bce5965d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/README.md",
"repo_name": "goodkid45/Fun",
"src_encoding": "UTF-8",
"text": "# Fun\nlearning to use github\n"
}
] | 2 |
AlexanderKhasanov/Tasks
|
https://github.com/AlexanderKhasanov/Tasks
|
2c581d435752cee46d39e1e438697979dbaa305a
|
f64dc5b35f0c93033e8b53ad029b497e92c492a8
|
ea1f0e50bbd2986aefa59765ef338d0ef0e29b17
|
refs/heads/master
| 2023-01-25T02:18:36.836239 | 2020-11-13T15:01:40 | 2020-11-13T15:01:40 | 311,805,435 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.4735023081302643,
"alphanum_fraction": 0.5702764987945557,
"avg_line_length": 27.933332443237305,
"blob_id": "f96f4d3c25d4989d0902dbbf3fd4a968aa4d1c47",
"content_id": "2c716df3ad808717490c48e3eae0d5e682d1e324",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 30,
"path": "/test_task1.py",
"repo_name": "AlexanderKhasanov/Tasks",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom task1 import delete_copy\n\nclass TestDelCopy(unittest.TestCase):\n def setUp(self):\n self.delete = delete_copy\n\n def test_1(self):\n self.assertCountEqual( self.delete([1,2,3,4,5]), [1,2,3,4,5] )\n\n def test_2(self):\n self.assertCountEqual( self.delete([1,1,1,1,1]), [1] )\n\n def test_3(self):\n self.assertCountEqual( self.delete([]), [] )\n\n def test_4(self):\n self.assertCountEqual( self.delete([1,1,2,2,3,3,4,4,5,5]), [1,2,3,4,5] )\n\n def test_5(self):\n self.assertCountEqual( self.delete([1,2,3,4,5,1,2,3,4,5]), [1,2,3,4,5] )\n\n def test_6(self):\n self.assertCountEqual( self.delete([4,3,1,2,5,2,3,3,1,3]), [4, 3, 1, 2, 5] )\n\n def test_7(self):\n self.assertCountEqual( self.delete([4,3,1,2,5,2,3,3,1,3]), [4, 3, 1, 2, 5] )\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.6086956262588501,
"alphanum_fraction": 0.6364734172821045,
"avg_line_length": 26.633333206176758,
"blob_id": "785de9abfe17566f5d014248575b31bf501f09b1",
"content_id": "0c672c9359d44fd4b5941bf7c8833177108d43a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 828,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/task1.py",
"repo_name": "AlexanderKhasanov/Tasks",
"src_encoding": "UTF-8",
"text": "def delete_copy( list_x ):\n dict_x = {}\n return [ dict_x.setdefault(x, x) for x in list_x if x not in dict_x ]\n\nclass Calculator:\n #empty constructor\n def __init__(self):\n pass\n #add method - given two numbers, return the addition\n def add(self, x1, x2):\n return x1 + x2\n #multiply method - given two numbers, return the \n #multiplication of the two\n def multiply(self, x1, x2):\n return x1 * x2\n #subtract method - given two numbers, return the value\n #of first value minus the second\n def subtract(self, x1, x2):\n return x1 - x2\n #divide method - given two numbers, return the value\n #of first value divided by the second\n def divide(self, x1, x2):\n if x2 != 0:\n return x1/x2\n\nif __name__ == \"__main__\":\n my_list = [ 1,1,1,1,1 ]\n\n new_list = delete_copy(my_list)\n print(new_list)"
}
] | 2 |
minsiang97/inventory-management
|
https://github.com/minsiang97/inventory-management
|
9a6ae96ed268cbae492ae79bd9b132096f0d5143
|
dab02def4b887f4d15a88502828d0bd0f9dd9e8e
|
c24287f63f56d8f5b059348661858824e5161ed2
|
refs/heads/master
| 2023-01-22T18:40:57.316559 | 2020-11-23T14:35:22 | 2020-11-23T14:35:22 | 304,224,810 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6698890328407288,
"alphanum_fraction": 0.6698890328407288,
"avg_line_length": 32.255950927734375,
"blob_id": "3377aa5ea261aafb912954b2469dbba9e0de00b9",
"content_id": "71bdef5331f62702662e7f0ed03de582cfb3f67a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5586,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 168,
"path": "/server.py",
"repo_name": "minsiang97/inventory-management",
"src_encoding": "UTF-8",
"text": "import os\nimport peeweedbevolve\nfrom flask import Flask, render_template, request, redirect, url_for, flash\nfrom models import db, Store, Warehouse , Product\napp = Flask(__name__)\napp.secret_key=os.getenv(\"SECRETKEY\")\n\[email protected]_request \ndef before_request():\n db.connect()\n\[email protected]_request \ndef after_request(response):\n db.close()\n return response\n\[email protected]() \ndef migrate(): \n db.evolve(ignore_tables={'base_model'})\n\[email protected](\"/\")\ndef index():\n return render_template('index.html')\n\n\[email protected](\"/store/new\", methods = ['GET'])\ndef store_new():\n return render_template('addstore.html')\n \[email protected](\"/store/\", methods =['POST'])\ndef store_created() :\n \n store_name = request.form.get(\"store_name\")\n store = Store(name=store_name)\n if store.save():\n flash(\"Successfully added\",\"success\")\n else :\n flash(\"Duplicate Entry!!\",\"danger\")\n return redirect(url_for(\"store_new\"))\n\[email protected](\"/store/\", methods = ['GET'])\ndef store_index():\n stores = Store.select()\n return render_template('store_index.html',stores=stores)\n \n \n\[email protected](\"/store/<store_id>\", methods = ['GET'])\ndef store_show(store_id):\n store = Store.get_by_id(store_id)\n return render_template('store_show.html', store=store) \n\[email protected](\"/store/<store_id>\", methods = ['POST'])\ndef store_update(store_id):\n store = Store.get_by_id(store_id)\n store.name = request.form.get(\"store_name\")\n if store.save():\n flash(\"Store name successfully updated.\", \"success\")\n else :\n flash(\"The name entered is same as the previous\", \"danger\")\n return redirect(url_for('store_show', store_id = store.id))\n\n\[email protected](\"/store/<store_id>/delete\", methods = ['POST'])\ndef store_delete(store_id):\n store = Store.get_by_id(store_id)\n if store.delete_instance():\n flash(\"Store successfull deleted.\", \"success\")\n return redirect(url_for('store_index'))\n\n\[email protected](\"/warehouse/new\", methods = ['GET'])\ndef warehouse_new() :\n stores = Store.select()\n return render_template(\"warehouse_new.html\", stores=stores)\n\[email protected](\"/warehouse/\", methods = ['POST'])\ndef warehouse_created() :\n store = request.form.get(\"store_id\")\n location = request.form.get(\"location\")\n w = Warehouse(store=store , location = location)\n if w.save() :\n flash(\"Warehouse Created!\",\"success\")\n else :\n flash(\"Warehouse Duplicated\",\"danger\")\n return redirect(url_for('warehouse_new'))\n\n\[email protected](\"/product/new\", methods = ['GET'])\ndef product_new() :\n warehouses = Warehouse.select()\n return render_template(\"product_new.html\", warehouses=warehouses)\n\[email protected](\"/product/\", methods = ['POST'])\ndef product_created() :\n warehouse = request.form.get(\"warehouse_id\")\n product_name = request.form.get(\"product_name\")\n product_description = request.form.get(\"product_description\")\n product_color = request.form.get(\"product_color\")\n p = Product(warehouse=warehouse , name= product_name, description = product_description, color = product_color)\n if p.save() :\n flash(\"Product Created!\",\"success\")\n else :\n flash(\"Product Duplicated\",\"danger\")\n return redirect(url_for('product_new'))\n\[email protected](\"/warehouse/\", methods = ['GET'])\ndef warehouse_index():\n warehouses = Warehouse.select()\n return render_template('warehouse_index.html',warehouses=warehouses)\n\[email protected](\"/warehouse/<warehouse_id>\", methods = ['GET'])\ndef warehouse_show(warehouse_id):\n warehouse = Warehouse.get_by_id(warehouse_id)\n return render_template('warehouse_show.html', warehouse=warehouse) \n\[email protected](\"/warehouse/<warehouse_id>\", methods = ['POST'])\ndef warehouse_update(warehouse_id):\n warehouse = Warehouse.get_by_id(warehouse_id)\n warehouse.location = request.form.get(\"warehouse_location\")\n if warehouse.save():\n flash(\"Warehouse location successfully updated.\", \"success\")\n else :\n flash(\"The location entered is same as the previous\", \"danger\")\n return redirect(url_for('warehouse_show', warehouse_id = warehouse.id))\n\[email protected](\"/warehouse/<warehouse_id>/delete\", methods = ['POST'])\ndef warehouse_delete(warehouse_id):\n warehouse = Warehouse.get_by_id(warehouse_id)\n if warehouse.delete_instance():\n flash(\"Warehouse successfull deleted.\", \"success\")\n return redirect(url_for('warehouse_index'))\n\[email protected](\"/product/\", methods = ['GET'])\ndef product_index():\n products = Product.select()\n return render_template('product_index.html',products=products)\n\[email protected](\"/product/<product_id>\", methods = ['GET'])\ndef product_show(product_id):\n product = Product.get_by_id(product_id)\n return render_template('product_show.html', product=product) \n\n\[email protected](\"/product/<product_id>\", methods = ['POST'])\ndef product_update(product_id):\n product = Product.get_by_id(product_id)\n product.name = request.form.get(\"product_name\")\n product.description = request.form.get(\"product_description\")\n product.color = request.form.get(\"product_color\")\n\n if product.save():\n flash(\"Product successfully updated.\", \"success\")\n else :\n flash(\"The product entered is same as the previous\", \"danger\")\n return redirect(url_for('product_show', product_id = product.id))\n\[email protected](\"/product/<product_id>/delete\", methods = ['POST'])\ndef product_delete(product_id):\n product = Product.get_by_id(product_id)\n if product.delete_instance():\n flash(\"Product successfull deleted.\", \"success\")\n return redirect(url_for('product_index'))\n\n\n\nif __name__ == '__main__' :\n app.run()"
}
] | 1 |
rshipp/aur2ccr
|
https://github.com/rshipp/aur2ccr
|
45f1f8769682c6676f6dc613db3b1759f29f4fa0
|
c4a5c4de0b7ee21aefd0497d42248d596177bd04
|
898c6410fe3e6b0bad0dc422db012bb26f249fcb
|
refs/heads/master
| 2021-01-15T23:40:37.780642 | 2012-06-24T21:26:03 | 2012-06-24T21:26:03 | 3,924,604 | 2 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.6039003133773804,
"alphanum_fraction": 0.608450710773468,
"avg_line_length": 33.699249267578125,
"blob_id": "aa623be6ede13d8aa8801f99ff94d0aa071123ea",
"content_id": "6d1556315662f78ec5e85fa619620aac874b37af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4615,
"license_type": "no_license",
"max_line_length": 168,
"num_lines": 133,
"path": "/getmirrors.py",
"repo_name": "rshipp/aur2ccr",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python2\n# inspired by a bash script from Arch \n# drop in replacement for getmirrors.sh\nfrom __future__ import print_function\n\nimport os\nimport sys\nimport urllib2\nimport contextlib\nimport re\nimport fileinput\n\n# needed for a trick to get a mirror if the user lives in an unknown country\nclass SmartDict(dict):\n \"\"\"return 'Any' as fallback if country is not in list\"\"\"\n\n def __missing__(self, key):\n return 'Any'\n\n# get enviroment variables\ntry:\n paconf = os.environ[\"paconf\"]\nexcept KeyError:\n paconf = \"./archrepos.pacman.conf\"\n\n# quiet mode\nif \"--quiet\" in sys.argv:\n quiet = True\nelse:\n quiet = False\n\n# all countries accepted by the arch website\nvalid_countries = [\n 'Australia', 'Belarus', 'Belgium', 'Brazil',\n 'Bulgaria', 'Canada', 'Chile', 'China',\n 'Colombia', 'Czech', 'Denmark', 'Estonia',\n 'Finland', 'France', 'Germany', 'Great Britain',\n 'Greece', 'Hungary', 'India', 'Indonesia', 'Ireland',\n 'Israel', 'Italy', 'Japan', 'Kazakhstan', 'Korea',\n 'Latvia', 'Luxembourg', 'Macedonia', 'Netherlands',\n 'New Caledonia', 'Norway', 'Poland', 'Portugal', 'Romania',\n 'Russia', 'Singapore', 'Slovakia', 'South Korea', 'Spain',\n 'Sweden', 'Switzerland', 'Taiwan', 'Turkey', 'Ukraine',\n 'United States', 'Uzbekistan', 'Any'\n ]\nalt_country_names = SmartDict() # store alternate country names\nalt_country_names[\"United Kingdom\"] = \"Great Britain\"\nalt_country_names[\"Argentina\"] = \"Brazil\"\n\n# the webadresses of duckduckgo and arch linux \nduckduckgo = \"https://duckduckgo.com/lite/?q=ip\"\narchlinux = \"http://www.archlinux.org/mirrorlist/?country={}&protocol=ftp&protocol=http&ip_version=4&use_mirror_status=on\"\n\n\ndef download(url):\n # downloads a file and returns a file like object if successful\n try:\n webfile = urllib2.urlopen(url)\n except (urllib2.URLError, urllib2.HTTPError):\n print(\"Opening {} failed because of {}.\".format(url,sys.exc_info()), \n sys.stderr)\n sys.exit(2)\n return contextlib.closing(webfile)\n\n\ndef get_location():\n regex_country = re.compile(r\"\"\"\n ,\\s # a comma followed by whitespace\n ((?P<oneword>([a-zA-Z])+?)\\.) # one-word countries\n | (?P<twoword>(([a-zA-Z])+?\\s[a-zA-Z]+))((\\s([,(]))|\\.) #two-word countries\n \"\"\", re.VERBOSE)\n with download(duckduckgo) as coun_file:\n country = \"\"\n for line in coun_file:\n if \"(your IP address)\" in line:\n try:\n result = re.search(regex_country, line).groupdict()\n except AttributeError:\n # this should never fail until the duckduckgo website changes\n print(line, file=sys.stderr)\n print(\"Oh no! DuckDuckGo doesn't know where you live!\\nWe'll use a generic server for now. For better performance you should run aur2ccr --setup\\n\")\n return \"Any\"\n country = result[\"oneword\"] if result[\"oneword\"] else result[\"twoword\"]\n break\n # test if there is a mirror list for the country\n if country not in valid_countries:\n country = alt_country_names[country]\n return country\n\n\ndef edit_conf(server, file=paconf):\n regex = re.compile(\"Server = .*\\$\")\n for line in fileinput.input(file, inplace=1):\n if re.match(regex, line):\n # if the line contains Server, replace it with the new server\n print(server)\n else: # else don't change anything\n print(line, end=\"\")\n\n\n\ndef main():\n country = get_location()\n\n # Give the user the chance to change the mirror if not in quiet mode\n if not quiet:\n usercountry = raw_input(\"Please enter your country: (leave blank to use {}): \".format(country))\n if usercountry:\n country = usercountry\n\n #create the fitting url\n url = archlinux.format(urllib2.quote(country))\n mirror = \"\"\n print(\"Generating pacman configuration for {}\".format(paconf))\n with download(url) as mirrorfile:\n for line in mirrorfile:\n if \"is not one of the available choiches\" in line:\n # should never happen\n print(\"Something went wrong in getmirrors.py. Please report this error.\", file=sys.stderr)\n sys.exit(1)\n tmp = re.match(\"\\#(Server.*)\",line)\n if tmp:\n # replace $arch with x86_64\n mirror = re.sub(\"\\$arch\",\"x86_64\",tmp.group(1))\n break \n if mirror:\n print(mirror)\n else:\n sys.exit(1)\n edit_conf(mirror)\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6370023488998413,
"alphanum_fraction": 0.6541764140129089,
"avg_line_length": 50.2400016784668,
"blob_id": "fee1dcf12069e21b86c1b05705b9897c3b8baba4",
"content_id": "e538fe06deaa5dd88ac2872037fce60f8fc451c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1281,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 25,
"path": "/old/getmirrors.sh",
"repo_name": "rshipp/aur2ccr",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# modified script, orginally from the Arch linux forum\n\n# determine the location of the user via a duckduckgo request\ncoun=\"$(wget -qO- \"https://duckduckgo.com/lite/?q=ip\" | grep \"(your IP\\ address)\" | sed 's/.*(your IP address) in: .*, \\(.*\\s*.*\\)\\..*/\\1/; s/ (.*)//')\"\n[[ \"$quiet\" == 1 ]] && (echo $coun; exit 0) && exit 0\n[[ -z \"$coun\" ]] && coun=Any # backup, in case autodetect fails\n\ncountry=\"${country-$coun}\" \necho -e \"detected country: $coun\\nusing: $country\"\napconf=\"${apconf-./archrepos.pacman.conf}\"\nurl=\"http://www.archlinux.org/mirrorlist/?country=$country&protocol=ftp&protocol=http&ip_version=4&use_mirror_status=on\"\ntmpfile=$(mktemp --suffix=-mirrorlist)\n\n# Get latest mirror list and save to tmpfile\nwget -qO- \"$url\" | sed 's/^#Server/Server/g' > \"$tmpfile\"\n\n# Check for invalid countries \ngrep -o \" $country is not one of the available choices.\" \"$tmpfile\" && exit 1\n\n# some sed magic: get all lines containing \"server\", drop all but the first\n# x86-64 works for all repos, i686 won't work with multilib\nserver=$(sed -n 's/^Server = //p' $tmpfile | head -1 | sed 's/$arch/x86_64/g')\n[[ -z \"$server\" ]] && server='http://ftp.osuosl.org/pub/archlinux/$repo/os/x86_64' # Use a known good server as a backup\nsed -i 's|= [^ ]*|= '\"$server\"'|g' \"$apconf\"\n"
}
] | 2 |
29233/29223
|
https://github.com/29233/29223
|
7f541e9c94960d0d8ea46e653acd16fdc102a0b2
|
fd0b0638027d095da8f297e64e424c45eac529c1
|
a4ac1ad95ba48aec996c6a56f17a69afeca0a3f4
|
refs/heads/main
| 2023-06-24T10:37:02.838079 | 2021-07-14T13:34:04 | 2021-07-14T13:34:04 | 385,951,659 | 0 | 0 | null | null | null | null | null |
[
{
"alpha_fraction": 0.36247724294662476,
"alphanum_fraction": 0.4280509948730469,
"avg_line_length": 23.045454025268555,
"blob_id": "60744b81ad3560b95ef842fdda7c7df1c4f343e5",
"content_id": "a06a8d0ddf1fb556a824c382d90c69ddb1fce63c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 647,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 22,
"path": "/BMI.py",
"repo_name": "29233/29223",
"src_encoding": "UTF-8",
"text": "#CalBMI++.py\r\ntry:\r\n w,h = eval(input(\"请输入您的身高体重并用逗号隔开\"))\r\nexcept:\r\n print(\"输入信息有误\")\r\nbmi = w / (h ** 2)\r\nwho,nat = \"正常\",\"正常\"\r\nprint(\"{:.2f}\".format(bmi))\r\nif 0 < w < 100000 and 0 < h < 100000 :\r\n if bmi < 18.5 :\r\n who,nat = \"偏瘦\",\"偏瘦\"\r\n elif 18.5 <= bmi< 24:\r\n who,nat = \"正常\",\"正常\"\r\n elif 24 <= bmi< 25:\r\n who,nat = \"正常\",\"偏胖\"\r\n elif 25 <= bmi< 28:\r\n who,nat = \"偏胖\",\"偏胖\"\r\n elif 28 <= bmi< 30:\r\n who,nat = \"偏胖\",\"肥胖\"\r\n else :\r\n who,nat = \"肥胖\",\"肥胖\"\r\nprint(who,nat)"
}
] | 1 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.